Spaces:
Running

Running
Alan Liu
commited on
Commit
•
3698d0a
1
Parent(s):
b9bd641
inference speed
Browse files- .gitignore +1 -0
- .vscode/launch.json +20 -0
- 1019_flexgen_high_throughput_genera.pdf +0 -0
- app.py +180 -0
- asset/cheatsheet.png +0 -0
- calc_util.py +156 -0
- model_util.py +18 -0
- ouyang-aouyang-meng-eecs-2023-thesis.pdf +0 -0
- render_util.py +22 -0
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
**__pycache__**
|
.vscode/launch.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
// Use IntelliSense to learn about possible attributes.
|
| 3 |
+
// Hover to view descriptions of existing attributes.
|
| 4 |
+
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
|
| 5 |
+
"version": "0.2.0",
|
| 6 |
+
"configurations": [
|
| 7 |
+
{
|
| 8 |
+
"name": "streamlit",
|
| 9 |
+
"type": "python",
|
| 10 |
+
"request": "launch",
|
| 11 |
+
"module": "streamlit",
|
| 12 |
+
"console": "integratedTerminal",
|
| 13 |
+
"justMyCode": true,
|
| 14 |
+
"args": [
|
| 15 |
+
"run",
|
| 16 |
+
"app.py"
|
| 17 |
+
]
|
| 18 |
+
}
|
| 19 |
+
]
|
| 20 |
+
}
|
1019_flexgen_high_throughput_genera.pdf
ADDED
|
Binary file (524 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ref: Ouyang, A. (2023). Understanding the Performance of Transformer Inference (Doctoral dissertation, Massachusetts Institute of Technology).
|
| 2 |
+
|
| 3 |
+
import streamlit as st
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from model_util import fetch_dictionary_content, load_parameter
|
| 6 |
+
from calc_util import *
|
| 7 |
+
from render_util import create_table, header4, header5
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
st.set_page_config(layout='wide')
|
| 11 |
+
if 'model_config' not in st.session_state:
|
| 12 |
+
st.session_state['model_config'] = {}
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def load_model_config(model_id):
|
| 16 |
+
if 'model_id' in st.session_state['model_config'] and st.session_state['model_config']['model_id'] == model_id:
|
| 17 |
+
return st.session_state['model_config']
|
| 18 |
+
model_config = {}
|
| 19 |
+
dictionary_content = fetch_dictionary_content(model_id)
|
| 20 |
+
if dictionary_content:
|
| 21 |
+
model_config['model_id'] = model_id
|
| 22 |
+
model_config['hidden_size'] = dictionary_content['hidden_size']
|
| 23 |
+
model_config['num_attention_heads'] = dictionary_content['num_attention_heads']
|
| 24 |
+
model_config['num_hidden_layers'] = dictionary_content['num_hidden_layers']
|
| 25 |
+
model_config['intermediate_size'] = load_parameter(dictionary_content, ['intermediate_size', 'ffn_dim'])
|
| 26 |
+
model_config['vocab_size'] = dictionary_content['vocab_size']
|
| 27 |
+
model_config['max_position_embeddings'] = dictionary_content['max_position_embeddings']
|
| 28 |
+
model_config['layernorm_operation'] = 2
|
| 29 |
+
else:
|
| 30 |
+
st.warning("Model Info is not public!")
