
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 600M
2.05B
| node_id
stringlengths 18
32
| number
int64 2
6.51k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | comments
sequencelengths 0
30
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/778/comments | https://api.github.com/repos/huggingface/datasets/issues/778/events | https://github.com/huggingface/datasets/issues/778 | 732,449,652 | MDU6SXNzdWU3MzI0NDk2NTI= | 778 | Unexpected behavior when loading cached csv file? | {
"avatar_url": "https://avatars.githubusercontent.com/u/15979778?v=4",
"events_url": "https://api.github.com/users/dcfidalgo/events{/privacy}",
"followers_url": "https://api.github.com/users/dcfidalgo/followers",
"following_url": "https://api.github.com/users/dcfidalgo/following{/other_user}",
"gists_url": "https://api.github.com/users/dcfidalgo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dcfidalgo",
"id": 15979778,
"login": "dcfidalgo",
"node_id": "MDQ6VXNlcjE1OTc5Nzc4",
"organizations_url": "https://api.github.com/users/dcfidalgo/orgs",
"received_events_url": "https://api.github.com/users/dcfidalgo/received_events",
"repos_url": "https://api.github.com/users/dcfidalgo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dcfidalgo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dcfidalgo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dcfidalgo"
} | [] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting.\r\nThe same issue was reported in #730 (but with the encodings instead of the delimiter). It was fixed by #770 .\r\nThe fix will be available in the next release :)",
"Thanks for the prompt reply and terribly sorry for the spam! \r\nLooking forward to the new release! "
] | "2020-10-29T16:06:10Z" | "2020-10-29T21:21:27Z" | "2020-10-29T21:21:27Z" | CONTRIBUTOR | null | null | null | I read a csv file from disk and forgot so specify the right delimiter. When i read the csv file again specifying the right delimiter it had no effect since it was using the cached dataset. I am not sure if this is unwanted behavior since i can always specify `download_mode="force_redownload"`. But i think it would be nice if the information what `delimiter` or what `column_names` were used would influence the identifier of the cached dataset.
Small snippet to reproduce the behavior:
```python
import datasets
with open("dummy_data.csv", "w") as file:
file.write("test,this;text\n")
print(datasets.load_dataset("csv", data_files="dummy_data.csv", split="train").column_names)
# ["test", "this;text"]
print(datasets.load_dataset("csv", data_files="dummy_data.csv", split="train", delimiter=";").column_names)
# still ["test", "this;text"]
```
By the way, thanks a lot for this amazing library! :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/778/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3462 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3462/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3462/comments | https://api.github.com/repos/huggingface/datasets/issues/3462/events | https://github.com/huggingface/datasets/issues/3462 | 1,085,049,661 | I_kwDODunzps5ArIs9 | 3,462 | Update swahili_news dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2021-12-20T17:44:01Z" | "2021-12-21T06:24:02Z" | "2021-12-21T06:24:01Z" | MEMBER | null | null | null | Please note also: the HuggingFace version at https://huggingface.co/datasets/swahili_news is outdated. An updated version, with deduplicated text and official splits, can be found at https://zenodo.org/record/5514203.
## Adding a Dataset
- **Name:** swahili_news
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Related to:
- bigscience-workshop/data_tooling#107
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3462/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3462/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1123 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1123/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1123/comments | https://api.github.com/repos/huggingface/datasets/issues/1123/events | https://github.com/huggingface/datasets/pull/1123 | 757,181,014 | MDExOlB1bGxSZXF1ZXN0NTMyNTk5ODQ3 | 1,123 | adding cdt dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1654113?v=4",
"events_url": "https://api.github.com/users/abecadel/events{/privacy}",
"followers_url": "https://api.github.com/users/abecadel/followers",
"following_url": "https://api.github.com/users/abecadel/following{/other_user}",
"gists_url": "https://api.github.com/users/abecadel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abecadel",
"id": 1654113,
"login": "abecadel",
"node_id": "MDQ6VXNlcjE2NTQxMTM=",
"organizations_url": "https://api.github.com/users/abecadel/orgs",
"received_events_url": "https://api.github.com/users/abecadel/received_events",
"repos_url": "https://api.github.com/users/abecadel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abecadel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abecadel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abecadel"
} | [] | closed | false | null | [] | null | [
"the `ms_terms` formatting CI fails is fixed on master",
"merging since the CI is fixed on master"
] | "2020-12-04T15:19:36Z" | "2020-12-04T17:05:56Z" | "2020-12-04T17:05:56Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1123.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1123",
"merged_at": "2020-12-04T17:05:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1123.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1123"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1123/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1123/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
] | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this default is a bit counterintuitive for the user. However, this is a personal opinion that might not be general. I think it is nice to have the actual (non-encoded) labels in the viewer. On the other hand, it would be nice to match what the user sees with what they get when they download a dataset. I don't know - I can see the difficulty of choosing a default :)\r\nMaybe having non-encoded labels as a default can be useful?\r\n\r\nAnyway, I think the issue has been addressed. Thanks a lot for your super-quick answer!\r\n\r\n ",
"Thanks for the 👍 in https://github.com/huggingface/datasets/issues/3673#issuecomment-1029008349 @mariosasko @gary149 @pietrolesci, but as I proposed various solutions, it's not clear to me which you prefer. Could you write your preferences as a comment?\r\n\r\n_(note for myself: one idea per comment in the future)_",
"As I am working with seq2seq, I prefer having the label in string form rather than numeric. So the viewer is fine and the underlying dataset should be \"decoded\" (from int to str). In this way, the user does not have to search for a mapping `int -> original name` (even though is trivial to find, I reckon). Also, encoding labels is rather easy.\r\n\r\nI hope this is useful",
"I like the idea of \"0 (neutral)\". The label name can even be greyed to make it clear that it's not part of the actual item in the dataset, it's just the meaning.",
"I like @lhoestq's idea of having grayed-out labels.",
"Proposals by @gary149. Which one do you prefer? Please vote with the thumbs\r\n\r\n- 👍 \r\n\r\n \r\n\r\n- 👎 \r\n\r\n 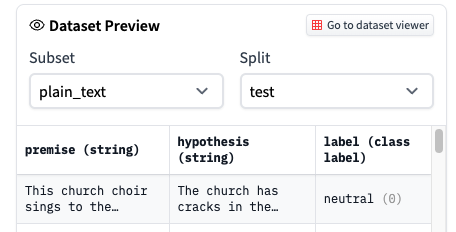\r\n\r\n",
"I like Option 1 better as it shows clearly what the user is downloading",
"Thanks! ",
"It's [live](https://huggingface.co/datasets/glue/viewer/cola/train):\r\n\r\n<img width=\"1126\" alt=\"Capture d’écran 2022-02-14 à 10 26 03\" src=\"https://user-images.githubusercontent.com/1676121/153836716-25f6205b-96af-42d8-880a-7c09cb24c420.png\">\r\n\r\nThanks all for the help to improve the UI!",
"Love it ! thanks :)"
] | "2022-02-03T12:10:43Z" | "2022-02-16T11:22:31Z" | "2022-02-11T17:01:21Z" | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4880/comments | https://api.github.com/repos/huggingface/datasets/issues/4880/events | https://github.com/huggingface/datasets/pull/4880 | 1,348,452,776 | PR_kwDODunzps49qyJr | 4,880 | Added names of less-studied languages | {
"avatar_url": "https://avatars.githubusercontent.com/u/23100612?v=4",
"events_url": "https://api.github.com/users/BenjaminGalliot/events{/privacy}",
"followers_url": "https://api.github.com/users/BenjaminGalliot/followers",
"following_url": "https://api.github.com/users/BenjaminGalliot/following{/other_user}",
"gists_url": "https://api.github.com/users/BenjaminGalliot/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BenjaminGalliot",
"id": 23100612,
"login": "BenjaminGalliot",
"node_id": "MDQ6VXNlcjIzMTAwNjEy",
"organizations_url": "https://api.github.com/users/BenjaminGalliot/orgs",
"received_events_url": "https://api.github.com/users/BenjaminGalliot/received_events",
"repos_url": "https://api.github.com/users/BenjaminGalliot/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BenjaminGalliot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BenjaminGalliot/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BenjaminGalliot"
} | [] | closed | false | null | [] | null | [
"OK, I removed Glottolog codes and only added ISO 639-3 ones. The former are for the moment in corpus card description, language details, and in subcorpora names.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4880). All of your documentation changes will be reflected on that endpoint."
] | "2022-08-23T19:32:38Z" | "2022-08-24T12:52:46Z" | "2022-08-24T12:52:46Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4880.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4880",
"merged_at": "2022-08-24T12:52:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4880.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4880"
} | Added names of less-studied languages (nru – Narua and jya – Japhug) for existing datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4880/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1527 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1527/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1527/comments | https://api.github.com/repos/huggingface/datasets/issues/1527/events | https://github.com/huggingface/datasets/pull/1527 | 764,638,504 | MDExOlB1bGxSZXF1ZXN0NTM4NjA3MjQw | 1,527 | Add : Conv AI 2 (Messed up original PR) | {
"avatar_url": "https://avatars.githubusercontent.com/u/22396042?v=4",
"events_url": "https://api.github.com/users/rkc007/events{/privacy}",
"followers_url": "https://api.github.com/users/rkc007/followers",
"following_url": "https://api.github.com/users/rkc007/following{/other_user}",
"gists_url": "https://api.github.com/users/rkc007/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rkc007",
"id": 22396042,
"login": "rkc007",
"node_id": "MDQ6VXNlcjIyMzk2MDQy",
"organizations_url": "https://api.github.com/users/rkc007/orgs",
"received_events_url": "https://api.github.com/users/rkc007/received_events",
"repos_url": "https://api.github.com/users/rkc007/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rkc007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rkc007/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rkc007"
} | [] | closed | false | null | [] | null | [] | "2020-12-13T00:21:14Z" | "2020-12-13T19:14:24Z" | "2020-12-13T19:14:24Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1527.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1527",
"merged_at": "2020-12-13T19:14:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1527.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1527"
} | @lhoestq Sorry I messed up the previous 2 PR's -> https://github.com/huggingface/datasets/pull/1462 -> https://github.com/huggingface/datasets/pull/1383. So created a new one. Also, everything is fixed in this PR. Can you please review it ?
Thanks in advance. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1527/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1527/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3809 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3809/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3809/comments | https://api.github.com/repos/huggingface/datasets/issues/3809/events | https://github.com/huggingface/datasets/issues/3809 | 1,158,143,480 | I_kwDODunzps5FB934 | 3,809 | Checksums didn't match for datasets on Google Drive | {
"avatar_url": "https://avatars.githubusercontent.com/u/11507045?v=4",
"events_url": "https://api.github.com/users/muelletm/events{/privacy}",
"followers_url": "https://api.github.com/users/muelletm/followers",
"following_url": "https://api.github.com/users/muelletm/following{/other_user}",
"gists_url": "https://api.github.com/users/muelletm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/muelletm",
"id": 11507045,
"login": "muelletm",
"node_id": "MDQ6VXNlcjExNTA3MDQ1",
"organizations_url": "https://api.github.com/users/muelletm/orgs",
"received_events_url": "https://api.github.com/users/muelletm/received_events",
"repos_url": "https://api.github.com/users/muelletm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/muelletm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muelletm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/muelletm"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Hi @muelletm, thanks for reporting.\r\n\r\nThis issue was already reported and its root cause is a change in the Google Drive service. See:\r\n- #3786 \r\n\r\nWe have already fixed it. See:\r\n- #3787 \r\n\r\nUntil our next `datasets` library release, you can get this fix by installing our library from the GitHub master branch:\r\n```shell\r\npip install git+https://github.com/huggingface/datasets#egg=datasets\r\n```\r\nThen, if you had previously tried to load the data and got the checksum error, you should force the redownload of the data (before the fix, you just downloaded and cached the virus scan warning page, instead of the data file):\r\n```shell\r\nload_dataset(\"...\", download_mode=\"force_redownload\")\r\n```"
] | "2022-03-03T09:01:10Z" | "2022-03-03T09:24:58Z" | "2022-03-03T09:24:05Z" | NONE | null | null | null | ## Describe the bug
Datasets hosted on Google Drive do not seem to work right now.
Loading them fails with a checksum error.
## Steps to reproduce the bug
```python
from datasets import load_dataset
for dataset in ["head_qa", "yelp_review_full"]:
try:
load_dataset(dataset)
except Exception as exception:
print("Error", dataset, exception)
```
Here is a [colab](https://colab.research.google.com/drive/1wOtHBmL8I65NmUYakzPV5zhVCtHhi7uQ#scrollTo=cDzdCLlk-Bo4).
## Expected results
The datasets should be loaded.
## Actual results
```
Downloading and preparing dataset head_qa/es (download: 75.69 MiB, generated: 2.86 MiB, post-processed: Unknown size, total: 78.55 MiB) to /root/.cache/huggingface/datasets/head_qa/es/1.1.0/583ab408e8baf54aab378c93715fadc4d8aa51b393e27c3484a877e2ac0278e9...
Error head_qa Checksums didn't match for dataset source files:
['https://drive.google.com/u/0/uc?export=download&id=1a_95N5zQQoUCq8IBNVZgziHbeM-QxG2t']
Downloading and preparing dataset yelp_review_full/yelp_review_full (download: 187.06 MiB, generated: 496.94 MiB, post-processed: Unknown size, total: 684.00 MiB) to /root/.cache/huggingface/datasets/yelp_review_full/yelp_review_full/1.0.0/13c31a618ba62568ec8572a222a283dfc29a6517776a3ac5945fb508877dde43...
Error yelp_review_full Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbZlU4dXhHTFhZQU0']
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3809/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3809/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3926 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3926/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3926/comments | https://api.github.com/repos/huggingface/datasets/issues/3926/events | https://github.com/huggingface/datasets/pull/3926 | 1,169,945,052 | PR_kwDODunzps40ehVP | 3,926 | Doc maintenance | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3926). All of your documentation changes will be reflected on that endpoint."
] | "2022-03-15T17:00:46Z" | "2022-03-15T19:27:15Z" | "2022-03-15T19:27:12Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3926.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3926",
"merged_at": "2022-03-15T19:27:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3926.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3926"
} | This PR adds some minor maintenance to the docs. The main fix is properly linking to pages in the callouts because some of the links would just redirect to a non-existent section on the same page. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3926/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3926/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1935/comments | https://api.github.com/repos/huggingface/datasets/issues/1935/events | https://github.com/huggingface/datasets/pull/1935 | 814,623,827 | MDExOlB1bGxSZXF1ZXN0NTc4NTgyMzk1 | 1,935 | add CoVoST2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patil-suraj",
"id": 27137566,
"login": "patil-suraj",
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patil-suraj"
} | [] | closed | false | null | [] | null | [
"@patrickvonplaten \r\nI removed the mp3 files, dummy_data is much smaller now!"
] | "2021-02-23T16:28:16Z" | "2021-02-24T18:09:32Z" | "2021-02-24T18:05:09Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1935.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1935",
"merged_at": "2021-02-24T18:05:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1935.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1935"
} | This PR adds the CoVoST2 dataset for speech translation and ASR.
https://github.com/facebookresearch/covost#covost-2
The dataset requires manual download as the download page requests an email address and the URLs are temporary.
The dummy data is a bit bigger because of the mp3 files and 36 configs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1935/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3324 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3324/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3324/comments | https://api.github.com/repos/huggingface/datasets/issues/3324/events | https://github.com/huggingface/datasets/issues/3324 | 1,064,661,212 | I_kwDODunzps4_dXDc | 3,324 | Can't import `datasets` in python 3.10 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [] | "2021-11-26T16:06:14Z" | "2021-11-26T16:31:23Z" | "2021-11-26T16:31:23Z" | MEMBER | null | null | null | When importing `datasets` I'm getting this error in python 3.10:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_dataset.py", line 47, in <module>
from .arrow_reader import ArrowReader
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_reader.py", line 33, in <module>
from .table import InMemoryTable, MemoryMappedTable, Table, concat_tables
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 334, in <module>
class InMemoryTable(TableBlock):
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 361, in InMemoryTable
def from_pandas(cls, *args, **kwargs):
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 24, in wrapper
out = wraps(arrow_table_method)(method)
File "/Users/quentinlhoest/.pyenv/versions/3.10.0/lib/python3.10/functools.py", line 61, in update_wrapper
wrapper.__wrapped__ = wrapped
AttributeError: readonly attribute
```
This makes the conda build fail.
I'm opening a PR to fix this and do a patch release 1.16.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3324/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3324/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/363/comments | https://api.github.com/repos/huggingface/datasets/issues/363/events | https://github.com/huggingface/datasets/pull/363 | 653,821,172 | MDExOlB1bGxSZXF1ZXN0NDQ2NjY0NDIy | 363 | Adding support for generic multi dimensional tensors and auxillary image data for multimodal datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/14030663?v=4",
"events_url": "https://api.github.com/users/eltoto1219/events{/privacy}",
"followers_url": "https://api.github.com/users/eltoto1219/followers",
"following_url": "https://api.github.com/users/eltoto1219/following{/other_user}",
"gists_url": "https://api.github.com/users/eltoto1219/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eltoto1219",
"id": 14030663,
"login": "eltoto1219",
"node_id": "MDQ6VXNlcjE0MDMwNjYz",
"organizations_url": "https://api.github.com/users/eltoto1219/orgs",
"received_events_url": "https://api.github.com/users/eltoto1219/received_events",
"repos_url": "https://api.github.com/users/eltoto1219/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eltoto1219/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eltoto1219/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eltoto1219"
} | [] | closed | false | null | [] | null | [
"Thank you! I just marked this as a draft PR. It probably would be better to create specific Array2D and Array3D classes as needed instead of a generic MultiArray for now, it should simplify the code a lot too so, I'll update it as such. Also i was meaning to reply earlier, but I wanted to thank you for the testing script you sent me earlier since it ended up being tremendously helpful. ",
"Okay, I just converted the MultiArray class to Array2D, and got rid of all those \"globals()\"! \r\n\r\nThe main issues I had were that when including a \"pa.ExtensionType\" as a column, the ordinary methods to batch the data would not work and it would throw me some mysterious error, so I first cleaned up my code to order the row to match the schema (because when including extension types the row is disordered ) and then made each row a pa.Table and then concatenated all the tables. Also each n-dimensional vector class we implement will be size invariant which is some good news. ",
"Okay awesome! I just added your suggestions and changed up my recursive functions. \r\n\r\nHere is the traceback for the when I use the original code in the write_on_file method:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 33, in <module>\r\n File \"/home/eltoto/nlp/src/nlp/arrow_writer.py\", line 214, in finalize\r\n self.write_on_file()\r\n File \"/home/eltoto/nlp/src/nlp/arrow_writer.py\", line 134, in write_on_file\r\n pa_array = pa.array(self.current_rows, type=self._type)\r\n File \"pyarrow/array.pxi\", line 269, in pyarrow.lib.array\r\n File \"pyarrow/array.pxi\", line 38, in pyarrow.lib._sequence_to_array\r\n File \"pyarrow/error.pxi\", line 106, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowNotImplementedError: MakeBuilder: cannot construct builder for type extension<arrow.py_extension_type>\r\n\r\nshell returned 1\r\n```\r\n\r\nI think when trying to cast an extension array within a list of dictionaries, some method gets called that bugs out Arrow and somehow doesn't get called when adding a single row to a a table and then appending multiple tables together. I tinkered with this for a while but could not find any workaround. \r\n\r\nIn the case that this new method causes bad compression/worse performance, we can explicitly set the batch size in the pa.Table.to_batches(***batch_size***) method, which will return a list of batches. Perhaps, we can check that the batch size is not too large converting the table to batches after X many rows are appended to it by following the batch_size check below.",
"> I think when trying to cast an extension array within a list of dictionaries, some method gets called that bugs out Arrow and somehow doesn't get called when adding a single row to a a table and then appending multiple tables together. I tinkered with this for a while but could not find any workaround.\r\n\r\nIndeed that's weird.\r\n\r\n> In the case that this new method causes bad compression/worse performance, we can explicitly set the batch size in the pa.Table.to_batches(batch_size) method, which will return a list of batches. Perhaps, we can check that the batch size is not too large converting the table to batches after X many rows are appended to it by following the batch_size check below.\r\n\r\nThe argument of `pa.Table.to_batches` is not `batch_size` but `max_chunksize`, which means that right now it would have no effects (each chunk is of length 1).\r\n\r\nWe can fix that just by doing `entries.combine_chunks().to_batches(batch_size)`. In that case it would write by chunk of 1000 which is what we want. I don't think it will slow down the writing by much, but we may have to do a benchmark just to make sure. If speed is ok we could even replace the original code to always write chunks this way.\r\n\r\nDo you still have errors that need to be fixed ?",
"@lhoestq Nope all should be good! \r\n\r\nWould you like me to add the entries.combine_chunks().to_batch_size() code + benchmark?",
"> @lhoestq Nope all should be good!\r\n\r\nAwesome :)\r\n\r\nI think it would be good to start to add some tests then.\r\nYou already have `test_multi_array.py` which is a good start, maybe you can place it in /tests and make it a `unittest.TestCase` ?\r\n\r\n> Would you like me to add the entries.combine_chunks().to_batch_size() code + benchmark?\r\n\r\nThat would be interesting. We don't want reading/writing to be the bottleneck of dataset processing for example in terms of speed. Maybe we could test the write + read speed of different datasets:\r\n- write speed + read speed a dataset with `nlp.Array2D` features\r\n- write speed + read speed a dataset with `nlp.Sequence(nlp.Sequence(nlp.Value(\"float32\")))` features\r\n- write speed + read speed a dataset with `nlp.Sequence(nlp.Value(\"float32\"))` features (same data but flatten)\r\nIt will be interesting to see the influence of `.combine_chunks()` on the `Array2D` test too.\r\n\r\nWhat do you think ?",
"Well actually it looks like we're still having the `print(dataset[0])` error no ?",
"I just tested your code to try to understand better.\r\n\r\n\r\n- First thing you must know is that we've switched from `dataset._data.to_pandas` to `dataset._data.to_pydict` by default when we call `dataset[0]` in #423 . Right now it raises an error but it can be fixed by adding this method to `ExtensionArray2D`:\r\n\r\n```python\r\n def to_pylist(self):\r\n return self.to_numpy().tolist()\r\n```\r\n\r\n- Second, I noticed that `ExtensionArray2D.to_numpy()` always return a (5, 5) shape in your example. I thought `ExtensionArray` was for possibly multiple examples and so I was expecting a shape like (1, 5, 5) for example. Did I miss something ?\r\nTherefore when I apply the fix I mentioned (adding to_pylist), it returns one example per row in each image (in your example of 2 images of shape 5x5, I get `len(dataset._data.to_pydict()[\"image\"]) == 10 # True`)\r\n\r\n[EDIT] I changed the reshape step in `ExtensionArray2D.to_numpy()` by\r\n```python\r\nnumpy_arr = numpy_arr.reshape(len(self), *ExtensionArray2D._construct_shape(self.storage))\r\n```\r\nand it did the job: `len(dataset._data.to_pydict()[\"image\"]) == 2 # True`\r\n\r\n- Finally, I was able to make `to_pandas` work though, by implementing custom array dtype in pandas with arrow conversion (I got inspiration from [here](https://gist.github.com/Eastsun/a59fb0438f65e8643cd61d8c98ec4c08) and [here](https://pandas.pydata.org/pandas-docs/version/1.0.0/development/extending.html#compatibility-with-apache-arrow))\r\n\r\nMaybe you could add me in your repo so I can open a PR to add these changes to your branch ?",
"`combine_chunks` doesn't seem to work btw:\r\n`ArrowNotImplementedError: concatenation of extension<arrow.py_extension_type>`",
"> > @lhoestq Nope all should be good!\r\n> \r\n> Awesome :)\r\n> \r\n> I think it would be good to start to add some tests then.\r\n> You already have `test_multi_array.py` which is a good start, maybe you can place it in /tests and make it a `unittest.TestCase` ?\r\n> \r\n> > Would you like me to add the entries.combine_chunks().to_batch_size() code + benchmark?\r\n> \r\n> That would be interesting. We don't want reading/writing to be the bottleneck of dataset processing for example in terms of speed. Maybe we could test the write + read speed of different datasets:\r\n> \r\n> * write speed + read speed a dataset with `nlp.Array2D` features\r\n> * write speed + read speed a dataset with `nlp.Sequence(nlp.Sequence(nlp.Value(\"float32\")))` features\r\n> * write speed + read speed a dataset with `nlp.Sequence(nlp.Value(\"float32\"))` features (same data but flatten)\r\n> It will be interesting to see the influence of `.combine_chunks()` on the `Array2D` test too.\r\n> \r\n> What do you think ?\r\n\r\nYa! that should be no problem at all, Ill use the timeit module and get back to you with the results sometime over the weekend.",
"Thank you for all your help getting the pandas and row indexing for the dataset to work! For `print(dataset[0])`, I considered the workaround of doing `print(dataset[\"col_name\"][0])` a temporary solution, but ya, I was never able to figure out how to previously get it to work. I'll add you to my repo right now, let me know if you do not see the invite. Also lastly, it is strange how the to_batches method is not working, so I can check that out while I add some speed tests + add the multi dim test under the unit tests this weekend. ",
"I created the PR :)\r\nI also tested `to_batches` and it works on my side",
"Sorry for the bit of delay! I just added the tests, the PR into my fork, and some speed tests. It should be fairly easy to add more tests if we need. Do you think there is anything else to checkout?",
"Cool thanks for adding the tests :) \r\n\r\nNext step is merge master into this branch.\r\nNot sure I understand what you did in your last commit, but it looks like you discarded all the changes from master ^^'\r\n\r\nWe've done some changes in the features logic on master, so let me know if you need help merging it.\r\n\r\nAs soon as we've merged from master, we'll have to make sure that we have extensive tests and we'll be good to do !\r\nAbout the lxmert dataset, we can probably keep it for another PR as soon as we have working 2d features. What do you think ?",
"We might want to merge this after tomorrow's release though to avoid potential side effects @lhoestq ",
"Yep I'm sure we can have it not for tomorrow's release but for the next one ;)",
"haha, when I tried to rebase, I ran into some conflicts. In that last commit, I restored the features.py from the previous commit on the branch in my fork because upon updating to master, the pandasdtypemanger and pandas extension types disappeared. If you actually could help me with merging in what is needed, that would actually help a lot. \r\n\r\nOther than that, ya let me go ahead and move the dataloader code out of this PR. Perhaps we could discuss in the slack channelk soon about what to do with that because we can either just support the pretraining corpus for lxmert or try to implement the full COCO and visual genome datasets (+VQA +GQA) which im sure people would be pretty happy about. \r\n\r\nAlso we can talk more tests soon too when you are free. \r\n\r\nGoodluck on the release tomorrow guys!",
"Not sure why github thinks there are conflicts here, as I just rebased from the current master branch.\r\nMerging into master locally works on my side without conflicts\r\n```\r\ngit checkout master\r\ngit reset --hard origin/master\r\ngit merge --no-ff eltoto1219/support_multi_dim_tensors_for_images\r\nMerge made by the 'recursive' strategy.\r\n datasets/lxmert_pretraining_beta/lxmert_pretraining_beta.py | 89 +++++++++++++++++++++++++++++++++++++\r\n datasets/lxmert_pretraining_beta/test_multi_array.py | 45 +++++++++++++++++++\r\n datasets/lxmert_pretraining_beta/to_arrow_data.py | 371 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\r\n src/nlp/arrow_dataset.py | 24 +++++-----\r\n src/nlp/arrow_writer.py | 22 ++++++++--\r\n src/nlp/features.py | 229 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++---\r\n tests/test_array_2d.py | 210 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\r\n 7 files changed, 969 insertions(+), 21 deletions(-)\r\n create mode 100644 datasets/lxmert_pretraining_beta/lxmert_pretraining_beta.py\r\n create mode 100644 datasets/lxmert_pretraining_beta/test_multi_array.py\r\n create mode 100644 datasets/lxmert_pretraining_beta/to_arrow_data.py\r\n create mode 100644 tests/test_array_2d.py\r\n```",
"I put everything inside one commit from the master branch but the merge conflicts on github'side were still there for some reason.\r\nClosing and re-opening the PR fixed the conflict check on github's side.",
"Almost done ! It still needs a pass on the docs/comments and maybe a few more tests.\r\n\r\nI had to do several changes for type inference in the ArrowWriter to make it support custom types.",
"Ok this is now ready for review ! Thanks for your awesome work in this @eltoto1219 \r\n\r\nSummary of the changes:\r\n- added new feature type `Array2D`, that can be instantiated like `Array2D(\"float32\")` for example\r\n- added pyarrow extension type `Array2DExtensionType` and array `Array2DExtensionArray` that take care of converting from and to arrow. `Array2DExtensionType`'s storage is a list of list of any pyarrow array.\r\n- added pandas extension type `PandasArrayExtensionType` and array `PandasArrayExtensionArray` for conversion from and to arrow/python objects\r\n- refactor of the `ArrowWriter` write and write_batch functions to support extension types while preserving the type inference behavior.\r\n- added a utility object `TypedSequence` that is helpful to combine extension arrays and type inference inside the writer's methods.\r\n- added speed test for sequences writing (printed as warnings in pytest)\r\n- breaking: set disable_nullable to False by default as pyarrow's type inference returns nullable fields\r\n\r\nAnd there are plenty of new tests, mainly in `test_array2d.py` and `test_arrow_writer.py`.\r\n\r\nNote that there are some collisions in `arrow_dataset.py` with #513 so let's be careful when we'll merge this one.\r\n\r\nI know this is a big PR so feel free to ask questions",
"I'll add Array3D, 4D.. tomorrow but it should take only a few lines. The rest won't change",
"I took your comments into account and I added Array[3-5]D.\r\nI changed the storage type to fixed lengths lists. I had to update the `to_numpy` function because of that. Indeed slicing a FixedLengthListArray returns a view a of the original array, while in the previous case slicing a ListArray copies the storage.\r\n"
] | "2020-07-09T07:10:30Z" | "2020-08-24T09:59:35Z" | "2020-08-24T09:59:35Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/363.diff",
"html_url": "https://github.com/huggingface/datasets/pull/363",
"merged_at": "2020-08-24T09:59:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/363.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/363"
} | nlp/features.py:
The main factory class is MultiArray, every single time this class is called, a corresponding pyarrow extension array and type class is generated (and added to the list of globals for future use) for a given root data type and set of dimensions/shape. I provide examples on working with this in datasets/lxmert_pretraining_beta/test_multi_array.py
src/nlp/arrow_writer.py
I had to add a method for writing batches that include extension array types because despite having a unique class for each multidimensional array shape, pyarrow is unable to write any other "array-like" data class to a batch object unless it is of the type pyarrow.ExtensionType. The problem in this is that when writing multiple batches, the order of the schema and data to be written get mixed up (where the pyarrow datatype in the schema only refers to as ExtensionAray, but each ExtensionArray subclass has a different shape) ... possibly I am missing something here and would be grateful if anyone else could take a look!
datasets/lxmert_pretraining_beta/lxmert_pretraining_beta.py & datasets/lxmert_pretraining_beta/to_arrow_data.py:
I have begun adding the data from the original LXMERT paper (https://arxiv.org/abs/1908.07490) hosted here: (https://github.com/airsplay/lxmert). The reason I am not pulling from the source of truth for each individual dataset is because it seems that there will also need to be functionality to aggregate multimodal datasets to create a pre-training corpus (:sleepy: ).
For now, this is just being used to test and run edge-cases for the MultiArray feature, so ive labeled it as "beta_pretraining"!
(still working on the pretraining, just wanted to push out the new functionality sooner than later) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/363/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5449 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5449/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5449/comments | https://api.github.com/repos/huggingface/datasets/issues/5449/events | https://github.com/huggingface/datasets/pull/5449 | 1,550,801,453 | PR_kwDODunzps5INgD9 | 5,449 | Support fsspec 2023.1.0 in CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008227 / 0.011353 (-0.003126) | 0.004496 / 0.011008 (-0.006512) | 0.099319 / 0.038508 (0.060811) | 0.029929 / 0.023109 (0.006820) | 0.296686 / 0.275898 (0.020788) | 0.355372 / 0.323480 (0.031892) | 0.006864 / 0.007986 (-0.001122) | 0.003458 / 0.004328 (-0.000871) | 0.077234 / 0.004250 (0.072983) | 0.037072 / 0.037052 (0.000020) | 0.311675 / 0.258489 (0.053186) | 0.338965 / 0.293841 (0.045124) | 0.033562 / 0.128546 (-0.094985) | 0.011399 / 0.075646 (-0.064248) | 0.322406 / 0.419271 (-0.096865) | 0.043034 / 0.043533 (-0.000499) | 0.298083 / 0.255139 (0.042944) | 0.323661 / 0.283200 (0.040462) | 0.089380 / 0.141683 (-0.052303) | 1.479363 / 1.452155 (0.027208) | 1.518337 / 1.492716 (0.025620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.177822 / 0.018006 (0.159816) | 0.400806 / 0.000490 (0.400317) | 0.002121 / 0.000200 (0.001921) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021986 / 0.037411 (-0.015426) | 0.096749 / 0.014526 (0.082223) | 0.101443 / 0.176557 (-0.075113) | 0.137519 / 0.737135 (-0.599616) | 0.105558 / 0.296338 (-0.190780) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418983 / 0.215209 (0.203774) | 4.189579 / 2.077655 (2.111924) | 1.877831 / 1.504120 (0.373711) | 1.666213 / 1.541195 (0.125019) | 1.680735 / 1.468490 (0.212245) | 0.693033 / 4.584777 (-3.891744) | 3.420553 / 3.745712 (-0.325160) | 1.819647 / 5.269862 (-3.450214) | 1.144934 / 4.565676 (-3.420743) | 0.082209 / 0.424275 (-0.342066) | 0.012433 / 0.007607 (0.004826) | 0.526781 / 0.226044 (0.300737) | 5.273689 / 2.268929 (3.004760) | 2.323468 / 55.444624 (-53.121156) | 1.960508 / 6.876477 (-4.915969) | 2.035338 / 2.142072 (-0.106735) | 0.812789 / 4.805227 (-3.992438) | 0.148429 / 6.500664 (-6.352235) | 0.064727 / 0.075469 (-0.010742) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253218 / 1.841788 (-0.588569) | 13.303426 / 8.074308 (5.229118) | 13.651074 / 10.191392 (3.459682) | 0.135178 / 0.680424 (-0.545246) | 0.028483 / 0.534201 (-0.505717) | 0.393284 / 0.579283 (-0.185999) | 0.401957 / 0.434364 (-0.032407) | 0.457136 / 0.540337 (-0.083201) | 0.535835 / 1.386936 (-0.851101) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006335 / 0.011353 (-0.005017) | 0.004454 / 0.011008 (-0.006554) | 0.097565 / 0.038508 (0.059057) | 0.026917 / 0.023109 (0.003808) | 0.350779 / 0.275898 (0.074881) | 0.391979 / 0.323480 (0.068499) | 0.004648 / 0.007986 (-0.003337) | 0.003204 / 0.004328 (-0.001124) | 0.076987 / 0.004250 (0.072737) | 0.035257 / 0.037052 (-0.001796) | 0.347193 / 0.258489 (0.088704) | 0.391462 / 0.293841 (0.097621) | 0.031244 / 0.128546 (-0.097302) | 0.011460 / 0.075646 (-0.064186) | 0.321606 / 0.419271 (-0.097665) | 0.041218 / 0.043533 (-0.002315) | 0.341884 / 0.255139 (0.086745) | 0.374920 / 0.283200 (0.091720) | 0.086383 / 0.141683 (-0.055300) | 1.501750 / 1.452155 (0.049595) | 1.565060 / 1.492716 (0.072344) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.165447 / 0.018006 (0.147441) | 0.401885 / 0.000490 (0.401395) | 0.000975 / 0.000200 (0.000775) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024494 / 0.037411 (-0.012917) | 0.097334 / 0.014526 (0.082808) | 0.105324 / 0.176557 (-0.071232) | 0.142430 / 0.737135 (-0.594705) | 0.107249 / 0.296338 (-0.189089) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441632 / 0.215209 (0.226423) | 4.407729 / 2.077655 (2.330074) | 2.078167 / 1.504120 (0.574047) | 1.864210 / 1.541195 (0.323015) | 1.885948 / 1.468490 (0.417458) | 0.693974 / 4.584777 (-3.890803) | 3.386837 / 3.745712 (-0.358875) | 1.840291 / 5.269862 (-3.429571) | 1.150524 / 4.565676 (-3.415153) | 0.082240 / 0.424275 (-0.342035) | 0.012488 / 0.007607 (0.004881) | 0.537589 / 0.226044 (0.311545) | 5.404007 / 2.268929 (3.135078) | 2.537467 / 55.444624 (-52.907157) | 2.190775 / 6.876477 (-4.685702) | 2.224746 / 2.142072 (0.082674) | 0.799524 / 4.805227 (-4.005703) | 0.150639 / 6.500664 (-6.350025) | 0.066473 / 0.075469 (-0.008997) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.258559 / 1.841788 (-0.583228) | 13.773583 / 8.074308 (5.699275) | 13.964322 / 10.191392 (3.772930) | 0.156295 / 0.680424 (-0.524129) | 0.016824 / 0.534201 (-0.517377) | 0.377476 / 0.579283 (-0.201807) | 0.390163 / 0.434364 (-0.044201) | 0.442541 / 0.540337 (-0.097796) | 0.529404 / 1.386936 (-0.857532) |\n\n</details>\n</details>\n\n\n"
] | "2023-01-20T12:53:17Z" | "2023-01-20T13:32:50Z" | "2023-01-20T13:26:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5449.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5449",
"merged_at": "2023-01-20T13:26:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5449.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5449"
} | Support fsspec 2023.1.0 in CI.
In the 2023.1.0 fsspec release, they replaced the type of `fsspec.registry`:
- from `ReadOnlyRegistry`, with an attribute called `target`
- to `MappingProxyType`, without that attribute
Consequently, we need to change our `mock_fsspec` fixtures, that were using the `target` attribute.
Fix #5448. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5449/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5449/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1925 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1925/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1925/comments | https://api.github.com/repos/huggingface/datasets/issues/1925/events | https://github.com/huggingface/datasets/pull/1925 | 813,600,902 | MDExOlB1bGxSZXF1ZXN0NTc3NzIyMzc3 | 1,925 | Fix: Wiki_dpr - fix when with_embeddings is False or index_name is "no_index" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Hi @lhoestq ,\r\n\r\nI am running into an issue now when trying to run RAG. Running exactly as described [here](https://huggingface.co/facebook/rag-token-nq?fbclid=IwAR3bTfhls5U_t9DqsX2Vzb7NhtRHxJxfQ-uwFT7VuCPMZUM2AdAlKF_qkI8#usage) I get the error below. Wondering if it's related to this.\r\n\r\nRunning Transformers 4.3.2 with datasets installed from source from `master` branch.\r\n\r\n```bash\r\n(venv) sergey_mkrtchyan datasets (master) $ python\r\nPython 3.8.6 (v3.8.6:db455296be, Sep 23 2020, 13:31:39)\r\n[Clang 6.0 (clang-600.0.57)] on darwin\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration\r\n>>> tokenizer = RagTokenizer.from_pretrained(\"facebook/rag-token-nq\")\r\n>>> retriever = RagRetriever.from_pretrained(\"facebook/rag-token-nq\", index_name=\"exact\", use_dummy_dataset=True)\r\nUsing custom data configuration dummy.psgs_w100.nq.no_index-dummy=True,with_index=False\r\nReusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.no_index-dummy=True,with_index=False/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)\r\nUsing custom data configuration dummy.psgs_w100.nq.exact-50b6cda57ff32ab4\r\nReusing dataset wiki_dpr (/Users/sergey_mkrtchyan/.cache/huggingface/datasets/wiki_dpr/dummy.psgs_w100.nq.exact-50b6cda57ff32ab4/0.0.0/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb)\r\n 0%| | 0/10 [00:00<?, ?it/s]\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py\", line 425, in from_pretrained\r\n return cls(\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py\", line 387, in __init__\r\n self.init_retrieval()\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py\", line 458, in init_retrieval\r\n self.index.init_index()\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/transformers/models/rag/retrieval_rag.py\", line 284, in init_index\r\n self.dataset = load_dataset(\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/load.py\", line 750, in load_dataset\r\n ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py\", line 734, in as_dataset\r\n datasets = utils.map_nested(\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/utils/py_utils.py\", line 195, in map_nested\r\n return function(data_struct)\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/builder.py\", line 769, in _build_single_dataset\r\n post_processed = self._post_process(ds, resources_paths)\r\n File \"/Users/sergey_mkrtchyan/.cache/huggingface/modules/datasets_modules/datasets/wiki_dpr/8a97e0f4fa5bc46e179474db6a61b09d5d2419d2911835bd3f91d110c936d8bb/wiki_dpr.py\", line 205, in _post_process\r\n dataset.add_faiss_index(\"embeddings\", custom_index=index)\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/arrow_dataset.py\", line 2516, in add_faiss_index\r\n super().add_faiss_index(\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py\", line 416, in add_faiss_index\r\n faiss_index.add_vectors(self, column=column, train_size=train_size, faiss_verbose=faiss_verbose)\r\n File \"/Users/sergey_mkrtchyan/workspace/huggingface/datasets/src/datasets/search.py\", line 281, in add_vectors\r\n self.faiss_index.add(vecs)\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/__init__.py\", line 104, in replacement_add\r\n self.add_c(n, swig_ptr(x))\r\n File \"/Users/sergey_mkrtchyan/workspace/cformers/venv/lib/python3.8/site-packages/faiss/swigfaiss.py\", line 3263, in add\r\n return _swigfaiss.IndexHNSW_add(self, n, x)\r\nRuntimeError: Error in virtual void faiss::IndexHNSW::add(faiss::Index::idx_t, const float *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/IndexHNSW.cpp:356: Error: 'is_trained' failed\r\n>>>\r\n```\r\n\r\nThe error message is hinting that it could be related to this, but I might be wrong. Any ideas?\r\n\r\n\r\nEdit: Can confirm it's working fine with datasets==1.2.0\r\n\r\nDouble Edit: Did some further digging. The issue is related to this commit: 8c5220307c33f00e01c3bf7b8. I opened a separate issue #1941 for proper tracking."
] | "2021-02-22T15:23:46Z" | "2021-02-25T01:33:48Z" | "2021-02-22T15:36:08Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1925.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1925",
"merged_at": "2021-02-22T15:36:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1925.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1925"
} | Fix the bugs noticed in #1915
There was a bug when `with_embeddings=False` where the configuration name was the same as if `with_embeddings=True`, which led the dataset builder to do bad verifications (for example it used to expect to download the embeddings for `with_embeddings=False`).
Another issue was that setting `index_name="no_index"` didn't set `with_index` to False.
I fixed both of them and added dummy data for those configurations for testing. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1925/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1925/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4358/comments | https://api.github.com/repos/huggingface/datasets/issues/4358/events | https://github.com/huggingface/datasets/issues/4358 | 1,237,147,692 | I_kwDODunzps5JvWAs | 4,358 | Missing dataset tags and sections in some dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"@lhoestq I can take this issue. Please can you point out to me where I can find the other positional arguments?",
"Hi @RohitRathore1 :)\r\n\r\nYou can find all the YAML tags in the tagging app here: https://hf.co/spaces/huggingface/datasets-tagging). They're all passed as arguments to a DatasetMetadata object used to validate the tags."
] | "2022-05-16T13:18:16Z" | "2022-05-30T15:36:52Z" | null | NONE | null | null | null | Summary of CircleCI errors for different dataset metadata:
- **BoolQ**: missing 8 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'
- **Conllpp**: expected some content in section `Citation Information` but it is empty.
- **GLUE**: 'annotations_creators', 'language_creators', 'source_datasets' :['unknown'] are not registered tags
- **ConLL2003**: field 'task_ids': ['part-of-speech-tagging'] are not registered tags for 'task_ids'
- **Hate_speech18:** Expected some content in section `Data Instances` but it is empty, Expected some content in section `Data Splits` but it is empty
- **Jjigsaw_toxicity_pred**: `Citation Information` but it is empty.
- **LIAR** : `Data Instances`,`Data Fields`, `Data Splits`, `Citation Information` are empty.
- **MSRA NER** : Dataset Summary`, `Data Instances`, `Data Fields`, `Data Splits`, `Citation Information` are empty.
- **sem_eval_2010_task_8**: missing 8 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'
- **sms_spam**: `Data Instances` and`Data Splits` are empty.
- **Quora** : Expected some content in section `Citation Information` but it is empty, missing 8 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'
- **sentiment140**: missing 8 required positional arguments: 'annotations_creators', 'language_creators', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids' | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4358/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5483/comments | https://api.github.com/repos/huggingface/datasets/issues/5483/events | https://github.com/huggingface/datasets/issues/5483 | 1,560,894,690 | I_kwDODunzps5dCVzi | 5,483 | Unable to upload dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yuvalkirstain",
"id": 57996478,
"login": "yuvalkirstain",
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yuvalkirstain"
} | [] | closed | false | null | [] | null | [
"Seems to work now, perhaps it was something internal with our university's network."
] | "2023-01-28T15:18:26Z" | "2023-01-29T08:09:49Z" | "2023-01-29T08:09:49Z" | NONE | null | null | null | ### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.push_to_hub("ttt111")
/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_hf_folder.py:92: UserWarning: A token has been found in `/a/home/cc/students/cs/kirstain/.huggingface/token`. This is the old path where tokens were stored. The new location is `/home/olab/kirstain/.cache/huggingface/token` which is configurable using `HF_HOME` environment variable. Your token has been copied to this new location. You can now safely delete the old token file manually or use `huggingface-cli logout`.
warnings.warn(
Creating parquet from Arrow format: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 279.94ba/s]
Upload 1 LFS files: 0%| | 0/1 [00:02<?, ?it/s]
Pushing dataset shards to the dataset hub: 0%| | 0/1 [00:04<?, ?it/s]
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 264, in hf_raise_for_status
response.raise_for_status()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 334, in _inner_upload_lfs_object
return _upload_lfs_object(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 391, in _upload_lfs_object
lfs_upload(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 273, in lfs_upload
_upload_single_part(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/lfs.py", line 305, in _upload_single_part
hf_raise_for_status(upload_res)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_errors.py", line 318, in hf_raise_for_status
raise HfHubHTTPError(str(e), response=response) from e
huggingface_hub.utils._errors.HfHubHTTPError: 403 Client Error: Forbidden for url: https://s3.us-east-1.amazonaws.com/lfs.huggingface.co/repos/cf/0c/cf0c5ab8a3f729e5f57a8b79a36ecea64a31126f13218591c27ed9a1c7bd9b41/ece885a4bb6bbc8c1bb51b45542b805283d74590f72cd4c45d3ba76628570386?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGO27GPWFUO%2F20230128%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230128T151640Z&X-Amz-Expires=900&X-Amz-Signature=89e78e9a9d70add7ed93d453334f4f93c6f29d889d46750a1f2da04af73978db&X-Amz-SignedHeaders=host&x-amz-storage-class=INTELLIGENT_TIERING&x-id=PutObject
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4909, in push_to_hub
repo_id, split, uploaded_size, dataset_nbytes, repo_files, deleted_size = self._push_parquet_shards_to_hub(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 4804, in _push_parquet_shards_to_hub
_retry(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/datasets/utils/file_utils.py", line 281, in _retry
return func(*func_args, **func_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2537, in upload_file
commit_info = self.create_commit(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/hf_api.py", line 2346, in create_commit
upload_lfs_files(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py", line 124, in _inner_fn
return fn(*args, **kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 346, in upload_lfs_files
thread_map(
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 94, in thread_map
return _executor_map(ThreadPoolExecutor, fn, *iterables, **tqdm_kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/contrib/concurrent.py", line 76, in _executor_map
return list(tqdm_class(ex.map(fn, *iterables, **map_args), **kwargs))
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 621, in result_iterator
yield _result_or_cancel(fs.pop())
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 319, in _result_or_cancel
return fut.result(timeout)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 458, in result
return self.__get_result()
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/concurrent/futures/thread.py", line 58, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/olab/kirstain/anaconda3/envs/datasets/lib/python3.10/site-packages/huggingface_hub/_commit_api.py", line 338, in _inner_upload_lfs_object
raise RuntimeError(
RuntimeError: Error while uploading 'data/train-00000-of-00001-6df93048e66df326.parquet' to the Hub.
