
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Create an Endpoint
After your first login, you will be directed to the [Endpoint creation page](https://ui.endpoints.huggingface.co/new). As an example, this guide will go through the steps to deploy [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) for text classification.
## 1. Enter the Hugging Face Repository ID and your desired endpoint name:
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/1_repository.png" alt="select repository" />
## 2. Select your Cloud Provider and region. Initially, only AWS will be available as a Cloud Provider with the `us-east-1` and `eu-west-1` regions. We will add Azure soon, and if you need to test Endpoints with other Cloud Providers or regions, please let us know.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/1_region.png" alt="select region" />
## 3. Define the [Security Level](security) for the Endpoint:
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/1_security.png" alt="define security" />
## 4. Create your Endpoint by clicking **Create Endpoint**. By default, your Endpoint is created with a medium CPU (2 x 4GB vCPUs with Intel Xeon Ice Lake) The cost estimate assumes the Endpoint will be up for an entire month, and does not take autoscaling into account.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/1_create_cost.png" alt="create endpoint" />
## 5. Wait for the Endpoint to build, initialize and run which can take between 1 to 5 minutes.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/overview.png" alt="overview" />
## 6. Test your Endpoint in the overview with the Inference widget 🏁 🎉!
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/1_inference.png" alt="run inference" />
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/create_endpoint.mdx |
Choosing a metric for your task
**So you've trained your model and want to see how well it’s doing on a dataset of your choice. Where do you start?**
There is no “one size fits all” approach to choosing an evaluation metric, but some good guidelines to keep in mind are:
## Categories of metrics
There are 3 high-level categories of metrics:
1. *Generic metrics*, which can be applied to a variety of situations and datasets, such as precision and accuracy.
2. *Task-specific metrics*, which are limited to a given task, such as Machine Translation (often evaluated using metrics [BLEU](https://huggingface.co/metrics/bleu) or [ROUGE](https://huggingface.co/metrics/rouge)) or Named Entity Recognition (often evaluated with [seqeval](https://huggingface.co/metrics/seqeval)).
3. *Dataset-specific metrics*, which aim to measure model performance on specific benchmarks: for instance, the [GLUE benchmark](https://huggingface.co/datasets/glue) has a dedicated [evaluation metric](https://huggingface.co/metrics/glue).
Let's look at each of these three cases:
### Generic metrics
Many of the metrics used in the Machine Learning community are quite generic and can be applied in a variety of tasks and datasets.
This is the case for metrics like [accuracy](https://huggingface.co/metrics/accuracy) and [precision](https://huggingface.co/metrics/precision), which can be used for evaluating labeled (supervised) datasets, as well as [perplexity](https://huggingface.co/metrics/perplexity), which can be used for evaluating different kinds of (unsupervised) generative tasks.
To see the input structure of a given metric, you can look at its metric card. For example, in the case of [precision](https://huggingface.co/metrics/precision), the format is:
```
>>> precision_metric = evaluate.load("precision")
>>> results = precision_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'precision': 1.0}
```
### Task-specific metrics
Popular ML tasks like Machine Translation and Named Entity Recognition have specific metrics that can be used to compare models. For example, a series of different metrics have been proposed for text generation, ranging from [BLEU](https://huggingface.co/metrics/bleu) and its derivatives such as [GoogleBLEU](https://huggingface.co/metrics/google_bleu) and [GLEU](https://huggingface.co/metrics/gleu), but also [ROUGE](https://huggingface.co/metrics/rouge), [MAUVE](https://huggingface.co/metrics/mauve), etc.
You can find the right metric for your task by:
- **Looking at the [Task pages](https://huggingface.co/tasks)** to see what metrics can be used for evaluating models for a given task.
- **Checking out leaderboards** on sites like [Papers With Code](https://paperswithcode.com/) (you can search by task and by dataset).
- **Reading the metric cards** for the relevant metrics and see which ones are a good fit for your use case. For example, see the [BLEU metric card](https://github.com/huggingface/evaluate/tree/main/metrics/bleu) or [SQuaD metric card](https://github.com/huggingface/evaluate/tree/main/metrics/squad).
- **Looking at papers and blog posts** published on the topic and see what metrics they report. This can change over time, so try to pick papers from the last couple of years!
### Dataset-specific metrics
Some datasets have specific metrics associated with them -- this is especially in the case of popular benchmarks like [GLUE](https://huggingface.co/metrics/glue) and [SQuAD](https://huggingface.co/metrics/squad).
<Tip warning={true}>
💡
GLUE is actually a collection of different subsets on different tasks, so first you need to choose the one that corresponds to the NLI task, such as mnli, which is described as “crowdsourced collection of sentence pairs with textual entailment annotations”
</Tip>
If you are evaluating your model on a benchmark dataset like the ones mentioned above, you can use its dedicated evaluation metric. Make sure you respect the format that they require. For example, to evaluate your model on the [SQuAD](https://huggingface.co/datasets/squad) dataset, you need to feed the `question` and `context` into your model and return the `prediction_text`, which should be compared with the `references` (based on matching the `id` of the question) :
```
>>> from evaluate import load
>>> squad_metric = load("squad")
>>> predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
>>> references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
>>> results = squad_metric.compute(predictions=predictions, references=references)
>>> results
{'exact_match': 100.0, 'f1': 100.0}
```
You can find examples of dataset structures by consulting the "Dataset Preview" function or the dataset card for a given dataset, and you can see how to use its dedicated evaluation function based on the metric card.
| huggingface/evaluate/blob/main/docs/source/choosing_a_metric.mdx |
主要特点
让我们来介绍一下 Gradio 最受欢迎的一些功能!这里是 Gradio 的主要特点:
1. [添加示例输入](#example-inputs)
2. [传递自定义错误消息](#errors)
3. [添加描述内容](#descriptive-content)
4. [设置旗标](#flagging)
5. [预处理和后处理](#preprocessing-and-postprocessing)
6. [样式化演示](#styling)
7. [排队用户](#queuing)
8. [迭代输出](#iterative-outputs)
9. [进度条](#progress-bars)
10. [批处理函数](#batch-functions)
11. [在协作笔记本上运行](#colab-notebooks)
## 示例输入
您可以提供用户可以轻松加载到 "Interface" 中的示例数据。这对于演示模型期望的输入类型以及演示数据集和模型一起探索的方式非常有帮助。要加载示例数据,您可以将嵌套列表提供给 Interface 构造函数的 `examples=` 关键字参数。外部列表中的每个子列表表示一个数据样本,子列表中的每个元素表示每个输入组件的输入。有关每个组件的示例数据格式在[Docs](https://gradio.app/docs#components)中有说明。
$code_calculator
$demo_calculator
您可以将大型数据集加载到示例中,通过 Gradio 浏览和与数据集进行交互。示例将自动分页(可以通过 Interface 的 `examples_per_page` 参数进行配置)。
继续了解示例,请参阅[更多示例](https://gradio.app/more-on-examples)指南。
## 错误
您希望向用户传递自定义错误消息。为此,with `gr.Error("custom message")` 来显示错误消息。如果在上面的计算器示例中尝试除以零,将显示自定义错误消息的弹出模态窗口。了解有关错误的更多信息,请参阅[文档](https://gradio.app/docs#error)。
## 描述性内容
在前面的示例中,您可能已经注意到 Interface 构造函数中的 `title=` 和 `description=` 关键字参数,帮助用户了解您的应用程序。
Interface 构造函数中有三个参数用于指定此内容应放置在哪里:
- `title`:接受文本,并可以将其显示在界面的顶部,也将成为页面标题。
- `description`:接受文本、Markdown 或 HTML,并将其放置在标题正下方。
- `article`:也接受文本、Markdown 或 HTML,并将其放置在界面下方。

如果您使用的是 `Blocks` API,则可以 with `gr.Markdown(...)` 或 `gr.HTML(...)` 组件在任何位置插入文本、Markdown 或 HTML,其中描述性内容位于 `Component` 构造函数内部。
另一个有用的关键字参数是 `label=`,它存在于每个 `Component` 中。这修改了每个 `Component` 顶部的标签文本。还可以为诸如 `Textbox` 或 `Radio` 之类的表单元素添加 `info=` 关键字参数,以提供有关其用法的进一步信息。
```python
gr.Number(label='年龄', info='以年为单位,必须大于0')
```
## 旗标
默认情况下,"Interface" 将有一个 "Flag" 按钮。当用户测试您的 `Interface` 时,如果看到有趣的输出,例如错误或意外的模型行为,他们可以将输入标记为您进行查看。在由 `Interface` 构造函数的 `flagging_dir=` 参数提供的目录中,将记录标记的输入到一个 CSV 文件中。如果界面涉及文件数据,例如图像和音频组件,将创建文件夹来存储这些标记的数据。
例如,对于上面显示的计算器界面,我们将在下面的旗标目录中存储标记的数据:
```directory
+-- calculator.py
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output
5,add,7,12
6,subtract,1.5,4.5
```
与早期显示的冷色界面相对应,我们将在下面的旗标目录中存储标记的数据:
```directory
+-- sepia.py
+-- flagged/
| +-- logs.csv
| +-- im/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output
im/0.png,Output/0.png
im/1.png,Output/1.png
```
如果您希望用户提供旗标原因,可以将字符串列表传递给 Interface 的 `flagging_options` 参数。用户在进行旗标时必须选择其中一个字符串,这将作为附加列保存到 CSV 中。
## 预处理和后处理 (Preprocessing and Postprocessing)

如您所见,Gradio 包括可以处理各种不同数据类型的组件,例如图像、音频和视频。大多数组件都可以用作输入或输出。
当组件用作输入时,Gradio 自动处理*预处理*,将数据从用户浏览器发送的类型(例如网络摄像头快照的 base64 表示)转换为您的函数可以接受的形式(例如 `numpy` 数组)。
同样,当组件用作输出时,Gradio 自动处理*后处理*,将数据从函数返回的形式(例如图像路径列表)转换为可以在用户浏览器中显示的形式(例如以 base64 格式显示图像的 `Gallery`)。
您可以使用构建图像组件时的参数控制*预处理*。例如,如果您使用以下参数实例化 `Image` 组件,它将将图像转换为 `PIL` 类型,并将其重塑为`(100, 100)`,而不管提交时的原始大小如何:
```py
img = gr.Image(shape=(100, 100), type="pil")
```
相反,这里我们保留图像的原始大小,但在将其转换为 numpy 数组之前反转颜色:
```py
img = gr.Image(invert_colors=True, type="numpy")
```
后处理要容易得多!Gradio 自动识别返回数据的格式(例如 `Image` 是 `numpy` 数组还是 `str` 文件路径?),并将其后处理为可以由浏览器显示的格式。
请查看[文档](https://gradio.app/docs),了解每个组件的所有与预处理相关的参数。
## 样式 (Styling)
Gradio 主题是自定义应用程序外观和感觉的最简单方法。您可以选择多种主题或创建自己的主题。要这样做,请将 `theme=` 参数传递给 `Interface` 构造函数。例如:
```python
demo = gr.Interface(..., theme=gr.themes.Monochrome())
```
Gradio 带有一组预先构建的主题,您可以从 `gr.themes.*` 加载。您可以扩展这些主题或从头开始创建自己的主题 - 有关更多详细信息,请参阅[主题指南](https://gradio.app/theming-guide)。
要增加额外的样式能力,您可以 with `css=` 关键字将任何 CSS 传递给您的应用程序。
Gradio 应用程序的基类是 `gradio-container`,因此以下是一个更改 Gradio 应用程序背景颜色的示例:
```python
with `gr.Interface(css=".gradio-container {background-color: red}") as demo:
...
```
## 队列 (Queuing)
如果您的应用程序预计会有大量流量,请 with `queue()` 方法来控制处理速率。这将排队处理调用,因此一次只处理一定数量的请求。队列使用 Websockets,还可以防止网络超时,因此如果您的函数的推理时间很长(> 1 分钟),应使用队列。
with `Interface`:
```python
demo = gr.Interface(...).queue()
demo.launch()
```
with `Blocks`:
```python
with gr.Blocks() as demo:
#...
demo.queue()
demo.launch()
```
您可以通过以下方式控制一次处理的请求数量:
```python
demo.queue(concurrency_count=3)
```
查看有关配置其他队列参数的[队列文档](/docs/#queue)。
在 Blocks 中指定仅对某些函数进行排队:
```python
with gr.Blocks() as demo2:
num1 = gr.Number()
num2 = gr.Number()
output = gr.Number()
gr.Button("Add").click(
lambda a, b: a + b, [num1, num2], output)
gr.Button("Multiply").click(
lambda a, b: a * b, [num1, num2], output, queue=True)
demo2.launch()
```
## 迭代输出 (Iterative Outputs)
在某些情况下,您可能需要传输一系列输出而不是一次显示单个输出。例如,您可能有一个图像生成模型,希望显示生成的每个步骤的图像,直到最终图像。或者您可能有一个聊天机器人,它逐字逐句地流式传输响应,而不是一次返回全部响应。
在这种情况下,您可以将**生成器**函数提供给 Gradio,而不是常规函数。在 Python 中创建生成器非常简单:函数不应该有一个单独的 `return` 值,而是应该 with `yield` 连续返回一系列值。通常,`yield` 语句放置在某种循环中。下面是一个简单示例,生成器只是简单计数到给定数字:
```python
def my_generator(x):
for i in range(x):
yield i
```
您以与常规函数相同的方式将生成器提供给 Gradio。例如,这是一个(虚拟的)图像生成模型,它在输出图像之前生成数个步骤的噪音:
$code_fake_diffusion
$demo_fake_diffusion
请注意,我们在迭代器中添加了 `time.sleep(1)`,以创建步骤之间的人工暂停,以便您可以观察迭代器的步骤(在真实的图像生成模型中,这可能是不必要的)。
将生成器提供给 Gradio **需要**在底层 Interface 或 Blocks 中启用队列(请参阅上面的队列部分)。
## 进度条
Gradio 支持创建自定义进度条,以便您可以自定义和控制向用户显示的进度更新。要启用此功能,只需为方法添加一个默认值为 `gr.Progress` 实例的参数即可。然后,您可以直接调用此实例并传入 0 到 1 之间的浮点数来更新进度级别,或者 with `Progress` 实例的 `tqdm()` 方法来跟踪可迭代对象上的进度,如下所示。必须启用队列以进行进度更新。
$code_progress_simple
$demo_progress_simple
如果您 with `tqdm` 库,并且希望从函数内部的任何 `tqdm.tqdm` 自动报告进度更新,请将默认参数设置为 `gr.Progress(track_tqdm=True)`!
## 批处理函数 (Batch Functions)
Gradio 支持传递*批处理*函数。批处理函数只是接受输入列表并返回预测列表的函数。
例如,这是一个批处理函数,它接受两个输入列表(一个单词列表和一个整数列表),并返回修剪过的单词列表作为输出:
```python
import time
def trim_words(words, lens):
trimmed_words = []
time.sleep(5)
for w, l in zip(words, lens):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
for w, l in zip(words, lens):
```
使用批处理函数的优点是,如果启用了队列,Gradio 服务器可以自动*批处理*传入的请求并并行处理它们,从而可能加快演示速度。以下是 Gradio 代码的示例(请注意 `batch=True` 和 `max_batch_size=16` - 这两个参数都可以传递给事件触发器或 `Interface` 类)
with `Interface`:
```python
demo = gr.Interface(trim_words, ["textbox", "number"], ["output"],
batch=True, max_batch_size=16)
demo.queue()
demo.launch()
```
with `Blocks`:
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
word = gr.Textbox(label="word")
leng = gr.Number(label="leng")
output = gr.Textbox(label="Output")
with gr.Row():
run = gr.Button()
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
demo.queue()
demo.launch()
```
在上面的示例中,可以并行处理 16 个请求(总推理时间为 5 秒),而不是分别处理每个请求(总推理时间为 80 秒)。许多 Hugging Face 的 `transformers` 和 `diffusers` 模型在 Gradio 的批处理模式下自然工作:这是[使用批处理生成图像的示例演示](https://github.com/gradio-app/gradio/blob/main/demo/diffusers_with_batching/run.py)
注意:使用 Gradio 的批处理函数 **requires** 在底层 Interface 或 Blocks 中启用队列(请参阅上面的队列部分)。
## Gradio 笔记本 (Colab Notebooks)
Gradio 可以在任何运行 Python 的地方运行,包括本地 Jupyter 笔记本和协作笔记本,如[Google Colab](https://colab.research.google.com/)。对于本地 Jupyter 笔记本和 Google Colab 笔记本,Gradio 在本地服务器上运行,您可以在浏览器中与之交互。(注意:对于 Google Colab,这是通过[服务工作器隧道](https://github.com/tensorflow/tensorboard/blob/master/docs/design/colab_integration.md)实现的,您的浏览器需要启用 cookies。)对于其他远程笔记本,Gradio 也将在服务器上运行,但您需要使用[SSH 隧道](https://coderwall.com/p/ohk6cg/remote-access-to-ipython-notebooks-via-ssh)在本地浏览器中查看应用程序。通常,更简单的选择是使用 Gradio 内置的公共链接,[在下一篇指南中讨论](/sharing-your-app/#sharing-demos)。
| gradio-app/gradio/blob/main/guides/cn/01_getting-started/02_key-features.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Training on TPU with TensorFlow
<Tip>
If you don't need long explanations and just want TPU code samples to get started with, check out [our TPU example notebook!](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)
</Tip>
### What is a TPU?
A TPU is a **Tensor Processing Unit.** They are hardware designed by Google, which are used to greatly speed up the tensor computations within neural networks, much like GPUs. They can be used for both network training and inference. They are generally accessed through Google’s cloud services, but small TPUs can also be accessed directly for free through Google Colab and Kaggle Kernels.
Because [all TensorFlow models in 🤗 Transformers are Keras models](https://huggingface.co/blog/tensorflow-philosophy), most of the methods in this document are generally applicable to TPU training for any Keras model! However, there are a few points that are specific to the HuggingFace ecosystem (hug-o-system?) of Transformers and Datasets, and we’ll make sure to flag them up when we get to them.
### What kinds of TPU are available?
New users are often very confused by the range of TPUs, and the different ways to access them. The first key distinction to understand is the difference between **TPU Nodes** and **TPU VMs.**
When you use a **TPU Node**, you are effectively indirectly accessing a remote TPU. You will need a separate VM, which will initialize your network and data pipeline and then forward them to the remote node. When you use a TPU on Google Colab, you are accessing it in the **TPU Node** style.
Using TPU Nodes can have some quite unexpected behaviour for people who aren’t used to them! In particular, because the TPU is located on a physically different system to the machine you’re running your Python code on, your data cannot be local to your machine - any data pipeline that loads from your machine’s internal storage will totally fail! Instead, data must be stored in Google Cloud Storage where your data pipeline can still access it, even when the pipeline is running on the remote TPU node.
<Tip>
If you can fit all your data in memory as `np.ndarray` or `tf.Tensor`, then you can `fit()` on that data even when using Colab or a TPU Node, without needing to upload it to Google Cloud Storage.
</Tip>
<Tip>
**🤗Specific Hugging Face Tip🤗:** The methods `Dataset.to_tf_dataset()` and its higher-level wrapper `model.prepare_tf_dataset()` , which you will see throughout our TF code examples, will both fail on a TPU Node. The reason for this is that even though they create a `tf.data.Dataset` it is not a “pure” `tf.data` pipeline and uses `tf.numpy_function` or `Dataset.from_generator()` to stream data from the underlying HuggingFace `Dataset`. This HuggingFace `Dataset` is backed by data that is on a local disc and which the remote TPU Node will not be able to read.
</Tip>
The second way to access a TPU is via a **TPU VM.** When using a TPU VM, you connect directly to the machine that the TPU is attached to, much like training on a GPU VM. TPU VMs are generally easier to work with, particularly when it comes to your data pipeline. All of the above warnings do not apply to TPU VMs!
This is an opinionated document, so here’s our opinion: **Avoid using TPU Node if possible.** It is more confusing and more difficult to debug than TPU VMs. It is also likely to be unsupported in future - Google’s latest TPU, TPUv4, can only be accessed as a TPU VM, which suggests that TPU Nodes are increasingly going to become a “legacy” access method. However, we understand that the only free TPU access is on Colab and Kaggle Kernels, which uses TPU Node - so we’ll try to explain how to handle it if you have to! Check the [TPU example notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) for code samples that explain this in more detail.
### What sizes of TPU are available?
A single TPU (a v2-8/v3-8/v4-8) runs 8 replicas. TPUs exist in **pods** that can run hundreds or thousands of replicas simultaneously. When you use more than a single TPU but less than a whole pod (for example, a v3-32), your TPU fleet is referred to as a **pod slice.**
When you access a free TPU via Colab, you generally get a single v2-8 TPU.
### I keep hearing about this XLA thing. What’s XLA, and how does it relate to TPUs?
XLA is an optimizing compiler, used by both TensorFlow and JAX. In JAX it is the only compiler, whereas in TensorFlow it is optional (but mandatory on TPU!). The easiest way to enable it when training a Keras model is to pass the argument `jit_compile=True` to `model.compile()`. If you don’t get any errors and performance is good, that’s a great sign that you’re ready to move to TPU!
Debugging on TPU is generally a bit harder than on CPU/GPU, so we recommend getting your code running on CPU/GPU with XLA first before trying it on TPU. You don’t have to train for long, of course - just for a few steps to make sure that your model and data pipeline are working like you expect them to.
<Tip>
XLA compiled code is usually faster - so even if you’re not planning to run on TPU, adding `jit_compile=True` can improve your performance. Be sure to note the caveats below about XLA compatibility, though!
</Tip>
<Tip warning={true}>
**Tip born of painful experience:** Although using `jit_compile=True` is a good way to get a speed boost and test if your CPU/GPU code is XLA-compatible, it can actually cause a lot of problems if you leave it in when actually training on TPU. XLA compilation will happen implicitly on TPU, so remember to remove that line before actually running your code on a TPU!
</Tip>
### How do I make my model XLA compatible?
In many cases, your code is probably XLA-compatible already! However, there are a few things that work in normal TensorFlow that don’t work in XLA. We’ve distilled them into three core rules below:
<Tip>
**🤗Specific HuggingFace Tip🤗:** We’ve put a lot of effort into rewriting our TensorFlow models and loss functions to be XLA-compatible. Our models and loss functions generally obey rule #1 and #2 by default, so you can skip over them if you’re using `transformers` models. Don’t forget about these rules when writing your own models and loss functions, though!
</Tip>
#### XLA Rule #1: Your code cannot have “data-dependent conditionals”
What that means is that any `if` statement cannot depend on values inside a `tf.Tensor`. For example, this code block cannot be compiled with XLA!
```python
if tf.reduce_sum(tensor) > 10:
tensor = tensor / 2.0
```
This might seem very restrictive at first, but most neural net code doesn’t need to do this. You can often get around this restriction by using `tf.cond` (see the documentation [here](https://www.tensorflow.org/api_docs/python/tf/cond)) or by removing the conditional and finding a clever math trick with indicator variables instead, like so:
```python
sum_over_10 = tf.cast(tf.reduce_sum(tensor) > 10, tf.float32)
tensor = tensor / (1.0 + sum_over_10)
```
This code has exactly the same effect as the code above, but by avoiding a conditional, we ensure it will compile with XLA without problems!
#### XLA Rule #2: Your code cannot have “data-dependent shapes”
What this means is that the shape of all of the `tf.Tensor` objects in your code cannot depend on their values. For example, the function `tf.unique` cannot be compiled with XLA, because it returns a `tensor` containing one instance of each unique value in the input. The shape of this output will obviously be different depending on how repetitive the input `Tensor` was, and so XLA refuses to handle it!
In general, most neural network code obeys rule #2 by default. However, there are a few common cases where it becomes a problem. One very common one is when you use **label masking**, setting your labels to a negative value to indicate that those positions should be ignored when computing the loss. If you look at NumPy or PyTorch loss functions that support label masking, you will often see code like this that uses [boolean indexing](https://numpy.org/doc/stable/user/basics.indexing.html#boolean-array-indexing):
```python
label_mask = labels >= 0
masked_outputs = outputs[label_mask]
masked_labels = labels[label_mask]
loss = compute_loss(masked_outputs, masked_labels)
mean_loss = torch.mean(loss)
```
This code is totally fine in NumPy or PyTorch, but it breaks in XLA! Why? Because the shape of `masked_outputs` and `masked_labels` depends on how many positions are masked - that makes it a **data-dependent shape.** However, just like for rule #1, we can often rewrite this code to yield exactly the same output without any data-dependent shapes.
```python
label_mask = tf.cast(labels >= 0, tf.float32)
loss = compute_loss(outputs, labels)
loss = loss * label_mask # Set negative label positions to 0
mean_loss = tf.reduce_sum(loss) / tf.reduce_sum(label_mask)
```
Here, we avoid data-dependent shapes by computing the loss for every position, but zeroing out the masked positions in both the numerator and denominator when we calculate the mean, which yields exactly the same result as the first block while maintaining XLA compatibility. Note that we use the same trick as in rule #1 - converting a `tf.bool` to `tf.float32` and using it as an indicator variable. This is a really useful trick, so remember it if you need to convert your own code to XLA!
#### XLA Rule #3: XLA will need to recompile your model for every different input shape it sees
This is the big one. What this means is that if your input shapes are very variable, XLA will have to recompile your model over and over, which will create huge performance problems. This commonly arises in NLP models, where input texts have variable lengths after tokenization. In other modalities, static shapes are more common and this rule is much less of a problem.
How can you get around rule #3? The key is **padding** - if you pad all your inputs to the same length, and then use an `attention_mask`, you can get the same results as you’d get from variable shapes, but without any XLA issues. However, excessive padding can cause severe slowdown too - if you pad all your samples to the maximum length in the whole dataset, you might end up with batches consisting endless padding tokens, which will waste a lot of compute and memory!
There isn’t a perfect solution to this problem. However, you can try some tricks. One very useful trick is to **pad batches of samples up to a multiple of a number like 32 or 64 tokens.** This often only increases the number of tokens by a small amount, but it hugely reduces the number of unique input shapes, because every input shape now has to be a multiple of 32 or 64. Fewer unique input shapes means fewer XLA compilations!
<Tip>
**🤗Specific HuggingFace Tip🤗:** Our tokenizers and data collators have methods that can help you here. You can use `padding="max_length"` or `padding="longest"` when calling tokenizers to get them to output padded data. Our tokenizers and data collators also have a `pad_to_multiple_of` argument that you can use to reduce the number of unique input shapes you see!
</Tip>
### How do I actually train my model on TPU?
Once your training is XLA-compatible and (if you’re using TPU Node / Colab) your dataset has been prepared appropriately, running on TPU is surprisingly easy! All you really need to change in your code is to add a few lines to initialize your TPU, and to ensure that your model and dataset are created inside a `TPUStrategy` scope. Take a look at [our TPU example notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) to see this in action!
### Summary
There was a lot in here, so let’s summarize with a quick checklist you can follow when you want to get your model ready for TPU training:
- Make sure your code follows the three rules of XLA
- Compile your model with `jit_compile=True` on CPU/GPU and confirm that you can train it with XLA
- Either load your dataset into memory or use a TPU-compatible dataset loading approach (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Migrate your code either to Colab (with accelerator set to “TPU”) or a TPU VM on Google Cloud
- Add TPU initializer code (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Create your `TPUStrategy` and make sure dataset loading and model creation are inside the `strategy.scope()` (see [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))
- Don’t forget to take `jit_compile=True` out again when you move to TPU!
- 🙏🙏🙏🥺🥺🥺
- Call model.fit()
- You did it! | huggingface/transformers/blob/main/docs/source/en/perf_train_tpu_tf.md |
Gradio Demo: blocks_random_slider
```
!pip install -q gradio
```
```
import gradio as gr
def func(slider_1, slider_2):
return slider_1 * 5 + slider_2
with gr.Blocks() as demo:
slider = gr.Slider(minimum=-10.2, maximum=15, label="Random Slider (Static)", randomize=True)
slider_1 = gr.Slider(minimum=100, maximum=200, label="Random Slider (Input 1)", randomize=True)
slider_2 = gr.Slider(minimum=10, maximum=23.2, label="Random Slider (Input 2)", randomize=True)
slider_3 = gr.Slider(value=3, label="Non random slider")
btn = gr.Button("Run")
btn.click(func, inputs=[slider_1, slider_2], outputs=gr.Number())
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_random_slider/run.ipynb |
Git over SSH
You can access and write data in repositories on huggingface.co using SSH (Secure Shell Protocol). When you connect via SSH, you authenticate using a private key file on your local machine.
Some actions, such as pushing changes, or cloning private repositories, will require you to upload your SSH public key to your account on huggingface.co.
You can use a pre-existing SSH key, or generate a new one specifically for huggingface.co.
## Checking for existing SSH keys
If you have an existing SSH key, you can use that key to authenticate Git operations over SSH.
SSH keys are usually located under `~/.ssh` on Mac & Linux, and under `C:\\Users\\<username>\\.ssh` on Windows. List files under that directory and look for files of the form:
- id_rsa.pub
- id_ecdsa.pub
- id_ed25519.pub
Those files contain your SSH public key.
If you don't have such file under `~/.ssh`, you will have to [generate a new key](#generating-a-new-ssh-keypair). Otherwise, you can [add your existing SSH public key(s) to your huggingface.co account](#add-a-ssh-key-to-your-account).
## Generating a new SSH keypair
If you don't have any SSH keys on your machine, you can use `ssh-keygen` to generate a new SSH key pair (public + private keys):
```
$ ssh-keygen -t ed25519 -C "[email protected]"
```
We recommend entering a passphrase when you are prompted to. A passphrase is an extra layer of security: it is a password that will be prompted whenever you use your SSH key.
Once your new key is generated, add it to your SSH agent with `ssh-add`:
```
$ ssh-add ~/.ssh/id_ed25519
```
If you chose a different location than the default to store your SSH key, you would have to replace `~/.ssh/id_ed25519` with the file location you used.
## Add a SSH key to your account
To access private repositories with SSH, or to push changes via SSH, you will need to add your SSH public key to your huggingface.co account. You can manage your SSH keys [in your user settings](https://huggingface.co/settings/keys).
To add a SSH key to your account, click on the "Add SSH key" button.
Then, enter a name for this key (for example, "Personal computer"), and copy and paste the content of your **public** SSH key in the area below. The public key is located in the `~/.ssh/id_XXXX.pub` file you found or generated in the previous steps.
Click on "Add key", and voilà! You have added a SSH key to your huggingface.co account.
## Testing your SSH authentication
Once you have added your SSH key to your huggingface.co account, you can test that the connection works as expected.
In a terminal, run:
```
$ ssh -T [email protected]
```
If you see a message with your username, congrats! Everything went well, you are ready to use git over SSH.
Otherwise, if the message states something like the following, make sure your SSH key is actually used by your SSH agent.
```
Hi anonymous, welcome to Hugging Face.
```
| huggingface/hub-docs/blob/main/docs/hub/security-git-ssh.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification with LayoutLMv3 (PyTorch version)
This directory contains a script, `run_funsd_cord.py`, that can be used to fine-tune (or evaluate) LayoutLMv3 on form understanding datasets, such as [FUNSD](https://guillaumejaume.github.io/FUNSD/) and [CORD](https://github.com/clovaai/cord).
The script `run_funsd_cord.py` leverages the 🤗 Datasets library and the Trainer API. You can easily customize it to your needs.
## Fine-tuning on FUNSD
Fine-tuning LayoutLMv3 for token classification on [FUNSD](https://guillaumejaume.github.io/FUNSD/) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name funsd \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--evaluation_strategy steps \
--eval_steps 100 \
--learning_rate 1e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-funsd
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd. By specifying the `push_to_hub` flag, the model gets uploaded automatically to the hub (regularly), together with a model card, which includes metrics such as precision, recall and F1. Note that you can easily update the model card, as it's just a README file of the respective repo on the hub.
There's also the "Training metrics" [tab](https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd/tensorboard), which shows Tensorboard logs over the course of training. Pretty neat, huh?
## Fine-tuning on CORD
Fine-tuning LayoutLMv3 for token classification on [CORD](https://github.com/clovaai/cord) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name cord \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--evaluation_strategy steps \
--eval_steps 100 \
--learning_rate 5e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-cord
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-cord. Note that a model card gets generated automatically in case you specify the `push_to_hub` flag. | huggingface/transformers/blob/main/examples/research_projects/layoutlmv3/README.md |
State in Blocks
We covered [State in Interfaces](https://gradio.app/interface-state), this guide takes a look at state in Blocks, which works mostly the same.
## Global State
Global state in Blocks works the same as in Interface. Any variable created outside a function call is a reference shared between all users.
## Session State
Gradio supports session **state**, where data persists across multiple submits within a page session, in Blocks apps as well. To reiterate, session data is _not_ shared between different users of your model. To store data in a session state, you need to do three things:
1. Create a `gr.State()` object. If there is a default value to this stateful object, pass that into the constructor.
2. In the event listener, put the `State` object as an input and output.
3. In the event listener function, add the variable to the input parameters and the return value.
Let's take a look at a game of hangman.
$code_hangman
$demo_hangman
Let's see how we do each of the 3 steps listed above in this game:
1. We store the used letters in `used_letters_var`. In the constructor of `State`, we set the initial value of this to `[]`, an empty list.
2. In `btn.click()`, we have a reference to `used_letters_var` in both the inputs and outputs.
3. In `guess_letter`, we pass the value of this `State` to `used_letters`, and then return an updated value of this `State` in the return statement.
With more complex apps, you will likely have many State variables storing session state in a single Blocks app.
Learn more about `State` in the [docs](https://gradio.app/docs#state).
| gradio-app/gradio/blob/main/guides/03_building-with-blocks/03_state-in-blocks.md |
如何使用地图组件绘制图表
Related spaces:
Tags: PLOTS, MAPS
## 简介
本指南介绍如何使用 Gradio 的 `Plot` 组件在地图上绘制地理数据。Gradio 的 `Plot` 组件可以与 Matplotlib、Bokeh 和 Plotly 一起使用。在本指南中,我们将使用 Plotly 进行操作。Plotly 可以让开发人员轻松创建各种地图来展示他们的地理数据。点击[这里](https://plotly.com/python/maps/)查看一些示例。
## 概述
我们将使用纽约市的 Airbnb 数据集,该数据集托管在 kaggle 上,点击[这里](https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data)。我已经将其上传到 Hugging Face Hub 作为一个数据集,方便使用和下载,点击[这里](https://huggingface.co/datasets/gradio/NYC-Airbnb-Open-Data)。使用这些数据,我们将在地图上绘制 Airbnb 的位置,并允许基于价格和位置进行筛选。下面是我们将要构建的演示。 ⚡️
$demo_map_airbnb
## 步骤 1-加载 CSV 数据 💾
让我们首先从 Hugging Face Hub 加载纽约市的 Airbnb 数据。
```python
from datasets import load_dataset
dataset = load_dataset("gradio/NYC-Airbnb-Open-Data", split="train")
df = dataset.to_pandas()
def filter_map(min_price, max_price, boroughs):
new_df = df[(df['neighbourhood_group'].isin(boroughs)) &
(df['price'] > min_price) & (df['price'] < max_price)]
names = new_df["name"].tolist()
prices = new_df["price"].tolist()
text_list = [(names[i], prices[i]) for i in range(0, len(names))]
```
在上面的代码中,我们先将 CSV 数据加载到一个 pandas dataframe 中。让我们首先定义一个函数,这将作为 gradio 应用程序的预测函数。该函数将接受最低价格、最高价格范围和筛选结果地区的列表作为参数。我们可以使用传入的值 (`min_price`、`max_price` 和地区列表) 来筛选数据框并创建 `new_df`。接下来,我们将创建包含每个 Airbnb 的名称和价格的 `text_list`,以便在地图上使用作为标签。
## 步骤 2-地图图表 🌐
Plotly 使得处理地图变得很容易。让我们看一下下面的代码,了解如何创建地图图表。
```python
import plotly.graph_objects as go
fig = go.Figure(go.Scattermapbox(
customdata=text_list,
lat=new_df['latitude'].tolist(),
lon=new_df['longitude'].tolist(),
mode='markers',
marker=go.scattermapbox.Marker(
size=6
),
hoverinfo="text",
hovertemplate='<b>Name</b>: %{customdata[0]}<br><b>Price</b>: $%{customdata[1]}'
))
fig.update_layout(
mapbox_style="open-street-map",
hovermode='closest',
mapbox=dict(
bearing=0,
center=go.layout.mapbox.Center(
lat=40.67,
lon=-73.90
),
pitch=0,
zoom=9
),
)
```
上面的代码中,我们通过传入经纬度列表来创建一个散点图。我们还传入了名称和价格的自定义数据,以便在鼠标悬停在每个标记上时显示额外的信息。接下来,我们使用 `update_layout` 来指定其他地图设置,例如缩放和居中。
有关使用 Mapbox 和 Plotly 创建散点图的更多信息,请点击[这里](https://plotly.com/python/scattermapbox/)。
## 步骤 3-Gradio 应用程序 ⚡️
我们将使用两个 `gr.Number` 组件和一个 `gr.CheckboxGroup` 组件,允许用户指定价格范围和地区位置。然后,我们将使用 `gr.Plot` 组件作为我们之前创建的 Plotly + Mapbox 地图的输出。
```python
with gr.Blocks() as demo:
with gr.Column():
with gr.Row():
min_price = gr.Number(value=250, label="Minimum Price")
max_price = gr.Number(value=1000, label="Maximum Price")
boroughs = gr.CheckboxGroup(choices=["Queens", "Brooklyn", "Manhattan", "Bronx", "Staten Island"], value=["Queens", "Brooklyn"], label="Select Boroughs:")
btn = gr.Button(value="Update Filter")
map = gr.Plot()
demo.load(filter_map, [min_price, max_price, boroughs], map)
btn.click(filter_map, [min_price, max_price, boroughs], map)
```
我们使用 `gr.Column` 和 `gr.Row` 布局这些组件,并为演示加载时和点击 " 更新筛选 " 按钮时添加了事件触发器,以触发地图更新新的筛选条件。
以下是完整演示代码:
$code_map_airbnb
## 步骤 4-部署 Deployment 🤗
如果你运行上面的代码,你的应用程序将在本地运行。
如果要获取临时共享链接,可以将 `share=True` 参数传递给 `launch`。
但如果你想要一个永久的部署解决方案呢?
让我们将我们的 Gradio 应用程序部署到免费的 HuggingFace Spaces 平台。
如果你以前没有使用过 Spaces,请按照之前的指南[这里](/using_hugging_face_integrations)。
## 结论 🎉
你已经完成了!这是构建地图演示所需的所有代码。
链接到演示:[地图演示](https://huggingface.co/spaces/gradio/map_airbnb)和[完整代码](https://huggingface.co/spaces/gradio/map_airbnb/blob/main/run.py)(在 Hugging Face Spaces)
| gradio-app/gradio/blob/main/guides/cn/05_tabular-data-science-and-plots/plot-component-for-maps.md |
SE-ResNet
**SE ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('seresnet152d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `seresnet152d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('seresnet152d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SE ResNet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: seresnet152d
In Collection: SE ResNet
Metadata:
FLOPs: 20161904304
Parameters: 66840000
File Size: 268144497
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnet152d
LR: 0.6
Epochs: 100
Layers: 152
Dropout: 0.2
Crop Pct: '0.94'
Momentum: 0.9
Batch Size: 1024
Image Size: '256'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1206
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet152d_ra2-04464dd2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.74%
Top 5 Accuracy: 96.77%
- Name: seresnet50
In Collection: SE ResNet
Metadata:
FLOPs: 5285062320
Parameters: 28090000
File Size: 112621903
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnet50
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1180
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet50_ra_224-8efdb4bb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.26%
Top 5 Accuracy: 95.07%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/se-resnet.mdx |
--
title: poseval
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
The poseval metric can be used to evaluate POS taggers. Since seqeval does not work well with POS data
that is not in IOB format the poseval is an alternative. It treats each token in the dataset as independant
observation and computes the precision, recall and F1-score irrespective of sentences. It uses scikit-learns's
classification report to compute the scores.
---
# Metric Card for peqeval
## Metric description
The poseval metric can be used to evaluate POS taggers. Since seqeval does not work well with POS data (see e.g. [here](https://stackoverflow.com/questions/71327693/how-to-disable-seqeval-label-formatting-for-pos-tagging)) that is not in IOB format the poseval is an alternative. It treats each token in the dataset as independant observation and computes the precision, recall and F1-score irrespective of sentences. It uses scikit-learns's [classification report](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html) to compute the scores.
## How to use
Poseval produces labelling scores along with its sufficient statistics from a source against references.
It takes two mandatory arguments:
`predictions`: a list of lists of predicted labels, i.e. estimated targets as returned by a tagger.
`references`: a list of lists of reference labels, i.e. the ground truth/target values.
It can also take several optional arguments:
`zero_division`: Which value to substitute as a metric value when encountering zero division. Should be one of [`0`,`1`,`"warn"`]. `"warn"` acts as `0`, but the warning is raised.
```python
>>> predictions = [['INTJ', 'ADP', 'PROPN', 'NOUN', 'PUNCT', 'INTJ', 'ADP', 'PROPN', 'VERB', 'SYM']]
>>> references = [['INTJ', 'ADP', 'PROPN', 'PROPN', 'PUNCT', 'INTJ', 'ADP', 'PROPN', 'PROPN', 'SYM']]
>>> poseval = evaluate.load("poseval")
>>> results = poseval.compute(predictions=predictions, references=references)
>>> print(list(results.keys()))
['ADP', 'INTJ', 'NOUN', 'PROPN', 'PUNCT', 'SYM', 'VERB', 'accuracy', 'macro avg', 'weighted avg']
>>> print(results["accuracy"])
0.8
>>> print(results["PROPN"]["recall"])
0.5
```
## Output values
This metric returns a a classification report as a dictionary with a summary of scores for overall and per type:
Overall (weighted and macro avg):
`accuracy`: the average [accuracy](https://huggingface.co/metrics/accuracy), on a scale between 0.0 and 1.0.
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), which is the harmonic mean of the precision and recall. It also has a scale of 0.0 to 1.0.
Per type (e.g. `MISC`, `PER`, `LOC`,...):
`precision`: the average [precision](https://huggingface.co/metrics/precision), on a scale between 0.0 and 1.0.
`recall`: the average [recall](https://huggingface.co/metrics/recall), on a scale between 0.0 and 1.0.
`f1`: the average [F1 score](https://huggingface.co/metrics/f1), on a scale between 0.0 and 1.0.
## Examples
```python
>>> predictions = [['INTJ', 'ADP', 'PROPN', 'NOUN', 'PUNCT', 'INTJ', 'ADP', 'PROPN', 'VERB', 'SYM']]
>>> references = [['INTJ', 'ADP', 'PROPN', 'PROPN', 'PUNCT', 'INTJ', 'ADP', 'PROPN', 'PROPN', 'SYM']]
>>> poseval = evaluate.load("poseval")
>>> results = poseval.compute(predictions=predictions, references=references)
>>> print(list(results.keys()))
['ADP', 'INTJ', 'NOUN', 'PROPN', 'PUNCT', 'SYM', 'VERB', 'accuracy', 'macro avg', 'weighted avg']
>>> print(results["accuracy"])
0.8
>>> print(results["PROPN"]["recall"])
0.5
```
## Limitations and bias
In contrast to [seqeval](https://github.com/chakki-works/seqeval), the poseval metric treats each token independently and computes the classification report over all concatenated sequences..
## Citation
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
- [README for seqeval at GitHub](https://github.com/chakki-works/seqeval)
- [Classification report](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html)
- [Issues with seqeval](https://stackoverflow.com/questions/71327693/how-to-disable-seqeval-label-formatting-for-pos-tagging) | huggingface/evaluate/blob/main/metrics/poseval/README.md |
--
title: "Large Language Models: A New Moore's Law?"
thumbnail: /blog/assets/33_large_language_models/01_model_size.jpg
authors:
- user: juliensimon
---
# Large Language Models: A New Moore's Law?
A few days ago, Microsoft and NVIDIA [introduced](https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/) Megatron-Turing NLG 530B, a Transformer-based model hailed as "*the world’s largest and most powerful generative language model*."
This is an impressive show of Machine Learning engineering, no doubt about it. Yet, should we be excited about this mega-model trend? I, for one, am not. Here's why.
<kbd>
<img src="assets/33_large_language_models/01_model_size.jpg">
</kbd>
### This is your Brain on Deep Learning
Researchers estimate that the human brain contains an average of [86 billion neurons](https://pubmed.ncbi.nlm.nih.gov/19226510/) and 100 trillion synapses. It's safe to assume that not all of them are dedicated to language either. Interestingly, GPT-4 is [expected](https://www.wired.com/story/cerebras-chip-cluster-neural-networks-ai/) to have about 100 trillion parameters... As crude as this analogy is, shouldn't we wonder whether building language models that are about the size of the human brain is the best long-term approach?
Of course, our brain is a marvelous device, produced by millions of years of evolution, while Deep Learning models are only a few decades old. Still, our intuition should tell us that something doesn't compute (pun intended).
### Deep Learning, Deep Pockets?
As you would expect, training a 530-billion parameter model on humongous text datasets requires a fair bit of infrastructure. In fact, Microsoft and NVIDIA used hundreds of DGX A100 multi-GPU servers. At $199,000 a piece, and factoring in networking equipment, hosting costs, etc., anyone looking to replicate this experiment would have to spend close to $100 million dollars. Want fries with that?
Seriously, which organizations have business use cases that would justify spending $100 million on Deep Learning infrastructure? Or even $10 million? Very few. So who are these models for, really?
### That Warm Feeling is your GPU Cluster
For all its engineering brilliance, training Deep Learning models on GPUs is a brute force technique. According to the spec sheet, each DGX server can consume up to 6.5 kilowatts. Of course, you'll need at least as much cooling power in your datacenter (or your server closet). Unless you're the Starks and need to keep Winterfell warm in winter, that's another problem you'll have to deal with.
In addition, as public awareness grows on climate and social responsibility issues, organizations need to account for their carbon footprint. According to this 2019 [study](https://arxiv.org/pdf/1906.02243.pdf) from the University of Massachusetts, "*training BERT on GPU is roughly equivalent to a trans-American flight*".
BERT-Large has 340 million parameters. One can only extrapolate what the footprint of Megatron-Turing could be... People who know me wouldn't call me a bleeding-heart environmentalist. Still, some numbers are hard to ignore.
### So?
Am I excited by Megatron-Turing NLG 530B and whatever beast is coming next? No. Do I think that the (relatively small) benchmark improvement is worth the added cost, complexity and carbon footprint? No. Do I think that building and promoting these huge models is helping organizations understand and adopt Machine Learning ? No.
I'm left wondering what's the point of it all. Science for the sake of science? Good old marketing? Technological supremacy? Probably a bit of each. I'll leave them to it, then.
Instead, let me focus on pragmatic and actionable techniques that you can all use to build high quality Machine Learning solutions.
### Use Pretrained Models
In the vast majority of cases, you won't need a custom model architecture. Maybe you'll *want* a custom one (which is a different thing), but there be dragons. Experts only!
A good starting point is to look for [models](https://huggingface.co/models) that have been pretrained for the task you're trying to solve (say, [summarizing English text](https://huggingface.co/models?language=en&pipeline_tag=summarization&sort=downloads)).
Then, you should quickly try out a few models to predict your own data. If metrics tell you that one works well enough, you're done! If you need a little more accuracy, you should consider fine-tuning the model (more on this in a minute).
### Use Smaller Models
When evaluating models, you should pick the smallest one that can deliver the accuracy you need. It will predict faster and require fewer hardware resources for training and inference. Frugality goes a long way.
It's nothing new either. Computer Vision practitioners will remember when [SqueezeNet](https://arxiv.org/abs/1602.07360) came out in 2017, achieving a 50x reduction in model size compared to [AlexNet](https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html), while meeting or exceeding its accuracy. How clever that was!
Downsizing efforts are also under way in the Natural Language Processing community, using transfer learning techniques such as [knowledge distillation](https://en.wikipedia.org/wiki/Knowledge_distillation). [DistilBERT](https://arxiv.org/abs/1910.01108) is perhaps its most widely known achievement. Compared to the original BERT model, it retains 97% of language understanding while being 40% smaller and 60% faster. You can try it [here](https://huggingface.co/distilbert-base-uncased). The same approach has been applied to other models, such as Facebook's [BART](https://arxiv.org/abs/1910.13461), and you can try DistilBART [here](https://huggingface.co/models?search=distilbart).
Recent models from the [Big Science](https://bigscience.huggingface.co/) project are also very impressive. As visible in this graph included in the [research paper](https://arxiv.org/abs/2110.08207), their T0 model outperforms GPT-3 on many tasks while being 16x smaller.
<kbd>
<img src="assets/33_large_language_models/02_t0.png">
</kbd>
You can try T0 [here](https://huggingface.co/bigscience/T0pp). This is the kind of research we need more of!
### Fine-Tune Models
If you need to specialize a model, there should be very few reasons to train it from scratch. Instead, you should fine-tune it, that is to say train it only for a few epochs on your own data. If you're short on data, maybe of one these [datasets](https://huggingface.co/datasets) can get you started.
You guessed it, that's another way to do transfer learning, and it'll help you save on everything!
* Less data to collect, store, clean and annotate,
* Faster experiments and iterations,
* Fewer resources required in production.
In other words: save time, save money, save hardware resources, save the world!
If you need a tutorial, the Hugging Face [course](https://huggingface.co/course) will get you started in no time.
### Use Cloud-Based Infrastructure
Like them or not, cloud companies know how to build efficient infrastructure. Sustainability studies show that cloud-based infrastructure is more energy and carbon efficient than the alternative: see [AWS](https://sustainability.aboutamazon.com/environment/the-cloud), [Azure](https://azure.microsoft.com/en-us/global-infrastructure/sustainability), and [Google](https://cloud.google.com/sustainability). Earth.org [says](https://earth.org/environmental-impact-of-cloud-computing/) that while cloud infrastructure is not perfect, "[*it's] more energy efficient than the alternative and facilitates environmentally beneficial services and economic growth.*"
Cloud certainly has a lot going for it when it comes to ease of use, flexibility and pay as you go. It's also a little greener than you probably thought. If you're short on GPUs, why not try fine-tune your Hugging Face models on [Amazon SageMaker](https://aws.amazon.com/sagemaker/), AWS' managed service for Machine Learning? We've got [plenty of examples](https://huggingface.co/docs/sagemaker/train) for you.
### Optimize Your Models
From compilers to virtual machines, software engineers have long used tools that automatically optimize their code for whatever hardware they're running on.
However, the Machine Learning community is still struggling with this topic, and for good reason. Optimizing models for size and speed is a devilishly complex task, which involves techniques such as:
* Specialized hardware that speeds up training ([Graphcore](https://www.graphcore.ai/), [Habana](https://habana.ai/)) and inference ([Google TPU](https://cloud.google.com/tpu), [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/)).
* Pruning: remove model parameters that have little or no impact on the predicted outcome.
* Fusion: merge model layers (say, convolution and activation).
* Quantization: storing model parameters in smaller values (say, 8 bits instead of 32 bits)
Fortunately, automated tools are starting to appear, such as the [Optimum](https://huggingface.co/hardware) open source library, and [Infinity](https://huggingface.co/infinity), a containerized solution that delivers Transformers accuracy at 1-millisecond latency.
### Conclusion
Large language model size has been increasing 10x every year for the last few years. This is starting to look like another [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law).
We've been there before, and we should know that this road leads to diminishing returns, higher cost, more complexity, and new risks. Exponentials tend not to end well. Remember [Meltdown and Spectre](https://meltdownattack.com/)? Do we want to find out what that looks like for AI?
Instead of chasing trillion-parameter models (place your bets), wouldn't all be better off if we built practical and efficient solutions that all developers can use to solve real-world problems?
