
Adding `safetensors` variant of this model
#1
by
ykhwang
- opened
- README.md +14 -14
- added_tokens.json +4 -44
- asset/42dot_LLM_EN_score_white_background.png +0 -0
- asset/42dot_LLM_PLM_KO_score_background.png +0 -0
- asset/plm_benchmark_en.png +0 -0
- asset/plm_benchmark_ko.png +0 -0
- special_tokens_map.json +0 -46
- tokenizer.json +6 -444
- tokenizer_config.json +2 -3
- vocab.json +0 -0
README.md
CHANGED
|
@@ -10,14 +10,14 @@ tags:
|
|
| 10 |
- 42dot_llm
|
| 11 |
license: cc-by-nc-4.0
|
| 12 |
---
|
| 13 |
-
#
|
| 14 |
|
| 15 |
-
**42dot
|
| 16 |
|
| 17 |
## Model Description
|
| 18 |
|
| 19 |
### Hyperparameters
|
| 20 |
-
42dot
|
| 21 |
|
| 22 |
| Params | Layers | Attention heads | Hidden size | FFN size |
|
| 23 |
| -- | -- | -- | -- | -- |
|
|
@@ -42,14 +42,14 @@ We used a set of publicly available text corpus, including:
|
|
| 42 |
The tokenizer is based on the Byte-level BPE algorithm. We trained its vocabulary from scratch using a subset of the pre-training corpus. For constructing a subset, 10M and 10M documents are sampled from Korean and English corpus respectively. The resulting vocabulary sizes about 50K.
|
| 43 |
|
| 44 |
### Zero-shot evaluations
|
| 45 |
-
We evaluate 42dot
|
| 46 |
#### Korean (KOBEST)
|
| 47 |
|
| 48 |
<figure align="center">
|
| 49 |
-
<img src="https://huggingface.co/42dot/
|
| 50 |
</figure>
|
| 51 |
|
| 52 |
-
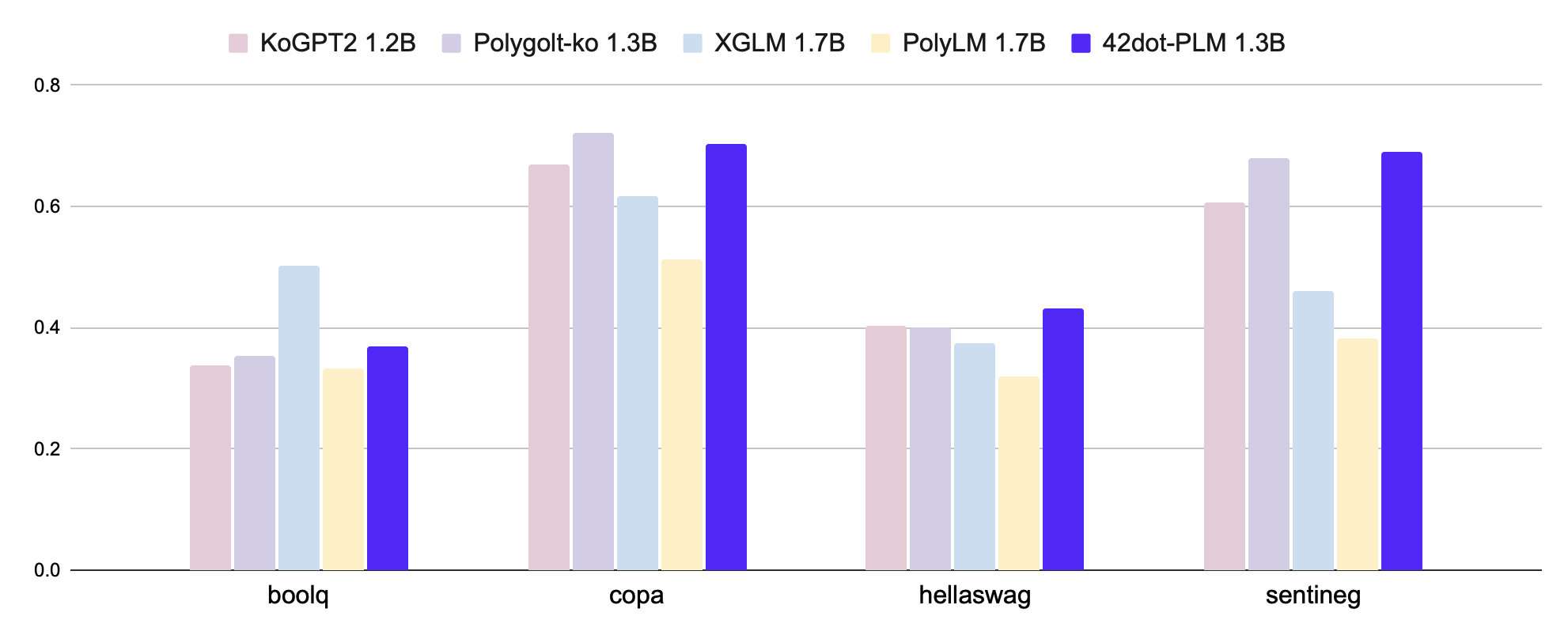
|Tasks / Macro-F1|[KoGPT2](https://github.com/SKT-AI/KoGPT2) <br>1.2B|[Polyglot-Ko](https://github.com/EleutherAI/polyglot) <br>1.3B|[XGLM](https://huggingface.co/facebook/xglm-1.7B) <br>1.7B|[PolyLM](https://huggingface.co/DAMO-NLP-MT/polylm-1.7b) <br>1.7B|42dot
|
| 53 |
|--------------|-----------|----------------|---------|-----------|------------------------|
|
| 54 |
|boolq |0.337 |0.355 |**0.502** |0.334 |0.369 |
|
| 55 |
|copa |0.67 |**0.721** |0.616 |0.513 |0.704 |
|
|
@@ -60,10 +60,10 @@ We evaluate 42dot LLM-PLM on a variety of academic benchmarks both in Korean and
|
|
| 60 |
#### English
|
| 61 |
|
| 62 |
<figure align="center">
|
| 63 |
-
<img src="https://huggingface.co/42dot/
|
| 64 |
</figure>
|
| 65 |
|
| 66 |
-
| Tasks / Metric | MPT <br>1B | OPT <br>1.3B | XGLM <br>1.7B | PolyLM <br>1.7B | 42dot
|
| 67 |
| ---------------------- | ------ | -------- | --------- | ----------- | ------------------------ |
|
| 68 |
| anli_r1/acc | 0.309 | **0.341** | 0.334 | 0.336 | 0.325 |
|
| 69 |
| anli_r2/acc | 0.334 | 0.339 | 0.331 | 0.314 | **0.34** |
|
|
@@ -86,25 +86,25 @@ We evaluate 42dot LLM-PLM on a variety of academic benchmarks both in Korean and