|
| 31 |
+
model_config['model_id'] = 'opt-1.3b'
|
| 32 |
+
model_config['hidden_size'] = 2048
|
| 33 |
+
model_config['num_attention_heads'] = 32
|
| 34 |
+
model_config['num_hidden_layers'] = 24
|
| 35 |
+
model_config['intermediate_size'] = 8192
|
| 36 |
+
model_config['vocab_size'] = 50272
|
| 37 |
+
model_config['max_position_embeddings'] = 2048
|
| 38 |
+
model_config['layernorm_operation'] = 2
|
| 39 |
+
|
| 40 |
+
st.session_state['model_config'] = model_config
|
| 41 |
+
return model_config
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
subtotal_parameters = [
|
| 45 |
+
'embedding_weights',
|
| 46 |
+
'attention_weights',
|
| 47 |
+
'mlp_weights',
|
| 48 |
+
'model_total_size'
|
| 49 |
+
]
|
| 50 |
+
|
| 51 |
+
subtotal_operations = [
|
| 52 |
+
'embeddings',
|
| 53 |
+
'attention',
|
| 54 |
+
'mlp',
|
| 55 |
+
'total',
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
col1, col2, col3, col4, col5 = st.columns(5)
|
| 61 |
+
|
| 62 |
+
inference_config = {}
|
| 63 |
+
parameter_count = {}
|
| 64 |
+
cached_parameter_count = {}
|
| 65 |
+
prefilling_operation_count = {}
|
| 66 |
+
generation_operation_count = {}
|
| 67 |
+
gpu_config = {}
|
| 68 |
+
inference_info = {}
|
| 69 |
+
|
| 70 |
+
with col1:
|
| 71 |
+
header4("Model")
|
| 72 |
+
model_id = st.text_input("huggingface model id", 'ArthurZ/opt-13b')
|
| 73 |
+
model_config = load_model_config(model_id)
|
| 74 |
+
model_config['hidden_size'] = st.number_input('hidden size', value=model_config['hidden_size'], format ="%d")
|
| 75 |
+
model_config['num_attention_heads'] = st.number_input('num attention heads', value=model_config['num_attention_heads'], format ="%d")
|
| 76 |
+
model_config['num_hidden_layers'] = st.number_input('num hidden layers', value=model_config['num_hidden_layers'], format ="%d")
|
| 77 |
+
model_config['intermediate_size'] = st.number_input('intermediate size', value=model_config['intermediate_size'], format ="%d")
|
| 78 |
+
model_config['vocab_size'] = st.number_input('vocab size', value= model_config['vocab_size'], format ="%d")
|
| 79 |
+
model_config['max_position_embeddings'] = st.number_input('max position embeddings', value=model_config['max_position_embeddings'], format ="%d")
|
| 80 |
+
|
| 81 |
+
header4("Inference Setting")
|
| 82 |
+
inference_config['batchsize'] = st.number_input('batchsize', value=1, format ="%d")
|
| 83 |
+
inference_config['input_seq_length'] = st.number_input('input seq length', value=1, format ="%d")
|
| 84 |
+
inference_config['output_seq_length'] = st.number_input('output seq length', value=1, format ="%d")
|
| 85 |
+
inference_config['byte_per_parameter'] = st.number_input('byte per parameter', value=2, format ="%d")
|
| 86 |
+
inference_config['KV_cache'] = st.checkbox("Use KV cache", value=True)
|
| 87 |
+
|
| 88 |
+
header4("GPU Setting")
|
| 89 |
+
gpu_config['Name'] = st.text_input('GPU Type', value="A6000")
|
| 90 |
+
gpu_config['TFLOP'] = st.number_input('TFLOP', value=38.7, format ="%2f")
|
| 91 |
+
gpu_config['memory_bandwidth'] = st.number_input('memory bandwidth (GB/s)', value=768, format ="%2d")
|
| 92 |
+
gpu_config['arithmetic_intensity'] = gpu_config['TFLOP']*10**12/gpu_config['memory_bandwidth']/1024**3
|
| 93 |
+
st.write(f"arithmetic_intensity: {gpu_config['arithmetic_intensity']:.3f}")
|
| 94 |
+
|
| 95 |
+
with col2:
|
| 96 |
+
parameter_count['word_embedding'] = model_config['vocab_size']*model_config['hidden_size']
|
| 97 |
+
