Spaces:
Runtime error

Runtime error
Delete Retrieval-based-Voice-Conversion-WebUI
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Retrieval-based-Voice-Conversion-WebUI/.env +0 -8
- Retrieval-based-Voice-Conversion-WebUI/.github/PULL_REQUEST_TEMPLATE.md +0 -30
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/docker.yml +0 -70
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/genlocale.yml +0 -38
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/pull_format.yml +0 -48
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/push_format.yml +0 -52
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/sync_dev.yml +0 -23
- Retrieval-based-Voice-Conversion-WebUI/.github/workflows/unitest.yml +0 -36
- Retrieval-based-Voice-Conversion-WebUI/.gitignore +0 -23
- Retrieval-based-Voice-Conversion-WebUI/Changelog_CN.md +0 -35
- Retrieval-based-Voice-Conversion-WebUI/Dockerfile +0 -47
- Retrieval-based-Voice-Conversion-WebUI/LICENSE +0 -23
- Retrieval-based-Voice-Conversion-WebUI/MIT协议暨相关引用库协议 +0 -45
- Retrieval-based-Voice-Conversion-WebUI/README.md +0 -177
- Retrieval-based-Voice-Conversion-WebUI/Retrieval_based_Voice_Conversion_WebUI.ipynb +0 -403
- Retrieval-based-Voice-Conversion-WebUI/Retrieval_based_Voice_Conversion_WebUI_v2.ipynb +0 -422
- Retrieval-based-Voice-Conversion-WebUI/assets/Synthesizer_inputs.pth +0 -3
- Retrieval-based-Voice-Conversion-WebUI/assets/hubert/.gitignore +0 -3
- Retrieval-based-Voice-Conversion-WebUI/assets/hubert/hubert_inputs.pth +0 -3
- Retrieval-based-Voice-Conversion-WebUI/assets/pretrained/.gitignore +0 -2
- Retrieval-based-Voice-Conversion-WebUI/assets/pretrained_v2/.gitignore +0 -2
- Retrieval-based-Voice-Conversion-WebUI/assets/rmvpe/.gitignore +0 -3
- Retrieval-based-Voice-Conversion-WebUI/assets/rmvpe/rmvpe_inputs.pth +0 -3
- Retrieval-based-Voice-Conversion-WebUI/assets/uvr5_weights/.gitignore +0 -2
- Retrieval-based-Voice-Conversion-WebUI/assets/weights/.gitignore +0 -2
- Retrieval-based-Voice-Conversion-WebUI/config.py +0 -117
- Retrieval-based-Voice-Conversion-WebUI/configs/32k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/40k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/48k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/config.json +0 -1
- Retrieval-based-Voice-Conversion-WebUI/configs/config.py +0 -251
- Retrieval-based-Voice-Conversion-WebUI/configs/v1/32k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/v1/40k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/v1/48k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/v2/32k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/configs/v2/48k.json +0 -46
- Retrieval-based-Voice-Conversion-WebUI/docker-compose.yml +0 -20
- Retrieval-based-Voice-Conversion-WebUI/docs/.DS_Store +0 -0
- Retrieval-based-Voice-Conversion-WebUI/docs/README.en.md +0 -102
- Retrieval-based-Voice-Conversion-WebUI/docs/README.ja.md +0 -106
- Retrieval-based-Voice-Conversion-WebUI/docs/README.ko.han.md +0 -102
- Retrieval-based-Voice-Conversion-WebUI/docs/README.ko.md +0 -102
- Retrieval-based-Voice-Conversion-WebUI/docs/cn/Changelog_CN.md +0 -109
- Retrieval-based-Voice-Conversion-WebUI/docs/cn/faq.md +0 -108
- Retrieval-based-Voice-Conversion-WebUI/docs/en/Changelog_EN.md +0 -105
- Retrieval-based-Voice-Conversion-WebUI/docs/en/README.en.md +0 -194
- Retrieval-based-Voice-Conversion-WebUI/docs/en/faiss_tips_en.md +0 -102
- Retrieval-based-Voice-Conversion-WebUI/docs/en/faq_en.md +0 -119
- Retrieval-based-Voice-Conversion-WebUI/docs/en/training_tips_en.md +0 -65
- Retrieval-based-Voice-Conversion-WebUI/docs/faiss_tips_en.md +0 -102
Retrieval-based-Voice-Conversion-WebUI/.env
DELETED
|
@@ -1,8 +0,0 @@
|
|
| 1 |
-
OPENBLAS_NUM_THREADS = 1
|
| 2 |
-
no_proxy = localhost, 127.0.0.1, ::1
|
| 3 |
-
|
| 4 |
-
# You can change the location of the model, etc. by changing here
|
| 5 |
-
weight_root = assets/weights
|
| 6 |
-
weight_uvr5_root = assets/uvr5_weights
|
| 7 |
-
index_root = logs
|
| 8 |
-
rmvpe_root = assets/rmvpe
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/PULL_REQUEST_TEMPLATE.md
DELETED
|
@@ -1,30 +0,0 @@
|
|
| 1 |
-
# Pull request checklist
|
| 2 |
-
|
| 3 |
-
- [ ] The PR has a proper title. Use [Semantic Commit Messages](https://seesparkbox.com/foundry/semantic_commit_messages). (No more branch-name title please)
|
| 4 |
-
- [ ] Make sure you are requesting the right branch: `dev`.
|
| 5 |
-
- [ ] Make sure this is ready to be merged into the relevant branch. Please don't create a PR and let it hang for a few days.
|
| 6 |
-
- [ ] Ensure all tests are passing.
|
| 7 |
-
- [ ] Ensure linting is passing.
|
| 8 |
-
|
| 9 |
-
# PR type
|
| 10 |
-
|
| 11 |
-
- Bug fix / new feature / chore
|
| 12 |
-
|
| 13 |
-
# Description
|
| 14 |
-
|
| 15 |
-
- Describe what this pull request is for.
|
| 16 |
-
- What will it affect.
|
| 17 |
-
|
| 18 |
-
# Screenshot
|
| 19 |
-
|
| 20 |
-
- Please include a screenshot if applicable
|
| 21 |
-
|
| 22 |
-
# Localhost url to test on
|
| 23 |
-
|
| 24 |
-
- Please include a url on localhost to test.
|
| 25 |
-
|
| 26 |
-
# Jira Link
|
| 27 |
-
|
| 28 |
-
- Please include a link to the ticket if applicable.
|
| 29 |
-
|
| 30 |
-
[Ticket]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/docker.yml
DELETED
|
@@ -1,70 +0,0 @@
|
|
| 1 |
-
name: Build and Push Docker Image
|
| 2 |
-
|
| 3 |
-
on:
|
| 4 |
-
workflow_dispatch:
|
| 5 |
-
push:
|
| 6 |
-
# Sequence of patterns matched against refs/tags
|
| 7 |
-
tags:
|
| 8 |
-
- 'v*' # Push events to matching v*, i.e. v1.0, v20.15.10
|
| 9 |
-
|
| 10 |
-
jobs:
|
| 11 |
-
build:
|
| 12 |
-
runs-on: ubuntu-latest
|
| 13 |
-
permissions:
|
| 14 |
-
packages: write
|
| 15 |
-
contents: read
|
| 16 |
-
steps:
|
| 17 |
-
- uses: actions/checkout@v3
|
| 18 |
-
- name: Set time zone
|
| 19 |
-
uses: szenius/[email protected]
|
| 20 |
-
with:
|
| 21 |
-
timezoneLinux: "Asia/Shanghai"
|
| 22 |
-
timezoneMacos: "Asia/Shanghai"
|
| 23 |
-
timezoneWindows: "China Standard Time"
|
| 24 |
-
|
| 25 |
-
# # 如果有 dockerhub 账户,可以在github的secrets中配置下面两个,然后取消下面注释的这几行,并在meta步骤的images增加一行 ${{ github.repository }}
|
| 26 |
-
# - name: Login to DockerHub
|
| 27 |
-
# uses: docker/login-action@v1
|
| 28 |
-
# with:
|
| 29 |
-
# username: ${{ secrets.DOCKERHUB_USERNAME }}
|
| 30 |
-
# password: ${{ secrets.DOCKERHUB_TOKEN }}
|
| 31 |
-
|
| 32 |
-
- name: Login to GHCR
|
| 33 |
-
uses: docker/login-action@v2
|
| 34 |
-
with:
|
| 35 |
-
registry: ghcr.io
|
| 36 |
-
username: ${{ github.repository_owner }}
|
| 37 |
-
password: ${{ secrets.GITHUB_TOKEN }}
|
| 38 |
-
|
| 39 |
-
- name: Extract metadata (tags, labels) for Docker
|
| 40 |
-
id: meta
|
| 41 |
-
uses: docker/metadata-action@v4
|
| 42 |
-
with:
|
| 43 |
-
images: |
|
| 44 |
-
ghcr.io/${{ github.repository }}
|
| 45 |
-
# generate Docker tags based on the following events/attributes
|
| 46 |
-
# nightly, master, pr-2, 1.2.3, 1.2, 1
|
| 47 |
-
tags: |
|
| 48 |
-
type=schedule,pattern=nightly
|
| 49 |
-
type=edge
|
| 50 |
-
type=ref,event=branch
|
| 51 |
-
type=ref,event=pr
|
| 52 |
-
type=semver,pattern={{version}}
|
| 53 |
-
type=semver,pattern={{major}}.{{minor}}
|
| 54 |
-
type=semver,pattern={{major}}
|
| 55 |
-
|
| 56 |
-
- name: Set up QEMU
|
| 57 |
-
uses: docker/setup-qemu-action@v2
|
| 58 |
-
|
| 59 |
-
- name: Set up Docker Buildx
|
| 60 |
-
uses: docker/setup-buildx-action@v2
|
| 61 |
-
|
| 62 |
-
- name: Build and push
|
| 63 |
-
id: docker_build
|
| 64 |
-
uses: docker/build-push-action@v4
|
| 65 |
-
with:
|
| 66 |
-
context: .
|
| 67 |
-
platforms: linux/amd64,linux/arm64
|
| 68 |
-
push: true
|
| 69 |
-
tags: ${{ steps.meta.outputs.tags }}
|
| 70 |
-
labels: ${{ steps.meta.outputs.labels }}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/genlocale.yml
DELETED
|
@@ -1,38 +0,0 @@
|
|
| 1 |
-
name: Generate and Sync Locale
|
| 2 |
-
on:
|
| 3 |
-
push:
|
| 4 |
-
branches:
|
| 5 |
-
- main
|
| 6 |
-
- dev
|
| 7 |
-
jobs:
|
| 8 |
-
genlocale:
|
| 9 |
-
runs-on: ubuntu-latest
|
| 10 |
-
steps:
|
| 11 |
-
- uses: actions/checkout@master
|
| 12 |
-
|
| 13 |
-
- name: Run locale generation
|
| 14 |
-
run: |
|
| 15 |
-
python3 i18n/scan_i18n.py
|
| 16 |
-
cd i18n
|
| 17 |
-
python3 locale_diff.py
|
| 18 |
-
|
| 19 |
-
- name: Commit back
|
| 20 |
-
if: ${{ !github.head_ref }}
|
| 21 |
-
id: commitback
|
| 22 |
-
continue-on-error: true
|
| 23 |
-
run: |
|
| 24 |
-
git config --local user.name 'github-actions[bot]'
|
| 25 |
-
git config --local user.email 'github-actions[bot]@users.noreply.github.com'
|
| 26 |
-
git add --all
|
| 27 |
-
git commit -m "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 28 |
-
|
| 29 |
-
- name: Create Pull Request
|
| 30 |
-
if: steps.commitback.outcome == 'success'
|
| 31 |
-
continue-on-error: true
|
| 32 |
-
uses: peter-evans/create-pull-request@v5
|
| 33 |
-
with:
|
| 34 |
-
delete-branch: true
|
| 35 |
-
body: "Automatically sync i18n translation jsons"
|
| 36 |
-
title: "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 37 |
-
commit-message: "chore(i18n): sync locale on ${{github.ref_name}}"
|
| 38 |
-
branch: genlocale-${{github.ref_name}}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/pull_format.yml
DELETED
|
@@ -1,48 +0,0 @@
|
|
| 1 |
-
name: Check Pull Format
|
| 2 |
-
|
| 3 |
-
on:
|
| 4 |
-
pull_request_target:
|
| 5 |
-
types: [opened, reopened]
|
| 6 |
-
|
| 7 |
-
jobs:
|
| 8 |
-
# This workflow closes invalid PR
|
| 9 |
-
close_pr:
|
| 10 |
-
# The type of runner that the job will run on
|
| 11 |
-
runs-on: ubuntu-latest
|
| 12 |
-
permissions: write-all
|
| 13 |
-
|
| 14 |
-
# Steps represent a sequence of tasks that will be executed as part of the job
|
| 15 |
-
steps:
|
| 16 |
-
- name: Close PR if it is not pointed to dev branch
|
| 17 |
-
if: github.event.pull_request.base.ref != 'dev'
|
| 18 |
-
uses: superbrothers/close-pull-request@v3
|
| 19 |
-
with:
|
| 20 |
-
# Optional. Post a issue comment just before closing a pull request.
|
| 21 |
-
comment: "Invalid PR to `non-dev` branch `${{ github.event.pull_request.base.ref }}`."
|
| 22 |
-
|
| 23 |
-
pull_format:
|
| 24 |
-
runs-on: ubuntu-latest
|
| 25 |
-
permissions:
|
| 26 |
-
contents: write
|
| 27 |
-
|
| 28 |
-
continue-on-error: true
|
| 29 |
-
|
| 30 |
-
steps:
|
| 31 |
-
- name: Checkout
|
| 32 |
-
continue-on-error: true
|
| 33 |
-
uses: actions/checkout@v3
|
| 34 |
-
with:
|
| 35 |
-
ref: ${{ github.head_ref }}
|
| 36 |
-
fetch-depth: 0
|
| 37 |
-
|
| 38 |
-
- name: Set up Python ${{ matrix.python-version }}
|
| 39 |
-
uses: actions/setup-python@v4
|
| 40 |
-
with:
|
| 41 |
-
python-version: ${{ matrix.python-version }}
|
| 42 |
-
|
| 43 |
-
- name: Install Black
|
| 44 |
-
run: pip install "black[jupyter]"
|
| 45 |
-
|
| 46 |
-
- name: Run Black
|
| 47 |
-
# run: black $(git ls-files '*.py')
|
| 48 |
-
run: black .
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/push_format.yml
DELETED
|
@@ -1,52 +0,0 @@
|
|
| 1 |
-
name: Standardize Code Format
|
| 2 |
-
|
| 3 |
-
on:
|
| 4 |
-
push:
|
| 5 |
-
branches:
|
| 6 |
-
- main
|
| 7 |
-
- dev
|
| 8 |
-
|
| 9 |
-
jobs:
|
| 10 |
-
push_format:
|
| 11 |
-
runs-on: ubuntu-latest
|
| 12 |
-
|
| 13 |
-
permissions:
|
| 14 |
-
contents: write
|
| 15 |
-
pull-requests: write
|
| 16 |
-
|
| 17 |
-
steps:
|
| 18 |
-
- uses: actions/checkout@v3
|
| 19 |
-
with:
|
| 20 |
-
ref: ${{github.ref_name}}
|
| 21 |
-
|
| 22 |
-
- name: Set up Python ${{ matrix.python-version }}
|
| 23 |
-
uses: actions/setup-python@v4
|
| 24 |
-
with:
|
| 25 |
-
python-version: ${{ matrix.python-version }}
|
| 26 |
-
|
| 27 |
-
- name: Install Black
|
| 28 |
-
run: pip install "black[jupyter]"
|
| 29 |
-
|
| 30 |
-
- name: Run Black
|
| 31 |
-
# run: black $(git ls-files '*.py')
|
| 32 |
-
run: black .
|
| 33 |
-
|
| 34 |
-
- name: Commit Back
|
| 35 |
-
continue-on-error: true
|
| 36 |
-
id: commitback
|
| 37 |
-
run: |
|
| 38 |
-
git config --local user.email "github-actions[bot]@users.noreply.github.com"
|
| 39 |
-
git config --local user.name "github-actions[bot]"
|
| 40 |
-
git add --all
|
| 41 |
-
git commit -m "chore(format): run black on ${{github.ref_name}}"
|
| 42 |
-
|
| 43 |
-
- name: Create Pull Request
|
| 44 |
-
if: steps.commitback.outcome == 'success'
|
| 45 |
-
continue-on-error: true
|
| 46 |
-
uses: peter-evans/create-pull-request@v5
|
| 47 |
-
with:
|
| 48 |
-
delete-branch: true
|
| 49 |
-
body: "Automatically apply code formatter change"
|
| 50 |
-
title: "chore(format): run black on ${{github.ref_name}}"
|
| 51 |
-
commit-message: "chore(format): run black on ${{github.ref_name}}"
|
| 52 |
-
branch: formatter-${{github.ref_name}}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/sync_dev.yml
DELETED
|
@@ -1,23 +0,0 @@
|
|
| 1 |
-
name: Merge dev into main
|
| 2 |
-
|
| 3 |
-
on:
|
| 4 |
-
workflow_dispatch:
|
| 5 |
-
|
| 6 |
-
jobs:
|
| 7 |
-
sync_dev:
|
| 8 |
-
runs-on: ubuntu-latest
|
| 9 |
-
|
| 10 |
-
permissions:
|
| 11 |
-
contents: write
|
| 12 |
-
pull-requests: write
|
| 13 |
-
|
| 14 |
-
steps:
|
| 15 |
-
- uses: actions/checkout@v3
|
| 16 |
-
with:
|
| 17 |
-
ref: main
|
| 18 |
-
|
| 19 |
-
- name: Create Pull Request
|
| 20 |
-
run: |
|
| 21 |
-
gh pr create --title "chore(sync): merge dev into main" --body "Merge dev to main" --base main --head dev
|
| 22 |
-
env:
|
| 23 |
-
GH_TOKEN: ${{ github.token }}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.github/workflows/unitest.yml
DELETED
|
@@ -1,36 +0,0 @@
|
|
| 1 |
-
name: Unit Test
|
| 2 |
-
on: [ push, pull_request ]
|
| 3 |
-
jobs:
|
| 4 |
-
build:
|
| 5 |
-
runs-on: ${{ matrix.os }}
|
| 6 |
-
strategy:
|
| 7 |
-
matrix:
|
| 8 |
-
python-version: ["3.8", "3.9", "3.10"]
|
| 9 |
-
os: [ubuntu-latest]
|
| 10 |
-
fail-fast: true
|
| 11 |
-
|
| 12 |
-
steps:
|
| 13 |
-
- uses: actions/checkout@master
|
| 14 |
-
- name: Set up Python ${{ matrix.python-version }}
|
| 15 |
-
uses: actions/setup-python@v4
|
| 16 |
-
with:
|
| 17 |
-
python-version: ${{ matrix.python-version }}
|
| 18 |
-
- name: Install dependencies
|
| 19 |
-
run: |
|
| 20 |
-
sudo apt update
|
| 21 |
-
sudo apt -y install ffmpeg
|
| 22 |
-
sudo apt -y install -qq aria2
|
| 23 |
-
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d ./ -o hubert_base.pt
|
| 24 |
-
python -m pip install --upgrade pip
|
| 25 |
-
python -m pip install --upgrade setuptools
|
| 26 |
-
python -m pip install --upgrade wheel
|
| 27 |
-
pip install torch torchvision torchaudio
|
| 28 |
-
pip install -r requirements.txt
|
| 29 |
-
- name: Test step 1 & 2
|
| 30 |
-
run: |
|
| 31 |
-
mkdir -p logs/mi-test
|
| 32 |
-
touch logs/mi-test/preprocess.log
|
| 33 |
-
python infer/modules/train/preprocess.py logs/mute/0_gt_wavs 48000 8 logs/mi-test True 3.7
|
| 34 |
-
touch logs/mi-test/extract_f0_feature.log
|
| 35 |
-
python infer/modules/train/extract/extract_f0_print.py logs/mi-test $(nproc) pm
|
| 36 |
-
python infer/modules/train/extract_feature_print.py cpu 1 0 0 logs/mi-test v1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/.gitignore
DELETED
|
@@ -1,23 +0,0 @@
|
|
| 1 |
-
.DS_Store
|
| 2 |
-
__pycache__
|
| 3 |
-
/TEMP
|
| 4 |
-
*.pyd
|
| 5 |
-
.venv
|
| 6 |
-
/opt
|
| 7 |
-
tools/aria2c/
|
| 8 |
-
tools/flag.txt
|
| 9 |
-
|
| 10 |
-
# Imported from huggingface.co/lj1995/VoiceConversionWebUI
|
| 11 |
-
/pretrained
|
| 12 |
-
/pretrained_v2
|
| 13 |
-
/uvr5_weights
|
| 14 |
-
hubert_base.pt
|
| 15 |
-
rmvpe.onnx
|
| 16 |
-
rmvpe.pt
|
| 17 |
-
|
| 18 |
-
# Generated by RVC
|
| 19 |
-
/logs
|
| 20 |
-
/weights
|
| 21 |
-
|
| 22 |
-
# To set a Python version for the project
|
| 23 |
-
.tool-versions
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/Changelog_CN.md
DELETED
|
@@ -1,35 +0,0 @@
|
|
| 1 |
-
### 20230409
|
| 2 |
-
- 修正训练参数,提升显卡平均利用率,A100最高从25%提升至90%左右,V100:50%->90%左右,2060S:60%->85%左右,P40:25%->95%左右,训练速度显著提升
|
| 3 |
-
- 修正参数:总batch_size改为每张卡的batch_size
|
| 4 |
-
- 修正total_epoch:最大限制100解锁至1000;默认10提升至默认20
|
| 5 |
-
- 修复ckpt提取识别是否带音高错误导致推理异常的问题
|
| 6 |
-
- 修复分布式训练每个rank都保存一次ckpt的问题
|
| 7 |
-
- 特征提取进行nan特征过滤
|
| 8 |
-
- 修复静音输入输出随机辅音or噪声的问题(老版模型需要重做训练集重训)
|
| 9 |
-
|
| 10 |
-
### 20230416更新
|
| 11 |
-
- 新增本地实时变声迷你GUI,双击go-realtime-gui.bat启动
|
| 12 |
-
- 训练推理均对<50Hz的频段进行滤波过滤
|
| 13 |
-
- 训练推理音高提取pyworld最低音高从默认80下降至50,50-80hz间的男声低音不会哑
|
| 14 |
-
- WebUI支持根据系统区域变更语言(现支持en_US,ja_JP,zh_CN,zh_HK,zh_SG,zh_TW,不支持的默认en_US)
|
| 15 |
-
- 修正部分显卡识别(例如V100-16G识别失败,P4识别失败)
|
| 16 |
-
|
| 17 |
-
### 20230428更新
|
| 18 |
-
- 升级faiss索引设置,速度更快,质量更高
|
| 19 |
-
- 取消total_npy依赖,后续分享模型不再需要填写total_npy
|
| 20 |
-
- 解锁16系限制。4G显存GPU给到4G的推理设置。
|
| 21 |
-
- 修复部分音频格式下UVR5人声伴奏分离的bug
|
| 22 |
-
- 实时变声迷你gui增加对非40k与不懈怠音高模型的支持
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
### 后续计划:
|
| 26 |
-
功能:
|
| 27 |
-
- 增加选项:每次epoch保存的小模型均进行提取
|
| 28 |
-
- 增加选项:推理额外导出mp3至填写的路径
|
| 29 |
-
- 支持多人训练选项卡(至多4人)
|
| 30 |
-
-
|
| 31 |
-
底模:
|
| 32 |
-
- 收集呼吸wav加入训练集修正呼吸变声电音的问题
|
| 33 |
-
- 我们正在训练增加了歌声训练集的底模,未来会公开
|
| 34 |
-
- 升级鉴别器
|
| 35 |
-
- 升级自监督特征结构
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/Dockerfile
DELETED
|
@@ -1,47 +0,0 @@
|
|
| 1 |
-
# syntax=docker/dockerfile:1
|
| 2 |
-
|
| 3 |
-
FROM nvidia/cuda:11.6.2-cudnn8-runtime-ubuntu20.04
|
| 4 |
-
|
| 5 |
-
EXPOSE 7865
|
| 6 |
-
|
| 7 |
-
WORKDIR /app
|
| 8 |
-
|
| 9 |
-
COPY . .