```
### Expected behavior
The dataset should be uploaded without any exceptions
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-4.15.0-65-generic-x86_64-with-glibc2.27
- Python version: 3.10.9
- PyArrow version: 11.0.0
- Pandas version: 1.5.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5483/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6321 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6321/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6321/comments | https://api.github.com/repos/huggingface/datasets/issues/6321/events | https://github.com/huggingface/datasets/pull/6321 | 1,952,643,483 | PR_kwDODunzps5dS3Mc | 6,321 | Fix typos | {
"avatar_url": "https://avatars.githubusercontent.com/u/3097956?v=4",
"events_url": "https://api.github.com/users/python273/events{/privacy}",
"followers_url": "https://api.github.com/users/python273/followers",
"following_url": "https://api.github.com/users/python273/following{/other_user}",
"gists_url": "https://api.github.com/users/python273/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/python273",
"id": 3097956,
"login": "python273",
"node_id": "MDQ6VXNlcjMwOTc5NTY=",
"organizations_url": "https://api.github.com/users/python273/orgs",
"received_events_url": "https://api.github.com/users/python273/received_events",
"repos_url": "https://api.github.com/users/python273/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/python273/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/python273/subscriptions",
"type": "User",
"url": "https://api.github.com/users/python273"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007809 / 0.011353 (-0.003544) | 0.004573 / 0.011008 (-0.006435) | 0.101201 / 0.038508 (0.062693) | 0.089703 / 0.023109 (0.066594) | 0.416502 / 0.275898 (0.140604) | 0.463352 / 0.323480 (0.139872) | 0.006101 / 0.007986 (-0.001885) | 0.003783 / 0.004328 (-0.000545) | 0.076531 / 0.004250 (0.072281) | 0.064017 / 0.037052 (0.026964) | 0.422453 / 0.258489 (0.163964) | 0.485926 / 0.293841 (0.192085) | 0.036797 / 0.128546 (-0.091749) | 0.010172 / 0.075646 (-0.065474) | 0.344442 / 0.419271 (-0.074829) | 0.062240 / 0.043533 (0.018707) | 0.422685 / 0.255139 (0.167546) | 0.451457 / 0.283200 (0.168257) | 0.027831 / 0.141683 (-0.113852) | 1.737187 / 1.452155 (0.285033) | 1.847631 / 1.492716 (0.354915) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.270336 / 0.018006 (0.252330) | 0.500540 / 0.000490 (0.500050) | 0.017042 / 0.000200 (0.016842) | 0.000704 / 0.000054 (0.000650) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033450 / 0.037411 (-0.003962) | 0.100314 / 0.014526 (0.085788) | 0.117216 / 0.176557 (-0.059340) | 0.182352 / 0.737135 (-0.554784) | 0.114903 / 0.296338 (-0.181436) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.458562 / 0.215209 (0.243353) | 4.570492 / 2.077655 (2.492837) | 2.230286 / 1.504120 (0.726167) | 2.032229 / 1.541195 (0.491034) | 2.130431 / 1.468490 (0.661941) | 0.563254 / 4.584777 (-4.021523) | 4.108455 / 3.745712 (0.362743) | 3.994059 / 5.269862 (-1.275802) | 2.424589 / 4.565676 (-2.141087) | 0.067534 / 0.424275 (-0.356741) | 0.008774 / 0.007607 (0.001167) | 0.546356 / 0.226044 (0.320312) | 5.527772 / 2.268929 (3.258843) | 2.934410 / 55.444624 (-52.510215) | 2.536871 / 6.876477 (-4.339605) | 2.598704 / 2.142072 (0.456632) | 0.676721 / 4.805227 (-4.128506) | 0.155904 / 6.500664 (-6.344760) | 0.073274 / 0.075469 (-0.002195) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.559170 / 1.841788 (-0.282618) | 23.228524 / 8.074308 (15.154216) | 16.743246 / 10.191392 (6.551854) | 0.184113 / 0.680424 (-0.496310) | 0.021804 / 0.534201 (-0.512397) | 0.466158 / 0.579283 (-0.113125) | 0.539911 / 0.434364 (0.105547) | 0.544377 / 0.540337 (0.004040) | 0.765779 / 1.386936 (-0.621157) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008249 / 0.011353 (-0.003104) | 0.004734 / 0.011008 (-0.006275) | 0.077083 / 0.038508 (0.038575) | 0.096959 / 0.023109 (0.073850) | 0.497501 / 0.275898 (0.221603) | 0.530687 / 0.323480 (0.207207) | 0.006379 / 0.007986 (-0.001607) | 0.003899 / 0.004328 (-0.000430) | 0.076165 / 0.004250 (0.071915) | 0.069406 / 0.037052 (0.032354) | 0.515847 / 0.258489 (0.257358) | 0.540639 / 0.293841 (0.246798) | 0.038334 / 0.128546 (-0.090213) | 0.010112 / 0.075646 (-0.065534) | 0.084918 / 0.419271 (-0.334353) | 0.056866 / 0.043533 (0.013333) | 0.495555 / 0.255139 (0.240416) | 0.518988 / 0.283200 (0.235789) | 0.028556 / 0.141683 (-0.113127) | 1.799320 / 1.452155 (0.347165) | 1.874647 / 1.492716 (0.381931) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.264283 / 0.018006 (0.246277) | 0.510278 / 0.000490 (0.509788) | 0.015219 / 0.000200 (0.015019) | 0.000160 / 0.000054 (0.000105) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038462 / 0.037411 (0.001051) | 0.115420 / 0.014526 (0.100894) | 0.124250 / 0.176557 (-0.052306) | 0.187724 / 0.737135 (-0.549411) | 0.126674 / 0.296338 (-0.169664) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.499345 / 0.215209 (0.284136) | 4.983924 / 2.077655 (2.906269) | 2.705099 / 1.504120 (1.200980) | 2.516344 / 1.541195 (0.975149) | 2.621103 / 1.468490 (1.152613) | 0.583254 / 4.584777 (-4.001523) | 4.231215 / 3.745712 (0.485503) | 4.028326 / 5.269862 (-1.241536) | 2.459171 / 4.565676 (-2.106505) | 0.069194 / 0.424275 (-0.355081) | 0.008850 / 0.007607 (0.001243) | 0.593878 / 0.226044 (0.367834) | 5.926478 / 2.268929 (3.657549) | 3.287435 / 55.444624 (-52.157189) | 2.902104 / 6.876477 (-3.974372) | 3.151307 / 2.142072 (1.009234) | 0.696922 / 4.805227 (-4.108306) | 0.161140 / 6.500664 (-6.339524) | 0.073728 / 0.075469 (-0.001741) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.636456 / 1.841788 (-0.205331) | 23.884606 / 8.074308 (15.810298) | 17.180875 / 10.191392 (6.989483) | 0.176782 / 0.680424 (-0.503642) | 0.023731 / 0.534201 (-0.510470) | 0.475191 / 0.579283 (-0.104092) | 0.506603 / 0.434364 (0.072239) | 0.571976 / 0.540337 (0.031638) | 0.826935 / 1.386936 (-0.560002) |\n\n</details>\n</details>\n\n\n"
] | "2023-10-19T16:24:35Z" | "2023-10-19T17:18:00Z" | "2023-10-19T17:07:35Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6321.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6321",
"merged_at": "2023-10-19T17:07:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6321.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6321"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6321/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6321/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3484/comments | https://api.github.com/repos/huggingface/datasets/issues/3484/events | https://github.com/huggingface/datasets/issues/3484 | 1,088,910,402 | I_kwDODunzps5A53RC | 3,484 | make shape verification to use ArrayXD instead of nested lists for map | {
"avatar_url": "https://avatars.githubusercontent.com/u/13161779?v=4",
"events_url": "https://api.github.com/users/tshu-w/events{/privacy}",
"followers_url": "https://api.github.com/users/tshu-w/followers",
"following_url": "https://api.github.com/users/tshu-w/following{/other_user}",
"gists_url": "https://api.github.com/users/tshu-w/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tshu-w",
"id": 13161779,
"login": "tshu-w",
"node_id": "MDQ6VXNlcjEzMTYxNzc5",
"organizations_url": "https://api.github.com/users/tshu-w/orgs",
"received_events_url": "https://api.github.com/users/tshu-w/received_events",
"repos_url": "https://api.github.com/users/tshu-w/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tshu-w/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tshu-w/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tshu-w"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi! \r\n\r\nYes, this makes sense for numeric values, but first I have to finish https://github.com/huggingface/datasets/pull/3336 because currently ArrayXD only allows the first dimension to be dynamic."
] | "2021-12-27T02:16:02Z" | "2022-01-05T13:54:03Z" | null | NONE | null | null | null | As describe in https://github.com/huggingface/datasets/issues/2005#issuecomment-793716753 and mentioned by @mariosasko in [image feature example](https://colab.research.google.com/drive/1mIrTnqTVkWLJWoBzT1ABSe-LFelIep1c#scrollTo=ow3XHDvf2I0B&line=1&uniqifier=1), IMO make shape verifcaiton to use ArrayXD instead of nested lists for map can help user reduce unnecessary cast. I notice datasets have done something special for `input_ids` and `attention_mask` which is also unnecessary after this feature added. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3484/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3484/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1802 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1802/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1802/comments | https://api.github.com/repos/huggingface/datasets/issues/1802/events | https://github.com/huggingface/datasets/pull/1802 | 797,924,468 | MDExOlB1bGxSZXF1ZXN0NTY0ODE4NDIy | 1,802 | add github of contributors | {
"avatar_url": "https://avatars.githubusercontent.com/u/53136577?v=4",
"events_url": "https://api.github.com/users/thevasudevgupta/events{/privacy}",
"followers_url": "https://api.github.com/users/thevasudevgupta/followers",
"following_url": "https://api.github.com/users/thevasudevgupta/following{/other_user}",
"gists_url": "https://api.github.com/users/thevasudevgupta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thevasudevgupta",
"id": 53136577,
"login": "thevasudevgupta",
"node_id": "MDQ6VXNlcjUzMTM2NTc3",
"organizations_url": "https://api.github.com/users/thevasudevgupta/orgs",
"received_events_url": "https://api.github.com/users/thevasudevgupta/received_events",
"repos_url": "https://api.github.com/users/thevasudevgupta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thevasudevgupta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thevasudevgupta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thevasudevgupta"
} | [] | closed | false | null | [] | null | [
"@lhoestq Can you confirm if this format is fine? I will update cards based on your feedback.",
"On HuggingFace side we also have a mapping of hf user => github user (GitHub info used to be required when signing up until not long ago – cc @gary149 @beurkinger) so we can also add a link to HF profile",
"All the dataset cards have been updated with GitHub ids :)"
] | "2021-02-01T03:49:19Z" | "2021-02-03T10:09:52Z" | "2021-02-03T10:06:30Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1802.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1802",
"merged_at": "2021-02-03T10:06:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1802.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1802"
} | This PR will add contributors GitHub id at the end of every dataset cards. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1802/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1802/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5947/comments | https://api.github.com/repos/huggingface/datasets/issues/5947/events | https://github.com/huggingface/datasets/issues/5947 | 1,754,359,316 | I_kwDODunzps5okWYU | 5,947 | Return the audio filename when decoding fails due to corrupt files | {
"avatar_url": "https://avatars.githubusercontent.com/u/8949105?v=4",
"events_url": "https://api.github.com/users/wetdog/events{/privacy}",
"followers_url": "https://api.github.com/users/wetdog/followers",
"following_url": "https://api.github.com/users/wetdog/following{/other_user}",
"gists_url": "https://api.github.com/users/wetdog/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wetdog",
"id": 8949105,
"login": "wetdog",
"node_id": "MDQ6VXNlcjg5NDkxMDU=",
"organizations_url": "https://api.github.com/users/wetdog/orgs",
"received_events_url": "https://api.github.com/users/wetdog/received_events",
"repos_url": "https://api.github.com/users/wetdog/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wetdog/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wetdog/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wetdog"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! The audio data don't always exist as files on disk - the blobs are often stored in the Arrow files. For now I'd suggest disabling decoding with `.cast_column(\"audio\", Audio(decode=False))` and apply your own decoding that handles corrupted files (maybe to filter them out ?)\r\n\r\ncc @sanchit-gandhi since it's related to our discussion about allowing users to make decoding return `None` and show a warning when there are corrupted files",
"Thanks @lhoestq, I wasn't aware of the decode flag. It makes more sense as you say to show a warning when there are corrupted files together with some metadata of the file that allows to filter them from the dataset.\r\n\r\nMy workaround was to catch the LibsndfileError and generate a dummy audio with an unsual sample rate to filter it later. However returning `None` seems better. \r\n\r\n`try:\r\n array, sampling_rate = sf.read(file)\r\nexcept sf.LibsndfileError:\r\n print(\"bad file\")\r\n array = np.array([0.0])\r\n sampling_rate = 99.000` \r\n\r\n"
] | "2023-06-13T08:44:09Z" | "2023-06-14T12:45:01Z" | null | NONE | null | null | null | ### Feature request
Return the audio filename when the audio decoding fails. Although currently there are some checks for mp3 and opus formats with the library version there are still cases when the audio decoding could fail, eg. Corrupt file.
### Motivation
When you try to load an object file dataset and the decoding fails you can't know which file is corrupt
```
raise LibsndfileError(err, prefix="Error opening {0!r}: ".format(self.name))
soundfile.LibsndfileError: Error opening <_io.BytesIO object at 0x7f5ab7e38290>: Format not recognised.
```
### Your contribution
Make a PR to Add exceptions for LIbsndfileError to return the audio filename or path when soundfile decoding fails. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5947/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5947/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2519 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2519/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2519/comments | https://api.github.com/repos/huggingface/datasets/issues/2519/events | https://github.com/huggingface/datasets/pull/2519 | 924,903,240 | MDExOlB1bGxSZXF1ZXN0NjczNDcyMzYy | 2,519 | Improve performance of pandas arrow extractor | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"Looks like this change\r\n```\r\npa_table[pa_table.column_names[0]].to_pandas(types_mapper=pandas_types_mapper)\r\n```\r\ndoesn't return a Series with the correct type.\r\nThis is related to https://issues.apache.org/jira/browse/ARROW-9664\r\n\r\nSince the types_mapper isn't taken into account, the ArrayXD types are not converted to the correct pandas extension dtype",
"@lhoestq I think I found a workaround... 😉 ",
"For some reason the benchmarks are not run Oo",
"Anyway, merging.\r\nWe'll see on master how much speed ups we got"
] | "2021-06-18T13:24:41Z" | "2021-06-21T09:06:06Z" | "2021-06-21T09:06:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2519.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2519",
"merged_at": "2021-06-21T09:06:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2519.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2519"
} | While reviewing PR #2505, I noticed that pandas arrow extractor could be refactored to be faster. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2519/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2519/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6185/comments | https://api.github.com/repos/huggingface/datasets/issues/6185/events | https://github.com/huggingface/datasets/issues/6185 | 1,868,077,748 | I_kwDODunzps5vWJq0 | 6,185 | Error in saving the PIL image into *.arrow files using datasets.arrow_writer | {
"avatar_url": "https://avatars.githubusercontent.com/u/14247682?v=4",
"events_url": "https://api.github.com/users/HaozheZhao/events{/privacy}",
"followers_url": "https://api.github.com/users/HaozheZhao/followers",
"following_url": "https://api.github.com/users/HaozheZhao/following{/other_user}",
"gists_url": "https://api.github.com/users/HaozheZhao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HaozheZhao",
"id": 14247682,
"login": "HaozheZhao",
"node_id": "MDQ6VXNlcjE0MjQ3Njgy",
"organizations_url": "https://api.github.com/users/HaozheZhao/orgs",
"received_events_url": "https://api.github.com/users/HaozheZhao/received_events",
"repos_url": "https://api.github.com/users/HaozheZhao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HaozheZhao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HaozheZhao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HaozheZhao"
} | [] | open | false | null | [] | null | [
"You can cast the `input_image` column to the `Image` type to fix the issue:\r\n```python\r\nds.cast_column(\"input_image\", datasets.Image())\r\n```"
] | "2023-08-26T12:15:57Z" | "2023-08-29T14:49:58Z" | null | NONE | null | null | null | ### Describe the bug
I am using the ArrowWriter from datasets.arrow_writer to save a json-style file as arrow files. Within the dictionary, it contains a feature called "image" which is a list of PIL.Image objects.
I am saving the json using the following script:
```
def save_to_arrow(path,temp):
with ArrowWriter(path=path,writer_batch_size=20) as writer:
writer.write_batch(temp)
writer.finalize()
```
However, when I attempt to restore the dataset and use the ```Dataset.from_file(path)``` function to load the arrow file, there seems to be an issue with the PIL.Image object in the dataset. The list of PIL.Images appears as follows rather than a normal PIL.Image object:

### Steps to reproduce the bug
1. Storing the data json into arrow files:
```
def save_to_arrow(path,temp):
with ArrowWriter(path=path,writer_batch_size=20) as writer:
writer.write_batch(temp)
writer.finalize()
save_to_arrow( path, json_file )
```
2. try to load the arrow file into the Dataset object using the ```Dataset.from_file(path)```
### Expected behavior
Except to saving the contained "image" feature as a list PIL.Image objects as the arrow file. And I can restore the dataset from the file.
### Environment info
- `datasets` version: 2.12.0
- Platform: Linux-5.4.0-150-generic-x86_64-with-glibc2.17
- Python version: 3.8.17
- Huggingface_hub version: 0.16.4
- PyArrow version: 12.0.1
- Pandas version: 1.4.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6185/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6185/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3464/comments | https://api.github.com/repos/huggingface/datasets/issues/3464/events | https://github.com/huggingface/datasets/issues/3464 | 1,085,399,097 | I_kwDODunzps5AseA5 | 3,464 | struct.error: 'i' format requires -2147483648 <= number <= 2147483647 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30341159?v=4",
"events_url": "https://api.github.com/users/koukoulala/events{/privacy}",
"followers_url": "https://api.github.com/users/koukoulala/followers",
"following_url": "https://api.github.com/users/koukoulala/following{/other_user}",
"gists_url": "https://api.github.com/users/koukoulala/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/koukoulala",
"id": 30341159,
"login": "koukoulala",
"node_id": "MDQ6VXNlcjMwMzQxMTU5",
"organizations_url": "https://api.github.com/users/koukoulala/orgs",
"received_events_url": "https://api.github.com/users/koukoulala/received_events",
"repos_url": "https://api.github.com/users/koukoulala/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/koukoulala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koukoulala/subscriptions",
"type": "User",
"url": "https://api.github.com/users/koukoulala"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! Can you try setting `datasets.config.MAX_TABLE_NBYTES_FOR_PICKLING` to a smaller value than `4 << 30` (4GiB), for example `500 << 20` (500MiB) ? It should reduce the maximum size of the arrow table being pickled during multiprocessing.\r\n\r\nIf it fixes the issue, we can consider lowering the default value for everyone.",
"@lhoestq I tried that just now but didn't seem to help."
] | "2021-12-21T03:29:01Z" | "2022-11-21T19:55:11Z" | null | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
using latest datasets=datasets-1.16.1-py3-none-any.whl
process my own multilingual dataset by following codes, and the number of rows in all dataset is 306000, the max_length of each sentence is 256:

then I get this error:

I have seen the issue in #2134 and #2150, so I don't understand why latest repo still can't deal with big dataset.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: linux docker
- Python version: 3.6
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3464/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3807 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3807/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3807/comments | https://api.github.com/repos/huggingface/datasets/issues/3807/events | https://github.com/huggingface/datasets/issues/3807 | 1,157,531,812 | I_kwDODunzps5E_oik | 3,807 | NonMatchingChecksumError in xcopa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/93286455?v=4",
"events_url": "https://api.github.com/users/afcruzs-ms/events{/privacy}",
"followers_url": "https://api.github.com/users/afcruzs-ms/followers",
"following_url": "https://api.github.com/users/afcruzs-ms/following{/other_user}",
"gists_url": "https://api.github.com/users/afcruzs-ms/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/afcruzs-ms",
"id": 93286455,
"login": "afcruzs-ms",
"node_id": "U_kgDOBY9wNw",
"organizations_url": "https://api.github.com/users/afcruzs-ms/orgs",
"received_events_url": "https://api.github.com/users/afcruzs-ms/received_events",
"repos_url": "https://api.github.com/users/afcruzs-ms/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/afcruzs-ms/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/afcruzs-ms/subscriptions",
"type": "User",
"url": "https://api.github.com/users/afcruzs-ms"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"@albertvillanova here's a separate issue for a bug similar to #3792",
"Hi @afcruzs-ms, thanks for opening this separate issue for your problem.\r\n\r\nThe root problem in the other issue (#3792) was a change in the service of Google Drive.\r\n\r\nBut in your case, the `xcopa` dataset is not hosted on Google Drive. Therefore, the root cause should be a different one.\r\n\r\nLet me look at it... ",
"@afcruzs-ms, I'm not able to reproduce the issue you reported:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: dataset = load_dataset(\"xcopa\", \"it\")\r\nDownloading builder script: 5.21kB [00:00, 2.75MB/s] \r\nDownloading metadata: 28.6kB [00:00, 14.5MB/s] \r\nDownloading and preparing dataset xcopa/it (download: 627.09 KiB, generated: 76.43 KiB, post-processed: Unknown size, total: 703.52 KiB) to .../.cache/huggingface/datasets/xcopa/it/1.0.0/e1fab65f984b24c8b66bcf7ac27a26a1182f84adfb2e74035861be65e214b9e6...\r\nDownloading data: 642kB [00:00, 5.42MB/s]\r\nDataset xcopa downloaded and prepared to .../.cache/huggingface/datasets/xcopa/it/1.0.0/e1fab65f984b24c8b66bcf7ac27a26a1182f84adfb2e74035861be65e214b9e6. Subsequent calls will reuse this data. \r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 733.27it/s]\r\n\r\nIn [2]: dataset\r\nOut[2]: \r\nDatasetDict({\r\n test: Dataset({\r\n features: ['premise', 'choice1', 'choice2', 'question', 'label', 'idx', 'changed'],\r\n num_rows: 500\r\n })\r\n validation: Dataset({\r\n features: ['premise', 'choice1', 'choice2', 'question', 'label', 'idx', 'changed'],\r\n num_rows: 100\r\n })\r\n})\r\n```\r\n\r\nMaybe you have some issue with your cached data... Could you please try to force the redownload of the data?\r\n```python\r\ndataset = load_dataset(\"xcopa\", \"it\", download_mode=\"force_redownload\")\r\n```",
"It works indeed, thanks! ",
"unfortunately, i am having a similar problem with the irc_disentaglement dataset :/\r\nmy code:\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"irc_disentangle\", download_mode=\"force_redownload\")\r\n```\r\n\r\nhowever, it produces the same error as @afcruzs-ms \r\n```\r\n[38](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=37) if len(bad_urls) > 0:\r\n [39](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=38) error_msg = \"Checksums didn't match\" + for_verification_name + \":\\n\"\r\n---> [40](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=39) raise NonMatchingChecksumError(error_msg + str(bad_urls))\r\n [41](file:///Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/datasets/utils/info_utils.py?line=40) logger.info(\"All the checksums matched successfully\" + for_verification_name)\r\n\r\nNonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://github.com/jkkummerfeld/irc-disentanglement/tarball/master']\r\n```\r\n\r\nI attempted to use the `ignore_verifications' as such:\r\n```\r\nds = datasets.load_dataset('irc_disentangle', download_mode=\"force_redownload\", ignore_verifications=True)\r\n\r\n```\r\n```\r\nDownloading builder script: 12.0kB [00:00, 5.92MB/s] \r\nDownloading metadata: 7.58kB [00:00, 3.48MB/s] \r\nNo config specified, defaulting to: irc_disentangle/ubuntu\r\nDownloading and preparing dataset irc_disentangle/ubuntu (download: 112.98 MiB, generated: 60.05 MiB, post-processed: Unknown size, total: 173.03 MiB) to /Users/laylabouzoubaa/.cache/huggingface/datasets/irc_disentangle/ubuntu/1.0.0/0f24ab262a21d8c1d989fa53ed20caa928f5880be26c162bfbc02445dbade7e5...\r\nDownloading data: 118MB [00:09, 12.1MB/s] \r\n \r\nDataset irc_disentangle downloaded and prepared to /Users/laylabouzoubaa/.cache/huggingface/datasets/irc_disentangle/ubuntu/1.0.0/0f24ab262a21d8c1d989fa53ed20caa928f5880be26c162bfbc02445dbade7e5. Subsequent calls will reuse this data.\r\n100%|██████████| 3/3 [00:00<00:00, 675.38it/s]\r\n```\r\nbut, this returns an empty set?\r\n\r\n```\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n test: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n validation: Dataset({\r\n features: ['id', 'raw', 'ascii', 'tokenized', 'date', 'connections'],\r\n num_rows: 0\r\n })\r\n})\r\n```\r\n\r\nnot sure what else to try at this point?\r\nThanks in advanced🤗",
"Thanks @labouz for reporting: yes, better opening a new GitHub issue as you did. I'm addressing it:\r\n- #4376"
] | "2022-03-02T18:10:19Z" | "2022-05-20T06:00:42Z" | "2022-03-03T17:40:31Z" | NONE | null | null | null | ## Describe the bug
Loading the xcopa dataset doesn't work, it fails due to a mismatch in the checksum.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("xcopa", "it")
```
## Expected results
The dataset should be loaded correctly.
## Actual results
Fails with:
```python
in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/cambridgeltl/xcopa/archive/master.zip']
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3, and 1.18.4.dev0
- Platform:
- Python version: 3.8
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3807/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3807/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/925 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/925/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/925/comments | https://api.github.com/repos/huggingface/datasets/issues/925/events | https://github.com/huggingface/datasets/pull/925 | 753,672,661 | MDExOlB1bGxSZXF1ZXN0NTI5NzA1MzM4 | 925 | Add Turku NLP Corpus for Finnish NER | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [
"> Did you generate the dummy data with the cli or manually ?\r\n\r\nIt was generated by the cli. Do you want me to make it smaller keep it like this?\r\n\r\n"
] | "2020-11-30T17:40:19Z" | "2020-12-03T14:07:11Z" | "2020-12-03T14:07:10Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/925.diff",
"html_url": "https://github.com/huggingface/datasets/pull/925",
"merged_at": "2020-12-03T14:07:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/925.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/925"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/925/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/925/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/4589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4589/comments | https://api.github.com/repos/huggingface/datasets/issues/4589/events | https://github.com/huggingface/datasets/issues/4589 | 1,287,600,029 | I_kwDODunzps5Mvzed | 4,589 | Permission denied: '/home/.cache' when load_dataset with local script | {
"avatar_url": "https://avatars.githubusercontent.com/u/24559732?v=4",
"events_url": "https://api.github.com/users/jiangh0/events{/privacy}",
"followers_url": "https://api.github.com/users/jiangh0/followers",
"following_url": "https://api.github.com/users/jiangh0/following{/other_user}",
"gists_url": "https://api.github.com/users/jiangh0/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jiangh0",
"id": 24559732,
"login": "jiangh0",
"node_id": "MDQ6VXNlcjI0NTU5NzMy",
"organizations_url": "https://api.github.com/users/jiangh0/orgs",
"received_events_url": "https://api.github.com/users/jiangh0/received_events",
"repos_url": "https://api.github.com/users/jiangh0/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jiangh0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiangh0/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jiangh0"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | "2022-06-28T16:26:03Z" | "2022-06-29T06:26:28Z" | "2022-06-29T06:25:08Z" | NONE | null | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4589/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4589/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4319 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4319/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4319/comments | https://api.github.com/repos/huggingface/datasets/issues/4319/events | https://github.com/huggingface/datasets/pull/4319 | 1,232,982,023 | PR_kwDODunzps43q0UY | 4,319 | Adding eval metadata for ade v2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sashavor",
"id": 14205986,
"login": "sashavor",
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"repos_url": "https://api.github.com/users/sashavor/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sashavor"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-11T17:36:20Z" | "2022-05-12T13:29:51Z" | "2022-05-12T13:22:19Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4319.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4319",
"merged_at": "2022-05-12T13:22:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4319.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4319"
} | Adding metadata to allow evaluation | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4319/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4319/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1645/comments | https://api.github.com/repos/huggingface/datasets/issues/1645/events | https://github.com/huggingface/datasets/pull/1645 | 775,473,106 | MDExOlB1bGxSZXF1ZXN0NTQ2MTQ4OTUx | 1,645 | Rename "part-of-speech-tagging" tag in some dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2020-12-28T16:09:09Z" | "2021-01-07T10:08:14Z" | "2021-01-07T10:08:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1645.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1645",
"merged_at": "2021-01-07T10:08:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1645.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1645"
} | `part-of-speech-tagging` was not part of the tagging taxonomy under `structure-prediction` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1645/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/552/comments | https://api.github.com/repos/huggingface/datasets/issues/552/events | https://github.com/huggingface/datasets/pull/552 | 690,079,429 | MDExOlB1bGxSZXF1ZXN0NDc3MDI4MzMx | 552 | Add multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Logging looks like\r\n\r\n```\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #0 will write at playground/tmp_00000_of_00004.arrow\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #1 will write at playground/tmp_00001_of_00004.arrow\r\nDone writing 21900 indices in 3854400 bytes .\r\nProcess #2 will write at playground/tmp_00002_of_00004.arrow\r\nDone writing 21899 indices in 3854224 bytes .\r\nProcess #3 will write at playground/tmp_00003_of_00004.arrow\r\nSpawning 4 processes\r\n#3: 100%|████████████████████████████████████████████████| 21899/21899 [00:02<00:00, 8027.41ex/s]\r\n#0: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7982.87ex/s]\r\n#1: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7923.89ex/s]\r\n#2: 100%|████████████████████████████████████████████████| 21900/21900 [00:02<00:00, 7920.04ex/s]\r\nConcatenating 4 shards from multiprocessing\r\n```",
"I added tests and improved logging.\r\nBoth `map` and `filter` support multiprocessing",
"A bit strange that the benchmarks on map/filter are worth than `master`.\r\n(maybe because they are not done on the same machine)",
"The benchmark also got worse in other PRs (see [here](https://github.com/huggingface/nlp/pull/550#commitcomment-41931609) for example, where we have 16sec for `map fast-tokenizer batched` and 18 sec for `map identity`)",
"Hi,\r\n\r\nwhen I use the multiprocessing in ```.map```:\r\n```\r\ndataset = load_dataset(\"text\", data_files=file_path, split=\"train\")\r\ndataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n truncation=True, max_length=args.block_size), batched=True, num_proc=16)\r\ndataset.set_format(type='torch', columns=['input_ids'])\r\n```\r\nI get the following error:\r\n```\r\nTraceback (most recent call last):\r\n File \"src/run.py\", line 373, in <module>\r\n main()\r\n File \"src/run.py\", line 295, in main\r\n get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None\r\n File \"src/run.py\", line 153, in get_dataset\r\n dataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1287, in map\r\n transformed_shards = [r.get() for r in results]\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1287, in <listcomp>\r\n transformed_shards = [r.get() for r in results]\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/pool.py\", line 771, in get\r\n raise self._value\r\n put(task)\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/connection.py\", line 206, in send\r\n self._send_bytes(_ForkingPickler.dumps(obj))\r\n File \"/root/miniconda3/envs/py3.8/lib/python3.8/multiprocessing/reduction.py\", line 51, in dumps\r\n cls(buf, protocol).dump(obj)\r\nAttributeError: Can't pickle local object 'get_dataset.<locals>.<lambda>'\r\n```\r\nI think you should use [pathos](https://github.com/uqfoundation/pathos) to pickle the lambda function and some others!\r\nI change the 30 line of src/datasets/arrow_dataset.py as following:\r\n```\r\n# 30 line: from multiprocessing import Pool, RLock\r\nimport pathos\r\nfrom pathos.multiprocessing import Pool\r\nfrom multiprocessing import RLock\r\n```\r\nand it works!",
"That's very cool indeed !\r\nShall we condiser adding this dependency @thomwolf ?",
"We already use `dill` so that's definitely a very interesting option indeed!",
"it gets stuck on debian 9 when num_proc > 1\r\n",
"Are you using a tokenizer ?\r\nDid you try to set `TOKENIZERS_PARALLELISM=false` ?\r\n\r\nFeel free to discuss it in #620 , we're discussing this issue",
"I set `TOKENIZERS_PARALLELISM=false`. Just the warning went away. The program was still stuck\r\n"
] | "2020-09-01T11:56:17Z" | "2020-09-22T15:11:56Z" | "2020-09-02T10:01:25Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/552.diff",
"html_url": "https://github.com/huggingface/datasets/pull/552",
"merged_at": "2020-09-02T10:01:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/552.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/552"
} | Adding multiprocessing to `.map`
It works in 3 steps:
- shard the dataset in `num_proc` shards
- spawn one process per shard and call `map` on them
- concatenate the resulting datasets
Example of usage:
```python
from nlp import load_dataset
dataset = load_dataset("squad", split="train")
def function(x):
return {"lowered": x.lower()}
processed = d.map(
function,
input_columns=["context"],
num_proc=4,
cache_file_name="playground/tmp.arrow",
load_from_cache_file=False
)
```
Here it writes 4 files depending on the process rank:
- `playground/tmp_00000_of_00004.arrow`
- `playground/tmp_00001_of_00004.arrow`
- `playground/tmp_00002_of_00004.arrow`
- `playground/tmp_00003_of_00004.arrow`
The suffix format can be specified by the user.
If the `cache_file_name` is not specified, it writes into separated files depending on the fingerprint, as usual.
I still need to:
- write tests for this
- try to improve the logging (currently it shows 4 progress bars, but if one finishes before the others, then the following messages are written over the progress bars)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/552/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/552/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6266 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6266/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6266/comments | https://api.github.com/repos/huggingface/datasets/issues/6266/events | https://github.com/huggingface/datasets/pull/6266 | 1,916,334,394 | PR_kwDODunzps5bYYb8 | 6,266 | Use LibYAML with PyYAML if available | {
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bryant1410",
"id": 3905501,
"login": "bryant1410",
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bryant1410"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6266). All of your documentation changes will be reflected on that endpoint.",
"On Ubuntu, if `libyaml-dev` is installed, you can install PyYAML 6.0.1 with LibYAML with the following command (as it's automatically detected):\r\n\r\n```bash\r\npip install git+https://github.com/yaml/[email protected]\r\n```",
"Are the failing tests flaky?",
"We use `huggingface_hub`'s RepoCard API instead of these modules to parse the YAML block (notice the deprecations), so the `huggingface_hub` repo is the right place to suggest these changes.\r\n\r\nPersonally, I'm not a fan of these changes, as a single non-standard usage of the `ClassLabel` type is not a sufficient reason to merge them. Also, the dataset in question stores data in a single Parquet file, with the features info embedded in its (schema) metadata, which means the YAML parsing can be skipped while preserving the features by directly loading the Parquet file:\r\n```python\r\nfrom datasets import load_dataset\r\nds = load_dataset(\"parquet\", data_files=\"https://huggingface.co/datasets/HuggingFaceM4/SugarCrepe_swap_obj/resolve/main/data/test-00000-of-00001-ca2ae6017a2336d7.parquet\")\r\n```\r\n\r\nPS: Yes, these tests are flaky. We are working on fixing them.",
"Oh, I didn't realize they were deprecated. Thanks for the tip on how to work around this issue!\r\n\r\nFor future reference, the places to change the code in `huggingface_hub` would be:\r\n\r\nhttps://github.com/huggingface/huggingface_hub/blob/89cc69105074f1d071e0471144605f3cdfe1dab3/src/huggingface_hub/repocard.py#L506\r\n\r\nhttps://github.com/huggingface/huggingface_hub/blob/89cc69105074f1d071e0471144605f3cdfe1dab3/src/huggingface_hub/utils/_fixes.py#L34"
] | "2023-09-27T21:13:36Z" | "2023-09-28T14:29:24Z" | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6266.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6266",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6266.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6266"
} | PyYAML, the YAML framework used in this library, allows the use of LibYAML to accelerate the methods `load` and `dump`. To use it, a user would need to first install a PyYAML version that uses LibYAML (not available in PyPI; needs to be manually installed). Then, to actually use them, PyYAML suggests importing the LibYAML version of the `Loader` and `Dumper` and falling back to the default ones. This PR implements this change. See [PyYAML docs](https://pyyaml.org/wiki/PyYAMLDocumentation) for more info.
This change was motivated after trying to use any of [the SugarCREPE datasets in the Hub](https://huggingface.co/datasets?search=sugarcrepe) provided by [the org HuggingFaceM4](https://huggingface.co/datasets/HuggingFaceM4). Such datasets save a lot of information (~1MB) in the YAML metadata from the `README.md` file and I noticed this slowed down the data loading process. BTW, I also noticed cache files for it is also slow because it tries to hash an instance of `DatasetInfo`, which in turn has all this metadata.
Also, I changed two list comprehensions into generator expressions to avoid allocating extra memory unnecessarily.
And BTW, there's [an issue in PyYAML suggesting to make this automatic](https://github.com/yaml/pyyaml/issues/437). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6266/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6266/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3866 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3866/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3866/comments | https://api.github.com/repos/huggingface/datasets/issues/3866/events | https://github.com/huggingface/datasets/pull/3866 | 1,162,833,848 | PR_kwDODunzps40HWcu | 3,866 | Bring back imgs so that forsk dont get broken | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mishig25",
"id": 11827707,
"login": "mishig25",
"node_id": "MDQ6VXNlcjExODI3NzA3",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"repos_url": "https://api.github.com/users/mishig25/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mishig25"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3866). All of your documentation changes will be reflected on that endpoint.",
"I think we just need to keep `datasets_logo_name.jpg` and `course_banner.png` because they appear in the README.md of the forks of `datasets`. The other images can be removed",
"Force pushed those two imgs only"
] | "2022-03-08T16:01:31Z" | "2022-03-08T17:37:02Z" | "2022-03-08T17:37:01Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3866.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3866",
"merged_at": "2022-03-08T17:37:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3866.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3866"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3866/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3866/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/980 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/980/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/980/comments | https://api.github.com/repos/huggingface/datasets/issues/980/events | https://github.com/huggingface/datasets/pull/980 | 754,899,301 | MDExOlB1bGxSZXF1ZXN0NTMwNzEzNjY3 | 980 | Wongnai - Thai reviews dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/643918?v=4",
"events_url": "https://api.github.com/users/mapmeld/events{/privacy}",
"followers_url": "https://api.github.com/users/mapmeld/followers",
"following_url": "https://api.github.com/users/mapmeld/following{/other_user}",
"gists_url": "https://api.github.com/users/mapmeld/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mapmeld",
"id": 643918,
"login": "mapmeld",
"node_id": "MDQ6VXNlcjY0MzkxOA==",
"organizations_url": "https://api.github.com/users/mapmeld/orgs",
"received_events_url": "https://api.github.com/users/mapmeld/received_events",
"repos_url": "https://api.github.com/users/mapmeld/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mapmeld/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mapmeld/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mapmeld"
} | [] | closed | false | null | [] | null | [
"Thank you for contributing a Thai dataset, @mapmeld ! I'm super hyped. \r\nOne comment I may add is that wongnai-corpus has two datasets: review classification (this) and word tokenization (https://github.com/wongnai/wongnai-corpus/blob/master/search/labeled_queries_by_judges.txt).\r\nWould it be possible for you to rename this one something along the line of `wongnai-reviews` so that when/if we include the word tokenization dataset, we will know which is which.\r\n\r\nThis helps solve my check_code_quality issue.\r\n```\r\nmake style\r\nblack --line-length 119 --target-version py36 datasets/wongnai\r\nflake8 datasets/wongnai\r\nisort datasets/wongnai/wongnai.py\r\n```",
"@cstorm125 thanks! following your suggestions on formatting and on naming the dataset\r\n\r\nI am writing a blog post about Thai NLP and transformers (example: mBERT does 1-2 character tokens instead of doing word segmentation), started adding this dataset to use as an example, and then saw you were adding other datasets. Great work! And if you know any Thai BERT models beyond https://github.com/ThAIKeras/bert we should maybe talk over email!"
] | "2020-12-02T03:20:08Z" | "2020-12-02T15:34:41Z" | "2020-12-02T15:30:05Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/980.diff",
"html_url": "https://github.com/huggingface/datasets/pull/980",
"merged_at": "2020-12-02T15:30:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/980.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/980"
} | 40,000 reviews, previously released on GitHub ( https://github.com/wongnai/wongnai-corpus ) with an LGPL license, and on a closed Kaggle competition ( https://www.kaggle.com/c/wongnai-challenge-review-rating-prediction/ ) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/980/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/980/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1800 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1800/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1800/comments | https://api.github.com/repos/huggingface/datasets/issues/1800/events | https://github.com/huggingface/datasets/pull/1800 | 797,798,689 | MDExOlB1bGxSZXF1ZXN0NTY0NzE5MjA3 | 1,800 | Add DuoRC Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani"
} | [] | closed | false | null | [] | null | [
"Thanks for approving @lhoestq!\r\nWill apply these changes for the other datasets I've added too."
] | "2021-01-31T20:01:59Z" | "2021-02-03T05:01:45Z" | "2021-02-02T22:49:26Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1800.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1800",
"merged_at": "2021-02-02T22:49:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1800.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1800"
} | Hi,
DuoRC SelfRC is one type of the [DuoRC Dataset](https://duorc.github.io/). DuoRC SelfRC is a crowdsourced Abstractive/Extractive Question-Answering dataset based on Wikipedia movie plots. It contains examples that may have answers in the movie plot, synthesized answers which are not present in the movie plot, or no answers. I have also added ParaphraseRC - the other type of DuoRC dataset where questions are based on Wikipedia movie plots and answers are based on corresponding IMDb movie plots.
Paper : [https://arxiv.org/abs/1804.07927](https://arxiv.org/abs/1804.07927)
I want to add this to 🤗 datasets to make it more accessible to the community. I have added all the details that I could find. Please let me know if anything else is needed from my end.
Thanks,
Gunjan
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1800/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1800/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2982 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2982/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2982/comments | https://api.github.com/repos/huggingface/datasets/issues/2982/events | https://github.com/huggingface/datasets/pull/2982 | 1,010,118,418 | PR_kwDODunzps4saVLh | 2,982 | Add the Math Aptitude Test of Heuristics dataset. | {
"avatar_url": "https://avatars.githubusercontent.com/u/91226467?v=4",
"events_url": "https://api.github.com/users/hacobe/events{/privacy}",
"followers_url": "https://api.github.com/users/hacobe/followers",
"following_url": "https://api.github.com/users/hacobe/following{/other_user}",
"gists_url": "https://api.github.com/users/hacobe/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hacobe",
"id": 91226467,
"login": "hacobe",
"node_id": "MDQ6VXNlcjkxMjI2NDY3",
"organizations_url": "https://api.github.com/users/hacobe/orgs",
"received_events_url": "https://api.github.com/users/hacobe/received_events",
"repos_url": "https://api.github.com/users/hacobe/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hacobe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hacobe/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hacobe"
} | [] | closed | false | null | [] | null | [] | "2021-09-28T19:18:37Z" | "2021-10-01T19:51:23Z" | "2021-10-01T12:21:00Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2982.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2982",
"merged_at": "2021-10-01T12:21:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2982.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2982"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2982/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2982/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/938 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/938/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/938/comments | https://api.github.com/repos/huggingface/datasets/issues/938/events | https://github.com/huggingface/datasets/pull/938 | 753,940,979 | MDExOlB1bGxSZXF1ZXN0NTI5OTIxNzU5 | 938 | V-1.0.0 of isizulu_ner_corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/7923902?v=4",
"events_url": "https://api.github.com/users/yvonnegitau/events{/privacy}",
"followers_url": "https://api.github.com/users/yvonnegitau/followers",
"following_url": "https://api.github.com/users/yvonnegitau/following{/other_user}",
"gists_url": "https://api.github.com/users/yvonnegitau/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yvonnegitau",
"id": 7923902,
"login": "yvonnegitau",
"node_id": "MDQ6VXNlcjc5MjM5MDI=",
"organizations_url": "https://api.github.com/users/yvonnegitau/orgs",
"received_events_url": "https://api.github.com/users/yvonnegitau/received_events",
"repos_url": "https://api.github.com/users/yvonnegitau/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yvonnegitau/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yvonnegitau/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yvonnegitau"
} | [] | closed | false | null | [] | null | [
"closing since it's been added in #957 "
] | "2020-12-01T02:04:32Z" | "2020-12-01T23:34:36Z" | "2020-12-01T23:34:36Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/938.diff",
"html_url": "https://github.com/huggingface/datasets/pull/938",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/938.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/938"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 1,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/938/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/938/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1905 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1905/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1905/comments | https://api.github.com/repos/huggingface/datasets/issues/1905/events | https://github.com/huggingface/datasets/pull/1905 | 811,384,174 | MDExOlB1bGxSZXF1ZXN0NTc1OTIxMDk1 | 1,905 | Standardizing datasets.dtypes | {
"avatar_url": "https://avatars.githubusercontent.com/u/7731709?v=4",
"events_url": "https://api.github.com/users/justin-yan/events{/privacy}",
"followers_url": "https://api.github.com/users/justin-yan/followers",
"following_url": "https://api.github.com/users/justin-yan/following{/other_user}",
"gists_url": "https://api.github.com/users/justin-yan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/justin-yan",
"id": 7731709,
"login": "justin-yan",
"node_id": "MDQ6VXNlcjc3MzE3MDk=",
"organizations_url": "https://api.github.com/users/justin-yan/orgs",
"received_events_url": "https://api.github.com/users/justin-yan/received_events",
"repos_url": "https://api.github.com/users/justin-yan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/justin-yan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/justin-yan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/justin-yan"
} | [] | closed | false | null | [] | null | [
"Also - I took a stab at updating the docs, but I'm not sure how to actually check the outputs to see if it's formatted properly."
] | "2021-02-18T19:15:31Z" | "2021-02-20T22:01:30Z" | "2021-02-20T22:01:30Z" | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1905.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1905",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1905.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1905"
} | This PR was further branched off of jdy-str-to-pyarrow-parsing, so it depends on https://github.com/huggingface/datasets/pull/1900 going first for the diff to be up-to-date (I'm not sure if there's a way for me to use jdy-str-to-pyarrow-parsing as a base branch while having it appear in the pull requests here).
This moves away from `str(pyarrow.DataType)` as the method of choice for creating dtypes, favoring an explicit mapping to a list of supported Value dtypes.
I believe in practice this should be backward compatible, since anyone previously using Value() would only have been able to use dtypes that had an identically named pyarrow factory function, which are all explicitly supported here. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1905/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1905/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1845 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1845/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1845/comments | https://api.github.com/repos/huggingface/datasets/issues/1845/events | https://github.com/huggingface/datasets/pull/1845 | 803,714,493 | MDExOlB1bGxSZXF1ZXN0NTY5NTk2MTIz | 1,845 | Enable logging propagation and remove logging handler | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"Thank you @lhoestq. This logging configuration makes more sense to me.\r\n\r\nOnce propagation is allowed, the end-user can customize logging behavior and add custom handlers to the proper top logger in the hierarchy.\r\n\r\nAnd I also agree with following the best practices and removing any custom handlers:\r\n- it is the end user who has to implement any custom handlers\r\n- indeed, the previous logging problem with TensorFlow was due to the fact that absl did not follow best practices and had implemented a custom handler\r\n\r\nOur errors/warnings will be displayed anyway, even if we do not implement any custom handler. Since Python 3.2, logging has a built-in \"default\" handler (logging.lastResort) with the expected default behavior (sending error/warning messages to sys.stderr), which is used only if the end user has not configured any custom handler."
] | "2021-02-08T16:22:13Z" | "2021-02-09T14:22:38Z" | "2021-02-09T14:22:37Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1845",
"merged_at": "2021-02-09T14:22:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1845"
} | We used to have logging propagation disabled because of this issue: https://github.com/tensorflow/tensorflow/issues/26691
But since it's now fixed we should re-enable it. This is important to keep the default logging behavior for users, and propagation is also needed for pytest fixtures as asked in #1826
I also removed the handler that was added since, according to the logging [documentation](https://docs.python.org/3/howto/logging.html#configuring-logging-for-a-library):
> It is strongly advised that you do not add any handlers other than NullHandler to your library’s loggers. This is because the configuration of handlers is the prerogative of the application developer who uses your library. The application developer knows their target audience and what handlers are most appropriate for their application: if you add handlers ‘under the hood’, you might well interfere with their ability to carry out unit tests and deliver logs which suit their requirements.
It could have been useful if we wanted to have a custom formatter for the logging but I think it's more important to keep the logging as default to not interfere with the users' logging management.
Therefore I also removed the two methods `datasets.logging.enable_default_handler` and `datasets.logging.disable_default_handler`.
cc @albertvillanova this should let you use capsys/caplog in pytest
cc @LysandreJik @sgugger if you want to do the same in `transformers` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1845/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1845/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1087/comments | https://api.github.com/repos/huggingface/datasets/issues/1087/events | https://github.com/huggingface/datasets/pull/1087 | 756,794,430 | MDExOlB1bGxSZXF1ZXN0NTMyMjc5NDI3 | 1,087 | Add Big Patent dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/46804938?v=4",
"events_url": "https://api.github.com/users/mattbui/events{/privacy}",
"followers_url": "https://api.github.com/users/mattbui/followers",
"following_url": "https://api.github.com/users/mattbui/following{/other_user}",
"gists_url": "https://api.github.com/users/mattbui/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mattbui",
"id": 46804938,
"login": "mattbui",
"node_id": "MDQ6VXNlcjQ2ODA0OTM4",
"organizations_url": "https://api.github.com/users/mattbui/orgs",
"received_events_url": "https://api.github.com/users/mattbui/received_events",
"repos_url": "https://api.github.com/users/mattbui/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mattbui/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mattbui/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mattbui"
} | [] | closed | false | null | [] | null | [
"@lhoestq reduced the dummy data size to around 19MB in total and added the dataset card.",
"@lhoestq so I ended up removing all the nested JSON objects in the gz datafile and keep only one object with minimal content: `{\"publication_number\": \"US-8230922-B2\", \"abstract\": \"dummy abstract\", \"application_number\": \"US-201113163519-A\", \"description\": \"dummy description\"}`. \r\n\r\nThey're reduced to 35KB in total (2.5KB per domain and 17.5KB for all domains), hopefully, they're small enough."
] | "2020-12-04T04:37:30Z" | "2020-12-06T17:21:00Z" | "2020-12-06T17:20:59Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1087",
"merged_at": "2020-12-06T17:20:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1087"
} | * More info on the dataset: https://evasharma.github.io/bigpatent/
* There's another raw version of the dataset available from tfds. However, they're quite large so I don't have the resources to fully test all the configs for that version yet. We'll try to add it later. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1087/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3069 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3069/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3069/comments | https://api.github.com/repos/huggingface/datasets/issues/3069/events | https://github.com/huggingface/datasets/issues/3069 | 1,024,818,680 | I_kwDODunzps49FX34 | 3,069 | CI fails on Windows with FileNotFoundError when stting up s3_base fixture | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | "2021-10-13T05:52:26Z" | "2021-10-13T08:05:49Z" | "2021-10-13T06:49:48Z" | MEMBER | null | null | null | ## Describe the bug
After commit 9353fc863d0c99ab0427f83cc5a4f04fcf52f1df, the CI fails on Windows with FileNotFoundError when stting up s3_base fixture. See: https://app.circleci.com/pipelines/github/huggingface/datasets/8151/workflows/5db8d154-badd-4d3d-b202-ca7a318997a2/jobs/50321
Error summary:
```
ERROR tests/test_arrow_dataset.py::test_dummy_dataset_serialize_s3 - FileNotF...
ERROR tests/test_dataset_dict.py::test_dummy_dataset_serialize_s3 - FileNotFo...
