
SmolVLM 256M & 500M
Collection
Collection for models & demos for even smoller SmolVLM release
•
12 items
•
Updated
•
69

SmolVLM-500M is a tiny multimodal model, member of the SmolVLM family. It accepts arbitrary sequences of image and text inputs to produce text outputs. It's designed for efficiency. SmolVLM can answer questions about images, describe visual content, or transcribe text. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks. It can run inference on one image with 1.23GB of GPU RAM.
SmolVLM can be used for inference on multimodal (image + text) tasks where the input comprises text queries along with one or more images. Text and images can be interleaved arbitrarily, enabling tasks like image captioning, visual question answering, and storytelling based on visual content. The model does not support image generation.
To fine-tune SmolVLM on a specific task, you can follow the fine-tuning tutorial.

SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces several changes compared to the larger SmolVLM 2.2B model:
More details about the training and architecture are available in our technical report.
You can use transformers to load, infer and fine-tune SmolVLM.
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-500M-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-500M-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Can you describe this image?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The image depicts a cityscape featuring a prominent landmark, the Statue of Liberty, prominently positioned on Liberty Island. The statue is a green, humanoid figure with a crown atop its head and is situated on a small island surrounded by water. The statue is characterized by its large, detailed structure, with a statue of a woman holding a torch above her head and a tablet in her left hand. The statue is surrounded by a small, rocky island, which is partially visible in the foreground.
In the background, the cityscape is dominated by numerous high-rise buildings, which are densely packed and vary in height. The buildings are primarily made of glass and steel, reflecting the sunlight and creating a bright, urban skyline. The skyline is filled with various architectural styles, including modern skyscrapers and older, more traditional buildings.
The water surrounding the island is calm, with a few small boats visible, indicating that the area is likely a popular tourist destination. The water is a deep blue, suggesting that it is a large body of water, possibly a river or a large lake.
In the foreground, there is a small strip of land with trees and grass, which adds a touch of natural beauty to the urban landscape. The trees are green, indicating that it is likely spring or summer.
The image captures a moment of tranquility and reflection, as the statue and the cityscape come together to create a harmonious and picturesque scene. The statue's presence in the foreground draws attention to the city's grandeur, while the calm water and natural elements in the background provide a sense of peace and serenity.
In summary, the image showcases the Statue of Liberty, a symbol of freedom and democracy, set against a backdrop of a bustling cityscape. The statue is a prominent and iconic representation of human achievement, while the cityscape is a testament to human ingenuity and progress. The image captures the beauty and complexity of urban life, with the statue serving as a symbol of hope and freedom, while the cityscape provides a glimpse into the modern world.
"""
Precision: For better performance, load and run the model in half-precision (torch.bfloat16) if your hardware supports it.
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
You can also load SmolVLM with 4/8-bit quantization using bitsandbytes, torchao or Quanto. Refer to this page for other options.
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
Vision Encoder Efficiency: Adjust the image resolution by setting size={"longest_edge": N*512} when initializing the processor, where N is your desired value. The default N=4 works well, which results in input images of
size 2048×2048. Decreasing N can save GPU memory and is appropriate for lower-resolution images. This is also useful if you want to fine-tune on videos.
SmolVLM is not intended for high-stakes scenarios or critical decision-making processes that affect an individual's well-being or livelihood. The model may produce content that appears factual but may not be accurate. Misuse includes, but is not limited to:
SmolVLM is built upon SigLIP as image encoder and SmolLM2 for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
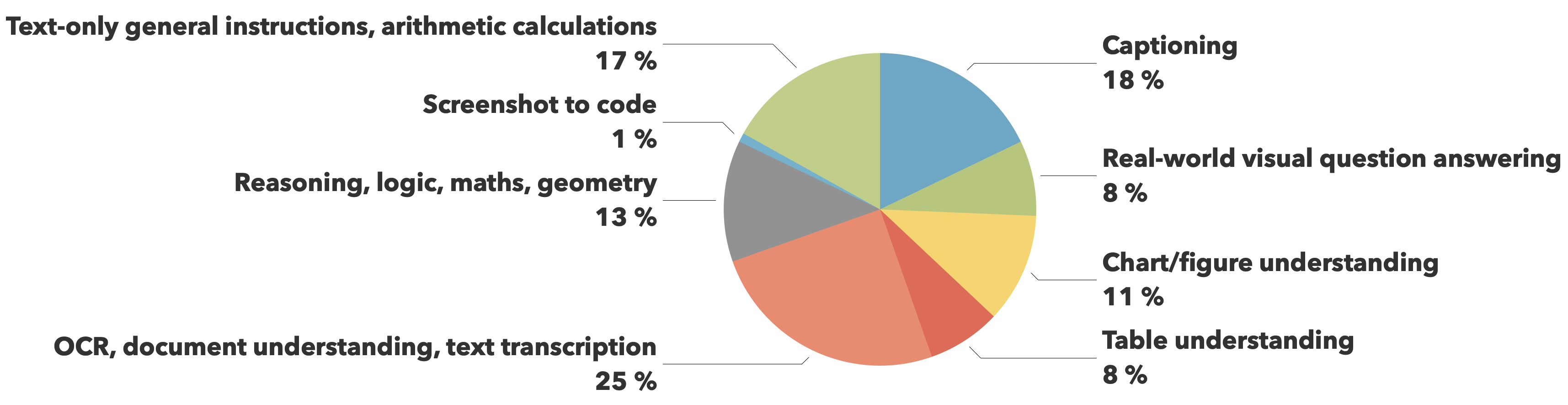
The training data comes from The Cauldron and Docmatix datasets, with emphasis on document understanding (25%) and image captioning (18%), while maintaining balanced coverage across other crucial capabilities like visual reasoning, chart comprehension, and general instruction following.
Base model
HuggingFaceTB/SmolLM2-360M-Instruct