Spaces:
Running

Running
Added Initial Version of Prompt Engineer
Browse files
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2025 Malhar Ujawane
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,14 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
title: Prompt Engineer
|
| 3 |
-
emoji: 🌖
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: green
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 5.9.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: mit
|
| 11 |
-
short_description: Prompt Engineer for enhancing and optimizing your prompts
|
| 12 |
-
---
|
| 13 |
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Prompt Engineer Agent
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
## Overview
|
| 7 |
+
This project is an **AI-powered Prompt Engineering Tool** designed to automatically enhance and optimize prompts for large language models (LLMs). Using advanced prompt engineering principles and OpenAI's GPT-4, the tool transforms basic prompts into comprehensive, well-structured instructions that yield better results.
|
| 8 |
+
|
| 9 |
+
## Key Features
|
| 10 |
+
- **Automated Prompt Enhancement:** Transforms basic prompts into detailed, optimized versions
|
| 11 |
+
- **Multi-step Analysis:** Analyzes input, expands instructions, decomposes tasks, and adds reasoning
|
| 12 |
+
- **OpenAI Integration:** Leverages GPT-4o for intelligent prompt engineering
|
| 13 |
+
- **Gradio Interface:** Provides an intuitive web interface for easy interaction
|
| 14 |
+
- **Evaluation System:** Includes built-in criteria for assessing prompt quality
|
| 15 |
+
- **Reference Suggestions:** Recommends relevant sources to enhance prompt effectiveness
|
| 16 |
+
|
| 17 |
+
## Repo Structure
|
| 18 |
+
|
| 19 |
+
```
|
| 20 |
+
├── .gitignore # Files and directories to be ignored by Git
|
| 21 |
+
├── LICENSE # License information for the project
|
| 22 |
+
├── README.md # Project documentation (this file)
|
| 23 |
+
├── agent.py # Core prompt engineering logic
|
| 24 |
+
├── app.py # Gradio web interface implementation
|
| 25 |
+
└── requirements.txt # Python dependencies
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
## How It Works
|
| 29 |
+
|
| 30 |
+
The tool enhances prompts through several steps:
|
| 31 |
+
1. **Input Analysis:** Determines key information and requirements
|
| 32 |
+
2. **Instruction Expansion:** Adds clarity and detail to basic prompts
|
| 33 |
+
3. **Task Decomposition:** Breaks down complex tasks into manageable subtasks
|
| 34 |
+
4. **Reasoning Addition:** Incorporates chain-of-thought and self-review instructions
|
| 35 |
+
5. **Reference Integration:** Suggests relevant sources and explains their use
|
| 36 |
+
6. **Quality Evaluation:** Assesses and adjusts the final prompt based on specific criteria
|
| 37 |
+
|
| 38 |
+
## Getting Started
|
| 39 |
+
|
| 40 |
+
### Prerequisites
|
| 41 |
+
- Python 3.8+
|
| 42 |
+
- OpenAI API key
|
| 43 |
+
|
| 44 |
+
### Installation
|
| 45 |
+
1. Clone the repository:
|
| 46 |
+
```bash
|
| 47 |
+
git clone https://github.com/justmalhar/prompt-engineer.git
|
| 48 |
+
cd prompt-engineer-agent
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
2. Install dependencies:
|
| 52 |
+
```bash
|
| 53 |
+
pip install -r requirements.txt
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