*Interested in how Hugging Face can help your organization build and deploy production-grade Machine Learning solutions? Get in touch at [[email protected]](mailto:[email protected]) (no recruiters, no sales pitches, please).*
| huggingface/blog/blob/main/large-language-models.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# VisionTextDualEncoder
## Overview
The [`VisionTextDualEncoderModel`] can be used to initialize a vision-text dual encoder model with
any pretrained vision autoencoding model as the vision encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit)) and any pretrained text autoencoding model as the text encoder (*e.g.* [RoBERTa](roberta), [BERT](bert)). Two projection layers are added on top of both the vision and text encoder to project the output embeddings
to a shared latent space. The projection layers are randomly initialized so the model should be fine-tuned on a
downstream task. This model can be used to align the vision-text embeddings using CLIP like contrastive image-text
training and then can be used for zero-shot vision tasks such image-classification or retrieval.
In [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991) it is shown how
leveraging pre-trained (locked/frozen) image and text model for contrastive learning yields significant improvement on
new zero-shot vision tasks such as image classification or retrieval.
## VisionTextDualEncoderConfig
[[autodoc]] VisionTextDualEncoderConfig
## VisionTextDualEncoderProcessor
[[autodoc]] VisionTextDualEncoderProcessor
<frameworkcontent>
<pt>
## VisionTextDualEncoderModel
[[autodoc]] VisionTextDualEncoderModel
- forward
</pt>
<tf>
## FlaxVisionTextDualEncoderModel
[[autodoc]] FlaxVisionTextDualEncoderModel
- __call__
</tf>
<jax>
## TFVisionTextDualEncoderModel
[[autodoc]] TFVisionTextDualEncoderModel
- call
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/vision-text-dual-encoder.md |
hat is dynamic padding? In the "Batching Inputs together" video, we have seen that to be able to group inputs of different lengths in the same batch, we need to add padding tokens to all the short inputs until they are all of the same length. Here for instance, the longest sentence is the third one, and we need to add 5, 2 and 7 pad tokens to the other to have four sentences of the same lengths. When dealing with a whole dataset, there are various padding strategies we can apply. The most obvious one is to pad all the elements of the dataset to the same length: the length of the longest sample. This will then give us batches that all have the same shape determined by the maximum sequence length. The downside is that batches composed from short sentences will have a lot of padding tokens which introduce more computations in the model we ultimately don't need. To avoid this, another strategy is to pad the elements when we batch them together, to the longest sentence inside the batch. This way batches composed of short inputs will be smaller than the batch containing the longest sentence in the dataset. This will yield some nice speedup on CPU and GPU. The downside is that all batches will then have different shapes, which slows down training on other accelerators like TPUs. Let's see how to apply both strategies in practice. We have actually seen how to apply fixed padding in the Datasets Overview video, when we preprocessed the MRPC dataset: after loading the dataset and tokenizer, we applied the tokenization to all the dataset with padding and truncation to make all samples of length 128. As a result, if we pass this dataset to a PyTorch DataLoader, we get batches of shape batch size (here 16) by 128. To apply dynamic padding, we must defer the padding to the batch preparation, so we remove that part from our tokenize function. We still leave the truncation part so that inputs that are bigger than the maximum length accepted by the model (usually 512) get truncated to that length. Then we pad our samples dynamically by using a data collator. Those classes in the Transformers library are responsible for applying all the final processing needed before forming a batch, here DataCollatorWithPadding will pad the samples to the maximum length inside the batch of sentences. We pass it to the PyTorch DataLoader as a collate function, then observe that the batches generated have various lenghs, all way below the 128 from before. Dynamic batching will almost always be faster on CPUs and GPUs, so you should apply it if you can. Remember to switch back to fixed padding however if you run your training script on TPU or need batches of fixed shapes. | huggingface/course/blob/main/subtitles/en/raw/chapter3/02d_dynamic-padding.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 3
Kandinsky 3 is created by [Vladimir Arkhipkin](https://github.com/oriBetelgeuse),[Anastasia Maltseva](https://github.com/NastyaMittseva),[Igor Pavlov](https://github.com/boomb0om),[Andrei Filatov](https://github.com/anvilarth),[Arseniy Shakhmatov](https://github.com/cene555),[Andrey Kuznetsov](https://github.com/kuznetsoffandrey),[Denis Dimitrov](https://github.com/denndimitrov), [Zein Shaheen](https://github.com/zeinsh)
The description from it's Github page:
*Kandinsky 3.0 is an open-source text-to-image diffusion model built upon the Kandinsky2-x model family. In comparison to its predecessors, enhancements have been made to the text understanding and visual quality of the model, achieved by increasing the size of the text encoder and Diffusion U-Net models, respectively.*
Its architecture includes 3 main components:
1. [FLAN-UL2](https://huggingface.co/google/flan-ul2), which is an encoder decoder model based on the T5 architecture.
2. New U-Net architecture featuring BigGAN-deep blocks doubles depth while maintaining the same number of parameters.
3. Sber-MoVQGAN is a decoder proven to have superior results in image restoration.
The original codebase can be found at [ai-forever/Kandinsky-3](https://github.com/ai-forever/Kandinsky-3).
<Tip>
Check out the [Kandinsky Community](https://huggingface.co/kandinsky-community) organization on the Hub for the official model checkpoints for tasks like text-to-image, image-to-image, and inpainting.
</Tip>
<Tip>
Make sure to check out the schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## Kandinsky3Pipeline
[[autodoc]] Kandinsky3Pipeline
- all
- __call__
## Kandinsky3Img2ImgPipeline
[[autodoc]] Kandinsky3Img2ImgPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/kandinsky3.md |
Datasets server - worker
> Workers that pre-compute and cache the response to /splits, /first-rows, /parquet, /info and /size.
## Configuration
Use environment variables to configure the workers. The prefix of each environment variable gives its scope.
### Uvicorn
The following environment variables are used to configure the Uvicorn server (`WORKER_UVICORN_` prefix). It is used for the /healthcheck and the /metrics endpoints:
- `WORKER_UVICORN_HOSTNAME`: the hostname. Defaults to `"localhost"`.
- `WORKER_UVICORN_NUM_WORKERS`: the number of uvicorn workers. Defaults to `2`.
- `WORKER_UVICORN_PORT`: the port. Defaults to `8000`.
### Prometheus
- `PROMETHEUS_MULTIPROC_DIR`: the directory where the uvicorn workers share their prometheus metrics. See https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn. Defaults to empty, in which case every uvicorn worker manages its own metrics, and the /metrics endpoint returns the metrics of a random worker.
## Worker configuration
Set environment variables to configure the worker.
- `WORKER_CONTENT_MAX_BYTES`: the maximum size in bytes of the response content computed by a worker (to prevent returning big responses in the REST API). Defaults to `10_000_000`.
- `WORKER_DIFFICULTY_MAX`: the maximum difficulty of the jobs to process. Defaults to None.
- `WORKER_DIFFICULTY_MIN`: the minimum difficulty of the jobs to process. Defaults to None.
- `WORKER_HEARTBEAT_INTERVAL_SECONDS`: the time interval between two heartbeats. Each heartbeat updates the job "last_heartbeat" field in the queue. Defaults to `60` (1 minute).
- `WORKER_JOB_TYPES_BLOCKED`: comma-separated list of job types that will not be processed, e.g. "dataset-config-names,dataset-split-names". If empty, no job type is blocked. Defaults to empty.
- `WORKER_JOB_TYPES_ONLY`: comma-separated list of the non-blocked job types to process, e.g. "dataset-config-names,dataset-split-names". If empty, the worker processes all the non-blocked jobs. Defaults to empty.
- `WORKER_KILL_LONG_JOB_INTERVAL_SECONDS`: the time interval at which the worker looks for long jobs to kill them. Defaults to `60` (1 minute).
- `WORKER_KILL_ZOMBIES_INTERVAL_SECONDS`: the time interval at which the worker looks for zombie jobs to kill them. Defaults to `600` (10 minutes).
- `WORKER_MAX_DISK_USAGE_PCT`: maximum disk usage of every storage disk in the list (in percentage) to allow a job to start. Set to 0 to disable the test. Defaults to 90.
- `WORKER_MAX_JOB_DURATION_SECONDS`: the maximum duration allowed for a job to run. If the job runs longer, it is killed (see `WORKER_KILL_LONG_JOB_INTERVAL_SECONDS`). Defaults to `1200` (20 minutes).
- `WORKER_MAX_LOAD_PCT`: maximum load of the machine (in percentage: the max between the 1m load and the 5m load divided by the number of CPUs \*100) allowed to start a job. Set to 0 to disable the test. Defaults to 70.
- `WORKER_MAX_MEMORY_PCT`: maximum memory (RAM + SWAP) usage of the machine (in percentage) allowed to start a job. Set to 0 to disable the test. Defaults to 80.
- `WORKER_MAX_MISSING_HEARTBEATS`: the number of hearbeats a job must have missed to be considered a zombie job. Defaults to `5`.
- `WORKER_SLEEP_SECONDS`: wait duration in seconds at each loop iteration before checking if resources are available and processing a job if any is available. Note that the loop doesn't wait just after finishing a job: the next job is immediately processed. Defaults to `15`.
- `WORKER_STORAGE_PATHS`: comma-separated list of paths to check for disk usage. Defaults to empty.
Also, it's possible to force the parent directory in which the temporary files (as the current job state file and its associated lock file) will be created by setting `TMPDIR` to a writable directory. If not set, the worker will use the default temporary directory of the system, as described in https://docs.python.org/3/library/tempfile.html#tempfile.gettempdir.
### Datasets based worker
Set environment variables to configure the datasets-based worker (`DATASETS_BASED_` prefix):
- `DATASETS_BASED_HF_DATASETS_CACHE`: directory where the `datasets` library will store the cached datasets' data. If not set, the datasets library will choose the default location. Defaults to None.
Also, set the modules cache configuration for the datasets-based worker. See [../../libs/libcommon/README.md](../../libs/libcommon/README.md). Note that this variable has no `DATASETS_BASED_` prefix:
- `HF_MODULES_CACHE`: directory where the `datasets` library will store the cached dataset scripts. If not set, the datasets library will choose the default location. Defaults to None.
Note that both directories will be appended to `WORKER_STORAGE_PATHS` (see [../../libs/libcommon/README.md](../../libs/libcommon/README.md)) to hold the workers when the disk is full.
### Numba library
Numba requires setting the `NUMBA_CACHE_DIR` environment variable to a writable directory to cache the compiled functions. Required on cloud infrastructure (see https://stackoverflow.com/a/63367171/7351594):
- `NUMBA_CACHE_DIR`: directory where the `numba` decorators (used by `librosa`) can write cache.
Note that this directory will be appended to `WORKER_STORAGE_PATHS` (see [../../libs/libcommon/README.md](../../libs/libcommon/README.md)) to hold the workers when the disk is full.
### Huggingface_hub library
If the Hub is not https://huggingface.co (i.e., if you set the `COMMON_HF_ENDPOINT` environment variable), you must set the `HF_ENDPOINT` environment variable to the same value. See https://github.com/huggingface/datasets/pull/5196#issuecomment-1322191411 for more details:
- `HF_ENDPOINT`: the URL of the Hub. Defaults to `https://huggingface.co`.
### First rows worker
Set environment variables to configure the `first-rows` worker (`FIRST_ROWS_` prefix):
- `FIRST_ROWS_MAX_BYTES`: the max size of the /first-rows response in bytes. Defaults to `1_000_000` (1 MB).
- `FIRST_ROWS_MAX_NUMBER`: the max number of rows fetched by the worker for the split and provided in the /first-rows response. Defaults to `100`.
- `FIRST_ROWS_MIN_CELL_BYTES`: the minimum size in bytes of a cell when truncating the content of a row (see `FIRST_ROWS_ROWS_MAX_BYTES`). Below this limit, the cell content will not be truncated. Defaults to `100`.
- `FIRST_ROWS_MIN_NUMBER`: the min number of rows fetched by the worker for the split and provided in the /first-rows response. Defaults to `10`.
- `FIRST_ROWS_COLUMNS_MAX_NUMBER`: the max number of columns (features) provided in the /first-rows response. If the number of columns is greater than the limit, an error is returned. Defaults to `1_000`.
Also, set the assets-related configuration for the first-rows worker. See [../../libs/libcommon/README.md](../../libs/libcommon/README.md).
### Parquet and info worker
Set environment variables to configure the `parquet-and-info` worker (`PARQUET_AND_INFO_` prefix):
- `PARQUET_AND_INFO_COMMIT_MESSAGE`: the git commit message when the worker uploads the parquet files to the Hub. Defaults to `Update parquet files`.
- `PARQUET_AND_INFO_COMMITTER_HF_TOKEN`: the HuggingFace token to commit the parquet files to the Hub. The token must be an app token associated with a user that has the right to 1. create the `refs/convert/parquet` branch (see `PARQUET_AND_INFO_TARGET_REVISION`) and 2. push commits to it on any dataset. [Datasets maintainers](https://huggingface.co/datasets-maintainers) members have these rights. The token must have permission to write. If not set, the worker will fail. Defaults to None.
- `PARQUET_AND_INFO_MAX_DATASET_SIZE_BYTES`: the maximum size in bytes of the dataset to pre-compute the parquet files. Bigger datasets, or datasets without that information, are partially streamed to get parquet files up to this value. Defaults to `100_000_000`.
- `PARQUET_AND_INFO_MAX_EXTERNAL_DATA_FILES`: the maximum number of external files of the datasets. Bigger datasets, or datasets without that information, are partially streamed to get parquet files up to `PARQUET_AND_INFO_MAX_DATASET_SIZE_BYTES` bytes. Defaults to `10_000`.
- `PARQUET_AND_INFO_MAX_ROW_GROUP_BYTE_SIZE_FOR_COPY`: the maximum size in bytes of the row groups of parquet datasets that are copied to the target revision. Bigger datasets, or datasets without that information, are partially streamed to get parquet files up to `PARQUET_AND_INFO_MAX_DATASET_SIZE_BYTES` bytes. Defaults to `100_000_000`.
- `PARQUET_AND_INFO_SOURCE_REVISION`: the git revision of the dataset to use to prepare the parquet files. Defaults to `main`.
- `PARQUET_AND_INFO_TARGET_REVISION`: the git revision of the dataset where to store the parquet files. Make sure the committer token (`PARQUET_AND_INFO_COMMITTER_HF_TOKEN`) has the permission to write there. Defaults to `refs/convert/parquet`.
- `PARQUET_AND_INFO_URL_TEMPLATE`: the URL template to build the parquet file URLs. Defaults to `/datasets/%s/resolve/%s/%s`.
### Duckdb Index worker
Set environment variables to configure the `duckdb-index` worker (`DUCKDB_INDEX_` prefix):
- `DUCKDB_INDEX_CACHE_DIRECTORY`: directory where the temporal duckdb index files are stored. Defaults to empty.
- `DUCKDB_INDEX_COMMIT_MESSAGE`: the git commit message when the worker uploads the duckdb index file to the Hub. Defaults to `Update duckdb index file`.
- `DUCKDB_INDEX_COMMITTER_HF_TOKEN`: the HuggingFace token to commit the duckdb index file to the Hub. The token must be an app token associated with a user that has the right to 1. create the `refs/convert/parquet` branch (see `DUCKDB_INDEX_TARGET_REVISION`) and 2. push commits to it on any dataset. [Datasets maintainers](https://huggingface.co/datasets-maintainers) members have these rights. The token must have permission to write. If not set, the worker will fail. Defaults to None.
- `DUCKDB_INDEX_MAX_DATASET_SIZE_BYTES`: the maximum size in bytes of the dataset's parquet files to index. Datasets with bigger size are ignored. Defaults to `100_000_000`.
- `DUCKDB_INDEX_TARGET_REVISION`: the git revision of the dataset where to store the duckdb index file. Make sure the committer token (`DUCKDB_INDEX_COMMITTER_HF_TOKEN`) has the permission to write there. Defaults to `refs/convert/parquet`.
- `DUCKDB_INDEX_URL_TEMPLATE`: the URL template to build the duckdb index file URL. Defaults to `/datasets/%s/resolve/%s/%s`.
- `DUCKDB_INDEX_EXTENSIONS_DIRECTORY`: directory where the duckdb extensions will be downloaded. Defaults to empty.
### Descriptive statistics worker
Set environment variables to configure the `descriptive-statistics` worker (`DESCRIPTIVE_STATISTICS_` prefix):
- `DESCRIPTIVE_STATISTICS_CACHE_DIRECTORY`: directory to which a dataset in parquet format is downloaded. Defaults to empty.
- `DESCRIPTIVE_STATISTICS_HISTOGRAM_NUM_BINS`: number of histogram bins (see examples below for more info).
- `DESCRIPTIVE_STATISTICS_MAX_PARQUET_SIZE_BYTES`: maximum size in bytes of the dataset's parquet files to compute statistics. Datasets with bigger size are ignored. Defaults to `100_000_000`.
#### How descriptive statistics are computed
Descriptive statistics are currently computed for the following data types: strings, floats, and ints (including `ClassLabel` int).
Response has two fields: `num_examples` and `statistics`. `statistics` field is a list of dicts with three keys: `column_name`, `column_type`, and `column_statistics`.
`column_type` is one of the following values:
* `class_label` - for `datasets.ClassLabel` feature
* `float` - for float dtypes ("float16", "float32", "float64")
* `int` - for integer dtypes ("int8", "int16", "int32", "int64", "uint8", "uint16", "uint32", "uint64")
* `string_label` - for string dtypes ("string", "large_string") - if there are less than or equal to `MAX_NUM_STRING_LABELS` unique values (hardcoded in worker's code, for now it's 30)
* `string_text` - for string dtypes ("string", "large_string") - if there are more than `MAX_NUM_STRING_LABELS` unique values
* `bool` - for boolean dtype ("bool")
`column_statistics` content depends on the feature type, see examples below.
##### class_label
<details><summary>example: </summary>
<p>
```python
{
"column_name": "class_col",
"column_type": "class_label",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"no_label_count": 0, # number of -1 values - special value of the `datasets` lib to encode `no label`
"no_label_proportion": 0.0,
"n_unique": 5, # number of unique values (excluding `no label` and nan)
"frequencies": { # mapping value -> its count
"this": 19834,
"are": 20159,
"random": 20109,
"words": 20172,
"test": 19726
}
}
}
```
</p>
</details>
##### float
Bin size for histogram is counted as `(max_value - min_value) / DESCRIPTIVE_STATISTICS_HISTOGRAM_NUM_BINS`
<details><summary>example: </summary>
<p>
```python
{
"column_name": "delay",
"column_type": "float",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": -10.206,
"max": 8.48053,
"mean": 2.10174,
"median": 3.4012,
"std": 3.12487,
"histogram": {
"hist": [
2,
34,
256,
15198,
9037,
2342,
12743,
45114,
14904,
370
],
"bin_edges": [
-10.206,
-8.33734,
-6.46869,
-4.60004,
-2.73139,
-0.86273,
1.00592,
2.87457,
4.74322,
6.61188,
8.48053 # includes maximum value, so len is always len(hist) + 1
]
}
}
}
```
</p>
</details>
##### int
As bin edges for integer values also must be integers, bin size is counted as `np.ceil((max_value - min_value + 1) / DESCRIPTIVE_STATISTICS_HISTOGRAM_NUM_BINS)`. Rounding up means that there might be smaller number of bins in response then provided `DESCRIPTIVE_STATISTICS_HISTOGRAM_NUM_BINS`. The last bin's size might be smaller than that of the others if the feature's range is not divisible by the rounded bin size.
<details><summary>examples: </summary>
<p>
```python
{
"column_name": "direction",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": 0,
"max": 1,
"mean": 0.49925,
"median": 0.0,
"std": 0.5,
"histogram": {
"hist": [
50075,
49925
],
"bin_edges": [
0,
1,
1 # if the last value is equal to the last but one, that means that this bin includes only this value
]
}
}
},
{
"column_name": "hour",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": 0,
"max": 23,
"mean": 13.44402,
"median": 14.0,
"std": 5.49455,
"histogram": {
"hist": [
2694,
2292,
16785,
16326,
16346,
17809,
16546,
11202
],
"bin_edges": [
0,
3,
6,
9,
12,
15,
18,
21,
23
]
}
}
},
{
"column_name": "humidity",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": 54,
"max": 99,
"mean": 83.89878,
"median": 85.0,
"std": 8.65174,
"histogram": {
"hist": [
554,
1662,
3823,
6532,
12512,
17536,
23871,
20355,
12896,
259
],
"bin_edges": [
54,
59,
64,
69,
74,
79,
84,
89,
94,
99,
99
]
}
}
},
{
"column_name": "weekday",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": 0,
"max": 6,
"mean": 3.08063,
"median": 3.0,
"std": 1.90347,
"histogram": {
"hist": [
10282,
15416,
15291,
15201,
15586,
15226,
12998
],
"bin_edges": [
0,
1,
2,
3,
4,
5,
6,
6
]
}
}
}
```
</p>
</details>
##### string_label
If the number of unique values in a column (within requested split) is <= `MAX_NUM_STRING_LABELS` (currently 30), the column is considered to be a category and the categories counts are computed.
<details><summary>examples: </summary>
<p>
```python
{
'column_name': 'string_col',
'column_type': 'string_label',
'column_statistics':
{
"nan_count": 0,
"nan_proportion": 0.0,
"n_unique": 5, # number of unique values (excluding nan)
"frequencies": { # mapping value -> its count
"this": 19834,
"are": 20159,
"random": 20109,
"words": 20172,
"test": 19726
}
}
}
```
</p>
</details>
##### string_text
If the number of unique values in a column (within requested split) is > `MAX_NUM_STRING_LABELS` (currently 30), the column is considered to be text and the distribution of text **lengths** is computed.
<details><summary>example: </summary>
<p>
```python
{
'column_name': 'text_col',
'column_type': 'string_text',
'column_statistics': {
'max': 296,
'mean': 97.46649,
'median': 88.0,
'min': 11,
'nan_count': 0,
'nan_proportion': 0.0,
'std': 55.82714,
'histogram': {
'bin_edges': [
11,
40,
69,
98,
127,
156,
185,
214,
243,
272,
296
],
'hist': [
171,
224,
235,
180,
102,
99,
53,
28,
10,
2
]
},
}
}
```
</p>
</details>
##### bool
<details><summary>example: </summary>
<p>
```python
{
'column_name': 'bool__nan_column',
'column_type': 'bool',
'column_statistics':
{
'nan_count': 3,
'nan_proportion': 0.15,
'frequencies': {
'False': 7,
'True': 10
}
}
}
```
</p>
</details>
### Splits worker
The `splits` worker does not need any additional configuration.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
| huggingface/datasets-server/blob/main/services/worker/README.md |
Differences between Dataset and IterableDataset
There are two types of dataset objects, a [`Dataset`] and an [`IterableDataset`].
Whichever type of dataset you choose to use or create depends on the size of the dataset.
In general, an [`IterableDataset`] is ideal for big datasets (think hundreds of GBs!) due to its lazy behavior and speed advantages, while a [`Dataset`] is great for everything else.
This page will compare the differences between a [`Dataset`] and an [`IterableDataset`] to help you pick the right dataset object for you.
## Downloading and streaming
When you have a regular [`Dataset`], you can access it using `my_dataset[0]`. This provides random access to the rows.
Such datasets are also called "map-style" datasets.
For example you can download ImageNet-1k like this and access any row:
```python
from datasets import load_dataset
imagenet = load_dataset("imagenet-1k", split="train") # downloads the full dataset
print(imagenet[0])
```
But one caveat is that you must have the entire dataset stored on your disk or in memory, which blocks you from accessing datasets bigger than the disk.
Because it can become inconvenient for big datasets, there exists another type of dataset, the [`IterableDataset`].
When you have an `IterableDataset`, you can access it using a `for` loop to load the data progressively as you iterate over the dataset.
This way, only a small fraction of examples is loaded in memory, and you don't write anything on disk.
For example, you can stream the ImageNet-1k dataset without downloading it on disk:
```python
from datasets import load_dataset
imagenet = load_dataset("imagenet-1k", split="train", streaming=True) # will start loading the data when iterated over
for example in imagenet:
print(example)
break
```
Streaming can read online data without writing any file to disk.
For example, you can stream datasets made out of multiple shards, each of which is hundreds of gigabytes like [C4](https://huggingface.co/datasets/c4), [OSCAR](https://huggingface.co/datasets/oscar) or [LAION-2B](https://huggingface.co/datasets/laion/laion2B-en).
Learn more about how to stream a dataset in the [Dataset Streaming Guide](./stream).
This is not the only difference though, because the "lazy" behavior of an `IterableDataset` is also present when it comes to dataset creation and processing.
## Creating map-style datasets and iterable datasets
You can create a [`Dataset`] using lists or dictionaries, and the data is entirely converted to Arrow so you can easily access any row:
```python
my_dataset = Dataset.from_dict({"col_1": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]})
print(my_dataset[0])
```
To create an `IterableDataset` on the other hand, you must provide a "lazy" way to load the data.
In Python, we generally use generator functions. These functions `yield` one example at a time, which means you can't access a row by slicing it like a regular `Dataset`:
```python
def my_generator(n):
for i in range(n):
yield {"col_1": i}
my_iterable_dataset = IterableDataset.from_generator(my_generator, gen_kwargs={"n": 10})
for example in my_iterable_dataset:
print(example)
break
```
## Loading local files entirely and progressively
It is possible to convert local or remote data files to an Arrow [`Dataset`] using [`load_dataset`]:
```python
data_files = {"train": ["path/to/data.csv"]}
my_dataset = load_dataset("csv", data_files=data_files, split="train")
print(my_dataset[0])
```
However, this requires a conversion step from CSV to Arrow format, which takes time and disk space if your dataset is big.
To save disk space and skip the conversion step, you can define an `IterableDataset` by streaming from the local files directly.
This way, the data is read progressively from the local files as you iterate over the dataset:
```python
data_files = {"train": ["path/to/data.csv"]}
my_iterable_dataset = load_dataset("csv", data_files=data_files, split="train", streaming=True)
for example in my_iterable_dataset: # this reads the CSV file progressively as you iterate over the dataset
print(example)
break
```
Many file formats are supported, like CSV, JSONL, and Parquet, as well as image and audio files.
You can find more information in the corresponding guides for loading [tabular](./tabular_load), [text](./nlp_load), [vision](./image_load), and [audio](./audio_load]) datasets.
## Eager data processing and lazy data processing
When you process a [`Dataset`] object using [`Dataset.map`], the entire dataset is processed immediately and returned.
This is similar to how `pandas` works for example.
```python
my_dataset = my_dataset.map(process_fn) # process_fn is applied on all the examples of the dataset
print(my_dataset[0])
```
On the other hand, due to the "lazy" nature of an `IterableDataset`, calling [`IterableDataset.map`] does not apply your `map` function over the full dataset.
Instead, your `map` function is applied on-the-fly.
Because of that, you can chain multiple processing steps and they will all run at once when you start iterating over the dataset:
```python
my_iterable_dataset = my_iterable_dataset.map(process_fn_1)
my_iterable_dataset = my_iterable_dataset.filter(filter_fn)
my_iterable_dataset = my_iterable_dataset.map(process_fn_2)
# process_fn_1, filter_fn and process_fn_2 are applied on-the-fly when iterating over the dataset
for example in my_iterable_dataset:
print(example)
break
```
## Exact and fast approximate shuffling
When you shuffle a [`Dataset`] using [`Dataset.shuffle`], you apply an exact shuffling of the dataset.
It works by taking a list of indices `[0, 1, 2, ... len(my_dataset) - 1]` and shuffling this list.
Then, accessing `my_dataset[0]` returns the row and index defined by the first element of the indices mapping that has been shuffled:
```python
my_dataset = my_dataset.shuffle(seed=42)
print(my_dataset[0])
```
Since we don't have random access to the rows in the case of an `IterableDataset`, we can't use a shuffled list of indices and access a row at an arbitrary position.
This prevents the use of exact shuffling.
Instead, a fast approximate shuffling is used in [`IterableDataset.shuffle`].
It uses a shuffle buffer to sample random examples iteratively from the dataset.
Since the dataset is still read iteratively, it provides excellent speed performance:
```python
my_iterable_dataset = my_iterable_dataset.shuffle(seed=42, buffer_size=100)
for example in my_iterable_dataset:
print(example)
break
```
But using a shuffle buffer is not enough to provide a satisfactory shuffling for machine learning model training. So [`IterableDataset.shuffle`] also shuffles the dataset shards if your dataset is made of multiple files or sources:
```python
# Stream from the internet
my_iterable_dataset = load_dataset("deepmind/code_contests", split="train", streaming=True)
my_iterable_dataset.n_shards # 39
# Stream from local files
data_files = {"train": [f"path/to/data_{i}.csv" for i in range(1024)]}
my_iterable_dataset = load_dataset("csv", data_files=data_files, split="train", streaming=True)
my_iterable_dataset.n_shards # 1024
# From a generator function
def my_generator(n, sources):
for source in sources:
for example_id_for_current_source in range(n):
yield {"example_id": f"{source}_{example_id_for_current_source}"}
gen_kwargs = {"n": 10, "sources": [f"path/to/data_{i}" for i in range(1024)]}
my_iterable_dataset = IterableDataset.from_generator(my_generator, gen_kwargs=gen_kwargs)
my_iterable_dataset.n_shards # 1024
```
## Speed differences
Regular [`Dataset`] objects are based on Arrow which provides fast random access to the rows.
Thanks to memory mapping and the fact that Arrow is an in-memory format, reading data from disk doesn't do expensive system calls and deserialization.
It provides even faster data loading when iterating using a `for` loop by iterating on contiguous Arrow record batches.
However as soon as your [`Dataset`] has an indices mapping (via [`Dataset.shuffle`] for example), the speed can become 10x slower.
This is because there is an extra step to get the row index to read using the indices mapping, and most importantly, you aren't reading contiguous chunks of data anymore.
To restore the speed, you'd need to rewrite the entire dataset on your disk again using [`Dataset.flatten_indices`], which removes the indices mapping.
This may take a lot of time depending of the size of your dataset though:
```python
my_dataset[0] # fast
my_dataset = my_dataset.shuffle(seed=42)
my_dataset[0] # up to 10x slower
my_dataset = my_dataset.flatten_indices() # rewrite the shuffled dataset on disk as contiguous chunks of data
my_dataset[0] # fast again
```
In this case, we recommend switching to an [`IterableDataset`] and leveraging its fast approximate shuffling method [`IterableDataset.shuffle`].
It only shuffles the shards order and adds a shuffle buffer to your dataset, which keeps the speed of your dataset optimal.
You can also reshuffle the dataset easily:
```python
for example in enumerate(my_iterable_dataset): # fast
pass
shuffled_iterable_dataset = my_iterable_dataset.shuffle(seed=42, buffer_size=100)
for example in enumerate(shuffled_iterable_dataset): # as fast as before
pass
shuffled_iterable_dataset = my_iterable_dataset.shuffle(seed=1337, buffer_size=100) # reshuffling using another seed is instantaneous
for example in enumerate(shuffled_iterable_dataset): # still as fast as before
pass
```
If you're using your dataset on multiple epochs, the effective seed to shuffle the shards order in the shuffle buffer is `seed + epoch`.
It makes it easy to reshuffle a dataset between epochs:
```python
for epoch in range(n_epochs):
my_iterable_dataset.set_epoch(epoch)
for example in my_iterable_dataset: # fast + reshuffled at each epoch using `effective_seed = seed + epoch`
pass
```
## Switch from map-style to iterable
If you want to benefit from the "lazy" behavior of an [`IterableDataset`] or their speed advantages, you can switch your map-style [`Dataset`] to an [`IterableDataset`]:
```python
my_iterable_dataset = my_dataset.to_iterable_dataset()
```
If you want to shuffle your dataset or [use it with a PyTorch DataLoader](./use_with_pytorch#stream-data), we recommend generating a sharded [`IterableDataset`]:
```python
my_iterable_dataset = my_dataset.to_iterable_dataset(num_shards=1024)
my_iterable_dataset.n_shards # 1024
```
| huggingface/datasets/blob/main/docs/source/about_mapstyle_vs_iterable.mdx |
Q-Learning Recap [[q-learning-recap]]
*Q-Learning* **is the RL algorithm that** :
- Trains a *Q-function*, an **action-value function** encoded, in internal memory, by a *Q-table* **containing all the state-action pair values.**
- Given a state and action, our Q-function **will search its Q-table for the corresponding value.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function-2.jpg" alt="Q function" width="100%"/>
- When the training is done, **we have an optimal Q-function, or, equivalently, an optimal Q-table.**
- And if we **have an optimal Q-function**, we
have an optimal policy, since we **know, for each state, the best action to take.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link value policy" width="100%"/>
But, in the beginning, our **Q-table is useless since it gives arbitrary values for each state-action pair (most of the time we initialize the Q-table to 0 values)**. But, as we explore the environment and update our Q-table it will give us a better and better approximation.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/q-learning.jpeg" alt="q-learning.jpeg" width="100%"/>
This is the Q-Learning pseudocode:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
| huggingface/deep-rl-class/blob/main/units/en/unit2/q-learning-recap.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zero-shot object detection
[[open-in-colab]]
Traditionally, models used for [object detection](object_detection) require labeled image datasets for training,
and are limited to detecting the set of classes from the training data.
Zero-shot object detection is supported by the [OWL-ViT](../model_doc/owlvit) model which uses a different approach. OWL-ViT
is an open-vocabulary object detector. It means that it can detect objects in images based on free-text queries without
the need to fine-tune the model on labeled datasets.
OWL-ViT leverages multi-modal representations to perform open-vocabulary detection. It combines [CLIP](../model_doc/clip) with
lightweight object classification and localization heads. Open-vocabulary detection is achieved by embedding free-text queries with the text encoder of CLIP and using them as input to the object classification and localization heads.
associate images and their corresponding textual descriptions, and ViT processes image patches as inputs. The authors
of OWL-ViT first trained CLIP from scratch and then fine-tuned OWL-ViT end to end on standard object detection datasets using
a bipartite matching loss.
With this approach, the model can detect objects based on textual descriptions without prior training on labeled datasets.
In this guide, you will learn how to use OWL-ViT:
- to detect objects based on text prompts
- for batch object detection
- for image-guided object detection
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
```
## Zero-shot object detection pipeline
The simplest way to try out inference with OWL-ViT is to use it in a [`pipeline`]. Instantiate a pipeline
for zero-shot object detection from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit):
```python
>>> from transformers import pipeline
>>> checkpoint = "google/owlvit-base-patch32"
>>> detector = pipeline(model=checkpoint, task="zero-shot-object-detection")
```
Next, choose an image you'd like to detect objects in. Here we'll use the image of astronaut Eileen Collins that is
a part of the [NASA](https://www.nasa.gov/multimedia/imagegallery/index.html) Great Images dataset.
```py
>>> import skimage
>>> import numpy as np
>>> from PIL import Image
>>> image = skimage.data.astronaut()
>>> image = Image.fromarray(np.uint8(image)).convert("RGB")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_1.png" alt="Astronaut Eileen Collins"/>
</div>
Pass the image and the candidate object labels to look for to the pipeline.
Here we pass the image directly; other suitable options include a local path to an image or an image url. We also pass text descriptions for all items we want to query the image for.
```py
>>> predictions = detector(
... image,
... candidate_labels=["human face", "rocket", "nasa badge", "star-spangled banner"],
... )
>>> predictions
[{'score': 0.3571370542049408,
'label': 'human face',
'box': {'xmin': 180, 'ymin': 71, 'xmax': 271, 'ymax': 178}},
{'score': 0.28099656105041504,
'label': 'nasa badge',
'box': {'xmin': 129, 'ymin': 348, 'xmax': 206, 'ymax': 427}},
{'score': 0.2110239565372467,
'label': 'rocket',
'box': {'xmin': 350, 'ymin': -1, 'xmax': 468, 'ymax': 288}},
{'score': 0.13790413737297058,
'label': 'star-spangled banner',
'box': {'xmin': 1, 'ymin': 1, 'xmax': 105, 'ymax': 509}},
{'score': 0.11950037628412247,
'label': 'nasa badge',
'box': {'xmin': 277, 'ymin': 338, 'xmax': 327, 'ymax': 380}},
{'score': 0.10649408400058746,
'label': 'rocket',
'box': {'xmin': 358, 'ymin': 64, 'xmax': 424, 'ymax': 280}}]
```
Let's visualize the predictions:
```py
>>> from PIL import ImageDraw
>>> draw = ImageDraw.Draw(image)
>>> for prediction in predictions:
... box = prediction["box"]
... label = prediction["label"]
... score = prediction["score"]
... xmin, ymin, xmax, ymax = box.values()
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{label}: {round(score,2)}", fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_2.png" alt="Visualized predictions on NASA image"/>
</div>
## Text-prompted zero-shot object detection by hand
Now that you've seen how to use the zero-shot object detection pipeline, let's replicate the same
result manually.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit).
Here we'll use the same checkpoint as before:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
Let's take a different image to switch things up.
```py
>>> import requests
>>> url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
>>> im = Image.open(requests.get(url, stream=True).raw)
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_3.png" alt="Beach photo"/>
</div>
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the
image for the model by resizing and normalizing it, and a [`CLIPTokenizer`] that takes care of the text inputs.
```py
>>> text_queries = ["hat", "book", "sunglasses", "camera"]
>>> inputs = processor(text=text_queries, images=im, return_tensors="pt")
```
Pass the inputs through the model, post-process, and visualize the results. Since the image processor resized images before
feeding them to the model, you need to use the [`~OwlViTImageProcessor.post_process_object_detection`] method to make sure the predicted bounding
boxes have the correct coordinates relative to the original image:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = torch.tensor([im.size[::-1]])
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(im)
>>> scores = results["scores"].tolist()
>>> labels = results["labels"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[label]}: {round(score,2)}", fill="white")
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## Batch processing
You can pass multiple sets of images and text queries to search for different (or same) objects in several images.
Let's use both an astronaut image and the beach image together.
For batch processing, you should pass text queries as a nested list to the processor and images as lists of PIL images,
PyTorch tensors, or NumPy arrays.
```py
>>> images = [image, im]
>>> text_queries = [
... ["human face", "rocket", "nasa badge", "star-spangled banner"],
... ["hat", "book", "sunglasses", "camera"],
... ]
>>> inputs = processor(text=text_queries, images=images, return_tensors="pt")
```
Previously for post-processing you passed the single image's size as a tensor, but you can also pass a tuple, or, in case
of several images, a list of tuples. Let's create predictions for the two examples, and visualize the second one (`image_idx = 1`).
```py
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = [x.size[::-1] for x in images]
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)
>>> image_idx = 1
>>> draw = ImageDraw.Draw(images[image_idx])
>>> scores = results[image_idx]["scores"].tolist()
>>> labels = results[image_idx]["labels"].tolist()
>>> boxes = results[image_idx]["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[image_idx][label]}: {round(score,2)}", fill="white")
>>> images[image_idx]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## Image-guided object detection
In addition to zero-shot object detection with text queries, OWL-ViT offers image-guided object detection. This means
you can use an image query to find similar objects in the target image.
Unlike text queries, only a single example image is allowed.
Let's take an image with two cats on a couch as a target image, and an image of a single cat
as a query:
```py
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image_target = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000524280.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
```
Let's take a quick look at the images:
```py
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(1, 2)
>>> ax[0].imshow(image_target)
>>> ax[1].imshow(query_image)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_5.png" alt="Cats"/>
</div>
In the preprocessing step, instead of text queries, you now need to use `query_images`:
```py
>>> inputs = processor(images=image_target, query_images=query_image, return_tensors="pt")
```
For predictions, instead of passing the inputs to the model, pass them to [`~OwlViTForObjectDetection.image_guided_detection`]. Draw the predictions
as before except now there are no labels.
```py
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
... target_sizes = torch.tensor([image_target.size[::-1]])
... results = processor.post_process_image_guided_detection(outputs=outputs, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(image_target)
>>> scores = results["scores"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="white", width=4)
>>> image_target
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_6.png" alt="Cats with bounding boxes"/>
</div>
If you'd like to interactively try out inference with OWL-ViT, check out this demo:
<iframe
src="https://adirik-owl-vit.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
| huggingface/transformers/blob/main/docs/source/en/tasks/zero_shot_object_detection.md |
Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
<Question
choices={[
{
text: "The bias-variance tradeoff reflects how my model is able to generalize the knowledge to previously tagged data we give to the model during training time.",
explain: "This is the traditional bias-variance tradeoff in Machine Learning. In our specific case of Reinforcement Learning, we don't have previously tagged data, but only a reward signal.",
correct: false,
},
{
text: "The bias-variance tradeoff reflects how well the reinforcement signal reflects the true reward the agent should get from the enviromment",
explain: "",
correct: true,
},
]}
/>
### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
<Question
choices={[
{
text: "An unbiased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "",
correct: true,
},
{
text: "A biased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "If a reward signal is biased, it means the reward signal we get differs from the real reward we should be getting from an environment",
correct: false,
},
{
text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "",
correct: true,
},
{
text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "If a reward signal has low variance, then it's less affected by the noise of the environment and produce similar values regardless the random elements in the environment",
correct: false,
},
]}
/>
### Q3: Which of the following statements are true about Monte Carlo method?
<Question
choices={[
{
text: "It's a sampling mechanism, which means we don't analyze all the possible states, but a sample of those",
explain: "",
correct: true,
},
{
text: "It's very resistant to stochasticity (random elements in the trajectory)",
explain: "Monte Carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
correct: false,
},
{
text: "To reduce the impact of stochastic elements in Monte Carlo, we take `n` strategies and average them, reducing their individual impact",
explain: "",
correct: true,
},
]}
/>
### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
<details>
<summary>Solution</summary>
The idea behind Actor-Critic is that we learn two function approximations:
1. A `policy` that controls how our agent acts (π)
2. A `value` function to assist the policy update by measuring how good the action taken is (q)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step2.jpg" alt="Actor-Critic, step 2"/>
</details>
### Q5: Which of the following statements are true about the Actor-Critic Method?
<Question
choices={[
{
text: "The Critic does not learn any function during the training process",
explain: "Both the Actor and the Critic function parameters are updated during training time",
correct: false,
},
{
text: "The Actor learns a policy function, while the Critic learns a value function",
explain: "",
correct: true,
},
{
text: "It adds resistance to stochasticity and reduces high variance",
explain: "",
correct: true,
},
]}
/>
### Q6: What is `Advantage` in the A2C method?
<details>
<summary>Solution</summary>
Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
In other words: how taking that action at a state is better compared to the average value of the state
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/advantage1.jpg" alt="Advantage in A2C"/>
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| huggingface/deep-rl-class/blob/main/units/en/unit6/quiz.mdx |
Access and read Logs
Hugging Face Endpoints provides access to the logs of your Endpoints through the UI in the “Logs” tab of your Endpoint.
You will have access to the build logs of your Image artifacts as well as access to the Container Logs during inference.
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/9_selection.png" alt="select logs" />
The Container Logs are only available when your Endpoint is in the “Running” state.
_Note: If your Endpoint creation is in the “Failed” state, you can check the Build Logs to see what the reason was, e.g. wrong version of a dependency, etc._
**Build Logs:**
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/9_build_logs.png" alt="build logs" />
**Container Logs:**
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/9_logs.png" alt="container logs" />
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/logs.mdx |
Gradio Demo: examples_component
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('images')
!wget -q -O images/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/examples_component/images/cheetah1.jpg
!wget -q -O images/lion.jpg https://github.com/gradio-app/gradio/raw/main/demo/examples_component/images/lion.jpg
!wget -q -O images/lion.webp https://github.com/gradio-app/gradio/raw/main/demo/examples_component/images/lion.webp
!wget -q -O images/logo.png https://github.com/gradio-app/gradio/raw/main/demo/examples_component/images/logo.png
```
```
import gradio as gr
import os
def flip(i):
return i.rotate(180)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
img_i = gr.Image(label="Input Image", type="pil")
with gr.Column():
img_o = gr.Image(label="Output Image")
with gr.Row():
btn = gr.Button(value="Flip Image")
btn.click(flip, inputs=[img_i], outputs=[img_o])
gr.Examples(
[
os.path.join(os.path.abspath(''), "images/cheetah1.jpg"),
os.path.join(os.path.abspath(''), "images/lion.jpg"),
],
img_i,
img_o,
flip,
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/examples_component/run.ipynb |
Additional Readings
These are **optional readings** if you want to go deeper.
## Introduction to Policy Optimization
- [Part 3: Intro to Policy Optimization - Spinning Up documentation](https://spinningup.openai.com/en/latest/spinningup/rl_intro3.html)
## Policy Gradient
- [https://johnwlambert.github.io/policy-gradients/](https://johnwlambert.github.io/policy-gradients/)
- [RL - Policy Gradient Explained](https://jonathan-hui.medium.com/rl-policy-gradients-explained-9b13b688b146)
- [Chapter 13, Policy Gradient Methods; Reinforcement Learning, an introduction by Richard Sutton and Andrew G. Barto](http://incompleteideas.net/book/RLbook2020.pdf)
## Implementation
- [PyTorch Reinforce implementation](https://github.com/pytorch/examples/blob/main/reinforcement_learning/reinforce.py)
- [Implementations from DDPG to PPO](https://github.com/MrSyee/pg-is-all-you-need)
| huggingface/deep-rl-class/blob/main/units/en/unit4/additional-readings.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Quantization
## ORTQuantizer
[[autodoc]] onnxruntime.quantization.ORTQuantizer
- all
| huggingface/optimum/blob/main/docs/source/onnxruntime/package_reference/quantization.mdx |
Gradio Demo: number_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Number()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/number_component/run.ipynb |
Gradio Demo: map_airbnb
### Display an interactive map of AirBnB locations with Plotly. Data is hosted on HuggingFace Datasets.
```
!pip install -q gradio plotly
```
```
import gradio as gr
import plotly.graph_objects as go
from datasets import load_dataset
dataset = load_dataset("gradio/NYC-Airbnb-Open-Data", split="train")
df = dataset.to_pandas()
def filter_map(min_price, max_price, boroughs):
filtered_df = df[(df['neighbourhood_group'].isin(boroughs)) &
(df['price'] > min_price) & (df['price'] < max_price)]
names = filtered_df["name"].tolist()
prices = filtered_df["price"].tolist()
text_list = [(names[i], prices[i]) for i in range(0, len(names))]
fig = go.Figure(go.Scattermapbox(
customdata=text_list,
lat=filtered_df['latitude'].tolist(),
lon=filtered_df['longitude'].tolist(),
mode='markers',
marker=go.scattermapbox.Marker(
size=6
),
hoverinfo="text",
hovertemplate='<b>Name</b>: %{customdata[0]}<br><b>Price</b>: $%{customdata[1]}'
))
fig.update_layout(
mapbox_style="open-street-map",
hovermode='closest',
mapbox=dict(
bearing=0,
center=go.layout.mapbox.Center(
lat=40.67,
lon=-73.90
),
pitch=0,
zoom=9
),
)
return fig
with gr.Blocks() as demo:
with gr.Column():
with gr.Row():
min_price = gr.Number(value=250, label="Minimum Price")
max_price = gr.Number(value=1000, label="Maximum Price")
boroughs = gr.CheckboxGroup(choices=["Queens", "Brooklyn", "Manhattan", "Bronx", "Staten Island"], value=["Queens", "Brooklyn"], label="Select Boroughs:")
btn = gr.Button(value="Update Filter")
map = gr.Plot()
demo.load(filter_map, [min_price, max_price, boroughs], map)
btn.click(filter_map, [min_price, max_price, boroughs], map)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/map_airbnb/run.ipynb |
Res2Net
**Res2Net** is an image model that employs a variation on bottleneck residual blocks, [Res2Net Blocks](https://paperswithcode.com/method/res2net-block). The motivation is to be able to represent features at multiple scales. This is achieved through a novel building block for CNNs that constructs hierarchical residual-like connections within one single residual block. This represents multi-scale features at a granular level and increases the range of receptive fields for each network layer.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('res2net101_26w_4s', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `res2net101_26w_4s`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('res2net101_26w_4s', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{Gao_2021,
title={Res2Net: A New Multi-Scale Backbone Architecture},
volume={43},
ISSN={1939-3539},
url={http://dx.doi.org/10.1109/TPAMI.2019.2938758},
DOI={10.1109/tpami.2019.2938758},
number={2},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
publisher={Institute of Electrical and Electronics Engineers (IEEE)},
author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
year={2021},
month={Feb},
pages={652–662}
}
```
<!--
Type: model-index
Collections:
- Name: Res2Net
Paper:
Title: 'Res2Net: A New Multi-scale Backbone Architecture'
URL: https://paperswithcode.com/paper/res2net-a-new-multi-scale-backbone
Models:
- Name: res2net101_26w_4s
In Collection: Res2Net
Metadata:
FLOPs: 10415881200
Parameters: 45210000
File Size: 181456059
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net101_26w_4s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L152
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net101_26w_4s-02a759a1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.19%
Top 5 Accuracy: 94.43%
- Name: res2net50_14w_8s
In Collection: Res2Net
Metadata:
FLOPs: 5403546768
Parameters: 25060000
File Size: 100638543
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_14w_8s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L196
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_14w_8s-6527dddc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.14%
Top 5 Accuracy: 93.86%
- Name: res2net50_26w_4s
In Collection: Res2Net
Metadata:
FLOPs: 5499974064
Parameters: 25700000
File Size: 103110087
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_4s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L141
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_4s-06e79181.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.85%
- Name: res2net50_26w_6s
In Collection: Res2Net
Metadata:
FLOPs: 8130156528
Parameters: 37050000
File Size: 148603239
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_6s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L163
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_6s-19041792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.57%
Top 5 Accuracy: 94.12%
- Name: res2net50_26w_8s
In Collection: Res2Net
Metadata:
FLOPs: 10760338992
Parameters: 48400000
File Size: 194085165
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_26w_8s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L174
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_26w_8s-2c7c9f12.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.19%
Top 5 Accuracy: 94.37%
- Name: res2net50_48w_2s
In Collection: Res2Net
Metadata:
FLOPs: 5375291520
Parameters: 25290000
File Size: 101421406
Architecture:
- Batch Normalization
- Convolution
- Global Average Pooling
- ReLU
- Res2Net Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x Titan Xp GPUs
ID: res2net50_48w_2s
LR: 0.1
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/res2net.py#L185
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-res2net/res2net50_48w_2s-afed724a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.53%
Top 5 Accuracy: 93.56%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/res2net.mdx |
ow to slice and dice a dataset. Most of the time, the data you work with won’t be perfectly prepared for training models. In this video we’ll explore various features that Datasets provides to clean up your datasets. The Datasets library provides several built-in methods that allow you to wrangle your data. In this video we'll see how you can shuffle and split your data, select the rows you're interested in, tweak the columns, and apply processing functions with the map() method. Let's start with shuffling. It is generally a good idea to apply shuffling to the training set so that your model doesn't learn any artificial ordering in the data. If you want to shuffle the whole dataset, you can apply the appropriately named shuffle() method to your dataset. You can see an example of this method in action here, where we've downloaded the training split of the SQUAD dataset and shuffled all the rows randomly.Another way to shuffle the data is to create random train and test splits. This can be useful if you have to create your own test splits from raw data. To do this, you just apply the train_test_split method and specify how large the test split should be. In this example, we've specified that the test set should be 10% of the total dataset size. You can see that the output of train_test_split is a DatasetDict object, whose keys correspond to the new splits. Now that we know how to shuffle a dataset, let's take a look at returning the rows we're interested in. The most common way to do this is with the select method. This method expects a list or generator of the dataset's indices, and will then return a new Dataset object containing just those rows. If you want to create a random sample of rows, you can do this by chaining the shuffle and select methods together. In this example, we've created a sample of 5 elements from the SQuAD dataset. The last way to pick out specific rows in a dataset is by applying the filter method. This method checks whether each rows fulfills some condition or not. For example, here we've created a small lambda function that checks whether the title starts with the letter "L". Once we apply this function with the filter method, we get a subset of the data consisting of just these titles. So far we've been talking about the rows of a dataset, but what about the columns? The Datasets library has two main methods for transforming columns: a rename_column method to change the name of a column, and a remove_columns method to delete them. You can see examples of both these method here. Some datasets have nested columns and you can expand these by applying the flatten method. For example in the SQUAD dataset, the answers column contains a text and answer_start field. If we want to promote them to their own separate columns, we can apply flatten as shown here. Of course, no discussion of the Datasets library would be complete without mentioning the famous map method. This method applies a custom processing function to each row in the dataset. For example,here we first define a lowercase_title function that simply lowercases the text in the title column and then we feed that to the map method and voila! we now have lowercase titles. The map method can also be used to feed batches of rows to the processing function. This is especially useful for tokenization, where the tokenizers are backed by the Tokenizers library can use fast multithreading to process batches in parallel. | huggingface/course/blob/main/subtitles/en/raw/chapter5/03a_slice-and-dice.md |
Gradio Demo: question-answering
```
!pip install -q gradio torch transformers
```
```
import gradio as gr
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/roberta-base-squad2"
nlp = pipeline("question-answering", model=model_name, tokenizer=model_name)
context = "The Amazon rainforest, also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
question = "Which continent is the Amazon rainforest in?"
def predict(context, question):
res = nlp({"question": question, "context": context})
return res["answer"], res["score"]
gr.Interface(
predict,
inputs=[
gr.Textbox(lines=7, value=context, label="Context Paragraph"),
gr.Textbox(lines=2, value=question, label="Question"),
],
outputs=[gr.Textbox(label="Answer"), gr.Textbox(label="Score")],
).launch()
```
| gradio-app/gradio/blob/main/demo/question-answering/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# IP-Adapter
[IP-Adapter](https://hf.co/papers/2308.06721) is a lightweight adapter that enables prompting a diffusion model with an image. This method decouples the cross-attention layers of the image and text features. The image features are generated from an image encoder. Files generated from IP-Adapter are only ~100MBs.
