
Update README.md
Browse files
README.md
CHANGED
|
@@ -22,7 +22,7 @@ metrics:
|
|
| 22 |
|
| 23 |
> [!TIP] This version of the model has [broken the 41.0 average](https://shorturl.at/jUqEk) maximum for 14B parameter models, and as of this writing, ranks #8 among models under 70B parameters on the Open LLM Leaderboard. Given the respectable performance in the 32B range, I think Lamarck deserves his shades. A little layer analysis in the 14B range goes a long, long way.
|
| 24 |
|
| 25 |
-
Lamarck 14B v0.7: A generalist merge with emphasis on multi-step reasoning, prose, and multi-language ability. The 14B parameter model has a lot of strong performers, and Lamarck strives to be well-rounded: 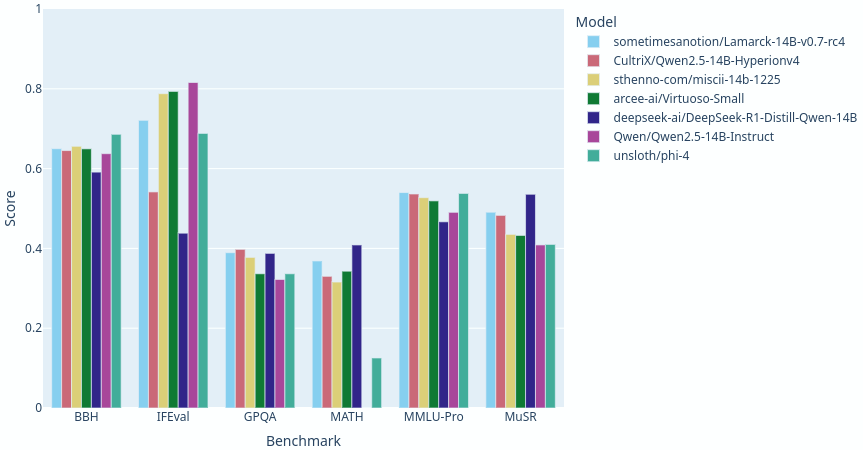
|
| 26 |
|
| 27 |
Lamarck is produced by a custom toolchain to automate a complex sequences of LoRAs and various layer-targeting merges:
|
| 28 |
|
|
@@ -36,4 +36,4 @@ Lamarck's performance comes from an ancestry that goes back through careful merg
|
|
| 36 |
|
| 37 |
More subjectively, its prose and translation abilities are boosted by repeated re-emphasis of [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B) and [underwoods/medius-erebus-magnum-14b](https://huggingface.co/underwoods/medius-erebus-magnum-14b). Other models found in [sometimesanotion/Qwenvergence-14B-v3-Prose](https://huggingface/sometimesanotion/Qwenvergence-14B-v3-Prose) have their impact on prose quality - and surprising synergy of reasoning.
|
| 38 |
|
| 39 |
-
|
|
|
|
| 22 |
|
| 23 |
> [!TIP] This version of the model has [broken the 41.0 average](https://shorturl.at/jUqEk) maximum for 14B parameter models, and as of this writing, ranks #8 among models under 70B parameters on the Open LLM Leaderboard. Given the respectable performance in the 32B range, I think Lamarck deserves his shades. A little layer analysis in the 14B range goes a long, long way.
|
| 24 |
|
| 25 |
+
Lamarck 14B v0.7: A generalist merge with emphasis on multi-step reasoning, prose, and multi-language ability. The 14B parameter model class has a lot of strong performers, and Lamarck strives to be well-rounded and solid: 
|
| 26 |
|
| 27 |
Lamarck is produced by a custom toolchain to automate a complex sequences of LoRAs and various layer-targeting merges:
|
| 28 |
|
|
|
|
| 36 |
|
| 37 |
More subjectively, its prose and translation abilities are boosted by repeated re-emphasis of [Krystalan/DRT-o1-14B](https://huggingface.co/Krystalan/DRT-o1-14B) and [underwoods/medius-erebus-magnum-14b](https://huggingface.co/underwoods/medius-erebus-magnum-14b). Other models found in [sometimesanotion/Qwenvergence-14B-v3-Prose](https://huggingface/sometimesanotion/Qwenvergence-14B-v3-Prose) have their impact on prose quality - and surprising synergy of reasoning.
|
| 38 |
|
| 39 |
+
Kudos to @arcee-ai, @deepseek-ai, @Krystalan, @underwoods, @VAGOSolutions, @CultriX, @sthenno-com, and @rombodawg whose models had the most influence. [Vimarckoso v3](https://huggingface.co/sometimesanotion/Qwen2.5-14B-Vimarckoso-v3) has the model card which documents its extended lineage.
|