
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 600M
2.05B
| node_id
stringlengths 18
32
| number
int64 2
6.51k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2469 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2469/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2469/comments | https://api.github.com/repos/huggingface/datasets/issues/2469/events | https://github.com/huggingface/datasets/pull/2469 | 916,440,418 | MDExOlB1bGxSZXF1ZXN0NjY2MTA1OTk1 | 2,469 | Bump tqdm version | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [
"i tried both the latest version of `tqdm` and the version required by `autonlp` - no luck with windows 😞 \r\n\r\nit's very weird that a progress bar would trigger these kind of errors, so i'll have a look to see if it's something unique to `datasets`",
"Closing since this is now fixed in #2482 "
] | "2021-06-09T17:24:40Z" | "2021-06-11T15:03:42Z" | "2021-06-11T15:03:36Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2469.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2469",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2469.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2469"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2469/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2469/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1373/comments | https://api.github.com/repos/huggingface/datasets/issues/1373/events | https://github.com/huggingface/datasets/pull/1373 | 760,280,869 | MDExOlB1bGxSZXF1ZXN0NTM1MTM5MTY0 | 1,373 | Add OPUS ECB Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-09T12:18:22Z" | "2020-12-10T15:25:55Z" | "2020-12-10T15:25:54Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1373.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1373",
"merged_at": "2020-12-10T15:25:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1373.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1373"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1373/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/964 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/964/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/964/comments | https://api.github.com/repos/huggingface/datasets/issues/964/events | https://github.com/huggingface/datasets/pull/964 | 754,474,660 | MDExOlB1bGxSZXF1ZXN0NTMwMzY4OTAy | 964 | Adding the WebNLG dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
} | [] | closed | false | null | [] | null | [
"This is task is part of the GEM suite so will actually need a more complete dataset card. I'm taking a break for now though and will get back to it before merging :) "
] | "2020-12-01T15:05:23Z" | "2020-12-02T17:34:05Z" | "2020-12-02T17:34:05Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/964.diff",
"html_url": "https://github.com/huggingface/datasets/pull/964",
"merged_at": "2020-12-02T17:34:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/964.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/964"
} | This PR adds data from the WebNLG challenge, with one configuration per release and challenge iteration.
More information can be found [here](https://webnlg-challenge.loria.fr/)
Unfortunately, the data itself comes from a pretty large number of small XML files, so the dummy data ends up being quite large (8.4 MB even keeping only one example per file). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/964/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/964/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3804 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3804/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3804/comments | https://api.github.com/repos/huggingface/datasets/issues/3804/events | https://github.com/huggingface/datasets/issues/3804 | 1,157,297,278 | I_kwDODunzps5E-vR- | 3,804 | Text builder with custom separator line boundaries | {
"avatar_url": "https://avatars.githubusercontent.com/u/18630848?v=4",
"events_url": "https://api.github.com/users/cronoik/events{/privacy}",
"followers_url": "https://api.github.com/users/cronoik/followers",
"following_url": "https://api.github.com/users/cronoik/following{/other_user}",
"gists_url": "https://api.github.com/users/cronoik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cronoik",
"id": 18630848,
"login": "cronoik",
"node_id": "MDQ6VXNlcjE4NjMwODQ4",
"organizations_url": "https://api.github.com/users/cronoik/orgs",
"received_events_url": "https://api.github.com/users/cronoik/received_events",
"repos_url": "https://api.github.com/users/cronoik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cronoik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cronoik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cronoik"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Gently pinging @lhoestq",
"Hi ! Interresting :)\r\n\r\nCould you give more details on what kind of separators you would like to use instead ?",
"In my case, I just want to use `\\n` but not `U+2028`.",
"Ok I see, maybe there can be a `sep` parameter to allow users to specify what line/paragraph separator they'd like to use",
"Related to:\r\n- #3729 \r\n- #3910",
"Thanks for requesting this enhancement. We have recently found a somehow related issue with another dataset:\r\n- #3704\r\n\r\nLet me make a PR proposal."
] | "2022-03-02T14:50:16Z" | "2022-03-16T15:53:59Z" | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
The current [Text](https://github.com/huggingface/datasets/blob/207be676bffe9d164740a41a883af6125edef135/src/datasets/packaged_modules/text/text.py#L23) builder implementation splits texts with `splitlines()` which splits the text on several line boundaries. Not all of them are always wanted.
**Describe the solution you'd like**
```python
if self.config.sample_by == "line":
batch_idx = 0
while True:
batch = f.read(self.config.chunksize)
if not batch:
break
batch += f.readline() # finish current line
if self.config.custom_newline is None:
batch = batch.splitlines(keepends=self.config.keep_linebreaks)
else:
batch = batch.split(self.config.custom_newline)[:-1]
pa_table = pa.Table.from_arrays([pa.array(batch)], schema=schema)
# Uncomment for debugging (will print the Arrow table size and elements)
# logger.warning(f"pa_table: {pa_table} num rows: {pa_table.num_rows}")
# logger.warning('\n'.join(str(pa_table.slice(i, 1).to_pydict()) for i in range(pa_table.num_rows)))
yield (file_idx, batch_idx), pa_table
batch_idx += 1
```
**A clear and concise description of what you want to happen.**
Creating the dataset rows with a subset of the `splitlines()` line boundaries. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3804/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3804/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1643/comments | https://api.github.com/repos/huggingface/datasets/issues/1643/events | https://github.com/huggingface/datasets/issues/1643 | 775,280,046 | MDU6SXNzdWU3NzUyODAwNDY= | 1,643 | Dataset social_bias_frames 404 | {
"avatar_url": "https://avatars.githubusercontent.com/u/7501517?v=4",
"events_url": "https://api.github.com/users/atemate/events{/privacy}",
"followers_url": "https://api.github.com/users/atemate/followers",
"following_url": "https://api.github.com/users/atemate/following{/other_user}",
"gists_url": "https://api.github.com/users/atemate/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/atemate",
"id": 7501517,
"login": "atemate",
"node_id": "MDQ6VXNlcjc1MDE1MTc=",
"organizations_url": "https://api.github.com/users/atemate/orgs",
"received_events_url": "https://api.github.com/users/atemate/received_events",
"repos_url": "https://api.github.com/users/atemate/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/atemate/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/atemate/subscriptions",
"type": "User",
"url": "https://api.github.com/users/atemate"
} | [] | closed | false | null | [] | null | [
"I see, master is already fixed in https://github.com/huggingface/datasets/commit/9e058f098a0919efd03a136b9b9c3dec5076f626"
] | "2020-12-28T08:35:34Z" | "2020-12-28T08:38:07Z" | "2020-12-28T08:38:07Z" | NONE | null | null | null | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("social_bias_frames")
...
Downloading and preparing dataset social_bias_frames/default
...
~/.pyenv/versions/3.7.6/lib/python3.7/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag)
484 )
485 elif response is not None and response.status_code == 404:
--> 486 raise FileNotFoundError("Couldn't find file at {}".format(url))
487 raise ConnectionError("Couldn't reach {}".format(url))
488
FileNotFoundError: Couldn't find file at https://homes.cs.washington.edu/~msap/social-bias-frames/SocialBiasFrames_v2.tgz
```
[Here](https://homes.cs.washington.edu/~msap/social-bias-frames/) we find button `Download data` with the correct URL for the data: https://homes.cs.washington.edu/~msap/social-bias-frames/SBIC.v2.tgz | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1643/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5655/comments | https://api.github.com/repos/huggingface/datasets/issues/5655/events | https://github.com/huggingface/datasets/pull/5655 | 1,634,030,017 | PR_kwDODunzps5MjWYy | 5,655 | Improve features decoding in to_iterable_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009691 / 0.011353 (-0.001662) | 0.006160 / 0.011008 (-0.004848) | 0.127528 / 0.038508 (0.089020) | 0.034445 / 0.023109 (0.011335) | 0.391483 / 0.275898 (0.115585) | 0.425922 / 0.323480 (0.102442) | 0.006621 / 0.007986 (-0.001365) | 0.004550 / 0.004328 (0.000221) | 0.099134 / 0.004250 (0.094884) | 0.051089 / 0.037052 (0.014037) | 0.398675 / 0.258489 (0.140186) | 0.456740 / 0.293841 (0.162899) | 0.052279 / 0.128546 (-0.076267) | 0.020878 / 0.075646 (-0.054768) | 0.414954 / 0.419271 (-0.004317) | 0.061903 / 0.043533 (0.018370) | 0.393088 / 0.255139 (0.137949) | 0.410289 / 0.283200 (0.127089) | 0.101684 / 0.141683 (-0.039998) | 1.747102 / 1.452155 (0.294947) | 1.896976 / 1.492716 (0.404260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203193 / 0.018006 (0.185187) | 0.495011 / 0.000490 (0.494521) | 0.006290 / 0.000200 (0.006090) | 0.000098 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034840 / 0.037411 (-0.002571) | 0.122529 / 0.014526 (0.108003) | 0.133870 / 0.176557 (-0.042686) | 0.207771 / 0.737135 (-0.529364) | 0.141441 / 0.296338 (-0.154897) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.604190 / 0.215209 (0.388981) | 6.040295 / 2.077655 (3.962641) | 2.405703 / 1.504120 (0.901583) | 2.062767 / 1.541195 (0.521572) | 2.079313 / 1.468490 (0.610823) | 1.240107 / 4.584777 (-3.344670) | 5.316583 / 3.745712 (1.570871) | 3.104758 / 5.269862 (-2.165103) | 2.056489 / 4.565676 (-2.509187) | 0.149060 / 0.424275 (-0.275215) | 0.014467 / 0.007607 (0.006860) | 0.736882 / 0.226044 (0.510838) | 7.324142 / 2.268929 (5.055213) | 3.048752 / 55.444624 (-52.395872) | 2.385013 / 6.876477 (-4.491463) | 2.457478 / 2.142072 (0.315405) | 1.459276 / 4.805227 (-3.345951) | 0.253882 / 6.500664 (-6.246782) | 0.076756 / 0.075469 (0.001287) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.499166 / 1.841788 (-0.342622) | 17.294165 / 8.074308 (9.219857) | 20.385668 / 10.191392 (10.194276) | 0.254633 / 0.680424 (-0.425791) | 0.026253 / 0.534201 (-0.507948) | 0.532928 / 0.579283 (-0.046355) | 0.606095 / 0.434364 (0.171731) | 0.615025 / 0.540337 (0.074687) | 0.728651 / 1.386936 (-0.658285) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009376 / 0.011353 (-0.001977) | 0.005981 / 0.011008 (-0.005027) | 0.109898 / 0.038508 (0.071390) | 0.033746 / 0.023109 (0.010637) | 0.410226 / 0.275898 (0.134328) | 0.470606 / 0.323480 (0.147126) | 0.006706 / 0.007986 (-0.001279) | 0.004482 / 0.004328 (0.000153) | 0.092280 / 0.004250 (0.088030) | 0.047988 / 0.037052 (0.010935) | 0.430628 / 0.258489 (0.172139) | 0.480668 / 0.293841 (0.186827) | 0.052099 / 0.128546 (-0.076447) | 0.018743 / 0.075646 (-0.056903) | 0.112204 / 0.419271 (-0.307068) | 0.059838 / 0.043533 (0.016305) | 0.418230 / 0.255139 (0.163091) | 0.451568 / 0.283200 (0.168368) | 0.107026 / 0.141683 (-0.034657) | 1.708111 / 1.452155 (0.255956) | 1.839268 / 1.492716 (0.346552) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229558 / 0.018006 (0.211552) | 0.488099 / 0.000490 (0.487609) | 0.004643 / 0.000200 (0.004443) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030461 / 0.037411 (-0.006951) | 0.120993 / 0.014526 (0.106467) | 0.130874 / 0.176557 (-0.045682) | 0.193550 / 0.737135 (-0.543585) | 0.138164 / 0.296338 (-0.158174) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.635709 / 0.215209 (0.420500) | 6.225112 / 2.077655 (4.147457) | 2.639584 / 1.504120 (1.135465) | 2.254487 / 1.541195 (0.713293) | 2.280478 / 1.468490 (0.811988) | 1.205712 / 4.584777 (-3.379065) | 5.367845 / 3.745712 (1.622133) | 3.020207 / 5.269862 (-2.249655) | 2.001897 / 4.565676 (-2.563779) | 0.149582 / 0.424275 (-0.274693) | 0.014867 / 0.007607 (0.007260) | 0.759050 / 0.226044 (0.533006) | 7.692969 / 2.268929 (5.424041) | 3.274009 / 55.444624 (-52.170615) | 2.635529 / 6.876477 (-4.240948) | 2.672960 / 2.142072 (0.530888) | 1.426487 / 4.805227 (-3.378740) | 0.253368 / 6.500664 (-6.247296) | 0.078650 / 0.075469 (0.003181) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.620265 / 1.841788 (-0.221523) | 17.674168 / 8.074308 (9.599860) | 21.120528 / 10.191392 (10.929136) | 0.244205 / 0.680424 (-0.436218) | 0.029646 / 0.534201 (-0.504555) | 0.510948 / 0.579283 (-0.068335) | 0.586255 / 0.434364 (0.151891) | 0.589286 / 0.540337 (0.048949) | 0.736561 / 1.386936 (-0.650375) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007778 / 0.011353 (-0.003575) | 0.005432 / 0.011008 (-0.005577) | 0.098776 / 0.038508 (0.060268) | 0.035196 / 0.023109 (0.012087) | 0.305646 / 0.275898 (0.029748) | 0.342661 / 0.323480 (0.019181) | 0.006513 / 0.007986 (-0.001472) | 0.005897 / 0.004328 (0.001568) | 0.075797 / 0.004250 (0.071547) | 0.056060 / 0.037052 (0.019007) | 0.306645 / 0.258489 (0.048156) | 0.352447 / 0.293841 (0.058606) | 0.037304 / 0.128546 (-0.091242) | 0.012514 / 0.075646 (-0.063132) | 0.334949 / 0.419271 (-0.084323) | 0.051600 / 0.043533 (0.008067) | 0.302302 / 0.255139 (0.047163) | 0.322238 / 0.283200 (0.039038) | 0.106896 / 0.141683 (-0.034787) | 1.483163 / 1.452155 (0.031008) | 1.587483 / 1.492716 (0.094767) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.292318 / 0.018006 (0.274312) | 0.541541 / 0.000490 (0.541051) | 0.008342 / 0.000200 (0.008142) | 0.000339 / 0.000054 (0.000285) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028287 / 0.037411 (-0.009124) | 0.107775 / 0.014526 (0.093250) | 0.119112 / 0.176557 (-0.057445) | 0.174002 / 0.737135 (-0.563134) | 0.126531 / 0.296338 (-0.169808) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401684 / 0.215209 (0.186475) | 4.024708 / 2.077655 (1.947053) | 1.812763 / 1.504120 (0.308643) | 1.629540 / 1.541195 (0.088345) | 1.731733 / 1.468490 (0.263243) | 0.711066 / 4.584777 (-3.873711) | 3.867499 / 3.745712 (0.121786) | 3.615968 / 5.269862 (-1.653893) | 1.876077 / 4.565676 (-2.689600) | 0.087003 / 0.424275 (-0.337272) | 0.012445 / 0.007607 (0.004838) | 0.499106 / 0.226044 (0.273061) | 4.975920 / 2.268929 (2.706992) | 2.279074 / 55.444624 (-53.165550) | 1.952311 / 6.876477 (-4.924166) | 2.167480 / 2.142072 (0.025408) | 0.855882 / 4.805227 (-3.949346) | 0.171378 / 6.500664 (-6.329287) | 0.066731 / 0.075469 (-0.008738) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.184226 / 1.841788 (-0.657561) | 15.383396 / 8.074308 (7.309088) | 15.069783 / 10.191392 (4.878391) | 0.161489 / 0.680424 (-0.518935) | 0.017763 / 0.534201 (-0.516438) | 0.427103 / 0.579283 (-0.152180) | 0.434295 / 0.434364 (-0.000069) | 0.496848 / 0.540337 (-0.043489) | 0.592572 / 1.386936 (-0.794364) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008014 / 0.011353 (-0.003339) | 0.005607 / 0.011008 (-0.005401) | 0.076826 / 0.038508 (0.038318) | 0.035283 / 0.023109 (0.012174) | 0.347809 / 0.275898 (0.071911) | 0.382482 / 0.323480 (0.059003) | 0.006276 / 0.007986 (-0.001709) | 0.005978 / 0.004328 (0.001650) | 0.074938 / 0.004250 (0.070687) | 0.054323 / 0.037052 (0.017271) | 0.344027 / 0.258489 (0.085538) | 0.397623 / 0.293841 (0.103783) | 0.037851 / 0.128546 (-0.090695) | 0.012649 / 0.075646 (-0.062997) | 0.086169 / 0.419271 (-0.333103) | 0.051510 / 0.043533 (0.007977) | 0.341112 / 0.255139 (0.085973) | 0.357957 / 0.283200 (0.074757) | 0.110949 / 0.141683 (-0.030734) | 1.479573 / 1.452155 (0.027419) | 1.578572 / 1.492716 (0.085855) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.310678 / 0.018006 (0.292672) | 0.525504 / 0.000490 (0.525015) | 0.000447 / 0.000200 (0.000247) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031262 / 0.037411 (-0.006149) | 0.113801 / 0.014526 (0.099275) | 0.124967 / 0.176557 (-0.051590) | 0.175226 / 0.737135 (-0.561909) | 0.129377 / 0.296338 (-0.166962) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420672 / 0.215209 (0.205463) | 4.181337 / 2.077655 (2.103682) | 1.985524 / 1.504120 (0.481404) | 1.803468 / 1.541195 (0.262273) | 1.952915 / 1.468490 (0.484425) | 0.710928 / 4.584777 (-3.873849) | 3.886245 / 3.745712 (0.140533) | 3.737837 / 5.269862 (-1.532024) | 1.806859 / 4.565676 (-2.758818) | 0.088461 / 0.424275 (-0.335814) | 0.013125 / 0.007607 (0.005518) | 0.522410 / 0.226044 (0.296365) | 5.232591 / 2.268929 (2.963663) | 2.451188 / 55.444624 (-52.993437) | 2.127725 / 6.876477 (-4.748751) | 2.232859 / 2.142072 (0.090786) | 0.854257 / 4.805227 (-3.950970) | 0.171004 / 6.500664 (-6.329661) | 0.066724 / 0.075469 (-0.008746) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257700 / 1.841788 (-0.584088) | 15.738605 / 8.074308 (7.664297) | 15.021698 / 10.191392 (4.830306) | 0.147422 / 0.680424 (-0.533002) | 0.017928 / 0.534201 (-0.516273) | 0.428121 / 0.579283 (-0.151162) | 0.432056 / 0.434364 (-0.002308) | 0.498318 / 0.540337 (-0.042020) | 0.591040 / 1.386936 (-0.795896) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007014 / 0.011353 (-0.004339) | 0.004792 / 0.011008 (-0.006216) | 0.099822 / 0.038508 (0.061314) | 0.029333 / 0.023109 (0.006224) | 0.306453 / 0.275898 (0.030555) | 0.344598 / 0.323480 (0.021118) | 0.005121 / 0.007986 (-0.002865) | 0.004850 / 0.004328 (0.000522) | 0.076668 / 0.004250 (0.072417) | 0.039980 / 0.037052 (0.002927) | 0.312276 / 0.258489 (0.053787) | 0.354722 / 0.293841 (0.060881) | 0.031653 / 0.128546 (-0.096893) | 0.011743 / 0.075646 (-0.063903) | 0.322998 / 0.419271 (-0.096274) | 0.042813 / 0.043533 (-0.000720) | 0.308855 / 0.255139 (0.053716) | 0.332650 / 0.283200 (0.049451) | 0.087155 / 0.141683 (-0.054528) | 1.454946 / 1.452155 (0.002791) | 1.550589 / 1.492716 (0.057873) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.192921 / 0.018006 (0.174914) | 0.411155 / 0.000490 (0.410666) | 0.004779 / 0.000200 (0.004579) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024462 / 0.037411 (-0.012950) | 0.100320 / 0.014526 (0.085794) | 0.105509 / 0.176557 (-0.071048) | 0.168533 / 0.737135 (-0.568602) | 0.110018 / 0.296338 (-0.186321) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415025 / 0.215209 (0.199816) | 4.144583 / 2.077655 (2.066928) | 1.871627 / 1.504120 (0.367507) | 1.671638 / 1.541195 (0.130443) | 1.734458 / 1.468490 (0.265968) | 0.693435 / 4.584777 (-3.891342) | 3.487999 / 3.745712 (-0.257713) | 3.196553 / 5.269862 (-2.073308) | 1.628499 / 4.565676 (-2.937178) | 0.082999 / 0.424275 (-0.341276) | 0.012822 / 0.007607 (0.005215) | 0.514904 / 0.226044 (0.288860) | 5.157525 / 2.268929 (2.888596) | 2.313093 / 55.444624 (-53.131531) | 1.968335 / 6.876477 (-4.908142) | 2.083462 / 2.142072 (-0.058610) | 0.804485 / 4.805227 (-4.000742) | 0.152290 / 6.500664 (-6.348374) | 0.066813 / 0.075469 (-0.008656) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.210370 / 1.841788 (-0.631418) | 14.261779 / 8.074308 (6.187471) | 14.268121 / 10.191392 (4.076729) | 0.149216 / 0.680424 (-0.531207) | 0.016529 / 0.534201 (-0.517672) | 0.378814 / 0.579283 (-0.200469) | 0.386304 / 0.434364 (-0.048060) | 0.439653 / 0.540337 (-0.100684) | 0.523658 / 1.386936 (-0.863278) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006979 / 0.011353 (-0.004374) | 0.004718 / 0.011008 (-0.006290) | 0.077023 / 0.038508 (0.038514) | 0.029080 / 0.023109 (0.005971) | 0.343145 / 0.275898 (0.067247) | 0.380633 / 0.323480 (0.057153) | 0.006057 / 0.007986 (-0.001928) | 0.003541 / 0.004328 (-0.000788) | 0.075773 / 0.004250 (0.071523) | 0.039112 / 0.037052 (0.002060) | 0.342355 / 0.258489 (0.083866) | 0.386002 / 0.293841 (0.092161) | 0.033238 / 0.128546 (-0.095308) | 0.011696 / 0.075646 (-0.063950) | 0.086178 / 0.419271 (-0.333093) | 0.045219 / 0.043533 (0.001686) | 0.360710 / 0.255139 (0.105571) | 0.367490 / 0.283200 (0.084290) | 0.093041 / 0.141683 (-0.048642) | 1.523670 / 1.452155 (0.071516) | 1.595280 / 1.492716 (0.102564) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235888 / 0.018006 (0.217882) | 0.410205 / 0.000490 (0.409715) | 0.000405 / 0.000200 (0.000205) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025752 / 0.037411 (-0.011659) | 0.103343 / 0.014526 (0.088818) | 0.108722 / 0.176557 (-0.067834) | 0.159241 / 0.737135 (-0.577894) | 0.113684 / 0.296338 (-0.182654) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441809 / 0.215209 (0.226600) | 4.410893 / 2.077655 (2.333238) | 2.104061 / 1.504120 (0.599941) | 1.854016 / 1.541195 (0.312821) | 1.947100 / 1.468490 (0.478610) | 0.697682 / 4.584777 (-3.887095) | 3.467513 / 3.745712 (-0.278199) | 1.911603 / 5.269862 (-3.358258) | 1.187479 / 4.565676 (-3.378197) | 0.083153 / 0.424275 (-0.341122) | 0.012651 / 0.007607 (0.005044) | 0.542081 / 0.226044 (0.316036) | 5.444622 / 2.268929 (3.175693) | 2.524236 / 55.444624 (-52.920388) | 2.190463 / 6.876477 (-4.686014) | 2.265764 / 2.142072 (0.123691) | 0.810778 / 4.805227 (-3.994450) | 0.152459 / 6.500664 (-6.348205) | 0.067815 / 0.075469 (-0.007654) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.334388 / 1.841788 (-0.507400) | 14.640459 / 8.074308 (6.566151) | 14.714874 / 10.191392 (4.523482) | 0.153479 / 0.680424 (-0.526945) | 0.016709 / 0.534201 (-0.517492) | 0.379427 / 0.579283 (-0.199856) | 0.391602 / 0.434364 (-0.042762) | 0.438297 / 0.540337 (-0.102041) | 0.524170 / 1.386936 (-0.862766) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-21T14:18:09Z" | "2023-03-23T13:19:27Z" | "2023-03-23T13:12:25Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5655.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5655",
"merged_at": "2023-03-23T13:12:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5655.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5655"
} | Following discussion at https://github.com/huggingface/datasets/pull/5589
Right now `to_iterable_dataset` on images/audio hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images/audios unnecessarily).
I fixed it by providing a generator that yields undecoded examples | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5655/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5276 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5276/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5276/comments | https://api.github.com/repos/huggingface/datasets/issues/5276/events | https://github.com/huggingface/datasets/issues/5276 | 1,459,363,442 | I_kwDODunzps5W_B5y | 5,276 | Bug in downloading common_voice data and snall chunk of it to one's own hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/48530104?v=4",
"events_url": "https://api.github.com/users/capsabogdan/events{/privacy}",
"followers_url": "https://api.github.com/users/capsabogdan/followers",
"following_url": "https://api.github.com/users/capsabogdan/following{/other_user}",
"gists_url": "https://api.github.com/users/capsabogdan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/capsabogdan",
"id": 48530104,
"login": "capsabogdan",
"node_id": "MDQ6VXNlcjQ4NTMwMTA0",
"organizations_url": "https://api.github.com/users/capsabogdan/orgs",
"received_events_url": "https://api.github.com/users/capsabogdan/received_events",
"repos_url": "https://api.github.com/users/capsabogdan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/capsabogdan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/capsabogdan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/capsabogdan"
} | [] | closed | false | null | [] | null | [
"Sounds like one of the file is not a valid one, can you make sure you uploaded valid mp3 files ?",
"Well I just sharded the original commonVoice dataset and pushed a small chunk of it in a private rep\n\nWhat did go wrong?\n\nHolen Sie sich Outlook für iOS<https://aka.ms/o0ukef>\n________________________________\nVon: Quentin Lhoest ***@***.***>\nGesendet: Tuesday, November 22, 2022 3:03:40 PM\nAn: huggingface/datasets ***@***.***>\nCc: capsabogdan ***@***.***>; Author ***@***.***>\nBetreff: Re: [huggingface/datasets] Bug in downloading common_voice data and snall chunk of it to one's own hub (Issue #5276)\n\n\nSounds like one of the file is not a valid one, can you make sure you uploaded valid mp3 files ?\n\n—\nReply to this email directly, view it on GitHub<https://github.com/huggingface/datasets/issues/5276#issuecomment-1323727434>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/ALSIFOAPAL2V4TBJTSPMAULWJTHDZANCNFSM6AAAAAASHQJ63U>.\nYou are receiving this because you authored the thread.Message ID: ***@***.***>\n",
"It should be all good then !\r\nCould you share a link to your repository for me to investigate what went wrong ?",
"https://huggingface.co/datasets/DTU54DL/common-voice-test16k\n\nAm Di., 22. Nov. 2022 um 16:43 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> It should be all good then !\n> Could you share a link to your repository for me to investigate what went\n> wrong ?\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1323876682>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOEUJRZWXAM7DYA5VJDWJTS3NANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you authored the thread.Message ID:\n> ***@***.***>\n>\n",
"I see ! This is a bug with MP3 files.\r\n\r\nWhen we store audio data in parquet, we store the bytes and the file name. From the file name extension we know if it's a WAV, an MP3 or else. But here it looks like the paths are all None.\r\n\r\nIt looks like it comes from here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/7feeb5648a63b6135a8259dedc3b1e19185ee4c7/src/datasets/features/audio.py#L212\r\n\r\nCc @polinaeterna maybe we should simply put the file name instead of None values ?",
"@lhoestq I remember we wanted to avoid storing redundant data but maybe it's not that crucial indeed to store one more string value. \r\nOr we can store paths only for mp3s, considering that for other formats we don't have such a problem with reading from bytes without format specified. ",
"It doesn't cost much to always store the file name IMO",
"thanks for the help!\n\ncan I do anything on my side? we are doing a DL project and we need the\ndata really quick.\n\nthanks\nbogdan\n\n> Message ID: ***@***.***>\n>\n",
"I opened a pull requests here: https://github.com/huggingface/datasets/pull/5285, we'll do a new release soon with this fix.\r\n\r\nOtherwise if you're really in a hurry you can install `datasets` from this PR",
"[image: image.png]\n\n> Message ID: ***@***.***>\n>\n",
"any idea on what's going wrong here?\n\nthanks\n\nAm So., 27. Nov. 2022 um 13:53 Uhr schrieb Bogdan Capsa <\n***@***.***>:\n\n> [image: image.png]\n>\n>> Message ID: ***@***.***>\n>>\n>\n",
"hi @capsabogdan! \r\ncould you please share more specifically what problem do you have now?",
"I have attached this screenshot above . can u pls help? So can not pip from pull request\r\n\r\n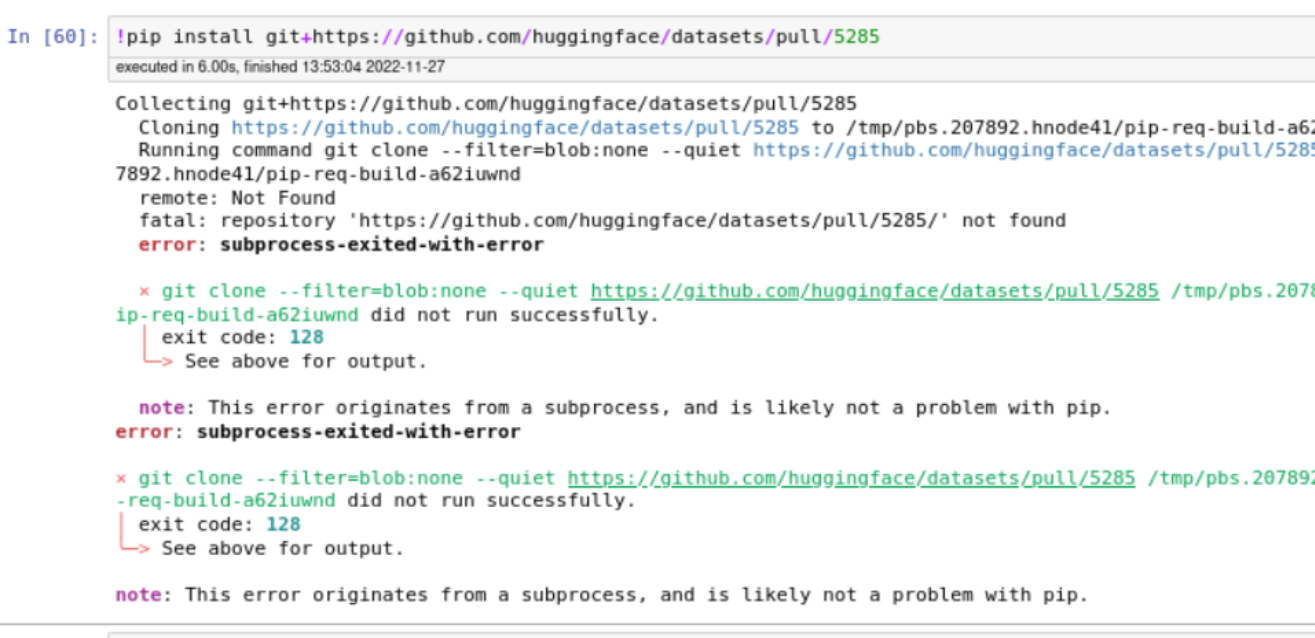\r\n",
"The pull request has been merged on `main`.\r\nYou can install `datasets` from `main` using\r\n```\r\npip install git+https://github.com/huggingface/datasets.git\r\n```",
"I've tried to load this dataset DTU54DL/common-voice-test16k, but am\ngetting the same error.\n\nSo the bug fix will fix only if I upload a new dataset, or also loading\npreviously uploaded datasets?\n\nthanks\n\nAm Mo., 28. Nov. 2022 um 19:51 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> The pull request has been merged on main.\n> You can install datasets from main using\n>\n> pip install git+https://github.com/huggingface/datasets.git\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1329587334>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOCNYYIGHM2EX3ZIO6DWKT5MXANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n",
"> So the bug fix will fix only if I upload a new dataset, or also loading\r\npreviously uploaded datasets?\r\n\r\nYou have to reupload the dataset, sorry for the inconvenience",
"thank you so much for the help! works like a charm!\n\nAm Di., 29. Nov. 2022 um 12:15 Uhr schrieb Quentin Lhoest <\n***@***.***>:\n\n> So the bug fix will fix only if I upload a new dataset, or also loading\n> previously uploaded datasets?\n>\n> You have to reupload the dataset, sorry for the inconvenience\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5276#issuecomment-1330468393>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ALSIFOBKEFZO57BAKY4IGW3WKXQUZANCNFSM6AAAAAASHQJ63U>\n> .\n> You are receiving this because you were mentioned.Message ID:\n> ***@***.***>\n>\n"
] | "2022-11-22T08:17:53Z" | "2023-07-21T14:33:10Z" | "2023-07-21T14:33:10Z" | NONE | null | null | null | ### Describe the bug
I'm trying to load the common voice dataset. Currently there is no implementation to download just par tof the data, and I need just one part of it, without downloading the entire dataset
Help please?

