
Commit
•
1c7d193
1
Parent(s):
75a8f22
initial commit
Browse files- README.md +143 -0
- assets/method_overview2.png +0 -0
- assets/teaser.png +0 -0
- ckpts/.gitkeep +0 -0
- ckpts/VITONHD.ckpt +3 -0
- ckpts/VITONHD_PBE_pose.ckpt +3 -0
- ckpts/VITONHD_VAE_finetuning.ckpt +3 -0
README.md
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
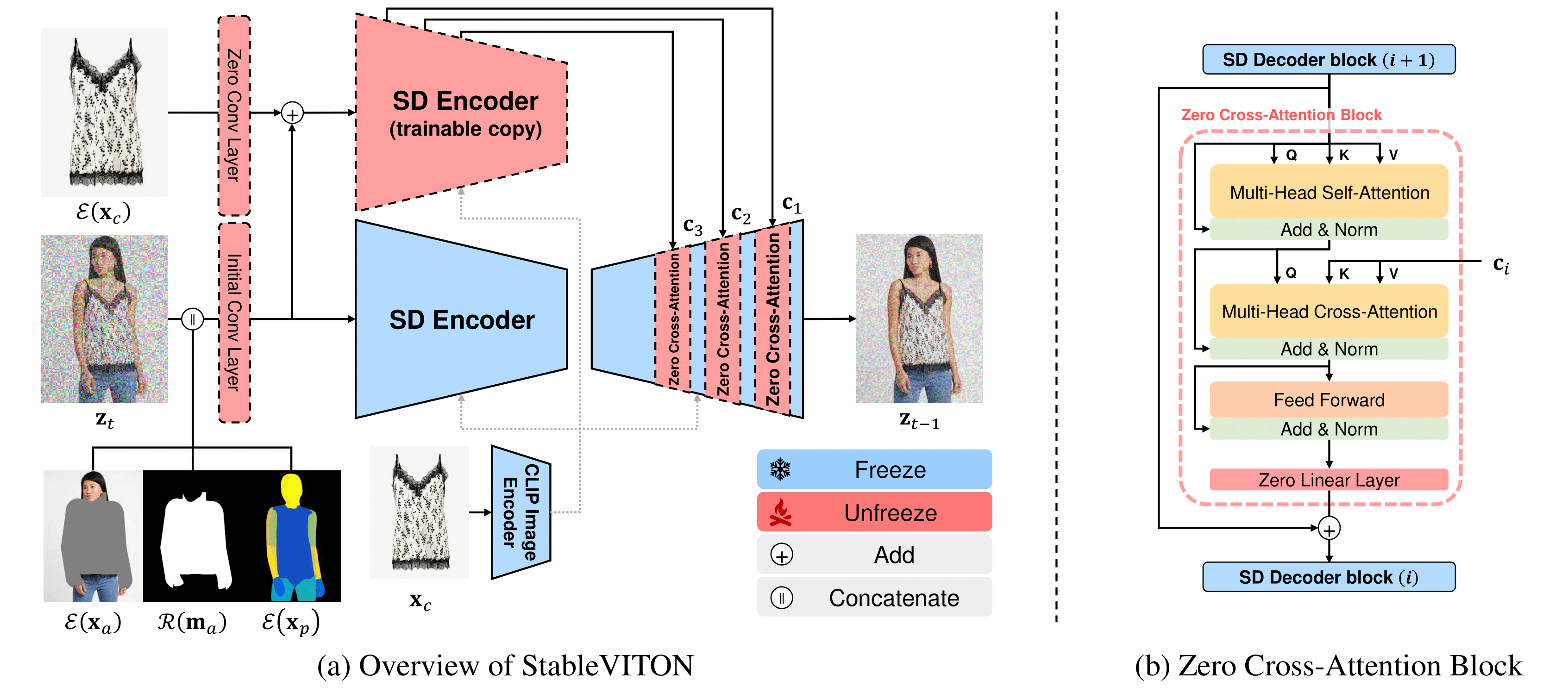
# [CVPR2024] StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
|
| 2 |
+
This repository is the official implementation of [StableVITON](https://arxiv.org/abs/2312.01725)
|
| 3 |
+
|
| 4 |
+
> **StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On**<br>
|
| 5 |
+
> [Jeongho Kim](https://scholar.google.co.kr/citations?user=ucoiLHQAAAAJ&hl=ko), [Gyojung Gu](https://www.linkedin.com/in/gyojung-gu-29033118b/), [Minho Park](https://pmh9960.github.io/), [Sunghyun Park](https://psh01087.github.io/), [Jaegul Choo](https://sites.google.com/site/jaegulchoo/)
|
| 6 |
+
|
| 7 |
+
[[Arxiv Paper](https://arxiv.org/abs/2312.01725)]
|
| 8 |
+
[[Website Page](https://rlawjdghek.github.io/StableVITON/)]
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
## TODO List
|
| 13 |
+
- [x] ~~Inference code~~
|
| 14 |
+
- [x] ~~Release model weights~~
|
| 15 |
+
- [x] ~~Training code~~
|
| 16 |
+
|
| 17 |
+
## Environments
|
| 18 |
+
```bash
|
| 19 |
+
git clone https://github.com/rlawjdghek/StableVITON
|
| 20 |
+
cd StableVITON
|
| 21 |
+
|
| 22 |
+
conda create --name StableVITON python=3.10 -y
|
| 23 |
+
conda activate StableVITON
|
| 24 |
+
|
| 25 |
+
# install packages
|
| 26 |
+
pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
|
| 27 |
+
pip install pytorch-lightning==1.5.0
|
| 28 |
+
pip install einops
|
| 29 |
+
pip install opencv-python==4.7.0.72
|
| 30 |
+
pip install matplotlib
|
| 31 |
+
pip install omegaconf
|
| 32 |
+
pip install albumentations
|
| 33 |
+
pip install transformers==4.33.2
|
| 34 |
+
pip install xformers==0.0.19
|
| 35 |
+
pip install triton==2.0.0
|
| 36 |
+
pip install open-clip-torch==2.19.0
|
| 37 |
+
pip install diffusers==0.20.2
|
| 38 |
+
pip install scipy==1.10.1
|
| 39 |
+
conda install -c anaconda ipython -y
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
## Weights and Data
|
| 43 |
+
Our [checkpoint](https://kaistackr-my.sharepoint.com/:f:/g/personal/rlawjdghek_kaist_ac_kr/EjzAZHJu9MlEoKIxG4tqPr0BM_Ry20NHyNw5Sic2vItxiA?e=5mGa1c) on VITONHD have been released! <br>
