
先坤
commited on
Commit
•
0dcfc8f
1
Parent(s):
f407e0e
update
Browse files- README.md +82 -13
- images/GREEDRL-Logo-Original-640.png +0 -0
- images/GREEDRL-Network.png +0 -0
README.md
CHANGED
|
@@ -7,9 +7,9 @@ tags:
|
|
| 7 |
- Reinforcement Learning
|
| 8 |
- Vehicle Routing Problem
|
| 9 |
---
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
|
| 14 |
# ✊GreedRL
|
| 15 |
|
|
@@ -37,16 +37,12 @@ Currently, various VRP variants such as CVRP, VRPTW and PDPTW, as well as proble
|
|
| 37 |
|
| 38 |
In order to achieve the ultimate performance, the framework implements some high-performance operators specifically for Combinatorial Optimization(CO) problems to replace pytorch operators, such as the Masked Addition Attention and Masked Softmax Sampling."
|
| 39 |
|
| 40 |
-
|
| 41 |
-
<img src="./images/GREEDRL-Framwork.png" width = "515" height = "380"/>
|
| 42 |
-
</div>
|
| 43 |
|
| 44 |
## Network design
|
| 45 |
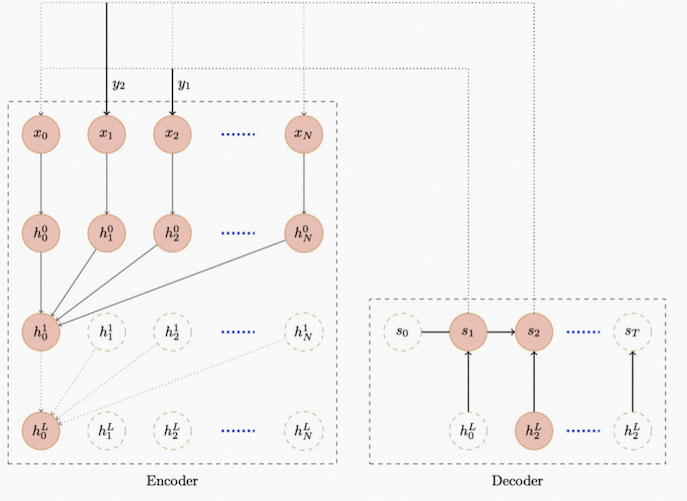
The neural network adopts the Seq2Seq architecture commonly used in Natural Language Processing(NLP), with the Transformer used in the Encoding part and RNN used in the decoding part, as shown in the diagram below.
|
| 46 |
|
| 47 |
-
|
| 48 |
-
<img src="./images/GREEDRL-Network.png" width = "515" height = "380"/>
|
| 49 |
-
</div>
|
| 50 |
|
| 51 |
## Modeling examples
|
| 52 |
|
|
@@ -73,11 +69,7 @@ features = [continuous_feature('worker_weight_limit'),
|
|
| 73 |
continuous_feature('task_due_time'),
|
| 74 |
continuous_feature('task_service_time'),
|
| 75 |
continuous_feature('distance_matrix')]
|
| 76 |
-
```
|
| 77 |
-
</details>
|
| 78 |
-
<details>
|
| 79 |
|
| 80 |
-
```python
|
| 81 |
variables = [task_demand_now('task_demand_now', feature='task_demand'),
|
| 82 |
task_demand_now('task_demand_this', feature='task_demand', only_this=True),
|
| 83 |
feature_variable('task_weight'),
|
|
@@ -137,7 +129,84 @@ class Objective:
|
|
| 137 |
</details>
|
| 138 |
|
| 139 |
### Pickup and Delivery Problem with Time Windows(PDPTW)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 140 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 141 |
|
| 142 |
## 🏆Award
|
| 143 |
|
|
|
|
| 7 |
- Reinforcement Learning
|
| 8 |
- Vehicle Routing Problem
|
| 9 |
---
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
|
| 14 |
# ✊GreedRL
|
| 15 |
|
|
|
|
| 37 |
|
| 38 |
In order to achieve the ultimate performance, the framework implements some high-performance operators specifically for Combinatorial Optimization(CO) problems to replace pytorch operators, such as the Masked Addition Attention and Masked Softmax Sampling."
|
| 39 |
|
| 40 |
+

|
|
|
|
|
|
|
| 41 |
|
| 42 |
## Network design
|
| 43 |
The neural network adopts the Seq2Seq architecture commonly used in Natural Language Processing(NLP), with the Transformer used in the Encoding part and RNN used in the decoding part, as shown in the diagram below.
|
| 44 |
|
| 45 |
+