### Steps to reproduce the bug
So here is what I have done:
1. Download common_voice data
2. Trim part of it and publish it to my own repo.
3. Download data from my own repo, but am getting this error.
### Expected behavior
There shouldn't be an error in downloading part of the data and publishing it to one's own repo
### Environment info
common_voice 11 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5276/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5276/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6023 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6023/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6023/comments | https://api.github.com/repos/huggingface/datasets/issues/6023/events | https://github.com/huggingface/datasets/pull/6023 | 1,801,272,420 | PR_kwDODunzps5VU7EG | 6,023 | Fix `ClassLabel` min max check for `None` values | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007108 / 0.011353 (-0.004245) | 0.004446 / 0.011008 (-0.006562) | 0.084013 / 0.038508 (0.045505) | 0.084271 / 0.023109 (0.061162) | 0.324496 / 0.275898 (0.048598) | 0.347783 / 0.323480 (0.024303) | 0.004382 / 0.007986 (-0.003604) | 0.005200 / 0.004328 (0.000872) | 0.065117 / 0.004250 (0.060866) | 0.063368 / 0.037052 (0.026316) | 0.328731 / 0.258489 (0.070242) | 0.356676 / 0.293841 (0.062835) | 0.031155 / 0.128546 (-0.097392) | 0.008672 / 0.075646 (-0.066975) | 0.287573 / 0.419271 (-0.131698) | 0.053692 / 0.043533 (0.010160) | 0.308796 / 0.255139 (0.053657) | 0.330521 / 0.283200 (0.047321) | 0.025010 / 0.141683 (-0.116672) | 1.498968 / 1.452155 (0.046813) | 1.552096 / 1.492716 (0.059380) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.263580 / 0.018006 (0.245574) | 0.559765 / 0.000490 (0.559275) | 0.003450 / 0.000200 (0.003250) | 0.000079 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029403 / 0.037411 (-0.008008) | 0.088154 / 0.014526 (0.073628) | 0.100372 / 0.176557 (-0.076185) | 0.157777 / 0.737135 (-0.579359) | 0.102273 / 0.296338 (-0.194066) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.387027 / 0.215209 (0.171818) | 3.854260 / 2.077655 (1.776605) | 1.875159 / 1.504120 (0.371039) | 1.703734 / 1.541195 (0.162539) | 1.814305 / 1.468490 (0.345815) | 0.482524 / 4.584777 (-4.102253) | 3.463602 / 3.745712 (-0.282110) | 4.004766 / 5.269862 (-1.265095) | 2.406751 / 4.565676 (-2.158925) | 0.057069 / 0.424275 (-0.367206) | 0.007448 / 0.007607 (-0.000159) | 0.465801 / 0.226044 (0.239757) | 4.636700 / 2.268929 (2.367771) | 2.329475 / 55.444624 (-53.115150) | 1.998330 / 6.876477 (-4.878146) | 2.264617 / 2.142072 (0.122544) | 0.577998 / 4.805227 (-4.227230) | 0.130846 / 6.500664 (-6.369818) | 0.059713 / 0.075469 (-0.015756) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.275931 / 1.841788 (-0.565857) | 20.396288 / 8.074308 (12.321980) | 13.875242 / 10.191392 (3.683850) | 0.164367 / 0.680424 (-0.516057) | 0.018573 / 0.534201 (-0.515628) | 0.397516 / 0.579283 (-0.181767) | 0.398977 / 0.434364 (-0.035387) | 0.462386 / 0.540337 (-0.077951) | 0.610129 / 1.386936 (-0.776807) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006912 / 0.011353 (-0.004441) | 0.004212 / 0.011008 (-0.006797) | 0.065707 / 0.038508 (0.027199) | 0.090435 / 0.023109 (0.067325) | 0.380539 / 0.275898 (0.104641) | 0.412692 / 0.323480 (0.089212) | 0.005545 / 0.007986 (-0.002441) | 0.003657 / 0.004328 (-0.000672) | 0.065380 / 0.004250 (0.061130) | 0.062901 / 0.037052 (0.025848) | 0.385931 / 0.258489 (0.127442) | 0.416272 / 0.293841 (0.122431) | 0.031974 / 0.128546 (-0.096572) | 0.008783 / 0.075646 (-0.066863) | 0.071424 / 0.419271 (-0.347847) | 0.049454 / 0.043533 (0.005921) | 0.374231 / 0.255139 (0.119092) | 0.386530 / 0.283200 (0.103331) | 0.025404 / 0.141683 (-0.116279) | 1.469869 / 1.452155 (0.017715) | 1.548629 / 1.492716 (0.055913) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218413 / 0.018006 (0.200406) | 0.573863 / 0.000490 (0.573373) | 0.004156 / 0.000200 (0.003956) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032610 / 0.037411 (-0.004801) | 0.088270 / 0.014526 (0.073744) | 0.106821 / 0.176557 (-0.069735) | 0.164498 / 0.737135 (-0.572638) | 0.106881 / 0.296338 (-0.189457) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433730 / 0.215209 (0.218520) | 4.323902 / 2.077655 (2.246247) | 2.308607 / 1.504120 (0.804487) | 2.138888 / 1.541195 (0.597693) | 2.246760 / 1.468490 (0.778269) | 0.486863 / 4.584777 (-4.097914) | 3.561826 / 3.745712 (-0.183886) | 5.592685 / 5.269862 (0.322824) | 3.318560 / 4.565676 (-1.247116) | 0.057348 / 0.424275 (-0.366927) | 0.007434 / 0.007607 (-0.000174) | 0.506767 / 0.226044 (0.280723) | 5.083097 / 2.268929 (2.814168) | 2.780618 / 55.444624 (-52.664006) | 2.456924 / 6.876477 (-4.419553) | 2.564184 / 2.142072 (0.422112) | 0.580693 / 4.805227 (-4.224534) | 0.134471 / 6.500664 (-6.366194) | 0.062883 / 0.075469 (-0.012586) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.346618 / 1.841788 (-0.495169) | 20.547998 / 8.074308 (12.473690) | 14.404159 / 10.191392 (4.212767) | 0.176612 / 0.680424 (-0.503812) | 0.018372 / 0.534201 (-0.515829) | 0.395636 / 0.579283 (-0.183647) | 0.410661 / 0.434364 (-0.023703) | 0.468782 / 0.540337 (-0.071555) | 0.637476 / 1.386936 (-0.749460) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009896 / 0.011353 (-0.001457) | 0.004658 / 0.011008 (-0.006351) | 0.101185 / 0.038508 (0.062677) | 0.075480 / 0.023109 (0.052371) | 0.410620 / 0.275898 (0.134722) | 0.470639 / 0.323480 (0.147159) | 0.007042 / 0.007986 (-0.000943) | 0.003909 / 0.004328 (-0.000419) | 0.079676 / 0.004250 (0.075425) | 0.066921 / 0.037052 (0.029869) | 0.423624 / 0.258489 (0.165135) | 0.473008 / 0.293841 (0.179167) | 0.048492 / 0.128546 (-0.080054) | 0.012833 / 0.075646 (-0.062813) | 0.335286 / 0.419271 (-0.083985) | 0.083506 / 0.043533 (0.039973) | 0.401918 / 0.255139 (0.146779) | 0.467975 / 0.283200 (0.184775) | 0.050025 / 0.141683 (-0.091658) | 1.679392 / 1.452155 (0.227237) | 1.852812 / 1.492716 (0.360095) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.248067 / 0.018006 (0.230061) | 0.584818 / 0.000490 (0.584328) | 0.021558 / 0.000200 (0.021358) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028572 / 0.037411 (-0.008839) | 0.097212 / 0.014526 (0.082686) | 0.121675 / 0.176557 (-0.054881) | 0.186597 / 0.737135 (-0.550538) | 0.122285 / 0.296338 (-0.174053) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.586279 / 0.215209 (0.371070) | 5.634402 / 2.077655 (3.556747) | 2.560648 / 1.504120 (1.056528) | 2.288796 / 1.541195 (0.747601) | 2.402580 / 1.468490 (0.934090) | 0.801453 / 4.584777 (-3.783324) | 5.036654 / 3.745712 (1.290942) | 8.319972 / 5.269862 (3.050110) | 4.665620 / 4.565676 (0.099944) | 0.107292 / 0.424275 (-0.316983) | 0.009206 / 0.007607 (0.001599) | 0.766505 / 0.226044 (0.540461) | 7.333784 / 2.268929 (5.064856) | 3.601875 / 55.444624 (-51.842749) | 2.886388 / 6.876477 (-3.990089) | 3.231797 / 2.142072 (1.089725) | 1.179509 / 4.805227 (-3.625718) | 0.224656 / 6.500664 (-6.276008) | 0.084749 / 0.075469 (0.009280) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.772345 / 1.841788 (-0.069443) | 24.138788 / 8.074308 (16.064480) | 20.712416 / 10.191392 (10.521024) | 0.254655 / 0.680424 (-0.425769) | 0.028858 / 0.534201 (-0.505343) | 0.499314 / 0.579283 (-0.079969) | 0.605797 / 0.434364 (0.171433) | 0.567628 / 0.540337 (0.027290) | 0.752288 / 1.386936 (-0.634648) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010134 / 0.011353 (-0.001219) | 0.004630 / 0.011008 (-0.006378) | 0.082282 / 0.038508 (0.043774) | 0.081722 / 0.023109 (0.058613) | 0.465018 / 0.275898 (0.189120) | 0.516392 / 0.323480 (0.192912) | 0.006618 / 0.007986 (-0.001368) | 0.004310 / 0.004328 (-0.000018) | 0.078990 / 0.004250 (0.074739) | 0.077729 / 0.037052 (0.040677) | 0.464892 / 0.258489 (0.206403) | 0.510551 / 0.293841 (0.216710) | 0.050750 / 0.128546 (-0.077796) | 0.014402 / 0.075646 (-0.061244) | 0.092587 / 0.419271 (-0.326685) | 0.074769 / 0.043533 (0.031237) | 0.468591 / 0.255139 (0.213452) | 0.508138 / 0.283200 (0.224938) | 0.047774 / 0.141683 (-0.093909) | 1.798354 / 1.452155 (0.346199) | 1.851431 / 1.492716 (0.358714) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.282528 / 0.018006 (0.264522) | 0.588286 / 0.000490 (0.587797) | 0.004892 / 0.000200 (0.004692) | 0.000136 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037048 / 0.037411 (-0.000364) | 0.101513 / 0.014526 (0.086987) | 0.133238 / 0.176557 (-0.043319) | 0.234799 / 0.737135 (-0.502336) | 0.120636 / 0.296338 (-0.175703) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.615377 / 0.215209 (0.400168) | 6.225717 / 2.077655 (4.148062) | 2.974137 / 1.504120 (1.470018) | 2.642168 / 1.541195 (1.100973) | 2.706051 / 1.468490 (1.237561) | 0.837171 / 4.584777 (-3.747606) | 5.143368 / 3.745712 (1.397656) | 4.560241 / 5.269862 (-0.709621) | 2.838375 / 4.565676 (-1.727301) | 0.092505 / 0.424275 (-0.331770) | 0.008962 / 0.007607 (0.001355) | 0.726361 / 0.226044 (0.500317) | 7.323998 / 2.268929 (5.055070) | 3.650531 / 55.444624 (-51.794094) | 2.960886 / 6.876477 (-3.915591) | 3.003889 / 2.142072 (0.861816) | 0.979264 / 4.805227 (-3.825963) | 0.204531 / 6.500664 (-6.296133) | 0.078285 / 0.075469 (0.002816) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.774225 / 1.841788 (-0.067563) | 26.399536 / 8.074308 (18.325228) | 22.312890 / 10.191392 (12.121498) | 0.244651 / 0.680424 (-0.435773) | 0.026950 / 0.534201 (-0.507251) | 0.493037 / 0.579283 (-0.086246) | 0.620399 / 0.434364 (0.186036) | 0.748985 / 0.540337 (0.208648) | 0.799766 / 1.386936 (-0.587170) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-12T15:46:12Z" | "2023-07-12T16:29:26Z" | "2023-07-12T16:18:04Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6023.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6023",
"merged_at": "2023-07-12T16:18:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6023.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6023"
} | Fix #6022 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6023/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6023/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3135 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3135/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3135/comments | https://api.github.com/repos/huggingface/datasets/issues/3135/events | https://github.com/huggingface/datasets/issues/3135 | 1,033,294,299 | I_kwDODunzps49ltHb | 3,135 | Make inspect.get_dataset_config_names always return a non-empty list of configs | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @severo, I guess this issue requests not only to be able to access the configuration name (by using `inspect.get_dataset_config_names`), but the configuration itself as well (I mean you use the name to get the configuration afterwards, maybe using `builder_cls.builder_configs`), is this right?",
"Yes, maybe the issue could be reformulated. As a user, I want to avoid having to manage special cases:\r\n- I want to be able to get the names of a dataset's configs, and use them in the rest of the API (get the data, get the split names, etc).\r\n- I don't want to have to manage datasets with named configs (`glue`) differently from datasets without named configs (`acronym_identification`, `Check/region_1`)"
] | "2021-10-22T08:02:50Z" | "2021-10-28T05:44:49Z" | "2021-10-28T05:44:49Z" | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, some datasets have a configuration, while others don't. It would be simpler for the user to always have configuration names to refer to
**Describe the solution you'd like**
In that sense inspect.get_dataset_config_names should always return at least one configuration name, be it `default` or `Check___region_1` (for community datasets like `Check/region_1`).
https://github.com/huggingface/datasets/blob/c5747a5e1dde2670b7f2ca6e79e2ffd99dff85af/src/datasets/inspect.py#L161
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3135/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3135/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4018 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4018/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4018/comments | https://api.github.com/repos/huggingface/datasets/issues/4018/events | https://github.com/huggingface/datasets/pull/4018 | 1,180,622,816 | PR_kwDODunzps41Aj7g | 4,018 | Replace yelp_review_full data url | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-25T10:37:18Z" | "2022-03-25T15:01:02Z" | "2022-03-25T14:56:10Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4018.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4018",
"merged_at": "2022-03-25T14:56:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4018.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4018"
} | I replaced the Google Drive URL of the Yelp review dataset by the FastAI one, since we've had some issues with Google Drive.
Close https://github.com/huggingface/datasets/issues/4005 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4018/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4018/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2125 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2125/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2125/comments | https://api.github.com/repos/huggingface/datasets/issues/2125/events | https://github.com/huggingface/datasets/issues/2125 | 842,690,570 | MDU6SXNzdWU4NDI2OTA1NzA= | 2,125 | Is dataset timit_asr broken? | {
"avatar_url": "https://avatars.githubusercontent.com/u/42398050?v=4",
"events_url": "https://api.github.com/users/kosuke-kitahara/events{/privacy}",
"followers_url": "https://api.github.com/users/kosuke-kitahara/followers",
"following_url": "https://api.github.com/users/kosuke-kitahara/following{/other_user}",
"gists_url": "https://api.github.com/users/kosuke-kitahara/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kosuke-kitahara",
"id": 42398050,
"login": "kosuke-kitahara",
"node_id": "MDQ6VXNlcjQyMzk4MDUw",
"organizations_url": "https://api.github.com/users/kosuke-kitahara/orgs",
"received_events_url": "https://api.github.com/users/kosuke-kitahara/received_events",
"repos_url": "https://api.github.com/users/kosuke-kitahara/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kosuke-kitahara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kosuke-kitahara/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kosuke-kitahara"
} | [] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthanks for the report, but this is a duplicate of #2052. ",
"@mariosasko \r\nThank you for your quick response! Following #2052, I've fixed the problem."
] | "2021-03-28T08:30:18Z" | "2021-03-28T12:29:25Z" | "2021-03-28T12:29:25Z" | NONE | null | null | null | Using `timit_asr` dataset, I saw all records are the same.
``` python
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit['train'].remove_columns(["file", "phonetic_detail", "word_detail", "dialect_region", "id",
"sentence_type", "speaker_id"]), num_examples=20)
```
`output`
<img width="312" alt="Screen Shot 2021-03-28 at 17 29 04" src="https://user-images.githubusercontent.com/42398050/112746646-21acee80-8feb-11eb-84f3-dbb5d4269724.png">
I double-checked it [here](https://huggingface.co/datasets/viewer/), and met the same problem.
<img width="1374" alt="Screen Shot 2021-03-28 at 17 32 07" src="https://user-images.githubusercontent.com/42398050/112746698-9bdd7300-8feb-11eb-97ed-5babead385f4.png">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2125/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2125/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5303 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5303/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5303/comments | https://api.github.com/repos/huggingface/datasets/issues/5303/events | https://github.com/huggingface/datasets/pull/5303 | 1,464,837,251 | PR_kwDODunzps5DuVTa | 5,303 | Skip dataset verifications by default | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"100% agree that the checksum verification is overkill and not super useful. But I think this PR would also disable the check on num_examples no ?\r\n \r\nAs a user I would like to know if the dataset I'm loading changed significantly.\r\nAnd I also think it can be useful to make sure the metadata are up to date.\r\n\r\nWhat do you think ?\r\n\r\nWe could have a default `ignore_verifications=\"ignore_checksums\"`",
"> We could have a default `ignore_verifications=\"ignore_checksums\"`\r\n\r\nAccepting multiple types (booleans and strings) at the same time is not the best design. Maybe we could define an enum for this parameter?",
"Yes an enum sounds good !",
"so we can have three verification levels, - smth like \"ignore_all\" (to skip both checksums and all other info like num_examples verification), \"ignore_checksums\" (to skip only checksums verification), and \"verify_all\" (to perform all verification)?\r\nand deprecate `ignore_verifications` param.\r\n\r\n@mariosasko if you're not going to work on this PR in the coming days, I can take over it if you want (this PR will help me with [this issue](https://github.com/huggingface/datasets/issues/5315), not super urgent though).",
"Okay, I propose deprecating `ignore_verifications` in favor of `verification_mode` (`load_dataset` already has `download_mode`; some other projects use this name for verification control). `verification_mode` would accept the following enum (or strings in the same manner as `download_mode` does):\r\n\r\n```python\r\nclass VerificationMode(enum.Enum):\r\n FULL = \"full\" # runs all verification checks \r\n BASIC = \"basic\" # default, runs only the cheap ones (skips the checksum check)\r\n NONE = \"none\" # skips all the checks\r\n```\r\n\r\nWDTY?",
"(copy paste from my message on slack)\r\n\r\nWhat do you think of a config variable in config.py to switch from one verification mode to another ? This way we don’t deprecate anything\r\n\r\nMany users are familiar with ignore_verifications=True, it might be overkill to deprecate it",
"@lhoestq So we have \"basic\" verification mode in `config.py` and continue to have `False` as a default \r\nvalue for `ignore_verifications`? That way running all verifications including checksums would not be possible without switching the config var, right? \r\n\r\nI like having a `VerificationMode` enum because it's aligned with `DownloadMode` and sounds more natural to me (`ignore_verifications` feels a bit semantically reverted but this is probably just my feeling) and it's flexible (no need to worry about `config.py`, I'm not sure that users even know it exists, wdyt?).\r\n\r\nThe usage point seems also valid to me, but cases when users are stuck with NonMatchingX errors also happen from time to time and to figure out what's wrong is non-trivial here. \r\n\r\nAs a note aside - I suggest to add instructions to the NonMatchingX error message (how to use `ignore_verifications` / `verification_mode`), this would save users who don't know about this param a lot of time.",
"Ok I see. I'm fine with the new parameter then (even though I had a small pref for the config variable) :)",
"I like the idea of an enum and the `verification_mode` parameter. \r\n\r\nIn relation with the config parameter, we could additionally add a `DEFAULT_VERIFICATION_MODE`, maybe only if users require it. Note that until now there wasn't any config parameter for a default `ignore_verifications` value: I guess people are explicitly passing `ignore_verifications=True`...\r\n\r\nAs a note aside, I like the suggestion by @polinaeterna: we could give actionable messages when verifying checksums. This could be done in other PR.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012891 / 0.011353 (0.001538) | 0.006474 / 0.011008 (-0.004535) | 0.144038 / 0.038508 (0.105530) | 0.036151 / 0.023109 (0.013042) | 0.404366 / 0.275898 (0.128468) | 0.479988 / 0.323480 (0.156508) | 0.010219 / 0.007986 (0.002233) | 0.005319 / 0.004328 (0.000990) | 0.099705 / 0.004250 (0.095455) | 0.046639 / 0.037052 (0.009586) | 0.398997 / 0.258489 (0.140508) | 0.478431 / 0.293841 (0.184590) | 0.069125 / 0.128546 (-0.059421) | 0.019603 / 0.075646 (-0.056043) | 0.400829 / 0.419271 (-0.018443) | 0.066549 / 0.043533 (0.023016) | 0.398343 / 0.255139 (0.143204) | 0.417928 / 0.283200 (0.134728) | 0.121124 / 0.141683 (-0.020559) | 1.751513 / 1.452155 (0.299358) | 1.821239 / 1.492716 (0.328523) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.251603 / 0.018006 (0.233597) | 0.579916 / 0.000490 (0.579427) | 0.003257 / 0.000200 (0.003058) | 0.000109 / 0.000054 (0.000054) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031502 / 0.037411 (-0.005909) | 0.134688 / 0.014526 (0.120162) | 0.152306 / 0.176557 (-0.024251) | 0.198943 / 0.737135 (-0.538192) | 0.142551 / 0.296338 (-0.153788) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.634672 / 0.215209 (0.419463) | 6.370215 / 2.077655 (4.292561) | 2.548123 / 1.504120 (1.044003) | 2.184263 / 1.541195 (0.643069) | 2.239026 / 1.468490 (0.770536) | 1.233340 / 4.584777 (-3.351437) | 5.791824 / 3.745712 (2.046112) | 5.093032 / 5.269862 (-0.176830) | 2.849833 / 4.565676 (-1.715844) | 0.143787 / 0.424275 (-0.280488) | 0.015279 / 0.007607 (0.007672) | 0.757984 / 0.226044 (0.531939) | 7.883604 / 2.268929 (5.614675) | 3.321591 / 55.444624 (-52.123033) | 2.671777 / 6.876477 (-4.204700) | 2.685215 / 2.142072 (0.543142) | 1.546709 / 4.805227 (-3.258519) | 0.247186 / 6.500664 (-6.253478) | 0.085117 / 0.075469 (0.009648) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.679809 / 1.841788 (-0.161979) | 18.528893 / 8.074308 (10.454585) | 23.168590 / 10.191392 (12.977198) | 0.277618 / 0.680424 (-0.402806) | 0.045109 / 0.534201 (-0.489092) | 0.568873 / 0.579283 (-0.010410) | 0.695017 / 0.434364 (0.260653) | 0.671024 / 0.540337 (0.130687) | 0.823817 / 1.386936 (-0.563119) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009809 / 0.011353 (-0.001544) | 0.006890 / 0.011008 (-0.004118) | 0.099211 / 0.038508 (0.060703) | 0.035387 / 0.023109 (0.012278) | 0.507603 / 0.275898 (0.231705) | 0.535553 / 0.323480 (0.212073) | 0.007346 / 0.007986 (-0.000640) | 0.007559 / 0.004328 (0.003231) | 0.099132 / 0.004250 (0.094882) | 0.048048 / 0.037052 (0.010996) | 0.518096 / 0.258489 (0.259607) | 0.561134 / 0.293841 (0.267294) | 0.057580 / 0.128546 (-0.070966) | 0.023665 / 0.075646 (-0.051982) | 0.138409 / 0.419271 (-0.280862) | 0.061989 / 0.043533 (0.018456) | 0.510568 / 0.255139 (0.255429) | 0.552722 / 0.283200 (0.269522) | 0.115990 / 0.141683 (-0.025693) | 1.884900 / 1.452155 (0.432745) | 1.990604 / 1.492716 (0.497888) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.280638 / 0.018006 (0.262632) | 0.592837 / 0.000490 (0.592347) | 0.000465 / 0.000200 (0.000265) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030253 / 0.037411 (-0.007158) | 0.141580 / 0.014526 (0.127054) | 0.135114 / 0.176557 (-0.041443) | 0.190003 / 0.737135 (-0.547133) | 0.160230 / 0.296338 (-0.136109) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.699762 / 0.215209 (0.484553) | 6.632344 / 2.077655 (4.554689) | 2.718803 / 1.504120 (1.214683) | 2.485294 / 1.541195 (0.944099) | 2.579889 / 1.468490 (1.111399) | 1.268795 / 4.584777 (-3.315982) | 5.777745 / 3.745712 (2.032033) | 3.232551 / 5.269862 (-2.037311) | 2.127699 / 4.565676 (-2.437977) | 0.146570 / 0.424275 (-0.277705) | 0.015971 / 0.007607 (0.008364) | 0.803181 / 0.226044 (0.577137) | 8.377192 / 2.268929 (6.108264) | 3.551242 / 55.444624 (-51.893382) | 2.865228 / 6.876477 (-4.011249) | 2.774869 / 2.142072 (0.632797) | 1.553856 / 4.805227 (-3.251371) | 0.264510 / 6.500664 (-6.236154) | 0.087918 / 0.075469 (0.012449) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.653396 / 1.841788 (-0.188391) | 18.703863 / 8.074308 (10.629555) | 22.067331 / 10.191392 (11.875939) | 0.257424 / 0.680424 (-0.422999) | 0.026448 / 0.534201 (-0.507753) | 0.550100 / 0.579283 (-0.029183) | 0.647296 / 0.434364 (0.212932) | 0.657476 / 0.540337 (0.117138) | 0.781119 / 1.386936 (-0.605817) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008889 / 0.011353 (-0.002464) | 0.004563 / 0.011008 (-0.006445) | 0.101627 / 0.038508 (0.063118) | 0.030526 / 0.023109 (0.007417) | 0.297175 / 0.275898 (0.021277) | 0.368454 / 0.323480 (0.044974) | 0.007246 / 0.007986 (-0.000740) | 0.003565 / 0.004328 (-0.000763) | 0.078644 / 0.004250 (0.074394) | 0.038616 / 0.037052 (0.001564) | 0.310521 / 0.258489 (0.052032) | 0.348014 / 0.293841 (0.054173) | 0.033463 / 0.128546 (-0.095083) | 0.011544 / 0.075646 (-0.064102) | 0.323281 / 0.419271 (-0.095990) | 0.040187 / 0.043533 (-0.003346) | 0.298015 / 0.255139 (0.042876) | 0.326392 / 0.283200 (0.043193) | 0.088730 / 0.141683 (-0.052952) | 1.503387 / 1.452155 (0.051233) | 1.548704 / 1.492716 (0.055988) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185983 / 0.018006 (0.167977) | 0.451889 / 0.000490 (0.451400) | 0.001433 / 0.000200 (0.001233) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023396 / 0.037411 (-0.014015) | 0.118236 / 0.014526 (0.103710) | 0.124594 / 0.176557 (-0.051962) | 0.159089 / 0.737135 (-0.578047) | 0.129369 / 0.296338 (-0.166969) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.423161 / 0.215209 (0.207952) | 4.228211 / 2.077655 (2.150556) | 1.853862 / 1.504120 (0.349742) | 1.649471 / 1.541195 (0.108276) | 1.708631 / 1.468490 (0.240141) | 0.697456 / 4.584777 (-3.887321) | 3.473244 / 3.745712 (-0.272468) | 1.942586 / 5.269862 (-3.327275) | 1.291592 / 4.565676 (-3.274084) | 0.082758 / 0.424275 (-0.341517) | 0.012256 / 0.007607 (0.004649) | 0.528355 / 0.226044 (0.302311) | 5.277620 / 2.268929 (3.008691) | 2.299604 / 55.444624 (-53.145020) | 1.954940 / 6.876477 (-4.921537) | 2.055543 / 2.142072 (-0.086529) | 0.814723 / 4.805227 (-3.990505) | 0.149937 / 6.500664 (-6.350727) | 0.064529 / 0.075469 (-0.010941) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266240 / 1.841788 (-0.575547) | 14.144016 / 8.074308 (6.069708) | 14.331733 / 10.191392 (4.140340) | 0.138963 / 0.680424 (-0.541461) | 0.029034 / 0.534201 (-0.505167) | 0.397325 / 0.579283 (-0.181958) | 0.405293 / 0.434364 (-0.029071) | 0.480745 / 0.540337 (-0.059592) | 0.573386 / 1.386936 (-0.813550) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007214 / 0.011353 (-0.004139) | 0.004569 / 0.011008 (-0.006439) | 0.078718 / 0.038508 (0.040209) | 0.031104 / 0.023109 (0.007995) | 0.342562 / 0.275898 (0.066664) | 0.387802 / 0.323480 (0.064322) | 0.005378 / 0.007986 (-0.002608) | 0.003414 / 0.004328 (-0.000915) | 0.077249 / 0.004250 (0.072999) | 0.044337 / 0.037052 (0.007285) | 0.341397 / 0.258489 (0.082907) | 0.385536 / 0.293841 (0.091695) | 0.033257 / 0.128546 (-0.095289) | 0.011825 / 0.075646 (-0.063821) | 0.086723 / 0.419271 (-0.332549) | 0.045951 / 0.043533 (0.002418) | 0.340914 / 0.255139 (0.085775) | 0.367126 / 0.283200 (0.083926) | 0.096326 / 0.141683 (-0.045357) | 1.608612 / 1.452155 (0.156458) | 1.687251 / 1.492716 (0.194534) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227595 / 0.018006 (0.209589) | 0.418502 / 0.000490 (0.418013) | 0.000392 / 0.000200 (0.000192) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026232 / 0.037411 (-0.011179) | 0.101020 / 0.014526 (0.086494) | 0.110017 / 0.176557 (-0.066539) | 0.153497 / 0.737135 (-0.583639) | 0.110602 / 0.296338 (-0.185737) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433789 / 0.215209 (0.218579) | 4.329350 / 2.077655 (2.251696) | 2.052136 / 1.504120 (0.548016) | 1.848457 / 1.541195 (0.307262) | 1.936791 / 1.468490 (0.468301) | 0.700609 / 4.584777 (-3.884168) | 3.391983 / 3.745712 (-0.353729) | 1.903220 / 5.269862 (-3.366642) | 1.179463 / 4.565676 (-3.386213) | 0.084025 / 0.424275 (-0.340250) | 0.012743 / 0.007607 (0.005136) | 0.536816 / 0.226044 (0.310772) | 5.420230 / 2.268929 (3.151302) | 2.507438 / 55.444624 (-52.937187) | 2.178907 / 6.876477 (-4.697570) | 2.228586 / 2.142072 (0.086514) | 0.812527 / 4.805227 (-3.992701) | 0.153382 / 6.500664 (-6.347282) | 0.069932 / 0.075469 (-0.005537) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256861 / 1.841788 (-0.584927) | 14.309236 / 8.074308 (6.234928) | 13.740323 / 10.191392 (3.548931) | 0.142698 / 0.680424 (-0.537726) | 0.016998 / 0.534201 (-0.517203) | 0.385489 / 0.579283 (-0.193794) | 0.391515 / 0.434364 (-0.042849) | 0.472704 / 0.540337 (-0.067633) | 0.565042 / 1.386936 (-0.821894) |\n\n</details>\n</details>\n\n\n",
"This is ready for review. \r\n\r\nIf `verification_mode` is None, it defaults to `VerificationMode.BASIC` instead of `VerificationMode.NONE`, so maybe we should find a better name for the latter to avoid confusion.\r\n\r\nPS: `ignore_verifications` is still present in the `test`/`run_beam` commands for simplicity. Let me know if you think these commands should support all three modes.",
"> I would also prefer to change the name for the NONE verification mode, but don't have really good ideas in mind. maybe smth like SKIP_ALL ?\r\n\r\nI decided to go with the following names:\r\n* `no_checks` (previously `none`)\r\n* `basic_checks` (previously `basic`)\r\n* `all_checks` (previously `full`)\r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008900 / 0.011353 (-0.002453) | 0.004492 / 0.011008 (-0.006516) | 0.100957 / 0.038508 (0.062449) | 0.030145 / 0.023109 (0.007036) | 0.302531 / 0.275898 (0.026633) | 0.344072 / 0.323480 (0.020592) | 0.007032 / 0.007986 (-0.000953) | 0.004150 / 0.004328 (-0.000178) | 0.078272 / 0.004250 (0.074021) | 0.034142 / 0.037052 (-0.002910) | 0.310798 / 0.258489 (0.052308) | 0.350077 / 0.293841 (0.056236) | 0.034497 / 0.128546 (-0.094050) | 0.011417 / 0.075646 (-0.064230) | 0.323427 / 0.419271 (-0.095844) | 0.045664 / 0.043533 (0.002132) | 0.304688 / 0.255139 (0.049549) | 0.336591 / 0.283200 (0.053391) | 0.086116 / 0.141683 (-0.055567) | 1.519278 / 1.452155 (0.067123) | 1.576728 / 1.492716 (0.084011) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.242482 / 0.018006 (0.224476) | 0.403548 / 0.000490 (0.403058) | 0.001217 / 0.000200 (0.001017) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023466 / 0.037411 (-0.013945) | 0.095220 / 0.014526 (0.080694) | 0.104119 / 0.176557 (-0.072438) | 0.141107 / 0.737135 (-0.596029) | 0.107236 / 0.296338 (-0.189102) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.416290 / 0.215209 (0.201081) | 4.159068 / 2.077655 (2.081413) | 1.846014 / 1.504120 (0.341894) | 1.634789 / 1.541195 (0.093594) | 1.724687 / 1.468490 (0.256196) | 0.696887 / 4.584777 (-3.887890) | 3.313861 / 3.745712 (-0.431851) | 1.907239 / 5.269862 (-3.362622) | 1.266815 / 4.565676 (-3.298861) | 0.081660 / 0.424275 (-0.342615) | 0.012290 / 0.007607 (0.004683) | 0.522866 / 0.226044 (0.296822) | 5.237356 / 2.268929 (2.968428) | 2.294645 / 55.444624 (-53.149979) | 1.946407 / 6.876477 (-4.930069) | 1.995441 / 2.142072 (-0.146632) | 0.808340 / 4.805227 (-3.996887) | 0.149670 / 6.500664 (-6.350994) | 0.065162 / 0.075469 (-0.010307) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219476 / 1.841788 (-0.622312) | 13.868709 / 8.074308 (5.794401) | 14.115783 / 10.191392 (3.924391) | 0.149403 / 0.680424 (-0.531021) | 0.028514 / 0.534201 (-0.505686) | 0.398194 / 0.579283 (-0.181089) | 0.410898 / 0.434364 (-0.023466) | 0.485763 / 0.540337 (-0.054574) | 0.574924 / 1.386936 (-0.812012) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006906 / 0.011353 (-0.004447) | 0.004446 / 0.011008 (-0.006562) | 0.075936 / 0.038508 (0.037428) | 0.027693 / 0.023109 (0.004584) | 0.339505 / 0.275898 (0.063607) | 0.383315 / 0.323480 (0.059835) | 0.005138 / 0.007986 (-0.002847) | 0.004636 / 0.004328 (0.000308) | 0.074829 / 0.004250 (0.070578) | 0.040327 / 0.037052 (0.003274) | 0.340516 / 0.258489 (0.082027) | 0.388569 / 0.293841 (0.094729) | 0.031562 / 0.128546 (-0.096984) | 0.011585 / 0.075646 (-0.064061) | 0.084753 / 0.419271 (-0.334518) | 0.041310 / 0.043533 (-0.002223) | 0.338272 / 0.255139 (0.083133) | 0.367243 / 0.283200 (0.084043) | 0.092653 / 0.141683 (-0.049029) | 1.515973 / 1.452155 (0.063818) | 1.582869 / 1.492716 (0.090152) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229366 / 0.018006 (0.211360) | 0.414404 / 0.000490 (0.413914) | 0.002922 / 0.000200 (0.002723) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026391 / 0.037411 (-0.011020) | 0.106754 / 0.014526 (0.092228) | 0.110718 / 0.176557 (-0.065839) | 0.145786 / 0.737135 (-0.591350) | 0.113180 / 0.296338 (-0.183159) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446340 / 0.215209 (0.231131) | 4.499756 / 2.077655 (2.422101) | 2.071485 / 1.504120 (0.567365) | 1.873223 / 1.541195 (0.332029) | 1.931562 / 1.468490 (0.463071) | 0.699270 / 4.584777 (-3.885507) | 3.452383 / 3.745712 (-0.293329) | 2.970630 / 5.269862 (-2.299232) | 1.300859 / 4.565676 (-3.264817) | 0.083971 / 0.424275 (-0.340304) | 0.012489 / 0.007607 (0.004882) | 0.544190 / 0.226044 (0.318146) | 5.460097 / 2.268929 (3.191169) | 2.700244 / 55.444624 (-52.744380) | 2.396694 / 6.876477 (-4.479783) | 2.376334 / 2.142072 (0.234262) | 0.812845 / 4.805227 (-3.992382) | 0.154441 / 6.500664 (-6.346223) | 0.069510 / 0.075469 (-0.005959) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278836 / 1.841788 (-0.562952) | 14.153158 / 8.074308 (6.078850) | 13.821290 / 10.191392 (3.629898) | 0.160464 / 0.680424 (-0.519960) | 0.016742 / 0.534201 (-0.517459) | 0.379840 / 0.579283 (-0.199443) | 0.391903 / 0.434364 (-0.042461) | 0.461646 / 0.540337 (-0.078691) | 0.550691 / 1.386936 (-0.836245) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009858 / 0.011353 (-0.001495) | 0.005383 / 0.011008 (-0.005625) | 0.100527 / 0.038508 (0.062019) | 0.037176 / 0.023109 (0.014067) | 0.295204 / 0.275898 (0.019306) | 0.364511 / 0.323480 (0.041031) | 0.008486 / 0.007986 (0.000500) | 0.004273 / 0.004328 (-0.000055) | 0.076538 / 0.004250 (0.072288) | 0.046250 / 0.037052 (0.009197) | 0.307102 / 0.258489 (0.048613) | 0.339313 / 0.293841 (0.045472) | 0.040783 / 0.128546 (-0.087763) | 0.012323 / 0.075646 (-0.063323) | 0.336216 / 0.419271 (-0.083055) | 0.050480 / 0.043533 (0.006947) | 0.293689 / 0.255139 (0.038550) | 0.315034 / 0.283200 (0.031834) | 0.113775 / 0.141683 (-0.027908) | 1.438738 / 1.452155 (-0.013416) | 1.499874 / 1.492716 (0.007157) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.202392 / 0.018006 (0.184386) | 0.442784 / 0.000490 (0.442295) | 0.003004 / 0.000200 (0.002804) | 0.000087 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027792 / 0.037411 (-0.009620) | 0.110886 / 0.014526 (0.096360) | 0.121041 / 0.176557 (-0.055515) | 0.166803 / 0.737135 (-0.570333) | 0.127617 / 0.296338 (-0.168722) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.409762 / 0.215209 (0.194553) | 4.073297 / 2.077655 (1.995643) | 1.836375 / 1.504120 (0.332255) | 1.651507 / 1.541195 (0.110312) | 1.734134 / 1.468490 (0.265644) | 0.690900 / 4.584777 (-3.893877) | 3.812045 / 3.745712 (0.066333) | 2.101378 / 5.269862 (-3.168483) | 1.438242 / 4.565676 (-3.127434) | 0.083256 / 0.424275 (-0.341020) | 0.012436 / 0.007607 (0.004829) | 0.501702 / 0.226044 (0.275658) | 5.007679 / 2.268929 (2.738751) | 2.315158 / 55.444624 (-53.129466) | 2.003934 / 6.876477 (-4.872543) | 2.154658 / 2.142072 (0.012586) | 0.831749 / 4.805227 (-3.973478) | 0.165058 / 6.500664 (-6.335606) | 0.062166 / 0.075469 (-0.013303) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.212435 / 1.841788 (-0.629353) | 15.022673 / 8.074308 (6.948365) | 14.649631 / 10.191392 (4.458239) | 0.172121 / 0.680424 (-0.508303) | 0.028791 / 0.534201 (-0.505410) | 0.440290 / 0.579283 (-0.138993) | 0.437359 / 0.434364 (0.002995) | 0.543603 / 0.540337 (0.003265) | 0.643241 / 1.386936 (-0.743695) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007572 / 0.011353 (-0.003781) | 0.005207 / 0.011008 (-0.005801) | 0.074427 / 0.038508 (0.035919) | 0.033384 / 0.023109 (0.010275) | 0.334538 / 0.275898 (0.058640) | 0.371556 / 0.323480 (0.048076) | 0.006453 / 0.007986 (-0.001532) | 0.004010 / 0.004328 (-0.000319) | 0.073488 / 0.004250 (0.069238) | 0.048082 / 0.037052 (0.011030) | 0.337325 / 0.258489 (0.078836) | 0.395143 / 0.293841 (0.101302) | 0.036714 / 0.128546 (-0.091832) | 0.012089 / 0.075646 (-0.063557) | 0.086008 / 0.419271 (-0.333263) | 0.049277 / 0.043533 (0.005744) | 0.333848 / 0.255139 (0.078709) | 0.354003 / 0.283200 (0.070803) | 0.105012 / 0.141683 (-0.036671) | 1.450769 / 1.452155 (-0.001386) | 1.554538 / 1.492716 (0.061821) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208407 / 0.018006 (0.190400) | 0.438778 / 0.000490 (0.438288) | 0.000399 / 0.000200 (0.000199) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030180 / 0.037411 (-0.007232) | 0.115432 / 0.014526 (0.100906) | 0.126106 / 0.176557 (-0.050451) | 0.167508 / 0.737135 (-0.569627) | 0.130566 / 0.296338 (-0.165772) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421408 / 0.215209 (0.206198) | 4.208492 / 2.077655 (2.130838) | 2.024177 / 1.504120 (0.520057) | 1.834356 / 1.541195 (0.293161) | 1.923234 / 1.468490 (0.454744) | 0.699548 / 4.584777 (-3.885229) | 3.933775 / 3.745712 (0.188063) | 2.124526 / 5.269862 (-3.145336) | 1.360934 / 4.565676 (-3.204742) | 0.086568 / 0.424275 (-0.337707) | 0.012351 / 0.007607 (0.004744) | 0.517431 / 0.226044 (0.291387) | 5.175428 / 2.268929 (2.906499) | 2.471031 / 55.444624 (-52.973593) | 2.131529 / 6.876477 (-4.744948) | 2.202512 / 2.142072 (0.060440) | 0.849364 / 4.805227 (-3.955863) | 0.171505 / 6.500664 (-6.329159) | 0.065864 / 0.075469 (-0.009605) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270054 / 1.841788 (-0.571734) | 15.254502 / 8.074308 (7.180194) | 13.874969 / 10.191392 (3.683577) | 0.144131 / 0.680424 (-0.536293) | 0.017743 / 0.534201 (-0.516458) | 0.421990 / 0.579283 (-0.157293) | 0.423924 / 0.434364 (-0.010439) | 0.522560 / 0.540337 (-0.017778) | 0.626159 / 1.386936 (-0.760777) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008643 / 0.011353 (-0.002710) | 0.004479 / 0.011008 (-0.006529) | 0.102372 / 0.038508 (0.063864) | 0.029703 / 0.023109 (0.006594) | 0.301479 / 0.275898 (0.025581) | 0.370970 / 0.323480 (0.047490) | 0.007044 / 0.007986 (-0.000942) | 0.004868 / 0.004328 (0.000540) | 0.079568 / 0.004250 (0.075318) | 0.035344 / 0.037052 (-0.001708) | 0.308091 / 0.258489 (0.049602) | 0.353812 / 0.293841 (0.059971) | 0.033406 / 0.128546 (-0.095140) | 0.011476 / 0.075646 (-0.064170) | 0.324343 / 0.419271 (-0.094929) | 0.040293 / 0.043533 (-0.003240) | 0.300007 / 0.255139 (0.044868) | 0.334410 / 0.283200 (0.051210) | 0.086553 / 0.141683 (-0.055130) | 1.463814 / 1.452155 (0.011659) | 1.501580 / 1.492716 (0.008864) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198032 / 0.018006 (0.180025) | 0.409970 / 0.000490 (0.409480) | 0.001075 / 0.000200 (0.000875) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022941 / 0.037411 (-0.014471) | 0.097320 / 0.014526 (0.082794) | 0.106445 / 0.176557 (-0.070111) | 0.139073 / 0.737135 (-0.598063) | 0.108408 / 0.296338 (-0.187930) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419315 / 0.215209 (0.204106) | 4.199273 / 2.077655 (2.121618) | 1.877689 / 1.504120 (0.373569) | 1.670442 / 1.541195 (0.129247) | 1.735034 / 1.468490 (0.266544) | 0.694691 / 4.584777 (-3.890086) | 3.323644 / 3.745712 (-0.422069) | 2.884349 / 5.269862 (-2.385513) | 1.518882 / 4.565676 (-3.046794) | 0.082390 / 0.424275 (-0.341886) | 0.012884 / 0.007607 (0.005277) | 0.525103 / 0.226044 (0.299058) | 5.277297 / 2.268929 (3.008369) | 2.328639 / 55.444624 (-53.115985) | 1.983210 / 6.876477 (-4.893267) | 2.037985 / 2.142072 (-0.104088) | 0.809520 / 4.805227 (-3.995707) | 0.150150 / 6.500664 (-6.350514) | 0.065578 / 0.075469 (-0.009891) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.221971 / 1.841788 (-0.619817) | 13.692361 / 8.074308 (5.618052) | 13.874582 / 10.191392 (3.683190) | 0.138182 / 0.680424 (-0.542242) | 0.028618 / 0.534201 (-0.505583) | 0.395104 / 0.579283 (-0.184179) | 0.397169 / 0.434364 (-0.037195) | 0.457509 / 0.540337 (-0.082829) | 0.537275 / 1.386936 (-0.849661) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006835 / 0.011353 (-0.004518) | 0.004585 / 0.011008 (-0.006423) | 0.076877 / 0.038508 (0.038369) | 0.027305 / 0.023109 (0.004196) | 0.349085 / 0.275898 (0.073187) | 0.401416 / 0.323480 (0.077936) | 0.004912 / 0.007986 (-0.003074) | 0.003315 / 0.004328 (-0.001014) | 0.075676 / 0.004250 (0.071425) | 0.038960 / 0.037052 (0.001907) | 0.346196 / 0.258489 (0.087707) | 0.403185 / 0.293841 (0.109344) | 0.032054 / 0.128546 (-0.096493) | 0.011742 / 0.075646 (-0.063905) | 0.086631 / 0.419271 (-0.332640) | 0.041633 / 0.043533 (-0.001900) | 0.343519 / 0.255139 (0.088380) | 0.385413 / 0.283200 (0.102213) | 0.091430 / 0.141683 (-0.050253) | 1.478886 / 1.452155 (0.026731) | 1.546873 / 1.492716 (0.054156) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.167882 / 0.018006 (0.149876) | 0.396464 / 0.000490 (0.395974) | 0.003629 / 0.000200 (0.003429) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024829 / 0.037411 (-0.012583) | 0.099607 / 0.014526 (0.085081) | 0.106187 / 0.176557 (-0.070370) | 0.142379 / 0.737135 (-0.594756) | 0.109307 / 0.296338 (-0.187032) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442276 / 0.215209 (0.227067) | 4.427099 / 2.077655 (2.349444) | 2.093407 / 1.504120 (0.589287) | 1.880973 / 1.541195 (0.339778) | 1.915592 / 1.468490 (0.447102) | 0.708196 / 4.584777 (-3.876581) | 3.417649 / 3.745712 (-0.328063) | 2.859953 / 5.269862 (-2.409909) | 1.528380 / 4.565676 (-3.037297) | 0.084054 / 0.424275 (-0.340221) | 0.012585 / 0.007607 (0.004978) | 0.537614 / 0.226044 (0.311569) | 5.409915 / 2.268929 (3.140987) | 2.555853 / 55.444624 (-52.888771) | 2.195075 / 6.876477 (-4.681402) | 2.232775 / 2.142072 (0.090703) | 0.814994 / 4.805227 (-3.990233) | 0.152882 / 6.500664 (-6.347782) | 0.067467 / 0.075469 (-0.008002) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.306007 / 1.841788 (-0.535780) | 13.923981 / 8.074308 (5.849673) | 13.385881 / 10.191392 (3.194489) | 0.150712 / 0.680424 (-0.529712) | 0.016731 / 0.534201 (-0.517470) | 0.376557 / 0.579283 (-0.202726) | 0.379396 / 0.434364 (-0.054968) | 0.456251 / 0.540337 (-0.084087) | 0.545731 / 1.386936 (-0.841205) |\n\n</details>\n</details>\n\n\n"
] | "2022-11-25T18:39:09Z" | "2023-02-13T16:50:42Z" | "2023-02-13T16:43:47Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5303.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5303",
"merged_at": "2023-02-13T16:43:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5303.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5303"
} | Skip the dataset verifications (split and checksum verifications, duplicate keys check) by default unless a dataset is being tested (`datasets-cli test/run_beam`). The main goal is to avoid running the checksum check in the default case due to how expensive it can be for large datasets.
