
Upload folder using huggingface_hub
Browse files- README.md +170 -0
- added_tokens.json +24 -0
- cal_data.safetensors +3 -0
- config.json +29 -0
- english_bench.pdf +0 -0
- english_bench.png +0 -0
- fewshot_bench.png +0 -0
- finetuned_gains.pdf +0 -0
- generation_config.json +6 -0
- help +1145 -0
- hidden_states.safetensors +3 -0
- job_new.json +0 -0
- measurement.json +0 -0
- merges.txt +0 -0
- multilingual_bench.png +0 -0
- output.safetensors +3 -0
- special_tokens_map.json +31 -0
- tokenizer.json +0 -0
- tokenizer_config.json +212 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- multilingual
|
| 5 |
+
tags:
|
| 6 |
+
- nlp
|
| 7 |
+
base_model: Qwen/Qwen2.5-0.5B
|
| 8 |
+
pipeline_tag: text-generation
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# NuExtract-tiny-v1.5 by NuMind 🔥
|
| 12 |
+
|
| 13 |
+
NuExtract-tiny-v1.5 is a fine-tuning of [Qwen/Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B), trained on a private high-quality dataset for structured information extraction. It supports long documents and several languages (English, French, Spanish, German, Portuguese, and Italian).
|
| 14 |
+
To use the model, provide an input text and a JSON template describing the information you need to extract.
|
| 15 |
+
|
| 16 |
+
Note: This model is trained to prioritize pure extraction, so in most cases all text generated by the model is present as is in the original text.
|
| 17 |
+
|
| 18 |
+
We also provide a 3.8B version which is based on Phi-3.5-mini-instruct: [NuExtract-v1.5](https://huggingface.co/numind/NuExtract-v1.5)
|
| 19 |
+
|
| 20 |
+
Check out the [blog post](https://numind.ai/blog/nuextract-1-5---multilingual-infinite-context-still-small-and-better-than-gpt-4o).
|
| 21 |
+
|
| 22 |
+
Try the 3.8B model here: [Playground](https://huggingface.co/spaces/numind/NuExtract-v1.5)
|
| 23 |
+
|
| 24 |
+
⚠️ We recommend using NuExtract with a temperature at or very close to 0. Some inference frameworks, such as Ollama, use a default of 0.7 which is not well suited to pure extraction tasks.
|
| 25 |
+
|
| 26 |
+
## Benchmark
|
| 27 |
+
|
| 28 |
+
Zero-shot performance (English):
|
| 29 |
+
|
| 30 |
+
<p align="left">
|
| 31 |
+
<img src="english_bench.png" style="width: 600; height: auto;">
|
| 32 |
+
</p>
|
| 33 |
+
|
| 34 |
+
Few-shot fine-tuning:
|
| 35 |
+
|
| 36 |
+
<p align="left">
|
| 37 |
+
<img src="fewshot_bench.png" style="width: 750; height: auto;">
|
| 38 |
+
</p>
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Usage
|
| 42 |
+
|
| 43 |
+
To use the model:
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
import json
|
| 47 |
+
import torch
|
| 48 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 49 |
+
|
| 50 |
+
def predict_NuExtract(model, tokenizer, texts, template, batch_size=1, max_length=10_000, max_new_tokens=4_000):
|
| 51 |
+
template = json.dumps(json.loads(template), indent=4)
|
| 52 |
+
prompts = [f"""<|input|>\n### Template:\n{template}\n### Text:\n{text}\n\n<|output|>""" for text in texts]
|
| 53 |
+
|
| 54 |
+
outputs = []
|
| 55 |
+
with torch.no_grad():
|
| 56 |
+
for i in range(0, len(prompts), batch_size):
|
| 57 |
+
batch_prompts = prompts[i:i+batch_size]
|
| 58 |
+
batch_encodings = tokenizer(batch_prompts, return_tensors="pt", truncation=True, padding=True, max_length=max_length).to(model.device)
|
| 59 |
+
|
| 60 |
+
pred_ids = model.generate(**batch_encodings, max_new_tokens=max_new_tokens)
|
| 61 |
+
outputs += tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
|
| 62 |
+
|
| 63 |
+
return [output.split("<|output|>")[1] for output in outputs]
|
| 64 |
+
|
| 65 |
+
model_name = "numind/NuExtract-tiny-v1.5"
|
| 66 |
+
device = "cuda"
|
| 67 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, trust_remote_code=True).to(device).eval()
|
| 68 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 69 |
+
|
| 70 |
+
text = """We introduce Mistral 7B, a 7–billion-parameter language model engineered for
|
| 71 |
+
superior performance and efficiency. Mistral 7B outperforms the best open 13B
|
| 72 |
+
model (Llama 2) across all evaluated benchmarks, and the best released 34B
|
| 73 |
+
model (Llama 1) in reasoning, mathematics, and code generation. Our model
|
| 74 |
+
leverages grouped-query attention (GQA) for faster inference, coupled with sliding
|
| 75 |
+
window attention (SWA) to effectively handle sequences of arbitrary length with a
|
| 76 |
+
reduced inference cost. We also provide a model fine-tuned to follow instructions,
|
| 77 |
+
Mistral 7B – Instruct, that surpasses Llama 2 13B – chat model both on human and
|
| 78 |
+
automated benchmarks. Our models are released under the Apache 2.0 license.
|
| 79 |
+
Code: <https://github.com/mistralai/mistral-src>
|
| 80 |
+
Webpage: <https://mistral.ai/news/announcing-mistral-7b/>"""
|
| 81 |
+
|
| 82 |
+
template = """{
|
| 83 |
+
"Model": {
|
| 84 |
+
"Name": "",
|
| 85 |
+
"Number of parameters": "",
|
| 86 |
+
"Number of max token": "",
|
| 87 |
+
"Architecture": []
|
| 88 |
+
},
|
| 89 |
+
"Usage": {
|
| 90 |
+
"Use case": [],
|
| 91 |
+
"Licence": ""
|
| 92 |
+
}
|
| 93 |
+
}"""
|
| 94 |
+
|
| 95 |
+
prediction = predict_NuExtract(model, tokenizer, [text], template)[0]
|
| 96 |
+
print(prediction)
|
| 97 |
+
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
Sliding window prompting:
|
| 101 |
+
|
| 102 |
+
```python
|
| 103 |
+
import json
|
| 104 |
+
|
| 105 |
+
MAX_INPUT_SIZE = 20_000
|
| 106 |
+
MAX_NEW_TOKENS = 6000
|
| 107 |
+
|
| 108 |
+
def clean_json_text(text):
|
| 109 |
+
text = text.strip()
|
| 110 |
+
text = text.replace("\#", "#").replace("\&", "&")
|
| 111 |
+
return text
|
| 112 |
+
|
| 113 |
+
def predict_chunk(text, template, current, model, tokenizer):
|
| 114 |
+
current = clean_json_text(current)
|
| 115 |
+
|
| 116 |
+
input_llm = f"<|input|>\n### Template:\n{template}\n### Current:\n{current}\n### Text:\n{text}\n\n<|output|>" + "{"
|
| 117 |
+
input_ids = tokenizer(input_llm, return_tensors="pt", truncation=True, max_length=MAX_INPUT_SIZE).to("cuda")
|
| 118 |
+
output = tokenizer.decode(model.generate(**input_ids, max_new_tokens=MAX_NEW_TOKENS)[0], skip_special_tokens=True)
|
| 119 |
+
|
| 120 |
+
return clean_json_text(output.split("<|output|>")[1])
|
| 121 |
+
|
| 122 |
+
def split_document(document, window_size, overlap):
|
| 123 |
+
tokens = tokenizer.tokenize(document)
|
| 124 |
+
print(f"\tLength of document: {len(tokens)} tokens")
|
| 125 |
+
|
| 126 |
+
chunks = []
|
| 127 |
+
if len(tokens) > window_size:
|
| 128 |
+
for i in range(0, len(tokens), window_size-overlap):
|
| 129 |
+
print(f"\t{i} to {i + len(tokens[i:i + window_size])}")
|
| 130 |
+
chunk = tokenizer.convert_tokens_to_string(tokens[i:i + window_size])
|
| 131 |
+
chunks.append(chunk)
|
| 132 |
+
|
| 133 |
+
if i + len(tokens[i:i + window_size]) >= len(tokens):
|
| 134 |
+
break
|
| 135 |
+
else:
|
| 136 |
+
chunks.append(document)
|
| 137 |
+
print(f"\tSplit into {len(chunks)} chunks")
|
| 138 |
+
|
| 139 |
+
return chunks
|
| 140 |
+
|
| 141 |
+
def handle_broken_output(pred, prev):
|
| 142 |
+
try:
|
| 143 |
+
if all([(v in ["", []]) for v in json.loads(pred).values()]):
|
| 144 |
+
# if empty json, return previous
|
| 145 |
+
pred = prev
|
| 146 |
+
except:
|
| 147 |
+
# if broken json, return previous
|
| 148 |
+
pred = prev
|
| 149 |
+
|
| 150 |
+
return pred
|
| 151 |
+
|
| 152 |
+
def sliding_window_prediction(text, template, model, tokenizer, window_size=4000, overlap=128):
|
| 153 |
+
# split text into chunks of n tokens
|
| 154 |
+
tokens = tokenizer.tokenize(text)
|
| 155 |
+
chunks = split_document(text, window_size, overlap)
|
| 156 |
+
|
| 157 |
+
# iterate over text chunks
|
| 158 |
+
prev = template
|
| 159 |
+
for i, chunk in enumerate(chunks):
|
| 160 |
+
print(f"Processing chunk {i}...")