<Tip>
Learn how to load an IP-Adapter checkpoint and image in the [IP-Adapter](../../using-diffusers/loading_adapters#ip-adapter) loading guide.
</Tip>
## IPAdapterMixin
[[autodoc]] loaders.ip_adapter.IPAdapterMixin
| huggingface/diffusers/blob/main/docs/source/en/api/loaders/ip_adapter.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Configuration
[`PeftConfigMixin`] is the base configuration class for storing the adapter configuration of a [`PeftModel`], and [`PromptLearningConfig`] is the base configuration class for soft prompt methods (p-tuning, prefix tuning, and prompt tuning). These base classes contain methods for saving and loading model configurations from the Hub, specifying the PEFT method to use, type of task to perform, and model configurations like number of layers and number of attention heads.
## PeftConfigMixin
[[autodoc]] config.PeftConfigMixin
- all
## PeftConfig
[[autodoc]] PeftConfig
- all
## PromptLearningConfig
[[autodoc]] PromptLearningConfig
- all
| huggingface/peft/blob/main/docs/source/package_reference/config.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg">
<img alt="Hugging Face Transformers Library" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/transformers-logo-light.svg" width="352" height="59" style="max-width: 100%;">
</picture>
<br/>
<br/>
</p>
<p align="center">
<a href="https://circleci.com/gh/huggingface/transformers">
<img alt="Build" src="https://img.shields.io/circleci/build/github/huggingface/transformers/main">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/transformers.svg?color=blue">
</a>
<a href="https://huggingface.co/docs/transformers/index">
<img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/transformers/index.svg?down_color=red&down_message=offline&up_message=online">
</a>
<a href="https://github.com/huggingface/transformers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/transformers.svg">
</a>
<a href="https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-v2.0%20adopted-ff69b4.svg">
</a>
<a href="https://zenodo.org/badge/latestdoi/155220641"><img src="https://zenodo.org/badge/155220641.svg" alt="DOI"></a>
</p>
<h4 align="center">
<p>
<a href="https://github.com/huggingface/transformers/blob/main/README.md">English</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hans.md">简体中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_zh-hant.md">繁體中文</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ko.md">한국어</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_es.md">Español</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_ja.md">日本語</a> |
<a href="https://github.com/huggingface/transformers/blob/main/README_hd.md">हिन्दी</a> |
<b>Русский</b>
<a href="https://github.com/huggingface/transformers//blob/main/README_te.md">తెలుగు</a> |
<p>
</h4>
<h3 align="center">
<p>Современное машинное обучение для JAX, PyTorch и TensorFlow</p>
</h3>
<h3 align="center">
<a href="https://hf.co/course"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/course_banner.png"></a>
</h3>
🤗 Transformers предоставляет тысячи предварительно обученных моделей для выполнения различных задач, таких как текст, зрение и аудио.
Эти модели могут быть применены к:
* 📝 Тексту для таких задач, как классификация текстов, извлечение информации, ответы на вопросы, обобщение, перевод, генерация текстов на более чем 100 языках.
* 🖼️ Изображениям для задач классификации изображений, обнаружения объектов и сегментации.
* 🗣️ Аудио для задач распознавания речи и классификации аудио.
Модели transformers также могут выполнять несколько задач, такие как ответы на табличные вопросы, распознавание оптических символов, извлечение информации из отсканированных документов, классификация видео и ответы на визуальные вопросы.
🤗 Transformers предоставляет API для быстрой загрузки и использования предварительно обученных моделей, их тонкой настройки на собственных датасетах и последующего взаимодействия ими с сообществом на нашем [сайте](https://huggingface.co/models). В то же время каждый python модуль, определяющий архитектуру, полностью автономен и может быть модифицирован для проведения быстрых исследовательских экспериментов.
🤗 Transformers опирается на три самые популярные библиотеки глубокого обучения - [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) и [TensorFlow](https://www.tensorflow.org/) - и легко интегрируется между ними. Это позволяет легко обучать модели с помощью одной из них, а затем загружать их для выводов с помощью другой.
## Онлайн демонстрация
Большинство наших моделей можно протестировать непосредственно на их страницах с [сайта](https://huggingface.co/models). Мы также предлагаем [привтаный хостинг моделей, контроль версий и API для выводов](https://huggingface.co/pricing) для публичных и частных моделей.
Вот несколько примеров:
В области NLP ( Обработка текстов на естественном языке ):
- [Маскированное заполнение слов с помощью BERT](https://huggingface.co/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
- [Распознавание сущностей с помощью Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
- [Генерация текста с помощью GPT-2](https://huggingface.co/gpt2?text=A+long+time+ago%2C+)
- [Выводы на естественном языке с помощью RoBERTa](https://huggingface.co/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
- [Обобщение с помощью BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
- [Ответы на вопросы с помощью DistilBERT](https://huggingface.co/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
- [Перевод с помощью T5](https://huggingface.co/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
В области компьютерного зрения:
- [Классификация изображений с помощью ViT](https://huggingface.co/google/vit-base-patch16-224)
- [Обнаружение объектов с помощью DETR](https://huggingface.co/facebook/detr-resnet-50)
- [Семантическая сегментация с помощью SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [Сегментация паноптикума с помощью MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
- [Оценка глубины с помощью DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
- [Классификация видео с помощью VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
- [Универсальная сегментация с помощью OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
В области звука:
- [Автоматическое распознавание речи с помощью Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
- [Поиск ключевых слов с помощью Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
- [Классификация аудиоданных с помощью траснформера аудиоспектрограмм](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
В мультимодальных задачах:
- [Ответы на вопросы по таблице с помощью TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
- [Визуальные ответы на вопросы с помощью ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
- [Zero-shot классификация изображений с помощью CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
- [Ответы на вопросы по документам с помощью LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
- [Zero-shot классификация видео с помощью X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
## 100 проектов, использующих Transformers
Transformers - это не просто набор инструментов для использования предварительно обученных моделей: это сообщество проектов, созданное на его основе, и
Hugging Face Hub. Мы хотим, чтобы Transformers позволил разработчикам, исследователям, студентам, профессорам, инженерам и всем желающим
создавать проекты своей мечты.
Чтобы отпраздновать 100 тысяч звезд Transformers, мы решили сделать акцент на сообществе, и создали страницу [awesome-transformers](./awesome-transformers.md), на которой перечислены 100
невероятных проектов, созданных с помощью transformers.
Если вы являетесь владельцем или пользователем проекта, который, по вашему мнению, должен быть включен в этот список, пожалуйста, откройте PR для его добавления!
## Если вы хотите получить индивидуальную поддержку от команды Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a><br>
## Быстрый гайд
Для использования модели на заданном входе (текст, изображение, звук, ...) мы предоставляем API `pipeline`. Конвейеры объединяют предварительно обученную модель с препроцессингом, который использовался при ее обучении. Вот как можно быстро использовать конвейер для классификации положительных и отрицательных текстов:
```python
>>> from transformers import pipeline
# Выделение конвейера для анализа настроений
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('Мы очень рады представить конвейер в transformers.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
```
Вторая строка кода загружает и кэширует предварительно обученную модель, используемую конвейером, а третья оценивает ее на заданном тексте. Здесь ответ "POSITIVE" с уверенностью 99,97%.
Во многих задачах, как в НЛП, так и в компьютерном зрении и речи, уже есть готовый `pipeline`. Например, мы можем легко извлечь обнаруженные объекты на изображении:
``` python
>>> import requests
>>> from PIL import Image
>>> from transformers import pipeline
# Скачиваем изображение с милыми котиками
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
>>> image_data = requests.get(url, stream=True).raw
>>> image = Image.open(image_data)
# Выделение конвейера для обнаружения объектов
>>> object_detector = pipeline('object-detection')
>>> object_detector(image)
[{'score': 0.9982201457023621,
'label': 'remote',
'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
{'score': 0.9960021376609802,
'label': 'remote',
'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
{'score': 0.9954745173454285,
'label': 'couch',
'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
{'score': 0.9988006353378296,
'label': 'cat',
'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
{'score': 0.9986783862113953,
'label': 'cat',
'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
```
Здесь мы получаем список объектов, обнаруженных на изображении, с рамкой вокруг объекта и оценкой достоверности. Слева - исходное изображение, справа прогнозы:
<h3 align="center">
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png" width="400"></a>
<a><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample_post_processed.png" width="400"></a>
</h3>
Подробнее о задачах, поддерживаемых API `pipeline`, можно узнать в [этом учебном пособии](https://huggingface.co/docs/transformers/task_sum)
В дополнение к `pipeline`, для загрузки и использования любой из предварительно обученных моделей в заданной задаче достаточно трех строк кода. Вот версия для PyTorch:
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Привет мир!", return_tensors="pt")
>>> outputs = model(**inputs)
```
А вот эквивалентный код для TensorFlow:
```python
>>> from transformers import AutoTokenizer, TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> model = TFAutoModel.from_pretrained("bert-base-uncased")
>>> inputs = tokenizer("Привет мир!", return_tensors="tf")
>>> outputs = model(**inputs)
```
Токенизатор отвечает за всю предварительную обработку, которую ожидает предварительно обученная модель, и может быть вызван непосредственно с помощью одной строки (как в приведенных выше примерах) или на списке. В результате будет получен словарь, который можно использовать в последующем коде или просто напрямую передать в модель с помощью оператора распаковки аргументов **.
Сама модель представляет собой обычный [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) или [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (в зависимости от используемого бэкенда), который можно использовать как обычно. [В этом руководстве](https://huggingface.co/docs/transformers/training) рассказывается, как интегрировать такую модель в классический цикл обучения PyTorch или TensorFlow, или как использовать наш API `Trainer` для быстрой тонкой настройки на новом датасете.
## Почему необходимо использовать transformers?
1. Простые в использовании современные модели:
- Высокая производительность в задачах понимания и генерации естественного языка, компьютерного зрения и аудио.
- Низкий входной барьер для преподавателей и практиков.
- Небольшое количество абстракций для пользователя и всего три класса для изучения.
- Единый API для использования всех наших предварительно обученных моделей.
1. Более низкие вычислительные затраты, меньший "углеродный след":
- Исследователи могут обмениваться обученными моделями вместо того, чтобы постоянно их переобучать.
- Практики могут сократить время вычислений и производственные затраты.
- Десятки архитектур с более чем 60 000 предварительно обученных моделей для всех модальностей.
1. Выбор подходящего фреймворка для каждого этапа жизни модели:
- Обучение самых современных моделей за 3 строки кода.
- Перемещайте одну модель между фреймворками TF2.0/PyTorch/JAX по своему усмотрению.
- Беспрепятственный выбор подходящего фреймворка для обучения, оценки и производства.
1. Легко настроить модель или пример под свои нужды:
- Мы предоставляем примеры для каждой архитектуры, чтобы воспроизвести результаты, опубликованные их авторами.
- Внутренние компоненты модели раскрываются максимально последовательно.
- Файлы моделей можно использовать независимо от библиотеки для проведения быстрых экспериментов.
## Почему я не должен использовать transformers?
- Данная библиотека не является модульным набором строительных блоков для нейронных сетей. Код в файлах моделей специально не рефакторится дополнительными абстракциями, чтобы исследователи могли быстро итеративно работать с каждой из моделей, не погружаясь в дополнительные абстракции/файлы.
- API обучения не предназначен для работы с любой моделью, а оптимизирован для работы с моделями, предоставляемыми библиотекой. Для работы с общими циклами машинного обучения следует использовать другую библиотеку (возможно, [Accelerate](https://huggingface.co/docs/accelerate)).
- Несмотря на то, что мы стремимся представить как можно больше примеров использования, скрипты в нашей папке [примеров](https://github.com/huggingface/transformers/tree/main/examples) являются именно примерами. Предполагается, что они не будут работать "из коробки" для решения вашей конкретной задачи, и вам придется изменить несколько строк кода, чтобы адаптировать их под свои нужды.
## Установка
### С помощью pip
Данный репозиторий протестирован на Python 3.8+, Flax 0.4.1+, PyTorch 1.10+ и TensorFlow 2.6+.
Устанавливать 🤗 Transformers следует в [виртуальной среде](https://docs.python.org/3/library/venv.html). Если вы не знакомы с виртуальными средами Python, ознакомьтесь с [руководством пользователя](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Сначала создайте виртуальную среду с той версией Python, которую вы собираетесь использовать, и активируйте ее.
Затем необходимо установить хотя бы один бекенд из Flax, PyTorch или TensorFlow.
Пожалуйста, обратитесь к страницам [TensorFlow установочная страница](https://www.tensorflow.org/install/), [PyTorch установочная страница](https://pytorch.org/get-started/locally/#start-locally) и/или [Flax](https://github.com/google/flax#quick-install) и [Jax](https://github.com/google/jax#installation), где описаны команды установки для вашей платформы.
После установки одного из этих бэкендов 🤗 Transformers может быть установлен с помощью pip следующим образом:
```bash
pip install transformers
```
Если вы хотите поиграть с примерами или вам нужен самый современный код и вы не можете ждать нового релиза, вы должны [установить библиотеку из исходного кода](https://huggingface.co/docs/transformers/installation#installing-from-source).
### С помощью conda
Начиная с версии Transformers v4.0.0, у нас появилсась поддержка conda: `huggingface`.
Установить Transformers с помощью conda можно следующим образом:
```bash
conda install -c huggingface transformers
```
О том, как установить Flax, PyTorch или TensorFlow с помощью conda, читайте на страницах, посвященных их установке.
> **_ЗАМЕТКА:_** В операционной системе Windows вам может быть предложено активировать режим разработчика, чтобы воспользоваться преимуществами кэширования. Если для вас это невозможно, сообщите нам об этом [здесь](https://github.com/huggingface/huggingface_hub/issues/1062).
## Модельные архитектуры
**[Все контрольные точки моделей](https://huggingface.co/models)**, предоставляемые 🤗 Transformers, беспрепятственно интегрируются с huggingface.co [model hub](https://huggingface.co/models), куда они загружаются непосредственно [пользователями](https://huggingface.co/users) и [организациями](https://huggingface.co/organizations).
Текущее количество контрольных точек: 
🤗 В настоящее время Transformers предоставляет следующие архитектуры (подробное описание каждой из них см. [здесь](https://huggingface.co/docs/transformers/model_summary)):
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](https://huggingface.co/docs/transformers/model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[AltCLIP](https://huggingface.co/docs/transformers/model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[Autoformer](https://huggingface.co/docs/transformers/model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
1. **[Bark](https://huggingface.co/docs/transformers/model_doc/bark)** (from Suno) released in the repository [suno-ai/bark](https://github.com/suno-ai/bark) by Suno AI team.
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](https://huggingface.co/docs/transformers/model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](https://huggingface.co/docs/transformers/model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](https://huggingface.co/docs/transformers/model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLIP-2](https://huggingface.co/docs/transformers/model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[BridgeTower](https://huggingface.co/docs/transformers/model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[BROS](https://huggingface.co/docs/transformers/model_doc/bros)** (from NAVER CLOVA) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLAP](https://huggingface.co/docs/transformers/model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[CodeLlama](https://huggingface.co/docs/transformers/model_doc/llama_code)** (from MetaAI) released with the paper [Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) by Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, Gabriel Synnaeve.
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](https://huggingface.co/docs/transformers/model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CPM-Ant](https://huggingface.co/docs/transformers/model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DePlot](https://huggingface.co/docs/transformers/model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
1. **[DETA](https://huggingface.co/docs/transformers/model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2)** (from Meta AI) released with the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski.
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientFormer](https://huggingface.co/docs/transformers/model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EnCodec](https://huggingface.co/docs/transformers/model_doc/encodec)** (from Meta AI) released with the paper [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ErnieM](https://huggingface.co/docs/transformers/model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[Falcon](https://huggingface.co/docs/transformers/model_doc/falcon)** (from Technology Innovation Institute) by Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme.
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FLAN-UL2](https://huggingface.co/docs/transformers/model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[FocalNet](https://huggingface.co/docs/transformers/model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[Fuyu](https://huggingface.co/docs/transformers/model_doc/fuyu)** (from ADEPT) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar. Released with the paper [blog post](https://www.adept.ai/blog/fuyu-8b)
1. **[GIT](https://huggingface.co/docs/transformers/model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](https://huggingface.co/docs/transformers/model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](https://huggingface.co/docs/transformers/model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[HerBERT](https://huggingface.co/docs/transformers/model_doc/herbert)** (from Allegro.pl, AGH University of Science and Technology) released with the paper [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, Ireneusz Gawlik.
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[IDEFICS](https://huggingface.co/docs/transformers/model_doc/idefics)** (from HuggingFace) released with the paper [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents](https://huggingface.co/papers/2306.16527) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh.
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](https://huggingface.co/docs/transformers/model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[InstructBLIP](https://huggingface.co/docs/transformers/model_doc/instructblip)** (from Salesforce) released with the paper [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MADLAD-400](https://huggingface.co/docs/transformers/model_doc/madlad-400)** (from Google) released with the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662) by Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Christopher A. Choquette-Choo, Katherine Lee, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, Orhan Firat.
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MatCha](https://huggingface.co/docs/transformers/model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[MEGA](https://huggingface.co/docs/transformers/model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](https://huggingface.co/docs/transformers/model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MMS](https://huggingface.co/docs/transformers/model_doc/mms)** (from Facebook) released with the paper [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516) by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli.
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MobileViTV2](https://huggingface.co/docs/transformers/model_doc/mobilevitv2)** (from Apple) released with the paper [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MPT](https://huggingface.co/docs/transformers/model_doc/mpt)** (from MosaiML) released with the repository [llm-foundry](https://github.com/mosaicml/llm-foundry/) by the MosaicML NLP Team.
1. **[MRA](https://huggingface.co/docs/transformers/model_doc/mra)** (from the University of Wisconsin - Madison) released with the paper [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, Vikas Singh.
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MusicGen](https://huggingface.co/docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[NLLB-MOE](https://huggingface.co/docs/transformers/model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](https://huggingface.co/docs/transformers/model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OpenLlama](https://huggingface.co/docs/transformers/model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[Persimmon](https://huggingface.co/docs/transformers/main/model_doc/persimmon)** (from ADEPT) released in a [blog post](https://www.adept.ai/blog/persimmon-8b) by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
1. **[Phi](https://huggingface.co/docs/main/transformers/model_doc/phi)** (from Microsoft Research) released with the papers - [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li, [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](https://huggingface.co/docs/transformers/model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[Pop2Piano](https://huggingface.co/docs/transformers/model_doc/pop2piano)** released with the paper [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[PVT](https://huggingface.co/docs/transformers/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](https://huggingface.co/docs/transformers/model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](https://huggingface.co/docs/transformers/model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](https://huggingface.co/docs/transformers/model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechT5](https://huggingface.co/docs/transformers/model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[SwiftFormer](https://huggingface.co/docs/transformers/model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](https://huggingface.co/docs/transformers/model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](https://huggingface.co/docs/transformers/model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](https://huggingface.co/docs/transformers/model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UMT5](https://huggingface.co/docs/transformers/model_doc/umt5)** (from Google Research) released with the paper [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](https://huggingface.co/docs/transformers/model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VitDet](https://huggingface.co/docs/transformers/model_doc/vitdet)** (from Meta AI) released with the paper [Exploring Plain Vision Transformer Backbones for Object Detection](https://arxiv.org/abs/2203.16527) by Yanghao Li, Hanzi Mao, Ross Girshick, Kaiming He.
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMatte](https://huggingface.co/docs/transformers/main/model_doc/vitmatte)** (from HUST-VL) rreleased with the paper [ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[VITS](https://huggingface.co/docs/transformers/model_doc/vits)** (from Kakao Enterprise) released with the paper [Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech](https://arxiv.org/abs/2106.06103) by Jaehyeon Kim, Jungil Kong, Juhee Son.
1. **[ViViT](https://huggingface.co/docs/transformers/model_doc/vivit)** (from Google Research) released with the paper [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691) by Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid.
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[X-MOD](https://huggingface.co/docs/transformers/model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLM-V](https://huggingface.co/docs/transformers/model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
1. Want to contribute a new model? We have added a **detailed guide and templates** to guide you in the process of adding a new model. You can find them in the [`templates`](./templates) folder of the repository. Be sure to check the [contributing guidelines](./CONTRIBUTING.md) and contact the maintainers or open an issue to collect feedbacks before starting your PR.
Чтобы проверить, есть ли у каждой модели реализация на Flax, PyTorch или TensorFlow, или связанный с ней токенизатор, поддерживаемый библиотекой 🤗 Tokenizers, обратитесь к [этой таблице](https://huggingface.co/docs/transformers/index#supported-frameworks).
Эти реализации были протестированы на нескольких наборах данных (см. примеры скриптов) и должны соответствовать производительности оригинальных реализаций. Более подробную информацию о производительности можно найти в разделе "Примеры" [документации](https://github.com/huggingface/transformers/tree/main/examples).
## Изучи больше
| Секция | Описание |
|-|-|
| [Документация](https://huggingface.co/docs/transformers/) | Полная документация по API и гайды |
| [Краткие описания задач](https://huggingface.co/docs/transformers/task_summary) | Задачи поддерживаются 🤗 Transformers |
| [Пособие по предварительной обработке](https://huggingface.co/docs/transformers/preprocessing) | Использование класса `Tokenizer` для подготовки данных для моделей |
| [Обучение и доработка](https://huggingface.co/docs/transformers/training) | Использование моделей, предоставляемых 🤗 Transformers, в цикле обучения PyTorch/TensorFlow и API `Trainer`. |
| [Быстрый тур: Тонкая настройка/скрипты использования](https://github.com/huggingface/transformers/tree/main/examples) | Примеры скриптов для тонкой настройки моделей на широком спектре задач |
| [Совместное использование и загрузка моделей](https://huggingface.co/docs/transformers/model_sharing) | Загружайте и делитесь с сообществом своими доработанными моделями |
## Цитирование
Теперь у нас есть [статья](https://www.aclweb.org/anthology/2020.emnlp-demos.6/), которую можно цитировать для библиотеки 🤗 Transformers:
```bibtex
@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}
```
| huggingface/transformers/blob/main/README_ru.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Share a model
The last two tutorials showed how you can fine-tune a model with PyTorch, Keras, and 🤗 Accelerate for distributed setups. The next step is to share your model with the community! At Hugging Face, we believe in openly sharing knowledge and resources to democratize artificial intelligence for everyone. We encourage you to consider sharing your model with the community to help others save time and resources.
In this tutorial, you will learn two methods for sharing a trained or fine-tuned model on the [Model Hub](https://huggingface.co/models):
- Programmatically push your files to the Hub.
- Drag-and-drop your files to the Hub with the web interface.
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
To share a model with the community, you need an account on [huggingface.co](https://huggingface.co/join). You can also join an existing organization or create a new one.
</Tip>
## Repository features
Each repository on the Model Hub behaves like a typical GitHub repository. Our repositories offer versioning, commit history, and the ability to visualize differences.
The Model Hub's built-in versioning is based on git and [git-lfs](https://git-lfs.github.com/). In other words, you can treat one model as one repository, enabling greater access control and scalability. Version control allows *revisions*, a method for pinning a specific version of a model with a commit hash, tag or branch.
As a result, you can load a specific model version with the `revision` parameter:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )
```
Files are also easily edited in a repository, and you can view the commit history as well as the difference:

## Setup
Before sharing a model to the Hub, you will need your Hugging Face credentials. If you have access to a terminal, run the following command in the virtual environment where 🤗 Transformers is installed. This will store your access token in your Hugging Face cache folder (`~/.cache/` by default):
```bash
huggingface-cli login
```
If you are using a notebook like Jupyter or Colaboratory, make sure you have the [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) library installed. This library allows you to programmatically interact with the Hub.
```bash
pip install huggingface_hub
```
Then use `notebook_login` to sign-in to the Hub, and follow the link [here](https://huggingface.co/settings/token) to generate a token to login with:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Convert a model for all frameworks
To ensure your model can be used by someone working with a different framework, we recommend you convert and upload your model with both PyTorch and TensorFlow checkpoints. While users are still able to load your model from a different framework if you skip this step, it will be slower because 🤗 Transformers will need to convert the checkpoint on-the-fly.
Converting a checkpoint for another framework is easy. Make sure you have PyTorch and TensorFlow installed (see [here](installation) for installation instructions), and then find the specific model for your task in the other framework.
<frameworkcontent>
<pt>
Specify `from_tf=True` to convert a checkpoint from TensorFlow to PyTorch:
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
Specify `from_pt=True` to convert a checkpoint from PyTorch to TensorFlow:
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
Then you can save your new TensorFlow model with its new checkpoint:
```py
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<jax>
If a model is available in Flax, you can also convert a checkpoint from PyTorch to Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Push a model during training
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
Sharing a model to the Hub is as simple as adding an extra parameter or callback. Remember from the [fine-tuning tutorial](training), the [`TrainingArguments`] class is where you specify hyperparameters and additional training options. One of these training options includes the ability to push a model directly to the Hub. Set `push_to_hub=True` in your [`TrainingArguments`]:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
Pass your training arguments as usual to [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
After you fine-tune your model, call [`~transformers.Trainer.push_to_hub`] on [`Trainer`] to push the trained model to the Hub. 🤗 Transformers will even automatically add training hyperparameters, training results and framework versions to your model card!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
Share a model to the Hub with [`PushToHubCallback`]. In the [`PushToHubCallback`] function, add:
- An output directory for your model.
- A tokenizer.
- The `hub_model_id`, which is your Hub username and model name.
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
Add the callback to [`fit`](https://keras.io/api/models/model_training_apis/), and 🤗 Transformers will push the trained model to the Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## Use the `push_to_hub` function
You can also call `push_to_hub` directly on your model to upload it to the Hub.
Specify your model name in `push_to_hub`:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
This creates a repository under your username with the model name `my-awesome-model`. Users can now load your model with the `from_pretrained` function:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
If you belong to an organization and want to push your model under the organization name instead, just add it to the `repo_id`:
```py
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
The `push_to_hub` function can also be used to add other files to a model repository. For example, add a tokenizer to a model repository:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
Or perhaps you'd like to add the TensorFlow version of your fine-tuned PyTorch model:
```py
>>> tf_model.push_to_hub("my-awesome-model")
```
Now when you navigate to your Hugging Face profile, you should see your newly created model repository. Clicking on the **Files** tab will display all the files you've uploaded to the repository.
For more details on how to create and upload files to a repository, refer to the Hub documentation [here](https://huggingface.co/docs/hub/how-to-upstream).
## Upload with the web interface
Users who prefer a no-code approach are able to upload a model through the Hub's web interface. Visit [huggingface.co/new](https://huggingface.co/new) to create a new repository:

From here, add some information about your model:
- Select the **owner** of the repository. This can be yourself or any of the organizations you belong to.
- Pick a name for your model, which will also be the repository name.
- Choose whether your model is public or private.
- Specify the license usage for your model.
Now click on the **Files** tab and click on the **Add file** button to upload a new file to your repository. Then drag-and-drop a file to upload and add a commit message.

## Add a model card
To make sure users understand your model's capabilities, limitations, potential biases and ethical considerations, please add a model card to your repository. The model card is defined in the `README.md` file. You can add a model card by:
* Manually creating and uploading a `README.md` file.
* Clicking on the **Edit model card** button in your model repository.
Take a look at the DistilBert [model card](https://huggingface.co/distilbert-base-uncased) for a good example of the type of information a model card should include. For more details about other options you can control in the `README.md` file such as a model's carbon footprint or widget examples, refer to the documentation [here](https://huggingface.co/docs/hub/models-cards).
| huggingface/transformers/blob/main/docs/source/en/model_sharing.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# LoRA
<Tip warning={true}>
This is experimental and the API may change in the future.
</Tip>
[LoRA (Low-Rank Adaptation of Large Language Models)](https://hf.co/papers/2106.09685) is a popular and lightweight training technique that significantly reduces the number of trainable parameters. It works by inserting a smaller number of new weights into the model and only these are trained. This makes training with LoRA much faster, memory-efficient, and produces smaller model weights (a few hundred MBs), which are easier to store and share. LoRA can also be combined with other training techniques like DreamBooth to speedup training.
<Tip>
LoRA is very versatile and supported for [DreamBooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py), [Kandinsky 2.2](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py), [Stable Diffusion XL](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora_sdxl.py), [text-to-image](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py), and [Wuerstchen](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py).
</Tip>
This guide will explore the [train_text_to_image_lora.py](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Navigate to the example folder with the training script and install the required dependencies for the script you're using:
<hfoptions id="installation">
<hfoption id="PyTorch">
```bash
cd examples/text_to_image
pip install -r requirements.txt
```
</hfoption>
<hfoption id="Flax">
```bash
cd examples/text_to_image
pip install -r requirements_flax.txt
```
</hfoption>
</hfoptions>
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/text_to_image_lora.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script has many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L85) function. Default values are provided for most parameters that work pretty well, but you can also set your own values in the training command if you'd like.
For example, to increase the number of epochs to train:
```bash
accelerate launch train_text_to_image_lora.py \
--num_train_epochs=150 \
```
Many of the basic and important parameters are described in the [Text-to-image](text2image#script-parameters) training guide, so this guide just focuses on the LoRA relevant parameters:
- `--rank`: the number of low-rank matrices to train
- `--learning_rate`: the default learning rate is 1e-4, but with LoRA, you can use a higher learning rate
## Training script
The dataset preprocessing code and training loop are found in the [`main()`](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L371) function, and if you need to adapt the training script, this is where you'll make your changes.
As with the script parameters, a walkthrough of the training script is provided in the [Text-to-image](text2image#training-script) training guide. Instead, this guide takes a look at the LoRA relevant parts of the script.
The script begins by adding the [new LoRA weights](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L447) to the attention layers. This involves correctly configuring the weight size for each block in the UNet. You'll see the `rank` parameter is used to create the [`~models.attention_processor.LoRAAttnProcessor`]:
```py
lora_attn_procs = {}
for name in unet.attn_processors.keys():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
lora_attn_procs[name] = LoRAAttnProcessor(
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
rank=args.rank,
)
unet.set_attn_processor(lora_attn_procs)
lora_layers = AttnProcsLayers(unet.attn_processors)
```
The [optimizer](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L519) is initialized with the `lora_layers` because these are the only weights that'll be optimized:
```py
optimizer = optimizer_cls(
lora_layers.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Aside from setting up the LoRA layers, the training script is more or less the same as train_text_to_image.py!
## Launch the script
Once you've made all your changes or you're okay with the default configuration, you're ready to launch the training script! 🚀
Let's train on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset to generate our yown Pokémon. Set the environment variables `MODEL_NAME` and `DATASET_NAME` to the model and dataset respectively. You should also specify where to save the model in `OUTPUT_DIR`, and the name of the model to save to on the Hub with `HUB_MODEL_ID`. The script creates and saves the following files to your repository:
- saved model checkpoints
- `pytorch_lora_weights.safetensors` (the trained LoRA weights)
If you're training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
<Tip warning={true}>
A full training run takes ~5 hours on a 2080 Ti GPU with 11GB of VRAM.
</Tip>
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 \
--center_crop \
--random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" \
--lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="A pokemon with blue eyes." \
--seed=1337
```
Once training has been completed, you can use your model for inference:
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
pipeline.load_lora_weights("path/to/lora/model", weight_name="pytorch_lora_weights.safetensors")
image = pipeline("A pokemon with blue eyes").images[0]
```
## Next steps
Congratulations on training a new model with LoRA! To learn more about how to use your new model, the following guides may be helpful:
- Learn how to [load different LoRA formats](../using-diffusers/loading_adapters#LoRA) trained using community trainers like Kohya and TheLastBen.
- Learn how to use and [combine multiple LoRA's](../tutorials/using_peft_for_inference) with PEFT for inference.
| huggingface/diffusers/blob/main/docs/source/en/training/lora.md |
--
title: MAPE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Mean Absolute Percentage Error (MAPE) is the mean percentage error difference between the predicted and actual
values.
---
# Metric Card for MAPE
## Metric Description
Mean Absolute Error (MAPE) is the mean of the percentage error of difference between the predicted $x_i$ and actual $y_i$ numeric values:
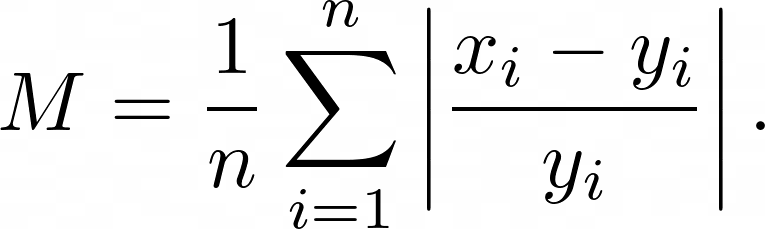
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mape_metric = evaluate.load("mape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mape_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MAPE `float` value is postive with the best value being 0.0.
Output Example(s):
```python
{'mape': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mape': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> mape_metric = evaluate.load("mape")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mape': 0.3273...}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> mape_metric = evaluate.load("mape", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
>>> results = mape_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mape': 0.8874...}
>>> results = mape_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mape': array([1.3749..., 0.4])}
```
## Limitations and Bias
One limitation of MAPE is that it cannot be used if the ground truth is zero or close to zero. This metric is also asymmetric in that it puts a heavier penalty on predictions less than the ground truth and a smaller penalty on predictions bigger than the ground truth and thus can lead to a bias of methods being select which under-predict if selected via this metric.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{DEMYTTENAERE201638,
title = {Mean Absolute Percentage Error for regression models},
journal = {Neurocomputing},
volume = {192},
pages = {38--48},
year = {2016},
note = {Advances in artificial neural networks, machine learning and computational intelligence},
issn = {0925-2312},
doi = {https://doi.org/10.1016/j.neucom.2015.12.114},
url = {https://www.sciencedirect.com/science/article/pii/S0925231216003325},
author = {Arnaud {de Myttenaere} and Boris Golden and Bénédicte {Le Grand} and Fabrice Rossi},
}
```
## Further References
- [Mean absolute percentage error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_percentage_error)
| huggingface/evaluate/blob/main/metrics/mape/README.md |
# Ensemble Adversarial Inception ResNet v2
**Inception-ResNet-v2** is a convolutional neural architecture that builds on the Inception family of architectures but incorporates [residual connections](https://paperswithcode.com/method/residual-connection) (replacing the filter concatenation stage of the Inception architecture).
This particular model was trained for study of adversarial examples (adversarial training).
The weights from this model were ported from [Tensorflow/Models](https://github.com/tensorflow/models).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ens_adv_inception_resnet_v2', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ens_adv_inception_resnet_v2`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ens_adv_inception_resnet_v2', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1804-00097,
author = {Alexey Kurakin and
Ian J. Goodfellow and
Samy Bengio and
Yinpeng Dong and
Fangzhou Liao and
Ming Liang and
Tianyu Pang and
Jun Zhu and
Xiaolin Hu and
Cihang Xie and
Jianyu Wang and
Zhishuai Zhang and
Zhou Ren and
Alan L. Yuille and
Sangxia Huang and
Yao Zhao and
Yuzhe Zhao and
Zhonglin Han and
Junjiajia Long and
Yerkebulan Berdibekov and
Takuya Akiba and
Seiya Tokui and
Motoki Abe},
title = {Adversarial Attacks and Defences Competition},
journal = {CoRR},
volume = {abs/1804.00097},
year = {2018},
url = {http://arxiv.org/abs/1804.00097},
archivePrefix = {arXiv},
eprint = {1804.00097},
timestamp = {Thu, 31 Oct 2019 16:31:22 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1804-00097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Ensemble Adversarial
Paper:
Title: Adversarial Attacks and Defences Competition
URL: https://paperswithcode.com/paper/adversarial-attacks-and-defences-competition
Models:
- Name: ens_adv_inception_resnet_v2
In Collection: Ensemble Adversarial
Metadata:
FLOPs: 16959133120
Parameters: 55850000
File Size: 223774238
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: ens_adv_inception_resnet_v2
Crop Pct: '0.897'
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_resnet_v2.py#L351
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/ens_adv_inception_resnet_v2-2592a550.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 1.0%
Top 5 Accuracy: 17.32%
--> | huggingface/pytorch-image-models/blob/main/docs/models/ensemble-adversarial.md |
Using Flair at Hugging Face
[Flair](https://github.com/flairNLP/flair) is a very simple framework for state-of-the-art NLP.
Developed by [Humboldt University of Berlin](https://www.informatik.hu-berlin.de/en/forschung-en/gebiete/ml-en/) and friends.
## Exploring Flair in the Hub
You can find `flair` models by filtering at the left of the [models page](https://huggingface.co/models?library=flair).
All models on the Hub come with these useful features:
1. An automatically generated model card with a brief description.
2. An interactive widget you can use to play with the model directly in the browser.
3. An Inference API that allows you to make inference requests.
## Installation
To get started, you can follow the [Flair installation guide](https://github.com/flairNLP/flair?tab=readme-ov-file#requirements-and-installation).
You can also use the following one-line install through pip:
```
$ pip install -U flair
```
## Using existing models
All `flair` models can easily be loaded from the Hub:
```py
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-multi")
```
Once loaded, you can use `predict()` to perform inference:
```py
sentence = Sentence("George Washington ging nach Washington.")
tagger.predict(sentence)
# print sentence
print(sentence)
```
It outputs the following:
```text
Sentence[6]: "George Washington ging nach Washington." → ["George Washington"/PER, "Washington"/LOC]
```
If you want to load a specific Flair model, you can click `Use in Flair` in the model card and you will be given a working snippet!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-flair_snippet1.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-flair_snippet1-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-flair_snippet2.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-flair_snippet2-dark.png"/>
</div>
## Additional resources
* Flair [repository](https://github.com/flairNLP/flair)
* Flair [docs](https://flairnlp.github.io/docs/intro)
* Official Flair [models](https://huggingface.co/flair) on the Hub (mainly trained by [@alanakbik](https://huggingface.co/alanakbik) and [@stefan-it](https://huggingface.co/stefan-it)) | huggingface/hub-docs/blob/main/docs/hub/flair.md |
`@gradio/button`
```html
<script>
import { Button } from "@gradio/button";
</script>
<button type="primary|secondary" href="string" on:click="{e.detail === href}">
content
</button>
```
| gradio-app/gradio/blob/main/js/accordion/README.md |
he Hugging Face Datasets library: A Quick overview. The Hugging Face Datasets library is a library that provides an API to quickly download many public datasets and preprocess them. In this video we will explore how to do that. The downloading part is easy: with the load_dataset function, you can directly download and cache a dataset from its identifier on the Dataset hub. Here we fetch the MRPC dataset from the GLUE benchmark, which is a dataset containing pairs of sentences where the task is to determine the paraphrases. The object returned by the load_dataset function is a DatasetDict, which is a sort of dictionary containing each split of our dataset. We can access each split by indexing with its name. This split is then an instance of the Dataset class, with columns (here sentence1, sentence2. label and idx) and rows. We can access a given element by its index. The amazing thing about the Hugging Face Datasets library is that everything is saved to disk using Apache Arrow, which means that even if your dataset is huge you won't get out of RAM: only the elements you request are loaded in memory. Accessing a slice of your dataset is as easy as one element. The result is then a dictionary with list of values for each keys (here the list of labels, the list of first sentences and the list of second sentences). The features attribute of a Dataset gives us more information about its columns. In particular, we can see here it gives us the correspondence between the integers and names for the labels. 0 stands for not equivalent and 1 for equivalent. To preprocess all the elements of our dataset, we need to tokenize them. Have a look at the video "Preprocess sentence pairs" for a refresher, but you just have to send the two sentences to the tokenizer with some additional keyword arguments. Here we indicate a maximum length of 128 and pad inputs shorter than this length, truncate inputs that are longer. We put all of this in a tokenize_function that we can directly apply to all the splits in our dataset with the map method. As long as the function returns a dictionary-like object, the map method will add new columns as needed or update existing ones. To speed up preprocessing and take advantage of the fact our tokenizer is backed by Rust thanks to the Hugging Face Tokenizers library, we can process several elements at the same time to our tokenize function, using the batched=True argument. Since the tokenizer can handle list of first/second sentences, the tokenize_function does not need to change for this. You can also use multiprocessing with the map method, check out its documentation! Once this is done, we are almost ready for training: we just remove the columns we don't need anymore with the remove_columns method, rename label to labels (since the models from Hugging Face Transformers expect that) and set the output format to our desired backend: torch, tensorflow or numpy. If needed, we can also generate a short sample of a dataset using the select method. | huggingface/course/blob/main/subtitles/en/raw/chapter3/02a_datasets-overview-pt.md |
--
title: "Why we’re switching to Hugging Face Inference Endpoints, and maybe you should too"
thumbnail: /blog/assets/78_ml_director_insights/mantis1.png
authors:
- user: mattupson
guest: true
---
# Why we’re switching to Hugging Face Inference Endpoints, and maybe you should too
Hugging Face recently launched [Inference Endpoints](https://huggingface.co/inference-endpoints); which as they put it: solves transformers in production. Inference Endpoints is a managed service that allows you to:
- Deploy (almost) any model on Hugging Face Hub
- To any cloud (AWS, and Azure, GCP on the way)
- On a range of instance types (including GPU)
- We’re switching some of our Machine Learning (ML) models that do inference on a CPU to this new service. This blog is about why, and why you might also want to consider it.
## What were we doing?
The models that we have switched over to Inference Endpoints were previously managed internally and were running on AWS [Elastic Container Service](https://aws.amazon.com/ecs/) (ECS) backed by [AWS Fargate](https://aws.amazon.com/fargate/). This gives you a serverless cluster which can run container based tasks. Our process was as follows:
- Train model on a GPU instance (provisioned by [CML](https://cml.dev/), trained with [transformers](https://huggingface.co/docs/transformers/main/))
- Upload to [Hugging Face Hub](https://huggingface.co/models)
- Build API to serve model [(FastAPI)](https://fastapi.tiangolo.com/)
- Wrap API in container [(Docker)](https://www.docker.com/)
- Upload container to AWS [Elastic Container Repository](https://aws.amazon.com/ecr/) (ECR)
- Deploy model to ECS Cluster
Now, you can reasonably argue that ECS was not the best approach to serving ML models, but it served us up until now, and also allowed ML models to sit alongside other container based services, so it reduced cognitive load.
## What do we do now?
With Inference Endpoints, our flow looks like this:
- Train model on a GPU instance (provisioned by [CML](https://cml.dev/), trained with [transformers](https://huggingface.co/docs/transformers/main/))
- Upload to [Hugging Face Hub](https://huggingface.co/models)
- Deploy using Hugging Face Inference Endpoints.
So this is significantly easier. We could also use another managed service such as [SageMaker](https://aws.amazon.com/es/sagemaker/), [Seldon](https://www.seldon.io/), or [Bento ML](https://www.bentoml.com/), etc., but since we are already uploading our model to Hugging Face hub to act as a model registry, and we’re pretty invested in Hugging Face’s other tools (like transformers, and [AutoTrain](https://huggingface.co/autotrain)) using Inference Endpoints makes a lot of sense for us.
## What about Latency and Stability?
Before switching to Inference Endpoints we tested different CPU endpoints types using [ab](https://httpd.apache.org/docs/2.4/programs/ab.html).
For ECS we didn’t test so extensively, but we know that a large container had a latency of about ~200ms from an instance in the same region. The tests we did for Inference Endpoints we based on text classification model fine tuned on [RoBERTa](https://huggingface.co/roberta-base) with the following test parameters:
- Requester region: eu-east-1
- Requester instance size: t3-medium
- Inference endpoint region: eu-east-1
- Endpoint Replicas: 1
- Concurrent connections: 1
- Requests: 1000 (1000 requests in 1–2 minutes even from a single connection would represent very heavy use for this particular application)
The following table shows latency (ms ± standard deviation and time to complete test in seconds) for four Intel Ice Lake equipped CPU endpoints.
```bash
size | vCPU (cores) | Memory (GB) | ECS (ms) | 🤗 (ms)
----------------------------------------------------------------------
small | 1 | 2 | _ | ~ 296
medium | 2 | 4 | _ | 156 ± 51 (158s)
large | 4 | 8 | ~200 | 80 ± 30 (80s)
xlarge | 8 | 16 | _ | 43 ± 31 (43s)
```
What we see from these results is pretty encouraging. The application that will consume these endpoints serves requests in real time, so we need as low latency as possible. We can see that the vanilla Hugging Face container was more than twice as fast as our bespoke container run on ECS — the slowest response we received from the large Inference Endpoint was just 108ms.
## What about the cost?
So how much does this all cost? The table below shows a price comparison for what we were doing previously (ECS + Fargate) and using Inference Endpoints.
```bash
size | vCPU | Memory (GB) | ECS | 🤗 | % diff
----------------------------------------------------------------------
small | 1 | 2 | $ 33.18 | $ 43.80 | 0.24
medium | 2 | 4 | $ 60.38 | $ 87.61 | 0.31
large | 4 | 8 | $ 114.78 | $ 175.22 | 0.34
xlarge | 8 | 16 | $ 223.59 | $ 350.44 | 0.5
```
We can say a couple of things about this. Firstly, we want a managed solution to deployment, we don’t have a dedicated MLOPs team (yet), so we’re looking for a solution that helps us minimize the time we spend on deploying models, even if it costs a little more than handling the deployments ourselves.
Inference Endpoints are more expensive that what we were doing before, there’s an increased cost of between 24% and 50%. At the scale we’re currently operating, this additional cost, a difference of ~$60 a month for a large CPU instance is nothing compared to the time and cognitive load we are saving by not having to worry about APIs, and containers. If we were deploying 100s of ML microservices we would probably want to think again, but that is probably true of many approaches to hosting.
## Some notes and caveats:
- You can find pricing for Inference Endpoints [here](https://huggingface.co/pricing#endpoints), but a different number is displayed when you deploy a new endpoint from the [GUI](https://ui.endpoints.huggingface.co/new). I’ve used the latter, which is higher.
- The values that I present in the table for ECS + Fargate are an underestimate, but probably not by much. I extracted them from the [fargate pricing page](https://aws.amazon.com/fargate/pricing/) and it includes just the cost of hosting the instance. I’m not including the data ingress/egress (probably the biggest thing is downloading the model from Hugging Face hub), nor have I included the costs related to ECR.
## Other considerations
### Deployment Options
Currently you can deploy an Inference Endpoint from the [GUI](https://ui.endpoints.huggingface.co/new) or using a [RESTful API](https://huggingface.co/docs/inference-endpoints/api_reference). You can also make use of our command line tool [hugie](https://github.com/MantisAI/hfie) (which will be the subject of a future blog) to launch Inference Endpoints in one line of code by passing a configuration, it’s really this simple:
```bash
hugie endpoint create example/development.json
```
For me, what’s lacking is a [custom terraform provider](https://www.hashicorp.com/blog/writing-custom-terraform-providers). It’s all well and good deploying an inference endpoint from a [GitHub action](https://github.com/features/actions) using hugie, as we do, but it would be better if we could use the awesome state machine that is terraform to keep track of these. I’m pretty sure that someone (if not Hugging Face) will write one soon enough — if not, we will.
### Hosting multiple models on a single endpoint
Philipp Schmid posted a really nice blog about how to write a custom [Endpoint Handler](https://www.philschmid.de/multi-model-inference-endpoints) class to allow you to host multiple models on a single endpoint, potentially saving you quite a bit of money. His blog was about GPU inference, and the only real limitation is how many models you can fit into the GPU memory. I assume this will also work for CPU instances, though I’ve not tried yet.
## To conclude…
We find Hugging Face Inference Endpoints to be a very simple and convenient way to deploy transformer (and [sklearn](https://huggingface.co/scikit-learn)) models into an endpoint so they can be consumed by an application. Whilst they cost a little more than the ECS approach we were using before, it’s well worth it because it saves us time on thinking about deployment, we can concentrate on the thing we want to: building NLP solutions for our clients to help solve their problems.
_If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co/inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_
_This article was originally published on February 15, 2023 [in Medium](https://medium.com/mantisnlp/why-were-switching-to-hugging-face-inference-endpoints-and-maybe-you-should-too-829371dcd330)._
| huggingface/blog/blob/main/mantis-case-study.md |
--
title: ROUGE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for
evaluating automatic summarization and machine translation software in natural language processing.
The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
Note that ROUGE is case insensitive, meaning that upper case letters are treated the same way as lower case letters.
This metrics is a wrapper around Google Research reimplementation of ROUGE:
https://github.com/google-research/google-research/tree/master/rouge
---
# Metric Card for ROUGE
## Metric Description
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
Note that ROUGE is case insensitive, meaning that upper case letters are treated the same way as lower case letters.
This metrics is a wrapper around the [Google Research reimplementation of ROUGE](https://github.com/google-research/google-research/tree/master/rouge)
## How to Use
At minimum, this metric takes as input a list of predictions and a list of references:
```python
>>> rouge = evaluate.load('rouge')
>>> predictions = ["hello there", "general kenobi"]
>>> references = ["hello there", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references)
>>> print(results)
{'rouge1': 1.0, 'rouge2': 1.0, 'rougeL': 1.0, 'rougeLsum': 1.0}
```
One can also pass a custom tokenizer which is especially useful for non-latin languages.
```python
>>> results = rouge.compute(predictions=predictions,
... references=references,
tokenizer=lambda x: x.split())
>>> print(results)
{'rouge1': 1.0, 'rouge2': 1.0, 'rougeL': 1.0, 'rougeLsum': 1.0}
```
It can also deal with lists of references for each predictions:
```python
>>> rouge = evaluate.load('rouge')
>>> predictions = ["hello there", "general kenobi"]
>>> references = [["hello", "there"], ["general kenobi", "general yoda"]]
>>> results = rouge.compute(predictions=predictions,
... references=references)
>>> print(results)
{'rouge1': 0.8333, 'rouge2': 0.5, 'rougeL': 0.8333, 'rougeLsum': 0.8333}```
```
### Inputs
- **predictions** (`list`): list of predictions to score. Each prediction
should be a string with tokens separated by spaces.
- **references** (`list` or `list[list]`): list of reference for each prediction or a list of several references per prediction. Each
reference should be a string with tokens separated by spaces.
- **rouge_types** (`list`): A list of rouge types to calculate. Defaults to `['rouge1', 'rouge2', 'rougeL', 'rougeLsum']`.
- Valid rouge types:
- `"rouge1"`: unigram (1-gram) based scoring
- `"rouge2"`: bigram (2-gram) based scoring
- `"rougeL"`: Longest common subsequence based scoring.
- `"rougeLSum"`: splits text using `"\n"`
- See [here](https://github.com/huggingface/datasets/issues/617) for more information
- **use_aggregator** (`boolean`): If True, returns aggregates. Defaults to `True`.
