

End of training
Browse files- README.md +2 -1
- all_results.json +8 -8
- eval_results.json +4 -4
- train_results.json +4 -4
- trainer_state.json +20 -20
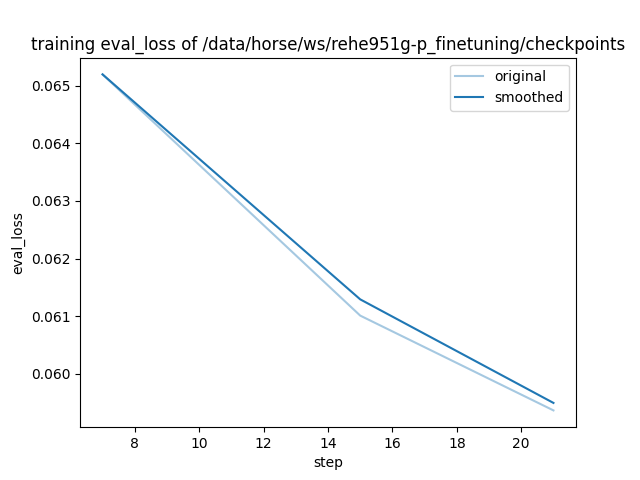
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3.1
|
|
| 4 |
base_model: meta-llama/Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: llama3_mammoth_dcft_ablation_original_50k
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# llama3_mammoth_dcft_ablation_original_50k
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 0.0594
|
| 21 |
|
|
|
|
| 4 |
base_model: meta-llama/Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: llama3_mammoth_dcft_ablation_original_50k
|
|
|
|
| 16 |
|
| 17 |
# llama3_mammoth_dcft_ablation_original_50k
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the mlfoundations-dev/wia_dcft_webinstruct_original_uniform_50k dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.0594
|
| 22 |
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime": 10.
|
| 5 |
-
"eval_samples_per_second": 19.
|
| 6 |
-
"eval_steps_per_second": 1.
|
| 7 |
"total_flos": 6.510485588200653e+16,
|
| 8 |
-
"train_loss": 0.
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second": 6.
|
| 11 |
-
"train_steps_per_second": 0.
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
+
"eval_loss": 0.059362392872571945,
|
| 4 |
+
"eval_runtime": 10.7049,
|
| 5 |
+
"eval_samples_per_second": 19.711,
|
| 6 |
+
"eval_steps_per_second": 1.308,
|
| 7 |
"total_flos": 6.510485588200653e+16,
|
| 8 |
+
"train_loss": 0.9951944351196289,
|
| 9 |
+
"train_runtime": 1792.4025,
|
| 10 |
+
"train_samples_per_second": 6.682,
|
| 11 |
+
"train_steps_per_second": 0.012
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime": 10.
|
| 5 |
-
"eval_samples_per_second": 19.
|
| 6 |
-
"eval_steps_per_second": 1.
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
+
"eval_loss": 0.059362392872571945,
|
| 4 |
+
"eval_runtime": 10.7049,
|
| 5 |
+
"eval_samples_per_second": 19.711,
|
| 6 |
+
"eval_steps_per_second": 1.308
|
| 7 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
"total_flos": 6.510485588200653e+16,
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second": 6.
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.768,
|
| 3 |
"total_flos": 6.510485588200653e+16,
|
| 4 |
+
"train_loss": 0.9951944351196289,
|
| 5 |
+
"train_runtime": 1792.4025,
|
| 6 |
+
"train_samples_per_second": 6.682,
|
| 7 |
+
"train_steps_per_second": 0.012
|
| 8 |
}
|
trainer_state.json
CHANGED
|
@@ -10,50 +10,50 @@
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.896,
|
| 13 |
-
"eval_loss": 0.
|
| 14 |
-
