Spaces:
Configuration error

Configuration error
Commit
·
32b1ab9
1
Parent(s):
f90585f
Upload 12 files
Browse files- P1M2_devin_lee.ipynb +0 -0
- README.md +233 -9
- Train.csv +0 -0
- app.py +38 -0
- distribution_.cost.png +0 -0
- eda.py +42 -0
- heatmap.png +0 -0
- histogram_customer_rating.png +0 -0
- model.pkl +3 -0
- model.py +57 -0
- model_inference_devin_lee.ipynb +187 -0
- requirements.txt +5 -0
P1M2_devin_lee.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
README.md
CHANGED
|
@@ -1,12 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[](https://classroom.github.com/a/bmC2MTjC)
|
| 2 |
+
[](https://classroom.github.com/online_ide?assignment_repo_id=12707707&assignment_repo_type=AssignmentRepo)
|
| 3 |
+
# Phase 1 Milestone 2
|
| 4 |
+
|
| 5 |
+
_Milestone 2 ini dibuat guna mengevaluasi pembelajaran pada Hacktiv8 Data Science Fulltime Program khususnya pada Phase 1._
|
| 6 |
+
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
## Assignment Objectives
|
| 10 |
+
|
| 11 |
+
Milestone 2 ini dibuat guna mengevaluasi konsep Machine Learning pada pembelajaran Phase 1 sebagai berikut:
|
| 12 |
+
|
| 13 |
+
- Mampu memahami konsep Machine Learning secara keseluruhan.
|
| 14 |
+
- Mampu mempersiapkan data untuk digunakan dalam model Supervised Learning (Classification atau Regression).
|
| 15 |
+
- Mampu mengimplementasikan Supervised Learning (Classification atau Regression) dengan data yang dipilih.
|
| 16 |
+
- Mampu melakukan Hyperparameter Tuning dan Model Improvement.
|
| 17 |
+
- Mampu melakukan Model Deployment.
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
## Topik
|
| 22 |
+
|
| 23 |
+
Anda dipersilakan untuk memilih salah satu topik mengenai Supervised Learning : Regression atau Classification.
|
| 24 |
+
|
| 25 |
+
---
|
| 26 |
+
|
| 27 |
+
## Dataset
|
| 28 |
+
|
| 29 |
+
### Ketentuan Dataset
|
| 30 |
+
1. Pilihlah dataset yang paling nyaman digunakan karena tidak ada batasan untuk memilih dataset dalam mengerjakan Milestone 2.
|
| 31 |
+
|
| 32 |
+
2. **Konsultasikan terlebih dahulu dataset yang hendak digunakan ke buddy masing-masing student. Jika disetujui, maka silakan dikerjakan. Jika tidak disetujui, maka cari dataset yang lain dan konsultasikan lagi mengenai dataset yang baru ini.**
|
| 33 |
+
|
| 34 |
+
3. Student tidak boleh menggunakan dataset yang sudah dipakai dalam tugas Live Code, Graded Challenge, Non Graded Challenge, dan Milestone dari Phase 0 hingga Phase 1.
|
| 35 |
+
|
| 36 |
+
4. Student juga tidak boleh menggunakan dataset yang sudah dipakai dalam sesi pembelajaran saat dikelas bersama instruktur. Carilah dataset yang baru untuk tugas Milestone 2 ini.
|
| 37 |
+
|
| 38 |
+
5. **Student dilarang untuk melakukan scraping dataset** karena dikhawatirkan proses pembuatan scraper dan proses scraping akan memakan waktu. Gunakan public dataset yang tersedia diberbagai macam situs Internet.
|
| 39 |
+
|
| 40 |
+
### Data Sources
|
| 41 |
+
Student dapat memilih dataset dari salah satu repository dibawah ini. Popular open data repositories :
|
| 42 |
+
|
| 43 |
+
- [UC Irvine Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php)
|
| 44 |
+
- [Kaggle datasets](https://www.kaggle.com/datasets)
|
| 45 |
+
- [Amazon’s AWS datasets](https://registry.opendata.aws/)
|
| 46 |
+
|
| 47 |
+
Meta portals :
|
| 48 |
+
|
| 49 |
+
- [Data Portals](http://dataportals.org/)
|
| 50 |
+
- [OpenDataMonitor](https://opendatamonitor.eu/frontend/web/index.php?r=dashboard%2Findex)
|
| 51 |
+
- [Quandl](https://www.quandl.com/)
|
| 52 |
+
- Sumber lain yang kredibel.
