
url
stringlengths 61
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 75
75
| comments_url
stringlengths 70
70
| events_url
stringlengths 68
68
| html_url
stringlengths 49
51
| id
int64 1.08B
1.73B
| node_id
stringlengths 18
19
| number
int64 3.45k
5.9k
| title
stringlengths 1
290
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
timestamp[s] | updated_at
timestamp[s] | closed_at
timestamp[s] | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 2
36.2k
⌀ | reactions
dict | timeline_url
stringlengths 70
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3750/comments | https://api.github.com/repos/huggingface/datasets/issues/3750/events | https://github.com/huggingface/datasets/issues/3750 | 1,142,408,331 | I_kwDODunzps5EF8SL | 3,750 | `NonMatchingSplitsSizesError` for cats_vs_dogs dataset | {
"login": "jaketae",
"id": 25360440,
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaketae",
"html_url": "https://github.com/jaketae",
"followers_url": "https://api.github.com/users/jaketae/followers",
"following_url": "https://api.github.com/users/jaketae/following{/other_user}",
"gists_url": "https://api.github.com/users/jaketae/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jaketae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jaketae/subscriptions",
"organizations_url": "https://api.github.com/users/jaketae/orgs",
"repos_url": "https://api.github.com/users/jaketae/repos",
"events_url": "https://api.github.com/users/jaketae/events{/privacy}",
"received_events_url": "https://api.github.com/users/jaketae/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thnaks for reporting @jaketae. We are fixing it. "
] | 2022-02-18T05:46:39 | 2022-02-18T14:56:11 | 2022-02-18T14:56:11 | CONTRIBUTOR | null | null | null | ## Describe the bug
Cannot download cats_vs_dogs dataset due to `NonMatchingSplitsSizesError`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("cats_vs_dogs")
```
## Expected results
Loading is successful.
## Actual results
```
NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=7503250, num_examples=23422, dataset_name='cats_vs_dogs'), 'recorded': SplitInfo(name='train', num_bytes=7262410, num_examples=23410, dataset_name='cats_vs_dogs')}]
```
## Environment info
Reproduced on a fresh [Colab notebook](https://colab.research.google.com/drive/13GTvrSJbBGvL2ybDdXCBZwATd6FOkMub?usp=sharing).
## Additional Context
Originally reported in https://github.com/huggingface/transformers/issues/15698.
cc @mariosasko | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3750/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3749/comments | https://api.github.com/repos/huggingface/datasets/issues/3749/events | https://github.com/huggingface/datasets/pull/3749 | 1,142,156,678 | PR_kwDODunzps4zCKqg | 3,749 | Add tqdm arguments | {
"login": "penguinwang96825",
"id": 28087825,
"node_id": "MDQ6VXNlcjI4MDg3ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/28087825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/penguinwang96825",
"html_url": "https://github.com/penguinwang96825",
"followers_url": "https://api.github.com/users/penguinwang96825/followers",
"following_url": "https://api.github.com/users/penguinwang96825/following{/other_user}",
"gists_url": "https://api.github.com/users/penguinwang96825/gists{/gist_id}",
"starred_url": "https://api.github.com/users/penguinwang96825/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/penguinwang96825/subscriptions",
"organizations_url": "https://api.github.com/users/penguinwang96825/orgs",
"repos_url": "https://api.github.com/users/penguinwang96825/repos",
"events_url": "https://api.github.com/users/penguinwang96825/events{/privacy}",
"received_events_url": "https://api.github.com/users/penguinwang96825/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! Thanks this will be very useful :)\r\n\r\nIt looks like there are some changes in the github diff that are not related to your contribution, can you try fixing this by merging `master` into your PR, or create a new PR from an updated version of `master` ?",
"I have already solved the conflict on this latest version. This is my first time sending PR, if there's anything I need to adjust just let me know~",
"Thanks, most changes are gone :)\r\nIt still seems to include changes though - do you mind try creating a new branch from upstream/master and create a new PR please ?",
"Yeah sure, I'll try to send a new PR today!",
"Please forward to [#3850](https://github.com/huggingface/datasets/pull/3850)",
"Thanks ! Closing this one in favor of https://github.com/huggingface/datasets/pull/3850/files"
] | 2022-02-18T01:34:46 | 2022-03-08T09:38:48 | 2022-03-08T09:38:48 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3749",
"html_url": "https://github.com/huggingface/datasets/pull/3749",
"diff_url": "https://github.com/huggingface/datasets/pull/3749.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3749.patch",
"merged_at": null
} | In this PR, tqdm arguments can be passed to the map() function and such, in order to be more flexible. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3749/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3749/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3748/comments | https://api.github.com/repos/huggingface/datasets/issues/3748/events | https://github.com/huggingface/datasets/pull/3748 | 1,142,128,763 | PR_kwDODunzps4zCEyM | 3,748 | Add tqdm arguments | {
"login": "penguinwang96825",
"id": 28087825,
"node_id": "MDQ6VXNlcjI4MDg3ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/28087825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/penguinwang96825",
"html_url": "https://github.com/penguinwang96825",
"followers_url": "https://api.github.com/users/penguinwang96825/followers",
"following_url": "https://api.github.com/users/penguinwang96825/following{/other_user}",
"gists_url": "https://api.github.com/users/penguinwang96825/gists{/gist_id}",
"starred_url": "https://api.github.com/users/penguinwang96825/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/penguinwang96825/subscriptions",
"organizations_url": "https://api.github.com/users/penguinwang96825/orgs",
"repos_url": "https://api.github.com/users/penguinwang96825/repos",
"events_url": "https://api.github.com/users/penguinwang96825/events{/privacy}",
"received_events_url": "https://api.github.com/users/penguinwang96825/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-18T00:47:55 | 2022-02-18T00:59:15 | 2022-02-18T00:59:15 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3748",
"html_url": "https://github.com/huggingface/datasets/pull/3748",
"diff_url": "https://github.com/huggingface/datasets/pull/3748.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3748.patch",
"merged_at": null
} | In this PR, there are two changes.
1. It is able to show the progress bar by adding the length of the iterator.
2. Pass in tqdm_kwargs so that can enable more feasibility for the control of tqdm library. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3748/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3747/comments | https://api.github.com/repos/huggingface/datasets/issues/3747/events | https://github.com/huggingface/datasets/issues/3747 | 1,141,688,854 | I_kwDODunzps5EDMoW | 3,747 | Passing invalid subset should throw an error | {
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 2022-02-17T18:16:11 | 2022-02-17T18:16:11 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Only some datasets have a subset (as in `load_dataset(name, subset)`). If you pass an invalid subset, an error should be thrown.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('rotten_tomatoes', 'asdfasdfa')
```
## Expected results
This should break, since `'asdfasdfa'` isn't a subset of the `rotten_tomatoes` dataset.
## Actual results
This API call silently succeeds. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3747/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3746/comments | https://api.github.com/repos/huggingface/datasets/issues/3746/events | https://github.com/huggingface/datasets/pull/3746 | 1,141,612,810 | PR_kwDODunzps4zAS-C | 3,746 | Use the same seed to shuffle shards and metadata in streaming mode | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-17T17:06:31 | 2022-02-23T15:00:59 | 2022-02-23T15:00:58 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3746",
"html_url": "https://github.com/huggingface/datasets/pull/3746",
"diff_url": "https://github.com/huggingface/datasets/pull/3746.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3746.patch",
"merged_at": "2022-02-23T15:00:58"
} | When shuffling in streaming mode, those two entangled lists are shuffled independently. In this PR I changed this to shuffle the lists of same length with the exact same seed, in order for the files and metadata to still be aligned.
```python
gen_kwargs = {
"files": [os.path.join(data_dir, filename) for filename in all_files],
"metadata_files": [all_metadata[filename] for filename in all_files],
}
```
IMO this is important to avoid big but silent issues.
Fix https://github.com/huggingface/datasets/issues/3744 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3746/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3745/comments | https://api.github.com/repos/huggingface/datasets/issues/3745/events | https://github.com/huggingface/datasets/pull/3745 | 1,141,520,953 | PR_kwDODunzps4y__m2 | 3,745 | Add mIoU metric | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hmm the doctest failed again - maybe the full result needs to be on one single line",
"cc @lhoestq for the final review",
"Cool ! Feel free to merge if it's all good for you"
] | 2022-02-17T15:52:17 | 2022-03-08T13:20:26 | 2022-03-08T13:20:26 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3745",
"html_url": "https://github.com/huggingface/datasets/pull/3745",
"diff_url": "https://github.com/huggingface/datasets/pull/3745.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3745.patch",
"merged_at": "2022-03-08T13:20:26"
} | This PR adds the mean Intersection-over-Union metric to the library, useful for tasks like semantic segmentation.
It is entirely based on mmseg's [implementation](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/core/evaluation/metrics.py).
I've removed any PyTorch dependency, and rely on Numpy only. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3745/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3744/comments | https://api.github.com/repos/huggingface/datasets/issues/3744/events | https://github.com/huggingface/datasets/issues/3744 | 1,141,461,165 | I_kwDODunzps5ECVCt | 3,744 | Better shards shuffling in streaming mode | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | [] | 2022-02-17T15:07:21 | 2022-02-23T15:00:58 | 2022-02-23T15:00:58 | MEMBER | null | null | null | Sometimes a dataset script has a `_split_generators` that returns several files as well as the corresponding metadata of each file. It often happens that they end up in two separate lists in the `gen_kwargs`:
```python
gen_kwargs = {
"files": [os.path.join(data_dir, filename) for filename in all_files],
"metadata_files": [all_metadata[filename] for filename in all_files],
}
```
It happened for Multilingual Spoken Words for example in #3666
However currently **the two lists are shuffled independently** when shuffling the shards in streaming mode. This leads to `_generate_examples` not having the right metadata for each file.
To prevent this issue I suggest that we always shuffle lists of the same length the exact same way to avoid such a big but silent issue.
cc @polinaeterna | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3744/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3744/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3743/comments | https://api.github.com/repos/huggingface/datasets/issues/3743/events | https://github.com/huggingface/datasets/pull/3743 | 1,141,176,011 | PR_kwDODunzps4y-2Do | 3,743 | initial monash time series forecasting repository | {
"login": "kashif",
"id": 8100,
"node_id": "MDQ6VXNlcjgxMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8100?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kashif",
"html_url": "https://github.com/kashif",
"followers_url": "https://api.github.com/users/kashif/followers",
"following_url": "https://api.github.com/users/kashif/following{/other_user}",
"gists_url": "https://api.github.com/users/kashif/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kashif/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kashif/subscriptions",
"organizations_url": "https://api.github.com/users/kashif/orgs",
"repos_url": "https://api.github.com/users/kashif/repos",
"events_url": "https://api.github.com/users/kashif/events{/privacy}",
"received_events_url": "https://api.github.com/users/kashif/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI fails are unrelated to this PR, merging !",
"thanks 🙇🏽 "
] | 2022-02-17T10:51:31 | 2022-03-21T09:54:41 | 2022-03-21T09:50:16 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3743",
"html_url": "https://github.com/huggingface/datasets/pull/3743",
"diff_url": "https://github.com/huggingface/datasets/pull/3743.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3743.patch",
"merged_at": "2022-03-21T09:50:16"
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3743/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3742/comments | https://api.github.com/repos/huggingface/datasets/issues/3742/events | https://github.com/huggingface/datasets/pull/3742 | 1,141,174,549 | PR_kwDODunzps4y-1v5 | 3,742 | Fix ValueError message formatting in int2str | {
"login": "akulchik",
"id": 41182803,
"node_id": "MDQ6VXNlcjQxMTgyODAz",
"avatar_url": "https://avatars.githubusercontent.com/u/41182803?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/akulchik",
"html_url": "https://github.com/akulchik",
"followers_url": "https://api.github.com/users/akulchik/followers",
"following_url": "https://api.github.com/users/akulchik/following{/other_user}",
"gists_url": "https://api.github.com/users/akulchik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/akulchik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/akulchik/subscriptions",
"organizations_url": "https://api.github.com/users/akulchik/orgs",
"repos_url": "https://api.github.com/users/akulchik/repos",
"events_url": "https://api.github.com/users/akulchik/events{/privacy}",
"received_events_url": "https://api.github.com/users/akulchik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-17T10:50:08 | 2022-02-17T15:32:02 | 2022-02-17T15:32:02 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3742",
"html_url": "https://github.com/huggingface/datasets/pull/3742",
"diff_url": "https://github.com/huggingface/datasets/pull/3742.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3742.patch",
"merged_at": "2022-02-17T15:32:02"
} | Hi!
I bumped into this particular `ValueError` during my work (because an instance of `np.int64` was passed instead of regular Python `int`), and so I had to `print(type(values))` myself. Apparently, it's just the missing `f` to make message an f-string.
It ain't much for a contribution, but it's honest work. Hope it spares someone else a few seconds in the future 😃 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3742/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3741/comments | https://api.github.com/repos/huggingface/datasets/issues/3741/events | https://github.com/huggingface/datasets/pull/3741 | 1,141,132,649 | PR_kwDODunzps4y-syt | 3,741 | Rm sphinx doc | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-17T10:11:37 | 2022-02-17T10:15:17 | 2022-02-17T10:15:12 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3741",
"html_url": "https://github.com/huggingface/datasets/pull/3741",
"diff_url": "https://github.com/huggingface/datasets/pull/3741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3741.patch",
"merged_at": null
} | Checklist
- [x] Update circle ci yaml
- [x] Delete sphinx static & python files in docs dir
- [x] Update readme in docs dir
- [ ] Update docs config in setup.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3740/comments | https://api.github.com/repos/huggingface/datasets/issues/3740/events | https://github.com/huggingface/datasets/pull/3740 | 1,140,720,739 | PR_kwDODunzps4y9XAP | 3,740 | Support streaming for pubmed | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@albertvillanova just FYI, since you were so helpful with the previous pubmed issue :) ",
"IIRC streaming from FTP is not fully tested yet, so I'm fine with switching to HTTPS for now, as long as the download speed/availability is great",
"@albertvillanova Thanks for pointing me to the `ET` module replacement. It should look a lot cleaner now.\r\n\r\nUnfortunately I tried keeping the `ftp://` protocol but was seeing timeout errors? in streaming mode (below). I think the `https://` performance is not an issue, when I was profiling the `open(..) -> f.read() -> etree.fromstring(xml_str)` codepath, most of the time was spent in the XML parsing rather than the data download.\r\n\r\n\r\nError when using `ftp://`:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/venv/lib/python3.8/site-packages/fsspec/implementations/ftp.py\", line 301, in _fetch_range\r\n self.fs.ftp.retrbinary(\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/ftplib.py\", line 430, in retrbinary\r\n callback(data)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/venv/lib/python3.8/site-packages/fsspec/implementations/ftp.py\", line 293, in callback\r\n raise TransferDone\r\nfsspec.implementations.ftp.TransferDone\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"test_pubmed_streaming.py\", line 9, in <module>\r\n print (next(iter(pubmed_train_streaming)))\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/iterable_dataset.py\", line 365, in __iter__\r\n for key, example in self._iter():\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/iterable_dataset.py\", line 362, in _iter\r\n yield from ex_iterable\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/iterable_dataset.py\", line 79, in __iter__\r\n yield from self.generate_examples_fn(**self.kwargs)\r\n File \"/Users/abhinav/.cache/huggingface/modules/datasets_modules/datasets/pubmed/af552ed918e2841e8427203530e3cfed3a8bc3213041d7853bea1ca67eec683d/pubmed.py\", line 362, in _generate_examples\r\n tree = ET.parse(filename)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/streaming.py\", line 65, in wrapper\r\n return function(*args, use_auth_token=use_auth_token, **kwargs)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/utils/streaming_download_manager.py\", line 636, in xet_parse\r\n return ET.parse(f, parser=parser)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py\", line 1202, in parse\r\n tree.parse(source, parser)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py\", line 595, in parse\r\n self._root = parser._parse_whole(source)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/abhi-datasets/src/datasets/utils/streaming_download_manager.py\", line 293, in read_with_retries\r\n out = read(*args, **kwargs)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/gzip.py\", line 292, in read\r\n return self._buffer.read(size)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/_compression.py\", line 68, in readinto\r\n data = self.read(len(byte_view))\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/gzip.py\", line 479, in read\r\n if not self._read_gzip_header():\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/gzip.py\", line 422, in _read_gzip_header\r\n magic = self._fp.read(2)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/gzip.py\", line 96, in read\r\n self.file.read(size-self._length+read)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/venv/lib/python3.8/site-packages/fsspec/spec.py\", line 1485, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/venv/lib/python3.8/site-packages/fsspec/caching.py\", line 153, in _fetch\r\n self.cache = self.fetcher(start, end) # new block replaces old\r\n File \"/Users/abhinav/Documents/mosaicml/hf_datasets/venv/lib/python3.8/site-packages/fsspec/implementations/ftp.py\", line 311, in _fetch_range\r\n self.fs.ftp.getmultiline()\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/ftplib.py\", line 224, in getmultiline\r\n line = self.getline()\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/ftplib.py\", line 206, in getline\r\n line = self.file.readline(self.maxline + 1)\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/socket.py\", line 669, in readinto\r\n return self._sock.recv_into(b)\r\nsocket.timeout: timed out\r\n```"
] | 2022-02-17T00:18:22 | 2022-02-18T14:42:13 | 2022-02-18T14:42:13 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3740",
"html_url": "https://github.com/huggingface/datasets/pull/3740",
"diff_url": "https://github.com/huggingface/datasets/pull/3740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3740.patch",
"merged_at": "2022-02-18T14:42:13"
} | This PR makes some minor changes to the `pubmed` dataset to allow for `streaming=True`. Fixes #3739.
Basically, I followed the C4 dataset which works in streaming mode as an example, and made the following changes:
* Change URL prefix from `ftp://` to `https://`
* Explicilty `open` the filename and pass the XML contents to `etree.fromstring(xml_str)`
The Github diff tool makes it look like the changes are larger than they are, sorry about that.
I tested locally and the `pubmed` dataset now works in both normal and streaming modes. There is some overhead at the start of each shard in streaming mode as building the XML tree online is quite slow (each pubmed .xml.gz file is ~20MB), but the overhead gets amortized over all the samples in the shard. On my laptop with a single CPU worker I am able to stream at about ~600 samples/s. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3740/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3739/comments | https://api.github.com/repos/huggingface/datasets/issues/3739/events | https://github.com/huggingface/datasets/issues/3739 | 1,140,329,189 | I_kwDODunzps5D-Arl | 3,739 | Pubmed dataset does not work in streaming mode | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Thanks for reporting, @abhi-mosaic (related to #3655).\r\n\r\nPlease note that `xml.etree.ElementTree.parse` already supports streaming:\r\n- #3476\r\n\r\nNo need to refactor to use `open`/`xopen`. Is is enough with importing the package `as ET` (instead of `as etree`)."
] | 2022-02-16T17:13:37 | 2022-02-18T14:42:13 | 2022-02-18T14:42:13 | CONTRIBUTOR | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset with `streaming=True` fails.
## Steps to reproduce the bug
```python
import datasets
pubmed_train = datasets.load_dataset('pubmed', split='train', streaming=True)
print (next(iter(pubmed_train)))
```
## Expected results
I would expect to see the first training sample from the pubmed dataset.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 367, in __iter__
for key, example in self._iter():
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 364, in _iter
yield from ex_iterable
File "/Users/abhinav/Documents/mosaicml/mosaicml_venv/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
for key, example in self.generate_examples_fn(**self.kwargs):
File "/Users/abhinav/.cache/huggingface/modules/datasets_modules/datasets/pubmed/9715addf10c42a7877a2149ae0c5f2fddabefc775cd1bd9b03ac3f012b86ce46/pubmed.py", line 373, in _generate_examples
tree = etree.parse(filename)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 1202, in parse
tree.parse(source, parser)
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/xml/etree/ElementTree.py", line 584, in parse
source = open(source, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'gzip://pubmed21n0001.xml::ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0001.xml.gz'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
## Comments
The error looks like an issue with `open` vs. `xopen` inside the `xml` package. It looks like it's trying to open the remote source URL, which has been edited with prefix `gzip://...`.
Maybe there can be an explicit `xopen` before passing the raw data to `etree`, something like:
```python
# Before
tree = etree.parse(filename)
root = tree.getroot()
# After
with xopen(filename) as f:
data_str = f.read()
root = etree.fromstring(data_str)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3739/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3738/comments | https://api.github.com/repos/huggingface/datasets/issues/3738/events | https://github.com/huggingface/datasets/issues/3738 | 1,140,164,253 | I_kwDODunzps5D9Yad | 3,738 | For data-only datasets, streaming and non-streaming don't behave the same | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Note that we might change the heuristic and create a different config per file, at least in that case.",
"Hi @severo, thanks for reporting.\r\n\r\nYes, this happens because when non-streaming, a cast of all data is done in order to \"concatenate\" it all into a single dataset (thus the error), while this casting is not done while yielding item by item in streaming mode.\r\n\r\nMaybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?",
"Why do we want to concatenate the files? Is it the expected behavior for most datasets that lack a script and dataset info?",
"These files are two different dataset configurations since they don't share the same schema.\r\n\r\nIMO the streaming mode should fail in this case, as @albertvillanova said.\r\n\r\nThere is one challenge though: inferring the schema from the first example is not robust enough in the general case - especially if some fields are nullable. I guess we can at least make sure that no new columns are added",
"OK. So, if we make the streaming also fail, the dataset https://huggingface.co/datasets/huggingface/transformers-metadata will never be [viewable](https://github.com/huggingface/datasets-preview-backend/issues/144) (be it using streaming or fallback to downloading the files), right?\r\n",
"Yes, until we have a way for the user to specify explicitly that those two files are different configurations.\r\n\r\nWe can maybe have some rule to detect this automatically, maybe checking the first line of each file ? That would mean that for dataset of 10,000+ files we would have to verify every single one of them just to know if there is one ore more configurations, so I'm not sure if this is a good idea",
"i think requiring the user to specify that those two files are different configurations is in that case perfectly reasonable.\r\n\r\n(Maybe at some point we could however detect this type of case and prompt them to define a config mapping etc)",
"OK, so, before closing the issue, what do you think should be done?\r\n\r\n> Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?\r\n\r\nor nothing?",
"We should at least raise an error if a new sample has column names that are missing, or if it has extra columns. No need to check for the type for now.\r\n\r\nI'm in favor of having an error especially because we want to avoid silent issues as much as possible - i.e. when something goes wrong (when schemas don't match or some data are missing) and no errors/warnings are raised.\r\n\r\nConsistency between streaming and non-streaming is also important."
] | 2022-02-16T15:20:57 | 2022-02-21T14:24:55 | null | CONTRIBUTOR | null | null | null | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3738/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3737/comments | https://api.github.com/repos/huggingface/datasets/issues/3737/events | https://github.com/huggingface/datasets/pull/3737 | 1,140,148,050 | PR_kwDODunzps4y7uFf | 3,737 | Make RedCaps streamable | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-16T15:12:23 | 2022-02-16T15:28:38 | 2022-02-16T15:28:37 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3737",
"html_url": "https://github.com/huggingface/datasets/pull/3737",
"diff_url": "https://github.com/huggingface/datasets/pull/3737.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3737.patch",
"merged_at": "2022-02-16T15:28:37"
} | Make RedCaps streamable.
@lhoestq Using `data/redcaps_v1.0_annotations.zip` as a download URL gives an error locally when running `datasets-cli test` (will investigate this another time) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3737/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3736/comments | https://api.github.com/repos/huggingface/datasets/issues/3736/events | https://github.com/huggingface/datasets/pull/3736 | 1,140,134,483 | PR_kwDODunzps4y7rMR | 3,736 | Local paths in common voice | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I just changed to `dl_manager.is_streaming` rather than an additional parameter `streaming` that has to be handled by the DatasetBuilder class - this way the streaming logic doesn't interfere with the base builder's code.\r\n\r\nI think it's better this way, but let me know if you preferred the previous way and I can revert\r\n\r\n> But on the other hand, IMHO, I think this specific solution adds complexity to handling streaming/non-streaming, and moves this complexity to the loading script and thus to the contributors/users who want to create the loading script for their canonical/community datasets (instead of keeping it hidden form the end users).\r\n\r\nI'm down to discuss this more in the future !",
"@lhoestq good idea: much cleaner this way! That way each class has its own responsibilities without mixing around..."