PS: Maybe we should deprecate `ignore_verifications`, which is `True` now by default, and give it a different name? | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5303/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5303/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/340/comments | https://api.github.com/repos/huggingface/datasets/issues/340/events | https://github.com/huggingface/datasets/pull/340 | 650,533,920 | MDExOlB1bGxSZXF1ZXN0NDQ0MDA2Nzcy | 340 | Update cfq.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/4437290?v=4",
"events_url": "https://api.github.com/users/brainshawn/events{/privacy}",
"followers_url": "https://api.github.com/users/brainshawn/followers",
"following_url": "https://api.github.com/users/brainshawn/following{/other_user}",
"gists_url": "https://api.github.com/users/brainshawn/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/brainshawn",
"id": 4437290,
"login": "brainshawn",
"node_id": "MDQ6VXNlcjQ0MzcyOTA=",
"organizations_url": "https://api.github.com/users/brainshawn/orgs",
"received_events_url": "https://api.github.com/users/brainshawn/received_events",
"repos_url": "https://api.github.com/users/brainshawn/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/brainshawn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brainshawn/subscriptions",
"type": "User",
"url": "https://api.github.com/users/brainshawn"
} | [] | closed | false | null | [] | null | [
"Thanks @brainshawn for this update"
] | "2020-07-03T11:23:19Z" | "2020-07-03T12:33:50Z" | "2020-07-03T12:33:50Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/340",
"merged_at": "2020-07-03T12:33:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/340"
} | Make the dataset name consistent with in the paper: Compositional Freebase Question => Compositional Freebase Questions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/340/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5269/comments | https://api.github.com/repos/huggingface/datasets/issues/5269/events | https://github.com/huggingface/datasets/issues/5269 | 1,456,485,799 | I_kwDODunzps5W0DWn | 5,269 | Shell completions | {
"avatar_url": "https://avatars.githubusercontent.com/u/32936898?v=4",
"events_url": "https://api.github.com/users/Freed-Wu/events{/privacy}",
"followers_url": "https://api.github.com/users/Freed-Wu/followers",
"following_url": "https://api.github.com/users/Freed-Wu/following{/other_user}",
"gists_url": "https://api.github.com/users/Freed-Wu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Freed-Wu",
"id": 32936898,
"login": "Freed-Wu",
"node_id": "MDQ6VXNlcjMyOTM2ODk4",
"organizations_url": "https://api.github.com/users/Freed-Wu/orgs",
"received_events_url": "https://api.github.com/users/Freed-Wu/received_events",
"repos_url": "https://api.github.com/users/Freed-Wu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Freed-Wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Freed-Wu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Freed-Wu"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"I don't think we need completion on the datasets-cli, since we're mainly developing huggingface-cli",
"I see."
] | "2022-11-19T13:48:59Z" | "2022-11-21T15:06:15Z" | "2022-11-21T15:06:14Z" | NONE | null | null | null | ### Feature request
Like <https://github.com/huggingface/huggingface_hub/issues/1197>, datasets-cli maybe need it, too.
### Motivation
See above.
### Your contribution
Maybe. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5269/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5269/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6220 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6220/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6220/comments | https://api.github.com/repos/huggingface/datasets/issues/6220/events | https://github.com/huggingface/datasets/pull/6220 | 1,884,285,980 | PR_kwDODunzps5ZspRb | 6,220 | Set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6220). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005950 / 0.011353 (-0.005403) | 0.003578 / 0.011008 (-0.007431) | 0.079327 / 0.038508 (0.040819) | 0.057862 / 0.023109 (0.034752) | 0.317288 / 0.275898 (0.041390) | 0.358210 / 0.323480 (0.034730) | 0.004685 / 0.007986 (-0.003301) | 0.002879 / 0.004328 (-0.001450) | 0.062355 / 0.004250 (0.058105) | 0.045093 / 0.037052 (0.008041) | 0.322520 / 0.258489 (0.064031) | 0.367114 / 0.293841 (0.073273) | 0.027233 / 0.128546 (-0.101313) | 0.007941 / 0.075646 (-0.067705) | 0.260511 / 0.419271 (-0.158761) | 0.044355 / 0.043533 (0.000822) | 0.332993 / 0.255139 (0.077854) | 0.351363 / 0.283200 (0.068163) | 0.020784 / 0.141683 (-0.120899) | 1.429044 / 1.452155 (-0.023111) | 1.489355 / 1.492716 (-0.003362) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.180903 / 0.018006 (0.162897) | 0.421566 / 0.000490 (0.421077) | 0.003259 / 0.000200 (0.003059) | 0.000068 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023765 / 0.037411 (-0.013646) | 0.072815 / 0.014526 (0.058289) | 0.084592 / 0.176557 (-0.091965) | 0.143556 / 0.737135 (-0.593579) | 0.083591 / 0.296338 (-0.212748) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401896 / 0.215209 (0.186687) | 4.006344 / 2.077655 (1.928689) | 2.092280 / 1.504120 (0.588160) | 1.937828 / 1.541195 (0.396633) | 2.026901 / 1.468490 (0.558411) | 0.499999 / 4.584777 (-4.084778) | 3.008715 / 3.745712 (-0.736997) | 2.789735 / 5.269862 (-2.480127) | 1.827319 / 4.565676 (-2.738358) | 0.057413 / 0.424275 (-0.366862) | 0.006716 / 0.007607 (-0.000891) | 0.473061 / 0.226044 (0.247016) | 4.733256 / 2.268929 (2.464327) | 2.403922 / 55.444624 (-53.040702) | 2.017466 / 6.876477 (-4.859011) | 2.209710 / 2.142072 (0.067638) | 0.590813 / 4.805227 (-4.214414) | 0.124760 / 6.500664 (-6.375904) | 0.060976 / 0.075469 (-0.014494) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.229172 / 1.841788 (-0.612616) | 17.924644 / 8.074308 (9.850336) | 13.697347 / 10.191392 (3.505955) | 0.128258 / 0.680424 (-0.552166) | 0.016780 / 0.534201 (-0.517421) | 0.329301 / 0.579283 (-0.249982) | 0.344527 / 0.434364 (-0.089837) | 0.379482 / 0.540337 (-0.160855) | 0.513851 / 1.386936 (-0.873085) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005962 / 0.011353 (-0.005391) | 0.003613 / 0.011008 (-0.007396) | 0.062428 / 0.038508 (0.023920) | 0.058151 / 0.023109 (0.035042) | 0.452926 / 0.275898 (0.177027) | 0.489740 / 0.323480 (0.166260) | 0.006137 / 0.007986 (-0.001848) | 0.002890 / 0.004328 (-0.001438) | 0.062880 / 0.004250 (0.058629) | 0.046175 / 0.037052 (0.009123) | 0.452416 / 0.258489 (0.193927) | 0.486047 / 0.293841 (0.192206) | 0.028517 / 0.128546 (-0.100029) | 0.008102 / 0.075646 (-0.067544) | 0.068251 / 0.419271 (-0.351020) | 0.040569 / 0.043533 (-0.002964) | 0.461306 / 0.255139 (0.206167) | 0.477675 / 0.283200 (0.194475) | 0.020944 / 0.141683 (-0.120739) | 1.414300 / 1.452155 (-0.037855) | 1.502108 / 1.492716 (0.009391) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217786 / 0.018006 (0.199780) | 0.410757 / 0.000490 (0.410267) | 0.002981 / 0.000200 (0.002781) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026846 / 0.037411 (-0.010565) | 0.080098 / 0.014526 (0.065572) | 0.090591 / 0.176557 (-0.085965) | 0.144674 / 0.737135 (-0.592461) | 0.091287 / 0.296338 (-0.205052) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458224 / 0.215209 (0.243015) | 4.590541 / 2.077655 (2.512886) | 2.511251 / 1.504120 (1.007131) | 2.329165 / 1.541195 (0.787970) | 2.379187 / 1.468490 (0.910696) | 0.507485 / 4.584777 (-4.077292) | 3.135011 / 3.745712 (-0.610701) | 2.805913 / 5.269862 (-2.463948) | 1.851382 / 4.565676 (-2.714295) | 0.057981 / 0.424275 (-0.366294) | 0.006557 / 0.007607 (-0.001050) | 0.532496 / 0.226044 (0.306452) | 5.348802 / 2.268929 (3.079874) | 2.993379 / 55.444624 (-52.451245) | 2.636372 / 6.876477 (-4.240104) | 2.753219 / 2.142072 (0.611147) | 0.591989 / 4.805227 (-4.213238) | 0.126691 / 6.500664 (-6.373973) | 0.062359 / 0.075469 (-0.013110) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.345498 / 1.841788 (-0.496290) | 18.335767 / 8.074308 (10.261458) | 15.115449 / 10.191392 (4.924057) | 0.147382 / 0.680424 (-0.533041) | 0.017729 / 0.534201 (-0.516472) | 0.334337 / 0.579283 (-0.244946) | 0.359035 / 0.434364 (-0.075329) | 0.386319 / 0.540337 (-0.154019) | 0.536378 / 1.386936 (-0.850558) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009136 / 0.011353 (-0.002216) | 0.005567 / 0.011008 (-0.005442) | 0.120320 / 0.038508 (0.081812) | 0.078082 / 0.023109 (0.054973) | 0.405579 / 0.275898 (0.129681) | 0.459714 / 0.323480 (0.136234) | 0.006327 / 0.007986 (-0.001659) | 0.007187 / 0.004328 (0.002859) | 0.084373 / 0.004250 (0.080122) | 0.059727 / 0.037052 (0.022675) | 0.418918 / 0.258489 (0.160429) | 0.486767 / 0.293841 (0.192927) | 0.047715 / 0.128546 (-0.080831) | 0.014417 / 0.075646 (-0.061229) | 0.379847 / 0.419271 (-0.039425) | 0.067472 / 0.043533 (0.023939) | 0.419304 / 0.255139 (0.164166) | 0.466260 / 0.283200 (0.183060) | 0.036872 / 0.141683 (-0.104811) | 1.876273 / 1.452155 (0.424119) | 2.043856 / 1.492716 (0.551140) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296266 / 0.018006 (0.278260) | 0.601843 / 0.000490 (0.601354) | 0.005663 / 0.000200 (0.005463) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033272 / 0.037411 (-0.004139) | 0.098839 / 0.014526 (0.084313) | 0.124658 / 0.176557 (-0.051899) | 0.190226 / 0.737135 (-0.546909) | 0.119288 / 0.296338 (-0.177051) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.600878 / 0.215209 (0.385668) | 6.011749 / 2.077655 (3.934095) | 2.611809 / 1.504120 (1.107689) | 2.314985 / 1.541195 (0.773790) | 2.398988 / 1.468490 (0.930498) | 0.835577 / 4.584777 (-3.749200) | 5.482848 / 3.745712 (1.737136) | 4.965393 / 5.269862 (-0.304469) | 3.082420 / 4.565676 (-1.483256) | 0.098048 / 0.424275 (-0.326227) | 0.009148 / 0.007607 (0.001541) | 0.725721 / 0.226044 (0.499676) | 7.297429 / 2.268929 (5.028501) | 3.558050 / 55.444624 (-51.886575) | 2.815884 / 6.876477 (-4.060593) | 3.094103 / 2.142072 (0.952031) | 1.023617 / 4.805227 (-3.781610) | 0.222453 / 6.500664 (-6.278211) | 0.081707 / 0.075469 (0.006238) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.788327 / 1.841788 (-0.053461) | 25.285829 / 8.074308 (17.211521) | 21.878811 / 10.191392 (11.687419) | 0.215494 / 0.680424 (-0.464930) | 0.032050 / 0.534201 (-0.502151) | 0.505210 / 0.579283 (-0.074073) | 0.623545 / 0.434364 (0.189181) | 0.583342 / 0.540337 (0.043005) | 0.826497 / 1.386936 (-0.560439) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009640 / 0.011353 (-0.001713) | 0.005479 / 0.011008 (-0.005529) | 0.088940 / 0.038508 (0.050432) | 0.084186 / 0.023109 (0.061077) | 0.552290 / 0.275898 (0.276392) | 0.583296 / 0.323480 (0.259816) | 0.006999 / 0.007986 (-0.000987) | 0.004597 / 0.004328 (0.000269) | 0.089407 / 0.004250 (0.085157) | 0.067210 / 0.037052 (0.030157) | 0.554968 / 0.258489 (0.296479) | 0.595635 / 0.293841 (0.301794) | 0.052245 / 0.128546 (-0.076301) | 0.015914 / 0.075646 (-0.059733) | 0.097037 / 0.419271 (-0.322235) | 0.063954 / 0.043533 (0.020421) | 0.533752 / 0.255139 (0.278614) | 0.573789 / 0.283200 (0.290589) | 0.036526 / 0.141683 (-0.105157) | 1.867713 / 1.452155 (0.415558) | 1.996901 / 1.492716 (0.504185) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.414967 / 0.018006 (0.396961) | 0.632367 / 0.000490 (0.631877) | 0.064061 / 0.000200 (0.063861) | 0.000565 / 0.000054 (0.000510) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035953 / 0.037411 (-0.001458) | 0.112603 / 0.014526 (0.098077) | 0.126227 / 0.176557 (-0.050330) | 0.196881 / 0.737135 (-0.540255) | 0.127635 / 0.296338 (-0.168704) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.674735 / 0.215209 (0.459526) | 6.614578 / 2.077655 (4.536923) | 3.208198 / 1.504120 (1.704078) | 2.870412 / 1.541195 (1.329217) | 2.979358 / 1.468490 (1.510868) | 0.872589 / 4.584777 (-3.712187) | 5.501771 / 3.745712 (1.756059) | 4.865191 / 5.269862 (-0.404671) | 3.075281 / 4.565676 (-1.490396) | 0.098048 / 0.424275 (-0.326227) | 0.009121 / 0.007607 (0.001514) | 0.801639 / 0.226044 (0.575595) | 8.062040 / 2.268929 (5.793111) | 3.996693 / 55.444624 (-51.447931) | 3.343770 / 6.876477 (-3.532706) | 3.555977 / 2.142072 (1.413904) | 1.035050 / 4.805227 (-3.770177) | 0.227552 / 6.500664 (-6.273112) | 0.097733 / 0.075469 (0.022264) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.897210 / 1.841788 (0.055422) | 25.762459 / 8.074308 (17.688151) | 22.771290 / 10.191392 (12.579898) | 0.252650 / 0.680424 (-0.427773) | 0.032534 / 0.534201 (-0.501667) | 0.521047 / 0.579283 (-0.058236) | 0.620850 / 0.434364 (0.186486) | 0.612750 / 0.540337 (0.072413) | 0.837486 / 1.386936 (-0.549451) |\n\n</details>\n</details>\n\n\n"
] | "2023-09-06T15:40:33Z" | "2023-09-06T15:52:33Z" | "2023-09-06T15:41:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6220.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6220",
"merged_at": "2023-09-06T15:41:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6220.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6220"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6220/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6220/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3411/comments | https://api.github.com/repos/huggingface/datasets/issues/3411/events | https://github.com/huggingface/datasets/issues/3411 | 1,075,846,272 | I_kwDODunzps5AIByA | 3,411 | [chinese wwm] load_datasets behavior not as expected when using run_mlm_wwm.py script | {
"avatar_url": "https://avatars.githubusercontent.com/u/52968111?v=4",
"events_url": "https://api.github.com/users/hyusterr/events{/privacy}",
"followers_url": "https://api.github.com/users/hyusterr/followers",
"following_url": "https://api.github.com/users/hyusterr/following{/other_user}",
"gists_url": "https://api.github.com/users/hyusterr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hyusterr",
"id": 52968111,
"login": "hyusterr",
"node_id": "MDQ6VXNlcjUyOTY4MTEx",
"organizations_url": "https://api.github.com/users/hyusterr/orgs",
"received_events_url": "https://api.github.com/users/hyusterr/received_events",
"repos_url": "https://api.github.com/users/hyusterr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hyusterr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hyusterr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hyusterr"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"@LysandreJik not so sure who to @\r\nCould you help?",
"Hi @hyusterr, I believe it is @wlhgtc from https://github.com/huggingface/transformers/pull/9887"
] | "2021-12-09T17:54:35Z" | "2021-12-22T11:21:33Z" | null | NONE | null | null | null | ## Describe the bug
Model I am using (Bert, XLNet ...): bert-base-chinese
The problem arises when using:
* [https://github.com/huggingface/transformers/blob/master/examples/research_projects/mlm_wwm/run_mlm_wwm.py] the official example scripts: `rum_mlm_wwm.py`
The tasks I am working on is: pretraining whole word masking with my own dataset and ref.json file
I tried follow the run_mlm_wwm.py procedure to do whole word masking on pretraining task. my file is in .txt form, where one line represents one sample, with `9,264,784` chinese lines in total. the ref.json file is also contains 9,264,784 lines of whole word masking reference data for my chinese corpus. but when I try to adapt the run_mlm_wwm.py script, it shows that somehow after
`datasets["train"] = load_dataset(...`
`len(datasets["train"])` returns `9,265,365`
then, after `tokenized_datasets = datasets.map(...`
`len(tokenized_datasets["train"])` returns `9,265,279`
I'm really confused and tried to trace code by myself but can't know what happened after a week trial.
I want to know what happened in the `load_dataset()` function and `datasets.map` here and how did I get more lines of data than I input. so I'm here to ask.
## To reproduce
Sorry that I can't provide my data here since it did not belong to me. but I'm sure I remove the blank lines.
## Expected behavior
I expect the code run as it should. but the AssertionError in line 167 keeps raise as the line of reference json and datasets['train'] differs.
Thanks for your patient reading!
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3411/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3411/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/704/comments | https://api.github.com/repos/huggingface/datasets/issues/704/events | https://github.com/huggingface/datasets/pull/704 | 713,572,556 | MDExOlB1bGxSZXF1ZXN0NDk2ODY2NTQ0 | 704 | Fix remote tests for new datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-10-02T12:08:04Z" | "2020-10-02T12:12:02Z" | "2020-10-02T12:12:01Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/704.diff",
"html_url": "https://github.com/huggingface/datasets/pull/704",
"merged_at": "2020-10-02T12:12:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/704.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/704"
} | When adding a new dataset, the remote tests fail because they try to get the new dataset from the master branch (i.e., where the dataset doesn't exist yet)
To fix that I reverted to the use of the HF API that fetch the available datasets on S3 that is synced with the master branch | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/704/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/704/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1595/comments | https://api.github.com/repos/huggingface/datasets/issues/1595/events | https://github.com/huggingface/datasets/pull/1595 | 770,153,693 | MDExOlB1bGxSZXF1ZXN0NTQxOTUwNDk4 | 1,595 | Logiqa en | {
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/aclifton314",
"id": 53267795,
"login": "aclifton314",
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"type": "User",
"url": "https://api.github.com/users/aclifton314"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"I'm getting an error when I try to create the dummy data:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ python datasets-cli dummy_data ./datasets/logiqa_en/ --auto_generate \r\n2021-01-07 10:50:12.024791: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-01-07 10:50:12.024814: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\nUsing custom data configuration default\r\nCouldn't generate dummy file 'datasets/dummy/1.1.0/dummy_data/master.zip/LogiQA-dataset-master/README.md'. Ignore that if this file is not useful for dummy data.\r\nDummy data generation done but dummy data test failed since splits ['train', 'test', 'validation'] have 0 examples for config 'default''.\r\nAutomatic dummy data generation failed for some configs of './datasets/logiqa_en/'\r\n```",
"Hi ! Sorry for the delay\r\n\r\nTo fix your issue for the dummy data you must increase the number of lines that will be kept to generate the dummy files. By default it's 5, and as you need at least 8 lines here to yield one example you must increase this.\r\n\r\nYou can increase the number of lines to 32 for example by doing\r\n```\r\ndatasets-cli dummy_data ./datasets/logica_en --auto_generate --n_lines 32\r\n```\r\n\r\nAlso it looks like there are changes about other datasets in this PR (imppres). Can you fix that ? You may need to create another branch and another PR.",
"To fix the branch issue, I went ahead and made a backup of the dataset then deleted my local copy of my fork of `datasets`. I then followed the [detailed guide](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md) from the beginning to reclone the fork and start a new branch. \r\n\r\nHowever, when it came time to create the dummy data I got the following error:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ datasets-cli dummy_data ./datasets/logiqa_en --auto_generate --n_lines 32\r\n2021-02-03 11:23:23.145885: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-02-03 11:23:23.145914: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\nUsing custom data configuration default\r\nCouldn't generate dummy file 'datasets/logiqa_en/dummy/1.1.0/dummy_data/master.zip/LogiQA-dataset-master/README.md'. Ignore that if this file is not useful for dummy data.\r\nTraceback (most recent call last):\r\n File \"/home/aclifton/anaconda3/bin/datasets-cli\", line 36, in <module>\r\n service.run()\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/commands/dummy_data.py\", line 317, in run\r\n keep_uncompressed=self._keep_uncompressed,\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/commands/dummy_data.py\", line 355, in _autogenerate_dummy_data\r\n dataset_builder._prepare_split(split_generator)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/builder.py\", line 905, in _prepare_split\r\n example = self.info.features.encode_example(record)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 799, in encode_example\r\n return encode_nested_example(self, example)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 710, in encode_nested_example\r\n (k, encode_nested_example(sub_schema, sub_obj)) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 710, in <genexpr>\r\n (k, encode_nested_example(sub_schema, sub_obj)) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 737, in encode_nested_example\r\n return schema.encode_example(obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 522, in encode_example\r\n example_data = self.str2int(example_data)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 481, in str2int\r\n output.append(self._str2int[str(value)])\r\nKeyError: \"Some Cantonese don't like chili, so some southerners don't like chili.\"\r\n```",
"Hi ! The error happens when the script is verifying that the generated dummy data work fine with the dataset script.\r\nApparently it fails because the text `\"Some Cantonese don't like chili, so some southerners don't like chili.\"` was given in a field that is a ClassLabel feature (probably the `answer` field), while it actually expects \"a\", \"b\", \"c\" or \"d\". Can you fix the script so that it returns the expected labels for this field instead of the text ?\r\n\r\nAlso it would be awesome to rename this field `answerKey` instead of `answer` to have the same column names as the other multiple-choice-QA datasets in the library :) ",
"Ok getting closer! I got the dummy data to work. However I am now getting the following error:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en\r\n===================================================================== test session starts ======================================================================\r\nplatform linux -- Python 3.7.6, pytest-5.3.5, py-1.8.1, pluggy-0.13.1\r\nrootdir: /home/aclifton/data/hf_datasets_sprint/datasets\r\nplugins: astropy-header-0.1.2, xdist-2.1.0, doctestplus-0.5.0, forked-1.3.0, hypothesis-5.5.4, arraydiff-0.3, remotedata-0.3.2, openfiles-0.4.0\r\ncollected 0 items / 1 error \r\n\r\n============================================================================ ERRORS ============================================================================\r\n________________________________________________________ ERROR collecting tests/test_dataset_common.py _________________________________________________________\r\nImportError while importing test module '/home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\ntests/test_dataset_common.py:42: in <module>\r\n from datasets.packaged_modules import _PACKAGED_DATASETS_MODULES\r\nE ModuleNotFoundError: No module named 'datasets.packaged_modules'\r\n----------------------------------------------------------------------- Captured stderr ------------------------------------------------------------------------\r\n2021-02-10 11:06:14.345510: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-02-10 11:06:14.345551: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n======================================================================= warnings summary =======================================================================\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses\r\n import imp\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:693\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:693: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n if not isinstance(type_params, collections.Iterable):\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:532\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:532: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n if not isinstance(type_params, (collections.Sequence, set)):\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/elasticsearch/compat.py:38\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/elasticsearch/compat.py:38: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n from collections import Mapping\r\n\r\n-- Docs: https://docs.pytest.org/en/latest/warnings.html\r\n================================================================= 4 warnings, 1 error in 2.74s =================================================================\r\nERROR: not found: /home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en\r\n(no name '/home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en' in any of [<Module test_dataset_common.py>])\r\n\r\n```",
"Hi ! It looks like the version of `datasets` that is installed in your environment doesn't match the version of `datasets` you're using for the tests. Can you try uninstalling datasets and reinstall it again ?\r\n```\r\npip uninstall datasets -y\r\npip install -e .\r\n```",
"Closer still!\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git commit\r\n[logiqa_en 2664fe7f] fixed several issues with logiqa_en.\r\n 4 files changed, 324 insertions(+)\r\n create mode 100644 datasets/logiqa_en/README.md\r\n create mode 100644 datasets/logiqa_en/dataset_infos.json\r\n create mode 100644 datasets/logiqa_en/dummy/1.1.0/dummy_data.zip\r\n create mode 100644 datasets/logiqa_en/logiqa_en.py\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git fetch upstream\r\nremote: Enumerating objects: 1, done.\r\nremote: Counting objects: 100% (1/1), done.\r\nremote: Total 1 (delta 0), reused 0 (delta 0), pack-reused 0\r\nUnpacking objects: 100% (1/1), 590 bytes | 590.00 KiB/s, done.\r\nFrom https://github.com/huggingface/datasets\r\n 6e114a0c..318b09eb master -> upstream/master\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git rebase upstream/master \r\nerror: cannot rebase: You have unstaged changes.\r\nerror: Please commit or stash them.\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git push -u origin logiqa_en\r\nUsername for 'https://github.com': aclifton314\r\nPassword for 'https://[email protected]': \r\nTo https://github.com/aclifton314/datasets\r\n ! [rejected] logiqa_en -> logiqa_en (non-fast-forward)\r\nerror: failed to push some refs to 'https://github.com/aclifton314/datasets'\r\nhint: Updates were rejected because the tip of your current branch is behind\r\nhint: its remote counterpart. Integrate the remote changes (e.g.\r\nhint: 'git pull ...') before pushing again.\r\nhint: See the 'Note about fast-forwards' in 'git push --help' for details.\r\n```",
"Thanks for your contribution, @aclifton314. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2020-12-17T15:42:00Z" | "2022-10-03T09:38:30Z" | "2022-10-03T09:38:30Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1595.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1595",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1595.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1595"
} | logiqa in english. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/719/comments | https://api.github.com/repos/huggingface/datasets/issues/719/events | https://github.com/huggingface/datasets/pull/719 | 716,492,263 | MDExOlB1bGxSZXF1ZXN0NDk5MjE5Mjg2 | 719 | Fix train_test_split output format | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-10-07T12:39:01Z" | "2020-10-07T13:38:08Z" | "2020-10-07T13:38:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/719.diff",
"html_url": "https://github.com/huggingface/datasets/pull/719",
"merged_at": "2020-10-07T13:38:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/719.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/719"
} | There was an issue in the `transmit_format` wrapper that returned bad formats when using train_test_split.
This was due to `column_names` being handled as a List[str] instead of Dict[str, List[str]] when the dataset transform (train_test_split) returns a DatasetDict (one set of column names per split).
This should fix @timothyjlaurent 's issue in #620 and fix #676
I added tests for `transmit_format` so that it doesn't happen again | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/719/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5543/comments | https://api.github.com/repos/huggingface/datasets/issues/5543/events | https://github.com/huggingface/datasets/issues/5543 | 1,588,951,379 | I_kwDODunzps5etXlT | 5,543 | the pile datasets url seems to change back | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https://api.github.com/users/wjfwzzc/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wjfwzzc",
"id": 5126316,
"login": "wjfwzzc",
"node_id": "MDQ6VXNlcjUxMjYzMTY=",
"organizations_url": "https://api.github.com/users/wjfwzzc/orgs",
"received_events_url": "https://api.github.com/users/wjfwzzc/received_events",
"repos_url": "https://api.github.com/users/wjfwzzc/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wjfwzzc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wjfwzzc/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wjfwzzc"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @wjfwzzc.\r\n\r\nI am transferring this issue to the corresponding dataset on the Hub: https://huggingface.co/datasets/bookcorpusopen/discussions/1",
"Thank you. All fixes are done:\r\n- [x] https://huggingface.co/datasets/bookcorpusopen/discussions/2\r\n- [x] https://huggingface.co/datasets/the_pile/discussions/1\r\n- [x] https://huggingface.co/datasets/the_pile_books3/discussions/1\r\n- [x] https://huggingface.co/datasets/the_pile_openwebtext2/discussions/2\r\n- [x] https://huggingface.co/datasets/the_pile_stack_exchange/discussions/2"
] | "2023-02-17T08:40:11Z" | "2023-02-21T06:37:00Z" | "2023-02-20T08:41:33Z" | NONE | null | null | null | ### Describe the bug
in #3627, the host url of the pile dataset became `https://mystic.the-eye.eu`. Now the new url is broken, but `https://the-eye.eu` seems to work again.