|
|
| 86 |
| truthfulqa_mc/mc2 | 0.387 | 0.386 | 0.373 | **0.428** | 0.387 |
|
| 87 |
| wic/acc | 0.498 | **0.509** | 0.503 | 0.5 | 0.502 |
|
| 88 |
| winogrande/acc | 0.574 | **0.595** | 0.55 | 0.519 | 0.583 |
|
| 89 |
-
| **
|
| 90 |
|
| 91 |
## Limitations and Ethical Considerations
|
| 92 |
-
42dot
|
| 93 |
|
| 94 |
## Disclaimer
|
| 95 |
The contents generated by 42dot LLM series ("42dot LLM") do not necessarily reflect the views or opinions of 42dot Inc. ("42dot"). 42dot disclaims any and all liability to any part for any direct, indirect, implied, punitive, special, incidental, or other consequential damages arising from any use of the 42dot LLM and its generated contents.
|
| 96 |
|
| 97 |
## License
|
| 98 |
-
The 42dot
|
| 99 |
|
| 100 |
## Citation
|
| 101 |
|
| 102 |
```
|
| 103 |
@misc{42dot2023llm,
|
| 104 |
title={42dot LLM: A Series of Large Language Model by 42dot},
|
| 105 |
-
author={
|
| 106 |
year={2023},
|
| 107 |
url = {https://github.com/42dot/42dot_LLM},
|
| 108 |
-
version = {
|
| 109 |
}
|
| 110 |
-
```
|
|
|
|
| 10 |
- 42dot_llm
|
| 11 |
license: cc-by-nc-4.0
|
| 12 |
---
|
| 13 |
+
# 42dot-PLM-1.3B
|
| 14 |
|
| 15 |
+
**42dot-PLM** is a pre-trained language model (PLM) developed by [**42dot**](https://42dot.ai/) and is a part of **42dot LLM** (large language model). 42dot-PLM is pre-trained using Korean and English text corpus and can be used as a foundation language model for several Korean and English natural language tasks. This repository contains a 1.3B-parameter version of the model.
|
| 16 |
|
| 17 |
## Model Description
|
| 18 |
|
| 19 |
### Hyperparameters
|
| 20 |
+
42dot-PLM is built upon a Transformer decoder architecture similar to the [LLaMA 2](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) and its hyperparameters are listed below.
|
| 21 |
|
| 22 |
| Params | Layers | Attention heads | Hidden size | FFN size |
|
| 23 |
| -- | -- | -- | -- | -- |
|
|
|
|
| 42 |
The tokenizer is based on the Byte-level BPE algorithm. We trained its vocabulary from scratch using a subset of the pre-training corpus. For constructing a subset, 10M and 10M documents are sampled from Korean and English corpus respectively. The resulting vocabulary sizes about 50K.
|
| 43 |
|
| 44 |
### Zero-shot evaluations
|
| 45 |
+
We evaluate 42dot-PLM on a variety of academic benchmarks both in Korean and English. All the results are obtained using [lm-eval-harness](https://github.com/EleutherAI/lm-evaluation-harness/tree/polyglot) and models released on the Hugging Face Hub.
