
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 600M
2.05B
| node_id
stringlengths 18
32
| number
int64 2
6.51k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2984/comments | https://api.github.com/repos/huggingface/datasets/issues/2984/events | https://github.com/huggingface/datasets/issues/2984 | 1,010,484,326 | I_kwDODunzps48OsRm | 2,984 | Exceeded maximum rows when reading large files | {
"avatar_url": "https://avatars.githubusercontent.com/u/25057983?v=4",
"events_url": "https://api.github.com/users/zijwang/events{/privacy}",
"followers_url": "https://api.github.com/users/zijwang/followers",
"following_url": "https://api.github.com/users/zijwang/following{/other_user}",
"gists_url": "https://api.github.com/users/zijwang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zijwang",
"id": 25057983,
"login": "zijwang",
"node_id": "MDQ6VXNlcjI1MDU3OTgz",
"organizations_url": "https://api.github.com/users/zijwang/orgs",
"received_events_url": "https://api.github.com/users/zijwang/received_events",
"repos_url": "https://api.github.com/users/zijwang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zijwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zijwang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zijwang"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @zijwang, thanks for reporting this issue.\r\n\r\nYou did not mention which `datasets` version you are using, but looking at the code in the stack trace, it seems you are using an old version.\r\n\r\nCould you please update `datasets` (`pip install -U datasets`) and check if the problem persists?"
] | "2021-09-29T04:49:22Z" | "2021-10-12T06:05:42Z" | "2021-10-12T06:05:42Z" | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
When using `load_dataset` with json files, if the files are too large, there will be "Exceeded maximum rows" error.
## Steps to reproduce the bug
```python
dataset = load_dataset('json', data_files=data_files) # data files have 3M rows in a single file
```
## Expected results
No error
## Actual results
```
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
134 with open(file, encoding="utf-8") as f:
--> 135 dataset = json.load(f)
136 except json.JSONDecodeError:
~/anaconda3/envs/python/lib/python3.9/json/__init__.py in load(fp, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
292 """
--> 293 return loads(fp.read(),
294 cls=cls, object_hook=object_hook,
~/anaconda3/envs/python/lib/python3.9/json/__init__.py in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
345 parse_constant is None and object_pairs_hook is None and not kw):
--> 346 return _default_decoder.decode(s)
347 if cls is None:
~/anaconda3/envs/python/lib/python3.9/json/decoder.py in decode(self, s, _w)
339 if end != len(s):
--> 340 raise JSONDecodeError("Extra data", s, end)
341 return obj
JSONDecodeError: Extra data: line 2 column 1 (char 20321)
During handling of the above exception, another exception occurred:
ArrowInvalid Traceback (most recent call last)
<ipython-input-20-ab3718a6482f> in <module>
----> 1 dataset = load_dataset('json', data_files=data_files)
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
841
842 # Download and prepare data
--> 843 builder_instance.download_and_prepare(
844 download_config=download_config,
845 download_mode=download_mode,
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
606 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
607 if not downloaded_from_gcs:
--> 608 self._download_and_prepare(
609 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
610 )
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
684 try:
685 # Prepare split will record examples associated to the split
--> 686 self._prepare_split(split_generator, **prepare_split_kwargs)
687 except OSError as e:
688 raise OSError(
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1153 generator = self._generate_tables(**split_generator.gen_kwargs)
1154 with ArrowWriter(features=self.info.features, path=fpath) as writer:
-> 1155 for key, table in utils.tqdm(
1156 generator, unit=" tables", leave=False, disable=bool(logging.get_verbosity() == logging.NOTSET)
1157 ):
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
135 dataset = json.load(f)
136 except json.JSONDecodeError:
--> 137 raise e
138 raise ValueError(
139 f"Not able to read records in the JSON file at {file}. "
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
114 while True:
115 try:
--> 116 pa_table = paj.read_json(
117 BytesIO(batch), read_options=paj.ReadOptions(block_size=block_size)
118 )
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/_json.pyx in pyarrow._json.read_json()
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Exceeded maximum rows
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Linux
- Python version: 3.9
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2984/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/655/comments | https://api.github.com/repos/huggingface/datasets/issues/655/events | https://github.com/huggingface/datasets/pull/655 | 705,672,208 | MDExOlB1bGxSZXF1ZXN0NDkwMzU4OTQ3 | 655 | added Winogrande debiased subset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TevenLeScao",
"id": 26709476,
"login": "TevenLeScao",
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TevenLeScao"
} | [] | closed | false | null | [] | null | [
"To fix the CI you just have to copy the dummy data to the 1.1.0 folder, and maybe create the dummy ones for the `debiased` configuration",
"Fixed! Thanks @lhoestq "
] | "2020-09-21T14:51:08Z" | "2020-09-21T16:20:40Z" | "2020-09-21T16:16:04Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/655.diff",
"html_url": "https://github.com/huggingface/datasets/pull/655",
"merged_at": "2020-09-21T16:16:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/655.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/655"
} | The [Winogrande](https://arxiv.org/abs/1907.10641) paper mentions a `debiased` subset that wasn't in the first release; this PR adds it. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/655/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6156/comments | https://api.github.com/repos/huggingface/datasets/issues/6156/events | https://github.com/huggingface/datasets/issues/6156 | 1,854,768,618 | I_kwDODunzps5ujYXq | 6,156 | Why not use self._epoch as seed to shuffle in distributed training with IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "https://api.github.com/users/npuichigo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/npuichigo",
"id": 11533479,
"login": "npuichigo",
"node_id": "MDQ6VXNlcjExNTMzNDc5",
"organizations_url": "https://api.github.com/users/npuichigo/orgs",
"received_events_url": "https://api.github.com/users/npuichigo/received_events",
"repos_url": "https://api.github.com/users/npuichigo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/npuichigo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/npuichigo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/npuichigo"
} | [] | closed | false | null | [] | null | [
"@lhoestq ",
"`_effective_generator` returns a RNG that takes into account `self._epoch` and the current dataset's base shuffling RNG (which can be set by specifying `seed=` in `.shuffle() for example`).\r\n\r\nTo fix your error you can pass `seed=` to `.shuffle()`. And the shuffling will depend on both this seed and `self._epoch`",
"Thanks for the reply"
] | "2023-08-17T10:58:20Z" | "2023-08-17T14:33:15Z" | "2023-08-17T14:33:14Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
Currently, distributed training with `IterableDataset` needs to pass fixed seed to shuffle to keep each node use the same seed to avoid overlapping.
https://github.com/huggingface/datasets/blob/a7f8d9019e7cb104eac4106bdc6ec0292f0dc61a/src/datasets/iterable_dataset.py#L1174-L1177
My question is why not directly use `self._epoch` which is set by `set_epoch` as seed? It's almost the same across nodes.
https://github.com/huggingface/datasets/blob/a7f8d9019e7cb104eac4106bdc6ec0292f0dc61a/src/datasets/iterable_dataset.py#L1790-L1801
If not using `self._epoch` as shuffling seed, what does this method do to prepare an epoch seeded generator?
https://github.com/huggingface/datasets/blob/a7f8d9019e7cb104eac4106bdc6ec0292f0dc61a/src/datasets/iterable_dataset.py#L1206
### Steps to reproduce the bug
As mentioned above.
### Expected behavior
As mentioned above.
### Environment info
Not related | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6156/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5756/comments | https://api.github.com/repos/huggingface/datasets/issues/5756/events | https://github.com/huggingface/datasets/issues/5756 | 1,669,678,080 | I_kwDODunzps5jhUQA | 5,756 | Calling shuffle on a IterableDataset with streaming=True, gives "ValueError: cannot reshape array" | {
"avatar_url": "https://avatars.githubusercontent.com/u/21077341?v=4",
"events_url": "https://api.github.com/users/rohfle/events{/privacy}",
"followers_url": "https://api.github.com/users/rohfle/followers",
"following_url": "https://api.github.com/users/rohfle/following{/other_user}",
"gists_url": "https://api.github.com/users/rohfle/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rohfle",
"id": 21077341,
"login": "rohfle",
"node_id": "MDQ6VXNlcjIxMDc3MzQx",
"organizations_url": "https://api.github.com/users/rohfle/orgs",
"received_events_url": "https://api.github.com/users/rohfle/received_events",
"repos_url": "https://api.github.com/users/rohfle/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rohfle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rohfle/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rohfle"
} | [] | closed | false | null | [] | null | [
"Hi! I've merged a PR on the Hub with a fix: https://huggingface.co/datasets/fashion_mnist/discussions/3",
"Thanks, this appears to have fixed the issue.\r\n\r\nI've created a PR for the same change in the mnist dataset: https://huggingface.co/datasets/mnist/discussions/3/files"
] | "2023-04-16T04:59:47Z" | "2023-04-18T03:40:56Z" | "2023-04-18T03:40:56Z" | NONE | null | null | null | ### Describe the bug
When calling shuffle on a IterableDataset with streaming=True, I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 937, in __iter__
for key, example in ex_iterable:
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 627, in __iter__
for x in self.ex_iterable:
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.10/site-packages/datasets/iterable_dataset.py", line 138, in __iter__
yield from self.generate_examples_fn(**kwargs_with_shuffled_shards)
File "/home/administrator/.cache/huggingface/modules/datasets_modules/datasets/mnist/fda16c03c4ecfb13f165ba7e29cf38129ce035011519968cdaf74894ce91c9d4/mnist.py", line 111, in _generate_examples
images = np.frombuffer(f.read(), dtype=np.uint8).reshape(size, 28, 28)
ValueError: cannot reshape array of size 59992 into shape (60000,28,28)
```
Tested with the fashion_mnist and mnist datasets
### Steps to reproduce the bug
Code to reproduce
```python
from datasets import load_dataset
SHUFFLE_SEED = 42
SHUFFLE_BUFFER_SIZE = 10_000
dataset = load_dataset('fashion_mnist', streaming=True).shuffle(seed=SHUFFLE_SEED, buffer_size=SHUFFLE_BUFFER_SIZE)
next(iter(dataset['train']))
```
### Expected behavior
A random item from the dataset and no error
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 2.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5756/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5753/comments | https://api.github.com/repos/huggingface/datasets/issues/5753/events | https://github.com/huggingface/datasets/issues/5753 | 1,668,659,536 | I_kwDODunzps5jdblQ | 5,753 | [IterableDatasets] Add column followed by interleave datasets gives bogus outputs | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sanchit-gandhi",
"id": 93869735,
"login": "sanchit-gandhi",
"node_id": "U_kgDOBZhWpw",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sanchit-gandhi"
} | [] | closed | false | null | [] | null | [
"Problem with the code snippet! Using global vars and functions was not a good idea with iterable datasets!\r\n\r\nIf we update to:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\noriginal_dataset = load_dataset(\"librispeech_asr\", \"clean\", split=\"validation\", streaming=True)\r\n\r\n# now add a new column to our streaming dataset using our hack\r\nname = \"new_column\"\r\ncolumn_1 = [f\"new dataset 1, row {i}\" for i in range(50)]\r\n\r\nnew_features = original_dataset.features.copy()\r\nnew_features[name] = new_features[\"file\"] # I know that \"file\" has the right column type to match our new feature\r\n\r\ndef add_column_fn_1(example, idx):\r\n if name in example:\r\n raise ValueError(f\"Error when adding {name}: column {name} is already in the dataset.\")\r\n return {name: column_1[idx]}\r\n\r\nmodified_dataset_1 = original_dataset.map(add_column_fn_1, with_indices=True, features=new_features)\r\n\r\n# now create a second modified dataset using the same trick\r\ncolumn_2 = [f\"new dataset 2, row {i}\" for i in range(50)]\r\n\r\ndef add_column_fn_2(example, idx):\r\n if name in example:\r\n raise ValueError(f\"Error when adding {name}: column {name} is already in the dataset.\")\r\n return {name: column_2[idx]}\r\n\r\nmodified_dataset_2 = original_dataset.map(add_column_fn_2, with_indices=True, features=new_features)\r\n\r\ninterleaved_dataset = interleave_datasets([modified_dataset_1, modified_dataset_2])\r\n\r\nfor i, sample in enumerate(interleaved_dataset):\r\n print(sample[\"new_column\"])\r\n if i == 10:\r\n break\r\n```\r\nwe get the correct outputs:\r\n```python\r\nnew dataset 1, row 0\r\nnew dataset 2, row 0\r\nnew dataset 1, row 1\r\nnew dataset 2, row 1\r\nnew dataset 1, row 2\r\nnew dataset 2, row 2\r\nnew dataset 1, row 3\r\nnew dataset 2, row 3\r\nnew dataset 1, row 4\r\nnew dataset 2, row 4\r\nnew dataset 1, row 5\r\n```\r\n"
] | "2023-04-14T17:32:31Z" | "2023-04-14T17:45:52Z" | "2023-04-14T17:36:37Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
If we add a new column to our iterable dataset using the hack described in #5752, when we then interleave datasets the new column is pinned to one value.
### Steps to reproduce the bug
What we're going to do here is:
1. Load an iterable dataset in streaming mode (`original_dataset`)
2. Add a new column to this dataset using the hack in #5752 (`modified_dataset_1`)
3. Create another new dataset by adding a column with the same key but different values (`modified_dataset_2`)
4. Interleave our new datasets (`modified_dataset_1` + `modified_dataset_2`)
5. Check the value of our newly added column (`new_column`)
```python
from datasets import load_dataset
# load an iterable dataset
original_dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
# now add a new column to our streaming dataset using our hack from 5752
name = "new_column"
column = [f"new dataset 1, row {i}" for i in range(50)]
new_features = original_dataset.features.copy()
new_features[name] = new_features["file"] # I know that "file" has the right column type to match our new feature
def add_column_fn(example, idx):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: column[idx]}
modified_dataset_1 = original_dataset.map(add_column_fn, with_indices=True, features=new_features)
# now create a second modified dataset using the same trick
column = [f"new dataset 2, row {i}" for i in range(50)]
def add_column_fn(example, idx):
if name in example:
raise ValueError(f"Error when adding {name}: column {name} is already in the dataset.")
return {name: column[idx]}
modified_dataset_2 = original_dataset.map(add_column_fn, with_indices=True, features=new_features)
# interleave these datasets
interleaved_dataset = interleave_datasets([modified_dataset_1, modified_dataset_2])
# now check what the value of the added column is
for i, sample in enumerate(interleaved_dataset):
print(sample["new_column"])
if i == 10:
break
```
**Print Output:**
```
new dataset 2, row 0
new dataset 2, row 0
new dataset 2, row 1
new dataset 2, row 1
new dataset 2, row 2
new dataset 2, row 2
new dataset 2, row 3
new dataset 2, row 3
new dataset 2, row 4
new dataset 2, row 4
new dataset 2, row 5
```
We see that we only get outputs from our second dataset.
### Expected behavior
We should interleave between dataset 1 and 2 and increase in row value:
```
new dataset 1, row 0
new dataset 2, row 0
new dataset 1, row 1
new dataset 2, row 1
new dataset 1, row 2
new dataset 2, row 2
...
```
### Environment info
- datasets version: 2.10.2.dev0
- Platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.13.3
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5753/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5753/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3541/comments | https://api.github.com/repos/huggingface/datasets/issues/3541/events | https://github.com/huggingface/datasets/issues/3541 | 1,095,033,828 | I_kwDODunzps5BROPk | 3,541 | Support 7-zip compressed data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"This should also resolve: https://github.com/huggingface/datasets/issues/3185."
] | "2022-01-06T07:11:03Z" | "2022-07-19T10:18:30Z" | null | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
We should support 7-zip compressed data files:
- [x] in `extract`:
- #4672
- [ ] in `iter_archive`: for streaming mode
both in streaming and non-streaming modes.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3541/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1836 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1836/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1836/comments | https://api.github.com/repos/huggingface/datasets/issues/1836/events | https://github.com/huggingface/datasets/issues/1836 | 803,531,837 | MDU6SXNzdWU4MDM1MzE4Mzc= | 1,836 | test.json has been removed from the limit dataset repo (breaks dataset) | {
"avatar_url": "https://avatars.githubusercontent.com/u/237550?v=4",
"events_url": "https://api.github.com/users/Paethon/events{/privacy}",
"followers_url": "https://api.github.com/users/Paethon/followers",
"following_url": "https://api.github.com/users/Paethon/following{/other_user}",
"gists_url": "https://api.github.com/users/Paethon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Paethon",
"id": 237550,
"login": "Paethon",
"node_id": "MDQ6VXNlcjIzNzU1MA==",
"organizations_url": "https://api.github.com/users/Paethon/orgs",
"received_events_url": "https://api.github.com/users/Paethon/received_events",
"repos_url": "https://api.github.com/users/Paethon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Paethon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Paethon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Paethon"
} | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"Thanks for the heads up ! I'm opening a PR to fix that"
] | "2021-02-08T12:45:53Z" | "2021-02-10T16:14:58Z" | "2021-02-10T16:14:58Z" | NONE | null | null | null | https://github.com/huggingface/datasets/blob/16042b233dbff2a7585110134e969204c69322c3/datasets/limit/limit.py#L51
The URL is not valid anymore since test.json has been removed in master for some reason. Directly referencing the last commit works:
`https://raw.githubusercontent.com/ilmgut/limit_dataset/0707d3989cd8848f0f11527c77dcf168fefd2b23/data` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1836/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1836/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3835 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3835/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3835/comments | https://api.github.com/repos/huggingface/datasets/issues/3835/events | https://github.com/huggingface/datasets/issues/3835 | 1,161,029,205 | I_kwDODunzps5FM-ZV | 3,835 | The link given on the gigaword does not work | {
"avatar_url": "https://avatars.githubusercontent.com/u/26357784?v=4",
"events_url": "https://api.github.com/users/martin6336/events{/privacy}",
"followers_url": "https://api.github.com/users/martin6336/followers",
"following_url": "https://api.github.com/users/martin6336/following{/other_user}",
"gists_url": "https://api.github.com/users/martin6336/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/martin6336",
"id": 26357784,
"login": "martin6336",
"node_id": "MDQ6VXNlcjI2MzU3Nzg0",
"organizations_url": "https://api.github.com/users/martin6336/orgs",
"received_events_url": "https://api.github.com/users/martin6336/received_events",
"repos_url": "https://api.github.com/users/martin6336/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/martin6336/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/martin6336/subscriptions",
"type": "User",
"url": "https://api.github.com/users/martin6336"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | "2022-03-07T07:56:42Z" | "2022-03-15T12:30:23Z" | "2022-03-15T12:30:23Z" | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3835/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3835/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1069 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1069/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1069/comments | https://api.github.com/repos/huggingface/datasets/issues/1069/events | https://github.com/huggingface/datasets/pull/1069 | 756,425,737 | MDExOlB1bGxSZXF1ZXN0NTMxOTcyNjYz | 1,069 | Test | {
"avatar_url": "https://avatars.githubusercontent.com/u/6687858?v=4",
"events_url": "https://api.github.com/users/manandey/events{/privacy}",
"followers_url": "https://api.github.com/users/manandey/followers",
"following_url": "https://api.github.com/users/manandey/following{/other_user}",
"gists_url": "https://api.github.com/users/manandey/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/manandey",
"id": 6687858,
"login": "manandey",
"node_id": "MDQ6VXNlcjY2ODc4NTg=",
"organizations_url": "https://api.github.com/users/manandey/orgs",
"received_events_url": "https://api.github.com/users/manandey/received_events",
"repos_url": "https://api.github.com/users/manandey/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/manandey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manandey/subscriptions",
"type": "User",
"url": "https://api.github.com/users/manandey"
} | [] | closed | false | null | [] | null | [] | "2020-12-03T18:01:45Z" | "2020-12-04T04:24:18Z" | "2020-12-04T04:24:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1069.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1069",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1069.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1069"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1069/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1069/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2769/comments | https://api.github.com/repos/huggingface/datasets/issues/2769/events | https://github.com/huggingface/datasets/pull/2769 | 963,240,802 | MDExOlB1bGxSZXF1ZXN0NzA1ODk5MTYy | 2,769 | Allow PyArrow from source | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | [] | "2021-08-07T14:26:44Z" | "2021-08-09T15:38:39Z" | "2021-08-09T15:38:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2769.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2769",
"merged_at": "2021-08-09T15:38:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2769.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2769"
} | When installing pyarrow from source the version is:
```python
>>> import pyarrow; pyarrow.__version__
'2.1.0.dev612'
```
-> however this breaks the install check at init of `datasets`. This PR makes sure that everything coming after the last `'.'` is removed. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2769/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2769/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6420/comments | https://api.github.com/repos/huggingface/datasets/issues/6420/events | https://github.com/huggingface/datasets/pull/6420 | 1,994,278,903 | PR_kwDODunzps5ffhdi | 6,420 | Set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6420). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004536 / 0.011353 (-0.006816) | 0.002979 / 0.011008 (-0.008030) | 0.061984 / 0.038508 (0.023476) | 0.029382 / 0.023109 (0.006273) | 0.245237 / 0.275898 (-0.030661) | 0.270571 / 0.323480 (-0.052909) | 0.003956 / 0.007986 (-0.004029) | 0.002453 / 0.004328 (-0.001876) | 0.047967 / 0.004250 (0.043717) | 0.043695 / 0.037052 (0.006643) | 0.248457 / 0.258489 (-0.010032) | 0.283293 / 0.293841 (-0.010548) | 0.023603 / 0.128546 (-0.104943) | 0.007225 / 0.075646 (-0.068422) | 0.200533 / 0.419271 (-0.218739) | 0.055310 / 0.043533 (0.011777) | 0.245152 / 0.255139 (-0.009987) | 0.267187 / 0.283200 (-0.016012) | 0.018158 / 0.141683 (-0.123525) | 1.126079 / 1.452155 (-0.326075) | 1.185137 / 1.492716 (-0.307580) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092436 / 0.018006 (0.074430) | 0.300132 / 0.000490 (0.299642) | 0.000206 / 0.000200 (0.000006) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018476 / 0.037411 (-0.018935) | 0.062827 / 0.014526 (0.048301) | 0.074605 / 0.176557 (-0.101952) | 0.119768 / 0.737135 (-0.617368) | 0.076044 / 0.296338 (-0.220294) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.279717 / 0.215209 (0.064508) | 2.752308 / 2.077655 (0.674654) | 1.434954 / 1.504120 (-0.069166) | 1.314700 / 1.541195 (-0.226495) | 1.347689 / 1.468490 (-0.120802) | 0.400332 / 4.584777 (-4.184445) | 2.383024 / 3.745712 (-1.362689) | 2.583130 / 5.269862 (-2.686732) | 1.567670 / 4.565676 (-2.998007) | 0.045446 / 0.424275 (-0.378829) | 0.004813 / 0.007607 (-0.002794) | 0.336191 / 0.226044 (0.110147) | 3.319837 / 2.268929 (1.050909) | 1.816808 / 55.444624 (-53.627817) | 1.539052 / 6.876477 (-5.337424) | 1.550765 / 2.142072 (-0.591307) | 0.484253 / 4.805227 (-4.320974) | 0.100494 / 6.500664 (-6.400170) | 0.041614 / 0.075469 (-0.033855) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.940857 / 1.841788 (-0.900931) | 11.784946 / 8.074308 (3.710638) | 10.397038 / 10.191392 (0.205646) | 0.141458 / 0.680424 (-0.538965) | 0.014193 / 0.534201 (-0.520008) | 0.268304 / 0.579283 (-0.310979) | 0.267059 / 0.434364 (-0.167305) | 0.309389 / 0.540337 (-0.230949) | 0.420628 / 1.386936 (-0.966308) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004776 / 0.011353 (-0.006577) | 0.002941 / 0.011008 (-0.008067) | 0.048659 / 0.038508 (0.010151) | 0.053334 / 0.023109 (0.030225) | 0.273342 / 0.275898 (-0.002556) | 0.302278 / 0.323480 (-0.021202) | 0.004001 / 0.007986 (-0.003984) | 0.002414 / 0.004328 (-0.001914) | 0.047504 / 0.004250 (0.043254) | 0.038581 / 0.037052 (0.001529) | 0.277768 / 0.258489 (0.019279) | 0.306772 / 0.293841 (0.012931) | 0.024146 / 0.128546 (-0.104400) | 0.007233 / 0.075646 (-0.068413) | 0.053308 / 0.419271 (-0.365964) | 0.032617 / 0.043533 (-0.010916) | 0.277390 / 0.255139 (0.022251) | 0.296015 / 0.283200 (0.012816) | 0.018733 / 0.141683 (-0.122950) | 1.124895 / 1.452155 (-0.327260) | 1.182579 / 1.492716 (-0.310137) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093375 / 0.018006 (0.075369) | 0.301555 / 0.000490 (0.301066) | 0.000217 / 0.000200 (0.000017) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021284 / 0.037411 (-0.016127) | 0.070158 / 0.014526 (0.055632) | 0.080187 / 0.176557 (-0.096370) | 0.119282 / 0.737135 (-0.617854) | 0.081672 / 0.296338 (-0.214666) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.314396 / 0.215209 (0.099187) | 2.975114 / 2.077655 (0.897459) | 1.724658 / 1.504120 (0.220539) | 1.604464 / 1.541195 (0.063269) | 1.652736 / 1.468490 (0.184246) | 0.395064 / 4.584777 (-4.189713) | 2.412768 / 3.745712 (-1.332944) | 2.564427 / 5.269862 (-2.705435) | 1.507627 / 4.565676 (-3.058050) | 0.045463 / 0.424275 (-0.378812) | 0.004797 / 0.007607 (-0.002810) | 0.383115 / 0.226044 (0.157071) | 3.501976 / 2.268929 (1.233048) | 2.087512 / 55.444624 (-53.357113) | 1.793132 / 6.876477 (-5.083345) | 1.804178 / 2.142072 (-0.337895) | 0.468287 / 4.805227 (-4.336940) | 0.097247 / 6.500664 (-6.403417) | 0.041139 / 0.075469 (-0.034330) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976034 / 1.841788 (-0.865754) | 12.431248 / 8.074308 (4.356940) | 10.896064 / 10.191392 (0.704672) | 0.129137 / 0.680424 (-0.551287) | 0.015636 / 0.534201 (-0.518565) | 0.268219 / 0.579283 (-0.311064) | 0.278345 / 0.434364 (-0.156019) | 0.302696 / 0.540337 (-0.237642) | 0.408465 / 1.386936 (-0.978471) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007703 / 0.011353 (-0.003650) | 0.004614 / 0.011008 (-0.006394) | 0.101425 / 0.038508 (0.062917) | 0.040122 / 0.023109 (0.017013) | 0.398890 / 0.275898 (0.122992) | 0.424392 / 0.323480 (0.100912) | 0.005411 / 0.007986 (-0.002575) | 0.003747 / 0.004328 (-0.000582) | 0.080494 / 0.004250 (0.076243) | 0.059392 / 0.037052 (0.022340) | 0.398025 / 0.258489 (0.139536) | 0.454293 / 0.293841 (0.160452) | 0.043662 / 0.128546 (-0.084884) | 0.013726 / 0.075646 (-0.061920) | 0.352910 / 0.419271 (-0.066362) | 0.088572 / 0.043533 (0.045039) | 0.401677 / 0.255139 (0.146538) | 0.421774 / 0.283200 (0.138575) | 0.033377 / 0.141683 (-0.108305) | 1.728499 / 1.452155 (0.276344) | 1.821557 / 1.492716 (0.328841) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230744 / 0.018006 (0.212738) | 0.496188 / 0.000490 (0.495698) | 0.010315 / 0.000200 (0.010115) | 0.000402 / 0.000054 (0.000348) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028859 / 0.037411 (-0.008552) | 0.089688 / 0.014526 (0.075163) | 0.111697 / 0.176557 (-0.064860) | 0.183238 / 0.737135 (-0.553898) | 0.112407 / 0.296338 (-0.183931) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.558394 / 0.215209 (0.343185) | 5.643048 / 2.077655 (3.565393) | 2.454622 / 1.504120 (0.950502) | 2.183338 / 1.541195 (0.642143) | 2.324793 / 1.468490 (0.856303) | 0.859482 / 4.584777 (-3.725295) | 4.959346 / 3.745712 (1.213634) | 4.599224 / 5.269862 (-0.670638) | 2.764382 / 4.565676 (-1.801295) | 0.089976 / 0.424275 (-0.334299) | 0.008144 / 0.007607 (0.000537) | 0.634675 / 0.226044 (0.408631) | 6.555693 / 2.268929 (4.286765) | 3.080252 / 55.444624 (-52.364373) | 2.442715 / 6.876477 (-4.433762) | 2.475126 / 2.142072 (0.333053) | 0.986459 / 4.805227 (-3.818768) | 0.193859 / 6.500664 (-6.306805) | 0.063652 / 0.075469 (-0.011817) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.545318 / 1.841788 (-0.296469) | 21.928751 / 8.074308 (13.854442) | 20.598229 / 10.191392 (10.406837) | 0.234046 / 0.680424 (-0.446377) | 0.025947 / 0.534201 (-0.508254) | 0.459773 / 0.579283 (-0.119510) | 0.598026 / 0.434364 (0.163662) | 0.555260 / 0.540337 (0.014922) | 0.782767 / 1.386936 (-0.604169) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009322 / 0.011353 (-0.002030) | 0.004650 / 0.011008 (-0.006358) | 0.079326 / 0.038508 (0.040818) | 0.079112 / 0.023109 (0.056003) | 0.428708 / 0.275898 (0.152810) | 0.481647 / 0.323480 (0.158168) | 0.006419 / 0.007986 (-0.001566) | 0.003878 / 0.004328 (-0.000450) | 0.079013 / 0.004250 (0.074762) | 0.058107 / 0.037052 (0.021055) | 0.436967 / 0.258489 (0.178478) | 0.501120 / 0.293841 (0.207279) | 0.052972 / 0.128546 (-0.075574) | 0.014414 / 0.075646 (-0.061232) | 0.098587 / 0.419271 (-0.320685) | 0.061626 / 0.043533 (0.018093) | 0.451623 / 0.255139 (0.196484) | 0.468893 / 0.283200 (0.185693) | 0.032479 / 0.141683 (-0.109203) | 1.911743 / 1.452155 (0.459588) | 1.969024 / 1.492716 (0.476308) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232015 / 0.018006 (0.214009) | 0.508637 / 0.000490 (0.508147) | 0.005470 / 0.000200 (0.005270) | 0.000131 / 0.000054 (0.000076) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035345 / 0.037411 (-0.002066) | 0.106319 / 0.014526 (0.091794) | 0.117205 / 0.176557 (-0.059352) | 0.176527 / 0.737135 (-0.560608) | 0.121566 / 0.296338 (-0.174773) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.584920 / 0.215209 (0.369711) | 5.745688 / 2.077655 (3.668034) | 2.519875 / 1.504120 (1.015755) | 2.197593 / 1.541195 (0.656398) | 2.296670 / 1.468490 (0.828180) | 0.831938 / 4.584777 (-3.752839) | 5.130594 / 3.745712 (1.384882) | 4.581385 / 5.269862 (-0.688476) | 2.829516 / 4.565676 (-1.736161) | 0.099015 / 0.424275 (-0.325260) | 0.011468 / 0.007607 (0.003861) | 0.702717 / 0.226044 (0.476672) | 6.856099 / 2.268929 (4.587170) | 3.372966 / 55.444624 (-52.071658) | 2.567664 / 6.876477 (-4.308812) | 2.699200 / 2.142072 (0.557127) | 0.992316 / 4.805227 (-3.812911) | 0.190463 / 6.500664 (-6.310201) | 0.063305 / 0.075469 (-0.012165) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.591491 / 1.841788 (-0.250296) | 21.696492 / 8.074308 (13.622184) | 19.695404 / 10.191392 (9.504012) | 0.222853 / 0.680424 (-0.457571) | 0.032936 / 0.534201 (-0.501265) | 0.431209 / 0.579283 (-0.148074) | 0.543101 / 0.434364 (0.108737) | 0.543427 / 0.540337 (0.003089) | 0.742102 / 1.386936 (-0.644834) |\n\n</details>\n</details>\n\n\n"
] | "2023-11-15T08:22:19Z" | "2023-11-15T08:33:36Z" | "2023-11-15T08:22:33Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6420.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6420",
"merged_at": "2023-11-15T08:22:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6420.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6420"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6420/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6420/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/51 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/51/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/51/comments | https://api.github.com/repos/huggingface/datasets/issues/51/events | https://github.com/huggingface/datasets/pull/51 | 613,266,668 | MDExOlB1bGxSZXF1ZXN0NDE0MDUyOTYw | 51 | [Testing] Improved testing structure | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | [
"Awesome!\r\nLet's have this in the doc at the end :-)"
] | "2020-05-06T12:03:07Z" | "2020-05-07T22:07:19Z" | "2020-05-06T13:20:18Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/51.diff",
"html_url": "https://github.com/huggingface/datasets/pull/51",
"merged_at": "2020-05-06T13:20:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/51.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/51"
} | This PR refactors the test design a bit and puts the mock download manager in the `utils` files as it is just a test helper class.
as @mariamabarham pointed out, creating a dummy folder structure can be quite hard to grasp.
This PR tries to change that to some extent.
It follows the following logic for the `dummy` folder structure now:
1.) The data bulider has no config -> the `dummy` folder structure is:
`dummy/<version>/dummy_data.zip`
2) The data builder has >= 1 configs -> the `dummy` folder structure is:
`dummy/<config_name_1>/<version>/dummy_data.zip`
`dummy/<config_name_2>/<version>/dummy_data.zip`
Now, the difficult part is how to create the `dummy_data.zip` file. There are two cases:
A) The `data_urs` parameter inserted into the `download_and_extract` fn is a **string**:
-> the `dummy_data.zip` file zips the folder:
`dummy_data/<relative_path_of_folder_structure_of_url>`
B) The `data_urs` parameter inserted into the `download_and_extract` fn is a **dict**:
-> the `dummy_data.zip` file zips the folder:
`dummy_data/<relative_path_of_folder_structure_of_url_behind _key_1>`
`dummy_data/<relative_path_of_folder_structure_of_url_behind _key_2>`
By relative folder structure I mean `url_path.split('./')[-1]`. As an example the dataset **xquad** by deepmind has the following url path behind the key `de`: `https://github.com/deepmind/xquad/blob/master/xquad.de.json`
-> This means that the relative url path should be `xquad.de.json`.
@mariamabarham B) is a change from how is was before and I think is makes more sense.
While before the `dummy_data.zip` file for xquad with config `de` looked like:
`dummy_data/de` it would now look like `dummy_data/xquad.de.json`. I think this is better and easier to understand.
Therefore there are currently 6 tests that would have to have changed their dummy folder structure, but which can easily be done (30min).
I also added a function: `print_dummy_data_folder_structure` that prints out the expected structures when testing which should be quite helpful. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/51/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/51/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/820/comments | https://api.github.com/repos/huggingface/datasets/issues/820/events | https://github.com/huggingface/datasets/pull/820 | 739,387,617 | MDExOlB1bGxSZXF1ZXN0NTE4MDYwMjQ0 | 820 | Update quail dataset to v1.3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/4889636?v=4",
"events_url": "https://api.github.com/users/ngdodd/events{/privacy}",
"followers_url": "https://api.github.com/users/ngdodd/followers",
"following_url": "https://api.github.com/users/ngdodd/following{/other_user}",
"gists_url": "https://api.github.com/users/ngdodd/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ngdodd",
"id": 4889636,
"login": "ngdodd",
"node_id": "MDQ6VXNlcjQ4ODk2MzY=",
"organizations_url": "https://api.github.com/users/ngdodd/orgs",
"received_events_url": "https://api.github.com/users/ngdodd/received_events",
"repos_url": "https://api.github.com/users/ngdodd/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ngdodd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ngdodd/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ngdodd"
} | [] | closed | false | null | [] | null | [] | "2020-11-09T21:49:26Z" | "2020-11-10T09:06:35Z" | "2020-11-10T09:06:35Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/820.diff",
"html_url": "https://github.com/huggingface/datasets/pull/820",
"merged_at": "2020-11-10T09:06:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/820.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/820"
} | Updated quail to most recent version, to address the problem originally discussed [here](https://github.com/huggingface/datasets/issues/806). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/820/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4231/comments | https://api.github.com/repos/huggingface/datasets/issues/4231/events | https://github.com/huggingface/datasets/pull/4231 | 1,216,651,960 | PR_kwDODunzps421pUX | 4,231 | Fix invalid url to CC-Aligned dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44451229?v=4",
"events_url": "https://api.github.com/users/juntang-zhuang/events{/privacy}",
"followers_url": "https://api.github.com/users/juntang-zhuang/followers",
"following_url": "https://api.github.com/users/juntang-zhuang/following{/other_user}",
"gists_url": "https://api.github.com/users/juntang-zhuang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/juntang-zhuang",
"id": 44451229,
"login": "juntang-zhuang",
"node_id": "MDQ6VXNlcjQ0NDUxMjI5",
"organizations_url": "https://api.github.com/users/juntang-zhuang/orgs",
"received_events_url": "https://api.github.com/users/juntang-zhuang/received_events",
"repos_url": "https://api.github.com/users/juntang-zhuang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/juntang-zhuang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/juntang-zhuang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/juntang-zhuang"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-27T01:07:01Z" | "2022-05-16T17:01:13Z" | "2022-05-16T16:53:12Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4231",
"merged_at": "2022-05-16T16:53:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4231"
} | The CC-Aligned dataset url has changed to https://data.statmt.org/cc-aligned/, the old address http://www.statmt.org/cc-aligned/ is no longer valid | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4231/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4999 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4999/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4999/comments | https://api.github.com/repos/huggingface/datasets/issues/4999/events | https://github.com/huggingface/datasets/pull/4999 | 1,379,610,030 | PR_kwDODunzps4_SQxL | 4,999 | Add EmptyDatasetError | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-09-20T15:28:05Z" | "2022-09-21T12:23:43Z" | "2022-09-21T12:21:24Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4999.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4999",
"merged_at": "2022-09-21T12:21:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4999.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4999"
} | examples:
from the hub:
```python
Traceback (most recent call last):
File "playground/ttest.py", line 3, in <module>
print(load_dataset("lhoestq/empty"))
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1686, in load_dataset
**config_kwargs,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1458, in load_dataset_builder
data_files=data_files,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1171, in dataset_module_factory
raise e1 from None
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1162, in dataset_module_factory
download_mode=download_mode,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 760, in get_module
else get_data_patterns_in_dataset_repository(hfh_dataset_info, self.data_dir)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/data_files.py", line 678, in get_data_patterns_in_dataset_repository
) from None
datasets.data_files.EmptyDatasetError: The dataset repository at 'lhoestq/empty' doesn't contain any data file.