|
| 161 |
+
pred = predict_chunk(chunk, template, prev, model, tokenizer)
|
| 162 |
+
|
| 163 |
+
# handle broken output
|
| 164 |
+
pred = handle_broken_output(pred, prev)
|
| 165 |
+
|
| 166 |
+
# iterate
|
| 167 |
+
prev = pred
|
| 168 |
+
|
| 169 |
+
return pred
|
| 170 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652
|
| 24 |
+
}
|
cal_data.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fd5e1ca32fb5a02397420920d3d542015344cf30d8777a35c712679bb4221872
|
| 3 |
+
size 1638488
|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "numind/NuExtract-tiny-v1.5",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151643,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 896,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 4864,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"max_window_layers": 24,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 14,
|
| 17 |
+
"num_hidden_layers": 24,
|
| 18 |
+
"num_key_value_heads": 2,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_theta": 1000000.0,
|
| 21 |
+
"sliding_window": null,
|
| 22 |
+
"tie_word_embeddings": true,
|
| 23 |
+
"torch_dtype": "bfloat16",
|
| 24 |
+
"transformers_version": "4.44.0",
|
| 25 |
+
"use_cache": true,
|
| 26 |
+
"use_mrope": false,
|
| 27 |
+
"use_sliding_window": false,
|
| 28 |
+
"vocab_size": 151936
|
| 29 |
+
}
|
english_bench.pdf
ADDED
|
Binary file (21.7 kB). View file
|
|
|
english_bench.png
ADDED

|
fewshot_bench.png
ADDED
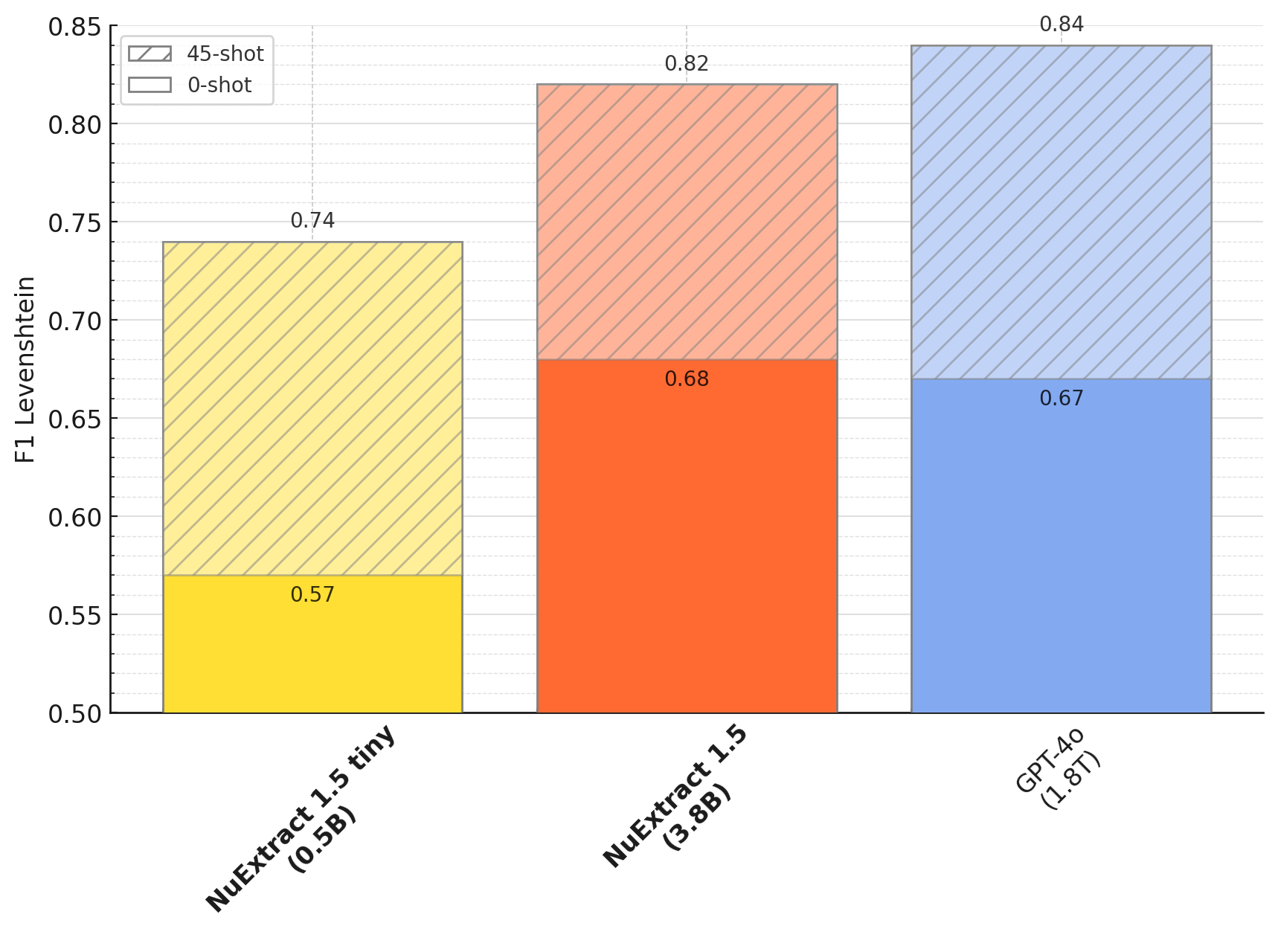
|
finetuned_gains.pdf
ADDED
|
Binary file (17.6 kB). View file
|
|
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"eos_token_id": 151643,
|
| 4 |
+
"max_new_tokens": 2048,
|
| 5 |
+
"transformers_version": "4.44.0"
|
| 6 |
+
}
|
help
ADDED
|
@@ -0,0 +1,1145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ripgrep 13.0.0
|
| 2 |
+
Andrew Gallant <[email protected]>
|
| 3 |
+
|
| 4 |
+
ripgrep (rg) recursively searches the current directory for a regex pattern.
|
| 5 |
+
By default, ripgrep will respect gitignore rules and automatically skip hidden
|
| 6 |
+
files/directories and binary files.
|
| 7 |
+
|
| 8 |
+
Use -h for short descriptions and --help for more details.
|
| 9 |
+
|
| 10 |
+
Project home page: https://github.com/BurntSushi/ripgrep
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
USAGE:
|
| 14 |
+
rg [OPTIONS] PATTERN [PATH ...]
|
| 15 |
+
rg [OPTIONS] -e PATTERN ... [PATH ...]
|
| 16 |
+
rg [OPTIONS] -f PATTERNFILE ... [PATH ...]
|
| 17 |
+
rg [OPTIONS] --files [PATH ...]
|
| 18 |
+
rg [OPTIONS] --type-list
|
| 19 |
+
command | rg [OPTIONS] PATTERN
|
| 20 |
+
rg [OPTIONS] --help
|
| 21 |
+
rg [OPTIONS] --version
|
| 22 |
+
|
| 23 |
+
ARGS:
|
| 24 |
+
<PATTERN>
|
| 25 |
+
A regular expression used for searching. To match a pattern beginning with a
|
| 26 |
+
dash, use the -e/--regexp flag.
|
| 27 |
+
|
| 28 |
+
For example, to search for the literal '-foo', you can use this flag:
|
| 29 |
+
|
| 30 |
+
rg -e -foo
|
| 31 |
+
|
| 32 |
+
You can also use the special '--' delimiter to indicate that no more flags
|
| 33 |
+
will be provided. Namely, the following is equivalent to the above:
|
| 34 |
+
|
| 35 |
+
rg -- -foo
|
| 36 |
+
|
| 37 |
+
<PATH>...
|
| 38 |
+
A file or directory to search. Directories are searched recursively. File paths
|
| 39 |
+
specified on the command line override glob and ignore rules.
|
| 40 |
+
|
| 41 |
+
OPTIONS:
|
| 42 |
+
-A, --after-context <NUM>
|
| 43 |
+
Show NUM lines after each match.
|
| 44 |
+
|
| 45 |
+
This overrides the --context and --passthru flags.
|
| 46 |
+
|
| 47 |
+
--auto-hybrid-regex
|
| 48 |
+
DEPRECATED. Use --engine instead.
|
| 49 |
+
|
| 50 |
+
When this flag is used, ripgrep will dynamically choose between supported regex
|
| 51 |
+
engines depending on the features used in a pattern. When ripgrep chooses a
|
| 52 |
+
regex engine, it applies that choice for every regex provided to ripgrep (e.g.,
|
| 53 |
+
via multiple -e/--regexp or -f/--file flags).
|
| 54 |
+
|
| 55 |
+
As an example of how this flag might behave, ripgrep will attempt to use
|
| 56 |
+
its default finite automata based regex engine whenever the pattern can be
|
| 57 |
+
successfully compiled with that regex engine. If PCRE2 is enabled and if the
|
| 58 |
+
pattern given could not be compiled with the default regex engine, then PCRE2
|
| 59 |
+
will be automatically used for searching. If PCRE2 isn't available, then this
|
| 60 |
+
flag has no effect because there is only one regex engine to choose from.
|
| 61 |
+
|
| 62 |
+
In the future, ripgrep may adjust its heuristics for how it decides which
|
| 63 |
+
regex engine to use. In general, the heuristics will be limited to a static
|
| 64 |
+
analysis of the patterns, and not to any specific runtime behavior observed
|
| 65 |
+
while searching files.
|
| 66 |
+
|
| 67 |
+
The primary downside of using this flag is that it may not always be obvious
|
| 68 |
+
which regex engine ripgrep uses, and thus, the match semantics or performance
|
| 69 |
+
profile of ripgrep may subtly and unexpectedly change. However, in many cases,
|
| 70 |
+
all regex engines will agree on what constitutes a match and it can be nice
|
| 71 |
+
to transparently support more advanced regex features like look-around and
|
| 72 |
+
backreferences without explicitly needing to enable them.
|
| 73 |
+
|
| 74 |
+
This flag can be disabled with --no-auto-hybrid-regex.
|
| 75 |
+
|
| 76 |
+
-B, --before-context <NUM>
|
| 77 |
+
Show NUM lines before each match.
|
| 78 |
+
|
| 79 |
+
This overrides the --context and --passthru flags.
|
| 80 |
+
|
| 81 |
+
--binary
|
| 82 |
+
Enabling this flag will cause ripgrep to search binary files. By default,
|
| 83 |
+
ripgrep attempts to automatically skip binary files in order to improve the
|
| 84 |
+
relevance of results and make the search faster.
|
| 85 |
+
|
| 86 |
+
Binary files are heuristically detected based on whether they contain a NUL
|
| 87 |
+
byte or not. By default (without this flag set), once a NUL byte is seen,
|
| 88 |
+
ripgrep will stop searching the file. Usually, NUL bytes occur in the beginning
|
| 89 |
+
of most binary files. If a NUL byte occurs after a match, then ripgrep will
|
| 90 |
+
still stop searching the rest of the file, but a warning will be printed.
|
| 91 |
+
|
| 92 |
+
In contrast, when this flag is provided, ripgrep will continue searching a file
|
| 93 |
+
even if a NUL byte is found. In particular, if a NUL byte is found then ripgrep
|
| 94 |
+
will continue searching until either a match is found or the end of the file is
|
| 95 |
+
reached, whichever comes sooner. If a match is found, then ripgrep will stop
|
| 96 |
+
and print a warning saying that the search stopped prematurely.
|
| 97 |
+
|
| 98 |
+
If you want ripgrep to search a file without any special NUL byte handling at
|
| 99 |
+
all (and potentially print binary data to stdout), then you should use the
|
| 100 |
+
'-a/--text' flag.
|
| 101 |
+
|
| 102 |
+
The '--binary' flag is a flag for controlling ripgrep's automatic filtering
|
| 103 |
+
mechanism. As such, it does not need to be used when searching a file
|
| 104 |
+
explicitly or when searching stdin. That is, it is only applicable when
|
| 105 |
+
recursively searching a directory.
