

End of training
Browse files- README.md +2 -1
- all_results.json +12 -0
- eval_results.json +7 -0
- train_results.json +8 -0
- trainer_state.json +185 -0
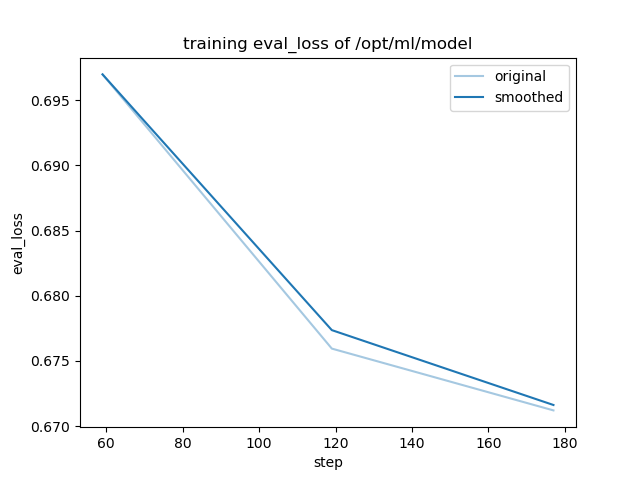
- training_eval_loss.png +0 -0
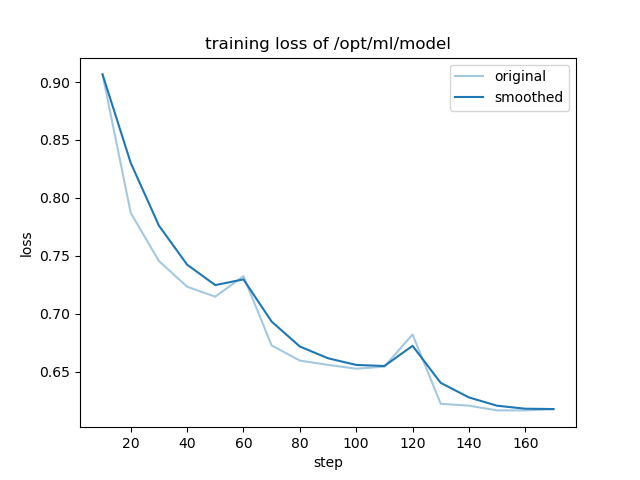
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3.1
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: camel_seeding_stackexchange_codegolf
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# camel_seeding_stackexchange_codegolf
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 0.6712
|
| 21 |
|
|
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: camel_seeding_stackexchange_codegolf
|
|
|
|
| 16 |
|
| 17 |
# camel_seeding_stackexchange_codegolf
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on the mlfoundations-dev/camel_seeding_stackexchange_codegolf dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.6712
|
| 22 |
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9727463312368974,
|
| 3 |
+
"eval_loss": 0.6712015867233276,
|
| 4 |
+
"eval_runtime": 65.4608,
|
| 5 |
+
"eval_samples_per_second": 24.549,
|
| 6 |
+
"eval_steps_per_second": 0.397,
|
| 7 |
+
"total_flos": 296272212787200.0,
|
| 8 |
+
"train_loss": 0.6840900243338892,
|
| 9 |
+
"train_runtime": 10713.9597,
|
| 10 |
+
"train_samples_per_second": 8.545,
|
| 11 |
+
"train_steps_per_second": 0.017
|
| 12 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9727463312368974,
|
| 3 |
+
"eval_loss": 0.6712015867233276,
|
| 4 |
+
"eval_runtime": 65.4608,
|
| 5 |
+
"eval_samples_per_second": 24.549,
|
| 6 |
+
"eval_steps_per_second": 0.397
|
| 7 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9727463312368974,
|
| 3 |
+
"total_flos": 296272212787200.0,
|
| 4 |
+
"train_loss": 0.6840900243338892,
|
| 5 |
+
"train_runtime": 10713.9597,
|
| 6 |
+
"train_samples_per_second": 8.545,
|
| 7 |
+
"train_steps_per_second": 0.017
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.9727463312368974,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 177,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.16771488469601678,
|
| 13 |
+
"grad_norm": 2.3957157024988684,
|
| 14 |
+
"learning_rate": 5e-06,
|
| 15 |
+
"loss": 0.9066,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.33542976939203356,
|
| 20 |
+
"grad_norm": 0.9746040571492541,
|
| 21 |
+
"learning_rate": 5e-06,
|
| 22 |
+
"loss": 0.787,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.5031446540880503,
|
| 27 |
+
"grad_norm": 0.8344916856818549,
|
| 28 |
+
"learning_rate": 5e-06,
|
| 29 |
+
"loss": 0.7455,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.6708595387840671,
|
| 34 |
+
"grad_norm": 0.6630661792183175,
|
| 35 |
+
"learning_rate": 5e-06,
|
| 36 |
+
"loss": 0.7233,
|
| 37 |
+
"step": 40
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 0.8385744234800838,
|
| 41 |
+
"grad_norm": 0.5831963334305033,
|
| 42 |
+
"learning_rate": 5e-06,
|
| 43 |
+
"loss": 0.7147,
|
| 44 |
+
"step": 50
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 0.989517819706499,
|
| 48 |
+
"eval_loss": 0.6969855427742004,
|
| 49 |
+
"eval_runtime": 65.5762,
|
| 50 |
+
"eval_samples_per_second": 24.506,
|
| 51 |
+
"eval_steps_per_second": 0.396,
|
| 52 |
+
"step": 59
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 1.0083857442348008,
|
| 56 |
+
"grad_norm": 1.2448623688206673,
|
| 57 |
+
"learning_rate": 5e-06,
|
| 58 |
+
"loss": 0.7324,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 1.1761006289308176,
|
| 63 |
+
"grad_norm": 0.664663255277509,
|
| 64 |
+
"learning_rate": 5e-06,
|
| 65 |
+
"loss": 0.6726,
|
| 66 |
+
"step": 70
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 1.3438155136268344,
