

license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
language:
- en
- zh
- vi
- id
- th
- ms
- km
- lo
- my
- tl
tags:
- multilingual
- sea

SeaLLM will be able to "see"!
SeaLMMM-7B - Large Multilingual Multimodal Models for Southeast Asia
Website 🤗 Tech Memo 🤗 DEMO Github Technical Report
We introduce and showcase the first iteration of SeaLMMM -- A unified multilingual and multimodal that excel in both text-only and vision tasks in multiple languages spoken in Southeast Asia.
SeaLMMM-7B abilities
- SeaLMMM-7B is one of the strongest 7B vision-language models at text-only tasks, with performance similar to SeaLLM-7B-v2. It is a text-first-vision-second model.
- SeaLMMM-7B is able to handle most SEA languages, making it more multilingual than En-only LLava, Bilingual (En+Zh) Qwen-VL or Yi-VL.
- Unlike LLava or specialized VLMs, which demand only one image at the begining, SeaLMMM-7B can seamlessly handle text-only conversations at the begining and visual instructions in the middle of the conversations and support topic and language switching.
- SeaLMMM-7B can carry multi-image generation or in-context visual learning, in which case, Better llava next should be applied to enable such feature.
Release and DEMO
- DEMO: SeaLLMs/SeaLLM-7b.
- Model weights:
- Explore SeaLLMs:
Terms of Use and License: By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our SeaLLMs Terms Of Use.
Disclaimer: We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation. Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations. In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
The logo was generated by DALL-E 3.
Overview
SeaLMMM-7B-v0.1 is a multimodal extension of SeaLLM-7B-v2. It adopts the Llava-1.6 (Llava-NEXT) architecture. It is trained by jointly train SeaLLM's multilingual text-only datasets along with Llava-1.5 English-only vision data, as well as in-house synthetically generated multilingual multimodal vision data and open-source data, such as ThaiIDCardSynt.
English Vision QA Tasks
| Multimodal Models | VQA2 | GQA | Vizwiz | SQA-IMG | TextQA |
|---|---|---|---|---|---|
| Qwen-VL-Chat | 78.20 | 57.50 | 38.90 | 68.20 | 61.50 |
| Llava-1.5-7b | 78.50 | 62.00 | 50.00 | 66.80 | 58.20 |
| Llava-1.5-13b | 80.00 | 63.30 | 53.60 | 71.60 | 61.30 |
| SeaLMMM-7B-v0.1 | ? | 61.58 | 58.00 | 71.79 | 63.47 |
Multilingual Text-only World Knowledge
We evaluate models on 3 benchmarks following the recommended default setups: 5-shot MMLU for En, 3-shot M3Exam (M3e) for En, Zh, Vi, Id, Th, and zero-shot VMLU for Vi.
On text-only benchmarks, SeaLMMM-7B-v0.1 is generally on-par with SeaLLM-7B-v2 - its base LLM model. This demonstrates that our multimodal training regime does not vastly degrade text-only performance.
| Model | Langs | En MMLU |
En M3e |
Zh M3e |
Vi M3e |
Id M3e |
Th M3e |
|---|---|---|---|---|---|---|---|
| GPT-3.5 | Multi | 68.90 | 75.46 | 60.20 | 58.64 | 49.27 | 37.41 |
| Vistral-7B-chat | Mono | 56.86 | 67.00 | 44.56 | 54.33 | 36.49 | 25.27 |
| Qwen1.5-7B-chat | Multi | 61.00 | 52.07 | 81.96 | 43.38 | 24.29 | 20.25 |
| SailorLM | Multi | 52.72 | 59.76 | 67.74 | 50.14 | 39.53 | 37.73 |
| SeaLLM-7B-v2 | Multi | 61.89 | 70.91 | 55.43 | 51.15 | 42.25 | 35.52 |
| SeaLLM-7B-v2.5 | Multi | 64.05 | 76.87 | 62.54 | 63.11 | 48.64 | 46.86 |
| --- | |||||||
| SeaLMMM-7B-v0.1 | Multi | 60.31 | 70.43 | 52.78 | 50.47 | 42.37 | 33.53 |
Multilingual Multimodal Showcases
SeaLMMM-7B-v0.1 has better vision understanding and solving abilities in languages beyond English and Chinese, especially SEA languages, such as Vietnamese and Indonesian.

Image: find "x" in Vietnamese. Left: Llava-1.6-34B. Right: SeaLMMM-7B-v0.1.

