
url
stringlengths 61
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 75
75
| comments_url
stringlengths 70
70
| events_url
stringlengths 68
68
| html_url
stringlengths 49
51
| id
int64 986M
1.61B
| node_id
stringlengths 18
32
| number
int64 2.87k
5.61k
| title
stringlengths 1
290
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
timestamp[s] | updated_at
timestamp[s] | closed_at
timestamp[s] | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 2
36.2k
⌀ | reactions
dict | timeline_url
stringlengths 70
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",
"gists_url": "https://api.github.com/users/davidgilbertson/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davidgilbertson/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidgilbertson/subscriptions",
"organizations_url": "https://api.github.com/users/davidgilbertson/orgs",
"repos_url": "https://api.github.com/users/davidgilbertson/repos",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"received_events_url": "https://api.github.com/users/davidgilbertson/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2023-03-05T05:27:15 | 2023-03-05T05:27:15 | null | NONE | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_disk` and then use `load_from_disk` to load the filtered version.
The performance of these two approaches is wildly different:
* Using `load_dataset` takes about 20 seconds to load the dataset, and a few seconds to re-filter (thanks to the brilliant filter/map caching)
* Using `load_from_disk` takes 14 minutes! And the second time I tried, the session just crashed (on a machine with 32GB of RAM)
I don't know if you'd call this a bug, but it seems like there shouldn't need to be two methods to load from disk, or that they should not take such wildly different amounts of time, or that one should not crash. Or maybe that the docs could offer some guidance about when to pick which method and why two methods exist, or just how do most people do it?
Something I couldn't work out from reading the docs was this: can I modify a dataset from the hub, save it (locally) and use `load_dataset` to load it? This [post seemed to suggest that the answer is no](https://discuss.huggingface.co/t/save-and-load-datasets/9260).
### Steps to reproduce the bug
See above
### Expected behavior
Load times should be about the same.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://api.github.com/users/jcho19/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jcho19/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jcho19/subscriptions",
"organizations_url": "https://api.github.com/users/jcho19/orgs",
"repos_url": "https://api.github.com/users/jcho19/repos",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"received_events_url": "https://api.github.com/users/jcho19/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2023-03-05T00:14:45 | 2023-03-05T00:14:45 | null | NONE | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the bug
x = load_dataset("audiofolder", data_dir="x")
### Expected behavior
x = load_dataset("audiofolder", data_dir="x") should create a dataset of 20,000 rows (files).
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-3.10.0-1160.80.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.16
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Don't save dataset info to cache dir when skipping verifications | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5607). All of your documentation changes will be reflected on that endpoint."
] | 2023-03-03T19:50:29 | 2023-03-03T20:13:36 | null | CONTRIBUTOR | null | I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not correspond to the ones in the repo which was the reason for using `verification_mode="no_checks"` first. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5607",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | open | false | null | [] | null | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667"
] | 2023-03-03T16:17:10 | 2023-03-04T06:27:08 | null | CONTRIBUTOR | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/followers",
"following_url": "https://api.github.com/users/gary149/following{/other_user}",
"gists_url": "https://api.github.com/users/gary149/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gary149/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gary149/subscriptions",
"organizations_url": "https://api.github.com/users/gary149/orgs",
"repos_url": "https://api.github.com/users/gary149/repos",
"events_url": "https://api.github.com/users/gary149/events{/privacy}",
"received_events_url": "https://api.github.com/users/gary149/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Are you sure it's safe to remove? https://github.com/huggingface/datasets/pull/3866",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009520 / 0.011353 (-0.001833) | 0.005319 / 0.011008 (-0.005690) | 0.099372 / 0.038508 (0.060863) | 0.036173 / 0.023109 (0.013064) | 0.295752 / 0.275898 (0.019853) | 0.362882 / 0.323480 (0.039402) | 0.008442 / 0.007986 (0.000456) | 0.004225 / 0.004328 (-0.000103) | 0.076645 / 0.004250 (0.072394) | 0.044198 / 0.037052 (0.007146) | 0.311948 / 0.258489 (0.053459) | 0.342963 / 0.293841 (0.049122) | 0.038613 / 0.128546 (-0.089933) | 0.012127 / 0.075646 (-0.063519) | 0.334427 / 0.419271 (-0.084844) | 0.048309 / 0.043533 (0.004776) | 0.297046 / 0.255139 (0.041907) | 0.314562 / 0.283200 (0.031363) | 0.105797 / 0.141683 (-0.035886) | 1.460967 / 1.452155 (0.008812) | 1.500907 / 1.492716 (0.008190) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216185 / 0.018006 (0.198179) | 0.438924 / 0.000490 (0.438435) | 0.001210 / 0.000200 (0.001011) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026193 / 0.037411 (-0.011219) | 0.105888 / 0.014526 (0.091363) | 0.115812 / 0.176557 (-0.060744) | 0.158748 / 0.737135 (-0.578387) | 0.121514 / 0.296338 (-0.174824) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399837 / 0.215209 (0.184628) | 3.996992 / 2.077655 (1.919338) | 1.784964 / 1.504120 (0.280844) | 1.591078 / 1.541195 (0.049883) | 1.666424 / 1.468490 (0.197934) | 0.711450 / 4.584777 (-3.873327) | 3.787814 / 3.745712 (0.042102) | 2.056776 / 5.269862 (-3.213085) | 1.332163 / 4.565676 (-3.233514) | 0.085755 / 0.424275 (-0.338520) | 0.012033 / 0.007607 (0.004426) | 0.511500 / 0.226044 (0.285455) | 5.098999 / 2.268929 (2.830071) | 2.288261 / 55.444624 (-53.156364) | 1.947483 / 6.876477 (-4.928994) | 1.987838 / 2.142072 (-0.154234) | 0.852241 / 4.805227 (-3.952986) | 0.164781 / 6.500664 (-6.335883) | 0.061825 / 0.075469 (-0.013644) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.202253 / 1.841788 (-0.639534) | 14.632608 / 8.074308 (6.558300) | 13.331320 / 10.191392 (3.139928) | 0.157944 / 0.680424 (-0.522480) | 0.029284 / 0.534201 (-0.504917) | 0.446636 / 0.579283 (-0.132647) | 0.437009 / 0.434364 (0.002645) | 0.521883 / 0.540337 (-0.018455) | 0.606687 / 1.386936 (-0.780249) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007528 / 0.011353 (-0.003825) | 0.005274 / 0.011008 (-0.005734) | 0.073524 / 0.038508 (0.035016) | 0.033893 / 0.023109 (0.010784) | 0.335432 / 0.275898 (0.059534) | 0.379981 / 0.323480 (0.056501) | 0.005954 / 0.007986 (-0.002031) | 0.004126 / 0.004328 (-0.000203) | 0.072891 / 0.004250 (0.068641) | 0.046517 / 0.037052 (0.009465) | 0.337241 / 0.258489 (0.078752) | 0.385562 / 0.293841 (0.091721) | 0.036410 / 0.128546 (-0.092136) | 0.012246 / 0.075646 (-0.063401) | 0.085974 / 0.419271 (-0.333298) | 0.049665 / 0.043533 (0.006133) | 0.330919 / 0.255139 (0.075780) | 0.352041 / 0.283200 (0.068841) | 0.103751 / 0.141683 (-0.037931) | 1.468851 / 1.452155 (0.016696) | 1.565380 / 1.492716 (0.072663) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260431 / 0.018006 (0.242425) | 0.444554 / 0.000490 (0.444064) | 0.016055 / 0.000200 (0.015855) | 0.000283 / 0.000054 (0.000228) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029130 / 0.037411 (-0.008281) | 0.112002 / 0.014526 (0.097476) | 0.120769 / 0.176557 (-0.055788) | 0.169345 / 0.737135 (-0.567790) | 0.129609 / 0.296338 (-0.166730) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432211 / 0.215209 (0.217002) | 4.293008 / 2.077655 (2.215353) | 2.071291 / 1.504120 (0.567171) | 1.859322 / 1.541195 (0.318127) | 1.971434 / 1.468490 (0.502943) | 0.704042 / 4.584777 (-3.880735) | 3.791696 / 3.745712 (0.045983) | 3.142632 / 5.269862 (-2.127230) | 1.735151 / 4.565676 (-2.830525) | 0.086203 / 0.424275 (-0.338072) | 0.012542 / 0.007607 (0.004935) | 0.534870 / 0.226044 (0.308826) | 5.326042 / 2.268929 (3.057113) | 2.547960 / 55.444624 (-52.896664) | 2.212730 / 6.876477 (-4.663747) | 2.296177 / 2.142072 (0.154105) | 0.840311 / 4.805227 (-3.964917) | 0.168353 / 6.500664 (-6.332311) | 0.065949 / 0.075469 (-0.009520) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255589 / 1.841788 (-0.586199) | 14.947344 / 8.074308 (6.873036) | 13.253721 / 10.191392 (3.062329) | 0.162349 / 0.680424 (-0.518075) | 0.017579 / 0.534201 (-0.516622) | 0.420758 / 0.579283 (-0.158525) | 0.430030 / 0.434364 (-0.004334) | 0.524669 / 0.540337 (-0.015669) | 0.623920 / 1.386936 (-0.763016) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"merged_at": "2023-03-03T21:50:17"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"login": "sentialx",
"id": 11065386,
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sentialx",
"html_url": "https://github.com/sentialx",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "https://api.github.com/users/sentialx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sentialx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sentialx/subscriptions",
"organizations_url": "https://api.github.com/users/sentialx/orgs",
"repos_url": "https://api.github.com/users/sentialx/repos",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"received_events_url": "https://api.github.com/users/sentialx/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2023-03-03T09:52:08 | 2023-03-03T09:52:08 | null | NONE | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
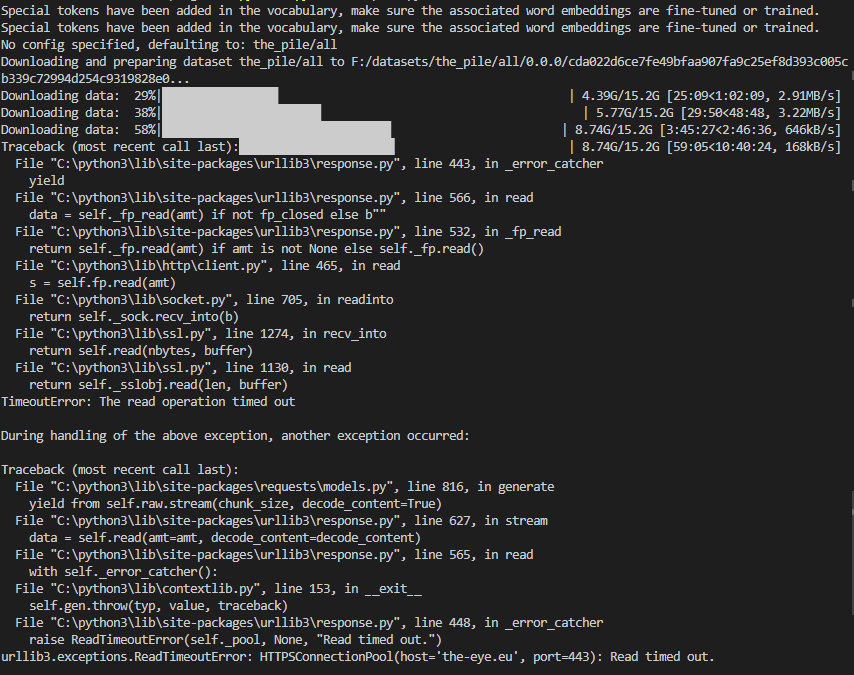
Here are the downloaded files:
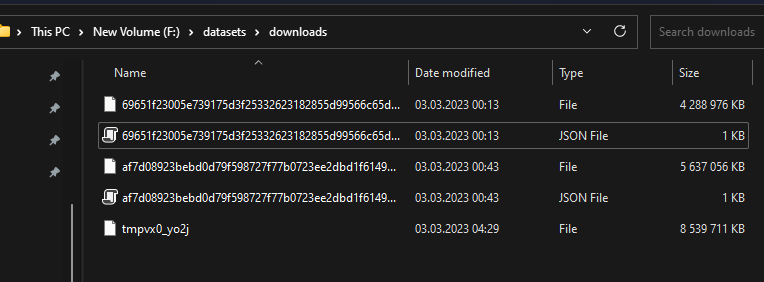
