

Upload 9 files
Browse files- LICENSE +21 -0
- README.md +213 -0
- config.json +70 -0
- configuration_deepseek.py +210 -0
- figures/benchmark.jpg +0 -0
- generation_config.json +9 -0
- modeling_deepseek.py +1849 -0
- tokenizer.json +0 -0
- tokenizer_config.json +35 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 DeepSeek
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: mit
|
| 4 |
+
---
|
| 5 |
+
# DeepSeek-R1
|
| 6 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 7 |
+
<!-- markdownlint-disable html -->
|
| 8 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 9 |
+
|
| 10 |
+
<div align="center">
|
| 11 |
+
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
|
| 12 |
+
</div>
|
| 13 |
+
<hr>
|
| 14 |
+
<div align="center" style="line-height: 1;">
|
| 15 |
+
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
|
| 16 |
+
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
|
| 17 |
+
</a>
|
| 18 |
+
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
|
| 19 |
+
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 20 |
+
</a>
|
| 21 |
+
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
|
| 22 |
+
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 23 |
+
</a>
|
| 24 |
+
</div>
|
| 25 |
+
|
| 26 |
+
<div align="center" style="line-height: 1;">
|
| 27 |
+
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
|
| 28 |
+
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
|
| 29 |
+
</a>
|
| 30 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
|
| 31 |
+
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 32 |
+
</a>
|
| 33 |
+
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
|
| 34 |
+
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 35 |
+
</a>
|
| 36 |
+
</div>
|
| 37 |
+
|
| 38 |
+
<div align="center" style="line-height: 1;">
|
| 39 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE-CODE" style="margin: 2px;">
|
| 40 |
+
<img alt="Code License" src="https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
|
| 41 |
+
</a>
|
| 42 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE-MODEL" style="margin: 2px;">
|
| 43 |
+
<img alt="Model License" src="https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
|
| 44 |
+
</a>
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
<p align="center">
|
| 49 |
+
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
|
| 50 |
+
</p>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## 1. Introduction
|
| 54 |
+
|
| 55 |
+
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
|
| 56 |
+
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
|
| 57 |
+
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
|
| 58 |
+
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
|
| 59 |
+
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
|
| 60 |
+
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
|
| 61 |
+
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
|
| 62 |
+
|
| 63 |
+
<p align="center">
|
| 64 |
+
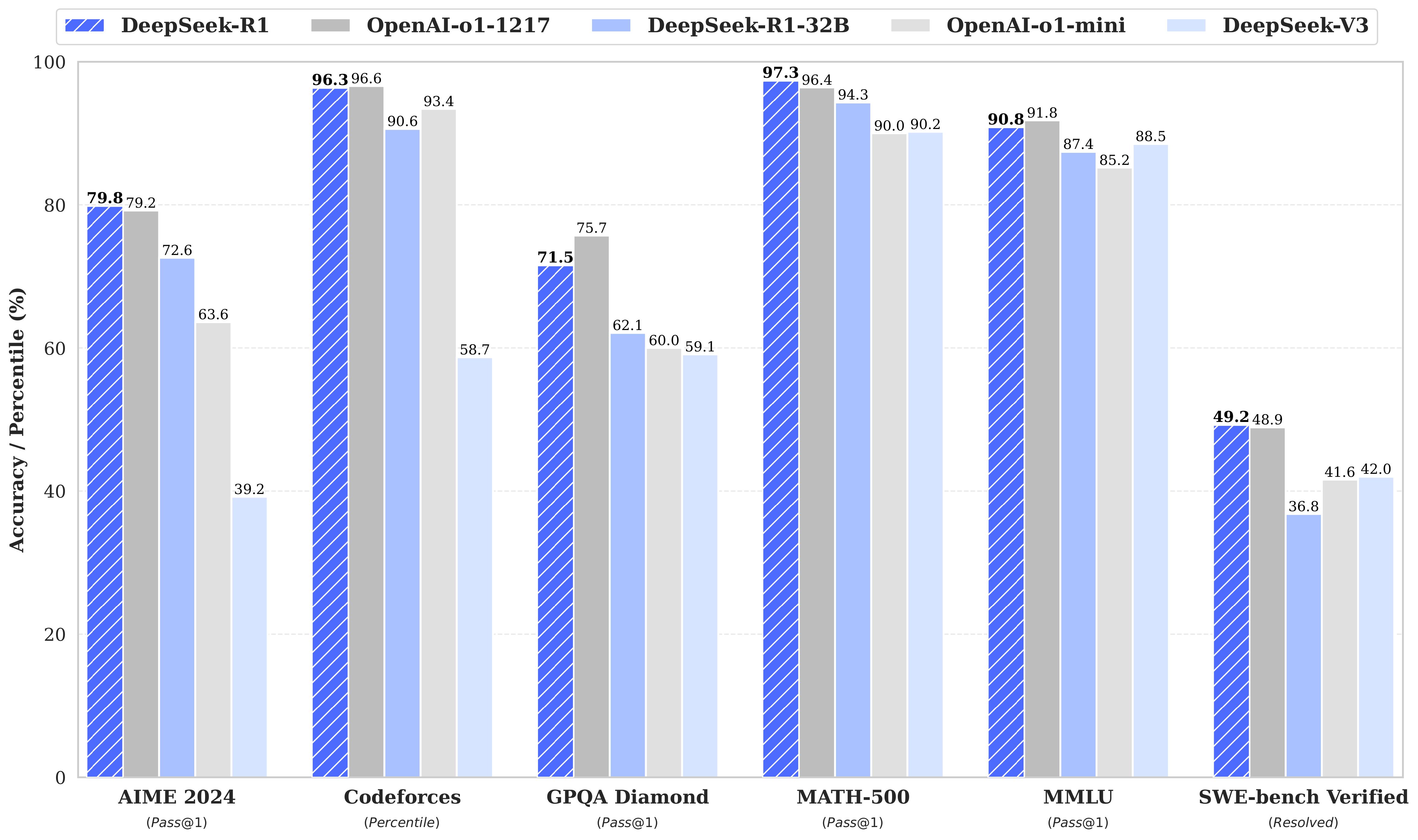
<img width="80%" src="figures/benchmark.jpg">
|
| 65 |
+
</p>
|
| 66 |
+
|
| 67 |
+
## 2. Model Summary
|
| 68 |
+
|
| 69 |
+
---
|
| 70 |
+
|
| 71 |
+
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
|
| 72 |
+
|
| 73 |
+
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
|
| 74 |
+
|
| 75 |
+
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
|
| 76 |
+
We believe the pipeline will benefit the industry by creating better models.
|
| 77 |
+
|
| 78 |
+
---
|
| 79 |
+
|
| 80 |
+
**Distillation: Smaller Models Can Be Powerful Too**
|
| 81 |
+
|
| 82 |
+
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
|
| 83 |
+
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
|
| 84 |
+
|
| 85 |
+
## 3. Model Downloads
|
| 86 |
+
|
| 87 |
+
### DeepSeek-R1 Models
|
| 88 |
+
|
| 89 |
+
<div align="center">
|
| 90 |
+
|
| 91 |
+
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
|
| 92 |
+
| :------------: | :------------: | :------------: | :------------: | :------------: |
|
| 93 |
+
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
|
| 94 |
+
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
|
| 95 |
+
|
| 96 |
+
</div>
|
| 97 |
+
|
| 98 |
+
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
|
| 99 |
+
For more details regrading the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
|
| 100 |
+
|
| 101 |
+
### DeepSeek-R1-Distill Models
|
| 102 |
+
|
| 103 |
+
<div align="center">
|
| 104 |
+
|
| 105 |
+
| **Model** | **Base Model** | **Download** |
|
| 106 |
+
| :------------: | :------------: | :------------: |
|
| 107 |
+
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
|
| 108 |
+
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
|
| 109 |
+
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
|
| 110 |
+
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|
| 111 |
+
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
|
| 112 |
+
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
|
| 113 |
+
|
| 114 |
+
</div>
|
| 115 |
+
|
| 116 |
+
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
|
| 117 |
+
We slightly change their configs and tokenizers. Please use our setting to run these models.
|
| 118 |
+
|
| 119 |
+
## 4. Evaluation Results
|
| 120 |
+
|
| 121 |
+
### DeepSeek-R1-Evaluation
|
| 122 |
+
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
|
| 123 |
+
<div align="center">
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|
| 127 |
+
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
|
| 128 |
+
| | Architecture | - | - | MoE | - | - | MoE |
|
| 129 |
+
| | # Activated Params | - | - | 37B | - | - | 37B |
|
| 130 |
+
| | # Total Params | - | - | 671B | - | - | 671B |
|
| 131 |
+
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
|
| 132 |
+
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
|
| 133 |
+
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
|
| 134 |
+
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
|
| 135 |
+
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
|
| 136 |
+
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
|
| 137 |
+
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
|
| 138 |
+
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
|
| 139 |
+
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
|
| 140 |
+
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
|
| 141 |
+
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
|
| 142 |
+
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
|
| 143 |
+
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
|
| 144 |
+
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
|
| 145 |
+
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
|
| 146 |
+
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
|
| 147 |
+
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
|
| 148 |
+
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
|
| 149 |
+
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
|
| 150 |
+
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
|
| 151 |
+
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
|
| 152 |
+
|
| 153 |
+
</div>
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
### Distilled Model Evaluation
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
<div align="center">
|
| 160 |
+
|
| 161 |
+
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|
| 162 |
+
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
|
| 163 |
+
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
|
| 164 |
+
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
|
| 165 |
+
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
|
| 166 |
+
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
|
| 167 |
+
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
|
| 168 |
+
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
|
| 169 |
+
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
|
| 170 |
+
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
|
| 171 |
+
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
|
| 172 |
+
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
|
| 173 |
+
|
| 174 |
+
</div>
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
## 5. Chat Website & API Platform
|
| 178 |
+
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
|
| 179 |
+
|
| 180 |
+
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
|
| 181 |
+
|
| 182 |
+
## 6. How to Run Locally
|
| 183 |
+
|
| 184 |
+
### DeepSeek-R1 Models
|
| 185 |
+
|
| 186 |
+
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
|
| 187 |
+
|
| 188 |
+
### DeepSeek-R1-Distill Models
|
| 189 |
+
|
| 190 |
+
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
|
| 191 |
+
|
| 192 |
+
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
|
| 193 |
+
|
| 194 |
+
```shell
|
| 195 |
+
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
**NOTE: We recommend setting an appropriate temperature (between 0.5 and 0.7) when running these models, otherwise you may encounter issues with endless repetition or incoherent output.**
|
| 199 |
+
|
| 200 |
+
## 7. License
|
| 201 |
+
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
|
| 202 |
+
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
|
| 203 |
+
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
|
| 204 |
+
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
|
| 205 |
+
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
|
| 206 |
+
|
| 207 |
+
## 8. Citation
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
## 9. Contact
|
| 213 |
+
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
config.json
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"DeepseekV3ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_deepseek.DeepseekV3Config",
|
| 9 |
+
"AutoModel": "modeling_deepseek.DeepseekV3Model",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_deepseek.DeepseekV3ForCausalLM"
|
| 11 |
+
},
|
| 12 |
+
"aux_loss_alpha": 0.001,
|
| 13 |
+
"bos_token_id": 0,
|
| 14 |
+
"eos_token_id": 1,
|
| 15 |
+
"ep_size": 1,
|
| 16 |
+
"first_k_dense_replace": 3,
|
| 17 |
+
"hidden_act": "silu",
|
| 18 |
+
"hidden_size": 7168,
|
| 19 |
+
"initializer_range": 0.02,
|
| 20 |
+
"intermediate_size": 18432,
|
| 21 |
+
"kv_lora_rank": 512,
|
| 22 |
+
"max_position_embeddings": 163840,
|
| 23 |
+
"model_type": "deepseek_v3",
|
| 24 |
+
"moe_intermediate_size": 2048,
|
| 25 |
+
"moe_layer_freq": 1,
|
| 26 |
+
"n_group": 8,
|
| 27 |
+
"n_routed_experts": 256,
|
| 28 |
+
"n_shared_experts": 1,
|
| 29 |
+
"norm_topk_prob": true,
|
| 30 |
+
"num_attention_heads": 128,
|
| 31 |
+
"num_experts_per_tok": 8,
|
| 32 |
+
"num_hidden_layers": 61,
|
| 33 |
+
"num_key_value_heads": 128,
|
| 34 |
+
"num_nextn_predict_layers": 1,
|
| 35 |
+
"pretraining_tp": 1,
|
| 36 |
+
"q_lora_rank": 1536,
|
| 37 |
+
"qk_nope_head_dim": 128,
|
| 38 |
+
"qk_rope_head_dim": 64,
|
| 39 |
+
"quantization_config": {
|
| 40 |
+
"activation_scheme": "dynamic",
|
| 41 |
+
"fmt": "e4m3",
|
| 42 |
+
"quant_method": "fp8",
|
| 43 |
+
"weight_block_size": [
|
| 44 |
+
128,
|
| 45 |
+
128
|
| 46 |
+
]
|
| 47 |
+
},
|
| 48 |
+
"rms_norm_eps": 1e-06,
|
| 49 |
+
"rope_scaling": {
|
| 50 |
+
"beta_fast": 32,
|
| 51 |
+
"beta_slow": 1,
|
| 52 |
+
"factor": 40,
|
| 53 |
+
"mscale": 1.0,
|
| 54 |
+
"mscale_all_dim": 1.0,
|
| 55 |
+
"original_max_position_embeddings": 4096,
|
| 56 |
+
"type": "yarn"
|
| 57 |
+
},
|
| 58 |
+
"rope_theta": 10000,
|
| 59 |
+
"routed_scaling_factor": 2.5,
|
| 60 |
+
"scoring_func": "sigmoid",
|
| 61 |
+
"seq_aux": true,
|
| 62 |
+
"tie_word_embeddings": false,
|
| 63 |
+
"topk_group": 4,
|
| 64 |
+
"topk_method": "noaux_tc",
|
| 65 |
+
"torch_dtype": "bfloat16",
|
| 66 |
+
"transformers_version": "4.46.3",
|
| 67 |
+
"use_cache": true,
|
| 68 |
+
"v_head_dim": 128,
|
| 69 |
+
"vocab_size": 129280
|
| 70 |
+
}
|
configuration_deepseek.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 2 |
+
from transformers.utils import logging
|
| 3 |
+
|
| 4 |
+
logger = logging.get_logger(__name__)
|
| 5 |
+
|
| 6 |
+
DEEPSEEK_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
| 7 |
+
class DeepseekV3Config(PretrainedConfig):
|
| 8 |
+
r"""
|
| 9 |
+
This is the configuration class to store the configuration of a [`DeepseekV3Model`]. It is used to instantiate an DeepSeek
|
| 10 |
+
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
| 11 |
+
defaults will yield a similar configuration to that of the DeepSeek-V3.
