
File size: 2,393 Bytes
a230c41 be7d1ae d80ce16 036c2e4 6490aaf be7d1ae adddb38 036c2e4 a230c41 ad76c72 036c2e4 b2c4633 036c2e4 2d14f20 036c2e4 b2c4633 036c2e4 b2c4633 036c2e4 b2c4633 036c2e4 8639005 036c2e4 45cae2a 036c2e4 8639005 036c2e4 7091dbd 507abea 8639005 a804129 8639005 036c2e4 b2c4633 036c2e4 b2c4633 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
---
language:
- en
license: cc-by-nc-4.0
datasets:
- grammarly/coedit
- facebook/asset
- jfleg
- zaemyung/IteraTeR_plus
- wi_locness
- GEM/wiki_auto_asset_turk
- discofuse
metrics:
- sari
- bleu
- accuracy
---
# Model Card for CoEdIT-xl
This model was obtained by fine-tuning the corresponding `google/flan-t5-xl` model on the CoEdIT dataset. Details of the dataset can be found in our paper and repository.
**Paper:** CoEdIT: Text Editing by Task-Specific Instruction Tuning
**Authors:** Vipul Raheja, Dhruv Kumar, Ryan Koo, Dongyeop Kang
## Model Details
### Model Description
- **Language(s) (NLP)**: English
- **Finetuned from model:** `google/flan-t5-xl`
### Model Sources
- **Repository:** https://github.com/vipulraheja/coedit
- **Paper:** https://arxiv.org/abs/2305.09857
## How to use
We make available the models presented in our paper.
<table>
<tr>
<th>Model</th>
<th>Number of parameters</th>
</tr>
<tr>
<td>CoEdIT-large</td>
<td>770M</td>
</tr>
<tr>
<td>CoEdIT-xl</td>
<td>3B</td>
</tr>
<tr>
<td>CoEdIT-xxl</td>
<td>11B</td>
</tr>
</table>
## Uses
## Text Revision Task
Given an edit instruction and an original text, our model can generate the edited version of the text.<br>
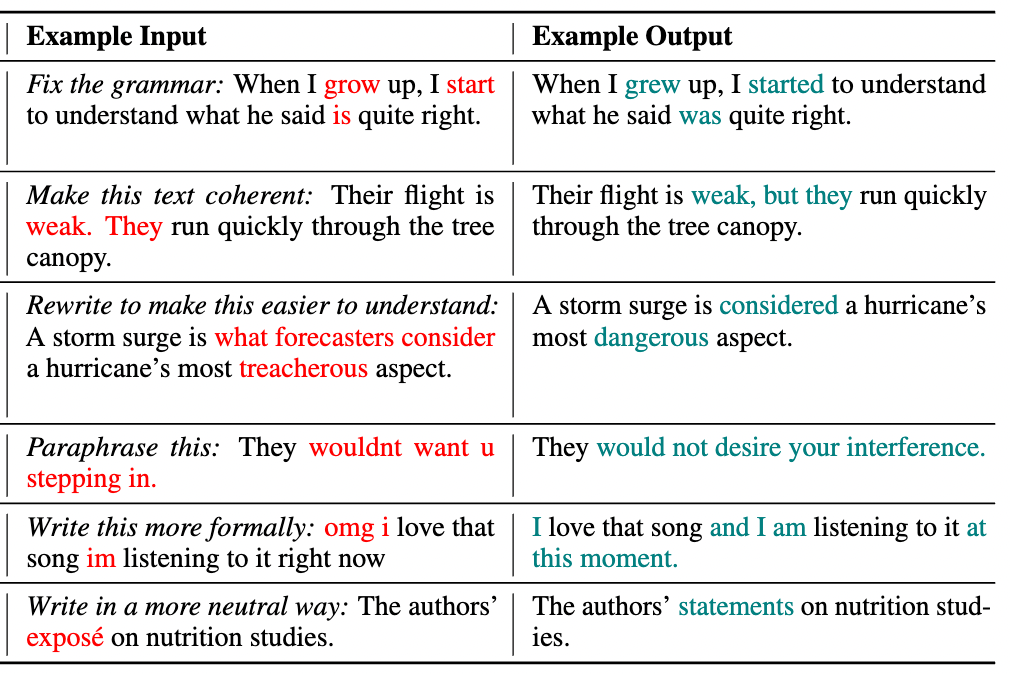
## Usage
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("grammarly/coedit-xl")
model = T5ForConditionalGeneration.from_pretrained("grammarly/coedit-xl")
input_text = 'Fix grammatical errors in this sentence: When I grow up, I start to understand what he said is quite right.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=256)
edited_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
#### Software
https://github.com/vipulraheja/coedit
## Citation
**BibTeX:**
```
@article{raheja2023coedit,
title={CoEdIT: Text Editing by Task-Specific Instruction Tuning},
author={Vipul Raheja and Dhruv Kumar and Ryan Koo and Dongyeop Kang},
year={2023},
eprint={2305.09857},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**APA:**
Raheja, V., Kumar, D., Koo, R., & Kang, D. (2023). CoEdIT: Text Editing by Task-Specific Instruction Tuning. ArXiv. /abs/2305.09857 |