```
from local directory:
```python
Traceback (most recent call last):
File "playground/ttest.py", line 3, in <module>
print(load_dataset("playground/empty"))
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1686, in load_dataset
**config_kwargs,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1458, in load_dataset_builder
data_files=data_files,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1107, in dataset_module_factory
path, data_dir=data_dir, data_files=data_files, download_mode=download_mode
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 625, in get_module
else get_data_patterns_locally(base_path)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/data_files.py", line 460, in get_data_patterns_locally
raise EmptyDatasetError(f"The directory at {base_path} doesn't contain any data file") from None
datasets.data_files.EmptyDatasetError: The directory at playground/empty doesn't contain any data file
```
Close https://github.com/huggingface/datasets/issues/4995 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4999/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4999/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1389/comments | https://api.github.com/repos/huggingface/datasets/issues/1389/events | https://github.com/huggingface/datasets/pull/1389 | 760,402,224 | MDExOlB1bGxSZXF1ZXN0NTM1MjM5OTYy | 1,389 | add amazon polarity dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29229602?v=4",
"events_url": "https://api.github.com/users/hfawaz/events{/privacy}",
"followers_url": "https://api.github.com/users/hfawaz/followers",
"following_url": "https://api.github.com/users/hfawaz/following{/other_user}",
"gists_url": "https://api.github.com/users/hfawaz/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hfawaz",
"id": 29229602,
"login": "hfawaz",
"node_id": "MDQ6VXNlcjI5MjI5NjAy",
"organizations_url": "https://api.github.com/users/hfawaz/orgs",
"received_events_url": "https://api.github.com/users/hfawaz/received_events",
"repos_url": "https://api.github.com/users/hfawaz/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hfawaz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hfawaz/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hfawaz"
} | [] | closed | false | null | [] | null | [
"`amazon_polarity` is probably a subset of `amazon_us_reviews` but I am not entirely sure about that.\r\nI guess `amazon_polarity` will help in reproducing results of papers using this dataset since even if it is a subset from `amazon_us_reviews`, it is not trivial how to extract `amazon_polarity` from `amazon_us_reviews`, especially since `amazon_us_reviews` was released after `amazon_polarity`. ",
"do you know what the problem would be ? should I pull the master before ? @lhoestq ",
"The error just appeared on master. I will try to fix it today.\r\nYou can ignore them since it's not related to the dataset you added",
"merging since the CI is fixed on master",
"Great thanks for the help. "
] | "2020-12-09T14:58:21Z" | "2020-12-11T11:45:39Z" | "2020-12-11T11:41:01Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1389.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1389",
"merged_at": "2020-12-11T11:41:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1389.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1389"
} | This corresponds to the amazon (binary dataset) requested in https://github.com/huggingface/datasets/issues/353 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1389/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1389/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2411/comments | https://api.github.com/repos/huggingface/datasets/issues/2411/events | https://github.com/huggingface/datasets/pull/2411 | 903,671,778 | MDExOlB1bGxSZXF1ZXN0NjU0OTAzNjg2 | 2,411 | Add DOI badge to README | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-05-27T12:36:47Z" | "2021-05-27T13:42:54Z" | "2021-05-27T13:42:54Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2411.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2411",
"merged_at": "2021-05-27T13:42:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2411.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2411"
} | Once published the latest release, the DOI badge has been automatically generated by Zenodo. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2411/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2411/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5683/comments | https://api.github.com/repos/huggingface/datasets/issues/5683/events | https://github.com/huggingface/datasets/pull/5683 | 1,646,001,197 | PR_kwDODunzps5NLUq1 | 5,683 | Fix verification_mode when ignore_verifications is passed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006935 / 0.011353 (-0.004418) | 0.004711 / 0.011008 (-0.006297) | 0.098461 / 0.038508 (0.059953) | 0.028889 / 0.023109 (0.005780) | 0.332167 / 0.275898 (0.056269) | 0.363309 / 0.323480 (0.039829) | 0.005179 / 0.007986 (-0.002807) | 0.004783 / 0.004328 (0.000455) | 0.074293 / 0.004250 (0.070043) | 0.038778 / 0.037052 (0.001726) | 0.318871 / 0.258489 (0.060382) | 0.362975 / 0.293841 (0.069134) | 0.032897 / 0.128546 (-0.095649) | 0.011685 / 0.075646 (-0.063961) | 0.322824 / 0.419271 (-0.096447) | 0.043842 / 0.043533 (0.000309) | 0.334789 / 0.255139 (0.079650) | 0.352922 / 0.283200 (0.069723) | 0.089692 / 0.141683 (-0.051991) | 1.490110 / 1.452155 (0.037955) | 1.601530 / 1.492716 (0.108813) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201882 / 0.018006 (0.183875) | 0.410875 / 0.000490 (0.410385) | 0.002472 / 0.000200 (0.002272) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023636 / 0.037411 (-0.013775) | 0.102168 / 0.014526 (0.087642) | 0.107247 / 0.176557 (-0.069310) | 0.171858 / 0.737135 (-0.565278) | 0.110619 / 0.296338 (-0.185720) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433740 / 0.215209 (0.218531) | 4.332121 / 2.077655 (2.254466) | 2.075398 / 1.504120 (0.571278) | 1.941074 / 1.541195 (0.399879) | 2.033331 / 1.468490 (0.564841) | 0.697134 / 4.584777 (-3.887643) | 3.463855 / 3.745712 (-0.281857) | 3.080446 / 5.269862 (-2.189416) | 1.575020 / 4.565676 (-2.990656) | 0.083054 / 0.424275 (-0.341221) | 0.012454 / 0.007607 (0.004847) | 0.537996 / 0.226044 (0.311951) | 5.366765 / 2.268929 (3.097836) | 2.464398 / 55.444624 (-52.980227) | 2.143912 / 6.876477 (-4.732564) | 2.245706 / 2.142072 (0.103634) | 0.801397 / 4.805227 (-4.003831) | 0.150954 / 6.500664 (-6.349710) | 0.066758 / 0.075469 (-0.008711) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.216412 / 1.841788 (-0.625376) | 13.679322 / 8.074308 (5.605014) | 14.055286 / 10.191392 (3.863894) | 0.130264 / 0.680424 (-0.550160) | 0.016566 / 0.534201 (-0.517635) | 0.379126 / 0.579283 (-0.200157) | 0.390815 / 0.434364 (-0.043549) | 0.437586 / 0.540337 (-0.102751) | 0.526822 / 1.386936 (-0.860114) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006898 / 0.011353 (-0.004455) | 0.004705 / 0.011008 (-0.006304) | 0.078592 / 0.038508 (0.040084) | 0.028635 / 0.023109 (0.005525) | 0.340143 / 0.275898 (0.064245) | 0.377526 / 0.323480 (0.054047) | 0.005645 / 0.007986 (-0.002340) | 0.003533 / 0.004328 (-0.000796) | 0.078441 / 0.004250 (0.074191) | 0.039408 / 0.037052 (0.002356) | 0.342303 / 0.258489 (0.083814) | 0.386837 / 0.293841 (0.092996) | 0.032427 / 0.128546 (-0.096119) | 0.011763 / 0.075646 (-0.063883) | 0.087984 / 0.419271 (-0.331287) | 0.042126 / 0.043533 (-0.001406) | 0.339951 / 0.255139 (0.084812) | 0.366165 / 0.283200 (0.082966) | 0.091414 / 0.141683 (-0.050269) | 1.502034 / 1.452155 (0.049880) | 1.597901 / 1.492716 (0.105184) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232122 / 0.018006 (0.214115) | 0.410205 / 0.000490 (0.409715) | 0.000418 / 0.000200 (0.000218) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026013 / 0.037411 (-0.011399) | 0.105520 / 0.014526 (0.090995) | 0.108649 / 0.176557 (-0.067908) | 0.159324 / 0.737135 (-0.577811) | 0.114033 / 0.296338 (-0.182306) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.455634 / 0.215209 (0.240425) | 4.508544 / 2.077655 (2.430889) | 2.087065 / 1.504120 (0.582945) | 1.872622 / 1.541195 (0.331427) | 1.935617 / 1.468490 (0.467127) | 0.696909 / 4.584777 (-3.887868) | 3.449365 / 3.745712 (-0.296348) | 3.008399 / 5.269862 (-2.261462) | 1.459245 / 4.565676 (-3.106431) | 0.083637 / 0.424275 (-0.340638) | 0.012358 / 0.007607 (0.004750) | 0.547232 / 0.226044 (0.321187) | 5.522395 / 2.268929 (3.253466) | 2.691019 / 55.444624 (-52.753605) | 2.408083 / 6.876477 (-4.468394) | 2.369239 / 2.142072 (0.227166) | 0.807148 / 4.805227 (-3.998080) | 0.152030 / 6.500664 (-6.348634) | 0.067883 / 0.075469 (-0.007586) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.336956 / 1.841788 (-0.504832) | 14.403730 / 8.074308 (6.329422) | 14.854084 / 10.191392 (4.662692) | 0.146530 / 0.680424 (-0.533894) | 0.016611 / 0.534201 (-0.517590) | 0.398557 / 0.579283 (-0.180726) | 0.393194 / 0.434364 (-0.041170) | 0.486824 / 0.540337 (-0.053513) | 0.572844 / 1.386936 (-0.814092) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-29T15:00:50Z" | "2023-03-29T17:36:06Z" | "2023-03-29T17:28:57Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5683.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5683",
"merged_at": "2023-03-29T17:28:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5683.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5683"
} | This PR fixes the values assigned to `verification_mode` when passing `ignore_verifications` to `load_dataset`.
Related to:
- #5303
Fix #5682. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5683/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5683/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5621/comments | https://api.github.com/repos/huggingface/datasets/issues/5621/events | https://github.com/huggingface/datasets/pull/5621 | 1,615,029,615 | PR_kwDODunzps5LjwD8 | 5,621 | Adding Oracle Cloud to docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/29129502?v=4",
"events_url": "https://api.github.com/users/ahosler/events{/privacy}",
"followers_url": "https://api.github.com/users/ahosler/followers",
"following_url": "https://api.github.com/users/ahosler/following{/other_user}",
"gists_url": "https://api.github.com/users/ahosler/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ahosler",
"id": 29129502,
"login": "ahosler",
"node_id": "MDQ6VXNlcjI5MTI5NTAy",
"organizations_url": "https://api.github.com/users/ahosler/orgs",
"received_events_url": "https://api.github.com/users/ahosler/received_events",
"repos_url": "https://api.github.com/users/ahosler/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ahosler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahosler/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ahosler"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006183 / 0.011353 (-0.005170) | 0.004377 / 0.011008 (-0.006631) | 0.096898 / 0.038508 (0.058390) | 0.027729 / 0.023109 (0.004620) | 0.336582 / 0.275898 (0.060684) | 0.353792 / 0.323480 (0.030312) | 0.004541 / 0.007986 (-0.003445) | 0.004349 / 0.004328 (0.000020) | 0.074403 / 0.004250 (0.070153) | 0.033918 / 0.037052 (-0.003134) | 0.341505 / 0.258489 (0.083016) | 0.380192 / 0.293841 (0.086351) | 0.031703 / 0.128546 (-0.096843) | 0.011561 / 0.075646 (-0.064086) | 0.321848 / 0.419271 (-0.097423) | 0.043407 / 0.043533 (-0.000126) | 0.330365 / 0.255139 (0.075226) | 0.364630 / 0.283200 (0.081430) | 0.084798 / 0.141683 (-0.056885) | 1.450908 / 1.452155 (-0.001246) | 1.522235 / 1.492716 (0.029519) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198267 / 0.018006 (0.180261) | 0.409554 / 0.000490 (0.409065) | 0.002501 / 0.000200 (0.002301) | 0.000270 / 0.000054 (0.000215) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021801 / 0.037411 (-0.015610) | 0.097429 / 0.014526 (0.082904) | 0.103259 / 0.176557 (-0.073298) | 0.161483 / 0.737135 (-0.575652) | 0.107843 / 0.296338 (-0.188496) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.427057 / 0.215209 (0.211848) | 4.259477 / 2.077655 (2.181823) | 1.945819 / 1.504120 (0.441699) | 1.733013 / 1.541195 (0.191819) | 1.748486 / 1.468490 (0.279996) | 0.702231 / 4.584777 (-3.882546) | 3.387608 / 3.745712 (-0.358104) | 1.890187 / 5.269862 (-3.379675) | 1.300465 / 4.565676 (-3.265211) | 0.083702 / 0.424275 (-0.340573) | 0.012674 / 0.007607 (0.005067) | 0.527978 / 0.226044 (0.301934) | 5.259610 / 2.268929 (2.990681) | 2.366512 / 55.444624 (-53.078113) | 2.013811 / 6.876477 (-4.862666) | 2.058175 / 2.142072 (-0.083898) | 0.815042 / 4.805227 (-3.990185) | 0.153496 / 6.500664 (-6.347168) | 0.065442 / 0.075469 (-0.010027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.227494 / 1.841788 (-0.614294) | 13.812921 / 8.074308 (5.738613) | 14.430149 / 10.191392 (4.238757) | 0.145422 / 0.680424 (-0.535002) | 0.016672 / 0.534201 (-0.517529) | 0.382126 / 0.579283 (-0.197157) | 0.388369 / 0.434364 (-0.045995) | 0.446133 / 0.540337 (-0.094204) | 0.531044 / 1.386936 (-0.855892) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006273 / 0.011353 (-0.005080) | 0.004557 / 0.011008 (-0.006452) | 0.077398 / 0.038508 (0.038890) | 0.027295 / 0.023109 (0.004185) | 0.340866 / 0.275898 (0.064968) | 0.373918 / 0.323480 (0.050438) | 0.004967 / 0.007986 (-0.003018) | 0.003337 / 0.004328 (-0.000991) | 0.076041 / 0.004250 (0.071791) | 0.036708 / 0.037052 (-0.000344) | 0.346126 / 0.258489 (0.087637) | 0.385177 / 0.293841 (0.091336) | 0.032272 / 0.128546 (-0.096275) | 0.011756 / 0.075646 (-0.063890) | 0.086512 / 0.419271 (-0.332759) | 0.049310 / 0.043533 (0.005777) | 0.339352 / 0.255139 (0.084213) | 0.372058 / 0.283200 (0.088859) | 0.089712 / 0.141683 (-0.051971) | 1.501964 / 1.452155 (0.049809) | 1.573753 / 1.492716 (0.081037) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.162075 / 0.018006 (0.144069) | 0.391462 / 0.000490 (0.390973) | 0.002868 / 0.000200 (0.002668) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024176 / 0.037411 (-0.013235) | 0.099631 / 0.014526 (0.085105) | 0.107544 / 0.176557 (-0.069013) | 0.157659 / 0.737135 (-0.579477) | 0.111130 / 0.296338 (-0.185209) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442086 / 0.215209 (0.226877) | 4.426311 / 2.077655 (2.348657) | 2.086133 / 1.504120 (0.582013) | 1.860415 / 1.541195 (0.319220) | 1.892306 / 1.468490 (0.423816) | 0.702752 / 4.584777 (-3.882025) | 3.394358 / 3.745712 (-0.351354) | 1.857396 / 5.269862 (-3.412466) | 1.167168 / 4.565676 (-3.398509) | 0.083549 / 0.424275 (-0.340726) | 0.012780 / 0.007607 (0.005173) | 0.547075 / 0.226044 (0.321031) | 5.466619 / 2.268929 (3.197691) | 2.548893 / 55.444624 (-52.895731) | 2.185574 / 6.876477 (-4.690903) | 2.188000 / 2.142072 (0.045928) | 0.810370 / 4.805227 (-3.994857) | 0.153320 / 6.500664 (-6.347344) | 0.068409 / 0.075469 (-0.007060) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330431 / 1.841788 (-0.511356) | 14.178916 / 8.074308 (6.104608) | 14.409594 / 10.191392 (4.218202) | 0.156270 / 0.680424 (-0.524154) | 0.016452 / 0.534201 (-0.517749) | 0.379837 / 0.579283 (-0.199447) | 0.389896 / 0.434364 (-0.044468) | 0.443892 / 0.540337 (-0.096446) | 0.531392 / 1.386936 (-0.855544) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-08T10:22:50Z" | "2023-03-11T00:57:18Z" | "2023-03-11T00:49:56Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5621.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5621",
"merged_at": "2023-03-11T00:49:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5621.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5621"
} | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5621/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4044 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4044/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4044/comments | https://api.github.com/repos/huggingface/datasets/issues/4044/events | https://github.com/huggingface/datasets/issues/4044 | 1,183,658,942 | I_kwDODunzps5GjTO- | 4,044 | CLI dummy data generation is broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2022-03-28T16:07:37Z" | "2022-03-31T14:59:06Z" | "2022-03-31T14:59:06Z" | MEMBER | null | null | null | ## Describe the bug
We get a TypeError when running CLI dummy data generation:
```shell
datasets-cli dummy_data datasets/<your-dataset-folder> --auto_generate
```
gives:
```
File ".../huggingface/datasets/src/datasets/commands/dummy_data.py", line 361, in _autogenerate_dummy_data
dataset_builder._prepare_split(split_generator)
TypeError: _prepare_split() missing 1 required positional argument: 'check_duplicate_keys'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4044/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4044/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3801 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3801/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3801/comments | https://api.github.com/repos/huggingface/datasets/issues/3801/events | https://github.com/huggingface/datasets/pull/3801 | 1,155,649,279 | PR_kwDODunzps4zvqjN | 3,801 | [Breaking] Align `map` when streaming: update instead of overwrite + add missing parameters | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Right ! Will add it in another PR :)"
] | "2022-03-01T18:06:43Z" | "2022-03-07T16:30:30Z" | "2022-03-07T16:30:29Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3801.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3801",
"merged_at": "2022-03-07T16:30:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3801.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3801"
} | Currently the datasets in streaming mode and in non-streaming mode have two distinct API for `map` processing.
In this PR I'm aligning the two by changing `map` in streamign mode. This includes a **major breaking change** and will require a major release of the library: **Datasets 2.0**
In particular, `Dataset.map` adds new columns (with dict.update) BUT `IterableDataset.map` used to discard previous columns (it overwrites the dict). In this PR I'm chaning the `IterableDataset.map` to behave the same way as `Dataset.map`: it will update the examples instead of overwriting them.
I'm also adding those missing parameters to streaming `map`: with_indices, input_columns, remove_columns
### TODO
- [x] tests
- [x] docs
Related to https://github.com/huggingface/datasets/issues/3444 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3801/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3801/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1238/comments | https://api.github.com/repos/huggingface/datasets/issues/1238/events | https://github.com/huggingface/datasets/pull/1238 | 758,321,688 | MDExOlB1bGxSZXF1ZXN0NTMzNTEzODUw | 1,238 | adding poem_sentiment | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patil-suraj",
"id": 27137566,
"login": "patil-suraj",
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patil-suraj"
} | [] | closed | false | null | [] | null | [] | "2020-12-07T09:11:52Z" | "2020-12-09T16:36:10Z" | "2020-12-09T16:02:45Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1238.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1238",
"merged_at": "2020-12-09T16:02:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1238.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1238"
} | Adding poem_sentiment dataset.
https://github.com/google-research-datasets/poem-sentiment | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1238/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1238/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4632/comments | https://api.github.com/repos/huggingface/datasets/issues/4632/events | https://github.com/huggingface/datasets/issues/4632 | 1,294,166,880 | I_kwDODunzps5NI2tg | 4,632 | 'sort' method sorts one column only | {
"avatar_url": "https://avatars.githubusercontent.com/u/42108562?v=4",
"events_url": "https://api.github.com/users/shachardon/events{/privacy}",
"followers_url": "https://api.github.com/users/shachardon/followers",
"following_url": "https://api.github.com/users/shachardon/following{/other_user}",
"gists_url": "https://api.github.com/users/shachardon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shachardon",
"id": 42108562,
"login": "shachardon",
"node_id": "MDQ6VXNlcjQyMTA4NTYy",
"organizations_url": "https://api.github.com/users/shachardon/orgs",
"received_events_url": "https://api.github.com/users/shachardon/received_events",
"repos_url": "https://api.github.com/users/shachardon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shachardon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shachardon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shachardon"
} | [] | closed | false | null | [] | null | [
"Hi ! `ds.sort()` does sort the full dataset, not just one column:\r\n```python\r\nfrom datasets import *\r\n\r\nds = Dataset.from_dict({\"foo\": [3, 2, 1], \"bar\": [\"c\", \"b\", \"a\"]})\r\nprint(d.sort(\"foo\").to_pandas()\r\n# foo bar\r\n# 0 1 a\r\n# 1 2 b\r\n# 2 3 c\r\n```\r\n\r\nWhat made you think it was not the case ? Did you experience a situation where it was only sorting one column ?",
"Hi! thank you for your quick reply!\r\nI wanted to sort the `cnn_dailymail` dataset by the length of the labels (num of characters). I added a new column to the dataset (`ds.add_column`) with the lengths and then sorted by this new column. Only the new length column was sorted, the reset left in their original order. ",
"That's unexpected, can you share the code you used to get this ?"
] | "2022-07-05T11:25:26Z" | "2023-07-25T15:04:27Z" | "2023-07-25T15:04:27Z" | NONE | null | null | null | The 'sort' method changes the order of one column only (the one defined by the argument 'column'), thus creating a mismatch between a sample fields. I would expect it to change the order of the samples as a whole, based on the 'column' order. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4632/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4952/comments | https://api.github.com/repos/huggingface/datasets/issues/4952/events | https://github.com/huggingface/datasets/pull/4952 | 1,366,354,604 | PR_kwDODunzps4-meM0 | 4,952 | Add test-datasets CI job | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Closing this one since the dataset scripts will be removed in https://github.com/huggingface/datasets/pull/4974"
] | "2022-09-08T13:38:30Z" | "2023-09-24T10:05:57Z" | "2022-09-16T13:25:48Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4952",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4952"
} | To avoid having too many conflicts in the datasets and metrics dependencies I split the CI into test and test-catalog
test does the test of the core of the `datasets` lib, while test-catalog tests the datasets scripts and metrics scripts
This also makes `pip install -e .[dev]` much smaller for developers
WDYT @albertvillanova ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4952/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2743/comments | https://api.github.com/repos/huggingface/datasets/issues/2743/events | https://github.com/huggingface/datasets/issues/2743 | 958,119,251 | MDU6SXNzdWU5NTgxMTkyNTE= | 2,743 | Dataset JSON is incorrect | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"As discussed, the metadata JSON files must be regenerated because the keys were nor properly generated and they will not be read by the builder:\r\n> Indeed there is some problem/bug while reading the datasets_info.json file: there is a mismatch with the config.name keys in the file...\r\nIn the meanwhile, in order to be able to use the datasets_info.json file content, you can create the builder without passing the name :\r\n```\r\nIn [25]: builder = datasets.load_dataset_builder(\"journalists_questions\")\r\nIn [26]: builder.info.splits\r\nOut[26]: {'train': SplitInfo(name='train', num_bytes=342296, num_examples=10077, dataset_name='journalists_questions')}\r\n```\r\n\r\nAfter regenerating the metadata JSON file for this dataset, I get the right key:\r\n```\r\n{\"plain_text\": {\"description\": \"The journalists_questions corpus (\r\n```",
"Thanks!"
] | "2021-08-02T13:01:26Z" | "2021-08-03T10:06:57Z" | "2021-08-03T09:25:33Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
The JSON file generated for https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/journalists_questions.py is https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/dataset_infos.json.
The only config should be `plain_text`, but the first key in the JSON is `journalists_questions` (the dataset id) instead.
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Steps to reproduce the bug
Look at the files.
## Expected results
The first key should be `plain_text`:
```json
{
"plain_text": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Actual results
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2743/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4989/comments | https://api.github.com/repos/huggingface/datasets/issues/4989/events | https://github.com/huggingface/datasets/issues/4989 | 1,376,832,233 | I_kwDODunzps5SEMrp | 4,989 | Running add_column() seems to corrupt existing sequence-type column info | {
"avatar_url": "https://avatars.githubusercontent.com/u/93728165?v=4",
"events_url": "https://api.github.com/users/derek-rocheleau/events{/privacy}",
"followers_url": "https://api.github.com/users/derek-rocheleau/followers",
"following_url": "https://api.github.com/users/derek-rocheleau/following{/other_user}",
"gists_url": "https://api.github.com/users/derek-rocheleau/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/derek-rocheleau",
"id": 93728165,
"login": "derek-rocheleau",
"node_id": "U_kgDOBZYtpQ",
"organizations_url": "https://api.github.com/users/derek-rocheleau/orgs",
"received_events_url": "https://api.github.com/users/derek-rocheleau/received_events",
"repos_url": "https://api.github.com/users/derek-rocheleau/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/derek-rocheleau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/derek-rocheleau/subscriptions",
"type": "User",
"url": "https://api.github.com/users/derek-rocheleau"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Nevermind, I was incorrect."
] | "2022-09-17T17:42:05Z" | "2022-09-19T12:54:54Z" | "2022-09-19T12:54:54Z" | NONE | null | null | null | I have a dataset that contains a column ("foo") that is a sequence type of length 4. So when I run .to_pandas() on it, the resulting dataframe correctly contains 4 columns - foo_0, foo_1, foo_2, foo_3. So the 1st row of the dataframe might look like:
ds = load_dataset(...)
df = ds.to_pandas()
df:
foo_0 | foo_1 | foo_2 | foo_3
0.0 | 1.0 | 2.0 | 3.0
If I run .add_column("new_col", data) on the dataset, and then .to_pandas() on the resulting new dataset, the resulting dataframe contains only 2 columns - foo, new_col. The values in column foo are lists of length 4, the 4 elements that should have been split into separate columns. Dataframe 1st row would be:
ds = load_dataset(...)
new_ds = ds.add_column("new_col", data)
df = new_ds.to_pandas()
df:
foo | new_col
[0.0, 1.0, 2.0, 3.0] | new_val
I've explored the 2 datasets in a debugger and haven't noticed any changes to any attributes related to the foo column, but I can't determine why the dataframes are so different. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4989/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/241 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/241/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/241/comments | https://api.github.com/repos/huggingface/datasets/issues/241/events | https://github.com/huggingface/datasets/pull/241 | 631,703,079 | MDExOlB1bGxSZXF1ZXN0NDI4NTQwMDM0 | 241 | Fix empty cache dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think",
"> Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think\r\n\r\nNo it shouldn't force to redownload"
] | "2020-06-05T15:45:22Z" | "2020-06-08T08:35:33Z" | "2020-06-08T08:35:31Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/241",
"merged_at": "2020-06-08T08:35:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/241"
} | If the cache dir of a dataset is empty, the dataset fails to load and throws a FileNotFounfError. We could end up with empty cache dir because there was a line in the code that created the cache dir without using a temp dir. Using a temp dir is useful as it gets renamed to the real cache dir only if the full process is successful.
So I removed this bad line, and I also reordered things a bit to make sure that we always use a temp dir. I also added warning if we still end up with empty cache dirs in the future.
This should fix #239
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/241/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/241/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1666/comments | https://api.github.com/repos/huggingface/datasets/issues/1666/events | https://github.com/huggingface/datasets/pull/1666 | 776,432,006 | MDExOlB1bGxSZXF1ZXN0NTQ2OTI2MzQw | 1,666 | Add language to dataset card for Makhzan dataset. | {
"avatar_url": "https://avatars.githubusercontent.com/u/14899066?v=4",
"events_url": "https://api.github.com/users/arkhalid/events{/privacy}",
"followers_url": "https://api.github.com/users/arkhalid/followers",
"following_url": "https://api.github.com/users/arkhalid/following{/other_user}",
"gists_url": "https://api.github.com/users/arkhalid/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/arkhalid",
"id": 14899066,
"login": "arkhalid",
"node_id": "MDQ6VXNlcjE0ODk5MDY2",
"organizations_url": "https://api.github.com/users/arkhalid/orgs",
"received_events_url": "https://api.github.com/users/arkhalid/received_events",
"repos_url": "https://api.github.com/users/arkhalid/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/arkhalid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arkhalid/subscriptions",
"type": "User",
"url": "https://api.github.com/users/arkhalid"
} | [] | closed | false | null | [] | null | [] | "2020-12-30T12:25:52Z" | "2020-12-30T17:20:35Z" | "2020-12-30T17:20:35Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1666.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1666",
"merged_at": "2020-12-30T17:20:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1666.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1666"
} | Add language to dataset card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1666/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1666/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/157 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/157/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/157/comments | https://api.github.com/repos/huggingface/datasets/issues/157/events | https://github.com/huggingface/datasets/issues/157 | 620,356,542 | MDU6SXNzdWU2MjAzNTY1NDI= | 157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | {
"avatar_url": "https://avatars.githubusercontent.com/u/47444392?v=4",
"events_url": "https://api.github.com/users/saahiluppal/events{/privacy}",
"followers_url": "https://api.github.com/users/saahiluppal/followers",
"following_url": "https://api.github.com/users/saahiluppal/following{/other_user}",
"gists_url": "https://api.github.com/users/saahiluppal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/saahiluppal",
"id": 47444392,
"login": "saahiluppal",
"node_id": "MDQ6VXNlcjQ3NDQ0Mzky",
"organizations_url": "https://api.github.com/users/saahiluppal/orgs",
"received_events_url": "https://api.github.com/users/saahiluppal/received_events",
"repos_url": "https://api.github.com/users/saahiluppal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/saahiluppal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saahiluppal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/saahiluppal"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
}
] | null | [
"You can just run: \r\n`val = nlp.load_dataset('squad')` \r\n\r\nif you want to have just the validation script you can also do:\r\n\r\n`val = nlp.load_dataset('squad', split=\"validation\")`",
"If you want to load a local dataset, make sure you include a `./` before the folder name. ",
"This happens by just doing run all cells on colab ... I assumed the colab example is broken. ",
"Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:\r\n```\r\n!pip uninstall -y -qq pyarrow\r\n!pip uninstall -y -qq nlp\r\n!pip install -qq git+https://github.com/huggingface/nlp.git\r\n```",
"> Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:\r\n> \r\n> ```\r\n> !pip uninstall -y -qq pyarrow\r\n> !pip uninstall -y -qq nlp\r\n> !pip install -qq git+https://github.com/huggingface/nlp.git\r\n> ```\r\n\r\nTried, having the same error.",
"Can you post a link here of your colab? I'll make a copy of it and see what's wrong",
"This should be fixed in the current version of the notebook. You can try it again",
"Also see: https://github.com/huggingface/nlp/issues/222",
"I am getting this error when running this command\r\n```\r\nval = nlp.load_dataset('squad', split=\"validation\")\r\n```\r\n\r\nFileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/datasets/squad/plain_text/1.0.0/dataset_info.json'\r\n\r\nCan anybody help?",
"It seems like your download was corrupted :-/ Can you run the following command: \r\n\r\n```\r\nrm -r /root/.cache/huggingface/datasets\r\n```\r\n\r\nto delete the cache completely and rerun the download? ",
"I tried the notebook again today and it worked without barfing. 👌 "
] | "2020-05-18T16:46:38Z" | "2020-06-05T08:08:58Z" | "2020-06-05T08:08:58Z" | NONE | null | null | null | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/157/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/157/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2793 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2793/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2793/comments | https://api.github.com/repos/huggingface/datasets/issues/2793/events | https://github.com/huggingface/datasets/pull/2793 | 968,967,773 | MDExOlB1bGxSZXF1ZXN0NzExMDQ4NDY2 | 2,793 | Fix type hint for data_files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-08-12T14:42:37Z" | "2021-08-12T15:35:29Z" | "2021-08-12T15:35:29Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2793.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2793",
"merged_at": "2021-08-12T15:35:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2793.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2793"
} | Fix type hint for `data_files` in signatures and docstrings. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2793/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2793/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5772/comments | https://api.github.com/repos/huggingface/datasets/issues/5772/events | https://github.com/huggingface/datasets/pull/5772 | 1,675,033,510 | PR_kwDODunzps5OreXV | 5,772 | Fix JSON builder when missing keys in first row | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009262 / 0.011353 (-0.002091) | 0.006157 / 0.011008 (-0.004851) | 0.125960 / 0.038508 (0.087451) | 0.036213 / 0.023109 (0.013104) | 0.399331 / 0.275898 (0.123433) | 0.453597 / 0.323480 (0.130117) | 0.006990 / 0.007986 (-0.000995) | 0.007320 / 0.004328 (0.002991) | 0.100321 / 0.004250 (0.096070) | 0.048870 / 0.037052 (0.011818) | 0.396284 / 0.258489 (0.137795) | 0.475619 / 0.293841 (0.181778) | 0.052329 / 0.128546 (-0.076217) | 0.019564 / 0.075646 (-0.056083) | 0.430942 / 0.419271 (0.011670) | 0.063224 / 0.043533 (0.019692) | 0.391717 / 0.255139 (0.136578) | 0.448342 / 0.283200 (0.165142) | 0.114055 / 0.141683 (-0.027628) | 1.793204 / 1.452155 (0.341049) | 1.895151 / 1.492716 (0.402435) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.283699 / 0.018006 (0.265693) | 0.597194 / 0.000490 (0.596704) | 0.007143 / 0.000200 (0.006944) | 0.000602 / 0.000054 (0.000548) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034761 / 0.037411 (-0.002651) | 0.124555 / 0.014526 (0.110030) | 0.149126 / 0.176557 (-0.027430) | 0.220335 / 0.737135 (-0.516801) | 0.153109 / 0.296338 (-0.143229) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.620210 / 0.215209 (0.405001) | 6.229937 / 2.077655 (4.152282) | 2.615203 / 1.504120 (1.111083) | 2.239337 / 1.541195 (0.698143) | 2.262138 / 1.468490 (0.793648) | 1.196498 / 4.584777 (-3.388279) | 5.609932 / 3.745712 (1.864220) | 3.031347 / 5.269862 (-2.238515) | 2.025530 / 4.565676 (-2.540146) | 0.139828 / 0.424275 (-0.284447) | 0.015476 / 0.007607 (0.007869) | 0.768964 / 0.226044 (0.542920) | 7.728677 / 2.268929 (5.459748) | 3.336407 / 55.444624 (-52.108217) | 2.700055 / 6.876477 (-4.176422) | 2.765223 / 2.142072 (0.623151) | 1.409073 / 4.805227 (-3.396155) | 0.246849 / 6.500664 (-6.253815) | 0.081231 / 0.075469 (0.005762) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.593836 / 1.841788 (-0.247952) | 18.020525 / 8.074308 (9.946216) | 21.766822 / 10.191392 (11.575430) | 0.258615 / 0.680424 (-0.421809) | 0.026895 / 0.534201 (-0.507306) | 0.529823 / 0.579283 (-0.049460) | 0.623470 / 0.434364 (0.189106) | 0.628171 / 0.540337 (0.087833) | 0.745249 / 1.386936 (-0.641687) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008624 / 0.011353 (-0.002729) | 0.006317 / 0.011008 (-0.004691) | 0.097315 / 0.038508 (0.058807) | 0.035217 / 0.023109 (0.012108) | 0.440197 / 0.275898 (0.164299) | 0.473863 / 0.323480 (0.150383) | 0.006722 / 0.007986 (-0.001264) | 0.006444 / 0.004328 (0.002116) | 0.102056 / 0.004250 (0.097806) | 0.047142 / 0.037052 (0.010089) | 0.452476 / 0.258489 (0.193986) | 0.487619 / 0.293841 (0.193778) | 0.052456 / 0.128546 (-0.076090) | 0.018735 / 0.075646 (-0.056911) | 0.114656 / 0.419271 (-0.304616) | 0.062577 / 0.043533 (0.019044) | 0.444471 / 0.255139 (0.189332) | 0.494264 / 0.283200 (0.211065) | 0.117112 / 0.141683 (-0.024571) | 1.848965 / 1.452155 (0.396810) | 1.984008 / 1.492716 (0.491292) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290494 / 0.018006 (0.272488) | 0.588415 / 0.000490 (0.587925) | 0.000459 / 0.000200 (0.000259) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032873 / 0.037411 (-0.004538) | 0.131139 / 0.014526 (0.116614) | 0.140268 / 0.176557 (-0.036289) | 0.204561 / 0.737135 (-0.532574) | 0.147443 / 0.296338 (-0.148895) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.636899 / 0.215209 (0.421690) | 6.236139 / 2.077655 (4.158484) | 2.801468 / 1.504120 (1.297348) | 2.398808 / 1.541195 (0.857613) | 2.493150 / 1.468490 (1.024659) | 1.228845 / 4.584777 (-3.355932) | 5.675874 / 3.745712 (1.930162) | 3.084939 / 5.269862 (-2.184922) | 2.061310 / 4.565676 (-2.504367) | 0.142285 / 0.424275 (-0.281990) | 0.014972 / 0.007607 (0.007365) | 0.786599 / 0.226044 (0.560555) | 7.876036 / 2.268929 (5.607107) | 3.476136 / 55.444624 (-51.968489) | 2.847922 / 6.876477 (-4.028555) | 3.040326 / 2.142072 (0.898253) | 1.448538 / 4.805227 (-3.356690) | 0.257230 / 6.500664 (-6.243434) | 0.085137 / 0.075469 (0.009668) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.668173 / 1.841788 (-0.173615) | 18.668520 / 8.074308 (10.594212) | 20.535542 / 10.191392 (10.344150) | 0.244580 / 0.680424 (-0.435844) | 0.026364 / 0.534201 (-0.507837) | 0.531753 / 0.579283 (-0.047530) | 0.616578 / 0.434364 (0.182214) | 0.618906 / 0.540337 (0.078569) | 0.738785 / 1.386936 (-0.648151) |\n\n</details>\n</details>\n\n\n"
] | "2023-04-19T14:32:57Z" | "2023-04-21T06:45:13Z" | "2023-04-21T06:35:27Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5772.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5772",
"merged_at": "2023-04-21T06:35:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5772.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5772"
} | Until now, the JSON builder only considered the keys present in the first element of the list:
- Either explicitly: by passing index 0 in `dataset[0].keys()`
- Or implicitly: `pa.Table.from_pylist(dataset)`, where "schema (default None): If not passed, will be inferred from the first row of the mapping values"
This PR fixes the bug by considering the union of the keys present in all the rows.
