
language:
- en
tags:
- stable-diffusion
- text-to-image
license: bigscience-bloom-rail-1.0
inference: false
project that probably won't lead to anything useful but is still interesting (Less VRAM requirement than finetuning Stable Diffusion, faster if you have all the images downloaded, less space taken up by the models since you only need CLIP)
a notebook for producing your own "stable inversions" is included in this repo but I wouldn't recommend doing so (they suck). It works on Colab free tier though.
link to notebook for you to download
how you can load this into a diffusers-based notebook like Doohickey might look something like this
from huggingface_hub import hf_hub_download
stable_inversion = "user/my-stable-inversion" #@param {type:"string"}
inversion_path = hf_hub_download(repo_id=stable_inversion, filename="token_embeddings.pt")
text_encoder.text_model.embeddings.token_embedding.weight = torch.load(inversion_path)
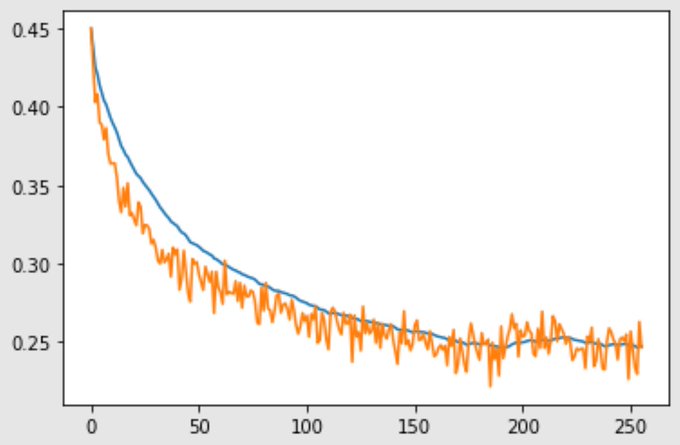
it was trained on 1024 images matching the 'genshin_impact' tag on safebooru, epochs 1 and 2 had the model being fed the full captions, epoch 3 had 50% of the tags in the caption, and epoch 4 had 25% of the tags in the caption. Learning rate was 1e-3 and the loss curve looked like this
Samples from this finetuned inversion for the prompt "beidou_(genshin_impact)" using just the 1-4 Stable Diffusion model




Sample for the same prompt BEFORE finetuning (matches seeds with first finetuned sample)