] | 2022-02-16T15:01:29 | 2022-09-21T14:58:38 | 2022-02-22T09:13:43 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3736",
"html_url": "https://github.com/huggingface/datasets/pull/3736",
"diff_url": "https://github.com/huggingface/datasets/pull/3736.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3736.patch",
"merged_at": "2022-02-22T09:13:43"
} | Continuation of https://github.com/huggingface/datasets/pull/3664:
- pass the `streaming` parameter to _split_generator
- update @anton-l's code to use this parameter for `common_voice`
- add a comment to explain why we use `download_and_extract` in non-streaming and `iter_archive` in streaming
Now the `common_voice` dataset has a local path back in `ds["path"]`, and this field is `None` in streaming mode.
cc @patrickvonplaten @anton-l @albertvillanova
Fix #3663. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3736/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3736/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3735/comments | https://api.github.com/repos/huggingface/datasets/issues/3735/events | https://github.com/huggingface/datasets/issues/3735 | 1,140,087,891 | I_kwDODunzps5D9FxT | 3,735 | Performance of `datasets` at scale | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"> using command line git-lfs - [...] 300MB/s!\r\n\r\nwhich server location did you upload from?",
"From GCP region `us-central1-a`.",
"The most surprising part to me is the saving time. Wondering if it could be due to compression (`ParquetWriter` uses SNAPPY compression by default; it can be turned off with `to_parquet(..., compression=None)`). ",
"+1 to what @mariosasko mentioned. Also, @lvwerra did you parallelize `to_parquet` using similar approach in #2747? (we used multiprocessing at the shard level). I'm working on a similar PR to add multi_proc in `to_parquet` which might give you further speed up. \r\nStas benchmarked his approach and mine in this [gist](https://gist.github.com/stas00/dc1597a1e245c5915cfeefa0eee6902c) for `lama` dataset when we were working on adding multi_proc support for `to_json`.",
"@mariosasko I did not turn it off but I can try the next time - I have to run the pipeline again, anyway. \r\n\r\n@bhavitvyamalik Yes, I also sharded the dataset and used multiprocessing to save each shard. I'll have a closer look at your approach, too."
] | 2022-02-16T14:23:32 | 2022-03-15T09:15:29 | null | MEMBER | null | null | null | # Performance of `datasets` at 1TB scale
## What is this?
During the processing of a large dataset I monitored the performance of the `datasets` library to see if there are any bottlenecks. The insights of this analysis could guide the decision making to improve the performance of the library.
## Dataset
The dataset is a 1.1TB extract from GitHub with 120M code files and is stored as 5000 `.json.gz` files. The goal of the preprocessing is to remove duplicates and filter files based on their stats. While the calculating of the hashes for deduplication and stats for filtering can be parallelized the filtering itself is run with a single process. After processing the files are pushed to the hub.
## Machine
The experiment was run on a `m1` machine on GCP with 96 CPU cores and 1.3TB RAM.
## Performance breakdown
- Loading the data **3.5h** (_30sec_ from cache)
- **1h57min** single core loading (not sure what is going on here, corresponds to second progress bar)
- **1h10min** multi core json reading
- **20min** remaining time before and after the two main processes mentioned above
- Process the data **2h** (_20min_ from cache)
- **20min** Getting reading for processing
- **40min** Hashing and files stats (96 workers)
- **58min** Deduplication filtering (single worker)
- Save parquet files **5h**
- Saving 1000 parquet files (16 workers)
- Push to hub **37min**
- **34min** git add
- **3min** git push (several hours with `Repository.git_push()`)
## Conclusion
It appears that loading and saving the data is the main bottleneck at that scale (**8.5h**) whereas processing (**2h**) and pushing the data to the hub (**0.5h**) is relatively fast. To optimize the performance at this scale it would make sense to consider such an end-to-end example and target the bottlenecks which seem to be loading from and saving to disk. The processing itself seems to run relatively fast.
## Notes
- map operation on a 1TB dataset with 96 workers requires >1TB RAM
- map operation does not maintain 100% CPU utilization with 96 workers
- sometimes when the script crashes all the data files have a corresponding `*.lock` file in the data folder (or multiple e.g. `*.lock.lock` when it happened a several times). This causes the cache **not** to be triggered (which is significant at that scale) - i guess because there are new data files
- parallelizing `to_parquet` decreased the saving time from 17h to 5h, however adding more workers at this point had almost no effect. not sure if this is:
a) a bug in my parallelization logic,
b) i/o limit to load data form disk to memory or
c) i/o limit to write from memory to disk.
- Using `Repository.git_push()` was much slower than using command line `git-lfs` - 10-20MB/s vs. 300MB/s! The `Dataset.push_to_hub()` function is even slower as it only uploads one file at a time with only a few MB/s, whereas `Repository.git_push()` pushes files in parallel (each at a similar speed).
cc @lhoestq @julien-c @LysandreJik @SBrandeis
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3735/reactions",
"total_count": 15,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 11,
"rocket": 0,
"eyes": 4
} | https://api.github.com/repos/huggingface/datasets/issues/3735/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3734/comments | https://api.github.com/repos/huggingface/datasets/issues/3734/events | https://github.com/huggingface/datasets/pull/3734 | 1,140,050,336 | PR_kwDODunzps4y7ZU2 | 3,734 | Fix bugs in NewsQA dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-16T13:51:28 | 2022-02-17T07:54:26 | 2022-02-17T07:54:25 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3734",
"html_url": "https://github.com/huggingface/datasets/pull/3734",
"diff_url": "https://github.com/huggingface/datasets/pull/3734.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3734.patch",
"merged_at": "2022-02-17T07:54:25"
} | Fix #3733. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3734/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3733/comments | https://api.github.com/repos/huggingface/datasets/issues/3733/events | https://github.com/huggingface/datasets/issues/3733 | 1,140,011,378 | I_kwDODunzps5D8zFy | 3,733 | Bugs in NewsQA dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 2022-02-16T13:17:37 | 2022-02-17T07:54:25 | 2022-02-17T07:54:25 | MEMBER | null | null | null | ## Describe the bug
NewsQA dataset has the following bugs:
- the field `validated_answers` is an exact copy of the field `answers` but with the addition of `'count': [0]` to each dict
- the field `badQuestion` does not appear in `answers` nor `validated_answers`
## Steps to reproduce the bug
By inspecting the dataset script we can see that:
- the parsing of `validated_answers` is a copy-paste of the one for `answers`
- the `badQuestion` field is ignored in the parsing of both `answers` and `validated_answers`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3733/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3732/comments | https://api.github.com/repos/huggingface/datasets/issues/3732/events | https://github.com/huggingface/datasets/pull/3732 | 1,140,004,022 | PR_kwDODunzps4y7PTU | 3,732 | Support streaming in size estimation function in `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"would this allow to include the size in the dataset info without downloading the files? related to https://github.com/huggingface/datasets/pull/3670",
"@severo I don't think so. We could use this to get `info.download_checksums[\"num_bytes\"]`, but we must process the files to get the rest of the size info. "
] | 2022-02-16T13:10:48 | 2022-02-21T18:18:45 | 2022-02-21T18:18:44 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3732",
"html_url": "https://github.com/huggingface/datasets/pull/3732",
"diff_url": "https://github.com/huggingface/datasets/pull/3732.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3732.patch",
"merged_at": "2022-02-21T18:18:44"
} | This PR adds the streamable version of `os.path.getsize` (`fsspec` can return `None`, so we fall back to `fs.open` to make it more robust) to account for possible streamable paths in the nested `extra_nbytes_visitor` function inside `push_to_hub`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3732/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3732/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3731/comments | https://api.github.com/repos/huggingface/datasets/issues/3731/events | https://github.com/huggingface/datasets/pull/3731 | 1,139,626,362 | PR_kwDODunzps4y5-hi | 3,731 | Fix Multi-News dataset metadata and card | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-16T07:14:57 | 2022-02-16T08:48:47 | 2022-02-16T08:48:47 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3731",
"html_url": "https://github.com/huggingface/datasets/pull/3731",
"diff_url": "https://github.com/huggingface/datasets/pull/3731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3731.patch",
"merged_at": "2022-02-16T08:48:46"
} | Fix #3730. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3730/comments | https://api.github.com/repos/huggingface/datasets/issues/3730/events | https://github.com/huggingface/datasets/issues/3730 | 1,139,545,613 | I_kwDODunzps5D7BYN | 3,730 | Checksum Error when loading multi-news dataset | {
"login": "byw2",
"id": 60560991,
"node_id": "MDQ6VXNlcjYwNTYwOTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/60560991?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/byw2",
"html_url": "https://github.com/byw2",
"followers_url": "https://api.github.com/users/byw2/followers",
"following_url": "https://api.github.com/users/byw2/following{/other_user}",
"gists_url": "https://api.github.com/users/byw2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/byw2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/byw2/subscriptions",
"organizations_url": "https://api.github.com/users/byw2/orgs",
"repos_url": "https://api.github.com/users/byw2/repos",
"events_url": "https://api.github.com/users/byw2/events{/privacy}",
"received_events_url": "https://api.github.com/users/byw2/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting @byw2.\r\nWe are fixing it.\r\nIn the meantime, you can load the dataset by passing `ignore_verifications=True`:\r\n ```python\r\ndataset = load_dataset(\"multi_news\", ignore_verifications=True)"
] | 2022-02-16T05:11:08 | 2022-02-16T20:05:06 | 2022-02-16T08:48:46 | NONE | null | null | null | ## Describe the bug
When using the load_dataset function from datasets module to load the Multi-News dataset, does not load the dataset but throws Checksum Error instead.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("multi_news")
```
## Expected results
Should download and load Multi-News dataset.
## Actual results
Throws the following error and cannot load data successfully:
```
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1vRY2wM6rlOZrf9exGTm5pXj5ExlVwJ0C']
```
Could this issue please be looked at? Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3730/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3729/comments | https://api.github.com/repos/huggingface/datasets/issues/3729/events | https://github.com/huggingface/datasets/issues/3729 | 1,139,398,442 | I_kwDODunzps5D6dcq | 3,729 | Wrong number of examples when loading a text dataset | {
"login": "kg-nlp",
"id": 58376804,
"node_id": "MDQ6VXNlcjU4Mzc2ODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/58376804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kg-nlp",
"html_url": "https://github.com/kg-nlp",
"followers_url": "https://api.github.com/users/kg-nlp/followers",
"following_url": "https://api.github.com/users/kg-nlp/following{/other_user}",
"gists_url": "https://api.github.com/users/kg-nlp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kg-nlp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kg-nlp/subscriptions",
"organizations_url": "https://api.github.com/users/kg-nlp/orgs",
"repos_url": "https://api.github.com/users/kg-nlp/repos",
"events_url": "https://api.github.com/users/kg-nlp/events{/privacy}",
"received_events_url": "https://api.github.com/users/kg-nlp/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @kg-nlp, thanks for reporting.\r\n\r\nThat is weird... I guess we would need some sample data file where this behavior appears to reproduce the bug for further investigation... ",
"ok, I found the reason why that two results are not same.\r\nthere is /u2029 in the text, the datasets will split sentence according to the /u2029,but when I use open function will not do that .\r\nso I want to know which function shell do that\r\nthanks"
] | 2022-02-16T01:13:31 | 2022-03-15T16:16:09 | 2022-03-15T16:16:09 | NONE | null | null | null | ## Describe the bug
when I use load_dataset to read a txt file I find that the number of the samples is incorrect
## Steps to reproduce the bug
```
fr = open('train.txt','r',encoding='utf-8').readlines()
print(len(fr)) # 1199637
datasets = load_dataset('text', data_files={'train': ['train.txt']}, streaming=False)
print(len(datasets['train'])) # 1199649
```
I also use command line operation to verify it
```
$ wc -l train.txt
1199637 train.txt
```
## Expected results
please fix that issue
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.3
- Platform:windows&linux
- Python version:3.7
- PyArrow version:6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3729/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3728/comments | https://api.github.com/repos/huggingface/datasets/issues/3728/events | https://github.com/huggingface/datasets/issues/3728 | 1,139,303,614 | I_kwDODunzps5D6GS- | 3,728 | VoxPopuli | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url": "https://api.github.com/users/VictorSanh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VictorSanh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VictorSanh/subscriptions",
"organizations_url": "https://api.github.com/users/VictorSanh/orgs",
"repos_url": "https://api.github.com/users/VictorSanh/repos",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"received_events_url": "https://api.github.com/users/VictorSanh/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"duplicate of https://github.com/huggingface/datasets/issues/2300"
] | 2022-02-15T23:04:55 | 2022-02-16T18:49:12 | 2022-02-16T18:49:12 | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** VoxPopuli
- **Description:** A Large-Scale Multilingual Speech Corpus
- **Paper:** https://arxiv.org/pdf/2101.00390.pdf
- **Data:** https://github.com/facebookresearch/voxpopuli
- **Motivation:** one of the largest (if not the largest) multilingual speech corpus: 400K hours of multilingual unlabeled speech + 17k hours of labeled speech
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
👀 @kahne @Molugan
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3728/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3727/comments | https://api.github.com/repos/huggingface/datasets/issues/3727/events | https://github.com/huggingface/datasets/pull/3727 | 1,138,979,732 | PR_kwDODunzps4y34JN | 3,727 | Patch all module attributes in its namespace | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-15T17:12:27 | 2022-02-17T17:06:18 | 2022-02-17T17:06:17 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3727",
"html_url": "https://github.com/huggingface/datasets/pull/3727",
"diff_url": "https://github.com/huggingface/datasets/pull/3727.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3727.patch",
"merged_at": "2022-02-17T17:06:17"
} | When patching module attributes, only those defined in its `__all__` variable were considered by default (only falling back to `__dict__` if `__all__` was None).
However those are only a subset of all the module attributes in its namespace (`__dict__` variable).
This PR fixes the problem of modules that have non-None `__all__` variable, but try to access an attribute present in `__dict__` (and not in `__all__`).
For example, `pandas` has attribute `__version__` only present in `__dict__`.
- Before version 1.4, pandas `__all__` was None, thus all attributes in `__dict__` were patched
- From version 1.4, pandas `__all__` is not None, thus attributes in `__dict__` not present in `__all__` are ignored
Fix #3724.
CC: @severo @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3727/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3727/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3726/comments | https://api.github.com/repos/huggingface/datasets/issues/3726/events | https://github.com/huggingface/datasets/pull/3726 | 1,138,870,362 | PR_kwDODunzps4y3iSv | 3,726 | Use config pandas version in CSV dataset builder | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-15T15:47:49 | 2022-02-15T16:55:45 | 2022-02-15T16:55:44 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3726",
"html_url": "https://github.com/huggingface/datasets/pull/3726",
"diff_url": "https://github.com/huggingface/datasets/pull/3726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3726.patch",
"merged_at": "2022-02-15T16:55:44"
} | Fix #3724. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3726/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3725/comments | https://api.github.com/repos/huggingface/datasets/issues/3725/events | https://github.com/huggingface/datasets/pull/3725 | 1,138,835,625 | PR_kwDODunzps4y3bOG | 3,725 | Pin pandas to avoid bug in streaming mode | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-15T15:21:00 | 2022-02-15T15:52:38 | 2022-02-15T15:52:37 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3725",
"html_url": "https://github.com/huggingface/datasets/pull/3725",
"diff_url": "https://github.com/huggingface/datasets/pull/3725.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3725.patch",
"merged_at": "2022-02-15T15:52:37"
} | Temporarily pin pandas version to avoid bug in streaming mode (patching no longer works).
Related to #3724. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3725/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3724/comments | https://api.github.com/repos/huggingface/datasets/issues/3724/events | https://github.com/huggingface/datasets/issues/3724 | 1,138,827,681 | I_kwDODunzps5D4SGh | 3,724 | Bug while streaming CSV dataset with pandas 1.4 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [] | 2022-02-15T15:16:19 | 2022-02-15T16:55:44 | 2022-02-15T16:55:44 | MEMBER | null | null | null | ## Describe the bug
If we upgrade to pandas `1.4`, the patching of the pandas module is no longer working
```
AttributeError: '_PatchedModuleObj' object has no attribute '__version__'
```
## Steps to reproduce the bug
```
pip install pandas==1.4
```
```python
from datasets import load_dataset
ds = load_dataset("lvwerra/red-wine", split="train", streaming=True)
item = next(iter(ds))
item
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3724/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3723/comments | https://api.github.com/repos/huggingface/datasets/issues/3723/events | https://github.com/huggingface/datasets/pull/3723 | 1,138,789,493 | PR_kwDODunzps4y3RuI | 3,723 | Fix flatten of complex feature types | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Apparently the merge brought back some tests that use `flatten_()` that we removed recently",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-02-15T14:45:33 | 2022-03-18T17:32:26 | 2022-03-18T17:28:14 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3723",
"html_url": "https://github.com/huggingface/datasets/pull/3723",
"diff_url": "https://github.com/huggingface/datasets/pull/3723.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3723.patch",
"merged_at": "2022-03-18T17:28:13"
} | Fix `flatten` for the following feature types: Image/Audio, Translation, and TranslationVariableLanguages.
Inspired by `cast`/`table_cast`, I've introduced a `table_flatten` function to handle the Image/Audio types.
CC: @SBrandeis
Fix #3686.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3723/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3723/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3722/comments | https://api.github.com/repos/huggingface/datasets/issues/3722/events | https://github.com/huggingface/datasets/pull/3722 | 1,138,770,211 | PR_kwDODunzps4y3NrP | 3,722 | added electricity load diagram dataset | {
"login": "kashif",
"id": 8100,
"node_id": "MDQ6VXNlcjgxMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8100?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kashif",
"html_url": "https://github.com/kashif",
"followers_url": "https://api.github.com/users/kashif/followers",
"following_url": "https://api.github.com/users/kashif/following{/other_user}",
"gists_url": "https://api.github.com/users/kashif/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kashif/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kashif/subscriptions",
"organizations_url": "https://api.github.com/users/kashif/orgs",
"repos_url": "https://api.github.com/users/kashif/repos",
"events_url": "https://api.github.com/users/kashif/events{/privacy}",
"received_events_url": "https://api.github.com/users/kashif/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-15T14:29:29 | 2022-02-16T18:53:21 | 2022-02-16T18:48:07 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3722",
"html_url": "https://github.com/huggingface/datasets/pull/3722",
"diff_url": "https://github.com/huggingface/datasets/pull/3722.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3722.patch",
"merged_at": "2022-02-16T18:48:07"
} | Initial Electricity Load Diagram time series dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3722/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3722/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3721/comments | https://api.github.com/repos/huggingface/datasets/issues/3721/events | https://github.com/huggingface/datasets/pull/3721 | 1,137,617,108 | PR_kwDODunzps4yzXCd | 3,721 | Multi-GPU support for `FaissIndex` | {
"login": "rentruewang",
"id": 32859905,
"node_id": "MDQ6VXNlcjMyODU5OTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/32859905?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rentruewang",
"html_url": "https://github.com/rentruewang",
"followers_url": "https://api.github.com/users/rentruewang/followers",
"following_url": "https://api.github.com/users/rentruewang/following{/other_user}",
"gists_url": "https://api.github.com/users/rentruewang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rentruewang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rentruewang/subscriptions",
"organizations_url": "https://api.github.com/users/rentruewang/orgs",
"repos_url": "https://api.github.com/users/rentruewang/repos",
"events_url": "https://api.github.com/users/rentruewang/events{/privacy}",
"received_events_url": "https://api.github.com/users/rentruewang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Any love?",
"Hi, any update?",
"@albertvillanova Sorry for bothering you again, quick follow up: is there anything else you want me to add / modify?",
"Hi @rentruewang , we updated the documentation on `master`, could you merge `master` into your branch please ?",
"@lhoestq I've merge `huggingface/datasets/master` into this PR. Please review. Thanks! 🤗\r\n\r\nEdit: Umm... I was experimenting with what renaming a branch would do to a pull request. Please ignore the `closed this PR` down below. 🤗"
] | 2022-02-14T17:26:51 | 2022-03-07T16:28:57 | 2022-03-07T16:28:56 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3721",
"html_url": "https://github.com/huggingface/datasets/pull/3721",
"diff_url": "https://github.com/huggingface/datasets/pull/3721.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3721.patch",
"merged_at": "2022-03-07T16:28:56"
} | Per #3716 , current implementation does not take into consideration that `faiss` can run on multiple GPUs.
In this commit, I provided multi-GPU support for `FaissIndex` by modifying the device management in `IndexableMixin.add_faiss_index` and `FaissIndex.load`.
Now users are able to pass in
1. a positive integer (as usual) to use 1 GPU
2. a negative integer `-1` to use all GPUs
3. a list of integers e.g. `[0, 1]` to run only on those GPUs
4. Of course, passing in nothing still runs on CPU.
This closes: #3716 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3721/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3720/comments | https://api.github.com/repos/huggingface/datasets/issues/3720/events | https://github.com/huggingface/datasets/issues/3720 | 1,137,537,080 | I_kwDODunzps5DzXA4 | 3,720 | Builder Configuration Update Required on Common Voice Dataset | {
"login": "aasem",
"id": 12482065,
"node_id": "MDQ6VXNlcjEyNDgyMDY1",
"avatar_url": "https://avatars.githubusercontent.com/u/12482065?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aasem",
"html_url": "https://github.com/aasem",
"followers_url": "https://api.github.com/users/aasem/followers",
"following_url": "https://api.github.com/users/aasem/following{/other_user}",
"gists_url": "https://api.github.com/users/aasem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aasem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aasem/subscriptions",
"organizations_url": "https://api.github.com/users/aasem/orgs",
"repos_url": "https://api.github.com/users/aasem/repos",
"events_url": "https://api.github.com/users/aasem/events{/privacy}",
"received_events_url": "https://api.github.com/users/aasem/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @aasem, thanks for reporting.\r\n\r\nPlease note that currently Commom Voice is hosted on our Hub as a community dataset by the Mozilla Foundation. See all Common Voice versions here: https://huggingface.co/mozilla-foundation\r\n\r\nMaybe we should add an explaining note in our \"legacy\" Common Voice canonical script? What do you think @lhoestq @mariosasko ?",
"Thank you, @albertvillanova, for the quick response. I am not sure about the exact flow but I guess adding the following lines under the `_Languages` dictionary definition in [common_voice.py](https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py) might resolve the issue. I guess the dataset is recently made available so the file needs updating.\r\n\r\n```\r\n\"ur\": {\r\n \"Language\": \"Urdu\",\r\n \"Date\": \"2022-01-19\",\r\n \"Size\": \"68 MB\",\r\n \"Version\": \"ur_3h_2022-01-19\",\r\n \"Validated_Hr_Total\": 1,\r\n \"Overall_Hr_Total\": 3,\r\n \"Number_Of_Voice\": 48,\r\n },\r\n```\r\n",
"@aasem for compliance reasons, we are no longer updating the `common_voice.py` script.\r\n\r\nWe agreed with Mozilla Foundation to use their community datasets instead, which will ask you to accept their terms of use:\r\n```\r\nYou need to share your contact information to access this dataset.\r\n\r\nThis repository is publicly accessible, but you have to register to access its content — don't worry, it's just one click!\r\n\r\nBy clicking on “Access repository” below, you accept that your contact information (email address and username) can be shared with the repository authors. This will let the authors get in touch for instance if some parts of the repository's contents need to be taken down for licensing reasons.\r\n\r\nBy clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the Common Voice dataset.\r\n\r\nYou will immediately be granted access to the contents of the dataset. \r\n```\r\n\r\nIn order to use e.g. their Common Voice dataset version 8.0, please:\r\n- First visit their dataset page: https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0\r\n- Accept their term of use by clicking \"Access repository\"\r\n- You can then load their dataset with:\r\n ```python\r\n load_dataset(\"mozilla-foundation/common_voice_8_0\", \"ur\", split=\"train+validation\")\r\n ```",
"@albertvillanova \r\n>Maybe we should add an explaining note in our \"legacy\" Common Voice canonical script?\r\n\r\nYes, I agree we should have a deprecation notice in the canonical script to redirect users to the new script.",
"@albertvillanova, \r\nI now get the following error after downloading my access token from the huggingface and passing it to `load_dataset` call:\r\n\r\n`AttributeError: 'DownloadManager' object has no attribute 'download_config'`\r\n\r\nAny quick pointer on how it might be resolved?",
"@aasem What version of `datasets` are you using? We renamed that attribute from `_download_config` to `download_conig` fairly recently, so updating to the newest version should resolve the issue:\r\n```\r\npip install -U datasets\r\n```",
"Thanks a lot, @mariosasko. That completely resolved the issue. "
] | 2022-02-14T16:21:41 | 2022-02-15T14:31:27 | null | NONE | null | null | null | Missing language in Common Voice dataset
**Link:** https://huggingface.co/datasets/common_voice
I tried to call the Urdu dataset using `load_dataset("common_voice", "ur", split="train+validation")` but couldn't due to builder configuration not found. I checked the source file here for the languages support:
https://github.com/huggingface/datasets/blob/master/datasets/common_voice/common_voice.py
and Urdu isn't included there. I assume a quick update will fix the issue as Urdu speech is now available at the Common Voice dataset.