|
| 53 |
+
|
| 54 |
---
|
| 55 |
+
|
| 56 |
+
## Conceptual Problems
|
| 57 |
+
|
| 58 |
+
*Jawab pertanyaan berikut:*
|
| 59 |
+
|
| 60 |
+
1. Jelaskan latar belakang adanya bagging dan cara kerja bagging !
|
| 61 |
+
|
| 62 |
+
2. Jelaskan perbedaan cara kerja algoritma Random Forest dengan algoritma boosting yang Anda pilih !
|
| 63 |
+
|
| 64 |
+
3. Jelaskan apa yang dimaksud dengan Cross Validation !
|
| 65 |
+
|
| 66 |
---
|
| 67 |
|
| 68 |
+
## Assignment Instructions
|
| 69 |
+
|
| 70 |
+
Milestones 2 dikerjakan dalam format ***notebook*** dan ***Model Deployment*** dengan beberapa *kriteria wajib* di bawah ini:
|
| 71 |
+
|
| 72 |
+
1. Machine learning framework yang digunakan adalah *Scikit-Learn*.
|
| 73 |
+
|
| 74 |
+
2. Ada penggunaan library visualisasi, seperti *matplotlib*, *seaborn*, atau yang lain.
|
| 75 |
+
|
| 76 |
+
3. Isi *notebook* harus mengikuti *outline* di bawah ini:
|
| 77 |
+
1. Perkenalan
|
| 78 |
+
> Bab pengenalan harus diisi dengan identitas, gambaran besar dataset yang digunakan, dan *objective* yang ingin dicapai.
|
| 79 |
+
|
| 80 |
+
2. Import Libraries
|
| 81 |
+
> *Cell* pertama pada *notebook* **harus berisi dan hanya berisi** semua *library* yang digunakan dalam *project*.
|
| 82 |
+
|
| 83 |
+
3. Data Loading
|
| 84 |
+
> Bagian ini berisi proses penyiapan data sebelum dilakukan eksplorasi data lebih lanjut. Proses Data Loading dapat berupa memberi nama baru untuk setiap kolom, mengecek ukuran dataset, dll.
|
| 85 |
+
|
| 86 |
+
4. Exploratory Data Analysis (EDA)
|
| 87 |
+
> Bagian ini berisi explorasi data pada dataset diatas dengan menggunakan query, grouping, visualisasi sederhana, dan lain sebagainya.
|
| 88 |
+
|
| 89 |
+
5. Feature Engineering
|
| 90 |
+
> Bagian ini berisi proses penyiapan data untuk proses pelatihan model, seperti pembagian data menjadi train-test, transformasi data (normalisasi, encoding, dll.), dan proses-proses lain yang dibutuhkan.
|
| 91 |
+
|
| 92 |
+
6. Model Definition
|
| 93 |
+
> Bagian ini berisi cell untuk mendefinisikan model. Jelaskan alasan menggunakan suatu algoritma/model, hyperparameter yang dipakai, jenis penggunaan metrics yang dipakai, dan hal lain yang terkait dengan model.
|
| 94 |
+
|
| 95 |
+
7. Model Training
|
| 96 |
+
> Cell pada bagian ini hanya berisi code untuk melatih model dan output yang dihasilkan. Lakukan beberapa kali proses training dengan hyperparameter yang berbeda untuk melihat hasil yang didapatkan. Analisis dan narasikan hasil ini pada bagian Model Evaluation.
|
| 97 |
+
|
| 98 |
+
8. Model Evaluation
|
| 99 |
+
> Pada bagian ini, dilakukan evaluasi model yang harus menunjukkan bagaimana performa model berdasarkan metrics yang dipilih. Hal ini harus dibuktikan dengan visualisasi tren performa dan/atau tingkat kesalahan model. **Lakukan analisis terkait dengan hasil pada model dan tuliskan hasil analisisnya**.
|
| 100 |
+
|
| 101 |
+
9. Model Saving
|
| 102 |
+
> Pada bagian ini, dilakukan proses penyimpanan model dan file-file lain yang terkait dengan hasil proses pembuatan model. **Dengan melihat hasil Model Evaluation, pilihlah satu model terbaik untuk disimpan. Model terbaik ini akan digunakan kembali dalam melakukan Model Inference dan Model Deployment.**
|
| 103 |
+
|
| 104 |
+
10. Model Inference
|
| 105 |
+
> Model yang sudah dilatih akan dicoba pada data yang bukan termasuk ke dalam train-set ataupun test-set. Data ini harus dalam format yang asli, bukan data yang sudah di-scaled. Gunakan model terbaik berdasarkan hasil Model Evaluation. Notebook Model Inference haruslah berbeda dengan notebook saat pembuatan model dilakukan.
|
| 106 |
+
|
| 107 |
+
11. Pengambilan Kesimpulan
|
| 108 |
+
> Pada bagian terakhir ini, **harus berisi** kesimpulan yang mencerminkan hasil yang didapat dengan *objective* yang sudah ditulis di bagian pengenalan.
|
| 109 |
+
|
| 110 |
+
4. Notebook harus diupload dalam akun GitHub masing-masing student untuk selanjutnya dinilai.
|
| 111 |
+
|
| 112 |
+
---
|
| 113 |
+
|
| 114 |
+
## Assignment Submission
|
| 115 |
+
|
| 116 |
+
- Simpan assignment pada sesi ini dengan nama :
|
| 117 |
+
* Modeling : `P1M2_<nama-student>.ipynb`, misal `P1M2_raka_ardhi.ipynb`.
|
| 118 |
+
* Model Inference : `P1M2_<nama-student>_inf.ipynb`, misal `P1M2_raka_ardhi_inf.ipynb`.
|
| 119 |
+
|
| 120 |
+
- Push Assigment yang telah Anda buat ke akun Github Classroom Anda masing-masing.
