
SwiftKV Models
Collection
SwiftKV reduces prefill compute by up to 50% by combining model rewiring and knowledge-preserving self-distillation.
•
4 items
•
Updated
•
5
The Snowflake AI Research team is releasing a series of SwiftKV optimized Llama-3.1 models. SwiftKV is a series of inference optimizations that goes beyond traditional key-value (KV) cache compression. This method reduces computational overhead during prompt processing by combining model rewiring and knowledge-preserving self-distillation, allowing prefill tokens to skip up to half the model's layers. SwiftKV achieves up to 2x improvements in throughput, latency, and cost efficiency with minimal accuracy loss, making LLM deployments more performant and economically viable.
For more details about SwiftKV and how to use it:
To evaluate SwiftKV’s performance, we focus on the following key metrics (see more details in our blog):
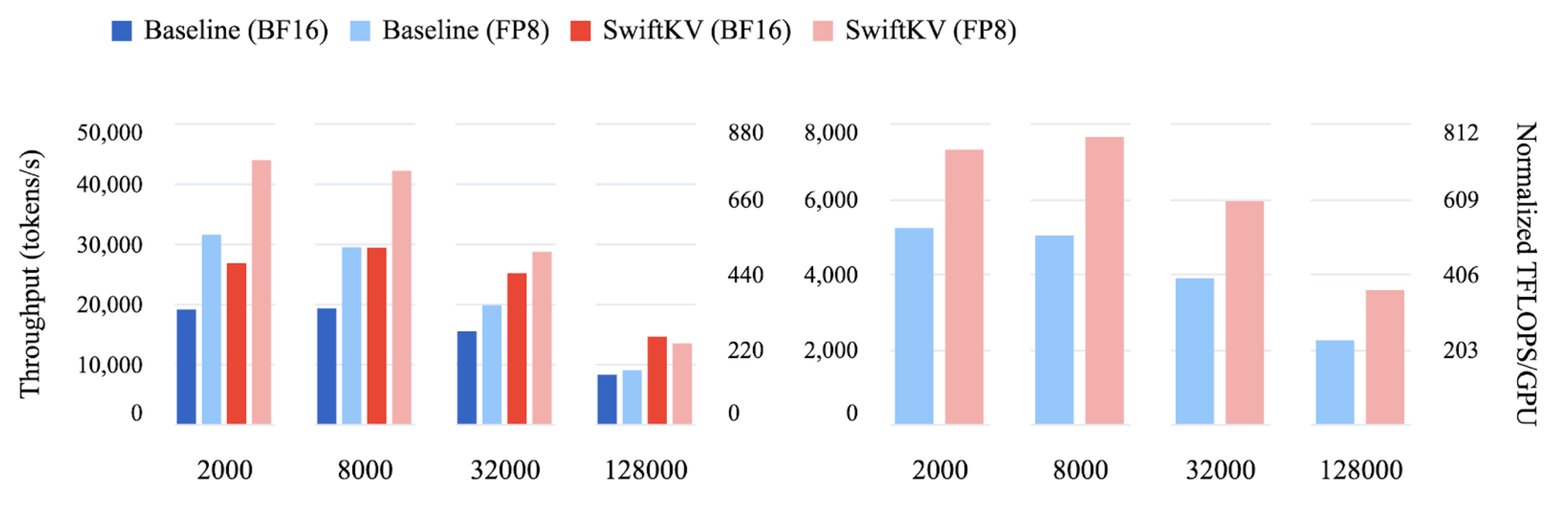
Combined input and output throughput for Llama 3.1 70B (left) and Llama 3.1 405B (right) across a range of input lengths (bottom).
