
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
16,359 | Graphite:由 AI 助力的基于网络的开源矢量图形编辑器 | https://news.itsfoss.com/graphite/ | 2023-11-07T23:33:00 | [
"图形编辑器"
] | https://linux.cn/article-16359-1.html | 
>
> 让我们了解更多即将亮相的矢量图形编辑器 Graphite。
>
>
>
此次,我们要介绍的是一个完全免费而开源的 **平面图形编辑器**,名为 “Graphite”,它专注于创建一个完善的 **非破坏性所见即所得编辑体验**。
许多为 Linux 提供 [出色的矢量图形编辑器](https://itsfoss.com/vector-graphics-editors-linux/#bonus-svg-edit-web-based-alternative-) 的应用都有一个专门的应用程序,但 Graphite 则选择了不同的路径,成为一个 **仅基于浏览器的应用**。不过,根据路线图,它计划为 Linux、Windows 和 macOS 提供桌面应用。
考虑到它能在网络上运行,它的目标是在提供所有必要功能的同时保持轻量级。
>
> ? 目前,此应用处于 alpha 开发阶段,许多计划中的功能还处在概念验证状态。
>
>
>
### Graphite:综述 ⭐

Graphite 是一个轻量级的、在网络浏览器上运行的 **基于 Rust 的矢量图形编辑器**。由 **Graphene 节点图组合引擎** 驱动,提供了一个易于访问、基于层的优秀编辑器。
其中 **最值得注意的特性** 包括:
* 精美、直观的界面
* 节点图图像效果
* AI 辅助艺术创作
* 实时协作
开发者分享的一段视频展示了几乎所有前述的特性。我被视频中如此直接简洁的编辑体验深深打动。
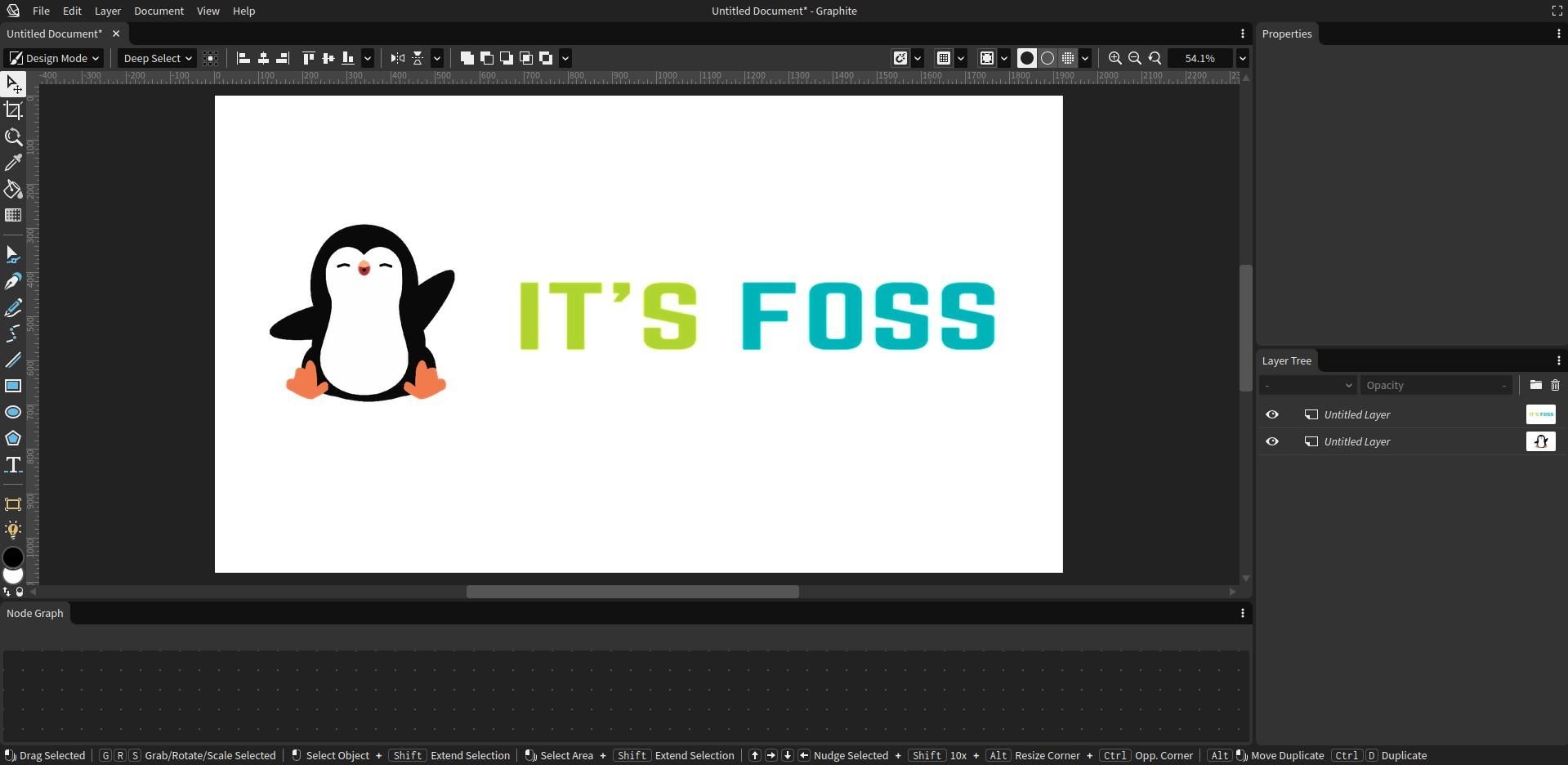
事实上,我亲自尝试使用它的 [开发版](https://news.itsfoss.com/graphite/dev.graphite.rs) 创作了下面的杰作,**编辑体验类似于你在大多数图形编辑器中所发现的**。
不过,我必须手动寻找各种选项,因为 Graphite **并没有官方文档**。
我之前与首席开发者交谈过,他告诉我他们正在努力提供文档,并且已经在期待它的发布了。
同时,值得注意的是,在一个轻量级应用上我们获得众多需要文档的选项,这听起来就很赞!

当然,目前的状态下我们还无法真正检验该应用的核心理念。然而,对我来说,如果 Graphite 矢量图形编辑器能实现其展示和承诺的话,那么它的影响将是 **颠覆性的**。
我也好奇他们会如何在他们的自由开源应用中添加 AI 辅助艺术创作功能。谁不想试用这个呢?对吧!?
与此同时,我建议你关注 [Graphite 的路线图](https://graphite.rs/features/) 和 [GitHub 仓库](https://github.com/GraphiteEditor/Graphite),以了解重要的开发里程碑或可以贡献你的智慧。
### ? 如何获取 Graphite
因为这是一个网络应用,它基本上可以 **在任何支持的网络浏览器上运行**,尽管我不确定智能手机上的编辑体验会怎样。然而,对于台式机、笔记本电脑,甚至是平板电脑,这都可能是个不错的选择。
你可以访问这个 [在线编辑器](https://editor.graphite.rs/) 来获取最新的 alpha 版本。如果你想获取最新的开发版本,可以试试 [开发版](https://dev.graphite.rs/)。
>
> **[Graphite](https://editor.graphite.rs/)**
>
>
>
? 你对 Graphite 矢量图形编辑器有什么看法?你喜欢它的概念吗?你认为他们能实现吗?欢迎分享你的想法。
---
via: <https://news.itsfoss.com/graphite/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

This time around, we have an **in-development 2D graphics editor** called 'Graphite' that is completely free and open-source. It focuses on providing a completely **non-destructive WYSIWYG editing experience**.
Some of the [best vector graphics editors](https://itsfoss.com/vector-graphics-editors-linux/?ref=news.itsfoss.com#bonus-svg-edit-web-based-alternative-) for Linux out there have a dedicated app to get the job done, but Graphite takes a different approach by being **a browser-only app**. Though, it has plans to provide desktop apps for Linux, Windows, and macOS as per its roadmap.
Considering it can run on the web, it aims to be a lightweight option while being loaded with all the essential features.
**Suggested Read **📖
[5 Best Vector Graphics Editors for LinuxHere we list the best vector graphics software for Linux that can be used as Adobe Illustrator alternative for Linux.](https://itsfoss.com/vector-graphics-editors-linux/?ref=news.itsfoss.com)

## Graphite: Overview ⭐

Graphite is a lightweight **Rust-based vector graphics editor **that runs on a web browser. Powered by the **Graphene node graph composition engine,** it provides a good layer-based editor that comes with great accessibility.
Some of the **most notable features** include:
**A sleek, intuitive interface.****Node graph image effects.****AI-assisted art creation.****Real-time collaboration.**
The developers share a video that depicts almost all the above-mentioned features. I was impressed with how straightforward the editing experience looks in the video.
Seeing that, I tried out my hand at making the following masterpiece using its [development build](dev.graphite.rs), the **editing experience was similar to what you find on most graphics editors** out there.
But, I had to look around for the various options manually, as there was **no official documentation** for Graphite.
I had a chat with the lead developer earlier, and he said that they are on it, and to expect it soon.
Not to forget, considering it is a lightweight app, we get numerous options that require documentation (which in itself sounds wonderful!).
Of course, we cannot test out the true essence of what the app aims to be in this state. However, to me, Graphite vector graphics editor sounds **disruptive**, if it manages to achieve what it showcases/promises.
I would also be curious to see how they add an AI-assisted art creation on a free and open-source app. Who wouldn't want to use that? I know right! 🤩
Meanwhile, I recommend you keep an eye on [Graphite's Roadmap](https://graphite.rs/features/?ref=news.itsfoss.com) and [GitHub repo](https://github.com/GraphiteEditor/Graphite?ref=news.itsfoss.com) to know about important development milestones or to join in to contribute.
## 📥 Get Graphite
As this is a web app, it can **basically run on any supported web browser**, though I am not certain how the editing experience on a smartphone will be. But for desktops, laptops, and even tablets, this can turn out to be the great option.
You can head over to the [online editor](https://editor.graphite.rs/?ref=news.itsfoss.com) to access the latest alpha build. If you want to access the latest development build, you can try the [dev version](https://dev.graphite.rs/?ref=news.itsfoss.com) as well.
*💬 What do you think about Graphite vector graphics editor? Do you like its concept? Do you think they can pull it off? Let me know your thoughts on the same.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,360 | Fedora 39 版本发布,新亮相一款不可变版本 | https://news.itsfoss.com/fedora-39-release/ | 2023-11-08T16:01:00 | [
"Fedora"
] | https://linux.cn/article-16360-1.html | 
>
> Fedora 39 的发布带来了许多令人兴奋的变化和完善。
>
>
>
Fedora 是众多 Ubuntu 替代品中的热门选择,或者还可以说,用其来替换任何其他基于 Debian 的发行版都是一个理想的选择。
每次升级后,Fedora 都会变得更好。现在让我们看一下最新的 Fedora 39 有哪些重要更新。
接下来,我将向你展示这个版本都包含了哪些新功能。
### ? Fedora 39 版本更新:都有哪些新内容?

得益于稳健强大的 [Linux 内核 6.5](https://news.itsfoss.com/linux-kernel-6-5-release/),Fedora 39 的发布包含了众多值得关注的新功能。其中一些关键的亮点包括:
* 安装程序的升级
* GNOME 45
* 应用/包的更新
* Fedora Onyx
#### 安装程序的升级

尽管安装程序并未更换,我们在全新安装 Fedora 时,会看到 **一个新的欢迎屏幕**。在更新后的 Fedora 38 ISO 中,你可能已经注意到了这一点。
此外,**Fedora 的安装程序现在支持更大的 EFI 系统分区**,这个分区的 **最小尺寸达到了 500 MB**。这样做是为了便于在现代硬件上进行固件更新,也为未来引导程序特性做好了准备。
你可能会在想,[Anaconda Web UI](https://news.itsfoss.com/fedora-new-web-ui-install-dev/) 出了什么情况?
其实,这个 UI 设计已经 [计划](https://fedoraproject.org/wiki/Changes/AnacondaWebUIforFedoraWorkstation) 在 Fedora 40 中推出了,我们都非常期待未来它的表现!
#### GNOME 45