parameter_count['positional_embedding'] = model_config['max_position_embeddings']*model_config['hidden_size']
|
| 98 |
+
|
| 99 |
+
parameter_count['attention_Q'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['hidden_size']/model_config['num_attention_heads']*model_config['num_attention_heads']
|
| 100 |
+
parameter_count['attention_K'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['hidden_size']/model_config['num_attention_heads']*model_config['num_attention_heads']
|
| 101 |
+
parameter_count['attention_V'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['hidden_size']/model_config['num_attention_heads']*model_config['num_attention_heads']
|
| 102 |
+
parameter_count['attention_out'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['hidden_size']/model_config['num_attention_heads']*model_config['num_attention_heads']
|
| 103 |
+
|
| 104 |
+
parameter_count['layernorm'] = 2*model_config['layernorm_operation']*model_config['num_hidden_layers']*model_config['hidden_size']
|
| 105 |
+
parameter_count['mlp1'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['intermediate_size']
|
| 106 |
+
parameter_count['mlp2'] = model_config['num_hidden_layers']*model_config['hidden_size']*model_config['intermediate_size']
|
| 107 |
+
parameter_count['embedding_weights'] = parameter_count['word_embedding'] + parameter_count['positional_embedding']
|
| 108 |
+
parameter_count['attention_weights'] = parameter_count['attention_out'] + parameter_count['attention_Q'] + parameter_count['attention_K'] + parameter_count['attention_V']
|
| 109 |
+
parameter_count['mlp_weights'] = parameter_count['mlp1'] + parameter_count['mlp2']
|
| 110 |
+
parameter_count['model_total_size'] = inference_config['byte_per_parameter'] * (
|
| 111 |
+
parameter_count['embedding_weights'] +
|
| 112 |
+
parameter_count['attention_weights'] +
|
| 113 |
+
parameter_count['mlp_weights'] +
|
| 114 |
+
parameter_count['layernorm'])
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
parameters_items = {key: "{:,}".format(int(parameter_count[key])) for key in parameter_count if key not in subtotal_parameters}
|
| 119 |
+
subtotal_parameters_items = {key: "{:,}".format(int(parameter_count[key])) for key in parameter_count if key in subtotal_parameters}
|
| 120 |
+
|
| 121 |
+
# Convert dictionaries to pandas dataframes for table display
|
| 122 |
+
df_parameters_items = pd.DataFrame(list(parameters_items.items()), columns=["Parameter", "Count"])
|
| 123 |
+
df_subtotal_parameters_items = pd.DataFrame(list(subtotal_parameters_items.items()), columns=["Parameter", "Count"])
|
| 124 |
+
|
| 125 |
+
header4("Model Parameters")
|
| 126 |
+
st.markdown(create_table(df_parameters_items))
|
| 127 |
+
|
| 128 |
+
header4("Parameters Summary")
|
| 129 |
+
st.markdown(create_table(df_subtotal_parameters_items))
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
with col3: # Prefilling
|
| 133 |
+
prefilling_operation_count = prefilling_operation(model_config, inference_config)
|
| 134 |
+
inference_info['inference_prefilling_time'] = prefilling_operation_count['total'] / (gpu_config['TFLOP']*10**12)
|
| 135 |
+
inference_info['inference_prefilling_throughput'] = inference_config['input_seq_length']/inference_info['inference_prefilling_time']
|
| 136 |
+
cached_parameter_count['kv_cache'] = 2 * (inference_config['batchsize'] * (model_config['hidden_size'] * model_config['num_hidden_layers'] * inference_config['input_seq_length']))
|
| 137 |
+
|
| 138 |
+