|
| 10 |
-
|
| 11 |
-
# Install dependenceis to add PPAs
|
| 12 |
-
RUN apt-get update && \
|
| 13 |
-
apt-get install -y -qq ffmpeg aria2 && apt clean && \
|
| 14 |
-
apt-get install -y software-properties-common && \
|
| 15 |
-
apt-get clean && \
|
| 16 |
-
rm -rf /var/lib/apt/lists/*
|
| 17 |
-
|
| 18 |
-
# Add the deadsnakes PPA to get Python 3.9
|
| 19 |
-
RUN add-apt-repository ppa:deadsnakes/ppa
|
| 20 |
-
|
| 21 |
-
# Install Python 3.9 and pip
|
| 22 |
-
RUN apt-get update && \
|
| 23 |
-
apt-get install -y build-essential python-dev python3-dev python3.9-distutils python3.9-dev python3.9 curl && \
|
| 24 |
-
apt-get clean && \
|
| 25 |
-
update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.9 1 && \
|
| 26 |
-
curl https://bootstrap.pypa.io/get-pip.py | python3.9
|
| 27 |
-
|
| 28 |
-
# Set Python 3.9 as the default
|
| 29 |
-
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3.9 1
|
| 30 |
-
|
| 31 |
-
RUN python3 -m pip install --no-cache-dir -r requirements.txt
|
| 32 |
-
|
| 33 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d assets/pretrained_v2/ -o D40k.pth
|
| 34 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d assets/pretrained_v2/ -o G40k.pth
|
| 35 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth -d assets/pretrained_v2/ -o f0D40k.pth
|
| 36 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth -d assets/pretrained_v2/ -o f0G40k.pth
|
| 37 |
-
|
| 38 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2-人声vocals+非人声instrumentals.pth -d assets/uvr5_weights/ -o HP2-人声vocals+非人声instrumentals.pth
|
| 39 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth -d assets/uvr5_weights/ -o HP5-主旋律人声vocals+其他instrumentals.pth
|
| 40 |
-
|
| 41 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d assets/hubert -o hubert_base.pt
|
| 42 |
-
|
| 43 |
-
RUN aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt -d assets/rmvpe -o rmvpe.pt
|
| 44 |
-
|
| 45 |
-
VOLUME [ "/app/weights", "/app/opt" ]
|
| 46 |
-
|
| 47 |
-
CMD ["python3", "infer-web.py"]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/LICENSE
DELETED
|
@@ -1,23 +0,0 @@
|
|
| 1 |
-
MIT License
|
| 2 |
-
|
| 3 |
-
Copyright (c) 2023 liujing04
|
| 4 |
-
Copyright (c) 2023 源文雨
|
| 5 |
-
Copyright (c) 2023 Ftps
|
| 6 |
-
|
| 7 |
-
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 8 |
-
of this software and associated documentation files (the "Software"), to deal
|
| 9 |
-
in the Software without restriction, including without limitation the rights
|
| 10 |
-
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 11 |
-
copies of the Software, and to permit persons to whom the Software is
|
| 12 |
-
furnished to do so, subject to the following conditions:
|
| 13 |
-
|
| 14 |
-
The above copyright notice and this permission notice shall be included in all
|
| 15 |
-
copies or substantial portions of the Software.
|
| 16 |
-
|
| 17 |
-
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 18 |
-
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 19 |
-
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 20 |
-
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 21 |
-
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 22 |
-
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 23 |
-
SOFTWARE.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/MIT协议暨相关引用库协议
DELETED
|
@@ -1,45 +0,0 @@
|
|
| 1 |
-
本软件及其相关代码以MIT协议开源,作者不对软件具备任何控制力,使用软件者、传播软件导出的声音者自负全责。
|
| 2 |
-
如不认可该条款,则不能使用或引用软件包内任何代码和文件。
|
| 3 |
-
|
| 4 |
-
特此授予任何获得本软件和相关文档文件(以下简称“软件”)副本的人免费使用、复制、修改、合并、出版、分发、再授权和/或销售本软件的权利,以及授予本软件所提供的人使用本软件的权利,但须符合以下条件:
|
| 5 |
-
上述版权声明和本许可声明应包含在软件的所有副本或实质部分中。
|
| 6 |
-
软件是“按原样”提供的,没有任何明示或暗示的保证,包括但不限于适销性、适用于特定目的和不侵权的保证。在任何情况下,作者或版权持有人均不承担因软件或软件的使用或其他交易而产生、产生或与之相关的任何索赔、损害赔偿或其他责任,无论是在合同诉讼、侵权诉讼还是其他诉讼中。
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
The LICENCEs for related libraries are as follows.
|
| 10 |
-
相关引用库协议如下:
|
| 11 |
-
|
| 12 |
-
ContentVec
|
| 13 |
-
https://github.com/auspicious3000/contentvec/blob/main/LICENSE
|
| 14 |
-
MIT License
|
| 15 |
-
|
| 16 |
-
VITS
|
| 17 |
-
https://github.com/jaywalnut310/vits/blob/main/LICENSE
|
| 18 |
-
MIT License
|
| 19 |
-
|
| 20 |
-
HIFIGAN
|
| 21 |
-
https://github.com/jik876/hifi-gan/blob/master/LICENSE
|
| 22 |
-
MIT License
|
| 23 |
-
|
| 24 |
-
gradio
|
| 25 |
-
https://github.com/gradio-app/gradio/blob/main/LICENSE
|
| 26 |
-
Apache License 2.0
|
| 27 |
-
|
| 28 |
-
ffmpeg
|
| 29 |
-
https://github.com/FFmpeg/FFmpeg/blob/master/COPYING.LGPLv3
|
| 30 |
-
https://github.com/BtbN/FFmpeg-Builds/releases/download/autobuild-2021-02-28-12-32/ffmpeg-n4.3.2-160-gfbb9368226-win64-lgpl-4.3.zip
|
| 31 |
-
LPGLv3 License
|
| 32 |
-
MIT License
|
| 33 |
-
|
| 34 |
-
ultimatevocalremovergui
|
| 35 |
-
https://github.com/Anjok07/ultimatevocalremovergui/blob/master/LICENSE
|
| 36 |
-
https://github.com/yang123qwe/vocal_separation_by_uvr5
|
| 37 |
-
MIT License
|
| 38 |
-
|
| 39 |
-
audio-slicer
|
| 40 |
-
https://github.com/openvpi/audio-slicer/blob/main/LICENSE
|
| 41 |
-
MIT License
|
| 42 |
-
|
| 43 |
-
PySimpleGUI
|
| 44 |
-
https://github.com/PySimpleGUI/PySimpleGUI/blob/master/license.txt
|
| 45 |
-
LPGLv3 License
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/README.md
DELETED
|
@@ -1,177 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
一个基于VITS的简单易用的变声框架<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
| 8 |
-
|
| 9 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 10 |
-
|
| 11 |
-
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 12 |
-
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 13 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 14 |
-
|
| 15 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 16 |
-
|
| 17 |
-
[**更新日志**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_CN.md) | [**常见问题解答**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94) | [**AutoDL·5毛钱训练AI歌手**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B) | [**对照实验记录**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Autodl%E8%AE%AD%E7%BB%83RVC%C2%B7AI%E6%AD%8C%E6%89%8B%E6%95%99%E7%A8%8B](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/%E5%AF%B9%E7%85%A7%E5%AE%9E%E9%AA%8C%C2%B7%E5%AE%9E%E9%AA%8C%E8%AE%B0%E5%BD%95)) | [**在线演示**](https://huggingface.co/spaces/Ricecake123/RVC-demo)
|
| 18 |
-
|
| 19 |
-
</div>
|
| 20 |
-
|
| 21 |
-
------
|
| 22 |
-
|
| 23 |
-
[**English**](./docs/en/README.en.md) | [**中文简体**](./README.md) | [**日本語**](./docs/jp/README.ja.md) | [**한국어**](./docs/kr/README.ko.md) ([**韓國語**](./docs/kr/README.ko.han.md)) | [**Français**](./docs/fr/README.fr.md)| [**Türkçe**](./docs/tr/README.tr.md)
|
| 24 |
-
|
| 25 |
-
点此查看我们的[演示视频](https://www.bilibili.com/video/BV1pm4y1z7Gm/) !
|
| 26 |
-
|
| 27 |
-
训练推理界面:go-web.bat
|
| 28 |
-
|
| 29 |
-
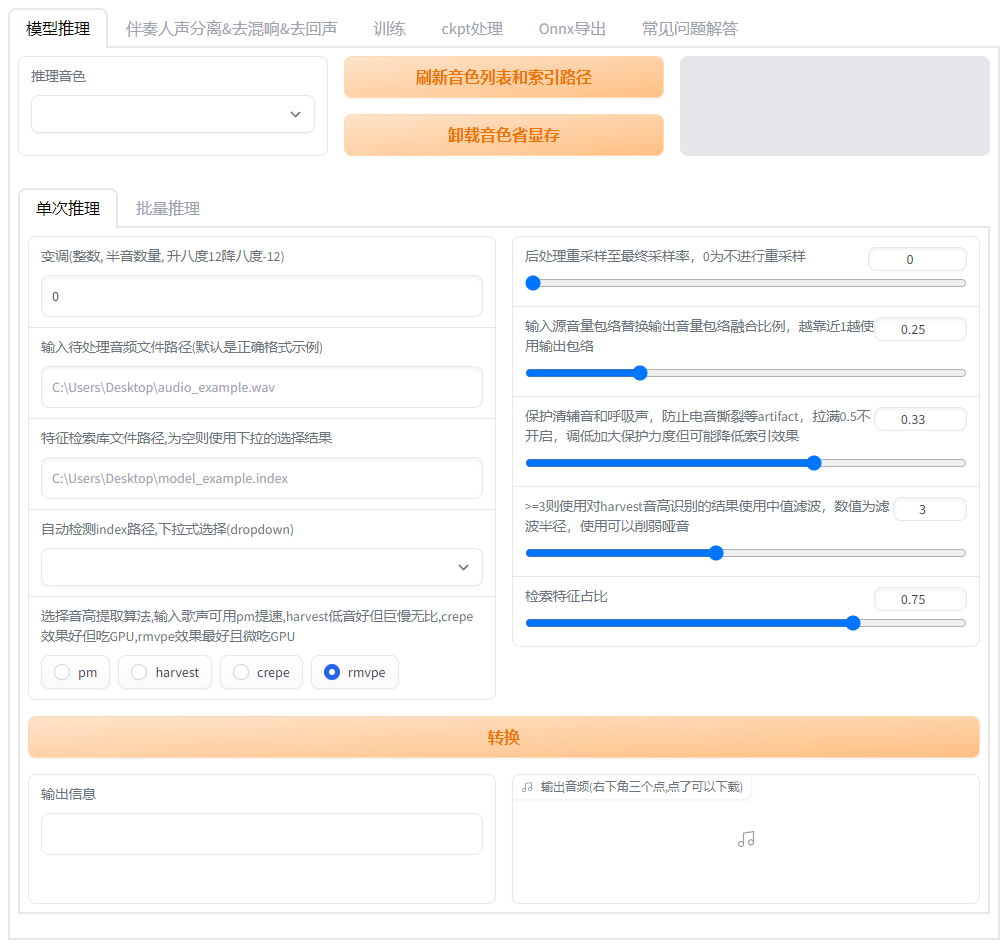
|
| 30 |
-
|
| 31 |
-
实时变声界面:go-realtime-gui.bat
|
| 32 |
-
|
| 33 |
-
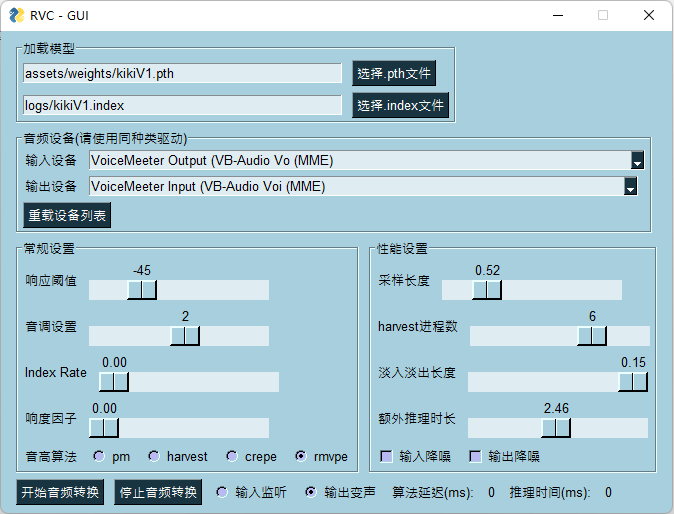
|
| 34 |
-
|
| 35 |
-
> 底模使用接近50小时的开源高质量VCTK训练集训练,无版权方面的顾虑,请大家放心使用
|
| 36 |
-
|
| 37 |
-
> 请期待RVCv3的底模,参数更大,数据更大,效果更好,基本持平的推理速度,需要训练数据量更少。
|
| 38 |
-
|
| 39 |
-
## 简介
|
| 40 |
-
本仓库具有以下特点
|
| 41 |
-
+ 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
|
| 42 |
-
+ 即便在相对较差的显卡上也能快速训练
|
| 43 |
-
+ 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
|
| 44 |
-
+ 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
|
| 45 |
-
+ 简单易用的网页界面
|
| 46 |
-
+ 可调用UVR5模型来快速分离人声和伴奏
|
| 47 |
-
+ 使用最先进的[人声音高提取算法InterSpeech2023-RMVPE](#参考项目)根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
|
| 48 |
-
+ A卡I卡加速支持
|
| 49 |
-
|
| 50 |
-
## 环境配置
|
| 51 |
-
以下指令需在 Python 版本大于3.8的环境中执行。
|
| 52 |
-
|
| 53 |
-
(Windows/Linux)
|
| 54 |
-
首先通过 pip 安装主要依赖:
|
| 55 |
-
```bash
|
| 56 |
-
# 安装Pytorch及其核心依赖,若已安装则跳过
|
| 57 |
-
# 参考自: https://pytorch.org/get-started/locally/
|
| 58 |
-
pip install torch torchvision torchaudio
|
| 59 |
-
|
| 60 |
-
#如果是win系统+Nvidia Ampere架构(RTX30xx),根据 #21 的经验,需要指定pytorch对应的cuda版本
|
| 61 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 62 |
-
```
|
| 63 |
-
|
| 64 |
-
可以使用 poetry 来安装依赖:
|
| 65 |
-
```bash
|
| 66 |
-
# 安装 Poetry 依赖管理工具, 若已安装则跳过
|
| 67 |
-
# 参考自: https://python-poetry.org/docs/#installation
|
| 68 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 69 |
-
|
| 70 |
-
# 通过poetry安装依赖
|
| 71 |
-
poetry install
|
| 72 |
-
```
|
| 73 |
-
|
| 74 |
-
你也可以通过 pip 来安装依赖:
|
| 75 |
-
```bash
|
| 76 |
-
N卡:
|
| 77 |
-
pip install -r requirements.txt
|
| 78 |
-
|
| 79 |
-
A卡/I卡:
|
| 80 |
-
pip install -r requirements-dml.txt
|
| 81 |
-
|
| 82 |
-
A卡Rocm(Linux):
|
| 83 |
-
pip install -r requirements-amd.txt
|
| 84 |
-
|
| 85 |
-
I卡IPEX(Linux):
|
| 86 |
-
pip install -r requirements-ipex.txt
|
| 87 |
-
```
|
| 88 |
-
|
| 89 |
-
------
|
| 90 |
-
Mac 用户可以通过 `run.sh` 来安装依赖:
|
| 91 |
-
```bash
|
| 92 |
-
sh ./run.sh
|
| 93 |
-
```
|
| 94 |
-
|
| 95 |
-
## 其他预模型准备
|
| 96 |
-
RVC需要其他一些预模型来推理和训练。
|
| 97 |
-
|
| 98 |
-
你可以从我们的[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)下载到这些模型。
|
| 99 |
-
|
| 100 |
-
以下是一份清单,包括了所有RVC所需的预模型和其他文件的名称:
|
| 101 |
-
```bash
|
| 102 |
-
./assets/hubert/hubert_base.pt
|
| 103 |
-
|
| 104 |
-
./assets/pretrained
|
| 105 |
-
|
| 106 |
-
./assets/uvr5_weights
|
| 107 |
-
|
| 108 |
-
想测试v2版本模型的话,需要额外下载
|
| 109 |
-
|
| 110 |
-
./assets/pretrained_v2
|
| 111 |
-
|
| 112 |
-
如果你正在使用Windows,则你可能需要这个文件,若ffmpeg和ffprobe已安装则跳过; ubuntu/debian 用户可以通过apt install ffmpeg来安装这2个库, Mac 用户则可以通过brew install ffmpeg来安装 (需要预先安装brew)
|
| 113 |
-
|
| 114 |
-
./ffmpeg
|
| 115 |
-
|
| 116 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
| 117 |
-
|
| 118 |
-
./ffprobe
|
| 119 |
-
|
| 120 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
| 121 |
-
|
| 122 |
-
如果你想使用最新的RMVPE人声音高提取算法,则你需要下载音高提取模型参数并放置于RVC根目录
|
| 123 |
-
|
| 124 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
| 125 |
-
|
| 126 |
-
A卡I卡用户需要的dml环境要请下载
|
| 127 |
-
|
| 128 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
| 129 |
-
|
| 130 |
-
```
|
| 131 |
-
之后使用以下指令来启动WebUI:
|
| 132 |
-
```bash
|
| 133 |
-
python infer-web.py
|
| 134 |
-
```
|
| 135 |
-
如果你正在使用Windows 或 macOS,你可以直接下载并解压`RVC-beta.7z`,前者可以运行`go-web.bat`以启动WebUI,后者则运行命令`sh ./run.sh`以启动WebUI。
|
| 136 |
-
|
| 137 |
-
对于需要使用IPEX技术的I卡用户,请先在终端执行`source /opt/intel/oneapi/setvars.sh`(仅Linux)。
|
| 138 |
-
|
| 139 |
-
仓库内还有一份`小白简易教程.doc`以供参考。
|
| 140 |
-
|
| 141 |
-
## AMD显卡Rocm相关(仅Linux)
|
| 142 |
-
如果你想基于AMD的Rocm技术在Linux系统上运行RVC,请先在[这里](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html)安装所需的驱动。
|
| 143 |
-
|
| 144 |
-
若你使用的是Arch Linux,可以使用pacman来安装所需驱动:
|
| 145 |
-
````
|
| 146 |
-
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 147 |
-
````
|
| 148 |
-
对于某些型号的显卡,你可能需要额外配置如下的环境变量(如:RX6700XT):
|
| 149 |
-
````
|
| 150 |
-
export ROCM_PATH=/opt/rocm
|
| 151 |
-
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 152 |
-
````
|
| 153 |
-
同时确保你的当前用户处于`render`与`video`用户组内:
|
| 154 |
-
````
|
| 155 |
-
sudo usermod -aG render $USERNAME
|
| 156 |
-
sudo usermod -aG video $USERNAME
|
| 157 |
-
````
|
| 158 |
-
之后运行WebUI:
|
| 159 |
-
```bash
|
| 160 |
-
python infer-web.py
|
| 161 |
-
```
|
| 162 |
-
|
| 163 |
-
## 参考项目
|
| 164 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 165 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 166 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 167 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 168 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 169 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 170 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 171 |
-
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
| 172 |
-
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
| 173 |
-
|
| 174 |
-
## 感谢所有贡献者作出的努力
|
| 175 |
-
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 176 |
-
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
| 177 |
-
</a>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/Retrieval_based_Voice_Conversion_WebUI.ipynb
DELETED
|
@@ -1,403 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"cells": [
|
| 3 |
-
{
|
| 4 |
-
"attachments": {},
|
| 5 |
-
"cell_type": "markdown",
|
| 6 |
-
"metadata": {},
|
| 7 |
-
"source": [
|
| 8 |
-
"# [Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) Training notebook"
|
| 9 |
-
]
|
| 10 |
-
},
|
| 11 |
-
{
|
| 12 |
-
"attachments": {},
|
| 13 |
-
"cell_type": "markdown",
|
| 14 |
-
"metadata": {
|
| 15 |
-
"id": "ZFFCx5J80SGa"
|
| 16 |
-
},
|
| 17 |
-
"source": [
|
| 18 |
-
"[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)"
|
| 19 |
-
]
|
| 20 |
-
},
|
| 21 |
-
{
|
| 22 |
-
"cell_type": "code",
|
| 23 |
-
"execution_count": null,
|
| 24 |
-
"metadata": {
|
| 25 |
-
"id": "GmFP6bN9dvOq"
|
| 26 |
-
},
|
| 27 |
-
"outputs": [],
|
| 28 |
-
"source": [
|
| 29 |
-
"# @title 查看显卡\n",
|
| 30 |
-
"!nvidia-smi"
|
| 31 |
-
]
|
| 32 |
-
},
|
| 33 |
-
{
|
| 34 |
-
"cell_type": "code",
|
| 35 |
-
"execution_count": null,
|
| 36 |
-
"metadata": {
|
| 37 |
-
"id": "jwu07JgqoFON"
|
| 38 |
-
},
|
| 39 |
-
"outputs": [],
|
| 40 |
-
"source": [
|
| 41 |
-
"# @title 挂载谷歌云盘\n",
|
| 42 |
-
"\n",
|
| 43 |
-
"from google.colab import drive\n",
|
| 44 |
-
"\n",
|
| 45 |
-
"drive.mount(\"/content/drive\")"
|
| 46 |
-
]
|
| 47 |
-
},
|
| 48 |
-
{
|
| 49 |
-
"cell_type": "code",
|
| 50 |
-
"execution_count": null,
|
| 51 |
-
"metadata": {
|
| 52 |
-
"id": "wjddIFr1oS3W"
|
| 53 |
-
},
|
| 54 |
-
"outputs": [],
|
| 55 |
-
"source": [
|
| 56 |
-
"# @title 安装依赖\n",
|
| 57 |
-
"!apt-get -y install build-essential python3-dev ffmpeg\n",
|
| 58 |
-
"!pip3 install --upgrade setuptools wheel\n",
|
| 59 |
-
"!pip3 install --upgrade pip\n",
|
| 60 |
-
"!pip3 install faiss-cpu==1.7.2 fairseq gradio==3.14.0 ffmpeg ffmpeg-python praat-parselmouth pyworld numpy==1.23.5 numba==0.56.4 librosa==0.9.2"
|
| 61 |
-
]
|
| 62 |
-
},
|
| 63 |
-
{
|
| 64 |
-
"cell_type": "code",
|
| 65 |
-
"execution_count": null,
|
| 66 |
-
"metadata": {
|
| 67 |
-
"id": "ge_97mfpgqTm"
|
| 68 |
-
},
|
| 69 |
-
"outputs": [],
|
| 70 |
-
"source": [
|
| 71 |
-
"# @title 克隆仓库\n",
|
| 72 |
-
"\n",
|
| 73 |
-
"!git clone --depth=1 -b stable https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI\n",
|
| 74 |
-
"%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
|
| 75 |
-
"!mkdir -p pretrained uvr5_weights"
|
| 76 |
-
]
|
| 77 |
-
},
|
| 78 |
-
{
|
| 79 |
-
"cell_type": "code",
|
| 80 |
-
"execution_count": null,
|
| 81 |
-
"metadata": {
|
| 82 |
-
"id": "BLDEZADkvlw1"
|
| 83 |
-
},
|
| 84 |
-
"outputs": [],
|
| 85 |
-
"source": [
|
| 86 |
-
"# @title 更新仓库(一般无需执行)\n",
|
| 87 |
-
"!git pull"
|
| 88 |
-
]
|
| 89 |
-
},
|
| 90 |
-
{
|
| 91 |
-
"cell_type": "code",
|
| 92 |
-
"execution_count": null,
|
| 93 |
-
"metadata": {
|
| 94 |
-
"id": "pqE0PrnuRqI2"
|
| 95 |
-
},
|
| 96 |
-
"outputs": [],
|
| 97 |
-
"source": [
|
| 98 |
-
"# @title 安装aria2\n",
|
| 99 |
-
"!apt -y install -qq aria2"
|
| 100 |
-
]
|
| 101 |
-
},
|
| 102 |
-
{
|
| 103 |
-
"cell_type": "code",
|
| 104 |
-
"execution_count": null,
|
| 105 |
-
"metadata": {
|
| 106 |
-
"id": "UG3XpUwEomUz"
|
| 107 |
-
},
|
| 108 |
-
"outputs": [],
|
| 109 |
-
"source": [
|
| 110 |
-
"# @title 下载底模\n",
|
| 111 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D32k.pth\n",
|
| 112 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D40k.pth\n",
|
| 113 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D48k.pth\n",
|
| 114 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G32k.pth\n",
|
| 115 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G40k.pth\n",
|
| 116 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G48k.pth\n",
|
| 117 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D32k.pth\n",
|
| 118 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D40k.pth\n",
|
| 119 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D48k.pth\n",
|
| 120 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G32k.pth\n",
|
| 121 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G40k.pth\n",
|
| 122 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G48k.pth"
|
| 123 |
-
]
|
| 124 |
-
},
|
| 125 |
-
{
|
| 126 |
-
"cell_type": "code",
|
| 127 |
-
"execution_count": null,
|
| 128 |
-
"metadata": {
|
| 129 |
-
"id": "HugjmZqZRuiF"
|
| 130 |
-
},
|
| 131 |
-
"outputs": [],
|
| 132 |
-
"source": [
|
| 133 |
-
"# @title 下载人声分离模型\n",
|
| 134 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2-人声vocals+非人声instrumentals.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/uvr5_weights -o HP2-人声vocals+非人声instrumentals.pth\n",
|
| 135 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/uvr5_weights -o HP5-主旋律人声vocals+其他instrumentals.pth"
|
| 136 |
-
]
|
| 137 |
-
},
|
| 138 |
-
{
|
| 139 |
-
"cell_type": "code",
|
| 140 |
-
"execution_count": null,
|
| 141 |
-
"metadata": {
|
| 142 |
-
"id": "2RCaT9FTR0ej"
|
| 143 |
-
},
|
| 144 |
-
"outputs": [],
|
| 145 |
-
"source": [
|
| 146 |
-
"# @title 下载hubert_base\n",
|
| 147 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d /content/Retrieval-based-Voice-Conversion-WebUI -o hubert_base.pt"
|
| 148 |
-
]
|
| 149 |
-
},
|
| 150 |
-
{
|
| 151 |
-
"cell_type": "code",
|
| 152 |
-
"execution_count": null,
|
| 153 |
-
"metadata": {},
|
| 154 |
-
"outputs": [],
|
| 155 |
-
"source": [
|
| 156 |
-
"# @title #下载rmvpe模型\n",
|
| 157 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt -d /content/Retrieval-based-Voice-Conversion-WebUI -o rmvpe.pt"
|
| 158 |
-
]
|
| 159 |
-
},
|
| 160 |
-
{
|
| 161 |
-
"cell_type": "code",
|
| 162 |
-
"execution_count": null,
|
| 163 |
-
"metadata": {
|
| 164 |
-
"id": "Mwk7Q0Loqzjx"
|
| 165 |
-
},
|
| 166 |
-
"outputs": [],
|
| 167 |
-
"source": [
|
| 168 |
-
"# @title 从谷歌云盘加载打包好的数据集到/content/dataset\n",
|
| 169 |
-
"\n",
|
| 170 |
-
"# @markdown 数据集位置\n",
|
| 171 |
-
"DATASET = (\n",
|
| 172 |
-
" \"/content/drive/MyDrive/dataset/lulu20230327_32k.zip\" # @param {type:\"string\"}\n",
|
| 173 |
-