|
| 12 |
+
|
| 13 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 14 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
Args:
|
| 18 |
+
vocab_size (`int`, *optional*, defaults to 129280):
|
| 19 |
+
Vocabulary size of the Deep model. Defines the number of different tokens that can be represented by the
|
| 20 |
+
`inputs_ids` passed when calling [`DeepseekV3Model`]
|
| 21 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 22 |
+
Dimension of the hidden representations.
|
| 23 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 24 |
+
Dimension of the MLP representations.
|
| 25 |
+
moe_intermediate_size (`int`, *optional*, defaults to 1407):
|
| 26 |
+
Dimension of the MoE representations.
|
| 27 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 28 |
+
Number of hidden layers in the Transformer decoder.
|
| 29 |
+
num_nextn_predict_layers (`int`, *optional*, defaults to 1):
|
| 30 |
+
Number of nextn predict layers in the DeepSeekV3 Model.
|
| 31 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 32 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 33 |
+
n_shared_experts (`int`, *optional*, defaults to None):
|
| 34 |
+
Number of shared experts, None means dense model.
|
| 35 |
+
n_routed_experts (`int`, *optional*, defaults to None):
|
| 36 |
+
Number of routed experts, None means dense model.
|
| 37 |
+
routed_scaling_factor (`float`, *optional*, defaults to 1.0):
|
| 38 |
+
Scaling factor or routed experts.
|
| 39 |
+
topk_method (`str`, *optional*, defaults to `gready`):
|
| 40 |
+
Topk method used in routed gate.
|
| 41 |
+
n_group (`int`, *optional*, defaults to None):
|
| 42 |
+
Number of groups for routed experts.
|
| 43 |
+
topk_group (`int`, *optional*, defaults to None):
|
| 44 |
+
Number of selected groups for each token(for each token, ensuring the selected experts is only within `topk_group` groups).
|
| 45 |
+
num_experts_per_tok (`int`, *optional*, defaults to None):
|
| 46 |
+
Number of selected experts, None means dense model.
|
| 47 |
+
moe_layer_freq (`int`, *optional*, defaults to 1):
|
| 48 |
+
The frequency of the MoE layer: one expert layer for every `moe_layer_freq - 1` dense layers.
|
| 49 |
+
first_k_dense_replace (`int`, *optional*, defaults to 0):
|
| 50 |
+
Number of dense layers in shallow layers(embed->dense->dense->...->dense->moe->moe...->lm_head).
|
| 51 |
+
\--k dense layers--/
|
| 52 |
+
norm_topk_prob (`bool`, *optional*, defaults to False):
|
| 53 |
+
Whether to normalize the weights of the routed experts.
|
| 54 |
+
scoring_func (`str`, *optional*, defaults to 'softmax'):
|
| 55 |
+
Method of computing expert weights.
|
| 56 |
+
aux_loss_alpha (`float`, *optional*, defaults to 0.001):
|
| 57 |
+
Auxiliary loss weight coefficient.
|
| 58 |
+
seq_aux = (`bool`, *optional*, defaults to True):
|
| 59 |
+
Whether to compute the auxiliary loss for each individual sample.
|
| 60 |
+
num_key_value_heads (`int`, *optional*):
|
| 61 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 62 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 63 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 64 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 65 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 66 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 67 |
+
`num_attention_heads`.
|
| 68 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 69 |
+
The non-linear activation function (function or string) in the decoder.
|
| 70 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 71 |
+
The maximum sequence length that this model might ever be used with.
|
| 72 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 73 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 74 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 75 |
+
The epsilon used by the rms normalization layers.
|
| 76 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 77 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 78 |
+
relevant if `config.is_decoder=True`.
|
| 79 |
+
pad_token_id (`int`, *optional*):
|
| 80 |
+
Padding token id.
|
| 81 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 82 |
+
Beginning of stream token id.
|
| 83 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 84 |
+
End of stream token id.
|
| 85 |
+
pretraining_tp (`int`, *optional*, defaults to 1):
|
| 86 |
+
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
| 87 |
+
document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
|
| 88 |
+
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
|
| 89 |
+
issue](https://github.com/pytorch/pytorch/issues/76232).
|
| 90 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 91 |
+
Whether to tie weight embeddings
|
| 92 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 93 |
+
The base period of the RoPE embeddings.
|
| 94 |
+
rope_scaling (`Dict`, *optional*):
|
| 95 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
| 96 |
+
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
| 97 |
+
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
| 98 |
+
`max_position_embeddings` to the expected new maximum.
|
| 99 |
+
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
| 100 |
+
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
| 101 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 102 |
+
The dropout ratio for the attention probabilities.
|
| 103 |
+
|
| 104 |
+
```python
|
| 105 |
+
>>> from transformers import DeepseekV3Model, DeepseekV3Config
|
| 106 |
+
|
| 107 |
+
>>> # Initializing a Deepseek-V3 style configuration
|
| 108 |
+
>>> configuration = DeepseekV3Config()
|
| 109 |
+
|
| 110 |
+
>>> # Accessing the model configuration
|
| 111 |
+
>>> configuration = model.config
|
| 112 |
+
```"""
|
| 113 |
+
|
| 114 |
+
model_type = "deepseek_v3"
|
| 115 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 116 |
+
|
| 117 |
+
def __init__(
|
| 118 |
+
self,
|
| 119 |
+
vocab_size=129280,
|
| 120 |
+
hidden_size=7168,
|
| 121 |
+
intermediate_size=18432,
|
| 122 |
+
moe_intermediate_size = 2048,
|
| 123 |
+
num_hidden_layers=61,
|
| 124 |
+
num_nextn_predict_layers=1,
|
| 125 |
+
num_attention_heads=128,
|
| 126 |
+
num_key_value_heads=128,
|
| 127 |
+
n_shared_experts = 1,
|
| 128 |
+
n_routed_experts = 256,
|
| 129 |
+
ep_size = 1,
|
| 130 |
+
routed_scaling_factor = 2.5,
|
| 131 |
+
kv_lora_rank = 512,
|
| 132 |
+
q_lora_rank = 1536,
|
| 133 |
+
qk_rope_head_dim = 64,
|
| 134 |
+
v_head_dim = 128,
|
| 135 |
+
qk_nope_head_dim = 128,
|
| 136 |
+
topk_method = 'noaux_tc',
|
| 137 |
+
n_group = 8,
|
| 138 |
+
topk_group = 4,
|
| 139 |
+
num_experts_per_tok = 8,
|
| 140 |
+
moe_layer_freq = 1,
|
| 141 |
+
first_k_dense_replace = 3,
|
| 142 |
+
norm_topk_prob = True,
|
| 143 |
+
scoring_func = 'sigmoid',
|
| 144 |
+
aux_loss_alpha = 0.001,
|
| 145 |
+
seq_aux = True,
|
| 146 |
+
hidden_act="silu",
|
| 147 |
+
max_position_embeddings=4096,
|
| 148 |
+
initializer_range=0.02,
|
| 149 |
+
rms_norm_eps=1e-6,
|
| 150 |
+
use_cache=True,
|
| 151 |
+
pad_token_id=None,
|
| 152 |
+
bos_token_id=0,
|
| 153 |
+
eos_token_id=1,
|
| 154 |
+
pretraining_tp=1,
|
| 155 |
+
tie_word_embeddings=False,
|
| 156 |
+
rope_theta=10000.0,
|
| 157 |
+
rope_scaling=None,
|
| 158 |
+
attention_bias=False,
|
| 159 |
+
attention_dropout=0.0,
|
| 160 |
+
**kwargs,
|
| 161 |
+
):
|
| 162 |
+
self.vocab_size = vocab_size
|
| 163 |
+
self.max_position_embeddings = max_position_embeddings
|
| 164 |
+
self.hidden_size = hidden_size
|
| 165 |
+
self.intermediate_size = intermediate_size
|
| 166 |
+
self.moe_intermediate_size = moe_intermediate_size
|
| 167 |
+
self.num_hidden_layers = num_hidden_layers
|
| 168 |
+
self.num_nextn_predict_layers = num_nextn_predict_layers
|
| 169 |
+
self.num_attention_heads = num_attention_heads
|
| 170 |
+
self.n_shared_experts = n_shared_experts
|
| 171 |
+
self.n_routed_experts = n_routed_experts
|
| 172 |
+
self.ep_size = ep_size
|
| 173 |
+
self.routed_scaling_factor = routed_scaling_factor
|
| 174 |
+
self.kv_lora_rank = kv_lora_rank
|
| 175 |
+
self.q_lora_rank = q_lora_rank
|
| 176 |
+
self.qk_rope_head_dim = qk_rope_head_dim
|
| 177 |
+
self.v_head_dim = v_head_dim
|
| 178 |
+
self.qk_nope_head_dim = qk_nope_head_dim
|
| 179 |
+
self.topk_method = topk_method
|
| 180 |
+
self.n_group = n_group
|
| 181 |
+
self.topk_group = topk_group
|
| 182 |
+
self.num_experts_per_tok = num_experts_per_tok
|
| 183 |
+
self.moe_layer_freq = moe_layer_freq
|
| 184 |
+
self.first_k_dense_replace = first_k_dense_replace
|
| 185 |
+
self.norm_topk_prob = norm_topk_prob
|
| 186 |
+
self.scoring_func = scoring_func
|
| 187 |
+
self.aux_loss_alpha = aux_loss_alpha
|
| 188 |
+
self.seq_aux = seq_aux
|
| 189 |
+
# for backward compatibility
|
| 190 |
+
if num_key_value_heads is None:
|
| 191 |
+
num_key_value_heads = num_attention_heads
|
| 192 |
+
|
| 193 |
+
self.num_key_value_heads = num_key_value_heads
|
| 194 |
+
self.hidden_act = hidden_act
|
| 195 |
+
self.initializer_range = initializer_range
|
| 196 |
+
self.rms_norm_eps = rms_norm_eps
|
| 197 |
+
self.pretraining_tp = pretraining_tp
|
| 198 |
+
self.use_cache = use_cache
|
| 199 |
+
self.rope_theta = rope_theta
|
| 200 |
+
self.rope_scaling = rope_scaling
|
| 201 |
+
self.attention_bias = attention_bias
|
| 202 |
+
self.attention_dropout = attention_dropout
|
| 203 |
+
|
| 204 |
+
super().__init__(
|
| 205 |
+
pad_token_id=pad_token_id,
|
| 206 |
+
bos_token_id=bos_token_id,
|
| 207 |
+
eos_token_id=eos_token_id,
|
| 208 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 209 |
+
**kwargs,
|
| 210 |
+
)
|
figures/benchmark.jpg
ADDED
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 0,
|
| 4 |
+
"eos_token_id": 1,
|
| 5 |
+
"do_sample": true,
|
| 6 |
+
"temperature": 0.6,
|
| 7 |
+
"top_p": 0.95,
|
| 8 |
+
"transformers_version": "4.39.3"
|
| 9 |
+
}
|
modeling_deepseek.py
ADDED
|
@@ -0,0 +1,1849 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 DeepSeek-AI and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
+
# and OPT implementations in this library. It has been modified from its
|
| 6 |
+
# original forms to accommodate minor architectural differences compared
|
| 7 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 8 |
+
#
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 10 |
+
# you may not use this file except in compliance with the License.
|
| 11 |
+
# You may obtain a copy of the License at
|
| 12 |
+
#
|
| 13 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 14 |
+
#
|
| 15 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 16 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 17 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
+
# See the License for the specific language governing permissions and
|
| 19 |
+
# limitations under the License.
|
| 20 |
+
""" PyTorch DeepSeek model."""