|
| 44 |
+
You can download the VITON-HD dataset from [here](https://github.com/shadow2496/VITON-HD).<br>
|
| 45 |
+
For both training and inference, the following dataset structure is required:
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
train
|
| 49 |
+
|-- image
|
| 50 |
+
|-- image-densepose
|
| 51 |
+
|-- agnostic
|
| 52 |
+
|-- agnostic-mask
|
| 53 |
+
|-- cloth
|
| 54 |
+
|-- cloth_mask
|
| 55 |
+
|-- gt_cloth_warped_mask (for ATV loss)
|
| 56 |
+
|
| 57 |
+
test
|
| 58 |
+
|-- image
|
| 59 |
+
|-- image-densepose
|
| 60 |
+
|-- agnostic
|
| 61 |
+
|-- agnostic-mask
|
| 62 |
+
|-- cloth
|
| 63 |
+
|-- cloth_mask
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
## Preprocessing
|
| 67 |
+
The VITON-HD dataset serves as a benchmark and provides an agnostic mask. However, you can attempt virtual try-on on **arbitrary images** using segmentation tools like [SAM](https://github.com/facebookresearch/segment-anything). Please note that for densepose, you should use the same densepose model as used in VITON-HD.
|
| 68 |
+
|
| 69 |
+
## Inference
|
| 70 |
+
```bash
|
| 71 |
+
#### paired
|
| 72 |
+
CUDA_VISIBLE_DEVICES=4 python inference.py \
|
| 73 |
+
--config_path ./configs/VITONHD.yaml \
|
| 74 |
+
--batch_size 4 \
|
| 75 |
+
--model_load_path <model weight path> \
|
| 76 |
+
--save_dir <save directory>
|
| 77 |
+
|
| 78 |
+
#### unpaired
|
| 79 |
+
CUDA_VISIBLE_DEVICES=4 python inference.py \
|
| 80 |
+
--config_path ./configs/VITONHD.yaml \
|
| 81 |
+
--batch_size 4 \
|
| 82 |
+
--model_load_path <model weight path> \
|
| 83 |
+
--unpair \
|
| 84 |
+
--save_dir <save directory>
|
| 85 |
+
|
| 86 |
+
#### paired repaint
|
| 87 |
+
CUDA_VISIBLE_DEVICES=4 python inference.py \
|
| 88 |
+
--config_path ./configs/VITONHD.yaml \
|
| 89 |
+
--batch_size 4 \
|
| 90 |
+
--model_load_path <model weight path>t \
|
| 91 |
+
--repaint \
|
| 92 |
+
--save_dir <save directory>
|
| 93 |
+
|
| 94 |
+
#### unpaired repaint
|
| 95 |
+
CUDA_VISIBLE_DEVICES=4 python inference.py \
|
| 96 |
+
--config_path ./configs/VITONHD.yaml \
|
| 97 |
+
--batch_size 4 \
|
| 98 |
+
--model_load_path <model weight path> \
|
| 99 |
+
--unpair \
|
| 100 |
+
--repaint \
|
| 101 |
+
--save_dir <save directory>
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
You can also preserve the unmasked region by '--repaint' option.