operation_items = {key: "{:,}".format(int(prefilling_operation_count[key])) for key in prefilling_operation_count if key not in subtotal_operations}
|
| 139 |
+
subtotal_operation_items = {key: "{:,}".format(int(prefilling_operation_count[key])) for key in prefilling_operation_count if key in subtotal_operations}
|
| 140 |
+
|
| 141 |
+
## Convert dictionaries to pandas dataframes for table display
|
| 142 |
+
df_operation_count = pd.DataFrame(list(operation_items.items()), columns=["Operation", "FLOPS"])
|
| 143 |
+
df_subtotal_operation_count = pd.DataFrame(list(subtotal_operation_items.items()), columns=["Operation", "FLOPS"])
|
| 144 |
+
|
| 145 |
+
header4("Inference Ops: Prefilling")
|
| 146 |
+
st.markdown(create_table(df_operation_count))
|
| 147 |
+
|
| 148 |
+
header5("Summary: Prefilling")
|
| 149 |
+
st.markdown(create_table(df_subtotal_operation_count))
|
| 150 |
+
st.write(f"Prefillng throughput (tokens/s): {inference_info['inference_prefilling_throughput']:.2f}")
|
| 151 |
+
|
| 152 |
+
if inference_config['KV_cache']:
|
| 153 |
+
st.write(f"kv cache (Byte): {cached_parameter_count['kv_cache']:,}")
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
with col4: # Prefilling
|
| 158 |
+
generation_operation_count = generation_operation(model_config, inference_config)
|
| 159 |
+
inference_info['inference_generation_time'] = generation_operation_count['total'] / (gpu_config['TFLOP']*10**12)
|
| 160 |
+
inference_info['inference_generation_throughput'] = inference_config['output_seq_length']/inference_info['inference_generation_time']
|
| 161 |
+
inference_info['inference_client_generation_throughput'] = inference_config['output_seq_length'] / (inference_info['inference_prefilling_time'] + inference_info['inference_generation_time'])
|
| 162 |
+
cached_parameter_count['kv_cache'] = 2 * (inference_config['batchsize'] * (model_config['hidden_size'] * model_config['num_hidden_layers'] * (inference_config['input_seq_length']+inference_config['output_seq_length'])))
|
| 163 |
+
|
| 164 |
+
operation_items = {key: "{:,}".format(int(generation_operation_count[key])) for key in generation_operation_count if key not in subtotal_operations}
|
| 165 |
+
subtotal_operation_items = {key: "{:,}".format(int(generation_operation_count[key])) for key in generation_operation_count if key in subtotal_operations}
|
| 166 |
+
|
| 167 |
+
## Convert dictionaries to pandas dataframes for table display
|
| 168 |
+
df_operation_count = pd.DataFrame(list(operation_items.items()), columns=["Operation", "FLOPS"])
|
| 169 |
+
df_subtotal_operation_count = pd.DataFrame(list(subtotal_operation_items.items()), columns=["Operation", "FLOPS"])
|
| 170 |
+
|
| 171 |
+
header4("Inference Ops: Generation")
|
| 172 |
+
st.markdown(create_table(df_operation_count))
|
| 173 |
+
|
| 174 |
+
header5("Summary: Generation")
|
| 175 |
+
st.markdown(create_table(df_subtotal_operation_count))
|
| 176 |
+
st.write(f"Generation-only throughput (tokens/s): {inference_info['inference_generation_throughput']:.2f}")
|
| 177 |
+
st.write(f"(Client) Generation throughput (tokens/s): {inference_info['inference_client_generation_throughput']:.2f}")
|
| 178 |
+
|
| 179 |
+
if inference_config['KV_cache']:
|
| 180 |
+
st.write(f"kv cache (Byte): {cached_parameter_count['kv_cache']:,}")
|
asset/cheatsheet.png
ADDED
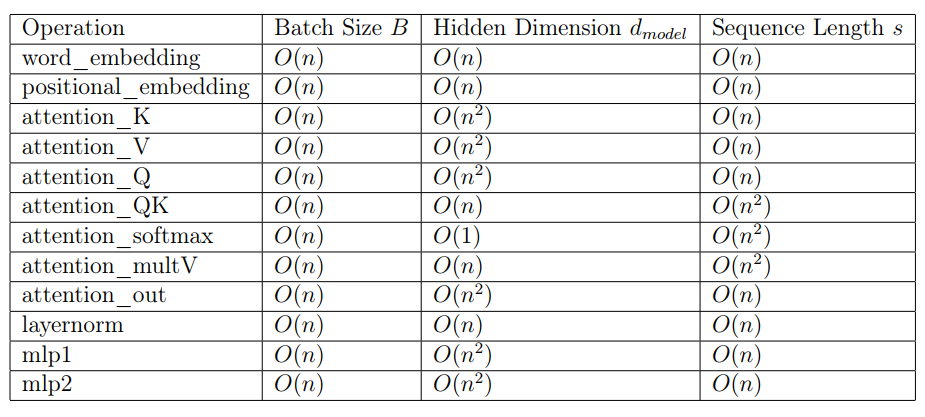
|
calc_util.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def multiplication_in_int64(array):
|
| 5 |
+
return np.cumprod(np.array(array, dtype=np.int64))[-1]
|
| 6 |
+
|