```
Stack trace:
```
______________ ERROR at setup of test_dummy_dataset_serialize_s3 ______________
[gw0] win32 -- Python 3.6.8 C:\tools\miniconda3\python.exe
@pytest.fixture()
def s3_base():
# writable local S3 system
import shlex
import subprocess
# Mocked AWS Credentials for moto.
old_environ = os.environ.copy()
os.environ.update(S3_FAKE_ENV_VARS)
> proc = subprocess.Popen(shlex.split("moto_server s3 -p %s" % s3_port))
tests\s3_fixtures.py:32:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
C:\tools\miniconda3\lib\subprocess.py:729: in __init__
restore_signals, start_new_session)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <subprocess.Popen object at 0x0000012BB8A4B908>
args = 'moto_server s3 -p 5555', executable = None, preexec_fn = None
close_fds = True, pass_fds = (), cwd = None, env = None
startupinfo = <subprocess.STARTUPINFO object at 0x0000012BB8177630>
creationflags = 0, shell = False, p2cread = -1, p2cwrite = -1, c2pread = -1
c2pwrite = -1, errread = -1, errwrite = -1, unused_restore_signals = True
unused_start_new_session = False
def _execute_child(self, args, executable, preexec_fn, close_fds,
pass_fds, cwd, env,
startupinfo, creationflags, shell,
p2cread, p2cwrite,
c2pread, c2pwrite,
errread, errwrite,
unused_restore_signals, unused_start_new_session):
"""Execute program (MS Windows version)"""
assert not pass_fds, "pass_fds not supported on Windows."
if not isinstance(args, str):
args = list2cmdline(args)
# Process startup details
if startupinfo is None:
startupinfo = STARTUPINFO()
if -1 not in (p2cread, c2pwrite, errwrite):
startupinfo.dwFlags |= _winapi.STARTF_USESTDHANDLES
startupinfo.hStdInput = p2cread
startupinfo.hStdOutput = c2pwrite
startupinfo.hStdError = errwrite
if shell:
startupinfo.dwFlags |= _winapi.STARTF_USESHOWWINDOW
startupinfo.wShowWindow = _winapi.SW_HIDE
comspec = os.environ.get("COMSPEC", "cmd.exe")
args = '{} /c "{}"'.format (comspec, args)
# Start the process
try:
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
# no special security
None, None,
int(not close_fds),
creationflags,
env,
os.fspath(cwd) if cwd is not None else None,
> startupinfo)
E FileNotFoundError: [WinError 2] The system cannot find the file specified
C:\tools\miniconda3\lib\subprocess.py:1017: FileNotFoundError
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3069/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3069/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4552/comments | https://api.github.com/repos/huggingface/datasets/issues/4552/events | https://github.com/huggingface/datasets/pull/4552 | 1,282,615,646 | PR_kwDODunzps46QSHV | 4,552 | Tell users to upload on the hub directly | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! I updated the two remaining files"
] | "2022-06-23T15:47:52Z" | "2022-06-26T15:49:46Z" | "2022-06-26T15:39:11Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4552.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4552",
"merged_at": "2022-06-26T15:39:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4552.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4552"
} | As noted in https://github.com/huggingface/datasets/pull/4534, it is still not clear that it is recommended to add datasets on the Hugging Face Hub directly instead of GitHub, so I updated some docs.
Moreover since users won't be able to get reviews from us on the Hub, I added a paragraph to tell users that they can open a discussion and tag `datasets` maintainers for reviews.
Finally I removed the _previous good reasons_ to add a dataset on GitHub to only keep this one:
> In some rare cases it makes more sense to open a PR on GitHub. For example when you are not the author of the dataset and there is no clear organization / namespace that you can put the dataset under.
Does it sound good to you @albertvillanova @julien-c ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4552/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4552/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3747/comments | https://api.github.com/repos/huggingface/datasets/issues/3747/events | https://github.com/huggingface/datasets/issues/3747 | 1,141,688,854 | I_kwDODunzps5EDMoW | 3,747 | Passing invalid subset should throw an error | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jxmorris12",
"id": 13238952,
"login": "jxmorris12",
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jxmorris12"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | "2022-02-17T18:16:11Z" | "2022-02-17T18:16:11Z" | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Only some datasets have a subset (as in `load_dataset(name, subset)`). If you pass an invalid subset, an error should be thrown.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('rotten_tomatoes', 'asdfasdfa')
```
## Expected results
This should break, since `'asdfasdfa'` isn't a subset of the `rotten_tomatoes` dataset.
## Actual results
This API call silently succeeds. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3747/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3747/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5209/comments | https://api.github.com/repos/huggingface/datasets/issues/5209/events | https://github.com/huggingface/datasets/issues/5209 | 1,438,367,678 | I_kwDODunzps5Vu7-- | 5,209 | Implement ability to define splits in metadata section of dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_url": "https://api.github.com/users/merveenoyan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/merveenoyan",
"id": 53175384,
"login": "merveenoyan",
"node_id": "MDQ6VXNlcjUzMTc1Mzg0",
"organizations_url": "https://api.github.com/users/merveenoyan/orgs",
"received_events_url": "https://api.github.com/users/merveenoyan/received_events",
"repos_url": "https://api.github.com/users/merveenoyan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/merveenoyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merveenoyan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/merveenoyan"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"@merveenoyan Do you want different files to be splits or configurations?\r\n\r\nFrom [what you specified in `Readme.md`](https://huggingface.co/datasets/inria-soda/tabular-benchmark/commit/fb4575853772c62a20203bdd6cc0202f5db4ce4e) I hypothesize that you want to have 4 **configs** corresponding to directories: `\"clf_cat\", \"clf_num\", \"reg_cat\", \"reg_num\"`. And inside each config you require to have as many splits as there are `csv` files\r\nso if you run \r\n```python\r\nload_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat\", split=\"compass\")\r\n```\r\nyou will generate the data only from `compass.csv` file.\r\nIn this case, running `load_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat\"`) without split parameter will return `DatasetDict` object with `\"KDDCup09_upselling\", \"cat_compass\", \"cat_covertype\", ... \"road_safety\"` keys (which values are splits - `Dataset` objects)\r\n\r\n**or**\r\ndo you want each file to be a separate config? Like:\r\n```python\r\nload_dataset(\"inria-soda/tabular-benchmark\", \"clf_cat_compass\") # returns DatasetDict with a single \"train\" split\r\n```\r\n**or**\r\nmaybe smth completely different? :smile: \r\n\r\nAnyway, now I have an impression that this is probably rather a matter of automatically inferring configs from repository structure rather than providing parameters in metadata yaml.\r\n",
"@polinaeterna I want the latter where you can think of every CSV file as a config, like MNLI from GLUE.",
"@merveenoyan @lhoestq I see two solutions to this case. \r\n1. Parse configurations automatically from directories names. That is, if you have data structure like:\r\n```\r\ntabular-benchmark\r\n └─clf_cat_compass\r\n └─compass.csv\r\n └─clf_cat_cat_covertype\r\n └─covertype.csv\r\n ...\r\n └─reg_cat_house_sales\r\n └─house_sales.csv\r\n```\r\nyou'll get \"clf_cat_compass\", \"clf_cat_cat_covertype\", ... \"reg_cat_house_sales\" configurations that would contain **only files from corresponding directories**. \r\n**\\+** this is a requested change and needed in general and would solve other problems, see https://github.com/huggingface/datasets/issues/4578, would also help with https://github.com/huggingface/datasets/pull/5213 which I'm working on currently\r\n**\\+** would allow users to do just `load_dataset(“inria-soda/tabular-benchmark”, “clf_cat_compass”)`, no `data_files` param required\r\n**\\-** in this specific case it would require restructuring of the data - putting each file in a directory named as a config name (to me personally it doesn't seem to be a big deal) \r\n\r\n2. More or less what we discussed before - add support for manually specifying parameters in the metadata. We can add new metadata yaml field (say, `\"custom_configs_info\"`), so that we can provide smth like:\r\n```yaml\r\n---\r\n...\r\ndataset_info:\r\n ... \r\ncustom_configs_info:\r\n- config_name: reg_cat_house_sales\r\n data_files:\r\n - reg_cat/house_sales.csv\r\n- config_name: clf_cat_compass\r\n data_files:\r\n - clf_cat/compass.csv\r\n...\r\n---\r\n```\r\n**\\+** Would be useful not only for tabular data and not only for `data_files` parameter - any packaged dataset’s viewer can be customized to use specific, non-default parameters. @merveenoyan do you maybe have any other examples/use cases in mind where you want to provide any specific parameters to the viewer? \r\n**\\-** I'm not sure here but assume that it might require changes in interaction with the viewer on the hub side - to parse these configurations, as they not default configurations (not in `BUILDER_CONFIGS` list). cc @severo But probably this can be solved on the `datasets` side too.\r\n\r\nOverall, I would start from implementing the first solution since it's related to what I'm doing now and is super useful for `datasets` in general. And then if we agree that having more flexibility in providing parameters to the viewer is required, I can implement the second one. Let me know what you think :) ",
"> We can add new metadata yaml field (say, \"custom_configs_info\"), so that we can provide smth like:\r\n\r\nLove it ! Some other ideas to name the \"custom_configs_info\" field: \"configs\", \"parameters\", \"config_args\", \"configurations\"\r\n\r\n> it might require changes in interaction with the viewer on the hub side - to parse these configurations, as they not default configurations (not in BUILDER_CONFIGS list)\r\n\r\nIf we update the `get_dataset_config_names()` function in `datasets` in inspect.py we should be fine - that's what the viewer is using\r\n\r\n> Overall, I would start from implementing the first solution since it's related to what I'm doing now and is super useful for datasets in general. And then if we agree that having more flexibility in providing parameters to the viewer is required, I can implement the second one. Let me know what you think :)\r\n\r\nActually I feel like the second solution includes the first use case you mentioned. If you implement the second solution, then users would just have to add a few lines of YAML and their directories would be considered configurations no ? Maybe there's no need to implement two different logics to do the same thing",
"is there any update on this? 🕵🏻",
"@merveenoyan I haven't started working on this yet, working on adding configs to packaged datasets instead: https://github.com/huggingface/datasets/pull/5213 because this both would allow you to solve your issue and is a frequently requested feature.\r\n\r\nadding arbitrary parameters to yaml would be my next task i think!",
"@merveenoyan ignore my comment above, I'm switching to this task now :D",
"I want to be able to create folders in a model.",
"Addressed in #5331 "
] | "2022-11-07T13:27:16Z" | "2023-07-21T14:36:02Z" | "2023-07-21T14:36:01Z" | CONTRIBUTOR | null | null | null | ### Feature request
If you go here: https://huggingface.co/datasets/inria-soda/tabular-benchmark/tree/main you will see bunch of folders that has various CSV files. I’d like dataset viewer to show these files instead of only one dataset like it currently does. (and also people to be able to load them as splits instead of loading through `data_files`)
e.g GLUE has various splits on viewer but it’s too overkill to ask people to implement loading script, so it would be better to let them define these in the README file instead.
Also pinging @polinaeterna @lhoestq @adrinjalali
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5209/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1849 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1849/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1849/comments | https://api.github.com/repos/huggingface/datasets/issues/1849/events | https://github.com/huggingface/datasets/issues/1849 | 804,292,971 | MDU6SXNzdWU4MDQyOTI5NzE= | 1,849 | Add TIMIT | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | closed | false | null | [] | null | [
"@patrickvonplaten Could you please help me with how the output text has to be represented in the data? TIMIT has Words, Phonemes and texts. Also has lot on info on the speaker and the dialect. Could you please help me? An example of how to arrange it would be super helpful!\r\n\r\n",
"Hey @vrindaprabhu - sure I'll help you :-) Could you open a first PR for TIMIT where you copy-paste more or less the `librispeech_asr` script: https://github.com/huggingface/datasets/blob/28be129db862ec89a87ac9349c64df6b6118aff4/datasets/librispeech_asr/librispeech_asr.py#L93 (obviously replacing all the naming and links correctly...) and then you can list all possible outputs in the features dict: https://github.com/huggingface/datasets/blob/28be129db862ec89a87ac9349c64df6b6118aff4/datasets/librispeech_asr/librispeech_asr.py#L104 (words, phonemes should probably be of kind `datasets.Sequence(datasets.Value(\"string\"))` and texts I think should be of type `\"text\": datasets.Value(\"string\")`.\r\n\r\nWhen you've opened a first PR, I think it'll be much easier for us to take a look together :-) ",
"I am sorry! I created the PR [#1903](https://github.com/huggingface/datasets/pull/1903#). Requesting your comments! CircleCI tests are failing, will address them along with your comments!"
] | "2021-02-09T07:29:41Z" | "2021-03-15T05:59:37Z" | "2021-03-15T05:59:37Z" | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** *TIMIT*
- **Description:** *The TIMIT corpus of read speech has been designed to provide speech data for the acquisition of acoustic-phonetic knowledge and for the development and evaluation of automatic speech recognition systems*
- **Paper:** *Homepage*: http://groups.inf.ed.ac.uk/ami/corpus/ / *Wikipedia*: https://en.wikipedia.org/wiki/TIMIT
- **Data:** *https://deepai.org/dataset/timit*
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1849/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1849/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5954/comments | https://api.github.com/repos/huggingface/datasets/issues/5954/events | https://github.com/huggingface/datasets/pull/5954 | 1,756,572,994 | PR_kwDODunzps5S-hSP | 5,954 | Better filenotfound for gated | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006374 / 0.011353 (-0.004979) | 0.004100 / 0.011008 (-0.006909) | 0.104031 / 0.038508 (0.065523) | 0.035186 / 0.023109 (0.012076) | 0.328904 / 0.275898 (0.053006) | 0.361409 / 0.323480 (0.037929) | 0.003855 / 0.007986 (-0.004130) | 0.004140 / 0.004328 (-0.000189) | 0.080406 / 0.004250 (0.076156) | 0.045658 / 0.037052 (0.008606) | 0.341133 / 0.258489 (0.082644) | 0.372688 / 0.293841 (0.078847) | 0.032025 / 0.128546 (-0.096521) | 0.008877 / 0.075646 (-0.066769) | 0.354784 / 0.419271 (-0.064488) | 0.068874 / 0.043533 (0.025341) | 0.335441 / 0.255139 (0.080302) | 0.356498 / 0.283200 (0.073298) | 0.113367 / 0.141683 (-0.028316) | 1.522458 / 1.452155 (0.070304) | 1.608046 / 1.492716 (0.115329) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231653 / 0.018006 (0.213647) | 0.446678 / 0.000490 (0.446188) | 0.003246 / 0.000200 (0.003046) | 0.000085 / 0.000054 (0.000030) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025299 / 0.037411 (-0.012112) | 0.111440 / 0.014526 (0.096914) | 0.118758 / 0.176557 (-0.057799) | 0.175037 / 0.737135 (-0.562098) | 0.124583 / 0.296338 (-0.171755) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418694 / 0.215209 (0.203484) | 4.174695 / 2.077655 (2.097041) | 1.890323 / 1.504120 (0.386203) | 1.683300 / 1.541195 (0.142106) | 1.781954 / 1.468490 (0.313464) | 0.546131 / 4.584777 (-4.038645) | 3.768055 / 3.745712 (0.022343) | 1.839878 / 5.269862 (-3.429983) | 1.111877 / 4.565676 (-3.453800) | 0.068568 / 0.424275 (-0.355707) | 0.011950 / 0.007607 (0.004343) | 0.527469 / 0.226044 (0.301425) | 5.274887 / 2.268929 (3.005958) | 2.391274 / 55.444624 (-53.053351) | 2.063837 / 6.876477 (-4.812640) | 2.140627 / 2.142072 (-0.001445) | 0.681508 / 4.805227 (-4.123719) | 0.148203 / 6.500664 (-6.352461) | 0.064456 / 0.075469 (-0.011013) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.221478 / 1.841788 (-0.620310) | 14.713705 / 8.074308 (6.639397) | 14.674184 / 10.191392 (4.482792) | 0.148411 / 0.680424 (-0.532012) | 0.017858 / 0.534201 (-0.516343) | 0.436166 / 0.579283 (-0.143117) | 0.437290 / 0.434364 (0.002926) | 0.521994 / 0.540337 (-0.018343) | 0.635488 / 1.386936 (-0.751448) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006108 / 0.011353 (-0.005245) | 0.003888 / 0.011008 (-0.007120) | 0.078424 / 0.038508 (0.039916) | 0.033618 / 0.023109 (0.010509) | 0.376284 / 0.275898 (0.100386) | 0.396957 / 0.323480 (0.073477) | 0.003799 / 0.007986 (-0.004187) | 0.003160 / 0.004328 (-0.001168) | 0.078358 / 0.004250 (0.074107) | 0.045597 / 0.037052 (0.008545) | 0.386396 / 0.258489 (0.127907) | 0.412985 / 0.293841 (0.119144) | 0.031610 / 0.128546 (-0.096936) | 0.008720 / 0.075646 (-0.066926) | 0.085944 / 0.419271 (-0.333328) | 0.050780 / 0.043533 (0.007247) | 0.378099 / 0.255139 (0.122960) | 0.381894 / 0.283200 (0.098694) | 0.098926 / 0.141683 (-0.042756) | 1.513842 / 1.452155 (0.061688) | 1.595040 / 1.492716 (0.102323) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208169 / 0.018006 (0.190163) | 0.431653 / 0.000490 (0.431163) | 0.000935 / 0.000200 (0.000735) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029600 / 0.037411 (-0.007812) | 0.116936 / 0.014526 (0.102410) | 0.125603 / 0.176557 (-0.050953) | 0.177007 / 0.737135 (-0.560129) | 0.130602 / 0.296338 (-0.165736) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457158 / 0.215209 (0.241949) | 4.563254 / 2.077655 (2.485599) | 2.303549 / 1.504120 (0.799429) | 2.107269 / 1.541195 (0.566074) | 2.130861 / 1.468490 (0.662371) | 0.548931 / 4.584777 (-4.035846) | 3.745578 / 3.745712 (-0.000134) | 1.820372 / 5.269862 (-3.449490) | 1.099316 / 4.565676 (-3.466361) | 0.068218 / 0.424275 (-0.356057) | 0.012336 / 0.007607 (0.004728) | 0.569721 / 0.226044 (0.343676) | 5.691312 / 2.268929 (3.422384) | 2.797483 / 55.444624 (-52.647141) | 2.422621 / 6.876477 (-4.453855) | 2.426187 / 2.142072 (0.284115) | 0.674777 / 4.805227 (-4.130451) | 0.144855 / 6.500664 (-6.355809) | 0.065805 / 0.075469 (-0.009664) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.305078 / 1.841788 (-0.536709) | 14.874315 / 8.074308 (6.800007) | 14.541301 / 10.191392 (4.349909) | 0.175818 / 0.680424 (-0.504606) | 0.018169 / 0.534201 (-0.516032) | 0.435836 / 0.579283 (-0.143447) | 0.458397 / 0.434364 (0.024033) | 0.506232 / 0.540337 (-0.034106) | 0.605306 / 1.386936 (-0.781630) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006138 / 0.011353 (-0.005215) | 0.003792 / 0.011008 (-0.007216) | 0.099417 / 0.038508 (0.060908) | 0.028739 / 0.023109 (0.005630) | 0.302835 / 0.275898 (0.026937) | 0.336397 / 0.323480 (0.012918) | 0.003537 / 0.007986 (-0.004449) | 0.002973 / 0.004328 (-0.001355) | 0.077461 / 0.004250 (0.073211) | 0.039493 / 0.037052 (0.002440) | 0.302367 / 0.258489 (0.043878) | 0.344936 / 0.293841 (0.051095) | 0.027813 / 0.128546 (-0.100733) | 0.008591 / 0.075646 (-0.067055) | 0.318975 / 0.419271 (-0.100297) | 0.045971 / 0.043533 (0.002438) | 0.301672 / 0.255139 (0.046533) | 0.328202 / 0.283200 (0.045003) | 0.091400 / 0.141683 (-0.050282) | 1.487215 / 1.452155 (0.035060) | 1.557730 / 1.492716 (0.065014) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208343 / 0.018006 (0.190336) | 0.426764 / 0.000490 (0.426275) | 0.001196 / 0.000200 (0.000996) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024332 / 0.037411 (-0.013079) | 0.101861 / 0.014526 (0.087335) | 0.108669 / 0.176557 (-0.067888) | 0.172042 / 0.737135 (-0.565093) | 0.113048 / 0.296338 (-0.183290) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421419 / 0.215209 (0.206210) | 4.200816 / 2.077655 (2.123162) | 1.913516 / 1.504120 (0.409396) | 1.712167 / 1.541195 (0.170972) | 1.762129 / 1.468490 (0.293639) | 0.561616 / 4.584777 (-4.023161) | 3.398122 / 3.745712 (-0.347590) | 1.744323 / 5.269862 (-3.525538) | 1.036023 / 4.565676 (-3.529653) | 0.067658 / 0.424275 (-0.356617) | 0.011145 / 0.007607 (0.003538) | 0.522803 / 0.226044 (0.296759) | 5.226245 / 2.268929 (2.957317) | 2.355148 / 55.444624 (-53.089476) | 2.014939 / 6.876477 (-4.861538) | 2.140028 / 2.142072 (-0.002044) | 0.695049 / 4.805227 (-4.110178) | 0.138428 / 6.500664 (-6.362236) | 0.066721 / 0.075469 (-0.008748) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219610 / 1.841788 (-0.622177) | 14.239576 / 8.074308 (6.165268) | 14.381955 / 10.191392 (4.190563) | 0.131208 / 0.680424 (-0.549216) | 0.016698 / 0.534201 (-0.517503) | 0.361373 / 0.579283 (-0.217910) | 0.382560 / 0.434364 (-0.051804) | 0.419427 / 0.540337 (-0.120911) | 0.508314 / 1.386936 (-0.878622) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006174 / 0.011353 (-0.005179) | 0.003893 / 0.011008 (-0.007115) | 0.079614 / 0.038508 (0.041106) | 0.028685 / 0.023109 (0.005576) | 0.368627 / 0.275898 (0.092729) | 0.411599 / 0.323480 (0.088119) | 0.003573 / 0.007986 (-0.004413) | 0.002989 / 0.004328 (-0.001340) | 0.078653 / 0.004250 (0.074402) | 0.041146 / 0.037052 (0.004094) | 0.362387 / 0.258489 (0.103898) | 0.417234 / 0.293841 (0.123393) | 0.027958 / 0.128546 (-0.100589) | 0.008695 / 0.075646 (-0.066952) | 0.084637 / 0.419271 (-0.334635) | 0.044188 / 0.043533 (0.000655) | 0.358514 / 0.255139 (0.103375) | 0.392314 / 0.283200 (0.109114) | 0.093986 / 0.141683 (-0.047697) | 1.535366 / 1.452155 (0.083212) | 1.605978 / 1.492716 (0.113262) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.196215 / 0.018006 (0.178209) | 0.429403 / 0.000490 (0.428913) | 0.003736 / 0.000200 (0.003536) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025281 / 0.037411 (-0.012130) | 0.104325 / 0.014526 (0.089799) | 0.111548 / 0.176557 (-0.065009) | 0.162326 / 0.737135 (-0.574809) | 0.113853 / 0.296338 (-0.182486) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.447600 / 0.215209 (0.232391) | 4.463422 / 2.077655 (2.385767) | 2.168028 / 1.504120 (0.663908) | 1.968699 / 1.541195 (0.427504) | 2.035531 / 1.468490 (0.567041) | 0.564575 / 4.584777 (-4.020202) | 3.435338 / 3.745712 (-0.310374) | 2.981930 / 5.269862 (-2.287932) | 1.492172 / 4.565676 (-3.073505) | 0.067981 / 0.424275 (-0.356294) | 0.011254 / 0.007607 (0.003647) | 0.544385 / 0.226044 (0.318340) | 5.441694 / 2.268929 (3.172765) | 2.650168 / 55.444624 (-52.794456) | 2.333974 / 6.876477 (-4.542503) | 2.383424 / 2.142072 (0.241351) | 0.669814 / 4.805227 (-4.135414) | 0.135456 / 6.500664 (-6.365209) | 0.067067 / 0.075469 (-0.008402) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.313275 / 1.841788 (-0.528513) | 14.527636 / 8.074308 (6.453328) | 14.470957 / 10.191392 (4.279565) | 0.144361 / 0.680424 (-0.536063) | 0.016847 / 0.534201 (-0.517354) | 0.365158 / 0.579283 (-0.214125) | 0.393809 / 0.434364 (-0.040555) | 0.428527 / 0.540337 (-0.111810) | 0.515816 / 1.386936 (-0.871120) |\n\n</details>\n</details>\n\n\n"
] | "2023-06-14T10:33:10Z" | "2023-06-14T12:33:27Z" | "2023-06-14T12:26:31Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5954",
"merged_at": "2023-06-14T12:26:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5954"
} | close https://github.com/huggingface/datasets/issues/5953
<img width="1292" alt="image" src="https://github.com/huggingface/datasets/assets/42851186/270fe5bc-1739-4878-b7bc-ab6d35336d4d">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3390/comments | https://api.github.com/repos/huggingface/datasets/issues/3390/events | https://github.com/huggingface/datasets/issues/3390 | 1,072,462,456 | I_kwDODunzps4_7Hp4 | 3,390 | Loading dataset throws "KeyError: 'Field "builder_name" does not exist in table schema'" | {
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/R4ZZ3",
"id": 25264037,
"login": "R4ZZ3",
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"type": "User",
"url": "https://api.github.com/users/R4ZZ3"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Got solved it with push_to_hub, closing"
] | "2021-12-06T18:22:49Z" | "2021-12-06T20:22:05Z" | "2021-12-06T20:22:05Z" | NONE | null | null | null | ## Describe the bug
I have prepared dataset to datasets and now I am trying to load it back Finnish-NLP/voxpopuli_fi
I get "KeyError: 'Field "builder_name" does not exist in table schema'"
My dataset folder and files should be like @patrickvonplaten has here https://huggingface.co/datasets/flax-community/german-common-voice-processed
How my voxpopuli dataset looks like:

Part of the processing (path column is the absolute path to audio files)
```
def add_audio_column(example):
example['audio'] = example['path']
return example
voxpopuli = voxpopuli.map(add_audio_column)
voxpopuli.cast_column("audio", Audio())
voxpopuli["audio"] <-- to my knowledge this does load the local files and prepares those arrays
voxpopuli = voxpopuli.cast_column("audio", Audio(sampling_rate=16_000)) resampling 16kHz
```
I have then saved it to disk_
`voxpopuli.save_to_disk('/asr_disk/datasets_processed_new/voxpopuli')`
and made folder structure same as @patrickvonplaten
I also get same error while trying to load_dataset from his repo:

## Steps to reproduce the bug
```python
dataset = load_dataset("Finnish-NLP/voxpopuli_fi")
```
## Expected results
Dataset is loaded correctly and looks like in the first picture
## Actual results
Loading throws keyError:
KeyError: 'Field "builder_name" does not exist in table schema'
Resources I have been trying to follow:
https://huggingface.co/docs/datasets/audio_process.html
https://huggingface.co/docs/datasets/share_dataset.html
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.2.dev0
- Platform: Ubuntu 20.04.2 LTS
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3390/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/703/comments | https://api.github.com/repos/huggingface/datasets/issues/703/events | https://github.com/huggingface/datasets/pull/703 | 713,559,718 | MDExOlB1bGxSZXF1ZXN0NDk2ODU1OTQ5 | 703 | Add hotpot QA | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gists_url": "https://api.github.com/users/ghomasHudson/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ghomasHudson",
"id": 13795113,
"login": "ghomasHudson",
"node_id": "MDQ6VXNlcjEzNzk1MTEz",
"organizations_url": "https://api.github.com/users/ghomasHudson/orgs",
"received_events_url": "https://api.github.com/users/ghomasHudson/received_events",
"repos_url": "https://api.github.com/users/ghomasHudson/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ghomasHudson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghomasHudson/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ghomasHudson"
} | [] | closed | false | null | [] | null | [
"Awesome :) \r\n\r\nDon't pay attention to the RemoteDatasetTest error, I'm fixing it right now",
"You can rebase from master to fix the CI test :)",
"If we're lucky we can even include this dataset in today's release",
"Just thinking since `type` can only be `comparison` or `bridge` and `level` can only be `easy`, `medium`, `hard` should they be `ClassLabel`?",
"> Just thinking since `type` can only be `comparison` or `bridge` and `level` can only be `easy`, `medium`, `hard` should they be `ClassLabel`?\r\n\r\nI think it's more a tag than a label. I guess a string is fine\r\n"
] | "2020-10-02T11:44:28Z" | "2020-10-02T12:54:41Z" | "2020-10-02T12:54:41Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/703",
"merged_at": "2020-10-02T12:54:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/703"
} | Added the [HotpotQA](https://github.com/hotpotqa/hotpot) multi-hop question answering dataset.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6367/comments | https://api.github.com/repos/huggingface/datasets/issues/6367/events | https://github.com/huggingface/datasets/pull/6367 | 1,971,015,861 | PR_kwDODunzps5eQy1D | 6,367 | Fix time measuring snippet in docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007683 / 0.011353 (-0.003670) | 0.004159 / 0.011008 (-0.006849) | 0.097017 / 0.038508 (0.058509) | 0.074216 / 0.023109 (0.051107) | 0.323115 / 0.275898 (0.047217) | 0.412836 / 0.323480 (0.089356) | 0.005151 / 0.007986 (-0.002834) | 0.004037 / 0.004328 (-0.000292) | 0.067881 / 0.004250 (0.063631) | 0.051395 / 0.037052 (0.014342) | 0.356391 / 0.258489 (0.097901) | 0.386744 / 0.293841 (0.092903) | 0.043571 / 0.128546 (-0.084975) | 0.012844 / 0.075646 (-0.062803) | 0.369440 / 0.419271 (-0.049832) | 0.056944 / 0.043533 (0.013411) | 0.316159 / 0.255139 (0.061020) | 0.435530 / 0.283200 (0.152330) | 0.033622 / 0.141683 (-0.108061) | 1.379602 / 1.452155 (-0.072553) | 1.766400 / 1.492716 (0.273683) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304151 / 0.018006 (0.286145) | 0.616365 / 0.000490 (0.615875) | 0.013588 / 0.000200 (0.013389) | 0.000441 / 0.000054 (0.000387) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032812 / 0.037411 (-0.004600) | 0.100914 / 0.014526 (0.086388) | 0.124004 / 0.176557 (-0.052552) | 0.195087 / 0.737135 (-0.542048) | 0.124388 / 0.296338 (-0.171951) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.575649 / 0.215209 (0.360440) | 5.665461 / 2.077655 (3.587806) | 2.474892 / 1.504120 (0.970773) | 2.142687 / 1.541195 (0.601492) | 2.254962 / 1.468490 (0.786472) | 0.816635 / 4.584777 (-3.768141) | 5.044279 / 3.745712 (1.298567) | 4.566728 / 5.269862 (-0.703134) | 2.867146 / 4.565676 (-1.698531) | 0.092994 / 0.424275 (-0.331281) | 0.008395 / 0.007607 (0.000788) | 0.680346 / 0.226044 (0.454302) | 6.909875 / 2.268929 (4.640946) | 3.275602 / 55.444624 (-52.169022) | 2.556000 / 6.876477 (-4.320477) | 2.581337 / 2.142072 (0.439264) | 0.997883 / 4.805227 (-3.807344) | 0.204109 / 6.500664 (-6.296555) | 0.069705 / 0.075469 (-0.005764) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.504573 / 1.841788 (-0.337215) | 22.219363 / 8.074308 (14.145055) | 19.078040 / 10.191392 (8.886648) | 0.234970 / 0.680424 (-0.445454) | 0.027324 / 0.534201 (-0.506877) | 0.427960 / 0.579283 (-0.151323) | 0.570258 / 0.434364 (0.135894) | 0.502335 / 0.540337 (-0.038003) | 0.788078 / 1.386936 (-0.598858) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008370 / 0.011353 (-0.002982) | 0.004573 / 0.011008 (-0.006435) | 0.073080 / 0.038508 (0.034572) | 0.068752 / 0.023109 (0.045643) | 0.439648 / 0.275898 (0.163750) | 0.499700 / 0.323480 (0.176220) | 0.006119 / 0.007986 (-0.001866) | 0.004300 / 0.004328 (-0.000028) | 0.073173 / 0.004250 (0.068923) | 0.055676 / 0.037052 (0.018624) | 0.464152 / 0.258489 (0.205663) | 0.476954 / 0.293841 (0.183113) | 0.046335 / 0.128546 (-0.082211) | 0.013373 / 0.075646 (-0.062274) | 0.092006 / 0.419271 (-0.327265) | 0.054802 / 0.043533 (0.011269) | 0.456594 / 0.255139 (0.201455) | 0.491931 / 0.283200 (0.208732) | 0.034021 / 0.141683 (-0.107662) | 1.575200 / 1.452155 (0.123045) | 1.689742 / 1.492716 (0.197026) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.299432 / 0.018006 (0.281426) | 0.605643 / 0.000490 (0.605153) | 0.006280 / 0.000200 (0.006080) | 0.000120 / 0.000054 (0.000066) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028414 / 0.037411 (-0.008997) | 0.085812 / 0.014526 (0.071286) | 0.109142 / 0.176557 (-0.067414) | 0.163458 / 0.737135 (-0.573677) | 0.100837 / 0.296338 (-0.195501) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.615557 / 0.215209 (0.400348) | 6.051599 / 2.077655 (3.973944) | 2.872353 / 1.504120 (1.368234) | 2.508322 / 1.541195 (0.967128) | 2.550073 / 1.468490 (1.081583) | 0.835793 / 4.584777 (-3.748983) | 5.208484 / 3.745712 (1.462772) | 4.361846 / 5.269862 (-0.908016) | 2.776164 / 4.565676 (-1.789513) | 0.090831 / 0.424275 (-0.333444) | 0.007320 / 0.007607 (-0.000287) | 0.725533 / 0.226044 (0.499488) | 7.051321 / 2.268929 (4.782393) | 3.515464 / 55.444624 (-51.929160) | 2.798193 / 6.876477 (-4.078284) | 3.022512 / 2.142072 (0.880440) | 0.986744 / 4.805227 (-3.818484) | 0.198050 / 6.500664 (-6.302615) | 0.069200 / 0.075469 (-0.006269) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.623759 / 1.841788 (-0.218029) | 22.269700 / 8.074308 (14.195392) | 19.577429 / 10.191392 (9.386037) | 0.215990 / 0.680424 (-0.464434) | 0.033005 / 0.534201 (-0.501196) | 0.436848 / 0.579283 (-0.142435) | 0.591442 / 0.434364 (0.157078) | 0.547701 / 0.540337 (0.007364) | 0.741695 / 1.386936 (-0.645241) |\n\n</details>\n</details>\n\n\n",
"CI failures are unrelated",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009027 / 0.011353 (-0.002326) | 0.006118 / 0.011008 (-0.004890) | 0.118939 / 0.038508 (0.080431) | 0.089979 / 0.023109 (0.066869) | 0.412425 / 0.275898 (0.136527) | 0.455706 / 0.323480 (0.132227) | 0.006762 / 0.007986 (-0.001224) | 0.004409 / 0.004328 (0.000080) | 0.088002 / 0.004250 (0.083751) | 0.063708 / 0.037052 (0.026656) | 0.417373 / 0.258489 (0.158884) | 0.489582 / 0.293841 (0.195741) | 0.050222 / 0.128546 (-0.078324) | 0.014386 / 0.075646 (-0.061260) | 0.435363 / 0.419271 (0.016092) | 0.069375 / 0.043533 (0.025842) | 0.410242 / 0.255139 (0.155103) | 0.436439 / 0.283200 (0.153239) | 0.039318 / 0.141683 (-0.102365) | 1.857574 / 1.452155 (0.405419) | 1.919402 / 1.492716 (0.426686) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.343916 / 0.018006 (0.325910) | 0.633639 / 0.000490 (0.633150) | 0.014756 / 0.000200 (0.014557) | 0.000707 / 0.000054 (0.000652) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031983 / 0.037411 (-0.005429) | 0.097222 / 0.014526 (0.082697) | 0.114644 / 0.176557 (-0.061912) | 0.187787 / 0.737135 (-0.549348) | 0.120595 / 0.296338 (-0.175743) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.605861 / 0.215209 (0.390652) | 6.039318 / 2.077655 (3.961664) | 2.699251 / 1.504120 (1.195132) | 2.436398 / 1.541195 (0.895203) | 2.493653 / 1.468490 (1.025163) | 0.889423 / 4.584777 (-3.695354) | 5.384769 / 3.745712 (1.639056) | 5.033033 / 5.269862 (-0.236829) | 3.056894 / 4.565676 (-1.508783) | 0.100683 / 0.424275 (-0.323592) | 0.009103 / 0.007607 (0.001495) | 0.737066 / 0.226044 (0.511021) | 7.370485 / 2.268929 (5.101556) | 3.422670 / 55.444624 (-52.021954) | 2.830392 / 6.876477 (-4.046084) | 2.985789 / 2.142072 (0.843717) | 0.999239 / 4.805227 (-3.805989) | 0.203506 / 6.500664 (-6.297158) | 0.076135 / 0.075469 (0.000666) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.697001 / 1.841788 (-0.144787) | 24.653975 / 8.074308 (16.579667) | 22.241622 / 10.191392 (12.050230) | 0.257075 / 0.680424 (-0.423349) | 0.029159 / 0.534201 (-0.505041) | 0.493329 / 0.579283 (-0.085954) | 0.596661 / 0.434364 (0.162297) | 0.569431 / 0.540337 (0.029094) | 0.812231 / 1.386936 (-0.574705) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009815 / 0.011353 (-0.001538) | 0.005136 / 0.011008 (-0.005872) | 0.078224 / 0.038508 (0.039716) | 0.103276 / 0.023109 (0.080166) | 0.512742 / 0.275898 (0.236844) | 0.544010 / 0.323480 (0.220530) | 0.007957 / 0.007986 (-0.000029) | 0.004629 / 0.004328 (0.000300) | 0.074983 / 0.004250 (0.070733) | 0.071831 / 0.037052 (0.034778) | 0.542752 / 0.258489 (0.284262) | 0.573176 / 0.293841 (0.279335) | 0.053939 / 0.128546 (-0.074607) | 0.015007 / 0.075646 (-0.060640) | 0.085389 / 0.419271 (-0.333882) | 0.063587 / 0.043533 (0.020055) | 0.509580 / 0.255139 (0.254441) | 0.563374 / 0.283200 (0.280174) | 0.037575 / 0.141683 (-0.104108) | 1.840740 / 1.452155 (0.388585) | 1.836414 / 1.492716 (0.343698) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.310188 / 0.018006 (0.292182) | 0.641478 / 0.000490 (0.640988) | 0.011057 / 0.000200 (0.010857) | 0.000173 / 0.000054 (0.000119) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.043280 / 0.037411 (0.005869) | 0.109256 / 0.014526 (0.094730) | 0.126701 / 0.176557 (-0.049856) | 0.199172 / 0.737135 (-0.537963) | 0.123584 / 0.296338 (-0.172755) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.649272 / 0.215209 (0.434063) | 6.487501 / 2.077655 (4.409846) | 3.170330 / 1.504120 (1.666210) | 2.960912 / 1.541195 (1.419718) | 3.024531 / 1.468490 (1.556041) | 0.905112 / 4.584777 (-3.679665) | 5.560961 / 3.745712 (1.815249) | 4.920463 / 5.269862 (-0.349399) | 3.158989 / 4.565676 (-1.406687) | 0.095444 / 0.424275 (-0.328831) | 0.008264 / 0.007607 (0.000657) | 0.819292 / 0.226044 (0.593247) | 7.982695 / 2.268929 (5.713767) | 4.098704 / 55.444624 (-51.345921) | 3.442330 / 6.876477 (-3.434147) | 3.763426 / 2.142072 (1.621354) | 1.065464 / 4.805227 (-3.739763) | 0.215089 / 6.500664 (-6.285575) | 0.085280 / 0.075469 (0.009811) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.881770 / 1.841788 (0.039983) | 25.671479 / 8.074308 (17.597171) | 22.367019 / 10.191392 (12.175627) | 0.241377 / 0.680424 (-0.439047) | 0.033555 / 0.534201 (-0.500646) | 0.501786 / 0.579283 (-0.077497) | 0.596376 / 0.434364 (0.162012) | 0.579674 / 0.540337 (0.039337) | 0.855534 / 1.386936 (-0.531402) |\n\n</details>\n</details>\n\n\n"
] | "2023-10-31T17:57:17Z" | "2023-10-31T18:35:53Z" | "2023-10-31T18:24:02Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6367.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6367",
"merged_at": "2023-10-31T18:24:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6367.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6367"
} | Fix https://discuss.huggingface.co/t/attributeerror-enter/60509 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6367/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6367/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5173 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5173/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5173/comments | https://api.github.com/repos/huggingface/datasets/issues/5173/events | https://github.com/huggingface/datasets/pull/5173 | 1,425,880,441 | PR_kwDODunzps5BreEm | 5,173 | Raise ffmpeg warnings only once | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-10-27T15:58:33Z" | "2022-10-28T16:03:05Z" | "2022-10-28T16:00:51Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5173.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5173",
"merged_at": "2022-10-28T16:00:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5173.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5173"
} | Our warnings looks nice now.
`librosa` warning that was raised at each decoding:
```
/usr/local/lib/python3.7/dist-packages/librosa/core/audio.py:165: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
```
is suppressed with `filterwarnings("ignore")` in a context manager. That means the first warning is also ignored (setting `filterwarnings("once")` didn't work!), so I added info that audioread is used for decoding to our message. Hope it's enough.
Tests failed at first because they used to check if the warning was raised at (each) decoding in `librosa` case but now we throw only one warning (at first decoding). I removed this check for warnings, do you think it's fine? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5173/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5173/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4156/comments | https://api.github.com/repos/huggingface/datasets/issues/4156/events | https://github.com/huggingface/datasets/pull/4156 | 1,202,220,531 | PR_kwDODunzps42HySw | 4,156 | Adding STSb-TR dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/12762065?v=4",
"events_url": "https://api.github.com/users/figenfikri/events{/privacy}",
"followers_url": "https://api.github.com/users/figenfikri/followers",
"following_url": "https://api.github.com/users/figenfikri/following{/other_user}",
"gists_url": "https://api.github.com/users/figenfikri/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/figenfikri",
"id": 12762065,
"login": "figenfikri",
"node_id": "MDQ6VXNlcjEyNzYyMDY1",
"organizations_url": "https://api.github.com/users/figenfikri/orgs",
"received_events_url": "https://api.github.com/users/figenfikri/received_events",
"repos_url": "https://api.github.com/users/figenfikri/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/figenfikri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/figenfikri/subscriptions",
"type": "User",
"url": "https://api.github.com/users/figenfikri"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @figenfikri.\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2022-04-12T18:10:05Z" | "2022-10-03T09:36:25Z" | "2022-10-03T09:36:25Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4156.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4156",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4156.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4156"
} | Semantic Textual Similarity benchmark Turkish (STSb-TR) dataset introduced in our paper [Semantic Similarity Based Evaluation for Abstractive News Summarization](https://aclanthology.org/2021.gem-1.3.pdf) added. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4156/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5823/comments | https://api.github.com/repos/huggingface/datasets/issues/5823/events | https://github.com/huggingface/datasets/issues/5823 | 1,697,024,789 | I_kwDODunzps5lJosV | 5,823 | [2.12.0] DatasetDict.save_to_disk not saving to S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/5233185?v=4",
"events_url": "https://api.github.com/users/thejamesmarq/events{/privacy}",
"followers_url": "https://api.github.com/users/thejamesmarq/followers",
"following_url": "https://api.github.com/users/thejamesmarq/following{/other_user}",
"gists_url": "https://api.github.com/users/thejamesmarq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thejamesmarq",
"id": 5233185,
"login": "thejamesmarq",
"node_id": "MDQ6VXNlcjUyMzMxODU=",
"organizations_url": "https://api.github.com/users/thejamesmarq/orgs",
"received_events_url": "https://api.github.com/users/thejamesmarq/received_events",
"repos_url": "https://api.github.com/users/thejamesmarq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thejamesmarq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thejamesmarq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thejamesmarq"
} | [] | closed | false | null | [] | null | [
"Hi ! Can you try adding the `s3://` prefix ?\r\n```python\r\nf\"s3://{s3_bucket}/{s3_dir}/{dataset_name}\"\r\n```",
"Ugh, yeah that was it. Thank you!"
] | "2023-05-05T05:22:59Z" | "2023-05-05T15:01:18Z" | "2023-05-05T15:01:17Z" | NONE | null | null | null | ### Describe the bug
When trying to save a `DatasetDict` to a private S3 bucket using `save_to_disk`, the artifacts are instead saved locally, and not in the S3 bucket.
I have tried using the deprecated `fs` as well as the `storage_options` arguments and I get the same results.
### Steps to reproduce the bug
1. Create a DatsetDict `dataset`
2. Create a S3FileSystem object
`s3 = datasets.filesystems.S3FileSystem(key=aws_access_key_id, secret=aws_secret_access_key)`
3. Save using `dataset_dict.save_to_disk(f"{s3_bucket}/{s3_dir}/{dataset_name}", storage_options=s3.storage_options)` or `dataset_dict.save_to_disk(f"{s3_bucket}/{s3_dir}/{dataset_name}", fs=s3)`
4. Check the corresponding S3 bucket and verify nothing has been uploaded
5. Check the path at f"{s3_bucket}/{s3_dir}/{dataset_name}" and verify that files have been saved there
### Expected behavior
Artifacts are uploaded at the f"{s3_bucket}/{s3_dir}/{dataset_name}" S3 location.
