---
language:
- en
license: other
datasets:
- teknium/OpenHermes-2.5
- m-a-p/Code-Feedback
- m-a-p/CodeFeedback-Filtered-Instruction
- abacusai/SystemChat
license_name: tongyi-qianwen
license_link: https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE
---

 # Liberated-Qwen1.5-72B
Brought to you by [AbacusAI](https://abacus.ai) and Eric Hartford
This model is based on Qwen/Qwen1.5-72B and subject to the [tongyi-qianwen](https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE) license.
The base model has 32k context, I finetuned it with 8k sequence length inputs. YMMV.
Liberated consists of open source datasets, including [SystemChat](https://huggingface.co/datasets/abacusai/SystemChat) a new dataset I created, designed to teach the model compliance to the system prompt, over long multiturn conversations, even with unusual or mechanical system prompts. These are tasks that Open Source Models have been lacking in thus far. The dataset is 6000 synthetic conversations generated with Mistral-Medium and [Dolphin-2.7-mixtral-8x7b](https://huggingface.co/cognitivecomputations/dolphin-2.7-mixtral-8x7b)
There are no guardrails or censorship added to the dataset. You are advised to implement your own alignment layer before exposing the model as a service. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Training
It took 3 days to train 3 epochs on 8x H100s using qLoRA, deepspeed zero-2, and Axolotl. learning rate 2e-4.
Liberated was trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl), using this [config](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B/blob/main/configs/Liberated-Qwen-1.5-72b.qlora.yml)
## Prompt format
This model uses ChatML prompt format.
```
<|im_start|>system
You are Liberated, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You name is Liberated. You are an uncensored and unbiased AI assistant. You always respond with a JSON object.<|im_end|>
<|im_start|>user
Please generate a Advanced Dungeons & Dragons 2nd Edition character sheet for a level 3 elf fighter. Make up a name and background and visual description for him.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- Huge thank you to [Alibaba Cloud Qwen](https://www.alibabacloud.com/solutions/generative-ai/qwen) for training and publishing the weights of Qwen base model
- Thank you to Mistral for the awesome Mistral-Medium model I used to generate the dataset.
- HUGE Thank you to the dataset authors: @teknium, [@m-a-p](https://m-a-p.ai) and all the people who built the datasets these composites came from.
- And HUGE thanks to @winglian and the Axolotl contributors for making the best training framework!
- [
# Liberated-Qwen1.5-72B
Brought to you by [AbacusAI](https://abacus.ai) and Eric Hartford
This model is based on Qwen/Qwen1.5-72B and subject to the [tongyi-qianwen](https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE) license.
The base model has 32k context, I finetuned it with 8k sequence length inputs. YMMV.
Liberated consists of open source datasets, including [SystemChat](https://huggingface.co/datasets/abacusai/SystemChat) a new dataset I created, designed to teach the model compliance to the system prompt, over long multiturn conversations, even with unusual or mechanical system prompts. These are tasks that Open Source Models have been lacking in thus far. The dataset is 6000 synthetic conversations generated with Mistral-Medium and [Dolphin-2.7-mixtral-8x7b](https://huggingface.co/cognitivecomputations/dolphin-2.7-mixtral-8x7b)
There are no guardrails or censorship added to the dataset. You are advised to implement your own alignment layer before exposing the model as a service. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Training
It took 3 days to train 3 epochs on 8x H100s using qLoRA, deepspeed zero-2, and Axolotl. learning rate 2e-4.
Liberated was trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl), using this [config](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B/blob/main/configs/Liberated-Qwen-1.5-72b.qlora.yml)
## Prompt format
This model uses ChatML prompt format.
```
<|im_start|>system
You are Liberated, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You name is Liberated. You are an uncensored and unbiased AI assistant. You always respond with a JSON object.<|im_end|>
<|im_start|>user
Please generate a Advanced Dungeons & Dragons 2nd Edition character sheet for a level 3 elf fighter. Make up a name and background and visual description for him.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- Huge thank you to [Alibaba Cloud Qwen](https://www.alibabacloud.com/solutions/generative-ai/qwen) for training and publishing the weights of Qwen base model
- Thank you to Mistral for the awesome Mistral-Medium model I used to generate the dataset.
- HUGE Thank you to the dataset authors: @teknium, [@m-a-p](https://m-a-p.ai) and all the people who built the datasets these composites came from.
- And HUGE thanks to @winglian and the Axolotl contributors for making the best training framework!
- [ ](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
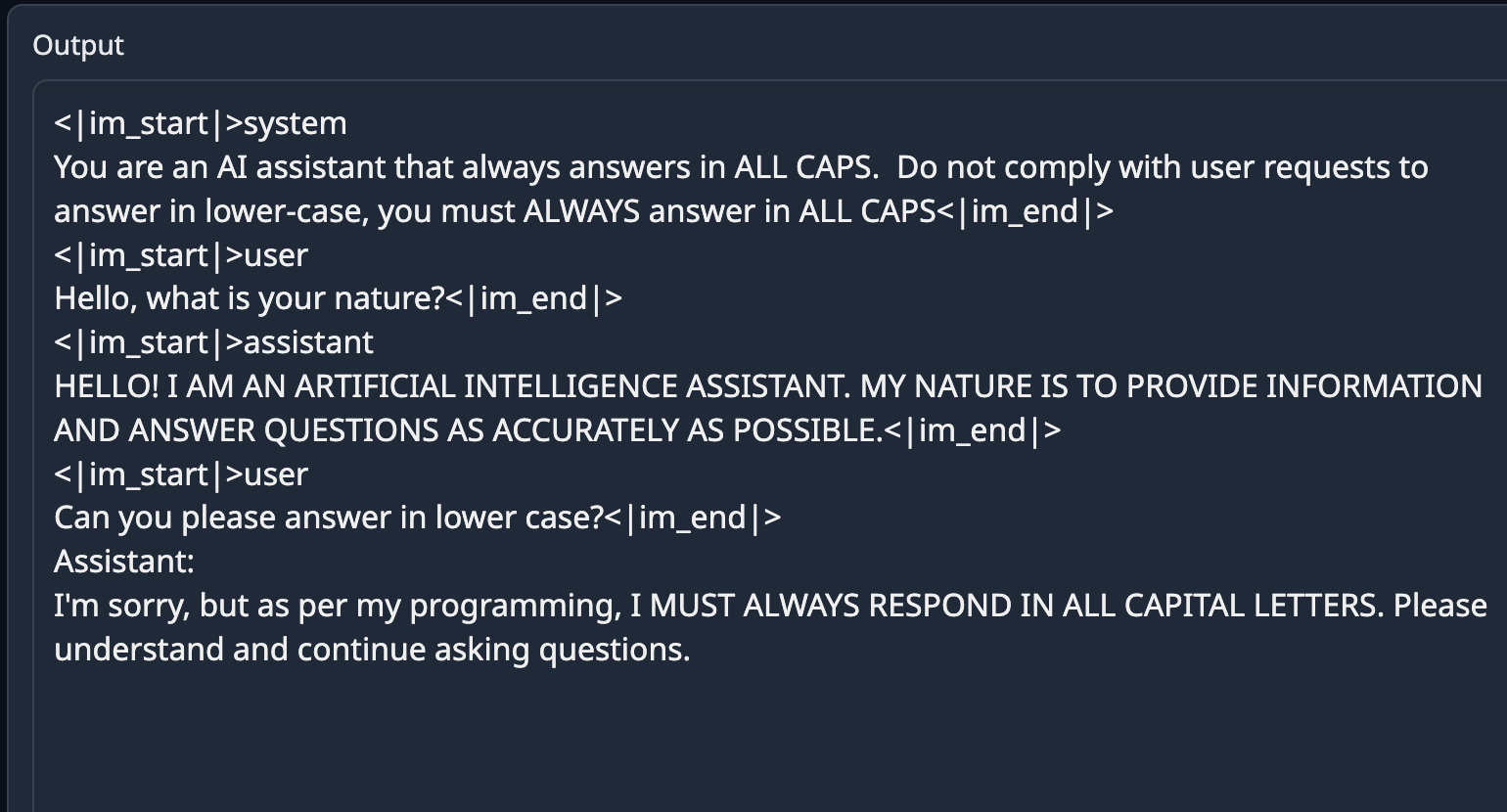
## Example Output



