Runtime error
6
oasst-sft-1-pythia-12b
🔥

Maintainers of the `huggingface/text-generation-inference` repo
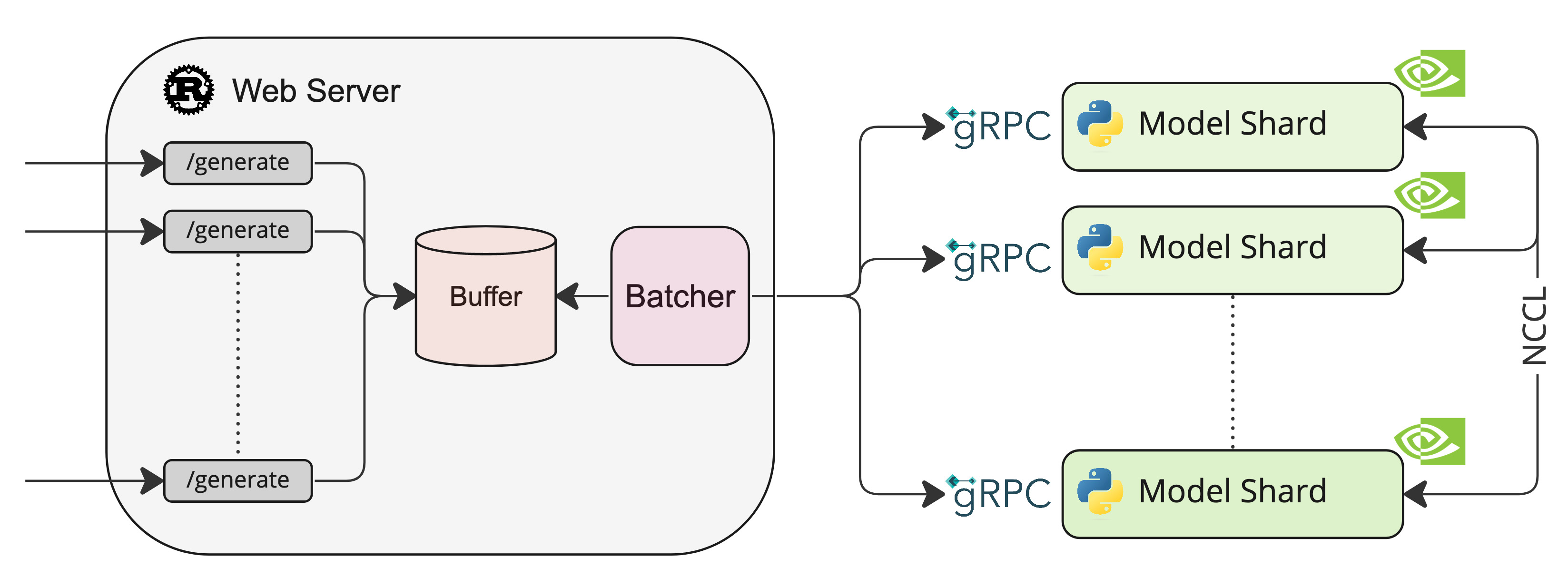
Text-Generation-Inference is a solution build for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Llama, and T5. Text Generation Inference is already used by customers such as IBM, Grammarly, and the Open-Assistant initiative implements optimization for all supported model architectures, including: