Spaces:
Runtime error

Runtime error
lhzstar
commited on
Commit
·
abca9bf
1
Parent(s):
370e3bc
new commits
Browse files- README.md +33 -0
- app.py +1 -1
- celebbot.py +5 -8
- img/flow_chart.jpg +0 -0
- requirements.txt +2 -1
- run_cli.py +2 -1
- run_eval.py +29 -3
- unlimiformer/__init__.py +2 -0
- unlimiformer/configs/data/contract_nli.json +12 -0
- unlimiformer/configs/data/gov_report.json +12 -0
- unlimiformer/configs/data/hotpotqa.json +12 -0
- unlimiformer/configs/data/hotpotqa_second_only.json +12 -0
- unlimiformer/configs/data/narative_qa.json +12 -0
- unlimiformer/configs/data/qasper.json +12 -0
- unlimiformer/configs/data/qmsum.json +12 -0
- unlimiformer/configs/data/quality.json +12 -0
- unlimiformer/configs/data/squad.json +12 -0
- unlimiformer/configs/data/squad_ordered_distractors.json +12 -0
- unlimiformer/configs/data/squad_shuffled_distractors.json +12 -0
- unlimiformer/configs/data/summ_screen_fd.json +12 -0
- unlimiformer/configs/model/bart_base_sled.json +6 -0
- unlimiformer/configs/model/bart_large_sled.json +6 -0
- unlimiformer/configs/model/primera_govreport_sled.json +9 -0
- unlimiformer/configs/training/base_training_args.json +22 -0
- unlimiformer/index_building.py +161 -0
- unlimiformer/metrics/__init__.py +1 -0
- unlimiformer/metrics/metrics.py +182 -0
- unlimiformer/model.py +1157 -0
- unlimiformer/random_training_unlimiformer.py +224 -0
- unlimiformer/run.py +1180 -0
- unlimiformer/run_generation.py +577 -0
- unlimiformer/usage.py +91 -0
- unlimiformer/utils/__init__.py +0 -0
- unlimiformer/utils/config.py +13 -0
- unlimiformer/utils/custom_hf_argument_parser.py +39 -0
- unlimiformer/utils/custom_seq2seq_trainer.py +328 -0
- unlimiformer/utils/decoding.py +59 -0
- unlimiformer/utils/duplicates.py +15 -0
- unlimiformer/utils/override_training_args.py +106 -0
- utils.py +24 -2
README.md
CHANGED
|
@@ -11,3 +11,36 @@ license: apache-2.0
|
|
| 11 |
---
|
| 12 |
|
| 13 |
# CelebChat
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
# CelebChat
|
| 14 |
+
CelebChat is a Hugging Face Space where the user can talk with nearly 50 virtual celebrities.
|
| 15 |
+
|
| 16 |
+
## System details
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
## Citation
|
| 20 |
+
```
|
| 21 |
+
@article{bertsch2023unlimiformer,
|
| 22 |
+
title={Unlimiformer: Long-Range Transformers with Unlimited Length Input},
|
| 23 |
+
author={Bertsch, Amanda and Alon, Uri and Neubig, Graham and Gormley, Matthew R},
|
| 24 |
+
journal={arXiv preprint arXiv:2305.01625},
|
| 25 |
+
year={2023}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
@misc{https://doi.org/10.48550/arxiv.2210.11416,
|
| 29 |
+
doi = {10.48550/ARXIV.2210.11416},
|
| 30 |
+
|
| 31 |
+
url = {https://arxiv.org/abs/2210.11416},
|
| 32 |
+
|
| 33 |
+
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
|
| 34 |
+
|
| 35 |
+
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
|
| 36 |
+
|
| 37 |
+
title = {Scaling Instruction-Finetuned Language Models},
|
| 38 |
+
|
| 39 |
+
publisher = {arXiv},
|
| 40 |
+
|
| 41 |
+
year = {2022},
|
| 42 |
+
|
| 43 |
+
copyright = {Creative Commons Attribution 4.0 International}
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
```
|
app.py
CHANGED
|
@@ -64,7 +64,7 @@ def main():
|
|
| 64 |
st.session_state["celeb_bot"] = CelebBot(st.session_state["celeb_name"],
|
| 65 |
celeb_gender,
|
| 66 |
get_tokenizer(st.session_state["QA_model_path"]),
|
| 67 |
-
get_seq2seq_model(st.session_state["QA_model_path"]) if "flan-t5" in st.session_state["QA_model_path"] else get_causal_model(st.session_state["QA_model_path"]),
|
| 68 |
get_tokenizer(st.session_state["sentTr_model_path"]),
|
| 69 |
get_auto_model(st.session_state["sentTr_model_path"]),
|
| 70 |
*preprocess_text(st.session_state["celeb_name"], knowledge, "en_core_web_lg")
|
|
|
|
| 64 |
st.session_state["celeb_bot"] = CelebBot(st.session_state["celeb_name"],
|
| 65 |
celeb_gender,
|
| 66 |
get_tokenizer(st.session_state["QA_model_path"]),
|
| 67 |
+
get_seq2seq_model(st.session_state["QA_model_path"], _tokenizer=get_tokenizer(st.session_state["QA_model_path"])) if "flan-t5" in st.session_state["QA_model_path"] else get_causal_model(st.session_state["QA_model_path"]),
|
| 68 |
get_tokenizer(st.session_state["sentTr_model_path"]),
|
| 69 |
get_auto_model(st.session_state["sentTr_model_path"]),
|
| 70 |
*preprocess_text(st.session_state["celeb_name"], knowledge, "en_core_web_lg")
|
celebbot.py
CHANGED
|
@@ -2,21 +2,17 @@ import datetime
|
|
| 2 |
import numpy as np
|
| 3 |
import torch
|
| 4 |
import torch.nn.functional as F
|
| 5 |
-
import os
|
| 6 |
-
import json
|
| 7 |
import speech_recognition as sr
|
| 8 |
import re
|
| 9 |
import time
|
| 10 |
-
import spacy
|
| 11 |
-
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, AutoModel
|
| 12 |
import pickle
|
| 13 |
-
import streamlit as st
|
| 14 |
from sklearn.metrics.pairwise import cosine_similarity
|
| 15 |
|
| 16 |
|
| 17 |
# Build the AI
|
| 18 |
class CelebBot():
|
| 19 |
-
|
|
|
|
| 20 |
self.name = name
|
| 21 |
self.gender = gender
|
| 22 |
print("--- starting up", self.name, self.gender, "---")
|
|
@@ -29,6 +25,7 @@ class CelebBot():
|
|
| 29 |
self.spacy_model = spacy_model
|
| 30 |
|
| 31 |
self.all_knowledge = knowledge_sents
|
|
|
|
| 32 |
|
| 33 |
def speech_to_text(self):
|
| 34 |
recognizer = sr.Recognizer()
|
|
@@ -83,7 +80,7 @@ class CelebBot():
|
|
| 83 |
all_knowledge_embeddings = self.sentence_embeds_inference(self.all_knowledge)
|
| 84 |
similarity = cosine_similarity(all_knowledge_embeddings.cpu(), question_embeddings.cpu())
|
| 85 |
similarity = np.reshape(similarity, (1, -1))[0]
|
| 86 |
-
K = min(
|
| 87 |
top_K = np.sort(np.argpartition(similarity, -K)[-K: ])
|
| 88 |
all_knowledge_assertions = np.array(self.all_knowledge)[top_K]
|
| 89 |
|
|
@@ -175,7 +172,7 @@ class CelebBot():
|
|
| 175 |
knowledge = self.retrieve_knowledge_assertions()
|
| 176 |
|
| 177 |
query = f"Context: {instruction} {knowledge}\n\nChat History: {chat_his}Question: {self.text}\n\nAnswer:"
|
| 178 |
-
input_ids = self.QA_tokenizer(f"{query}", return_tensors="pt").input_ids.to(self.QA_model.device)
|
| 179 |
outputs = self.QA_model.generate(input_ids, max_length=1024, min_length=8, repetition_penalty=2.5)
|
| 180 |
self.text = self.QA_tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 181 |
return self.text
|
|
|
|
| 2 |
import numpy as np
|
| 3 |
import torch
|
| 4 |
import torch.nn.functional as F
|
|
|
|
|
|
|
| 5 |
import speech_recognition as sr
|
| 6 |
import re
|
| 7 |
import time
|
|
|
|
|
|
|
| 8 |
import pickle
|
|
|
|
| 9 |
from sklearn.metrics.pairwise import cosine_similarity
|
| 10 |
|
| 11 |
|
| 12 |
# Build the AI
|
| 13 |
class CelebBot():
|
| 14 |
+
|
| 15 |
+
def __init__(self, name, gender, QA_tokenizer, QA_model, sentTr_tokenizer, sentTr_model, spacy_model, knowledge_sents, top_k = 8):
|
| 16 |
self.name = name
|
| 17 |
self.gender = gender
|
| 18 |
print("--- starting up", self.name, self.gender, "---")
|
|
|
|
| 25 |
self.spacy_model = spacy_model
|
| 26 |
|
| 27 |
self.all_knowledge = knowledge_sents
|
| 28 |
+
self.top_k = top_k
|
| 29 |
|
| 30 |
def speech_to_text(self):
|
| 31 |
recognizer = sr.Recognizer()
|
|
|
|
| 80 |
all_knowledge_embeddings = self.sentence_embeds_inference(self.all_knowledge)
|
| 81 |
similarity = cosine_similarity(all_knowledge_embeddings.cpu(), question_embeddings.cpu())
|
| 82 |
similarity = np.reshape(similarity, (1, -1))[0]
|
| 83 |
+
K = min(self.top_k, len(self.all_knowledge))
|
| 84 |
top_K = np.sort(np.argpartition(similarity, -K)[-K: ])
|
| 85 |
all_knowledge_assertions = np.array(self.all_knowledge)[top_K]
|
| 86 |
|
|
|
|
| 172 |
knowledge = self.retrieve_knowledge_assertions()
|
| 173 |
|
| 174 |
query = f"Context: {instruction} {knowledge}\n\nChat History: {chat_his}Question: {self.text}\n\nAnswer:"
|
| 175 |
+
input_ids = self.QA_tokenizer(f"{query}", truncation=False, return_tensors="pt").input_ids.to(self.QA_model.device)
|
| 176 |
outputs = self.QA_model.generate(input_ids, max_length=1024, min_length=8, repetition_penalty=2.5)
|
| 177 |
self.text = self.QA_tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 178 |
return self.text
|
img/flow_chart.jpg
ADDED
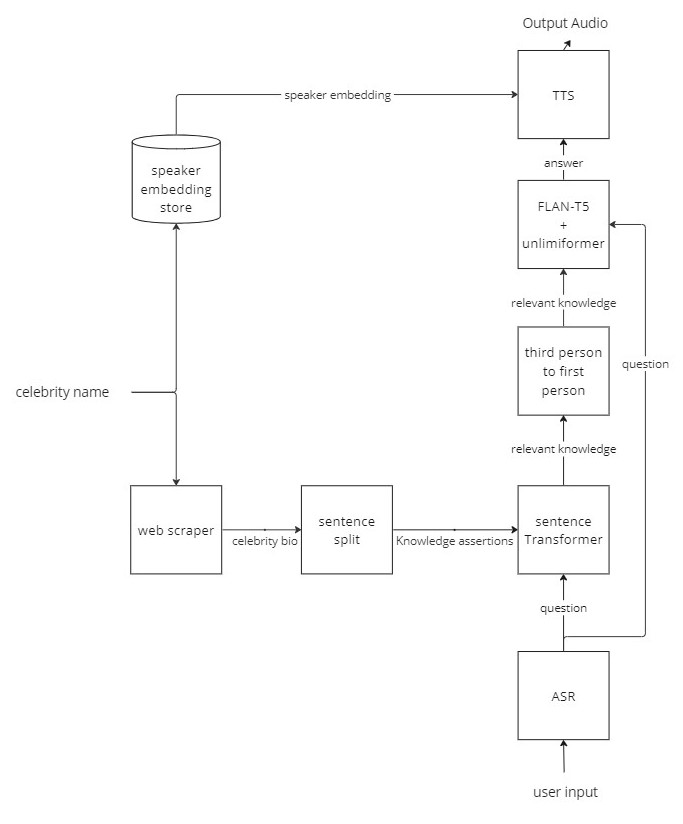
|
requirements.txt
CHANGED
|
@@ -30,4 +30,5 @@ sentence-transformers==2.2.2
|
|
| 30 |
evaluate==0.4.1
|
| 31 |
https://huggingface.co/spacy/en_core_web_lg/resolve/main/en_core_web_lg-any-py3-none-any.whl
|
| 32 |
protobuf==3.20
|
| 33 |
-
streamlit_mic_recorder==0.0.2
|
|
|
|
|
|
| 30 |
evaluate==0.4.1
|
| 31 |
https://huggingface.co/spacy/en_core_web_lg/resolve/main/en_core_web_lg-any-py3-none-any.whl
|
| 32 |
protobuf==3.20
|
| 33 |
+
streamlit_mic_recorder==0.0.2
|
| 34 |
+
faiss-cpu==1.7.4
|
run_cli.py
CHANGED
|
@@ -5,7 +5,7 @@ import spacy
|
|
| 5 |
from celebbot import CelebBot
|
| 6 |
from utils import *
|
| 7 |
|
| 8 |
-
DEBUG =
|
| 9 |
QA_MODEL_ID = "google/flan-t5-large"
|
| 10 |
SENTTR_MODEL_ID = "sentence-transformers/all-mpnet-base-v2"
|
| 11 |
|
|
@@ -52,6 +52,7 @@ def main():
|
|
| 52 |
print("me --> ", ai.text)
|
| 53 |
|
| 54 |
answers.append(ai.question_answer())
|
|
|
|
| 55 |
|
| 56 |
if not DEBUG:
|
| 57 |
ai.text_to_speech()
|
|
|
|
| 5 |
from celebbot import CelebBot
|
| 6 |
from utils import *
|
| 7 |
|
| 8 |
+
DEBUG = True
|
| 9 |
QA_MODEL_ID = "google/flan-t5-large"
|
| 10 |
SENTTR_MODEL_ID = "sentence-transformers/all-mpnet-base-v2"
|
| 11 |
|
|
|
|
| 52 |
print("me --> ", ai.text)
|
| 53 |
|
| 54 |
answers.append(ai.question_answer())
|
| 55 |
+
print("bot --> ", ai.text)
|
| 56 |
|
| 57 |
if not DEBUG:
|
| 58 |
ai.text_to_speech()
|
run_eval.py
CHANGED
|
@@ -4,15 +4,19 @@ import spacy
|
|
| 4 |
import json
|
| 5 |
import evaluate
|
| 6 |
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, AutoModel
|
|
|
|
| 7 |
import torch
|
| 8 |
|
| 9 |
from utils import *
|
| 10 |
from celebbot import CelebBot
|
| 11 |
|
| 12 |
-
QA_MODEL_ID = "google/flan-t5-
|
| 13 |
SENTTR_MODEL_ID = "sentence-transformers/all-mpnet-base-v2"
|
| 14 |
celeb_names = ["Cate Blanchett", "David Beckham", "Emma Watson", "Lady Gaga", "Madonna", "Mark Zuckerberg"]
|
| 15 |
|
|
|
|
|
|
|
|
|
|
| 16 |
celeb_data = get_celeb_data("data.json")
|
| 17 |
references = [val['answers'] for key, val in list(celeb_data.items()) if key in celeb_names]
|
| 18 |
references = list(itertools.chain.from_iterable(references))
|
|
@@ -20,7 +24,29 @@ predictions = []
|
|
| 20 |
|
| 21 |
device = 'cpu'
|
| 22 |
QA_tokenizer = AutoTokenizer.from_pretrained(QA_MODEL_ID)
|
| 23 |
-
QA_model = AutoModelForSeq2SeqLM.from_pretrained(QA_MODEL_ID)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
sentTr_tokenizer = AutoTokenizer.from_pretrained(SENTTR_MODEL_ID)
|
| 25 |
sentTr_model = AutoModel.from_pretrained(SENTTR_MODEL_ID).to(device)
|
| 26 |
|
|
@@ -37,7 +63,7 @@ for celeb_name in celeb_names:
|
|
| 37 |
spacy_model = spacy.load("en_core_web_lg")
|
| 38 |
knowledge_sents = [i.text.strip() for i in spacy_model(knowledge).sents]
|
| 39 |
|
| 40 |
-
ai = CelebBot(celeb_name, gender, QA_tokenizer, QA_model, sentTr_tokenizer, sentTr_model, spacy_model, knowledge_sents)
|
| 41 |
for q in celeb_data[celeb_name]["questions"]:
|
| 42 |
ai.text = q
|
| 43 |
response = ai.question_answer()
|
|
|
|
| 4 |
import json
|
| 5 |
import evaluate
|
| 6 |
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, AutoModel
|
| 7 |
+
from unlimiformer import Unlimiformer, UnlimiformerArguments
|
| 8 |
import torch
|
| 9 |
|
| 10 |
from utils import *
|
| 11 |
from celebbot import CelebBot
|
| 12 |
|
| 13 |
+
QA_MODEL_ID = "google/flan-t5-xl"
|
| 14 |
SENTTR_MODEL_ID = "sentence-transformers/all-mpnet-base-v2"
|
| 15 |
celeb_names = ["Cate Blanchett", "David Beckham", "Emma Watson", "Lady Gaga", "Madonna", "Mark Zuckerberg"]
|
| 16 |
|
| 17 |
+
USE_UNLIMIFORMER = True
|
| 18 |
+
TOP_K = 8
|
| 19 |
+
|
| 20 |
celeb_data = get_celeb_data("data.json")
|
| 21 |
references = [val['answers'] for key, val in list(celeb_data.items()) if key in celeb_names]
|
| 22 |
references = list(itertools.chain.from_iterable(references))
|
|
|
|
| 24 |
|
| 25 |
device = 'cpu'
|
| 26 |
QA_tokenizer = AutoTokenizer.from_pretrained(QA_MODEL_ID)
|
| 27 |
+
QA_model = AutoModelForSeq2SeqLM.from_pretrained(QA_MODEL_ID)
|
| 28 |
+
if USE_UNLIMIFORMER:
|
| 29 |
+
defaults = UnlimiformerArguments()
|
| 30 |
+
unlimiformer_kwargs = {
|
| 31 |
+
'layer_begin': defaults.layer_begin,
|
| 32 |
+
'layer_end': defaults.layer_end,
|
| 33 |
+
'unlimiformer_head_num': defaults.unlimiformer_head_num,
|
| 34 |
+
'exclude_attention': defaults.unlimiformer_exclude,
|
| 35 |
+
'chunk_overlap': defaults.unlimiformer_chunk_overlap,
|
| 36 |
+
'model_encoder_max_len': defaults.unlimiformer_chunk_size,
|
| 37 |
+
'verbose': defaults.unlimiformer_verbose, 'tokenizer': QA_tokenizer,
|
| 38 |
+
'unlimiformer_training': defaults.unlimiformer_training,
|
| 39 |
+
'use_datastore': defaults.use_datastore,
|
| 40 |
+
'flat_index': defaults.flat_index,
|
| 41 |
+
'test_datastore': defaults.test_datastore,
|
| 42 |
+
'reconstruct_embeddings': defaults.reconstruct_embeddings,
|
| 43 |
+
'gpu_datastore': defaults.gpu_datastore,
|
| 44 |
+
'gpu_index': defaults.gpu_index
|
| 45 |
+
}
|
| 46 |
+
QA_model =Unlimiformer.convert_model(QA_model, **unlimiformer_kwargs).to(device)
|
| 47 |
+
else:
|
| 48 |
+
QA_model = QA_model.to(device)
|
| 49 |
+
|
| 50 |
sentTr_tokenizer = AutoTokenizer.from_pretrained(SENTTR_MODEL_ID)
|
| 51 |
sentTr_model = AutoModel.from_pretrained(SENTTR_MODEL_ID).to(device)
|
| 52 |
|
|
|
|
| 63 |
spacy_model = spacy.load("en_core_web_lg")
|
| 64 |
knowledge_sents = [i.text.strip() for i in spacy_model(knowledge).sents]
|
| 65 |
|
| 66 |
+
ai = CelebBot(celeb_name, gender, QA_tokenizer, QA_model, sentTr_tokenizer, sentTr_model, spacy_model, knowledge_sents, top_k=TOP_K)
|
| 67 |
for q in celeb_data[celeb_name]["questions"]:
|
| 68 |
ai.text = q
|
| 69 |
response = ai.question_answer()
|
unlimiformer/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .model import Unlimiformer
|
| 2 |
+
from .usage import UnlimiformerArguments
|
unlimiformer/configs/data/contract_nli.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "contract_nli",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"generation_max_length": 8,
|
| 8 |
+
"num_train_epochs": 20,
|
| 9 |
+
"metric_names": ["exact_match"],
|
| 10 |
+
"metric_for_best_model": "exact_match",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/gov_report.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "gov_report",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"generation_max_length": 1024,
|
| 6 |
+
"max_prefix_length": 0,
|
| 7 |
+
"pad_prefix": false,
|
| 8 |
+
"num_train_epochs": 10,
|
| 9 |
+
"metric_names": ["rouge"],
|
| 10 |
+
"metric_for_best_model": "rouge/geometric_mean",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/hotpotqa.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "hotpotqa",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"generation_max_length": 128,
|
| 8 |
+
"num_train_epochs": 9,
|
| 9 |
+
"metric_names": ["f1", "exact_match"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/hotpotqa_second_only.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "hotpotqa_second_only",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"generation_max_length": 128,
|
| 8 |
+
"num_train_epochs": 9,
|
| 9 |
+
"metric_names": ["f1", "exact_match"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/narative_qa.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "narrative_qa",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 2,
|
| 8 |
+
"generation_max_length": 128,
|
| 9 |
+
"metric_names": ["f1"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/qasper.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "qasper",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"generation_max_length": 128,
|
| 8 |
+
"num_train_epochs": 20,
|
| 9 |
+
"metric_names": ["f1"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/qmsum.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "qmsum",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 20,
|
| 8 |
+
"generation_max_length": 1024,
|
| 9 |
+
"metric_names": ["rouge"],
|
| 10 |
+
"metric_for_best_model": "rouge/geometric_mean",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/quality.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "quality",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 160,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 20,
|
| 8 |
+
"generation_max_length": 128,
|
| 9 |
+
"metric_names": ["exact_match"],
|
| 10 |
+
"metric_for_best_model": "exact_match",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/squad.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "squad",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 3,
|
| 8 |
+
"generation_max_length": 128,
|
| 9 |
+
"metric_names": ["f1", "exact_match"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/squad_ordered_distractors.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "squad_ordered_distractors",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 3,
|
| 8 |
+
"generation_max_length": 128,
|
| 9 |
+
"metric_names": ["f1", "exact_match"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/squad_shuffled_distractors.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "squad_shuffled_distractors",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 64,
|
| 6 |
+
"pad_prefix": true,
|
| 7 |
+
"num_train_epochs": 3,
|
| 8 |
+
"generation_max_length": 128,
|
| 9 |
+
"metric_names": ["f1", "exact_match"],
|
| 10 |
+
"metric_for_best_model": "f1",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/data/summ_screen_fd.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_name": "tau/sled",
|
| 3 |
+
"dataset_config_name": "summ_screen_fd",
|
| 4 |
+
"max_source_length": 16384,
|
| 5 |
+
"max_prefix_length": 0,
|
| 6 |
+
"pad_prefix": false,
|
| 7 |
+
"num_train_epochs": 10,
|
| 8 |
+
"generation_max_length": 1024,
|
| 9 |
+
"metric_names": ["rouge"],
|
| 10 |
+
"metric_for_best_model": "rouge/geometric_mean",
|
| 11 |
+
"greater_is_better": true
|
| 12 |
+
}
|
unlimiformer/configs/model/bart_base_sled.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name_or_path": "tau/bart-base-sled",
|
| 3 |
+
"use_auth_token": false,
|
| 4 |
+
"max_target_length": 1024,
|
| 5 |
+
"fp16": true
|
| 6 |
+
}
|
unlimiformer/configs/model/bart_large_sled.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name_or_path": "tau/bart-large-sled",
|
| 3 |
+
"use_auth_token": false,
|
| 4 |
+
"max_target_length": 1024,
|
| 5 |
+
"fp16": true
|
| 6 |
+
}
|
unlimiformer/configs/model/primera_govreport_sled.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "tau/sled",
|
| 3 |
+
"underlying_config": "allenai/PRIMERA",
|
| 4 |
+
"context_size": 4096,
|
| 5 |
+
"window_fraction": 0.5,
|
| 6 |
+
"prepend_prefix": true,
|
| 7 |
+
"encode_prefix": true,
|
| 8 |
+
"sliding_method": "dynamic"
|
| 9 |
+
}
|
unlimiformer/configs/training/base_training_args.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eval_steps_override": 0.5,
|
| 3 |
+
"save_steps_override": 0.5,
|
| 4 |
+
"evaluation_strategy": "steps",
|
| 5 |
+
"eval_fraction": 1000,
|
| 6 |
+
"predict_with_generate": true,
|
| 7 |
+
"gradient_checkpointing": true,
|
| 8 |
+
"do_train": true,
|
| 9 |
+
"do_eval": true,
|
| 10 |
+
"seed": 42,
|
| 11 |
+
"warmup_ratio": 0.1,
|
| 12 |
+
"save_total_limit": 2,
|
| 13 |
+
"preprocessing_num_workers": 1,
|
| 14 |
+
"load_best_model_at_end": true,
|
| 15 |
+
"lr_scheduler": "linear",
|
| 16 |
+
"adam_epsilon": 1e-6,
|
| 17 |
+
"adam_beta1": 0.9,
|
| 18 |
+
"adam_beta2": 0.98,
|
| 19 |
+
"weight_decay": 0.001,
|
| 20 |
+
"patience": 10,
|
| 21 |
+
"extra_metrics": "bertscore"
|
| 22 |
+
}
|
unlimiformer/index_building.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import faiss
|
| 2 |
+
import faiss.contrib.torch_utils
|
| 3 |
+
import time
|
| 4 |
+
import logging
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
code_size = 64
|
| 10 |
+
|
| 11 |
+
class DatastoreBatch():
|
| 12 |
+
def __init__(self, dim, batch_size, flat_index=False, gpu_index=False, verbose=False, index_device=None) -> None:
|
| 13 |
+
self.indices = []
|
| 14 |
+
self.batch_size = batch_size
|
| 15 |
+
self.device = index_device if index_device is not None else torch.device('cuda' if gpu_index else 'cpu')
|
| 16 |
+
for i in range(batch_size):
|
| 17 |
+
self.indices.append(Datastore(dim, use_flat_index=flat_index, gpu_index=gpu_index, verbose=verbose, device=self.device))
|
| 18 |
+
|
| 19 |
+
def move_to_gpu(self):
|
| 20 |
+
for i in range(self.batch_size):
|
| 21 |
+
self.indices[i].move_to_gpu()
|
| 22 |
+
|
| 23 |
+
def add_keys(self, keys, num_keys_to_add_at_a_time=100000):
|
| 24 |
+
for i in range(self.batch_size):
|
| 25 |
+
self.indices[i].add_keys(keys[i], num_keys_to_add_at_a_time)
|
| 26 |
+
|
| 27 |
+
def train_index(self, keys):
|
| 28 |
+
for index, example_keys in zip(self.indices, keys):
|
| 29 |
+
index.train_index(example_keys)
|
| 30 |
+
|
| 31 |
+
def search(self, queries, k):
|
| 32 |
+
found_scores, found_values = [], []
|
| 33 |
+
for i in range(self.batch_size):
|
| 34 |
+
scores, values = self.indices[i].search(queries[i], k)
|
| 35 |
+
found_scores.append(scores)
|
| 36 |
+
found_values.append(values)
|
| 37 |
+
return torch.stack(found_scores, dim=0), torch.stack(found_values, dim=0)
|
| 38 |
+
|
| 39 |
+
def search_and_reconstruct(self, queries, k):
|
| 40 |
+
found_scores, found_values = [], []
|
| 41 |
+
found_vectors = []
|
| 42 |
+
for i in range(self.batch_size):
|
| 43 |
+
scores, values, vectors = self.indices[i].search_and_reconstruct(queries[i], k)
|
| 44 |
+
found_scores.append(scores)
|
| 45 |
+
found_values.append(values)
|
| 46 |
+
found_vectors.append(vectors)
|
| 47 |
+
return torch.stack(found_scores, dim=0), torch.stack(found_values, dim=0), torch.stack(found_vectors, dim=0)
|
| 48 |
+
|
| 49 |
+
class Datastore():
|
| 50 |
+
def __init__(self, dim, use_flat_index=False, gpu_index=False, verbose=False, device=None) -> None:
|
| 51 |
+
self.dimension = dim
|
| 52 |
+
self.device = device if device is not None else torch.device('cuda' if gpu_index else 'cpu')
|
| 53 |
+
self.logger = logging.getLogger('index_building')
|
| 54 |
+
self.logger.setLevel(20)