Fedora 39 引入了最近发布的 [GNOME 45](https://news.itsfoss.com/gnome-45-release/)。对于此次更新,我是期待已久。
早先的 “<ruby> 活动 <rt> Activities </rt></ruby>” 按钮已被替代,现在,你将看到一个 **药丸形状的动态指示器**,它可以清晰的显示出当前的工作空间,以及其他可供切换的工作空间。
你可以通过滚动它或者点击圆点来切换工作空间。
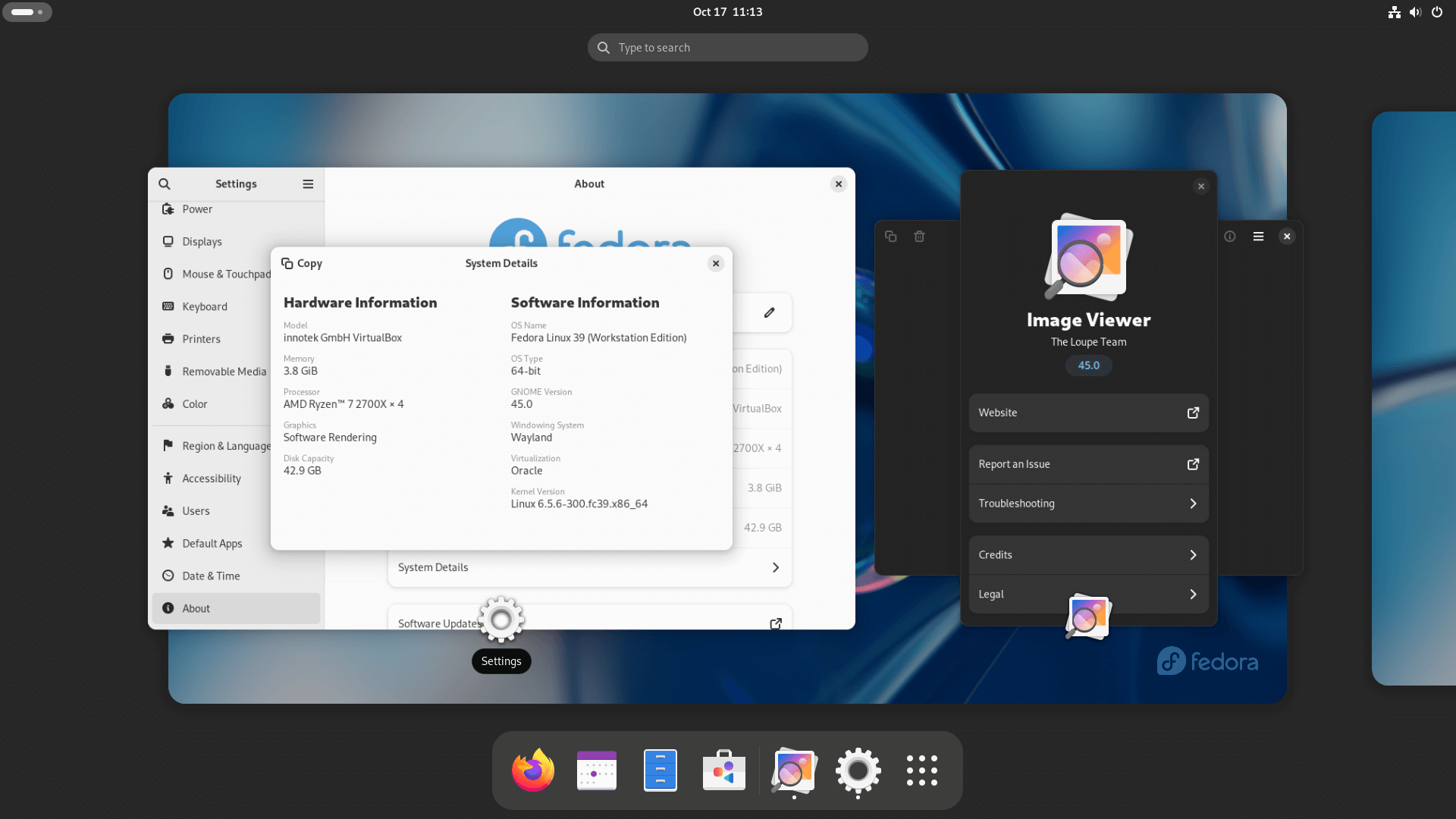
“<ruby> 设置 <rt> Settings </rt></ruby>” 应用程序里也陆续出现了一些新的变化,例如像 **经过翻新的 “<ruby> 隐私 <rt> Privacy </rt></ruby>” 标签页**,以及在 “<ruby> 关于 <rt> About </rt></ruby>” 菜单下新增的 “<ruby> 系统细节 <rt> System Details </rt></ruby>” 子菜单。
此外,有一些新的核心应用程序,比如新的图像查看器以及其他应用的更新,我强烈建议你查看我们所有关于 GNOME 45 的内容:
>
> **[GNOME 45 发布,弃用“活动”按钮](/article-16215-1.html)**
>
>
>
#### 应用/包的更新情况