| 7 |
+
def matrix_operation(shapeA, shapeB):
|
| 8 |
+
assert(shapeA[-1] == shapeB[0])
|
| 9 |
+
op = np.cumprod(np.array(shapeA[:-1], np.float64))
|
| 10 |
+
return multiplication_in_int64([2, op[-1], shapeA[-1], shapeB[-1]])
|
| 11 |
+
|
| 12 |
+
def word_embedding_operation(model_config, inference_config):
|
| 13 |
+
#Given:
|
| 14 |
+
#\begin{itemize}
|
| 15 |
+
# \item Matrix \( X \) of size \( B \times s \) (representing the batch size and sequence length respectively).
|
| 16 |
+
# \item Embedding matrix \( W_e \) of size \( n_{vocab} \times d_{model} \).
|
| 17 |
+
#\end{itemize}
|
| 18 |
+
|
| 19 |
+
#The resultant matrix after the multiplication will be of size \( B \times s \times d_{model} \).
|
| 20 |
+
#For each element in this resultant matrix, the number of FLOPs required is \( 2 \times n_{vocab} \). This is because for a single element in the output matrix, we have \( 2N \) FLOPs (with \( N \) being the common dimension), leading to the matrix multiplication FLOP count as:
|
| 21 |
+
#\begin{equation}
|
| 22 |
+
#2 \times B \times s \times n_{vocab} \times d_{model}
|
| 23 |
+
#\end{equation}
|
| 24 |
+
A = [inference_config['batchsize'], inference_config['input_seq_length'], model_config['vocab_size']]
|
| 25 |
+
B = [model_config['vocab_size'], model_config['hidden_size']]
|
| 26 |
+
return matrix_operation(A, B)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def positional_embedding_operation(model_config, inference_config):
|
| 30 |
+
return multiplication_in_int64([inference_config['batchsize'], inference_config['input_seq_length'], model_config['hidden_size']])
|
| 31 |
+
|
| 32 |
+
### Below three are the same
|
| 33 |
+
def attention_K_operation(model_config, inference_config, seq_length):
|
| 34 |
+
A = [inference_config['batchsize'], seq_length, model_config['hidden_size']]
|
| 35 |
+
B = [model_config['hidden_size'], model_config['hidden_size']/model_config['num_attention_heads']]
|
| 36 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads'] * matrix_operation(A, B)
|
| 37 |
+
|
| 38 |
+
def attention_Q_operation(model_config, inference_config, seq_length):
|
| 39 |
+
A = [inference_config['batchsize'], seq_length, model_config['hidden_size']]
|
| 40 |
+
B = [model_config['hidden_size'], model_config['hidden_size']/model_config['num_attention_heads']]
|
| 41 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads'] * matrix_operation(A, B)
|
| 42 |
+
|
| 43 |
+
def attention_V_operation(model_config, inference_config, seq_length):
|
| 44 |
+
A = [inference_config['batchsize'], seq_length, model_config['hidden_size']]
|
| 45 |
+
B = [model_config['hidden_size'], model_config['hidden_size']/model_config['num_attention_heads']]
|
| 46 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads'] * matrix_operation(A, B)
|
| 47 |
+
|
| 48 |
+
##
|
| 49 |
+
def attention_QK_operation(model_config, inference_config, seq_length_Q, seq_length_K):
|
| 50 |
+
A = [inference_config['batchsize'], seq_length_Q, model_config['hidden_size']/model_config['num_attention_heads']]
|
| 51 |
+
B = [model_config['hidden_size']/model_config['num_attention_heads'], seq_length_K]
|
| 52 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads']* matrix_operation(A, B)
|
| 53 |
+
|
| 54 |
+
def attention_softmax_operation(model_config, inference_config,seq_length):
|
| 55 |
+
# Ref: Ouyang, A. (2023). Understanding the Performance of Transformer Inference (Doctoral dissertation, Massachusetts Institute of Technology).
