Spaces:
Running

Running

Update Space (evaluate main: 7e21410f)
Browse files
README.md
CHANGED
|
@@ -1,12 +1,129 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: MAPE
|
| 3 |
+
emoji: 🤗
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 3.0.2
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
+
tags:
|
| 11 |
+
- evaluate
|
| 12 |
+
- metric
|
| 13 |
+
description: >-
|
| 14 |
+
Mean Absolute Percentage Error (MAPE) is the mean percentage error difference between the predicted and actual
|
| 15 |
+
values.
|
| 16 |
---
|
| 17 |
|
| 18 |
+
# Metric Card for MAPE
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Metric Description
|
| 22 |
+
|
| 23 |
+
Mean Absolute Error (MAPE) is the mean of the percentage error of difference between the predicted $x_i$ and actual $y_i$ numeric values:
|
| 24 |
+
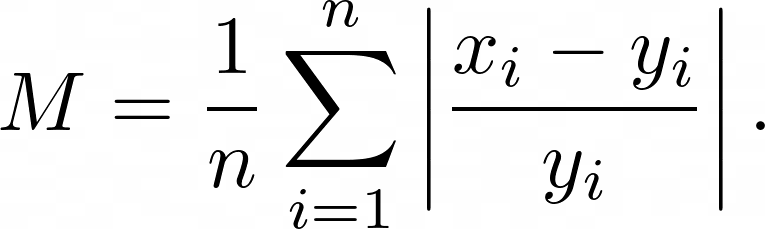
|
| 25 |
+
|
| 26 |
+
## How to Use
|
| 27 |
+
|
| 28 |
+
At minimum, this metric requires predictions and references as inputs.
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
>>> mape_metric = evaluate.load("mape")
|
| 32 |
+
>>> predictions = [2.5, 0.0, 2, 8]
|
| 33 |
+
>>> references = [3, -0.5, 2, 7]
|
| 34 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references)
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
### Inputs
|
| 38 |
+
|
| 39 |
+
Mandatory inputs:
|
| 40 |
+
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
|
| 41 |
+
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
|
| 42 |
+
|
| 43 |
+
Optional arguments:
|
| 44 |
+
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
|
| 45 |
+
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
|
| 46 |
+
- `raw_values` returns a full set of errors in case of multioutput input.
|
| 47 |
+
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
|
| 48 |
+
- the array-like value defines weights used to average errors.
|
| 49 |
+
|
| 50 |
+
### Output Values
|
| 51 |
+
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
|
| 52 |
+
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
|
| 53 |
+
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
|
| 54 |
+
|
| 55 |
+
Each MAPE `float` value is postive with the best value being 0.0.
|
| 56 |
+
|
| 57 |
+
Output Example(s):
|
| 58 |
+
```python
|
| 59 |
+
{'mape': 0.5}
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
If `multioutput="raw_values"`:
|
| 63 |
+
```python
|
| 64 |
+
{'mape': array([0.5, 1. ])}
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
#### Values from Popular Papers
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
### Examples
|
| 71 |
+
|
| 72 |
+
Example with the `uniform_average` config:
|
| 73 |
+
```python
|
| 74 |
+
>>> mape_metric = evaluate.load("mape")
|
| 75 |
+
>>> predictions = [2.5, 0.0, 2, 8]
|
| 76 |
+
>>> references = [3, -0.5, 2, 7]
|
| 77 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references)
|
| 78 |
+
>>> print(results)
|
| 79 |
+
{'mape': 0.3273...}
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
Example with multi-dimensional lists, and the `raw_values` config:
|
| 83 |
+
```python
|
| 84 |
+
>>> mape_metric = evaluate.load("mape", "multilist")
|
| 85 |
+
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
|
| 86 |
+
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
|
| 87 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references)
|
| 88 |
+
>>> print(results)
|
| 89 |
+
{'mape': 0.8874...}
|
| 90 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
|
| 91 |
+
>>> print(results)
|
| 92 |
+
{'mape': array([1.3749..., 0.4])}
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
## Limitations and Bias
|
| 96 |
+
One limitation of MAPE is that it cannot be used if the ground truth is zero or close to zero. This metric is also asymmetric in that it puts a heavier penalty on predictions less than the ground truth and a smaller penalty on predictions bigger than the ground truth and thus can lead to a bias of methods being select which under-predict if selected via this metric.