Fedora 39 同样更新了一套应用程序和软件包。主要的更新包括:
* [LibreOffice 7.6](https://news.itsfoss.com/libreoffice-7-6/)
* [LLVM 17](https://releases.llvm.org/17.0.1/docs/ReleaseNotes.html)
* [Golang 1.21](https://go.dev/blog/go1.21)
* IBus 1.5.29
* Perl 5.38
* RPM 4.19
* Python 3.12
#### Fedora Onyx 的介绍

今年早些时候,Fedora 的不可变版本阵容迎来了一个新成员,叫做 “[Fedora Onyx](https://news.itsfoss.com/fedora-onyx-official/)”。
那时,**我们并不知道它的具体发布日期**,但现在,它终于在 **Fedora 39 的版本更新中有所呈现**。
这使得 Fedora 的不可变版本阵容 **增长到了四个**,其它分别是 [Fedora Silverblue](https://silverblue.fedoraproject.org/)、[Fedora Kinoite](https://kinoite.fedoraproject.org/),以及 [Fedora Sericea](https://fedoraproject.org/sericea/)。
**推荐阅读** ?
>
> **[11 个不可变 Linux 发行版,适合那些想要拥抱未来的人们](/article-15841-1.html)**
>
>
>
#### ?️ 其他变化和改进
其他的变化包括一些注目的内容:
* Fedora 39 提供了一个绿色的 Bash 提示符。
* 移除了 Fedora 工作站的自定义 Qt 主题设计。
* 对于 Indic(印度)语言,实现了谷歌 [Noto](https://fonts.google.com/noto) 字体。
* Flatpak 不再使用模块进行构建,而是采用了一个独立的构建目标。
你还可以通过我们针对 [Fedora 39 特性](/article-16207-1.html) 的报道和查阅 [官方更改日志](https://fedoraproject.org/wiki/Releases/39/ChangeSet) 来更深入地了解这次的版本发布。
### ? 如何下载 Fedora 39
和往常一样,Fedora 的新版本更新带来了大量的改进和升级。你可以转到 [官方网站](https://fedoraproject.org/workstation/download/) 获取你所需要的 ISO 文件。
你也可以点击下面的按钮直接下载。
>
> **[点击获取 Fedora 39](https://fedoraproject.org/workstation/download/)**
>
>
>
**对于现有用户** ,我们有一个很实用的升级指南可以帮助你开始升级操作:
>
> **[如何从 Fedora 38 升级到 Fedora 39](https://itsfoss.com/upgrade-fedora-version/)**
>
>
>
*(题图:MJ/f6e0a56a-5e8b-4c0f-89c2-596375bba00f)*
---
via: <https://news.itsfoss.com/fedora-39-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Fedora is one of the **most popular alternatives to Ubuntu**, or any other Debian-based distro for that matter.
With every upgrade, it gets better. **Fedora 39, **the latest in line is here.
Allow me to show you what's being offered with this release.
## 🆕 Fedora 39 Release: What's New?
Powered by the robust [Linux kernel 6.5](https://news.itsfoss.com/linux-kernel-6-5-release/), the Fedora 39 release has a lot to offer. Some key highlights include:
**Installer Upgrades****GNOME 45****Updated Application/Packages****Fedora Onyx**
### Installer Upgrades

Even though the installer has remained unchanged, we now have **a new welcome screen** that shows up when starting a fresh installation of Fedora. You might have noticed it with updated Fedora 38 ISOs as well.
Furthermore, **the Fedora installer now features a bigger EFI System Partition** at a **minimum size of 500 MB** to facilitate firmware updates on modern hardware, as well as for future bootloader features.
You're maybe wondering; **what happened to the **
**Anaconda Web UI**?
Well, that is [targeted](https://fedoraproject.org/wiki/Changes/AnacondaWebUIforFedoraWorkstation?ref=news.itsfoss.com) for a Fedora 40 debut, and we can't wait to see how it turns out!