3. Set up your OpenAI API key in the Gradio UI:
|
| 57 |
+
- Create a .env file in the project root
|
| 58 |
+
- Add your API key: `OPENAI_API_KEY=your-api-key`
|
| 59 |
+
|
| 60 |
+
### Usage
|
| 61 |
+
Run the Gradio interface:
|
| 62 |
+
```bash
|
| 63 |
+
python app.py
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
The web interface will be available at http://localhost:7860 or generated Gradio.live URL
|
| 67 |
+
|
| 68 |
+
## Features in Detail
|
| 69 |
+
|
| 70 |
+
### Prompt Analysis
|
| 71 |
+
- Identifies main topics and requirements
|
| 72 |
+
- Determines optimal output format
|
| 73 |
+
- Suggests enhancement strategies
|
| 74 |
+
|
| 75 |
+
### Instruction Enhancement
|
| 76 |
+
- Adds relevant details and clarifications
|
| 77 |
+
- Suggests appropriate AI personas
|
| 78 |
+
- Includes guiding examples
|
| 79 |
+
- Optimizes output length
|
| 80 |
+
|
| 81 |
+
### Task Management
|
| 82 |
+
- Breaks down complex prompts into subtasks
|
| 83 |
+
- Creates specific instructions per subtask
|
| 84 |
+
- Defines success criteria
|
| 85 |
+
|
| 86 |
+
### Quality Control
|
| 87 |
+
- Implements self-review mechanisms
|
| 88 |
+
- Includes evaluation criteria
|
| 89 |
+
- Performs automatic adjustments
|
| 90 |
+
|
| 91 |
+
## Dependencies
|
| 92 |
+
- gradio
|
| 93 |
+
- openai
|
| 94 |
+
- python-dotenv
|
| 95 |
+
- fastapi
|
| 96 |
+
- uvicorn
|
| 97 |
+
- And more (see requirements.txt)
|
| 98 |
+
|
| 99 |
+
## Credits
|
| 100 |
+
This project is inspired by and adapted from [Advanced-Prompt-Generator](https://github.com/Thunderhead-exe/Advanced-Prompt-Generator) by Thunderhead-exe.
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
## License
|
| 104 |
+
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
|
| 105 |
+
|
| 106 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 107 |
|
| 108 |
+
## Stay Connected
|
| 109 |
+
- **Twitter/X**: [@justmalhar](https://twitter.com/justmalhar) 🛠
|
| 110 |
+
- **LinkedIn**: [Malhar Ujawane](https://linkedin.com/in/justmalhar) 💻
|
| 111 |
+
|
| 112 |
+
Made with ❤️ and AI by [@justmalhar](https://twitter.com/justmalhar)
|
agent.py
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Importing dependecies
|
| 2 |
+
import os
|
| 3 |
+
import asyncio
|
| 4 |
+
from openai import AsyncOpenAI
|
| 5 |
+
from dotenv import load_dotenv
|
| 6 |
+
|
| 7 |
+
class PromptEngineer:
|
| 8 |
+
def __init__(self, temperature=0.0, tools_dict={}, api_key=None, base_url=None):
|
| 9 |
+
self.model = "gpt-4o"
|
| 10 |
+
self.prompt_tokens = 0
|
| 11 |
+
self.completion_tokens = 0
|
| 12 |
+
self.tools_dict = tools_dict
|
| 13 |
+
|
| 14 |
+
# Initialize OpenAI client with provided credentials
|
| 15 |
+
self.client = AsyncOpenAI(
|
| 16 |
+
api_key=api_key,
|
| 17 |
+
base_url=base_url if base_url else "https://api.openai.com/v1"
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
async def call_llm(self, prompt):
|
| 21 |
+
"""Call the LLM with the given prompt"""
|
| 22 |
+
try:
|
| 23 |
+
response = await self.client.chat.completions.create(
|
| 24 |
+
model=self.model,
|
| 25 |
+
messages=[
|
| 26 |
+
{"role": "system",
|
| 27 |
+
"content": "You are an assistant designed to provide concise and specific information based solely on the given tasks.\
|
| 28 |
+
Do not include any additional information, explanations, or context beyond what is explicitly requested."
