Spaces:
Runtime error


Runtime error
Patrick Esser
commited on
Commit
·
69e4d47
1
Parent(s):
0c94d78
Release under CreativeML Open RAIL M License
Browse filesUpdate license, readme, models, model card, requirements and sampling
script.
Former-commit-id: 69ae4b35e0a0f6ee1af8bb9a5d0016ccb27e36dc
- LICENSE +82 -14
- README.md +31 -25
- Stable_Diffusion_v1_Model_Card.md +15 -11
- assets/rick.jpeg +0 -0
- assets/v1-variants-scores.jpg +0 -0
- environment.yaml +2 -0
- scripts/tests/test_watermark.py +18 -0
- scripts/txt2img.py +45 -6
LICENSE
CHANGED
|
@@ -1,14 +1,82 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2022 Robin Rombach and Patrick Esser and contributors
|
| 2 |
+
|
| 3 |
+
CreativeML Open RAIL-M
|
| 4 |
+
dated August 22, 2022
|
| 5 |
+
|
| 6 |
+
Section I: PREAMBLE
|
| 7 |
+
|
| 8 |
+
Multimodal generative models are being widely adopted and used, and have the potential to transform the way artists, among other individuals, conceive and benefit from AI or ML technologies as a tool for content creation.
|
| 9 |
+
|
| 10 |
+
Notwithstanding the current and potential benefits that these artifacts can bring to society at large, there are also concerns about potential misuses of them, either due to their technical limitations or ethical considerations.
|
| 11 |
+
|
| 12 |
+
In short, this license strives for both the open and responsible downstream use of the accompanying model. When it comes to the open character, we took inspiration from open source permissive licenses regarding the grant of IP rights. Referring to the downstream responsible use, we added use-based restrictions not permitting the use of the Model in very specific scenarios, in order for the licensor to be able to enforce the license in case potential misuses of the Model may occur. At the same time, we strive to promote open and responsible research on generative models for art and content generation.
|
| 13 |
+
|
| 14 |
+
Even though downstream derivative versions of the model could be released under different licensing terms, the latter will always have to include - at minimum - the same use-based restrictions as the ones in the original license (this license). We believe in the intersection between open and responsible AI development; thus, this License aims to strike a balance between both in order to enable responsible open-science in the field of AI.
|
| 15 |
+
|
| 16 |
+
This License governs the use of the model (and its derivatives) and is informed by the model card associated with the model.
|
| 17 |
+
|
| 18 |
+
NOW THEREFORE, You and Licensor agree as follows:
|
| 19 |
+
|
| 20 |
+
1. Definitions
|
| 21 |
+
|
| 22 |
+
- "License" means the terms and conditions for use, reproduction, and Distribution as defined in this document.
|
| 23 |
+
- "Data" means a collection of information and/or content extracted from the dataset used with the Model, including to train, pretrain, or otherwise evaluate the Model. The Data is not licensed under this License.
|
| 24 |
+
- "Output" means the results of operating a Model as embodied in informational content resulting therefrom.
|
| 25 |
+
- "Model" means any accompanying machine-learning based assemblies (including checkpoints), consisting of learnt weights, parameters (including optimizer states), corresponding to the model architecture as embodied in the Complementary Material, that have been trained or tuned, in whole or in part on the Data, using the Complementary Material.
|
| 26 |
+
- "Derivatives of the Model" means all modifications to the Model, works based on the Model, or any other model which is created or initialized by transfer of patterns of the weights, parameters, activations or output of the Model, to the other model, in order to cause the other model to perform similarly to the Model, including - but not limited to - distillation methods entailing the use of intermediate data representations or methods based on the generation of synthetic data by the Model for training the other model.
|
| 27 |
+
- "Complementary Material" means the accompanying source code and scripts used to define, run, load, benchmark or evaluate the Model, and used to prepare data for training or evaluation, if any. This includes any accompanying documentation, tutorials, examples, etc, if any.
|
| 28 |
+
- "Distribution" means any transmission, reproduction, publication or other sharing of the Model or Derivatives of the Model to a third party, including providing the Model as a hosted service made available by electronic or other remote means - e.g. API-based or web access.
|
| 29 |
+
- "Licensor" means the copyright owner or entity authorized by the copyright owner that is granting the License, including the persons or entities that may have rights in the Model and/or distributing the Model.
|
| 30 |
+
- "You" (or "Your") means an individual or Legal Entity exercising permissions granted by this License and/or making use of the Model for whichever purpose and in any field of use, including usage of the Model in an end-use application - e.g. chatbot, translator, image generator.
|
| 31 |
+
- "Third Parties" means individuals or legal entities that are not under common control with Licensor or You.
|
| 32 |
+
- "Contribution" means any work of authorship, including the original version of the Model and any modifications or additions to that Model or Derivatives of the Model thereof, that is intentionally submitted to Licensor for inclusion in the Model by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Model, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
|
| 33 |
+
- "Contributor" means Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Model.