|
| 121 |
+
|
| 122 |
+
- Untuk Model Deployment :
|
| 123 |
+
* Buat sebuah folder bernama `deployment` dan masukkan semua file yang berkaitan dengan deployment ke folder ini.
|
| 124 |
+
* Buat sebuah file bernama `url.txt` yang berisi URL Dataset dan URL deployment.
|
| 125 |
+
* Contoh bentuk isi repository dengan Model Deployment.
|
| 126 |
+
```
|
| 127 |
+
├── deployment/
|
| 128 |
+
│ ├── app.py
|
| 129 |
+
│ └── eda.py
|
| 130 |
+
│ └── prediction.py
|
| 131 |
+
│ └── model.pkl
|
| 132 |
+
├── P1M2_raka_ardhi.ipynb
|
| 133 |
+
├── P1M2_raka_ardhi_inf.ipynb
|
| 134 |
+
├── url.txt
|
| 135 |
+
└── README.md
|
| 136 |
+
```
|
| 137 |
+
---
|
| 138 |
+
|
| 139 |
+
## Assignment Rubrics
|
| 140 |
+
|
| 141 |
+
### Code Review
|
| 142 |
+
|
| 143 |
+
| Criteria | Meet Expectations | Points |
|
| 144 |
+
| --- | --- | --- |
|
| 145 |
+
| Feature Engineering | Mampu melakukan preprocessing dataset sebelum melakukan proses modeling (split data, normalisasi, encoding, dll) | 35 pts |
|
| 146 |
+
| KNN | Mengimplementasikan algoritma KNN pada domain kasus yang dipilih | 5 pts |
|
| 147 |
+
| SVM | Mengimplementasikan algoritma SVM pada domain kasus yang dipilih | 5 pts |
|
| 148 |
+
| Decision Tree | Mengimplementasikan algoritma Decision Tree pada domain kasus yang dipilih | 5 pts |
|
| 149 |
+
| Random Forest | Mengimplementasikan algoritma Random Forest pada domain kasus yang dipilih | 5 pts |
|
| 150 |
+
| Boosting | Mengimplementasikan salah satu algoritma Boosting pada domain kasus yang dipilih | 5 pts |
|
| 151 |
+
| Pipelines | Mengimplementasikan Pipeline pada domain kasus yang dipilih | 20 pts |
|
| 152 |
+
| Cross Validation | Mengimplementasikan Cross Validation dengan Scikit-Learn | 25 pts |
|
| 153 |
+
| Hyperparameter Tuning | Mengimplementasikan Hyperparameter Tuning dengan Scikit-Learn | 20 pts |
|
| 154 |
+
| Model Inference | Mencoba model yang telah dibuat dengan data baru | 10 pts |
|
| 155 |
+
| Runs Perfectly | Kode berjalan tanpa ada error. Seluruh kode berfungsi dan dibuat dengan benar. | 10 pts |
|
| 156 |
+
|
| 157 |
+
```
|
| 158 |
+
Pada rubrik Milestone 2 diatas terdapat point Cross Validation dan Hyperparameter Tuning (GridSearchCV, RandomSearchCV, dll).
|
| 159 |
+
Kedua hal yang dimaksud ini adalah dua hal yang berbeda bukan satu kesatuan. Petunjuk :
|
| 160 |
+
|
| 161 |
+
1. Lakukan model training dengan menggunakan parameter default (baseline model) dari setiap algoritma yang diminta.
|
| 162 |
+
2. Kemudian, gunakan `cross_val_score` atau `cross_validate` untuk mencari nilai performansi `mean` dan `std` dari setiap model.
|
| 163 |
+
3. Pilih agoritma yang terbaik dari hasil poin 2.
|
| 164 |
+
4. Lakukan Hyperparameter Tuning pada algoritma terbaik (berdasarkan poin 2) dengan menggunakan GridSearchCV, RandomSearchCV, dll.
|
| 165 |
+
5. Bandingkan performansi antara sebelum dan sesudah dilakukan Hyperparameter Tuning.
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
### Concepts
|
| 169 |
+
|
| 170 |
+
| Criteria | Meet Expectations | Points |
|
| 171 |
+
| --- | --- | --- |
|
| 172 |
+
| Classifications | Mampu menjawab pertanyaan dengan singkat, jelas, dan padat serta sesuai dengan konsep dan logika yang ada mengenai Conceptual Problems (10 pts each) | 30 pts |
|
| 173 |
+
|
| 174 |
+
### Readability
|
| 175 |
+
|
| 176 |
+
| Criteria | Meet Expectations | Points |
|
| 177 |
+
| --- | --- | --- |
|
| 178 |
+
| Tertata Dengan Baik | Semua baris kode terdokumentasi dengan baik dengan Markdown untuk penjelasan kode | 15 pts |
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
Kriteria tertata dengan baik diantaranya adalah:
