# 360LayoutAnalysis
[Chinese](./README.md)
## I. Background
In the current digital era, **Document Layout Analysis** is one of the key steps for information extraction and document comprehension. Also known as document image analysis or document layout analysis, it is the process of identifying and extracting text, images, tables, and other elements from scanned document images. This technology has a wide range of applications in areas such as automated document processing, electronic data interchange, and the digitization of historical documents.
Traditional document layout analysis models often struggle to accurately distinguish between paragraphs and other layout elements within documents, which restricts further processing and utilization of document information. However, the development of deep learning and pattern recognition technologies has brought new opportunities for document layout analysis. By training on datasets, the models' understanding of document structure can be enhanced. Yet, high-quality annotated datasets are fundamental to training effective models.
In document layout analysis, fine-grained annotation is essential, especially the annotation of **paragraphs**, as it directly affects semantic understanding and information extraction of the text. Currently, in the field of layout analysis, to our knowledge, open-source datasets such as CDLA (A Chinese document layout analysis) lack annotations for paragraph information; layout analysis models for the research report scenario are relatively scarce.
Therefore, to address this issue, we have manually annotated and fine-tuned the CDLA with granular tags and data optimization, and have built a fine-grained layout analysis dataset for the research report scenario. Utilizing these annotated datasets, we have trained several new Chinese document layout analysis models, which have shown **excellent performance on the closed test set**.
