|
--- |
|
library_name: transformers |
|
language: |
|
- da |
|
license: openrail |
|
base_model: facebook/wav2vec2-xls-r-300m |
|
datasets: |
|
- alexandrainst/coral |
|
metrics: |
|
- wer |
|
- cer |
|
model-index: |
|
- name: roest-315m |
|
results: |
|
- task: |
|
name: Automatic Speech Recognition |
|
type: automatic-speech-recognition |
|
dataset: |
|
name: CoRal read-aloud |
|
type: alexandrainst/coral |
|
split: test |
|
args: read_aloud |
|
metrics: |
|
- name: CER |
|
type: cer |
|
value: 6.6% ± 0.2% |
|
- name: WER |
|
type: wer |
|
value: 17.0% ± 0.4% |
|
- task: |
|
name: Automatic Speech Recognition |
|
type: automatic-speech-recognition |
|
dataset: |
|
name: Danish Common Voice 17 |
|
type: mozilla-foundation/common_voice_17_0 |
|
split: test |
|
args: da |
|
metrics: |
|
- name: CER |
|
type: cer |
|
value: 6.6% ± 0.6% |
|
- name: WER |
|
type: wer |
|
value: 16.7% ± 0.8% |
|
pipeline_tag: automatic-speech-recognition |
|
--- |
|
|
|
# Røst-315m |
|
|
|
This is a Danish state-of-the-art speech recognition model, trained by [the Alexandra |
|
Institute](https://alexandra.dk/). |
|
|
|
Try it out in [our interactive demo](https://huggingface.co/spaces/alexandrainst/roest-demo)! |
|
|
|
|
|
## Quick Start |
|
Start by installing the required libraries: |
|
|
|
```shell |
|
$ pip install transformers kenlm pyctcdecode |
|
``` |
|
|
|
Next you can use the model using the `transformers` Python package as follows: |
|
|
|
```python |
|
>>> from transformers import pipeline |
|
>>> audio = get_audio() # 16kHz raw audio array |
|
>>> transcriber = pipeline(model="alexandrainst/roest-315m") |
|
>>> transcriber(audio) |
|
{'text': 'your transcription'} |
|
``` |
|
|
|
|
|
## Evaluation Results |
|
|
|
We have evaluated both our and existing models on the CoRal test set as well as the |
|
Danish Common Voice 17 test set. To ensure as robust an evaluation as possible, we have |
|
bootstrapped the results 1000 times and report here the mean scores along with a 95% |
|
confidence interval (lower is better; best scores in **bold**, second-best in |
|
*italics*): |
|
|
|
| Model | Number of parameters | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) CER | [CoRal](https://huggingface.co/datasets/alexandrainst/coral/viewer/read_aloud/test) WER | [Danish Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da/test) CER | [Danish Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da/test) WER | |