### Steps to reproduce the bug
```python3
from datasets import load_dataset
dataset = load_dataset("bookcorpusopen")
```
shows
```python3
ConnectionError: Couldn't reach https://mystic.the-eye.eu/public/AI/pile_preliminary_components/books1.tar.gz (ProxyError(MaxRetryError("HTTPSConnectionPool(host='mystic.the-eye.eu', port=443): Max retries exceeded with url: /public/AI/pile_pr
eliminary_components/books1.tar.gz (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 504 Gateway Timeout')))")))
```
### Expected behavior
Downloading as normal.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.4.143.bsk.7-amd64-x86_64-with-glibc2.31
- Python version: 3.9.2
- PyArrow version: 6.0.1
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5543/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5543/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5409/comments | https://api.github.com/repos/huggingface/datasets/issues/5409/events | https://github.com/huggingface/datasets/pull/5409 | 1,520,374,219 | PR_kwDODunzps5Gs3nL | 5,409 | Fix deprecation warning when use_auth_token passed to download_and_prepare | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008627 / 0.011353 (-0.002726) | 0.004572 / 0.011008 (-0.006436) | 0.099653 / 0.038508 (0.061145) | 0.030010 / 0.023109 (0.006901) | 0.300492 / 0.275898 (0.024594) | 0.360443 / 0.323480 (0.036963) | 0.007125 / 0.007986 (-0.000860) | 0.003431 / 0.004328 (-0.000897) | 0.078103 / 0.004250 (0.073852) | 0.036884 / 0.037052 (-0.000168) | 0.312289 / 0.258489 (0.053800) | 0.345795 / 0.293841 (0.051954) | 0.034001 / 0.128546 (-0.094545) | 0.011405 / 0.075646 (-0.064242) | 0.321258 / 0.419271 (-0.098013) | 0.040591 / 0.043533 (-0.002942) | 0.301114 / 0.255139 (0.045975) | 0.337226 / 0.283200 (0.054027) | 0.088055 / 0.141683 (-0.053628) | 1.451892 / 1.452155 (-0.000263) | 1.494881 / 1.492716 (0.002164) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186749 / 0.018006 (0.168743) | 0.414089 / 0.000490 (0.413600) | 0.002475 / 0.000200 (0.002275) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022413 / 0.037411 (-0.014999) | 0.097547 / 0.014526 (0.083021) | 0.104196 / 0.176557 (-0.072361) | 0.139819 / 0.737135 (-0.597316) | 0.108345 / 0.296338 (-0.187994) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424750 / 0.215209 (0.209541) | 4.261513 / 2.077655 (2.183859) | 2.150888 / 1.504120 (0.646768) | 1.935925 / 1.541195 (0.394730) | 1.867456 / 1.468490 (0.398966) | 0.694384 / 4.584777 (-3.890393) | 3.370539 / 3.745712 (-0.375173) | 1.886714 / 5.269862 (-3.383148) | 1.256542 / 4.565676 (-3.309135) | 0.082841 / 0.424275 (-0.341434) | 0.012344 / 0.007607 (0.004737) | 0.529801 / 0.226044 (0.303757) | 5.315438 / 2.268929 (3.046509) | 2.460517 / 55.444624 (-52.984107) | 2.261840 / 6.876477 (-4.614637) | 2.338710 / 2.142072 (0.196638) | 0.818433 / 4.805227 (-3.986794) | 0.150571 / 6.500664 (-6.350093) | 0.066524 / 0.075469 (-0.008945) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253086 / 1.841788 (-0.588702) | 13.862614 / 8.074308 (5.788306) | 14.145149 / 10.191392 (3.953757) | 0.165867 / 0.680424 (-0.514557) | 0.029269 / 0.534201 (-0.504932) | 0.397579 / 0.579283 (-0.181704) | 0.401113 / 0.434364 (-0.033251) | 0.463269 / 0.540337 (-0.077068) | 0.551494 / 1.386936 (-0.835442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006610 / 0.011353 (-0.004743) | 0.004583 / 0.011008 (-0.006425) | 0.096680 / 0.038508 (0.058172) | 0.027352 / 0.023109 (0.004242) | 0.409292 / 0.275898 (0.133394) | 0.445790 / 0.323480 (0.122310) | 0.004987 / 0.007986 (-0.002999) | 0.003462 / 0.004328 (-0.000866) | 0.074472 / 0.004250 (0.070221) | 0.037875 / 0.037052 (0.000822) | 0.411496 / 0.258489 (0.153007) | 0.454721 / 0.293841 (0.160880) | 0.031884 / 0.128546 (-0.096662) | 0.011682 / 0.075646 (-0.063964) | 0.318831 / 0.419271 (-0.100441) | 0.041781 / 0.043533 (-0.001752) | 0.411247 / 0.255139 (0.156108) | 0.436215 / 0.283200 (0.153016) | 0.090021 / 0.141683 (-0.051662) | 1.492385 / 1.452155 (0.040231) | 1.565182 / 1.492716 (0.072465) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221263 / 0.018006 (0.203257) | 0.399074 / 0.000490 (0.398584) | 0.000405 / 0.000200 (0.000205) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025139 / 0.037411 (-0.012272) | 0.097952 / 0.014526 (0.083426) | 0.106078 / 0.176557 (-0.070479) | 0.143231 / 0.737135 (-0.593904) | 0.109177 / 0.296338 (-0.187161) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441668 / 0.215209 (0.226459) | 4.403247 / 2.077655 (2.325592) | 2.072749 / 1.504120 (0.568629) | 1.866248 / 1.541195 (0.325053) | 1.906418 / 1.468490 (0.437927) | 0.697234 / 4.584777 (-3.887543) | 3.412016 / 3.745712 (-0.333696) | 1.852572 / 5.269862 (-3.417289) | 1.168270 / 4.565676 (-3.397407) | 0.082132 / 0.424275 (-0.342144) | 0.013191 / 0.007607 (0.005584) | 0.548932 / 0.226044 (0.322888) | 5.503891 / 2.268929 (3.234962) | 2.539784 / 55.444624 (-52.904841) | 2.181292 / 6.876477 (-4.695184) | 2.242197 / 2.142072 (0.100125) | 0.804027 / 4.805227 (-4.001200) | 0.151649 / 6.500664 (-6.349015) | 0.067088 / 0.075469 (-0.008381) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.296267 / 1.841788 (-0.545520) | 13.986484 / 8.074308 (5.912176) | 13.440705 / 10.191392 (3.249313) | 0.140787 / 0.680424 (-0.539637) | 0.017132 / 0.534201 (-0.517069) | 0.381899 / 0.579283 (-0.197384) | 0.385535 / 0.434364 (-0.048829) | 0.439957 / 0.540337 (-0.100380) | 0.532980 / 1.386936 (-0.853956) |\n\n</details>\n</details>\n\n\n"
] | "2023-01-05T09:10:58Z" | "2023-01-06T11:06:16Z" | "2023-01-06T10:59:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5409.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5409",
"merged_at": "2023-01-06T10:59:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5409.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5409"
} | The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, so that no deprecation warning is raised.
Fix #5407. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5409/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5409/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1436/comments | https://api.github.com/repos/huggingface/datasets/issues/1436/events | https://github.com/huggingface/datasets/pull/1436 | 760,873,132 | MDExOlB1bGxSZXF1ZXN0NTM1NjI1MDM0 | 1,436 | add ALT | {
"avatar_url": "https://avatars.githubusercontent.com/u/6429850?v=4",
"events_url": "https://api.github.com/users/chameleonTK/events{/privacy}",
"followers_url": "https://api.github.com/users/chameleonTK/followers",
"following_url": "https://api.github.com/users/chameleonTK/following{/other_user}",
"gists_url": "https://api.github.com/users/chameleonTK/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/chameleonTK",
"id": 6429850,
"login": "chameleonTK",
"node_id": "MDQ6VXNlcjY0Mjk4NTA=",
"organizations_url": "https://api.github.com/users/chameleonTK/orgs",
"received_events_url": "https://api.github.com/users/chameleonTK/received_events",
"repos_url": "https://api.github.com/users/chameleonTK/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/chameleonTK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chameleonTK/subscriptions",
"type": "User",
"url": "https://api.github.com/users/chameleonTK"
} | [] | closed | false | null | [] | null | [
"The errors in de CI are fixed on master so it's fine"
] | "2020-12-10T04:17:21Z" | "2020-12-13T16:14:18Z" | "2020-12-11T15:52:41Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1436.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1436",
"merged_at": "2020-12-11T15:52:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1436.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1436"
} | ALT dataset -- https://www2.nict.go.jp/astrec-att/member/mutiyama/ALT/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1436/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1436/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1674/comments | https://api.github.com/repos/huggingface/datasets/issues/1674/events | https://github.com/huggingface/datasets/issues/1674 | 777,321,840 | MDU6SXNzdWU3NzczMjE4NDA= | 1,674 | dutch_social can't be loaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/10134844?v=4",
"events_url": "https://api.github.com/users/koenvandenberge/events{/privacy}",
"followers_url": "https://api.github.com/users/koenvandenberge/followers",
"following_url": "https://api.github.com/users/koenvandenberge/following{/other_user}",
"gists_url": "https://api.github.com/users/koenvandenberge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/koenvandenberge",
"id": 10134844,
"login": "koenvandenberge",
"node_id": "MDQ6VXNlcjEwMTM0ODQ0",
"organizations_url": "https://api.github.com/users/koenvandenberge/orgs",
"received_events_url": "https://api.github.com/users/koenvandenberge/received_events",
"repos_url": "https://api.github.com/users/koenvandenberge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/koenvandenberge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koenvandenberge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/koenvandenberge"
} | [] | closed | false | null | [] | null | [
"exactly the same issue in some other datasets.\r\nDid you find any solution??\r\n",
"Hi @koenvandenberge and @alighofrani95!\r\nThe datasets you're experiencing issues with were most likely added recently to the `datasets` library, meaning they have not been released yet. They will be released with the v2 of the library.\r\nMeanwhile, you can still load the datasets using one of the techniques described in this issue: #1641 \r\nLet me know if this helps!",
"Maybe we should do a small release on Monday in the meantime @lhoestq ?",
"Yes sure !",
"I just did the release :)\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `dutch_social` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"dutch_social\")\r\n```",
"@lhoestq could you also shed light on the Hindi Wikipedia Dataset for issue number #1673. Will this also be available in the new release that you committed recently?",
"The issue is different for this one, let me give more details in the issue",
"Okay. Could you comment on the #1673 thread? Actually @thomwolf had commented that if i use datasets library from source, it would allow me to download the Hindi Wikipedia Dataset but even the version 1.1.3 gave me the same issue. The details are there in the issue #1673 thread."
] | "2021-01-01T17:37:08Z" | "2022-10-05T13:03:26Z" | "2022-10-05T13:03:26Z" | NONE | null | null | null | Hi all,
I'm trying to import the `dutch_social` dataset described [here](https://huggingface.co/datasets/dutch_social).
However, the code that should load the data doesn't seem to be working, in particular because the corresponding files can't be found at the provided links.
```
(base) Koens-MacBook-Pro:~ koenvandenberge$ python
Python 3.7.4 (default, Aug 13 2019, 15:17:50)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from datasets import load_dataset
dataset = load_dataset(
'dutch_social')
>>> dataset = load_dataset(
... 'dutch_social')
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at dutch_social/dutch_social.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1674/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1674/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/934 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/934/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/934/comments | https://api.github.com/repos/huggingface/datasets/issues/934/events | https://github.com/huggingface/datasets/pull/934 | 753,860,095 | MDExOlB1bGxSZXF1ZXN0NTI5ODU2ODY4 | 934 | small updates to the "add new dataset" guide | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/VictorSanh",
"id": 16107619,
"login": "VictorSanh",
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"type": "User",
"url": "https://api.github.com/users/VictorSanh"
} | [] | closed | false | null | [] | null | [
"cc @yjernite @lhoestq @thomwolf "
] | "2020-11-30T22:49:10Z" | "2020-12-01T04:56:22Z" | "2020-11-30T23:14:00Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/934.diff",
"html_url": "https://github.com/huggingface/datasets/pull/934",
"merged_at": "2020-11-30T23:14:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/934.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/934"
} | small updates (corrections/typos) to the "add new dataset" guide | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/934/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/934/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4667/comments | https://api.github.com/repos/huggingface/datasets/issues/4667/events | https://github.com/huggingface/datasets/issues/4667 | 1,299,735,703 | I_kwDODunzps5NeGSX | 4,667 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | {
"avatar_url": "https://avatars.githubusercontent.com/u/21364546?v=4",
"events_url": "https://api.github.com/users/hungnmai/events{/privacy}",
"followers_url": "https://api.github.com/users/hungnmai/followers",
"following_url": "https://api.github.com/users/hungnmai/following{/other_user}",
"gists_url": "https://api.github.com/users/hungnmai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hungnmai",
"id": 21364546,
"login": "hungnmai",
"node_id": "MDQ6VXNlcjIxMzY0NTQ2",
"organizations_url": "https://api.github.com/users/hungnmai/orgs",
"received_events_url": "https://api.github.com/users/hungnmai/received_events",
"repos_url": "https://api.github.com/users/hungnmai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hungnmai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hungnmai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hungnmai"
} | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
] | null | [] | "2022-07-09T18:03:15Z" | "2022-07-11T07:47:15Z" | "2022-07-11T07:47:15Z" | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4667/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/956 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/956/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/956/comments | https://api.github.com/repos/huggingface/datasets/issues/956/events | https://github.com/huggingface/datasets/pull/956 | 754,368,378 | MDExOlB1bGxSZXF1ZXN0NTMwMjgwMzU1 | 956 | Add Norwegian NER | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | [
"Merging this one, good job and thank you @jplu :) "
] | "2020-12-01T12:51:02Z" | "2020-12-02T08:53:11Z" | "2020-12-01T18:09:21Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/956.diff",
"html_url": "https://github.com/huggingface/datasets/pull/956",
"merged_at": "2020-12-01T18:09:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/956.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/956"
} | This PR adds the [Norwegian NER](https://github.com/ljos/navnkjenner) dataset.
I have added the `conllu` package as a test dependency. This is required to properly parse the `.conllu` files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/956/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/956/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5159 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5159/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5159/comments | https://api.github.com/repos/huggingface/datasets/issues/5159/events | https://github.com/huggingface/datasets/pull/5159 | 1,422,172,080 | PR_kwDODunzps5BfBN9 | 5,159 | fsspec lock reset in multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-25T09:41:59Z" | "2022-11-03T20:51:15Z" | "2022-11-03T20:48:53Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5159.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5159",
"merged_at": "2022-11-03T20:48:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5159.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5159"
} | `fsspec` added a clean way of resetting its lock - instead of doing it manually | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5159/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5159/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2220 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2220/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2220/comments | https://api.github.com/repos/huggingface/datasets/issues/2220/events | https://github.com/huggingface/datasets/pull/2220 | 857,774,626 | MDExOlB1bGxSZXF1ZXN0NjE1MTM4NDQz | 2,220 | Fix infinite loop in WindowsFileLock | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"How is it possible to get an infinite loop ? Can you add more details ?",
"Yes, in Windows, if the filename is too long, a `FileNotFoundError` is raised. The exception should be raised in this case. Otherwise, we get into an infinite loop.\r\n\r\nIf other process has the file locked, then `PermissionError` is raised. In this case, `pass` is OK.",
"Note that the filelock module comes from this project that hasn't changed in years - while still being used by ten of thousands of projects:\r\nhttps://github.com/benediktschmitt/py-filelock\r\n\r\nUnless we have proper tests for this, I wouldn't recommend to change it",
"I'm pretty sure many things from the library could break for windows users that haven't disabled the max path length limit.\r\nMaybe it would be simpler to simply raise an error on startup. For exampe, for windows users the error could ask them to disable the limit if it's not been disabled yet ?"
] | "2021-04-14T10:49:58Z" | "2021-04-14T14:59:50Z" | "2021-04-14T14:59:34Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2220.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2220",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2220.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2220"
} | Raise exception to avoid infinite loop. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2220/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2220/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2227/comments | https://api.github.com/repos/huggingface/datasets/issues/2227/events | https://github.com/huggingface/datasets/pull/2227 | 859,771,526 | MDExOlB1bGxSZXF1ZXN0NjE2Nzk1NjMx | 2,227 | Use update_metadata_with_features decorator in class_encode_column method | {
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SBrandeis",
"id": 33657802,
"login": "SBrandeis",
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SBrandeis"
} | [] | closed | false | null | [] | null | [] | "2021-04-16T12:31:41Z" | "2021-04-16T13:49:40Z" | "2021-04-16T13:49:39Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2227.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2227",
"merged_at": "2021-04-16T13:49:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2227.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2227"
} | Following @mariosasko 's comment | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2227/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4144 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4144/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4144/comments | https://api.github.com/repos/huggingface/datasets/issues/4144/events | https://github.com/huggingface/datasets/pull/4144 | 1,200,016,983 | PR_kwDODunzps42ARmu | 4,144 | Fix splits in local packaged modules, local datasets without script and hub datasets without script | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks !\r\nI'm in favor of this change, even though it's a breaking change:\r\n\r\nif you had a dataset\r\n```\r\ndata/\r\n train.csv\r\n test.csv\r\n```\r\n\r\nthen running this code would now return both train and test splits:\r\n```python\r\nload_dataset(\"csv\", data_dir=\"data/\")\r\n```\r\nwhereas right now it returns only a train split with the data from both CSV files.\r\n\r\nIn my opinion it's ok do do this breaking change because:\r\n- it makes this behavior consistent with `load_dataset(\"path/to/data\")` that also returns both splits: data_files resolution must be the same\r\n- I don't expect too many affected users (unless people really wanted to group train and test images in the train split on purpose ?) compared to the many new users to come (especially with #4069 )\r\n- this usage will become more and more common as we add packaged builder and imagefolder/audiofolder usage grows, so it may be better to do this change early\r\n\r\nLet me know if you think this is acceptable @mariosasko @albertvillanova or not, and if you think we need to first have a warning for some time before switching to this new behavior",
"Also, if people really want to put train and test, say, images in a single train split they could do \r\n`load_dataset(\"imagefolder\", data_files={\"train\": \"/path/to/data/**})`. Probably (arguably :)), if this is a more counterintuitive case, then it should require manual files specification, not a default one (in which we expect that users do want to infer splits from filenames / dir structure but currently they have to pass smth like `{\"train\": \"/path/to/data/train*\", \"test\": \"/path/to/data/test*\"}` explicitly as `data_files`) ",
"I also like this change, and I don't think we even need a warning during the transition period, considering I've been asked several times since the release of `imagefolder` why splits are not correctly inferred if the directory structure is as follows:\r\n```\r\ndata_dir\r\n train\r\n label_a\r\n 0.jpg\r\n ...\r\n label_b \r\n 0.jpg\r\n ...\r\n test\r\n label_a\r\n 0.jpg\r\n ...\r\n label_b \r\n 0.jpg\r\n ...\r\n```",
"Cool ! Feel free to add a test (maybe something similar to `test_PackagedDatasetModuleFactory_with_data_dir` but with a data_dir that contains several splits) and mark this PR as ready for review then @polinaeterna :)",
"@lhoestq @mariosasko do you think it's a good idea to do the same with `HubDatasetModuleFactoryWithoutScript` and `LocalDatasetModuleFactoryWithoutScript` (see the latest change). If we agree on the current change, doing \r\n```python\r\nds = load_dataset(\"polinaeterna/jsonl_test\", data_dir=\"data/\")\r\n```\r\non dataset with the following structure:\r\n```\r\ntrain.jsonl\r\ntest.jsonl\r\ndata/\r\n train.jsonl\r\n test.jsonl\r\n```\r\nwill result in having two splits from files under `data/` dir in specified repo, while master version returns a single train split. \r\nThe same would be for local dataset without script if doing smth like:\r\n```python\r\nds = load_dataset(\"/home/polina/workspace/repos/jsonl_test\", data_dir=\"/home/polina/workspace/repos/jsonl_test/data\")\r\n```\r\n(though I'm not sure I understand this use case :D)\r\nLet me know if you think we should preserve the same logic for all factories or if I should roll back this change.",
"@lhoestq to test passing subdirectory (`base_path`) to data_files functions and methods, I extended the temporary test directory with data so that it contains subdirectory. Because of that the number of files in this directory increased, so I had to change some numbers and patterns to account for this change - [907ddf0](https://github.com/huggingface/datasets/pull/4144/commits/907ddf09d3afece5afbae18675c859d6e453f2bf)\r\n\r\nDo you think it's ok? Another option is to create another tmp dir and do all the checks inside it. "
] | "2022-04-11T13:57:33Z" | "2022-04-29T09:12:14Z" | "2022-04-28T21:02:45Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4144.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4144",
"merged_at": "2022-04-28T21:02:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4144.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4144"
} | fixes #4150
I suggest to infer splits structure from files when `data_dir` is passed with `get_patterns_locally`, analogous to what's done in `LocalDatasetModuleFactoryWithoutScript` with `self.path`, instead of generating files with `data_dir/**` patterns and putting them all into a single default (train) split.
I would also suggest to align `HubDatasetModuleFactoryWithoutScript` and `LocalDatasetModuleFactoryWithoutScript` with this logic (remove `data_files = os.path.join(data_dir, "**")`). It's not reflected in the current code now as I'd like to discuss it cause I might be unaware of some use cases. @lhoestq @mariosasko @albertvillanova WDYT? | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4144/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4144/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5626/comments | https://api.github.com/repos/huggingface/datasets/issues/5626/events | https://github.com/huggingface/datasets/pull/5626 | 1,619,252,984 | PR_kwDODunzps5LyBT4 | 5,626 | Support streaming datasets with numpy.load | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006607 / 0.011353 (-0.004746) | 0.004610 / 0.011008 (-0.006398) | 0.100673 / 0.038508 (0.062165) | 0.027739 / 0.023109 (0.004630) | 0.326290 / 0.275898 (0.050392) | 0.344296 / 0.323480 (0.020816) | 0.005021 / 0.007986 (-0.002964) | 0.003327 / 0.004328 (-0.001002) | 0.077779 / 0.004250 (0.073529) | 0.040237 / 0.037052 (0.003185) | 0.308992 / 0.258489 (0.050503) | 0.355017 / 0.293841 (0.061176) | 0.031203 / 0.128546 (-0.097343) | 0.011749 / 0.075646 (-0.063898) | 0.327431 / 0.419271 (-0.091840) | 0.043033 / 0.043533 (-0.000500) | 0.309713 / 0.255139 (0.054574) | 0.336550 / 0.283200 (0.053351) | 0.084891 / 0.141683 (-0.056792) | 1.555641 / 1.452155 (0.103487) | 1.613214 / 1.492716 (0.120497) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216269 / 0.018006 (0.198262) | 0.422066 / 0.000490 (0.421576) | 0.004055 / 0.000200 (0.003855) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023759 / 0.037411 (-0.013652) | 0.096937 / 0.014526 (0.082411) | 0.105312 / 0.176557 (-0.071244) | 0.167840 / 0.737135 (-0.569295) | 0.107998 / 0.296338 (-0.188340) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458315 / 0.215209 (0.243106) | 4.584803 / 2.077655 (2.507148) | 2.193641 / 1.504120 (0.689521) | 1.981494 / 1.541195 (0.440299) | 2.020358 / 1.468490 (0.551868) | 0.696763 / 4.584777 (-3.888014) | 3.388432 / 3.745712 (-0.357280) | 3.335038 / 5.269862 (-1.934823) | 1.648551 / 4.565676 (-2.917126) | 0.083753 / 0.424275 (-0.340522) | 0.012855 / 0.007607 (0.005248) | 0.562331 / 0.226044 (0.336286) | 5.649259 / 2.268929 (3.380330) | 2.680309 / 55.444624 (-52.764315) | 2.319297 / 6.876477 (-4.557180) | 2.444016 / 2.142072 (0.301943) | 0.809821 / 4.805227 (-3.995407) | 0.152855 / 6.500664 (-6.347809) | 0.067756 / 0.075469 (-0.007713) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.213318 / 1.841788 (-0.628470) | 13.887822 / 8.074308 (5.813514) | 14.276325 / 10.191392 (4.084933) | 0.156227 / 0.680424 (-0.524197) | 0.016377 / 0.534201 (-0.517824) | 0.377080 / 0.579283 (-0.202203) | 0.386561 / 0.434364 (-0.047803) | 0.435631 / 0.540337 (-0.104707) | 0.520863 / 1.386936 (-0.866073) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006740 / 0.011353 (-0.004613) | 0.004704 / 0.011008 (-0.006304) | 0.076840 / 0.038508 (0.038331) | 0.027519 / 0.023109 (0.004409) | 0.343219 / 0.275898 (0.067321) | 0.376810 / 0.323480 (0.053330) | 0.005048 / 0.007986 (-0.002938) | 0.003356 / 0.004328 (-0.000972) | 0.077098 / 0.004250 (0.072848) | 0.038601 / 0.037052 (0.001548) | 0.345723 / 0.258489 (0.087233) | 0.388635 / 0.293841 (0.094794) | 0.033612 / 0.128546 (-0.094934) | 0.011689 / 0.075646 (-0.063957) | 0.086446 / 0.419271 (-0.332825) | 0.044390 / 0.043533 (0.000857) | 0.343763 / 0.255139 (0.088624) | 0.368591 / 0.283200 (0.085392) | 0.091605 / 0.141683 (-0.050078) | 1.478615 / 1.452155 (0.026461) | 1.580858 / 1.492716 (0.088142) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223547 / 0.018006 (0.205541) | 0.411243 / 0.000490 (0.410753) | 0.000916 / 0.000200 (0.000716) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025223 / 0.037411 (-0.012189) | 0.100970 / 0.014526 (0.086445) | 0.108178 / 0.176557 (-0.068378) | 0.156827 / 0.737135 (-0.580308) | 0.111431 / 0.296338 (-0.184907) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434168 / 0.215209 (0.218959) | 4.361874 / 2.077655 (2.284219) | 2.060735 / 1.504120 (0.556615) | 1.861100 / 1.541195 (0.319906) | 1.920692 / 1.468490 (0.452202) | 0.697909 / 4.584777 (-3.886868) | 3.477036 / 3.745712 (-0.268676) | 3.002469 / 5.269862 (-2.267392) | 1.449325 / 4.565676 (-3.116351) | 0.083034 / 0.424275 (-0.341241) | 0.012805 / 0.007607 (0.005198) | 0.531391 / 0.226044 (0.305347) | 5.323015 / 2.268929 (3.054086) | 2.488605 / 55.444624 (-52.956020) | 2.158254 / 6.876477 (-4.718222) | 2.189633 / 2.142072 (0.047560) | 0.805972 / 4.805227 (-3.999256) | 0.153105 / 6.500664 (-6.347559) | 0.068909 / 0.075469 (-0.006561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.276851 / 1.841788 (-0.564937) | 14.431510 / 8.074308 (6.357202) | 14.544788 / 10.191392 (4.353396) | 0.146589 / 0.680424 (-0.533835) | 0.016890 / 0.534201 (-0.517311) | 0.379897 / 0.579283 (-0.199387) | 0.389153 / 0.434364 (-0.045211) | 0.440097 / 0.540337 (-0.100241) | 0.524191 / 1.386936 (-0.862745) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-10T16:33:39Z" | "2023-03-21T06:36:05Z" | "2023-03-21T06:28:54Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5626.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5626",
"merged_at": "2023-03-21T06:28:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5626.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5626"
} | Support streaming datasets with `numpy.load`.
See: https://huggingface.co/datasets/qgallouedec/gia_dataset/discussions/1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5626/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3938 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3938/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3938/comments | https://api.github.com/repos/huggingface/datasets/issues/3938/events | https://github.com/huggingface/datasets/pull/3938 | 1,170,875,417 | PR_kwDODunzps40hnjM | 3,938 | Avoid info log messages from transformers in FrugalScore metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3938). All of your documentation changes will be reflected on that endpoint."
] | "2022-03-16T11:11:29Z" | "2022-03-17T08:37:25Z" | "2022-03-17T08:37:24Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3938.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3938",
"merged_at": "2022-03-17T08:37:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3938.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3938"
} | Fix #3928. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3938/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3938/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6451/comments | https://api.github.com/repos/huggingface/datasets/issues/6451/events | https://github.com/huggingface/datasets/issues/6451 | 2,010,693,912 | I_kwDODunzps532MEY | 6,451 | Unable to read "marsyas/gtzan" data | {
"avatar_url": "https://avatars.githubusercontent.com/u/32300890?v=4",
"events_url": "https://api.github.com/users/gerald-wrona/events{/privacy}",
"followers_url": "https://api.github.com/users/gerald-wrona/followers",
"following_url": "https://api.github.com/users/gerald-wrona/following{/other_user}",
"gists_url": "https://api.github.com/users/gerald-wrona/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gerald-wrona",
"id": 32300890,
"login": "gerald-wrona",
"node_id": "MDQ6VXNlcjMyMzAwODkw",
"organizations_url": "https://api.github.com/users/gerald-wrona/orgs",
"received_events_url": "https://api.github.com/users/gerald-wrona/received_events",
"repos_url": "https://api.github.com/users/gerald-wrona/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gerald-wrona/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gerald-wrona/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gerald-wrona"
} | [] | closed | false | null | [] | null | [
"Hi! We've merged a [PR](https://huggingface.co/datasets/marsyas/gtzan/discussions/1) that fixes the script's path logic on Windows.",
"I have transferred the discussion to the corresponding dataset: https://huggingface.co/datasets/marsyas/gtzan/discussions/2\r\n\r\nLet's continue there.",
"@mariosasko @albertvillanova \r\n\r\nThank you both very much for the speedy resolution :)"
] | "2023-11-25T15:13:17Z" | "2023-12-01T12:53:46Z" | "2023-11-27T09:36:25Z" | NONE | null | null | null | Hi, this is my code and the error:
```
from datasets import load_dataset
gtzan = load_dataset("marsyas/gtzan", "all")
```
[error_trace.txt](https://github.com/huggingface/datasets/files/13464397/error_trace.txt)
[audio_yml.txt](https://github.com/huggingface/datasets/files/13464410/audio_yml.txt)
Python 3.11.5
Jupyter Notebook 6.5.4
Windows 10
I'm able to download and work with other datasets, but not this one. For example, both these below work fine:
```
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "pl", split="train", streaming=True)
minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
Thanks for your help
https://huggingface.co/datasets/marsyas/gtzan/tree/main | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6451/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6451/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2112 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2112/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2112/comments | https://api.github.com/repos/huggingface/datasets/issues/2112/events | https://github.com/huggingface/datasets/pull/2112 | 841,098,008 | MDExOlB1bGxSZXF1ZXN0NjAwODgyMjA0 | 2,112 | Support for legal NLP datasets (EURLEX and ECtHR cases) | {
"avatar_url": "https://avatars.githubusercontent.com/u/1626984?v=4",
"events_url": "https://api.github.com/users/iliaschalkidis/events{/privacy}",
"followers_url": "https://api.github.com/users/iliaschalkidis/followers",
"following_url": "https://api.github.com/users/iliaschalkidis/following{/other_user}",
"gists_url": "https://api.github.com/users/iliaschalkidis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/iliaschalkidis",
"id": 1626984,
"login": "iliaschalkidis",
"node_id": "MDQ6VXNlcjE2MjY5ODQ=",
"organizations_url": "https://api.github.com/users/iliaschalkidis/orgs",
"received_events_url": "https://api.github.com/users/iliaschalkidis/received_events",
"repos_url": "https://api.github.com/users/iliaschalkidis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/iliaschalkidis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iliaschalkidis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/iliaschalkidis"
} | [] | closed | false | null | [] | null | [] | "2021-03-25T16:24:17Z" | "2021-03-25T18:39:31Z" | "2021-03-25T18:34:31Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2112.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2112",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2112.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2112"
} | Add support for two legal NLP datasets:
- EURLEX (https://www.aclweb.org/anthology/P19-1636/)
- ECtHR cases (https://arxiv.org/abs/2103.13084) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2112/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2112/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1038 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1038/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1038/comments | https://api.github.com/repos/huggingface/datasets/issues/1038/events | https://github.com/huggingface/datasets/pull/1038 | 755,987,997 | MDExOlB1bGxSZXF1ZXN0NTMxNjA2Njgw | 1,038 | add med_hop | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patil-suraj",
"id": 27137566,
"login": "patil-suraj",
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patil-suraj"
} | [] | closed | false | null | [] | null | [] | "2020-12-03T08:40:27Z" | "2020-12-03T16:53:13Z" | "2020-12-03T16:52:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1038.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1038",
"merged_at": "2020-12-03T16:52:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1038.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1038"
} | This PR adds the MedHop dataset from the QAngaroo multi hop reading comprehension datasets
More info:
http://qangaroo.cs.ucl.ac.uk/index.html | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1038/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1038/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4137 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4137/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4137/comments | https://api.github.com/repos/huggingface/datasets/issues/4137/events | https://github.com/huggingface/datasets/pull/4137 | 1,199,000,453 | PR_kwDODunzps419D6A | 4,137 | Add single dataset citations for TweetEval | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The `test_dataset_cards` method is failing with the error:\r\n\r\n```\r\nif error_messages:\r\n> raise ValueError(\"\\n\".join(error_messages))\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE YAML tags:\r\nE The following typing errors are found: {'annotations_creators': \"(Expected `typing.List` with length > 0. Found value of type: `<class 'list'>`, with length: 0.\\n)\\nOR\\n(Expected `typing.Dict` with length > 0. Found value of type: `<class 'list'>`, with length: 0.\\n)\"}\r\n```\r\n\r\nAdding `found` as annotation creators."
] | "2022-04-10T11:51:54Z" | "2022-04-12T07:57:22Z" | "2022-04-12T07:51:15Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4137.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4137",
"merged_at": "2022-04-12T07:51:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4137.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4137"
} | This PR adds single data citations as per request of the original creators of the TweetEval dataset.
This is a recent email from the creator:
> Could I ask you a favor? Would you be able to add at the end of the README the citations of the single datasets as well? You can just copy our readme maybe? https://github.com/cardiffnlp/tweeteval#citing-tweeteval
(just to be sure that the creator of the single datasets also get credits when tweeteval is used)
Please let me know if this looks okay or if any changes are needed.
Thanks,
Gunjan
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4137/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4137/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4175/comments | https://api.github.com/repos/huggingface/datasets/issues/4175/events | https://github.com/huggingface/datasets/pull/4175 | 1,205,589,842 | PR_kwDODunzps42SqF- | 4,175 | Add WIT Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomasw21",
"id": 24695242,
"login": "thomasw21",
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomasw21"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi! Coming in late with some context.\r\n\r\nThere are two versions of the WIT dataset:\r\n1. The original source dataset managed by Wikimedia. It has more information, raw image representations, and each row corresponds to an image linked to all of its captions wherever it happens in Wikipedia (in multiple languages)\r\n2. The Google version, corresponding to the data script in this PR, which duplicates image instances and requires the user to download the images themselves from the provided URL (note that a basic implementation will have them download the same picture several time. @thomasw21 using our download manager instead of `urllib` could help with that, but it wouldn't be required if people had access to the first version)\r\n\r\nThe Wikimedia folks were really interested in us hosting a ready-to-go streaming version of this dataset where users don't have to download the version themselves, which is why we have the pre-processed versions on an HF bucket, with the raw images and a pre-computed embedding (don't remember the model, we can keep it ). That's the data script currently in https://github.com/huggingface/datasets/pull/2981 . It's nearly ready to go, the one thing we should do is move the raw data from our HF google Cloud bucket to the Hub.\r\n\r\nHow do you want to move forward? IMO the best way would be to have a WIT dataset under the Wikimedia org with both configurations, but it depends on everyone's timelines",
"Okay after offline discussion. We'll improve this versions and push it to the hub under `google` namespace. \r\n\r\n> which duplicates image instances and requires the user to download the images themselves from the provided URL (note that a basic implementation will have them download the same picture several time. @thomasw21 using our download manager instead of urllib could help with that, but it wouldn't be required if people had access to the first version)\r\n\r\nAh interesting wasn't aware of this duplication issue, concretely it'll just mean that our dataset in bigger than expected ... I think this should be handled after this loading script (though I have to figure our how to spawn a dl_manager).\r\n\r\n> The Wikimedia folks were really interested in us hosting a ready-to-go streaming version of this dataset where users don't have to download the version themselves, which is why we have the pre-processed versions on an HF bucket, with the raw images and a pre-computed embedding (don't remember the model, we can keep it ). That's the data script currently in https://github.com/huggingface/datasets/pull/2981 . It's nearly ready to go, the one thing we should do is move the raw data from our HF google Cloud bucket to the Hub.\r\n\r\nSimilarly a script will be written and pushed to `wikimedia` organisation.",
"@mariosasko can you make one last review concerning the text description changes? Then I'll handle putting it under `google` namespace and close this PR.",
"Looks all good now. Great job! ",
"Closing as this has been migrated to the hub under `google` namespace: https://huggingface.co/datasets/google/wit"
] | "2022-04-15T13:42:32Z" | "2023-09-24T10:02:38Z" | "2022-05-02T14:26:41Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4175.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4175",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4175.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4175"
} | closes #2981 #2810
@nateraw @hassiahk I've listed you guys as co-author as you've contributed previously to this dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4175/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5029 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5029/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5029/comments | https://api.github.com/repos/huggingface/datasets/issues/5029/events | https://github.com/huggingface/datasets/pull/5029 | 1,387,600,960 | PR_kwDODunzps4_r8-j | 5,029 | Fix import in `ClassLabel` docstring example | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alvarobartt",
"id": 36760800,
"login": "alvarobartt",
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alvarobartt"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-09-27T11:35:29Z" | "2022-09-27T14:03:24Z" | "2022-09-27T12:27:50Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5029.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5029",
"merged_at": "2022-09-27T12:27:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5029.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5029"
} | This PR addresses a super-simple fix: adding a missing `import` to the `ClassLabel` docstring example, as it was formatted as `from datasets Features`, so it's been fixed to `from datasets import Features`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5029/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5029/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4205 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4205/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4205/comments | https://api.github.com/repos/huggingface/datasets/issues/4205/events | https://github.com/huggingface/datasets/pull/4205 | 1,212,466,138 | PR_kwDODunzps42oVFE | 4,205 | Fix `convert_file_size_to_int` for kilobits and megabits | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-22T14:56:21Z" | "2022-05-03T15:28:42Z" | "2022-05-03T15:21:48Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4205.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4205",
"merged_at": "2022-05-03T15:21:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4205.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4205"
} | Minor change to fully align this function with the recent change in Transformers (https://github.com/huggingface/transformers/pull/16891) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4205/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4205/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3959 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3959/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3959/comments | https://api.github.com/repos/huggingface/datasets/issues/3959/events | https://github.com/huggingface/datasets/issues/3959 | 1,172,872,695 | I_kwDODunzps5F6J33 | 3,959 | Medium-sized dataset conversion from pandas causes a crash | {
"avatar_url": "https://avatars.githubusercontent.com/u/641005?v=4",
"events_url": "https://api.github.com/users/Antymon/events{/privacy}",
"followers_url": "https://api.github.com/users/Antymon/followers",
"following_url": "https://api.github.com/users/Antymon/following{/other_user}",
"gists_url": "https://api.github.com/users/Antymon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Antymon",
"id": 641005,
"login": "Antymon",
"node_id": "MDQ6VXNlcjY0MTAwNQ==",
"organizations_url": "https://api.github.com/users/Antymon/orgs",
"received_events_url": "https://api.github.com/users/Antymon/received_events",
"repos_url": "https://api.github.com/users/Antymon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Antymon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Antymon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Antymon"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! It looks like an issue with pyarrow, could you try updating pyarrow and try again ?",
"@albertvillanova did you find a solution to this?",
"I´m getting the same problem with some files, @albertvillanova did you find a solution to this?"