Am I the one who added this dataset? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3720/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3720/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3719/comments | https://api.github.com/repos/huggingface/datasets/issues/3719/events | https://github.com/huggingface/datasets/pull/3719 | 1,137,237,622 | PR_kwDODunzps4yyFv7 | 3,719 | Check if indices values in `Dataset.select` are within bounds | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-14T12:31:41 | 2022-02-14T19:19:22 | 2022-02-14T19:19:22 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3719",
"html_url": "https://github.com/huggingface/datasets/pull/3719",
"diff_url": "https://github.com/huggingface/datasets/pull/3719.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3719.patch",
"merged_at": "2022-02-14T19:19:21"
} | Fix #3707
Instead of reusing `_check_valid_index_key` from `datasets.formatting`, I defined a new function to provide a more meaningful error message.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3719/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3719/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3718/comments | https://api.github.com/repos/huggingface/datasets/issues/3718/events | https://github.com/huggingface/datasets/pull/3718 | 1,137,196,388 | PR_kwDODunzps4yx8r2 | 3,718 | Fix Evidence Infer Treatment dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-14T11:58:07 | 2022-02-14T13:21:45 | 2022-02-14T13:21:44 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3718",
"html_url": "https://github.com/huggingface/datasets/pull/3718",
"diff_url": "https://github.com/huggingface/datasets/pull/3718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3718.patch",
"merged_at": "2022-02-14T13:21:43"
} | This PR:
- fixes a bug in the script, by removing an unnamed column with the row index: fix KeyError
- fix the metadata JSON, by adding both configurations (1.1 and 2.0): fix ExpectedMoreDownloadedFiles
- updates the dataset card
Fix #3515. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3718/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3717/comments | https://api.github.com/repos/huggingface/datasets/issues/3717/events | https://github.com/huggingface/datasets/issues/3717 | 1,137,183,015 | I_kwDODunzps5DyAkn | 3,717 | wrong condition in `Features ClassLabel encode_example` | {
"login": "Tudyx",
"id": 56633664,
"node_id": "MDQ6VXNlcjU2NjMzNjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/56633664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tudyx",
"html_url": "https://github.com/Tudyx",
"followers_url": "https://api.github.com/users/Tudyx/followers",
"following_url": "https://api.github.com/users/Tudyx/following{/other_user}",
"gists_url": "https://api.github.com/users/Tudyx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Tudyx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tudyx/subscriptions",
"organizations_url": "https://api.github.com/users/Tudyx/orgs",
"repos_url": "https://api.github.com/users/Tudyx/repos",
"events_url": "https://api.github.com/users/Tudyx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Tudyx/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @Tudyx, \r\n\r\nPlease note that in Python, the boolean NOT operator (`not`) has lower precedence than comparison operators (`<=`, `<`), thus the expression you mention is equivalent to:\r\n```python\r\n not (-1 <= example_data < self.num_classes)\r\n```\r\n\r\nAlso note that as expected, the exception is raised if:\r\n- `example_data < -1`\r\n- or `example_data >= self.num_classes`\r\n\r\nThe raise of the exception is expected when `example_data` equals 4 and `self.num_classes` equals 4 too."
] | 2022-02-14T11:44:35 | 2022-02-14T15:09:36 | 2022-02-14T15:07:43 | NONE | null | null | null | ## Describe the bug
The `encode_example` function in *features.py* seems to have a wrong condition.
```python
if not -1 <= example_data < self.num_classes:
raise ValueError(f"Class label {example_data:d} greater than configured num_classes {self.num_classes}")
```
## Expected results
The `not - 1` condition change the result of the condition. For instance, if `example_data` equals 4 and ` self.num_classes` equals 4 too, `example_data < self.num_classes` will give `False` as expected . But if i add the `not - 1` condition, `not -1 <= example_data < self.num_classes` will give `True` and raise an exception.
## Environment info
- `datasets` version: 1.18.3
- Python version: 3.8.10
- PyArrow version: 7.00
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3717/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3717/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3716/comments | https://api.github.com/repos/huggingface/datasets/issues/3716/events | https://github.com/huggingface/datasets/issues/3716 | 1,136,831,092 | I_kwDODunzps5Dwqp0 | 3,716 | `FaissIndex` to support multiple GPU and `custom_index` | {
"login": "rentruewang",
"id": 32859905,
"node_id": "MDQ6VXNlcjMyODU5OTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/32859905?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rentruewang",
"html_url": "https://github.com/rentruewang",
"followers_url": "https://api.github.com/users/rentruewang/followers",
"following_url": "https://api.github.com/users/rentruewang/following{/other_user}",
"gists_url": "https://api.github.com/users/rentruewang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rentruewang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rentruewang/subscriptions",
"organizations_url": "https://api.github.com/users/rentruewang/orgs",
"repos_url": "https://api.github.com/users/rentruewang/repos",
"events_url": "https://api.github.com/users/rentruewang/events{/privacy}",
"received_events_url": "https://api.github.com/users/rentruewang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi @rentruewang, thansk for reporting and for your PR!!! We should definitely support this. ",
"@albertvillanova Great! :)"
] | 2022-02-14T06:21:43 | 2022-03-07T16:28:56 | 2022-03-07T16:28:56 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, because `device` is of the type `int | None`, to leverage `faiss-gpu`'s multi-gpu support, you need to create a `custom_index`. However, if using a `custom_index` created by e.g. `faiss.index_cpu_to_all_gpus`, then `FaissIndex.save` does not work properly because it checks the device id (which is an int, so no multiple GPUs).
**Describe the solution you'd like**
I would like `FaissIndex` to support multiple GPUs, by passing in a list to `add_faiss_index`.
**Describe alternatives you've considered**
Alternatively, I would like it to at least provide a warning cause it wasn't the behavior that I expected.
**Additional context**
Relavent source code here:
https://github.com/huggingface/datasets/blob/6ed6ac9448311930557810383d2cfd4fe6aae269/src/datasets/search.py#L340-L349
Device management needs changing to support multiple GPUs, probably by `isinstance` calls.
I can provide a PR if you like :)
Thanks for reading!
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3716/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3716/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3715/comments | https://api.github.com/repos/huggingface/datasets/issues/3715/events | https://github.com/huggingface/datasets/pull/3715 | 1,136,107,879 | PR_kwDODunzps4yuKJj | 3,715 | Fix bugs in msr_sqa dataset | {
"login": "Timothyxxx",
"id": 47296835,
"node_id": "MDQ6VXNlcjQ3Mjk2ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/47296835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timothyxxx",
"html_url": "https://github.com/Timothyxxx",
"followers_url": "https://api.github.com/users/Timothyxxx/followers",
"following_url": "https://api.github.com/users/Timothyxxx/following{/other_user}",
"gists_url": "https://api.github.com/users/Timothyxxx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timothyxxx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timothyxxx/subscriptions",
"organizations_url": "https://api.github.com/users/Timothyxxx/orgs",
"repos_url": "https://api.github.com/users/Timothyxxx/repos",
"events_url": "https://api.github.com/users/Timothyxxx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timothyxxx/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"It shows below when I run test:\r\n\r\nFAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_msr_sqa - ValueError: Unknown split \"validation\". Should be one of ['train', 'test'].\r\n\r\nIt make no sense for me😂. \r\n",
"@albertvillanova Does this PR has some additional fixes compared to https://github.com/huggingface/datasets/pull/3771 or we can close it?",
"@mariosasko besides the fix of the DuplicatedKeysError, this PR:\r\n- changes the reading of one of the files: use pandas instead of splitting by comma\r\n- changes the splits: modifying train and adding validation\r\n- adds some extra logic in the processing of the data: adding a new field \"question_and_history\"\r\n\r\nWe should decide whether validating these additional changes.\r\n- for example, if we accept as pertinent the addition of the field \"question_and_history\", this should be added as feature to the info, and the matadata should be regenerated...",
"Hi guys, anything we can do to fix that bug👀? @mariosasko @albertvillanova @lhoestq ",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-02-13T16:37:30 | 2022-10-03T09:10:02 | 2022-10-03T09:08:06 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3715",
"html_url": "https://github.com/huggingface/datasets/pull/3715",
"diff_url": "https://github.com/huggingface/datasets/pull/3715.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3715.patch",
"merged_at": "2022-10-03T09:08:06"
} | The last version has many problems,
1) Errors in table load-in. Split by a single comma instead of using pandas is wrong.
2) id reduplicated in _generate_examples function.
3) Missing information of history questions which make it hard to use.
I fix it refer to https://github.com/HKUNLP/UnifiedSKG. And we test it to perform normally. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3715/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3714/comments | https://api.github.com/repos/huggingface/datasets/issues/3714/events | https://github.com/huggingface/datasets/issues/3714 | 1,136,105,530 | I_kwDODunzps5Dt5g6 | 3,714 | tatoeba_mt: File not found error and key error | {
"login": "jorgtied",
"id": 614718,
"node_id": "MDQ6VXNlcjYxNDcxOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/614718?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jorgtied",
"html_url": "https://github.com/jorgtied",
"followers_url": "https://api.github.com/users/jorgtied/followers",
"following_url": "https://api.github.com/users/jorgtied/following{/other_user}",
"gists_url": "https://api.github.com/users/jorgtied/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jorgtied/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jorgtied/subscriptions",
"organizations_url": "https://api.github.com/users/jorgtied/orgs",
"repos_url": "https://api.github.com/users/jorgtied/repos",
"events_url": "https://api.github.com/users/jorgtied/events{/privacy}",
"received_events_url": "https://api.github.com/users/jorgtied/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Looks like I solved my problems ..."
] | 2022-02-13T16:35:45 | 2022-02-13T20:44:04 | 2022-02-13T20:44:04 | NONE | null | null | null | ## Dataset viewer issue for 'tatoeba_mt'
**Link:** https://huggingface.co/datasets/Helsinki-NLP/tatoeba_mt
My data loader script does not seem to work.
The files are part of the local repository but cannot be found. An example where it should work is the subset for "afr-eng".
Another problem is that I do not have validation data for all subsets and I don't know how to properly check whether validation exists in the configuration before I try to download it. An example is the subset for "afr-deu".
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3714/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3714/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3713/comments | https://api.github.com/repos/huggingface/datasets/issues/3713/events | https://github.com/huggingface/datasets/pull/3713 | 1,135,692,572 | PR_kwDODunzps4yso6D | 3,713 | Rm sphinx doc | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for pushing this :)\r\nOne minor comment regarding the PR itself - I noticed that some changes are coming from the upstream master, this might be due to a rebase. Would be nice if this PR doesn't include them for readabily, feel free to open a new one if necessary",
"Closing in favour https://github.com/huggingface/datasets/pull/3741"
] | 2022-02-13T11:26:31 | 2022-02-17T10:18:46 | 2022-02-17T10:12:09 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3713",
"html_url": "https://github.com/huggingface/datasets/pull/3713",
"diff_url": "https://github.com/huggingface/datasets/pull/3713.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3713.patch",
"merged_at": null
} | Checklist
- [x] Update circle ci yaml
- [x] Delete sphinx static & python files in docs dir
- [x] Update readme in docs dir
- [ ] Update docs config in setup.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3713/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3712/comments | https://api.github.com/repos/huggingface/datasets/issues/3712/events | https://github.com/huggingface/datasets/pull/3712 | 1,134,252,505 | PR_kwDODunzps4ynVYy | 3,712 | Fix the error of msr_sqa dataset | {
"login": "Timothyxxx",
"id": 47296835,
"node_id": "MDQ6VXNlcjQ3Mjk2ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/47296835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timothyxxx",
"html_url": "https://github.com/Timothyxxx",
"followers_url": "https://api.github.com/users/Timothyxxx/followers",
"following_url": "https://api.github.com/users/Timothyxxx/following{/other_user}",
"gists_url": "https://api.github.com/users/Timothyxxx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timothyxxx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timothyxxx/subscriptions",
"organizations_url": "https://api.github.com/users/Timothyxxx/orgs",
"repos_url": "https://api.github.com/users/Timothyxxx/repos",
"events_url": "https://api.github.com/users/Timothyxxx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timothyxxx/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-12T16:27:54 | 2022-02-13T11:21:05 | 2022-02-13T11:21:05 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3712",
"html_url": "https://github.com/huggingface/datasets/pull/3712",
"diff_url": "https://github.com/huggingface/datasets/pull/3712.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3712.patch",
"merged_at": null
} | Fix the error of _load_table_data function in msr_sqa dataset, it is wrong to use comma to split each row. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3712/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3711/comments | https://api.github.com/repos/huggingface/datasets/issues/3711/events | https://github.com/huggingface/datasets/pull/3711 | 1,134,050,545 | PR_kwDODunzps4ymmlK | 3,711 | Fix the error of _load_table_data function in msr_sqa dataset | {
"login": "Timothyxxx",
"id": 47296835,
"node_id": "MDQ6VXNlcjQ3Mjk2ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/47296835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Timothyxxx",
"html_url": "https://github.com/Timothyxxx",
"followers_url": "https://api.github.com/users/Timothyxxx/followers",
"following_url": "https://api.github.com/users/Timothyxxx/following{/other_user}",
"gists_url": "https://api.github.com/users/Timothyxxx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Timothyxxx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Timothyxxx/subscriptions",
"organizations_url": "https://api.github.com/users/Timothyxxx/orgs",
"repos_url": "https://api.github.com/users/Timothyxxx/repos",
"events_url": "https://api.github.com/users/Timothyxxx/events{/privacy}",
"received_events_url": "https://api.github.com/users/Timothyxxx/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-12T13:20:53 | 2022-02-12T13:30:43 | 2022-02-12T13:30:43 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3711",
"html_url": "https://github.com/huggingface/datasets/pull/3711",
"diff_url": "https://github.com/huggingface/datasets/pull/3711.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3711.patch",
"merged_at": null
} | The _load_table_data function from the last version is wrong, it is wrong to use comma to split each row. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3711/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3710/comments | https://api.github.com/repos/huggingface/datasets/issues/3710/events | https://github.com/huggingface/datasets/pull/3710 | 1,133,955,393 | PR_kwDODunzps4ymQMQ | 3,710 | Fix CI code quality issue | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-12T12:05:39 | 2022-02-12T12:58:05 | 2022-02-12T12:58:04 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3710",
"html_url": "https://github.com/huggingface/datasets/pull/3710",
"diff_url": "https://github.com/huggingface/datasets/pull/3710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3710.patch",
"merged_at": "2022-02-12T12:58:04"
} | Fix CI code quality issue introduced by #3695. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3710/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3710/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3709/comments | https://api.github.com/repos/huggingface/datasets/issues/3709/events | https://github.com/huggingface/datasets/pull/3709 | 1,132,997,904 | PR_kwDODunzps4yi0J4 | 3,709 | Set base path to hub url for canonical datasets | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"If we agree to have data files in a dedicated directory \"data/\" then we should be fine. You're right we should not try to edit a dataset script from the repository directly, but from github, in order to avoid conflicts"
] | 2022-02-11T19:23:20 | 2022-02-16T14:02:28 | 2022-02-16T14:02:27 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3709",
"html_url": "https://github.com/huggingface/datasets/pull/3709",
"diff_url": "https://github.com/huggingface/datasets/pull/3709.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3709.patch",
"merged_at": "2022-02-16T14:02:27"
} | This should allow canonical datasets to use relative paths to download data files from the Hub
cc @polinaeterna this will be useful if we have audio datasets that are canonical and for which you'd like to host data files | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3709/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3709/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3708/comments | https://api.github.com/repos/huggingface/datasets/issues/3708/events | https://github.com/huggingface/datasets/issues/3708 | 1,132,968,402 | I_kwDODunzps5Dh7nS | 3,708 | Loading JSON gets stuck with many workers/threads | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! Note that it does `block_size *= 2` until `block_size > len(batch)`, so it doesn't loop indefinitely. What do you mean by \"get stuck indefinitely\" then ? Is this the actual call to `paj.read_json` that hangs ?\r\n\r\n> increasing the `chunksize` argument decreases the chance of getting stuck\r\n\r\nCould you share the values of chunksize that you're using to observe this ? And maybe the order of magnitude of number of bytes per line of JSON ?",
"To clarify, I don't think it loops indefinitely but the `paj.read_json` gets stuck after the first try. That's why I think it could be an issue with a lock somewhere. \r\n\r\nUsing `load_dataset(..., chunksize=40<<20)` worked without errors.",
"@lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.\r\n```\r\ntrain_dataset = datasets.load_dataset(\"json\", \r\n data_files=corpus_jsonl_path,\r\n keep_in_memory=False,\r\n cache_dir=model_args.cache_dir,\r\n streaming=False)\r\ntrain_dataset.set_transform(psg_parse_fn)\r\n```\r\n",
"I couldn't I think your problem is unrelated to this issue @memray\r\nIndeed this issue discusses a bug when doing `load_dataset`, while your case has to do with the dataloader in a multiprocessing setup. Can you open a new issue and provide more details (share your env and what psg_parse_fn does) ?",
"I also encountered a similar issue when loading a 190GB dataset of jsonl files (255 files with less than 1Gb) where it got stuck for over 20h at tables generation (fig below), increasing the `chunksize` with `load_dataset(..., chunksize=40<<20)` fixed the issue\r\n\r\n<img width=\"560\" alt=\"image\" src=\"https://user-images.githubusercontent.com/44069155/195605603-548a106e-7ad3-4269-8cdd-2ad3e975bf16.png\">\r\n",
"> @lhoestq I encountered another related issue. I use load_dataset() for my json data and set_transform() for preprocessing. But it hangs at the end of the epoch if `dataloader_num_workers>=1`. It appears to be working fine with num_worker=0, but it's slow.\r\n> \r\n> ```\r\n> train_dataset = datasets.load_dataset(\"json\", \r\n> data_files=corpus_jsonl_path,\r\n> keep_in_memory=False,\r\n> cache_dir=model_args.cache_dir,\r\n> streaming=False)\r\n> train_dataset.set_transform(psg_parse_fn)\r\n> ```\r\n\r\nIn case people also get this problem, I found a way to fix it by adding `persistent_workers=True` when initializing DataLoader, like:\r\n`train_loader = DataLoader(\r\n train_dataset,\r\n batch_size=self._train_batch_size,\r\n sampler=train_sampler,\r\n collate_fn=data_collator,\r\n num_workers=self.args.dataloader_num_workers,\r\n persistent_workers=True\r\n )`\r\n\r\nThe error was `CUDA error: initialization error Exception raised from insert_events at ../c10/cuda/CUDACachingAllocator.cpp:1266` after the 1st epoch, I guess it's because the data_loader worker is killed after each epoch and the data supply is cut off. This error only occurs when num_workers>1.\r\n\r\n\r\n"
] | 2022-02-11T18:50:48 | 2023-01-17T19:03:54 | null | MEMBER | null | null | null | ## Describe the bug
Loading a JSON dataset with `load_dataset` can get stuck when running on a machine with many CPUs. This is especially an issue when loading a large dataset on a large machine.
## Steps to reproduce the bug
I originally created the following script to reproduce the issue:
```python
from datasets import load_dataset
from multiprocessing import Process
from tqdm import tqdm
import datasets
from transformers import set_seed
def run_tasks_in_parallel(tasks, ds_list):
for _ in tqdm(range(1000)):
print('new batch')
running_tasks = [Process(target=task, args=(ds, i)) for i, (task, ds) in enumerate(zip(tasks, ds_list))]
for running_task in running_tasks:
running_task.start()
for running_task in running_tasks:
running_task.join()
def get_dataset():
dataset_name = 'transformersbook/codeparrot'
ds = load_dataset(dataset_name+'-train', split="train", streaming=True)
ds = ds.shuffle(buffer_size=1000, seed=1)
return iter(ds)
def get_next_element(ds, process_id, N=10000):
for _ in range(N):
_ = next(ds)['content']
print(f'process {process_id} done')
return
set_seed(1)
datasets.utils.logging.set_verbosity_debug()
n_processes = 8
tasks = [get_next_element for _ in range(n_processes)]
args = [get_dataset() for _ in range(n_processes)]
run_tasks_in_parallel(tasks, args)
```
Today I noticed that it can happen when running it on a single process on a machine with many cores without streaming. So just `load_dataset("transformersbook/codeparrot-train")` alone might cause the issue after waiting long enough or trying many times. It's a slightly random process which makes it especially hard to track down. When I encountered it today it had already processed 17GB of data (the size of the cache folder when it got stuck) before getting stuck.
Here's my current understanding of the error. As far as I can tell it happens in the following block: https://github.com/huggingface/datasets/blob/be701e9e89ab38022612c7263edc015bc7feaff9/src/datasets/packaged_modules/json/json.py#L119-L139
When the try on line 121 fails and the `block_size` is increased it can happen that it can't read the JSON again and gets stuck indefinitely. A hint that points in that direction is that increasing the `chunksize` argument decreases the chance of getting stuck and vice versa. Maybe it is an issue with a lock on the file that is not properly released.
## Expected results
Read a JSON before the end of the universe.
## Actual results
Read a JSON not before the end of the universe.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-4.19.0-18-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.10
- PyArrow version: 7.0.0
@lhoestq we dicsussed this a while ago. @albertvillanova we discussed this today :)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3708/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3708/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3707/comments | https://api.github.com/repos/huggingface/datasets/issues/3707/events | https://github.com/huggingface/datasets/issues/3707 | 1,132,741,903 | I_kwDODunzps5DhEUP | 3,707 | `.select`: unexpected behavior with `indices` | {
"login": "gabegma",
"id": 36087158,
"node_id": "MDQ6VXNlcjM2MDg3MTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gabegma",
"html_url": "https://github.com/gabegma",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https://api.github.com/users/gabegma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gabegma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabegma/subscriptions",
"organizations_url": "https://api.github.com/users/gabegma/orgs",
"repos_url": "https://api.github.com/users/gabegma/repos",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"received_events_url": "https://api.github.com/users/gabegma/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).\r\n\r\n@albertvillanova @lhoestq wdyt?",
"I agree. I think `index % len(dset)` was used to support negative indices.\r\n\r\nI think this needs to be fixed in `datasets.formatting.formatting._check_valid_index_key` if I'm not mistaken"
] | 2022-02-11T15:20:01 | 2022-02-14T19:19:21 | 2022-02-14T19:19:21 | NONE | null | null | null | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": ["d", "e", "f"], "label": [4, 5, 6]})
res1 = ds.select([1, 2, 3])['text']
res2 = ds.select([1000])['text']
```
## Expected results
Both results should throw an `Error`.
## Actual results
`res1` will give `['e', 'f', 'd']`
`res2` will give `['e']`
## Environment info
Bug found from this environment:
- `datasets` version: 1.16.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.7
- PyArrow version: 6.0.1
It was also replicated on `master`.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3707/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3706/comments | https://api.github.com/repos/huggingface/datasets/issues/3706/events | https://github.com/huggingface/datasets/issues/3706 | 1,132,218,874 | I_kwDODunzps5DfEn6 | 3,706 | Unable to load dataset 'big_patent' | {
"login": "ankitk2109",
"id": 26432753,
"node_id": "MDQ6VXNlcjI2NDMyNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/26432753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ankitk2109",
"html_url": "https://github.com/ankitk2109",
"followers_url": "https://api.github.com/users/ankitk2109/followers",
"following_url": "https://api.github.com/users/ankitk2109/following{/other_user}",
"gists_url": "https://api.github.com/users/ankitk2109/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ankitk2109/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ankitk2109/subscriptions",
"organizations_url": "https://api.github.com/users/ankitk2109/orgs",
"repos_url": "https://api.github.com/users/ankitk2109/repos",
"events_url": "https://api.github.com/users/ankitk2109/events{/privacy}",
"received_events_url": "https://api.github.com/users/ankitk2109/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @ankitk2109,\r\n\r\nHave you tried passing the split name with the keyword `split=`? See e.g. an example in our Quick Start docs: https://huggingface.co/docs/datasets/quickstart.html#load-the-dataset-and-model\r\n```python\r\n ds = load_dataset(\"big_patent\", \"d\", split=\"validation\")",
"Hi @albertvillanova,\r\n\r\nThanks for your response.\r\n\r\nYes, I tried the `split='validation'` as well. But getting the same issue. ",
"I'm sorry, but I can't reproduce your problem:\r\n```python\r\nIn [5]: ds = load_dataset(\"big_patent\", \"d\", split=\"validation\")\r\nDownloading and preparing dataset big_patent/d (download: 6.01 GiB, generated: 169.61 MiB, post-processed: Unknown size, total: 6.17 GiB) to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c...\r\nDownloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6.45G/6.45G [27:36<00:00, 3.89MB/s]\r\nExtracting data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [03:18<00:00, 66.08s/it]\r\nDataset big_patent downloaded and prepared to .../.cache/big_patent/d/1.0.0/bdefa7c0b39fba8bba1c6331b70b738e30d63c8ad4567f983ce315a5fef6131c. Subsequent calls will reuse this data. \r\n\r\nIn [6]: ds\r\nOut[6]: \r\nDataset({\r\n features: ['description', 'abstract'],\r\n num_rows: 565\r\n})\r\n",
"Maybe you had a connection issue while downloading the file and this was corrupted?\r\nOur cache system uses the file you downloaded first time.\r\nIf so, you could try forcing redownload of the file with:\r\n```python\r\nds = load_dataset(\"big_patent\", \"d\", split=\"validation\", download_mode=\"force_redownload\")",
"I am able to download the dataset with ``` download_mode=\"force_redownload\"```. As you mentioned it was an issue with the cached version which was failed earlier due to a network issue. I am closing the issue now, once again thank you."