")\n",
|
| 174 |
-
"\n",
|
| 175 |
-
"!mkdir -p /content/dataset\n",
|
| 176 |
-
"!unzip -d /content/dataset -B {DATASET}"
|
| 177 |
-
]
|
| 178 |
-
},
|
| 179 |
-
{
|
| 180 |
-
"cell_type": "code",
|
| 181 |
-
"execution_count": null,
|
| 182 |
-
"metadata": {
|
| 183 |
-
"id": "PDlFxWHWEynD"
|
| 184 |
-
},
|
| 185 |
-
"outputs": [],
|
| 186 |
-
"source": [
|
| 187 |
-
"# @title 重命名数据集中的重名文件\n",
|
| 188 |
-
"!ls -a /content/dataset/\n",
|
| 189 |
-
"!rename 's/(\\w+)\\.(\\w+)~(\\d*)/$1_$3.$2/' /content/dataset/*.*~*"
|
| 190 |
-
]
|
| 191 |
-
},
|
| 192 |
-
{
|
| 193 |
-
"cell_type": "code",
|
| 194 |
-
"execution_count": null,
|
| 195 |
-
"metadata": {
|
| 196 |
-
"id": "7vh6vphDwO0b"
|
| 197 |
-
},
|
| 198 |
-
"outputs": [],
|
| 199 |
-
"source": [
|
| 200 |
-
"# @title 启动web\n",
|
| 201 |
-
"%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
|
| 202 |
-
"# %load_ext tensorboard\n",
|
| 203 |
-
"# %tensorboard --logdir /content/Retrieval-based-Voice-Conversion-WebUI/logs\n",
|
| 204 |
-
"!python3 infer-web.py --colab --pycmd python3"
|
| 205 |
-
]
|
| 206 |
-
},
|
| 207 |
-
{
|
| 208 |
-
"cell_type": "code",
|
| 209 |
-
"execution_count": null,
|
| 210 |
-
"metadata": {
|
| 211 |
-
"id": "FgJuNeAwx5Y_"
|
| 212 |
-
},
|
| 213 |
-
"outputs": [],
|
| 214 |
-
"source": [
|
| 215 |
-
"# @title 手动将训练后的模型文件备份到谷歌云盘\n",
|
| 216 |
-
"# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
|
| 217 |
-
"\n",
|
| 218 |
-
"# @markdown 模型名\n",
|
| 219 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 220 |
-
"# @markdown 模型epoch\n",
|
| 221 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 222 |
-
"\n",
|
| 223 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 224 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 225 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/added_*.index /content/drive/MyDrive/\n",
|
| 226 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/total_*.npy /content/drive/MyDrive/\n",
|
| 227 |
-
"\n",
|
| 228 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth"
|
| 229 |
-
]
|
| 230 |
-
},
|
| 231 |
-
{
|
| 232 |
-
"cell_type": "code",
|
| 233 |
-
"execution_count": null,
|
| 234 |
-
"metadata": {
|
| 235 |
-
"id": "OVQoLQJXS7WX"
|
| 236 |
-
},
|
| 237 |
-
"outputs": [],
|
| 238 |
-
"source": [
|
| 239 |
-
"# @title 从谷歌云盘恢复pth\n",
|
| 240 |
-
"# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
|
| 241 |
-
"\n",
|
| 242 |
-
"# @markdown 模型名\n",
|
| 243 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 244 |
-
"# @markdown 模型epoch\n",
|
| 245 |
-
"MODELEPOCH = 7500 # @param {type:\"integer\"}\n",
|
| 246 |
-
"\n",
|
| 247 |
-
"!mkdir -p /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 248 |
-
"\n",
|
| 249 |
-
"!cp /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 250 |
-
"!cp /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 251 |
-
"!cp /content/drive/MyDrive/*.index /content/\n",
|
| 252 |
-
"!cp /content/drive/MyDrive/*.npy /content/\n",
|
| 253 |
-
"!cp /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth"
|
| 254 |
-
]
|
| 255 |
-
},
|
| 256 |
-
{
|
| 257 |
-
"cell_type": "code",
|
| 258 |
-
"execution_count": null,
|
| 259 |
-
"metadata": {
|
| 260 |
-
"id": "ZKAyuKb9J6dz"
|
| 261 |
-
},
|
| 262 |
-
"outputs": [],
|
| 263 |
-
"source": [
|
| 264 |
-
"# @title 手动预处理(不推荐)\n",
|
| 265 |
-
"# @markdown 模型名\n",
|
| 266 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 267 |
-
"# @markdown 采样率\n",
|
| 268 |
-
"BITRATE = 48000 # @param {type:\"integer\"}\n",
|
| 269 |
-
"# @markdown 使用的进程数\n",
|
| 270 |
-
"THREADCOUNT = 8 # @param {type:\"integer\"}\n",
|
| 271 |
-
"\n",
|
| 272 |
-
"!python3 trainset_preprocess_pipeline_print.py /content/dataset {BITRATE} {THREADCOUNT} logs/{MODELNAME} True"
|
| 273 |
-
]
|
| 274 |
-
},
|
| 275 |
-
{
|
| 276 |
-
"cell_type": "code",
|
| 277 |
-
"execution_count": null,
|
| 278 |
-
"metadata": {
|
| 279 |
-
"id": "CrxJqzAUKmPJ"
|
| 280 |
-
},
|
| 281 |
-
"outputs": [],
|
| 282 |
-
"source": [
|
| 283 |
-
"# @title 手动提取特征(不推荐)\n",
|
| 284 |
-
"# @markdown 模型名\n",
|
| 285 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 286 |
-
"# @markdown 使用的进程数\n",
|
| 287 |
-
"THREADCOUNT = 8 # @param {type:\"integer\"}\n",
|
| 288 |
-
"# @markdown 音高提取算法\n",
|
| 289 |
-
"ALGO = \"harvest\" # @param {type:\"string\"}\n",
|
| 290 |
-
"\n",
|
| 291 |
-
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
| 292 |
-
"\n",
|
| 293 |
-
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
| 294 |
-
]
|
| 295 |
-
},
|
| 296 |
-
{
|
| 297 |
-
"cell_type": "code",
|
| 298 |
-
"execution_count": null,
|
| 299 |
-
"metadata": {
|
| 300 |
-
"id": "IMLPLKOaKj58"
|
| 301 |
-
},
|
| 302 |
-
"outputs": [],
|
| 303 |
-
"source": [
|
| 304 |
-
"# @title 手动训练(不推荐)\n",
|
| 305 |
-
"# @markdown 模型名\n",
|
| 306 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 307 |
-
"# @markdown 使用的GPU\n",
|
| 308 |
-
"USEGPU = \"0\" # @param {type:\"string\"}\n",
|
| 309 |
-
"# @markdown 批大小\n",
|
| 310 |
-
"BATCHSIZE = 32 # @param {type:\"integer\"}\n",
|
| 311 |
-
"# @markdown 停止的epoch\n",
|
| 312 |
-
"MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
|
| 313 |
-
"# @markdown 保存epoch间隔\n",
|
| 314 |
-
"EPOCHSAVE = 100 # @param {type:\"integer\"}\n",
|
| 315 |
-
"# @markdown 采样率\n",
|
| 316 |
-
"MODELSAMPLE = \"48k\" # @param {type:\"string\"}\n",
|
| 317 |
-
"# @markdown 是否缓存训练集\n",
|
| 318 |
-
"CACHEDATA = 1 # @param {type:\"integer\"}\n",
|
| 319 |
-
"# @markdown 是否仅保存最新的ckpt文件\n",
|
| 320 |
-
"ONLYLATEST = 0 # @param {type:\"integer\"}\n",
|
| 321 |
-
"\n",
|
| 322 |
-
"!python3 train_nsf_sim_cache_sid_load_pretrain.py -e lulu -sr {MODELSAMPLE} -f0 1 -bs {BATCHSIZE} -g {USEGPU} -te {MODELEPOCH} -se {EPOCHSAVE} -pg pretrained/f0G{MODELSAMPLE}.pth -pd pretrained/f0D{MODELSAMPLE}.pth -l {ONLYLATEST} -c {CACHEDATA}"
|
| 323 |
-
]
|
| 324 |
-
},
|
| 325 |
-
{
|
| 326 |
-
"cell_type": "code",
|
| 327 |
-
"execution_count": null,
|
| 328 |
-
"metadata": {
|
| 329 |
-
"id": "haYA81hySuDl"
|
| 330 |
-
},
|
| 331 |
-
"outputs": [],
|
| 332 |
-
"source": [
|
| 333 |
-
"# @title 删除其它pth,只留选中的(慎点,仔细看代码)\n",
|
| 334 |
-
"# @markdown 模型名\n",
|
| 335 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 336 |
-
"# @markdown 选中模型epoch\n",
|
| 337 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 338 |
-
"\n",
|
| 339 |
-
"!echo \"备份选中的模型。。。\"\n",
|
| 340 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 341 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 342 |
-
"\n",
|
| 343 |
-
"!echo \"正在删除。。。\"\n",
|
| 344 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 345 |
-
"!rm /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*.pth\n",
|
| 346 |
-
"\n",
|
| 347 |
-
"!echo \"恢复选中的模型。。。\"\n",
|
| 348 |
-
"!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 349 |
-
"!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 350 |
-
"\n",
|
| 351 |
-
"!echo \"删除完成\"\n",
|
| 352 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
|
| 353 |
-
]
|
| 354 |
-
},
|
| 355 |
-
{
|
| 356 |
-
"cell_type": "code",
|
| 357 |
-
"execution_count": null,
|
| 358 |
-
"metadata": {
|
| 359 |
-
"id": "QhSiPTVPoIRh"
|
| 360 |
-
},
|
| 361 |
-
"outputs": [],
|
| 362 |
-
"source": [
|
| 363 |
-
"# @title 清除项目下所有文件,只留选中的模型(慎点,仔细看代码)\n",
|
| 364 |
-
"# @markdown 模型名\n",
|
| 365 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 366 |
-
"# @markdown 选中模型epoch\n",
|
| 367 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 368 |
-
"\n",
|
| 369 |
-
"!echo \"备份选中的模型。。。\"\n",
|
| 370 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 371 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 372 |
-
"\n",
|
| 373 |
-
"!echo \"正��删除。。。\"\n",
|
| 374 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 375 |
-
"!rm -rf /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*\n",
|
| 376 |
-
"\n",
|
| 377 |
-
"!echo \"恢复选中的模型。。。\"\n",
|
| 378 |
-
"!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 379 |
-
"!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 380 |
-
"\n",
|
| 381 |
-
"!echo \"删除完成\"\n",
|
| 382 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
|
| 383 |
-
]
|
| 384 |
-
}
|
| 385 |
-
],
|
| 386 |
-
"metadata": {
|
| 387 |
-
"accelerator": "GPU",
|
| 388 |
-
"colab": {
|
| 389 |
-
"private_outputs": true,
|
| 390 |
-
"provenance": []
|
| 391 |
-
},
|
| 392 |
-
"gpuClass": "standard",
|
| 393 |
-
"kernelspec": {
|
| 394 |
-
"display_name": "Python 3",
|
| 395 |
-
"name": "python3"
|
| 396 |
-
},
|
| 397 |
-
"language_info": {
|
| 398 |
-
"name": "python"
|
| 399 |
-
}
|
| 400 |
-
},
|
| 401 |
-
"nbformat": 4,
|
| 402 |
-
"nbformat_minor": 0
|
| 403 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/Retrieval_based_Voice_Conversion_WebUI_v2.ipynb
DELETED
|
@@ -1,422 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"cells": [
|
| 3 |
-
{
|
| 4 |
-
"attachments": {},
|
| 5 |
-
"cell_type": "markdown",
|
| 6 |
-
"metadata": {},
|
| 7 |
-
"source": [
|
| 8 |
-
"# [Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) Training notebook"
|
| 9 |
-
]
|
| 10 |
-
},
|
| 11 |
-
{
|
| 12 |
-
"attachments": {},
|
| 13 |
-
"cell_type": "markdown",
|
| 14 |
-
"metadata": {
|
| 15 |
-
"id": "ZFFCx5J80SGa"
|
| 16 |
-
},
|
| 17 |
-
"source": [
|
| 18 |
-
"[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI_v2.ipynb)"
|
| 19 |
-
]
|
| 20 |
-
},
|
| 21 |
-
{
|
| 22 |
-
"cell_type": "code",
|
| 23 |
-
"execution_count": null,
|
| 24 |
-
"metadata": {
|
| 25 |
-
"id": "GmFP6bN9dvOq"
|
| 26 |
-
},
|
| 27 |
-
"outputs": [],
|
| 28 |
-
"source": [
|
| 29 |
-
"# @title #查看显卡\n",
|
| 30 |
-
"!nvidia-smi"
|
| 31 |
-
]
|
| 32 |
-
},
|
| 33 |
-
{
|
| 34 |
-
"cell_type": "code",
|
| 35 |
-
"execution_count": null,
|
| 36 |
-
"metadata": {
|
| 37 |
-
"id": "jwu07JgqoFON"
|
| 38 |
-
},
|
| 39 |
-
"outputs": [],
|
| 40 |
-
"source": [
|
| 41 |
-
"# @title 挂载谷歌云盘\n",
|
| 42 |
-
"\n",
|
| 43 |
-
"from google.colab import drive\n",
|
| 44 |
-
"\n",
|
| 45 |
-
"drive.mount(\"/content/drive\")"
|
| 46 |
-
]
|
| 47 |
-
},
|
| 48 |
-
{
|
| 49 |
-
"cell_type": "code",
|
| 50 |
-
"execution_count": null,
|
| 51 |
-
"metadata": {
|
| 52 |
-
"id": "wjddIFr1oS3W"
|
| 53 |
-
},
|
| 54 |
-
"outputs": [],
|
| 55 |
-
"source": [
|
| 56 |
-
"# @title #安装依赖\n",
|
| 57 |
-
"!apt-get -y install build-essential python3-dev ffmpeg\n",
|
| 58 |
-
"!pip3 install --upgrade setuptools wheel\n",
|
| 59 |
-
"!pip3 install --upgrade pip\n",
|
| 60 |
-
"!pip3 install faiss-cpu==1.7.2 fairseq gradio==3.14.0 ffmpeg ffmpeg-python praat-parselmouth pyworld numpy==1.23.5 numba==0.56.4 librosa==0.9.2"
|
| 61 |
-
]
|
| 62 |
-
},
|
| 63 |
-
{
|
| 64 |
-
"cell_type": "code",
|
| 65 |
-
"execution_count": null,
|
| 66 |
-
"metadata": {
|
| 67 |
-
"id": "ge_97mfpgqTm"
|
| 68 |
-
},
|
| 69 |
-
"outputs": [],
|
| 70 |
-
"source": [
|
| 71 |
-
"# @title #克隆仓库\n",
|
| 72 |
-
"\n",
|
| 73 |
-
"!mkdir Retrieval-based-Voice-Conversion-WebUI\n",
|
| 74 |
-
"%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
|
| 75 |
-
"!git init\n",
|
| 76 |
-
"!git remote add origin https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git\n",
|
| 77 |
-
"!git fetch origin cfd984812804ddc9247d65b14c82cd32e56c1133 --depth=1\n",
|
| 78 |
-
"!git reset --hard FETCH_HEAD"
|
| 79 |
-
]
|
| 80 |
-
},
|
| 81 |
-
{
|
| 82 |
-
"cell_type": "code",
|
| 83 |
-
"execution_count": null,
|
| 84 |
-
"metadata": {
|
| 85 |
-
"id": "BLDEZADkvlw1"
|
| 86 |
-
},
|
| 87 |
-
"outputs": [],
|
| 88 |
-
"source": [
|
| 89 |
-
"# @title #更新仓库(一般无需执行)\n",
|
| 90 |
-
"!git pull"
|
| 91 |
-
]
|
| 92 |
-
},
|
| 93 |
-
{
|
| 94 |
-
"cell_type": "code",
|
| 95 |
-
"execution_count": null,
|
| 96 |
-
"metadata": {
|
| 97 |
-
"id": "pqE0PrnuRqI2"
|
| 98 |
-
},
|
| 99 |
-
"outputs": [],
|
| 100 |
-
"source": [
|
| 101 |
-
"# @title #安装aria2\n",
|
| 102 |
-
"!apt -y install -qq aria2"
|
| 103 |
-
]
|
| 104 |
-
},
|
| 105 |
-
{
|
| 106 |
-
"cell_type": "code",
|
| 107 |
-
"execution_count": null,
|
| 108 |
-
"metadata": {
|
| 109 |
-
"id": "UG3XpUwEomUz"
|
| 110 |
-
},
|
| 111 |
-
"outputs": [],
|
| 112 |
-
"source": [
|
| 113 |
-
"# @title 下载底模\n",
|
| 114 |
-
"\n",
|
| 115 |
-
"# v1\n",
|
| 116 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D32k.pth\n",
|
| 117 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D40k.pth\n",
|
| 118 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o D48k.pth\n",
|
| 119 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G32k.pth\n",
|
| 120 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G40k.pth\n",
|
| 121 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o G48k.pth\n",
|
| 122 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D32k.pth\n",
|
| 123 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D40k.pth\n",
|
| 124 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0D48k.pth\n",
|
| 125 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G32k.pth\n",
|
| 126 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G40k.pth\n",
|
| 127 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained/f0G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained -o f0G48k.pth\n",
|
| 128 |
-
"\n",
|
| 129 |
-
"# v2\n",
|
| 130 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o D32k.pth\n",
|
| 131 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o D40k.pth\n",
|
| 132 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o D48k.pth\n",
|
| 133 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o G32k.pth\n",
|
| 134 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o G40k.pth\n",
|
| 135 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o G48k.pth\n",
|
| 136 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0D32k.pth\n",
|
| 137 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0D40k.pth\n",
|
| 138 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0D48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0D48k.pth\n",
|
| 139 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G32k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0G32k.pth\n",
|
| 140 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G40k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0G40k.pth\n",
|
| 141 |
-
"# !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/pretrained_v2/f0G48k.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/pretrained_v2 -o f0G48k.pth"
|
| 142 |
-
]
|
| 143 |
-
},
|
| 144 |
-
{
|
| 145 |
-
"cell_type": "code",
|
| 146 |
-
"execution_count": null,
|
| 147 |
-
"metadata": {
|
| 148 |
-
"id": "HugjmZqZRuiF"
|
| 149 |
-
},
|
| 150 |
-
"outputs": [],
|
| 151 |
-
"source": [
|
| 152 |
-
"# @title #下载人声分离模型\n",
|
| 153 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP2-人声vocals+非人声instrumentals.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/uvr5_weights -o HP2-人声vocals+非人声instrumentals.pth\n",
|
| 154 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/uvr5_weights/HP5-主旋律人声vocals+其他instrumentals.pth -d /content/Retrieval-based-Voice-Conversion-WebUI/uvr5_weights -o HP5-主旋律人声vocals+其他instrumentals.pth"
|
| 155 |
-
]
|
| 156 |
-
},
|
| 157 |
-
{
|
| 158 |
-
"cell_type": "code",
|
| 159 |
-
"execution_count": null,
|
| 160 |
-
"metadata": {
|
| 161 |
-
"id": "2RCaT9FTR0ej"
|
| 162 |
-
},
|
| 163 |
-
"outputs": [],
|
| 164 |
-
"source": [
|
| 165 |
-
"# @title #下载hubert_base\n",
|
| 166 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -d /content/Retrieval-based-Voice-Conversion-WebUI -o hubert_base.pt"
|
| 167 |
-
]
|
| 168 |
-
},
|
| 169 |
-
{
|
| 170 |
-
"cell_type": "code",
|
| 171 |
-
"execution_count": null,
|
| 172 |
-
"metadata": {},
|
| 173 |
-
"outputs": [],
|
| 174 |
-
"source": [
|
| 175 |
-
"# @title #下载rmvpe模型\n",
|
| 176 |
-
"!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/rmvpe.pt -d /content/Retrieval-based-Voice-Conversion-WebUI -o rmvpe.pt"
|
| 177 |
-
]
|
| 178 |
-
},
|
| 179 |
-
{
|
| 180 |
-
"cell_type": "code",
|
| 181 |
-
"execution_count": null,
|
| 182 |
-
"metadata": {
|
| 183 |
-
"id": "Mwk7Q0Loqzjx"
|
| 184 |
-
},
|
| 185 |
-
"outputs": [],
|
| 186 |
-
"source": [
|
| 187 |
-
"# @title #从谷歌云盘加载打包好的数据集到/content/dataset\n",
|
| 188 |
-
"\n",
|
| 189 |
-
"# @markdown 数据集位置\n",
|
| 190 |
-
"DATASET = (\n",
|
| 191 |
-
" \"/content/drive/MyDrive/dataset/lulu20230327_32k.zip\" # @param {type:\"string\"}\n",
|
| 192 |
-
")\n",
|
| 193 |
-
"\n",
|
| 194 |
-
"!mkdir -p /content/dataset\n",
|
| 195 |
-
"!unzip -d /content/dataset -B {DATASET}"
|
| 196 |
-
]
|
| 197 |
-
},
|
| 198 |
-
{
|
| 199 |
-
"cell_type": "code",
|
| 200 |
-
"execution_count": null,
|
| 201 |
-
"metadata": {
|
| 202 |
-
"id": "PDlFxWHWEynD"
|
| 203 |
-
},
|
| 204 |
-
"outputs": [],
|
| 205 |
-
"source": [
|
| 206 |
-
"# @title #重命名数据集中的重名文件\n",
|
| 207 |
-
"!ls -a /content/dataset/\n",
|
| 208 |
-
"!rename 's/(\\w+)\\.(\\w+)~(\\d*)/$1_$3.$2/' /content/dataset/*.*~*"
|
| 209 |
-
]
|
| 210 |
-
},
|
| 211 |
-
{
|
| 212 |
-
"cell_type": "code",
|
| 213 |
-
"execution_count": null,
|
| 214 |
-
"metadata": {
|
| 215 |
-
"id": "7vh6vphDwO0b"
|
| 216 |
-
},
|
| 217 |
-
"outputs": [],
|
| 218 |
-
"source": [
|
| 219 |
-
"# @title #启动webui\n",
|
| 220 |
-
"%cd /content/Retrieval-based-Voice-Conversion-WebUI\n",
|
| 221 |
-
"# %load_ext tensorboard\n",
|
| 222 |
-
"# %tensorboard --logdir /content/Retrieval-based-Voice-Conversion-WebUI/logs\n",
|
| 223 |
-
"!python3 infer-web.py --colab --pycmd python3"
|
| 224 |
-
]
|
| 225 |
-
},
|
| 226 |
-
{
|
| 227 |
-
"cell_type": "code",
|
| 228 |
-
"execution_count": null,
|
| 229 |
-
"metadata": {
|
| 230 |
-
"id": "FgJuNeAwx5Y_"
|
| 231 |
-
},
|
| 232 |
-
"outputs": [],
|
| 233 |
-
"source": [
|
| 234 |
-
"# @title #手动将训练后的模型文件备份到谷歌云盘\n",
|
| 235 |
-
"# @markdown #需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
|
| 236 |
-
"\n",
|
| 237 |
-
"# @markdown #模型名\n",
|
| 238 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 239 |
-