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5604/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5603/comments | https://api.github.com/repos/huggingface/datasets/issues/5603/events | https://github.com/huggingface/datasets/pull/5603 | 1,607,143,509 | PR_kwDODunzps5LJZzG | 5,603 | Don't compute checksums if not necessary in `datasets-cli test` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008550 / 0.011353 (-0.002803) | 0.004476 / 0.011008 (-0.006532) | 0.100902 / 0.038508 (0.062394) | 0.029684 / 0.023109 (0.006575) | 0.308081 / 0.275898 (0.032183) | 0.363435 / 0.323480 (0.039955) | 0.006987 / 0.007986 (-0.000999) | 0.003401 / 0.004328 (-0.000927) | 0.078218 / 0.004250 (0.073967) | 0.036657 / 0.037052 (-0.000395) | 0.319670 / 0.258489 (0.061181) | 0.349952 / 0.293841 (0.056111) | 0.033416 / 0.128546 (-0.095130) | 0.011511 / 0.075646 (-0.064135) | 0.323888 / 0.419271 (-0.095384) | 0.042429 / 0.043533 (-0.001104) | 0.307310 / 0.255139 (0.052171) | 0.329459 / 0.283200 (0.046259) | 0.085209 / 0.141683 (-0.056474) | 1.475893 / 1.452155 (0.023739) | 1.502782 / 1.492716 (0.010065) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200137 / 0.018006 (0.182131) | 0.411269 / 0.000490 (0.410780) | 0.000415 / 0.000200 (0.000215) | 0.000061 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022626 / 0.037411 (-0.014785) | 0.097045 / 0.014526 (0.082519) | 0.102955 / 0.176557 (-0.073602) | 0.148411 / 0.737135 (-0.588725) | 0.107238 / 0.296338 (-0.189100) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421683 / 0.215209 (0.206474) | 4.203031 / 2.077655 (2.125376) | 1.908232 / 1.504120 (0.404112) | 1.698867 / 1.541195 (0.157672) | 1.743561 / 1.468490 (0.275071) | 0.693199 / 4.584777 (-3.891578) | 3.361022 / 3.745712 (-0.384690) | 2.989610 / 5.269862 (-2.280251) | 1.533036 / 4.565676 (-3.032641) | 0.082675 / 0.424275 (-0.341601) | 0.012419 / 0.007607 (0.004812) | 0.531543 / 0.226044 (0.305499) | 5.330595 / 2.268929 (3.061666) | 2.347519 / 55.444624 (-53.097105) | 1.975672 / 6.876477 (-4.900804) | 2.039541 / 2.142072 (-0.102532) | 0.810281 / 4.805227 (-3.994946) | 0.148917 / 6.500664 (-6.351747) | 0.065441 / 0.075469 (-0.010028) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266213 / 1.841788 (-0.575574) | 13.628106 / 8.074308 (5.553798) | 13.852191 / 10.191392 (3.660799) | 0.149004 / 0.680424 (-0.531420) | 0.028549 / 0.534201 (-0.505652) | 0.399824 / 0.579283 (-0.179459) | 0.401231 / 0.434364 (-0.033133) | 0.473251 / 0.540337 (-0.067086) | 0.561094 / 1.386936 (-0.825842) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006669 / 0.011353 (-0.004684) | 0.004477 / 0.011008 (-0.006532) | 0.077514 / 0.038508 (0.039006) | 0.027489 / 0.023109 (0.004380) | 0.341935 / 0.275898 (0.066037) | 0.377392 / 0.323480 (0.053912) | 0.004947 / 0.007986 (-0.003039) | 0.004600 / 0.004328 (0.000271) | 0.075938 / 0.004250 (0.071687) | 0.039586 / 0.037052 (0.002534) | 0.344966 / 0.258489 (0.086477) | 0.392181 / 0.293841 (0.098340) | 0.031838 / 0.128546 (-0.096708) | 0.011572 / 0.075646 (-0.064075) | 0.085811 / 0.419271 (-0.333461) | 0.042250 / 0.043533 (-0.001283) | 0.345605 / 0.255139 (0.090466) | 0.367814 / 0.283200 (0.084615) | 0.090683 / 0.141683 (-0.051000) | 1.483168 / 1.452155 (0.031014) | 1.559724 / 1.492716 (0.067008) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235655 / 0.018006 (0.217649) | 0.399016 / 0.000490 (0.398527) | 0.003096 / 0.000200 (0.002896) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024454 / 0.037411 (-0.012957) | 0.100710 / 0.014526 (0.086185) | 0.107950 / 0.176557 (-0.068606) | 0.161560 / 0.737135 (-0.575576) | 0.111840 / 0.296338 (-0.184498) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441362 / 0.215209 (0.226153) | 4.428105 / 2.077655 (2.350450) | 2.074501 / 1.504120 (0.570381) | 1.866672 / 1.541195 (0.325477) | 1.928266 / 1.468490 (0.459776) | 0.703561 / 4.584777 (-3.881216) | 3.396537 / 3.745712 (-0.349175) | 3.047369 / 5.269862 (-2.222492) | 1.595133 / 4.565676 (-2.970543) | 0.084028 / 0.424275 (-0.340247) | 0.012349 / 0.007607 (0.004741) | 0.539354 / 0.226044 (0.313310) | 5.401535 / 2.268929 (3.132606) | 2.499874 / 55.444624 (-52.944750) | 2.161406 / 6.876477 (-4.715071) | 2.197385 / 2.142072 (0.055313) | 0.810864 / 4.805227 (-3.994363) | 0.152277 / 6.500664 (-6.348387) | 0.067266 / 0.075469 (-0.008203) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.280900 / 1.841788 (-0.560887) | 13.815731 / 8.074308 (5.741423) | 13.007438 / 10.191392 (2.816046) | 0.129711 / 0.680424 (-0.550713) | 0.016852 / 0.534201 (-0.517349) | 0.380775 / 0.579283 (-0.198508) | 0.384143 / 0.434364 (-0.050221) | 0.459954 / 0.540337 (-0.080383) | 0.549335 / 1.386936 (-0.837601) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009570 / 0.011353 (-0.001783) | 0.005219 / 0.011008 (-0.005789) | 0.098472 / 0.038508 (0.059964) | 0.035429 / 0.023109 (0.012320) | 0.303086 / 0.275898 (0.027188) | 0.365926 / 0.323480 (0.042446) | 0.008797 / 0.007986 (0.000811) | 0.004220 / 0.004328 (-0.000108) | 0.076670 / 0.004250 (0.072419) | 0.045596 / 0.037052 (0.008543) | 0.309476 / 0.258489 (0.050987) | 0.343958 / 0.293841 (0.050117) | 0.038741 / 0.128546 (-0.089805) | 0.011990 / 0.075646 (-0.063657) | 0.332326 / 0.419271 (-0.086945) | 0.048897 / 0.043533 (0.005364) | 0.296002 / 0.255139 (0.040863) | 0.322048 / 0.283200 (0.038849) | 0.104403 / 0.141683 (-0.037280) | 1.461777 / 1.452155 (0.009622) | 1.516362 / 1.492716 (0.023645) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201565 / 0.018006 (0.183559) | 0.435781 / 0.000490 (0.435291) | 0.004215 / 0.000200 (0.004015) | 0.000282 / 0.000054 (0.000227) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027272 / 0.037411 (-0.010139) | 0.106157 / 0.014526 (0.091631) | 0.116948 / 0.176557 (-0.059609) | 0.160404 / 0.737135 (-0.576731) | 0.122518 / 0.296338 (-0.173820) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397721 / 0.215209 (0.182512) | 3.966433 / 2.077655 (1.888778) | 1.755410 / 1.504120 (0.251290) | 1.566480 / 1.541195 (0.025285) | 1.623684 / 1.468490 (0.155194) | 0.696820 / 4.584777 (-3.887957) | 3.750437 / 3.745712 (0.004725) | 2.105875 / 5.269862 (-3.163986) | 1.442026 / 4.565676 (-3.123650) | 0.085026 / 0.424275 (-0.339249) | 0.012239 / 0.007607 (0.004632) | 0.502613 / 0.226044 (0.276569) | 5.049016 / 2.268929 (2.780087) | 2.314499 / 55.444624 (-53.130126) | 1.967943 / 6.876477 (-4.908534) | 2.033507 / 2.142072 (-0.108565) | 0.861908 / 4.805227 (-3.943319) | 0.167784 / 6.500664 (-6.332880) | 0.063022 / 0.075469 (-0.012447) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.210434 / 1.841788 (-0.631353) | 14.979319 / 8.074308 (6.905011) | 14.095263 / 10.191392 (3.903871) | 0.174203 / 0.680424 (-0.506221) | 0.028547 / 0.534201 (-0.505654) | 0.442509 / 0.579283 (-0.136774) | 0.445811 / 0.434364 (0.011447) | 0.531313 / 0.540337 (-0.009024) | 0.636541 / 1.386936 (-0.750395) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007341 / 0.011353 (-0.004012) | 0.005197 / 0.011008 (-0.005811) | 0.075413 / 0.038508 (0.036905) | 0.033261 / 0.023109 (0.010152) | 0.339596 / 0.275898 (0.063698) | 0.376051 / 0.323480 (0.052571) | 0.005827 / 0.007986 (-0.002159) | 0.005473 / 0.004328 (0.001144) | 0.074851 / 0.004250 (0.070600) | 0.049059 / 0.037052 (0.012007) | 0.357182 / 0.258489 (0.098693) | 0.384589 / 0.293841 (0.090748) | 0.037122 / 0.128546 (-0.091424) | 0.012298 / 0.075646 (-0.063348) | 0.088191 / 0.419271 (-0.331081) | 0.052002 / 0.043533 (0.008469) | 0.343216 / 0.255139 (0.088077) | 0.364534 / 0.283200 (0.081334) | 0.105462 / 0.141683 (-0.036221) | 1.486717 / 1.452155 (0.034562) | 1.584725 / 1.492716 (0.092009) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199210 / 0.018006 (0.181203) | 0.439069 / 0.000490 (0.438580) | 0.000436 / 0.000200 (0.000236) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029931 / 0.037411 (-0.007480) | 0.109564 / 0.014526 (0.095038) | 0.122284 / 0.176557 (-0.054273) | 0.170819 / 0.737135 (-0.566317) | 0.125886 / 0.296338 (-0.170452) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422724 / 0.215209 (0.207515) | 4.210304 / 2.077655 (2.132650) | 2.001481 / 1.504120 (0.497361) | 1.810818 / 1.541195 (0.269623) | 1.901367 / 1.468490 (0.432877) | 0.686004 / 4.584777 (-3.898773) | 3.768850 / 3.745712 (0.023138) | 2.079501 / 5.269862 (-3.190360) | 1.326970 / 4.565676 (-3.238706) | 0.085991 / 0.424275 (-0.338284) | 0.012298 / 0.007607 (0.004690) | 0.526878 / 0.226044 (0.300833) | 5.267241 / 2.268929 (2.998312) | 2.451781 / 55.444624 (-52.992843) | 2.109143 / 6.876477 (-4.767333) | 2.185426 / 2.142072 (0.043353) | 0.830165 / 4.805227 (-3.975063) | 0.166167 / 6.500664 (-6.334497) | 0.064077 / 0.075469 (-0.011392) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270430 / 1.841788 (-0.571358) | 14.844852 / 8.074308 (6.770544) | 13.196672 / 10.191392 (3.005280) | 0.162853 / 0.680424 (-0.517571) | 0.017727 / 0.534201 (-0.516474) | 0.424803 / 0.579283 (-0.154480) | 0.439970 / 0.434364 (0.005606) | 0.530691 / 0.540337 (-0.009647) | 0.630474 / 1.386936 (-0.756462) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-02T16:42:39 | 2023-03-03T15:45:32 | 2023-03-03T15:38:28 | MEMBER | null | we only need them if there exists a `dataset_infos.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5603/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5603/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5603",
"html_url": "https://github.com/huggingface/datasets/pull/5603",
"diff_url": "https://github.com/huggingface/datasets/pull/5603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5603.patch",
"merged_at": "2023-03-03T15:38:28"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5602/comments | https://api.github.com/repos/huggingface/datasets/issues/5602/events | https://github.com/huggingface/datasets/pull/5602 | 1,607,054,110 | PR_kwDODunzps5LJGfa | 5,602 | Return dict structure if columns are lists - to_tf_dataset | {
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5602). All of your documentation changes will be reflected on that endpoint.",
"This is a great PR! Thinking about the UX though, maybe we could do it without the extra argument? Before this PR, the logic in `to_tf_dataset` was that if the user passed a single column name in either `columns` or `label_cols`, we converted it to a length-1 list. Then, later in the code, we convert output dicts with only one key to naked Tensors.\r\n\r\nWould it be easier if we removed the argument, but instead treated the cases differently? Passing a column name as a string could yield a single naked Tensor in the output as before, but passing a list of length 1 would yield a full dict? That way if you wanted dict output with a single key you could just say `columns=[col_name]`.\r\n\r\n(I'm not totally convinced this is a good idea yet, it just seems like it might be more intuitive)",
"@Rocketknight1 Happy to implement it that way - it's certainly cleaner to not have another arg. In this case, am I right in saying we'd effectively set `return_dict` [here](https://github.com/huggingface/datasets/blob/6569014a9948eab7d031a3587405e64ba92d6c59/src/datasets/arrow_dataset.py#L410) - where columns are made into a list if they were a string? \r\n\r\nThere only concern I have is this changes the default behaviour, which might break things for people who were happily using `columns=[\"my_col_str\"]` before. \r\n\r\n\r\n",
"@amyeroberts That's correct! Probably the simplest way to implement it would be to just add the flag there.\r\n\r\nAnd yeah, I'm aware this might be a slightly breaking change, but we've mostly tried to move users to `prepare_tf_dataset` in `transformers` at this point, so hopefully as long as that method doesn't break then most users won't be negatively affected by the change.",
"@lhoestq @Rocketknight1 - I've remove the `return_dict` argument and implemented @Rocketknight1 's suggestion. LMK what you think :) ",
"@lhoestq Of course :) I've opened a draft PR here for the updates needed in transformers examples and docs to keep the returned data structure consistent: https://github.com/huggingface/transformers/pull/21935. Note: even with the different structure, `model.fit` can still successfully be called. \r\n\r\nFor the [link you shared](https://github.com/huggingface/datasets/pull/url) - for me it returns a 404 error. Is there another link I could follow to see how to run the transformers CI with this branch? \r\n\r\nCurrently looking into the failing tests 😭 ",
"Oh sorry - I fixed the URL: https://github.com/huggingface/transformers/commit/4eb55bbd593adf2e49362613ee32a11ddc4a854d",
"The error shows `There appear to be 80 leaked shared_memory objects to clean up at shutdown`. IIRC to_tf_dataset does some shared memory stuff for multiprocessing - maybe @Rocketknight1 you know what's going on ?"
