

Upload 2 files
Browse files- README.md +211 -1
- main_results.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,213 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
|
| 3 |
+
language_creators:
|
| 4 |
+
- unknown
|
| 5 |
+
language:
|
| 6 |
+
- tr
|
| 7 |
+
license:
|
| 8 |
+
- mit
|
| 9 |
+
multilingualism:
|
| 10 |
+
- monolingual
|
| 11 |
+
pretty_name: unknown
|
| 12 |
+
size_categories:
|
| 13 |
+
- unknown
|
| 14 |
+
source_datasets: []
|
| 15 |
+
task_categories:
|
| 16 |
+
- unknown
|
| 17 |
+
task_ids:
|
| 18 |
+
- unknown
|
| 19 |
---
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# TurkishBERTweet
|
| 23 |
+
|
| 24 |
+
#### Table of contents
|
| 25 |
+
1. [Introduction](#introduction)
|
| 26 |
+
2. [Main results](#results)
|
| 27 |
+
3. [Using TurkishBERTweet with `transformers`](#transformers)
|
| 28 |
+
- [Model](#trainedModels)
|
| 29 |
+
- [Lora Adapter]($loraAdapter)
|
| 30 |
+
- [Example usage](#usage2)
|
| 31 |
+
- [Twitter Preprocessor](#preprocess)
|
| 32 |
+
- [Feature Extraction](#feature_extraction)
|
| 33 |
+
- [Sentiment Classification](#sa_lora)
|
| 34 |
+
- [HateSpeech Detection](#hs_lora)
|
| 35 |
+
|
| 36 |
+
4. [Citation](#citation)
|
| 37 |
+
# <a name="introduction"></a> TurkishBERTweet in the shadow of Large Language Models
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
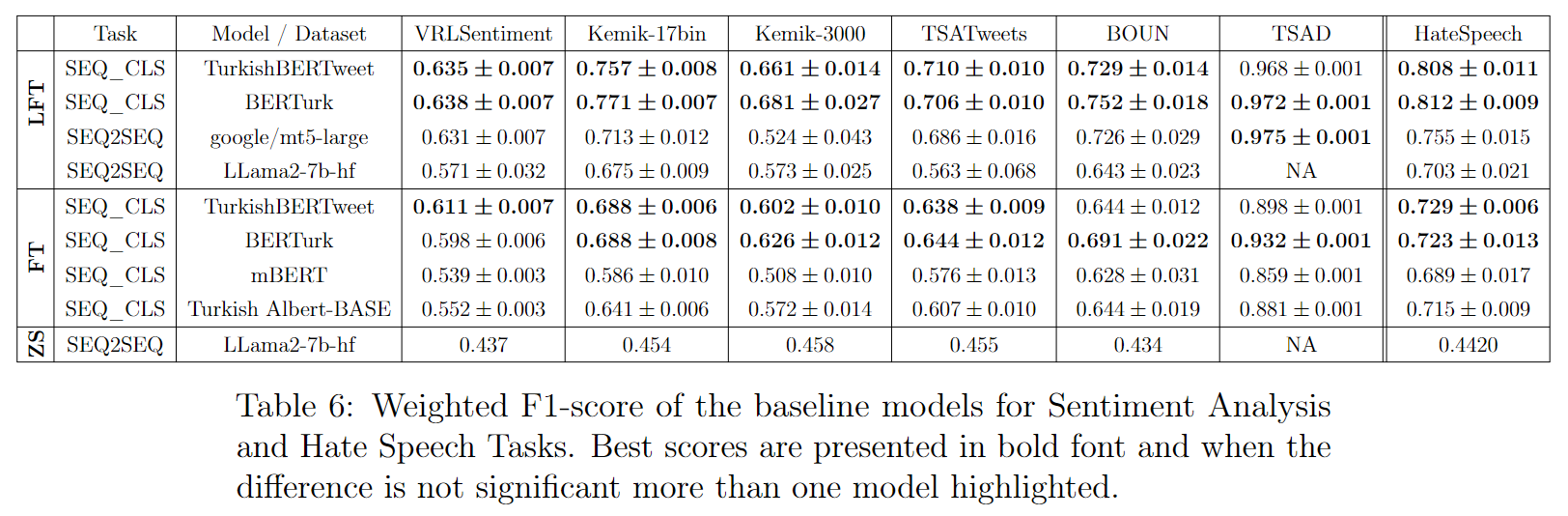
# <a name="results"></a> Main Results
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
<!-- https://huggingface.co/VRLLab/TurkishBERTweet -->
|
| 46 |
+
# <a name="trainedModels"></a> Model
|
| 47 |
+
Model | #params | Arch. | Max length | Pre-training data
|
| 48 |
+
---|---|---|---|---
|
| 49 |
+
`VRLLab/TurkishBERTweet` | 163M | base | 128 | 894M Turkish Tweets (uncased)
|
| 50 |
+
|
| 51 |
+
# <a name="loraAdapter"></a> Lora Adapters
|
| 52 |
+
Model | train f1 | dev f1 | test f1 | Dataset Size
|
| 53 |
+
---|---|---|---|---
|
| 54 |
+
`VRLLab/TurkishBERTweet-Lora-SA` | 0.799 | 0.687 | 0.692 | 42,476 Turkish Tweets
|
| 55 |
+
`VRLLab/TurkishBERTweet-Lora-HS` | 0.915 | 0.796 | 0.831 | 4,683 Turkish Tweets
|
| 56 |
+
# <a name="usage2"></a> Example usage
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## <a name="preprocess"></a> Twitter Preprocessor
|
| 60 |
+
```python
|
| 61 |
+
from Preprocessor import preprocess
|
| 62 |
+
|
| 63 |
+
text = """Lab'ımıza "viral" adını verdik çünkü amacımız disiplinler arası sınırları aşmak ve aralarında yeni bağlantılar kurmak! 🔬 #ViralLab
|
| 64 |
+
https://varollab.com/"""
|
| 65 |
+
|
| 66 |
+
preprocessed_text = preprocess(text)
|
| 67 |
+
print(preprocessed_text)
|
| 68 |
+
```
|
| 69 |
+
Output:
|
| 70 |
+
```output
|
| 71 |
+
lab'ımıza "viral" adını verdik çünkü amacımız disiplinler arası sınırları aşmak ve aralarında yeni bağlantılar kurmak! <emoji> mikroskop </emoji> <hashtag> virallab </hashtag> <http> varollab.com </http>
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## <a name="feature_extraction"></a> Feature Extraction
|
| 76 |
+
|
| 77 |
+
```python
|