- **use_stemmer** (`boolean`): If `True`, uses Porter stemmer to strip word suffixes. Defaults to `False`.
### Output Values
The output is a dictionary with one entry for each rouge type in the input list `rouge_types`. If `use_aggregator=False`, each dictionary entry is a list of scores, with one score for each sentence. E.g. if `rouge_types=['rouge1', 'rouge2']` and `use_aggregator=False`, the output is:
```python
{'rouge1': [0.6666666666666666, 1.0], 'rouge2': [0.0, 1.0]}
```
If `rouge_types=['rouge1', 'rouge2']` and `use_aggregator=True`, the output is of the following format:
```python
{'rouge1': 1.0, 'rouge2': 1.0}
```
The ROUGE values are in the range of 0 to 1.
#### Values from Popular Papers
### Examples
An example without aggregation:
```python
>>> rouge = evaluate.load('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references,
... use_aggregator=False)
>>> print(list(results.keys()))
['rouge1', 'rouge2', 'rougeL', 'rougeLsum']
>>> print(results["rouge1"])
[0.5, 0.0]
```
The same example, but with aggregation:
```python
>>> rouge = evaluate.load('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references,
... use_aggregator=True)
>>> print(list(results.keys()))
['rouge1', 'rouge2', 'rougeL', 'rougeLsum']
>>> print(results["rouge1"])
0.25
```
The same example, but only calculating `rouge_1`:
```python
>>> rouge = evaluate.load('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references,
... rouge_types=['rouge_1'],
... use_aggregator=True)
>>> print(list(results.keys()))
['rouge1']
>>> print(results["rouge1"])
0.25
```
## Limitations and Bias
See [Schluter (2017)](https://aclanthology.org/E17-2007/) for an in-depth discussion of many of ROUGE's limits.
## Citation
```bibtex
@inproceedings{lin-2004-rouge,
title = "{ROUGE}: A Package for Automatic Evaluation of Summaries",
author = "Lin, Chin-Yew",
booktitle = "Text Summarization Branches Out",
month = jul,
year = "2004",
address = "Barcelona, Spain",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W04-1013",
pages = "74--81",
}
```
## Further References
- This metrics is a wrapper around the [Google Research reimplementation of ROUGE](https://github.com/google-research/google-research/tree/master/rouge) | huggingface/evaluate/blob/main/metrics/rouge/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# AudioLDM
AudioLDM was proposed in [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://huggingface.co/papers/2301.12503) by Haohe Liu et al. Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM
is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
sound effects, human speech and music.
The abstract from the paper is:
*Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose AudioLDM, a TTA system that is built on a latent space to learn the continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The pretrained CLAP models enable us to train LDMs with audio embedding while providing text embedding as a condition during sampling. By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency. Trained on AudioCaps with a single GPU, AudioLDM achieves state-of-the-art TTA performance measured by both objective and subjective metrics (e.g., frechet distance). Moreover, AudioLDM is the first TTA system that enables various text-guided audio manipulations (e.g., style transfer) in a zero-shot fashion. Our implementation and demos are available at [this https URL](https://audioldm.github.io/).*
The original codebase can be found at [haoheliu/AudioLDM](https://github.com/haoheliu/AudioLDM).
## Tips
When constructing a prompt, keep in mind:
* Descriptive prompt inputs work best; you can use adjectives to describe the sound (for example, "high quality" or "clear") and make the prompt context specific (for example, "water stream in a forest" instead of "stream").
* It's best to use general terms like "cat" or "dog" instead of specific names or abstract objects the model may not be familiar with.
During inference:
* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument; higher steps give higher quality audio at the expense of slower inference.
* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## AudioLDMPipeline
[[autodoc]] AudioLDMPipeline
- all
- __call__
## AudioPipelineOutput
[[autodoc]] pipelines.AudioPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/audioldm.md |
efore diving in character-based tokenization, understanding why this kind of tokenization is interesting requires understanding the flaws of word-based tokenization. If you haven't seen the first video on word-based tokenization we recommend you check it out before looking at this video. Let's take a look at character-based tokenization. We now split our text into individual characters, rather than words. There are generally a lot of different words in languages, while the number of characters stays low. Here for example, for the English language that has an estimated 170,000 different words, we would need a very large vocabulary to encompass all words. With a character-based vocabulary, we can get by with only 256 characters! Even languages with a lot of different characters like the Chinese languages have dictionaries with ~20,000 different characters but more than 375,000 different words. Character-based vocabularies let us fewer different tokens than the word-based tokenization dictionaries we would otherwise use. These vocabularies are also more complete than their word-based vocabularies counterparts. As our vocabulary contains all characters used in a language, even words unseen during the tokenizer training can still be tokenized, so out-of-vocabulary tokens will be less frequent. This includes the ability to correctly tokenize misspelled words, rather than discarding them as unknown straight away. However, this algorithm isn't perfect either! Intuitively, characters do not hold as much information individually as a word would hold. For example, "Let's" holds more information than "l". Of course, this is not true for all languages, as some languages like ideogram-based languages have a lot of information held in single characters, but for others like roman-based languages, the model will have to make sense of multiple tokens at a time to get the information held in a single word. This leads to another issue with character-based tokenizers: their sequences are translated into very large amount of tokens to be processed by the model. This can have an impact on the size of the context the model will carry around, and will reduce the size of the text we can use as input for our model. This tokenization, while it has some issues, has seen some very good results in the past and should be considered when approaching a new problem as it solves some issues encountered in the word-based algorithm. | huggingface/course/blob/main/subtitles/en/raw/chapter2/04c_character-based-tokenizers.md |
Hands-on
Now that you learned the basics of multi-agents, you're ready to train your first agents in a multi-agent system: **a 2vs2 soccer team that needs to beat the opponent team**.
And you’re going to participate in AI vs. AI challenges where your trained agent will compete against other classmates’ **agents every day and be ranked on a new leaderboard.**
To validate this hands-on for the certification process, you just need to push a trained model. There **are no minimal results to attain to validate it.**
For more information about the certification process, check this section 👉 [https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)
This hands-on will be different since to get correct results **you need to train your agents from 4 hours to 8 hours**. And given the risk of timeout in Colab, we advise you to train on your computer. You don’t need a supercomputer: a simple laptop is good enough for this exercise.
Let's get started! 🔥
## What is AI vs. AI?
AI vs. AI is an open-source tool we developed at Hugging Face to compete agents on the Hub against one another in a multi-agent setting. These models are then ranked in a leaderboard.
The idea of this tool is to have a robust evaluation tool: **by evaluating your agent with a lot of others, you’ll get a good idea of the quality of your policy.**
More precisely, AI vs. AI is three tools:
- A *matchmaking process* defining the matches (which model against which) and running the model fights using a background task in the Space.
- A *leaderboard* getting the match history results and displaying the models’ ELO ratings: [https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
- A *Space demo* to visualize your agents playing against others: [https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
In addition to these three tools, your classmate cyllum created a 🤗 SoccerTwos Challenge Analytics where you can check the detailed match results of a model: [https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
We're [wrote a blog post to explain this AI vs. AI tool in detail](https://huggingface.co/blog/aivsai), but to give you the big picture it works this way:
- Every four hours, our algorithm **fetches all the available models for a given environment (in our case ML-Agents-SoccerTwos).**
- It creates a **queue of matches with the matchmaking algorithm.**
- We simulate the match in a Unity headless process and **gather the match result** (1 if the first model won, 0.5 if it’s a draw, 0 if the second model won) in a Dataset.
- Then, when all matches from the matches queue are done, **we update the ELO score for each model and update the leaderboard.**
### Competition Rules
This first AI vs. AI competition **is an experiment**: the goal is to improve the tool in the future with your feedback. So some **breakups can happen during the challenge**. But don't worry
**all the results are saved in a dataset so we can always restart the calculation correctly without losing information**.
In order for your model to get correctly evaluated against others you need to follow these rules:
1. **You can't change the observation space or action space of the agent.** By doing that your model will not work during evaluation.
2. You **can't use a custom trainer for now,** you need to use the Unity MLAgents ones.
3. We provide executables to train your agents. You can also use the Unity Editor if you prefer **, but to avoid bugs, we advise that you use our executables**.
What will make the difference during this challenge are **the hyperparameters you choose**.
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
### Chat with your classmates, share advice and ask questions on Discord
- We created a new channel called `ai-vs-ai-challenge` to exchange advice and ask questions.
- If you didn’t join the discord server yet, you can [join here](https://discord.gg/ydHrjt3WP5)
## Step 0: Install MLAgents and download the correct executable
We advise you to use [conda](https://docs.conda.io/en/latest/) as a package manager and create a new environment.
With conda, we create a new environment called rl with **Python 3.10.12**:
```bash
conda create --name rl python=3.10.12
conda activate rl
```
To be able to train our agents correctly and push to the Hub, we need to install ML-Agents
```bash
git clone https://github.com/Unity-Technologies/ml-agents
```
When the cloning is done (it takes 2.63 GB), we go inside the repository and install the package
```bash
cd ml-agents
pip install -e ./ml-agents-envs
pip install -e ./ml-agents
```
Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
Linux (Ubuntu): Download [this executable](https://drive.google.com/file/d/1KuqBKYiXiIcU4kNMqEzhgypuFP5_45CL/view?usp=sharing)
Mac: Download [this executable](https://drive.google.com/drive/folders/1h7YB0qwjoxxghApQdEUQmk95ZwIDxrPG?usp=share_link)
⚠ For Mac you need also to call this `xattr -cr training-envs-executables/SoccerTwos/SoccerTwos.app` to be able to run SoccerTwos
## Step 1: Understand the environment
The environment is called `SoccerTwos`. The Unity MLAgents Team made it. You can find its documentation [here](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md#soccer-twos)
The goal in this environment **is to get the ball into the opponent's goal while preventing the ball from entering your own goal.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccertwos.gif" alt="SoccerTwos"/>
<figcaption>This environment was made by the <a href="https://github.com/Unity-Technologies/ml-agents"> Unity MLAgents Team</a></figcaption>
</figure>
### The reward function
The reward function is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccerreward.png" alt="SoccerTwos Reward"/>
### The observation space
The observation space is composed of vectors of size 336:
- 11 ray-casts forward distributed over 120 degrees (264 state dimensions)
- 3 ray-casts backward distributed over 90 degrees (72 state dimensions)
- Both of these ray-casts can detect 6 objects:
- Ball
- Blue Goal
- Purple Goal
- Wall
- Blue Agent
- Purple Agent
### The action space
The action space is three discrete branches:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/socceraction.png" alt="SoccerTwos Action"/>
## Step 2: Understand MA-POCA
We know how to train agents to play against others: **we can use self-play.** This is a perfect technique for a 1vs1.
But in our case we’re 2vs2, and each team has 2 agents. How then can we **train cooperative behavior for groups of agents?**
As explained in the [Unity Blog](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors), agents typically receive a reward as a group (+1 - penalty) when the team scores a goal. This implies that **every agent on the team is rewarded even if each agent didn’t contribute the same to the win**, which makes it difficult to learn what to do independently.
The Unity MLAgents team developed the solution in a new multi-agent trainer called *MA-POCA (Multi-Agent POsthumous Credit Assignment)*.
The idea is simple but powerful: a centralized critic **processes the states of all agents in the team to estimate how well each agent is doing**. Think of this critic as a coach.
This allows each agent to **make decisions based only on what it perceives locally**, and **simultaneously evaluate how good its behavior is in the context of the whole group**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/mapoca.png" alt="MA POCA"/>
<figcaption>This illustrates MA-POCA’s centralized learning and decentralized execution. Source: <a href="https://blog.unity.com/technology/ml-agents-plays-dodgeball">MLAgents Plays Dodgeball</a>
</figcaption>
</figure>
The solution then is to use Self-Play with an MA-POCA trainer (called poca). The poca trainer will help us to train cooperative behavior and self-play to win against an opponent team.
If you want to dive deeper into this MA-POCA algorithm, you need to read the paper they published [here](https://arxiv.org/pdf/2111.05992.pdf) and the sources we put on the additional readings section.
## Step 3: Define the config file
We already learned in [Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction) that in ML-Agents, you define **the training hyperparameters in `config.yaml` files.**
There are multiple hyperparameters. To understand them better, you should read the explanations for each of them in **[the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**
The config file we’re going to use here is in `./config/poca/SoccerTwos.yaml`. It looks like this:
```csharp
behaviors:
SoccerTwos:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 5000000
time_horizon: 1000
summary_freq: 10000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 2000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
```
Compared to Pyramids or SnowballTarget, we have new hyperparameters with a self-play part. How you modify them can be critical in getting good results.
The advice I can give you here is to check the explanation and recommended value for each parameters (especially self-play ones) against **[the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md).**
Now that you’ve modified our config file, you’re ready to train your agents.
## Step 4: Start the training
To train the agents, we need to **launch mlagents-learn and select the executable containing the environment.**
We define four parameters:
1. `mlagents-learn <config>`: the path where the hyperparameter config file is.
2. `-env`: where the environment executable is.
3. `-run_id`: the name you want to give to your training run id.
4. `-no-graphics`: to not launch the visualization during the training.
Depending on your hardware, 5M timesteps (the recommended value, but you can also try 10M) will take 5 to 8 hours of training. You can continue using your computer in the meantime, but I advise deactivating the computer standby mode to prevent the training from being stopped.
Depending on the executable you use (windows, ubuntu, mac) the training command will look like this (your executable path can be different so don’t hesitate to check before running).
```bash
mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos.exe --run-id="SoccerTwos" --no-graphics
```
The executable contains 8 copies of SoccerTwos.
⚠️ It’s normal if you don’t see a big increase of ELO score (and even a decrease below 1200) before 2M timesteps, since your agents will spend most of their time moving randomly on the field before being able to goal.
⚠️ You can stop the training with Ctrl + C but beware of typing this command only once to stop the training since MLAgents needs to generate a final .onnx file before closing the run.
## Step 5: **Push the agent to the Hugging Face Hub**
Now that we trained our agents, we’re **ready to push them to the Hub to be able to participate in the AI vs. AI challenge and visualize them playing on your browser🔥.**
To be able to share your model with the community, there are three more steps to follow:
1️⃣ (If it’s not already done) create an account to HF ➡ [https://huggingface.co/join](https://huggingface.co/join)
2️⃣ Sign in and store your authentication token from the Hugging Face website.
Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
Copy the token, run this, and paste the token
```bash
huggingface-cli login
```
Then, we need to run `mlagents-push-to-hf`.
And we define four parameters:
1. `-run-id`: the name of the training run id.
2. `-local-dir`: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.
3. `-repo-id`: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name>
If the repo does not exist **it will be created automatically**
4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
In my case
```bash
mlagents-push-to-hf --run-id="SoccerTwos" --local-dir="./results/SoccerTwos" --repo-id="ThomasSimonini/poca-SoccerTwos" --commit-message="First Push"`
```
```bash
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message="First Push"
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
Your model is pushed to the Hub. You can view your model here: https://huggingface.co/ThomasSimonini/poca-SoccerTwos
It's the link to your model. It contains a model card that explains how to use it, your Tensorboard, and your config file. **What's awesome is that it's a git repository, which means you can have different commits, update your repository with a new push, etc.**
## Step 6: Verify that your model is ready for AI vs AI Challenge
Now that your model is pushed to the Hub, **it’s going to be added automatically to the AI vs AI Challenge model pool.** It can take a little bit of time before your model is added to the leaderboard given we do a run of matches every 4h.
But to ensure that everything works perfectly you need to check:
1. That you have this tag in your model: ML-Agents-SoccerTwos. This is the tag we use to select models to be added to the challenge pool. To do that go to your model and check the tags
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify1.png" alt="Verify"/>
If it’s not the case you just need to modify the readme and add it
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify2.png" alt="Verify"/>
2. That you have a `SoccerTwos.onnx` file
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify3.png" alt="Verify"/>
We strongly suggest that you create a new model when you push to the Hub if you want to train it again or train a new version.
## Step 7: Visualize some match in our demo
Now that your model is part of AI vs AI Challenge, **you can visualize how good it is compared to others**: https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
In order to do that, you just need to go to this demo:
- Select your model as team blue (or team purple if you prefer) and another model to compete against. The best opponents to compare your model to are either whoever is on top of the leaderboard or the [baseline model](https://huggingface.co/unity/MLAgents-SoccerTwos)
The matches you see live are not used in the calculation of your result **but they are a good way to visualize how good your agent is**.
And don't hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
| huggingface/deep-rl-class/blob/main/units/en/unit7/hands-on.mdx |
Gradio Demo: sales_projections
```
!pip install -q gradio pandas numpy matplotlib
```
```
import matplotlib.pyplot as plt
import numpy as np
import gradio as gr
def sales_projections(employee_data):
sales_data = employee_data.iloc[:, 1:4].astype("int").to_numpy()
regression_values = np.apply_along_axis(
lambda row: np.array(np.poly1d(np.polyfit([0, 1, 2], row, 2))), 0, sales_data
)
projected_months = np.repeat(
np.expand_dims(np.arange(3, 12), 0), len(sales_data), axis=0
)
projected_values = np.array(
[
month * month * regression[0] + month * regression[1] + regression[2]
for month, regression in zip(projected_months, regression_values)
]
)
plt.plot(projected_values.T)
plt.legend(employee_data["Name"])
return employee_data, plt.gcf(), regression_values
demo = gr.Interface(
sales_projections,
gr.Dataframe(
headers=["Name", "Jan Sales", "Feb Sales", "Mar Sales"],
value=[["Jon", 12, 14, 18], ["Alice", 14, 17, 2], ["Sana", 8, 9.5, 12]],
),
["dataframe", "plot", "numpy"],
description="Enter sales figures for employees to predict sales trajectory over year.",
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/sales_projections/run.ipynb |
Metric Card for F1
## Metric Description
The F1 score is the harmonic mean of the precision and recall. It can be computed with the equation:
F1 = 2 * (precision * recall) / (precision + recall)
## How to Use
At minimum, this metric requires predictions and references as input
```python
>>> f1_metric = datasets.load_metric("f1")
>>> results = f1_metric.compute(predictions=[0, 1], references=[0, 1])
>>> print(results)
["{'f1': 1.0}"]
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **labels** (`list` of `int`): The set of labels to include when `average` is not set to `'binary'`, and the order of the labels if `average` is `None`. Labels present in the data can be excluded, for example to calculate a multiclass average ignoring a majority negative class. Labels not present in the data will result in 0 components in a macro average. For multilabel targets, labels are column indices. By default, all labels in `predictions` and `references` are used in sorted order. Defaults to None.
- **pos_label** (`int`): The class to be considered the positive class, in the case where `average` is set to `binary`. Defaults to 1.
- **average** (`string`): This parameter is required for multiclass/multilabel targets. If set to `None`, the scores for each class are returned. Otherwise, this determines the type of averaging performed on the data. Defaults to `'binary'`.
- 'binary': Only report results for the class specified by `pos_label`. This is applicable only if the classes found in `predictions` and `references` are binary.
- 'micro': Calculate metrics globally by counting the total true positives, false negatives and false positives.
- 'macro': Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.
- 'weighted': Calculate metrics for each label, and find their average weighted by support (the number of true instances for each label). This alters `'macro'` to account for label imbalance. This option can result in an F-score that is not between precision and recall.
- 'samples': Calculate metrics for each instance, and find their average (only meaningful for multilabel classification).
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **f1**(`float` or `array` of `float`): F1 score or list of f1 scores, depending on the value passed to `average`. Minimum possible value is 0. Maximum possible value is 1. Higher f1 scores are better.
Output Example(s):
```python
{'f1': 0.26666666666666666}
```
```python
{'f1': array([0.8, 0.0, 0.0])}
```
This metric outputs a dictionary, with either a single f1 score, of type `float`, or an array of f1 scores, with entries of type `float`.
#### Values from Popular Papers
### Examples
Example 1-A simple binary example
```python
>>> f1_metric = datasets.load_metric("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0])
>>> print(results)
{'f1': 0.5}
```
Example 2-The same simple binary example as in Example 1, but with `pos_label` set to `0`.
```python
>>> f1_metric = datasets.load_metric("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], pos_label=0)
>>> print(round(results['f1'], 2))
0.67
```
Example 3-The same simple binary example as in Example 1, but with `sample_weight` included.
```python
>>> f1_metric = datasets.load_metric("f1")
>>> results = f1_metric.compute(references=[0, 1, 0, 1, 0], predictions=[0, 0, 1, 1, 0], sample_weight=[0.9, 0.5, 3.9, 1.2, 0.3])
>>> print(round(results['f1'], 2))
0.35
```
Example 4-A multiclass example, with different values for the `average` input.
```python
>>> predictions = [0, 2, 1, 0, 0, 1]
>>> references = [0, 1, 2, 0, 1, 2]
>>> results = f1_metric.compute(predictions=predictions, references=references, average="macro")
>>> print(round(results['f1'], 2))
0.27
>>> results = f1_metric.compute(predictions=predictions, references=references, average="micro")
>>> print(round(results['f1'], 2))
0.33
>>> results = f1_metric.compute(predictions=predictions, references=references, average="weighted")
>>> print(round(results['f1'], 2))
0.27
>>> results = f1_metric.compute(predictions=predictions, references=references, average=None)
>>> print(results)
{'f1': array([0.8, 0. , 0. ])}
```
## Limitations and Bias
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References | huggingface/datasets/blob/main/metrics/f1/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TimeSformer
## Overview
The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
This work is a milestone in action-recognition field being the first video transformer. It inspired many transformer based video understanding and classification papers.
The abstract from the paper is the following:
*We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long). Code and models are available at: [this https URL](https://github.com/facebookresearch/TimeSformer).*
This model was contributed by [fcakyon](https://huggingface.co/fcakyon).
The original code can be found [here](https://github.com/facebookresearch/TimeSformer).
## Usage tips
There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover,
the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
## Resources
- [Video classification task guide](../tasks/video_classification)
## TimesformerConfig
[[autodoc]] TimesformerConfig
## TimesformerModel
[[autodoc]] TimesformerModel
- forward
## TimesformerForVideoClassification
[[autodoc]] TimesformerForVideoClassification
- forward | huggingface/transformers/blob/main/docs/source/en/model_doc/timesformer.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Swin Transformer V2
## Overview
The Swin Transformer V2 model was proposed in [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
The abstract from the paper is the following:
*Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.*
This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer v2.
<PipelineTag pipeline="image-classification"/>
- [`Swinv2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
Besides that:
- [`Swinv2ForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Swinv2Config
[[autodoc]] Swinv2Config
## Swinv2Model
[[autodoc]] Swinv2Model
- forward
## Swinv2ForMaskedImageModeling
[[autodoc]] Swinv2ForMaskedImageModeling
- forward
## Swinv2ForImageClassification
[[autodoc]] transformers.Swinv2ForImageClassification
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/swinv2.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RemBERT
## Overview
The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
The abstract from the paper is the following:
*We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art
pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to
significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By
reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on
standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that
allocating additional capacity to the output embedding provides benefits to the model that persist through the
fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger
output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage
Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these
findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
number of parameters at the fine-tuning stage.*
## Usage tips
For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
also similar to the Albert one rather than the BERT one.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RemBertConfig
[[autodoc]] RemBertConfig
## RemBertTokenizer
[[autodoc]] RemBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RemBertTokenizerFast
[[autodoc]] RemBertTokenizerFast
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## RemBertModel
[[autodoc]] RemBertModel
- forward
## RemBertForCausalLM
[[autodoc]] RemBertForCausalLM
- forward
## RemBertForMaskedLM
[[autodoc]] RemBertForMaskedLM
- forward
## RemBertForSequenceClassification
[[autodoc]] RemBertForSequenceClassification
- forward
## RemBertForMultipleChoice
[[autodoc]] RemBertForMultipleChoice
- forward
## RemBertForTokenClassification
[[autodoc]] RemBertForTokenClassification
- forward
## RemBertForQuestionAnswering
[[autodoc]] RemBertForQuestionAnswering
- forward
</pt>
<tf>
## TFRemBertModel
[[autodoc]] TFRemBertModel
- call
## TFRemBertForMaskedLM
[[autodoc]] TFRemBertForMaskedLM
- call
## TFRemBertForCausalLM
[[autodoc]] TFRemBertForCausalLM
- call
## TFRemBertForSequenceClassification
[[autodoc]] TFRemBertForSequenceClassification
- call
## TFRemBertForMultipleChoice
[[autodoc]] TFRemBertForMultipleChoice
- call
## TFRemBertForTokenClassification
[[autodoc]] TFRemBertForTokenClassification
- call
## TFRemBertForQuestionAnswering
[[autodoc]] TFRemBertForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/rembert.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Performing inference with LCM-LoRA
Latent Consistency Models (LCM) enable quality image generation in typically 2-4 steps making it possible to use diffusion models in almost real-time settings.
From the [official website](https://latent-consistency-models.github.io/):
> LCMs can be distilled from any pre-trained Stable Diffusion (SD) in only 4,000 training steps (~32 A100 GPU Hours) for generating high quality 768 x 768 resolution images in 2~4 steps or even one step, significantly accelerating text-to-image generation. We employ LCM to distill the Dreamshaper-V7 version of SD in just 4,000 training iterations.
For a more technical overview of LCMs, refer to [the paper](https://huggingface.co/papers/2310.04378).
However, each model needs to be distilled separately for latent consistency distillation. The core idea with LCM-LoRA is to train just a few adapter layers, the adapter being LoRA in this case.
This way, we don't have to train the full model and keep the number of trainable parameters manageable. The resulting LoRAs can then be applied to any fine-tuned version of the model without distilling them separately.
Additionally, the LoRAs can be applied to image-to-image, ControlNet/T2I-Adapter, inpainting, AnimateDiff etc.
The LCM-LoRA can also be combined with other LoRAs to generate styled images in very few steps (4-8).
LCM-LoRAs are available for [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5), [stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and the [SSD-1B](https://huggingface.co/segmind/SSD-1B) model. All the checkpoints can be found in this [collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6).
For more details about LCM-LoRA, refer to [the technical report](https://huggingface.co/papers/2311.05556).
This guide shows how to perform inference with LCM-LoRAs for
- text-to-image
- image-to-image
- combined with styled LoRAs
- ControlNet/T2I-Adapter
- inpainting
- AnimateDiff
Before going through this guide, we'll take a look at the general workflow for performing inference with LCM-LoRAs.
LCM-LoRAs are similar to other Stable Diffusion LoRAs so they can be used with any [`DiffusionPipeline`] that supports LoRAs.
- Load the task specific pipeline and model.
- Set the scheduler to [`LCMScheduler`].
- Load the LCM-LoRA weights for the model.
- Reduce the `guidance_scale` between `[1.0, 2.0]` and set the `num_inference_steps` between [4, 8].
- Perform inference with the pipeline with the usual parameters.
Let's look at how we can perform inference with LCM-LoRAs for different tasks.
First, make sure you have [peft](https://github.com/huggingface/peft) installed, for better LoRA support.
```bash
pip install -U peft
```
## Text-to-image
You'll use the [`StableDiffusionXLPipeline`] with the scheduler: [`LCMScheduler`] and then load the LCM-LoRA. Together with the LCM-LoRA and the scheduler, the pipeline enables a fast inference workflow overcoming the slow iterative nature of diffusion models.
```python
import torch
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
generator = torch.manual_seed(42)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=1.0
).images[0]
```

Notice that we use only 4 steps for generation which is way less than what's typically used for standard SDXL.
<Tip>
You may have noticed that we set `guidance_scale=1.0`, which disables classifer-free-guidance. This is because the LCM-LoRA is trained with guidance, so the batch size does not have to be doubled in this case. This leads to a faster inference time, with the drawback that negative prompts don't have any effect on the denoising process.
You can also use guidance with LCM-LoRA, but due to the nature of training the model is very sensitve to the `guidance_scale` values, high values can lead to artifacts in the generated images. In our experiments, we found that the best values are in the range of [1.0, 2.0].
</Tip>
### Inference with a fine-tuned model
As mentioned above, the LCM-LoRA can be applied to any fine-tuned version of the model without having to distill them separately. Let's look at how we can perform inference with a fine-tuned model. In this example, we'll use the [animagine-xl](https://huggingface.co/Linaqruf/animagine-xl) model, which is a fine-tuned version of the SDXL model for generating anime.
```python
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"Linaqruf/animagine-xl",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "face focus, cute, masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, night, turtleneck"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt, num_inference_steps=4, generator=generator, guidance_scale=1.0
).images[0]
```

## Image-to-image
LCM-LoRA can be applied to image-to-image tasks too. Let's look at how we can perform image-to-image generation with LCMs. For this example we'll use the [dreamshaper-7](https://huggingface.co/Lykon/dreamshaper-7) model and the LCM-LoRA for `stable-diffusion-v1-5 `.
```python
import torch
from diffusers import AutoPipelineForImage2Image, LCMScheduler
from diffusers.utils import make_image_grid, load_image
pipe = AutoPipelineForImage2Image.from_pretrained(
"Lykon/dreamshaper-7",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
# prepare image
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-init.png"
init_image = load_image(url)
prompt = "Astronauts in a jungle, cold color palette, muted colors, detailed, 8k"
# pass prompt and image to pipeline
generator = torch.manual_seed(0)
image = pipe(
prompt,
image=init_image,
num_inference_steps=4,
guidance_scale=1,
strength=0.6,
generator=generator
).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```

<Tip>
You can get different results based on your prompt and the image you provide. To get the best results, we recommend trying different values for `num_inference_steps`, `strength`, and `guidance_scale` parameters and choose the best one.
</Tip>
## Combine with styled LoRAs
LCM-LoRA can be combined with other LoRAs to generate styled-images in very few steps (4-8). In the following example, we'll use the LCM-LoRA with the [papercut LoRA](TheLastBen/Papercut_SDXL).
To learn more about how to combine LoRAs, refer to [this guide](https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference#combine-multiple-adapters).
```python
import torch
from diffusers import DiffusionPipeline, LCMScheduler
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
torch_dtype=torch.float16
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LoRAs
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl", adapter_name="lcm")
pipe.load_lora_weights("TheLastBen/Papercut_SDXL", weight_name="papercut.safetensors", adapter_name="papercut")
# Combine LoRAs
pipe.set_adapters(["lcm", "papercut"], adapter_weights=[1.0, 0.8])
prompt = "papercut, a cute fox"
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=4, guidance_scale=1, generator=generator).images[0]
image
```

## ControlNet/T2I-Adapter
Let's look at how we can perform inference with ControlNet/T2I-Adapter and LCM-LoRA.
### ControlNet
For this example, we'll use the SD-v1-5 model and the LCM-LoRA for SD-v1-5 with canny ControlNet.
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, LCMScheduler
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
).resize((512, 512))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
torch_dtype=torch.float16,
safety_checker=None,
variant="fp16"
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
generator = torch.manual_seed(0)
image = pipe(
"the mona lisa",
image=canny_image,
num_inference_steps=4,
guidance_scale=1.5,
controlnet_conditioning_scale=0.8,
cross_attention_kwargs={"scale": 1},
generator=generator,
).images[0]
make_image_grid([canny_image, image], rows=1, cols=2)
```

<Tip>
The inference parameters in this example might not work for all examples, so we recommend you to try different values for `num_inference_steps`, `guidance_scale`, `controlnet_conditioning_scale` and `cross_attention_kwargs` parameters and choose the best one.
</Tip>
### T2I-Adapter
This example shows how to use the LCM-LoRA with the [Canny T2I-Adapter](TencentARC/t2i-adapter-canny-sdxl-1.0) and SDXL.
```python
import torch
import cv2
import numpy as np
from PIL import Image
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, LCMScheduler
from diffusers.utils import load_image, make_image_grid
# Prepare image
# Detect the canny map in low resolution to avoid high-frequency details
image = load_image(
"https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_canny.jpg"
).resize((384, 384))
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image).resize((1024, 1024))
# load adapter
adapter = T2IAdapter.from_pretrained("TencentARC/t2i-adapter-canny-sdxl-1.0", torch_dtype=torch.float16, varient="fp16").to("cuda")
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
adapter=adapter,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl")
prompt = "Mystical fairy in real, magic, 4k picture, high quality"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=canny_image,
num_inference_steps=4,
guidance_scale=1.5,
adapter_conditioning_scale=0.8,
adapter_conditioning_factor=1,
generator=generator,
).images[0]
make_image_grid([canny_image, image], rows=1, cols=2)
```

## Inpainting
LCM-LoRA can be used for inpainting as well.
```python
import torch
from diffusers import AutoPipelineForInpainting, LCMScheduler
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained(
"runwayml/stable-diffusion-inpainting",
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5")
# load base and mask image
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint.png")
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inpaint_mask.png")
# generator = torch.Generator("cuda").manual_seed(92)
prompt = "concept art digital painting of an elven castle, inspired by lord of the rings, highly detailed, 8k"
generator = torch.manual_seed(0)
image = pipe(
prompt=prompt,
image=init_image,
mask_image=mask_image,
generator=generator,
num_inference_steps=4,
guidance_scale=4,
).images[0]
make_image_grid([init_image, mask_image, image], rows=1, cols=3)
```

## AnimateDiff
[`AnimateDiff`] allows you to animate images using Stable Diffusion models. To get good results, we need to generate multiple frames (16-24), and doing this with standard SD models can be very slow.
LCM-LoRA can be used to speed up the process significantly, as you just need to do 4-8 steps for each frame. Let's look at how we can perform animation with LCM-LoRA and AnimateDiff.
```python
import torch
from diffusers import MotionAdapter, AnimateDiffPipeline, DDIMScheduler, LCMScheduler
from diffusers.utils import export_to_gif
adapter = MotionAdapter.from_pretrained("diffusers/animatediff-motion-adapter-v1-5")
pipe = AnimateDiffPipeline.from_pretrained(
"frankjoshua/toonyou_beta6",
motion_adapter=adapter,
).to("cuda")
# set scheduler
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
# load LCM-LoRA
pipe.load_lora_weights("latent-consistency/lcm-lora-sdv1-5", adapter_name="lcm")
pipe.load_lora_weights("guoyww/animatediff-motion-lora-zoom-in", weight_name="diffusion_pytorch_model.safetensors", adapter_name="motion-lora")
pipe.set_adapters(["lcm", "motion-lora"], adapter_weights=[0.55, 1.2])
prompt = "best quality, masterpiece, 1girl, looking at viewer, blurry background, upper body, contemporary, dress"
generator = torch.manual_seed(0)
frames = pipe(
prompt=prompt,
num_inference_steps=5,
guidance_scale=1.25,
cross_attention_kwargs={"scale": 1},
num_frames=24,
generator=generator
).frames[0]
export_to_gif(frames, "animation.gif")
```
 | huggingface/diffusers/blob/main/docs/source/en/using-diffusers/inference_with_lcm_lora.md |
Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill SDXL for inference with few timesteps.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example, and for illustrative purposes only. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/). You may also need to search the hyperparameter space according to the dataset you use.
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sdxl_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=1024 \
--learning_rate=1e-6 --loss_type="huber" --use_fix_crop_and_size --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/).
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_lora_sdxl_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=1024 \
--lora_rank=64 \
--learning_rate=1e-6 --loss_type="huber" --use_fix_crop_and_size --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
``` | huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Autoformer
## Overview
The Autoformer model was proposed in [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
This model augments the Transformer as a deep decomposition architecture, which can progressively decompose the trend and seasonal components during the forecasting process.
The abstract from the paper is the following:
*Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the long-term forecasting problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Going beyond Transformers, we design Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We break with the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.*
This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
The original code can be found [here](https://github.com/thuml/Autoformer).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Check out the Autoformer blog-post in HuggingFace blog: [Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)](https://huggingface.co/blog/autoformer)
## AutoformerConfig
[[autodoc]] AutoformerConfig
## AutoformerModel
[[autodoc]] AutoformerModel
- forward
## AutoformerForPrediction
[[autodoc]] AutoformerForPrediction
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/autoformer.md |
--
title: "DuckDB: analyze 50,000+ datasets stored on the Hugging Face Hub"
thumbnail: /blog/assets/hub_duckdb/hub_duckdb.png
authors:
- user: stevhliu
- user: lhoestq
- user: severo
---
# DuckDB: run SQL queries on 50,000+ datasets on the Hugging Face Hub
The Hugging Face Hub is dedicated to providing open access to datasets for everyone and giving users the tools to explore and understand them. You can find many of the datasets used to train popular large language models (LLMs) like [Falcon](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k), [MPT](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf), and [StarCoder](https://huggingface.co/datasets/bigcode/the-stack). There are tools for addressing fairness and bias in datasets like [Disaggregators](https://huggingface.co/spaces/society-ethics/disaggregators), and tools for previewing examples inside a dataset like the Dataset Viewer.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets-server/oasst1_light.png"/>
</div>
<small>A preview of the OpenAssistant dataset with the Dataset Viewer.</small>
We are happy to share that we recently added another feature to help you analyze datasets on the Hub; you can run SQL queries with DuckDB on any dataset stored on the Hub! According to the 2022 [StackOverflow Developer Survey](https://survey.stackoverflow.co/2022/#section-most-popular-technologies-programming-scripting-and-markup-languages), SQL is the 3rd most popular programming language. We also wanted a fast database management system (DBMS) designed for running analytical queries, which is why we’re excited about integrating with [DuckDB](https://duckdb.org/). We hope this allows even more users to access and analyze datasets on the Hub!
## TLDR
[Datasets Server](https://huggingface.co/docs/datasets-server/index) **automatically converts all public datasets on the Hub to Parquet files**, that you can see by clicking on the "Auto-converted to Parquet" button at the top of a dataset page. You can also access the list of the Parquet files URLs with a simple HTTP call.
```py
r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus")
j = r.json()
urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train']
urls
['https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet',
'https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00001-of-00002.parquet']
```
Create a connection to DuckDB and install and load the `httpfs` extension to allow reading and writing remote files:
```py
import duckdb
url = "https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet"
con = duckdb.connect()
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
```
Once you’re connected, you can start writing SQL queries!
```sql
con.sql(f"""SELECT horoscope,
count(*),
AVG(LENGTH(text)) AS avg_blog_length
FROM '{url}'
GROUP BY horoscope
ORDER BY avg_blog_length
DESC LIMIT(5)"""
)
```
To learn more, check out the [documentation](https://huggingface.co/docs/datasets-server/parquet_process).
## From dataset to Parquet
[Parquet](https://parquet.apache.org/docs/) files are columnar, making them more efficient to store, load and analyze. This is especially important when you're working with large datasets, which we’re seeing more and more of in the LLM era. To support this, Datasets Server automatically converts and publishes any public dataset on the Hub as Parquet files. The URL to the Parquet files can be retrieved with the [`/parquet`](https://huggingface.co/docs/datasets-server/quick_start#access-parquet-files) endpoint.
## Analyze with DuckDB
DuckDB offers super impressive performance for running complex analytical queries. It is able to execute a SQL query directly on a remote Parquet file without any overhead. With the [`httpfs`](https://duckdb.org/docs/extensions/httpfs) extension, DuckDB is able to query remote files such as datasets stored on the Hub using the URL provided from the `/parquet` endpoint. DuckDB also supports querying multiple Parquet files which is really convenient because Datasets Server shards big datasets into smaller 500MB chunks.
## Looking forward
Knowing what’s inside a dataset is important for developing models because it can impact model quality in all sorts of ways! By allowing users to write and execute any SQL query on Hub datasets, this is another way for us to enable open access to datasets and help users be more aware of the datasets contents. We are excited for you to try this out, and we’re looking forward to what kind of insights your analysis uncovers!
| huggingface/blog/blob/main/hub-duckdb.md |
Gradio and W&B Integration
Related spaces: https://huggingface.co/spaces/akhaliq/JoJoGAN
Tags: WANDB, SPACES
Contributed by Gradio team
## Introduction
In this Guide, we'll walk you through:
- Introduction of Gradio, and Hugging Face Spaces, and Wandb
- How to setup a Gradio demo using the Wandb integration for JoJoGAN
- How to contribute your own Gradio demos after tracking your experiments on wandb to the Wandb organization on Hugging Face
## What is Wandb?
Weights and Biases (W&B) allows data scientists and machine learning scientists to track their machine learning experiments at every stage, from training to production. Any metric can be aggregated over samples and shown in panels in a customizable and searchable dashboard, like below:
<img alt="Screen Shot 2022-08-01 at 5 54 59 PM" src="https://user-images.githubusercontent.com/81195143/182252755-4a0e1ca8-fd25-40ff-8c91-c9da38aaa9ec.png">
## What are Hugging Face Spaces & Gradio?
### Gradio
Gradio lets users demo their machine learning models as a web app, all in a few lines of Python. Gradio wraps any Python function (such as a machine learning model's inference function) into a user interface and the demos can be launched inside jupyter notebooks, colab notebooks, as well as embedded in your own website and hosted on Hugging Face Spaces for free.
Get started [here](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ spaces currently on Hugging Face. Learn more about spaces [here](https://huggingface.co/spaces/launch).
## Setting up a Gradio Demo for JoJoGAN
Now, let's walk you through how to do this on your own. We'll make the assumption that you're new to W&B and Gradio for the purposes of this tutorial.
Let's get started!
1. Create a W&B account
Follow [these quick instructions](https://app.wandb.ai/login) to create your free account if you don’t have one already. It shouldn't take more than a couple minutes. Once you're done (or if you've already got an account), next, we'll run a quick colab.
2. Open Colab Install Gradio and W&B
We'll be following along with the colab provided in the JoJoGAN repo with some minor modifications to use Wandb and Gradio more effectively.
[](https://colab.research.google.com/github/mchong6/JoJoGAN/blob/main/stylize.ipynb)
Install Gradio and Wandb at the top:
```sh
pip install gradio wandb
```
3. Finetune StyleGAN and W&B experiment tracking
This next step will open a W&B dashboard to track your experiments and a gradio panel showing pretrained models to choose from a drop down menu from a Gradio Demo hosted on Huggingface Spaces. Here's the code you need for that:
```python
alpha = 1.0
alpha = 1-alpha
preserve_color = True
num_iter = 100
log_interval = 50
samples = []
column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"]
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
# load discriminator for perceptual loss
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
# reset generator
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
# Which layers to swap for generating a family of plausible real images -> fake image
if preserve_color:
id_swap = [9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
for idx in tqdm(range(num_iter)):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
table_data = [
wandb.Image(transforms.ToPILImage()(target_im)),
wandb.Image(img),
wandb.Image(my_sample),
]
samples.append(table_data)
g_optim.zero_grad()
loss.backward()
g_optim.step()
out_table = wandb.Table(data=samples, columns=column_names)
wandb.log({"Current Samples": out_table})
```
alpha = 1.0
alpha = 1-alpha
preserve_color = True
num_iter = 100
log_interval = 50
samples = []
column_names = ["Referece (y)", "Style Code(w)", "Real Face Image(x)"]
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
# load discriminator for perceptual loss
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
# reset generator
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
# Which layers to swap for generating a family of plausible real images -> fake image
if preserve_color:
id_swap = [9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
for idx in tqdm(range(num_iter)):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
table_data = [
wandb.Image(transforms.ToPILImage()(target_im)),
wandb.Image(img),
wandb.Image(my_sample),
]
samples.append(table_data)
g_optim.zero_grad()
loss.backward()
g_optim.step()
out_table = wandb.Table(data=samples, columns=column_names)
wandb.log({"Current Samples": out_table})
````
4. Save, Download, and Load Model
Here's how to save and download your model.
```python
from PIL import Image
import torch
torch.backends.cudnn.benchmark = True
from torchvision import transforms, utils
from util import *
import math
import random
import numpy as np
from torch import nn, autograd, optim
from torch.nn import functional as F
from tqdm import tqdm
import lpips
from model import *
from e4e_projection import projection as e4e_projection
from copy import deepcopy
import imageio
import os
import sys
import torchvision.transforms as transforms
from argparse import Namespace
from e4e.models.psp import pSp
from util import *
from huggingface_hub import hf_hub_download
from google.colab import files
torch.save({"g": generator.state_dict()}, "your-model-name.pt")
files.download('your-model-name.pt')
latent_dim = 512
device="cuda"
model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt")
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
mean_latent = original_generator.mean_latent(10000)
generator = deepcopy(original_generator)
ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage)
generator.load_state_dict(ckpt["g"], strict=False)
generator.eval()
plt.rcParams['figure.dpi'] = 150
transform = transforms.Compose(
[
transforms.Resize((1024, 1024)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
def inference(img):
img.save('out.jpg')
aligned_face = align_face('out.jpg')
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
with torch.no_grad():
my_sample = generator(my_w, input_is_latent=True)
npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy()
imageio.imwrite('filename.jpeg', npimage)
return 'filename.jpeg'
````
5. Build a Gradio Demo
```python
import gradio as gr
title = "JoJoGAN"
description = "Gradio Demo for JoJoGAN: One Shot Face Stylization. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below."
demo = gr.Interface(
inference,
gr.Image(type="pil"),
gr.Image(type="file"),
title=title,
description=description
)
demo.launch(share=True)
```
6. Integrate Gradio into your W&B Dashboard
The last step—integrating your Gradio demo with your W&B dashboard—is just one extra line:
```python
demo.integrate(wandb=wandb)
```
Once you call integrate, a demo will be created and you can integrate it into your dashboard or report
Outside of W&B with Web components, using the gradio-app tags allows anyone can embed Gradio demos on HF spaces directly into their blogs, websites, documentation, etc.:
```html
<gradio-app space="akhaliq/JoJoGAN"> </gradio-app>
```
7. (Optional) Embed W&B plots in your Gradio App
It's also possible to embed W&B plots within Gradio apps. To do so, you can create a W&B Report of your plots and
embed them within your Gradio app within a `gr.HTML` block.
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
```python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() as demo:
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
report = wandb_report(report_url)
demo.launch(share=True)
```
## Conclusion
We hope you enjoyed this brief demo of embedding a Gradio demo to a W&B report! Thanks for making it to the end. To recap:
- Only one single reference image is needed for fine-tuning JoJoGAN which usually takes about 1 minute on a GPU in colab. After training, style can be applied to any input image. Read more in the paper.
- W&B tracks experiments with just a few lines of code added to a colab and you can visualize, sort, and understand your experiments in a single, centralized dashboard.
- Gradio, meanwhile, demos the model in a user friendly interface to share anywhere on the web.
## How to contribute Gradio demos on HF spaces on the Wandb organization
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join wandb organization [here](https://huggingface.co/wandb).
- Once approved transfer model from your username to Wandb organization
| gradio-app/gradio/blob/main/guides/06_integrating-other-frameworks/Gradio-and-Wandb-Integration.md |
Gradio Demo: duplicatebutton_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.DuplicateButton()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/duplicatebutton_component/run.ipynb |
Widget Examples
Note that each widget example can also optionally describe the corresponding model output, directly in the `output` property. See [the spec](./models-widgets#example-outputs) for more details.
## Natural Language Processing
### Fill-Mask
```yaml
widget:
- text: "Paris is the <mask> of France."
example_title: "Capital"
- text: "The goal of life is <mask>."
example_title: "Philosophy"
```
### Question Answering
```yaml
widget:
- text: "What's my name?"
context: "My name is Clara and I live in Berkeley."
example_title: "Name"
- text: "Where do I live?"
context: "My name is Sarah and I live in London"
example_title: "Location"
```
### Summarization
```yaml
widget:
- text: "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct."
example_title: "Eiffel Tower"
- text: "Laika, a dog that was the first living creature to be launched into Earth orbit, on board the Soviet artificial satellite Sputnik 2, on November 3, 1957. It was always understood that Laika would not survive the mission, but her actual fate was misrepresented for decades. Laika was a small (13 pounds [6 kg]), even-tempered, mixed-breed dog about two years of age. She was one of a number of stray dogs that were taken into the Soviet spaceflight program after being rescued from the streets. Only female dogs were used because they were considered to be anatomically better suited than males for close confinement."
example_title: "First in Space"
```
### Table Question Answering
```yaml
widget:
- text: "How many stars does the transformers repository have?"
table:
Repository:
- "Transformers"
- "Datasets"
- "Tokenizers"
Stars:
- 36542
- 4512
- 3934
Contributors:
- 651
- 77
- 34
Programming language:
- "Python"
- "Python"
- "Rust, Python and NodeJS"
example_title: "Github stars"
```
### Text Classification
```yaml
widget:
- text: "I love football so much"
example_title: "Positive"
- text: "I don't really like this type of food"
example_title: "Negative"
```
### Text Generation
```yaml
widget:
- text: "My name is Julien and I like to"
example_title: "Julien"
- text: "My name is Merve and my favorite"
example_title: "Merve"
```
### Text2Text Generation
```yaml
widget:
- text: "My name is Julien and I like to"
example_title: "Julien"
- text: "My name is Merve and my favorite"
example_title: "Merve"
```
### Token Classification
```yaml
widget:
- text: "My name is Sylvain and I live in Paris"
example_title: "Parisian"
- text: "My name is Sarah and I live in London"
example_title: "Londoner"
```
### Translation
```yaml
widget:
- text: "My name is Sylvain and I live in Paris"
example_title: "Parisian"
- text: "My name is Sarah and I live in London"
example_title: "Londoner"
```
### Zero-Shot Classification
```yaml
widget:
- text: "I have a problem with my car that needs to be resolved asap!!"
candidate_labels: "urgent, not urgent, phone, tablet, computer"
multi_class: true
example_title: "Car problem"
- text: "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app."
candidate_labels: "mobile, website, billing, account access"
multi_class: false
example_title: "Phone issue"
```
### Sentence Similarity
```yaml
widget:
- source_sentence: "That is a happy person"
sentences:
- "That is a happy dog"
- "That is a very happy person"
- "Today is a sunny day"
example_title: "Happy"
```
### Conversational
```yaml
widget:
- text: "Hey my name is Julien! How are you?"
example_title: "Julien"
- text: "Hey my name is Clara! How are you?"
example_title: "Clara"
```
### Feature Extraction
```yaml
widget:
- text: "My name is Sylvain and I live in Paris"
example_title: "Parisian"
- text: "My name is Sarah and I live in London"
example_title: "Londoner"
```
## Audio
### Text-to-Speech
```yaml
widget:
- text: "My name is Sylvain and I live in Paris"
example_title: "Parisian"
- text: "My name is Sarah and I live in London"
example_title: "Londoner"
```
### Automatic Speech Recognition
```yaml
widget:
- src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
example_title: Librispeech sample 1
- src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
example_title: Librispeech sample 2
```
### Audio-to-Audio
```yaml
widget:
- src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
example_title: Librispeech sample 1
- src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
example_title: Librispeech sample 2
```
### Audio Classification
```yaml
widget:
- src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
example_title: Librispeech sample 1
- src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
example_title: Librispeech sample 2
```
### Voice Activity Detection
```yaml
widget:
- src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
example_title: Librispeech sample 1
- src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
example_title: Librispeech sample 2
```
## Computer Vision
### Image Classification
```yaml
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
```
### Object Detection
```yaml
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
example_title: Football Match
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/airport.jpg
example_title: Airport
```
### Image Segmentation
```yaml
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
example_title: Football Match
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/airport.jpg
example_title: Airport
```
### Image-to-Image
```yaml
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/canny-edge.jpg
prompt: Girl with Pearl Earring # `prompt` field is optional in case the underlying model supports text guidance
```
### Text-to-Image
```yaml
widget:
- text: "A cat playing with a ball"
example_title: "Cat"
- text: "A dog jumping over a fence"
example_title: "Dog"
```
### Document Question Answering
```yaml
widget:
- text: "What is the invoice number?"
src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png"
- text: "What is the purchase amount?"
src: "https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/contract.jpeg"
```
### Visual Question Answering
```yaml
widget:
- text: "What animal is it?"
src: "https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg"
- text: "Where is it?"
src: "https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg"
```
### Zero-Shot Image Classification
```yaml
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
```
## Other
### Structured Data Classification
```yaml
widget:
- structured_data:
fixed_acidity:
- 7.4
- 7.8
- 10.3
volatile_acidity:
- 0.7
- 0.88
- 0.32
citric_acid:
- 0
- 0
- 0.45
residual_sugar:
- 1.9
- 2.6
- 6.4
chlorides:
- 0.076
- 0.098
- 0.073
free_sulfur_dioxide:
- 11
- 25
- 5
total_sulfur_dioxide:
- 34
- 67
- 13
density:
- 0.9978
- 0.9968
- 0.9976
pH:
- 3.51
- 3.2
- 3.23
sulphates:
- 0.56
- 0.68
- 0.82
alcohol:
- 9.4
- 9.8
- 12.6
example_title: "Wine"
```
| huggingface/hub-docs/blob/main/docs/hub/models-widgets-examples.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UNet1DModel
The [UNet](https://huggingface.co/papers/1505.04597) model was originally introduced by Ronneberger et al. for biomedical image segmentation, but it is also commonly used in 🤗 Diffusers because it outputs images that are the same size as the input. It is one of the most important components of a diffusion system because it facilitates the actual diffusion process. There are several variants of the UNet model in 🤗 Diffusers, depending on it's number of dimensions and whether it is a conditional model or not. This is a 1D UNet model.