] | 2023-03-02T15:51:12 | 2023-03-03T21:21:39 | null | CONTRIBUTOR | null | This PR introduces new logic to `to_tf_dataset` affecting the returned data structure, enabling a dictionary structure to be returned, even if only one feature column is selected.
If the passed in `columns` or `label_cols` to `to_tf_dataset` are a list, they are returned as a dictionary, respectively. If they are a string, the tensor is returned.
An outline of the behaviour:
```
dataset,to_tf_dataset(columns=["col_1"], label_cols="col_2")
# ({'col_1': col_1}, col_2}
dataset,to_tf_dataset(columns="col1", label_cols="col_2")
# (col1, col2)
dataset,to_tf_dataset(columns="col1")
# col1
dataset,to_tf_dataset(columns=["col_1"], labels=["col_2"])
# ({'col1': tensor}, {'col2': tensor}}
dataset,to_tf_dataset(columns="col_1", labels=["col_2"])
# (col1, {'col2': tensor}}
```
## Motivation
Currently, when calling `to_tf_dataset`, the returned dataset will always return a tuple structure if a single feature column is used. This can cause issues when calling `model.fit` on models which train without labels e.g. [TFVitMAEForPreTraining](https://github.com/huggingface/transformers/blob/b6f47b539377ac1fd845c7adb4ccaa5eb514e126/src/transformers/models/vit_mae/modeling_vit_mae.py#L849). Specifically, [this line](https://github.com/huggingface/transformers/blob/d9e28d91a8b2d09b51a33155d3a03ad9fcfcbd1f/src/transformers/modeling_tf_utils.py#L1521) where it's assumed the input `x` is a dictionary if there is no label.
## Example
Previous behaviour
```python
In [1]: import tensorflow as tf
...: from datasets import load_dataset
...:
...:
...: def transform(batch):
...: def _transform_img(img):
...: img = img.convert("RGB")
...: img = tf.keras.utils.img_to_array(img)
...: img = tf.image.resize(img, (224, 224))
...: img /= 255.0
...: img = tf.transpose(img, perm=[2, 0, 1])
...: return img
...: batch['pixel_values'] = [_transform_img(pil_img) for pil_img in batch['img']]
...: return batch
...:
...:
...: def collate_fn(examples):
...: pixel_values = tf.stack([example["pixel_values"] for example in examples])
...: return {"pixel_values": pixel_values}
...:
...:
...: dataset = load_dataset('cifar10')['train']
...: dataset = dataset.with_transform(transform)
...: dataset.to_tf_dataset(batch_size=8, columns=['pixel_values'], collate_fn=collate_fn)
Out[1]: <PrefetchDataset element_spec=TensorSpec(shape=(None, 3, 224, 224), dtype=tf.float32, name=None)>
```
New behaviour
```python
In [1]: import tensorflow as tf
...: from datasets import load_dataset
...:
...:
...: def transform(batch):
...: def _transform_img(img):
...: img = img.convert("RGB")
...: img = tf.keras.utils.img_to_array(img)
...: img = tf.image.resize(img, (224, 224))
...: img /= 255.0
...: img = tf.transpose(img, perm=[2, 0, 1])
...: return img
...: batch['pixel_values'] = [_transform_img(pil_img) for pil_img in batch['img']]
...: return batch
...:
...:
...: def collate_fn(examples):
...: pixel_values = tf.stack([example["pixel_values"] for example in examples])
...: return {"pixel_values": pixel_values}
...:
...:
...: dataset = load_dataset('cifar10')['train']
...: dataset = dataset.with_transform(transform)
...: dataset.to_tf_dataset(batch_size=8, columns=['pixel_values'], collate_fn=collate_fn)
Out[1]: <PrefetchDataset element_spec={'pixel_values': TensorSpec(shape=(None, 3, 224, 224), dtype=tf.float32, name=None)}>
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5602/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5602",
"html_url": "https://github.com/huggingface/datasets/pull/5602",
"diff_url": "https://github.com/huggingface/datasets/pull/5602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5602.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5601/comments | https://api.github.com/repos/huggingface/datasets/issues/5601/events | https://github.com/huggingface/datasets/issues/5601 | 1,606,685,976 | I_kwDODunzps5fxBUY | 5,601 | Authorization error | {
"login": "OleksandrKorovii",
"id": 107404835,
"node_id": "U_kgDOBmbeIw",
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OleksandrKorovii",
"html_url": "https://github.com/OleksandrKorovii",
"followers_url": "https://api.github.com/users/OleksandrKorovii/followers",
"following_url": "https://api.github.com/users/OleksandrKorovii/following{/other_user}",
"gists_url": "https://api.github.com/users/OleksandrKorovii/gists{/gist_id}",
"starred_url": "https://api.github.com/users/OleksandrKorovii/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/OleksandrKorovii/subscriptions",
"organizations_url": "https://api.github.com/users/OleksandrKorovii/orgs",
"repos_url": "https://api.github.com/users/OleksandrKorovii/repos",
"events_url": "https://api.github.com/users/OleksandrKorovii/events{/privacy}",
"received_events_url": "https://api.github.com/users/OleksandrKorovii/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2023-03-02T12:08:39 | 2023-03-03T07:32:54 | null | NONE | null | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingface.co/datasets/namespace/your_dataset_name`
4.
```
cp /somewhere/data/*.json .
git lfs track *.json
git add .gitattributes
git add *.json
git commit -m "add json files"
```
but when I execute `git push` I got the error:
```
Uploading LFS objects: 0% (0/1), 0 B | 0 B/s, done.
batch response: Authorization error.
error: failed to push some refs to 'https://huggingface.co/datasets/zeusfsx/ukrainian-news'
```
Size of data ~100Gb. I have five json files - different parts.
### Expected behavior
All my data pushed into hub
### Environment info
- `datasets` version: 2.10.1
- Platform: macOS-13.2.1-arm64-arm-64bit
- Python version: 3.10.10
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"login": "salahiguiliz",
"id": 76955987,
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salahiguiliz",
"html_url": "https://github.com/salahiguiliz",
"followers_url": "https://api.github.com/users/salahiguiliz/followers",
"following_url": "https://api.github.com/users/salahiguiliz/following{/other_user}",
"gists_url": "https://api.github.com/users/salahiguiliz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/salahiguiliz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/salahiguiliz/subscriptions",
"organizations_url": "https://api.github.com/users/salahiguiliz/orgs",
"repos_url": "https://api.github.com/users/salahiguiliz/repos",
"events_url": "https://api.github.com/users/salahiguiliz/events{/privacy}",
"received_events_url": "https://api.github.com/users/salahiguiliz/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 2023-03-02T11:00:27 | 2023-03-02T11:00:27 | null | NONE | null | ### Describe the bug
Dataloader getitem is not working as before (see example of DreamboothDatasets)
moving to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset to load some images
2- error after loading when trying to visualise the images
### Expected behavior
I was expecting a numpy array of the image
### Environment info
- Platform: Linux-5.10.147+-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5598/comments | https://api.github.com/repos/huggingface/datasets/issues/5598/events | https://github.com/huggingface/datasets/pull/5598 | 1,605,018,478 | PR_kwDODunzps5LCMiX | 5,598 | Fix push_to_hub with no dataset_infos | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008823 / 0.011353 (-0.002529) | 0.004738 / 0.011008 (-0.006270) | 0.102338 / 0.038508 (0.063830) | 0.030603 / 0.023109 (0.007494) | 0.302995 / 0.275898 (0.027097) | 0.362080 / 0.323480 (0.038600) | 0.007096 / 0.007986 (-0.000889) | 0.003493 / 0.004328 (-0.000835) | 0.079129 / 0.004250 (0.074878) | 0.037966 / 0.037052 (0.000914) | 0.310412 / 0.258489 (0.051923) | 0.346740 / 0.293841 (0.052899) | 0.033795 / 0.128546 (-0.094751) | 0.011595 / 0.075646 (-0.064051) | 0.325189 / 0.419271 (-0.094083) | 0.041679 / 0.043533 (-0.001854) | 0.302339 / 0.255139 (0.047200) | 0.322519 / 0.283200 (0.039319) | 0.089058 / 0.141683 (-0.052625) | 1.496223 / 1.452155 (0.044068) | 1.512562 / 1.492716 (0.019845) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.009298 / 0.018006 (-0.008709) | 0.406726 / 0.000490 (0.406236) | 0.003753 / 0.000200 (0.003553) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023327 / 0.037411 (-0.014084) | 0.098175 / 0.014526 (0.083649) | 0.106040 / 0.176557 (-0.070516) | 0.151934 / 0.737135 (-0.585201) | 0.108465 / 0.296338 (-0.187873) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419073 / 0.215209 (0.203864) | 4.188012 / 2.077655 (2.110358) | 1.857667 / 1.504120 (0.353547) | 1.664124 / 1.541195 (0.122929) | 1.704341 / 1.468490 (0.235851) | 0.699671 / 4.584777 (-3.885106) | 3.391110 / 3.745712 (-0.354602) | 1.871136 / 5.269862 (-3.398725) | 1.176794 / 4.565676 (-3.388882) | 0.083322 / 0.424275 (-0.340953) | 0.012450 / 0.007607 (0.004843) | 0.525058 / 0.226044 (0.299014) | 5.265425 / 2.268929 (2.996497) | 2.320672 / 55.444624 (-53.123952) | 1.964806 / 6.876477 (-4.911671) | 2.027055 / 2.142072 (-0.115017) | 0.819768 / 4.805227 (-3.985459) | 0.149638 / 6.500664 (-6.351026) | 0.064774 / 0.075469 (-0.010695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.204575 / 1.841788 (-0.637212) | 13.651878 / 8.074308 (5.577570) | 13.751973 / 10.191392 (3.560581) | 0.154781 / 0.680424 (-0.525643) | 0.028887 / 0.534201 (-0.505314) | 0.404905 / 0.579283 (-0.174379) | 0.411320 / 0.434364 (-0.023043) | 0.485026 / 0.540337 (-0.055311) | 0.579690 / 1.386936 (-0.807246) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006615 / 0.011353 (-0.004737) | 0.004606 / 0.011008 (-0.006402) | 0.076099 / 0.038508 (0.037591) | 0.027247 / 0.023109 (0.004137) | 0.360731 / 0.275898 (0.084833) | 0.393688 / 0.323480 (0.070208) | 0.005079 / 0.007986 (-0.002906) | 0.003345 / 0.004328 (-0.000984) | 0.077184 / 0.004250 (0.072934) | 0.037850 / 0.037052 (0.000797) | 0.379738 / 0.258489 (0.121249) | 0.400474 / 0.293841 (0.106633) | 0.031581 / 0.128546 (-0.096966) | 0.011508 / 0.075646 (-0.064138) | 0.084966 / 0.419271 (-0.334306) | 0.041740 / 0.043533 (-0.001793) | 0.349887 / 0.255139 (0.094748) | 0.384405 / 0.283200 (0.101205) | 0.089022 / 0.141683 (-0.052661) | 1.503448 / 1.452155 (0.051293) | 1.564870 / 1.492716 (0.072154) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.233581 / 0.018006 (0.215574) | 0.413819 / 0.000490 (0.413330) | 0.000398 / 0.000200 (0.000198) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024805 / 0.037411 (-0.012607) | 0.101348 / 0.014526 (0.086822) | 0.108701 / 0.176557 (-0.067856) | 0.160011 / 0.737135 (-0.577124) | 0.111696 / 0.296338 (-0.184642) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436303 / 0.215209 (0.221094) | 4.368684 / 2.077655 (2.291029) | 2.082366 / 1.504120 (0.578247) | 1.888108 / 1.541195 (0.346913) | 1.958295 / 1.468490 (0.489804) | 0.700858 / 4.584777 (-3.883919) | 3.408321 / 3.745712 (-0.337391) | 1.872960 / 5.269862 (-3.396902) | 1.165116 / 4.565676 (-3.400560) | 0.083556 / 0.424275 (-0.340719) | 0.012348 / 0.007607 (0.004741) | 0.536551 / 0.226044 (0.310506) | 5.359974 / 2.268929 (3.091045) | 2.539043 / 55.444624 (-52.905581) | 2.200314 / 6.876477 (-4.676162) | 2.222051 / 2.142072 (0.079979) | 0.808567 / 4.805227 (-3.996661) | 0.151222 / 6.500664 (-6.349442) | 0.066351 / 0.075469 (-0.009118) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.265502 / 1.841788 (-0.576286) | 13.692066 / 8.074308 (5.617758) | 13.124507 / 10.191392 (2.933115) | 0.129545 / 0.680424 (-0.550879) | 0.016827 / 0.534201 (-0.517374) | 0.380326 / 0.579283 (-0.198957) | 0.387268 / 0.434364 (-0.047096) | 0.463722 / 0.540337 (-0.076616) | 0.553681 / 1.386936 (-0.833255) |\n\n</details>\n</details>\n\n\n"