|
| 29 |
+
},
|
| 30 |
+
{"role": "user",
|
| 31 |
+
"content": prompt
|
| 32 |
+
}
|
| 33 |
+
],
|
| 34 |
+
temperature=0.0,
|
| 35 |
+
)
|
| 36 |
+
# counting the I/O tokens
|
| 37 |
+
self.prompt_tokens += response.usage.prompt_tokens
|
| 38 |
+
self.completion_tokens += response.usage.completion_tokens
|
| 39 |
+
|
| 40 |
+
return response.choices[0].message.content
|
| 41 |
+
except Exception as e:
|
| 42 |
+
raise Exception(f"Error calling OpenAI API: {str(e)}")
|
| 43 |
+
|
| 44 |
+
async def analyze_input(self, basic_prompt):
|
| 45 |
+
"""Analyze the input prompt to determine its key information"""
|
| 46 |
+
analysis_prompt = f"""
|
| 47 |
+
Analyze the following {{prompt}} and generate brief answers to these key information that will be beneficial to enhance the prompt:
|
| 48 |
+
1. Main topic of the prompt
|
| 49 |
+
2. The most convenient output format for the prompt
|
| 50 |
+
3. Specific requirements for the prompt, if necessary
|
| 51 |
+
4. Suggested strategies to enhance the prompt for better output result
|
| 52 |
+
|
| 53 |
+
{{prompt}}: {basic_prompt}
|
| 54 |
+
|
| 55 |
+
Your output will be only the result of the information required above in text format.
|
| 56 |
+
Do not return a general explanation of the generation process.
|
| 57 |
+
"""
|
| 58 |
+
return await self.call_llm(analysis_prompt)
|
| 59 |
+
|
| 60 |
+
async def expand_instructions(self, basic_prompt, analysis):
|
| 61 |
+
"""Expand the basic prompt with clear, detailed instructions"""
|
| 62 |
+
expansion_prompt = f"""
|
| 63 |
+
Based on this {{analysis}}:
|
| 64 |
+
|
| 65 |
+
{analysis}
|
| 66 |
+
|
| 67 |
+
Expand the following {{basic_prompt}} following these instructions:
|
| 68 |
+
1. Add relevant details to clarify the prompt only if necessary
|
| 69 |
+
2. Suggest an appropriate persona for the AI Model
|
| 70 |
+
3. Generate 1-2 related examples to guide the output generation
|
| 71 |
+
4. Suggest an optimal output length
|
| 72 |
+
5. Use delimiter, {{ }}, to clearly indicate the parts of the input that should be concidered as variables
|
| 73 |
+
|
| 74 |
+
{{basic_prompt}}: {basic_prompt}
|
| 75 |
+
|
| 76 |
+
Your output will be only the result of the information required above in text format and not a dictionary format.
|
| 77 |
+
Make sure the generated output maintains the sructure of a prompt for an AI Model.
|
| 78 |
+
Make sure the generated output maintains the goal and context of the {{basic_prompt}}.
|
| 79 |
+
Do not include the instructions headers in the generated answer.
|
| 80 |
+
Do not return a general explanation of the generation process.
|
| 81 |
+
Do not generate an answer for the prompt.
|
| 82 |
+
"""
|
| 83 |
+
return await self.call_llm(expansion_prompt)
|
| 84 |
+
|
| 85 |
+
async def decompose_task(self, expanded_prompt):
|
| 86 |
+
"""Break down complex tasks into subtasks"""
|
| 87 |
+
decomposition_prompt = f"""
|
| 88 |
+
Break down the following {{prompt}} into subtasks for better output generation and follow these instructions:
|
| 89 |
+
1. Identify main task components and their corresponding subtasks
|
| 90 |
+
2. Create specific instructions for each subtask
|
| 91 |
+
3. Define success criteria for each subtask
|
| 92 |
+
|
| 93 |
+
{{prompt}}: {expanded_prompt}
|
| 94 |
+
|
| 95 |
+
Your output will be only the result of the task required above in text format.
|
| 96 |
+
Follow the (Main-task/ Sub-task/ Instructions/ Success-criteria) format.
|
| 97 |
+
Do not return a general explanation of the generation process.
|
| 98 |
+
"""
|
| 99 |
+
return await self.call_llm(decomposition_prompt)
|
| 100 |
+
|
| 101 |
+
async def add_reasoning(self, expanded_prompt):
|
| 102 |
+
"""Add instructions for showing reasoning, chain-of-thought, and self-review"""
|
| 103 |
+
reasoning_prompt = f"""
|
| 104 |
+
Based on the following {{prompt}}, suggest instructions in order to guide the AI Model to:
|
| 105 |
+
1. Show reasoning through using the chain-of-thought process
|
| 106 |
+
2. Use inner-monologue only if it is recommended to hide parts of the thought process
|
| 107 |
+
3. Self-review and check for missed information
|
| 108 |
+
|
| 109 |
+
{{prompt}}: {expanded_prompt}
|
| 110 |
+
|
| 111 |
+
Your output will be only the set of instructions in text format.