|
| 182 |
+
|
| 183 |
+
1. Terdapat section Perkenalan yang jelas dan lengkap terkait masalah dan latar belakang masalah yang akan diselesaikan.
|
| 184 |
+
2. Tidak menyalin markdown dari tugas lain.
|
| 185 |
+
3. Import library rapih (terdapat dalam 1 cell dan tidak ada unused libs).
|
| 186 |
+
4. Pemakaian fungsi markdown yang optimal (Heading, text formating, dll).
|
| 187 |
+
5. Terdapat komentar pada setiap baris kode.
|
| 188 |
+
6. Adanya pemisah yang jelas antar section, dll.
|
| 189 |
+
7. Tidak adanya typo.
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
### Analysis
|
| 193 |
+
|
| 194 |
+
| Criteria | Meet Expectations | Points|
|
| 195 |
+
| --- | --- | --- |
|
| 196 |
+
| Model Analysis | Menganalisa informasi dari model yang telah dibuat | 35 pts |
|
| 197 |
+
| Overall Analysis | Menarik informasi/kesimpulan dari keseluruhan kegiatan yang dilakukan | 20 pts |
|
| 198 |
+
|
| 199 |
+
```
|
| 200 |
+
Contoh kriteria analisa yang baik diantaranya adalah:
|
| 201 |
+
|
| 202 |
+
1. Terdapat penjelasan macam-macam hasil metric evaluasi dan interpretasinya terhadap kasus yang diselesaikan.
|
| 203 |
+
2. Dapat menjelaskan KELEBIHAN dan KELEMAHAN dari model yang dibuat DENGAN KAITANNYA DENGAN DOMAIN BUSINESS YANG DIHADAPI yang dibuktikan dengan eksplorasi sederhana (grafik, plot, teori, dll).
|
| 204 |
+
3. Dapat memberikan statement untuk improvement selanjutnya dari model yang dibuat.
|
| 205 |
+
4. Dapat menyebutkan insight yang dapat diambil setelah proses EDA, dll.
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
### Model Deployment
|
| 209 |
+
|
| 210 |
+
| Criteria | Meet Expectations | Points |
|
| 211 |
+
| --- | --- | --- |
|
| 212 |
+
| Model Deployment | Membuat webapps terhadap project yang telah dibuat. | 15 pts |
|
| 213 |
+
|
| 214 |
+
```
|
| 215 |
+
Catatan mengenai Model Deployment :
|
| 216 |
+
|
| 217 |
+
1. Ketiadaan URL deployment ataupun source code deployment di repository, akan tetap diperhitungkan untuk menilai bagian Model Deployment.
|
| 218 |
+
2. Tidak diperkenankan adanya informasi tambahan/informasi susulan seperti lupa memberikan URL deployment atau lupa mengupload source code via apapun (DM buddy, email, atau yang lain).
|
| 219 |
+
3. Student akan dianggap tidak melakukan Model Deployment jika tidak ada URL deployment dan source code deployment di repository.
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
---
|
| 223 |
+
|
| 224 |
+
```
|
| 225 |
+
Total Points : 260
|
| 226 |
+
|
| 227 |
+
Catatan : Penilaian Milestone 2 juga dapat dipengaruhi oleh aktivitas student selama Phase 1 berlangsung, baik sesi kelas maupun sesi mentoring dengan buddy-nya masing-masing sehingga terdapat kemungkinan adanya penambahan atau pengurangan nilai diluar rubric yang telah disebutkan diatas.
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
---
|
| 231 |
+
|
| 232 |
+
## Notes
|
| 233 |
+
|
| 234 |
+
* **Deadline : P1W4D4 pukul 18:00 WIB.**
|
| 235 |
+
|
| 236 |
+
* **Keterlambatan pengumpulan tugas mengakibatkan skor Milestone 2 menjadi 0.**
|
Train.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
app.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Milestone 2
|
| 3 |
+
Nama: Devin Yaung Lee
|
| 4 |
+
Batch: HCK-009
|
| 5 |
+
program ini untuk mendeploy model
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import streamlit as st
|
| 9 |
+
import eda
|
| 10 |
+
import model
|
| 11 |
+
|
| 12 |
+
page = st.sidebar.selectbox(label="Select Page:", options=["Home Page", "Exploratory Data Analysis", "Predict On Time"])
|
| 13 |
+
|
| 14 |
+
if page == "Home Page":
|
| 15 |
+
st.title("Home Page")
|
| 16 |
+
st.write('')
|
| 17 |
+
st.write("Milestone 2")
|
| 18 |
+
st.write("Name : Devin Yaung Lee")
|
| 19 |
+
st.write("Batch : HCK-009")
|
| 20 |
+
st.write("Aplikasi ini memiliki tujuan utama untuk menampilkan hasil untuk memprediksi apakah pengiriman product berdasarkan parameter-parameter tententu, pengiriman on time atau tidak.")
|
| 21 |
+
st.write('')
|
| 22 |
+
st.write('')
|
| 23 |
+
st.write('')
|
| 24 |
+
|
| 25 |
+
with st.expander("Background Information"):
|
| 26 |
+
st.caption("Dataset ini membahas tentang E-Commerce Shipping Data. Dimana data ini membahas tentang bagaimana proses pegiriman data yang berbeda-beda, dimana ada jalur darat, jalur laut, dan jalur udara. Dari ketiga hal ini akan dilihat juga bagaimana rating dari tiap-tiap proses jalur, dan tujuan utama pembuatan model ini adalah untuk mengetahui apakah dari parameter-parameter column ini, pengiriman on time atau tidak.")