] | "2022-03-17T20:20:35Z" | "2022-12-12T17:14:06Z" | "2022-04-20T12:35:37Z" | NONE | null | null | null | Hi, I am suffering from the following issue:
## Describe the bug
Conversion to arrow dataset from pandas dataframe of a certain size deterministically causes the following crash:
```
File "/home/datasets_crash.py", line 7, in <module>
arrow=datasets.Dataset.from_pandas(d)
File "/home/.conda/envs/tools/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 783, in from_pandas
table = InMemoryTable.from_pandas(
File "/home/.conda/envs/tools/lib/python3.9/site-packages/datasets/table.py", line 379, in from_pandas
return cls(pa.Table.from_pandas(*args, **kwargs))
File "pyarrow/table.pxi", line 1487, in pyarrow.lib.Table.from_pandas
File "pyarrow/table.pxi", line 1532, in pyarrow.lib.Table.from_arrays
File "pyarrow/table.pxi", line 1181, in pyarrow.lib.Table.validate
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Column 1: In chunk 0: Invalid: List child array invalid: Invalid: Struct child array #1 has length smaller than expected for struct array (1192457 < 1192458)
```
## Steps to reproduce the bug
I have a dataset made from replicated single example mocking a dict representation of a publication.
I copy over this example 140k times and create a pandas frame.
I use 'Dataset.from_pandas' and boom
```python
# Sample code to reproduce the bug
import copy
import datasets
import pandas
# serialized dict is quite long to be realistic representation of a publication content
paper_as_dict=eval("{'article_id': '2020-11-05T14:25:05.321Z02bc3286-91b7-486a-9c74-4f457fbc586a', 'sections': [{'section_id': 'body.0', 'paragraphs': [{'sentences': ['11010111001000000011010011110011101110111011000100001010011100101001111010110111101011101111101010101110001111011110111010111', '1101100110110010010101010100110011000111001100100000011100010111010000011100001101111000000011010111001111001010101111110011010010111011000110100110010', '101011011000010100000010011001011011000000110011011110000101001110110000010001100110111100011100110101010010110000101', '1101101110101010101000000010101011111001111000101000110001110100111000100000011001110100110000110100111011001010110011101001001110']}]}, {'section_id': 'body.1', 'paragraphs': [{'sentences': ['11111100100100111000101001011110100110011001011011001001100110100111011010000110011000010001010100101110001001101011110111110101111100001001001000011110110010110011100110110111110011100011111000101010111010101011001110000100000001001010010010011101111100011010', '10101000110000110111110011101111000101010010001001010000001111001100000010001000001110111110010011101000000111011', '111010011111101111110011111110110001000111100101001000100110101111110000111000111111110000101001101000110011010111011101001010110110001000100000001110001111100110110001110001001100011010100110100010100111000110110100010010100101011110000110000101010010001110101100000']}, {'sentences': ['111110011110110110001111001101011110010110100011101010110101011001101110110111100000111101010110011110111101001111000101110001001010010101100111111001001000011101000100110000101', '011101101101111101001100101010000010111101100101110100101000001100010100110011010010100001101001110111100011010011011111000111111101110001010111010011010110001000010101100110000100010110101110110011001010011001100111101100001001', '1110001011011010101001100001110001110001000111111111101110100001011101101001110100000110000011010001101010101110101110101101001010100100010000000010110010010010', '11101111000111111100111110010000111101110010010101001111011001111110011000011100110001010010000100101010', '111000110110110010101100010010100001100100110010101000001000011101000100101011011010000011001011011111001101100001110010100001111110111001001010101100100110001011011100000101010010000000001100010000101100110110111101110010100010011101110110111010011011000011001010111011100000000010101001011000100000011010100011101001011001010010011110100100']}, {'sentences': ['001101111100001101001001001110000110010101011101001001111111011000111001111011101011110111000000100001110110101110001010001111110100010', '0000110010110101001100011011000011001101001110001000000110010101000011101011110110000000100111000001010000101011111011110001001100001110101010101110101011111000000011001111011110001010010111010000100100000001111001011100101111010101111001001101100101001101111000111011010110010001010010010111010000001101101111100101000111101011001000101', '00000101100101100111101010000101011100101100001100011001100100001100001010001010010011001001111001000010100010000110100111110000001000101000111100010111110011000100000111100010000100010111100010101', '111100110010100110000010010101010101110011110100000101110000000111010101111001011110010101001110000001001000010110010010011110111110010110100101110011001101110111001111100011100100011110010010100101011111111']}, {'sentences': ['1100001110101111000001011001100110001011100011110110010011001000101000011110010101010011011000111010000101010011010000000111011001000010100101000011111101000000000101111000', '1110101000100110001111000011000101110111001100101010011001100011010011111111111010101011010101010011000101001100100000110010100110110110110001101100', '00010001100100101100100111111110111111101000100110101111101111110101110001010001011100000000000011010101101001111010001110101101110011001011111101110100010000111101', '011100011101011001000110010110100100000010100010010110011000000010101110011111111101010010010001100110101010010001100010110011110001011011101010111111100100110110010111101001100101010111001', '10111000011010101111110110011010101011111001000001010010111111010010111111100100010100110100101101110100110011001000110100000111000100110000001000111010', '0010011111111011100111010001111001011101001010000010110000010111000101001101000011101110100100000000100100010010101010100011100101001000100110110000010111111110000011011101111000111010']}]}, {'section_id': 'body.2.0', 'paragraphs': [{'sentences': ['110010010011001110100100011001111100010011110111101011011011001010010010010011101011', '000110101110011011101011000000100011111000001100011011110101101011000110011010001010001101101100000111100101001011111001001101111', '1000011100100000100100100010010000111011000100110010000011110111100110110001101001010100011111010100101000111', '11110111111000110010000000000100010010110001100010001010000111011000101100011010010101110110011010110101001101110011101011101100000001000100101011010110110100101011101010010101101000011110000010101011001011000001000000001010110000100010000100011110101001111100001000100000111000001010011111111110101010100011011000010000111000110', '1001000111011000111110001111111001100001000000101000111011101101100101010110001101000000001111010111100011111000000100001001110', '100110010111010101111010100000010001110101111001010010001100001110100100100101110011010101001000100101000100100011001110001100111000010010011011000010011010010000110001000000100011110010110110011010001100111010111110011']}, {'sentences': ['10010101011100010111011111001001001010100011001001111101101001000000001111101110000111101011000001001011101110101001100010010001101111001110000100010010001001101111011111110010011011110011', '110001110010110000101111000000110010010010100000010100001111101101000101100000000110000000011111011001111000010110110001011010011011101100100110011000100110101010111010111111000111001111010110010001001110100001011011000110000000111101110000001111011011101110100000100010000110001000000110100000', '101010000000010000110110111000110000100111000001110100101101101010001010010010101010100111010110001001000101011110010011001001001110111001101101100100011110011011110101100010110111001010000001000110100000001010011111111110111010011110001001110100011011000101011000110110011011010110100100011111111011100111110110000110011011110110110011101010101111001101010110101000000001100101111010000101110', '1010100110111111111000110110111110010100000100001110101110111001011000010001110110001111111110000101001001110010001110000111010101111010111111011100100011100111111101101111000010001100101000010001100110110100110111111100100011001011000001111110010100110111000010011110111011001101100000101011111110101000011000010', '00000001110000101001110101110011101001110011000111111101111101111000010011100000101000001011001110', '101000111010010000011010011010011010010010100010110100011100100111011101010100101110100111010001000000', '01101000110001101011001101100010100011011010000000001010101000010101000110100010000000110001110001010010000000101101000011000100000110011101100001010100011111101010010110001101110101010111101100001110000011001101', '0010010111000011110010011110001010100000111100001011010100100010101010010011101101100110001001111001000110000111011110010000110101010110111111010110100000011010001001010001000110001101101000101110001011110000101101110000110010110010111001100010011011100011', '00110111110000000100110111101011000100100110001000001001101011001000010100100001100111100110000110110101111010000010101000000101000011001011101001', '0100100001000111001110110110000001000100111001101101110100100111010111110001110010110111100110011111001001000011101110100101111011000110100000111010011101']}, {'sentences': ['100001001011101111111100110111011110001101111101100001000110110000100101011000000100000', '10101001001111110101001010100110011110101101001']}]}, {'section_id': 'body.2.0.0', 'paragraphs': [{'sentences': ['1110101100001100011000101000010000100010101101010110101011100101110110110111010101001100100000000111011001000100011110101011111010100101001010000010001001101010100011110010101110011001100010000100110011000011101010001000111001000001100', '101000000011001001110101000100101010000111000111100010010001111111100110001100000100011010011010010101101111010101010000110011101001111001111011111001110001010000110101101011101111010000001100', '01100001011110010100000101001101111101010011100010011001011110110010010011100101000', '0011100111000101111000010001111100000111000101110001111010001100001000111010000101100001110101100111111', '00001100000011110001011010010110000000111110110001111000110000011011001110000000100011001010110000010000010001101010101100000010011011000101011111100010010', '1011101011101111000001100100111000011000010010011110011000110111010010111100111101100110011010000110000111000110111110101111000001000010011101111000110000100011110101101101001101000110010000001000010011011010101100', '1000010011100011100000010011011111111110101101111011101010010111000000101011000000110101111000010011', '01100000110011001110101111101101011001011101000010001100101010100011010101010100111011011110100010100111', '011011010100011011110010101000110001111110110']}]}, {'section_id': 'body.2.0.1', 'paragraphs': [{'sentences': ['00111011011101000100100111000001101001011000111100100010101001010011001011000010011111001100000100010001100101110011001000110001101011010111011111011000010011010010111010011111101000110111011100010011100111111110110111011', '011011010101101101010000001011010110011111011110100111010101010110001101000010011111000011100', '110001000110010000000111101110111110101110111000101000010001110101000101001000111000010001011101010000110001010001101001001110111110111010111010011101000101101010000', '001000111110100110000001111100000111001110111001110111001000111010001001100111001101000001001001010111000111011100001111011001111110001011000111110011111101011101000100101001111011100001000110101010101111111110011111111011000101110001000000000100111011111011001100111', '11010101100010010100010010010101001011001011000001100010101111111101001101110011001010010100000111010101', '01110000110011111000110010011010000011100000010010001111100010010100100001011011111110001100', '011101111100011101100111110101111001101010010001001110101100001101000000111000']}]}, {'section_id': 'body.2.0.2', 'paragraphs': [{'sentences': ['0111011000110100110000001011001110111000011110100111011000000001000010001111111001101111011100101110101101000111000101000010000111011010110000011101111110111110100111000111000011', '00100110111000110101100111000110100010011010010101001010011000000101000110100110011010011111000100000011000000010001010000100111101011111111101010001111010000001011100001110100000101001101101010011011101000', '000001110001010010100101010100010101001100011001001101101101110111011111101010010111010110110111011110101100001000011110111011001', '0001110010111110100110110011000001111100100100110101011010010101010100101000010101000100101000011011', '1000010010010101001100101110010111010100000110101110000000111001111111001011111010000011110001011001001001000101', '0001111100111010010100010111010110011011000000001111010010110001000011010001100111101110001110000011010101111100001000011010110100000100100001111011110110000000101000010001111001010010110101110111101101110111000100', '1000101100001000100001101110111110000100000001000010101111010011010010010111011010100011001000100100001010001100110']}]}, {'section_id': 'body.2.0.3', 'paragraphs': [{'sentences': ['1010100111100011110110101011100001011010011010100100010011000110111000001010010110111001001101111000010100100110101001010001010001000110010000001', '100010101010100111000011111101010100101110011000100011100100100111000010000011001010010111011010000101010011011110111001010110', '0110000110110110110011011000011010010000001010011000010001011110110010000100011111010100110111111010010111000101111', '10100100000011100010110110011111011011101101111000001001010100001001011010000011001010101100000', '1011111111100001001100000010000100110010101000010100111111110010110011101110000101101011101', '10001111110000011100100000101100000000010000100000011100110000011110111010011101010111101001111000100000000110000011010010001100110111100001001011101011001111110010100111001001010001010011010010010111001101110101110000101011', '101101111111101101010010000110111110000110000111001001010011111101011001011010101100010100110101101011100111100100110010001011110001110010000011101100100100001001110010000010011111100110101']}]}, {'section_id': 'body.2.1', 'paragraphs': [{'sentences': ['1010010011010011001111111001000110010001101111101011001011011000101001010101010001000110100011110101110001110110111010010010100100111000101100100101111110100000011111001101010111101010100101011011110111111110', '000010101101111100000110010110011001111100001101011101000100010001001001000000101101000001110000011010111100000010010000010101110101100010011000101110110111111001000101000111000110100001001100001010101010100011', '0000000011101110111100100010111100101010110001111101110110010000100100010000101001101111001111001001100110010011010000101001110010000000100101011101001010100100011101101001011000010111110100101010110110011001110000110010010111110110101100001011101001100111010001000010111010001010000100010010011110111100110011100011111101101000011100111110101010100110001100100000100011011010111000111110010110100010111101001001101000001100100010000111110000011101111100111101000000000']}, {'sentences': ['01011000010110011000000101101000110101011010100111011001001001100001101101111101111001101111100101111001101011011001011110110110110100001100111111010100101110111111101000101100101010110011111011100101101010100110111001111100100011001110011101000110100000001100001100110001110101001000011010000110101011010000001111100100000100101110011000001001010011011101100011000001100000011', '1001100000101000000011110100110001100001101001100011010000111111010110101111001000100111000011010100100000110110001', '10010011000110110111010110000010010000000111101000100101100111101101001100111110101001001111100001110011110000010101000001000000010100011011110011000100110101001100110111111001101000011010100110000000011110001000101010101000110010010']}]}, {'section_id': 'body.2.2', 'paragraphs': [{'sentences': ['000011000000010011000001101111000101000111111111111010001011110000011001010111010101010110001111110000010', '10101001101011101010001111011000110100000100011110010001100111111101101100010010111110110101101011000011000001101110010111011111100111110000000101110010111', '100001011110010111010110001101101001100000000001000010110101011001111100101101101111010010111111000000111001111010011111000100010001111011110001010000110010101010111110100101011011100001010101000001011011111111101', '1000110111111011101000110101001111111111000100011001000011010100001010011110001111010011011111000111011100101001011111001000010101110110101000111011111111010010001101001010110111000011110101011000010000110', '1011100000100000010101101111001001100110111000010001011010111111000000001010101001111011101011010101101001111101101100101001011101000011011010001001101100100111101111111100010011010101111011100001100001000100101100100110101000010000011000000011001100000110000001', '0001001101111001111111010000001101010110110110100110110100000100110101101010010101011000010010111011000010111110000001110101110111000010011000100110111001000111011000100101110111111', '0110010010011000011010001111001100101001100001001000010100101100010110000000101010110001001010001100111101010001110010010000111011100101101010111111101001100010001011100110010100110111010101000100001110000101110011111011111000010101010110101100010010111100100010010100111110111100101010100011101001110110010000011110001010101010000100010000100111001111011101', '000001010000010001100000101011000000110101000100010111111100101111111000110111001001110110101111110011100001001000011001010000011011', '0101101001010101001101010100011000111011001000100001110100110011100000001001010110001101010110011100111111100101101111101111011001111111110010111010011011011111011011110000101011010', '11000001110111000001100100001110000111001010000101011011101010111001011100010010010111111111000011111110010111100011100110001001100011111010100111110111001110010', '0100010110100001010101110111100011100100010111111011101001100101111110101011010010101111001000101001111000001110001100011001110010100110101100110100100000001010101101011110011001000101100111001001001110100', '100000100010011111001101010000100110011110001100000010010110110100000111111011010100101111010111001110101000100001111101001110000011010110000010100', '00100110000011100101000110110001000011101000011010101000010001111011100001111111001011100111101000001000000110110001000101111010010010001100111', '0110110100011001110011001111100010101001011111011001011001101101010010101101110101010100001000100100000111101110001001110111000110011101101010100000101', '0011111010010011011101010110100110000011000011100100101011011001110110001110001111000011010111011000110100111111011101110111000010010000011011010011011100000011101100110110100100000010110101110100110101001100111011101001010111011011110100110101110010011011010001010111110011001000010100010101010010110010010110000100110001000011010011000100101011010100100111010']}]}]}")
d=pandas.DataFrame.from_records(copy.deepcopy(paper_as_dict) for _ in range(140_100))
arrow=datasets.Dataset.from_pandas(d)
```
## Expected results
The dataset should be converted without error.
## Actual results
Error `pyarrow.lib.ArrowInvalid: Column 1: In chunk 0: Invalid: List child array invalid: Invalid: Struct child array #1 has length smaller than expected for struct array (1192457 < 1192458)`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: datasets==1.18.4 pandas==1.3.5
- Platform: macOS 11.6 or CentOS Linux 7 (Core)
- Python version: Python 3.9.7
- PyArrow version: pyarrow==3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3959/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3959/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3780 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3780/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3780/comments | https://api.github.com/repos/huggingface/datasets/issues/3780/events | https://github.com/huggingface/datasets/pull/3780 | 1,148,186,272 | PR_kwDODunzps4zWVSM | 3,780 | Add ElkarHizketak v1.0 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7646055?v=4",
"events_url": "https://api.github.com/users/antxa/events{/privacy}",
"followers_url": "https://api.github.com/users/antxa/followers",
"following_url": "https://api.github.com/users/antxa/following{/other_user}",
"gists_url": "https://api.github.com/users/antxa/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/antxa",
"id": 7646055,
"login": "antxa",
"node_id": "MDQ6VXNlcjc2NDYwNTU=",
"organizations_url": "https://api.github.com/users/antxa/orgs",
"received_events_url": "https://api.github.com/users/antxa/received_events",
"repos_url": "https://api.github.com/users/antxa/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/antxa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antxa/subscriptions",
"type": "User",
"url": "https://api.github.com/users/antxa"
} | [] | closed | false | null | [] | null | [
"I also filled some missing sections in the dataset card"
] | "2022-02-23T14:44:17Z" | "2022-03-04T19:04:29Z" | "2022-03-04T19:04:29Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3780.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3780",
"merged_at": "2022-03-04T19:04:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3780.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3780"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3780/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3780/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3990/comments | https://api.github.com/repos/huggingface/datasets/issues/3990/events | https://github.com/huggingface/datasets/issues/3990 | 1,176,976,247 | I_kwDODunzps5GJzt3 | 3,990 | Improve AutomaticSpeechRecognition task template | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"There is an open PR to do that: #3364. I just haven't had time to finish it... ",
"> There is an open PR to do that: #3364. I just haven't had time to finish it...\r\n\r\n😬 thanks..."
] | "2022-03-22T15:41:08Z" | "2022-03-23T17:12:40Z" | "2022-03-23T17:12:40Z" | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
[AutomaticSpeechRecognition task template](https://github.com/huggingface/datasets/blob/master/src/datasets/tasks/automatic_speech_recognition.py) is outdated as it uses path to audiofile as an audio column instead of a Audio feature itself (I guess it's because Audio feature didn't exist at the time this template was created).
**Describe the solution you'd like**
Change audio columns from string path to Audio feature.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3990/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1986/comments | https://api.github.com/repos/huggingface/datasets/issues/1986/events | https://github.com/huggingface/datasets/issues/1986 | 822,176,290 | MDU6SXNzdWU4MjIxNzYyOTA= | 1,986 | wmt datasets fail to load | {
"avatar_url": "https://avatars.githubusercontent.com/u/32322564?v=4",
"events_url": "https://api.github.com/users/sabania/events{/privacy}",
"followers_url": "https://api.github.com/users/sabania/followers",
"following_url": "https://api.github.com/users/sabania/following{/other_user}",
"gists_url": "https://api.github.com/users/sabania/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sabania",
"id": 32322564,
"login": "sabania",
"node_id": "MDQ6VXNlcjMyMzIyNTY0",
"organizations_url": "https://api.github.com/users/sabania/orgs",
"received_events_url": "https://api.github.com/users/sabania/received_events",
"repos_url": "https://api.github.com/users/sabania/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sabania/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sabania/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sabania"
} | [] | closed | false | null | [] | null | [
"caching issue, seems to work again.."
] | "2021-03-04T14:18:55Z" | "2021-03-04T14:31:07Z" | "2021-03-04T14:31:07Z" | NONE | null | null | null | ~\.cache\huggingface\modules\datasets_modules\datasets\wmt14\43e717d978d2261502b0194999583acb874ba73b0f4aed0ada2889d1bb00f36e\wmt_utils.py in _split_generators(self, dl_manager)
758 # Extract manually downloaded files.
759 manual_files = dl_manager.extract(manual_paths_dict)
--> 760 extraction_map = dict(downloaded_files, **manual_files)
761
762 for language in self.config.language_pair:
TypeError: type object argument after ** must be a mapping, not list | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1986/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3145/comments | https://api.github.com/repos/huggingface/datasets/issues/3145/events | https://github.com/huggingface/datasets/issues/3145 | 1,033,580,009 | I_kwDODunzps49my3p | 3,145 | [when Image type will exist] provide a way to get the data as binary + filename | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"@severo, maybe somehow related to this PR ?\r\n- #3129",
"@severo I'll keep that in mind.\r\n\r\nYou can track progress on the Image feature in #3163 (still in the early stage). ",
"Hi ! As discussed with @severo offline it looks like the dataset viewer already supports reading PIL images, so maybe the dataset viewer doesn't need to disable decoding after all",
"Fixed with https://github.com/huggingface/datasets/pull/3163"
] | "2021-10-22T13:23:49Z" | "2021-12-22T11:05:37Z" | "2021-12-22T11:05:36Z" | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
When a dataset cell contains a value of type Image (be it from a remote URL, an Array2D/3D, or any other way to represent images), I want to be able to write the image to the disk, with the correct filename, and optionally to know its mimetype, in order to serve it on the web.
Note: this issue would apply exactly the same for the `Audio` type.
**Describe the solution you'd like**
If a "cell" has the type `Image`, provide a way to get the binary content of the file, and the filename, eg as:
```python
filename: str
data: bytes
```
**Describe alternatives you've considered**
A way to write the cell to the disk (passing a local directory), and then return the pathname, filename, and mimetype.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3145/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3145/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4016 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4016/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4016/comments | https://api.github.com/repos/huggingface/datasets/issues/4016/events | https://github.com/huggingface/datasets/pull/4016 | 1,180,557,828 | PR_kwDODunzps41AWBk | 4,016 | Support streaming blimp dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-25T09:39:10Z" | "2022-03-25T11:19:18Z" | "2022-03-25T11:14:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4016.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4016",
"merged_at": "2022-03-25T11:14:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4016.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4016"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4016/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4016/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/982 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/982/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/982/comments | https://api.github.com/repos/huggingface/datasets/issues/982/events | https://github.com/huggingface/datasets/pull/982 | 754,946,337 | MDExOlB1bGxSZXF1ZXN0NTMwNzUxMzYx | 982 | add prachathai67k take2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/15519308?v=4",
"events_url": "https://api.github.com/users/cstorm125/events{/privacy}",
"followers_url": "https://api.github.com/users/cstorm125/followers",
"following_url": "https://api.github.com/users/cstorm125/following{/other_user}",
"gists_url": "https://api.github.com/users/cstorm125/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cstorm125",
"id": 15519308,
"login": "cstorm125",
"node_id": "MDQ6VXNlcjE1NTE5MzA4",
"organizations_url": "https://api.github.com/users/cstorm125/orgs",
"received_events_url": "https://api.github.com/users/cstorm125/received_events",
"repos_url": "https://api.github.com/users/cstorm125/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cstorm125/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cstorm125/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cstorm125"
} | [] | closed | false | null | [] | null | [] | "2020-12-02T05:12:01Z" | "2020-12-02T10:18:11Z" | "2020-12-02T10:18:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/982.diff",
"html_url": "https://github.com/huggingface/datasets/pull/982",
"merged_at": "2020-12-02T10:18:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/982.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/982"
} | I decided it will be faster to create a new pull request instead of fixing the rebase issues.
continuing from https://github.com/huggingface/datasets/pull/954
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/982/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/982/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1773/comments | https://api.github.com/repos/huggingface/datasets/issues/1773/events | https://github.com/huggingface/datasets/issues/1773 | 792,708,160 | MDU6SXNzdWU3OTI3MDgxNjA= | 1,773 | bug in loading datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghost",
"id": 10137,
"login": "ghost",
"node_id": "MDQ6VXNlcjEwMTM3",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"repos_url": "https://api.github.com/users/ghost/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghost"
} | [] | closed | false | null | [] | null | [
"Looks like an issue with your csv file. Did you use the right delimiter ?\r\nApparently at line 37 the CSV reader from pandas reads 2 fields instead of 1.",
"Note that you can pass any argument you would pass to `pandas.read_csv` as kwargs to `load_dataset`. For example you can do\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('csv', data_files=data_files, sep=\"\\t\")\r\n```\r\n\r\nfor example to use a tab separator.\r\n\r\nYou can see the full list of arguments here: https://github.com/huggingface/datasets/blob/master/src/datasets/packaged_modules/csv/csv.py\r\n\r\n(I've not found the list in the documentation though, we definitely must add them !)",
"You can try to convert the file to (CSV UTF-8)"
] | "2021-01-24T02:53:45Z" | "2021-09-06T08:54:46Z" | "2021-08-04T18:13:01Z" | NONE | null | null | null | Hi,
I need to load a dataset, I use these commands:
```
from datasets import load_dataset
dataset = load_dataset('csv', data_files={'train': 'sick/train.csv',
'test': 'sick/test.csv',
'validation': 'sick/validation.csv'})
print(dataset['validation'])
```
the dataset in sick/train.csv are simple csv files representing the data. I am getting this error, do you have an idea how I can solve this? thank you @lhoestq
```
Using custom data configuration default
Downloading and preparing dataset csv/default-61468fc71a743ec1 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2...
Traceback (most recent call last):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 485, in incomplete_dir
yield tmp_dir
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 604, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 959, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/tqdm-4.49.0-py3.7.egg/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/julia/cache_home_2/modules/datasets_modules/datasets/csv/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2/csv.py", line 129, in _generate_tables
for batch_idx, df in enumerate(csv_file_reader):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1029, in __next__
return self.get_chunk()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1079, in get_chunk
return self.read(nrows=size)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1052, in read
index, columns, col_dict = self._engine.read(nrows)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 2056, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 1 fields in line 37, saw 2
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "write_sick.py", line 19, in <module>
'validation': 'sick/validation.csv'})
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 534, in download_and_prepare
self._save_info()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/contextlib.py", line 130, in __exit__
self.gen.throw(type, value, traceback)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 491, in incomplete_dir
shutil.rmtree(tmp_dir)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 498, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 496, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2.incomplete'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1773/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/637/comments | https://api.github.com/repos/huggingface/datasets/issues/637/events | https://github.com/huggingface/datasets/pull/637 | 703,539,909 | MDExOlB1bGxSZXF1ZXN0NDg4NjMwNzk4 | 637 | Add MATINF | {
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JetRunner",
"id": 22514219,
"login": "JetRunner",
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JetRunner"
} | [] | closed | false | null | [] | null | [] | "2020-09-17T12:24:53Z" | "2020-09-17T13:23:18Z" | "2020-09-17T13:23:17Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/637.diff",
"html_url": "https://github.com/huggingface/datasets/pull/637",
"merged_at": "2020-09-17T13:23:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/637.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/637"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/637/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/358/comments | https://api.github.com/repos/huggingface/datasets/issues/358/events | https://github.com/huggingface/datasets/pull/358 | 653,645,121 | MDExOlB1bGxSZXF1ZXN0NDQ2NTI0NjQ5 | 358 | Starting to add some real doc | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | [
"Ok this is starting to be really big so it's probably good to merge this first version of the doc and continue in another PR :)\r\n\r\nThis first version of the doc can be explored here: https://2219-250213286-gh.circle-artifacts.com/0/docs/_build/html/index.html"
] | "2020-07-08T22:53:03Z" | "2020-07-14T09:58:17Z" | "2020-07-14T09:58:15Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/358",
"merged_at": "2020-07-14T09:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/358"
} | Adding a lot of documentation for:
- load a dataset
- explore the dataset object
- process data with the dataset
- add a new dataset script
- share a dataset script
- full package reference
This version of the doc can be explored here: https://2219-250213286-gh.circle-artifacts.com/0/docs/_build/html/index.html
Also:
- fix a bug in `train_test_split`
- update the `csv` script
- add a verbose argument to the dataset processing methods
Still missing:
- doc for the metrics
- how to directly upload a community provided dataset with the CLI
- clean up more docstrings
- add the `features` argument to `load_dataset` (should be another PR) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/358/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1104/comments | https://api.github.com/repos/huggingface/datasets/issues/1104/events | https://github.com/huggingface/datasets/pull/1104 | 757,020,934 | MDExOlB1bGxSZXF1ZXN0NTMyNDY1NzA4 | 1,104 | add TLC | {
"avatar_url": "https://avatars.githubusercontent.com/u/6429850?v=4",
"events_url": "https://api.github.com/users/chameleonTK/events{/privacy}",
"followers_url": "https://api.github.com/users/chameleonTK/followers",
"following_url": "https://api.github.com/users/chameleonTK/following{/other_user}",
"gists_url": "https://api.github.com/users/chameleonTK/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/chameleonTK",
"id": 6429850,
"login": "chameleonTK",
"node_id": "MDQ6VXNlcjY0Mjk4NTA=",
"organizations_url": "https://api.github.com/users/chameleonTK/orgs",
"received_events_url": "https://api.github.com/users/chameleonTK/received_events",
"repos_url": "https://api.github.com/users/chameleonTK/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/chameleonTK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chameleonTK/subscriptions",
"type": "User",
"url": "https://api.github.com/users/chameleonTK"
} | [] | closed | false | null | [] | null | [] | "2020-12-04T11:14:58Z" | "2020-12-04T14:29:23Z" | "2020-12-04T14:29:23Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1104.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1104",
"merged_at": "2020-12-04T14:29:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1104.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1104"
} | Added TLC dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1104/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1104/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5109 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5109/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5109/comments | https://api.github.com/repos/huggingface/datasets/issues/5109/events | https://github.com/huggingface/datasets/issues/5109 | 1,407,434,706 | I_kwDODunzps5T47_S | 5,109 | Map caching not working for some class methods | {
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mouhanedg56",
"id": 23029765,
"login": "Mouhanedg56",
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mouhanedg56"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"The hash used for caching is computed by pickling recursively the function passed to `map`. Maybe some objects don't have the same hash across sessions. In particular you can check the hash of your model using\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nobj = AutoModel.from_config(config=config, add_pooling_layer=False)\r\nprint(Hasher.hash(obj))\r\n```\r\n\r\nYou can find mode info here: https://huggingface.co/docs/datasets/about_cache\r\n\r\nYou can also provide your own unique hash in `map` if you want, with the `new_fingerprint` argument",
"Indeed, the hash is changing. The `dumps` function serialize the model object in different ways because the model object is not deterministic\r\n```python\r\nfrom datasets.utils.py_utils import dumps\r\nobj1 = AutoModel.from_config(config=config, add_pooling_layer=False)\r\nobj2 = AutoModel.from_config(config=config, add_pooling_layer=False)\r\n\r\ndumps(bert) == dumps(bert2). # False\r\n```\r\n\r\n> You can find mode info here: https://huggingface.co/docs/datasets/about_cache\r\n> \r\n> You can also provide your own unique hash in map if you want, with the new_fingerprint argument\r\n\r\n\r\nThanks, the doc is so helpful. Indeed, we can fix the hash and get cache hit using `new_fingerprint`. Closing the issue."
] | "2022-10-13T09:12:58Z" | "2022-10-17T10:38:45Z" | "2022-10-17T10:38:45Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
The cache loading is not working as expected for some class methods with a model stored in an attribute.
The new fingerprint for `_map_single` is not the same at each run. The hasher generate a different hash for the class method.
This comes from `dumps` function in `datasets.utils.py_utils` which generates a different dump at each run.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from transformers import AutoConfig, AutoModel, AutoTokenizer
dataset = load_dataset("ethos", "binary")
BASE_MODELNAME = "sentence-transformers/all-MiniLM-L6-v2"
class Object:
def __init__(self):
config = AutoConfig.from_pretrained(BASE_MODELNAME)
self.bert = AutoModel.from_config(config=config, add_pooling_layer=False)
self.tok = AutoTokenizer.from_pretrained(BASE_MODELNAME)
def tokenize(self, examples):
tokenized_texts = self.tok(
examples["text"],
padding="max_length",
truncation=True,
max_length=256,
)
return tokenized_texts
instance = Object()
result = dict()
for phase in ["train"]:
result[phase] = dataset[phase].map(instance.tokenize, batched=True, load_from_cache_file=True, num_proc=2)
```
## Expected results
Load cache instead of recompute result.
## Actual results
Result recomputed from scratch at each run.
The cache works fine when deleting `bert` attribute.
## Environment info
- `datasets` version: 2.5.3.dev0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.13
- PyArrow version: 7.0.0
- Pandas version: 1.5.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5109/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5109/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2470 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2470/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2470/comments | https://api.github.com/repos/huggingface/datasets/issues/2470/events | https://github.com/huggingface/datasets/issues/2470 | 916,724,260 | MDU6SXNzdWU5MTY3MjQyNjA= | 2,470 | Crash when `num_proc` > dataset length for `map()` on a `datasets.Dataset`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1170062?v=4",
"events_url": "https://api.github.com/users/mbforbes/events{/privacy}",
"followers_url": "https://api.github.com/users/mbforbes/followers",
"following_url": "https://api.github.com/users/mbforbes/following{/other_user}",
"gists_url": "https://api.github.com/users/mbforbes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mbforbes",
"id": 1170062,
"login": "mbforbes",
"node_id": "MDQ6VXNlcjExNzAwNjI=",
"organizations_url": "https://api.github.com/users/mbforbes/orgs",
"received_events_url": "https://api.github.com/users/mbforbes/received_events",
"repos_url": "https://api.github.com/users/mbforbes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mbforbes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mbforbes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mbforbes"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! It looks like the issue comes from pyarrow. What version of pyarrow are you using ? How did you install it ?",
"Thank you for the quick reply! I have `pyarrow==4.0.0`, and I am installing with `pip`. It's not one of my explicit dependencies, so I assume it came along with something else.",
"Could you trying reinstalling pyarrow with pip ?\r\nI'm not sure why it would check in your multicurtural-sc directory for source files.",
"Sure! I tried reinstalling to get latest. pip was mad because it looks like Datasets currently wants <4.0.0 (which is interesting, because apparently I ended up with 4.0.0 already?), but I gave it a shot anyway:\r\n\r\n```bash\r\n$ pip install --upgrade --force-reinstall pyarrow\r\nCollecting pyarrow\r\n Downloading pyarrow-4.0.1-cp39-cp39-manylinux2014_x86_64.whl (21.9 MB)\r\n |████████████████████████████████| 21.9 MB 23.8 MB/s\r\nCollecting numpy>=1.16.6\r\n Using cached numpy-1.20.3-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.4 MB)\r\nInstalling collected packages: numpy, pyarrow\r\n Attempting uninstall: numpy\r\n Found existing installation: numpy 1.20.3\r\n Uninstalling numpy-1.20.3:\r\n Successfully uninstalled numpy-1.20.3\r\n Attempting uninstall: pyarrow\r\n Found existing installation: pyarrow 3.0.0\r\n Uninstalling pyarrow-3.0.0:\r\n Successfully uninstalled pyarrow-3.0.0\r\nERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\r\ndatasets 1.8.0 requires pyarrow<4.0.0,>=1.0.0, but you have pyarrow 4.0.1 which is incompatible.\r\nSuccessfully installed numpy-1.20.3 pyarrow-4.0.1\r\n```\r\n\r\nTrying it, the same issue:\r\n\r\n\r\n\r\nI tried installing `\"pyarrow<4.0.0\"`, which gave me 3.0.0. Running, still, same issue.\r\n\r\nI agree it's weird that pyarrow is checking the source code directory for its files. (There is no `pyarrow/` directory there.) To me, that makes it seem like an issue with how pyarrow is called.\r\n\r\nOut of curiosity, I tried running this with fewer workers to see when the error arises:\r\n\r\n- 1: ✅\r\n- 2: ✅\r\n- 4: ✅\r\n- 8: ✅\r\n- 10: ✅\r\n- 11: ❌ 🤔\r\n- 12: ❌\r\n- 16: ❌\r\n- 32: ❌\r\n\r\nchecking my datasets:\r\n\r\n```python\r\n>>> datasets\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['text'],\r\n num_rows: 389290\r\n })\r\n validation.sc: Dataset({\r\n features: ['text'],\r\n num_rows: 10 # 🤔\r\n })\r\n validation.wvs: Dataset({\r\n features: ['text'],\r\n num_rows: 93928\r\n })\r\n})\r\n```\r\n\r\nNew hypothesis: crash if `num_proc` > length of a dataset? 😅\r\n\r\nIf so, this might be totally my fault, as the caller. Could be a docs fix, or maybe this library could do a check to limit `num_proc` for this case?",
"Good catch ! Not sure why it could raise such a weird issue from pyarrow though\r\nWe should definitely reduce num_proc to the length of the dataset if needed and log a warning.",
"This has been fixed in #2566, thanks @connor-mccarthy !\r\nWe'll make a new release soon that includes the fix ;)"
] | "2021-06-09T22:40:22Z" | "2021-07-01T09:34:54Z" | "2021-07-01T09:11:13Z" | NONE | null | null | null | ## Describe the bug
Crash if when using `num_proc` > 1 (I used 16) for `map()` on a `datasets.Dataset`.
