Spaces:
Build error

Build error
first commit
Browse files- README 2.md +117 -0
- README.md +1 -1
- __init__.py +0 -0
- __pycache__/embeddings.cpython-310.pyc +0 -0
- __pycache__/prompts.cpython-310.pyc +0 -0
- __pycache__/utils.cpython-310.pyc +0 -0
- app.py +116 -0
- embeddings.py +115 -0
- prompts.py +26 -0
- requirements.txt +10 -0
- utils.py +167 -0
README 2.md
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align="center">
|
| 2 |
+
FileGPT 🤖
|
| 3 |
+
</h1>
|
| 4 |
+
|
| 5 |
+
Read the article to know how it works: <a href="">Medium Article</a>
|
| 6 |
+
|
| 7 |
+
With File GPT you will be able to extract all the information from a file.
|
| 8 |
+
You will obtain the transcription, the embedding of each segment and also ask questions to the file through a chat.
|
| 9 |
+
|
| 10 |
+
All code was written with the help of <a href="https://codegpt.co">Code GPT</a>
|
| 11 |
+
|
| 12 |
+
<a href="https://codegpt.co" target="_blank"><img width="753" alt="Captura de Pantalla 2023-02-08 a la(s) 9 16 43 p m" src="https://user-images.githubusercontent.com/6216945/217699939-eca3ae47-c488-44da-9cf6-c7caef69e1a7.png"></a>