|
| 106 |
+
|
| 107 |
+
Note that when the '-u/--unrestricted' flag is provided for a third time, then
|
| 108 |
+
this flag is automatically enabled.
|
| 109 |
+
|
| 110 |
+
This flag can be disabled with '--no-binary'. It overrides the '-a/--text'
|
| 111 |
+
flag.
|
| 112 |
+
|
| 113 |
+
--block-buffered
|
| 114 |
+
When enabled, ripgrep will use block buffering. That is, whenever a matching
|
| 115 |
+
line is found, it will be written to an in-memory buffer and will not be
|
| 116 |
+
written to stdout until the buffer reaches a certain size. This is the default
|
| 117 |
+
when ripgrep's stdout is redirected to a pipeline or a file. When ripgrep's
|
| 118 |
+
stdout is connected to a terminal, line buffering will be used. Forcing block
|
| 119 |
+
buffering can be useful when dumping a large amount of contents to a terminal.
|
| 120 |
+
|
| 121 |
+
Forceful block buffering can be disabled with --no-block-buffered. Note that
|
| 122 |
+
using --no-block-buffered causes ripgrep to revert to its default behavior of
|
| 123 |
+
automatically detecting the buffering strategy. To force line buffering, use
|
| 124 |
+
the --line-buffered flag.
|
| 125 |
+
|
| 126 |
+
-b, --byte-offset
|
| 127 |
+
Print the 0-based byte offset within the input file before each line of output.
|
| 128 |
+
If -o (--only-matching) is specified, print the offset of the matching part
|
| 129 |
+
itself.
|
| 130 |
+
|
| 131 |
+
If ripgrep does transcoding, then the byte offset is in terms of the the result
|
| 132 |
+
of transcoding and not the original data. This applies similarly to another
|
| 133 |
+
transformation on the source, such as decompression or a --pre filter. Note
|
| 134 |
+
that when the PCRE2 regex engine is used, then UTF-8 transcoding is done by
|
| 135 |
+
default.
|
| 136 |
+
|
| 137 |
+
-s, --case-sensitive
|
| 138 |
+
Search case sensitively.
|
| 139 |
+
|
| 140 |
+
This overrides the -i/--ignore-case and -S/--smart-case flags.
|
| 141 |
+
|
| 142 |
+
--color <WHEN>
|
| 143 |
+
This flag controls when to use colors. The default setting is 'auto', which
|
| 144 |
+
means ripgrep will try to guess when to use colors. For example, if ripgrep is
|
| 145 |
+
printing to a terminal, then it will use colors, but if it is redirected to a
|
| 146 |
+
file or a pipe, then it will suppress color output. ripgrep will suppress color
|
| 147 |
+
output in some other circumstances as well. For example, if the TERM
|
| 148 |
+
environment variable is not set or set to 'dumb', then ripgrep will not use
|
| 149 |
+
colors.
|
| 150 |
+
|
| 151 |
+
The possible values for this flag are:
|
| 152 |
+
|
| 153 |
+
never Colors will never be used.
|
| 154 |
+
auto The default. ripgrep tries to be smart.
|
| 155 |
+
always Colors will always be used regardless of where output is sent.
|
| 156 |
+
ansi Like 'always', but emits ANSI escapes (even in a Windows console).
|
| 157 |
+
|
| 158 |
+
When the --vimgrep flag is given to ripgrep, then the default value for the
|
| 159 |
+
--color flag changes to 'never'.
|
| 160 |
+
|
| 161 |
+
--colors <COLOR_SPEC>...
|
| 162 |
+
This flag specifies color settings for use in the output. This flag may be
|
| 163 |
+
provided multiple times. Settings are applied iteratively. Colors are limited
|
| 164 |
+
to one of eight choices: red, blue, green, cyan, magenta, yellow, white and
|
| 165 |
+
black. Styles are limited to nobold, bold, nointense, intense, nounderline
|
| 166 |
+
or underline.
|
| 167 |
+
|
| 168 |
+
The format of the flag is '{type}:{attribute}:{value}'. '{type}' should be
|
| 169 |
+
one of path, line, column or match. '{attribute}' can be fg, bg or style.
|
| 170 |
+
'{value}' is either a color (for fg and bg) or a text style. A special format,
|
| 171 |
+
'{type}:none', will clear all color settings for '{type}'.
|
| 172 |
+
|
| 173 |
+
For example, the following command will change the match color to magenta and
|
| 174 |
+
the background color for line numbers to yellow:
|
| 175 |
+
|
| 176 |
+
rg --colors 'match:fg:magenta' --colors 'line:bg:yellow' foo.
|
| 177 |
+
|
| 178 |
+
Extended colors can be used for '{value}' when the terminal supports ANSI color
|
| 179 |
+
sequences. These are specified as either 'x' (256-color) or 'x,x,x' (24-bit
|
| 180 |
+
truecolor) where x is a number between 0 and 255 inclusive. x may be given as
|
| 181 |
+
a normal decimal number or a hexadecimal number, which is prefixed by `0x`.
|
| 182 |
+
|
| 183 |
+
For example, the following command will change the match background color to
|
| 184 |
+
that represented by the rgb value (0,128,255):
|
| 185 |
+
|
| 186 |
+
rg --colors 'match:bg:0,128,255'
|
| 187 |
+
|
| 188 |
+
or, equivalently,
|
| 189 |
+
|
| 190 |
+
rg --colors 'match:bg:0x0,0x80,0xFF'
|
| 191 |
+
|
| 192 |
+
Note that the the intense and nointense style flags will have no effect when
|
| 193 |
+
used alongside these extended color codes.
|
| 194 |
+
|
| 195 |
+
--column
|
| 196 |
+
Show column numbers (1-based). This only shows the column numbers for the first
|
| 197 |
+
match on each line. This does not try to account for Unicode. One byte is equal
|
| 198 |
+
to one column. This implies --line-number.
|
| 199 |
+
|
| 200 |
+
This flag can be disabled with --no-column.
|
| 201 |
+
|
| 202 |
+
-C, --context <NUM>
|
| 203 |
+
Show NUM lines before and after each match. This is equivalent to providing
|
| 204 |
+
both the -B/--before-context and -A/--after-context flags with the same value.
|
| 205 |
+
|
| 206 |
+
This overrides both the -B/--before-context and -A/--after-context flags,
|
| 207 |
+
in addition to the --passthru flag.
|
| 208 |
+
|
| 209 |
+
--context-separator <SEPARATOR>
|
| 210 |
+
The string used to separate non-contiguous context lines in the output. This
|
| 211 |
+
is only used when one of the context flags is used (-A, -B or -C). Escape
|
| 212 |
+
sequences like \x7F or \t may be used. The default value is --.
|
| 213 |
+
|
| 214 |
+
When the context separator is set to an empty string, then a line break
|
| 215 |
+
is still inserted. To completely disable context separators, use the
|
| 216 |
+
--no-context-separator flag.
|
| 217 |
+
|
| 218 |
+
-c, --count
|
| 219 |
+
This flag suppresses normal output and shows the number of lines that match
|
| 220 |
+
the given patterns for each file searched. Each file containing a match has its
|
| 221 |
+
path and count printed on each line. Note that this reports the number of lines
|
| 222 |
+
that match and not the total number of matches, unless -U/--multiline is
|
| 223 |
+
enabled. In multiline mode, --count is equivalent to --count-matches.
|
| 224 |
+
|
| 225 |
+
If only one file is given to ripgrep, then only the count is printed if there
|
| 226 |
+
is a match. The --with-filename flag can be used to force printing the file
|
| 227 |
+
path in this case. If you need a count to be printed regardless of whether
|
| 228 |
+
there is a match, then use --include-zero.
|
| 229 |
+
|
| 230 |
+
This overrides the --count-matches flag. Note that when --count is combined
|
| 231 |
+
with --only-matching, then ripgrep behaves as if --count-matches was given.
|
| 232 |
+
|
| 233 |
+
--count-matches
|
| 234 |
+
This flag suppresses normal output and shows the number of individual
|
| 235 |
+
matches of the given patterns for each file searched. Each file
|
| 236 |
+
containing matches has its path and match count printed on each line.
|
| 237 |
+
Note that this reports the total number of individual matches and not
|
| 238 |
+
the number of lines that match.
|
| 239 |
+
|
| 240 |
+
If only one file is given to ripgrep, then only the count is printed if there
|
| 241 |
+
is a match. The --with-filename flag can be used to force printing the file
|
| 242 |
+
path in this case.
|
| 243 |
+
|
| 244 |
+
This overrides the --count flag. Note that when --count is combined with
|
| 245 |
+
--only-matching, then ripgrep behaves as if --count-matches was given.
|
| 246 |
+
|
| 247 |
+
--crlf
|
| 248 |
+
When enabled, ripgrep will treat CRLF ('\r\n') as a line terminator instead
|
| 249 |
+
of just '\n'.
|
| 250 |
+
|
| 251 |
+
Principally, this permits '$' in regex patterns to match just before CRLF
|
| 252 |
+
instead of just before LF. The underlying regex engine may not support this
|
| 253 |
+
natively, so ripgrep will translate all instances of '$' to '(?:\r??$)'. This
|
| 254 |
+
may produce slightly different than desired match offsets. It is intended as a
|
| 255 |
+
work-around until the regex engine supports this natively.
|
| 256 |
+
|
| 257 |
+
CRLF support can be disabled with --no-crlf.
|
| 258 |
+
|
| 259 |
+
--debug
|
| 260 |
+
Show debug messages. Please use this when filing a bug report.
|
| 261 |
+
|
| 262 |
+
The --debug flag is generally useful for figuring out why ripgrep skipped
|
| 263 |
+
searching a particular file. The debug messages should mention all files
|
| 264 |
+
skipped and why they were skipped.
|
| 265 |
+
|
| 266 |
+
To get even more debug output, use the --trace flag, which implies --debug
|
| 267 |
+
along with additional trace data. With --trace, the output could be quite
|
| 268 |
+
large and is generally more useful for development.
|
| 269 |
+
|
| 270 |
+
--dfa-size-limit <NUM+SUFFIX?>
|
| 271 |
+
The upper size limit of the regex DFA. The default limit is 10M. This should
|
| 272 |
+
only be changed on very large regex inputs where the (slower) fallback regex
|
| 273 |
+
engine may otherwise be used if the limit is reached.
|
| 274 |
+
|
| 275 |
+
The argument accepts the same size suffixes as allowed in with the
|
| 276 |
+
--max-filesize flag.