"# @markdown #模型epoch\n",
|
| 240 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 241 |
-
"\n",
|
| 242 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 243 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 244 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/added_*.index /content/drive/MyDrive/\n",
|
| 245 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/total_*.npy /content/drive/MyDrive/\n",
|
| 246 |
-
"\n",
|
| 247 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth"
|
| 248 |
-
]
|
| 249 |
-
},
|
| 250 |
-
{
|
| 251 |
-
"cell_type": "code",
|
| 252 |
-
"execution_count": null,
|
| 253 |
-
"metadata": {
|
| 254 |
-
"id": "OVQoLQJXS7WX"
|
| 255 |
-
},
|
| 256 |
-
"outputs": [],
|
| 257 |
-
"source": [
|
| 258 |
-
"# @title 从谷歌云盘恢复pth\n",
|
| 259 |
-
"# @markdown 需要自己查看logs文件夹下模型的文件名,手动修改下方命令末尾的文件名\n",
|
| 260 |
-
"\n",
|
| 261 |
-
"# @markdown 模型名\n",
|
| 262 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 263 |
-
"# @markdown 模型epoch\n",
|
| 264 |
-
"MODELEPOCH = 7500 # @param {type:\"integer\"}\n",
|
| 265 |
-
"\n",
|
| 266 |
-
"!mkdir -p /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 267 |
-
"\n",
|
| 268 |
-
"!cp /content/drive/MyDrive/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 269 |
-
"!cp /content/drive/MyDrive/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 270 |
-
"!cp /content/drive/MyDrive/*.index /content/\n",
|
| 271 |
-
"!cp /content/drive/MyDrive/*.npy /content/\n",
|
| 272 |
-
"!cp /content/drive/MyDrive/{MODELNAME}{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/weights/{MODELNAME}.pth"
|
| 273 |
-
]
|
| 274 |
-
},
|
| 275 |
-
{
|
| 276 |
-
"cell_type": "code",
|
| 277 |
-
"execution_count": null,
|
| 278 |
-
"metadata": {
|
| 279 |
-
"id": "ZKAyuKb9J6dz"
|
| 280 |
-
},
|
| 281 |
-
"outputs": [],
|
| 282 |
-
"source": [
|
| 283 |
-
"# @title 手动预处理(不推荐)\n",
|
| 284 |
-
"# @markdown 模型名\n",
|
| 285 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 286 |
-
"# @markdown 采样率\n",
|
| 287 |
-
"BITRATE = 48000 # @param {type:\"integer\"}\n",
|
| 288 |
-
"# @markdown 使用的进程数\n",
|
| 289 |
-
"THREADCOUNT = 8 # @param {type:\"integer\"}\n",
|
| 290 |
-
"\n",
|
| 291 |
-
"!python3 trainset_preprocess_pipeline_print.py /content/dataset {BITRATE} {THREADCOUNT} logs/{MODELNAME} True"
|
| 292 |
-
]
|
| 293 |
-
},
|
| 294 |
-
{
|
| 295 |
-
"cell_type": "code",
|
| 296 |
-
"execution_count": null,
|
| 297 |
-
"metadata": {
|
| 298 |
-
"id": "CrxJqzAUKmPJ"
|
| 299 |
-
},
|
| 300 |
-
"outputs": [],
|
| 301 |
-
"source": [
|
| 302 |
-
"# @title 手动提取特征(不推荐)\n",
|
| 303 |
-
"# @markdown 模型名\n",
|
| 304 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 305 |
-
"# @markdown 使用的进程数\n",
|
| 306 |
-
"THREADCOUNT = 8 # @param {type:\"integer\"}\n",
|
| 307 |
-
"# @markdown 音高提取算法\n",
|
| 308 |
-
"ALGO = \"harvest\" # @param {type:\"string\"}\n",
|
| 309 |
-
"\n",
|
| 310 |
-
"!python3 extract_f0_print.py logs/{MODELNAME} {THREADCOUNT} {ALGO}\n",
|
| 311 |
-
"\n",
|
| 312 |
-
"!python3 extract_feature_print.py cpu 1 0 0 logs/{MODELNAME}"
|
| 313 |
-
]
|
| 314 |
-
},
|
| 315 |
-
{
|
| 316 |
-
"cell_type": "code",
|
| 317 |
-
"execution_count": null,
|
| 318 |
-
"metadata": {
|
| 319 |
-
"id": "IMLPLKOaKj58"
|
| 320 |
-
},
|
| 321 |
-
"outputs": [],
|
| 322 |
-
"source": [
|
| 323 |
-
"# @title 手动训练(不推荐)\n",
|
| 324 |
-
"# @markdown 模型名\n",
|
| 325 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 326 |
-
"# @markdown 使用的GPU\n",
|
| 327 |
-
"USEGPU = \"0\" # @param {type:\"string\"}\n",
|
| 328 |
-
"# @markdown 批大小\n",
|
| 329 |
-
"BATCHSIZE = 32 # @param {type:\"integer\"}\n",
|
| 330 |
-
"# @markdown 停止的epoch\n",
|
| 331 |
-
"MODELEPOCH = 3200 # @param {type:\"integer\"}\n",
|
| 332 |
-
"# @markdown 保存epoch间隔\n",
|
| 333 |
-
"EPOCHSAVE = 100 # @param {type:\"integer\"}\n",
|
| 334 |
-
"# @markdown 采样率\n",
|
| 335 |
-
"MODELSAMPLE = \"48k\" # @param {type:\"string\"}\n",
|
| 336 |
-
"# @markdown 是否缓存训练集\n",
|
| 337 |
-
"CACHEDATA = 1 # @param {type:\"integer\"}\n",
|
| 338 |
-
"# @markdown 是否仅保存最新的ckpt文件\n",
|
| 339 |
-
"ONLYLATEST = 0 # @param {type:\"integer\"}\n",
|
| 340 |
-
"\n",
|
| 341 |
-
"!python3 train_nsf_sim_cache_sid_load_pretrain.py -e lulu -sr {MODELSAMPLE} -f0 1 -bs {BATCHSIZE} -g {USEGPU} -te {MODELEPOCH} -se {EPOCHSAVE} -pg pretrained/f0G{MODELSAMPLE}.pth -pd pretrained/f0D{MODELSAMPLE}.pth -l {ONLYLATEST} -c {CACHEDATA}"
|
| 342 |
-
]
|
| 343 |
-
},
|
| 344 |
-
{
|
| 345 |
-
"cell_type": "code",
|
| 346 |
-
"execution_count": null,
|
| 347 |
-
"metadata": {
|
| 348 |
-
"id": "haYA81hySuDl"
|
| 349 |
-
},
|
| 350 |
-
"outputs": [],
|
| 351 |
-
"source": [
|
| 352 |
-
"# @title 删除其它pth,只留选中的(慎点,仔细看代码)\n",
|
| 353 |
-
"# @markdown 模型名\n",
|
| 354 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 355 |
-
"# @markdown 选中模型epoch\n",
|
| 356 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 357 |
-
"\n",
|
| 358 |
-
"!echo \"备份选中的模型。。。\"\n",
|
| 359 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 360 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 361 |
-
"\n",
|
| 362 |
-
"!echo \"正在删除。。。\"\n",
|
| 363 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 364 |
-
"!rm /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*.pth\n",
|
| 365 |
-
"\n",
|
| 366 |
-
"!echo \"恢复选中的模型。。。\"\n",
|
| 367 |
-
"!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 368 |
-
"!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 369 |
-
"\n",
|
| 370 |
-
"!echo \"删除完成\"\n",
|
| 371 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
|
| 372 |
-
]
|
| 373 |
-
},
|
| 374 |
-
{
|
| 375 |
-
"cell_type": "code",
|
| 376 |
-
"execution_count": null,
|
| 377 |
-
"metadata": {
|
| 378 |
-
"id": "QhSiPTVPoIRh"
|
| 379 |
-
},
|
| 380 |
-
"outputs": [],
|
| 381 |
-
"source": [
|
| 382 |
-
"# @title 清除项目下所有文件,只留选中的模型(慎点,仔细看代码)\n",
|
| 383 |
-
"# @markdown 模型名\n",
|
| 384 |
-
"MODELNAME = \"lulu\" # @param {type:\"string\"}\n",
|
| 385 |
-
"# @markdown 选中模型epoch\n",
|
| 386 |
-
"MODELEPOCH = 9600 # @param {type:\"integer\"}\n",
|
| 387 |
-
"\n",
|
| 388 |
-
"!echo \"备份选中的模型。。。\"\n",
|
| 389 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth /content/{MODELNAME}_D_{MODELEPOCH}.pth\n",
|
| 390 |
-
"!cp /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth /content/{MODELNAME}_G_{MODELEPOCH}.pth\n",
|
| 391 |
-
"\n",
|
| 392 |
-
"!echo \"正在删除。。。\"\n",
|
| 393 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}\n",
|
| 394 |
-
"!rm -rf /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/*\n",
|
| 395 |
-
"\n",
|
| 396 |
-
"!echo \"恢复选中的模型。。。\"\n",
|
| 397 |
-
"!mv /content/{MODELNAME}_D_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/G_{MODELEPOCH}.pth\n",
|
| 398 |
-
"!mv /content/{MODELNAME}_G_{MODELEPOCH}.pth /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}/D_{MODELEPOCH}.pth\n",
|
| 399 |
-
"\n",
|
| 400 |
-
"!echo \"删除完成\"\n",
|
| 401 |
-
"!ls /content/Retrieval-based-Voice-Conversion-WebUI/logs/{MODELNAME}"
|
| 402 |
-
]
|
| 403 |
-
}
|
| 404 |
-
],
|
| 405 |
-
"metadata": {
|
| 406 |
-
"accelerator": "GPU",
|
| 407 |
-
"colab": {
|
| 408 |
-
"private_outputs": true,
|
| 409 |
-
"provenance": []
|
| 410 |
-
},
|
| 411 |
-
"gpuClass": "standard",
|
| 412 |
-
"kernelspec": {
|
| 413 |
-
"display_name": "Python 3",
|
| 414 |
-
"name": "python3"
|
| 415 |
-
},
|
| 416 |
-
"language_info": {
|
| 417 |
-
"name": "python"
|
| 418 |
-
}
|
| 419 |
-
},
|
| 420 |
-
"nbformat": 4,
|
| 421 |
-
"nbformat_minor": 0
|
| 422 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/Synthesizer_inputs.pth
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:4c5ae8cd034b02bbc325939e9b9debbedb43ee9d71a654daaff8804815bd957d
|
| 3 |
-
size 122495
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/hubert/.gitignore
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
| 3 |
-
!hubert_inputs.pth
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/hubert/hubert_inputs.pth
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:bbd4741d4be8a71333170c0df5320f605a9d210b96547b391555da078167861f
|
| 3 |
-
size 169434
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/pretrained/.gitignore
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/pretrained_v2/.gitignore
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/rmvpe/.gitignore
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
| 3 |
-
!rmvpe_inputs.pth
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/rmvpe/rmvpe_inputs.pth
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:339fcb7e1476b302e9aecef4a951e918c20852b2e871de5eea13b06e554e0a3a
|
| 3 |
-
size 33527
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/uvr5_weights/.gitignore
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/assets/weights/.gitignore
DELETED
|
@@ -1,2 +0,0 @@
|
|
| 1 |
-
*
|
| 2 |
-
!.gitignore
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/config.py
DELETED
|
@@ -1,117 +0,0 @@
|
|
| 1 |
-
import argparse
|
| 2 |
-
import glob
|
| 3 |
-
import sys
|
| 4 |
-
import torch
|
| 5 |
-
from multiprocessing import cpu_count
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
class Config:
|
| 9 |
-
def __init__(self):
|
| 10 |
-
self.device = "cuda:0"
|
| 11 |
-
self.is_half = True
|
| 12 |
-
self.n_cpu = 0
|
| 13 |
-
self.gpu_name = None
|
| 14 |
-
self.gpu_mem = None
|
| 15 |
-
(
|
| 16 |
-
self.python_cmd,
|
| 17 |
-
self.listen_port,
|
| 18 |
-
self.iscolab,
|
| 19 |
-
self.noparallel,
|
| 20 |
-
self.noautoopen,
|
| 21 |
-
) = self.arg_parse()
|
| 22 |
-
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
| 23 |
-
|
| 24 |
-
def arg_parse(self) -> tuple:
|
| 25 |
-
parser = argparse.ArgumentParser()
|
| 26 |
-
parser.add_argument("--port", type=int, default=7865, help="Listen port")
|
| 27 |
-
parser.add_argument(
|
| 28 |
-
"--pycmd", type=str, default="python", help="Python command"
|
| 29 |
-
)
|
| 30 |
-
parser.add_argument("--colab", action="store_true", help="Launch in colab")
|
| 31 |
-
parser.add_argument(
|
| 32 |
-
"--noparallel", action="store_true", help="Disable parallel processing"
|
| 33 |
-
)
|
| 34 |
-
parser.add_argument(
|
| 35 |
-
"--noautoopen",
|
| 36 |
-
action="store_true",
|
| 37 |
-
help="Do not open in browser automatically",
|
| 38 |
-
)
|
| 39 |
-
cmd_opts = parser.parse_args()
|
| 40 |
-
|
| 41 |
-
cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
|
| 42 |
-
|
| 43 |
-
return (
|
| 44 |
-
cmd_opts.pycmd,
|
| 45 |
-
cmd_opts.port,
|
| 46 |
-
cmd_opts.colab,
|
| 47 |
-
cmd_opts.noparallel,
|
| 48 |
-
cmd_opts.noautoopen,
|
| 49 |
-
)
|
| 50 |
-
|
| 51 |
-
def device_config(self) -> tuple:
|
| 52 |
-
if torch.cuda.is_available():
|
| 53 |
-
i_device = int(self.device.split(":")[-1])
|
| 54 |
-
self.gpu_name = torch.cuda.get_device_name(i_device)
|
| 55 |
-
if (
|
| 56 |
-
("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
|
| 57 |
-
or "P40" in self.gpu_name.upper()
|
| 58 |
-
or "1060" in self.gpu_name
|
| 59 |
-
or "1070" in self.gpu_name
|
| 60 |
-
or "1080" in self.gpu_name
|
| 61 |
-
):
|
| 62 |
-
print("16系/10系显卡和P40强制单精度")
|
| 63 |
-
self.is_half = False
|
| 64 |
-
for config_file in ["32k.json", "40k.json", "48k.json"]:
|
| 65 |
-
with open(f"configs/{config_file}", "r") as f:
|
| 66 |
-
strr = f.read().replace("true", "false")
|
| 67 |
-
with open(f"configs/{config_file}", "w") as f:
|
| 68 |
-
f.write(strr)
|
| 69 |
-
with open("trainset_preprocess_pipeline_print.py", "r") as f:
|
| 70 |
-
strr = f.read().replace("3.7", "3.0")
|
| 71 |
-
with open("trainset_preprocess_pipeline_print.py", "w") as f:
|
| 72 |
-
f.write(strr)
|
| 73 |
-
else:
|
| 74 |
-
self.gpu_name = None
|
| 75 |
-
self.gpu_mem = int(
|
| 76 |
-
torch.cuda.get_device_properties(i_device).total_memory
|
| 77 |
-
/ 1024
|
| 78 |
-
/ 1024
|
| 79 |
-
/ 1024
|
| 80 |
-
+ 0.4
|
| 81 |
-
)
|
| 82 |
-
if self.gpu_mem <= 4:
|
| 83 |
-
with open("trainset_preprocess_pipeline_print.py", "r") as f:
|
| 84 |
-
strr = f.read().replace("3.7", "3.0")
|
| 85 |
-
with open("trainset_preprocess_pipeline_print.py", "w") as f:
|
| 86 |
-
f.write(strr)
|
| 87 |
-
elif torch.backends.mps.is_available():
|
| 88 |
-
print("没有发现支持的N卡, 使用MPS进行推理")
|
| 89 |
-
self.device = "mps"
|
| 90 |
-
else:
|
| 91 |
-
print("没有发现支持的N卡, 使用CPU进行推理")
|
| 92 |
-
self.device = "cpu"
|
| 93 |
-
self.is_half = True
|
| 94 |
-
|
| 95 |
-
if self.n_cpu == 0:
|
| 96 |
-
self.n_cpu = cpu_count()
|
| 97 |
-
|
| 98 |
-
if self.is_half:
|
| 99 |
-
# 6G显存配置
|
| 100 |
-
x_pad = 3
|
| 101 |
-
x_query = 10
|
| 102 |
-
x_center = 60
|
| 103 |
-
x_max = 65
|
| 104 |
-
else:
|
| 105 |
-
# 5G显存配置
|
| 106 |
-
x_pad = 1
|
| 107 |
-
x_query = 6
|
| 108 |
-
x_center = 38
|
| 109 |
-
x_max = 41
|
| 110 |
-
|
| 111 |
-
if self.gpu_mem != None and self.gpu_mem <= 4:
|
| 112 |
-
x_pad = 1
|
| 113 |
-
x_query = 5
|
| 114 |
-
x_center = 30
|
| 115 |
-
x_max = 32
|
| 116 |
-
|
| 117 |
-
return x_pad, x_query, x_center, x_max
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/32k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 12800,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 32000,
|
| 21 |
-
"filter_length": 1024,
|
| 22 |
-
"hop_length": 320,
|
| 23 |
-
"win_length": 1024,
|
| 24 |
-
"n_mel_channels": 80,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,4,2,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/40k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 12800,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 40000,
|
| 21 |
-
"filter_length": 2048,
|
| 22 |
-
"hop_length": 400,
|
| 23 |
-
"win_length": 2048,
|
| 24 |
-
"n_mel_channels": 125,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,10,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/48k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 11520,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 48000,
|
| 21 |
-
"filter_length": 2048,
|
| 22 |
-
"hop_length": 480,
|
| 23 |
-
"win_length": 2048,
|
| 24 |
-
"n_mel_channels": 128,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,6,2,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/config.json
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
{"pth_path": "assets/weights/kikiV1.pth", "index_path": "logs/kikiV1.index", "sg_input_device": "VoiceMeeter Output (VB-Audio Vo (MME)", "sg_output_device": "VoiceMeeter Input (VB-Audio Voi (MME)", "threhold": -45.0, "pitch": 2.0, "rms_mix_rate": 0.0, "index_rate": 0.0, "block_time": 0.52, "crossfade_length": 0.15, "extra_time": 2.46, "n_cpu": 6.0, "use_jit": false, "f0method": "rmvpe"}
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/config.py
DELETED
|
@@ -1,251 +0,0 @@
|
|
| 1 |
-
import argparse
|
| 2 |
-
import os
|
| 3 |
-
import sys
|
| 4 |
-
import json
|
| 5 |
-
from multiprocessing import cpu_count
|
| 6 |
-
|
| 7 |
-
import torch
|
| 8 |
-
|
| 9 |
-
try:
|
| 10 |
-
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
| 11 |
-
|
| 12 |
-
if torch.xpu.is_available():
|
| 13 |
-
from infer.modules.ipex import ipex_init
|
| 14 |
-
|
| 15 |
-
ipex_init()
|
| 16 |
-
except Exception: # pylint: disable=broad-exception-caught
|
| 17 |
-
pass
|
| 18 |
-
import logging
|
| 19 |
-
|
| 20 |
-
logger = logging.getLogger(__name__)
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
version_config_list = [
|
| 24 |
-
"v1/32k.json",
|
| 25 |
-
"v1/40k.json",
|
| 26 |
-
"v1/48k.json",
|
| 27 |
-
"v2/48k.json",
|
| 28 |
-
"v2/32k.json",
|
| 29 |
-
]
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
def singleton_variable(func):
|
| 33 |
-
def wrapper(*args, **kwargs):
|
| 34 |
-
if not wrapper.instance:
|
| 35 |
-
wrapper.instance = func(*args, **kwargs)
|
| 36 |
-
return wrapper.instance
|
| 37 |
-
|
| 38 |
-
wrapper.instance = None
|
| 39 |
-
return wrapper
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
@singleton_variable
|
| 43 |
-
class Config:
|
| 44 |
-
def __init__(self):
|
| 45 |
-
self.device = "cuda:0"
|
| 46 |
-
self.is_half = True
|
| 47 |
-
self.use_jit = False
|
| 48 |
-
self.n_cpu = 0
|
| 49 |
-
self.gpu_name = None
|
| 50 |
-
self.json_config = self.load_config_json()
|
| 51 |
-
self.gpu_mem = None
|
| 52 |
-
(
|
| 53 |
-
self.python_cmd,
|
| 54 |
-
self.listen_port,
|
| 55 |
-
self.iscolab,
|
| 56 |
-
self.noparallel,
|
| 57 |
-
self.noautoopen,
|
| 58 |
-
self.dml,
|
| 59 |
-
) = self.arg_parse()
|
| 60 |
-
self.instead = ""
|
| 61 |
-
self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config()
|
| 62 |
-
|
| 63 |
-
@staticmethod
|
| 64 |
-
def load_config_json() -> dict:
|
| 65 |
-
d = {}
|
| 66 |
-
for config_file in version_config_list:
|
| 67 |
-
with open(f"configs/{config_file}", "r") as f:
|
| 68 |
-
d[config_file] = json.load(f)
|
| 69 |
-
return d
|
| 70 |
-
|
| 71 |
-
@staticmethod
|
| 72 |
-
def arg_parse() -> tuple:
|
| 73 |
-
exe = sys.executable or "python"
|
| 74 |
-
parser = argparse.ArgumentParser()
|
| 75 |
-
parser.add_argument("--port", type=int, default=7865, help="Listen port")
|
| 76 |
-
parser.add_argument("--pycmd", type=str, default=exe, help="Python command")
|
| 77 |
-
parser.add_argument("--colab", action="store_true", help="Launch in colab")
|
| 78 |
-
parser.add_argument(
|
| 79 |
-
"--noparallel", action="store_true", help="Disable parallel processing"
|
| 80 |
-
)
|
| 81 |
-
parser.add_argument(
|
| 82 |
-
"--noautoopen",
|
| 83 |
-
action="store_true",
|
| 84 |
-
help="Do not open in browser automatically",
|
| 85 |
-
)
|
| 86 |
-
parser.add_argument(
|
| 87 |
-
"--dml",
|
| 88 |
-
action="store_true",
|
| 89 |
-
help="torch_dml",
|
| 90 |
-
)
|
| 91 |
-
cmd_opts = parser.parse_args()
|
| 92 |
-
|
| 93 |
-
cmd_opts.port = cmd_opts.port if 0 <= cmd_opts.port <= 65535 else 7865
|
| 94 |
-
|
| 95 |
-
return (
|
| 96 |
-
cmd_opts.pycmd,
|
| 97 |
-
cmd_opts.port,
|
| 98 |
-
cmd_opts.colab,
|
| 99 |
-
cmd_opts.noparallel,
|
| 100 |
-
cmd_opts.noautoopen,
|
| 101 |
-
cmd_opts.dml,
|
| 102 |
-
)