|
| 70 |
+
"grad_norm": 0.6046916264157929,
|
| 71 |
+
"learning_rate": 5e-06,
|
| 72 |
+
"loss": 0.6595,
|
| 73 |
+
"step": 80
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 1.5115303983228512,
|
| 77 |
+
"grad_norm": 0.5743588500421465,
|
| 78 |
+
"learning_rate": 5e-06,
|
| 79 |
+
"loss": 0.6558,
|
| 80 |
+
"step": 90
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"epoch": 1.6792452830188678,
|
| 84 |
+
"grad_norm": 0.43743628219913383,
|
| 85 |
+
"learning_rate": 5e-06,
|
| 86 |
+
"loss": 0.6525,
|
| 87 |
+
"step": 100
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"epoch": 1.8469601677148848,
|
| 91 |
+
"grad_norm": 0.46309281832033367,
|
| 92 |
+
"learning_rate": 5e-06,
|
| 93 |
+
"loss": 0.6543,
|
| 94 |
+
"step": 110
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"epoch": 1.9979035639412999,
|
| 98 |
+
"eval_loss": 0.6759442090988159,
|
| 99 |
+
"eval_runtime": 65.7618,
|
| 100 |
+
"eval_samples_per_second": 24.437,
|
| 101 |
+
"eval_steps_per_second": 0.395,
|
| 102 |
+
"step": 119
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"epoch": 2.0167714884696015,
|
| 106 |
+
"grad_norm": 1.5249649463375206,
|
| 107 |
+
"learning_rate": 5e-06,
|
| 108 |
+
"loss": 0.6821,
|
| 109 |
+
"step": 120
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"epoch": 2.1844863731656186,
|
| 113 |
+
"grad_norm": 0.7389955715272274,
|
| 114 |
+
"learning_rate": 5e-06,
|
| 115 |
+
"loss": 0.6222,
|
| 116 |
+
"step": 130
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"epoch": 2.352201257861635,
|
| 120 |
+
"grad_norm": 0.6349772661501074,
|
| 121 |
+
"learning_rate": 5e-06,
|
| 122 |
+
"loss": 0.6206,
|
| 123 |
+
"step": 140
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 2.519916142557652,
|
| 127 |
+
"grad_norm": 0.545238991522723,
|
| 128 |
+
"learning_rate": 5e-06,
|
| 129 |
+
"loss": 0.6165,
|
| 130 |
+
"step": 150
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"epoch": 2.6876310272536688,
|
| 134 |
+
"grad_norm": 0.6862197330555269,
|
| 135 |
+
"learning_rate": 5e-06,
|
| 136 |
+
"loss": 0.6165,
|
| 137 |
+
"step": 160
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"epoch": 2.8553459119496853,
|
| 141 |
+
"grad_norm": 0.4711708638765378,
|
| 142 |
+
"learning_rate": 5e-06,
|
| 143 |
+
"loss": 0.6175,
|
| 144 |
+
"step": 170
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"epoch": 2.9727463312368974,
|
| 148 |
+
"eval_loss": 0.6712015867233276,
|
| 149 |
+
"eval_runtime": 64.8268,
|
| 150 |
+
"eval_samples_per_second": 24.789,
|
| 151 |
+
"eval_steps_per_second": 0.401,
|
| 152 |
+
"step": 177
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"epoch": 2.9727463312368974,
|
| 156 |
+
"step": 177,
|
| 157 |
+
"total_flos": 296272212787200.0,
|
| 158 |
+
"train_loss": 0.6840900243338892,
|
| 159 |
+
"train_runtime": 10713.9597,
|
| 160 |
+
"train_samples_per_second": 8.545,
|
| 161 |
+
"train_steps_per_second": 0.017
|
| 162 |
+
}
|
| 163 |
+
],
|
| 164 |
+
"logging_steps": 10,
|
| 165 |
+
"max_steps": 177,
|
| 166 |
+
"num_input_tokens_seen": 0,
|
| 167 |
+
"num_train_epochs": 3,
|
| 168 |
+
"save_steps": 500,
|
| 169 |
+
"stateful_callbacks": {
|
| 170 |
+
"TrainerControl": {
|
| 171 |
+
"args": {
|
| 172 |
+
"should_epoch_stop": false,
|
| 173 |
+
"should_evaluate": false,
|
| 174 |
+
"should_log": false,
|
| 175 |
+
"should_save": true,
|
| 176 |
+
"should_training_stop": true
|
| 177 |
+
},
|
| 178 |
+
"attributes": {}
|
| 179 |
+
}
|
| 180 |
+
},
|
| 181 |
+
"total_flos": 296272212787200.0,
|
| 182 |
+
"train_batch_size": 8,
|
| 183 |
+
"trial_name": null,
|
| 184 |
+
"trial_params": null
|
| 185 |
+
}
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|