|
| 46 |
#### Korean (KOBEST)
|
| 47 |
|
| 48 |
<figure align="center">
|
| 49 |
+
<img src="https://huggingface.co/42dot/42dot-plm-1.3b/resolve/main/asset/plm_benchmark_ko.png" width="90%" height="90%"/>
|
| 50 |
</figure>
|
| 51 |
|
| 52 |
+
|Tasks / Macro-F1|[KoGPT2](https://github.com/SKT-AI/KoGPT2) <br>1.2B|[Polyglot-Ko](https://github.com/EleutherAI/polyglot) <br>1.3B|[XGLM](https://huggingface.co/facebook/xglm-1.7B) <br>1.7B|[PolyLM](https://huggingface.co/DAMO-NLP-MT/polylm-1.7b) <br>1.7B|42dot-PLM <br>1.3B|
|
| 53 |
|--------------|-----------|----------------|---------|-----------|------------------------|
|
| 54 |
|boolq |0.337 |0.355 |**0.502** |0.334 |0.369 |
|
| 55 |
|copa |0.67 |**0.721** |0.616 |0.513 |0.704 |
|
|
|
|
| 60 |
#### English
|
| 61 |
|
| 62 |
<figure align="center">
|
| 63 |
+
<img src="https://huggingface.co/42dot/42dot-plm-1.3b/resolve/main/asset/plm_benchmark_en.png" width="90%" height="90%"/>
|
| 64 |
</figure>
|
| 65 |
|
| 66 |
+
| Tasks / Metric | MPT <br>1B | OPT <br>1.3B | XGLM <br>1.7B | PolyLM <br>1.7B | 42dot-PLM <br>1.3B |
|
| 67 |
| ---------------------- | ------ | -------- | --------- | ----------- | ------------------------ |
|
| 68 |
| anli_r1/acc | 0.309 | **0.341** | 0.334 | 0.336 | 0.325 |
|
| 69 |
| anli_r2/acc | 0.334 | 0.339 | 0.331 | 0.314 | **0.34** |
|
|
|
|
| 86 |
| truthfulqa_mc/mc2 | 0.387 | 0.386 | 0.373 | **0.428** | 0.387 |
|
| 87 |
| wic/acc | 0.498 | **0.509** | 0.503 | 0.5 | 0.502 |
|
| 88 |
| winogrande/acc | 0.574 | **0.595** | 0.55 | 0.519 | 0.583 |
|
| 89 |
+
| **avearge** | 0.479 | 0.482 | 0.452 | 0.429 | **0.492** |
|
| 90 |
|
| 91 |
## Limitations and Ethical Considerations
|
| 92 |
+
42dot-PLM shares a number of well-known limitations of other large language models (LLMs). For example, it may generate false and misinformative content since 42dot-PLM is also subject to [hallucination](https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)). In addition, 42dot-PLM may generate toxic, harmful, and biased content due to the use of web-available training data. We strongly suggest that 42dot-PLM users should be aware of those limitations and take necessary steps to mitigate those issues.
|
| 93 |
|
| 94 |
## Disclaimer
|
| 95 |
The contents generated by 42dot LLM series ("42dot LLM") do not necessarily reflect the views or opinions of 42dot Inc. ("42dot"). 42dot disclaims any and all liability to any part for any direct, indirect, implied, punitive, special, incidental, or other consequential damages arising from any use of the 42dot LLM and its generated contents.
|
| 96 |
|
| 97 |
## License
|
| 98 |
+
The 42dot-PLM is licensed under the Creative Commons Attribution-NonCommercial 4.0 (CC BY-NC 4.0).
|
| 99 |
|
| 100 |
## Citation
|
| 101 |
|
| 102 |
```
|
| 103 |
@misc{42dot2023llm,
|
| 104 |
title={42dot LLM: A Series of Large Language Model by 42dot},
|
| 105 |
+
author={Woo-Jong Ryu and Sang-Kil Park and Jinwoo Park and Seongmin Lee and Yongkeun Hwang},
|
| 106 |
year={2023},
|
| 107 |
url = {https://github.com/42dot/42dot_LLM},
|
| 108 |
+
version = {pre-release},
|
| 109 |
}
|
| 110 |
+
```
|
added_tokens.json
CHANGED
|
@@ -1,46 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"
|
| 3 |
-
"<||
|
| 4 |
-
"<||
|
| 5 |
-
"<||
|
| 6 |
-
"<||unused14||>": 50273,
|
| 7 |
-
"<||unused15||>": 50274,
|
| 8 |
-
"<||unused16||>": 50275,
|
| 9 |
-
"<||unused17||>": 50276,
|
| 10 |
-
"<||unused18||>": 50277,
|
| 11 |
-
"<||unused19||>": 50278,
|
| 12 |
-
"<||unused1||>": 50260,
|
| 13 |