|
| 13 |
+
|
| 14 |
+
<hr>
|
| 15 |
+
<br>
|
| 16 |
+
|
| 17 |
+
# Features
|
| 18 |
+
|
| 19 |
+
- Read any pdf, docx, txt or csv file
|
| 20 |
+
- Embedding texts segments with Langchain and OpenAI (**text-embedding-ada-002**)
|
| 21 |
+
- Chat with the file using **streamlit-chat** and LangChain QA with source and (**text-davinci-003**)
|
| 22 |
+
|
| 23 |
+
# Example
|
| 24 |
+
For this example we are going to use this video from The PyCoach
|
| 25 |
+
https://youtu.be/lKO3qDLCAnk
|
| 26 |
+
|
| 27 |
+
Add the video URL and then click Start Analysis
|
| 28 |
+
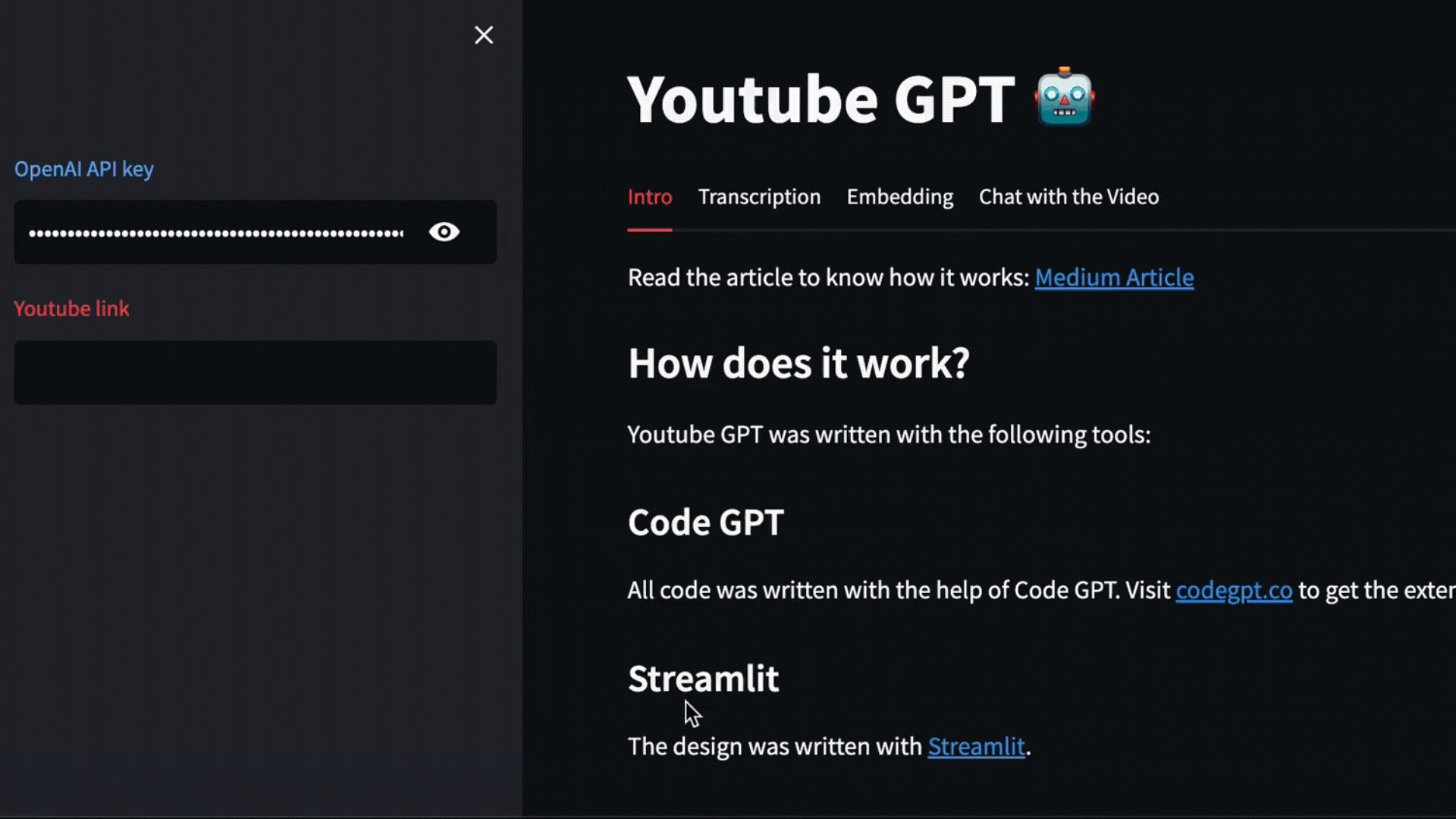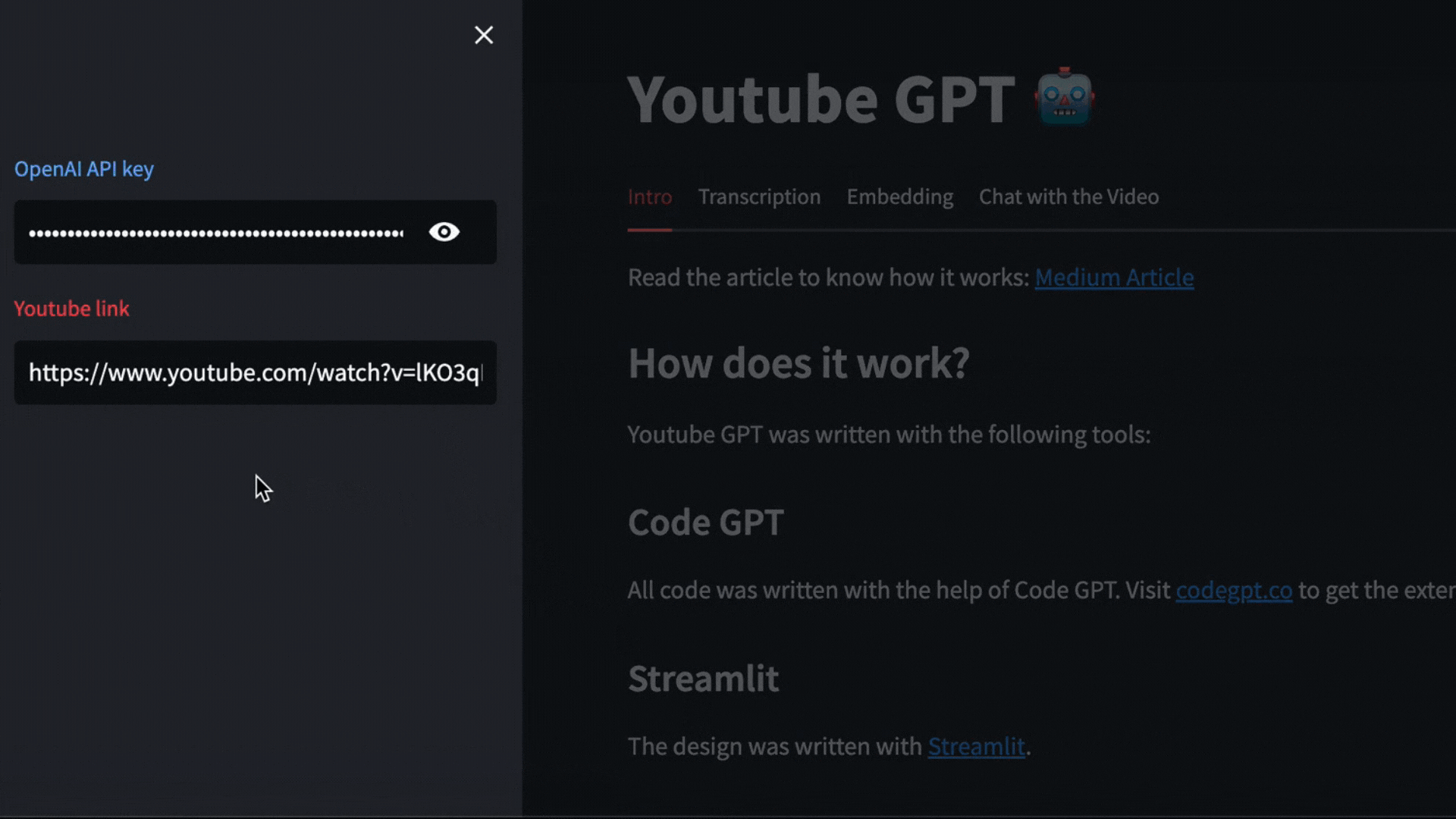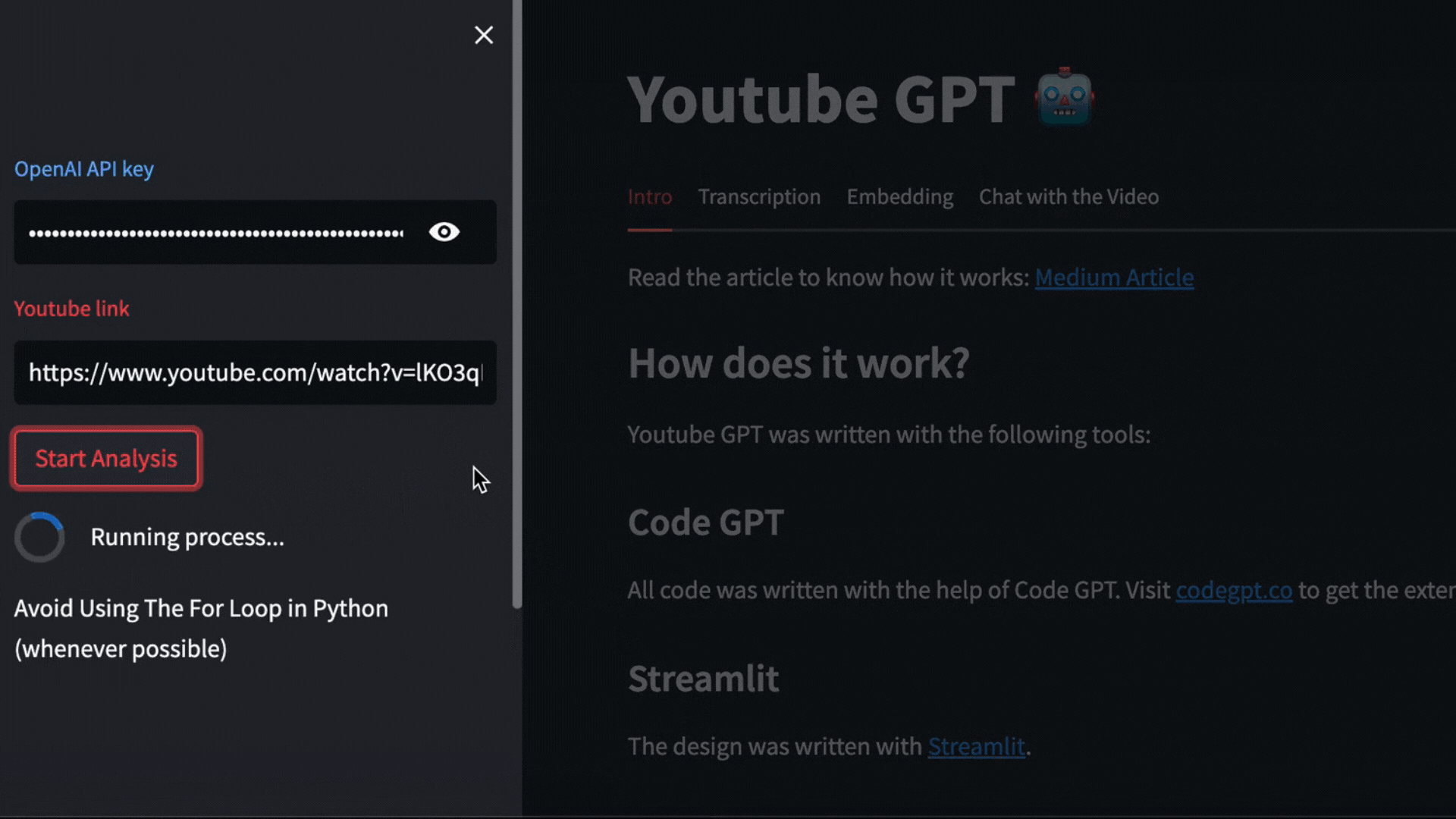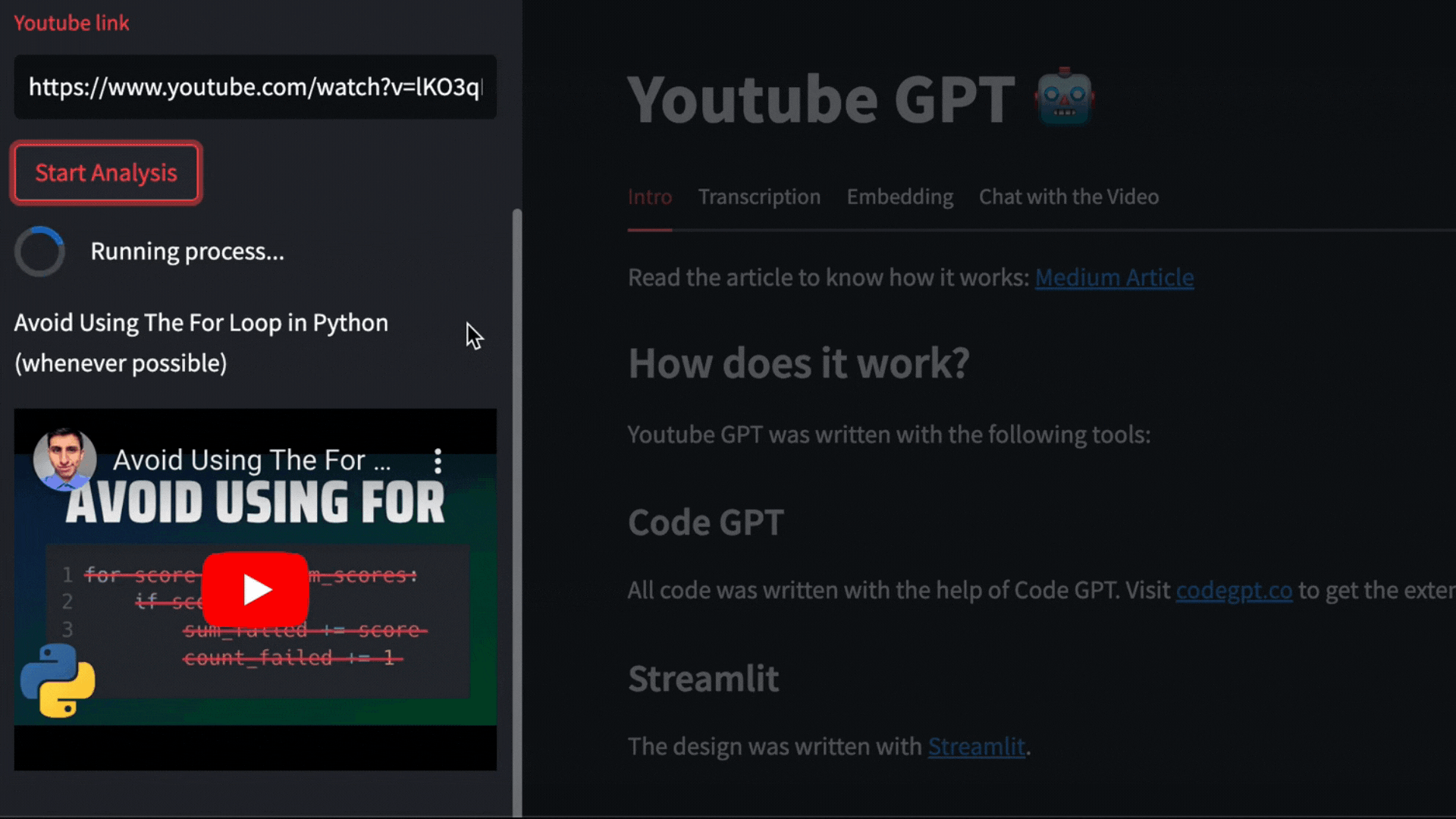
|
| 29 |
+
|
| 30 |
+
## Pytube and OpenAI Whisper
|
| 31 |
+
The video will be downloaded with pytube and then OpenAI Whisper will take care of transcribing and segmenting the video.
|
| 32 |
+
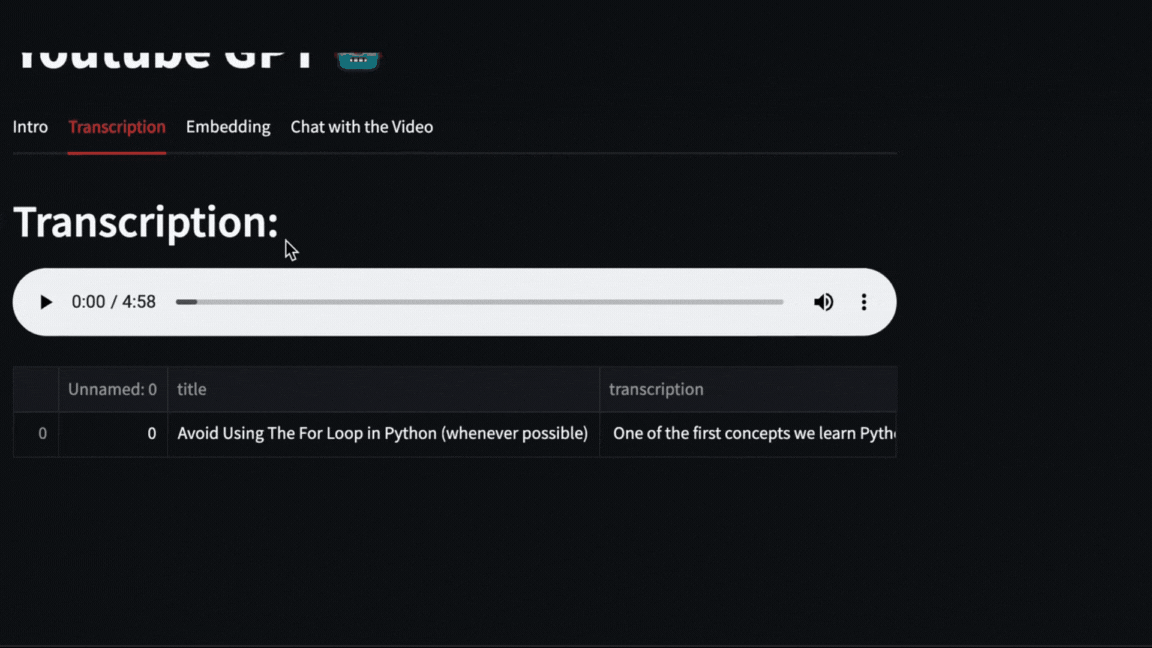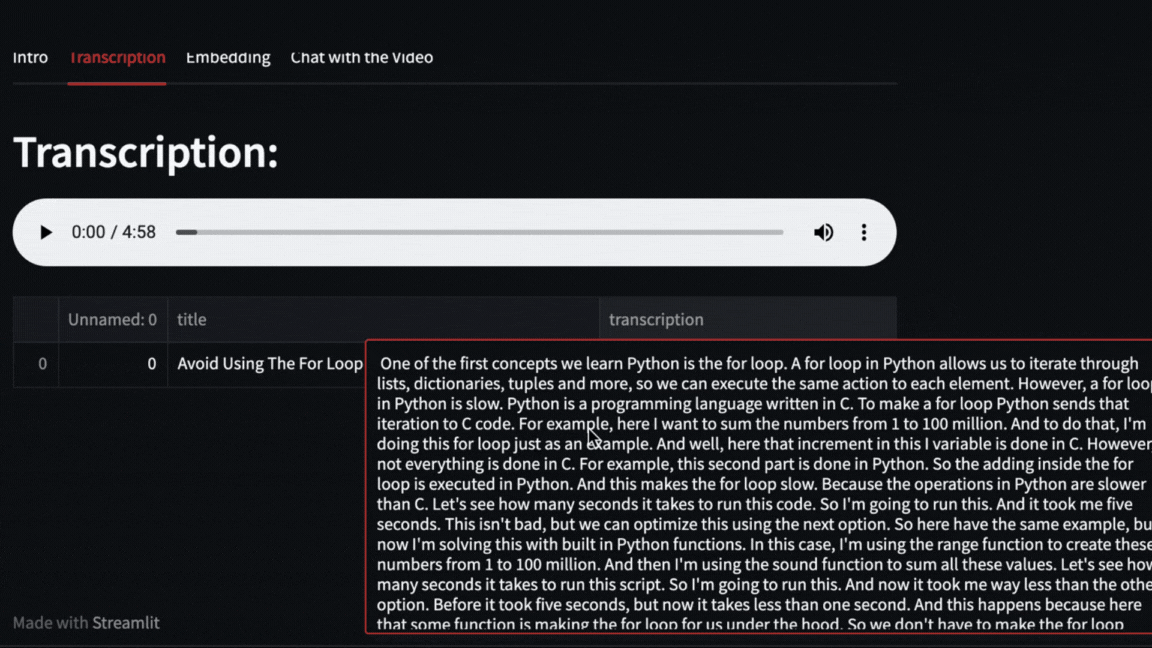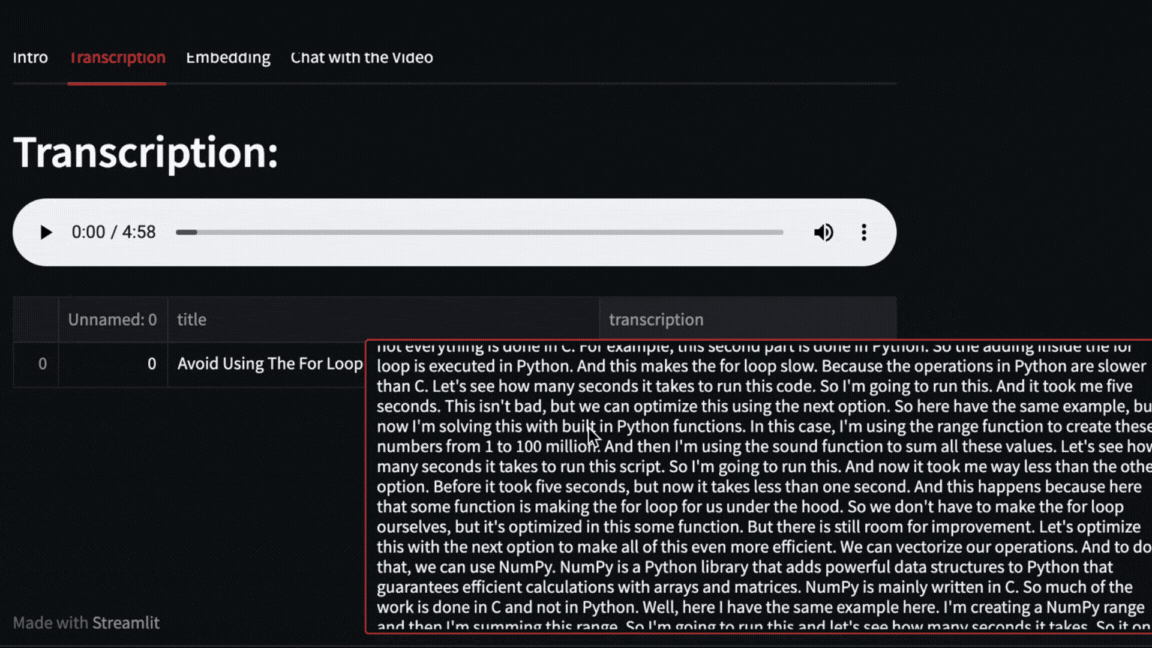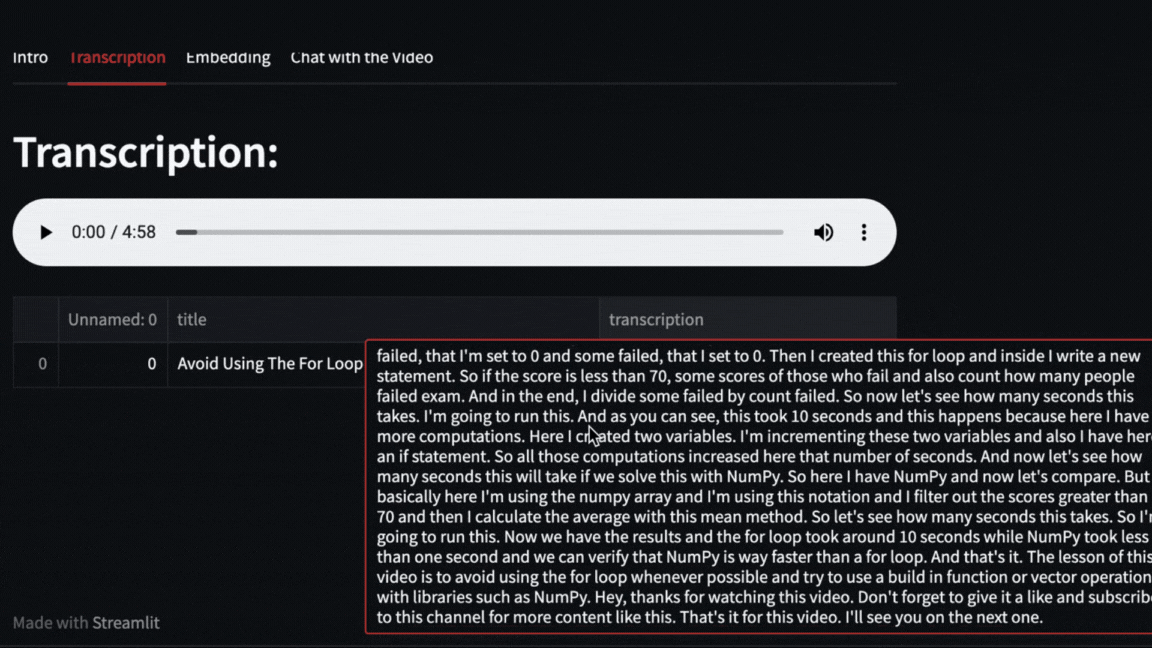
|
| 33 |
+
|
| 34 |
+
```python
|
| 35 |
+
# Get the video
|
| 36 |
+
youtube_video = YouTube(youtube_link)
|
| 37 |
+
streams = youtube_video.streams.filter(only_audio=True)
|
| 38 |
+
mp4_video = stream.download(filename='youtube_video.mp4')
|
| 39 |
+
audio_file = open(mp4_video, 'rb')
|
| 40 |
+
|
| 41 |
+
# whisper load base model
|
| 42 |
+
model = whisper.load_model('base')
|
| 43 |
+
|
| 44 |
+
# Whisper transcription
|
| 45 |
+
output = model.transcribe("youtube_video.mp4")
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
## Embedding with "text-embedding-ada-002"
|
| 49 |
+
We obtain the vectors with **text-embedding-ada-002** of each segment delivered by whisper
|
| 50 |
+
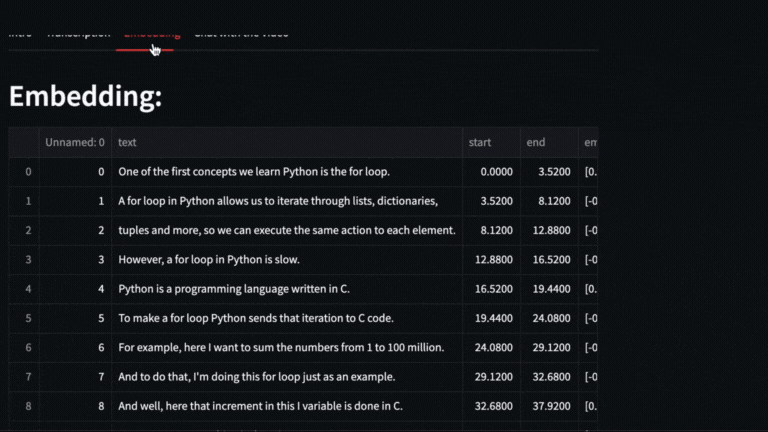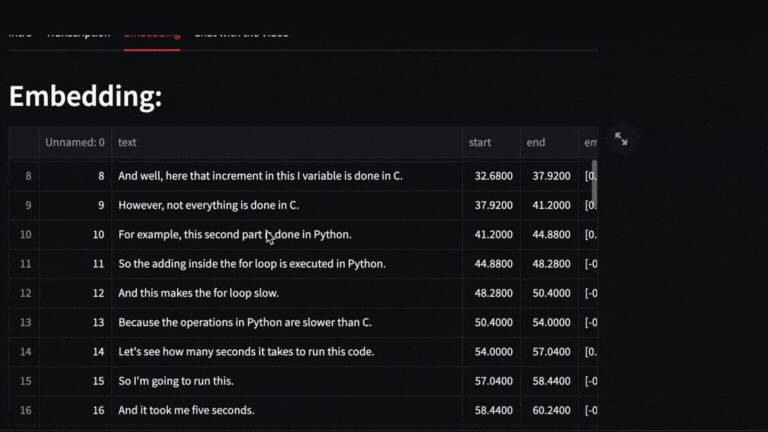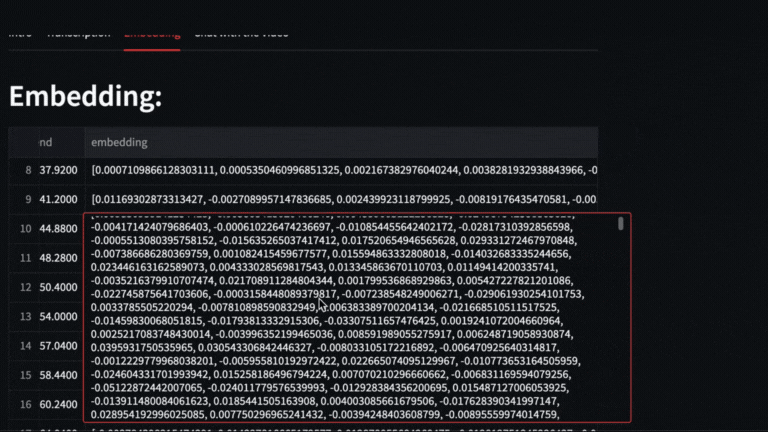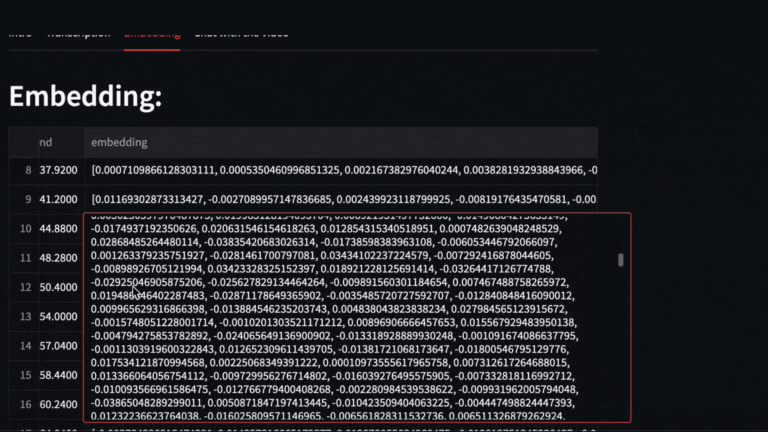
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
# Embeddings
|
| 54 |
+
segments = output['segments']
|
| 55 |
+
for segment in segments:
|
| 56 |
+
openai.api_key = user_secret
|
| 57 |
+
response = openai.Embedding.create(
|
| 58 |
+
input= segment["text"].strip(),
|
| 59 |
+
model="text-embedding-ada-002"
|
| 60 |
+
)
|
| 61 |
+
embeddings = response['data'][0]['embedding']
|
| 62 |
+
meta = {
|
| 63 |
+
"text": segment["text"].strip(),
|
| 64 |
+
"start": segment['start'],
|
| 65 |
+
"end": segment['end'],
|
| 66 |
+
"embedding": embeddings
|
| 67 |
+
}
|
| 68 |
+
data.append(meta)
|
| 69 |
+
pd.DataFrame(data).to_csv('word_embeddings.csv')
|
| 70 |
+
```
|
| 71 |
+
## OpenAI GPT-3
|
| 72 |
+
We make a question to the vectorized text, we do the search of the context and then we send the prompt with the context to the model "text-davinci-003"
|
| 73 |
+
|
| 74 |
+
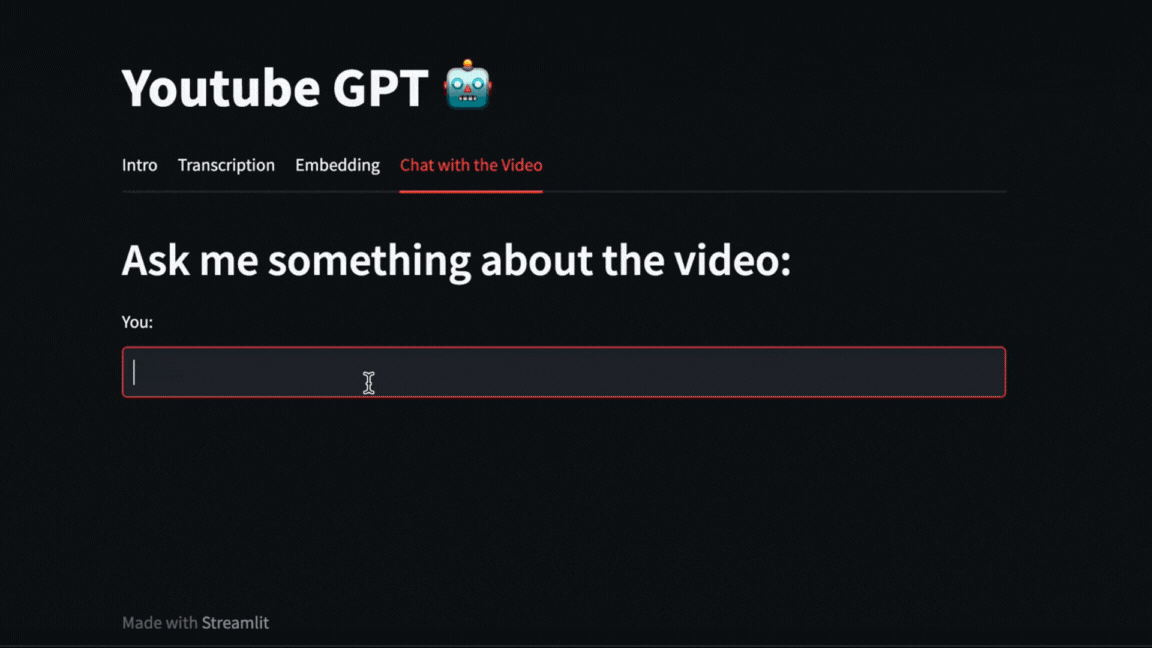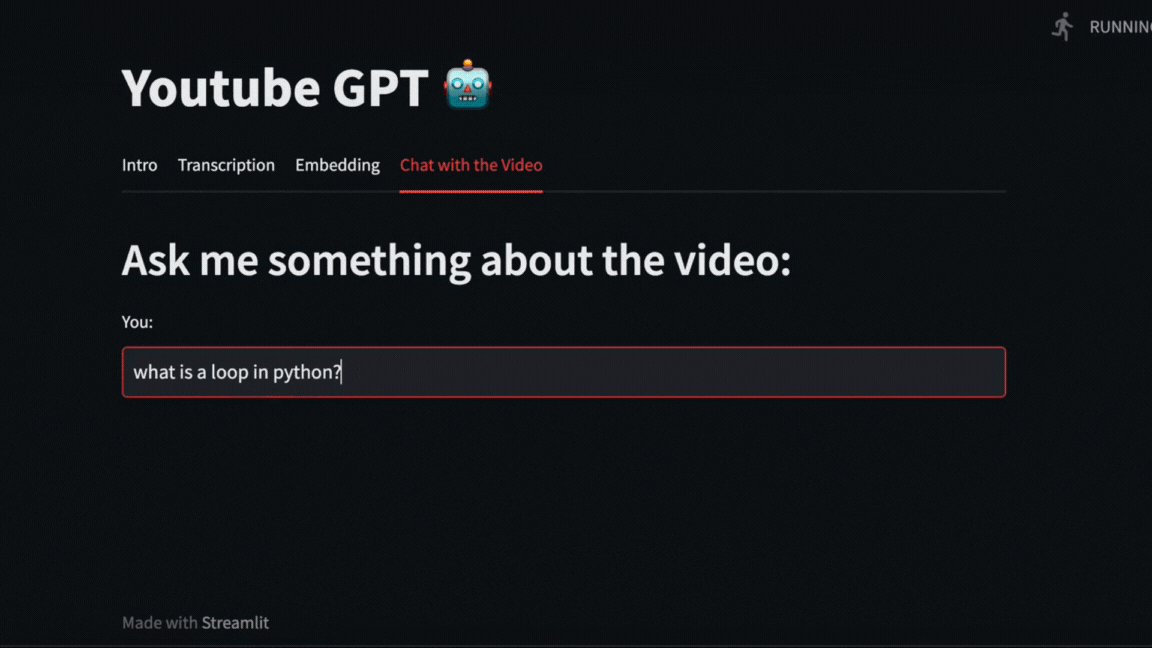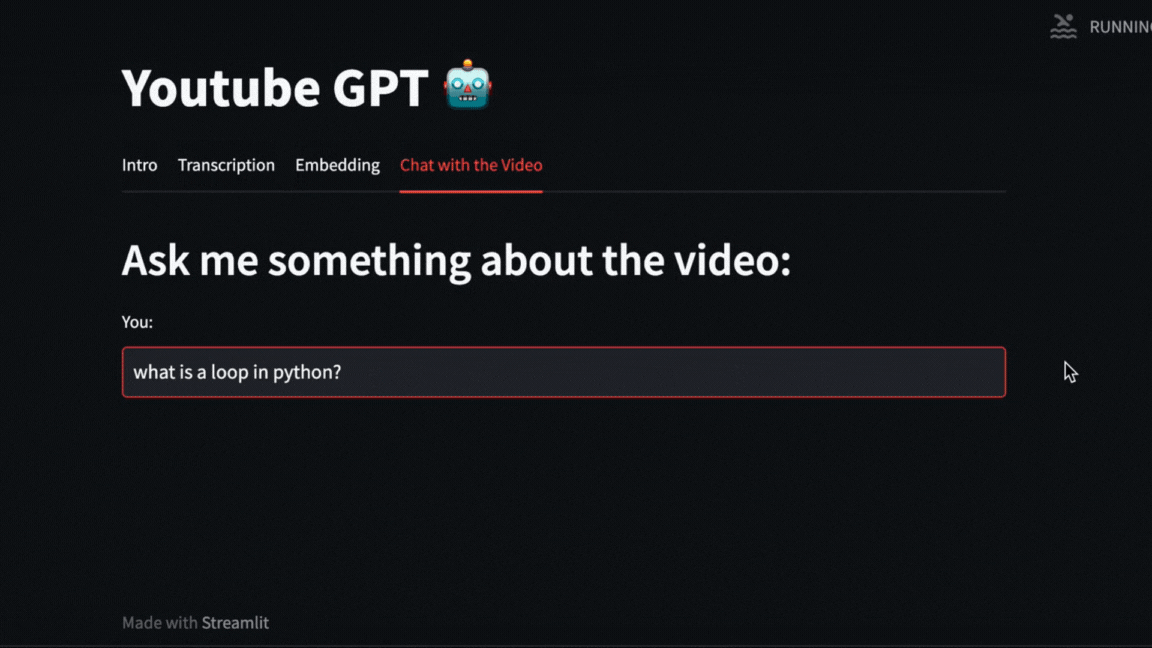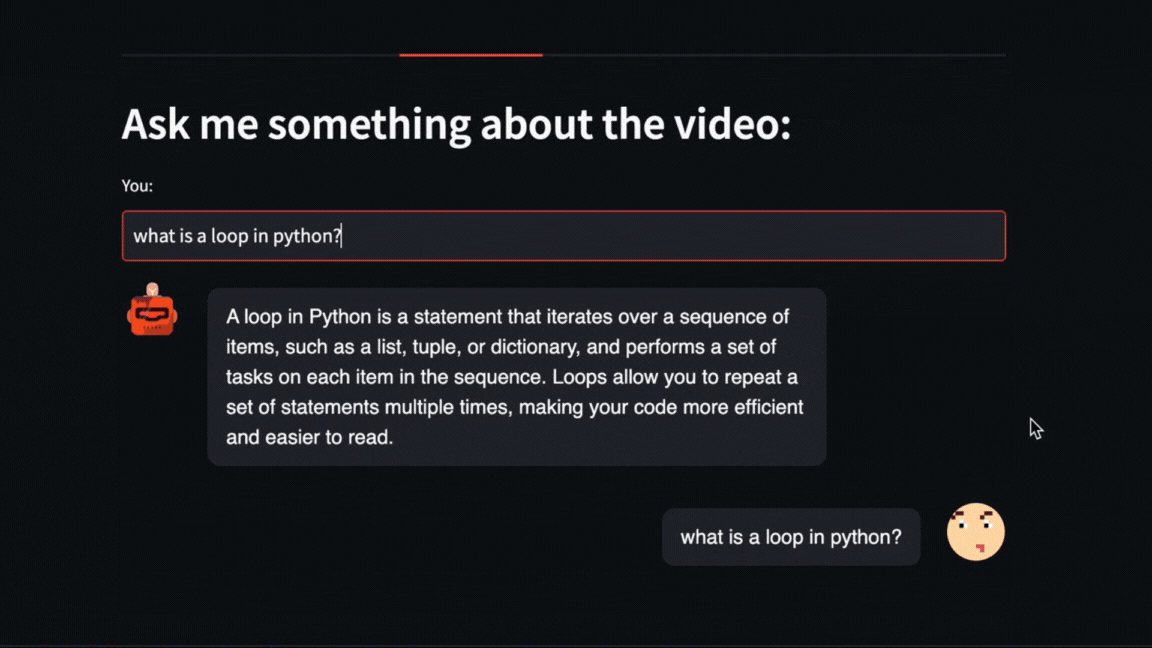
|
| 75 |
+
|
| 76 |
+
We can even ask direct questions about what happened in the video. For example, here we ask about how long the exercise with Numpy that Pycoach did in the video took.