|
| 34 |
+
|
| 35 |
+
Section II: INTELLECTUAL PROPERTY RIGHTS
|
| 36 |
+
|
| 37 |
+
Both copyright and patent grants apply to the Model, Derivatives of the Model and Complementary Material. The Model and Derivatives of the Model are subject to additional terms as described in Section III.
|
| 38 |
+
|
| 39 |
+
2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare, publicly display, publicly perform, sublicense, and distribute the Complementary Material, the Model, and Derivatives of the Model.
|
| 40 |
+
3. Grant of Patent License. Subject to the terms and conditions of this License and where and as applicable, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this paragraph) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model and the Complementary Material, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Model to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model and/or Complementary Material or a Contribution incorporated within the Model and/or Complementary Material constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for the Model and/or Work shall terminate as of the date such litigation is asserted or filed.
|
| 41 |
+
|
| 42 |
+
Section III: CONDITIONS OF USAGE, DISTRIBUTION AND REDISTRIBUTION
|
| 43 |
+
|
| 44 |
+
4. Distribution and Redistribution. You may host for Third Party remote access purposes (e.g. software-as-a-service), reproduce and distribute copies of the Model or Derivatives of the Model thereof in any medium, with or without modifications, provided that You meet the following conditions:
|
| 45 |
+
Use-based restrictions as referenced in paragraph 5 MUST be included as an enforceable provision by You in any type of legal agreement (e.g. a license) governing the use and/or distribution of the Model or Derivatives of the Model, and You shall give notice to subsequent users You Distribute to, that the Model or Derivatives of the Model are subject to paragraph 5. This provision does not apply to the use of Complementary Material.
|
| 46 |
+
You must give any Third Party recipients of the Model or Derivatives of the Model a copy of this License;
|
| 47 |
+
You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 48 |
+
You must retain all copyright, patent, trademark, and attribution notices excluding those notices that do not pertain to any part of the Model, Derivatives of the Model.
|
| 49 |
+
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions - respecting paragraph 4.a. - for use, reproduction, or Distribution of Your modifications, or for any such Derivatives of the Model as a whole, provided Your use, reproduction, and Distribution of the Model otherwise complies with the conditions stated in this License.
|
| 50 |
+
5. Use-based restrictions. The restrictions set forth in Attachment A are considered Use-based restrictions. Therefore You cannot use the Model and the Derivatives of the Model for the specified restricted uses. You may use the Model subject to this License, including only for lawful purposes and in accordance with the License. Use may include creating any content with, finetuning, updating, running, training, evaluating and/or reparametrizing the Model. You shall require all of Your users who use the Model or a Derivative of the Model to comply with the terms of this paragraph (paragraph 5).
|
| 51 |
+
6. The Output You Generate. Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
|
| 52 |
+
|
| 53 |
+
Section IV: OTHER PROVISIONS
|
| 54 |
+
|
| 55 |
+
7. Updates and Runtime Restrictions. To the maximum extent permitted by law, Licensor reserves the right to restrict (remotely or otherwise) usage of the Model in violation of this License, update the Model through electronic means, or modify the Output of the Model based on updates. You shall undertake reasonable efforts to use the latest version of the Model.
|
| 56 |
+
8. Trademarks and related. Nothing in this License permits You to make use of Licensors’ trademarks, trade names, logos or to otherwise suggest endorsement or misrepresent the relationship between the parties; and any rights not expressly granted herein are reserved by the Licensors.
|
| 57 |
+
9. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Model and the Complementary Material (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Model, Derivatives of the Model, and the Complementary Material and assume any risks associated with Your exercise of permissions under this License.
|
| 58 |
+
10. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model and the Complementary Material (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
|
| 59 |
+
11. Accepting Warranty or Additional Liability. While redistributing the Model, Derivatives of the Model and the Complementary Material thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
|
| 60 |
+
12. If any provision of this License is held to be invalid, illegal or unenforceable, the remaining provisions shall be unaffected thereby and remain valid as if such provision had not been set forth herein.
|
| 61 |
+
|
| 62 |
+
END OF TERMS AND CONDITIONS
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
Attachment A
|
| 68 |
+
|
| 69 |
+
Use Restrictions
|
| 70 |
+
|
| 71 |
+
You agree not to use the Model or Derivatives of the Model:
|
| 72 |
+
- In any way that violates any applicable national, federal, state, local or international law or regulation;
|
| 73 |
+
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 74 |
+
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
|
| 75 |
+
- To generate or disseminate personal identifiable information that can be used to harm an individual;
|
| 76 |
+
- To defame, disparage or otherwise harass others;
|
| 77 |
+
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
|
| 78 |
+
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
|
| 79 |
+
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 80 |
+
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories;
|
| 81 |
+
- To provide medical advice and medical results interpretation;
|
| 82 |
+
- To generate or disseminate information for the purpose to be used for administration of justice, law enforcement, immigration or asylum processes, such as predicting an individual will commit fraud/crime commitment (e.g. by text profiling, drawing causal relationships between assertions made in documents, indiscriminate and arbitrarily-targeted use).