|
| 55 |
+
self.use_flat_index = use_flat_index
|
| 56 |
+
self.gpu_index = gpu_index
|
| 57 |
+
|
| 58 |
+
# Initialize faiss index
|
| 59 |
+
# TODO: is preprocessing efficient enough to spend time on?
|
| 60 |
+
if not use_flat_index:
|
| 61 |
+
self.index = faiss.IndexFlatIP(self.dimension) # inner product index because we use IP attention
|
| 62 |
+
|
| 63 |
+
# need to wrap in index ID map to enable add_with_ids
|
| 64 |
+
# self.index = faiss.IndexIDMap(self.index)
|
| 65 |
+
|
| 66 |
+
self.index_size = 0
|
| 67 |
+
# if self.gpu_index:
|
| 68 |
+
# self.move_to_gpu()
|
| 69 |
+
|
| 70 |
+
def move_to_gpu(self):
|
| 71 |
+
if self.use_flat_index:
|
| 72 |
+
# self.keys = self.keys.to(self.device)
|
| 73 |
+
return
|
| 74 |
+
else:
|
| 75 |
+
co = faiss.GpuClonerOptions()
|
| 76 |
+
co.useFloat16 = True
|
| 77 |
+
self.index = faiss.index_cpu_to_gpu(faiss.StandardGpuResources(), self.device.index, self.index, co)
|
| 78 |
+
|
| 79 |
+
def train_index(self, keys):
|
| 80 |
+
if self.use_flat_index:
|
| 81 |
+
self.add_keys(keys=keys, index_is_trained=True)
|
| 82 |
+
else:
|
| 83 |
+
keys = keys.cpu().float()
|
| 84 |
+
ncentroids = int(keys.shape[0] / 128)
|
| 85 |
+
self.index = faiss.IndexIVFPQ(self.index, self.dimension,
|
| 86 |
+
ncentroids, code_size, 8)
|
| 87 |
+
self.index.nprobe = min(32, ncentroids)
|
| 88 |
+
# if not self.gpu_index:
|
| 89 |
+
# keys = keys.cpu()
|
| 90 |
+
|
| 91 |
+
self.logger.info('Training index')
|
| 92 |
+
start_time = time.time()
|
| 93 |
+
self.index.train(keys)
|
| 94 |
+
self.logger.info(f'Training took {time.time() - start_time} s')
|
| 95 |
+
self.add_keys(keys=keys, index_is_trained=True)
|
| 96 |
+
# self.keys = None
|
| 97 |
+
if self.gpu_index:
|
| 98 |
+
self.move_to_gpu()
|
| 99 |
+
|
| 100 |
+
def add_keys(self, keys, num_keys_to_add_at_a_time=1000000, index_is_trained=False):
|
| 101 |
+
self.keys = keys
|
| 102 |
+
if not self.use_flat_index and index_is_trained:
|
| 103 |
+
start = 0
|
| 104 |
+
while start < keys.shape[0]:
|
| 105 |
+
end = min(len(keys), start + num_keys_to_add_at_a_time)
|
| 106 |
+
to_add = keys[start:end]
|
| 107 |
+
# if not self.gpu_index:
|
| 108 |
+
# to_add = to_add.cpu()
|
| 109 |
+
# self.index.add_with_ids(to_add, torch.arange(start+self.index_size, end+self.index_size))
|
| 110 |
+
self.index.add(to_add)
|
| 111 |
+
self.index_size += end - start
|
| 112 |
+
start += end
|
| 113 |
+
if (start % 1000000) == 0:
|
| 114 |
+
self.logger.info(f'Added {start} tokens so far')
|
| 115 |
+
# else:
|
| 116 |
+
# self.keys.append(keys)
|
| 117 |
+
|
| 118 |
+
# self.logger.info(f'Adding total {start} keys')
|
| 119 |
+
# self.logger.info(f'Adding took {time.time() - start_time} s')
|
| 120 |
+
|
| 121 |
+
def search_and_reconstruct(self, queries, k):
|
| 122 |
+
if len(queries.shape) == 1: # searching for only 1 vector, add one extra dim
|
| 123 |
+
self.logger.info("Searching for a single vector; unsqueezing")
|
| 124 |
+
queries = queries.unsqueeze(0)
|
| 125 |
+
# self.logger.info("Searching with reconstruct")
|
| 126 |
+
assert queries.shape[-1] == self.dimension # query vectors are same shape as "key" vectors
|
| 127 |
+
scores, values, vectors = self.index.index.search_and_reconstruct(queries.cpu().detach(), k)
|
| 128 |
+
# self.logger.info("Searching done")
|
| 129 |
+
return scores, values, vectors
|
| 130 |
+
|
| 131 |
+
def search(self, queries, k):
|
| 132 |
+
# model_device = queries.device
|
| 133 |
+
# model_dtype = queries.dtype
|
| 134 |
+
if len(queries.shape) == 1: # searching for only 1 vector, add one extra dim
|
| 135 |
+
self.logger.info("Searching for a single vector; unsqueezing")
|
| 136 |
+
queries = queries.unsqueeze(0)
|
| 137 |
+
assert queries.shape[-1] == self.dimension # query vectors are same shape as "key" vectors
|
| 138 |
+
# if not self.gpu_index:
|
| 139 |
+
# queries = queries.cpu()
|
| 140 |
+
# else:
|
| 141 |
+
# queries = queries.to(self.device)
|
| 142 |
+
if self.use_flat_index:
|
| 143 |
+
if self.gpu_index:
|
| 144 |
+
scores, values = faiss.knn_gpu(faiss.StandardGpuResources(), queries, self.keys, k,
|
| 145 |
+
metric=faiss.METRIC_INNER_PRODUCT, device=self.device.index)
|
| 146 |
+
else:
|
| 147 |
+
scores, values = faiss.knn(queries, self.keys, k, metric=faiss.METRIC_INNER_PRODUCT)
|
| 148 |
+
scores = torch.from_numpy(scores).to(queries.dtype)
|
| 149 |
+
values = torch.from_numpy(values) #.to(model_dtype)
|
| 150 |
+
else:
|
| 151 |
+
scores, values = self.index.search(queries.float(), k)
|
| 152 |
+
|
| 153 |
+
# avoid returning -1 as a value
|
| 154 |
+
# TODO: get a handle on the attention mask and mask the values that were -1
|
| 155 |
+
values = torch.where(torch.logical_or(values < 0, values >= self.keys.shape[0]), torch.zeros_like(values), values)
|
| 156 |
+
# self.logger.info("Searching done")
|
| 157 |
+
# return scores.to(model_dtype).to(model_device), values.to(model_device)
|
| 158 |
+
return scores, values
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
|
unlimiformer/metrics/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .metrics import load_metric, download_metric
|
unlimiformer/metrics/metrics.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Dict
|
| 2 |
+
import os
|
| 3 |
+
import importlib
|
| 4 |
+
from abc import ABC, abstractmethod
|
| 5 |
+
import inspect
|
| 6 |
+
import shutil
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
from utils.decoding import decode
|
| 11 |
+
from datasets import load_metric as hf_load_metric
|
| 12 |
+
from huggingface_hub import hf_hub_download
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Metric(ABC):
|
| 16 |
+
def __init__(self, **kwargs) -> None:
|
| 17 |
+
super().__init__()
|
| 18 |
+
self._kwargs = kwargs
|
| 19 |
+
|
| 20 |
+
self.prefix = os.path.splitext(os.path.basename(inspect.getfile(self.__class__)))[0]
|
| 21 |
+
self.requires_decoded = False
|
| 22 |
+
|
| 23 |
+
def __call__(self, id_to_pred, id_to_labels, is_decoded=False):
|
| 24 |
+
if self.requires_decoded and is_decoded is False:
|
| 25 |
+
id_to_pred = self._decode(id_to_pred)
|
| 26 |
+
id_to_labels = self._decode(id_to_labels)
|
| 27 |
+
return self._compute_metrics(id_to_pred, id_to_labels)
|
| 28 |
+
|
| 29 |
+
@abstractmethod
|
| 30 |
+
def _compute_metrics(self, id_to_pred, id_to_labels) -> Dict[str, float]:
|
| 31 |
+
return
|
| 32 |
+
|
| 33 |
+
def _decode(self, id_to_something):
|
| 34 |
+
tokenizer = self._kwargs.get("tokenizer")
|
| 35 |
+
data_args = self._kwargs.get("data_args")
|
| 36 |
+
return decode(id_to_something, tokenizer, data_args)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class MetricCollection(Metric):
|
| 40 |
+
def __init__(self, metrics: List[Metric], **kwargs):
|
| 41 |
+
super().__init__(**kwargs)
|
| 42 |
+
self._metrics = metrics
|
| 43 |
+
|
| 44 |
+
def __call__(self, id_to_pred, id_to_labels):
|
| 45 |
+
return self._compute_metrics(id_to_pred, id_to_labels)
|
| 46 |
+
|
| 47 |
+
def _compute_metrics(self, id_to_pred, id_to_labels):
|
| 48 |
+
results = {}
|
| 49 |
+
|
| 50 |
+
id_to_pred_decoded = None
|
| 51 |
+
id_to_labels_decoded = None
|
| 52 |
+
for metric in self._metrics:
|
| 53 |
+
metric_prefix = f"{metric.prefix}/" if metric.prefix else ""
|
| 54 |
+
if metric.requires_decoded:
|
| 55 |
+
if id_to_pred_decoded is None:
|
| 56 |
+
id_to_pred_decoded = self._decode(id_to_pred)
|
| 57 |
+
if id_to_labels_decoded is None:
|
| 58 |
+
id_to_labels_decoded = self._decode(id_to_labels)
|
| 59 |
+
|
| 60 |
+
result = metric(id_to_pred_decoded, id_to_labels_decoded, is_decoded=True)
|
| 61 |
+
else:
|
| 62 |
+
result = metric(id_to_pred, id_to_labels)
|
| 63 |
+
|
| 64 |
+
results.update({f"{metric_prefix}{k}": np.mean(v) if type(v) is list else v for k, v in result.items() if type(v) is not str})
|
| 65 |
+
|
| 66 |
+
results["num_predicted"] = len(id_to_pred)
|
| 67 |
+
results["mean_prediction_length_characters"] = np.mean([len(pred) for pred in id_to_pred_decoded.values()])
|
| 68 |
+
|
| 69 |
+
elem = next(iter(id_to_pred.values()))
|
| 70 |
+
if not ((isinstance(elem, list) and isinstance(elem[0], str)) or isinstance(elem, str)):
|
| 71 |
+
tokenizer = self._kwargs["tokenizer"]
|
| 72 |
+
results["mean_prediction_length_tokens"] = np.mean(
|
| 73 |
+
[np.count_nonzero(np.array(pred) != tokenizer.pad_token_id) for pred in id_to_pred.values()]
|
| 74 |
+
) # includes BOS/EOS tokens
|
| 75 |
+
|
| 76 |
+
results = {key: round(value, 4) for key, value in results.items()}
|
| 77 |
+
return results
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def load_metric(paths: List[str], **kwargs):
|
| 81 |
+
if paths is None or len(paths) == 0:
|
| 82 |
+
return None
|
| 83 |
+
if isinstance(paths, str):
|
| 84 |
+
paths = [paths]
|
| 85 |
+
else:
|
| 86 |
+
paths = [path for path in paths]
|
| 87 |
+
|
| 88 |
+
metric_cls_list = []
|
| 89 |
+
|
| 90 |
+
scrolls_custom_metrics = []
|
| 91 |
+
to_remove = []
|
| 92 |
+
for i, path in enumerate(paths):
|
| 93 |
+
if not os.path.isfile(path):
|
| 94 |
+
scrolls_custom_metrics.append(path)
|
| 95 |
+
to_remove.append(i)
|
| 96 |
+
for i in sorted(to_remove, reverse=True):
|
| 97 |
+
del paths[i]
|
| 98 |
+
if len(scrolls_custom_metrics) > 0:
|
| 99 |
+
scrolls_custom_metrics.insert(0, "") # In order to have an identifying comma in the beginning
|
| 100 |
+
metric_cls_list.append(ScrollsWrapper(",".join(scrolls_custom_metrics), **kwargs))
|
| 101 |
+
|
| 102 |
+
for path in paths:
|
| 103 |
+
path = path.strip()
|
| 104 |
+
if len(path) == 0:
|
| 105 |
+
continue
|
| 106 |
+
if os.path.isfile(path) is False:
|
| 107 |
+
path = os.path.join("src", "metrics", f"{path}.py")
|
| 108 |
+
|
| 109 |
+
module = path[:-3].replace(os.sep, ".")
|
| 110 |
+
|
| 111 |
+
metric_cls = import_main_class(module)
|
| 112 |
+
metric_cls_list.append(metric_cls(**kwargs))
|
| 113 |
+
|
| 114 |
+
return MetricCollection(metric_cls_list, **kwargs)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# Modified from datasets.load
|
| 118 |
+
def import_main_class(module_path):
|
| 119 |
+
"""Import a module at module_path and return its main class"""
|
| 120 |
+
module = importlib.import_module(module_path)
|
| 121 |
+
|
| 122 |
+
main_cls_type = Metric
|
| 123 |
+
|
| 124 |
+
# Find the main class in our imported module
|
| 125 |
+
module_main_cls = None
|
| 126 |
+
for name, obj in module.__dict__.items():
|
| 127 |
+
if isinstance(obj, type) and issubclass(obj, main_cls_type):
|
| 128 |
+
if inspect.isabstract(obj):
|
| 129 |
+
continue
|
| 130 |
+
module_main_cls = obj
|
| 131 |
+
break
|
| 132 |
+
|
| 133 |
+
return module_main_cls
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class ScrollsWrapper(Metric):
|
| 137 |
+
def __init__(self, comma_separated_metric_names, **kwargs) -> None:
|
| 138 |
+
super().__init__(**kwargs)
|
| 139 |
+
self.prefix = None
|
| 140 |
+
|
| 141 |
+
self._metric = hf_load_metric(download_metric(), comma_separated_metric_names, keep_in_memory=True)
|
| 142 |
+
|
| 143 |
+
self.requires_decoded = True
|
| 144 |
+
|
| 145 |
+
def _compute_metrics(self, id_to_pred, id_to_labels) -> Dict[str, float]:
|
| 146 |
+
return self._metric.compute(**self._metric.convert_from_map_format(id_to_pred, id_to_labels))
|
| 147 |
+
|
| 148 |
+
class HFMetricWrapper(Metric):
|
| 149 |
+
def __init__(self, metric_name, **kwargs) -> None:
|
| 150 |
+
super().__init__(**kwargs)
|
| 151 |
+
self._metric = hf_load_metric(metric_name)
|
| 152 |
+
self.kwargs = HFMetricWrapper.metric_specific_kwargs.get(metric_name, {})
|
| 153 |
+
self.requires_decoded = True
|
| 154 |
+
self.prefix = metric_name
|
| 155 |
+
self.requires_decoded = True
|
| 156 |
+
|
| 157 |
+
def _compute_metrics(self, id_to_pred, id_to_labels) -> Dict[str, float]:
|
| 158 |
+
return self._metric.compute(**self.convert_from_map_format(id_to_pred, id_to_labels), **self.kwargs)
|
| 159 |
+
|
| 160 |
+
def convert_from_map_format(self, id_to_pred, id_to_labels):
|
| 161 |
+
index_to_id = list(id_to_pred.keys())
|
| 162 |
+
predictions = [id_to_pred[id_] for id_ in index_to_id]
|
| 163 |
+
references = [id_to_labels[id_] for id_ in index_to_id]
|
| 164 |
+
return {"predictions": predictions, "references": references}
|
| 165 |
+
|
| 166 |
+
metric_specific_kwargs = {
|
| 167 |
+
'bertscore': {
|
| 168 |
+
# 'model_type': 'microsoft/deberta-large-mnli' or the larger 'microsoft/deberta-xlarge-mnli'
|
| 169 |
+
'model_type': 'facebook/bart-large-mnli', # has context window of 1024,
|
| 170 |
+
'num_layers': 11 # according to: https://docs.google.com/spreadsheets/d/1RKOVpselB98Nnh_EOC4A2BYn8_201tmPODpNWu4w7xI/edit#gid=0
|
| 171 |
+
}
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def download_metric():
|
| 176 |
+
# here we load the custom metrics
|
| 177 |
+
scrolls_metric_path = hf_hub_download(repo_id="tau/scrolls", filename="metrics/scrolls.py", repo_type='dataset')
|
| 178 |
+
updated_scrolls_metric_path = (
|
| 179 |
+
os.path.dirname(scrolls_metric_path) + os.path.basename(scrolls_metric_path).replace(".", "_") + ".py"
|
| 180 |
+
)
|
| 181 |
+
shutil.copy(scrolls_metric_path, updated_scrolls_metric_path)
|
| 182 |
+
return updated_scrolls_metric_path
|
unlimiformer/model.py
ADDED
|
@@ -0,0 +1,1157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from enum import Enum, auto
|
| 6 |
+
from transformers import BartModel, BartForConditionalGeneration, \
|
| 7 |
+
T5Model, T5ForConditionalGeneration, \
|
| 8 |
+
LEDModel, LEDForConditionalGeneration, \
|
| 9 |
+
AutoModelForCausalLM, AutoModelForSeq2SeqLM, \
|
| 10 |
+
MODEL_WITH_LM_HEAD_MAPPING, MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
|
| 11 |
+
|
| 12 |
+
from typing import TypeVar, Generic
|
| 13 |
+
|
| 14 |
+
from .index_building import Datastore, DatastoreBatch
|
| 15 |
+
|
| 16 |
+
logger = logging.getLogger('Unlimiformer')
|
| 17 |
+
logger.setLevel(20)
|
| 18 |
+
|
| 19 |
+
ModelType = TypeVar('ModelType')
|
| 20 |
+
class Unlimiformer(Generic[ModelType]):
|
| 21 |
+
def __init__(self, model: ModelType,
|
| 22 |
+
layer_begin=-1, layer_end=None,
|
| 23 |
+
unlimiformer_head_num=None,
|
| 24 |
+
exclude_attention=False,
|
| 25 |
+
model_encoder_max_len=None,
|
| 26 |
+
chunk_overlap=0,
|
| 27 |
+
verbose=False, save_heatmap=False,
|
| 28 |
+
tokenizer=None, unlimiformer_training=False,
|
| 29 |
+
use_datastore=False,
|
| 30 |
+
flat_index=False,
|
| 31 |
+
test_datastore=False, reconstruct_embeddings=False,
|
| 32 |
+
gpu_datastore=False, gpu_index=False,
|
| 33 |
+
index_devices=(0,), datastore_device=0,
|
| 34 |
+
):
|
| 35 |
+
super().__init__()
|
| 36 |
+
self.model = model
|
| 37 |
+
model.unlimiformer = self
|
| 38 |
+
self.layer_begin = layer_begin
|
| 39 |
+
self.layer_end = layer_end
|
| 40 |
+
self.specific_head = unlimiformer_head_num
|
| 41 |
+
self.exclude_attention = exclude_attention
|
| 42 |
+
self.actual_model_window_size = None
|
| 43 |
+
self.model_encoder_max_len = model_encoder_max_len
|
| 44 |
+
self.chunk_overlap = chunk_overlap
|
| 45 |
+
self.verbose = verbose
|
| 46 |
+
self.save_heatmap = save_heatmap
|
| 47 |
+
self.tokenizer = tokenizer
|
| 48 |
+
self.unlimiformer_training = unlimiformer_training
|
| 49 |
+
|
| 50 |
+
self.use_datastore = use_datastore
|
| 51 |
+
self.flat_index = flat_index
|
| 52 |
+
self.reconstruct_embeddings = reconstruct_embeddings
|
| 53 |
+
self.gpu_datastore = gpu_datastore
|
| 54 |
+
self.gpu_index = gpu_index
|
| 55 |
+
# if torch.cuda.is_available() and gpu_index:
|
| 56 |
+
# self.index_devices = [torch.device(f'cuda:{i}') for i in index_devices]
|
| 57 |
+
# else:
|
| 58 |
+
self.index_devices = [torch.device('cpu')]
|
| 59 |
+
self.datastore_device = torch.device('cpu')
|
| 60 |
+
self.test_datastore = test_datastore # flag for debugging
|
| 61 |
+
|
| 62 |
+
self.device = torch.device('cpu')
|
| 63 |
+
self.activation_capturer = None
|
| 64 |
+
self.is_encoder_decoder = model.config.is_encoder_decoder
|
| 65 |
+
self.hook_handles = []
|
| 66 |
+
self.is_input_encoding_pass = False
|
| 67 |
+
self.is_first_test_decoding_step = False
|
| 68 |
+
self.prev_tokens = None
|
| 69 |
+
self.last_beam_idx = None
|
| 70 |
+
self.heatmap = None
|
| 71 |
+
self.cur_decoder_layer_index = None
|
| 72 |
+
self.datastore = None
|
| 73 |
+
|
| 74 |
+
self.break_into(model)
|
| 75 |
+
|
| 76 |
+
def break_into(self, model):
|
| 77 |
+
self.actual_model_window_size = self.window_size()
|
| 78 |
+
if self.model_encoder_max_len is None:
|
| 79 |
+
self.model_encoder_max_len = self.actual_model_window_size
|
| 80 |
+
self.window_margin = int(self.model_encoder_max_len * self.chunk_overlap / 2)
|
| 81 |
+
self.num_heads = model.config.num_attention_heads
|
| 82 |
+
if self.specific_head is None:
|
| 83 |
+
self.head_nums = Ellipsis # torch.arange(0, self.num_heads, device=self.device)
|
| 84 |
+
else:
|
| 85 |
+
self.head_nums = self.specific_head
|
| 86 |
+
self.hooks_injected = False
|
| 87 |
+
self.training_hooks_injected = False
|
| 88 |
+
self.original_forward_func = model.forward
|
| 89 |
+
|
| 90 |
+
# Activate Unlimiformer when calling model.eval(), deactivate for model.train()
|
| 91 |
+
self.original_model_eval_func = model.eval
|
| 92 |
+
model.eval = self.pre_eval_hook
|
| 93 |
+
self.original_model_train_func = model.train
|
| 94 |
+
model.train = self.pre_train_hook
|
| 95 |
+
|
| 96 |
+
def pre_eval_hook(self):
|
| 97 |
+
self.remove_training_hooks(self.model)
|
| 98 |
+
self.inject_hooks(self.model)
|
| 99 |
+
self.original_model_eval_func()
|
| 100 |
+
|
| 101 |
+
def pre_train_hook(self, mode=True):
|
| 102 |
+
# mode=True means model.train() is called
|
| 103 |
+
# mode=False means model.eval() is called
|
| 104 |
+
torch.cuda.empty_cache()
|
| 105 |
+
if mode is True:
|
| 106 |
+
self.break_out(self.model)
|
| 107 |
+
if self.unlimiformer_training:
|
| 108 |
+
self.inject_training_hooks(self.model)
|
| 109 |
+
self.original_model_train_func(mode)
|
| 110 |
+
|
| 111 |
+
def inject_hooks(self, model):
|
| 112 |
+
if self.hooks_injected:
|
| 113 |
+
return
|
| 114 |
+
# Inject our activation_capturer to capture the activations at every forward pass
|
| 115 |
+
attention_layers_to_capture = self.activation_to_capture(self.layer_begin, self.layer_end)
|
| 116 |
+
self.activation_capturer = []
|
| 117 |
+
for layer in attention_layers_to_capture:
|
| 118 |
+
if type(layer) is list:
|
| 119 |
+
layer_capturers = []
|
| 120 |
+
for k_or_v in layer:
|
| 121 |
+
capturer = ActivationCapturer(k_or_v, capture_input=False)
|
| 122 |
+
layer_capturers.append(capturer)
|
| 123 |
+
self.register_hook(k_or_v, capturer)
|
| 124 |
+
self.activation_capturer.append(layer_capturers)
|
| 125 |
+
else:
|
| 126 |
+
capturer = ActivationCapturer(layer, capture_input=False)
|
| 127 |
+
self.register_hook(layer, capturer)
|
| 128 |
+
self.activation_capturer.append(capturer)
|
| 129 |
+
|
| 130 |
+
# Inject our main function after the main attention function
|
| 131 |
+
attention_layers_to_run = self.attention_op_to_run(self.layer_begin, self.layer_end)
|
| 132 |
+
for layer in attention_layers_to_run:
|
| 133 |
+
self.register_hook(layer, self.attention_forward_hook)
|
| 134 |
+
|
| 135 |
+
decoder_layers_to_run = self.attention_layer_to_run(self.layer_begin, self.layer_end)
|
| 136 |
+
self.original_decoder_layer_cross_attn_forward_funcs = []
|
| 137 |
+
for i, decoder_layer in enumerate(decoder_layers_to_run):
|
| 138 |
+
decoder_layer_cross_attention = self.cross_attention(decoder_layer)
|
| 139 |
+
self.original_decoder_layer_cross_attn_forward_funcs.append(decoder_layer_cross_attention.forward)
|
| 140 |
+
decoder_layer_cross_attention.forward = self.create_cross_attn_pre_forward_hook(decoder_layer_cross_attention.forward, i)
|
| 141 |
+
|
| 142 |
+
# Inject our hook function in the beginning of generation.
|
| 143 |
+
# When the "model.generate()" will be called, it will first call our "reset_generation()" function,
|
| 144 |
+
# and only then call "model.generate()"
|
| 145 |
+
self.original_generate_func = model.generate
|
| 146 |
+
model.generate = self.pre_generate_hook
|
| 147 |
+
|
| 148 |
+
model.forward = self.pre_forward_hook
|
| 149 |
+
|
| 150 |
+
self.original_reorder_cache_func = model._reorder_cache
|
| 151 |
+
model._reorder_cache = self.reorder_cache_hook
|
| 152 |
+
self.hooks_injected = True
|
| 153 |
+
|
| 154 |
+
def inject_training_hooks(self, model):
|
| 155 |
+
if self.training_hooks_injected:
|
| 156 |
+
return
|
| 157 |
+
# self.original_forward_func = model.forward
|
| 158 |
+
model.forward = self.pre_forward_hook
|
| 159 |
+
|
| 160 |
+
decoder_layers_to_run = self.attention_layer_to_run(self.layer_begin, self.layer_end)
|
| 161 |
+
|
| 162 |
+
self.original_decoder_layer_self_attn_forward_funcs = []
|
| 163 |
+
for decoder_layer in decoder_layers_to_run:
|
| 164 |
+
attention = self.self_attention(decoder_layer)
|
| 165 |
+
self.original_decoder_layer_self_attn_forward_funcs.append(attention.forward)
|
| 166 |
+
attention.forward = self.create_self_attn_pre_forward_hook(attention.forward)
|
| 167 |
+
|
| 168 |
+
self.original_decoder_layer_cross_attn_forward_funcs = []
|
| 169 |
+
for i, decoder_layer in enumerate(decoder_layers_to_run):
|
| 170 |
+
decoder_layer_cross_attention = self.cross_attention(decoder_layer)
|
| 171 |
+
self.original_decoder_layer_cross_attn_forward_funcs.append(decoder_layer_cross_attention.forward)
|
| 172 |
+
decoder_layer_cross_attention.forward = self.create_cross_attn_pre_forward_hook(decoder_layer_cross_attention.forward, i)
|
| 173 |
+
|
| 174 |
+
self.original_decoder_layer_forward_funcs = []
|
| 175 |
+
for decoder_layer in decoder_layers_to_run:
|
| 176 |
+
self.original_decoder_layer_forward_funcs.append(decoder_layer.forward)
|
| 177 |
+
decoder_layer.forward = self.create_decoder_layer_func(decoder_layer.forward, decoder_layer)
|
| 178 |
+
|
| 179 |
+
self.inject_hooks_for_unaffected_layers(model, decoder_layers_to_run)
|
| 180 |
+
|
| 181 |
+
attention_layers_to_run = self.attention_op_to_run(self.layer_begin, self.layer_end)
|
| 182 |
+
for layer in attention_layers_to_run:
|
| 183 |
+
self.register_hook(layer, self.train_attention_forward_hook)
|
| 184 |
+
|
| 185 |
+
self.training_hooks_injected = True
|
| 186 |
+
|
| 187 |
+
def inject_hooks_for_unaffected_layers(self, model, decoder_layers_to_run):
|
| 188 |
+
self.original_non_injected_decoder_layer_forward_funcs = []
|
| 189 |
+
non_injected_decoder_layers = [l for l in self.attention_layer_to_run(0, None)
|
| 190 |
+
if l not in decoder_layers_to_run]
|
| 191 |
+
for decoder_layer in non_injected_decoder_layers:
|
| 192 |
+
self.original_non_injected_decoder_layer_forward_funcs.append(decoder_layer.forward)
|
| 193 |
+
decoder_layer.forward = self.create_noninjected_decoder_layer_func(decoder_layer.forward, decoder_layer)
|
| 194 |
+
|
| 195 |
+
def create_self_attn_pre_forward_hook(self, original_self_attn_forward_func):
|
| 196 |
+
def self_attention_pre_forward_hook(*args, **kwargs):
|
| 197 |
+
kwargs['past_key_value'] = None
|
| 198 |
+
return original_self_attn_forward_func(*args, **kwargs)
|
| 199 |
+
|
| 200 |
+
return self_attention_pre_forward_hook
|
| 201 |
+
|
| 202 |
+
def create_decoder_layer_func(self, decoder_layer_original_forward_func, decoder_layer):
|
| 203 |
+
def checkpointed_decoder_layer(
|
| 204 |
+
hidden_states: torch.Tensor,
|
| 205 |
+
attention_mask=None,
|
| 206 |
+
encoder_hidden_states=None,
|
| 207 |
+
encoder_attention_mask=None,
|
| 208 |
+
layer_head_mask=None,
|
| 209 |
+
cross_attn_layer_head_mask=None,
|
| 210 |
+
past_key_value=None,
|
| 211 |
+
output_attentions=False,
|
| 212 |
+
position_bias=None,
|
| 213 |
+
encoder_decoder_position_bias=None,
|
| 214 |
+
use_cache=True):
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
def forward_with_all_keys(hidden_states, attention_mask,
|
| 218 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 219 |
+
cross_attn_layer_head_mask, past_key_value,
|
| 220 |
+
output_attentions, use_cache, long_inputs, long_inputs_mask,
|
| 221 |
+
position_bias, encoder_decoder_position_bias):
|
| 222 |
+
|
| 223 |
+
key, value = self.create_key_value(long_inputs, decoder_layer)
|
| 224 |
+
decoder_layer_args = self.create_decoder_layer_args(
|
| 225 |
+
hidden_states=hidden_states,
|
| 226 |
+
attention_mask=attention_mask,
|
| 227 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 228 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 229 |
+
layer_head_mask=layer_head_mask,
|
| 230 |
+
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
|
| 231 |
+
past_key_value=past_key_value,
|
| 232 |
+
output_attentions=output_attentions,
|
| 233 |
+
position_bias=position_bias,
|
| 234 |
+
encoder_decoder_position_bias=encoder_decoder_position_bias,
|
| 235 |
+
use_cache=use_cache,
|
| 236 |
+
key=key,value=value)
|
| 237 |
+
return decoder_layer_original_forward_func(**decoder_layer_args)
|
| 238 |
+
|
| 239 |
+
return torch.utils.checkpoint.checkpoint(
|
| 240 |
+
forward_with_all_keys, hidden_states, attention_mask,
|
| 241 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 242 |
+
cross_attn_layer_head_mask, None,
|
| 243 |
+
output_attentions, use_cache, self.long_inputs_encoded, self.long_inputs_mask,
|
| 244 |
+
position_bias, encoder_decoder_position_bias)
|
| 245 |
+
|
| 246 |
+
return checkpointed_decoder_layer
|
| 247 |
+
|
| 248 |
+
def create_noninjected_decoder_layer_func(self, decoder_layer_original_forward_func, decoder_layer):
|
| 249 |
+
def checkpointed_decoder_layer(
|
| 250 |
+
hidden_states: torch.Tensor,
|
| 251 |
+
attention_mask=None,
|
| 252 |
+
encoder_hidden_states=None,
|
| 253 |
+
encoder_attention_mask=None,
|
| 254 |
+
layer_head_mask=None,
|
| 255 |
+
cross_attn_layer_head_mask=None,
|
| 256 |
+
past_key_value=None,
|
| 257 |
+
output_attentions=False,
|
| 258 |
+
position_bias=None,
|
| 259 |
+
encoder_decoder_position_bias=None,
|
| 260 |
+
use_cache=True):
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
def forward_with_all_keys(hidden_states, attention_mask,
|
| 264 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 265 |
+
cross_attn_layer_head_mask, past_key_value,
|
| 266 |
+
output_attentions, use_cache, long_inputs, long_inputs_mask,
|
| 267 |
+
position_bias, encoder_decoder_position_bias):
|
| 268 |
+
|
| 269 |
+
decoder_layer_args = self.create_decoder_layer_args(
|
| 270 |
+
hidden_states=hidden_states,
|
| 271 |
+
attention_mask=attention_mask,
|
| 272 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 273 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 274 |
+
layer_head_mask=layer_head_mask,
|
| 275 |
+
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
|
| 276 |
+
past_key_value=past_key_value,
|
| 277 |
+
output_attentions=output_attentions,
|
| 278 |
+
position_bias=position_bias,
|
| 279 |
+
encoder_decoder_position_bias=encoder_decoder_position_bias,
|
| 280 |
+
use_cache=use_cache, key=None, value=None)
|
| 281 |
+
return decoder_layer_original_forward_func(**decoder_layer_args)
|
| 282 |
+
|
| 283 |
+
return torch.utils.checkpoint.checkpoint(
|
| 284 |
+
forward_with_all_keys, hidden_states, attention_mask,
|
| 285 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 286 |
+
cross_attn_layer_head_mask, None,
|
| 287 |
+
output_attentions, use_cache, self.long_inputs_encoded, self.long_inputs_mask,
|
| 288 |
+
position_bias, encoder_decoder_position_bias)
|
| 289 |
+
|
| 290 |
+
return checkpointed_decoder_layer
|
| 291 |
+
|
| 292 |
+
def register_hook(self, layer, func, pre=False):
|
| 293 |
+
handle = layer.register_forward_pre_hook(func) if pre else layer.register_forward_hook(func)
|
| 294 |
+
self.hook_handles.append(handle)
|
| 295 |
+
|
| 296 |
+
def break_out(self, model):
|
| 297 |
+
self.prompt_keys = []
|
| 298 |
+
self.prompt_values = []
|
| 299 |
+
self.prompt_attention_mask = []
|
| 300 |
+
self.generated_input_ids = []
|
| 301 |
+
torch.cuda.empty_cache()
|
| 302 |
+
if not self.hooks_injected:
|
| 303 |
+
return
|
| 304 |
+
|
| 305 |
+
for h in self.hook_handles:
|
| 306 |
+
h.remove()
|
| 307 |
+
model.generate = self.original_generate_func
|
| 308 |
+
model.forward = self.original_forward_func
|
| 309 |
+
model._reorder_cache = self.original_reorder_cache_func
|
| 310 |
+
|
| 311 |
+
decoder_layers_to_run = self.attention_layer_to_run(self.layer_begin, self.layer_end)
|
| 312 |
+
for decoder_layer, original_func in zip(decoder_layers_to_run, self.original_decoder_layer_cross_attn_forward_funcs):
|
| 313 |
+
self.cross_attention(decoder_layer).forward = original_func
|
| 314 |
+
self.hooks_injected = False
|
| 315 |
+
|
| 316 |
+
def remove_training_hooks(self, model):
|
| 317 |
+
self.long_inputs_encoded, self.long_inputs_mask = None, None
|
| 318 |
+
if not self.training_hooks_injected:
|
| 319 |
+
return
|
| 320 |
+
for h in self.hook_handles:
|
| 321 |
+
h.remove()
|
| 322 |
+
model.forward = self.original_forward_func
|
| 323 |
+
|
| 324 |
+
decoder_layers_to_run = self.attention_layer_to_run(self.layer_begin, self.layer_end)
|
| 325 |
+
for decoder_layer, original_func in zip(decoder_layers_to_run, self.original_decoder_layer_self_attn_forward_funcs):
|
| 326 |
+
self.self_attention(decoder_layer).forward = original_func
|
| 327 |
+
for decoder_layer, original_func in zip(decoder_layers_to_run, self.original_decoder_layer_cross_attn_forward_funcs):
|
| 328 |
+
self.cross_attention(decoder_layer).forward = original_func
|
| 329 |
+
for decoder_layer, original_func in zip(decoder_layers_to_run, self.original_decoder_layer_forward_funcs):
|
| 330 |
+
decoder_layer.forward = original_func
|
| 331 |
+
|
| 332 |
+
non_injected_decoder_layers = [l for l in self.attention_layer_to_run(0, None)
|
| 333 |
+
if l not in decoder_layers_to_run]
|
| 334 |
+
for decoder_layer, original_func in zip(non_injected_decoder_layers, self.original_non_injected_decoder_layer_forward_funcs):
|
| 335 |
+
decoder_layer.forward = original_func
|
| 336 |
+
|
| 337 |
+
self.training_hooks_injected = False
|
| 338 |
+
|
| 339 |
+
def reset_memory(self, input_ids, attention_mask):
|
| 340 |
+
if self.use_datastore:
|
| 341 |
+
if self.is_encoder_decoder:
|
| 342 |
+
self.datastore = [DatastoreBatch(dim=self.model.config.hidden_size, batch_size=input_ids.shape[0], flat_index=self.flat_index,
|
| 343 |
+
gpu_index=self.gpu_index, index_device=self.index_devices[0])]
|
| 344 |
+
self.hidden_states = [[]]
|
| 345 |
+
else:
|
| 346 |
+
self.datastore = [DatastoreBatch(dim=self.model.config.hidden_size, batch_size=input_ids.shape[0], flat_index=self.flat_index,
|
| 347 |
+
gpu_index=self.gpu_index, index_device=self.index_devices[i % len(self.index_devices)])
|
| 348 |
+
for i in range(self.model.config.num_hidden_layers)[self.layer_begin:self.layer_end]]
|
| 349 |
+
self.hidden_states = [[] for _ in range(self.model.config.num_hidden_layers)[self.layer_begin:self.layer_end]]
|
| 350 |
+
torch.cuda.empty_cache()
|
| 351 |
+
self.prompt_input_ids = input_ids
|
| 352 |
+
self.input_ids_size = input_ids.shape[-1]
|
| 353 |
+
self.prompt_keys, self.prompt_values = None, None
|
| 354 |
+
self.prev_tokens = [None for _ in range(len(self.original_decoder_layer_cross_attn_forward_funcs))]
|
| 355 |
+
self.last_beam_idx = None
|
| 356 |
+
self.cur_layer_key_value_placeholder = None
|
| 357 |
+
self.is_input_encoding_pass = True
|
| 358 |
+
if self.is_encoder_decoder:
|
| 359 |
+
dummy_labels = torch.zeros((input_ids.shape[0], 1), dtype=torch.long, device=input_ids.device)
|
| 360 |
+
else:
|
| 361 |
+
dummy_labels = None
|
| 362 |
+
if self.save_heatmap:
|
| 363 |
+
if self.heatmap is not None:
|
| 364 |
+
print(f'Generated: {self.tokenizer.decode(self.generated_input_ids[0])}')
|
| 365 |
+
self.plot_heatmap(self.heatmap[0].detach().cpu().numpy())
|
| 366 |
+
self.heatmap = torch.tensor([], dtype=torch.float, device=input_ids.device)
|
| 367 |
+
self.generated_input_ids = torch.tensor([], dtype=torch.long, device=input_ids.device)
|
| 368 |
+
|
| 369 |
+
self.prompt_keys = [[] for _ in range(self.model.config.num_hidden_layers)[self.layer_begin:self.layer_end]]
|
| 370 |
+
self.prompt_values = [[] for _ in range(self.model.config.num_hidden_layers)[self.layer_begin:self.layer_end]]
|
| 371 |
+
self.prompt_attention_mask = []
|
| 372 |
+
window_indices = self.window_indices(input_ids.shape[-1])
|
| 373 |
+
|
| 374 |
+
for context_start_ind, context_end_ind, update_start_ind, update_end_ind in window_indices:
|
| 375 |
+
logger.info(f'Encoding {context_start_ind} to {context_end_ind} out of {input_ids.shape[-1]}')
|
| 376 |
+
chunk = input_ids[:, context_start_ind:context_end_ind].to(self.device)
|
| 377 |
+
chunk_attention_mask = attention_mask[:, context_start_ind:context_end_ind].to(self.device)
|
| 378 |
+
with torch.inference_mode():
|
| 379 |
+
_ = self.model(chunk, attention_mask=chunk_attention_mask, labels=dummy_labels) # , return_dict=True, output_hidden_states=True)
|
| 380 |
+
if self.use_datastore:
|
| 381 |
+
# TODO: verify with BART as well
|
| 382 |
+
# hidden_states_to_index = [hidden_states.encoder_last_hidden_state] # list of length 1 of (batch, chunked_source_len, dim)
|
| 383 |
+
hidden_states_to_index = [
|
| 384 |
+
layer_capturer.captured for layer_capturer in self.activation_capturer
|
| 385 |
+
]
|
| 386 |
+
# hidden_states_to_index = list(hidden_states.hidden_states)[:-1][self.layer_begin:self.layer_end]
|
| 387 |
+
to_add = [state[:, update_start_ind:update_end_ind].detach() for state in hidden_states_to_index]
|
| 388 |
+
to_apply_mask = chunk_attention_mask[:, update_start_ind:update_end_ind]
|
| 389 |
+
# to_apply_mask = to_apply_mask.log().to(to_add[0].dtype)
|
| 390 |
+
to_apply_mask = to_apply_mask.to(to_add[0].dtype)
|
| 391 |
+
if not self.reconstruct_embeddings:
|
| 392 |
+
to_add_embeddings = to_add
|
| 393 |
+
if not self.gpu_datastore:
|
| 394 |
+
to_add_embeddings = [states.cpu() for states in to_add_embeddings]
|
| 395 |
+
to_apply_mask = to_apply_mask.cpu()
|
| 396 |
+
for i, layer_states in enumerate(to_add_embeddings):
|
| 397 |
+
layer_states = layer_states * to_apply_mask.unsqueeze(-1)
|
| 398 |
+
self.hidden_states[i].append(layer_states.to(self.datastore_device))
|
| 399 |
+
# list of len layers, inside it there is a list of len batch, each item is (masked_time, dim)
|
| 400 |
+
# for i, to_add_layer in enumerate(to_add):
|
| 401 |
+
# keys = [key[mask.bool()] for key, mask in zip(to_add_layer, to_apply_mask)]
|
| 402 |
+
# self.datastore[i].add_keys(keys)
|
| 403 |
+
if (not self.use_datastore) or self.test_datastore:
|
| 404 |
+
layers_kv = [
|
| 405 |
+
self.process_key_value(layer_capturer) # (batch, head, time, dim)
|
| 406 |
+
for layer_capturer in self.activation_capturer
|
| 407 |
+
] # list of pairs of (batch, head, time, dim)
|
| 408 |
+
|
| 409 |
+
# list of (batch, head, chunked_time, dim)
|
| 410 |
+
key = [layer[0][:, :, update_start_ind:update_end_ind] for layer in layers_kv]
|
| 411 |
+
value = [layer[1][:, :, update_start_ind:update_end_ind] for layer in layers_kv]
|
| 412 |
+
chunk_attention_mask = chunk_attention_mask[:, update_start_ind:update_end_ind] # (batch, chunked_time)
|
| 413 |
+
|
| 414 |
+
# key = torch.stack(key, dim=0) # (num_layers, batch, head, time, dim)
|
| 415 |
+
# value = torch.stack(value, dim=0) # (num_layers, batch, head, time, dim)
|
| 416 |
+
|
| 417 |
+
for i, (layer_key, layer_value) in enumerate(zip(key, value)):
|
| 418 |
+
self.prompt_keys[i].append(layer_key) # (num_layers, batch, head, chunked_source_len, dim)
|
| 419 |
+
self.prompt_values[i].append(layer_value) # (num_layers, batch, head, chunked_source_len, dim)
|
| 420 |
+
self.prompt_attention_mask.append(chunk_attention_mask) # (batch, chunked_source_len)
|
| 421 |
+
|
| 422 |
+
if self.use_datastore:
|
| 423 |
+
# keys are all in datastore already!
|
| 424 |
+
if not self.reconstruct_embeddings:
|
| 425 |
+
# self.hidden_states = [torch.cat(layer_hidden_states, axis=1) for layer_hidden_states in self.hidden_states]
|
| 426 |
+
concat_hidden_states = []
|
| 427 |
+
for i in range(len(self.hidden_states)):
|
| 428 |
+
concat_hidden_states.append(torch.cat(self.hidden_states[i], axis=1))
|
| 429 |
+
self.hidden_states[i] = None
|
| 430 |
+
self.hidden_states = concat_hidden_states
|
| 431 |
+
for datastore, layer_hidden_states in zip(self.datastore, self.hidden_states):
|
| 432 |
+
datastore.train_index(layer_hidden_states)
|
| 433 |
+
if (not self.use_datastore) or self.test_datastore:
|
| 434 |
+
for i, (layer_keys, layer_values) in enumerate(zip(self.prompt_keys, self.prompt_values)):
|
| 435 |
+
self.prompt_keys[i] = torch.cat(layer_keys, dim=-2)
|
| 436 |
+
self.prompt_values[i] = torch.cat(layer_values, dim=-2)
|
| 437 |
+
# self.prompt_keys = torch.cat(self.prompt_keys, dim=-2) # (num_layers, batch, head, source_len, dim)
|
| 438 |
+
# self.prompt_values = torch.cat(self.prompt_values, dim=-2) # (num_layers, batch, head, source_len, dim)
|
| 439 |
+
self.prompt_attention_mask = torch.cat(self.prompt_attention_mask, dim=-1) # (batch, source_len)
|
| 440 |
+
|
| 441 |
+
self.is_input_encoding_pass = False
|
| 442 |
+
if self.verbose:
|
| 443 |
+
print(f'Input: '
|
| 444 |
+
f'{self.tokenizer.decode(input_ids[0][:self.actual_model_window_size], skip_special_tokens=True)} ||| '
|
| 445 |
+
f'{self.tokenizer.decode(input_ids[0][self.actual_model_window_size:], skip_special_tokens=True)}')
|
| 446 |
+
print()
|
| 447 |
+
|
| 448 |
+
def chunked_encode_input(self, input_ids, attention_mask):
|
| 449 |
+
long_inputs_encoded = []
|
| 450 |
+
long_inputs_mask = []
|
| 451 |
+
window_indices = self.window_indices(input_ids.shape[-1])
|
| 452 |
+
|
| 453 |
+
self.is_input_encoding_pass = True
|
| 454 |
+
for context_start_ind, context_end_ind, update_start_ind, update_end_ind in window_indices:
|
| 455 |
+
chunk = input_ids[:, context_start_ind:context_end_ind]
|
| 456 |
+
chunk_attention_mask = attention_mask[:, context_start_ind:context_end_ind]
|
| 457 |
+
output = self.model.base_model.encoder(chunk, attention_mask=chunk_attention_mask, return_dict=True, output_hidden_states=True)
|
| 458 |
+
encoder_last_hidden_state = output.last_hidden_state # (batch, time, dim)
|
| 459 |
+
|
| 460 |
+
# list of (batch, head, chunked_time, dim)
|
| 461 |
+
encoder_last_hidden_state = encoder_last_hidden_state[:, update_start_ind:update_end_ind] # (batch, chunked_time, dim)
|
| 462 |
+
chunk_attention_mask = chunk_attention_mask[:, update_start_ind:update_end_ind] # (batch, chunked_time)
|
| 463 |
+
|
| 464 |
+
long_inputs_encoded.append(encoder_last_hidden_state) # (batch, chunked_source_len, dim)
|
| 465 |
+
long_inputs_mask.append(chunk_attention_mask) # (batch, chunked_source_len)
|
| 466 |
+
|
| 467 |
+
long_inputs_encoded = torch.cat(long_inputs_encoded, dim=1) # (batch, source_len, dim)
|
| 468 |
+
long_inputs_mask = torch.cat(long_inputs_mask, dim=1) # (batch, source_len)
|
| 469 |
+
|
| 470 |
+
self.is_input_encoding_pass = False
|
| 471 |
+
if self.verbose:
|
| 472 |
+
print(f'Input: '
|
| 473 |
+
f'{self.tokenizer.decode(input_ids[0][:self.actual_model_window_size], skip_special_tokens=True)} ||| '
|
| 474 |
+
f'{self.tokenizer.decode(input_ids[0][self.actual_model_window_size:], skip_special_tokens=True)}')
|
| 475 |
+
print()
|
| 476 |
+
return long_inputs_encoded, long_inputs_mask
|
| 477 |
+
|
| 478 |
+
def window_indices(self, total_seq_len):
|
| 479 |
+
# Copied from SLED (Ivgy et al., 2022)
|
| 480 |
+
# https://github.com/Mivg/SLED/blob/main/sled/modeling_sled.py#L467
|
| 481 |
+
if total_seq_len <= self.model_encoder_max_len:
|
| 482 |
+
return [(0, total_seq_len, 0, total_seq_len)]
|
| 483 |
+
else:
|
| 484 |
+
results = []
|
| 485 |
+
# if self.chunk_overlap == 0:
|
| 486 |
+
# stride = self.model_encoder_max_len
|
| 487 |
+
stride = self.model_encoder_max_len - 2 * self.window_margin
|
| 488 |
+
context_start = update_start_ind = 0
|
| 489 |
+
context_end = self.model_encoder_max_len
|
| 490 |
+
if self.is_encoder_decoder:
|
| 491 |
+
update_end_ind = context_end - self.window_margin
|
| 492 |
+
else:
|
| 493 |
+
update_end_ind = context_end
|
| 494 |
+
# first window always should update from the beginning
|
| 495 |
+
results.append((context_start, context_end, update_start_ind, update_end_ind))
|
| 496 |
+
|
| 497 |
+
while context_end < total_seq_len:
|
| 498 |
+
context_end = min(total_seq_len, context_end + stride)
|
| 499 |
+
context_start = (
|
| 500 |
+
context_start + stride if context_end < total_seq_len else total_seq_len - self.model_encoder_max_len
|
| 501 |
+
)
|
| 502 |
+
update_start_ind = max(update_start_ind + stride, update_end_ind)
|
| 503 |
+
# last window always should update until the end
|
| 504 |
+
update_end_ind = (
|
| 505 |
+
min(total_seq_len, update_end_ind + stride) if context_end < total_seq_len else total_seq_len
|
| 506 |
+
)
|
| 507 |
+
|
| 508 |
+
cs, ce, us, ue = context_start, context_end, update_start_ind - context_start, \
|
| 509 |
+
update_end_ind - context_start
|
| 510 |
+
|
| 511 |
+
results.append((cs, ce, us, ue))
|
| 512 |
+
return results
|
| 513 |
+
|
| 514 |
+
def pre_generate_hook(self, input_ids, **kwargs):
|
| 515 |
+
if 'attention_mask' not in kwargs:
|
| 516 |
+
kwargs['attention_mask'] = torch.ones_like(input_ids)
|
| 517 |
+
self.reset_memory(input_ids, kwargs['attention_mask'])
|
| 518 |
+
new_kwargs = kwargs
|
| 519 |
+
if 'attention_mask' in kwargs:
|
| 520 |
+
new_kwargs = {k: v for k, v in kwargs.items() if k != 'attention_mask'}
|
| 521 |
+
new_kwargs['attention_mask'] = kwargs['attention_mask'][:, :self.actual_model_window_size].to(self.device)
|
| 522 |
+
new_kwargs['use_cache'] = True
|
| 523 |
+
if self.is_encoder_decoder:
|
| 524 |
+
input_ids_prefix = input_ids[:, :self.actual_model_window_size]
|
| 525 |
+
else:
|
| 526 |
+
input_ids_prefix = input_ids[:, -self.actual_model_window_size:]
|
| 527 |
+
input_ids_prefix = input_ids_prefix.to(self.device)
|
| 528 |
+
return self.original_generate_func(input_ids_prefix, **new_kwargs)
|
| 529 |
+
|
| 530 |
+
def pre_forward_hook(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
|
| 531 |
+
self.set_gradient_checkpointing(False)
|
| 532 |
+
if not self.is_input_encoding_pass:
|
| 533 |
+
if self.model.training:
|
| 534 |
+
# self.reset_memory(input_ids, attention_mask)
|
| 535 |
+
self.long_inputs_encoded, self.long_inputs_mask = self.chunked_encode_input(input_ids=input_ids, attention_mask=attention_mask)
|
| 536 |
+
input_ids = input_ids[:, :self.actual_model_window_size]
|
| 537 |
+
attention_mask = attention_mask[:, :self.actual_model_window_size] if attention_mask is not None else None
|
| 538 |
+
# input_ids = input_ids[:, :self.model_encoder_max_len]
|
| 539 |
+
# labels = labels[:, :self.model_encoder_max_len] if labels is not None else None
|
| 540 |
+
else:
|
| 541 |
+
if kwargs.get('past_key_values') is None:
|
| 542 |
+
self.is_first_test_decoding_step = True
|
| 543 |
+
|
| 544 |
+
if input_ids is not None:
|
| 545 |
+
# self.input_ids_size += input_ids.shape[-1]
|
| 546 |
+
self.input_ids_size += 1
|
| 547 |
+
if kwargs.get('decoder_input_ids') is not None:
|
| 548 |
+
self.generated_input_ids = torch.cat([self.generated_input_ids, kwargs['decoder_input_ids']], axis=-1)
|
| 549 |
+
|
| 550 |
+
result = self.original_forward_func(input_ids=input_ids, labels=labels, attention_mask=attention_mask, **kwargs)
|
| 551 |
+
self.is_first_test_decoding_step = False
|
| 552 |
+
return result
|
| 553 |
+
|
| 554 |
+
def create_cross_attn_pre_forward_hook(self, original_cross_attn_forward_func, cur_layer_num):
|
| 555 |
+
def attention_pre_forward_hook(hidden_states, attention_mask=None, *args, **kwargs):
|
| 556 |
+
self.cur_decoder_layer_index = cur_layer_num
|
| 557 |
+
if kwargs.get('past_key_value') is not None:
|
| 558 |
+
# it's a tuple, and we convert it to a list to be able to perform assignment
|
| 559 |
+
# and modify its items from our attention_forward_hook
|
| 560 |
+
self.cur_layer_key_value_placeholder = \
|
| 561 |
+
kwargs['past_key_value'] = list(kwargs['past_key_value']) # (batch, head, time, attn_dim)
|
| 562 |
+
|
| 563 |
+
batch_size, tgt_len, dim = hidden_states.shape
|
| 564 |
+
if self.model.training:
|
| 565 |
+
# from: (batch, tgt_len, dim) to: (batch * tgt_len, 1, dim)
|
| 566 |
+
hidden_states = hidden_states.reshape(-1, 1, hidden_states.shape[-1])
|
| 567 |
+
# from: (batch, 1, tgt_len, dim) to: (batch * tgt_len, 1, 1, dim)
|
| 568 |
+
attention_mask = attention_mask.reshape(-1, 1, 1, attention_mask.shape[-1])
|
| 569 |
+
|
| 570 |
+
attn_output, attn_weights_reshaped, past_key_value = original_cross_attn_forward_func(hidden_states=hidden_states, attention_mask=attention_mask, *args, **kwargs)
|
| 571 |
+
attn_output = attn_output.reshape(batch_size, tgt_len, dim)
|
| 572 |
+
result = (attn_output, attn_weights_reshaped, past_key_value)
|
| 573 |
+
else:
|
| 574 |
+
result = original_cross_attn_forward_func(hidden_states=hidden_states, attention_mask=attention_mask, *args, **kwargs)
|
| 575 |
+
# Uri: this part adds the generated tokens to the prompt.
|
| 576 |
+
# However it was commented out because currently we always keep the generated tokens in the attention window
|
| 577 |
+
# if not self.is_encoder_decoder and not self.is_input_encoding_pass and \
|
| 578 |
+
# past_key_value[0].shape[2] > self.prompt_keys[self.cur_decoder_layer_index].shape[2]:
|
| 579 |
+
# self.prompt_keys[self.cur_decoder_layer_index] = torch.cat([self.prompt_keys[self.cur_decoder_layer_index], past_key_value[0][:,:,-1:]], dim=-2)
|
| 580 |
+
# self.prompt_values[self.cur_decoder_layer_index] = torch.cat([self.prompt_values[self.cur_decoder_layer_index], past_key_value[1][:,:,-1:]], dim=-2)
|
| 581 |
+
# if self.cur_decoder_layer_index == self.model.config.num_hidden_layers - 1:
|
| 582 |
+
# self.prompt_attention_mask = torch.cat([
|
| 583 |
+
# self.prompt_attention_mask,
|
| 584 |
+
# torch.ones([self.prompt_attention_mask.shape[0], 1], dtype=self.prompt_attention_mask.dtype).to(self.device)], dim=-1)
|
| 585 |
+
|
| 586 |
+
return result
|
| 587 |
+
return attention_pre_forward_hook
|
| 588 |
+
|
| 589 |
+
|
| 590 |
+
def attention_forward_hook(self, module, input, output):
|
| 591 |
+
# output: (batch, time, 3 * heads * attention_dim)
|
| 592 |
+
if self.is_input_encoding_pass or self.is_first_test_decoding_step:
|
| 593 |
+
return
|
| 594 |
+
with torch.no_grad():
|
| 595 |
+
prompt_size = self.prompt_input_ids.shape[1]
|
| 596 |
+
generated_size = self.input_ids_size - prompt_size
|
| 597 |
+
window_size = self.cur_layer_key_value_placeholder[0].shape[-2]
|
| 598 |
+
# topk = min(self.actual_model_window_size, attn_weights.shape[-1])
|
| 599 |
+
topk = min(prompt_size, window_size)
|
| 600 |
+
if not self.is_encoder_decoder:
|
| 601 |
+
topk = min(topk, window_size - generated_size + 1)
|
| 602 |
+
if self.gpu_index:
|
| 603 |
+
topk = min(topk, 2048)
|
| 604 |
+
|
| 605 |
+
query = self.process_query(output)[:,-1] # (batch * beam, head, dim)
|
| 606 |
+
query = query[:, self.head_nums] # (batch * beam, head, dim)
|
| 607 |
+
|
| 608 |
+
if self.use_datastore:
|
| 609 |
+
# query: (batch, beam, head, dim)
|
| 610 |
+
# need to multiply by key vector
|
| 611 |
+
# query.view(query.shape[0], query.shape[1] * query.shape[2])
|
| 612 |
+
# k_proj in attention?
|
| 613 |
+
datastore_index = 0 if self.is_encoder_decoder else self.cur_decoder_layer_index
|
| 614 |
+
attention_layer_list = self.get_kv_projections(self.layer_begin, self.layer_end)
|
| 615 |
+
k_proj_layer = [layers[0] for layers in attention_layer_list][self.cur_decoder_layer_index]
|
| 616 |
+
v_proj_layer = [layers[1] for layers in attention_layer_list][self.cur_decoder_layer_index]
|
| 617 |
+
|
| 618 |
+
# modify query by k_projs
|
| 619 |
+
k_proj = k_proj_layer.weight
|
| 620 |
+
datastore_query = self.preprocess_query(query, k_proj) # (batch * beam, num_heads, embed_dim)
|
| 621 |
+
batch_size = self.datastore[datastore_index].batch_size
|
| 622 |
+
datastore_query = datastore_query.view((batch_size, -1, datastore_query.shape[2])) # (batch, beam * num_heads, embed_dim)
|
| 623 |
+
# then search
|
| 624 |
+
if self.reconstruct_embeddings:
|
| 625 |
+
# embeddings: (batch, beam * head, actual_model_window_size, dim)
|
| 626 |
+
_, top_search_key_indices, embeddings = self.datastore[datastore_index].search_and_reconstruct(datastore_query, k=topk)
|
| 627 |
+
else:
|
| 628 |
+
_, top_search_key_indices = self.datastore[datastore_index].search(datastore_query, k=topk)
|
| 629 |
+
# self.embeddings: (batch, src_len, dim)
|
| 630 |
+
# indices: (batch, beam * head, actual_model_window_size)
|
| 631 |
+
# embeddings: (batch, beam * head, actual_model_window_size, dim)
|
| 632 |
+
embeddings = torch.take_along_dim(input=self.hidden_states[datastore_index].unsqueeze(1),
|
| 633 |
+
indices=top_search_key_indices.unsqueeze(-1).to(self.hidden_states[datastore_index].device), dim=-2)
|
| 634 |
+
embeddings = embeddings.to(self.device)
|
| 635 |
+
# (batch, beam, head, actual_model_window_size)
|
| 636 |
+
# top_search_key_scores = top_search_key_scores.reshape(batch_size, -1, *top_search_key_scores.shape[1:])
|
| 637 |
+
top_search_key_indices = top_search_key_indices.reshape(batch_size, -1, *top_search_key_indices.shape[1:])
|
| 638 |
+
# embeddings: (batch, beam, head, actual_model_window_size, dim)
|
| 639 |
+
embeddings = embeddings.reshape(batch_size, -1, self.num_heads, *embeddings.shape[2:])
|
| 640 |
+
|
| 641 |
+
# raw_values are actually token indices; need to look them up
|
| 642 |
+
if (not self.use_datastore) or self.test_datastore:
|
| 643 |
+
this_layer_prompt_keys = self.prompt_keys[self.cur_decoder_layer_index]
|
| 644 |
+
this_layer_prompt_values = self.prompt_values[self.cur_decoder_layer_index]
|
| 645 |
+
# query: (batch * beam, head, dim)
|
| 646 |
+
batch_size = self.prompt_input_ids.shape[0]
|
| 647 |
+
beam_size = query.shape[0] // batch_size
|
| 648 |
+
# query: (batch, beam, head, dim)
|
| 649 |
+
query = query.reshape(batch_size, beam_size, *query.shape[1:])
|
| 650 |
+
# this_layer_prompt_keys: (batch, head, source_len, dim)
|
| 651 |
+
# this_layer_prompt_keys.unsqueeze(1): (batch, 1, head, source_len, dim)
|
| 652 |
+
# query.unsqueeze(-1): (batch, beam, head, dim, 1)
|
| 653 |
+
# attn_weights: (batch, beam, head, source_len)
|
| 654 |
+
attn_weights = torch.matmul(this_layer_prompt_keys.unsqueeze(1)[:, :, self.head_nums], query.unsqueeze(-1)).squeeze(-1)
|
| 655 |
+
# attn_weights = torch.matmul(query.unsqueeze(-2), this_layer_prompt_keys.unsqueeze(1)[:, :, self.head_nums]).squeeze(-2)
|
| 656 |
+
prompt_attention_mask_to_add = (1 - self.prompt_attention_mask) * -1e9 # (batch, source_len)
|
| 657 |
+
prompt_attention_mask_to_add = prompt_attention_mask_to_add.unsqueeze(1).unsqueeze(1)
|
| 658 |
+
attn_weights += prompt_attention_mask_to_add # (batch, beam, head, source_len)
|
| 659 |
+
if self.exclude_attention and attn_weights.shape[-1] > self.actual_model_window_size:
|
| 660 |
+
attn_weights[..., :self.actual_model_window_size] -= 1e9
|
| 661 |
+
|
| 662 |
+
# target_keys, target_values, topk = self.get_target_slices(output)
|
| 663 |
+
top_key_scores, top_key_indices = torch.topk(attn_weights, k=topk, dim=-1, sorted=True) # (batch, beam, head, trunc_source)
|
| 664 |
+
if self.save_heatmap:
|
| 665 |
+
# heatrow: (beam, heads, source_len)
|
| 666 |
+
heatrow = torch.zeros([top_key_indices.shape[1], top_key_indices.shape[2], this_layer_prompt_keys.shape[-2]], dtype=torch.float)
|
| 667 |
+
heatrow = heatrow.scatter(index=top_key_indices[0], src=torch.ones_like(top_key_scores[0]), dim=-1)
|
| 668 |
+
# heatrow = torch.nn.functional.softmax(heatrow, dim=-1)
|
| 669 |
+
# self.heatmap: (beam, heads, targets, source_len)
|
| 670 |
+
self.heatmap = torch.cat([self.heatmap, heatrow.unsqueeze(-2)], axis=-2)
|
| 671 |
+
|
| 672 |
+
if self.test_datastore:
|
| 673 |
+
assert top_key_indices.shape == top_search_key_indices.shape
|
| 674 |
+
assert torch.mean((top_key_indices == top_search_key_indices).float()) > 0.99
|
| 675 |
+
|
| 676 |
+
if self.verbose:
|
| 677 |
+
if self.is_encoder_decoder:
|
| 678 |
+
for i, beam in enumerate(self.generated_input_ids):
|
| 679 |
+
print(f'({i}) Generated: {self.tokenizer.decode(beam)}')
|
| 680 |
+
# else:
|
| 681 |
+
# print(f'Generated: {self.tokenizer.decode(self.input_ids)}')
|
| 682 |
+
print()
|
| 683 |
+
|
| 684 |
+
if self.use_datastore:
|
| 685 |
+
# k_proj_layer.weight, v_proj_layer.weight: (embed_dim, embed_dim)
|
| 686 |
+
# embeddings: (batch, beam, head, encoder_len, embed_dim)
|
| 687 |
+
retrieved_keys, retrieved_values = self.post_process_retrieved(embeddings, k_proj_layer, v_proj_layer, top_search_key_indices)
|
| 688 |
+
else:
|
| 689 |
+
# this_layer_prompt_keys: (batch, head, source_len, dim)
|
| 690 |
+
# top_key_indices: (batch, beam, head, trunc_source)
|
| 691 |
+
retrieved_keys = torch.take_along_dim(this_layer_prompt_keys.unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 692 |
+
dim=-2) # (batch, head, trunc_source, attn_dim)
|
| 693 |
+
retrieved_values = torch.take_along_dim(this_layer_prompt_values.unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 694 |
+
dim=-2) # (batch, head, trunc_source, attn_dim)
|
| 695 |
+
|
| 696 |
+
if self.test_datastore:
|
| 697 |
+
correct_keys = torch.take_along_dim(this_layer_prompt_keys.unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 698 |
+
dim=-2) # (batch, head, trunc_source, attn_dim)
|
| 699 |
+
correct_values = torch.take_along_dim(this_layer_prompt_values.unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 700 |
+
dim=-2) # (batch, head, trunc_source, attn_dim)
|
| 701 |
+
assert correct_keys.shape == retrieved_keys.shape
|
| 702 |
+
assert correct_values.shape == retrieved_values.shape
|
| 703 |
+
assert torch.mean(torch.isclose(correct_keys, retrieved_keys, rtol=1e-3, atol=1e-3).float()) > 0.99
|
| 704 |
+
assert torch.mean(torch.isclose(correct_values, retrieved_values, rtol=1e-3, atol=1e-3).float()) > 0.99
|
| 705 |
+
|
| 706 |
+
# retrieved_keys, retrieved_values: (batch * beam, head, encoder_len, attn_dim)
|
| 707 |
+
retrieved_keys = retrieved_keys.flatten(0, 1)[:,:,:topk]
|
| 708 |
+
retrieved_values = retrieved_values.flatten(0, 1)[:,:,:topk]
|
| 709 |
+
self.cur_layer_key_value_placeholder[0] = torch.cat([retrieved_keys, self.cur_layer_key_value_placeholder[0][:,:,topk:]], dim=-2)
|
| 710 |
+
self.cur_layer_key_value_placeholder[1] = torch.cat([retrieved_values, self.cur_layer_key_value_placeholder[1][:,:,topk:]], dim=-2)
|
| 711 |
+
return
|
| 712 |
+
|
| 713 |
+
def train_attention_forward_hook(self, module, input, output):
|
| 714 |
+
# output: (batch, time, 3 * heads * attention_dim)
|
| 715 |
+
if self.is_input_encoding_pass or self.is_first_test_decoding_step:
|
| 716 |
+
return
|
| 717 |
+
this_layer_prompt_keys = self.cur_layer_key_value_placeholder[0]
|
| 718 |
+
this_layer_prompt_values = self.cur_layer_key_value_placeholder[1]
|
| 719 |
+
with torch.no_grad():
|
| 720 |
+
query = self.process_query(output) # (batch * beam, tgt_len, head, dim)
|
| 721 |
+
# query = query[:, :, self.head_nums] # (batch * beam, head, dim)
|
| 722 |
+
|
| 723 |
+
# query: (batch * beam, tgt_len, head, dim)
|
| 724 |
+
batch_size = this_layer_prompt_keys.shape[0]
|
| 725 |
+
tgt_len = query.shape[0] // batch_size
|
| 726 |
+
# query: (batch, tgt, head, dim)
|
| 727 |
+
query = query.reshape(batch_size, tgt_len, *query.shape[2:])
|
| 728 |
+
# this_layer_prompt_keys: (batch, head, source_len, dim)
|
| 729 |
+
# this_layer_prompt_keys.unsqueeze(1): (batch, 1, head, source_len, dim)
|
| 730 |
+
# attn_weights: (batch, tgt_len, head, 1, source_len)
|
| 731 |
+
# attn_weights = torch.matmul(query.unsqueeze(-2), this_layer_prompt_keys.unsqueeze(1).permute(0,1,2,4,3))
|
| 732 |
+
attn_weights = torch.matmul(this_layer_prompt_keys.unsqueeze(1), query.unsqueeze(-1)) \
|
| 733 |
+
.reshape(batch_size, tgt_len, query.shape[-2], 1, this_layer_prompt_keys.shape[-2])
|
| 734 |
+
# attn_weights = torch.matmul(query.unsqueeze(-2), this_layer_prompt_keys.unsqueeze(1)[:, :, self.head_nums]).squeeze(-2)
|
| 735 |
+
prompt_attention_mask_to_add = (1 - self.long_inputs_mask) * -1e9 # (batch, source_len)
|
| 736 |
+
prompt_attention_mask_to_add = prompt_attention_mask_to_add.unsqueeze(1).unsqueeze(1).unsqueeze(1)
|
| 737 |
+
attn_weights += prompt_attention_mask_to_add # (batch, beam, head, source_len)
|
| 738 |
+
|
| 739 |
+
# target_keys, target_values, topk = self.get_target_slices(output)
|
| 740 |
+
topk = min(self.actual_model_window_size, attn_weights.shape[-1])
|
| 741 |
+
top_key_scores, top_key_indices = torch.topk(attn_weights, k=min(topk, attn_weights.shape[-1]), dim=-1, sorted=True) # (batch, beam, head, tgt, trunc_source)
|
| 742 |
+
|
| 743 |
+
|
| 744 |
+
# this_layer_prompt_keys: (batch, head, source_len, dim)
|
| 745 |
+
# top_key_indices: (batch, tgt_len, head, 1, trunc_source)
|
| 746 |
+
new_keys = torch.take_along_dim(this_layer_prompt_keys.unsqueeze(2).unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 747 |
+
dim=-2) # (batch, tgt_len, head, 1, trunc_source, attn_dim)
|
| 748 |
+
new_values = torch.take_along_dim(this_layer_prompt_values.unsqueeze(2).unsqueeze(1), indices=top_key_indices.unsqueeze(-1),
|
| 749 |
+
dim=-2) # (batch, tgt_len, head, 1, trunc_source, attn_dim)
|
| 750 |
+
|
| 751 |
+
# (batch * beam, head, tgt_len, trunc_source, attn_dim)
|
| 752 |
+
self.cur_layer_key_value_placeholder[0] = new_keys.flatten(0, 1).squeeze(2)
|
| 753 |
+
self.cur_layer_key_value_placeholder[1] = new_values.flatten(0, 1).squeeze(2)
|
| 754 |
+
return
|
| 755 |
+
|
| 756 |
+
|
| 757 |
+
def preprocess_query(self, query, k_proj_weight):
|
| 758 |
+
k_proj = k_proj_weight.view(1, self.num_heads, query.shape[-1], k_proj_weight.shape[0]) # (1, num_heads, attn_dim, embed_dim)
|
| 759 |
+
datastore_query = query.unsqueeze(-2) # (batch * beam, num_heads, 1, attn_dim)
|
| 760 |
+
datastore_query = torch.matmul(datastore_query, k_proj) # (batch * beam, num_heads, 1, embed_dim)
|
| 761 |
+
datastore_query = datastore_query.squeeze(-2) # (batch * beam, num_heads, embed_dim)
|
| 762 |
+
return datastore_query
|
| 763 |
+
|
| 764 |
+
def post_process_retrieved(self, embeddings, k_proj_layer, v_proj_layer, top_search_key_indices):
|
| 765 |
+
embed_dim = embeddings.shape[-1]
|
| 766 |
+
k_weight = k_proj_layer.weight.view(1, 1, self.num_heads, embed_dim // self.num_heads, embed_dim).transpose(-2,-1) # (1, 1, heads, embed_dim, attn_dim)
|
| 767 |
+
k_bias = 0
|
| 768 |
+
if k_proj_layer.bias is not None:
|
| 769 |
+
k_bias = k_proj_layer.bias.view(1, self.num_heads, embed_dim // self.num_heads).unsqueeze(-2).unsqueeze(0)
|
| 770 |
+
v_weight = v_proj_layer.weight.view(1, 1, self.num_heads, embed_dim // self.num_heads, embed_dim).transpose(-2,-1) # (1, heads, embed_dim, attn_dim)
|
| 771 |
+
v_bias = 0
|
| 772 |
+
if v_proj_layer.bias is not None:
|
| 773 |
+
v_bias = v_proj_layer.bias.view(1, self.num_heads, embed_dim // self.num_heads).unsqueeze(-2).unsqueeze(0)
|
| 774 |
+
# new_keys, new_values: (batch, beam, head, encoder_len, attn_dim)
|
| 775 |
+
retrieved_keys = torch.matmul(embeddings, k_weight) + k_bias # (beam, head, encoder_len, embed_dim)
|
| 776 |
+
retrieved_values = torch.matmul(embeddings, v_weight) + v_bias # (beam, head, encoder_len, embed_dim)
|
| 777 |
+
return retrieved_keys, retrieved_values
|
| 778 |
+
|
| 779 |
+
def set_gradient_checkpointing(self, value):
|
| 780 |
+
self.model.base_model.decoder.gradient_checkpointing = value
|
| 781 |
+
|
| 782 |
+
def reorder_cache_hook(self, past, beam_idx):
|
| 783 |
+
self.last_beam_idx = beam_idx
|
| 784 |
+
self.generated_input_ids = self.generated_input_ids[beam_idx]
|
| 785 |
+
for i, layer_prev_tokens in enumerate(self.prev_tokens):
|
| 786 |
+
if layer_prev_tokens is not None:
|
| 787 |
+
self.prev_tokens[i] = layer_prev_tokens.flatten(0, 1)[beam_idx].reshape(layer_prev_tokens.shape)
|
| 788 |
+
if self.save_heatmap and self.heatmap.numel() > 0:
|
| 789 |
+
self.heatmap = self.heatmap[beam_idx]
|
| 790 |
+
return self.original_reorder_cache_func(past, beam_idx)
|
| 791 |
+
|
| 792 |
+
@classmethod
|
| 793 |
+
def convert_model(cls, model, *args, **kwargs):
|
| 794 |
+
# if type(model.config) in MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING:
|
| 795 |
+
# elif type(model.config) in MODEL_WITH_LM_HEAD_MAPPING:
|
| 796 |
+
# else:
|
| 797 |
+
# raise ValueError(f'Unsupported model type: {type(model.config)}')
|
| 798 |
+
# if model.config.is_encoder_decoder:
|
| 799 |
+
# model_clone = AutoModelForSeq2SeqLM.from_config(model.config)
|
| 800 |
+
# else:
|
| 801 |
+
# model_clone = AutoModelForCausalLM.from_config(model.config)
|
| 802 |
+
# model_clone.load_state_dict(model.state_dict()).to(args.device)
|
| 803 |
+
type_to_class = {
|
| 804 |
+
BartModel: UnlimiformerBART,
|
| 805 |
+
BartForConditionalGeneration: UnlimiformerBART,
|
| 806 |
+
T5Model: UnlimiformerT5,
|
| 807 |
+
T5ForConditionalGeneration: UnlimiformerT5,
|
| 808 |
+
LEDModel: UnlimiformerLED,
|
| 809 |
+
LEDForConditionalGeneration: UnlimiformerLED,
|
| 810 |
+
# LlamaModel: UnlimiformerLLaMa,
|
| 811 |
+
# LlamaForCausalLM: UnlimiformerLLaMa,
|
| 812 |
+
}
|
| 813 |
+
type_to_class[type(model)](model, *args, **kwargs)
|
| 814 |
+
return model
|
| 815 |
+
|
| 816 |
+
|
| 817 |
+
def plot_heatmap(self, data, xticklabels='auto', yticklabels='auto'):