] | 2023-03-01T13:54:06 | 2023-03-02T13:47:13 | 2023-03-02T13:40:17 | MEMBER | null | As reported in https://github.com/vijaydwivedi75/lrgb/issues/10, `push_to_hub` fails if the remote repository already exists and has a README.md without `dataset_info` in the YAML tags
cc @clefourrier | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5598/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5598/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5598",
"html_url": "https://github.com/huggingface/datasets/pull/5598",
"diff_url": "https://github.com/huggingface/datasets/pull/5598.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5598.patch",
"merged_at": "2023-03-02T13:40:17"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url": "https://api.github.com/users/speedcell4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/speedcell4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/speedcell4/subscriptions",
"organizations_url": "https://api.github.com/users/speedcell4/orgs",
"repos_url": "https://api.github.com/users/speedcell4/repos",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"received_events_url": "https://api.github.com/users/speedcell4/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not loaded in memory, and therefore the new dataset actually use the same buffers as the old one.",
"Thank you for your detailed reply.\r\n\r\n> In your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nI understand this, but it still copies the old dataset to create the new one, is this correct? So maybe it is not memory-consuming, but time-consuming?",
"Indeed, and because of that it is more efficient to add multiple rows at once instead of one by one, using `concatenate_datasets` for example."
] | 2023-03-01T12:58:18 | 2023-03-02T13:30:41 | 2023-03-02T03:47:00 | NONE | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Dataset.from_list([])
ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: [],
>>> num_rows: 0
>>> })
ds = ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: ['a', 'b'],
>>> num_rows: 1
>>> })
```
### Feature request
Call for in-place dataset update functions, that update the existing `Dataset` in place without creating a new copy. The interface is supposed to keep the same style as PyTorch, such as the in-place version of a `function` is named `function_`. For example, the in-pace version of `add_item`, i.e., `add_item_`, immediately updates the `Dataset`.
```python
from datasets import Dataset
ds = Dataset.from_list([])
ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: [],
>>> num_rows: 0
>>> })
ds.add_item_({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: ['a', 'b'],
>>> num_rows: 1
>>> })
```
### Related Functions
* `.map`
* `.filter`
* `.add_item` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated the dataset to remove the extra `labels` field from some files, closing this issue. Thanks!"
] | 2023-03-01T12:53:08 | 2023-03-02T11:12:11 | 2023-03-02T11:12:11 | NONE | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wrapper
return func(array, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 2132, in cast_array_to_feature
raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
TypeError: Couldn't cast array of type
struct<type: string, action: string, datetime: timestamp[s], author: string, title: string, description: string, comment_id: int64, comment: string, labels: list<item: string>>
to
{'type': Value(dtype='string', id=None), 'action': Value(dtype='string', id=None), 'datetime': Value(dtype='timestamp[s]', id=None), 'author': Value(dtype='string', id=None), 'title': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'comment_id': Value(dtype='int64', id=None), 'comment': Value(dtype='string', id=None)}
```
But I can succesfully load a subset of the dataset, for example this works:
```python
ds = load_dataset('bigcode-data/the-stack-gh-issues', split="train", data_files=[f"data/data-{x}.jsonl" for x in range(10)])
```
and `ds.features` returns:
```
{'repo': Value(dtype='string', id=None),
'org': Value(dtype='string', id=None),
'issue_id': Value(dtype='int64', id=None),
'issue_number': Value(dtype='int64', id=None),
'pull_request': {'user_login': Value(dtype='string', id=None),
'repo': Value(dtype='string', id=None),
'number': Value(dtype='int64', id=None)},
'events': [{'type': Value(dtype='string', id=None),
'action': Value(dtype='string', id=None),
'datetime': Value(dtype='timestamp[s]', id=None),
'author': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None),
'description': Value(dtype='string', id=None),
'comment_id': Value(dtype='int64', id=None),
'comment': Value(dtype='string', id=None)}]}
```
So I'm not sure if there's an issue with just some of the files. Grateful if you have any suggestions to fix the issue.
Side note:
I saw this related [issue](https://github.com/huggingface/datasets/issues/3637) and tried to write a loading script to have `events` as a `Sequence` and not `list` [here](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues/blob/main/loading.py) (the script was renamed). It worked with a subset locally but doesn't for the remote dataset it can't find https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues/resolve/main/data.
### Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset('bigcode-data/the-stack-gh-issues', split="train")
```
### Expected behavior
Load the entire dataset succesfully.
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- PyArrow version: 9.0.0
- Pandas version: 1.3.4 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5595/comments | https://api.github.com/repos/huggingface/datasets/issues/5595/events | https://github.com/huggingface/datasets/pull/5595 | 1,604,070,629 | PR_kwDODunzps5K--V9 | 5,595 | Unpins sqlAlchemy | {
"login": "lazarust",
"id": 46943923,
"node_id": "MDQ6VXNlcjQ2OTQzOTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/46943923?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lazarust",
"html_url": "https://github.com/lazarust",
"followers_url": "https://api.github.com/users/lazarust/followers",
"following_url": "https://api.github.com/users/lazarust/following{/other_user}",
"gists_url": "https://api.github.com/users/lazarust/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lazarust/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lazarust/subscriptions",
"organizations_url": "https://api.github.com/users/lazarust/orgs",
"repos_url": "https://api.github.com/users/lazarust/repos",
"events_url": "https://api.github.com/users/lazarust/events{/privacy}",
"received_events_url": "https://api.github.com/users/lazarust/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5595). All of your documentation changes will be reflected on that endpoint."
] | 2023-03-01T01:33:45 | 2023-03-03T16:44:09 | null | NONE | null | Closes #5477 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5595/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5595",
"html_url": "https://github.com/huggingface/datasets/pull/5595",
"diff_url": "https://github.com/huggingface/datasets/pull/5595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5595.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"login": "simran-khanuja",
"id": 24687672,
"node_id": "MDQ6VXNlcjI0Njg3Njcy",
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simran-khanuja",
"html_url": "https://github.com/simran-khanuja",
"followers_url": "https://api.github.com/users/simran-khanuja/followers",
"following_url": "https://api.github.com/users/simran-khanuja/following{/other_user}",
"gists_url": "https://api.github.com/users/simran-khanuja/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simran-khanuja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simran-khanuja/subscriptions",
"organizations_url": "https://api.github.com/users/simran-khanuja/orgs",
"repos_url": "https://api.github.com/users/simran-khanuja/repos",
"events_url": "https://api.github.com/users/simran-khanuja/events{/privacy}",
"received_events_url": "https://api.github.com/users/simran-khanuja/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi! I cannot reproduce this error on my machine.\r\n\r\nThe raised error could mean that one of the downloaded files is corrupted. To verify this is not the case, you can run `load_dataset` as follows:\r\n```python\r\ntrain_dataset = load_dataset('xtreme', 'udpos.English', split=\"train\", cache_dir=args.cache_dir, download_mode=\"force_redownload\", verification_mode=\"all_checks\")\r\n```"
] | 2023-02-28T23:40:53 | 2023-03-01T22:07:07 | null | NONE | null | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1095448aad0713b425bdc1ff9a4a128a56e4...