The abstract from the paper is:
*There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net.*
## UNet1DModel
[[autodoc]] UNet1DModel
## UNet1DOutput
[[autodoc]] models.unet_1d.UNet1DOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/unet.md |
--
title: "Building an AI WebTV"
thumbnail: /blog/assets/156_ai_webtv/thumbnail.gif
authors:
- user: jbilcke-hf
---
# Building an AI WebTV
The AI WebTV is an experimental demo to showcase the latest advancements in automatic video and music synthesis.
👉 Watch the stream now by going to the [AI WebTV Space](https://huggingface.co/spaces/jbilcke-hf/AI-WebTV).
If you are using a mobile device, you can view the stream from the [Twitch mirror](https://www.twitch.tv/ai_webtv).

# Concept
The motivation for the AI WebTV is to demo videos generated with open-source [text-to-video models](https://huggingface.co/tasks/text-to-video) such as Zeroscope and MusicGen, in an entertaining and accessible way.
You can find those open-source models on the Hugging Face hub:
- For video: [zeroscope_v2_576](https://huggingface.co/cerspense/zeroscope_v2_576w) and [zeroscope_v2_XL](https://huggingface.co/cerspense/zeroscope_v2_XL)
- For music: [musicgen-melody](https://huggingface.co/facebook/musicgen-melody)
The individual video sequences are purposely made to be short, meaning the WebTV should be seen as a tech demo/showreel rather than an actual show (with an art direction or programming).
# Architecture
The AI WebTV works by taking a sequence of [video shot](https://en.wikipedia.org/wiki/Shot_(filmmaking)) prompts and passing them to a [text-to-video model](https://huggingface.co/tasks/text-to-video) to generate a sequence of [takes](https://en.wikipedia.org/wiki/Take).
Additionally, a base theme and idea (written by a human) are passed through a LLM (in this case, ChatGPT), in order to generate a variety of individual prompts for each video clip.
Here's a diagram of the current architecture of the AI WebTV:

# Implementing the pipeline
The WebTV is implemented in NodeJS and TypeScript, and uses various services hosted on Hugging Face.
## The text-to-video model
The central video model is Zeroscope V2, a model based on [ModelScope](https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis).
Zeroscope is comprised of two parts that can be chained together:
- A first pass with [zeroscope_v2_576](https://huggingface.co/cerspense/zeroscope_v2_576w), to generate a 576x320 video clip
- An optional second pass with [zeroscope_v2_XL](https://huggingface.co/cerspense/zeroscope_v2_XL) to upscale the video to 1024x576
👉 You will need to use the same prompt for both the generation and upscaling.
## Calling the video chain
To make a quick prototype, the WebTV runs Zeroscope from two duplicated Hugging Face Spaces running [Gradio](https://github.com/gradio-app/gradio/), which are called using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) NPM package. You can find the original spaces here:
- [zeroscope-v2](https://huggingface.co/spaces/hysts/zeroscope-v2/tree/main) by @hysts
- [Zeroscope XL](https://huggingface.co/spaces/fffiloni/zeroscope-XL) by @fffiloni
Other spaces deployed by the community can also be found if you [search for Zeroscope on the Hub](https://huggingface.co/spaces?search=zeroscope).
👉 Public Spaces may become overcrowded and paused at any time. If you intend to deploy your own system, please duplicate those Spaces and run them under your own account.
## Using a model hosted on a Space
Spaces using Gradio have the ability to [expose a REST API](https://www.gradio.app/guides/sharing-your-app#api-page), which can then be called from Node using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) module.
Here is an example:
```typescript
import { client } from "@gradio/client"
export const generateVideo = async (prompt: string) => {
const api = await client("*** URL OF THE SPACE ***")
// call the "run()" function with an array of parameters
const { data } = await api.predict("/run", [
prompt,
42, // seed
24, // nbFrames
35 // nbSteps
])
const { orig_name } = data[0][0]
const remoteUrl = `${instance}/file=${orig_name}`
// the file can then be downloaded and stored locally
}
```
## Post-processing
Once an individual take (a video clip) is upscaled, it is then passed to FILM (Frame Interpolation for Large Motion), a frame interpolation algorithm:
- Original links: [website](https://film-net.github.io/), [source code](https://github.com/google-research/frame-interpolation)
- Model on Hugging Face: [/frame-interpolation-film-style](https://huggingface.co/akhaliq/frame-interpolation-film-style)
- A Hugging Face Space you can duplicate: [video_frame_interpolation](https://huggingface.co/spaces/fffiloni/video_frame_interpolation/blob/main/app.py) by @fffiloni
During post-processing, we also add music generated with MusicGen:
- Original links: [website](https://ai.honu.io/papers/musicgen/), [source code](https://github.com/facebookresearch/audiocraft)
- Hugging Face Space you can duplicate: [MusicGen](https://huggingface.co/spaces/facebook/MusicGen)
## Broadcasting the stream
Note: there are multiple tools you can use to create a video stream. The AI WebTV currently uses [FFmpeg](https://ffmpeg.org/documentation.html) to read a playlist made of mp4 videos files and m4a audio files.
Here is an example of creating such a playlist:
```typescript
import { promises as fs } from "fs"
import path from "path"
const allFiles = await fs.readdir("** PATH TO VIDEO FOLDER **")
const allVideos = allFiles
.map(file => path.join(dir, file))
.filter(filePath => filePath.endsWith('.mp4'))
let playlist = 'ffconcat version 1.0\n'
allFilePaths.forEach(filePath => {
playlist += `file '${filePath}'\n`
})
await fs.promises.writeFile("playlist.txt", playlist)
```
This will generate the following playlist content:
```bash
ffconcat version 1.0
file 'video1.mp4'
file 'video2.mp4'
...
```
FFmpeg is then used again to read this playlist and send a [FLV stream](https://en.wikipedia.org/wiki/Flash_Video) to a [RTMP server](https://en.wikipedia.org/wiki/Real-Time_Messaging_Protocol). FLV is an old format but still popular in the world of real-time streaming due to its low latency.
```bash
ffmpeg -y -nostdin \
-re \
-f concat \
-safe 0 -i channel_random.txt -stream_loop -1 \
-loglevel error \
-c:v libx264 -preset veryfast -tune zerolatency \
-shortest \
-f flv rtmp://<SERVER>
```
There are many different configuration options for FFmpeg, for more information in the [official documentation](http://trac.ffmpeg.org/wiki/StreamingGuide).
For the RTMP server, you can find [open-source implementations on GitHub](https://github.com/topics/rtmp-server), such as the [NGINX-RTMP module](https://github.com/arut/nginx-rtmp-module).
The AI WebTV itself uses [node-media-server](https://github.com/illuspas/Node-Media-Server).
💡 You can also directly stream to [one of the Twitch RTMP entrypoints](https://help.twitch.tv/s/twitch-ingest-recommendation?language=en_US). Check out the Twitch documentation for more details.
# Observations and examples
Here are some examples of the generated content.
The first thing we notice is that applying the second pass of Zeroscope XL significantly improves the quality of the image. The impact of frame interpolation is also clearly visible.
## Characters and scene composition
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo4.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo4.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Photorealistic movie of a <strong>llama acting as a programmer, wearing glasses and a hoodie</strong>, intensely <strong>staring at a screen</strong> with lines of code, in a cozy, <strong>dimly lit room</strong>, Canon EOS, ambient lighting, high details, cinematic, trending on artstation</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo5.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo5.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>3D rendered animation showing a group of food characters <strong>forming a pyramid</strong>, with a <strong>banana</strong> standing triumphantly on top. In a city with <strong>cotton candy clouds</strong> and <strong>chocolate road</strong>, Pixar's style, CGI, ambient lighting, direct sunlight, rich color scheme, ultra realistic, cinematic, photorealistic.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo7.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo7.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Intimate <strong>close-up of a red fox, gazing into the camera with sharp eyes</strong>, ambient lighting creating a high contrast silhouette, IMAX camera, <strong>high detail</strong>, <strong>cinematic effect</strong>, golden hour, film grain.</i></figcaption>
</figure>
## Simulation of dynamic scenes
Something truly fascinating about text-to-video models is their ability to emulate real-life phenomena they have been trained on.
We've seen it with large language models and their ability to synthesize convincing content that mimics human responses, but this takes things to a whole new dimension when applied to video.
A video model predicts the next frames of a scene, which might include objects in motion such as fluids, people, animals, or vehicles. Today, this emulation isn't perfect, but it will be interesting to evaluate future models (trained on larger or specialized datasets, such as animal locomotion) for their accuracy when reproducing physical phenomena, and also their ability to simulate the behavior of agents.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo17.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo17.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Cinematic movie shot of <strong>bees energetically buzzing around a flower</strong>, sun rays illuminating the scene, captured in 4k IMAX with a soft bokeh background.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo8.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo8.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i><strong>Dynamic footage of a grizzly bear catching a salmon in a rushing river</strong>, ambient lighting highlighting the splashing water, low angle, IMAX camera, 4K movie quality, golden hour, film grain.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo18.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo18.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Aerial footage of a quiet morning at the coast of California, with <strong>waves gently crashing against the rocky shore</strong>. A startling sunrise illuminates the coast with vibrant colors, captured beautifully with a DJI Phantom 4 Pro. Colors and textures of the landscape come alive under the soft morning light. Film grain, cinematic, imax, movie</i></figcaption>
</figure>
💡 It will be interesting to see these capabilities explored more in the future, for instance by training video models on larger video datasets covering more phenomena.
## Styling and effects
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo0.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo0.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>
<strong>3D rendered video</strong> of a friendly broccoli character wearing a hat, walking in a candy-filled city street with gingerbread houses, under a <strong>bright sun and blue skies</strong>, <strong>Pixar's style</strong>, cinematic, photorealistic, movie, <strong>ambient lighting</strong>, natural lighting, <strong>CGI</strong>, wide-angle view, daytime, ultra realistic.</i>
</figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo2.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo2.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i><strong>Cinematic movie</strong>, shot of an astronaut and a llama at dawn, the mountain landscape bathed in <strong>soft muted colors</strong>, early morning fog, dew glistening on fur, craggy peaks, vintage NASA suit, Canon EOS, high detailed skin, epic composition, high quality, 4K, trending on artstation, beautiful</i>
</figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo1.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo1.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Panda and black cat <strong>navigating down the flowing river</strong> in a small boat, Studio Ghibli style > Cinematic, beautiful composition > IMAX <strong>camera panning following the boat</strong> > High quality, cinematic, movie, mist effect, film grain, trending on Artstation</i>
</figcaption>
</figure>
## Failure cases
**Wrong direction:** the model sometimes has trouble with movement and direction. For instance, here the clip seems to be played in reverse. Also the modifier keyword ***green*** was not taken into account.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail1.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail1.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Movie showing a <strong>green pumpkin</strong> falling into a bed of nails, slow-mo explosion with chunks flying all over, ambient fog adding to the dramatic lighting, filmed with IMAX camera, 8k ultra high definition, high quality, trending on artstation.</i>
</figcaption>
</figure>
**Rendering errors on realistic scenes:** sometimes we can see artifacts such as moving vertical lines or waves. It is unclear what causes this, but it may be due to the combination of keywords used.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail2.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail2.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Film shot of a captivating flight above the Grand Canyon, ledges and plateaus etched in orange and red. <strong>Deep shadows contrast</strong> with the fiery landscape under the midday sun, shot with DJI Phantom 4 Pro. The camera rotates to capture the vastness, <strong>textures</strong> and colors, in imax quality. Film <strong>grain</strong>, cinematic, movie.</i>
</figcaption>
</figure>
**Text or objects inserted into the image:** the model sometimes injects words from the prompt into the scene, such as "IMAX". Mentioning "Canon EOS" or "Drone footage" in the prompt can also make those objects appear in the video.
In the following example, we notice the word "llama" inserts a llama but also two occurrences of the word llama in flames.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail3.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail3.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Movie scene of a <strong>llama</strong> acting as a firefighter, in firefighter uniform, dramatically spraying water at <strong>roaring flames</strong>, amidst a chaotic urban scene, Canon EOS, ambient lighting, high quality, award winning, highly detailed fur, cinematic, trending on artstation.</i>
</figcaption>
</figure>
# Recommendations
Here are some early recommendations that can be made from the previous observations:
## Using video-specific prompt keywords
You may already know that if you don’t prompt a specific aspect of the image with Stable Diffusion, things like the color of clothes or the time of the day might become random, or be assigned a generic value such as a neutral mid-day light.
The same is true for video models: you will want to be specific about things. Examples include camera and character movement, their orientation, speed and direction. You can leave it unspecified for creative purposes (idea generation), but this might not always give you the results you want (e.g., entities animated in reverse).
## Maintaining consistency between scenes
If you plan to create sequences of multiple videos, you will want to make sure you add as many details as possible in each prompt, otherwise you may lose important details from one sequence to another, such as the color.
💡 This will also improve the quality of the image since the prompt is used for the upscaling part with Zeroscope XL.
## Leverage frame interpolation
Frame interpolation is a powerful tool which can repair small rendering errors and turn many defects into features, especially in scenes with a lot of animation, or where a cartoon effect is acceptable. The [FILM algorithm](https://film-net.github.io/) will smoothen out elements of a frame with previous and following events in the video clip.
This works great to displace the background when the camera is panning or rotating, and will also give you creative freedom, such as control over the number of frames after the generation, to make slow-motion effects.
# Future work
We hope you enjoyed watching the AI WebTV stream and that it will inspire you to build more in this space.
As this was a first trial, a lot of things were not the focus of the tech demo: generating longer and more varied sequences, adding audio (sound effects, dialogue), generating and orchestrating complex scenarios, or letting a language model agent have more control over the pipeline.
Some of these ideas may make their way into future updates to the AI WebTV, but we also can’t wait to see what the community of researchers, engineers and builders will come up with!
| huggingface/blog/blob/main/ai-webtv.md |
Stable Diffusion
## Overview
Stable Diffusion was proposed in [Stable Diffusion Announcement](https://stability.ai/blog/stable-diffusion-announcement) by Patrick Esser and Robin Rombach and the Stability AI team.
The summary of the model is the following:
*Stable Diffusion is a text-to-image model that will empower billions of people to create stunning art within seconds. It is a breakthrough in speed and quality meaning that it can run on consumer GPUs. You can see some of the amazing output that has been created by this model without pre or post-processing on this page. The model itself builds upon the work of the team at CompVis and Runway in their widely used latent diffusion model combined with insights from the conditional diffusion models by our lead generative AI developer Katherine Crowson, Dall-E 2 by Open AI, Imagen by Google Brain and many others. We are delighted that AI media generation is a cooperative field and hope it can continue this way to bring the gift of creativity to all.*
## Tips:
- Stable Diffusion has the same architecture as [Latent Diffusion](https://arxiv.org/abs/2112.10752) but uses a frozen CLIP Text Encoder instead of training the text encoder jointly with the diffusion model.
- An in-detail explanation of the Stable Diffusion model can be found under [Stable Diffusion with 🧨 Diffusers](https://huggingface.co/blog/stable_diffusion).
- If you don't want to rely on the Hugging Face Hub and having to pass a authentication token, you can
download the weights with `git lfs install; git clone https://huggingface.co/runwayml/stable-diffusion-v1-5` and instead pass the local path to the cloned folder to `from_pretrained` as shown below.
- Stable Diffusion can work with a variety of different samplers as is shown below.
## Available Pipelines:
| Pipeline | Tasks | Colab
|---|---|:---:|
| [pipeline_stable_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
| [pipeline_stable_diffusion_img2img](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
| [pipeline_stable_diffusion_inpaint](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py) | *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
## Examples:
### Using Stable Diffusion without being logged into the Hub.
If you want to download the model weights using a single Python line, you need to be logged in via `huggingface-cli login`.
```python
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
```
This however can make it difficult to build applications on top of `diffusers` as you will always have to pass the token around. A potential way to solve this issue is by downloading the weights to a local path `"./stable-diffusion-v1-5"`:
```
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
and simply passing the local path to `from_pretrained`:
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
```
### Text-to-Image with default PLMS scheduler
```python
# make sure you're logged in with `huggingface-cli login`
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
### Text-to-Image with DDIM scheduler
```python
# make sure you're logged in with `huggingface-cli login`
from diffusers import StableDiffusionPipeline, DDIMScheduler
scheduler = DDIMScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
scheduler=scheduler,
).to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
### Text-to-Image with K-LMS scheduler
```python
# make sure you're logged in with `huggingface-cli login`
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
lms = LMSDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
scheduler=lms,
).to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
### CycleDiffusion using Stable Diffusion and DDIM scheduler
```python
import requests
import torch
from PIL import Image
from io import BytesIO
from diffusers import CycleDiffusionPipeline, DDIMScheduler
# load the scheduler. CycleDiffusion only supports stochastic schedulers.
# load the pipeline
# make sure you're logged in with `huggingface-cli login`
model_id_or_path = "CompVis/stable-diffusion-v1-4"
scheduler = DDIMScheduler.from_pretrained(model_id_or_path, subfolder="scheduler")
pipe = CycleDiffusionPipeline.from_pretrained(model_id_or_path, scheduler=scheduler).to("cuda")
# let's download an initial image
url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/An%20astronaut%20riding%20a%20horse.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((512, 512))
init_image.save("horse.png")
# let's specify a prompt
source_prompt = "An astronaut riding a horse"
prompt = "An astronaut riding an elephant"
# call the pipeline
image = pipe(
prompt=prompt,
source_prompt=source_prompt,
image=init_image,
num_inference_steps=100,
eta=0.1,
strength=0.8,
guidance_scale=2,
source_guidance_scale=1,
).images[0]
image.save("horse_to_elephant.png")
# let's try another example
# See more samples at the original repo: https://github.com/ChenWu98/cycle-diffusion
url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/A%20black%20colored%20car.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((512, 512))
init_image.save("black.png")
source_prompt = "A black colored car"
prompt = "A blue colored car"
# call the pipeline
torch.manual_seed(0)
image = pipe(
prompt=prompt,
source_prompt=source_prompt,
image=init_image,
num_inference_steps=100,
eta=0.1,
strength=0.85,
guidance_scale=3,
source_guidance_scale=1,
).images[0]
image.save("black_to_blue.png")
```
| huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/README.md |
p align="center">
<br/>
<img alt="huggingface_hub library logo" src="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/huggingface_hub.svg" width="376" height="59" style="max-width: 100%;">
<br/>
</p>
<p align="center">
<i>Huggingface Hub के लिए आधिकारिक पायथन क्लाइंट।</i>
</p>
<p align="center">
<a href="https://huggingface.co/docs/huggingface_hub/ko/index"><img alt="Documentation" src="https://img.shields.io/website/http/huggingface.co/docs/huggingface_hub/index.svg?down_color=red&down_message=offline&up_message=online&label=doc"></a>
<a href="https://github.com/huggingface/huggingface_hub/releases"><img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/huggingface_hub.svg"></a>
<a href="https://github.com/huggingface/huggingface_hub"><img alt="PyPi version" src="https://img.shields.io/pypi/pyversions/huggingface_hub.svg"></a>
<a href="https://pypi.org/project/huggingface-hub"><img alt="downloads" src="https://static.pepy.tech/badge/huggingface_hub/month"></a>
<a href="https://codecov.io/gh/huggingface/huggingface_hub"><img alt="Code coverage" src="https://codecov.io/gh/huggingface/huggingface_hub/branch/main/graph/badge.svg?token=RXP95LE2XL"></a>
</p>
<h4 align="center">
<p>
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README.md">English</a> |
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_de.md">Deutsch</a> |
<b>हिंदी</b> |
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_ko.md">한국어</a> |
<a href="https://github.com/huggingface/huggingface_hub/blob/main/README_cn.md">中文(简体)</a>
<p>
</h4>
---
**दस्तावेज़ीकरण**: <a href="https://hf.co/docs/huggingface_hub" target="_blank">https://hf.co/docs/huggingface_hub</a>
**सोर्स कोड**: <a href="https://github.com/huggingface/huggingface_hub" target="_blank">https://github.com/huggingface/huggingface_hub</a>
---
## huggingface_hub लाइब्रेरी में आपका स्वागत है
`huggingface_hub` लाइब्रेरी आपको [हगिंग फेस हब](https://huggingface.co/) के साथ बातचीत करने की अनुमति देती है, जो रचनाकारों और सहयोगियों के लिए ओपन-सोर्स मशीन लर्निंग का लोकतंत्रीकरण करने वाला एक मंच है। अपनी परियोजनाओं के लिए पूर्व-प्रशिक्षित मॉडल और डेटासेट खोजें या हब पर होस्ट किए गए हजारों मशीन लर्निंग ऐप्स के साथ खेलें। आप समुदाय के साथ अपने स्वयं के मॉडल, डेटासेट और डेमो भी बना और साझा कर सकते हैं। `huggingface_hub` लाइब्रेरी पायथन के साथ इन सभी चीजों को करने का एक आसान तरीका प्रदान करती है।
## प्रमुख विशेषताऐं
- [फ़ाइलें डाउनलोड करें](https://huggingface.co/docs/huggingface_hub/en/guides/download) हब से।
- [फ़ाइलें अपलोड करें](https://huggingface.co/docs/huggingface_hub/en/guides/upload) हब पर।
- [अपनी रिपॉजिटरी प्रबंधित करें](https://huggingface.co/docs/huggingface_hub/en/guides/repository)।
- तैनात मॉडलों पर [अनुमान चलाएँ](https://huggingface.co/docs/huggingface_hub/en/guides/inference)।
- मॉडल, डेटासेट और स्पेस के लिए [खोज](https://huggingface.co/docs/huggingface_hub/en/guides/search)।
- [मॉडल कार्ड साझा करें](https://huggingface.co/docs/huggingface_hub/en/guides/model-cards) अपने मॉडलों का दस्तावेजीकरण करने के लिए।
- [समुदाय के साथ जुड़ें](https://huggingface.co/docs/huggingface_hub/en/guides/community) पीआर और टिप्पणियों के माध्यम से।
## स्थापना
[pip](https://pypi.org/project/huggingface-hub/) के साथ `huggingface_hub` पैकेज इंस्टॉल करें:
```bash
pip install huggingface_hub
```
यदि आप चाहें, तो आप इसे [conda](https://huggingface.co/docs/huggingface_hub/en/installation#install-with-conda) से भी इंस्टॉल कर सकते हैं।
पैकेज को डिफ़ॉल्ट रूप से न्यूनतम रखने के लिए, `huggingface_hub` कुछ उपयोग मामलों के लिए उपयोगी वैकल्पिक निर्भरता के साथ आता है। उदाहरण के लिए, यदि आप अनुमान के लिए संपूर्ण अनुभव चाहते हैं, तो चलाएँ:
```bash
pip install huggingface_hub[inference]
```
अधिक इंस्टॉलेशन और वैकल्पिक निर्भरता जानने के लिए, [इंस्टॉलेशन गाइड](https://huggingface.co/docs/huggingface_hub/en/installation) देखें।
## जल्दी शुरू
### फ़ाइलें डाउनलोड करें
एकल फ़ाइल डाउनलोड करें
```py
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="tiiuae/falcon-7b-instruct", filename="config.json")
```
या एक संपूर्ण भंडार
```py
from huggingface_hub import snapshot_download
snapshot_download("stabilityai/stable-diffusion-2-1")
```
फ़ाइलें स्थानीय कैश फ़ोल्डर में डाउनलोड की जाएंगी. [this_guide] में अधिक विवरण (https://huggingface.co/docs/huggingface_hub/en/guides/manage-cache)।
### लॉग इन करें
Hugging Face Hub एप्लिकेशन को प्रमाणित करने के लिए टोकन का उपयोग करता है (देखें [docs](https://huggingface.co/docs/hub/security-tokens))। अपनी मशीन में लॉगिन करने के लिए, निम्नलिखित सीएलआई चलाएँ:
```bash
huggingface-cli login
# या कृपया इसे एक पर्यावरण चर के रूप में निर्दिष्ट करें।
huggingface-cli login --token $HUGGINGFACE_TOKEN
```
### एक रिपॉजिटरी बनाएं
```py
from huggingface_hub import create_repo
create_repo(repo_id="super-cool-model")
```
### फाइलें अपलोड करें
एकल फ़ाइल अपलोड करें
```py
from huggingface_hub import upload_file
upload_file(
path_or_fileobj="/home/lysandre/dummy-test/README.md",
path_in_repo="README.md",
repo_id="lysandre/test-model",
)
```
या एक संपूर्ण फ़ोल्डर
```py
from huggingface_hub import upload_folder
upload_folder(
folder_path="/path/to/local/space",
repo_id="username/my-cool-space",
repo_type="space",
)
```
[अपलोड गाइड](https://huggingface.co/docs/huggingface_hub/en/guides/upload) में विवरण के लिए।
## हब से एकीकरण।
हम मुफ्त मॉडल होस्टिंग और वर्जनिंग प्रदान करने के लिए शानदार ओपन सोर्स एमएल लाइब्रेरीज़ के साथ साझेदारी कर रहे हैं। आप मौजूदा एकीकरण [यहां](https://huggingface.co/docs/hub/libraries) पा सकते हैं।
फायदे ये हैं:
- पुस्तकालयों और उनके उपयोगकर्ताओं के लिए निःशुल्क मॉडल या डेटासेट होस्टिंग।
- गिट-आधारित दृष्टिकोण के कारण, बहुत बड़ी फ़ाइलों के साथ भी अंतर्निहित फ़ाइल संस्करणिंग।
- सभी मॉडलों के लिए होस्टेड अनुमान एपीआई सार्वजनिक रूप से उपलब्ध है।
- अपलोड किए गए मॉडलों के साथ खेलने के लिए इन-ब्राउज़र विजेट।
- कोई भी आपकी लाइब्रेरी के लिए एक नया मॉडल अपलोड कर सकता है, उन्हें मॉडल को खोजने योग्य बनाने के लिए बस संबंधित टैग जोड़ना होगा।
- तेज़ डाउनलोड! हम डाउनलोड को जियो-रेप्लिकेट करने के लिए क्लाउडफ्रंट (एक सीडीएन) का उपयोग करते हैं ताकि वे दुनिया में कहीं से भी तेजी से चमक सकें।
- उपयोग आँकड़े और अधिक सुविधाएँ आने वाली हैं।
यदि आप अपनी लाइब्रेरी को एकीकृत करना चाहते हैं, तो चर्चा शुरू करने के लिए बेझिझक एक मुद्दा खोलें। हमने ❤️ के साथ एक [चरण-दर-चरण मार्गदर्शिका](https://huggingface.co/docs/hub/adding-a-library) लिखी, जिसमें दिखाया गया कि यह एकीकरण कैसे करना है।
## योगदान (सुविधा अनुरोध, बग, आदि) का अति स्वागत है 💙💚💛💜🧡❤️
योगदान के लिए हर किसी का स्वागत है और हम हर किसी के योगदान को महत्व देते हैं। कोड समुदाय की मदद करने का एकमात्र तरीका नहीं है।
प्रश्नों का उत्तर देना, दूसरों की मदद करना, उन तक पहुंचना और दस्तावेज़ों में सुधार करना समुदाय के लिए बेहद मूल्यवान है।
हमने संक्षेप में बताने के लिए एक [योगदान मार्गदर्शिका](https://github.com/huggingface/huggingface_hub/blob/main/CONTRIBUTING.md) लिखी है
इस भंडार में योगदान करने की शुरुआत कैसे करें।
| huggingface/huggingface_hub/blob/main/README_hi.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LXMERT
## Overview
The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
(one for the vision modality, one for the language modality, and then one to fuse both modalities) pretrained using a
combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked
visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. The pretraining
consists of multiple multi-modal datasets: MSCOCO, Visual-Genome + Visual-Genome Question Answering, VQA 2.0, and GQA.
The abstract from the paper is the following:
*Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly,
the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality
Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we
build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language
encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language
semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative
pretraining tasks: masked language modeling, masked object prediction (feature regression and label classification),
cross-modality matching, and image question answering. These tasks help in learning both intra-modality and
cross-modality relationships. After fine-tuning from our pretrained parameters, our model achieves the state-of-the-art
results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our
pretrained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR, and improve the previous
best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel
model components and pretraining strategies significantly contribute to our strong results; and also present several
attention visualizations for the different encoders*
This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). The original code can be found [here](https://github.com/airsplay/lxmert).
## Usage tips
- Bounding boxes are not necessary to be used in the visual feature embeddings, any kind of visual-spacial features
will work.
- Both the language hidden states and the visual hidden states that LXMERT outputs are passed through the
cross-modality layer, so they contain information from both modalities. To access a modality that only attends to
itself, select the vision/language hidden states from the first input in the tuple.
- The bidirectional cross-modality encoder attention only returns attention values when the language modality is used
as the input and the vision modality is used as the context vector. Further, while the cross-modality encoder
contains self-attention for each respective modality and cross-attention, only the cross attention is returned and
both self attention outputs are disregarded.
## Resources
- [Question answering task guide](../tasks/question_answering)
## LxmertConfig
[[autodoc]] LxmertConfig
## LxmertTokenizer
[[autodoc]] LxmertTokenizer
## LxmertTokenizerFast
[[autodoc]] LxmertTokenizerFast
## Lxmert specific outputs
[[autodoc]] models.lxmert.modeling_lxmert.LxmertModelOutput
[[autodoc]] models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput
[[autodoc]] models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput
[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput
[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput
<frameworkcontent>
<pt>
## LxmertModel
[[autodoc]] LxmertModel
- forward
## LxmertForPreTraining
[[autodoc]] LxmertForPreTraining
- forward
## LxmertForQuestionAnswering
[[autodoc]] LxmertForQuestionAnswering
- forward
</pt>
<tf>
## TFLxmertModel
[[autodoc]] TFLxmertModel
- call
## TFLxmertForPreTraining
[[autodoc]] TFLxmertForPreTraining
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/lxmert.md |
The tokenization pipeline
When calling `Tokenizer.encode` or
`Tokenizer.encode_batch`, the input
text(s) go through the following pipeline:
- `normalization`
- `pre-tokenization`
- `model`
- `post-processing`
We'll see in details what happens during each of those steps in detail,
as well as when you want to `decode <decoding>` some token ids, and how the 🤗 Tokenizers library allows you
to customize each of those steps to your needs. If you're already
familiar with those steps and want to learn by seeing some code, jump to
`our BERT from scratch example <example>`.
For the examples that require a `Tokenizer` we will use the tokenizer we trained in the
`quicktour`, which you can load with:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START reload_tokenizer",
"end-before": "END reload_tokenizer",
"dedent": 12}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_reload_tokenizer",
"end-before": "END pipeline_reload_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START reload_tokenizer",
"end-before": "END reload_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
## Normalization
Normalization is, in a nutshell, a set of operations you apply to a raw
string to make it less random or "cleaner". Common operations include
stripping whitespace, removing accented characters or lowercasing all
text. If you're familiar with [Unicode
normalization](https://unicode.org/reports/tr15), it is also a very
common normalization operation applied in most tokenizers.
Each normalization operation is represented in the 🤗 Tokenizers library
by a `Normalizer`, and you can combine
several of those by using a `normalizers.Sequence`. Here is a normalizer applying NFD Unicode normalization
and removing accents as an example:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START setup_normalizer",
"end-before": "END setup_normalizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_setup_normalizer",
"end-before": "END pipeline_setup_normalizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START setup_normalizer",
"end-before": "END setup_normalizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
You can manually test that normalizer by applying it to any string:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START test_normalizer",
"end-before": "END test_normalizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_test_normalizer",
"end-before": "END pipeline_test_normalizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START test_normalizer",
"end-before": "END test_normalizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
When building a `Tokenizer`, you can
customize its normalizer by just changing the corresponding attribute:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START replace_normalizer",
"end-before": "END replace_normalizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_replace_normalizer",
"end-before": "END pipeline_replace_normalizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START replace_normalizer",
"end-before": "END replace_normalizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
Of course, if you change the way a tokenizer applies normalization, you
should probably retrain it from scratch afterward.
## Pre-Tokenization
Pre-tokenization is the act of splitting a text into smaller objects
that give an upper bound to what your tokens will be at the end of
training. A good way to think of this is that the pre-tokenizer will
split your text into "words" and then, your final tokens will be parts
of those words.
An easy way to pre-tokenize inputs is to split on spaces and
punctuations, which is done by the
`pre_tokenizers.Whitespace`
pre-tokenizer:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START setup_pre_tokenizer",
"end-before": "END setup_pre_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_setup_pre_tokenizer",
"end-before": "END pipeline_setup_pre_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START setup_pre_tokenizer",
"end-before": "END setup_pre_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
The output is a list of tuples, with each tuple containing one word and
its span in the original sentence (which is used to determine the final
`offsets` of our `Encoding`). Note that splitting on
punctuation will split contractions like `"I'm"` in this example.
You can combine together any `PreTokenizer` together. For instance, here is a pre-tokenizer that will
split on space, punctuation and digits, separating numbers in their
individual digits:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START combine_pre_tokenizer",
"end-before": "END combine_pre_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_combine_pre_tokenizer",
"end-before": "END pipeline_combine_pre_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START combine_pre_tokenizer",
"end-before": "END combine_pre_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
As we saw in the `quicktour`, you can
customize the pre-tokenizer of a `Tokenizer` by just changing the corresponding attribute:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START replace_pre_tokenizer",
"end-before": "END replace_pre_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_replace_pre_tokenizer",
"end-before": "END pipeline_replace_pre_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START replace_pre_tokenizer",
"end-before": "END replace_pre_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
Of course, if you change the way the pre-tokenizer, you should probably
retrain your tokenizer from scratch afterward.
## Model
Once the input texts are normalized and pre-tokenized, the
`Tokenizer` applies the model on the
pre-tokens. This is the part of the pipeline that needs training on your
corpus (or that has been trained if you are using a pretrained
tokenizer).
The role of the model is to split your "words" into tokens, using the
rules it has learned. It's also responsible for mapping those tokens to
their corresponding IDs in the vocabulary of the model.
This model is passed along when intializing the
`Tokenizer` so you already know how to
customize this part. Currently, the 🤗 Tokenizers library supports:
- `models.BPE`
- `models.Unigram`
- `models.WordLevel`
- `models.WordPiece`
For more details about each model and its behavior, you can check
[here](components#models)
## Post-Processing
Post-processing is the last step of the tokenization pipeline, to
perform any additional transformation to the
`Encoding` before it's returned, like
adding potential special tokens.
As we saw in the quick tour, we can customize the post processor of a
`Tokenizer` by setting the
corresponding attribute. For instance, here is how we can post-process
to make the inputs suitable for the BERT model:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START setup_processor",
"end-before": "END setup_processor",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_setup_processor",
"end-before": "END pipeline_setup_processor",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START setup_processor",
"end-before": "END setup_processor",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
Note that contrarily to the pre-tokenizer or the normalizer, you don't
need to retrain a tokenizer after changing its post-processor.
## All together: a BERT tokenizer from scratch
Let's put all those pieces together to build a BERT tokenizer. First,
BERT relies on WordPiece, so we instantiate a new
`Tokenizer` with this model:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_setup_tokenizer",
"end-before": "END bert_setup_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_setup_tokenizer",
"end-before": "END bert_setup_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_setup_tokenizer",
"end-before": "END bert_setup_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
Then we know that BERT preprocesses texts by removing accents and
lowercasing. We also use a unicode normalizer:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_setup_normalizer",
"end-before": "END bert_setup_normalizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_setup_normalizer",
"end-before": "END bert_setup_normalizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_setup_normalizer",
"end-before": "END bert_setup_normalizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
The pre-tokenizer is just splitting on whitespace and punctuation:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_setup_pre_tokenizer",
"end-before": "END bert_setup_pre_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_setup_pre_tokenizer",
"end-before": "END bert_setup_pre_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_setup_pre_tokenizer",
"end-before": "END bert_setup_pre_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
And the post-processing uses the template we saw in the previous
section:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_setup_processor",
"end-before": "END bert_setup_processor",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_setup_processor",
"end-before": "END bert_setup_processor",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_setup_processor",
"end-before": "END bert_setup_processor",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
We can use this tokenizer and train on it on wikitext like in the
`quicktour`:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_train_tokenizer",
"end-before": "END bert_train_tokenizer",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_train_tokenizer",
"end-before": "END bert_train_tokenizer",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_train_tokenizer",
"end-before": "END bert_train_tokenizer",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
## Decoding
On top of encoding the input texts, a `Tokenizer` also has an API for decoding, that is converting IDs
generated by your model back to a text. This is done by the methods
`Tokenizer.decode` (for one predicted text) and `Tokenizer.decode_batch` (for a batch of predictions).
The `decoder` will first convert the IDs back to tokens
(using the tokenizer's vocabulary) and remove all special tokens, then
join those tokens with spaces:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START test_decoding",
"end-before": "END test_decoding",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START pipeline_test_decoding",
"end-before": "END pipeline_test_decoding",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START test_decoding",
"end-before": "END test_decoding",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
If you used a model that added special characters to represent subtokens
of a given "word" (like the `"##"` in
WordPiece) you will need to customize the `decoder` to treat
them properly. If we take our previous `bert_tokenizer` for instance the
default decoding will give:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_test_decoding",
"end-before": "END bert_test_decoding",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_test_decoding",
"end-before": "END bert_test_decoding",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_test_decoding",
"end-before": "END bert_test_decoding",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
But by changing it to a proper decoder, we get:
<tokenizerslangcontent>
<python>
<literalinclude>
{"path": "../../bindings/python/tests/documentation/test_pipeline.py",
"language": "python",
"start-after": "START bert_proper_decoding",
"end-before": "END bert_proper_decoding",
"dedent": 8}
</literalinclude>
</python>
<rust>
<literalinclude>
{"path": "../../tokenizers/tests/documentation.rs",
"language": "rust",
"start-after": "START bert_proper_decoding",
"end-before": "END bert_proper_decoding",
"dedent": 4}
</literalinclude>
</rust>
<node>
<literalinclude>
{"path": "../../bindings/node/examples/documentation/pipeline.test.ts",
"language": "js",
"start-after": "START bert_proper_decoding",
"end-before": "END bert_proper_decoding",
"dedent": 8}
</literalinclude>
</node>
</tokenizerslangcontent>
| huggingface/tokenizers/blob/main/docs/source-doc-builder/pipeline.mdx |
TResNet
A **TResNet** is a variant on a [ResNet](https://paperswithcode.com/method/resnet) that aim to boost accuracy while maintaining GPU training and inference efficiency. They contain several design tricks including a SpaceToDepth stem, [Anti-Alias downsampling](https://paperswithcode.com/method/anti-alias-downsampling), In-Place Activated BatchNorm, Blocks selection and [squeeze-and-excitation layers](https://paperswithcode.com/method/squeeze-and-excitation-block).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('tresnet_l', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tresnet_l`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('tresnet_l', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{ridnik2020tresnet,
title={TResNet: High Performance GPU-Dedicated Architecture},
author={Tal Ridnik and Hussam Lawen and Asaf Noy and Emanuel Ben Baruch and Gilad Sharir and Itamar Friedman},
year={2020},
eprint={2003.13630},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: TResNet
Paper:
Title: 'TResNet: High Performance GPU-Dedicated Architecture'
URL: https://paperswithcode.com/paper/tresnet-high-performance-gpu-dedicated
Models:
- Name: tresnet_l
In Collection: TResNet
Metadata:
FLOPs: 10873416792
Parameters: 53456696
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_l
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L267
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_81_5-235b486c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.49%
Top 5 Accuracy: 95.62%
- Name: tresnet_l_448
In Collection: TResNet
Metadata:
FLOPs: 43488238584
Parameters: 53456696
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_l_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L285
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_448-940d0cd1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.26%
Top 5 Accuracy: 95.98%
- Name: tresnet_m
In Collection: TResNet
Metadata:
FLOPs: 5733048064
Parameters: 41282200
File Size: 125861314
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
Training Time: < 24 hours
ID: tresnet_m
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L261
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_m_80_8-dbc13962.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.8%
Top 5 Accuracy: 94.86%
- Name: tresnet_m_448
In Collection: TResNet
Metadata:
FLOPs: 22929743104
Parameters: 29278464
File Size: 125861314
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_m_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L279
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_m_448-bc359d10.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.72%
Top 5 Accuracy: 95.57%
- Name: tresnet_xl
In Collection: TResNet
Metadata:
FLOPs: 15162534034
Parameters: 75646610
File Size: 314378965
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_xl
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L273
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_xl_82_0-a2d51b00.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.05%
Top 5 Accuracy: 95.93%
- Name: tresnet_xl_448
In Collection: TResNet
Metadata:
FLOPs: 60641712730
Parameters: 75646610
File Size: 224440219
Architecture:
- 1x1 Convolution
- Anti-Alias Downsampling
- Convolution
- Global Average Pooling
- InPlace-ABN
- Leaky ReLU
- ReLU
- Residual Connection
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- AutoAugment
- Cutout
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA 100 GPUs
ID: tresnet_xl_448
LR: 0.01
Epochs: 300
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '448'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/tresnet.py#L291
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/tresnet_l_448-940d0cd1.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.06%
Top 5 Accuracy: 96.19%
--> | huggingface/pytorch-image-models/blob/main/docs/models/tresnet.md |
Configure the Dataset Viewer
The Dataset Viewer supports many [data files formats](./datasets-adding#file-formats), from text to tabular and from image to audio formats.
It also separates the train/validation/test splits based on file and folder names.
To configure the Dataset Viewer for your dataset, first make sure your dataset is in a [supported data format](./datasets-adding#files-formats).
## Configure dropdowns for splits or subsets
In the Dataset Viewer you can view the [train/validation/test](https://en.wikipedia.org/wiki/Training,_validation,_and_test_data_sets) splits of datasets, and sometimes additionally choose between multiple subsets (e.g. one per language).
To define those dropdowns, you can name the data files or their folder after their split names (train/validation/test).
It is also possible to customize your splits manually using YAML.
For more information, feel free to check out the documentation on [Data files Configuration](./datasets-data-files-configuration).
## Disable the viewer
The dataset viewer can be disabled. To do this, add a YAML section to the dataset's `README.md` file (create one if it does not already exist) and add a `viewer` property with the value `false`.
```
---
viewer: false
---
```
Note that the viewer is always disabled on the private datasets.
| huggingface/hub-docs/blob/main/docs/hub/datasets-viewer-configure.md |
Author: [@vasudevgupta7](https://github.com/thevasudevgupta/)
## Intro
In this project, we fine-tuned [**BigBird**](https://arxiv.org/abs/2007.14062) on [**natural-questions**](https://huggingface.co/datasets/natural_questions) dataset for **question-answering** task on long documents. **BigBird**, is a **sparse-attention based transformer** which extends Transformer based models, such as BERT to much **longer sequences**.
Read more about BigBird at https://huggingface.co/blog/big-bird
## Fine-tuning
**Setup**
You need to install jax yourself by following the official docs ([refer this](https://github.com/google/jax#installation)). Other requirements for this project can be installed by running following command:
```shell
pip3 install -qr requirements.txt
```
**Download & prepare dataset**
The Natural Questions corpus contains questions from real users, and it requires QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. This corpus takes ~100 GB on disk. We have used HuggingFace datasets to download & process the dataset.
```shell
# just run following CMD
python3 prepare_natural_questions.py
# this will download the whole dataset from HuggingFace Hub & will make it ready for training
# this script takes ~3 hours to process the dataset
```
**Launch Training**
We have trained on Cloud's TPU v3-8. Each epoch took around 4.5 hours and the model got converged in just 2 epochs. You can see complete training args in [this script](bigbird_flax.py).
```shell
# just run following CMD
python3 train.py
# In case, you want to try hparams tuning, you can run wandb sweep
wandb sweep --project=bigbird sweep_flax.yaml
wandb agent <agent-id-obtained-by-above-CMD>
```
## Evaluation
Our evaluation script is different from the original script and we are evaluating sequences with length up to 4096 for simplicity. We managed to get the **EM score of ~55.2** using our evaluation script.
```shell
# download validation-dataset first
mkdir natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/natural_questions-validation.arrow -P natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/dataset_info.json -P natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/state.json -P natural-questions-validation
# simply run following command
python3 evaluate.py
```
You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repositary](https://github.com/thevasudevgupta/bigbird).
| huggingface/transformers/blob/main/examples/research_projects/jax-projects/big_bird/README.md |
--
title: Fine tuning CLIP with Remote Sensing (Satellite) images and captions
thumbnail: /blog/assets/30_clip_rsicd/clip_schematic.png
authors:
- user: arampacha
guest: true
- user: devv
guest: true
- user: goutham794
guest: true
- user: cataluna84
guest: true
- user: ghosh-r
guest: true
- user: sujitpal
guest: true
---
# Fine tuning CLIP with Remote Sensing (Satellite) images and captions
## Fine tuning CLIP with Remote Sensing (Satellite) images and captions
<img src="/blog/assets/30_clip_rsicd/clip-rsicd-header-image.png"/>
In July this year, [Hugging Face](https://huggingface.co/) organized a [Flax/JAX Community Week](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md), and invited the community to submit projects to train Hugging Face [transformers](https://github.com/huggingface/transformers) models in the areas of Natural Language Processing (NLP) and Computer Vision (CV).
Participants used Tensor Processing Units (TPUs) with [Flax](https://github.com/google/flax) and [JAX](https://github.com/google/jax). JAX is a linear algebra library (like `numpy`) that can do automatic differentiation ([Autograd](https://github.com/hips/autograd)) and compile down to [XLA](https://www.tensorflow.org/xla), and Flax is a neural network library and ecosystem for JAX. TPU compute time was provided free by [Google Cloud](https://cloud.google.com/), who co-sponsored the event.
Over the next two weeks, teams participated in lectures from Hugging Face and Google, trained one or more models using JAX/Flax, shared them with the community, and provided a [Hugging Face Spaces](https://huggingface.co/spaces) demo showcasing the capabilities of their model. Approximately 100 teams participated in the event, and it resulted in 170 models and 36 demos.
Our team, like probably many others, is a distributed one, spanning 12 time zones. Our common thread is that we all belong to the [TWIML Slack Channel](https://twimlai.slack.com/), where we came together based on a shared interest in Artificial Intelligence (AI) and Machine Learning (ML) topics.
We fine-tuned the [CLIP Network from OpenAI](https://openai.comclip/) with satellite images and captions from the [RSICD dataset](https://github.com/201528014227051/RSICD_optimal). The CLIP network learns visual concepts by being trained with image and caption pairs in a self-supervised manner, by using text paired with images found across the Internet. During inference, the model can predict the most relevant image given a text description or the most relevant text description given an image. CLIP is powerful enough to be used in zero-shot manner on everyday images. However, we felt that satellite images were sufficiently different from everyday images that it would be useful to fine-tune CLIP with them. Our intuition turned out to be correct, as the evaluation results (described below) shows. In this post, we describe details of our training and evaluation process, and our plans for future work on this project.
The goal of our project was to provide a useful service and demonstrate how to use CLIP for practical use cases. Our model can be used by applications to search through large collections of satellite images using textual queries. Such queries could describe the image in totality (for example, beach, mountain, airport, baseball field, etc) or search or mention specific geographic or man-made features within these images. CLIP can similarly be fine-tuned for other domains as well, as shown by the [medclip-demo team](https://huggingface.co/spaces/flax-community/medclip-demo) for medical images.
The ability to search through large collections of images using text queries is an immensely powerful feature, and can be used as much for social good as for malign purposes. Possible applications include national defense and anti-terrorism activities, the ability to spot and address effects of climate change before they become unmanageable, etc. Unfortunately, this power can also be misused, such as for military and police surveillance by authoritarian nation-states, so it does raise some ethical questions as well.
You can read about the project on our [project page](https://github.com/arampacha/CLIP-rsicd), download our [trained model](https://huggingface.co/flax-community/clip-rsicd-v2) to use for inference on your own data, or see it in action on our [demo](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo).
### Training
#### Dataset
We fine-tuned the CLIP model primarily with the [RSICD dataset](https://github.com/201528014227051/RSICD_optimal). This dataset consists of about 10,000 images collected from Google Earth, Baidu Map, MapABC, and Tianditu. It is provided freely to the research community to advance remote sensing captioning via [Exploring Models and Data for Remote Sensing Image Caption Generation](https://arxiv.org/abs/1712.0783) (Lu et al, 2017). The images are (224, 224) RGB images at various resolutions, and each image has up to 5 captions associated with it.
<img src="/blog/assets/30_clip_rsicd/rsicd-images-sampling.png"/>
<center><i>Some examples of images from the RSICD dataset</i></center>
In addition, we used the [UCM Dataset](https://mega.nz/folder/wCpSzSoS#RXzIlrv--TDt3ENZdKN8JA) and the [Sydney dataset](https://mega.nz/folder/pG4yTYYA#4c4buNFLibryZnlujsrwEQ) for training, The UCM dataset is based on the UC Merced Land Use dataset. It consists of 2100 images belonging to 21 classes (100 images per class), and each image has 5 captions. The Sydney dataset contains images of Sydney, Australia from Google Earth. It contains 613 images belonging to 7 classes. Images are (500, 500) RGB and provides 5 captions for each image. We used these additional datasets because we were not sure if the RSICD dataset would be large enough to fine-tune CLIP.
#### Model
Our model is just the fine-tuned version of the original CLIP model shown below. Inputs to the model are a batch of captions and a batch of images passed through the CLIP text encoder and image encoder respectively. The training process uses [contrastive learning](https://towardsdatascience.com/understanding-contrastive-learning-d5b19fd96607) to learn a joint embedding representation of image and captions. In this embedding space, images and their respective captions are pushed close together, as are similar images and similar captions. Conversely, images and captions for different images, or dissimilar images and captions, are likely to be pushed further apart.
<img src="/blog/assets/30_clip_rsicd/clip_schematic.png"/>
<center><i>CLIP Training and Inference (Image Credit: CLIP: Connecting Text and Images (https://openai.comclip/))</i></center>
#### Data Augmentation
In order to regularize our dataset and prevent overfitting due to the size of the dataset, we used both image and text augmentation.
Image augmentation was done inline using built-in transforms from Pytorch's [Torchvision](https://pytorch.org/vision/stable/index.html) package. The transformations used were Random Cropping, Random Resizing and Cropping, Color Jitter, and Random Horizontal and Vertical flipping.
We augmented the text with backtranslation to generate captions for images with less than 5 unique captions per image. The [Marian MT]((https://huggingface.co/transformers/model_doc/marian.html)) family of models from Hugging Face was used to translate the existing captions into French, Spanish, Italian, and Portuguese and back to English to fill out the captions for these images.
As shown in these loss plots below, image augmentation reduced overfitting significantly, and text and image augmentation reduced overfitting even further.
<img src="/blog/assets/30_clip_rsicd/image-augment-loss.png"/>
<img src="/blog/assets/30_clip_rsicd/image-text-aug-loss.png"/>
<center><i>Evaluation and Training loss plots comparing (top) no augmentation vs image augmentation, and (bottom) image augmentation vs text+image augmentation</i></center>
### Evaluation
#### Metrics
A subset of the RSICD test set was used for evaluation. We found 30 categories of images in this subset. The evaluation was done by comparing each image with a set of 30 caption sentences of the form `"An aerial photograph of {category}"`. The model produced a ranked list of the 30 captions, from most relevant to least relevant. Categories corresponding to captions with the top k scores (for k=1, 3, 5, and 10) were compared with the category provided via the image file name. The scores are averaged over the entire set of images used for evaluation and reported for various values of k, as shown below.