|
| 818 |
+
# data: (heads, targets, source_len)
|
| 819 |
+
import seaborn as sb
|
| 820 |
+
import matplotlib.pyplot as plt
|
| 821 |
+
# print('gat = np.array([')
|
| 822 |
+
# for row in data[0]:
|
| 823 |
+
# rowstr = ', '.join([f'{x:.2f}' for x in row])
|
| 824 |
+
# print(f' [{rowstr}],')
|
| 825 |
+
# print(']')
|
| 826 |
+
|
| 827 |
+
# sb.set(font_scale=1.5, rc={'text.usetex': True})
|
| 828 |
+
for i in range(data.shape[0]):
|
| 829 |
+
fig, axes = plt.subplots(1, 1, figsize=(40, 100))
|
| 830 |
+
cur_ax = axes
|
| 831 |
+
axes.set_title(f'Head #{i}, length: {data.shape[2]}, target length: {data.shape[1]}')
|
| 832 |
+
cur_ax = axes
|
| 833 |
+
# annot = [[x for x in row] for row in data]
|
| 834 |
+
ax = sb.heatmap(data[i], annot=False, fmt='.2f',
|
| 835 |
+
xticklabels=512, yticklabels=yticklabels, ax=cur_ax)
|
| 836 |
+
ax.xaxis.tick_top()
|
| 837 |
+
plt.savefig(f'knns_head{i}.pdf')
|
| 838 |
+
# plt.savefig('gat_s10_contrast.pdf')
|
| 839 |
+
plt.show()
|
| 840 |
+
|
| 841 |
+
|
| 842 |
+
class UnlimiformerBART(Unlimiformer[BartModel]):
|
| 843 |
+
def __init__(self, model: BartModel, *args, **kwargs):
|
| 844 |
+
super().__init__(model, *args, **kwargs)
|
| 845 |
+
|
| 846 |
+
def create_key_value(self, encoder_hidden_states, decoder_layer):
|
| 847 |
+
# (batch, time, hidden_dim)
|
| 848 |
+
attention = decoder_layer.encoder_attn
|
| 849 |
+
# key, value: (batch, heads, time, attn_dim)
|
| 850 |
+
key = attention.k_proj(encoder_hidden_states)
|
| 851 |
+
key = key.view(key.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 852 |
+
value = attention.v_proj(encoder_hidden_states)
|
| 853 |
+
value = value.view(value.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 854 |
+
# key, value: (batch, heads, time, attn_dim)
|
| 855 |
+
return key, value
|
| 856 |
+
|
| 857 |
+
def process_key_value(self, capturers):
|
| 858 |
+
key_capturer, value_capturer = capturers
|
| 859 |
+
key, value = key_capturer.captured, value_capturer.captured
|
| 860 |
+
# (batch, time, heads, attn_dim)
|
| 861 |
+
attention = self.model.base_model.decoder.layers[-1].encoder_attn
|
| 862 |
+
|
| 863 |
+
# query, key, value: (batch, heads, time, attn_dim)
|
| 864 |
+
# query = query.view(query.shape[0], query.shape[1], attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 865 |
+
key = key.view(key.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 866 |
+
value = value.view(value.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 867 |
+
|
| 868 |
+
return key, value
|
| 869 |
+
|
| 870 |
+
def process_query(self, output):
|
| 871 |
+
# (batch, time, heads, attn_dim)
|
| 872 |
+
attention = self.model.base_model.decoder.layers[-1].encoder_attn
|
| 873 |
+
# query: (batch, heads, time, attn_dim)
|
| 874 |
+
# query = output.view(output.shape[0], output.shape[1], attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 875 |
+
query = output.view(output.shape[0], output.shape[1], attention.num_heads, attention.head_dim).contiguous()
|
| 876 |
+
return query
|
| 877 |
+
|
| 878 |
+
def get_kv_projections(self, layer_begin, layer_end):
|
| 879 |
+
return [
|
| 880 |
+
[layer.encoder_attn.k_proj, layer.encoder_attn.v_proj]
|
| 881 |
+
for layer in self.model.base_model.decoder.layers[layer_begin:layer_end]
|
| 882 |
+
]
|
| 883 |
+
|
| 884 |
+
def activation_to_capture(self, layer_begin, layer_end):
|
| 885 |
+
if self.use_datastore:
|
| 886 |
+
return [self.model.base_model.encoder.layers[-1]]
|
| 887 |
+
else:
|
| 888 |
+
return self.get_kv_projections(layer_begin, layer_end)
|
| 889 |
+
|
| 890 |
+
def attention_op_to_run(self, layer_begin, layer_end):
|
| 891 |
+
return [
|
| 892 |
+
layer.encoder_attn.q_proj
|
| 893 |
+
for layer in self.model.base_model.decoder.layers[layer_begin:layer_end]
|
| 894 |
+
]
|
| 895 |
+
|
| 896 |
+
def attention_layer_to_run(self, layer_begin, layer_end):
|
| 897 |
+
return self.model.base_model.decoder.layers[layer_begin:layer_end]
|
| 898 |
+
|
| 899 |
+
def self_attention(self, decoder_layer):
|
| 900 |
+
return decoder_layer.self_attn
|
| 901 |
+
|
| 902 |
+
def cross_attention(self, decoder_layer):
|
| 903 |
+
return decoder_layer.encoder_attn
|
| 904 |
+
|
| 905 |
+
def window_size(self):
|
| 906 |
+
return self.model.config.max_position_embeddings
|
| 907 |
+
|
| 908 |
+
def create_decoder_layer_args(self, hidden_states, attention_mask, encoder_hidden_states,
|
| 909 |
+
encoder_attention_mask, layer_head_mask, cross_attn_layer_head_mask,
|
| 910 |
+
past_key_value, output_attentions, position_bias,
|
| 911 |
+
encoder_decoder_position_bias, use_cache, key, value):
|
| 912 |
+
args = {'hidden_states': hidden_states,
|
| 913 |
+
'attention_mask': attention_mask,
|
| 914 |
+
'encoder_hidden_states': encoder_hidden_states,
|
| 915 |
+
'encoder_attention_mask': encoder_attention_mask,
|
| 916 |
+
'layer_head_mask': layer_head_mask,
|
| 917 |
+
'cross_attn_layer_head_mask': cross_attn_layer_head_mask,
|
| 918 |
+
'past_key_value': (None, None, key, value),
|
| 919 |
+
'output_attentions': output_attentions,
|
| 920 |
+
'use_cache': use_cache,}
|
| 921 |
+
if key is None and value is None:
|
| 922 |
+
args['past_key_value'] = None
|
| 923 |
+
return args
|
| 924 |
+
|
| 925 |
+
class UnlimiformerT5(Unlimiformer[T5Model]):
|
| 926 |
+
def __init__(self, model: T5Model, *args, **kwargs):
|
| 927 |
+
super().__init__(model, *args, **kwargs)
|
| 928 |
+
|
| 929 |
+
def create_key_value(self, encoder_hidden_states, decoder_layer):
|
| 930 |
+
# (batch, time, hidden_dim)
|
| 931 |
+
attention = decoder_layer.layer[1].EncDecAttention
|
| 932 |
+
# key, value: (batch, heads, time, attn_dim)
|
| 933 |
+
key = attention.k(encoder_hidden_states)
|
| 934 |
+
key = key.view(key.shape[0], -1, attention.n_heads, attention.key_value_proj_dim).transpose(1, 2).contiguous()
|
| 935 |
+
value = attention.v(encoder_hidden_states)
|
| 936 |
+
value = value.view(value.shape[0], -1, attention.n_heads, attention.key_value_proj_dim).transpose(1, 2).contiguous()
|
| 937 |
+
|
| 938 |
+
return key, value
|
| 939 |
+
|
| 940 |
+
def process_key_value(self, capturers):
|
| 941 |
+
key_capturer, value_capturer = capturers
|
| 942 |
+
key, value = key_capturer.captured, value_capturer.captured
|
| 943 |
+
# (batch, time, heads, attn_dim)
|
| 944 |
+
attention = self.model.base_model.decoder.block[-1].layer[1].EncDecAttention
|
| 945 |
+
|
| 946 |
+
# query, key, value: (batch, heads, time, attn_dim)
|
| 947 |
+
# query = query.view(query.shape[0], query.shape[1], attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 948 |
+
key = key.view(key.shape[0], -1, attention.n_heads, attention.key_value_proj_dim).transpose(1, 2).contiguous()
|
| 949 |
+
value = value.view(value.shape[0], -1, attention.n_heads, attention.key_value_proj_dim).transpose(1, 2).contiguous()
|
| 950 |
+
|
| 951 |
+
return key, value
|
| 952 |
+
|
| 953 |
+
def process_query(self, output):
|
| 954 |
+
# (batch, time, heads, attn_dim)
|
| 955 |
+
attention = self.model.base_model.decoder.block[-1].layer[1].EncDecAttention
|
| 956 |
+
# query: (batch, heads, time, attn_dim)
|
| 957 |
+
query = output.view(output.shape[0], -1, attention.n_heads, attention.key_value_proj_dim).contiguous()
|
| 958 |
+
return query
|
| 959 |
+
|
| 960 |
+
def get_kv_projections(self, layer_begin, layer_end):
|
| 961 |
+
return [
|
| 962 |
+
[layer.layer[1].EncDecAttention.k, layer.layer[1].EncDecAttention.v]
|
| 963 |
+
for layer in self.model.base_model.decoder.block[layer_begin:layer_end]
|
| 964 |
+
]
|
| 965 |
+
|
| 966 |
+
def activation_to_capture(self, layer_begin, layer_end):
|
| 967 |
+
if self.use_datastore:
|
| 968 |
+
return [self.model.base_model.encoder.layers[-1]]
|
| 969 |
+
else:
|
| 970 |
+
return self.get_kv_projections(layer_begin, layer_end)
|
| 971 |
+
|
| 972 |
+
def attention_op_to_run(self, layer_begin, layer_end):
|
| 973 |
+
return [
|
| 974 |
+
layer.layer[1].EncDecAttention.q
|
| 975 |
+
for layer in self.model.base_model.decoder.block[layer_begin:layer_end]
|
| 976 |
+
]
|
| 977 |
+
|
| 978 |
+
def attention_layer_to_run(self, layer_begin, layer_end):
|
| 979 |
+
return self.model.base_model.decoder.block[layer_begin:layer_end]
|
| 980 |
+
|
| 981 |
+
def self_attention(self, decoder_layer):
|
| 982 |
+
return decoder_layer.layer[0]
|
| 983 |
+
|
| 984 |
+
def cross_attention(self, decoder_layer):
|
| 985 |
+
return decoder_layer.layer[1]
|
| 986 |
+
|
| 987 |
+
def window_size(self):
|
| 988 |
+
try:
|
| 989 |
+
size = self.model.config.n_positions
|
| 990 |
+
except AttributeError:
|
| 991 |
+
size = 1024
|
| 992 |
+
return size
|
| 993 |
+
|
| 994 |
+
def create_decoder_layer_args(self, hidden_states, attention_mask, encoder_hidden_states,
|
| 995 |
+
encoder_attention_mask, layer_head_mask, cross_attn_layer_head_mask,
|
| 996 |
+
past_key_value, output_attentions, position_bias,
|
| 997 |
+
encoder_decoder_position_bias, use_cache, key, value):
|
| 998 |
+
args = {'hidden_states': hidden_states,
|
| 999 |
+
'attention_mask': attention_mask,
|
| 1000 |
+
'position_bias': position_bias,
|
| 1001 |
+
'encoder_hidden_states': encoder_hidden_states,
|
| 1002 |
+
'encoder_attention_mask': encoder_attention_mask,
|
| 1003 |
+
'encoder_decoder_position_bias': encoder_decoder_position_bias,
|
| 1004 |
+
'layer_head_mask': layer_head_mask,
|
| 1005 |
+
'cross_attn_layer_head_mask': cross_attn_layer_head_mask,
|
| 1006 |
+
'past_key_value': (None, None, key, value),
|
| 1007 |
+
'use_cache': use_cache,
|
| 1008 |
+
'output_attentions': output_attentions}
|
| 1009 |
+
if key is None and value is None:
|
| 1010 |
+
args['past_key_value'] = None
|
| 1011 |
+
return args
|
| 1012 |
+
|
| 1013 |
+
class UnlimiformerLED(UnlimiformerBART):
|
| 1014 |
+
def __init__(self, model: LEDModel, *args, **kwargs):
|
| 1015 |
+
super().__init__(model, *args, **kwargs)
|
| 1016 |
+
|
| 1017 |
+
def window_size(self):
|
| 1018 |
+
return self.model.config.max_encoder_position_embeddings
|
| 1019 |
+
|
| 1020 |
+
# class UnlimiformerLLaMa(Unlimiformer[LlamaModel]):
|
| 1021 |
+
# def __init__(self, model: LlamaModel, *args, **kwargs):
|
| 1022 |
+
# super().__init__(model, *args, **kwargs)
|
| 1023 |
+
|
| 1024 |
+
# def get_kv_projections(self, layer_begin, layer_end):
|
| 1025 |
+
# return [
|
| 1026 |
+
# [layer.self_attn.k_proj, layer.self_attn.v_proj]
|
| 1027 |
+
# for layer in self.model.base_model.layers[layer_begin:layer_end]
|
| 1028 |
+
# ]
|
| 1029 |
+
|
| 1030 |
+
# def activation_to_capture(self, layer_begin, layer_end):
|
| 1031 |
+
# if self.use_datastore:
|
| 1032 |
+
# return [
|
| 1033 |
+
# layer.input_layernorm
|
| 1034 |
+
# for layer in self.model.base_model.layers[layer_begin:layer_end]
|
| 1035 |
+
# ]
|
| 1036 |
+
# else:
|
| 1037 |
+
# return self.get_kv_projections(layer_begin, layer_end)
|
| 1038 |
+
|
| 1039 |
+
# def attention_op_to_run(self, layer_begin, layer_end):
|
| 1040 |
+
# return [
|
| 1041 |
+
# layer.self_attn.q_proj
|
| 1042 |
+
# for layer in self.model.base_model.layers[layer_begin:layer_end]
|
| 1043 |
+
# ]
|
| 1044 |
+
|
| 1045 |
+
# def attention_layer_to_run(self, layer_begin, layer_end):
|
| 1046 |
+
# return self.model.base_model.layers[layer_begin:layer_end]
|
| 1047 |
+
|
| 1048 |
+
# def self_attention(self, decoder_layer):
|
| 1049 |
+
# return decoder_layer.self_attn
|
| 1050 |
+
|
| 1051 |
+
# def cross_attention(self, decoder_layer):
|
| 1052 |
+
# return decoder_layer.self_attn
|
| 1053 |
+
|
| 1054 |
+
# def window_size(self):
|
| 1055 |
+
# return self.model.config.max_position_embeddings
|
| 1056 |
+
|
| 1057 |
+
# def set_gradient_checkpointing(self, value):
|
| 1058 |
+
# self.model.base_model.gradient_checkpointing = value
|
| 1059 |
+
|
| 1060 |
+
# def process_key_value(self, capturers):
|
| 1061 |
+
# key_capturer, value_capturer = capturers
|
| 1062 |
+
# # (batch, time, heads * attn_dim)
|
| 1063 |
+
# key, value = key_capturer.captured, value_capturer.captured
|
| 1064 |
+
# attention = self.model.base_model.layers[-1].self_attn
|
| 1065 |
+
|
| 1066 |
+
# # (batch, heads, time, attn_dim)
|
| 1067 |
+
# key = key.view(key.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 1068 |
+
# value = value.view(value.shape[0], -1, attention.num_heads, attention.head_dim).transpose(1, 2).contiguous()
|
| 1069 |
+
|
| 1070 |
+
# return key, value
|
| 1071 |
+
|
| 1072 |
+
# def process_query(self, output):
|
| 1073 |
+
# # output: (batch, time, heads * attn_dim)
|
| 1074 |
+
# attention = self.model.base_model.layers[-1].self_attn
|
| 1075 |
+
|
| 1076 |
+
# # query: (batch, time, heads, attn_dim)
|
| 1077 |
+
# query = output.view(output.shape[0], output.shape[1], attention.num_heads, attention.head_dim).contiguous()
|
| 1078 |
+
# return query
|
| 1079 |
+
|
| 1080 |
+
# def rotate_half(self, x):
|
| 1081 |
+
# """Rotates half the hidden dims of the input."""
|
| 1082 |
+
# x1 = x[..., : x.shape[-1] // 2]
|
| 1083 |
+
# x2 = x[..., x.shape[-1] // 2 :]
|
| 1084 |
+
# return torch.cat((-x2, x1), dim=-1)
|
| 1085 |
+
|
| 1086 |
+
# def preprocess_query(self, query, k_proj_weight):
|
| 1087 |
+
# # query: (batch * time, head, dim)
|
| 1088 |
+
# attention = self.model.base_model.layers[-1].self_attn
|
| 1089 |
+
# num_generated = min(self.input_ids_size - self.prompt_input_ids.shape[1], self.actual_model_window_size)
|
| 1090 |
+
# cos, sin = attention.rotary_emb(query, seq_len=num_generated)
|
| 1091 |
+
# cos = cos[:,:,-1] # [1, 1, dim]
|
| 1092 |
+
# sin = sin[:,:,-1] # [1, 1, dim]
|
| 1093 |
+
# # cos = cos[-1].unsqueeze(0).unsqueeze(0) # [bs, 1, seq_len, dim]
|
| 1094 |
+
# # sin = sin[-1].unsqueeze(0) # [bs, 1, seq_len, dim]
|
| 1095 |
+
# query = (query * cos) + (self.rotate_half(query) * sin)
|
| 1096 |
+
|
| 1097 |
+
# k_proj = k_proj_weight.view(1, self.num_heads, query.shape[-1], k_proj_weight.shape[0]) # (1, num_heads, attn_dim, embed_dim)
|
| 1098 |
+
# k_proj_l = k_proj[..., :k_proj.shape[-2] // 2, :]
|
| 1099 |
+
# k_proj_r = k_proj[..., k_proj.shape[-2] // 2:, :]
|
| 1100 |
+
# k_proj_rotated = torch.cat([-k_proj_l, k_proj_r], dim=-2)
|
| 1101 |
+
|
| 1102 |
+
# datastore_query = query.unsqueeze(-2) # (batch * beam, num_heads, 1, attn_dim)
|
| 1103 |
+
# datastore_query = torch.matmul(datastore_query, k_proj + k_proj_rotated) # (batch * beam, num_heads, 1, embed_dim)
|
| 1104 |
+
# datastore_query = datastore_query.squeeze(-2) # (batch * beam, num_heads, embed_dim)
|
| 1105 |
+
# return datastore_query
|
| 1106 |
+
|
| 1107 |
+
# def post_process_retrieved(self, embeddings, k_proj_layer, v_proj_layer, top_search_key_indices):
|
| 1108 |
+
# embed_dim = embeddings.shape[-1]
|
| 1109 |
+
# k_weight = k_proj_layer.weight.view(1, 1, self.num_heads, embed_dim // self.num_heads, embed_dim).transpose(-2,-1) # (1, 1, heads, embed_dim, attn_dim)
|
| 1110 |
+
# k_bias = 0
|
| 1111 |
+
# if k_proj_layer.bias is not None:
|
| 1112 |
+
# k_bias = k_proj_layer.bias.view(1, self.num_heads, embed_dim // self.num_heads).unsqueeze(-2).unsqueeze(0)
|
| 1113 |
+
# v_weight = v_proj_layer.weight.view(1, 1, self.num_heads, embed_dim // self.num_heads, embed_dim).transpose(-2,-1) # (1, heads, embed_dim, attn_dim)
|
| 1114 |
+
# v_bias = 0
|
| 1115 |
+
# if v_proj_layer.bias is not None:
|
| 1116 |
+
# v_bias = v_proj_layer.bias.view(1, self.num_heads, embed_dim // self.num_heads).unsqueeze(-2).unsqueeze(0)
|
| 1117 |
+
# # new_keys, new_values: (batch, beam, head, encoder_len, attn_dim)
|
| 1118 |
+
# retrieved_keys = torch.matmul(embeddings, k_weight) + k_bias # (beam, head, encoder_len, embed_dim)
|
| 1119 |
+
# retrieved_values = torch.matmul(embeddings, v_weight) + v_bias # (beam, head, encoder_len, embed_dim)
|
| 1120 |
+
|
| 1121 |
+
# attention = self.model.base_model.layers[-1].self_attn
|
| 1122 |
+
# cos, sin = attention.rotary_emb(retrieved_values, seq_len=self.hidden_states[0].shape[1])
|
| 1123 |
+
# cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
|
| 1124 |
+
# sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
|
| 1125 |
+
# if self.prompt_input_ids.shape[1] > self.actual_model_window_size:
|
| 1126 |
+
# # scale the top key indices to the actual model window size, such that the model will not see
|
| 1127 |
+
# # positional embeddings that did not appear at training time
|
| 1128 |
+
# scaled_key_indices = ((top_search_key_indices / self.prompt_input_ids.shape[1]) * self.actual_model_window_size).int()
|
| 1129 |
+
# else:
|
| 1130 |
+
# scaled_key_indices = top_search_key_indices
|
| 1131 |
+
# # top_search_key_indices = top_search_key_indices.to(cos.device)
|
| 1132 |
+
# scaled_key_indices = scaled_key_indices.to(cos.device)
|
| 1133 |
+
# cos = cos[scaled_key_indices] # [bs, 1, seq_len, dim]
|
| 1134 |
+
# sin = sin[scaled_key_indices] # [bs, 1, seq_len, dim]
|
| 1135 |
+
# retrieved_keys = (retrieved_keys * cos) + (self.rotate_half(retrieved_keys) * sin)
|
| 1136 |
+
# return retrieved_keys, retrieved_values
|
| 1137 |
+
|
| 1138 |
+
|
| 1139 |
+
class ActivationCapturer(nn.Module):
|
| 1140 |
+
def __init__(self, layer, capture_input=False):
|
| 1141 |
+
super().__init__()
|
| 1142 |
+
self.layer = layer
|
| 1143 |
+
self.capture_input = capture_input
|
| 1144 |
+
|
| 1145 |
+
self.captured = None
|
| 1146 |
+
|
| 1147 |
+
def unwrap_tuple(self, t):
|
| 1148 |
+
if isinstance(t, tuple) and len(t) == 1:
|
| 1149 |
+
t = t[0]
|
| 1150 |
+
return t
|
| 1151 |
+
|
| 1152 |
+
def forward(self, module, layer_input, layer_output):
|
| 1153 |
+
if self.capture_input:
|
| 1154 |
+
self.captured = self.unwrap_tuple(layer_input)
|
| 1155 |
+
else:
|
| 1156 |
+
self.captured = self.unwrap_tuple(layer_output)
|
| 1157 |
+
|
unlimiformer/random_training_unlimiformer.py
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import contextlib
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from enum import Enum, auto
|
| 6 |
+
from .model import Unlimiformer, ModelType, UnlimiformerBART, UnlimiformerT5, UnlimiformerLED
|
| 7 |
+
from transformers import BartModel, BartForConditionalGeneration, \
|
| 8 |
+
T5Model, T5ForConditionalGeneration, \
|
| 9 |
+
LEDModel, LEDForConditionalGeneration, \
|
| 10 |
+
AutoModelForSeq2SeqLM
|
| 11 |
+
|
| 12 |
+
class RandomTrainingUnlimiformer(Unlimiformer[ModelType]):
|
| 13 |
+
def __init__(self, model: ModelType, *args, **kwargs):
|
| 14 |
+
super().__init__(model, *args, **kwargs)
|
| 15 |
+
self.training_hooks_injected = False
|
| 16 |
+
self.train_step = 0
|
| 17 |
+
|
| 18 |
+
@classmethod
|
| 19 |
+
def convert_model(cls, model, *args, **kwargs):
|
| 20 |
+
# model_clone = AutoModelForSeq2SeqLM.from_config(model.config)
|
| 21 |
+
# model_clone.load_state_dict(model.state_dict()).to(args.device)
|
| 22 |
+
type_to_class = {
|
| 23 |
+
BartModel: RandomUnlimiformerBART,
|
| 24 |
+
BartForConditionalGeneration: RandomUnlimiformerBART,
|
| 25 |
+
T5Model: RandomUnlimiformerT5,
|
| 26 |
+
T5ForConditionalGeneration: RandomUnlimiformerT5,
|
| 27 |
+
LEDModel: RandomUnlimiformerLED,
|
| 28 |
+
LEDForConditionalGeneration: RandomUnlimiformerLED,
|
| 29 |
+
}
|
| 30 |
+
type_to_class[type(model)](model, *args, **kwargs)
|
| 31 |
+
return model
|
| 32 |
+
|
| 33 |
+
def pre_eval_hook(self):
|
| 34 |
+
self.remove_training_hooks(self.model)
|
| 35 |
+
self.inject_hooks(self.model)
|
| 36 |
+
self.original_model_eval_func()
|
| 37 |
+
|
| 38 |
+
def pre_train_hook(self, mode=True):
|
| 39 |
+
# mode=True means model.train() is called
|
| 40 |
+
# mode=False means model.eval() is called
|
| 41 |
+
torch.cuda.empty_cache()
|
| 42 |
+
if mode is True:
|
| 43 |
+
self.break_out(self.model)
|
| 44 |
+
self.remove_training_hooks(self.model)
|
| 45 |
+
if self.unlimiformer_training and self.train_step % 2 == 0:
|
| 46 |
+
super().inject_training_hooks(self.model)
|
| 47 |
+
else:
|
| 48 |
+
self.inject_training_hooks(self.model)
|
| 49 |
+
self.train_step += 1
|
| 50 |
+
self.original_model_train_func(mode)
|
| 51 |
+
|
| 52 |
+
def inject_training_hooks(self, model):
|
| 53 |
+
if self.training_hooks_injected:
|
| 54 |
+
return
|
| 55 |
+
# self.original_forward_func = model.forward
|
| 56 |
+
model.forward = self.random_inputs_forward_hook
|
| 57 |
+
|
| 58 |
+
decoder_layers_to_run = self.attention_layer_to_run(self.layer_begin, self.layer_end)
|
| 59 |
+
|
| 60 |
+
self.original_decoder_layer_self_attn_forward_funcs = []
|
| 61 |
+
for decoder_layer in decoder_layers_to_run:
|
| 62 |
+
attention = self.self_attention(decoder_layer)
|
| 63 |
+
self.original_decoder_layer_self_attn_forward_funcs.append(attention.forward)
|
| 64 |
+
attention.forward = self.create_self_attn_random_pre_forward_hook(attention.forward)
|
| 65 |
+
|
| 66 |
+
self.original_decoder_layer_forward_funcs = []
|
| 67 |
+
for decoder_layer in decoder_layers_to_run:
|
| 68 |
+
self.original_decoder_layer_forward_funcs.append(decoder_layer.forward)
|
| 69 |
+
decoder_layer.forward = self.create_decoder_layer_random_func(decoder_layer.forward, decoder_layer)
|
| 70 |
+
|
| 71 |
+
self.original_decoder_layer_cross_attn_forward_funcs = []
|
| 72 |
+
for i, decoder_layer in enumerate(decoder_layers_to_run):
|
| 73 |
+
attention = self.cross_attention(decoder_layer)
|
| 74 |
+
self.original_decoder_layer_cross_attn_forward_funcs.append(attention.forward)
|
| 75 |
+
|
| 76 |
+
self.inject_hooks_for_unaffected_layers(model, decoder_layers_to_run)
|
| 77 |
+
|
| 78 |
+
self.training_hooks_injected = True
|
| 79 |
+
|
| 80 |
+
def create_self_attn_random_pre_forward_hook(self, original_self_attn_forward_func):
|
| 81 |
+
def self_attention_pre_forward_hook(*args, **kwargs):
|
| 82 |
+
kwargs['past_key_value'] = None
|
| 83 |
+
return original_self_attn_forward_func(*args, **kwargs)
|
| 84 |
+
|
| 85 |
+
return self_attention_pre_forward_hook
|
| 86 |
+
|
| 87 |
+
def create_decoder_layer_random_func(self, decoder_layer_original_forward_func, decoder_layer):
|
| 88 |
+
def checkpointed_decoder_layer(
|
| 89 |
+
hidden_states: torch.Tensor,
|
| 90 |
+
attention_mask=None,
|
| 91 |
+
encoder_hidden_states=None,
|
| 92 |
+
encoder_attention_mask=None,
|
| 93 |
+
layer_head_mask=None,
|
| 94 |
+
cross_attn_layer_head_mask=None,
|
| 95 |
+
past_key_value=None,
|
| 96 |
+
output_attentions=False,
|
| 97 |
+
position_bias=None,
|
| 98 |
+
encoder_decoder_position_bias=None,
|
| 99 |
+
use_cache=True):
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def sample_and_forward(hidden_states, attention_mask,
|
| 104 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 105 |
+
cross_attn_layer_head_mask, past_key_value,
|
| 106 |
+
output_attentions, use_cache, long_inputs, long_inputs_mask, rand_indices,
|
| 107 |
+
position_bias, encoder_decoder_position_bias):
|
| 108 |
+
|
| 109 |
+
sampled_input, _ = self.sample_long_input(long_inputs, long_inputs_mask, rand_indices)
|
| 110 |
+
key, value = self.create_key_value(sampled_input, decoder_layer)
|
| 111 |
+
decoder_layer_args = self.create_decoder_layer_args(
|
| 112 |
+
hidden_states=hidden_states,
|
| 113 |
+
attention_mask=attention_mask,
|
| 114 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 115 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 116 |
+
layer_head_mask=layer_head_mask,
|
| 117 |
+
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
|
| 118 |
+
past_key_value=past_key_value,
|
| 119 |
+
output_attentions=output_attentions,
|
| 120 |
+
position_bias=position_bias,
|
| 121 |
+
encoder_decoder_position_bias=encoder_decoder_position_bias,
|
| 122 |
+
use_cache=use_cache,
|
| 123 |
+
key=key,value=value
|
| 124 |
+
)
|
| 125 |
+
return decoder_layer_original_forward_func(**decoder_layer_args)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
with torch.no_grad():
|
| 129 |
+
# This sampling must be done outside of the checkpoint, to ensure that the same sampling happens
|
| 130 |
+
# both in "forward" and "backward" passes
|
| 131 |
+
rand_indices = self.sample_random_indices()
|
| 132 |
+
|
| 133 |
+
return torch.utils.checkpoint.checkpoint(
|
| 134 |
+
sample_and_forward, hidden_states, attention_mask,
|
| 135 |
+
encoder_hidden_states, encoder_attention_mask, layer_head_mask,
|
| 136 |
+
cross_attn_layer_head_mask, None,
|
| 137 |
+
output_attentions, use_cache, self.long_inputs_encoded, self.long_inputs_mask, rand_indices,
|
| 138 |
+
position_bias, encoder_decoder_position_bias)
|
| 139 |
+
|
| 140 |
+
return checkpointed_decoder_layer
|
| 141 |
+
|
| 142 |
+
def sample_random_indices(self):
|
| 143 |
+
rand_indices_list = []
|
| 144 |
+
seq_lens = self.long_inputs_mask.sum(-1).tolist()
|
| 145 |
+
for seq_len in seq_lens:
|
| 146 |
+
if seq_len < self.actual_model_window_size:
|
| 147 |
+
rand_indices = torch.arange(self.actual_model_window_size).to(self.device)
|
| 148 |
+
rand_indices_list.append(rand_indices)
|
| 149 |
+
continue
|
| 150 |
+
|
| 151 |
+
rand_indices = torch.torch.randperm(seq_len)[:self.actual_model_window_size].to(self.device)
|
| 152 |
+
if seq_len < self.actual_model_window_size:
|
| 153 |
+
padding = max(self.actual_model_window_size - seq_len, 0)
|
| 154 |
+
rand_indices = torch.cat([rand_indices, torch.arange(padding).to(self.device) + seq_len], axis=-1).to(self.device)
|
| 155 |
+
rand_indices_list.append(rand_indices)
|
| 156 |
+
rand_indices = torch.stack(rand_indices_list, dim=0)
|
| 157 |
+
return rand_indices
|
| 158 |
+
|
| 159 |
+
def random_inputs_forward_hook(self, input_ids=None, attention_mask=None, labels=None, **kwargs):
|
| 160 |
+
self.model.base_model.decoder.gradient_checkpointing = False
|
| 161 |
+
self.long_inputs_encoded, self.long_inputs_mask = self.chunked_encode_input(input_ids=input_ids, attention_mask=attention_mask)