|
| 103 |
-
|
| 104 |
-
# has_mps is only available in nightly pytorch (for now) and MasOS 12.3+.
|
| 105 |
-
# check `getattr` and try it for compatibility
|
| 106 |
-
@staticmethod
|
| 107 |
-
def has_mps() -> bool:
|
| 108 |
-
if not torch.backends.mps.is_available():
|
| 109 |
-
return False
|
| 110 |
-
try:
|
| 111 |
-
torch.zeros(1).to(torch.device("mps"))
|
| 112 |
-
return True
|
| 113 |
-
except Exception:
|
| 114 |
-
return False
|
| 115 |
-
|
| 116 |
-
@staticmethod
|
| 117 |
-
def has_xpu() -> bool:
|
| 118 |
-
if hasattr(torch, "xpu") and torch.xpu.is_available():
|
| 119 |
-
return True
|
| 120 |
-
else:
|
| 121 |
-
return False
|
| 122 |
-
|
| 123 |
-
def use_fp32_config(self):
|
| 124 |
-
for config_file in version_config_list:
|
| 125 |
-
self.json_config[config_file]["train"]["fp16_run"] = False
|
| 126 |
-
with open(f"configs/{config_file}", "r") as f:
|
| 127 |
-
strr = f.read().replace("true", "false")
|
| 128 |
-
with open(f"configs/{config_file}", "w") as f:
|
| 129 |
-
f.write(strr)
|
| 130 |
-
with open("infer/modules/train/preprocess.py", "r") as f:
|
| 131 |
-
strr = f.read().replace("3.7", "3.0")
|
| 132 |
-
with open("infer/modules/train/preprocess.py", "w") as f:
|
| 133 |
-
f.write(strr)
|
| 134 |
-
print("overwrite preprocess and configs.json")
|
| 135 |
-
|
| 136 |
-
def device_config(self) -> tuple:
|
| 137 |
-
if torch.cuda.is_available():
|
| 138 |
-
if self.has_xpu():
|
| 139 |
-
self.device = self.instead = "xpu:0"
|
| 140 |
-
self.is_half = True
|
| 141 |
-
i_device = int(self.device.split(":")[-1])
|
| 142 |
-
self.gpu_name = torch.cuda.get_device_name(i_device)
|
| 143 |
-
if (
|
| 144 |
-
("16" in self.gpu_name and "V100" not in self.gpu_name.upper())
|
| 145 |
-
or "P40" in self.gpu_name.upper()
|
| 146 |
-
or "P10" in self.gpu_name.upper()
|
| 147 |
-
or "1060" in self.gpu_name
|
| 148 |
-
or "1070" in self.gpu_name
|
| 149 |
-
or "1080" in self.gpu_name
|
| 150 |
-
):
|
| 151 |
-
logger.info("Found GPU %s, force to fp32", self.gpu_name)
|
| 152 |
-
self.is_half = False
|
| 153 |
-
self.use_fp32_config()
|
| 154 |
-
else:
|
| 155 |
-
logger.info("Found GPU %s", self.gpu_name)
|
| 156 |
-
self.gpu_mem = int(
|
| 157 |
-
torch.cuda.get_device_properties(i_device).total_memory
|
| 158 |
-
/ 1024
|
| 159 |
-
/ 1024
|
| 160 |
-
/ 1024
|
| 161 |
-
+ 0.4
|
| 162 |
-
)
|
| 163 |
-
if self.gpu_mem <= 4:
|
| 164 |
-
with open("infer/modules/train/preprocess.py", "r") as f:
|
| 165 |
-
strr = f.read().replace("3.7", "3.0")
|
| 166 |
-
with open("infer/modules/train/preprocess.py", "w") as f:
|
| 167 |
-
f.write(strr)
|
| 168 |
-
elif self.has_mps():
|
| 169 |
-
logger.info("No supported Nvidia GPU found")
|
| 170 |
-
self.device = self.instead = "mps"
|
| 171 |
-
self.is_half = False
|
| 172 |
-
self.use_fp32_config()
|
| 173 |
-
else:
|
| 174 |
-
logger.info("No supported Nvidia GPU found")
|
| 175 |
-
self.device = self.instead = "cpu"
|
| 176 |
-
self.is_half = False
|
| 177 |
-
self.use_fp32_config()
|
| 178 |
-
|
| 179 |
-
if self.n_cpu == 0:
|
| 180 |
-
self.n_cpu = cpu_count()
|
| 181 |
-
|
| 182 |
-
if self.is_half:
|
| 183 |
-
# 6G显存配置
|
| 184 |
-
x_pad = 3
|
| 185 |
-
x_query = 10
|
| 186 |
-
x_center = 60
|
| 187 |
-
x_max = 65
|
| 188 |
-
else:
|
| 189 |
-
# 5G显存配置
|
| 190 |
-
x_pad = 1
|
| 191 |
-
x_query = 6
|
| 192 |
-
x_center = 38
|
| 193 |
-
x_max = 41
|
| 194 |
-
|
| 195 |
-
if self.gpu_mem is not None and self.gpu_mem <= 4:
|
| 196 |
-
x_pad = 1
|
| 197 |
-
x_query = 5
|
| 198 |
-
x_center = 30
|
| 199 |
-
x_max = 32
|
| 200 |
-
if self.dml:
|
| 201 |
-
logger.info("Use DirectML instead")
|
| 202 |
-
if (
|
| 203 |
-
os.path.exists(
|
| 204 |
-
"runtime\Lib\site-packages\onnxruntime\capi\DirectML.dll"
|
| 205 |
-
)
|
| 206 |
-
== False
|
| 207 |
-
):
|
| 208 |
-
try:
|
| 209 |
-
os.rename(
|
| 210 |
-
"runtime\Lib\site-packages\onnxruntime",
|
| 211 |
-
"runtime\Lib\site-packages\onnxruntime-cuda",
|
| 212 |
-
)
|
| 213 |
-
except:
|
| 214 |
-
pass
|
| 215 |
-
try:
|
| 216 |
-
os.rename(
|
| 217 |
-
"runtime\Lib\site-packages\onnxruntime-dml",
|
| 218 |
-
"runtime\Lib\site-packages\onnxruntime",
|
| 219 |
-
)
|
| 220 |
-
except:
|
| 221 |
-
pass
|
| 222 |
-
# if self.device != "cpu":
|
| 223 |
-
import torch_directml
|
| 224 |
-
|
| 225 |
-
self.device = torch_directml.device(torch_directml.default_device())
|
| 226 |
-
self.is_half = False
|
| 227 |
-
else:
|
| 228 |
-
if self.instead:
|
| 229 |
-
logger.info(f"Use {self.instead} instead")
|
| 230 |
-
if (
|
| 231 |
-
os.path.exists(
|
| 232 |
-
"runtime\Lib\site-packages\onnxruntime\capi\onnxruntime_providers_cuda.dll"
|
| 233 |
-
)
|
| 234 |
-
== False
|
| 235 |
-
):
|
| 236 |
-
try:
|
| 237 |
-
os.rename(
|
| 238 |
-
"runtime\Lib\site-packages\onnxruntime",
|
| 239 |
-
"runtime\Lib\site-packages\onnxruntime-dml",
|
| 240 |
-
)
|
| 241 |
-
except:
|
| 242 |
-
pass
|
| 243 |
-
try:
|
| 244 |
-
os.rename(
|
| 245 |
-
"runtime\Lib\site-packages\onnxruntime-cuda",
|
| 246 |
-
"runtime\Lib\site-packages\onnxruntime",
|
| 247 |
-
)
|
| 248 |
-
except:
|
| 249 |
-
pass
|
| 250 |
-
print("is_half:%s, device:%s" % (self.is_half, self.device))
|
| 251 |
-
return x_pad, x_query, x_center, x_max
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/v1/32k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 12800,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 32000,
|
| 21 |
-
"filter_length": 1024,
|
| 22 |
-
"hop_length": 320,
|
| 23 |
-
"win_length": 1024,
|
| 24 |
-
"n_mel_channels": 80,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,4,2,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/v1/40k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 12800,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 40000,
|
| 21 |
-
"filter_length": 2048,
|
| 22 |
-
"hop_length": 400,
|
| 23 |
-
"win_length": 2048,
|
| 24 |
-
"n_mel_channels": 125,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,10,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/v1/48k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 11520,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 48000,
|
| 21 |
-
"filter_length": 2048,
|
| 22 |
-
"hop_length": 480,
|
| 23 |
-
"win_length": 2048,
|
| 24 |
-
"n_mel_channels": 128,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,6,2,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/v2/32k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 12800,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 32000,
|
| 21 |
-
"filter_length": 1024,
|
| 22 |
-
"hop_length": 320,
|
| 23 |
-
"win_length": 1024,
|
| 24 |
-
"n_mel_channels": 80,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [10,8,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [20,16,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/configs/v2/48k.json
DELETED
|
@@ -1,46 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"train": {
|
| 3 |
-
"log_interval": 200,
|
| 4 |
-
"seed": 1234,
|
| 5 |
-
"epochs": 20000,
|
| 6 |
-
"learning_rate": 1e-4,
|
| 7 |
-
"betas": [0.8, 0.99],
|
| 8 |
-
"eps": 1e-9,
|
| 9 |
-
"batch_size": 4,
|
| 10 |
-
"fp16_run": true,
|
| 11 |
-
"lr_decay": 0.999875,
|
| 12 |
-
"segment_size": 17280,
|
| 13 |
-
"init_lr_ratio": 1,
|
| 14 |
-
"warmup_epochs": 0,
|
| 15 |
-
"c_mel": 45,
|
| 16 |
-
"c_kl": 1.0
|
| 17 |
-
},
|
| 18 |
-
"data": {
|
| 19 |
-
"max_wav_value": 32768.0,
|
| 20 |
-
"sampling_rate": 48000,
|
| 21 |
-
"filter_length": 2048,
|
| 22 |
-
"hop_length": 480,
|
| 23 |
-
"win_length": 2048,
|
| 24 |
-
"n_mel_channels": 128,
|
| 25 |
-
"mel_fmin": 0.0,
|
| 26 |
-
"mel_fmax": null
|
| 27 |
-
},
|
| 28 |
-
"model": {
|
| 29 |
-
"inter_channels": 192,
|
| 30 |
-
"hidden_channels": 192,
|
| 31 |
-
"filter_channels": 768,
|
| 32 |
-
"n_heads": 2,
|
| 33 |
-
"n_layers": 6,
|
| 34 |
-
"kernel_size": 3,
|
| 35 |
-
"p_dropout": 0,
|
| 36 |
-
"resblock": "1",
|
| 37 |
-
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
-
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
-
"upsample_rates": [12,10,2,2],
|
| 40 |
-
"upsample_initial_channel": 512,
|
| 41 |
-
"upsample_kernel_sizes": [24,20,4,4],
|
| 42 |
-
"use_spectral_norm": false,
|
| 43 |
-
"gin_channels": 256,
|
| 44 |
-
"spk_embed_dim": 109
|
| 45 |
-
}
|
| 46 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docker-compose.yml
DELETED
|
@@ -1,20 +0,0 @@
|
|
| 1 |
-
version: "3.8"
|
| 2 |
-
services:
|
| 3 |
-
rvc:
|
| 4 |
-
build:
|
| 5 |
-
context: .
|
| 6 |
-
dockerfile: Dockerfile
|
| 7 |
-
container_name: rvc
|
| 8 |
-
volumes:
|
| 9 |
-
- ./weights:/app/assets/weights
|
| 10 |
-
- ./opt:/app/opt
|
| 11 |
-
# - ./dataset:/app/dataset # you can use this folder in order to provide your dataset for model training
|
| 12 |
-
ports:
|
| 13 |
-
- 7865:7865
|
| 14 |
-
deploy:
|
| 15 |
-
resources:
|
| 16 |
-
reservations:
|
| 17 |
-
devices:
|
| 18 |
-
- driver: nvidia
|
| 19 |
-
count: 1
|
| 20 |
-
capabilities: [gpu]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/.DS_Store
DELETED
|
Binary file (6.15 kB)
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/README.en.md
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
An easy-to-use SVC framework based on VITS.<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)
|
| 7 |
-
|
| 8 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 9 |
-
|
| 10 |
-
[](https://colab.research.google.com/github/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 11 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/%E4%BD%BF%E7%94%A8%E9%9C%80%E9%81%B5%E5%AE%88%E7%9A%84%E5%8D%8F%E8%AE%AE-LICENSE.txt)
|
| 12 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 13 |
-
|
| 14 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 15 |
-
|
| 16 |
-
</div>
|
| 17 |
-
|
| 18 |
-
------
|
| 19 |
-
[**Changelog**](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Changelog_CN.md)
|
| 20 |
-
|
| 21 |
-
[**English**](./README.en.md) | [**中文简体**](../README.md) | [**日本語**](./README.ja.md) | [**한국어**](./README.ko.md) ([**韓國語**](./README.ko.han.md))
|
| 22 |
-
|
| 23 |
-
> Check our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
| 24 |
-
|
| 25 |
-
> Realtime Voice Conversion Software using RVC : [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 26 |
-
|
| 27 |
-
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
|
| 28 |
-
|
| 29 |
-
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
|
| 30 |
-
## Summary
|
| 31 |
-
This repository has the following features:
|
| 32 |
-
+ Reduce tone leakage by replacing source feature to training-set feature using top1 retrieval;
|
| 33 |
-
+ Easy and fast training, even on relatively poor graphics cards;
|
| 34 |
-
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
|
| 35 |
-
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
| 36 |
-
+ Easy-to-use Webui interface;
|
| 37 |
-
+ Use the UVR5 model to quickly separate vocals and instruments.
|
| 38 |
-
## Preparing the environment
|
| 39 |
-
We recommend you install the dependencies through poetry.
|
| 40 |
-
|
| 41 |
-
The following commands need to be executed in the environment of Python version 3.8 or higher:
|
| 42 |
-
```bash
|
| 43 |
-
# Install PyTorch-related core dependencies, skip if installed
|
| 44 |
-
# Reference: https://pytorch.org/get-started/locally/
|
| 45 |
-
pip install torch torchvision torchaudio
|
| 46 |
-
|
| 47 |
-
#For Windows + Nvidia Ampere Architecture(RTX30xx), you need to specify the cuda version corresponding to pytorch according to the experience of https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/issues/21
|
| 48 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 49 |
-
|
| 50 |
-
# Install the Poetry dependency management tool, skip if installed
|
| 51 |
-
# Reference: https://python-poetry.org/docs/#installation
|
| 52 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 53 |
-
|
| 54 |
-
# Install the project dependencies
|
| 55 |
-
poetry install
|
| 56 |
-
```
|
| 57 |
-
You can also use pip to install the dependencies
|
| 58 |
-
|
| 59 |
-
**Notice**: `faiss 1.7.2` will raise Segmentation Fault: 11 under `MacOS`, please use `pip install faiss-cpu==1.7.0` if you use pip to install it manually.
|
| 60 |
-
|
| 61 |
-
```bash
|
| 62 |
-
pip install -r requirements.txt
|
| 63 |
-
```
|
| 64 |
-
|
| 65 |
-
## Preparation of other Pre-models
|
| 66 |
-
RVC requires other pre-models to infer and train.
|
| 67 |
-
|
| 68 |
-
You need to download them from our [Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
| 69 |
-
|
| 70 |
-
Here's a list of Pre-models and other files that RVC needs:
|
| 71 |
-
```bash
|
| 72 |
-
hubert_base.pt
|
| 73 |
-
|
| 74 |
-
./pretrained
|
| 75 |
-
|
| 76 |
-
./uvr5_weights
|
| 77 |
-
|
| 78 |
-
#If you are using Windows, you may also need this dictionary, skip if FFmpeg is installed
|
| 79 |
-
ffmpeg.exe
|
| 80 |
-
```
|
| 81 |
-
Then use this command to start Webui:
|
| 82 |
-
```bash
|
| 83 |
-
python infer-web.py
|
| 84 |
-
```
|
| 85 |
-
If you are using Windows, you can download and extract `RVC-beta.7z` to use RVC directly and use `go-web.bat` to start Webui.
|
| 86 |
-
|
| 87 |
-
There's also a tutorial on RVC in Chinese and you can check it out if needed.
|
| 88 |
-
|
| 89 |
-
## Credits
|
| 90 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 91 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 92 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 93 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 94 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 95 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 96 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 97 |
-
## Thanks to all contributors for their efforts
|
| 98 |
-
|
| 99 |
-
<a href="https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 100 |
-
<img src="https://contrib.rocks/image?repo=liujing04/Retrieval-based-Voice-Conversion-WebUI" />
|
| 101 |
-
</a>
|
| 102 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/README.ja.md
DELETED
|
@@ -1,106 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
VITSに基づく使いやすい音声変換(voice changer)framework<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)
|
| 7 |
-
|
| 8 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 9 |
-
|
| 10 |
-
[](https://colab.research.google.com/github/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 11 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/%E4%BD%BF%E7%94%A8%E9%9C%80%E9%81%B5%E5%AE%88%E7%9A%84%E5%8D%8F%E8%AE%AE-LICENSE.txt)
|
| 12 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 13 |
-
|
| 14 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 15 |
-
|
| 16 |
-
</div>
|
| 17 |
-
|
| 18 |
-
------
|
| 19 |
-
|
| 20 |
-
[**更新日誌**](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Changelog_CN.md)
|
| 21 |
-
|
| 22 |
-
[**English**](./README.en.md) | [**中文简体**](../README.md) | [**日本語**](./README.ja.md) | [**한국어**](./README.ko.md) ([**韓國語**](./README.ko.han.md))
|
| 23 |
-
|
| 24 |
-
> デモ動画は[こちら](https://www.bilibili.com/video/BV1pm4y1z7Gm/)でご覧ください。
|
| 25 |
-
|
| 26 |
-
> RVCによるリアルタイム音声変換: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 27 |
-
|
| 28 |
-
> 著作権侵害を心配することなく使用できるように、基底モデルは約50時間の高品質なオープンソースデータセットで訓練されています。
|
| 29 |
-
|
| 30 |
-
> 今後も、次々と使用許可のある高品質な歌声の資料集を追加し、基底モデルを訓練する予定です。
|
| 31 |
-
|
| 32 |
-
## はじめに
|
| 33 |
-
本リポジトリには下記の特徴があります。
|
| 34 |
-
|
| 35 |
-
+ Top1検索を用いることで、生の特徴量を訓練用データセット特徴量に変換し、トーンリーケージを削減します。
|
| 36 |
-
+ 比較的貧弱なGPUでも、高速かつ簡単に訓練できます。
|
| 37 |
-
+ 少量のデータセットからでも、比較的良い結果を得ることができます。(10分以上のノイズの少ない音声を推奨します。)
|
| 38 |
-
+ モデルを融合することで、音声を混ぜることができます。(ckpt processingタブの、ckpt mergeを使用します。)
|
| 39 |
-
+ 使いやすいWebUI。
|
| 40 |
-
+ UVR5 Modelも含んでいるため、人の声とBGMを素早く分離できます。
|
| 41 |
-
|
| 42 |
-
## 環境構築
|
| 43 |
-
Poetryで依存関係をインストールすることをお勧めします。
|
| 44 |
-
|
| 45 |
-
下記のコマンドは、Python3.8以上の環境で実行する必要があります:
|
| 46 |
-
```bash
|
| 47 |
-
# PyTorch関連の依存関係をインストール。インストール済の場合は省略。
|
| 48 |
-
# 参照先: https://pytorch.org/get-started/locally/
|
| 49 |
-
pip install torch torchvision torchaudio
|
| 50 |
-
|
| 51 |
-
#Windows+ Nvidia Ampere Architecture(RTX30xx)の場合、 #21 に従い、pytorchに対応するcuda versionを指定する必要があります。
|
| 52 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 53 |
-
|
| 54 |
-
# PyTorch関連の依存関係をインストール。インストール済の場合は省略。
|
| 55 |
-
# 参照先: https://python-poetry.org/docs/#installation
|
| 56 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 57 |
-
|
| 58 |
-
# Poetry経由で依存関係をインストール
|
| 59 |
-
poetry install
|
| 60 |
-
```
|
| 61 |
-
|
| 62 |
-
pipでも依存関係のインストールが可能です:
|
| 63 |
-
|
| 64 |
-
**注意**:`faiss 1.7.2`は`macOS`で`Segmentation Fault: 11`を起こすので、マニュアルインストールする場合は、 `pip install faiss-cpu==1.7.0`を実行してください。
|
| 65 |
-
|
| 66 |
-
```bash
|
| 67 |
-
pip install -r requirements.txt
|
| 68 |
-
```
|
| 69 |
-
|
| 70 |
-
## 基底modelsを準備
|
| 71 |
-
RVCは推論/訓練のために、様々な事前訓練を行った基底モデルを必要とします。
|
| 72 |
-
|
| 73 |
-
modelsは[Hugging Face space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)からダウンロードできます。
|
| 74 |
-
|
| 75 |
-
以下は、RVCに必要な基底モデルやその他のファイルの一覧です。
|
| 76 |
-
```bash
|
| 77 |
-
hubert_base.pt
|
| 78 |
-
|
| 79 |
-
./pretrained
|
| 80 |
-
|
| 81 |
-
./uvr5_weights
|
| 82 |
-
|
| 83 |
-
# ffmpegがすでにinstallされている場合は省略
|
| 84 |
-
./ffmpeg
|
| 85 |
-
```
|
| 86 |
-
その後、下記のコマンドでWebUIを起動します。
|
| 87 |
-
```bash
|
| 88 |
-
python infer-web.py
|
| 89 |
-
```
|
| 90 |
-
Windowsをお使いの方は、直接`RVC-beta.7z`をダウンロード後に展開し、`go-web.bat`をクリックすることで、WebUIを起動することができます。(7zipが必要です。)
|
| 91 |
-
|
| 92 |
-
また、リポジトリに[小白简易教程.doc](./小白简易教程.doc)がありますので、参考にしてください(中国語版のみ)。
|
| 93 |
-
|
| 94 |
-
## 参考プロジェクト
|
| 95 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 96 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 97 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 98 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 99 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 100 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 101 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 102 |
-
|
| 103 |
-
## 貢献者(contributor)の皆様の尽力に感謝します
|
| 104 |
-
<a href="https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 105 |
-
<img src="https://contrib.rocks/image?repo=liujing04/Retrieval-based-Voice-Conversion-WebUI" />
|
| 106 |
-
</a>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/README.ko.han.md
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
VITS基盤의 簡單하고使用하기 쉬운音聲變換틀<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)
|
| 7 |
-
|
| 8 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 9 |
-
|
| 10 |
-
[](https://colab.research.google.com/github/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 11 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/%E4%BD%BF%E7%94%A8%E9%9C%80%E9%81%B5%E5%AE%88%E7%9A%84%E5%8D%8F%E8%AE%AE-LICENSE.txt)
|
| 12 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 13 |
-
|
| 14 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 15 |
-
|
| 16 |
-
</div>
|
| 17 |
-
|
| 18 |
-
------
|
| 19 |
-
[**更新日誌**](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Changelog_CN.md)
|
| 20 |
-
|
| 21 |
-
[**English**](./README.en.md) | [**中文简体**](../README.md) | [**日本語**](./README.ja.md) | [**한국어**](./README.ko.md) ([**韓國語**](./README.ko.han.md))
|
| 22 |
-
|
| 23 |
-
> [示範映像](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 確認해 보세요!
|
| 24 |
-
|
| 25 |
-
> RVC를活用한實時間音聲變換: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 26 |
-
|
| 27 |
-
> 基本모델은 50時間假量의 高品質 오픈 소스 VCTK 데이터셋을 使用하였으므로, 著作權上의 念慮가 없으니 安心하고 使用하시기 바랍니다.
|
| 28 |
-
|
| 29 |
-
> 著作權問題가 없는 高品質의 노래를 以後에도 繼續해서 訓練할 豫定입니다.
|
| 30 |
-
|
| 31 |
-
## 紹介
|
| 32 |
-
本Repo는 다음과 같은 特徵을 가지고 있습니다:
|
| 33 |
-
+ top1檢索을利用하여 入力音色特徵을 訓練세트音色特徵으로 代替하여 音色의漏出을 防止;
|
| 34 |
-
+ 相對的으로 낮은性能의 GPU에서도 빠른訓練可能;
|
| 35 |
-
+ 적은量의 데이터로 訓練해도 좋은 結果를 얻을 수 있음 (最小10分以上의 低雜음音聲데이터를 使用하는 것을 勸獎);
|
| 36 |
-
+ 모델融合을通한 音色의 變調可能 (ckpt處理탭->ckpt混合選擇);
|
| 37 |
-
+ 使用하기 쉬운 WebUI (웹 使用者인터페이스);
|
| 38 |
-
+ UVR5 모델을 利用하여 목소리와 背景音樂의 빠른 分離;
|
| 39 |
-
|
| 40 |
-
## 環境의準備
|
| 41 |
-
poetry를通해 依存를設置하는 것을 勸獎합니다.
|
| 42 |
-
|
| 43 |
-
다음命令은 Python 버전3.8以上의環境에서 實行되어야 합니다:
|
| 44 |
-
```bash
|
| 45 |
-
# PyTorch 關聯主要依存設置, 이미設置되어 있는 境遇 건너뛰기 可能
|
| 46 |
-
# 參照: https://pytorch.org/get-started/locally/
|
| 47 |
-
pip install torch torchvision torchaudio
|
| 48 |
-
|
| 49 |
-
# Windows + Nvidia Ampere Architecture(RTX30xx)를 使用하고 있다面, #21 에서 명시된 것과 같이 PyTorch에 맞는 CUDA 버전을 指定해야 합니다.
|
| 50 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 51 |
-
|
| 52 |
-
# Poetry 設置, 이미設置되어 있는 境遇 건너뛰기 可能
|
| 53 |
-
# Reference: https://python-poetry.org/docs/#installation
|
| 54 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 55 |
-
|
| 56 |
-
# 依存設置
|
| 57 |
-
poetry install
|
| 58 |
-
```
|
| 59 |
-
pip를 活用하여依存를 設置하여도 無妨합니다.
