

End of training
Browse files- README.md +2 -1
- all_results.json +12 -0
- eval_results.json +7 -0
- train_results.json +8 -0
- trainer_state.json +171 -0
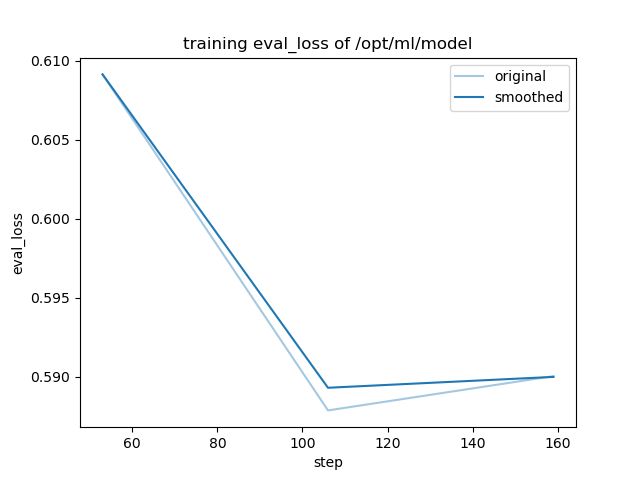
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3.1
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: evolinstruct_seeding_stackexchange_codegolf
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# evolinstruct_seeding_stackexchange_codegolf
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 0.5901
|
| 21 |
|
|
|
|
| 4 |
base_model: meta-llama/Meta-Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: evolinstruct_seeding_stackexchange_codegolf
|
|
|
|
| 16 |
|
| 17 |
# evolinstruct_seeding_stackexchange_codegolf
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B) on the mlfoundations-dev/evolinstruct_seeding_stackexchange_codegolf dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.5901
|
| 22 |
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9859154929577465,
|
| 3 |
+
"eval_loss": 0.5900523066520691,
|
| 4 |
+
"eval_runtime": 58.522,
|
| 5 |
+
"eval_samples_per_second": 24.504,
|
| 6 |
+
"eval_steps_per_second": 0.393,
|
| 7 |
+
"total_flos": 266121542369280.0,
|
| 8 |
+
"train_loss": 0.5896026683303545,
|
| 9 |
+
"train_runtime": 9662.9595,
|
| 10 |
+
"train_samples_per_second": 8.459,
|
| 11 |
+
"train_steps_per_second": 0.016
|
| 12 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9859154929577465,
|
| 3 |
+
"eval_loss": 0.5900523066520691,
|
| 4 |
+
"eval_runtime": 58.522,
|
| 5 |
+
"eval_samples_per_second": 24.504,
|
| 6 |
+
"eval_steps_per_second": 0.393
|
| 7 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.9859154929577465,
|
| 3 |
+
"total_flos": 266121542369280.0,
|
| 4 |
+
"train_loss": 0.5896026683303545,
|
| 5 |
+
"train_runtime": 9662.9595,
|
| 6 |
+
"train_samples_per_second": 8.459,
|
| 7 |
+
"train_steps_per_second": 0.016
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.9859154929577465,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 159,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.18779342723004694,
|
| 13 |
+
"grad_norm": 1.2853285209837433,
|
| 14 |
+
"learning_rate": 5e-06,
|
| 15 |
+
"loss": 0.7828,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.3755868544600939,
|
| 20 |
+
"grad_norm": 1.5703679315137147,
|
| 21 |
+
"learning_rate": 5e-06,
|
| 22 |
+
"loss": 0.6839,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.5633802816901409,
|
| 27 |
+
"grad_norm": 0.8050661506952912,
|
| 28 |
+
"learning_rate": 5e-06,
|
| 29 |
+
"loss": 0.6552,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.7511737089201878,
|
| 34 |
+
"grad_norm": 0.7119286963130127,
|
| 35 |
+
"learning_rate": 5e-06,
|
| 36 |
+
"loss": 0.6355,
|
| 37 |
+
"step": 40
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 0.9389671361502347,
|
| 41 |
+
"grad_norm": 0.7729364900144268,
|
| 42 |
+
"learning_rate": 5e-06,
|
| 43 |
+
"loss": 0.6241,
|
| 44 |
+
"step": 50
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 0.9953051643192489,
|
| 48 |
+
"eval_loss": 0.6091234683990479,
|
| 49 |
+
"eval_runtime": 58.3471,
|
| 50 |
+
"eval_samples_per_second": 24.577,
|
| 51 |
+
"eval_steps_per_second": 0.394,
|
| 52 |
+
"step": 53
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"epoch": 1.1267605633802817,
|
| 56 |
+
"grad_norm": 0.8140362088385064,
|
| 57 |
+
"learning_rate": 5e-06,
|
| 58 |
+
"loss": 0.6425,
|
| 59 |
+
"step": 60
|
| 60 |
+
},
|
| 61 |
+
{
|
| 62 |