|
| 56 |
+
# 3 is a modeled value
|
| 57 |
+
softmax_operation = (3*inference_config['batchsize']*seq_length*seq_length)
|
| 58 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads'] * softmax_operation
|
| 59 |
+
|
| 60 |
+
def attention_multV_operation(model_config, inference_config, seq_length_Q, seq_length_V):
|
| 61 |
+
A = [inference_config['batchsize'], seq_length_Q, seq_length_V]
|
| 62 |
+
B = [seq_length_V, model_config['hidden_size']/model_config['num_attention_heads']]
|
| 63 |
+
return model_config['num_hidden_layers'] * model_config['num_attention_heads']* matrix_operation(A, B)
|
| 64 |
+
|
| 65 |
+
def attention_out_operation(model_config, inference_config, seq_length):
|
| 66 |
+
A = [inference_config['batchsize'], seq_length, model_config['hidden_size']]
|
| 67 |
+
B = [model_config['hidden_size'], model_config['hidden_size']]
|
| 68 |
+
return model_config['num_hidden_layers'] * matrix_operation(A, B)
|
| 69 |
+
|
| 70 |
+
def layernorm_operation(model_config, inference_config, seq_length):
|
| 71 |
+
# Ref: Ouyang, A. (2023). Understanding the Performance of Transformer Inference (Doctoral dissertation, Massachusetts Institute of Technology).
|
| 72 |
+
# 5 is a modeled value
|
| 73 |
+
layernorm_operation = (5*inference_config['batchsize']*seq_length*model_config['hidden_size'])
|
| 74 |
+
return model_config['num_hidden_layers'] * model_config['layernorm_operation'] * layernorm_operation
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def mlp1_operation(model_config, inference_config, seq_length):
|
| 78 |
+
A = [inference_config['batchsize'], seq_length, model_config['hidden_size']]
|
| 79 |
+
B = [model_config['hidden_size'], model_config['intermediate_size']]
|
| 80 |
+
return model_config['num_hidden_layers'] * matrix_operation(A, B)
|
| 81 |
+
|
| 82 |
+
def mlp2_operation(model_config, inference_config, seq_length):
|
| 83 |
+
A = [inference_config['batchsize'], seq_length, model_config['intermediate_size']]
|
| 84 |
+
B = [model_config['intermediate_size'], model_config['hidden_size']]
|
| 85 |
+
return model_config['num_hidden_layers'] * matrix_operation(A, B)
|
| 86 |
+
|
| 87 |
+
def prefilling_operation(model_config, inference_config):
|
| 88 |
+
prefilling_operation_count = {}
|
| 89 |
+
prefilling_operation_count['word_embedding'] = word_embedding_operation(model_config, inference_config)
|
| 90 |
+
prefilling_operation_count['positional_embedding'] = positional_embedding_operation(model_config, inference_config)
|
| 91 |
+
|
| 92 |
+
prefilling_operation_count['attention_Q'] = attention_Q_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 93 |
+
prefilling_operation_count['attention_K'] = attention_K_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 94 |
+
prefilling_operation_count['attention_V'] = attention_V_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 95 |
+
prefilling_operation_count['attention_QK'] = attention_QK_operation(model_config, inference_config, inference_config['input_seq_length'], inference_config['input_seq_length'])
|
| 96 |
+
prefilling_operation_count['attention_softmax'] = attention_softmax_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 97 |
+
prefilling_operation_count['attention_multV'] = attention_multV_operation(model_config, inference_config, inference_config['input_seq_length'], inference_config['input_seq_length'])
|
| 98 |
+
