
zwanto
commited on
Commit
•
4b9ec57
1
Parent(s):
16de5d2
init
Browse files- .gitattributes +2 -0
- README.md +78 -0
- assets/Accuracy_cat.png +0 -0
- assets/confusion_cat_m_0.2.png +0 -0
- config.json +103 -0
- merges.txt +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +1 -0
- tf_model.h5 +3 -0
- tokenizer_config.json +1 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -14,3 +14,5 @@
|
|
| 14 |
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 15 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 16 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 14 |
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 15 |
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 16 |
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
pytorch_model.bin filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
tf_model.h5 filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- fr
|
| 4 |
+
|
| 5 |
+
license: mit
|
| 6 |
+
|
| 7 |
+
datasets:
|
| 8 |
+
- MLSUM
|
| 9 |
+
|
| 10 |
+
pipeline_tag: "text-classification"
|
| 11 |
+
|
| 12 |
+
widget:
|
| 13 |
+
- text: La bourse de paris en forte baisse après que des canards ont envahit le parlement.
|
| 14 |
+
|
| 15 |
+
tags:
|
| 16 |
+
- text-classification
|
| 17 |
+
- flaubert
|
| 18 |
+
---
|
| 19 |
+
|
| 20 |
+
# Classification d'articles de presses avec Flaubert :fire:
|
| 21 |
+
|
| 22 |
+
Ce modèle ce base sur le modèle [`flaubert/flaubert_base_cased`](https://huggingface.co/flaubert/flaubert_base_cased) à et à été fine-tuné en utilisant des articles de presses issus de la base de données MLSUM.
|
| 23 |
+
Dans leur papier, les équipes de ReciTAl et de la Sorbonne ont proposé comme ouverture de faire de la détection de topic sur les articles de presses.
|
| 24 |
+
|
| 25 |
+
Les topics ont été exraient à partir des URL et nous avons effectué une étapes de regroupement de topic pour éléminer ceux avec un trop faible volumes et ceux qui paraissaient redondants.
|
| 26 |
+
|
| 27 |
+
Nous avons finalement utilisé la liste de topic suivant:
|
| 28 |
+
* Culture
|
| 29 |
+
* Economie
|
| 30 |
+
* Education
|
| 31 |
+
* Environement
|
| 32 |
+
* Justice
|
| 33 |
+
* Opinion
|
| 34 |
+
* Politique
|
| 35 |
+
* Societe
|
| 36 |
+
* Sport
|
| 37 |
+
* Technologie
|
| 38 |
+
|
| 39 |
+
## Entrainement
|
| 40 |
+
|
| 41 |
+
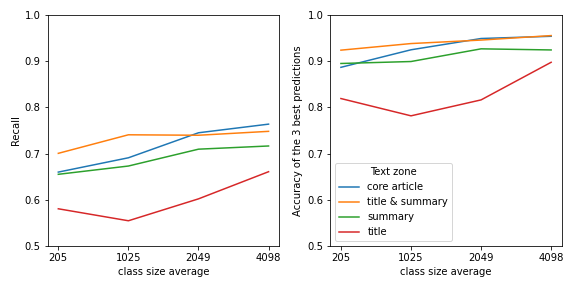
Nous avons benchmarké différents modèles en les entrainants sur différentes parties de l'articles (titre, résumé, corps et titre+résumé) et avec des échantillons d'apprentissage de tailles différentes.
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
Les modèles ont été entrainé sur un cloud Azure avec des Tesla V100.
|
| 46 |
+
|
| 47 |
+
## Résulats
|
| 48 |
+
|
| 49 |
+

|
| 50 |
+
*Les lignes correspondent aux labels prédient et les colonnes aux véritables topics. Les pourcentages sont calculés sur les colonnes.*
|
| 51 |
+
|
| 52 |
+
## Utilisation
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 56 |
+
from transformers import TextClassificationPipeline
|
| 57 |
+
|
| 58 |
+
model_name = 'lincoln/flaubert-mlsum-topic-classification'
|
| 59 |
+
|
| 60 |
+
loaded_tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 61 |
+
loaded_model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 62 |
+
|
| 63 |
+
nlp = TextClassificationPipeline(model=loaded_model, tokenizer=loaded_tokenizer)
|
| 64 |
+
nlp("Le Bayern Munich prend la grenadine.")