|
| 105 |
+
|
| 106 |
+
## Training
|
| 107 |
+
For VITON training, we increased the first block of U-Net from 9 to 13 channels (add zero conv) based on the Paint-by-Example (PBE) model. Therefore, you should download the modified checkpoint (named as 'VITONHD_PBE_pose.ckpt') from the [Link](https://kaistackr-my.sharepoint.com/:f:/g/personal/rlawjdghek_kaist_ac_kr/EjzAZHJu9MlEoKIxG4tqPr0BM_Ry20NHyNw5Sic2vItxiA?e=5mGa1c) and place it in the './ckpts/' folder first.
|
| 108 |
+
|
| 109 |
+
Additionally, for more refined person texture, we utilized a VAE fine-tuned on the VITONHD dataset. You should also download the checkpoint (named as VITONHD_VAE_finetuning.ckpt') from the [Link](https://kaistackr-my.sharepoint.com/:f:/g/personal/rlawjdghek_kaist_ac_kr/EjzAZHJu9MlEoKIxG4tqPr0BM_Ry20NHyNw5Sic2vItxiA?e=5mGa1c) and place it in the './ckpts/' folder.
|
| 110 |
+
|
| 111 |
+
```bash
|
| 112 |
+
### Base model training
|
| 113 |
+
CUDA_VISIBLE_DEVICES=3,4 python train.py \
|
| 114 |
+
--config_name VITONHD \
|
| 115 |
+
--transform_size shiftscale3 hflip \
|
| 116 |
+
--transform_color hsv bright_contrast \
|
| 117 |
+
--save_name Base_test
|
| 118 |
+
|
| 119 |
+
### ATV loss finetuning
|
| 120 |
+
CUDA_VISIBLE_DEVICES=5,6 python train.py \
|
| 121 |
+
--config_name VITONHD \
|
| 122 |
+
--transform_size shiftscale3 hflip \
|
| 123 |
+
--transform_color hsv bright_contrast \
|
| 124 |
+
--use_atv_loss \
|
| 125 |
+
--resume_path <first stage model path> \
|
| 126 |
+
--save_name ATVloss_test
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
## Citation
|
| 130 |
+
If you find our work useful for your research, please cite us:
|
| 131 |
+
```
|
| 132 |
+
@artical{kim2023stableviton,
|
| 133 |
+
title={StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On},
|
| 134 |
+
author={Kim, Jeongho and Gu, Gyojung and Park, Minho and Park, Sunghyun and Choo, Jaegul},
|
| 135 |
+
booktitle={arXiv preprint arxiv:2312.01725},
|
| 136 |
+
year={2023}
|
| 137 |
+
}
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
**Acknowledgements** Sunghyun Park is the corresponding author.
|
| 141 |
+
|
| 142 |
+
## License
|
| 143 |
+
Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
|
assets/method_overview2.png
ADDED
|
assets/teaser.png
ADDED

|
ckpts/.gitkeep
ADDED
|
File without changes
|
ckpts/VITONHD.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d4e44bc58b68f289cd7c1660e06a0db5f6fcb5786c037c9e8217eea45a75688f
|
| 3 |
+
size 10198120487
|
ckpts/VITONHD_PBE_pose.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8615f6c134f3b996ca58de4cb8fa35134b93aa469e8e8811bb2b01655ebc49ca
|
| 3 |
+
size 7355677815
|
ckpts/VITONHD_VAE_finetuning.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:281dc0dbe8b385454de06ed4502c331d483ed3617948841a3f94a21ef0cd988d
|
| 3 |
+
size 789623121
|