### Environment info
- `datasets` version: 2.12.0
- Platform: macOS-13.3.1-x86_64-i386-64bit
- Python version: 3.11.2
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5823/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1709/comments | https://api.github.com/repos/huggingface/datasets/issues/1709/events | https://github.com/huggingface/datasets/issues/1709 | 781,875,640 | MDU6SXNzdWU3ODE4NzU2NDA= | 1,709 | Databases | {
"avatar_url": "https://avatars.githubusercontent.com/u/68724553?v=4",
"events_url": "https://api.github.com/users/JimmyJim1/events{/privacy}",
"followers_url": "https://api.github.com/users/JimmyJim1/followers",
"following_url": "https://api.github.com/users/JimmyJim1/following{/other_user}",
"gists_url": "https://api.github.com/users/JimmyJim1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JimmyJim1",
"id": 68724553,
"login": "JimmyJim1",
"node_id": "MDQ6VXNlcjY4NzI0NTUz",
"organizations_url": "https://api.github.com/users/JimmyJim1/orgs",
"received_events_url": "https://api.github.com/users/JimmyJim1/received_events",
"repos_url": "https://api.github.com/users/JimmyJim1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JimmyJim1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JimmyJim1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JimmyJim1"
} | [] | closed | false | null | [] | null | [] | "2021-01-08T06:14:03Z" | "2021-01-08T09:00:08Z" | "2021-01-08T09:00:08Z" | NONE | null | null | null | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1709/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6244/comments | https://api.github.com/repos/huggingface/datasets/issues/6244/events | https://github.com/huggingface/datasets/pull/6244 | 1,898,861,422 | PR_kwDODunzps5adtD3 | 6,244 | Add support for `fsspec>=2023.9.0` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006410 / 0.011353 (-0.004943) | 0.003995 / 0.011008 (-0.007013) | 0.083585 / 0.038508 (0.045076) | 0.074285 / 0.023109 (0.051176) | 0.307163 / 0.275898 (0.031265) | 0.344691 / 0.323480 (0.021212) | 0.004277 / 0.007986 (-0.003708) | 0.004192 / 0.004328 (-0.000136) | 0.065156 / 0.004250 (0.060905) | 0.056774 / 0.037052 (0.019721) | 0.315483 / 0.258489 (0.056994) | 0.361911 / 0.293841 (0.068070) | 0.030454 / 0.128546 (-0.098092) | 0.008600 / 0.075646 (-0.067047) | 0.286692 / 0.419271 (-0.132579) | 0.052354 / 0.043533 (0.008821) | 0.308997 / 0.255139 (0.053858) | 0.337847 / 0.283200 (0.054647) | 0.022459 / 0.141683 (-0.119224) | 1.482758 / 1.452155 (0.030604) | 1.572853 / 1.492716 (0.080137) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.288603 / 0.018006 (0.270597) | 0.632903 / 0.000490 (0.632413) | 0.013702 / 0.000200 (0.013502) | 0.000284 / 0.000054 (0.000230) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028448 / 0.037411 (-0.008964) | 0.082441 / 0.014526 (0.067916) | 0.099048 / 0.176557 (-0.077508) | 0.154370 / 0.737135 (-0.582765) | 0.146143 / 0.296338 (-0.150195) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399250 / 0.215209 (0.184040) | 3.986683 / 2.077655 (1.909028) | 1.962606 / 1.504120 (0.458486) | 1.782653 / 1.541195 (0.241459) | 1.830251 / 1.468490 (0.361761) | 0.492498 / 4.584777 (-4.092278) | 3.549581 / 3.745712 (-0.196131) | 3.200056 / 5.269862 (-2.069806) | 2.028109 / 4.565676 (-2.537568) | 0.058222 / 0.424275 (-0.366053) | 0.007629 / 0.007607 (0.000022) | 0.482083 / 0.226044 (0.256039) | 4.824728 / 2.268929 (2.555800) | 2.448772 / 55.444624 (-52.995852) | 2.079629 / 6.876477 (-4.796848) | 2.267739 / 2.142072 (0.125667) | 0.586712 / 4.805227 (-4.218515) | 0.134073 / 6.500664 (-6.366591) | 0.060565 / 0.075469 (-0.014904) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.263244 / 1.841788 (-0.578544) | 18.964498 / 8.074308 (10.890190) | 14.125062 / 10.191392 (3.933670) | 0.167635 / 0.680424 (-0.512789) | 0.018469 / 0.534201 (-0.515732) | 0.390395 / 0.579283 (-0.188888) | 0.406055 / 0.434364 (-0.028309) | 0.460717 / 0.540337 (-0.079620) | 0.642746 / 1.386936 (-0.744190) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006637 / 0.011353 (-0.004716) | 0.003972 / 0.011008 (-0.007036) | 0.064569 / 0.038508 (0.026061) | 0.075450 / 0.023109 (0.052341) | 0.405250 / 0.275898 (0.129352) | 0.433530 / 0.323480 (0.110050) | 0.005625 / 0.007986 (-0.002361) | 0.004118 / 0.004328 (-0.000211) | 0.065092 / 0.004250 (0.060842) | 0.057979 / 0.037052 (0.020927) | 0.413732 / 0.258489 (0.155243) | 0.451983 / 0.293841 (0.158142) | 0.032170 / 0.128546 (-0.096377) | 0.008690 / 0.075646 (-0.066957) | 0.071792 / 0.419271 (-0.347479) | 0.048560 / 0.043533 (0.005027) | 0.410312 / 0.255139 (0.155173) | 0.427294 / 0.283200 (0.144095) | 0.023006 / 0.141683 (-0.118677) | 1.496319 / 1.452155 (0.044164) | 1.566744 / 1.492716 (0.074027) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.266812 / 0.018006 (0.248805) | 0.540277 / 0.000490 (0.539788) | 0.008998 / 0.000200 (0.008799) | 0.000101 / 0.000054 (0.000047) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032496 / 0.037411 (-0.004915) | 0.091387 / 0.014526 (0.076861) | 0.107516 / 0.176557 (-0.069041) | 0.160019 / 0.737135 (-0.577116) | 0.107686 / 0.296338 (-0.188652) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433321 / 0.215209 (0.218111) | 4.330221 / 2.077655 (2.252566) | 2.367215 / 1.504120 (0.863095) | 2.192464 / 1.541195 (0.651269) | 2.200204 / 1.468490 (0.731714) | 0.488057 / 4.584777 (-4.096720) | 3.625429 / 3.745712 (-0.120283) | 3.282859 / 5.269862 (-1.987003) | 2.038716 / 4.565676 (-2.526960) | 0.057968 / 0.424275 (-0.366307) | 0.007753 / 0.007607 (0.000146) | 0.509133 / 0.226044 (0.283089) | 5.086445 / 2.268929 (2.817516) | 2.846017 / 55.444624 (-52.598607) | 2.469546 / 6.876477 (-4.406931) | 2.673218 / 2.142072 (0.531145) | 0.591228 / 4.805227 (-4.213999) | 0.131920 / 6.500664 (-6.368744) | 0.059967 / 0.075469 (-0.015502) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.375634 / 1.841788 (-0.466153) | 19.506752 / 8.074308 (11.432444) | 14.677876 / 10.191392 (4.486484) | 0.165071 / 0.680424 (-0.515353) | 0.020614 / 0.534201 (-0.513587) | 0.395967 / 0.579283 (-0.183316) | 0.424358 / 0.434364 (-0.010006) | 0.469954 / 0.540337 (-0.070384) | 0.643169 / 1.386936 (-0.743767) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006072 / 0.011353 (-0.005281) | 0.003691 / 0.011008 (-0.007318) | 0.081683 / 0.038508 (0.043175) | 0.059114 / 0.023109 (0.036005) | 0.317053 / 0.275898 (0.041155) | 0.357672 / 0.323480 (0.034192) | 0.003577 / 0.007986 (-0.004408) | 0.003890 / 0.004328 (-0.000438) | 0.063667 / 0.004250 (0.059417) | 0.048233 / 0.037052 (0.011181) | 0.322854 / 0.258489 (0.064365) | 0.368014 / 0.293841 (0.074173) | 0.027750 / 0.128546 (-0.100796) | 0.008137 / 0.075646 (-0.067509) | 0.263906 / 0.419271 (-0.155366) | 0.045402 / 0.043533 (0.001870) | 0.315414 / 0.255139 (0.060275) | 0.340906 / 0.283200 (0.057707) | 0.023475 / 0.141683 (-0.118208) | 1.443922 / 1.452155 (-0.008233) | 1.550332 / 1.492716 (0.057616) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211914 / 0.018006 (0.193908) | 0.423577 / 0.000490 (0.423088) | 0.003436 / 0.000200 (0.003236) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024675 / 0.037411 (-0.012737) | 0.072550 / 0.014526 (0.058024) | 0.084533 / 0.176557 (-0.092024) | 0.146106 / 0.737135 (-0.591029) | 0.085523 / 0.296338 (-0.210816) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.403498 / 0.215209 (0.188289) | 4.019000 / 2.077655 (1.941345) | 1.984821 / 1.504120 (0.480701) | 1.805071 / 1.541195 (0.263876) | 1.860906 / 1.468490 (0.392416) | 0.499570 / 4.584777 (-4.085207) | 3.088424 / 3.745712 (-0.657288) | 2.833693 / 5.269862 (-2.436169) | 1.869731 / 4.565676 (-2.695945) | 0.057606 / 0.424275 (-0.366669) | 0.006960 / 0.007607 (-0.000647) | 0.476085 / 0.226044 (0.250040) | 4.774063 / 2.268929 (2.505134) | 2.458079 / 55.444624 (-52.986545) | 2.106075 / 6.876477 (-4.770402) | 2.248373 / 2.142072 (0.106301) | 0.589767 / 4.805227 (-4.215460) | 0.124382 / 6.500664 (-6.376282) | 0.060705 / 0.075469 (-0.014764) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.287031 / 1.841788 (-0.554756) | 17.662455 / 8.074308 (9.588147) | 14.288812 / 10.191392 (4.097420) | 0.156168 / 0.680424 (-0.524256) | 0.016795 / 0.534201 (-0.517406) | 0.333726 / 0.579283 (-0.245557) | 0.362327 / 0.434364 (-0.072037) | 0.387773 / 0.540337 (-0.152564) | 0.547232 / 1.386936 (-0.839704) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006494 / 0.011353 (-0.004859) | 0.003762 / 0.011008 (-0.007247) | 0.062373 / 0.038508 (0.023864) | 0.066357 / 0.023109 (0.043247) | 0.448687 / 0.275898 (0.172789) | 0.482445 / 0.323480 (0.158965) | 0.004990 / 0.007986 (-0.002996) | 0.002945 / 0.004328 (-0.001384) | 0.062444 / 0.004250 (0.058194) | 0.051381 / 0.037052 (0.014329) | 0.449310 / 0.258489 (0.190821) | 0.483188 / 0.293841 (0.189347) | 0.029078 / 0.128546 (-0.099468) | 0.008146 / 0.075646 (-0.067501) | 0.067369 / 0.419271 (-0.351903) | 0.041732 / 0.043533 (-0.001801) | 0.451675 / 0.255139 (0.196536) | 0.470445 / 0.283200 (0.187246) | 0.021053 / 0.141683 (-0.120630) | 1.483627 / 1.452155 (0.031472) | 1.541594 / 1.492716 (0.048878) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210247 / 0.018006 (0.192240) | 0.424663 / 0.000490 (0.424173) | 0.005394 / 0.000200 (0.005194) | 0.000076 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026894 / 0.037411 (-0.010517) | 0.081324 / 0.014526 (0.066798) | 0.091362 / 0.176557 (-0.085195) | 0.145602 / 0.737135 (-0.591533) | 0.091896 / 0.296338 (-0.204443) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469662 / 0.215209 (0.254453) | 4.689495 / 2.077655 (2.611840) | 2.596462 / 1.504120 (1.092342) | 2.422584 / 1.541195 (0.881389) | 2.476710 / 1.468490 (1.008220) | 0.507049 / 4.584777 (-4.077728) | 3.185519 / 3.745712 (-0.560193) | 2.879842 / 5.269862 (-2.390019) | 1.882643 / 4.565676 (-2.683034) | 0.058046 / 0.424275 (-0.366229) | 0.006797 / 0.007607 (-0.000811) | 0.545245 / 0.226044 (0.319201) | 5.449248 / 2.268929 (3.180319) | 3.057341 / 55.444624 (-52.387283) | 2.728385 / 6.876477 (-4.148092) | 2.898945 / 2.142072 (0.756873) | 0.600035 / 4.805227 (-4.205192) | 0.126337 / 6.500664 (-6.374327) | 0.061333 / 0.075469 (-0.014136) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.332966 / 1.841788 (-0.508821) | 17.960805 / 8.074308 (9.886497) | 14.978838 / 10.191392 (4.787446) | 0.148852 / 0.680424 (-0.531572) | 0.018307 / 0.534201 (-0.515894) | 0.335234 / 0.579283 (-0.244050) | 0.389659 / 0.434364 (-0.044704) | 0.393259 / 0.540337 (-0.147078) | 0.549237 / 1.386936 (-0.837699) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008808 / 0.011353 (-0.002545) | 0.005001 / 0.011008 (-0.006008) | 0.110022 / 0.038508 (0.071514) | 0.078015 / 0.023109 (0.054906) | 0.384724 / 0.275898 (0.108826) | 0.441354 / 0.323480 (0.117874) | 0.005116 / 0.007986 (-0.002870) | 0.004308 / 0.004328 (-0.000020) | 0.081679 / 0.004250 (0.077429) | 0.061386 / 0.037052 (0.024333) | 0.398149 / 0.258489 (0.139660) | 0.464859 / 0.293841 (0.171018) | 0.047443 / 0.128546 (-0.081104) | 0.014693 / 0.075646 (-0.060954) | 0.365438 / 0.419271 (-0.053833) | 0.081689 / 0.043533 (0.038156) | 0.400458 / 0.255139 (0.145319) | 0.449958 / 0.283200 (0.166758) | 0.038266 / 0.141683 (-0.103417) | 1.795043 / 1.452155 (0.342888) | 1.908819 / 1.492716 (0.416102) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.297911 / 0.018006 (0.279905) | 0.601640 / 0.000490 (0.601150) | 0.015406 / 0.000200 (0.015206) | 0.000163 / 0.000054 (0.000108) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034520 / 0.037411 (-0.002891) | 0.092657 / 0.014526 (0.078131) | 0.113992 / 0.176557 (-0.062564) | 0.189075 / 0.737135 (-0.548061) | 0.106602 / 0.296338 (-0.189736) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.585838 / 0.215209 (0.370629) | 5.719281 / 2.077655 (3.641627) | 2.525914 / 1.504120 (1.021794) | 2.231908 / 1.541195 (0.690713) | 2.215272 / 1.468490 (0.746782) | 0.814425 / 4.584777 (-3.770352) | 5.243406 / 3.745712 (1.497694) | 4.476642 / 5.269862 (-0.793220) | 2.929438 / 4.565676 (-1.636239) | 0.092070 / 0.424275 (-0.332205) | 0.009358 / 0.007607 (0.001751) | 0.713975 / 0.226044 (0.487931) | 6.948846 / 2.268929 (4.679918) | 3.361125 / 55.444624 (-52.083500) | 2.575224 / 6.876477 (-4.301253) | 2.783082 / 2.142072 (0.641009) | 1.016205 / 4.805227 (-3.789022) | 0.202578 / 6.500664 (-6.298086) | 0.076696 / 0.075469 (0.001227) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.650889 / 1.841788 (-0.190898) | 23.358273 / 8.074308 (15.283965) | 19.882450 / 10.191392 (9.691058) | 0.228971 / 0.680424 (-0.451453) | 0.027736 / 0.534201 (-0.506465) | 0.472405 / 0.579283 (-0.106878) | 0.581799 / 0.434364 (0.147435) | 0.533000 / 0.540337 (-0.007338) | 0.815588 / 1.386936 (-0.571348) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009151 / 0.011353 (-0.002202) | 0.005074 / 0.011008 (-0.005934) | 0.078709 / 0.038508 (0.040201) | 0.077696 / 0.023109 (0.054586) | 0.522356 / 0.275898 (0.246458) | 0.562345 / 0.323480 (0.238865) | 0.006411 / 0.007986 (-0.001575) | 0.004379 / 0.004328 (0.000051) | 0.082402 / 0.004250 (0.078151) | 0.064223 / 0.037052 (0.027170) | 0.518184 / 0.258489 (0.259695) | 0.566221 / 0.293841 (0.272380) | 0.046796 / 0.128546 (-0.081750) | 0.013987 / 0.075646 (-0.061659) | 0.094925 / 0.419271 (-0.324346) | 0.058810 / 0.043533 (0.015277) | 0.520252 / 0.255139 (0.265113) | 0.566403 / 0.283200 (0.283203) | 0.034720 / 0.141683 (-0.106963) | 1.796809 / 1.452155 (0.344654) | 1.913787 / 1.492716 (0.421070) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.317449 / 0.018006 (0.299443) | 0.620154 / 0.000490 (0.619664) | 0.007066 / 0.000200 (0.006866) | 0.000126 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035252 / 0.037411 (-0.002160) | 0.111648 / 0.014526 (0.097122) | 0.120692 / 0.176557 (-0.055864) | 0.193202 / 0.737135 (-0.543933) | 0.127905 / 0.296338 (-0.168434) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.661012 / 0.215209 (0.445803) | 6.626680 / 2.077655 (4.549026) | 3.243065 / 1.504120 (1.738945) | 2.904053 / 1.541195 (1.362858) | 2.880516 / 1.468490 (1.412026) | 0.875650 / 4.584777 (-3.709127) | 5.381993 / 3.745712 (1.636281) | 4.743997 / 5.269862 (-0.525864) | 3.020736 / 4.565676 (-1.544940) | 0.106573 / 0.424275 (-0.317702) | 0.011151 / 0.007607 (0.003544) | 0.821990 / 0.226044 (0.595946) | 8.225383 / 2.268929 (5.956454) | 3.963232 / 55.444624 (-51.481392) | 3.288916 / 6.876477 (-3.587561) | 3.579435 / 2.142072 (1.437363) | 1.043379 / 4.805227 (-3.761848) | 0.207508 / 6.500664 (-6.293156) | 0.085109 / 0.075469 (0.009640) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.723798 / 1.841788 (-0.117990) | 24.709848 / 8.074308 (16.635540) | 22.484674 / 10.191392 (12.293282) | 0.260357 / 0.680424 (-0.420067) | 0.033539 / 0.534201 (-0.500662) | 0.487814 / 0.579283 (-0.091469) | 0.610171 / 0.434364 (0.175807) | 0.585012 / 0.540337 (0.044674) | 0.803764 / 1.386936 (-0.583172) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006661 / 0.011353 (-0.004692) | 0.004022 / 0.011008 (-0.006987) | 0.084269 / 0.038508 (0.045760) | 0.070707 / 0.023109 (0.047598) | 0.315035 / 0.275898 (0.039137) | 0.339830 / 0.323480 (0.016350) | 0.003994 / 0.007986 (-0.003991) | 0.004129 / 0.004328 (-0.000199) | 0.065383 / 0.004250 (0.061133) | 0.055493 / 0.037052 (0.018441) | 0.320521 / 0.258489 (0.062032) | 0.354301 / 0.293841 (0.060460) | 0.031177 / 0.128546 (-0.097370) | 0.008724 / 0.075646 (-0.066922) | 0.288298 / 0.419271 (-0.130974) | 0.052418 / 0.043533 (0.008885) | 0.319122 / 0.255139 (0.063983) | 0.335859 / 0.283200 (0.052659) | 0.026260 / 0.141683 (-0.115423) | 1.450039 / 1.452155 (-0.002115) | 1.545172 / 1.492716 (0.052455) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.234232 / 0.018006 (0.216226) | 0.454983 / 0.000490 (0.454493) | 0.007590 / 0.000200 (0.007390) | 0.000550 / 0.000054 (0.000495) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028714 / 0.037411 (-0.008698) | 0.083686 / 0.014526 (0.069160) | 0.162986 / 0.176557 (-0.013570) | 0.167574 / 0.737135 (-0.569561) | 0.273158 / 0.296338 (-0.023180) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.388275 / 0.215209 (0.173066) | 3.862034 / 2.077655 (1.784379) | 1.843561 / 1.504120 (0.339441) | 1.675224 / 1.541195 (0.134029) | 1.730394 / 1.468490 (0.261904) | 0.495259 / 4.584777 (-4.089518) | 3.627155 / 3.745712 (-0.118557) | 3.290590 / 5.269862 (-1.979272) | 2.032432 / 4.565676 (-2.533245) | 0.058212 / 0.424275 (-0.366063) | 0.007815 / 0.007607 (0.000208) | 0.460625 / 0.226044 (0.234580) | 4.616845 / 2.268929 (2.347916) | 2.339280 / 55.444624 (-53.105344) | 1.957216 / 6.876477 (-4.919261) | 2.129511 / 2.142072 (-0.012562) | 0.591782 / 4.805227 (-4.213446) | 0.136391 / 6.500664 (-6.364273) | 0.059627 / 0.075469 (-0.015842) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278998 / 1.841788 (-0.562789) | 18.485496 / 8.074308 (10.411188) | 14.161273 / 10.191392 (3.969881) | 0.164346 / 0.680424 (-0.516078) | 0.018144 / 0.534201 (-0.516057) | 0.391601 / 0.579283 (-0.187682) | 0.424391 / 0.434364 (-0.009973) | 0.458209 / 0.540337 (-0.082129) | 0.645124 / 1.386936 (-0.741812) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006799 / 0.011353 (-0.004554) | 0.004023 / 0.011008 (-0.006985) | 0.065206 / 0.038508 (0.026698) | 0.074386 / 0.023109 (0.051277) | 0.437399 / 0.275898 (0.161501) | 0.467382 / 0.323480 (0.143903) | 0.005467 / 0.007986 (-0.002519) | 0.003324 / 0.004328 (-0.001005) | 0.064289 / 0.004250 (0.060039) | 0.057257 / 0.037052 (0.020205) | 0.440035 / 0.258489 (0.181546) | 0.477138 / 0.293841 (0.183298) | 0.032171 / 0.128546 (-0.096375) | 0.008400 / 0.075646 (-0.067247) | 0.070877 / 0.419271 (-0.348395) | 0.048180 / 0.043533 (0.004648) | 0.441274 / 0.255139 (0.186135) | 0.461386 / 0.283200 (0.178187) | 0.022576 / 0.141683 (-0.119106) | 1.520914 / 1.452155 (0.068759) | 1.575593 / 1.492716 (0.082877) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221551 / 0.018006 (0.203545) | 0.447213 / 0.000490 (0.446723) | 0.004435 / 0.000200 (0.004235) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032123 / 0.037411 (-0.005288) | 0.091809 / 0.014526 (0.077283) | 0.103938 / 0.176557 (-0.072618) | 0.156878 / 0.737135 (-0.580258) | 0.105071 / 0.296338 (-0.191268) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.430389 / 0.215209 (0.215180) | 4.293496 / 2.077655 (2.215841) | 2.292801 / 1.504120 (0.788681) | 2.135320 / 1.541195 (0.594126) | 2.195720 / 1.468490 (0.727229) | 0.493277 / 4.584777 (-4.091500) | 3.685617 / 3.745712 (-0.060096) | 3.278897 / 5.269862 (-1.990965) | 2.036939 / 4.565676 (-2.528737) | 0.058766 / 0.424275 (-0.365509) | 0.007783 / 0.007607 (0.000176) | 0.511165 / 0.226044 (0.285120) | 5.126757 / 2.268929 (2.857829) | 2.756690 / 55.444624 (-52.687935) | 2.421745 / 6.876477 (-4.454732) | 2.597249 / 2.142072 (0.455177) | 0.647206 / 4.805227 (-4.158021) | 0.143392 / 6.500664 (-6.357273) | 0.060110 / 0.075469 (-0.015359) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.340289 / 1.841788 (-0.501499) | 19.057620 / 8.074308 (10.983312) | 14.832892 / 10.191392 (4.641500) | 0.167730 / 0.680424 (-0.512694) | 0.020178 / 0.534201 (-0.514023) | 0.394060 / 0.579283 (-0.185223) | 0.433976 / 0.434364 (-0.000388) | 0.474417 / 0.540337 (-0.065921) | 0.640653 / 1.386936 (-0.746283) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007661 / 0.011353 (-0.003692) | 0.004541 / 0.011008 (-0.006467) | 0.100547 / 0.038508 (0.062039) | 0.084257 / 0.023109 (0.061148) | 0.377627 / 0.275898 (0.101729) | 0.433764 / 0.323480 (0.110284) | 0.005995 / 0.007986 (-0.001990) | 0.003810 / 0.004328 (-0.000518) | 0.076409 / 0.004250 (0.072158) | 0.063411 / 0.037052 (0.026359) | 0.382504 / 0.258489 (0.124015) | 0.449721 / 0.293841 (0.155880) | 0.036499 / 0.128546 (-0.092047) | 0.009942 / 0.075646 (-0.065705) | 0.343839 / 0.419271 (-0.075433) | 0.062147 / 0.043533 (0.018614) | 0.383244 / 0.255139 (0.128105) | 0.415606 / 0.283200 (0.132406) | 0.027475 / 0.141683 (-0.114207) | 1.740413 / 1.452155 (0.288258) | 1.862210 / 1.492716 (0.369493) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260064 / 0.018006 (0.242058) | 0.499001 / 0.000490 (0.498511) | 0.015811 / 0.000200 (0.015611) | 0.000119 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033599 / 0.037411 (-0.003812) | 0.099354 / 0.014526 (0.084828) | 0.114693 / 0.176557 (-0.061864) | 0.180231 / 0.737135 (-0.556904) | 0.114715 / 0.296338 (-0.181623) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459884 / 0.215209 (0.244675) | 4.580806 / 2.077655 (2.503151) | 2.270770 / 1.504120 (0.766650) | 2.077127 / 1.541195 (0.535932) | 2.167175 / 1.468490 (0.698685) | 0.570593 / 4.584777 (-4.014184) | 4.120926 / 3.745712 (0.375214) | 3.817595 / 5.269862 (-1.452267) | 2.404782 / 4.565676 (-2.160894) | 0.067972 / 0.424275 (-0.356304) | 0.009378 / 0.007607 (0.001771) | 0.549642 / 0.226044 (0.323597) | 5.490369 / 2.268929 (3.221440) | 2.905264 / 55.444624 (-52.539361) | 2.452935 / 6.876477 (-4.423542) | 2.700760 / 2.142072 (0.558688) | 0.700407 / 4.805227 (-4.104820) | 0.159349 / 6.500664 (-6.341315) | 0.074605 / 0.075469 (-0.000864) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.517803 / 1.841788 (-0.323985) | 22.343700 / 8.074308 (14.269392) | 16.411639 / 10.191392 (6.220247) | 0.169816 / 0.680424 (-0.510608) | 0.021532 / 0.534201 (-0.512668) | 0.470161 / 0.579283 (-0.109122) | 0.473412 / 0.434364 (0.039048) | 0.539690 / 0.540337 (-0.000647) | 0.774011 / 1.386936 (-0.612925) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007629 / 0.011353 (-0.003724) | 0.004651 / 0.011008 (-0.006357) | 0.075162 / 0.038508 (0.036654) | 0.085365 / 0.023109 (0.062256) | 0.493272 / 0.275898 (0.217374) | 0.535776 / 0.323480 (0.212296) | 0.006323 / 0.007986 (-0.001663) | 0.003785 / 0.004328 (-0.000544) | 0.076161 / 0.004250 (0.071911) | 0.065982 / 0.037052 (0.028929) | 0.513355 / 0.258489 (0.254866) | 0.549219 / 0.293841 (0.255378) | 0.038052 / 0.128546 (-0.090494) | 0.010055 / 0.075646 (-0.065592) | 0.083744 / 0.419271 (-0.335527) | 0.056708 / 0.043533 (0.013175) | 0.496273 / 0.255139 (0.241135) | 0.523709 / 0.283200 (0.240509) | 0.026502 / 0.141683 (-0.115181) | 1.793032 / 1.452155 (0.340877) | 1.870534 / 1.492716 (0.377817) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.252288 / 0.018006 (0.234281) | 0.490380 / 0.000490 (0.489890) | 0.005884 / 0.000200 (0.005684) | 0.000109 / 0.000054 (0.000054) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038238 / 0.037411 (0.000827) | 0.110010 / 0.014526 (0.095485) | 0.125497 / 0.176557 (-0.051059) | 0.188154 / 0.737135 (-0.548981) | 0.126112 / 0.296338 (-0.170227) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.515837 / 0.215209 (0.300628) | 5.135153 / 2.077655 (3.057498) | 2.761740 / 1.504120 (1.257620) | 2.552718 / 1.541195 (1.011523) | 2.636425 / 1.468490 (1.167935) | 0.588442 / 4.584777 (-3.996335) | 4.220833 / 3.745712 (0.475120) | 3.874637 / 5.269862 (-1.395225) | 2.424668 / 4.565676 (-2.141009) | 0.069979 / 0.424275 (-0.354296) | 0.009349 / 0.007607 (0.001742) | 0.608936 / 0.226044 (0.382891) | 6.081209 / 2.268929 (3.812280) | 3.348067 / 55.444624 (-52.096557) | 2.919130 / 6.876477 (-3.957347) | 3.159093 / 2.142072 (1.017020) | 0.704059 / 4.805227 (-4.101169) | 0.158417 / 6.500664 (-6.342247) | 0.071321 / 0.075469 (-0.004148) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.595287 / 1.841788 (-0.246501) | 23.096619 / 8.074308 (15.022311) | 17.258041 / 10.191392 (7.066649) | 0.186197 / 0.680424 (-0.494227) | 0.023633 / 0.534201 (-0.510567) | 0.472181 / 0.579283 (-0.107102) | 0.493817 / 0.434364 (0.059453) | 0.567657 / 0.540337 (0.027320) | 0.793789 / 1.386936 (-0.593147) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007084 / 0.011353 (-0.004268) | 0.004093 / 0.011008 (-0.006915) | 0.086395 / 0.038508 (0.047887) | 0.087734 / 0.023109 (0.064625) | 0.356936 / 0.275898 (0.081038) | 0.386413 / 0.323480 (0.062933) | 0.005531 / 0.007986 (-0.002454) | 0.003462 / 0.004328 (-0.000866) | 0.065503 / 0.004250 (0.061252) | 0.058973 / 0.037052 (0.021920) | 0.354151 / 0.258489 (0.095662) | 0.398812 / 0.293841 (0.104971) | 0.031508 / 0.128546 (-0.097038) | 0.008537 / 0.075646 (-0.067109) | 0.290942 / 0.419271 (-0.128329) | 0.053537 / 0.043533 (0.010004) | 0.352067 / 0.255139 (0.096928) | 0.375142 / 0.283200 (0.091943) | 0.025658 / 0.141683 (-0.116025) | 1.468496 / 1.452155 (0.016341) | 1.556926 / 1.492716 (0.064210) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.238858 / 0.018006 (0.220852) | 0.460018 / 0.000490 (0.459528) | 0.009613 / 0.000200 (0.009414) | 0.000326 / 0.000054 (0.000272) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030333 / 0.037411 (-0.007078) | 0.088431 / 0.014526 (0.073905) | 0.098130 / 0.176557 (-0.078427) | 0.155160 / 0.737135 (-0.581975) | 0.099963 / 0.296338 (-0.196375) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.385769 / 0.215209 (0.170560) | 3.836723 / 2.077655 (1.759069) | 1.861065 / 1.504120 (0.356945) | 1.685159 / 1.541195 (0.143965) | 1.780679 / 1.468490 (0.312189) | 0.491865 / 4.584777 (-4.092912) | 3.581139 / 3.745712 (-0.164573) | 3.366278 / 5.269862 (-1.903584) | 2.093094 / 4.565676 (-2.472583) | 0.058063 / 0.424275 (-0.366212) | 0.007903 / 0.007607 (0.000296) | 0.464866 / 0.226044 (0.238821) | 4.647754 / 2.268929 (2.378825) | 2.316466 / 55.444624 (-53.128158) | 1.984079 / 6.876477 (-4.892398) | 2.235020 / 2.142072 (0.092948) | 0.592591 / 4.805227 (-4.212636) | 0.135586 / 6.500664 (-6.365078) | 0.061434 / 0.075469 (-0.014035) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.282940 / 1.841788 (-0.558848) | 19.635975 / 8.074308 (11.561667) | 14.426135 / 10.191392 (4.234743) | 0.166732 / 0.680424 (-0.513692) | 0.018438 / 0.534201 (-0.515763) | 0.393173 / 0.579283 (-0.186110) | 0.417291 / 0.434364 (-0.017073) | 0.459188 / 0.540337 (-0.081149) | 0.632568 / 1.386936 (-0.754368) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007166 / 0.011353 (-0.004187) | 0.004254 / 0.011008 (-0.006754) | 0.064667 / 0.038508 (0.026159) | 0.085142 / 0.023109 (0.062033) | 0.410081 / 0.275898 (0.134183) | 0.445803 / 0.323480 (0.122323) | 0.005600 / 0.007986 (-0.002385) | 0.003520 / 0.004328 (-0.000809) | 0.064148 / 0.004250 (0.059897) | 0.059869 / 0.037052 (0.022817) | 0.407439 / 0.258489 (0.148950) | 0.451169 / 0.293841 (0.157329) | 0.032619 / 0.128546 (-0.095927) | 0.008706 / 0.075646 (-0.066940) | 0.071230 / 0.419271 (-0.348041) | 0.048499 / 0.043533 (0.004966) | 0.416401 / 0.255139 (0.161262) | 0.430737 / 0.283200 (0.147537) | 0.022511 / 0.141683 (-0.119172) | 1.517296 / 1.452155 (0.065141) | 1.581704 / 1.492716 (0.088988) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220738 / 0.018006 (0.202732) | 0.454026 / 0.000490 (0.453536) | 0.004695 / 0.000200 (0.004495) | 0.000087 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033202 / 0.037411 (-0.004209) | 0.097506 / 0.014526 (0.082980) | 0.106661 / 0.176557 (-0.069896) | 0.160554 / 0.737135 (-0.576581) | 0.109203 / 0.296338 (-0.187135) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432013 / 0.215209 (0.216804) | 4.310399 / 2.077655 (2.232744) | 2.296529 / 1.504120 (0.792409) | 2.139929 / 1.541195 (0.598734) | 2.227432 / 1.468490 (0.758942) | 0.493697 / 4.584777 (-4.091080) | 3.639877 / 3.745712 (-0.105835) | 3.323165 / 5.269862 (-1.946697) | 2.084527 / 4.565676 (-2.481150) | 0.058812 / 0.424275 (-0.365463) | 0.007813 / 0.007607 (0.000206) | 0.512366 / 0.226044 (0.286321) | 5.119660 / 2.268929 (2.850732) | 2.783819 / 55.444624 (-52.660806) | 2.490669 / 6.876477 (-4.385808) | 2.696653 / 2.142072 (0.554581) | 0.627161 / 4.805227 (-4.178066) | 0.137032 / 6.500664 (-6.363632) | 0.064040 / 0.075469 (-0.011429) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.369578 / 1.841788 (-0.472210) | 20.421182 / 8.074308 (12.346873) | 15.719347 / 10.191392 (5.527955) | 0.166150 / 0.680424 (-0.514274) | 0.020262 / 0.534201 (-0.513939) | 0.395645 / 0.579283 (-0.183638) | 0.430363 / 0.434364 (-0.004001) | 0.477843 / 0.540337 (-0.062494) | 0.638501 / 1.386936 (-0.748435) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006141 / 0.011353 (-0.005211) | 0.003683 / 0.011008 (-0.007325) | 0.081127 / 0.038508 (0.042618) | 0.064285 / 0.023109 (0.041176) | 0.323038 / 0.275898 (0.047140) | 0.347280 / 0.323480 (0.023800) | 0.003518 / 0.007986 (-0.004467) | 0.002958 / 0.004328 (-0.001370) | 0.063093 / 0.004250 (0.058843) | 0.050682 / 0.037052 (0.013629) | 0.321222 / 0.258489 (0.062733) | 0.359266 / 0.293841 (0.065425) | 0.027515 / 0.128546 (-0.101032) | 0.007964 / 0.075646 (-0.067682) | 0.261305 / 0.419271 (-0.157966) | 0.044897 / 0.043533 (0.001365) | 0.320684 / 0.255139 (0.065545) | 0.335722 / 0.283200 (0.052522) | 0.023378 / 0.141683 (-0.118305) | 1.418211 / 1.452155 (-0.033943) | 1.523728 / 1.492716 (0.031011) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222316 / 0.018006 (0.204310) | 0.426943 / 0.000490 (0.426454) | 0.008785 / 0.000200 (0.008585) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024716 / 0.037411 (-0.012695) | 0.075341 / 0.014526 (0.060816) | 0.089532 / 0.176557 (-0.087024) | 0.147638 / 0.737135 (-0.589498) | 0.085697 / 0.296338 (-0.210641) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396395 / 0.215209 (0.181186) | 3.947280 / 2.077655 (1.869625) | 1.894762 / 1.504120 (0.390642) | 1.712094 / 1.541195 (0.170899) | 1.779049 / 1.468490 (0.310559) | 0.509206 / 4.584777 (-4.075571) | 3.073951 / 3.745712 (-0.671761) | 2.886826 / 5.269862 (-2.383035) | 1.894444 / 4.565676 (-2.671232) | 0.059519 / 0.424275 (-0.364756) | 0.006951 / 0.007607 (-0.000656) | 0.468213 / 0.226044 (0.242169) | 4.667134 / 2.268929 (2.398206) | 2.342516 / 55.444624 (-53.102108) | 1.992047 / 6.876477 (-4.884430) | 2.142059 / 2.142072 (-0.000014) | 0.600507 / 4.805227 (-4.204720) | 0.128982 / 6.500664 (-6.371682) | 0.062100 / 0.075469 (-0.013369) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.234500 / 1.841788 (-0.607288) | 17.951646 / 8.074308 (9.877338) | 13.862763 / 10.191392 (3.671371) | 0.143133 / 0.680424 (-0.537291) | 0.016643 / 0.534201 (-0.517558) | 0.333174 / 0.579283 (-0.246109) | 0.366956 / 0.434364 (-0.067408) | 0.384569 / 0.540337 (-0.155769) | 0.546830 / 1.386936 (-0.840106) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006146 / 0.011353 (-0.005207) | 0.003725 / 0.011008 (-0.007283) | 0.062099 / 0.038508 (0.023591) | 0.064117 / 0.023109 (0.041008) | 0.456100 / 0.275898 (0.180202) | 0.490794 / 0.323480 (0.167314) | 0.005652 / 0.007986 (-0.002334) | 0.002897 / 0.004328 (-0.001432) | 0.061909 / 0.004250 (0.057659) | 0.050634 / 0.037052 (0.013582) | 0.454422 / 0.258489 (0.195933) | 0.493208 / 0.293841 (0.199367) | 0.028822 / 0.128546 (-0.099724) | 0.008115 / 0.075646 (-0.067531) | 0.067214 / 0.419271 (-0.352058) | 0.041529 / 0.043533 (-0.002004) | 0.458016 / 0.255139 (0.202877) | 0.476059 / 0.283200 (0.192859) | 0.019926 / 0.141683 (-0.121757) | 1.465345 / 1.452155 (0.013190) | 1.533518 / 1.492716 (0.040802) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.218830 / 0.018006 (0.200823) | 0.418869 / 0.000490 (0.418380) | 0.005154 / 0.000200 (0.004954) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027648 / 0.037411 (-0.009763) | 0.083842 / 0.014526 (0.069316) | 0.092300 / 0.176557 (-0.084257) | 0.146098 / 0.737135 (-0.591037) | 0.093441 / 0.296338 (-0.202898) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.464426 / 0.215209 (0.249217) | 4.632705 / 2.077655 (2.555051) | 2.642091 / 1.504120 (1.137971) | 2.461768 / 1.541195 (0.920573) | 2.535554 / 1.468490 (1.067064) | 0.507506 / 4.584777 (-4.077271) | 3.095485 / 3.745712 (-0.650227) | 2.884261 / 5.269862 (-2.385601) | 1.908943 / 4.565676 (-2.656734) | 0.058622 / 0.424275 (-0.365653) | 0.006892 / 0.007607 (-0.000715) | 0.536045 / 0.226044 (0.310001) | 5.377448 / 2.268929 (3.108519) | 3.076023 / 55.444624 (-52.368602) | 2.745586 / 6.876477 (-4.130890) | 2.939582 / 2.142072 (0.797510) | 0.595639 / 4.805227 (-4.209589) | 0.125086 / 6.500664 (-6.375578) | 0.061075 / 0.075469 (-0.014394) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.342820 / 1.841788 (-0.498968) | 18.326240 / 8.074308 (10.251932) | 15.007094 / 10.191392 (4.815702) | 0.133037 / 0.680424 (-0.547387) | 0.018702 / 0.534201 (-0.515499) | 0.330245 / 0.579283 (-0.249038) | 0.381494 / 0.434364 (-0.052870) | 0.393705 / 0.540337 (-0.146633) | 0.533676 / 1.386936 (-0.853260) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007644 / 0.011353 (-0.003709) | 0.004759 / 0.011008 (-0.006249) | 0.100569 / 0.038508 (0.062061) | 0.089645 / 0.023109 (0.066536) | 0.376679 / 0.275898 (0.100781) | 0.413214 / 0.323480 (0.089735) | 0.006087 / 0.007986 (-0.001899) | 0.003832 / 0.004328 (-0.000496) | 0.075892 / 0.004250 (0.071641) | 0.064635 / 0.037052 (0.027582) | 0.376874 / 0.258489 (0.118385) | 0.436756 / 0.293841 (0.142915) | 0.036372 / 0.128546 (-0.092174) | 0.010047 / 0.075646 (-0.065599) | 0.345073 / 0.419271 (-0.074198) | 0.062092 / 0.043533 (0.018559) | 0.380503 / 0.255139 (0.125364) | 0.414800 / 0.283200 (0.131600) | 0.028274 / 0.141683 (-0.113409) | 1.732463 / 1.452155 (0.280308) | 1.859049 / 1.492716 (0.366333) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267129 / 0.018006 (0.249123) | 0.509109 / 0.000490 (0.508619) | 0.012329 / 0.000200 (0.012130) | 0.000432 / 0.000054 (0.000377) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033773 / 0.037411 (-0.003638) | 0.102800 / 0.014526 (0.088274) | 0.114256 / 0.176557 (-0.062300) | 0.182048 / 0.737135 (-0.555087) | 0.118225 / 0.296338 (-0.178113) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457553 / 0.215209 (0.242344) | 4.588212 / 2.077655 (2.510557) | 2.184138 / 1.504120 (0.680018) | 2.003570 / 1.541195 (0.462375) | 2.093217 / 1.468490 (0.624727) | 0.585679 / 4.584777 (-3.999098) | 4.175319 / 3.745712 (0.429607) | 3.914168 / 5.269862 (-1.355693) | 2.452992 / 4.565676 (-2.112684) | 0.068363 / 0.424275 (-0.355912) | 0.009314 / 0.007607 (0.001707) | 0.543640 / 0.226044 (0.317595) | 5.440853 / 2.268929 (3.171925) | 2.782415 / 55.444624 (-52.662210) | 2.332359 / 6.876477 (-4.544118) | 2.628520 / 2.142072 (0.486448) | 0.696838 / 4.805227 (-4.108389) | 0.160653 / 6.500664 (-6.340012) | 0.075599 / 0.075469 (0.000130) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.545305 / 1.841788 (-0.296483) | 23.073174 / 8.074308 (14.998866) | 16.974977 / 10.191392 (6.783585) | 0.183719 / 0.680424 (-0.496705) | 0.021633 / 0.534201 (-0.512568) | 0.471202 / 0.579283 (-0.108081) | 0.479385 / 0.434364 (0.045021) | 0.550872 / 0.540337 (0.010535) | 0.766825 / 1.386936 (-0.620111) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007918 / 0.011353 (-0.003435) | 0.004793 / 0.011008 (-0.006215) | 0.077273 / 0.038508 (0.038765) | 0.092079 / 0.023109 (0.068969) | 0.483269 / 0.275898 (0.207371) | 0.524919 / 0.323480 (0.201439) | 0.006273 / 0.007986 (-0.001713) | 0.004018 / 0.004328 (-0.000310) | 0.077188 / 0.004250 (0.072937) | 0.067891 / 0.037052 (0.030839) | 0.478531 / 0.258489 (0.220042) | 0.526956 / 0.293841 (0.233115) | 0.038309 / 0.128546 (-0.090237) | 0.010133 / 0.075646 (-0.065513) | 0.083892 / 0.419271 (-0.335379) | 0.057369 / 0.043533 (0.013836) | 0.509427 / 0.255139 (0.254288) | 0.506574 / 0.283200 (0.223374) | 0.027987 / 0.141683 (-0.113696) | 1.897469 / 1.452155 (0.445314) | 1.893102 / 1.492716 (0.400385) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.243003 / 0.018006 (0.224997) | 0.500267 / 0.000490 (0.499777) | 0.007442 / 0.000200 (0.007242) | 0.000110 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.039266 / 0.037411 (0.001855) | 0.114438 / 0.014526 (0.099912) | 0.124528 / 0.176557 (-0.052029) | 0.189399 / 0.737135 (-0.547736) | 0.126703 / 0.296338 (-0.169635) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.518139 / 0.215209 (0.302930) | 5.162058 / 2.077655 (3.084403) | 2.835111 / 1.504120 (1.330991) | 2.640919 / 1.541195 (1.099724) | 2.736800 / 1.468490 (1.268310) | 0.582813 / 4.584777 (-4.001964) | 4.246269 / 3.745712 (0.500557) | 3.891161 / 5.269862 (-1.378701) | 2.445392 / 4.565676 (-2.120285) | 0.068943 / 0.424275 (-0.355332) | 0.009248 / 0.007607 (0.001641) | 0.604859 / 0.226044 (0.378815) | 6.030660 / 2.268929 (3.761731) | 3.409778 / 55.444624 (-52.034846) | 2.990488 / 6.876477 (-3.885988) | 3.281317 / 2.142072 (1.139245) | 0.697705 / 4.805227 (-4.107523) | 0.159502 / 6.500664 (-6.341162) | 0.072471 / 0.075469 (-0.002999) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.625428 / 1.841788 (-0.216360) | 23.602509 / 8.074308 (15.528201) | 18.091474 / 10.191392 (7.900082) | 0.172816 / 0.680424 (-0.507608) | 0.023708 / 0.534201 (-0.510493) | 0.473768 / 0.579283 (-0.105515) | 0.493713 / 0.434364 (0.059349) | 0.566326 / 0.540337 (0.025989) | 0.788670 / 1.386936 (-0.598266) |\n\n</details>\n</details>\n\n\n",
"> Thanks. Any comment on my comment below?\r\n> \r\n> >Maybe we should update the docstring of get_data_patterns accordingly? Currently it only gives examples of outputs with ** not in a single path segment (i.e. not with a / as prefix or suffix).\r\n\r\nYea right we need to update it indeed, the outputs are the ones from older versions of fsspec, and from older patterns that we don't use anymore.\r\n\r\nIn general in docstrings I also think we should encourage users to use `**/*` instead of `**` (which has a behavior that is unique to fsspec)",
"Also just noticed that `KEYWORDS_IN_DIR_NAME_BASE_PATTERNS` seems to include `KEYWORDS_IN_FILENAME_BASE_PATTERNS`. I guess we can try to remove the filename one in another PR to remove this redundancy \r\n\r\n(noticed this by checking that the data pattern is the same for both the dir name and filename examples in the get_data_patterns docstring)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006922 / 0.011353 (-0.004431) | 0.004459 / 0.011008 (-0.006549) | 0.084742 / 0.038508 (0.046234) | 0.089002 / 0.023109 (0.065893) | 0.310886 / 0.275898 (0.034988) | 0.340518 / 0.323480 (0.017038) | 0.007011 / 0.007986 (-0.000975) | 0.004566 / 0.004328 (0.000237) | 0.067260 / 0.004250 (0.063009) | 0.066349 / 0.037052 (0.029297) | 0.324029 / 0.258489 (0.065540) | 0.373785 / 0.293841 (0.079944) | 0.031780 / 0.128546 (-0.096766) | 0.009208 / 0.075646 (-0.066438) | 0.288871 / 0.419271 (-0.130401) | 0.054548 / 0.043533 (0.011015) | 0.313344 / 0.255139 (0.058205) | 0.336430 / 0.283200 (0.053231) | 0.029037 / 0.141683 (-0.112646) | 1.483797 / 1.452155 (0.031642) | 1.581884 / 1.492716 (0.089167) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.370520 / 0.018006 (0.352514) | 0.796720 / 0.000490 (0.796230) | 0.009329 / 0.000200 (0.009129) | 0.000109 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033002 / 0.037411 (-0.004410) | 0.083442 / 0.014526 (0.068916) | 0.106468 / 0.176557 (-0.070088) | 0.165315 / 0.737135 (-0.571820) | 0.103048 / 0.296338 (-0.193291) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386800 / 0.215209 (0.171591) | 3.843312 / 2.077655 (1.765658) | 1.848953 / 1.504120 (0.344834) | 1.679508 / 1.541195 (0.138313) | 1.733578 / 1.468490 (0.265088) | 0.488455 / 4.584777 (-4.096322) | 3.613594 / 3.745712 (-0.132118) | 3.533334 / 5.269862 (-1.736528) | 2.176216 / 4.565676 (-2.389460) | 0.056915 / 0.424275 (-0.367360) | 0.007349 / 0.007607 (-0.000258) | 0.465132 / 0.226044 (0.239088) | 4.638479 / 2.268929 (2.369550) | 2.354741 / 55.444624 (-53.089883) | 1.991777 / 6.876477 (-4.884700) | 2.249823 / 2.142072 (0.107751) | 0.582748 / 4.805227 (-4.222480) | 0.133829 / 6.500664 (-6.366835) | 0.060949 / 0.075469 (-0.014520) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.252027 / 1.841788 (-0.589760) | 20.660234 / 8.074308 (12.585926) | 14.328496 / 10.191392 (4.137104) | 0.164872 / 0.680424 (-0.515552) | 0.018867 / 0.534201 (-0.515334) | 0.392850 / 0.579283 (-0.186433) | 0.425684 / 0.434364 (-0.008679) | 0.461776 / 0.540337 (-0.078562) | 0.663688 / 1.386936 (-0.723248) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007010 / 0.011353 (-0.004343) | 0.004791 / 0.011008 (-0.006217) | 0.064738 / 0.038508 (0.026230) | 0.088648 / 0.023109 (0.065539) | 0.418106 / 0.275898 (0.142208) | 0.446767 / 0.323480 (0.123287) | 0.006761 / 0.007986 (-0.001224) | 0.004649 / 0.004328 (0.000320) | 0.066345 / 0.004250 (0.062094) | 0.068326 / 0.037052 (0.031274) | 0.423426 / 0.258489 (0.164937) | 0.463160 / 0.293841 (0.169319) | 0.032689 / 0.128546 (-0.095858) | 0.009299 / 0.075646 (-0.066347) | 0.071321 / 0.419271 (-0.347951) | 0.048752 / 0.043533 (0.005219) | 0.418932 / 0.255139 (0.163793) | 0.440673 / 0.283200 (0.157473) | 0.027898 / 0.141683 (-0.113785) | 1.531860 / 1.452155 (0.079705) | 1.620456 / 1.492716 (0.127739) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.354917 / 0.018006 (0.336911) | 0.792432 / 0.000490 (0.791943) | 0.006626 / 0.000200 (0.006426) | 0.000124 / 0.000054 (0.000070) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036190 / 0.037411 (-0.001222) | 0.093052 / 0.014526 (0.078526) | 0.111927 / 0.176557 (-0.064629) | 0.165571 / 0.737135 (-0.571564) | 0.112159 / 0.296338 (-0.184180) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437798 / 0.215209 (0.222589) | 4.367166 / 2.077655 (2.289511) | 2.343292 / 1.504120 (0.839172) | 2.169298 / 1.541195 (0.628103) | 2.224471 / 1.468490 (0.755981) | 0.487317 / 4.584777 (-4.097460) | 3.627825 / 3.745712 (-0.117887) | 3.500914 / 5.269862 (-1.768947) | 2.175862 / 4.565676 (-2.389815) | 0.057975 / 0.424275 (-0.366300) | 0.007509 / 0.007607 (-0.000098) | 0.517389 / 0.226044 (0.291345) | 5.169694 / 2.268929 (2.900766) | 2.850993 / 55.444624 (-52.593631) | 2.473111 / 6.876477 (-4.403366) | 2.746731 / 2.142072 (0.604659) | 0.586597 / 4.805227 (-4.218630) | 0.134082 / 6.500664 (-6.366582) | 0.061035 / 0.075469 (-0.014434) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.375186 / 1.841788 (-0.466602) | 20.960817 / 8.074308 (12.886509) | 15.035071 / 10.191392 (4.843679) | 0.169494 / 0.680424 (-0.510930) | 0.020654 / 0.534201 (-0.513547) | 0.398047 / 0.579283 (-0.181236) | 0.438117 / 0.434364 (0.003753) | 0.483896 / 0.540337 (-0.056441) | 0.690728 / 1.386936 (-0.696208) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006892 / 0.011353 (-0.004461) | 0.004087 / 0.011008 (-0.006921) | 0.084695 / 0.038508 (0.046187) | 0.078084 / 0.023109 (0.054975) | 0.322976 / 0.275898 (0.047078) | 0.355332 / 0.323480 (0.031852) | 0.004235 / 0.007986 (-0.003750) | 0.003450 / 0.004328 (-0.000879) | 0.065355 / 0.004250 (0.061104) | 0.058593 / 0.037052 (0.021541) | 0.335761 / 0.258489 (0.077272) | 0.370392 / 0.293841 (0.076551) | 0.031720 / 0.128546 (-0.096827) | 0.008611 / 0.075646 (-0.067036) | 0.288213 / 0.419271 (-0.131059) | 0.053374 / 0.043533 (0.009842) | 0.321863 / 0.255139 (0.066724) | 0.341587 / 0.283200 (0.058387) | 0.025694 / 0.141683 (-0.115989) | 1.470502 / 1.452155 (0.018348) | 1.565068 / 1.492716 (0.072352) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231063 / 0.018006 (0.213057) | 0.464996 / 0.000490 (0.464506) | 0.007316 / 0.000200 (0.007116) | 0.000288 / 0.000054 (0.000233) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029244 / 0.037411 (-0.008167) | 0.086303 / 0.014526 (0.071777) | 0.097281 / 0.176557 (-0.079276) | 0.153552 / 0.737135 (-0.583583) | 0.098488 / 0.296338 (-0.197850) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382753 / 0.215209 (0.167544) | 3.826503 / 2.077655 (1.748848) | 1.848439 / 1.504120 (0.344319) | 1.688519 / 1.541195 (0.147324) | 1.787867 / 1.468490 (0.319377) | 0.489708 / 4.584777 (-4.095069) | 3.576780 / 3.745712 (-0.168932) | 3.341536 / 5.269862 (-1.928325) | 2.108787 / 4.565676 (-2.456889) | 0.057409 / 0.424275 (-0.366866) | 0.007325 / 0.007607 (-0.000282) | 0.459536 / 0.226044 (0.233492) | 4.590609 / 2.268929 (2.321681) | 2.313005 / 55.444624 (-53.131620) | 1.972389 / 6.876477 (-4.904087) | 2.218511 / 2.142072 (0.076439) | 0.613817 / 4.805227 (-4.191410) | 0.133846 / 6.500664 (-6.366818) | 0.062190 / 0.075469 (-0.013279) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279860 / 1.841788 (-0.561928) | 19.549777 / 8.074308 (11.475469) | 14.225844 / 10.191392 (4.034452) | 0.164682 / 0.680424 (-0.515741) | 0.018321 / 0.534201 (-0.515880) | 0.389874 / 0.579283 (-0.189409) | 0.408597 / 0.434364 (-0.025767) | 0.454327 / 0.540337 (-0.086011) | 0.645571 / 1.386936 (-0.741365) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007021 / 0.011353 (-0.004332) | 0.004119 / 0.011008 (-0.006889) | 0.065393 / 0.038508 (0.026885) | 0.085005 / 0.023109 (0.061896) | 0.412221 / 0.275898 (0.136323) | 0.438266 / 0.323480 (0.114786) | 0.005594 / 0.007986 (-0.002392) | 0.003499 / 0.004328 (-0.000829) | 0.065053 / 0.004250 (0.060802) | 0.060608 / 0.037052 (0.023555) | 0.413938 / 0.258489 (0.155449) | 0.446192 / 0.293841 (0.152351) | 0.032232 / 0.128546 (-0.096314) | 0.008617 / 0.075646 (-0.067029) | 0.071296 / 0.419271 (-0.347976) | 0.048756 / 0.043533 (0.005223) | 0.404977 / 0.255139 (0.149838) | 0.426801 / 0.283200 (0.143602) | 0.023650 / 0.141683 (-0.118033) | 1.526928 / 1.452155 (0.074773) | 1.627504 / 1.492716 (0.134787) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224318 / 0.018006 (0.206312) | 0.469717 / 0.000490 (0.469227) | 0.005539 / 0.000200 (0.005339) | 0.000098 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034240 / 0.037411 (-0.003171) | 0.096449 / 0.014526 (0.081923) | 0.107309 / 0.176557 (-0.069247) | 0.160246 / 0.737135 (-0.576889) | 0.107595 / 0.296338 (-0.188743) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434266 / 0.215209 (0.219057) | 4.325571 / 2.077655 (2.247916) | 2.324066 / 1.504120 (0.819946) | 2.140238 / 1.541195 (0.599044) | 2.244593 / 1.468490 (0.776103) | 0.486259 / 4.584777 (-4.098518) | 3.644120 / 3.745712 (-0.101592) | 3.372330 / 5.269862 (-1.897531) | 2.074779 / 4.565676 (-2.490897) | 0.057154 / 0.424275 (-0.367121) | 0.007304 / 0.007607 (-0.000303) | 0.516944 / 0.226044 (0.290899) | 5.174300 / 2.268929 (2.905372) | 2.816269 / 55.444624 (-52.628356) | 2.462943 / 6.876477 (-4.413534) | 2.735851 / 2.142072 (0.593779) | 0.589028 / 4.805227 (-4.216200) | 0.131804 / 6.500664 (-6.368860) | 0.060173 / 0.075469 (-0.015296) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.354540 / 1.841788 (-0.487248) | 20.436511 / 8.074308 (12.362203) | 15.541981 / 10.191392 (5.350589) | 0.168399 / 0.680424 (-0.512025) | 0.020716 / 0.534201 (-0.513485) | 0.396275 / 0.579283 (-0.183008) | 0.427232 / 0.434364 (-0.007132) | 0.475121 / 0.540337 (-0.065216) | 0.648579 / 1.386936 (-0.738357) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009071 / 0.011353 (-0.002282) | 0.005820 / 0.011008 (-0.005188) | 0.119974 / 0.038508 (0.081466) | 0.092145 / 0.023109 (0.069036) | 0.445349 / 0.275898 (0.169451) | 0.442488 / 0.323480 (0.119008) | 0.005352 / 0.007986 (-0.002634) | 0.004332 / 0.004328 (0.000003) | 0.084397 / 0.004250 (0.080147) | 0.064624 / 0.037052 (0.027572) | 0.430938 / 0.258489 (0.172448) | 0.503574 / 0.293841 (0.209733) | 0.047900 / 0.128546 (-0.080647) | 0.014237 / 0.075646 (-0.061409) | 0.366145 / 0.419271 (-0.053127) | 0.066344 / 0.043533 (0.022811) | 0.424582 / 0.255139 (0.169443) | 0.451845 / 0.283200 (0.168646) | 0.041409 / 0.141683 (-0.100274) | 1.886998 / 1.452155 (0.434843) | 2.011676 / 1.492716 (0.518960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.301008 / 0.018006 (0.283001) | 0.608670 / 0.000490 (0.608180) | 0.011963 / 0.000200 (0.011763) | 0.000117 / 0.000054 (0.000063) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031996 / 0.037411 (-0.005415) | 0.102274 / 0.014526 (0.087748) | 0.121437 / 0.176557 (-0.055120) | 0.181647 / 0.737135 (-0.555489) | 0.121634 / 0.296338 (-0.174704) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.597070 / 0.215209 (0.381861) | 5.973808 / 2.077655 (3.896154) | 2.486345 / 1.504120 (0.982225) | 2.125395 / 1.541195 (0.584201) | 2.270864 / 1.468490 (0.802374) | 0.880031 / 4.584777 (-3.704746) | 5.396522 / 3.745712 (1.650809) | 4.702005 / 5.269862 (-0.567857) | 3.023087 / 4.565676 (-1.542589) | 0.097093 / 0.424275 (-0.327182) | 0.008457 / 0.007607 (0.000850) | 0.712164 / 0.226044 (0.486120) | 7.112867 / 2.268929 (4.843938) | 3.364509 / 55.444624 (-52.080115) | 2.646953 / 6.876477 (-4.229524) | 2.795967 / 2.142072 (0.653894) | 1.067182 / 4.805227 (-3.738046) | 0.218297 / 6.500664 (-6.282368) | 0.071720 / 0.075469 (-0.003750) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.640477 / 1.841788 (-0.201311) | 24.875163 / 8.074308 (16.800855) | 22.125706 / 10.191392 (11.934314) | 0.247267 / 0.680424 (-0.433157) | 0.033717 / 0.534201 (-0.500484) | 0.492422 / 0.579283 (-0.086862) | 0.578323 / 0.434364 (0.143959) | 0.579503 / 0.540337 (0.039165) | 0.816721 / 1.386936 (-0.570215) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009372 / 0.011353 (-0.001981) | 0.005449 / 0.011008 (-0.005559) | 0.095371 / 0.038508 (0.056863) | 0.086320 / 0.023109 (0.063211) | 0.539573 / 0.275898 (0.263675) | 0.580338 / 0.323480 (0.256858) | 0.007028 / 0.007986 (-0.000958) | 0.004196 / 0.004328 (-0.000133) | 0.082710 / 0.004250 (0.078460) | 0.064336 / 0.037052 (0.027284) | 0.521490 / 0.258489 (0.263001) | 0.567942 / 0.293841 (0.274101) | 0.049659 / 0.128546 (-0.078887) | 0.017297 / 0.075646 (-0.058350) | 0.093874 / 0.419271 (-0.325398) | 0.061664 / 0.043533 (0.018131) | 0.524476 / 0.255139 (0.269337) | 0.563255 / 0.283200 (0.280055) | 0.039990 / 0.141683 (-0.101693) | 1.854438 / 1.452155 (0.402283) | 1.819321 / 1.492716 (0.326605) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.298817 / 0.018006 (0.280811) | 0.629381 / 0.000490 (0.628891) | 0.006259 / 0.000200 (0.006059) | 0.000690 / 0.000054 (0.000635) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.041009 / 0.037411 (0.003598) | 0.123845 / 0.014526 (0.109319) | 0.138606 / 0.176557 (-0.037951) | 0.215042 / 0.737135 (-0.522093) | 0.129572 / 0.296338 (-0.166767) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.668823 / 0.215209 (0.453614) | 6.596762 / 2.077655 (4.519108) | 3.275429 / 1.504120 (1.771309) | 2.921747 / 1.541195 (1.380553) | 2.963748 / 1.468490 (1.495258) | 0.897588 / 4.584777 (-3.687188) | 5.683618 / 3.745712 (1.937906) | 5.051102 / 5.269862 (-0.218760) | 3.178855 / 4.565676 (-1.386822) | 0.107446 / 0.424275 (-0.316829) | 0.008967 / 0.007607 (0.001360) | 0.785577 / 0.226044 (0.559532) | 8.236556 / 2.268929 (5.967628) | 3.914725 / 55.444624 (-51.529899) | 3.129068 / 6.876477 (-3.747409) | 3.368383 / 2.142072 (1.226310) | 1.004307 / 4.805227 (-3.800920) | 0.204788 / 6.500664 (-6.295876) | 0.078250 / 0.075469 (0.002780) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.778574 / 1.841788 (-0.063213) | 25.583659 / 8.074308 (17.509351) | 23.505866 / 10.191392 (13.314474) | 0.228759 / 0.680424 (-0.451665) | 0.038348 / 0.534201 (-0.495853) | 0.468980 / 0.579283 (-0.110303) | 0.630194 / 0.434364 (0.195830) | 0.587535 / 0.540337 (0.047198) | 0.831761 / 1.386936 (-0.555175) |\n\n</details>\n</details>\n\n\n",