|
| 60 |
-
|
| 61 |
-
**公知**: `MacOS`에서 `faiss 1.7.2`를 使用하면 Segmentation Fault: 11 誤謬가 發生할 수 있습니다. 手動으로 pip를 使用하여 設置하는境遇 `pip install faiss-cpu==1.7.0`을 使用해야 합니다.
|
| 62 |
-
|
| 63 |
-
```bash
|
| 64 |
-
pip install -r requirements.txt
|
| 65 |
-
```
|
| 66 |
-
|
| 67 |
-
## 其他預備모델準備
|
| 68 |
-
RVC 모델은 推論과訓練을 依하여 다른 預備모델이 必要합니다.
|
| 69 |
-
|
| 70 |
-
[Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)를 通해서 다운로드 할 수 있습니다.
|
| 71 |
-
|
| 72 |
-
다음은 RVC에 必要한 預備모델 및 其他 파일 目錄입니다:
|
| 73 |
-
```bash
|
| 74 |
-
hubert_base.pt
|
| 75 |
-
|
| 76 |
-
./pretrained
|
| 77 |
-
|
| 78 |
-
./uvr5_weights
|
| 79 |
-
|
| 80 |
-
# Windows를 使用하는境遇 이 사전도 必要할 수 있습니다. FFmpeg가 設置되어 있으면 건너뛰어도 됩니다.
|
| 81 |
-
ffmpeg.exe
|
| 82 |
-
```
|
| 83 |
-
그後 以下의 命令을 使用하여 WebUI를 始作할 수 있습니다:
|
| 84 |
-
```bash
|
| 85 |
-
python infer-web.py
|
| 86 |
-
```
|
| 87 |
-
Windows를 使用하는境遇 `RVC-beta.7z`를 다운로드 및 壓縮解除하여 RVC를 直接使用하거나 `go-web.bat`을 使用하여 WebUi를 直接할 수 있습니다.
|
| 88 |
-
|
| 89 |
-
## 參考
|
| 90 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 91 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 92 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 93 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 94 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 95 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 96 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 97 |
-
## 모든寄與者분들의勞力에感謝드립니다
|
| 98 |
-
|
| 99 |
-
<a href="https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 100 |
-
<img src="https://contrib.rocks/image?repo=liujing04/Retrieval-based-Voice-Conversion-WebUI" />
|
| 101 |
-
</a>
|
| 102 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/README.ko.md
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
VITS 기반의 간단하고 사용하기 쉬운 음성 변환 프레임워크.<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)
|
| 7 |
-
|
| 8 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 9 |
-
|
| 10 |
-
[](https://colab.research.google.com/github/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 11 |
-
[](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/%E4%BD%BF%E7%94%A8%E9%9C%80%E9%81%B5%E5%AE%88%E7%9A%84%E5%8D%8F%E8%AE%AE-LICENSE.txt)
|
| 12 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 13 |
-
|
| 14 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 15 |
-
|
| 16 |
-
</div>
|
| 17 |
-
|
| 18 |
-
------
|
| 19 |
-
[**업데이트 로그**](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Changelog_CN.md)
|
| 20 |
-
|
| 21 |
-
[**English**](./README.en.md) | [**中文简体**](../README.md) | [**日本語**](./README.ja.md) | [**한국어**](./README.ko.md) ([**韓國語**](./README.ko.han.md))
|
| 22 |
-
|
| 23 |
-
> [데모 영상](https://www.bilibili.com/video/BV1pm4y1z7Gm/)을 확인해 보세요!
|
| 24 |
-
|
| 25 |
-
> RVC를 활용한 실시간 음성변환: [w-okada/voice-changer](https://github.com/w-okada/voice-changer)
|
| 26 |
-
|
| 27 |
-
> 기본 모델은 50시간 가량의 고퀄리티 오픈 소스 VCTK 데이터셋을 사용하였으므로, 저작권상의 염려가 없으니 안심하고 사용하시기 바랍니다.
|
| 28 |
-
|
| 29 |
-
> 저작권 문제가 없는 고퀄리티의 노래를 이후에도 계속해서 훈련할 예정입니다.
|
| 30 |
-
|
| 31 |
-
## 소개
|
| 32 |
-
본 Repo는 다음과 같은 특징을 가지고 있습니다:
|
| 33 |
-
+ top1 검색을 이용하여 입력 음색 특징을 훈련 세트 음색 특징으로 대체하여 음색의 누출을 방지;
|
| 34 |
-
+ 상대적으로 낮은 성능의 GPU에서도 빠른 훈련 가능;
|
| 35 |
-
+ 적은 양의 데이터로 훈련해도 좋은 결과를 얻을 수 있음 (최소 10분 이상의 저잡음 음성 데이터를 사용하는 것을 권장);
|
| 36 |
-
+ 모델 융합을 통한 음색의 변조 가능 (ckpt 처리 탭->ckpt 병합 선택);
|
| 37 |
-
+ 사용하기 쉬운 WebUI (웹 인터페이스);
|
| 38 |
-
+ UVR5 모델을 이용하여 목소리와 배경음악의 빠른 분리;
|
| 39 |
-
|
| 40 |
-
## 환경의 준비
|
| 41 |
-
poetry를 통해 dependecies를 설치하는 것을 권장합니다.
|
| 42 |
-
|
| 43 |
-
다음 명령은 Python 버전 3.8 이상의 환경에서 실행되어야 합니다:
|
| 44 |
-
```bash
|
| 45 |
-
# PyTorch 관련 주요 dependencies 설치, 이미 설치되어 있는 경우 건너뛰기 가능
|
| 46 |
-
# 참조: https://pytorch.org/get-started/locally/
|
| 47 |
-
pip install torch torchvision torchaudio
|
| 48 |
-
|
| 49 |
-
# Windows + Nvidia Ampere Architecture(RTX30xx)를 사용하고 있다면, https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/issues/21 에서 명시된 것과 같이 PyTorch에 맞는 CUDA 버전을 지정해야 합니다.
|
| 50 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 51 |
-
|
| 52 |
-
# Poetry 설치, 이미 설치되어 있는 경우 건너뛰기 가능
|
| 53 |
-
# Reference: https://python-poetry.org/docs/#installation
|
| 54 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 55 |
-
|
| 56 |
-
# Dependecies 설치
|
| 57 |
-
poetry install
|
| 58 |
-
```
|
| 59 |
-
pip를 활용하여 dependencies를 설치하여도 무방합니다.
|
| 60 |
-
|
| 61 |
-
**공지**: `MacOS`에서 `faiss 1.7.2`를 사용하면 Segmentation Fault: 11 오류가 발생할 수 있습니다. 수동으로 pip를 사용하여 설치하는 경우 `pip install faiss-cpu==1.7.0`을 사용해야 합니다.
|
| 62 |
-
|
| 63 |
-
```bash
|
| 64 |
-
pip install -r requirements.txt
|
| 65 |
-
```
|
| 66 |
-
|
| 67 |
-
## 기타 사전 모델 준비
|
| 68 |
-
RVC 모델은 추론과 훈련을 위하여 다른 사전 모델이 필요합니다.
|
| 69 |
-
|
| 70 |
-
[Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)를 통해서 다운로드 할 수 있습니다.
|
| 71 |
-
|
| 72 |
-
다음은 RVC에 필요한 사전 모델 및 기타 파일 목록입니다:
|
| 73 |
-
```bash
|
| 74 |
-
hubert_base.pt
|
| 75 |
-
|
| 76 |
-
./pretrained
|
| 77 |
-
|
| 78 |
-
./uvr5_weights
|
| 79 |
-
|
| 80 |
-
# Windows를 사용하는 경우 이 사전도 필요할 수 있습니다. FFmpeg가 설치되어 있으면 건너뛰어도 됩니다.
|
| 81 |
-
ffmpeg.exe
|
| 82 |
-
```
|
| 83 |
-
그 후 이하의 명령을 사용하여 WebUI를 시작할 수 있습니다:
|
| 84 |
-
```bash
|
| 85 |
-
python infer-web.py
|
| 86 |
-
```
|
| 87 |
-
Windows를 사용하는 경우 `RVC-beta.7z`를 다운로드 및 압축 해제하여 RVC를 직접 사용하거나 `go-web.bat`을 사용하여 WebUi를 시작할 수 있습니다.
|
| 88 |
-
|
| 89 |
-
## 참고
|
| 90 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 91 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 92 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 93 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 94 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 95 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 96 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 97 |
-
## 모든 기여자 분들의 노력에 감사드립니다.
|
| 98 |
-
|
| 99 |
-
<a href="https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 100 |
-
<img src="https://contrib.rocks/image?repo=liujing04/Retrieval-based-Voice-Conversion-WebUI" />
|
| 101 |
-
</a>
|
| 102 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/cn/Changelog_CN.md
DELETED
|
@@ -1,109 +0,0 @@
|
|
| 1 |
-
### 20231006更新
|
| 2 |
-
|
| 3 |
-
我们制作了一个用于实时变声的界面go-realtime-gui.bat/gui_v1.py(事实上早就存在了),本次更新重点也优化了实时变声的性能。对比0813版:
|
| 4 |
-
- 1、优优化界面操作:参数热更新(调整参数不需要中止再启动),懒加载模型(已加载过的模型不需要重新加载),增加响度因子参数(响度向输入音频靠近)
|
| 5 |
-
- 2、优化自带降噪效果与速度
|
| 6 |
-
- 3、大幅优化推理速度
|
| 7 |
-
|
| 8 |
-
注意输入输出设备应该选择同种类型,例如都选MME类型。
|
| 9 |
-
|
| 10 |
-
1006版本整体的更新为:
|
| 11 |
-
- 1、继续提升rmvpe音高提取算法效果,对于男低音有更大的提升
|
| 12 |
-
- 2、优化推理界面布局
|
| 13 |
-
|
| 14 |
-
### 20230813更新
|
| 15 |
-
1-常规bug修复
|
| 16 |
-
- 保存频率总轮数最低改为1 总轮数最低改为2
|
| 17 |
-
- 修复无pretrain模型训练报错
|
| 18 |
-
- 增加伴奏人声分离完毕清理显存
|
| 19 |
-
- faiss保存路径绝对路径改为相对路径
|
| 20 |
-
- 支持路径包含空格(训练集路径+实验名称均支持,不再会报错)
|
| 21 |
-
- filelist取消强制utf8编码
|
| 22 |
-
- 解决实时变声中开启索引导致的CPU极大占用问题
|
| 23 |
-
|
| 24 |
-
2-重点更新
|
| 25 |
-
- 训练出当前最强开源人声音高提取模型RMVPE,并用于RVC的训练、离线/实时推理,支持pytorch/onnx/DirectML
|
| 26 |
-
- 通过pytorch-dml支持A卡和I卡的
|
| 27 |
-
(1)实时变声(2)推理(3)人声伴奏分离(4)训练暂未支持,会切换至CPU训练;通过onnx_dml支持rmvpe_gpu的推理
|
| 28 |
-
|
| 29 |
-
### 20230618更新
|
| 30 |
-
- v2增加32k和48k两个新预训练模型
|
| 31 |
-
- 修复非f0模型推理报错
|
| 32 |
-
- 对于超过一小时的训练集的索引建立环节,自动kmeans缩小特征处理以加速索引训练、加入和查询
|
| 33 |
-
- 附送一个人声转吉他玩具仓库
|
| 34 |
-
- 数据处理剔除异常值切片
|
| 35 |
-
- onnx导出选项卡
|
| 36 |
-
|
| 37 |
-
失败的实验:
|
| 38 |
-
- ~~特征检索增加时序维度:寄,没啥效果~~
|
| 39 |
-
- ~~特征检索增加PCAR降维可选项:寄,数据大用kmeans缩小数据量,数据小降维操作耗时比省下的匹配耗时还多~~
|
| 40 |
-
- ~~支持onnx推理(附带仅推理的小压缩包):寄,生成nsf还是需要pytorch~~
|
| 41 |
-
- ~~训练时在音高、gender、eq、噪声等方面对输入进行随机增强:寄,没啥效果~~
|
| 42 |
-
- ~~接入小型声码器调研:寄,效果变差~~
|
| 43 |
-
|
| 44 |
-
todolist:
|
| 45 |
-
- ~~训练集音高识别支持crepe:已经被RMVPE取代,不需要~~
|
| 46 |
-
- ~~多进程harvest推理:已经被RMVPE取代,不需要~~
|
| 47 |
-
- ~~crepe的精度支持和RVC-config同步:已经被RMVPE取代,不需要。支持这个还要同步torchcrepe的库,麻烦~~
|
| 48 |
-
- 对接F0编辑器
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
### 20230528更新
|
| 52 |
-
- 增加v2的jupyter notebook,韩文changelog,增加一些环境依赖
|
| 53 |
-
- 增加呼吸、清辅音、齿音保护模式
|
| 54 |
-
- 支持crepe-full推理
|
| 55 |
-
- UVR5人声伴奏分离加上3个去延迟模型和MDX-Net去混响模型,增加HP3人声提取模型
|
| 56 |
-
- 索引名称增加版本和实验名称
|
| 57 |
-
- 人声伴奏分离、推理批量导出增加音频导出格式选项
|
| 58 |
-
- 废弃32k模型的训练
|
| 59 |
-
|
| 60 |
-
### 20230513更新
|
| 61 |
-
- 清除一键包内部老版本runtime内残留的lib.infer_pack和uvr5_pack
|
| 62 |
-
- 修复训练集预处理伪多进程的bug
|
| 63 |
-
- 增加harvest识别音高可选通过中值滤波削弱哑音现象,可调整中值滤波半径
|
| 64 |
-
- 导出音频增加后处理重采样
|
| 65 |
-
- 训练n_cpu进程数从"仅调整f0提取"改为"调整数据预处理和f0提取"
|
| 66 |
-
- 自动检测logs文件夹下的index路径,提供下拉列表功能
|
| 67 |
-
- tab页增加"常见问题解答"(也可参考github-rvc-wiki)
|
| 68 |
-
- 相同路径的输入音频推理增加了音高缓存(用途:使用harvest音高提取,整个pipeline会经历漫长且重复的音高提取过程,如果不使用缓存,实验不同音色、索引、音高中值滤波半径参数的用户在第一次测试后的等待结果会非常痛苦)
|
| 69 |
-
|
| 70 |
-
### 20230514更新
|
| 71 |
-
- 音量包络对齐输入混合(可以缓解“输入静音输出小幅度噪声”的问题。如果输入音频背景底噪大则不建议开启,默认不开启(值为1可视为不开启))
|
| 72 |
-
- 支持按照指定频率保存提取的小模型(假如你想尝试不同epoch下的推理效果,但是不想保存所有大checkpoint并且每次都要ckpt手工处理提取小模型,这项功能会非常实用)
|
| 73 |
-
- 通过设置环境变量解决服务端开了系统全局代理导致浏览器连接错误的问题
|
| 74 |
-
- 支持v2预训练模型(目前只公开了40k版本进行测试,另外2个采样率还没有训练完全)
|
| 75 |
-
- 推理前限制超过1的过大音量
|
| 76 |
-
- 微调数据预处理参数
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
### 20230409更新
|
| 80 |
-
- 修正训练参数,提升显卡平均利用率,A100最高从25%提升至90%左右,V100:50%->90%左右,2060S:60%->85%左右,P40:25%->95%左右,训练速度显著提升
|
| 81 |
-
- 修正参数:总batch_size改为每张卡的batch_size
|
| 82 |
-
- 修正total_epoch:最大限制100解锁至1000;默认10提升至默认20
|
| 83 |
-
- 修复ckpt提取识别是否带音高错误导致推理异常的问题
|
| 84 |
-
- 修复分布式训练每个rank都保存一次ckpt���问题
|
| 85 |
-
- 特征提取进行nan特征过滤
|
| 86 |
-
- 修复静音输入输出随机辅音or噪声的问题(老版模型需要重做训练集重训)
|
| 87 |
-
|
| 88 |
-
### 20230416更新
|
| 89 |
-
- 新增本地实时变声迷你GUI,双击go-realtime-gui.bat启动
|
| 90 |
-
- 训练推理均对<50Hz的频段进行滤波过滤
|
| 91 |
-
- 训练推理音高提取pyworld最低音高从默认80下降至50,50-80hz间的男声低音不会哑
|
| 92 |
-
- WebUI支持根据系统区域变更语言(现支持en_US,ja_JP,zh_CN,zh_HK,zh_SG,zh_TW,不支持的默认en_US)
|
| 93 |
-
- 修正部分显卡识别(例如V100-16G识别失败,P4识别失败)
|
| 94 |
-
|
| 95 |
-
### 20230428更新
|
| 96 |
-
- 升级faiss索引设置,速度更快,质量更高
|
| 97 |
-
- 取消total_npy依赖,后续分享模型不再需要填写total_npy
|
| 98 |
-
- 解锁16系限制。4G显存GPU给到4G的推理设置。
|
| 99 |
-
- 修复部分音频格式下UVR5人声伴奏分离的bug
|
| 100 |
-
- 实时变声迷你gui增加对非40k与不懈怠音高模型的支持
|
| 101 |
-
|
| 102 |
-
### 后续计划:
|
| 103 |
-
功能:
|
| 104 |
-
- 支持多人训练选项卡(至多4人)
|
| 105 |
-
|
| 106 |
-
底模:
|
| 107 |
-
- 收集呼吸wav加入训练集修正呼吸变声电音的问题
|
| 108 |
-
- 我们正在训练增加了歌声训练集的底模,未来会公开
|
| 109 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/cn/faq.md
DELETED
|
@@ -1,108 +0,0 @@
|
|
| 1 |
-
## Q1:ffmpeg error/utf8 error.
|
| 2 |
-
|
| 3 |
-
大概率不是ffmpeg问题,而是音频路径问题;<br>
|
| 4 |
-
ffmpeg读取路径带空格、()等特殊符号,可能出现ffmpeg error;训练集音频带中文路径,在写入filelist.txt的时候可能出现utf8 error;<br>
|
| 5 |
-
|
| 6 |
-
## Q2:一键训练结束没有索引
|
| 7 |
-
|
| 8 |
-
显示"Training is done. The program is closed."则模型训练成功,后续紧邻的报错是假的;<br>
|
| 9 |
-
|
| 10 |
-
一键训练结束完成没有added开头的索引文件,可能是因为训练集太大卡住了添加索引的步骤;已通过批处理add索引解决内存add索引对内存需求过大的问题。临时可尝试再次点击"训练索引"按钮。<br>
|
| 11 |
-
|
| 12 |
-
## Q3:训练结束推理没看到训练集的音色
|
| 13 |
-
点刷新音色再看看,如果还没有看看训练有没有报错,控制台和webui的截图,logs/实验名下的log,都可以发给开发者看看。<br>
|
| 14 |
-
|
| 15 |
-
## Q4:如何分享模型
|
| 16 |
-
rvc_root/logs/实验名 下面存储的pth不是用来分享模型用来推理的,而是为了存储实验状态供复现,以及继续训练用的。用来分享的模型应该是weights文件夹下大小为60+MB的pth文件;<br>
|
| 17 |
-
后续将把weights/exp_name.pth和logs/exp_name/added_xxx.index合并打包成weights/exp_name.zip省去填写index的步骤,那么zip文件用来分享,不要分享pth文件,除非是想换机器继续训练;<br>
|
| 18 |
-
如果你把logs文件夹下的几百MB的pth文件复制/分享到weights文件夹下强行用于推理,可能会出现f0,tgt_sr等各种key不存在的报错。你需要用ckpt选项卡最下面,手工或自动(本地logs下如果能找到相关信息则会自动)选择是否携带音高、目标音频采样率的选项后进行ckpt小模型提取(输入路径填G开头的那个),提取完在weights文件夹下会出现60+MB的pth文件,刷新音色后可以选择使用。<br>
|
| 19 |
-
|
| 20 |
-
## Q5:Connection Error.
|
| 21 |
-
也许你关闭了控制台(黑色窗口)。<br>
|
| 22 |
-
|
| 23 |
-
## Q6:WebUI弹出Expecting value: line 1 column 1 (char 0).
|
| 24 |
-
请关闭系统局域网代理/全局代理。<br>
|
| 25 |
-
|
| 26 |
-
这个不仅是客户端的代理,也包括服务端的代理(例如你使用autodl设置了http_proxy和https_proxy学术加速,使用时也需要unset关掉)<br>
|
| 27 |
-
|
| 28 |
-
## Q7:不用WebUI如何通过命令训练推理
|
| 29 |
-
训练脚本:<br>
|
| 30 |
-
可先跑通WebUI,消息窗内会显示数据集处理和训练用命令行;<br>
|
| 31 |
-
|
| 32 |
-
推理脚本:<br>
|
| 33 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
| 34 |
-
|
| 35 |
-
例子:<br>
|
| 36 |
-
|
| 37 |
-
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
| 38 |
-
|
| 39 |
-
f0up_key=sys.argv[1]<br>
|
| 40 |
-
input_path=sys.argv[2]<br>
|
| 41 |
-
index_path=sys.argv[3]<br>
|
| 42 |
-
f0method=sys.argv[4]#harvest or pm<br>
|
| 43 |
-
opt_path=sys.argv[5]<br>
|
| 44 |
-
model_path=sys.argv[6]<br>
|
| 45 |
-
index_rate=float(sys.argv[7])<br>
|
| 46 |
-
device=sys.argv[8]<br>
|
| 47 |
-
is_half=bool(sys.argv[9])<br>
|
| 48 |
-
|
| 49 |
-
## Q8:Cuda error/Cuda out of memory.
|
| 50 |
-
小概率是cuda配置问题、设备不支持;大概率是显存不够(out of memory);<br>
|
| 51 |
-
|
| 52 |
-
训练的话缩小batch size(如果缩小到1还不够只能更换显卡训练),推理的话酌情缩小config.py结尾的x_pad,x_query,x_center,x_max。4G以下显存(例如1060(3G)和各种2G显卡)可以直接放弃,4G显存显卡还有救。<br>
|
| 53 |
-
|
| 54 |
-
## Q9:total_epoch调多少比较好
|
| 55 |
-
|
| 56 |
-
如果训练集音质差底噪大,20~30足够了,调太高,底模音质无法带高你的低音质训练集<br>
|
| 57 |
-
如果训练集音质高底噪低时长多,可以调高,200是ok的(训练速度很快,既然你有条件准备高音质训练集,显卡想必条件也不错,肯定不在乎多一些训练时间)<br>
|
| 58 |
-
|
| 59 |
-
## Q10:需要多少训练集时长
|
| 60 |
-
推荐10min至50min<br>
|
| 61 |
-
保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善<br>
|
| 62 |
-
高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩<br>
|
| 63 |
-
也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;<br>
|
| 64 |
-
1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。<br>
|
| 65 |
-
|
| 66 |
-
## Q11:index rate干嘛用的,怎么调(科普)
|
| 67 |
-
如果底模和推理源的音质高于训练集的音质,他们可以带高推理结果的音质,但代价可能是音色往底模/推理源的音色靠,这种现象叫做"音色泄露";<br>
|
| 68 |
-
index rate用来削减/解决音色泄露问题。调到1,则理论上不存在推理源的音色泄露问题,但音质更倾向于训练集。如果训练集音质比推理源低,则index rate调高可能降低音质。调到0,则不具备利用检索混合来保护训练集音色的效果;<br>
|
| 69 |
-
如果训练集优质时长多,可调高total_epoch,此时模型本身不太会引用推理源和底模的音色,很少存在"音色泄露"问题,此时index_rate不重要,你甚至可以不建立/分享index索引文件。<br>
|
| 70 |
-
|
| 71 |
-
## Q11:推理怎么选gpu
|
| 72 |
-
config.py文件里device cuda:后面选择卡号;<br>
|
| 73 |
-
卡号和显卡的映射关系,在训练选项卡的显卡信息栏里能看到。<br>
|
| 74 |
-
|
| 75 |
-
## Q12:如何推理训练中间保存的pth
|
| 76 |
-
通过ckpt选项卡最下面提取小模型。<br>
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
## Q13:如何中断和继续训练
|
| 80 |
-
现阶段只能关闭WebUI控制台双击go-web.bat重启程序。网页参数也要刷新重新填写;<br>
|
| 81 |
-
继续训练:相同网页参数点训练模型,就会接着上次的checkpoint继续训练。<br>
|
| 82 |
-
|
| 83 |
-
## Q14:训练时出现文件页面/内存error
|
| 84 |
-
进程开太多了,内存炸了。你可能可以通过如下方式解决<br>
|
| 85 |
-
1、"提取音高和处理数据使用的CPU进程数" 酌情拉低;<br>
|
| 86 |
-
2、训练集音频手工切一下,不要太长。<br>
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
## Q15:如何中途加数据训练
|
| 90 |
-
1、所有数据新建一个实验名;<br>
|
| 91 |
-
2、拷贝上一次的最新的那个G和D文件(或者你想基于哪个中间ckpt训练,也可以拷贝中间的)到新实验名;下<br>
|
| 92 |
-
3、一键训练新实验名,他会继续上一次的最新进度训练。<br>
|
| 93 |
-
|
| 94 |
-
## Q16: error about llvmlite.dll
|
| 95 |
-
|
| 96 |
-
OSError: Could not load shared object file: llvmlite.dll
|
| 97 |
-
|
| 98 |
-
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
| 99 |
-
|
| 100 |
-
win平台会报这个错,装上https://aka.ms/vs/17/release/vc_redist.x64.exe这个再重启WebUI就好了。
|
| 101 |
-
|
| 102 |
-
## Q17: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
|
| 103 |
-
|
| 104 |
-
wavs16k文件夹下,找到文件大小显著比其他都小的一些音频文件,删掉,点击训练模型,就不会报错了,不过由于一键流程中断了你训练完模型还要点训练索引。
|
| 105 |
-
|
| 106 |
-
## Q18: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
|
| 107 |
-
|
| 108 |
-
不要中途变更采样率继续训练。如果一定要变更,应更换实验名从头训练。当然你也可以把上次提取的音高和特征(0/1/2/2b folders)拷贝过去加速训练流程。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/en/Changelog_EN.md
DELETED
|
@@ -1,105 +0,0 @@
|
|
| 1 |
-
### 2023-10-06
|
| 2 |
-
- We have created a GUI for real-time voice change: go-realtime-gui.bat/gui_v1.py (Note that you should choose the same type of input and output device, e.g. MME and MME).