"eval_runtime": 11.
|
| 15 |
-
"eval_samples_per_second": 18.
|
| 16 |
-
"eval_steps_per_second": 1.
|
| 17 |
"step": 7
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.32,
|
| 21 |
-
"grad_norm":
|
| 22 |
"learning_rate": 5e-06,
|
| 23 |
-
"loss": 1.
|
| 24 |
"step": 10
|
| 25 |
},
|
| 26 |
{
|
| 27 |
"epoch": 1.96,
|
| 28 |
-
"eval_loss": 0.
|
| 29 |
-
"eval_runtime":
|
| 30 |
-
"eval_samples_per_second":
|
| 31 |
-
"eval_steps_per_second": 1.
|
| 32 |
"step": 15
|
| 33 |
},
|
| 34 |
{
|
| 35 |
"epoch": 2.64,
|
| 36 |
-
"grad_norm": 1.
|
| 37 |
"learning_rate": 5e-06,
|
| 38 |
-
"loss": 0.
|
| 39 |
"step": 20
|
| 40 |
},
|
| 41 |
{
|
| 42 |
"epoch": 2.768,
|
| 43 |
-
"eval_loss": 0.
|
| 44 |
-
"eval_runtime": 10.
|
| 45 |
-
"eval_samples_per_second": 20.
|
| 46 |
-
"eval_steps_per_second": 1.
|
| 47 |
"step": 21
|
| 48 |
},
|
| 49 |
{
|
| 50 |
"epoch": 2.768,
|
| 51 |
"step": 21,
|
| 52 |
"total_flos": 6.510485588200653e+16,
|
| 53 |
-
"train_loss": 0.
|
| 54 |
-
"train_runtime":
|
| 55 |
-
"train_samples_per_second": 6.
|
| 56 |
-
"train_steps_per_second": 0.
|
| 57 |
}
|
| 58 |
],
|
| 59 |
"logging_steps": 10,
|
|
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.896,
|
| 13 |
+
"eval_loss": 0.06519919633865356,
|
| 14 |
+
"eval_runtime": 11.4862,
|
| 15 |
+
"eval_samples_per_second": 18.37,
|
| 16 |
+
"eval_steps_per_second": 1.219,
|
| 17 |
"step": 7
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"epoch": 1.32,
|
| 21 |
+
"grad_norm": 2.263052502532022,
|
| 22 |
"learning_rate": 5e-06,
|
| 23 |
+
"loss": 1.0796,
|
| 24 |
"step": 10
|
| 25 |
},
|
| 26 |
{
|
| 27 |
"epoch": 1.96,
|
| 28 |
+
"eval_loss": 0.06100919470191002,
|
| 29 |
+
"eval_runtime": 10.9243,
|
| 30 |
+
"eval_samples_per_second": 19.315,
|
| 31 |
+
"eval_steps_per_second": 1.282,
|
| 32 |
"step": 15
|
| 33 |
},
|
| 34 |
{
|
| 35 |
"epoch": 2.64,
|
| 36 |
+
"grad_norm": 1.3239833760351767,
|
| 37 |
"learning_rate": 5e-06,
|
| 38 |
+
"loss": 0.9233,
|
| 39 |
"step": 20
|
| 40 |
},
|
| 41 |
{
|
| 42 |
"epoch": 2.768,
|
| 43 |
+
"eval_loss": 0.059362392872571945,
|
| 44 |
+
"eval_runtime": 10.2315,
|
| 45 |
+
"eval_samples_per_second": 20.622,
|
| 46 |
+
"eval_steps_per_second": 1.368,
|
| 47 |
"step": 21
|
| 48 |
},
|
| 49 |
{
|
| 50 |
"epoch": 2.768,
|
| 51 |
"step": 21,
|
| 52 |
"total_flos": 6.510485588200653e+16,
|
| 53 |
+
"train_loss": 0.9951944351196289,
|
| 54 |
+
"train_runtime": 1792.4025,
|
| 55 |
+
"train_samples_per_second": 6.682,
|
| 56 |
+
"train_steps_per_second": 0.012
|
| 57 |
}
|
| 58 |
],
|
| 59 |
"logging_steps": 10,
|
training_eval_loss.png
CHANGED

|
|
training_loss.png
CHANGED

|

|