Spaces:
Sleeping

Sleeping
prasunsrivastava
commited on
Commit
·
d063a8d
1
Parent(s):
acf7a2c
Update the assignment answers
Browse files- BuildingAChainlitApp.md +214 -0
- README.md +340 -1
- chainlit.md +3 -0
- images/docchain_img.png +0 -0
BuildingAChainlitApp.md
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Building a Chainlit App
|
| 2 |
+
|
| 3 |
+
What if we want to take our Week 1 Day 2 assignment - [Pythonic RAG](https://github.com/AI-Maker-Space/AIE4/tree/main/Week%201/Day%202) - and bring it out of the notebook?
|
| 4 |
+
|
| 5 |
+
Well - we'll cover exactly that here!
|
| 6 |
+
|
| 7 |
+
## Anatomy of a Chainlit Application
|
| 8 |
+
|
| 9 |
+
[Chainlit](https://docs.chainlit.io/get-started/overview) is a Python package similar to Streamlit that lets users write a backend and a front end in a single (or multiple) Python file(s). It is mainly used for prototyping LLM-based Chat Style Applications - though it is used in production in some settings with 1,000,000s of MAUs (Monthly Active Users).
|
| 10 |
+
|
| 11 |
+
The primary method of customizing and interacting with the Chainlit UI is through a few critical [decorators](https://blog.hubspot.com/website/decorators-in-python).
|
| 12 |
+
|
| 13 |
+
> NOTE: Simply put, the decorators (in Chainlit) are just ways we can "plug-in" to the functionality in Chainlit.
|
| 14 |
+
|
| 15 |
+
We'll be concerning ourselves with three main scopes:
|
| 16 |
+
|
| 17 |
+
1. On application start - when we start the Chainlit application with a command like `chainlit run app.py`
|
| 18 |
+
2. On chat start - when a chat session starts (a user opens the web browser to the address hosting the application)
|
| 19 |
+
3. On message - when the users sends a message through the input text box in the Chainlit UI
|
| 20 |
+
|
| 21 |
+
Let's dig into each scope and see what we're doing!
|
| 22 |
+
|
| 23 |
+
## On Application Start:
|
| 24 |
+
|
| 25 |
+
The first thing you'll notice is that we have the traditional "wall of imports" this is to ensure we have everything we need to run our application.
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
import os
|
| 29 |
+
from typing import List
|
| 30 |
+
from chainlit.types import AskFileResponse
|
| 31 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 32 |
+
from aimakerspace.openai_utils.prompts import (
|
| 33 |
+
UserRolePrompt,
|
| 34 |
+
SystemRolePrompt,
|
| 35 |
+
AssistantRolePrompt,
|
| 36 |
+
)
|
| 37 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 38 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 39 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 40 |
+
import chainlit as cl
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Next up, we have some prompt templates. As all sessions will use the same prompt templates without modification, and we don't need these templates to be specific per template - we can set them up here - at the application scope.
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
system_template = """\
|
| 47 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 48 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 49 |
+
|
| 50 |
+
user_prompt_template = """\
|
| 51 |
+
Context:
|
| 52 |
+
{context}
|
| 53 |
+
|
| 54 |
+
Question:
|
| 55 |
+
{question}
|
| 56 |
+
"""
|
| 57 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
> NOTE: You'll notice that these are the exact same prompt templates we used from the Pythonic RAG Notebook in Week 1 Day 2!
|
| 61 |
+
|
| 62 |
+
Following that - we can create the Python Class definition for our RAG pipeline - or *chain*, as we'll refer to it in the rest of this walkthrough.
|
| 63 |
+
|
| 64 |
+
Let's look at the definition first:
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
class RetrievalAugmentedQAPipeline:
|
| 68 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 69 |
+
self.llm = llm
|
| 70 |
+
self.vector_db_retriever = vector_db_retriever
|
| 71 |
+
|
| 72 |
+
async def arun_pipeline(self, user_query: str):
|
| 73 |
+
### RETRIEVAL
|
| 74 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 75 |
+
|
| 76 |
+
context_prompt = ""
|
| 77 |
+
for context in context_list:
|
| 78 |
+
context_prompt += context[0] + "\n"
|
| 79 |
+
|
| 80 |
+
### AUGMENTED
|
| 81 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 82 |
+
|
| 83 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
### GENERATION
|
| 87 |
+
async def generate_response():
|
| 88 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 89 |
+
yield chunk
|
| 90 |
+
|
| 91 |
+
return {"response": generate_response(), "context": context_list}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
Notice a few things:
|
| 95 |
+
|
| 96 |
+
1. We have modified this `RetrievalAugmentedQAPipeline` from the initial notebook to support streaming.
|
| 97 |
+
2. In essence, our pipeline is *chaining* a few events together:
|
| 98 |
+
1. We take our user query, and chain it into our Vector Database to collect related chunks
|
| 99 |
+
2. We take those contexts and our user's questions and chain them into the prompt templates
|
| 100 |
+
3. We take that prompt template and chain it into our LLM call
|
| 101 |
+
4. We chain the response of the LLM call to the user
|
| 102 |
+
3. We are using a lot of `async` again!
|
| 103 |
+
|
| 104 |
+
Now, we're going to create a helper function for processing uploaded text files.
|
| 105 |
+
|
| 106 |
+
First, we'll instantiate a shared `CharacterTextSplitter`.
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
text_splitter = CharacterTextSplitter()
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
Now we can define our helper.
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
def process_text_file(file: AskFileResponse):
|
| 116 |
+
import tempfile
|
| 117 |
+
|
| 118 |
+
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=".txt") as temp_file:
|
| 119 |
+
temp_file_path = temp_file.name
|
| 120 |
+
|
| 121 |
+
with open(temp_file_path, "wb") as f:
|
| 122 |
+
f.write(file.content)
|
| 123 |
+
|
| 124 |
+
text_loader = TextFileLoader(temp_file_path)
|
| 125 |
+
documents = text_loader.load_documents()
|
| 126 |
+
texts = text_splitter.split_texts(documents)
|
| 127 |
+
return texts
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Simply put, this downloads the file as a temp file, we load it in with `TextFileLoader` and then split it with our `TextSplitter`, and returns that list of strings!
|
| 131 |
+
|
| 132 |
+
#### QUESTION #1:
|
| 133 |
+
|
| 134 |
+
Why do we want to support streaming? What about streaming is important, or useful?
|
| 135 |
+
|
| 136 |
+
## On Chat Start:
|
| 137 |
+
|
| 138 |
+
The next scope is where "the magic happens". On Chat Start is when a user begins a chat session. This will happen whenever a user opens a new chat window, or refreshes an existing chat window.
|
| 139 |
+
|
| 140 |
+
You'll see that our code is set-up to immediately show the user a chat box requesting them to upload a file.
|
| 141 |
+
|
| 142 |
+
```python
|
| 143 |
+
while files == None:
|
| 144 |
+
files = await cl.AskFileMessage(
|
| 145 |
+
content="Please upload a Text File file to begin!",
|
| 146 |
+
accept=["text/plain"],
|
| 147 |
+
max_size_mb=2,
|
| 148 |
+
timeout=180,
|
| 149 |
+
).send()
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
Once we've obtained the text file - we'll use our processing helper function to process our text!
|
| 153 |
+
|
| 154 |
+
After we have processed our text file - we'll need to create a `VectorDatabase` and populate it with our processed chunks and their related embeddings!
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
vector_db = VectorDatabase()
|
| 158 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
Once we have that piece completed - we can create the chain we'll be using to respond to user queries!
|
| 162 |
+
|
| 163 |
+
```python
|
| 164 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 165 |
+
vector_db_retriever=vector_db,
|
| 166 |
+
llm=chat_openai
|
| 167 |
+
)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
Now, we'll save that into our user session!
|
| 171 |
+
|
| 172 |
+
> NOTE: Chainlit has some great documentation about [User Session](https://docs.chainlit.io/concepts/user-session).
|
| 173 |
+
|
| 174 |
+
### QUESTION #2:
|
| 175 |
+
|
| 176 |
+
Why are we using User Session here? What about Python makes us need to use this? Why not just store everything in a global variable?
|
| 177 |
+
|
| 178 |
+
## On Message
|
| 179 |
+
|
| 180 |
+
First, we load our chain from the user session:
|
| 181 |
+
|
| 182 |
+
```python
|
| 183 |
+
chain = cl.user_session.get("chain")
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
Then, we run the chain on the content of the message - and stream it to the front end - that's it!