|
| 277 |
+
|
| 278 |
+
-E, --encoding <ENCODING>
|
| 279 |
+
Specify the text encoding that ripgrep will use on all files searched. The
|
| 280 |
+
default value is 'auto', which will cause ripgrep to do a best effort automatic
|
| 281 |
+
detection of encoding on a per-file basis. Automatic detection in this case
|
| 282 |
+
only applies to files that begin with a UTF-8 or UTF-16 byte-order mark (BOM).
|
| 283 |
+
No other automatic detection is performed. One can also specify 'none' which
|
| 284 |
+
will then completely disable BOM sniffing and always result in searching the
|
| 285 |
+
raw bytes, including a BOM if it's present, regardless of its encoding.
|
| 286 |
+
|
| 287 |
+
Other supported values can be found in the list of labels here:
|
| 288 |
+
https://encoding.spec.whatwg.org/#concept-encoding-get
|
| 289 |
+
|
| 290 |
+
For more details on encoding and how ripgrep deals with it, see GUIDE.md.
|
| 291 |
+
|
| 292 |
+
This flag can be disabled with --no-encoding.
|
| 293 |
+
|
| 294 |
+
--engine <ENGINE>
|
| 295 |
+
Specify which regular expression engine to use. When you choose a regex engine,
|
| 296 |
+
it applies that choice for every regex provided to ripgrep (e.g., via multiple
|
| 297 |
+
-e/--regexp or -f/--file flags).
|
| 298 |
+
|
| 299 |
+
Accepted values are 'default', 'pcre2', or 'auto'.
|
| 300 |
+
|
| 301 |
+
The default value is 'default', which is the fastest and should be good for
|
| 302 |
+
most use cases. The 'pcre2' engine is generally useful when you want to use
|
| 303 |
+
features such as look-around or backreferences. 'auto' will dynamically choose
|
| 304 |
+
between supported regex engines depending on the features used in a pattern on
|
| 305 |
+
a best effort basis.
|
| 306 |
+
|
| 307 |
+
Note that the 'pcre2' engine is an optional ripgrep feature. If PCRE2 wasn't
|
| 308 |
+
included in your build of ripgrep, then using this flag will result in ripgrep
|
| 309 |
+
printing an error message and exiting.
|
| 310 |
+
|
| 311 |
+
This overrides previous uses of --pcre2 and --auto-hybrid-regex flags.
|
| 312 |
+
[default: default]
|
| 313 |
+
--field-context-separator <SEPARATOR>
|
| 314 |
+
Set the field context separator, which is used to delimit file paths, line
|
| 315 |
+
numbers, columns and the context itself, when printing contextual lines. The
|
| 316 |
+
separator may be any number of bytes, including zero. Escape sequences like
|
| 317 |
+
\x7F or \t may be used. The default value is -.
|
| 318 |
+
|
| 319 |
+
--field-match-separator <SEPARATOR>
|
| 320 |
+
Set the field match separator, which is used to delimit file paths, line
|
| 321 |
+
numbers, columns and the match itself. The separator may be any number of
|
| 322 |
+
bytes, including zero. Escape sequences like \x7F or \t may be used. The
|
| 323 |
+
default value is -.
|
| 324 |
+
|
| 325 |
+
-f, --file <PATTERNFILE>...
|
| 326 |
+
Search for patterns from the given file, with one pattern per line. When this
|
| 327 |
+
flag is used multiple times or in combination with the -e/--regexp flag,
|
| 328 |
+
then all patterns provided are searched. Empty pattern lines will match all
|
| 329 |
+
input lines, and the newline is not counted as part of the pattern.
|
| 330 |
+
|
| 331 |
+
A line is printed if and only if it matches at least one of the patterns.
|
| 332 |
+
|
| 333 |
+
--files
|
| 334 |
+
Print each file that would be searched without actually performing the search.
|
| 335 |
+
This is useful to determine whether a particular file is being searched or not.
|
| 336 |
+
|
| 337 |
+
-l, --files-with-matches
|
| 338 |
+
Print the paths with at least one match and suppress match contents.
|
| 339 |
+
|
| 340 |
+
This overrides --files-without-match.
|
| 341 |
+
|
| 342 |
+
--files-without-match
|
| 343 |
+
Print the paths that contain zero matches and suppress match contents. This
|
| 344 |
+
inverts/negates the --files-with-matches flag.
|
| 345 |
+
|
| 346 |
+
This overrides --files-with-matches.
|
| 347 |
+
|
| 348 |
+
-F, --fixed-strings
|
| 349 |
+
Treat the pattern as a literal string instead of a regular expression. When
|
| 350 |
+
this flag is used, special regular expression meta characters such as .(){}*+
|
| 351 |
+
do not need to be escaped.
|
| 352 |
+
|
| 353 |
+
This flag can be disabled with --no-fixed-strings.
|
| 354 |
+
|
| 355 |
+
-L, --follow
|
| 356 |
+
When this flag is enabled, ripgrep will follow symbolic links while traversing
|
| 357 |
+
directories. This is disabled by default. Note that ripgrep will check for
|
| 358 |
+
symbolic link loops and report errors if it finds one.
|
| 359 |
+
|
| 360 |
+
This flag can be disabled with --no-follow.
|
| 361 |
+
|
| 362 |
+
-g, --glob <GLOB>...
|
| 363 |
+
Include or exclude files and directories for searching that match the given
|
| 364 |
+
glob. This always overrides any other ignore logic. Multiple glob flags may be
|
| 365 |
+
used. Globbing rules match .gitignore globs. Precede a glob with a ! to exclude
|
| 366 |
+
it. If multiple globs match a file or directory, the glob given later in the
|
| 367 |
+
command line takes precedence.
|
| 368 |
+
|
| 369 |
+
As an extension, globs support specifying alternatives: *-g ab{c,d}* is
|
| 370 |
+
equivalet to *-g abc -g abd*. Empty alternatives like *-g ab{,c}* are not
|
| 371 |
+
currently supported. Note that this syntax extension is also currently enabled
|
| 372 |
+
in gitignore files, even though this syntax isn't supported by git itself.
|
| 373 |
+
ripgrep may disable this syntax extension in gitignore files, but it will
|
| 374 |
+
always remain available via the -g/--glob flag.
|
| 375 |
+
|
| 376 |
+
When this flag is set, every file and directory is applied to it to test for
|
| 377 |
+
a match. So for example, if you only want to search in a particular directory
|
| 378 |
+
'foo', then *-g foo* is incorrect because 'foo/bar' does not match the glob
|
| 379 |
+
'foo'. Instead, you should use *-g 'foo/**'*.
|
| 380 |
+
|
| 381 |
+
--glob-case-insensitive
|
| 382 |
+
Process glob patterns given with the -g/--glob flag case insensitively. This
|
| 383 |
+
effectively treats --glob as --iglob.
|
| 384 |
+
|
| 385 |
+
This flag can be disabled with the --no-glob-case-insensitive flag.
|
| 386 |
+
|
| 387 |
+
-h, --help
|
| 388 |
+
Prints help information. Use --help for more details.
|
| 389 |
+
|
| 390 |
+
--heading
|
| 391 |
+
This flag prints the file path above clusters of matches from each file instead
|
| 392 |
+
of printing the file path as a prefix for each matched line. This is the
|
| 393 |
+
default mode when printing to a terminal.
|
| 394 |
+
|
| 395 |
+
This overrides the --no-heading flag.
|
| 396 |
+
|
| 397 |
+
-., --hidden
|
| 398 |
+
Search hidden files and directories. By default, hidden files and directories
|
| 399 |
+
are skipped. Note that if a hidden file or a directory is whitelisted in an
|
| 400 |
+
ignore file, then it will be searched even if this flag isn't provided.
|
| 401 |
+
|
| 402 |
+
A file or directory is considered hidden if its base name starts with a dot
|
| 403 |
+
character ('.'). On operating systems which support a `hidden` file attribute,
|
| 404 |
+
like Windows, files with this attribute are also considered hidden.
|
| 405 |
+
|
| 406 |
+
This flag can be disabled with --no-hidden.
|
| 407 |
+
|
| 408 |
+
--iglob <GLOB>...
|
| 409 |
+
Include or exclude files and directories for searching that match the given
|
| 410 |
+
glob. This always overrides any other ignore logic. Multiple glob flags may be
|
| 411 |
+
used. Globbing rules match .gitignore globs. Precede a glob with a ! to exclude
|
| 412 |
+
it. Globs are matched case insensitively.
|
| 413 |
+
|
| 414 |
+
-i, --ignore-case
|
| 415 |
+
When this flag is provided, the given patterns will be searched case
|
| 416 |
+
insensitively. The case insensitivity rules used by ripgrep conform to
|
| 417 |
+
Unicode's "simple" case folding rules.
|
| 418 |
+
|
| 419 |
+
This flag overrides -s/--case-sensitive and -S/--smart-case.
|
| 420 |
+
|
| 421 |
+
--ignore-file <PATH>...
|
| 422 |
+
Specifies a path to one or more .gitignore format rules files. These patterns
|
| 423 |
+
are applied after the patterns found in .gitignore and .ignore are applied
|
| 424 |
+
and are matched relative to the current working directory. Multiple additional
|
| 425 |
+
ignore files can be specified by using the --ignore-file flag several times.
|
| 426 |
+
When specifying multiple ignore files, earlier files have lower precedence
|
| 427 |
+
than later files.
|
| 428 |
+
|
| 429 |
+
If you are looking for a way to include or exclude files and directories
|
| 430 |
+
directly on the command line, then used -g instead.
|
| 431 |
+
|
| 432 |
+
--ignore-file-case-insensitive
|
| 433 |
+
Process ignore files (.gitignore, .ignore, etc.) case insensitively. Note that
|
| 434 |
+
this comes with a performance penalty and is most useful on case insensitive
|
| 435 |
+
file systems (such as Windows).
|
| 436 |
+
|
| 437 |
+
This flag can be disabled with the --no-ignore-file-case-insensitive flag.
|
| 438 |
+
|
| 439 |
+
--include-zero
|
| 440 |
+
When used with --count or --count-matches, print the number of matches for
|
| 441 |
+
each file even if there were zero matches. This is disabled by default but can
|
| 442 |
+
be enabled to make ripgrep behave more like grep.
|
| 443 |
+
|
| 444 |
+
-v, --invert-match
|
| 445 |
+
Invert matching. Show lines that do not match the given patterns.
|
| 446 |
+
|
| 447 |
+
--json
|
| 448 |
+
Enable printing results in a JSON Lines format.
|
| 449 |
+
|
| 450 |
+
When this flag is provided, ripgrep will emit a sequence of messages, each
|
| 451 |
+
encoded as a JSON object, where there are five different message types:
|
| 452 |
+
|
| 453 |
+
**begin** - A message that indicates a file is being searched and contains at
|
| 454 |
+
least one match.
