
Update README.md
Browse files
README.md
CHANGED
|
@@ -23,9 +23,9 @@ pipeline_tag: text-generation
|
|
| 23 |
|
| 24 |
### Overview:
|
| 25 |
|
| 26 |
-
Lamarck-14B is a carefully designed merge which emphasizes [arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small) in early and finishing layers, and midway features strong influence on reasoning and prose from [CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge) especially, but a
|
| 27 |
|
| 28 |
-
|
| 29 |
|
| 30 |
For GGUFs, [mradermacher/Lamarck-14B-v0.3-i1-GGUF](https://huggingface.co/mradermacher/Lamarck-14B-v0.3-i1-GGUF) has you covered. Thank you @mradermacher!
|
| 31 |
|
|
@@ -38,10 +38,12 @@ For GGUFs, [mradermacher/Lamarck-14B-v0.3-i1-GGUF](https://huggingface.co/mrader
|
|
| 38 |
|
| 39 |
|
| 40 |
|
|
|
|
|
|
|
| 41 |
### Thanks go to:
|
| 42 |
|
| 43 |
- @arcee-ai's team for the ever-capable mergekit, and the exceptional Virtuoso Small model.
|
| 44 |
-
- @CultriX for the helpful examples of memory-efficient sliced merges and evolutionary merging. Their contribution of tinyevals on version 0.1 of Lamarck did much to validate the hypotheses of the process used here.
|
| 45 |
- The authors behind the capable models that appear in the model_stock. The boost to prose quality is already noticeable.
|
| 46 |
|
| 47 |
### Models Merged:
|
|
|
|
| 23 |
|
| 24 |
### Overview:
|
| 25 |
|
| 26 |
+
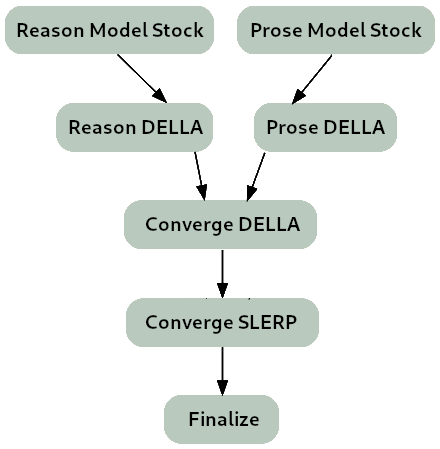
Lamarck-14B is a carefully designed merge which emphasizes [arcee-ai/Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small) in early and finishing layers, and midway features strong influence on reasoning and prose from [CultriX/SeQwence-14B-EvolMerge](http://huggingface.co/CultriX/SeQwence-14B-EvolMerge) especially, but a number of other models as well through its model_stock.
|
| 27 |
|
| 28 |
+
Version 0.3 is the product of a carefully planned and tested sequence of templated merges, produced by a toolchain which wraps around Arcee's mergekit.
|
| 29 |
|
| 30 |
For GGUFs, [mradermacher/Lamarck-14B-v0.3-i1-GGUF](https://huggingface.co/mradermacher/Lamarck-14B-v0.3-i1-GGUF) has you covered. Thank you @mradermacher!
|
| 31 |
|
|
|
|
| 38 |
|
| 39 |

|
| 40 |
|
| 41 |
+
The first two layers come entirely from Virtuoso. The choice to leave these layers untouched comes from [arxiv.org/abs/2307.03172](https://arxiv.org/abs/2307.03172) which identify attention glitches as a chief cause of hallucinations. Layers 3-8 feature a SLERP gradient into introducing the DELLA merge tree.
|
| 42 |
+
|
| 43 |
### Thanks go to:
|
| 44 |
|
| 45 |
- @arcee-ai's team for the ever-capable mergekit, and the exceptional Virtuoso Small model.
|
| 46 |
+
- @CultriX for the helpful examples of memory-efficient sliced merges and evolutionary merging. Their contribution of tinyevals on version 0.1 of Lamarck did much to validate the hypotheses of the DELLA->SLERP gradient process used here.
|
| 47 |
- The authors behind the capable models that appear in the model_stock. The boost to prose quality is already noticeable.
|
| 48 |
|
| 49 |
### Models Merged:
|