|
|:---|---:|---:|---:|---:|---:| |
|
| Røst-315m (this model) | 315M | **6.6% ± 0.2%** | **17.0% ± 0.4%** | 6.6% ± 0.6% | 16.7% ± 0.8% | |
|
| [chcaa/xls-r-300m-danish-nst-cv9](https://hf.co/chcaa/xls-r-300m-danish-nst-cv9) | 315M | 14.4% ± 0.3% | 36.5% ± 0.6% | **4.1% ± 0.5%** | **12.0% ± 0.8%** | |
|
| [mhenrichsen/hviske](https://hf.co/mhenrichsen/hviske) | 1540M | 14.2% ± 0.5% | 33.2% ± 0.7% | *5.2% ± 0.4%* | *14.2% ± 0.8%* | |
|
| [openai/whisper-large-v3](https://hf.co/openai/whisper-large-v3) | 1540M | *11.4% ± 0.3%* | *28.3% ± 0.6%* | *5.5% ± 0.4%* | *14.8% ± 0.8%* | |
|
| [openai/whisper-large-v2](https://hf.co/openai/whisper-large-v2) | 1540M | 13.9% ± 0.9% | 32.6% ± 1.2% | 7.2% ± 0.5% | 18.5% ± 0.9% | |
|
| [openai/whisper-large](https://hf.co/openai/whisper-large) | 1540M | 14.5% ± 0.3% | 35.4% ± 0.6% | 9.2% ± 0.5% | 22.9% ± 1.0% | |
|
| [openai/whisper-medium](https://hf.co/openai/whisper-medium) | 764M | 17.2% ± 1.3% | 40.5% ± 2.1% | 9.4% ± 0.5% | 24.0% ± 1.0% | |
|
| [openai/whisper-small](https://hf.co/openai/whisper-small) | 242M | 23.4% ± 1.2% | 55.2% ± 2.3% | 15.9% ± 1.0% | 38.9% ± 1.2% | |
|
| [openai/whisper-base](https://hf.co/openai/whisper-base) | 73M | 43.5% ± 3.1% | 89.3% ± 4.6% | 33.4% ± 4.7% | 71.4% ± 7.0% | |
|
| [openai/whisper-tiny](https://hf.co/openai/whisper-tiny) | 38M | 52.0% ± 2.5% | 103.7% ± 3.5% | 42.2% ± 3.9% | 83.6% ± 2.7% | |
|
|
|
|
|
### Detailed Evaluation Across Demographics on the CoRal Test Set |
|
|
|
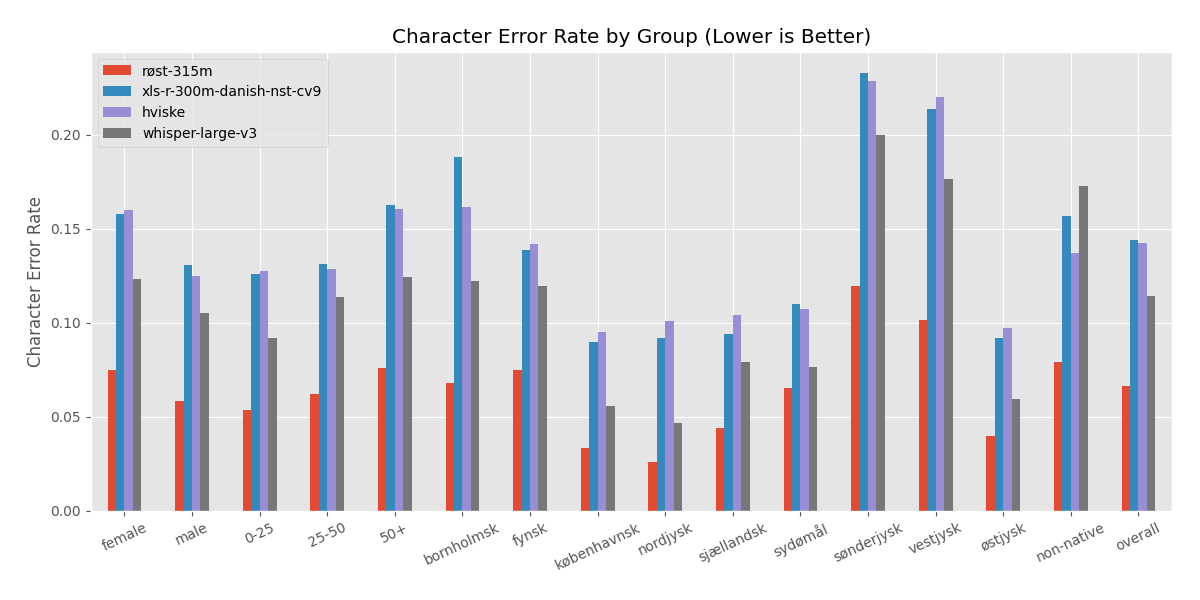 |
|
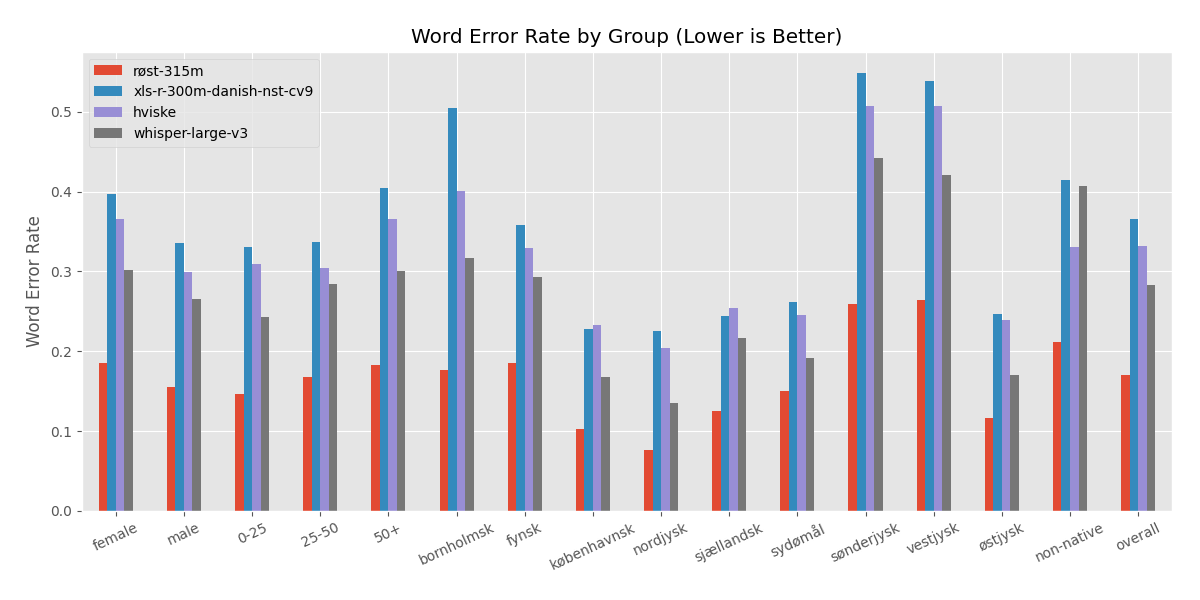 |
|
|
|
|
|
## Training Data |
|
|
|
This model is the result of four different stages of training: |
|
|
|
1. "Pretraining" on 436,000 hours of unlabelled multilingual publicly available data, |
|
13,628 hours of which is Danish. Pretraining here means that the model learnt to |
|
"fill in" gaps of raw audio - no transcriptions were used (or available) during |
|
this process. The pretraining data is distributed as follows: |
|
- 372,000 hours from [VoxPopuli](https://aclanthology.org/2021.acl-long.80/), being |
|
speeches from the European Parliament in 23 European languages. |