Fix #5726. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5772/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5772/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/following{/other_user}",
"gists_url": "https://api.github.com/users/ErfanMoosaviMonazzah/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ErfanMoosaviMonazzah",
"id": 79091831,
"login": "ErfanMoosaviMonazzah",
"node_id": "MDQ6VXNlcjc5MDkxODMx",
"organizations_url": "https://api.github.com/users/ErfanMoosaviMonazzah/orgs",
"received_events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/received_events",
"repos_url": "https://api.github.com/users/ErfanMoosaviMonazzah/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ErfanMoosaviMonazzah/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ErfanMoosaviMonazzah/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ErfanMoosaviMonazzah"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi!\r\n\r\nYou can also use names other than \"train\", \"validation\" and \"test\". As an example, check the [script](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/blob/e095840f23f3dffc1056c078c2f9320dad9ca74d/common_voice_11_0.py#L139) of the Common Voice 11 dataset. "
] | "2023-03-12T17:21:43Z" | "2023-03-24T14:13:00Z" | "2023-03-24T14:13:00Z" | NONE | null | null | null | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (currently i can have more splits when I am loading datasets from urls, but not hub)
### Motivation
Easier access to more splits
### Your contribution
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5271/comments | https://api.github.com/repos/huggingface/datasets/issues/5271/events | https://github.com/huggingface/datasets/pull/5271 | 1,456,807,738 | PR_kwDODunzps5DTDX1 | 5,271 | Fix #5269 | {
"avatar_url": "https://avatars.githubusercontent.com/u/32936898?v=4",
"events_url": "https://api.github.com/users/Freed-Wu/events{/privacy}",
"followers_url": "https://api.github.com/users/Freed-Wu/followers",
"following_url": "https://api.github.com/users/Freed-Wu/following{/other_user}",
"gists_url": "https://api.github.com/users/Freed-Wu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Freed-Wu",
"id": 32936898,
"login": "Freed-Wu",
"node_id": "MDQ6VXNlcjMyOTM2ODk4",
"organizations_url": "https://api.github.com/users/Freed-Wu/orgs",
"received_events_url": "https://api.github.com/users/Freed-Wu/received_events",
"repos_url": "https://api.github.com/users/Freed-Wu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Freed-Wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Freed-Wu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Freed-Wu"
} | [] | closed | false | null | [] | null | [
"See <https://github.com/huggingface/datasets/issues/5269>"
] | "2022-11-20T07:50:49Z" | "2022-11-21T15:07:19Z" | "2022-11-21T15:06:38Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5271.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5271",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5271.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5271"
} | ```
$ datasets-cli convert --datasets_directory <TAB>
datasets_directory
benchmarks/ docs/ metrics/ notebooks/ src/ templates/ tests/ utils/
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5271/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4930/comments | https://api.github.com/repos/huggingface/datasets/issues/4930/events | https://github.com/huggingface/datasets/pull/4930 | 1,362,193,587 | PR_kwDODunzps4-Yflc | 4,930 | Add cc-by-nc-2.0 to list of licenses | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"this list needs to be kept in sync with the ones in moon-landing and hub-docs :)",
"@julien-c don't you think it might be better to a have a single file (source of truth) in one of the repos and then use it in every other repo, instead of having 3 copies of the same file that must be kept in sync?\r\n\r\nAlso note that the licenses we are adding were all already present in our previous `licenses.json` file: are we regenerating it, step by step? Why don't we use a file with ALL the licenses we previously had in the list?\r\n\r\nLicenses added:\r\n- #4887\r\n- #4930 \r\n\r\nPrevious `licenses.json` file:\r\n- https://github.com/huggingface/datasets/blob/b7612754928e0fd43b9e3c3becb906ec280ff5d4/src/datasets/utils/resources/licenses.json\r\n- removed in this commit: https://github.com/huggingface/datasets/pull/4613/commits/9f7725412dac1089b3e057f9e3fcf39cc222bc26\r\n\r\nLet me know what you think and I can take care of this.",
"> Let me know what you think and I can take care of this.\r\n\r\nWhat I think is that we shouldn't add licenses that are just used in a couple of datasets, and just use `license_details` for this.\r\n\r\n> don't you think it might be better to a have a single file (source of truth) in one of the repos and then use it in every other repo, instead of having 3 copies of the same file that must be kept in sync?\r\n\r\nYes, in my opinion we can just delete this file from `datasets`, the validation is happening hub-side anyways now? \r\n",
"Feel free to delete the license list in `datasets` @albertvillanova ;)\r\n\r\nAlso FYI in #4926 I also removed all the validation steps anyway (language, license, types etc.)"
] | "2022-09-05T15:37:32Z" | "2022-09-06T16:43:32Z" | "2022-09-05T17:01:04Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4930.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4930",
"merged_at": "2022-09-05T17:01:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4930.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4930"
} | This PR adds the `cc-by-nc-2.0` to the list of licenses because it is required by `scifact` dataset: https://github.com/allenai/scifact/blob/master/LICENSE.md | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4930/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/959 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/959/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/959/comments | https://api.github.com/repos/huggingface/datasets/issues/959/events | https://github.com/huggingface/datasets/pull/959 | 754,418,610 | MDExOlB1bGxSZXF1ZXN0NTMwMzIxOTM1 | 959 | Add Tunizi Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-01T13:59:39Z" | "2020-12-03T14:21:41Z" | "2020-12-03T14:21:40Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/959.diff",
"html_url": "https://github.com/huggingface/datasets/pull/959",
"merged_at": "2020-12-03T14:21:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/959.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/959"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/959/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/959/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3387/comments | https://api.github.com/repos/huggingface/datasets/issues/3387/events | https://github.com/huggingface/datasets/pull/3387 | 1,071,836,456 | PR_kwDODunzps4vbAyC | 3,387 | Create Language Modeling task | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | "2021-12-06T07:56:07Z" | "2021-12-17T17:18:28Z" | "2021-12-17T17:18:27Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3387.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3387",
"merged_at": "2021-12-17T17:18:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3387.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3387"
} | Create Language Modeling task to be able to specify the input "text" column in a dataset.
This can be useful for datasets which are not exclusively used for language modeling and have more than one column:
- for text classification datasets (with columns "review" and "rating", for example), the Language Modeling task can be used to specify the "text" column ("review" in this case).
TODO:
- [ ] Add the LanguageModeling task to all dataset scripts which can be used for language modeling | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3387/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3387/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5168 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5168/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5168/comments | https://api.github.com/repos/huggingface/datasets/issues/5168/events | https://github.com/huggingface/datasets/pull/5168 | 1,424,368,572 | PR_kwDODunzps5BmYnq | 5,168 | Fix CI require beam | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I'm merging this PR because it is quite a trivial fix and this is required by:\r\n- #5166"
] | "2022-10-26T16:49:33Z" | "2022-10-27T09:25:19Z" | "2022-10-27T09:23:26Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5168.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5168",
"merged_at": "2022-10-27T09:23:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5168.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5168"
} | This PR:
- Fixes the CI `require_beam`: before it was requiring PyTorch instead
```python
def require_beam(test_case):
if not config.TORCH_AVAILABLE:
test_case = unittest.skip("test requires PyTorch")(test_case)
return test_case
```
- Fixes a missing `require_beam` in `test_beam_based_builder_download_and_prepare_as_parquet`
- Refactors `require_beam` to use `pytest` (`skipif`) instead | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5168/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5168/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/297/comments | https://api.github.com/repos/huggingface/datasets/issues/297/events | https://github.com/huggingface/datasets/issues/297 | 643,444,625 | MDU6SXNzdWU2NDM0NDQ2MjU= | 297 | Error in Demo for Specific Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/60150701?v=4",
"events_url": "https://api.github.com/users/s-jse/events{/privacy}",
"followers_url": "https://api.github.com/users/s-jse/followers",
"following_url": "https://api.github.com/users/s-jse/following{/other_user}",
"gists_url": "https://api.github.com/users/s-jse/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/s-jse",
"id": 60150701,
"login": "s-jse",
"node_id": "MDQ6VXNlcjYwMTUwNzAx",
"organizations_url": "https://api.github.com/users/s-jse/orgs",
"received_events_url": "https://api.github.com/users/s-jse/received_events",
"repos_url": "https://api.github.com/users/s-jse/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/s-jse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/s-jse/subscriptions",
"type": "User",
"url": "https://api.github.com/users/s-jse"
} | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | [] | null | [
"Thanks for reporting these errors :)\r\n\r\nI can actually see two issues here.\r\n\r\nFirst, datasets like `natural_questions` require apache_beam to be processed. Right now the import is not at the right place so we have this error message. However, even the imports are fixed, the nlp viewer doesn't actually have the resources to process NQ right now so we'll have to wait until we have a version that we've already processed on our google storage (that's what we've done for wikipedia for example).\r\n\r\nSecond, datasets like `newsroom` require manual downloads as we're not allowed to redistribute the data ourselves (if I'm not wrong). An error message should be displayed saying that we're not allowed to show the dataset.\r\n\r\nI can fix the first issue with the imports but for the second one I think we'll have to see with @srush to show a message for datasets that require manual downloads (it can be checked whether a dataset requires manual downloads if `dataset_builder_instance.manual_download_instructions is not None`).\r\n\r\n",
"I added apache-beam to the viewer. We can think about how to add newsroom. ",
"We don't plan to host the source files of newsroom ourselves for now.\r\nYou can still get the dataset if you follow the download instructions given by `dataset = load_dataset('newsroom')` though.\r\nThe viewer also shows the instructions now.\r\n\r\nClosing this one. If you have other questions, feel free to re-open :)"
] | "2020-06-23T00:38:42Z" | "2020-07-17T17:43:06Z" | "2020-07-17T17:43:06Z" | NONE | null | null | null | Selecting `natural_questions` or `newsroom` dataset in the online demo results in an error similar to the following.

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/297/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6419/comments | https://api.github.com/repos/huggingface/datasets/issues/6419/events | https://github.com/huggingface/datasets/pull/6419 | 1,994,257,873 | PR_kwDODunzps5ffc7d | 6,419 | Release: 2.14.7 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004943 / 0.011353 (-0.006410) | 0.002900 / 0.011008 (-0.008109) | 0.061495 / 0.038508 (0.022987) | 0.053575 / 0.023109 (0.030466) | 0.249318 / 0.275898 (-0.026580) | 0.271773 / 0.323480 (-0.051706) | 0.003074 / 0.007986 (-0.004911) | 0.003738 / 0.004328 (-0.000590) | 0.047624 / 0.004250 (0.043373) | 0.045141 / 0.037052 (0.008089) | 0.255467 / 0.258489 (-0.003022) | 0.286577 / 0.293841 (-0.007264) | 0.023113 / 0.128546 (-0.105433) | 0.007189 / 0.075646 (-0.068458) | 0.204441 / 0.419271 (-0.214830) | 0.036829 / 0.043533 (-0.006704) | 0.252474 / 0.255139 (-0.002665) | 0.270960 / 0.283200 (-0.012239) | 0.019666 / 0.141683 (-0.122017) | 1.095139 / 1.452155 (-0.357015) | 1.158659 / 1.492716 (-0.334057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091046 / 0.018006 (0.073040) | 0.298346 / 0.000490 (0.297856) | 0.000215 / 0.000200 (0.000015) | 0.000043 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018702 / 0.037411 (-0.018709) | 0.062213 / 0.014526 (0.047687) | 0.073364 / 0.176557 (-0.103193) | 0.119841 / 0.737135 (-0.617294) | 0.074070 / 0.296338 (-0.222268) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282388 / 0.215209 (0.067179) | 2.792029 / 2.077655 (0.714375) | 1.471483 / 1.504120 (-0.032637) | 1.386236 / 1.541195 (-0.154959) | 1.377489 / 1.468490 (-0.091001) | 0.410335 / 4.584777 (-4.174442) | 2.424866 / 3.745712 (-1.320846) | 2.610609 / 5.269862 (-2.659253) | 1.574636 / 4.565676 (-2.991041) | 0.046716 / 0.424275 (-0.377559) | 0.004768 / 0.007607 (-0.002839) | 0.339831 / 0.226044 (0.113787) | 3.297579 / 2.268929 (1.028651) | 1.851410 / 55.444624 (-53.593214) | 1.550048 / 6.876477 (-5.326428) | 1.576647 / 2.142072 (-0.565425) | 0.482538 / 4.805227 (-4.322689) | 0.101381 / 6.500664 (-6.399283) | 0.042066 / 0.075469 (-0.033403) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.972664 / 1.841788 (-0.869123) | 11.580700 / 8.074308 (3.506392) | 10.586747 / 10.191392 (0.395355) | 0.127844 / 0.680424 (-0.552580) | 0.014270 / 0.534201 (-0.519931) | 0.269678 / 0.579283 (-0.309605) | 0.264022 / 0.434364 (-0.170342) | 0.309395 / 0.540337 (-0.230942) | 0.429228 / 1.386936 (-0.957708) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004815 / 0.011353 (-0.006538) | 0.002890 / 0.011008 (-0.008119) | 0.048039 / 0.038508 (0.009531) | 0.053029 / 0.023109 (0.029920) | 0.271346 / 0.275898 (-0.004552) | 0.294488 / 0.323480 (-0.028992) | 0.003983 / 0.007986 (-0.004003) | 0.002439 / 0.004328 (-0.001889) | 0.048250 / 0.004250 (0.044000) | 0.038855 / 0.037052 (0.001803) | 0.284723 / 0.258489 (0.026234) | 0.303604 / 0.293841 (0.009763) | 0.024384 / 0.128546 (-0.104163) | 0.007021 / 0.075646 (-0.068625) | 0.053850 / 0.419271 (-0.365422) | 0.032177 / 0.043533 (-0.011356) | 0.270039 / 0.255139 (0.014900) | 0.289669 / 0.283200 (0.006469) | 0.018840 / 0.141683 (-0.122842) | 1.122191 / 1.452155 (-0.329963) | 1.187083 / 1.492716 (-0.305634) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090609 / 0.018006 (0.072603) | 0.298915 / 0.000490 (0.298425) | 0.000216 / 0.000200 (0.000016) | 0.000043 / 0.000054 (-0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020919 / 0.037411 (-0.016492) | 0.070474 / 0.014526 (0.055948) | 0.082421 / 0.176557 (-0.094135) | 0.126967 / 0.737135 (-0.610168) | 0.083447 / 0.296338 (-0.212892) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.300153 / 0.215209 (0.084944) | 2.958992 / 2.077655 (0.881337) | 1.631228 / 1.504120 (0.127108) | 1.497991 / 1.541195 (-0.043204) | 1.536963 / 1.468490 (0.068473) | 0.403047 / 4.584777 (-4.181730) | 2.448782 / 3.745712 (-1.296930) | 2.571954 / 5.269862 (-2.697908) | 1.556346 / 4.565676 (-3.009331) | 0.045992 / 0.424275 (-0.378283) | 0.004785 / 0.007607 (-0.002822) | 0.357448 / 0.226044 (0.131404) | 3.558808 / 2.268929 (1.289880) | 1.992624 / 55.444624 (-53.452001) | 1.695027 / 6.876477 (-5.181450) | 1.695183 / 2.142072 (-0.446889) | 0.477001 / 4.805227 (-4.328226) | 0.097485 / 6.500664 (-6.403179) | 0.040530 / 0.075469 (-0.034939) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.976342 / 1.841788 (-0.865445) | 12.141698 / 8.074308 (4.067390) | 10.881101 / 10.191392 (0.689709) | 0.142443 / 0.680424 (-0.537981) | 0.015583 / 0.534201 (-0.518618) | 0.269727 / 0.579283 (-0.309556) | 0.275890 / 0.434364 (-0.158474) | 0.306351 / 0.540337 (-0.233987) | 0.412003 / 1.386936 (-0.974933) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004946 / 0.011353 (-0.006407) | 0.002863 / 0.011008 (-0.008146) | 0.061888 / 0.038508 (0.023380) | 0.050664 / 0.023109 (0.027554) | 0.242635 / 0.275898 (-0.033263) | 0.271741 / 0.323480 (-0.051739) | 0.003023 / 0.007986 (-0.004963) | 0.003088 / 0.004328 (-0.001241) | 0.049286 / 0.004250 (0.045036) | 0.044699 / 0.037052 (0.007647) | 0.249581 / 0.258489 (-0.008908) | 0.285633 / 0.293841 (-0.008208) | 0.023048 / 0.128546 (-0.105499) | 0.007235 / 0.075646 (-0.068412) | 0.202989 / 0.419271 (-0.216282) | 0.036357 / 0.043533 (-0.007175) | 0.245980 / 0.255139 (-0.009159) | 0.277486 / 0.283200 (-0.005713) | 0.019215 / 0.141683 (-0.122468) | 1.096456 / 1.452155 (-0.355699) | 1.152196 / 1.492716 (-0.340520) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.092026 / 0.018006 (0.074020) | 0.303038 / 0.000490 (0.302549) | 0.000209 / 0.000200 (0.000009) | 0.000048 / 0.000054 (-0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018670 / 0.037411 (-0.018741) | 0.061972 / 0.014526 (0.047446) | 0.072963 / 0.176557 (-0.103594) | 0.119984 / 0.737135 (-0.617151) | 0.074074 / 0.296338 (-0.222265) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282444 / 0.215209 (0.067235) | 2.754571 / 2.077655 (0.676916) | 1.482635 / 1.504120 (-0.021485) | 1.352039 / 1.541195 (-0.189155) | 1.359333 / 1.468490 (-0.109157) | 0.399690 / 4.584777 (-4.185087) | 2.364844 / 3.745712 (-1.380868) | 2.603942 / 5.269862 (-2.665919) | 1.569512 / 4.565676 (-2.996164) | 0.046074 / 0.424275 (-0.378201) | 0.004745 / 0.007607 (-0.002862) | 0.339066 / 0.226044 (0.113022) | 3.363456 / 2.268929 (1.094527) | 1.822213 / 55.444624 (-53.622411) | 1.536622 / 6.876477 (-5.339854) | 1.574772 / 2.142072 (-0.567300) | 0.474418 / 4.805227 (-4.330809) | 0.099572 / 6.500664 (-6.401092) | 0.041824 / 0.075469 (-0.033645) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.956300 / 1.841788 (-0.885487) | 11.648886 / 8.074308 (3.574578) | 10.645700 / 10.191392 (0.454308) | 0.138924 / 0.680424 (-0.541499) | 0.013936 / 0.534201 (-0.520265) | 0.270319 / 0.579283 (-0.308964) | 0.269735 / 0.434364 (-0.164629) | 0.309699 / 0.540337 (-0.230639) | 0.429139 / 1.386936 (-0.957797) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004838 / 0.011353 (-0.006515) | 0.002937 / 0.011008 (-0.008072) | 0.048094 / 0.038508 (0.009586) | 0.053131 / 0.023109 (0.030022) | 0.271893 / 0.275898 (-0.004005) | 0.291025 / 0.323480 (-0.032454) | 0.004058 / 0.007986 (-0.003928) | 0.002410 / 0.004328 (-0.001919) | 0.047939 / 0.004250 (0.043689) | 0.038996 / 0.037052 (0.001944) | 0.274983 / 0.258489 (0.016494) | 0.306175 / 0.293841 (0.012334) | 0.024388 / 0.128546 (-0.104159) | 0.007242 / 0.075646 (-0.068404) | 0.054011 / 0.419271 (-0.365261) | 0.032750 / 0.043533 (-0.010783) | 0.271147 / 0.255139 (0.016008) | 0.288163 / 0.283200 (0.004963) | 0.018383 / 0.141683 (-0.123299) | 1.116134 / 1.452155 (-0.336021) | 1.185964 / 1.492716 (-0.306752) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093289 / 0.018006 (0.075283) | 0.303058 / 0.000490 (0.302568) | 0.000241 / 0.000200 (0.000041) | 0.000044 / 0.000054 (-0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021422 / 0.037411 (-0.015990) | 0.069974 / 0.014526 (0.055449) | 0.081164 / 0.176557 (-0.095392) | 0.119991 / 0.737135 (-0.617144) | 0.082154 / 0.296338 (-0.214184) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.292298 / 0.215209 (0.077089) | 2.851475 / 2.077655 (0.773821) | 1.558283 / 1.504120 (0.054163) | 1.432431 / 1.541195 (-0.108764) | 1.479282 / 1.468490 (0.010792) | 0.413124 / 4.584777 (-4.171653) | 2.473005 / 3.745712 (-1.272707) | 2.548779 / 5.269862 (-2.721082) | 1.520776 / 4.565676 (-3.044900) | 0.046476 / 0.424275 (-0.377799) | 0.004814 / 0.007607 (-0.002794) | 0.347036 / 0.226044 (0.120992) | 3.424928 / 2.268929 (1.155999) | 1.963274 / 55.444624 (-53.481351) | 1.653794 / 6.876477 (-5.222683) | 1.643874 / 2.142072 (-0.498198) | 0.469086 / 4.805227 (-4.336141) | 0.097417 / 6.500664 (-6.403247) | 0.040468 / 0.075469 (-0.035002) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.972783 / 1.841788 (-0.869005) | 12.122994 / 8.074308 (4.048686) | 10.876396 / 10.191392 (0.685004) | 0.130573 / 0.680424 (-0.549850) | 0.016693 / 0.534201 (-0.517508) | 0.270952 / 0.579283 (-0.308331) | 0.273834 / 0.434364 (-0.160530) | 0.305049 / 0.540337 (-0.235289) | 0.408776 / 1.386936 (-0.978160) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004606 / 0.011353 (-0.006747) | 0.002433 / 0.011008 (-0.008576) | 0.061985 / 0.038508 (0.023477) | 0.048853 / 0.023109 (0.025744) | 0.244506 / 0.275898 (-0.031392) | 0.270159 / 0.323480 (-0.053321) | 0.003962 / 0.007986 (-0.004024) | 0.002376 / 0.004328 (-0.001952) | 0.048067 / 0.004250 (0.043817) | 0.041864 / 0.037052 (0.004812) | 0.249743 / 0.258489 (-0.008746) | 0.287723 / 0.293841 (-0.006117) | 0.022954 / 0.128546 (-0.105593) | 0.006845 / 0.075646 (-0.068801) | 0.206313 / 0.419271 (-0.212959) | 0.035780 / 0.043533 (-0.007753) | 0.244286 / 0.255139 (-0.010853) | 0.270026 / 0.283200 (-0.013173) | 0.018177 / 0.141683 (-0.123506) | 1.083998 / 1.452155 (-0.368157) | 1.156086 / 1.492716 (-0.336630) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093754 / 0.018006 (0.075748) | 0.302157 / 0.000490 (0.301667) | 0.000215 / 0.000200 (0.000015) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018745 / 0.037411 (-0.018666) | 0.061707 / 0.014526 (0.047181) | 0.074356 / 0.176557 (-0.102200) | 0.121643 / 0.737135 (-0.615492) | 0.075885 / 0.296338 (-0.220454) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.289156 / 0.215209 (0.073947) | 2.881327 / 2.077655 (0.803672) | 1.483568 / 1.504120 (-0.020552) | 1.355933 / 1.541195 (-0.185262) | 1.389693 / 1.468490 (-0.078797) | 0.402834 / 4.584777 (-4.181943) | 2.390634 / 3.745712 (-1.355078) | 2.596761 / 5.269862 (-2.673101) | 1.527602 / 4.565676 (-3.038074) | 0.046434 / 0.424275 (-0.377841) | 0.004783 / 0.007607 (-0.002824) | 0.341017 / 0.226044 (0.114972) | 3.429023 / 2.268929 (1.160095) | 1.832988 / 55.444624 (-53.611637) | 1.526510 / 6.876477 (-5.349967) | 1.539382 / 2.142072 (-0.602690) | 0.475734 / 4.805227 (-4.329493) | 0.098710 / 6.500664 (-6.401954) | 0.041136 / 0.075469 (-0.034333) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.922023 / 1.841788 (-0.919765) | 11.428215 / 8.074308 (3.353907) | 10.356668 / 10.191392 (0.165276) | 0.139575 / 0.680424 (-0.540848) | 0.014541 / 0.534201 (-0.519660) | 0.271359 / 0.579283 (-0.307924) | 0.266701 / 0.434364 (-0.167663) | 0.309449 / 0.540337 (-0.230888) | 0.422047 / 1.386936 (-0.964889) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004892 / 0.011353 (-0.006461) | 0.002792 / 0.011008 (-0.008216) | 0.048027 / 0.038508 (0.009519) | 0.059256 / 0.023109 (0.036147) | 0.270150 / 0.275898 (-0.005748) | 0.294530 / 0.323480 (-0.028950) | 0.004162 / 0.007986 (-0.003823) | 0.002470 / 0.004328 (-0.001858) | 0.047993 / 0.004250 (0.043743) | 0.040380 / 0.037052 (0.003328) | 0.275247 / 0.258489 (0.016758) | 0.305684 / 0.293841 (0.011843) | 0.025072 / 0.128546 (-0.103474) | 0.007183 / 0.075646 (-0.068463) | 0.054875 / 0.419271 (-0.364397) | 0.033053 / 0.043533 (-0.010480) | 0.271281 / 0.255139 (0.016142) | 0.288057 / 0.283200 (0.004858) | 0.018692 / 0.141683 (-0.122991) | 1.125224 / 1.452155 (-0.326930) | 1.171083 / 1.492716 (-0.321633) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.103102 / 0.018006 (0.085096) | 0.309099 / 0.000490 (0.308609) | 0.000232 / 0.000200 (0.000032) | 0.000052 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021532 / 0.037411 (-0.015879) | 0.069927 / 0.014526 (0.055401) | 0.080920 / 0.176557 (-0.095637) | 0.122214 / 0.737135 (-0.614921) | 0.082268 / 0.296338 (-0.214071) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.298121 / 0.215209 (0.082912) | 2.933000 / 2.077655 (0.855345) | 1.608782 / 1.504120 (0.104662) | 1.554083 / 1.541195 (0.012889) | 1.552700 / 1.468490 (0.084209) | 0.400576 / 4.584777 (-4.184201) | 2.412914 / 3.745712 (-1.332798) | 2.545706 / 5.269862 (-2.724155) | 1.548797 / 4.565676 (-3.016879) | 0.045553 / 0.424275 (-0.378722) | 0.004751 / 0.007607 (-0.002857) | 0.343002 / 0.226044 (0.116958) | 3.402866 / 2.268929 (1.133937) | 1.969910 / 55.444624 (-53.474715) | 1.686639 / 6.876477 (-5.189838) | 1.768474 / 2.142072 (-0.373599) | 0.471299 / 4.805227 (-4.333928) | 0.097696 / 6.500664 (-6.402968) | 0.041693 / 0.075469 (-0.033776) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.971380 / 1.841788 (-0.870408) | 12.686033 / 8.074308 (4.611725) | 11.370946 / 10.191392 (1.179554) | 0.138377 / 0.680424 (-0.542047) | 0.015623 / 0.534201 (-0.518578) | 0.270935 / 0.579283 (-0.308348) | 0.276235 / 0.434364 (-0.158129) | 0.310196 / 0.540337 (-0.230141) | 0.416908 / 1.386936 (-0.970028) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004581 / 0.011353 (-0.006772) | 0.002468 / 0.011008 (-0.008541) | 0.061420 / 0.038508 (0.022912) | 0.047685 / 0.023109 (0.024575) | 0.237756 / 0.275898 (-0.038142) | 0.267548 / 0.323480 (-0.055932) | 0.003899 / 0.007986 (-0.004086) | 0.002338 / 0.004328 (-0.001990) | 0.048794 / 0.004250 (0.044543) | 0.042485 / 0.037052 (0.005433) | 0.250165 / 0.258489 (-0.008324) | 0.278791 / 0.293841 (-0.015050) | 0.022371 / 0.128546 (-0.106175) | 0.006923 / 0.075646 (-0.068723) | 0.201401 / 0.419271 (-0.217870) | 0.035867 / 0.043533 (-0.007665) | 0.244628 / 0.255139 (-0.010511) | 0.271137 / 0.283200 (-0.012063) | 0.017257 / 0.141683 (-0.124426) | 1.097261 / 1.452155 (-0.354894) | 1.163314 / 1.492716 (-0.329402) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089060 / 0.018006 (0.071054) | 0.297489 / 0.000490 (0.296999) | 0.000207 / 0.000200 (0.000007) | 0.000050 / 0.000054 (-0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018583 / 0.037411 (-0.018828) | 0.061974 / 0.014526 (0.047449) | 0.073300 / 0.176557 (-0.103256) | 0.118871 / 0.737135 (-0.618264) | 0.075513 / 0.296338 (-0.220826) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.285544 / 0.215209 (0.070335) | 2.799871 / 2.077655 (0.722216) | 1.479871 / 1.504120 (-0.024249) | 1.351128 / 1.541195 (-0.190067) | 1.377540 / 1.468490 (-0.090950) | 0.393056 / 4.584777 (-4.191721) | 2.341791 / 3.745712 (-1.403921) | 2.546854 / 5.269862 (-2.723007) | 1.547368 / 4.565676 (-3.018309) | 0.046056 / 0.424275 (-0.378219) | 0.004765 / 0.007607 (-0.002842) | 0.336384 / 0.226044 (0.110339) | 3.283277 / 2.268929 (1.014348) | 1.784535 / 55.444624 (-53.660089) | 1.557809 / 6.876477 (-5.318667) | 1.581728 / 2.142072 (-0.560344) | 0.470527 / 4.805227 (-4.334700) | 0.098383 / 6.500664 (-6.402281) | 0.041563 / 0.075469 (-0.033906) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.946924 / 1.841788 (-0.894863) | 11.202775 / 8.074308 (3.128467) | 10.249760 / 10.191392 (0.058368) | 0.142337 / 0.680424 (-0.538087) | 0.013784 / 0.534201 (-0.520417) | 0.267237 / 0.579283 (-0.312046) | 0.264142 / 0.434364 (-0.170222) | 0.306343 / 0.540337 (-0.233994) | 0.423681 / 1.386936 (-0.963255) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004786 / 0.011353 (-0.006567) | 0.002398 / 0.011008 (-0.008610) | 0.047325 / 0.038508 (0.008817) | 0.050753 / 0.023109 (0.027644) | 0.271132 / 0.275898 (-0.004766) | 0.290854 / 0.323480 (-0.032626) | 0.003953 / 0.007986 (-0.004033) | 0.002238 / 0.004328 (-0.002090) | 0.047463 / 0.004250 (0.043213) | 0.038504 / 0.037052 (0.001451) | 0.273182 / 0.258489 (0.014693) | 0.303449 / 0.293841 (0.009608) | 0.024069 / 0.128546 (-0.104477) | 0.006712 / 0.075646 (-0.068934) | 0.053032 / 0.419271 (-0.366239) | 0.032221 / 0.043533 (-0.011312) | 0.271770 / 0.255139 (0.016631) | 0.287876 / 0.283200 (0.004677) | 0.018040 / 0.141683 (-0.123643) | 1.138749 / 1.452155 (-0.313405) | 1.192048 / 1.492716 (-0.300668) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.089132 / 0.018006 (0.071126) | 0.298636 / 0.000490 (0.298146) | 0.000220 / 0.000200 (0.000020) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020808 / 0.037411 (-0.016603) | 0.069506 / 0.014526 (0.054980) | 0.079412 / 0.176557 (-0.097145) | 0.118188 / 0.737135 (-0.618947) | 0.083044 / 0.296338 (-0.213294) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.293502 / 0.215209 (0.078293) | 2.863692 / 2.077655 (0.786037) | 1.590877 / 1.504120 (0.086757) | 1.483634 / 1.541195 (-0.057561) | 1.502113 / 1.468490 (0.033623) | 0.402170 / 4.584777 (-4.182607) | 2.414188 / 3.745712 (-1.331524) | 2.500146 / 5.269862 (-2.769716) | 1.506977 / 4.565676 (-3.058699) | 0.045849 / 0.424275 (-0.378426) | 0.004755 / 0.007607 (-0.002852) | 0.343073 / 0.226044 (0.117029) | 3.354985 / 2.268929 (1.086056) | 1.952594 / 55.444624 (-53.492030) | 1.664084 / 6.876477 (-5.212392) | 1.664203 / 2.142072 (-0.477869) | 0.475858 / 4.805227 (-4.329370) | 0.097539 / 6.500664 (-6.403125) | 0.040201 / 0.075469 (-0.035268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.980051 / 1.841788 (-0.861736) | 11.615291 / 8.074308 (3.540983) | 10.492092 / 10.191392 (0.300700) | 0.130450 / 0.680424 (-0.549974) | 0.015883 / 0.534201 (-0.518318) | 0.267575 / 0.579283 (-0.311708) | 0.276981 / 0.434364 (-0.157383) | 0.310221 / 0.540337 (-0.230116) | 0.417143 / 1.386936 (-0.969793) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004721 / 0.011353 (-0.006632) | 0.002931 / 0.011008 (-0.008077) | 0.061948 / 0.038508 (0.023440) | 0.051066 / 0.023109 (0.027957) | 0.245431 / 0.275898 (-0.030467) | 0.295627 / 0.323480 (-0.027852) | 0.003997 / 0.007986 (-0.003988) | 0.002408 / 0.004328 (-0.001920) | 0.048292 / 0.004250 (0.044041) | 0.044716 / 0.037052 (0.007664) | 0.255119 / 0.258489 (-0.003371) | 0.287384 / 0.293841 (-0.006457) | 0.022835 / 0.128546 (-0.105711) | 0.007162 / 0.075646 (-0.068484) | 0.201352 / 0.419271 (-0.217920) | 0.036626 / 0.043533 (-0.006906) | 0.249590 / 0.255139 (-0.005549) | 0.270822 / 0.283200 (-0.012378) | 0.018152 / 0.141683 (-0.123531) | 1.097046 / 1.452155 (-0.355109) | 1.160461 / 1.492716 (-0.332255) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.091712 / 0.018006 (0.073705) | 0.299121 / 0.000490 (0.298631) | 0.000244 / 0.000200 (0.000044) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018998 / 0.037411 (-0.018413) | 0.062811 / 0.014526 (0.048285) | 0.076348 / 0.176557 (-0.100209) | 0.123898 / 0.737135 (-0.613238) | 0.076249 / 0.296338 (-0.220090) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.282780 / 0.215209 (0.067571) | 2.739028 / 2.077655 (0.661373) | 1.472564 / 1.504120 (-0.031556) | 1.347343 / 1.541195 (-0.193852) | 1.387130 / 1.468490 (-0.081360) | 0.403348 / 4.584777 (-4.181429) | 2.369924 / 3.745712 (-1.375788) | 2.612875 / 5.269862 (-2.656987) | 1.588079 / 4.565676 (-2.977598) | 0.045233 / 0.424275 (-0.379042) | 0.004767 / 0.007607 (-0.002840) | 0.336614 / 0.226044 (0.110570) | 3.300485 / 2.268929 (1.031556) | 1.834365 / 55.444624 (-53.610259) | 1.559799 / 6.876477 (-5.316677) | 1.601265 / 2.142072 (-0.540808) | 0.468158 / 4.805227 (-4.337069) | 0.099811 / 6.500664 (-6.400853) | 0.042688 / 0.075469 (-0.032782) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.934097 / 1.841788 (-0.907691) | 11.687713 / 8.074308 (3.613405) | 10.412723 / 10.191392 (0.221331) | 0.139276 / 0.680424 (-0.541148) | 0.014042 / 0.534201 (-0.520159) | 0.270306 / 0.579283 (-0.308978) | 0.266609 / 0.434364 (-0.167755) | 0.314179 / 0.540337 (-0.226158) | 0.437744 / 1.386936 (-0.949192) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.004893 / 0.011353 (-0.006460) | 0.002952 / 0.011008 (-0.008056) | 0.050441 / 0.038508 (0.011933) | 0.051838 / 0.023109 (0.028729) | 0.271163 / 0.275898 (-0.004735) | 0.293031 / 0.323480 (-0.030449) | 0.003976 / 0.007986 (-0.004010) | 0.002396 / 0.004328 (-0.001933) | 0.048103 / 0.004250 (0.043852) | 0.038732 / 0.037052 (0.001680) | 0.274276 / 0.258489 (0.015787) | 0.305112 / 0.293841 (0.011271) | 0.024112 / 0.128546 (-0.104434) | 0.007203 / 0.075646 (-0.068443) | 0.053502 / 0.419271 (-0.365770) | 0.032360 / 0.043533 (-0.011173) | 0.270154 / 0.255139 (0.015015) | 0.286689 / 0.283200 (0.003489) | 0.018285 / 0.141683 (-0.123397) | 1.141421 / 1.452155 (-0.310734) | 1.244062 / 1.492716 (-0.248654) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.090960 / 0.018006 (0.072954) | 0.286134 / 0.000490 (0.285644) | 0.000207 / 0.000200 (0.000007) | 0.000045 / 0.000054 (-0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.020789 / 0.037411 (-0.016622) | 0.070850 / 0.014526 (0.056324) | 0.080750 / 0.176557 (-0.095807) | 0.120046 / 0.737135 (-0.617089) | 0.083630 / 0.296338 (-0.212708) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.290654 / 0.215209 (0.075445) | 2.846669 / 2.077655 (0.769014) | 1.561752 / 1.504120 (0.057632) | 1.442968 / 1.541195 (-0.098227) | 1.503551 / 1.468490 (0.035061) | 0.399731 / 4.584777 (-4.185046) | 2.430099 / 3.745712 (-1.315613) | 2.556169 / 5.269862 (-2.713692) | 1.545591 / 4.565676 (-3.020085) | 0.045967 / 0.424275 (-0.378309) | 0.004851 / 0.007607 (-0.002756) | 0.340167 / 0.226044 (0.114122) | 3.392738 / 2.268929 (1.123809) | 1.943577 / 55.444624 (-53.501047) | 1.650057 / 6.876477 (-5.226420) | 1.686872 / 2.142072 (-0.455201) | 0.470305 / 4.805227 (-4.334923) | 0.097296 / 6.500664 (-6.403368) | 0.041399 / 0.075469 (-0.034070) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.985660 / 1.841788 (-0.856128) | 12.300826 / 8.074308 (4.226518) | 10.972591 / 10.191392 (0.781199) | 0.131512 / 0.680424 (-0.548912) | 0.015742 / 0.534201 (-0.518459) | 0.270630 / 0.579283 (-0.308653) | 0.276039 / 0.434364 (-0.158325) | 0.302288 / 0.540337 (-0.238050) | 0.409415 / 1.386936 (-0.977521) |\n\n</details>\n</details>\n\n\n"
] | "2023-11-15T08:07:37Z" | "2023-11-15T17:35:30Z" | "2023-11-15T08:12:59Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6419.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6419",
"merged_at": "2023-11-15T08:12:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6419.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6419"
} | Release 2.14.7. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6419/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5420/comments | https://api.github.com/repos/huggingface/datasets/issues/5420/events | https://github.com/huggingface/datasets/pull/5420 | 1,532,265,742 | PR_kwDODunzps5HVAhL | 5,420 | ci: 🎡 remove two obsolete issue templates | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008450 / 0.011353 (-0.002902) | 0.004478 / 0.011008 (-0.006530) | 0.100440 / 0.038508 (0.061931) | 0.029568 / 0.023109 (0.006459) | 0.296705 / 0.275898 (0.020807) | 0.354565 / 0.323480 (0.031085) | 0.006887 / 0.007986 (-0.001098) | 0.003415 / 0.004328 (-0.000914) | 0.078876 / 0.004250 (0.074626) | 0.034927 / 0.037052 (-0.002125) | 0.307695 / 0.258489 (0.049206) | 0.340917 / 0.293841 (0.047076) | 0.033630 / 0.128546 (-0.094916) | 0.011626 / 0.075646 (-0.064020) | 0.322644 / 0.419271 (-0.096627) | 0.040254 / 0.043533 (-0.003279) | 0.297419 / 0.255139 (0.042280) | 0.321584 / 0.283200 (0.038384) | 0.086202 / 0.141683 (-0.055481) | 1.465579 / 1.452155 (0.013425) | 1.521456 / 1.492716 (0.028740) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200890 / 0.018006 (0.182884) | 0.410300 / 0.000490 (0.409811) | 0.001647 / 0.000200 (0.001447) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022569 / 0.037411 (-0.014843) | 0.096062 / 0.014526 (0.081536) | 0.102474 / 0.176557 (-0.074082) | 0.138596 / 0.737135 (-0.598539) | 0.106262 / 0.296338 (-0.190077) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415976 / 0.215209 (0.200766) | 4.144322 / 2.077655 (2.066667) | 1.871783 / 1.504120 (0.367663) | 1.669478 / 1.541195 (0.128283) | 1.718214 / 1.468490 (0.249724) | 0.687870 / 4.584777 (-3.896907) | 3.362084 / 3.745712 (-0.383628) | 1.844127 / 5.269862 (-3.425735) | 1.149611 / 4.565676 (-3.416066) | 0.081410 / 0.424275 (-0.342865) | 0.012278 / 0.007607 (0.004671) | 0.518245 / 0.226044 (0.292200) | 5.185164 / 2.268929 (2.916236) | 2.299029 / 55.444624 (-53.145595) | 1.960021 / 6.876477 (-4.916456) | 2.009751 / 2.142072 (-0.132322) | 0.803759 / 4.805227 (-4.001468) | 0.147340 / 6.500664 (-6.353324) | 0.063896 / 0.075469 (-0.011573) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254142 / 1.841788 (-0.587646) | 13.799683 / 8.074308 (5.725375) | 13.940387 / 10.191392 (3.748995) | 0.151246 / 0.680424 (-0.529178) | 0.028709 / 0.534201 (-0.505491) | 0.391600 / 0.579283 (-0.187683) | 0.405750 / 0.434364 (-0.028614) | 0.455479 / 0.540337 (-0.084858) | 0.541022 / 1.386936 (-0.845914) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006462 / 0.011353 (-0.004891) | 0.004462 / 0.011008 (-0.006547) | 0.096588 / 0.038508 (0.058080) | 0.026931 / 0.023109 (0.003822) | 0.344595 / 0.275898 (0.068697) | 0.378743 / 0.323480 (0.055264) | 0.005672 / 0.007986 (-0.002314) | 0.003345 / 0.004328 (-0.000984) | 0.074363 / 0.004250 (0.070112) | 0.037300 / 0.037052 (0.000248) | 0.346895 / 0.258489 (0.088406) | 0.388585 / 0.293841 (0.094744) | 0.031459 / 0.128546 (-0.097088) | 0.011522 / 0.075646 (-0.064124) | 0.318507 / 0.419271 (-0.100764) | 0.041145 / 0.043533 (-0.002388) | 0.343866 / 0.255139 (0.088727) | 0.366490 / 0.283200 (0.083291) | 0.086793 / 0.141683 (-0.054890) | 1.483859 / 1.452155 (0.031704) | 1.574006 / 1.492716 (0.081290) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220436 / 0.018006 (0.202430) | 0.402988 / 0.000490 (0.402498) | 0.000435 / 0.000200 (0.000235) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024573 / 0.037411 (-0.012838) | 0.099190 / 0.014526 (0.084664) | 0.106796 / 0.176557 (-0.069761) | 0.142387 / 0.737135 (-0.594748) | 0.109991 / 0.296338 (-0.186347) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473452 / 0.215209 (0.258243) | 4.749554 / 2.077655 (2.671899) | 2.433482 / 1.504120 (0.929362) | 2.224276 / 1.541195 (0.683082) | 2.261579 / 1.468490 (0.793088) | 0.699876 / 4.584777 (-3.884901) | 3.378366 / 3.745712 (-0.367346) | 1.835062 / 5.269862 (-3.434799) | 1.161249 / 4.565676 (-3.404427) | 0.082967 / 0.424275 (-0.341308) | 0.012745 / 0.007607 (0.005138) | 0.580006 / 0.226044 (0.353962) | 5.789868 / 2.268929 (3.520939) | 2.909496 / 55.444624 (-52.535128) | 2.539196 / 6.876477 (-4.337280) | 2.617737 / 2.142072 (0.475665) | 0.810320 / 4.805227 (-3.994907) | 0.152501 / 6.500664 (-6.348163) | 0.067201 / 0.075469 (-0.008268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257844 / 1.841788 (-0.583943) | 13.865295 / 8.074308 (5.790987) | 14.169073 / 10.191392 (3.977680) | 0.135655 / 0.680424 (-0.544769) | 0.016597 / 0.534201 (-0.517604) | 0.374915 / 0.579283 (-0.204368) | 0.382771 / 0.434364 (-0.051593) | 0.431934 / 0.540337 (-0.108403) | 0.524617 / 1.386936 (-0.862319) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008748 / 0.011353 (-0.002605) | 0.004489 / 0.011008 (-0.006519) | 0.100923 / 0.038508 (0.062415) | 0.031436 / 0.023109 (0.008326) | 0.306508 / 0.275898 (0.030610) | 0.365110 / 0.323480 (0.041630) | 0.007161 / 0.007986 (-0.000824) | 0.005489 / 0.004328 (0.001160) | 0.078909 / 0.004250 (0.074658) | 0.036097 / 0.037052 (-0.000955) | 0.307907 / 0.258489 (0.049418) | 0.370277 / 0.293841 (0.076436) | 0.034184 / 0.128546 (-0.094362) | 0.011613 / 0.075646 (-0.064033) | 0.322896 / 0.419271 (-0.096375) | 0.041829 / 0.043533 (-0.001704) | 0.299669 / 0.255139 (0.044530) | 0.322217 / 0.283200 (0.039017) | 0.087751 / 0.141683 (-0.053932) | 1.476277 / 1.452155 (0.024122) | 1.548196 / 1.492716 (0.055480) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183002 / 0.018006 (0.164995) | 0.415627 / 0.000490 (0.415138) | 0.003272 / 0.000200 (0.003072) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024881 / 0.037411 (-0.012531) | 0.103424 / 0.014526 (0.088898) | 0.106446 / 0.176557 (-0.070110) | 0.142806 / 0.737135 (-0.594330) | 0.110938 / 0.296338 (-0.185401) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421669 / 0.215209 (0.206460) | 4.207457 / 2.077655 (2.129802) | 1.882176 / 1.504120 (0.378056) | 1.677609 / 1.541195 (0.136415) | 1.734065 / 1.468490 (0.265575) | 0.695915 / 4.584777 (-3.888862) | 3.416731 / 3.745712 (-0.328981) | 1.872575 / 5.269862 (-3.397286) | 1.163612 / 4.565676 (-3.402064) | 0.082710 / 0.424275 (-0.341565) | 0.012659 / 0.007607 (0.005052) | 0.528785 / 0.226044 (0.302741) | 5.305328 / 2.268929 (3.036399) | 2.299850 / 55.444624 (-53.144774) | 1.968137 / 6.876477 (-4.908339) | 2.028326 / 2.142072 (-0.113746) | 0.813157 / 4.805227 (-3.992070) | 0.149997 / 6.500664 (-6.350668) | 0.066739 / 0.075469 (-0.008730) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206332 / 1.841788 (-0.635456) | 13.795510 / 8.074308 (5.721202) | 14.367695 / 10.191392 (4.176303) | 0.138106 / 0.680424 (-0.542318) | 0.028760 / 0.534201 (-0.505441) | 0.394822 / 0.579283 (-0.184461) | 0.403291 / 0.434364 (-0.031073) | 0.463273 / 0.540337 (-0.077065) | 0.540881 / 1.386936 (-0.846055) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006830 / 0.011353 (-0.004523) | 0.004606 / 0.011008 (-0.006402) | 0.097763 / 0.038508 (0.059255) | 0.027832 / 0.023109 (0.004723) | 0.422970 / 0.275898 (0.147072) | 0.460313 / 0.323480 (0.136833) | 0.005110 / 0.007986 (-0.002876) | 0.003428 / 0.004328 (-0.000901) | 0.075047 / 0.004250 (0.070797) | 0.038374 / 0.037052 (0.001322) | 0.422762 / 0.258489 (0.164273) | 0.469886 / 0.293841 (0.176045) | 0.032391 / 0.128546 (-0.096155) | 0.011804 / 0.075646 (-0.063843) | 0.320439 / 0.419271 (-0.098832) | 0.041939 / 0.043533 (-0.001594) | 0.422521 / 0.255139 (0.167382) | 0.446420 / 0.283200 (0.163220) | 0.090715 / 0.141683 (-0.050968) | 1.484578 / 1.452155 (0.032423) | 1.556154 / 1.492716 (0.063438) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260735 / 0.018006 (0.242728) | 0.415586 / 0.000490 (0.415096) | 0.026960 / 0.000200 (0.026760) | 0.000296 / 0.000054 (0.000241) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024926 / 0.037411 (-0.012486) | 0.099651 / 0.014526 (0.085125) | 0.107810 / 0.176557 (-0.068747) | 0.148685 / 0.737135 (-0.588451) | 0.112725 / 0.296338 (-0.183614) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472669 / 0.215209 (0.257460) | 4.718827 / 2.077655 (2.641172) | 2.475583 / 1.504120 (0.971463) | 2.260862 / 1.541195 (0.719667) | 2.307820 / 1.468490 (0.839330) | 0.699464 / 4.584777 (-3.885313) | 3.376282 / 3.745712 (-0.369431) | 1.872650 / 5.269862 (-3.397211) | 1.176399 / 4.565676 (-3.389277) | 0.082854 / 0.424275 (-0.341421) | 0.012845 / 0.007607 (0.005237) | 0.582088 / 0.226044 (0.356044) | 5.861609 / 2.268929 (3.592681) | 2.930728 / 55.444624 (-52.513896) | 2.624310 / 6.876477 (-4.252167) | 2.762130 / 2.142072 (0.620058) | 0.811902 / 4.805227 (-3.993325) | 0.152516 / 6.500664 (-6.348149) | 0.067670 / 0.075469 (-0.007799) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289790 / 1.841788 (-0.551997) | 14.267607 / 8.074308 (6.193299) | 14.120655 / 10.191392 (3.929263) | 0.128442 / 0.680424 (-0.551982) | 0.017079 / 0.534201 (-0.517121) | 0.381807 / 0.579283 (-0.197476) | 0.400546 / 0.434364 (-0.033818) | 0.447629 / 0.540337 (-0.092709) | 0.532006 / 1.386936 (-0.854930) |\n\n</details>\n</details>\n\n\n"
] | "2023-01-13T12:58:43Z" | "2023-01-13T13:36:00Z" | "2023-01-13T13:29:01Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5420.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5420",
"merged_at": "2023-01-13T13:29:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5420.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5420"
} | add-dataset is not needed anymore since the "canonical" datasets are on the Hub. And dataset-viewer is managed within the datasets-server project.
