

Commit
•
b84dc74
1
Parent(s):
3caf9b5
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
---
|
| 2 |
license: other
|
| 3 |
license_name: glm-4
|
| 4 |
-
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/LICENSE
|
| 5 |
|
| 6 |
language:
|
| 7 |
- zh
|
|
@@ -13,7 +13,7 @@ tags:
|
|
| 13 |
inference: false
|
| 14 |
---
|
| 15 |
|
| 16 |
-
#
|
| 17 |
|
| 18 |
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
|
| 19 |
在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。
|
|
@@ -23,52 +23,52 @@ GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开
|
|
| 23 |
|
| 24 |
## 评测结果
|
| 25 |
|
| 26 |
-
我们在一些经典任务上对 GLM-4-9B
|
| 27 |
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
| Model | AlignBench | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|
| 31 |
|:--------------------|:-------------:|:--------:|:------:|:----:|:------:|:-----:|:----:|:---------:|:----:|
|
| 32 |
-
| Llama-3-8B-Instruct |
|
| 33 |
-
| ChatGLM3-6B |
|
| 34 |
-
| GLM-4-9B-Chat |
|
| 35 |
|
| 36 |
|
| 37 |
### 长文本
|
| 38 |
|
| 39 |
在 1M 的上下文长度下进行[大海捞针实验](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py),结果如下:
|
| 40 |
|
| 41 |
-
:
|
|
| 112 |
from transformers import AutoTokenizer
|
| 113 |
from vllm import LLM, SamplingParams
|
| 114 |
|
| 115 |
-
|
|
|
|
| 116 |
model_name = "THUDM/glm-4-9b-chat"
|
| 117 |
prompt = '你好'
|
| 118 |
|
|
@@ -123,8 +124,6 @@ llm = LLM(
|
|
| 123 |
max_model_len=max_model_len,
|
| 124 |
trust_remote_code=True,
|
| 125 |
enforce_eager=True,
|
| 126 |
-
enable_chunked_prefill=True,
|
| 127 |
-
max_num_batched_tokens=8192
|
| 128 |
)
|
| 129 |
stop_token_ids = [151329, 151336, 151338]
|
| 130 |
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