|
| 455 |
+
|
| 456 |
+
**end** - A message the indicates a file is done being searched. This message
|
| 457 |
+
also include summary statistics about the search for a particular file.
|
| 458 |
+
|
| 459 |
+
**match** - A message that indicates a match was found. This includes the text
|
| 460 |
+
and offsets of the match.
|
| 461 |
+
|
| 462 |
+
**context** - A message that indicates a contextual line was found. This
|
| 463 |
+
includes the text of the line, along with any match information if the search
|
| 464 |
+
was inverted.
|
| 465 |
+
|
| 466 |
+
**summary** - The final message emitted by ripgrep that contains summary
|
| 467 |
+
statistics about the search across all files.
|
| 468 |
+
|
| 469 |
+
Since file paths or the contents of files are not guaranteed to be valid UTF-8
|
| 470 |
+
and JSON itself must be representable by a Unicode encoding, ripgrep will emit
|
| 471 |
+
all data elements as objects with one of two keys: 'text' or 'bytes'. 'text' is
|
| 472 |
+
a normal JSON string when the data is valid UTF-8 while 'bytes' is the base64
|
| 473 |
+
encoded contents of the data.
|
| 474 |
+
|
| 475 |
+
The JSON Lines format is only supported for showing search results. It cannot
|
| 476 |
+
be used with other flags that emit other types of output, such as --files,
|
| 477 |
+
--files-with-matches, --files-without-match, --count or --count-matches.
|
| 478 |
+
ripgrep will report an error if any of the aforementioned flags are used in
|
| 479 |
+
concert with --json.
|
| 480 |
+
|
| 481 |
+
Other flags that control aspects of the standard output such as
|
| 482 |
+
--only-matching, --heading, --replace, --max-columns, etc., have no effect
|
| 483 |
+
when --json is set.
|
| 484 |
+
|
| 485 |
+
A more complete description of the JSON format used can be found here:
|
| 486 |
+
https://docs.rs/grep-printer/*/grep_printer/struct.JSON.html
|
| 487 |
+
|
| 488 |
+
The JSON Lines format can be disabled with --no-json.
|
| 489 |
+
|
| 490 |
+
--line-buffered
|
| 491 |
+
When enabled, ripgrep will use line buffering. That is, whenever a matching
|
| 492 |
+
line is found, it will be flushed to stdout immediately. This is the default
|
| 493 |
+
when ripgrep's stdout is connected to a terminal, but otherwise, ripgrep will
|
| 494 |
+
use block buffering, which is typically faster. This flag forces ripgrep to
|
| 495 |
+
use line buffering even if it would otherwise use block buffering. This is
|
| 496 |
+
typically useful in shell pipelines, e.g.,
|
| 497 |
+
'tail -f something.log | rg foo --line-buffered | rg bar'.
|
| 498 |
+
|
| 499 |
+
Forceful line buffering can be disabled with --no-line-buffered. Note that
|
| 500 |
+
using --no-line-buffered causes ripgrep to revert to its default behavior of
|
| 501 |
+
automatically detecting the buffering strategy. To force block buffering, use
|
| 502 |
+
the --block-buffered flag.
|
| 503 |
+
|
| 504 |
+
-n, --line-number
|
| 505 |
+
Show line numbers (1-based). This is enabled by default when searching in a
|
| 506 |
+
terminal.
|
| 507 |
+
|
| 508 |
+
-x, --line-regexp
|
| 509 |
+
Only show matches surrounded by line boundaries. This is equivalent to putting
|
| 510 |
+
^...$ around all of the search patterns. In other words, this only prints lines
|
| 511 |
+
where the entire line participates in a match.
|
| 512 |
+
|
| 513 |
+
This overrides the --word-regexp flag.
|
| 514 |
+
|
| 515 |
+
-M, --max-columns <NUM>
|
| 516 |
+
Don't print lines longer than this limit in bytes. Longer lines are omitted,
|
| 517 |
+
and only the number of matches in that line is printed.
|
| 518 |
+
|
| 519 |
+
When this flag is omitted or is set to 0, then it has no effect.
|
| 520 |
+
|
| 521 |
+
--max-columns-preview
|
| 522 |
+
When the '--max-columns' flag is used, ripgrep will by default completely
|
| 523 |
+
replace any line that is too long with a message indicating that a matching
|
| 524 |
+
line was removed. When this flag is combined with '--max-columns', a preview
|
| 525 |
+
of the line (corresponding to the limit size) is shown instead, where the part
|
| 526 |
+
of the line exceeding the limit is not shown.
|
| 527 |
+
|
| 528 |
+
If the '--max-columns' flag is not set, then this has no effect.
|
| 529 |
+
|
| 530 |
+
This flag can be disabled with '--no-max-columns-preview'.
|
| 531 |
+
|
| 532 |
+
-m, --max-count <NUM>
|
| 533 |
+
Limit the number of matching lines per file searched to NUM.
|
| 534 |
+
|
| 535 |
+
--max-depth <NUM>
|
| 536 |
+
Limit the depth of directory traversal to NUM levels beyond the paths given. A
|
| 537 |
+
value of zero only searches the explicitly given paths themselves.
|
| 538 |
+
|
| 539 |
+
For example, 'rg --max-depth 0 dir/' is a no-op because dir/ will not be
|
| 540 |
+
descended into. 'rg --max-depth 1 dir/' will search only the direct children of
|
| 541 |
+
'dir'.
|
| 542 |
+
|
| 543 |
+
--max-filesize <NUM+SUFFIX?>
|
| 544 |
+
Ignore files larger than NUM in size. This does not apply to directories.
|
| 545 |
+
|
| 546 |
+
The input format accepts suffixes of K, M or G which correspond to kilobytes,
|
| 547 |
+
megabytes and gigabytes, respectively. If no suffix is provided the input is
|
| 548 |
+
treated as bytes.
|
| 549 |
+
|
| 550 |
+
Examples: --max-filesize 50K or --max-filesize 80M
|
| 551 |
+
|
| 552 |
+
--mmap
|
| 553 |
+
Search using memory maps when possible. This is enabled by default when ripgrep
|
| 554 |
+
thinks it will be faster.
|
| 555 |
+
|
| 556 |
+
Memory map searching doesn't currently support all options, so if an
|
| 557 |
+
incompatible option (e.g., --context) is given with --mmap, then memory maps
|
| 558 |
+
will not be used.
|
| 559 |
+
|
| 560 |
+
Note that ripgrep may abort unexpectedly when --mmap if it searches a file that
|
| 561 |
+
is simultaneously truncated.
|
| 562 |
+
|
| 563 |
+
This flag overrides --no-mmap.
|
| 564 |
+
|
| 565 |
+
-U, --multiline
|
| 566 |
+
Enable matching across multiple lines.
|
| 567 |
+
|
| 568 |
+
When multiline mode is enabled, ripgrep will lift the restriction that a match
|
| 569 |
+
cannot include a line terminator. For example, when multiline mode is not
|
| 570 |
+
enabled (the default), then the regex '\p{any}' will match any Unicode
|
| 571 |
+
codepoint other than '\n'. Similarly, the regex '\n' is explicitly forbidden,
|
| 572 |
+
and if you try to use it, ripgrep will return an error. However, when multiline
|
| 573 |
+
mode is enabled, '\p{any}' will match any Unicode codepoint, including '\n',
|
| 574 |
+
and regexes like '\n' are permitted.
|
| 575 |
+
|
| 576 |
+
An important caveat is that multiline mode does not change the match semantics
|
| 577 |
+
of '.'. Namely, in most regex matchers, a '.' will by default match any
|
| 578 |
+
character other than '\n', and this is true in ripgrep as well. In order to
|
| 579 |
+
make '.' match '\n', you must enable the "dot all" flag inside the regex.
|
| 580 |
+
For example, both '(?s).' and '(?s:.)' have the same semantics, where '.' will
|
| 581 |
+
match any character, including '\n'. Alternatively, the '--multiline-dotall'
|
| 582 |
+
flag may be passed to make the "dot all" behavior the default. This flag only
|
| 583 |
+
applies when multiline search is enabled.
|
| 584 |
+
|
| 585 |
+
There is no limit on the number of the lines that a single match can span.
|
| 586 |
+
|
| 587 |
+
**WARNING**: Because of how the underlying regex engine works, multiline
|
| 588 |
+
searches may be slower than normal line-oriented searches, and they may also
|
| 589 |
+
use more memory. In particular, when multiline mode is enabled, ripgrep
|
| 590 |
+
requires that each file it searches is laid out contiguously in memory
|
| 591 |
+
(either by reading it onto the heap or by memory-mapping it). Things that
|
| 592 |
+
cannot be memory-mapped (such as stdin) will be consumed until EOF before
|
| 593 |
+
searching can begin. In general, ripgrep will only do these things when
|
| 594 |
+
necessary. Specifically, if the --multiline flag is provided but the regex
|
| 595 |
+
does not contain patterns that would match '\n' characters, then ripgrep
|
| 596 |
+
will automatically avoid reading each file into memory before searching it.
|
| 597 |
+
Nevertheless, if you only care about matches spanning at most one line, then it
|
| 598 |
+
is always better to disable multiline mode.
|
| 599 |
+
|
| 600 |
+
This flag can be disabled with --no-multiline.
|
| 601 |
+
|
| 602 |
+
--multiline-dotall
|
| 603 |
+
This flag enables "dot all" in your regex pattern, which causes '.' to match
|
| 604 |
+
newlines when multiline searching is enabled. This flag has no effect if
|
| 605 |
+
multiline searching isn't enabled with the --multiline flag.
|
| 606 |
+
|
| 607 |
+
Normally, a '.' will match any character except newlines. While this behavior
|
| 608 |
+
typically isn't relevant for line-oriented matching (since matches can span at
|
| 609 |
+
most one line), this can be useful when searching with the -U/--multiline flag.
|
| 610 |
+
By default, the multiline mode runs without this flag.
|
| 611 |
+
|
| 612 |
+
This flag is generally intended to be used in an alias or your ripgrep config
|
| 613 |
+
file if you prefer "dot all" semantics by default. Note that regardless of
|
| 614 |
+
whether this flag is used, "dot all" semantics can still be controlled via
|
| 615 |
+
inline flags in the regex pattern itself, e.g., '(?s:.)' always enables "dot
|
| 616 |
+
all" whereas '(?-s:.)' always disables "dot all".
|
| 617 |
+
|
| 618 |
+
This flag can be disabled with --no-multiline-dotall.
|
| 619 |
+
|
| 620 |
+
--no-config
|
| 621 |
+
Never read configuration files. When this flag is present, ripgrep will not
|
| 622 |
+
respect the RIPGREP_CONFIG_PATH environment variable.