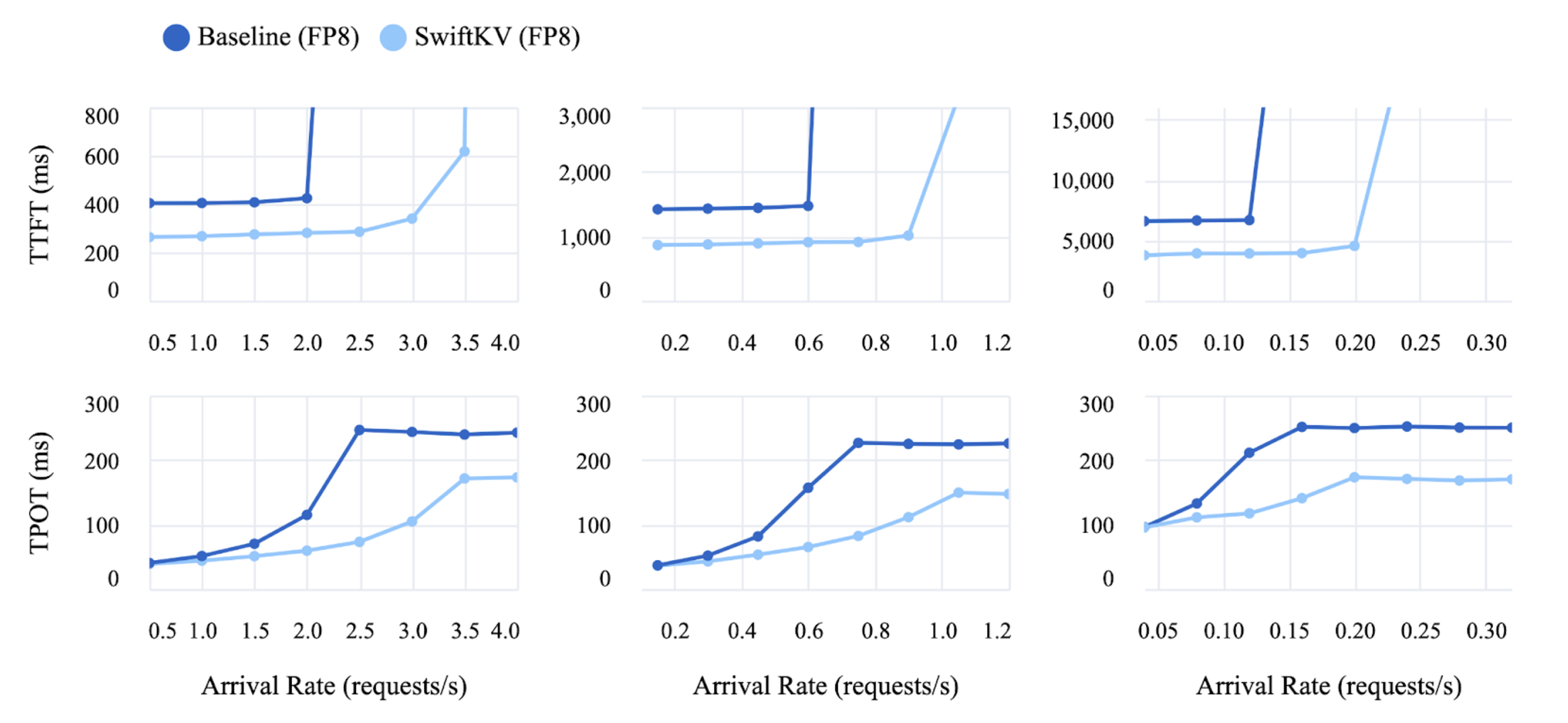
TTFT (top) and TPOT (bottom) for input lengths 2000 (left), 8000 (middle), and 32000 (right) for Llama 3.1 405B fp8 model. For each experiment, a range of different request arrival rates is simulated. Each request generates 256 output tokens.
For a full breakdown on evaluation metrics and performance impact please refer to our blog and arXiv paper but below we've outlined some relevant evaluation metrics.
| Llama-3.1-405B-Instruct-FP8 | Arc Challenge | Winogrande | HellaSwag | TruthfulQA | MMLU | MMLU cot | GSM8K | Avg |
|---|---|---|---|---|---|---|---|---|
| Baseline | 94.7 | 87.0 | 88.3 | 64.7 | 87.5 | 88.1 | 96.1 | 86.6 |
| 50% SingleInputKV | 94.0 | 86.3 | 88.1 | 64.2 | 85.7 | 87.5 | 95.2 | 85.9 |
| Llama-3.1-8B-Instruct | Arc Challenge | Winogrande | HellaSwag | TruthfulQA | MMLU | MMLU cot | GSM8K | Avg |
|---|---|---|---|---|---|---|---|---|
| Baseline | 82.00 | 77.90 | 80.40 | 54.56 | 67.90 | 70.63 | 82.56 | 73.71 |
| 50% SingleInputKV | 80.38 | 78.22 | 79.30 | 54.54 | 67.30 | 69.73 | 79.45 | 72.70 |
Instructions on how to use vLLM for both evaluation and performance benchmarks: https://github.com/Snowflake-Labs/vllm/tree/swiftkv/examples/swiftkv

Base model
meta-llama/Llama-3.1-405B