
Upload README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: pt
|
| 3 |
+
datasets:
|
| 4 |
+
- coraa_ser
|
| 5 |
+
- emovo
|
| 6 |
+
- ravdess
|
| 7 |
+
- baved
|
| 8 |
+
metrics:
|
| 9 |
+
- f1
|
| 10 |
+
tags:
|
| 11 |
+
- audio
|
| 12 |
+
- speech
|
| 13 |
+
- wav2vec2
|
| 14 |
+
- pt
|
| 15 |
+
- portuguese-speech-corpus
|
| 16 |
+
- italian-speech-corpus
|
| 17 |
+
- english-speech-corpus
|
| 18 |
+
- arabic-speech-corpus
|
| 19 |
+
- spontaneous
|
| 20 |
+
- speech
|
| 21 |
+
- PyTorch
|
| 22 |
+
license: apache-2.0
|
| 23 |
+
model_index:
|
| 24 |
+
name: wav2vec2-xls-r-300m-pt-br-spontaneous-speech-emotion-recognition
|
| 25 |
+
---
|
| 26 |
+
|
| 27 |
+
# Wav2vec 2.0 XLS-R For Spontaneous Speech Recognition
|
| 28 |
+
|
| 29 |
+
This is the model that got first place in the SER track of the Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022) Workshop.
|
| 30 |
+
|
| 31 |
+
The following datasets were used in the training:
|
| 32 |
+
|
| 33 |
+
- [CORAA SER v1.0](https://github.com/rmarcacini/ser-coraa-pt-br/): a dataset composed of spontaneous portuguese speech and approximately 50 minutes of audio segments labeled in three classes: neutral, non-neutral female, and non-neutral male.
|
| 34 |
+
|
| 35 |
+
- [EMOVO Corpus](https://aclanthology.org/L14-1478/): a database of emotional speech for the Italian language, built from the voices of up to 6 actors who played 14 sentences simulating 6 emotional states (disgust, fear, anger, joy, surprise, sadness) plus the neutral state.
|
| 36 |
+
|
| 37 |
+
- [RAVDESS]((https://zenodo.org/record/1188976#.YO6yI-gzaUk)): a dataset that provides 1440 samples of recordings from actors performing on 8 different emotions in English, which are: angry, calm, disgust, fearful, happy, neutral, sad and surprised.
|
| 38 |
+
|
| 39 |
+
- [BAVED](https://github.com/40uf411/Basic-Arabic-Vocal-Emotions-Dataset): a collection of audio recordings of Arabic words spoken with varying degrees of emotion. The dataset contains seven words: like, unlike, this, file, good, neutral, and bad, which are spoken at three emotional levels: low emotion (tired or feeling down), neutral emotion (the way the speaker speaks daily), and high emotion (positive or negative emotions such as happiness, joy, sadness, anger).
|
| 40 |
+
|
| 41 |
+
The test set used is a part of the CORAA SER v1.0 that has been set aside for this purpose.
|
| 42 |
+
|
| 43 |
+
It achieves the following results on the test set:
|
| 44 |
+
- Accuracy: 0.9090
|
| 45 |
+
- Macro Precision: 0.8171
|
| 46 |
+
- Macro Recall: 0.8397
|
| 47 |
+
- Macro F1-Score: 0.8187
|
| 48 |
+
|
| 49 |
+
## Datasets Details
|
| 50 |
+
|
| 51 |
+
The following image shows the overall distribution of the datasets:
|
| 52 |
+
|
| 53 |
+

|
| 54 |
+
|
| 55 |
+
The following image shows the number of instances by label:
|
| 56 |
+
|
| 57 |
+
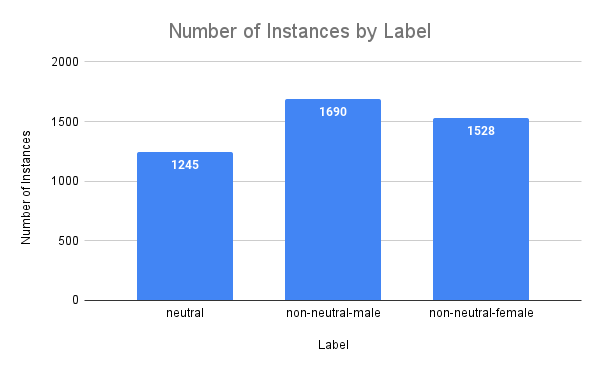
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
## Repository
|
| 61 |
+
|
| 62 |
+
The repository that implements the model to be trained and tested is avaible [here](https://github.com/alefiury/SE-R-2022-SER-Track).
|