

Upload folder using huggingface_hub (#2)
Browse files- bce8d6006f4e1314089607fe73264e3dc435a64715bdec8392348abf09b76dbb (10fe1e38d4b5d2ea6b303e6aeae47a349c0ca5c4)
- a384f7baac778b54e756e200531c5cc67259fc490ef5c32c865baa59b59d07d9 (daa53fd737b4bc3a264d2c36b3d3bf87faed14f9)
- README.md +3 -2
- config.json +1 -1
- plots.png +0 -0
- results.json +24 -20
- smash_config.json +5 -5
README.md
CHANGED
|
@@ -1,5 +1,6 @@
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
|
|
|
| 3 |
metrics:
|
| 4 |
- memory_disk
|
| 5 |
- memory_inference
|
|
@@ -59,9 +60,9 @@ You can run the smashed model with these steps:
|
|
| 59 |
2. Load & run the model.
|
| 60 |
```python
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
-
|
| 63 |
|
| 64 |
-
model =
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("MaziyarPanahi/Llama-3-8B-Instruct-64k")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
|
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
+
base_model: MaziyarPanahi/Llama-3-8B-Instruct-64k
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
| 6 |
- memory_inference
|
|
|
|
| 60 |
2. Load & run the model.
|
| 61 |
```python
|
| 62 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 63 |
+
from awq import AutoAWQForCausalLM
|
| 64 |
|
| 65 |
+
model = AutoAWQForCausalLM.from_quantized("PrunaAI/MaziyarPanahi-Llama-3-8B-Instruct-64k-AWQ-4bit-smashed", trust_remote_code=True, device_map='auto')
|
| 66 |
tokenizer = AutoTokenizer.from_pretrained("MaziyarPanahi/Llama-3-8B-Instruct-64k")
|
| 67 |
|
| 68 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpe413c_m0",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED

|
|
results.json
CHANGED
|
@@ -1,26 +1,30 @@
|
|
| 1 |
{
|
| 2 |
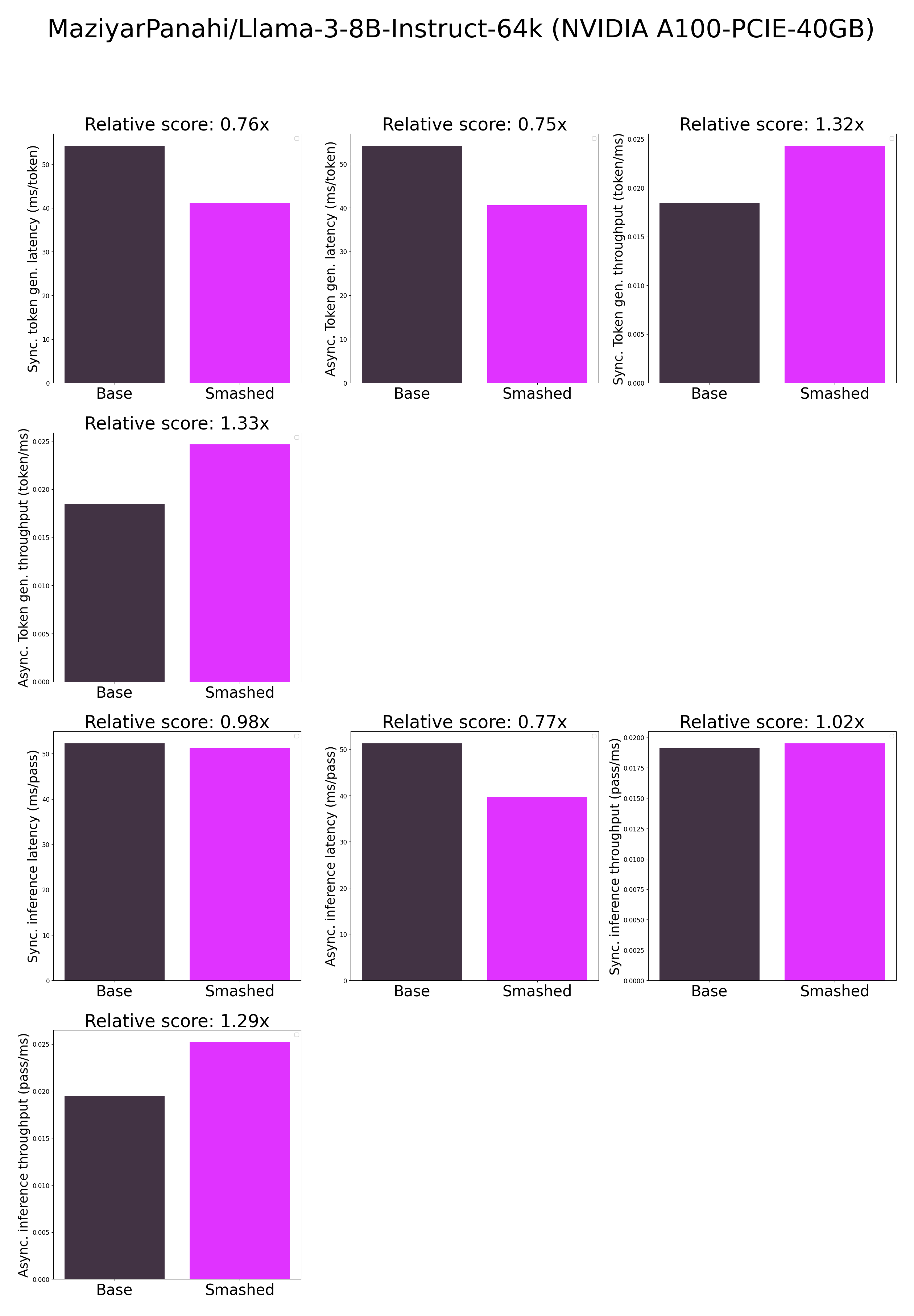
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"base_token_generation_latency_sync":
|
| 5 |
-
"base_token_generation_latency_async":
|
| 6 |
-
"base_token_generation_throughput_sync": 0.