-
"<||unused20||>": 50279,
|
| 14 |
-
"<||unused21||>": 50280,
|
| 15 |
-
"<||unused22||>": 50281,
|
| 16 |
-
"<||unused23||>": 50282,
|
| 17 |
-
"<||unused24||>": 50283,
|
| 18 |
-
"<||unused25||>": 50284,
|
| 19 |
-
"<||unused26||>": 50285,
|
| 20 |
-
"<||unused27||>": 50286,
|
| 21 |
-
"<||unused28||>": 50287,
|
| 22 |
-
"<||unused29||>": 50288,
|
| 23 |
-
"<||unused2||>": 50261,
|
| 24 |
-
"<||unused30||>": 50289,
|
| 25 |
-
"<||unused31||>": 50290,
|
| 26 |
-
"<||unused32||>": 50291,
|
| 27 |
-
"<||unused33||>": 50292,
|
| 28 |
-
"<||unused34||>": 50293,
|
| 29 |
-
"<||unused35||>": 50294,
|
| 30 |
-
"<||unused36||>": 50295,
|
| 31 |
-
"<||unused37||>": 50296,
|
| 32 |
-
"<||unused38||>": 50297,
|
| 33 |
-
"<||unused39||>": 50298,
|
| 34 |
-
"<||unused3||>": 50262,
|
| 35 |
-
"<||unused40||>": 50299,
|
| 36 |
-
"<||unused41||>": 50300,
|
| 37 |
-
"<||unused42||>": 50301,
|
| 38 |
-
"<||unused43||>": 50302,
|
| 39 |
-
"<||unused44||>": 50303,
|
| 40 |
-
"<||unused4||>": 50263,
|
| 41 |
-
"<||unused5||>": 50264,
|
| 42 |
-
"<||unused6||>": 50265,
|
| 43 |
-
"<||unused7||>": 50266,
|
| 44 |
-
"<||unused8||>": 50267,
|
| 45 |
-
"<||unused9||>": 50268
|
| 46 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"<|endoftext|>": 50256,
|
| 3 |
+
"<||bos||>": 50257,
|
| 4 |
+
"<||pad||>": 50258,
|
| 5 |
+
"<||unk||>": 50259
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
}
|
asset/42dot_LLM_EN_score_white_background.png
DELETED
|
Binary file (80.5 kB)
|
|
|
asset/42dot_LLM_PLM_KO_score_background.png
DELETED
|
Binary file (84.9 kB)
|
|
|
asset/plm_benchmark_en.png
ADDED

|
asset/plm_benchmark_ko.png
ADDED
|
special_tokens_map.json
CHANGED
|
@@ -1,50 +1,4 @@
|
|
| 1 |
{
|
| 2 |
-
"additional_special_tokens": [
|
| 3 |
-
"<||unused1||>",
|
| 4 |
-
"<||unused2||>",
|
| 5 |
-
"<||unused3||>",
|
| 6 |
-
"<||unused4||>",
|
| 7 |
-
"<||unused5||>",
|
| 8 |
-
"<||unused6||>",
|
| 9 |
-
"<||unused7||>",
|
| 10 |
-
"<||unused8||>",
|
| 11 |
-
"<||unused9||>",
|
| 12 |
-
"<||unused10||>",
|
| 13 |
-
"<||unused11||>",
|
| 14 |
-
"<||unused12||>",
|
| 15 |
-
"<||unused13||>",
|
| 16 |
-
"<||unused14||>",
|
| 17 |
-
"<||unused15||>",
|
| 18 |
-
"<||unused16||>",
|
| 19 |
-
"<||unused17||>",
|
| 20 |
-
"<||unused18||>",
|
| 21 |
-
"<||unused19||>",
|
| 22 |
-
"<||unused20||>",
|
| 23 |
-
"<||unused21||>",
|
| 24 |
-
"<||unused22||>",
|
| 25 |
-
"<||unused23||>",
|
| 26 |
-
"<||unused24||>",
|
| 27 |
-
"<||unused25||>",
|
| 28 |
-
"<||unused26||>",
|
| 29 |
-
"<||unused27||>",
|
| 30 |
-
"<||unused28||>",
|
| 31 |
-
"<||unused29||>",
|
| 32 |
-
"<||unused30||>",
|
| 33 |
-
"<||unused31||>",
|
| 34 |
-
"<||unused32||>",
|
| 35 |
-
"<||unused33||>",
|
| 36 |
-
"<||unused34||>",
|
| 37 |
-
"<||unused35||>",
|
| 38 |
-
"<||unused36||>",
|
| 39 |
-
"<||unused37||>",
|
| 40 |
-
"<||unused38||>",
|
| 41 |
-
"<||unused39||>",
|
| 42 |
-
"<||unused40||>",
|
| 43 |
-
"<||unused41||>",
|
| 44 |
-
"<||unused42||>",
|
| 45 |
-
"<||unused43||>",
|
| 46 |
-
"<||unused44||>"
|
| 47 |
-
],
|
| 48 |
"bos_token": "<||bos||>",
|
| 49 |
"eos_token": {
|
| 50 |
"content": "<|endoftext|>",
|
|
|
|
| 1 |
{
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
"bos_token": "<||bos||>",
|
| 3 |
"eos_token": {
|
| 4 |
"content": "<|endoftext|>",
|
tokenizer.json
CHANGED
|
@@ -38,402 +38,6 @@
|
|
| 38 |
"rstrip": false,
|
| 39 |
"normalized": false,
|
| 40 |
"special": true
|
| 41 |
-
},
|
| 42 |
-
{
|
| 43 |
-
"id": 50260,
|
| 44 |
-
"content": "<||unused1||>",
|
| 45 |
-
"single_word": false,