|
| 162 |
+
|
| 163 |
+
# TODO: should the inputs be sampled or the truncated beginning?
|
| 164 |
+
# if self.random_knn_initial_inputs:
|
| 165 |
+
# encoded_inputs, encoded_inputs_mask = self.sample_long_input(self.long_inputs_encoded, self.long_inputs_mask)
|
| 166 |
+
# else:
|
| 167 |
+
encoded_inputs = self.long_inputs_encoded[:, :self.actual_model_window_size]
|
| 168 |
+
encoded_inputs_mask = self.long_inputs_mask[:, :self.actual_model_window_size]
|
| 169 |
+
return self.original_forward_func(encoder_outputs=(encoded_inputs, ), labels=labels, attention_mask=encoded_inputs_mask, **kwargs)
|
| 170 |
+
|
| 171 |
+
def sample_long_input(self, long_inputs_encoded, long_inputs_mask, random_indices=None):
|
| 172 |
+
if long_inputs_mask.shape[-1] < self.actual_model_window_size:
|
| 173 |
+
return long_inputs_encoded, long_inputs_mask
|
| 174 |
+
batch_size = long_inputs_encoded.shape[0]
|
| 175 |
+
|
| 176 |
+
if random_indices is None:
|
| 177 |
+
random_indices = self.sample_random_indices()
|
| 178 |
+
random_mask = torch.zeros_like(long_inputs_mask).to(self.device) \
|
| 179 |
+
.scatter_(dim=-1, index=random_indices, src=torch.ones_like(random_indices)).bool().to(self.device)
|
| 180 |
+
sampled_input = long_inputs_encoded[random_mask].reshape(batch_size, self.actual_model_window_size, -1).to(self.device)
|
| 181 |
+
sampled_mask = long_inputs_mask[random_mask].reshape(batch_size, self.actual_model_window_size).to(self.device)
|
| 182 |
+
return sampled_input, sampled_mask
|
| 183 |
+
|
| 184 |
+
def chunked_encode_input(self, input_ids, attention_mask):
|
| 185 |
+
long_inputs_encoded = []
|
| 186 |
+
long_inputs_mask = []
|
| 187 |
+
window_indices = self.window_indices(input_ids.shape[-1])
|
| 188 |
+
|
| 189 |
+
self.is_input_encoding_pass = True
|
| 190 |
+
for context_start_ind, context_end_ind, update_start_ind, update_end_ind in window_indices:
|
| 191 |
+
chunk = input_ids[:, context_start_ind:context_end_ind]
|
| 192 |
+
chunk_attention_mask = attention_mask[:, context_start_ind:context_end_ind]
|
| 193 |
+
output = self.model.base_model.encoder(chunk, attention_mask=chunk_attention_mask, return_dict=True, output_hidden_states=True)
|
| 194 |
+
encoder_last_hidden_state = output.last_hidden_state # (batch, time, dim)
|
| 195 |
+
|
| 196 |
+
# list of (batch, head, chunked_time, dim)
|
| 197 |
+
encoder_last_hidden_state = encoder_last_hidden_state[:, update_start_ind:update_end_ind] # (batch, chunked_time, dim)
|
| 198 |
+
chunk_attention_mask = chunk_attention_mask[:, update_start_ind:update_end_ind] # (batch, chunked_time)
|
| 199 |
+
|
| 200 |
+
long_inputs_encoded.append(encoder_last_hidden_state) # (batch, chunked_source_len, dim)
|
| 201 |
+
long_inputs_mask.append(chunk_attention_mask) # (batch, chunked_source_len)
|
| 202 |
+
|
| 203 |
+
long_inputs_encoded = torch.cat(long_inputs_encoded, dim=1) # (batch, source_len, dim)
|
| 204 |
+
long_inputs_mask = torch.cat(long_inputs_mask, dim=1) # (batch, source_len)
|
| 205 |
+
|
| 206 |
+
self.is_input_encoding_pass = False
|
| 207 |
+
if self.verbose:
|
| 208 |
+
print(f'Input: '
|
| 209 |
+
f'{self.tokenizer.decode(input_ids[0][:self.actual_model_window_size], skip_special_tokens=True)} ||| '
|
| 210 |
+
f'{self.tokenizer.decode(input_ids[0][self.actual_model_window_size:], skip_special_tokens=True)}')
|
| 211 |
+
print()
|
| 212 |
+
return long_inputs_encoded, long_inputs_mask
|
| 213 |
+
|
| 214 |
+
class RandomUnlimiformerBART(RandomTrainingUnlimiformer[BartModel], UnlimiformerBART):
|
| 215 |
+
def __init__(self, model: BartModel, *args, **kwargs):
|
| 216 |
+
super().__init__(model, *args, **kwargs)
|
| 217 |
+
|
| 218 |
+
class RandomUnlimiformerT5(RandomTrainingUnlimiformer[T5Model], UnlimiformerT5):
|
| 219 |
+
def __init__(self, model: T5Model, *args, **kwargs):
|
| 220 |
+
super().__init__(model, *args, **kwargs)
|
| 221 |
+
|
| 222 |
+
class RandomUnlimiformerLED(RandomTrainingUnlimiformer[LEDModel], UnlimiformerLED):
|
| 223 |
+
def __init__(self, model: LEDModel, *args, **kwargs):
|
| 224 |
+
super().__init__(model, *args, **kwargs)
|
unlimiformer/run.py
ADDED
|
@@ -0,0 +1,1180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# coding=utf-8
|
| 3 |
+
# Copyright 2021 The HuggingFace Team. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for sequence to sequence.
|
| 18 |
+
"""
|
| 19 |
+
# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
|
| 20 |
+
import logging
|
| 21 |
+
import os
|
| 22 |
+
import sys
|
| 23 |
+
|
| 24 |
+
import numpy as np
|
| 25 |
+
from unlimiformer import Unlimiformer
|
| 26 |
+
from random_training_unlimiformer import RandomTrainingUnlimiformer
|
| 27 |
+
|
| 28 |
+
import nltk
|
| 29 |
+
|
| 30 |
+
# we import the logging frameworks before any other import to make sure all monkey patching for the logging are active
|
| 31 |
+
# from sled import SledConfig
|
| 32 |
+
|
| 33 |
+
import wandb
|
| 34 |
+
import torch
|
| 35 |
+
|
| 36 |
+
sys.path.insert(0, os.path.dirname(__file__)) # seq2seq package path
|
| 37 |
+
sys.path.insert(0, os.getcwd())
|
| 38 |
+
|
| 39 |
+
from dataclasses import dataclass, field, replace
|
| 40 |
+
from typing import List, Optional
|
| 41 |
+
import json
|
| 42 |
+
from copy import deepcopy
|
| 43 |
+
import torch.nn.functional as F
|
| 44 |
+
|
| 45 |
+
import datasets
|
| 46 |
+
|
| 47 |
+
import transformers
|
| 48 |
+
from transformers import (
|
| 49 |
+
AutoConfig,
|
| 50 |
+
AutoModelForSeq2SeqLM,
|
| 51 |
+
AutoTokenizer,
|
| 52 |
+
EarlyStoppingCallback,
|
| 53 |
+
set_seed, WEIGHTS_NAME,
|
| 54 |
+
)
|
| 55 |
+
from transformers.trainer_utils import get_last_checkpoint
|
| 56 |
+
from transformers import DataCollatorForSeq2Seq
|
| 57 |
+
|
| 58 |
+
from datasets import load_dataset
|
| 59 |
+
|
| 60 |
+
# noinspection PyUnresolvedReferences
|
| 61 |
+
# import sled # *** required so that SledModels will be registered for the AutoClasses ***
|
| 62 |
+
|
| 63 |
+
from utils.config import handle_args_to_ignore
|
| 64 |
+
from utils.decoding import decode
|
| 65 |
+
from metrics import load_metric
|
| 66 |
+
from utils.duplicates import drop_duplicates_in_input
|
| 67 |
+
from utils.override_training_args import TrainingOverridesArguments
|
| 68 |
+
from utils.custom_seq2seq_trainer import CustomTrainer
|
| 69 |
+
from utils.custom_hf_argument_parser import CustomHfArgumentParser
|
| 70 |
+
from metrics.metrics import HFMetricWrapper, MetricCollection
|
| 71 |
+
|
| 72 |
+
logger = logging.getLogger('sled')
|
| 73 |
+
|
| 74 |
+
PREFIX_DOC_SEP = '\n\n'
|
| 75 |
+
|
| 76 |
+
DEBUG = os.environ.get('DEBUG', 'false').lower() in {'1', 'true', 'yes'} # If set, will set some configuration to help debug
|
| 77 |
+
if DEBUG:
|
| 78 |
+
assert not torch.cuda.is_available() or torch.cuda.device_count() == 1
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
@dataclass
|
| 82 |
+
class ModelArguments:
|
| 83 |
+
"""
|
| 84 |
+
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
model_name_or_path: str = field(
|
| 88 |
+
default=None, metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
|
| 89 |
+
)
|
| 90 |
+
config_name: Optional[str] = field(
|
| 91 |
+
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
|
| 92 |
+
)
|
| 93 |
+
tokenizer_name: Optional[str] = field(
|
| 94 |
+
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
|
| 95 |
+
)
|
| 96 |
+
cache_dir: Optional[str] = field(
|
| 97 |
+
default=None,
|
| 98 |
+
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
|
| 99 |
+
)
|
| 100 |
+
use_fast_tokenizer: bool = field(
|
| 101 |
+
default=True,
|
| 102 |
+
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
|
| 103 |
+
)
|
| 104 |
+
model_revision: str = field(
|
| 105 |
+
default="main",
|
| 106 |
+
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
|
| 107 |
+
)
|
| 108 |
+
drop_duplicates_in_eval: bool = field(
|
| 109 |
+
default=True,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
def __post_init__(self):
|
| 113 |
+
pass
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
@dataclass
|
| 118 |
+
class DataTrainingArguments:
|
| 119 |
+
"""
|
| 120 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
dataset_name: Optional[str] = field(
|
| 124 |
+
default=None,
|
| 125 |
+
metadata={
|
| 126 |
+
"help": "The name of the dataset to use (via the datasets library) or name of the file in src/data."
|
| 127 |
+
},
|
| 128 |
+
)
|
| 129 |
+
dataset_config_name: Optional[str] = field(
|
| 130 |
+
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
|
| 131 |
+
)
|
| 132 |
+
metric_names: Optional[List[str]] = field(
|
| 133 |
+
default=None,
|
| 134 |
+
metadata={"help": "The name of the metric to use (from src/metrics)."},
|
| 135 |
+
)
|
| 136 |
+
input_column: Optional[str] = field(
|
| 137 |
+
default=None,
|
| 138 |
+
metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
|
| 139 |
+
)
|
| 140 |
+
input_prefix_column: Optional[str] = field(
|
| 141 |
+
default=None,
|
| 142 |
+
metadata={"help": "The name of the column in the datasets containing the input prefix (e.g. questions), when those exist."},
|
| 143 |
+
)
|
| 144 |
+
output_column: Optional[str] = field(
|
| 145 |
+
default=None,
|
| 146 |
+
metadata={"help": "The name of the column in the datasets containing the summaries (for summarization)."},
|
| 147 |
+
)
|
| 148 |
+
train_file: Optional[str] = field(
|
| 149 |
+
default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
|
| 150 |
+
)
|
| 151 |
+
validation_file: Optional[str] = field(
|
| 152 |
+
default=None,
|
| 153 |
+
metadata={
|
| 154 |
+
"help": "An optional input evaluation data file to evaluate the metrics (rouge) on "
|
| 155 |
+
"(a jsonlines or csv file)."
|
| 156 |
+
},
|
| 157 |
+
)
|
| 158 |
+
test_file: Optional[str] = field(
|
| 159 |
+
default=None,
|
| 160 |
+
metadata={
|
| 161 |
+
"help": "An optional input test data file to evaluate the metrics (rouge) on " "(a jsonlines or csv file)."
|
| 162 |
+
},
|
| 163 |
+
)
|
| 164 |
+
overwrite_cache: bool = field(
|
| 165 |
+
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
|
| 166 |
+
)
|
| 167 |
+
preprocessing_num_workers: Optional[int] = field(
|
| 168 |
+
default=None,
|
| 169 |
+
metadata={"help": "The number of processes to use for the preprocessing."},
|
| 170 |
+
)
|
| 171 |
+
max_source_length: Optional[int] = field(
|
| 172 |
+
default=None,
|
| 173 |
+
metadata={
|
| 174 |
+
"help": "The maximum total input sequence length after tokenization. Sequences longer "
|
| 175 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 176 |
+
},
|
| 177 |
+
)
|
| 178 |
+
eval_max_source_length: Optional[int] = field(
|
| 179 |
+
default=None,
|
| 180 |
+
metadata={"help": "if None, will be same as max_source_length"},
|
| 181 |
+
)
|
| 182 |
+
max_prefix_length: Optional[int] = field(
|
| 183 |
+
default=0,
|
| 184 |
+
metadata={
|
| 185 |
+
"help": "The maximum total input_prefix sequence length after tokenization. Sequences longer "
|
| 186 |
+
"than this will be truncated, sequences shorter will be padded from the left "
|
| 187 |
+
"(only used if prefixes are not merged)."
|
| 188 |
+
},
|
| 189 |
+
)
|
| 190 |
+
max_target_length: Optional[int] = field(
|
| 191 |
+
default=128,
|
| 192 |
+
metadata={
|
| 193 |
+
"help": "The maximum total sequence length for target text after tokenization. Sequences longer "
|
| 194 |
+
"than this will be truncated, sequences shorter will be padded."
|
| 195 |
+
},
|
| 196 |
+
)
|
| 197 |
+
val_max_target_length: Optional[int] = field(
|
| 198 |
+
default=None,
|
| 199 |
+
metadata={
|
| 200 |
+
"help": "The maximum total sequence length for validation target text after tokenization. Sequences longer "
|
| 201 |
+
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`."
|
| 202 |
+
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
|
| 203 |
+
"during ``evaluate`` and ``predict``."
|
| 204 |
+
},
|
| 205 |
+
)
|
| 206 |
+
pad_to_max_length: bool = field(
|
| 207 |
+
default=False,
|
| 208 |
+
metadata={
|
| 209 |
+
"help": "Whether to pad all samples to model maximum sentence length. "
|
| 210 |
+
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
|
| 211 |
+
"efficient on GPU but very bad for TPU."
|
| 212 |
+
},
|
| 213 |
+
)
|
| 214 |
+
max_train_samples: Optional[int] = field(
|
| 215 |
+
default=None,
|
| 216 |
+
metadata={
|
| 217 |
+
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
| 218 |
+
"value if set."
|
| 219 |
+
},
|
| 220 |
+
)
|
| 221 |
+
max_eval_samples: Optional[int] = field(
|
| 222 |
+
default=None,
|
| 223 |
+
metadata={
|
| 224 |
+
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
| 225 |
+
"value if set."
|
| 226 |
+
},
|
| 227 |
+
)
|
| 228 |
+
max_predict_samples: Optional[int] = field(
|
| 229 |
+
default=None,
|
| 230 |
+
metadata={
|
| 231 |
+
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
|
| 232 |
+
"value if set."
|
| 233 |
+
},
|
| 234 |
+
)
|
| 235 |
+
num_beams: Optional[int] = field(
|
| 236 |
+
default=None,
|
| 237 |
+
metadata={
|
| 238 |
+
"help": "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
|
| 239 |
+
"which is used during ``evaluate`` and ``predict``."
|
| 240 |
+
},
|
| 241 |
+
)
|
| 242 |
+
ignore_pad_token_for_loss: bool = field(
|
| 243 |
+
default=True,
|
| 244 |
+
metadata={
|
| 245 |
+
"help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
|
| 246 |
+
},
|
| 247 |
+
)
|
| 248 |
+
source_prefix: Optional[str] = field(
|
| 249 |
+
default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
|
| 250 |
+
)
|
| 251 |
+
data_dir: Optional[str] = field(
|
| 252 |
+
default=None,
|
| 253 |
+
metadata={"help": "Defining the data_dir of the dataset configuration."},
|
| 254 |
+
)
|
| 255 |
+
download_mode: Optional[str] = field(
|
| 256 |
+
default=None,
|
| 257 |
+
metadata={
|
| 258 |
+
"help": "Defining the download_mode when loading the dataset. Options are `reuse_dataset_if_exists` (default), `reuse_cache_if_exists` and `force_redownload`."
|
| 259 |
+
},
|
| 260 |
+
)
|
| 261 |
+
evaluate_on_training_data: bool = field(
|
| 262 |
+
default=False,
|
| 263 |
+
metadata={"help": "Whether to evaluate on training data or not, to make sure the model can overfit."},
|
| 264 |
+
)
|
| 265 |
+
folder_suffix: str = field(
|
| 266 |
+
default="",
|
| 267 |
+
metadata={"help": "args to be suffixes for the output folder of the run"},
|
| 268 |
+
)
|
| 269 |
+
preprocess_only: bool = field(
|
| 270 |
+
default=False,
|
| 271 |
+
metadata={"help": "Preprocess only: Don't start training, just do the things before"},
|
| 272 |
+
)
|
| 273 |
+
assign_zero_to_too_long_val_examples: bool = field(
|
| 274 |
+
default=False,
|
| 275 |
+
metadata={
|
| 276 |
+
"help": "If true, all sequences longer then max_source_length will be assign a score of 0 in the metric evaluation"
|
| 277 |
+
},
|
| 278 |
+
)
|
| 279 |
+
shared_storage: bool = field(
|
| 280 |
+
default=True,
|
| 281 |
+
metadata={"help": "Whether nodes share the same storage"},
|
| 282 |
+
)
|
| 283 |
+
trim_very_long_strings: bool = field(
|
| 284 |
+
default=False,
|
| 285 |
+
metadata={"help": "Whether to trim very long strings before tokenizing them"},
|
| 286 |
+
)
|
| 287 |
+
pad_prefix: bool = field(
|
| 288 |
+
default=False,
|
| 289 |
+
metadata={
|
| 290 |
+
"help": "Whether to pad the prefix if it exists to max_prefix_length. "
|
| 291 |
+
"Note - important if you are using a SLED model on an input that contains an input_prefix"
|
| 292 |
+
},
|
| 293 |
+
)
|
| 294 |
+
test_start_ind: Optional[int] = field(
|
| 295 |
+
default=None,
|
| 296 |
+
metadata={"help": "if given, uses the test set starting from this index"},
|
| 297 |
+
)
|
| 298 |
+
test_end_ind: Optional[int] = field(
|
| 299 |
+
default=None,
|
| 300 |
+
metadata={"help": "if given, uses the test set ending at this index"},
|
| 301 |
+
)
|
| 302 |
+
# Uri:
|
| 303 |
+
patience: Optional[int] = field(
|
| 304 |
+
default=None,
|
| 305 |
+
)
|
| 306 |
+
length_penalty: Optional[float] = field(
|
| 307 |
+
default=1.0,
|
| 308 |
+
)
|
| 309 |
+
extra_metrics: Optional[List[str]] = field(
|
| 310 |
+
default=None,
|
| 311 |
+
metadata={"help": "The name of the metric to use (from src/metrics)."},
|
| 312 |
+
)
|
| 313 |
+
chunked_training_size: Optional[int] = field(
|
| 314 |
+
default=None,
|
| 315 |
+
)
|
| 316 |
+
oracle_training: Optional[bool] = field(
|
| 317 |
+
default=False,
|
| 318 |
+
metadata={"help": "If True, train on the input sentences that provide the highest ROUGE score with the labels"}
|
| 319 |
+
)
|
| 320 |
+
oracle_merge: Optional[bool] = field(
|
| 321 |
+
default=False,
|
| 322 |
+
metadata={"help": "If True, merge the oracle dataset and the standard training dataset"}
|
| 323 |
+
)
|
| 324 |
+
def __post_init__(self):
|
| 325 |
+
if self.val_max_target_length is None:
|
| 326 |
+
self.val_max_target_length = self.max_target_length
|
| 327 |
+
if self.pad_prefix and self.max_prefix_length == 0:
|
| 328 |
+
raise ValueError('When padding prefix, you must set a max_prefix_length')
|
| 329 |
+
assert self.max_prefix_length == 0 or self.max_prefix_length <= 0.5*self.max_source_length,\
|
| 330 |
+
'If max_prefix_length is given, it must be much shorter than the total input'
|
| 331 |
+
# Uri:
|
| 332 |
+
if self.eval_max_source_length is None:
|
| 333 |
+
self.eval_max_source_length = self.max_source_length
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
@dataclass
|
| 337 |
+
class UnlimiformerArguments:
|
| 338 |
+
"""
|
| 339 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 340 |
+
"""
|
| 341 |
+
test_unlimiformer: Optional[bool] = field(
|
| 342 |
+
default=False,
|
| 343 |
+
metadata={
|
| 344 |
+
"help": "whether to use KNN."
|
| 345 |
+
},
|
| 346 |
+
)
|
| 347 |
+
unlimiformer_verbose: Optional[bool] = field(
|
| 348 |
+
default=False,
|
| 349 |
+
metadata={
|
| 350 |
+
"help": "whether to print KNN intermediate predictions (mostly for debugging)."
|
| 351 |
+
},
|
| 352 |
+
)
|
| 353 |
+
layer_begin: Optional[int] = field(
|
| 354 |
+
default=0,
|
| 355 |
+
metadata={"help": "The layer to begin applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 356 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 357 |
+
)
|
| 358 |
+
layer_end: Optional[int] = field(
|
| 359 |
+
default=None,
|
| 360 |
+
metadata={"help": "The layer to end applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 361 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 362 |
+
)
|
| 363 |
+
unlimiformer_chunk_overlap: Optional[float] = field(
|
| 364 |
+
default=0.5,
|
| 365 |
+
metadata={"help": "The fraction of overlap between input chunks"},
|
| 366 |
+
)
|
| 367 |
+
unlimiformer_chunk_size: Optional[int] = field(
|
| 368 |
+
default=None,
|
| 369 |
+
metadata={"help": "The size of each input chunk"},
|
| 370 |
+
)
|
| 371 |
+
unlimiformer_head_num: Optional[int] = field(
|
| 372 |
+
default=None,
|
| 373 |
+
metadata={"help": "The head to apply KNN to (if None, apply to all heads)"},
|
| 374 |
+
)
|
| 375 |
+
unlimiformer_exclude: Optional[bool] = field(
|
| 376 |
+
default=False,
|
| 377 |
+
metadata={
|
| 378 |
+
"help": "If True, prioritize the inputs that are **not** in the standard attention window."
|
| 379 |
+
},
|
| 380 |
+
)
|
| 381 |
+
random_unlimiformer_training: Optional[bool] = field(
|
| 382 |
+
default=False,
|
| 383 |
+
)
|
| 384 |
+
unlimiformer_training: Optional[bool] = field(
|
| 385 |
+
default=False,
|
| 386 |
+
)
|
| 387 |
+
use_datastore: Optional[bool] = field(default=False)
|
| 388 |
+
flat_index: Optional[bool] = field(default=False)
|
| 389 |
+
test_datastore: Optional[bool] = field(default=False)
|
| 390 |
+
reconstruct_embeddings: Optional[bool] = field(default=False)
|
| 391 |
+
gpu_datastore: Optional[bool] = field(default=True)
|
| 392 |
+
gpu_index: Optional[bool] = field(default=True)
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
def main():
|
| 396 |
+
handle_args_to_ignore(sys.argv) # Just for sweeps
|
| 397 |
+
|
| 398 |
+
# See all possible arguments in src/transformers/training_args.py
|
| 399 |
+
# or by passing the --help flag to this script.
|
| 400 |
+
# We now keep distinct sets of args, for a cleaner separation of concerns.
|
| 401 |
+
|
| 402 |
+
parser = CustomHfArgumentParser((ModelArguments, DataTrainingArguments, TrainingOverridesArguments, UnlimiformerArguments))
|
| 403 |
+
model_args, data_args, training_args, unlimiformer_args = parser.parse_dictionary_and_args()
|
| 404 |
+
|
| 405 |
+
set_up_logging(training_args)
|
| 406 |
+
logger.info(f"Training Arguments: {training_args}")
|
| 407 |
+
logger.info(f"Data Arguments: {data_args}")
|
| 408 |
+
logger.info(f"Model Arguments: {model_args}")
|
| 409 |
+
logger.info(f"Unlimiformer Arguments: {unlimiformer_args}")
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
# Added to avoid wandb.errors.UsageError: Error communicating with wandb process
|
| 413 |
+
wandb.init(settings=wandb.Settings(start_method="fork"), name=training_args.output_dir)
|
| 414 |
+
|
| 415 |
+
# Used to find missing dependencies early on
|
| 416 |
+
load_metric(data_args.metric_names, **locals())
|
| 417 |
+
load_extra_metrics(data_args.extra_metrics)
|
| 418 |
+
|
| 419 |
+
if data_args.source_prefix is None and model_args.model_name_or_path in [
|
| 420 |
+
"t5-small",
|
| 421 |
+
"t5-base",
|
| 422 |
+
"t5-large",
|
| 423 |
+
"t5-3b",
|
| 424 |
+
"t5-11b",
|
| 425 |
+
]:
|
| 426 |
+
logger.warning(
|
| 427 |
+
"You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
|
| 428 |
+
"`--source_prefix 'summarize: ' `"
|
| 429 |
+
)
|
| 430 |
+
|
| 431 |
+
# Detecting last checkpoint.
|
| 432 |
+
last_checkpoint = _detect_last_checkpoint(training_args)
|
| 433 |
+
|
| 434 |
+
# Set seed before initializing model.
|
| 435 |
+
set_seed(training_args.seed)
|
| 436 |
+
|
| 437 |
+
seq2seq_dataset = _get_dataset(data_args, model_args, training_args)
|
| 438 |
+
|
| 439 |
+
# Load pretrained model and tokenizer
|
| 440 |
+
#
|
| 441 |
+
# Distributed training:
|
| 442 |
+
# The .from_pretrained methods guarantee that only one local process can concurrently
|
| 443 |
+
# download model & vocab.
|
| 444 |
+
config_name = None
|
| 445 |
+
if model_args.config_name:
|
| 446 |
+
config_name = model_args.config_name
|
| 447 |
+
else:
|
| 448 |
+
if os.path.isfile(model_args.model_name_or_path):
|
| 449 |
+
config_name = os.path.dirname(model_args.model_name_or_path)
|
| 450 |
+
else:
|
| 451 |
+
config_name = model_args.model_name_or_path
|
| 452 |
+
|
| 453 |
+
config_overrides = {}
|
| 454 |
+
if training_args.gradient_checkpointing is not None:
|
| 455 |
+
config_overrides["gradient_checkpointing"] = training_args.gradient_checkpointing
|
| 456 |
+
|
| 457 |
+
config = AutoConfig.from_pretrained(
|
| 458 |
+
config_name,
|
| 459 |
+
cache_dir=model_args.cache_dir,
|
| 460 |
+
revision=model_args.model_revision,
|
| 461 |
+
use_auth_token=training_args.use_auth_token,
|
| 462 |
+
**config_overrides
|
| 463 |
+
)
|
| 464 |
+
# override for sled models to make sure we are explicit in our request
|
| 465 |
+
# if isinstance(config, SledConfig) and (not data_args.pad_prefix or data_args.max_prefix_length == 0):
|
| 466 |
+
# logger.warning('Setting prepend_prefix to False if using a SLED model, as the input does not have a prefix or '
|
| 467 |
+
# 'pad_prefix is False (all prefixes must be of the same length for SLED). If you do not use SLED '
|
| 468 |
+
# 'or finetune on a dataset with no prefixes, ignore this warning')
|
| 469 |
+
# config.prepend_prefix = False
|
| 470 |
+
|
| 471 |
+
if model_args.model_name_or_path is None:
|
| 472 |
+
# Padding for divisibility by 8
|
| 473 |
+
if config.vocab_size % 8 != 0 and training_args.fp16_padding:
|
| 474 |
+
config.vocab_size += 8 - (config.vocab_size % 8)
|
| 475 |
+
|
| 476 |
+
tokenizer_name = None
|
| 477 |
+
if model_args.tokenizer_name:
|
| 478 |
+
tokenizer_name = model_args.tokenizer_name
|
| 479 |
+
else:
|
| 480 |
+
if os.path.isfile(model_args.model_name_or_path):
|
| 481 |
+
tokenizer_name = os.path.dirname(model_args.model_name_or_path)
|
| 482 |
+
else:
|
| 483 |
+
tokenizer_name = model_args.model_name_or_path
|
| 484 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 485 |
+
tokenizer_name,
|
| 486 |
+
cache_dir=model_args.cache_dir,
|
| 487 |
+
use_fast=model_args.use_fast_tokenizer,
|
| 488 |
+
revision=model_args.model_revision,
|
| 489 |
+
use_auth_token=training_args.use_auth_token,
|
| 490 |
+
)
|
| 491 |
+
if model_args.model_name_or_path is not None:
|
| 492 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(
|
| 493 |
+
model_args.model_name_or_path,
|
| 494 |
+
from_tf=bool(".ckpt" in model_args.model_name_or_path),
|
| 495 |
+
config=config,
|
| 496 |
+
cache_dir=model_args.cache_dir,
|
| 497 |
+
revision=model_args.model_revision,
|
| 498 |
+
use_auth_token=training_args.use_auth_token,
|
| 499 |
+
)
|
| 500 |
+
else:
|
| 501 |
+
model = AutoModelForSeq2SeqLM.from_config(
|
| 502 |
+
config,
|
| 503 |
+
)
|
| 504 |
+
if unlimiformer_args.test_unlimiformer:
|
| 505 |
+
unlimiformer_kwargs = {
|
| 506 |
+
'layer_begin': unlimiformer_args.layer_begin,
|
| 507 |
+
'layer_end': unlimiformer_args.layer_end,
|
| 508 |
+
'unlimiformer_head_num': unlimiformer_args.unlimiformer_head_num,
|
| 509 |
+
'exclude_attention': unlimiformer_args.unlimiformer_exclude,
|
| 510 |
+
'chunk_overlap': unlimiformer_args.unlimiformer_chunk_overlap,
|
| 511 |
+
'model_encoder_max_len': unlimiformer_args.unlimiformer_chunk_size,
|
| 512 |
+
'verbose': unlimiformer_args.unlimiformer_verbose, 'tokenizer': tokenizer,
|
| 513 |
+
'unlimiformer_training': unlimiformer_args.unlimiformer_training,
|
| 514 |
+
'use_datastore': unlimiformer_args.use_datastore,
|
| 515 |
+
'flat_index': unlimiformer_args.flat_index,
|
| 516 |
+
'test_datastore': unlimiformer_args.test_datastore,
|
| 517 |
+
'reconstruct_embeddings': unlimiformer_args.reconstruct_embeddings,
|
| 518 |
+
'gpu_datastore': unlimiformer_args.gpu_datastore,
|
| 519 |
+
'gpu_index': unlimiformer_args.gpu_index
|
| 520 |
+
}
|
| 521 |
+
if unlimiformer_args.random_unlimiformer_training:
|
| 522 |
+
model = RandomTrainingUnlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 523 |
+
else:
|
| 524 |
+
model = Unlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 525 |
+
|
| 526 |
+
model.config.use_cache = True
|
| 527 |
+
if training_args.gradient_checkpointing and getattr(model.config, 'use_cache', False) and training_args.do_train:
|
| 528 |
+
logger.warning('Cannot use cache in models when using gradient checkpointing. turning it off')
|
| 529 |
+
model.config.use_cache = False
|
| 530 |
+
|
| 531 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 532 |
+
|
| 533 |
+
if model.config.decoder_start_token_id is None:
|
| 534 |
+
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
|
| 535 |
+
|
| 536 |
+
prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
|
| 537 |
+
|
| 538 |
+
# Preprocessing the datasets.
|
| 539 |
+
# We need to tokenize inputs and targets.
|
| 540 |
+
if training_args.do_train:
|
| 541 |
+
column_names = seq2seq_dataset["train"].column_names
|
| 542 |
+
elif training_args.do_eval:
|
| 543 |
+
column_names = seq2seq_dataset["validation"].column_names
|
| 544 |
+
elif training_args.do_predict:
|
| 545 |
+
column_names = seq2seq_dataset["test"].column_names
|
| 546 |
+
else:
|
| 547 |
+
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
|
| 548 |
+
return
|
| 549 |
+
|
| 550 |
+
# Get the column names for input/target.
|
| 551 |
+
if data_args.input_column is None:
|
| 552 |
+
input_column = "input"
|
| 553 |
+
else:
|
| 554 |
+
input_column = data_args.input_column
|
| 555 |
+
if input_column not in column_names:
|
| 556 |
+
raise ValueError(
|
| 557 |
+
f"--input_column' value '{data_args.input_column}' needs to be one of: {', '.join(column_names)}"
|
| 558 |
+
)
|
| 559 |
+
if data_args.input_prefix_column is None:
|
| 560 |
+
input_prefix_column = "input_prefix"
|
| 561 |
+
else:
|
| 562 |
+
input_prefix_column = data_args.input_prefix_column
|
| 563 |
+
if input_prefix_column not in column_names:
|
| 564 |
+
raise ValueError(
|
| 565 |
+
f"--input_prefix_column' value '{data_args.input_prefix_column}' needs to be one of: {', '.join(column_names)}"
|
| 566 |
+
)
|
| 567 |
+
if data_args.output_column is None:
|
| 568 |
+
output_column = "output"
|
| 569 |
+
else:
|
| 570 |
+
output_column = data_args.output_column
|
| 571 |
+
if output_column not in column_names:
|
| 572 |
+
raise ValueError(
|
| 573 |
+
f"--output_column' value '{data_args.output_column}' needs to be one of: {', '.join(column_names)}"
|
| 574 |
+
)