The `baseline` model represents the pre-trained `openai/clip-vit-base-path32` CLIP model. This model was fine-tuned with captions and images from the RSICD dataset, which resulted in a significant performance boost, as shown below.
Our best model was trained with image and text augmentation, with batch size 1024 (128 on each of the 8 TPU cores), and the Adam optimizer with learning rate 5e-6. We trained our second base model with the same hyperparameters, except that we used the Adafactor optimizer with learning rate 1e-4. You can download either model from their model repos linked to in the table below.
| Model-name | k=1 | k=3 | k=5 | k=10 |
| ---------------------------------------- | ----- | ----- | ----- | ----- |
| baseline | 0.572 | 0.745 | 0.837 | 0.939 |
| bs128x8-lr1e-4-augs/ckpt-2 | 0.819 | 0.950 | 0.974 | 0.994 |
| bs128x8-lr1e-4-imgaugs/ckpt-2 | 0.812 | 0.942 | 0.970 | 0.991 |
| [bs128x8-lr1e-4-imgaugs-textaugs/ckpt-4](https://huggingface.co/flax-community/clip-rsicd)<sup>2</sup> | 0.843 | 0.958 | 0.977 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs/ckpt-8 | 0.831 | 0.959 | 0.977 | 0.994 |
| bs128x8-lr5e-5-imgaugs/ckpt-4 | 0.746 | 0.906 | 0.956 | 0.989 |
| bs128x8-lr5e-5-imgaugs-textaugs-2/ckpt-4 | 0.811 | 0.945 | 0.972 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs-3/ckpt-5 | 0.823 | 0.946 | 0.971 | 0.992 |
| bs128x8-lr5e-5-wd02/ckpt-4 | 0.820 | 0.946 | 0.965 | 0.990 |
| [bs128x8-lr5e-6-adam/ckpt-1](https://huggingface.co/flax-community/clip-rsicd-v2)<sup>1</sup> | **0.883** | **0.968** | **0.982** | **0.998** |
_1 - our best model, 2 - our second best model_
#### Demo
You can access the [CLIP-RSICD Demo](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo) here. It uses our fine-tuned CLIP model to provide the following functionality:
* Text to Image search
* Image to Image search
* Find text feature in image
The first two functionalities use the RSICD test set as its image corpus. They are encoded using our best fine-tuned CLIP model and stored in a [NMSLib](https://github.com/nmslib/nmslib) index which allows Approximate Nearest Neighbor based retrieval. For text-to-image and image-to-image search respectively, the query text or image are encoded with our model and matched against the image vectors in the corpus. For the third functionality, we divide the incoming image into patches and encode them, encode the queried text feature, match the text vector with each image patch vector, and return the probability of finding the feature in each patch.
### Future Work
We are grateful that we have been given an opportunity to further refine our model. Some ideas we have for future work are as follows:
1. Construct a sequence to sequence model using a CLIP encoder and a GPT-3 decoder and train it for image captioning.
2. Fine-tune the model on more image caption pairs from other datasets and investigate if we can improve its performance.
3. Investigate how fine-tuning affects the performance of model on non-RSICD image caption pairs.
4. Investigate the capability of the fine-tuned model to classify outside the categories it has been fine-tuned on.
5. Evaluate the model using other criteria such as image classification.
| huggingface/blog/blob/main/fine-tune-clip-rsicd.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Transformers Notebooks
You can find here a list of the official notebooks provided by Hugging Face.
Also, we would like to list here interesting content created by the community.
If you wrote some notebook(s) leveraging 🤗 Transformers and would like to be listed here, please open a
Pull Request so it can be included under the Community notebooks.
## Hugging Face's notebooks 🤗
### Documentation notebooks
You can open any page of the documentation as a notebook in Colab (there is a button directly on said pages) but they are also listed here if you need them:
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Quicktour of the library](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb) | A presentation of the various APIs in Transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/en/transformers_doc/quicktour.ipynb)|
| [Summary of the tasks](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb) | How to run the models of the Transformers library task by task |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)|
| [Preprocessing data](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb) | How to use a tokenizer to preprocess your data |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)|
| [Fine-tuning a pretrained model](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb) | How to use the Trainer to fine-tune a pretrained model |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)|
| [Summary of the tokenizers](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb) | The differences between the tokenizers algorithm |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)|
| [Multilingual models](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb) | How to use the multilingual models of the library |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)|
### PyTorch Examples
#### Natural Language Processing[[pytorch-nlp]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)|
| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)|
| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)|
| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)|
| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)|
| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)|
| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation.ipynb)|
| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)|
| [How to train a language model from scratch](https://github.com/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| Highlight all the steps to effectively train Transformer model on custom data | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)|
| [How to generate text](https://github.com/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| How to use different decoding methods for language generation with transformers | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)|
| [How to generate text (with constraints)](https://github.com/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| How to guide language generation with user-provided constraints | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)|
| [Reformer](https://github.com/huggingface/blog/blob/main/notebooks/03_reformer.ipynb)| How Reformer pushes the limits of language modeling | [](https://colab.research.google.com/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)| [](https://studiolab.sagemaker.aws/import/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)|
#### Computer Vision[[pytorch-cv]]
| Notebook | Description | | |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------:|
| [How to fine-tune a model on image classification (Torchvision)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | Show how to preprocess the data using Torchvision and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)|
| [How to fine-tune a model on image classification (Albumentations)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | Show how to preprocess the data using Albumentations and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)|
| [How to fine-tune a model on image classification (Kornia)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | Show how to preprocess the data using Kornia and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)|
| [How to perform zero-shot object detection with OWL-ViT](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb) | Show how to perform zero-shot object detection on images with text queries | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)|
| [How to fine-tune an image captioning model](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | Show how to fine-tune BLIP for image captioning on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb)|
| [How to build an image similarity system with Transformers](https://github.com/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | Show how to build an image similarity system | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb)|
| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)|
| [How to fine-tune a VideoMAE model on video classification](https://github.com/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | Show how to preprocess the data and fine-tune a pretrained VideoMAE model on Video Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb)|
#### Audio[[pytorch-audio]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to fine-tune a speech recognition model in English](https://github.com/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on TIMIT | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)|
| [How to fine-tune a speech recognition model in any language](https://github.com/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a multi-lingually pretrained speech model on Common Voice | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)|
| [How to fine-tune a model on audio classification](https://github.com/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on Keyword Spotting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)|
#### Biological Sequences[[pytorch-bio]]
| Notebook | Description | | |
|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) |
| [How to generate protein folds](https://github.com/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | See how to go from protein sequence to a full protein model and PDB file | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) |
| [How to fine-tune a Nucleotide Transformer model](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | See how to tokenize DNA and fine-tune a large pre-trained DNA "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) |
| [Fine-tune a Nucleotide Transformer model with LoRA](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | Train even larger DNA models in a memory-efficient way | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) |
#### Other modalities[[pytorch-other]]
| Notebook | Description | | |
|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
| [Probabilistic Time Series Forecasting](https://github.com/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | See how to train Time Series Transformer on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) |
#### Utility notebooks[[pytorch-utility]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to export model to ONNX](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| Highlight how to export and run inference workloads through ONNX |
| [How to use Benchmarks](https://github.com/huggingface/notebooks/blob/main/examples/benchmark.ipynb)| How to benchmark models with transformers | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/benchmark.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/benchmark.ipynb)|
### TensorFlow Examples
#### Natural Language Processing[[tensorflow-nlp]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)|
| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)|
| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)|
| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)|
| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)|
| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)|
| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)|
| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)|
#### Computer Vision[[tensorflow-cv]]
| Notebook | Description | | |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|:-------------|------:|
| [How to fine-tune a model on image classification](https://github.com/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb) | Show how to preprocess the data and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)|
| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)|
#### Biological Sequences[[tensorflow-bio]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) |
#### Utility notebooks[[tensorflow-utility]]
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to train TF/Keras models on TPU](https://github.com/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | See how to train at high speed on Google's TPU hardware | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) |
### Optimum notebooks
🤗 [Optimum](https://github.com/huggingface/optimum) is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on targeted hardwares.
| Notebook | Description | | |
|:----------|:-------------|:-------------|------:|
| [How to quantize a model with ONNX Runtime for text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| Show how to apply static and dynamic quantization on a model using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)|
| [How to quantize a model with Intel Neural Compressor for text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)| Show how to apply static, dynamic and aware training quantization on a model using [Intel Neural Compressor (INC)](https://github.com/intel/neural-compressor) for any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_inc.ipynb)|
| [How to fine-tune a model on text classification with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| Show how to preprocess the data and fine-tune a model on any GLUE task using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)|
| [How to fine-tune a model on summarization with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| Show how to preprocess the data and fine-tune a model on XSUM using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)|
## Community notebooks:
More notebooks developed by the community are available [here](https://hf.co/docs/transformers/community#community-notebooks).
| huggingface/transformers/blob/main/notebooks/README.md |
--
title: "Multivariate Probabilistic Time Series Forecasting with Informer"
thumbnail: /blog/assets/134_informer/thumbnail.png
authors:
- user: elisim
guest: true
- user: nielsr
- user: kashif
---
# Multivariate Probabilistic Time Series Forecasting with Informer
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multivariate_informer.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
A few months ago we introduced the [Time Series Transformer](https://huggingface.co/blog/time-series-transformers), which is the vanilla Transformer ([Vaswani et al., 2017](https://arxiv.org/abs/1706.03762)) applied to forecasting, and showed an example for the **univariate** probabilistic forecasting task (i.e. predicting each time series' 1-d distribution individually). In this post we introduce the _Informer_ model ([Zhou, Haoyi, et al., 2021](https://arxiv.org/abs/2012.07436)), AAAI21 best paper which is [now available](https://huggingface.co/docs/transformers/main/en/model_doc/informer) in 🤗 Transformers. We will show how to use the Informer model for the **multivariate** probabilistic forecasting task, i.e., predicting the distribution of a future **vector** of time-series target values. Note that this will also work for the vanilla Time Series Transformer model.
## Multivariate Probabilistic Time Series Forecasting
As far as the modeling aspect of probabilistic forecasting is concerned, the Transformer/Informer will require no change when dealing with multivariate time series. In both the univariate and multivariate setting, the model will receive a sequence of vectors and thus the only change is on the output or emission side.
Modeling the full joint conditional distribution of high dimensional data can get computationally expensive and thus methods resort to some approximation of the distribution, the easiest being to model the data as an independent distribution from the same family, or some low-rank approximation to the full covariance, etc. Here we will just resort to the independent (or diagonal) emissions which are supported for the families of distributions we have implemented [here](https://huggingface.co/docs/transformers/main/en/internal/time_series_utils).
## Informer - Under The Hood
Based on the vanilla Transformer ([Vaswani et al., 2017](https://arxiv.org/abs/1706.03762)), Informer employs two major improvements. To understand these improvements, let's recall the drawbacks of the vanilla Transformer:
1. **Quadratic computation of canonical self-attention:** The vanilla Transformer has a computational complexity of \\(O(T^2 D)\\) where \\(T\\) is the time series length and \\(D\\) is the dimension of the hidden states. For long sequence time-series forecasting (also known as the _LSTF problem_), this might be really computationally expensive. To solve this problem, Informer employs a new self-attention mechanism called _ProbSparse_ attention, which has \\(O(T \log T)\\) time and space complexity.
1. **Memory bottleneck when stacking layers:** When stacking \\(N\\) encoder/decoder layers, the vanilla Transformer has a memory usage of \\(O(N T^2)\\), which limits the model's capacity for long sequences. Informer uses a _Distilling_ operation, for reducing the input size between layers into its half slice. By doing so, it reduces the whole memory usage to be \\(O(N\cdot T \log T)\\).
As you can see, the motivation for the Informer model is similar to Longformer ([Beltagy et el., 2020](https://arxiv.org/abs/2004.05150)), Sparse Transformer ([Child et al., 2019](https://arxiv.org/abs/1904.10509)) and other NLP papers for reducing the quadratic complexity of the self-attention mechanism **when the input sequence is long**. Now, let's dive into _ProbSparse_ attention and the _Distilling_ operation with code examples.
### ProbSparse Attention
The main idea of ProbSparse is that the canonical self-attention scores form a long-tail distribution, where the "active" queries lie in the "head" scores and "lazy" queries lie in the "tail" area. By "active" query we mean a query \\(q_i\\) such that the dot-product \\(\langle q_i,k_i \rangle\\) **contributes** to the major attention, whereas a "lazy" query forms a dot-product which generates **trivial** attention. Here, \\(q_i\\) and \\(k_i\\) are the \\(i\\)-th rows in \\(Q\\) and \\(K\\) attention matrices respectively.
|  |
|:--:|
| Vanilla self attention vs ProbSparse attention from [Autoformer (Wu, Haixu, et al., 2021)](https://wuhaixu2016.github.io/pdf/NeurIPS2021_Autoformer.pdf) |
Given the idea of "active" and "lazy" queries, the ProbSparse attention selects the "active" queries, and creates a reduced query matrix \\(Q_{reduced}\\) which is used to calculate the attention weights in \\(O(T \log T)\\). Let's see this more in detail with a code example.
Recall the canonical self-attention formula:
$$
\textrm{Attention}(Q, K, V) = \textrm{softmax}(\frac{QK^T}{\sqrt{d_k}} )V
$$
Where \\(Q\in \mathbb{R}^{L_Q \times d}\\), \\(K\in \mathbb{R}^{L_K \times d}\\) and \\(V\in \mathbb{R}^{L_V \times d}\\). Note that in practice, the input length of queries and keys are typically equivalent in the self-attention computation, i.e. \\(L_Q = L_K = T\\) where \\(T\\) is the time series length. Therefore, the \\(QK^T\\) multiplication takes \\(O(T^2 \cdot d)\\) computational complexity. In ProbSparse attention, our goal is to create a new \\(Q_{reduce}\\) matrix and define:
$$
\textrm{ProbSparseAttention}(Q, K, V) = \textrm{softmax}(\frac{Q_{reduce}K^T}{\sqrt{d_k}} )V
$$
where the \\(Q_{reduce}\\) matrix only selects the Top \\(u\\) "active" queries. Here, \\(u = c \cdot \log L_Q\\) and \\(c\\) called the _sampling factor_ hyperparameter for the ProbSparse attention. Since \\(Q_{reduce}\\) selects only the Top \\(u\\) queries, its size is \\(c\cdot \log L_Q \times d\\), so the multiplication \\(Q_{reduce}K^T\\) takes only \\(O(L_K \log L_Q) = O(T \log T)\\).
This is good! But how can we select the \\(u\\) "active" queries to create \\(Q_{reduce}\\)? Let's define the _Query Sparsity Measurement_.
#### Query Sparsity Measurement
Query Sparsity Measurement \\(M(q_i, K)\\) is used for selecting the \\(u\\) "active" queries \\(q_i\\) in \\(Q\\) to create \\(Q_{reduce}\\). In theory, the dominant \\(\langle q_i,k_i \rangle\\) pairs encourage the "active" \\(q_i\\)'s probability distribution **away** from the uniform distribution as can be seen in the figure below. Hence, the [KL divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between the actual queries distribution and the uniform distribution is used to define the sparsity measurement.
|  |
|:--:|
| The illustration of ProbSparse Attention from official [repository](https://github.com/zhouhaoyi/Informer2020)|
In practice, the measurement is defined as:
$$
M(q_i, K) = \max_j \frac{q_ik_j^T}{\sqrt{d}}-\frac{1}{L_k} \sum_{j=1}^{L_k}\frac{q_ik_j^T}{\sqrt{d}}
$$
The important thing to understand here is when \\(M(q_i, K)\\) is larger, the query \\(q_i\\) should be in \\(Q_{reduce}\\) and vice versa.
But how can we calculate the term \\(q_ik_j^T\\) in non-quadratic time? Recall that most of the dot-product \\(\langle q_i,k_i \rangle\\) generate either way the trivial attention (i.e. long-tail distribution property), so it is enough to randomly sample a subset of keys from \\(K\\), which will be called `K_sample` in the code.
Now, we are ready to see the code of `probsparse_attention`:
```python
from torch import nn
import math
def probsparse_attention(query_states, key_states, value_states, sampling_factor=5):
"""
Compute the probsparse self-attention.
Input shape: Batch x Time x Channel
Note the additional `sampling_factor` input.
"""
# get input sizes with logs
L_K = key_states.size(1)
L_Q = query_states.size(1)
log_L_K = np.ceil(np.log1p(L_K)).astype("int").item()
log_L_Q = np.ceil(np.log1p(L_Q)).astype("int").item()
# calculate a subset of samples to slice from K and create Q_K_sample
U_part = min(sampling_factor * L_Q * log_L_K, L_K)
# create Q_K_sample (the q_i * k_j^T term in the sparsity measurement)
index_sample = torch.randint(0, L_K, (U_part,))
K_sample = key_states[:, index_sample, :]
Q_K_sample = torch.bmm(query_states, K_sample.transpose(1, 2))
# calculate the query sparsity measurement with Q_K_sample
M = Q_K_sample.max(dim=-1)[0] - torch.div(Q_K_sample.sum(dim=-1), L_K)
# calculate u to find the Top-u queries under the sparsity measurement
u = min(sampling_factor * log_L_Q, L_Q)
M_top = M.topk(u, sorted=False)[1]
# calculate Q_reduce as query_states[:, M_top]
dim_for_slice = torch.arange(query_states.size(0)).unsqueeze(-1)
Q_reduce = query_states[dim_for_slice, M_top] # size: c*log_L_Q x channel
# and now, same as the canonical
d_k = query_states.size(-1)
attn_scores = torch.bmm(Q_reduce, key_states.transpose(-2, -1)) # Q_reduce x K^T
attn_scores = attn_scores / math.sqrt(d_k)
attn_probs = nn.functional.softmax(attn_scores, dim=-1)
attn_output = torch.bmm(attn_probs, value_states)
return attn_output, attn_scores
```
Note that in the implementation, \\(U_{part}\\) contain \\(L_Q\\) in the calculation, for stability issues (see [this disccusion](https://discuss.huggingface.co/t/probsparse-attention-in-informer/34428) for more information).
We did it! Please be aware that this is only a partial implementation of the `probsparse_attention`, and the full implementation can be found in 🤗 Transformers.
### Distilling
Because of the ProbSparse self-attention, the encoder’s feature map has some redundancy that can be removed. Therefore,
the distilling operation is used to reduce the input size between encoder layers into its half slice, thus in theory removing this redundancy. In practice, Informer's "distilling" operation just adds 1D convolution layers with max pooling between each of the encoder layers. Let \\(X_n\\) be the output of the \\(n\\)-th encoder layer, the distilling operation is then defined as:
$$
X_{n+1} = \textrm{MaxPool} ( \textrm{ELU}(\textrm{Conv1d}(X_n))
$$
Let's see this in code:
```python
from torch import nn
# ConvLayer is a class with forward pass applying ELU and MaxPool1d
def informer_encoder_forward(x_input, num_encoder_layers=3, distil=True):
# Initialize the convolution layers
if distil:
conv_layers = nn.ModuleList([ConvLayer() for _ in range(num_encoder_layers - 1)])
conv_layers.append(None)
else:
conv_layers = [None] * num_encoder_layers
# Apply conv_layer between each encoder_layer
for encoder_layer, conv_layer in zip(encoder_layers, conv_layers):
output = encoder_layer(x_input)
if conv_layer is not None:
output = conv_layer(loutput)
return output
```
By reducing the input of each layer by two, we get a memory usage of \\(O(N\cdot T \log T)\\) instead of \\(O(N\cdot T^2)\\) where \\(N\\) is the number of encoder/decoder layers. This is what we wanted!
The Informer model in [now available](https://huggingface.co/docs/transformers/main/en/model_doc/informer) in the 🤗 Transformers library, and simply called `InformerModel`. In the sections below, we will show how to train this model on a custom multivariate time-series dataset.
## Set-up Environment
First, let's install the necessary libraries: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate and [GluonTS](https://github.com/awslabs/gluonts).
As we will show, GluonTS will be used for transforming the data to create features as well as for creating appropriate training, validation and test batches.
```python
!pip install -q transformers datasets evaluate accelerate gluonts ujson
```
## Load Dataset
In this blog post, we'll use the `traffic_hourly` dataset, which is available on the [Hugging Face Hub](https://huggingface.co/datasets/monash_tsf). This dataset contains the San Francisco Traffic dataset used by [Lai et al. (2017)](https://arxiv.org/abs/1703.07015). It contains 862 hourly time series showing the road occupancy rates in the range \\([0, 1]\\) on the San Francisco Bay area freeways from 2015 to 2016.
This dataset is part of the [Monash Time Series Forecasting](https://forecastingdata.org/) repository, a collection of time series datasets from a number of domains. It can be viewed as the [GLUE benchmark](https://gluebenchmark.com/) of time series forecasting.
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "traffic_hourly")
```
As can be seen, the dataset contains 3 splits: train, validation and test.
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
})
```
Each example contains a few keys, of which `start` and `target` are the most important ones. Let us have a look at the first time series in the dataset:
```python
train_example = dataset["train"][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The `start` simply indicates the start of the time series (as a datetime), and the `target` contains the actual values of the time series.
The `start` will be useful to add time related features to the time series values, as extra input to the model (such as "month of year"). Since we know the frequency of the data is `hourly`, we know for instance that the second value has the timestamp `2015-01-01 01:00:01`, `2015-01-01 02:00:01`, etc.
```python
print(train_example["start"])
print(len(train_example["target"]))
>>> 2015-01-01 00:00:01
17448
```
The validation set contains the same data as the training set, just for a `prediction_length` longer amount of time. This allows us to validate the model's predictions against the ground truth.
The test set is again one `prediction_length` longer data compared to the validation set (or some multiple of `prediction_length` longer data compared to the training set for testing on multiple rolling windows).
```python
validation_example = dataset["validation"][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The initial values are exactly the same as the corresponding training example. However, this example has `prediction_length=48` (48 hours, or 2 days) additional values compared to the training example. Let us verify it.
```python
freq = "1H"
prediction_length = 48
assert len(train_example["target"]) + prediction_length == len(
dataset["validation"][0]["target"]
)
```
Let's visualize this:
```python
import matplotlib.pyplot as plt
num_of_samples = 150
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
validation_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()
```

Let's split up the data:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## Update `start` to `pd.Period`
The first thing we'll do is convert the `start` feature of each time series to a pandas `Period` index using the data's `freq`:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
We now use `datasets`' [`set_transform`](https://huggingface.co/docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) functionality to do this on-the-fly in place:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
Now, let's convert the dataset into a multivariate time series using the `MultivariateGrouper` from GluonTS. This grouper will convert the individual 1-dimensional time series into a single 2D matrix.
```python
from gluonts.dataset.multivariate_grouper import MultivariateGrouper
num_of_variates = len(train_dataset)
train_grouper = MultivariateGrouper(max_target_dim=num_of_variates)
test_grouper = MultivariateGrouper(
max_target_dim=num_of_variates,
num_test_dates=len(test_dataset) // num_of_variates, # number of rolling test windows
)
multi_variate_train_dataset = train_grouper(train_dataset)
multi_variate_test_dataset = test_grouper(test_dataset)
```
Note that the target is now 2-dimensional, where the first dimension is the number of variates (number of time series) and the second is the time series values (time dimension):
```python
multi_variate_train_example = multi_variate_train_dataset[0]
print("multi_variate_train_example["target"].shape =", multi_variate_train_example["target"].shape)
>>> multi_variate_train_example["target"].shape = (862, 17448)
```
## Define the Model
Next, let's instantiate a model. The model will be trained from scratch, hence we won't use the `from_pretrained` method here, but rather randomly initialize the model from a [`config`](https://huggingface.co/docs/transformers/main/en/model_doc/informer#transformers.InformerConfig).
We specify a couple of additional parameters to the model:
- `prediction_length` (in our case, `48` hours): this is the horizon that the decoder of the Informer will learn to predict for;
- `context_length`: the model will set the `context_length` (input of the encoder) equal to the `prediction_length`, if no `context_length` is specified;
- `lags` for a given frequency: these specify an efficient "look back" mechanism, where we concatenate values from the past to the current values as additional features, e.g. for a `Daily` frequency we might consider a look back of `[1, 7, 30, ...]` or for `Minute` data we might consider `[1, 30, 60, 60*24, ...]` etc.;
- the number of time features: in our case, this will be `5` as we'll add `HourOfDay`, `DayOfWeek`, ..., and `Age` features (see below).
Let us check the default lags provided by GluonTS for the given frequency ("hourly"):
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 23, 24, 25, 47, 48, 49, 71, 72, 73, 95, 96, 97, 119, 120,
121, 143, 144, 145, 167, 168, 169, 335, 336, 337, 503, 504, 505, 671, 672, 673, 719, 720, 721]
```
This means that this would look back up to 721 hours (~30 days) for each time step, as additional features. However, the resulting feature vector would end up being of size `len(lags_sequence)*num_of_variates` which for our case will be 34480! This is not going to work so we will use our own sensible lags.
Let us also check the default time features which GluonTS provides us:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function hour_of_day at 0x7f3809539240>, <function day_of_week at 0x7f3809539360>, <function day_of_month at 0x7f3809539480>, <function day_of_year at 0x7f38095395a0>]
```
In this case, there are four additional features, namely "hour of day", "day of week", "day of month" and "day of year". This means that for each time step, we'll add these features as a scalar values. For example, consider the timestamp `2015-01-01 01:00:01`. The four additional features will be:
```python
from pandas.core.arrays.period import period_array
timestamp = pd.Period("2015-01-01 01:00:01", freq=freq)
timestamp_as_index = pd.PeriodIndex(data=period_array([timestamp]))
additional_features = [
(time_feature.__name__, time_feature(timestamp_as_index))
for time_feature in time_features
]
print(dict(additional_features))
>>> {'hour_of_day': array([-0.45652174]), 'day_of_week': array([0.]), 'day_of_month': array([-0.5]), 'day_of_year': array([-0.5])}
```
Note that hours and days are encoded as values between `[-0.5, 0.5]` from GluonTS. For more information about `time_features`, please see [this](https://github.com/awslabs/gluonts/blob/dev/src/gluonts/time_feature/_base.py). Besides those 4 features, we'll also add an "age" feature as we'll see later on in the data transformations.
We now have everything to define the model:
```python
from transformers import InformerConfig, InformerForPrediction
config = InformerConfig(
# in the multivariate setting, input_size is the number of variates in the time series per time step
input_size=num_of_variates,
# prediction length:
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags value copied from 1 week before:
lags_sequence=[1, 24 * 7],
# we'll add 5 time features ("hour_of_day", ..., and "age"):
num_time_features=len(time_features) + 1,
# informer params:
dropout=0.1,
encoder_layers=6,
decoder_layers=4,
# project input from num_of_variates*len(lags_sequence)+num_time_features to:
d_model=64,
)
model = InformerForPrediction(config)
```
By default, the model uses a diagonal Student-t distribution (but this is [configurable](https://huggingface.co/docs/transformers/main/en/internal/time_series_utils)):
```python
model.config.distribution_output
>>> 'student_t'
```
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
Again, we'll use the GluonTS library for this. We define a `Chain` of transformations (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
```python
from gluonts.time_feature import TimeFeature
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
The transformations below are annotated with comments, to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# create list of fields to remove later
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in the life the value of the time series is
# sort of running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the model due to time- and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create DataLoaders
Next, it's time to create the DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from all the possible transformed time series, 1 in our case)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=multi_variate_train_dataset,
batch_size=256,
num_batches_per_epoch=100,
num_workers=2,
)
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=multi_variate_test_dataset,
batch_size=32,
)
```
Let's check the first batch:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 264, 5]) torch.FloatTensor
past_values torch.Size([256, 264, 862]) torch.FloatTensor
past_observed_mask torch.Size([256, 264, 862]) torch.FloatTensor
future_time_features torch.Size([256, 48, 5]) torch.FloatTensor
future_values torch.Size([256, 48, 862]) torch.FloatTensor
future_observed_mask torch.Size([256, 48, 862]) torch.FloatTensor
```
As can be seen, we don't feed `input_ids` and `attention_mask` to the encoder (as would be the case for NLP models), but rather `past_values`, along with `past_observed_mask`, `past_time_features` and `static_real_features`.
The decoder inputs consist of `future_values`, `future_observed_mask` and `future_time_features`. The `future_values` can be seen as the equivalent of `decoder_input_ids` in NLP.
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/informer#transformers.InformerModel.forward.past_values) for a detailed explanation for each of them.
## Forward Pass
Let's perform a single forward pass with the batch we just created:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: -1071.5718994140625
```
Note that the model is returning a loss. This is possible as the decoder automatically shifts the `future_values` one position to the right in order to have the labels. This allows computing a loss between the predicted values and the labels. The loss is the negative log-likelihood of the predicted distribution with respect to the ground truth values and tends to negative infinity.
Also note that the decoder uses a causal mask to not look into the future as the values it needs to predict are in the `future_values` tensor.
## Train the Model
It's time to train the model! We'll use a standard PyTorch training loop.
We will use the 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) library here, which automatically places the model, optimizer and dataloader on the appropriate `device`.
```python
from accelerate import Accelerator
from torch.optim import AdamW
epochs = 25
loss_history = []
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(epochs):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
loss_history.append(loss.item())
if idx % 100 == 0:
print(loss.item())
>>> -1081.978515625
...
-2877.723876953125
```
```python
# view training
loss_history = np.array(loss_history).reshape(-1)
x = range(loss_history.shape[0])
plt.figure(figsize=(10, 5))
plt.plot(x, loss_history, label="train")
plt.title("Loss", fontsize=15)
plt.legend(loc="upper right")
plt.xlabel("iteration")
plt.ylabel("nll")
plt.show()
```

## Inference
At inference time, it's recommended to use the `generate()` method for autoregressive generation, similar to NLP models.
Forecasting involves getting data from the test instance sampler, which will sample the very last `context_length` sized window of values from each time series in the dataset, and pass it to the model. Note that we pass `future_time_features`, which are known ahead of time, to the decoder.
The model will autoregressively sample a certain number of values from the predicted distribution and pass them back to the decoder to return the prediction outputs:
```python
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`, `input_size`).
In this case, we get `100` possible values for the next `48` hours for each of the `862` time series (for each example in the batch which is of size `1` since we only have a single multivariate time series):
```python
forecasts_[0].shape
>>> (1, 100, 48, 862)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset (just in case there are more time series in the test set):
```python
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (1, 100, 48, 862)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. For that, we'll use the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library, which includes the [MASE](https://huggingface.co/spaces/evaluate-metric/mase) and [sMAPE](https://huggingface.co/spaces/evaluate-metric/smape) metrics.
We calculate both metrics for each time series variate in the dataset:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1).squeeze(0).T
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq),
)
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.1913437728068093
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.5322665081607634
```
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.2)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```

To plot the prediction for any time series variate with respect the ground truth test data we define the following helper:
```python
import matplotlib.dates as mdates
def plot(ts_index, mv_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=multi_variate_test_dataset[ts_index][FieldName.START],
periods=len(multi_variate_test_dataset[ts_index][FieldName.TARGET]),
freq=multi_variate_test_dataset[ts_index][FieldName.START].freq,
).to_timestamp()
ax.xaxis.set_minor_locator(mdates.HourLocator())
ax.plot(
index[-2 * prediction_length :],
multi_variate_test_dataset[ts_index]["target"][mv_index, -2 * prediction_length :],
label="actual",
)
ax.plot(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(axis=0),
label="mean",
)
ax.fill_between(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(0)
- forecasts[ts_index, ..., mv_index].std(axis=0),
forecasts[ts_index, ..., mv_index].mean(0)
+ forecasts[ts_index, ..., mv_index].std(axis=0),
alpha=0.2,
interpolate=True,
label="+/- 1-std",
)
ax.legend()
fig.autofmt_xdate()
```
For example:
```python
plot(0, 344)
```

## Conclusion
How do we compare against other models? The [Monash Time Series Repository](https://forecastingdata.org/#results) has a comparison table of test set MASE metrics which we can add to:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| Transformer (uni.) | **Informer (mv. our)**|
|:------------------:|:-----------------:|:--:|:--:|:--:|:--:|:--:|:--:|:---:|:---:|:--:|:--:|:--:|:--:|
|Traffic Hourly | 1.922 | 1.922 | 2.482 | 2.294| 2.535| 1.281| 1.571 |0.892| 0.825 |1.100| 1.066 | **0.821** | 1.191 |
As can be seen, and perhaps surprising to some, the multivariate forecasts are typically _worse_ than the univariate ones, the reason being the difficulty in estimating the cross-series correlations/relationships. The additional variance added by the estimates often harms the resulting forecasts or the model learns spurious correlations. We refer to [this paper](https://openreview.net/forum?id=GpW327gxLTF) for further reading. Multivariate models tend to work well when trained on a lot of data.
So the vanilla Transformer still performs best here! In the future, we hope to better benchmark these models in a central place to ease reproducing the results of several papers. Stay tuned for more!
## Resources
We recommend to check out the [Informer docs](https://huggingface.co/docs/transformers/main/en/model_doc/informer) and the [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/multivariate_informer.ipynb) linked at the top of this blog post.
| huggingface/blog/blob/main/informer.md |
SE-ResNet
**SE ResNet** is a variant of a [ResNet](https://www.paperswithcode.com/method/resnet) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('seresnet152d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `seresnet152d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('seresnet152d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SE ResNet
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: seresnet152d
In Collection: SE ResNet
Metadata:
FLOPs: 20161904304
Parameters: 66840000
File Size: 268144497
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnet152d
LR: 0.6
Epochs: 100
Layers: 152
Dropout: 0.2
Crop Pct: '0.94'
Momentum: 0.9
Batch Size: 1024
Image Size: '256'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1206
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet152d_ra2-04464dd2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 83.74%
Top 5 Accuracy: 96.77%
- Name: seresnet50
In Collection: SE ResNet
Metadata:
FLOPs: 5285062320
Parameters: 28090000
File Size: 112621903
Architecture:
- 1x1 Convolution
- Batch Normalization
- Bottleneck Residual Block
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: seresnet50
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/resnet.py#L1180
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnet50_ra_224-8efdb4bb.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.26%
Top 5 Accuracy: 95.07%
--> | huggingface/pytorch-image-models/blob/main/docs/models/se-resnet.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky 2.2
Kandinsky 2.2 is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Vladimir Arkhipkin](https://github.com/oriBetelgeuse), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey), and [Denis Dimitrov](https://github.com/denndimitrov).
The description from it's GitHub page is:
*Kandinsky 2.2 brings substantial improvements upon its predecessor, Kandinsky 2.1, by introducing a new, more powerful image encoder - CLIP-ViT-G and the ControlNet support. The switch to CLIP-ViT-G as the image encoder significantly increases the model's capability to generate more aesthetic pictures and better understand text, thus enhancing the model's overall performance. The addition of the ControlNet mechanism allows the model to effectively control the process of generating images. This leads to more accurate and visually appealing outputs and opens new possibilities for text-guided image manipulation.*
The original codebase can be found at [ai-forever/Kandinsky-2](https://github.com/ai-forever/Kandinsky-2).
<Tip>
Check out the [Kandinsky Community](https://huggingface.co/kandinsky-community) organization on the Hub for the official model checkpoints for tasks like text-to-image, image-to-image, and inpainting.
</Tip>
<Tip>
Make sure to check out the schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## KandinskyV22PriorPipeline
[[autodoc]] KandinskyV22PriorPipeline
- all
- __call__
- interpolate
## KandinskyV22Pipeline
[[autodoc]] KandinskyV22Pipeline
- all
- __call__
## KandinskyV22CombinedPipeline
[[autodoc]] KandinskyV22CombinedPipeline
- all
- __call__
## KandinskyV22ControlnetPipeline
[[autodoc]] KandinskyV22ControlnetPipeline
- all
- __call__
## KandinskyV22PriorEmb2EmbPipeline
[[autodoc]] KandinskyV22PriorEmb2EmbPipeline
- all
- __call__
- interpolate
## KandinskyV22Img2ImgPipeline
[[autodoc]] KandinskyV22Img2ImgPipeline
- all
- __call__
## KandinskyV22Img2ImgCombinedPipeline
[[autodoc]] KandinskyV22Img2ImgCombinedPipeline
- all
- __call__
## KandinskyV22ControlnetImg2ImgPipeline
[[autodoc]] KandinskyV22ControlnetImg2ImgPipeline
- all
- __call__
## KandinskyV22InpaintPipeline
[[autodoc]] KandinskyV22InpaintPipeline
- all
- __call__
## KandinskyV22InpaintCombinedPipeline
[[autodoc]] KandinskyV22InpaintCombinedPipeline
- all
- __call__
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/kandinsky_v22.md |
--
title: "Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub"
thumbnail: blog/assets/156_huggylingo/Huggy_Lingo.png
authors:
- user: davanstrien
---
## Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub
**tl;dr**: We're using machine learning to detect the language of Hub datasets with no language metadata, and [librarian-bots](https://huggingface.co/librarian-bots) to make pull requests to add this metadata.
The Hugging Face Hub has become the repository where the community shares machine learning models, datasets, and applications. As the number of datasets grows, metadata becomes increasingly important as a tool for finding the right resource for your use case.
In this blog post, I'm excited to share some early experiments which seek to use machine learning to improve the metadata for datasets hosted on the Hugging Face Hub.
### Language Metadata for Datasets on the Hub
There are currently ~50K public datasets on the Hugging Face Hub. Metadata about the language used in a dataset can be specified using a [YAML](https://en.wikipedia.org/wiki/YAML) field at the top of the [dataset card](https://huggingface.co/docs/datasets/upload_dataset#create-a-dataset-card).
All public datasets specify 1,716 unique languages via a language tag in their metadata. Note that some of them will be the result of languages being specified in different ways i.e. `en` vs `eng` vs `english` vs `English`.
For example, the [IMDB dataset](https://huggingface.co/datasets/imdb) specifies `en` in the YAML metadata (indicating English):
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_metadata.png" alt="Screenshot of YAML metadata"><br>
<em>Section of the YAML metadata for the IMDB dataset</em>
</p>
It is perhaps unsurprising that English is by far the most common language for datasets on the Hub, with around 19% of datasets on the Hub listing their language as `en` (not including any variations of `en`, so the actual percentage is likely much higher).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_freq.png" alt="Distribution of language tags"><br>
<em>The frequency and percentage frequency for datasets on the Hugging Face Hub</em>
</p>
What does the distribution of languages look like if we exclude English? We can see that there is a grouping of a few dominant languages and after that there is a pretty smooth fall in the frequencies at which languages appear.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/lang_freq_distribution.png" alt="Distribution of language tags"><br>
<em>Distribution of language tags for datasets on the hub excluding English.</em>
</p>
However, there is a major caveat to this. Most datasets (around 87%) do not specify the language used; only approximately 13% of datasets include language information in their metadata.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/has_lang_info_bar.png" alt="Barchart"><br>
<em>The percent of datasets which have language metadata. True indicates language metadata is specified, False means no language data is listed. No card data means that there isn't any metadata or it couldn't be loaded by the `huggingface_hub` Python library.</em>
</p>
#### Why is Language Metadata Important?
Language metadata can be a vital tool for finding relevant datasets. The Hugging Face Hub allows you to filter datasets by language. For example, if we want to find datasets with Dutch language we can use [a filter](https://huggingface.co/datasets?language=language:nl&sort=trending) on the Hub to include only datasets with Dutch data.
Currently this filter returns 184 datasets. However, there are datasets on the Hub which include Dutch but don't specify this in the metadata. These datasets become more difficult to find, particularly as the number of datasets on the Hub grows.
Many people want to be able to find datasets for a particular language. One of the major barriers to training good open source LLMs for a particular language is a lack of high quality training data.
If we switch to the task of finding relevant machine learning models, knowing what languages were included in the training data for a model can help us find models for the language we are interested in. This relies on the dataset specifying this information.
Finally, knowing what languages are represented on the Hub (and which are not), helps us understand the language biases of the Hub and helps inform community efforts to address gaps in particular languages.
### Predicting the Languages of Datasets Using Machine Learning
We’ve already seen that many of the datasets on the Hugging Face Hub haven’t included metadata for the language used. However, since these datasets are already shared openly, perhaps we can look at the dataset and try to identify the language using machine learning.
#### Getting the Data
One way we could access some examples from a dataset is by using the datasets library to download the datasets i.e.
```python
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")
```
However, for some of the datasets on the Hub, we might be keen not to download the whole dataset. We could instead try to load a sample of the dataset. However, depending on how the dataset was created, we might still end up downloading more data than we’d need onto the machine we’re working on.
Luckily, many datasets on the Hub are available via the [datasets server](https://huggingface.co/docs/datasets-server/index). The datasets server is an API that allows us to access datasets hosted on the Hub without downloading the dataset locally. The Datasets Server powers the Datasets Viewer preview you will see for many datasets hosted on the Hub.
For this first experiment with predicting language for datasets, we define a list of column names and data types likely to contain textual content i.e. `text` or `prompt` column names and `string` features are likely to be relevant `image` is not. This means we can avoid predicting the language for datasets where language information is less relevant, for example, image classification datasets. We use the Datasets Server to get 20 rows of text data to pass to a machine learning model (we could modify this to take more or fewer examples from the dataset).
This approach means that for the majority of datasets on the Hub we can quickly request the contents of likely text columns for the first 20 rows in a dataset.
#### Predicting the Language of a Dataset
Once we have some examples of text from a dataset, we need to predict the language. There are various options here, but for this work, we used the [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model created by [Meta](https://huggingface.co/facebook) as part of the [No Language Left Behind](https://ai.facebook.com/research/no-language-left-behind/) work. This model can detect 217 languages which will likely represent the majority of languages for datasets hosted on the Hub.
We pass 20 examples to the model representing rows from a dataset. This results in 20 individual language predictions (one per row) for each dataset.
Once we have these predictions, we do some additional filtering to determine if we will accept the predictions as a metadata suggestion. This roughly consists of:
- Grouping the predictions for each dataset by language: some datasets return predictions for multiple languages. We group these predictions by the language predicted i.e. if a dataset returns predictions for English and Dutch, we group the English and Dutch predictions together.
- For datasets with multiple languages predicted, we count how many predictions we have for each language. If a language is predicted less than 20% of the time, we discard this prediction. i.e. if we have 18 predictions for English and only 2 for Dutch we discard the Dutch predictions.
- We calculate the mean score for all predictions for a language. If the mean score associated with a languages prediction is below 80% we discard this prediction.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/huggy_lingo/prediction-flow.png" alt="Prediction workflow"><br>
<em>Diagram showing how predictions are handled.</em>
</p>
Once we’ve done this filtering, we have a further step of deciding how to use these predictions. The fastText language prediction model returns predictions as an [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) code (an international standard for language codes) along with a script type. i.e. `kor_Hang` is the ISO 693-3 language code for Korean (kor) + Hangul script (Hang) a [ISO 15924](https://en.wikipedia.org/wiki/ISO_15924) code representing the script of a language.
We discard the script information since this isn't currently captured consistently as metadata on the Hub and, where possible, we convert the language prediction returned by the model from [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) to [ISO 639-1](https://en.wikipedia.org/wiki/ISO_639-1) language codes. This is largely done because these language codes have better support in the Hub UI for navigating datasets.
For some ISO 639-3 codes, there is no ISO 639-1 equivalent. For these cases we manually specify a mapping if we deem it to make sense, for example Standard Arabic (`arb`) is mapped to Arabic (`ar`). Where an obvious mapping is not possible, we currently don't suggest metadata for this dataset. In future iterations of this work we may take a different approach. It is important to recognise this approach does come with downsides, since it reduces the diversity of languages which might be suggested and also relies on subjective judgments about what languages can be mapped to others.
But the process doesn't stop here. After all, what use is predicting the language of the datasets if we can't share that information with the rest of the community?
### Using Librarian-Bot to Update Metadata
To ensure this valuable language metadata is incorporated back into the Hub, we turn to Librarian-Bot! Librarian-Bot takes the language predictions generated by Meta's [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model and opens pull requests to add this information to the metadata of each respective dataset.
This system not only updates the datasets with language information, but also does it swiftly and efficiently, without requiring manual work from humans. If the owner of a repo decided to approve and merge the pull request, then the language metadata becomes available for all users, significantly enhancing the usability of the Hugging Face Hub. You can keep track of what the librarian-bot is doing [here](https://huggingface.co/librarian-bot/activity/community)!
#### Next Steps
As the number of datasets on the Hub grows, metadata becomes increasingly important. Language metadata, in particular, can be incredibly valuable for identifying the correct dataset for your use case.
With the assistance of the Datasets Server and the [Librarian-Bots](https://huggingface.co/librarian-bots), we can update our dataset metadata at a scale that wouldn't be possible manually. As a result, we're enriching the Hub and making it an even more powerful tool for data scientists, linguists, and AI enthusiasts around the world.
As the machine learning librarian at Hugging Face, I continue exploring opportunities for automatic metadata enrichment for machine learning artefacts hosted on the Hub. Feel free to reach out (daniel at thiswebsite dot co) if you have ideas or want to collaborate on this effort!
| huggingface/blog/blob/main/huggy-lingo.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer
The [`Trainer`] class provides an API for feature-complete training in PyTorch, and it supports distributed training on multiple GPUs/TPUs, mixed precision for [NVIDIA GPUs](https://nvidia.github.io/apex/), [AMD GPUs](https://rocm.docs.amd.com/en/latest/rocm.html), and [`torch.amp`](https://pytorch.org/docs/stable/amp.html) for PyTorch. [`Trainer`] goes hand-in-hand with the [`TrainingArguments`] class, which offers a wide range of options to customize how a model is trained. Together, these two classes provide a complete training API.
[`Seq2SeqTrainer`] and [`Seq2SeqTrainingArguments`] inherit from the [`Trainer`] and [`TrainingArgument`] classes and they're adapted for training models for sequence-to-sequence tasks such as summarization or translation.
<Tip warning={true}>
The [`Trainer`] class is optimized for 🤗 Transformers models and can have surprising behaviors
when used with other models. When using it with your own model, make sure:
- your model always return tuples or subclasses of [`~utils.ModelOutput`]
- your model can compute the loss if a `labels` argument is provided and that loss is returned as the first
element of the tuple (if your model returns tuples)
- your model can accept multiple label arguments (use `label_names` in [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`
</Tip>
## Trainer[[api-reference]]
[[autodoc]] Trainer
- all
## Seq2SeqTrainer
[[autodoc]] Seq2SeqTrainer
- evaluate
- predict
## TrainingArguments
[[autodoc]] TrainingArguments
- all
## Seq2SeqTrainingArguments
[[autodoc]] Seq2SeqTrainingArguments
- all
| huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md |
Gradio Demo: upload_button_component_events
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
upload_btn = gr.UploadButton(label="Upload Single File", file_count="single")
with gr.Column():
output_file_1 = gr.File(label="Upload Single File Output", file_count="single")
num_load_btn_1 = gr.Number(label="# Load Upload Single File", value=0)
output_click_1 = gr.Number(label="# Click Upload Single File Output", value=0)
upload_btn.upload(lambda s,n: (s, n + 1), [upload_btn, num_load_btn_1], [output_file_1, num_load_btn_1])
upload_btn.click(lambda n: (n + 1), output_click_1, [output_click_1])
with gr.Row():
with gr.Column():
upload_btn_multiple = gr.UploadButton(label="Upload Multiple Files", file_count="multiple")
with gr.Column():
output_file_2 = gr.File(label="Upload Multiple Files Output", file_count="multiple")
num_load_btn_2 = gr.Number(label="# Load Upload Multiple Files", value=0)
output_click_2 = gr.Number(label="# Click Upload Multiple Files Output", value=0)
upload_btn_multiple.upload(lambda s,n: (s, n + 1), [upload_btn_multiple, num_load_btn_2], [output_file_2, num_load_btn_2])
upload_btn_multiple.click(lambda n: (n + 1), output_click_2, [output_click_2])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/upload_button_component_events/run.ipynb |
Normalization and pre-tokenization[[normalization-and-pre-tokenization]]
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section4.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section4.ipynb"},
]} />
Before we dive more deeply into the three most common subword tokenization algorithms used with Transformer models (Byte-Pair Encoding [BPE], WordPiece, and Unigram), we'll first take a look at the preprocessing that each tokenizer applies to text. Here's a high-level overview of the steps in the tokenization pipeline:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/tokenization_pipeline.svg" alt="The tokenization pipeline.">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/tokenization_pipeline-dark.svg" alt="The tokenization pipeline.">
</div>
Before splitting a text into subtokens (according to its model), the tokenizer performs two steps: _normalization_ and _pre-tokenization_.
## Normalization[[normalization]]
<Youtube id="4IIC2jI9CaU"/>
The normalization step involves some general cleanup, such as removing needless whitespace, lowercasing, and/or removing accents. If you're familiar with [Unicode normalization](http://www.unicode.org/reports/tr15/) (such as NFC or NFKC), this is also something the tokenizer may apply.
The 🤗 Transformers `tokenizer` has an attribute called `backend_tokenizer` that provides access to the underlying tokenizer from the 🤗 Tokenizers library:
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(type(tokenizer.backend_tokenizer))
```
```python out
<class 'tokenizers.Tokenizer'>
```
The `normalizer` attribute of the `tokenizer` object has a `normalize_str()` method that we can use to see how the normalization is performed:
```py
print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
```
```python out
'hello how are u?'
```
In this example, since we picked the `bert-base-uncased` checkpoint, the normalization applied lowercasing and removed the accents.
<Tip>
✏️ **Try it out!** Load a tokenizer from the `bert-base-cased` checkpoint and pass the same example to it. What are the main differences you can see between the cased and uncased versions of the tokenizer?
</Tip>
## Pre-tokenization[[pre-tokenization]]
<Youtube id="grlLV8AIXug"/>
As we will see in the next sections, a tokenizer cannot be trained on raw text alone. Instead, we first need to split the texts into small entities, like words. That's where the pre-tokenization step comes in. As we saw in [Chapter 2](/course/chapter2), a word-based tokenizer can simply split a raw text into words on whitespace and punctuation. Those words will be the boundaries of the subtokens the tokenizer can learn during its training.
To see how a fast tokenizer performs pre-tokenization, we can use the `pre_tokenize_str()` method of the `pre_tokenizer` attribute of the `tokenizer` object:
```py
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
```
```python out
[('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
```
Notice how the tokenizer is already keeping track of the offsets, which is how it can give us the offset mapping we used in the previous section. Here the tokenizer ignores the two spaces and replaces them with just one, but the offset jumps between `are` and `you` to account for that.
Since we're using a BERT tokenizer, the pre-tokenization involves splitting on whitespace and punctuation. Other tokenizers can have different rules for this step. For example, if we use the GPT-2 tokenizer:
```py
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
```
it will split on whitespace and punctuation as well, but it will keep the spaces and replace them with a `Ġ` symbol, enabling it to recover the original spaces if we decode the tokens:
```python out
[('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)),
('?', (19, 20))]
```
Also note that unlike the BERT tokenizer, this tokenizer does not ignore the double space.
For a last example, let's have a look at the T5 tokenizer, which is based on the SentencePiece algorithm:
```py
tokenizer = AutoTokenizer.from_pretrained("t5-small")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
```
```python out
[('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
```
Like the GPT-2 tokenizer, this one keeps spaces and replaces them with a specific token (`_`), but the T5 tokenizer only splits on whitespace, not punctuation. Also note that it added a space by default at the beginning of the sentence (before `Hello`) and ignored the double space between `are` and `you`.
Now that we've seen a little of how some different tokenizers process text, we can start to explore the underlying algorithms themselves. We'll begin with a quick look at the broadly widely applicable SentencePiece; then, over the next three sections, we'll examine how the three main algorithms used for subword tokenization work.
## SentencePiece[[sentencepiece]]
[SentencePiece](https://github.com/google/sentencepiece) is a tokenization algorithm for the preprocessing of text that you can use with any of the models we will see in the next three sections. It considers the text as a sequence of Unicode characters, and replaces spaces with a special character, `▁`. Used in conjunction with the Unigram algorithm (see [section 7](/course/chapter7/7)), it doesn't even require a pre-tokenization step, which is very useful for languages where the space character is not used (like Chinese or Japanese).