"I've addressed the comments. Let me know if it looks all good now :)",
"Actually just found out that the current `**/*[-._ 0-9/]train[-._ 0-9/]**` doesn't match `data/train.csv` in bash (but does match in fsspec right now).\r\n\r\nSo there might be a risk that this pattern breaks in the future no ?",
"@lhoestq `fsspec` has tests to check their specific (non-posix) behavior, so I think merging in the current state is fine. And if they make a breaking change in the future, we can align the patterns once again :) ",
"Yea after more thoughts I also think it's fine. Feel free to merge !",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006920 / 0.011353 (-0.004433) | 0.004182 / 0.011008 (-0.006826) | 0.084629 / 0.038508 (0.046121) | 0.086052 / 0.023109 (0.062943) | 0.326062 / 0.275898 (0.050164) | 0.344190 / 0.323480 (0.020710) | 0.005393 / 0.007986 (-0.002593) | 0.003410 / 0.004328 (-0.000918) | 0.064327 / 0.004250 (0.060076) | 0.056556 / 0.037052 (0.019504) | 0.319255 / 0.258489 (0.060766) | 0.357943 / 0.293841 (0.064102) | 0.032097 / 0.128546 (-0.096450) | 0.008778 / 0.075646 (-0.066868) | 0.291057 / 0.419271 (-0.128215) | 0.053225 / 0.043533 (0.009692) | 0.307713 / 0.255139 (0.052574) | 0.350058 / 0.283200 (0.066858) | 0.024380 / 0.141683 (-0.117303) | 1.459482 / 1.452155 (0.007328) | 1.555711 / 1.492716 (0.062994) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.239487 / 0.018006 (0.221480) | 0.467604 / 0.000490 (0.467114) | 0.010742 / 0.000200 (0.010542) | 0.000285 / 0.000054 (0.000230) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029394 / 0.037411 (-0.008018) | 0.087404 / 0.014526 (0.072879) | 0.098701 / 0.176557 (-0.077855) | 0.154145 / 0.737135 (-0.582990) | 0.099726 / 0.296338 (-0.196612) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.389008 / 0.215209 (0.173799) | 3.873165 / 2.077655 (1.795510) | 1.860676 / 1.504120 (0.356556) | 1.679668 / 1.541195 (0.138474) | 1.782347 / 1.468490 (0.313857) | 0.489469 / 4.584777 (-4.095308) | 3.678706 / 3.745712 (-0.067006) | 3.404076 / 5.269862 (-1.865785) | 2.110972 / 4.565676 (-2.454704) | 0.057478 / 0.424275 (-0.366797) | 0.007443 / 0.007607 (-0.000164) | 0.464780 / 0.226044 (0.238736) | 4.643606 / 2.268929 (2.374678) | 2.355744 / 55.444624 (-53.088881) | 1.993992 / 6.876477 (-4.882485) | 2.245520 / 2.142072 (0.103447) | 0.592773 / 4.805227 (-4.212454) | 0.135369 / 6.500664 (-6.365295) | 0.062478 / 0.075469 (-0.012991) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257537 / 1.841788 (-0.584251) | 19.828010 / 8.074308 (11.753702) | 14.709260 / 10.191392 (4.517868) | 0.168359 / 0.680424 (-0.512065) | 0.018907 / 0.534201 (-0.515294) | 0.397223 / 0.579283 (-0.182060) | 0.421760 / 0.434364 (-0.012604) | 0.464597 / 0.540337 (-0.075740) | 0.665905 / 1.386936 (-0.721031) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007247 / 0.011353 (-0.004106) | 0.004104 / 0.011008 (-0.006904) | 0.065008 / 0.038508 (0.026500) | 0.083485 / 0.023109 (0.060376) | 0.399808 / 0.275898 (0.123910) | 0.433374 / 0.323480 (0.109894) | 0.005453 / 0.007986 (-0.002532) | 0.003479 / 0.004328 (-0.000850) | 0.065126 / 0.004250 (0.060876) | 0.059945 / 0.037052 (0.022893) | 0.402018 / 0.258489 (0.143529) | 0.437927 / 0.293841 (0.144086) | 0.032654 / 0.128546 (-0.095892) | 0.008717 / 0.075646 (-0.066929) | 0.071737 / 0.419271 (-0.347534) | 0.048903 / 0.043533 (0.005370) | 0.402107 / 0.255139 (0.146968) | 0.417602 / 0.283200 (0.134402) | 0.024821 / 0.141683 (-0.116862) | 1.474471 / 1.452155 (0.022316) | 1.559571 / 1.492716 (0.066855) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232010 / 0.018006 (0.214003) | 0.460768 / 0.000490 (0.460278) | 0.005250 / 0.000200 (0.005050) | 0.000109 / 0.000054 (0.000055) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033839 / 0.037411 (-0.003573) | 0.101617 / 0.014526 (0.087091) | 0.107984 / 0.176557 (-0.068573) | 0.160923 / 0.737135 (-0.576212) | 0.110367 / 0.296338 (-0.185971) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433087 / 0.215209 (0.217878) | 4.324100 / 2.077655 (2.246445) | 2.312937 / 1.504120 (0.808817) | 2.159903 / 1.541195 (0.618708) | 2.240235 / 1.468490 (0.771745) | 0.500659 / 4.584777 (-4.084118) | 3.743801 / 3.745712 (-0.001911) | 3.441350 / 5.269862 (-1.828512) | 2.141370 / 4.565676 (-2.424306) | 0.059078 / 0.424275 (-0.365197) | 0.007468 / 0.007607 (-0.000139) | 0.508108 / 0.226044 (0.282064) | 5.076738 / 2.268929 (2.807809) | 2.825939 / 55.444624 (-52.618685) | 2.467762 / 6.876477 (-4.408715) | 2.705079 / 2.142072 (0.563006) | 0.603363 / 4.805227 (-4.201864) | 0.136267 / 6.500664 (-6.364397) | 0.062887 / 0.075469 (-0.012582) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.359344 / 1.841788 (-0.482443) | 20.581510 / 8.074308 (12.507202) | 15.534489 / 10.191392 (5.343097) | 0.192068 / 0.680424 (-0.488356) | 0.020831 / 0.534201 (-0.513370) | 0.403330 / 0.579283 (-0.175953) | 0.429536 / 0.434364 (-0.004828) | 0.479906 / 0.540337 (-0.060431) | 0.674170 / 1.386936 (-0.712766) |\n\n</details>\n</details>\n\n\n"
] | "2023-09-15T17:58:25Z" | "2023-09-26T15:41:38Z" | "2023-09-26T15:32:51Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6244",
"merged_at": "2023-09-26T15:32:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6244"
} | Fix #6214 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6244/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5545/comments | https://api.github.com/repos/huggingface/datasets/issues/5545/events | https://github.com/huggingface/datasets/pull/5545 | 1,590,315,972 | PR_kwDODunzps5KRKct | 5,545 | Added return methods for URL-references to the pushed dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/25269220?v=4",
"events_url": "https://api.github.com/users/davidberenstein1957/events{/privacy}",
"followers_url": "https://api.github.com/users/davidberenstein1957/followers",
"following_url": "https://api.github.com/users/davidberenstein1957/following{/other_user}",
"gists_url": "https://api.github.com/users/davidberenstein1957/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/davidberenstein1957",
"id": 25269220,
"login": "davidberenstein1957",
"node_id": "MDQ6VXNlcjI1MjY5MjIw",
"organizations_url": "https://api.github.com/users/davidberenstein1957/orgs",
"received_events_url": "https://api.github.com/users/davidberenstein1957/received_events",
"repos_url": "https://api.github.com/users/davidberenstein1957/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/davidberenstein1957/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidberenstein1957/subscriptions",
"type": "User",
"url": "https://api.github.com/users/davidberenstein1957"
} | [] | open | false | null | [] | null | [
"Hi ! Maybe we'd need to align with `transformers` and other libraries that implement `push_to_hub` to agree on what it should return.\r\n\r\ne.g. in `transformers` the typing says it returns a string, but in practice it returns a `CommitInfo`.\r\n\r\nTherefore I'd not add an output to `push_to_hub` here unless we had a chance to discuss more broadly.\r\n\r\nAnyway in my opinion it should no just return the URL of the repository, but ideally the URL at the revision where the data were pushed",
"Perhaps a mixin or something similar could be defined on the `hfh` side to ensure the `push_to_hub` API is aligned across our projects. \r\n\r\nPS: this would also mean that the PRs such as https://github.com/huggingface/datasets/pull/5528 would no longer be our responsibility\r\n\r\ncc @Wauplin ",
"I agree, with universability and the idea is more about returning at least something that references where to find the uploaded file/model or otherwise. \r\n\r\nIdeally, the referenced PR would work.",
"imo this would be a good use case to just use `huggingface_hub` and align to what we do there :)",
"@mariosasko, can you give me some pointers to where I might help implementing this for the `huggingface-hub`?",
"> @mariosasko: Perhaps a mixin or something similar could be defined on the hfh side to ensure the push_to_hub API is aligned across our projects.\r\n\r\n> @julien-c: imo this would be a good use case to just use huggingface_hub and align to what we do there :)\r\n\r\nI (finally) opened a PR to harmonize return types: https://github.com/huggingface/huggingface_hub/pull/1921. It should hopefully be shipped in next release later this week (:crossed_fingers:). "
] | "2023-02-18T11:26:25Z" | "2023-12-18T16:57:56Z" | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5545",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5545"
} | Hi,
I was missing the ability to easily open the pushed dataset and it seemed like a quick fix.
Maybe we also want to log this info somewhere, but let me know if I need to add that too.
Cheers,
David | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5545/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2540 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2540/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2540/comments | https://api.github.com/repos/huggingface/datasets/issues/2540/events | https://github.com/huggingface/datasets/pull/2540 | 928,433,892 | MDExOlB1bGxSZXF1ZXN0Njc2NDM5NTM1 | 2,540 | Remove task templates if required features are removed during `Dataset.map` | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [] | "2021-06-23T16:20:25Z" | "2021-06-24T14:41:15Z" | "2021-06-24T13:34:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2540.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2540",
"merged_at": "2021-06-24T13:34:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2540.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2540"
} | This PR fixes a bug reported by @craffel where removing a dataset's columns during `Dataset.map` triggered a `KeyError` because the `TextClassification` template tried to access the removed columns during `DatasetInfo.__post_init__`:
```python
from datasets import load_dataset
# `yelp_polarity` comes with a `TextClassification` template
ds = load_dataset("yelp_polarity", split="test")
ds
# Dataset({
# features: ['text', 'label'],
# num_rows: 38000
# })
# Triggers KeyError: 'label' - oh noes!
ds.map(lambda x: {"inputs": 0}, remove_columns=ds.column_names)
```
I wrote a unit test to make sure I could reproduce the error and then patched a fix. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2540/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2540/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3574/comments | https://api.github.com/repos/huggingface/datasets/issues/3574/events | https://github.com/huggingface/datasets/pull/3574 | 1,101,781,401 | PR_kwDODunzps4w7vu6 | 3,574 | Fix qa4mre tags | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [] | "2022-01-13T13:56:59Z" | "2022-01-13T14:03:02Z" | "2022-01-13T14:03:01Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3574.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3574",
"merged_at": "2022-01-13T14:03:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3574.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3574"
} | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3574/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2152 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2152/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2152/comments | https://api.github.com/repos/huggingface/datasets/issues/2152/events | https://github.com/huggingface/datasets/pull/2152 | 845,751,273 | MDExOlB1bGxSZXF1ZXN0NjA0ODk0MDkz | 2,152 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/22306304?v=4",
"events_url": "https://api.github.com/users/JieyuZhao/events{/privacy}",
"followers_url": "https://api.github.com/users/JieyuZhao/followers",
"following_url": "https://api.github.com/users/JieyuZhao/following{/other_user}",
"gists_url": "https://api.github.com/users/JieyuZhao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JieyuZhao",
"id": 22306304,
"login": "JieyuZhao",
"node_id": "MDQ6VXNlcjIyMzA2MzA0",
"organizations_url": "https://api.github.com/users/JieyuZhao/orgs",
"received_events_url": "https://api.github.com/users/JieyuZhao/received_events",
"repos_url": "https://api.github.com/users/JieyuZhao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JieyuZhao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JieyuZhao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JieyuZhao"
} | [] | closed | false | null | [] | null | [] | "2021-03-31T03:21:19Z" | "2021-04-01T10:20:37Z" | "2021-04-01T10:20:36Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2152.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2152",
"merged_at": "2021-04-01T10:20:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2152.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2152"
} | Updated some descriptions of Wino_Bias dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2152/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2152/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3256 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3256/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3256/comments | https://api.github.com/repos/huggingface/datasets/issues/3256/events | https://github.com/huggingface/datasets/pull/3256 | 1,052,000,613 | PR_kwDODunzps4udTqg | 3,256 | asserts replaced by exception for text classification task with test. | {
"avatar_url": "https://avatars.githubusercontent.com/u/153142?v=4",
"events_url": "https://api.github.com/users/manisnesan/events{/privacy}",
"followers_url": "https://api.github.com/users/manisnesan/followers",
"following_url": "https://api.github.com/users/manisnesan/following{/other_user}",
"gists_url": "https://api.github.com/users/manisnesan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/manisnesan",
"id": 153142,
"login": "manisnesan",
"node_id": "MDQ6VXNlcjE1MzE0Mg==",
"organizations_url": "https://api.github.com/users/manisnesan/orgs",
"received_events_url": "https://api.github.com/users/manisnesan/received_events",
"repos_url": "https://api.github.com/users/manisnesan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/manisnesan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manisnesan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/manisnesan"
} | [] | closed | false | null | [] | null | [
"Haha it looks like you got the chance of being reviewed twice at the same time and got the same suggestion twice x)\r\nAnyway it's all good now so we can merge !",
"Thanks for the feedback. "
] | "2021-11-12T14:05:36Z" | "2021-11-12T15:09:33Z" | "2021-11-12T14:59:32Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3256.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3256",
"merged_at": "2021-11-12T14:59:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3256.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3256"
} | I have replaced only a single assert in text_classification.py along with a unit test to verify an exception is raised based on https://github.com/huggingface/datasets/issues/3171 .
I would like to first understand the code contribution workflow. So keeping the change to a single file rather than making too many changes. Once this gets approved, I will look into the rest.
Thanks. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3256/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3256/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4354/comments | https://api.github.com/repos/huggingface/datasets/issues/4354/events | https://github.com/huggingface/datasets/issues/4354 | 1,236,404,383 | I_kwDODunzps5Jsgif | 4,354 | Problems with WMT dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8884008?v=4",
"events_url": "https://api.github.com/users/eldarkurtic/events{/privacy}",
"followers_url": "https://api.github.com/users/eldarkurtic/followers",
"following_url": "https://api.github.com/users/eldarkurtic/following{/other_user}",
"gists_url": "https://api.github.com/users/eldarkurtic/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eldarkurtic",
"id": 8884008,
"login": "eldarkurtic",
"node_id": "MDQ6VXNlcjg4ODQwMDg=",
"organizations_url": "https://api.github.com/users/eldarkurtic/orgs",
"received_events_url": "https://api.github.com/users/eldarkurtic/received_events",
"repos_url": "https://api.github.com/users/eldarkurtic/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eldarkurtic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eldarkurtic/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eldarkurtic"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"Hi! Yes, the docs are outdated. Expect this to be fixed soon. \r\n\r\nIn the meantime, you can try to fix the issue yourself.\r\n\r\nThese are the configs/language pairs supported by `wmt15` from which you can choose:\r\n* `cs-en` (Czech - English)\r\n* `de-en` (German - English)\r\n* `fi-en` (Finnish- English)\r\n* `fr-en` (French - English)\r\n* `ru-en` (Russian - English)\r\n\r\nAnd the current implementation always uses all the subsets available for a language, so to define custom subsets, you'll have to clone the repo from the Hub and replace the line https://huggingface.co/datasets/wmt15/blob/main/wmt_utils.py#L688 with:\r\n`for split, ss_names in (self._subsets if self.config.subsets is None else self.config.subsets).items()`\r\n\r\nThen, you can load the dataset as follows:\r\n```python\r\nfrom datasets import load_dataset\r\ndset = load_dataset(\"path/to/local/wmt15_folder\", \"<one of 5 available configs>\", subsets=...)",
"@mariosasko thanks a lot for the suggested fix! ",
"Hi @mariosasko \r\n\r\nAre the docs updated? If not, I would like to get on it. I am new around here, would we helpful, if you can guide.\r\n\r\nThanks",
"Hi @khushmeeet! The docs haven't been updated, so feel free to work on this issue. This is a tricky issue, so I'll give the steps you can follow to fix this:\r\n\r\nFirst, this code:\r\nhttps://github.com/huggingface/datasets/blob/7cff5b9726a223509dbd6224de3f5f452c8d924f/src/datasets/load.py#L113-L118\r\n\r\nneeds to be replaced with (makes the dataset builder search more robust and allows us to remove the ABC stuff from `wmt_utils.py`):\r\n```python\r\n for name, obj in module.__dict__.items():\r\n if inspect.isclass(obj) and issubclass(obj, main_cls_type):\r\n if inspect.isabstract(obj):\r\n continue\r\n module_main_cls = obj\r\n obj_module = inspect.getmodule(obj)\r\n if obj_module is not None and module == obj_module:\r\n break\r\n```\r\n\r\nThen, all the `wmt_utils.py` scripts need to be updated as follows (these are the diffs with the requiered changes):\r\n````diff\r\n import os\r\n import re\r\n import xml.etree.cElementTree as ElementTree\r\n-from abc import ABC, abstractmethod\r\n\r\n import datasets\r\n````\r\n\r\n````diff\r\nlogger = datasets.logging.get_logger(__name__)\r\n\r\n\r\n _DESCRIPTION = \"\"\"\\\r\n-Translate dataset based on the data from statmt.org.\r\n+Translation dataset based on the data from statmt.org.\r\n\r\n-Versions exists for the different years using a combination of multiple data\r\n-sources. The base `wmt_translate` allows you to create your own config to choose\r\n-your own data/language pair by creating a custom `datasets.translate.wmt.WmtConfig`.\r\n+Versions exist for different years using a combination of data\r\n+sources. The base `wmt` allows you to create a custom dataset by choosing\r\n+your own data/language pair. This can be done as follows:\r\n\r\n ```\r\n-config = datasets.wmt.WmtConfig(\r\n- version=\"0.0.1\",\r\n+from datasets import inspect_dataset, load_dataset_builder\r\n+\r\n+inspect_dataset(\"<insert the dataset name\", \"path/to/scripts\")\r\n+builder = load_dataset_builder(\r\n+ \"path/to/scripts/wmt_utils.py\",\r\n language_pair=(\"fr\", \"de\"),\r\n subsets={\r\n datasets.Split.TRAIN: [\"commoncrawl_frde\"],\r\n datasets.Split.VALIDATION: [\"euelections_dev2019\"],\r\n },\r\n )\r\n-builder = datasets.builder(\"wmt_translate\", config=config)\r\n-```\r\n\r\n+# Standard version\r\n+builder.download_and_prepare()\r\n+ds = builder.as_dataset()\r\n+\r\n+# Streamable version\r\n+ds = builder.as_streaming_dataset()\r\n+```\r\n \"\"\"\r\n````\r\n\r\n````diff\r\n+class Wmt(datasets.GeneratorBasedBuilder):\r\n \"\"\"WMT translation dataset.\"\"\"\r\n+\r\n+ BUILDER_CONFIG_CLASS = WmtConfig\r\n\r\n def __init__(self, *args, **kwargs):\r\n- if type(self) == Wmt and \"config\" not in kwargs: # pylint: disable=unidiomatic-typecheck\r\n- raise ValueError(\r\n- \"The raw `wmt_translate` can only be instantiated with the config \"\r\n- \"kwargs. You may want to use one of the `wmtYY_translate` \"\r\n- \"implementation instead to get the WMT dataset for a specific year.\"\r\n- )\r\n super(Wmt, self).__init__(*args, **kwargs)\r\n\r\n @property\r\n- @abstractmethod\r\n def _subsets(self):\r\n \"\"\"Subsets that make up each split of the dataset.\"\"\"\r\n````\r\n```diff\r\n \"\"\"Subsets that make up each split of the dataset for the language pair.\"\"\"\r\n source, target = self.config.language_pair\r\n filtered_subsets = {}\r\n- for split, ss_names in self._subsets.items():\r\n+ subsets = self._subsets if self.config.subsets is None else self.config.subsets\r\n+ for split, ss_names in subsets.items():\r\n filtered_subsets[split] = []\r\n for ss_name in ss_names:\r\n dataset = DATASET_MAP[ss_name]\r\n```\r\n\r\n`wmt14`, `wmt15`, `wmt16`, `wmt17`, `wmt18`, `wmt19` and `wmt_t2t` have this script, so all of them need to be updated. Also, the dataset summaries from the READMEs of these datasets need to be updated to match the new `_DESCRIPTION` string. And that's it! Let me know if you need additional help.",
"Hi @mariosasko ,\r\n\r\nI have made the changes as suggested by you and have opened a PR #4537.\r\n\r\nThanks",
"Resolved via #4554 "
] | "2022-05-15T20:58:26Z" | "2022-07-11T14:54:02Z" | "2022-07-11T14:54:01Z" | NONE | null | null | null | ## Describe the bug
I am trying to load WMT15 dataset and to define which data-sources to use for train/validation/test splits, but unfortunately it seems that the official documentation at [https://huggingface.co/datasets/wmt15#:~:text=Versions%20exists%20for,wmt_translate%22%2C%20config%3Dconfig)](https://huggingface.co/datasets/wmt15#:~:text=Versions%20exists%20for,wmt_translate%22%2C%20config%3Dconfig)) doesn't work anymore.
## Steps to reproduce the bug
```shell
>>> import datasets
>>> a = datasets.translate.wmt.WmtConfig()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'datasets' has no attribute 'translate'
>>> a = datasets.wmt.WmtConfig()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'datasets' has no attribute 'wmt'
```
## Expected results
To load WMT15 with given data-sources.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: Linux-5.10.0-10-amd64-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4354/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/394/comments | https://api.github.com/repos/huggingface/datasets/issues/394/events | https://github.com/huggingface/datasets/pull/394 | 657,425,548 | MDExOlB1bGxSZXF1ZXN0NDQ5NTQzNTE0 | 394 | Remove remaining nested dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
} | [] | closed | false | null | [] | null | [] | "2020-07-15T15:05:52Z" | "2020-07-16T07:39:52Z" | "2020-07-16T07:39:51Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/394.diff",
"html_url": "https://github.com/huggingface/datasets/pull/394",
"merged_at": "2020-07-16T07:39:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/394.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/394"
} | This PR deletes the remaining unnecessary nested dict
#378 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/394/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5003 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5003/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5003/comments | https://api.github.com/repos/huggingface/datasets/issues/5003/events | https://github.com/huggingface/datasets/pull/5003 | 1,380,617,353 | PR_kwDODunzps4_Vdko | 5,003 | Fix missing use_auth_token in streaming docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-09-21T09:27:03Z" | "2022-09-21T16:24:01Z" | "2022-09-21T16:20:59Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5003.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5003",
"merged_at": "2022-09-21T16:20:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5003.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5003"
} | This PRs fixes docstrings:
- adds the missing `use_auth_token` param
- updates syntax of param types
- adds params to docstrings without them
- fixes return/yield types
- fixes syntax | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5003/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5003/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4645/comments | https://api.github.com/repos/huggingface/datasets/issues/4645/events | https://github.com/huggingface/datasets/pull/4645 | 1,296,027,785 | PR_kwDODunzps468oZ6 | 4,645 | Set HF_SCRIPTS_VERSION to main | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-07-06T15:43:21Z" | "2022-07-06T15:56:21Z" | "2022-07-06T15:45:05Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4645.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4645",
"merged_at": "2022-07-06T15:45:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4645.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4645"
} | After renaming "master" to "main", the CI fails with
```
AssertionError: 'https://raw.githubusercontent.com/huggingface/datasets/main/datasets/_dummy/_dummy.py' not found in "Couldn't find a dataset script at /home/circleci/datasets/_dummy/_dummy.py or any data file in the same directory. Couldn't find '_dummy' on the Hugging Face Hub either: FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/_dummy/_dummy.py"
```
This is because in the CI we were still using `HF_SCRIPTS_VERSION=master`. I changed it to "main" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4645/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2955/comments | https://api.github.com/repos/huggingface/datasets/issues/2955/events | https://github.com/huggingface/datasets/pull/2955 | 1,003,999,469 | PR_kwDODunzps4sHuRu | 2,955 | Update legacy Python image for CI tests in Linux | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"There is an exception when running `pip install .[tests]`:\r\n```\r\nProcessing /home/circleci/datasets\r\nCollecting numpy>=1.17 (from datasets==1.12.2.dev0)\r\n Downloading https://files.pythonhosted.org/packages/45/b2/6c7545bb7a38754d63048c7696804a0d947328125d81bf12beaa692c3ae3/numpy-1.19.5-cp36-cp36m-manylinux1_x86_64.whl (13.4MB)\r\n 100% |████████████████████████████████| 13.4MB 3.9MB/s eta 0:00:011\r\n\r\n...\r\n\r\nCollecting faiss-cpu (from datasets==1.12.2.dev0)\r\n Downloading https://files.pythonhosted.org/packages/87/91/bf8ea0d42733cbb04f98d3bf27808e4919ceb5ec71102e21119398a97237/faiss-cpu-1.7.1.post2.tar.gz (41kB)\r\n 100% |████████████████████████████████| 51kB 30.9MB/s ta 0:00:01\r\n Complete output from command python setup.py egg_info:\r\n Traceback (most recent call last):\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 154, in save_modules\r\n yield saved\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 195, in setup_context\r\n yield\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 250, in run_setup\r\n _execfile(setup_script, ns)\r\n File \"/home/circleci/.pyenv/versions/3.6.14/lib/python3.6/site-packages/setuptools/sandbox.py\", line 45, in _execfile\r\n exec(code, globals, locals)\r\n File \"/tmp/easy_install-1pop4blm/numpy-1.21.2/setup.py\", line 34, in <module>\r\n method can be invoked.\r\n RuntimeError: Python version >= 3.7 required.\r\n```\r\n\r\nApparently, `numpy-1.21.2` tries to be installed in the temporary directory `/tmp/easy_install-1pop4blm` instead of the downloaded `numpy-1.19.5` (requirement of `datasets`).\r\n\r\nThis is caused because `pip` downloads the `.tar.gz` (instead of the `.whl`) and tries to build it in a tmp dir."
] | "2021-09-22T08:25:27Z" | "2021-09-24T10:36:05Z" | "2021-09-24T10:36:05Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2955.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2955",
"merged_at": "2021-09-24T10:36:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2955.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2955"
} | Instead of legacy, use next-generation convenience images, built from the ground up with CI, efficiency, and determinism in mind. Here are some of the highlights:
- Faster spin-up time - In Docker terminology, these next-gen images will generally have fewer and smaller layers. Using these new images will lead to faster image downloads when a build starts, and a higher likelihood that the image is already cached on the host.
- Improved reliability and stability - The existing legacy convenience images are rebuilt practically every day with potential changes from upstream that we cannot always test fast enough. This leads to frequent breaking changes, which is not the best environment for stable, deterministic builds. Next-gen images will only be rebuilt for security and critical-bugs, leading to more stable and deterministic images.
More info: https://circleci.com/docs/2.0/circleci-images | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2955/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2955/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5189/comments | https://api.github.com/repos/huggingface/datasets/issues/5189/events | https://github.com/huggingface/datasets/issues/5189 | 1,432,769,143 | I_kwDODunzps5VZlJ3 | 5,189 | Reduce friction in tabular dataset workflow by eliminating having splits when dataset is loaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_url": "https://api.github.com/users/merveenoyan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/merveenoyan",
"id": 53175384,
"login": "merveenoyan",
"node_id": "MDQ6VXNlcjUzMTc1Mzg0",
"organizations_url": "https://api.github.com/users/merveenoyan/orgs",
"received_events_url": "https://api.github.com/users/merveenoyan/received_events",
"repos_url": "https://api.github.com/users/merveenoyan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/merveenoyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merveenoyan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/merveenoyan"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"I have to admit I'm not a fan of this idea, as this would result in a non-consistent behavior between tabular and non-tabular datasets, which is confusing if done without the context you provided. Instead, we could consider returning a `Dataset` object rather than `DatasetDict` if there is only one split in the generated dataset. But then again, I think this lib is a bit too old to make such changes. @lhoestq @albertvillanova WDYT?\r\n\r\n",
"We can brainstorm here to see how we could make it happen ? And then depending on the options we see if it's a change we can do.\r\n\r\nI'm starting with a first reasoning\r\n\r\nCurrently not passing `split=` in `load_dataset` means \"return a dict with each split\".\r\n\r\nNow what would happen if a dataset has no split ? Ideally it should return one Dataset. And passing `split=` would have no sense. So depending on the dataset content, not passing `split=` should return a dict or a Dataset. In particular, those two cases should work:\r\n```python\r\n# case 1: dataset without split\r\nds = load_dataset(\"dataset_without_split\")\r\nds[0], ds[\"column_name\"], list(ds) # we want this\r\n\r\n# case 2: dataset with splits\r\nds = load_dataset(\"dataset_with_splits\")\r\nds[\"train\"] # this works and can't be changed\r\nds = load_dataset(\"dataset_with_splits\", split=\"train\")\r\nds[0], ds[\"column_name\"], list(ds) # this works and can't be changed\r\n```\r\n\r\nI can see several ideas:\r\n1. allowing `load_dataset` to return a different object based on the dataset content - either a Dataset or a DatasetDict\r\n - we can update `get_dataset_split_names` to return None or a list if users want to know in advance what object will be returned. They can also use `isinstance` _a posteriori_\r\n - but in this case we expect users to be careful when loading datasets and always to extra steps to check if they got a Dataset or DatasetDict\r\n2. merge Dataset and DatasetDict objects\r\n - they already share many functions: map, filter, push_to_hub etc.\r\n - we can define `ds[0]` to be the first item of the first split, and consider that the uses accesses rows from the full table of all the splits concatenated\r\n - however there is a collision when doing `ds[\"column_name\"]` or `ds[\"train\"]` that we need to address: the first returns a list, while the other returns a Dataset.\r\n\r\nWhat are your opinions on those two ideas ? Do you have other ideas in mind ?",
"I like the first idea more (concatenating splits doesn't seem useful, no?). This is a significant breaking change, so I think we should do a poll (or something similar) to gather more info on the actual \"expected behavior\" and wait for Datasets 3.0 if we decide to implement it.\r\n\r\nPS: @thomwolf also suggested the same thing a while ago (https://github.com/huggingface/datasets/issues/743#issuecomment-746074641).",
"I think it's an interesting improvement to the user experience for a case that comes often (no split) so I would definitively support it.\r\n\r\nI would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed",
"Related: if a dataset only has one split, we don't show the splits select control in the dataset viewer on the Hub, eg. compare https://huggingface.co/datasets/hf-internal-testing/fixtures_image_utils/viewer/image/test with https://huggingface.co/datasets/glue/viewer/mnli/test.\r\n\r\nSee https://github.com/huggingface/moon-landing/pull/3858 for more details (internal)",
"I feel like the second idea is a bit more overkill. \r\n@severo I would say it's a bit irrelevant to the problem we have but is a separate problem @polinaeterna is solving at the moment. 😅 (also discussed on slack)",
"OK, sorry for polluting the thread. The relation I saw with the dataset viewer is that from a UX point of view, we hide the concepts of split and configuration whenever possible -> this issue feels like doing the same in the datasets library.",
"I would agree that returning different types based on the content of the dataset might be confusing.\r\n\r\nWe can do something similar to what `fetch_*` or `load_*` from `sklearn.datasets` do, which is to have an arg which changes the type of the returned type. For instance, `load_iris` would return a dict, but `load_iris(..., return_X_y=True)` would return a tuple.\r\n\r\nHere we can have a similar arg such as `return_X` which would then only return a single `DataSet` or an array.",
"> I feel like the second idea is a bit more overkill.\r\n\r\nOverkill in what sense ?\r\n\r\n> Here we can have a similar arg such as return_X which would then only return a single DataSet or an array.\r\n\r\nRight now one can already pass `split=\"all\"` to get one `Dataset` object with all the data in it (unsplit). We could also have something like `return_all=True` so make the API clearer.\r\n\r\n> I would be more in favor of option 2 rather than returning various types of objects from load_dataset and handling carefully the possible collisions indeed\r\n\r\nI think it would be ok to handle the collision by allowing both `ds[\"train\"]` and `ds[\"column_name\"]` (and maybe adding something like `ds.splits` for those who want to iterate over the splits or add new ones)",
"Would it make sense to remove the notion of \"split\" in `load_dataset`? I feel a lof of it comes from the want to have some sort of group of more or less similar dataset. \"train\"/\"test\"/\"validation\" are the traditional ones, but there are some datasets that have much more splits.\r\n\r\nWould it make sense to force `load_dataset` to only load a single `Dataset` object, and fail if it doesn't point to one. And have another method that's like `load_dataset_group_info` that can return a very arbitrary info class (Dict, List whatever), but you need to pass individual infos to `load_dataset` to run anything? Typically I don't think `DatasetDict.map` is really that helpful, but that's my personal opinion. This would help make things more readable (typically knowing if an object is a `Dataset` or a `DatasetDict`)",
"> Would it make sense to remove the notion of \"split\" in load_dataset?\r\n\r\nI think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\n> Would it make sense to force load_dataset to only load a single Dataset object, and fail if it doesn't point to one.\r\n\r\nWe need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one",
"> I think we need to keep it - though in practice people can name the splits whatever they want anyway.\r\n\r\nIt was my understanding that the whole issue was that `load_dataset` returned multiple types of objects.\r\n\r\n> We need to keep backward compatibility ideally - in particular the load_dataset + ds[\"train\"] one\r\n\r\nYeah sorry I meant ideally. One can always start developing `load_dataset_v2` can deprecate the first one and remove it in the longer term.",
"> It was my understanding that the whole issue was that load_dataset returned multiple types of objects.\r\n\r\nYes indeed, but we still want to keep a way to load the train/val/test/whatever splits alone ;)",
"@thomasw21's solution is good but it will break backwards compatibility. 😅",
"Started to experiment with merging Dataset and DatasetDict. My plan is to define the splits of a Dataset in Dataset.info.splits (already exists, but never used). A Dataset would then be the concatenation of its splits if they exist.\r\n\r\nNot sure yet this is the way to go. My plan is to play with it and see and share it with you, so we can see if it makes sense from a UX point of view.",
"So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\nImagine \"potato\" a dataset containing train/validation split:\r\n```\r\nload_dataset(\"potato\") # returns the concatenation of all the splits\r\n```\r\nPreviously the design would force you to choose a split (it would raise otherwise), or manually concat them if you really wanted to play with concatenated splits. Now it would potentially run without raising for a bit of time until you figure out that you've been training on both train and validation split.\r\n\r\nWould it make sense to use a dataset specific default instead of using the concatenation, typically \"potato\" dataset's default would be train?\r\n```\r\nload_dataset(\"potato\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"train\") # returns \"train\" split\r\nload_dataset(\"potato\", split=\"validation\") # returns \"validation\" split\r\nconcatenate_datasets([load_dataset(\"potato\", split=\"train\"), load_dataset(\"potato\", split=\"validation\")]) # returns concatenation\r\n```",
"> load_dataset(\"potato\") # returns \"train\" split\r\n\r\nTo avoid a breaking change we need to be able to do `load_dataset(\"potato\")[\"validation\"]` as well.\r\n\r\nIn that case I'd wonder where the validation split comes from, since the rows of the dataset wouldn't contain the validation split according to your example. That's why I'm more in favor of concatenating.\r\n\r\nA dataset is one table, that optionally has some split info about subsets (e.g. for training an evaluation)\r\n\r\nThis also allows anyone to re-split the dataset the way they want if they're not happy with the default:\r\n\r\n```python\r\nds = load_dataset(\"potato\").train_test_split(test_size=0.2)\r\ntrain_ds = ds[\"train\"]\r\ntest_ds = ds[\"test\"]\r\n```",
"Just thinking about this, we could just have `to_dataframe()` as `load_dataset(\"blah\").to_dataframe()` to get the whole dataset, and not change anything else.",
"I have a first implementation of option 2 (merging Dataset and DatasetDict) in this PR: https://github.com/huggingface/datasets/pull/5301/\r\n\r\nFeel free to play with it if you're interested, and let me know what you think. In this PR, a dataset is one table that optionally has some split info about subsets.",
"@adrinjalali we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict), I was wondering if it makes sense to have this as I don't know portion of people who load non-tabular datasets into dataframes. @lhoestq I saw your PR and it will break a lot of things imo, WDYT of this option? ",
"> we already have [to_pandas](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_pandas) AFAIK that essentially does the same thing (for a dataset, not for a dataset dict)\r\n\r\nyes correct :)\r\n\r\n> I saw your PR and it will break a lot of things imo\r\n\r\nDo you have concrete examples you can share ?\r\n\r\n> WDYT of this option?\r\n\r\nThe to_dataframe option ? I think it not enough, since you'd still get a `DatasetDict({\"train\": Dataset()})` if you load a dataset with no splits (e.g. one CSV), and this doesn't really make sense.\r\n\r\nNote that in the PR I opened you can do\r\n```python\r\nds = load_dataset(\"dataset_with_just_one_csv\") # Dataset type\r\ndf = load_dataset(\"dataset_with_just_one_csv\").to_pandas() # DataFrame type\r\n```",
"@lhoestq no I think @adrinjalali and I meant when user calls `to_dataframe` if there's only train split in `DatasetDict` we could directly load that into dataframe. This might cause a confusion given there's to_pandas but I think it's more intuitive and least breaking change. (given people -who use `datasets` for tabular workflows- will eventually call `to_pandas` anyway) ",
"So in that case it would be fine to still end up with a dataset dict with a \"train\" split ?",
"yeah what I mean is this:\r\n\r\n```py\r\ndataset = load_dataset(\"blah\")\r\n\r\n# deal with a split of the dataset\r\ntrain = dataset[\"train\"]\r\ntrain_df = dataset[\"train\"].to_dataframe()\r\n\r\n# deal with the whole dataset\r\ndataset_df = dataset.to_dataframe()\r\n```\r\n\r\nSo we do two things to improve tabular experience:\r\n- allow datasets to have a single split\r\n- add `to_dataframe` to the root dict level so that users can simply call `df = load_dataset(\"blah\").to_dataframe()` and have it in their `pandas.DataFrame` object.",
"Ok ! Note that we already have `Dataset.to_pandas()` so for consistency I'd call it `DatasetDict.to_pandas()` as well, does it sound good to you ? This is something we can add pretty easily",
"yeah that sounds perfect @lhoestq !",
"> So just to make sure that I understand the current direction, people will have to be extra careful when handling splits right?\r\n\r\nWe can raise an error if someone does `load_dataset(...)[0]` if the dataset is made of several splits, and return the first example if there's one or zero splits (i.e. when it's not ambiguous). Had this idea from the dicussions in #5312 WDYT @thomasw21 ?",
"> We can raise an error if someone does load_dataset(...)[0] if the dataset is made of several splits,\r\n\r\nBut then how is that different to have the distinction between DatasetDict and Dataset then? Is it just that \"default behaviour when there are no splits or single split, it returns directly the split when there's no ambiguity\".\r\n\r\nAlso I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?",
"> But then how is that different to have the distinction between DatasetDict and Dataset then?\r\n\r\nBecause it doesn't make sense to be able to do `example = ds[0]` or `examples = list(ds)` on a class named `DatasetDict` of type `Dict[str, Dataset]`.\r\n\r\n> Also I was wondering how the concatenation could have heavy impacts when running mapping functions/filtering in batch? Typically can batch be somehow mixed?\r\n\r\nNo, we run each function on each split separated",
"> Because it doesn't make sense to be able to do example = ds[0] or examples = list(ds) on a class named DatasetDict of type Dict[str, Dataset].\r\n\r\nHum but you're still going to raise an exception in both those cases with your current change no? (actually list(ds) would return the name of the splits no?)\r\n\r\n> No, we run each function on each split separated\r\n\r\nNice!"
] | "2022-11-02T09:15:02Z" | "2022-12-06T12:13:17Z" | null | CONTRIBUTOR | null | null | null | ### Feature request
Sorry for cryptic name but I'd like to explain using code itself. When I want to load a specific dataset from a repository (for instance, this: https://huggingface.co/datasets/inria-soda/tabular-benchmark)
```python
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
print(next(iter(dataset["train"])))
```
`datasets` library is essentially designed for people who'd like to use benchmark datasets on various modalities to fine-tune their models, and these benchmark datasets usually have pre-defined train and test splits. However, for tabular workflows, having train and test splits usually ends up model overfitting to validation split so usually the users would like to do validation techniques like `StratifiedKFoldCrossValidation` or when they tune for hyperparameters they do `GridSearchCrossValidation` so often the behavior is to create their own splits. Even [in this paper](https://hal.archives-ouvertes.fr/hal-03723551) a benchmark is introduced but the split is done by authors.
It's a bit confusing for average tabular user to try and load a dataset and see `"train"` so it would be nice if we would not load dataset into a split called `train `by default.