|
| 46 |
-
"lstrip": false,
|
| 47 |
-
"rstrip": false,
|
| 48 |
-
"normalized": false,
|
| 49 |
-
"special": true
|
| 50 |
-
},
|
| 51 |
-
{
|
| 52 |
-
"id": 50261,
|
| 53 |
-
"content": "<||unused2||>",
|
| 54 |
-
"single_word": false,
|
| 55 |
-
"lstrip": false,
|
| 56 |
-
"rstrip": false,
|
| 57 |
-
"normalized": false,
|
| 58 |
-
"special": true
|
| 59 |
-
},
|
| 60 |
-
{
|
| 61 |
-
"id": 50262,
|
| 62 |
-
"content": "<||unused3||>",
|
| 63 |
-
"single_word": false,
|
| 64 |
-
"lstrip": false,
|
| 65 |
-
"rstrip": false,
|
| 66 |
-
"normalized": false,
|
| 67 |
-
"special": true
|
| 68 |
-
},
|
| 69 |
-
{
|
| 70 |
-
"id": 50263,
|
| 71 |
-
"content": "<||unused4||>",
|
| 72 |
-
"single_word": false,
|
| 73 |
-
"lstrip": false,
|
| 74 |
-
"rstrip": false,
|
| 75 |
-
"normalized": false,
|
| 76 |
-
"special": true
|
| 77 |
-
},
|
| 78 |
-
{
|
| 79 |
-
"id": 50264,
|
| 80 |
-
"content": "<||unused5||>",
|
| 81 |
-
"single_word": false,
|
| 82 |
-
"lstrip": false,
|
| 83 |
-
"rstrip": false,
|
| 84 |
-
"normalized": false,
|
| 85 |
-
"special": true
|
| 86 |
-
},
|
| 87 |
-
{
|
| 88 |
-
"id": 50265,
|
| 89 |
-
"content": "<||unused6||>",
|
| 90 |
-
"single_word": false,
|
| 91 |
-
"lstrip": false,
|
| 92 |
-
"rstrip": false,
|
| 93 |
-
"normalized": false,
|
| 94 |
-
"special": true
|
| 95 |
-
},
|
| 96 |
-
{
|
| 97 |
-
"id": 50266,
|
| 98 |
-
"content": "<||unused7||>",
|
| 99 |
-
"single_word": false,
|
| 100 |
-
"lstrip": false,
|
| 101 |
-
"rstrip": false,
|
| 102 |
-
"normalized": false,
|
| 103 |
-
"special": true
|
| 104 |
-
},
|
| 105 |
-
{
|
| 106 |
-
"id": 50267,
|
| 107 |
-
"content": "<||unused8||>",
|
| 108 |
-
"single_word": false,
|
| 109 |
-
"lstrip": false,
|
| 110 |
-
"rstrip": false,
|
| 111 |
-
"normalized": false,
|
| 112 |
-
"special": true
|
| 113 |
-
},
|
| 114 |
-
{
|
| 115 |
-
"id": 50268,
|
| 116 |
-
"content": "<||unused9||>",
|
| 117 |
-
"single_word": false,
|
| 118 |
-
"lstrip": false,
|
| 119 |
-
"rstrip": false,
|
| 120 |
-
"normalized": false,
|
| 121 |
-
"special": true
|
| 122 |
-
},
|
| 123 |
-
{
|
| 124 |
-
"id": 50269,
|
| 125 |
-
"content": "<||unused10||>",
|
| 126 |
-
"single_word": false,
|
| 127 |
-
"lstrip": false,
|
| 128 |
-
"rstrip": false,
|
| 129 |
-
"normalized": false,
|
| 130 |
-
"special": true
|
| 131 |
-
},
|
| 132 |
-
{
|
| 133 |
-
"id": 50270,
|
| 134 |
-
"content": "<||unused11||>",
|
| 135 |
-
"single_word": false,
|
| 136 |
-
"lstrip": false,
|
| 137 |
-
"rstrip": false,
|
| 138 |
-
"normalized": false,
|
| 139 |
-
"special": true
|
| 140 |
-
},
|
| 141 |
-
{
|
| 142 |
-
"id": 50271,
|
| 143 |
-
"content": "<||unused12||>",
|
| 144 |
-
"single_word": false,
|
| 145 |
-
"lstrip": false,
|
| 146 |
-
"rstrip": false,
|
| 147 |
-
"normalized": false,
|
| 148 |
-
"special": true
|
| 149 |
-
},
|
| 150 |
-
{
|
| 151 |
-
"id": 50272,
|
| 152 |
-
"content": "<||unused13||>",
|
| 153 |
-
"single_word": false,
|
| 154 |
-
"lstrip": false,
|
| 155 |
-
"rstrip": false,
|
| 156 |
-
"normalized": false,
|
| 157 |
-
"special": true
|
| 158 |
-
},
|
| 159 |
-
{
|
| 160 |
-
"id": 50273,
|
| 161 |
-
"content": "<||unused14||>",
|
| 162 |
-
"single_word": false,
|
| 163 |
-
"lstrip": false,
|
| 164 |
-
"rstrip": false,
|
| 165 |
-
"normalized": false,
|
| 166 |
-
"special": true
|
| 167 |
-
},
|
| 168 |
-
{
|
| 169 |
-
"id": 50274,
|
| 170 |
-
"content": "<||unused15||>",
|
| 171 |
-
"single_word": false,
|
| 172 |
-
"lstrip": false,
|
| 173 |
-
"rstrip": false,
|
| 174 |
-
"normalized": false,
|
| 175 |
-