|
README.md
CHANGED
|
@@ -7,10 +7,8 @@
|
|
| 7 |
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 8 |
[Patrick Esser](https://github.com/pesser),
|
| 9 |
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
which is available on [GitHub](https://github.com/CompVis/latent-diffusion). PDF at [arXiv](https://arxiv.org/abs/2112.10752). Please also visit our [Project page](https://ommer-lab.com/research/latent-diffusion-models/).
|
| 14 |
|
| 15 |

|
| 16 |
[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
|
|
@@ -35,7 +33,7 @@ You can also update an existing [latent diffusion](https://github.com/CompVis/la
|
|
| 35 |
|
| 36 |
```
|
| 37 |
conda install pytorch torchvision -c pytorch
|
| 38 |
-
pip install transformers==4.19.2
|
| 39 |
pip install -e .
|
| 40 |
```
|
| 41 |
|
|
@@ -49,23 +47,23 @@ then finetuned on 512x512 images.
|
|
| 49 |
|
| 50 |
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
|
| 51 |
in its training data.
|
| 52 |
-
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](
|
| 53 |
-
Research into the safe deployment of general text-to-image models is an ongoing effort. To prevent misuse and harm, we currently provide access to the checkpoints only for [academic research purposes upon request](https://stability.ai/academia-access-form).
|
| 54 |
-
**This is an experiment in safe and community-driven publication of a capable and general text-to-image model. We are working on a public release with a more permissive license that also incorporates ethical considerations.***
|
| 55 |
|
| 56 |
-
|
|
|
|
|
|
|
| 57 |
|
| 58 |
### Weights
|
| 59 |
|
| 60 |
-
We currently provide
|
| 61 |
-
which were trained as follows,
|
| 62 |
|
| 63 |
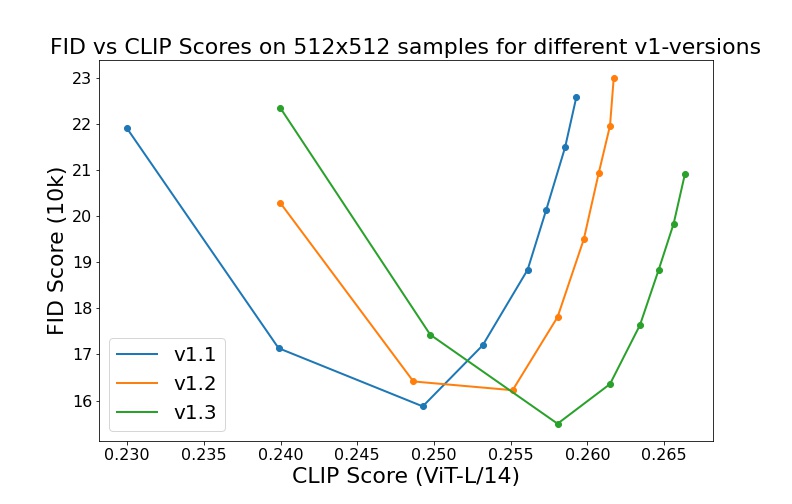
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 64 |
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 65 |
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 66 |
-
515k steps at resolution `512x512` on
|
| 67 |
-
filtered to images with an original size `>= 512x512`,
|
| 68 |
-
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-
|
|
|
|
| 69 |
|
| 70 |
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 71 |
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
|
@@ -79,11 +77,20 @@ steps show the relative improvements of the checkpoints:
|
|
| 79 |

|
| 80 |
|
| 81 |
Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) text embeddings of a CLIP ViT-L/14 text encoder.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
|
|
|
|
| 83 |
|
| 84 |
-
|
|
|
|
|
|
|
|
|
|
| 85 |
|
| 86 |
-
After [obtaining the weights](#weights), link them
|
| 87 |
```
|
| 88 |
mkdir -p models/ldm/stable-diffusion-v1/
|
| 89 |
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
|
|
@@ -96,9 +103,11 @@ python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse"
|
|
| 96 |
By default, this uses a guidance scale of `--scale 7.5`, [Katherine Crowson's implementation](https://github.com/CompVis/latent-diffusion/pull/51) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler,
|
| 97 |
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type `python scripts/txt2img.py --help`).