|
|
|
|
| 1 |
---
|
| 2 |
license: other
|
| 3 |
license_name: glm-4
|
| 4 |
+
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/blob/main/LICENSE
|
| 5 |
|
| 6 |
language:
|
| 7 |
- zh
|
|
|
|
| 13 |
inference: false
|
| 14 |
---
|
| 15 |
|
| 16 |
+
# GLM-4-9B-Chat
|
| 17 |
|
| 18 |
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
|
| 19 |
在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。
|
|
|
|
| 23 |
|
| 24 |
## 评测结果
|
| 25 |
|
| 26 |
+
我们在一些经典任务上对 GLM-4-9B-Chat 模型进行了评测,并得到了如下的结果:
|
| 27 |
|
| 28 |
+
| Model | AlignBench-v2 | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|
|
|
|
|
|
|
| 29 |
|:--------------------|:-------------:|:--------:|:------:|:----:|:------:|:-----:|:----:|:---------:|:----:|
|
| 30 |
+
| Llama-3-8B-Instruct | 5.12 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
|
| 31 |
+
| ChatGLM3-6B | 3.97 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
|
| 32 |
+
| GLM-4-9B-Chat | 6.61 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
|
| 33 |
|
| 34 |
|
| 35 |
### 长文本
|
| 36 |
|
| 37 |
在 1M 的上下文长度下进行[大海捞针实验](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py),结果如下:
|
| 38 |
|
| 39 |
+
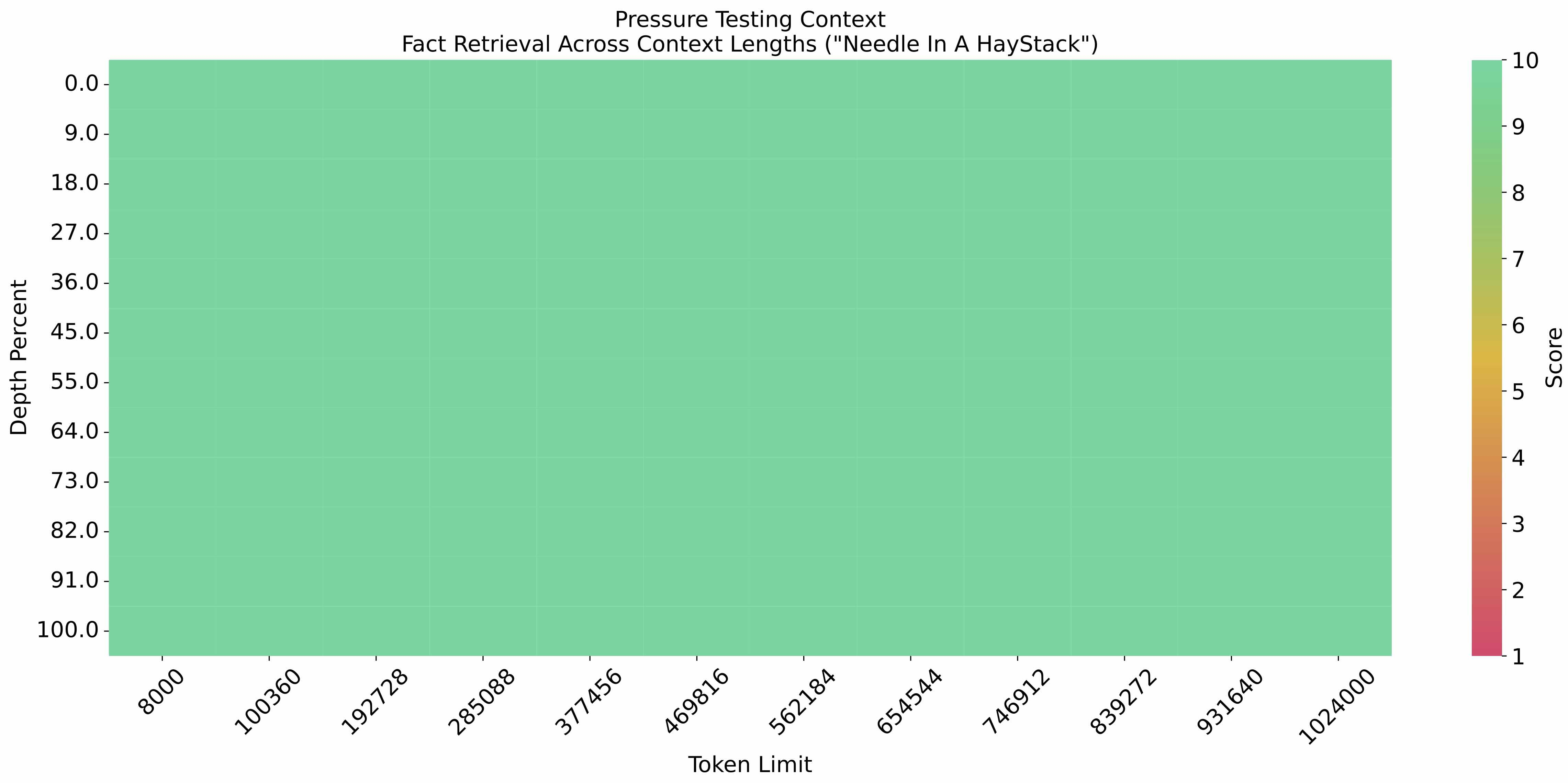
|
| 40 |
|
| 41 |
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
|
| 42 |
|
| 43 |
+
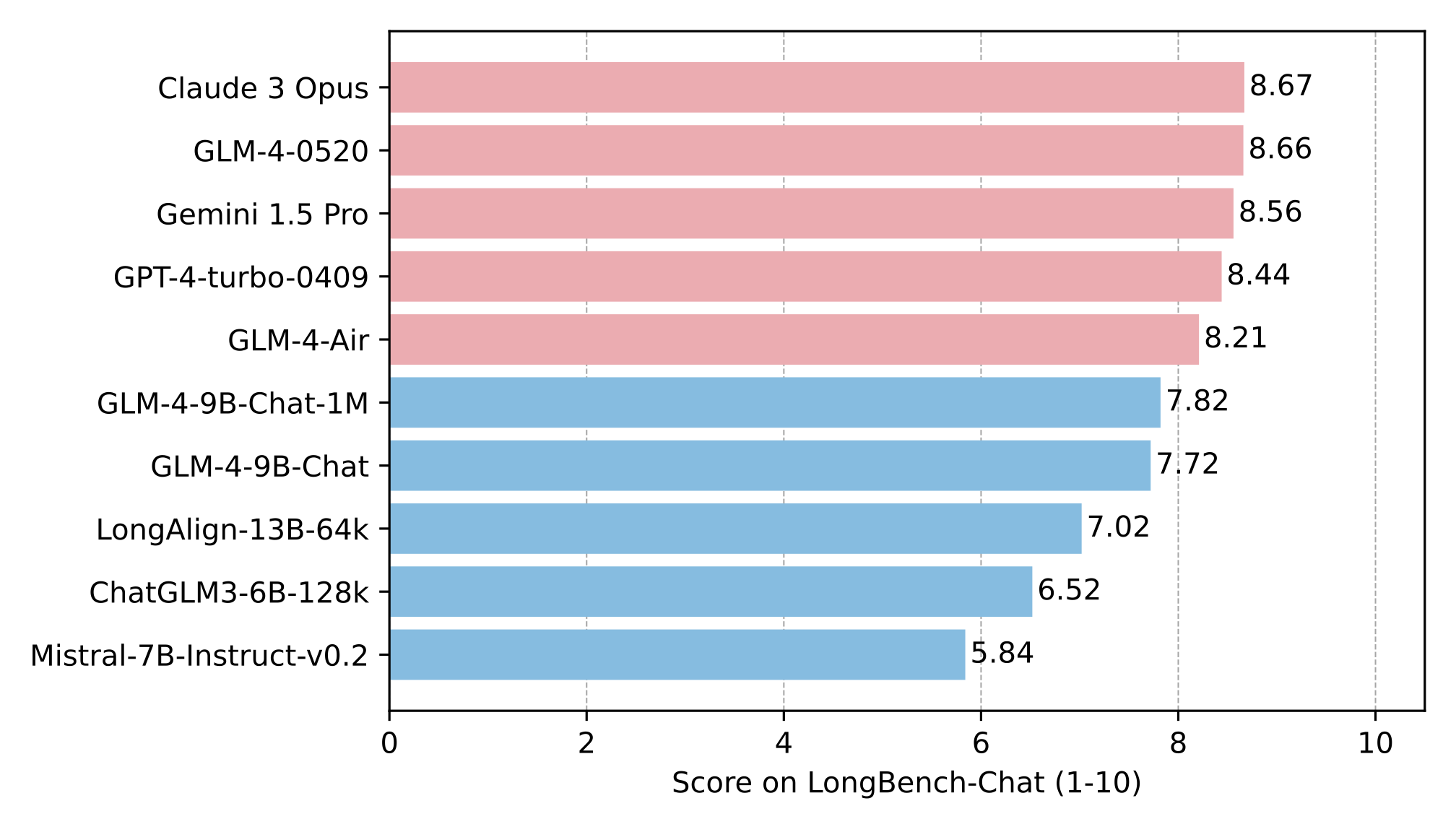
|
| 44 |
|
| 45 |
### 多语言能力
|
| 46 |
|
| 47 |
+
在六个多语言数据集上对 GLM-4-9B-Chat 和 Llama-3-8B-Instruct 进行了测试,测试结果及数据集对应选取语言如下表
|
| 48 |
+
|
| 49 |
+
| Dataset | Llama-3-8B-Instruct | GLM-4-9B-Chat | Languages
|
| 50 |
+
|:------------|:-------------------:|:-------------:|:----------------------------------------------------------------------------------------------:|
