---
license: apache-2.0
language:
- en
- zh
base_model:
- Qwen/Qwen2.5-7B-Instruct
- BlinkDL/rwkv-7-world
pipeline_tag: text-generation
library_name: transformers
---
ARWKV🪿
Paper Link👁️ | Github✅
# ARWKV-7B-GATE-MLP (Preview 0.1)
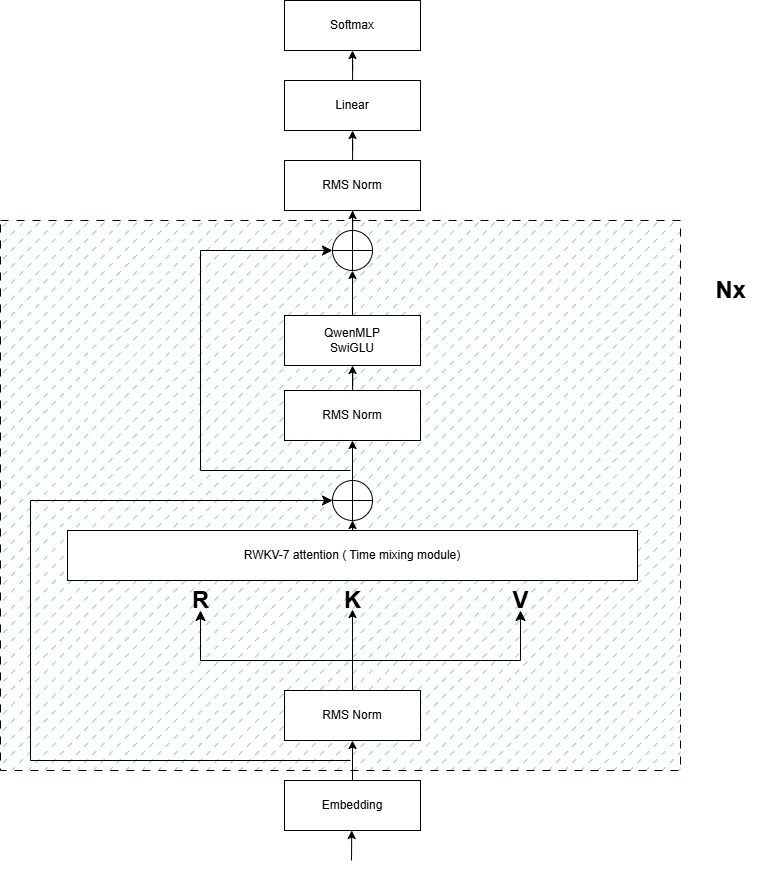 *Preview version with **RWKV-7** time mixing and Transformer MLP*
## 📌 Overview
**ALL YOU NEED IS RWKV**
This is an **early preview** of our 7B parameter hybrid RNN-Transformer model, trained on 2k context length **(only stage-2 applied, without SFT or DPO)** through 3-stage knowledge distillation from Qwen2.5-7B-Instruct. While being a foundational version, it demonstrates:
- ✅ RWKV-7's efficient recurrence mechanism
- ✅ No self-attention, fully O(n)
- ✅ Constant VRAM usage
- ✅ Single-GPU trainability
**Roadmap Notice**: We will soon open-source different enhanced versions with:
- 🚀 16k+ context capability
- 🧮 Math-specific improvements
- 📚 RL enhanced reasoning model
## How to use
```shell
pip3 install --upgrade rwkv-fla transformers
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1",
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1"
)
```
## 🔑 Key Features
| Component | Specification | Note |
|-----------|---------------|------|
| Architecture | RWKV-7 TimeMix + SwiGLU | Hybrid design |
| Context Window | 2048 training CTX | *Preview limitation* |
| Training Tokens | 40M | Distillation-focused |
| Precision | FP16 inference recommended(16G Vram required) | 15%↑ vs BF16 |
## 🏗️ Architecture Highlights
### Core Modification Flow
```diff
Qwen2.5 Decoder Layer:
- Grouped Query Attention
+ RWKV-7 Time Mixing (Eq.3)
- RoPE Positional Encoding
+ State Recurrence
= Hybrid Layer Output
```
*Preview version with **RWKV-7** time mixing and Transformer MLP*
## 📌 Overview
**ALL YOU NEED IS RWKV**
This is an **early preview** of our 7B parameter hybrid RNN-Transformer model, trained on 2k context length **(only stage-2 applied, without SFT or DPO)** through 3-stage knowledge distillation from Qwen2.5-7B-Instruct. While being a foundational version, it demonstrates:
- ✅ RWKV-7's efficient recurrence mechanism
- ✅ No self-attention, fully O(n)
- ✅ Constant VRAM usage
- ✅ Single-GPU trainability
**Roadmap Notice**: We will soon open-source different enhanced versions with:
- 🚀 16k+ context capability
- 🧮 Math-specific improvements
- 📚 RL enhanced reasoning model
## How to use
```shell
pip3 install --upgrade rwkv-fla transformers
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1",
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(
"RWKV-Red-Team/ARWKV-7B-Preview-0.1"
)
```
## 🔑 Key Features
| Component | Specification | Note |
|-----------|---------------|------|
| Architecture | RWKV-7 TimeMix + SwiGLU | Hybrid design |
| Context Window | 2048 training CTX | *Preview limitation* |
| Training Tokens | 40M | Distillation-focused |
| Precision | FP16 inference recommended(16G Vram required) | 15%↑ vs BF16 |
## 🏗️ Architecture Highlights
### Core Modification Flow
```diff
Qwen2.5 Decoder Layer:
- Grouped Query Attention
+ RWKV-7 Time Mixing (Eq.3)
- RoPE Positional Encoding
+ State Recurrence
= Hybrid Layer Output
```