|
| 97 |
+
|
| 98 |
+
## Citation(s)
|
| 99 |
+
```bibtex
|
| 100 |
+
@article{scikit-learn,
|
| 101 |
+
title={Scikit-learn: Machine Learning in {P}ython},
|
| 102 |
+
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
|
| 103 |
+
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
|
| 104 |
+
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
|
| 105 |
+
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
|
| 106 |
+
journal={Journal of Machine Learning Research},
|
| 107 |
+
volume={12},
|
| 108 |
+
pages={2825--2830},
|
| 109 |
+
year={2011}
|
| 110 |
+
}
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
```bibtex
|
| 114 |
+
@article{DEMYTTENAERE201638,
|
| 115 |
+
title = {Mean Absolute Percentage Error for regression models},
|
| 116 |
+
journal = {Neurocomputing},
|
| 117 |
+
volume = {192},
|
| 118 |
+
pages = {38--48},
|
| 119 |
+
year = {2016},
|
| 120 |
+
note = {Advances in artificial neural networks, machine learning and computational intelligence},
|
| 121 |
+
issn = {0925-2312},
|
| 122 |
+
doi = {https://doi.org/10.1016/j.neucom.2015.12.114},
|
| 123 |
+
url = {https://www.sciencedirect.com/science/article/pii/S0925231216003325},
|
| 124 |
+
author = {Arnaud {de Myttenaere} and Boris Golden and Bénédicte {Le Grand} and Fabrice Rossi},
|
| 125 |
+
}
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
## Further References
|
| 129 |
+
- [Mean absolute percentage error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_percentage_error)
|
app.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import evaluate
|
| 2 |
+
from evaluate.utils import launch_gradio_widget
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
module = evaluate.load("mape")
|
| 6 |
+
launch_gradio_widget(module)
|
mape.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 The HuggingFace Datasets Authors and the current dataset script contributor.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""MAPE - Mean Absolute Percentage Error Metric"""
|
| 15 |
+
|
| 16 |
+
import datasets
|
| 17 |
+
from sklearn.metrics import mean_absolute_percentage_error
|
| 18 |
+
|
| 19 |
+
import evaluate
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
_CITATION = """\
|
| 23 |
+
@article{scikit-learn,
|
| 24 |
+
title={Scikit-learn: Machine Learning in {P}ython},
|
| 25 |
+
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
|
| 26 |
+
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
|
| 27 |
+
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
|
| 28 |
+
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
|
| 29 |
+
journal={Journal of Machine Learning Research},
|
| 30 |
+
volume={12},
|
| 31 |
+
pages={2825--2830},
|
| 32 |
+
year={2011}
|
| 33 |
+
}
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
_DESCRIPTION = """\
|
| 37 |
+
Mean Absolute Percentage Error (MAPE) is the mean percentage error difference between the predicted and actual
|
| 38 |
+
values.
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
_KWARGS_DESCRIPTION = """
|
| 43 |
+
Args:
|
| 44 |
+
predictions: array-like of shape (n_samples,) or (n_samples, n_outputs)
|
| 45 |
+
Estimated target values.
|
| 46 |
+
references: array-like of shape (n_samples,) or (n_samples, n_outputs)
|
| 47 |
+
Ground truth (correct) target values.
|
| 48 |
+
sample_weight: array-like of shape (n_samples,), default=None
|
| 49 |
+
Sample weights.
|
| 50 |
+
multioutput: {"raw_values", "uniform_average"} or array-like of shape (n_outputs,), default="uniform_average"
|
| 51 |
+
Defines aggregating of multiple output values. Array-like value defines weights used to average errors.
|
| 52 |
+
|
| 53 |
+
"raw_values" : Returns a full set of errors in case of multioutput input.
|
| 54 |
+
|
| 55 |
+
"uniform_average" : Errors of all outputs are averaged with uniform weight.
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
mape : mean absolute percentage error.
|
| 59 |
+
If multioutput is "raw_values", then mean absolute percentage error is returned for each output separately. If multioutput is "uniform_average" or an ndarray of weights, then the weighted average of all output errors is returned.
|
| 60 |
+
MAPE output is non-negative floating point. The best value is 0.0.
|
| 61 |
+
Examples:
|
| 62 |
+
|
| 63 |
+
>>> mape_metric = evaluate.load("mape")
|
| 64 |
+
>>> predictions = [2.5, 0.0, 2, 8]
|
| 65 |
+
>>> references = [3, -0.5, 2, 7]
|
| 66 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references)
|
| 67 |
+
>>> print(results)
|
| 68 |
+
{'mape': 0.3273809523809524}
|
| 69 |
+
|
| 70 |
+
If you're using multi-dimensional lists, then set the config as follows :
|
| 71 |
+
|
| 72 |
+
>>> mape_metric = evaluate.load("mape", "multilist")
|
| 73 |
+
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
|
| 74 |
+
>>> references = [[0.1, 2], [-1, 2], [8, -5]]
|
| 75 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references)
|
| 76 |
+
>>> print(results)
|
| 77 |
+
{'mape': 0.8874999875823658}
|
| 78 |
+
>>> results = mape_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
|
| 79 |
+
>>> print(results)
|
| 80 |
+
{'mape': array([1.37499998, 0.4 ])}
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
@evaluate.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
|
| 85 |
+
class Mape(evaluate.Metric):
|
| 86 |
+
def _info(self):
|
| 87 |
+
return evaluate.MetricInfo(
|
| 88 |
+
description=_DESCRIPTION,
|
| 89 |
+
citation=_CITATION,
|
| 90 |
+
inputs_description=_KWARGS_DESCRIPTION,
|
| 91 |
+
features=datasets.Features(self._get_feature_types()),
|
| 92 |
+
reference_urls=[
|
| 93 |
+
"https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_absolute_percentage_error.html"
|
| 94 |
+
],
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
def _get_feature_types(self):
|
| 98 |
+
if self.config_name == "multilist":
|
| 99 |
+
return {
|
| 100 |
+
"predictions": datasets.Sequence(datasets.Value("float")),
|
| 101 |
+
"references": datasets.Sequence(datasets.Value("float")),
|
| 102 |
+
}
|
| 103 |
+
else:
|
| 104 |
+
return {
|
| 105 |
+
"predictions": datasets.Value("float"),
|
| 106 |
+
"references": datasets.Value("float"),
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
def _compute(self, predictions, references, sample_weight=None, multioutput="uniform_average"):
|
| 110 |
+
|
| 111 |
+
mape_score = mean_absolute_percentage_error(
|
| 112 |
+
references,
|
| 113 |
+
predictions,
|
| 114 |
+
sample_weight=sample_weight,
|
| 115 |
+
multioutput=multioutput,
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
return {"mape": mape_score}
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
git+https://github.com/huggingface/evaluate@7e21410f9bcff651452f188b702cc80ecd3530e6
|
| 2 |
+
sklearn
|