|
| 51 |
+
| M-MMLU | 49.6 | 56.6 | all
|
| 52 |
+
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no
|
| 53 |
+
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th
|
| 54 |
+
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt
|
| 55 |
+
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te
|
| 56 |
+
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi
|
| 57 |
+
|
| 58 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
|
| 60 |
### 工具调用能力
|
| 61 |
|
| 62 |
+
我们在 [Berkeley Function Calling Leaderboard](https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard)上进行了测试并得到了以下结果:
|
| 63 |
+
|
| 64 |
+
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|
| 65 |
+
|:-----------------------|:------------:|:-----------:|:------------:|:---------:|
|
| 66 |
+
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
|
| 67 |
+
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
|
| 68 |
+
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
|
| 69 |
+
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
|
| 70 |
|
| 71 |
+
**本仓库是 GLM-4-9B-Chat 的模型仓库,支持`128K`上下文长度。**
|
| 72 |
|
| 73 |
## 运行模型
|
| 74 |
|
|
|
|
| 112 |
from transformers import AutoTokenizer
|
| 113 |
from vllm import LLM, SamplingParams
|
| 114 |
|
| 115 |
+
# GLM-4-9B-Chat
|
| 116 |
+
max_model_len, tp_size = 131072, 1
|
| 117 |
model_name = "THUDM/glm-4-9b-chat"
|
| 118 |
prompt = '你好'
|
| 119 |
|
|
|
|
| 124 |
max_model_len=max_model_len,
|
| 125 |
trust_remote_code=True,
|
| 126 |
enforce_eager=True,
|
|
|
|
|
|
|
| 127 |
)
|
| 128 |
stop_token_ids = [151329, 151336, 151338]
|
| 129 |
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
|