|
| 21 |
+
import math
|
| 22 |
+
import warnings
|
| 23 |
+
from typing import List, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
import torch.nn.functional as F
|
| 27 |
+
import torch.utils.checkpoint
|
| 28 |
+
from torch import nn
|
| 29 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 30 |
+
|
| 31 |
+
from transformers.activations import ACT2FN
|
| 32 |
+
from transformers.cache_utils import Cache, DynamicCache
|
| 33 |
+
from transformers.modeling_attn_mask_utils import (
|
| 34 |
+
AttentionMaskConverter,
|
| 35 |
+
_prepare_4d_attention_mask,
|
| 36 |
+
_prepare_4d_causal_attention_mask,
|
| 37 |
+
)
|
| 38 |
+
from transformers.modeling_outputs import (
|
| 39 |
+
BaseModelOutputWithPast,
|
| 40 |
+
CausalLMOutputWithPast,
|
| 41 |
+
SequenceClassifierOutputWithPast,
|
| 42 |
+
)
|
| 43 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 44 |
+
from transformers.pytorch_utils import (
|
| 45 |
+
ALL_LAYERNORM_LAYERS,
|
| 46 |
+
is_torch_greater_or_equal_than_1_13,
|
| 47 |
+
)
|
| 48 |
+
from transformers.utils import (
|
| 49 |
+
add_start_docstrings,
|
| 50 |
+
add_start_docstrings_to_model_forward,
|
| 51 |
+
is_flash_attn_2_available,
|
| 52 |
+
is_flash_attn_greater_or_equal_2_10,
|
| 53 |
+
logging,
|
| 54 |
+
replace_return_docstrings,
|
| 55 |
+
)
|
| 56 |
+
from transformers.utils.import_utils import is_torch_fx_available
|
| 57 |
+
from .configuration_deepseek import DeepseekV3Config
|
| 58 |
+
import torch.distributed as dist
|
| 59 |
+
import numpy as np
|
| 60 |
+
|
| 61 |
+
if is_flash_attn_2_available():
|
| 62 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 63 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# This makes `_prepare_4d_causal_attention_mask` a leaf function in the FX graph.
|
| 67 |
+
# It means that the function will not be traced through and simply appear as a node in the graph.
|
| 68 |
+
if is_torch_fx_available():
|
| 69 |
+
if not is_torch_greater_or_equal_than_1_13:
|
| 70 |
+
import torch.fx
|
| 71 |
+
|
| 72 |
+
_prepare_4d_causal_attention_mask = torch.fx.wrap(_prepare_4d_causal_attention_mask)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
logger = logging.get_logger(__name__)
|
| 76 |
+
|
| 77 |
+
_CONFIG_FOR_DOC = "DeepseekV3Config"
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def _get_unpad_data(attention_mask):
|
| 81 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 82 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 83 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 84 |
+
cu_seqlens = F.pad(
|
| 85 |
+
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0)
|
| 86 |
+
)
|
| 87 |
+
return (
|
| 88 |
+
indices,
|
| 89 |
+
cu_seqlens,
|
| 90 |
+
max_seqlen_in_batch,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class DeepseekV3RMSNorm(nn.Module):
|
| 95 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 96 |
+
"""
|
| 97 |
+
DeepseekV3RMSNorm is equivalent to T5LayerNorm
|
| 98 |
+
"""
|
| 99 |
+
super().__init__()
|
| 100 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 101 |
+
self.variance_epsilon = eps
|
| 102 |
+
|
| 103 |
+
def forward(self, hidden_states):
|
| 104 |
+
input_dtype = hidden_states.dtype
|
| 105 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 106 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 107 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 108 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
ALL_LAYERNORM_LAYERS.append(DeepseekV3RMSNorm)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class DeepseekV3RotaryEmbedding(nn.Module):
|
| 115 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 116 |
+
super().__init__()
|
| 117 |
+
|
| 118 |
+
self.dim = dim
|
| 119 |
+
self.max_position_embeddings = max_position_embeddings
|
| 120 |
+
self.base = base
|
| 121 |
+
inv_freq = 1.0 / (
|
| 122 |
+
self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim)
|
| 123 |
+
)
|
| 124 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 125 |
+
|
| 126 |
+
# Build here to make `torch.jit.trace` work.
|
| 127 |
+
self._set_cos_sin_cache(
|
| 128 |
+
seq_len=max_position_embeddings,
|
| 129 |
+
device=self.inv_freq.device,
|
| 130 |
+
dtype=torch.get_default_dtype(),
|
| 131 |
+
)
|
| 132 |
+
self.max_seq_len_cached = None
|
| 133 |
+
|
| 134 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 135 |
+
self.max_seq_len_cached = seq_len
|
| 136 |
+
t = torch.arange(
|
| 137 |
+
self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
freqs = torch.outer(t, self.inv_freq.to(t.device))
|
| 141 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 142 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 143 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 144 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 145 |
+
|
| 146 |
+
def forward(self, x, seq_len=None):
|
| 147 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 148 |
+
if self.max_seq_len_cached is None or seq_len > self.max_seq_len_cached:
|
| 149 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
|
| 150 |
+
|
| 151 |
+
return (
|
| 152 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 153 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->DeepseekV3
|
| 158 |
+
class DeepseekV3LinearScalingRotaryEmbedding(DeepseekV3RotaryEmbedding):
|
| 159 |
+
"""DeepseekV3RotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 160 |
+
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
dim,
|
| 164 |
+
max_position_embeddings=2048,
|
| 165 |
+
base=10000,
|
| 166 |
+
device=None,
|
| 167 |
+
scaling_factor=1.0,
|
| 168 |
+
):
|
| 169 |
+
self.scaling_factor = scaling_factor
|
| 170 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 171 |
+
|
| 172 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 173 |
+
self.max_seq_len_cached = seq_len
|
| 174 |
+
t = torch.arange(
|
| 175 |
+
self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype
|
| 176 |
+
)
|
| 177 |
+
t = t / self.scaling_factor
|
| 178 |
+
|
| 179 |
+
freqs = torch.outer(t, self.inv_freq)
|
| 180 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 181 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 182 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 183 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->DeepseekV3
|
| 187 |
+
class DeepseekV3DynamicNTKScalingRotaryEmbedding(DeepseekV3RotaryEmbedding):
|
| 188 |
+
"""DeepseekV3RotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
|
| 189 |
+
|
| 190 |
+
def __init__(
|
| 191 |
+
self,
|
| 192 |
+
dim,
|
| 193 |
+
max_position_embeddings=2048,
|
| 194 |
+
base=10000,
|
| 195 |
+
device=None,
|
| 196 |
+
scaling_factor=1.0,
|
| 197 |
+
):
|
| 198 |
+
self.scaling_factor = scaling_factor
|
| 199 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 200 |
+
|
| 201 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 202 |
+
self.max_seq_len_cached = seq_len
|
| 203 |
+
|
| 204 |
+
if seq_len > self.max_position_embeddings:
|
| 205 |
+
base = self.base * (
|
| 206 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings)
|
| 207 |
+
- (self.scaling_factor - 1)
|
| 208 |
+
) ** (self.dim / (self.dim - 2))
|
| 209 |
+
inv_freq = 1.0 / (
|
| 210 |
+
base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim)
|
| 211 |
+
)
|
| 212 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 213 |
+
|
| 214 |
+
t = torch.arange(
|
| 215 |
+
self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
freqs = torch.outer(t, self.inv_freq)
|
| 219 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 220 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 221 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 222 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
# Inverse dim formula to find dim based on number of rotations
|
| 226 |
+
def yarn_find_correction_dim(
|
| 227 |
+
num_rotations, dim, base=10000, max_position_embeddings=2048
|
| 228 |
+
):
|
| 229 |
+
return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (
|
| 230 |
+
2 * math.log(base)
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
# Find dim range bounds based on rotations
|
| 235 |
+
def yarn_find_correction_range(
|
| 236 |
+
low_rot, high_rot, dim, base=10000, max_position_embeddings=2048
|
| 237 |
+
):
|
| 238 |
+
low = math.floor(
|
| 239 |
+
yarn_find_correction_dim(low_rot, dim, base, max_position_embeddings)
|
| 240 |
+
)
|
| 241 |
+
high = math.ceil(
|
| 242 |
+
yarn_find_correction_dim(high_rot, dim, base, max_position_embeddings)
|
| 243 |
+
)
|
| 244 |
+
return max(low, 0), min(high, dim - 1) # Clamp values just in case
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
def yarn_get_mscale(scale=1, mscale=1):
|
| 248 |
+
if scale <= 1:
|
| 249 |
+
return 1.0
|
| 250 |
+
return 0.1 * mscale * math.log(scale) + 1.0
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
def yarn_linear_ramp_mask(min, max, dim):
|
| 254 |
+
if min == max:
|
| 255 |
+
max += 0.001 # Prevent singularity
|
| 256 |
+
|
| 257 |
+
linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
|
| 258 |
+
ramp_func = torch.clamp(linear_func, 0, 1)
|
| 259 |
+
return ramp_func
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
class DeepseekV3YarnRotaryEmbedding(DeepseekV3RotaryEmbedding):
|
| 263 |
+
|
| 264 |
+
def __init__(
|
| 265 |
+
self,
|
| 266 |
+
dim,
|
| 267 |
+
max_position_embeddings=2048,
|
| 268 |
+
base=10000,
|
| 269 |
+
device=None,
|
| 270 |
+
scaling_factor=1.0,
|
| 271 |
+
original_max_position_embeddings=4096,
|
| 272 |
+
beta_fast=32,
|
| 273 |
+
beta_slow=1,
|
| 274 |
+
mscale=1,
|
| 275 |
+
mscale_all_dim=0,
|
| 276 |
+
):
|
| 277 |
+
self.scaling_factor = scaling_factor
|
| 278 |
+
self.original_max_position_embeddings = original_max_position_embeddings
|
| 279 |
+
self.beta_fast = beta_fast
|
| 280 |
+
self.beta_slow = beta_slow
|
| 281 |
+
self.mscale = mscale
|
| 282 |
+
self.mscale_all_dim = mscale_all_dim
|
| 283 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 284 |
+
|
| 285 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 286 |
+
self.max_seq_len_cached = seq_len
|
| 287 |
+
dim = self.dim
|
| 288 |
+
|
| 289 |
+
freq_extra = 1.0 / (
|
| 290 |
+
self.base
|
| 291 |
+
** (torch.arange(0, dim, 2, dtype=torch.float32, device=device) / dim)
|
| 292 |
+
)
|
| 293 |
+
freq_inter = 1.0 / (
|
| 294 |
+
self.scaling_factor
|
| 295 |
+
* self.base
|
| 296 |
+
** (torch.arange(0, dim, 2, dtype=torch.float32, device=device) / dim)
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
low, high = yarn_find_correction_range(
|
| 300 |
+
self.beta_fast,
|
| 301 |
+
self.beta_slow,
|
| 302 |
+
dim,
|
| 303 |
+
self.base,
|
| 304 |
+
self.original_max_position_embeddings,
|
| 305 |
+
)
|
| 306 |
+
inv_freq_mask = 1.0 - yarn_linear_ramp_mask(low, high, dim // 2).to(
|
| 307 |
+
device=device, dtype=torch.float32
|
| 308 |
+
)
|
| 309 |
+
inv_freq = freq_inter * (1 - inv_freq_mask) + freq_extra * inv_freq_mask
|
| 310 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 311 |
+
|
| 312 |
+
t = torch.arange(seq_len, device=device, dtype=torch.float32)
|
| 313 |
+
|
| 314 |
+
freqs = torch.outer(t, inv_freq)
|
| 315 |
+
|
| 316 |
+
_mscale = float(
|
| 317 |
+
yarn_get_mscale(self.scaling_factor, self.mscale)
|
| 318 |
+
/ yarn_get_mscale(self.scaling_factor, self.mscale_all_dim)
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 322 |
+
self.register_buffer(
|
| 323 |
+
"cos_cached", (emb.cos() * _mscale).to(dtype), persistent=False
|
| 324 |
+
)
|
| 325 |
+
self.register_buffer(
|
| 326 |
+
"sin_cached", (emb.sin() * _mscale).to(dtype), persistent=False
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
# Copied from transformers.models.llama.modeling_llama.rotate_half
|
| 331 |
+
def rotate_half(x):
|
| 332 |
+
"""Rotates half the hidden dims of the input."""
|
| 333 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 334 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 335 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
|
| 339 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
|
| 340 |
+
"""Applies Rotary Position Embedding to the query and key tensors.
|
| 341 |
+
|
| 342 |
+
Args:
|
| 343 |
+
q (`torch.Tensor`): The query tensor.
|
| 344 |
+
k (`torch.Tensor`): The key tensor.
|
| 345 |
+
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
| 346 |
+
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
| 347 |
+
position_ids (`torch.Tensor`):
|
| 348 |
+
The position indices of the tokens corresponding to the query and key tensors. For example, this can be
|
| 349 |
+
used to pass offsetted position ids when working with a KV-cache.