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
# Running Locally
|
| 81 |
+
|
| 82 |
+
1. Clone the repository
|
| 83 |
+
|
| 84 |
+
```bash
|
| 85 |
+
git clone https://github.com/davila7/youtube-gpt
|
| 86 |
+
cd youtube-gpt
|
| 87 |
+
```
|
| 88 |
+
2. Install dependencies
|
| 89 |
+
|
| 90 |
+
These dependencies are required to install with the requirements.txt file:
|
| 91 |
+
|
| 92 |
+
* streamlit
|
| 93 |
+
* streamlit_chat
|
| 94 |
+
* matplotlib
|
| 95 |
+
* plotly
|
| 96 |
+
* scipy
|
| 97 |
+
* sklearn
|
| 98 |
+
* pandas
|
| 99 |
+
* numpy
|
| 100 |
+
* git+https://github.com/openai/whisper.git
|
| 101 |
+
* pytube
|
| 102 |
+
* openai-whisper
|
| 103 |
+
|
| 104 |
+
```bash
|
| 105 |
+
pip install -r requirements.txt
|
| 106 |
+
```
|
| 107 |
+
3. Run the Streamlit server
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
streamlit run app.py
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
## Upcoming Features 🚀
|
| 114 |
+
|
| 115 |
+
- Semantic search with embedding
|
| 116 |
+
- Chart with emotional analysis
|
| 117 |
+
- Connect with Pinecone
|
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🐢
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: green
|
|
|
|
| 1 |
---
|
| 2 |
+
title: FileGPT
|
| 3 |
emoji: 🐢
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: green
|
__init__.py
ADDED
|
File without changes
|
__pycache__/embeddings.cpython-310.pyc
ADDED
|
Binary file (4.42 kB). View file
|
|
|
__pycache__/prompts.cpython-310.pyc
ADDED
|
Binary file (2.19 kB). View file
|
|
|
__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (5.02 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_chat import message
|
| 3 |
+
import os
|
| 4 |
+
from utils import (
|
| 5 |
+
parse_docx,
|
| 6 |
+
parse_pdf,
|
| 7 |
+
parse_txt,
|
| 8 |
+
parse_csv,
|
| 9 |
+
search_docs,
|
| 10 |
+
embed_docs,
|
| 11 |
+
text_to_docs,
|
| 12 |
+
get_answer,
|
| 13 |
+
get_sources,
|
| 14 |
+
wrap_text_in_html,
|
| 15 |
+
)
|
| 16 |
+
from openai.error import OpenAIError
|
| 17 |
+
|
| 18 |
+
def clear_submit():
|
| 19 |
+
st.session_state["submit"] = False
|
| 20 |
+
|
| 21 |
+
def set_openai_api_key(api_key: str):
|
| 22 |
+
st.session_state["OPENAI_API_KEY"] = api_key
|
| 23 |
+
|
| 24 |
+
st.markdown('<h1>File GPT 🤖<small> by <a href="https://codegpt.co">Code GPT</a></small></h1>', unsafe_allow_html=True)
|
| 25 |
+
|
| 26 |
+
# Sidebar
|
| 27 |
+
index = None
|
| 28 |
+
doc = None
|
| 29 |
+
with st.sidebar:
|
| 30 |
+
user_secret = st.text_input(
|
| 31 |
+
"OpenAI API Key",
|
| 32 |
+
type="password",
|
| 33 |
+
placeholder="Paste your OpenAI API key here (sk-...)",
|
| 34 |
+
help="You can get your API key from https://platform.openai.com/account/api-keys.",
|
| 35 |
+
value=st.session_state.get("OPENAI_API_KEY", ""),
|
| 36 |
+
)
|
| 37 |
+
if user_secret:
|
| 38 |
+
set_openai_api_key(user_secret)
|
| 39 |
+
|
| 40 |
+
uploaded_file = st.file_uploader(
|
| 41 |
+
"Upload a pdf, docx, or txt file",
|
| 42 |
+
type=["pdf", "docx", "txt", "csv"],
|
| 43 |
+
help="Scanned documents are not supported yet!",
|
| 44 |
+
on_change=clear_submit,
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
if uploaded_file is not None:
|
| 48 |
+
if uploaded_file.name.endswith(".pdf"):
|
| 49 |
+
doc = parse_pdf(uploaded_file)
|
| 50 |
+
elif uploaded_file.name.endswith(".docx"):
|
| 51 |
+
doc = parse_docx(uploaded_file)
|
| 52 |
+
elif uploaded_file.name.endswith(".csv"):
|
| 53 |
+
doc = parse_csv(uploaded_file)
|
| 54 |
+
elif uploaded_file.name.endswith(".txt"):
|
| 55 |
+
doc = parse_txt(uploaded_file)
|
| 56 |
+
else:
|
| 57 |
+
st.error("File type not supported")
|
| 58 |
+
doc = None
|
| 59 |
+
text = text_to_docs(doc)
|
| 60 |
+
try:
|
| 61 |
+
with st.spinner("Indexing document... This may take a while⏳"):
|
| 62 |
+
index = embed_docs(text)
|
| 63 |
+
st.session_state["api_key_configured"] = True
|
| 64 |
+
except OpenAIError as e:
|
| 65 |
+
st.error(e._message)
|
| 66 |
+
|
| 67 |
+
tab1, tab2 = st.tabs(["Intro", "Chat with the File"])
|
| 68 |
+
with tab1:
|
| 69 |
+
st.markdown("### How does it work?")
|
| 70 |
+
st.markdown('Read the article to know how it works: [Medium Article]("https://medium.com/@dan.avila7")')
|
| 71 |
+
st.write("File GPT was written with the following tools:")
|
| 72 |
+
st.markdown("#### Code GPT")
|
| 73 |
+
st.write("All code was written with the help of Code GPT. Visit [codegpt.co]('https://codegpt.co') to get the extension.")
|
| 74 |
+
st.markdown("#### Streamlit")
|
| 75 |
+
st.write("The design was written with [Streamlit]('https://streamlit.io/').")
|
| 76 |
+
st.markdown("#### LangChain")
|
| 77 |
+
st.write("Question answering with source [Langchain QA]('https://langchain.readthedocs.io/en/latest/use_cases/question_answering.html#adding-in-sources').")
|
| 78 |
+
st.markdown("#### Embedding")
|
| 79 |
+
st.write('[Embedding]("https://platform.openai.com/docs/guides/embeddings") is done via the OpenAI API with "text-embedding-ada-002"')
|
| 80 |
+
st.markdown("""---""")
|
| 81 |
+
st.write('Author: [Daniel Ávila](https://www.linkedin.com/in/daniel-avila-arias/)')
|
| 82 |
+
st.write('Repo: [Github](https://github.com/davila7/file-gpt)')
|
| 83 |
+
st.write("This software was developed with Code GPT, for more information visit: https://codegpt.co")
|
| 84 |
+
|
| 85 |
+
with tab2:
|
| 86 |
+
st.write('To obtain an API Key you must create an OpenAI account at the following link: https://openai.com/api/')
|
| 87 |
+
if 'generated' not in st.session_state:
|
| 88 |
+
st.session_state['generated'] = []
|
| 89 |
+
|
| 90 |
+
if 'past' not in st.session_state:
|
| 91 |
+
st.session_state['past'] = []
|
| 92 |
+
|
| 93 |
+
def get_text():
|
| 94 |
+
if user_secret:
|
| 95 |
+
st.header("Ask me something about the document:")
|
| 96 |
+
input_text = st.text_area("You:", on_change=clear_submit)
|
| 97 |
+
return input_text
|
| 98 |
+
user_input = get_text()
|
| 99 |
+
|
| 100 |
+
button = st.button("Submit")
|
| 101 |
+
if button or st.session_state.get("submit"):
|
| 102 |
+
if not user_input:
|
| 103 |
+
st.error("Please enter a question!")
|
| 104 |
+
else:
|
| 105 |
+
st.session_state["submit"] = True
|
| 106 |
+
sources = search_docs(index, user_input)
|
| 107 |
+
try:
|
| 108 |
+
answer = get_answer(sources, user_input)
|
| 109 |
+
st.session_state.past.append(user_input)
|
| 110 |
+
st.session_state.generated.append(answer["output_text"].split("SOURCES: ")[0])
|
| 111 |
+
except OpenAIError as e:
|
| 112 |
+
st.error(e._message)
|
| 113 |
+
if st.session_state['generated']:
|
| 114 |
+
for i in range(len(st.session_state['generated'])-1, -1, -1):
|
| 115 |
+
message(st.session_state["generated"][i], key=str(i))
|
| 116 |
+
message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
|
embeddings.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Wrapper around OpenAI embedding models."""