|
| 27 |
+
with st.expander("Conclusion"):
|
| 28 |
+
st.caption("""
|
| 29 |
+
- Didapatkan bahwa pada saat melalakukan pengecheckan nilai skewness, column prior_purchases dan discount_offered didapatkan bahwa nilai skewness pada column tersebut mengalami skew, hal ini kemungkinan dikarenakan terdapat outliers pada kedua columns tersebut. Maka perlu dilakukan handling outliers. Pada kasus ini jika tidak ingin menghilangkan data, maka handling outliers yang paling cocok adalah dengan menggunakan winsorizer yang nanti akan dilakukan di proses selanjutnya.
|
| 30 |
+
- Berdasarkan dari hasil visualisasi didapatkan bahwa ada keterdapatan outliers pada beberapa column tertentu, dan dilakukan handling outliers menggunakan winsorizer
|
| 31 |
+
- Berdasarkan dari analisa model, dari baseline model, hyperparameter tuning, dan boosting, didapatkan bahwa model terbaik adalah menggunakan model SVM.
|
| 32 |
+
""")
|
| 33 |
+
|
| 34 |
+
elif page == "Exploratory Data Analysis":
|
| 35 |
+
eda.run() # Calls the run function from eda
|
| 36 |
+
|
| 37 |
+
else:
|
| 38 |
+
model.run() # Calls the run function from model
|
distribution_.cost.png
ADDED

|
eda.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Milestone 2
|
| 3 |
+
Nama: Devin Yaung Lee
|
| 4 |
+
Batch: HCK-009
|
| 5 |
+
// eda.py //
|
| 6 |
+
program ini untuk mendeploy model EDA interface.
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import streamlit as st
|
| 10 |
+
import pandas as pd
|
| 11 |
+
|
| 12 |
+
# Function to run in app.py
|
| 13 |
+
def run():
|
| 14 |
+
st.title("Explatoratory Data Analysis")
|
| 15 |
+
|
| 16 |
+
df = pd.read_csv("../Train.csv")
|
| 17 |
+
|
| 18 |
+
# The first 5 data
|
| 19 |
+
st.header("The first 5 data entry")
|
| 20 |
+
st.table(df.head(5))
|
| 21 |
+
|
| 22 |
+
# The last 5 data
|
| 23 |
+
st.header("The last 5 data entry")
|
| 24 |
+
st.table(df.tail(5))
|
| 25 |
+
|
| 26 |
+
# Heatmap correlation
|
| 27 |
+
st.header("Correlation heatmap")
|
| 28 |
+
st.image("heatmap.png", caption="Figure 1")
|
| 29 |
+
with st.expander("Explanation"):
|
| 30 |
+
st.caption("Berdasarkan dari hasil ini dapat dikatakan ada beberapa column yang memiliki korelasi. Ada beberapa column yang memiliki korelasi sampai 30% - 40%, dan ada juga korelasi minus yang dapat dikatakan bahwa column tersebut tidak memiliki atau hampir tidak memiliki korelasi satu sama lain")
|
| 31 |
+
|
| 32 |
+
# Histogram Distribution of Customer Rating
|
| 33 |
+
st.header("Histogram Distribution of Customer Rating")
|
| 34 |
+
st.image("histogram_customer_rating.png", caption="Figure 2")
|
| 35 |
+
with st.expander("Explanation"):
|
| 36 |
+
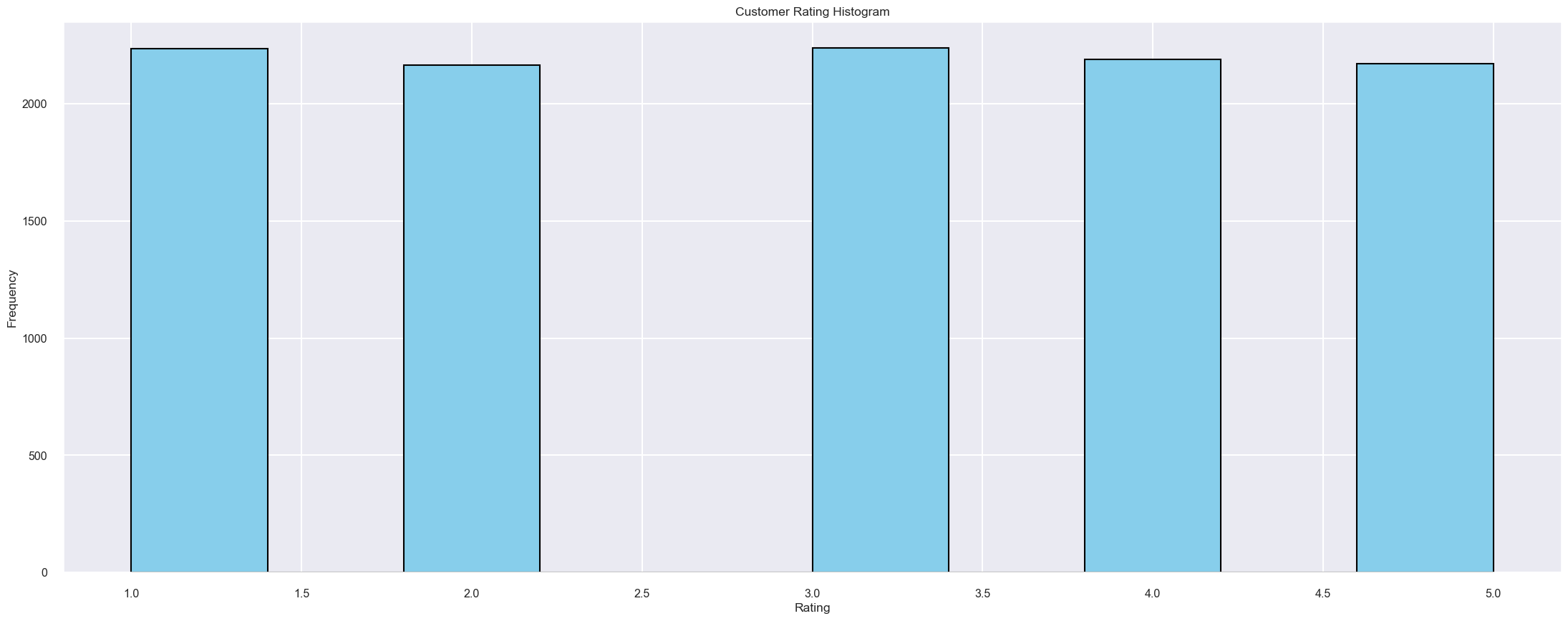
st.caption("Berdasarkan dari hasil data histogram, didapatkan bahwa persebaran nilai customer rating memiliki persebaran yang relatif sama besar. Hal ini ada beberapa kemungkinan data ini terbagi rata untuk pada saat data entry. Dan jika dilihat secara detail, didapatkan nilai tertinggi persebaran/distribusinya adalah rating 1 dan rating 3. Besar kemungkinan pada proses shipping ini sering terjadi problem yang membuat customer tidak merasa puas dengan pelayanan shippingnya.")