See https://github.com/huggingface/datasets/issues/new/choose
<img width="1245" alt="Capture d’écran 2023-01-13 à 13 59 58" src="https://user-images.githubusercontent.com/1676121/212325813-2d4c30e2-343e-4aa2-8cce-b2b77f45628e.png">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5420/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5420/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2208/comments | https://api.github.com/repos/huggingface/datasets/issues/2208/events | https://github.com/huggingface/datasets/pull/2208 | 855,343,835 | MDExOlB1bGxSZXF1ZXN0NjEzMTAxMzMw | 2,208 | Remove Python2 leftovers | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | "2021-04-11T16:08:03Z" | "2021-04-14T22:05:36Z" | "2021-04-14T13:40:51Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2208",
"merged_at": "2021-04-14T13:40:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2208"
} | This PR removes Python2 leftovers since this project aims for Python3.6+ (and as of 2020 Python2 is no longer officially supported) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2208/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4600/comments | https://api.github.com/repos/huggingface/datasets/issues/4600/events | https://github.com/huggingface/datasets/pull/4600 | 1,289,177,042 | PR_kwDODunzps46l3P1 | 4,600 | Remove multiple config section | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-06-29T19:09:21Z" | "2022-07-04T17:41:20Z" | "2022-07-04T17:29:41Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4600.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4600",
"merged_at": "2022-07-04T17:29:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4600.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4600"
} | This PR removes docs for a future feature and redirects to #4578 instead. See this [discussion](https://huggingface.slack.com/archives/C034N0A7H09/p1656107063801969) for more details :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4600/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4884 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4884/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4884/comments | https://api.github.com/repos/huggingface/datasets/issues/4884/events | https://github.com/huggingface/datasets/pull/4884 | 1,349,105,946 | PR_kwDODunzps49s6Aj | 4,884 | Fix documentation card of math_qa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4884). All of your documentation changes will be reflected on that endpoint."
] | "2022-08-24T09:00:56Z" | "2022-08-24T11:33:17Z" | "2022-08-24T11:33:16Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4884.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4884",
"merged_at": "2022-08-24T11:33:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4884.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4884"
} | Fix documentation card of math_qa dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4884/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4884/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | https://api.github.com/repos/huggingface/datasets/issues/5354/events | https://github.com/huggingface/datasets/issues/5354 | 1,492,174,125 | I_kwDODunzps5Y8MUt | 5,354 | Consider using "Sequence" instead of "List" | {
"avatar_url": "https://avatars.githubusercontent.com/u/15568078?v=4",
"events_url": "https://api.github.com/users/tranhd95/events{/privacy}",
"followers_url": "https://api.github.com/users/tranhd95/followers",
"following_url": "https://api.github.com/users/tranhd95/following{/other_user}",
"gists_url": "https://api.github.com/users/tranhd95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tranhd95",
"id": 15568078,
"login": "tranhd95",
"node_id": "MDQ6VXNlcjE1NTY4MDc4",
"organizations_url": "https://api.github.com/users/tranhd95/orgs",
"received_events_url": "https://api.github.com/users/tranhd95/received_events",
"repos_url": "https://api.github.com/users/tranhd95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tranhd95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tranhd95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tranhd95"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avinashsai",
"id": 22453634,
"login": "avinashsai",
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avinashsai"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avinashsai",
"id": 22453634,
"login": "avinashsai",
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avinashsai"
}
] | null | [
"Hi! Linking a comment to provide more info on the issue: https://stackoverflow.com/a/39458225. This means we should replace all (most of) the occurrences of `List` with `Sequence` in function signatures.\r\n\r\n@tranhd95 Would you be interested in submitting a PR?",
"Hi all! I tried to reproduce this issue and didn't work for me. Also in your example i noticed that the variables have different names: `list_of_filenames` and `list_of_files`, could this be related to that?\r\n```python\r\n#I found random data in parquet format:\r\n!wget \"https://github.com/Teradata/kylo/raw/master/samples/sample-data/parquet/userdata1.parquet\"\r\n!wget \"https://github.com/Teradata/kylo/raw/master/samples/sample-data/parquet/userdata2.parquet\"\r\n\r\n#Then i try reproduce\r\nlist_of_files = [\"userdata1.parquet\", \"userdata2.parquet\"]\r\nds = Dataset.from_parquet(list_of_files)\r\n```\r\n**My output:**\r\n```python\r\nWARNING:datasets.builder:Using custom data configuration default-e287d097dc54e046\r\nDownloading and preparing dataset parquet/default to /root/.cache/huggingface/datasets/parquet/default-e287d097dc54e046/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...\r\nDownloading data files: 100%\r\n1/1 [00:00<00:00, 40.38it/s]\r\nExtracting data files: 100%\r\n1/1 [00:00<00:00, 23.43it/s]\r\nDataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/default-e287d097dc54e046/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec. Subsequent calls will reuse this data.\r\n```\r\nP.S. This is my first experience with open source. So do not judge strictly if I do not understand something)",
"@dantema There is indeed a typo in variable names. Nevertheless, I'm sorry if I was not clear but the output is from `mypy` type checker. You can run the code snippet without issues. The problem is with the type checking.",
"However, I found out that the type annotation is actually misleading. The [`from_parquet`](https://github.com/huggingface/datasets/blob/5ef1ab1cc06c2b7a574bf2df454cd9fcb071ccb2/src/datasets/arrow_dataset.py#L1039) method should also accept list of [`PathLike`](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/typing.py#L8) objects which includes [`os.PathLike`](https://docs.python.org/3/library/os.html#os.PathLike). But if I would ran the code snippet below, an exception is thrown.\r\n\r\n**Code**\r\n```py\r\nfrom pathlib import Path\r\n\r\nlist_of_filenames = [Path(\"foo.parquet\"), Path(\"bar.parquet\")]\r\nds = Dataset.from_parquet(list_of_filenames)\r\n```\r\n**Output**\r\n```py\r\n[/usr/local/lib/python3.8/dist-packages/datasets/arrow_dataset.py](https://localhost:8080/#) in from_parquet(path_or_paths, split, features, cache_dir, keep_in_memory, columns, **kwargs)\r\n 1071 from .io.parquet import ParquetDatasetReader\r\n 1072 \r\n-> 1073 return ParquetDatasetReader(\r\n 1074 path_or_paths,\r\n 1075 split=split,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/io/parquet.py](https://localhost:8080/#) in __init__(self, path_or_paths, split, features, cache_dir, keep_in_memory, streaming, **kwargs)\r\n 35 path_or_paths = path_or_paths if isinstance(path_or_paths, dict) else {self.split: path_or_paths}\r\n 36 hash = _PACKAGED_DATASETS_MODULES[\"parquet\"][1]\r\n---> 37 self.builder = Parquet(\r\n 38 cache_dir=cache_dir,\r\n 39 data_files=path_or_paths,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in __init__(self, cache_dir, config_name, hash, base_path, info, features, use_auth_token, repo_id, data_files, data_dir, name, **config_kwargs)\r\n 298 \r\n 299 if data_files is not None and not isinstance(data_files, DataFilesDict):\r\n--> 300 data_files = DataFilesDict.from_local_or_remote(\r\n 301 sanitize_patterns(data_files), base_path=base_path, use_auth_token=use_auth_token\r\n 302 )\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)\r\n 794 for key, patterns_for_key in patterns.items():\r\n 795 out[key] = (\r\n--> 796 DataFilesList.from_local_or_remote(\r\n 797 patterns_for_key,\r\n 798 base_path=base_path,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)\r\n 762 ) -> \"DataFilesList\":\r\n 763 base_path = base_path if base_path is not None else str(Path().resolve())\r\n--> 764 data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)\r\n 765 origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)\r\n 766 return cls(data_files, origin_metadata)\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)\r\n 357 data_files = []\r\n 358 for pattern in patterns:\r\n--> 359 if is_remote_url(pattern):\r\n 360 data_files.append(Url(pattern))\r\n 361 else:\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py](https://localhost:8080/#) in is_remote_url(url_or_filename)\r\n 62 \r\n 63 def is_remote_url(url_or_filename: str) -> bool:\r\n---> 64 parsed = urlparse(url_or_filename)\r\n 65 return parsed.scheme in (\"http\", \"https\", \"s3\", \"gs\", \"hdfs\", \"ftp\")\r\n 66 \r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in urlparse(url, scheme, allow_fragments)\r\n 373 Note that we don't break the components up in smaller bits\r\n 374 (e.g. netloc is a single string) and we don't expand % escapes.\"\"\"\r\n--> 375 url, scheme, _coerce_result = _coerce_args(url, scheme)\r\n 376 splitresult = urlsplit(url, scheme, allow_fragments)\r\n 377 scheme, netloc, url, query, fragment = splitresult\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in _coerce_args(*args)\r\n 125 if str_input:\r\n 126 return args + (_noop,)\r\n--> 127 return _decode_args(args) + (_encode_result,)\r\n 128 \r\n 129 # Result objects are more helpful than simple tuples\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in _decode_args(args, encoding, errors)\r\n 109 def _decode_args(args, encoding=_implicit_encoding,\r\n 110 errors=_implicit_errors):\r\n--> 111 return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n 112 \r\n 113 def _coerce_args(*args):\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in <genexpr>(.0)\r\n 109 def _decode_args(args, encoding=_implicit_encoding,\r\n 110 errors=_implicit_errors):\r\n--> 111 return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n 112 \r\n 113 def _coerce_args(*args):\r\n\r\nAttributeError: 'PosixPath' object has no attribute 'decode'\r\n```\r\n\r\n@mariosasko Should I create a new issue? ",
"@mariosasko I would like to take this issue up. ",
"@avinashsai Hi, I've assigned you the issue.\r\n\r\n@tranhd95 Yes, feel free to report this in a new issue.",
"@avinashsai Are you still working on this? If not I would like to give it a try.",
"@mariosasko I would like to take this issue up!"
] | "2022-12-12T15:39:45Z" | "2023-11-23T01:47:03Z" | null | NONE | null | null | null | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
list_of_filenames = ["foo.parquet", "bar.parquet"]
ds = Dataset.from_parquet(list_of_filenames)
```
**Expected mypy output:**
```
Success: no issues found
```
**Actual mypy output:**
```py
test.py:19: error: Argument 1 to "from_parquet" of "Dataset" has incompatible type "List[str]"; expected "Union[Union[str, bytes, PathLike[Any]], List[Union[str, bytes, PathLike[Any]]]]" [arg-type]
test.py:19: note: "List" is invariant -- see https://mypy.readthedocs.io/en/stable/common_issues.html#variance
test.py:19: note: Consider using "Sequence" instead, which is covariant
```
**Env:** mypy 0.991, Python 3.10.0, datasets 2.7.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5354/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5928/comments | https://api.github.com/repos/huggingface/datasets/issues/5928/events | https://github.com/huggingface/datasets/pull/5928 | 1,744,098,371 | PR_kwDODunzps5SUXPC | 5,928 | Fix link to quickstart docs in README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006693 / 0.011353 (-0.004660) | 0.004331 / 0.011008 (-0.006677) | 0.098022 / 0.038508 (0.059514) | 0.032764 / 0.023109 (0.009654) | 0.295812 / 0.275898 (0.019914) | 0.325029 / 0.323480 (0.001550) | 0.005779 / 0.007986 (-0.002206) | 0.005381 / 0.004328 (0.001052) | 0.075785 / 0.004250 (0.071535) | 0.048759 / 0.037052 (0.011707) | 0.308986 / 0.258489 (0.050497) | 0.348000 / 0.293841 (0.054159) | 0.027686 / 0.128546 (-0.100860) | 0.008839 / 0.075646 (-0.066807) | 0.328389 / 0.419271 (-0.090883) | 0.062173 / 0.043533 (0.018640) | 0.312257 / 0.255139 (0.057119) | 0.325024 / 0.283200 (0.041824) | 0.103886 / 0.141683 (-0.037797) | 1.440215 / 1.452155 (-0.011940) | 1.528665 / 1.492716 (0.035948) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210082 / 0.018006 (0.192076) | 0.442480 / 0.000490 (0.441990) | 0.006559 / 0.000200 (0.006359) | 0.000092 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026774 / 0.037411 (-0.010637) | 0.108362 / 0.014526 (0.093837) | 0.117631 / 0.176557 (-0.058926) | 0.176657 / 0.737135 (-0.560478) | 0.124154 / 0.296338 (-0.172184) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428136 / 0.215209 (0.212927) | 4.270287 / 2.077655 (2.192632) | 2.014728 / 1.504120 (0.510608) | 1.806772 / 1.541195 (0.265577) | 1.946284 / 1.468490 (0.477794) | 0.525542 / 4.584777 (-4.059235) | 3.667025 / 3.745712 (-0.078687) | 1.878751 / 5.269862 (-3.391111) | 1.048321 / 4.565676 (-3.517356) | 0.065550 / 0.424275 (-0.358725) | 0.011881 / 0.007607 (0.004274) | 0.529873 / 0.226044 (0.303829) | 5.289641 / 2.268929 (3.020712) | 2.489403 / 55.444624 (-52.955221) | 2.141037 / 6.876477 (-4.735440) | 2.230735 / 2.142072 (0.088662) | 0.639781 / 4.805227 (-4.165447) | 0.141410 / 6.500664 (-6.359254) | 0.064374 / 0.075469 (-0.011095) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.159462 / 1.841788 (-0.682325) | 14.524730 / 8.074308 (6.450422) | 13.578070 / 10.191392 (3.386678) | 0.152138 / 0.680424 (-0.528286) | 0.017255 / 0.534201 (-0.516946) | 0.387607 / 0.579283 (-0.191676) | 0.413652 / 0.434364 (-0.020712) | 0.453644 / 0.540337 (-0.086693) | 0.550051 / 1.386936 (-0.836885) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006668 / 0.011353 (-0.004685) | 0.004677 / 0.011008 (-0.006331) | 0.075950 / 0.038508 (0.037442) | 0.032439 / 0.023109 (0.009329) | 0.381839 / 0.275898 (0.105941) | 0.419411 / 0.323480 (0.095931) | 0.005813 / 0.007986 (-0.002172) | 0.004090 / 0.004328 (-0.000238) | 0.075052 / 0.004250 (0.070802) | 0.048453 / 0.037052 (0.011401) | 0.388076 / 0.258489 (0.129587) | 0.431793 / 0.293841 (0.137952) | 0.028408 / 0.128546 (-0.100138) | 0.009028 / 0.075646 (-0.066618) | 0.082569 / 0.419271 (-0.336702) | 0.046772 / 0.043533 (0.003239) | 0.380182 / 0.255139 (0.125043) | 0.401828 / 0.283200 (0.118629) | 0.105388 / 0.141683 (-0.036294) | 1.453356 / 1.452155 (0.001201) | 1.561483 / 1.492716 (0.068767) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.008922 / 0.018006 (-0.009084) | 0.444112 / 0.000490 (0.443623) | 0.002756 / 0.000200 (0.002556) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030408 / 0.037411 (-0.007003) | 0.112924 / 0.014526 (0.098399) | 0.124625 / 0.176557 (-0.051932) | 0.176915 / 0.737135 (-0.560220) | 0.129141 / 0.296338 (-0.167198) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448197 / 0.215209 (0.232987) | 4.476548 / 2.077655 (2.398893) | 2.243977 / 1.504120 (0.739857) | 2.054060 / 1.541195 (0.512865) | 2.130680 / 1.468490 (0.662190) | 0.526815 / 4.584777 (-4.057962) | 3.759312 / 3.745712 (0.013600) | 3.333618 / 5.269862 (-1.936244) | 1.579611 / 4.565676 (-2.986065) | 0.065714 / 0.424275 (-0.358561) | 0.011939 / 0.007607 (0.004332) | 0.550313 / 0.226044 (0.324269) | 5.476946 / 2.268929 (3.208018) | 2.726521 / 55.444624 (-52.718104) | 2.364977 / 6.876477 (-4.511499) | 2.450624 / 2.142072 (0.308551) | 0.647174 / 4.805227 (-4.158053) | 0.141265 / 6.500664 (-6.359399) | 0.065493 / 0.075469 (-0.009976) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.249702 / 1.841788 (-0.592085) | 15.205647 / 8.074308 (7.131338) | 14.678310 / 10.191392 (4.486918) | 0.141539 / 0.680424 (-0.538884) | 0.017323 / 0.534201 (-0.516878) | 0.387602 / 0.579283 (-0.191681) | 0.415106 / 0.434364 (-0.019258) | 0.458146 / 0.540337 (-0.082192) | 0.553318 / 1.386936 (-0.833618) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008567 / 0.011353 (-0.002786) | 0.005245 / 0.011008 (-0.005763) | 0.115074 / 0.038508 (0.076566) | 0.032567 / 0.023109 (0.009458) | 0.352297 / 0.275898 (0.076399) | 0.393403 / 0.323480 (0.069923) | 0.006402 / 0.007986 (-0.001583) | 0.004353 / 0.004328 (0.000025) | 0.087903 / 0.004250 (0.083653) | 0.048424 / 0.037052 (0.011372) | 0.370078 / 0.258489 (0.111588) | 0.410192 / 0.293841 (0.116351) | 0.042396 / 0.128546 (-0.086150) | 0.014426 / 0.075646 (-0.061220) | 0.411358 / 0.419271 (-0.007914) | 0.059546 / 0.043533 (0.016013) | 0.364721 / 0.255139 (0.109582) | 0.385100 / 0.283200 (0.101901) | 0.100572 / 0.141683 (-0.041111) | 1.741457 / 1.452155 (0.289302) | 1.933134 / 1.492716 (0.440418) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217177 / 0.018006 (0.199171) | 0.510399 / 0.000490 (0.509909) | 0.005542 / 0.000200 (0.005342) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026852 / 0.037411 (-0.010559) | 0.125580 / 0.014526 (0.111054) | 0.132164 / 0.176557 (-0.044392) | 0.189073 / 0.737135 (-0.548063) | 0.135980 / 0.296338 (-0.160358) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.601924 / 0.215209 (0.386715) | 5.891397 / 2.077655 (3.813743) | 2.389494 / 1.504120 (0.885375) | 2.044013 / 1.541195 (0.502818) | 2.019367 / 1.468490 (0.550877) | 0.883807 / 4.584777 (-3.700970) | 5.141349 / 3.745712 (1.395636) | 2.607415 / 5.269862 (-2.662446) | 1.567268 / 4.565676 (-2.998409) | 0.102738 / 0.424275 (-0.321537) | 0.013480 / 0.007607 (0.005873) | 0.744979 / 0.226044 (0.518934) | 7.404182 / 2.268929 (5.135254) | 2.983406 / 55.444624 (-52.461219) | 2.331847 / 6.876477 (-4.544630) | 2.465119 / 2.142072 (0.323047) | 1.106725 / 4.805227 (-3.698502) | 0.205779 / 6.500664 (-6.294885) | 0.081019 / 0.075469 (0.005550) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.527840 / 1.841788 (-0.313947) | 16.989487 / 8.074308 (8.915179) | 18.016123 / 10.191392 (7.824731) | 0.216157 / 0.680424 (-0.464266) | 0.025393 / 0.534201 (-0.508808) | 0.496743 / 0.579283 (-0.082540) | 0.575365 / 0.434364 (0.141002) | 0.559978 / 0.540337 (0.019641) | 0.677474 / 1.386936 (-0.709462) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008913 / 0.011353 (-0.002440) | 0.005540 / 0.011008 (-0.005469) | 0.100001 / 0.038508 (0.061493) | 0.034432 / 0.023109 (0.011323) | 0.419824 / 0.275898 (0.143926) | 0.443566 / 0.323480 (0.120086) | 0.006372 / 0.007986 (-0.001614) | 0.004405 / 0.004328 (0.000077) | 0.094927 / 0.004250 (0.090677) | 0.050300 / 0.037052 (0.013248) | 0.424806 / 0.258489 (0.166317) | 0.480793 / 0.293841 (0.186952) | 0.050869 / 0.128546 (-0.077677) | 0.015899 / 0.075646 (-0.059747) | 0.111413 / 0.419271 (-0.307859) | 0.058093 / 0.043533 (0.014560) | 0.430575 / 0.255139 (0.175436) | 0.483786 / 0.283200 (0.200586) | 0.106878 / 0.141683 (-0.034805) | 1.763576 / 1.452155 (0.311422) | 1.837750 / 1.492716 (0.345033) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011565 / 0.018006 (-0.006441) | 0.484411 / 0.000490 (0.483922) | 0.004869 / 0.000200 (0.004669) | 0.000111 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030706 / 0.037411 (-0.006706) | 0.126901 / 0.014526 (0.112375) | 0.130367 / 0.176557 (-0.046190) | 0.206568 / 0.737135 (-0.530567) | 0.146505 / 0.296338 (-0.149834) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.627266 / 0.215209 (0.412057) | 6.314049 / 2.077655 (4.236394) | 2.582920 / 1.504120 (1.078800) | 2.249401 / 1.541195 (0.708206) | 2.244960 / 1.468490 (0.776470) | 0.907770 / 4.584777 (-3.677007) | 5.349622 / 3.745712 (1.603910) | 4.591244 / 5.269862 (-0.678618) | 2.301612 / 4.565676 (-2.264064) | 0.108813 / 0.424275 (-0.315462) | 0.013187 / 0.007607 (0.005580) | 0.806071 / 0.226044 (0.580027) | 7.843903 / 2.268929 (5.574974) | 3.405968 / 55.444624 (-52.038656) | 2.564301 / 6.876477 (-4.312176) | 2.652208 / 2.142072 (0.510135) | 1.168142 / 4.805227 (-3.637086) | 0.218551 / 6.500664 (-6.282113) | 0.078120 / 0.075469 (0.002651) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.562517 / 1.841788 (-0.279271) | 17.519325 / 8.074308 (9.445017) | 20.727083 / 10.191392 (10.535691) | 0.207135 / 0.680424 (-0.473288) | 0.028208 / 0.534201 (-0.505993) | 0.496157 / 0.579283 (-0.083126) | 0.569239 / 0.434364 (0.134875) | 0.566137 / 0.540337 (0.025799) | 0.704208 / 1.386936 (-0.682728) |\n\n</details>\n</details>\n\n\n"
] | "2023-06-06T15:23:01Z" | "2023-06-06T15:52:34Z" | "2023-06-06T15:43:53Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5928",
"merged_at": "2023-06-06T15:43:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5928"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5928/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/398/comments | https://api.github.com/repos/huggingface/datasets/issues/398/events | https://github.com/huggingface/datasets/pull/398 | 657,511,962 | MDExOlB1bGxSZXF1ZXN0NDQ5NjE1OTk1 | 398 | Add inline links | {
"avatar_url": "https://avatars.githubusercontent.com/u/13381361?v=4",
"events_url": "https://api.github.com/users/bharatr21/events{/privacy}",
"followers_url": "https://api.github.com/users/bharatr21/followers",
"following_url": "https://api.github.com/users/bharatr21/following{/other_user}",
"gists_url": "https://api.github.com/users/bharatr21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bharatr21",
"id": 13381361,
"login": "bharatr21",
"node_id": "MDQ6VXNlcjEzMzgxMzYx",
"organizations_url": "https://api.github.com/users/bharatr21/orgs",
"received_events_url": "https://api.github.com/users/bharatr21/received_events",
"repos_url": "https://api.github.com/users/bharatr21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bharatr21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bharatr21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bharatr21"
} | [] | closed | false | null | [] | null | [
"Do you mind adding a link to the much more extended pages on adding and sharing a dataset in the new documentation?",
"Sure, I will do that too"
] | "2020-07-15T17:04:04Z" | "2020-07-22T10:14:22Z" | "2020-07-22T10:14:22Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/398.diff",
"html_url": "https://github.com/huggingface/datasets/pull/398",
"merged_at": "2020-07-22T10:14:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/398.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/398"
} | Add inline links to `Contributing.md` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/398/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/398/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "https://api.github.com/users/sentialx/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sentialx",
"id": 11065386,
"login": "sentialx",
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"organizations_url": "https://api.github.com/users/sentialx/orgs",
"received_events_url": "https://api.github.com/users/sentialx/received_events",
"repos_url": "https://api.github.com/users/sentialx/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sentialx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sentialx/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sentialx"
} | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\datasets', download_config=DownloadConfig(resume_download=True))\r\n```\r\n\r\n",
"@mariosasko , I used your suggestion but its not saving anything , just stops and runs from the same point .\r\nbelow is the script to download and save on disk .\r\n\r\n```\r\nfrom datasets import load_dataset, DownloadConfig\r\n\r\n\r\n#load the Pile dataset from Hugging Face Datasets\r\n#dataset = load_dataset('the_pile')\r\ndataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n\r\n\r\n# save each file in the dataset to disk\r\nfor i, example in enumerate(dataset['train']):\r\n filename = f'pile_file_{i}.json'\r\n with open(filename, 'w') as f:\r\n f.write(str(example))\r\n\r\nprint(\"Finished saving Pile dataset files to disk.\")\r\n```\r\n",
"@mariosasko , it shows nothing in dataset folder\r\n\r\n```\r\n du -sh /mnt/nlp/hugging_face/*\r\n20K /mnt/nlp/hugging_face/datasets\r\n4.0K /mnt/nlp/hugging_face/download_pile.py\r\n```\r\n",
"@mariosasko \r\n\r\n```\r\nroot@d20f0ab8f4f8:/mnt/hugging_face# python3 download_pile.py\r\nNo config specified, defaulting to: the_pile/all\r\nDownloading and preparing dataset the_pile/all to /mnt/hugging_face/datasets/the_pile/all/0.0.0/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349...\r\nDownloading data files: 0%| | 0/3 [00:00<?, ?it/s]\r\n\r\n\r\n\r\n\r\n\r\nDownloading data: 70%|████████████████████████████████████████████████████████████████████▊ | 10.7G/15.2G [12:09<11:53, 6.36MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [22:15<00:00, 7.25MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [46:17<00:00, 5.48MB/s]\r\nDownloading data: 40%|██████████████████████████████████████▏ | 6.07G/15.3G [50:49<1:17:02, 1.99MB/s]\r\nTraceback (most recent call last):██████████████████████████▊ | 6.07G/15.3G [50:49<25:35:23, 99.9kB/s]\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 444, in _error_catcher\r\n yield\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 567, in read\r\n data = self._fp_read(amt) if not fp_closed else b\"\"\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 525, in _fp_read\r\n data = self._fp.read(chunk_amt)\r\n File \"/usr/lib/python3.8/http/client.py\", line 459, in read\r\n n = self.readinto(b)\r\n File \"/usr/lib/python3.8/http/client.py\", line 503, in readinto\r\n n = self.fp.readinto(b)\r\n File \"/usr/lib/python3.8/socket.py\", line 669, in readinto\r\n return self._sock.recv_into(b)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1241, in recv_into\r\n return self.read(nbytes, buffer)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1099, in read\r\n return self._sslobj.read(len, buffer)\r\nConnectionResetError: [Errno 104] Connection reset by peer\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 816, in generate\r\n yield from self.raw.stream(chunk_size, decode_content=True)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 628, in stream\r\n data = self.read(amt=amt, decode_content=decode_content)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 593, in read\r\n raise IncompleteRead(self._fp_bytes_read, self.length_remaining)\r\n File \"/usr/lib/python3.8/contextlib.py\", line 131, in __exit__\r\n self.gen.throw(type, value, traceback)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 461, in _error_catcher\r\n raise ProtocolError(\"Connection broken: %r\" % e, e)\r\nurllib3.exceptions.ProtocolError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"download_pile.py\", line 6, in <module>\r\n dataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/load.py\", line 1782, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 872, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1649, in _download_and_prepare\r\n super()._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 945, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/datasets/the_pile/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349/the_pile.py\", line 192, in _split_generators\r\n data_dir = dl_manager.download(_DATA_URLS[self.config.name])\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 427, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 443, in map_nested\r\n mapped = [\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 444, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in _single_map_nested\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in <listcomp>\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return function(data_struct)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 453, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 182, in cached_path\r\n output_path = get_from_cache(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 575, in get_from_cache\r\n http_get(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 379, in http_get\r\n for chunk in response.iter_content(chunk_size=1024):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 818, in generate\r\n raise ChunkedEncodingError(e)\r\nrequests.exceptions.ChunkedEncodingError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n```\r\n",
"Users with slow internet speed are doomed (4MB/s). The dataset downloads fine at minimum speed 10MB/s.\n\nAlso, when the train splits were generated and then I removed the downloads folder to save up disk space, it started redownloading the whole dataset. Is there any way to use the already generated splits instead?",
"@sentialx @mariosasko , anytime on my above script , am I downloading and saving dataset correctly . Please suggest :)",
"@sentialx probably worth noting that `resume_download=True` doesn't directly save the dataset to disk, but instead just helps in resuming the dataset resume on interruption as @mariosasko mentions. resolving resumptions after a crash is [an open issue](https://github.com/huggingface/datasets/issues/5380) at the moment."