] | 2022-02-11T09:48:34 | 2022-02-14T15:26:03 | 2022-02-14T15:26:03 | NONE | null | null | null | ## Describe the bug
Unable to load the "big_patent" dataset
## Steps to reproduce the bug
```python
load_dataset('big_patent', 'd', 'validation')
```
## Expected results
Download big_patents' validation split from the 'd' subset
## Getting an error saying:
{FileNotFoundError}Local file ..\huggingface\datasets\downloads\6159313604f4f2c01e7d1cac52139343b6c07f73f6de348d09be6213478455c5\bigPatentData\train.tar.gz doesn't exist
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.18.3
- Platform: Windows
- Python version:3.8
- PyArrow version:7.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3706/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3706/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3705/comments | https://api.github.com/repos/huggingface/datasets/issues/3705/events | https://github.com/huggingface/datasets/pull/3705 | 1,132,053,226 | PR_kwDODunzps4yfhyj | 3,705 | Raise informative error when loading a save_to_disk dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-11T08:21:03 | 2022-02-11T22:56:40 | 2022-02-11T22:56:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3705",
"html_url": "https://github.com/huggingface/datasets/pull/3705",
"diff_url": "https://github.com/huggingface/datasets/pull/3705.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3705.patch",
"merged_at": "2022-02-11T22:56:39"
} | People recurrently report error when trying to load a dataset (using `load_dataset`) that was previously saved using `save_to_disk`.
This PR raises an informative error message telling them they should use `load_from_disk` instead.
Close #3700. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3705/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3704/comments | https://api.github.com/repos/huggingface/datasets/issues/3704/events | https://github.com/huggingface/datasets/issues/3704 | 1,132,042,631 | I_kwDODunzps5DeZmH | 3,704 | OSCAR-2109 datasets are misaligned and truncated | {
"login": "adrianeboyd",
"id": 5794899,
"node_id": "MDQ6VXNlcjU3OTQ4OTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5794899?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adrianeboyd",
"html_url": "https://github.com/adrianeboyd",
"followers_url": "https://api.github.com/users/adrianeboyd/followers",
"following_url": "https://api.github.com/users/adrianeboyd/following{/other_user}",
"gists_url": "https://api.github.com/users/adrianeboyd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/adrianeboyd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adrianeboyd/subscriptions",
"organizations_url": "https://api.github.com/users/adrianeboyd/orgs",
"repos_url": "https://api.github.com/users/adrianeboyd/repos",
"events_url": "https://api.github.com/users/adrianeboyd/events{/privacy}",
"received_events_url": "https://api.github.com/users/adrianeboyd/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @adrianeboyd, thanks for reporting.\r\n\r\nThere is indeed a bug in that community dataset:\r\nLine:\r\n```python\r\nmetadata_and_text_files = list(zip(metadata_files, text_files))\r\n``` \r\nshould be replaced with\r\n```python\r\nmetadata_and_text_files = list(zip(sorted(metadata_files), sorted(text_files)))\r\n```\r\n\r\nI am going to contact their owners (https://huggingface.co/oscar-corpus) in order to inform them about the bug.\r\n\r\nI keep you informed.",
"That fix is part of it, but it's clearly not the only issue.\r\n\r\nI also already contacted the OSCAR creators, but I reported it here because it looked like huggingface members were the main authors in the git history. Is there a better place to have reported this?",
"Hello,\r\n\r\nWe've had an issue that could be linked to this one here: https://github.com/oscar-corpus/corpus/issues/15.\r\n\r\nI have been spot checking the source (`.txt`/`.jsonl`) files for a while, and have not found issues, especially in the start/end of corpora (but I conceed that more integration testing would be necessary on our side).\r\n\r\nThe text and metadata files are designed to be used in sync (with `lang_part_n.txt` and `lang_meta_part_n.jsonl` working together), while staying independent from part to part, so that anyone could randomly choose a part and work with it.\r\n\r\nThe fix @albertvillanova proposed should fix the problem, as the parts will be in sync again.\r\n\r\nLet me know if you need help or more details, I'd be glad to help!",
"I'm happy to move the discussion to the other repo!\r\n\r\nMerely sorting the files only **maybe** fixes the processing of the first part. If the first part contains non-unix newlines, it will still be misaligned/truncated, and all the following parts will be truncated with incorrect text offsets and metadata due the offset and newline bugs.",
"Fixed:\r\n- https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/3cd7e95aa1799b73c5ea8afc3989635f3e19b86b",
"Hi @Uinelj, This is a total noobs question but how can I integrate that bugfix into my code? I reinstalled the datasets library this time from source. Should that have fixed the issue? I am still facing the misalignment issue. Do I need to download the dataset from scratch?",
"Hi, I re-downloaded the dataset and still have the problem. See: https://github.com/oscar-corpus/corpus/issues/18",
"Sorry @norakassner for the late reply.\r\n\r\nThere are indeed several issues creating the misalignment, as @adrianeboyd cleverly pointed out:\r\n- https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/3cd7e95aa1799b73c5ea8afc3989635f3e19b86b fixed one of them\r\n- but there are still others to be fixed",
"Normally, the issues should be fixed now:\r\n- Fix offset initialization for each file: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/1ad9b7bfe00798a9258a923b887bb1c8d732b833\r\n- Disable default universal newline support: https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/commit/0c2f307d3167f03632f502af361ac6c3c393f510\r\n\r\nFeel free to reopen if you find additional misalignments/truncations.\r\n\r\nCC: @adrianeboyd @norakassner @Uinelj ",
"Thanks for the updates!\r\n\r\nThe purist in me would still like to have the rstrip not strip additional characters from the original text (unicode whitespace mainly in practice, I think), but the differences are extremely small in practice and it doesn't actually matter for my current task:\r\n\r\n```python\r\ntext = \"\".join([text_f.readline() for _ in range(meta[\"nb_sentences\"])]).rstrip(\"\\n\")\r\n```"
] | 2022-02-11T08:14:59 | 2022-03-17T18:01:04 | 2022-03-16T16:21:28 | NONE | null | null | null | ## Describe the bug
The `oscar-corpus/OSCAR-2109` data appears to be misaligned and truncated by the dataset builder for subsets that contain more than one part and for cases where the texts contain non-unix newlines.
## Steps to reproduce the bug
A few examples, although I'm not sure how deterministic the particular (mis)alignment is in various configurations:
```python
from datasets import load_dataset
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_fi", split="train", use_auth_token=True)
entry = dataset[0]
# entry["text"] is from fi_part_3.txt.gz
# entry["meta"] is from fi_meta_part_2.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_no", split="train", use_auth_token=True)
entry = dataset[900000]
# entry["text"] is from no_part_3.txt.gz and contains a blank line
# entry["meta"] is from no_meta_part_1.jsonl.gz
dataset = load_dataset("oscar-corpus/OSCAR-2109", "deduplicated_mk", split="train", streaming=True, use_auth_token=True)
# 9088 texts in the dataset are empty
```
For `deduplicated_fi`, all exported raw texts from the dataset are 17GB rather than 20GB as reported in the data splits overview table. The token count with `wc -w` for the raw texts is 2,067,556,874 rather than the expected 2,357,264,196 from the data splits table.
For `deduplicated_no` all exported raw texts contain 624,040,887 rather than the expected 776,354,517 tokens.
For `deduplicated_mk` it is 122,236,936 rather than 134,544,934 tokens.
I'm not expecting the `wc -w` counts to line up exactly with the data splits table, but for comparison the `wc -w` count for `deduplicated_mk` on the raw texts is 134,545,424.
## Issues
* The meta / text files are not paired correctly when loading, so the extracted texts do not have the right offsets, the metadata is not associated with the correct text, and the text files may not be processed to the end or may be processed beyond the end (empty texts).
* The line count offset is not reset per file so the texts aren't aligned to the right offsets in any parts beyond the first part, leading to truncation when in effect blank lines are not skipped.
* Non-unix newline characters are treated as newlines when reading the text files while the metadata only counts unix newlines for its line offsets, leading to further misalignments between the metadata and the extracted texts, and which also results in truncation.
## Expected results
All texts from the OSCAR release are extracted according to the metadata and aligned with the correct metadata.
## Fixes
Not necessarily the exact fixes/checks you may want to use (I didn't test all languages or do any cross-platform testing, I'm not sure all the details are compatible with streaming), however to highlight the issues:
```diff
diff --git a/OSCAR-2109.py b/OSCAR-2109.py
index bbac1076..5eee8de7 100644
--- a/OSCAR-2109.py
+++ b/OSCAR-2109.py
@@ -20,6 +20,7 @@
import collections
import gzip
import json
+import os
import datasets
@@ -387,9 +388,20 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
with open(checksum_file, encoding="utf-8") as f:
data_filenames = [line.split()[1] for line in f if line]
data_urls = [self.config.base_data_path + data_filename for data_filename in data_filenames]
- text_files = dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")])
- metadata_files = dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")])
+ # sort filenames so corresponding parts are aligned
+ text_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".txt.gz")]))
+ metadata_files = sorted(dl_manager.download([url for url in data_urls if url.endswith(".jsonl.gz")]))
+ assert len(text_files) == len(metadata_files)
metadata_and_text_files = list(zip(metadata_files, text_files))
+ for meta_path, text_path in metadata_and_text_files:
+ # check that meta/text part numbers are the same
+ if "part" in os.path.basename(text_path):
+ assert (
+ os.path.basename(text_path).replace(".txt.gz", "").split("_")[-1]
+ == os.path.basename(meta_path).replace(".jsonl.gz", "").split("_")[-1]
+ )
+ else:
+ assert len(metadata_and_text_files) == 1
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"metadata_and_text_files": metadata_and_text_files}),
]
@@ -397,10 +409,14 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
def _generate_examples(self, metadata_and_text_files):
"""This function returns the examples in the raw (text) form by iterating on all the files."""
id_ = 0
- offset = 0
for meta_path, text_path in metadata_and_text_files:
+ # line offsets are per text file
+ offset = 0
logger.info("generating examples from = %s", text_path)
- with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8") as text_f:
+ # some texts contain non-Unix newlines that should not be
+ # interpreted as line breaks for the line counts in the metadata
+ # with readline()
+ with gzip.open(open(text_path, "rb"), "rt", encoding="utf-8", newline="\n") as text_f:
with gzip.open(open(meta_path, "rb"), "rt", encoding="utf-8") as meta_f:
for line in meta_f:
# read meta
@@ -411,7 +427,12 @@ class Oscar2109(datasets.GeneratorBasedBuilder):
offset += 1
text_f.readline()
# read text
- text = "".join([text_f.readline() for _ in range(meta["nb_sentences"])]).rstrip()
+ text_lines = [text_f.readline() for _ in range(meta["nb_sentences"])]
+ # all lines contain text (no blank lines or EOF)
+ assert all(text_lines)
+ assert "\n" not in text_lines
offset += meta["nb_sentences"]
+ # only strip the trailing newline
+ text = "".join(text_lines).rstrip("\n")
yield id_, {"id": id_, "text": text, "meta": meta}
id_ += 1
```
I've tested this with a number of smaller deduplicated languages with 1-20 parts and the resulting datasets looked correct in terms of word count and size when compared to the data splits table and raw texts, and the text/metadata alignments were correct in all my spot checks. However, there are many many languages I didn't test and I'm not sure that there aren't any texts containing blank lines in the corpus, for instance. For the cases I tested, the assertions related to blank lines and EOF made it easier to verify that the text and metadata were aligned as intended, since there would be little chance of spurious alignments of variable-length texts across so much data. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3704/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3703/comments | https://api.github.com/repos/huggingface/datasets/issues/3703/events | https://github.com/huggingface/datasets/issues/3703 | 1,131,882,772 | I_kwDODunzps5DdykU | 3,703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | {
"login": "zhangyifei1",
"id": 28425091,
"node_id": "MDQ6VXNlcjI4NDI1MDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/28425091?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhangyifei1",
"html_url": "https://github.com/zhangyifei1",
"followers_url": "https://api.github.com/users/zhangyifei1/followers",
"following_url": "https://api.github.com/users/zhangyifei1/following{/other_user}",
"gists_url": "https://api.github.com/users/zhangyifei1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhangyifei1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhangyifei1/subscriptions",
"organizations_url": "https://api.github.com/users/zhangyifei1/orgs",
"repos_url": "https://api.github.com/users/zhangyifei1/repos",
"events_url": "https://api.github.com/users/zhangyifei1/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhangyifei1/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"\r\nMy datasets version",
"\r\n",
"Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.",
"> Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.\r\nI installed seqeval, but still reported the same error. That's too bad.\r\n",
"> > Hi! Some of our metrics require additional dependencies to work. In your case, simply installing the `seqeval` package with `pip install seqeval` should resolve the issue.\r\n> > I installed seqeval, but still reported the same error. That's too bad.\r\n\r\nSame issue here. What should I do to fix this error? Please help! Thank you.",
"I tried to install **seqeval** package through anaconda instead of pip:\r\n`conda install -c conda-forge seqeval`\r\nIt worked for me!",
"I can run it through the following steps:\r\n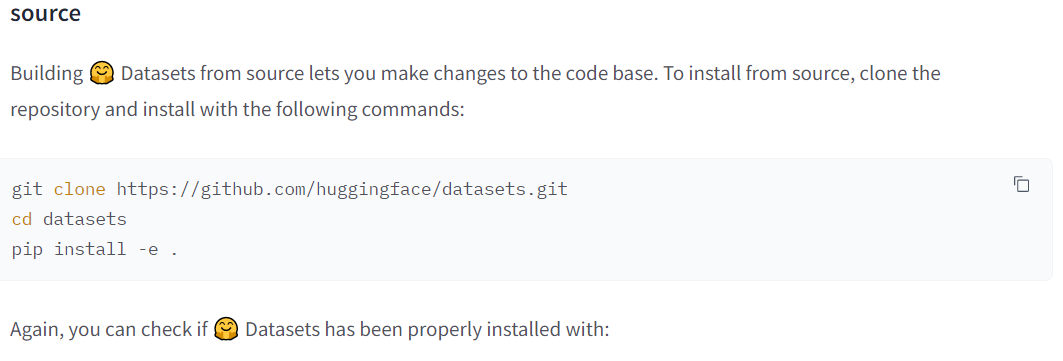\r\nThank you for answering for me!",
"just change the file name seqeval.py to myseqeval.py"
] | 2022-02-11T06:38:42 | 2023-03-09T08:41:33 | null | NONE | null | null | null | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 604, in <module>
main()
File "/home/ubuntu/Python3.6_project/zyf_project/transformers/examples/pytorch/token-classification/run_ner.py", line 481, in main
metric = load_metric(path='mymetric/seqeval/seqeval.py')
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 610, in load_metric
dataset=False,
File "/home/ubuntu/Python3.6_project/zyf_project/transformers_venv_0209/lib/python3.7/site-packages/datasets/load.py", line 450, in prepare_module
f"To be able to use this {module_type}, you need to install the following dependencies"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
**What should I do? Please help me, thank you**
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3703/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3702/comments | https://api.github.com/repos/huggingface/datasets/issues/3702/events | https://github.com/huggingface/datasets/pull/3702 | 1,130,666,707 | PR_kwDODunzps4yahKc | 3,702 | Update data URL of lm1b dataset | {
"login": "yazdanbakhsh",
"id": 7105134,
"node_id": "MDQ6VXNlcjcxMDUxMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazdanbakhsh",
"html_url": "https://github.com/yazdanbakhsh",
"followers_url": "https://api.github.com/users/yazdanbakhsh/followers",
"following_url": "https://api.github.com/users/yazdanbakhsh/following{/other_user}",
"gists_url": "https://api.github.com/users/yazdanbakhsh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazdanbakhsh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazdanbakhsh/subscriptions",
"organizations_url": "https://api.github.com/users/yazdanbakhsh/orgs",
"repos_url": "https://api.github.com/users/yazdanbakhsh/repos",
"events_url": "https://api.github.com/users/yazdanbakhsh/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazdanbakhsh/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"Hi ! I'm getting some 503 from both the http and https addresses. Do you think we could host this data somewhere else ? (please check if there is a license and if it allows redistribution)",
"Both HTTP and HTTPS links are working now.\r\n\r\nWe are closing this PR."
] | 2022-02-10T18:46:30 | 2022-09-23T11:52:39 | 2022-09-23T11:52:39 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3702",
"html_url": "https://github.com/huggingface/datasets/pull/3702",
"diff_url": "https://github.com/huggingface/datasets/pull/3702.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3702.patch",
"merged_at": null
} | The http address doesn't work anymore | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3702/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3702/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3701/comments | https://api.github.com/repos/huggingface/datasets/issues/3701/events | https://github.com/huggingface/datasets/pull/3701 | 1,130,498,738 | PR_kwDODunzps4yZ8Dw | 3,701 | Pin ElasticSearch | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-10T17:15:26 | 2022-02-10T17:31:13 | 2022-02-10T17:31:12 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3701",
"html_url": "https://github.com/huggingface/datasets/pull/3701",
"diff_url": "https://github.com/huggingface/datasets/pull/3701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3701.patch",
"merged_at": "2022-02-10T17:31:12"
} | Until we manage to support ES 8.0, I'm setting the version to `<8.0.0`
Currently we're getting this error on 8.0:
```python
ValueError: Either 'hosts' or 'cloud_id' must be specified
```
When instantiating a `Elasticsearch()` object | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3701/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3700/comments | https://api.github.com/repos/huggingface/datasets/issues/3700/events | https://github.com/huggingface/datasets/issues/3700 | 1,130,252,496 | I_kwDODunzps5DXkjQ | 3,700 | Unable to load a dataset | {
"login": "PaulchauvinAI",
"id": 97964230,
"node_id": "U_kgDOBdbQxg",
"avatar_url": "https://avatars.githubusercontent.com/u/97964230?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PaulchauvinAI",
"html_url": "https://github.com/PaulchauvinAI",
"followers_url": "https://api.github.com/users/PaulchauvinAI/followers",
"following_url": "https://api.github.com/users/PaulchauvinAI/following{/other_user}",
"gists_url": "https://api.github.com/users/PaulchauvinAI/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PaulchauvinAI/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PaulchauvinAI/subscriptions",
"organizations_url": "https://api.github.com/users/PaulchauvinAI/orgs",
"repos_url": "https://api.github.com/users/PaulchauvinAI/repos",
"events_url": "https://api.github.com/users/PaulchauvinAI/events{/privacy}",
"received_events_url": "https://api.github.com/users/PaulchauvinAI/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! `load_dataset` is intended to be used to load a canonical dataset (`wikipedia`), a packaged dataset (`csv`, `json`, ...) or a dataset hosted on the Hub. For local datasets saved with `save_to_disk(\"path/to/dataset\")`, use `load_from_disk(\"path/to/dataset\")`.",
"Maybe we should raise an informative error message in this case..."
] | 2022-02-10T15:05:53 | 2022-02-11T22:56:39 | 2022-02-11T22:56:39 | NONE | null | null | null | ## Describe the bug
Unable to load a dataset from Huggingface that I have just saved.
## Steps to reproduce the bug
On Google colab
`! pip install datasets `
`from datasets import load_dataset`
`my_path = "wiki_dataset"`
`dataset = load_dataset('wikipedia', "20200501.fr")`
`dataset.save_to_disk(my_path)`
`dataset = load_dataset(my_path)`
## Expected results
Loading the dataset
## Actual results
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: null
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: string
to
{'builder_name': Value(dtype='string', id=None), 'citation': Value(dtype='string', id=None), 'config_name': Value(dtype='string', id=None), 'dataset_size': Value(dtype='int64', id=None), 'description': Value(dtype='string', id=None), 'download_checksums': {}, 'download_size': Value(dtype='int64', id=None), 'features': {'title': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}, 'text': {'dtype': Value(dtype='string', id=None), 'id': Value(dtype='null', id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'post_processed': Value(dtype='null', id=None), 'post_processing_size': Value(dtype='null', id=None), 'size_in_bytes': Value(dtype='int64', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='string', id=None)}}, 'supervised_keys': Value(dtype='null', id=None), 'task_templates': Value(dtype='null', id=None), 'version': {'version_str': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'major': Value(dtype='int64', id=None), 'minor': Value(dtype='int64', id=None), 'patch': Value(dtype='int64', id=None)}}
because column names don't match
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3700/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3700/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3699/comments | https://api.github.com/repos/huggingface/datasets/issues/3699/events | https://github.com/huggingface/datasets/pull/3699 | 1,130,200,593 | PR_kwDODunzps4yY49I | 3,699 | Add dev-only config to Natural Questions dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Great thanks ! I think we can fix the CI by copying the NQ folder on gcs to 0.0.3. Does that sound good ?",
"I've copied the 0.0.2 folder content to 0.0.3, as suggested.\r\n\r\nI'm updating the dataset card..."
] | 2022-02-10T14:42:24 | 2022-02-11T09:50:22 | 2022-02-11T09:50:21 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3699",
"html_url": "https://github.com/huggingface/datasets/pull/3699",
"diff_url": "https://github.com/huggingface/datasets/pull/3699.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3699.patch",
"merged_at": "2022-02-11T09:50:21"
} | As suggested by @lhoestq and @thomwolf, a new config has been added to Natural Questions dataset, so that only dev split can be downloaded.
Fix #413. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3699/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3699/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3698/comments | https://api.github.com/repos/huggingface/datasets/issues/3698/events | https://github.com/huggingface/datasets/pull/3698 | 1,129,864,282 | PR_kwDODunzps4yXtyQ | 3,698 | Add finetune-data CodeFill | {
"login": "rgismondi",
"id": 49989029,
"node_id": "MDQ6VXNlcjQ5OTg5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/49989029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rgismondi",
"html_url": "https://github.com/rgismondi",
"followers_url": "https://api.github.com/users/rgismondi/followers",
"following_url": "https://api.github.com/users/rgismondi/following{/other_user}",
"gists_url": "https://api.github.com/users/rgismondi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rgismondi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rgismondi/subscriptions",
"organizations_url": "https://api.github.com/users/rgismondi/orgs",
"repos_url": "https://api.github.com/users/rgismondi/repos",
"events_url": "https://api.github.com/users/rgismondi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rgismondi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @rgismondi. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] | 2022-02-10T11:12:51 | 2022-10-03T09:36:18 | 2022-10-03T09:36:18 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3698",
"html_url": "https://github.com/huggingface/datasets/pull/3698",
"diff_url": "https://github.com/huggingface/datasets/pull/3698.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3698.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3698/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3698/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3697/comments | https://api.github.com/repos/huggingface/datasets/issues/3697/events | https://github.com/huggingface/datasets/pull/3697 | 1,129,795,724 | PR_kwDODunzps4yXeXo | 3,697 | Add code-fill datasets for pretraining/finetuning/evaluating | {
"login": "rgismondi",
"id": 49989029,
"node_id": "MDQ6VXNlcjQ5OTg5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/49989029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rgismondi",
"html_url": "https://github.com/rgismondi",
"followers_url": "https://api.github.com/users/rgismondi/followers",
"following_url": "https://api.github.com/users/rgismondi/following{/other_user}",
"gists_url": "https://api.github.com/users/rgismondi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rgismondi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rgismondi/subscriptions",
"organizations_url": "https://api.github.com/users/rgismondi/orgs",
"repos_url": "https://api.github.com/users/rgismondi/repos",
"events_url": "https://api.github.com/users/rgismondi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rgismondi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! Thanks for adding this dataset :)\r\n\r\nIt looks like your PR contains many changes in files that are unrelated to your changes, I think it might come from running `make style` with an outdated version of `black`. Could you try opening a new PR that only contains your additions ? (or force push to this PR)"
] | 2022-02-10T10:31:48 | 2022-07-06T15:19:58 | 2022-07-06T15:19:58 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3697",
"html_url": "https://github.com/huggingface/datasets/pull/3697",
"diff_url": "https://github.com/huggingface/datasets/pull/3697.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3697.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3697/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3697/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3696/comments | https://api.github.com/repos/huggingface/datasets/issues/3696/events | https://github.com/huggingface/datasets/pull/3696 | 1,129,764,534 | PR_kwDODunzps4yXXgH | 3,696 | Force unique keys in newsqa dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-10T10:09:19 | 2022-02-14T08:37:20 | 2022-02-14T08:37:19 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3696",
"html_url": "https://github.com/huggingface/datasets/pull/3696",
"diff_url": "https://github.com/huggingface/datasets/pull/3696.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3696.patch",
"merged_at": "2022-02-14T08:37:19"
} | Currently, it may raise `DuplicatedKeysError`.
Fix #3630. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3696/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3696/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3695/comments | https://api.github.com/repos/huggingface/datasets/issues/3695/events | https://github.com/huggingface/datasets/pull/3695 | 1,129,730,148 | PR_kwDODunzps4yXP44 | 3,695 | Fix ClassLabel to/from dict when passed names_file | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-10T09:47:10 | 2022-02-11T23:02:32 | 2022-02-11T23:02:31 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3695",
"html_url": "https://github.com/huggingface/datasets/pull/3695",
"diff_url": "https://github.com/huggingface/datasets/pull/3695.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3695.patch",
"merged_at": "2022-02-11T23:02:31"
} | Currently, `names_file` is a field of the data class `ClassLabel`, thus appearing when transforming it to dict (when saving infos). Afterwards, when trying to read it from infos, it conflicts with the other field `names`.