Downloading data: 16%|██████████████▏ | 56.9M/355M [03:11<16:43, 297kB/s]
Generating train split: 0%| | 0/6075 [00:00<?, ? examples/s]Traceback (most recent call last):
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 1608, in _prepare_split_single
for key, record in generator:
File "/home/skhanuja/.cache/huggingface/modules/datasets_modules/datasets/xtreme/29f5d57a48779f37ccb75cb8708d1095448aad0713b425bdc1ff9a4a128a56e4/xtreme.py", line 732, in _generate_examples
yield from UdposParser.generate_examples(config=self.config, filepath=filepath, **kwargs)
File "/home/skhanuja/.cache/huggingface/modules/datasets_modules/datasets/xtreme/29f5d57a48779f37ccb75cb8708d1095448aad0713b425bdc1ff9a4a128a56e4/xtreme.py", line 921, in generate_examples
for path, file in filepath:
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/download/download_manager.py", line 158, in __iter__
yield from self.generator(*self.args, **self.kwargs)
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/download/download_manager.py", line 211, in _iter_from_path
yield from cls._iter_tar(f)
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/download/download_manager.py", line 167, in _iter_tar
for tarinfo in stream:
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/tarfile.py", line 2475, in __iter__
tarinfo = self.next()
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/tarfile.py", line 2344, in next
raise ReadError("unexpected end of data")
tarfile.ReadError: unexpected end of data
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/skhanuja/Optimal-Resource-Allocation-for-Multilingual-Finetuning/src/train_al.py", line 855, in <module>
main()
File "/home/skhanuja/Optimal-Resource-Allocation-for-Multilingual-Finetuning/src/train_al.py", line 487, in main
train_dataset = load_dataset(dataset_name, source_language, split="train", cache_dir=args.cache_dir, download_mode="force_redownload")
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/load.py", line 1782, in load_dataset
builder_instance.download_and_prepare(
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 872, in download_and_prepare
self._download_and_prepare(
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 1649, in _download_and_prepare
super()._download_and_prepare(
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 967, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 1488, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/skhanuja/miniconda3/envs/multilingual_ft/lib/python3.10/site-packages/datasets/builder.py", line 1644, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
```
### Steps to reproduce the bug
```
train_dataset = load_dataset('xtreme', 'udpos.English', split="train", cache_dir=args.cache_dir, download_mode="force_redownload")
```
### Expected behavior
Download the udpos dataset
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-3.10.0-957.1.3.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5592/comments | https://api.github.com/repos/huggingface/datasets/issues/5592/events | https://github.com/huggingface/datasets/pull/5592 | 1,603,619,124 | PR_kwDODunzps5K9dWr | 5,592 | Fix docstring example | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009526 / 0.011353 (-0.001827) | 0.005132 / 0.011008 (-0.005876) | 0.101312 / 0.038508 (0.062804) | 0.035703 / 0.023109 (0.012594) | 0.301788 / 0.275898 (0.025890) | 0.368411 / 0.323480 (0.044932) | 0.008163 / 0.007986 (0.000177) | 0.005462 / 0.004328 (0.001134) | 0.077282 / 0.004250 (0.073031) | 0.044139 / 0.037052 (0.007086) | 0.312280 / 0.258489 (0.053791) | 0.351870 / 0.293841 (0.058029) | 0.038266 / 0.128546 (-0.090281) | 0.012051 / 0.075646 (-0.063595) | 0.335109 / 0.419271 (-0.084163) | 0.047596 / 0.043533 (0.004064) | 0.300931 / 0.255139 (0.045792) | 0.325705 / 0.283200 (0.042505) | 0.100472 / 0.141683 (-0.041211) | 1.475037 / 1.452155 (0.022882) | 1.520059 / 1.492716 (0.027343) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211096 / 0.018006 (0.193089) | 0.442988 / 0.000490 (0.442498) | 0.003644 / 0.000200 (0.003444) | 0.000090 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027492 / 0.037411 (-0.009919) | 0.108981 / 0.014526 (0.094455) | 0.117836 / 0.176557 (-0.058720) | 0.161220 / 0.737135 (-0.575915) | 0.124765 / 0.296338 (-0.171574) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413480 / 0.215209 (0.198271) | 4.111355 / 2.077655 (2.033700) | 1.933024 / 1.504120 (0.428904) | 1.727467 / 1.541195 (0.186272) | 1.827106 / 1.468490 (0.358616) | 0.688209 / 4.584777 (-3.896568) | 3.759672 / 3.745712 (0.013960) | 2.163806 / 5.269862 (-3.106056) | 1.473521 / 4.565676 (-3.092155) | 0.082859 / 0.424275 (-0.341416) | 0.012320 / 0.007607 (0.004713) | 0.515321 / 0.226044 (0.289277) | 5.158651 / 2.268929 (2.889722) | 2.489123 / 55.444624 (-52.955501) | 2.218910 / 6.876477 (-4.657566) | 2.257306 / 2.142072 (0.115233) | 0.861477 / 4.805227 (-3.943750) | 0.165857 / 6.500664 (-6.334807) | 0.063723 / 0.075469 (-0.011746) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.195163 / 1.841788 (-0.646625) | 14.954518 / 8.074308 (6.880210) | 14.272289 / 10.191392 (4.080897) | 0.167420 / 0.680424 (-0.513004) | 0.028907 / 0.534201 (-0.505294) | 0.450117 / 0.579283 (-0.129166) | 0.448532 / 0.434364 (0.014168) | 0.534406 / 0.540337 (-0.005931) | 0.633468 / 1.386936 (-0.753468) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007658 / 0.011353 (-0.003694) | 0.005266 / 0.011008 (-0.005742) | 0.075293 / 0.038508 (0.036785) | 0.034442 / 0.023109 (0.011333) | 0.346558 / 0.275898 (0.070660) | 0.391496 / 0.323480 (0.068017) | 0.005852 / 0.007986 (-0.002133) | 0.004121 / 0.004328 (-0.000207) | 0.074254 / 0.004250 (0.070004) | 0.048361 / 0.037052 (0.011309) | 0.344613 / 0.258489 (0.086124) | 0.401497 / 0.293841 (0.107656) | 0.037243 / 0.128546 (-0.091303) | 0.012505 / 0.075646 (-0.063142) | 0.087188 / 0.419271 (-0.332084) | 0.050114 / 0.043533 (0.006581) | 0.340454 / 0.255139 (0.085315) | 0.361087 / 0.283200 (0.077887) | 0.104692 / 0.141683 (-0.036991) | 1.419432 / 1.452155 (-0.032722) | 1.524709 / 1.492716 (0.031993) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231820 / 0.018006 (0.213814) | 0.445791 / 0.000490 (0.445301) | 0.000442 / 0.000200 (0.000242) | 0.000061 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030445 / 0.037411 (-0.006967) | 0.111183 / 0.014526 (0.096657) | 0.123494 / 0.176557 (-0.053063) | 0.173121 / 0.737135 (-0.564014) | 0.124968 / 0.296338 (-0.171371) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428854 / 0.215209 (0.213645) | 4.270262 / 2.077655 (2.192608) | 2.012075 / 1.504120 (0.507955) | 1.826564 / 1.541195 (0.285370) | 1.931699 / 1.468490 (0.463209) | 0.728762 / 4.584777 (-3.856015) | 3.879640 / 3.745712 (0.133928) | 3.325715 / 5.269862 (-1.944147) | 1.818573 / 4.565676 (-2.747104) | 0.087879 / 0.424275 (-0.336396) | 0.012530 / 0.007607 (0.004923) | 0.530249 / 0.226044 (0.304204) | 5.286110 / 2.268929 (3.017181) | 2.566649 / 55.444624 (-52.877975) | 2.210162 / 6.876477 (-4.666315) | 2.297562 / 2.142072 (0.155490) | 0.906161 / 4.805227 (-3.899066) | 0.171914 / 6.500664 (-6.328750) | 0.064182 / 0.075469 (-0.011287) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285781 / 1.841788 (-0.556006) | 16.159072 / 8.074308 (8.084763) | 14.087492 / 10.191392 (3.896100) | 0.148789 / 0.680424 (-0.531635) | 0.018078 / 0.534201 (-0.516123) | 0.427748 / 0.579283 (-0.151535) | 0.447079 / 0.434364 (0.012715) | 0.535917 / 0.540337 (-0.004421) | 0.627491 / 1.386936 (-0.759445) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-28T18:42:37 | 2023-02-28T19:26:33 | 2023-02-28T19:19:15 | MEMBER | null | Fixes #5581 to use the correct output for the `set_format` method. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5592/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5592",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"merged_at": "2023-02-28T19:19:15"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5591/comments | https://api.github.com/repos/huggingface/datasets/issues/5591/events | https://github.com/huggingface/datasets/pull/5591 | 1,603,571,407 | PR_kwDODunzps5K9S79 | 5,591 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5591). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008826 / 0.011353 (-0.002527) | 0.004595 / 0.011008 (-0.006413) | 0.103387 / 0.038508 (0.064879) | 0.030241 / 0.023109 (0.007132) | 0.351202 / 0.275898 (0.075303) | 0.417601 / 0.323480 (0.094121) | 0.007121 / 0.007986 (-0.000865) | 0.003497 / 0.004328 (-0.000831) | 0.079256 / 0.004250 (0.075006) | 0.037617 / 0.037052 (0.000564) | 0.380542 / 0.258489 (0.122053) | 0.397863 / 0.293841 (0.104022) | 0.034291 / 0.128546 (-0.094255) | 0.011767 / 0.075646 (-0.063879) | 0.323737 / 0.419271 (-0.095534) | 0.041502 / 0.043533 (-0.002031) | 0.352982 / 0.255139 (0.097843) | 0.378618 / 0.283200 (0.095418) | 0.091671 / 0.141683 (-0.050012) | 1.499278 / 1.452155 (0.047123) | 1.517489 / 1.492716 (0.024773) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.190108 / 0.018006 (0.172102) | 0.414404 / 0.000490 (0.413915) | 0.001064 / 0.000200 (0.000864) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023214 / 0.037411 (-0.014198) | 0.099351 / 0.014526 (0.084825) | 0.105227 / 0.176557 (-0.071330) | 0.150620 / 0.737135 (-0.586516) | 0.109323 / 0.296338 (-0.187015) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412463 / 0.215209 (0.197254) | 4.138123 / 2.077655 (2.060469) | 1.845163 / 1.504120 (0.341043) | 1.641108 / 1.541195 (0.099913) | 1.715471 / 1.468490 (0.246981) | 0.697397 / 4.584777 (-3.887380) | 3.449829 / 3.745712 (-0.295883) | 1.959309 / 5.269862 (-3.310553) | 1.285754 / 4.565676 (-3.279923) | 0.082746 / 0.424275 (-0.341529) | 0.012523 / 0.007607 (0.004916) | 0.524745 / 0.226044 (0.298700) | 5.257085 / 2.268929 (2.988156) | 2.293163 / 55.444624 (-53.151461) | 1.958309 / 6.876477 (-4.918168) | 2.016106 / 2.142072 (-0.125966) | 0.814359 / 4.805227 (-3.990869) | 0.149443 / 6.500664 (-6.351221) | 0.066013 / 0.075469 (-0.009456) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.248495 / 1.841788 (-0.593292) | 14.303301 / 8.074308 (6.228993) | 14.238533 / 10.191392 (4.047141) | 0.161421 / 0.680424 (-0.519003) | 0.028779 / 0.534201 (-0.505422) | 0.396511 / 0.579283 (-0.182772) | 0.412784 / 0.434364 (-0.021580) | 0.473984 / 0.540337 (-0.066353) | 0.569610 / 1.386936 (-0.817327) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007003 / 0.011353 (-0.004350) | 0.004621 / 0.011008 (-0.006387) | 0.079418 / 0.038508 (0.040910) | 0.028659 / 0.023109 (0.005550) | 0.340594 / 0.275898 (0.064696) | 0.377972 / 0.323480 (0.054492) | 0.005421 / 0.007986 (-0.002565) | 0.004852 / 0.004328 (0.000523) | 0.077579 / 0.004250 (0.073329) | 0.042662 / 0.037052 (0.005610) | 0.342264 / 0.258489 (0.083775) | 0.387255 / 0.293841 (0.093414) | 0.032574 / 0.128546 (-0.095972) | 0.011820 / 0.075646 (-0.063826) | 0.087960 / 0.419271 (-0.331312) | 0.045199 / 0.043533 (0.001667) | 0.341785 / 0.255139 (0.086646) | 0.365014 / 0.283200 (0.081814) | 0.096129 / 0.141683 (-0.045554) | 1.498962 / 1.452155 (0.046807) | 1.557331 / 1.492716 (0.064615) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236216 / 0.018006 (0.218210) | 0.440189 / 0.000490 (0.439699) | 0.000399 / 0.000200 (0.000199) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026357 / 0.037411 (-0.011055) | 0.104485 / 0.014526 (0.089959) | 0.109616 / 0.176557 (-0.066941) | 0.163005 / 0.737135 (-0.574130) | 0.113859 / 0.296338 (-0.182479) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437452 / 0.215209 (0.222243) | 4.371854 / 2.077655 (2.294199) | 2.056845 / 1.504120 (0.552725) | 1.856071 / 1.541195 (0.314876) | 1.957978 / 1.468490 (0.489488) | 0.703171 / 4.584777 (-3.881606) | 3.433889 / 3.745712 (-0.311823) | 1.968321 / 5.269862 (-3.301541) | 1.204947 / 4.565676 (-3.360729) | 0.084499 / 0.424275 (-0.339777) | 0.012729 / 0.007607 (0.005122) | 0.537534 / 0.226044 (0.311490) | 5.383346 / 2.268929 (3.114417) | 2.522136 / 55.444624 (-52.922488) | 2.192715 / 6.876477 (-4.683762) | 2.243579 / 2.142072 (0.101507) | 0.811136 / 4.805227 (-3.994091) | 0.154015 / 6.500664 (-6.346649) | 0.069324 / 0.075469 (-0.006145) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294232 / 1.841788 (-0.547556) | 14.809448 / 8.074308 (6.735140) | 13.510074 / 10.191392 (3.318682) | 0.158033 / 0.680424 (-0.522391) | 0.016703 / 0.534201 (-0.517498) | 0.393976 / 0.579283 (-0.185307) | 0.385983 / 0.434364 (-0.048381) | 0.476691 / 0.540337 (-0.063646) | 0.565694 / 1.386936 (-0.821242) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009155 / 0.011353 (-0.002198) | 0.005227 / 0.011008 (-0.005781) | 0.099767 / 0.038508 (0.061259) | 0.035338 / 0.023109 (0.012229) | 0.293913 / 0.275898 (0.018015) | 0.366976 / 0.323480 (0.043496) | 0.007802 / 0.007986 (-0.000184) | 0.005286 / 0.004328 (0.000958) | 0.075117 / 0.004250 (0.070867) | 0.042336 / 0.037052 (0.005284) | 0.304690 / 0.258489 (0.046201) | 0.343496 / 0.293841 (0.049655) | 0.038745 / 0.128546 (-0.089802) | 0.012275 / 0.075646 (-0.063371) | 0.334455 / 0.419271 (-0.084817) | 0.052611 / 0.043533 (0.009078) | 0.293229 / 0.255139 (0.038090) | 0.314340 / 0.283200 (0.031140) | 0.108676 / 0.141683 (-0.033007) | 1.444495 / 1.452155 (-0.007659) | 1.492244 / 1.492716 (-0.000472) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204852 / 0.018006 (0.186846) | 0.438202 / 0.000490 (0.437712) | 0.005043 / 0.000200 (0.004843) | 0.000282 / 0.000054 (0.000228) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027268 / 0.037411 (-0.010143) | 0.109497 / 0.014526 (0.094972) | 0.117187 / 0.176557 (-0.059369) | 0.162551 / 0.737135 (-0.574584) | 0.124175 / 0.296338 (-0.172164) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401667 / 0.215209 (0.186458) | 4.010274 / 2.077655 (1.932619) | 1.882617 / 1.504120 (0.378497) | 1.721960 / 1.541195 (0.180765) | 1.806874 / 1.468490 (0.338384) | 0.711253 / 4.584777 (-3.873524) | 3.806585 / 3.745712 (0.060873) | 3.713011 / 5.269862 (-1.556851) | 1.896558 / 4.565676 (-2.669119) | 0.086092 / 0.424275 (-0.338184) | 0.012129 / 0.007607 (0.004522) | 0.504905 / 0.226044 (0.278861) | 5.050794 / 2.268929 (2.781865) | 2.324331 / 55.444624 (-53.120293) | 2.020170 / 6.876477 (-4.856307) | 2.079685 / 2.142072 (-0.062388) | 0.854782 / 4.805227 (-3.950445) | 0.166754 / 6.500664 (-6.333910) | 0.062434 / 0.075469 (-0.013035) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.187897 / 1.841788 (-0.653891) | 14.618517 / 8.074308 (6.544209) | 13.205760 / 10.191392 (3.014368) | 0.154322 / 0.680424 (-0.526102) | 0.029243 / 0.534201 (-0.504958) | 0.442390 / 0.579283 (-0.136893) | 0.434651 / 0.434364 (0.000287) | 0.523082 / 0.540337 (-0.017256) | 0.602675 / 1.386936 (-0.784261) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007214 / 0.011353 (-0.004139) | 0.005225 / 0.011008 (-0.005783) | 0.076497 / 0.038508 (0.037989) | 0.032761 / 0.023109 (0.009652) | 0.336005 / 0.275898 (0.060107) | 0.373547 / 0.323480 (0.050067) | 0.005460 / 0.007986 (-0.002526) | 0.003933 / 0.004328 (-0.000395) | 0.074540 / 0.004250 (0.070289) | 0.047785 / 0.037052 (0.010733) | 0.341917 / 0.258489 (0.083428) | 0.396978 / 0.293841 (0.103137) | 0.036763 / 0.128546 (-0.091783) | 0.012043 / 0.075646 (-0.063603) | 0.087632 / 0.419271 (-0.331640) | 0.049376 / 0.043533 (0.005843) | 0.335169 / 0.255139 (0.080030) | 0.354852 / 0.283200 (0.071652) | 0.100180 / 0.141683 (-0.041503) | 1.443422 / 1.452155 (-0.008733) | 1.518618 / 1.492716 (0.025901) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209593 / 0.018006 (0.191587) | 0.444028 / 0.000490 (0.443538) | 0.004545 / 0.000200 (0.004345) | 0.000100 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029676 / 0.037411 (-0.007735) | 0.115444 / 0.014526 (0.100918) | 0.121765 / 0.176557 (-0.054791) | 0.171037 / 0.737135 (-0.566098) | 0.128592 / 0.296338 (-0.167746) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.428556 / 0.215209 (0.213347) | 4.228531 / 2.077655 (2.150877) | 2.039190 / 1.504120 (0.535070) | 1.836518 / 1.541195 (0.295324) | 1.897040 / 1.468490 (0.428550) | 0.698893 / 4.584777 (-3.885884) | 3.753998 / 3.745712 (0.008286) | 2.097731 / 5.269862 (-3.172131) | 1.338315 / 4.565676 (-3.227361) | 0.087119 / 0.424275 (-0.337156) | 0.012149 / 0.007607 (0.004542) | 0.520774 / 0.226044 (0.294730) | 5.227420 / 2.268929 (2.958492) | 2.522235 / 55.444624 (-52.922389) | 2.194213 / 6.876477 (-4.682264) | 2.241406 / 2.142072 (0.099333) | 0.843119 / 4.805227 (-3.962109) | 0.169128 / 6.500664 (-6.331536) | 0.065071 / 0.075469 (-0.010398) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254490 / 1.841788 (-0.587298) | 15.037137 / 8.074308 (6.962829) | 13.115333 / 10.191392 (2.923941) | 0.181743 / 0.680424 (-0.498681) | 0.017748 / 0.534201 (-0.516453) | 0.425758 / 0.579283 (-0.153525) | 0.429926 / 0.434364 (-0.004438) | 0.524386 / 0.540337 (-0.015951) | 0.643044 / 1.386936 (-0.743892) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-28T18:09:05 | 2023-02-28T18:16:31 | 2023-02-28T18:09:15 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5591/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5591",
"html_url": "https://github.com/huggingface/datasets/pull/5591",
"diff_url": "https://github.com/huggingface/datasets/pull/5591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5591.patch",
"merged_at": "2023-02-28T18:09:15"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5590/comments | https://api.github.com/repos/huggingface/datasets/issues/5590/events | https://github.com/huggingface/datasets/pull/5590 | 1,603,549,504 | PR_kwDODunzps5K9N_H | 5,590 | Release: 2.10.1 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008717 / 0.011353 (-0.002636) | 0.004570 / 0.011008 (-0.006439) | 0.100228 / 0.038508 (0.061720) | 0.030076 / 0.023109 (0.006967) | 0.317919 / 0.275898 (0.042021) | 0.366360 / 0.323480 (0.042880) | 0.007008 / 0.007986 (-0.000978) | 0.003498 / 0.004328 (-0.000831) | 0.077607 / 0.004250 (0.073356) | 0.036106 / 0.037052 (-0.000946) | 0.314128 / 0.258489 (0.055639) | 0.351450 / 0.293841 (0.057609) | 0.033697 / 0.128546 (-0.094849) | 0.011424 / 0.075646 (-0.064222) | 0.323867 / 0.419271 (-0.095404) | 0.042073 / 0.043533 (-0.001460) | 0.304564 / 0.255139 (0.049425) | 0.334865 / 0.283200 (0.051665) | 0.087791 / 0.141683 (-0.053892) | 1.488075 / 1.452155 (0.035920) | 1.513676 / 1.492716 (0.020959) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010936 / 0.018006 (-0.007070) | 0.409610 / 0.000490 (0.409121) | 0.004820 / 0.000200 (0.004620) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023931 / 0.037411 (-0.013481) | 0.096826 / 0.014526 (0.082300) | 0.105764 / 0.176557 (-0.070792) | 0.153241 / 0.737135 (-0.583895) | 0.108976 / 0.296338 (-0.187363) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412833 / 0.215209 (0.197624) | 4.129735 / 2.077655 (2.052081) | 1.819049 / 1.504120 (0.314929) | 1.617411 / 1.541195 (0.076216) | 1.682353 / 1.468490 (0.213863) | 0.688987 / 4.584777 (-3.895790) | 3.388276 / 3.745712 (-0.357436) | 1.857452 / 5.269862 (-3.412410) | 1.158020 / 4.565676 (-3.407657) | 0.082161 / 0.424275 (-0.342114) | 0.012319 / 0.007607 (0.004712) | 0.523052 / 0.226044 (0.297008) | 5.237726 / 2.268929 (2.968797) | 2.275605 / 55.444624 (-53.169020) | 1.931664 / 6.876477 (-4.944813) | 1.970026 / 2.142072 (-0.172046) | 0.805240 / 4.805227 (-3.999988) | 0.148431 / 6.500664 (-6.352233) | 0.064707 / 0.075469 (-0.010762) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.196456 / 1.841788 (-0.645332) | 13.750113 / 8.074308 (5.675805) | 13.853543 / 10.191392 (3.662151) | 0.137892 / 0.680424 (-0.542532) | 0.028304 / 0.534201 (-0.505897) | 0.400128 / 0.579283 (-0.179155) | 0.410409 / 0.434364 (-0.023955) | 0.479165 / 0.540337 (-0.061172) | 0.575002 / 1.386936 (-0.811934) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006587 / 0.011353 (-0.004766) | 0.004526 / 0.011008 (-0.006482) | 0.075673 / 0.038508 (0.037165) | 0.027429 / 0.023109 (0.004320) | 0.341808 / 0.275898 (0.065910) | 0.379520 / 0.323480 (0.056040) | 0.004972 / 0.007986 (-0.003014) | 0.003354 / 0.004328 (-0.000975) | 0.075373 / 0.004250 (0.071123) | 0.038347 / 0.037052 (0.001294) | 0.343671 / 0.258489 (0.085181) | 0.389632 / 0.293841 (0.095791) | 0.031694 / 0.128546 (-0.096853) | 0.011458 / 0.075646 (-0.064188) | 0.084210 / 0.419271 (-0.335062) | 0.042662 / 0.043533 (-0.000871) | 0.339436 / 0.255139 (0.084297) | 0.367493 / 0.283200 (0.084294) | 0.091604 / 0.141683 (-0.050079) | 1.526762 / 1.452155 (0.074607) | 1.569110 / 