|
| 3 |
-
- We trained a better pitch extract RMVPE model.
|
| 4 |
-
- Optimize inference GUI layout.
|
| 5 |
-
|
| 6 |
-
### 2023-08-13
|
| 7 |
-
1-Regular bug fix
|
| 8 |
-
- Change the minimum total epoch number to 1, and change the minimum total epoch number to 2
|
| 9 |
-
- Fix training errors of not using pre-train models
|
| 10 |
-
- After accompaniment vocals separation, clear graphics memory
|
| 11 |
-
- Change faiss save path absolute path to relative path
|
| 12 |
-
- Support path containing spaces (both training set path and experiment name are supported, and errors will no longer be reported)
|
| 13 |
-
- Filelist cancels mandatory utf8 encoding
|
| 14 |
-
- Solve the CPU consumption problem caused by faiss searching during real-time voice changes
|
| 15 |
-
|
| 16 |
-
2-Key updates
|
| 17 |
-
- Train the current strongest open-source vocal pitch extraction model RMVPE, and use it for RVC training, offline/real-time inference, supporting PyTorch/Onnx/DirectML
|
| 18 |
-
- Support for AMD and Intel graphics cards through Pytorch_DML
|
| 19 |
-
|
| 20 |
-
(1) Real time voice change (2) Inference (3) Separation of vocal accompaniment (4) Training not currently supported, will switch to CPU training; supports RMVPE inference of gpu by Onnx_Dml
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
### 2023-06-18
|
| 24 |
-
- New pretrained v2 models: 32k and 48k
|
| 25 |
-
- Fix non-f0 model inference errors
|
| 26 |
-
- For training-set exceeding 1 hour, do automatic minibatch-kmeans to reduce feature shape, so that index training, adding, and searching will be much faster.
|
| 27 |
-
- Provide a toy vocal2guitar huggingface space
|
| 28 |
-
- Auto delete outlier short cut training-set audios
|
| 29 |
-
- Onnx export tab
|
| 30 |
-
|
| 31 |
-
Failed experiments:
|
| 32 |
-
- ~~Feature retrieval: add temporal feature retrieval: not effective~~
|
| 33 |
-
- ~~Feature retrieval: add PCAR dimensionality reduction: searching is even slower~~
|
| 34 |
-
- ~~Random data augmentation when training: not effective~~
|
| 35 |
-
|
| 36 |
-
todolist:
|
| 37 |
-
- ~~Vocos-RVC (tiny vocoder): not effective~~
|
| 38 |
-
- ~~Crepe support for training:replaced by RMVPE~~
|
| 39 |
-
- ~~Half precision crepe inference:replaced by RMVPE. And hard to achive.~~
|
| 40 |
-
- F0 editor support
|
| 41 |
-
|
| 42 |
-
### 2023-05-28
|
| 43 |
-
- Add v2 jupyter notebook, korean changelog, fix some environment requirments
|
| 44 |
-
- Add voiceless consonant and breath protection mode
|
| 45 |
-
- Support crepe-full pitch detect
|
| 46 |
-
- UVR5 vocal separation: support dereverb models and de-echo models
|
| 47 |
-
- Add experiment name and version on the name of index
|
| 48 |
-
- Support users to manually select export format of output audios when batch voice conversion processing and UVR5 vocal separation
|
| 49 |
-
- v1 32k model training is no more supported
|
| 50 |
-
|
| 51 |
-
### 2023-05-13
|
| 52 |
-
- Clear the redundant codes in the old version of runtime in the one-click-package: lib.infer_pack and uvr5_pack
|
| 53 |
-
- Fix pseudo multiprocessing bug in training set preprocessing
|
| 54 |
-
- Adding median filtering radius adjustment for harvest pitch recognize algorithm
|
| 55 |
-
- Support post processing resampling for exporting audio
|
| 56 |
-
- Multi processing "n_cpu" setting for training is changed from "f0 extraction" to "data preprocessing and f0 extraction"
|
| 57 |
-
- Automatically detect the index paths under the logs folder and provide a drop-down list function
|
| 58 |
-
- Add "Frequently Asked Questions and Answers" on the tab page (you can also refer to github RVC wiki)
|
| 59 |
-
- When inference, harvest pitch is cached when using same input audio path (purpose: using harvest pitch extraction, the entire pipeline will go through a long and repetitive pitch extraction process. If caching is not used, users who experiment with different timbre, index, and pitch median filtering radius settings will experience a very painful waiting process after the first inference)
|
| 60 |
-
|
| 61 |
-
### 2023-05-14
|
| 62 |
-
- Use volume envelope of input to mix or replace the volume envelope of output (can alleviate the problem of "input muting and output small amplitude noise". If the input audio background noise is high, it is not recommended to turn it on, and it is not turned on by default (1 can be considered as not turned on)
|
| 63 |
-
- Support saving extracted small models at a specified frequency (if you want to see the performance under different epochs, but do not want to save all large checkpoints and manually extract small models by ckpt-processing every time, this feature will be very practical)
|
| 64 |
-
- Resolve the issue of "connection errors" caused by the server's global proxy by setting environment variables
|
| 65 |
-
- Supports pre-trained v2 models (currently only 40k versions are publicly available for testing, and the other two sampling rates have not been fully trained yet)
|
| 66 |
-
- Limit excessive volume exceeding 1 before inference
|
| 67 |
-
- Slightly adjusted the settings of training-set preprocessing
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
#######################
|
| 71 |
-
|
| 72 |
-
History changelogs:
|
| 73 |
-
|
| 74 |
-
### 2023-04-09
|
| 75 |
-
- Fixed training parameters to improve GPU utilization rate: A100 increased from 25% to around 90%, V100: 50% to around 90%, 2060S: 60% to around 85%, P40: 25% to around 95%; significantly improved training speed
|
| 76 |
-
- Changed parameter: total batch_size is now per GPU batch_size
|
| 77 |
-
- Changed total_epoch: maximum limit increased from 100 to 1000; default increased from 10 to 20
|
| 78 |
-
- Fixed issue of ckpt extraction recognizing pitch incorrectly, causing abnormal inference
|
| 79 |
-
- Fixed issue of distributed training saving ckpt for each rank
|
| 80 |
-
- Applied nan feature filtering for feature extraction
|
| 81 |
-
- Fixed issue with silent input/output producing random consonants or noise (old models need to retrain with a new dataset)
|
| 82 |
-
|
| 83 |
-
### 2023-04-16 Update
|
| 84 |
-
- Added local real-time voice changing mini-GUI, start by double-clicking go-realtime-gui.bat
|
| 85 |
-
- Applied filtering for frequency bands below 50Hz during training and inference
|
| 86 |
-
- Lowered the minimum pitch extraction of pyworld from the default 80 to 50 for training and inference, allowing male low-pitched voices between 50-80Hz not to be muted
|
| 87 |
-
- WebUI supports changing languages according to system locale (currently supporting en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW; defaults to en_US if not supported)
|
| 88 |
-
- Fixed recognition of some GPUs (e.g., V100-16G recognition failure, P4 recognition failure)
|
| 89 |
-
|
| 90 |
-
### 2023-04-28 Update
|
| 91 |
-
- Upgraded faiss index settings for faster speed and higher quality
|
| 92 |
-
- Removed dependency on total_npy; future model sharing will not require total_npy input
|
| 93 |
-
- Unlocked restrictions for the 16-series GPUs, providing 4GB inference settings for 4GB VRAM GPUs
|
| 94 |
-
- Fixed bug in UVR5 vocal accompaniment separation for certain audio formats
|
| 95 |
-
- Real-time voice changing mini-GUI now supports non-40k and non-lazy pitch models
|
| 96 |
-
|
| 97 |
-
### Future Plans:
|
| 98 |
-
Features:
|
| 99 |
-
- Add option: extract small models for each epoch save
|
| 100 |
-
- Add option: export additional mp3 to the specified path during inference
|
| 101 |
-
- Support multi-person training tab (up to 4 people)
|
| 102 |
-
|
| 103 |
-
Base model:
|
| 104 |
-
- Collect breathing wav files to add to the training dataset to fix the issue of distorted breath sounds
|
| 105 |
-
- We are currently training a base model with an extended singing dataset, which will be released in the future
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/en/README.en.md
DELETED
|
@@ -1,194 +0,0 @@
|
|
| 1 |
-
<div align="center">
|
| 2 |
-
|
| 3 |
-
<h1>Retrieval-based-Voice-Conversion-WebUI</h1>
|
| 4 |
-
An easy-to-use Voice Conversion framework based on VITS.<br><br>
|
| 5 |
-
|
| 6 |
-
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
| 8 |
-
|
| 9 |
-
<img src="https://counter.seku.su/cmoe?name=rvc&theme=r34" /><br>
|
| 10 |
-
|
| 11 |
-
[](https://colab.research.google.com/github/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
|
| 12 |
-
[](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/LICENSE)
|
| 13 |
-
[](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/)
|
| 14 |
-
|
| 15 |
-
[](https://discord.gg/HcsmBBGyVk)
|
| 16 |
-
|
| 17 |
-
</div>
|
| 18 |
-
|
| 19 |
-
------
|
| 20 |
-
[**Changelog**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/Changelog_EN.md) | [**FAQ (Frequently Asked Questions)**](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/FAQ-(Frequently-Asked-Questions))
|
| 21 |
-
|
| 22 |
-
[**English**](../en/README.en.md) | [**中文简体**](../../README.md) | [**日本語**](../jp/README.ja.md) | [**한국어**](../kr/README.ko.md) ([**韓國語**](../kr/README.ko.han.md)) | [**Türkçe**](../tr/README.tr.md)
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
Check our [Demo Video](https://www.bilibili.com/video/BV1pm4y1z7Gm/) here!
|
| 26 |
-
|
| 27 |
-
Training/Inference WebUI:go-web.bat
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
Realtime Voice Conversion GUI:go-realtime-gui.bat
|
| 32 |
-
|
| 33 |
-

|
| 34 |
-
|
| 35 |
-
> The dataset for the pre-training model uses nearly 50 hours of high quality VCTK open source dataset.
|
| 36 |
-
|
| 37 |
-
> High quality licensed song datasets will be added to training-set one after another for your use, without worrying about copyright infringement.
|
| 38 |
-
|
| 39 |
-
> Please look forward to the pretrained base model of RVCv3, which has larger parameters, more training data, better results, unchanged inference speed, and requires less training data for training.
|
| 40 |
-
|
| 41 |
-
## Summary
|
| 42 |
-
This repository has the following features:
|
| 43 |
-
+ Reduce tone leakage by replacing the source feature to training-set feature using top1 retrieval;
|
| 44 |
-
+ Easy and fast training, even on relatively poor graphics cards;
|
| 45 |
-
+ Training with a small amount of data also obtains relatively good results (>=10min low noise speech recommended);
|
| 46 |
-
+ Supporting model fusion to change timbres (using ckpt processing tab->ckpt merge);
|
| 47 |
-
+ Easy-to-use Webui interface;
|
| 48 |
-
+ Use the UVR5 model to quickly separate vocals and instruments.
|
| 49 |
-
+ Use the most powerful High-pitch Voice Extraction Algorithm [InterSpeech2023-RMVPE](#Credits) to prevent the muted sound problem. Provides the best results (significantly) and is faster, with even lower resource consumption than Crepe_full.
|
| 50 |
-
+ AMD/Intel graphics cards acceleration supported.
|
| 51 |
-
+ Intel ARC graphics cards acceleration with IPEX supported.
|
| 52 |
-
|
| 53 |
-
## Preparing the environment
|
| 54 |
-
The following commands need to be executed in the environment of Python version 3.8 or higher.
|
| 55 |
-
|
| 56 |
-
(Windows/Linux)
|
| 57 |
-
First install the main dependencies through pip:
|
| 58 |
-
```bash
|
| 59 |
-
# Install PyTorch-related core dependencies, skip if installed
|
| 60 |
-
# Reference: https://pytorch.org/get-started/locally/
|
| 61 |
-
pip install torch torchvision torchaudio
|
| 62 |
-
|
| 63 |
-
#For Windows + Nvidia Ampere Architecture(RTX30xx), you need to specify the cuda version corresponding to pytorch according to the experience of https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/21
|
| 64 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
|
| 65 |
-
|
| 66 |
-
#For Linux + AMD Cards, you need to use the following pytorch versions:
|
| 67 |
-
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
|
| 68 |
-
```
|
| 69 |
-
|
| 70 |
-
Then can use poetry to install the other dependencies:
|
| 71 |
-
```bash
|
| 72 |
-
# Install the Poetry dependency management tool, skip if installed
|
| 73 |
-
# Reference: https://python-poetry.org/docs/#installation
|
| 74 |
-
curl -sSL https://install.python-poetry.org | python3 -
|
| 75 |
-
|
| 76 |
-
# Install the project dependencies
|
| 77 |
-
poetry install
|
| 78 |
-
```
|
| 79 |
-
|
| 80 |
-
You can also use pip to install them:
|
| 81 |
-
```bash
|
| 82 |
-
|
| 83 |
-
for Nvidia graphics cards
|
| 84 |
-
pip install -r requirements.txt
|
| 85 |
-
|
| 86 |
-
for AMD/Intel graphics cards on Windows (DirectML):
|
| 87 |
-
pip install -r requirements-dml.txt
|
| 88 |
-
|
| 89 |
-
for Intel ARC graphics cards on Linux / WSL using Python 3.10:
|
| 90 |
-
pip install -r requirements-ipex.txt
|
| 91 |
-
|
| 92 |
-
for AMD graphics cards on Linux (ROCm):
|
| 93 |
-
pip install -r requirements-amd.txt
|
| 94 |
-
```
|
| 95 |
-
|
| 96 |
-
------
|
| 97 |
-
Mac users can install dependencies via `run.sh`:
|
| 98 |
-
```bash
|
| 99 |
-
sh ./run.sh
|
| 100 |
-
```
|
| 101 |
-
|
| 102 |
-
## Preparation of other Pre-models
|
| 103 |
-
RVC requires other pre-models to infer and train.
|
| 104 |
-
|
| 105 |
-
```bash
|
| 106 |
-
#Download all needed models from https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/
|
| 107 |
-
python tools/download_models.py
|
| 108 |
-
```
|
| 109 |
-
|
| 110 |
-
Or just download them by yourself from our [Huggingface space](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main/).
|
| 111 |
-
|
| 112 |
-
Here's a list of Pre-models and other files that RVC needs:
|
| 113 |
-
```bash
|
| 114 |
-
./assets/hubert/hubert_base.pt
|
| 115 |
-
|
| 116 |
-
./assets/pretrained
|
| 117 |
-
|
| 118 |
-
./assets/uvr5_weights
|
| 119 |
-
|
| 120 |
-
Additional downloads are required if you want to test the v2 version of the model.
|
| 121 |
-
|
| 122 |
-
./assets/pretrained_v2
|
| 123 |
-
|
| 124 |
-
If you want to test the v2 version model (the v2 version model has changed the input from the 256 dimensional feature of 9-layer Hubert+final_proj to the 768 dimensional feature of 12-layer Hubert, and has added 3 period discriminators), you will need to download additional features
|
| 125 |
-
|
| 126 |
-
./assets/pretrained_v2
|
| 127 |
-
|
| 128 |
-
#If you are using Windows, you may also need these two files, skip if FFmpeg and FFprobe are installed
|
| 129 |
-
ffmpeg.exe
|
| 130 |
-
|
| 131 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
|
| 132 |
-
|
| 133 |
-
ffprobe.exe
|
| 134 |
-
|
| 135 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
|
| 136 |
-
|
| 137 |
-
If you want to use the latest SOTA RMVPE vocal pitch extraction algorithm, you need to download the RMVPE weights and place them in the RVC root directory
|
| 138 |
-
|
| 139 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt
|
| 140 |
-
|
| 141 |
-
For AMD/Intel graphics cards users you need download:
|
| 142 |
-
|
| 143 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.onnx
|
| 144 |
-
|
| 145 |
-
```
|
| 146 |
-
|
| 147 |
-
Intel ARC graphics cards users needs to run `source /opt/intel/oneapi/setvars.sh` command before starting Webui.
|
| 148 |
-
|
| 149 |
-
Then use this command to start Webui:
|
| 150 |
-
```bash
|
| 151 |
-
python infer-web.py
|
| 152 |
-
```
|
| 153 |
-
|
| 154 |
-
If you are using Windows or macOS, you can download and extract `RVC-beta.7z` to use RVC directly by using `go-web.bat` on windows or `sh ./run.sh` on macOS to start Webui.
|
| 155 |
-
|
| 156 |
-
## ROCm Support for AMD graphic cards (Linux only)
|
| 157 |
-
To use ROCm on Linux install all required drivers as described [here](https://rocm.docs.amd.com/en/latest/deploy/linux/os-native/install.html).
|
| 158 |
-
|
| 159 |
-
On Arch use pacman to install the driver:
|
| 160 |
-
````
|
| 161 |
-
pacman -S rocm-hip-sdk rocm-opencl-sdk
|
| 162 |
-
````
|
| 163 |
-
|
| 164 |
-
You might also need to set these environment variables (e.g. on a RX6700XT):
|
| 165 |
-
````
|
| 166 |
-
export ROCM_PATH=/opt/rocm
|
| 167 |
-
export HSA_OVERRIDE_GFX_VERSION=10.3.0
|
| 168 |
-
````
|
| 169 |
-
Also make sure your user is part of the `render` and `video` group:
|
| 170 |
-
````
|
| 171 |
-
sudo usermod -aG render $USERNAME
|
| 172 |
-
sudo usermod -aG video $USERNAME
|
| 173 |
-
````
|
| 174 |
-
After that you can run the WebUI:
|
| 175 |
-
```bash
|
| 176 |
-
python infer-web.py
|
| 177 |
-
```
|
| 178 |
-
|
| 179 |
-
## Credits
|
| 180 |
-
+ [ContentVec](https://github.com/auspicious3000/contentvec/)
|
| 181 |
-
+ [VITS](https://github.com/jaywalnut310/vits)
|
| 182 |
-
+ [HIFIGAN](https://github.com/jik876/hifi-gan)
|
| 183 |
-
+ [Gradio](https://github.com/gradio-app/gradio)
|
| 184 |
-
+ [FFmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 185 |
-
+ [Ultimate Vocal Remover](https://github.com/Anjok07/ultimatevocalremovergui)
|
| 186 |
-
+ [audio-slicer](https://github.com/openvpi/audio-slicer)
|
| 187 |
-
+ [Vocal pitch extraction:RMVPE](https://github.com/Dream-High/RMVPE)
|
| 188 |
-
+ The pretrained model is trained and tested by [yxlllc](https://github.com/yxlllc/RMVPE) and [RVC-Boss](https://github.com/RVC-Boss).
|
| 189 |
-
|
| 190 |
-
## Thanks to all contributors for their efforts
|
| 191 |
-
<a href="https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/graphs/contributors" target="_blank">
|
| 192 |
-
<img src="https://contrib.rocks/image?repo=RVC-Project/Retrieval-based-Voice-Conversion-WebUI" />
|
| 193 |
-
</a>
|
| 194 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/en/faiss_tips_en.md
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
faiss tuning TIPS
|
| 2 |
-
==================
|
| 3 |
-
# about faiss
|
| 4 |
-
faiss is a library of neighborhood searches for dense vectors, developed by facebook research, which efficiently implements many approximate neighborhood search methods.
|
| 5 |
-
Approximate Neighbor Search finds similar vectors quickly while sacrificing some accuracy.
|
| 6 |
-
|
| 7 |
-
## faiss in RVC
|
| 8 |
-
In RVC, for the embedding of features converted by HuBERT, we search for embeddings similar to the embedding generated from the training data and mix them to achieve a conversion that is closer to the original speech. However, since this search takes time if performed naively, high-speed conversion is realized by using approximate neighborhood search.
|
| 9 |
-
|
| 10 |
-
# implementation overview
|
| 11 |
-
In '/logs/your-experiment/3_feature256' where the model is located, features extracted by HuBERT from each voice data are located.
|
| 12 |
-
From here we read the npy files in order sorted by filename and concatenate the vectors to create big_npy. (This vector has shape [N, 256].)
|
| 13 |
-
After saving big_npy as /logs/your-experiment/total_fea.npy, train it with faiss.
|
| 14 |
-
|
| 15 |
-
In this article, I will explain the meaning of these parameters.
|
| 16 |
-
|
| 17 |
-
# Explanation of the method
|
| 18 |
-
## index factory
|
| 19 |
-
An index factory is a unique faiss notation that expresses a pipeline that connects multiple approximate neighborhood search methods as a string.
|
| 20 |
-
This allows you to try various approximate neighborhood search methods simply by changing the index factory string.
|
| 21 |
-
In RVC it is used like this:
|
| 22 |
-
|
| 23 |
-
```python
|
| 24 |
-
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
| 25 |
-
```
|
| 26 |
-
Among the arguments of index_factory, the first is the number of dimensions of the vector, the second is the index factory string, and the third is the distance to use.
|
| 27 |
-
|
| 28 |
-
For more detailed notation
|
| 29 |
-
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
| 30 |
-
|
| 31 |
-
## index for distance
|
| 32 |
-
There are two typical indexes used as similarity of embedding as follows.
|
| 33 |
-
|
| 34 |
-
- Euclidean distance (METRIC_L2)
|
| 35 |
-
- inner product (METRIC_INNER_PRODUCT)
|
| 36 |
-
|
| 37 |
-
Euclidean distance takes the squared difference in each dimension, sums the differences in all dimensions, and then takes the square root. This is the same as the distance in 2D and 3D that we use on a daily basis.
|
| 38 |
-
The inner product is not used as an index of similarity as it is, and the cosine similarity that takes the inner product after being normalized by the L2 norm is generally used.
|
| 39 |
-
|
| 40 |
-
Which is better depends on the case, but cosine similarity is often used in embedding obtained by word2vec and similar image retrieval models learned by ArcFace. If you want to do l2 normalization on vector X with numpy, you can do it with the following code with eps small enough to avoid 0 division.
|
| 41 |
-
|
| 42 |
-
```python
|
| 43 |
-
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
| 44 |
-
```
|
| 45 |
-
|
| 46 |
-
Also, for the index factory, you can change the distance index used for calculation by choosing the value to pass as the third argument.
|
| 47 |
-
|
| 48 |
-
```python
|
| 49 |
-
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
| 50 |
-
```
|
| 51 |
-
|
| 52 |
-
## IVF
|
| 53 |
-
IVF (Inverted file indexes) is an algorithm similar to the inverted index in full-text search.
|
| 54 |
-
During learning, the search target is clustered with kmeans, and Voronoi partitioning is performed using the cluster center. Each data point is assigned a cluster, so we create a dictionary that looks up the data points from the clusters.
|
| 55 |
-
|
| 56 |
-
For example, if clusters are assigned as follows
|
| 57 |
-
|index|Cluster|
|
| 58 |
-
|-----|-------|
|
| 59 |
-
|1|A|
|
| 60 |
-
|2|B|
|
| 61 |
-
|3|A|
|
| 62 |
-
|4|C|
|
| 63 |
-
|5|B|
|
| 64 |
-
|
| 65 |
-
The resulting inverted index looks like this:
|
| 66 |
-
|
| 67 |
-
|cluster|index|
|
| 68 |
-
|-------|-----|
|
| 69 |
-
|A|1, 3|
|
| 70 |
-
|B|2, 5|
|
| 71 |
-
|C|4|
|
| 72 |
-
|
| 73 |
-
When searching, we first search n_probe clusters from the clusters, and then calculate the distances for the data points belonging to each cluster.
