
BUT Czech LLMs
Collection
5 items
•
Updated
This is our GPT-2 XL trained as a part of the research involved in SemANT project.
15,621,685,248 token/78,48 GB/10,900,000,000 word/18,800,000 paragraph corpus of Czech obtained by Web Crawling.266,44 GB.
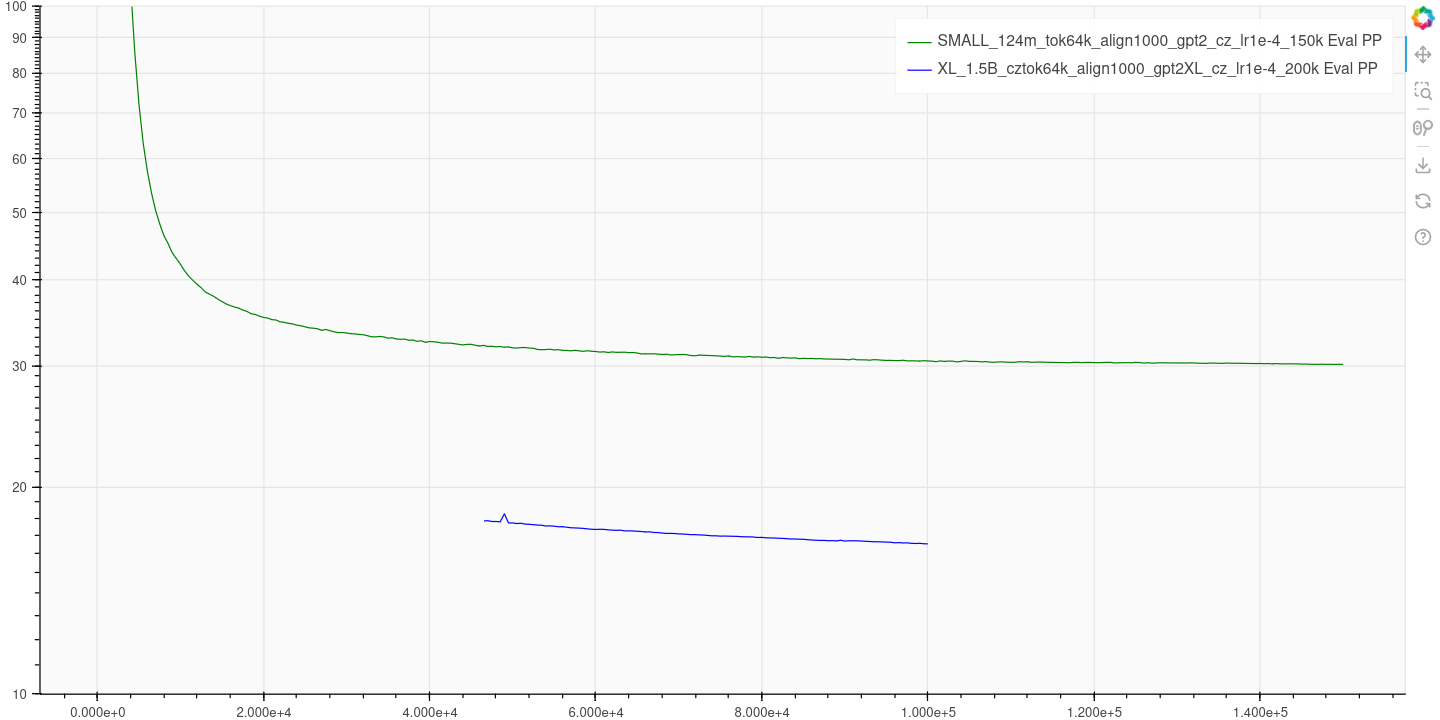
Not mentioned parameters are the same as for GPT-2.
| Name | Value | Note |
|---|---|---|
| dataset_type | Concat | Sequences at the model's input were concatenated up to $max_seq_len, divided by EOS token. |
| tokenizer_size | 64k | |
| max_seq_len | 1024 | |
| batch_size | 1024 | |
| learning_rate | 1.0e-4 | |
| optimizer | LionW | |
| optimizer_betas | 0.9/0.95 | |
| optimizer_weight_decay | 0 | |
| optimizer_eps | 1.0e-08 | |
| gradient_clipping_max_norm | 1.0 | |
| attn_impl | flash2 | |
| dropout | 0.1 | for residuals, attention, embeddings |
| fsdp | SHARD_GRAD_OP | (optimized for A100 40GB GPUs) |
| precision | bf16 | |
| scheduler | linear | |
| scheduler_warmup | 10,000 steps | |
| scheduler_steps | 200,000 | |
| scheduler_alpha | 0.1 | So LR on last step is 0.1*(vanilla LR) |
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
t = AutoTokenizer.from_pretrained("BUT-FIT/Czech-GPT-2-XL-133k")
m = AutoModelForCausalLM.from_pretrained("BUT-FIT/Czech-GPT-2-XL-133k").eval()
# Try the model inference
prompt = "Nejznámějším českým spisovatelem "
input_ids = t.encode(prompt, return_tensors="pt")
with torch.no_grad():
generated_text = m.generate(input_ids=input_ids,
do_sample=True,
top_p=0.95,
repetition_penalty=1.0,
temperature=0.8,
max_new_tokens=64,
num_return_sequences=1)
print(t.decode(generated_text[0], skip_special_tokens=True))
We observed 10-shot result improvement over the course of training for sentiment analysis, and hellaswag-like commonsense reasoning. There were some tasks where there was no such improvement, such as grammar error classification (does the sentence contain grammatical error?). We will release the precise results once we advance with the work on our Czech evaluation kit.
This is an intermediate result of our work-in-progress. This is a probabilistic model, and authors are not responsible for the model outputs. Use at your own risk.
For further questions, turn to [email protected].
This work was supported by NAKI III program of Ministry of Culture Czech Republic, project semANT ---
"Sémantický průzkumník textového kulturního dědictví" grant no. DH23P03OVV060 and
by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90254).