1.492716 (0.076394) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211496 / 0.018006 (0.193489) | 0.404868 / 0.000490 (0.404379) | 0.004267 / 0.000200 (0.004067) | 0.000083 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025189 / 0.037411 (-0.012222) | 0.099139 / 0.014526 (0.084613) | 0.105898 / 0.176557 (-0.070659) | 0.160997 / 0.737135 (-0.576138) | 0.110158 / 0.296338 (-0.186180) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444286 / 0.215209 (0.229077) | 4.445479 / 2.077655 (2.367824) | 2.118920 / 1.504120 (0.614800) | 1.908296 / 1.541195 (0.367102) | 1.947211 / 1.468490 (0.478721) | 0.704850 / 4.584777 (-3.879927) | 3.395990 / 3.745712 (-0.349723) | 1.892529 / 5.269862 (-3.377332) | 1.172190 / 4.565676 (-3.393486) | 0.084235 / 0.424275 (-0.340040) | 0.012588 / 0.007607 (0.004981) | 0.546962 / 0.226044 (0.320918) | 5.475842 / 2.268929 (3.206913) | 2.575280 / 55.444624 (-52.869344) | 2.245658 / 6.876477 (-4.630818) | 2.274767 / 2.142072 (0.132695) | 0.813755 / 4.805227 (-3.991473) | 0.151927 / 6.500664 (-6.348737) | 0.067167 / 0.075469 (-0.008302) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.267666 / 1.841788 (-0.574122) | 13.658905 / 8.074308 (5.584597) | 13.207249 / 10.191392 (3.015857) | 0.128590 / 0.680424 (-0.551833) | 0.016531 / 0.534201 (-0.517670) | 0.385050 / 0.579283 (-0.194233) | 0.388945 / 0.434364 (-0.045419) | 0.472378 / 0.540337 (-0.067959) | 0.568929 / 1.386936 (-0.818007) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009339 / 0.011353 (-0.002014) | 0.005197 / 0.011008 (-0.005811) | 0.100698 / 0.038508 (0.062190) | 0.035484 / 0.023109 (0.012375) | 0.299030 / 0.275898 (0.023132) | 0.366603 / 0.323480 (0.043124) | 0.007909 / 0.007986 (-0.000077) | 0.005683 / 0.004328 (0.001355) | 0.077719 / 0.004250 (0.073469) | 0.042147 / 0.037052 (0.005094) | 0.310174 / 0.258489 (0.051685) | 0.342720 / 0.293841 (0.048879) | 0.039679 / 0.128546 (-0.088867) | 0.012042 / 0.075646 (-0.063605) | 0.335663 / 0.419271 (-0.083609) | 0.051137 / 0.043533 (0.007604) | 0.298218 / 0.255139 (0.043079) | 0.316398 / 0.283200 (0.033198) | 0.108906 / 0.141683 (-0.032776) | 1.422823 / 1.452155 (-0.029331) | 1.472955 / 1.492716 (-0.019761) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.205845 / 0.018006 (0.187839) | 0.445942 / 0.000490 (0.445453) | 0.003553 / 0.000200 (0.003353) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025506 / 0.037411 (-0.011906) | 0.107494 / 0.014526 (0.092969) | 0.116226 / 0.176557 (-0.060331) | 0.157313 / 0.737135 (-0.579822) | 0.123822 / 0.296338 (-0.172516) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400908 / 0.215209 (0.185699) | 3.980232 / 2.077655 (1.902578) | 1.805410 / 1.504120 (0.301290) | 1.615698 / 1.541195 (0.074503) | 1.677213 / 1.468490 (0.208723) | 0.697882 / 4.584777 (-3.886895) | 3.752781 / 3.745712 (0.007069) | 2.076062 / 5.269862 (-3.193800) | 1.446909 / 4.565676 (-3.118768) | 0.084572 / 0.424275 (-0.339703) | 0.011917 / 0.007607 (0.004310) | 0.511815 / 0.226044 (0.285771) | 5.121487 / 2.268929 (2.852558) | 2.277642 / 55.444624 (-53.166982) | 1.930393 / 6.876477 (-4.946084) | 1.965855 / 2.142072 (-0.176218) | 0.843391 / 4.805227 (-3.961837) | 0.163581 / 6.500664 (-6.337083) | 0.062547 / 0.075469 (-0.012922) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.223930 / 1.841788 (-0.617858) | 14.354466 / 8.074308 (6.280158) | 14.015159 / 10.191392 (3.823767) | 0.148658 / 0.680424 (-0.531766) | 0.028469 / 0.534201 (-0.505732) | 0.437614 / 0.579283 (-0.141669) | 0.435452 / 0.434364 (0.001089) | 0.523623 / 0.540337 (-0.016715) | 0.625109 / 1.386936 (-0.761827) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006917 / 0.011353 (-0.004436) | 0.005080 / 0.011008 (-0.005928) | 0.075806 / 0.038508 (0.037298) | 0.032402 / 0.023109 (0.009293) | 0.331105 / 0.275898 (0.055207) | 0.361226 / 0.323480 (0.037746) | 0.005694 / 0.007986 (-0.002292) | 0.003810 / 0.004328 (-0.000518) | 0.076886 / 0.004250 (0.072635) | 0.046158 / 0.037052 (0.009106) | 0.338791 / 0.258489 (0.080302) | 0.385733 / 0.293841 (0.091892) | 0.035590 / 0.128546 (-0.092956) | 0.011997 / 0.075646 (-0.063649) | 0.087854 / 0.419271 (-0.331417) | 0.048985 / 0.043533 (0.005452) | 0.331248 / 0.255139 (0.076109) | 0.354633 / 0.283200 (0.071434) | 0.101609 / 0.141683 (-0.040074) | 1.496899 / 1.452155 (0.044745) | 1.570469 / 1.492716 (0.077753) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.180871 / 0.018006 (0.162865) | 0.449417 / 0.000490 (0.448928) | 0.004300 / 0.000200 (0.004100) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029054 / 0.037411 (-0.008358) | 0.110888 / 0.014526 (0.096362) | 0.121736 / 0.176557 (-0.054821) | 0.172563 / 0.737135 (-0.564572) | 0.126565 / 0.296338 (-0.169773) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419545 / 0.215209 (0.204336) | 4.193685 / 2.077655 (2.116031) | 2.049967 / 1.504120 (0.545847) | 1.855038 / 1.541195 (0.313843) | 1.899822 / 1.468490 (0.431332) | 0.709123 / 4.584777 (-3.875654) | 3.795939 / 3.745712 (0.050227) | 2.076055 / 5.269862 (-3.193807) | 1.335864 / 4.565676 (-3.229812) | 0.085555 / 0.424275 (-0.338720) | 0.012197 / 0.007607 (0.004590) | 0.516164 / 0.226044 (0.290119) | 5.158983 / 2.268929 (2.890054) | 2.445581 / 55.444624 (-52.999044) | 2.122256 / 6.876477 (-4.754221) | 2.160011 / 2.142072 (0.017939) | 0.840251 / 4.805227 (-3.964976) | 0.165924 / 6.500664 (-6.334740) | 0.064080 / 0.075469 (-0.011389) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285292 / 1.841788 (-0.556495) | 14.561084 / 8.074308 (6.486776) | 12.899269 / 10.191392 (2.707877) | 0.185657 / 0.680424 (-0.494767) | 0.017866 / 0.534201 (-0.516335) | 0.425365 / 0.579283 (-0.153918) | 0.427183 / 0.434364 (-0.007181) | 0.529773 / 0.540337 (-0.010564) | 0.642061 / 1.386936 (-0.744875) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008995 / 0.011353 (-0.002357) | 0.004540 / 0.011008 (-0.006469) | 0.099675 / 0.038508 (0.061167) | 0.030338 / 0.023109 (0.007229) | 0.307167 / 0.275898 (0.031269) | 0.338789 / 0.323480 (0.015309) | 0.007293 / 0.007986 (-0.000692) | 0.004681 / 0.004328 (0.000352) | 0.077475 / 0.004250 (0.073225) | 0.036399 / 0.037052 (-0.000654) | 0.304615 / 0.258489 (0.046126) | 0.351611 / 0.293841 (0.057770) | 0.034449 / 0.128546 (-0.094097) | 0.011565 / 0.075646 (-0.064082) | 0.322765 / 0.419271 (-0.096506) | 0.041971 / 0.043533 (-0.001562) | 0.307492 / 0.255139 (0.052354) | 0.327240 / 0.283200 (0.044040) | 0.087110 / 0.141683 (-0.054573) | 1.484600 / 1.452155 (0.032445) | 1.536651 / 1.492716 (0.043934) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185876 / 0.018006 (0.167869) | 0.404276 / 0.000490 (0.403787) | 0.001592 / 0.000200 (0.001392) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023272 / 0.037411 (-0.014139) | 0.096273 / 0.014526 (0.081747) | 0.105400 / 0.176557 (-0.071157) | 0.149720 / 0.737135 (-0.587416) | 0.107807 / 0.296338 (-0.188532) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420072 / 0.215209 (0.204863) | 4.184108 / 2.077655 (2.106454) | 1.880690 / 1.504120 (0.376570) | 1.673103 / 1.541195 (0.131909) | 1.715792 / 1.468490 (0.247302) | 0.695771 / 4.584777 (-3.889006) | 3.450224 / 3.745712 (-0.295488) | 2.999218 / 5.269862 (-2.270644) | 1.585571 / 4.565676 (-2.980106) | 0.082105 / 0.424275 (-0.342170) | 0.012453 / 0.007607 (0.004846) | 0.528538 / 0.226044 (0.302494) | 5.287951 / 2.268929 (3.019023) | 2.289127 / 55.444624 (-53.155497) | 1.956503 / 6.876477 (-4.919974) | 2.004498 / 2.142072 (-0.137575) | 0.813547 / 4.805227 (-3.991681) | 0.151574 / 6.500664 (-6.349090) | 0.063763 / 0.075469 (-0.011706) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239125 / 1.841788 (-0.602662) | 13.627676 / 8.074308 (5.553368) | 13.747815 / 10.191392 (3.556423) | 0.157745 / 0.680424 (-0.522679) | 0.028590 / 0.534201 (-0.505611) | 0.397472 / 0.579283 (-0.181811) | 0.405925 / 0.434364 (-0.028439) | 0.477942 / 0.540337 (-0.062396) | 0.572379 / 1.386936 (-0.814557) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006637 / 0.011353 (-0.004716) | 0.004657 / 0.011008 (-0.006351) | 0.082056 / 0.038508 (0.043548) | 0.027974 / 0.023109 (0.004865) | 0.342887 / 0.275898 (0.066989) | 0.375938 / 0.323480 (0.052458) | 0.004958 / 0.007986 (-0.003028) | 0.004738 / 0.004328 (0.000409) | 0.080449 / 0.004250 (0.076198) | 0.038138 / 0.037052 (0.001085) | 0.345636 / 0.258489 (0.087147) | 0.385992 / 0.293841 (0.092151) | 0.033265 / 0.128546 (-0.095281) | 0.011965 / 0.075646 (-0.063681) | 0.091441 / 0.419271 (-0.327830) | 0.051407 / 0.043533 (0.007874) | 0.353758 / 0.255139 (0.098619) | 0.372118 / 0.283200 (0.088919) | 0.093947 / 0.141683 (-0.047735) | 1.468197 / 1.452155 (0.016042) | 1.554677 / 1.492716 (0.061960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222034 / 0.018006 (0.204027) | 0.403658 / 0.000490 (0.403169) | 0.003242 / 0.000200 (0.003042) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025335 / 0.037411 (-0.012076) | 0.100404 / 0.014526 (0.085878) | 0.107858 / 0.176557 (-0.068698) | 0.156115 / 0.737135 (-0.581021) | 0.113967 / 0.296338 (-0.182372) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437567 / 0.215209 (0.222358) | 4.362486 / 2.077655 (2.284832) | 2.067315 / 1.504120 (0.563195) | 1.857669 / 1.541195 (0.316475) | 1.926380 / 1.468490 (0.457890) | 0.703905 / 4.584777 (-3.880872) | 3.437139 / 3.745712 (-0.308573) | 3.051931 / 5.269862 (-2.217930) | 1.356494 / 4.565676 (-3.209182) | 0.083679 / 0.424275 (-0.340596) | 0.012507 / 0.007607 (0.004900) | 0.539572 / 0.226044 (0.313528) | 5.405790 / 2.268929 (3.136861) | 2.532769 / 55.444624 (-52.911855) | 2.181950 / 6.876477 (-4.694527) | 2.212627 / 2.142072 (0.070554) | 0.807468 / 4.805227 (-3.997759) | 0.152146 / 6.500664 (-6.348518) | 0.068891 / 0.075469 (-0.006578) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.286972 / 1.841788 (-0.554816) | 13.987186 / 8.074308 (5.912878) | 13.115065 / 10.191392 (2.923673) | 0.162143 / 0.680424 (-0.518281) | 0.016767 / 0.534201 (-0.517434) | 0.384766 / 0.579283 (-0.194517) | 0.397438 / 0.434364 (-0.036926) | 0.470850 / 0.540337 (-0.069487) | 0.562216 / 1.386936 (-0.824720) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010877 / 0.011353 (-0.000476) | 0.005739 / 0.011008 (-0.005269) | 0.118542 / 0.038508 (0.080034) | 0.042266 / 