|
| 98 |
|
|
|
|
| 99 |
```commandline
|
| 100 |
-
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
|
| 101 |
-
[--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
|
|
|
|
| 102 |
|
| 103 |
optional arguments:
|
| 104 |
-h, --help show this help message and exit
|
|
@@ -128,7 +137,6 @@ optional arguments:
|
|
| 128 |
--seed SEED the seed (for reproducible sampling)
|
| 129 |
--precision {full,autocast}
|
| 130 |
evaluate at this precision
|
| 131 |
-
|
| 132 |
```
|
| 133 |
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
|
| 134 |
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
|
|
@@ -138,16 +146,16 @@ which contain both types of weights. For these, `use_ema=False` will load and us
|
|
| 138 |
|
| 139 |
#### Diffusers Integration
|
| 140 |
|
| 141 |
-
|
| 142 |
```py
|
| 143 |
# make sure you're logged in with `huggingface-cli login`
|
| 144 |
from torch import autocast
|
| 145 |
-
from diffusers import StableDiffusionPipeline
|
| 146 |
|
| 147 |
pipe = StableDiffusionPipeline.from_pretrained(
|
| 148 |
-
"CompVis/stable-diffusion-v1-
|
| 149 |
use_auth_token=True
|
| 150 |
-
)
|
| 151 |
|
| 152 |
prompt = "a photo of an astronaut riding a horse on mars"
|
| 153 |
with autocast("cuda"):
|
|
@@ -157,7 +165,6 @@ image.save("astronaut_rides_horse.png")
|
|
| 157 |
```
|
| 158 |
|
| 159 |
|
| 160 |
-
|
| 161 |
### Image Modification with Stable Diffusion
|
| 162 |
|
| 163 |
By using a diffusion-denoising mechanism as first proposed by [SDEdit](https://arxiv.org/abs/2108.01073), the model can be used for different
|
|
@@ -203,7 +210,6 @@ Thanks for open-sourcing!
|
|
| 203 |
archivePrefix={arXiv},
|
| 204 |
primaryClass={cs.CV}
|
| 205 |
}
|
| 206 |
-
|
| 207 |
```
|
| 208 |
|
| 209 |
|
|
|
|
| 7 |
[Dominik Lorenz](https://github.com/qp-qp)\,
|
| 8 |
[Patrick Esser](https://github.com/pesser),
|
| 9 |
[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)<br/>
|
| 10 |
+
_[CVPR '22 Oral](https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html) |
|
| 11 |
+
[GitHub](https://github.com/CompVis/latent-diffusion) | [arXiv](https://arxiv.org/abs/2112.10752) | [Project page](https://ommer-lab.com/research/latent-diffusion-models/)_
|
|
|
|
|
|
|
| 12 |
|
| 13 |

|
| 14 |
[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
|
|
|
|
| 33 |
|
| 34 |
```
|
| 35 |
conda install pytorch torchvision -c pytorch
|
| 36 |
+
pip install transformers==4.19.2 diffusers invisible-watermark
|
| 37 |
pip install -e .
|
| 38 |
```
|
| 39 |
|
|
|
|
| 47 |
|
| 48 |
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
|
| 49 |
in its training data.
|
| 50 |
+
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](Stable_Diffusion_v1_Model_Card.md).*
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
The weights are available via [the CompVis organization at Hugging Face](https://huggingface.co/CompVis) under [a license which contains specific use-based restrictions to prevent misuse and harm as informed by the model card, but otherwise remains permissive](LICENSE). While commercial use is permitted under the terms of the license, **we do not recommend using the provided weights for services or products without additional safety mechanisms and considerations**, since there are [known limitations and biases](Stable_Diffusion_v1_Model_Card.md#limitations-and-bias) of the weights, and research on safe and ethical deployment of general text-to-image models is an ongoing effort. **The weights are research artifacts and should be treated as such.**
|
| 53 |
+
|
| 54 |
+
[The CreativeML OpenRAIL M license](LICENSE) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
|
| 55 |
|
| 56 |
### Weights
|
| 57 |
|
| 58 |
+
We currently provide the following checkpoints:
|
|
|
|
| 59 |
|
| 60 |
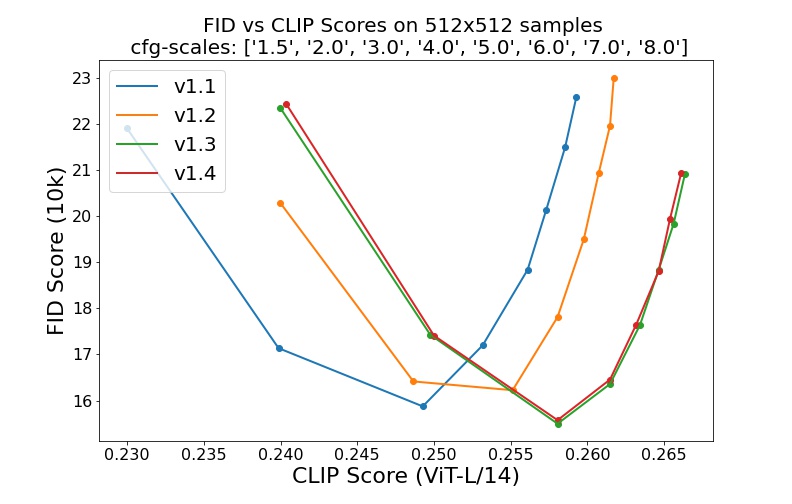
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 61 |
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 62 |
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 63 |
+
515k steps at resolution `512x512` on [laion-aesthetics v2 5+](https://laion.ai/blog/laion-aesthetics/) (a subset of laion2B-en with estimated aesthetics score `> 5.0`, and additionally
|
| 64 |
+
filtered to images with an original size `>= 512x512`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the [LAION-5B](https://laion.ai/blog/laion-5b/) metadata, the aesthetics score is estimated using the [LAION-Aesthetics Predictor V2](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
|
| 65 |
+
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 66 |
+
- `sd-v1-4.ckpt`: Resumed from `sd-v1-2.ckpt`. 225k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 67 |
|
| 68 |
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
| 69 |
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
|
|
|
| 77 |

|
| 78 |
|
| 79 |
Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) text embeddings of a CLIP ViT-L/14 text encoder.