|
| 187 |
+
|
| 188 |
+
```python
|
| 189 |
+
msg = cl.Message(content="")
|
| 190 |
+
result = await chain.arun_pipeline(message.content)
|
| 191 |
+
|
| 192 |
+
async for stream_resp in result["response"]:
|
| 193 |
+
await msg.stream_token(stream_resp)
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
## 🎉
|
| 197 |
+
|
| 198 |
+
With that - you've created a Chainlit application that moves our Pythonic RAG notebook to a Chainlit application!
|
| 199 |
+
|
| 200 |
+
## 🚧 CHALLENGE MODE 🚧
|
| 201 |
+
|
| 202 |
+
For an extra challenge - modify the behaviour of your applciation by integrating changes you made to your Pythonic RAG notebook (using new retrieval methods, etc.)
|
| 203 |
+
|
| 204 |
+
If you're still looking for a challenge, or didn't make any modifications to your Pythonic RAG notebook:
|
| 205 |
+
|
| 206 |
+
1) Allow users to upload PDFs (this will require you to build a PDF parser as well)
|
| 207 |
+
2) Modify the VectorStore to leverage [Qdrant](https://python-client.qdrant.tech/)
|
| 208 |
+
|
| 209 |
+
> NOTE: The motivation for these challenges is simple - the beginning of the course is extremely information dense, and people come from all kinds of different technical backgrounds. In order to ensure that all learners are able to engage with the content confidently and comfortably, we want to focus on the basic units of technical competency required. This leads to a situation where some learners, who came in with more robust technical skills, find the introductory material to be too simple - and these open-ended challenges help us do this!
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
|
README.md
CHANGED
|
@@ -8,4 +8,343 @@ pinned: false
|
|
| 8 |
short_description: A bare bones python based RAG
|
| 9 |
---
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
short_description: A bare bones python based RAG
|
| 9 |
---
|
| 10 |
|
| 11 |
+
# Deploying Pythonic Chat With Your Text File Application
|
| 12 |
+
|
| 13 |
+
In today's breakout rooms, we will be following the process that you saw during the challenge.
|
| 14 |
+
|
| 15 |
+
Today, we will repeat the same process - but powered by our Pythonic RAG implementation we created last week.
|
| 16 |
+
|
| 17 |
+
You'll notice a few differences in the `app.py` logic - as well as a few changes to the `aimakerspace` package to get things working smoothly with Chainlit.
|
| 18 |
+
|
| 19 |
+
> NOTE: If you want to run this locally - be sure to use `uv sync`, and then `uv run chainlit run app.py` to start the application outside of Docker.