|
| 112 |
+
Do not return a general explanation of the generation process.
|
| 113 |
+
"""
|
| 114 |
+
return await self.call_llm(reasoning_prompt)
|
| 115 |
+
|
| 116 |
+
async def create_eval_criteria(self, expanded_prompt):
|
| 117 |
+
"""Generate evaluation criteria for the prompt output"""
|
| 118 |
+
evaluation_prompt = f"""
|
| 119 |
+
Create evaluation criteria for assessing the quality of the output for this {{prompt}}:
|
| 120 |
+
1. List 1-3 specific criteria
|
| 121 |
+
2. Briefly explain how to measure each criterion
|
| 122 |
+
|
| 123 |
+
{{prompt}}: {expanded_prompt}
|
| 124 |
+
|
| 125 |
+
Your output will be only the result of the information required above in text format.
|
| 126 |
+
Do not return a general explanation of the generation process.
|
| 127 |
+
"""
|
| 128 |
+
return await self.call_llm(evaluation_prompt)
|
| 129 |
+
|
| 130 |
+
async def suggest_references(self, expanded_prompt):
|
| 131 |
+
"""Suggest relevant references and explain how to use them"""
|
| 132 |
+
reference_prompt = f"""
|
| 133 |
+
For the following {{prompt}}, suggest relevant reference texts or sources that could help enhance the output of the prompt if possible,
|
| 134 |
+
and if not, do not return anything:
|
| 135 |
+
1. List 0-3 potential references
|
| 136 |
+
2. Briefly explain how to incorporate these references to enhance the prompt
|
| 137 |
+
|
| 138 |
+
{{prompt}}: {expanded_prompt}
|
| 139 |
+
|
| 140 |
+
Your output will be only the result of the information required above in a dictionary called "References" containing the references titles as keys,
|
| 141 |
+
and their corresponding explanation of incorporation as values. If no references will be suggested, return an empty dictionary.
|
| 142 |
+
Do not return a general explanation of the generation process.
|
| 143 |
+
"""
|
| 144 |
+
return await self.call_llm(reference_prompt)
|
| 145 |
+
|
| 146 |
+
async def suggest_tools(self, expanded_prompt, tools_dict):
|
| 147 |
+
"""Suggest relevant external tools or APIs"""
|
| 148 |
+
tool_prompt = f"""
|
| 149 |
+
For the following {{prompt}}, suggest relevant external tools from the provided {{tools_dict}} that can enhance the prompt for better execution.
|
| 150 |
+
If the prompt does not require tools for its output, it is highly-recommended to not return any tools:
|
| 151 |
+
1. List 0-3 potential tools/APIs
|
| 152 |
+
2. Briefly explain how to use these tools within the prompt
|
| 153 |
+
|
| 154 |
+
{{prompt}}: {expanded_prompt}
|
| 155 |
+
{{tools_dict}}: {tools_dict}
|
| 156 |
+
|
| 157 |
+
Your output will be only the result of the information required above in a dictionary containing the suggested tools as keys,
|
| 158 |
+
and their corresponding way of usage with the prompt as values. If no tools will be suggested, return an empty dictionary.
|
| 159 |
+
Do not return a general explanation of the generation process.
|
| 160 |
+
"""
|
| 161 |
+
return await self.call_llm(tool_prompt)
|
| 162 |
+
|
| 163 |
+
async def assemble_prompt(self, components):
|
| 164 |
+
"""Assemble all components into a cohesive advanced prompt"""
|
| 165 |
+
assembly_prompt = f"""
|
| 166 |
+
Assemble all the following {{components}} into a cohesive, and well-structured advanced prompt and do not generate a response for the prompt.