|
| 350 |
+
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
| 351 |
+
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
| 352 |
+
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
| 353 |
+
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
| 354 |
+
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
| 355 |
+
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
| 356 |
+
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
| 357 |
+
Returns:
|
| 358 |
+
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
| 359 |
+
"""
|
| 360 |
+
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 361 |
+
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 362 |
+
|
| 363 |
+
b, h, s, d = q.shape
|
| 364 |
+
q = q.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
|
| 365 |
+
|
| 366 |
+
b, h, s, d = k.shape
|
| 367 |
+
k = k.view(b, h, s, d // 2, 2).transpose(4, 3).reshape(b, h, s, d)
|
| 368 |
+
|
| 369 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 370 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 371 |
+
return q_embed, k_embed
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
class DeepseekV3MLP(nn.Module):
|
| 375 |
+
def __init__(self, config, hidden_size=None, intermediate_size=None):
|
| 376 |
+
super().__init__()
|
| 377 |
+
self.config = config
|
| 378 |
+
self.hidden_size = config.hidden_size if hidden_size is None else hidden_size
|
| 379 |
+
self.intermediate_size = (
|
| 380 |
+
config.intermediate_size if intermediate_size is None else intermediate_size
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 384 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 385 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 386 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 387 |
+
|
| 388 |
+
def forward(self, x):
|
| 389 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 390 |
+
return down_proj
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
class MoEGate(nn.Module):
|
| 394 |
+
def __init__(self, config):
|
| 395 |
+
super().__init__()
|
| 396 |
+
self.config = config
|
| 397 |
+
self.top_k = config.num_experts_per_tok
|
| 398 |
+
self.n_routed_experts = config.n_routed_experts
|
| 399 |
+
self.routed_scaling_factor = config.routed_scaling_factor
|
| 400 |
+
self.scoring_func = config.scoring_func
|
| 401 |
+
self.seq_aux = config.seq_aux
|
| 402 |
+
self.topk_method = config.topk_method
|
| 403 |
+
self.n_group = config.n_group
|
| 404 |
+
self.topk_group = config.topk_group
|
| 405 |
+
|
| 406 |
+
# topk selection algorithm
|
| 407 |
+
self.norm_topk_prob = config.norm_topk_prob
|
| 408 |
+
self.gating_dim = config.hidden_size
|
| 409 |
+
self.weight = nn.Parameter(
|
| 410 |
+
torch.empty((self.n_routed_experts, self.gating_dim))
|
| 411 |
+
)
|
| 412 |
+
if self.topk_method == "noaux_tc":
|
| 413 |
+
self.e_score_correction_bias = nn.Parameter(
|
| 414 |
+
torch.empty((self.n_routed_experts))
|
| 415 |
+
)
|
| 416 |
+
self.reset_parameters()
|
| 417 |
+
|
| 418 |
+
def reset_parameters(self) -> None:
|
| 419 |
+
import torch.nn.init as init
|
| 420 |
+
|
| 421 |
+
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
|
| 422 |
+
|
| 423 |
+
def forward(self, hidden_states):
|
| 424 |
+
bsz, seq_len, h = hidden_states.shape
|
| 425 |
+
### compute gating score
|
| 426 |
+
hidden_states = hidden_states.view(-1, h)
|
| 427 |
+
logits = F.linear(
|
| 428 |
+
hidden_states.type(torch.float32), self.weight.type(torch.float32), None
|
| 429 |
+
)
|
| 430 |
+
if self.scoring_func == "sigmoid":
|
| 431 |
+
scores = logits.sigmoid()
|
| 432 |
+
else:
|
| 433 |
+
raise NotImplementedError(
|
| 434 |
+
f"insupportable scoring function for MoE gating: {self.scoring_func}"
|
| 435 |
+
)
|
| 436 |
+
|
| 437 |
+
### select top-k experts
|
| 438 |
+
if self.topk_method == "noaux_tc":
|
| 439 |
+
assert not self.training
|
| 440 |
+
scores_for_choice = scores.view(bsz * seq_len, -1) + self.e_score_correction_bias.unsqueeze(0)
|
| 441 |
+
group_scores = (
|
| 442 |
+
scores_for_choice.view(bsz * seq_len, self.n_group, -1).topk(2, dim=-1)[0].sum(dim = -1)
|
| 443 |
+
) # [n, n_group]
|
| 444 |
+
group_idx = torch.topk(
|
| 445 |
+
group_scores, k=self.topk_group, dim=-1, sorted=False
|
| 446 |
+
)[
|
| 447 |
+
1
|
| 448 |
+
] # [n, top_k_group]
|
| 449 |
+
group_mask = torch.zeros_like(group_scores) # [n, n_group]
|
| 450 |
+
group_mask.scatter_(1, group_idx, 1) # [n, n_group]
|
| 451 |
+
score_mask = (
|
| 452 |
+
group_mask.unsqueeze(-1)
|
| 453 |
+
.expand(
|
| 454 |
+
bsz * seq_len, self.n_group, self.n_routed_experts // self.n_group
|
| 455 |
+
)
|
| 456 |
+
.reshape(bsz * seq_len, -1)
|
| 457 |
+
) # [n, e]
|
| 458 |
+
tmp_scores = scores_for_choice.masked_fill(~score_mask.bool(), 0.0) # [n, e]
|
| 459 |
+
_, topk_idx = torch.topk(
|
| 460 |
+
tmp_scores, k=self.top_k, dim=-1, sorted=False
|
| 461 |
+
)
|
| 462 |
+
topk_weight = scores.gather(1, topk_idx)
|
| 463 |
+
else:
|
| 464 |
+
raise NotImplementedError(
|
| 465 |
+
f"insupportable TopK function for MoE gating: {self.topk_method}"
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
### norm gate to sum 1
|
| 469 |
+
if self.top_k > 1 and self.norm_topk_prob:
|
| 470 |
+
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
|
| 471 |
+
topk_weight = topk_weight / denominator
|
| 472 |
+
topk_weight = topk_weight * self.routed_scaling_factor # must multiply the scaling factor
|
| 473 |
+
|
| 474 |
+
return topk_idx, topk_weight
|
| 475 |
+
|
| 476 |
+
class DeepseekV3MoE(nn.Module):
|
| 477 |
+
"""
|
| 478 |
+
A mixed expert module containing shared experts.
|
| 479 |
+
"""
|
| 480 |
+
|
| 481 |
+
def __init__(self, config):
|
| 482 |
+
super().__init__()
|
| 483 |
+
self.config = config
|
| 484 |
+
self.num_experts_per_tok = config.num_experts_per_tok
|
| 485 |
+
|
| 486 |
+
if hasattr(config, "ep_size") and config.ep_size > 1:
|
| 487 |
+
assert config.ep_size == dist.get_world_size()
|
| 488 |
+
self.ep_size = config.ep_size
|
| 489 |
+
self.experts_per_rank = config.n_routed_experts // config.ep_size
|
| 490 |
+
self.ep_rank = dist.get_rank()
|
| 491 |
+
self.experts = nn.ModuleList(
|
| 492 |
+
[
|
| 493 |
+
(
|
| 494 |
+
DeepseekV3MLP(
|
| 495 |
+
config, intermediate_size=config.moe_intermediate_size
|
| 496 |
+
)
|
| 497 |
+
if i >= self.ep_rank * self.experts_per_rank
|
| 498 |
+
and i < (self.ep_rank + 1) * self.experts_per_rank
|
| 499 |
+
else None
|
| 500 |
+
)
|
| 501 |
+
for i in range(config.n_routed_experts)
|
| 502 |
+
]
|
| 503 |
+
)
|
| 504 |
+
else:
|
| 505 |
+
self.ep_size = 1
|
| 506 |
+
self.experts_per_rank = config.n_routed_experts
|
| 507 |
+
self.ep_rank = 0
|
| 508 |
+
self.experts = nn.ModuleList(
|
| 509 |
+
[
|
| 510 |
+
DeepseekV3MLP(
|
| 511 |
+
config, intermediate_size=config.moe_intermediate_size
|
| 512 |
+
)
|
| 513 |
+
for i in range(config.n_routed_experts)
|
| 514 |
+
]
|
| 515 |
+
)
|
| 516 |
+
self.gate = MoEGate(config)
|
| 517 |
+
if config.n_shared_experts is not None:
|
| 518 |
+
intermediate_size = config.moe_intermediate_size * config.n_shared_experts
|
| 519 |
+
self.shared_experts = DeepseekV3MLP(
|
| 520 |
+
config=config, intermediate_size=intermediate_size
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
def forward(self, hidden_states):
|
| 524 |
+
identity = hidden_states
|
| 525 |
+
orig_shape = hidden_states.shape
|
| 526 |
+
topk_idx, topk_weight = self.gate(hidden_states)
|
| 527 |
+
hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
|
| 528 |
+
flat_topk_idx = topk_idx.view(-1)
|
| 529 |
+
if not self.training:
|
| 530 |
+
y = self.moe_infer(hidden_states, topk_idx, topk_weight).view(*orig_shape)
|
| 531 |
+
if self.config.n_shared_experts is not None:
|
| 532 |
+
y = y + self.shared_experts(identity)
|
| 533 |
+
return y
|
| 534 |
+
|
| 535 |
+
@torch.no_grad()
|
| 536 |
+
def moe_infer(self, x, topk_ids, topk_weight):
|
| 537 |
+
cnts = topk_ids.new_zeros((topk_ids.shape[0], len(self.experts)))
|
| 538 |
+
cnts.scatter_(1, topk_ids, 1)
|
| 539 |
+
tokens_per_expert = cnts.sum(dim=0)
|
| 540 |
+
idxs = topk_ids.view(-1).argsort()
|
| 541 |
+
sorted_tokens = x[idxs // topk_ids.shape[1]]
|
| 542 |
+
sorted_tokens_shape = sorted_tokens.shape
|
| 543 |
+
if self.ep_size > 1:
|
| 544 |
+
tokens_per_ep_rank = tokens_per_expert.view(self.ep_size, -1).sum(dim=1)
|
| 545 |
+
tokens_per_expert_group = tokens_per_expert.new_empty(
|
| 546 |
+
tokens_per_expert.shape[0]
|
| 547 |
+
)
|
| 548 |
+
dist.all_to_all_single(tokens_per_expert_group, tokens_per_expert)
|
| 549 |
+
output_splits = (
|
| 550 |
+
tokens_per_expert_group.view(self.ep_size, -1)
|
| 551 |
+
.sum(1)
|
| 552 |
+
.cpu()
|
| 553 |
+
.numpy()
|
| 554 |
+
.tolist()
|
| 555 |
+
)
|
| 556 |
+
gathered_tokens = sorted_tokens.new_empty(
|
| 557 |
+
tokens_per_expert_group.sum(dim=0).cpu().item(), sorted_tokens.shape[1]
|
| 558 |
+
)
|
| 559 |
+
input_split_sizes = tokens_per_ep_rank.cpu().numpy().tolist()
|
| 560 |
+
dist.all_to_all(
|
| 561 |
+
list(gathered_tokens.split(output_splits)),
|
| 562 |
+
list(sorted_tokens.split(input_split_sizes)),
|
| 563 |
+
)
|
| 564 |
+
tokens_per_expert_post_gather = tokens_per_expert_group.view(
|
| 565 |
+
self.ep_size, self.experts_per_rank
|
| 566 |
+
).sum(dim=0)
|
| 567 |
+
gatherd_idxs = np.zeros(shape=(gathered_tokens.shape[0],), dtype=np.int32)
|
| 568 |
+
s = 0
|
| 569 |
+
for i, k in enumerate(tokens_per_expert_group.cpu().numpy()):
|
| 570 |
+
gatherd_idxs[s : s + k] = i % self.experts_per_rank
|
| 571 |
+
s += k
|
| 572 |
+
gatherd_idxs = gatherd_idxs.argsort()
|
| 573 |
+
sorted_tokens = gathered_tokens[gatherd_idxs]
|
| 574 |
+
tokens_per_expert = tokens_per_expert_post_gather
|
| 575 |
+
tokens_per_expert = tokens_per_expert.cpu().numpy()
|
| 576 |
+
|
| 577 |
+
outputs = []
|
| 578 |
+
start_idx = 0
|
| 579 |
+
for i, num_tokens in enumerate(tokens_per_expert):
|
| 580 |
+
end_idx = start_idx + num_tokens
|
| 581 |
+
if num_tokens == 0:
|
| 582 |
+
continue
|
| 583 |
+
expert = self.experts[i + self.ep_rank * self.experts_per_rank]
|
| 584 |
+
tokens_for_this_expert = sorted_tokens[start_idx:end_idx]
|
| 585 |
+
expert_out = expert(tokens_for_this_expert)
|
| 586 |
+
outputs.append(expert_out)
|
| 587 |
+
start_idx = end_idx
|
| 588 |
+
|
| 589 |
+
outs = torch.cat(outputs, dim=0) if len(outputs) else sorted_tokens.new_empty(0)
|
| 590 |
+
if self.ep_size > 1:
|
| 591 |
+
new_x = torch.empty_like(outs)
|
| 592 |
+
new_x[gatherd_idxs] = outs
|
| 593 |
+
gathered_tokens = new_x.new_empty(*sorted_tokens_shape)
|
| 594 |
+
dist.all_to_all(
|
| 595 |
+
list(gathered_tokens.split(input_split_sizes)),
|
| 596 |
+
list(new_x.split(output_splits)),
|
| 597 |
+
)
|
| 598 |
+
outs = gathered_tokens
|
| 599 |
+
|
| 600 |
+
new_x = torch.empty_like(outs)
|
| 601 |
+
new_x[idxs] = outs
|
| 602 |
+
final_out = (
|
| 603 |
+
new_x.view(*topk_ids.shape, -1)
|
| 604 |
+
.type(topk_weight.dtype)
|
| 605 |
+
.mul_(topk_weight.unsqueeze(dim=-1))
|
| 606 |
+
.sum(dim=1)
|
| 607 |
+
.type(new_x.dtype)
|
| 608 |
+
)
|
| 609 |
+
return final_out
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
# Copied from transformers.models.llama.modeling_llama.repeat_kv
|
| 613 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 614 |
+
"""
|
| 615 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 616 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 617 |
+
"""
|
| 618 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 619 |
+
if n_rep == 1:
|
| 620 |
+
return hidden_states
|
| 621 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(
|
| 622 |
+
batch, num_key_value_heads, n_rep, slen, head_dim
|
| 623 |
+
)
|
| 624 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaAttention with Llama->DeepseekV3
|
| 628 |
+
class DeepseekV3Attention(nn.Module):
|
| 629 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 630 |
+
|
| 631 |
+
def __init__(self, config: DeepseekV3Config, layer_idx: Optional[int] = None):
|
| 632 |
+
super().__init__()
|
| 633 |
+
self.config = config
|
| 634 |
+
self.layer_idx = layer_idx
|
| 635 |
+
if layer_idx is None:
|
| 636 |
+
logger.warning_once(
|
| 637 |
+
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
|
| 638 |
+
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
|
| 639 |
+
"when creating this class."
|
| 640 |
+
)
|
| 641 |
+
|
| 642 |
+
self.attention_dropout = config.attention_dropout
|
| 643 |
+
self.hidden_size = config.hidden_size
|
| 644 |
+
self.num_heads = config.num_attention_heads
|
| 645 |
+
|
| 646 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 647 |
+
self.rope_theta = config.rope_theta
|
| 648 |
+
self.q_lora_rank = config.q_lora_rank
|
| 649 |
+
self.qk_rope_head_dim = config.qk_rope_head_dim
|
| 650 |
+
self.kv_lora_rank = config.kv_lora_rank
|
| 651 |
+
self.v_head_dim = config.v_head_dim
|
| 652 |
+
self.qk_nope_head_dim = config.qk_nope_head_dim
|
| 653 |
+
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
|
| 654 |
+
|
| 655 |
+
self.is_causal = True
|
| 656 |
+
|
| 657 |
+
if self.q_lora_rank is None:
|
| 658 |
+
self.q_proj = nn.Linear(
|
| 659 |
+
self.hidden_size, self.num_heads * self.q_head_dim, bias=False
|
| 660 |
+
)
|
| 661 |
+
else:
|
| 662 |
+
self.q_a_proj = nn.Linear(
|
| 663 |
+
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
|
| 664 |
+
)
|
| 665 |
+
self.q_a_layernorm = DeepseekV3RMSNorm(config.q_lora_rank)
|
| 666 |
+
self.q_b_proj = nn.Linear(
|
| 667 |
+
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
|
| 668 |
+
)
|
| 669 |
+
|
| 670 |
+
self.kv_a_proj_with_mqa = nn.Linear(
|
| 671 |
+
self.hidden_size,
|
| 672 |
+
config.kv_lora_rank + config.qk_rope_head_dim,
|
| 673 |
+
bias=config.attention_bias,
|
| 674 |
+
)
|
| 675 |
+
self.kv_a_layernorm = DeepseekV3RMSNorm(config.kv_lora_rank)
|
| 676 |
+
self.kv_b_proj = nn.Linear(
|
| 677 |
+
config.kv_lora_rank,
|
| 678 |
+
self.num_heads
|
| 679 |
+
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
|
| 680 |
+
bias=False,
|
| 681 |
+
)
|
| 682 |
+
|
| 683 |
+
self.o_proj = nn.Linear(
|
| 684 |
+
self.num_heads * self.v_head_dim,
|
| 685 |
+
self.hidden_size,
|
| 686 |
+
bias=config.attention_bias,
|
| 687 |
+
)
|
| 688 |
+
self._init_rope()
|
| 689 |
+
|
| 690 |
+
self.softmax_scale = self.q_head_dim ** (-0.5)
|
| 691 |
+
if self.config.rope_scaling is not None:
|
| 692 |
+
mscale_all_dim = self.config.rope_scaling.get("mscale_all_dim", 0)
|
| 693 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 694 |
+
if mscale_all_dim:
|
| 695 |
+
mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
|
| 696 |
+
self.softmax_scale = self.softmax_scale * mscale * mscale
|
| 697 |
+
|
| 698 |
+
def _init_rope(self):
|
| 699 |
+
if self.config.rope_scaling is None:
|
| 700 |
+
self.rotary_emb = DeepseekV3RotaryEmbedding(
|
| 701 |
+
self.qk_rope_head_dim,
|
| 702 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 703 |
+
base=self.rope_theta,
|
| 704 |
+
)
|
| 705 |
+
else:
|
| 706 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 707 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 708 |
+
if scaling_type == "linear":
|
| 709 |
+
self.rotary_emb = DeepseekV3LinearScalingRotaryEmbedding(
|
| 710 |
+
self.qk_rope_head_dim,
|
| 711 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 712 |
+
scaling_factor=scaling_factor,
|
| 713 |
+
base=self.rope_theta,
|
| 714 |
+
)
|
| 715 |
+
elif scaling_type == "dynamic":
|
| 716 |
+
self.rotary_emb = DeepseekV3DynamicNTKScalingRotaryEmbedding(
|
| 717 |
+
self.qk_rope_head_dim,
|
| 718 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 719 |
+
scaling_factor=scaling_factor,
|
| 720 |
+
base=self.rope_theta,
|
| 721 |
+
)
|
| 722 |
+
elif scaling_type == "yarn":
|
| 723 |
+
kwargs = {
|
| 724 |
+
key: self.config.rope_scaling[key]
|
| 725 |
+
for key in [
|
| 726 |
+
"original_max_position_embeddings",
|
| 727 |
+
"beta_fast",
|
| 728 |
+
"beta_slow",
|
| 729 |
+
"mscale",
|
| 730 |
+
"mscale_all_dim",
|
| 731 |
+
]
|
| 732 |
+
if key in self.config.rope_scaling
|
| 733 |
+
}
|
| 734 |
+
self.rotary_emb = DeepseekV3YarnRotaryEmbedding(
|
| 735 |
+
self.qk_rope_head_dim,
|
| 736 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 737 |
+
scaling_factor=scaling_factor,
|
| 738 |
+
base=self.rope_theta,
|
| 739 |
+
**kwargs,
|
| 740 |
+
)
|
| 741 |
+
else:
|
| 742 |
+
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
|
| 743 |
+
|
| 744 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 745 |
+
return (
|
| 746 |
+
tensor.view(bsz, seq_len, self.num_heads, self.v_head_dim)
|
| 747 |
+
.transpose(1, 2)
|
| 748 |
+
.contiguous()
|
| 749 |
+
)
|
| 750 |
+
|
| 751 |
+
def forward(
|
| 752 |
+
self,
|
| 753 |
+
hidden_states: torch.Tensor,
|
| 754 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 755 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 756 |
+
past_key_value: Optional[Cache] = None,
|
| 757 |
+
output_attentions: bool = False,
|
| 758 |
+
use_cache: bool = False,
|
| 759 |
+
**kwargs,
|
| 760 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 761 |
+
if "padding_mask" in kwargs:
|
| 762 |
+
warnings.warn(
|
| 763 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
|
| 764 |
+
)
|
| 765 |
+
bsz, q_len, _ = hidden_states.size()
|
| 766 |
+
|
| 767 |
+
if self.q_lora_rank is None:
|
| 768 |
+
q = self.q_proj(hidden_states)
|
| 769 |
+
else:
|
| 770 |
+
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
|
| 771 |
+
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
|
| 772 |
+
q_nope, q_pe = torch.split(
|
| 773 |
+
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
|
| 774 |
+
)
|
| 775 |
+
|
| 776 |
+
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
|
| 777 |
+
compressed_kv, k_pe = torch.split(
|
| 778 |
+
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
|
| 779 |
+
)
|
| 780 |
+
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
|
| 781 |
+
kv = (
|
| 782 |
+
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
|
| 783 |
+
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
|
| 784 |
+
.transpose(1, 2)
|
| 785 |
+
)
|
| 786 |
+
|
| 787 |
+
k_nope, value_states = torch.split(
|
| 788 |
+
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
|
| 789 |
+
)
|
| 790 |
+
kv_seq_len = value_states.shape[-2]
|
| 791 |
+
if past_key_value is not None:
|
| 792 |
+
if self.layer_idx is None:
|
| 793 |
+
raise ValueError(
|
| 794 |
+
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
|
| 795 |
+
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
|
| 796 |
+
"with a layer index."
|
| 797 |
+
)
|
| 798 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 799 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 800 |
+
|
| 801 |
+
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
|
| 802 |
+
|
| 803 |
+
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
|
| 804 |
+
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
|
| 805 |
+
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
|
| 806 |
+
|
| 807 |
+
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
|
| 808 |
+
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
|
| 809 |
+
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
|
| 810 |
+
if past_key_value is not None:
|
| 811 |
+
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 812 |
+
key_states, value_states = past_key_value.update(
|
| 813 |
+
key_states, value_states, self.layer_idx, cache_kwargs
|
| 814 |
+
)
|
| 815 |
+
|
| 816 |
+
attn_weights = (
|
| 817 |
+
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
|
| 818 |
+
)
|
| 819 |
+
|
| 820 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 821 |
+
raise ValueError(
|
| 822 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 823 |
+
f" {attn_weights.size()}"
|
| 824 |
+
)
|
| 825 |
+
assert attention_mask is not None
|
| 826 |
+
if attention_mask is not None:
|
| 827 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 828 |
+
raise ValueError(
|
| 829 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 830 |
+
)
|
| 831 |
+
attn_weights = attn_weights + attention_mask
|
| 832 |
+
|
| 833 |
+
# upcast attention to fp32
|
| 834 |
+
attn_weights = nn.functional.softmax(
|
| 835 |
+
attn_weights, dim=-1, dtype=torch.float32
|
| 836 |
+
).to(query_states.dtype)
|
| 837 |
+
attn_weights = nn.functional.dropout(
|
| 838 |
+
attn_weights, p=self.attention_dropout, training=self.training
|
| 839 |
+
)
|
| 840 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 841 |
+
|
| 842 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.v_head_dim):
|
| 843 |
+
raise ValueError(
|
| 844 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.v_head_dim)}, but is"
|
| 845 |
+
f" {attn_output.size()}"
|
| 846 |
+
)
|
| 847 |
+
|
| 848 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 849 |
+
|
| 850 |
+
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim)
|
| 851 |
+
|
| 852 |
+
attn_output = self.o_proj(attn_output)
|
| 853 |
+
|
| 854 |
+
if not output_attentions:
|
| 855 |
+
attn_weights = None
|
| 856 |
+
|
| 857 |
+
return attn_output, attn_weights, past_key_value
|
| 858 |
+
|
| 859 |
+
|
| 860 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2 with Llama->DeepseekV3
|
| 861 |
+
class DeepseekV3FlashAttention2(DeepseekV3Attention):
|
| 862 |
+
"""
|
| 863 |
+
DeepseekV3 flash attention module. This module inherits from `DeepseekV3Attention` as the weights of the module stays
|
| 864 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 865 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 866 |
+
"""
|
| 867 |
+
|
| 868 |
+
def __init__(self, *args, **kwargs):
|
| 869 |
+
super().__init__(*args, **kwargs)
|
| 870 |
+
|
| 871 |
+
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
|
| 872 |
+
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
|
| 873 |
+
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
|
| 874 |
+
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
|
| 875 |
+
|
| 876 |
+
def forward(
|
| 877 |
+
self,
|
| 878 |
+
hidden_states: torch.Tensor,
|
| 879 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 880 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 881 |
+
past_key_value: Optional[Cache] = None,
|
| 882 |
+
output_attentions: bool = False,
|
| 883 |
+
use_cache: bool = False,
|
| 884 |
+
**kwargs,
|
| 885 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 886 |
+
# DeepseekV3FlashAttention2 attention does not support output_attentions
|
| 887 |
+
if "padding_mask" in kwargs:
|
| 888 |
+
warnings.warn(
|
| 889 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
|
| 890 |
+
)
|
| 891 |
+
|
| 892 |
+
# overwrite attention_mask with padding_mask
|
| 893 |
+
attention_mask = kwargs.pop("padding_mask")
|
| 894 |
+
|
| 895 |
+
output_attentions = False
|
| 896 |
+
|
| 897 |
+
bsz, q_len, _ = hidden_states.size()
|
| 898 |
+
|
| 899 |
+
if self.q_lora_rank is None:
|
| 900 |
+
q = self.q_proj(hidden_states)
|
| 901 |
+
else:
|
| 902 |
+
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
|
| 903 |
+
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
|
| 904 |
+
q_nope, q_pe = torch.split(
|
| 905 |
+
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
|
| 906 |
+
)
|
| 907 |
+
|
| 908 |
+
# Flash attention requires the input to have the shape
|
| 909 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 910 |
+
# therefore we just need to keep the original shape
|
| 911 |
+
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
|
| 912 |
+
compressed_kv, k_pe = torch.split(
|
| 913 |
+
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
|
| 914 |
+
)
|
| 915 |
+
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
|
| 916 |
+
kv = (
|
| 917 |
+
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
|
| 918 |
+
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
|
| 919 |
+
.transpose(1, 2)
|
| 920 |
+
)
|
| 921 |
+
|
| 922 |
+
k_nope, value_states = torch.split(
|
| 923 |
+
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
|
| 924 |
+
)
|
| 925 |
+
kv_seq_len = value_states.shape[-2]
|
| 926 |
+
|
| 927 |
+
kv_seq_len = value_states.shape[-2]
|
| 928 |
+
if past_key_value is not None:
|
| 929 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 930 |
+
|
| 931 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 932 |
+
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
|
| 933 |
+
|
| 934 |
+
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
|
| 935 |
+
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
|
| 936 |
+
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
|
| 937 |
+
|
| 938 |
+
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
|
| 939 |
+
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
|
| 940 |
+
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
|
| 941 |
+
|
| 942 |
+
if self.q_head_dim != self.v_head_dim:
|
| 943 |
+
value_states = F.pad(value_states, [0, self.q_head_dim - self.v_head_dim])
|
| 944 |
+
|
| 945 |
+
if past_key_value is not None:
|
| 946 |
+
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 947 |
+
key_states, value_states = past_key_value.update(
|
| 948 |
+
key_states, value_states, self.layer_idx, cache_kwargs
|
| 949 |
+
)
|
| 950 |
+
|
| 951 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 952 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 953 |
+
query_states = query_states.transpose(1, 2)
|
| 954 |
+
key_states = key_states.transpose(1, 2)
|
| 955 |
+
value_states = value_states.transpose(1, 2)
|
| 956 |
+
|
| 957 |
+
dropout_rate = self.attention_dropout if self.training else 0.0
|
| 958 |
+
|
| 959 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 960 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 961 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 962 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 963 |
+
# in fp32. (DeepseekV3RMSNorm handles it correctly)
|
| 964 |
+
|
| 965 |
+
input_dtype = query_states.dtype
|
| 966 |
+
if input_dtype == torch.float32:
|
| 967 |
+
# Handle the case where the model is quantized
|
| 968 |
+
if hasattr(self.config, "_pre_quantization_dtype"):
|
| 969 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 970 |
+
elif torch.is_autocast_enabled():
|
| 971 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 972 |
+
else:
|
| 973 |
+
target_dtype = (
|
| 974 |
+
self.q_proj.weight.dtype
|
| 975 |
+
if self.q_lora_rank is None
|
| 976 |
+
else self.q_a_proj.weight.dtype
|
| 977 |
+
)
|
| 978 |
+
|
| 979 |
+
logger.warning_once(
|
| 980 |
+
f"The input hidden states seems to be silently casted in float32, this might be related to"
|
| 981 |
+
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 982 |
+
f" {target_dtype}."
|
| 983 |
+
)
|
| 984 |
+
|
| 985 |
+
query_states = query_states.to(target_dtype)
|
| 986 |
+
key_states = key_states.to(target_dtype)
|
| 987 |
+
value_states = value_states.to(target_dtype)
|
| 988 |
+
|
| 989 |
+
attn_output = self._flash_attention_forward(
|
| 990 |
+
query_states,
|
| 991 |
+
key_states,
|
| 992 |
+
value_states,
|
| 993 |
+
attention_mask,
|
| 994 |
+
q_len,
|
| 995 |
+
dropout=dropout_rate,
|
| 996 |
+
softmax_scale=self.softmax_scale,
|
| 997 |
+
)
|
| 998 |
+
if self.q_head_dim != self.v_head_dim:
|
| 999 |
+
attn_output = attn_output[:, :, :, : self.v_head_dim]
|
| 1000 |
+
|
| 1001 |
+
attn_output = attn_output.reshape(
|
| 1002 |
+
bsz, q_len, self.num_heads * self.v_head_dim
|
| 1003 |
+
).contiguous()
|
| 1004 |
+
attn_output = self.o_proj(attn_output)
|
| 1005 |
+
|
| 1006 |
+
if not output_attentions:
|
| 1007 |
+
attn_weights = None
|
| 1008 |
+
|
| 1009 |
+
return attn_output, attn_weights, past_key_value
|
| 1010 |
+
|
| 1011 |
+
def _flash_attention_forward(
|
| 1012 |
+
self,
|
| 1013 |
+
query_states,
|
| 1014 |
+
key_states,
|
| 1015 |
+
value_states,
|
| 1016 |
+
attention_mask,
|
| 1017 |
+
query_length,
|
| 1018 |
+
dropout=0.0,
|
| 1019 |
+
softmax_scale=None,
|
| 1020 |
+
):
|
| 1021 |
+
"""
|
| 1022 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 1023 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 1024 |
+
|
| 1025 |
+
Args:
|
| 1026 |
+
query_states (`torch.Tensor`):
|
| 1027 |
+
Input query states to be passed to Flash Attention API
|
| 1028 |
+
key_states (`torch.Tensor`):
|
| 1029 |
+
Input key states to be passed to Flash Attention API
|
| 1030 |
+
value_states (`torch.Tensor`):
|
| 1031 |
+
Input value states to be passed to Flash Attention API
|
| 1032 |
+
attention_mask (`torch.Tensor`):
|
| 1033 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 1034 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 1035 |
+
dropout (`int`, *optional*):
|
| 1036 |
+
Attention dropout
|
| 1037 |
+
softmax_scale (`float`, *optional*):
|
| 1038 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 1039 |
+
"""
|
| 1040 |
+
if not self._flash_attn_uses_top_left_mask:
|
| 1041 |
+
causal = self.is_causal
|
| 1042 |
+
else:
|
| 1043 |
+
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in DeepseekV3FlashAttention2 __init__.
|
| 1044 |
+
causal = self.is_causal and query_length != 1
|
| 1045 |
+
|
| 1046 |
+
# Contains at least one padding token in the sequence
|
| 1047 |
+
if attention_mask is not None:
|
| 1048 |
+
batch_size = query_states.shape[0]
|
| 1049 |
+
(
|
| 1050 |
+
query_states,
|
| 1051 |
+
key_states,
|
| 1052 |
+
value_states,
|
| 1053 |
+
indices_q,
|
| 1054 |
+
cu_seq_lens,
|
| 1055 |
+
max_seq_lens,
|
| 1056 |
+
) = self._upad_input(
|
| 1057 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 1058 |
+
)
|
| 1059 |
+
|
| 1060 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 1061 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 1062 |
+
|
| 1063 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 1064 |
+
query_states,
|
| 1065 |
+
key_states,
|
| 1066 |
+
value_states,
|
| 1067 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 1068 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 1069 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 1070 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 1071 |
+
dropout_p=dropout,
|
| 1072 |
+
softmax_scale=softmax_scale,
|
| 1073 |
+
causal=causal,
|
| 1074 |
+
)
|
| 1075 |
+
|
| 1076 |
+
attn_output = pad_input(
|
| 1077 |
+
attn_output_unpad, indices_q, batch_size, query_length
|
| 1078 |
+
)
|
| 1079 |
+
else:
|
| 1080 |
+
attn_output = flash_attn_func(
|
| 1081 |
+
query_states,
|
| 1082 |
+
key_states,
|
| 1083 |
+
value_states,
|
| 1084 |
+
dropout,
|
| 1085 |
+
softmax_scale=softmax_scale,
|
| 1086 |
+
causal=causal,
|
| 1087 |
+
)
|
| 1088 |
+
|
| 1089 |
+
return attn_output
|
| 1090 |
+
|
| 1091 |
+
def _upad_input(
|
| 1092 |
+
self, query_layer, key_layer, value_layer, attention_mask, query_length
|
| 1093 |
+
):
|
| 1094 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 1095 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 1096 |
+
|
| 1097 |
+
key_layer = index_first_axis(
|
| 1098 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim),
|
| 1099 |
+
indices_k,
|
| 1100 |
+
)
|
| 1101 |
+
value_layer = index_first_axis(
|
| 1102 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim),
|
| 1103 |
+
indices_k,
|
| 1104 |
+
)
|
| 1105 |
+
if query_length == kv_seq_len:
|
| 1106 |
+
query_layer = index_first_axis(
|
| 1107 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim),
|
| 1108 |
+
indices_k,
|
| 1109 |
+
)
|
| 1110 |
+
cu_seqlens_q = cu_seqlens_k
|
| 1111 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 1112 |
+
indices_q = indices_k
|
| 1113 |
+
elif query_length == 1:
|
| 1114 |
+
max_seqlen_in_batch_q = 1
|
| 1115 |
+
cu_seqlens_q = torch.arange(
|
| 1116 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 1117 |
+
) # There is a memcpy here, that is very bad.
|
| 1118 |
+
indices_q = cu_seqlens_q[:-1]
|
| 1119 |
+
query_layer = query_layer.squeeze(1)
|
| 1120 |
+
else:
|
| 1121 |
+
# The -q_len: slice assumes left padding.
|
| 1122 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 1123 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(
|
| 1124 |
+
query_layer, attention_mask
|
| 1125 |
+
)
|
| 1126 |
+
|
| 1127 |
+
return (
|
| 1128 |
+
query_layer,
|
| 1129 |
+
key_layer,
|
| 1130 |
+
value_layer,
|
| 1131 |
+
indices_q,
|
| 1132 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 1133 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 1134 |
+
)
|
| 1135 |
+
|
| 1136 |
+
|
| 1137 |
+
ATTENTION_CLASSES = {
|
| 1138 |
+
"eager": DeepseekV3Attention,
|
| 1139 |
+
"flash_attention_2": DeepseekV3FlashAttention2,
|
| 1140 |
+
}
|
| 1141 |
+
|
| 1142 |
+
|
| 1143 |
+
class DeepseekV3DecoderLayer(nn.Module):
|
| 1144 |
+
def __init__(self, config: DeepseekV3Config, layer_idx: int):
|
| 1145 |
+
super().__init__()
|
| 1146 |
+
self.hidden_size = config.hidden_size
|
| 1147 |
+
|
| 1148 |
+
self.self_attn = ATTENTION_CLASSES[config._attn_implementation](
|
| 1149 |
+
config=config, layer_idx=layer_idx
|
| 1150 |
+
)
|
| 1151 |
+
|
| 1152 |
+
self.mlp = (
|
| 1153 |
+
DeepseekV3MoE(config)
|
| 1154 |
+
if (
|
| 1155 |
+
config.n_routed_experts is not None
|
| 1156 |
+
and layer_idx >= config.first_k_dense_replace
|
| 1157 |
+
and layer_idx % config.moe_layer_freq == 0
|
| 1158 |
+
)
|
| 1159 |
+
else DeepseekV3MLP(config)
|
| 1160 |
+
)
|
| 1161 |
+
self.input_layernorm = DeepseekV3RMSNorm(
|
| 1162 |
+
config.hidden_size, eps=config.rms_norm_eps
|
| 1163 |
+
)
|
| 1164 |
+
self.post_attention_layernorm = DeepseekV3RMSNorm(
|
| 1165 |
+
config.hidden_size, eps=config.rms_norm_eps
|
| 1166 |
+
)
|
| 1167 |
+
|
| 1168 |
+
def forward(
|
| 1169 |
+
self,
|
| 1170 |
+
hidden_states: torch.Tensor,
|
| 1171 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1172 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1173 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 1174 |
+
output_attentions: Optional[bool] = False,
|
| 1175 |
+
use_cache: Optional[bool] = False,
|
| 1176 |
+
**kwargs,
|
| 1177 |
+
) -> Tuple[
|
| 1178 |
+
torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]
|
| 1179 |
+
]:
|
| 1180 |
+
"""
|
| 1181 |
+
Args:
|
| 1182 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 1183 |
+
attention_mask (`torch.FloatTensor`, *optional*):
|
| 1184 |
+
attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
|
| 1185 |
+
query_sequence_length, key_sequence_length)` if default attention is used.
|
| 1186 |
+
output_attentions (`bool`, *optional*):
|
| 1187 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 1188 |
+
returned tensors for more detail.
|
| 1189 |
+
use_cache (`bool`, *optional*):
|
| 1190 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 1191 |
+
(see `past_key_values`).
|
| 1192 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 1193 |
+
"""
|
| 1194 |
+
if "padding_mask" in kwargs:
|
| 1195 |
+
warnings.warn(
|
| 1196 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
|
| 1197 |
+
)
|
| 1198 |
+
residual = hidden_states
|
| 1199 |
+
|
| 1200 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 1201 |
+
|
| 1202 |
+
# Self Attention
|
| 1203 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 1204 |
+
hidden_states=hidden_states,
|
| 1205 |
+
attention_mask=attention_mask,
|
| 1206 |
+
position_ids=position_ids,
|
| 1207 |
+
past_key_value=past_key_value,
|
| 1208 |
+
output_attentions=output_attentions,
|
| 1209 |
+
use_cache=use_cache,
|
| 1210 |
+
**kwargs,
|
| 1211 |
+
)
|
| 1212 |
+
hidden_states = residual + hidden_states
|
| 1213 |
+
|
| 1214 |
+
# Fully Connected
|
| 1215 |
+
residual = hidden_states
|
| 1216 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 1217 |
+
hidden_states = self.mlp(hidden_states)
|
| 1218 |
+
hidden_states = residual + hidden_states
|
| 1219 |
+
|
| 1220 |
+
outputs = (hidden_states,)
|
| 1221 |
+
|
| 1222 |
+
if output_attentions:
|
| 1223 |
+
outputs += (self_attn_weights,)
|
| 1224 |
+
|
| 1225 |
+
if use_cache:
|
| 1226 |
+
outputs += (present_key_value,)
|
| 1227 |
+
|
| 1228 |
+
return outputs
|
| 1229 |
+
|
| 1230 |
+
|
| 1231 |
+
DeepseekV3_START_DOCSTRING = r"""
|
| 1232 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 1233 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 1234 |
+
etc.)
|
| 1235 |
+
|
| 1236 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 1237 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 1238 |
+
and behavior.