|
| 7 |
-
"base_token_generation_throughput_async": 0.
|
| 8 |
-
"base_token_generation_CO2_emissions":
|
| 9 |
-
"base_token_generation_energy_consumption":
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
|
|
|
|
|
|
| 14 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 15 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 16 |
-
"smashed_token_generation_latency_sync":
|
| 17 |
-
"smashed_token_generation_latency_async":
|
| 18 |
-
"smashed_token_generation_throughput_sync": 0.
|
| 19 |
-
"smashed_token_generation_throughput_async": 0.
|
| 20 |
-
"smashed_token_generation_CO2_emissions":
|
| 21 |
-
"smashed_token_generation_energy_consumption":
|
| 22 |
-
"smashed_inference_latency_sync":
|
| 23 |
-
"smashed_inference_latency_async":
|
| 24 |
-
"smashed_inference_throughput_sync": 0.
|
| 25 |
-
"smashed_inference_throughput_async": 0.
|
|
|
|
|
|
|
| 26 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_token_generation_latency_sync": 54.22916030883789,
|
| 5 |
+
"base_token_generation_latency_async": 54.13356442004442,
|
| 6 |
+
"base_token_generation_throughput_sync": 0.018440263398971105,
|
| 7 |
+
"base_token_generation_throughput_async": 0.018472827546336907,
|
| 8 |
+
"base_token_generation_CO2_emissions": null,
|
| 9 |
+
"base_token_generation_energy_consumption": null,
|
| 10 |
+
"base_inference_latency_sync": 52.29578285217285,
|
| 11 |
+
"base_inference_latency_async": 51.306843757629395,
|
| 12 |
+
"base_inference_throughput_sync": 0.019122000770630986,
|
| 13 |
+
"base_inference_throughput_async": 0.019490577216636887,
|
| 14 |
+
"base_inference_CO2_emissions": null,
|
| 15 |
+
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
+
"smashed_token_generation_latency_sync": 41.130767822265625,
|
| 19 |
+
"smashed_token_generation_latency_async": 40.58046396821737,
|
| 20 |
+
"smashed_token_generation_throughput_sync": 0.024312699542133578,
|
| 21 |
+
"smashed_token_generation_throughput_async": 0.024642399376783867,
|
| 22 |
+
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
+
"smashed_token_generation_energy_consumption": null,
|
| 24 |
+
"smashed_inference_latency_sync": 51.22703399658203,
|
| 25 |
+
"smashed_inference_latency_async": 39.65771198272705,
|
| 26 |
+
"smashed_inference_throughput_sync": 0.01952094279100215,
|
| 27 |
+
"smashed_inference_throughput_async": 0.025215776453153697,
|
| 28 |
+
"smashed_inference_CO2_emissions": null,
|
| 29 |
+
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
smash_config.json
CHANGED
|
@@ -2,19 +2,19 @@
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
-
"pruners": "
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
-
"factorizers": "
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
-
"output_deviation": 0.
|
| 11 |
-
"compilers": "
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "MaziyarPanahi/Llama-3-8B-Instruct-64k",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
+
"factorizers": "None",
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
+
"output_deviation": 0.005,
|
| 11 |
+
"compilers": "None",
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsvigq773l",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "MaziyarPanahi/Llama-3-8B-Instruct-64k",
|
| 20 |
"task": "text_text_generation",
|