
Update README.md
Browse files
README.md
CHANGED
|
@@ -21,10 +21,10 @@ pipeline_tag: text-generation
|
|
| 21 |

|
| 22 |
---
|
| 23 |
|
| 24 |
-
**Update:** Lamarck has, for the moment, taken the [#1 average score](https://shorturl.at/STz7B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) for general text-generation assistant language models underneath 14 billion. Including 32 billion parameter models, as of this writing, it's currently #7. This validates the complex merge techniques which combined the complementary strengths of other work in this community into one model. A little layer analysis goes a long way.
|
| 25 |
-
|
| 26 |
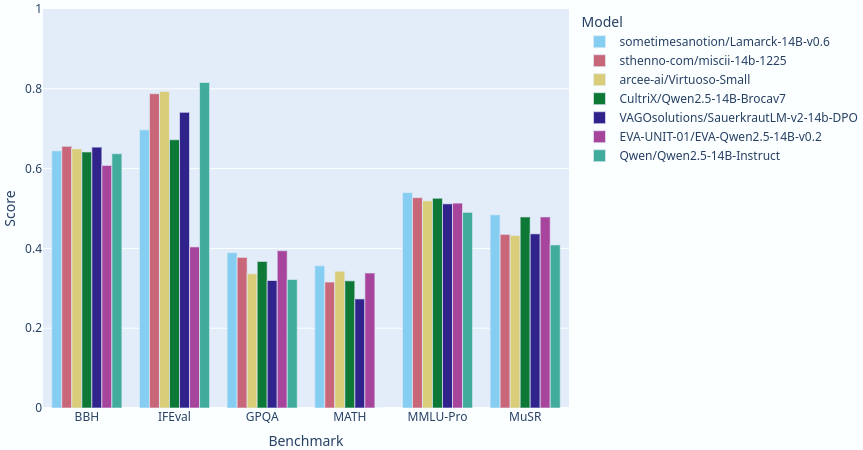
Lamarck 14B v0.6: A generalist merge focused on multi-step reasoning, prose, and multi-language ability. It is based on components that have punched above their weight in the 14 billion parameter class. Here you can see a comparison between Lamarck and other top-performing merges and finetunes:
|
| 27 |
|
|
|
|
|
|
|
| 28 |
|
| 29 |
|
| 30 |
A notable contribution to the middle to upper layers of Lamarck v0.6 comes from [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B). It has a fascinating research paper: [DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought](https://huggingface.co/papers/2412.17498).
|
|
|
|
| 21 |

|
| 22 |
---
|
| 23 |
|
|
|
|
|
|
|
| 24 |
Lamarck 14B v0.6: A generalist merge focused on multi-step reasoning, prose, and multi-language ability. It is based on components that have punched above their weight in the 14 billion parameter class. Here you can see a comparison between Lamarck and other top-performing merges and finetunes:
|
| 25 |
|
| 26 |
+
**Update:** Lamarck has, for the moment, taken the [#1 average score](https://shorturl.at/STz7B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) for general text-generation assistant language models underneath 14 billion. Including 32 billion parameter models, as of this writing, it's currently #10. This validates the complex merge techniques which combined the complementary strengths of other work in this community into one model. A little layer analysis goes a long way.
|
| 27 |
+
|
| 28 |

|
| 29 |
|
| 30 |
A notable contribution to the middle to upper layers of Lamarck v0.6 comes from [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B). It has a fascinating research paper: [DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought](https://huggingface.co/papers/2412.17498).
|