"special": true
|
| 176 |
-
},
|
| 177 |
-
{
|
| 178 |
-
"id": 50275,
|
| 179 |
-
"content": "<||unused16||>",
|
| 180 |
-
"single_word": false,
|
| 181 |
-
"lstrip": false,
|
| 182 |
-
"rstrip": false,
|
| 183 |
-
"normalized": false,
|
| 184 |
-
"special": true
|
| 185 |
-
},
|
| 186 |
-
{
|
| 187 |
-
"id": 50276,
|
| 188 |
-
"content": "<||unused17||>",
|
| 189 |
-
"single_word": false,
|
| 190 |
-
"lstrip": false,
|
| 191 |
-
"rstrip": false,
|
| 192 |
-
"normalized": false,
|
| 193 |
-
"special": true
|
| 194 |
-
},
|
| 195 |
-
{
|
| 196 |
-
"id": 50277,
|
| 197 |
-
"content": "<||unused18||>",
|
| 198 |
-
"single_word": false,
|
| 199 |
-
"lstrip": false,
|
| 200 |
-
"rstrip": false,
|
| 201 |
-
"normalized": false,
|
| 202 |
-
"special": true
|
| 203 |
-
},
|
| 204 |
-
{
|
| 205 |
-
"id": 50278,
|
| 206 |
-
"content": "<||unused19||>",
|
| 207 |
-
"single_word": false,
|
| 208 |
-
"lstrip": false,
|
| 209 |
-
"rstrip": false,
|
| 210 |
-
"normalized": false,
|
| 211 |
-
"special": true
|
| 212 |
-
},
|
| 213 |
-
{
|
| 214 |
-
"id": 50279,
|
| 215 |
-
"content": "<||unused20||>",
|
| 216 |
-
"single_word": false,
|
| 217 |
-
"lstrip": false,
|
| 218 |
-
"rstrip": false,
|
| 219 |
-
"normalized": false,
|
| 220 |
-
"special": true
|
| 221 |
-
},
|
| 222 |
-
{
|
| 223 |
-
"id": 50280,
|
| 224 |
-
"content": "<||unused21||>",
|
| 225 |
-
"single_word": false,
|
| 226 |
-
"lstrip": false,
|
| 227 |
-
"rstrip": false,
|
| 228 |
-
"normalized": false,
|
| 229 |
-
"special": true
|
| 230 |
-
},
|
| 231 |
-
{
|
| 232 |
-
"id": 50281,
|
| 233 |
-
"content": "<||unused22||>",
|
| 234 |
-
"single_word": false,
|
| 235 |
-
"lstrip": false,
|
| 236 |
-
"rstrip": false,
|
| 237 |
-
"normalized": false,
|
| 238 |
-
"special": true
|
| 239 |
-
},
|
| 240 |
-
{
|
| 241 |
-
"id": 50282,
|
| 242 |
-
"content": "<||unused23||>",
|
| 243 |
-
"single_word": false,
|
| 244 |
-
"lstrip": false,
|
| 245 |
-
"rstrip": false,
|
| 246 |
-
"normalized": false,
|
| 247 |
-
"special": true
|
| 248 |
-
},
|
| 249 |
-
{
|
| 250 |
-
"id": 50283,
|
| 251 |
-
"content": "<||unused24||>",
|
| 252 |
-
"single_word": false,
|
| 253 |
-
"lstrip": false,
|
| 254 |
-
"rstrip": false,
|
| 255 |
-
"normalized": false,
|
| 256 |
-
"special": true
|
| 257 |
-
},
|
| 258 |
-
{
|
| 259 |
-
"id": 50284,
|
| 260 |
-
"content": "<||unused25||>",
|
| 261 |
-
"single_word": false,
|
| 262 |
-
"lstrip": false,
|
| 263 |
-
"rstrip": false,
|
| 264 |
-
"normalized": false,
|
| 265 |
-
"special": true
|
| 266 |
-
},
|
| 267 |
-
{
|
| 268 |
-
"id": 50285,
|
| 269 |
-
"content": "<||unused26||>",
|
| 270 |
-
"single_word": false,
|
| 271 |
-
"lstrip": false,
|
| 272 |
-
"rstrip": false,
|
| 273 |
-
"normalized": false,
|
| 274 |
-
"special": true
|
| 275 |
-
},
|
| 276 |
-
{
|
| 277 |
-
"id": 50286,
|
| 278 |
-
"content": "<||unused27||>",
|
| 279 |
-
"single_word": false,
|
| 280 |
-
"lstrip": false,
|
| 281 |
-
"rstrip": false,
|
| 282 |
-
"normalized": false,
|
| 283 |
-
"special": true
|
| 284 |
-
},
|
| 285 |
-
{
|
| 286 |
-
"id": 50287,
|
| 287 |
-
"content": "<||unused28||>",
|
| 288 |
-
"single_word": false,
|
| 289 |
-
"lstrip": false,
|
| 290 |
-
"rstrip": false,
|
| 291 |
-
"normalized": false,
|
| 292 |
-
"special": true
|
| 293 |
-
},
|
| 294 |
-
{
|
| 295 |
-
"id": 50288,
|
| 296 |
-
"content": "<||unused29||>",
|
| 297 |
-
"single_word": false,
|
| 298 |
-
"lstrip": false,
|
| 299 |
-
"rstrip": false,
|
| 300 |
-
"normalized": false,
|
| 301 |
-
"special": true
|
| 302 |
-
},
|
| 303 |
-
{
|
| 304 |