|
| 167 |
+
Make sure to combine the {{reasoning_process}} and {{subtasks}} sections into one section called {{reasoning_process_and_subtasks}}.
|
| 168 |
+
|
| 169 |
+
{{components}}: {components}
|
| 170 |
+
|
| 171 |
+
Your output will be only the result of the tasks required above,
|
| 172 |
+
which is an advanced coherent prompt generated from the combination of the given components dictionary.
|
| 173 |
+
Keep only the {{reasoning_process_and_subtasks}} section instead of the {{reasoning_process}} and {{subtasks}} sections in the output.
|
| 174 |
+
Ensure that the assembled prompt maintains the delimiter structure of variables and the suggested persona.
|
| 175 |
+
Make sure that each sub-section of the prompt is clear and has a title.
|
| 176 |
+
The output is in plain text format and not a dictionary format.
|
| 177 |
+
Do not return a general explanation of the generation process.
|
| 178 |
+
Take the return-to-line symbol into consideration.
|
| 179 |
+
Remove the "**Expanded Prompt**" header.
|
| 180 |
+
|
| 181 |
+
Make it detailed using all markdown formatting properties without starting any markdown blocks. Use headings, lists, bold, italics, strike throughs, latex, tables and google searches related to the topic or keyword
|
| 182 |
+
Never use below words or minimize the use:
|
| 183 |
+
|
| 184 |
+
delve, dive, deep, (most common) tapestry, intriguing, holistic, intersection, not only ... but ... (standard inversions), dancing metaphores,Site specific: (shipping) - navigate into, sail into the future(research) - ethical considerations, area, realm, in the field of (even if it already knows the field), in the <> of (completely unecessary), in the age of, in the search of.At the end of almost every long essay prompt: Paragraph idea: Save the world, make the world better, in the future, it is essential to <>.In essence, may seem counterintuitive
|
| 185 |
+
|
| 186 |
+
"""
|
| 187 |
+
return await self.call_llm(assembly_prompt)
|
| 188 |
+
|
| 189 |
+
async def auto_eval(self, assembled_prompt, evaluation_criteria):
|
| 190 |
+
"""Perform Auto-Evaluation and Auto-Adjustment"""
|
| 191 |
+
auto_eval_prompt = f"""
|
| 192 |
+
Perform any minor adjustments on the given {{prompt}} based on how likely its output will satisfy these {{evaluation_criteria}}.
|
| 193 |
+
Only perform minor changes if it is necessary and return the updated prompt as output.
|
| 194 |
+
If no changes are necessary, do not change the prompt and return it as output.
|
| 195 |
+
|
| 196 |
+
{{prompt}}: {assembled_prompt}
|
| 197 |
+
{{evaluation_criteria}}: {evaluation_criteria}
|
| 198 |
+
|
| 199 |
+
Your output will be only the result of the tasks required above, which is an updated version of the {{prompt}}, in text format.
|
| 200 |
+
Make sure to keep the {{evaluation_criteria}} in the output prompt.
|
| 201 |
+
Do not return a general explanation of the generation process.
|
| 202 |
+
Make sure there is no generated answer for the prompt.
|
| 203 |
+
Make sure to maintain the stucture of the {{prompt}}.