The other main feature of SentencePiece is *reversible tokenization*: since there is no special treatment of spaces, decoding the tokens is done simply by concatenating them and replacing the `_`s with spaces -- this results in the normalized text. As we saw earlier, the BERT tokenizer removes repeating spaces, so its tokenization is not reversible.
## Algorithm overview[[algorithm-overview]]
In the following sections, we'll dive into the three main subword tokenization algorithms: BPE (used by GPT-2 and others), WordPiece (used for example by BERT), and Unigram (used by T5 and others). Before we get started, here's a quick overview of how they each work. Don't hesitate to come back to this table after reading each of the next sections if it doesn't make sense to you yet.
Model | BPE | WordPiece | Unigram
:----:|:---:|:---------:|:------:
Training | Starts from a small vocabulary and learns rules to merge tokens | Starts from a small vocabulary and learns rules to merge tokens | Starts from a large vocabulary and learns rules to remove tokens
Training step | Merges the tokens corresponding to the most common pair | Merges the tokens corresponding to the pair with the best score based on the frequency of the pair, privileging pairs where each individual token is less frequent | Removes all the tokens in the vocabulary that will minimize the loss computed on the whole corpus
Learns | Merge rules and a vocabulary | Just a vocabulary | A vocabulary with a score for each token
Encoding | Splits a word into characters and applies the merges learned during training | Finds the longest subword starting from the beginning that is in the vocabulary, then does the same for the rest of the word | Finds the most likely split into tokens, using the scores learned during training
Now let's dive into BPE! | huggingface/course/blob/main/chapters/en/chapter6/4.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Map pools
Map pools allow you to instantiate multiple versions of your environment on the backend, the enables higher
throughput with parallelization of interaction in simulations and embodied environments.
Using map pools is simple with 🤗 Simulate. First define a function that will generate your environment, we call each environment instance a "map".
```
def generate_map(index):
root = sm.Asset(name=f"root_{index}")
root += sm.Box(
name=f"floor_{index}",
position=[0, -0.05, 0],
scaling=[10, 0.1, 10],
material=sm.Material.BLUE,
with_collider=True,
)
root += sm.Box(
name=f"wall1_{index}",
position=[-1, 0.5, 0],
scaling=[0.1, 1, 5.1],
material=sm.Material.GRAY75,
with_collider=True,
)
root += sm.Box(
name=f"wall2_{index}",
position=[1, 0.5, 0],
scaling=[0.1, 1, 5.1],
material=sm.Material.GRAY75,
with_collider=True,
)
root += sm.Box(
name=f"wall3_{index}",
position=[0, 0.5, 4.5],
scaling=[5.9, 1, 0.1],
material=sm.Material.GRAY75,
with_collider=True,
)
# add actors, sensors, reward functions etc ...
return root
```
You can then provide the `generate_map` method as an argument to the `sm.ParallelRLEnv` class, which will instantiate `n_maps`.
Training with a subset of the maps is possible using the `n_show` option. At each environment reset, it cycles through to the next map.
[[autodoc]] ParallelRLEnv
| huggingface/simulate/blob/main/docs/source/howto/map_pools.mdx |
@gradio/imageeditor
## 0.2.0
### Features
- [#6809](https://github.com/gradio-app/gradio/pull/6809) [`1401d99`](https://github.com/gradio-app/gradio/commit/1401d99ade46d87da75b5f5808a3354c49f1d1ea) - Fix `ImageEditor` interaction story. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.5
### Fixes
- [#6799](https://github.com/gradio-app/gradio/pull/6799) [`c352811`](https://github.com/gradio-app/gradio/commit/c352811f76d4126613ece0a584f8c552fdd8d1f6) - Adds docstrings for `gr.WaveformOptions`, `gr.Brush`, and `gr.Eraser`, fixes examples for `ImageEditor`, and allows individual images to be used as the initial `value` for `ImageEditor`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.1.4
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.3
### Patch Changes
- Updated dependencies [[`6a9151d`](https://github.com/gradio-app/gradio/commit/6a9151d5c9432c724098da7d88a539aaaf5ffe88), [`21cfb0a`](https://github.com/gradio-app/gradio/commit/21cfb0acc309bb1a392f4d8a8e42f6be864c5978), [`d76bcaa`](https://github.com/gradio-app/gradio/commit/d76bcaaaf0734aaf49a680f94ea9d4d22a602e70), [`67ddd40`](https://github.com/gradio-app/gradio/commit/67ddd40b4b70d3a37cb1637c33620f8d197dbee0), [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`bdf81fe`](https://github.com/gradio-app/gradio/commit/bdf81fead86e1d5a29e6b036f1fff677f6480e6b), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00), [`5177132`](https://github.com/gradio-app/gradio/commit/5177132d718c77f6d47869b4334afae6380394cb)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.2
### Patch Changes
- Updated dependencies [[`b639e04`](https://github.com/gradio-app/gradio/commit/b639e040741e6c0d9104271c81415d7befbd8cf3), [`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.1
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/[email protected]
- @gradio/[email protected]
- @gradio/[email protected]
## 0.1.0
### Highlights
#### New `ImageEditor` component ([#6169](https://github.com/gradio-app/gradio/pull/6169) [`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8))
A brand new component, completely separate from `Image` that provides simple editing capabilities.
- Set background images from file uploads, webcam, or just paste!
- Crop images with an improved cropping UI. App authors can event set specific crop size, or crop ratios (`1:1`, etc)
- Paint on top of any image (or no image) and erase any mistakes!
- The ImageEditor supports layers, confining draw and erase actions to that layer.
- More flexible access to data. The image component returns a composite image representing the final state of the canvas as well as providing the background and all layers as individual images.
- Fully customisable. All features can be enabled and disabled. Even the brush color swatches can be customised.
<video src="https://user-images.githubusercontent.com/12937446/284027169-31188926-fd16-4a1c-8718-998e7aae4695.mp4" autoplay muted></video>
```py
def fn(im):
im["composite"] # the full canvas
im["background"] # the background image
im["layers"] # a list of individual layers
im = gr.ImageEditor(
# decide which sources you'd like to accept
sources=["upload", "webcam", "clipboard"],
# set a cropsize constraint, can either be a ratio or a concrete [width, height]
crop_size="1:1",
# enable crop (or disable it)
transforms=["crop"],
# customise the brush
brush=Brush(
default_size="25", # or leave it as 'auto'
color_mode="fixed", # 'fixed' hides the user swatches and colorpicker, 'defaults' shows it
default_color="hotpink", # html names are supported
colors=[
"rgba(0, 150, 150, 1)", # rgb(a)
"#fff", # hex rgb
"hsl(360, 120, 120)" # in fact any valid colorstring
]
),
brush=Eraser(default_size="25")
)
```
Thanks [@pngwn](https://github.com/pngwn)!
### Fixes
- [#6502](https://github.com/gradio-app/gradio/pull/6502) [`070f71c93`](https://github.com/gradio-app/gradio/commit/070f71c933d846ce8e2fe11cdd9bc0f3f897f29f) - Ensure image editor crop and draw cursor works as expected when the scroll position changes. Thanks [@pngwn](https://github.com/pngwn)!
# @gradio/image | gradio-app/gradio/blob/main/js/imageeditor/CHANGELOG.md |
How to contribute to simulate?
[](CODE_OF_CONDUCT.md)
Simulation environments is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporting bugs, proposing enhancements,
improving the documentation, fixing bugs,...
Many thanks in advance to every contributor.
In order to facilitate healthy, constructive behavior in an open and inclusive community, we all respect and abide by
our [code of conduct](CODE_OF_CONDUCT.md).
## How to work on an open Issue?
You have the list of open Issues at: https://github.com/huggingface/simulate/issues
Some of them may have the label `help wanted`: that means that any contributor is welcomed!
If you would like to work on any of the open Issues:
1. Make sure it is not already assigned to someone else. You have the assignee (if any) on the top of the right column of the Issue page.
2. You can self-assign it by commenting on the Issue page with one of the keywords: `#take` or `#self-assign`.
3. Work on your self-assigned issue and eventually create a Pull Request.
## How to create a Pull Request?
1. Fork the [repository](https://github.com/huggingface/simulate) by clicking on the 'Fork' button on the repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone [email protected]:<your Github handle>/simulate.git
cd simulate
git remote add upstream https://github.com/huggingface/simulate.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
**do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
(If simulate was already installed in the virtual environment, remove
it with `pip uninstall simulate` before reinstalling it in editable
mode with the `-e` flag.)
5. Develop the features on your branch. If you want to add a dataset see more in-detail instructions in the section [*How to add a dataset*](#how-to-add-a-dataset).
6. Format your code. Run black and isort so that your newly added files look nice with the following command:
```bash
make style
```
7. Once you're happy with your dataset script file, add your changes and make a commit to record your changes locally:
```bash
git add simulate/<your_dataset_name>
git commit
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/main
```
Push the changes to your account using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
8. Once you are satisfied, go the webpage of your fork on GitHub. Click on "Pull request" to send your to the project maintainers for review.
## Code of conduct
This project adheres to the HuggingFace [code of conduct](CODE_OF_CONDUCT.md).
By participating, you are expected to uphold this code.
| huggingface/simulate/blob/main/CONTRIBUTING.md |
Gradio Demo: chatinterface_system_prompt
```
!pip install -q gradio
```
```
import gradio as gr
import time
def echo(message, history, system_prompt, tokens):
response = f"System prompt: {system_prompt}\n Message: {message}."
for i in range(min(len(response), int(tokens))):
time.sleep(0.05)
yield response[: i+1]
demo = gr.ChatInterface(echo,
additional_inputs=[
gr.Textbox("You are helpful AI.", label="System Prompt"),
gr.Slider(10, 100)
]
)
if __name__ == "__main__":
demo.queue().launch()
```
| gradio-app/gradio/blob/main/demo/chatinterface_system_prompt/run.ipynb |
CSP-ResNeXt
**CSPResNeXt** is a convolutional neural network where we apply the Cross Stage Partial Network (CSPNet) approach to [ResNeXt](https://paperswithcode.com/method/resnext). The CSPNet partitions the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('cspresnext50', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspresnext50`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('cspresnext50', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{wang2019cspnet,
title={CSPNet: A New Backbone that can Enhance Learning Capability of CNN},
author={Chien-Yao Wang and Hong-Yuan Mark Liao and I-Hau Yeh and Yueh-Hua Wu and Ping-Yang Chen and Jun-Wei Hsieh},
year={2019},
eprint={1911.11929},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP ResNeXt
Paper:
Title: 'CSPNet: A New Backbone that can Enhance Learning Capability of CNN'
URL: https://paperswithcode.com/paper/cspnet-a-new-backbone-that-can-enhance
Models:
- Name: cspresnext50
In Collection: CSP ResNeXt
Metadata:
FLOPs: 3962945536
Parameters: 20570000
File Size: 82562887
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Polynomial Learning Rate Decay
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 1x GPU
ID: cspresnext50
LR: 0.1
Layers: 50
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 128
Image Size: '224'
Weight Decay: 0.005
Interpolation: bilinear
Training Steps: 8000000
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L430
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspresnext50_ra_224-648b4713.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.05%
Top 5 Accuracy: 94.94%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/csp-resnext.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# MultiDiffusion
[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation](https://huggingface.co/papers/2302.08113) is by Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel.
The abstract from the paper is:
*Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.*
You can find additional information about MultiDiffusion on the [project page](https://multidiffusion.github.io/), [original codebase](https://github.com/omerbt/MultiDiffusion), and try it out in a [demo](https://huggingface.co/spaces/weizmannscience/MultiDiffusion).
## Tips
While calling [`StableDiffusionPanoramaPipeline`], it's possible to specify the `view_batch_size` parameter to be > 1.
For some GPUs with high performance, this can speedup the generation process and increase VRAM usage.
To generate panorama-like images make sure you pass the width parameter accordingly. We recommend a width value of 2048 which is the default.
Circular padding is applied to ensure there are no stitching artifacts when working with panoramas to ensure a seamless transition from the rightmost part to the leftmost part. By enabling circular padding (set `circular_padding=True`), the operation applies additional crops after the rightmost point of the image, allowing the model to "see” the transition from the rightmost part to the leftmost part. This helps maintain visual consistency in a 360-degree sense and creates a proper “panorama” that can be viewed using 360-degree panorama viewers. When decoding latents in Stable Diffusion, circular padding is applied to ensure that the decoded latents match in the RGB space.
For example, without circular padding, there is a stitching artifact (default):

But with circular padding, the right and the left parts are matching (`circular_padding=True`):

<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## StableDiffusionPanoramaPipeline
[[autodoc]] StableDiffusionPanoramaPipeline
- __call__
- all
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/panorama.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Actors
[[autodoc]] SimpleActor
[[autodoc]] EgocentricCameraActor
Under construction 🚧. | huggingface/simulate/blob/main/docs/source/api/actors.mdx |
ow to preprocess pairs of sentences? We have seen how to tokenize single sentences and batch them together in the "Batching inputs together" video. If this code look unfamiliar to you, be sure to check that video again! Here we will focus on tasks that classify pairs of sentences. For instance, we may want to classify whether two texts are paraphrases or not. Here is an example taken from the Quora Question Pairs dataset, which focuses on identifying duplicate questions. In the first pair, the two questions are duplicates; in the second, they are not. Another pair classification problem is when we want to know if two sentences are logically related or not (a problem called Natural Language Inference or NLI). In this example taken from the MultiNLI dataset, we have a pair of sentences for each possible label: contradiction, neutral or entailment (which is a fancy way of saying the first sentence implies the second). So classifying pairs of sentences is a problem worth studying. In fact, in the GLUE benchmark (which is an academic benchmark for text classification), 8 of the 10 datasets are focused on tasks using pairs of sentences. That's why models like BERT are often pretrained with a dual objective: on top of the language modeling objective, they often have an objective related to sentence pairs. For instance, during pretraining, BERT is shown pairs of sentences and must predict both the value of randomly masked tokens and whether the second sentence follows from the first. Fortunately, the tokenizer from the Transformers library has a nice API to deal with pairs of sentences: you just have to pass them as two arguments to the tokenizer. On top of the input IDs and the attention mask we studied already, it returns a new field called token type IDs, which tells the model which tokens belong to the first sentence and which ones belong to the second sentence. Zooming in a little bit, here are the input IDs, aligned with the tokens they correspond to, their respective token type ID and attention mask. We can see the tokenizer also added special tokens so we have a CLS token, the tokens from the first sentence, a SEP token, the tokens from the second sentence, and a final SEP token. If we have several pairs of sentences, we can tokenize them together by passing the list of first sentences, then the list of second sentences and all the keyword arguments we studied already, like padding=True. Zooming in at the result, we can see how the tokenizer added padding to the second pair of sentences, to make the two outputs the same length, and properly dealt with token type IDS and attention masks for the two sentences. This is then all ready to pass through our model! | huggingface/course/blob/main/subtitles/en/raw/chapter3/02c_preprocess-sentence-pairs-pt.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Download files from the Hub
The `huggingface_hub` library provides functions to download files from the repositories
stored on the Hub. You can use these functions independently or integrate them into your
own library, making it more convenient for your users to interact with the Hub. This
guide will show you how to:
* Download and cache a single file.
* Download and cache an entire repository.
* Download files to a local folder.
## Download a single file
The [`hf_hub_download`] function is the main function for downloading files from the Hub.
It downloads the remote file, caches it on disk (in a version-aware way), and returns its local file path.
<Tip>
The returned filepath is a pointer to the HF local cache. Therefore, it is important to not modify the file to avoid
having a corrupted cache. If you are interested in getting to know more about how files are cached, please refer to our
[caching guide](./manage-cache).
</Tip>
### From latest version
Select the file to download using the `repo_id`, `repo_type` and `filename` parameters. By default, the file will
be considered as being part of a `model` repo.
```python
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")
'/root/.cache/huggingface/hub/models--lysandre--arxiv-nlp/snapshots/894a9adde21d9a3e3843e6d5aeaaf01875c7fade/config.json'
# Download from a dataset
>>> hf_hub_download(repo_id="google/fleurs", filename="fleurs.py", repo_type="dataset")
'/root/.cache/huggingface/hub/datasets--google--fleurs/snapshots/199e4ae37915137c555b1765c01477c216287d34/fleurs.py'
```
### From specific version
By default, the latest version from the `main` branch is downloaded. However, in some cases you want to download a file
at a particular version (e.g. from a specific branch, a PR, a tag or a commit hash).
To do so, use the `revision` parameter:
```python
# Download from the `v1.0` tag
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", revision="v1.0")
# Download from the `test-branch` branch
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", revision="test-branch")
# Download from Pull Request #3
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", revision="refs/pr/3")
# Download from a specific commit hash
>>> hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json", revision="877b84a8f93f2d619faa2a6e514a32beef88ab0a")
```
**Note:** When using the commit hash, it must be the full-length hash instead of a 7-character commit hash.
### Construct a download URL
In case you want to construct the URL used to download a file from a repo, you can use [`hf_hub_url`] which returns a URL.
Note that it is used internally by [`hf_hub_download`].
## Download an entire repository
[`snapshot_download`] downloads an entire repository at a given revision. It uses internally [`hf_hub_download`] which
means all downloaded files are also cached on your local disk. Downloads are made concurrently to speed-up the process.
To download a whole repository, just pass the `repo_id` and `repo_type`:
```python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="lysandre/arxiv-nlp")
'/home/lysandre/.cache/huggingface/hub/models--lysandre--arxiv-nlp/snapshots/894a9adde21d9a3e3843e6d5aeaaf01875c7fade'
# Or from a dataset
>>> snapshot_download(repo_id="google/fleurs", repo_type="dataset")
'/home/lysandre/.cache/huggingface/hub/datasets--google--fleurs/snapshots/199e4ae37915137c555b1765c01477c216287d34'
```
[`snapshot_download`] downloads the latest revision by default. If you want a specific repository revision, use the
`revision` parameter:
```python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="lysandre/arxiv-nlp", revision="refs/pr/1")
```
### Filter files to download
[`snapshot_download`] provides an easy way to download a repository. However, you don't always want to download the
entire content of a repository. For example, you might want to prevent downloading all `.bin` files if you know you'll
only use the `.safetensors` weights. You can do that using `allow_patterns` and `ignore_patterns` parameters.
These parameters accept either a single pattern or a list of patterns. Patterns are Standard Wildcards (globbing
patterns) as documented [here](https://tldp.org/LDP/GNU-Linux-Tools-Summary/html/x11655.htm). The pattern matching is
based on [`fnmatch`](https://docs.python.org/3/library/fnmatch.html).
For example, you can use `allow_patterns` to only download JSON configuration files:
```python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="lysandre/arxiv-nlp", allow_patterns="*.json")
```
On the other hand, `ignore_patterns` can exclude certain files from being downloaded. The
following example ignores the `.msgpack` and `.h5` file extensions:
```python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="lysandre/arxiv-nlp", ignore_patterns=["*.msgpack", "*.h5"])
```
Finally, you can combine both to precisely filter your download. Here is an example to download all json and markdown
files except `vocab.json`.
```python
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="gpt2", allow_patterns=["*.md", "*.json"], ignore_patterns="vocab.json")
```
## Download file(s) to local folder
The recommended (and default) way to download files from the Hub is to use the [cache-system](./manage-cache).
You can define your cache location by setting `cache_dir` parameter (both in [`hf_hub_download`] and [`snapshot_download`]).
However, in some cases you want to download files and move them to a specific folder. This is useful to get a workflow
closer to what `git` commands offer. You can do that using the `local_dir` and `local_dir_use_symlinks` parameters:
- `local_dir` must be a path to a folder on your system. The downloaded files will keep the same file structure as in the
repo. For example if `filename="data/train.csv"` and `local_dir="path/to/folder"`, then the returned filepath will be
`"path/to/folder/data/train.csv"`.
- `local_dir_use_symlinks` defines how the file must be saved in your local folder.
- The default behavior (`"auto"`) is to duplicate small files (<5MB) and use symlinks for bigger files. Symlinks allow
to optimize both bandwidth and disk usage. However manually editing a symlinked file might corrupt the cache, hence
the duplication for small files. The 5MB threshold can be configured with the `HF_HUB_LOCAL_DIR_AUTO_SYMLINK_THRESHOLD`
environment variable.
- If `local_dir_use_symlinks=True` is set, all files are symlinked for an optimal disk space optimization. This is
for example useful when downloading a huge dataset with thousands of small files.
- Finally, if you don't want symlinks at all you can disable them (`local_dir_use_symlinks=False`). The cache directory
will still be used to check wether the file is already cached or not. If already cached, the file is **duplicated**
from the cache (i.e. saves bandwidth but increases disk usage). If the file is not already cached, it will be
downloaded and moved directly to the local dir. This means that if you need to reuse it somewhere else later, it
will be **re-downloaded**.
Here is a table that summarizes the different options to help you choose the parameters that best suit your use case.
<!-- Generated with https://www.tablesgenerator.com/markdown_tables -->
| Parameters | File already cached | Returned path | Can read path? | Can save to path? | Optimized bandwidth | Optimized disk usage |
|---|:---:|:---:|:---:|:---:|:---:|:---:|
| `local_dir=None` | | symlink in cache | ✅ | ❌<br>_(save would corrupt the cache)_ | ✅ | ✅ |
| `local_dir="path/to/folder"`<br>`local_dir_use_symlinks="auto"` | | file or symlink in folder | ✅ | ✅ _(for small files)_ <br> ⚠️ _(for big files do not resolve path before saving)_ | ✅ | ✅ |
| `local_dir="path/to/folder"`<br>`local_dir_use_symlinks=True` | | symlink in folder | ✅ | ⚠️<br>_(do not resolve path before saving)_ | ✅ | ✅ |
| `local_dir="path/to/folder"`<br>`local_dir_use_symlinks=False` | No | file in folder | ✅ | ✅ | ❌<br>_(if re-run, file is re-downloaded)_ | ⚠️<br>(multiple copies if ran in multiple folders) |
| `local_dir="path/to/folder"`<br>`local_dir_use_symlinks=False` | Yes | file in folder | ✅ | ✅ | ⚠️<br>_(file has to be cached first)_ | ❌<br>_(file is duplicated)_ |
**Note:** if you are on a Windows machine, you need to enable developer mode or run `huggingface_hub` as admin to enable
symlinks. Check out the [cache limitations](../guides/manage-cache#limitations) section for more details.
## Download from the CLI
You can use the `huggingface-cli download` command from the terminal to directly download files from the Hub.
Internally, it uses the same [`hf_hub_download`] and [`snapshot_download`] helpers described above and prints the
returned path to the terminal.
```bash
>>> huggingface-cli download gpt2 config.json
/home/wauplin/.cache/huggingface/hub/models--gpt2/snapshots/11c5a3d5811f50298f278a704980280950aedb10/config.json
```
You can download multiple files at once which displays a progress bar and returns the snapshot path in which the files
are located:
```bash
>>> huggingface-cli download gpt2 config.json model.safetensors
Fetching 2 files: 100%|████████████████████████████████████████████| 2/2 [00:00<00:00, 23831.27it/s]
/home/wauplin/.cache/huggingface/hub/models--gpt2/snapshots/11c5a3d5811f50298f278a704980280950aedb10
```
For more details about the CLI download command, please refer to the [CLI guide](./cli#huggingface-cli-download).
## Faster downloads
If you are running on a machine with high bandwidth, you can increase your download speed with [`hf_transfer`](https://github.com/huggingface/hf_transfer), a Rust-based library developed to speed up file transfers with the Hub. To enable it, install the package (`pip install hf_transfer`) and set `HF_HUB_ENABLE_HF_TRANSFER=1` as an environment variable.
<Tip>
Progress bars are supported in `hf_transfer` starting from version `0.1.4`. Consider upgrading (`pip install -U hf-transfer`) if you plan to enable faster downloads.
</Tip>
<Tip warning={true}>
`hf_transfer` is a power user tool! It is tested and production-ready, but it lacks user-friendly features like advanced error handling or proxies. For more details, please take a look at this [section](https://huggingface.co/docs/huggingface_hub/hf_transfer).
</Tip> | huggingface/huggingface_hub/blob/main/docs/source/en/guides/download.md |
Two types of value-based methods [[two-types-value-based-methods]]
In value-based methods, **we learn a value function** that **maps a state to the expected value of being at that state.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/vbm-1.jpg" alt="Value Based Methods"/>
The value of a state is the **expected discounted return** the agent can get if it **starts at that state and then acts according to our policy.**
<Tip>
But what does it mean to act according to our policy? After all, we don't have a policy in value-based methods since we train a value function and not a policy.
</Tip>
Remember that the goal of an **RL agent is to have an optimal policy π\*.**
To find the optimal policy, we learned about two different methods:
- *Policy-based methods:* **Directly train the policy** to select what action to take given a state (or a probability distribution over actions at that state). In this case, we **don't have a value function.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/two-approaches-2.jpg" alt="Two RL approaches"/>
The policy takes a state as input and outputs what action to take at that state (deterministic policy: a policy that output one action given a state, contrary to stochastic policy that output a probability distribution over actions).
And consequently, **we don't define by hand the behavior of our policy; it's the training that will define it.**
- *Value-based methods:* **Indirectly, by training a value function** that outputs the value of a state or a state-action pair. Given this value function, our policy **will take an action.**
Since the policy is not trained/learned, **we need to specify its behavior.** For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, **we'll create a Greedy Policy.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/two-approaches-3.jpg" alt="Two RL approaches"/>
<figcaption>Given a state, our action-value function (that we train) outputs the value of each action at that state. Then, our pre-defined Greedy Policy selects the action that will yield the highest value given a state or a state action pair.</figcaption>
</figure>
Consequently, whatever method you use to solve your problem, **you will have a policy**. In the case of value-based methods, you don't train the policy: your policy **is just a simple pre-specified function** (for instance, the Greedy Policy) that uses the values given by the value-function to select its actions.
So the difference is:
- In policy-based training, **the optimal policy (denoted π\*) is found by training the policy directly.**
- In value-based training, **finding an optimal value function (denoted Q\* or V\*, we'll study the difference below) leads to having an optimal policy.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link between value and policy"/>
In fact, most of the time, in value-based methods, you'll use **an Epsilon-Greedy Policy** that handles the exploration/exploitation trade-off; we'll talk about this when we talk about Q-Learning in the second part of this unit.
As we mentioned above, we have two types of value-based functions:
## The state-value function [[state-value-function]]
We write the state value function under a policy π like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/state-value-function-1.jpg" alt="State value function"/>
For each state, the state-value function outputs the expected return if the agent **starts at that state** and then follows the policy forever afterward (for all future timesteps, if you prefer).
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/state-value-function-2.jpg" alt="State value function"/>
<figcaption>If we take the state with value -7: it's the expected return starting at that state and taking actions according to our policy (greedy policy), so right, right, right, down, down, right, right.</figcaption>
</figure>
## The action-value function [[action-value-function]]
In the action-value function, for each state and action pair, the action-value function **outputs the expected return** if the agent starts in that state, takes that action, and then follows the policy forever after.
The value of taking action \\(a\\) in state \\(s\\) under a policy \\(π\\) is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/action-state-value-function-1.jpg" alt="Action State value function"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/action-state-value-function-2.jpg" alt="Action State value function"/>
We see that the difference is:
- For the state-value function, we calculate **the value of a state \\(S_t\\)**
- For the action-value function, we calculate **the value of the state-action pair ( \\(S_t, A_t\\) ) hence the value of taking that action at that state.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/two-types.jpg" alt="Two types of value function"/>
<figcaption>
Note: We didn't fill all the state-action pairs for the example of Action-value function</figcaption>
</figure>
In either case, whichever value function we choose (state-value or action-value function), **the returned value is the expected return.**
However, the problem is that **to calculate EACH value of a state or a state-action pair, we need to sum all the rewards an agent can get if it starts at that state.**
This can be a computationally expensive process, and that's **where the Bellman equation comes in to help us.**
| huggingface/deep-rl-class/blob/main/units/en/unit2/two-types-value-based-methods.mdx |
The Hugging Face Course
This repo contains the content that's used to create the **[Hugging Face course](https://huggingface.co/course/chapter1/1)**. The course teaches you about applying Transformers to various tasks in natural language processing and beyond. Along the way, you'll learn how to use the [Hugging Face](https://huggingface.co/) ecosystem — [🤗 Transformers](https://github.com/huggingface/transformers), [🤗 Datasets](https://github.com/huggingface/datasets), [🤗 Tokenizers](https://github.com/huggingface/tokenizers), and [🤗 Accelerate](https://github.com/huggingface/accelerate) — as well as the [Hugging Face Hub](https://huggingface.co/models). It's completely free and open-source!
## 🌎 Languages and translations
| Language | Source | Authors |
|:------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [English](https://huggingface.co/course/en/chapter1/1) | [`chapters/en`](https://github.com/huggingface/course/tree/main/chapters/en) | [@sgugger](https://github.com/sgugger), [@lewtun](https://github.com/lewtun), [@LysandreJik](https://github.com/LysandreJik), [@Rocketknight1](https://github.com/Rocketknight1), [@sashavor](https://github.com/sashavor), [@osanseviero](https://github.com/osanseviero), [@SaulLu](https://github.com/SaulLu), [@lvwerra](https://github.com/lvwerra) |
| [Bengali](https://huggingface.co/course/bn/chapter1/1) (WIP) | [`chapters/bn`](https://github.com/huggingface/course/tree/main/chapters/bn) | [@avishek-018](https://github.com/avishek-018), [@eNipu](https://github.com/eNipu) |
| [German](https://huggingface.co/course/de/chapter1/1) (WIP) | [`chapters/de`](https://github.com/huggingface/course/tree/main/chapters/de) | [@JesperDramsch](https://github.com/JesperDramsch), [@MarcusFra](https://github.com/MarcusFra), [@fabridamicelli](https://github.com/fabridamicelli) |
| [Spanish](https://huggingface.co/course/es/chapter1/1) (WIP) | [`chapters/es`](https://github.com/huggingface/course/tree/main/chapters/es) | [@camartinezbu](https://github.com/camartinezbu), [@munozariasjm](https://github.com/munozariasjm), [@fordaz](https://github.com/fordaz) |
| [Persian](https://huggingface.co/course/fa/chapter1/1) (WIP) | [`chapters/fa`](https://github.com/huggingface/course/tree/main/chapters/fa) | [@jowharshamshiri](https://github.com/jowharshamshiri), [@schoobani](https://github.com/schoobani) |
| [French](https://huggingface.co/course/fr/chapter1/1) | [`chapters/fr`](https://github.com/huggingface/course/tree/main/chapters/fr) | [@lbourdois](https://github.com/lbourdois), [@ChainYo](https://github.com/ChainYo), [@melaniedrevet](https://github.com/melaniedrevet), [@abdouaziz](https://github.com/abdouaziz) |
| [Gujarati](https://huggingface.co/course/gu/chapter1/1) (WIP) | [`chapters/gu`](https://github.com/huggingface/course/tree/main/chapters/gu) | [@pandyaved98](https://github.com/pandyaved98) |
| [Hebrew](https://huggingface.co/course/he/chapter1/1) (WIP) | [`chapters/he`](https://github.com/huggingface/course/tree/main/chapters/he) | [@omer-dor](https://github.com/omer-dor) |
| [Hindi](https://huggingface.co/course/hi/chapter1/1) (WIP) | [`chapters/hi`](https://github.com/huggingface/course/tree/main/chapters/hi) | [@pandyaved98](https://github.com/pandyaved98) |
| [Bahasa Indonesia](https://huggingface.co/course/id/chapter1/1) (WIP) | [`chapters/id`](https://github.com/huggingface/course/tree/main/chapters/id) | [@gstdl](https://github.com/gstdl) |
| [Italian](https://huggingface.co/course/it/chapter1/1) (WIP) | [`chapters/it`](https://github.com/huggingface/course/tree/main/chapters/it) | [@CaterinaBi](https://github.com/CaterinaBi), [@ClonedOne](https://github.com/ClonedOne), [@Nolanogenn](https://github.com/Nolanogenn), [@EdAbati](https://github.com/EdAbati), [@gdacciaro](https://github.com/gdacciaro) |
| [Japanese](https://huggingface.co/course/ja/chapter1/1) (WIP) | [`chapters/ja`](https://github.com/huggingface/course/tree/main/chapters/ja) | [@hiromu166](https://github.com/@hiromu166), [@younesbelkada](https://github.com/@younesbelkada), [@HiromuHota](https://github.com/@HiromuHota) |
| [Korean](https://huggingface.co/course/ko/chapter1/1) (WIP) | [`chapters/ko`](https://github.com/huggingface/course/tree/main/chapters/ko) | [@Doohae](https://github.com/Doohae), [@wonhyeongseo](https://github.com/wonhyeongseo), [@dlfrnaos19](https://github.com/dlfrnaos19), [@nsbg](https://github.com/nsbg) |
| [Portuguese](https://huggingface.co/course/pt/chapter1/1) (WIP) | [`chapters/pt`](https://github.com/huggingface/course/tree/main/chapters/pt) | [@johnnv1](https://github.com/johnnv1), [@victorescosta](https://github.com/victorescosta), [@LincolnVS](https://github.com/LincolnVS) |
| [Russian](https://huggingface.co/course/ru/chapter1/1) (WIP) | [`chapters/ru`](https://github.com/huggingface/course/tree/main/chapters/ru) | [@pdumin](https://github.com/pdumin), [@svv73](https://github.com/svv73) |
| [Thai](https://huggingface.co/course/th/chapter1/1) (WIP) | [`chapters/th`](https://github.com/huggingface/course/tree/main/chapters/th) | [@peeraponw](https://github.com/peeraponw), [@a-krirk](https://github.com/a-krirk), [@jomariya23156](https://github.com/jomariya23156), [@ckingkan](https://github.com/ckingkan) |
| [Turkish](https://huggingface.co/course/tr/chapter1/1) (WIP) | [`chapters/tr`](https://github.com/huggingface/course/tree/main/chapters/tr) | [@tanersekmen](https://github.com/tanersekmen), [@mertbozkir](https://github.com/mertbozkir), [@ftarlaci](https://github.com/ftarlaci), [@akkasayaz](https://github.com/akkasayaz) |
| [Vietnamese](https://huggingface.co/course/vi/chapter1/1) | [`chapters/vi`](https://github.com/huggingface/course/tree/main/chapters/vi) | [@honghanhh](https://github.com/honghanhh) |
| [Chinese (simplified)](https://huggingface.co/course/zh-CN/chapter1/1) | [`chapters/zh-CN`](https://github.com/huggingface/course/tree/main/chapters/zh-CN) | [@zhlhyx](https://github.com/zhlhyx), [petrichor1122](https://github.com/petrichor1122), [@1375626371](https://github.com/1375626371) |
| [Chinese (traditional)](https://huggingface.co/course/zh-TW/chapter1/1) (WIP) | [`chapters/zh-TW`](https://github.com/huggingface/course/tree/main/chapters/zh-TW) | [@davidpeng86](https://github.com/davidpeng86) |
### Translating the course into your language
As part of our mission to democratise machine learning, we'd love to have the course available in many more languages! Please follow the steps below if you'd like to help translate the course into your language 🙏.
**🗞️ Open an issue**
To get started, navigate to the [_Issues_](https://github.com/huggingface/course/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the _Translation template_ from the _New issue_ button.
Once an issue is created, post a comment to indicate which chapters you'd like to work on and we'll add your name to the list.
**🗣 Join our Discord**
Since it can be difficult to discuss translation details quickly over GitHub issues, we have created dedicated channels for each language on our Discord server. If you'd like to join, follow the instructions at this channel 👉: [https://discord.gg/JfAtkvEtRb](https://discord.gg/JfAtkvEtRb)
**🍴 Fork the repository**
Next, you'll need to [fork this repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
```bash
git clone https://github.com/YOUR-USERNAME/course
```
**📋 Copy-paste the English files with a new language code**
The course files are organised under a main directory:
* [`chapters`](https://github.com/huggingface/course/tree/main/chapters): all the text and code snippets associated with the course.
You'll only need to copy the files in the [`chapters/en`](https://github.com/huggingface/course/tree/main/chapters/en) directory, so first navigate to your fork of the repo and run the following:
```bash
cd ~/path/to/course
cp -r chapters/en/CHAPTER-NUMBER chapters/LANG-ID/CHAPTER-NUMBER
```
Here, `CHAPTER-NUMBER` refers to the chapter you'd like to work on and `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
**✍️ Start translating**
Now comes the fun part - translating the text! The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your chapter. This file is used to render the table of contents on the website and provide the links to the Colab notebooks. The only fields you should change are the `title`, ones -- for example, here are the parts of `_toctree.yml` that we'd translate for [Chapter 0](https://huggingface.co/course/chapter0/1?fw=pt):
```yaml
- title: 0. Setup # Translate this!
sections:
- local: chapter0/1 # Do not change this!
title: Introduction # Translate this!
```
> 🚨 Make sure the `_toctree.yml` file only contains the sections that have been translated! Otherwise you won't be able to build the content on the website or locally (see below how).
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your chapter.
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can simply create one by copy-pasting from the English version and deleting the sections that aren't related to your chapter. Just make sure it exists in the `chapters/LANG-ID/` directory!
**👷♂️ Build the course locally**
Once you're happy with your changes, you can preview how they'll look by first installing the [`doc-builder`](https://github.com/huggingface/doc-builder) tool that we use for building all documentation at Hugging Face:
```
pip install hf-doc-builder
```
```
doc-builder preview course ../course/chapters/LANG-ID --not_python_module
```
**`preview` command does not work with Windows.
This will build and render the course on [http://localhost:3000/](http://localhost:3000/). Although the content looks much nicer on the Hugging Face website, this step will still allow you to check that everything is formatted correctly.
**🚀 Submit a pull request**
If the translations look good locally, the final step is to prepare the content for a pull request. Here, the first think to check is that the files are formatted correctly. For that you can run:
```
pip install -r requirements.txt
make style
```
Once that's run, commit any changes, open a pull request, and tag [@lewtun](https://github.com/lewtun) for a review. Congratulations, you've now completed your first translation 🥳!
> 🚨 To build the course on the website, double-check your language code exists in `languages` field of the `build_documentation.yml` and `build_pr_documentation.yml` files in the `.github` folder. If not, just add them in their alphabetical order.
## 📔 Jupyter notebooks
The Jupyter notebooks containing all the code from the course are hosted on the [`huggingface/notebooks`](https://github.com/huggingface/notebooks) repo. If you wish to generate them locally, first install the required dependencies:
```bash
python -m pip install -r requirements.txt
```
Then run the following script:
```bash
python utils/generate_notebooks.py --output_dir nbs
```
This script extracts all the code snippets from the chapters and stores them as notebooks in the `nbs` folder (which is ignored by Git by default).
## ✍️ Contributing a new chapter
> Note: we are not currently accepting community contributions for new chapters. These instructions are for the Hugging Face authors.
Adding a new chapter to the course is quite simple:
1. Create a new directory under `chapters/en/chapterX`, where `chapterX` is the chapter you'd like to add.
2. Add numbered MDX files `sectionX.mdx` for each section. If you need to include images, place them in the [huggingface-course/documentation-images](https://huggingface.co/datasets/huggingface-course/documentation-images) repository and use the [HTML Images Syntax](https://www.w3schools.com/html/html_images.asp) with the path `https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/{langY}/{chapterX}/{your-image.png}`.
3. Update the `_toctree.yml` file to include your chapter sections -- this information will render the table of contents on the website. If your section involves both the PyTorch and TensorFlow APIs of `transformers`, make sure you include links to both Colabs in the `colab` field.
If you get stuck, check out one of the existing chapters -- this will often show you the expected syntax.
Once you are happy with the content, open a pull request and tag [@lewtun](https://github.com/lewtun) for a review. We recommend adding the first chapter draft as a single pull request -- the team will then provide feedback internally to iterate on the content 🤗!
## 🙌 Acknowledgements
The structure of this repo and README are inspired by the wonderful [Advanced NLP with spaCy](https://github.com/ines/spacy-course) course.
| huggingface/course/blob/main/README.md |
The advantages and disadvantages of policy-gradient methods
At this point, you might ask, "but Deep Q-Learning is excellent! Why use policy-gradient methods?". To answer this question, let's study the **advantages and disadvantages of policy-gradient methods**.
## Advantages
There are multiple advantages over value-based methods. Let's see some of them:
### The simplicity of integration
We can estimate the policy directly without storing additional data (action values).
### Policy-gradient methods can learn a stochastic policy
Policy-gradient methods can **learn a stochastic policy while value functions can't**.
This has two consequences:
1. We **don't need to implement an exploration/exploitation trade-off by hand**. Since we output a probability distribution over actions, the agent explores **the state space without always taking the same trajectory.**
2. We also get rid of the problem of **perceptual aliasing**. Perceptual aliasing is when two states seem (or are) the same but need different actions.
Let's take an example: we have an intelligent vacuum cleaner whose goal is to suck the dust and avoid killing the hamsters.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/hamster1.jpg" alt="Hamster 1"/>
</figure>
Our vacuum cleaner can only perceive where the walls are.
The problem is that the **two red (colored) states are aliased states because the agent perceives an upper and lower wall for each**.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/hamster2.jpg" alt="Hamster 1"/>
</figure>
Under a deterministic policy, the policy will either always move right when in a red state or always move left. **Either case will cause our agent to get stuck and never suck the dust**.
Under a value-based Reinforcement learning algorithm, we learn a **quasi-deterministic policy** ("greedy epsilon strategy"). Consequently, our agent can **spend a lot of time before finding the dust**.
On the other hand, an optimal stochastic policy **will randomly move left or right in red (colored) states**. Consequently, **it will not be stuck and will reach the goal state with a high probability**.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/hamster3.jpg" alt="Hamster 1"/>
</figure>
### Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces
The problem with Deep Q-learning is that their **predictions assign a score (maximum expected future reward) for each possible action**, at each time step, given the current state.
But what if we have an infinite possibility of actions?
For instance, with a self-driving car, at each state, you can have a (near) infinite choice of actions (turning the wheel at 15°, 17.2°, 19,4°, honking, etc.). **We'll need to output a Q-value for each possible action**! And **taking the max action of a continuous output is an optimization problem itself**!
Instead, with policy-gradient methods, we output a **probability distribution over actions.**
### Policy-gradient methods have better convergence properties
In value-based methods, we use an aggressive operator to **change the value function: we take the maximum over Q-estimates**.
Consequently, the action probabilities may change dramatically for an arbitrarily small change in the estimated action values if that change results in a different action having the maximal value.
For instance, if during the training, the best action was left (with a Q-value of 0.22) and the training step after it's right (since the right Q-value becomes 0.23), we dramatically changed the policy since now the policy will take most of the time right instead of left.
On the other hand, in policy-gradient methods, stochastic policy action preferences (probability of taking action) **change smoothly over time**.
## Disadvantages
Naturally, policy-gradient methods also have some disadvantages:
- **Frequently, policy-gradient methods converges to a local maximum instead of a global optimum.**
- Policy-gradient goes slower, **step by step: it can take longer to train (inefficient).**
- Policy-gradient can have high variance. We'll see in the actor-critic unit why, and how we can solve this problem.
👉 If you want to go deeper into the advantages and disadvantages of policy-gradient methods, [you can check this video](https://youtu.be/y3oqOjHilio).
| huggingface/deep-rl-class/blob/main/units/en/unit4/advantages-disadvantages.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Shap-E
The Shap-E model was proposed in [Shap-E: Generating Conditional 3D Implicit Functions](https://huggingface.co/papers/2305.02463) by Alex Nichol and Heewoo Jun from [OpenAI](https://github.com/openai).
The abstract from the paper is:
*We present Shap-E, a conditional generative model for 3D assets. Unlike recent work on 3D generative models which produce a single output representation, Shap-E directly generates the parameters of implicit functions that can be rendered as both textured meshes and neural radiance fields. We train Shap-E in two stages: first, we train an encoder that deterministically maps 3D assets into the parameters of an implicit function; second, we train a conditional diffusion model on outputs of the encoder. When trained on a large dataset of paired 3D and text data, our resulting models are capable of generating complex and diverse 3D assets in a matter of seconds. When compared to Point-E, an explicit generative model over point clouds, Shap-E converges faster and reaches comparable or better sample quality despite modeling a higher-dimensional, multi-representation output space.*
The original codebase can be found at [openai/shap-e](https://github.com/openai/shap-e).
<Tip>
See the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## ShapEPipeline
[[autodoc]] ShapEPipeline
- all
- __call__
## ShapEImg2ImgPipeline
[[autodoc]] ShapEImg2ImgPipeline
- all
- __call__
## ShapEPipelineOutput
[[autodoc]] pipelines.shap_e.pipeline_shap_e.ShapEPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/shap_e.md |
Gradio Demo: streaming_wav2vec
```
!pip install -q gradio torch transformers
```
```
from transformers import pipeline
import gradio as gr
import time
p = pipeline("automatic-speech-recognition")
def transcribe(audio, state=""):
time.sleep(2)
text = p(audio)["text"]
state += text + " "
return state, state
demo = gr.Interface(
fn=transcribe,
inputs=[
gr.Audio(sources=["microphone"], type="filepath", streaming=True),
"state"
],
outputs=[
"textbox",
"state"
],
live=True
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/streaming_wav2vec/run.ipynb |
Adding a Sign-In with HF button to your Space
You can enable a built-in sign-in flow in your Space by seamlessly creating and associating an [OAuth/OpenID connect](https://developer.okta.com/blog/2019/10/21/illustrated-guide-to-oauth-and-oidc) app so users can log in with their HF account.
This enables new use cases for your Space. For instance, when combined with [Persistent Storage](https://huggingface.co/docs/hub/spaces-storage), a generative AI Space could allow users to log in to access their previous generations, only accessible to them.
<Tip>
This guide will take you through the process of integrating a *Sign-In with HF* button into any Space. If you're seeking a fast and simple method to implement this in a **Gradio** Space, take a look at its [built-in integration](https://www.gradio.app/guides/sharing-your-app#o-auth-login-via-hugging-face).
</Tip>
<Tip>
You can also use the HF OAuth flow to create a "Sign in with HF" flow in any website or App, outside of Spaces. [Read our general OAuth page](./oauth).
</Tip>
## Create an OAuth app
All you need to do is add `hf_oauth: true` to your Space's metadata inside your `README.md` file.
Here's an example of metadata for a Gradio Space:
```yaml
title: Gradio Oauth Test
emoji: 🏆
colorFrom: pink
colorTo: pink
sdk: gradio
sdk_version: 3.40.0
python_version: 3.10.6
app_file: app.py
hf_oauth: true
# optional, see "Scopes" below. "openid profile" is always included.
hf_oauth_scopes:
- read-repos
- write-repos
- manage-repos
- inference-api
```
You can check out the [configuration reference docs](./spaces-config-reference) for more information.
This will add the following [environment variables](https://huggingface.co/docs/hub/spaces-overview#helper-environment-variables) to your space:
- `OAUTH_CLIENT_ID`: the client ID of your OAuth app (public)
- `OAUTH_CLIENT_SECRET`: the client secret of your OAuth app
- `OAUTH_SCOPES`: scopes accessible by your OAuth app.
- `OPENID_PROVIDER_URL`: The URL of the OpenID provider. The OpenID metadata will be available at [`{OPENID_PROVIDER_URL}/.well-known/openid-configuration`](https://huggingface.co/.well-known/openid-configuration).
As for any other environment variable, you can use them in your code by using `os.getenv("OAUTH_CLIENT_ID")`, for example.
## Redirect URLs
You can use any redirect URL you want, as long as it targets your Space.
Note that `SPACE_HOST` is [available](https://huggingface.co/docs/hub/spaces-overview#helper-environment-variables) as an environment variable.
For example, you can use `https://{SPACE_HOST}/login/callback` as a redirect URI.
## Scopes
The following scopes are always included for Spaces:
- `openid`: Get the ID token in addition to the access token.
- `profile`: Get the user's profile information (username, avatar, etc.)
Those scopes are optional and can be added by setting `hf_oauth_scopes` in your Space's metadata:
- `email`: Get the user's email address.
- `read-repos`: Get read access to the user's personal repos.
- `write-repos`: Get write access to the user's personal repos. Does not grant read access on its own, you need to include `read-repos` as well.
- `manage-repos`: Get access to a repo's settings. Also grants repo creation and deletion.
- `inference-api`: Get access to the [Inference API](https://huggingface.co/docs/api-inference/index), you will be able to make inference requests on behalf of the user.
## Adding the button to your Space
You now have all the information to add a "Sign-in with HF" button to your Space. Some libraries ([Python](https://github.com/lepture/authlib), [NodeJS](https://github.com/panva/node-openid-client)) can help you implement the OpenID/OAuth protocol. Gradio also provides **built-in support**, making implementing the Sign-in with HF button a breeze; you can [check out the associated guide](https://www.gradio.app/guides/sharing-your-app#o-auth-login-via-hugging-face).
Basically, you need to:
- Redirect the user to `https://huggingface.co/oauth/authorize?redirect_uri={REDIRECT_URI}&scope=openid%20profile&client_id={CLIENT_ID}&state={STATE}`, where `STATE` is a random string that you will need to verify later.
- Handle the callback on `/auth/callback` or `/login/callback` (or your own custom callback URL) and verify the `state` parameter.
- Use the `code` query parameter to get an access token and id token from `https://huggingface.co/oauth/token` (POST request with `client_id`, `code`, `grant_type=authorization_code` and `redirect_uri` as form data, and with `Authorization: Basic {base64(client_id:client_secret)}` as a header).
<Tip warning={true}>
You should use `target=_blank` on the button to open the sign-in page in a new tab, unless you run the space outside its `iframe`. Otherwise, you might encounter issues with cookies on some browsers.
</Tip>
## Examples:
- [Gradio test app](https://huggingface.co/spaces/Wauplin/gradio-oauth-test)
- [Hugging Chat (NodeJS/SvelteKit)](https://huggingface.co/spaces/huggingchat/chat-ui)
- [Inference Widgets (Auth.js/SvelteKit)](https://huggingface.co/spaces/huggingfacejs/inference-widgets), uses the `inference-api` scope to make inference requests on behalf of the user.
| huggingface/hub-docs/blob/main/docs/hub/spaces-oauth.md |
!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🧨 Diffusers Examples
Diffusers examples are a collection of scripts to demonstrate how to effectively use the `diffusers` library
for a variety of use cases involving training or fine-tuning.
**Note**: If you are looking for **official** examples on how to use `diffusers` for inference, please have a look at [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
Our examples aspire to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
More specifically, this means:
- **Self-contained**: An example script shall only depend on "pip-install-able" Python packages that can be found in a `requirements.txt` file. Example scripts shall **not** depend on any local files. This means that one can simply download an example script, *e.g.* [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py), install the required dependencies, *e.g.* [requirements.txt](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/requirements.txt) and execute the example script.
- **Easy-to-tweak**: While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data and the training loop to allow you to tweak and edit them as required.
- **Beginner-friendly**: We do not aim for providing state-of-the-art training scripts for the newest models, but rather examples that can be used as a way to better understand diffusion models and how to use them with the `diffusers` library. We often purposefully leave out certain state-of-the-art methods if we consider them too complex for beginners.
- **One-purpose-only**: Examples should show one task and one task only. Even if a task is from a modeling point of view very similar, *e.g.* image super-resolution and image modification tend to use the same model and training method, we want examples to showcase only one task to keep them as readable and easy-to-understand as possible.
We provide **official** examples that cover the most popular tasks of diffusion models.
*Official* examples are **actively** maintained by the `diffusers` maintainers and we try to rigorously follow our example philosophy as defined above.
If you feel like another important example should exist, we are more than happy to welcome a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) or directly a [Pull Request](https://github.com/huggingface/diffusers/compare) from you!