This PR, removes `names_file` as a field of the data class `ClassLabel`.
- it is only used at instantiation to generate the `labels` field
Fix #3631. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3695/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3695/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3693/comments | https://api.github.com/repos/huggingface/datasets/issues/3693/events | https://github.com/huggingface/datasets/pull/3693 | 1,128,554,365 | PR_kwDODunzps4yTTcQ | 3,693 | Standardize to `Example::` | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing because https://github.com/huggingface/datasets/pull/3690/commits/ee0e0935d6105c1390b0e14a7622fbaad3044dbb"
] | 2022-02-09T13:37:13 | 2022-02-17T10:20:55 | 2022-02-17T10:20:52 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3693",
"html_url": "https://github.com/huggingface/datasets/pull/3693",
"diff_url": "https://github.com/huggingface/datasets/pull/3693.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3693.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3693/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3693/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3692/comments | https://api.github.com/repos/huggingface/datasets/issues/3692/events | https://github.com/huggingface/datasets/pull/3692 | 1,128,320,004 | PR_kwDODunzps4yShiu | 3,692 | Update data URL in pubmed dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"- I updated the previous dummy data: I just had to rename the file and its directory\r\n - the dummy data zip contains only a single file: `pubmed22n0001.xml.gz`\r\n\r\nThen I discover it fails: https://app.circleci.com/pipelines/github/huggingface/datasets/9800/workflows/173a4433-8feb-4fc6-ab9e-59762084e3e1/jobs/60437\r\n```\r\nNo such file or directory: '.../dummy_data/pubmed22n0002.xml.gz'\r\n```\r\n- it needs dummy data for all the 1114 files: \r\n `_URLs = [f\"ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed22n{i:04d}.xml.gz\" for i in range(1, 1115)]`\r\n- this confirms me that it never passed the test: these dummy data files were not present before my PR\r\n- therefore, is it really useful the data test if we just ignore it when it does not pass?\r\n\r\nIn relation with JSON metadata, I was generating the file for `pubmed` (see above) in a GCP instance: after running during ~12h without finishing, I decided to stop the process.",
"Hi ! Yes I remembered we hardcoded an exception for this one:\r\nhttps://github.com/huggingface/datasets/blob/36db39c75179a0a491c69a4491f7ae7e4615e66f/src/datasets/utils/mock_download_manager.py#L174-L176\r\n\r\nThe exception was used to only require one dummy data file, feel free to update it if you want"
] | 2022-02-09T10:06:21 | 2022-02-14T14:15:42 | 2022-02-14T14:15:41 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3692",
"html_url": "https://github.com/huggingface/datasets/pull/3692",
"diff_url": "https://github.com/huggingface/datasets/pull/3692.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3692.patch",
"merged_at": "2022-02-14T14:15:41"
} | Fix #3655. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3692/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3692/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3691/comments | https://api.github.com/repos/huggingface/datasets/issues/3691/events | https://github.com/huggingface/datasets/pull/3691 | 1,127,629,306 | PR_kwDODunzps4yQThV | 3,691 | Upgrade black to version ~=22.0 | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-08T18:45:19 | 2022-02-08T19:56:40 | 2022-02-08T19:56:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3691",
"html_url": "https://github.com/huggingface/datasets/pull/3691",
"diff_url": "https://github.com/huggingface/datasets/pull/3691.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3691.patch",
"merged_at": "2022-02-08T19:56:39"
} | Upgrades the `datasets` library quality tool `black` to use the first stable release of `black`, version 22.0. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3691/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3690/comments | https://api.github.com/repos/huggingface/datasets/issues/3690/events | https://github.com/huggingface/datasets/pull/3690 | 1,127,493,538 | PR_kwDODunzps4yP2p5 | 3,690 | Update docs to new frontend/UI | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"We can have the docstrings of the properties that are missing docstrings (from discussion [here](https://github.com/huggingface/doc-builder/pull/96)) here by using your new `inject_arrow_table_documentation` onthem as well ?",
"@sgugger & @lhoestq could you help me with what should the `docs` section in setup.py be changed to [here](https://github.com/huggingface/datasets/blob/master/setup.py#L212-L227) ?\r\n\r\nas a reference, here is a transformers setup.py docs [section](https://github.com/huggingface/transformers/blob/master/setup.py#L304-L308)",
"For now, you can put an empty list. Once the `doc-builder` is in a PyPi package (with the bug we fixed on Datasets but still waiting on the standing PR with the code switch) we can put it there.",
"None of those dependencies are needed from this list?\r\n\r\n```py\r\n \"docs\": [\r\n \"docutils==0.16.0\",\r\n \"recommonmark\",\r\n \"sphinx==3.1.2\",\r\n \"sphinx-markdown-tables\",\r\n \"sphinx-rtd-theme==0.4.3\",\r\n \"sphinxext-opengraph==0.4.1\",\r\n \"sphinx-copybutton\",\r\n \"fsspec<2021.9.0\",\r\n \"s3fs\",\r\n \"sphinx-panels\",\r\n \"sphinx-inline-tabs\",\r\n \"myst-parser\",\r\n \"Markdown!=3.3.5\",\r\n ],\r\n```",
"No, that was all for sphinx. The only thing needed to build the doc is a pip install of `doc-builder` (only from git right now).",
"@lhoestq feel free to request reviews from other maintainers 😊",
"Thanks ! @mariosasko and @albertvillanova feel free to take a look :)\r\nI can do a thorough review this afternoon",
"Cool thanks ! Feel free to merge master into this branch and run `make style` to fix the python code formatting",
"Love the colorful vibes here!\r\n ",
"I just fixed the conflicts with the `master` branch :)\r\n\r\nCould you update preprod please ? Or is there a preview somewhere I can check to make sure everything is ok ?",
"> Could you update preprod please ? Or is there a preview somewhere I can check to make sure everything is ok ?\r\n\r\nI'll let you know once preprod gets updated",
"@lhoestq @stevhliu updated [preprod](https://moon-preprod.huggingface.co/docs/datasets/index) with the latest; please let e know if you see any errors",
"One more tiny error that doesn't seem specific to Datasets (Transformers example [here](https://huggingface.co/docs/transformers/multilingual#xlm-language-embeddings)), but apostrophes and symbols aren't properly displayed in the right navbar:\r\n\r\n",
"In the latest commit https://github.com/huggingface/datasets/pull/3690/commits/20bddf28b22798c309e6eb1198a716f055889e1b, I tried to reflect changes from https://github.com/huggingface/transformers/pull/15903 , however, the gh workflow is not being triggered. @lhoestq do you know why it might be the case?\r\n\r\neve though, we have \r\nhttps://github.com/huggingface/datasets/blob/20bddf28b22798c309e6eb1198a716f055889e1b/.github/workflows/build_dev_documentation.yml#L3-L7",
"I removed this line to trigger the job\r\n```\r\n pull_request:\r\n```\r\n\r\nbut got this error\r\n```\r\n[Error: .github#L1](https://github.com/huggingface/datasets/commit/033fe623c556b9dbc964708b672ff9bb4896c906#annotation_2897984435)\r\na step cannot have both the `uses` and `run` keys\r\n```",
"It seems to be running again, and I re-added the line I removed.\r\n\r\nNow the error is\r\n```\r\n> Run cd doc-build-dev && ...\r\nREADME.md\r\ndatasets\r\ntransformers\r\nOn branch main\r\nYour branch is up to date with 'origin/main'.\r\n\r\nnothing to commit, working tree clean\r\nError: Process completed with exit code 1.\r\n```",
"@lhoestq if the CI passes, Im gonna merge this PR\r\nplease let me know if that sounds good"
] | 2022-02-08T16:38:09 | 2022-03-03T20:04:21 | 2022-03-03T20:04:20 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3690",
"html_url": "https://github.com/huggingface/datasets/pull/3690",
"diff_url": "https://github.com/huggingface/datasets/pull/3690.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3690.patch",
"merged_at": "2022-03-03T20:04:20"
} | ### TLDR: Update `datasets` `docs` to the new syntax (markdown and mdx files) & frontend (as how it looks on [hf.co/transformers](https://huggingface.co/docs/transformers/index))
| Light mode | Dark mode |
|-----------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|
| <img width="400" alt="Screenshot 2022-02-17 at 14 15 34" src="https://user-images.githubusercontent.com/11827707/154489358-e2fb3708-8d72-4fb6-93f0-51d4880321c0.png"> | <img width="400" alt="Screenshot 2022-02-17 at 14 16 27" src="https://user-images.githubusercontent.com/11827707/154489596-c5a1311b-181c-4341-adb3-d60a7d3abe85.png"> |
## Checklist
- [x] update datasets docs to new syntax (should call `doc-builder convert`) (this PR)
- [x] discuss `@property` methods frontend https://github.com/huggingface/doc-builder/pull/87
- [x] discuss `inject_arrow_table_documentation` (this PR) https://github.com/huggingface/datasets/pull/3690#discussion_r801847860
- [x] update datasets docs path on moon-landing https://github.com/huggingface/moon-landing/pull/2089
- [x] convert pyarrow docstring from Numpydoc style to groups style https://github.com/huggingface/doc-builder/pull/89(https://stackoverflow.com/a/24385103/6558628)
- [x] handle `Raises` section on frontend and doc-builder https://github.com/huggingface/doc-builder/pull/86
- [x] check imgs path (this PR) (nothing to update here)
- [x] doc exaples block has to follow format `Examples::` https://github.com/huggingface/datasets/pull/3693
- [x] fix [this docstring](https://github.com/huggingface/datasets/blob/6ed6ac9448311930557810383d2cfd4fe6aae269/src/datasets/arrow_dataset.py#L3339) (causing svelte compilation error)
- [x] Delete sphinx related files
- [x] Delete sphinx CI
- [x] Update docs config in setup.py
- [x] add `versions.yml` in doc-build https://github.com/huggingface/doc-build/pull/1
- [x] add `versions.yml` in doc-build-dev https://github.com/huggingface/doc-build-dev/pull/1
- [x] https://github.com/huggingface/moon-landing/pull/2089
- [x] format docstrings for example `datasets.DatasetBuilder.download_and_prepare` args format look wrong
- [x] create new github actions. (can probably be in a separate PR) (see the transformers equivalents below)
1. [build_dev_documentation.yml](https://github.com/huggingface/transformers/blob/master/.github/workflows/build_dev_documentation.yml)
2. [build_documentation.yml](https://github.com/huggingface/transformers/blob/master/.github/workflows/build_documentation.yml)
3. [delete_dev_documentation.yml](https://github.com/huggingface/transformers/blob/master/.github/workflows/delete_dev_documentation.yml)
## Note to reviewers
The number of changed files is a lot (100+) because I've converted all `.rst` files to `.mdx` files & they are compiling fine on the svelte side (also, moved all the imgs to to [doc-imgs repo](https://huggingface.co/datasets/huggingface/documentation-images/tree/main/datasets)). Moreover, you should just review them on preprod and see if the rendering look fine.
_Therefore, I'd suggest to focus on the changed_ **`.py`** and **CI files** (github workflows, etc. you can use [this filter here](https://github.com/huggingface/datasets/pull/3690/files?file-filters%5B%5D=.py&file-filters%5B%5D=.yml&show-deleted-files=true&show-viewed-files=true)) during the review & ignore `.mdx` files. (if there's a bug in `.mdx` files, we can always handle it in a separate PR afterwards). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3690/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 4,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3690/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3689/comments | https://api.github.com/repos/huggingface/datasets/issues/3689/events | https://github.com/huggingface/datasets/pull/3689 | 1,127,422,478 | PR_kwDODunzps4yPnp7 | 3,689 | Fix streaming for servers not supporting HTTP range requests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Does it mean that huge files might end up being downloaded? It would go against the purpose of streaming, I think. At least, this fallback should be an option that could be disabled",
"Yes, it is against the purpose of streaming, but streaming is not possible if the server does not allow HTTP range requests.\n\nWe have two options: either we download the file or we throw an error.",
"I think we simply cannot fallback to downloading the file if streaming fails without the user being aware of it. Some options: \r\n- make the fallback optional (using an env var? or a function param)\r\n- use the fallback only if the dataset size is under some threshold (provided we have the data in the DatasetInfo) -> it's the option I use in `datasets-preview-backend` ([here](https://github.com/huggingface/datasets-preview-backend/blob/48ac19e49c19809763e8d640986bf2c3d792faed/src/datasets_preview_backend/models/typed_row.py#L40) and [here](https://github.com/huggingface/datasets-preview-backend/blob/aa86c5493b275c9e2dbae7dab7bd469da5773a41/src/datasets_preview_backend/models/split.py#L31-L37))\r\n- throw an exception and let the user decide what to do\r\n",
"IMO in general we should throw an exception and ask the user to not use streaming mode in that case.\r\n\r\nYour second point is also interesting but I feel like it could be confusing for users sometimes: it doesn't feel natural that the streaming-ability should depend on the size of the file.",
"Sure, I think we should just throw an exception\r\n",
"Current behavior is already throwing an Exception:\r\n```\r\nValueError: Cannot seek streaming HTTP file\r\n```\r\n\r\nWe could customize the exception class and/or the exception message.",
"I'm not sure we really need to change anything. I opened the issue https://github.com/huggingface/datasets/issues/3677 because discovery was streamable and is not anymore (according to my test suite in https://github.com/huggingface/datasets-preview-backend): I was not sure if it was due to some regression in the library, or to some change in the dataset itself.",
"I'm wondering why it worked before and it is no longer working...",
"> We could customize the exception class and/or the exception message.\r\n\r\nYup a message that says that the host doesn't support streaming because it doesn't support HTTP Range requests would be useful !",
"DONE, @lhoestq. "
] | 2022-02-08T15:41:05 | 2022-02-10T16:51:25 | 2022-02-10T16:51:25 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3689",
"html_url": "https://github.com/huggingface/datasets/pull/3689",
"diff_url": "https://github.com/huggingface/datasets/pull/3689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3689.patch",
"merged_at": "2022-02-10T16:51:24"
} | Some servers do not support HTTP range requests, whereas this is required to stream some file formats (like ZIP).
~~This PR implements a workaround for those cases, by download the files locally in a temporary directory (cleaned up by the OS once the process is finished).~~
This PR raises custom error explaining that streaming is not possible because data host server does not support HTTP range requests.
Fix #3677. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3689/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3688/comments | https://api.github.com/repos/huggingface/datasets/issues/3688/events | https://github.com/huggingface/datasets/issues/3688 | 1,127,218,321 | I_kwDODunzps5DL_yR | 3,688 | Pyarrow version error | {
"login": "Zaker237",
"id": 49993443,
"node_id": "MDQ6VXNlcjQ5OTkzNDQz",
"avatar_url": "https://avatars.githubusercontent.com/u/49993443?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zaker237",
"html_url": "https://github.com/Zaker237",
"followers_url": "https://api.github.com/users/Zaker237/followers",
"following_url": "https://api.github.com/users/Zaker237/following{/other_user}",
"gists_url": "https://api.github.com/users/Zaker237/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Zaker237/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Zaker237/subscriptions",
"organizations_url": "https://api.github.com/users/Zaker237/orgs",
"repos_url": "https://api.github.com/users/Zaker237/repos",
"events_url": "https://api.github.com/users/Zaker237/events{/privacy}",
"received_events_url": "https://api.github.com/users/Zaker237/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @Zaker237, thanks for reporting.\r\n\r\nThis is weird: the error you get is only thrown if the installed pyarrow version is less than 3.0.0.\r\n\r\nCould you please check that you install pyarrow in the same Python virtual environment where you installed datasets?\r\n\r\nFrom the Python command line (or terminal) where you get the error, please type:\r\n```\r\nimport pyarrow\r\nprint(pyarrow.__version__)\r\nimport datasets\r\nprint(datasets.__version__)\r\n``` ",
"hi @albertvillanova i try yesterday to create a new python environement with python 7 and try it on the environement and it worked. so i think that the error was not the package but may be jupyter notebook on conda. still yet i'm not yet sure but it worked in an environment created with venv",
"OK, thanks @Zaker237 for your feedback.\r\n\r\nI close this issue then. Please, feel free to reopen it if the problem arises again."
] | 2022-02-08T12:53:59 | 2022-02-09T06:35:33 | 2022-02-09T06:35:32 | NONE | null | null | null | ## Describe the bug
I installed datasets(version 1.17.0, 1.18.0, 1.18.3) but i'm right now nor able to import it because of pyarrow. when i try to import it, i get the following error:
`To use datasets, the module pyarrow>=3.0.0 is required, and the current version of pyarrow doesn't match this condition`.
i tryed with all version of pyarrow execpt `4.0.0` but still get the same error.
## Steps to reproduce the bug
```python
import datasets
```
## Expected results
A clear and concise description of the expected results.
## Actual results
AttributeError Traceback (most recent call last)
<ipython-input-19-652e886d387f> in <module>
----> 1 import datasets
~\AppData\Local\Continuum\anaconda3\lib\site-packages\datasets\__init__.py in <module>
26
27
---> 28 if _version.parse(pyarrow.__version__).major < 3:
29 raise ImportWarning(
30 "To use `datasets`, the module `pyarrow>=3.0.0` is required, and the current version of `pyarrow` doesn't match this condition.\n"
AttributeError: 'Version' object has no attribute 'major'
## Environment info
Traceback (most recent call last):
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\Alex\AppData\Local\Continuum\anaconda3\Scripts\datasets-cli.exe\__main__.py", line 5, in <module>
File "c:\users\alex\appdata\local\continuum\anaconda3\lib\site-packages\datasets\__init__.py", line 28, in <module>
if _version.parse(pyarrow.__version__).major < 3:
AttributeError: 'Version' object has no attribute 'major'
- `datasets` version:
- Platform: Linux(Ubuntu) and Windows: conda on the both
- Python version: 3.7
- PyArrow version: 7.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3688/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3687/comments | https://api.github.com/repos/huggingface/datasets/issues/3687/events | https://github.com/huggingface/datasets/issues/3687 | 1,127,154,766 | I_kwDODunzps5DLwRO | 3,687 | Can't get the text data when calling to_tf_dataset | {
"login": "phrasenmaeher",
"id": 82086367,
"node_id": "MDQ6VXNlcjgyMDg2MzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/82086367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phrasenmaeher",
"html_url": "https://github.com/phrasenmaeher",
"followers_url": "https://api.github.com/users/phrasenmaeher/followers",
"following_url": "https://api.github.com/users/phrasenmaeher/following{/other_user}",
"gists_url": "https://api.github.com/users/phrasenmaeher/gists{/gist_id}",
"starred_url": "https://api.github.com/users/phrasenmaeher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phrasenmaeher/subscriptions",
"organizations_url": "https://api.github.com/users/phrasenmaeher/orgs",
"repos_url": "https://api.github.com/users/phrasenmaeher/repos",
"events_url": "https://api.github.com/users/phrasenmaeher/events{/privacy}",
"received_events_url": "https://api.github.com/users/phrasenmaeher/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"cc @Rocketknight1 ",
"You are correct that `to_tf_dataset` only handles numerical columns right now, yes, though this is a limitation we might remove in future! The main reason we do this is that our models mostly do not include the tokenizer as a model layer, because it's very difficult to compile some of them in TF. So the \"normal\" Huggingface workflow is to first tokenize your dataset, and then pass tokenized tensors to the model.\r\n\r\nFor your use case, would you prefer to pass strings to the model, and use some text processing layers instead of the built-in tokenizers?",
"Also tagging @gante just so he's aware, but I can handle this one!",
"Thanks for the quick follow-up to my issue.\r\n\r\nFor my use-case, instead of the built-in tokenizers I wanted to use the `TextVectorization` layer to map from strings to integers. To achieve this, I came up with the following solution:\r\n\r\n```\r\nfrom datasets import load_dataset\r\nfrom transformers import DefaultDataCollator\r\nimport tensorflow as tf\r\nimport string\r\nimport re\r\nfrom tensorflow.keras.layers.experimental.preprocessing import TextVectorization\r\n\r\n#some hyper-parameters for the text-to-integer mapping\r\nmax_features = 20000\r\nembedding_dim = 128\r\nsequence_length = 210\r\n\r\ndata_collator = DefaultDataCollator(return_tensors=\"tf\")\r\ndataset = load_dataset(\"sst\", \"default\")\r\n\r\n#adapt the vectorization layer on train data only\r\nvectorize_layer.adapt(dataset[\"train\"].to_dict(batched=False)[\"sentence\"])\r\n\r\ndef prepare_features(text, label):\r\n text = tf.expand_dims(text, -1)\r\n return {\"vectorized_text\": vectorize_layer(text)[0], \"label\": tf.expand_dims(label, axis=-1)}\r\n\r\nencoded_dataset = dataset.map(lambda example: prepare_features(example[\"sentence\"], example[\"label\"]), batched=False)\r\n\r\n\r\ndef custom_standardization(input_data):\r\n lowercase = tf.strings.lower(input_data)\r\n return tf.strings.regex_replace(\r\n lowercase, f\"[{re.escape(string.punctuation)}]\", \"\"\r\n )\r\n\r\nvectorize_layer = TextVectorization(\r\n standardize=custom_standardization,\r\n max_tokens=max_features,\r\n output_mode=\"int\",\r\n output_sequence_length=sequence_length,\r\n)\r\n\r\ntrain_dataset = encoded_dataset[\"train\"].to_tf_dataset(columns=['vectorized_text'], label_cols=[\"label\"],\r\n shuffle=True, batch_size=1, collate_fn=data_collator).unbatch()\r\n#similar for the other sub-sets\r\n\r\n```\r\n\r\nSince the strings would have been mapped to integers or floats at some point, it's no drawback that this mapping is done early in the process. \r\n\r\nFor the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float. For now, this can be done by calling `to_dict`.",
"> For the future, however, it'd be more convenient to get the string data, since I am also inspecting the dataset (longest sentence, shortest sentence), which is more challenging when working with integer or float.\r\n\r\nYes, I agree, so let's keep this issue open.",
"Going to close this now - methods like `to_tf_dataset` and `prepare_tf_dataset` now support string data, and have done for a while! If anyone sees this and is encountering issues with string data in those methods, please file a new issue!"
] | 2022-02-08T11:52:10 | 2023-01-19T14:55:18 | 2023-01-19T14:55:18 | NONE | null | null | null | I am working with the SST2 dataset, and am using TensorFlow 2.5
I'd like to convert it to a `tf.data.Dataset` by calling the `to_tf_dataset` method.
The following snippet is what I am using to achieve this:
```
from datasets import load_dataset
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors="tf")
dataset = load_dataset("sst")
train_dataset = dataset["train"].to_tf_dataset(columns=['sentence'], label_cols="label", shuffle=True, batch_size=8,collate_fn=data_collator)
```
However, this only gets me the labels; the text--the most important part--is missing:
```
for s in train_dataset.take(1):
print(s) #prints something like: ({}, <tf.Tensor: shape=(8,), ...>)
```
As you can see, it only returns the label part, not the data, as indicated by the empty dictionary, `{}`. So far, I've played with various settings of the method arguments, but to no avail; I do not want to perform any text processing at this time. On my quest to achieve what I want ( a `tf.data.Dataset`), I've consulted these resources:
[https://www.philschmid.de/huggingface-transformers-keras-tf](https://www.philschmid.de/huggingface-transformers-keras-tf)
[https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow](https://huggingface.co/docs/datasets/use_dataset.html?highlight=tensorflow)
I was surprised to not find more extensive examples on how to transform a Hugginface dataset to one compatible with TensorFlow.
If you could point me to where I am going wrong, please do so.
Thanks in advance for your support.
---
Edit: In the [docs](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.to_tf_dataset), I found the following description:
_In general, only columns that the model can use as input should be included here (numeric data only)._
Does this imply that no textual, i.e., `string` data can be loaded?
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3687/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3686/comments | https://api.github.com/repos/huggingface/datasets/issues/3686/events | https://github.com/huggingface/datasets/issues/3686 | 1,127,137,290 | I_kwDODunzps5DLsAK | 3,686 | `Translation` features cannot be `flatten`ed | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting, @SBrandeis! Some additional feature types that don't behave as expected when flattened: `Audio`, `Image` and `TranslationVariableLanguages`"
] | 2022-02-08T11:33:48 | 2022-03-18T17:28:13 | 2022-03-18T17:28:13 | CONTRIBUTOR | null | null | null | ## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train[:10]")
print(dataset.features)
# {'translation': Translation(languages=['en', 'fr'], id=None)}
print(dataset[0])
# {'translation': {'en': 'Vaccination against hepatitis C is not yet available.', 'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
dataset.flatten()
```
## Expected results
`dataset.flatten` should flatten the `Translation` column as if it were a dict of `Value("string")`
```python
dataset[0]
# {'translation.en': 'Vaccination against hepatitis C is not yet available.', 'translation.fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.' }
dataset.features
# {'translation.en': Value("string"), 'translation.fr': Value("string")}
```
## Actual results
```python
In [31]: dset.flatten()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-bb88eb5276ee> in <module>
----> 1 dset.flatten()
[...]\site-packages\datasets\fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
[...]\site-packages\datasets\arrow_dataset.py in flatten(self, new_fingerprint, max_depth)
1294 break
1295 dataset.info.features = self.features.flatten(max_depth=max_depth)
-> 1296 dataset._data = update_metadata_with_features(dataset._data, dataset.features)
1297 logger.info(f'Flattened dataset from depth {depth} to depth {1 if depth + 1 < max_depth else "unknown"}.')