|
| 575 |
+
|
| 576 |
+
# Temporarily set max_target_length for training.
|
| 577 |
+
max_target_length = data_args.max_target_length
|
| 578 |
+
padding = "max_length" if data_args.pad_to_max_length else False
|
| 579 |
+
|
| 580 |
+
if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
|
| 581 |
+
logger.warning(
|
| 582 |
+
"label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for"
|
| 583 |
+
f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
def preprocess_function_kwargs_fn():
|
| 587 |
+
return {
|
| 588 |
+
"tokenizer": deepcopy(tokenizer),
|
| 589 |
+
"prefix": prefix,
|
| 590 |
+
"input_column": input_column,
|
| 591 |
+
"input_prefix_column": input_prefix_column,
|
| 592 |
+
"output_column": output_column,
|
| 593 |
+
"max_source_length": data_args.max_source_length,
|
| 594 |
+
"max_prefix_length": data_args.max_prefix_length,
|
| 595 |
+
"max_target_length": max_target_length,
|
| 596 |
+
"prefix_sep": PREFIX_DOC_SEP,
|
| 597 |
+
"padding": padding,
|
| 598 |
+
"ignore_pad_token_for_loss": data_args.ignore_pad_token_for_loss,
|
| 599 |
+
"assign_zero_to_too_long_val_examples": data_args.assign_zero_to_too_long_val_examples,
|
| 600 |
+
"trim_very_long_strings": data_args.trim_very_long_strings,
|
| 601 |
+
"pad_prefix": data_args.pad_prefix
|
| 602 |
+
}
|
| 603 |
+
|
| 604 |
+
if training_args.do_train:
|
| 605 |
+
if "train" not in seq2seq_dataset:
|
| 606 |
+
raise ValueError("--do_train requires a train dataset")
|
| 607 |
+
logger.info("")
|
| 608 |
+
logger.info("Training examples before tokenization:")
|
| 609 |
+
if input_prefix_column in column_names:
|
| 610 |
+
logger.info(f"input_prefix #0: {seq2seq_dataset['train'][0][input_prefix_column]}")
|
| 611 |
+
# logger.info(f"input #0: {seq2seq_dataset['train'][0]['input']}")
|
| 612 |
+
# logger.info(f"output #0: {seq2seq_dataset['train'][0]['output']}")
|
| 613 |
+
if input_prefix_column in column_names:
|
| 614 |
+
logger.info(f"input_prefix #1: {seq2seq_dataset['train'][1][input_prefix_column]}")
|
| 615 |
+
# logger.info(f"input #1: {seq2seq_dataset['train'][1]['input']}")
|
| 616 |
+
# logger.info(f"output #1: {seq2seq_dataset['train'][1]['output']}")
|
| 617 |
+
logger.info("")
|
| 618 |
+
untokenized_train_dataset = seq2seq_dataset["train"]
|
| 619 |
+
if data_args.max_train_samples is not None:
|
| 620 |
+
untokenized_train_dataset = untokenized_train_dataset.select(range(data_args.max_train_samples))
|
| 621 |
+
|
| 622 |
+
if DEBUG:
|
| 623 |
+
# In debug mode, we want to recreate the data
|
| 624 |
+
data_args.shared_storage = False
|
| 625 |
+
data_args.overwrite_cache = True
|
| 626 |
+
with training_args.main_process_first(
|
| 627 |
+
local=not data_args.shared_storage, desc="train dataset map pre-processing"
|
| 628 |
+
):
|
| 629 |
+
|
| 630 |
+
if data_args.oracle_training:
|
| 631 |
+
logger.info("Using oracle training")
|
| 632 |
+
oracle_processed_dir = f'oracle_input_{data_args.dataset_config_name}'
|
| 633 |
+
if os.path.isdir(oracle_processed_dir):
|
| 634 |
+
logger.info(f"Using oracle training from {oracle_processed_dir}")
|
| 635 |
+
oracle_training_set = datasets.load_from_disk(oracle_processed_dir)
|
| 636 |
+
else:
|
| 637 |
+
rouge_scorer = datasets.load_metric('rouge')
|
| 638 |
+
oracle_training_set = untokenized_train_dataset.map(
|
| 639 |
+
extract_oracle_sent_batch,
|
| 640 |
+
fn_kwargs={'max_length': data_args.max_source_length,
|
| 641 |
+
'tokenizer': tokenizer,
|
| 642 |
+
'rouge_scorer': rouge_scorer},
|
| 643 |
+
batched=True,
|
| 644 |
+
batch_size=1,
|
| 645 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 646 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 647 |
+
desc="Extracting oracle sentences from every training example",
|
| 648 |
+
)
|
| 649 |
+
oracle_training_set.save_to_disk(oracle_processed_dir)
|
| 650 |
+
|
| 651 |
+
|
| 652 |
+
if data_args.oracle_merge:
|
| 653 |
+
untokenized_train_dataset = datasets.concatenate_datasets([untokenized_train_dataset, oracle_training_set])
|
| 654 |
+
untokenized_train_dataset = untokenized_train_dataset.shuffle(seed=training_args.seed)
|
| 655 |
+
else:
|
| 656 |
+
untokenized_train_dataset = oracle_training_set
|
| 657 |
+
|
| 658 |
+
train_dataset = untokenized_train_dataset.map(
|
| 659 |
+
preprocess_function,
|
| 660 |
+
fn_kwargs=preprocess_function_kwargs_fn(),
|
| 661 |
+
batched=True,
|
| 662 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 663 |
+
remove_columns=untokenized_train_dataset.column_names,
|
| 664 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 665 |
+
desc="Running tokenizer on train dataset",
|
| 666 |
+
)
|
| 667 |
+
|
| 668 |
+
if data_args.chunked_training_size is not None:
|
| 669 |
+
train_dataset = train_dataset.map(
|
| 670 |
+
chunk_dataset_function,
|
| 671 |
+
fn_kwargs={'chunk_size': data_args.chunked_training_size},
|
| 672 |
+
batched=True,
|
| 673 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 674 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 675 |
+
desc="Chunking train dataset source",
|
| 676 |
+
)
|
| 677 |
+
train_dataset = train_dataset.shuffle(seed=training_args.seed)
|
| 678 |
+
|
| 679 |
+
if training_args.do_eval:
|
| 680 |
+
max_target_length = data_args.val_max_target_length
|
| 681 |
+
preprocess_function_kwargs = preprocess_function_kwargs_fn()
|
| 682 |
+
preprocess_function_kwargs["max_target_length"] = max_target_length
|
| 683 |
+
preprocess_function_kwargs['max_source_length'] = data_args.eval_max_source_length
|
| 684 |
+
if "validation" not in seq2seq_dataset:
|
| 685 |
+
raise ValueError("--do_eval requires a validation dataset")
|
| 686 |
+
logger.info("")
|
| 687 |
+
logger.info("Validation examples before tokenization:")
|
| 688 |
+
if input_prefix_column in column_names:
|
| 689 |
+
logger.info(f"input_prefix #0: {seq2seq_dataset['validation'][0][input_prefix_column]}")
|
| 690 |
+
# logger.info(f"input #0: {seq2seq_dataset['validation'][0]['input']}")
|
| 691 |
+
# logger.info(f"output #0: {seq2seq_dataset['validation'][0]['output']}")
|
| 692 |
+
if input_prefix_column in column_names:
|
| 693 |
+
logger.info(f"input_prefix #1: {seq2seq_dataset['validation'][1][input_prefix_column]}")
|
| 694 |
+
# logger.info(f"input #1: {seq2seq_dataset['validation'][1]['input']}")
|
| 695 |
+
# logger.info(f"output #1: {seq2seq_dataset['validation'][1]['output']}")
|
| 696 |
+
logger.info("")
|
| 697 |
+
untokenized_eval_dataset = seq2seq_dataset["validation"]
|
| 698 |
+
if data_args.max_eval_samples is not None:
|
| 699 |
+
untokenized_eval_dataset = untokenized_eval_dataset.select(range(data_args.max_eval_samples))
|
| 700 |
+
if model_args.drop_duplicates_in_eval is True:
|
| 701 |
+
untokenized_eval_dataset = drop_duplicates_in_input(untokenized_eval_dataset)
|
| 702 |
+
untokenized_eval_dataset_orig = untokenized_eval_dataset
|
| 703 |
+
assert training_args.eval_fraction > 0
|
| 704 |
+
n = len(untokenized_eval_dataset)
|
| 705 |
+
training_args = replace(training_args, eval_fraction = min(training_args.eval_fraction, n))
|
| 706 |
+
if training_args.eval_fraction != 1:
|
| 707 |
+
if training_args.eval_fraction > 1:
|
| 708 |
+
assert training_args.eval_fraction == int(training_args.eval_fraction)
|
| 709 |
+
logger.info(f'using predetermined absolute samples from eval set ({training_args.eval_fraction} )')
|
| 710 |
+
training_args = replace(training_args, eval_fraction = training_args.eval_fraction / n)
|
| 711 |
+
indices = np.random.permutation(n)[:int(np.ceil(max(1, training_args.eval_fraction * n)))]
|
| 712 |
+
untokenized_eval_dataset = type(untokenized_eval_dataset).from_dict(untokenized_eval_dataset[indices])
|
| 713 |
+
logger.info(f'During training, will only use {training_args.eval_fraction:.3%} samples of the eval set '
|
| 714 |
+
f'which amounts to {len(untokenized_eval_dataset)} out of {n} samples')
|
| 715 |
+
|
| 716 |
+
eval_dataset = process_eval_set(data_args, preprocess_function_kwargs, training_args, untokenized_eval_dataset)
|
| 717 |
+
eval_dataset_orig = eval_dataset
|
| 718 |
+
if training_args.eval_fraction < 1:
|
| 719 |
+
eval_dataset_orig = process_eval_set(data_args, preprocess_function_kwargs, training_args,
|
| 720 |
+
untokenized_eval_dataset_orig)
|
| 721 |
+
|
| 722 |
+
if training_args.do_predict:
|
| 723 |
+
max_target_length = data_args.val_max_target_length
|
| 724 |
+
preprocess_function_kwargs = preprocess_function_kwargs_fn()
|
| 725 |
+
preprocess_function_kwargs["max_target_length"] = max_target_length
|
| 726 |
+
preprocess_function_kwargs['max_source_length'] = data_args.eval_max_source_length
|
| 727 |
+
if "test" not in seq2seq_dataset:
|
| 728 |
+
raise ValueError("--do_predict requires a test dataset")
|
| 729 |
+
untokenized_predict_dataset = seq2seq_dataset["test"]
|
| 730 |
+
if data_args.max_predict_samples is not None:
|
| 731 |
+
untokenized_predict_dataset = untokenized_predict_dataset.select(range(data_args.max_predict_samples))
|
| 732 |
+
if model_args.drop_duplicates_in_eval is True:
|
| 733 |
+
untokenized_predict_dataset = drop_duplicates_in_input(untokenized_predict_dataset)
|
| 734 |
+
|
| 735 |
+
if output_column in untokenized_predict_dataset.column_names:
|
| 736 |
+
untokenized_predict_dataset = untokenized_predict_dataset.remove_columns(output_column)
|
| 737 |
+
|
| 738 |
+
if data_args.test_start_ind is not None:
|
| 739 |
+
sind = data_args.test_start_ind
|
| 740 |
+
eind = -1 if data_args.test_end_ind is None else data_args.test_end_ind
|
| 741 |
+
logger.info(f'Using only a subset of the test dataset [{sind}, {eind}]')
|
| 742 |
+
untokenized_predict_dataset = type(untokenized_predict_dataset).from_dict(untokenized_predict_dataset[sind:eind])
|
| 743 |
+
|
| 744 |
+
with training_args.main_process_first(
|
| 745 |
+
local=not data_args.shared_storage, desc="prediction dataset map pre-processing"
|
| 746 |
+
):
|
| 747 |
+
predict_dataset = untokenized_predict_dataset.map(
|
| 748 |
+
preprocess_function,
|
| 749 |
+
fn_kwargs=preprocess_function_kwargs,
|
| 750 |
+
batched=True,
|
| 751 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 752 |
+
remove_columns=untokenized_predict_dataset.column_names,
|
| 753 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 754 |
+
desc="Running tokenizer on prediction dataset",
|
| 755 |
+
)
|
| 756 |
+
|
| 757 |
+
if data_args.preprocess_only:
|
| 758 |
+
logger.info(f"With --preprocess_only, exiting after preprocess_on the data")
|
| 759 |
+
exit()
|
| 760 |
+
|
| 761 |
+
# Data collator
|
| 762 |
+
label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
|
| 763 |
+
pad_to = 8 if training_args.fp16 and training_args.fp16_padding else None
|
| 764 |
+
|
| 765 |
+
|
| 766 |
+
data_collator = DataCollatorForSeq2Seq(
|
| 767 |
+
tokenizer,
|
| 768 |
+
model=model,
|
| 769 |
+
label_pad_token_id=label_pad_token_id,
|
| 770 |
+
pad_to_multiple_of=pad_to,
|
| 771 |
+
)
|
| 772 |
+
|
| 773 |
+
# Metric
|
| 774 |
+
compute_metrics = load_metric(data_args.metric_names, **locals())
|
| 775 |
+
compute_metrics = load_extra_metrics(data_args.extra_metrics, compute_metrics)
|
| 776 |
+
|
| 777 |
+
# Initialize our Trainer
|
| 778 |
+
trainer = CustomTrainer(
|
| 779 |
+
model=model,
|
| 780 |
+
args=training_args,
|
| 781 |
+
train_dataset=train_dataset if training_args.do_train else None,
|
| 782 |
+
eval_dataset=eval_dataset if training_args.do_eval else None,
|
| 783 |
+
untokenized_eval_dataset=untokenized_eval_dataset if training_args.do_eval else None,
|
| 784 |
+
tokenizer=tokenizer,
|
| 785 |
+
data_collator=data_collator,
|
| 786 |
+
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
|
| 787 |
+
output_dir=training_args.output_dir,
|
| 788 |
+
data_args=data_args,
|
| 789 |
+
callbacks=[EarlyStoppingCallback(early_stopping_patience=data_args.patience)] if data_args.patience is not None else None,
|
| 790 |
+
)
|
| 791 |
+
|
| 792 |
+
# setup_cometml_trainer_callback(trainer)
|
| 793 |
+
|
| 794 |
+
# Training
|
| 795 |
+
if training_args.do_train:
|
| 796 |
+
checkpoint = None
|
| 797 |
+
if training_args.resume_from_checkpoint is not None:
|
| 798 |
+
checkpoint = training_args.resume_from_checkpoint
|
| 799 |
+
elif last_checkpoint is not None:
|
| 800 |
+
checkpoint = last_checkpoint # look for checkpoints in the outdir
|
| 801 |
+
|
| 802 |
+
train_result = trainer.train(resume_from_checkpoint=checkpoint)
|
| 803 |
+
logger.info('Done training')
|
| 804 |
+
trainer.save_model() # Saves the tokenizer too for easy upload
|
| 805 |
+
|
| 806 |
+
metrics = train_result.metrics
|
| 807 |
+
max_train_samples = (
|
| 808 |
+
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
|
| 809 |
+
)
|
| 810 |
+
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
|
| 811 |
+
|
| 812 |
+
trainer.log_metrics("train", metrics)
|
| 813 |
+
trainer.save_metrics("train", metrics)
|
| 814 |
+
trainer.save_state()
|
| 815 |
+
|
| 816 |
+
# Evaluation
|
| 817 |
+
results = {}
|
| 818 |
+
if training_args.do_eval:
|
| 819 |
+
logger.info("*** Evaluate ***")
|
| 820 |
+
|
| 821 |
+
if training_args.eval_fraction < 1:
|
| 822 |
+
logger.info('setting the eval set back to the full one')
|
| 823 |
+
trainer.eval_dataset = eval_dataset_orig
|
| 824 |
+
trainer._untokenized_eval_dataset = untokenized_eval_dataset_orig
|
| 825 |
+
|
| 826 |
+
metrics = trainer.evaluate(metric_key_prefix="eval", use_cache=True, length_penalty=data_args.length_penalty)
|
| 827 |
+
logger.info('Done evaluating')
|
| 828 |
+
|
| 829 |
+
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
|
| 830 |
+
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
|
| 831 |
+
|
| 832 |
+
trainer.log_metrics("eval", metrics)
|
| 833 |
+
trainer.save_metrics("eval", metrics)
|
| 834 |
+
|
| 835 |
+
if training_args.do_predict:
|
| 836 |
+
logger.info("*** Predict ***")
|
| 837 |
+
trainer.args.predict_with_generate = True # during prediction, we don't have labels
|
| 838 |
+
|
| 839 |
+
# load last (and best) model, or the one specified if any
|
| 840 |
+
logger.info("*** Loading model weights before the prediction ***")
|
| 841 |
+
last_checkpoint = model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else _detect_last_checkpoint(training_args)
|
| 842 |
+
if last_checkpoint is not None and os.path.isdir(last_checkpoint):
|
| 843 |
+
logger.info(f'Loading weights from {last_checkpoint} for the prediction')
|
| 844 |
+
state_dict = torch.load(os.path.join(last_checkpoint, WEIGHTS_NAME), map_location="cpu")
|
| 845 |
+
# If the model is on the GPU, it still works!
|
| 846 |
+
# trainer._load_state_dict_in_model(state_dict)
|
| 847 |
+
# release memory
|
| 848 |
+
del state_dict
|
| 849 |
+
logger.info("*** Done loading weights ***")
|
| 850 |
+
elif training_args.do_train:
|
| 851 |
+
raise ValueError('Could not find a model to load for prediction')
|
| 852 |
+
else:
|
| 853 |
+
logger.info(f'Using {model_args.model_name_or_path} as the model for the prediction')
|
| 854 |
+
|
| 855 |
+
predict_results = trainer.predict(predict_dataset, metric_key_prefix="predict", use_cache=True)
|
| 856 |
+
logger.info('Done predicting')
|
| 857 |
+
|
| 858 |
+
metrics = predict_results.metrics
|
| 859 |
+
max_predict_samples = (
|
| 860 |
+
data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
|
| 861 |
+
)
|
| 862 |
+
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
|
| 863 |
+
|
| 864 |
+
trainer.log_metrics("predict", metrics)
|
| 865 |
+
trainer.save_metrics("predict", metrics)
|
| 866 |
+
|
| 867 |
+
if trainer.is_world_process_zero():
|
| 868 |
+
if training_args.predict_with_generate:
|
| 869 |
+
id_to_prediction = {}
|
| 870 |
+
for i, instance in enumerate(untokenized_predict_dataset):
|
| 871 |
+
id_to_prediction[instance["id"]] = predict_results.predictions[i]
|
| 872 |
+
predictions = decode(id_to_prediction, tokenizer, data_args)
|
| 873 |
+
output_name = "generated_predictions.json"
|
| 874 |
+
if data_args.test_start_ind is not None:
|
| 875 |
+
output_name = f"generated_predictions_{data_args.test_start_ind}_{data_args.test_end_ind}.json"
|
| 876 |
+
output_prediction_file = os.path.join(training_args.output_dir, output_name)
|
| 877 |
+
with open(output_prediction_file, "w") as writer:
|
| 878 |
+
json.dump(predictions, writer, indent=4)
|
| 879 |
+
|
| 880 |
+
if training_args.push_to_hub:
|
| 881 |
+
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "summarization"}
|
| 882 |
+
if data_args.dataset_name is not None:
|
| 883 |
+
kwargs["dataset_tags"] = data_args.dataset_name
|
| 884 |
+
if data_args.dataset_config_name is not None:
|
| 885 |
+
kwargs["dataset_args"] = data_args.dataset_config_name
|
| 886 |
+
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
|
| 887 |
+
else:
|
| 888 |
+
kwargs["dataset"] = data_args.dataset_name
|
| 889 |
+
|
| 890 |
+
trainer.push_to_hub(**kwargs)
|
| 891 |
+
|
| 892 |
+
return results
|
| 893 |
+
|
| 894 |
+
def _detect_last_checkpoint(training_args):
|
| 895 |
+
last_checkpoint = None
|
| 896 |
+
if os.path.isdir(training_args.output_dir) and training_args.do_train:
|
| 897 |
+
if not training_args.overwrite_output_dir:
|
| 898 |
+
last_checkpoint = get_last_checkpoint(training_args.output_dir)
|
| 899 |
+
|
| 900 |
+
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
|
| 901 |
+
logger.info(
|
| 902 |
+
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
|
| 903 |
+
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
|
| 904 |
+
)
|
| 905 |
+
return last_checkpoint
|
| 906 |
+
|
| 907 |
+
def process_eval_set(data_args, preprocess_function_kwargs, training_args, untokenized_eval_dataset):
|
| 908 |
+
with training_args.main_process_first(
|
| 909 |
+
local=not data_args.shared_storage, desc="validation dataset map pre-processing"
|
| 910 |
+
):
|
| 911 |
+
eval_dataset = untokenized_eval_dataset.map(
|
| 912 |
+
preprocess_function,
|
| 913 |
+
fn_kwargs=preprocess_function_kwargs,
|
| 914 |
+
batched=True,
|
| 915 |
+
num_proc=data_args.preprocessing_num_workers,
|
| 916 |
+
remove_columns=untokenized_eval_dataset.column_names,
|
| 917 |
+
load_from_cache_file=not data_args.overwrite_cache,
|
| 918 |
+
desc="Running tokenizer on validation dataset",
|
| 919 |
+
)
|
| 920 |
+
return eval_dataset
|
| 921 |
+
|
| 922 |
+
|
| 923 |
+
def _get_dataset(data_args, model_args, training_args):
|
| 924 |
+
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
|
| 925 |
+
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
|
| 926 |
+
# (the dataset will be downloaded automatically from the datasets Hub).
|
| 927 |
+
#
|
| 928 |
+
# For CSV/JSON files this script will use the first column for the full texts and the second column for the
|
| 929 |
+
# summaries (unless you specify column names for this with the `input_column` and `output_column` arguments).
|
| 930 |
+
#
|
| 931 |
+
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
|
| 932 |
+
# download the dataset.
|
| 933 |
+
data_files = None
|
| 934 |
+
if data_args.train_file is not None or data_args.validation_file is not None or data_args.test_file is not None:
|
| 935 |
+
data_files = {}
|
| 936 |
+
if data_args.train_file is not None:
|
| 937 |
+
data_files["train"] = data_args.train_file
|
| 938 |
+
if data_args.validation_file is not None:
|
| 939 |
+
data_files["validation"] = data_args.validation_file
|
| 940 |
+
if data_args.test_file is not None:
|
| 941 |
+
data_files["test"] = data_args.test_file
|
| 942 |
+
# Downloading and loading a dataset from the hub/local script.
|
| 943 |
+
seq2seq_dataset = load_dataset(
|
| 944 |
+
data_args.dataset_name,
|
| 945 |
+
data_args.dataset_config_name,
|
| 946 |
+
verification_mode='no_checks',
|
| 947 |
+
cache_dir=model_args.cache_dir,
|
| 948 |
+
data_dir=data_args.data_dir,
|
| 949 |
+
data_files=data_files,
|
| 950 |
+
download_mode=data_args.download_mode,
|
| 951 |
+
use_auth_token=training_args.use_auth_token
|
| 952 |
+
)
|
| 953 |
+
if training_args.do_train:
|
| 954 |
+
training_args.apply_overrides(len(seq2seq_dataset['train']))
|
| 955 |
+
if data_args.evaluate_on_training_data:
|
| 956 |
+
seq2seq_dataset["validation"] = seq2seq_dataset["train"]
|
| 957 |
+
|
| 958 |
+
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
|
| 959 |
+
# https://huggingface.co/docs/datasets/loading_datasets.html.
|
| 960 |
+
|
| 961 |
+
return seq2seq_dataset
|
| 962 |
+
|
| 963 |
+
|
| 964 |
+
def set_up_logging(training_args):
|
| 965 |
+
logging.basicConfig(
|
| 966 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 967 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 968 |
+
handlers=[logging.StreamHandler(sys.stdout)],
|
| 969 |
+
)
|
| 970 |
+
log_level = training_args.get_process_log_level()
|
| 971 |
+
logger.setLevel(log_level)
|
| 972 |
+
datasets.utils.logging.set_verbosity(log_level)
|
| 973 |
+
transformers.utils.logging.set_verbosity(log_level)
|
| 974 |
+
transformers.utils.logging.enable_default_handler()
|
| 975 |
+
transformers.utils.logging.enable_explicit_format()
|
| 976 |
+
# Log on each process the small summary:
|
| 977 |
+
logger.warning(
|
| 978 |
+
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
|
| 979 |
+
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
|
| 980 |
+
)
|
| 981 |
+
logger.info(f"Training/evaluation parameters {training_args}")
|
| 982 |
+
|
| 983 |
+
def extract_oracle_sent_batch(examples, max_length, tokenizer, rouge_scorer):
|
| 984 |
+
items = examples.data.items()
|
| 985 |
+
keys = [item[0] for item in items]
|
| 986 |
+
values = [item[1] for item in items]
|
| 987 |
+
extracted = {k: [] for k in keys}
|
| 988 |
+
input_str = 'input'
|
| 989 |
+
|
| 990 |
+
for ex in zip(*values):
|
| 991 |
+
ex = dict(zip(keys, ex))
|
| 992 |
+
ex_input = ex[input_str]
|
| 993 |
+
extracted_input = extract_oracle_sentences(ex_input, ex['output'], max_length, tokenizer, rouge_scorer)
|
| 994 |
+
extracted[input_str].append(extracted_input)
|
| 995 |
+
for k in set(keys) - {input_str}:
|
| 996 |
+
extracted[k].append(ex[k])
|
| 997 |
+
return extracted
|
| 998 |
+
|
| 999 |
+
def extract_oracle_sentences(input_sequence, output, max_length, tokenizer, rouge_scorer, criterion='rouge/geometric_mean'):
|
| 1000 |
+
sentences = nltk.sent_tokenize(input_sequence)
|
| 1001 |
+
selected_mask = [False for _ in sentences]
|
| 1002 |
+
|
| 1003 |
+
max_rouge = 0.0
|
| 1004 |
+
joined_selection = ''
|
| 1005 |
+
counter = 0
|
| 1006 |
+
while len(tokenizer(joined_selection)) < max_length and counter < 100:
|
| 1007 |
+
cur_max_rouge = max_rouge
|
| 1008 |
+
max_index = -1
|
| 1009 |
+
|
| 1010 |
+
cur_candidate_indices = []
|
| 1011 |
+
cur_candidates = []
|
| 1012 |
+
for i in range(len(sentences)):
|
| 1013 |
+
if selected_mask[i]:
|
| 1014 |
+
# We already selected this sentence
|
| 1015 |
+
continue
|
| 1016 |
+
candidate_mask = list(selected_mask)
|
| 1017 |
+
candidate_mask[i] = True
|
| 1018 |
+
candidate_prediction = ' '.join(sent for sent, mask in zip(sentences, candidate_mask) if mask)
|
| 1019 |
+
cur_candidates.append(candidate_prediction)
|
| 1020 |
+
cur_candidate_indices.append(i)
|
| 1021 |
+
|
| 1022 |
+
rouge = rouge_scorer.compute(predictions=cur_candidates, references=[[output]] * len(cur_candidates), use_aggregator=False)
|
| 1023 |
+
aggregated_rouge_types = [s1.fmeasure * s2.fmeasure * sL.fmeasure for s1, s2, sL in zip(rouge['rouge1'], rouge['rouge2'], rouge['rougeLsum'])]
|
| 1024 |
+
max_index = np.argmax(aggregated_rouge_types)
|
| 1025 |
+
cur_max_rouge = aggregated_rouge_types[max_index]
|
| 1026 |
+
|
| 1027 |
+
if max_rouge >= cur_max_rouge:
|
| 1028 |
+
# No sentence improves the score
|
| 1029 |
+
break
|
| 1030 |
+
|
| 1031 |
+
selected_mask[cur_candidate_indices[max_index]] = True
|
| 1032 |
+
max_rouge = cur_max_rouge
|
| 1033 |
+
joined_selection = ' '.join(sent for sent, mask in zip(sentences, selected_mask) if mask)
|
| 1034 |
+
counter += 1
|
| 1035 |
+
|
| 1036 |
+
return joined_selection
|
| 1037 |
+
|
| 1038 |
+
|
| 1039 |
+
def chunk_dataset_function(examples, chunk_size):
|
| 1040 |
+
input_ids_str = 'input_ids'
|
| 1041 |
+
attention_mask_str = 'attention_mask'
|
| 1042 |
+
items = examples.data.items()
|
| 1043 |
+
keys = [item[0] for item in items]
|
| 1044 |
+
values = [item[1] for item in items]
|
| 1045 |
+
chunked = {k: [] for k in keys}
|
| 1046 |
+
for ex in zip(*values):
|
| 1047 |
+
ex = dict(zip(keys, ex))
|
| 1048 |
+
for i in range(0, len(ex[input_ids_str]), chunk_size):
|
| 1049 |
+
chunked_input_ids_st = ex[input_ids_str][i:i + chunk_size]
|
| 1050 |
+
chunked_attention_mask = ex[attention_mask_str][i:i + chunk_size]
|
| 1051 |
+
|
| 1052 |
+
if sum(chunked_attention_mask) < 10:
|
| 1053 |
+
continue
|
| 1054 |
+
chunked[input_ids_str].append(chunked_input_ids_st)
|
| 1055 |
+
chunked[attention_mask_str].append(chunked_attention_mask)
|
| 1056 |
+
for k in set(keys) - {input_ids_str, attention_mask_str}:
|
| 1057 |
+
chunked[k].append(ex[k])
|
| 1058 |
+
return chunked
|
| 1059 |
+
|
| 1060 |
+
|
| 1061 |
+
|
| 1062 |
+
def preprocess_function(
|
| 1063 |
+
examples,
|
| 1064 |
+
tokenizer,
|
| 1065 |
+
prefix,
|
| 1066 |
+
input_column,
|
| 1067 |
+
input_prefix_column,
|
| 1068 |
+
output_column,
|
| 1069 |
+
max_source_length,
|
| 1070 |
+
max_prefix_length,
|
| 1071 |
+
max_target_length,
|
| 1072 |
+
prefix_sep,
|
| 1073 |
+
padding,
|
| 1074 |
+
ignore_pad_token_for_loss,
|
| 1075 |
+
assign_zero_to_too_long_val_examples,
|
| 1076 |
+
trim_very_long_strings,
|
| 1077 |
+
pad_prefix
|
| 1078 |
+
):
|
| 1079 |
+
if not isinstance(examples[input_column][0], str):
|
| 1080 |
+
model_inputs = _preprocess_tokenized_inputs()
|
| 1081 |
+
else:
|
| 1082 |
+
model_inputs = _preprocess_raw_inputs(assign_zero_to_too_long_val_examples, examples, input_column, input_prefix_column,
|
| 1083 |
+
max_source_length, padding, prefix, tokenizer, trim_very_long_strings, max_prefix_length,
|
| 1084 |
+
prefix_sep, pad_prefix)
|
| 1085 |
+
|
| 1086 |
+
_preprocess_targets(examples, ignore_pad_token_for_loss, max_target_length, model_inputs, output_column, padding, tokenizer)
|
| 1087 |
+
model_inputs["length"] = [len(x) for x in model_inputs["input_ids"]]
|
| 1088 |
+
return model_inputs
|
| 1089 |
+
|
| 1090 |
+
|
| 1091 |
+
def _preprocess_raw_inputs(assign_zero_to_too_long_val_examples, examples, input_column, input_prefix_column,
|
| 1092 |
+
max_source_length, padding, prefix, tokenizer, trim_very_long_strings, max_prefix_length,
|
| 1093 |
+
prefix_sep, pad_prefix):
|
| 1094 |
+
inputs = examples[input_column]
|
| 1095 |
+
|
| 1096 |
+
# the given prefix is what used in models like T5 (e.g. "summarize: ")
|
| 1097 |
+
# if prefix exists, it is added to the input_prefixes
|
| 1098 |
+
if input_prefix_column in examples.keys():
|
| 1099 |
+
input_prefixes = [inp + prefix_sep for inp in examples[input_prefix_column]]
|
| 1100 |
+
if prefix != "":
|
| 1101 |
+
input_prefixes = [prefix + inp for inp in input_prefixes]
|
| 1102 |
+
elif prefix != "":
|
| 1103 |
+
inputs = [prefix + inp for inp in inputs]
|
| 1104 |
+
|
| 1105 |
+
# tokenize the input prefix if it exists
|
| 1106 |
+
model_prefix_inputs = None
|
| 1107 |
+
if input_prefix_column in examples.keys():
|
| 1108 |
+
if trim_very_long_strings:
|
| 1109 |
+
input_prefixes = [inp[: max_prefix_length * 7] for inp in input_prefixes]
|
| 1110 |
+
if pad_prefix:
|
| 1111 |
+
model_prefix_inputs = tokenizer(input_prefixes, max_length=max_prefix_length, padding='max_length', truncation=True)
|
| 1112 |
+
else:
|
| 1113 |
+
# for led, we do not pad the prefix
|
| 1114 |
+
model_prefix_inputs = tokenizer(input_prefixes, max_length=max_source_length, padding='do_not_pad', truncation=True)
|
| 1115 |
+
|
| 1116 |
+
if trim_very_long_strings:
|
| 1117 |
+
inputs = [inp[: max_source_length * 7] for inp in inputs]
|
| 1118 |
+
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
|
| 1119 |
+
|
| 1120 |
+
if max_source_length is not None and assign_zero_to_too_long_val_examples:
|
| 1121 |
+
model_inputs_untrimmed = tokenizer(inputs)
|
| 1122 |
+
model_inputs["not_valid_for_eval"] = [
|
| 1123 |
+
len(token_ids) > max_source_length for token_ids in model_inputs_untrimmed["input_ids"]
|
| 1124 |
+
]
|
| 1125 |
+
else:
|
| 1126 |
+
model_inputs["not_valid_for_eval"] = [False] * len(model_inputs["input_ids"])
|
| 1127 |
+
|
| 1128 |
+
# now, combine the concat prefix to the input, trimming it to max_source_length if given
|
| 1129 |
+
if model_prefix_inputs is not None:
|
| 1130 |
+
max_source_length = max_source_length or -1
|
| 1131 |
+
model_inputs['input_ids'] = [(inp1+inp2)[:max_source_length] for inp1, inp2
|
| 1132 |
+
in zip(model_prefix_inputs['input_ids'], model_inputs['input_ids'])]
|
| 1133 |
+
model_inputs['attention_mask'] = [(inp1+inp2)[:max_source_length] for inp1, inp2
|
| 1134 |
+
in zip(model_prefix_inputs['attention_mask'], model_inputs['attention_mask'])]
|
| 1135 |
+
# add prefix_length
|
| 1136 |
+
if pad_prefix:
|
| 1137 |
+
# no need to go over them as they will all be of the same length
|
| 1138 |
+
model_inputs['prefix_length'] = [max_prefix_length] * len(model_inputs['input_ids'])
|
| 1139 |
+
else:
|
| 1140 |
+
model_inputs['prefix_length'] = [len(inp) for inp in model_prefix_inputs['input_ids']]
|
| 1141 |
+
|
| 1142 |
+
return model_inputs
|
| 1143 |
+
|
| 1144 |
+
def _preprocess_targets(examples, ignore_pad_token_for_loss, max_target_length, model_inputs, output_column, padding, tokenizer):
|
| 1145 |
+
targets = examples[output_column] if output_column in examples else None
|
| 1146 |
+
if targets is not None:
|
| 1147 |
+
if not isinstance(targets[0], str):
|
| 1148 |
+
if max_target_length is not None:
|
| 1149 |
+
targets = [target[:max_target_length] for target in targets]
|
| 1150 |
+
model_inputs["labels"] = targets
|
| 1151 |
+
else:
|
| 1152 |
+
# Setup the tokenizer for targets
|
| 1153 |
+
with tokenizer.as_target_tokenizer():
|
| 1154 |
+
labels = tokenizer(targets, max_length=max_target_length, padding=padding, truncation=True)
|
| 1155 |
+
|
| 1156 |
+
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
|
| 1157 |
+
# padding in the loss.
|
| 1158 |
+
if padding == "max_length" and ignore_pad_token_for_loss:
|
| 1159 |
+
labels["input_ids"] = [
|
| 1160 |
+
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
|
| 1161 |
+
]
|
| 1162 |
+
|
| 1163 |
+
model_inputs["labels"] = labels["input_ids"]
|
| 1164 |
+
|
| 1165 |
+
def load_extra_metrics(metric_names, loaded_metrics=None):
|
| 1166 |
+
if loaded_metrics is None:
|
| 1167 |
+
loaded_metrics = MetricCollection([])
|
| 1168 |
+
if metric_names is not None:
|
| 1169 |
+
for metric_name in metric_names:
|
| 1170 |
+
if len(metric_name) > 0:
|
| 1171 |
+
loaded_metrics._metrics.append(HFMetricWrapper(metric_name))
|
| 1172 |
+
return loaded_metrics
|
| 1173 |
+
|
| 1174 |
+
def _mp_fn(index):
|
| 1175 |
+
# For xla_spawn (TPUs)
|
| 1176 |
+
main()
|
| 1177 |
+
|
| 1178 |
+
|
| 1179 |
+
if __name__ == "__main__":
|
| 1180 |
+
main()
|
unlimiformer/run_generation.py
ADDED
|
@@ -0,0 +1,577 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# coding=utf-8
|
| 3 |
+
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
|
| 4 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 5 |
+
#
|
| 6 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 7 |
+
# you may not use this file except in compliance with the License.
|
| 8 |
+
# You may obtain a copy of the License at
|
| 9 |
+
#
|
| 10 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 11 |
+
#
|
| 12 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 13 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 14 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 15 |
+
# See the License for the specific language governing permissions and
|
| 16 |
+
# limitations under the License.
|
| 17 |
+
""" Conditional text generation with the auto-regressive models of the library (GPT/GPT-2/CTRL/Transformer-XL/XLNet)
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
import argparse
|
| 22 |
+
import inspect
|
| 23 |
+
import logging
|
| 24 |
+
|
| 25 |
+
from dataclasses import dataclass, field
|
| 26 |
+
from typing import Tuple, List, Optional, Union
|
| 27 |
+
|
| 28 |
+
import numpy as np
|
| 29 |
+
import torch
|
| 30 |
+
import os
|
| 31 |
+
|
| 32 |
+
normal_repr = torch.Tensor.__repr__
|
| 33 |
+
torch.Tensor.__repr__ = lambda self: f"{self.shape}_{normal_repr(self)}"
|
| 34 |
+
|
| 35 |
+
from transformers import (
|
| 36 |
+
AutoTokenizer,
|
| 37 |
+
BloomForCausalLM,
|
| 38 |
+
BloomTokenizerFast,
|
| 39 |
+
CTRLLMHeadModel,
|
| 40 |
+
CTRLTokenizer,
|
| 41 |
+
GenerationMixin,
|
| 42 |
+
GPT2LMHeadModel,
|
| 43 |
+
GPT2Tokenizer,
|
| 44 |
+
GPTJForCausalLM,
|
| 45 |
+
HfArgumentParser,
|
| 46 |
+
LlamaForCausalLM,
|
| 47 |
+
LlamaTokenizer,
|
| 48 |
+
OpenAIGPTLMHeadModel,
|
| 49 |
+
OpenAIGPTTokenizer,
|
| 50 |
+
OPTForCausalLM,
|
| 51 |
+
TransfoXLLMHeadModel,
|
| 52 |
+
TransfoXLTokenizer,
|
| 53 |
+
XLMTokenizer,
|
| 54 |
+
XLMWithLMHeadModel,
|
| 55 |
+
XLNetLMHeadModel,
|
| 56 |
+
XLNetTokenizer,
|
| 57 |
+
TextStreamer,
|
| 58 |
+
)
|
| 59 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 60 |
+
|
| 61 |
+
from unlimiformer import Unlimiformer
|
| 62 |
+
from random_training_unlimiformer import RandomTrainingUnlimiformer
|
| 63 |
+
|
| 64 |
+
@dataclass
|
| 65 |
+
class UnlimiformerArguments:
|
| 66 |
+
"""
|
| 67 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 68 |
+
"""
|
| 69 |
+
test_unlimiformer: Optional[bool] = field(
|
| 70 |
+
default=False,
|
| 71 |
+
metadata={
|
| 72 |
+
"help": "whether to use KNN."