```diff
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-benchmark", data_files=["reg_cat/house_sales.csv"], streaming=True)
-print(next(iter(dataset["train"])))
+print(next(iter(dataset)))
```
### Motivation
I explained it above 😅
### Your contribution
I think this is quite a big change that seems small (e.g. how to determine datasets that will not be load to train split?), it's best if we discuss first! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5189/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2996 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2996/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2996/comments | https://api.github.com/repos/huggingface/datasets/issues/2996/events | https://github.com/huggingface/datasets/pull/2996 | 1,013,266,373 | PR_kwDODunzps4sjrP6 | 2,996 | Remove all query parameters when extracting protocol | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"Beware of cases like: `http://ufal.ms.mff.cuni.cz/umc/005-en-ur/download.php?f=umc005-corpus.zip` or `gzip://bg-cs.xml::https://opus.nlpl.eu/download.php?f=Europarl/v8/xml/bg-cs.xml.gz`. I see these URLs in the errors (https://observablehq.com/@huggingface/quality-assessment-of-datasets-loading?collection=@huggingface/datasets), but not in the `Extraction protocol for file at xxx is not implemented yet` error, so I'm not sure if they would break now or not.\r\n\r\nMaybe: first try to find an extension, and if none, try to remove the `?...` part and retry to find the extension.\r\n\r\nBy the way, here is the list of URLs for errors of this type, with a '?' in the URL:\r\n\r\n```\r\nhttps://dl.orangedox.com/WyaCpL?dl=1\r\nhttps://drive.google.com/u/0/uc?id=0Bz8a_Dbh9QhbaW12WVVZS2drcnM&export=download\r\nhttps://drive.google.com/u/0/uc?id=1-CaP3xHgZxOGjQ3pXC5tr9YnIajmel-t&export=download\r\nhttps://drive.google.com/u/0/uc?id=11EBGHMAswT5JDO60xh7gnZfYjpMQs7h7&export=download\r\nhttps://drive.google.com/u/0/uc?id=13JCCr-IjZK7uhbLXeufptr_AxvsKinVl&export=download\r\nhttps://drive.google.com/u/0/uc?id=13ZyFc2qepAYSg9WIFaeJ9y402gblsl2e&export=download\r\nhttps://drive.google.com/u/0/uc?id=15auwrFAlq52JJ61u7eSfnhT9rZtI5sjk&export=download\r\nhttps://drive.google.com/u/0/uc?id=16OgJ_OrfzUF_i3ftLjFn9kpcyoi7UJeO&export=download\r\nhttps://drive.google.com/u/0/uc?id=1BFYF05rx-DK9Eb5hgoIgd6EcB8zOI-zu&export=download\r\nhttps://drive.google.com/u/0/uc?id=1Cz1Un9p8Xn9IpEMMrg2kXSDt0dnjxc4z&export=download\r\nhttps://drive.google.com/u/0/uc?id=1H7FphKVVCYoH49sUXl79CuztEfJLaKoF&export=download\r\nhttps://drive.google.com/u/0/uc?id=1NAeuWLgYBzLwU5jCdkrtj4_PRUocuvlb&export=download\r\nhttps://drive.google.com/u/0/uc?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh&export=download\r\nhttps://drive.google.com/u/0/uc?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh&export=download/\r\nhttps://drive.google.com/u/0/uc?id=1R1jR4DcH2UEaM1ZwDSRHdfTGvkCNu6NW&export=download\r\nhttps://drive.google.com/u/0/uc?id=1hDHeoFIfQzJec1NgZNXh3CTNbchiIvuG&export=download\r\nhttps://drive.google.com/u/0/uc?id=1wxwqnWGRzwvc_-ugRoFX8BPgpO3Q7sch&export=download\r\nhttps://drive.google.com/u/0/uc?id=1ydsOTvBZXKqcRvXawOuePrJ99slOEbkk&export=download\r\nhttps://drive.google.com/uc?export=download&id=0BwmD_VLjROrfTHk4NFg2SndKcjQ\r\nhttps://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbQ2Vic1kxMmZZQ1k\r\nhttps://drive.google.com/uc?export=download&id=0Bz8a_Dbh9QhbZlU4dXhHTFhZQU0\r\nhttps://drive.google.com/uc?export=download&id=0Bz8a_Dbh9Qhbd2JNdDBsQUdocVU\r\nhttps://drive.google.com/uc?export=download&id=1-w-0uqaC6hnRn1F_3XqJEvi09zlcTIhX\r\nhttps://drive.google.com/uc?export=download&id=11wMGqNVSwwk6zUnDaJEgm3qT71kAHeff\r\nhttps://drive.google.com/uc?export=download&id=17FGi8KI9N9SuGe7elM8qU8_3fx4sfgTr\r\nhttps://drive.google.com/uc?export=download&id=1AHUm1-_V9GCtGuDcc8XrMUCJE8B-HHoL\r\nhttps://drive.google.com/uc?export=download&id=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U\r\nhttps://drive.google.com/uc?export=download&id=1Ev4RqWcPsLI9rgOGAKh-_dFKqcEZ1u-G\r\nhttps://drive.google.com/uc?export=download&id=1GTHUJxxmjLmG2lnF9dwRgIDRFZaOY3-F\r\nhttps://drive.google.com/uc?export=download&id=1GcUN6mytEcOMBBOvjJOQzBmEkc-LdgQg\r\nhttps://drive.google.com/uc?export=download&id=1J3mucMFTWrgAYa3LuBZoLRR3CzzYD3fa\r\nhttps://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P\r\nhttps://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil\r\nhttps://drive.google.com/uc?export=download&id=1M1M5yIOyjKWGprc3LUeVVwxgKXxgpqxm\r\nhttps://drive.google.com/uc?export=download&id=1Nug7-Sri50mkJL4GrWw6C2ZIbfeU-6Am\r\nhttps://drive.google.com/uc?export=download&id=1PGa8j1_IqxiGTc3SU6NMB38sAzxCPS34\r\nhttps://drive.google.com/uc?export=download&id=1QsV8C5EPJrQl37mwva_5-IJOrCaOi2tH\r\nhttps://drive.google.com/uc?export=download&id=1RsGLINVce-0GsDkCLDuLZmoLuzfmoCuQ\r\nhttps://drive.google.com/uc?export=download&id=1TuWH7uwu6V90QWmZn25qhou1rm97Egmn\r\nhttps://drive.google.com/uc?export=download&id=1U7WdBpd9kJ85S7BbBhWUSiy9NnXrKdO6\r\nhttps://drive.google.com/uc?export=download&id=1USoQ8lJgN8kAWnUnRrupMGrPMLlDVqlV\r\nhttps://drive.google.com/uc?export=download&id=1Uit4Og1pk-br_0UJIO5sdhApyhTuHzqo\r\nhttps://drive.google.com/uc?export=download&id=1Z2ty5hU0tIGRZRDlFQZLO7b5vijRfvo0\r\nhttps://drive.google.com/uc?export=download&id=1ZyFGufe4puX3vjGPbp4xg9Hca3Gwq22g\r\nhttps://drive.google.com/uc?export=download&id=1ZzlIQvw1KNBG97QQCfdatvVrrbeLaM1u\r\nhttps://drive.google.com/uc?export=download&id=1_AckYkinAnhqmRQtGsQgUKAnTHxxX5J0\r\nhttps://drive.google.com/uc?export=download&id=1__EjA6oZsgXQpggPm-h54jZu3kP6Y6zu\r\nhttps://drive.google.com/uc?export=download&id=1aHPVfC5TrlnUjehtagVZoDfq4VccgaNT\r\nhttps://drive.google.com/uc?export=download&id=1cqu_YAgvlyVSzzjcUyP1Cz7q0k8Pw7vN\r\nhttps://drive.google.com/uc?export=download&id=1dUIqVwvoZAtbX_-z5axCoe97XNcFo1No\r\nhttps://drive.google.com/uc?export=download&id=1eTtRs5cUlBP5dXsx-FTAlmXuB6JQi2qj\r\nhttps://drive.google.com/uc?export=download&id=1fUR3MqJ8jTMka6owA0S-Fe6aHmiophc_\r\nhttps://drive.google.com/uc?export=download&id=1ffWfITKFMJeqjT8loC8aiCLRNJpc_XnF\r\nhttps://drive.google.com/uc?export=download&id=1g89WgFHMRbr4QrvA0ngh26PY081Nv3lx\r\nhttps://drive.google.com/uc?export=download&id=1meSNZHxd_0TZLKCRCYGN-Ke3IA5c1qOE\r\nhttps://drive.google.com/uc?export=download&id=1okwGJiOZmTpNRNgJLCnjFF4Q0H1z4l6_\r\nhttps://drive.google.com/uc?export=download&id=1phryJg4FjCFkn0mSCqIOP2-FscAeKGV0\r\nhttps://drive.google.com/uc?export=download&id=1s8NSFT4Kz0caKZ4VybPNzt88F8ZanprY\r\nhttps://drive.google.com/uc?export=download&id=1vRY2wM6rlOZrf9exGTm5pXj5ExlVwJ0C\r\nhttps://drive.google.com/uc?export=download&id=1ytVZ4AhubFDOEL7o7XrIRIyhU8g9wvKA\r\nhttps://drive.google.com/uc?id=12Uz59TYg_NtxOy7SXraYeXPMRT7oaO7X\r\nhttps://drive.google.com/uc?id=1PGH5H_oW7wUvMw_5xaXvbEN7DFll-wDX\r\nhttps://github.com/MaazAmjad/Datasets-for-Urdu-news/blob/master/Urdu%20Fake%20News%20Dataset.zip?raw=true\r\nhttps://github.com/TevenLeScao/glucose/blob/master/GLUCOSE_training_data.zip?raw=true\r\nhttps://github.com/TevenLeScao/what-time-is-it/blob/master/gutenberg_time_phrases.zip?raw=true\r\nhttps://github.com/aviaefrat/cryptonite/blob/main/data/cryptonite-official-split.zip?raw=true\r\nhttps://github.com/facebookresearch/Imppres/blob/master/dataset/IMPPRES.zip?raw=true\r\nhttps://github.com/ljos/navnkjenner/blob/master/data/bokmaal/no_bokmaal-ud-train.bioes?raw=true\r\nhttps://github.com/ljos/navnkjenner/blob/master/data/nynorsk/no_nynorsk-ud-train.bioes?raw=true\r\nhttps://github.com/ljos/navnkjenner/blob/master/data/samnorsk/no_samnorsk-ud-train.bioes?raw=true\r\nhttps://github.com/mirfan899/Urdu/blob/master/sentiment/imdb_urdu_reviews.csv.tar.gz?raw=true\r\nhttps://github.com/omilab/Neural-Sentiment-Analyzer-for-Modern-Hebrew/blob/master/data/morph_train.tsv?raw=true\r\nhttps://github.com/omilab/Neural-Sentiment-Analyzer-for-Modern-Hebrew/blob/master/data/token_train.tsv?raw=true\r\nhttps://lindat.mff.cuni.cz/repository/xmlui/bitstream/handle/11858/00-097C-0000-0023-625F-0/hindencorp05.plaintext.gz?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/299/nchlt_afrikaans_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/312/nchlt_isixhosa_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/319/nchlt_isizulu_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/328/nchlt_sepedi_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/334/nchlt_sesotho_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/341/nchlt_setswana_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://repo.sadilar.org/bitstream/handle/20.500.12185/346/nchlt_siswati_named_entity_annotated_corpus.zip?sequence=3&isAllowed=y\r\nhttps://www.dropbox.com/s/tohrsllcfy7rch4/SimpleQuestions_v2.tgz?dl=1\r\nhttps://zenodo.org/record/1043504/files/corpus-webis-tldr-17.zip?download=1\r\nhttps://zenodo.org/record/1489920/files/articles-training-byarticle-20181122.zip?download=1\r\nhttps://zenodo.org/record/1489920/files/articles-training-bypublisher-20181122.zip?download=1\r\nhttps://zenodo.org/record/2787612/files/SICK.zip?download=1\r\nhttps://zenodo.org/record/3553423/files/Swahili%20data.zip?download=1\r\nhttps://zenodo.org/record/3707949/files/tapaco_v1.0.zip?download=1\r\nhttps://zenodo.org/record/4300294/files/train.csv?download=1\r\n```\r\n\r\n",
"Hi @severo, I just saw your comment. Thank you.\r\n\r\nFinally I just swapped the 2 parsings: first I extract extension and then I remove query parameters. 😉 ",
"OK :) Maybe we should add some unit tests to ensure we improve the detection without regressions (it's Friday afternoon, I trust the unit tests more than my analysis of the code)",
"Great! For the tests, I think we should also add some URLs in the form: `http://ufal.ms.mff.cuni.cz/umc/005-en-ur/download.php?f=umc005-corpus.zip` to be sure they are still correctly detected."
] | "2021-10-01T12:05:34Z" | "2021-10-04T08:48:13Z" | "2021-10-04T08:48:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2996.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2996",
"merged_at": "2021-10-04T08:48:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2996.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2996"
} | Fix `_get_extraction_protocol` to remove all query parameters, like `?raw=true`, `?dl=1`,... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2996/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2996/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/846 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/846/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/846/comments | https://api.github.com/repos/huggingface/datasets/issues/846/events | https://github.com/huggingface/datasets/issues/846 | 741,885,174 | MDU6SXNzdWU3NDE4ODUxNzQ= | 846 | Add HoVer multi-hop fact verification dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "https://api.github.com/users/yjernite/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yjernite",
"id": 10469459,
"login": "yjernite",
"node_id": "MDQ6VXNlcjEwNDY5NDU5",
"organizations_url": "https://api.github.com/users/yjernite/orgs",
"received_events_url": "https://api.github.com/users/yjernite/received_events",
"repos_url": "https://api.github.com/users/yjernite/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yjernite/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yjernite/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yjernite"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hi @yjernite I'm new but wanted to contribute. Has anyone already taken this problem and do you think it is suitable for newbies?",
"Hi @tenjjin! This dataset is still up for grabs! Here's the link with the guide to add it. You should play around with the library first (download and look at a few datasets), then follow the steps here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md",
"Closed by #1399 "
] | "2020-11-12T19:55:46Z" | "2020-12-10T21:47:33Z" | "2020-12-10T21:47:33Z" | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** HoVer
- **Description:** https://twitter.com/YichenJiang9/status/1326954363806429186 contains 20K claim verification examples
- **Paper:** https://arxiv.org/abs/2011.03088
- **Data:** https://hover-nlp.github.io/
- **Motivation:** There are still few multi-hop information extraction benchmarks (HotpotQA, which dataset wase based off, notwithstanding)
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/846/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/846/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4524/comments | https://api.github.com/repos/huggingface/datasets/issues/4524/events | https://github.com/huggingface/datasets/issues/4524 | 1,275,909,186 | I_kwDODunzps5MDNRC | 4,524 | Downloading via Apache Pipeline, client cancelled (org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException) | {
"avatar_url": "https://avatars.githubusercontent.com/u/45244059?v=4",
"events_url": "https://api.github.com/users/dan-the-meme-man/events{/privacy}",
"followers_url": "https://api.github.com/users/dan-the-meme-man/followers",
"following_url": "https://api.github.com/users/dan-the-meme-man/following{/other_user}",
"gists_url": "https://api.github.com/users/dan-the-meme-man/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dan-the-meme-man",
"id": 45244059,
"login": "dan-the-meme-man",
"node_id": "MDQ6VXNlcjQ1MjQ0MDU5",
"organizations_url": "https://api.github.com/users/dan-the-meme-man/orgs",
"received_events_url": "https://api.github.com/users/dan-the-meme-man/received_events",
"repos_url": "https://api.github.com/users/dan-the-meme-man/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dan-the-meme-man/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dan-the-meme-man/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dan-the-meme-man"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi @dan-the-meme-man, thanks for reporting.\r\n\r\nWe are investigating a similar issue but with Beam+Dataflow (instead of Beam+Flink): \r\n- #4525\r\n\r\nIn order to go deeper into the root cause, we need as much information as possible: logs from the main process + logs from the workers are very informative.\r\n\r\nIn the case of the issue with Beam+Dataflow, the logs from the workers report an out of memory issue.",
"As I continued working on this today, I came to suspect that it is in fact an out of memory issue - I have a few more notebooks that I've left running, and if they produce the same error, I will try to get the logs. In the meantime, if there's any chance that there is a repo out there with those three languages already as .arrow files, or if you know about how much memory would be needed to actually download those sets, please let me know!"
] | "2022-06-18T23:36:45Z" | "2022-06-21T00:38:20Z" | null | NONE | null | null | null | ## Describe the bug
When downloading some `wikipedia` languages (in particular, I'm having a hard time with Spanish, Cebuano, and Russian) via FlinkRunner, I encounter the exception in the title. I have been playing with package versions a lot, because unfortunately, the different dependencies required by these packages seem to be incompatible in terms of versions (dill and requests, for instance). It should be noted that the following code runs for several hours without issue, executing the `load_dataset()` function, before the exception occurs.
## Steps to reproduce the bug
```python
# bash commands
!pip install datasets
!pip install apache-beam[interactive]
!pip install mwparserfromhell
!pip install dill==0.3.5.1
!pip install requests==2.23.0
# imports
import os
from datasets import load_dataset
import apache_beam as beam
import mwparserfromhell
from google.colab import drive
import dill
import requests
# mount drive
drive_dir = os.path.join(os.getcwd(), 'drive')
drive.mount(drive_dir)
# confirming the versions of these two packages are the ones that are suggested by the outputs from the bash commands
print(dill.__version__)
print(requests.__version__)
lang = 'es' # or 'ru' or 'ceb' - these are the ones causing the issue
lang_dir = os.path.join(drive_dir, 'path/to/my/folder', lang)
if not os.path.exists(lang_dir):
x = None
x = load_dataset('wikipedia', '20220301.' + lang, beam_runner='Flink',
split='train')
x.save_to_disk(lang_dir)
```
## Expected results
Although some warnings are generally produced by this code (run in Colab Notebook), most languages I've tried have been successfully downloaded. It should simply go through without issue, but for these languages, I am continually encountering this error.
## Actual results
Traceback below:
```
Exception in thread run_worker_3-1:
Traceback (most recent call last):
File "/usr/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/usr/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 234, in run
for work_request in self._control_stub.Control(get_responses()):
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "Socket closed"
debug_error_string = "{"created":"@1655593643.871830638","description":"Error received from peer ipv4:127.0.0.1:44441","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Socket closed","grpc_status":14}"
>
Traceback (most recent call last):
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 267, in _execute
response = task()
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 340, in <lambda>
lambda: self.create_worker().do_instruction(request), request)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 581, in do_instruction
getattr(request, request_type), request.instruction_id)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 618, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 996, in process_bundle
element.data)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 221, in process_encoded
self.output(decoded_value)
File "apache_beam/runners/worker/operations.py", line 346, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 348, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 215, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive
File "apache_beam/runners/worker/operations.py", line 707, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/worker/operations.py", line 708, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/common.py", line 1200, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 1281, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
ERROR:apache_beam.runners.worker.sdk_worker:Error processing instruction 26. Original traceback is
Traceback (most recent call last):
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 267, in _execute
response = task()
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 340, in <lambda>
lambda: self.create_worker().do_instruction(request), request)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 581, in do_instruction
getattr(request, request_type), request.instruction_id)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 618, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 996, in process_bundle
element.data)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 221, in process_encoded
self.output(decoded_value)
File "apache_beam/runners/worker/operations.py", line 346, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 348, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam/runners/worker/operations.py", line 215, in apache_beam.runners.worker.operations.SingletonConsumerSet.receive
File "apache_beam/runners/worker/operations.py", line 707, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/worker/operations.py", line 708, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam/runners/common.py", line 1200, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 1281, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam/runners/common.py", line 1198, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam/runners/common.py", line 718, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam/runners/common.py", line 782, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/bundle_processor.py", line 426, in __getitem__
self._cache[target_window] = self._side_input_data.view_fn(raw_view)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 391, in <lambda>
lambda iterable: from_runtime_iterable(iterable, view_options))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/pvalue.py", line 512, in _from_runtime_iterable
head = list(itertools.islice(it, 2))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1228, in _lazy_iterator
self._underlying.get_raw(state_key, continuation_token))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1019, in get_raw
continuation_token=continuation_token)))
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/sdk_worker.py", line 1060, in _blocking_request
raise RuntimeError(response.error)
RuntimeError: Unknown process bundle instruction id '26' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
ERROR:root:org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException: CANCELLED: client cancelled
ERROR:apache_beam.runners.worker.data_plane:Failed to read inputs in the data plane.
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 634, in _read_inputs
for elements in elements_iterator:
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.CANCELLED
details = "Multiplexer hanging up"
debug_error_string = "{"created":"@1655593654.436885887","description":"Error received from peer ipv4:127.0.0.1:43263","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Multiplexer hanging up","grpc_status":1}"
>
Exception in thread read_grpc_client_inputs:
Traceback (most recent call last):
File "/usr/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/usr/lib/python3.7/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 651, in <lambda>
target=lambda: self._read_inputs(elements_iterator),
File "/usr/local/lib/python3.7/dist-packages/apache_beam/runners/worker/data_plane.py", line 634, in _read_inputs
for elements in elements_iterator:
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 426, in __next__
return self._next()
File "/usr/local/lib/python3.7/dist-packages/grpc/_channel.py", line 826, in _next
raise self
grpc._channel._MultiThreadedRendezvous: <_MultiThreadedRendezvous of RPC that terminated with:
status = StatusCode.CANCELLED
details = "Multiplexer hanging up"
debug_error_string = "{"created":"@1655593654.436885887","description":"Error received from peer ipv4:127.0.0.1:43263","file":"src/core/lib/surface/call.cc","file_line":952,"grpc_message":"Multiplexer hanging up","grpc_status":1}"
>
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
[/tmp/ipykernel_219/3869142325.py](https://localhost:8080/#) in <module>
18 x = None
19 x = load_dataset('wikipedia', '20220301.' + lang, beam_runner='Flink',
---> 20 split='train')
21 x.save_to_disk(lang_dir)
3 frames
[/usr/local/lib/python3.7/dist-packages/apache_beam/runners/portability/portable_runner.py](https://localhost:8080/#) in wait_until_finish(self, duration)
604
605 if self._runtime_exception:
--> 606 raise self._runtime_exception
607
608 return self._state
RuntimeError: Pipeline BeamApp-root-0618220708-b3b59a0e_d8efcf67-9119-4f76-b013-70de7b29b54d failed in state FAILED: org.apache.beam.vendor.grpc.v1p43p2.io.grpc.StatusRuntimeException: CANCELLED: client cancelled
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- PyArrow version: 6.0.1
- Pandas version: 1.3.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4524/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4524/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5623/comments | https://api.github.com/repos/huggingface/datasets/issues/5623/events | https://github.com/huggingface/datasets/pull/5623 | 1,616,712,665 | PR_kwDODunzps5Lpb4q | 5,623 | Remove set_access_token usage + fail tests if FutureWarning | {
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https://api.github.com/users/Wauplin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Wauplin",
"id": 11801849,
"login": "Wauplin",
"node_id": "MDQ6VXNlcjExODAxODQ5",
"organizations_url": "https://api.github.com/users/Wauplin/orgs",
"received_events_url": "https://api.github.com/users/Wauplin/received_events",
"repos_url": "https://api.github.com/users/Wauplin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Wauplin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wauplin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Wauplin"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008505 / 0.011353 (-0.002848) | 0.004445 / 0.011008 (-0.006563) | 0.102197 / 0.038508 (0.063689) | 0.029886 / 0.023109 (0.006776) | 0.305387 / 0.275898 (0.029489) | 0.355986 / 0.323480 (0.032507) | 0.006814 / 0.007986 (-0.001172) | 0.003298 / 0.004328 (-0.001030) | 0.079204 / 0.004250 (0.074954) | 0.035618 / 0.037052 (-0.001434) | 0.320430 / 0.258489 (0.061941) | 0.353330 / 0.293841 (0.059490) | 0.033280 / 0.128546 (-0.095266) | 0.011300 / 0.075646 (-0.064347) | 0.324627 / 0.419271 (-0.094644) | 0.040405 / 0.043533 (-0.003128) | 0.308760 / 0.255139 (0.053621) | 0.331885 / 0.283200 (0.048685) | 0.084605 / 0.141683 (-0.057077) | 1.576598 / 1.452155 (0.124443) | 1.530694 / 1.492716 (0.037977) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191142 / 0.018006 (0.173136) | 0.404042 / 0.000490 (0.403552) | 0.001185 / 0.000200 (0.000985) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022889 / 0.037411 (-0.014523) | 0.095862 / 0.014526 (0.081336) | 0.104382 / 0.176557 (-0.072175) | 0.139407 / 0.737135 (-0.597728) | 0.106813 / 0.296338 (-0.189525) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419083 / 0.215209 (0.203874) | 4.188702 / 2.077655 (2.111047) | 1.897854 / 1.504120 (0.393734) | 1.689544 / 1.541195 (0.148350) | 1.714032 / 1.468490 (0.245542) | 0.695541 / 4.584777 (-3.889236) | 3.370584 / 3.745712 (-0.375128) | 3.205549 / 5.269862 (-2.064313) | 1.641202 / 4.565676 (-2.924474) | 0.081849 / 0.424275 (-0.342426) | 0.012043 / 0.007607 (0.004436) | 0.529618 / 0.226044 (0.303574) | 5.314167 / 2.268929 (3.045238) | 2.357271 / 55.444624 (-53.087353) | 1.979684 / 6.876477 (-4.896793) | 2.030057 / 2.142072 (-0.112015) | 0.813013 / 4.805227 (-3.992214) | 0.150165 / 6.500664 (-6.350499) | 0.064595 / 0.075469 (-0.010874) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237824 / 1.841788 (-0.603964) | 13.552178 / 8.074308 (5.477870) | 14.089433 / 10.191392 (3.898041) | 0.149325 / 0.680424 (-0.531099) | 0.028543 / 0.534201 (-0.505658) | 0.396848 / 0.579283 (-0.182435) | 0.396230 / 0.434364 (-0.038134) | 0.466317 / 0.540337 (-0.074021) | 0.539579 / 1.386936 (-0.847357) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006224 / 0.011353 (-0.005128) | 0.004429 / 0.011008 (-0.006579) | 0.075740 / 0.038508 (0.037232) | 0.026717 / 0.023109 (0.003608) | 0.341685 / 0.275898 (0.065787) | 0.383671 / 0.323480 (0.060191) | 0.004682 / 0.007986 (-0.003304) | 0.004681 / 0.004328 (0.000352) | 0.076638 / 0.004250 (0.072387) | 0.034577 / 0.037052 (-0.002476) | 0.341160 / 0.258489 (0.082671) | 0.407590 / 0.293841 (0.113749) | 0.031121 / 0.128546 (-0.097425) | 0.011479 / 0.075646 (-0.064167) | 0.085299 / 0.419271 (-0.333973) | 0.042005 / 0.043533 (-0.001528) | 0.339682 / 0.255139 (0.084543) | 0.377669 / 0.283200 (0.094469) | 0.087751 / 0.141683 (-0.053932) | 1.523910 / 1.452155 (0.071756) | 1.607487 / 1.492716 (0.114771) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225605 / 0.018006 (0.207599) | 0.395851 / 0.000490 (0.395361) | 0.004404 / 0.000200 (0.004204) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024489 / 0.037411 (-0.012922) | 0.099813 / 0.014526 (0.085287) | 0.107392 / 0.176557 (-0.069165) | 0.139567 / 0.737135 (-0.597568) | 0.110080 / 0.296338 (-0.186258) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.449051 / 0.215209 (0.233841) | 4.463098 / 2.077655 (2.385443) | 2.122548 / 1.504120 (0.618428) | 1.913863 / 1.541195 (0.372669) | 1.963988 / 1.468490 (0.495498) | 0.698442 / 4.584777 (-3.886335) | 3.330425 / 3.745712 (-0.415287) | 1.867843 / 5.269862 (-3.402019) | 1.163740 / 4.565676 (-3.401937) | 0.083209 / 0.424275 (-0.341066) | 0.012594 / 0.007607 (0.004987) | 0.547074 / 0.226044 (0.321030) | 5.474779 / 2.268929 (3.205851) | 2.548025 / 55.444624 (-52.896599) | 2.202435 / 6.876477 (-4.674041) | 2.220330 / 2.142072 (0.078257) | 0.810104 / 4.805227 (-3.995124) | 0.151141 / 6.500664 (-6.349523) | 0.066204 / 0.075469 (-0.009265) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.272075 / 1.841788 (-0.569712) | 13.749523 / 8.074308 (5.675215) | 14.270974 / 10.191392 (4.079582) | 0.141285 / 0.680424 (-0.539139) | 0.016526 / 0.534201 (-0.517675) | 0.393175 / 0.579283 (-0.186109) | 0.391577 / 0.434364 (-0.042787) | 0.492824 / 0.540337 (-0.047513) | 0.580069 / 1.386936 (-0.806867) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008901 / 0.011353 (-0.002452) | 0.005017 / 0.011008 (-0.005991) | 0.099340 / 0.038508 (0.060832) | 0.034218 / 0.023109 (0.011109) | 0.295927 / 0.275898 (0.020029) | 0.330087 / 0.323480 (0.006607) | 0.008041 / 0.007986 (0.000056) | 0.005013 / 0.004328 (0.000685) | 0.074255 / 0.004250 (0.070004) | 0.049634 / 0.037052 (0.012582) | 0.299972 / 0.258489 (0.041483) | 0.349879 / 0.293841 (0.056038) | 0.038500 / 0.128546 (-0.090047) | 0.011980 / 0.075646 (-0.063666) | 0.332408 / 0.419271 (-0.086863) | 0.048385 / 0.043533 (0.004852) | 0.300393 / 0.255139 (0.045254) | 0.316972 / 0.283200 (0.033772) | 0.101674 / 0.141683 (-0.040009) | 1.424300 / 1.452155 (-0.027854) | 1.520658 / 1.492716 (0.027942) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.270084 / 0.018006 (0.252078) | 0.538612 / 0.000490 (0.538123) | 0.004439 / 0.000200 (0.004240) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026841 / 0.037411 (-0.010570) | 0.106454 / 0.014526 (0.091928) | 0.118371 / 0.176557 (-0.058186) | 0.155545 / 0.737135 (-0.581590) | 0.125119 / 0.296338 (-0.171220) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395794 / 0.215209 (0.180585) | 3.958195 / 2.077655 (1.880540) | 1.789010 / 1.504120 (0.284890) | 1.601380 / 1.541195 (0.060186) | 1.641062 / 1.468490 (0.172572) | 0.679547 / 4.584777 (-3.905230) | 3.778018 / 3.745712 (0.032306) | 2.101232 / 5.269862 (-3.168630) | 1.463932 / 4.565676 (-3.101745) | 0.083639 / 0.424275 (-0.340636) | 0.012339 / 0.007607 (0.004732) | 0.498708 / 0.226044 (0.272663) | 4.995178 / 2.268929 (2.726249) | 2.272650 / 55.444624 (-53.171975) | 1.907879 / 6.876477 (-4.968598) | 2.012666 / 2.142072 (-0.129407) | 0.829564 / 4.805227 (-3.975663) | 0.165049 / 6.500664 (-6.335615) | 0.062291 / 0.075469 (-0.013178) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.193977 / 1.841788 (-0.647811) | 14.816939 / 8.074308 (6.742631) | 14.369729 / 10.191392 (4.178337) | 0.156339 / 0.680424 (-0.524084) | 0.029151 / 0.534201 (-0.505050) | 0.449362 / 0.579283 (-0.129921) | 0.451895 / 0.434364 (0.017531) | 0.520324 / 0.540337 (-0.020013) | 0.610716 / 1.386936 (-0.776220) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007145 / 0.011353 (-0.004207) | 0.005299 / 0.011008 (-0.005710) | 0.074216 / 0.038508 (0.035708) | 0.033015 / 0.023109 (0.009906) | 0.337117 / 0.275898 (0.061219) | 0.367161 / 0.323480 (0.043682) | 0.005898 / 0.007986 (-0.002088) | 0.005283 / 0.004328 (0.000955) | 0.073795 / 0.004250 (0.069544) | 0.049253 / 0.037052 (0.012201) | 0.343327 / 0.258489 (0.084838) | 0.396417 / 0.293841 (0.102576) | 0.037162 / 0.128546 (-0.091384) | 0.012456 / 0.075646 (-0.063191) | 0.086668 / 0.419271 (-0.332604) | 0.049937 / 0.043533 (0.006404) | 0.335138 / 0.255139 (0.079999) | 0.358111 / 0.283200 (0.074912) | 0.107328 / 0.141683 (-0.034355) | 1.482290 / 1.452155 (0.030135) | 1.557872 / 1.492716 (0.065156) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.343759 / 0.018006 (0.325752) | 0.542697 / 0.000490 (0.542207) | 0.025943 / 0.000200 (0.025743) | 0.000264 / 0.000054 (0.000209) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028469 / 0.037411 (-0.008943) | 0.108620 / 0.014526 (0.094094) | 0.123667 / 0.176557 (-0.052890) | 0.168829 / 0.737135 (-0.568306) | 0.125875 / 0.296338 (-0.170464) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424640 / 0.215209 (0.209431) | 4.227611 / 2.077655 (2.149956) | 2.003605 / 1.504120 (0.499486) | 1.810696 / 1.541195 (0.269501) | 1.882700 / 1.468490 (0.414210) | 0.701361 / 4.584777 (-3.883416) | 3.808054 / 3.745712 (0.062342) | 3.234896 / 5.269862 (-2.034966) | 1.872195 / 4.565676 (-2.693482) | 0.088102 / 0.424275 (-0.336173) | 0.012810 / 0.007607 (0.005203) | 0.551855 / 0.226044 (0.325810) | 5.245654 / 2.268929 (2.976725) | 2.557123 / 55.444624 (-52.887502) | 2.238897 / 6.876477 (-4.637580) | 2.256260 / 2.142072 (0.114187) | 0.849804 / 4.805227 (-3.955424) | 0.170557 / 6.500664 (-6.330107) | 0.064718 / 0.075469 (-0.010751) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.271701 / 1.841788 (-0.570087) | 14.925010 / 8.074308 (6.850702) | 14.966948 / 10.191392 (4.775556) | 0.162966 / 0.680424 (-0.517458) | 0.017618 / 0.534201 (-0.516583) | 0.433484 / 0.579283 (-0.145799) | 0.430047 / 0.434364 (-0.004316) | 0.537356 / 0.540337 (-0.002981) | 0.639237 / 1.386936 (-0.747699) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012054 / 0.011353 (0.000702) | 0.005923 / 0.011008 (-0.005085) | 0.129531 / 0.038508 (0.091023) | 0.036283 / 0.023109 (0.013173) | 0.374406 / 0.275898 (0.098508) | 0.452538 / 0.323480 (0.129058) | 0.009419 / 0.007986 (0.001434) | 0.004783 / 0.004328 (0.000454) | 0.095292 / 0.004250 (0.091042) | 0.041290 / 0.037052 (0.004238) | 0.403940 / 0.258489 (0.145451) | 0.443091 / 0.293841 (0.149250) | 0.054635 / 0.128546 (-0.073911) | 0.019062 / 0.075646 (-0.056584) | 0.417053 / 0.419271 (-0.002218) | 0.060865 / 0.043533 (0.017332) | 0.378535 / 0.255139 (0.123396) | 0.401036 / 0.283200 (0.117836) | 0.122959 / 0.141683 (-0.018724) | 1.768517 / 1.452155 (0.316362) | 1.794700 / 1.492716 (0.301984) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246529 / 0.018006 (0.228523) | 0.576887 / 0.000490 (0.576397) | 0.005031 / 0.000200 (0.004831) | 0.000125 / 0.000054 (0.000070) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027363 / 0.037411 (-0.010049) | 0.119037 / 0.014526 (0.104511) | 0.148109 / 0.176557 (-0.028447) | 0.179370 / 0.737135 (-0.557765) | 0.145105 / 0.296338 (-0.151234) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.588748 / 0.215209 (0.373539) | 5.934433 / 2.077655 (3.856778) | 2.549811 / 1.504120 (1.045691) | 2.234616 / 1.541195 (0.693421) | 2.268002 / 1.468490 (0.799512) | 1.154643 / 4.584777 (-3.430134) | 5.333935 / 3.745712 (1.588223) | 2.971065 / 5.269862 (-2.298796) | 2.131427 / 4.565676 (-2.434250) | 0.127737 / 0.424275 (-0.296538) | 0.014699 / 0.007607 (0.007091) | 0.735160 / 0.226044 (0.509115) | 7.403838 / 2.268929 (5.134909) | 3.298169 / 55.444624 (-52.146455) | 2.661285 / 6.876477 (-4.215192) | 2.688877 / 2.142072 (0.546805) | 1.344110 / 4.805227 (-3.461118) | 0.242016 / 6.500664 (-6.258648) | 0.077418 / 0.075469 (0.001948) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.566426 / 1.841788 (-0.275362) | 17.144308 / 8.074308 (9.070000) | 19.360598 / 10.191392 (9.169206) | 0.238554 / 0.680424 (-0.441870) | 0.044946 / 0.534201 (-0.489255) | 0.554183 / 0.579283 (-0.025100) | 0.630175 / 0.434364 (0.195811) | 0.630319 / 0.540337 (0.089982) | 0.745060 / 1.386936 (-0.641876) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009255 / 0.011353 (-0.002098) | 0.006951 / 0.011008 (-0.004057) | 0.092021 / 0.038508 (0.053513) | 0.035588 / 0.023109 (0.012479) | 0.415564 / 0.275898 (0.139666) | 0.446393 / 0.323480 (0.122913) | 0.006532 / 0.007986 (-0.001453) | 0.005099 / 0.004328 (0.000771) | 0.094801 / 0.004250 (0.090550) | 0.044926 / 0.037052 (0.007874) | 0.439125 / 0.258489 (0.180636) | 0.473004 / 0.293841 (0.179163) | 0.057025 / 0.128546 (-0.071522) | 0.018711 / 0.075646 (-0.056935) | 0.110844 / 0.419271 (-0.308427) | 0.058347 / 0.043533 (0.014814) | 0.435721 / 0.255139 (0.180583) | 0.434624 / 0.283200 (0.151424) | 0.114505 / 0.141683 (-0.027178) | 1.722379 / 1.452155 (0.270225) | 1.775836 / 1.492716 (0.283120) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.275893 / 0.018006 (0.257887) | 0.552590 / 0.000490 (0.552100) | 0.007919 / 0.000200 (0.007719) | 0.000122 / 0.000054 (0.000068) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030003 / 0.037411 (-0.007408) | 0.130145 / 0.014526 (0.115619) | 0.131878 / 0.176557 (-0.044678) | 0.194693 / 0.737135 (-0.542442) | 0.137689 / 0.296338 (-0.158650) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.619591 / 0.215209 (0.404382) | 6.324095 / 2.077655 (4.246441) | 2.756563 / 1.504120 (1.252444) | 2.384744 / 1.541195 (0.843549) | 2.450407 / 1.468490 (0.981917) | 1.235391 / 4.584777 (-3.349386) | 5.535383 / 3.745712 (1.789671) | 4.831927 / 5.269862 (-0.437934) | 2.757158 / 4.565676 (-1.808519) | 0.133980 / 0.424275 (-0.290295) | 0.014965 / 0.007607 (0.007358) | 0.731423 / 0.226044 (0.505379) | 7.401850 / 2.268929 (5.132921) | 3.346585 / 55.444624 (-52.098039) | 2.705523 / 6.876477 (-4.170953) | 2.637397 / 2.142072 (0.495324) | 1.347745 / 4.805227 (-3.457482) | 0.248658 / 6.500664 (-6.252006) | 0.077427 / 0.075469 (0.001958) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.520860 / 1.841788 (-0.320928) | 17.153000 / 8.074308 (9.078692) | 19.051393 / 10.191392 (8.860001) | 0.236840 / 0.680424 (-0.443584) | 0.026638 / 0.534201 (-0.507563) | 0.518417 / 0.579283 (-0.060866) | 0.607555 / 0.434364 (0.173191) | 0.637381 / 0.540337 (0.097044) | 0.767109 / 1.386936 (-0.619827) |\n\n</details>\n</details>\n\n\n",
"Great, I merged it. Thanks for the review :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006711 / 0.011353 (-0.004641) | 0.004472 / 0.011008 (-0.006536) | 0.099581 / 0.038508 (0.061073) | 0.028036 / 0.023109 (0.004927) | 0.301197 / 0.275898 (0.025298) | 0.339341 / 0.323480 (0.015861) | 0.005107 / 0.007986 (-0.002879) | 0.003312 / 0.004328 (-0.001017) | 0.075823 / 0.004250 (0.071573) | 0.040861 / 0.037052 (0.003809) | 0.303407 / 0.258489 (0.044918) | 0.350717 / 0.293841 (0.056876) | 0.031657 / 0.128546 (-0.096889) | 0.011627 / 0.075646 (-0.064020) | 0.325465 / 0.419271 (-0.093806) | 0.052671 / 0.043533 (0.009138) | 0.301953 / 0.255139 (0.046814) | 0.327164 / 0.283200 (0.043964) | 0.091264 / 0.141683 (-0.050419) | 1.508947 / 1.452155 (0.056792) | 1.605685 / 1.492716 (0.112968) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.202977 / 0.018006 (0.184971) | 0.400602 / 0.000490 (0.400112) | 0.003253 / 0.000200 (0.003053) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022453 / 0.037411 (-0.014958) | 0.098633 / 0.014526 (0.084107) | 0.105996 / 0.176557 (-0.070561) | 0.162428 / 0.737135 (-0.574707) | 0.107139 / 0.296338 (-0.189199) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.453061 / 0.215209 (0.237852) | 4.530844 / 2.077655 (2.453190) | 2.286394 / 1.504120 (0.782274) | 2.076479 / 1.541195 (0.535284) | 2.143730 / 1.468490 (0.675240) | 0.702540 / 4.584777 (-3.882237) | 3.442688 / 3.745712 (-0.303024) | 1.874429 / 5.269862 (-3.395433) | 1.172331 / 4.565676 (-3.393346) | 0.083643 / 0.424275 (-0.340632) | 0.012519 / 0.007607 (0.004911) | 0.556859 / 0.226044 (0.330814) | 5.582843 / 2.268929 (3.313915) | 2.753734 / 55.444624 (-52.690890) | 2.415771 / 6.876477 (-4.460705) | 2.531428 / 2.142072 (0.389356) | 0.813005 / 4.805227 (-3.992222) | 0.153322 / 6.500664 (-6.347343) | 0.068061 / 0.075469 (-0.007408) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.180481 / 1.841788 (-0.661306) | 13.623933 / 8.074308 (5.549625) | 14.431288 / 10.191392 (4.239896) | 0.127580 / 0.680424 (-0.552844) | 0.016714 / 0.534201 (-0.517487) | 0.394236 / 0.579283 (-0.185047) | 0.381718 / 0.434364 (-0.052646) | 0.486749 / 0.540337 (-0.053589) | 0.565939 / 1.386936 (-0.820997) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006720 / 0.011353 (-0.004633) | 0.004518 / 0.011008 (-0.006491) | 0.076819 / 0.038508 (0.038311) | 0.027272 / 0.023109 (0.004163) | 0.340890 / 0.275898 (0.064992) | 0.381435 / 0.323480 (0.057955) | 0.004980 / 0.007986 (-0.003005) | 0.003382 / 0.004328 (-0.000947) | 0.076368 / 0.004250 (0.072117) | 0.037365 / 0.037052 (0.000313) | 0.341484 / 0.258489 (0.082995) | 0.388917 / 0.293841 (0.095076) | 0.032004 / 0.128546 (-0.096543) | 0.011612 / 0.075646 (-0.064034) | 0.084929 / 0.419271 (-0.334342) | 0.041861 / 0.043533 (-0.001671) | 0.350392 / 0.255139 (0.095253) | 0.369745 / 0.283200 (0.086546) | 0.088301 / 0.141683 (-0.053382) | 1.587296 / 1.452155 (0.135141) | 1.629761 / 1.492716 (0.137045) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.174825 / 0.018006 (0.156818) | 0.414371 / 0.000490 (0.413881) | 0.001595 / 0.000200 (0.001395) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025403 / 0.037411 (-0.012009) | 0.099593 / 0.014526 (0.085067) | 0.108819 / 0.176557 (-0.067738) | 0.161613 / 0.737135 (-0.575523) | 0.112302 / 0.296338 (-0.184037) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.439234 / 0.215209 (0.224024) | 4.389073 / 2.077655 (2.311418) | 2.063215 / 1.504120 (0.559095) | 1.852550 / 1.541195 (0.311356) | 1.920014 / 1.468490 (0.451524) | 0.710255 / 4.584777 (-3.874522) | 3.430549 / 3.745712 (-0.315164) | 1.886072 / 5.269862 (-3.383790) | 1.177490 / 4.565676 (-3.388186) | 0.084877 / 0.424275 (-0.339398) | 0.012894 / 0.007607 (0.005287) | 0.544950 / 0.226044 (0.318906) | 5.467347 / 2.268929 (3.198419) | 2.508169 / 55.444624 (-52.936455) | 2.167756 / 6.876477 (-4.708721) | 2.212817 / 2.142072 (0.070744) | 0.824762 / 4.805227 (-3.980465) | 0.154387 / 6.500664 (-6.346277) | 0.068535 / 0.075469 (-0.006934) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.284165 / 1.841788 (-0.557623) | 14.153006 / 8.074308 (6.078697) | 14.152569 / 10.191392 (3.961177) | 0.130083 / 0.680424 (-0.550341) | 0.016556 / 0.534201 (-0.517645) | 0.383828 / 0.579283 (-0.195455) | 0.388241 / 0.434364 (-0.046123) | 0.477982 / 0.540337 (-0.062355) | 0.565583 / 1.386936 (-0.821353) |\n\n</details>\n</details>\n\n\n"
] | "2023-03-09T08:46:01Z" | "2023-03-09T15:39:00Z" | "2023-03-09T15:31:59Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5623.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5623",
"merged_at": "2023-03-09T15:31:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5623.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5623"
} | `set_access_token` is deprecated and will be removed in `huggingface_hub>=0.14`.
This PR removes it from the tests (it was not used in `datasets` source code itself). FYI, it was not needed since `set_access_token` was just setting git credentials and `datasets` doesn't seem to use git anywhere.
In the future, use `set_git_credential` if needed. It is a git-credential-agnostic helper, i.e. you can store your git token in `git-credential-cache`, `git-credential-store`, `osxkeychain`, etc. The legacy `set_access_token` could only set in `git-credential-store` no matter the user preference.
(for context, I found out about this while working on https://github.com/huggingface/huggingface_hub/pull/1381)
---
In addition to this, I have added
```
filterwarnings =
error::FutureWarning:huggingface_hub*
```
to the `setup.cfg` config file to fail on future warnings from `huggingface_hub`. In `hfh`'s CI we trigger on FutureWarning from any package but it's less robust (any package update leads can lead to a failure). No obligation to keep it like that (I can remove it if you prefer) but I think it's a good idea in order to track future FutureWarnings.
FYI, in `huggingface_hub` tests we use `-Werror::FutureWarning --log-cli-level=INFO -sv --durations=0`
- FutureWarning are processed as error
- verbose mode / INFO logs (and above) are captured for easier debugging in github report
- track each test duration, just to see where we can improve. We have a quite long CI (~10min) so it helped improve that. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4773/comments | https://api.github.com/repos/huggingface/datasets/issues/4773/events | https://github.com/huggingface/datasets/pull/4773 | 1,322,796,721 | PR_kwDODunzps48WNV3 | 4,773 | Document loading from relative path | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the feedback!\r\n\r\nI agree that adding it to `load_hub.mdx` is probably a bit too specific, especially for beginners reading the tutorials. Since this clarification is closely related to loading from the Hub (the only difference being the presence/absence of a loading script), I think it makes the most sense to keep it somewhere in `loading.mdx`. What do you think about adding a Warning in Loading >>> Hugging Face Hub that explains the difference between relative/absolute paths when there is a script?",
"What about updating the section about \"manual download\" ? I think it goes there no ?\r\n\r\nhttps://huggingface.co/docs/datasets/v2.4.0/en/loading#manual-download",
"Updated the manual download section :)",
"Thanks ! Pinging @albertvillanova to review this change, and then I think we're good to merge"
] | "2022-07-29T23:32:21Z" | "2022-08-25T18:36:45Z" | "2022-08-25T18:34:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4773.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4773",
"merged_at": "2022-08-25T18:34:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4773.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4773"
} | This PR describes loading a dataset from the Hub by specifying a relative path in `data_dir` or `data_files` in `load_dataset` (see #4757). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4773/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4436/comments | https://api.github.com/repos/huggingface/datasets/issues/4436/events | https://github.com/huggingface/datasets/pull/4436 | 1,257,758,834 | PR_kwDODunzps449FsU | 4,436 | Fix directory names for LDC data in timit_asr dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-06-02T06:45:04Z" | "2022-06-02T09:32:56Z" | "2022-06-02T09:24:27Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4436.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4436",
"merged_at": "2022-06-02T09:24:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4436.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4436"
} | Related to:
- #4422 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4436/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4436/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3971 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3971/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3971/comments | https://api.github.com/repos/huggingface/datasets/issues/3971/events | https://github.com/huggingface/datasets/pull/3971 | 1,174,329,442 | PR_kwDODunzps40sS4W | 3,971 | Applied index-filters on scores in search.py. | {
"avatar_url": "https://avatars.githubusercontent.com/u/36671559?v=4",
"events_url": "https://api.github.com/users/vishalsrao/events{/privacy}",
"followers_url": "https://api.github.com/users/vishalsrao/followers",
"following_url": "https://api.github.com/users/vishalsrao/following{/other_user}",
"gists_url": "https://api.github.com/users/vishalsrao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vishalsrao",
"id": 36671559,
"login": "vishalsrao",
"node_id": "MDQ6VXNlcjM2NjcxNTU5",
"organizations_url": "https://api.github.com/users/vishalsrao/orgs",
"received_events_url": "https://api.github.com/users/vishalsrao/received_events",
"repos_url": "https://api.github.com/users/vishalsrao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vishalsrao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vishalsrao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vishalsrao"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-03-19T18:43:42Z" | "2022-04-12T14:48:23Z" | "2022-04-12T14:41:58Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3971.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3971",
"merged_at": "2022-04-12T14:41:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3971.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3971"
} | Updated search.py to resolve the issue mentioned in https://github.com/huggingface/datasets/issues/3961.
Applied index-filters on scores in get_nearest_examples and get_nearest_examples_batch methods of search.py. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3971/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3971/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
}
] | null | [
"Note that torchaudio is maybe less practical to use for TF or JAX users.\r\nThis is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice",
"> Note that torchaudio is maybe less practical to use for TF or JAX users. This is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice\r\n\r\n@lhoestq so maybe don't do this PR? :) if it doesn't work anyway with an opened file, only with path",
"Yes as discussed offline there seems to be issues with torchaudio on opened files. Feel free to close this PR if it's better to stick with soundfile because of that",
"We should be able to remove torchaudio, which has torch as a hard dependency, soon and use only soundfile for decoding: https://github.com/bastibe/python-soundfile/issues/252#issuecomment-1000246773 (opus + mp3 support is on the way)."