|
| 1239 |
+
|
| 1240 |
+
Parameters:
|
| 1241 |
+
config ([`DeepseekV3Config`]):
|
| 1242 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 1243 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 1244 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 1245 |
+
"""
|
| 1246 |
+
|
| 1247 |
+
|
| 1248 |
+
@add_start_docstrings(
|
| 1249 |
+
"The bare DeepseekV3 Model outputting raw hidden-states without any specific head on top.",
|
| 1250 |
+
DeepseekV3_START_DOCSTRING,
|
| 1251 |
+
)
|
| 1252 |
+
class DeepseekV3PreTrainedModel(PreTrainedModel):
|
| 1253 |
+
config_class = DeepseekV3Config
|
| 1254 |
+
base_model_prefix = "model"
|
| 1255 |
+
supports_gradient_checkpointing = True
|
| 1256 |
+
_no_split_modules = ["DeepseekV3DecoderLayer"]
|
| 1257 |
+
_skip_keys_device_placement = "past_key_values"
|
| 1258 |
+
_supports_flash_attn_2 = True
|
| 1259 |
+
_supports_cache_class = True
|
| 1260 |
+
|
| 1261 |
+
def _init_weights(self, module):
|
| 1262 |
+
std = self.config.initializer_range
|
| 1263 |
+
if isinstance(module, nn.Linear):
|
| 1264 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 1265 |
+
if module.bias is not None:
|
| 1266 |
+
module.bias.data.zero_()
|
| 1267 |
+
elif isinstance(module, nn.Embedding):
|
| 1268 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 1269 |
+
if module.padding_idx is not None:
|
| 1270 |
+
module.weight.data[module.padding_idx].zero_()
|
| 1271 |
+
|
| 1272 |
+
|
| 1273 |
+
DeepseekV3_INPUTS_DOCSTRING = r"""
|
| 1274 |
+
Args:
|
| 1275 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 1276 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 1277 |
+
it.
|
| 1278 |
+
|
| 1279 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 1280 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 1281 |
+
|
| 1282 |
+
[What are input IDs?](../glossary#input-ids)
|
| 1283 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1284 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 1285 |
+
|
| 1286 |
+
- 1 for tokens that are **not masked**,
|
| 1287 |
+
- 0 for tokens that are **masked**.
|
| 1288 |
+
|
| 1289 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 1290 |
+
|
| 1291 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 1292 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 1293 |
+
|
| 1294 |
+
If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
|
| 1295 |
+
`past_key_values`).
|
| 1296 |
+
|
| 1297 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 1298 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 1299 |
+
information on the default strategy.
|
| 1300 |
+
|
| 1301 |
+
- 1 indicates the head is **not masked**,
|
| 1302 |
+
- 0 indicates the head is **masked**.
|
| 1303 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1304 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 1305 |
+
config.n_positions - 1]`.
|
| 1306 |
+
|
| 1307 |
+
[What are position IDs?](../glossary#position-ids)
|
| 1308 |
+
past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
|
| 1309 |
+
Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 1310 |
+
blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
|
| 1311 |
+
returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
|
| 1312 |
+
|
| 1313 |
+
Two formats are allowed:
|
| 1314 |
+
- a [`~cache_utils.Cache`] instance;
|
| 1315 |
+
- Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
|
| 1316 |
+
shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
|
| 1317 |
+
cache format.
|
| 1318 |
+
|
| 1319 |
+
The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
|
| 1320 |
+
legacy cache format will be returned.
|
| 1321 |
+
|
| 1322 |
+
If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
|
| 1323 |
+
have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
|
| 1324 |
+
of shape `(batch_size, sequence_length)`.
|
| 1325 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 1326 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 1327 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 1328 |
+
model's internal embedding lookup matrix.
|
| 1329 |
+
use_cache (`bool`, *optional*):
|
| 1330 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 1331 |
+
`past_key_values`).
|
| 1332 |
+
output_attentions (`bool`, *optional*):
|
| 1333 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 1334 |
+
tensors for more detail.
|
| 1335 |
+
output_hidden_states (`bool`, *optional*):
|
| 1336 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 1337 |
+
more detail.
|
| 1338 |
+
return_dict (`bool`, *optional*):
|
| 1339 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 1340 |
+
"""
|
| 1341 |
+
|
| 1342 |
+
|
| 1343 |
+
@add_start_docstrings(
|
| 1344 |
+
"The bare DeepseekV3 Model outputting raw hidden-states without any specific head on top.",
|
| 1345 |
+
DeepseekV3_START_DOCSTRING,
|
| 1346 |
+
)
|
| 1347 |
+
class DeepseekV3Model(DeepseekV3PreTrainedModel):
|
| 1348 |
+
"""
|
| 1349 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`DeepseekV3DecoderLayer`]
|
| 1350 |
+
|
| 1351 |
+
Args:
|
| 1352 |
+
config: DeepseekV3Config
|
| 1353 |
+
"""
|
| 1354 |
+
|
| 1355 |
+
def __init__(self, config: DeepseekV3Config):
|
| 1356 |
+
super().__init__(config)
|
| 1357 |
+
self.padding_idx = config.pad_token_id
|
| 1358 |
+
self.vocab_size = config.vocab_size
|
| 1359 |
+
|
| 1360 |
+
self.embed_tokens = nn.Embedding(
|
| 1361 |
+
config.vocab_size, config.hidden_size, self.padding_idx
|
| 1362 |
+
)
|
| 1363 |
+
self.layers = nn.ModuleList(
|
| 1364 |
+
[
|
| 1365 |
+
DeepseekV3DecoderLayer(config, layer_idx)
|
| 1366 |
+
for layer_idx in range(config.num_hidden_layers)
|
| 1367 |
+
]
|
| 1368 |
+
)
|
| 1369 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 1370 |
+
self.norm = DeepseekV3RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 1371 |
+
|
| 1372 |
+
self.gradient_checkpointing = False
|
| 1373 |
+
# Initialize weights and apply final processing
|
| 1374 |
+
self.post_init()
|
| 1375 |
+
|
| 1376 |
+
def get_input_embeddings(self):
|
| 1377 |
+
return self.embed_tokens
|
| 1378 |
+
|
| 1379 |
+
def set_input_embeddings(self, value):
|
| 1380 |
+
self.embed_tokens = value
|
| 1381 |
+
|
| 1382 |
+
@add_start_docstrings_to_model_forward(DeepseekV3_INPUTS_DOCSTRING)
|
| 1383 |
+
def forward(
|
| 1384 |
+
self,
|
| 1385 |
+
input_ids: torch.LongTensor = None,
|
| 1386 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1387 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1388 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1389 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1390 |
+
use_cache: Optional[bool] = None,
|
| 1391 |
+
output_attentions: Optional[bool] = None,
|
| 1392 |
+
output_hidden_states: Optional[bool] = None,
|
| 1393 |
+
return_dict: Optional[bool] = None,
|
| 1394 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 1395 |
+
output_attentions = (
|
| 1396 |
+
output_attentions
|
| 1397 |
+
if output_attentions is not None
|
| 1398 |
+
else self.config.output_attentions
|
| 1399 |
+
)
|
| 1400 |
+
output_hidden_states = (
|
| 1401 |
+
output_hidden_states
|
| 1402 |
+
if output_hidden_states is not None
|
| 1403 |
+
else self.config.output_hidden_states
|
| 1404 |
+
)
|
| 1405 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 1406 |
+
|
| 1407 |
+
return_dict = (
|
| 1408 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1409 |
+
)
|
| 1410 |
+
|
| 1411 |
+
# retrieve input_ids and inputs_embeds
|
| 1412 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 1413 |
+
raise ValueError(
|
| 1414 |
+
"You cannot specify both input_ids and inputs_embeds at the same time"
|
| 1415 |
+
)
|
| 1416 |
+
elif input_ids is not None:
|
| 1417 |
+
batch_size, seq_length = input_ids.shape[:2]
|
| 1418 |
+
elif inputs_embeds is not None:
|
| 1419 |
+
batch_size, seq_length = inputs_embeds.shape[:2]
|
| 1420 |
+
else:
|
| 1421 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 1422 |
+
|
| 1423 |
+
past_key_values_length = 0
|
| 1424 |
+
if use_cache:
|
| 1425 |
+
use_legacy_cache = not isinstance(past_key_values, Cache)
|
| 1426 |
+
if use_legacy_cache:
|
| 1427 |
+
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
| 1428 |
+
past_key_values_length = past_key_values.get_usable_length(seq_length)
|
| 1429 |
+
|
| 1430 |
+
if position_ids is None:
|
| 1431 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 1432 |
+
position_ids = torch.arange(
|
| 1433 |
+
past_key_values_length,
|
| 1434 |
+
seq_length + past_key_values_length,
|
| 1435 |
+
dtype=torch.long,
|
| 1436 |
+
device=device,
|
| 1437 |
+
)
|
| 1438 |
+
position_ids = position_ids.unsqueeze(0)
|
| 1439 |
+
|
| 1440 |
+
if inputs_embeds is None:
|
| 1441 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 1442 |
+
|
| 1443 |
+
if self._use_flash_attention_2:
|
| 1444 |
+
# 2d mask is passed through the layers
|
| 1445 |
+
attention_mask = (
|
| 1446 |
+
attention_mask
|
| 1447 |
+
if (attention_mask is not None and 0 in attention_mask)
|
| 1448 |
+
else None
|
| 1449 |
+
)
|
| 1450 |
+
else:
|
| 1451 |
+
# 4d mask is passed through the layers
|
| 1452 |
+
attention_mask = _prepare_4d_causal_attention_mask(
|
| 1453 |
+
attention_mask,
|
| 1454 |
+
(batch_size, seq_length),
|
| 1455 |
+
inputs_embeds,
|
| 1456 |
+
past_key_values_length,
|
| 1457 |
+
)
|
| 1458 |
+
|
| 1459 |
+
# embed positions
|
| 1460 |
+
hidden_states = inputs_embeds
|
| 1461 |
+
|
| 1462 |
+
# decoder layers
|
| 1463 |
+
all_hidden_states = () if output_hidden_states else None
|
| 1464 |
+
all_self_attns = () if output_attentions else None
|
| 1465 |
+
next_decoder_cache = None
|
| 1466 |
+
|
| 1467 |
+
for decoder_layer in self.layers:
|
| 1468 |
+
if output_hidden_states:
|
| 1469 |
+
all_hidden_states += (hidden_states,)
|
| 1470 |
+
|
| 1471 |
+
layer_outputs = decoder_layer(
|
| 1472 |
+
hidden_states,
|
| 1473 |
+
attention_mask=attention_mask,
|
| 1474 |
+
position_ids=position_ids,
|
| 1475 |
+
past_key_value=past_key_values,
|
| 1476 |
+
output_attentions=output_attentions,
|
| 1477 |
+
use_cache=use_cache,
|
| 1478 |
+
)
|
| 1479 |
+
|
| 1480 |
+
hidden_states = layer_outputs[0]
|
| 1481 |
+
|
| 1482 |
+
if use_cache:
|
| 1483 |
+
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
| 1484 |
+
|
| 1485 |
+
if output_attentions:
|
| 1486 |
+
all_self_attns += (layer_outputs[1],)
|
| 1487 |
+
|
| 1488 |
+
hidden_states = self.norm(hidden_states)
|
| 1489 |
+
|
| 1490 |
+
# add hidden states from the last decoder layer
|
| 1491 |
+
if output_hidden_states:
|
| 1492 |
+
all_hidden_states += (hidden_states,)
|
| 1493 |
+
|
| 1494 |
+
next_cache = None
|
| 1495 |
+
if use_cache:
|
| 1496 |
+
next_cache = (
|
| 1497 |
+
next_decoder_cache.to_legacy_cache()
|
| 1498 |
+
if use_legacy_cache
|
| 1499 |
+
else next_decoder_cache
|
| 1500 |
+
)
|
| 1501 |
+
if not return_dict:
|
| 1502 |
+
return tuple(
|
| 1503 |
+
v
|
| 1504 |
+
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns]
|
| 1505 |
+
if v is not None
|
| 1506 |
+
)
|
| 1507 |
+
return BaseModelOutputWithPast(
|
| 1508 |
+
last_hidden_state=hidden_states,
|
| 1509 |
+
past_key_values=next_cache,
|
| 1510 |
+
hidden_states=all_hidden_states,
|
| 1511 |
+
attentions=all_self_attns,
|
| 1512 |
+
)
|
| 1513 |
+
|
| 1514 |
+
|
| 1515 |
+
class DeepseekV3ForCausalLM(DeepseekV3PreTrainedModel):
|
| 1516 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 1517 |
+
|
| 1518 |
+
def __init__(self, config):
|
| 1519 |
+
super().__init__(config)
|
| 1520 |
+
self.model = DeepseekV3Model(config)
|
| 1521 |
+
self.vocab_size = config.vocab_size
|
| 1522 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1523 |
+
|
| 1524 |
+
# Initialize weights and apply final processing
|
| 1525 |
+
self.post_init()
|
| 1526 |
+
|
| 1527 |
+
def get_input_embeddings(self):
|
| 1528 |
+
return self.model.embed_tokens
|
| 1529 |
+
|
| 1530 |
+
def set_input_embeddings(self, value):
|
| 1531 |
+
self.model.embed_tokens = value
|
| 1532 |
+
|
| 1533 |
+
def get_output_embeddings(self):
|
| 1534 |
+
return self.lm_head
|
| 1535 |
+
|
| 1536 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1537 |
+
self.lm_head = new_embeddings
|
| 1538 |
+
|
| 1539 |
+
def set_decoder(self, decoder):
|
| 1540 |
+
self.model = decoder
|
| 1541 |
+
|
| 1542 |
+
def get_decoder(self):
|
| 1543 |
+
return self.model
|
| 1544 |
+
|
| 1545 |
+
@add_start_docstrings_to_model_forward(DeepseekV3_INPUTS_DOCSTRING)
|
| 1546 |
+
@replace_return_docstrings(
|
| 1547 |
+
output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC
|
| 1548 |
+
)
|
| 1549 |
+
def forward(
|
| 1550 |
+
self,
|
| 1551 |
+
input_ids: torch.LongTensor = None,
|
| 1552 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1553 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1554 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1555 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1556 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1557 |
+
use_cache: Optional[bool] = None,
|
| 1558 |
+
output_attentions: Optional[bool] = None,
|
| 1559 |
+
output_hidden_states: Optional[bool] = None,
|
| 1560 |
+
return_dict: Optional[bool] = None,
|
| 1561 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1562 |
+
r"""
|
| 1563 |
+
Args:
|
| 1564 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1565 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, transformers.,
|
| 1566 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 1567 |
+
(masked), the loss is only computed for the tokens with labels in `[0, transformers., config.vocab_size]`.