|
| 80 |
+
We provide a [reference script for sampling](#reference-sampling-script), but
|
| 81 |
+
there also exists a [diffusers integration](#diffusers-integration), which we
|
| 82 |
+
expect to see more active community development.
|
| 83 |
+
|
| 84 |
+
#### Reference Sampling Script
|
| 85 |
|
| 86 |
+
We provide a reference sampling script, which incorporates
|
| 87 |
|
| 88 |
+
- a [Safety Checker Module](https://github.com/CompVis/stable-diffusion/pull/36),
|
| 89 |
+
to reduce the probability of explicit outputs,
|
| 90 |
+
- an [invisible watermarking](https://github.com/ShieldMnt/invisible-watermark)
|
| 91 |
+
of the outputs, to help viewers [identify the images as machine-generated](scripts/tests/test_watermark.py).
|
| 92 |
|
| 93 |
+
After [obtaining the `stable-diffusion-v1-*-original` weights](#weights), link them
|
| 94 |
```
|
| 95 |
mkdir -p models/ldm/stable-diffusion-v1/
|
| 96 |
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
|
|
|
|
| 103 |
By default, this uses a guidance scale of `--scale 7.5`, [Katherine Crowson's implementation](https://github.com/CompVis/latent-diffusion/pull/51) of the [PLMS](https://arxiv.org/abs/2202.09778) sampler,
|
| 104 |
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type `python scripts/txt2img.py --help`).
|
| 105 |
|
| 106 |
+
|
| 107 |
```commandline
|
| 108 |
+
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
|
| 109 |
+
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
|
| 110 |
+
[--seed SEED] [--precision {full,autocast}]
|
| 111 |
|
| 112 |
optional arguments:
|
| 113 |
-h, --help show this help message and exit
|
|
|
|
| 137 |
--seed SEED the seed (for reproducible sampling)
|
| 138 |
--precision {full,autocast}
|
| 139 |
evaluate at this precision
|
|
|
|
| 140 |
```
|
| 141 |
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
|
| 142 |
For this reason `use_ema=False` is set in the configuration, otherwise the code will try to switch from
|
|
|
|
| 146 |
|
| 147 |
#### Diffusers Integration
|
| 148 |
|
| 149 |
+
A simple way to download and sample Stable Diffusion is by using the [diffusers library](https://github.com/huggingface/diffusers/tree/main#new--stable-diffusion-is-now-fully-compatible-with-diffusers):
|
| 150 |
```py
|
| 151 |
# make sure you're logged in with `huggingface-cli login`
|
| 152 |
from torch import autocast
|
| 153 |
+
from diffusers import StableDiffusionPipeline
|
| 154 |
|
| 155 |
pipe = StableDiffusionPipeline.from_pretrained(
|
| 156 |
+
"CompVis/stable-diffusion-v1-4",
|
| 157 |
use_auth_token=True
|
| 158 |
+
).to("cuda")
|
| 159 |
|
| 160 |
prompt = "a photo of an astronaut riding a horse on mars"
|
| 161 |
with autocast("cuda"):
|
|
|
|
| 165 |
```
|
| 166 |
|
| 167 |
|
|
|
|
| 168 |
### Image Modification with Stable Diffusion
|
| 169 |
|
| 170 |
By using a diffusion-denoising mechanism as first proposed by [SDEdit](https://arxiv.org/abs/2108.01073), the model can be used for different
|
|
|
|
| 210 |
archivePrefix={arXiv},
|
| 211 |
primaryClass={cs.CV}
|
| 212 |
}
|
|
|
|
| 213 |
```
|
| 214 |
|
| 215 |
|
Stable_Diffusion_v1_Model_Card.md
CHANGED
|
@@ -36,10 +36,11 @@ Excluded uses are described below.