prefilling_operation_count['attention_out'] = attention_out_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 99 |
+
|
| 100 |
+
prefilling_operation_count['layernorm'] =layernorm_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 101 |
+
|
| 102 |
+
prefilling_operation_count['mlp1'] = mlp1_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 103 |
+
prefilling_operation_count['mlp2'] = mlp2_operation(model_config, inference_config, inference_config['input_seq_length'])
|
| 104 |
+
|
| 105 |
+
prefilling_operation_count['embeddings'] = prefilling_operation_count['word_embedding'] + prefilling_operation_count['positional_embedding']
|
| 106 |
+
prefilling_operation_count['attention'] = sum([v for k,v in prefilling_operation_count.items() if 'attention' in k])
|
| 107 |
+
prefilling_operation_count['mlp'] = prefilling_operation_count['mlp1'] + prefilling_operation_count['mlp2']
|
| 108 |
+
prefilling_operation_count['total'] = (prefilling_operation_count['embeddings'] + prefilling_operation_count['attention'] + prefilling_operation_count['mlp'] + prefilling_operation_count['layernorm'])
|
| 109 |
+
|
| 110 |
+
return prefilling_operation_count
|
| 111 |
+
|
| 112 |
+
def generation_operation(model_config, inference_config):
|
| 113 |
+
generation_operation_count = {}
|
| 114 |
+
generation_operation_count['word_embedding'] = 0
|
| 115 |
+
generation_operation_count['positional_embedding'] = 0
|
| 116 |
+
generation_operation_count['attention_K'] = 0
|
| 117 |
+
generation_operation_count['attention_V'] = 0
|
| 118 |
+
generation_operation_count['attention_Q'] = 0
|
| 119 |
+
generation_operation_count['attention_QK'] = 0
|
| 120 |
+
generation_operation_count['attention_softmax'] = 0
|
| 121 |
+
generation_operation_count['attention_multV'] = 0
|
| 122 |
+
generation_operation_count['attention_out'] = 0
|
| 123 |
+
generation_operation_count['mlp1'] = 0
|
| 124 |
+
generation_operation_count['mlp2'] = 0
|
| 125 |
+
generation_operation_count['layernorm'] = 0
|
| 126 |
+
|
| 127 |
+
for t in range(inference_config['output_seq_length']):
|
| 128 |
+
if inference_config['KV_cache']:
|
| 129 |
+
generation_operation_count['attention_K'] += attention_K_operation(model_config, inference_config, 1)
|
| 130 |
+
generation_operation_count['attention_V'] += attention_V_operation(model_config, inference_config, 1)
|
| 131 |
+
generation_operation_count['attention_Q'] += attention_Q_operation(model_config, inference_config, 1)
|
| 132 |
+
generation_operation_count['attention_QK'] += attention_QK_operation(model_config, inference_config, seq_length_Q=1, seq_length_K=(t+1)+inference_config['input_seq_length'])
|
| 133 |
+
generation_operation_count['attention_softmax'] += attention_softmax_operation(model_config, inference_config, 1)
|
| 134 |
+
generation_operation_count['attention_multV'] += attention_multV_operation(model_config, inference_config, seq_length_Q=1, seq_length_V=(t+1)+inference_config['input_seq_length'])
|
| 135 |
+
generation_operation_count['attention_out'] += attention_out_operation(model_config, inference_config, 1)
|
| 136 |
+
generation_operation_count['mlp1'] += mlp1_operation(model_config, inference_config, 1)
|
| 137 |
+
generation_operation_count['mlp2'] += mlp2_operation(model_config, inference_config, 1)
|
| 138 |
+
else:
|
| 139 |
+
generation_operation_count['attention_K'] += attention_K_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 140 |
+