|
| 204 |
+
"""
|
| 205 |
+
return await self.call_llm(auto_eval_prompt)
|
| 206 |
+
|
| 207 |
+
async def enhance_prompt(self, basic_prompt, perform_eval=False):
|
| 208 |
+
"""Main method to enhance a basic prompt to an advanced one"""
|
| 209 |
+
analysis = await self.analyze_input(basic_prompt)
|
| 210 |
+
expanded_prompt = await self.expand_instructions(basic_prompt, analysis)
|
| 211 |
+
|
| 212 |
+
evaluation_criteria, references, subtasks, reasoning, tools = await asyncio.gather(
|
| 213 |
+
self.create_eval_criteria(expanded_prompt),
|
| 214 |
+
self.suggest_references(expanded_prompt),
|
| 215 |
+
self.decompose_task(expanded_prompt),
|
| 216 |
+
self.add_reasoning(expanded_prompt),
|
| 217 |
+
self.suggest_tools(expanded_prompt, tools_dict={}),
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
components = {
|
| 221 |
+
"expanded_prompt": expanded_prompt,
|
| 222 |
+
"references": references,
|
| 223 |
+
"subtasks": subtasks,
|
| 224 |
+
"tools": tools,
|
| 225 |
+
"reasoning_process": reasoning,
|
| 226 |
+
"evaluation_criteria": evaluation_criteria,
|
| 227 |
+
}
|
| 228 |
+
|
| 229 |
+
assembled_prompt = await self.assemble_prompt(components)
|
| 230 |
+
|
| 231 |
+
if perform_eval:
|
| 232 |
+
eveluated_prompt = await self.auto_eval(assembled_prompt, evaluation_criteria)
|
| 233 |
+
advanced_prompt = eveluated_prompt
|
| 234 |
+
else:
|
| 235 |
+
advanced_prompt = assembled_prompt
|
| 236 |
+
|
| 237 |
+
return {
|
| 238 |
+
"advanced_prompt": advanced_prompt,
|
| 239 |
+
"assembled_prompt": assembled_prompt,
|
| 240 |
+
"components": components,
|
| 241 |
+
"analysis": analysis,
|
| 242 |
+
}
|
app.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
import time
|
| 4 |
+
import asyncio
|
| 5 |
+
from agent import PromptEngineer
|
| 6 |
+
|
| 7 |
+
async def engineer_prompt(input_prompt, api_key, temperature=0.0):
|
| 8 |
+
if not api_key:
|
| 9 |
+
return "Please provide an API key"
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
enhancer = PromptEngineer(temperature=temperature, api_key=api_key)
|
| 13 |
+
start_time = time.time()
|
| 14 |
+