|
|
| 36 |
### Misuse, Malicious Use, and Out-of-Scope Use
|
| 37 |
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
|
| 38 |
|
| 39 |
-
|
| 40 |
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
|
|
|
|
| 41 |
#### Out-of-Scope Use
|
| 42 |
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
|
|
|
| 43 |
#### Misuse and Malicious Use
|
| 44 |
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
|
| 45 |
|
|
@@ -66,14 +67,17 @@ Using the model to generate content that is cruel to individuals is a misuse of
|
|
| 66 |
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
|
| 67 |
and is not fit for product use without additional safety mechanisms and
|
| 68 |
considerations.
|
|
|
|
|
|
|
| 69 |
|
| 70 |
### Bias
|
| 71 |
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 72 |
-
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
| 73 |
-
which consists of images that are
|
| 74 |
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 75 |
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 76 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
|
|
|
| 77 |
|
| 78 |
|
| 79 |
## Training
|
|
@@ -81,7 +85,7 @@ ability of the model to generate content with non-English prompts is significant
|
|
| 81 |
**Training Data**
|
| 82 |
The model developers used the following dataset for training the model:
|
| 83 |
|
| 84 |
-
- LAION-
|
| 85 |
|
| 86 |
**Training Procedure**
|
| 87 |
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
|
@@ -91,16 +95,15 @@ Stable Diffusion v1 is a latent diffusion model which combines an autoencoder wi
|
|
| 91 |
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
|
| 92 |
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
|
| 93 |
|
| 94 |
-
We currently provide
|
| 95 |
-
which were trained as follows,
|
| 96 |
|
| 97 |
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 98 |
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 99 |
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 100 |
-
515k steps at resolution `512x512` on
|
| 101 |
-
filtered to images with an original size `>= 512x512`,
|
| 102 |
-
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-
|
| 103 |
-
|
| 104 |
|
| 105 |
- **Hardware:** 32 x 8 x A100 GPUs
|
| 106 |
- **Optimizer:** AdamW
|
|
@@ -116,6 +119,7 @@ steps show the relative improvements of the checkpoints:
|
|
| 116 |

|
| 117 |
|
| 118 |
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
|
|
|
| 119 |
## Environmental Impact
|
| 120 |
|
| 121 |
**Stable Diffusion v1** **Estimated Emissions**
|
|
@@ -126,6 +130,7 @@ Based on that information, we estimate the following CO2 emissions using the [Ma
|
|
| 126 |
- **Cloud Provider:** AWS
|
| 127 |
- **Compute Region:** US-east
|
| 128 |
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
|
|
|
|
| 129 |
## Citation
|
| 130 |
@InProceedings{Rombach_2022_CVPR,
|
| 131 |
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
|
|
@@ -137,4 +142,3 @@ Based on that information, we estimate the following CO2 emissions using the [Ma
|
|
| 137 |
}
|
| 138 |
|
| 139 |
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
| 140 |
-
|
|
|
|
| 36 |
### Misuse, Malicious Use, and Out-of-Scope Use
|
| 37 |
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
|
| 38 |
|
|
|
|
| 39 |
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
|
| 40 |
+
|
| 41 |
#### Out-of-Scope Use
|
| 42 |
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 43 |
+
|
| 44 |
#### Misuse and Malicious Use
|
| 45 |
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
|
| 46 |
|
|
|
|
| 67 |
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
|
| 68 |
and is not fit for product use without additional safety mechanisms and
|
| 69 |
considerations.
|
| 70 |
+
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
|
| 71 |
+
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
|
| 72 |
|
| 73 |
### Bias
|
| 74 |
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 75 |
+
Stable Diffusion v1 was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
| 76 |
+
which consists of images that are limited to English descriptions.
