Spaces:
Sleeping

Sleeping
update docs
Browse files- docs/classifier_model.md +62 -0
- docs/images/iteration1_cm.png +0 -0
- docs/images/test_labels.png +0 -0
- docs/images/train_labels.png +0 -0
docs/classifier_model.md
CHANGED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Classification Model
|
| 2 |
+
|
| 3 |
+
**Table of Contents**
|
| 4 |
+
1. Objectives
|
| 5 |
+
2. Iteration 1
|
| 6 |
+
3. Conclusion
|
| 7 |
+
|
| 8 |
+
## 1. Objectives
|
| 9 |
+
Given some arabic text, the goal is to classify it into one of 21 labels:
|
| 10 |
+
- Egypt
|
| 11 |
+
- Iraq
|
| 12 |
+
- Saudi_Arabia
|
| 13 |
+
- Mauritania
|
| 14 |
+
- Algeria
|
| 15 |
+
- Syria
|
| 16 |
+
- Oman
|
| 17 |
+
- Tunisia
|
| 18 |
+
- Lebanon
|
| 19 |
+
- Morocco
|
| 20 |
+
- Djibouti
|
| 21 |
+
- United_Arab_Emirates
|
| 22 |
+
- Kuwait
|
| 23 |
+
- Libya
|
| 24 |
+
- Bahtain
|
| 25 |
+
- Qatar
|
| 26 |
+
- Yemen
|
| 27 |
+
- Palestine
|
| 28 |
+
- Jordan
|
| 29 |
+
- Somalia
|
| 30 |
+
- Sudan
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
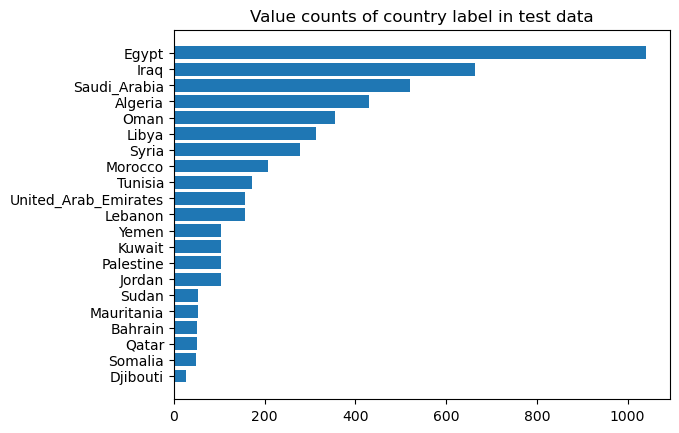
Some countries don't have a lot of observations, which means that it might be harder to detect their dialects. We need to take this into consideration when training and evaluating the model (by assigning weights/oversampling, and by choosing appropriate evaluation metrics):
|
| 34 |
+

|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
## 2. Iteration 1
|
| 38 |
+
For the first iteration, we will convert the tweets into vector embeddings using the AraBART model. We will extract those embeddings from the output of the last hidden layer of the AraBART model. After that, we will train a multinomial logistic regression using these embeddings as features.
|
| 39 |
+
|
| 40 |
+
We get the following results:
|
| 41 |
+
|
| 42 |
+
Logistic Regression
|
| 43 |
+
--------------------------------------------------
|
| 44 |
+
Train set:
|
| 45 |
+
Accuracy: 0.3448095238095238
|
| 46 |
+
F1 macro average: 0.30283202516650803
|
| 47 |
+
F1 weighted average: 0.35980803167526537
|
| 48 |
+
--------------------------------------------------
|
| 49 |
+
Test set:
|
| 50 |
+
Accuracy: 0.2324
|
| 51 |
+
F1 macro average: 0.15894661492139023
|
| 52 |
+
F1 weighted average: 0.2680459740545796
|
| 53 |
+
|
| 54 |
+
We see that the model is struggling to correctly classify the different dialects, (which makes sense because everything is in arabic at the end of the day). Let's have a look at the confusion matrix.
|
| 55 |
+

|
| 56 |
+
|
| 57 |
+
From the confusion matrix, we see that the model is only really able to detect Egyptian arabic, and to a lesser extent Iraqi and Algerian.
|
| 58 |
+
|
| 59 |
+
## 3. Conclusion
|
| 60 |
+
|
| 61 |
+
It is hard to classify the arabic dialects with a simple approach such as a multinomial logistic regression trained on top of those vector embeddings. One potential reason could be related to the limitations of the training dataset:
|
| 62 |
+
Due to the way it was collected, it is labeling the text because of the location of the tweet, instead of the actual content of the text. As a result, it is possible that a lot of the tweets labeled as a dialect of a given country, contain in reality some text in Modern Standard Arabic, or in another dialect, or also possibly in a mix of dialects, which are all common ways in which arabic is used on social media.
|
docs/images/iteration1_cm.png
ADDED

|
docs/images/test_labels.png
ADDED
|
docs/images/train_labels.png
ADDED

|