] | "2022-02-02T15:23:14Z" | "2022-02-04T15:29:38Z" | "2022-02-04T15:29:38Z" | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667"
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4909/comments | https://api.github.com/repos/huggingface/datasets/issues/4909/events | https://github.com/huggingface/datasets/pull/4909 | 1,353,997,788 | PR_kwDODunzps499Fhe | 4,909 | Update GLUE evaluation metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-08-29T09:43:44Z" | "2022-08-29T14:53:29Z" | "2022-08-29T14:51:18Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4909.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4909",
"merged_at": "2022-08-29T14:51:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4909.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4909"
} | This PR updates the evaluation metadata for GLUE to:
* Include defaults for all configs except `ax` (which only has a `test` split with no known labels)
* Fix the default split from `test` to `validation` since `test` splits in GLUE have no labels (they're private)
* Fix the `task_id` for some existing defaults
cc @sashavor @douwekiela | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4909/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4909/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4407/comments | https://api.github.com/repos/huggingface/datasets/issues/4407/events | https://github.com/huggingface/datasets/issues/4407 | 1,248,671,778 | I_kwDODunzps5KbTgi | 4,407 | Dataset Viewer issue for conll2012_ontonotesv5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/39762734?v=4",
"events_url": "https://api.github.com/users/jiangwangyi/events{/privacy}",
"followers_url": "https://api.github.com/users/jiangwangyi/followers",
"following_url": "https://api.github.com/users/jiangwangyi/following{/other_user}",
"gists_url": "https://api.github.com/users/jiangwangyi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jiangwangyi",
"id": 39762734,
"login": "jiangwangyi",
"node_id": "MDQ6VXNlcjM5NzYyNzM0",
"organizations_url": "https://api.github.com/users/jiangwangyi/orgs",
"received_events_url": "https://api.github.com/users/jiangwangyi/received_events",
"repos_url": "https://api.github.com/users/jiangwangyi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jiangwangyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiangwangyi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jiangwangyi"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
}
] | null | [
"Thanks for reporting, @jiangwy99.\r\n\r\nI guess this could be addressed only once we fix our issue with irresponsive backend endpoint.\r\n\r\nCC: @severo ",
"I've just sent the forcing of the refresh of the preview to the new endpoint.",
"Fixed, thanks for the patience. The issue was the amount of RAM allowed to extract the first rows of the dataset was not sufficient."
] | "2022-05-25T20:18:33Z" | "2022-06-07T18:39:16Z" | "2022-06-07T18:39:16Z" | NONE | null | null | null | ### Link
https://huggingface.co/datasets/conll2012_ontonotesv5
### Description
Dataset viewer outage.
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4407/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4321 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4321/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4321/comments | https://api.github.com/repos/huggingface/datasets/issues/4321/events | https://github.com/huggingface/datasets/pull/4321 | 1,233,273,351 | PR_kwDODunzps43ryW7 | 4,321 | Adding dataset enwik8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/22773355?v=4",
"events_url": "https://api.github.com/users/HallerPatrick/events{/privacy}",
"followers_url": "https://api.github.com/users/HallerPatrick/followers",
"following_url": "https://api.github.com/users/HallerPatrick/following{/other_user}",
"gists_url": "https://api.github.com/users/HallerPatrick/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/HallerPatrick",
"id": 22773355,
"login": "HallerPatrick",
"node_id": "MDQ6VXNlcjIyNzczMzU1",
"organizations_url": "https://api.github.com/users/HallerPatrick/orgs",
"received_events_url": "https://api.github.com/users/HallerPatrick/received_events",
"repos_url": "https://api.github.com/users/HallerPatrick/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/HallerPatrick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HallerPatrick/subscriptions",
"type": "User",
"url": "https://api.github.com/users/HallerPatrick"
} | [] | closed | false | null | [] | null | [
"@lhoestq Thank you for the great feedback! Looks like all tests are passing now :)",
"_The documentation is not available anymore as the PR was closed or merged._"
] | "2022-05-11T23:25:02Z" | "2022-06-01T14:27:30Z" | "2022-06-01T14:04:06Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4321.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4321",
"merged_at": "2022-06-01T14:04:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4321.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4321"
} | Because I regularly work with enwik8, I would like to contribute the dataset loader 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4321/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4321/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1456 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1456/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1456/comments | https://api.github.com/repos/huggingface/datasets/issues/1456/events | https://github.com/huggingface/datasets/pull/1456 | 761,231,296 | MDExOlB1bGxSZXF1ZXN0NTM1OTI4MTc2 | 1,456 | Add CC100 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/abhishekkrthakur",
"id": 1183441,
"login": "abhishekkrthakur",
"node_id": "MDQ6VXNlcjExODM0NDE=",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"type": "User",
"url": "https://api.github.com/users/abhishekkrthakur"
} | [] | closed | false | null | [] | null | [] | "2020-12-10T13:14:37Z" | "2020-12-14T10:20:09Z" | "2020-12-14T10:20:08Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1456.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1456",
"merged_at": "2020-12-14T10:20:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1456.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1456"
} | Closes #773 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1456/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1456/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4769/comments | https://api.github.com/repos/huggingface/datasets/issues/4769/events | https://github.com/huggingface/datasets/issues/4769 | 1,322,121,554 | I_kwDODunzps5OzflS | 4,769 | Fail to process SQuADv1.1 datasets with max_seq_length=128, doc_stride=96. | {
"avatar_url": "https://avatars.githubusercontent.com/u/5491519?v=4",
"events_url": "https://api.github.com/users/zhuango/events{/privacy}",
"followers_url": "https://api.github.com/users/zhuango/followers",
"following_url": "https://api.github.com/users/zhuango/following{/other_user}",
"gists_url": "https://api.github.com/users/zhuango/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zhuango",
"id": 5491519,
"login": "zhuango",
"node_id": "MDQ6VXNlcjU0OTE1MTk=",
"organizations_url": "https://api.github.com/users/zhuango/orgs",
"received_events_url": "https://api.github.com/users/zhuango/received_events",
"repos_url": "https://api.github.com/users/zhuango/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zhuango/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhuango/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zhuango"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [] | "2022-07-29T11:18:24Z" | "2022-07-29T11:18:24Z" | null | NONE | null | null | null | ## Describe the bug
datasets fail to process SQuADv1.1 with max_seq_length=128, doc_stride=96 when calling datasets["train"].train_dataset.map().
## Steps to reproduce the bug
I used huggingface[ TF2 question-answering examples](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering). And my scripts are as follows:
```
python run_qa.py \
--model_name_or_path $BERT_DIR \
--dataset_name $SQUAD_DIR \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 96 \
--output_dir $OUTPUT \
--save_steps 10000 \
--overwrite_cache \
--overwrite_output_dir \
```
## Expected results
Normally process SQuADv1.1 datasets with max_seq_length=128, doc_stride=96.
## Actual results
```
INFO:__main__:Padding all batches to max length because argument was set or we're on TPU.
WARNING:datasets.fingerprint:Parameter 'function'=<function main.<locals>.prepare_train_features at 0x7f15bc2d07a0> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
0%| | 0/88 [00:00<?, ?ba/s]thread '<unnamed>' panicked at 'assertion failed: stride < max_len', /__w/tokenizers/tokenizers/tokenizers/src/tokenizer/encoding.rs:311:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
0%| | 0/88 [00:00<?, ?ba/s]
Traceback (most recent call last):
File "run_qa.py", line 743, in <module>
main()
File "run_qa.py", line 485, in main
load_from_cache_file=not data_args.overwrite_cache,
File "/anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2394, in map
desc=desc,
File "/anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 551, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 518, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/anaconda3/envs/py37/lib/python3.7/site-packages/datasets/fingerprint.py", line 458, in wrapper
out = func(self, *args, **kwargs)
File "anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2768, in _map_single
offset=offset,
File "anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2644, in apply_function_on_filtered_inputs
processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
File "anaconda3/envs/py37/lib/python3.7/site-packages/datasets/arrow_dataset.py", line 2336, in decorated
result = f(decorated_item, *args, **kwargs)
File "run_qa.py", line 410, in prepare_train_features
padding=padding,
File "anaconda3/envs/py37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2512, in __call__
**kwargs,
File "anaconda3/envs/py37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2703, in batch_encode_plus
**kwargs,
File "anaconda3/envs/py37/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 429, in _batch_encode_plus
is_pretokenized=is_split_into_words,
pyo3_runtime.PanicException: assertion failed: stride < max_len
Traceback (most recent call last):
File "./data/SQuADv1.1/evaluate-v1.1.py", line 92, in <module>
with open(args.prediction_file) as prediction_file:
FileNotFoundError: [Errno 2] No such file or directory: './output/bert_base_squadv1.1_tf2/eval_predictions.json'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Ubuntu, pytorch=1.11.0, tensorflow-gpu=2.9.1
- Python version: 2.7
- PyArrow version: 8.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4769/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4769/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2447 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2447/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2447/comments | https://api.github.com/repos/huggingface/datasets/issues/2447/events | https://github.com/huggingface/datasets/issues/2447 | 912,299,527 | MDU6SXNzdWU5MTIyOTk1Mjc= | 2,447 | dataset adversarial_qa has no answers in the "test" set | {
"avatar_url": "https://avatars.githubusercontent.com/u/22728060?v=4",
"events_url": "https://api.github.com/users/bjascob/events{/privacy}",
"followers_url": "https://api.github.com/users/bjascob/followers",
"following_url": "https://api.github.com/users/bjascob/following{/other_user}",
"gists_url": "https://api.github.com/users/bjascob/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bjascob",
"id": 22728060,
"login": "bjascob",
"node_id": "MDQ6VXNlcjIyNzI4MDYw",
"organizations_url": "https://api.github.com/users/bjascob/orgs",
"received_events_url": "https://api.github.com/users/bjascob/received_events",
"repos_url": "https://api.github.com/users/bjascob/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bjascob/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bjascob/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bjascob"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! I'm pretty sure that the answers are not made available for the test set on purpose because it is part of the DynaBench benchmark, for which you can submit your predictions on the website.\r\nIn any case we should mention this in the dataset card of this dataset.",
"Makes sense, but not intuitive for someone searching through the datasets. Thanks for adding the note to clarify."
] | "2021-06-05T14:57:38Z" | "2021-06-07T11:13:07Z" | "2021-06-07T11:13:07Z" | NONE | null | null | null | ## Describe the bug
When loading the adversarial_qa dataset the 'test' portion has no answers. Only the 'train' and 'validation' portions do. This occurs with all four of the configs ('adversarialQA', 'dbidaf', 'dbert', 'droberta')
## Steps to reproduce the bug
```
from datasets import load_dataset
examples = load_dataset('adversarial_qa', 'adversarialQA', script_version="master")['test']
print('Loaded {:,} examples'.format(len(examples)))
has_answers = 0
for e in examples:
if e['answers']['text']:
has_answers += 1
print('{:,} have answers'.format(has_answers))
>>> Loaded 3,000 examples
>>> 0 have answers
examples = load_dataset('adversarial_qa', 'adversarialQA', script_version="master")['validation']
<...code above...>
>>> Loaded 3,000 examples
>>> 3,000 have answers
```
## Expected results
If 'test' is a valid dataset, it should have answers. Also note that all of the 'train' and 'validation' sets have answers, there are no "no answer" questions with this set (not sure if this is correct or not).
## Environment info
- `datasets` version: 1.7.0
- Platform: Linux-5.8.0-53-generic-x86_64-with-glibc2.29
- Python version: 3.8.5
- PyArrow version: 1.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2447/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2447/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/357/comments | https://api.github.com/repos/huggingface/datasets/issues/357/events | https://github.com/huggingface/datasets/pull/357 | 653,642,292 | MDExOlB1bGxSZXF1ZXN0NDQ2NTIyMzU2 | 357 | Add hashes to cnn_dailymail | {
"avatar_url": "https://avatars.githubusercontent.com/u/2238344?v=4",
"events_url": "https://api.github.com/users/jbragg/events{/privacy}",
"followers_url": "https://api.github.com/users/jbragg/followers",
"following_url": "https://api.github.com/users/jbragg/following{/other_user}",
"gists_url": "https://api.github.com/users/jbragg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jbragg",
"id": 2238344,
"login": "jbragg",
"node_id": "MDQ6VXNlcjIyMzgzNDQ=",
"organizations_url": "https://api.github.com/users/jbragg/orgs",
"received_events_url": "https://api.github.com/users/jbragg/received_events",
"repos_url": "https://api.github.com/users/jbragg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jbragg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jbragg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jbragg"
} | [] | closed | false | null | [] | null | [
"Looks you to me :)\r\n\r\nCould you also update the json file that goes with the dataset script by doing \r\n```\r\nnlp-cli test ./datasets/cnn_dailymail --save_infos --all_configs\r\n```\r\nIt will update the features metadata and the size of the dataset with your changes.",
"@lhoestq I ran that command.\r\n\r\nThanks for the helpful repository!"
] | "2020-07-08T22:45:21Z" | "2020-07-13T14:16:38Z" | "2020-07-13T14:16:38Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/357.diff",
"html_url": "https://github.com/huggingface/datasets/pull/357",
"merged_at": "2020-07-13T14:16:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/357.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/357"
} | The URL hashes are helpful for comparing results from other sources. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/357/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/357/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1842 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1842/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1842/comments | https://api.github.com/repos/huggingface/datasets/issues/1842/events | https://github.com/huggingface/datasets/issues/1842 | 803,563,149 | MDU6SXNzdWU4MDM1NjMxNDk= | 1,842 | Add AMI Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",
"default": false,
"description": "",
"id": 2725241052,
"name": "speech",
"node_id": "MDU6TGFiZWwyNzI1MjQxMDUy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/speech"
}
] | closed | false | null | [] | null | [
"Available here: ~https://huggingface.co/datasets/ami~ https://huggingface.co/datasets/edinburghcstr/ami",
"@mariosasko actually the \"official\" AMI dataset can be found here: https://huggingface.co/datasets/edinburghcstr/ami -> the old one under `datasets/ami` doesn't work and should be deleted. \r\n\r\nThe new one was tested by fine-tuning a Wav2Vec2 model on it + we uploaded all the processed audio directly into it",
"@patrickvonplaten Thanks for correcting me! I've updated the link."
] | "2021-02-08T13:25:00Z" | "2023-02-28T16:29:22Z" | "2023-02-28T16:29:22Z" | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** *AMI*
- **Description:** *The AMI Meeting Corpus is a multi-modal data set consisting of 100 hours of meeting recordings. For a gentle introduction to the corpus, see the corpus overview. To access the data, follow the directions given there. Around two-thirds of the data has been elicited using a scenario in which the participants play different roles in a design team, taking a design project from kick-off to completion over the course of a day. The rest consists of naturally occurring meetings in a range of domains. Detailed information can be found in the documentation section.*
- **Paper:** *Homepage*: http://groups.inf.ed.ac.uk/ami/corpus/
- **Data:** *http://groups.inf.ed.ac.uk/ami/download/* - Select all cases in 1) and select "Individual Headsets" & "Microphone array" for 2)
- **Motivation:** Important speech dataset
If interested in tackling this issue, feel free to tag @patrickvonplaten
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1842/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1842/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4312 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4312/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4312/comments | https://api.github.com/repos/huggingface/datasets/issues/4312/events | https://github.com/huggingface/datasets/pull/4312 | 1,231,662,775 | PR_kwDODunzps43mlug | 4,312 | added TR-News dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/25901065?v=4",
"events_url": "https://api.github.com/users/batubayk/events{/privacy}",
"followers_url": "https://api.github.com/users/batubayk/followers",
"following_url": "https://api.github.com/users/batubayk/following{/other_user}",
"gists_url": "https://api.github.com/users/batubayk/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/batubayk",
"id": 25901065,
"login": "batubayk",
"node_id": "MDQ6VXNlcjI1OTAxMDY1",
"organizations_url": "https://api.github.com/users/batubayk/orgs",
"received_events_url": "https://api.github.com/users/batubayk/received_events",
"repos_url": "https://api.github.com/users/batubayk/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/batubayk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/batubayk/subscriptions",
"type": "User",
"url": "https://api.github.com/users/batubayk"
} | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @batubayk.\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nI would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | "2022-05-10T20:33:00Z" | "2022-10-03T09:36:45Z" | "2022-10-03T09:36:45Z" | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4312.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4312",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4312.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4312"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4312/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4312/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"events_url": "https://api.github.com/users/eerio/events{/privacy}",
"followers_url": "https://api.github.com/users/eerio/followers",
"following_url": "https://api.github.com/users/eerio/following{/other_user}",
"gists_url": "https://api.github.com/users/eerio/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eerio",
"id": 11250555,
"login": "eerio",
"node_id": "MDQ6VXNlcjExMjUwNTU1",
"organizations_url": "https://api.github.com/users/eerio/orgs",
"received_events_url": "https://api.github.com/users/eerio/received_events",
"repos_url": "https://api.github.com/users/eerio/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eerio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eerio/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eerio"
} | [] | closed | false | null | [] | null | [
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem."
] | "2023-03-13T13:14:44Z" | "2023-03-13T17:54:19Z" | "2023-03-13T17:54:19Z" | NONE | null | null | null | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Please see 'steps to reproduce the bug' for the specific error, as steps to reproduce is just importing the library
### Steps to reproduce the bug
```
$ python3
Python 3.8.15 (default, Nov 24 2022, 15:19:38)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/__init__.py", line 33, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 59, in <module>
from .arrow_reader import ArrowReader
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/datasets/arrow_reader.py", line 27, in <module>
import pyarrow.parquet as pq
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/parquet/__init__.py", line 20, in <module>
from .core import *
File "/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/parquet/core.py", line 37, in <module>
from pyarrow._parquet import (ParquetReader, Statistics, # noqa
ImportError: cannot import name 'FileEncryptionProperties' from 'pyarrow._parquet' (/home/jack/.conda/envs/jack_zpp/lib/python3.8/site-packages/pyarrow/_parquet.cpython-38-x86_64-linux-gnu.so)
```
### Expected behavior
I would expect for the statement `import datasets` to cause no error
### Environment info
Output of `conda list`:
```
# packages in environment at /home/jack/.conda/envs/pbalawender_zpp:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
abseil-cpp 20210324.2 h2531618_0
advertools 0.13.2 pypi_0 pypi
aiofiles 0.8.0 pypi_0 pypi
aiohttp 3.8.3 py38h5eee18b_0
aiosignal 1.2.0 pyhd3eb1b0_0
aiosqlite 0.17.0 pypi_0 pypi
anyio 3.6.2 pypi_0 pypi
aquirdturtle-collapsible-headings 3.1.0 pypi_0 pypi
argon2-cffi 21.3.0 pypi_0 pypi
argon2-cffi-bindings 21.2.0 pypi_0 pypi
arrow 1.2.3 pypi_0 pypi
arrow-cpp 3.0.0 py38h6b21186_4
asttokens 2.2.0 pypi_0 pypi
async-timeout 4.0.2 py38h06a4308_0
attrs 22.1.0 py38h06a4308_0
automat 22.10.0 pypi_0 pypi
aws-c-common 0.4.57 he6710b0_1
aws-c-event-stream 0.1.6 h2531618_5
aws-checksums 0.1.9 he6710b0_0
aws-sdk-cpp 1.8.185 hce553d0_0
babel 2.11.0 pypi_0 pypi
backcall 0.2.0 pyhd3eb1b0_0
beautifulsoup4 4.11.1 pypi_0 pypi
blas 1.0 mkl
bleach 5.0.1 pypi_0 pypi
boost-cpp 1.73.0 h27cfd23_11
bottleneck 1.3.5 py38h7deecbd_0
brotli 1.0.9 h5eee18b_7
brotli-bin 1.0.9 h5eee18b_7
brotlipy 0.7.0 py38h27cfd23_1003
bzip2 1.0.8 h7b6447c_0
c-ares 1.18.1 h7f8727e_0
ca-certificates 2023.01.10 h06a4308_0
certifi 2022.9.24 pypi_0 pypi
cffi 1.15.1 py38h5eee18b_3
charset-normalizer 2.1.1 pypi_0 pypi
click 8.1.3 pypi_0 pypi
constantly 15.1.0 pypi_0 pypi
contourpy 1.0.6 pypi_0 pypi
cryptography 38.0.4 pypi_0 pypi
cssselect 1.2.0 pypi_0 pypi
cudatoolkit 10.1.243 h8cb64d8_10 conda-forge
cycler 0.11.0 pypi_0 pypi
dacite 1.6.0 pypi_0 pypi
dataclasses 0.8 pyh6d0b6a4_7
datasets 1.18.4 py_0 huggingface
datetime 4.7 pypi_0 pypi
debugpy 1.6.4 pypi_0 pypi
decorator 5.1.1 pyhd3eb1b0_0
defusedxml 0.7.1 pypi_0 pypi
dill 0.3.6 py38h06a4308_0
docker-pycreds 0.4.0 pypi_0 pypi
double-conversion 3.1.5 he6710b0_1
entrypoints 0.4 py38h06a4308_0
executing 0.8.3 pyhd3eb1b0_0
filelock 3.8.0 pypi_0 pypi
flake8 6.0.0 pypi_0 pypi
flask 2.1.3 py38h06a4308_0
flit-core 3.6.0 pyhd3eb1b0_0
fonttools 4.38.0 pypi_0 pypi
fqdn 1.5.1 pypi_0 pypi
freetype 2.12.1 h4a9f257_0
frozenlist 1.3.3 py38h5eee18b_0
fsspec 2022.11.0 py38h06a4308_0
gensim 4.2.0 pypi_0 pypi
gflags 2.2.2 he6710b0_0
giflib 5.2.1 h5eee18b_3
gitdb 4.0.10 pypi_0 pypi
gitpython 3.1.30 pypi_0 pypi
glog 0.5.0 h2531618_0
grpc-cpp 1.39.0 hae934f6_5
huggingface-hub 0.11.1 pypi_0 pypi
huggingface_hub 0.13.1 py_0 huggingface
hyperlink 21.0.0 pypi_0 pypi
icu 58.2 he6710b0_3
idna 3.4 py38h06a4308_0
importlib-metadata 5.1.0 pypi_0 pypi
importlib_metadata 4.11.3 hd3eb1b0_0
importlib_resources 5.2.0 pyhd3eb1b0_1
incremental 22.10.0 pypi_0 pypi
intel-openmp 2021.4.0 h06a4308_3561
ipykernel 6.17.1 pyh210e3f2_0 conda-forge
ipython 8.7.0 pypi_0 pypi
ipython-genutils 0.2.0 pypi_0 pypi
ipywidgets 8.0.2 pyhd8ed1ab_1 conda-forge
isoduration 20.11.0 pypi_0 pypi
itemadapter 0.7.0 pypi_0 pypi
itemloaders 1.0.6 pypi_0 pypi
itsdangerous 2.0.1 pyhd3eb1b0_0
jedi 0.18.2 pypi_0 pypi
jinja2 3.1.2 py38h06a4308_0
jmespath 1.0.1 pypi_0 pypi
joblib 1.2.0 pypi_0 pypi
jpeg 9b h024ee3a_2
json5 0.9.10 pypi_0 pypi
jsonpickle 3.0.0 pypi_0 pypi
jsonpointer 2.3 pypi_0 pypi
jsonschema 4.17.3 py38h06a4308_0
jupyter-core 5.1.0 pypi_0 pypi
jupyter-events 0.5.0 pypi_0 pypi
jupyter-server 1.23.3 pypi_0 pypi
jupyter-server-fileid 0.6.0 pypi_0 pypi
jupyter-server-ydoc 0.4.0 pypi_0 pypi
jupyter-ydoc 0.2.2 pypi_0 pypi
jupyter_client 7.4.9 py38h06a4308_0
jupyter_core 5.2.0 py38h06a4308_0
jupyterlab 3.6.0a4 pypi_0 pypi
jupyterlab-pygments 0.2.2 pypi_0 pypi
jupyterlab-server 2.16.3 pypi_0 pypi
jupyterlab_widgets 3.0.3 pyhd8ed1ab_0 conda-forge
kiwisolver 1.4.4 pypi_0 pypi
krb5 1.19.4 h568e23c_0
lcms2 2.12 h3be6417_0
ld_impl_linux-64 2.38 h1181459_1
libboost 1.73.0 h3ff78a5_11
libbrotlicommon 1.0.9 h5eee18b_7
libbrotlidec 1.0.9 h5eee18b_7
libbrotlienc 1.0.9 h5eee18b_7
libcurl 7.88.1 h91b91d3_0
libedit 3.1.20221030 h5eee18b_0
libev 4.33 h7f8727e_1
libevent 2.1.12 h8f2d780_0
libffi 3.4.2 h6a678d5_6
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libnghttp2 1.46.0 hce63b2e_0
libpng 1.6.39 h5eee18b_0
libprotobuf 3.17.2 h4ff587b_1
libsodium 1.0.18 h7b6447c_0
libssh2 1.10.0 h8f2d780_0
libstdcxx-ng 11.2.0 h1234567_1
libthrift 0.14.2 hcc01f38_0
libtiff 4.1.0 h2733197_1
libuv 1.44.2 h5eee18b_0
libwebp 1.2.0 h89dd481_0
lz4-c 1.9.4 h6a678d5_0
markupsafe 2.1.1 py38h7f8727e_0
matplotlib 3.6.2 pypi_0 pypi
matplotlib-inline 0.1.6 py38h06a4308_0
mccabe 0.7.0 pypi_0 pypi
mistune 2.0.4 pypi_0 pypi
mkl 2021.4.0 h06a4308_640
mkl-service 2.4.0 py38h7f8727e_0
mkl_fft 1.3.1 py38hd3c417c_0
mkl_random 1.2.2 py38h51133e4_0
morfeusz2 1.99.6 pypi_0 pypi
multidict 6.0.2 py38h5eee18b_0
multiprocess 0.70.14 py38h06a4308_0
nbclassic 0.4.8 pypi_0 pypi
nbclient 0.7.2 pypi_0 pypi
nbconvert 7.2.5 pypi_0 pypi
nbformat 5.7.0 py38h06a4308_0
ncurses 6.4 h6a678d5_0
nest-asyncio 1.5.6 py38h06a4308_0
ninja 1.10.2 h06a4308_5
ninja-base 1.10.2 hd09550d_5
notebook 6.5.2 pypi_0 pypi
notebook-shim 0.2.2 pypi_0 pypi
numexpr 2.8.4 py38he184ba9_0
numpy 1.23.5 py38h14f4228_0
numpy-base 1.23.5 py38h31eccc5_0
oauthlib 3.2.2 pypi_0 pypi
opencv-python 4.6.0.66 pypi_0 pypi
openssl 1.1.1t h7f8727e_0
orc 1.6.9 ha97a36c_3
packaging 22.0 py38h06a4308_0
pandas 1.5.2 pypi_0 pypi
pandocfilters 1.5.0 pypi_0 pypi
parsel 1.7.0 pypi_0 pypi
parso 0.8.3 pyhd3eb1b0_0
pathlib 1.0.1 pypi_0 pypi
pathtools 0.1.2 pypi_0 pypi
pexpect 4.8.0 pyhd3eb1b0_3
pickleshare 0.7.5 pyhd3eb1b0_1003
pillow 9.3.0 pypi_0 pypi
pip 22.2.2 py38h06a4308_0
pkgutil-resolve-name 1.3.10 py38h06a4308_0
platformdirs 2.5.4 pypi_0 pypi
prometheus-client 0.15.0 pypi_0 pypi
promise 2.3 pypi_0 pypi
prompt-toolkit 3.0.33 pypi_0 pypi
protego 0.2.1 pypi_0 pypi
protobuf 4.21.12 pypi_0 pypi
psutil 5.9.0 py38h5eee18b_0
ptyprocess 0.7.0 pyhd3eb1b0_2
pure_eval 0.2.2 pyhd3eb1b0_0
pyarrow 10.0.1 pypi_0 pypi
pyasn1 0.4.8 pypi_0 pypi
pyasn1-modules 0.2.8 pypi_0 pypi
pycodestyle 2.10.0 pypi_0 pypi
pycparser 2.21 pyhd3eb1b0_0
pydispatcher 2.0.6 pypi_0 pypi
pyflakes 3.0.1 pypi_0 pypi
pygments 2.11.2 pyhd3eb1b0_0
pyopenssl 22.1.0 pypi_0 pypi
pyrsistent 0.18.0 py38heee7806_0
pysocks 1.7.1 py38h06a4308_0
python 3.8.15 h7a1cb2a_2
python-dateutil 2.8.2 pyhd3eb1b0_0
python-dotenv 0.21.0 pypi_0 pypi
python-fastjsonschema 2.16.2 py38h06a4308_0
python-json-logger 2.0.4 pypi_0 pypi
python-xxhash 2.0.2 py38h5eee18b_1
pytorch 1.7.1 py3.8_cuda10.1.243_cudnn7.6.3_0 pytorch
pytz 2022.6 pypi_0 pypi
pyyaml 6.0 py38h5eee18b_1
pyzmq 23.2.0 py38h6a678d5_0
queuelib 1.6.2 pypi_0 pypi
re2 2022.04.01 h295c915_0
readline 8.2 h5eee18b_0
regex 2022.10.31 pypi_0 pypi
requests 2.28.1 py38h06a4308_0
requests-file 1.5.1 pypi_0 pypi
requests-oauthlib 1.3.1 pypi_0 pypi
rfc3339-validator 0.1.4 pypi_0 pypi
rfc3986-validator 0.1.1 pypi_0 pypi
scikit-learn 1.1.3 pypi_0 pypi
scipy 1.9.3 pypi_0 pypi
scrapy 2.7.1 pypi_0 pypi
seaborn 0.12.1 pypi_0 pypi
send2trash 1.8.0 pypi_0 pypi
sentry-sdk 1.12.1 pypi_0 pypi
service-identity 21.1.0 pypi_0 pypi
setproctitle 1.3.2 pypi_0 pypi
setuptools 65.6.3 pypi_0 pypi
shortuuid 1.0.11 pypi_0 pypi
six 1.16.0 pyhd3eb1b0_1
smart-open 6.2.0 pypi_0 pypi
smmap 5.0.0 pypi_0 pypi
snappy 1.1.9 h295c915_0
sniffio 1.3.0 pypi_0 pypi
soupsieve 2.3.2.post1 pypi_0 pypi
sqlite 3.40.1 h5082296_0
stack-data 0.6.2 pypi_0 pypi
stack_data 0.2.0 pyhd3eb1b0_0
terminado 0.17.0 pypi_0 pypi
threadpoolctl 3.1.0 pypi_0 pypi
tinycss2 1.2.1 pypi_0 pypi
tk 8.6.12 h1ccaba5_0
tldextract 3.4.0 pypi_0 pypi
tokenizers 0.13.2 pypi_0 pypi
tomli 2.0.1 pypi_0 pypi
torchvision 0.8.2 py38_cu101 pytorch
tornado 6.2 py38h5eee18b_0
tqdm 4.64.1 py38h06a4308_0
traitlets 5.6.0 pypi_0 pypi
transformers 4.25.1 pypi_0 pypi
tweepy 4.12.1 pypi_0 pypi
twisted 22.10.0 pypi_0 pypi
twython 3.9.1 pypi_0 pypi
typing-extensions 4.4.0 py38h06a4308_0
typing_extensions 4.4.0 py38h06a4308_0
uri-template 1.2.0 pypi_0 pypi
uriparser 0.9.3 he6710b0_1
urllib3 1.26.13 pypi_0 pypi
utf8proc 2.6.1 h27cfd23_0
w3lib 2.1.0 pypi_0 pypi
wandb 0.13.7 pypi_0 pypi
wcwidth 0.2.5 pyhd3eb1b0_0
webcolors 1.12 pypi_0 pypi
webencodings 0.5.1 pypi_0 pypi
websocket-client 1.4.2 pypi_0 pypi
werkzeug 2.2.2 py38h06a4308_0
wheel 0.38.4 py38h06a4308_0
widgetsnbextension 4.0.3 py38h06a4308_0
xxhash 0.8.0 h7f8727e_3
xz 5.2.10 h5eee18b_1
y-py 0.5.4 pypi_0 pypi
yaml 0.2.5 h7b6447c_0
yarl 1.8.1 py38h5eee18b_0
ypy-websocket 0.5.0 pypi_0 pypi
zeromq 4.3.4 h2531618_0
zipp 3.11.0 py38h06a4308_0
zlib 1.2.13 h5eee18b_0
zope-interface 5.5.2 pypi_0 pypi
zstd 1.4.9 haebb681_0
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4916/comments | https://api.github.com/repos/huggingface/datasets/issues/4916/events | https://github.com/huggingface/datasets/issues/4916 | 1,357,076,940 | I_kwDODunzps5Q41nM | 4,916 | Apache Beam unable to write the downloaded wikipedia dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/71849081?v=4",
"events_url": "https://api.github.com/users/Shilpac20/events{/privacy}",
"followers_url": "https://api.github.com/users/Shilpac20/followers",
"following_url": "https://api.github.com/users/Shilpac20/following{/other_user}",
"gists_url": "https://api.github.com/users/Shilpac20/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Shilpac20",
"id": 71849081,
"login": "Shilpac20",
"node_id": "MDQ6VXNlcjcxODQ5MDgx",
"organizations_url": "https://api.github.com/users/Shilpac20/orgs",
"received_events_url": "https://api.github.com/users/Shilpac20/received_events",
"repos_url": "https://api.github.com/users/Shilpac20/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Shilpac20/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shilpac20/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Shilpac20"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"See:\r\n- #4915"
] | "2022-08-31T09:39:25Z" | "2022-08-31T10:53:19Z" | "2022-08-31T10:53:19Z" | NONE | null | null | null | ## Describe the bug
Hi, I am currently trying to download wikipedia dataset using
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner'). However, I end up in getting filenotfound error. I get this error for any language I try to download. It downloads the file but while saving it in hugging face cache it fails to write. This happens for any available date of any language in wikipedia dump. I had raised another issue earlier #4915 but probably was not that clear and the solution provider misunderstood my problem. Hence raising one more issue. Any help is appreciated.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner')
```
## Expected results
to load the dataset
## Actual results
I am pasting the error trace here:
Downloading builder script: 35.9kB [00:00, ?B/s]
Downloading metadata: 30.4kB [00:00, 1.94MB/s]
Using custom data configuration 20220401.aa-date=20220401,language=aa
Downloading and preparing dataset wikipedia/20220401.aa to C:\Users\Shilpa.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...
Downloading data: 100%|████████████████████████████████████████████████████████████| 11.1k/11.1k [00:00<00:00, 712kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.82s/it]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████| 1/1 [00:00<?, ?it/s]
Downloading data: 100%|███████████████████████████████████████████████████████████| 35.6k/35.6k [00:00<00:00, 84.3kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.93s/it]
Traceback (most recent call last):
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in init
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\Shilpa\.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "G:/abc/temp.py", line 32, in
beam_runner='DirectRunner')
File "G:\Python3.7\lib\site-packages\datasets\load.py", line 1751, in load_dataset
use_auth_token=use_auth_token,
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 705, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 1394, in _download_and_prepare
pipeline_results = pipeline.run()
File "G:\Python3.7\lib\site-packages\apache_beam\pipeline.py", line 574, in run
return self.runner.run_pipeline(self, self._options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\direct\direct_runner.py", line 131, in run_pipeline
return runner.run_pipeline(pipeline, options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 201, in run_pipeline
options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 212, in run_via_runner_api
return self.run_stages(stage_context, stages)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 443, in run_stages
runner_execution_context, bundle_context_manager, bundle_input)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 776, in _execute_bundle
bundle_manager))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1000, in _run_bundle
data_input, data_output, input_timers, expected_timer_output)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1309, in process_bundle
result_future = self._worker_handler.control_conn.push(process_bundle_req)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\worker_handlers.py", line 380, in push
response = self.worker.do_instruction(request)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 598, in do_instruction
getattr(request, request_type), request.instruction_id)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 635, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 1004, in process_bundle
element.data)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 227, in process_encoded
self.output(decoded_value)
File "apache_beam\runners\worker\operations.py", line 526, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 528, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 237, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 324, in apache_beam.runners.worker.operations.GeneralPurposeConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 905, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1507, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in init
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
RuntimeError: FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\Shilpa\.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
## Environment info
Python: 3.7.6
Windows 10 Pro
datasets :2.4.0
apache_beam: 2.41.0
mwparserfromhell: 0.6.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4916/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6471 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6471/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6471/comments | https://api.github.com/repos/huggingface/datasets/issues/6471/events | https://github.com/huggingface/datasets/pull/6471 | 2,026,100,761 | PR_kwDODunzps5hLEni | 6,471 | Remove delete doc CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6471). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005573 / 0.011353 (-0.005780) | 0.003449 / 0.011008 (-0.007559) | 0.063323 / 0.038508 (0.024815) | 0.049369 / 0.023109 (0.026260) | 0.254280 / 0.275898 (-0.021618) | 0.267721 / 0.323480 (-0.055759) | 0.002894 / 0.007986 (-0.005092) | 0.002646 / 0.004328 (-0.001683) | 0.049284 / 0.004250 (0.045033) | 0.037947 / 0.037052 (0.000895) | 0.251654 / 0.258489 (-0.006836) | 0.279729 / 0.293841 (-0.014112) | 0.028022 / 0.128546 (-0.100525) | 0.010653 / 0.075646 (-0.064993) | 0.208567 / 0.419271 (-0.210704) | 0.035863 / 0.043533 (-0.007670) | 0.248522 / 0.255139 (-0.006617) | 0.270274 / 0.283200 (-0.012925) | 0.019683 / 0.141683 (-0.122000) | 1.136342 / 1.452155 (-0.315812) | 1.206757 / 1.492716 (-0.285960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.094682 / 0.018006 (0.076676) | 0.304092 / 0.000490 (0.303602) | 0.000220 / 0.000200 (0.000020) | 0.000051 / 0.000054 (-0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.018606 / 0.037411 (-0.018805) | 0.060568 / 0.014526 (0.046042) | 0.074067 / 0.176557 (-0.102490) | 0.118979 / 0.737135 (-0.618156) | 0.075676 / 0.296338 (-0.220663) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.290452 / 0.215209 (0.075243) | 2.848868 / 2.077655 (0.771213) | 1.534932 / 1.504120 (0.030812) | 1.386717 / 1.541195 (-0.154478) | 1.416645 / 1.468490 (-0.051845) | 0.569020 / 4.584777 (-4.015757) | 2.421168 / 3.745712 (-1.324545) | 2.781358 / 5.269862 (-2.488503) | 1.758495 / 4.565676 (-2.807182) | 0.063851 / 0.424275 (-0.360424) | 0.004968 / 0.007607 (-0.002639) | 0.339198 / 0.226044 (0.113154) | 3.356392 / 2.268929 (1.087464) | 1.858145 / 55.444624 (-53.586479) | 1.589000 / 6.876477 (-5.287477) | 1.569175 / 2.142072 (-0.572897) | 0.650571 / 4.805227 (-4.154657) | 0.120288 / 6.500664 (-6.380376) | 0.042489 / 0.075469 (-0.032980) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.939963 / 1.841788 (-0.901824) | 11.493612 / 8.074308 (3.419304) | 10.353780 / 10.191392 (0.162388) | 0.141945 / 0.680424 (-0.538479) | 0.014397 / 0.534201 (-0.519804) | 0.286971 / 0.579283 (-0.292312) | 0.266787 / 0.434364 (-0.167577) | 0.330385 / 0.540337 (-0.209952) | 0.438542 / 1.386936 (-0.948394) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005360 / 0.011353 (-0.005993) | 0.003720 / 0.011008 (-0.007288) | 0.048790 / 0.038508 (0.010282) | 0.050256 / 0.023109 (0.027147) | 0.275445 / 0.275898 (-0.000453) | 0.297725 / 0.323480 (-0.025755) | 0.004077 / 0.007986 (-0.003909) | 0.002759 / 0.004328 (-0.001569) | 0.047653 / 0.004250 (0.043403) | 0.040205 / 0.037052 (0.003153) | 0.281028 / 0.258489 (0.022539) | 0.304682 / 0.293841 (0.010841) | 0.030158 / 0.128546 (-0.098388) | 0.010957 / 0.075646 (-0.064689) | 0.058193 / 0.419271 (-0.361079) | 0.033277 / 0.043533 (-0.010256) | 0.279501 / 0.255139 (0.024362) | 0.295381 / 0.283200 (0.012181) | 0.017889 / 0.141683 (-0.123794) | 1.121354 / 1.452155 (-0.330801) | 1.225702 / 1.492716 (-0.267014) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.093385 / 0.018006 (0.075378) | 0.304642 / 0.000490 (0.304152) | 0.000219 / 0.000200 (0.000019) | 0.000052 / 0.000054 (-0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.021456 / 0.037411 (-0.015955) | 0.068536 / 0.014526 (0.054010) | 0.080867 / 0.176557 (-0.095689) | 0.119093 / 0.737135 (-0.618042) | 0.081875 / 0.296338 (-0.214464) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.304434 / 0.215209 (0.089225) | 2.990303 / 2.077655 (0.912649) | 1.616959 / 1.504120 (0.112839) | 1.493256 / 1.541195 (-0.047939) | 1.542857 / 1.468490 (0.074367) | 0.575517 / 4.584777 (-4.009260) | 2.455165 / 3.745712 (-1.290547) | 2.810089 / 5.269862 (-2.459773) | 1.756502 / 4.565676 (-2.809175) | 0.064801 / 0.424275 (-0.359475) | 0.004969 / 0.007607 (-0.002638) | 0.360227 / 0.226044 (0.134183) | 3.575029 / 2.268929 (1.306100) | 1.989955 / 55.444624 (-53.454669) | 1.705306 / 6.876477 (-5.171171) | 1.688523 / 2.142072 (-0.453550) | 0.663266 / 4.805227 (-4.141962) | 0.121852 / 6.500664 (-6.378812) | 0.041853 / 0.075469 (-0.033616) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.983535 / 1.841788 (-0.858252) | 11.827656 / 8.074308 (3.753348) | 10.663265 / 10.191392 (0.471873) | 0.145942 / 0.680424 (-0.534482) | 0.016004 / 0.534201 (-0.518197) | 0.288907 / 0.579283 (-0.290376) | 0.279100 / 0.434364 (-0.155264) | 0.328061 / 0.540337 (-0.212276) | 0.570253 / 1.386936 (-0.816683) |\n\n</details>\n</details>\n\n\n"
] | "2023-12-05T12:37:50Z" | "2023-12-05T12:44:59Z" | "2023-12-05T12:38:50Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6471.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6471",
"merged_at": "2023-12-05T12:38:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6471.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6471"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6471/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6471/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5218/comments | https://api.github.com/repos/huggingface/datasets/issues/5218/events | https://github.com/huggingface/datasets/issues/5218 | 1,441,254,194 | I_kwDODunzps5V58sy | 5,218 | Delta Tables usage using Datasets Library | {
"avatar_url": "https://avatars.githubusercontent.com/u/103188035?v=4",
"events_url": "https://api.github.com/users/rcv-koo/events{/privacy}",
"followers_url": "https://api.github.com/users/rcv-koo/followers",
"following_url": "https://api.github.com/users/rcv-koo/following{/other_user}",
"gists_url": "https://api.github.com/users/rcv-koo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcv-koo",
"id": 103188035,
"login": "rcv-koo",
"node_id": "U_kgDOBiaGQw",
"organizations_url": "https://api.github.com/users/rcv-koo/orgs",
"received_events_url": "https://api.github.com/users/rcv-koo/received_events",
"repos_url": "https://api.github.com/users/rcv-koo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcv-koo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcv-koo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcv-koo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | "2022-11-09T02:42:18Z" | "2022-11-09T02:42:36Z" | "2022-11-09T02:42:36Z" | NONE | null | null | null | ### Feature request
Adding compatibility of Datasets library with Delta Format. Elevating the utilities of Datasets library from Machine Learning Scope to Data Engineering Scope as well.
### Motivation
We know datasets library can absorb csv, json, parquet, etc. file formats but it would be great if Datasets library could work with Delta Tables (with delta format) as it has different features such as time travelling, layout optimization, query performance, aids in Data Engineering.
This will help and enhance Datasets library from Machine Learning utility to Data Engineering utilities and expand horizons thereafter. I am totally using Datasets library in all my usecases and as my role expands so does the work, compatibility with Datasets library is something I don't want to lose.
### Your contribution
Would love to work on this feature, even if this has to picked up from scratch, including design paradigms and patterns.
I have basic idea about Delta Live Tables, would brush it easily for this feature. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5218/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4647/comments | https://api.github.com/repos/huggingface/datasets/issues/4647/events | https://github.com/huggingface/datasets/issues/4647 | 1,296,311,270 | I_kwDODunzps5NRCPm | 4,647 | Add Reddit dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_url": "https://api.github.com/users/omarespejel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/omarespejel",
"id": 4755430,
"login": "omarespejel",
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"organizations_url": "https://api.github.com/users/omarespejel/orgs",
"received_events_url": "https://api.github.com/users/omarespejel/received_events",
"repos_url": "https://api.github.com/users/omarespejel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/omarespejel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omarespejel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/omarespejel"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [] | "2022-07-06T19:49:18Z" | "2022-07-06T19:49:18Z" | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *Reddit comments (2015-2018)*
- **Description:** *Reddit is an American social news aggregation website, where users can post links, and take part in discussions on these posts. These threaded discussions provide a large corpus, which is converted into a conversational dataset using the tools in this directory.*
- **Paper:** *https://arxiv.org/abs/1904.06472*
- **Data:** *https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4647/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/815/comments | https://api.github.com/repos/huggingface/datasets/issues/815/events | https://github.com/huggingface/datasets/issues/815 | 738,842,092 | MDU6SXNzdWU3Mzg4NDIwOTI= | 815 | Is dataset iterative or not? | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rabeehkarimimahabadi",
"id": 73364383,
"login": "rabeehkarimimahabadi",
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rabeehkarimimahabadi"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hello !\r\nCould you give more details ?\r\n\r\nIf you mean iter through one dataset then yes, `Dataset` object does implement the `__iter__` method so you can use \r\n```python\r\nfor example in dataset:\r\n # do something\r\n```\r\n\r\nIf you want to iter through several datasets you can first concatenate them\r\n```python\r\nfrom datasets import concatenate_datasets\r\n\r\nnew_dataset = concatenate_datasets([dataset1, dataset2])\r\n```\r\nLet me know if this helps !",
"Hi Huggingface/Datasets team,\nI want to use the datasets inside Seq2SeqDataset here\nhttps://github.com/huggingface/transformers/blob/master/examples/seq2seq/utils.py\nand there I need to return back each line from the datasets and I am not\nsure how to access each line and implement this?\nIt seems it also has get_item attribute? so I was not sure if this is\niterative dataset? or if this is non-iterable datasets?\nthanks.\n\n\n\nOn Mon, Nov 9, 2020 at 10:18 AM Quentin Lhoest <[email protected]>\nwrote:\n\n> Hello !\n> Could you give more details ?\n>\n> If you mean iter through one dataset then yes, Dataset object does\n> implement the __iter__ method so you can use\n>\n> for example in dataset:\n> # do something\n>\n> If you want to iter through several datasets you can first concatenate them\n>\n> from datasets import concatenate_datasets\n> new_dataset = concatenate_datasets([dataset1, dataset2])\n>\n> Let me know if this helps !\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/815#issuecomment-723881199>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ARPXHHYRLSSYW6NZN2HYDBTSO6XV5ANCNFSM4TPB7OWA>\n> .\n>\n",
"could you tell me please if datasets also has __getitem__ any idea on how\nto integrate it with Seq2SeqDataset is appreciated thanks\n\nOn Mon, Nov 9, 2020 at 10:22 AM Rabeeh Karimi Mahabadi <[email protected]>\nwrote:\n\n> Hi Huggingface/Datasets team,\n> I want to use the datasets inside Seq2SeqDataset here\n> https://github.com/huggingface/transformers/blob/master/examples/seq2seq/utils.py\n> and there I need to return back each line from the datasets and I am not\n> sure how to access each line and implement this?\n> It seems it also has get_item attribute? so I was not sure if this is\n> iterative dataset? or if this is non-iterable datasets?\n> thanks.\n>\n>\n>\n> On Mon, Nov 9, 2020 at 10:18 AM Quentin Lhoest <[email protected]>\n> wrote:\n>\n>> Hello !\n>> Could you give more details ?\n>>\n>> If you mean iter through one dataset then yes, Dataset object does\n>> implement the __iter__ method so you can use\n>>\n>> for example in dataset:\n>> # do something\n>>\n>> If you want to iter through several datasets you can first concatenate\n>> them\n>>\n>> from datasets import concatenate_datasets\n>> new_dataset = concatenate_datasets([dataset1, dataset2])\n>>\n>> Let me know if this helps !\n>>\n>> —\n>> You are receiving this because you authored the thread.\n>> Reply to this email directly, view it on GitHub\n>> <https://github.com/huggingface/datasets/issues/815#issuecomment-723881199>,\n>> or unsubscribe\n>> <https://github.com/notifications/unsubscribe-auth/ARPXHHYRLSSYW6NZN2HYDBTSO6XV5ANCNFSM4TPB7OWA>\n>> .\n>>\n>\n",
"`datasets.Dataset` objects implement indeed `__getitem__`. It returns a dictionary with one field per column.\r\n\r\nWe've not added the integration of the datasets library for the seq2seq utilities yet. The current seq2seq utilities are based on text files.\r\n\r\nHowever as soon as you have a `datasets.Dataset` with columns \"tgt_texts\" (str), \"src_texts\" (str), and \"id\" (int) you should be able to implement your own Seq2SeqDataset class that wraps your dataset object. Does that make sense to you ?",
"Hi\nI am sorry for asking it multiple times but I am not getting the dataloader\ntype, could you confirm if the dataset library returns back an iterable\ntype dataloader or a mapping type one where one has access to __getitem__,\nin the former case, one can iterate with __iter__, and how I can configure\nit to return the data back as the iterative type? I am dealing with\nlarge-scale datasets and I do not want to bring all in memory\nthanks for your help\nBest regards\nRabeeh\n\nOn Mon, Nov 9, 2020 at 11:17 AM Quentin Lhoest <[email protected]>\nwrote:\n\n> datasets.Dataset objects implement indeed __getitem__. It returns a\n> dictionary with one field per column.\n>\n> We've not added the integration of the datasets library for the seq2seq\n> utilities yet. The current seq2seq utilities are based on text files.\n>\n> However as soon as you have a datasets.Dataset with columns \"tgt_texts\"\n> (str), \"src_texts\" (str), and \"id\" (int) you should be able to implement\n> your own Seq2SeqDataset class that wraps your dataset object. Does that\n> make sense ?\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/815#issuecomment-723915556>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ARPXHHYOC22EM7F666BZSOTSO66R3ANCNFSM4TPB7OWA>\n> .\n>\n",
"`datasets.Dataset` objects are both iterative and mapping types: it has both `__iter__` and `__getitem__`\r\nFor example you can do\r\n```python\r\nfor example in dataset:\r\n # do something\r\n```\r\nor\r\n```python\r\nfor i in range(len(dataset)):\r\n example = dataset[i]\r\n # do something\r\n```\r\nWhen you do that, one and only one example is loaded into memory at a time.",
"Hi there, \r\nHere is what I am trying, this is not working for me in map-style datasets, could you please tell me how to use datasets with being able to access ___getitem__ ? could you assist me please correcting this example? I need map-style datasets which is formed from concatenation of two datasets from your library. thanks \r\n\r\n\r\n```\r\nimport datasets\r\ndataset1 = load_dataset(\"squad\", split=\"train[:10]\")\r\ndataset1 = dataset1.map(lambda example: {\"src_texts\": \"question: {0} context: {1} \".format(\r\n example[\"question\"], example[\"context\"]),\r\n \"tgt_texts\": example[\"answers\"][\"text\"][0]}, remove_columns=dataset1.column_names)\r\ndataset2 = load_dataset(\"imdb\", split=\"train[:10]\")\r\ndataset2 = dataset2.map(lambda example: {\"src_texts\": \"imdb: \" + example[\"text\"],\r\n \"tgt_texts\": str(example[\"label\"])}, remove_columns=dataset2.column_names)\r\ntrain_dataset = datasets.concatenate_datasets([dataset1, dataset2])\r\ntrain_dataset.set_format(type='torch', columns=['src_texts', 'tgt_texts'])\r\ndataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)\r\nfor id, batch in enumerate(dataloader):\r\n print(batch)\r\n\r\n```",
"closed since I found this response on the issue https://github.com/huggingface/datasets/issues/469"
] | "2020-11-09T09:11:48Z" | "2020-11-10T10:50:03Z" | "2020-11-10T10:50:03Z" | NONE | null | null | null | Hi
I want to use your library for large-scale training, I am not sure if this is implemented as iterative datasets or not?
could you provide me with example how I can use datasets as iterative datasets?
thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/815/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/815/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2072/comments | https://api.github.com/repos/huggingface/datasets/issues/2072/events | https://github.com/huggingface/datasets/pull/2072 | 834,054,837 | MDExOlB1bGxSZXF1ZXN0NTk0OTQ5NjA4 | 2,072 | Fix docstring issues | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"I think I will stop pushing to this PR, so that it can me merged for today release. \r\n\r\nI will open another PR for further fixing docs.\r\n\r\nDo you agree, @lhoestq ?",
"Sounds good thanks !"