|
| 77 |
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 78 |
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 79 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 80 |
+
Stable Diffusion v1 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
|
| 81 |
|
| 82 |
|
| 83 |
## Training
|
|
|
|
| 85 |
**Training Data**
|
| 86 |
The model developers used the following dataset for training the model:
|
| 87 |
|
| 88 |
+
- LAION-5B and subsets thereof (see next section)
|
| 89 |
|
| 90 |
**Training Procedure**
|
| 91 |
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
|
|
|
| 95 |
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
|
| 96 |
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
|
| 97 |
|
| 98 |
+
We currently provide the following checkpoints:
|
|
|
|
| 99 |
|
| 100 |
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
|
| 101 |
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
|
| 102 |
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
|
| 103 |
+
515k steps at resolution `512x512` on [laion-aesthetics v2 5+](https://laion.ai/blog/laion-aesthetics/) (a subset of laion2B-en with estimated aesthetics score `> 5.0`, and additionally
|
| 104 |
+
filtered to images with an original size `>= 512x512`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the [LAION-5B](https://laion.ai/blog/laion-5b/) metadata, the aesthetics score is estimated using the [LAION-Aesthetics Predictor V2](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
|
| 105 |
+
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 106 |
+
- `sd-v1-4.ckpt`: Resumed from `sd-v1-2.ckpt`. 225k steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
|
| 107 |
|
| 108 |
- **Hardware:** 32 x 8 x A100 GPUs
|
| 109 |
- **Optimizer:** AdamW
|
|
|
|
| 119 |

|
| 120 |
|
| 121 |
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
| 122 |
+
|
| 123 |
## Environmental Impact
|
| 124 |
|
| 125 |
**Stable Diffusion v1** **Estimated Emissions**
|
|
|
|
| 130 |
- **Cloud Provider:** AWS
|
| 131 |
- **Compute Region:** US-east
|
| 132 |
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
|
| 133 |
+
|
| 134 |
## Citation
|
| 135 |
@InProceedings{Rombach_2022_CVPR,
|
| 136 |
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
|
|
|
|
| 142 |
}
|
| 143 |
|
| 144 |
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
|
|
assets/rick.jpeg
ADDED

|
assets/v1-variants-scores.jpg
CHANGED
|
|
environment.yaml
CHANGED
|
@@ -11,8 +11,10 @@ dependencies:
|
|
| 11 |
- numpy=1.19.2
|
| 12 |
- pip:
|
| 13 |
- albumentations==0.4.3
|
|
|
|
| 14 |
- opencv-python==4.1.2.30
|
| 15 |
- pudb==2019.2
|
|
|
|
| 16 |
- imageio==2.9.0
|
| 17 |
- imageio-ffmpeg==0.4.2
|
| 18 |
- pytorch-lightning==1.4.2
|
|
|
|
| 11 |
- numpy=1.19.2
|
| 12 |
- pip:
|
| 13 |
- albumentations==0.4.3
|
| 14 |
+
- diffusers
|
| 15 |
- opencv-python==4.1.2.30
|
| 16 |
- pudb==2019.2
|
| 17 |
+
- invisible-watermark
|
| 18 |
- imageio==2.9.0
|
| 19 |
- imageio-ffmpeg==0.4.2
|
| 20 |
- pytorch-lightning==1.4.2
|
scripts/tests/test_watermark.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import fire
|
| 3 |
+
from imwatermark import WatermarkDecoder
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def testit(img_path):
|
| 7 |
+
bgr = cv2.imread(img_path)
|
| 8 |
+
decoder = WatermarkDecoder('bytes', 136)
|
| 9 |
+
watermark = decoder.decode(bgr, 'dwtDct')
|
| 10 |
+
try:
|
| 11 |
+
dec = watermark.decode('utf-8')
|
| 12 |
+
except:
|
| 13 |
+
dec = "null"
|
| 14 |
+
print(dec)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
if __name__ == "__main__":
|
| 18 |
+
fire.Fire(testit)
|
scripts/txt2img.py
CHANGED
|
@@ -1,9 +1,11 @@
|
|
| 1 |
import argparse, os, sys, glob
|
|
|
|
| 2 |
import torch
|
| 3 |
import numpy as np
|
| 4 |
from omegaconf import OmegaConf
|
| 5 |
from PIL import Image
|
| 6 |
from tqdm import tqdm, trange
|
|
|
|
| 7 |
from itertools import islice
|
| 8 |
from einops import rearrange
|
| 9 |
from torchvision.utils import make_grid
|
|
@@ -19,11 +21,13 @@ from ldm.models.diffusion.plms import PLMSSampler
|
|
| 19 |
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 20 |
from transformers import AutoFeatureExtractor
|
| 21 |
|
|
|
|
| 22 |
# load safety model
|
| 23 |
safety_model_id = "CompVis/stable-diffusion-safety-checker"
|
| 24 |
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
|
| 25 |
safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)
|
| 26 |
|
|
|
|
| 27 |
def chunk(it, size):
|
| 28 |
it = iter(it)
|
| 29 |
return iter(lambda: tuple(islice(it, size)), ())
|
|
@@ -61,6 +65,35 @@ def load_model_from_config(config, ckpt, verbose=False):
|
|
| 61 |
return model
|
| 62 |
|
| 63 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
def main():
|
| 65 |
parser = argparse.ArgumentParser()
|
| 66 |
|
|
@@ -217,6 +250,11 @@ def main():
|
|
| 217 |
os.makedirs(opt.outdir, exist_ok=True)