1298 dataset._fingerprint = new_fingerprint
[...]\site-packages\datasets\arrow_dataset.py in update_metadata_with_features(table, features)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
[...]\site-packages\datasets\arrow_dataset.py in <dictcomp>(.0)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
KeyError: 'translation.en'
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3686/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3686/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3685/comments | https://api.github.com/repos/huggingface/datasets/issues/3685/events | https://github.com/huggingface/datasets/pull/3685 | 1,126,240,444 | PR_kwDODunzps4yLw3m | 3,685 | Add support for `Audio` and `Image` feature in `push_to_hub` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> Cool thanks !\r\n> \r\n> Also cc @patrickvonplaten @anton-l it means that when calling push_to_hub, the audio bytes are embedded in the parquet files (we don't upload the audio files themselves)\r\n\r\nJust to verify quickly the size of the dataset doesn't change in this case no? E.g. if a dataset has say 20GB in size when stored in `.mp3` format it could have up to 100GB when stored in WAV. But since we are just taking the bytes here a 20GB .mp3 dataset would also have 20GB when stored in parquet no?",
"@lhoestq I've addressed your comments. Additionally, I've modified `cast_storage` to account for possible null (`None`) values.\r\n\r\n@patrickvonplaten Yes, the dataset size stays the same (at least because Parquet files are compressed).",
"Feel free to merge if it's all good to you :)"
] | 2022-02-07T16:47:16 | 2022-02-14T18:14:57 | 2022-02-14T18:04:58 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3685",
"html_url": "https://github.com/huggingface/datasets/pull/3685",
"diff_url": "https://github.com/huggingface/datasets/pull/3685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3685.patch",
"merged_at": "2022-02-14T18:04:58"
} | Add support for the `Audio` and the `Image` feature in `push_to_hub`.
The idea is to remove local path information and store file content under "bytes" in the Arrow table before the push.
My initial approach (https://github.com/huggingface/datasets/commit/34c652afeff9686b6b8bf4e703c84d2205d670aa) was to use a map transform similar to [`decode_nested_example`](https://github.com/huggingface/datasets/blob/5e0f6068741464f833ff1802e24ecc2064aaea9f/src/datasets/features/features.py#L1023-L1056) while having decoding turned off, but I wasn't satisfied with the code quality, so I ended up using the `temporary_assignment` decorator to override `cast_storage`, which allows me to directly modify the underlying storage (the final op is similar to `Dataset.cast`) and results in a much simpler code.
Additionally, I added the `allow_cast` flag that can disable this behavior in the situations where it's not needed (e.g. the dataset is already in the correct format for the Hub, etc.)
EDIT:
`allow_cast` renamed to `embed_external_files` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3685/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3684/comments | https://api.github.com/repos/huggingface/datasets/issues/3684/events | https://github.com/huggingface/datasets/pull/3684 | 1,125,133,664 | PR_kwDODunzps4yIOer | 3,684 | [fix]: iwslt2017 download urls | {
"login": "msarmi9",
"id": 48395294,
"node_id": "MDQ6VXNlcjQ4Mzk1Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/48395294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msarmi9",
"html_url": "https://github.com/msarmi9",
"followers_url": "https://api.github.com/users/msarmi9/followers",
"following_url": "https://api.github.com/users/msarmi9/following{/other_user}",
"gists_url": "https://api.github.com/users/msarmi9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/msarmi9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msarmi9/subscriptions",
"organizations_url": "https://api.github.com/users/msarmi9/orgs",
"repos_url": "https://api.github.com/users/msarmi9/repos",
"events_url": "https://api.github.com/users/msarmi9/events{/privacy}",
"received_events_url": "https://api.github.com/users/msarmi9/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for the fix ! Do you know where this new URL comes from ?\r\n\r\nAlso we try to not use Google Drive if possible, since it has download quota limitations. Do you know if the data is available from another host than Google Drive ?",
"Oh, I found it just by following the link from the [IWSLT2017 homepage](https://wit3.fbk.eu/2017-01). Not sure if it's available from another host.",
"Ok cool ! I guess it's ok to use this URL for now, and we can see later if we need to change it.\r\n\r\nBefore merging, could you update the `dataset_infos.json` file by running this command please ?\r\n```\r\ndatasets-cli test ./datasets/iwslt2017 --save_infos --all_configs\r\n```",
"sure thing. lmk if there's anything else i can do to help.",
"just checking in. is there anything i can do to help on my end to get this merged? (the dummy data tests are failing due an incorrect path, i think)",
"Thanks ! I also fixed the dummy data :)\r\n\r\nTo fix the CI, feel free to merge the `master` branch into your PR.\r\n\r\nIf you have some time, feel free to also take a look at the missing YAML tags at the top of the README.md file of this dataset:\r\n```\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE YAML tags:\r\nE missing 9 required tags: 'annotations_creators', 'language_creators', 'languages', 'licenses', 'multilinguality', 'size_categories', 'source_datasets', 'task_categories', and 'task_ids'\r\n```\r\nyou can use the dataset tagging app here: https://huggingface.co/spaces/huggingface/datasets-tagging",
"I guess this PR was superseded by this other:\r\n- #4481\r\n\r\nThanks for your contribution anyway, @msarmi9. "
] | 2022-02-06T07:56:55 | 2022-09-22T16:20:19 | 2022-09-22T16:20:18 | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3684",
"html_url": "https://github.com/huggingface/datasets/pull/3684",
"diff_url": "https://github.com/huggingface/datasets/pull/3684.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3684.patch",
"merged_at": null
} | Fixes #2076. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3684/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3684/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3683/comments | https://api.github.com/repos/huggingface/datasets/issues/3683/events | https://github.com/huggingface/datasets/pull/3683 | 1,124,458,371 | PR_kwDODunzps4yGKoj | 3,683 | added told-br (brazilian hate speech) dataset | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/users/JAugusto97/followers",
"following_url": "https://api.github.com/users/JAugusto97/following{/other_user}",
"gists_url": "https://api.github.com/users/JAugusto97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JAugusto97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JAugusto97/subscriptions",
"organizations_url": "https://api.github.com/users/JAugusto97/orgs",
"repos_url": "https://api.github.com/users/JAugusto97/repos",
"events_url": "https://api.github.com/users/JAugusto97/events{/privacy}",
"received_events_url": "https://api.github.com/users/JAugusto97/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Amazing thank you ! Feel free to regenerate the `dataset_infos.json` to account for the feature type change, and then I think we'll be good to merge :)",
"Great thank you ! merging :)"
] | 2022-02-04T17:44:32 | 2022-02-07T21:14:52 | 2022-02-07T21:14:52 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3683",
"html_url": "https://github.com/huggingface/datasets/pull/3683",
"diff_url": "https://github.com/huggingface/datasets/pull/3683.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3683.patch",
"merged_at": "2022-02-07T21:14:52"
} | Hey,
Adding ToLD-Br. Feel free to ask for modifications.
Thanks!! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3683/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3683/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3682/comments | https://api.github.com/repos/huggingface/datasets/issues/3682/events | https://github.com/huggingface/datasets/pull/3682 | 1,124,434,330 | PR_kwDODunzps4yGFml | 3,682 | adding told-br for toxic/abusive hatespeech detection | {
"login": "JAugusto97",
"id": 26556320,
"node_id": "MDQ6VXNlcjI2NTU2MzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/26556320?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JAugusto97",
"html_url": "https://github.com/JAugusto97",
"followers_url": "https://api.github.com/users/JAugusto97/followers",
"following_url": "https://api.github.com/users/JAugusto97/following{/other_user}",
"gists_url": "https://api.github.com/users/JAugusto97/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JAugusto97/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JAugusto97/subscriptions",
"organizations_url": "https://api.github.com/users/JAugusto97/orgs",
"repos_url": "https://api.github.com/users/JAugusto97/repos",
"events_url": "https://api.github.com/users/JAugusto97/events{/privacy}",
"received_events_url": "https://api.github.com/users/JAugusto97/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sorry for using multiple github accounts, I didn't notice I was using my professional account to commit/push. Please consider this @JAugusto97 account as the correct one.",
"Will remake the PR with the correct github account."
] | 2022-02-04T17:18:29 | 2022-02-07T03:23:24 | 2022-02-04T17:36:40 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3682",
"html_url": "https://github.com/huggingface/datasets/pull/3682",
"diff_url": "https://github.com/huggingface/datasets/pull/3682.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3682.patch",
"merged_at": null
} | Hey,
I'm adding our dataset from our paper published at AACL 2020. Feel free to ask for modifications.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3682/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3681/comments | https://api.github.com/repos/huggingface/datasets/issues/3681/events | https://github.com/huggingface/datasets/pull/3681 | 1,124,237,458 | PR_kwDODunzps4yFcpM | 3,681 | Fix TestCommand to move dataset_infos instead of copying | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"All the datasets that are loaded normally with `load_dataset`, if `dataset_infos.json` exists, have this file in the importable directory. So it's fine if we copy the file instead of moving it but it's not a big deal.\r\n\r\nAny reason to prefer moving it rather than copying it ?",
"@lvwerra reported than when generating the `dataset_infos.json` for multiple dataset directories containing only JSONL files, subsequent `dataset_infos.json` files contained all previous directories as configs:\r\n- First generate metadata for dataset in dir `dir1`: dataset_infos.json contains one config for `dir1`\r\n- Then generate metadata for dataset in dir `dir2`: dataset_infos.json contains 2 configs, for `dir1` and `dir2`\r\n\r\nThe reason is that all dataset_infos.json files are first created in the same dir (the one containing the json builder) and then **copied** to the user dir.\r\n\r\nSubsequent calls of TestCommand don't replace the dataset_infos.json already present in the dir of the json builder, but append to it.\r\n\r\nMAYBE: we should just move for this use case, and copy for the other use cases? See this use case here:\r\n- #3680",
"@lhoestq aren't you mentioning the case in the else clause?\r\n```python\r\nelse: # in case of a remote dataset\r\n dataset_dir = None\r\n```\r\n\r\nIn that case `dataset_infos.json` is not copied: `dataset_dir = None`",
"When using the JSON loader, calling `get_imported_module_dir()` returns a path inside the pip installed packages, so we shouldn't write files in it anyway, and the dataset_infos.json file should be written directly in the user's directory instead (some users don't have write access to the pip installed packages for example).\r\n\r\nMaybe the packaged modules like `json` should override `_save_infos` to save them in the user's directory instead of next to the builder's script. What do you think ?",
"Anyway as a hotfix we can just add an exception for the `json` builder for now, if the issue has to be fixed soon"
] | 2022-02-04T14:01:52 | 2022-07-06T15:19:51 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3681",
"html_url": "https://github.com/huggingface/datasets/pull/3681",
"diff_url": "https://github.com/huggingface/datasets/pull/3681.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3681.patch",
"merged_at": null
} | Why do we copy instead of moving the file?
CC: @lhoestq @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3681/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3680/comments | https://api.github.com/repos/huggingface/datasets/issues/3680/events | https://github.com/huggingface/datasets/pull/3680 | 1,124,213,416 | PR_kwDODunzps4yFXm8 | 3,680 | Fix TestCommand to copy dataset_infos to local dir with only data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-04T13:36:46 | 2022-02-08T10:32:55 | 2022-02-08T10:32:55 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3680",
"html_url": "https://github.com/huggingface/datasets/pull/3680",
"diff_url": "https://github.com/huggingface/datasets/pull/3680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3680.patch",
"merged_at": "2022-02-08T10:32:55"
} | Currently this case is missed.
CC: @lvwerra | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3680/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3679/comments | https://api.github.com/repos/huggingface/datasets/issues/3679/events | https://github.com/huggingface/datasets/issues/3679 | 1,124,062,133 | I_kwDODunzps5C_9O1 | 3,679 | Download datasets from a private hub | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/users/juliensimon/followers",
"following_url": "https://api.github.com/users/juliensimon/following{/other_user}",
"gists_url": "https://api.github.com/users/juliensimon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/juliensimon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/juliensimon/subscriptions",
"organizations_url": "https://api.github.com/users/juliensimon/orgs",
"repos_url": "https://api.github.com/users/juliensimon/repos",
"events_url": "https://api.github.com/users/juliensimon/events{/privacy}",
"received_events_url": "https://api.github.com/users/juliensimon/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3814924348,
"node_id": "LA_kwDODunzps7jYyA8",
"url": "https://api.github.com/repos/huggingface/datasets/labels/private-hub",
"name": "private-hub",
"color": "A929D8",
"default": false,
"description": ""
}
] | closed | false | null | [] | null | [
"For reference:\r\nhttps://github.com/huggingface/transformers/issues/15514\r\nhttps://github.com/huggingface/huggingface_hub/issues/650",
"Hi ! For information one can set the environment variable `HF_ENDPOINT` (default is `https://huggingface.co`) if they want to use a private hub.\r\n\r\nWe may need to coordinate with the other libraries to have a consistent way of changing the hub endpoint",
"Yes, I tested it successfully this morning. Thanks."
] | 2022-02-04T10:49:06 | 2022-02-22T11:08:07 | 2022-02-22T11:08:07 | NONE | null | null | null | In the context of a private hub deployment, customers would like to use load_dataset() to load datasets from their hub, not from the public hub. This doesn't seem to be configurable at the moment and it would be nice to add this feature.
The obvious workaround is to clone the repo first and then load it from local storage, but this adds an extra step. It'd be great to have the same experience regardless of where the hub is hosted.
The same issue exists with the transformers library and the CLI. I'm going to create issues there as well, and I'll reference them below. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3679/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-03T18:09:02 | 2022-02-21T09:14:56 | 2022-02-04T13:21:39 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"merged_at": "2022-02-04T13:21:39"
} | Close #3292. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Seems like a regression from https://github.com/huggingface/datasets/pull/2843\r\n\r\nOr maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected\r\n\r\n",
"Hi @severo, thanks for reporting.\r\n\r\nSome servers do not support HTTP range requests, and those are required to stream some file formats (like ZIP in this case).\r\n\r\nLet me try to propose a workaround. "
] | 2022-02-03T15:02:03 | 2022-02-10T16:51:24 | 2022-02-10T16:51:24 | CONTRIBUTOR | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3676/comments | https://api.github.com/repos/huggingface/datasets/issues/3676/events | https://github.com/huggingface/datasets/issues/3676 | 1,123,096,362 | I_kwDODunzps5C8Rcq | 3,676 | `None` replaced by `[]` after first batch in map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"It looks like this is because of this behavior in pyarrow:\r\n```python\r\nimport pyarrow as pa\r\n\r\narr = pa.array([None, [0]])\r\nreconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)\r\nprint(reconstructed_arr.to_pylist())\r\n# [[], [0]]\r\n```\r\n\r\nIt seems that `arr.offsets` can reconstruct the array properly, but an offsets array with null values can:\r\n```python\r\nfixed_offsets = pa.array([None, 0, 1])\r\nfixed_arr = pa.ListArray.from_arrays(fixed_offsets, arr.values)\r\nprint(fixed_arr.to_pylist())\r\n# [None, [0]]\r\n\r\nprint(arr.offsets.to_pylist())\r\n# [0, 0, 1]\r\nprint(fixed_offsets.to_pylist())\r\n# [None, 0, 1]\r\n```\r\nEDIT: this is because `arr.offsets` is not enough to reconstruct the array, we also need the validity bitmap",
"The offsets don't have nulls because they don't include the validity bitmap from `arr.buffers()[0]`, which is used to say which values are null and which values are non-null.\r\n\r\nThough the validity bitmap also seems to be wrong:\r\n```python\r\nbin(int(arr.buffers()[0].hex(), 16))\r\n# '0b10'\r\n# it should be 0b110 - 1 corresponds to non-null and 0 corresponds to null, if you take the bits in reverse order\r\n```\r\n\r\nSo apparently I can't even create the fixed offsets array using this.\r\n\r\nIf I understand correctly it's always missing the 1 on the left, so I can add it manually as a hack to fix the issue until this is fixed in pyarrow EDIT: actually it may be more complicated than that\r\n\r\nEDIT2: actuall it's right, it corresponds to the validity bitmap of the array of logical length 2. So if we use the offsets array, the values array, and this validity bitmap it should be possible to reconstruct the array properly",
"I created an issue on Apache Arrow's JIRA: https://issues.apache.org/jira/browse/ARROW-15837",
"And another one: https://issues.apache.org/jira/browse/ARROW-15839",
"FYI the behavior is the same with:\r\n- `datasets` version: 1.18.3\r\n- Platform: Linux-5.8.0-50-generic-x86_64-with-debian-bullseye-sid\r\n- Python version: 3.7.11\r\n- PyArrow version: 6.0.1\r\n\r\n\r\nbut not with:\r\n- `datasets` version: 1.8.0\r\n- Platform: Linux-4.18.0-305.40.2.el8_4.x86_64-x86_64-with-redhat-8.4-Ootpa\r\n- Python version: 3.7.11\r\n- PyArrow version: 3.0.0\r\n\r\ni.e. it outputs:\r\n```py\r\n0 [None, [0]]\r\n1 [None, [0]]\r\n2 [None, [0]]\r\n3 [None, [0]]\r\n```\r\n",
"Thanks for the insights @PaulLerner !\r\n\r\nI found a way to workaround this issue for the code example presented in this issue.\r\n\r\nNote that empty lists will still appear when you explicitly `cast` a list of lists that contain None values like [None, [0]] to a new feature type (e.g. to change the integer precision). In this case it will show a warning that it happened. If you don't cast anything, then the None values will be kept as expected.\r\n\r\nLet me know what you think !",
"Hi! I feel like I’m missing something in your answer, *what* is the workaround? Is it fixed in some `datasets` version?",
"`pa.ListArray.from_arrays` returns empty lists instead of None values. The workaround I added inside `datasets` simply consists in not using `pa.ListArray.from_arrays` :)\r\n\r\nOnce this PR [here ](https://github.com/huggingface/datasets/pull/4282)is merged, we'll release a new version of `datasets` that currectly returns the None values in the case described in this issue\r\n\r\nEDIT: released :) but let's keep this issue open because it might happen again if users change the integer precision for example"
] | 2022-02-03T13:36:48 | 2022-10-28T13:13:20 | 2022-10-28T13:13:20 | MEMBER | null | null | null | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3676/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/datasets/issues/3676/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3675/comments | https://api.github.com/repos/huggingface/datasets/issues/3675/events | https://github.com/huggingface/datasets/issues/3675 | 1,123,078,408 | I_kwDODunzps5C8NEI | 3,675 | Add CodeContests dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"@mariosasko Can I take this up?",
"This dataset is now available here: https://huggingface.co/datasets/deepmind/code_contests."
] | 2022-02-03T13:20:00 | 2022-07-20T11:07:05 | 2022-07-20T11:07:05 | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** CodeContests
- **Description:** CodeContests is a competitive programming dataset for machine-learning.
- **Paper:**
- **Data:** https://github.com/deepmind/code_contests
- **Motivation:** This dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3675/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3674/comments | https://api.github.com/repos/huggingface/datasets/issues/3674/events | https://github.com/huggingface/datasets/pull/3674 | 1,123,027,874 | PR_kwDODunzps4yBe17 | 3,674 | Add FrugalScore metric | {
"login": "moussaKam",
"id": 28675016,
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moussaKam",
"html_url": "https://github.com/moussaKam",
"followers_url": "https://api.github.com/users/moussaKam/followers",
"following_url": "https://api.github.com/users/moussaKam/following{/other_user}",
"gists_url": "https://api.github.com/users/moussaKam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moussaKam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moussaKam/subscriptions",
"organizations_url": "https://api.github.com/users/moussaKam/orgs",
"repos_url": "https://api.github.com/users/moussaKam/repos",
"events_url": "https://api.github.com/users/moussaKam/events{/privacy}",
"received_events_url": "https://api.github.com/users/moussaKam/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq \r\n\r\nThe model used by default (`moussaKam/frugalscore_tiny_bert-base_bert-score`) is a tiny model.\r\n\r\nI still want to make one modification before merging.\r\nI would like to load the model checkpoint once. Do you think it's a good idea if I load it in `_download_and_prepare`? In this case should the model name be the `self.config_name` or another variable say `self.model_name` ? ",
"OK, I added a commit that loads the checkpoint in `_download_and_prepare`. Please let me know if it looks good. ",
"@lhoestq is everything OK to merge? ",
"I triggered the CI and it's failing, can you merge the `master` branch into yours ? It should fix the issues.\r\n\r\nAlso the doctest apparently raises an error because it outputs `{'scores': [0.6307542, 0.6449357]}` instead of `{'scores': [0.631, 0.645]}` - feel free to edit the code example in the docstring to round the scores, that should fix it",
"@lhoestq hope it's OK now"
] | 2022-02-03T12:28:52 | 2022-02-21T15:58:44 | 2022-02-21T15:58:44 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3674",
"html_url": "https://github.com/huggingface/datasets/pull/3674",
"diff_url": "https://github.com/huggingface/datasets/pull/3674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3674.patch",
"merged_at": "2022-02-21T15:58:44"
} | This pull request add FrugalScore metric for NLG systems evaluation.
FrugalScore is a reference-based metric for NLG models evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
Paper: https://arxiv.org/abs/2110.08559?context=cs
Github: https://github.com/moussaKam/FrugalScore
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3674/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this default is a bit counterintuitive for the user. However, this is a personal opinion that might not be general. I think it is nice to have the actual (non-encoded) labels in the viewer. On the other hand, it would be nice to match what the user sees with what they get when they download a dataset. I don't know - I can see the difficulty of choosing a default :)\r\nMaybe having non-encoded labels as a default can be useful?\r\n\r\nAnyway, I think the issue has been addressed. Thanks a lot for your super-quick answer!\r\n\r\n ",
"Thanks for the 👍 in https://github.com/huggingface/datasets/issues/3673#issuecomment-1029008349 @mariosasko @gary149 @pietrolesci, but as I proposed various solutions, it's not clear to me which you prefer. Could you write your preferences as a comment?\r\n\r\n_(note for myself: one idea per comment in the future)_",
"As I am working with seq2seq, I prefer having the label in string form rather than numeric. So the viewer is fine and the underlying dataset should be \"decoded\" (from int to str). In this way, the user does not have to search for a mapping `int -> original name` (even though is trivial to find, I reckon). Also, encoding labels is rather easy.\r\n\r\nI hope this is useful",
"I like the idea of \"0 (neutral)\". The label name can even be greyed to make it clear that it's not part of the actual item in the dataset, it's just the meaning.",
"I like @lhoestq's idea of having grayed-out labels.",
"Proposals by @gary149. Which one do you prefer? Please vote with the thumbs\r\n\r\n- 👍 \r\n\r\n \r\n\r\n- 👎 \r\n\r\n 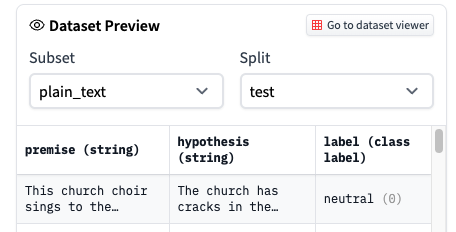\r\n\r\n",
"I like Option 1 better as it shows clearly what the user is downloading",
"Thanks! ",
"It's [live](https://huggingface.co/datasets/glue/viewer/cola/train):\r\n\r\n<img width=\"1126\" alt=\"Capture d’écran 2022-02-14 à 10 26 03\" src=\"https://user-images.githubusercontent.com/1676121/153836716-25f6205b-96af-42d8-880a-7c09cb24c420.png\">\r\n\r\nThanks all for the help to improve the UI!",
"Love it ! thanks :)"
] | 2022-02-03T12:10:43 | 2022-02-16T11:22:31 | 2022-02-11T17:01:21 | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3672/comments | https://api.github.com/repos/huggingface/datasets/issues/3672/events | https://github.com/huggingface/datasets/pull/3672 | 1,122,980,556 | PR_kwDODunzps4yBUrZ | 3,672 | Prioritize `module.builder_kwargs` over defaults in `TestCommand` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-03T11:38:42 | 2022-02-04T12:37:20 | 2022-02-04T12:37:19 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3672",
"html_url": "https://github.com/huggingface/datasets/pull/3672",
"diff_url": "https://github.com/huggingface/datasets/pull/3672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3672.patch",
"merged_at": "2022-02-04T12:37:19"
} | This fixes a bug in the `TestCommand` where multiple kwargs for `name` were passed if it was set in both default and `module.builder_kwargs`. Example error:
```Python
Traceback (most recent call last):
File "create_metadata.py", line 96, in <module>
main(**vars(args))
File "create_metadata.py", line 86, in main
metadata_command.run()
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 144, in run
for j, builder in enumerate(get_builders()):
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 141, in get_builders
name=name, cache_dir=self._cache_dir, data_dir=self._data_dir, **module.builder_kwargs
TypeError: type object got multiple values for keyword argument 'name'
```
Let me know what you think. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3672/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3671/comments | https://api.github.com/repos/huggingface/datasets/issues/3671/events | https://github.com/huggingface/datasets/issues/3671 | 1,122,864,253 | I_kwDODunzps5C7Yx9 | 3,671 | Give an estimate of the dataset size in DatasetInfo | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 2022-02-03T09:47:10 | 2022-02-03T09:47:10 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, only part of the datasets provide `dataset_size`, `download_size`, `size_in_bytes` (and `num_bytes` and `num_examples` inside `splits`). I would want to get this information, or an estimation, for all the datasets.