|
This includes 13,600 hours of Danish speech. |
|
- 51,000 hours from [Multilingual |
|
LibriSpeech](https://doi.org/10.21437/Interspeech.2020-2826), being audiobooks in |
|
8 European languages. This does not include any Danish speech. |
|
- 7,000 hours from [Common Voice 6](https://doi.org/10.48550/arXiv.1912.06670), |
|
being read-aloud speech in 60 diverse languages. This does not include any Danish |
|
speech. |
|
- 6,600 hours from [VoxLingua107](https://doi.org/10.1109/SLT48900.2021.9383459), |
|
being audio from YouTube videos in 107 languages. This includes 28 hours of |
|
Danish speech. |
|
- 1,000 hours from [BABEL](https://eprints.whiterose.ac.uk/152840/), being |
|
conversational telephone speech in 17 African and Asian languages. This does not |
|
include any Danish speech. |
|
2. "Finetuning" on 373 hours of labelled Danish publicly available data. "Finetuning" |
|
indicates that this stage of training was supervised, i.e. the model was trained on |
|
both audio and transcriptions to perform the speech-to-text task (also known as |
|
automatic speech recognition). The finetuning data is as follows: |
|
- The read-aloud training split of the [CoRal |
|
dataset](https://huggingface.co/datasets/alexandrainst/coral) (revision |
|
fb20199b3966d3373e0d3a5ded2c5920c70de99c), consisting of 361 hours of Danish |
|
read-aloud speech, diverse across dialects, accents, ages and genders. |
|
3. An n-gram language model has been trained separately, and is used to guide the |
|
transcription generation of the finetuned speech recognition model. This n-gram |
|
language model has been trained on the following datasets: |
|
- [Danish |
|
Wikipedia](https://huggingface.co/datasets/alexandrainst/scandi-wiki/viewer/da) |
|
(approximately 287,000 articles). |
|
- [Danish Common Voice 17 training |
|
split](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0/viewer/da) |
|
(approximately 3,500 comments). |
|
- [Danish |
|
Reddit](https://huggingface.co/datasets/alexandrainst/scandi-reddit/viewer/da) |
|
(approximately 5 million comments). |
|
Note that all samples from the CoRal test dataset have been removed from all of |
|
these datasets, to ensure that the n-gram model has not seen the test data. |
|
|
|
The first step was trained by [Babu et al. |