-
"id": 50289,
|
| 305 |
-
"content": "<||unused30||>",
|
| 306 |
-
"single_word": false,
|
| 307 |
-
"lstrip": false,
|
| 308 |
-
"rstrip": false,
|
| 309 |
-
"normalized": false,
|
| 310 |
-
"special": true
|
| 311 |
-
},
|
| 312 |
-
{
|
| 313 |
-
"id": 50290,
|
| 314 |
-
"content": "<||unused31||>",
|
| 315 |
-
"single_word": false,
|
| 316 |
-
"lstrip": false,
|
| 317 |
-
"rstrip": false,
|
| 318 |
-
"normalized": false,
|
| 319 |
-
"special": true
|
| 320 |
-
},
|
| 321 |
-
{
|
| 322 |
-
"id": 50291,
|
| 323 |
-
"content": "<||unused32||>",
|
| 324 |
-
"single_word": false,
|
| 325 |
-
"lstrip": false,
|
| 326 |
-
"rstrip": false,
|
| 327 |
-
"normalized": false,
|
| 328 |
-
"special": true
|
| 329 |
-
},
|
| 330 |
-
{
|
| 331 |
-
"id": 50292,
|
| 332 |
-
"content": "<||unused33||>",
|
| 333 |
-
"single_word": false,
|
| 334 |
-
"lstrip": false,
|
| 335 |
-
"rstrip": false,
|
| 336 |
-
"normalized": false,
|
| 337 |
-
"special": true
|
| 338 |
-
},
|
| 339 |
-
{
|
| 340 |
-
"id": 50293,
|
| 341 |
-
"content": "<||unused34||>",
|
| 342 |
-
"single_word": false,
|
| 343 |
-
"lstrip": false,
|
| 344 |
-
"rstrip": false,
|
| 345 |
-
"normalized": false,
|
| 346 |
-
"special": true
|
| 347 |
-
},
|
| 348 |
-
{
|
| 349 |
-
"id": 50294,
|
| 350 |
-
"content": "<||unused35||>",
|
| 351 |
-
"single_word": false,
|
| 352 |
-
"lstrip": false,
|
| 353 |
-
"rstrip": false,
|
| 354 |
-
"normalized": false,
|
| 355 |
-
"special": true
|
| 356 |
-
},
|
| 357 |
-
{
|
| 358 |
-
"id": 50295,
|
| 359 |
-
"content": "<||unused36||>",
|
| 360 |
-
"single_word": false,
|
| 361 |
-
"lstrip": false,
|
| 362 |
-
"rstrip": false,
|
| 363 |
-
"normalized": false,
|
| 364 |
-
"special": true
|
| 365 |
-
},
|
| 366 |
-
{
|
| 367 |
-
"id": 50296,
|
| 368 |
-
"content": "<||unused37||>",
|
| 369 |
-
"single_word": false,
|
| 370 |
-
"lstrip": false,
|
| 371 |
-
"rstrip": false,
|
| 372 |
-
"normalized": false,
|
| 373 |
-
"special": true
|
| 374 |
-
},
|
| 375 |
-
{
|
| 376 |
-
"id": 50297,
|
| 377 |
-
"content": "<||unused38||>",
|
| 378 |
-
"single_word": false,
|
| 379 |
-
"lstrip": false,
|
| 380 |
-
"rstrip": false,
|
| 381 |
-
"normalized": false,
|
| 382 |
-
"special": true
|
| 383 |
-
},
|
| 384 |
-
{
|
| 385 |
-
"id": 50298,
|
| 386 |
-
"content": "<||unused39||>",
|
| 387 |
-
"single_word": false,
|
| 388 |
-
"lstrip": false,
|
| 389 |
-
"rstrip": false,
|
| 390 |
-
"normalized": false,
|
| 391 |
-
"special": true
|
| 392 |
-
},
|
| 393 |
-
{
|
| 394 |
-
"id": 50299,
|
| 395 |
-
"content": "<||unused40||>",
|
| 396 |
-
"single_word": false,
|
| 397 |
-
"lstrip": false,
|
| 398 |
-
"rstrip": false,
|
| 399 |
-
"normalized": false,
|
| 400 |
-
"special": true
|
| 401 |
-
},
|
| 402 |
-
{
|
| 403 |
-
"id": 50300,
|
| 404 |
-
"content": "<||unused41||>",
|
| 405 |
-
"single_word": false,
|
| 406 |
-
"lstrip": false,
|
| 407 |
-
"rstrip": false,
|
| 408 |
-
"normalized": false,
|
| 409 |
-
"special": true
|
| 410 |
-
},
|
| 411 |
-
{
|
| 412 |
-
"id": 50301,
|
| 413 |
-
"content": "<||unused42||>",
|
| 414 |
-
"single_word": false,
|
| 415 |
-
"lstrip": false,
|
| 416 |
-
"rstrip": false,
|
| 417 |
-
"normalized": false,
|
| 418 |
-
"special": true
|
| 419 |
-
},
|
| 420 |
-
{
|
| 421 |
-
"id": 50302,
|
| 422 |
-
"content": "<||unused43||>",
|
| 423 |
-
"single_word": false,
|
| 424 |
-
"lstrip": false,
|
| 425 |
-
"rstrip": false,
|
| 426 |
-
"normalized": false,
|
| 427 |
-
"special": true
|
| 428 |
-
},
|
| 429 |
-
{
|
| 430 |
-
"id": 50303,
|
| 431 |
-
"content": "<||unused44||>",