I believe I've had cases where `num_proc` > 1 works before, but now it seems either inconsistent, or depends on my data. I'm not sure whether the issue is on my end, because it's difficult for me to debug! Any tips greatly appreciated, I'm happy to provide more info if it would helps us diagnose.
## Steps to reproduce the bug
```python
# this function will be applied with map()
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding=PaddingStrategy.DO_NOT_PAD,
truncation=True,
)
# data_files is a Dict[str, str] mapping name -> path
datasets = load_dataset("text", data_files={...})
# this is where the error happens if num_proc = 16,
# but is fine if num_proc = 1
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
num_proc=num_workers,
)
```
## Expected results
The `map()` function succeeds with `num_proc` > 1.
## Actual results


## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.6.2
- Platform: Linux-5.4.0-73-generic-x86_64-with-glibc2.31
- Python version: 3.9.5
- PyTorch version (GPU?): 1.8.1+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes, but I think N/A for this issue
- Using distributed or parallel set-up in script?: Multi-GPU on one machine, but I think also N/A for this issue
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2470/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2470/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2482/comments | https://api.github.com/repos/huggingface/datasets/issues/2482/events | https://github.com/huggingface/datasets/pull/2482 | 918,846,027 | MDExOlB1bGxSZXF1ZXN0NjY4MjMyMzI5 | 2,482 | Allow to use tqdm>=4.50.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-06-11T14:49:21Z" | "2021-06-11T15:11:51Z" | "2021-06-11T15:11:50Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2482.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2482",
"merged_at": "2021-06-11T15:11:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2482.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2482"
} | We used to have permission errors on windows whith the latest versions of tqdm (see [here](https://app.circleci.com/pipelines/github/huggingface/datasets/6365/workflows/24f7c960-3176-43a5-9652-7830a23a981e/jobs/39232))
They were due to open arrow files not properly closed by pyarrow.
Since https://github.com/huggingface/datasets/commit/42320a110d9d072703814e1f630a0d90d626a1e6 gc.collect is called each time we don't need an arrow file to make sure that the files are closed.
close https://github.com/huggingface/datasets/issues/2471
cc @lewtun | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2482/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4247/comments | https://api.github.com/repos/huggingface/datasets/issues/4247/events | https://github.com/huggingface/datasets/issues/4247 | 1,218,320,882 | I_kwDODunzps5Inhny | 4,247 | The data preview of XGLUE | {
"avatar_url": "https://avatars.githubusercontent.com/u/49108847?v=4",
"events_url": "https://api.github.com/users/czq1999/events{/privacy}",
"followers_url": "https://api.github.com/users/czq1999/followers",
"following_url": "https://api.github.com/users/czq1999/following{/other_user}",
"gists_url": "https://api.github.com/users/czq1999/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/czq1999",
"id": 49108847,
"login": "czq1999",
"node_id": "MDQ6VXNlcjQ5MTA4ODQ3",
"organizations_url": "https://api.github.com/users/czq1999/orgs",
"received_events_url": "https://api.github.com/users/czq1999/received_events",
"repos_url": "https://api.github.com/users/czq1999/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/czq1999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/czq1999/subscriptions",
"type": "User",
"url": "https://api.github.com/users/czq1999"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"\r\n",
"Thanks for reporting @czq1999.\r\n\r\nNote that the dataset viewer uses the dataset in streaming mode and that not all datasets support streaming yet.\r\n\r\nThat is the case for XGLUE dataset (as the error message points out): this must be refactored to support streaming. ",
"Fixed, thanks @albertvillanova !\r\n\r\nhttps://huggingface.co/datasets/xglue\r\n\r\n<img width=\"824\" alt=\"Capture d’écran 2022-04-29 à 10 23 14\" src=\"https://user-images.githubusercontent.com/1676121/165909391-9f98d98a-665a-4e57-822d-8baa2dc9b7c9.png\">\r\n"
] | "2022-04-28T07:30:50Z" | "2022-04-29T08:23:28Z" | "2022-04-28T16:08:03Z" | NONE | null | null | null | It seems that something wrong with the data previvew of XGLUE | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4247/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1429/comments | https://api.github.com/repos/huggingface/datasets/issues/1429/events | https://github.com/huggingface/datasets/pull/1429 | 760,737,818 | MDExOlB1bGxSZXF1ZXN0NTM1NTE5MjY5 | 1,429 | extract rar files | {
"avatar_url": "https://avatars.githubusercontent.com/u/15667714?v=4",
"events_url": "https://api.github.com/users/zaidalyafeai/events{/privacy}",
"followers_url": "https://api.github.com/users/zaidalyafeai/followers",
"following_url": "https://api.github.com/users/zaidalyafeai/following{/other_user}",
"gists_url": "https://api.github.com/users/zaidalyafeai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zaidalyafeai",
"id": 15667714,
"login": "zaidalyafeai",
"node_id": "MDQ6VXNlcjE1NjY3NzE0",
"organizations_url": "https://api.github.com/users/zaidalyafeai/orgs",
"received_events_url": "https://api.github.com/users/zaidalyafeai/received_events",
"repos_url": "https://api.github.com/users/zaidalyafeai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zaidalyafeai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zaidalyafeai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zaidalyafeai"
} | [] | closed | false | null | [] | null | [] | "2020-12-09T23:01:10Z" | "2020-12-18T15:03:37Z" | "2020-12-18T15:03:37Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1429",
"merged_at": "2020-12-18T15:03:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1429"
} | Unfortunately, I didn't find any native python libraries for extracting rar files. The user has to manually install `sudo apt-get install unrar`. Discussion with @yjernite is in the slack channel. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1429/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1879 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1879/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1879/comments | https://api.github.com/repos/huggingface/datasets/issues/1879/events | https://github.com/huggingface/datasets/pull/1879 | 808,541,442 | MDExOlB1bGxSZXF1ZXN0NTczNTY1NDAx | 1,879 | Replace flatten_nested | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"Hi @lhoestq. If you agree to merge this, I will start separating the logic for NestedDataStructure.map ;)"
] | "2021-02-15T13:29:40Z" | "2021-02-19T18:35:14Z" | "2021-02-19T18:35:14Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1879.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1879",
"merged_at": "2021-02-19T18:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1879.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1879"
} | Replace `flatten_nested` with `NestedDataStructure.flatten`.
This is a first step towards having all NestedDataStructure logic as a separated concern, independent of the caller/user of the data structure.
Eventually, all checks (whether the underlying data is list, dict, etc.) will be only inside this class.
I have also generalized the flattening, and now it handles multiple levels of nesting. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1879/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1879/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/429/comments | https://api.github.com/repos/huggingface/datasets/issues/429/events | https://github.com/huggingface/datasets/pull/429 | 664,412,137 | MDExOlB1bGxSZXF1ZXN0NDU1NjU2MDk5 | 429 | mlsum | {
"avatar_url": "https://avatars.githubusercontent.com/u/36986299?v=4",
"events_url": "https://api.github.com/users/RachelKer/events{/privacy}",
"followers_url": "https://api.github.com/users/RachelKer/followers",
"following_url": "https://api.github.com/users/RachelKer/following{/other_user}",
"gists_url": "https://api.github.com/users/RachelKer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/RachelKer",
"id": 36986299,
"login": "RachelKer",
"node_id": "MDQ6VXNlcjM2OTg2Mjk5",
"organizations_url": "https://api.github.com/users/RachelKer/orgs",
"received_events_url": "https://api.github.com/users/RachelKer/received_events",
"repos_url": "https://api.github.com/users/RachelKer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/RachelKer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RachelKer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/RachelKer"
} | [] | closed | false | null | [] | null | [
"Thanks @RachelKer for this PR.\r\n\r\nI think the dummy_data structure does not also match. In the `_split_generator` you have something like `os.path.join(downloaded_files[\"validation\"], lang+'_val.jsonl')` but in you dummy_data you have `os.path.join(downloaded_files[\"validation\"], lang+\"_val.zip\", lang+'_val.jsonl')`. I think ` jsonl` files should be directly in the `dummy_data` folder without the sub-folder \r\n\r\n@lhoestq ",
"Hi @RachelKer :)\r\nThanks for adding MLSUM !\r\n\r\nTo fix the CI I think you just have to rebase from master",
"Great, I think it is working now. Thanks :)",
"It looks like your PR does tons of changes in other datasets. \r\nMaybe this is because of the merge from master ?",
"Hmm, I see, sorry I messed up somewhere. Maybe it's easier if we close the pull request and I do another one ?",
"Yea if it's easier for you feel free to re-open a PR"
] | "2020-07-23T11:52:39Z" | "2020-07-31T11:46:20Z" | "2020-07-31T11:46:20Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/429",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/429"
} | Hello,
The tests for the load_real_data fail, as there is no default language subset to download it looks for a file that does not exist. This bug does not happen when using the load_dataset function, as it asks you to specify a language if you do not, so I submit this PR anyway. The dataset is avalaible on : https://gitlab.lip6.fr/scialom/mlsum_data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/429/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5262/comments | https://api.github.com/repos/huggingface/datasets/issues/5262/events | https://github.com/huggingface/datasets/issues/5262 | 1,455,171,100 | I_kwDODunzps5WvCYc | 5,262 | AttributeError: 'Value' object has no attribute 'names' | {
"avatar_url": "https://avatars.githubusercontent.com/u/102913847?v=4",
"events_url": "https://api.github.com/users/emnaboughariou/events{/privacy}",
"followers_url": "https://api.github.com/users/emnaboughariou/followers",
"following_url": "https://api.github.com/users/emnaboughariou/following{/other_user}",
"gists_url": "https://api.github.com/users/emnaboughariou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/emnaboughariou",
"id": 102913847,
"login": "emnaboughariou",
"node_id": "U_kgDOBiJXNw",
"organizations_url": "https://api.github.com/users/emnaboughariou/orgs",
"received_events_url": "https://api.github.com/users/emnaboughariou/received_events",
"repos_url": "https://api.github.com/users/emnaboughariou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/emnaboughariou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emnaboughariou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/emnaboughariou"
} | [] | closed | false | null | [] | null | [
"Hi ! It looks like your \"isDif\" column is a Sequence of Value(\"string\"), not a Sequence of ClassLabel.\r\n\r\nYou can convert your Value(\"string\") feature type to a ClassLabel feature type this way:\r\n```python\r\nfrom datasets import ClassLabel, Sequence\r\n\r\n# provide the label_names yourself\r\nlabel_names = [...]\r\n# OR get them from the dataset\r\nlabel_names = sorted(set(label for labels in raw_datasets[\"train\"][\"isDif\"] for label in labels))\r\n\r\n# Cast to ClassLabel\r\nraw_datasets = raw_datasets.cast_column(\"isDif\", Sequence(ClassLabel(names=label_names)))\r\n```\r\n",
"thank you \r\nit works 💯 "
] | "2022-11-18T13:58:42Z" | "2022-11-22T10:09:24Z" | "2022-11-22T10:09:23Z" | NONE | null | null | null | Hello
I'm trying to build a model for custom token classification
I already followed the token classification course on huggingface
while adapting the code to my work, this message occures :
'Value' object has no attribute 'names'
Here's my code:
`raw_datasets`
generates
DatasetDict({
train: Dataset({
features: ['isDisf', 'pos', 'tokens', 'id'],
num_rows: 14
})
})
`raw_datasets["train"][3]["isDisf"]`
generates
['B_RM', 'I_RM', 'I_RM', 'B_RP', 'I_RP', 'O', 'O']
`dis_feature = raw_datasets["train"].features["isDisf"]
dis_feature`
generates
Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)
and
`label_names = dis_feature.feature.names
label_names`
generates
AttributeError Traceback (most recent call last)
[<ipython-input-28-972fd54a869a>](https://localhost:8080/#) in <module>
----> 1 label_names = dis_feature.feature.names
2 label_names
AttributeError: 'Value' object has
AttributeError: 'Value' object has no attribute 'names'
Thank you for your help | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5262/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
"gists_url": "https://api.github.com/users/kyoto7250/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kyoto7250",
"id": 50972773,
"login": "kyoto7250",
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"organizations_url": "https://api.github.com/users/kyoto7250/orgs",
"received_events_url": "https://api.github.com/users/kyoto7250/received_events",
"repos_url": "https://api.github.com/users/kyoto7250/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kyoto7250/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kyoto7250/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kyoto7250"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! `Table.to_pylist` requires PyArrow 7.0+, and our minimal version requirement is 6.0, so we need to bump the version requirement to avoid CI failure. I'll do this in a separate PR.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006857 / 0.011353 (-0.004496) | 0.004711 / 0.011008 (-0.006297) | 0.098332 / 0.038508 (0.059824) | 0.028547 / 0.023109 (0.005438) | 0.307647 / 0.275898 (0.031749) | 0.334891 / 0.323480 (0.011411) | 0.005252 / 0.007986 (-0.002734) | 0.003495 / 0.004328 (-0.000833) | 0.075529 / 0.004250 (0.071279) | 0.042167 / 0.037052 (0.005114) | 0.308509 / 0.258489 (0.050020) | 0.348294 / 0.293841 (0.054453) | 0.032042 / 0.128546 (-0.096504) | 0.011684 / 0.075646 (-0.063962) | 0.321740 / 0.419271 (-0.097531) | 0.057725 / 0.043533 (0.014193) | 0.309431 / 0.255139 (0.054292) | 0.326818 / 0.283200 (0.043618) | 0.093261 / 0.141683 (-0.048422) | 1.475344 / 1.452155 (0.023190) | 1.563952 / 1.492716 (0.071236) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.205056 / 0.018006 (0.187050) | 0.421656 / 0.000490 (0.421166) | 0.004167 / 0.000200 (0.003967) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023935 / 0.037411 (-0.013476) | 0.097220 / 0.014526 (0.082695) | 0.104942 / 0.176557 (-0.071615) | 0.170339 / 0.737135 (-0.566796) | 0.107556 / 0.296338 (-0.188782) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424509 / 0.215209 (0.209300) | 4.223637 / 2.077655 (2.145982) | 2.090700 / 1.504120 (0.586580) | 1.902537 / 1.541195 (0.361343) | 1.981192 / 1.468490 (0.512701) | 0.695272 / 4.584777 (-3.889505) | 3.570169 / 3.745712 (-0.175544) | 1.885007 / 5.269862 (-3.384854) | 1.162828 / 4.565676 (-3.402848) | 0.084956 / 0.424275 (-0.339319) | 0.012818 / 0.007607 (0.005210) | 0.534395 / 0.226044 (0.308351) | 5.354318 / 2.268929 (3.085389) | 2.436875 / 55.444624 (-53.007749) | 2.111365 / 6.876477 (-4.765112) | 2.232874 / 2.142072 (0.090802) | 0.804703 / 4.805227 (-4.000524) | 0.152406 / 6.500664 (-6.348258) | 0.066926 / 0.075469 (-0.008543) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.198621 / 1.841788 (-0.643166) | 13.907491 / 8.074308 (5.833183) | 14.356286 / 10.191392 (4.164894) | 0.140714 / 0.680424 (-0.539710) | 0.016440 / 0.534201 (-0.517761) | 0.380868 / 0.579283 (-0.198415) | 0.396004 / 0.434364 (-0.038360) | 0.448275 / 0.540337 (-0.092062) | 0.537818 / 1.386936 (-0.849118) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006789 / 0.011353 (-0.004564) | 0.004652 / 0.011008 (-0.006356) | 0.076449 / 0.038508 (0.037941) | 0.028389 / 0.023109 (0.005280) | 0.378644 / 0.275898 (0.102746) | 0.423870 / 0.323480 (0.100391) | 0.005824 / 0.007986 (-0.002162) | 0.003398 / 0.004328 (-0.000931) | 0.075575 / 0.004250 (0.071324) | 0.039656 / 0.037052 (0.002604) | 0.370072 / 0.258489 (0.111583) | 0.441812 / 0.293841 (0.147971) | 0.031817 / 0.128546 (-0.096729) | 0.011701 / 0.075646 (-0.063946) | 0.085759 / 0.419271 (-0.333513) | 0.042328 / 0.043533 (-0.001205) | 0.364103 / 0.255139 (0.108964) | 0.413910 / 0.283200 (0.130711) | 0.090871 / 0.141683 (-0.050812) | 1.505749 / 1.452155 (0.053594) | 1.608555 / 1.492716 (0.115839) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212533 / 0.018006 (0.194527) | 0.404519 / 0.000490 (0.404030) | 0.000373 / 0.000200 (0.000174) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024849 / 0.037411 (-0.012562) | 0.100769 / 0.014526 (0.086243) | 0.110450 / 0.176557 (-0.066107) | 0.161715 / 0.737135 (-0.575420) | 0.113599 / 0.296338 (-0.182739) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436780 / 0.215209 (0.221571) | 4.387103 / 2.077655 (2.309448) | 2.081942 / 1.504120 (0.577822) | 1.873661 / 1.541195 (0.332466) | 1.947718 / 1.468490 (0.479228) | 0.696434 / 4.584777 (-3.888343) | 3.405300 / 3.745712 (-0.340412) | 1.897388 / 5.269862 (-3.372474) | 1.169969 / 4.565676 (-3.395707) | 0.083085 / 0.424275 (-0.341190) | 0.012480 / 0.007607 (0.004873) | 0.535635 / 0.226044 (0.309591) | 5.364462 / 2.268929 (3.095533) | 2.531168 / 55.444624 (-52.913457) | 2.184324 / 6.876477 (-4.692153) | 2.228613 / 2.142072 (0.086541) | 0.807127 / 4.805227 (-3.998100) | 0.151971 / 6.500664 (-6.348693) | 0.068430 / 0.075469 (-0.007039) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.306401 / 1.841788 (-0.535387) | 14.479552 / 8.074308 (6.405244) | 14.428398 / 10.191392 (4.237006) | 0.159505 / 0.680424 (-0.520919) | 0.016856 / 0.534201 (-0.517344) | 0.375197 / 0.579283 (-0.204086) | 0.384328 / 0.434364 (-0.050036) | 0.440688 / 0.540337 (-0.099650) | 0.524998 / 1.386936 (-0.861938) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-06T11:21:57Z" | "2023-03-27T13:34:19Z" | "2023-03-27T13:26:38Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"merged_at": "2023-03-27T13:26:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5611"
} | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5414/comments | https://api.github.com/repos/huggingface/datasets/issues/5414/events | https://github.com/huggingface/datasets/issues/5414 | 1,525,733,818 | I_kwDODunzps5a8Nm6 | 5,414 | Sharding error with Multilingual LibriSpeech | {
"avatar_url": "https://avatars.githubusercontent.com/u/19574344?v=4",
"events_url": "https://api.github.com/users/Nithin-Holla/events{/privacy}",
"followers_url": "https://api.github.com/users/Nithin-Holla/followers",
"following_url": "https://api.github.com/users/Nithin-Holla/following{/other_user}",
"gists_url": "https://api.github.com/users/Nithin-Holla/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nithin-Holla",
"id": 19574344,
"login": "Nithin-Holla",
"node_id": "MDQ6VXNlcjE5NTc0MzQ0",
"organizations_url": "https://api.github.com/users/Nithin-Holla/orgs",
"received_events_url": "https://api.github.com/users/Nithin-Holla/received_events",
"repos_url": "https://api.github.com/users/Nithin-Holla/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nithin-Holla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nithin-Holla/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nithin-Holla"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @Nithin-Holla.\r\n\r\nThis is a known issue for multiple datasets and we are investigating it:\r\n- See e.g.: https://huggingface.co/datasets/ami/discussions/3",
"Main issue:\r\n- #5415",
"@albertvillanova Thanks! As a workaround for now, can I use the dataset in streaming mode?",
"Yes, @Nithin-Holla, in the meantime you can use this dataset in streaming mode."
] | "2023-01-09T14:45:31Z" | "2023-01-18T14:09:04Z" | "2023-01-18T14:09:04Z" | NONE | null | null | null | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/2.1.0/1904af50f57a5c370c9364cc337699cfe496d4e9edcae6648a96be23086362d0...
Downloading data files: 100%
3/3 [00:00<00:00, 107.23it/s]
Downloading data files: 100%
1/1 [00:00<00:00, 35.08it/s]
Downloading data files: 100%
6/6 [00:00<00:00, 303.36it/s]
Downloading data files: 100%
3/3 [00:00<00:00, 130.37it/s]
Downloading data files: 100%
1049/1049 [00:00<00:00, 4491.40it/s]
Downloading data files: 100%
37/37 [00:00<00:00, 1096.78it/s]
Downloading data files: 100%
40/40 [00:00<00:00, 1003.93it/s]
Extracting data files: 100%
3/3 [00:11<00:00, 2.62s/it]
Generating train split:
469942/0 [34:13<00:00, 273.21 examples/s]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-74fa6d092bdc> in <module>
----> 1 mls = load_dataset(MLS_DATASET,
2 LANGUAGE,
3 cache_dir="~/datadrive/cache/huggingface/datasets",
4 ignore_verifications=True)
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1755
1756 # Download and prepare data
-> 1757 builder_instance.download_and_prepare(
1758 download_config=download_config,
1759 download_mode=download_mode,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
858 if num_proc is not None:
859 prepare_split_kwargs["num_proc"] = num_proc
--> 860 self._download_and_prepare(
861 dl_manager=dl_manager,
862 verify_infos=verify_infos,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1609
1610 def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
...
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_archives has length 1049
- key local_extracted_archive has length 1049
- key limited_ids_paths has length 1
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
### Steps to reproduce the bug
Here is the code to reproduce it:
```python
from datasets import load_dataset
MLS_DATASET = "facebook/multilingual_librispeech"
LANGUAGE = "german"
mls = load_dataset(MLS_DATASET,
LANGUAGE,
cache_dir="~/datadrive/cache/huggingface/datasets",
ignore_verifications=True)
```
### Expected behavior
The expected behaviour is that the dataset is successfully loaded.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-1094-azure-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 10.0.1
- Pandas version: 1.2.4 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5414/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5414/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3340/comments | https://api.github.com/repos/huggingface/datasets/issues/3340/events | https://github.com/huggingface/datasets/pull/3340 | 1,067,292,636 | PR_kwDODunzps4vMP6Z | 3,340 | Fix JSON ClassLabel casting for integers | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2021-11-30T14:19:54Z" | "2021-12-01T11:27:30Z" | "2021-12-01T11:27:30Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3340",
"merged_at": "2021-12-01T11:27:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3340"
} | Loading a JSON dataset with ClassLabel feature types currently fails if the JSON data already has integers. Indeed currently it tries to convert the strings to integers without even checking if the data are not integers already.
For example this currently fails:
```python
from datasets import load_dataset, Features, ClassLabel
path = "data.json"
f = Features({"a": ClassLabel(names=["neg", "pos"])})
d = load_dataset("json", data_files=path, features=f)
```
data.json
```json
{"a": 0}
{"a": 1}
```
I fixed that by adding a line that checks the type of the JSON data before trying to convert them
cc @albertvillanova let me know if it sounds good to you | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3340/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5402/comments | https://api.github.com/repos/huggingface/datasets/issues/5402/events | https://github.com/huggingface/datasets/issues/5402 | 1,517,409,429 | I_kwDODunzps5acdSV | 5,402 | Missing state.json when creating a cloud dataset using a dataset_builder | {
"avatar_url": "https://avatars.githubusercontent.com/u/22022514?v=4",
"events_url": "https://api.github.com/users/danielfleischer/events{/privacy}",
"followers_url": "https://api.github.com/users/danielfleischer/followers",
"following_url": "https://api.github.com/users/danielfleischer/following{/other_user}",
"gists_url": "https://api.github.com/users/danielfleischer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danielfleischer",
"id": 22022514,
"login": "danielfleischer",
"node_id": "MDQ6VXNlcjIyMDIyNTE0",
"organizations_url": "https://api.github.com/users/danielfleischer/orgs",
"received_events_url": "https://api.github.com/users/danielfleischer/received_events",
"repos_url": "https://api.github.com/users/danielfleischer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danielfleischer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielfleischer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danielfleischer"
} | [] | open | false | null | [] | null | [
"`load_from_disk` must be used on datasets saved using `save_to_disk`: they correspond to fully serialized datasets including their state.\r\n\r\nOn the other hand, `download_and_prepare` just downloads the raw data and convert them to arrow (or parquet if you want). We are working on allowing you to reload a dataset saved on S3 with `download_and_prepare` using `load_dataset` in #5281 \r\n\r\nFor now I'd encourage you to keep using `save_to_disk`",
"Thanks, I'll follow that issue. \r\n\r\nI was following the [cloud storage](https://huggingface.co/docs/datasets/filesystems) docs section and perhaps I'm missing some part of the flow; start with `load_dataset_builder` + `download_and_prepare`. You say I need an explicit `save_to_disk` but what object needs to be saved? the builder? is that related to the other issue?",
"Right now `load_dataset_builder` + `download_and_prepare` is to be used with tools like dask or spark, but `load_dataset` will support private cloud storage soon as well so you'll be able to reload the dataset with `datasets`.\r\n\r\nRight now the only function that can load a dataset from a cloud storage is `load_from_disk`, that must be used with a dataset serialized with `save_to_disk`."
] | "2023-01-03T13:39:59Z" | "2023-01-04T17:23:57Z" | null | NONE | null | null | null | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
As a comparison, if you use the non lazy `load_dataset`, it works and the S3 folder has different structure + state.json files. Example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_dataset, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
dataset = load_dataset("imdb",)
dataset.save_to_disk(output_dir, fs=fs)
load_from_disk(output_dir, fs=fs) # WORKS
```
You still want the 1st option for the laziness and the parquet conversion. Thanks!
### Steps to reproduce the bug
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
BTW, you need the AioSession as s3fs is now based on aiobotocore, see https://github.com/fsspec/s3fs/issues/385.
### Expected behavior
Expected to be able to load the dataset from S3.
### Environment info
```
s3fs 2022.11.0
s3transfer 0.6.0
datasets 2.8.0
aiobotocore 2.4.2
boto3 1.24.59
botocore 1.27.59
```
python 3.7.15. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5402/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2475/comments | https://api.github.com/repos/huggingface/datasets/issues/2475/events | https://github.com/huggingface/datasets/issues/2475 | 917,650,882 | MDU6SXNzdWU5MTc2NTA4ODI= | 2,475 | Issue in timit_asr database | {
"avatar_url": "https://avatars.githubusercontent.com/u/85702107?v=4",
"events_url": "https://api.github.com/users/hrahamim/events{/privacy}",
"followers_url": "https://api.github.com/users/hrahamim/followers",
"following_url": "https://api.github.com/users/hrahamim/following{/other_user}",
"gists_url": "https://api.github.com/users/hrahamim/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hrahamim",
"id": 85702107,
"login": "hrahamim",
"node_id": "MDQ6VXNlcjg1NzAyMTA3",
"organizations_url": "https://api.github.com/users/hrahamim/orgs",
"received_events_url": "https://api.github.com/users/hrahamim/received_events",
"repos_url": "https://api.github.com/users/hrahamim/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hrahamim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hrahamim/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hrahamim"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This bug was fixed in #1995. Upgrading datasets to version 1.6 fixes the issue!",
"Indeed was a fixed bug.\r\nWorks on version 1.8\r\nThanks "
] | "2021-06-10T18:05:29Z" | "2021-06-13T08:13:50Z" | "2021-06-13T08:13:13Z" | NONE | null | null | null | ## Describe the bug
I am trying to load the timit_asr dataset however only the first record is shown (duplicated over all the rows).
I am using the next code line
dataset = load_dataset(“timit_asr”, split=“test”).shuffle().select(range(10))
The above code result with the same sentence duplicated ten times.
It also happens when I use the dataset viewer at Streamlit .
## Steps to reproduce the bug
from datasets import load_dataset
dataset = load_dataset(“timit_asr”, split=“test”).shuffle().select(range(10))
data = dataset.to_pandas()
# Sample code to reproduce the bug
```
## Expected results
table with different row information
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.4.1 (also occur in the latest version)
- Platform: Linux-4.15.0-143-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.8.1+cu102 (False)
- Tensorflow version (GPU?): 1.15.3 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
- `datasets` version:
- Platform:
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2475/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4799 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4799/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4799/comments | https://api.github.com/repos/huggingface/datasets/issues/4799/events | https://github.com/huggingface/datasets/issues/4799 | 1,330,889,854 | I_kwDODunzps5PU8R- | 4,799 | video dataset loader/parser | {
"avatar_url": "https://avatars.githubusercontent.com/u/26421036?v=4",
"events_url": "https://api.github.com/users/verbose-avocado/events{/privacy}",
"followers_url": "https://api.github.com/users/verbose-avocado/followers",
"following_url": "https://api.github.com/users/verbose-avocado/following{/other_user}",
"gists_url": "https://api.github.com/users/verbose-avocado/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/verbose-avocado",
"id": 26421036,
"login": "verbose-avocado",
"node_id": "MDQ6VXNlcjI2NDIxMDM2",
"organizations_url": "https://api.github.com/users/verbose-avocado/orgs",
"received_events_url": "https://api.github.com/users/verbose-avocado/received_events",
"repos_url": "https://api.github.com/users/verbose-avocado/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/verbose-avocado/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/verbose-avocado/subscriptions",
"type": "User",
"url": "https://api.github.com/users/verbose-avocado"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! We've just started discussing the video support in `datasets` (decoding backends, video feature type, etc.), so I believe we should have something tangible by the end of this year.\r\n\r\nAlso, if you have additional video features in mind that you would like to see, feel free to let us know",
"Coool thanks @mariosasko ",
"Hey @mariosasko, I was wondering if there's a way to load video data currently in the library? \r\nAlternatively is there a way I could hack it through the dataset.from_dict() method? I tried to hack it, but the issue I run into is that earlier I was doing a `cast_column()` call for the `Image` feature, but now I'm not sure about to do if I want the dataset to have the following keys when I call from_dict on it:\r\n`{\"caption\":[list of text captions], \"video_frames\": [list of image lists with one image list corresponding to one video]}`\r\n\r\nMaybe something like `cast_column(\"video_frames\", List(Image))` ..\r\n(This is assuming I have already extracted frames from video)"
] | "2022-08-07T01:54:12Z" | "2023-10-01T00:08:31Z" | "2022-08-09T16:42:51Z" | CONTRIBUTOR | null | null | null | you know how you can [use `load_dataset` with any arbitrary csv file](https://huggingface.co/docs/datasets/loading#csv)? and you can also [use it to load a local image dataset](https://huggingface.co/docs/datasets/image_load#local-files)?
could you please add functionality to load a video dataset? it would be really cool if i could point it to a bunch of video files and use pytorch to start looping through batches of videos. like if my batch size is 16, each sample in the batch is a frame from a video. i'm competing in the [minerl challenge](https://www.aicrowd.com/challenges/neurips-2022-minerl-basalt-competition), and it would be awesome to use the HF ecosystem. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4799/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4799/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/674/comments | https://api.github.com/repos/huggingface/datasets/issues/674/events | https://github.com/huggingface/datasets/issues/674 | 709,661,006 | MDU6SXNzdWU3MDk2NjEwMDY= | 674 | load_dataset() won't download in Windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/34422661?v=4",
"events_url": "https://api.github.com/users/ThisDavehead/events{/privacy}",
"followers_url": "https://api.github.com/users/ThisDavehead/followers",
"following_url": "https://api.github.com/users/ThisDavehead/following{/other_user}",
"gists_url": "https://api.github.com/users/ThisDavehead/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ThisDavehead",
"id": 34422661,
"login": "ThisDavehead",
"node_id": "MDQ6VXNlcjM0NDIyNjYx",
"organizations_url": "https://api.github.com/users/ThisDavehead/orgs",
"received_events_url": "https://api.github.com/users/ThisDavehead/received_events",
"repos_url": "https://api.github.com/users/ThisDavehead/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ThisDavehead/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ThisDavehead/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ThisDavehead"
} | [] | closed | false | null | [] | null | [
"I have the same issue. Tried to download a few of them and not a single one is downloaded successfully.\r\n\r\nThis is the output:\r\n```\r\n>>> dataset = load_dataset('blended_skill_talk', split='train')\r\nUsing custom data configuration default <-- This step never ends\r\n```",
"This was fixed in #644 \r\nI'll do a new release soon :)\r\n\r\nIn the meantime you can run it by installing from source",
"Closing since version 1.1.0 got released with Windows support :) \r\nLet me know if it works for you now"
] | "2020-09-27T03:56:25Z" | "2020-10-05T08:28:18Z" | "2020-10-05T08:28:18Z" | NONE | null | null | null | I don't know if this is just me or Windows. Maybe other Windows users can chime in if they don't have this problem. I've been trying to get some of the tutorials working on Windows, but when I use the load_dataset() function, it just stalls and the script keeps running indefinitely without downloading anything. I've waited upwards of 18 hours to download the 'multi-news' dataset (which isn't very big), and still nothing. I've tried running it through different IDE's and the command line, but it had the same behavior. I've also tried it with all virus and malware protection turned off. I've made sure python and all IDE's are exceptions to the firewall and all the requisite permissions are enabled.
Additionally, I checked to see if other packages could download content such as an nltk corpus, and they could. I've also run the same script using Ubuntu and it downloaded fine (and quickly). When I copied the downloaded datasets from my Ubuntu drive to my Windows .cache folder it worked fine by reusing the already-downloaded dataset, but it's cumbersome to do that for every dataset I want to try in my Windows environment.
Could this be a bug, or is there something I'm doing wrong or not thinking of?