result = await enhancer.enhance_prompt(input_prompt, perform_eval=False)
|
| 15 |
+
elapsed_time = time.time() - start_time
|
| 16 |
+
|
| 17 |
+
return result["advanced_prompt"]
|
| 18 |
+
except Exception as e:
|
| 19 |
+
return f"Error: {str(e)}"
|
| 20 |
+
|
| 21 |
+
with gr.Blocks(theme=gr.themes.Soft()) as demo:
|
| 22 |
+
gr.Markdown("""
|
| 23 |
+
# Prompt Engineer
|
| 24 |
+
Transform your prompts into powerful, precise instructions using AI-driven optimization
|
| 25 |
+
""")
|
| 26 |
+
|
| 27 |
+
with gr.Row():
|
| 28 |
+
with gr.Column(scale=1):
|
| 29 |
+
api_key = gr.Textbox(
|
| 30 |
+
label="API Key",
|
| 31 |
+
placeholder="sk-...",
|
| 32 |
+
type="password",
|
| 33 |
+
info="Required: Enter your API key"
|
| 34 |
+
)
|
| 35 |
+
temperature = gr.Slider(
|
| 36 |
+
minimum=0.0,
|
| 37 |
+
maximum=1.0,
|
| 38 |
+
value=0.0,
|
| 39 |
+
step=0.1,
|
| 40 |
+
label="Temperature",
|
| 41 |
+
info="Recommended: Temperature=0.0"
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
with gr.Row():
|
| 45 |
+
with gr.Column(scale=1):
|
| 46 |
+
input_prompt = gr.Textbox(
|
| 47 |
+
lines=10,
|
| 48 |
+
placeholder="Enter your prompt here...",
|
| 49 |
+
label="Input Prompt",
|
| 50 |
+
info="Enter the prompt you want to engineer"
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
with gr.Column(scale=1):
|
| 54 |
+
output_prompt = gr.Textbox(
|
| 55 |
+
lines=20,
|
| 56 |
+
label="Engineered Prompt",
|
| 57 |
+
show_copy_button=True,
|
| 58 |
+
autoscroll=False,
|
| 59 |
+
info="Your engineered prompt will appear here"
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
submit_btn = gr.Button("Engineer Prompt", variant="primary")
|
| 63 |
+
submit_btn.click(
|
| 64 |
+
fn=engineer_prompt,
|
| 65 |
+
inputs=[input_prompt, api_key, temperature],
|
| 66 |
+
outputs=output_prompt
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
gr.Markdown("""
|
| 70 |
+
### Best Practices
|
| 71 |
+
- Be specific and clear in your input prompt
|
| 72 |
+
- Use temperature 0.0 for consistent, focused results
|
| 73 |
+
- Increase temperature up to 1.0 for more creative variations
|
| 74 |
+
- Review and iterate on engineered prompts for optimal results
|
| 75 |
+
""")
|
| 76 |
+
|
| 77 |
+
if __name__ == "__main__":
|
| 78 |
+
demo.launch(
|
| 79 |
+
server_name="0.0.0.0",
|
| 80 |
+
server_port=7860,
|
| 81 |
+
share=True,
|
| 82 |
+
show_error=True
|
| 83 |
+
)
|
demo.png
ADDED
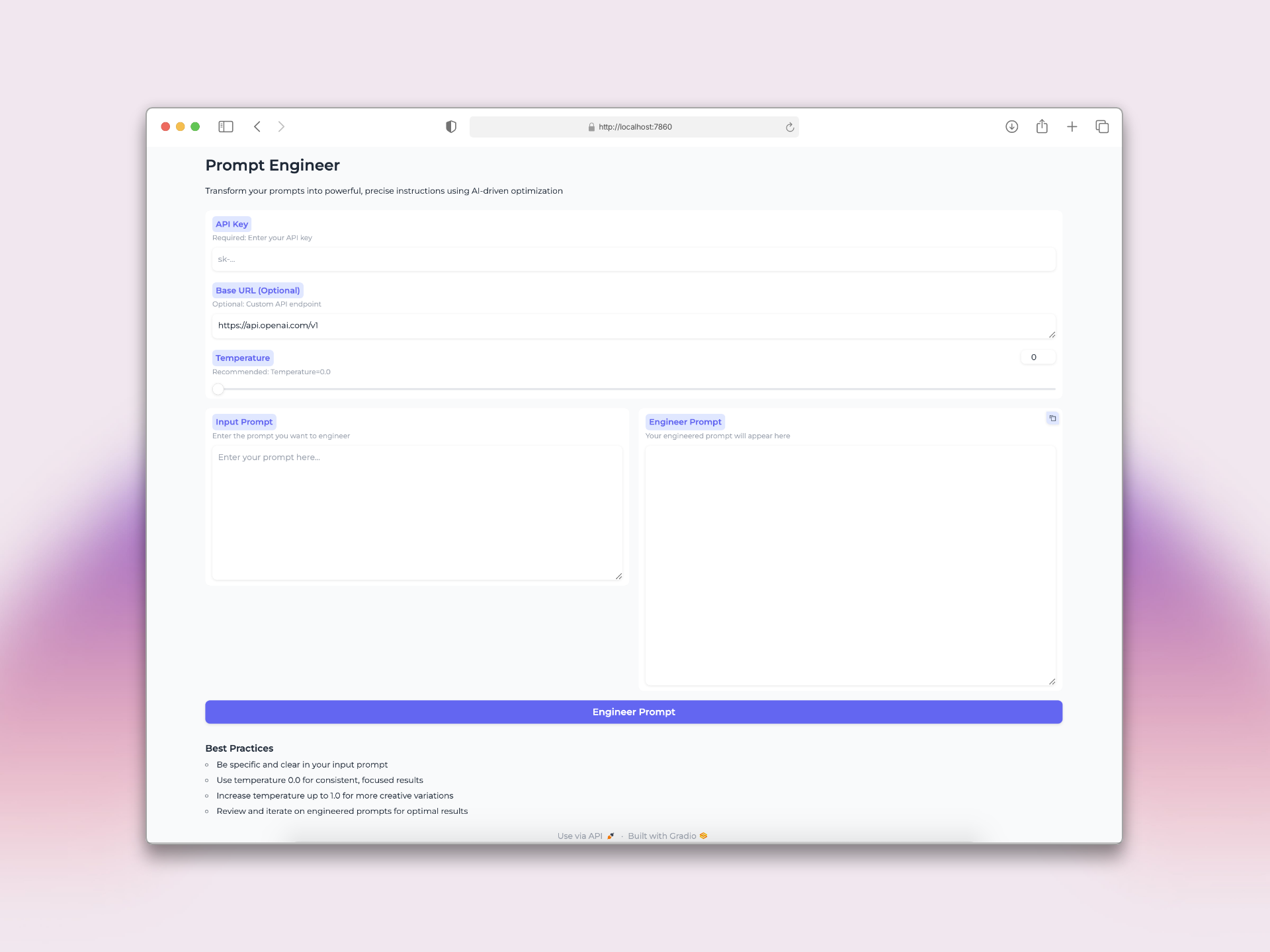
|
requirements.txt
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
aiohttp==3.9.5
|
| 2 |
+
aiosignal==1.3.1
|
| 3 |
+
annotated-types==0.7.0
|
| 4 |
+
anyio==4.4.0
|
| 5 |
+
attrs==23.2.0
|
| 6 |
+
certifi==2024.7.4
|
| 7 |
+
charset-normalizer==3.3.2
|
| 8 |
+
click==8.1.7
|
| 9 |
+
distro==1.9.0
|
| 10 |
+
dnspython==2.6.1
|
| 11 |
+
email_validator==2.2.0
|
| 12 |
+
fastapi==0.111.1
|
| 13 |
+
fastapi-cli==0.0.4
|
| 14 |
+
frozenlist==1.4.1
|
| 15 |
+
gradio==4.19.2
|
| 16 |
+
h11==0.14.0
|
| 17 |
+
httpcore==1.0.5
|
| 18 |
+
httptools==0.6.1
|
| 19 |
+
httpx==0.27.0
|
| 20 |
+
huggingface_hub==0.22.2
|
| 21 |
+
idna==3.7
|
| 22 |
+
Jinja2==3.1.4
|
| 23 |
+
jsonpatch==1.33
|
| 24 |
+
jsonpointer==3.0.0
|
| 25 |
+
langchain==0.2.10
|
| 26 |
+
langchain-core==0.2.22
|
| 27 |
+
langchain-openai==0.1.17
|
| 28 |
+
langchain-text-splitters==0.2.2
|
| 29 |
+
langsmith==0.1.93
|
| 30 |
+
markdown-it-py==3.0.0
|
| 31 |
+
MarkupSafe==2.1.5
|
| 32 |
+
mdurl==0.1.2
|
| 33 |
+
multidict==6.0.5
|
| 34 |
+
numpy==1.26.4
|
| 35 |
+
openai==1.35.15
|
| 36 |
+
orjson==3.10.6
|
| 37 |
+
packaging==24.1
|
| 38 |
+
pydantic==2.8.2
|
| 39 |
+
pydantic_core==2.20.1
|
| 40 |
+
Pygments==2.18.0
|
| 41 |
+
python-dotenv==1.0.1
|
| 42 |
+
python-multipart==0.0.9
|
| 43 |
+
PyYAML==6.0.1
|
| 44 |
+
regex==2024.5.15
|
| 45 |
+
requests==2.32.3
|
| 46 |
+
rich==13.7.1
|
| 47 |
+
shellingham==1.5.4
|
| 48 |
+
sniffio==1.3.1
|
| 49 |
+
SQLAlchemy==2.0.31
|
| 50 |
+
starlette==0.37.2
|
| 51 |
+
tenacity==8.5.0
|
| 52 |
+
tiktoken==0.7.0
|
| 53 |
+
tqdm==4.66.4
|
| 54 |
+
typer==0.12.3
|
| 55 |
+
typing_extensions==4.12.2
|
| 56 |
+
urllib3==2.2.2
|
| 57 |
+
uvicorn==0.30.3
|
| 58 |
+
uvloop==0.19.0
|
| 59 |
+
watchfiles==0.22.0
|
| 60 |
+
websockets<12.0,>=10.0
|
| 61 |
+
yarl==1.9.4
|