| 78 |
+
import torch
|
| 79 |
+
from transformers import AutoTokenizer, AutoModel
|
| 80 |
+
from Preprocessor import preprocess
|
| 81 |
+
|
| 82 |
+
tokenizer = AutoTokenizer.from_pretrained("VRLLab/TurkishBERTweet")
|
| 83 |
+
turkishBERTweet = AutoModel.from_pretrained("VRLLab/TurkishBERTweet")
|
| 84 |
+
|
| 85 |
+
text = """Lab'ımıza "viral" adını verdik çünkü amacımız disiplinler arası sınırları aşmak ve aralarında yeni bağlantılar kurmak! 💥🔬 #ViralLab #DisiplinlerArası #YenilikçiBağlantılar"""
|
| 86 |
+
|
| 87 |
+
preprocessed_text = preprocess(text)
|
| 88 |
+
input_ids = torch.tensor([tokenizer.encode(preprocessed_text)])
|
| 89 |
+
|
| 90 |
+
with torch.no_grad():
|
| 91 |
+
features = turkishBERTweet(input_ids) # Models outputs are now tuples
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
## <a name="sa_lora"></a> Sentiment Classification
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
import torch
|
| 99 |
+
from peft import (
|
| 100 |
+
PeftModel,
|
| 101 |
+
PeftConfig,
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
from transformers import (
|
| 105 |
+
AutoModelForSequenceClassification,
|
| 106 |
+
AutoTokenizer)
|
| 107 |
+
from Preprocessor import preprocess
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
peft_model = "VRLLab/TurkishBERTweet-Lora-SA"
|
| 111 |
+
peft_config = PeftConfig.from_pretrained(peft_model)
|
| 112 |
+
|
| 113 |
+
# loading Tokenizer
|
| 114 |
+
padding_side = "right"
|
| 115 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 116 |
+
peft_config.base_model_name_or_path, padding_side=padding_side
|
| 117 |
+
)
|
| 118 |
+
if getattr(tokenizer, "pad_token_id") is None:
|
| 119 |
+
tokenizer.pad_token_id = tokenizer.eos_token_id
|
| 120 |
+
|
| 121 |
+
id2label_sa = {0: "negative", 2: "positive", 1: "neutral"}
|
| 122 |
+
turkishBERTweet_sa = AutoModelForSequenceClassification.from_pretrained(
|
| 123 |
+
peft_config.base_model_name_or_path, return_dict=True, num_labels=len(id2label_sa), id2label=id2label_sa
|
| 124 |
+
)
|
| 125 |
+
turkishBERTweet_sa = PeftModel.from_pretrained(turkishBERTweet_sa, peft_model)
|
| 126 |
+
|
| 127 |
+
sample_texts = [
|
| 128 |
+
"Viral lab da insanlar hep birlikte çalışıyorlar. hepbirlikte çalışan insanlar birbirlerine yakın oluyorlar.",
|
| 129 |
+
"americanin diplatlari turkiyeye gelmesin 😤",
|
| 130 |
+
"Mark Zuckerberg ve Elon Musk'un boks müsabakası süper olacak! 🥷",
|
| 131 |
+
"Adam dun ne yediğini unuttu"
|
| 132 |
+
]
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
preprocessed_texts = [preprocess(s) for s in sample_texts]
|
| 136 |
+
with torch.no_grad():
|
| 137 |
+
for s in preprocessed_texts:
|
| 138 |
+
ids = tokenizer.encode_plus(s, return_tensors="pt")
|
| 139 |
+
label_id = turkishBERTweet_sa(**ids).logits.argmax(-1).item()
|
| 140 |
+
print(id2label_sa[label_id],":", s)
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
```output
|
| 144 |
+
positive : viral lab da insanlar hep birlikte çalışıyorlar. hepbirlikte çalışan insanlar birbirlerine yakın oluyorlar.