Thanks. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/674/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/674/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4133 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4133/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4133/comments | https://api.github.com/repos/huggingface/datasets/issues/4133/events | https://github.com/huggingface/datasets/issues/4133 | 1,197,830,623 | I_kwDODunzps5HZXHf | 4,133 | HANS dataset preview broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci"
} | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | null | [] | null | [
"The dataset cannot be loaded, be it in normal or streaming mode.\r\n\r\n```python\r\n>>> import datasets\r\n>>> dataset=datasets.load_dataset(\"hans\", split=\"train\", streaming=True)\r\n>>> next(iter(dataset))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 497, in __iter__\r\n for key, example in self._iter():\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 494, in _iter\r\n yield from ex_iterable\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py\", line 87, in __iter__\r\n yield from self.generate_examples_fn(**self.kwargs)\r\n File \"/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/hans/1bbcb735c482acd54f2e118074b59cfd2bf5f7a5a285d4d540d1e632216672ac/hans.py\", line 121, in _generate_examples\r\n for idx, line in enumerate(open(filepath, \"rb\")):\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1595, in __next__\r\n out = self.readline()\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1592, in readline\r\n return self.readuntil(b\"\\n\")\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1581, in readuntil\r\n self.seek(start + found + len(char))\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 676, in seek\r\n raise ValueError(\"Cannot seek streaming HTTP file\")\r\nValueError: Cannot seek streaming HTTP file\r\n>>> dataset=datasets.load_dataset(\"hans\", split=\"train\", streaming=False)\r\nDownloading and preparing dataset hans/plain_text (download: 29.51 MiB, generated: 30.34 MiB, post-processed: Unknown size, total: 59.85 MiB) to /home/slesage/.cache/huggingface/datasets/hans/plain_text/1.0.0/1bbcb735c482acd54f2e118074b59cfd2bf5f7a5a285d4d540d1e632216672ac...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/load.py\", line 1687, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py\", line 605, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py\", line 1104, in _download_and_prepare\r\n super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py\", line 694, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py\", line 1087, in _prepare_split\r\n for key, record in logging.tqdm(\r\n File \"/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/tqdm/std.py\", line 1180, in __iter__\r\n for obj in iterable:\r\n File \"/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/hans/1bbcb735c482acd54f2e118074b59cfd2bf5f7a5a285d4d540d1e632216672ac/hans.py\", line 121, in _generate_examples\r\n for idx, line in enumerate(open(filepath, \"rb\")):\r\nValueError: readline of closed file\r\n```\r\n\r\n",
"Hi! I've opened a PR that should make this dataset stremable. You can test it as follows:\r\n```python\r\nfrom datasets import load_dataset\r\ndset = load_dataset(\"hans\", split=\"train\", streaming=True, revision=\"49decd29839c792ecc24ac88f861cbdec30c1c40\")\r\n```\r\n\r\n@severo The current script doesn't throw an error in normal mode (only in streaming mode) on my local machine or in Colab. Can you update your installation of `datasets` and see if that fixes the issue?",
"Thanks for this. It works well, thanks! The dataset viewer is using https://github.com/huggingface/datasets/releases/tag/2.0.0, I'm eager to upgrade to 2.0.1 😉"
] | "2022-04-08T21:06:15Z" | "2022-04-13T11:57:34Z" | "2022-04-13T11:57:34Z" | NONE | null | null | null | ## Dataset viewer issue for '*hans*'
**Link:** [https://huggingface.co/datasets/hans](https://huggingface.co/datasets/hans)
HANS dataset preview is broken with error 400
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4133/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4133/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2614/comments | https://api.github.com/repos/huggingface/datasets/issues/2614/events | https://github.com/huggingface/datasets/pull/2614 | 940,762,427 | MDExOlB1bGxSZXF1ZXN0Njg2Nzg2NTg3 | 2,614 | Convert numpy scalar to python float in Pearsonr output | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | [] | "2021-07-09T13:22:55Z" | "2021-07-12T14:13:02Z" | "2021-07-09T14:04:38Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2614.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2614",
"merged_at": "2021-07-09T14:04:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2614.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2614"
} | Following of https://github.com/huggingface/datasets/pull/2612 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2614/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6130/comments | https://api.github.com/repos/huggingface/datasets/issues/6130/events | https://github.com/huggingface/datasets/issues/6130 | 1,843,158,846 | I_kwDODunzps5t3F8- | 6,130 | default config name doesn't work when config kwargs are specified. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "https://api.github.com/users/npuichigo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/npuichigo",
"id": 11533479,
"login": "npuichigo",
"node_id": "MDQ6VXNlcjExNTMzNDc5",
"organizations_url": "https://api.github.com/users/npuichigo/orgs",
"received_events_url": "https://api.github.com/users/npuichigo/received_events",
"repos_url": "https://api.github.com/users/npuichigo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/npuichigo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/npuichigo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/npuichigo"
} | [] | closed | false | null | [] | null | [
"@lhoestq ",
"What should be the behavior in this case ? Should it override the default config with the added parameter ?",
"I know why it should be treated as a new config if overriding parameters are passed. But in some case, I just pass in some common fields like `data_dir`.\r\n\r\nFor example, I want to extend the FolderBasedBuilder as a multi-config version, the `data_dir` or `data_files` are always passed by user and should not be considered as overriding the default config. In current state, I cannot leverage the feature of default config since passing `data_dir` will disable the default config.",
"Thinking more about it I think the current behavior is the right one.\r\n\r\nProvided parameters should be passed to instantiate a new BuilderConfig.\r\n\r\nWhat's the error you're getting ?",
"For example, this works to use default config with name '_all_':\r\n```python\r\ndatasets.load_dataset(\"indonesian-nlp/librivox-indonesia\", split=\"train\")\r\n```\r\nwhile this failed to use default config\r\n```python\r\ndatasets.load_dataset(\"indonesian-nlp/librivox-indonesia\", split=\"train\", data_dir='.')\r\n```\r\nAfter manually specifying it, it works again.\r\n```python\r\ndatasets.load_dataset(\"indonesian-nlp/librivox-indonesia\", \"_all_\", split=\"train\", data_dir='.')\r\n```",
"@lhoestq ",
"It should work if you explicitly ask for the config you want to override\r\n\r\n```python\r\nload_dataset('/dataset/with/multiple/config', 'name_of_the_default_config', some_field_in_config='some')\r\n```\r\n\r\nAlternatively you can have a BuilderConfig class that when instantiated returns a config with the right default values. In this case this code would instantiate this config with the default values except for the parameter to override:\r\n\r\n```python\r\nload_dataset('/dataset/with/multiple/config', some_field_in_config='some')\r\n```",
"@lhoestq Yes. But it doesn't work for me.\r\n\r\nHere's my dataset for example.\r\n```\r\nlass MyDatasetConfig(datasets.BuilderConfig):\r\n def __init__(self, name: str, version: str, **kwargs):\r\n self.option1 = kwargs.pop(\"option1\", False)\r\n self.option2 = kwargs.pop(\"option2\", 5)\r\n\r\n super().__init__(\r\n name=name,\r\n version=datasets.Version(version),\r\n **kwargs)\r\n\r\n\r\nclass MyDataset(datasets.GeneratorBasedBuilder):\r\n DEFAULT_CONFIG_NAME = \"v1\"\r\n\r\n BUILDER_CONFIGS = [\r\n UnifiedTtsDatasetConfig(\r\n name=\"v1\",\r\n version=\"1.0.0\",\r\n description=\"Initial version of the dataset\"\r\n ),\r\n ]\r\n\r\n def _info(self) -> DatasetInfo:\r\n _ = self.option1\r\n ....\r\n```\r\n\r\nHere it's okay to use `load_dataset('my_dataset.py')` for loading the default config `v1`.\r\n\r\nBut if I want to override the default values in config with `load_dataset('my_dataset.py', option2=3)`, it failed to find my default config `v1.\r\n\r\nUnless I use `load_dataset('my_dataset.py', 'v1', option2=3)`\r\n\r\nSo according to your advice, how can I modify my dataset to be able to override default config without manually specifying it.",
"What's the error ? It should try to instantiate `MyDatasetConfig` with `option2=3`",
"@lhoestq The error is\r\n```\r\ndef _info(self) -> DatasetInfo:\r\n _ = self.option1 <-\r\n ....\r\nAttributeError: 'BuilderConfig' object has no attribute 'option1'\r\n```\r\nwhich seems to find another unknown config.\r\n\r\nYou can try this line `datasets.load_dataset(\"indonesian-nlp/librivox-indonesia\", split=\"train\", data_dir='.')`, it's a multi-config dataset on HF hub and the error is the same.\r\n\r\nMy insights:\r\nhttps://github.com/huggingface/datasets/blob/12cfc1196e62847e2e8239fbd727a02cbc86ddec/src/datasets/builder.py#L518\r\nif `config_kwargs` is provided here, the if branch is skipped.",
"I see, you just have to set this class attribute to your builder class :)\r\n\r\n```python\r\nBUILDER_CONFIG_CLASS = MyDatasetConfig\r\n```",
"So what does this attribute do? In most cases it's not used and the [documents for multi-config dataset](https://huggingface.co/docs/datasets/main/en/image_dataset#multiple-configurations) never mentioned that.",
"It tells which builder config class to instantiate if additional config parameters are passed to load_dataset",
"@lhoestq maybe we can enhance the document to say something about the common attributes of `DatasetBuilder`",
"Ah indeed it's missing in the docs, thanks for reporting. I'm opening a PR"
] | "2023-08-09T12:43:15Z" | "2023-11-22T11:50:49Z" | "2023-11-22T11:50:48Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
https://github.com/huggingface/datasets/blob/12cfc1196e62847e2e8239fbd727a02cbc86ddec/src/datasets/builder.py#L518-L522
If `config_name` is `None`, `DEFAULT_CONFIG_NAME` should be select. But once users pass `config_kwargs` to their customized `BuilderConfig`, the logic is ignored, and dataset cannot select the default config from multiple configs.
### Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('/dataset/with/multiple/config'') # Ok
datasets.load_dataset('/dataset/with/multiple/config', some_field_in_config='some') # Err
```
### Expected behavior
Default config behavior should be consistent.
### Environment info
- `datasets` version: 2.14.3
- Platform: Linux-5.15.0-76-generic-x86_64-with-glibc2.17
- Python version: 3.8.15
- Huggingface_hub version: 0.16.4
- PyArrow version: 12.0.1
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6130/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1728/comments | https://api.github.com/repos/huggingface/datasets/issues/1728/events | https://github.com/huggingface/datasets/issues/1728 | 784,458,342 | MDU6SXNzdWU3ODQ0NTgzNDI= | 1,728 | Add an entry to an arrow dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/18645407?v=4",
"events_url": "https://api.github.com/users/ameet-1997/events{/privacy}",
"followers_url": "https://api.github.com/users/ameet-1997/followers",
"following_url": "https://api.github.com/users/ameet-1997/following{/other_user}",
"gists_url": "https://api.github.com/users/ameet-1997/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ameet-1997",
"id": 18645407,
"login": "ameet-1997",
"node_id": "MDQ6VXNlcjE4NjQ1NDA3",
"organizations_url": "https://api.github.com/users/ameet-1997/orgs",
"received_events_url": "https://api.github.com/users/ameet-1997/received_events",
"repos_url": "https://api.github.com/users/ameet-1997/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ameet-1997/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ameet-1997/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ameet-1997"
} | [] | closed | false | null | [] | null | [
"Hi @ameet-1997,\r\nI think what you are looking for is the `concatenate_datasets` function: https://huggingface.co/docs/datasets/processing.html?highlight=concatenate#concatenate-several-datasets\r\n\r\nFor your use case, I would use the [`map` method](https://huggingface.co/docs/datasets/processing.html?highlight=concatenate#processing-data-with-map) to transform the SQuAD sentences and the `concatenate` the original and mapped dataset.\r\n\r\nLet me know If this helps!",
"That's a great idea! Thank you so much!\r\n\r\nWhen I try that solution, I get the following error when I try to concatenate `datasets` and `modified_dataset`. I have also attached the output I get when I print out those two variables. Am I missing something?\r\n\r\nCode:\r\n``` python\r\ncombined_dataset = concatenate_datasets([datasets, modified_dataset])\r\n```\r\n\r\nError:\r\n```\r\nAttributeError: 'DatasetDict' object has no attribute 'features'\r\n```\r\n\r\nOutput:\r\n```\r\n(Pdb) datasets\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['attention_mask', 'input_ids', 'special_tokens_mask'],\r\n num_rows: 493\r\n })\r\n})\r\n(Pdb) modified_dataset\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['attention_mask', 'input_ids', 'special_tokens_mask'],\r\n num_rows: 493\r\n })\r\n})\r\n```\r\n\r\nThe error is stemming from the fact that the attribute `datasets.features` does not exist. Would it not be possible to use `concatenate_datasets` in such a case? Is there an alternate solution?",
"You should do `combined_dataset = concatenate_datasets([datasets['train'], modified_dataset['train']])`\r\n\r\nDidn't we talk about returning a Dataset instead of a DatasetDict with load_dataset and no split provided @lhoestq? Not sure it's the way to go but I'm wondering if it's not simpler for some use-cases.",
"> Didn't we talk about returning a Dataset instead of a DatasetDict with load_dataset and no split provided @lhoestq? Not sure it's the way to go but I'm wondering if it's not simpler for some use-cases.\r\n\r\nMy opinion is that users should always know in advance what type of objects they're going to get. Otherwise the development workflow on their side is going to be pretty chaotic with sometimes unexpected behaviors.\r\nFor instance is `split=` is not specified it's currently always returning a DatasetDict. And if `split=\"train\"` is given for example it's always returning a Dataset.",
"Thanks @thomwolf. Your solution worked!"
] | "2021-01-12T18:01:47Z" | "2021-01-18T19:15:32Z" | "2021-01-18T19:15:32Z" | NONE | null | null | null | Is it possible to add an entry to a dataset object?
**Motivation: I want to transform the sentences in the dataset and add them to the original dataset**
For example, say we have the following code:
``` python
from datasets import load_dataset
# Load a dataset and print the first examples in the training set
squad_dataset = load_dataset('squad')
print(squad_dataset['train'][0])
```
Is it possible to add an entry to `squad_dataset`? Something like the following?
``` python
squad_dataset.append({'text': "This is a new sentence"})
```
The motivation for doing this is that I want to transform the sentences in the squad dataset and add them to the original dataset.
If the above doesn't work, is there any other way of achieving the motivation mentioned above? Perhaps by creating a new arrow dataset by using the older one and the transformer sentences?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1728/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1728/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/225/comments | https://api.github.com/repos/huggingface/datasets/issues/225/events | https://github.com/huggingface/datasets/issues/225 | 628,083,366 | MDU6SXNzdWU2MjgwODMzNjY= | 225 | [ROUGE] Different scores with `files2rouge` | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul"
} | [
{
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics",
"id": 2067400959,
"name": "Metric discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
}
] | null | [
"@Colanim unfortunately there are different implementations of the ROUGE metric floating around online which yield different results, and we had to chose one for the package :) We ended up including the one from the google-research repository, which does minimal post-processing before computing the P/R/F scores. If I recall correctly, files2rouge relies on the Perl, script, which among other things normalizes all numbers to a special token: in the case you presented, this should account for a good chunk of the difference.\r\n\r\nWe may end up adding in more versions of the metric, but probably not for a while (@lhoestq correct me if I'm wrong). However, feel free to take a stab at adding it in yourself and submitting a PR if you're interested!",
"Thank you for your kind answer.\r\n\r\nAs a side question : Isn't it better to have a package that normalize more ?\r\n\r\nI understand to idea of having a package that does minimal post-processing for transparency.\r\n\r\nBut it means that people using different architecture (with different tokenizers for example) will have difference in ROUGE scores even if their predictions are actually similar. \r\nThe goal of `nlp` is to have _one package to rule them all_, right ?\r\n\r\nI will look into it but I'm not sure I have the required skill for this ^^ ",
"You're right, there's a pretty interesting trade-off here between robustness and sensitivity :) The flip side of your argument is that we also still want the metric to be sensitive to model mistakes. How we think about number normalization for example has evolved a fair bit since the Perl script was written: at the time, ROUGE was used mostly to evaluate short-medium text summarization systems, where there were only a few numbers in the input and it was assumed that the most popular methods in use at the time would get those right. However, as your example showcases, that assumption does not hold any more, and we do want to be able to penalize a model that generates a wrong numerical value.\r\n\r\nAlso, we think that abstracting away tokenization differences is the role of the model/tokenizer: if you use the 🤗Tokenizers library for example, it will handle that for you ;)\r\n\r\nFinally, there is a lot of active research on developing model-powered metrics that are both more sensitive and more robust than ROUGE. Check out for example BERTscore, which is implemented in this library!"
] | "2020-06-01T00:50:36Z" | "2020-06-03T15:27:18Z" | "2020-06-03T15:27:18Z" | NONE | null | null | null | It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.14574333776191592
rougeL 0.2321187823256159
`files2rouge` :
>Running ROUGE...
===========================
1 ROUGE-1 Average_R: 0.48873 (95%-conf.int. 0.41192 - 0.56339)
1 ROUGE-1 Average_P: 0.29010 (95%-conf.int. 0.23605 - 0.34445)
1 ROUGE-1 Average_F: 0.34761 (95%-conf.int. 0.29479 - 0.39871)
===========================
1 ROUGE-2 Average_R: 0.20280 (95%-conf.int. 0.14969 - 0.26244)
1 ROUGE-2 Average_P: 0.12772 (95%-conf.int. 0.08603 - 0.17752)
1 ROUGE-2 Average_F: 0.14798 (95%-conf.int. 0.10517 - 0.19240)
===========================
1 ROUGE-L Average_R: 0.32960 (95%-conf.int. 0.26501 - 0.39676)
1 ROUGE-L Average_P: 0.19880 (95%-conf.int. 0.15257 - 0.25136)
1 ROUGE-L Average_F: 0.23619 (95%-conf.int. 0.19073 - 0.28663)
---
When using longer predictions/gold, the difference is bigger.
**How can I reproduce same score as `files2rouge` ?**
@lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/225/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1378/comments | https://api.github.com/repos/huggingface/datasets/issues/1378/events | https://github.com/huggingface/datasets/pull/1378 | 760,313,108 | MDExOlB1bGxSZXF1ZXN0NTM1MTY1OTE3 | 1,378 | Add FACTCK.BR dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1206395?v=4",
"events_url": "https://api.github.com/users/hugoabonizio/events{/privacy}",
"followers_url": "https://api.github.com/users/hugoabonizio/followers",
"following_url": "https://api.github.com/users/hugoabonizio/following{/other_user}",
"gists_url": "https://api.github.com/users/hugoabonizio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hugoabonizio",
"id": 1206395,
"login": "hugoabonizio",
"node_id": "MDQ6VXNlcjEyMDYzOTU=",
"organizations_url": "https://api.github.com/users/hugoabonizio/orgs",
"received_events_url": "https://api.github.com/users/hugoabonizio/received_events",
"repos_url": "https://api.github.com/users/hugoabonizio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hugoabonizio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hugoabonizio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hugoabonizio"
} | [] | closed | false | null | [] | null | [
"@lhoestq done!",
"merging since the CI is fixed on master"
] | "2020-12-09T13:06:22Z" | "2020-12-17T12:38:45Z" | "2020-12-15T15:34:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1378.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1378",
"merged_at": "2020-12-15T15:34:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1378.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1378"
} | This PR adds [FACTCK.BR](https://github.com/jghm-f/FACTCK.BR) dataset from [FACTCK.BR: a new dataset to study fake news](https://dl.acm.org/doi/10.1145/3323503.3361698). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1378/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4330 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4330/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4330/comments | https://api.github.com/repos/huggingface/datasets/issues/4330/events | https://github.com/huggingface/datasets/pull/4330 | 1,233,992,681 | PR_kwDODunzps43uIwm | 4,330 | Adding eval metadata to Allociné dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [] | closed | false | null | [] | null | [] | "2022-05-12T13:31:39Z" | "2022-05-12T21:03:05Z" | "2022-05-12T21:03:05Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4330.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4330",
"merged_at": "2022-05-12T21:03:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4330.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4330"
} | Adding eval metadata to Allociné dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4330/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4330/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5104/comments | https://api.github.com/repos/huggingface/datasets/issues/5104/events | https://github.com/huggingface/datasets/pull/5104 | 1,405,973,102 | PR_kwDODunzps5Ao9Mq | 5,104 | Fix loading how to guide (#5102) | {
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/riccardobucco",
"id": 9295277,
"login": "riccardobucco",
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"type": "User",
"url": "https://api.github.com/users/riccardobucco"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-12T10:34:42Z" | "2022-10-12T11:34:07Z" | "2022-10-12T11:31:55Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5104.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5104",
"merged_at": "2022-10-12T11:31:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5104.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5104"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5104/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5104/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2994 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2994/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2994/comments | https://api.github.com/repos/huggingface/datasets/issues/2994/events | https://github.com/huggingface/datasets/pull/2994 | 1,013,000,475 | PR_kwDODunzps4si4I2 | 2,994 | Fix loading compressed CSV without streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-10-01T07:28:59Z" | "2021-10-01T15:53:16Z" | "2021-10-01T15:53:16Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2994.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2994",
"merged_at": "2021-10-01T15:53:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2994.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2994"
} | When implementing support to stream CSV files (https://github.com/huggingface/datasets/commit/ad489d4597381fc2d12c77841642cbeaecf7a2e0#diff-6f60f8d0552b75be8b3bfd09994480fd60dcd4e7eb08d02f721218c3acdd2782), a regression was introduced preventing loading compressed CSV files in non-streaming mode.
This PR fixes it, allowing loading compressed/uncompressed CSV files in streaming/non-streaming mode.
Fix #2977. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2994/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2994/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/885/comments | https://api.github.com/repos/huggingface/datasets/issues/885/events | https://github.com/huggingface/datasets/issues/885 | 750,789,052 | MDU6SXNzdWU3NTA3ODkwNTI= | 885 | Very slow cold-start | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://api.github.com/users/AmitMY/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AmitMY",
"id": 5757359,
"login": "AmitMY",
"node_id": "MDQ6VXNlcjU3NTczNTk=",
"organizations_url": "https://api.github.com/users/AmitMY/orgs",
"received_events_url": "https://api.github.com/users/AmitMY/received_events",
"repos_url": "https://api.github.com/users/AmitMY/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AmitMY/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AmitMY/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AmitMY"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Good point!",
"Yes indeed. We can probably improve that by using lazy imports",
"#1690 added fast start-up of the library "
] | "2020-11-25T12:47:58Z" | "2021-01-13T11:31:25Z" | "2021-01-13T11:31:25Z" | CONTRIBUTOR | null | null | null | Hi,
I expect when importing `datasets` that nothing major happens in the background, and so the import should be insignificant.
When I load a metric, or a dataset, its fine that it takes time.
The following ranges from 3 to 9 seconds:
```
python -m timeit -n 1 -r 1 'from datasets import load_dataset'
```
edit:
sorry for the mis-tag, not sure how I added it. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/885/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4462 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4462/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4462/comments | https://api.github.com/repos/huggingface/datasets/issues/4462/events | https://github.com/huggingface/datasets/issues/4462 | 1,265,079,347 | I_kwDODunzps5LZ5Qz | 4,462 | BigBench: NonMatchingSplitsSizesError when passing a dataset configuration parameter | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Why not adding `max_examples` as part of the config name?",
"Yup it can also work, and maybe it's simpler this way. Opening a PR to fix bigbench instead of https://github.com/huggingface/datasets/pull/4463",
"Hi @lhoestq,\r\n\r\nThank you for taking a look at this issue, and proposing a solution. \r\nUnfortunately, after trying the fix in #4465 I still see the same issue.\r\n\r\nI think there is some subtlety where the config name gets overwritten somewhere when `BUILDER_CONFIGS`[(link)](https://github.com/huggingface/datasets/blob/master/datasets/bigbench/bigbench.py#L126) is defined. \r\n\r\nIf I print out the `self.config.name` in the current version (with the fix in #4465), I see just the task name, but if I comment out `BUILDER_CONFIGS`, the `num_shots` and `max_examples` gets appended as was meant by #4465.\r\n\r\nI haven't managed to track down where this happens, but I thought you might know? \r\n\r\n(Another comment on your fix: the `name` variable is used to fetch the task from the bigbench API, so modifying it causes an error if it's actually called. This can easily be fixed by having `config_name` variable in addition to the `task_name`)\r\n\r\n\r\n"
] | "2022-06-08T17:31:24Z" | "2022-07-05T07:39:55Z" | null | MEMBER | null | null | null | As noticed in https://github.com/huggingface/datasets/pull/4125 when a dataset config class has a parameter that reduces the number of examples (e.g. named `max_examples`), then loading the dataset and passing `max_examples` raises `NonMatchingSplitsSizesError`.
This is because it will check for expected the number of examples of the config with the same name without taking into account the `max_examples` parameter. This can be fixed by checking the expected number of examples using the **config id** instead of name. Indeed the config id corresponds to the config name + an optional suffix that depends on the config parameters | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4462/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4462/timeline | null | reopened | false |
https://api.github.com/repos/huggingface/datasets/issues/1857 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1857/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1857/comments | https://api.github.com/repos/huggingface/datasets/issues/1857/events | https://github.com/huggingface/datasets/issues/1857 | 805,391,107 | MDU6SXNzdWU4MDUzOTExMDc= | 1,857 | Unable to upload "community provided" dataset - 400 Client Error | {
"avatar_url": "https://avatars.githubusercontent.com/u/1376337?v=4",
"events_url": "https://api.github.com/users/mwrzalik/events{/privacy}",
"followers_url": "https://api.github.com/users/mwrzalik/followers",
"following_url": "https://api.github.com/users/mwrzalik/following{/other_user}",
"gists_url": "https://api.github.com/users/mwrzalik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mwrzalik",
"id": 1376337,
"login": "mwrzalik",
"node_id": "MDQ6VXNlcjEzNzYzMzc=",
"organizations_url": "https://api.github.com/users/mwrzalik/orgs",
"received_events_url": "https://api.github.com/users/mwrzalik/received_events",
"repos_url": "https://api.github.com/users/mwrzalik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mwrzalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mwrzalik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mwrzalik"
} | [] | closed | false | null | [] | null | [
"Hi ! We're in the process of switching the community datasets to git repos, exactly like what we're doing for models.\r\nYou can find an example here:\r\nhttps://huggingface.co/datasets/lhoestq/custom_squad/tree/main\r\n\r\nWe'll update the CLI in the coming days and do a new release :)\r\n\r\nAlso cc @julien-c maybe we can make improve the error message ?"
] | "2021-02-10T10:39:01Z" | "2021-08-03T05:06:13Z" | "2021-08-03T05:06:13Z" | CONTRIBUTOR | null | null | null | Hi,
i'm trying to a upload a dataset as described [here](https://huggingface.co/docs/datasets/v1.2.0/share_dataset.html#sharing-a-community-provided-dataset). This is what happens:
```
$ datasets-cli login
$ datasets-cli upload_dataset my_dataset
About to upload file /path/to/my_dataset/dataset_infos.json to S3 under filename my_dataset/dataset_infos.json and namespace username
About to upload file /path/to/my_dataset/my_dataset.py to S3 under filename my_dataset/my_dataset.py and namespace username
Proceed? [Y/n] Y
Uploading... This might take a while if files are large
400 Client Error: Bad Request for url: https://huggingface.co/api/datasets/presign
huggingface.co migrated to a new model hosting system.
You need to upgrade to transformers v3.5+ to upload new models.
More info at https://discuss.hugginface.co or https://twitter.com/julien_c. Thank you!
```
I'm using the latest releases of datasets and transformers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1857/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1857/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4395/comments | https://api.github.com/repos/huggingface/datasets/issues/4395/events | https://github.com/huggingface/datasets/pull/4395 | 1,245,436,486 | PR_kwDODunzps44TrBA | 4,395 | Add Pascal VOC dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Some CI fails are unrelated to your PR and fixed on master, feel free to merge master into your branch :)",
"Thanks @nateraw for the addition of this dataset.\r\n\r\nI would suggest to transfer it to the Hugging Face Hub, under a \"pascal\" organization namespace: \"pascal/voc\".\r\n\r\nWhat do you think?",
"FYI I think this dataset is also available at (internal) https://huggingface.co/datasets/HuggingFaceM4/pascal_voc",
"@lhoestq @albertvillanova what do you think best path forward is? No idea when I'll get to looking at this again, but would be nice to know plan so when I find time I can just get it done in one sitting. ",
"My (not strong) opinion on this:\r\n- as we are removing dataset scripts from GitHub, this dataset should be created directly on the Hub\r\n- I proposed doing it under some kind of \"official\" org namespace, like pascal or pascal2; other suggestions are welcome\r\n- the link given by @lhoestq might serve as inspiration for your implementation (I think yours misses data about action classification): their implementation comprises tasks: classification/detection, segmentation, action classification, person layout; it misses other tasks though\r\n\r\nWhat do you think?"
] | "2022-05-23T16:34:05Z" | "2023-09-24T09:37:05Z" | "2022-10-03T09:36:56Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4395",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4395"
} | This PR adds the Pascal VOC dataset in the same way TFDS has it added. I believe we can iterate on this dataset and in future versions include more data, such as segmentation masks, but for now I think it is a good idea to just add it the same way as TFDS to get a solid first version out there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4395/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4371/comments | https://api.github.com/repos/huggingface/datasets/issues/4371/events | https://github.com/huggingface/datasets/pull/4371 | 1,241,500,906 | PR_kwDODunzps44GzSZ | 4,371 | Add missing language tags for udhr dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-19T09:34:10Z" | "2022-06-08T12:03:24Z" | "2022-05-20T09:43:10Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4371.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4371",
"merged_at": "2022-05-20T09:43:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4371.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4371"
} | Related to #4362. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4371/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4302 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4302/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4302/comments | https://api.github.com/repos/huggingface/datasets/issues/4302/events | https://github.com/huggingface/datasets/pull/4302 | 1,230,651,117 | PR_kwDODunzps43jPE5 | 4,302 | Remove hacking license tags when mirroring datasets on the Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The Hub doesn't allow these characters in the YAML tags, and git push fails if you want to push a dataset card containing these characters.",
"Ok, let me rename the bad config names :) I think I can also keep backward compatibility with a warning",
"Almost done with it btw, will submit a PR that shows all the configuration name changes (from a bit more than 20 datasets)",
"Please, let me know when the renaming of configs is done. If not enough bandwidth, I can take care of it...",
"Will focus on this this afternoon ;)",
"I realized when renaming all the configurations with dots in https://github.com/huggingface/datasets/pull/4365 that it's not ideal for certain cases. For example:\r\n- many configurations have a version like \"1.0.0\" in their names\r\n- to avoid breaking changes we need to replace dots with underscores in the user input and show a warning, which hurts the experience\r\n- our second most downloaded dataset at the moment is affected: `newsgroup`\r\n- if we disallow dots, then we'll never be able to make the [allenai/c4](https://huggingface.co/datasets/allenai/c4) work with its different configurations since they contain dots, and we can't rename them because they are the official download links\r\n\r\nI was thinking of other alternatives:\r\n1. just stop separating tags per config name completely, and have a single flat YAML for all configurations. Dataset search doesn't use this info anyway\r\n2. use another YAML structure to avoid having config names as keys, such as\r\n```yaml\r\nlanguages:\r\n- config: 20220301_en\r\n values:\r\n - en\r\n```\r\n\r\nI'm down for 1, to keep things simple",
"@lhoestq I agree:\r\n- better not changing config names (so that we do not introduce any braking change)\r\n- therefore, we should not use them as keys\r\n\r\nIn relation with the proposed solutions, I have no strong opinion:\r\n- option 1 is simpler and aligns better with current usage on the Hub (configs are ignored)\r\n- however:\r\n - we will lose all the information per config we already have (for those datasets containing config keys; contributors made an effort to put that information per config)\r\n - and this information might be useful on the Hub in the future, in case we would like to enrich the search feature with more granularity; this is only applicable if this feature could eventually make sense\r\n\r\nSo, no strong opinion...",
"Closing in favor of https://github.com/huggingface/datasets/pull/4367"
] | "2022-05-10T05:52:46Z" | "2022-05-20T09:48:30Z" | "2022-05-20T09:40:20Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4302.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4302",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4302.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4302"
} | Currently, when mirroring datasets on the Hub, the license tags are hacked: removed of characters "." and "$". On the contrary, this hacking is not applied to community datasets on the Hub. This generates multiple variants of the same tag on the Hub.
I guess this hacking is no longer necessary:
- it is not applied to community datasets
- all canonical datasets are validated by maintainers before being merged: CI + maintainers make sure license tags are the right ones
Fix #4298. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4302/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4302/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/676/comments | https://api.github.com/repos/huggingface/datasets/issues/676/events | https://github.com/huggingface/datasets/issues/676 | 710,014,319 | MDU6SXNzdWU3MTAwMTQzMTk= | 676 | train_test_split returns empty dataset item | {
"avatar_url": "https://avatars.githubusercontent.com/u/26648528?v=4",
"events_url": "https://api.github.com/users/mojave-pku/events{/privacy}",
"followers_url": "https://api.github.com/users/mojave-pku/followers",
"following_url": "https://api.github.com/users/mojave-pku/following{/other_user}",
"gists_url": "https://api.github.com/users/mojave-pku/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mojave-pku",
"id": 26648528,
"login": "mojave-pku",
"node_id": "MDQ6VXNlcjI2NjQ4NTI4",
"organizations_url": "https://api.github.com/users/mojave-pku/orgs",
"received_events_url": "https://api.github.com/users/mojave-pku/received_events",
"repos_url": "https://api.github.com/users/mojave-pku/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mojave-pku/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mojave-pku/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mojave-pku"
} | [] | closed | false | null | [] | null | [
"The problem still exists after removing the cache files.",
"Can you reproduce this example in a Colab so we can investigate? (or give more information on your software/hardware config)",
"Thanks for reporting.\r\nI just found the issue, I'm creating a PR",
"We'll do a release pretty soon to include the fix :)\r\nIn the meantime you can install the lib from source if you want to "
] | "2020-09-28T07:19:33Z" | "2020-10-07T13:46:33Z" | "2020-10-07T13:38:06Z" | NONE | null | null | null | I try to split my dataset by `train_test_split`, but after that the item in `train` and `test` `Dataset` is empty.
The codes:
```
yelp_data = datasets.load_from_disk('/home/ssd4/huanglianzhe/test_yelp')
print(yelp_data[0])
yelp_data = yelp_data.train_test_split(test_size=0.1)
print(yelp_data)
print(yelp_data['test'])
print(yelp_data['test'][0])
```
The outputs:
```
{'stars': 2.0, 'text': 'xxxx'}
Loading cached split indices for dataset at /home/ssd4/huanglianzhe/test_yelp/cache-f9b22d8b9d5a7346.arrow and /home/ssd4/huanglianzhe/test_yelp/cache-4aa26fa4005059d1.arrow
DatasetDict({'train': Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 7219009), 'test': Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 802113)})
Dataset(features: {'stars': Value(dtype='float64', id=None), 'text': Value(dtype='string', id=None)}, num_rows: 802113)
{} # yelp_data['test'][0] is empty
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/676/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1080 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1080/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1080/comments | https://api.github.com/repos/huggingface/datasets/issues/1080/events | https://github.com/huggingface/datasets/pull/1080 | 756,663,464 | MDExOlB1bGxSZXF1ZXN0NTMyMTc3NDg5 | 1,080 | Add WikiANN NER dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [
"Dataset card added, so ready for review!"
] | "2020-12-03T23:09:24Z" | "2020-12-06T17:18:55Z" | "2020-12-06T17:18:55Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1080.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1080",
"merged_at": "2020-12-06T17:18:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1080.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1080"
} | This PR adds the full set of 176 languages from the balanced train/dev/test splits of WikiANN / PAN-X from: https://github.com/afshinrahimi/mmner
Until now, only 40 of these languages were available in `datasets` as part of the XTREME benchmark
Courtesy of the dataset author, we can now download this dataset from a Dropbox URL without needing a manual download anymore 🥳, so at some point it would be worth updating the PAN-X subset of XTREME as well 😄
Link to gist with some snippets for producing dummy data: https://gist.github.com/lewtun/5b93294ab6dbcf59d1493dbe2cfd6bb9
P.S. @yjernite I think I was confused about needing to generate a set of YAML tags per config, so ended up just adding a single one in the README. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1080/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1080/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1693/comments | https://api.github.com/repos/huggingface/datasets/issues/1693/events | https://github.com/huggingface/datasets/pull/1693 | 780,268,595 | MDExOlB1bGxSZXF1ZXN0NTUwMTc3MDEx | 1,693 | Fix reuters metadata parsing errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/2238344?v=4",
"events_url": "https://api.github.com/users/jbragg/events{/privacy}",
"followers_url": "https://api.github.com/users/jbragg/followers",
"following_url": "https://api.github.com/users/jbragg/following{/other_user}",
"gists_url": "https://api.github.com/users/jbragg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jbragg",
"id": 2238344,
"login": "jbragg",
"node_id": "MDQ6VXNlcjIyMzgzNDQ=",
"organizations_url": "https://api.github.com/users/jbragg/orgs",
"received_events_url": "https://api.github.com/users/jbragg/received_events",
"repos_url": "https://api.github.com/users/jbragg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jbragg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jbragg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jbragg"
} | [] | closed | false | null | [] | null | [] | "2021-01-06T08:26:03Z" | "2021-01-07T23:53:47Z" | "2021-01-07T14:01:22Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1693.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1693",
"merged_at": "2021-01-07T14:01:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1693.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1693"
} | Was missing the last entry in each metadata category | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1693/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1693/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4553/comments | https://api.github.com/repos/huggingface/datasets/issues/4553/events | https://github.com/huggingface/datasets/pull/4553 | 1,282,779,560 | PR_kwDODunzps46Q1q7 | 4,553 | Stop dropping columns in to_tf_dataset() before we load batches | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq Rebasing fixed the test failures, so this should be ready to review now! There's still a failure on Win but it seems unrelated.",
"Gentle ping @lhoestq ! This is a simple fix (dropping columns after loading a batch from the dataset rather than with `.remove_columns()` to make sure we don't break transforms), and tests are green so we're ready for review!",
"@lhoestq Test is in!"
] | "2022-06-23T18:21:05Z" | "2022-07-04T19:00:13Z" | "2022-07-04T18:49:01Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4553",
"merged_at": "2022-07-04T18:49:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4553"
} | `to_tf_dataset()` dropped unnecessary columns before loading batches from the dataset, but this is causing problems when using a transform, because the dropped columns might be needed to compute the transform. Since there's no real way to check which columns the transform might need, we skip dropping columns and instead drop keys from the batch after we load it.
cc @amyeroberts and https://github.com/huggingface/notebooks/pull/202 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4553/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/247/comments | https://api.github.com/repos/huggingface/datasets/issues/247/events | https://github.com/huggingface/datasets/pull/247 | 632,380,078 | MDExOlB1bGxSZXF1ZXN0NDI5MTMwMzQ2 | 247 | Make all dataset downloads deterministic by applying `sorted` to glob and os.listdir | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | [
"That's great!\r\n\r\nI think it would be nice to test \"deterministic-ness\" of datasets in CI if we can do it (should be left for future PR of course)\r\n\r\nHere is a possibility (maybe there are other ways to do it): given that we may soon have efficient and large-scale hashing (cf our discussion on versioning/tracability), we could incorporate a hash of the final Arrow Dataset to the `dataset.json` file and have a test on it as well as CI on a diversity of platform to test the hash (Win/Mac/Linux + various python/env).\r\nWhat do you think @lhoestq @patrickvonplaten?",
"> That's great!\r\n> \r\n> I think it would be nice to test \"deterministic-ness\" of datasets in CI if we can do it (should be left for future PR of course)\r\n> \r\n> Here is a possibility (maybe there are other ways to do it): given that we may soon have efficient and large-scale hashing (cf our discussion on versioning/tracability), we could incorporate a hash of the final Arrow Dataset to the `dataset.json` file and have a test on it as well as CI on a diversity of platform to test the hash (Win/Mac/Linux + various python/env).\r\n> What do you think @lhoestq @patrickvonplaten?\r\n\r\nI think that's a great idea! The test should be a `RUN_SLOW` test, since it takes a considerable amount of time to download the dataset and generate the examples, but I think we should add some kind of hash test for each dataset.",
"Really nice!!"
] | "2020-06-06T11:02:10Z" | "2020-06-08T09:18:16Z" | "2020-06-08T09:18:14Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/247.diff",
"html_url": "https://github.com/huggingface/datasets/pull/247",
"merged_at": "2020-06-08T09:18:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/247.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/247"
} | This PR makes all datasets loading deterministic by applying `sorted()` to all `glob.glob` and `os.listdir` statements.
Are there other "non-deterministic" functions apart from `glob.glob()` and `os.listdir()` that you can think of @thomwolf @lhoestq @mariamabarham @jplu ?