generation_operation_count['attention_V'] += attention_V_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 141 |
+
generation_operation_count['attention_Q'] += attention_Q_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 142 |
+
generation_operation_count['attention_QK'] += attention_QK_operation(model_config, inference_config, seq_length_Q=(t+1)+inference_config['input_seq_length'], seq_length_K=(t+1)+inference_config['input_seq_length'])
|
| 143 |
+
generation_operation_count['attention_softmax'] += attention_softmax_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 144 |
+
generation_operation_count['attention_multV'] += attention_multV_operation(model_config, inference_config, seq_length_Q=(t+1)+inference_config['input_seq_length'], seq_length_V=(t+1)+inference_config['input_seq_length'])
|
| 145 |
+
generation_operation_count['attention_out'] += attention_out_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 146 |
+
generation_operation_count['mlp1'] += mlp1_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 147 |
+
generation_operation_count['mlp2'] += mlp2_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 148 |
+
|
| 149 |
+
generation_operation_count['layernorm'] += layernorm_operation(model_config, inference_config, (t+1)+inference_config['input_seq_length'])
|
| 150 |
+
|
| 151 |
+
generation_operation_count['embeddings'] = generation_operation_count['word_embedding'] + generation_operation_count['positional_embedding']
|
| 152 |
+
generation_operation_count['attention'] = sum([v for k,v in generation_operation_count.items() if 'attention' in k])
|
| 153 |
+
generation_operation_count['mlp'] = generation_operation_count['mlp1'] + generation_operation_count['mlp2']
|
| 154 |
+
generation_operation_count['total'] = (generation_operation_count['attention'] + generation_operation_count['mlp'] + generation_operation_count['layernorm'])
|
| 155 |
+
|
| 156 |
+
return generation_operation_count
|
model_util.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def fetch_dictionary_content(model_id):
|
| 5 |
+
MODEL_URL = "https://huggingface.co/{model_id}/raw/main/config.json"
|
| 6 |
+
response = requests.get(MODEL_URL.format(model_id=model_id))
|
| 7 |
+
|
| 8 |
+
# Check if the request was successful
|
| 9 |
+
if response.status_code == 200:
|
| 10 |
+
return response.json() # Parse the JSON content into a Python dictionary
|
| 11 |
+
else:
|
| 12 |
+
return None
|
| 13 |
+
|
| 14 |
+
def load_parameter(model_dict, cand_keys):
|
| 15 |
+
for k in cand_keys:
|
| 16 |
+
if k in model_dict:
|
| 17 |
+
return model_dict[k]
|
| 18 |
+
return 0
|
ouyang-aouyang-meng-eecs-2023-thesis.pdf
ADDED
|
Binary file (705 kB). View file
|
|
|
render_util.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
def create_table(df):
|
| 4 |
+
# Table header based on df columns
|
| 5 |
+
header = "| " + " | ".join(df.columns) + " |"
|
| 6 |
+
# Number of columns in df to set table divider accordingly
|
| 7 |
+
divider = "|:---" * len(df.columns[:-1]) + "|-----:|"
|
| 8 |
+
rows = [header, divider]
|
| 9 |
+
|
| 10 |
+
for _, row in df.iterrows():
|
| 11 |
+
rows.append("| " + " | ".join(row.astype(str)) + " |")
|
| 12 |
+
|
| 13 |
+
return "\n".join(rows)
|
| 14 |
+
|
| 15 |
+
def header3(text):
|
| 16 |
+
st.markdown(f"### {text}")
|
| 17 |
+
|
| 18 |
+
def header4(text):
|
| 19 |
+
st.markdown(f"#### {text}")
|
| 20 |
+
|
| 21 |
+
def header5(text):
|
| 22 |
+
st.markdown(f"##### {text}")
|