

Upload CoQAR.py
Browse files
CoQAR.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
+
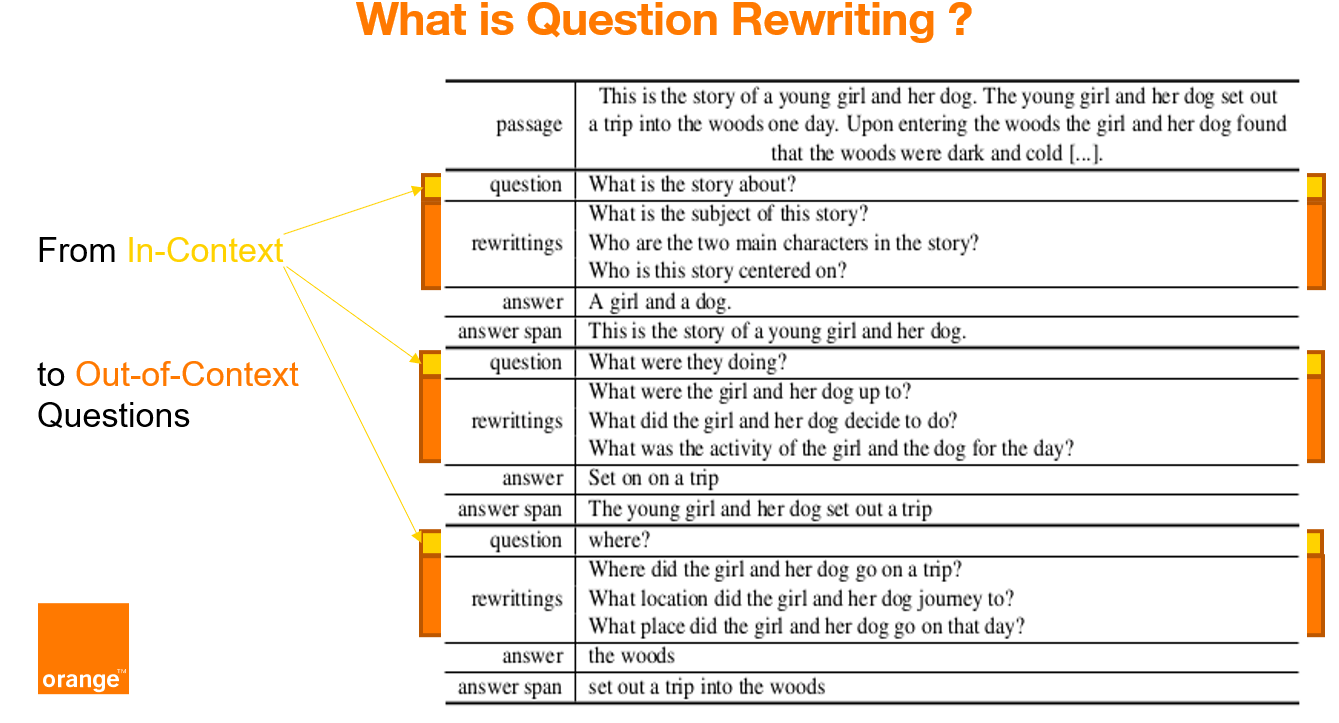
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
|
| 17 |
+
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
|
| 18 |
+
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
|
| 19 |
+
|
| 20 |
+
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
The annotations are published under the licence CC-BY-SA 4.0.
|
| 25 |
+
The original content of the dataset CoQA is under the distinct licences described below.
|
| 26 |
+
|
| 27 |
+
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
|
| 28 |
+
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
|
| 29 |
+
- Children's stories are collected from MCTest which comes with MSR-LA license.
|
| 30 |
+
- Middle/High school exam passages are collected from RACE which comes with its own license.
|
| 31 |
+
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)).
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
import csv
|
| 36 |
+
import json
|
| 37 |
+
import os
|
| 38 |
+
|
| 39 |
+
import datasets
|
| 40 |
+
|
| 41 |
+
_CITATION = """\
|
| 42 |
+
@inproceedings{brabant-etal-2022-coqar,
|
| 43 |
+
title = "{C}o{QAR}: Question Rewriting on {C}o{QA}",
|
| 44 |
+
author = "Brabant, Quentin and
|
| 45 |
+
Lecorv{\'e}, Gw{\'e}nol{\'e} and
|
| 46 |
+
Rojas Barahona, Lina M.",
|
| 47 |
+
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
|
| 48 |
+
month = jun,
|
| 49 |
+
year = "2022",
|
| 50 |
+
address = "Marseille, France",
|
| 51 |
+
publisher = "European Language Resources Association",
|
| 52 |
+
url = "https://aclanthology.org/2022.lrec-1.13",
|
| 53 |
+
pages = "119--126"
|
| 54 |
+
}
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
_DESCRIPTION = """\
|
| 58 |
+
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
|
| 59 |
+
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
|
| 60 |
+
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
|
| 61 |
+
|
| 62 |
+
We annotated each original question of CoQA with at least 2 at most 3 out-of-context rewritings.
|
| 63 |
+
|
| 64 |
+

|
| 65 |
+
|
| 66 |
+
The annotations are published under the licence CC-BY-SA 4.0.
|
| 67 |
+
The original content of the dataset CoQA is under the distinct licences described below.
|
| 68 |
+
|
| 69 |
+
The corpus CoQA contains passages from seven domains, which are public under the following licenses:
|
| 70 |
+
- Literature and Wikipedia passages are shared under CC BY-SA 4.0 license.
|
| 71 |
+
- Children's stories are collected from MCTest which comes with MSR-LA license.
|
| 72 |
+
- Middle/High school exam passages are collected from RACE which comes with its own license.
|
| 73 |
+
- News passages are collected from the DeepMind CNN dataset which comes with Apache license (see [K. M. Hermann, T. Kočiský and E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, P. Blunsom, Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems (NIPS), 2015](http://arxiv.org/abs/1506.03340)).