|
| 145 |
+
negative : americanin diplatlari turkiyeye gelmesin <emoji> burundan_buharla_yüzleşmek </emoji>
|
| 146 |
+
positive : mark zuckerberg ve elon musk'un boks müsabakası süper olacak! <emoji> kadın_muhafız_koyu_ten_tonu </emoji>
|
| 147 |
+
neutral : adam dun ne yediğini unuttu
|
| 148 |
+
```
|
| 149 |
+
## <a name="hs_lora"></a> HateSpeech Detection
|
| 150 |
+
```python
|
| 151 |
+
from peft import (
|
| 152 |
+
PeftModel,
|
| 153 |
+
PeftConfig,
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
from transformers import (
|
| 157 |
+
AutoModelForSequenceClassification,
|
| 158 |
+
AutoTokenizer)
|
| 159 |
+
from Preprocessor import preprocess
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
peft_model = "VRLLab/TurkishBERTweet-Lora-HS"
|
| 163 |
+
peft_config = PeftConfig.from_pretrained(peft_model)
|
| 164 |
+
|
| 165 |
+
# loading Tokenizer
|
| 166 |
+
padding_side = "right"
|
| 167 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 168 |
+
peft_config.base_model_name_or_path, padding_side=padding_side
|
| 169 |
+
)
|
| 170 |
+
if getattr(tokenizer, "pad_token_id") is None:
|
| 171 |
+
tokenizer.pad_token_id = tokenizer.eos_token_id
|
| 172 |
+
|
| 173 |
+
id2label_hs = {0: "No", 1: "Yes"}
|
| 174 |
+
turkishBERTweet_hs = AutoModelForSequenceClassification.from_pretrained(
|
| 175 |
+
peft_config.base_model_name_or_path, return_dict=True, num_labels=len(id2label_hs), id2label=id2label_hs
|
| 176 |
+
)
|
| 177 |
+
turkishBERTweet_hs = PeftModel.from_pretrained(turkishBERTweet_hs, peft_model)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
sample_texts = [
|
| 181 |
+
"Viral lab da insanlar hep birlikte çalışıyorlar. hepbirlikte çalışan insanlar birbirlerine yakın oluyorlar.",
|
| 182 |
+
"kasmayin artik ya kac kere tanik olduk bu azgin tehlikeli \u201cmultecilerin\u201d yaptiklarina? bir afgan taragindan kafasi tasla ezilip tecavuz edilen kiza da git boyle cihangir solculugu yap yerse?",
|
| 183 |
+
]
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
preprocessed_texts = [preprocess(s) for s in sample_texts]
|
| 187 |
+
with torch.no_grad():
|
| 188 |
+
for s in preprocessed_texts:
|
| 189 |
+
ids = tokenizer.encode_plus(s, return_tensors="pt")
|
| 190 |
+
label_id = best_model_hs(**ids).logits.argmax(-1).item()
|
| 191 |
+
print(id2label_hs[label_id],":", s)
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
```output
|
| 195 |
+
No : viral lab da insanlar hep birlikte çalışıyorlar. hepbirlikte çalışan insanlar birbirlerine yakın oluyorlar.
|
| 196 |
+
Yes : kasmayin artik ya kac kere tanik olduk bu azgin tehlikeli “multecilerin” yaptiklarina? bir afgan taragindan kafasi tasla ezilip tecavuz edilen kiza da git boyle cihangir solculugu yap yerse?
|
| 197 |
+
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
# <a name="citation"></a> Citation
|
| 202 |
+
```bibtex
|
| 203 |
+
@article{najafi2022TurkishBERTweet,
|
| 204 |
+
title={TurkishBERTweet in the shadow of Large Language Models},
|
| 205 |
+
author={Najafi, Ali and Varol, Onur},
|
| 206 |
+
journal={arXiv preprint },
|
| 207 |
+
year={2023}
|
| 208 |
+
}
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
## Acknowledgments
|
| 212 |
+
We thank [Fatih Amasyali](https://avesis.yildiz.edu.tr/amasyali) for providing access to Tweet Sentiment datasets from Kemik group.
|
| 213 |
+
This material is based upon work supported by the Google Cloud Research Credits program with the award GCP19980904. We also thank TUBITAK (121C220 and 222N311) for funding this project.
|
main_results.png
ADDED
|