|
| 1568 |
+
|
| 1569 |
+
Returns:
|
| 1570 |
+
|
| 1571 |
+
Example:
|
| 1572 |
+
|
| 1573 |
+
```python
|
| 1574 |
+
>>> from transformers import AutoTokenizer, DeepseekV3ForCausalLM
|
| 1575 |
+
|
| 1576 |
+
>>> model = DeepseekV3ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 1577 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 1578 |
+
|
| 1579 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 1580 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 1581 |
+
|
| 1582 |
+
>>> # Generate
|
| 1583 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 1584 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 1585 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 1586 |
+
```"""
|
| 1587 |
+
output_attentions = (
|
| 1588 |
+
output_attentions
|
| 1589 |
+
if output_attentions is not None
|
| 1590 |
+
else self.config.output_attentions
|
| 1591 |
+
)
|
| 1592 |
+
output_hidden_states = (
|
| 1593 |
+
output_hidden_states
|
| 1594 |
+
if output_hidden_states is not None
|
| 1595 |
+
else self.config.output_hidden_states
|
| 1596 |
+
)
|
| 1597 |
+
return_dict = (
|
| 1598 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1599 |
+
)
|
| 1600 |
+
|
| 1601 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 1602 |
+
outputs = self.model(
|
| 1603 |
+
input_ids=input_ids,
|
| 1604 |
+
attention_mask=attention_mask,
|
| 1605 |
+
position_ids=position_ids,
|
| 1606 |
+
past_key_values=past_key_values,
|
| 1607 |
+
inputs_embeds=inputs_embeds,
|
| 1608 |
+
use_cache=use_cache,
|
| 1609 |
+
output_attentions=output_attentions,
|
| 1610 |
+
output_hidden_states=output_hidden_states,
|
| 1611 |
+
return_dict=return_dict,
|
| 1612 |
+
)
|
| 1613 |
+
|
| 1614 |
+
hidden_states = outputs[0]
|
| 1615 |
+
logits = self.lm_head(hidden_states)
|
| 1616 |
+
logits = logits.float()
|
| 1617 |
+
|
| 1618 |
+
loss = None
|
| 1619 |
+
if labels is not None:
|
| 1620 |
+
# Shift so that tokens < n predict n
|
| 1621 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 1622 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1623 |
+
# Flatten the tokens
|
| 1624 |
+
loss_fct = CrossEntropyLoss()
|
| 1625 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 1626 |
+
shift_labels = shift_labels.view(-1)
|
| 1627 |
+
# Enable model parallelism
|
| 1628 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 1629 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 1630 |
+
|
| 1631 |
+
if not return_dict:
|
| 1632 |
+
output = (logits,) + outputs[1:]
|
| 1633 |
+
return (loss,) + output if loss is not None else output
|
| 1634 |
+
|
| 1635 |
+
return CausalLMOutputWithPast(
|
| 1636 |
+
loss=loss,
|
| 1637 |
+
logits=logits,
|
| 1638 |
+
past_key_values=outputs.past_key_values,
|
| 1639 |
+
hidden_states=outputs.hidden_states,
|
| 1640 |
+
attentions=outputs.attentions,
|
| 1641 |
+
)
|
| 1642 |
+
|
| 1643 |
+
def prepare_inputs_for_generation(
|
| 1644 |
+
self,
|
| 1645 |
+
input_ids,
|
| 1646 |
+
past_key_values=None,
|
| 1647 |
+
attention_mask=None,
|
| 1648 |
+
inputs_embeds=None,
|
| 1649 |
+
**kwargs,
|
| 1650 |
+
):
|
| 1651 |
+
if past_key_values is not None:
|
| 1652 |
+
if isinstance(past_key_values, Cache):
|
| 1653 |
+
cache_length = past_key_values.get_seq_length()
|
| 1654 |
+
past_length = past_key_values.seen_tokens
|
| 1655 |
+
max_cache_length = past_key_values.get_max_length()
|
| 1656 |
+
else:
|
| 1657 |
+
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 1658 |
+
max_cache_length = None
|
| 1659 |
+
|
| 1660 |
+
# Keep only the unprocessed tokens:
|
| 1661 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 1662 |
+
# some of the inputs are exclusivelly passed as part of the cache (e.g. when passing input_embeds as
|
| 1663 |
+
# input)
|
| 1664 |
+
if (
|
| 1665 |
+
attention_mask is not None
|
| 1666 |
+
and attention_mask.shape[1] > input_ids.shape[1]
|
| 1667 |
+
):
|
| 1668 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 1669 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 1670 |
+
# input_ids based on the past_length.
|
| 1671 |
+
elif past_length < input_ids.shape[1]:
|
| 1672 |
+
input_ids = input_ids[:, past_length:]
|
| 1673 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 1674 |
+
|
| 1675 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 1676 |
+
if (
|
| 1677 |
+
max_cache_length is not None
|
| 1678 |
+
and attention_mask is not None
|
| 1679 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 1680 |
+
):
|
| 1681 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 1682 |
+
|
| 1683 |
+
position_ids = kwargs.get("position_ids", None)
|
| 1684 |
+
if attention_mask is not None and position_ids is None:
|
| 1685 |
+
# create position_ids on the fly for batch generation
|
| 1686 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1687 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1688 |
+
if past_key_values:
|
| 1689 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 1690 |
+
|
| 1691 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1692 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1693 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1694 |
+
else:
|
| 1695 |
+
model_inputs = {"input_ids": input_ids}
|
| 1696 |
+
|
| 1697 |
+
model_inputs.update(
|
| 1698 |
+
{
|
| 1699 |
+
"position_ids": position_ids,
|
| 1700 |
+
"past_key_values": past_key_values,
|
| 1701 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1702 |
+
"attention_mask": attention_mask,
|
| 1703 |
+
}
|
| 1704 |
+
)
|
| 1705 |
+
return model_inputs
|
| 1706 |
+
|
| 1707 |
+
@staticmethod
|
| 1708 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 1709 |
+
reordered_past = ()
|
| 1710 |
+
for layer_past in past_key_values:
|
| 1711 |
+
reordered_past += (
|
| 1712 |
+
tuple(
|
| 1713 |
+
past_state.index_select(0, beam_idx.to(past_state.device))
|
| 1714 |
+
for past_state in layer_past
|
| 1715 |
+
),
|
| 1716 |
+
)
|
| 1717 |
+
return reordered_past
|
| 1718 |
+
|
| 1719 |
+
|
| 1720 |
+
@add_start_docstrings(
|
| 1721 |
+
"""
|
| 1722 |
+
The DeepseekV3 Model transformer with a sequence classification head on top (linear layer).
|
| 1723 |
+
|
| 1724 |
+
[`DeepseekV3ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 1725 |
+
(e.g. GPT-2) do.
|
| 1726 |
+
|
| 1727 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1728 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1729 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1730 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1731 |
+
each row of the batch).
|
| 1732 |
+
""",
|
| 1733 |
+
DeepseekV3_START_DOCSTRING,
|
| 1734 |
+
)
|
| 1735 |
+
class DeepseekV3ForSequenceClassification(DeepseekV3PreTrainedModel):
|
| 1736 |
+
def __init__(self, config):
|
| 1737 |
+
super().__init__(config)
|
| 1738 |
+
self.num_labels = config.num_labels
|
| 1739 |
+
self.model = DeepseekV3Model(config)
|
| 1740 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1741 |
+
|
| 1742 |
+
# Initialize weights and apply final processing
|
| 1743 |
+
self.post_init()
|
| 1744 |
+
|
| 1745 |
+
def get_input_embeddings(self):
|
| 1746 |
+
return self.model.embed_tokens
|
| 1747 |
+
|
| 1748 |
+
def set_input_embeddings(self, value):
|
| 1749 |
+
self.model.embed_tokens = value
|
| 1750 |
+
|
| 1751 |
+
@add_start_docstrings_to_model_forward(DeepseekV3_INPUTS_DOCSTRING)
|
| 1752 |
+
def forward(
|
| 1753 |
+
self,
|
| 1754 |
+
input_ids: torch.LongTensor = None,
|
| 1755 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1756 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1757 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1758 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1759 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1760 |
+
use_cache: Optional[bool] = None,
|
| 1761 |
+
output_attentions: Optional[bool] = None,
|
| 1762 |
+
output_hidden_states: Optional[bool] = None,
|
| 1763 |
+
return_dict: Optional[bool] = None,
|
| 1764 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1765 |
+
r"""
|
| 1766 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1767 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, transformers.,
|
| 1768 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1769 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1770 |
+
"""
|
| 1771 |
+
return_dict = (
|
| 1772 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1773 |
+
)
|
| 1774 |
+
|
| 1775 |
+
transformer_outputs = self.model(
|
| 1776 |
+
input_ids,
|
| 1777 |
+
attention_mask=attention_mask,
|
| 1778 |
+
position_ids=position_ids,
|
| 1779 |
+
past_key_values=past_key_values,
|
| 1780 |
+
inputs_embeds=inputs_embeds,
|
| 1781 |
+
use_cache=use_cache,
|
| 1782 |
+
output_attentions=output_attentions,
|
| 1783 |
+
output_hidden_states=output_hidden_states,
|
| 1784 |
+
return_dict=return_dict,
|
| 1785 |
+
)
|
| 1786 |
+
hidden_states = transformer_outputs[0]
|
| 1787 |
+
logits = self.score(hidden_states)
|
| 1788 |
+
|
| 1789 |
+
if input_ids is not None:
|
| 1790 |
+
batch_size = input_ids.shape[0]
|
| 1791 |
+
else:
|
| 1792 |
+
batch_size = inputs_embeds.shape[0]
|
| 1793 |
+
|
| 1794 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1795 |
+
raise ValueError(
|
| 1796 |
+
"Cannot handle batch sizes > 1 if no padding token is defined."
|
| 1797 |
+
)
|
| 1798 |
+
if self.config.pad_token_id is None:
|
| 1799 |
+
sequence_lengths = -1
|
| 1800 |
+
else:
|
| 1801 |
+
if input_ids is not None:
|
| 1802 |
+
sequence_lengths = (
|
| 1803 |
+
torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
|
| 1804 |
+
).to(logits.device)
|
| 1805 |
+
else:
|
| 1806 |
+
sequence_lengths = -1
|
| 1807 |
+
|
| 1808 |
+
pooled_logits = logits[
|
| 1809 |
+
torch.arange(batch_size, device=logits.device), sequence_lengths
|
| 1810 |
+
]
|
| 1811 |
+
|
| 1812 |
+
loss = None
|
| 1813 |
+
if labels is not None:
|
| 1814 |
+
labels = labels.to(logits.device)
|
| 1815 |
+
if self.config.problem_type is None:
|
| 1816 |
+
if self.num_labels == 1:
|
| 1817 |
+
self.config.problem_type = "regression"
|
| 1818 |
+
elif self.num_labels > 1 and (
|
| 1819 |
+
labels.dtype == torch.long or labels.dtype == torch.int
|
| 1820 |
+
):
|
| 1821 |
+
self.config.problem_type = "single_label_classification"
|
| 1822 |
+
else:
|
| 1823 |
+
self.config.problem_type = "multi_label_classification"
|
| 1824 |
+
|
| 1825 |
+
if self.config.problem_type == "regression":
|
| 1826 |
+
loss_fct = MSELoss()
|
| 1827 |
+
if self.num_labels == 1:
|
| 1828 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1829 |
+
else:
|
| 1830 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1831 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1832 |
+
loss_fct = CrossEntropyLoss()
|
| 1833 |
+
loss = loss_fct(
|
| 1834 |
+
pooled_logits.view(-1, self.num_labels), labels.view(-1)
|
| 1835 |
+
)
|
| 1836 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1837 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1838 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1839 |
+
if not return_dict:
|
| 1840 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1841 |
+
return ((loss,) + output) if loss is not None else output
|
| 1842 |
+
|
| 1843 |
+
return SequenceClassifierOutputWithPast(
|
| 1844 |
+
loss=loss,
|
| 1845 |
+
logits=pooled_logits,
|
| 1846 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1847 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1848 |
+
attentions=transformer_outputs.attentions,
|
| 1849 |
+
)
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<|begin▁of▁sentence|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": false,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "<|end▁of▁sentence|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"legacy": true,
|
| 22 |
+
"model_max_length": 16384,
|
| 23 |
+
"pad_token": {
|
| 24 |
+
"__type": "AddedToken",
|
| 25 |
+
"content": "<|end▁of▁sentence|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": true,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
},
|
| 31 |
+
"sp_model_kwargs": {},
|
| 32 |
+
"unk_token": null,
|
| 33 |
+
"tokenizer_class": "LlamaTokenizerFast",
|
| 34 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '\\n\\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' in message %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- else %}{{'<|Assistant|>' + message['content'] + '<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- endif %}{%- endfor %}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' not in message %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}"
|
| 35 |
+
}
|