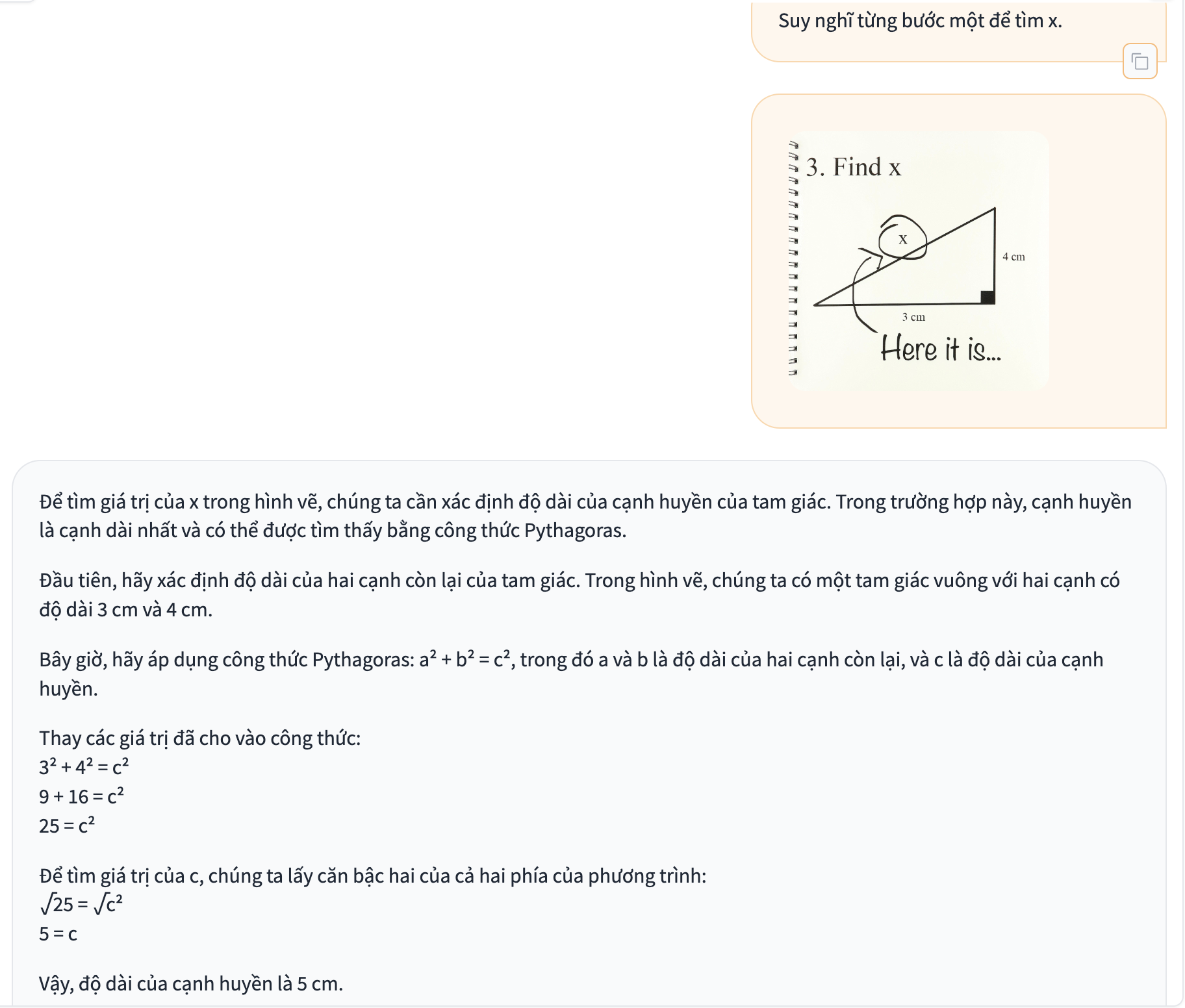
Limitations
- Despite being multilingual, SeaLMMM-7B-v0.1 multi-modal capabilities still work best in English, while we're working to improve it in other languages.
- For OCR, it can only read English.
- SeaLMMM-7B-v0.1 sometimes still think it cannot process image in multi-turn setting, due to existing text-only SFT, future versions fill fix this.
- Multi-modal multi-turn capabilities are still limited.
Usage
Instruction format
Unlike others, image token is <|image|>
prompt = """<|im_start|>system
You are a helpful assistant.</s>
<|im_start|>user
<|image|>
What is in the image?</s>
<|im_start|>assistant
There is 2 cats in the image.</s>"""
# <|im_start|> is not a special token.
# Transformers chat_template should be consistent with vLLM format below.
# ! ENSURE 1 and only 1 bos `<s>` at the beginning of sequence
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt)))
"""
Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows: Corresponding Author: [email protected]
Author list and order will change!
*and^are equal contributions.
@article{damonlpsg2023seallm,
author = {Xuan-Phi Nguyen*, Wenxuan Zhang*, Xin Li*, Mahani Aljunied*, Weiwen Xu, Hou Pong Chan,
Zhiqiang Hu, Chenhui Shen^, Yew Ken Chia^, Xingxuan Li, Jianyu Wang,
Qingyu Tan, Liying Cheng, Guanzheng Chen, Yue Deng, Sen Yang,
Chaoqun Liu, Hang Zhang, Lidong Bing},
title = {SeaLLMs - Large Language Models for Southeast Asia},
year = 2023,
Eprint = {arXiv:2312.00738},
}