
File size: 849 Bytes
ddf35be |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
proof of concept of a failed project
how you can load this into a diffusers-based notebook like [Doohickey](https://github.com/aicrumb/doohickey) might look something like this
```
from huggingface_hub import hf_hub_download
stable_inversion = "user/my-stable-inversion" #@param {type:"string"}
if len(stable_inversion)>1:
g = hf_hub_download(repo_id=stable_inversion, filename="token_embeddings.pt")
text_encoder.text_model.embeddings.token_embedding.weight = torch.load(g)
```
it was trained on 1024 images matching the 'genshin_impact' tag on safebooru, epochs 1 and 2 had the model being fed the full captions, epoch 3 had 50% of the tags in the caption, and epoch 4 had 25% of the tags in the caption. Learning rate was 1e-3 and the loss curve looked like this 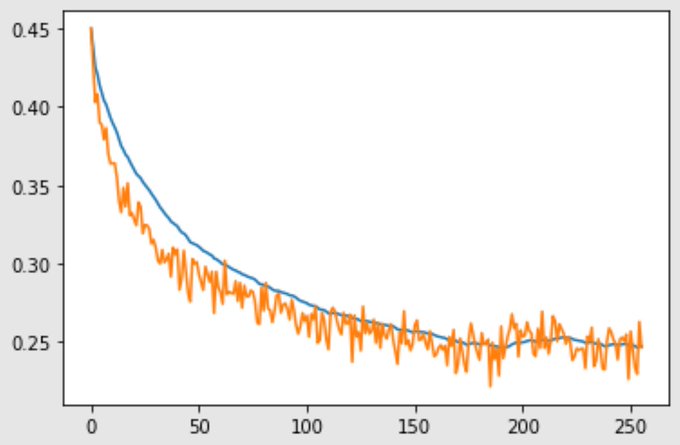
|