] | "2023-03-03T09:52:08Z" | "2023-10-14T02:15:52Z" | "2023-03-24T12:44:25Z" | NONE | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
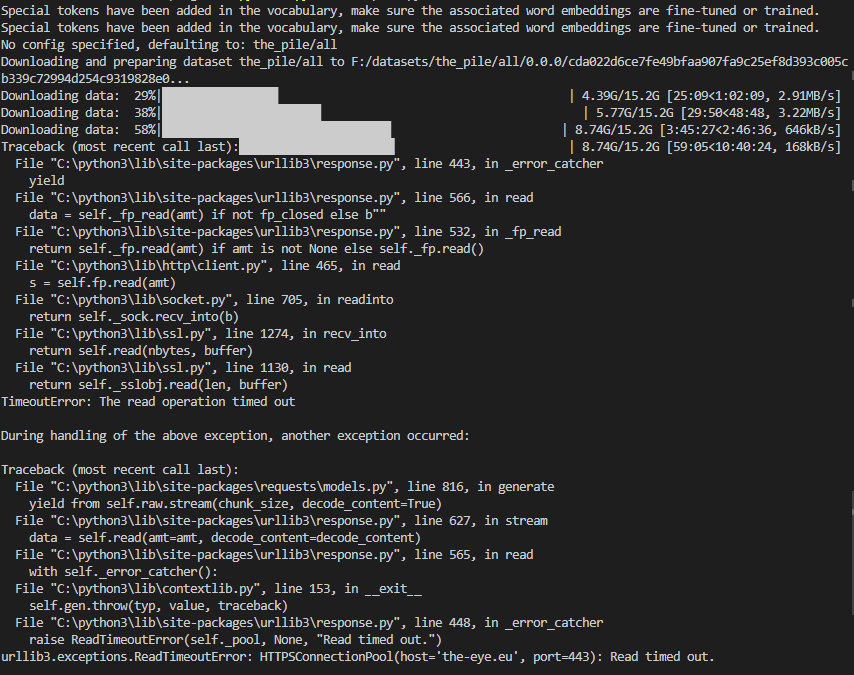
Here are the downloaded files:
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5604/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5604/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4686/comments | https://api.github.com/repos/huggingface/datasets/issues/4686/events | https://github.com/huggingface/datasets/pull/4686 | 1,305,974,924 | PR_kwDODunzps47d8Jf | 4,686 | Align logging with Transformers (again) | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4686). All of your documentation changes will be reflected on that endpoint.",
"I wasn't aware of https://github.com/huggingface/datasets/pull/1845 before opening this PR. This issue seems much more complex now ..."
] | "2022-07-15T12:24:29Z" | "2023-09-24T10:05:34Z" | "2023-07-11T18:29:27Z" | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4686.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4686",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4686.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4686"
} | Fix #2832 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4686/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6460 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6460/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6460/comments | https://api.github.com/repos/huggingface/datasets/issues/6460/events | https://github.com/huggingface/datasets/issues/6460 | 2,017,433,899 | I_kwDODunzps54P5kr | 6,460 | jsonlines files don't load with `load_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/41377532?v=4",
"events_url": "https://api.github.com/users/serenalotreck/events{/privacy}",
"followers_url": "https://api.github.com/users/serenalotreck/followers",
"following_url": "https://api.github.com/users/serenalotreck/following{/other_user}",
"gists_url": "https://api.github.com/users/serenalotreck/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/serenalotreck",
"id": 41377532,
"login": "serenalotreck",
"node_id": "MDQ6VXNlcjQxMzc3NTMy",
"organizations_url": "https://api.github.com/users/serenalotreck/orgs",
"received_events_url": "https://api.github.com/users/serenalotreck/received_events",
"repos_url": "https://api.github.com/users/serenalotreck/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/serenalotreck/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serenalotreck/subscriptions",
"type": "User",
"url": "https://api.github.com/users/serenalotreck"
} | [] | closed | false | null | [] | null | [
"Hi @serenalotreck,\r\n\r\nWe use Apache Arrow `pyarrow` to read jsonlines and it throws an error when trying to load your data files:\r\n```python\r\nIn [1]: import pyarrow as pa\r\n\r\nIn [2]: data = pa.json.read_json(\"train.jsonl\")\r\n---------------------------------------------------------------------------\r\nArrowInvalid Traceback (most recent call last)\r\n<ipython-input-14-e9b104832528> in <module>\r\n----> 1 data = pa.json.read_json(\"train.jsonl\")\r\n\r\n.../huggingface/datasets/venv/lib/python3.9/site-packages/pyarrow/_json.pyx in pyarrow._json.read_json()\r\n\r\n.../huggingface/datasets/venv/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()\r\n\r\n.../huggingface/datasets/venv/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: JSON parse error: Column(/ner/[]/[]/[]) changed from number to string in row 0\r\n```\r\n\r\nI think it has to do with the data structure of the fields \"ner\" (and also \"relations\"):\r\n```json\r\n\"ner\": [\r\n [\r\n [0, 4, \"Biochemical_process\"], \r\n [15, 16, \"Protein\"]\r\n ], \r\n```\r\nArrow interprets this data structure as an array, an arrays contain just a single data type: \r\n- when reading sequentially, it finds first the `0` and infers that the data is of type `number`;\r\n- when it finds the string `\"Biochemical_process\"`, it cannot cast it to number and throws the `ArrowInvalid` error\r\n\r\nOne solution could be to change the data structure of your data files. Any other ideas, @huggingface/datasets ?",
"Hi @albertvillanova, \r\n\r\nThanks for the explanation! To the best of my knowledge, arrays in a json [can contain multiple data types](https://docs.actian.com/ingres/11.2/index.html#page/SQLRef/Data_Types.htm), and I'm able to read these files with the `jsonlines` package. Is the requirement for arrays to only have one data type specific to PyArrow?\r\n\r\nI'd prefer to keep the data structure as is, since it's a specific input requirement for the models this data was generated for. Any thoughts on how to enable the use of `load_dataset` with this dataset would be great!",
"Hi again @serenalotreck,\r\n\r\nYes, it is specific to PyArrow: as far as I know, Arrow does not support arrays with multiple data types.\r\n\r\nAs this is related specifically to your dataset structure (and not the `datasets` library), I have created a dedicated issue in your dataset page: https://huggingface.co/datasets/slotreck/pickle/discussions/1\r\n\r\nLet's continue the discussion there! :hugs: "
] | "2023-11-29T21:20:11Z" | "2023-12-05T14:02:12Z" | "2023-12-05T13:30:53Z" | NONE | null | null | null | ### Describe the bug
While [the docs](https://huggingface.co/docs/datasets/upload_dataset#upload-dataset) seem to state that `.jsonl` is a supported extension for `datasets`, loading the dataset results in a `JSONDecodeError`.
### Steps to reproduce the bug
Code:
```
from datasets import load_dataset
dset = load_dataset('slotreck/pickle')
```
Traceback:
```
Downloading readme: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 925/925 [00:00<00:00, 3.11MB/s]
Downloading and preparing dataset json/slotreck--pickle to /mnt/home/lotrecks/.cache/huggingface/datasets/slotreck___json/slotreck--pickle-0c311f36ed032b04/0.0.0/8bb11242116d547c741b2e8a1f18598ffdd40a1d4f2a2872c7a28b697434bc96...
Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 589k/589k [00:00<00:00, 18.9MB/s]
Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 104k/104k [00:00<00:00, 4.61MB/s]
Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 170k/170k [00:00<00:00, 7.71MB/s]
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 3.77it/s]
Extracting data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 523.92it/s]
Generating train split: 0 examples [00:00, ? examples/s]Failed to read file '/mnt/home/lotrecks/.cache/huggingface/datasets/downloads/6ec07bb2f279c9377036af6948532513fa8f48244c672d2644a2d7018ee5c9cb' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Column(/ner/[]/[]/[]) changed from number to string in row 0
Traceback (most recent call last):
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/packaged_modules/json/json.py", line 144, in _generate_tables
dataset = json.load(f)
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/json/__init__.py", line 296, in load
parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw)
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/json/__init__.py", line 348, in loads
return _default_decoder.decode(s)
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/json/decoder.py", line 340, in decode
raise JSONDecodeError("Extra data", s, end)
json.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 3086)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/builder.py", line 1879, in _prepare_split_single
for _, table in generator:
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/packaged_modules/json/json.py", line 147, in _generate_tables
raise e
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/packaged_modules/json/json.py", line 122, in _generate_tables
io.BytesIO(batch), read_options=paj.ReadOptions(block_size=block_size)
File "pyarrow/_json.pyx", line 259, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 144, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Column(/ner/[]/[]/[]) changed from number to string in row 0
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/load.py", line 1815, in load_dataset
storage_options=storage_options,
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/builder.py", line 913, in download_and_prepare
**download_and_prepare_kwargs,
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/builder.py", line 1004, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/builder.py", line 1768, in _prepare_split
gen_kwargs=gen_kwargs, job_id=job_id, **_prepare_split_args
File "/mnt/home/lotrecks/anaconda3/envs/pickle/lib/python3.7/site-packages/datasets/builder.py", line 1912, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Expected behavior
For the dataset to be loaded without error.
### Environment info
- `datasets` version: 2.13.1
- Platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.7.12
- Huggingface_hub version: 0.15.1
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6460/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6460/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2565/comments | https://api.github.com/repos/huggingface/datasets/issues/2565/events | https://github.com/huggingface/datasets/pull/2565 | 932,445,439 | MDExOlB1bGxSZXF1ZXN0Njc5Nzg3NTI4 | 2,565 | Inject templates for ASR datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [
"Wait until #2567 is merged so we can benefit from the tagger :)",
"thanks for the feedback @lhoestq! i've added the new language codes and this PR should be ready for a merge :)"
] | "2021-06-29T10:02:01Z" | "2021-07-05T14:26:26Z" | "2021-07-05T14:26:26Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2565.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2565",
"merged_at": "2021-07-05T14:26:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2565.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2565"
} | This PR adds ASR templates for 5 of the most common speech datasets on the Hub, where "common" is defined by the number of models trained on them.
I also fixed a bunch of the tags in the READMEs 😎 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2565/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2565/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1336/comments | https://api.github.com/repos/huggingface/datasets/issues/1336/events | https://github.com/huggingface/datasets/pull/1336 | 759,706,932 | MDExOlB1bGxSZXF1ZXN0NTM0NjY0NjIw | 1,336 | Add dataset Yoruba BBC Topic Classification | {
"avatar_url": "https://avatars.githubusercontent.com/u/1858628?v=4",
"events_url": "https://api.github.com/users/michael-aloys/events{/privacy}",
"followers_url": "https://api.github.com/users/michael-aloys/followers",
"following_url": "https://api.github.com/users/michael-aloys/following{/other_user}",
"gists_url": "https://api.github.com/users/michael-aloys/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/michael-aloys",
"id": 1858628,
"login": "michael-aloys",
"node_id": "MDQ6VXNlcjE4NTg2Mjg=",
"organizations_url": "https://api.github.com/users/michael-aloys/orgs",
"received_events_url": "https://api.github.com/users/michael-aloys/received_events",
"repos_url": "https://api.github.com/users/michael-aloys/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/michael-aloys/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michael-aloys/subscriptions",
"type": "User",
"url": "https://api.github.com/users/michael-aloys"
} | [] | closed | false | null | [] | null | [] | "2020-12-08T19:12:18Z" | "2020-12-10T11:27:41Z" | "2020-12-10T11:27:41Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1336.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1336",
"merged_at": "2020-12-10T11:27:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1336.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1336"
} | Added new dataset Yoruba BBC Topic Classification
Contains loading script as well as dataset card including YAML tags. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1336/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/102/comments | https://api.github.com/repos/huggingface/datasets/issues/102/events | https://github.com/huggingface/datasets/pull/102 | 618,231,216 | MDExOlB1bGxSZXF1ZXN0NDE3OTk3MDQz | 102 | Run save infos | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Haha that cornell dialogue dataset - that ran for 3h on my computer as well. The `generate_examples` method in this script is one of the most inefficient code samples I've ever seen :D ",
"Indeed it's been 3 hours already\r\n```73111 examples [3:07:48, 2.40 examples/s]```"
] | "2020-05-14T13:27:26Z" | "2020-05-14T15:43:04Z" | "2020-05-14T15:43:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/102.diff",
"html_url": "https://github.com/huggingface/datasets/pull/102",
"merged_at": "2020-05-14T15:43:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/102.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/102"
} | I replaced the old checksum file with the new `dataset_infos.json` by running the script on almost all the datasets we have. The only one that is still running on my side is the cornell dialog | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/102/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/102/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5012 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5012/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5012/comments | https://api.github.com/repos/huggingface/datasets/issues/5012/events | https://github.com/huggingface/datasets/issues/5012 | 1,382,851,096 | I_kwDODunzps5SbKIY | 5,012 | Force JSON format regardless of file naming on S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/112650299?v=4",
"events_url": "https://api.github.com/users/junwang-wish/events{/privacy}",
"followers_url": "https://api.github.com/users/junwang-wish/followers",
"following_url": "https://api.github.com/users/junwang-wish/following{/other_user}",
"gists_url": "https://api.github.com/users/junwang-wish/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/junwang-wish",
"id": 112650299,
"login": "junwang-wish",
"node_id": "U_kgDOBrboOw",
"organizations_url": "https://api.github.com/users/junwang-wish/orgs",
"received_events_url": "https://api.github.com/users/junwang-wish/received_events",
"repos_url": "https://api.github.com/users/junwang-wish/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/junwang-wish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junwang-wish/subscriptions",
"type": "User",
"url": "https://api.github.com/users/junwang-wish"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! Support for URIs like `s3://...` is not implemented yet in `data_files=`. You can use the HTTP URL instead if your data is public in the meantime",
"Hi,\r\nI want to make sure I understand this response. I have a set of files on S3 that are private for security reasons. Because they are not public files I cannot read those files (many are parquet) into my hf notebooks in Kaggle? That can't be correct, can it? ",
"Hi ! There is a discussion at https://github.com/huggingface/datasets/issues/5281\r\n\r\nUsing the latest `datasets` 2.11 you can try passing fsspec URLs to private buckets to `data_files` in `load_dataset()`. Though this is still experimental and undocumented, so feedback is welcome. You may not have the best experience though, since anything related to performance and caching hasn't been tested properly yet.",
"closing this one since data_files supports fsspec (still experimental/untested/undocumented for s3 though)"
] | "2022-09-22T18:28:15Z" | "2023-08-16T09:58:36Z" | "2023-08-16T09:58:36Z" | NONE | null | null | null | I have a file on S3 created by Data Version Control, it looks like `s3://dvc/ac/badff5b134382a0f25248f1b45d7b2` but contains a json file. If I run
```python
dataset = load_dataset(
"json",
data_files='s3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
)
```
It gives me
```
InvalidSchema: No connection adapters were found for 's3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
```
However, I cannot go ahead and change the names of the s3 file. Is there a way to "force" load a S3 url with certain decoder (JSON, CSV, etc.) regardless of s3 URL naming? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5012/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5012/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4204 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4204/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4204/comments | https://api.github.com/repos/huggingface/datasets/issues/4204/events | https://github.com/huggingface/datasets/pull/4204 | 1,212,431,764 | PR_kwDODunzps42oN0j | 4,204 | Add Recall Metric Card | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "https://api.github.com/users/emibaylor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/emibaylor",
"id": 27527747,
"login": "emibaylor",
"node_id": "MDQ6VXNlcjI3NTI3NzQ3",
"organizations_url": "https://api.github.com/users/emibaylor/orgs",
"received_events_url": "https://api.github.com/users/emibaylor/received_events",
"repos_url": "https://api.github.com/users/emibaylor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/emibaylor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emibaylor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/emibaylor"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"This looks good to me! "
] | "2022-04-22T14:24:26Z" | "2022-05-03T13:23:23Z" | "2022-05-03T13:16:24Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4204.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4204",
"merged_at": "2022-05-03T13:16:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4204.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4204"
} | What this PR mainly does:
- add metric card for recall metric
- update docs in recall python file
Note: I've also included a .json file with all of the metric card information. I've started compiling the relevant information in this type of .json files, and then using a script I wrote to generate the formatted metric card, as well as the docs to go in the .py file. I figured I'd upload the .json because it could be useful, especially if I also make a PR with the script I'm using (let me know if that's something you think would be beneficial!) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4204/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4204/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2933 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2933/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2933/comments | https://api.github.com/repos/huggingface/datasets/issues/2933/events | https://github.com/huggingface/datasets/pull/2933 | 999,392,566 | PR_kwDODunzps4r5MHs | 2,933 | Replace script_version with revision | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"I'm also fine with the removal in 1.15"
] | "2021-09-17T14:04:39Z" | "2021-09-20T09:52:10Z" | "2021-09-20T09:52:10Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2933.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2933",
"merged_at": "2021-09-20T09:52:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2933.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2933"
} | As discussed in https://github.com/huggingface/datasets/pull/2718#discussion_r707013278, the parameter name `script_version` is no longer applicable to datasets without loading script (i.e., datasets only with raw data files).
This PR replaces the parameter name `script_version` with `revision`.
This way, we are also aligned with:
- Transformers: `AutoTokenizer.from_pretrained(..., revision=...)`
- Hub: `HfApi.dataset_info(..., revision=...)`, `HfApi.upload_file(..., revision=...)` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2933/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2933/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6242/comments | https://api.github.com/repos/huggingface/datasets/issues/6242/events | https://github.com/huggingface/datasets/issues/6242 | 1,896,899,123 | I_kwDODunzps5xEGIz | 6,242 | Data alteration when loading dataset with unspecified inner sequence length | {
"avatar_url": "https://avatars.githubusercontent.com/u/45557362?v=4",
"events_url": "https://api.github.com/users/qgallouedec/events{/privacy}",
"followers_url": "https://api.github.com/users/qgallouedec/followers",
"following_url": "https://api.github.com/users/qgallouedec/following{/other_user}",
"gists_url": "https://api.github.com/users/qgallouedec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qgallouedec",
"id": 45557362,
"login": "qgallouedec",
"node_id": "MDQ6VXNlcjQ1NTU3MzYy",
"organizations_url": "https://api.github.com/users/qgallouedec/orgs",
"received_events_url": "https://api.github.com/users/qgallouedec/received_events",
"repos_url": "https://api.github.com/users/qgallouedec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qgallouedec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qgallouedec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qgallouedec"
} | [] | closed | false | null | [] | null | [
"While this issue may seem specific, it led to a silent problem in my workflow that took days to diagnose. If this feature is not intended to be supported, an error should be raised when encountering this configuration to prevent such issues.",
"Thanks for reporting! This is a MRE:\r\n\r\n```python\r\nimport pyarrow as pa\r\nfrom datasets.table import cast_array_to_feature\r\nfrom datasets import Sequence, Value\r\ndata = [\r\n [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]],\r\n [[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]],\r\n]\r\narr = pa.array(data, pa.list_(pa.list_(pa.float32(), 3)))\r\ncast_array_to_feature(arr, Sequence(Sequence(Value(\"float32\"))))\r\n```\r\n\r\nI've opened a PR with a fix."
] | "2023-09-14T16:12:45Z" | "2023-09-19T17:53:18Z" | "2023-09-19T17:53:18Z" | CONTRIBUTOR | null | null | null | ### Describe the bug
When a dataset saved with a specified inner sequence length is loaded without specifying that length, the original data is altered and becomes inconsistent.
### Steps to reproduce the bug
```python
from datasets import Dataset, Features, Value, Sequence, load_dataset
# Repository ID
repo_id = "my_repo_id"
# Define features with a specific length of 3 for each inner sequence
specified_features = Features({"key": Sequence(Sequence(Value("float32"), length=3))})
# Create a dataset with the specified features
data = [
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]],
[[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]],
]
dataset = Dataset.from_dict({"key": data}, features=specified_features)
# Push the dataset to the hub
dataset.push_to_hub(repo_id)
# Define features without specifying the length
unspecified_features = Features({"key": Sequence(Sequence(Value("float32")))})
# Load the dataset from the hub with this new feature definition
dataset = load_dataset(f"qgallouedec/{repo_id}", split="train", features=unspecified_features)
# The obtained data is altered
print(dataset.to_dict()) # {'key': [[[1.0], [2.0]], [[3.0], [4.0]]]}
```
### Expected behavior
```python
print(dataset.to_dict()) # {'key': [[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]], [[7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]]}
```
### Environment info
- `datasets` version: 2.14.4
- Platform: Linux-6.2.0-32-generic-x86_64-with-glibc2.35
- Python version: 3.9.12
- Huggingface_hub version: 0.15.1
- PyArrow version: 12.0.1
- Pandas version: 2.0.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6242/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3684/comments | https://api.github.com/repos/huggingface/datasets/issues/3684/events | https://github.com/huggingface/datasets/pull/3684 | 1,125,133,664 | PR_kwDODunzps4yIOer | 3,684 | [fix]: iwslt2017 download urls | {
"avatar_url": "https://avatars.githubusercontent.com/u/48395294?v=4",
"events_url": "https://api.github.com/users/msarmi9/events{/privacy}",
"followers_url": "https://api.github.com/users/msarmi9/followers",
"following_url": "https://api.github.com/users/msarmi9/following{/other_user}",
"gists_url": "https://api.github.com/users/msarmi9/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/msarmi9",
"id": 48395294,
"login": "msarmi9",
"node_id": "MDQ6VXNlcjQ4Mzk1Mjk0",
"organizations_url": "https://api.github.com/users/msarmi9/orgs",
"received_events_url": "https://api.github.com/users/msarmi9/received_events",
"repos_url": "https://api.github.com/users/msarmi9/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/msarmi9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msarmi9/subscriptions",
"type": "User",
"url": "https://api.github.com/users/msarmi9"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for the fix ! Do you know where this new URL comes from ?\r\n\r\nAlso we try to not use Google Drive if possible, since it has download quota limitations. Do you know if the data is available from another host than Google Drive ?",
"Oh, I found it just by following the link from the [IWSLT2017 homepage](https://wit3.fbk.eu/2017-01). Not sure if it's available from another host.",
"Ok cool ! I guess it's ok to use this URL for now, and we can see later if we need to change it.\r\n\r\nBefore merging, could you update the `dataset_infos.json` file by running this command please ?\r\n```\r\ndatasets-cli test ./datasets/iwslt2017 --save_infos --all_configs\r\n```",
"sure thing. lmk if there's anything else i can do to help.",
"just checking in. is there anything i can do to help on my end to get this merged? (the dummy data tests are failing due an incorrect path, i think)",
"Thanks ! I also fixed the dummy data :)\r\n\r\nTo fix the CI, feel free to merge the `master` branch into your PR.\r\n\r\nIf you have some time, feel free to also take a look at the missing YAML tags at the top of the README.md file of this dataset:\r\n```\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE YAML tags:\r\nE missing 9 required tags: 'annotations_creators', 'language_creators', 'languages', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'\r\n```\r\nyou can use the dataset tagging app here: https://huggingface.co/spaces/huggingface/datasets-tagging",
"I guess this PR was superseded by this other:\r\n- #4481\r\n\r\nThanks for your contribution anyway, @msarmi9. "
] | "2022-02-06T07:56:55Z" | "2022-09-22T16:20:19Z" | "2022-09-22T16:20:18Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3684.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3684",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3684.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3684"
} | Fixes #2076. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3684/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3684/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6005 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6005/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6005/comments | https://api.github.com/repos/huggingface/datasets/issues/6005/events | https://github.com/huggingface/datasets/pull/6005 | 1,788,103,576 | PR_kwDODunzps5UoJ91 | 6,005 | Drop Python 3.7 support | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006152 / 0.011353 (-0.005200) | 0.003916 / 0.011008 (-0.007092) | 0.097355 / 0.038508 (0.058847) | 0.037228 / 0.023109 (0.014119) | 0.315753 / 0.275898 (0.039855) | 0.387949 / 0.323480 (0.064470) | 0.004804 / 0.007986 (-0.003181) | 0.002975 / 0.004328 (-0.001353) | 0.076932 / 0.004250 (0.072682) | 0.053497 / 0.037052 (0.016445) | 0.331143 / 0.258489 (0.072654) | 0.388347 / 0.293841 (0.094506) | 0.027535 / 0.128546 (-0.101011) | 0.008509 / 0.075646 (-0.067137) | 0.312639 / 0.419271 (-0.106632) | 0.047212 / 0.043533 (0.003679) | 0.316875 / 0.255139 (0.061736) | 0.352191 / 0.283200 (0.068992) | 0.021380 / 0.141683 (-0.120303) | 1.541401 / 1.452155 (0.089247) | 1.519420 / 1.492716 (0.026704) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206332 / 0.018006 (0.188326) | 0.412252 / 0.000490 (0.411762) | 0.005119 / 0.000200 (0.004919) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023856 / 0.037411 (-0.013556) | 0.098216 / 0.014526 (0.083691) | 0.106553 / 0.176557 (-0.070003) | 0.168767 / 0.737135 (-0.568369) | 0.109244 / 0.296338 (-0.187094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457580 / 0.215209 (0.242371) | 4.583246 / 2.077655 (2.505591) | 2.296356 / 1.504120 (0.792236) | 2.096216 / 1.541195 (0.555021) | 2.159086 / 1.468490 (0.690596) | 0.557905 / 4.584777 (-4.026872) | 3.345910 / 3.745712 (-0.399802) | 1.767436 / 5.269862 (-3.502426) | 1.021583 / 4.565676 (-3.544094) | 0.067265 / 0.424275 (-0.357011) | 0.011411 / 0.007607 (0.003804) | 0.559841 / 0.226044 (0.333797) | 5.586892 / 2.268929 (3.317963) | 2.735520 / 55.444624 (-52.709104) | 2.429393 / 6.876477 (-4.447084) | 2.544901 / 2.142072 (0.402829) | 0.667603 / 4.805227 (-4.137625) | 0.136244 / 6.500664 (-6.364421) | 0.066961 / 0.075469 (-0.008508) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206529 / 1.841788 (-0.635259) | 13.988306 / 8.074308 (5.913998) | 13.481813 / 10.191392 (3.290421) | 0.161901 / 0.680424 (-0.518523) | 0.016850 / 0.534201 (-0.517351) | 0.367657 / 0.579283 (-0.211626) | 0.393343 / 0.434364 (-0.041021) | 0.465288 / 0.540337 (-0.075050) | 0.559888 / 1.386936 (-0.827048) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005956 / 0.011353 (-0.005397) | 0.003734 / 0.011008 (-0.007274) | 0.077841 / 0.038508 (0.039333) | 0.036532 / 0.023109 (0.013422) | 0.438923 / 0.275898 (0.163025) | 0.490133 / 0.323480 (0.166653) | 0.004651 / 0.007986 (-0.003335) | 0.002881 / 0.004328 (-0.001448) | 0.077868 / 0.004250 (0.073618) | 0.051700 / 0.037052 (0.014647) | 0.448018 / 0.258489 (0.189529) | 0.500304 / 0.293841 (0.206464) | 0.029051 / 0.128546 (-0.099496) | 0.008498 / 0.075646 (-0.067148) | 0.082932 / 0.419271 (-0.336339) | 0.043665 / 0.043533 (0.000132) | 0.431613 / 0.255139 (0.176474) | 0.458749 / 0.283200 (0.175549) | 0.021951 / 0.141683 (-0.119731) | 1.556043 / 1.452155 (0.103888) | 1.588391 / 1.492716 (0.095675) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220674 / 0.018006 (0.202667) | 0.415408 / 0.000490 (0.414918) | 0.002613 / 0.000200 (0.002413) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025548 / 0.037411 (-0.011863) | 0.103633 / 0.014526 (0.089107) | 0.115193 / 0.176557 (-0.061364) | 0.163971 / 0.737135 (-0.573164) | 0.114754 / 0.296338 (-0.181585) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456823 / 0.215209 (0.241614) | 4.569950 / 2.077655 (2.492296) | 2.196339 / 1.504120 (0.692219) | 1.985822 / 1.541195 (0.444628) | 2.044083 / 1.468490 (0.575593) | 0.567919 / 4.584777 (-4.016858) | 3.397515 / 3.745712 (-0.348197) | 1.741087 / 5.269862 (-3.528775) | 1.041237 / 4.565676 (-3.524440) | 0.068963 / 0.424275 (-0.355313) | 0.011677 / 0.007607 (0.004070) | 0.565010 / 0.226044 (0.338966) | 5.625886 / 2.268929 (3.356957) | 2.670658 / 55.444624 (-52.773967) | 2.300279 / 6.876477 (-4.576198) | 2.392178 / 2.142072 (0.250106) | 0.680226 / 4.805227 (-4.125001) | 0.139119 / 6.500664 (-6.361545) | 0.067953 / 0.075469 (-0.007516) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303280 / 1.841788 (-0.538507) | 14.458686 / 8.074308 (6.384378) | 14.409369 / 10.191392 (4.217977) | 0.144581 / 0.680424 (-0.535843) | 0.016634 / 0.534201 (-0.517567) | 0.364607 / 0.579283 (-0.214676) | 0.394521 / 0.434364 (-0.039843) | 0.433417 / 0.540337 (-0.106921) | 0.527127 / 1.386936 (-0.859809) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006245 / 0.011353 (-0.005108) | 0.003871 / 0.011008 (-0.007138) | 0.098823 / 0.038508 (0.060315) | 0.039853 / 0.023109 (0.016744) | 0.314989 / 0.275898 (0.039091) | 0.376733 / 0.323480 (0.053254) | 0.004754 / 0.007986 (-0.003232) | 0.002971 / 0.004328 (-0.001357) | 0.078451 / 0.004250 (0.074201) | 0.053160 / 0.037052 (0.016107) | 0.324443 / 0.258489 (0.065954) | 0.361488 / 0.293841 (0.067647) | 0.027942 / 0.128546 (-0.100604) | 0.008535 / 0.075646 (-0.067111) | 0.315526 / 0.419271 (-0.103745) | 0.045706 / 0.043533 (0.002174) | 0.329614 / 0.255139 (0.074475) | 0.336339 / 0.283200 (0.053139) | 0.021278 / 0.141683 (-0.120405) | 1.529710 / 1.452155 (0.077555) | 1.566833 / 1.492716 (0.074116) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215263 / 0.018006 (0.197257) | 0.440320 / 0.000490 (0.439830) | 0.002627 / 0.000200 (0.002427) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023971 / 0.037411 (-0.013441) | 0.100549 / 0.014526 (0.086023) | 0.106995 / 0.176557 (-0.069561) | 0.169630 / 0.737135 (-0.567505) | 0.111614 / 0.296338 (-0.184724) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424911 / 0.215209 (0.209702) | 4.246920 / 2.077655 (2.169266) | 1.923321 / 1.504120 (0.419202) | 1.714795 / 1.541195 (0.173600) | 1.772906 / 1.468490 (0.304416) | 0.554676 / 4.584777 (-4.030101) | 3.478896 / 3.745712 (-0.266816) | 2.800494 / 5.269862 (-2.469368) | 1.382630 / 4.565676 (-3.183047) | 0.067271 / 0.424275 (-0.357004) | 0.010967 / 0.007607 (0.003360) | 0.526769 / 0.226044 (0.300725) | 5.288564 / 2.268929 (3.019636) | 2.337459 / 55.444624 (-53.107165) | 1.999975 / 6.876477 (-4.876502) | 2.102680 / 2.142072 (-0.039392) | 0.672181 / 4.805227 (-4.133046) | 0.135097 / 6.500664 (-6.365567) | 0.066950 / 0.075469 (-0.008519) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.264365 / 1.841788 (-0.577423) | 14.282440 / 8.074308 (6.208132) | 14.220200 / 10.191392 (4.028808) | 0.139055 / 0.680424 (-0.541369) | 0.016681 / 0.534201 (-0.517520) | 0.367936 / 0.579283 (-0.211348) | 0.393959 / 0.434364 (-0.040404) | 0.424438 / 0.540337 (-0.115900) | 0.508065 / 1.386936 (-0.878872) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006514 / 0.011353 (-0.004839) | 0.003890 / 0.011008 (-0.007118) | 0.078871 / 0.038508 (0.040363) | 0.038080 / 0.023109 (0.014971) | 0.358282 / 0.275898 (0.082384) | 0.430654 / 0.323480 (0.107174) | 0.005712 / 0.007986 (-0.002273) | 0.003030 / 0.004328 (-0.001299) | 0.078636 / 0.004250 (0.074386) | 0.057771 / 0.037052 (0.020719) | 0.368814 / 0.258489 (0.110325) | 0.437047 / 0.293841 (0.143206) | 0.029470 / 0.128546 (-0.099076) | 0.008523 / 0.075646 (-0.067124) | 0.083334 / 0.419271 (-0.335938) | 0.044505 / 0.043533 (0.000972) | 0.357484 / 0.255139 (0.102345) | 0.393839 / 0.283200 (0.110639) | 0.023340 / 0.141683 (-0.118343) | 1.561033 / 1.452155 (0.108878) | 1.595560 / 1.492716 (0.102844) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204149 / 0.018006 (0.186143) | 0.442747 / 0.000490 (0.442257) | 0.003105 / 0.000200 (0.002905) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027002 / 0.037411 (-0.010409) | 0.105595 / 0.014526 (0.091070) | 0.108695 / 0.176557 (-0.067861) | 0.163182 / 0.737135 (-0.573953) | 0.114999 / 0.296338 (-0.181339) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.483713 / 0.215209 (0.268504) | 4.836063 / 2.077655 (2.758409) | 2.488072 / 1.504120 (0.983952) | 2.289556 / 1.541195 (0.748361) | 2.342912 / 1.468490 (0.874422) | 0.565937 / 4.584777 (-4.018840) | 3.479085 / 3.745712 (-0.266627) | 1.770922 / 5.269862 (-3.498940) | 1.046084 / 4.565676 (-3.519592) | 0.067857 / 0.424275 (-0.356418) | 0.011283 / 0.007607 (0.003676) | 0.592966 / 0.226044 (0.366921) | 5.932842 / 2.268929 (3.663914) | 2.956252 / 55.444624 (-52.488372) | 2.602704 / 6.876477 (-4.273772) | 2.715625 / 2.142072 (0.573552) | 0.674299 / 4.805227 (-4.130929) | 0.136039 / 6.500664 (-6.364625) | 0.067629 / 0.075469 (-0.007840) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.333734 / 1.841788 (-0.508054) | 14.561943 / 8.074308 (6.487634) | 14.455385 / 10.191392 (4.263993) | 0.132020 / 0.680424 (-0.548404) | 0.016893 / 0.534201 (-0.517308) | 0.367146 / 0.579283 (-0.212137) | 0.399623 / 0.434364 (-0.034741) | 0.432658 / 0.540337 (-0.107680) | 0.530475 / 1.386936 (-0.856461) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006045 / 0.011353 (-0.005308) | 0.003906 / 0.011008 (-0.007103) | 0.097558 / 0.038508 (0.059050) | 0.038827 / 0.023109 (0.015718) | 0.393564 / 0.275898 (0.117666) | 0.442459 / 0.323480 (0.118980) | 0.004792 / 0.007986 (-0.003194) | 0.002984 / 0.004328 (-0.001345) | 0.076419 / 0.004250 (0.072169) | 0.053606 / 0.037052 (0.016554) | 0.409743 / 0.258489 (0.151254) | 0.445753 / 0.293841 (0.151912) | 0.027753 / 0.128546 (-0.100793) | 0.008428 / 0.075646 (-0.067219) | 0.310267 / 0.419271 (-0.109004) | 0.057582 / 0.043533 (0.014049) | 0.396624 / 0.255139 (0.141485) | 0.416288 / 0.283200 (0.133089) | 0.029048 / 0.141683 (-0.112635) | 1.495362 / 1.452155 (0.043207) | 1.546331 / 1.492716 (0.053615) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203832 / 0.018006 (0.185826) | 0.423649 / 0.000490 (0.423160) | 0.004533 / 0.000200 (0.004333) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023084 / 0.037411 (-0.014328) | 0.100503 / 0.014526 (0.085977) | 0.105058 / 0.176557 (-0.071499) | 0.168506 / 0.737135 (-0.568629) | 0.112019 / 0.296338 (-0.184320) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425877 / 0.215209 (0.210668) | 4.251278 / 2.077655 (2.173624) | 1.931339 / 1.504120 (0.427219) | 1.730578 / 1.541195 (0.189383) | 1.750637 / 1.468490 (0.282147) | 0.559307 / 4.584777 (-4.025470) | 3.461665 / 3.745712 (-0.284047) | 2.826959 / 5.269862 (-2.442903) | 1.418448 / 4.565676 (-3.147229) | 0.067881 / 0.424275 (-0.356394) | 0.011394 / 0.007607 (0.003787) | 0.533226 / 0.226044 (0.307181) | 5.341849 / 2.268929 (3.072921) | 2.367832 / 55.444624 (-53.076792) | 2.027240 / 6.876477 (-4.849236) | 2.095852 / 2.142072 (-0.046220) | 0.673790 / 4.805227 (-4.131437) | 0.136044 / 6.500664 (-6.364620) | 0.066350 / 0.075469 (-0.009119) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203740 / 1.841788 (-0.638048) | 13.720879 / 8.074308 (5.646571) | 13.405939 / 10.191392 (3.214547) | 0.146792 / 0.680424 (-0.533632) | 0.016844 / 0.534201 (-0.517357) | 0.373455 / 0.579283 (-0.205828) | 0.394596 / 0.434364 (-0.039768) | 0.464715 / 0.540337 (-0.075623) | 0.558931 / 1.386936 (-0.828005) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006118 / 0.011353 (-0.005235) | 0.003817 / 0.011008 (-0.007191) | 0.077494 / 0.038508 (0.038985) | 0.037507 / 0.023109 (0.014398) | 0.387030 / 0.275898 (0.111132) | 0.437352 / 0.323480 (0.113872) | 0.004810 / 0.007986 (-0.003176) | 0.002935 / 0.004328 (-0.001394) | 0.077143 / 0.004250 (0.072892) | 0.053986 / 0.037052 (0.016933) | 0.393164 / 0.258489 (0.134675) | 0.449603 / 0.293841 (0.155762) | 0.029303 / 0.128546 (-0.099244) | 0.008481 / 0.075646 (-0.067165) | 0.083363 / 0.419271 (-0.335908) | 0.043877 / 0.043533 (0.000344) | 0.378175 / 0.255139 (0.123036) | 0.403996 / 0.283200 (0.120797) | 0.021688 / 0.141683 (-0.119995) | 1.541606 / 1.452155 (0.089452) | 1.552996 / 1.492716 (0.060280) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236759 / 0.018006 (0.218752) | 0.416221 / 0.000490 (0.415732) | 0.000862 / 0.000200 (0.000662) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025543 / 0.037411 (-0.011868) | 0.101731 / 0.014526 (0.087206) | 0.108482 / 0.176557 (-0.068075) | 0.160290 / 0.737135 (-0.576845) | 0.111392 / 0.296338 (-0.184946) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457767 / 0.215209 (0.242558) | 4.565976 / 2.077655 (2.488321) | 2.245413 / 1.504120 (0.741294) | 2.031458 / 1.541195 (0.490264) | 2.073193 / 1.468490 (0.604702) | 0.560461 / 4.584777 (-4.024316) | 3.422536 / 3.745712 (-0.323176) | 2.977017 / 5.269862 (-2.292845) | 1.377021 / 4.565676 (-3.188655) | 0.068444 / 0.424275 (-0.355831) | 0.011036 / 0.007607 (0.003429) | 0.571501 / 0.226044 (0.345456) | 5.702652 / 2.268929 (3.433723) | 2.727132 / 55.444624 (-52.717492) | 2.399269 / 6.876477 (-4.477208) | 2.574281 / 2.142072 (0.432208) | 0.682600 / 4.805227 (-4.122627) | 0.136943 / 6.500664 (-6.363722) | 0.067126 / 0.075469 (-0.008343) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.322196 / 1.841788 (-0.519592) | 14.239509 / 8.074308 (6.165201) | 14.235779 / 10.191392 (4.044387) | 0.148262 / 0.680424 (-0.532162) | 0.016566 / 0.534201 (-0.517635) | 0.364034 / 0.579283 (-0.215249) | 0.399157 / 0.434364 (-0.035207) | 0.426348 / 0.540337 (-0.113990) | 0.520804 / 1.386936 (-0.866132) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007808 / 0.011353 (-0.003545) | 0.004706 / 0.011008 (-0.006303) | 0.100530 / 0.038508 (0.062022) | 0.052052 / 0.023109 (0.028943) | 0.419300 / 0.275898 (0.143402) | 0.488451 / 0.323480 (0.164971) | 0.006350 / 0.007986 (-0.001636) | 0.003875 / 0.004328 (-0.000453) | 0.076489 / 0.004250 (0.072238) | 0.077554 / 0.037052 (0.040502) | 0.435863 / 0.258489 (0.177373) | 0.483241 / 0.293841 (0.189400) | 0.037518 / 0.128546 (-0.091028) | 0.009857 / 0.075646 (-0.065789) | 0.340933 / 0.419271 (-0.078339) | 0.087046 / 0.043533 (0.043514) | 0.410721 / 0.255139 (0.155582) | 0.428995 / 0.283200 (0.145795) | 0.041701 / 0.141683 (-0.099982) | 1.821017 / 1.452155 (0.368862) | 1.837021 / 1.492716 (0.344305) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228444 / 0.018006 (0.210438) | 0.480446 / 0.000490 (0.479956) | 0.004963 / 0.000200 (0.004763) | 0.000101 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032485 / 0.037411 (-0.004926) | 0.096500 / 0.014526 (0.081974) | 0.111547 / 0.176557 (-0.065010) | 0.178842 / 0.737135 (-0.558294) | 0.111099 / 0.296338 (-0.185240) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467159 / 0.215209 (0.251950) | 4.701676 / 2.077655 (2.624021) | 2.390560 / 1.504120 (0.886440) | 2.197722 / 1.541195 (0.656528) | 2.264705 / 1.468490 (0.796215) | 0.568667 / 4.584777 (-4.016110) | 4.200724 / 3.745712 (0.455012) | 3.777625 / 5.269862 (-1.492236) | 2.372451 / 4.565676 (-2.193225) | 0.067562 / 0.424275 (-0.356714) | 0.008947 / 0.007607 (0.001340) | 0.556910 / 0.226044 (0.330865) | 5.528927 / 2.268929 (3.259998) | 2.902780 / 55.444624 (-52.541844) | 2.507933 / 6.876477 (-4.368544) | 2.734627 / 2.142072 (0.592554) | 0.683305 / 4.805227 (-4.121922) | 0.158288 / 6.500664 (-6.342376) | 0.071252 / 0.075469 (-0.004217) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.487502 / 1.841788 (-0.354286) | 22.193341 / 8.074308 (14.119033) | 15.922607 / 10.191392 (5.731215) | 0.172189 / 0.680424 (-0.508235) | 0.021502 / 0.534201 (-0.512699) | 0.471198 / 0.579283 (-0.108085) | 0.475979 / 0.434364 (0.041615) | 0.544675 / 0.540337 (0.004338) | 0.756102 / 1.386936 (-0.630834) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007635 / 0.011353 (-0.003717) | 0.004614 / 0.011008 (-0.006394) | 0.075852 / 0.038508 (0.037344) | 0.049700 / 0.023109 (0.026591) | 0.425957 / 0.275898 (0.150059) | 0.512590 / 0.323480 (0.189110) | 0.006921 / 0.007986 (-0.001065) | 0.003714 / 0.004328 (-0.000615) | 0.075536 / 0.004250 (0.071286) | 0.070206 / 0.037052 (0.033153) | 0.455706 / 0.258489 (0.197217) | 0.512231 / 0.293841 (0.218390) | 0.036685 / 0.128546 (-0.091861) | 0.009793 / 0.075646 (-0.065853) | 0.084208 / 0.419271 (-0.335064) | 0.065262 / 0.043533 (0.021729) | 0.423761 / 0.255139 (0.168622) | 0.456791 / 0.283200 (0.173591) | 0.044539 / 0.141683 (-0.097144) | 1.797029 / 1.452155 (0.344874) | 1.864124 / 1.492716 (0.371408) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.366840 / 0.018006 (0.348834) | 0.479254 / 0.000490 (0.478765) | 0.070383 / 0.000200 (0.070183) | 0.000762 / 0.000054 (0.000707) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034233 / 0.037411 (-0.003178) | 0.103140 / 0.014526 (0.088614) | 0.117099 / 0.176557 (-0.059457) | 0.178532 / 0.737135 (-0.558603) | 0.120092 / 0.296338 (-0.176247) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.492993 / 0.215209 (0.277784) | 4.878776 / 2.077655 (2.801121) | 2.566666 / 1.504120 (1.062547) | 2.356383 / 1.541195 (0.815188) | 2.454723 / 1.468490 (0.986233) | 0.571432 / 4.584777 (-4.013345) | 4.240554 / 3.745712 (0.494842) | 7.509259 / 5.269862 (2.239398) | 4.040294 / 4.565676 (-0.525382) | 0.067409 / 0.424275 (-0.356866) | 0.008657 / 0.007607 (0.001050) | 0.585751 / 0.226044 (0.359707) | 5.967668 / 2.268929 (3.698739) | 3.195573 / 55.444624 (-52.249052) | 2.839772 / 6.876477 (-4.036704) | 2.806319 / 2.142072 (0.664246) | 0.681502 / 4.805227 (-4.123725) | 0.158673 / 6.500664 (-6.341991) | 0.073224 / 0.075469 (-0.002245) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.623335 / 1.841788 (-0.218453) | 22.490806 / 8.074308 (14.416498) | 16.762435 / 10.191392 (6.571043) | 0.180961 / 0.680424 (-0.499463) | 0.022716 / 0.534201 (-0.511485) | 0.472910 / 0.579283 (-0.106373) | 0.471616 / 0.434364 (0.037252) | 0.548192 / 0.540337 (0.007854) | 0.734357 / 1.386936 (-0.652579) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005858 / 0.011353 (-0.005495) | 0.003512 / 0.011008 (-0.007497) | 0.079739 / 0.038508 (0.041231) | 0.057736 / 0.023109 (0.034627) | 0.317640 / 0.275898 (0.041742) | 0.354157 / 0.323480 (0.030677) | 0.004772 / 0.007986 (-0.003214) | 0.002824 / 0.004328 (-0.001504) | 0.063288 / 0.004250 (0.059037) | 0.049542 / 0.037052 (0.012489) | 0.323974 / 0.258489 (0.065485) | 0.372149 / 0.293841 (0.078308) | 0.026841 / 0.128546 (-0.101705) | 0.007846 / 0.075646 (-0.067800) | 0.262546 / 0.419271 (-0.156725) | 0.051952 / 0.043533 (0.008420) | 0.319439 / 0.255139 (0.064300) | 0.343862 / 0.283200 (0.060663) | 0.027021 / 0.141683 (-0.114662) | 1.445211 / 1.452155 (-0.006944) | 1.485006 / 1.492716 (-0.007711) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183174 / 0.018006 (0.165167) | 0.422794 / 0.000490 (0.422304) | 0.004148 / 0.000200 (0.003948) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023037 / 0.037411 (-0.014374) | 0.071300 / 0.014526 (0.056775) | 0.083022 / 0.176557 (-0.093535) | 0.146215 / 0.737135 (-0.590920) | 0.082549 / 0.296338 (-0.213789) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422846 / 0.215209 (0.207637) | 4.215280 / 2.077655 (2.137626) | 2.256802 / 1.504120 (0.752682) | 2.056867 / 1.541195 (0.515673) | 2.102478 / 1.468490 (0.633988) | 0.497552 / 4.584777 (-4.087225) | 3.049716 / 3.745712 (-0.695996) | 4.209227 / 5.269862 (-1.060635) | 2.599947 / 4.565676 (-1.965730) | 0.059131 / 0.424275 (-0.365144) | 0.006459 / 0.007607 (-0.001148) | 0.495047 / 0.226044 (0.269003) | 4.952332 / 2.268929 (2.683404) | 2.675260 / 55.444624 (-52.769365) | 2.333223 / 6.876477 (-4.543254) | 2.449573 / 2.142072 (0.307500) | 0.583420 / 4.805227 (-4.221807) | 0.125140 / 6.500664 (-6.375524) | 0.060209 / 0.075469 (-0.015260) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.215033 / 1.841788 (-0.626755) | 18.101107 / 8.074308 (10.026799) | 13.489222 / 10.191392 (3.297830) | 0.147122 / 0.680424 (-0.533302) | 0.016567 / 0.534201 (-0.517634) | 0.329909 / 0.579283 (-0.249374) | 0.340952 / 0.434364 (-0.093412) | 0.379166 / 0.540337 (-0.161172) | 0.510767 / 1.386936 (-0.876169) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005942 / 0.011353 (-0.005411) | 0.003628 / 0.011008 (-0.007380) | 0.061975 / 0.038508 (0.023467) | 0.058331 / 0.023109 (0.035221) | 0.393277 / 0.275898 (0.117379) | 0.410740 / 0.323480 (0.087261) | 0.004546 / 0.007986 (-0.003440) | 0.002826 / 0.004328 (-0.001503) | 0.062216 / 0.004250 (0.057966) | 0.049801 / 0.037052 (0.012748) | 0.394070 / 0.258489 (0.135581) | 0.414407 / 0.293841 (0.120566) | 0.027161 / 0.128546 (-0.101385) | 0.007901 / 0.075646 (-0.067746) | 0.066778 / 0.419271 (-0.352493) | 0.041354 / 0.043533 (-0.002179) | 0.379432 / 0.255139 (0.124293) | 0.402966 / 0.283200 (0.119766) | 0.020279 / 0.141683 (-0.121404) | 1.416986 / 1.452155 (-0.035169) | 1.474335 / 1.492716 (-0.018382) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226147 / 0.018006 (0.208140) | 0.404361 / 0.000490 (0.403871) | 0.000358 / 0.000200 (0.000158) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025105 / 0.037411 (-0.012306) | 0.075849 / 0.014526 (0.061323) | 0.084781 / 0.176557 (-0.091775) | 0.137415 / 0.737135 (-0.599720) | 0.086288 / 0.296338 (-0.210051) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445925 / 0.215209 (0.230716) | 4.453478 / 2.077655 (2.375823) | 2.419048 / 1.504120 (0.914928) | 2.246363 / 1.541195 (0.705168) | 2.304022 / 1.468490 (0.835532) | 0.499132 / 4.584777 (-4.085645) | 3.001336 / 3.745712 (-0.744376) | 2.902593 / 5.269862 (-2.367269) | 1.819843 / 4.565676 (-2.745834) | 0.057210 / 0.424275 (-0.367065) | 0.006338 / 0.007607 (-0.001269) | 0.523280 / 0.226044 (0.297236) | 5.235969 / 2.268929 (2.967040) | 2.897585 / 55.444624 (-52.547039) | 2.541586 / 6.876477 (-4.334891) | 2.564233 / 2.142072 (0.422160) | 0.584714 / 4.805227 (-4.220513) | 0.124611 / 6.500664 (-6.376053) | 0.061774 / 0.075469 (-0.013695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.349799 / 1.841788 (-0.491988) | 18.225076 / 8.074308 (10.150768) | 13.781518 / 10.191392 (3.590126) | 0.130562 / 0.680424 (-0.549862) | 0.016434 / 0.534201 (-0.517767) | 0.331607 / 0.579283 (-0.247676) | 0.343456 / 0.434364 (-0.090908) | 0.380437 / 0.540337 (-0.159900) | 0.522793 / 1.386936 (-0.864143) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.013721 / 0.011353 (0.002368) | 0.005715 / 0.011008 (-0.005293) | 0.090116 / 0.038508 (0.051608) | 0.087185 / 0.023109 (0.064075) | 0.427813 / 0.275898 (0.151915) | 0.390614 / 0.323480 (0.067135) | 0.006976 / 0.007986 (-0.001009) | 0.004231 / 0.004328 (-0.000098) | 0.078320 / 0.004250 (0.074070) | 0.066235 / 0.037052 (0.029183) | 0.439904 / 0.258489 (0.181415) | 0.424119 / 0.293841 (0.130278) | 0.050362 / 0.128546 (-0.078184) | 0.014992 / 0.075646 (-0.060654) | 0.293519 / 0.419271 (-0.125753) | 0.066906 / 0.043533 (0.023373) | 0.449657 / 0.255139 (0.194518) | 0.393800 / 0.283200 (0.110600) | 0.032258 / 0.141683 (-0.109425) | 1.539534 / 1.452155 (0.087379) | 1.675292 / 1.492716 (0.182576) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210515 / 0.018006 (0.192508) | 0.506817 / 0.000490 (0.506327) | 0.001938 / 0.000200 (0.001738) | 0.000118 / 0.000054 (0.000064) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026019 / 0.037411 (-0.011393) | 0.080635 / 0.014526 (0.066109) | 0.103050 / 0.176557 (-0.073507) | 0.160597 / 0.737135 (-0.576538) | 0.095844 / 0.296338 (-0.200495) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.506359 / 0.215209 (0.291150) | 5.041586 / 2.077655 (2.963931) | 2.198288 / 1.504120 (0.694168) | 1.987544 / 1.541195 (0.446349) | 1.866790 / 1.468490 (0.398300) | 0.681642 / 4.584777 (-3.903135) | 4.719306 / 3.745712 (0.973593) | 7.669869 / 5.269862 (2.400008) | 4.466082 / 4.565676 (-0.099595) | 0.092974 / 0.424275 (-0.331301) | 0.008196 / 0.007607 (0.000589) | 0.707656 / 0.226044 (0.481612) | 6.974507 / 2.268929 (4.705579) | 3.254206 / 55.444624 (-52.190418) | 2.499019 / 6.876477 (-4.377457) | 2.509089 / 2.142072 (0.367017) | 0.915952 / 4.805227 (-3.889276) | 0.192119 / 6.500664 (-6.308545) | 0.065473 / 0.075469 (-0.009996) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.309078 / 1.841788 (-0.532710) | 19.660348 / 8.074308 (11.586040) | 16.659582 / 10.191392 (6.468190) | 0.194315 / 0.680424 (-0.486109) | 0.027773 / 0.534201 (-0.506428) | 0.401241 / 0.579283 (-0.178042) | 0.515799 / 0.434364 (0.081435) | 0.488772 / 0.540337 (-0.051566) | 0.604790 / 1.386936 (-0.782146) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006823 / 0.011353 (-0.004530) | 0.003940 / 0.011008 (-0.007068) | 0.061533 / 0.038508 (0.023025) | 0.065241 / 0.023109 (0.042132) | 0.411790 / 0.275898 (0.135892) | 0.475720 / 0.323480 (0.152241) | 0.005376 / 0.007986 (-0.002609) | 0.003433 / 0.004328 (-0.000895) | 0.065703 / 0.004250 (0.061452) | 0.050736 / 0.037052 (0.013683) | 0.435890 / 0.258489 (0.177401) | 0.436698 / 0.293841 (0.142857) | 0.040357 / 0.128546 (-0.088189) | 0.011578 / 0.075646 (-0.064069) | 0.072831 / 0.419271 (-0.346440) | 0.055698 / 0.043533 (0.012165) | 0.408225 / 0.255139 (0.153086) | 0.439551 / 0.283200 (0.156352) | 0.030469 / 0.141683 (-0.111214) | 1.443866 / 1.452155 (-0.008289) | 1.502022 / 1.492716 (0.009306) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290338 / 0.018006 (0.272332) | 0.540726 / 0.000490 (0.540236) | 0.003244 / 0.000200 (0.003044) | 0.000170 / 0.000054 (0.000116) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030865 / 0.037411 (-0.006547) | 0.090866 / 0.014526 (0.076340) | 0.106224 / 0.176557 (-0.070332) | 0.166583 / 0.737135 (-0.570553) | 0.104448 / 0.296338 (-0.191891) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.518025 / 0.215209 (0.302816) | 6.027065 / 2.077655 (3.949410) | 2.671840 / 1.504120 (1.167720) | 2.273949 / 1.541195 (0.732754) | 2.414892 / 1.468490 (0.946402) | 0.774318 / 4.584777 (-3.810459) | 5.020364 / 3.745712 (1.274652) | 4.146927 / 5.269862 (-1.122934) | 2.584598 / 4.565676 (-1.981078) | 0.089519 / 0.424275 (-0.334756) | 0.009181 / 0.007607 (0.001574) | 0.654467 / 0.226044 (0.428423) | 6.421595 / 2.268929 (4.152666) | 3.091589 / 55.444624 (-52.353036) | 2.554798 / 6.876477 (-4.321679) | 2.441354 / 2.142072 (0.299282) | 0.943386 / 4.805227 (-3.861841) | 0.173641 / 6.500664 (-6.327023) | 0.072209 / 0.075469 (-0.003260) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.557147 / 1.841788 (-0.284641) | 19.980747 / 8.074308 (11.906439) | 17.816813 / 10.191392 (7.625421) | 0.212078 / 0.680424 (-0.468346) | 0.025435 / 0.534201 (-0.508766) | 0.396200 / 0.579283 (-0.183084) | 0.546249 / 0.434364 (0.111885) | 0.459632 / 0.540337 (-0.080705) | 0.616548 / 1.386936 (-0.770388) |\n\n</details>\n</details>\n\n\n"
] | "2023-07-04T15:02:37Z" | "2023-07-06T15:32:41Z" | "2023-07-06T15:22:43Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6005.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6005",
"merged_at": "2023-07-06T15:22:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6005.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6005"
} | `hfh` and `transformers` have dropped Python 3.7 support, so we should do the same :).
(Based on the stats, it seems less than 10% of the users use `datasets` with Python 3.7) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6005/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6005/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5888 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5888/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5888/comments | https://api.github.com/repos/huggingface/datasets/issues/5888/events | https://github.com/huggingface/datasets/issues/5888 | 1,722,290,363 | I_kwDODunzps5mqBC7 | 5,888 | A way to upload and visualize .mp4 files (millions of them) as part of a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10792502?v=4",
"events_url": "https://api.github.com/users/AntreasAntoniou/events{/privacy}",
"followers_url": "https://api.github.com/users/AntreasAntoniou/followers",
"following_url": "https://api.github.com/users/AntreasAntoniou/following{/other_user}",
"gists_url": "https://api.github.com/users/AntreasAntoniou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/AntreasAntoniou",
"id": 10792502,
"login": "AntreasAntoniou",
"node_id": "MDQ6VXNlcjEwNzkyNTAy",
"organizations_url": "https://api.github.com/users/AntreasAntoniou/orgs",
"received_events_url": "https://api.github.com/users/AntreasAntoniou/received_events",
"repos_url": "https://api.github.com/users/AntreasAntoniou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/AntreasAntoniou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AntreasAntoniou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/AntreasAntoniou"
} | [] | open | false | null | [] | null | [
"Hi! \r\n\r\nYou want to use `push_to_hub` (creates Parquet files) instead of `save_to_disk` (creates Arrow files) when creating a Hub dataset. Parquet is designed for long-term storage and takes less space than the Arrow format, and, most importantly, `load_dataset` can parse it, which should fix the viewer. \r\n\r\nRegarding the dataset generation, `Dataset.from_generator` with the video data represented as `datasets.Value(\"binary\")` followed by `push_to_hub` should work (if the `push_to_hub` step times out, restart it to resume uploading)\r\n\r\nPS: Once the dataset is uploaded, to make working with the dataset easier, it's a good idea to add a [transform](https://huggingface.co/docs/datasets/main/en/process#format-transform) to the README that shows how to decode the binary video data into something a model can understand. Also, if you get an `ArrowInvalid` error (can happen when working with large binary data) in `Dataset.from_generator`, reduce the value of `writer_batch_size` (the default is 1000) to fix it.",
"One issue here is that Dataset.from_generator can work well for the non 'infinite sampling' version of the dataset. The training set for example is often sampled dynamically given the video files that I have uploaded. I worry that storing the video data as binary means that I'll end up duplicating a lot of the data. Furthermore, storing video data as anything but .mp4 would quickly make the dataset size from 1.9TB to 1PB. ",
"> storing video data as anything but .mp4\r\n\r\nWhat I mean by storing as `datasets.Value(\"binary\")` is embedding raw MP4 bytes in the Arrow table, but, indeed, this would waste a lot of space if there are duplicates.\r\n\r\nSo I see two options:\r\n* if one video is not mapped to too many samples, you can embed the video bytes and do \"group by\" on the rest of the columns (this would turn them into lists) to avoid duplicating them (then, it should be easy to define a `map` in the README that samples the video data to \"unpack\" the samples)\r\n* you can create a dataset script that downloads the video files and embeds their file paths into the Arrow file\r\n\r\nAlso, I misread MP4 as MP3. We need to add a `Video` feature to the `datasets` lib to support MP4 files in the viewer (a bit trickier to implement than the `Image` feature due to the Arrow limitations).",
"I'm transferring this issue to the `datasets` repo, as it's not related to `huggingface_hub`",
"@mariosasko Right. If I want my dataset to be streamable, what are the necessary requirements to achieve that within the context of .mp4 binaries like we have here? I guess your second point here would not support that right?",
"The streaming would work, but the video paths would require using `fsspec.open` to get the content.",
"Are there any plans to make video playable on the hub?",
"Not yet. The (open source) tooling for video is not great in terms of ease of use/performance, so we are discussing internally the best way to support it (one option is creating a new library for video IO, but this will require a lot of work)",
"True. I spend a good 4 months just mixing and matching existing solutions so I could get performance that would not IO bound my model training. \r\n\r\nThis is what I ended up with, in case it's useful\r\n\r\nhttps://github.com/AntreasAntoniou/TALI/blob/045cf9e5aa75b1bf2c6d5351fb910fa10e3ff32c/tali/data/data_plus.py#L85"
] | "2023-05-22T18:05:26Z" | "2023-06-23T03:37:16Z" | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
I recently chose to use huggingface hub as the home for a large multi modal dataset I've been building. https://huggingface.co/datasets/Antreas/TALI
It combines images, text, audio and video. Now, I could very easily upload a dataset made via datasets.Dataset.from_generator, as long as it did not include video files. I found that including .mp4 files in the entries would not auto-upload those files.
Hence I tried to upload them myself. I quickly found out that uploading many small files is a very bad way to use git lfs, and that it would take ages, so, I resorted to using 7z to pack them all up. But then I had a new problem.
My dataset had a size of 1.9TB. Trying to upload such a large file with the default huggingface_hub API always resulted in time outs etc. So I decided to split the large files into chunks of 5GB each and reupload.
So, eventually it all worked out. But now the dataset can't be properly and natively used by the datasets API because of all the needed preprocessing -- and furthermore the hub is unable to visualize things.
**Describe the solution you'd like**
A native way to upload large datasets that include .mp4 or other video types.
**Describe alternatives you've considered**
Already explained earlier
**Additional context**
https://huggingface.co/datasets/Antreas/TALI
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5888/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5888/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1375/comments | https://api.github.com/repos/huggingface/datasets/issues/1375/events | https://github.com/huggingface/datasets/pull/1375 | 760,294,931 | MDExOlB1bGxSZXF1ZXN0NTM1MTUwOTk2 | 1,375 | Add OPUS EMEA Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-09T12:39:44Z" | "2020-12-10T16:11:09Z" | "2020-12-10T16:11:08Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1375",
"merged_at": "2020-12-10T16:11:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1375"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1375/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/5741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5741/comments | https://api.github.com/repos/huggingface/datasets/issues/5741/events | https://github.com/huggingface/datasets/pull/5741 | 1,665,860,919 | PR_kwDODunzps5OM9nZ | 5,741 | Fix CI warnings | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007448 / 0.011353 (-0.003905) | 0.005182 / 0.011008 (-0.005826) | 0.098718 / 0.038508 (0.060210) | 0.034594 / 0.023109 (0.011485) | 0.317301 / 0.275898 (0.041403) | 0.357800 / 0.323480 (0.034320) | 0.005860 / 0.007986 (-0.002126) | 0.004267 / 0.004328 (-0.000061) | 0.074876 / 0.004250 (0.070626) | 0.048002 / 0.037052 (0.010950) | 0.333360 / 0.258489 (0.074871) | 0.362080 / 0.293841 (0.068239) | 0.035957 / 0.128546 (-0.092589) | 0.012245 / 0.075646 (-0.063401) | 0.332970 / 0.419271 (-0.086301) | 0.050825 / 0.043533 (0.007293) | 0.313936 / 0.255139 (0.058797) | 0.340684 / 0.283200 (0.057485) | 0.106630 / 0.141683 (-0.035053) | 1.427898 / 1.452155 (-0.024257) | 1.547518 / 1.492716 (0.054801) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296952 / 0.018006 (0.278945) | 0.515708 / 0.000490 (0.515218) | 0.004225 / 0.000200 (0.004025) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029365 / 0.037411 (-0.008046) | 0.111142 / 0.014526 (0.096616) | 0.124414 / 0.176557 (-0.052142) | 0.185227 / 0.737135 (-0.551908) | 0.129545 / 0.296338 (-0.166793) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.403303 / 0.215209 (0.188094) | 4.044138 / 2.077655 (1.966483) | 1.803622 / 1.504120 (0.299502) | 1.615436 / 1.541195 (0.074242) | 1.703576 / 1.468490 (0.235086) | 0.706398 / 4.584777 (-3.878379) | 3.912995 / 3.745712 (0.167283) | 4.004575 / 5.269862 (-1.265287) | 2.101592 / 4.565676 (-2.464085) | 0.087280 / 0.424275 (-0.336995) | 0.012564 / 0.007607 (0.004957) | 0.508484 / 0.226044 (0.282440) | 5.089351 / 2.268929 (2.820422) | 2.269022 / 55.444624 (-53.175602) | 1.933375 / 6.876477 (-4.943102) | 2.136783 / 2.142072 (-0.005289) | 0.862624 / 4.805227 (-3.942603) | 0.172107 / 6.500664 (-6.328557) | 0.066694 / 0.075469 (-0.008775) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.172513 / 1.841788 (-0.669275) | 15.877519 / 8.074308 (7.803211) | 14.687476 / 10.191392 (4.496084) | 0.189392 / 0.680424 (-0.491032) | 0.017334 / 0.534201 (-0.516866) | 0.420201 / 0.579283 (-0.159082) | 0.418502 / 0.434364 (-0.015862) | 0.489130 / 0.540337 (-0.051207) | 0.580678 / 1.386936 (-0.806258) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007942 / 0.011353 (-0.003411) | 0.005312 / 0.011008 (-0.005696) | 0.074684 / 0.038508 (0.036176) | 0.035952 / 0.023109 (0.012843) | 0.349672 / 0.275898 (0.073774) | 0.377157 / 0.323480 (0.053678) | 0.006399 / 0.007986 (-0.001586) | 0.005769 / 0.004328 (0.001441) | 0.074283 / 0.004250 (0.070032) | 0.053217 / 0.037052 (0.016165) | 0.342545 / 0.258489 (0.084056) | 0.383663 / 0.293841 (0.089822) | 0.037234 / 0.128546 (-0.091312) | 0.012349 / 0.075646 (-0.063298) | 0.086522 / 0.419271 (-0.332749) | 0.049888 / 0.043533 (0.006355) | 0.337686 / 0.255139 (0.082547) | 0.361564 / 0.283200 (0.078365) | 0.104902 / 0.141683 (-0.036781) | 1.478259 / 1.452155 (0.026104) | 1.576376 / 1.492716 (0.083660) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.339760 / 0.018006 (0.321753) | 0.530946 / 0.000490 (0.530456) | 0.000474 / 0.000200 (0.000274) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029685 / 0.037411 (-0.007726) | 0.109409 / 0.014526 (0.094883) | 0.125579 / 0.176557 (-0.050978) | 0.175378 / 0.737135 (-0.561757) | 0.130672 / 0.296338 (-0.165667) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428456 / 0.215209 (0.213247) | 4.238731 / 2.077655 (2.161077) | 2.046703 / 1.504120 (0.542583) | 1.850701 / 1.541195 (0.309506) | 1.909290 / 1.468490 (0.440800) | 0.714314 / 4.584777 (-3.870463) | 3.816056 / 3.745712 (0.070344) | 2.118567 / 5.269862 (-3.151295) | 1.348017 / 4.565676 (-3.217659) | 0.087140 / 0.424275 (-0.337135) | 0.012546 / 0.007607 (0.004938) | 0.538041 / 0.226044 (0.311997) | 5.381822 / 2.268929 (3.112893) | 2.525685 / 55.444624 (-52.918939) | 2.178659 / 6.876477 (-4.697817) | 2.381054 / 2.142072 (0.238981) | 0.844404 / 4.805227 (-3.960823) | 0.171802 / 6.500664 (-6.328862) | 0.065630 / 0.075469 (-0.009839) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262187 / 1.841788 (-0.579600) | 16.197668 / 8.074308 (8.123360) | 15.148636 / 10.191392 (4.957244) | 0.152601 / 0.680424 (-0.527823) | 0.020238 / 0.534201 (-0.513963) | 0.420141 / 0.579283 (-0.159142) | 0.416295 / 0.434364 (-0.018068) | 0.487051 / 0.540337 (-0.053286) | 0.581942 / 1.386936 (-0.804994) |\n\n</details>\n</details>\n\n\n"
] | "2023-04-13T07:17:02Z" | "2023-04-13T09:48:10Z" | "2023-04-13T09:40:50Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5741.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5741",
"merged_at": "2023-04-13T09:40:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5741.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5741"
} | Fix warnings in our CI tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5741/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3087/comments | https://api.github.com/repos/huggingface/datasets/issues/3087/events | https://github.com/huggingface/datasets/issues/3087 | 1,026,780,469 | I_kwDODunzps49M201 | 3,087 | Removing label column in a text classification dataset yields to errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sgugger",
"id": 35901082,
"login": "sgugger",
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"repos_url": "https://api.github.com/users/sgugger/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sgugger"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | "2021-10-14T20:12:50Z" | "2021-10-15T10:11:04Z" | "2021-10-15T10:11:04Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
This looks like #3059 but it's not linked to the cache this time. Removing the `label` column from a text classification dataset and then performing any processing will result in an error.
To reproduce:
```py
from datasets import load_dataset
from transformers import AutoTokenizer
raw_datasets = load_dataset("imdb")
raw_datasets = raw_datasets.remove_columns("label")
model_checkpoint = "distilbert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
context_length = 128
def tokenize_pad_and_truncate(texts):
return tokenizer(texts["text"], truncation=True, padding="max_length", max_length=context_length)
tokenized_datasets = raw_datasets.map(tokenize_pad_and_truncate, batched=True)
```
Traceback:
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-1-ba61bb32f786> in <module>
12 return tokenizer(texts["text"], truncation=True, padding="max_length", max_length=context_length)
13
---> 14 tokenized_datasets = raw_datasets.map(tokenize_pad_and_truncate, batched=True)
~/git/datasets/src/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, desc)
500 desc=desc,
501 )
--> 502 for k, dataset in self.items()
503 }
504 )
~/git/datasets/src/datasets/dataset_dict.py in <dictcomp>(.0)
500 desc=desc,
501 )
--> 502 for k, dataset in self.items()
503 }
504 )
~/git/datasets/src/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
2051 new_fingerprint=new_fingerprint,
2052 disable_tqdm=disable_tqdm,
-> 2053 desc=desc,
2054 )
2055 else:
~/git/datasets/src/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
501 self: "Dataset" = kwargs.pop("self")
502 # apply actual function
--> 503 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
504 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
505 for dataset in datasets:
~/git/datasets/src/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
468 }
469 # apply actual function
--> 470 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
471 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
472 # re-apply format to the output
~/git/datasets/src/datasets/fingerprint.py in wrapper(*args, **kwargs)
404 # Call actual function
405
--> 406 out = func(self, *args, **kwargs)
407
408 # Update fingerprint of in-place transforms + update in-place history of transforms
~/git/datasets/src/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, disable_tqdm, desc, cache_only)
2243 if os.path.exists(cache_file_name) and load_from_cache_file:
2244 logger.warning("Loading cached processed dataset at %s", cache_file_name)
-> 2245 info = self.info.copy()
2246 info.features = features
2247 info.task_templates = None
~/git/datasets/src/datasets/info.py in copy(self)
278
279 def copy(self) -> "DatasetInfo":
--> 280 return self.__class__(**{k: copy.deepcopy(v) for k, v in self.__dict__.items()})
281
282
~/git/datasets/src/datasets/info.py in __init__(self, description, citation, homepage, license, features, post_processed, supervised_keys, task_templates, builder_name, config_name, version, splits, download_checksums, download_size, post_processing_size, dataset_size, size_in_bytes)
~/git/datasets/src/datasets/info.py in __post_init__(self)
177 for idx, template in enumerate(self.task_templates):
178 if isinstance(template, TextClassification):
--> 179 labels = self.features[template.label_column].names
180 self.task_templates[idx] = TextClassification(
181 text_column=template.text_column, label_column=template.label_column, labels=labels
KeyError: 'label'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3087/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5022 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5022/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5022/comments | https://api.github.com/repos/huggingface/datasets/issues/5022/events | https://github.com/huggingface/datasets/pull/5022 | 1,385,432,859 | PR_kwDODunzps4_kxYe | 5,022 | Fix languages of X-CSQA configs in xcsr dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks @lhoestq, I had missed that... ",
"thx for the super fast work @albertvillanova ! any estimate for when the relevant release will happen?\r\n\r\nThanks again ",
"@thesofakillers after a recent change in our library (see #4059), now fixes in all datasets are immediately accessible. You can try it:\r\n```python\r\nfrench = datasets.load_dataset(\"xcsr\", \"X-CSQA-fr\")\r\n```\r\n\r\nPlease note there is an additional fix to that dataset in progress (to be merged today):\r\n- #5024"
] | "2022-09-26T05:13:39Z" | "2022-09-26T12:27:20Z" | "2022-09-26T10:57:30Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5022.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5022",
"merged_at": "2022-09-26T10:57:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5022.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5022"
} | Fix #5017.
CC: @yangxqiao, @yuchenlin | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5022/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5022/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1224/comments | https://api.github.com/repos/huggingface/datasets/issues/1224/events | https://github.com/huggingface/datasets/pull/1224 | 758,022,998 | MDExOlB1bGxSZXF1ZXN0NTMzMjY2Njg1 | 1,224 | adding conceptnet5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8900094?v=4",
"events_url": "https://api.github.com/users/ontocord/events{/privacy}",
"followers_url": "https://api.github.com/users/ontocord/followers",
"following_url": "https://api.github.com/users/ontocord/following{/other_user}",
"gists_url": "https://api.github.com/users/ontocord/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ontocord",
"id": 8900094,
"login": "ontocord",
"node_id": "MDQ6VXNlcjg5MDAwOTQ=",
"organizations_url": "https://api.github.com/users/ontocord/orgs",
"received_events_url": "https://api.github.com/users/ontocord/received_events",
"repos_url": "https://api.github.com/users/ontocord/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ontocord/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ontocord/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ontocord"
} | [] | closed | false | null | [] | null | [
"Thank you. I'll make those changes. but I'm having problems trying to push my changes to my fork\r\n",
"Hi, I've removed the TODO, and added a README.md. How do I push these changes?\r\n",
"Also, what docstring are you recommending?\r\n",
"> Hi, I've removed the TODO, and added a README.md. How do I push these changes?\r\n\r\nyou can just commit and push your changes to the same branch as your first commit.",
"@ghomasHudson I've tried it but still getting code quality error. I've removed all blank lines, etc. required by flake8. Don't know what else to do",
"> @ghomasHudson I've tried it but still getting code quality error. I've removed all blank lines, etc. required by flake8. Don't know what else to do\r\n\r\nDid you run `make style` before committing? When I run it, it fixes some things (e.g. Splitting line 96 which is currently too long).",
"I think @yjernite is looking into this. I did \"make style\" but nothing happens",
"looks like your PR includes changes about many other files than the ones related to conceptnet5\r\n\r\ncould you create another branch and another PR please ?",
"@lhoestq I'm not sure what I did wrong. What did I push that wasn't conceptnet5? How do I see this?\r\n\r\n did this\r\n\r\nmake style\r\nflake8 datasets\r\ngit add datasets/<your_dataset_name>\r\ngit commit\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit pull\r\ngit push -u origin conceptnet5",
"Thanks for rebasing and force push :) ",
"Yeah! Thank you @lhoestq, @ghomasHudson and @yjernite !"