|
| 73 |
+
},
|
| 74 |
+
)
|
| 75 |
+
unlimiformer_verbose: Optional[bool] = field(
|
| 76 |
+
default=False,
|
| 77 |
+
metadata={
|
| 78 |
+
"help": "whether to print KNN intermediate predictions (mostly for debugging)."
|
| 79 |
+
},
|
| 80 |
+
)
|
| 81 |
+
layer_begin: Optional[int] = field(
|
| 82 |
+
default=0,
|
| 83 |
+
metadata={"help": "The layer to begin applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 84 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 85 |
+
)
|
| 86 |
+
layer_end: Optional[int] = field(
|
| 87 |
+
default=None,
|
| 88 |
+
metadata={"help": "The layer to end applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 89 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 90 |
+
)
|
| 91 |
+
unlimiformer_chunk_overlap: Optional[float] = field(
|
| 92 |
+
default=0.5,
|
| 93 |
+
metadata={"help": "The fraction of overlap between input chunks"},
|
| 94 |
+
)
|
| 95 |
+
unlimiformer_chunk_size: Optional[int] = field(
|
| 96 |
+
default=None,
|
| 97 |
+
metadata={"help": "The size of each input chunk"},
|
| 98 |
+
)
|
| 99 |
+
unlimiformer_head_num: Optional[int] = field(
|
| 100 |
+
default=None,
|
| 101 |
+
metadata={"help": "The head to apply KNN to (if None, apply to all heads)"},
|
| 102 |
+
)
|
| 103 |
+
unlimiformer_exclude: Optional[bool] = field(
|
| 104 |
+
default=False,
|
| 105 |
+
metadata={
|
| 106 |
+
"help": "If True, prioritize the inputs that are **not** in the standard attention window."
|
| 107 |
+
},
|
| 108 |
+
)
|
| 109 |
+
random_unlimiformer_training: Optional[bool] = field(
|
| 110 |
+
default=False,
|
| 111 |
+
)
|
| 112 |
+
unlimiformer_training: Optional[bool] = field(
|
| 113 |
+
default=False,
|
| 114 |
+
)
|
| 115 |
+
index_devices: Optional[List[int]] = field(
|
| 116 |
+
default_factory=lambda: (0,),
|
| 117 |
+
)
|
| 118 |
+
datastore_device: Optional[int] = field(
|
| 119 |
+
default=0,
|
| 120 |
+
)
|
| 121 |
+
use_datastore: Optional[bool] = field(default=True)
|
| 122 |
+
flat_index: Optional[bool] = field(default=True)
|
| 123 |
+
test_datastore: Optional[bool] = field(default=False)
|
| 124 |
+
reconstruct_embeddings: Optional[bool] = field(default=False)
|
| 125 |
+
gpu_datastore: Optional[bool] = field(default=True)
|
| 126 |
+
gpu_index: Optional[bool] = field(default=True)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
logging.basicConfig(
|
| 130 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 131 |
+
datefmt="%m/%d/%Y %H:%M:%S",
|
| 132 |
+
level=logging.INFO,
|
| 133 |
+
)
|
| 134 |
+
logger = logging.getLogger(__name__)
|
| 135 |
+
|
| 136 |
+
MAX_LENGTH = int(10000) # Hardcoded max length to avoid infinite loop
|
| 137 |
+
|
| 138 |
+
MODEL_CLASSES = {
|
| 139 |
+
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
|
| 140 |
+
"ctrl": (CTRLLMHeadModel, CTRLTokenizer),
|
| 141 |
+
"openai-gpt": (OpenAIGPTLMHeadModel, OpenAIGPTTokenizer),
|
| 142 |
+
"xlnet": (XLNetLMHeadModel, XLNetTokenizer),
|
| 143 |
+
"transfo-xl": (TransfoXLLMHeadModel, TransfoXLTokenizer),
|
| 144 |
+
"xlm": (XLMWithLMHeadModel, XLMTokenizer),
|
| 145 |
+
"gptj": (GPTJForCausalLM, AutoTokenizer),
|
| 146 |
+
"bloom": (BloomForCausalLM, BloomTokenizerFast),
|
| 147 |
+
"llama": (LlamaForCausalLM, LlamaTokenizer),
|
| 148 |
+
"opt": (OPTForCausalLM, GPT2Tokenizer),
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
# Padding text to help Transformer-XL and XLNet with short prompts as proposed by Aman Rusia
|
| 152 |
+
# in https://github.com/rusiaaman/XLNet-gen#methodology
|
| 153 |
+
# and https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e
|
| 154 |
+
PREFIX = """In 1991, the remains of Russian Tsar Nicholas II and his family
|
| 155 |
+
(except for Alexei and Maria) are discovered.
|
| 156 |
+
The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
|
| 157 |
+
remainder of the story. 1883 Western Siberia,
|
| 158 |
+
a young Grigori Rasputin is asked by his father and a group of men to perform magic.
|
| 159 |
+
Rasputin has a vision and denounces one of the men as a horse thief. Although his
|
| 160 |
+
father initially slaps him for making such an accusation, Rasputin watches as the
|
| 161 |
+
man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
|
| 162 |
+
the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
|
| 163 |
+
with people, even a bishop, begging for his blessing. <eod> </s> <eos>"""
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def set_seed(args):
|
| 167 |
+
np.random.seed(args.seed)
|
| 168 |
+
torch.manual_seed(args.seed)
|
| 169 |
+
if args.n_gpu > 0:
|
| 170 |
+
torch.cuda.manual_seed_all(args.seed)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
#
|
| 174 |
+
# Functions to prepare models' input
|
| 175 |
+
#
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def prepare_ctrl_input(args, _, tokenizer, prompt_text):
|
| 179 |
+
if args.temperature > 0.7:
|
| 180 |
+
logger.info("CTRL typically works better with lower temperatures (and lower top_k).")
|
| 181 |
+
|
| 182 |
+
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False)
|
| 183 |
+
if not any(encoded_prompt[0] == x for x in tokenizer.control_codes.values()):
|
| 184 |
+
logger.info("WARNING! You are not starting your generation from a control code so you won't get good results")
|
| 185 |
+
return prompt_text
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def prepare_xlm_input(args, model, tokenizer, prompt_text):
|
| 189 |
+
# kwargs = {"language": None, "mask_token_id": None}
|
| 190 |
+
|
| 191 |
+
# Set the language
|
| 192 |
+
use_lang_emb = hasattr(model.config, "use_lang_emb") and model.config.use_lang_emb
|
| 193 |
+
if hasattr(model.config, "lang2id") and use_lang_emb:
|
| 194 |
+
available_languages = model.config.lang2id.keys()
|
| 195 |
+
if args.xlm_language in available_languages:
|
| 196 |
+
language = args.xlm_language
|
| 197 |
+
else:
|
| 198 |
+
language = None
|
| 199 |
+
while language not in available_languages:
|
| 200 |
+
language = input("Using XLM. Select language in " + str(list(available_languages)) + " >>> ")
|
| 201 |
+
|
| 202 |
+
model.config.lang_id = model.config.lang2id[language]
|
| 203 |
+
# kwargs["language"] = tokenizer.lang2id[language]
|
| 204 |
+
|
| 205 |
+
# TODO fix mask_token_id setup when configurations will be synchronized between models and tokenizers
|
| 206 |
+
# XLM masked-language modeling (MLM) models need masked token
|
| 207 |
+
# is_xlm_mlm = "mlm" in args.model_name_or_path
|
| 208 |
+
# if is_xlm_mlm:
|
| 209 |
+
# kwargs["mask_token_id"] = tokenizer.mask_token_id
|
| 210 |
+
|
| 211 |
+
return prompt_text
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def prepare_xlnet_input(args, _, tokenizer, prompt_text):
|
| 215 |
+
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
|
| 216 |
+
prompt_text = prefix + prompt_text
|
| 217 |
+
return prompt_text
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def prepare_transfoxl_input(args, _, tokenizer, prompt_text):
|
| 221 |
+
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
|
| 222 |
+
prompt_text = prefix + prompt_text
|
| 223 |
+
return prompt_text
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
PREPROCESSING_FUNCTIONS = {
|
| 227 |
+
"ctrl": prepare_ctrl_input,
|
| 228 |
+
"xlm": prepare_xlm_input,
|
| 229 |
+
"xlnet": prepare_xlnet_input,
|
| 230 |
+
"transfo-xl": prepare_transfoxl_input,
|
| 231 |
+
}
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def adjust_length_to_model(length, max_sequence_length):
|
| 235 |
+
if length < 0 and max_sequence_length > 0:
|
| 236 |
+
length = max_sequence_length
|
| 237 |
+
elif 0 < max_sequence_length < length:
|
| 238 |
+
length = max_sequence_length # No generation bigger than model size
|
| 239 |
+
elif length < 0:
|
| 240 |
+
length = MAX_LENGTH # avoid infinite loop
|
| 241 |
+
return length
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def sparse_model_config(model_config):
|
| 245 |
+
embedding_size = None
|
| 246 |
+
if hasattr(model_config, "hidden_size"):
|
| 247 |
+
embedding_size = model_config.hidden_size
|
| 248 |
+
elif hasattr(model_config, "n_embed"):
|
| 249 |
+
embedding_size = model_config.n_embed
|
| 250 |
+
elif hasattr(model_config, "n_embd"):
|
| 251 |
+
embedding_size = model_config.n_embd
|
| 252 |
+
|
| 253 |
+
num_head = None
|
| 254 |
+
if hasattr(model_config, "num_attention_heads"):
|
| 255 |
+
num_head = model_config.num_attention_heads
|
| 256 |
+
elif hasattr(model_config, "n_head"):
|
| 257 |
+
num_head = model_config.n_head
|
| 258 |
+
|
| 259 |
+
if embedding_size is None or num_head is None or num_head == 0:
|
| 260 |
+
raise ValueError("Check the model config")
|
| 261 |
+
|
| 262 |
+
num_embedding_size_per_head = int(embedding_size / num_head)
|
| 263 |
+
if hasattr(model_config, "n_layer"):
|
| 264 |
+
num_layer = model_config.n_layer
|
| 265 |
+
elif hasattr(model_config, "num_hidden_layers"):
|
| 266 |
+
num_layer = model_config.num_hidden_layers
|
| 267 |
+
else:
|
| 268 |
+
raise ValueError("Number of hidden layers couldn't be determined from the model config")
|
| 269 |
+
|
| 270 |
+
return num_layer, num_head, num_embedding_size_per_head
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def generate_past_key_values(model, batch_size, seq_len):
|
| 274 |
+
num_block_layers, num_attention_heads, num_embedding_size_per_head = sparse_model_config(model.config)
|
| 275 |
+
if model.config.model_type == "bloom":
|
| 276 |
+
past_key_values = tuple(
|
| 277 |
+
(
|
| 278 |
+
torch.empty(int(num_attention_heads * batch_size), num_embedding_size_per_head, seq_len)
|
| 279 |
+
.to(model.dtype)
|
| 280 |
+
.to(model.device),
|
| 281 |
+
torch.empty(int(num_attention_heads * batch_size), seq_len, num_embedding_size_per_head)
|
| 282 |
+
.to(model.dtype)
|
| 283 |
+
.to(model.device),
|
| 284 |
+
)
|
| 285 |
+
for _ in range(num_block_layers)
|
| 286 |
+
)
|
| 287 |
+
else:
|
| 288 |
+
past_key_values = tuple(
|
| 289 |
+
(
|
| 290 |
+
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
|
| 291 |
+
.to(model.dtype)
|
| 292 |
+
.to(model.device),
|
| 293 |
+
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
|
| 294 |
+
.to(model.dtype)
|
| 295 |
+
.to(model.device),
|
| 296 |
+
)
|
| 297 |
+
for _ in range(num_block_layers)
|
| 298 |
+
)
|
| 299 |
+
return past_key_values
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
def prepare_jit_inputs(inputs, model, tokenizer):
|
| 303 |
+
batch_size = len(inputs)
|
| 304 |
+
dummy_input = tokenizer.batch_encode_plus(inputs, return_tensors="pt")
|
| 305 |
+
dummy_input = dummy_input.to(model.device)
|
| 306 |
+
if model.config.use_cache:
|
| 307 |
+
dummy_input["past_key_values"] = generate_past_key_values(model, batch_size, 1)
|
| 308 |
+
dummy_input["attention_mask"] = torch.cat(
|
| 309 |
+
[
|
| 310 |
+
torch.zeros(dummy_input["attention_mask"].shape[0], 1)
|
| 311 |
+
.to(dummy_input["attention_mask"].dtype)
|
| 312 |
+
.to(model.device),
|
| 313 |
+
dummy_input["attention_mask"],
|
| 314 |
+
],
|
| 315 |
+
-1,
|
| 316 |
+
)
|
| 317 |
+
return dummy_input
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
class _ModelFallbackWrapper(GenerationMixin):
|
| 321 |
+
__slots__ = ("_optimized", "_default")
|
| 322 |
+
|
| 323 |
+
def __init__(self, optimized, default):
|
| 324 |
+
self._optimized = optimized
|
| 325 |
+
self._default = default
|
| 326 |
+
|
| 327 |
+
def __call__(self, *args, **kwargs):
|
| 328 |
+
if kwargs["past_key_values"] is None and self._default.config.use_cache:
|
| 329 |
+
kwargs["past_key_values"] = generate_past_key_values(self._default, kwargs["input_ids"].shape[0], 0)
|
| 330 |
+
kwargs.pop("position_ids", None)
|
| 331 |
+
for k in list(kwargs.keys()):
|
| 332 |
+
if kwargs[k] is None or isinstance(kwargs[k], bool):
|
| 333 |
+
kwargs.pop(k)
|
| 334 |
+
outputs = self._optimized(**kwargs)
|
| 335 |
+
lm_logits = outputs[0]
|
| 336 |
+
past_key_values = outputs[1]
|
| 337 |
+
fixed_output = CausalLMOutputWithPast(
|
| 338 |
+
loss=None,
|
| 339 |
+
logits=lm_logits,
|
| 340 |
+
past_key_values=past_key_values,
|
| 341 |
+
hidden_states=None,
|
| 342 |
+
attentions=None,
|
| 343 |
+
)
|
| 344 |
+
return fixed_output
|
| 345 |
+
|
| 346 |
+
def __getattr__(self, item):
|
| 347 |
+
return getattr(self._default, item)
|
| 348 |
+
|
| 349 |
+
def prepare_inputs_for_generation(
|
| 350 |
+
self, input_ids, past_key_values=None, inputs_embeds=None, use_cache=None, **kwargs
|
| 351 |
+
):
|
| 352 |
+
return self._default.prepare_inputs_for_generation(
|
| 353 |
+
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, use_cache=use_cache, **kwargs
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
def _reorder_cache(
|
| 357 |
+
self, past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
|
| 358 |
+
) -> Tuple[Tuple[torch.Tensor]]:
|
| 359 |
+
"""
|
| 360 |
+
This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
|
| 361 |
+
[`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
|
| 362 |
+
beam_idx at every generation step.
|
| 363 |
+
"""
|
| 364 |
+
return self._default._reorder_cache(past_key_values, beam_idx)
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
def main():
|
| 368 |
+
parser = argparse.ArgumentParser()
|
| 369 |
+
parser.add_argument(
|
| 370 |
+
"--model_type",
|
| 371 |
+
default=None,
|
| 372 |
+
type=str,
|
| 373 |
+
required=True,
|
| 374 |
+
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
|
| 375 |
+
)
|
| 376 |
+
parser.add_argument(
|
| 377 |
+
"--model_name_or_path",
|
| 378 |
+
default=None,
|
| 379 |
+
type=str,
|
| 380 |
+
required=True,
|
| 381 |
+
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
parser.add_argument("--prompt", type=str, default="")
|
| 385 |
+
parser.add_argument("--length", type=int, default=100)
|
| 386 |
+
parser.add_argument("--num_hidden_layers", type=int, default=None)
|
| 387 |
+
parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
|
| 388 |
+
|
| 389 |
+
parser.add_argument(
|
| 390 |
+
"--temperature",
|
| 391 |
+
type=float,
|
| 392 |
+
default=1.0,
|
| 393 |
+
help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
|
| 394 |
+
)
|
| 395 |
+
parser.add_argument(
|
| 396 |
+
"--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
|
| 397 |
+
)
|
| 398 |
+
parser.add_argument("--k", type=int, default=0)
|
| 399 |
+
parser.add_argument("--p", type=float, default=0.9)
|
| 400 |
+
|
| 401 |
+
parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
|
| 402 |
+
parser.add_argument("--suffix", type=str, default="", help="Text added after the input.")
|
| 403 |
+
parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
|
| 404 |
+
parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
|
| 405 |
+
|
| 406 |
+
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
|
| 407 |
+
parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
|
| 408 |
+
parser.add_argument("--stream_output", action="store_true")
|
| 409 |
+
parser.add_argument("--num_return_sequences", type=int, default=1, help="The number of samples to generate.")
|
| 410 |
+
parser.add_argument(
|
| 411 |
+
"--fp16",
|
| 412 |
+
action="store_true",
|
| 413 |
+
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
|
| 414 |
+
)
|
| 415 |
+
parser.add_argument("--jit", action="store_true", help="Whether or not to use jit trace to accelerate inference")
|
| 416 |
+
|
| 417 |
+
# args = parser.parse_args()
|
| 418 |
+
args, unknown_args = parser.parse_known_args()
|
| 419 |
+
|
| 420 |
+
hf_parser = HfArgumentParser(UnlimiformerArguments)
|
| 421 |
+
unlimiformer_args, unknown_unlimiformer_args = hf_parser.parse_known_args()
|
| 422 |
+
|
| 423 |
+
if len(set(unknown_args) & set(unknown_unlimiformer_args)) > 0:
|
| 424 |
+
raise ValueError(f"Unknown arguments detected: {set(unknown_args) & set(unknown_unlimiformer_args)}")
|
| 425 |
+
|
| 426 |
+
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
| 427 |
+
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
|
| 428 |
+
|
| 429 |
+
logger.warning(f"device: {args.device}, n_gpu: {args.n_gpu}, 16-bits training: {args.fp16}")
|
| 430 |
+
|
| 431 |
+
set_seed(args)
|
| 432 |
+
|
| 433 |
+
# Initialize the model and tokenizer
|
| 434 |
+
try:
|
| 435 |
+
args.model_type = args.model_type.lower()
|
| 436 |
+
model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
|
| 437 |
+
except KeyError:
|
| 438 |
+
raise KeyError("the model {} you specified is not supported. You are welcome to add it and open a PR :)")
|
| 439 |
+
|
| 440 |
+
tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
|
| 441 |
+
if tokenizer.pad_token is None:
|
| 442 |
+
tokenizer.pad_token = tokenizer.eos_token
|
| 443 |
+
model_kwargs = {}
|
| 444 |
+
if args.num_hidden_layers is not None:
|
| 445 |
+
model_kwargs["num_hidden_layers"] = args.num_hidden_layers
|
| 446 |
+
model = model_class.from_pretrained(args.model_name_or_path, **model_kwargs)
|
| 447 |
+
|
| 448 |
+
if args.fp16:
|
| 449 |
+
model.half()
|
| 450 |
+
model.to(args.device)
|
| 451 |
+
|
| 452 |
+
max_seq_length = getattr(model.config, "max_position_embeddings", 0)
|
| 453 |
+
args.length = adjust_length_to_model(args.length, max_sequence_length=max_seq_length)
|
| 454 |
+
logger.info(args)
|
| 455 |
+
|
| 456 |
+
if unlimiformer_args.test_unlimiformer:
|
| 457 |
+
unlimiformer_kwargs = {
|
| 458 |
+
'layer_begin': unlimiformer_args.layer_begin,
|
| 459 |
+
'layer_end': unlimiformer_args.layer_end,
|
| 460 |
+
'unlimiformer_head_num': unlimiformer_args.unlimiformer_head_num,
|
| 461 |
+
'exclude_attention': unlimiformer_args.unlimiformer_exclude,
|
| 462 |
+
'chunk_overlap': unlimiformer_args.unlimiformer_chunk_overlap,
|
| 463 |
+
'model_encoder_max_len': unlimiformer_args.unlimiformer_chunk_size,
|
| 464 |
+
'verbose': unlimiformer_args.unlimiformer_verbose, 'tokenizer': tokenizer,
|
| 465 |
+
'unlimiformer_training': unlimiformer_args.unlimiformer_training,
|
| 466 |
+
'use_datastore': unlimiformer_args.use_datastore,
|
| 467 |
+
'flat_index': unlimiformer_args.flat_index,
|
| 468 |
+
'test_datastore': unlimiformer_args.test_datastore,
|
| 469 |
+
'reconstruct_embeddings': unlimiformer_args.reconstruct_embeddings,
|
| 470 |
+
'gpu_datastore': unlimiformer_args.gpu_datastore,
|
| 471 |
+
'gpu_index': unlimiformer_args.gpu_index,
|
| 472 |
+
'index_devices': unlimiformer_args.index_devices,
|
| 473 |
+
'datastore_device': unlimiformer_args.datastore_device,
|
| 474 |
+
}
|
| 475 |
+
if unlimiformer_args.random_unlimiformer_training:
|
| 476 |
+
model = RandomTrainingUnlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 477 |
+
else:
|
| 478 |
+
model = Unlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 479 |
+
|
| 480 |
+
prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
|
| 481 |
+
# Check if prompt_text is a valid file name:
|
| 482 |
+
if os.path.exists(prompt_text):
|
| 483 |
+
with open(prompt_text, "r") as f:
|
| 484 |
+
prompt_text = f.read()
|
| 485 |
+
|
| 486 |
+
# Different models need different input formatting and/or extra arguments
|
| 487 |
+
requires_preprocessing = args.model_type in PREPROCESSING_FUNCTIONS.keys()
|
| 488 |
+
if requires_preprocessing:
|
| 489 |
+
prepare_input = PREPROCESSING_FUNCTIONS.get(args.model_type)
|
| 490 |
+
preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)
|
| 491 |
+
|
| 492 |
+
if model.__class__.__name__ in ["TransfoXLLMHeadModel"]:
|
| 493 |
+
tokenizer_kwargs = {"add_space_before_punct_symbol": True}
|
| 494 |
+
else:
|
| 495 |
+
tokenizer_kwargs = {}
|
| 496 |
+
|
| 497 |
+
encoded_prompt = tokenizer.encode(
|
| 498 |
+
preprocessed_prompt_text, add_special_tokens=False, return_tensors="pt", **tokenizer_kwargs
|
| 499 |
+
)
|
| 500 |
+
else:
|
| 501 |
+
# prefix = args.prefix if args.prefix else args.padding_text
|
| 502 |
+
prompt_text = f'{args.prefix}{prompt_text}{args.suffix}'
|
| 503 |
+
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False, return_tensors="pt")
|
| 504 |
+
|
| 505 |
+
if not unlimiformer_args.test_unlimiformer:
|
| 506 |
+
encoded_prompt = encoded_prompt[:, -2048:]
|
| 507 |
+
encoded_prompt = encoded_prompt.to(args.device)
|
| 508 |
+
|
| 509 |
+
if encoded_prompt.size()[-1] == 0:
|
| 510 |
+
input_ids = None
|
| 511 |
+
else:
|
| 512 |
+
input_ids = encoded_prompt
|
| 513 |
+
|
| 514 |
+
if args.jit:
|
| 515 |
+
jit_input_texts = ["enable jit"]
|
| 516 |
+
jit_inputs = prepare_jit_inputs(jit_input_texts, model, tokenizer)
|
| 517 |
+
torch._C._jit_set_texpr_fuser_enabled(False)
|
| 518 |
+
model.config.return_dict = False
|
| 519 |
+
if hasattr(model, "forward"):
|
| 520 |
+
sig = inspect.signature(model.forward)
|
| 521 |
+
else:
|
| 522 |
+
sig = inspect.signature(model.__call__)
|
| 523 |
+
jit_inputs = tuple(jit_inputs[key] for key in sig.parameters if jit_inputs.get(key, None) is not None)
|
| 524 |
+
traced_model = torch.jit.trace(model, jit_inputs, strict=False)
|
| 525 |
+
traced_model = torch.jit.freeze(traced_model.eval())
|
| 526 |
+
traced_model(*jit_inputs)
|
| 527 |
+
traced_model(*jit_inputs)
|
| 528 |
+
|
| 529 |
+
model = _ModelFallbackWrapper(traced_model, model)
|
| 530 |
+
|
| 531 |
+
model.eval()
|
| 532 |
+
output_sequences = model.generate(
|
| 533 |
+
input_ids=input_ids,
|
| 534 |
+
# max_length=args.length + len(encoded_prompt[0]),
|
| 535 |
+
max_new_tokens=args.length,
|
| 536 |
+
temperature=args.temperature,
|
| 537 |
+
top_k=args.k,
|
| 538 |
+
top_p=args.p,
|
| 539 |
+
repetition_penalty=args.repetition_penalty,
|
| 540 |
+
do_sample=True,
|
| 541 |
+
num_return_sequences=args.num_return_sequences,
|
| 542 |
+
streamer=TextStreamer(tokenizer, skip_prompt=True) if args.stream_output else None,
|
| 543 |
+
)
|
| 544 |
+
|
| 545 |
+
# Remove the batch dimension when returning multiple sequences
|
| 546 |
+
if len(output_sequences.shape) > 2:
|
| 547 |
+
output_sequences.squeeze_()
|
| 548 |
+
|
| 549 |
+
generated_sequences = []
|
| 550 |
+
|
| 551 |
+
for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
|
| 552 |
+
print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} (input length: {input_ids.shape[-1]}) ===")
|
| 553 |
+
generated_sequence = generated_sequence.tolist()
|
| 554 |
+
# generated_sequence = generated_sequence[len(encoded_prompt[0]):] + tokenizer.encode(' <end_of_prompt> ') + generated_sequence[:len(encoded_prompt[0])]
|
| 555 |
+
|
| 556 |
+
# Decode text
|
| 557 |
+
# text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
|
| 558 |
+
prompt_length = min(input_ids.shape[-1], model.unlimiformer.window_size()) if unlimiformer_args.test_unlimiformer else input_ids.shape[-1]
|
| 559 |
+
completion = tokenizer.decode(generated_sequence[prompt_length:])
|
| 560 |
+
|
| 561 |
+
# Remove all text after the stop token
|
| 562 |
+
# text = text[: text.find(args.stop_token) if args.stop_token else None]
|
| 563 |
+
|
| 564 |
+
# Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
|
| 565 |
+
total_sequence = (
|
| 566 |
+
# prompt_text +
|
| 567 |
+
'|||' + completion
|
| 568 |
+
)
|
| 569 |
+
|
| 570 |
+
generated_sequences.append(total_sequence)
|
| 571 |
+
print(total_sequence)
|
| 572 |
+
|
| 573 |
+
return generated_sequences
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
if __name__ == "__main__":
|
| 577 |
+
main()
|
unlimiformer/usage.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .model import Unlimiformer
|
| 2 |
+
from .random_training_unlimiformer import RandomTrainingUnlimiformer
|
| 3 |
+
|
| 4 |
+
from dataclasses import dataclass, field
|
| 5 |
+
from typing import List, Optional
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
@dataclass
|
| 9 |
+
class UnlimiformerArguments:
|
| 10 |
+
"""
|
| 11 |
+
Arguments pertaining to what data we are going to input our model for training and eval.
|
| 12 |
+
"""
|
| 13 |
+
test_unlimiformer: Optional[bool] = field(
|
| 14 |
+
default=True,
|
| 15 |
+
metadata={
|
| 16 |
+
"help": "whether to use KNN."
|
| 17 |
+
},
|
| 18 |
+
)
|
| 19 |
+
unlimiformer_verbose: Optional[bool] = field(
|
| 20 |
+
default=False,
|
| 21 |
+
metadata={
|
| 22 |
+
"help": "whether to print KNN intermediate predictions (mostly for debugging)."
|
| 23 |
+
},
|
| 24 |
+
)
|
| 25 |
+
layer_begin: Optional[int] = field(
|
| 26 |
+
default=0,
|
| 27 |
+
metadata={"help": "The layer to begin applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 28 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 29 |
+
)
|
| 30 |
+
layer_end: Optional[int] = field(
|
| 31 |
+
default=None,
|
| 32 |
+
metadata={"help": "The layer to end applying KNN to. KNN will be applied to layers[knn_layer_begin:layer_end]. "
|
| 33 |
+
"By default, it will be applied to all layers: [0:None]]"},
|
| 34 |
+
)
|
| 35 |
+
unlimiformer_chunk_overlap: Optional[float] = field(
|
| 36 |
+
default=0.5,
|
| 37 |
+
metadata={"help": "The fraction of overlap between input chunks"},
|
| 38 |
+
)
|
| 39 |
+
unlimiformer_chunk_size: Optional[int] = field(
|
| 40 |
+
default=None,
|
| 41 |
+
metadata={"help": "The size of each input chunk"},
|
| 42 |
+
)
|
| 43 |
+
unlimiformer_head_num: Optional[int] = field(
|
| 44 |
+
default=None,
|
| 45 |
+
metadata={"help": "The head to apply KNN to (if None, apply to all heads)"},
|
| 46 |
+
)
|
| 47 |
+
unlimiformer_exclude: Optional[bool] = field(
|
| 48 |
+
default=False,
|
| 49 |
+
metadata={
|
| 50 |
+
"help": "If True, prioritize the inputs that are **not** in the standard attention window."
|
| 51 |
+
},
|
| 52 |
+
)
|
| 53 |
+
random_unlimiformer_training: Optional[bool] = field(
|
| 54 |
+
default=False,
|
| 55 |
+
)
|
| 56 |
+
unlimiformer_training: Optional[bool] = field(
|
| 57 |
+
default=False,
|
| 58 |
+
)
|
| 59 |
+
use_datastore: Optional[bool] = field(default=False)
|
| 60 |
+
flat_index: Optional[bool] = field(default=False)
|
| 61 |
+
test_datastore: Optional[bool] = field(default=False)
|
| 62 |
+
reconstruct_embeddings: Optional[bool] = field(default=False)
|
| 63 |
+
gpu_datastore: Optional[bool] = field(default=True)
|
| 64 |
+
gpu_index: Optional[bool] = field(default=True)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
# include these lines in your code somewhere before model training
|
| 69 |
+
def training_addin():
|
| 70 |
+
if unlimiformer_args.test_unlimiformer:
|
| 71 |
+
unlimiformer_kwargs = {
|
| 72 |
+
'layer_begin': unlimiformer_args.layer_begin,
|
| 73 |
+
'layer_end': unlimiformer_args.layer_end,
|
| 74 |
+
'unlimiformer_head_num': unlimiformer_args.unlimiformer_head_num,
|
| 75 |
+
'exclude_attention': unlimiformer_args.unlimiformer_exclude,
|
| 76 |
+
'chunk_overlap': unlimiformer_args.unlimiformer_chunk_overlap,
|
| 77 |
+
'model_encoder_max_len': unlimiformer_args.unlimiformer_chunk_size,
|
| 78 |
+
'verbose': unlimiformer_args.unlimiformer_verbose, 'tokenizer': tokenizer,
|
| 79 |
+
'unlimiformer_training': unlimiformer_args.unlimiformer_training,
|
| 80 |
+
'use_datastore': unlimiformer_args.use_datastore,
|
| 81 |
+
'flat_index': unlimiformer_args.flat_index,
|
| 82 |
+
'test_datastore': unlimiformer_args.test_datastore,
|
| 83 |
+
'reconstruct_embeddings': unlimiformer_args.reconstruct_embeddings,
|
| 84 |
+
'gpu_datastore': unlimiformer_args.gpu_datastore,
|
| 85 |
+
'gpu_index': unlimiformer_args.gpu_index
|
| 86 |
+
}
|
| 87 |
+
if unlimiformer_args.random_unlimiformer_training:
|
| 88 |
+
model = RandomTrainingUnlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 89 |
+
else:
|
| 90 |
+
model = Unlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 91 |
+
|
unlimiformer/utils/__init__.py
ADDED
|
File without changes
|
unlimiformer/utils/config.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def handle_args_to_ignore(args: List[str]):
|
| 5 |
+
indices_to_remove = []
|
| 6 |
+
for i, arg in enumerate(args):
|
| 7 |
+
if "_ignore_" in arg:
|
| 8 |
+
indices_to_remove.append(i)
|
| 9 |
+
if not arg.startswith("-"):
|
| 10 |
+
indices_to_remove.append(i - 1)
|
| 11 |
+
|
| 12 |
+
for i in sorted(indices_to_remove, reverse=True):
|
| 13 |
+
del args[i]
|
unlimiformer/utils/custom_hf_argument_parser.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import sys
|
| 4 |
+
from typing import Tuple
|
| 5 |
+
|
| 6 |
+
from transformers import HfArgumentParser
|
| 7 |
+
from transformers.hf_argparser import DataClass
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class CustomHfArgumentParser(HfArgumentParser):
|
| 11 |
+
def parse_dictionary_and_args(self) -> Tuple[DataClass, ...]:
|
| 12 |
+
"""
|
| 13 |
+
Alternative helper method that does not use `argparse` at all, instead loading a json file and populating the
|
| 14 |
+
dataclass types.