**Describe the solution you'd like**
- get access to the git information for the dataset files hosted on the hub
- look at the [`Content-Length`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length) for the files served by HTTP
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3671/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"It's a first attempt at solving https://github.com/huggingface/datasets/issues/3013.",
"I only kept these ones:\r\n```\r\n path: str,\r\n data_files: Optional[Union[Dict, List, str]] = None,\r\n download_config: Optional[DownloadConfig] = None,\r\n download_mode: Optional[GenerateMode] = None,\r\n revision: Optional[Union[str, Version]] = None,\r\n use_auth_token: Optional[Union[bool, str]] = None,\r\n **config_kwargs,\r\n```\r\n\r\nLet me know if it's better for you now !\r\n\r\n(note that there's no breaking change since the ones that are removed can be passed as config_kwargs if you really want)",
"(https://github.com/huggingface/datasets/pull/3670/commits/5636911880ea4306c27c7f5825fa3f9427ccc2b6 and https://github.com/huggingface/datasets/pull/3670/commits/07c3f0800dd34dfebb9674ad46c67a907b08ded8 -> I has forgotten to update black in my venv)"
] | 2022-02-02T22:11:56 | 2022-02-21T15:57:11 | 2022-02-21T15:57:10 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"merged_at": "2022-02-21T15:57:10"
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"login": "shalymin-amzn",
"id": 98762373,
"node_id": "U_kgDOBeL-hQ",
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shalymin-amzn",
"html_url": "https://github.com/shalymin-amzn",
"followers_url": "https://api.github.com/users/shalymin-amzn/followers",
"following_url": "https://api.github.com/users/shalymin-amzn/following{/other_user}",
"gists_url": "https://api.github.com/users/shalymin-amzn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shalymin-amzn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shalymin-amzn/subscriptions",
"organizations_url": "https://api.github.com/users/shalymin-amzn/orgs",
"repos_url": "https://api.github.com/users/shalymin-amzn/repos",
"events_url": "https://api.github.com/users/shalymin-amzn/events{/privacy}",
"received_events_url": "https://api.github.com/users/shalymin-amzn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @patrickvonplaten - could you please advise whether this would be a welcomed change, and if so, who I consult regarding the unit-tests?",
"I'd be happy with adding this change. @anton-l @lhoestq - what do you think?",
"Cool ! I just fixed the tests by adding a dummy `validated.tsv` file in the dummy data archive of common_voice\r\n\r\nI wonder if you should separate the train/valid/test configuration from the validated/invalidated configuration of the splits ? \r\nIn particular having `validated` along with the train/valid/test splits could be a bit weird since it comprises them. We can do that if you think it makes more sense. Otherwise it's also good as it is right now :)\r\n",
"Thanks! I think that there are 2 cases for using the validated partition: 1) trainset = {validated - dev - test}, dev and test as they come; 2) train, dev, and test sampled from validated manually with the desired ratios.\r\nIn either case, I think that it's quite a big change on the HF interface part, so could as well be taken care of in the client code. Or is it not? (In which case, what's the most compact way to implement this?)",
"What's important IMO is to let the users as much flexibility as they need - so we try to not do too much regarding splits to not constrain users. So I guess the way it is right now is ok. Can you confirm that it's ok @patrickvonplaten and that it won't break some speech training script out there ?",
"@lhoestq all split names are explicit in our example scripts, so this shouldn't break anything, feel free to merge :)\r\nI'll go ahead and add this to the official `mozilla-foundation` datasets as well ",
"Good for me! This has no real down-sides IMO and surely won't break any training scripts."
] | 2022-02-02T20:04:43 | 2022-02-08T17:26:52 | 2022-02-08T17:23:12 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"merged_at": "2022-02-08T17:23:12"
} | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be useful to train better models where no strict comparison with the previous work is intended. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.\r\n\r\nIf you manage to share a reproducible code example that would be perfect",
"Hi,\r\n\r\nI think my team mate got this solved. Clolsing it for now and will reopen if I experience this again.\r\nThanks :) ",
"Hi @R4ZZ3,\r\n\r\nIf it is not too much of a bother, can you please help me how to resolve this error? I am exactly getting the same error where I am going as per the documentation guideline:\r\n\r\n`my_audio_dataset = my_audio_dataset.cast_column(\"audio_paths\", Audio())`\r\n\r\nwhere `\"audio_paths\"` is a dataset column (feature) having strings of absolute paths to mp3 files of the dataset.\r\n\r\n",
"I was having the same issue with this code:\r\n\r\n```\r\ndataset = dataset.map(\r\n lambda batch: {\"full_path\" : os.path.join(self.data_path, batch[\"path\"])},\r\n num_procs = 4\r\n)\r\nmy_audio_dataset = dataset.cast_column(\"full_path\", Audio(sampling_rate=16_000))\r\n```\r\n\r\nRemoving the \"num_procs\" argument fixed it somehow.\r\nUsing a mac with m1 chip",
"Hi @Hubert-Bonisseur, I think this will be fixed by https://github.com/huggingface/datasets/pull/4614"
] | 2022-02-02T18:33:29 | 2022-07-19T13:36:24 | 2022-07-19T13:36:24 | NONE | null | null | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
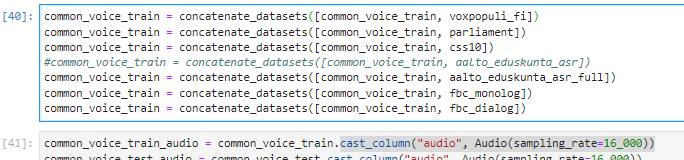
but get error:
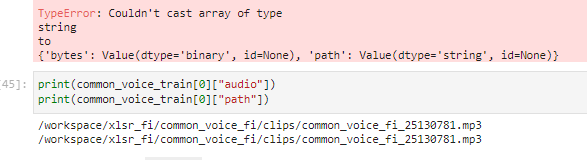
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Note that torchaudio is maybe less practical to use for TF or JAX users.\r\nThis is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice",
"> Note that torchaudio is maybe less practical to use for TF or JAX users. This is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice\r\n\r\n@lhoestq so maybe don't do this PR? :) if it doesn't work anyway with an opened file, only with path",
"Yes as discussed offline there seems to be issues with torchaudio on opened files. Feel free to close this PR if it's better to stick with soundfile because of that",
"We should be able to remove torchaudio, which has torch as a hard dependency, soon and use only soundfile for decoding: https://github.com/bastibe/python-soundfile/issues/252#issuecomment-1000246773 (opus + mp3 support is on the way)."
] | 2022-02-02T15:23:14 | 2022-02-04T15:29:38 | 2022-02-04T15:29:38 | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"merged_at": null
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | process .opus files (for Multilingual Spoken Words) | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I still have problems with processing `.opus` files with `soundfile` so I actually cannot fully check that it works but it should... Maybe this should be investigated in case of someone else would also have problems with that.\r\n\r\nAlso, as the data is in a private repo on the hub (before we come to a decision about audio data privacy), the needed checks cannot be done right now.",
"@lhoestq I check the data redownloading for configs sharing the same languages, you were right: the data is downloaded once for each language. But samples are generated from scratch each time. Is it a supposed behavior? ",
"> But samples are generated from scratch each time. Is it a supposed behavior?\r\n\r\nYea that's the way it works right now, because we generate one arrow file per configuration. Since changing the languages creates a new configuration, then it generates a new arrow file."
] | 2022-02-02T15:21:48 | 2022-02-22T10:04:03 | 2022-02-22T10:03:53 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"merged_at": "2022-02-22T10:03:53"
} | Opus files requires `libsndfile>=1.0.30`. Add check for this version and tests.
**outdated:**
Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=["ar", "tt"])
```
1. I didn't take into account that each time you pass a set of languages the data for a specific language is downloaded even if it was downloaded before (since these are custom configs like `ar+tt` and `ar+tt+br`. Maybe that wasn't a good idea?
2. The script will have to be slightly changed after merge of https://github.com/huggingface/datasets/pull/3664
2. Just can't figure out what wrong with dummy files... 😞 Maybe we should get rid of them at some point 😁 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-02-02T10:31:45 | 2022-02-02T10:52:26 | 2022-02-02T10:52:26 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"merged_at": "2022-02-02T10:52:25"
} | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Cool thanks for giving it a try @anton-l ! \r\n\r\nWould be very much in favor of having \"real\" paths to the audio files again for non-streaming use cases. At the same time it would be nice to make the audio data loading script as understandable as possible so that the community can easily add audio datasets in the future by looking at this one as an example. Think if it's clear for a contributor how to add an audio datasets script that works for the standard non-streaming case while it is easy to extend it afterwards to a streaming dataset script, then this would be perfect",
"@anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? 🤔 ",
"> @anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? thinking\r\n\r\nNot sure @lhoestq - what do you think? \r\n\r\nNow that we've corrected the previous resampling bug, think this one here is of high importance. @lhoestq - what do you think how we should proceed here? ",
"> @anton-l @patrickvonplaten @lhoestq Is it possible somehow to provide this logic inside the library instead of a loading script so that we don't need to completely rewrite all the scripts for audio datasets and users don't have to care about two different loading approaches in the same script? 🤔\r\n\r\nYes let's do this :)\r\n\r\nMaybe we can change the behavior of `DownloadManager.iter_archive` back to extracting the TAR archive locally, and return an iterable of (local path, file obj). And the `StreamingDownloadManager.iter_archive` can return an iterable of (relative path inside the archive, file obj) ?\r\n\r\nIn this case, a dataset would need to have something like this:\r\n```python\r\nfor path, f in files:\r\n yield id_, {\"audio\": {\"path\": path, \"bytes\": f.read() if not is_local_file(path) else None}}\r\n```\r\n\r\nAlternatively, we can allow this if we consider that `Audio.encode_example` sets the \"bytes\" field to `None` automatically if `path` is a local path:\r\n```python\r\nfor path, f in files:\r\n yield id_, {\"audio\": {\"path\": path, \"bytes\": f.read()}}\r\n```\r\nNote that in this case the file is read for nothing though (maybe it's not a big deal ?)\r\n\r\nLet me know if it sounds good to you and what you'd prefer !",
"@lhoestq I'm very much in favor of your first aproach! With the full paths returned I think we won't even need to mess with `os.path.join` vs `\"/\".join()\"` and other local/streaming differences 👍 ",
"@lhoestq I also like the idea and favor your first approach to avoid an unnecessary read and make yielding faster.",
"Looks cool - thanks for working on this. I just feel strongly about `path` being an absolute `path` that exist and can be inspected in the non-streaming case :-) For streaming=True IMO it's absolutely fine if we only have access to the bytes",
"Hi ! I started implementing this but I noticed that returning an absolute path is breaking for many datasets that do things like\r\n```python\r\nfor path, f in files:\r\n if path.startswith(data_dir):\r\n ...\r\n```\r\nso I think I will have to add a parameter to `iter_archive` like `extract_locally=True` to avoid the breaking change, does that sound good to you ?\r\n\r\nThis makes me also think that in streaming mode it could also return a local path too, if we think that writing and deleting temporary files on-the-fly while iterating over the streaming dataset is ok.",
"@lhoestq I think it is a good idea to rollback to extracting the archives locally in non-streaming mode, as far as (as you mentioned) we do not store the bytes in the Arrow file for those cases to avoid \"doubling\" the disk space usage.\r\n\r\nOn the other hand, I don't like:\r\n- neither the possibility to avoid extracting locally in non-streaming: the behavior should be consistent; thus we always extract in non-streaming\r\n - which could be the criterium to decide whether an archive should or should not be extracted? Just because I want to make a condition on path.startswith?\r\n- nor the option to download/delete temporary files in streaming (see discussion here: https://github.com/huggingface/datasets/pull/3689#issuecomment-1032858345)\r\n\r\nUnfortunately, in order to fix the datasets that are breaking after the rollback, I would suggest fixing their scripts so that the paths are handled more robustly (considering that they can be absolute or relative).",
"I agree with Albert, fixing all of the audio datasets isn't too big of a deal (yet). I can help with those if needed :)",
"Ok cool ! I'm completely rolling it back then",
"Alright I did the rollback and now you can get local paths :)\r\nFeel free to try it out and let me know if it's good for you",
"I'll fix the CI tomorrow x)",
"Ok according to the CI there around 60+ datasets to fix",
"> fixing all of the audio datasets isn't too big of a deal (yet). I can help with those if needed :)\r\n\r\nI can help with them too :)\r\n",
"Here is the full list to keep track of things:\r\n\r\n- [x] air_dialogue\r\n- [x] id_nergrit_corpus\r\n- [ ] id_newspapers_2018\r\n- [x] imdb\r\n- [ ] indic_glue\r\n- [ ] inquisitive_qg\r\n- [x] klue\r\n- [x] lama\r\n- [x] lex_glue\r\n- [ ] lm1b\r\n- [x] amazon_polarity\r\n- [ ] mac_morpho\r\n- [ ] math_dataset\r\n- [ ] md_gender_bias\r\n- [ ] mdd\r\n- [ ] assin\r\n- [ ] atomic\r\n- [ ] babi_qa\r\n- [ ] mlqa\r\n- [ ] mocha\r\n- [ ] blended_skill_talk\r\n- [ ] capes\r\n- [ ] cbt\r\n- [ ] newsgroup\r\n- [ ] cifar10\r\n- [ ] cifar100\r\n- [ ] norec\r\n- [ ] ohsumed\r\n- [ ] code_x_glue_cc_clone_detection_poj104\r\n- [x] openslr\r\n- [ ] orange_sum\r\n- [ ] paws\r\n- [ ] paws-x\r\n- [ ] cppe-5\r\n- [ ] polyglot_ner\r\n- [ ] dbrd\r\n- [ ] empathetic_dialogues\r\n- [ ] eraser_multi_rc\r\n- [ ] flores\r\n- [ ] flue\r\n- [ ] food101\r\n- [ ] py_ast\r\n- [ ] qasc\r\n- [ ] qasper\r\n- [ ] race\r\n- [ ] reuters21578\r\n- [ ] ropes\r\n- [ ] rotten_tomatoes\r\n- [x] vivos\r\n- [ ] wi_locness\r\n- [ ] wiki_movies\r\n- [ ] wikiann\r\n- [ ] wmt20_mlqe_task1\r\n- [ ] wmt20_mlqe_task2\r\n- [ ] wmt20_mlqe_task3\r\n- [ ] scicite\r\n- [ ] xsum\r\n- [ ] scielo\r\n- [ ] scifact\r\n- [ ] setimes\r\n- [ ] social_bias_frames\r\n- [ ] sogou_news\r\n- [x] speech_commands\r\n- [ ] ted_hrlr\r\n- [ ] ted_multi\r\n- [ ] tlc\r\n- [ ] turku_ner_corpus\r\n\r\n",
"I'll do my best to fix as many as possible tomorrow :)",
"the audio datasets are fixed if I didn't forget anything :)\r\n\r\nbtw what are we gonna do with the community ones that would be broken after the fix?",
"Closing in favor of https://github.com/huggingface/datasets/pull/3736"
] | 2022-02-01T21:48:27 | 2022-02-22T09:14:06 | 2022-02-22T09:14:06 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"merged_at": null
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor the heck out of this PR to avoid completely copying the logic between the two generators | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
},
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
},
{
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
},
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Having talked to @lhoestq, I see that this feature is no longer supported. \r\n\r\nI really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audio files automatically, but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files - e.g. `common_voice` doesn't work anymore in a TF training script. Note this worked perfectly fine before making the change (think it was done [here](https://github.com/huggingface/datasets/pull/3290) no?)\r\n\r\nIMO, it's really important to think about a solution here and I strongly favor to make a difference here between loading a dataset in streaming mode and in non-streaming mode, so that in non-streaming mode the actual downloaded file is displayed. It's really crucial for people to be able to analyse the original files IMO when the dataset is not downloaded in streaming mode. \r\n\r\nThere are the following reasons why it is paramount to have access to the **original** audio file in my opinion (in non-streaming mode):\r\n- There are a wide variety of different libraries to load audio data with varying support on different platforms. For me it was quite clear that there is simply to single good library to load audio files for all platforms - so we have to leave the option to the user to decide which loading to use.\r\n- We had support for audio datasets a long time before streaming audio was possible. There were quite some versions where we advertised **everywhere** to load the audio from the path name (and there are many places where we still do even though it's not possible anymore). To give some examples:\r\n - Official example of TF Wav2Vec2: https://github.com/huggingface/transformers/blob/f427e750490b486944cc9be3c99834ad5cf78b57/src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py#L1423 Wav2Vec2 is as important for speech as BERT is for NLP - so it's **very** important. The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment. Same goes for Flax.\r\n - The most downloaded non-nlp checkpoint: https://huggingface.co/facebook/wav2vec2-base-960h#usage has a usage example which doesn't work anymore with the current datasets implementation. I'll update this now, but we have >1000 wav2vec2 checkpoints on the Hub and we can't update all the model cards.\r\n => This is a big breaking change with no current solution. For `transformers` breaking changes are one of the biggest complaints.\r\n- Similar to this we also shouldn't assume that there is only one resampling method for Audio. I think it's good to have one offered automatically by `datasets`, but we have to leave the user the freedom to choose her/his own resampling as well. Resampling can take very different filtering windows and other parameters which are currently somewhat hardcoded in `datasets`, which users might very well want to change.\r\n\r\n\r\n=> IMO, it's a **very** big priority to again have the correct absolute path in non-streaming mode. The other solution of providing a path-like object derived from the bytes stocked in the `.array` file is not nearly as user-friendly, but better than nothing. ",
"Agree that we need to have access to the original sound files. Few days ago I was looking for these original files because I suspected there is bug in the audio resampling (confirmed in https://github.com/huggingface/datasets/issues/3662) and I want to do my own resampling to workaround the bug, which is now not possible anymore due to the unavailability of the original files.",
"@patrickvonplaten \r\n> The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing\r\n\r\nJust to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?\r\n\r\n> The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment\r\n\r\nI'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 (https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627).\r\n\r\nYour concern is reasonable, but there are situations where we can only serve bytes (see https://github.com/huggingface/datasets/pull/3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column(\"audio\", Audio(decode=False))`).\r\n",
"Related to this discussion: in https://github.com/huggingface/datasets/pull/3664#issuecomment-1031866858 I propose how we could change `iter_archive` to work for streaming and also return local paths (as it used too !). I'd love your opinions on this",
"> @patrickvonplaten\r\n> \r\n> > The other solution of providing a path-like object derived from the bytes stocked in the .array file is not nearly as user-friendly, but better than nothing\r\n> \r\n> Just to clarify, here you describe the approach that uses the `Audio.decode` attribute to access the underlying bytes?\r\n\r\nYes! \r\n\r\n> \r\n> > The official example currently doesn't work and we don't even have a workaround for it for MP3 files at the moment\r\n> \r\n> I'd assume this is because we use `sox_io` as a backend for decoding. However, soon we should be able to use `soundfile`, which supports path-like objects, for MP3 ([#3667 (comment)](https://github.com/huggingface/datasets/pull/3667#issuecomment-1030090627)). \r\n> Your concern is reasonable, but there are situations where we can only serve bytes (see #3685 for instance). IMO it makes sense to fix the affected datasets for now, but I don't think we should care too much whether we rely on local paths or bytes after soundfile adds support for MP3 as long as our examples work (shouldn't be too hard to update the `map_to_array` functions) and we properly document how to access the underlying path/bytes for custom decoding (via `ds.cast_column(\"audio\", Audio(decode=False))`).\r\n\r\nYes this might be, but I highly doubt that `soundfile` is the go-to library for audio then. @anton-l and I have tried out a bunch of different audio loading libraries (`soundfile`, `librosa`, `torchaudio`, pure `ffmpeg`, `audioread`, ...). One thing that was pretty clear to me is that there is just no \"de-facto standard\" library and they all have pros and cons. None of the libraries really supports \"batch\"-ed audio loading. Some depend on PyTorch. `torchaudio` is 100x faster (really!) than `librosa's` fallback on MP3. `torchaudio` often has problems with multi-proessing, ... Also we should keep in mind that resampling is similarly not as simple as reading a text file. It's a pretty complex signal processing transform and people very well might want to use special filters, etc...at the moment we just hard-code `torchaudio's` or `librosa's` default filter when doing resampling.\r\n\r\n=> All this to say that we **should definitely** care about whether we rely on local paths or bytes IMO. We don't want to loose all users that are forced to use `datasets` decoding or resampling or have to built a very much not intuitive way of loading bytes into a numpy array. It's much more intuitive to be able to inspect a local file. I feel pretty strongly about this and am happy to also jump on a call. Keeping libraries flexible and lean as well as exposing internals is very important IMO (this philosophy has worked quite well so far with Transformers).\r\n\r\n",
"Thanks a lot for the very detailed explanation. Now everything makes much more sense.",
"From https://github.com/huggingface/datasets/pull/3736 the Common Voice dataset now gives access to the local audio files as before",
"I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).\r\n\r\nRegardless of whether it is a breaking change, however, I don't see the other arguments.\r\n\r\n> but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files\r\n\r\nI don't exactly understand this. Why not?\r\n\r\nWhy does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?\r\n\r\nBut even if you just provide the raw bytes to TF, on TF you could just use sth like `tfio.audio.decode_mp3` or `tf.audio.decode_ogg` or `tfio.audio.decode_flac`?\r\n\r\n> There are the following reasons why it is paramount to have access to the original audio file in my opinion ...\r\n\r\nI don't really understand the arguments (despite that it maybe breaks existing code). You anyway have the original audio files but it is just embedded in the dataset? I don't really know about any library which cannot also load the audio from memory (i.e. from the dataset).\r\n\r\nBtw, on librosa being slow for decoding audio files, I saw that as well, so we have this comment RETURNN:\r\n\r\n> Don't use librosa.load which internally uses audioread which would use Gstreamer as a backend which has multiple issues:\r\n> https://github.com/beetbox/audioread/issues/62\r\n> https://github.com/beetbox/audioread/issues/63\r\n> Instead, use PySoundFile (soundfile), which is also faster. See here for discussions:\r\n> https://github.com/beetbox/audioread/issues/64\r\n> https://github.com/librosa/librosa/issues/681\r\n\r\nResampling is also a separate aspect, which is also less straightforward and with different compromises between speed and quality. So there the different tradeoffs and different implementations can make a difference.\r\n\r\nHowever, I don't see how this is related to the question whether there should be the raw bytes inside the dataset or as separate local files.\r\n",
"Thanks for your comments here @albertz - cool to get your input! \r\n\r\nAnswering a bit here between the lines:\r\n\r\n> I understand the argument that it is bad to have a breaking change. How to deal with the introduction of breaking changes is a topic of its own and not sure how you want to deal with that (or is the policy this is never allowed, and there must be a `load_dataset_v2` or so if you really want to introduce a breaking change?).\r\n> \r\n> Regardless of whether it is a breaking change, however, I don't see the other arguments.\r\n> \r\n> > but **really** bad for Tensorflow and Flax where we **currently cannot** even use `datasets` to load `.mp3` files\r\n> \r\n> I don't exactly understand this. Why not?\r\n\r\n> Why does the HF dataset on-the-fly decoding mechanism not work? Why is it anyway specific to PyTorch or TensorFlow? Isn't this independent?\r\n\r\nThe problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.\r\n\r\nSo for TF and Flax it's important that users can load audio files or bytes they way the want to - this might become less important if we find (or make) a good library with few dependencies that is fast for all kinds of platforms / use cases.\r\n\r\n\r\nNow the question is whether it's better to store audio data as a path to a file or as raw bytes I guess.\\\r\nMy main arguments for storing the audio data as a path to a file is pretty much all about users experience - I don't really expect our users to understand the inner workings of datasets:\r\n\r\n- 1. It's not straightforward to know which function to use to decode it - not all `load_audio(...)` or `read_audio(...)` work on raw bytes. E.g. Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes . There are also some functions of other libraries which only work on files which would require the user to save the bytes as a file first before being able to load it.\r\n- 2. It's difficult to see which format the bytes are coming from (mp3, ogg, ...) - guess this could be remedied by adding the format to each sample though\r\n- 3. It is a bit scary IMO to see raw bytes for users. Overall, I think it's better to leave the data in it's raw form as this way it's much easier for people to play around with the audio files, less need to read docs because people don't worry about what happened to the audio files (are the bytes already resampled?)\r\n\r\nBut the argument that the audio should be loadable directly from memory is good - haven't thought about this too much. \r\nI guess it's still very much possible for the user to do this:\r\n\r\n```python\r\ndef save_as_bytes:\r\n batch[\"bytes\"] = read_in_bytes_from_file(batch[\"file\"])\\\r\n os.remove(batch[\"file\"])\r\n\r\nds = ds.map(save_as_bytes)\r\n\r\nds.save_to_disk(...)\r\n```\r\n\r\nGuess the question is more a bit about what should be the default case?",
"> The problem with decoding on the fly is that we currently rely on `torchaudio` for this now which relies on `torch` which is not necessarily something people would like to install when using `tensorflow` or `flax`. Therefore we cannot just rely on people using the decoding on the fly method. We just didn't find a library that is ML framework independent and fast enough for all formats. `torchaudio` is currently in our opinion by far the best here.\r\n\r\nBut how is this relevant for this issue here? I thought this issue here is about having the (correct) path in the dataset or having raw bytes in the dataset.\r\n\r\nHow did TF users use it at all then? Or they just do not use on-the-fly decoding? I did not even notice this problem (maybe because I had `torchaudio` installed). But what do they use instead?\r\n\r\nBut as I outlined before, they could just use `tfio.audio.decode_flac` and co, where it would be more natural if you already provide the raw bytes.\r\n\r\n> Looking at https://pytorch.org/audio/stable/torchaudio.html?highlight=load#torchaudio.load one would not see directly how to load raw bytes\r\n\r\nI was not really familiar with `torchaudio`. It seems that they really don't provide an easy/direct API to operate on raw bytes. Which is very strange and unfortunate because as far as I can see, all the underlying backend libraries (e.g. soundfile) easily allow that. So I would say that this is the fault of `torchaudio` then. But despite, if you anyway use `torchaudio` with `soundfile` backend, why not just use `soundfile` directly. It's very simple to use and crossplatform.\r\n\r\nBut ok, now we are just discussing how to handle the on-the-fly decoding. I still think this is a separate issue and having raw bytes in the dataset instead of local files should just be fine as well.\r\n\r\n\r\n> It is a bit scary IMO to see raw bytes for users.\r\n\r\nI think nobody who writes code is scared by seeing the raw bytes content of a binary file. :)\r\n\r\n\r\n> I guess it's still very much possible for the user to do this:\r\n> \r\n> ```python\r\n> def save_as_bytes:\r\n> batch[\"bytes\"] = read_in_bytes_from_file(batch[\"file\"])\\\r\n> os.remove(batch[\"file\"])\r\n> \r\n> ds = ds.map(save_as_bytes)\r\n> \r\n> ds.save_to_disk(...)\r\n> ```\r\n\r\nIn https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this `map` is not needed anymore and `save_to_disk` could do it automatically (maybe via some option)?\r\n\r\n> Guess the question is more a bit about what should be the default case?\r\n\r\nYea this is up to you. I'm happy as long as we can get it the way we want easily and this is a well supported use case. :)\r\n",
"> In https://github.com/huggingface/datasets/pull/4184#issuecomment-1105191639, you said/proposed that this map is not needed anymore and save_to_disk could do it automatically (maybe via some option)?\r\n\r\nYes! Should be super easy now see discussion here: https://github.com/rwth-i6/i6_core/issues/257#issuecomment-1105494468\r\n\r\nThanks for the super useful input :-)",
"Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)",
"> Despite the comments that this has been fixed, I am finding the exact same problem is occurring again (with datasets version 2.3.2)\r\n\r\nIt appears downgrading to torchaudio 0.11.0 fixed this problem.",
"@DCNemesis, sorry which problem exactly is occuring again? Also cc @lhoestq @polinaeterna here",
"@patrickvonplaten @lhoestq @polinaeterna I was unable to load audio from Common Voice using 🤗 with the current version of torchaudio, but downgrading to torchaudio 0.11.0 fixed it. This is probably more of a torch problem than a Hugging Face problem.",
"@DCNemesis that's interesting, could you please share the error message if you still can access it? ",
"@polinaeterna I believe it is the same exact error as above. It occurs on other .mp3 sources as well, but the problem is with torchaudio > 0.11.0. I've created a short colab notebook that reproduces the error, and the fix here: https://colab.research.google.com/drive/18wsuwdHwBPN3JkcnhEtk8MUYqF9swuWZ?usp=sharing",
"Hi @DCNemesis,\r\n\r\nYour issue was slightly different from the original one in this issue page. Yours seems related to a change in the backend used by `torchaudio` (`ffmpeg` instead of `sox`). Refer to the issue page here:\r\n- #4776\r\n\r\nNormally, it should be circumvented with the patch made by @polinaeterna in:\r\n- #4923",
"I think the original issue reported here was already fixed by:\r\n- #3736\r\n\r\nOtherwise, feel free to reopen."