|
| 37 |
+
|
| 38 |
+
# Distribution of Cost of the Product
|
| 39 |
+
st.header("Distribution of Cost of the Product")
|
| 40 |
+
st.image("distribution_.cost.png", caption="Figure 4")
|
| 41 |
+
with st.expander("Explanation"):
|
| 42 |
+
st.caption("> Berdasarkan dari hasil diatas didapatkan bahwa distribusi untuk cost of the product rata-rata berada dikisaran harga $250, hal ini dapat dikatakan bahwa besarnya biaya per product ini dapat dikarenakan biaya pengiriman yang mahal ataupun jarak tempuh pengiriman")
|
heatmap.png
ADDED

|
histogram_customer_rating.png
ADDED
|
model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:588a1d3936d2e9030fd98160cb7350361245a0248bc54603fccd25891fa78257
|
| 3 |
+
size 994350
|
model.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Milestone 2
|
| 3 |
+
Nama: Devin Yaung Lee
|
| 4 |
+
Batch: HCK-009
|
| 5 |
+
// eda.py //
|
| 6 |
+
program ini menjadi base model EDA interface.
|
| 7 |
+
"""
|
| 8 |
+
import streamlit as st
|
| 9 |
+
import pandas as pd
|
| 10 |
+
import pickle
|
| 11 |
+
|
| 12 |
+
import streamlit as st
|
| 13 |
+
import pandas as pd
|
| 14 |
+
import pickle
|
| 15 |
+
|
| 16 |
+
def run():
|
| 17 |
+
st.title("Predict the Shipping On Time")
|
| 18 |
+
with open('model.pkl', 'rb') as file:
|
| 19 |
+
full_process = pickle.load(file)
|
| 20 |
+
|
| 21 |
+
# Collecting user input
|
| 22 |
+
warehouse_block = st.selectbox('Warehouse Block', ['A', 'B', 'C', 'D', 'E'])
|
| 23 |
+
mode_of_shipment = st.selectbox('Mode of Shipment', ['Flight', 'Ship', 'Road'])
|
| 24 |
+
customer_care_calls = st.selectbox('Customer Care Calls', [1, 2, 3, 4, 5, 6, 7])
|
| 25 |
+
customer_rating = st.selectbox('Customer Rating', [1, 2, 3, 4, 5])
|
| 26 |
+
cost_of_the_product = st.number_input('Cost of the Product (in USD)', min_value=0)
|
| 27 |
+
prior_purchases = st.selectbox('Prior Purchases', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
|
| 28 |
+
product_importance = st.selectbox('Product Importance', ['low', 'medium', 'high'])
|
| 29 |
+
gender = st.selectbox('Gender', ['F', 'M'])
|
| 30 |
+
discount_offered = st.number_input('Discount Offered (in %)', min_value=0)
|
| 31 |
+
weight_in_gms = st.number_input('Weight (in grams)', min_value=0)
|
| 32 |
+
|
| 33 |
+
# Creating a DataFrame with the user input
|
| 34 |
+
data_inf = pd.DataFrame({
|
| 35 |
+
'warehouse_block': [warehouse_block],
|
| 36 |
+
'mode_of_shipment': [mode_of_shipment],
|
| 37 |
+
'customer_care_calls': [customer_care_calls],
|
| 38 |
+
'customer_rating': [customer_rating],
|
| 39 |
+
'cost_of_the_product': [cost_of_the_product],
|
| 40 |
+
'prior_purchases': [prior_purchases],
|
| 41 |
+
'product_importance': [product_importance],
|
| 42 |
+
'gender': [gender],
|
| 43 |
+
'discount_offered': [discount_offered],
|
| 44 |
+
'weight_in_gms': [weight_in_gms]
|
| 45 |
+
})
|
| 46 |
+
|
| 47 |
+
st.write('Review your input:')
|
| 48 |
+
st.table(data_inf)
|
| 49 |
+
|
| 50 |
+
if st.button('Predict'):
|
| 51 |
+
# Make prediction
|
| 52 |
+
prediction = full_process.predict(data_inf)
|
| 53 |
+
if prediction == 0:
|
| 54 |
+
st.success("The model predicts the shipment will not be on time!")