|
| 2 |
+
from typing import Any, Dict, List, Optional
|
| 3 |
+
|
| 4 |
+
from pydantic import BaseModel, Extra, root_validator
|
| 5 |
+
|
| 6 |
+
from langchain.embeddings.base import Embeddings
|
| 7 |
+
from langchain.utils import get_from_dict_or_env
|
| 8 |
+
|
| 9 |
+
from tenacity import (
|
| 10 |
+
retry,
|
| 11 |
+
retry_if_exception_type,
|
| 12 |
+
stop_after_attempt,
|
| 13 |
+
wait_exponential,
|
| 14 |
+
)
|
| 15 |
+
from openai.error import Timeout, APIError, APIConnectionError, RateLimitError
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class OpenAIEmbeddings(BaseModel, Embeddings):
|
| 19 |
+
"""Wrapper around OpenAI embedding models.
|
| 20 |
+
To use, you should have the ``openai`` python package installed, and the
|
| 21 |
+
environment variable ``OPENAI_API_KEY`` set with your API key or pass it
|
| 22 |
+
as a named parameter to the constructor.
|
| 23 |
+
Example:
|
| 24 |
+
.. code-block:: python
|
| 25 |
+
from langchain.embeddings import OpenAIEmbeddings
|
| 26 |
+
openai = OpenAIEmbeddings(openai_api_key="my-api-key")
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
client: Any #: :meta private:
|
| 30 |
+
document_model_name: str = "text-embedding-ada-002"
|
| 31 |
+
query_model_name: str = "text-embedding-ada-002"
|
| 32 |
+
openai_api_key: Optional[str] = None
|
| 33 |
+
|
| 34 |
+
class Config:
|
| 35 |
+
"""Configuration for this pydantic object."""
|
| 36 |
+
|
| 37 |
+
extra = Extra.forbid
|
| 38 |
+
|
| 39 |
+
# TODO: deprecate this
|
| 40 |
+
@root_validator(pre=True, allow_reuse=True)
|
| 41 |
+
def get_model_names(cls, values: Dict) -> Dict:
|
| 42 |
+
"""Get model names from just old model name."""
|
| 43 |
+
if "model_name" in values:
|
| 44 |
+
if "document_model_name" in values:
|
| 45 |
+
raise ValueError(
|
| 46 |
+
"Both `model_name` and `document_model_name` were provided, "
|
| 47 |
+
"but only one should be."
|
| 48 |
+
)
|
| 49 |
+
if "query_model_name" in values:
|
| 50 |
+
raise ValueError(
|
| 51 |
+
"Both `model_name` and `query_model_name` were provided, "
|
| 52 |
+
"but only one should be."
|
| 53 |
+
)
|
| 54 |
+
model_name = values.pop("model_name")
|
| 55 |
+
values["document_model_name"] = f"text-search-{model_name}-doc-001"
|
| 56 |
+
values["query_model_name"] = f"text-search-{model_name}-query-001"
|
| 57 |
+
return values
|
| 58 |
+
|
| 59 |
+
@root_validator(allow_reuse=True)
|
| 60 |
+
def validate_environment(cls, values: Dict) -> Dict:
|
| 61 |
+
"""Validate that api key and python package exists in environment."""
|
| 62 |
+
openai_api_key = get_from_dict_or_env(
|
| 63 |
+
values, "openai_api_key", "OPENAI_API_KEY"
|
| 64 |
+
)
|
| 65 |
+
try:
|
| 66 |
+
import openai
|
| 67 |
+
|
| 68 |
+
openai.api_key = openai_api_key
|
| 69 |
+
values["client"] = openai.Embedding
|
| 70 |
+
except ImportError:
|
| 71 |
+
raise ValueError(
|
| 72 |
+
"Could not import openai python package. "
|
| 73 |
+
"Please it install it with `pip install openai`."
|
| 74 |
+
)
|
| 75 |
+
return values
|
| 76 |
+
|
| 77 |
+
@retry(
|
| 78 |
+
reraise=True,
|
| 79 |
+
stop=stop_after_attempt(100),
|
| 80 |
+
wait=wait_exponential(multiplier=1, min=10, max=60),
|
| 81 |
+
retry=(
|
| 82 |
+
retry_if_exception_type(Timeout)
|
| 83 |
+
| retry_if_exception_type(APIError)
|
| 84 |
+
| retry_if_exception_type(APIConnectionError)
|
| 85 |
+
| retry_if_exception_type(RateLimitError)
|
| 86 |
+
),
|
| 87 |
+
)
|
| 88 |
+
def _embedding_func(self, text: str, *, engine: str) -> List[float]:
|
| 89 |
+
"""Call out to OpenAI's embedding endpoint with exponential backoff."""
|
| 90 |
+
# replace newlines, which can negatively affect performance.
|
| 91 |
+
text = text.replace("\n", " ")
|
| 92 |
+
return self.client.create(input=[text], engine=engine)["data"][0]["embedding"]
|
| 93 |
+
|
| 94 |
+
def embed_documents(self, texts: List[str]) -> List[List[float]]:
|
| 95 |
+
"""Call out to OpenAI's embedding endpoint for embedding search docs.
|
| 96 |
+
Args:
|
| 97 |
+
texts: The list of texts to embed.
|
| 98 |
+
Returns:
|
| 99 |
+
List of embeddings, one for each text.
|
| 100 |
+
"""
|
| 101 |
+
responses = [
|
| 102 |
+
self._embedding_func(text, engine=self.document_model_name)
|
| 103 |
+
for text in texts
|
| 104 |
+
]
|
| 105 |
+
return responses
|
| 106 |
+
|
| 107 |
+
def embed_query(self, text: str) -> List[float]:
|
| 108 |
+
"""Call out to OpenAI's embedding endpoint for embedding query text.
|
| 109 |
+
Args:
|
| 110 |
+
text: The text to embed.
|
| 111 |
+
Returns:
|
| 112 |
+
Embeddings for the text.
|
| 113 |
+
"""
|
| 114 |
+
embedding = self._embedding_func(text, engine=self.query_model_name)
|
| 115 |
+
return embedding
|
prompts.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.prompts import PromptTemplate
|
| 2 |
+
|
| 3 |
+
## Use a shorter template to reduce the number of tokens in the prompt
|
| 4 |
+
template = """Create a final answer to the given questions using the provided document excerpts(in no particular order) as references. ALWAYS include a "SOURCES" section in your answer including only the minimal set of sources needed to answer the question. If you are unable to answer the question, simply state that you do not know. Do not attempt to fabricate an answer and leave the SOURCES section empty.
|
| 5 |
+
---------
|
| 6 |
+
QUESTION: What is the purpose of ARPA-H?
|
| 7 |
+
=========
|
| 8 |
+
Content: More support for patients and families. \n\nTo get there, I call on Congress to fund ARPA-H, the Advanced Research Projects Agency for Health. \n\nIt’s based on DARPA—the Defense Department project that led to the Internet, GPS, and so much more. \n\nARPA-H will have a singular purpose—to drive breakthroughs in cancer, Alzheimer’s, diabetes, and more.
|
| 9 |
+
Source: 1-32
|
| 10 |
+
Content: While we’re at it, let’s make sure every American can get the health care they need. \n\nWe’ve already made historic investments in health care. \n\nWe’ve made it easier for Americans to get the care they need, when they need it. \n\nWe’ve made it easier for Americans to get the treatments they need, when they need them. \n\nWe’ve made it easier for Americans to get the medications they need, when they need them.
|
| 11 |
+
Source: 1-33
|
| 12 |
+
Content: The V.A. is pioneering new ways of linking toxic exposures to disease, already helping veterans get the care they deserve. \n\nWe need to extend that same care to all Americans. \n\nThat’s why I’m calling on Congress to pass legislation that would establish a national registry of toxic exposures, and provide health care and financial assistance to those affected.
|
| 13 |
+
Source: 1-30
|
| 14 |
+
=========
|
| 15 |
+
FINAL ANSWER: The purpose of ARPA-H is to drive breakthroughs in cancer, Alzheimer’s, diabetes, and more.