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
## Citation
|
| 68 |
+
|
| 69 |
+
```bibtex
|
| 70 |
+
@article{scialom2020mlsum,
|
| 71 |
+
title={MLSUM: The Multilingual Summarization Corpus},
|
| 72 |
+
author={Thomas Scialom and Paul-Alexis Dray and Sylvain Lamprier and Benjamin Piwowarski and Jacopo Staiano},
|
| 73 |
+
year={2020},
|
| 74 |
+
eprint={2004.14900},
|
| 75 |
+
archivePrefix={arXiv},
|
| 76 |
+
primaryClass={cs.CL}
|
| 77 |
+
}
|
| 78 |
+
```
|
assets/Accuracy_cat.png
ADDED
|
assets/confusion_cat_m_0.2.png
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": ".",
|
| 3 |
+
"amp": 1,
|
| 4 |
+
"architectures": [
|
| 5 |
+
"FlaubertForSequenceClassification"
|
| 6 |
+
],
|
| 7 |
+
"asm": false,
|
| 8 |
+
"attention_dropout": 0.1,
|
| 9 |
+
"bos_index": 0,
|
| 10 |
+
"bos_token_id": 0,
|
| 11 |
+
"bptt": 512,
|
| 12 |
+
"causal": false,
|
| 13 |
+
"clip_grad_norm": 5,
|
| 14 |
+
"dropout": 0.1,
|
| 15 |
+
"emb_dim": 768,
|
| 16 |
+
"embed_init_std": 0.02209708691207961,
|
| 17 |
+
"encoder_only": true,
|
| 18 |
+
"end_n_top": 5,
|
| 19 |
+
"eos_index": 1,
|
| 20 |
+
"fp16": true,
|
| 21 |
+
"gelu_activation": true,
|
| 22 |
+
"group_by_size": true,
|
| 23 |
+
"id2label": {
|
| 24 |
+
"0": "Culture",
|
| 25 |
+
"1": "economie",
|
| 26 |
+
"2": "education",
|
| 27 |
+
"3": "environement",
|
| 28 |
+
"4": "justice",
|
| 29 |
+
"5": "opinion",
|
| 30 |
+
"6": "politique",
|
| 31 |
+
"7": "societe",
|
| 32 |
+
"8": "sport",
|
| 33 |
+
"9": "technologie"
|
| 34 |
+
},
|
| 35 |
+
"id2lang": {
|
| 36 |
+
"0": "fr"
|
| 37 |
+
},
|
| 38 |
+
"init_std": 0.02,
|
| 39 |
+
"is_encoder": true,
|
| 40 |
+
"label2id": {
|
| 41 |
+
"Culture": 0,
|
| 42 |
+
"economie": 1,
|
| 43 |
+
"education": 2,
|
| 44 |
+
"environement": 3,
|
| 45 |
+
"justice": 4,
|
| 46 |
+
"opinion": 5,
|
| 47 |
+
"politique": 6,
|
| 48 |
+
"societe": 7,
|
| 49 |
+
"sport": 8,
|
| 50 |
+
"technologie": 9
|
| 51 |
+
},
|
| 52 |
+
"lang2id": {
|
| 53 |
+
"fr": 0
|
| 54 |
+
},
|
| 55 |
+
"lang_id": 0,
|
| 56 |
+
"langs": [
|
| 57 |
+
"fr"
|
| 58 |
+
],
|
| 59 |
+
"layer_norm_eps": 1e-12,
|
| 60 |
+
"layerdrop": 0.0,
|
| 61 |
+
"lg_sampling_factor": -1,
|
| 62 |
+
"lgs": "fr",
|
| 63 |
+
"mask_index": 5,
|
| 64 |
+
"mask_token_id": 0,
|
| 65 |
+
"max_batch_size": 0,
|
| 66 |
+
"max_position_embeddings": 512,
|
| 67 |
+
"max_vocab": -1,
|
| 68 |
+
"mlm_steps": [
|
| 69 |
+
[
|
| 70 |
+
"fr",
|
| 71 |
+
null
|
| 72 |
+
]
|
| 73 |
+
],
|
| 74 |
+
"model_type": "flaubert",
|
| 75 |
+
"n_heads": 12,
|
| 76 |
+
"n_langs": 1,
|
| 77 |
+
"n_layers": 12,
|
| 78 |
+
"pad_index": 2,
|
| 79 |
+
"pad_token_id": 2,
|
| 80 |
+
"pre_norm": false,
|
| 81 |
+
"sample_alpha": 0,
|
| 82 |
+
"share_inout_emb": true,
|
| 83 |
+
"sinusoidal_embeddings": false,
|
| 84 |
+
"start_n_top": 5,
|
| 85 |
+
"summary_activation": null,
|
| 86 |
+
"summary_first_dropout": 0.1,
|
| 87 |
+
"summary_proj_to_labels": true,
|
| 88 |
+
"summary_type": "first",
|
| 89 |
+
"summary_use_proj": true,
|
| 90 |
+
"tokens_per_batch": -1,
|
| 91 |
+
"transformers_version": "4.2.2",
|
| 92 |
+
"unk_index": 3,
|
| 93 |
+
"use_lang_emb": true,
|
| 94 |
+
"vocab_size": 68729,
|
| 95 |
+
"word_blank": 0,
|
| 96 |
+
"word_dropout": 0,
|
| 97 |
+
"word_keep": 0.1,
|
| 98 |
+
"word_mask": 0.8,
|
| 99 |
+
"word_mask_keep_rand": "0.8,0.1,0.1",
|
| 100 |
+
"word_pred": 0.15,
|
| 101 |
+
"word_rand": 0.1,
|
| 102 |
+
"word_shuffle": 0
|
| 103 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c87938490bbcd79d2a57d7fa14846abb6159c834dfe1f752f070f0a2e7eff0ab
|
| 3 |
+
size 553042606
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "unk_token": "<unk>", "sep_token": "</s>", "pad_token": "<pad>", "cls_token": "</s>", "mask_token": "<special1>", "additional_special_tokens": ["<special0>", "<special1>", "<special2>", "<special3>", "<special4>", "<special5>", "<special6>", "<special7>", "<special8>", "<special9>"]}
|
tf_model.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:542ca2881b48d8fdea2dc7f4c105e5a9f770f49d54656f01848aca6bb403b47f
|
| 3 |
+
size 553182776
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"unk_token": "<unk>", "bos_token": "<s>", "sep_token": "</s>", "pad_token": "<pad>", "cls_token": "</s>", "mask_token": "<special1>", "additional_special_tokens": ["<special0>", "<special1>", "<special2>", "<special3>", "<special4>", "<special5>", "<special6>", "<special7>", "<special8>", "<special9>"], "lang2id": null, "id2lang": null, "do_lowercase_and_remove_accent": true, "model_max_length": 512, "name_or_path": "flaubert/flaubert_base_cased"}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|