0.023109 (0.019157) | 0.359317 / 0.275898 (0.083419) | 0.412995 / 0.323480 (0.089515) | 0.009158 / 0.007986 (0.001173) | 0.006343 / 0.004328 (0.002014) | 0.089587 / 0.004250 (0.085336) | 0.047899 / 0.037052 (0.010847) | 0.358745 / 0.258489 (0.100256) | 0.421316 / 0.293841 (0.127476) | 0.044540 / 0.128546 (-0.084006) | 0.013872 / 0.075646 (-0.061774) | 0.399856 / 0.419271 (-0.019415) | 0.056484 / 0.043533 (0.012951) | 0.356922 / 0.255139 (0.101783) | 0.385598 / 0.283200 (0.102398) | 0.116039 / 0.141683 (-0.025644) | 1.726095 / 1.452155 (0.273940) | 1.888643 / 1.492716 (0.395927) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269517 / 0.018006 (0.251511) | 0.511204 / 0.000490 (0.510714) | 0.001906 / 0.000200 (0.001706) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031133 / 0.037411 (-0.006278) | 0.128513 / 0.014526 (0.113987) | 0.139639 / 0.176557 (-0.036918) | 0.189778 / 0.737135 (-0.547358) | 0.145219 / 0.296338 (-0.151120) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.486693 / 0.215209 (0.271484) | 4.851999 / 2.077655 (2.774344) | 2.255334 / 1.504120 (0.751214) | 2.052271 / 1.541195 (0.511077) | 2.143262 / 1.468490 (0.674772) | 0.835765 / 4.584777 (-3.749012) | 4.451280 / 3.745712 (0.705568) | 2.534392 / 5.269862 (-2.735469) | 1.747817 / 4.565676 (-2.817859) | 0.101186 / 0.424275 (-0.323089) | 0.014281 / 0.007607 (0.006674) | 0.616164 / 0.226044 (0.390120) | 6.161789 / 2.268929 (3.892860) | 2.815347 / 55.444624 (-52.629277) | 2.408305 / 6.876477 (-4.468172) | 2.508240 / 2.142072 (0.366167) | 1.017709 / 4.805227 (-3.787519) | 0.198272 / 6.500664 (-6.302392) | 0.075663 / 0.075469 (0.000194) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.435501 / 1.841788 (-0.406287) | 18.149581 / 8.074308 (10.075273) | 16.619011 / 10.191392 (6.427619) | 0.205080 / 0.680424 (-0.475344) | 0.033780 / 0.534201 (-0.500421) | 0.515768 / 0.579283 (-0.063515) | 0.542628 / 0.434364 (0.108264) | 0.634067 / 0.540337 (0.093730) | 0.757841 / 1.386936 (-0.629095) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008541 / 0.011353 (-0.002812) | 0.005733 / 0.011008 (-0.005275) | 0.089859 / 0.038508 (0.051351) | 0.039379 / 0.023109 (0.016270) | 0.402037 / 0.275898 (0.126139) | 0.454046 / 0.323480 (0.130566) | 0.006652 / 0.007986 (-0.001334) | 0.004555 / 0.004328 (0.000227) | 0.087651 / 0.004250 (0.083401) | 0.054934 / 0.037052 (0.017881) | 0.404468 / 0.258489 (0.145979) | 0.467127 / 0.293841 (0.173286) | 0.042034 / 0.128546 (-0.086512) | 0.014225 / 0.075646 (-0.061421) | 0.103281 / 0.419271 (-0.315990) | 0.057767 / 0.043533 (0.014234) | 0.396391 / 0.255139 (0.141252) | 0.429364 / 0.283200 (0.146165) | 0.120193 / 0.141683 (-0.021489) | 1.794029 / 1.452155 (0.341875) | 1.875431 / 1.492716 (0.382714) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.325707 / 0.018006 (0.307701) | 0.503841 / 0.000490 (0.503351) | 0.010224 / 0.000200 (0.010024) | 0.000137 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035289 / 0.037411 (-0.002123) | 0.139018 / 0.014526 (0.124492) | 0.145112 / 0.176557 (-0.031445) | 0.202616 / 0.737135 (-0.534519) | 0.152975 / 0.296338 (-0.143363) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.493110 / 0.215209 (0.277901) | 4.885713 / 2.077655 (2.808058) | 2.344417 / 1.504120 (0.840297) | 2.135734 / 1.541195 (0.594540) | 2.254118 / 1.468490 (0.785628) | 0.811516 / 4.584777 (-3.773261) | 4.484454 / 3.745712 (0.738742) | 2.459913 / 5.269862 (-2.809948) | 1.553106 / 4.565676 (-3.012570) | 0.100943 / 0.424275 (-0.323332) | 0.014848 / 0.007607 (0.007241) | 0.626214 / 0.226044 (0.400170) | 6.206925 / 2.268929 (3.937997) | 2.986549 / 55.444624 (-52.458076) | 2.521895 / 6.876477 (-4.354582) | 2.610917 / 2.142072 (0.468845) | 0.998496 / 4.805227 (-3.806731) | 0.199405 / 6.500664 (-6.301260) | 0.077355 / 0.075469 (0.001886) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.525135 / 1.841788 (-0.316653) | 18.708407 / 8.074308 (10.634099) | 16.049482 / 10.191392 (5.858090) | 0.170986 / 0.680424 (-0.509437) | 0.021090 / 0.534201 (-0.513111) | 0.511734 / 0.579283 (-0.067549) | 0.495507 / 0.434364 (0.061143) | 0.628578 / 0.540337 (0.088241) | 0.749546 / 1.386936 (-0.637390) |\n\n</details>\n</details>\n\n\n"
] | 2023-02-28T17:58:11 | 2023-02-28T18:16:27 | 2023-02-28T18:06:08 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5590/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5590",
"html_url": "https://github.com/huggingface/datasets/pull/5590",
"diff_url": "https://github.com/huggingface/datasets/pull/5590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5590.patch",
"merged_at": "2023-02-28T18:06:08"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5589/comments | https://api.github.com/repos/huggingface/datasets/issues/5589/events | https://github.com/huggingface/datasets/pull/5589 | 1,603,535,704 | PR_kwDODunzps5K9K1i | 5,589 | Revert "pass the dataset features to the IterableDataset.from_generator" | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5589). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008442 / 0.011353 (-0.002911) | 0.004567 / 0.011008 (-0.006441) | 0.100688 / 0.038508 (0.062180) | 0.029568 / 0.023109 (0.006459) | 0.306993 / 0.275898 (0.031095) | 0.362626 / 0.323480 (0.039146) | 0.006983 / 0.007986 (-0.001002) | 0.003424 / 0.004328 (-0.000905) | 0.079050 / 0.004250 (0.074799) | 0.036087 / 0.037052 (-0.000966) | 0.318205 / 0.258489 (0.059716) | 0.353882 / 0.293841 (0.060041) | 0.033091 / 0.128546 (-0.095455) | 0.011468 / 0.075646 (-0.064178) | 0.321125 / 0.419271 (-0.098146) | 0.040645 / 0.043533 (-0.002888) | 0.309827 / 0.255139 (0.054688) | 0.344848 / 0.283200 (0.061648) | 0.087100 / 0.141683 (-0.054583) | 1.465123 / 1.452155 (0.012968) | 1.499457 / 1.492716 (0.006741) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.171619 / 0.018006 (0.153613) | 0.410198 / 0.000490 (0.409709) | 0.002391 / 0.000200 (0.002191) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022913 / 0.037411 (-0.014499) | 0.097275 / 0.014526 (0.082749) | 0.103902 / 0.176557 (-0.072655) | 0.148855 / 0.737135 (-0.588281) | 0.107247 / 0.296338 (-0.189092) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413139 / 0.215209 (0.197930) | 4.131760 / 2.077655 (2.054105) | 1.854491 / 1.504120 (0.350371) | 1.625524 / 1.541195 (0.084329) | 1.666665 / 1.468490 (0.198175) | 0.687105 / 4.584777 (-3.897672) | 3.327124 / 3.745712 (-0.418588) | 1.830820 / 5.269862 (-3.439042) | 1.147930 / 4.565676 (-3.417746) | 0.081586 / 0.424275 (-0.342689) | 0.012422 / 0.007607 (0.004815) | 0.523723 / 0.226044 (0.297678) | 5.246977 / 2.268929 (2.978049) | 2.288350 / 55.444624 (-53.156275) | 1.933740 / 6.876477 (-4.942737) | 1.954356 / 2.142072 (-0.187716) | 0.804434 / 4.805227 (-4.000793) | 0.147621 / 6.500664 (-6.353043) | 0.064835 / 0.075469 (-0.010634) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244841 / 1.841788 (-0.596947) | 13.758465 / 8.074308 (5.684157) | 13.984576 / 10.191392 (3.793184) | 0.144860 / 0.680424 (-0.535564) | 0.028616 / 0.534201 (-0.505584) | 0.401928 / 0.579283 (-0.177355) | 0.415294 / 0.434364 (-0.019069) | 0.476483 / 0.540337 (-0.063854) | 0.569257 / 1.386936 (-0.817679) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006556 / 0.011353 (-0.004797) | 0.004502 / 0.011008 (-0.006507) | 0.074828 / 0.038508 (0.036319) | 0.027537 / 0.023109 (0.004427) | 0.339961 / 0.275898 (0.064063) | 0.372491 / 0.323480 (0.049011) | 0.005010 / 0.007986 (-0.002976) | 0.004624 / 0.004328 (0.000295) | 0.074459 / 0.004250 (0.070208) | 0.037539 / 0.037052 (0.000486) | 0.341031 / 0.258489 (0.082542) | 0.383397 / 0.293841 (0.089556) | 0.031706 / 0.128546 (-0.096840) | 0.011542 / 0.075646 (-0.064104) | 0.084882 / 0.419271 (-0.334389) | 0.041860 / 0.043533 (-0.001673) | 0.338699 / 0.255139 (0.083560) | 0.365666 / 0.283200 (0.082467) | 0.088966 / 0.141683 (-0.052717) | 1.502493 / 1.452155 (0.050339) | 1.570746 / 1.492716 (0.078030) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217547 / 0.018006 (0.199541) | 0.392407 / 0.000490 (0.391918) | 0.000388 / 0.000200 (0.000188) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024571 / 0.037411 (-0.012840) | 0.099259 / 0.014526 (0.084734) | 0.107850 / 0.176557 (-0.068707) | 0.157686 / 0.737135 (-0.579449) | 0.109761 / 0.296338 (-0.186578) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434791 / 0.215209 (0.219582) | 4.323099 / 2.077655 (2.245444) | 2.063610 / 1.504120 (0.559490) | 1.866136 / 1.541195 (0.324941) | 1.910185 / 1.468490 (0.441695) | 0.696584 / 4.584777 (-3.888193) | 3.398017 / 3.745712 (-0.347695) | 1.848473 / 5.269862 (-3.421388) | 1.168238 / 4.565676 (-3.397438) | 0.083222 / 0.424275 (-0.341053) | 0.012332 / 0.007607 (0.004725) | 0.538953 / 0.226044 (0.312909) | 5.421273 / 2.268929 (3.152344) | 2.499877 / 55.444624 (-52.944747) | 2.161853 / 6.876477 (-4.714624) | 2.183941 / 2.142072 (0.041868) | 0.803916 / 4.805227 (-4.001311) | 0.150266 / 6.500664 (-6.350398) | 0.067399 / 0.075469 (-0.008070) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.280479 / 1.841788 (-0.561309) | 13.728074 / 8.074308 (5.653766) | 12.946098 / 10.191392 (2.754706) | 0.128459 / 0.680424 (-0.551965) | 0.016567 / 0.534201 (-0.517634) | 0.374461 / 0.579283 (-0.204822) | 0.386973 / 0.434364 (-0.047391) | 0.459754 / 0.540337 (-0.080583) | 0.543870 / 1.386936 (-0.843066) |\n\n</details>\n</details>\n\n\n",
"Instead of reverting the change, maybe we can use the same conversion in `to_iterable_dataset` as in `ArrowBasedBuilder._as_streaming_dataset` to avoid decoding images twice?"
] | 2023-02-28T17:52:04 | 2023-03-03T16:52:24 | null | MEMBER | null | This reverts commit b91070b9c09673e2e148eec458036ab6a62ac042 (temporarily)
It hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images unnecessarily). I think we need to fix this before re-adding it
cc @mariosasko @Hubert-Bonisseur | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5589/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5589",
"html_url": "https://github.com/huggingface/datasets/pull/5589",
"diff_url": "https://github.com/huggingface/datasets/pull/5589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5589.patch",
"merged_at": null
} | true |
End of preview. Expand
in Dataset Viewer.
- Downloads last month
- 35