|
| 74 |
-
|
| 75 |
-
# recommend parameter
|
| 76 |
-
There are official guidelines on how to choose an index, so I will explain accordingly.
|
| 77 |
-
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
| 78 |
-
|
| 79 |
-
For datasets below 1M, 4bit-PQ is the most efficient method available in faiss as of April 2023.
|
| 80 |
-
Combining this with IVF, narrowing down the candidates with 4bit-PQ, and finally recalculating the distance with an accurate index can be described by using the following index factory.
|
| 81 |
-
|
| 82 |
-
```python
|
| 83 |
-
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
| 84 |
-
```
|
| 85 |
-
|
| 86 |
-
## Recommended parameters for IVF
|
| 87 |
-
Consider the case of too many IVFs. For example, if coarse quantization by IVF is performed for the number of data, this is the same as a naive exhaustive search and is inefficient.
|
| 88 |
-
For 1M or less, IVF values are recommended between 4*sqrt(N) ~ 16*sqrt(N) for N number of data points.
|
| 89 |
-
|
| 90 |
-
Since the calculation time increases in proportion to the number of n_probes, please consult with the accuracy and choose appropriately. Personally, I don't think RVC needs that much accuracy, so n_probe = 1 is fine.
|
| 91 |
-
|
| 92 |
-
## FastScan
|
| 93 |
-
FastScan is a method that enables high-speed approximation of distances by Cartesian product quantization by performing them in registers.
|
| 94 |
-
Cartesian product quantization performs clustering independently for each d dimension (usually d = 2) during learning, calculates the distance between clusters in advance, and creates a lookup table. At the time of prediction, the distance of each dimension can be calculated in O(1) by looking at the lookup table.
|
| 95 |
-
So the number you specify after PQ usually specifies half the dimension of the vector.
|
| 96 |
-
|
| 97 |
-
For a more detailed description of FastScan, please refer to the official documentation.
|
| 98 |
-
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
| 99 |
-
|
| 100 |
-
## RFlat
|
| 101 |
-
RFlat is an instruction to recalculate the rough distance calculated by FastScan with the exact distance specified by the third argument of index factory.
|
| 102 |
-
When getting k neighbors, k*k_factor points are recalculated.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/en/faq_en.md
DELETED
|
@@ -1,119 +0,0 @@
|
|
| 1 |
-
## Q1:ffmpeg error/utf8 error.
|
| 2 |
-
It is most likely not a FFmpeg issue, but rather an audio path issue;
|
| 3 |
-
|
| 4 |
-
FFmpeg may encounter an error when reading paths containing special characters like spaces and (), which may cause an FFmpeg error; and when the training set's audio contains Chinese paths, writing it into filelist.txt may cause a utf8 error.<br>
|
| 5 |
-
|
| 6 |
-
## Q2:Cannot find index file after "One-click Training".
|
| 7 |
-
If it displays "Training is done. The program is closed," then the model has been trained successfully, and the subsequent errors are fake;
|
| 8 |
-
|
| 9 |
-
The lack of an 'added' index file after One-click training may be due to the training set being too large, causing the addition of the index to get stuck; this has been resolved by using batch processing to add the index, which solves the problem of memory overload when adding the index. As a temporary solution, try clicking the "Train Index" button again.<br>
|
| 10 |
-
|
| 11 |
-
## Q3:Cannot find the model in “Inferencing timbre” after training
|
| 12 |
-
Click “Refresh timbre list” and check again; if still not visible, check if there are any errors during training and send screenshots of the console, web UI, and logs/experiment_name/*.log to the developers for further analysis.<br>
|
| 13 |
-
|
| 14 |
-
## Q4:How to share a model/How to use others' models?
|
| 15 |
-
The pth files stored in rvc_root/logs/experiment_name are not meant for sharing or inference, but for storing the experiment checkpoits for reproducibility and further training. The model to be shared should be the 60+MB pth file in the weights folder;
|
| 16 |
-
|
| 17 |
-
In the future, weights/exp_name.pth and logs/exp_name/added_xxx.index will be merged into a single weights/exp_name.zip file to eliminate the need for manual index input; so share the zip file, not the pth file, unless you want to continue training on a different machine;
|
| 18 |
-
|
| 19 |
-
Copying/sharing the several hundred MB pth files from the logs folder to the weights folder for forced inference may result in errors such as missing f0, tgt_sr, or other keys. You need to use the ckpt tab at the bottom to manually or automatically (if the information is found in the logs/exp_name), select whether to include pitch infomation and target audio sampling rate options and then extract the smaller model. After extraction, there will be a 60+ MB pth file in the weights folder, and you can refresh the voices to use it.<br>
|
| 20 |
-
|
| 21 |
-
## Q5:Connection Error.
|
| 22 |
-
You may have closed the console (black command line window).<br>
|
| 23 |
-
|
| 24 |
-
## Q6:WebUI popup 'Expecting value: line 1 column 1 (char 0)'.
|
| 25 |
-
Please disable system LAN proxy/global proxy and then refresh.<br>
|
| 26 |
-
|
| 27 |
-
## Q7:How to train and infer without the WebUI?
|
| 28 |
-
Training script:<br>
|
| 29 |
-
You can run training in WebUI first, and the command-line versions of dataset preprocessing and training will be displayed in the message window.<br>
|
| 30 |
-
|
| 31 |
-
Inference script:<br>
|
| 32 |
-
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py<br>
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
e.g.<br>
|
| 36 |
-
|
| 37 |
-
runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True<br>
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
f0up_key=sys.argv[1]<br>
|
| 41 |
-
input_path=sys.argv[2]<br>
|
| 42 |
-
index_path=sys.argv[3]<br>
|
| 43 |
-
f0method=sys.argv[4]#harvest or pm<br>
|
| 44 |
-
opt_path=sys.argv[5]<br>
|
| 45 |
-
model_path=sys.argv[6]<br>
|
| 46 |
-
index_rate=float(sys.argv[7])<br>
|
| 47 |
-
device=sys.argv[8]<br>
|
| 48 |
-
is_half=bool(sys.argv[9])<br>
|
| 49 |
-
|
| 50 |
-
## Q8:Cuda error/Cuda out of memory.
|
| 51 |
-
There is a small chance that there is a problem with the CUDA configuration or the device is not supported; more likely, there is not enough memory (out of memory).<br>
|
| 52 |
-
|
| 53 |
-
For training, reduce the batch size (if reducing to 1 is still not enough, you may need to change the graphics card); for inference, adjust the x_pad, x_query, x_center, and x_max settings in the config.py file as needed. 4G or lower memory cards (e.g. 1060(3G) and various 2G cards) can be abandoned, while 4G memory cards still have a chance.<br>
|
| 54 |
-
|
| 55 |
-
## Q9:How many total_epoch are optimal?
|
| 56 |
-
If the training dataset's audio quality is poor and the noise floor is high, 20-30 epochs are sufficient. Setting it too high won't improve the audio quality of your low-quality training set.<br>
|
| 57 |
-
|
| 58 |
-
If the training set audio quality is high, the noise floor is low, and there is sufficient duration, you can increase it. 200 is acceptable (since training is fast, and if you're able to prepare a high-quality training set, your GPU likely can handle a longer training duration without issue).<br>
|
| 59 |
-
|
| 60 |
-
## Q10:How much training set duration is needed?
|
| 61 |
-
|
| 62 |
-
A dataset of around 10min to 50min is recommended.<br>
|
| 63 |
-
|
| 64 |
-
With guaranteed high sound quality and low bottom noise, more can be added if the dataset's timbre is uniform.<br>
|
| 65 |
-
|
| 66 |
-
For a high-level training set (lean + distinctive tone), 5min to 10min is fine.<br>
|
| 67 |
-
|
| 68 |
-
There are some people who have trained successfully with 1min to 2min data, but the success is not reproducible by others and is not very informative. <br>This requires that the training set has a very distinctive timbre (e.g. a high-frequency airy anime girl sound) and the quality of the audio is high;
|
| 69 |
-
Data of less than 1min duration has not been successfully attempted so far. This is not recommended.<br>
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
## Q11:What is the index rate for and how to adjust it?
|
| 73 |
-
If the tone quality of the pre-trained model and inference source is higher than that of the training set, they can bring up the tone quality of the inference result, but at the cost of a possible tone bias towards the tone of the underlying model/inference source rather than the tone of the training set, which is generally referred to as "tone leakage".<br>
|
| 74 |
-
|
| 75 |
-
The index rate is used to reduce/resolve the timbre leakage problem. If the index rate is set to 1, theoretically there is no timbre leakage from the inference source and the timbre quality is more biased towards the training set. If the training set has a lower sound quality than the inference source, then a higher index rate may reduce the sound quality. Turning it down to 0 does not have the effect of using retrieval blending to protect the training set tones.<br>
|
| 76 |
-
|
| 77 |
-
If the training set has good audio quality and long duration, turn up the total_epoch, when the model itself is less likely to refer to the inferred source and the pretrained underlying model, and there is little "tone leakage", the index_rate is not important and you can even not create/share the index file.<br>
|
| 78 |
-
|
| 79 |
-
## Q12:How to choose the gpu when inferring?
|
| 80 |
-
In the config.py file, select the card number after "device cuda:".<br>
|
| 81 |
-
|
| 82 |
-
The mapping between card number and graphics card can be seen in the graphics card information section of the training tab.<br>
|
| 83 |
-
|
| 84 |
-
## Q13:How to use the model saved in the middle of training?
|
| 85 |
-
Save via model extraction at the bottom of the ckpt processing tab.
|
| 86 |
-
|
| 87 |
-
## Q14:File/memory error(when training)?
|
| 88 |
-
Too many processes and your memory is not enough. You may fix it by:
|
| 89 |
-
|
| 90 |
-
1、decrease the input in field "Threads of CPU".
|
| 91 |
-
|
| 92 |
-
2、pre-cut trainset to shorter audio files.
|
| 93 |
-
|
| 94 |
-
## Q15: How to continue training using more data
|
| 95 |
-
|
| 96 |
-
step1: put all wav data to path2.
|
| 97 |
-
|
| 98 |
-
step2: exp_name2+path2 -> process dataset and extract feature.
|
| 99 |
-
|
| 100 |
-
step3: copy the latest G and D file of exp_name1 (your previous experiment) into exp_name2 folder.
|
| 101 |
-
|
| 102 |
-
step4: click "train the model", and it will continue training from the beginning of your previous exp model epoch.
|
| 103 |
-
|
| 104 |
-
## Q16: error about llvmlite.dll
|
| 105 |
-
|
| 106 |
-
OSError: Could not load shared object file: llvmlite.dll
|
| 107 |
-
|
| 108 |
-
FileNotFoundError: Could not find module lib\site-packages\llvmlite\binding\llvmlite.dll (or one of its dependencies). Try using the full path with constructor syntax.
|
| 109 |
-
|
| 110 |
-
The issue will happen in windows, install https://aka.ms/vs/17/release/vc_redist.x64.exe and it will be fixed.
|
| 111 |
-
|
| 112 |
-
## Q17: RuntimeError: The expanded size of the tensor (17280) must match the existing size (0) at non-singleton dimension 1. Target sizes: [1, 17280]. Tensor sizes: [0]
|
| 113 |
-
|
| 114 |
-
Delete the wav files whose size is significantly smaller than others, and that won't happen again. Than click "train the model"and "train the index".
|
| 115 |
-
|
| 116 |
-
## Q18: RuntimeError: The size of tensor a (24) must match the size of tensor b (16) at non-singleton dimension 2
|
| 117 |
-
|
| 118 |
-
Do not change the sampling rate and then continue training. If it is necessary to change, the exp name should be changed and the model will be trained from scratch. You can also copy the pitch and features (0/1/2/2b folders) extracted last time to accelerate the training process.
|
| 119 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/en/training_tips_en.md
DELETED
|
@@ -1,65 +0,0 @@
|
|
| 1 |
-
Instructions and tips for RVC training
|
| 2 |
-
======================================
|
| 3 |
-
This TIPS explains how data training is done.
|
| 4 |
-
|
| 5 |
-
# Training flow
|
| 6 |
-
I will explain along the steps in the training tab of the GUI.
|
| 7 |
-
|
| 8 |
-
## step1
|
| 9 |
-
Set the experiment name here.
|
| 10 |
-
|
| 11 |
-
You can also set here whether the model should take pitch into account.
|
| 12 |
-
If the model doesn't consider pitch, the model will be lighter, but not suitable for singing.
|
| 13 |
-
|
| 14 |
-
Data for each experiment is placed in `/logs/your-experiment-name/`.
|
| 15 |
-
|
| 16 |
-
## step2a
|
| 17 |
-
Loads and preprocesses audio.
|
| 18 |
-
|
| 19 |
-
### load audio
|
| 20 |
-
If you specify a folder with audio, the audio files in that folder will be read automatically.
|
| 21 |
-
For example, if you specify `C:Users\hoge\voices`, `C:Users\hoge\voices\voice.mp3` will be loaded, but `C:Users\hoge\voices\dir\voice.mp3` will Not loaded.
|
| 22 |
-
|
| 23 |
-
Since ffmpeg is used internally for reading audio, if the extension is supported by ffmpeg, it will be read automatically.
|
| 24 |
-
After converting to int16 with ffmpeg, convert to float32 and normalize between -1 to 1.
|
| 25 |
-
|
| 26 |
-
### denoising
|
| 27 |
-
The audio is smoothed by scipy's filtfilt.
|
| 28 |
-
|
| 29 |
-
### Audio Split
|
| 30 |
-
First, the input audio is divided by detecting parts of silence that last longer than a certain period (max_sil_kept=5 seconds?). After splitting the audio on silence, split the audio every 4 seconds with an overlap of 0.3 seconds. For audio separated within 4 seconds, after normalizing the volume, convert the wav file to `/logs/your-experiment-name/0_gt_wavs` and then convert it to 16k sampling rate to `/logs/your-experiment-name/1_16k_wavs ` as a wav file.
|
| 31 |
-
|
| 32 |
-
## step2b
|
| 33 |
-
### Extract pitch
|
| 34 |
-
Extract pitch information from wav files. Extract the pitch information (=f0) using the method built into parselmouth or pyworld and save it in `/logs/your-experiment-name/2a_f0`. Then logarithmically convert the pitch information to an integer between 1 and 255 and save it in `/logs/your-experiment-name/2b-f0nsf`.
|
| 35 |
-
|
| 36 |
-
### Extract feature_print
|
| 37 |
-
Convert the wav file to embedding in advance using HuBERT. Read the wav file saved in `/logs/your-experiment-name/1_16k_wavs`, convert the wav file to 256-dimensional features with HuBERT, and save in npy format in `/logs/your-experiment-name/3_feature256`.
|
| 38 |
-
|
| 39 |
-
## step3
|
| 40 |
-
train the model.
|
| 41 |
-
### Glossary for Beginners
|
| 42 |
-
In deep learning, the data set is divided and the learning proceeds little by little. In one model update (step), batch_size data are retrieved and predictions and error corrections are performed. Doing this once for a dataset counts as one epoch.
|
| 43 |
-
|
| 44 |
-
Therefore, the learning time is the learning time per step x (the number of data in the dataset / batch size) x the number of epochs. In general, the larger the batch size, the more stable the learning becomes (learning time per step ÷ batch size) becomes smaller, but it uses more GPU memory. GPU RAM can be checked with the nvidia-smi command. Learning can be done in a short time by increasing the batch size as much as possible according to the machine of the execution environment.
|
| 45 |
-
|
| 46 |
-
### Specify pretrained model
|
| 47 |
-
RVC starts training the model from pretrained weights instead of from 0, so it can be trained with a small dataset.
|
| 48 |
-
|
| 49 |
-
By default
|
| 50 |
-
|
| 51 |
-
- If you consider pitch, it loads `rvc-location/pretrained/f0G40k.pth` and `rvc-location/pretrained/f0D40k.pth`.
|
| 52 |
-
- If you don't consider pitch, it loads `rvc-location/pretrained/f0G40k.pth` and `rvc-location/pretrained/f0D40k.pth`.
|
| 53 |
-
|
| 54 |
-
When learning, model parameters are saved in `logs/your-experiment-name/G_{}.pth` and `logs/your-experiment-name/D_{}.pth` for each save_every_epoch, but by specifying this path, you can start learning. You can restart or start training from model weights learned in a different experiment.
|
| 55 |
-
|
| 56 |
-
### learning index
|
| 57 |
-
RVC saves the HuBERT feature values used during training, and during inference, searches for feature values that are similar to the feature values used during learning to perform inference. In order to perform this search at high speed, the index is learned in advance.
|
| 58 |
-
For index learning, we use the approximate neighborhood search library faiss. Read the feature value of `logs/your-experiment-name/3_feature256` and use it to learn the index, and save it as `logs/your-experiment-name/add_XXX.index`.
|
| 59 |
-
|
| 60 |
-
(From the 20230428update version, it is read from the index, and saving / specifying is no longer necessary.)
|
| 61 |
-
|
| 62 |
-
### Button description
|
| 63 |
-
- Train model: After executing step2b, press this button to train the model.
|
| 64 |
-
- Train feature index: After training the model, perform index learning.
|
| 65 |
-
- One-click training: step2b, model training and feature index training all at once.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Retrieval-based-Voice-Conversion-WebUI/docs/faiss_tips_en.md
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
faiss tuning TIPS
|
| 2 |
-
==================
|
| 3 |
-
# about faiss
|
| 4 |
-
faiss is a library of neighborhood searches for dense vectors, developed by facebook research, which efficiently implements many approximate neighborhood search methods.
|
| 5 |
-
Approximate Neighbor Search finds similar vectors quickly while sacrificing some accuracy.
|
| 6 |
-
|
| 7 |
-
## faiss in RVC
|
| 8 |
-
In RVC, for the embedding of features converted by HuBERT, we search for embeddings similar to the embedding generated from the training data and mix them to achieve a conversion that is closer to the original speech. However, since this search takes time if performed naively, high-speed conversion is realized by using approximate neighborhood search.
|
| 9 |
-
|
| 10 |
-
# implementation overview
|
| 11 |
-
In '/logs/your-experiment/3_feature256' where the model is located, features extracted by HuBERT from each voice data are located.
|
| 12 |
-
From here we read the npy files in order sorted by filename and concatenate the vectors to create big_npy. (This vector has shape [N, 256].)
|
| 13 |
-
After saving big_npy as /logs/your-experiment/total_fea.npy, train it with faiss.
|
| 14 |
-
|
| 15 |
-
In this article, I will explain the meaning of these parameters.
|
| 16 |
-
|
| 17 |
-
# Explanation of the method
|
| 18 |
-
## index factory
|
| 19 |
-
An index factory is a unique faiss notation that expresses a pipeline that connects multiple approximate neighborhood search methods as a string.
|
| 20 |
-
This allows you to try various approximate neighborhood search methods simply by changing the index factory string.
|
| 21 |
-
In RVC it is used like this:
|
| 22 |
-
|
| 23 |
-
```python
|
| 24 |
-
index = faiss.index_factory(256, "IVF%s,Flat" % n_ivf)
|
| 25 |
-
```
|
| 26 |
-
Among the arguments of index_factory, the first is the number of dimensions of the vector, the second is the index factory string, and the third is the distance to use.
|
| 27 |
-
|
| 28 |
-
For more detailed notation
|
| 29 |
-
https://github.com/facebookresearch/faiss/wiki/The-index-factory
|
| 30 |
-
|
| 31 |
-
## index for distance
|
| 32 |
-
There are two typical indexes used as similarity of embedding as follows.
|
| 33 |
-
|
| 34 |
-
- Euclidean distance (METRIC_L2)
|
| 35 |
-
- inner product (METRIC_INNER_PRODUCT)
|
| 36 |
-
|
| 37 |
-
Euclidean distance takes the squared difference in each dimension, sums the differences in all dimensions, and then takes the square root. This is the same as the distance in 2D and 3D that we use on a daily basis.
|
| 38 |
-
The inner product is not used as an index of similarity as it is, and the cosine similarity that takes the inner product after being normalized by the L2 norm is generally used.
|
| 39 |
-
|
| 40 |
-
Which is better depends on the case, but cosine similarity is often used in embedding obtained by word2vec and similar image retrieval models learned by ArcFace. If you want to do l2 normalization on vector X with numpy, you can do it with the following code with eps small enough to avoid 0 division.
|
| 41 |
-
|
| 42 |
-
```python
|
| 43 |
-
X_normed = X / np.maximum(eps, np.linalg.norm(X, ord=2, axis=-1, keepdims=True))
|
| 44 |
-
```
|
| 45 |
-
|
| 46 |
-
Also, for the index factory, you can change the distance index used for calculation by choosing the value to pass as the third argument.
|
| 47 |
-
|
| 48 |
-
```python
|
| 49 |
-
index = faiss.index_factory(dimention, text, faiss.METRIC_INNER_PRODUCT)
|
| 50 |
-
```
|
| 51 |
-
|
| 52 |
-
## IVF
|
| 53 |
-
IVF (Inverted file indexes) is an algorithm similar to the inverted index in full-text search.
|
| 54 |
-
During learning, the search target is clustered with kmeans, and Voronoi partitioning is performed using the cluster center. Each data point is assigned a cluster, so we create a dictionary that looks up the data points from the clusters.
|
| 55 |
-
|
| 56 |
-
For example, if clusters are assigned as follows
|
| 57 |
-
|index|Cluster|
|
| 58 |
-
|-----|-------|
|
| 59 |
-
|1|A|
|
| 60 |
-
|2|B|
|
| 61 |
-
|3|A|
|
| 62 |
-
|4|C|
|
| 63 |
-
|5|B|
|
| 64 |
-
|
| 65 |
-
The resulting inverted index looks like this:
|
| 66 |
-
|
| 67 |
-
|cluster|index|
|
| 68 |
-
|-------|-----|
|
| 69 |
-
|A|1, 3|
|
| 70 |
-
|B|2, 5|
|
| 71 |
-
|C|4|
|
| 72 |
-
|
| 73 |
-
When searching, we first search n_probe clusters from the clusters, and then calculate the distances for the data points belonging to each cluster.
|
| 74 |
-
|
| 75 |
-
# recommend parameter
|
| 76 |
-
There are official guidelines on how to choose an index, so I will explain accordingly.
|
| 77 |
-
https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
|
| 78 |
-
|
| 79 |
-
For datasets below 1M, 4bit-PQ is the most efficient method available in faiss as of April 2023.
|
| 80 |
-
Combining this with IVF, narrowing down the candidates with 4bit-PQ, and finally recalculating the distance with an accurate index can be described by using the following index factory.
|
| 81 |
-
|
| 82 |
-
```python
|
| 83 |
-
index = faiss.index_factory(256, "IVF1024,PQ128x4fs,RFlat")
|
| 84 |
-
```
|
| 85 |
-
|
| 86 |
-
## Recommended parameters for IVF
|
| 87 |
-
Consider the case of too many IVFs. For example, if coarse quantization by IVF is performed for the number of data, this is the same as a naive exhaustive search and is inefficient.
|
| 88 |
-
For 1M or less, IVF values are recommended between 4*sqrt(N) ~ 16*sqrt(N) for N number of data points.
|
| 89 |
-
|
| 90 |
-
Since the calculation time increases in proportion to the number of n_probes, please consult with the accuracy and choose appropriately. Personally, I don't think RVC needs that much accuracy, so n_probe = 1 is fine.
|
| 91 |
-
|
| 92 |
-
## FastScan
|
| 93 |
-
FastScan is a method that enables high-speed approximation of distances by Cartesian product quantization by performing them in registers.
|
| 94 |
-
Cartesian product quantization performs clustering independently for each d dimension (usually d = 2) during learning, calculates the distance between clusters in advance, and creates a lookup table. At the time of prediction, the distance of each dimension can be calculated in O(1) by looking at the lookup table.
|
| 95 |
-
So the number you specify after PQ usually specifies half the dimension of the vector.
|
| 96 |
-
|
| 97 |
-
For a more detailed description of FastScan, please refer to the official documentation.
|
| 98 |
-
https://github.com/facebookresearch/faiss/wiki/Fast-accumulation-of-PQ-and-AQ-codes-(FastScan)
|
| 99 |
-
|
| 100 |
-
## RFlat
|
| 101 |
-
RFlat is an instruction to recalculate the rough distance calculated by FastScan with the exact distance specified by the third argument of index factory.
|
| 102 |
-
When getting k neighbors, k*k_factor points are recalculated.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|