
Bhasha embed v0 model
This is an embedding model that can embed texts in Hindi (Devanagari script), English and Romanized Hindi. There are many multilingual embedding models which work well for Hindi and English texts individually, but lack the following capabilities.
- Romanized Hindi support: This is the first embedding model to support Romanized Hindi (transliterated Hindi / hin_Latn).
- Cross-lingual alignment: This model outputs language-agnostic embedding. This enables querying a multilingual candidate pool containing a mix of Hindi, English and Romanised Hindi texts.
Model Details
- Supported Languages: Hindi, English, Romanised Hindi
- Base model: google/muril-base-cased
- Training GPUs: 1xRTX4090
- Training methodology: Distillation from English embedding model and Fine-tuning on triplet data.
- Maximum Sequence Length: 512 tokens
- Output Dimensionality: 768 tokens
- Similarity Function: Cosine Similarity
Model Sources
- Repository: github_link
- Developer: Akshita Sukhlecha
Results

Results for English-Hindi cross-lingual alignment : Tasks with corpus containing texts in Hindi as well as English
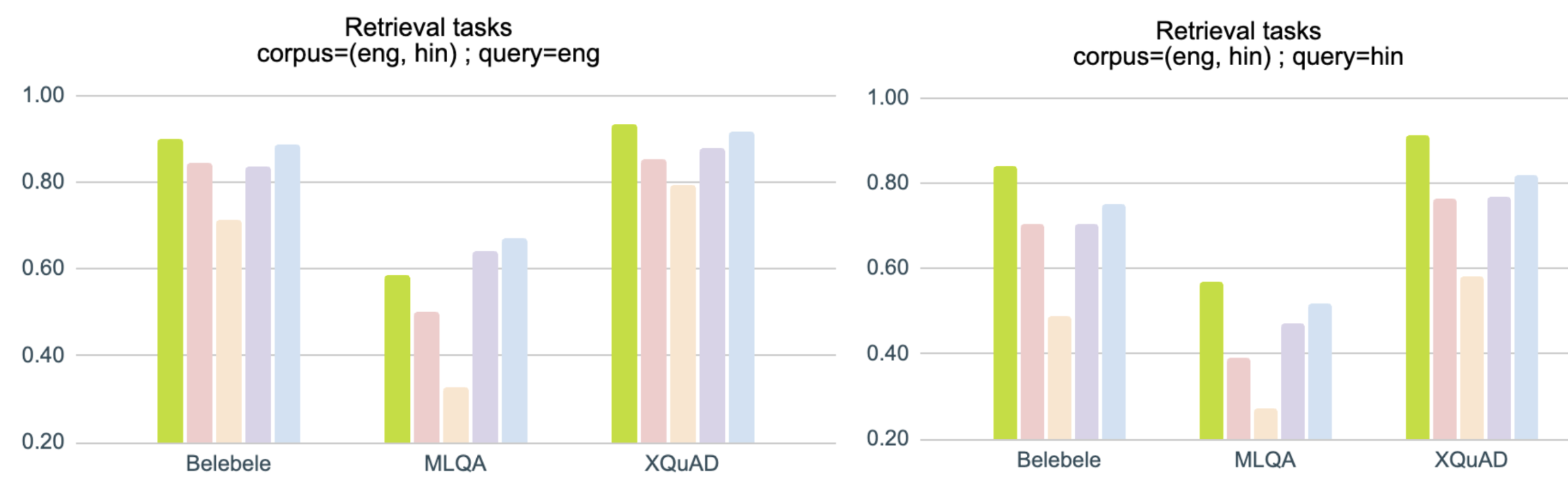
Results for Romanised Hindi tasks : Tasks with texts in Romanised Hindi

Results for retrieval tasks with multilingual corpus : Retrieval task with corpus containing texts in Hindi, English as well as Romanised Hindi