|
| 15 |
+
"""
|
| 16 |
+
args = []
|
| 17 |
+
data = {}
|
| 18 |
+
for i in range(1, len(sys.argv)):
|
| 19 |
+
if not sys.argv[i].endswith('.json'):
|
| 20 |
+
break
|
| 21 |
+
|
| 22 |
+
with open(sys.argv[i]) as f:
|
| 23 |
+
new_data = json.load(f)
|
| 24 |
+
conflicting_keys = set(new_data.keys()).intersection(data.keys())
|
| 25 |
+
if len(conflicting_keys) > 0:
|
| 26 |
+
raise ValueError(f'There are conflicting keys in the config files: {conflicting_keys}')
|
| 27 |
+
data.update(new_data)
|
| 28 |
+
|
| 29 |
+
for k, v in data.items():
|
| 30 |
+
# if any options were given explicitly through the CLA then they override anything defined in the config files
|
| 31 |
+
if f'--{k}' in sys.argv:
|
| 32 |
+
logging.info(f'While {k}={v} was given in a config file, a manual override was set through the CLA')
|
| 33 |
+
continue
|
| 34 |
+
args.extend(
|
| 35 |
+
["--" + k, *(v if isinstance(v, list) else [str(v)])]
|
| 36 |
+
) # add the file arguments first so command line args has precedence
|
| 37 |
+
args += sys.argv[i:]
|
| 38 |
+
|
| 39 |
+
return self.parse_args_into_dataclasses(args=args, look_for_args_file=False)
|
unlimiformer/utils/custom_seq2seq_trainer.py
ADDED
|
@@ -0,0 +1,328 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import math
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
from collections import defaultdict
|
| 6 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from datasets import Dataset
|
| 10 |
+
from torch import nn
|
| 11 |
+
from transformers.debug_utils import DebugOption
|
| 12 |
+
from transformers.deepspeed import is_deepspeed_zero3_enabled
|
| 13 |
+
from transformers.trainer_utils import speed_metrics
|
| 14 |
+
|
| 15 |
+
from transformers.utils import logging
|
| 16 |
+
from transformers import Seq2SeqTrainer, is_torch_tpu_available
|
| 17 |
+
|
| 18 |
+
import gc
|
| 19 |
+
|
| 20 |
+
if is_torch_tpu_available(check_device=False):
|
| 21 |
+
import torch_xla.core.xla_model as xm
|
| 22 |
+
import torch_xla.debug.metrics as met
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
from utils.decoding import decode
|
| 26 |
+
|
| 27 |
+
logger = logging.get_logger(__name__)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def _clean_memory():
|
| 31 |
+
gc.collect()
|
| 32 |
+
torch.cuda.empty_cache()
|
| 33 |
+
|
| 34 |
+
# This custom trainer is based on the trainer defined in https://github.com/huggingface/transformers/compare/main...eladsegal:public-transformers:scrolls
|
| 35 |
+
class CustomTrainer(Seq2SeqTrainer):
|
| 36 |
+
def __init__(
|
| 37 |
+
self, *args, untokenized_eval_dataset=None, data_args=None, output_dir: Optional[str] = None, **kwargs
|
| 38 |
+
):
|
| 39 |
+
super().__init__(*args, **kwargs)
|
| 40 |
+
self._untokenized_eval_dataset = untokenized_eval_dataset
|
| 41 |
+
self._max_length = data_args.val_max_target_length
|
| 42 |
+
self._num_beams = data_args.num_beams
|
| 43 |
+
self._output_dir = output_dir
|
| 44 |
+
self._data_args = data_args
|
| 45 |
+
self.mock_predictions_to_assign_zero_metric_score = self.tokenizer.encode("TOO_MANY_INPUT_TOKENS",return_tensors="np")[0]
|
| 46 |
+
|
| 47 |
+
def prediction_step(
|
| 48 |
+
self,
|
| 49 |
+
model: nn.Module,
|
| 50 |
+
inputs: Dict[str, Union[torch.Tensor, Any]],
|
| 51 |
+
prediction_loss_only: bool,
|
| 52 |
+
ignore_keys: Optional[List[str]] = None,
|
| 53 |
+
) -> Tuple[Optional[float], Optional[torch.Tensor], Optional[torch.Tensor]]:
|
| 54 |
+
"""
|
| 55 |
+
Perform an evaluation step on `model` using `inputs`.
|
| 56 |
+
|
| 57 |
+
Subclass and override to inject custom behavior.
|
| 58 |
+
|
| 59 |
+
Args:
|
| 60 |
+
model (`nn.Module`):
|
| 61 |
+
The model to evaluate.
|
| 62 |
+
inputs (`Dict[str, Union[torch.Tensor, Any]]`):
|
| 63 |
+
The inputs and targets of the model.
|
| 64 |
+
|
| 65 |
+
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
|
| 66 |
+
argument `labels`. Check your model's documentation for all accepted arguments.
|
| 67 |
+
prediction_loss_only (`bool`):
|
| 68 |
+
Whether or not to ret`urn the loss only.
|
| 69 |
+
|
| 70 |
+
Return:
|
| 71 |
+
Tuple[Optional[float], Optional[torch.Tensor], Optional[torch.Tensor]]: A tuple with the loss, logits and
|
| 72 |
+
labels (each being optional).
|
| 73 |
+
"""
|
| 74 |
+
if not ("labels" in inputs or 'decoder_input_ids' in inputs):
|
| 75 |
+
if model.training:
|
| 76 |
+
logger.warning('When computing loss, must give labels or decoder_input_ids. '
|
| 77 |
+
'If you only perform prediction, you can safely ignore this message')
|
| 78 |
+
# This is an issue here because the input may be longer than the max-output length of the model,
|
| 79 |
+
# and if nothing was given it will shift the input and use it to compute loss (and later discard it).
|
| 80 |
+
# This may cause an indexing error when absolute embeddings are used (CUDA device side assert)
|
| 81 |
+
inputs['decoder_input_ids'] = inputs['input_ids'][:,:2].clone() # dummy outputs
|
| 82 |
+
|
| 83 |
+
if not self.args.predict_with_generate or prediction_loss_only:
|
| 84 |
+
return super().prediction_step(
|
| 85 |
+
model, inputs, prediction_loss_only=prediction_loss_only, ignore_keys=ignore_keys
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
has_labels = "labels" in inputs
|
| 89 |
+
inputs = self._prepare_inputs(inputs)
|
| 90 |
+
|
| 91 |
+
# XXX: adapt synced_gpus for fairscale as well
|
| 92 |
+
gen_kwargs = self._gen_kwargs.copy()
|
| 93 |
+
gen_kwargs["max_length"] = (
|
| 94 |
+
gen_kwargs["max_length"] if gen_kwargs.get("max_length") is not None else self.model.config.max_length
|
| 95 |
+
)
|
| 96 |
+
gen_kwargs["num_beams"] = (
|
| 97 |
+
gen_kwargs["num_beams"] if gen_kwargs.get("num_beams") is not None else self.model.config.num_beams
|
| 98 |
+
)
|
| 99 |
+
default_synced_gpus = True if is_deepspeed_zero3_enabled() else False
|
| 100 |
+
gen_kwargs["synced_gpus"] = (
|
| 101 |
+
gen_kwargs["synced_gpus"] if gen_kwargs.get("synced_gpus") is not None else default_synced_gpus
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
if "attention_mask" in inputs:
|
| 105 |
+
gen_kwargs["attention_mask"] = inputs.get("attention_mask", None)
|
| 106 |
+
if "global_attention_mask" in inputs:
|
| 107 |
+
gen_kwargs["global_attention_mask"] = inputs.get("global_attention_mask", None)
|
| 108 |
+
|
| 109 |
+
# --------------------- addition compared to the source file --------------------
|
| 110 |
+
if 'prefix_length' in inputs:
|
| 111 |
+
gen_kwargs['prefix_length'] = inputs['prefix_length']
|
| 112 |
+
_clean_memory()
|
| 113 |
+
# ------------------------------------------------------------------------------
|
| 114 |
+
|
| 115 |
+
# prepare generation inputs
|
| 116 |
+
# some encoder-decoder models can have varying encoder's and thus
|
| 117 |
+
# varying model input names
|
| 118 |
+
if hasattr(self.model, "encoder") and self.model.encoder.main_input_name != self.model.main_input_name:
|
| 119 |
+
generation_inputs = inputs[self.model.encoder.main_input_name]
|
| 120 |
+
else:
|
| 121 |
+
generation_inputs = inputs[self.model.main_input_name]
|
| 122 |
+
|
| 123 |
+
# Uri: to make sure we use cache even during mid-training evaluation, where this is disabled in general:
|
| 124 |
+
gen_kwargs['use_cache'] = True
|
| 125 |
+
|
| 126 |
+
generated_tokens = self.model.generate(
|
| 127 |
+
generation_inputs,
|
| 128 |
+
**gen_kwargs,
|
| 129 |
+
)
|
| 130 |
+
# --------------------- addition compared to the source file --------------------
|
| 131 |
+
_clean_memory()
|
| 132 |
+
# ------------------------------------------------------------------------------
|
| 133 |
+
# in case the batch is shorter than max length, the output should be padded
|
| 134 |
+
if generated_tokens.shape[-1] < gen_kwargs["max_length"]:
|
| 135 |
+
generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_kwargs["max_length"])
|
| 136 |
+
|
| 137 |
+
if has_labels: # changed the order of the if's here because there is no point going through the model if there are no labels to compute the loss on..
|
| 138 |
+
with torch.no_grad():
|
| 139 |
+
with self.compute_loss_context_manager():
|
| 140 |
+
outputs = model(**inputs)
|
| 141 |
+
if self.label_smoother is not None:
|
| 142 |
+
loss = self.label_smoother(outputs, inputs["labels"]).mean().detach()
|
| 143 |
+
else:
|
| 144 |
+
loss = (outputs["loss"] if isinstance(outputs, dict) else outputs[0]).mean().detach()
|
| 145 |
+
else:
|
| 146 |
+
loss = None
|
| 147 |
+
|
| 148 |
+
if self.args.prediction_loss_only:
|
| 149 |
+
return (loss, None, None)
|
| 150 |
+
|
| 151 |
+
if has_labels:
|
| 152 |
+
labels = inputs["labels"]
|
| 153 |
+
if labels.shape[-1] < gen_kwargs["max_length"]:
|
| 154 |
+
labels = self._pad_tensors_to_max_len(labels, gen_kwargs["max_length"])
|
| 155 |
+
else:
|
| 156 |
+
labels = None
|
| 157 |
+
|
| 158 |
+
return (loss, generated_tokens, labels)
|
| 159 |
+
|
| 160 |
+
@property
|
| 161 |
+
def _restart_generator(self):
|
| 162 |
+
if getattr(self, '_is_restart_generator', False):
|
| 163 |
+
self._is_restart_generator = False
|
| 164 |
+
return True
|
| 165 |
+
return False
|
| 166 |
+
|
| 167 |
+
def set_restart_generator(self):
|
| 168 |
+
self._is_restart_generator = True
|
| 169 |
+
|
| 170 |
+
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
| 171 |
+
sampler = super()._get_train_sampler()
|
| 172 |
+
try:
|
| 173 |
+
if self._restart_generator:
|
| 174 |
+
sampler.generator.manual_seed(self._initial_seed)
|
| 175 |
+
else:
|
| 176 |
+
self._initial_seed = sampler.generator.initial_seed()
|
| 177 |
+
except Exception as e:
|
| 178 |
+
logger.warning(f'Cannot save or set the seed of the generator: {e}')
|
| 179 |
+
return sampler
|
| 180 |
+
|
| 181 |
+
def _post_process_function(self, untokenized_eval_dataset, predictions):
|
| 182 |
+
id_to_prediction = {}
|
| 183 |
+
id_to_label_ids = defaultdict(list)
|
| 184 |
+
|
| 185 |
+
assert len(untokenized_eval_dataset) == len(self.eval_dataset)
|
| 186 |
+
|
| 187 |
+
for i, (instance, not_valid_for_eval) in enumerate(zip(untokenized_eval_dataset, self.eval_dataset["not_valid_for_eval"])):
|
| 188 |
+
if not_valid_for_eval:
|
| 189 |
+
id_to_prediction[instance["id"]] = self.mock_predictions_to_assign_zero_metric_score
|
| 190 |
+
else:
|
| 191 |
+
id_to_prediction[instance["id"]] = predictions[i]
|
| 192 |
+
|
| 193 |
+
if "outputs" in instance:
|
| 194 |
+
id_to_label_ids[instance["id"]] = instance["outputs"]
|
| 195 |
+
else:
|
| 196 |
+
id_to_label_ids[instance["id"]].append(instance["output"])
|
| 197 |
+
|
| 198 |
+
return id_to_prediction, id_to_label_ids
|
| 199 |
+
|
| 200 |
+
def evaluate(
|
| 201 |
+
self,
|
| 202 |
+
eval_dataset: Optional[Dataset] = None,
|
| 203 |
+
ignore_keys: Optional[List[str]] = None,
|
| 204 |
+
metric_key_prefix: str = "eval",
|
| 205 |
+
untokenized_eval_dataset: Optional[Dataset] = None,
|
| 206 |
+
**gen_kwargs
|
| 207 |
+
) -> Dict[str, float]:
|
| 208 |
+
"""
|
| 209 |
+
Run evaluation and returns metrics.
|
| 210 |
+
|
| 211 |
+
The calling script will be responsible for providing a method to compute metrics, as they are task-dependent
|
| 212 |
+
(pass it to the init `compute_metrics` argument).
|
| 213 |
+
|
| 214 |
+
You can also subclass and override this method to inject custom behavior.
|
| 215 |
+
|
| 216 |
+
Args:
|
| 217 |
+
eval_dataset (`Dataset`, *optional*):
|
| 218 |
+
Pass a dataset if you wish to override `self.eval_dataset`. If it is an [`~datasets.Dataset`], columns
|
| 219 |
+
not accepted by the `model.forward()` method are automatically removed. It must implement the `__len__`
|
| 220 |
+
method.
|
| 221 |
+
ignore_keys (`List[str]`, *optional*):
|
| 222 |
+
A list of keys in the output of your model (if it is a dictionary) that should be ignored when
|
| 223 |
+
gathering predictions.
|
| 224 |
+
metric_key_prefix (`str`, *optional*, defaults to `"eval"`):
|
| 225 |
+
An optional prefix to be used as the metrics key prefix. For example the metrics "bleu" will be named
|
| 226 |
+
"eval_bleu" if the prefix is `"eval"` (default)
|
| 227 |
+
max_length (`int`, *optional*):
|
| 228 |
+
The maximum target length to use when predicting with the generate method.
|
| 229 |
+
num_beams (`int`, *optional*):
|
| 230 |
+
Number of beams for beam search that will be used when predicting with the generate method. 1 means no
|
| 231 |
+
beam search.
|
| 232 |
+
gen_kwargs:
|
| 233 |
+
Additional `generate` specific kwargs.
|
| 234 |
+
|
| 235 |
+
Returns:
|
| 236 |
+
A dictionary containing the evaluation loss and the potential metrics computed from the predictions. The
|
| 237 |
+
dictionary also contains the epoch number which comes from the training state.
|
| 238 |
+
"""
|
| 239 |
+
|
| 240 |
+
gen_kwargs = gen_kwargs.copy()
|
| 241 |
+
gen_kwargs["max_length"] = (
|
| 242 |
+
gen_kwargs["max_length"] if gen_kwargs.get("max_length") is not None else self.args.generation_max_length
|
| 243 |
+
)
|
| 244 |
+
gen_kwargs["num_beams"] = (
|
| 245 |
+
gen_kwargs["num_beams"] if gen_kwargs.get("num_beams") is not None else self.args.generation_num_beams
|
| 246 |
+
)
|
| 247 |
+
self._gen_kwargs = gen_kwargs
|
| 248 |
+
|
| 249 |
+
self._memory_tracker.start()
|
| 250 |
+
|
| 251 |
+
eval_dataloader = self.get_eval_dataloader(eval_dataset)
|
| 252 |
+
# ----------------------------------- Added -----------------------------------
|
| 253 |
+
untokenized_eval_dataset = (
|
| 254 |
+
self._untokenized_eval_dataset if untokenized_eval_dataset is None else untokenized_eval_dataset
|
| 255 |
+
)
|
| 256 |
+
compute_metrics = self.compute_metrics
|
| 257 |
+
self.compute_metrics = None
|
| 258 |
+
# -----------------------------------------------------------------------------
|
| 259 |
+
|
| 260 |
+
start_time = time.time()
|
| 261 |
+
|
| 262 |
+
eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
|
| 263 |
+
try:
|
| 264 |
+
output = eval_loop(
|
| 265 |
+
eval_dataloader,
|
| 266 |
+
description="Evaluation",
|
| 267 |
+
# No point gathering the predictions if there are no metrics, otherwise we defer to
|
| 268 |
+
# self.args.prediction_loss_only
|
| 269 |
+
prediction_loss_only=None, # MODIFIED since we need the predictions
|
| 270 |
+
ignore_keys=ignore_keys,
|
| 271 |
+
metric_key_prefix=metric_key_prefix,
|
| 272 |
+
)
|
| 273 |
+
finally:
|
| 274 |
+
# ----------------------------------- Added -----------------------------------
|
| 275 |
+
# revert the compute metrics back
|
| 276 |
+
self.compute_metrics = compute_metrics
|
| 277 |
+
# -----------------------------------------------------------------------------
|
| 278 |
+
|
| 279 |
+
# ----------------------------------- Added -----------------------------------
|
| 280 |
+
# compute our metrics
|
| 281 |
+
if output.predictions is not None:
|
| 282 |
+
eval_preds = self._post_process_function(untokenized_eval_dataset, output.predictions)
|
| 283 |
+
|
| 284 |
+
if self._output_dir is not None and self.is_world_process_zero():
|
| 285 |
+
predictions = decode(eval_preds[0], self.tokenizer, self._data_args)
|
| 286 |
+
output_prediction_file = os.path.join(
|
| 287 |
+
self._output_dir, f"generated_predictions_eval_{self.state.global_step}.json"
|
| 288 |
+
)
|
| 289 |
+
with open(output_prediction_file, "w") as writer:
|
| 290 |
+
json.dump(predictions, writer, indent=4)
|
| 291 |
+
|
| 292 |
+
output_labels_file = os.path.join(
|
| 293 |
+
self._output_dir, f"eval_labels.json"
|
| 294 |
+
)
|
| 295 |
+
if not os.path.isfile(output_labels_file):
|
| 296 |
+
with open(output_labels_file, "w") as writer:
|
| 297 |
+
json.dump(eval_preds[1], writer, indent=4)
|
| 298 |
+
|
| 299 |
+
if self.compute_metrics is not None:
|
| 300 |
+
output.metrics.update(self.compute_metrics(*eval_preds))
|
| 301 |
+
|
| 302 |
+
# Prefix all keys with metric_key_prefix + '_'
|
| 303 |
+
for key in list(output.metrics.keys()):
|
| 304 |
+
if not key.startswith(f"{metric_key_prefix}_"):
|
| 305 |
+
output.metrics[f"{metric_key_prefix}_{key}"] = output.metrics.pop(key)
|
| 306 |
+
# -----------------------------------------------------------------------------
|
| 307 |
+
|
| 308 |
+
total_batch_size = self.args.eval_batch_size * self.args.world_size
|
| 309 |
+
output.metrics.update(
|
| 310 |
+
speed_metrics(
|
| 311 |
+
metric_key_prefix,
|
| 312 |
+
start_time,
|
| 313 |
+
num_samples=output.num_samples,
|
| 314 |
+
num_steps=math.ceil(output.num_samples / total_batch_size),
|
| 315 |
+
)
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
self.log(output.metrics)
|
| 319 |
+
|
| 320 |
+
if DebugOption.TPU_METRICS_DEBUG in self.args.debug:
|
| 321 |
+
# tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
|
| 322 |
+
xm.master_print(met.metrics_report())
|
| 323 |
+
|
| 324 |
+
self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, output.metrics)
|
| 325 |
+
|
| 326 |
+
self._memory_tracker.stop_and_update_metrics(output.metrics)
|
| 327 |
+
|
| 328 |
+
return output.metrics
|
unlimiformer/utils/decoding.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def decode(id_to_something, tokenizer=None, data_args=None):
|
| 6 |
+
decode_fn = None
|
| 7 |
+
switch_case = None
|
| 8 |
+
elem = next(iter(id_to_something.values()))
|
| 9 |
+
if isinstance(elem, str):
|
| 10 |
+
switch_case = -1
|
| 11 |
+
decode_fn = lambda text: text.strip()
|
| 12 |
+
elif isinstance(elem, list) and not isinstance(elem[0], int):
|
| 13 |
+
if isinstance(elem[0], str):
|
| 14 |
+
switch_case = 0
|
| 15 |
+
decode_fn = lambda texts: [text.strip() for text in texts]
|
| 16 |
+
else:
|
| 17 |
+
switch_case = 1
|
| 18 |
+
decode_fn = lambda token_ids_list: [
|
| 19 |
+
text.strip()
|
| 20 |
+
for text in partial(
|
| 21 |
+
tokenizer.batch_decode, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 22 |
+
)(token_ids_list)
|
| 23 |
+
]
|
| 24 |
+
else:
|
| 25 |
+
switch_case = 2
|
| 26 |
+
decode_fn = lambda token_ids: partial(
|
| 27 |
+
tokenizer.decode, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 28 |
+
)(token_ids).strip()
|
| 29 |
+
|
| 30 |
+
id_to_text = {}
|
| 31 |
+
for id_, something in id_to_something.items():
|
| 32 |
+
if switch_case == -1 or switch_case == 0:
|
| 33 |
+
obj_to_decode = something
|
| 34 |
+
else:
|
| 35 |
+
if data_args is None:
|
| 36 |
+
data_args = {}
|
| 37 |
+
if not isinstance(data_args, dict):
|
| 38 |
+
data_args = vars(data_args)
|
| 39 |
+
if data_args.get("ignore_pad_token_for_loss", True):
|
| 40 |
+
# Replace -100 in the token_ids as we can't decode them.
|
| 41 |
+
if switch_case == 1:
|
| 42 |
+
token_ids_list = something
|
| 43 |
+
for i in range(len(token_ids_list)):
|
| 44 |
+
token_ids_list[i] = _replace_padding(token_ids_list[i], tokenizer.pad_token_id)
|
| 45 |
+
obj_to_decode = token_ids_list
|
| 46 |
+
elif switch_case == 2:
|
| 47 |
+
token_ids = something
|
| 48 |
+
token_ids = _replace_padding(token_ids, tokenizer.pad_token_id)
|
| 49 |
+
obj_to_decode = token_ids
|
| 50 |
+
else:
|
| 51 |
+
obj_to_decode = something
|
| 52 |
+
|
| 53 |
+
id_to_text[id_] = decode_fn(obj_to_decode)
|
| 54 |
+
|
| 55 |
+
return id_to_text
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def _replace_padding(token_ids: np.array, pad_token_id):
|
| 59 |
+
return np.where(token_ids != -100, token_ids, pad_token_id)
|
unlimiformer/utils/duplicates.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def drop_duplicates_in_input(untokenized_dataset):
|
| 2 |
+
indices_to_keep = []
|
| 3 |
+
id_to_idx = {}
|
| 4 |
+
outputs = []
|
| 5 |
+
for i, (id_, output) in enumerate(zip(untokenized_dataset["id"], untokenized_dataset["output"])):
|
| 6 |
+
if id_ in id_to_idx:
|
| 7 |
+
outputs[id_to_idx[id_]].append(output)
|
| 8 |
+
continue
|
| 9 |
+
indices_to_keep.append(i)
|
| 10 |
+
id_to_idx[id_] = len(outputs)
|
| 11 |
+
outputs.append([output])
|
| 12 |
+
untokenized_dataset = untokenized_dataset.select(indices_to_keep).flatten_indices()
|
| 13 |
+
untokenized_dataset = untokenized_dataset.remove_columns("output")
|
| 14 |
+
untokenized_dataset = untokenized_dataset.add_column("outputs", outputs)
|
| 15 |
+
return untokenized_dataset
|
unlimiformer/utils/override_training_args.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
import torch.cuda
|
| 6 |
+
from transformers.utils import logging
|
| 7 |
+
|
| 8 |
+
sys.path.insert(0, os.getcwd())
|
| 9 |
+
|
| 10 |
+
from dataclasses import dataclass, field
|
| 11 |
+
|
| 12 |
+
from transformers.trainer_utils import IntervalStrategy
|
| 13 |
+
from transformers import Seq2SeqTrainingArguments
|
| 14 |
+
|
| 15 |
+
logger = logging.get_logger('swed_logger')
|
| 16 |
+
|
| 17 |
+
@dataclass
|
| 18 |
+
class TrainingOverridesArguments(Seq2SeqTrainingArguments):
|
| 19 |
+
"""
|
| 20 |
+
To use if, it requires evaluation_strategy == IntervalStrategy.STEPS
|
| 21 |
+
"""
|
| 22 |
+
eval_steps_override: float = field(default=0, metadata={"help": "a fraction, to set the the save_steps w.r.t to number of steps in "
|
| 23 |
+
"a single epoch. changes eval_steps. 0 to disable (default)"})
|
| 24 |
+
save_steps_override: float = field(default=0, metadata={"help": "a fraction, to set the the save_steps w.r.t to number of steps in "
|
| 25 |
+
"a single epoch. changes save_steps. must be a multiple of eval_steps"
|
| 26 |
+
" (or eval_steps_override if given). 0 to disable (default)"})
|
| 27 |
+
|
| 28 |
+
eval_fraction: float = field(default=1, metadata={
|
| 29 |
+
"help": "A float in (0,1] that corresponds to how much of the eval set to use during evaluations "
|
| 30 |
+
"(same subset all the time) or an integer >= 2 which amounts to the absolute number of training "
|
| 31 |
+
"samples to use. 1. to disable it and use the entire eval set "})
|
| 32 |
+
|
| 33 |
+
use_auth_token: bool = field(
|
| 34 |
+
default=False,
|
| 35 |
+
metadata={
|
| 36 |
+
"help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
|
| 37 |
+
"with private models). If AUTH_TOKEN is set as an environment variable, would use that"
|
| 38 |
+
},
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
fp16_padding: bool = field(
|
| 42 |
+
default=False,
|
| 43 |
+
metadata={"help": "Whether to use padding for fp16"},
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def __post_init__(self):
|
| 48 |
+
super(TrainingOverridesArguments, self).__post_init__()
|
| 49 |
+
if self.eval_steps_override > 0 or self.save_steps_override > 0:
|
| 50 |
+
if self.evaluation_strategy != IntervalStrategy.STEPS:
|
| 51 |
+
raise ValueError(
|
| 52 |
+
f"using eval/save steps override requires evaluation strategy to be {IntervalStrategy.STEPS}"
|
| 53 |
+
)
|
| 54 |
+
if self.save_steps_override == 0 or self.eval_steps_override == 0:
|
| 55 |
+
raise ValueError(
|
| 56 |
+
f"using eval/save steps override requires both overrides to be non zero"
|
| 57 |
+
)
|
| 58 |
+
diff = (self.save_steps_override / self.eval_steps_override) % 1
|
| 59 |
+
if min(1-diff, diff) > 1e-5: # we do it like that to support fractions modulo as well, with loss of precision
|
| 60 |
+
raise ValueError(
|
| 61 |
+
f"using eval/save steps override requires save steps override to be a multiple of eval_steps_override"
|
| 62 |
+
)
|
| 63 |
+
if self.use_auth_token and 'AUTH_TOKEN' in os.environ:
|
| 64 |
+
self.use_auth_token = os.getenv('AUTH_TOKEN')
|
| 65 |
+
|
| 66 |
+
@property
|
| 67 |
+
def effective_batch_size(self):
|
| 68 |
+
if not hasattr(self, '_ebs'):
|
| 69 |
+
n_gpu = self.n_gpu if torch.cuda.is_available() else 1 # may be on cpu
|
| 70 |
+
self._ebs = self.per_device_train_batch_size * self.gradient_accumulation_steps * n_gpu
|
| 71 |
+
logger.warning(f'Training with {self.per_device_train_batch_size} per_device_train_size, {self.n_gpu} gpus and '
|
| 72 |
+
f'{self.gradient_accumulation_steps} gradient accumulation steps, resulting in {self._ebs} effective batch size')
|
| 73 |
+
return self._ebs
|
| 74 |
+
|
| 75 |
+
def apply_overrides(self, dataset_size):
|
| 76 |
+
# Uri:
|
| 77 |
+
return
|
| 78 |
+
|
| 79 |
+
if self.eval_steps_override == 0:
|
| 80 |
+
return
|
| 81 |
+
es, ss = self.eval_steps, self.save_steps
|
| 82 |
+
total_steps_per_epoch = dataset_size / self.effective_batch_size # note that this may not be an integer
|
| 83 |
+
eval_steps = int(total_steps_per_epoch * self.eval_steps_override)
|
| 84 |
+
if eval_steps >= self.logging_steps:
|
| 85 |
+
if eval_steps % self.logging_steps != 0:
|
| 86 |
+
logger.warning(f'Eval steps override would result in eval every {eval_steps} steps, but it is not a '
|
| 87 |
+
f'multiple of logging steps ({self.logging_steps}) so changing to '
|
| 88 |
+
f'{eval_steps + self.logging_steps - eval_steps % self.logging_steps}')
|
| 89 |
+
eval_steps = eval_steps + self.logging_steps - eval_steps % self.logging_steps
|
| 90 |
+
elif eval_steps < self.logging_steps:
|
| 91 |
+
logger.warning(f'Eval steps override would result in eval every {eval_steps} steps, but it is not a '
|
| 92 |
+
f'multiple of logging steps ({self.logging_steps}) so changing to {self.logging_steps}')
|
| 93 |
+
eval_steps = self.logging_steps
|
| 94 |
+
self.eval_steps = eval_steps
|
| 95 |
+
|
| 96 |
+
save_steps = int(total_steps_per_epoch * self.save_steps_override)
|
| 97 |
+
if save_steps < eval_steps or save_steps % eval_steps != 0:
|
| 98 |
+
logger.warning(f'Save steps override would result in eval every {save_steps} steps, but it is not a '
|
| 99 |
+
f'multiple of eval steps ({eval_steps}) so changing to '
|
| 100 |
+
f'{save_steps + eval_steps - save_steps % self.eval_steps}')
|
| 101 |
+
save_steps = save_steps + eval_steps - save_steps % self.eval_steps
|
| 102 |
+
self.save_steps = save_steps
|
| 103 |
+
|
| 104 |
+
logger.warning(f'Using overrides with dataset of size {dataset_size} and effective batch size of '
|
| 105 |
+
f'{self.effective_batch_size}, moving from (eval_steps, save_steps) '
|
| 106 |
+
f'of {(es, ss)} to {(self.eval_steps, self.save_steps)}')
|
utils.py
CHANGED
|
@@ -2,6 +2,7 @@ import re
|
|
| 2 |
import spacy
|
| 3 |
import json
|
| 4 |
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, AutoModelForCausalLM, AutoModel
|
|
|
|
| 5 |
import streamlit as st
|
| 6 |
from urllib.request import Request, urlopen, HTTPError
|
| 7 |
from bs4 import BeautifulSoup
|
|
@@ -16,8 +17,29 @@ def hide_footer():
|
|
| 16 |
st.markdown(hide_st_style, unsafe_allow_html=True)
|
| 17 |
|
| 18 |
@st.cache_resource
|
| 19 |
-
def get_seq2seq_model(model_id):
|
| 20 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
@st.cache_resource
|
| 23 |
def get_causal_model(model_id):
|
|
|
|
| 2 |
import spacy
|
| 3 |
import json
|
| 4 |
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, AutoModelForCausalLM, AutoModel
|
| 5 |
+
from unlimiformer import Unlimiformer, UnlimiformerArguments
|
| 6 |
import streamlit as st
|
| 7 |
from urllib.request import Request, urlopen, HTTPError
|
| 8 |
from bs4 import BeautifulSoup
|
|
|
|
| 17 |
st.markdown(hide_st_style, unsafe_allow_html=True)
|
| 18 |
|
| 19 |
@st.cache_resource
|
| 20 |
+
def get_seq2seq_model(model_id, use_unlimiformer=True, _tokenizer=None):
|
| 21 |
+
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)
|
| 22 |
+
if use_unlimiformer:
|
| 23 |
+
defaults = UnlimiformerArguments()
|
| 24 |
+
unlimiformer_kwargs = {
|
| 25 |
+
'layer_begin': defaults.layer_begin,
|
| 26 |
+
'layer_end': defaults.layer_end,
|
| 27 |
+
'unlimiformer_head_num': defaults.unlimiformer_head_num,
|
| 28 |
+
'exclude_attention': defaults.unlimiformer_exclude,
|
| 29 |
+
'chunk_overlap': defaults.unlimiformer_chunk_overlap,
|
| 30 |
+
'model_encoder_max_len': defaults.unlimiformer_chunk_size,
|
| 31 |
+
'verbose': defaults.unlimiformer_verbose, 'tokenizer': _tokenizer,
|
| 32 |
+
'unlimiformer_training': defaults.unlimiformer_training,
|
| 33 |
+
'use_datastore': defaults.use_datastore,
|
| 34 |
+
'flat_index': defaults.flat_index,
|
| 35 |
+
'test_datastore': defaults.test_datastore,
|
| 36 |
+
'reconstruct_embeddings': defaults.reconstruct_embeddings,
|
| 37 |
+
'gpu_datastore': defaults.gpu_datastore,
|
| 38 |
+
'gpu_index': defaults.gpu_index
|
| 39 |
+
}
|
| 40 |
+
return Unlimiformer.convert_model(model, **unlimiformer_kwargs)
|
| 41 |
+
else:
|
| 42 |
+
return model
|
| 43 |
|
| 44 |
@st.cache_resource
|
| 45 |
def get_causal_model(model_id):
|