|
--- |
|
datasets: |
|
- animelover/danbooru2022 |
|
base_model: |
|
- microsoft/Florence-2-base |
|
--- |
|
This model serves as a proof of concept. You will *very likely* have better captioning results using [`SmilingWolf/wd-eva02-large-tagger-v3`](https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3). |
|
|
|
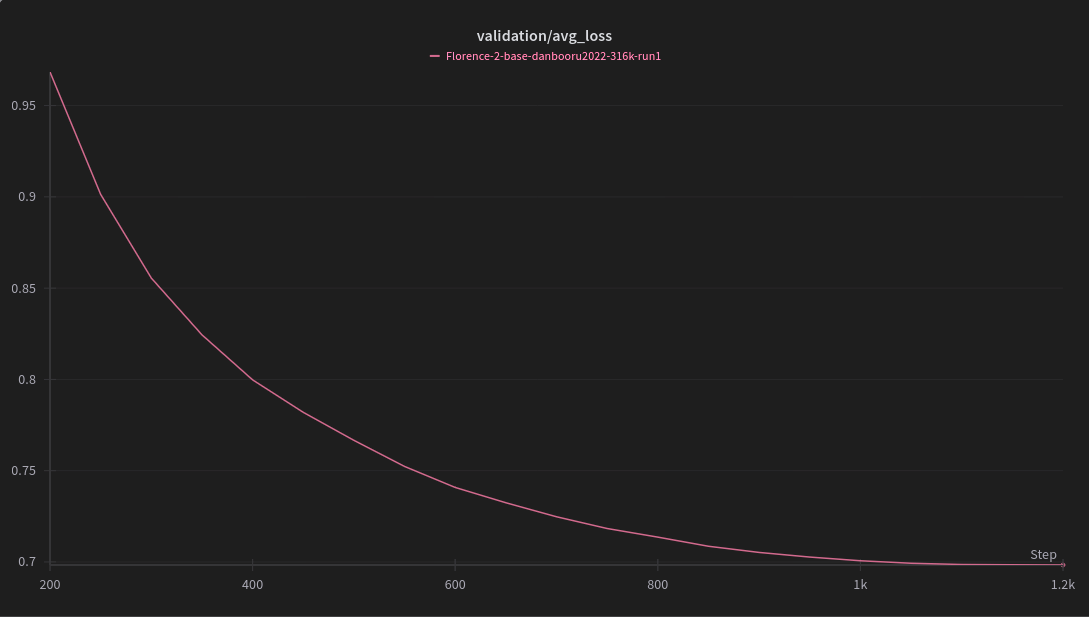
Trained with [Florence-2ner](https://github.com/xzuyn/Florence-2ner) using this config and 316K images from the [`animelover/danbooru2022` dataset](https://huggingface.co/datasets/animelover/danbooru2022) (`data-0880.zip` to `data-0943.zip`). |
|
|
|
```json |
|
{ |
|
"model_name": "microsoft/Florence-2-base", |
|
"dataset_path": "./0000_Datasets/danbooru2022", |
|
"run_name": "Florence-2-base-danbooru2022-316k-run1", |
|
"epochs": 1, |
|
"learning_rate": 1e-5, |
|
"gradient_checkpointing": true, |
|
"freeze_vision": false, |
|
"freeze_language": false, |
|
"freeze_other": false, |
|
"train_batch_size": 8, |
|
"eval_batch_size": 16, |
|
"gradient_accumulation_steps": 32, |
|
"clip_grad_norm": 1, |
|
"weight_decay": 1e-5, |
|
"save_total_limit": 3, |
|
"save_steps": 50, |
|
"eval_steps": 50, |
|
"warmup_steps": 50, |
|
"eval_split_ratio": 0.01, |
|
"seed": 42, |
|
"filtering_processes": 128, |
|
"attn_implementation": "sdpa" |
|
} |
|
``` |
|
|
|
 |