|
| 432 |
-
"single_word": false,
|
| 433 |
-
"lstrip": false,
|
| 434 |
-
"rstrip": false,
|
| 435 |
-
"normalized": false,
|
| 436 |
-
"special": true
|
| 437 |
}
|
| 438 |
],
|
| 439 |
"normalizer": null,
|
|
@@ -444,52 +48,10 @@
|
|
| 444 |
"use_regex": true
|
| 445 |
},
|
| 446 |
"post_processor": {
|
| 447 |
-
"type": "
|
| 448 |
-
"
|
| 449 |
-
|
| 450 |
-
|
| 451 |
-
"id": "<||bos||>",
|
| 452 |
-
"type_id": 0
|
| 453 |
-
}
|
| 454 |
-
},
|
| 455 |
-
{
|
| 456 |
-
"Sequence": {
|
| 457 |
-
"id": "A",
|
| 458 |
-
"type_id": 0
|
| 459 |
-
}
|
| 460 |
-
}
|
| 461 |
-
],
|
| 462 |
-
"pair": [
|
| 463 |
-
{
|
| 464 |
-
"SpecialToken": {
|
| 465 |
-
"id": "<||bos||>",
|
| 466 |
-
"type_id": 0
|
| 467 |
-
}
|
| 468 |
-
},
|
| 469 |
-
{
|
| 470 |
-
"Sequence": {
|
| 471 |
-
"id": "A",
|
| 472 |
-
"type_id": 0
|
| 473 |
-
}
|
| 474 |
-
},
|
| 475 |
-
{
|
| 476 |
-
"Sequence": {
|
| 477 |
-
"id": "B",
|
| 478 |
-
"type_id": 1
|
| 479 |
-
}
|
| 480 |
-
}
|
| 481 |
-
],
|
| 482 |
-
"special_tokens": {
|
| 483 |
-
"<||bos||>": {
|
| 484 |
-
"id": "<||bos||>",
|
| 485 |
-
"ids": [
|
| 486 |
-
50257
|
| 487 |
-
],
|
| 488 |
-
"tokens": [
|
| 489 |
-
"<||bos||>"
|
| 490 |
-
]
|
| 491 |
-
}
|
| 492 |
-
}
|
| 493 |
},
|
| 494 |
"decoder": {
|
| 495 |
"type": "ByteLevel",
|
|
@@ -501,8 +63,8 @@
|
|
| 501 |
"type": "BPE",
|
| 502 |
"dropout": null,
|
| 503 |
"unk_token": null,
|
| 504 |
-
"continuing_subword_prefix":
|
| 505 |
-
"end_of_word_suffix":
|
| 506 |
"fuse_unk": false,
|
| 507 |
"byte_fallback": false,
|
| 508 |
"vocab": {
|
|
|
|
| 38 |
"rstrip": false,
|
| 39 |
"normalized": false,
|
| 40 |
"special": true
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
}
|
| 42 |
],
|
| 43 |
"normalizer": null,
|
|
|
|
| 48 |
"use_regex": true
|
| 49 |
},
|
| 50 |
"post_processor": {
|
| 51 |
+
"type": "ByteLevel",
|
| 52 |
+
"add_prefix_space": true,
|
| 53 |
+
"trim_offsets": true,
|
| 54 |
+
"use_regex": true
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
},
|
| 56 |
"decoder": {
|
| 57 |
"type": "ByteLevel",
|
|
|
|
| 63 |
"type": "BPE",
|
| 64 |
"dropout": null,
|
| 65 |
"unk_token": null,
|
| 66 |
+
"continuing_subword_prefix": null,
|
| 67 |
+
"end_of_word_suffix": null,
|
| 68 |
"fuse_unk": false,
|
| 69 |
"byte_fallback": false,
|
| 70 |
"vocab": {
|
tokenizer_config.json
CHANGED
|
@@ -3,7 +3,7 @@
|
|
| 3 |
"add_prefix_space": false,
|
| 4 |
"bos_token": {
|
| 5 |
"__type": "AddedToken",
|
| 6 |
-
"content": "
|
| 7 |
"lstrip": false,
|
| 8 |
"normalized": true,
|
| 9 |
"rstrip": false,
|
|
@@ -21,11 +21,10 @@
|
|
| 21 |
"errors": "replace",
|
| 22 |
"model_max_length": 8192,
|
| 23 |
"pad_token": null,
|
| 24 |
-
"padding_side": "right",
|
| 25 |
"tokenizer_class": "GPT2Tokenizer",
|
| 26 |
"unk_token": {
|
| 27 |
"__type": "AddedToken",
|
| 28 |
-
"content": "
|
| 29 |
"lstrip": false,
|
| 30 |
"normalized": true,
|
| 31 |
"rstrip": false,
|
|
|
|
| 3 |
"add_prefix_space": false,
|
| 4 |
"bos_token": {
|
| 5 |
"__type": "AddedToken",
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
"lstrip": false,
|
| 8 |
"normalized": true,
|
| 9 |
"rstrip": false,
|
|
|
|
| 21 |
"errors": "replace",
|
| 22 |
"model_max_length": 8192,
|
| 23 |
"pad_token": null,
|
|
|
|
| 24 |
"tokenizer_class": "GPT2Tokenizer",
|
| 25 |
"unk_token": {
|
| 26 |
"__type": "AddedToken",
|
| 27 |
+
"content": "<|endoftext|>",
|
| 28 |
"lstrip": false,
|
| 29 |
"normalized": true,
|
| 30 |
"rstrip": false,
|
vocab.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|