Results for Hindi tasks : Tasks with texts in Hindi (Devanagari script)
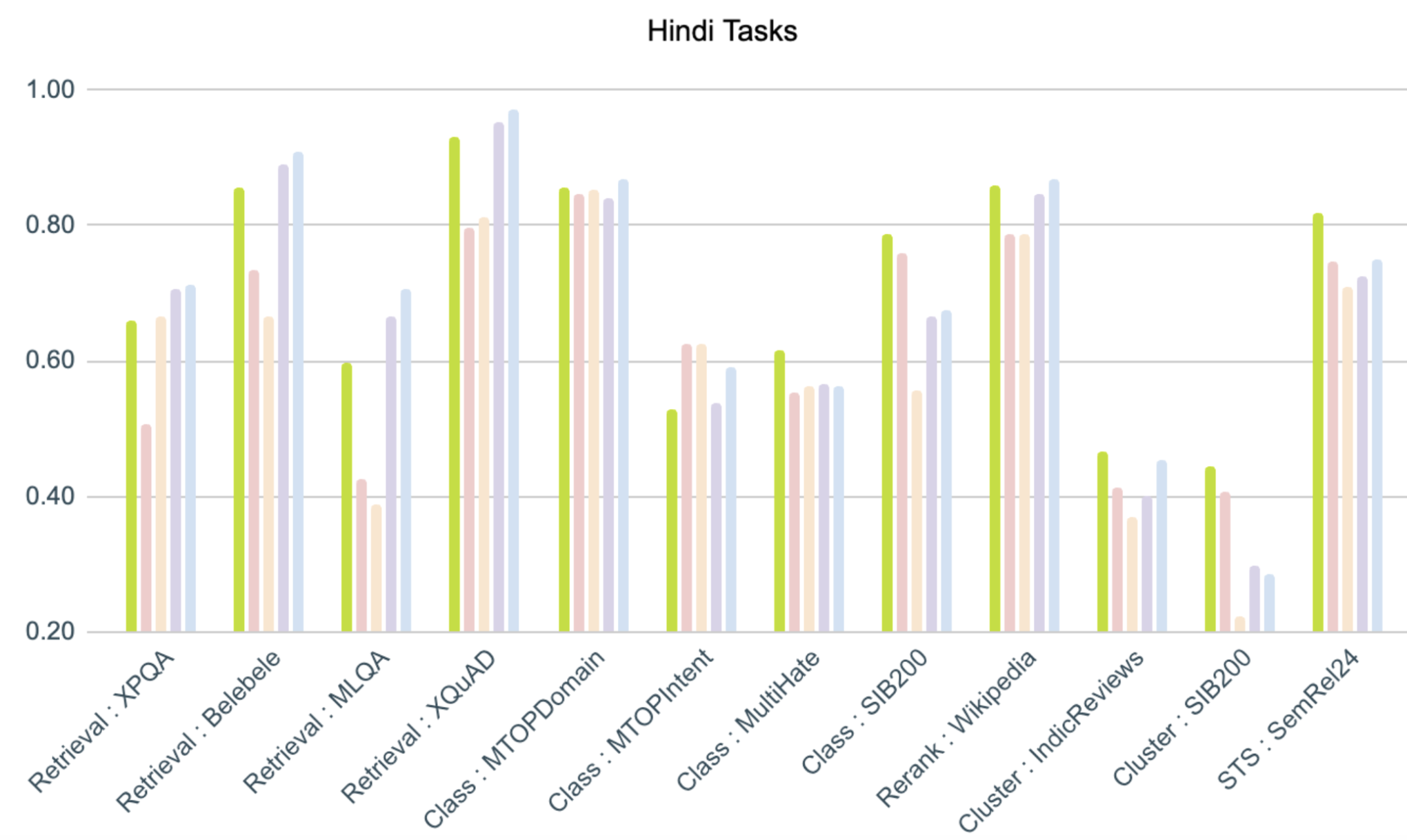
Additional information
- Some task dataset links: Belebele, MLQA, XQuAD, SemRel24
- hin_Latn tasks: Most hin_Latn tasks have been created by transliterating hindi texts using indic-trans library
- Detailed results: github_link
- Script to reproduce the results: github_link
Sample outputs
Example 1

Example 2

Example 3

Example 4

Usage
Below are examples to encode queries and passages and compute similarity scores using Sentence Transformers and 🤗 Transformers.
Using Sentence Transformers
First install the Sentence Transformers library (pip install -U sentence-transformers) and then run the following code:
import numpy as np
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("AkshitaS/bhasha-embed-v0")
queries = [
"प्रणव ने कानून की पढ़ाई की और ३० की उम्र में राजनीति से जुड़ गए",
"Pranav studied law and became a politician at the age of 30.",
"Pranav ne kanoon ki padhai kari aur 30 ki umar mein rajneeti se jud gaye"
]
documents = [
"प्रणव ने कानून की पढ़ाई की और ३० की उम्र में राजनीति से जुड़ गए",
"Pranav studied law and became a politician at the age of 30.",
"Pranav ne kanoon ki padhai kari aur 30 ki umar mein rajneeti se jud gaye",
"प्रणव का जन्म राजनीतिज्ञों के परिवार में हुआ था",
"Pranav was born in a family of politicians",
"Pranav ka janm rajneetigyon ke parivar mein hua tha"
]
query_embeddings = model.encode(queries, normalize_embeddings=True)
document_embeddings = model.encode(documents, normalize_embeddings=True)
similarity_matrix = (query_embeddings @ document_embeddings.T)
print(similarity_matrix.shape)
# (3, 6)
print(np.round(similarity_matrix, 2))
#[[1.00 0.97 0.97 0.92 0.90 0.91]
# [0.97 1.00 0.96 0.90 0.91 0.91]
# [0.97 0.96 1.00 0.89 0.90 0.92]]
Using 🤗 Transformers
import numpy as np
from torch import Tensor
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor, attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
model_id = "AkshitaS/bhasha-embed-v0"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
queries = [
"प्रणव ने कानून की पढ़ाई की और ३० की उम्र में राजनीति से जुड़ गए",
"Pranav studied law and became a politician at the age of 30.",
"Pranav ne kanoon ki padhai kari aur 30 ki umar mein rajneeti se jud gaye"
]
documents = [
"प्रणव ने कानून की पढ़ाई की और ३० की उम्र में राजनीति से जुड़ गए",
"Pranav studied law and became a politician at the age of 30.",
"Pranav ne kanoon ki padhai kari aur 30 ki umar mein rajneeti se jud gaye",
"प्रणव का जन्म राजनीतिज्ञों के परिवार में हुआ था",
"Pranav was born in a family of politicians",
"Pranav ka janm rajneetigyon ke parivar mein hua tha"
]
input_texts = queries + documents
batch_dict = tokenizer(input_texts, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
similarity_matrix = (embeddings[:len(queries)] @ embeddings[len(queries):].T).detach().numpy()
print(similarity_matrix.shape)
# (3, 6)
print(np.round(similarity_matrix, 2))
#[[1.00 0.97 0.97 0.92 0.90 0.91]
# [0.97 1.00 0.96 0.90 0.91 0.91]
# [0.97 0.96 1.00 0.89 0.90 0.92]]
Citation
To cite this model:
@misc{sukhlecha_2024_bhasha_embed_v0,
author = {Sukhlecha, Akshita},
title = {Bhasha-embed-v0},
howpublished = {Hugging Face},
month = {June},
year = {2024},
url = {https://huggingface.co/AkshitaS/bhasha-embed-v0}
}
- Downloads last month
- 408