] | "2021-03-17T18:13:44Z" | "2021-03-24T08:20:57Z" | "2021-03-18T12:41:21Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2072.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2072",
"merged_at": "2021-03-18T12:41:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2072.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2072"
} | Fix docstring issues. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2072/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2072/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2954/comments | https://api.github.com/repos/huggingface/datasets/issues/2954/events | https://github.com/huggingface/datasets/pull/2954 | 1,003,904,803 | PR_kwDODunzps4sHa8O | 2,954 | Run tests in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"There is a speed up in Windows machines:\r\n- From `13m 52s` to `11m 10s`\r\n\r\nIn Linux machines, some workers crash with error message:\r\n```\r\nOSError: [Errno 12] Cannot allocate memory\r\n```",
"There is also a speed up in Linux machines:\r\n- From `7m 30s` to `5m 32s`"
] | "2021-09-22T07:00:44Z" | "2021-09-28T06:55:51Z" | "2021-09-28T06:55:51Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2954",
"merged_at": "2021-09-28T06:55:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2954"
} | Run CI tests in parallel to speed up the test suite.
Speed up results:
- Linux: from `7m 30s` to `5m 32s`
- Windows: from `13m 52s` to `11m 10s`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5560/comments | https://api.github.com/repos/huggingface/datasets/issues/5560/events | https://github.com/huggingface/datasets/pull/5560 | 1,593,809,978 | PR_kwDODunzps5Kcml6 | 5,560 | Ensure last tqdm update in `map` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011060 / 0.011353 (-0.000293) | 0.005752 / 0.011008 (-0.005256) | 0.120349 / 0.038508 (0.081841) | 0.045303 / 0.023109 (0.022194) | 0.359196 / 0.275898 (0.083298) | 0.406351 / 0.323480 (0.082871) | 0.009474 / 0.007986 (0.001489) | 0.004524 / 0.004328 (0.000195) | 0.091990 / 0.004250 (0.087739) | 0.050034 / 0.037052 (0.012982) | 0.372479 / 0.258489 (0.113990) | 0.418907 / 0.293841 (0.125067) | 0.044300 / 0.128546 (-0.084247) | 0.013989 / 0.075646 (-0.061657) | 0.397406 / 0.419271 (-0.021866) | 0.056070 / 0.043533 (0.012537) | 0.357597 / 0.255139 (0.102458) | 0.382938 / 0.283200 (0.099738) | 0.117060 / 0.141683 (-0.024623) | 1.670869 / 1.452155 (0.218714) | 1.780944 / 1.492716 (0.288227) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229578 / 0.018006 (0.211572) | 0.493711 / 0.000490 (0.493222) | 0.008413 / 0.000200 (0.008213) | 0.000118 / 0.000054 (0.000063) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033364 / 0.037411 (-0.004047) | 0.135953 / 0.014526 (0.121427) | 0.141942 / 0.176557 (-0.034614) | 0.225891 / 0.737135 (-0.511244) | 0.151010 / 0.296338 (-0.145328) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.470937 / 0.215209 (0.255728) | 4.710258 / 2.077655 (2.632603) | 2.132025 / 1.504120 (0.627905) | 1.913134 / 1.541195 (0.371939) | 2.025993 / 1.468490 (0.557503) | 0.835993 / 4.584777 (-3.748784) | 4.446678 / 3.745712 (0.700965) | 4.260014 / 5.269862 (-1.009847) | 2.193078 / 4.565676 (-2.372598) | 0.100132 / 0.424275 (-0.324143) | 0.014163 / 0.007607 (0.006556) | 0.599252 / 0.226044 (0.373208) | 5.976377 / 2.268929 (3.707448) | 2.678116 / 55.444624 (-52.766508) | 2.309311 / 6.876477 (-4.567166) | 2.410284 / 2.142072 (0.268212) | 1.002415 / 4.805227 (-3.802813) | 0.194588 / 6.500664 (-6.306076) | 0.074921 / 0.075469 (-0.000548) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.432389 / 1.841788 (-0.409399) | 17.915288 / 8.074308 (9.840980) | 17.190906 / 10.191392 (6.999514) | 0.238469 / 0.680424 (-0.441955) | 0.036270 / 0.534201 (-0.497931) | 0.537320 / 0.579283 (-0.041963) | 0.512876 / 0.434364 (0.078512) | 0.629022 / 0.540337 (0.088685) | 0.750109 / 1.386936 (-0.636827) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008544 / 0.011353 (-0.002809) | 0.005933 / 0.011008 (-0.005075) | 0.088879 / 0.038508 (0.050371) | 0.040387 / 0.023109 (0.017278) | 0.406392 / 0.275898 (0.130494) | 0.449572 / 0.323480 (0.126092) | 0.006623 / 0.007986 (-0.001362) | 0.004727 / 0.004328 (0.000398) | 0.086745 / 0.004250 (0.082495) | 0.054335 / 0.037052 (0.017283) | 0.405652 / 0.258489 (0.147163) | 0.473934 / 0.293841 (0.180093) | 0.042157 / 0.128546 (-0.086390) | 0.014249 / 0.075646 (-0.061397) | 0.102130 / 0.419271 (-0.317141) | 0.056815 / 0.043533 (0.013282) | 0.407945 / 0.255139 (0.152806) | 0.431720 / 0.283200 (0.148521) | 0.119901 / 0.141683 (-0.021781) | 1.738381 / 1.452155 (0.286227) | 1.838981 / 1.492716 (0.346265) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.251926 / 0.018006 (0.233919) | 0.498117 / 0.000490 (0.497627) | 0.000439 / 0.000200 (0.000239) | 0.000065 / 0.000054 (0.000010) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034526 / 0.037411 (-0.002886) | 0.133038 / 0.014526 (0.118512) | 0.147494 / 0.176557 (-0.029063) | 0.234392 / 0.737135 (-0.502743) | 0.152361 / 0.296338 (-0.143978) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.495144 / 0.215209 (0.279935) | 4.936646 / 2.077655 (2.858991) | 2.385549 / 1.504120 (0.881429) | 2.173817 / 1.541195 (0.632622) | 2.327508 / 1.468490 (0.859018) | 0.851899 / 4.584777 (-3.732878) | 4.820388 / 3.745712 (1.074676) | 2.500304 / 5.269862 (-2.769558) | 1.621246 / 4.565676 (-2.944430) | 0.102858 / 0.424275 (-0.321417) | 0.014719 / 0.007607 (0.007112) | 0.611880 / 0.226044 (0.385836) | 6.100737 / 2.268929 (3.831808) | 2.955681 / 55.444624 (-52.488943) | 2.563533 / 6.876477 (-4.312943) | 2.659030 / 2.142072 (0.516958) | 1.004737 / 4.805227 (-3.800490) | 0.198379 / 6.500664 (-6.302285) | 0.078705 / 0.075469 (0.003236) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.501155 / 1.841788 (-0.340633) | 18.381513 / 8.074308 (10.307205) | 16.173893 / 10.191392 (5.982501) | 0.209497 / 0.680424 (-0.470927) | 0.021640 / 0.534201 (-0.512561) | 0.505905 / 0.579283 (-0.073378) | 0.513446 / 0.434364 (0.079082) | 0.652704 / 0.540337 (0.112366) | 0.761038 / 1.386936 (-0.625898) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009085 / 0.011353 (-0.002268) | 0.004589 / 0.011008 (-0.006419) | 0.100820 / 0.038508 (0.062312) | 0.030677 / 0.023109 (0.007568) | 0.306702 / 0.275898 (0.030804) | 0.360623 / 0.323480 (0.037144) | 0.007377 / 0.007986 (-0.000608) | 0.003480 / 0.004328 (-0.000848) | 0.077813 / 0.004250 (0.073562) | 0.037293 / 0.037052 (0.000241) | 0.314137 / 0.258489 (0.055648) | 0.343394 / 0.293841 (0.049554) | 0.034202 / 0.128546 (-0.094344) | 0.011417 / 0.075646 (-0.064230) | 0.322584 / 0.419271 (-0.096687) | 0.041524 / 0.043533 (-0.002009) | 0.308116 / 0.255139 (0.052977) | 0.324527 / 0.283200 (0.041327) | 0.090973 / 0.141683 (-0.050710) | 1.515941 / 1.452155 (0.063787) | 1.548975 / 1.492716 (0.056259) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185901 / 0.018006 (0.167895) | 0.420742 / 0.000490 (0.420252) | 0.002958 / 0.000200 (0.002758) | 0.000086 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024242 / 0.037411 (-0.013170) | 0.098827 / 0.014526 (0.084302) | 0.107609 / 0.176557 (-0.068947) | 0.172228 / 0.737135 (-0.564908) | 0.110042 / 0.296338 (-0.186296) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429647 / 0.215209 (0.214438) | 4.265406 / 2.077655 (2.187751) | 1.924514 / 1.504120 (0.420394) | 1.709881 / 1.541195 (0.168686) | 1.764872 / 1.468490 (0.296382) | 0.698089 / 4.584777 (-3.886688) | 3.439154 / 3.745712 (-0.306558) | 1.925058 / 5.269862 (-3.344804) | 1.267506 / 4.565676 (-3.298171) | 0.082167 / 0.424275 (-0.342108) | 0.012450 / 0.007607 (0.004843) | 0.523077 / 0.226044 (0.297033) | 5.240422 / 2.268929 (2.971494) | 2.363666 / 55.444624 (-53.080959) | 2.021903 / 6.876477 (-4.854574) | 2.136430 / 2.142072 (-0.005643) | 0.816377 / 4.805227 (-3.988850) | 0.151516 / 6.500664 (-6.349148) | 0.066590 / 0.075469 (-0.008879) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.216477 / 1.841788 (-0.625310) | 13.685044 / 8.074308 (5.610736) | 14.082620 / 10.191392 (3.891228) | 0.148399 / 0.680424 (-0.532025) | 0.028337 / 0.534201 (-0.505864) | 0.405379 / 0.579283 (-0.173904) | 0.405650 / 0.434364 (-0.028714) | 0.492658 / 0.540337 (-0.047679) | 0.578836 / 1.386936 (-0.808100) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006863 / 0.011353 (-0.004490) | 0.004746 / 0.011008 (-0.006262) | 0.075802 / 0.038508 (0.037294) | 0.027950 / 0.023109 (0.004840) | 0.347613 / 0.275898 (0.071715) | 0.401201 / 0.323480 (0.077721) | 0.005765 / 0.007986 (-0.002221) | 0.003567 / 0.004328 (-0.000762) | 0.074188 / 0.004250 (0.069937) | 0.041209 / 0.037052 (0.004157) | 0.346541 / 0.258489 (0.088052) | 0.425729 / 0.293841 (0.131888) | 0.032430 / 0.128546 (-0.096116) | 0.011708 / 0.075646 (-0.063938) | 0.084667 / 0.419271 (-0.334604) | 0.042155 / 0.043533 (-0.001378) | 0.341210 / 0.255139 (0.086071) | 0.389759 / 0.283200 (0.106559) | 0.092640 / 0.141683 (-0.049042) | 1.526093 / 1.452155 (0.073938) | 1.556277 / 1.492716 (0.063561) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232383 / 0.018006 (0.214377) | 0.412353 / 0.000490 (0.411863) | 0.004009 / 0.000200 (0.003809) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025854 / 0.037411 (-0.011557) | 0.102660 / 0.014526 (0.088134) | 0.108420 / 0.176557 (-0.068137) | 0.175834 / 0.737135 (-0.561301) | 0.113472 / 0.296338 (-0.182867) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443595 / 0.215209 (0.228386) | 4.420959 / 2.077655 (2.343305) | 2.112790 / 1.504120 (0.608670) | 1.908836 / 1.541195 (0.367641) | 1.998340 / 1.468490 (0.529850) | 0.706096 / 4.584777 (-3.878681) | 3.400871 / 3.745712 (-0.344841) | 2.803315 / 5.269862 (-2.466547) | 1.539392 / 4.565676 (-3.026284) | 0.083523 / 0.424275 (-0.340752) | 0.012541 / 0.007607 (0.004934) | 0.543428 / 0.226044 (0.317383) | 5.467416 / 2.268929 (3.198488) | 2.551970 / 55.444624 (-52.892654) | 2.212708 / 6.876477 (-4.663768) | 2.266169 / 2.142072 (0.124096) | 0.809943 / 4.805227 (-3.995284) | 0.152300 / 6.500664 (-6.348364) | 0.068591 / 0.075469 (-0.006878) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330141 / 1.841788 (-0.511646) | 14.292734 / 8.074308 (6.218426) | 13.556157 / 10.191392 (3.364765) | 0.155949 / 0.680424 (-0.524475) | 0.016464 / 0.534201 (-0.517737) | 0.377906 / 0.579283 (-0.201377) | 0.390385 / 0.434364 (-0.043979) | 0.471867 / 0.540337 (-0.068471) | 0.557794 / 1.386936 (-0.829142) |\n\n</details>\n</details>\n\n\n",
"I just tried on colab and it didn't finish the progress bar for some reason.\r\n\r\nMaybe we need to call `pbar.close()` before `return`\r\n\r\n<img width=\"729\" alt=\"image\" src=\"https://user-images.githubusercontent.com/42851186/220417517-919438a4-5462-4e87-8f84-e9399a9be27c.png\">\r\n",
"(just added .close() - let me try quickly if it works now)",
"it worked ! :)\r\n\r\n<img width=\"575\" alt=\"image\" src=\"https://user-images.githubusercontent.com/42851186/220419220-8108f225-13cb-4968-acff-fe4543d5a324.png\">\r\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008465 / 0.011353 (-0.002888) | 0.004622 / 0.011008 (-0.006387) | 0.100365 / 0.038508 (0.061857) | 0.029453 / 0.023109 (0.006344) | 0.358041 / 0.275898 (0.082143) | 0.424777 / 0.323480 (0.101298) | 0.006930 / 0.007986 (-0.001055) | 0.004756 / 0.004328 (0.000428) | 0.077128 / 0.004250 (0.072878) | 0.036338 / 0.037052 (-0.000715) | 0.367613 / 0.258489 (0.109124) | 0.397798 / 0.293841 (0.103957) | 0.033500 / 0.128546 (-0.095047) | 0.011427 / 0.075646 (-0.064219) | 0.321617 / 0.419271 (-0.097654) | 0.040937 / 0.043533 (-0.002596) | 0.345358 / 0.255139 (0.090219) | 0.366932 / 0.283200 (0.083733) | 0.086506 / 0.141683 (-0.055177) | 1.482434 / 1.452155 (0.030280) | 1.522773 / 1.492716 (0.030057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.188815 / 0.018006 (0.170809) | 0.404689 / 0.000490 (0.404200) | 0.000390 / 0.000200 (0.000190) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023165 / 0.037411 (-0.014246) | 0.095934 / 0.014526 (0.081408) | 0.105788 / 0.176557 (-0.070769) | 0.169908 / 0.737135 (-0.567227) | 0.107871 / 0.296338 (-0.188467) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457543 / 0.215209 (0.242334) | 4.563209 / 2.077655 (2.485554) | 2.172272 / 1.504120 (0.668152) | 1.965064 / 1.541195 (0.423870) | 2.020811 / 1.468490 (0.552321) | 0.705138 / 4.584777 (-3.879638) | 3.353430 / 3.745712 (-0.392283) | 1.861970 / 5.269862 (-3.407892) | 1.159201 / 4.565676 (-3.406476) | 0.083187 / 0.424275 (-0.341088) | 0.012750 / 0.007607 (0.005143) | 0.566377 / 0.226044 (0.340333) | 5.662645 / 2.268929 (3.393717) | 2.609565 / 55.444624 (-52.835059) | 2.244519 / 6.876477 (-4.631957) | 2.284111 / 2.142072 (0.142038) | 0.821974 / 4.805227 (-3.983253) | 0.151080 / 6.500664 (-6.349584) | 0.065373 / 0.075469 (-0.010096) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.230960 / 1.841788 (-0.610828) | 13.930408 / 8.074308 (5.856100) | 13.989082 / 10.191392 (3.797690) | 0.151961 / 0.680424 (-0.528462) | 0.028770 / 0.534201 (-0.505431) | 0.392269 / 0.579283 (-0.187015) | 0.400490 / 0.434364 (-0.033874) | 0.459770 / 0.540337 (-0.080568) | 0.534174 / 1.386936 (-0.852762) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006740 / 0.011353 (-0.004613) | 0.004496 / 0.011008 (-0.006512) | 0.076886 / 0.038508 (0.038377) | 0.027593 / 0.023109 (0.004484) | 0.339570 / 0.275898 (0.063672) | 0.379915 / 0.323480 (0.056435) | 0.004999 / 0.007986 (-0.002987) | 0.004253 / 0.004328 (-0.000076) | 0.074973 / 0.004250 (0.070722) | 0.037321 / 0.037052 (0.000269) | 0.344720 / 0.258489 (0.086230) | 0.398919 / 0.293841 (0.105078) | 0.032146 / 0.128546 (-0.096400) | 0.011694 / 0.075646 (-0.063952) | 0.085134 / 0.419271 (-0.334138) | 0.042328 / 0.043533 (-0.001205) | 0.339384 / 0.255139 (0.084245) | 0.368031 / 0.283200 (0.084831) | 0.092088 / 0.141683 (-0.049595) | 1.492313 / 1.452155 (0.040158) | 1.538406 / 1.492716 (0.045690) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.265619 / 0.018006 (0.247613) | 0.415478 / 0.000490 (0.414988) | 0.030221 / 0.000200 (0.030021) | 0.000277 / 0.000054 (0.000223) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024489 / 0.037411 (-0.012922) | 0.099920 / 0.014526 (0.085395) | 0.108301 / 0.176557 (-0.068256) | 0.179525 / 0.737135 (-0.557610) | 0.111492 / 0.296338 (-0.184847) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440759 / 0.215209 (0.225550) | 4.382754 / 2.077655 (2.305100) | 2.088686 / 1.504120 (0.584566) | 1.890557 / 1.541195 (0.349363) | 1.947461 / 1.468490 (0.478971) | 0.701751 / 4.584777 (-3.883025) | 3.368896 / 3.745712 (-0.376816) | 1.867238 / 5.269862 (-3.402624) | 1.166787 / 4.565676 (-3.398890) | 0.083427 / 0.424275 (-0.340848) | 0.012406 / 0.007607 (0.004799) | 0.539467 / 0.226044 (0.313423) | 5.376083 / 2.268929 (3.107154) | 2.516566 / 55.444624 (-52.928058) | 2.177991 / 6.876477 (-4.698486) | 2.207438 / 2.142072 (0.065366) | 0.803316 / 4.805227 (-4.001911) | 0.150900 / 6.500664 (-6.349764) | 0.066328 / 0.075469 (-0.009141) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.295308 / 1.841788 (-0.546480) | 14.081343 / 8.074308 (6.007035) | 13.516853 / 10.191392 (3.325461) | 0.160530 / 0.680424 (-0.519894) | 0.016516 / 0.534201 (-0.517685) | 0.380160 / 0.579283 (-0.199123) | 0.443484 / 0.434364 (0.009120) | 0.466645 / 0.540337 (-0.073692) | 0.555339 / 1.386936 (-0.831597) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011321 / 0.011353 (-0.000031) | 0.006365 / 0.011008 (-0.004643) | 0.125613 / 0.038508 (0.087105) | 0.035327 / 0.023109 (0.012218) | 0.391998 / 0.275898 (0.116100) | 0.475402 / 0.323480 (0.151923) | 0.009579 / 0.007986 (0.001593) | 0.005621 / 0.004328 (0.001293) | 0.106097 / 0.004250 (0.101846) | 0.042774 / 0.037052 (0.005722) | 0.420850 / 0.258489 (0.162361) | 0.454501 / 0.293841 (0.160660) | 0.056885 / 0.128546 (-0.071661) | 0.021718 / 0.075646 (-0.053928) | 0.419422 / 0.419271 (0.000150) | 0.056690 / 0.043533 (0.013157) | 0.405375 / 0.255139 (0.150236) | 0.444404 / 0.283200 (0.161204) | 0.136912 / 0.141683 (-0.004771) | 1.846363 / 1.452155 (0.394208) | 1.747433 / 1.492716 (0.254717) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.282260 / 0.018006 (0.264254) | 0.615813 / 0.000490 (0.615323) | 0.000515 / 0.000200 (0.000315) | 0.000106 / 0.000054 (0.000052) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029913 / 0.037411 (-0.007499) | 0.135568 / 0.014526 (0.121042) | 0.134476 / 0.176557 (-0.042081) | 0.206974 / 0.737135 (-0.530161) | 0.136976 / 0.296338 (-0.159362) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.605241 / 0.215209 (0.390032) | 6.125097 / 2.077655 (4.047442) | 2.390102 / 1.504120 (0.885982) | 2.082196 / 1.541195 (0.541001) | 2.226527 / 1.468490 (0.758037) | 1.244807 / 4.584777 (-3.339970) | 5.476437 / 3.745712 (1.730725) | 3.014970 / 5.269862 (-2.254891) | 1.963428 / 4.565676 (-2.602249) | 0.137813 / 0.424275 (-0.286462) | 0.013794 / 0.007607 (0.006187) | 0.766149 / 0.226044 (0.540104) | 7.566103 / 2.268929 (5.297175) | 3.048958 / 55.444624 (-52.395666) | 2.394819 / 6.876477 (-4.481658) | 2.416021 / 2.142072 (0.273949) | 1.369896 / 4.805227 (-3.435331) | 0.245159 / 6.500664 (-6.255506) | 0.076848 / 0.075469 (0.001379) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.530448 / 1.841788 (-0.311340) | 18.580227 / 8.074308 (10.505919) | 20.108470 / 10.191392 (9.917078) | 0.227124 / 0.680424 (-0.453300) | 0.052050 / 0.534201 (-0.482151) | 0.604565 / 0.579283 (0.025282) | 0.686475 / 0.434364 (0.252111) | 0.672298 / 0.540337 (0.131960) | 0.770552 / 1.386936 (-0.616384) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010043 / 0.011353 (-0.001310) | 0.006445 / 0.011008 (-0.004563) | 0.099486 / 0.038508 (0.060978) | 0.037720 / 0.023109 (0.014610) | 0.425571 / 0.275898 (0.149673) | 0.467031 / 0.323480 (0.143551) | 0.007394 / 0.007986 (-0.000591) | 0.005008 / 0.004328 (0.000679) | 0.096176 / 0.004250 (0.091926) | 0.053694 / 0.037052 (0.016641) | 0.418653 / 0.258489 (0.160164) | 0.492441 / 0.293841 (0.198600) | 0.054593 / 0.128546 (-0.073953) | 0.023410 / 0.075646 (-0.052236) | 0.113825 / 0.419271 (-0.305446) | 0.066000 / 0.043533 (0.022467) | 0.418127 / 0.255139 (0.162988) | 0.457416 / 0.283200 (0.174217) | 0.119911 / 0.141683 (-0.021771) | 1.733805 / 1.452155 (0.281651) | 1.961252 / 1.492716 (0.468536) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.296126 / 0.018006 (0.278120) | 0.602169 / 0.000490 (0.601680) | 0.000454 / 0.000200 (0.000254) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032970 / 0.037411 (-0.004442) | 0.124071 / 0.014526 (0.109545) | 0.143800 / 0.176557 (-0.032757) | 0.227168 / 0.737135 (-0.509967) | 0.142817 / 0.296338 (-0.153521) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.626239 / 0.215209 (0.411030) | 6.438629 / 2.077655 (4.360974) | 2.760747 / 1.504120 (1.256627) | 2.355419 / 1.541195 (0.814224) | 2.384924 / 1.468490 (0.916434) | 1.210543 / 4.584777 (-3.374234) | 5.440389 / 3.745712 (1.694677) | 5.047939 / 5.269862 (-0.221922) | 2.759618 / 4.565676 (-1.806059) | 0.132757 / 0.424275 (-0.291518) | 0.013163 / 0.007607 (0.005556) | 0.745721 / 0.226044 (0.519677) | 7.660327 / 2.268929 (5.391398) | 3.559385 / 55.444624 (-51.885240) | 2.764344 / 6.876477 (-4.112133) | 2.975274 / 2.142072 (0.833202) | 1.460346 / 4.805227 (-3.344881) | 0.257222 / 6.500664 (-6.243443) | 0.081106 / 0.075469 (0.005637) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.698245 / 1.841788 (-0.143543) | 18.754129 / 8.074308 (10.679821) | 19.065596 / 10.191392 (8.874204) | 0.228237 / 0.680424 (-0.452187) | 0.030688 / 0.534201 (-0.503513) | 0.532561 / 0.579283 (-0.046722) | 0.601133 / 0.434364 (0.166769) | 0.620218 / 0.540337 (0.079881) | 0.751392 / 1.386936 (-0.635545) |\n\n</details>\n</details>\n\n\n",
"(the BadZipFile error is unrelated to the changes)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009368 / 0.011353 (-0.001984) | 0.005143 / 0.011008 (-0.005865) | 0.100675 / 0.038508 (0.062167) | 0.036033 / 0.023109 (0.012924) | 0.297391 / 0.275898 (0.021493) | 0.362230 / 0.323480 (0.038750) | 0.008041 / 0.007986 (0.000055) | 0.004041 / 0.004328 (-0.000287) | 0.075395 / 0.004250 (0.071144) | 0.043020 / 0.037052 (0.005968) | 0.308936 / 0.258489 (0.050447) | 0.343723 / 0.293841 (0.049883) | 0.038416 / 0.128546 (-0.090131) | 0.012086 / 0.075646 (-0.063560) | 0.335102 / 0.419271 (-0.084170) | 0.047718 / 0.043533 (0.004185) | 0.297856 / 0.255139 (0.042717) | 0.317326 / 0.283200 (0.034126) | 0.101462 / 0.141683 (-0.040221) | 1.459965 / 1.452155 (0.007810) | 1.491194 / 1.492716 (-0.001522) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211311 / 0.018006 (0.193305) | 0.443663 / 0.000490 (0.443174) | 0.003654 / 0.000200 (0.003454) | 0.000076 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027316 / 0.037411 (-0.010095) | 0.109929 / 0.014526 (0.095403) | 0.117170 / 0.176557 (-0.059387) | 0.182494 / 0.737135 (-0.554641) | 0.124693 / 0.296338 (-0.171646) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395904 / 0.215209 (0.180695) | 3.950906 / 2.077655 (1.873251) | 1.768807 / 1.504120 (0.264687) | 1.578979 / 1.541195 (0.037784) | 1.689976 / 1.468490 (0.221486) | 0.696458 / 4.584777 (-3.888319) | 3.750491 / 3.745712 (0.004778) | 2.117863 / 5.269862 (-3.151998) | 1.340403 / 4.565676 (-3.225274) | 0.085752 / 0.424275 (-0.338523) | 0.012206 / 0.007607 (0.004599) | 0.505561 / 0.226044 (0.279517) | 5.048721 / 2.268929 (2.779792) | 2.256623 / 55.444624 (-53.188001) | 1.905912 / 6.876477 (-4.970565) | 1.988400 / 2.142072 (-0.153672) | 0.843066 / 4.805227 (-3.962161) | 0.165717 / 6.500664 (-6.334947) | 0.062910 / 0.075469 (-0.012559) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.225668 / 1.841788 (-0.616120) | 14.660082 / 8.074308 (6.585773) | 14.295369 / 10.191392 (4.103977) | 0.171075 / 0.680424 (-0.509348) | 0.029279 / 0.534201 (-0.504922) | 0.441559 / 0.579283 (-0.137724) | 0.445382 / 0.434364 (0.011018) | 0.525350 / 0.540337 (-0.014987) | 0.608493 / 1.386936 (-0.778443) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007288 / 0.011353 (-0.004065) | 0.004999 / 0.011008 (-0.006009) | 0.074656 / 0.038508 (0.036147) | 0.033897 / 0.023109 (0.010788) | 0.345826 / 0.275898 (0.069928) | 0.390891 / 0.323480 (0.067411) | 0.005811 / 0.007986 (-0.002174) | 0.003976 / 0.004328 (-0.000353) | 0.073546 / 0.004250 (0.069295) | 0.047245 / 0.037052 (0.010193) | 0.351851 / 0.258489 (0.093362) | 0.403217 / 0.293841 (0.109376) | 0.036771 / 0.128546 (-0.091775) | 0.012240 / 0.075646 (-0.063407) | 0.086720 / 0.419271 (-0.332552) | 0.049440 / 0.043533 (0.005907) | 0.339520 / 0.255139 (0.084381) | 0.372160 / 0.283200 (0.088961) | 0.100813 / 0.141683 (-0.040870) | 1.436436 / 1.452155 (-0.015718) | 1.514723 / 1.492716 (0.022007) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231394 / 0.018006 (0.213388) | 0.440825 / 0.000490 (0.440336) | 0.000994 / 0.000200 (0.000794) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028999 / 0.037411 (-0.008412) | 0.111391 / 0.014526 (0.096865) | 0.123058 / 0.176557 (-0.053498) | 0.194348 / 0.737135 (-0.542787) | 0.125730 / 0.296338 (-0.170609) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431950 / 0.215209 (0.216741) | 4.298724 / 2.077655 (2.221069) | 2.064116 / 1.504120 (0.559996) | 1.892062 / 1.541195 (0.350867) | 1.985441 / 1.468490 (0.516951) | 0.707028 / 4.584777 (-3.877749) | 3.812976 / 3.745712 (0.067264) | 3.078704 / 5.269862 (-2.191158) | 1.832737 / 4.565676 (-2.732939) | 0.086182 / 0.424275 (-0.338093) | 0.012289 / 0.007607 (0.004681) | 0.530265 / 0.226044 (0.304220) | 5.283122 / 2.268929 (3.014194) | 2.558491 / 55.444624 (-52.886134) | 2.237046 / 6.876477 (-4.639431) | 2.354548 / 2.142072 (0.212475) | 0.848947 / 4.805227 (-3.956280) | 0.167907 / 6.500664 (-6.332757) | 0.064998 / 0.075469 (-0.010471) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.248287 / 1.841788 (-0.593500) | 14.976327 / 8.074308 (6.902019) | 13.596143 / 10.191392 (3.404751) | 0.145730 / 0.680424 (-0.534694) | 0.017340 / 0.534201 (-0.516861) | 0.430111 / 0.579283 (-0.149172) | 0.433462 / 0.434364 (-0.000902) | 0.540365 / 0.540337 (0.000028) | 0.650586 / 1.386936 (-0.736350) |\n\n</details>\n</details>\n\n\n"
] | "2023-02-21T16:56:17Z" | "2023-02-21T18:26:23Z" | "2023-02-21T18:19:09Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5560.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5560",
"merged_at": "2023-02-21T18:19:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5560.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5560"
} | This PR modifies `map` to:
* ensure the TQDM bar gets the last progress update
* when a map function fails, avoid throwing a chained exception in the single-proc mode | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5560/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5437/comments | https://api.github.com/repos/huggingface/datasets/issues/5437/events | https://github.com/huggingface/datasets/issues/5437 | 1,536,837,144 | I_kwDODunzps5bmkYY | 5,437 | Can't load png dataset with 4 channel (RGBA) | {
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"events_url": "https://api.github.com/users/WiNE-iNEFF/events{/privacy}",
"followers_url": "https://api.github.com/users/WiNE-iNEFF/followers",
"following_url": "https://api.github.com/users/WiNE-iNEFF/following{/other_user}",
"gists_url": "https://api.github.com/users/WiNE-iNEFF/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/WiNE-iNEFF",
"id": 41611046,
"login": "WiNE-iNEFF",
"node_id": "MDQ6VXNlcjQxNjExMDQ2",
"organizations_url": "https://api.github.com/users/WiNE-iNEFF/orgs",
"received_events_url": "https://api.github.com/users/WiNE-iNEFF/received_events",
"repos_url": "https://api.github.com/users/WiNE-iNEFF/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/WiNE-iNEFF/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WiNE-iNEFF/subscriptions",
"type": "User",
"url": "https://api.github.com/users/WiNE-iNEFF"
} | [] | closed | false | null | [] | null | [
"Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.\r\n\r\n",
"> Hi! Can you please share the directory structure of your image folder and the `load_dataset` call? We decode images with Pillow, and Pillow supports RGBA PNGs, so this shouldn't be a problem.\n> \n> \n\nI have only 1 folder that I use in the load_dataset function with the name \"IMGDATA\" and all my 9000 images are located in this folder.\n`\nfrom datasets import load_dataset\n\ndataset = load_dataset(\"IMGDATA\")\n`\nAt the same time, using another data set with images consisting of 3 RGB channels, everything works",
"Okay, I figured out what was wrong. When uploading my dataset via Google Drive, the images broke and Pillow couldn't open them. As a result, I solved the problem by downloading the ZIP archive"
] | "2023-01-17T18:22:27Z" | "2023-01-18T20:20:15Z" | "2023-01-18T20:20:15Z" | NONE | null | null | null | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5437/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5437/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4154/comments | https://api.github.com/repos/huggingface/datasets/issues/4154/events | https://github.com/huggingface/datasets/pull/4154 | 1,202,145,721 | PR_kwDODunzps42Hh14 | 4,154 | Generate tasks.json taxonomy from `huggingface_hub` | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/julien-c",
"id": 326577,
"login": "julien-c",
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"repos_url": "https://api.github.com/users/julien-c/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"type": "User",
"url": "https://api.github.com/users/julien-c"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Ok recomputed the json file, this should be ready to review now! @lhoestq ",
"Note: the generated JSON from `hf/hub-docs` can be found in the output of a GitHub Action run on that repo, for instance in https://github.com/huggingface/hub-docs/runs/6006686983?check_suite_focus=true\r\n\r\n(click on \"Run export-tasks script\")",
"Should we not add the tasks with hideInDatasets?",
"yes, probably true – i'll change that in a PR in `hub-docs`",
"Yes that's good :) feel free to merge",
"thanks to the both of you!"
] | "2022-04-12T17:12:46Z" | "2022-04-14T10:32:32Z" | "2022-04-14T10:26:13Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4154.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4154",
"merged_at": "2022-04-14T10:26:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4154.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4154"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4154/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4154/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3298/comments | https://api.github.com/repos/huggingface/datasets/issues/3298/events | https://github.com/huggingface/datasets/issues/3298 | 1,058,420,201 | I_kwDODunzps4_FjXp | 3,298 | Agnews dataset viewer is not working | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pietrolesci",
"id": 61748653,
"login": "pietrolesci",
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pietrolesci"
} | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting\r\nWe've already fixed the code that generates the preview for this dataset, we'll release the fix soon :)",
"Hi @lhoestq, thanks for your feedback!",
"Fixed in the viewer.\r\n\r\nhttps://huggingface.co/datasets/ag_news"
] | "2021-11-19T11:18:59Z" | "2021-12-21T16:24:05Z" | "2021-12-21T16:24:05Z" | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** https://huggingface.co/datasets/ag_news
Hi there, the `ag_news` dataset viewer is not working.
Am I the one who added this dataset? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3298/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3298/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2464/comments | https://api.github.com/repos/huggingface/datasets/issues/2464/events | https://github.com/huggingface/datasets/pull/2464 | 915,485,601 | MDExOlB1bGxSZXF1ZXN0NjY1Mjk1MDE5 | 2,464 | fix: adjusting indexing for the labels. | {
"avatar_url": "https://avatars.githubusercontent.com/u/5406908?v=4",
"events_url": "https://api.github.com/users/drugilsberg/events{/privacy}",
"followers_url": "https://api.github.com/users/drugilsberg/followers",
"following_url": "https://api.github.com/users/drugilsberg/following{/other_user}",
"gists_url": "https://api.github.com/users/drugilsberg/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/drugilsberg",
"id": 5406908,
"login": "drugilsberg",
"node_id": "MDQ6VXNlcjU0MDY5MDg=",
"organizations_url": "https://api.github.com/users/drugilsberg/orgs",
"received_events_url": "https://api.github.com/users/drugilsberg/received_events",
"repos_url": "https://api.github.com/users/drugilsberg/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/drugilsberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/drugilsberg/subscriptions",
"type": "User",
"url": "https://api.github.com/users/drugilsberg"
} | [] | closed | false | null | [] | null | [
"> Good catch ! Thanks for fixing it\r\n\r\nMy pleasure🙏"
] | "2021-06-08T20:47:25Z" | "2021-06-09T10:15:46Z" | "2021-06-09T09:10:28Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2464.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2464",
"merged_at": "2021-06-09T09:10:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2464.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2464"
} | The labels index were mismatching the actual ones used in the dataset. Specifically `0` is used for `SUPPORTS` and `1` is used for `REFUTES`
After this change, the `README.md` now reflects the content of `dataset_infos.json`.
Signed-off-by: Matteo Manica <[email protected]> | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2464/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/689/comments | https://api.github.com/repos/huggingface/datasets/issues/689/events | https://github.com/huggingface/datasets/pull/689 | 712,095,262 | MDExOlB1bGxSZXF1ZXN0NDk1NjMzNjMy | 689 | Switch to pandas reader for text dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"If the windows tests in the CI pass, today will be a happy day"
] | "2020-09-30T16:28:12Z" | "2020-09-30T16:45:32Z" | "2020-09-30T16:45:31Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/689.diff",
"html_url": "https://github.com/huggingface/datasets/pull/689",
"merged_at": "2020-09-30T16:45:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/689.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/689"
} | Following the discussion in #622 , it appears that there's no appropriate ways to use the payrrow csv reader to read text files because of the separator.
In this PR I switched to pandas to read the file.
Moreover pandas allows to read the file by chunk, which means that you can build the arrow dataset from a text file that is bigger than RAM (we used to have to shard text files an mentioned in https://github.com/huggingface/datasets/issues/610#issuecomment-691672919)
From a test that I did locally on a 1GB text file, the pyarrow reader used to run in 150ms while the new one takes 650ms (multithreading off for pyarrow). This is probably due to chunking since I am having the same speed difference by calling `read()` and calling `read(chunksize)` + `readline()` to read the text file. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/689/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/689/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2965 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2965/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2965/comments | https://api.github.com/repos/huggingface/datasets/issues/2965/events | https://github.com/huggingface/datasets/issues/2965 | 1,007,084,153 | I_kwDODunzps48BuJ5 | 2,965 | Invalid download URL of WMT17 `zh-en` data | {
"avatar_url": "https://avatars.githubusercontent.com/u/3339950?v=4",
"events_url": "https://api.github.com/users/Ririkoo/events{/privacy}",
"followers_url": "https://api.github.com/users/Ririkoo/followers",
"following_url": "https://api.github.com/users/Ririkoo/following{/other_user}",
"gists_url": "https://api.github.com/users/Ririkoo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Ririkoo",
"id": 3339950,
"login": "Ririkoo",
"node_id": "MDQ6VXNlcjMzMzk5NTA=",
"organizations_url": "https://api.github.com/users/Ririkoo/orgs",
"received_events_url": "https://api.github.com/users/Ririkoo/received_events",
"repos_url": "https://api.github.com/users/Ririkoo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Ririkoo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ririkoo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Ririkoo"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"Fixed in the current release. Close this issue."
] | "2021-09-25T13:17:32Z" | "2022-08-31T06:47:11Z" | "2022-08-31T06:47:10Z" | NONE | null | null | null | ## Describe the bug
Partial data (wmt17 zh-en) cannot be downloaded due to an invalid URL.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('wmt17','zh-en')
```
## Expected results
ConnectionError: Couldn't reach ftp://cwmt-wmt:[email protected]/parallel/casia2015.zip | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2965/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2965/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1999 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1999/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1999/comments | https://api.github.com/repos/huggingface/datasets/issues/1999/events | https://github.com/huggingface/datasets/pull/1999 | 823,753,591 | MDExOlB1bGxSZXF1ZXN0NTg2MTM5ODMy | 1,999 | Add FashionMNIST dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gchhablani",
"id": 29076344,
"login": "gchhablani",
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gchhablani"
} | [] | closed | false | null | [] | null | [
"Hi @lhoestq,\r\n\r\nI have added the changes from the review."
] | "2021-03-06T21:36:57Z" | "2021-03-09T09:52:11Z" | "2021-03-09T09:52:11Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1999.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1999",
"merged_at": "2021-03-09T09:52:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1999.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1999"
} | This PR adds [FashionMNIST](https://github.com/zalandoresearch/fashion-mnist) dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1999/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1999/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1177 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1177/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1177/comments | https://api.github.com/repos/huggingface/datasets/issues/1177/events | https://github.com/huggingface/datasets/pull/1177 | 757,778,684 | MDExOlB1bGxSZXF1ZXN0NTMzMDkxMTQ3 | 1,177 | Add Korean NER dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https://api.github.com/users/jaketae/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jaketae",
"id": 25360440,
"login": "jaketae",
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"organizations_url": "https://api.github.com/users/jaketae/orgs",
"received_events_url": "https://api.github.com/users/jaketae/received_events",
"repos_url": "https://api.github.com/users/jaketae/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jaketae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaketae/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jaketae"
} | [] | closed | false | null | [] | null | [
"Closed via #1219 "
] | "2020-12-05T20:56:00Z" | "2020-12-06T20:19:48Z" | "2020-12-06T20:19:48Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1177.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1177",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1177.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1177"
} | This PR adds the [Korean named entity recognition dataset](https://github.com/kmounlp/NER). This dataset has been used in many downstream tasks, such as training [KoBERT](https://github.com/SKTBrain/KoBERT) for NER, as seen in this [KoBERT-CRF implementation](https://github.com/eagle705/pytorch-bert-crf-ner). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1177/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1177/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1062 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1062/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1062/comments | https://api.github.com/repos/huggingface/datasets/issues/1062/events | https://github.com/huggingface/datasets/pull/1062 | 756,373,187 | MDExOlB1bGxSZXF1ZXN0NTMxOTI4NDY5 | 1,062 | Add KorNLU dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28291870?v=4",
"events_url": "https://api.github.com/users/sumanthd17/events{/privacy}",
"followers_url": "https://api.github.com/users/sumanthd17/followers",
"following_url": "https://api.github.com/users/sumanthd17/following{/other_user}",
"gists_url": "https://api.github.com/users/sumanthd17/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sumanthd17",
"id": 28291870,
"login": "sumanthd17",
"node_id": "MDQ6VXNlcjI4MjkxODcw",
"organizations_url": "https://api.github.com/users/sumanthd17/orgs",
"received_events_url": "https://api.github.com/users/sumanthd17/received_events",
"repos_url": "https://api.github.com/users/sumanthd17/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sumanthd17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sumanthd17/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sumanthd17"
} | [] | closed | false | null | [] | null | [
"Nice thank you !\r\nCan you regenerate the dataset_infos.json file ? Since we changed the features we must update it\r\n\r\nThen I think we'll be good to merge :)"
] | "2020-12-03T16:52:39Z" | "2020-12-04T11:05:19Z" | "2020-12-04T11:05:19Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1062.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1062",
"merged_at": "2020-12-04T11:05:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1062.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1062"
} | Added Korean NLU datasets. The link to the dataset can be found [here](https://github.com/kakaobrain/KorNLUDatasets) and the paper can be found [here](https://arxiv.org/abs/2004.03289)
**Note**: The MNLI tsv file is broken, so this code currently excludes the file. Please suggest other alternative if any @lhoestq
- [x] Followed the instructions in CONTRIBUTING.md
- [x] Ran the tests successfully
- [x] Created the dummy data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1062/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1062/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1531 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1531/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1531/comments | https://api.github.com/repos/huggingface/datasets/issues/1531/events | https://github.com/huggingface/datasets/pull/1531 | 764,752,882 | MDExOlB1bGxSZXF1ZXN0NTM4NjcwNzcz | 1,531 | adding hate-speech-and-offensive-language | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MisbahKhan789",
"id": 15351802,
"login": "MisbahKhan789",
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MisbahKhan789"
} | [] | closed | false | null | [] | null | [] | "2020-12-13T01:59:07Z" | "2020-12-13T02:17:02Z" | "2020-12-13T02:17:02Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1531.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1531",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1531.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1531"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1531/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1531/timeline | null | null | true |
|
https://api.github.com/repos/huggingface/datasets/issues/2102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2102/comments | https://api.github.com/repos/huggingface/datasets/issues/2102/events | https://github.com/huggingface/datasets/pull/2102 | 838,794,090 | MDExOlB1bGxSZXF1ZXN0NTk4OTEyNzUw | 2,102 | Move Dataset.to_csv to csv module | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "B67A40",
"default": false,
"description": "Restructuring existing code without changing its external behavior",
"id": 2851292821,
"name": "refactoring",
"node_id": "MDU6TGFiZWwyODUxMjkyODIx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/refactoring"
}
] | closed | false | null | [] | null | [] | "2021-03-23T14:35:46Z" | "2021-03-24T14:07:35Z" | "2021-03-24T14:07:34Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2102.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2102",
"merged_at": "2021-03-24T14:07:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2102.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2102"
} | Move the implementation of `Dataset.to_csv` to module `datasets.io.csv`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2102/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2102/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6109 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6109/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6109/comments | https://api.github.com/repos/huggingface/datasets/issues/6109/events | https://github.com/huggingface/datasets/issues/6109 | 1,830,753,793 | I_kwDODunzps5tHxYB | 6,109 | Problems in downloading Amazon reviews from HF | {
"avatar_url": "https://avatars.githubusercontent.com/u/52964960?v=4",
"events_url": "https://api.github.com/users/610v4nn1/events{/privacy}",
"followers_url": "https://api.github.com/users/610v4nn1/followers",
"following_url": "https://api.github.com/users/610v4nn1/following{/other_user}",
"gists_url": "https://api.github.com/users/610v4nn1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/610v4nn1",
"id": 52964960,
"login": "610v4nn1",
"node_id": "MDQ6VXNlcjUyOTY0OTYw",
"organizations_url": "https://api.github.com/users/610v4nn1/orgs",
"received_events_url": "https://api.github.com/users/610v4nn1/received_events",
"repos_url": "https://api.github.com/users/610v4nn1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/610v4nn1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/610v4nn1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/610v4nn1"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @610v4nn1.\r\n\r\nIndeed, the source data files are no longer available. We have contacted the authors of the dataset and they report that Amazon has decided to stop distributing the multilingual reviews dataset.\r\n\r\nWe are adding a notification about this issue to the dataset card.\r\n\r\nSee: https://huggingface.co/datasets/amazon_reviews_multi/discussions/4#64c3898db63057f1fd3ce1a0 "
] | "2023-08-01T08:38:29Z" | "2023-08-02T07:12:07Z" | "2023-08-02T07:12:07Z" | NONE | null | null | null | ### Describe the bug
I have a script downloading `amazon_reviews_multi`.
When the download starts, I get
```
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 243B [00:00, 1.43MB/s]
Downloading data files: 100%|██████████| 1/1 [00:01<00:00, 1.54s/it]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 842.40it/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 243B [00:00, 928kB/s]
Downloading data files: 100%|██████████| 1/1 [00:01<00:00, 1.42s/it]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 832.70it/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 243B [00:00, 1.81MB/s]
Downloading data files: 100%|██████████| 1/1 [00:01<00:00, 1.40s/it]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 1294.14it/s]
Generating train split: 0%| | 0/200000 [00:00<?, ? examples/s]
```
the file is clearly too small to contain the requested dataset, in fact it contains en error message:
```
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>AGJWSY3ZADT2QVWE</RequestId><HostId>Gx1O2KXnxtQFqvzDLxyVSTq3+TTJuTnuVFnJL3SP89Yp8UzvYLPTVwd1PpniE4EvQzT3tCaqEJw=</HostId></Error>
```
obviously the script fails:
```
> raise DatasetGenerationError("An error occurred while generating the dataset") from e
E datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
1. load_dataset("amazon_reviews_multi", name="en", split="train", cache_dir="ADDYOURPATHHERE")
### Expected behavior
I would expect the dataset to be downloaded and processed
### Environment info
* The problem is present with both datasets 2.12.0 and 2.14.2
* python version 3.10.12 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6109/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6109/timeline | null | not_planned | false |