|
| 20 |
+
|
| 21 |
+
## Reference Diagram (It's Busy, but it works)
|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
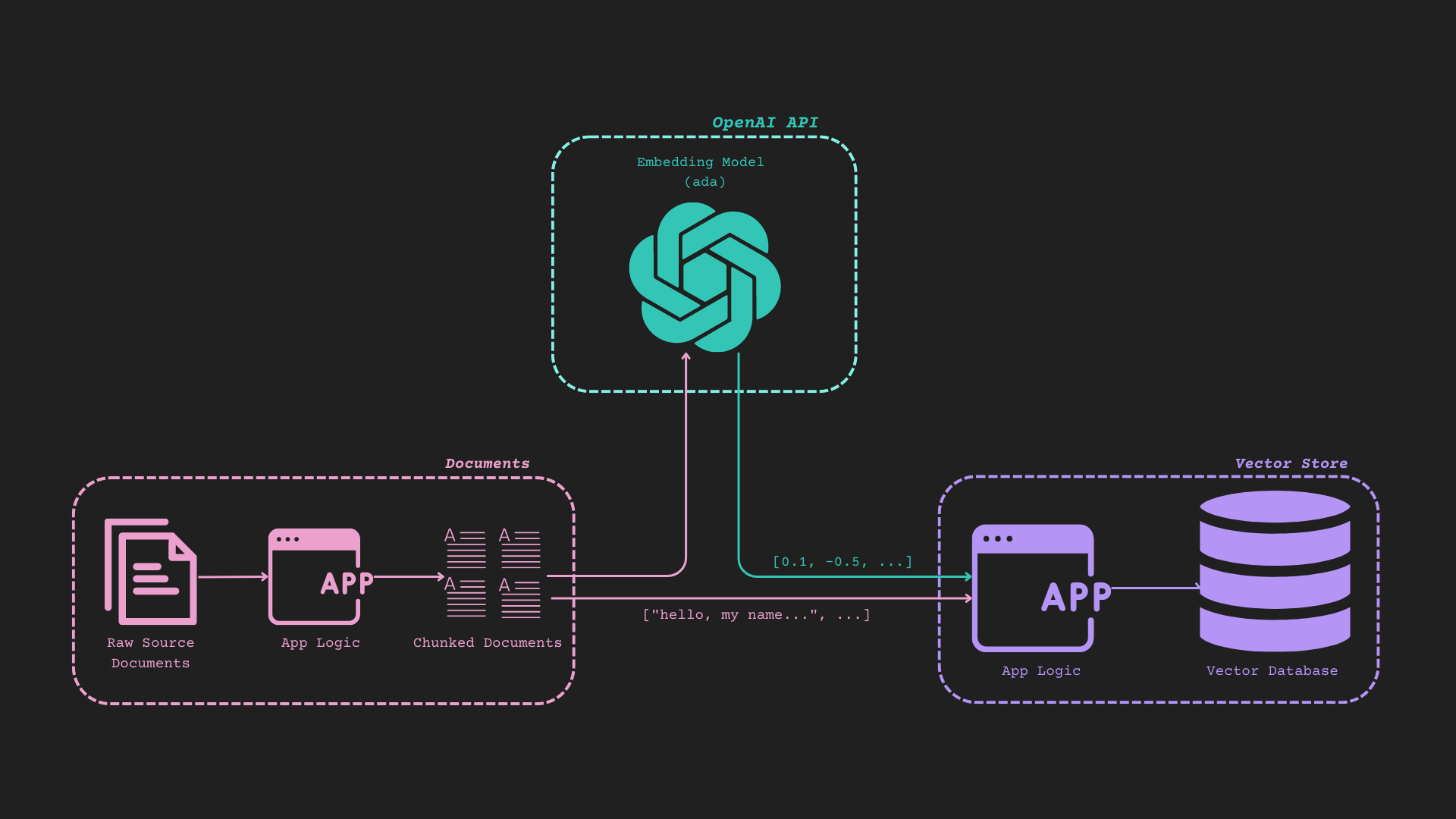
### Anatomy of a Chainlit Application
|
| 26 |
+
|
| 27 |
+
[Chainlit](https://docs.chainlit.io/get-started/overview) is a Python package similar to Streamlit that lets users write a backend and a front end in a single (or multiple) Python file(s). It is mainly used for prototyping LLM-based Chat Style Applications - though it is used in production in some settings with 1,000,000s of MAUs (Monthly Active Users).
|
| 28 |
+
|
| 29 |
+
The primary method of customizing and interacting with the Chainlit UI is through a few critical [decorators](https://blog.hubspot.com/website/decorators-in-python).
|
| 30 |
+
|
| 31 |
+
> NOTE: Simply put, the decorators (in Chainlit) are just ways we can "plug-in" to the functionality in Chainlit.
|
| 32 |
+
|
| 33 |
+
We'll be concerning ourselves with three main scopes:
|
| 34 |
+
|
| 35 |
+
1. On application start - when we start the Chainlit application with a command like `chainlit run app.py`
|
| 36 |
+
2. On chat start - when a chat session starts (a user opens the web browser to the address hosting the application)
|
| 37 |
+
3. On message - when the users sends a message through the input text box in the Chainlit UI
|
| 38 |
+
|
| 39 |
+
Let's dig into each scope and see what we're doing!
|
| 40 |
+
|
| 41 |
+
### On Application Start:
|
| 42 |
+
|
| 43 |
+
The first thing you'll notice is that we have the traditional "wall of imports" this is to ensure we have everything we need to run our application.
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
import os
|
| 47 |
+
from typing import List
|
| 48 |
+
from chainlit.types import AskFileResponse
|
| 49 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 50 |
+
from aimakerspace.openai_utils.prompts import (
|
| 51 |
+
UserRolePrompt,
|
| 52 |
+
SystemRolePrompt,
|
| 53 |
+
AssistantRolePrompt,
|
| 54 |
+
)
|
| 55 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 56 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 57 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 58 |
+
import chainlit as cl
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
Next up, we have some prompt templates. As all sessions will use the same prompt templates without modification, and we don't need these templates to be specific per template - we can set them up here - at the application scope.