+
"epoch": 1.3145539906103285,
|
| 63 |
+
"grad_norm": 0.8133655444184705,
|
| 64 |
+
"learning_rate": 5e-06,
|
| 65 |
+
"loss": 0.5674,
|
| 66 |
+
"step": 70
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 1.5023474178403755,
|
| 70 |
+
"grad_norm": 0.6492306561049654,
|
| 71 |
+
"learning_rate": 5e-06,
|
| 72 |
+
"loss": 0.5654,
|
| 73 |
+
"step": 80
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 1.6901408450704225,
|
| 77 |
+
"grad_norm": 0.7508356214374524,
|
| 78 |
+
"learning_rate": 5e-06,
|
| 79 |
+
"loss": 0.5662,
|
| 80 |
+
"step": 90
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"epoch": 1.8779342723004695,
|
| 84 |
+
"grad_norm": 1.39871277191206,
|
| 85 |
+
"learning_rate": 5e-06,
|
| 86 |
+
"loss": 0.5597,
|
| 87 |
+
"step": 100
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"epoch": 1.9906103286384975,
|
| 91 |
+
"eval_loss": 0.5878855586051941,
|
| 92 |
+
"eval_runtime": 58.1368,
|
| 93 |
+
"eval_samples_per_second": 24.666,
|
| 94 |
+
"eval_steps_per_second": 0.396,
|
| 95 |
+
"step": 106
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"epoch": 2.0657276995305165,
|
| 99 |
+
"grad_norm": 1.0731318648601569,
|
| 100 |
+
"learning_rate": 5e-06,
|
| 101 |
+
"loss": 0.5894,
|
| 102 |
+
"step": 110
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"epoch": 2.2535211267605635,
|
| 106 |
+
"grad_norm": 0.7948806860624125,
|
| 107 |
+
"learning_rate": 5e-06,
|
| 108 |
+
"loss": 0.5112,
|
| 109 |
+
"step": 120
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"epoch": 2.4413145539906105,
|
| 113 |
+
"grad_norm": 0.7896383757774875,
|
| 114 |
+
"learning_rate": 5e-06,
|
| 115 |
+
"loss": 0.5115,
|
| 116 |
+
"step": 130
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"epoch": 2.629107981220657,
|
| 120 |
+
"grad_norm": 1.107201714560591,
|
| 121 |
+
"learning_rate": 5e-06,
|
| 122 |
+
"loss": 0.5121,
|
| 123 |
+
"step": 140
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 2.816901408450704,
|
| 127 |
+
"grad_norm": 0.8878715217566517,
|
| 128 |
+
"learning_rate": 5e-06,
|
| 129 |
+
"loss": 0.513,
|
| 130 |
+
"step": 150
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"epoch": 2.9859154929577465,
|
| 134 |
+
"eval_loss": 0.5900523066520691,
|
| 135 |
+
"eval_runtime": 57.5361,
|
| 136 |
+
"eval_samples_per_second": 24.923,
|
| 137 |
+
"eval_steps_per_second": 0.4,
|
| 138 |
+
"step": 159
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"epoch": 2.9859154929577465,
|
| 142 |
+
"step": 159,
|
| 143 |
+
"total_flos": 266121542369280.0,
|
| 144 |
+
"train_loss": 0.5896026683303545,
|
| 145 |
+
"train_runtime": 9662.9595,
|
| 146 |
+
"train_samples_per_second": 8.459,
|
| 147 |
+
"train_steps_per_second": 0.016
|
| 148 |
+
}
|
| 149 |
+
],
|
| 150 |
+
"logging_steps": 10,
|
| 151 |
+
"max_steps": 159,
|
| 152 |
+
"num_input_tokens_seen": 0,
|
| 153 |
+
"num_train_epochs": 3,
|
| 154 |
+
"save_steps": 500,
|
| 155 |
+
"stateful_callbacks": {
|
| 156 |
+
"TrainerControl": {
|
| 157 |
+
"args": {
|
| 158 |
+
"should_epoch_stop": false,
|
| 159 |
+
"should_evaluate": false,
|
| 160 |
+
"should_log": false,
|
| 161 |
+
"should_save": true,
|
| 162 |
+
"should_training_stop": true
|
| 163 |
+
},
|
| 164 |
+
"attributes": {}
|
| 165 |
+
}
|
| 166 |
+
},
|
| 167 |
+
"total_flos": 266121542369280.0,
|
| 168 |
+
"train_batch_size": 8,
|
| 169 |
+
"trial_name": null,
|
| 170 |
+
"trial_params": null
|
| 171 |
+
}
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED

|