|
| 55 |
+
else:
|
| 56 |
+
st.success("The model predicts the shipment will be on time!")
|
| 57 |
+
|
model_inference_devin_lee.ipynb
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 7,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"# Import Libraries\n",
|
| 10 |
+
"import pandas as pd\n",
|
| 11 |
+
"import pickle"
|
| 12 |
+
]
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"cell_type": "code",
|
| 16 |
+
"execution_count": 17,
|
| 17 |
+
"metadata": {},
|
| 18 |
+
"outputs": [],
|
| 19 |
+
"source": [
|
| 20 |
+
"with open('model.pkl', 'rb') as model_pipeline:\n",
|
| 21 |
+
" model = pickle.load(model_pipeline)"
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "code",
|
| 26 |
+
"execution_count": 18,
|
| 27 |
+
"metadata": {},
|
| 28 |
+
"outputs": [
|
| 29 |
+
{
|
| 30 |
+
"data": {
|
| 31 |
+
"text/html": [
|
| 32 |
+
"<div>\n",
|
| 33 |
+
"<style scoped>\n",
|
| 34 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 35 |
+
" vertical-align: middle;\n",
|
| 36 |
+
" }\n",
|
| 37 |
+
"\n",
|
| 38 |
+
" .dataframe tbody tr th {\n",
|
| 39 |
+
" vertical-align: top;\n",
|
| 40 |
+
" }\n",
|
| 41 |
+
"\n",
|
| 42 |
+
" .dataframe thead th {\n",
|
| 43 |
+
" text-align: right;\n",
|
| 44 |
+
" }\n",
|
| 45 |
+
"</style>\n",
|
| 46 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 47 |
+
" <thead>\n",
|
| 48 |
+
" <tr style=\"text-align: right;\">\n",
|
| 49 |
+
" <th></th>\n",
|
| 50 |
+
" <th>warehouse_block</th>\n",
|
| 51 |
+
" <th>mode_of_shipment</th>\n",
|
| 52 |
+
" <th>customer_care_calls</th>\n",
|
| 53 |
+
" <th>customer_rating</th>\n",
|
| 54 |
+
" <th>cost_of_the_product</th>\n",
|
| 55 |
+
" <th>prior_purchases</th>\n",
|
| 56 |
+
" <th>product_importance</th>\n",
|
| 57 |
+
" <th>gender</th>\n",
|
| 58 |
+
" <th>discount_offered</th>\n",
|
| 59 |
+
" <th>weight_in_gms</th>\n",
|
| 60 |
+
" </tr>\n",
|
| 61 |
+
" </thead>\n",
|
| 62 |
+
" <tbody>\n",
|
| 63 |
+
" <tr>\n",
|
| 64 |
+
" <th>0</th>\n",
|
| 65 |
+
" <td>A</td>\n",
|
| 66 |
+
" <td>Flight</td>\n",
|
| 67 |
+
" <td>1</td>\n",
|
| 68 |
+
" <td>5</td>\n",
|
| 69 |
+
" <td>300</td>\n",
|
| 70 |
+
" <td>6</td>\n",
|
| 71 |
+
" <td>medium</td>\n",
|
| 72 |
+
" <td>M</td>\n",
|
| 73 |
+
" <td>30</td>\n",
|
| 74 |
+
" <td>3500</td>\n",
|
| 75 |
+
" </tr>\n",
|
| 76 |
+
" <tr>\n",
|
| 77 |
+
" <th>1</th>\n",
|
| 78 |
+
" <td>D</td>\n",
|
| 79 |
+
" <td>Road</td>\n",
|
| 80 |
+
" <td>5</td>\n",
|
| 81 |
+
" <td>1</td>\n",
|
| 82 |
+
" <td>20</td>\n",
|
| 83 |
+
" <td>2</td>\n",
|
| 84 |
+
" <td>low</td>\n",
|
| 85 |
+
" <td>F</td>\n",
|
| 86 |
+
" <td>10</td>\n",
|
| 87 |
+
" <td>3800</td>\n",
|
| 88 |
+
" </tr>\n",
|
| 89 |
+
" </tbody>\n",
|
| 90 |
+
"</table>\n",
|
| 91 |
+
"</div>"
|
| 92 |
+
],
|
| 93 |
+
"text/plain": [
|
| 94 |
+
" warehouse_block mode_of_shipment customer_care_calls customer_rating \\\n",
|
| 95 |
+
"0 A Flight 1 5 \n",
|
| 96 |
+
"1 D Road 5 1 \n",
|
| 97 |
+
"\n",
|
| 98 |
+
" cost_of_the_product prior_purchases product_importance gender \\\n",
|
| 99 |
+
"0 300 6 medium M \n",
|
| 100 |
+
"1 20 2 low F \n",
|
| 101 |
+
"\n",
|
| 102 |
+
" discount_offered weight_in_gms \n",
|