] | 2022-02-01T18:40:10 | 2022-09-21T15:03:09 | 2022-09-21T14:56:22 | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks @lhoestq for finding the reason of incorrect resampling. This issue affects all languages which have sound files with different sampling rates such as Turkish and Luganda.",
"@cahya-wirawan - do you know how many languages have different sampling rates in Common Voice? I'm quite surprised to see this for multiple languages actually",
"@cahya-wirawan, I can reproduce the problem for Common Voice 7 for Turkish. Here a script you can use:\r\n\r\n\r\n```python\r\n#!/usr/bin/env python3\r\nfrom datasets import load_dataset\r\nimport torchaudio\r\nfrom io import BytesIO\r\nfrom datasets import Audio\r\nfrom collections import Counter\r\nimport sys\r\n\r\nds_name = str(sys.argv[1])\r\nlang = str(sys.argv[2])\r\n\r\nds = load_dataset(ds_name, lang, split=\"train\", use_auth_token=True)\r\nds = ds.cast_column(\"audio\", Audio(decode=False))\r\n\r\nall_sampling_rates = []\r\n\r\n\r\ndef print_sampling_rate(x):\r\n x, sr = torchaudio.load(BytesIO(x[\"audio\"][\"bytes\"]), format=\"mp3\")\r\n all_sampling_rates.append(sr)\r\n\r\nds.map(print_sampling_rate)\r\n\r\n\r\nprint(Counter(all_sampling_rates))\r\n```\r\n\r\ncan be run with:\r\n\r\n```bash\r\npython run.py mozilla-foundation/common_voice_7_0 tr\r\n```\r\n\r\nFor CV 6.1 all samples seem to have the same audio",
"It actually shows that many more samples are in 32kHz format than it 48kHz which is unexpected. Thanks a lot for flagging! Will contact Common Voice about this as well",
"I only checked the CV 7.0 for Turkish, Luganda and Indonesian, they have audio files with difference sampling rates, and all of them are affected by this issue. Percentage of incorrect resampling as follow, Turkish: 9.1%, Luganda: 88.2% and Indonesian: 64.1%.\r\nI checked it using the original CV files. I check the original sampling rates and the length of audio array of each files and compare it with the length of audio array (and the sampling rate which is always 48kHz) from mozilla-foundation/common_voice_7_0 datasets. if the length of audio array from dataset is not equal to 48kHz/original sampling rate * length of audio array of the original audio file then it is affected,",
"Ok wow, thanks a lot for checking this - you've found a pretty big bug :sweat_smile: It seems like **a lot** more datasets are actually affected than I original thought. We'll try to solve this as soon as possible and make an announcement tomorrow."
] | 2022-02-01T17:55:04 | 2022-02-02T10:52:25 | 2022-02-02T10:52:25 | MEMBER | null | null | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI failure is only because of the datasets is missing some sections in their cards - we can ignore that since it's unrelated to this PR"
] | 2022-02-01T17:29:27 | 2022-02-07T16:57:27 | 2022-02-07T16:02:42 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"merged_at": "2022-02-07T16:02:42"
} | Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3660/comments | https://api.github.com/repos/huggingface/datasets/issues/3660/events | https://github.com/huggingface/datasets/pull/3660 | 1,120,982,671 | PR_kwDODunzps4x6xr8 | 3,660 | Change HTTP links to HTTPS | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2022-02-01T17:12:51 | 2022-09-21T15:16:32 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3660",
"html_url": "https://github.com/huggingface/datasets/pull/3660",
"diff_url": "https://github.com/huggingface/datasets/pull/3660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3660.patch",
"merged_at": null
} | I tested the links. I also fixed some typos.
Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3660/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @thomas-happify, please note that the preview may take some time before rendering the data.\r\n\r\nI've seen it is already working.\r\n\r\nI close this issue. Please feel free to reopen it if the problem arises again."
] | 2022-02-01T16:23:57 | 2022-02-09T08:00:37 | 2022-02-09T08:00:37 | NONE | null | null | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | {
"login": "jeffistyping",
"id": 22351555,
"node_id": "MDQ6VXNlcjIyMzUxNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/22351555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffistyping",
"html_url": "https://github.com/jeffistyping",
"followers_url": "https://api.github.com/users/jeffistyping/followers",
"following_url": "https://api.github.com/users/jeffistyping/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffistyping/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffistyping/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffistyping/subscriptions",
"organizations_url": "https://api.github.com/users/jeffistyping/orgs",
"repos_url": "https://api.github.com/users/jeffistyping/repos",
"events_url": "https://api.github.com/users/jeffistyping/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffistyping/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The error is now:\r\n\r\n```\r\nStatus code: 400\r\nException: Status400Error\r\nMessage: this dataset is not supported for now.\r\n```\r\n\r\nWe've disabled the dataset viewer for several big datasets like this one. We hope being able to reenable it soon.",
"The list of splits cannot be obtained. cc @huggingface/datasets ",
"```\r\nError code: SplitsNamesError\r\nException: SplitsNotFoundError\r\nMessage: The split names could not be parsed from the dataset config.\r\nTraceback: Traceback (most recent call last):\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 354, in get_dataset_config_info\r\n for split_generator in builder._split_generators(\r\n File \"/tmp/modules-cache/datasets_modules/datasets/bigscience--P3/12c0badfecad4564ecb8a6f81b5d0559656f269f08b13c59c93283f3a84134ba/P3.py\", line 154, in _split_generators\r\n data_dir = dl_manager.download_and_extract(_URLs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 944, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 907, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 393, in map_nested\r\n mapped = [\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 394, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 346, in <dictcomp>\r\n return {k: _single_map_nested((function, v, types, None, True, None)) for k, v in pbar}\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 330, in _single_map_nested\r\n return function(data_struct)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 912, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 402, in _get_extraction_protocol\r\n return _get_extraction_protocol_with_magic_number(f)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 367, in _get_extraction_protocol_with_magic_number\r\n magic_number = f.read(MAGIC_NUMBER_MAX_LENGTH)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 574, in read\r\n return super().read(length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/spec.py\", line 1575, in read\r\n out = self.cache._fetch(self.loc, self.loc + length)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/caching.py\", line 377, in _fetch\r\n self.cache = self.fetcher(start, bend)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 111, in wrapper\r\n return sync(self.loop, func, *args, **kwargs)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 96, in sync\r\n raise return_result\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/asyn.py\", line 53, in _runner\r\n result[0] = await coro\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 616, in async_fetch_range\r\n out = await r.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/client_reqrep.py\", line 1036, in read\r\n self._body = await self.content.read()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 375, in read\r\n block = await self.readany()\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 397, in readany\r\n await self._wait(\"readany\")\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/aiohttp/streams.py\", line 304, in _wait\r\n await waiter\r\n aiohttp.client_exceptions.ClientPayloadError: Response payload is not completed\r\n \r\n The above exception was the direct cause of the following exception:\r\n \r\n Traceback (most recent call last):\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 75, in get_splits_response\r\n split_full_names = get_dataset_split_full_names(dataset, hf_token)\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 35, in get_dataset_split_full_names\r\n return [\r\n File \"/src/services/worker/src/worker/responses/splits.py\", line 38, in <listcomp>\r\n for split in get_dataset_split_names(dataset, config, use_auth_token=hf_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 404, in get_dataset_split_names\r\n info = get_dataset_config_info(\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 359, in get_dataset_config_info\r\n raise SplitsNotFoundError(\"The split names could not be parsed from the dataset config.\") from err\r\n datasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.\r\n```"
] | 2022-02-01T15:57:56 | 2022-09-08T08:18:28 | null | NONE | null | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm impatient to see if it has an impact on the number of valid datasets for the dataset viewer. For the record, today:\r\n\r\n<img width=\"660\" alt=\"Capture d’écran 2022-02-01 à 14 32 19\" src=\"https://user-images.githubusercontent.com/1676121/151977579-b5a239d9-6662-4aeb-bfd1-eef6b8249991.png\">\r\n",
"This is now available in `datasets` 1.18.3 :)",
"I'm on it https://github.com/huggingface/datasets-preview-backend/issues/130\r\n",
"The result:\r\n<img width=\"671\" alt=\"Capture d’écran 2022-02-03 à 23 45 55\" src=\"https://user-images.githubusercontent.com/1676121/152442169-bfdac643-9a00-4901-bfa7-1d60a1679d4b.png\">\r\n\r\nNot very different. Maybe it fixed issues in the community datasets... But I'm not 100% the two states are comparable (datasets have been created, or updated, meanwhile)"
] | 2022-02-01T12:21:24 | 2022-02-03T22:49:06 | 2022-02-02T11:22:01 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"merged_at": "2022-02-02T11:22:01"
} | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-streaming
python -c "from datasets import get_dataset_split_names; print(get_dataset_split_names('facebook/multilingual_librispeech', 'german', download_mode='force_redownload', revision='137923f945552c6afdd8b60e4a7b43e3088972c1'))"
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"login": "RensDimmendaal",
"id": 9828683,
"node_id": "MDQ6VXNlcjk4Mjg2ODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RensDimmendaal",
"html_url": "https://github.com/RensDimmendaal",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
"gists_url": "https://api.github.com/users/RensDimmendaal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RensDimmendaal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RensDimmendaal/subscriptions",
"organizations_url": "https://api.github.com/users/RensDimmendaal/orgs",
"repos_url": "https://api.github.com/users/RensDimmendaal/repos",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"received_events_url": "https://api.github.com/users/RensDimmendaal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] \r\nDownloading metadata: 17.7kB [00:00, 8.51MB/s] \r\nDownloading and preparing dataset subjqa/electronics (download: 10.86 MiB, generated: 3.01 MiB, post-processed: Unknown size, total: 13.86 MiB) to .../.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd...\r\nDownloading data: 11.4MB [00:03, 3.50MB/s]\r\nDataset subjqa downloaded and prepared to .../.cache/huggingface/datasets/subjqa/electronics/1.1.0/e5588f9298ff2d70686a00cc377e4bdccf4e32287459e3c6baf2dc5ab57fe7fd. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 605.09it/s]\r\n\r\nIn [2]: ds\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 1295\r\n })\r\n test: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 358\r\n })\r\n validation: Dataset({\r\n features: ['domain', 'nn_mod', 'nn_asp', 'query_mod', 'query_asp', 'q_reviews_id', 'question_subj_level', 'ques_subj_score', 'is_ques_subjective', 'review_id', 'id', 'title', 'context', 'question', 'answers'],\r\n num_rows: 255\r\n })\r\n})\r\n```\r\n\r\nCould you please try again and see if the problem persists?\r\n\r\nIf that is the case, you can circumvent the issue by passing `ignore_verifications`:\r\n```python\r\nds = load_dataset(\"subjqa\", \"electronics\", ignore_verifications=True)",
"Thanks checking!\r\n\r\nYou're totally right. I don't know what's changed, but I'm glad it's working now!\r\n\r\n"
] | 2022-02-01T10:53:33 | 2022-02-10T10:56:59 | 2022-02-10T10:56:38 | NONE | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-d2857d460155> in <module>()
2 from datasets import load_dataset
3
----> 4 subjqa = load_dataset("subjqa","electronics")
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/lewtun/SubjQA/archive/refs/heads/master.zip']
```
## Environment info
Google colab
- `datasets` version: 1.18.2
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Hi @abhi-mosaic, thanks for reporting.\r\n\r\nI'm looking at it... ",
"also hitting this issue",
"Hey @albertvillanova, sorry to reopen this... I can confirm that on `master` branch the dataset is downloadable now but it is still broken in streaming mode:\r\n\r\n```python\r\n >>> import datasets\r\n >>> pubmed_train = datasets.load_dataset('pubmed', split='train', streaming=True)\r\n >>> next(iter(pubmed_train))\r\n```\r\n```\r\n No such file or directory: 'gzip://pubmed22n0001.xml::ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed22n0001.xml.gz'\r\n```\r\n",
"Hi @abhi-mosaic, would you mind opening another issue for this new problem?\r\n\r\nFirst issue (already solved) was a ConnectionError due to the yearly update release of PubMed: we fixed it by updating the URLs from year 2021 to year 2022.\r\n\r\nHowever this is another problem: to make pubmed streamable. Please note that NOT all our datastes are streamable: we are making streamable more and more of them... but this is an on-going process...\r\n\r\nThanks.",
"@albertvillanova \r\nWhen I tried below codes, I got the similar error\r\n\r\n```\r\n\r\ndataset=load_dataset(\"pubmed\",split=\"train\")\r\n\r\nCouldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0601.xml.gz\r\n```",
"@y-rok you need to update `datasets`:\r\n```shell\r\npip install -U datasets\r\n```"
] | 2022-01-31T18:45:47 | 2022-12-19T19:18:10 | 2022-02-14T14:15:41 | CONTRIBUTOR | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionError: Couldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz (InvalidSchema("No connection adapters were found for 'ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz'"))
```
## Environment info
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I've created a notebook for you to see the difference: https://colab.research.google.com/drive/1by3EqnoKvC2p-yKW4lPDGOFOZHyGVyeQ?usp=sharing.\r\n\r\nFeel free to suggest better descriptions for the progress bars. \r\n\r\nIf everything looks good, think we can merge."
] | 2022-01-31T17:22:43 | 2022-02-03T15:55:34 | 2022-02-03T15:55:33 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"merged_at": "2022-02-03T15:55:33"
} | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tqdm/commit/f7722edecc3010cb35cc1c923ac4850a76336f82)
* adds the missing `drop_last_batch` and `with_ranks` params to `DatasetDict.map`
* correctly computes the number of iterations in `map` and the CSV/JSON loader when `batched=True` to fix `tqdm` progress bars
* removes the `bool(logging.get_verbosity() == logging.NOTSET)` (or simplifies `bool(logging.get_verbosity() == logging.NOTSET) or not utils.is_progress_bar_enabled()` to `not utils.is_progress_bar_enabled()`) condition and uses `utils.is_progress_bar_enabled` to check if `tqdm` output is enabled (this comment from @stas00 explains why the `bool(logging.get_verbosity() == logging.NOTSET)` check is problematic: https://github.com/huggingface/transformers/issues/14889#issue-1087318463)
Fix #2630 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3653/comments | https://api.github.com/repos/huggingface/datasets/issues/3653/events | https://github.com/huggingface/datasets/issues/3653 | 1,119,186,952 | I_kwDODunzps5CtXAI | 3,653 | `to_json` in multiprocessing fashion sometimes deadlock | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 2022-01-31T09:35:07 | 2022-01-31T09:35:07 | null | MEMBER | null | null | null | ## Describe the bug
`to_json` in multiprocessing fashion sometimes deadlock, instead of raising exceptions. Temporary solution is to see that it deadlocks, and then reduce the number of processes or batch size in order to reduce the memory footprint.
As @lhoestq pointed out, this might be related to https://bugs.python.org/issue22393#msg315684 where `multiprocessing` fails to raise the OOM exception. One suggested alternative is not use `concurrent.futures` instead.
## Steps to reproduce the bug
## Expected results
Script fails when one worker hits OOM, and raise appropriate error.
## Actual results
Deadlock
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.1
- Platform: Linux
- Python version: 3.8
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3653/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3652/comments | https://api.github.com/repos/huggingface/datasets/issues/3652/events | https://github.com/huggingface/datasets/pull/3652 | 1,118,808,738 | PR_kwDODunzps4xzinr | 3,652 | sp. Columbia => Colombia | {
"login": "serapio",
"id": 3781280,
"node_id": "MDQ6VXNlcjM3ODEyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3781280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/serapio",
"html_url": "https://github.com/serapio",
"followers_url": "https://api.github.com/users/serapio/followers",
"following_url": "https://api.github.com/users/serapio/following{/other_user}",
"gists_url": "https://api.github.com/users/serapio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/serapio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serapio/subscriptions",
"organizations_url": "https://api.github.com/users/serapio/orgs",
"repos_url": "https://api.github.com/users/serapio/repos",
"events_url": "https://api.github.com/users/serapio/events{/privacy}",
"received_events_url": "https://api.github.com/users/serapio/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The original openslr site mixed both names https://openslr.org/72/ :-)",
"Yeah, I filed the issue to have it fixed there last year, but it looks like they missed a few."
] | 2022-01-31T00:41:03 | 2022-02-09T16:55:25 | 2022-01-31T08:29:07 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3652",
"html_url": "https://github.com/huggingface/datasets/pull/3652",
"diff_url": "https://github.com/huggingface/datasets/pull/3652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3652.patch",
"merged_at": "2022-01-31T08:29:07"
} | "Columbia" is various places in North America. The country is "Colombia". | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3651/comments | https://api.github.com/repos/huggingface/datasets/issues/3651/events | https://github.com/huggingface/datasets/pull/3651 | 1,118,597,647 | PR_kwDODunzps4xy3De | 3,651 | Update link in wiki_bio dataset | {
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> all the tests pass, but I'm still not able to import the dataset\r\n\r\nSince it's not merged on `master` yet, you have to provide the path to your local `wiki_bio.py` to use it.\r\nIndeed the library downloads the dataset files from `master` if you have a dev installation of the library.\r\n\r\nI agree it would be nice to change that, and use the local dataset scripts from the `datasets` directory - it feels definitely more natural.",
"Cool, thanks for your help and I agree!"
] | 2022-01-30T16:28:54 | 2022-01-31T14:50:48 | 2022-01-31T08:38:09 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3651",
"html_url": "https://github.com/huggingface/datasets/pull/3651",
"diff_url": "https://github.com/huggingface/datasets/pull/3651.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3651.patch",
"merged_at": "2022-01-31T08:38:09"
} | Fixes #3580 and makes the wiki_bio dataset work again. I changed the link and some documentation, and all the tests pass. Thanks @lhoestq for uploading the dataset to the HuggingFace data bucket.
@lhoestq -- all the tests pass, but I'm still not able to import the dataset, as the old Google Drive link is cached somewhere:
```python
>>> from datasets import load_dataset
load_dataset("wiki_bio>>> load_dataset("wiki_bio")
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
...
File "/home/jxm3/random/datasets/src/datasets/utils/file_utils.py", line 612, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil
```
what do I have to do to invalidate the cache and actually import the dataset? It's clearly set up correctly, since the data is downloaded and processed by the tests.
As an aside, this caching-loading-scripts behavior makes for a really bad developer experience. I just wasted an hour trying to figure out where the caching was happening and how to disable it, and I don't know. All I wanted to do was update the link and submit a pull request! I recommend that you all either change this behavior (i.e. updating the link to a dataset should "just work") or document it, since I couldn't find any information about this in the contributing.md or readme or anywhere else! Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3651/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3650/comments | https://api.github.com/repos/huggingface/datasets/issues/3650/events | https://github.com/huggingface/datasets/pull/3650 | 1,118,537,429 | PR_kwDODunzps4xyr2o | 3,650 | Allow 'to_json' to run in unordered fashion in order to lower memory footprint | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @thomasw21, I remember suggesting `imap_unordered` to @lhoestq at that time to speed up `to_json` further but after trying `pool_imap` on multiple datasets (>9GB) , memory utilisation was almost constant and we decided to go ahead with that only. \r\n\r\n1. Did you try this without `gzip`? Because `gzip` feature was introduced recently and I didn't check multi_proc thing with `gzip`. One thing I know is that `gzip` is slow in our implementation than `zip` (it's a WIP #3551) \r\n2. You can try reducing your batch size, this can also help in avoiding OOM errors!",
"Thanks @bhavitvyamalik ! I see. I'm not sure this PR actually fixes things for me either (I ended up reducing the num_proc/batch_size to lower it). It does allow the process to run for longer, but I think the reason why it was waiting is that one of the process crashes .... Unfortunately I was working on a setup with a low RAM/cpu core ratio. I'm actually very surprised that it doesn't change memory utilization, otherwise I don't see the purpose of `imap_unordered` existing. I think it's main purpose are when you have high variance in samples (in terms of bytes), which causes unecessary accumulation in `imap`\r\n 1. Did not try without `gzip`\r\n 2. Yeah or `num_proc`",
"Can you please try without `gzip` to see how it performs? If it works fine then we can improve `gzip` from our side (I'm already working on it)",
"I'll be busy for next few weeks on another project, will do as soon as I have some bandwidth.\r\n"
] | 2022-01-30T13:23:19 | 2022-07-06T15:19:50 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"merged_at": null
} | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in memory.
In order to flush memory, I propose we use optional `imap_unordered`. This will prevent one process to block the other ones. The logical thinking is that index are rarily relevant, and in one wants to keep an index, one can still create another column and reconstruct from there. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3650/timeline | null | null | true |