Spaces:
Runtime error

Runtime error
File size: 8,522 Bytes
13b4c2a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 |
<div align="center">
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
An easy-to-use Voice Conversion framework based on VITS.<br><br>
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
[](https://discord.gg/HcsmBBGyVk)
</div>
------
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
Check our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
Training/Inference WebUI:go-web.bat
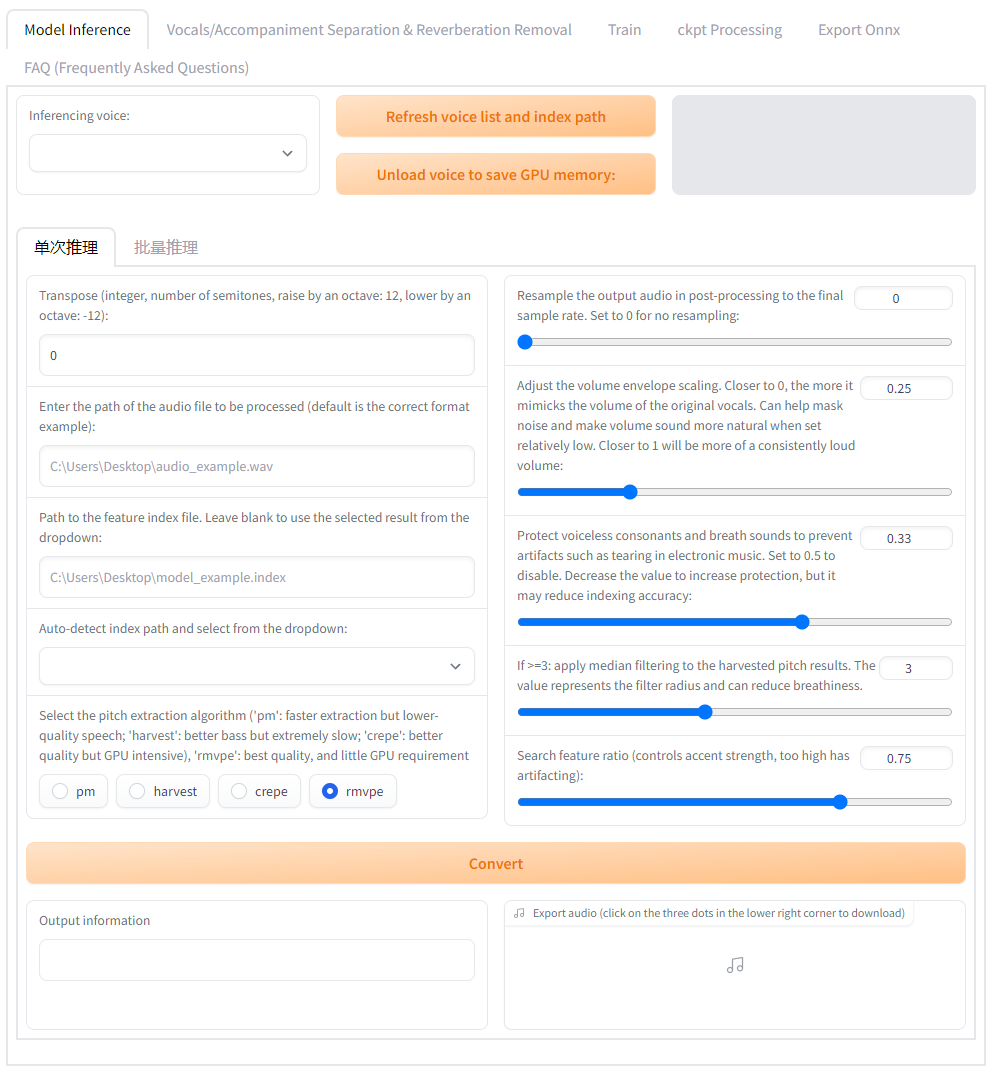
Realtime Voice Conversion GUI:go-realtime-gui.bat
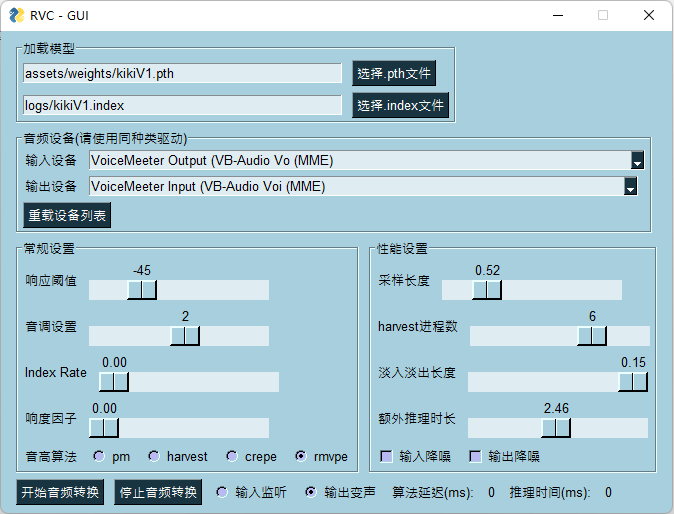
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
## Summary
This repository has the following features:
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
+ Easy and fast training, even on relatively poor graphics cards;
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
+ Easy-to-use Webui interface;
+ Use the UVR5 model to quickly separate vocals and instruments.