|
|
|
|
|
|
|
| 46 |
|
| 47 |
## Modeling examples
|
| 48 |
|
|
|
|
| 69 |
continuous_feature('task_due_time'),
|
| 70 |
continuous_feature('task_service_time'),
|
| 71 |
continuous_feature('distance_matrix')]
|
|
|
|
|
|
|
|
|
|
| 72 |
|
|
|
|
| 73 |
variables = [task_demand_now('task_demand_now', feature='task_demand'),
|
| 74 |
task_demand_now('task_demand_this', feature='task_demand', only_this=True),
|
| 75 |
feature_variable('task_weight'),
|
|
|
|
| 129 |
</details>
|
| 130 |
|
| 131 |
### Pickup and Delivery Problem with Time Windows(PDPTW)
|
| 132 |
+
<details>
|
| 133 |
+
<summary>PDPTW</summary>
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
from greedrl.model import runner
|
| 137 |
+
from greedrl.feature import *
|
| 138 |
+
from greedrl.variable import *
|
| 139 |
+
from greedrl.function import *
|
| 140 |
+
from greedrl import Problem, Solution, Solver
|
| 141 |
+
|
| 142 |
+
features = [local_category('task_group'),
|
| 143 |
+
global_category('task_priority', 2),
|
| 144 |
+
variable_feature('distance_this_to_task'),
|
| 145 |
+
variable_feature('distance_task_to_end')]
|
| 146 |
|
| 147 |
+
variables = [task_demand_now('task_demand_now', feature='task_demand'),
|
| 148 |
+
task_demand_now('task_demand_this', feature='task_demand', only_this=True),
|
| 149 |
+
feature_variable('task_weight'),
|
| 150 |
+
feature_variable('task_group'),
|
| 151 |
+
feature_variable('task_priority'),
|
| 152 |
+
feature_variable('task_due_time2', feature='task_due_time'),
|
| 153 |
+
task_variable('task_due_time'),
|
| 154 |
+
task_variable('task_service_time'),
|
| 155 |
+
task_variable('task_due_time_penalty'),
|
| 156 |
+
worker_variable('worker_basic_cost'),
|
| 157 |
+
worker_variable('worker_distance_cost'),
|
| 158 |
+
worker_variable('worker_due_time'),
|
| 159 |
+
worker_variable('worker_weight_limit'),
|
| 160 |
+
worker_used_resource('worker_used_weight', task_require='task_weight'),
|
| 161 |
+
worker_used_resource('worker_used_time', 'distance_matrix', 'task_service_time', 'task_ready_time',
|
| 162 |
+
'worker_ready_time'),
|
| 163 |
+
edge_variable('distance_last_to_this', feature='distance_matrix', last_to_this=True),
|
| 164 |
+
edge_variable('distance_this_to_task', feature='distance_matrix', this_to_task=True),
|
| 165 |
+
edge_variable('distance_task_to_end', feature='distance_matrix', task_to_end=True)]
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class Constraint:
|
| 169 |
+
|
| 170 |
+
def do_task(self):
|
| 171 |
+
return self.task_demand_this
|
| 172 |
+
|
| 173 |
+
def mask_worker_end(self):
|
| 174 |
+
return task_group_split(self.task_group, self.task_demand_now <= 0)
|
| 175 |
+
|
| 176 |
+
def mask_task(self):
|
| 177 |
+
mask = self.task_demand_now <= 0
|
| 178 |
+
mask |= task_group_priority(self.task_group, self.task_priority, mask)
|
| 179 |
+
|
| 180 |
+
worker_used_time = self.worker_used_time[:, None] + self.distance_this_to_task
|
| 181 |
+
mask |= (worker_used_time > self.task_due_time2) & (self.task_priority == 0)
|
| 182 |
+
|
| 183 |
+
# 容量约束
|
| 184 |
+
worker_weight_limit = self.worker_weight_limit - self.worker_used_weight
|
| 185 |
+
mask |= self.task_demand_now * self.task_weight > worker_weight_limit[:, None]
|
| 186 |
+
return mask
|
| 187 |
+
|
| 188 |
+
def finished(self):
|
| 189 |
+
return torch.all(self.task_demand_now <= 0, 1)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class Objective:
|
| 193 |
+
|
| 194 |
+
def step_worker_start(self):
|
| 195 |
+
return self.worker_basic_cost
|
| 196 |
+
|
| 197 |
+
def step_worker_end(self):
|
| 198 |
+
feasible = self.worker_used_time <= self.worker_due_time
|
| 199 |
+
return self.distance_last_to_this * self.worker_distance_cost, feasible
|
| 200 |
+
|
| 201 |
+
def step_task(self):
|
| 202 |
+
worker_used_time = self.worker_used_time - self.task_service_time
|
| 203 |
+
feasible = worker_used_time <= self.task_due_time
|
| 204 |
+
feasible &= worker_used_time <= self.worker_due_time
|
| 205 |
+
cost = self.distance_last_to_this * self.worker_distance_cost
|
| 206 |
+
return torch.where(feasible, cost, cost + self.task_due_time_penalty), feasible
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
</details>
|
| 210 |
|
| 211 |
## 🏆Award
|
| 212 |
|
images/GREEDRL-Logo-Original-640.png
CHANGED
|
|
|
|
images/GREEDRL-Network.png
CHANGED

|
|