|
| 623 |
+
|
| 624 |
+
If ripgrep ever grows a feature to automatically read configuration files in
|
| 625 |
+
pre-defined locations, then this flag will also disable that behavior as well.
|
| 626 |
+
|
| 627 |
+
-I, --no-filename
|
| 628 |
+
Never print the file path with the matched lines. This is the default when
|
| 629 |
+
ripgrep is explicitly instructed to search one file or stdin.
|
| 630 |
+
|
| 631 |
+
This flag overrides --with-filename.
|
| 632 |
+
|
| 633 |
+
--no-heading
|
| 634 |
+
Don't group matches by each file. If --no-heading is provided in addition to
|
| 635 |
+
the -H/--with-filename flag, then file paths will be printed as a prefix for
|
| 636 |
+
every matched line. This is the default mode when not printing to a terminal.
|
| 637 |
+
|
| 638 |
+
This overrides the --heading flag.
|
| 639 |
+
|
| 640 |
+
--no-ignore
|
| 641 |
+
Don't respect ignore files (.gitignore, .ignore, etc.). This implies
|
| 642 |
+
--no-ignore-dot, --no-ignore-exclude, --no-ignore-global, no-ignore-parent and
|
| 643 |
+
--no-ignore-vcs.
|
| 644 |
+
|
| 645 |
+
This does *not* imply --no-ignore-files, since --ignore-file is specified
|
| 646 |
+
explicitly as a command line argument.
|
| 647 |
+
|
| 648 |
+
When given only once, the -u flag is identical in behavior to --no-ignore and
|
| 649 |
+
can be considered an alias. However, subsequent -u flags have additional
|
| 650 |
+
effects; see --unrestricted.
|
| 651 |
+
|
| 652 |
+
This flag can be disabled with the --ignore flag.
|
| 653 |
+
|
| 654 |
+
--no-ignore-dot
|
| 655 |
+
Don't respect .ignore files.
|
| 656 |
+
|
| 657 |
+
This does *not* affect whether ripgrep will ignore files and directories
|
| 658 |
+
whose names begin with a dot. For that, see the -./--hidden flag.
|
| 659 |
+
|
| 660 |
+
This flag can be disabled with the --ignore-dot flag.
|
| 661 |
+
|
| 662 |
+
--no-ignore-exclude
|
| 663 |
+
Don't respect ignore files that are manually configured for the repository
|
| 664 |
+
such as git's '.git/info/exclude'.
|
| 665 |
+
|
| 666 |
+
This flag can be disabled with the --ignore-exclude flag.
|
| 667 |
+
|
| 668 |
+
--no-ignore-files
|
| 669 |
+
When set, any --ignore-file flags, even ones that come after this flag, are
|
| 670 |
+
ignored.
|
| 671 |
+
|
| 672 |
+
This flag can be disabled with the --ignore-files flag.
|
| 673 |
+
|
| 674 |
+
--no-ignore-global
|
| 675 |
+
Don't respect ignore files that come from "global" sources such as git's
|
| 676 |
+
`core.excludesFile` configuration option (which defaults to
|
| 677 |
+
`$HOME/.config/git/ignore`).
|
| 678 |
+
|
| 679 |
+
This flag can be disabled with the --ignore-global flag.
|
| 680 |
+
|
| 681 |
+
--no-ignore-messages
|
| 682 |
+
Suppresses all error messages related to parsing ignore files such as .ignore
|
| 683 |
+
or .gitignore.
|
| 684 |
+
|
| 685 |
+
This flag can be disabled with the --ignore-messages flag.
|
| 686 |
+
|
| 687 |
+
--no-ignore-parent
|
| 688 |
+
Don't respect ignore files (.gitignore, .ignore, etc.) in parent directories.
|
| 689 |
+
|
| 690 |
+
This flag can be disabled with the --ignore-parent flag.
|
| 691 |
+
|
| 692 |
+
--no-ignore-vcs
|
| 693 |
+
Don't respect version control ignore files (.gitignore, etc.). This implies
|
| 694 |
+
--no-ignore-parent for VCS files. Note that .ignore files will continue to be
|
| 695 |
+
respected.
|
| 696 |
+
|
| 697 |
+
This flag can be disabled with the --ignore-vcs flag.
|
| 698 |
+
|
| 699 |
+
-N, --no-line-number
|
| 700 |
+
Suppress line numbers. This is enabled by default when not searching in a
|
| 701 |
+
terminal.
|
| 702 |
+
|
| 703 |
+
--no-messages
|
| 704 |
+
Suppress all error messages related to opening and reading files. Error
|
| 705 |
+
messages related to the syntax of the pattern given are still shown.
|
| 706 |
+
|
| 707 |
+
This flag can be disabled with the --messages flag.
|
| 708 |
+
|
| 709 |
+
--no-mmap
|
| 710 |
+
Never use memory maps, even when they might be faster.
|
| 711 |
+
|
| 712 |
+
This flag overrides --mmap.
|
| 713 |
+
|
| 714 |
+
--no-pcre2-unicode
|
| 715 |
+
DEPRECATED. Use --no-unicode instead.
|
| 716 |
+
|
| 717 |
+
This flag is now an alias for --no-unicode. And --pcre2-unicode is an alias
|
| 718 |
+
for --unicode.
|
| 719 |
+
|
| 720 |
+
--no-require-git
|
| 721 |
+
By default, ripgrep will only respect global gitignore rules, .gitignore rules
|
| 722 |
+
and local exclude rules if ripgrep detects that you are searching inside a
|
| 723 |
+
git repository. This flag allows you to relax this restriction such that
|
| 724 |
+
ripgrep will respect all git related ignore rules regardless of whether you're
|
| 725 |
+
searching in a git repository or not.
|
| 726 |
+
|
| 727 |
+
This flag can be disabled with --require-git.
|
| 728 |
+
|
| 729 |
+
--no-unicode
|
| 730 |
+
By default, ripgrep will enable "Unicode mode" in all of its regexes. This
|
| 731 |
+
has a number of consequences:
|
| 732 |
+
|
| 733 |
+
* '.' will only match valid UTF-8 encoded scalar values.
|
| 734 |
+
* Classes like '\w', '\s', '\d' are all Unicode aware and much bigger
|
| 735 |
+
than their ASCII only versions.
|
| 736 |
+
* Case insensitive matching will use Unicode case folding.
|
| 737 |
+
* A large array of classes like '\p{Emoji}' are available.
|
| 738 |
+
* Word boundaries ('\b' and '\B') use the Unicode definition of a word
|
| 739 |
+
character.
|
| 740 |
+
|
| 741 |
+
In some cases it can be desirable to turn these things off. The --no-unicode
|
| 742 |
+
flag will do exactly that.
|
| 743 |
+
|
| 744 |
+
For PCRE2 specifically, Unicode mode represents a critical trade off in the
|
| 745 |
+
user experience of ripgrep. In particular, unlike the default regex engine,
|
| 746 |
+
PCRE2 does not support the ability to search possibly invalid UTF-8 with
|
| 747 |
+
Unicode features enabled. Instead, PCRE2 *requires* that everything it searches
|
| 748 |
+
when Unicode mode is enabled is valid UTF-8. (Or valid UTF-16/UTF-32, but for
|
| 749 |
+
the purposes of ripgrep, we only discuss UTF-8.) This means that if you have
|
| 750 |
+
PCRE2's Unicode mode enabled and you attempt to search invalid UTF-8, then
|
| 751 |
+
the search for that file will halt and print an error. For this reason, when
|
| 752 |
+
PCRE2's Unicode mode is enabled, ripgrep will automatically "fix" invalid
|
| 753 |
+
UTF-8 sequences by replacing them with the Unicode replacement codepoint. This
|
| 754 |
+
penalty does not occur when using the default regex engine.
|
| 755 |
+
|
| 756 |
+
If you would rather see the encoding errors surfaced by PCRE2 when Unicode mode
|
| 757 |
+
is enabled, then pass the --no-encoding flag to disable all transcoding.
|
| 758 |
+
|
| 759 |
+
The --no-unicode flag can be disabled with --unicode. Note that
|
| 760 |
+
--no-pcre2-unicode and --pcre2-unicode are aliases for --no-unicode and
|
| 761 |
+
--unicode, respectively.
|
| 762 |
+
|
| 763 |
+
-0, --null
|
| 764 |
+
Whenever a file path is printed, follow it with a NUL byte. This includes
|
| 765 |
+
printing file paths before matches, and when printing a list of matching files
|
| 766 |
+
such as with --count, --files-with-matches and --files. This option is useful
|
| 767 |
+
for use with xargs.
|
| 768 |
+
|
| 769 |
+
--null-data
|
| 770 |
+
Enabling this option causes ripgrep to use NUL as a line terminator instead of
|
| 771 |
+
the default of '\n'.
|
| 772 |
+
|
| 773 |
+
This is useful when searching large binary files that would otherwise have very
|
| 774 |
+
long lines if '\n' were used as the line terminator. In particular, ripgrep
|
| 775 |
+
requires that, at a minimum, each line must fit into memory. Using NUL instead
|
| 776 |
+
can be a useful stopgap to keep memory requirements low and avoid OOM (out of
|
| 777 |
+
memory) conditions.
|
| 778 |
+
|
| 779 |
+
This is also useful for processing NUL delimited data, such as that emitted
|
| 780 |
+
when using ripgrep's -0/--null flag or find's --print0 flag.
|
| 781 |
+
|
| 782 |
+
Using this flag implies -a/--text.
|
| 783 |
+
|
| 784 |
+
--one-file-system
|
| 785 |
+
When enabled, ripgrep will not cross file system boundaries relative to where
|
| 786 |
+
the search started from.
|
| 787 |
+
|
| 788 |
+
Note that this applies to each path argument given to ripgrep. For example, in
|
| 789 |
+
the command 'rg --one-file-system /foo/bar /quux/baz', ripgrep will search both
|
| 790 |
+
'/foo/bar' and '/quux/baz' even if they are on different file systems, but will
|
| 791 |
+
not cross a file system boundary when traversing each path's directory tree.
|
| 792 |
+
|
| 793 |
+
This is similar to find's '-xdev' or '-mount' flag.
|
| 794 |
+
|
| 795 |
+
This flag can be disabled with --no-one-file-system.
|
| 796 |
+
|
| 797 |
+
-o, --only-matching
|
| 798 |
+
Print only the matched (non-empty) parts of a matching line, with each such
|
| 799 |
+
part on a separate output line.
|
| 800 |
+
|
| 801 |
+
--passthru
|
| 802 |
+
Print both matching and non-matching lines.
|
| 803 |
+
|
| 804 |
+
Another way to achieve a similar effect is by modifying your pattern to match
|
| 805 |
+
the empty string. For example, if you are searching using 'rg foo' then using
|
| 806 |
+
'rg "^|foo"' instead will emit every line in every file searched, but only
|
| 807 |
+
occurrences of 'foo' will be highlighted. This flag enables the same behavior
|
| 808 |
+
without needing to modify the pattern.