|
(2021)](https://doi.org/10.48550/arXiv.2111.09296) and the second and third step by |
|
[Nielsen et al. (2024)](https://huggingface.co/alexandrainst/roest-315m). |
|
|
|
The final product is then the combination of the finetuned model along with the n-gram |
|
model, and this is what is used when you use the model as mentioned in the Quick Start |
|
section above. |
|
|
|
|
|
## Intended use cases |
|
|
|
This model is intended to be used for Danish automatic speech recognition. |
|
|
|
Note that Biometric Identification is not allowed using the CoRal dataset and/or derived |
|
models. For more information, see addition 4 in our |
|
[license](https://huggingface.co/alexandrainst/roest-315m/blob/main/LICENSE). |
|
|
|
|
|
## Why the name Røst? |
|
|
|
Røst is both the [Danish word for the human |
|
voice](https://ordnet.dk/ddo/ordbog?query=r%C3%B8st) as well as being the name of [one |
|
of the cold-water coral reefs in |
|
Scandinavia](https://da.wikipedia.org/wiki/Koralrev#Koldtvandskoralrev). |
|
|
|
|
|
## License |
|
The dataset is licensed under a custom license, adapted from OpenRAIL-M, which allows |
|
commercial use with a few restrictions (speech synthesis and biometric identification). |
|
See |
|
[license](https://huggingface.co/alexandrainst/roest-315m/blob/main/LICENSE). |
|
|
|
|
|
## Creators and Funders |
|
The CoRal project is funded by the [Danish Innovation |
|
Fund](https://innovationsfonden.dk/) and consists of the following partners: |
|
|
|
- [Alexandra Institute](https://alexandra.dk/) |
|
- [University of Copenhagen](https://www.ku.dk/) |
|
- [Agency for Digital Government](https://digst.dk/) |
|
- [Alvenir](https://www.alvenir.ai/) |
|
- [Corti](https://www.corti.ai/) |
|
|
|
|
|
## Citation |
|
|
|
We will submit a research paper soon, but until then, if you use this model in your |
|
research or development, please cite it as follows: |
|
|
|
```bibtex |
|
@dataset{coral2024, |
|
author = {Dan Saattrup Nielsen, Sif Bernstorff Lehmann, Simon Leminen Madsen, Anders Jess Pedersen, Anna Katrine van Zee, Anders Søgaard and Torben Blach}, |
|
title = {CoRal: A Diverse Danish ASR Dataset Covering Dialects, Accents, Genders, and Age Groups}, |
|
year = {2024}, |
|
url = {https://hf.co/datasets/alexandrainst/coral}, |
|
} |
|
``` |