|
| 62 |
+
|
| 63 |
+
```python
|
| 64 |
+
system_template = """\
|
| 65 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 66 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 67 |
+
|
| 68 |
+
user_prompt_template = """\
|
| 69 |
+
Context:
|
| 70 |
+
{context}
|
| 71 |
+
|
| 72 |
+
Question:
|
| 73 |
+
{question}
|
| 74 |
+
"""
|
| 75 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
> NOTE: You'll notice that these are the exact same prompt templates we used from the Pythonic RAG Notebook in Week 1 Day 2!
|
| 79 |
+
|
| 80 |
+
Following that - we can create the Python Class definition for our RAG pipeline - or _chain_, as we'll refer to it in the rest of this walkthrough.
|
| 81 |
+
|
| 82 |
+
Let's look at the definition first:
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
class RetrievalAugmentedQAPipeline:
|
| 86 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 87 |
+
self.llm = llm
|
| 88 |
+
self.vector_db_retriever = vector_db_retriever
|
| 89 |
+
|
| 90 |
+
async def arun_pipeline(self, user_query: str):
|
| 91 |
+
### RETRIEVAL
|
| 92 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 93 |
+
|
| 94 |
+
context_prompt = ""
|
| 95 |
+
for context in context_list:
|
| 96 |
+
context_prompt += context[0] + "\n"
|
| 97 |
+
|
| 98 |
+
### AUGMENTED
|
| 99 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 100 |
+
|
| 101 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
### GENERATION
|
| 105 |
+
async def generate_response():
|
| 106 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 107 |
+
yield chunk
|
| 108 |
+
|
| 109 |
+
return {"response": generate_response(), "context": context_list}
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
Notice a few things:
|
| 113 |
+
|
| 114 |
+
1. We have modified this `RetrievalAugmentedQAPipeline` from the initial notebook to support streaming.
|
| 115 |
+
2. In essence, our pipeline is _chaining_ a few events together:
|
| 116 |
+
1. We take our user query, and chain it into our Vector Database to collect related chunks
|
| 117 |
+
2. We take those contexts and our user's questions and chain them into the prompt templates
|
| 118 |
+
3. We take that prompt template and chain it into our LLM call
|
| 119 |
+
4. We chain the response of the LLM call to the user
|
| 120 |
+
3. We are using a lot of `async` again!
|
| 121 |
+
|
| 122 |
+
Now, we're going to create a helper function for processing uploaded text files.
|
| 123 |
+
|
| 124 |
+
First, we'll instantiate a shared `CharacterTextSplitter`.
|
| 125 |
+
|
| 126 |
+
```python
|
| 127 |
+
text_splitter = CharacterTextSplitter()
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Now we can define our helper.
|
| 131 |
+
|
| 132 |
+
```python
|
| 133 |
+
def process_file(file: AskFileResponse):
|
| 134 |
+
import tempfile
|
| 135 |
+
import shutil
|
| 136 |
+
|
| 137 |
+
print(f"Processing file: {file.name}")
|
| 138 |
+
|
| 139 |
+
# Create a temporary file with the correct extension
|
| 140 |
+
suffix = f".{file.name.split('.')[-1]}"
|
| 141 |
+
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as temp_file:
|
| 142 |
+
# Copy the uploaded file content to the temporary file
|
| 143 |
+
shutil.copyfile(file.path, temp_file.name)
|
| 144 |
+
print(f"Created temporary file at: {temp_file.name}")
|
| 145 |
+
|
| 146 |
+
# Create appropriate loader
|
| 147 |
+
if file.name.lower().endswith('.pdf'):
|
| 148 |
+
loader = PDFLoader(temp_file.name)
|
| 149 |
+
else:
|
| 150 |
+
loader = TextFileLoader(temp_file.name)
|
| 151 |
+
|
| 152 |
+
try:
|
| 153 |
+
# Load and process the documents
|
| 154 |
+
documents = loader.load_documents()
|
| 155 |
+
texts = text_splitter.split_texts(documents)
|
| 156 |
+
return texts
|
| 157 |
+
finally:
|
| 158 |
+
# Clean up the temporary file
|
| 159 |
+
try:
|
| 160 |
+
os.unlink(temp_file.name)
|
| 161 |
+
except Exception as e:
|
| 162 |
+
print(f"Error cleaning up temporary file: {e}")
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
Simply put, this downloads the file as a temp file, we load it in with `TextFileLoader` and then split it with our `TextSplitter`, and returns that list of strings!
|
| 166 |
+
|
| 167 |
+
#### ❓ QUESTION #1:
|
| 168 |
+
|
| 169 |
+
Why do we want to support streaming? What about streaming is important, or useful?