| 103 |
+
"0 30 3500 \n",
|
| 104 |
+
"1 10 3800 "
|
| 105 |
+
]
|
| 106 |
+
},
|
| 107 |
+
"execution_count": 18,
|
| 108 |
+
"metadata": {},
|
| 109 |
+
"output_type": "execute_result"
|
| 110 |
+
}
|
| 111 |
+
],
|
| 112 |
+
"source": [
|
| 113 |
+
"data_inf = {\n",
|
| 114 |
+
" 'warehouse_block':['A','D'] , # Block Warehouse A, Block Warehouse D\n",
|
| 115 |
+
" 'mode_of_shipment': ['Flight','Road'], # Shipment Flight, Road\n",
|
| 116 |
+
" 'customer_care_calls':[1,5], # Enquiry Calls 1 Time, Enquiry Calls 5 Times\n",
|
| 117 |
+
" 'customer_rating': [5,1], # Rating 5 (highest), Rating 1 (Lowest)\n",
|
| 118 |
+
" 'cost_of_the_product':[300,20], # Cost $300, Cost $20\n",
|
| 119 |
+
" 'prior_purchases':[6,2], # Prior Purchase 6 Times Before, Prior Purchase 2 Times Before\n",
|
| 120 |
+
" 'product_importance':['medium','low'], # Importance Product Medium, Importance Product Low\n",
|
| 121 |
+
" 'gender':['M','F'], # Male, Female\n",
|
| 122 |
+
" 'discount_offered':[30,10], # Discount 30%, Discount 10%\n",
|
| 123 |
+
" 'weight_in_gms':[3500,3800], # Weight 3500 grams, Weight 3800 grams\n",
|
| 124 |
+
"}\n",
|
| 125 |
+
"data_inf = pd.DataFrame(data_inf)\n",
|
| 126 |
+
"data_inf"
|
| 127 |
+
]
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"cell_type": "code",
|
| 131 |
+
"execution_count": 19,
|
| 132 |
+
"metadata": {},
|
| 133 |
+
"outputs": [],
|
| 134 |
+
"source": [
|
| 135 |
+
"def label_cluster(cluster_number):\n",
|
| 136 |
+
" if cluster_number == 0:\n",
|
| 137 |
+
" return \"Shipping Not On Time !\"\n",
|
| 138 |
+
" elif cluster_number == 1:\n",
|
| 139 |
+
" return \"Shipping On Time !\"\n",
|
| 140 |
+
" else:\n",
|
| 141 |
+
" return \"Unknown\""
|
| 142 |
+
]
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"cell_type": "code",
|
| 146 |
+
"execution_count": 22,
|
| 147 |
+
"metadata": {},
|
| 148 |
+
"outputs": [
|
| 149 |
+
{
|
| 150 |
+
"name": "stdout",
|
| 151 |
+
"output_type": "stream",
|
| 152 |
+
"text": [
|
| 153 |
+
"['Shipping On Time !', 'Shipping Not On Time !']\n"
|
| 154 |
+
]
|
| 155 |
+
}
|
| 156 |
+
],
|
| 157 |
+
"source": [
|
| 158 |
+
"data_inf_pred = model.predict(data_inf)\n",
|
| 159 |
+
"data_inf_pred\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"labels = [label_cluster(cluster) for cluster in data_inf_pred]\n",
|
| 162 |
+
"print(labels)"
|
| 163 |
+
]
|
| 164 |
+
}
|
| 165 |
+
],
|
| 166 |
+
"metadata": {
|
| 167 |
+
"kernelspec": {
|
| 168 |
+
"display_name": "base",
|
| 169 |
+
"language": "python",
|
| 170 |
+
"name": "python3"
|
| 171 |
+
},
|
| 172 |
+
"language_info": {
|
| 173 |
+
"codemirror_mode": {
|
| 174 |
+
"name": "ipython",
|
| 175 |
+
"version": 3
|
| 176 |
+
},
|
| 177 |
+
"file_extension": ".py",
|
| 178 |
+
"mimetype": "text/x-python",
|
| 179 |
+
"name": "python",
|
| 180 |
+
"nbconvert_exporter": "python",
|
| 181 |
+
"pygments_lexer": "ipython3",
|
| 182 |
+
"version": "3.11.4"
|
| 183 |
+
}
|
| 184 |
+
},
|
| 185 |
+
"nbformat": 4,
|
| 186 |
+
"nbformat_minor": 2
|
| 187 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pandas
|
| 2 |
+
numpy
|
| 3 |
+
scikit-learn
|
| 4 |
+
matplotlib
|
| 5 |
+
seaborn
|