In this open-source release, we have prioritized the release of lightweight model weights and corresponding label systems for **academic papers** and **research reports**, aiming to identify paragraph boundaries and accurately distinguish between text, images, tables, formulas, and other elements, ultimately promoting industry development.
## II. Usage
- Weights download link: [🤗LINK](https://huggingface.co/qihoo360)
- Usage:
The open-source weights are trained with `yolov8`, and the prediction method is as follows:
```python
from ultralytics import YOLO
image_path = '' # Path to the image to be predicted
model_path = '' # Path to the weights
model = YOLO(model_path)
result = model(image_path, save=True, conf=0.5, save_crop=False, line_width=2)
print(result)
```
## III. Layout Analysis
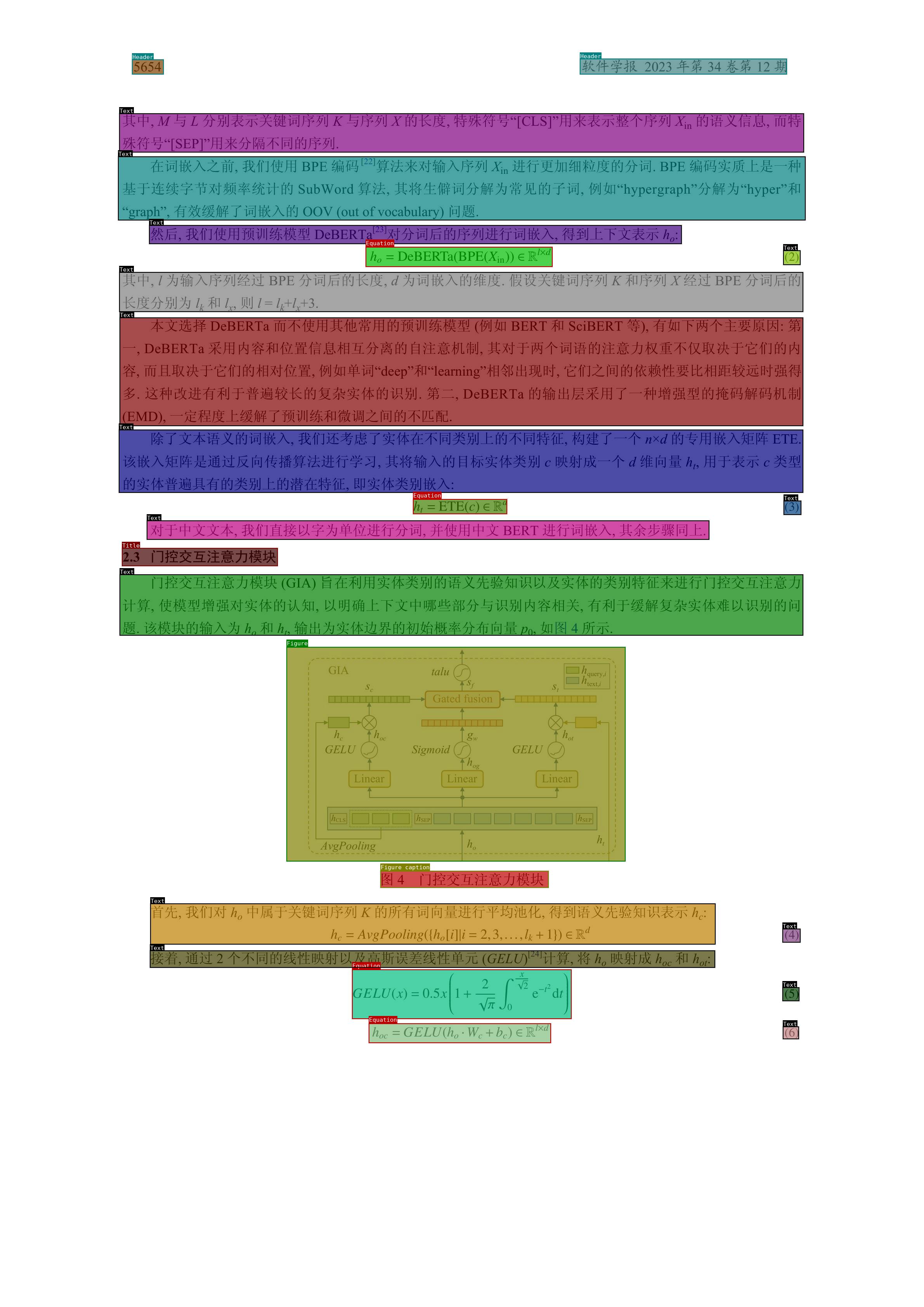
### 3.1 Academic Paper Scenario
- Label Categories
| Element | Name |
| -------------- | --------------------- |
| Text | Main Text (Paragraph) |
| Title | Title |
| Figure | Image |
| Figure caption | Image Caption |
| Table | Table |
| Table caption | Table Caption |
| Header | Header |
| Footer | Footer |
| Reference | Reference |
| Equation | Equation |
- Example
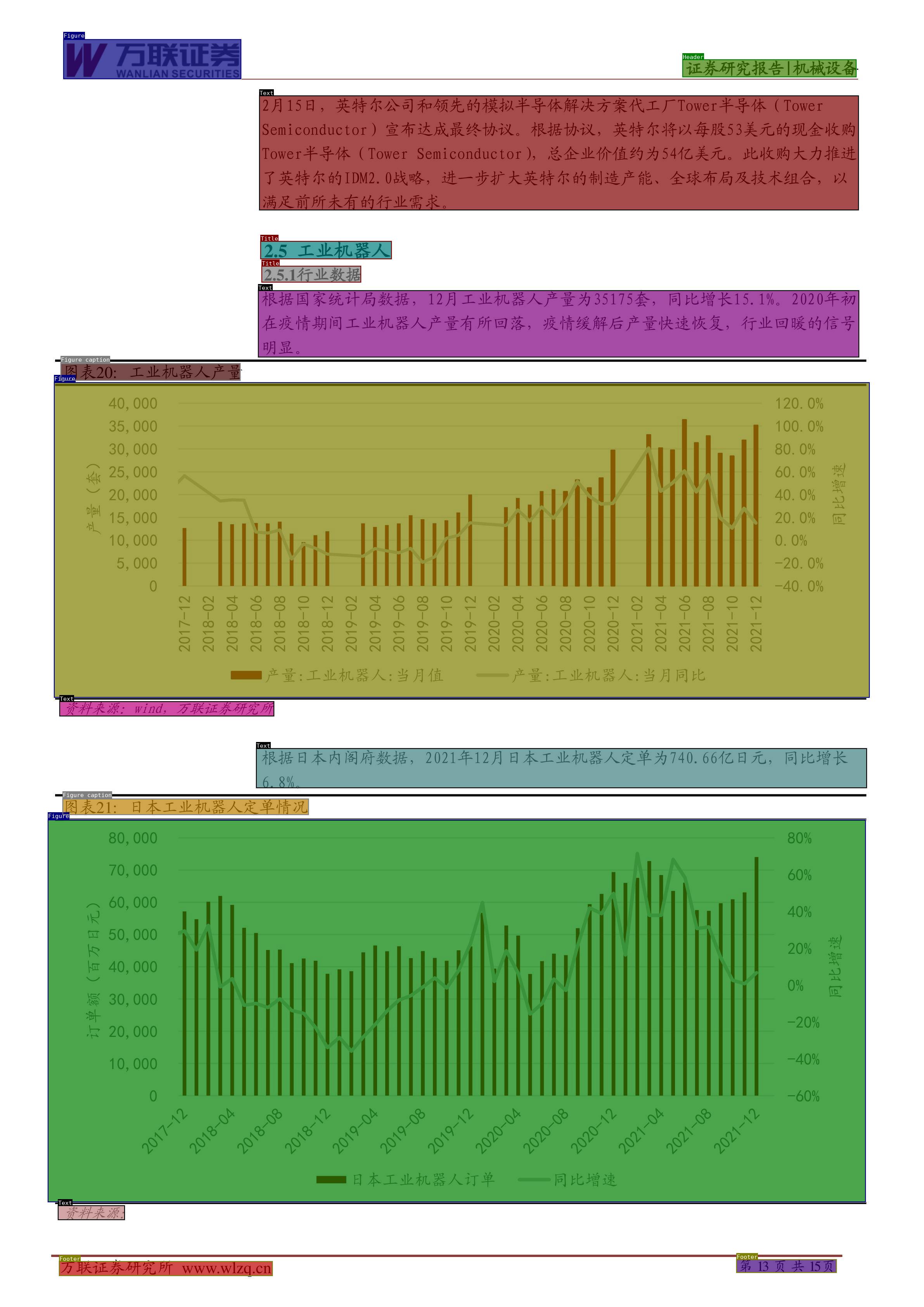
### 3.2 Research Report Scenario
- Label Categories
| Element | Name |
| -------------- | --------------------- |
| Text | Main Text (Paragraph) |
| Title | Title |
| Figure | Image |
| Figure caption | Image Caption |
| Table | Table |
| Table caption | Table Caption |
| Header | Header |
| Footer | Footer |
| Toc | Table of Contents |
- Example
## License
This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses. The content of this project itself is licensed under the [Apache license 2.0](./LICENSE.txt).
## License
The source code of this repository follows the open-source license Apache 2.0. The 360LayoutAnalysis model open-source model supports commercial use. If you need to use this model and its derivative models for commercial purposes, please apply through the email ([360ailab-nlp@360.cn](mailto:360ailab-nlp@360.cn)), and see the specific license agreement in ["360LayoutAnalysis Model Open Source Model License"](./360LayoutAnalysis开源模型许可证.txt).