|
| 170 |
+
|
| 171 |
+
**Answer: Since the response from LLMs can be slow, we tend to use streaming to start sending the tokens back as the LLM generates the tokens. It gives a user quick feedback and the app does not seem unresponsive or slow.**
|
| 172 |
+
|
| 173 |
+
### On Chat Start:
|
| 174 |
+
|
| 175 |
+
The next scope is where "the magic happens". On Chat Start is when a user begins a chat session. This will happen whenever a user opens a new chat window, or refreshes an existing chat window.
|
| 176 |
+
|
| 177 |
+
You'll see that our code is set-up to immediately show the user a chat box requesting them to upload a file.
|
| 178 |
+
|
| 179 |
+
```python
|
| 180 |
+
while files == None:
|
| 181 |
+
files = await cl.AskFileMessage(
|
| 182 |
+
content="Please upload a Text or PDF file to begin!",
|
| 183 |
+
accept=["text/plain", "application/pdf"],
|
| 184 |
+
max_size_mb=2,
|
| 185 |
+
timeout=180,
|
| 186 |
+
).send()
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
Once we've obtained the text file - we'll use our processing helper function to process our text!
|
| 190 |
+
|
| 191 |
+
After we have processed our text file - we'll need to create a `VectorDatabase` and populate it with our processed chunks and their related embeddings!
|
| 192 |
+
|
| 193 |
+
```python
|
| 194 |
+
vector_db = VectorDatabase()
|
| 195 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
Once we have that piece completed - we can create the chain we'll be using to respond to user queries!
|
| 199 |
+
|
| 200 |
+
```python
|
| 201 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 202 |
+
vector_db_retriever=vector_db,
|
| 203 |
+
llm=chat_openai
|
| 204 |
+
)
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
Now, we'll save that into our user session!
|
| 208 |
+
|
| 209 |
+
> NOTE: Chainlit has some great documentation about [User Session](https://docs.chainlit.io/concepts/user-session).
|
| 210 |
+
|
| 211 |
+
#### ❓ QUESTION #2:
|
| 212 |
+
|
| 213 |
+
Why are we using User Session here? What about Python makes us need to use this? Why not just store everything in a global variable?
|
| 214 |
+
|
| 215 |
+
**Answer: We cannot store everything in a global variable as some state will be specific to a user that is having a chat. We cannot expose the messages of one user chat session to another session. That would be incorrect. That is why each new chat has to be associated to a user session. In chainlit, the chat session related data is also saved in the user session itself. If the user is authnticated, the user specific details are saved in the user session.**
|
| 216 |
+
|
| 217 |
+
### On Message
|
| 218 |
+
|
| 219 |
+
First, we load our chain from the user session:
|
| 220 |
+
|
| 221 |
+
```python
|
| 222 |
+
chain = cl.user_session.get("chain")
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
Then, we run the chain on the content of the message - and stream it to the front end - that's it!
|
| 226 |
+
|
| 227 |
+
```python
|
| 228 |
+
msg = cl.Message(content="")
|
| 229 |
+
result = await chain.arun_pipeline(message.content)
|
| 230 |
+
|
| 231 |
+
async for stream_resp in result["response"]:
|
| 232 |
+
await msg.stream_token(stream_resp)
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
### 🎉
|
| 236 |
+
|
| 237 |
+
With that - you've created a Chainlit application that moves our Pythonic RAG notebook to a Chainlit application!
|
| 238 |
+
|
| 239 |
+
## Deploying the Application to Hugging Face Space
|
| 240 |
+
|
| 241 |
+
Due to the way the repository is created - it should be straightforward to deploy this to a Hugging Face Space!
|
| 242 |
+
|
| 243 |
+
> NOTE: If you wish to go through the local deployments using `uv run chainlit run app.py` and Docker - please feel free to do so!
|
| 244 |
+
|
| 245 |
+
<details>
|
| 246 |
+
<summary>Creating a Hugging Face Space</summary>
|
| 247 |
+
|
| 248 |
+
1. Navigate to the `Spaces` tab.
|
| 249 |
+
|
| 250 |
+

|
| 251 |
+
|
| 252 |
+
2. Click on `Create new Space`
|
| 253 |
+
|
| 254 |
+

|
| 255 |
+
|
| 256 |
+
3. Create the Space by providing values in the form. Make sure you've selected "Docker" as your Space SDK.
|
| 257 |
+
|
| 258 |
+

|
| 259 |
+
|
| 260 |
+
</details>
|
| 261 |
+
|
| 262 |
+
<details>
|
| 263 |
+
<summary>Adding this Repository to the Newly Created Space</summary>
|
| 264 |
+
|
| 265 |
+
1. Collect the SSH address from the newly created Space.
|
| 266 |
+
|
| 267 |
+

|
| 268 |
+
|
| 269 |
+
> NOTE: The address is the component that starts with `[email protected]:spaces/`.