] | "2020-12-06T21:06:53Z" | "2020-12-09T16:38:16Z" | "2020-12-09T14:37:17Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1224.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1224",
"merged_at": "2020-12-09T14:37:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1224.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1224"
} | Adding the conceptnet5 and omcs txt files used to create the conceptnet5 dataset. Conceptne5 is a common sense dataset. More info can be found here: https://github.com/commonsense/conceptnet5/wiki | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1224/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6264/comments | https://api.github.com/repos/huggingface/datasets/issues/6264/events | https://github.com/huggingface/datasets/pull/6264 | 1,914,958,781 | PR_kwDODunzps5bTvzh | 6,264 | Temporarily pin tensorflow < 2.14.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008356 / 0.011353 (-0.002997) | 0.004553 / 0.011008 (-0.006455) | 0.101025 / 0.038508 (0.062517) | 0.090194 / 0.023109 (0.067085) | 0.427127 / 0.275898 (0.151229) | 0.469116 / 0.323480 (0.145636) | 0.007593 / 0.007986 (-0.000393) | 0.003751 / 0.004328 (-0.000578) | 0.077432 / 0.004250 (0.073182) | 0.082744 / 0.037052 (0.045692) | 0.433638 / 0.258489 (0.175149) | 0.482387 / 0.293841 (0.188546) | 0.040658 / 0.128546 (-0.087888) | 0.009799 / 0.075646 (-0.065848) | 0.345274 / 0.419271 (-0.073998) | 0.076642 / 0.043533 (0.033109) | 0.424417 / 0.255139 (0.169278) | 0.457045 / 0.283200 (0.173846) | 0.033642 / 0.141683 (-0.108041) | 1.765446 / 1.452155 (0.313291) | 1.859279 / 1.492716 (0.366562) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.273629 / 0.018006 (0.255623) | 0.505743 / 0.000490 (0.505253) | 0.009300 / 0.000200 (0.009100) | 0.000359 / 0.000054 (0.000305) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032510 / 0.037411 (-0.004901) | 0.099628 / 0.014526 (0.085103) | 0.112904 / 0.176557 (-0.063652) | 0.179118 / 0.737135 (-0.558018) | 0.115946 / 0.296338 (-0.180393) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456431 / 0.215209 (0.241222) | 4.556559 / 2.077655 (2.478904) | 2.207893 / 1.504120 (0.703773) | 2.024706 / 1.541195 (0.483512) | 2.165424 / 1.468490 (0.696934) | 0.571745 / 4.584777 (-4.013031) | 4.341017 / 3.745712 (0.595305) | 3.980520 / 5.269862 (-1.289342) | 2.333077 / 4.565676 (-2.232599) | 0.067200 / 0.424275 (-0.357075) | 0.008563 / 0.007607 (0.000956) | 0.545294 / 0.226044 (0.319250) | 5.445152 / 2.268929 (3.176224) | 2.740657 / 55.444624 (-52.703968) | 2.370635 / 6.876477 (-4.505842) | 2.451642 / 2.142072 (0.309570) | 0.679385 / 4.805227 (-4.125842) | 0.155967 / 6.500664 (-6.344697) | 0.072812 / 0.075469 (-0.002657) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.494483 / 1.841788 (-0.347305) | 23.673700 / 8.074308 (15.599392) | 16.608529 / 10.191392 (6.417137) | 0.170220 / 0.680424 (-0.510204) | 0.021630 / 0.534201 (-0.512571) | 0.470771 / 0.579283 (-0.108512) | 0.535874 / 0.434364 (0.101510) | 0.550376 / 0.540337 (0.010039) | 0.776633 / 1.386936 (-0.610303) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007899 / 0.011353 (-0.003454) | 0.004581 / 0.011008 (-0.006427) | 0.076520 / 0.038508 (0.038012) | 0.090374 / 0.023109 (0.067265) | 0.495016 / 0.275898 (0.219118) | 0.532384 / 0.323480 (0.208904) | 0.006160 / 0.007986 (-0.001825) | 0.003780 / 0.004328 (-0.000548) | 0.077164 / 0.004250 (0.072914) | 0.064444 / 0.037052 (0.027391) | 0.501642 / 0.258489 (0.243153) | 0.549170 / 0.293841 (0.255329) | 0.038051 / 0.128546 (-0.090495) | 0.010081 / 0.075646 (-0.065565) | 0.083752 / 0.419271 (-0.335520) | 0.061334 / 0.043533 (0.017801) | 0.493502 / 0.255139 (0.238363) | 0.518018 / 0.283200 (0.234818) | 0.029534 / 0.141683 (-0.112149) | 1.929432 / 1.452155 (0.477277) | 1.889985 / 1.492716 (0.397268) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254802 / 0.018006 (0.236795) | 0.494463 / 0.000490 (0.493974) | 0.005040 / 0.000200 (0.004840) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038372 / 0.037411 (0.000960) | 0.112247 / 0.014526 (0.097721) | 0.124365 / 0.176557 (-0.052191) | 0.187142 / 0.737135 (-0.549993) | 0.126070 / 0.296338 (-0.170269) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.513418 / 0.215209 (0.298209) | 5.132267 / 2.077655 (3.054613) | 2.773676 / 1.504120 (1.269556) | 2.576840 / 1.541195 (1.035645) | 2.681729 / 1.468490 (1.213238) | 0.581809 / 4.584777 (-4.002968) | 4.327075 / 3.745712 (0.581363) | 4.040264 / 5.269862 (-1.229598) | 2.436192 / 4.565676 (-2.129484) | 0.067819 / 0.424275 (-0.356456) | 0.008760 / 0.007607 (0.001153) | 0.610765 / 0.226044 (0.384720) | 6.105679 / 2.268929 (3.836750) | 3.341341 / 55.444624 (-52.103284) | 2.926695 / 6.876477 (-3.949781) | 3.017269 / 2.142072 (0.875196) | 0.707289 / 4.805227 (-4.097938) | 0.157379 / 6.500664 (-6.343285) | 0.072549 / 0.075469 (-0.002920) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.666738 / 1.841788 (-0.175050) | 23.698567 / 8.074308 (15.624259) | 17.806437 / 10.191392 (7.615045) | 0.172103 / 0.680424 (-0.508321) | 0.023508 / 0.534201 (-0.510693) | 0.473171 / 0.579283 (-0.106112) | 0.524834 / 0.434364 (0.090470) | 0.562562 / 0.540337 (0.022224) | 0.788667 / 1.386936 (-0.598269) |\n\n</details>\n</details>\n\n\n",
"CI 404 errors are unrelated. See:\r\n- #6262 ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006657 / 0.011353 (-0.004696) | 0.003975 / 0.011008 (-0.007033) | 0.084614 / 0.038508 (0.046106) | 0.074557 / 0.023109 (0.051448) | 0.309213 / 0.275898 (0.033315) | 0.338245 / 0.323480 (0.014765) | 0.005375 / 0.007986 (-0.002610) | 0.003355 / 0.004328 (-0.000973) | 0.064406 / 0.004250 (0.060156) | 0.061763 / 0.037052 (0.024711) | 0.313405 / 0.258489 (0.054916) | 0.352149 / 0.293841 (0.058308) | 0.031597 / 0.128546 (-0.096949) | 0.008499 / 0.075646 (-0.067147) | 0.289098 / 0.419271 (-0.130174) | 0.054415 / 0.043533 (0.010882) | 0.313210 / 0.255139 (0.058071) | 0.326728 / 0.283200 (0.043528) | 0.024597 / 0.141683 (-0.117086) | 1.449916 / 1.452155 (-0.002239) | 1.526314 / 1.492716 (0.033598) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231435 / 0.018006 (0.213429) | 0.537224 / 0.000490 (0.536734) | 0.007287 / 0.000200 (0.007088) | 0.000227 / 0.000054 (0.000172) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028340 / 0.037411 (-0.009071) | 0.084085 / 0.014526 (0.069560) | 0.428211 / 0.176557 (0.251655) | 0.157360 / 0.737135 (-0.579775) | 0.139470 / 0.296338 (-0.156868) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.389311 / 0.215209 (0.174102) | 3.871329 / 2.077655 (1.793674) | 1.861533 / 1.504120 (0.357413) | 1.688082 / 1.541195 (0.146887) | 1.804036 / 1.468490 (0.335546) | 0.489154 / 4.584777 (-4.095623) | 3.603843 / 3.745712 (-0.141869) | 3.424868 / 5.269862 (-1.844994) | 2.013525 / 4.565676 (-2.552152) | 0.057387 / 0.424275 (-0.366888) | 0.007274 / 0.007607 (-0.000333) | 0.462340 / 0.226044 (0.236295) | 4.620095 / 2.268929 (2.351167) | 2.326641 / 55.444624 (-53.117984) | 1.990082 / 6.876477 (-4.886395) | 2.037841 / 2.142072 (-0.104232) | 0.581973 / 4.805227 (-4.223254) | 0.135932 / 6.500664 (-6.364732) | 0.061092 / 0.075469 (-0.014377) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.249586 / 1.841788 (-0.592202) | 19.036233 / 8.074308 (10.961925) | 14.083365 / 10.191392 (3.891973) | 0.169802 / 0.680424 (-0.510622) | 0.018547 / 0.534201 (-0.515654) | 0.392926 / 0.579283 (-0.186357) | 0.409993 / 0.434364 (-0.024371) | 0.460081 / 0.540337 (-0.080257) | 0.643836 / 1.386936 (-0.743100) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006889 / 0.011353 (-0.004464) | 0.004060 / 0.011008 (-0.006948) | 0.064332 / 0.038508 (0.025824) | 0.077067 / 0.023109 (0.053958) | 0.401235 / 0.275898 (0.125337) | 0.437139 / 0.323480 (0.113659) | 0.005510 / 0.007986 (-0.002476) | 0.003338 / 0.004328 (-0.000991) | 0.064446 / 0.004250 (0.060195) | 0.055537 / 0.037052 (0.018485) | 0.432689 / 0.258489 (0.174200) | 0.460005 / 0.293841 (0.166164) | 0.033122 / 0.128546 (-0.095424) | 0.008637 / 0.075646 (-0.067010) | 0.071088 / 0.419271 (-0.348183) | 0.049024 / 0.043533 (0.005491) | 0.400258 / 0.255139 (0.145119) | 0.419324 / 0.283200 (0.136124) | 0.022050 / 0.141683 (-0.119632) | 1.475744 / 1.452155 (0.023589) | 1.546565 / 1.492716 (0.053848) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226241 / 0.018006 (0.208235) | 0.448574 / 0.000490 (0.448085) | 0.004732 / 0.000200 (0.004533) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033260 / 0.037411 (-0.004151) | 0.092622 / 0.014526 (0.078096) | 0.105501 / 0.176557 (-0.071056) | 0.157981 / 0.737135 (-0.579155) | 0.105993 / 0.296338 (-0.190345) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445716 / 0.215209 (0.230507) | 4.451848 / 2.077655 (2.374194) | 2.404769 / 1.504120 (0.900649) | 2.232594 / 1.541195 (0.691399) | 2.312735 / 1.468490 (0.844245) | 0.491208 / 4.584777 (-4.093569) | 3.561629 / 3.745712 (-0.184083) | 3.444269 / 5.269862 (-1.825592) | 2.060365 / 4.565676 (-2.505311) | 0.057723 / 0.424275 (-0.366552) | 0.007392 / 0.007607 (-0.000215) | 0.526447 / 0.226044 (0.300403) | 5.264307 / 2.268929 (2.995379) | 2.951481 / 55.444624 (-52.493143) | 2.593178 / 6.876477 (-4.283299) | 2.689780 / 2.142072 (0.547707) | 0.588649 / 4.805227 (-4.216579) | 0.133566 / 6.500664 (-6.367098) | 0.060462 / 0.075469 (-0.015008) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.381008 / 1.841788 (-0.460780) | 19.452394 / 8.074308 (11.378086) | 15.255912 / 10.191392 (5.064520) | 0.171043 / 0.680424 (-0.509381) | 0.020395 / 0.534201 (-0.513806) | 0.396429 / 0.579283 (-0.182854) | 0.422820 / 0.434364 (-0.011544) | 0.477305 / 0.540337 (-0.063032) | 0.658274 / 1.386936 (-0.728663) |\n\n</details>\n</details>\n\n\n"
] | "2023-09-27T08:16:06Z" | "2023-09-27T08:45:24Z" | "2023-09-27T08:36:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6264",
"merged_at": "2023-09-27T08:36:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6264"
} | Temporarily pin tensorflow < 2.14.0 until permanent solution is found.
Hot fix #6263. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6264/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1606/comments | https://api.github.com/repos/huggingface/datasets/issues/1606/events | https://github.com/huggingface/datasets/pull/1606 | 771,116,455 | MDExOlB1bGxSZXF1ZXN0NTQyNzMwNTEw | 1,606 | added Semantic Scholar Open Research Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bhavitvyamalik",
"id": 19718818,
"login": "bhavitvyamalik",
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bhavitvyamalik"
} | [] | closed | false | null | [] | null | [
"I think we’ll need complete dataset_infos.json to create YAML tags. I ran the script again with 100 files after going through your comments and it was occupying ~16 GB space. So in total it should take ~960GB and I don’t have this much memory available with me. Also, I'll have to download the whole dataset for generating dummy data, right?"
] | "2020-12-18T19:21:24Z" | "2021-02-03T09:30:59Z" | "2021-02-03T09:30:59Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1606.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1606",
"merged_at": "2021-02-03T09:30:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1606.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1606"
} | I picked up this dataset [Semantic Scholar Open Research Corpus](https://allenai.org/data/s2orc) but it contains 6000 files to be downloaded. I tried the current code with 100 files and it worked fine (took ~15GB space). For 6000 files it would occupy ~900GB space which I don’t have. Can someone from the HF team with that much of disk space help me with generate dataset_infos and dummy_data? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1606/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1482/comments | https://api.github.com/repos/huggingface/datasets/issues/1482/events | https://github.com/huggingface/datasets/pull/1482 | 762,686,820 | MDExOlB1bGxSZXF1ZXN0NTM3MjA4NDk3 | 1,482 | Adding medical database chinese and english | {
"avatar_url": "https://avatars.githubusercontent.com/u/16264631?v=4",
"events_url": "https://api.github.com/users/vrindaprabhu/events{/privacy}",
"followers_url": "https://api.github.com/users/vrindaprabhu/followers",
"following_url": "https://api.github.com/users/vrindaprabhu/following{/other_user}",
"gists_url": "https://api.github.com/users/vrindaprabhu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vrindaprabhu",
"id": 16264631,
"login": "vrindaprabhu",
"node_id": "MDQ6VXNlcjE2MjY0NjMx",
"organizations_url": "https://api.github.com/users/vrindaprabhu/orgs",
"received_events_url": "https://api.github.com/users/vrindaprabhu/received_events",
"repos_url": "https://api.github.com/users/vrindaprabhu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vrindaprabhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vrindaprabhu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vrindaprabhu"
} | [] | closed | false | null | [] | null | [
"Let me know it that helps !\r\nAlso feel free to ping me if you have other questions or if I can help you.",
"Now I am getting an Assertion Error!\r\n\r\n",
"All tests have passed. However, PyTest is still failing with the `AssertionError` as before. Also _datasets_info.json_ actually does not seem to provide much info. Please review and let me know what has to be improved.\r\n\r\nThanks!",
"[PR-1503](https://github.com/huggingface/datasets/pull/1503) on the COVID dialog dataset from the same University has similar features. I kept it separate because it is only on COVID qa. Also consists of only single files per language. Kindly let me know if it has to be added as two more configurations to this existing dataset itself. If it has to be added, then can I still freeze the file names like in PR-1503?",
"It's ok to have them separate"
] | "2020-12-11T17:50:39Z" | "2021-02-16T05:28:36Z" | "2020-12-15T18:23:53Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1482.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1482",
"merged_at": "2020-12-15T18:23:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1482.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1482"
} | Error in creating dummy dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1482/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1497 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1497/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1497/comments | https://api.github.com/repos/huggingface/datasets/issues/1497/events | https://github.com/huggingface/datasets/pull/1497 | 763,180,824 | MDExOlB1bGxSZXF1ZXN0NTM3NjYxNzY2 | 1,497 | adding fake-news-english-5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [
"made suggested changes and created a PR here: https://github.com/huggingface/datasets/pull/1598"
] | "2020-12-12T02:13:11Z" | "2020-12-17T20:07:17Z" | "2020-12-17T20:07:17Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1497.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1497",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1497.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1497"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1497/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1497/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2976 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2976/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2976/comments | https://api.github.com/repos/huggingface/datasets/issues/2976/events | https://github.com/huggingface/datasets/issues/2976 | 1,008,647,889 | I_kwDODunzps48Hr7R | 2,976 | Can't load dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/77006774?v=4",
"events_url": "https://api.github.com/users/mskovalova/events{/privacy}",
"followers_url": "https://api.github.com/users/mskovalova/followers",
"following_url": "https://api.github.com/users/mskovalova/following{/other_user}",
"gists_url": "https://api.github.com/users/mskovalova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mskovalova",
"id": 77006774,
"login": "mskovalova",
"node_id": "MDQ6VXNlcjc3MDA2Nzc0",
"organizations_url": "https://api.github.com/users/mskovalova/orgs",
"received_events_url": "https://api.github.com/users/mskovalova/received_events",
"repos_url": "https://api.github.com/users/mskovalova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mskovalova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mskovalova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mskovalova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @mskovalova, \r\n\r\nSome datasets have multiple configurations. Therefore, in order to load them, you have to specify both the *dataset name* and the *configuration name*.\r\n\r\nIn the error message you got, you have a usage example:\r\n- To load the 'wikitext-103-raw-v1' configuration of the 'wikitext' dataset, you should use: \r\n ```python\r\n load_dataset('wikitext', 'wikitext-103-raw-v1')\r\n ```\r\n\r\nIn your case, if you would like to load the 'wikitext-2-v1' configuration of the 'wikitext' dataset, please use:\r\n```python\r\nraw_datasets = load_dataset(\"wikitext\", \"wikitext-2-v1\")\r\n```",
"Hi, if I want to load the dataset from local file, then how to specify the configuration name?"
] | "2021-09-27T21:38:14Z" | "2022-12-01T09:12:29Z" | "2021-09-28T06:53:01Z" | NONE | null | null | null | I'm trying to load a wikitext dataset
```
from datasets import load_dataset
raw_datasets = load_dataset("wikitext")
```
ValueError: Config name is missing.
Please pick one among the available configs: ['wikitext-103-raw-v1', 'wikitext-2-raw-v1', 'wikitext-103-v1', 'wikitext-2-v1']
Example of usage:
`load_dataset('wikitext', 'wikitext-103-raw-v1')`.
If I try
```
from datasets import load_dataset
raw_datasets = load_dataset("wikitext-2-v1")
```
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.12.1/datasets/wikitext-2-v1/wikitext-2-v1.py
#### Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic (colab)
- Python version: 3.7.12
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2976/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2976/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1653/comments | https://api.github.com/repos/huggingface/datasets/issues/1653/events | https://github.com/huggingface/datasets/pull/1653 | 775,632,945 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjc0Njc0 | 1,653 | harem dataset: add data splits info | {
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jonatasgrosman",
"id": 5097052,
"login": "jonatasgrosman",
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jonatasgrosman"
} | [] | closed | false | null | [] | null | [] | "2020-12-28T23:58:20Z" | "2020-12-30T16:49:03Z" | "2020-12-30T16:49:03Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1653.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1653",
"merged_at": "2020-12-30T16:49:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1653.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1653"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1653/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/5391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | https://api.github.com/repos/huggingface/datasets/issues/5391/events | https://github.com/huggingface/datasets/issues/5391 | 1,510,350,400 | I_kwDODunzps5aBh5A | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | {
"avatar_url": "https://avatars.githubusercontent.com/u/12885107?v=4",
"events_url": "https://api.github.com/users/catswithbats/events{/privacy}",
"followers_url": "https://api.github.com/users/catswithbats/followers",
"following_url": "https://api.github.com/users/catswithbats/following{/other_user}",
"gists_url": "https://api.github.com/users/catswithbats/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/catswithbats",
"id": 12885107,
"login": "catswithbats",
"node_id": "MDQ6VXNlcjEyODg1MTA3",
"organizations_url": "https://api.github.com/users/catswithbats/orgs",
"received_events_url": "https://api.github.com/users/catswithbats/received_events",
"repos_url": "https://api.github.com/users/catswithbats/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/catswithbats/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/catswithbats/subscriptions",
"type": "User",
"url": "https://api.github.com/users/catswithbats"
} | [] | closed | false | null | [] | null | [
"Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448). \r\n\r\nThere are two options here:\r\n1. Increase the model's `max_length` parameter: \r\n```python\r\nmodel.config.max_length = 512\r\n```\r\n2. Filter data with labels longer than max length: https://discuss.huggingface.co/t/open-to-the-community-whisper-fine-tuning-event/26681/21?u=sanchit-gandhi\r\n\r\nNote that the datasets repo is reserved for issues directly related to the HF datasets library. Issues related to custom fine-tuning implementations are more applicable to the HF Forum: https://discuss.huggingface.co. You're more likely to get a response by posting your issue in the most applicable place and boost the chance of someone sharing a working solution!",
"@sanchit-gandhi Thank you for all your work on this topic.\r\n\r\nI'm finding that changing the `max_length` value does not make this error go away."
] | "2022-12-25T15:17:14Z" | "2023-07-21T14:29:47Z" | "2023-07-21T14:29:47Z" | NONE | null | null | null | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 - WEB](https://discuss.huggingface.co/t/trainer-runtimeerror-the-size-of-tensor-a-462-must-match-the-size-of-tensor-b-448-at-non-singleton-dimension-1/26010/10 ) - another person experiencing the same issue. But could not resolve the issue with the google/fleurs data. __Not clear what can be modified in the PY code to resolve the input data size mismatch, as the training data is already very small__.
Tried posting on Discord, @sanchit-gandhi and @vaibhavs10. Was hoping that the event is over and some input/help is now available. [Hugging Face - whisper-small-amet](https://huggingface.co/drmeeseeks/whisper-small-amet).
The paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356) am_et is a low resource language (Table E), with the WER results ranging from 120-229, based on model size. (Whisper small WER=120.2).
# ---> Initial Training Output
/usr/local/lib/python3.8/dist-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
[INFO|trainer.py:1641] 2022-12-18 05:23:28,799 >> ***** Running training *****
[INFO|trainer.py:1642] 2022-12-18 05:23:28,799 >> Num examples = 446
[INFO|trainer.py:1643] 2022-12-18 05:23:28,799 >> Num Epochs = 72
[INFO|trainer.py:1644] 2022-12-18 05:23:28,799 >> Instantaneous batch size per device = 16
[INFO|trainer.py:1645] 2022-12-18 05:23:28,799 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:1646] 2022-12-18 05:23:28,799 >> Gradient Accumulation steps = 2
[INFO|trainer.py:1647] 2022-12-18 05:23:28,800 >> Total optimization steps = 1000
[INFO|trainer.py:1648] 2022-12-18 05:23:28,801 >> Number of trainable parameters = 241734912
# ---> Error
14% 9/65 [07:07<48:34, 52.04s/it][INFO|configuration_utils.py:523] 2022-12-18 05:03:07,941 >> Generate config GenerationConfig {
"begin_suppress_tokens": [
220,
50257
],
"bos_token_id": 50257,
"decoder_start_token_id": 50258,
"eos_token_id": 50257,
"max_length": 448,
"pad_token_id": 50257,
"transformers_version": "4.26.0.dev0",
"use_cache": false
}
Traceback (most recent call last):
File "run_speech_recognition_seq2seq_streaming.py", line 629, in <module>
main()
File "run_speech_recognition_seq2seq_streaming.py", line 578, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1534, in train
return inner_training_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1859, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2122, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 78, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2818, in evaluate
output = eval_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 3000, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 213, in prediction_step
outputs = model(**inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1197, in forward
outputs = self.model(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1066, in forward
decoder_outputs = self.decoder(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 873, in forward
hidden_states = inputs_embeds + positions
RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1
100% 1000/1000 [2:52:21<00:00, 10.34s/it]
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5391/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5391/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3797 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3797/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3797/comments | https://api.github.com/repos/huggingface/datasets/issues/3797/events | https://github.com/huggingface/datasets/pull/3797 | 1,154,383,063 | PR_kwDODunzps4zrgAD | 3,797 | Reddit dataset card contribution | {
"avatar_url": "https://avatars.githubusercontent.com/u/56791604?v=4",
"events_url": "https://api.github.com/users/anna-kay/events{/privacy}",
"followers_url": "https://api.github.com/users/anna-kay/followers",
"following_url": "https://api.github.com/users/anna-kay/following{/other_user}",
"gists_url": "https://api.github.com/users/anna-kay/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anna-kay",
"id": 56791604,
"login": "anna-kay",
"node_id": "MDQ6VXNlcjU2NzkxNjA0",
"organizations_url": "https://api.github.com/users/anna-kay/orgs",
"received_events_url": "https://api.github.com/users/anna-kay/received_events",
"repos_url": "https://api.github.com/users/anna-kay/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anna-kay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anna-kay/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anna-kay"
} | [] | closed | false | null | [] | null | [] | "2022-02-28T17:53:18Z" | "2023-03-09T22:08:58Z" | "2022-03-01T12:58:57Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3797.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3797",
"merged_at": "2022-03-01T12:58:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3797.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3797"
} | Description tags for webis-tldr-17 added. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3797/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3797/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2983 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2983/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2983/comments | https://api.github.com/repos/huggingface/datasets/issues/2983/events | https://github.com/huggingface/datasets/pull/2983 | 1,010,263,058 | PR_kwDODunzps4saw_v | 2,983 | added SwissJudgmentPrediction dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_url": "https://api.github.com/users/JoelNiklaus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JoelNiklaus",
"id": 3775944,
"login": "JoelNiklaus",
"node_id": "MDQ6VXNlcjM3NzU5NDQ=",
"organizations_url": "https://api.github.com/users/JoelNiklaus/orgs",
"received_events_url": "https://api.github.com/users/JoelNiklaus/received_events",
"repos_url": "https://api.github.com/users/JoelNiklaus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JoelNiklaus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JoelNiklaus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JoelNiklaus"
} | [] | closed | false | null | [] | null | [] | "2021-09-28T22:17:56Z" | "2021-10-01T16:03:05Z" | "2021-10-01T16:03:05Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2983.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2983",
"merged_at": "2021-10-01T16:03:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2983.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2983"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2983/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2983/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2860 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2860/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2860/comments | https://api.github.com/repos/huggingface/datasets/issues/2860/events | https://github.com/huggingface/datasets/issues/2860 | 985,013,339 | MDU6SXNzdWU5ODUwMTMzMzk= | 2,860 | Cannot download TOTTO dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mrm8488",
"id": 3653789,
"login": "mrm8488",
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mrm8488"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hola @mrm8488, thanks for reporting.\r\n\r\nApparently, the data source host changed their URL one week ago: https://github.com/google-research-datasets/ToTTo/commit/cebeb430ec2a97747e704d16a9354f7d9073ff8f\r\n\r\nI'm fixing it."
] | "2021-09-01T11:04:10Z" | "2021-09-02T06:47:40Z" | "2021-09-02T06:47:40Z" | CONTRIBUTOR | null | null | null | Error: Couldn't find file at https://storage.googleapis.com/totto/totto_data.zip
`datasets version: 1.11.0`
# How to reproduce:
```py
from datasets import load_dataset
dataset = load_dataset('totto')
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2860/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2860/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2258/comments | https://api.github.com/repos/huggingface/datasets/issues/2258/events | https://github.com/huggingface/datasets/pull/2258 | 866,870,588 | MDExOlB1bGxSZXF1ZXN0NjIyNjcxNTQy | 2,258 | Fix incorrect update_metadata_with_features calls in ArrowDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"@lhoestq Maybe a test that runs the functions that call `update_metadata_with_features` and checks if metadata was updated would be nice to prevent this from happening in the future."
] | "2021-04-25T00:48:38Z" | "2021-04-26T17:16:30Z" | "2021-04-26T16:54:04Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2258.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2258",
"merged_at": "2021-04-26T16:54:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2258.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2258"
} | Fixes bugs in the `unpdate_metadata_with_features` calls (caused by changes in #2151) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2258/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2258/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1396/comments | https://api.github.com/repos/huggingface/datasets/issues/1396/events | https://github.com/huggingface/datasets/pull/1396 | 760,455,295 | MDExOlB1bGxSZXF1ZXN0NTM1MjgzOTAw | 1,396 | initial commit for MultiReQA for second PR | {
"avatar_url": "https://avatars.githubusercontent.com/u/13200370?v=4",
"events_url": "https://api.github.com/users/Karthik-Bhaskar/events{/privacy}",
"followers_url": "https://api.github.com/users/Karthik-Bhaskar/followers",
"following_url": "https://api.github.com/users/Karthik-Bhaskar/following{/other_user}",
"gists_url": "https://api.github.com/users/Karthik-Bhaskar/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Karthik-Bhaskar",
"id": 13200370,
"login": "Karthik-Bhaskar",
"node_id": "MDQ6VXNlcjEzMjAwMzcw",
"organizations_url": "https://api.github.com/users/Karthik-Bhaskar/orgs",
"received_events_url": "https://api.github.com/users/Karthik-Bhaskar/received_events",
"repos_url": "https://api.github.com/users/Karthik-Bhaskar/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Karthik-Bhaskar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Karthik-Bhaskar/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Karthik-Bhaskar"
} | [] | closed | false | null | [] | null | [
"Subsequent [PR #1426 ](https://github.com/huggingface/datasets/pull/1426) since this PR has uploaded other files along with the MultiReQA dataset.",
"closing this one since a new PR has been created"
] | "2020-12-09T16:00:35Z" | "2020-12-10T18:20:12Z" | "2020-12-10T18:20:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1396",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1396"
} | Since last PR #1349 had some issues passing the tests. So, a new PR is generated. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1396/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3838 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3838/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3838/comments | https://api.github.com/repos/huggingface/datasets/issues/3838/events | https://github.com/huggingface/datasets/issues/3838 | 1,161,137,406 | I_kwDODunzps5FNYz- | 3,838 | Add a data type for labeled images (image segmentation) | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [] | "2022-03-07T09:38:15Z" | "2022-04-10T13:34:59Z" | null | CONTRIBUTOR | null | null | null | It might be a mix of Image and ClassLabel, and the color palette might be generated automatically.
---
### Example
every pixel in the images of the annotation column (in https://huggingface.co/datasets/scene_parse_150) has a value that gives its class, and the dataset itself is associated with a color palette (eg https://github.com/open-mmlab/mmsegmentation/blob/98a353b674c6052d319e7de4e5bcd65d670fcf84/mmseg/datasets/ade.py#L47) that maps every class with a color.
So we might want to render the image as a colored image instead of a black and white one.
<img width="785" alt="156741519-fbae6844-2606-4c28-837e-279d83d00865" src="https://user-images.githubusercontent.com/1676121/157005263-7058c584-2b70-465a-ad94-8a982f726cf4.png">
See https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/core/features/labeled_image.py for reference in Tensorflow | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3838/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3838/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/85 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/85/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/85/comments | https://api.github.com/repos/huggingface/datasets/issues/85/events | https://github.com/huggingface/datasets/pull/85 | 617,253,428 | MDExOlB1bGxSZXF1ZXN0NDE3MjA0ODA4 | 85 | Add boolq | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Awesome :-) Thanks for adding the function to the Mock DL Manager"
] | "2020-05-13T08:32:27Z" | "2020-05-13T09:09:39Z" | "2020-05-13T09:09:38Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/85.diff",
"html_url": "https://github.com/huggingface/datasets/pull/85",
"merged_at": "2020-05-13T09:09:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/85.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/85"
} | I just added the dummy data for this dataset.
This one was uses `tf.io.gfile.copy` to download the data but I added the support for custom download in the mock_download_manager. I also had to add a `tensorflow` dependency for tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/85/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/85/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3234/comments | https://api.github.com/repos/huggingface/datasets/issues/3234/events | https://github.com/huggingface/datasets/pull/3234 | 1,047,634,236 | PR_kwDODunzps4uPHRk | 3,234 | Avoid PyArrow type optimization if it fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"That's good to have a way to disable this easily :)\r\nI just find it a bit unfortunate that users would have to experience the error once and then do `DISABLE_PYARROW_TYPES_OPTIMIZATION=1`. Do you know if there's a way to simply fallback on disabling it automatically when it fails ?",
"@lhoestq Actually, I agree a fallback makes more sense. The current approach is not very practical indeed and would require a mention in the docs.\r\n",
"Replaced the env variable with a fallback!",
"Hmm if the fallback automatically happens without the user knowing it, then I don't think we really need to mention it. But if you really wanted to, I think the [Improve performance](https://huggingface.co/docs/datasets/cache.html#improve-performance) section would be a great place for it! ",
"Yea I think this could just end up in a note that says that `datasets` automatically picks the most optimized integer precision for your tokenized text data to save you disk space. Maybe later if we have a page on text processing we can add this note, but for now I agree it doesn't fit well into the doc.\r\n\r\nIn particular in the \"Improve performance\" section we mention what users can do to speed up their computations, while this behavior is just some internal feature that users don't have control over anyway."
] | "2021-11-08T16:10:27Z" | "2021-11-10T12:04:29Z" | "2021-11-10T12:04:28Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3234",
"merged_at": "2021-11-10T12:04:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3234"
} | Adds a new variable, `DISABLE_PYARROW_TYPES_OPTIMIZATION`, to `config.py` for easier control of the Arrow type optimization.
Fix #2206 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3234/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2233 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2233/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2233/comments | https://api.github.com/repos/huggingface/datasets/issues/2233/events | https://github.com/huggingface/datasets/pull/2233 | 860,097,084 | MDExOlB1bGxSZXF1ZXN0NjE3MDYwMTkw | 2,233 | Fix `xnli` dataset tuple key | {
"avatar_url": "https://avatars.githubusercontent.com/u/42388668?v=4",
"events_url": "https://api.github.com/users/NikhilBartwal/events{/privacy}",
"followers_url": "https://api.github.com/users/NikhilBartwal/followers",
"following_url": "https://api.github.com/users/NikhilBartwal/following{/other_user}",
"gists_url": "https://api.github.com/users/NikhilBartwal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NikhilBartwal",
"id": 42388668,
"login": "NikhilBartwal",
"node_id": "MDQ6VXNlcjQyMzg4NjY4",
"organizations_url": "https://api.github.com/users/NikhilBartwal/orgs",
"received_events_url": "https://api.github.com/users/NikhilBartwal/received_events",
"repos_url": "https://api.github.com/users/NikhilBartwal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NikhilBartwal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NikhilBartwal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NikhilBartwal"
} | [] | closed | false | null | [] | null | [] | "2021-04-16T19:12:42Z" | "2021-04-19T08:56:42Z" | "2021-04-19T08:56:42Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2233.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2233",
"merged_at": "2021-04-19T08:56:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2233.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2233"
} | Closes #2229
The `xnli` dataset yields a tuple key in case of `ar` which is inconsistant with the acceptable key types (str/int).