|
| 218 |
outpath = opt.outdir
|
| 219 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 220 |
batch_size = opt.n_samples
|
| 221 |
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
|
| 222 |
if not opt.from_file:
|
|
@@ -268,17 +306,16 @@ def main():
|
|
| 268 |
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
|
| 269 |
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
|
| 270 |
|
| 271 |
-
|
| 272 |
-
safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
|
| 273 |
-
x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
|
| 274 |
|
| 275 |
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
|
| 276 |
|
| 277 |
if not opt.skip_save:
|
| 278 |
for x_sample in x_checked_image_torch:
|
| 279 |
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
|
| 280 |
-
Image.fromarray(x_sample.astype(np.uint8))
|
| 281 |
-
|
|
|
|
| 282 |
base_count += 1
|
| 283 |
|
| 284 |
if not opt.skip_grid:
|
|
@@ -292,7 +329,9 @@ def main():
|
|
| 292 |
|
| 293 |
# to image
|
| 294 |
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
|
| 295 |
-
Image.fromarray(grid.astype(np.uint8))
|
|
|
|
|
|
|
| 296 |
grid_count += 1
|
| 297 |
|
| 298 |
toc = time.time()
|
|
|
|
| 1 |
import argparse, os, sys, glob
|
| 2 |
+
import cv2
|
| 3 |
import torch
|
| 4 |
import numpy as np
|
| 5 |
from omegaconf import OmegaConf
|
| 6 |
from PIL import Image
|
| 7 |
from tqdm import tqdm, trange
|
| 8 |
+
from imwatermark import WatermarkEncoder
|
| 9 |
from itertools import islice
|
| 10 |
from einops import rearrange
|
| 11 |
from torchvision.utils import make_grid
|
|
|
|
| 21 |
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 22 |
from transformers import AutoFeatureExtractor
|
| 23 |
|
| 24 |
+
|
| 25 |
# load safety model
|
| 26 |
safety_model_id = "CompVis/stable-diffusion-safety-checker"
|
| 27 |
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
|
| 28 |
safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)
|
| 29 |
|
| 30 |
+
|
| 31 |
def chunk(it, size):
|
| 32 |
it = iter(it)
|
| 33 |
return iter(lambda: tuple(islice(it, size)), ())
|
|
|
|
| 65 |
return model
|
| 66 |
|
| 67 |
|
| 68 |
+
def put_watermark(img, wm_encoder=None):
|
| 69 |
+
if wm_encoder is not None:
|
| 70 |
+
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
|
| 71 |
+
img = wm_encoder.encode(img, 'dwtDct')
|
| 72 |
+
img = Image.fromarray(img[:, :, ::-1])
|
| 73 |
+
return img
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def load_replacement(x):
|
| 77 |
+
try:
|
| 78 |
+
hwc = x.shape
|
| 79 |
+
y = Image.open("assets/rick.jpeg").convert("RGB").resize((hwc[1], hwc[0]))
|
| 80 |
+
y = (np.array(y)/255.0).astype(x.dtype)
|
| 81 |
+
assert y.shape == x.shape
|
| 82 |
+
return y
|
| 83 |
+
except Exception:
|
| 84 |
+
return x
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def check_safety(x_image):
|
| 88 |
+
safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
|
| 89 |
+
x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
|
| 90 |
+
assert x_checked_image.shape[0] == len(has_nsfw_concept)
|
| 91 |
+
for i in range(len(has_nsfw_concept)):
|
| 92 |
+
if has_nsfw_concept[i]:
|
| 93 |
+
x_checked_image[i] = load_replacement(x_checked_image[i])
|
| 94 |
+
return x_checked_image, has_nsfw_concept
|
| 95 |
+
|
| 96 |
+
|
| 97 |
def main():
|
| 98 |
parser = argparse.ArgumentParser()
|
| 99 |
|
|
|
|
| 250 |
os.makedirs(opt.outdir, exist_ok=True)
|
| 251 |
outpath = opt.outdir
|
| 252 |
|
| 253 |
+
print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...")
|
| 254 |
+
wm = "StableDiffusionV1"
|
| 255 |
+
wm_encoder = WatermarkEncoder()
|
| 256 |
+
wm_encoder.set_watermark('bytes', wm.encode('utf-8'))
|
| 257 |
+
|
| 258 |
batch_size = opt.n_samples
|
| 259 |
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
|
| 260 |
if not opt.from_file:
|
|
|
|
| 306 |
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
|
| 307 |
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
|
| 308 |
|
| 309 |
+
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
|
|
|
|
|
|
|
| 310 |
|
| 311 |
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
|
| 312 |
|
| 313 |
if not opt.skip_save:
|
| 314 |
for x_sample in x_checked_image_torch:
|
| 315 |
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
|
| 316 |
+
img = Image.fromarray(x_sample.astype(np.uint8))
|
| 317 |
+
img = put_watermark(img, wm_encoder)
|
| 318 |
+
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
|
| 319 |
base_count += 1
|
| 320 |
|
| 321 |
if not opt.skip_grid:
|
|
|
|
| 329 |
|
| 330 |
# to image
|
| 331 |
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
|
| 332 |
+
img = Image.fromarray(grid.astype(np.uint8))
|
| 333 |
+
img = put_watermark(img, wm_encoder)
|
| 334 |
+
img.save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
|
| 335 |
grid_count += 1
|
| 336 |
|
| 337 |
toc = time.time()
|