+ Use the most powerful High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent the muted sound problem. Provides the best results (significantly) and is faster, with even lower resource consumption than Crepe_full.
+ AMD/Intel graphics cards acceleration supported.
+ Intel ARC graphics cards acceleration with IPEX supported.
## Preparing the environment
The following commands need to be executed in the environment of Python version 3.8 or higher.
(Windows/Linux)
First install the main dependencies through pip:
```bash
# Install PyTorch-related core dependencies, skip if installed
# Reference: https://pytorch.org/get-started/locally/
pip install torch torchvision torchaudio
#For Windows + Nvidia Ampere Architecture(RTX30xx), you need to specify the cuda version corresponding to pytorch according to the experience of https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/21
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
#For Linux + AMD Cards, you need to use the following pytorch versions:
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
```
Then can use poetry to install the other dependencies:
```bash
# Install the Poetry dependency management tool, skip if installed
# Reference: https://python-poetry.org/docs/#installation
curl -sSL https://install.python-poetry.org | python3 -
# Install the project dependencies
poetry install
```
You can also use pip to install them:
```bash
for Nvidia graphics cards
pip install -r requirements.txt
for AMD/Intel graphics cards on Windows (DirectML):
pip install -r requirements-dml.txt
for Intel ARC graphics cards on Linux / WSL using Python 3.10:
pip install -r requirements-ipex.txt
for AMD graphics cards on Linux (ROCm):
pip install -r requirements-amd.txt
```
------
Mac users can install dependencies via `run.sh`:
```bash
sh ./run.sh
```
## Preparation of other Pre-models
RVC requires other pre-models to infer and train.
```bash
#Download all needed models from https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
python tools/download_models.py
```
Or just download them by yourself from our [Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
Here's a list of Pre-models and other files that RVC needs:
```bash
./assets/hubert/hubert_base.pt
./assets/pretrained
./assets/uvr5_weights
Additional downloads are required if you want to test the v2 version of the model.
./assets/pretrained_v2
If you want to test the v2 version model (the v2 version model has changed the input from the 256 dimensional feature of 9-layer Hubert+final_proj to the 768 dimensional feature of 12-layer Hubert, and has added 3 period discriminators), you will need to download additional features
./assets/pretrained_v2
#If you are using Windows, you may also need these two files, skip if FFmpeg and FFprobe are installed
ffmpeg.exe
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
ffprobe.exe
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
If you want to use the latest SOTA RMVPE vocal pitch extraction algorithm, you need to download the RMVPE weights and place them in the RVC root directory
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
For AMD/Intel graphics cards users you need download:
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
```
Intel ARC graphics cards users needs to run `source /opt/intel/oneapi/setvars.sh` command before starting Webui.
Then use this command to start Webui:
```bash
python infer-web.py
```
If you are using Windows or macOS, you can download and extract `RVC-beta.7z` to use RVC directly by using `go-web.bat` on windows or `sh ./run.sh` on macOS to start Webui.
## ROCm Support for AMD graphic cards (Linux only)
To use ROCm on Linux install all required drivers as described [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
On Arch use pacman to install the driver:
````
pacman -S rocm-hip-sdk rocm-opencl-sdk
````
You might also need to set these environment variables (e.g. on a RX6700XT):
````
export ROCM_PATH=/opt/rocm
export HSA_OVERRIDE_GFX_VERSION=10.3.0
````
Also make sure your user is part of the `render` and `video` group:
````
sudo usermod -aG render $USERNAME
sudo usermod -aG video $USERNAME
````
After that you can run the WebUI:
```bash
python infer-web.py
```
## Credits
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
+ [VITS](https://github.com/jaywalnut310/vits)
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
+ [Gradio](https://github.com/gradio-app/gradio)
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
## Thanks to all contributors for their efforts
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
</a>
|