|
| 270 |
+
|
| 271 |
+
2. Use the command:
|
| 272 |
+
|
| 273 |
+
```bash
|
| 274 |
+
git remote add hf HF_SPACE_SSH_ADDRESS_HERE
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
3. Use the command:
|
| 278 |
+
|
| 279 |
+
```bash
|
| 280 |
+
git pull hf main --no-rebase --allow-unrelated-histories -X ours
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
4. Use the command:
|
| 284 |
+
|
| 285 |
+
```bash
|
| 286 |
+
git add .
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
5. Use the command:
|
| 290 |
+
|
| 291 |
+
```bash
|
| 292 |
+
git commit -m "Deploying Pythonic RAG"
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
6. Use the command:
|
| 296 |
+
|
| 297 |
+
```bash
|
| 298 |
+
git push hf main
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
7. The Space should automatically build as soon as the push is completed!
|
| 302 |
+
|
| 303 |
+
> NOTE: The build will fail before you complete the following steps!
|
| 304 |
+
|
| 305 |
+
</details>
|
| 306 |
+
|
| 307 |
+
<details>
|
| 308 |
+
<summary>Adding OpenAI Secrets to the Space</summary>
|
| 309 |
+
|
| 310 |
+
1. Navigate to your Space settings.
|
| 311 |
+
|
| 312 |
+

|
| 313 |
+
|
| 314 |
+
2. Navigate to `Variables and secrets` on the Settings page and click `New secret`:
|
| 315 |
+
|
| 316 |
+

|
| 317 |
+
|
| 318 |
+
3. In the `Name` field - input `OPENAI_API_KEY` in the `Value (private)` field, put your OpenAI API Key.
|
| 319 |
+
|
| 320 |
+

|
| 321 |
+
|
| 322 |
+
4. The Space will begin rebuilding!
|
| 323 |
+
|
| 324 |
+
</details>
|
| 325 |
+
|
| 326 |
+
## 🎉
|
| 327 |
+
|
| 328 |
+
You just deployed Pythonic RAG!
|
| 329 |
+
|
| 330 |
+
Try uploading a text file and asking some questions!
|
| 331 |
+
|
| 332 |
+
#### ❓ Discussion Question #1:
|
| 333 |
+
|
| 334 |
+
Upload a PDF file of the recent DeepSeek-R1 paper and ask the following questions:
|
| 335 |
+
|
| 336 |
+
1. What is RL and how does it help reasoning?
|
| 337 |
+
2. What is the difference between DeepSeek-R1 and DeepSeek-R1-Zero?
|
| 338 |
+
3. What is this paper about?
|
| 339 |
+
|
| 340 |
+
Does this application pass your vibe check? Are there any immediate pitfalls you're noticing?
|
| 341 |
+
|
| 342 |
+
**The application is not able to reason through the questions asked. In my initial try, the application was not able to generate a coherent answer to the second question. It seemed as if it got lost in the details and faced challenges in creating a coherent response. However, subsequently, I have found that it does answer the question and does a decent job but can tend to get lost sometimes. Also, it was unable to answer the last question which leads me to think that the model is not able to digest large pieces of information.**
|
| 343 |
+
|
| 344 |
+
## 🚧 CHALLENGE MODE 🚧
|
| 345 |
+
|
| 346 |
+
For the challenge mode, please instead create a simple FastAPI backend with a simple React (or any other JS framework) frontend.
|
| 347 |
+
|
| 348 |
+
You can use the same prompt templates and RAG pipeline as we did here - but you'll need to modify the code to work with FastAPI and React.
|
| 349 |
+
|
| 350 |
+
Deploy this application to Hugging Face Spaces!
|
chainlit.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Welcome to Chat with Your Text File
|
| 2 |
+
|
| 3 |
+
With this application, you can chat with an uploaded text file that is smaller than 2MB!
|
images/docchain_img.png
ADDED
|