|
| 16 |
+
SOURCES: 1-32
|
| 17 |
+
---------
|
| 18 |
+
QUESTION: {question}
|
| 19 |
+
=========
|
| 20 |
+
{summaries}
|
| 21 |
+
=========
|
| 22 |
+
FINAL ANSWER:"""
|
| 23 |
+
|
| 24 |
+
STUFF_PROMPT = PromptTemplate(
|
| 25 |
+
template=template, input_variables=["summaries", "question"]
|
| 26 |
+
)
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
openai
|
| 2 |
+
pypdf
|
| 3 |
+
scikit-learn
|
| 4 |
+
numpy
|
| 5 |
+
tiktoken
|
| 6 |
+
docx2txt
|
| 7 |
+
langchain
|
| 8 |
+
pydantic
|
| 9 |
+
typing
|
| 10 |
+
faiss-cpu
|
utils.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 2 |
+
from langchain.vectorstores.faiss import FAISS
|
| 3 |
+
from langchain import OpenAI, Cohere
|
| 4 |
+
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
|
| 5 |
+
from embeddings import OpenAIEmbeddings
|
| 6 |
+
from langchain.llms import OpenAI
|
| 7 |
+
from langchain.docstore.document import Document
|
| 8 |
+
from langchain.vectorstores import FAISS, VectorStore
|
| 9 |
+
import docx2txt
|
| 10 |
+
from typing import List, Dict, Any
|
| 11 |
+
import re
|
| 12 |
+
import numpy as np
|
| 13 |
+
from io import StringIO
|
| 14 |
+
from io import BytesIO
|
| 15 |
+
import streamlit as st
|
| 16 |
+
from prompts import STUFF_PROMPT
|
| 17 |
+
from pypdf import PdfReader
|
| 18 |
+
from openai.error import AuthenticationError
|
| 19 |
+
|
| 20 |
+
@st.experimental_memo()
|
| 21 |
+
def parse_docx(file: BytesIO) -> str:
|
| 22 |
+
text = docx2txt.process(file)
|
| 23 |
+
# Remove multiple newlines
|
| 24 |
+
text = re.sub(r"\n\s*\n", "\n\n", text)
|
| 25 |
+
return text
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@st.experimental_memo()
|
| 29 |
+
def parse_pdf(file: BytesIO) -> List[str]:
|
| 30 |
+
pdf = PdfReader(file)
|
| 31 |
+
output = []
|
| 32 |
+
for page in pdf.pages:
|
| 33 |
+
text = page.extract_text()
|
| 34 |
+
# Merge hyphenated words
|
| 35 |
+
text = re.sub(r"(\w+)-\n(\w+)", r"\1\2", text)
|
| 36 |
+
# Fix newlines in the middle of sentences
|
| 37 |
+
text = re.sub(r"(?<!\n\s)\n(?!\s\n)", " ", text.strip())
|
| 38 |
+
# Remove multiple newlines
|
| 39 |
+
text = re.sub(r"\n\s*\n", "\n\n", text)
|
| 40 |
+
|
| 41 |
+
output.append(text)
|
| 42 |
+
|
| 43 |
+
return output
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
@st.experimental_memo()
|
| 47 |
+
def parse_txt(file: BytesIO) -> str:
|
| 48 |
+
text = file.read().decode("utf-8")
|
| 49 |
+
# Remove multiple newlines
|
| 50 |
+
text = re.sub(r"\n\s*\n", "\n\n", text)
|
| 51 |
+
return text
|
| 52 |
+
|
| 53 |
+
@st.experimental_memo()
|
| 54 |
+
def parse_csv(uploaded_file):
|
| 55 |
+
# To read file as bytes:
|
| 56 |
+
#bytes_data = uploaded_file.getvalue()
|
| 57 |
+
#st.write(bytes_data)
|
| 58 |
+
|
| 59 |
+
# To convert to a string based IO:
|
| 60 |
+
stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
|
| 61 |
+
#st.write(stringio)
|
| 62 |
+
|
| 63 |
+
# To read file as string:
|
| 64 |
+
string_data = stringio.read()
|
| 65 |
+
#st.write(string_data)
|
| 66 |
+
|
| 67 |
+
# Can be used wherever a "file-like" object is accepted:
|
| 68 |
+
# dataframe = pd.read_csv(uploaded_file)
|
| 69 |
+
return string_data
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
@st.cache(allow_output_mutation=True)
|
| 73 |
+
def text_to_docs(text: str | List[str]) -> List[Document]:
|
| 74 |
+
"""Converts a string or list of strings to a list of Documents
|
| 75 |
+
with metadata."""
|
| 76 |
+
if isinstance(text, str):
|
| 77 |
+
# Take a single string as one page
|
| 78 |
+
text = [text]
|
| 79 |
+
page_docs = [Document(page_content=page) for page in text]
|
| 80 |
+
|
| 81 |
+
# Add page numbers as metadata
|
| 82 |
+
for i, doc in enumerate(page_docs):
|
| 83 |
+
doc.metadata["page"] = i + 1
|
| 84 |
+
|
| 85 |
+
# Split pages into chunks
|
| 86 |
+
doc_chunks = []
|
| 87 |
+
|
| 88 |
+
for doc in page_docs:
|
| 89 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 90 |
+
chunk_size=800,
|
| 91 |
+
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""],
|
| 92 |
+
chunk_overlap=0,
|
| 93 |
+
)
|
| 94 |
+
chunks = text_splitter.split_text(doc.page_content)
|
| 95 |
+
for i, chunk in enumerate(chunks):
|
| 96 |
+
doc = Document(
|
| 97 |
+
page_content=chunk, metadata={"page": doc.metadata["page"], "chunk": i}
|
| 98 |
+
)
|
| 99 |
+
# Add sources a metadata
|
| 100 |
+
doc.metadata["source"] = f"{doc.metadata['page']}-{doc.metadata['chunk']}"
|
| 101 |
+
doc_chunks.append(doc)
|
| 102 |
+
return doc_chunks
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
@st.cache(allow_output_mutation=True, show_spinner=False)
|
| 106 |
+
def embed_docs(docs: List[Document]) -> VectorStore:
|
| 107 |
+
"""Embeds a list of Documents and returns a FAISS index"""
|
| 108 |
+
|
| 109 |
+
if not st.session_state.get("OPENAI_API_KEY"):
|
| 110 |
+
raise AuthenticationError(
|
| 111 |
+
"Enter your OpenAI API key in the sidebar. You can get a key at https://platform.openai.com/account/api-keys."
|
| 112 |
+
)
|
| 113 |
+
else:
|
| 114 |
+
# Embed the chunks
|
| 115 |
+
embeddings = OpenAIEmbeddings(openai_api_key=st.session_state.get("OPENAI_API_KEY")) # type: ignore
|
| 116 |
+
index = FAISS.from_documents(docs, embeddings)
|
| 117 |
+
|
| 118 |
+
return index
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
@st.cache(allow_output_mutation=True)
|
| 122 |
+
def search_docs(index: VectorStore, query: str) -> List[Document]:
|
| 123 |
+
"""Searches a FAISS index for similar chunks to the query
|
| 124 |
+
and returns a list of Documents."""
|
| 125 |
+
|
| 126 |
+
# Search for similar chunks
|
| 127 |
+
docs = index.similarity_search(query, k=5)
|
| 128 |
+
return docs
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
@st.cache(allow_output_mutation=True)
|
| 132 |
+
def get_answer(docs: List[Document], query: str) -> Dict[str, Any]:
|
| 133 |
+
"""Gets an answer to a question from a list of Documents."""
|
| 134 |
+
|
| 135 |
+
# Get the answer
|
| 136 |
+
|
| 137 |
+
chain = load_qa_with_sources_chain(OpenAI(temperature=0, openai_api_key=st.session_state.get("OPENAI_API_KEY")), chain_type="stuff", prompt=STUFF_PROMPT) # type: ignore
|
| 138 |
+
|
| 139 |
+
# Cohere doesn't work very well as of now.
|
| 140 |
+
# chain = load_qa_with_sources_chain(Cohere(temperature=0), chain_type="stuff", prompt=STUFF_PROMPT) # type: ignore
|
| 141 |
+
answer = chain(
|
| 142 |
+
{"input_documents": docs, "question": query}, return_only_outputs=True
|
| 143 |
+
)
|
| 144 |
+
return answer
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
@st.cache(allow_output_mutation=True)
|
| 148 |
+
def get_sources(answer: Dict[str, Any], docs: List[Document]) -> List[Document]:
|
| 149 |
+
"""Gets the source documents for an answer."""
|
| 150 |
+
|
| 151 |
+
# Get sources for the answer
|
| 152 |
+
source_keys = [s for s in answer["output_text"].split("SOURCES: ")[-1].split(", ")]
|
| 153 |
+
|
| 154 |
+
source_docs = []
|
| 155 |
+
for doc in docs:
|
| 156 |
+
if doc.metadata["source"] in source_keys:
|
| 157 |
+
source_docs.append(doc)
|
| 158 |
+
|
| 159 |
+
return source_docs
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def wrap_text_in_html(text: str | List[str]) -> str:
|
| 163 |
+
"""Wraps each text block separated by newlines in <p> tags"""
|
| 164 |
+
if isinstance(text, list):
|
| 165 |
+
# Add horizontal rules between pages
|
| 166 |
+
text = "\n<hr/>\n".join(text)
|
| 167 |
+
return "".join([f"<p>{line}</p>" for line in text.split("\n")])
|