|
| 809 |
+
|
| 810 |
+
This overrides the --context, --after-context and --before-context flags.
|
| 811 |
+
|
| 812 |
+
--path-separator <SEPARATOR>
|
| 813 |
+
Set the path separator to use when printing file paths. This defaults to your
|
| 814 |
+
platform's path separator, which is / on Unix and \ on Windows. This flag is
|
| 815 |
+
intended for overriding the default when the environment demands it (e.g.,
|
| 816 |
+
cygwin). A path separator is limited to a single byte.
|
| 817 |
+
|
| 818 |
+
-P, --pcre2
|
| 819 |
+
When this flag is present, ripgrep will use the PCRE2 regex engine instead of
|
| 820 |
+
its default regex engine.
|
| 821 |
+
|
| 822 |
+
This is generally useful when you want to use features such as look-around
|
| 823 |
+
or backreferences.
|
| 824 |
+
|
| 825 |
+
Note that PCRE2 is an optional ripgrep feature. If PCRE2 wasn't included in
|
| 826 |
+
your build of ripgrep, then using this flag will result in ripgrep printing
|
| 827 |
+
an error message and exiting. PCRE2 may also have worse user experience in
|
| 828 |
+
some cases, since it has fewer introspection APIs than ripgrep's default regex
|
| 829 |
+
engine. For example, if you use a '\n' in a PCRE2 regex without the
|
| 830 |
+
'-U/--multiline' flag, then ripgrep will silently fail to match anything
|
| 831 |
+
instead of reporting an error immediately (like it does with the default
|
| 832 |
+
regex engine).
|
| 833 |
+
|
| 834 |
+
Related flags: --no-pcre2-unicode
|
| 835 |
+
|
| 836 |
+
This flag can be disabled with --no-pcre2.
|
| 837 |
+
|
| 838 |
+
--pcre2-version
|
| 839 |
+
When this flag is present, ripgrep will print the version of PCRE2 in use,
|
| 840 |
+
along with other information, and then exit. If PCRE2 is not available, then
|
| 841 |
+
ripgrep will print an error message and exit with an error code.
|
| 842 |
+
|
| 843 |
+
--pre <COMMAND>
|
| 844 |
+
For each input FILE, search the standard output of COMMAND FILE rather than the
|
| 845 |
+
contents of FILE. This option expects the COMMAND program to either be an
|
| 846 |
+
absolute path or to be available in your PATH. Either an empty string COMMAND
|
| 847 |
+
or the '--no-pre' flag will disable this behavior.
|
| 848 |
+
|
| 849 |
+
WARNING: When this flag is set, ripgrep will unconditionally spawn a
|
| 850 |
+
process for every file that is searched. Therefore, this can incur an
|
| 851 |
+
unnecessarily large performance penalty if you don't otherwise need the
|
| 852 |
+
flexibility offered by this flag. One possible mitigation to this is to use
|
| 853 |
+
the '--pre-glob' flag to limit which files a preprocessor is run with.
|
| 854 |
+
|
| 855 |
+
A preprocessor is not run when ripgrep is searching stdin.
|
| 856 |
+
|
| 857 |
+
When searching over sets of files that may require one of several decoders
|
| 858 |
+
as preprocessors, COMMAND should be a wrapper program or script which first
|
| 859 |
+
classifies FILE based on magic numbers/content or based on the FILE name and
|
| 860 |
+
then dispatches to an appropriate preprocessor. Each COMMAND also has its
|
| 861 |
+
standard input connected to FILE for convenience.
|
| 862 |
+
|
| 863 |
+
For example, a shell script for COMMAND might look like:
|
| 864 |
+
|
| 865 |
+
case "$1" in
|
| 866 |
+
*.pdf)
|
| 867 |
+
exec pdftotext "$1" -
|
| 868 |
+
;;
|
| 869 |
+
*)
|
| 870 |
+
case $(file "$1") in
|
| 871 |
+
*Zstandard*)
|
| 872 |
+
exec pzstd -cdq
|
| 873 |
+
;;
|
| 874 |
+
*)
|
| 875 |
+
exec cat
|
| 876 |
+
;;
|
| 877 |
+
esac
|
| 878 |
+
;;
|
| 879 |
+
esac
|
| 880 |
+
|
| 881 |
+
The above script uses `pdftotext` to convert a PDF file to plain text. For
|
| 882 |
+
all other files, the script uses the `file` utility to sniff the type of the
|
| 883 |
+
file based on its contents. If it is a compressed file in the Zstandard format,
|
| 884 |
+
then `pzstd` is used to decompress the contents to stdout.
|
| 885 |
+
|
| 886 |
+
This overrides the -z/--search-zip flag.
|
| 887 |
+
|
| 888 |
+
--pre-glob <GLOB>...
|
| 889 |
+
This flag works in conjunction with the --pre flag. Namely, when one or more
|
| 890 |
+
--pre-glob flags are given, then only files that match the given set of globs
|
| 891 |
+
will be handed to the command specified by the --pre flag. Any non-matching
|
| 892 |
+
files will be searched without using the preprocessor command.
|
| 893 |
+
|
| 894 |
+
This flag is useful when searching many files with the --pre flag. Namely,
|
| 895 |
+
it permits the ability to avoid process overhead for files that don't need
|
| 896 |
+
preprocessing. For example, given the following shell script, 'pre-pdftotext':
|
| 897 |
+
|
| 898 |
+
#!/bin/sh
|
| 899 |
+
|
| 900 |
+
pdftotext "$1" -
|
| 901 |
+
|
| 902 |
+
then it is possible to use '--pre pre-pdftotext --pre-glob '*.pdf'' to make
|
| 903 |
+
it so ripgrep only executes the 'pre-pdftotext' command on files with a '.pdf'
|
| 904 |
+
extension.
|
| 905 |
+
|
| 906 |
+
Multiple --pre-glob flags may be used. Globbing rules match .gitignore globs.
|
| 907 |
+
Precede a glob with a ! to exclude it.
|
| 908 |
+
|
| 909 |
+
This flag has no effect if the --pre flag is not used.
|
| 910 |
+
|
| 911 |
+
-p, --pretty
|
| 912 |
+
This is a convenience alias for '--color always --heading --line-number'. This
|
| 913 |
+
flag is useful when you still want pretty output even if you're piping ripgrep
|
| 914 |
+
to another program or file. For example: 'rg -p foo | less -R'.
|
| 915 |
+
|
| 916 |
+
-q, --quiet
|
| 917 |
+
Do not print anything to stdout. If a match is found in a file, then ripgrep
|
| 918 |
+
will stop searching. This is useful when ripgrep is used only for its exit
|
| 919 |
+
code (which will be an error if no matches are found).
|
| 920 |
+
|
| 921 |
+
When --files is used, then ripgrep will stop finding files after finding the
|
| 922 |
+
first file that matches all ignore rules.
|
| 923 |
+
|
| 924 |
+
--regex-size-limit <NUM+SUFFIX?>
|
| 925 |
+
The upper size limit of the compiled regex. The default limit is 10M.
|
| 926 |
+
|
| 927 |
+
The argument accepts the same size suffixes as allowed in the --max-filesize
|
| 928 |
+
flag.
|
| 929 |
+
|
| 930 |
+
-e, --regexp <PATTERN>...
|
| 931 |
+
A pattern to search for. This option can be provided multiple times, where
|
| 932 |
+
all patterns given are searched. Lines matching at least one of the provided
|
| 933 |
+
patterns are printed. This flag can also be used when searching for patterns
|
| 934 |
+
that start with a dash.
|
| 935 |
+
|
| 936 |
+
For example, to search for the literal '-foo', you can use this flag:
|
| 937 |
+
|
| 938 |
+
rg -e -foo
|
| 939 |
+
|
| 940 |
+
You can also use the special '--' delimiter to indicate that no more flags
|
| 941 |
+
will be provided. Namely, the following is equivalent to the above:
|
| 942 |
+
|
| 943 |
+
rg -- -foo
|
| 944 |
+
|
| 945 |
+
-r, --replace <REPLACEMENT_TEXT>
|
| 946 |
+
Replace every match with the text given when printing results. Neither this
|
| 947 |
+
flag nor any other ripgrep flag will modify your files.
|
| 948 |
+
|
| 949 |
+
Capture group indices (e.g., $5) and names (e.g., $foo) are supported in the
|
| 950 |
+
replacement string. Capture group indices are numbered based on the position of
|
| 951 |
+
the opening parenthesis of the group, where the leftmost such group is $1. The
|
| 952 |
+
special $0 group corresponds to the entire match.
|
| 953 |
+
|
| 954 |
+
In shells such as Bash and zsh, you should wrap the pattern in single quotes
|
| 955 |
+
instead of double quotes. Otherwise, capture group indices will be replaced by
|
| 956 |
+
expanded shell variables which will most likely be empty.
|
| 957 |
+
|
| 958 |
+
To write a literal '$', use '$$'.
|
| 959 |
+
|
| 960 |
+
Note that the replacement by default replaces each match, and NOT the entire
|
| 961 |
+
line. To replace the entire line, you should match the entire line.
|
| 962 |
+
|
| 963 |
+
This flag can be used with the -o/--only-matching flag.
|
| 964 |
+
|
| 965 |
+
-z, --search-zip
|
| 966 |
+
Search in compressed files. Currently gzip, bzip2, xz, LZ4, LZMA, Brotli and
|
| 967 |
+
Zstd files are supported. This option expects the decompression binaries to be
|
| 968 |
+
available in your PATH.
|
| 969 |
+
|
| 970 |
+
This flag can be disabled with --no-search-zip.
|
| 971 |
+
|
| 972 |
+
-S, --smart-case
|
| 973 |
+
Searches case insensitively if the pattern is all lowercase. Search case
|
| 974 |
+
sensitively otherwise.
|
| 975 |
+
|
| 976 |
+
A pattern is considered all lowercase if both of the following rules hold:
|
| 977 |
+
|
| 978 |
+
First, the pattern contains at least one literal character. For example, 'a\w'
|
| 979 |
+
contains a literal ('a') but just '\w' does not.
|
| 980 |
+
|
| 981 |
+
Second, of the literals in the pattern, none of them are considered to be
|
| 982 |
+
uppercase according to Unicode. For example, 'foo\pL' has no uppercase
|
| 983 |
+
literals but 'Foo\pL' does.
|
| 984 |
+
|
| 985 |
+
This overrides the -s/--case-sensitive and -i/--ignore-case flags.