Training examples show how to pretrain or fine-tune diffusion models for a variety of tasks. Currently we support:
| Task | 🤗 Accelerate | 🤗 Datasets | Colab
|---|---|:---:|:---:|
| [**Unconditional Image Generation**](./unconditional_image_generation) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
| [**Text-to-Image fine-tuning**](./text_to_image) | ✅ | ✅ |
| [**Textual Inversion**](./textual_inversion) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
| [**Dreambooth**](./dreambooth) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb)
| [**ControlNet**](./controlnet) | ✅ | ✅ | -
| [**InstructPix2Pix**](./instruct_pix2pix) | ✅ | ✅ | -
| [**Reinforcement Learning for Control**](https://github.com/huggingface/diffusers/blob/main/examples/reinforcement_learning/run_diffusers_locomotion.py) | - | - | coming soon.
## Community
In addition, we provide **community** examples, which are examples added and maintained by our community.
Community examples can consist of both *training* examples or *inference* pipelines.
For such examples, we are more lenient regarding the philosophy defined above and also cannot guarantee to provide maintenance for every issue.
Examples that are useful for the community, but are either not yet deemed popular or not yet following our above philosophy should go into the [community examples](https://github.com/huggingface/diffusers/tree/main/examples/community) folder. The community folder therefore includes training examples and inference pipelines.
**Note**: Community examples can be a [great first contribution](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) to show to the community how you like to use `diffusers` 🪄.
## Research Projects
We also provide **research_projects** examples that are maintained by the community as defined in the respective research project folders. These examples are useful and offer the extended capabilities which are complementary to the official examples. You may refer to [research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) for details.
## Important note
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder of your choice and run
```bash
pip install -r requirements.txt
```
| huggingface/diffusers/blob/main/examples/README.md |
Fine-tuning for image classification using LoRA and 🤗 PEFT
## Vision Transformer model from transformers
[](https://colab.research.google.com/github/huggingface/peft/blob/main/examples/image_classification/image_classification_peft_lora.ipynb)
We provide a notebook (`image_classification_peft_lora.ipynb`) where we learn how to use [LoRA](https://arxiv.org/abs/2106.09685) from 🤗 PEFT to fine-tune an image classification model by ONLY using **0.7%** of the original trainable parameters of the model.
LoRA adds low-rank "update matrices" to certain blocks in the underlying model (in this case the attention blocks) and ONLY trains those matrices during fine-tuning. During inference, these update matrices are _merged_ with the original model parameters. For more details, check out the [original LoRA paper](https://arxiv.org/abs/2106.09685).
## PoolFormer model from timm
[](https://colab.research.google.com/github/huggingface/peft/blob/main/examples/image_classification/image_classification_timm_peft_lora.ipynb)
The notebook `image_classification_timm_peft_lora.ipynb` showcases fine-tuning an image classification model using from the [timm](https://huggingface.co/docs/timm/index) library. Again, LoRA is used to reduce the numberof trainable parameters to a fraction of the total.
| huggingface/peft/blob/main/examples/image_classification/README.md |
--
title: "Generating Human-level Text with Contrastive Search in Transformers 🤗"
thumbnail: /blog/assets/115_introducing_contrastive_search/thumbnail.png
authors:
- user: GMFTBY
---
# Generating Human-level Text with Contrastive Search in Transformers 🤗
****
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
### 1. Introduction:
Natural language generation (i.e. text generation) is one of the core tasks in natural language processing (NLP). In this blog, we introduce the current state-of-the-art decoding method, ___Contrastive Search___, for neural text generation. Contrastive search is originally proposed in _"A Contrastive Framework for Neural Text Generation"_ <a href='#references'>[1]</a> ([[Paper]](https://arxiv.org/abs/2202.06417)[[Official Implementation]](https://github.com/yxuansu/SimCTG)) at NeurIPS 2022. Moreover, in this follow-up work, _"Contrastive Search Is What You Need For Neural Text Generation"_ <a href='#references'>[2]</a> ([[Paper]](https://arxiv.org/abs/2210.14140) [[Official Implementation]](https://github.com/yxuansu/Contrastive_Search_Is_What_You_Need)), the authors further demonstrate that contrastive search can generate human-level text using **off-the-shelf** language models across **16** languages.
**[Remark]** For users who are not familiar with text generation, please refer more details to [this blog post](https://huggingface.co/blog/how-to-generate).
****
<span id='demo'/>
### 2. Hugging Face 🤗 Demo of Contrastive Search:
Contrastive Search is now available on 🤗 `transformers`, both on PyTorch and TensorFlow. You can interact with the examples shown in this blog post using your framework of choice in [this Colab notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb), which is linked at the top. We have also built this awesome [demo](https://huggingface.co/spaces/joaogante/contrastive_search_generation) which directly compares contrastive search with other popular decoding methods (e.g. beam search, top-k sampling <a href='#references'>[3]</a>, and nucleus sampling <a href='#references'>[4]</a>).
****
<span id='installation'/>
### 3. Environment Installation:
Before running the experiments in the following sections, please install the update-to-date version of `transformers` as
```yaml
pip install torch
pip install "transformers==4.24.0"
```
****
<span id='problems_of_decoding_methods'/>
### 4. Problems of Existing Decoding Methods:
Decoding methods can be divided into two categories: (i) deterministic methods and (ii) stochastic methods. Let's discuss both!
<span id='deterministic_methods'/>
#### 4.1. Deterministic Methods:
Deterministic methods, e.g. greedy search and beam search, generate text by selecting the text continuation with the highest likelihood measured by the language model. However, as widely discussed in previous studies <a href='#references'>[3]</a><a href='#references'>[4]</a>, deterministic methods often lead to the problem of _model degeneration_, i.e., the generated text is unnatural and contains undesirable repetitions.
Below, let's see an example of generated text from greedy search using GPT-2 model.
```python
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
output = model.generate(input_ids, max_length=128)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leading AI research company, with a focus on deep learning and deep
learning-based systems.
The company's research is focused on the development of deep learning-based systems that
can learn from large amounts of data, and that can be used to solve real-world problems.
DeepMind's research is also used by the UK government to develop new technologies for the
UK's National Health Service.
DeepMind's research is also used by the UK government to develop new technologies for the
UK's National Health Service.
DeepMind's research is also used by the UK government to develop new technologies
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** From the result generated by greedy search, we can see obvious pattern of repetitions.
<span id='stochastic_methods'/>
#### 4.2. Stochastic Methods:
To address the issues posed by deterministic methods, stochastic methods generate text by introducing randomness during the decoding process. Two widely-used stochastic methods are (i) top-k sampling <a href='#references'>[3]</a> and (ii) nucleus sampling (also called top-p sampling) <a href='#references'>[4]</a>.
Below, we illustrate an example of generated text by nucleus sampling (p=0.95) using the GPT-2 model.
```python
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=128, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leading provider of AI-based research, development, and delivery of
AI solutions for security, infrastructure, machine learning, communications, and so on."
'AI is not journalism'
Worse still was the message its researchers hoped would reach the world's media — that it
was not really research, but rather a get-rich-quick scheme to profit from living forces'
ignorance.
"The thing is, we know that people don't consciously assess the value of the others'
information. They understand they will get the same on their own."
One example? Given the details of today
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** While nucleus sampling can generate text free of repetitions, the semantic coherence of the generated text is not well-maintained. For instance, the generated phrase _'AI is not journalism'_ is incoherent with respect to the given prefix, i.e. _'DeepMind Company'_.
We note that this semantic inconsistency problem can partially be remedied by lowering the temperature. However, reducing the temperature brings nucleus sampling closer to greedy search, which can be seen as a trade-off between greedy search and nucleus sampling. Generally, it is challenging to find a prompt and model-independent temperature that avoids both the pitfalls of greedy search and nucleus sampling.
****
<span id='contrastive_search'/>
### 5. Contrastive Search:
In this section, we introduce a new decoding method, ___Contrastive Search___, in details.
<span id='contrastive_objective'/>
#### 5.1. Decoding Objective:
Given the prefix text \\(x_{< t}\\), the selection of the output token \\(x_{t}\\) follows
<center class="half">
<img src="assets/115_introducing_contrastive_search/formulation.png" width="750"/>
</center>
where \\(V^{(k)}\\) is the set of top-k predictions from the language model's probability distribution \\(p_{\theta}(v|x_{< t})\\). The first term, i.e. _model confidence_, is the probability of the candidate \\(v\\) predicted by the language model. The second term, _degeneration penalty_, measures how discriminative of \\(v\\) with respect to the previous context \\( x_{< t}\\) and the function \\(s(\cdot, \cdot)\\) computes the cosine similarity between the token representations. More specifically, the degeneration penalty is defined as the maximum cosine similarity between the token representation of \\(v\\), i.e. \\(h_{v}\\), and that of all tokens in the context \\(x_{< t}\\). Here, the candidate representation \\(h_{v}\\) is computed by the language model given the concatenation of \\(x_{< t}\\) and \\(v\\). Intuitively, a larger degeneration penalty of \\(v\\) means it is more similar (in the representation space) to the context, therefore more likely leading to the problem of model degeneration. The hyperparameter \\(\alpha\\) regulates the importance of these two components. When \\(\alpha=0\\), contrastive search degenerates to the vanilla greedy search.
**[Remark]** When generating output, contrastive search jointly considers (i) the probability predicted by the language model to maintain the semantic coherence between the generated text and the prefix text; and (ii) the similarity with respect to the previous context to avoid model degeneration.
<span id='contrastive_generation'/>
#### 5.2. Generating Text with Contrastive Search:
Below, we use the same prefix text (i.e. _"DeepMind Company is"_) as in Section <a href='#deterministic_methods'>4.1</a> and <a href='#stochastic_methods'>4.2</a>, and generate the text with contrastive search (k=4 and \\(\alpha=0.6\\)). To fully demonstrate the superior capability of contrastive search, we let the language model generate a **long** document with **512** tokens as
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = 'gpt2-large'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model.eval()
# prepare the prefix
prefix_text = r'DeepMind Company is'
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
# generate the result with contrastive search
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=512)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
The arguments are as follows:
* `--top_k`: The hyperparameter \\(k\\) in contrastive search.
* `--penalty_alpha`: The hyperparameter \\(\alpha\\) in contrastive search.
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leader in artificial intelligence (AI). We have a long history of working
with companies such as Google, Facebook, Amazon, and Microsoft to build products that improve
people's lives, and today we are excited to announce that DeepMind's AlphaGo program has won the
game of Go, becoming the first program to defeat a professional Go player.
The victory is a testament to the power of deep learning, and to the incredible work of our
research team, which has been at the forefront of AI research for the past five years. AlphaGo
is one of the most advanced Go programs ever created, and its performance is an important step
towards the goal of human-level AI.
"This is the culmination of a decade of hard work," said Andy Ng, co-founder and CTO of DeepMind.
"We are thrilled to have achieved this milestone and look forward to continuing to develop AI that
can be used in a wide range of applications and to help people live better lives."
DeepMind's work on Go began in 2010, when it began to train a neural network to play Go using
millions of games played by top Go players around the world. Since then, the team has refined the
algorithm, adding more and more layers of reinforcement learning to make it better at recognizing
patterns and making decisions based on those patterns. In the past year and a half, the team has
made significant progress in the game, winning a record-tying 13 games in a row to move into the
top four of the world rankings.
"The game of Go is a complex game in which players have to be very careful not to overextend their
territory, and this is something that we have been able to improve over and over again," said
Dr. Demis Hassabis, co-founder and Chief Scientific Officer of DeepMind. "We are very proud of our
team's work, and we hope that it will inspire others to take the next step in their research and
apply the same techniques to other problems."
In addition to the win in Go, DeepMind has also developed an AI system that can learn to play a
number of different games, including poker, Go, and chess. This AI system, called Tarsier, was
developed in partnership with Carnegie Mellon University and the University of California,
Berkeley, and is being used to teach computer vision and machine learning to identify objects in
images and recognize speech in natural language. Tarsier has been trained to play the game of Go
and other games on a
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** We see that the generated text is of exceptionally high quality. The entire document is grammatically fluent as well as semantically coherent. Meanwhile, the generated text also well maintains its factually correctness. For instance, in the first paragraph, it elaborates _"AlphaGo"_ as the _"first program to defeat a professional Go player"_.
<span id='contrastive_visual_demonstration'/>
#### 5.3. Visual Demonstration of Contrastive Search:
To better understand how contrastive search works, we provide a visual comparison between greedy search (<a href='#deterministic_methods'>Section 4.1</a>) and contrastive search. Specifically, we visualize the token similarity matrix of the generated text from greedy search and contrastive search, respectively. The similarity between two tokens is defined as the cosine similarity between their token representations (i.e. the hidden states of the last transformer layer). The results of greedy search (top) and contrastive search (bottom) are shown in the Figure below.
<center class="half">
<img src="assets/115_introducing_contrastive_search/greedy_search_visualization.png" width="400"/>
<img src="assets/115_introducing_contrastive_search/contrastive_search_visualization.png" width="400"/>
</center>
**[Remark]** From the result of greedy search, we see high similarity scores in the off-diagonal entries which clearly indicates the generated repetitions by greedy search. On the contrary, in the result of contrastive search, the high similarity scores mostly appear in the diagonal entries which verifies that the degeneration problem is successfully addressed. This nice property of contrastive search is achieved by the introduction of degeneration penalty (see <a href='#contrastive_objective'>Section 5.1</a>) during the decoding process.
****
<span id='more_examples'/>
### 6. More Generated Examples:
In this section, we provide more generated examples to compare different decoding methods.
<span id='gpt2_example_one'/>
#### 6.1. Example One - GPT-2:
In this part, we use GPT-2 to generate text with the prefix text from the original [OpenAI blog](https://openai.com/blog/better-language-models/) that announced the release of GPT-2.
> _In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English._
<details open>
<summary><b> Load the language model and prepare the prefix text:</b></summary>
```python
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
prefix_text = r"In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
```
</details>
<span id='gpt2_greedy_example_one'/>
##### 6.1.1. Generating Text with Greedy Search:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
output = model.generate(input_ids, max_length=512)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously
unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact
that the unicorns spoke perfect English.
The researchers, led by Dr. David R. Williams of the University of California, Santa Cruz,
discovered the unicorns in the Andes Mountains of Peru. The area is known for its unique geology
and is home to a number of rare species of animals.
The researchers found the unicorns in the Andes Mountains of Peru.
"We were surprised to find that the unicorns were able to communicate with each other," Williams
said. "We were also surprised to find that they were able to communicate in English."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago
----------------------------------------------------------------------------------------------------
```
</details>
<span id='gpt2_nucleus_example_one'/>
##### 6.1.2. Generating Text with Nucleus Sampling:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=512, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously
unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact
that the unicorns spoke perfect English. The study was published in the Journal of Zoology in
March 2016.
Polygynous mammals such as unicorns have remained largely unknown to science. Professor Gustavo
Giacota, from the University of Oxford who led the study, said that they had been documented as
far as Eastern Siberia in Russia, but had only been seen a handful of times in the Gobi Desert.
Tiny animals with pale and shiny coats live in the presence of human beings and are hardly likely
to be victims of any cruelty. However, there is some evidence of the condition occurring in both
humans and animals in remote regions, which might have similarities to "black moles" that coexist
on the skin.
It is thought that Unicorns could be inside themselves, that they have different scents depending
on their current environment, or just fall out and there are plenty of legends of how they have
survived. Experts speculate that the moths and other animals could be remnants of the Yezidi Isis
and Charon, which literally is both the word which means great bird, and the Greek word for sound.
It is said that the Isis and Charon taught their young the use of voice in the form of calling out
to others.
The scientists think that it could be ancient folklore that has survived and is no longer attributed
to a real entity
----------------------------------------------------------------------------------------------------
```
</details>
<span id='gpt2_contrastive_example_one'/>
##### 6.1.3. Generating Text with Contrastive Search:
<details open>
<summary><b>Code:</b></summary>
```python
output = model.generate(input_ids, max_length=512, penalty_alpha=0.6, top_k=4)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored
valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns
spoke perfect English.
According to the BBC, a team of scientists led by Dr David MacKay, from the University of Bristol, spent
two years searching for the unicorn herd, which they discovered during a survey of the area.
"It's a very rare find," MacKay told the BBC. "There are a few in the Himalayas, but this is the first
time we've been able to find one in such a remote area."
The team was surprised to find a herd of unicorns living in a region that has been known to be a hotbed
of poaching, with many of the animals poached for their horns, which are used in traditional Chinese
medicine to treat everything from rheumatism to cancer.
"We knew that the area was rich in rhino horn, but we had no idea how many there were, or what they were
doing there," MacKay said. "This is an area of high poaching pressure, and we wanted to find out what was
going on."
In order to do so, the team used GPS collars to track the animals as they moved around the mountain and
the surrounding area. The GPS data was then compared with information gathered from local villagers, who
had a wealth of information about the animals' movements, including where they were eating, what they were
doing at night, and how much time they spent in the mountains each day.
After analyzing the data, the team determined that the herd consisted of at least three species of unicorns,
including a male and two females. One of the females was the mother of the male, and the other two were her
daughters. All three had the same horn color, which is believed to be a sign of purity in the animal kingdom.
While the discovery is exciting, it's not the first time scientists have discovered an animal that speaks
English. Last year, scientists discovered a species of porcupine that can be heard by humans, and has been
dubbed "Porcupine Man" for his ability to converse with the human race.
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_example_two'/>
#### 6.2. Example Two - OPT:
In this part, we use the OPT model <a href='#references'>[5]</a> which is recently released by Meta to generate text by taking the first two sentences from the abstract of the prestigious ResNet paper <a href='#references'>[6]</a>.
> Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously.
<details open>
<summary><b> Load the language model and prepare the prefix text:</b></summary>
```python
import torch
from transformers import AutoTokenizer, OPTForCausalLM
model_name = r'facebook/opt-1.3b'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OPTForCausalLM.from_pretrained(model_name)
prefix_text = r"Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
```
</details>
<span id='opt_greedy_example_two'/>
##### 6.2.1. Generating Text with Greedy Search:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
output = model.generate(input_ids, max_length=256)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease
the training of networks that are substantially deeper than those used previously. We show that the
residual learning framework can be used to train deep neural networks that are significantly more
difficult to train than those used previously. We also show that the residual learning framework can
be used to train deep neural networks that are significantly more difficult to train than those used
previously.
The paper presents a new residual learning framework for deep neural networks that is based on the
concept of residuals. The residuals are the residuals of the network that are not used in the training
process. The residuals are computed by taking the residuals of the network that are used in the training
process and subtracting the residuals of the network that are not used in the training process. The
residuals are then used to train the network. The residuals are computed by taking the residuals of
the network that are used in the training process and subtracting the residuals of the network that
are not used in the training process. The residuals are then used to train the network. The residuals
are computed by taking the residuals of the network that are used in the training process and
subtracting the residuals of the
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_greedy_example_two'/>
##### 6.2.2. Generating Text with Nucleus Sampling:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=256, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the
training of networks that are substantially deeper than those used previously. The theory focuses on
several aspects of learning, including the dynamics of replicative and non-replicative aspects of learning.
This framework emphasizes learning by entropy. New randomized algorithms enable training networks with
residual learning, so that deep networks can be deployed as reliably and as efficiently as their more
conventional counterparts.
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_contrastive_example_two'/>
##### 6.2.3. Generating Text with Contrastive Search:
<details open>
<summary><b>Code:</b></summary>
```python
output = model.generate(input_ids, max_length=256, penalty_alpha=0.6, top_k=6)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease
the training of networks that are substantially deeper than those used previously.
In this paper, we propose a model-based residual learning (MBRL) framework that is based on neural
networks trained on data that is sparse in terms of dimensionality (e.g., 1, 2, 3, etc.). The network
parameters are chosen such that there is a high probability of convergence, i.e., the number of
iterations is large enough to minimize the variance of the residuals. This is achieved by training
the network on a set of training data, in which the data is sparse in terms of dimensionality, and
then discarding the nonparametric part of the data after training is complete.
We show that MBRL outperforms other methods for deep reinforcement learning (RL) and deep convolutional
neural networks (CNNs) by a factor of at least 2. In addition, we show that, compared to CNNs, MBRL
performs better in two-dimensional (2D) and three-dimensional (3D) cases.
----------------------------------------------------------------------------------------------------
```
</details>
****
<span id='resources'/>
### 7. Resources:
For more details of contrastive search, please check our papers and code as
* **A Contrastive Framework for Neural Text Generation**: (1) [Paper](https://arxiv.org/abs/2202.06417) and (2) [Official Implementation](https://github.com/yxuansu/SimCTG).
* **Contrastive Search Is What You Need For Neural Text Generation**: (1) [Paper](https://arxiv.org/abs/2210.14140) and (2) [Official Implementation](https://github.com/yxuansu/Contrastive_Search_Is_What_You_Need).
****
<span id='citation'/>
### 8. Citation:
```bibtex
@inproceedings{su2022a,
title={A Contrastive Framework for Neural Text Generation},
author={Yixuan Su and Tian Lan and Yan Wang and Dani Yogatama and Lingpeng Kong and Nigel Collier},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=V88BafmH9Pj}
}
@article{su2022contrastiveiswhatyouneed,
title={Contrastive Search Is What You Need For Neural Text Generation},
author={Su, Yixuan and Collier, Nigel},
journal={arXiv preprint arXiv:2210.14140},
year={2022}
}
```
****
<span id='references'/>
## Reference:
> [1] Su et al., 2022 ["A Contrastive Framework for Neural Text Generation"](https://arxiv.org/abs/2202.06417), NeurIPS 2022
> [2] Su and Collier, 2022 ["Contrastive Search Is What You Need For Neural Text Generation"](https://arxiv.org/abs/2210.14140), Arxiv 2022
> [3] Fan et al., 2018 ["Hierarchical Neural Story Generation"](https://arxiv.org/abs/1805.04833), ACL 2018
> [4] Holtzman et al., 2020 ["The Curious Case of Neural Text Degeneration"](https://arxiv.org/abs/1904.09751), ICLR 2020
> [5] Zhang et al., 2022 ["OPT: Open Pre-trained Transformer Language Models"](https://arxiv.org/abs/2205.01068), Arxiv 2022
> [6] He et al., 2016 ["Deep Residual Learning for Image Recognition"](https://arxiv.org/abs/1512.03385), CVPR 2016
****
*- Written by Yixuan Su and Tian Lan*
****
<span id='acknowledgements'/>
## Acknowledgements:
We would like to thank Joao Gante ([@joaogante](https://huggingface.co/joaogante)), Patrick von Platen ([@patrickvonplaten](https://huggingface.co/patrickvonplaten)), and Sylvain Gugger ([@sgugger](https://github.com/sgugger)) for their help and guidance in adding contrastive search mentioned in this blog post into the `transformers` library.
| huggingface/blog/blob/main/introducing-csearch.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Export functions
## Main functions
[[autodoc]] exporters.tflite.convert.export
## Utility functions
[[autodoc]] exporters.tflite.convert.validate_model_outputs
| huggingface/optimum/blob/main/docs/source/exporters/tflite/package_reference/export.mdx |
--
title: "AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU"
thumbnail: /blog/assets/optimum_amd/amd_hf_logo_fixed.png
authors:
- user: fxmarty
- user: IlyasMoutawwakil
- user: mohitsha
- user: echarlaix
- user: seungrokj
guest: true
- user: mfuntowicz
---
# AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU
Earlier this year, [AMD and Hugging Face announced a partnership](https://huggingface.co/blog/huggingface-and-amd) to accelerate AI models during the AMD's AI Day event. We have been hard at work to bring this vision to reality, and make it easy for the Hugging Face community to run the latest AI models on AMD hardware with the best possible performance.
AMD is powering some of the most powerful supercomputers in the World, including the fastest European one, [LUMI](https://www.lumi-supercomputer.eu/lumi-retains-its-position-as-europes-fastest-supercomputer/), which operates over 10,000 MI250X AMD GPUs. At this event, AMD revealed their latest generation of server GPUs, the AMD [Instinct™ MI300](https://www.amd.com/fr/graphics/instinct-server-accelerators) series accelerators, which will soon become generally available.
In this blog post, we provide an update on our progress towards providing great out-of-the-box support for AMD GPUs, and improving the interoperability for the latest server-grade AMD Instinct GPUs
## Out-of-the-box Acceleration
Can you spot AMD-specific code changes below? Don't hurt your eyes, there's none compared to running on NVIDIA GPUs 🤗.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "01-ai/Yi-6B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
with torch.device("cuda"):
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16)
inp = tokenizer(["Today I am in Paris and"], padding=True, return_tensors="pt").to("cuda")
res = model.generate(**inp, max_new_tokens=30)
print(tokenizer.batch_decode(res))
```
One of the major aspects we have been working on is the ability to run Hugging Face Transformers models without any code change. We now support all Transformers models and tasks on AMD Instinct GPUs. And our collaboration is not stopping here, as we explore out-of-the-box support for diffusers models, and other libraries as well as other AMD GPUs.
Achieving this milestone has been a significant effort and collaboration between our teams and companies. To maintain support and performances for the Hugging Face community, we have built integrated testing of Hugging Face open source libraries on AMD Instinct GPUs in our datacenters - and were able to minimize the carbon impact of these new workloads working with Verne Global to deploy the AMD Instinct servers in [Iceland](https://verneglobal.com/about-us/locations/iceland/).
On top of native support, another major aspect of our collaboration is to provide integration for the latest innovations and features available on AMD GPUs. Through the collaboration of Hugging Face team, AMD engineers and open source community members, we are happy to announce [support for](https://huggingface.co/docs/optimum/amd/index):
* Flash Attention v2 from AMD Open Source efforts in [ROCmSoftwarePlatform/flash-attention](https://github.com/ROCmSoftwarePlatform/flash-attention) integrated natively in [Transformers](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2) and [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/quicktour).
* Paged Attention from [vLLM](https://github.com/vllm-project/vllm/pull/1313), and various fused kernels available in [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/quicktour) for ROCm.
* [DeepSpeed](https://github.com/microsoft/DeepSpeed) for ROCm-powered GPUs using Transformers is also now officially validated and supported.
* GPTQ, a common weight compression technique used to reduce the model memory requirements, is supported on ROCm GPUs through a direct integration with [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) and [Transformers](https://huggingface.co/blog/gptq-integration).
* [Optimum-Benchmark](https://github.com/huggingface/optimum-benchmark), a utility to easily benchmark the performance of Transformers on AMD GPUs, in normal and distributed settings, with supported optimizations and quantization schemes.
* Support of ONNX models execution on ROCm-powered GPUs using ONNX Runtime through the [ROCMExecutionProvider](https://onnxruntime.ai/docs/execution-providers/ROCm-ExecutionProvider.html) using [Optimum library](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu).
We are very excited to make these state of the art acceleration tools available and easy to use to Hugging Face users, and offer maintained support and performance with direct integration in our new continuous integration and development pipeline for AMD Instinct GPUs.
One AMD Instinct MI250 GPU with 128 GB of High Bandwidth Memory has two distinct ROCm devices (GPU 0 and 1), each of them having 64 GB of High Bandwidth Memory.
<br>
<figure class="image table text-center m-0 w-full">
<img alt="" src="assets/optimum_amd/rocmsmi.png" />
<figcaption>MI250 two devices as displayed by `rocm-smi`</figcaption>
</figure>
<br>
This means that with just one MI250 GPU card, we have two PyTorch devices that can be used very easily with tensor and data parallelism to achieve higher throughputs and lower latencies.
In the rest of the blog post, we report performance results for the two steps involved during the text generation through large language models:
* **Prefill latency**: The time it takes for the model to compute the representation for the user's provided input or prompt (also referred to as "Time To First Token").
* **Decoding per token latency**: The time it takes to generate each new token in an autoregressive manner after the prefill step.
* **Decoding throughput**: The number of tokens generated per second during the decoding phase.
Using [`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark) and running [inference benchmarks](https://github.com/huggingface/optimum-benchmark/tree/main/examples/running-llamas) on an MI250 and an A100 GPU with and without optimizations, we get the following results:
<br>
<figure class="image table text-center m-0 w-full">
<img alt="" src="assets/optimum_amd/transformers_bench.png" />
<figcaption>Inference benchmarks using Transformers and PEFT libraries. FA2 stands for "Flash Attention 2", TP for "Tensor Parallelism", DDP for "Distributed Data Parallel".</figcaption>
</figure>
<br>
In the plots above, we can see how performant the MI250 is, especially for production settings where requests are processed in big batches, delivering more than 2.33x more tokens (decode throughput) and taking half the time to the first token (prefill latency), compared to an A100 card.
Running [training benchmarks](https://github.com/huggingface/optimum-benchmark/tree/main/examples/training-llamas) as seen below, one MI250 card fits larger batches of training samples and reaches higher training throughput.
<br>
<figure class="image table text-center m-0 w-9/12">
<img alt="" src="assets/optimum_amd/training_bench.png" />
<figcaption>Training benchmark using Transformers library at maximum batch size (power of two) that can fit on a given card</figcaption>
</figure>
<br>
## Production Solutions
Another important focus for our collaboration is to build support for Hugging Face production solutions, starting with Text Generation Inference (TGI). TGI provides an end-to-end solution to deploy large language models for inference at scale.
Initially, TGI was mostly driven towards Nvidia GPUs, leveraging most of the recent optimizations made for post Ampere architecture, such as Flash Attention v1 and v2, GPTQ weight quantization and Paged Attention.
Today, we are happy to announce initial support for AMD Instinct MI210 and MI250 GPUs in TGI, leveraging all the great open-source work detailed above, integrated in a complete end-to-end solution, ready to be deployed.
Performance-wise, we spent a lot of time benchmarking Text Generation Inference on AMD Instinct GPUs to validate and discover where we should focus on optimizations. As such, and with the support of AMD GPUs Engineers, we have been able to achieve matching performance compared to what TGI was already offering.
In this context, and with the long-term relationship we are building between AMD and Hugging Face, we have been integrating and testing with the AMD GeMM Tuner tool which allows us to tune the GeMM (matrix multiplication) kernels we are using in TGI to find the best setup towards increased performances. GeMM Tuner tool is expected to be released [as part of PyTorch](https://github.com/pytorch/pytorch/pull/114894) in a coming release for everyone to benefit from it.
With all of the above being said, we are thrilled to show the very first performance numbers demonstrating the latest AMD technologies, putting Text Generation Inference on AMD GPUs at the forefront of efficient inferencing solutions with Llama model family.
<br>
<figure class="image table text-center m-0 w-full">
<img alt="" src="assets/optimum_amd/tgi_34b.png" />
<figcaption>TGI latency results for Llama 34B, comparing one AMD Instinct MI250 against A100-SXM4-80GB. As explained above one MI250 corresponds to two PyTorch devices.</figcaption>
</figure>
<br>
<br>
<figure class="image table text-center m-0 w-full">
<img alt="" src="assets/optimum_amd/tgi_70b.png" />
<figcaption>TGI latency results for Llama 70B, comparing two AMD Instinct MI250 against two A100-SXM4-80GB (using tensor parallelism)</figcaption>
</figure>
<br>
Missing bars for A100 correspond to out of memory errors, as Llama 70B weights 138 GB in float16, and enough free memory is necessary for intermediate activations, KV cache buffer (>5GB for 2048 sequence length, batch size 8), CUDA context, etc. The Instinct MI250 GPU has 128 GB global memory while an A100 has 80GB which explains the ability to run larger workloads (longer sequences, larger batches) on MI250.
Text Generation Inference is [ready to be deployed](https://huggingface.co/docs/text-generation-inference/quicktour) in production on AMD Instinct GPUs through the docker image `ghcr.io/huggingface/text-generation-inference:1.2-rocm`. Make sure to refer to the [documentation](https://huggingface.co/docs/text-generation-inference/supported_models#supported-hardware) concerning the support and its limitations.
## What's next?
We hope this blog post got you as excited as we are at Hugging Face about this partnership with AMD. Of course, this is just the very beginning of our journey, and we look forward to enabling more use cases on more AMD hardware.
In the coming months, we will be working on bringing more support and validation for AMD Radeon GPUs, the same GPUs you can put in your own desktop for local usage, lowering down the accessibility barrier and paving the way for even more versatility for our users.
Of course we'll soon be working on performance optimization for the MI300 lineup, ensuring that both the Open Source and the Solutions provide with the latest innovations at the highest stability level we are always looking for at Hugging Face.
Another area of focus for us will be around AMD Ryzen AI technology, powering the latest generation of AMD laptop CPUs, allowing to run AI at the edge, on the device. At the time where Coding Assistant, Image Generation tools and Personal Assistant are becoming more and more broadly available, it is important to offer solutions which can meet the needs of privacy to leverage these powerful tools. In this context, Ryzen AI compatible models are already being made available on the [Hugging Face Hub](https://huggingface.co/models?other=RyzenAI) and we're working closely with AMD to bring more of them in the coming months.
| huggingface/blog/blob/main/huggingface-and-optimum-amd.md |
RexNet
**Rank Expansion Networks** (ReXNets) follow a set of new design principles for designing bottlenecks in image classification models. Authors refine each layer by 1) expanding the input channel size of the convolution layer and 2) replacing the [ReLU6s](https://www.paperswithcode.com/method/relu6).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('rexnet_100', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `rexnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('rexnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{han2020rexnet,
title={ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network},
author={Dongyoon Han and Sangdoo Yun and Byeongho Heo and YoungJoon Yoo},
year={2020},
eprint={2007.00992},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: RexNet
Paper:
Title: 'ReXNet: Diminishing Representational Bottleneck on Convolutional Neural
Network'
URL: https://paperswithcode.com/paper/rexnet-diminishing-representational
Models:
- Name: rexnet_100
In Collection: RexNet
Metadata:
FLOPs: 509989377
Parameters: 4800000
File Size: 19417552
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_100
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L212
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_100-1b4dddf4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.86%
Top 5 Accuracy: 93.88%
- Name: rexnet_130
In Collection: RexNet
Metadata:
FLOPs: 848364461
Parameters: 7560000
File Size: 30508197
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_130
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L218
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_130-590d768e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.49%
Top 5 Accuracy: 94.67%
- Name: rexnet_150
In Collection: RexNet
Metadata:
FLOPs: 1122374469
Parameters: 9730000
File Size: 39227315
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_150
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L224
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_150-bd1a6aa8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.31%
Top 5 Accuracy: 95.16%
- Name: rexnet_200
In Collection: RexNet
Metadata:
FLOPs: 1960224938
Parameters: 16370000
File Size: 65862221
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_200
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L230
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_200-8c0b7f2d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.63%
Top 5 Accuracy: 95.67%
--> | huggingface/pytorch-image-models/blob/main/docs/models/rexnet.md |
RegNetY
**RegNetY** is a convolutional network design space with simple, regular models with parameters: depth $d$, initial width $w\_{0} > 0$, and slope $w\_{a} > 0$, and generates a different block width $u\_{j}$ for each block $j < d$. The key restriction for the RegNet types of model is that there is a linear parameterisation of block widths (the design space only contains models with this linear structure):
$$ u\_{j} = w\_{0} + w\_{a}\cdot{j} $$
For **RegNetX** authors have additional restrictions: we set $b = 1$ (the bottleneck ratio), $12 \leq d \leq 28$, and $w\_{m} \geq 2$ (the width multiplier).
For **RegNetY** authors make one change, which is to include [Squeeze-and-Excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('regnety_002', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `regnety_002`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('regnety_002', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{radosavovic2020designing,
title={Designing Network Design Spaces},
author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
year={2020},
eprint={2003.13678},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: RegNetY
Paper:
Title: Designing Network Design Spaces
URL: https://paperswithcode.com/paper/designing-network-design-spaces
Models:
- Name: regnety_002
In Collection: RegNetY
Metadata:
FLOPs: 255754236
Parameters: 3160000
File Size: 12782926
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_002
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L409
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_002-e68ca334.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 70.28%
Top 5 Accuracy: 89.55%
- Name: regnety_004
In Collection: RegNetY
Metadata:
FLOPs: 515664568
Parameters: 4340000
File Size: 17542753
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_004
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L415
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_004-0db870e6.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.02%
Top 5 Accuracy: 91.76%
- Name: regnety_006
In Collection: RegNetY
Metadata:
FLOPs: 771746928
Parameters: 6060000
File Size: 24394127
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_006
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L421
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_006-c67e57ec.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.27%
Top 5 Accuracy: 92.53%
- Name: regnety_008
In Collection: RegNetY
Metadata:
FLOPs: 1023448952
Parameters: 6260000
File Size: 25223268
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_008
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L427
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_008-dc900dbe.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.32%
Top 5 Accuracy: 93.07%
- Name: regnety_016
In Collection: RegNetY
Metadata:
FLOPs: 2070895094
Parameters: 11200000
File Size: 45115589
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_016
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L433
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_016-54367f74.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.87%
Top 5 Accuracy: 93.73%
- Name: regnety_032
In Collection: RegNetY
Metadata:
FLOPs: 4081118714
Parameters: 19440000
File Size: 78084523
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_032
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L439
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/regnety_032_ra-7f2439f9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.01%
Top 5 Accuracy: 95.91%
- Name: regnety_040
In Collection: RegNetY
Metadata:
FLOPs: 5105933432
Parameters: 20650000
File Size: 82913909
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_040
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L445
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_040-f0d569f9.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.23%
Top 5 Accuracy: 94.64%
- Name: regnety_064
In Collection: RegNetY
Metadata:
FLOPs: 8167730444
Parameters: 30580000
File Size: 122751416
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_064
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L451
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_064-0a48325c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.73%
Top 5 Accuracy: 94.76%
- Name: regnety_080
In Collection: RegNetY
Metadata:
FLOPs: 10233621420
Parameters: 39180000
File Size: 157124671
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_080
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L457
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_080-e7f3eb93.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.87%
Top 5 Accuracy: 94.83%
- Name: regnety_120
In Collection: RegNetY
Metadata:
FLOPs: 15542094856
Parameters: 51820000
File Size: 207743949
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_120
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L463
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_120-721ba79a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.38%
Top 5 Accuracy: 95.12%
- Name: regnety_160
In Collection: RegNetY
Metadata:
FLOPs: 20450196852
Parameters: 83590000
File Size: 334916722
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_160
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L469
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_160-d64013cd.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.28%
Top 5 Accuracy: 94.97%
- Name: regnety_320
In Collection: RegNetY
Metadata:
FLOPs: 41492618394
Parameters: 145050000
File Size: 580891965
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- ReLU
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA V100 GPUs
ID: regnety_320
Epochs: 100
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 5.0e-05
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/regnet.py#L475
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-regnet/regnety_320-ba464b29.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.8%
Top 5 Accuracy: 95.25%
--> | huggingface/pytorch-image-models/blob/main/docs/models/regnety.md |
Feature Extraction
All of the models in `timm` have consistent mechanisms for obtaining various types of features from the model for tasks besides classification.
## Penultimate Layer Features (Pre-Classifier Features)
The features from the penultimate model layer can be obtained in several ways without requiring model surgery (although feel free to do surgery). One must first decide if they want pooled or un-pooled features.
### Unpooled
There are three ways to obtain unpooled features.
Without modifying the network, one can call `model.forward_features(input)` on any model instead of the usual `model(input)`. This will bypass the head classifier and global pooling for networks.
If one wants to explicitly modify the network to return unpooled features, they can either create the model without a classifier and pooling, or remove it later. Both paths remove the parameters associated with the classifier from the network.
#### forward_features()
```python hl_lines="3 6"
import torch
import timm
m = timm.create_model('xception41', pretrained=True)
o = m(torch.randn(2, 3, 299, 299))
print(f'Original shape: {o.shape}')
o = m.forward_features(torch.randn(2, 3, 299, 299))
print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Unpooled shape: torch.Size([2, 2048, 10, 10])
```
#### Create with no classifier and pooling
```python hl_lines="3"
import torch
import timm
m = timm.create_model('resnet50', pretrained=True, num_classes=0, global_pool='')
o = m(torch.randn(2, 3, 224, 224))
print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Unpooled shape: torch.Size([2, 2048, 7, 7])
```
#### Remove it later
```python hl_lines="3 6"
import torch
import timm
m = timm.create_model('densenet121', pretrained=True)
o = m(torch.randn(2, 3, 224, 224))
print(f'Original shape: {o.shape}')
m.reset_classifier(0, '')
o = m(torch.randn(2, 3, 224, 224))
print(f'Unpooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Unpooled shape: torch.Size([2, 1024, 7, 7])
```
### Pooled
To modify the network to return pooled features, one can use `forward_features()` and pool/flatten the result themselves, or modify the network like above but keep pooling intact.
#### Create with no classifier
```python hl_lines="3"
import torch
import timm
m = timm.create_model('resnet50', pretrained=True, num_classes=0)
o = m(torch.randn(2, 3, 224, 224))
print(f'Pooled shape: {o.shape}')
```
Output:
```text
Pooled shape: torch.Size([2, 2048])
```
#### Remove it later
```python hl_lines="3 6"
import torch
import timm
m = timm.create_model('ese_vovnet19b_dw', pretrained=True)
o = m(torch.randn(2, 3, 224, 224))
print(f'Original shape: {o.shape}')
m.reset_classifier(0)
o = m(torch.randn(2, 3, 224, 224))
print(f'Pooled shape: {o.shape}')
```
Output:
```text
Original shape: torch.Size([2, 1000])
Pooled shape: torch.Size([2, 1024])
```
## Multi-scale Feature Maps (Feature Pyramid)
Object detection, segmentation, keypoint, and a variety of dense pixel tasks require access to feature maps from the backbone network at multiple scales. This is often done by modifying the original classification network. Since each network varies quite a bit in structure, it's not uncommon to see only a few backbones supported in any given obj detection or segmentation library.
`timm` allows a consistent interface for creating any of the included models as feature backbones that output feature maps for selected levels.
A feature backbone can be created by adding the argument `features_only=True` to any `create_model` call. By default 5 strides will be output from most models (not all have that many), with the first starting at 2 (some start at 1 or 4).
### Create a feature map extraction model
```python hl_lines="3"
import torch
import timm
m = timm.create_model('resnest26d', features_only=True, pretrained=True)
o = m(torch.randn(2, 3, 224, 224))
for x in o:
print(x.shape)
```
Output:
```text
torch.Size([2, 64, 112, 112])
torch.Size([2, 256, 56, 56])
torch.Size([2, 512, 28, 28])
torch.Size([2, 1024, 14, 14])
torch.Size([2, 2048, 7, 7])
```
### Query the feature information
After a feature backbone has been created, it can be queried to provide channel or resolution reduction information to the downstream heads without requiring static config or hardcoded constants. The `.feature_info` attribute is a class encapsulating the information about the feature extraction points.
```python hl_lines="3 4"
import torch
import timm
m = timm.create_model('regnety_032', features_only=True, pretrained=True)
print(f'Feature channels: {m.feature_info.channels()}')
o = m(torch.randn(2, 3, 224, 224))
for x in o:
print(x.shape)
```
Output:
```text
Feature channels: [32, 72, 216, 576, 1512]
torch.Size([2, 32, 112, 112])
torch.Size([2, 72, 56, 56])
torch.Size([2, 216, 28, 28])
torch.Size([2, 576, 14, 14])
torch.Size([2, 1512, 7, 7])
```
### Select specific feature levels or limit the stride
There are two additional creation arguments impacting the output features.
* `out_indices` selects which indices to output
* `output_stride` limits the feature output stride of the network (also works in classification mode BTW)
`out_indices` is supported by all models, but not all models have the same index to feature stride mapping. Look at the code or check feature_info to compare. The out indices generally correspond to the `C(i+1)th` feature level (a `2^(i+1)` reduction). For most models, index 0 is the stride 2 features, and index 4 is stride 32.
`output_stride` is achieved by converting layers to use dilated convolutions. Doing so is not always straightforward, some networks only support `output_stride=32`.
```python hl_lines="3 4 5"
import torch
import timm
m = timm.create_model('ecaresnet101d', features_only=True, output_stride=8, out_indices=(2, 4), pretrained=True)
print(f'Feature channels: {m.feature_info.channels()}')
print(f'Feature reduction: {m.feature_info.reduction()}')
o = m(torch.randn(2, 3, 320, 320))
for x in o:
print(x.shape)
```
Output:
```text
Feature channels: [512, 2048]
Feature reduction: [8, 8]
torch.Size([2, 512, 40, 40])
torch.Size([2, 2048, 40, 40])
```
| huggingface/pytorch-image-models/blob/main/docs/feature_extraction.md |
component-styles
## Textbox
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of text input |
| `border` | `bool` or `(bool, bool, bool, bool)` | borders of text input |
| `container` | `bool` | show or hide the container box |
## Number
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of text input |
| `border` | `bool` or `(bool, bool, bool, bool)` | borders of text input |
| `container` | `bool` | show or hide the container box |
## Slider
| name | type | description |
| ----------- | ------ | ------------------------------ |
| `container` | `bool` | show or hide the container box |
## Checkbox
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of checkbox |
| `border` | `bool` or `(bool, bool, bool, bool)` | borders of checkbox |
| `container` | `bool` | show or hide the container box |
## Checkbox Group
| name | type | description |
| ---------------- | ------------------------------------ | ----------------------------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of checkboxes |
| `container` | `bool` | show or hide the container box |
| `item_container` | `bool` | show or hide the checkbox container boxes |
## Radio
| name | type | description |
| ---------------- | ------ | -------------------------------------- |
| `container` | `bool` | show or hide the container box |
| `item_container` | `bool` | show or hide the radio container boxes |
## Dropdown
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of input |
| `border` | `bool` or `(bool, bool, bool, bool)` | borders of input |
| `container` | `bool` | show or hide the container box |
## Image
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Video
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Audio
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## File
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Dataframe
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Timeseries
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Label
| name | type | description |
| ----------- | ------ | ------------------------------ |
| `container` | `bool` | show or hide the container box |
## HighlightedText
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of labels |
| `color_map` | `Dict[str, str]` | color map of labels and colors |
| `container` | `bool` | show or hide the container box |
## JSON
| name | type | description |
| ----------- | ------ | ------------------------------ |
| `container` | `bool` | show or hide the container box |
## HTML
Nothing
## Gallery
| name | type | description |
| ----------- | ----------------------------------------- | ----------------------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of images |
| `grid` | `int` or `(int, int, int, int, int, int)` | grid for images |
| `height` | `"auto"` | height of gallery (auto or default) |
| `container` | `bool` | show or hide the container box |
## Chatbot
| name | type | description |
| ----------- | ------------------------------------ | ------------------------------------------------ |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of chat bubbles |
| `color_map` | `Dict[str, str]` | color map of user and bot color for chat bubbles |
## Model3D
| name | type | description |
| --------- | ------------------------------------ | ------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of main box |
## Plot
Nothing (yet)
## Markdown
Nothing
## Button
| name | type | description |
| ------------ | ------------------------------------ | --------------------------------------- |
| `rounded` | `bool` or `(bool, bool, bool, bool)` | corners of button |
| `border` | `bool` or `(bool, bool, bool, bool)` | borders of button |
| `full_width` | `bool` | whether button expand to fill container |
## Dataset
Nothing
## Variable
Nothing
| gradio-app/gradio/blob/main/style.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BigBird
## Overview
The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
has been shown that applying sparse, global, and random attention approximates full attention, while being
computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
BigBird has shown improved performance on various long document NLP tasks, such as question answering and
summarization, compared to BERT or RoBERTa.
The abstract from the paper is the following:
*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
propose novel applications to genomics data.*
This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
[here](https://github.com/google-research/bigbird).
## Usage tips
- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
**original_full** is advised as there is no benefit in using **block_sparse** attention.
- The code currently uses window size of 3 blocks and 2 global blocks.
- Sequence length must be divisible by block size.
- Current implementation supports only **ITC**.
- Current implementation doesn't support **num_random_blocks = 0**
- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## BigBirdConfig
[[autodoc]] BigBirdConfig
## BigBirdTokenizer
[[autodoc]] BigBirdTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BigBirdTokenizerFast
[[autodoc]] BigBirdTokenizerFast
## BigBird specific outputs
[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
<frameworkcontent>
<pt>
## BigBirdModel
[[autodoc]] BigBirdModel
- forward
## BigBirdForPreTraining
[[autodoc]] BigBirdForPreTraining
- forward
## BigBirdForCausalLM
[[autodoc]] BigBirdForCausalLM
- forward
## BigBirdForMaskedLM
[[autodoc]] BigBirdForMaskedLM
- forward
## BigBirdForSequenceClassification
[[autodoc]] BigBirdForSequenceClassification
- forward
## BigBirdForMultipleChoice
[[autodoc]] BigBirdForMultipleChoice
- forward
## BigBirdForTokenClassification
[[autodoc]] BigBirdForTokenClassification
- forward
## BigBirdForQuestionAnswering
[[autodoc]] BigBirdForQuestionAnswering
- forward
</pt>
<jax>
## FlaxBigBirdModel
[[autodoc]] FlaxBigBirdModel
- __call__
## FlaxBigBirdForPreTraining
[[autodoc]] FlaxBigBirdForPreTraining
- __call__
## FlaxBigBirdForCausalLM
[[autodoc]] FlaxBigBirdForCausalLM
- __call__
## FlaxBigBirdForMaskedLM
[[autodoc]] FlaxBigBirdForMaskedLM
- __call__
## FlaxBigBirdForSequenceClassification
[[autodoc]] FlaxBigBirdForSequenceClassification
- __call__
## FlaxBigBirdForMultipleChoice
[[autodoc]] FlaxBigBirdForMultipleChoice
- __call__
## FlaxBigBirdForTokenClassification
[[autodoc]] FlaxBigBirdForTokenClassification
- __call__
## FlaxBigBirdForQuestionAnswering
[[autodoc]] FlaxBigBirdForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/big_bird.md |
User access tokens
## What are User Access Tokens?
User Access Tokens are the preferred way to authenticate an application or notebook to Hugging Face services. You can manage your access tokens in your [settings](https://huggingface.co/settings/tokens).
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/User-Access-Token.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/User-Access-Token-dark.png"/>
</div>
Access tokens allow applications and notebooks to perform specific actions specified by the scope of the roles shown in the following:
- `read`: tokens with this role can only be used to provide read access to repositories you could read. That includes public and private repositories that you, or an organization you're a member of, own. Use this role if you only need to read content from the Hugging Face Hub (e.g. when downloading private models or doing inference).
- `write`: tokens with this role additionally grant write access to the repositories you have write access to. Use this token if you need to create or push content to a repository (e.g., when training a model or modifying a model card).
Note that Organization API Tokens have been deprecated:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/API-token.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/API-token_dark.png"/>
</div>
If you are a member of an organization with read/write/admin role, then your User Access Tokens will be able to read/write the resources according to the token permission (read/write) and organization membership (read/write/admin).
## How to manage User Access Tokens?
To create an access token, go to your settings, then click on the [Access Tokens tab](https://huggingface.co/settings/tokens). Click on the **New token** button to create a new User Access Token.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/new-token.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/new-token-dark.png"/>
</div>
Select a role and a name for your token and voilà - you're ready to go!
You can delete and refresh User Access Tokens by clicking on the **Manage** button.
<div class="flex justify-center">
<img class="block dark:hidden" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/delete-token.png"/>
<img class="hidden dark:block" width="350" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/delete-token-dark.png"/>
</div>
## How to use User Access Tokens?
There are plenty of ways to use a User Access Token to access the Hugging Face Hub, granting you the flexibility you need to build awesome apps on top of it.
User Access Tokens can be:
- used **in place of a password** to access the Hugging Face Hub with git or with basic authentication.
- passed as a **bearer token** when calling the [Inference API](https://huggingface.co/inference-api).
- used in the Hugging Face Python libraries, such as `transformers` or `datasets`:
```python
from transformers import AutoModel
access_token = "hf_..."
model = AutoModel.from_pretrained("private/model", token=access_token)
```
<Tip warning={true}>
Try not to leak your token! Though you can always rotate it, anyone will be able to read or write your private repos in the meantime which is 💩
</Tip>
### Best practices
We recommend you create one access token per app or usage. For instance, you could have a separate token for:
* A local machine.
* A Colab notebook.
* An awesome custom inference server.
This way, you can invalidate one token without impacting your other usages.
We also recommend only giving the appropriate role to each token you create. If you only need read access (e.g., loading a dataset with the `datasets` library or retrieving the weights of a model), only give your access token the `read` role.
| huggingface/hub-docs/blob/main/docs/hub/security-tokens.md |