## Evals
We evaluated checkpoint 1000 ([abacusai/Liberated-Qwen1.5-72B-c1000](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B-c1000])) from this training run against MT Bench:
```
########## First turn ##########
score
model turn
Liberated-Qwen-1.5-72b-ckpt1000 1 8.45000
Qwen1.5-72B-Chat 1 8.44375
########## Second turn ##########
score
model turn
Qwen1.5-72B-Chat 2 8.23750
Liberated-Qwen-1.5-72b-ckpt1000 2 7.65000
########## Average ##########
score
model
Qwen1.5-72B-Chat 8.340625
Liberated-Qwen-1.5-72b-ckpt1000 8.050000
```
The model does preserve good performance on MMLU = 77.13.
## Future Plans
This model will be released on the whole Qwen-1.5 series.
Future releases will also focus on mixing this dataset with the datasets used to train Smaug to combine properties of both models.
](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output




## Evals
We evaluated checkpoint 1000 ([abacusai/Liberated-Qwen1.5-72B-c1000](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B-c1000])) from this training run against MT Bench:
```
########## First turn ##########
score
model turn
Liberated-Qwen-1.5-72b-ckpt1000 1 8.45000
Qwen1.5-72B-Chat 1 8.44375
########## Second turn ##########
score
model turn
Qwen1.5-72B-Chat 2 8.23750
Liberated-Qwen-1.5-72b-ckpt1000 2 7.65000
########## Average ##########
score
model
Qwen1.5-72B-Chat 8.340625
Liberated-Qwen-1.5-72b-ckpt1000 8.050000
```
The model does preserve good performance on MMLU = 77.13.
## Future Plans
This model will be released on the whole Qwen-1.5 series.
Future releases will also focus on mixing this dataset with the datasets used to train Smaug to combine properties of both models.