**Important**
It does break backward compatibility for these datasets because
1. When loading the complete dataset the order in which the examples are saved is different now
2. When loading only part of a split, the examples themselves might be different.
@patrickvonplaten - the nlp / longformer notebook has to be updated since the examples might now be different | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/247/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3687/comments | https://api.github.com/repos/huggingface/datasets/issues/3687/events | https://github.com/huggingface/datasets/issues/3687 | 1,127,154,766 | I_kwDODunzps5DLwRO | 3,687 | Can't get the text data when calling to_tf_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/82086367?v=4",
"events_url": "https://api.github.com/users/phrasenmaeher/events{/privacy}",
"followers_url": "https://api.github.com/users/phrasenmaeher/followers",
"following_url": "https://api.github.com/users/phrasenmaeher/following{/other_user}",
"gists_url": "https://api.github.com/users/phrasenmaeher/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/phrasenmaeher",
"id": 82086367,
"login": "phrasenmaeher",
"node_id": "MDQ6VXNlcjgyMDg2MzY3",
"organizations_url": "https://api.github.com/users/phrasenmaeher/orgs",
"received_events_url": "https://api.github.com/users/phrasenmaeher/received_events",
"repos_url": "https://api.github.com/users/phrasenmaeher/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/phrasenmaeher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phrasenmaeher/subscriptions",
"type": "User",
"url": "https://api.github.com/users/phrasenmaeher"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
}
] | null | [
"cc @Rocketknight1 ",
"You are correct that `to_tf_dataset` only handles numerical columns right now, yes, though this is a limitation we might remove in future! The main reason we do this is that our models mostly do not include the tokenizer as a model layer, because it's very difficult to compile some of them in TF. So the \"normal\" Huggingface workflow is to first tokenize your dataset, and then pass tokenized tensors to the model.\r\n\r\nFor your use case, would you prefer to pass strings to the model, and use some text processing layers instead of the built-in tokenizers?",
"Also tagging @gante just so he's aware, but I can handle this one!",
"Thanks for the quick follow-up to my issue.\r\n\r\nFor my use-case, instead of the built-in tokenizers I wanted to use the `TextVectorization` layer to map from strings to integers. To achieve this, I came up with the following solution:\r\n\r\n```\r\nfrom datasets import load_dataset\r\nfrom transformers import DefaultDataCollator\r\nimport tensorflow as tf\r\nimport string\r\nimport re\r\nfrom tensorflow.keras.layers.experimental.preprocessing import TextVectorization\r\n\r\n#some hyper-parameters for the text-to-integer mapping\r\nmax_features = 20000\r\nembedding_dim = 128\r\nsequence_length = 210\r\n\r\ndata_collator = DefaultDataCollator(return_tensors=\"tf\")\r\ndataset = load_dataset(\"sst\", \"default\")\r\n\r\n#adapt the vectorization layer on train data only\r\nvectorize_layer.adapt(dataset[\"train\"].to_dict(batched=False)[\"sentence\"])\r\n\r\ndef prepare_features(text, label):\r\n text = tf.expand_dims(text, -1)\r\n return {\"vectorized_text\": vectorize_layer(text)[0], \"label\": tf.expand_dims(label, axis=-1)}\r\n\r\nencoded_dataset = dataset.map(lambda example: prepare_features(example[\"sentence\"], example[\"label\"]), batched=False)\r\n\r\n\r\ndef custom_standardization(input_data):\r\n lowercase = tf.strings.lower(input_data)\r\n return tf.strings.regex_replace(\r\n lowercase, f\"[{re.escape(string.punctuation)}]\", \"\"\r\n )\r\n\r\nvectorize_layer = TextVectorization(\r\n standardize=custom_standardization,\r\n max_tokens=max_features,\r\n output_mode=\"int\",\r\n output_sequence_length=sequence_length,\r\n)\r\n\r\ntrain_dataset = encoded_dataset[\"train\"].to_tf_dataset(columns=['vectorized_text'], label_cols=[\"label\"],\r\n shuffle=True, batch_size=1, collate_fn=data_collator).unbatch()\r\n#similar for the other sub-sets\r\n\r\n```\r\n\r\nSince the strings would have been mapped to integers or floats at some point, it's no drawback that this mapping is done early in the process. \r\n\r\nFor the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float. For now, this can be done by calling `to_dict`.",
"> For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float.\r\n\r\nYes, I agree, so let's keep this issue open.",
"Going to close this now - methods like `to_tf_dataset` and `prepare_tf_dataset` now support string data, and have done for a while! If anyone sees this and is encountering issues with string data in those methods, please file a new issue!"
] | "2022-02-08T11:52:10Z" | "2023-01-19T14:55:18Z" | "2023-01-19T14:55:18Z" | NONE | null | null | null | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3687/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3687/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1044 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1044/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1044/comments | https://api.github.com/repos/huggingface/datasets/issues/1044/events | https://github.com/huggingface/datasets/pull/1044 | 756,111,647 | MDExOlB1bGxSZXF1ZXN0NTMxNzA5MTg0 | 1,044 | Add AMTTL Chinese Word Segmentation Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JetRunner",
"id": 22514219,
"login": "JetRunner",
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JetRunner"
} | [] | closed | false | null | [] | null | [] | "2020-12-03T11:27:52Z" | "2020-12-03T17:13:14Z" | "2020-12-03T17:13:13Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1044.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1044",
"merged_at": "2020-12-03T17:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1044.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1044"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1044/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1044/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/6030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6030/comments | https://api.github.com/repos/huggingface/datasets/issues/6030/events | https://github.com/huggingface/datasets/pull/6030 | 1,803,864,744 | PR_kwDODunzps5Vd0ZG | 6,030 | fixed typo in comment | {
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
"gists_url": "https://api.github.com/users/NightMachinery/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NightMachinery",
"id": 36224762,
"login": "NightMachinery",
"node_id": "MDQ6VXNlcjM2MjI0NzYy",
"organizations_url": "https://api.github.com/users/NightMachinery/orgs",
"received_events_url": "https://api.github.com/users/NightMachinery/received_events",
"repos_url": "https://api.github.com/users/NightMachinery/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NightMachinery/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NightMachinery/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NightMachinery"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005855 / 0.011353 (-0.005498) | 0.003556 / 0.011008 (-0.007452) | 0.079430 / 0.038508 (0.040922) | 0.056754 / 0.023109 (0.033645) | 0.311718 / 0.275898 (0.035820) | 0.346731 / 0.323480 (0.023251) | 0.004414 / 0.007986 (-0.003571) | 0.002835 / 0.004328 (-0.001493) | 0.062138 / 0.004250 (0.057888) | 0.044259 / 0.037052 (0.007206) | 0.314681 / 0.258489 (0.056192) | 0.359802 / 0.293841 (0.065961) | 0.026684 / 0.128546 (-0.101862) | 0.008023 / 0.075646 (-0.067623) | 0.260148 / 0.419271 (-0.159123) | 0.043734 / 0.043533 (0.000202) | 0.312081 / 0.255139 (0.056942) | 0.340004 / 0.283200 (0.056805) | 0.019559 / 0.141683 (-0.122124) | 1.488758 / 1.452155 (0.036604) | 1.510828 / 1.492716 (0.018111) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.181376 / 0.018006 (0.163370) | 0.441726 / 0.000490 (0.441236) | 0.001722 / 0.000200 (0.001522) | 0.000066 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023760 / 0.037411 (-0.013651) | 0.071847 / 0.014526 (0.057321) | 0.082642 / 0.176557 (-0.093915) | 0.145555 / 0.737135 (-0.591580) | 0.084554 / 0.296338 (-0.211784) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401688 / 0.215209 (0.186479) | 4.000994 / 2.077655 (1.923339) | 2.047109 / 1.504120 (0.542989) | 1.891874 / 1.541195 (0.350679) | 1.970599 / 1.468490 (0.502109) | 0.500646 / 4.584777 (-4.084131) | 3.006623 / 3.745712 (-0.739089) | 4.248359 / 5.269862 (-1.021503) | 2.613946 / 4.565676 (-1.951730) | 0.057921 / 0.424275 (-0.366354) | 0.006407 / 0.007607 (-0.001200) | 0.470676 / 0.226044 (0.244631) | 4.722280 / 2.268929 (2.453352) | 2.448530 / 55.444624 (-52.996095) | 2.175841 / 6.876477 (-4.700635) | 2.352287 / 2.142072 (0.210214) | 0.589049 / 4.805227 (-4.216179) | 0.125145 / 6.500664 (-6.375519) | 0.060829 / 0.075469 (-0.014640) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.189225 / 1.841788 (-0.652563) | 16.753085 / 8.074308 (8.678777) | 13.086512 / 10.191392 (2.895120) | 0.132371 / 0.680424 (-0.548052) | 0.016933 / 0.534201 (-0.517268) | 0.328258 / 0.579283 (-0.251025) | 0.344074 / 0.434364 (-0.090290) | 0.374042 / 0.540337 (-0.166296) | 0.515307 / 1.386936 (-0.871629) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005963 / 0.011353 (-0.005390) | 0.003484 / 0.011008 (-0.007525) | 0.062618 / 0.038508 (0.024110) | 0.057217 / 0.023109 (0.034108) | 0.426760 / 0.275898 (0.150862) | 0.464422 / 0.323480 (0.140942) | 0.005276 / 0.007986 (-0.002709) | 0.002872 / 0.004328 (-0.001456) | 0.062636 / 0.004250 (0.058385) | 0.045953 / 0.037052 (0.008900) | 0.433221 / 0.258489 (0.174732) | 0.475087 / 0.293841 (0.181246) | 0.027217 / 0.128546 (-0.101329) | 0.007965 / 0.075646 (-0.067681) | 0.067749 / 0.419271 (-0.351522) | 0.041235 / 0.043533 (-0.002298) | 0.425424 / 0.255139 (0.170285) | 0.453390 / 0.283200 (0.170190) | 0.020217 / 0.141683 (-0.121466) | 1.436354 / 1.452155 (-0.015801) | 1.492372 / 1.492716 (-0.000345) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226896 / 0.018006 (0.208889) | 0.411935 / 0.000490 (0.411445) | 0.000356 / 0.000200 (0.000156) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024705 / 0.037411 (-0.012706) | 0.076232 / 0.014526 (0.061706) | 0.086949 / 0.176557 (-0.089608) | 0.141867 / 0.737135 (-0.595269) | 0.088199 / 0.296338 (-0.208140) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419748 / 0.215209 (0.204539) | 4.198597 / 2.077655 (2.120942) | 2.338477 / 1.504120 (0.834357) | 2.195741 / 1.541195 (0.654547) | 2.278145 / 1.468490 (0.809655) | 0.502365 / 4.584777 (-4.082412) | 2.987773 / 3.745712 (-0.757939) | 2.896526 / 5.269862 (-2.373336) | 1.841610 / 4.565676 (-2.724067) | 0.058032 / 0.424275 (-0.366243) | 0.006470 / 0.007607 (-0.001137) | 0.496969 / 0.226044 (0.270925) | 4.960984 / 2.268929 (2.692056) | 2.648615 / 55.444624 (-52.796009) | 2.286846 / 6.876477 (-4.589631) | 2.320176 / 2.142072 (0.178104) | 0.600550 / 4.805227 (-4.204678) | 0.125652 / 6.500664 (-6.375012) | 0.062177 / 0.075469 (-0.013292) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.293063 / 1.841788 (-0.548725) | 18.294204 / 8.074308 (10.219896) | 13.720502 / 10.191392 (3.529110) | 0.146480 / 0.680424 (-0.533944) | 0.016965 / 0.534201 (-0.517236) | 0.330137 / 0.579283 (-0.249146) | 0.352051 / 0.434364 (-0.082313) | 0.381754 / 0.540337 (-0.158584) | 0.517935 / 1.386936 (-0.869001) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-13T22:49:57Z" | "2023-07-14T14:21:58Z" | "2023-07-14T14:13:38Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6030.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6030",
"merged_at": "2023-07-14T14:13:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6030.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6030"
} | This mistake was a bit confusing, so I thought it was worth sending a PR over. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6030/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4757/comments | https://api.github.com/repos/huggingface/datasets/issues/4757/events | https://github.com/huggingface/datasets/issues/4757 | 1,320,602,532 | I_kwDODunzps5Otsuk | 4,757 | Document better when relative paths are transformed to URLs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
}
] | null | [] | "2022-07-28T08:46:27Z" | "2022-08-25T18:34:24Z" | "2022-08-25T18:34:24Z" | MEMBER | null | null | null | As discussed with @ydshieh, when passing a relative path as `data_dir` to `load_dataset` of a dataset hosted on the Hub, the relative path is transformed to the corresponding URL of the Hub dataset.
Currently, we mention this in our docs here: [Create a dataset loading script > Download data files and organize splits](https://huggingface.co/docs/datasets/v2.4.0/en/dataset_script#download-data-files-and-organize-splits)
> If the data files live in the same folder or repository of the dataset script, you can just pass the relative paths to the files instead of URLs.
Maybe we should document better how relative paths are handled, not only when creating a dataset loading script, but also when passing to `load_dataset`:
- `data_dir`
- `data_files`
CC: @stevhliu | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4757/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3242/comments | https://api.github.com/repos/huggingface/datasets/issues/3242/events | https://github.com/huggingface/datasets/issues/3242 | 1,048,527,232 | I_kwDODunzps4-f0GA | 3,242 | Adding ANERcorp-CAMeLLab dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/33824221?v=4",
"events_url": "https://api.github.com/users/vitalyshalumov/events{/privacy}",
"followers_url": "https://api.github.com/users/vitalyshalumov/followers",
"following_url": "https://api.github.com/users/vitalyshalumov/following{/other_user}",
"gists_url": "https://api.github.com/users/vitalyshalumov/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vitalyshalumov",
"id": 33824221,
"login": "vitalyshalumov",
"node_id": "MDQ6VXNlcjMzODI0MjIx",
"organizations_url": "https://api.github.com/users/vitalyshalumov/orgs",
"received_events_url": "https://api.github.com/users/vitalyshalumov/received_events",
"repos_url": "https://api.github.com/users/vitalyshalumov/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vitalyshalumov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vitalyshalumov/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vitalyshalumov"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [
"Adding ANERcorp dataset\r\n\r\n## Adding a Dataset\r\n- **Name:** *ANERcorp-CAMeLLab*\r\n- **Description:** *Since its creation in 2008, the ANERcorp dataset (Benajiba & Rosso, 2008) has been a standard reference used by Arabic named entity recognition researchers around the world. However, over time, this dataset was copied over from user to user, modified slightly here and there, and split in many different configurations that made it hard to compare fairly across papers and systems.\r\n\r\nIn 2020, a group of researchers from CAMeL Lab (Habash, Alhafni and Oudah), and Mind Lab (Antoun and Baly) met with the creator of the corpus, Yassine Benajiba, to consult with him and collectively agree on an exact split, and accepted minor corrections from the original dataset. Bashar Alhafni from CAMeL Lab working with Nizar Habash implemented the decisions provided in this release.*\r\n\r\n- **Paper:** *(a) Benajiba, Yassine, Paolo Rosso, and José Miguel Benedí Ruiz. \"Anersys: An Arabic named entity recognition system based on maximum entropy.\" In International Conference on Intelligent Text Processing and Computational Linguistics, pp. 143-153. Springer, Berlin, Heidelberg, 2007.\r\n\r\n(b)Ossama Obeid, Nasser Zalmout, Salam Khalifa, Dima Taji, Mai Oudah, Bashar Alhafni, Go Inoue, Fadhl Eryani, Alexander Erdmann, and Nizar Habash. \"CAMeL Tools: An Open Source Python Toolkit, for Arabic Natural Language Processing.\" In Proceedings of the Conference on Language Resources and Evaluation (LREC 2020), Marseille, 2020.*\r\n- **Data:** *https://camel.abudhabi.nyu.edu/anercorp/*\r\n- **Motivation:** This is the standard dataset for evaluating NER performance in Arabic*\r\n\r\nInstructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md)."
] | "2021-11-09T12:04:04Z" | "2021-11-09T12:41:15Z" | null | NONE | null | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3242/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4679/comments | https://api.github.com/repos/huggingface/datasets/issues/4679/events | https://github.com/huggingface/datasets/pull/4679 | 1,303,980,648 | PR_kwDODunzps47XX67 | 4,679 | Added method to remove excess nesting in a DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/37946988?v=4",
"events_url": "https://api.github.com/users/CakeCrusher/events{/privacy}",
"followers_url": "https://api.github.com/users/CakeCrusher/followers",
"following_url": "https://api.github.com/users/CakeCrusher/following{/other_user}",
"gists_url": "https://api.github.com/users/CakeCrusher/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/CakeCrusher",
"id": 37946988,
"login": "CakeCrusher",
"node_id": "MDQ6VXNlcjM3OTQ2OTg4",
"organizations_url": "https://api.github.com/users/CakeCrusher/orgs",
"received_events_url": "https://api.github.com/users/CakeCrusher/received_events",
"repos_url": "https://api.github.com/users/CakeCrusher/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/CakeCrusher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CakeCrusher/subscriptions",
"type": "User",
"url": "https://api.github.com/users/CakeCrusher"
} | [] | closed | false | null | [] | null | [
"Hi ! I think the issue you linked is closed and suggests to use `remove_columns`.\r\n\r\nMoreover if you end up with a dataset with an unnecessarily nested data, please modify your processing functions to not output nested data, or use `map(..., batched=True)` if you function take batches as input",
"Hi @lhoestq , you are right about the issues this pull has steered beyond that issue. I created this [colab notebook](https://colab.research.google.com/drive/16aLu6QrDSV_aUYRdpufl5E4iS08qkUGj?usp=sharing) to present the error. I tried using batch and that won't resolve it either. I'm looking into that error right now.",
"I think you just need to pass one example at a time to your tokenizer, this way you don't end up with nested data:\r\n```python\r\n\r\ndef preprocessFunction(row):\r\n collatedContext = tokenizer.eos_token.join([row[\"context\"+str(i+1)] for i in range(int(AMT_OF_CONTEXT))])\r\n response = row[\"response\"]\r\n tokenizedContext = tokenizer(\r\n collatedContext, max_length=max_context_length, truncation=True # don't pass as a list here\r\n )\r\n with tokenizer.as_target_tokenizer():\r\n tokenized_response = tokenizer(\r\n response, max_length=max_response_length, truncation=True # don't pass a a list here\r\n )\r\n tokenizedContext[\"labels\"] = tokenized_response[\"input_ids\"]\r\n return tokenizedContext\r\n```",
"Yes that is correct, the purpose of this pull is to advise of a more general solution like with `def remove_excess_nesting(self)` or maybe automate the solution (stas00 advised not to automate it as it could \"not be backwards compatible\").",
"I'm not sure I understand how having `remove_excess_nesting` would make more sense than just fixing the preprocessFunction to simply not return nested samples, can you elaborate ?",
"Figuring out the issue can be a bit difficult to figure out. Only until I added batch does it make a little more sense with the error\r\n\r\n> sequence item 0: expected str instance, list found\r\n\r\nbut batch was never intended.\r\n\r\nWhen you run the colab you will notice that only until collating do you learn there is this error. So i figured it would be better to address it during at the `DatasetDict` level.\r\nI think it would be ideal if the user could be notified at the preprocess function.",
"I'm not arguing that `remove_excess_nesting` is the right solution but what I aim to address is dealing with unnecessary nesting as early as possible.",
"> When you run the colab you will notice that only until collating do you learn there is this error.\r\n\r\nI think users can just check the `dataset.features` and they would notice that the data are nested\r\n```python\r\n{\r\n 'input_ids': Sequence(Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None), length=-1, id=None)\r\n ...\r\n}\r\n```\r\n\r\nSometime nested data are intentional, so you can't know in advance if it's a user's mistake or something planned.",
"Yes, I understand, it could be intentional and only the collator has problems with it. So, it is not worth handling it any differently in any other non-erroneous data. \r\n\r\nThat being said do you think there is any use for the `remove_excess_nesting` method? Or maybe it should be applied in a different way? If not feel free to close this PR. ",
"I think users can write it and use `map` themselves if needed, it is pretty straightforward to implement.\r\n\r\nI'm closing this PR if you don't mind, and thank you for the discussion :)",
"No problem @lhoestq , thanks for walking me through it."
] | "2022-07-13T21:49:37Z" | "2022-07-21T15:55:26Z" | "2022-07-21T10:55:02Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4679.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4679",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4679.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4679"
} | Added the ability for a DatasetDict to remove additional nested layers within its features to avoid conflicts when collating. It is meant to accompany [this PR](https://github.com/huggingface/transformers/pull/18119) to resolve the same issue [#15505](https://github.com/huggingface/transformers/issues/15505).
@stas00 @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4679/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4679/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4874 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4874/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4874/comments | https://api.github.com/repos/huggingface/datasets/issues/4874/events | https://github.com/huggingface/datasets/pull/4874 | 1,347,618,197 | PR_kwDODunzps49n_nI | 4,874 | [docs] Some tiny doc tweaks | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/julien-c",
"id": 326577,
"login": "julien-c",
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"repos_url": "https://api.github.com/users/julien-c/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"type": "User",
"url": "https://api.github.com/users/julien-c"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4874). All of your documentation changes will be reflected on that endpoint."
] | "2022-08-23T09:19:40Z" | "2022-08-24T17:27:57Z" | "2022-08-24T17:27:56Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4874.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4874",
"merged_at": "2022-08-24T17:27:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4874.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4874"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4874/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4874/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2487/comments | https://api.github.com/repos/huggingface/datasets/issues/2487/events | https://github.com/huggingface/datasets/pull/2487 | 919,452,407 | MDExOlB1bGxSZXF1ZXN0NjY4Nzc5Mjk0 | 2,487 | Set configurable extracted datasets path | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | {
"closed_at": "2021-07-09T05:50:07Z",
"closed_issues": 12,
"created_at": "2021-05-31T16:13:06Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-07-08T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/5",
"id": 6808903,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/5/labels",
"node_id": "MDk6TWlsZXN0b25lNjgwODkwMw==",
"number": 5,
"open_issues": 0,
"state": "closed",
"title": "1.9",
"updated_at": "2021-07-12T14:12:00Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/5"
} | [
"Let me push a small fix... 😉 ",
"Thanks !"
] | "2021-06-12T05:47:29Z" | "2021-06-14T09:30:17Z" | "2021-06-14T09:02:56Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2487",
"merged_at": "2021-06-14T09:02:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2487"
} | Part of #2480. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2487/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5715/comments | https://api.github.com/repos/huggingface/datasets/issues/5715/events | https://github.com/huggingface/datasets/issues/5715 | 1,657,479,788 | I_kwDODunzps5iyyJs | 5,715 | Return Numpy Array (fixed length) Mode, in __get_item__, Instead of List | {
"avatar_url": "https://avatars.githubusercontent.com/u/34066771?v=4",
"events_url": "https://api.github.com/users/jungbaepark/events{/privacy}",
"followers_url": "https://api.github.com/users/jungbaepark/followers",
"following_url": "https://api.github.com/users/jungbaepark/following{/other_user}",
"gists_url": "https://api.github.com/users/jungbaepark/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jungbaepark",
"id": 34066771,
"login": "jungbaepark",
"node_id": "MDQ6VXNlcjM0MDY2Nzcx",
"organizations_url": "https://api.github.com/users/jungbaepark/orgs",
"received_events_url": "https://api.github.com/users/jungbaepark/received_events",
"repos_url": "https://api.github.com/users/jungbaepark/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jungbaepark/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jungbaepark/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jungbaepark"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can use [`.set_format(\"np\")`](https://huggingface.co/docs/datasets/process#format) to get NumPy arrays (or Pytorch tensors with `.set_format(\"torch\")`) in `__getitem__`.\r\n\r\nAlso, have you been able to reproduce the linked PyTorch issue with a HF dataset?\r\n "
] | "2023-04-06T13:57:48Z" | "2023-04-20T17:16:26Z" | "2023-04-20T17:16:26Z" | NONE | null | null | null | ### Feature request
There are old known issues, but they can be easily forgettable problems in multiprocessing with pytorch-dataloader:
Too high usage of RAM or shared-memory in pytorch when we set num workers > 1 and returning type of dataset or dataloader is "List" or "Dict".
https://github.com/pytorch/pytorch/issues/13246
With huggingface datasets, unfortunately, the default return type is the list, so the problem is raised too often if we do not set anything for the issue.
However, this issue can be released when the returning output is fixed in length.
Therefore, I request the mode, returning outputs with fixed length (e.g. numpy array) rather than list.
The design would be good when we load datasets as
```python
load_dataset(..., with_return_as_fixed_tensor=True)
```
### Motivation
The general solution for this issue is already in the comments: https://github.com/pytorch/pytorch/issues/13246#issuecomment-905703662
: Numpy or Pandas seems not to have problems, while both have the string type.
(I'm not sure that the sequence of huggingface datasets can solve this problem as well)
### Your contribution
I'll read it ! thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5715/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4039 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4039/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4039/comments | https://api.github.com/repos/huggingface/datasets/issues/4039/events | https://github.com/huggingface/datasets/pull/4039 | 1,183,468,927 | PR_kwDODunzps41KFIf | 4,039 | Support streaming xcopa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-28T13:45:55Z" | "2022-03-28T16:26:48Z" | "2022-03-28T16:21:46Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4039.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4039",
"merged_at": "2022-03-28T16:21:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4039.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4039"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4039/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4039/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6435 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6435/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6435/comments | https://api.github.com/repos/huggingface/datasets/issues/6435/events | https://github.com/huggingface/datasets/issues/6435 | 2,000,690,513 | I_kwDODunzps53QB1R | 6,435 | Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method | {
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.github.com/users/kopyl/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kopyl",
"id": 17604849,
"login": "kopyl",
"node_id": "MDQ6VXNlcjE3NjA0ODQ5",
"organizations_url": "https://api.github.com/users/kopyl/orgs",
"received_events_url": "https://api.github.com/users/kopyl/received_events",
"repos_url": "https://api.github.com/users/kopyl/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kopyl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kopyl/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kopyl"
} | [] | closed | false | null | [] | null | [
"[This doc section](https://huggingface.co/docs/datasets/main/en/process#multiprocessing) explains how to modify the script to avoid this error.",
"@mariosasko thank you very much, i'll check it"
] | "2023-11-19T04:21:16Z" | "2023-12-04T16:57:44Z" | "2023-12-04T16:57:43Z" | NONE | null | null | null | ### Describe the bug
1. I ran dataset mapping with `num_proc=6` in it and got this error:
`RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method`
I can't actually find a way to run multi-GPU dataset mapping. Can you help?
### Steps to reproduce the bug
1. Rund SDXL training with `num_proc=6`: https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py
### Expected behavior
Should work well
### Environment info
6x A100 SXM, Linux | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6435/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6435/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2063 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2063/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2063/comments | https://api.github.com/repos/huggingface/datasets/issues/2063/events | https://github.com/huggingface/datasets/pull/2063 | 832,993,705 | MDExOlB1bGxSZXF1ZXN0NTk0MDY2NzI5 | 2,063 | [Common Voice] Adapt dataset script so that no manual data download is actually needed | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | [] | "2021-03-16T16:33:44Z" | "2021-03-17T09:42:52Z" | "2021-03-17T09:42:37Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2063.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2063",
"merged_at": "2021-03-17T09:42:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2063.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2063"
} | This PR changes the dataset script so that no manual data dir is needed anymore. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2063/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2063/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/224/comments | https://api.github.com/repos/huggingface/datasets/issues/224/events | https://github.com/huggingface/datasets/issues/224 | 627,791,693 | MDU6SXNzdWU2Mjc3OTE2OTM= | 224 | [Feature Request/Help] BLEURT model -> PyTorch | {
"avatar_url": "https://avatars.githubusercontent.com/u/6889910?v=4",
"events_url": "https://api.github.com/users/adamwlev/events{/privacy}",
"followers_url": "https://api.github.com/users/adamwlev/followers",
"following_url": "https://api.github.com/users/adamwlev/following{/other_user}",
"gists_url": "https://api.github.com/users/adamwlev/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adamwlev",
"id": 6889910,
"login": "adamwlev",
"node_id": "MDQ6VXNlcjY4ODk5MTA=",
"organizations_url": "https://api.github.com/users/adamwlev/orgs",
"received_events_url": "https://api.github.com/users/adamwlev/received_events",
"repos_url": "https://api.github.com/users/adamwlev/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adamwlev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adamwlev/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adamwlev"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
}
] | null | [
"Is there any update on this? \r\n\r\nThanks!",
"Hitting this error when using bleurt with PyTorch ...\r\n\r\n```\r\nUnrecognizedFlagError: Unknown command line flag 'f'\r\n```\r\n... and I'm assuming because it was built for TF specifically. Is there a way to use this metric in PyTorch?",
"We currently provide a wrapper on the TensorFlow implementation: https://huggingface.co/metrics/bleurt\r\n\r\nWe have long term plans to better handle model-based metrics, but they probably won't be implemented right away\r\n\r\n@adamwlev it would still be cool to add the BLEURT checkpoints to the transformers repo if you're interested, but that would best be discussed there :) \r\n\r\nclosing for now",
"Hi there. We ran into the same problem this year (converting BLEURT to PyTorch) and thanks to @adamwlev found his colab notebook which didn't work but served as a good starting point. Finally, we **made it work** by doing just two simple conceptual fixes: \r\n\r\n1. Transposing 'kernel' layers instead of 'dense' ones when copying params from the original model;\r\n2. Taking pooler_output as a cls_state in forward function of the BleurtModel class.\r\n\r\nPlus few minor syntactical fixes for the outdated parts. The result is still not exactly the same, but is very close to the expected one (1.0483 vs 1.0474).\r\n\r\nFind the fixed version here (fixes are commented): https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing \r\n",
"I created a new model based on `transformers` that can load every BLEURT checkpoints released so far. https://github.com/lucadiliello/bleurt-pytorch",
"@LoraIpsum Thanks for sharing your work here. However, I'm unable to reproduce the results. That's strange because you are. FYI, I am trying to convert a finetuned BLEURT to PyTorch. Any suggestions on how I can reproduce results?"
] | "2020-05-30T18:30:40Z" | "2023-08-26T17:38:48Z" | "2021-01-04T09:53:32Z" | NONE | null | null | null | Hi, I am interested in porting google research's new BLEURT learned metric to PyTorch (because I wish to do something experimental with language generation and backpropping through BLEURT). I noticed that you guys don't have it yet so I am partly just asking if you plan to add it (@thomwolf said you want to do so on Twitter).
I had a go of just like manually using the checkpoint that they publish which includes the weights. It seems like the architecture is exactly aligned with the out-of-the-box BertModel in transformers just with a single linear layer on top of the CLS embedding. I loaded all the weights to the PyTorch model but I am not able to get the same numbers as the BLEURT package's python api. Here is my colab notebook where I tried https://colab.research.google.com/drive/1Bfced531EvQP_CpFvxwxNl25Pj6ptylY?usp=sharing . If you have any pointers on what might be going wrong that would be much appreciated!
Thank you muchly! | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/224/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2390/comments | https://api.github.com/repos/huggingface/datasets/issues/2390/events | https://github.com/huggingface/datasets/pull/2390 | 897,903,642 | MDExOlB1bGxSZXF1ZXN0NjQ5ODQ0NjQ2 | 2,390 | Add check for task templates on dataset load | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [
"LGTM now, thank you =)"
] | "2021-05-21T10:16:57Z" | "2021-05-21T15:49:09Z" | "2021-05-21T15:49:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2390.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2390",
"merged_at": "2021-05-21T15:49:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2390.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2390"
} | This PR adds a check that the features of a dataset match the schema of each compatible task template. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2390/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5855/comments | https://api.github.com/repos/huggingface/datasets/issues/5855/events | https://github.com/huggingface/datasets/issues/5855 | 1,708,784,943 | I_kwDODunzps5l2f0v | 5,855 | `to_tf_dataset` consumes too much memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/28751760?v=4",
"events_url": "https://api.github.com/users/massquantity/events{/privacy}",
"followers_url": "https://api.github.com/users/massquantity/followers",
"following_url": "https://api.github.com/users/massquantity/following{/other_user}",
"gists_url": "https://api.github.com/users/massquantity/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/massquantity",
"id": 28751760,
"login": "massquantity",
"node_id": "MDQ6VXNlcjI4NzUxNzYw",
"organizations_url": "https://api.github.com/users/massquantity/orgs",
"received_events_url": "https://api.github.com/users/massquantity/received_events",
"repos_url": "https://api.github.com/users/massquantity/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/massquantity/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/massquantity/subscriptions",
"type": "User",
"url": "https://api.github.com/users/massquantity"
} | [] | closed | false | null | [] | null | [
"Cc @amyeroberts @Rocketknight1 \r\n\r\nIndded I think it's because it does something like this under the hood when there's no multiprocessing:\r\n\r\n```python\r\ntf_dataset = tf_dataset.shuffle(len(dataset))\r\n```\r\n\r\nPS: with multiprocessing it appears to be different:\r\n\r\n```python\r\nindices = np.arange(len(dataset))\r\nif shuffle:\r\n np.random.shuffle(indices)\r\n```",
"Hi @massquantity, the dataset being shuffled there is not the full dataset. If you look at [the line above](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/tf_utils.py#L182), the dataset is actually just a single indices array at that point, and that array is the only thing that gets fully loaded into memory and shuffled. We then load samples from the dataset by applying a transform function to the shuffled dataset, which fetches samples based on the indices it receives.\r\n\r\nIf your dataset is **really** gigantic, then this index tensor might be a memory issue, but since it's just an int64 tensor it will only use 1GB of memory per 125 million samples.\r\n\r\nStill, if you're encountering memory issues, there might be another cause here - can you share some code to reproduce the error, or does it depend on some internal/proprietary dataset?",
"Hi @Rocketknight1, you're right and I also noticed that only indices are used in shuffling. My data has shape (50000000, 10), but really the problem doesn't relate to a specific dataset. Simply running the following code costs me 10GB of memory.\r\n\r\n```python\r\nfrom datasets import Dataset\r\n\r\ndef gen():\r\n for i in range(50000000):\r\n yield {\"data\": i}\r\n\r\nds = Dataset.from_generator(gen, cache_dir=\"./huggingface\")\r\n\r\ntf_ds = ds.to_tf_dataset(\r\n batch_size=1,\r\n shuffle=True,\r\n drop_remainder=False,\r\n prefetch=True,\r\n)\r\ntf_ds = iter(tf_ds)\r\nnext(tf_ds)\r\n# {'data': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}\r\n```\r\n\r\nI just realized maybe it was an issue from tensorflow (I'm using tf 2.12). So I tried the following code, and it used 10GB of memory too.\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\n\r\ndata_size = 50000000\r\ntf_dataset = tf.data.Dataset.from_tensor_slices(np.arange(data_size))\r\ntf_dataset = iter(tf_dataset.shuffle(data_size))\r\nnext(tf_dataset)\r\n# <tf.Tensor: shape=(), dtype=int64, numpy=24774043>\r\n```\r\n\r\nBy the way, as @lhoestq mentioned, multiprocessing uses numpy shuffling, and it uses less than 1 GB of memory:\r\n```python\r\ntf_ds_mp = ds.to_tf_dataset(\r\n batch_size=1,\r\n shuffle=True,\r\n drop_remainder=False,\r\n prefetch=True,\r\n num_workers=2,\r\n)\r\n```",
"Thanks for that reproduction script - I've confirmed the same issue is occurring for me. Investigating it now!",
"Update: The memory usage is occurring in creation of the index and shuffle buffer. You can reproduce it very simply with:\r\n\r\n```python\r\nimport tensorflow as tf\r\nindices = tf.range(50_000_000, dtype=tf.int64)\r\ndataset = tf.data.Dataset.from_tensor_slices(indices)\r\ndataset = dataset.shuffle(len(dataset))\r\nprint(next(iter(dataset))\r\n```\r\nWhen I wrote this code I thought `tf.data` had an optimization for shuffling an entire tensor that wouldn't create the entire shuffle buffer, but evidently it's just creating the enormous buffer in memory. I'll see if I can find a more efficient way to do this - we might end up moving everything to the `numpy` multiprocessing path to avoid it.",
"I opened a PR to fix this - will continue the discussion there!"
] | "2023-05-14T01:22:29Z" | "2023-06-08T16:32:52Z" | "2023-06-08T16:32:52Z" | NONE | null | null | null | ### Describe the bug
Hi, I'm using `to_tf_dataset` to convert a _large_ dataset to `tf.data.Dataset`. I observed that the data loading *before* training took a lot of time and memory, even with `batch_size=1`.
After some digging, i believe the reason lies in the shuffle behavior. The [source code](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/tf_utils.py#L185) uses `len(dataset)` as the `buffer_size`, which may load all the data into the memory, and the [tf.data doc](https://www.tensorflow.org/guide/data#randomly_shuffling_input_data) also states that "While large buffer_sizes shuffle more thoroughly, they can take a lot of memory, and significant time to fill".
### Steps to reproduce the bug
```python
from datasets import Dataset
def gen(): # some large data
for i in range(50000000):
yield {"data": i}
ds = Dataset.from_generator(gen, cache_dir="./huggingface")
tf_ds = ds.to_tf_dataset(
batch_size=64,
shuffle=False, # no shuffle
drop_remainder=False,
prefetch=True,
)
# fast and memory friendly 🤗
for batch in tf_ds:
...
tf_ds_shuffle = ds.to_tf_dataset(
batch_size=64,
shuffle=True,
drop_remainder=False,
prefetch=True,
)
# slow and memory hungry for simple iteration 😱
for batch in tf_ds_shuffle:
...
```
### Expected behavior
Shuffling should not load all the data into the memory. Would adding a `buffer_size` parameter in the `to_tf_dataset` API alleviate the problem?
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.17.1-051701-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5855/timeline | null | completed | false |