|
| 986 |
+
|
| 987 |
+
--sort <SORTBY>
|
| 988 |
+
This flag enables sorting of results in ascending order. The possible values
|
| 989 |
+
for this flag are:
|
| 990 |
+
|
| 991 |
+
none (Default) Do not sort results. Fastest. Can be multi-threaded.
|
| 992 |
+
path Sort by file path. Always single-threaded.
|
| 993 |
+
modified Sort by the last modified time on a file. Always single-threaded.
|
| 994 |
+
accessed Sort by the last accessed time on a file. Always single-threaded.
|
| 995 |
+
created Sort by the creation time on a file. Always single-threaded.
|
| 996 |
+
|
| 997 |
+
If the chosen (manually or by-default) sorting criteria isn't available on your
|
| 998 |
+
system (for example, creation time is not available on ext4 file systems), then
|
| 999 |
+
ripgrep will attempt to detect this, print an error and exit without searching.
|
| 1000 |
+
|
| 1001 |
+
To sort results in reverse or descending order, use the --sortr flag. Also,
|
| 1002 |
+
this flag overrides --sortr.
|
| 1003 |
+
|
| 1004 |
+
Note that sorting results currently always forces ripgrep to abandon
|
| 1005 |
+
parallelism and run in a single thread.
|
| 1006 |
+
|
| 1007 |
+
--sortr <SORTBY>
|
| 1008 |
+
This flag enables sorting of results in descending order. The possible values
|
| 1009 |
+
for this flag are:
|
| 1010 |
+
|
| 1011 |
+
none (Default) Do not sort results. Fastest. Can be multi-threaded.
|
| 1012 |
+
path Sort by file path. Always single-threaded.
|
| 1013 |
+
modified Sort by the last modified time on a file. Always single-threaded.
|
| 1014 |
+
accessed Sort by the last accessed time on a file. Always single-threaded.
|
| 1015 |
+
created Sort by the creation time on a file. Always single-threaded.
|
| 1016 |
+
|
| 1017 |
+
If the chosen (manually or by-default) sorting criteria isn't available on your
|
| 1018 |
+
system (for example, creation time is not available on ext4 file systems), then
|
| 1019 |
+
ripgrep will attempt to detect this, print an error and exit without searching.
|
| 1020 |
+
|
| 1021 |
+
To sort results in ascending order, use the --sort flag. Also, this flag
|
| 1022 |
+
overrides --sort.
|
| 1023 |
+
|
| 1024 |
+
Note that sorting results currently always forces ripgrep to abandon
|
| 1025 |
+
parallelism and run in a single thread.
|
| 1026 |
+
|
| 1027 |
+
--stats
|
| 1028 |
+
Print aggregate statistics about this ripgrep search. When this flag is
|
| 1029 |
+
present, ripgrep will print the following stats to stdout at the end of the
|
| 1030 |
+
search: number of matched lines, number of files with matches, number of files
|
| 1031 |
+
searched, and the time taken for the entire search to complete.
|
| 1032 |
+
|
| 1033 |
+
This set of aggregate statistics may expand over time.
|
| 1034 |
+
|
| 1035 |
+
Note that this flag has no effect if --files, --files-with-matches or
|
| 1036 |
+
--files-without-match is passed.
|
| 1037 |
+
|
| 1038 |
+
This flag can be disabled with --no-stats.
|
| 1039 |
+
|
| 1040 |
+
-a, --text
|
| 1041 |
+
Search binary files as if they were text. When this flag is present, ripgrep's
|
| 1042 |
+
binary file detection is disabled. This means that when a binary file is
|
| 1043 |
+
searched, its contents may be printed if there is a match. This may cause
|
| 1044 |
+
escape codes to be printed that alter the behavior of your terminal.
|
| 1045 |
+
|
| 1046 |
+
When binary file detection is enabled it is imperfect. In general, it uses
|
| 1047 |
+
a simple heuristic. If a NUL byte is seen during search, then the file is
|
| 1048 |
+
considered binary and search stops (unless this flag is present).
|
| 1049 |
+
Alternatively, if the '--binary' flag is used, then ripgrep will only quit
|
| 1050 |
+
when it sees a NUL byte after it sees a match (or searches the entire file).
|
| 1051 |
+
|
| 1052 |
+
This flag can be disabled with '--no-text'. It overrides the '--binary' flag.
|
| 1053 |
+
|
| 1054 |
+
-j, --threads <NUM>
|
| 1055 |
+
The approximate number of threads to use. A value of 0 (which is the default)
|
| 1056 |
+
causes ripgrep to choose the thread count using heuristics.
|
| 1057 |
+
|
| 1058 |
+
--trim
|
| 1059 |
+
When set, all ASCII whitespace at the beginning of each line printed will be
|
| 1060 |
+
trimmed.
|
| 1061 |
+
|
| 1062 |
+
This flag can be disabled with --no-trim.
|
| 1063 |
+
|
| 1064 |
+
-t, --type <TYPE>...
|
| 1065 |
+
Only search files matching TYPE. Multiple type flags may be provided. Use the
|
| 1066 |
+
--type-list flag to list all available types.
|
| 1067 |
+
|
| 1068 |
+
This flag supports the special value 'all', which will behave as if --type
|
| 1069 |
+
was provided for every file type supported by ripgrep (including any custom
|
| 1070 |
+
file types). The end result is that '--type all' causes ripgrep to search in
|
| 1071 |
+
"whitelist" mode, where it will only search files it recognizes via its type
|
| 1072 |
+
definitions.
|
| 1073 |
+
|
| 1074 |
+
--type-add <TYPE_SPEC>...
|
| 1075 |
+
Add a new glob for a particular file type. Only one glob can be added at a
|
| 1076 |
+
time. Multiple --type-add flags can be provided. Unless --type-clear is used,
|
| 1077 |
+
globs are added to any existing globs defined inside of ripgrep.
|
| 1078 |
+
|
| 1079 |
+
Note that this MUST be passed to every invocation of ripgrep. Type settings are
|
| 1080 |
+
NOT persisted. See CONFIGURATION FILES for a workaround.
|
| 1081 |
+
|
| 1082 |
+
Example:
|
| 1083 |
+
|
| 1084 |
+
rg --type-add 'foo:*.foo' -tfoo PATTERN.
|
| 1085 |
+
|
| 1086 |
+
--type-add can also be used to include rules from other types with the special
|
| 1087 |
+
include directive. The include directive permits specifying one or more other
|
| 1088 |
+
type names (separated by a comma) that have been defined and its rules will
|
| 1089 |
+
automatically be imported into the type specified. For example, to create a
|
| 1090 |
+
type called src that matches C++, Python and Markdown files, one can use:
|
| 1091 |
+
|
| 1092 |
+
--type-add 'src:include:cpp,py,md'
|
| 1093 |
+
|
| 1094 |
+
Additional glob rules can still be added to the src type by using the
|
| 1095 |
+
--type-add flag again:
|
| 1096 |
+
|
| 1097 |
+
--type-add 'src:include:cpp,py,md' --type-add 'src:*.foo'
|
| 1098 |
+
|
| 1099 |
+
Note that type names must consist only of Unicode letters or numbers.
|
| 1100 |
+
Punctuation characters are not allowed.
|
| 1101 |
+
|
| 1102 |
+
--type-clear <TYPE>...
|
| 1103 |
+
Clear the file type globs previously defined for TYPE. This only clears the
|
| 1104 |
+
default type definitions that are found inside of ripgrep.
|
| 1105 |
+
|
| 1106 |
+
Note that this MUST be passed to every invocation of ripgrep. Type settings are
|
| 1107 |
+
NOT persisted. See CONFIGURATION FILES for a workaround.
|
| 1108 |
+
|
| 1109 |
+
--type-list
|
| 1110 |
+
Show all supported file types and their corresponding globs.
|
| 1111 |
+
|
| 1112 |
+
-T, --type-not <TYPE>...
|
| 1113 |
+
Do not search files matching TYPE. Multiple type-not flags may be provided. Use
|
| 1114 |
+
the --type-list flag to list all available types.
|
| 1115 |
+
|
| 1116 |
+
-u, --unrestricted
|
| 1117 |
+
Reduce the level of "smart" searching. A single -u won't respect .gitignore
|
| 1118 |
+
(etc.) files (--no-ignore). Two -u flags will additionally search hidden files
|
| 1119 |
+
and directories (-./--hidden). Three -u flags will additionally search binary
|
| 1120 |
+
files (--binary).
|
| 1121 |
+
|
| 1122 |
+
'rg -uuu' is roughly equivalent to 'grep -r'.
|
| 1123 |
+
|
| 1124 |
+
-V, --version
|
| 1125 |
+
Prints version information
|
| 1126 |
+
|
| 1127 |
+
--vimgrep
|
| 1128 |
+
Show results with every match on its own line, including line numbers and
|
| 1129 |
+
column numbers. With this option, a line with more than one match will be
|
| 1130 |
+
printed more than once.
|
| 1131 |
+
|
| 1132 |
+
-H, --with-filename
|
| 1133 |
+
Display the file path for matches. This is the default when more than one
|
| 1134 |
+
file is searched. If --heading is enabled (the default when printing to a
|
| 1135 |
+
terminal), the file path will be shown above clusters of matches from each
|
| 1136 |
+
file; otherwise, the file name will be shown as a prefix for each matched line.
|
| 1137 |
+
|
| 1138 |
+
This flag overrides --no-filename.
|
| 1139 |
+
|
| 1140 |
+
-w, --word-regexp
|
| 1141 |
+
Only show matches surrounded by word boundaries. This is roughly equivalent to
|
| 1142 |
+
putting \b before and after all of the search patterns.
|
| 1143 |
+
|
| 1144 |
+
This overrides the --line-regexp flag.
|
| 1145 |
+
|
hidden_states.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:84ba39c72479239c2225136593bb2632f929c5a0cb0dfd5d477fec9f034945c9
|
| 3 |
+
size 367010144
|
job_new.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
measurement.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
multilingual_bench.png
ADDED

|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3608ae351548299035cc8fb31966ec5b25a1fd6e9aa22e4442f355b7f298b974
|
| 3 |
+
size 586061146
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 199 |
+
"clean_up_tokenization_spaces": false,
|
| 200 |
+
"eos_token": "<|endoftext|>",
|
| 201 |
+
"errors": "replace",
|
| 202 |
+
"max_length": 2500,
|
| 203 |
+
"model_max_length": 131072,
|
| 204 |
+
"pad_token": "<|endoftext|>",
|
| 205 |
+
"padding_side": "left",
|
| 206 |
+
"split_special_tokens": false,
|
| 207 |
+
"stride": 0,
|
| 208 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 209 |
+
"truncation_side": "right",
|
| 210 |
+
"truncation_strategy": "longest_first",
|
| 211 |
+
"unk_token": null
|
| 212 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|