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
_HOMEPAGE = "https://github.com/Orange-OpenSource/COQAR/"
|
| 77 |
+
|
| 78 |
+
_LICENSE = """
|
| 79 |
+
- Annotations, litterature and Wikipedia passages: licence CC-BY-SA 4.0.
|
| 80 |
+
- Children's stories are from MCTest (MSR-LA license).
|
| 81 |
+
- Exam passages come from RACE which has its own license.
|
| 82 |
+
- News passages are from the DeepMind CNN dataset (Apache license).
|
| 83 |
+
"""
|
| 84 |
+
|
| 85 |
+
_URLS = {
|
| 86 |
+
"train": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/train/coqar-train-v1.0.json",
|
| 87 |
+
"dev": "https://raw.githubusercontent.com/Orange-OpenSource/COQAR/master/data/CoQAR/dev/coqar-dev-v1.0.json"
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class CoQAR(datasets.GeneratorBasedBuilder):
|
| 92 |
+
"""
|
| 93 |
+
CoQAR is a corpus containing 4.5K conversations from the open-source dataset [Conversational Question-Answering dataset CoQA](https://stanfordnlp.github.io/coqa/), for a total of 53K follow-up question-answer pairs.
|
| 94 |
+
In CoQAR each original question was manually annotated with at least 2 at most 3 out-of-context rewritings.
|
| 95 |
+
COQAR can be used for (at least) three NLP tasks: question paraphrasing, question rewriting and conversational question answering.
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
VERSION = datasets.Version("1.1.0")
|
| 99 |
+
|
| 100 |
+
def _info(self):
|
| 101 |
+
features = datasets.Features(
|
| 102 |
+
{
|
| 103 |
+
'conversation_id' : datasets.Value("string"),
|
| 104 |
+
'turn_id': datasets.Value("int16"),
|
| 105 |
+
'original_question' : datasets.Value("string"),
|
| 106 |
+
'question_paraphrases' : datasets.Sequence(feature=datasets.Value("string")),
|
| 107 |
+
'answer' : datasets.Value("string"),
|
| 108 |
+
'answer_span_start' : datasets.Value("int32"),
|
| 109 |
+
'answer_span_end' : datasets.Value("int32"),
|
| 110 |
+
'answer_span_text' : datasets.Value("string"),
|
| 111 |
+
'conversation_history' : datasets.Sequence(feature=datasets.Value("string")),
|
| 112 |
+
'file_name' : datasets.Value("string"),
|
| 113 |
+
'story': datasets.Value("string"),
|
| 114 |
+
'name': datasets.Value("string"),
|
| 115 |
+
}
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
return datasets.DatasetInfo(
|
| 119 |
+
# This is the description that will appear on the datasets page.
|
| 120 |
+
description=_DESCRIPTION,
|
| 121 |
+
# This defines the different columns of the dataset and their types
|
| 122 |
+
features=features,
|
| 123 |
+
homepage=_HOMEPAGE,
|
| 124 |
+
# License for the dataset if available
|
| 125 |
+
license=_LICENSE,
|
| 126 |
+
# Citation for the dataset
|
| 127 |
+
citation=_CITATION,
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
def _split_generators(self, dl_manager):
|
| 131 |
+
data_dir = dl_manager.download_and_extract(_URLS)
|
| 132 |
+
|
| 133 |
+
return [
|
| 134 |
+
datasets.SplitGenerator(
|
| 135 |
+
name=datasets.Split.TRAIN,
|
| 136 |
+
gen_kwargs={
|
| 137 |
+
"filepath": data_dir['train'],
|
| 138 |
+
"split": "train",
|
| 139 |
+
},
|
| 140 |
+
),
|
| 141 |
+
datasets.SplitGenerator(
|
| 142 |
+
name=datasets.Split.VALIDATION,
|
| 143 |
+
gen_kwargs={
|
| 144 |
+
"filepath": data_dir['dev'],
|
| 145 |
+
"split": "dev",
|
| 146 |
+
},
|
| 147 |
+
)
|
| 148 |
+
]
|
| 149 |
+
|
| 150 |
+
# method parameters are unpacked from `gen_kwargs` as given in `_split_generators`
|
| 151 |
+
def _generate_examples(self, filepath, split):
|
| 152 |
+
with open(filepath, 'r') as f:
|
| 153 |
+
dic = json.load(f)
|
| 154 |
+
i = 0
|
| 155 |
+
for datum in dic['data']:
|
| 156 |
+
history = []
|
| 157 |
+
for question, answer in zip(datum['questions'], datum['answers']):
|
| 158 |
+
yield i, {
|
| 159 |
+
'conversation_id' : datum['id'],
|
| 160 |
+
'turn_id': question['turn_id'],
|
| 161 |
+
'original_question' :question['input_text'],
|
| 162 |
+
'question_paraphrases' : question['paraphrase'],
|
| 163 |
+
'answer' : answer['input_text'],
|
| 164 |
+
'answer_span_start' : answer['span_start'],
|
| 165 |
+
'answer_span_end' : answer['span_end'],
|
| 166 |
+
'answer_span_text' : answer['span_text'],
|
| 167 |
+
'conversation_history' : list(history),
|
| 168 |
+
'file_name' : datum['filename'],
|
| 169 |
+
'story': datum['story'],
|
| 170 |
+
'name': datum['name']
|
| 171 |
+
}
|
| 172 |
+
history.append(question['input_text'])
|
| 173 |
+
history.append(answer['input_text'])
|
| 174 |
+
i+=1
|