The key was thus ported to `str` keeping the original information intact. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2233/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2233/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3693/comments | https://api.github.com/repos/huggingface/datasets/issues/3693/events | https://github.com/huggingface/datasets/pull/3693 | 1,128,554,365 | PR_kwDODunzps4yTTcQ | 3,693 | Standardize to `Example::` | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mishig25",
"id": 11827707,
"login": "mishig25",
"node_id": "MDQ6VXNlcjExODI3NzA3",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"repos_url": "https://api.github.com/users/mishig25/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mishig25"
} | [] | closed | false | null | [] | null | [
"Closing because https://github.com/huggingface/datasets/pull/3690/commits/ee0e0935d6105c1390b0e14a7622fbaad3044dbb"
] | "2022-02-09T13:37:13Z" | "2022-02-17T10:20:55Z" | "2022-02-17T10:20:52Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3693.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3693",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3693.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3693"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3693/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3693/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5557/comments | https://api.github.com/repos/huggingface/datasets/issues/5557/events | https://github.com/huggingface/datasets/pull/5557 | 1,593,545,324 | PR_kwDODunzps5Kbube | 5,557 | Add filter desc | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008477 / 0.011353 (-0.002875) | 0.004565 / 0.011008 (-0.006443) | 0.101640 / 0.038508 (0.063132) | 0.029581 / 0.023109 (0.006472) | 0.296524 / 0.275898 (0.020625) | 0.363175 / 0.323480 (0.039695) | 0.006961 / 0.007986 (-0.001024) | 0.003365 / 0.004328 (-0.000963) | 0.079689 / 0.004250 (0.075439) | 0.034881 / 0.037052 (-0.002171) | 0.310979 / 0.258489 (0.052489) | 0.348663 / 0.293841 (0.054822) | 0.034549 / 0.128546 (-0.093997) | 0.011463 / 0.075646 (-0.064184) | 0.326218 / 0.419271 (-0.093053) | 0.041393 / 0.043533 (-0.002140) | 0.297604 / 0.255139 (0.042465) | 0.335751 / 0.283200 (0.052551) | 0.086521 / 0.141683 (-0.055162) | 1.478906 / 1.452155 (0.026752) | 1.512777 / 1.492716 (0.020060) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.008767 / 0.018006 (-0.009239) | 0.397386 / 0.000490 (0.396897) | 0.003136 / 0.000200 (0.002936) | 0.000096 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022804 / 0.037411 (-0.014608) | 0.097591 / 0.014526 (0.083066) | 0.103189 / 0.176557 (-0.073368) | 0.138165 / 0.737135 (-0.598970) | 0.107464 / 0.296338 (-0.188874) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428956 / 0.215209 (0.213747) | 4.269656 / 2.077655 (2.192001) | 2.154418 / 1.504120 (0.650298) | 1.914176 / 1.541195 (0.372982) | 1.818452 / 1.468490 (0.349962) | 0.701381 / 4.584777 (-3.883396) | 3.425190 / 3.745712 (-0.320522) | 1.862545 / 5.269862 (-3.407316) | 1.166271 / 4.565676 (-3.399405) | 0.083678 / 0.424275 (-0.340597) | 0.012254 / 0.007607 (0.004647) | 0.535710 / 0.226044 (0.309665) | 5.342528 / 2.268929 (3.073600) | 2.627135 / 55.444624 (-52.817489) | 2.308313 / 6.876477 (-4.568164) | 2.325568 / 2.142072 (0.183496) | 0.818318 / 4.805227 (-3.986909) | 0.149812 / 6.500664 (-6.350853) | 0.064559 / 0.075469 (-0.010910) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253611 / 1.841788 (-0.588176) | 13.646763 / 8.074308 (5.572455) | 14.387630 / 10.191392 (4.196238) | 0.159937 / 0.680424 (-0.520487) | 0.029123 / 0.534201 (-0.505078) | 0.400909 / 0.579283 (-0.178374) | 0.422830 / 0.434364 (-0.011534) | 0.488205 / 0.540337 (-0.052133) | 0.577982 / 1.386936 (-0.808954) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006430 / 0.011353 (-0.004923) | 0.004433 / 0.011008 (-0.006576) | 0.077459 / 0.038508 (0.038951) | 0.026949 / 0.023109 (0.003840) | 0.350276 / 0.275898 (0.074378) | 0.376189 / 0.323480 (0.052709) | 0.004945 / 0.007986 (-0.003041) | 0.003280 / 0.004328 (-0.001048) | 0.076465 / 0.004250 (0.072215) | 0.037510 / 0.037052 (0.000457) | 0.350410 / 0.258489 (0.091921) | 0.386778 / 0.293841 (0.092937) | 0.031933 / 0.128546 (-0.096613) | 0.011691 / 0.075646 (-0.063956) | 0.086519 / 0.419271 (-0.332753) | 0.042490 / 0.043533 (-0.001043) | 0.355930 / 0.255139 (0.100791) | 0.366500 / 0.283200 (0.083301) | 0.089542 / 0.141683 (-0.052141) | 1.492859 / 1.452155 (0.040704) | 1.548626 / 1.492716 (0.055910) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220123 / 0.018006 (0.202117) | 0.396970 / 0.000490 (0.396480) | 0.000398 / 0.000200 (0.000198) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024831 / 0.037411 (-0.012580) | 0.099681 / 0.014526 (0.085156) | 0.108922 / 0.176557 (-0.067635) | 0.143004 / 0.737135 (-0.594131) | 0.109671 / 0.296338 (-0.186667) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444237 / 0.215209 (0.229028) | 4.430330 / 2.077655 (2.352675) | 2.235003 / 1.504120 (0.730883) | 2.010499 / 1.541195 (0.469305) | 2.030585 / 1.468490 (0.562095) | 0.701938 / 4.584777 (-3.882839) | 3.334569 / 3.745712 (-0.411144) | 1.861680 / 5.269862 (-3.408181) | 1.166072 / 4.565676 (-3.399604) | 0.083870 / 0.424275 (-0.340405) | 0.012615 / 0.007607 (0.005008) | 0.548789 / 0.226044 (0.322744) | 5.488064 / 2.268929 (3.219136) | 2.614926 / 55.444624 (-52.829698) | 2.246455 / 6.876477 (-4.630022) | 2.277439 / 2.142072 (0.135367) | 0.808449 / 4.805227 (-3.996778) | 0.152434 / 6.500664 (-6.348230) | 0.066709 / 0.075469 (-0.008760) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.316880 / 1.841788 (-0.524908) | 13.965269 / 8.074308 (5.890961) | 13.660187 / 10.191392 (3.468795) | 0.157801 / 0.680424 (-0.522623) | 0.016580 / 0.534201 (-0.517621) | 0.382834 / 0.579283 (-0.196449) | 0.394717 / 0.434364 (-0.039647) | 0.465138 / 0.540337 (-0.075200) | 0.552399 / 1.386936 (-0.834537) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009341 / 0.011353 (-0.002012) | 0.005303 / 0.011008 (-0.005705) | 0.099287 / 0.038508 (0.060779) | 0.035587 / 0.023109 (0.012478) | 0.295146 / 0.275898 (0.019248) | 0.370470 / 0.323480 (0.046990) | 0.008910 / 0.007986 (0.000925) | 0.004358 / 0.004328 (0.000029) | 0.076298 / 0.004250 (0.072047) | 0.047187 / 0.037052 (0.010135) | 0.309025 / 0.258489 (0.050536) | 0.346659 / 0.293841 (0.052818) | 0.038378 / 0.128546 (-0.090168) | 0.012475 / 0.075646 (-0.063172) | 0.334370 / 0.419271 (-0.084901) | 0.048391 / 0.043533 (0.004858) | 0.298613 / 0.255139 (0.043474) | 0.317329 / 0.283200 (0.034130) | 0.108748 / 0.141683 (-0.032934) | 1.450454 / 1.452155 (-0.001701) | 1.519883 / 1.492716 (0.027167) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011513 / 0.018006 (-0.006494) | 0.498941 / 0.000490 (0.498451) | 0.005098 / 0.000200 (0.004898) | 0.000096 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030523 / 0.037411 (-0.006888) | 0.105478 / 0.014526 (0.090952) | 0.121101 / 0.176557 (-0.055456) | 0.159951 / 0.737135 (-0.577184) | 0.126766 / 0.296338 (-0.169572) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399101 / 0.215209 (0.183892) | 3.997069 / 2.077655 (1.919414) | 1.851592 / 1.504120 (0.347472) | 1.695708 / 1.541195 (0.154513) | 1.759504 / 1.468490 (0.291014) | 0.708241 / 4.584777 (-3.876536) | 3.786724 / 3.745712 (0.041012) | 3.523731 / 5.269862 (-1.746131) | 1.899474 / 4.565676 (-2.666203) | 0.086680 / 0.424275 (-0.337595) | 0.012232 / 0.007607 (0.004625) | 0.508507 / 0.226044 (0.282462) | 5.086320 / 2.268929 (2.817391) | 2.234906 / 55.444624 (-53.209718) | 1.911090 / 6.876477 (-4.965386) | 1.989232 / 2.142072 (-0.152841) | 0.863660 / 4.805227 (-3.941567) | 0.169334 / 6.500664 (-6.331330) | 0.063273 / 0.075469 (-0.012196) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237590 / 1.841788 (-0.604198) | 15.417631 / 8.074308 (7.343323) | 15.235308 / 10.191392 (5.043916) | 0.209431 / 0.680424 (-0.470993) | 0.029214 / 0.534201 (-0.504987) | 0.444767 / 0.579283 (-0.134516) | 0.447776 / 0.434364 (0.013413) | 0.538440 / 0.540337 (-0.001897) | 0.635760 / 1.386936 (-0.751176) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007758 / 0.011353 (-0.003594) | 0.005539 / 0.011008 (-0.005469) | 0.077011 / 0.038508 (0.038503) | 0.034305 / 0.023109 (0.011196) | 0.363352 / 0.275898 (0.087454) | 0.411882 / 0.323480 (0.088403) | 0.006286 / 0.007986 (-0.001700) | 0.004378 / 0.004328 (0.000050) | 0.075504 / 0.004250 (0.071253) | 0.052728 / 0.037052 (0.015675) | 0.370122 / 0.258489 (0.111633) | 0.421910 / 0.293841 (0.128069) | 0.038444 / 0.128546 (-0.090102) | 0.012602 / 0.075646 (-0.063045) | 0.088540 / 0.419271 (-0.330731) | 0.060321 / 0.043533 (0.016788) | 0.350502 / 0.255139 (0.095363) | 0.393211 / 0.283200 (0.110011) | 0.113057 / 0.141683 (-0.028626) | 1.453275 / 1.452155 (0.001120) | 1.541033 / 1.492716 (0.048317) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.333603 / 0.018006 (0.315597) | 0.510548 / 0.000490 (0.510058) | 0.003573 / 0.000200 (0.003373) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032783 / 0.037411 (-0.004628) | 0.111943 / 0.014526 (0.097418) | 0.127154 / 0.176557 (-0.049403) | 0.171716 / 0.737135 (-0.565420) | 0.132441 / 0.296338 (-0.163898) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439110 / 0.215209 (0.223901) | 4.440874 / 2.077655 (2.363220) | 2.145850 / 1.504120 (0.641730) | 1.909566 / 1.541195 (0.368371) | 2.032199 / 1.468490 (0.563709) | 0.711295 / 4.584777 (-3.873482) | 3.845729 / 3.745712 (0.100017) | 3.583555 / 5.269862 (-1.686307) | 1.836856 / 4.565676 (-2.728820) | 0.085966 / 0.424275 (-0.338309) | 0.012479 / 0.007607 (0.004872) | 0.545379 / 0.226044 (0.319334) | 5.425724 / 2.268929 (3.156796) | 2.648304 / 55.444624 (-52.796321) | 2.286369 / 6.876477 (-4.590108) | 2.367714 / 2.142072 (0.225642) | 0.831035 / 4.805227 (-3.974192) | 0.167603 / 6.500664 (-6.333061) | 0.064721 / 0.075469 (-0.010748) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244495 / 1.841788 (-0.597292) | 15.304267 / 8.074308 (7.229958) | 13.912185 / 10.191392 (3.720793) | 0.156459 / 0.680424 (-0.523965) | 0.019181 / 0.534201 (-0.515019) | 0.425940 / 0.579283 (-0.153343) | 0.427956 / 0.434364 (-0.006408) | 0.529126 / 0.540337 (-0.011212) | 0.628360 / 1.386936 (-0.758576) |\n\n</details>\n</details>\n\n\n"
] | "2023-02-21T14:04:42Z" | "2023-02-21T14:19:54Z" | "2023-02-21T14:12:39Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5557",
"merged_at": "2023-02-21T14:12:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5557"
} | Otherwise it would show a `Map` progress bar, since it uses `map` under the hood | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5557/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5557/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3171/comments | https://api.github.com/repos/huggingface/datasets/issues/3171/events | https://github.com/huggingface/datasets/issues/3171 | 1,037,728,059 | I_kwDODunzps492nk7 | 3,171 | Raise exceptions instead of using assertions for control flow | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Adding the remaining tasks for this issue to help new code contributors. \r\n$ cd src/datasets && ack assert -lc \r\n- [x] commands/convert.py:1\r\n- [x] arrow_reader.py:3\r\n- [x] load.py:7\r\n- [x] utils/py_utils.py:2\r\n- [x] features/features.py:9\r\n- [x] arrow_writer.py:7\r\n- [x] search.py:6\r\n- [x] table.py:1\r\n- [x] metric.py:3\r\n- [x] tasks/image_classification.py:1\r\n- [x] arrow_dataset.py:17\r\n- [x] fingerprint.py:6\r\n- [x] io/json.py:1\r\n- [x] io/csv.py:1",
"Hi all,\r\nI am interested in taking up `fingerprint.py`, `search.py`, `arrow_writer.py` and `metric.py`. Will raise a PR soon!",
"Let me look into `arrow_dataset.py`, `table.py`, `data_files.py` & `features.py` ",
"All the tasks are completed for this issue. This can be closed. "
] | "2021-10-27T18:26:52Z" | "2021-12-23T16:40:37Z" | "2021-12-23T16:40:37Z" | CONTRIBUTOR | null | null | null | Motivated by https://github.com/huggingface/transformers/issues/12789 in Transformers, one welcoming change would be replacing assertions with proper exceptions. The only type of assertions we should keep are those used as sanity checks.
Currently, there is a total of 87 files with the `assert` statements (located under `datasets` and `src/datasets`), so when working on this, to manage the PR size, only modify 4-5 files at most before submitting a PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3171/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5711/comments | https://api.github.com/repos/huggingface/datasets/issues/5711/events | https://github.com/huggingface/datasets/issues/5711 | 1,655,971,647 | I_kwDODunzps5itB8_ | 5,711 | load_dataset in v2.11.0 raises "ValueError: seek of closed file" in np.load() | {
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https://api.github.com/users/rcasero/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcasero",
"id": 1219084,
"login": "rcasero",
"node_id": "MDQ6VXNlcjEyMTkwODQ=",
"organizations_url": "https://api.github.com/users/rcasero/orgs",
"received_events_url": "https://api.github.com/users/rcasero/received_events",
"repos_url": "https://api.github.com/users/rcasero/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcasero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcasero/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcasero"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"It seems like https://github.com/huggingface/datasets/pull/5626 has introduced this error. \r\n\r\ncc @albertvillanova \r\n\r\nI think replacing:\r\nhttps://github.com/huggingface/datasets/blob/0803a006db1c395ac715662cc6079651f77c11ea/src/datasets/download/streaming_download_manager.py#L777-L778\r\nwith:\r\n```python\r\nreturn np.load(xopen(filepath_or_buffer, \"rb\", use_auth_token=use_auth_token), *args, **kwargs)\r\n```\r\nshould fix the issue.\r\n\r\n(Maybe this is also worth doing a patch release afterward)",
"Thanks for reporting, @rcasero.\r\n\r\nI can have a look..."
] | "2023-04-05T16:46:49Z" | "2023-04-07T09:16:59Z" | "2023-04-07T09:16:59Z" | NONE | null | null | null | ### Describe the bug
Hi,
I have some `dataset_load()` code of a custom offline dataset that works with datasets v2.10.1.
```python
ds = datasets.load_dataset(path=dataset_dir,
name=configuration,
data_dir=dataset_dir,
cache_dir=cache_dir,
aux_dir=aux_dir,
# download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD,
num_proc=18)
```
When upgrading datasets to 2.11.0, it fails with error
```
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/site-packages/datasets/load.py", line 1791, in load_dataset
builder_instance.download_and_prepare(
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/site-packages/datasets/builder.py", line 891, in download_and_prepare
self._download_and_prepare(
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/site-packages/datasets/builder.py", line 1651, in _download_and_prepare
super()._download_and_prepare(
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/site-packages/datasets/builder.py", line 964, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/ramon.casero/.cache/huggingface/modules/datasets_modules/datasets/71f67f69e6e00e139903a121f96b71f39b65a6b6aaeb0862e6a5da3a3f565b4c/mydataset.py", line 682, in _split_generators
self.some_function()
File "/home/ramon.casero/.cache/huggingface/modules/datasets_modules/datasets/71f67f69e6e00e139903a121f96b71f39b65a6b6aaeb0862e6a5da3a3f565b4c/mydataset.py", line 1314, in some_function()
x_df = pd.DataFrame({'cell_type_descriptor': fp['x'].tolist()})
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/site-packages/numpy/lib/npyio.py", line 248, in __getitem__
bytes = self.zip.open(key)
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/zipfile.py", line 1530, in open
fheader = zef_file.read(sizeFileHeader)
File "/home/ramon.casero/opt/miniconda3/envs/myenv/lib/python3.10/zipfile.py", line 744, in read
self._file.seek(self._pos)
ValueError: seek of closed file
```
### Steps to reproduce the bug
Sorry, I cannot share the data or code because they are not mine to share, but the point of failure is a call in `some_function()`
```python
with np.load(embedding_filename) as fp:
x_df = pd.DataFrame({'feature': fp['x'].tolist()})
```
I'll try to generate a short snippet that reproduces the error.
### Expected behavior
I would expect that `load_dataset` works on the custom datasets generation script for v2.11.0 the same way it works for 2.10.1, without making `np.load()` give a `ValueError: seek of closed file` error.
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-4.18.0-483.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.8
- Huggingface_hub version: 0.12.0
- PyArrow version: 11.0.0
- Pandas version: 1.5.2
- numpy: 1.24.2
- This is an offline dataset that uses `datasets.config.HF_DATASETS_OFFLINE = True` in the generation script.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5711/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5711/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6497 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6497/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6497/comments | https://api.github.com/repos/huggingface/datasets/issues/6497/events | https://github.com/huggingface/datasets/issues/6497 | 2,041,994,274 | I_kwDODunzps55tlwi | 6,497 | Support setting a default config name in push_to_hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2023-12-14T15:59:03Z" | "2023-12-18T11:50:04Z" | "2023-12-18T11:50:04Z" | MEMBER | null | null | null | In order to convert script-datasets to no-script datasets, we need to support setting a default config name for those scripts that set one. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6497/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6497/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5232/comments | https://api.github.com/repos/huggingface/datasets/issues/5232/events | https://github.com/huggingface/datasets/issues/5232 | 1,446,294,165 | I_kwDODunzps5WNLKV | 5,232 | Incompatible dill versions in datasets 2.6.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/10574123?v=4",
"events_url": "https://api.github.com/users/vinaykakade/events{/privacy}",
"followers_url": "https://api.github.com/users/vinaykakade/followers",
"following_url": "https://api.github.com/users/vinaykakade/following{/other_user}",
"gists_url": "https://api.github.com/users/vinaykakade/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vinaykakade",
"id": 10574123,
"login": "vinaykakade",
"node_id": "MDQ6VXNlcjEwNTc0MTIz",
"organizations_url": "https://api.github.com/users/vinaykakade/orgs",
"received_events_url": "https://api.github.com/users/vinaykakade/received_events",
"repos_url": "https://api.github.com/users/vinaykakade/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vinaykakade/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vinaykakade/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vinaykakade"
} | [] | closed | false | null | [] | null | [
"Thanks for reporting, @vinaykakade.\r\n\r\nWe are discussing about making a release early this week.\r\n\r\nPlease note that in the meantime, in your specific case (as we also pointed out here: https://github.com/huggingface/datasets/issues/5162#issuecomment-1291720293), you can circumvent the issue by pinning `multiprocess` to 0.70.13 version (instead of using latest 0.70.14).\r\n\r\nDuplicate of:\r\n- https://github.com/huggingface/datasets/issues/5162",
"You can also make `pip-compile` work by using the backtracking resolver (instead of the legacy one): https://pip-tools.readthedocs.io/en/latest/#a-note-on-resolvers\r\n```\r\npip-compile --resolver=backtracking requirements.in\r\n```\r\nThis resolver will automatically use `multiprocess` 0.70.13 version.\r\n"
] | "2022-11-12T06:46:23Z" | "2022-11-14T08:24:43Z" | "2022-11-14T08:07:59Z" | NONE | null | null | null | ### Describe the bug
datasets version 2.6.1 has a dependency on dill<0.3.6. This causes a conflict with dill>=0.3.6 used by multiprocess dependency in datasets 2.6.1
This issue is already fixed in https://github.com/huggingface/datasets/pull/5166/files, but not yet been released. Please release a new version of the datasets library to fix this.
### Steps to reproduce the bug
1. Create requirements.in with only dependency being datasets (or datasets[s3])
2. Run pip-compile
3. The output is as follows:
```
Could not find a version that matches dill<0.3.6,>=0.3.6 (from datasets[s3]==2.6.1->-r requirements.in (line 1))
Tried: 0.2, 0.2, 0.2.1, 0.2.1, 0.2.2, 0.2.2, 0.2.3, 0.2.3, 0.2.4, 0.2.4, 0.2.5, 0.2.5, 0.2.6, 0.2.7, 0.2.7.1, 0.2.8, 0.2.8.1, 0.2.8.2, 0.2.9, 0.3.0, 0.3.1, 0.3.1.1, 0.3.2, 0.3.3, 0.3.3, 0.3.4, 0.3.4, 0.3.5, 0.3.5, 0.3.5.1, 0.3.5.1, 0.3.6, 0.3.6
Skipped pre-versions: 0.1a1, 0.2a1, 0.2a1, 0.2b1, 0.2b1
There are incompatible versions in the resolved dependencies:
dill<0.3.6 (from datasets[s3]==2.6.1->-r requirements.in (line 1))
dill>=0.3.6 (from multiprocess==0.70.14->datasets[s3]==2.6.1->-r requirements.in (line 1))
```
### Expected behavior
pip-compile produces requirements.txt without any conflicts
### Environment info
datasets version 2.6.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5232/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1597/comments | https://api.github.com/repos/huggingface/datasets/issues/1597/events | https://github.com/huggingface/datasets/pull/1597 | 770,276,140 | MDExOlB1bGxSZXF1ZXN0NTQyMDUwMTc5 | 1,597 | adding hate-speech-and-offensive-language | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [
"made suggested changes and opened PR https://github.com/huggingface/datasets/pull/1628"
] | "2020-12-17T18:35:15Z" | "2020-12-23T23:27:17Z" | "2020-12-23T23:27:16Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1597.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1597",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1597.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1597"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1597/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3111/comments | https://api.github.com/repos/huggingface/datasets/issues/3111/events | https://github.com/huggingface/datasets/issues/3111 | 1,030,598,983 | I_kwDODunzps49bbFH | 3,111 | concatenate_datasets removes ClassLabel typing. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dref360",
"id": 8976546,
"login": "Dref360",
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"repos_url": "https://api.github.com/users/Dref360/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dref360"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"Something like this would fix it I think: https://github.com/huggingface/datasets/compare/master...Dref360:HF-3111/concatenate_types?expand=1"
] | "2021-10-19T18:05:31Z" | "2021-10-21T14:50:21Z" | "2021-10-21T14:50:21Z" | CONTRIBUTOR | null | null | null | ## Describe the bug
When concatenating two datasets, we lose typing of ClassLabel columns.
I can work on this if this is a legitimate bug,
## Steps to reproduce the bug
```python
import datasets
from datasets import Dataset, ClassLabel, Value, concatenate_datasets
DS_LEN = 100
my_dataset = Dataset.from_dict(
{
"sentence": [f"{chr(i % 10)}" for i in range(DS_LEN)],
"label": [i % 2 for i in range(DS_LEN)]
}
)
my_predictions = Dataset.from_dict(
{
"pred": [(i + 1) % 2 for i in range(DS_LEN)]
}
)
my_dataset = my_dataset.cast(datasets.Features({"sentence": Value("string"), "label": ClassLabel(2, names=["POS", "NEG"])}))
print("Original")
print(my_dataset)
print(my_dataset.features)
concat_ds = concatenate_datasets([my_dataset, my_predictions], axis=1)
print("Concatenated")
print(concat_ds)
print(concat_ds.features)
```
## Expected results
The features of `concat_ds` should contain ClassLabel.
## Actual results
On master, I get:
```
{'sentence': Value(dtype='string', id=None), 'label': Value(dtype='int64', id=None), 'pred': Value(dtype='int64', id=None)}
```
## Environment info
- `datasets` version: 1.14.1.dev0
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3111/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3111/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4245/comments | https://api.github.com/repos/huggingface/datasets/issues/4245/events | https://github.com/huggingface/datasets/pull/4245 | 1,217,959,400 | PR_kwDODunzps426AUR | 4,245 | Add code examples for DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-27T22:52:22Z" | "2022-04-29T18:19:34Z" | "2022-04-29T18:13:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4245.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4245",
"merged_at": "2022-04-29T18:13:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4245.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4245"
} | This PR adds code examples for `DatasetDict` in the API reference :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4245/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4305/comments | https://api.github.com/repos/huggingface/datasets/issues/4305/events | https://github.com/huggingface/datasets/pull/4305 | 1,231,099,934 | PR_kwDODunzps43kt4P | 4,305 | Fixes FrugalScore | {
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"events_url": "https://api.github.com/users/moussaKam/events{/privacy}",
"followers_url": "https://api.github.com/users/moussaKam/followers",
"following_url": "https://api.github.com/users/moussaKam/following{/other_user}",
"gists_url": "https://api.github.com/users/moussaKam/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/moussaKam",
"id": 28675016,
"login": "moussaKam",
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"organizations_url": "https://api.github.com/users/moussaKam/orgs",
"received_events_url": "https://api.github.com/users/moussaKam/received_events",
"repos_url": "https://api.github.com/users/moussaKam/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/moussaKam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moussaKam/subscriptions",
"type": "User",
"url": "https://api.github.com/users/moussaKam"
} | [
{
"color": "E3165C",
"default": false,
"description": "",
"id": 4190228726,
"name": "transfer-to-evaluate",
"node_id": "LA_kwDODunzps75wdD2",
"url": "https://api.github.com/repos/huggingface/datasets/labels/transfer-to-evaluate"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4305). All of your documentation changes will be reflected on that endpoint.",
"> predictions and references are swapped. Basically Frugalscore is commutative, however some tiny differences can occur if we swap the references and the predictions. I decided to swap them just to obtain the exact results as reported in the paper.\r\n\r\nWhat is the order of magnitude of the difference ? Do you know what causes this ?\r\n\r\n> I switched to dynamic padding that was was used in the training, forcing the padding to max_length introduces errors for some reason that I ignore.\r\n\r\nWhat error ?"
] | "2022-05-10T12:44:06Z" | "2022-09-22T16:42:06Z" | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4305.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4305",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4305.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4305"
} | There are two minor modifications in this PR:
1) `predictions` and `references` are swapped. Basically Frugalscore is commutative, however some tiny differences can occur if we swap the references and the predictions. I decided to swap them just to obtain the exact results as reported in the paper.
2) I switched to dynamic padding that was was used in the training, forcing the padding to `max_length` introduces errors for some reason that I ignore.
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4305/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3923/comments | https://api.github.com/repos/huggingface/datasets/issues/3923/events | https://github.com/huggingface/datasets/pull/3923 | 1,169,773,869 | PR_kwDODunzps40d9YU | 3,923 | Add methods to IterableDatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3923). All of your documentation changes will be reflected on that endpoint.",
"Is this feature stale or needs any help to it ? If so I can quickly send a PR. Thanks\r\n\r\nCC : @lhoestq, @albertvillanova ",
"These features have been merged and are already available, thanks :)",
"Hello @lhoestq, I see that `IterableDataset` doesn't allow features like `take`, `len`, `slice` which can enable a lot of stuffs. Is it worth an addition ? Or is it intended that they didn't have those features ?",
"IterableDataset objects don't have `len` or `slice` because they can be possibly unbounded (you don't know in advance how many items they contain). Though IterableDataset.take and IterableDataset.skip do exist."
] | "2022-03-15T14:46:03Z" | "2022-07-06T15:40:20Z" | "2022-03-15T16:45:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3923.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3923",
"merged_at": "2022-03-15T16:45:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3923.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3923"
} | Following the new methods added in #3826 and https://github.com/huggingface/datasets/pull/3862 I added several methods to IterableDatasetDict:
- map
- filter
- shuffle
- with_format
- cast
- cast_column
- remove_columns
- rename_column
- rename_columns
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3923/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1907 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1907/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1907/comments | https://api.github.com/repos/huggingface/datasets/issues/1907/events | https://github.com/huggingface/datasets/issues/1907 | 811,520,569 | MDU6SXNzdWU4MTE1MjA1Njk= | 1,907 | DBPedia14 Dataset Checksum bug? | {
"avatar_url": "https://avatars.githubusercontent.com/u/918006?v=4",
"events_url": "https://api.github.com/users/francisco-perez-sorrosal/events{/privacy}",
"followers_url": "https://api.github.com/users/francisco-perez-sorrosal/followers",
"following_url": "https://api.github.com/users/francisco-perez-sorrosal/following{/other_user}",
"gists_url": "https://api.github.com/users/francisco-perez-sorrosal/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/francisco-perez-sorrosal",
"id": 918006,
"login": "francisco-perez-sorrosal",
"node_id": "MDQ6VXNlcjkxODAwNg==",
"organizations_url": "https://api.github.com/users/francisco-perez-sorrosal/orgs",
"received_events_url": "https://api.github.com/users/francisco-perez-sorrosal/received_events",
"repos_url": "https://api.github.com/users/francisco-perez-sorrosal/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/francisco-perez-sorrosal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/francisco-perez-sorrosal/subscriptions",
"type": "User",
"url": "https://api.github.com/users/francisco-perez-sorrosal"
} | [] | closed | false | null | [] | null | [
"Hi ! :)\r\n\r\nThis looks like the same issue as https://github.com/huggingface/datasets/issues/1856 \r\nBasically google drive has quota issues that makes it inconvenient for downloading files.\r\n\r\nIf the quota of a file is exceeded, you have to wait 24h for the quota to reset (which is painful).\r\n\r\nThe error says that the checksum of the downloaded file doesn't match because google drive returns a text file with the \"Quota Exceeded\" error instead of the actual data file.",
"Thanks @lhoestq! Yes, it seems back to normal after a couple of days."
] | "2021-02-18T22:25:48Z" | "2021-02-22T23:22:05Z" | "2021-02-22T23:22:04Z" | CONTRIBUTOR | null | null | null | Hi there!!!
I've been using successfully the DBPedia dataset (https://huggingface.co/datasets/dbpedia_14) with my codebase in the last couple of weeks, but in the last couple of days now I get this error:
```
Traceback (most recent call last):
File "./conditional_classification/basic_pipeline.py", line 178, in <module>
main()
File "./conditional_classification/basic_pipeline.py", line 128, in main
corpus.load_data(limit_train_examples_per_class=args.data_args.train_examples_per_class,
File "/home/fp/dev/conditional_classification/conditional_classification/datasets_base.py", line 83, in load_data
datasets = load_dataset(self.name, split=dataset_split)
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/load.py", line 609, in load_dataset
builder_instance.download_and_prepare(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/builder.py", line 526, in download_and_prepare
self._download_and_prepare(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/builder.py", line 586, in _download_and_prepare
verify_checksums(
File "/home/fp/anaconda3/envs/conditional/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 39, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k']
```
I've seen this has happened before in other datasets as reported in #537.
I've tried clearing my cache and call again `load_dataset` but still is not working. My same codebase is successfully downloading and using other datasets (e.g. AGNews) without any problem, so I guess something has happened specifically to the DBPedia dataset in the last few days.
Can you please check if there's a problem with the checksums?
Or this is related to any other stuff? I've seen that the path in the cache for the dataset is `/home/fp/.cache/huggingface/datasets/d_bpedia14/dbpedia_14/2.0.0/a70413e39e7a716afd0e90c9e53cb053691f56f9ef5fe317bd07f2c368e8e897...` and includes `d_bpedia14` instead maybe of `dbpedia_14`. Was this maybe a bug introduced recently?
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1907/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1907/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1958/comments | https://api.github.com/repos/huggingface/datasets/issues/1958/events | https://github.com/huggingface/datasets/issues/1958 | 818,037,548 | MDU6SXNzdWU4MTgwMzc1NDg= | 1,958 | XSum dataset download link broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/1156974?v=4",
"events_url": "https://api.github.com/users/himat/events{/privacy}",
"followers_url": "https://api.github.com/users/himat/followers",
"following_url": "https://api.github.com/users/himat/following{/other_user}",
"gists_url": "https://api.github.com/users/himat/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/himat",
"id": 1156974,
"login": "himat",
"node_id": "MDQ6VXNlcjExNTY5NzQ=",
"organizations_url": "https://api.github.com/users/himat/orgs",
"received_events_url": "https://api.github.com/users/himat/received_events",
"repos_url": "https://api.github.com/users/himat/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/himat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/himat/subscriptions",
"type": "User",
"url": "https://api.github.com/users/himat"
} | [] | closed | false | null | [] | null | [
"Never mind, I ran it again and it worked this time. Strange."
] | "2021-02-27T21:47:56Z" | "2021-02-27T21:50:16Z" | "2021-02-27T21:50:16Z" | NONE | null | null | null | I did
```
from datasets import load_dataset
dataset = load_dataset("xsum")
```
This returns
`ConnectionError: Couldn't reach http://bollin.inf.ed.ac.uk/public/direct/XSUM-EMNLP18-Summary-Data-Original.tar.gz` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1958/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3488/comments | https://api.github.com/repos/huggingface/datasets/issues/3488/events | https://github.com/huggingface/datasets/issues/3488 | 1,089,345,653 | I_kwDODunzps5A7hh1 | 3,488 | URL query parameters are set as path in the compression hop for fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"I think the test passes because it simply ignore what's after `gzip://`.\r\n\r\nThe returned urlpath is expected to look like `gzip://filename::url`, and the filename is currently considered to be what's after the final `/`, hence the result.\r\n\r\nWe can decide to change this and simply have `gzip://::url`, this way we don't need to guess the filename, what do you think ?"
] | "2021-12-27T16:29:00Z" | "2022-01-05T15:15:25Z" | null | MEMBER | null | null | null | ## Describe the bug
There is an ssue with `StreamingDownloadManager._extract`.
I don't know how the test `test_streaming_gg_drive_gzipped` passes:
For
```python
TEST_GG_DRIVE_GZIPPED_URL = "https://drive.google.com/uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz"
urlpath = StreamingDownloadManager().download_and_extract(TEST_GG_DRIVE_GZIPPED_URL)
```
gives `urlpath`:
```python
'gzip://uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz::https://drive.google.com/uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz'
```
The gzip path makes no sense: `gzip://uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz`
## Steps to reproduce the bug
```python
from datasets.utils.streaming_download_manager import StreamingDownloadManager
dl_manager = StreamingDownloadManager()
urlpath = dl_manager.extract("https://drive.google.com/uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz")
print(urlpath)
```
## Expected results
The query parameters should not be set as part of the path.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3488/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4106 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4106/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4106/comments | https://api.github.com/repos/huggingface/datasets/issues/4106/events | https://github.com/huggingface/datasets/pull/4106 | 1,194,393,892 | PR_kwDODunzps41uPpa | 4,106 | Support huggingface_hub 0.5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Looks like GH actions is not able to resolve `huggingface_hub` 0.5.0, I'm investivating",
"_The documentation is not available anymore as the PR was closed or merged._",
"I'm glad to see changes in `huggingface_hub` are simplifying code here.",
"seems to supersede #4102, feel free to close mine :)",
"maybe just cherry-pick the docstring fix",
"I think I've found the issue:\r\n- https://github.com/huggingface/huggingface_hub/pull/790",
"Good catch, `huggingface_hub` doesn't support python 3.6 anymore indeed, therefore we should keep support for 0.4.0. I'm reverting the requirement version bump for now.\r\n\r\nWe can update the requirement once we drop support for python 3.6 in `datasets`",
"@lhoestq, I've opened this PR on `huggingface_hub`: \r\n- https://github.com/huggingface/huggingface_hub/pull/823\r\n\r\nIs there any strong reason why `huggingface_hub` no longer supports Python 3.6? ",
"I think `datasets` can drop support for 3.6 soon. But for now maybe let's keep support for 0.4.0, python 3.6 users are not affected by https://github.com/huggingface/datasets/issues/4105 anyway.\r\n\r\n`huggingface_hub` doesn't not have to support 3.6 again just for the CI IMO",
"@lhoestq I commented on the PR, that IMO it is not a good practice to drop support for Python 3.6 without a previous deprecation cycle.",
"Re-added support for older versions. I ended up checking `huggingface_hub` version to use the old, deprecated API for <0.5.0",
"I find it good practice to have all dependency version related code in a single file so that when you decide to remove support for an old version of a dependency it's easy to find and remove them, hence suggesting `utils/_fixes.py` in https://github.com/huggingface/datasets/issues/4105#issuecomment-1090041204",
"good idea, thanks !",
"I used your suggestion @adrinjalali , I just replace the try/except with a check on the version of `huggingface_hub`"
] | "2022-04-06T10:15:25Z" | "2022-04-08T10:28:43Z" | "2022-04-08T10:22:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4106.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4106",
"merged_at": "2022-04-08T10:22:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4106.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4106"
} | Following https://github.com/huggingface/datasets/issues/4105
`huggingface_hub` deprecated some parameters in `HfApi` in 0.5. This PR updates all the calls to HfApi to remove all the deprecations, <s>and I set the `hugginface_hub` requirement to `>=0.5.0`</s>
cc @adrinjalali @LysandreJik | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4106/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4106/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4708/comments | https://api.github.com/repos/huggingface/datasets/issues/4708/events | https://github.com/huggingface/datasets/pull/4708 | 1,308,279,700 | PR_kwDODunzps47lewm | 4,708 | Fix require torchaudio and refactor test requirements | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-07-18T17:24:28Z" | "2022-07-22T06:30:56Z" | "2022-07-22T06:18:11Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4708.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4708",
"merged_at": "2022-07-22T06:18:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4708.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4708"
} | Currently there is a bug in `require_torchaudio` (indeed it is requiring `sox` instead):
```python
def require_torchaudio(test_case):
if find_spec("sox") is None:
...
```
The bug was introduced by:
- #3685
- Commit: https://github.com/huggingface/datasets/pull/3685/commits/b5a3e7122d49c4dcc9333b1d8d18a833fc04b940
which moved
```python
require_sndfile = pytest.mark.skipif(
# In Windows and OS X, soundfile installs sndfile
(sys.platform != "linux" and find_spec("soundfile") is None)
# In Linux, soundfile throws RuntimeError if sndfile not installed with distribution package manager
or (sys.platform == "linux" and find_library("sndfile") is None),
reason="Test requires 'sndfile': `pip install soundfile`; "
"Linux requires sndfile installed with distribution package manager, e.g.: `sudo apt-get install libsndfile1`",
)
require_sox = pytest.mark.skipif(
find_library("sox") is None,
reason="Test requires 'sox'; only available in non-Windows, e.g.: `sudo apt-get install sox`",
)
require_torchaudio = pytest.mark.skipif(find_spec("torchaudio") is None, reason="Test requires 'torchaudio'")
```
to
```python
def require_sndfile(test_case):
"""
Decorator marking a test that requires soundfile.
These tests are skipped when soundfile isn't installed.
"""
if (sys.platform != "linux" and find_spec("soundfile") is None) or (
sys.platform == "linux" and find_library("sndfile") is None
):
test_case = unittest.skip(
"test requires 'sndfile': `pip install soundfile`; "
"Linux requires sndfile installed with distribution package manager, e.g.: `sudo apt-get install libsndfile1`",
)(test_case)
return test_case
def require_sox(test_case):
"""
Decorator marking a test that requires sox.
These tests are skipped when sox isn't installed.
"""
if find_library("sox") is None:
return unittest.skip("test requires 'sox'; only available in non-Windows, e.g.: `sudo apt-get install sox`")(
test_case
)
return test_case
def require_torchaudio(test_case):
"""
Decorator marking a test that requires torchaudio.
These tests are skipped when torchaudio isn't installed.
"""
if find_spec("sox") is None:
return unittest.skip("test requires 'torchaudio'")(test_case)
return test_case
```
This PR;
- fixes the bug in `require_torchaudio`
- refactors the test requirements back to using `pytest` instead of `unittest`
- the text in `pytest.skipif` `reason` can be used if needed in a test body: `require_torchaudio.kwargs["reason"]` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4708/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4251 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4251/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4251/comments | https://api.github.com/repos/huggingface/datasets/issues/4251/events | https://github.com/huggingface/datasets/pull/4251 | 1,219,116,354 | PR_kwDODunzps4293dB | 4,251 | Metric card for the XTREME-S dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-04-28T18:32:19Z" | "2022-04-29T16:46:11Z" | "2022-04-29T16:38:46Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4251.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4251",
"merged_at": "2022-04-29T16:38:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4251.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4251"
} | Proposing a metric card for the XTREME-S dataset :hugs: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4251/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4251/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4353/comments | https://api.github.com/repos/huggingface/datasets/issues/4353/events | https://github.com/huggingface/datasets/pull/4353 | 1,236,092,176 | PR_kwDODunzps43016x | 4,353 | Don't strip proceeding hyphen | {
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url": "https://api.github.com/users/JohnGiorgi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JohnGiorgi",
"id": 8917831,
"login": "JohnGiorgi",
"node_id": "MDQ6VXNlcjg5MTc4MzE=",
"organizations_url": "https://api.github.com/users/JohnGiorgi/orgs",
"received_events_url": "https://api.github.com/users/JohnGiorgi/received_events",
"repos_url": "https://api.github.com/users/JohnGiorgi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JohnGiorgi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JohnGiorgi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JohnGiorgi"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-14T18:25:29Z" | "2022-05-16T18:51:38Z" | "2022-05-16T13:52:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4353",
"merged_at": "2022-05-16T13:52:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4353"
} | Closes #4320. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4353/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4070 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4070/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4070/comments | https://api.github.com/repos/huggingface/datasets/issues/4070/events | https://github.com/huggingface/datasets/pull/4070 | 1,186,810,205 | PR_kwDODunzps41VMYq | 4,070 | Create metric card for seqeval | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-30T18:08:01Z" | "2022-04-01T19:02:58Z" | "2022-04-01T18:57:25Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4070.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4070",
"merged_at": "2022-04-01T18:57:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4070.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4070"
} | Proposing metric card for seqeval. Not sure which values to report for Popular papers though. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4070/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4070/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2224/comments | https://api.github.com/repos/huggingface/datasets/issues/2224/events | https://github.com/huggingface/datasets/issues/2224 | 857,983,361 | MDU6SXNzdWU4NTc5ODMzNjE= | 2,224 | Raise error if Windows max path length is not disabled | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | open | false | null | [] | null | [] | "2021-04-14T14:57:20Z" | "2021-04-14T14:59:13Z" | null | MEMBER | null | null | null | On startup, raise an error if Windows max path length is not disabled; ask the user to disable it.
Linked to discussion in #2220. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2224/timeline | null | null | false |