### GNOME 45
Fedora 39 features the recently released [GNOME 45](https://news.itsfoss.com/gnome-45-release/). This was something I was looking forward to.
The old “Activities” button has been ditched in favor of** a pill-shaped dynamic indicator** that now shows you the current workspace, as well as the other workspaces.
You can either switch workspaces by scrolling on it, or by clicking on the individual dots.
The 'Settings' app has also received some changes, such as **the revamped 'Privacy' tab**, and a new “**System Details**” sub-menu under the 'About' menu.
There are some new core applications like a new image viewer and updates to the rest, I highly suggest you go through our GNOME 45 coverage to explore all the details:
[GNOME 45 Release Ditches the “Activities” ButtonThe latest and greatest of GNOME desktop is here.](https://news.itsfoss.com/gnome-45-release/)

### Updated Application/Packages
Fedora 39 also features an updated suite of applications and packages. The major ones include:
[LibreOffice 7.6](https://news.itsfoss.com/libreoffice-7-6/)[LLVM 17](https://releases.llvm.org/17.0.1/docs/ReleaseNotes.html?ref=news.itsfoss.com)[Golang 1.21](https://go.dev/blog/go1.21?ref=news.itsfoss.com)- IBus 1.5.29
- Perl 5.38
- RPM 4.19
- Python 3.12
### Fedora Onyx
Earlier this year, a new immutable distro was accepted into Fedora's immutable spins' lineup, called '[ Fedora Onyx](https://news.itsfoss.com/fedora-onyx-official/)'.
Back then, we **didn't have a concrete release date** for it, but now it is **finally here with Fedora 39**.
This **sees Fedora's immutable spins lineup grow to a total of four**, joining the likes of [Fedora Silverblue](https://silverblue.fedoraproject.org/?ref=news.itsfoss.com), [Fedora Kinoite](https://kinoite.fedoraproject.org/?ref=news.itsfoss.com), and [Fedora Sericea](https://fedoraproject.org/sericea/?ref=news.itsfoss.com).
**Suggested Read **📖
[11 Future-Proof Immutable Linux DistributionsImmutability is a concept in trend. Take a look at what are the options you have for an immutable Linux distribution.](https://itsfoss.com/immutable-linux-distros/?ref=news.itsfoss.com)

### 🛠️ Other Changes and Improvements
As for the rest of the changes, here are some notable ones:
- Fedora 39 features a green colored bash prompt.
- Removal of custom Qt theming for Fedora Workstation.
- Implementation of Google
[Noto](https://fonts.google.com/noto?ref=news.itsfoss.com)fonts for Indic (Indian) languages. - Flatpaks are now not built using modules, instead they use a separate build target.
**Suggested Read **📖
[17 Things to Do After Installing Fedora 39Installed Fedora 39 on your system? Here are some tips for you to follow to enhance your desktop experience.](https://itsfoss.com/things-to-do-after-installing-fedora/?ref=news.itsfoss.com)

You can also go through our [Fedora 39 features](https://news.itsfoss.com/fedora-39-features/) coverage and the [official changelog](https://fedoraproject.org/wiki/Releases/39/ChangeSet?ref=news.itsfoss.com) to dive deeper into this release.
## 📥 Download Fedora 39
As usual, this release of Fedora is packed with improvements and upgrades. Head over to the [official site](https://fedoraproject.org/workstation/download/?ref=news.itsfoss.com) to grab the ISO of your choice.
You can also click on the button below for the same.
**For existing users**, we have a handy upgrade guide to get you started:
[How to Upgrade From Fedora 38 to Fedora 39This tutorial shows you how to upgrade the Fedora version to a new major release.](https://itsfoss.com/upgrade-fedora-version/?ref=news.itsfoss.com)

## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,362 | Fedora Workstation 39 的新特性 | https://fedoramagazine.org/whats-new-fedora-workstation-39/ | 2023-11-09T14:32:00 | [
"Fedora"
] | https://linux.cn/article-16362-1.html | 
作为领先的开源桌面操作系统,Fedora Workstation 由全球社区共同携手打造。本文将向你展示最新版本 Fedora Workstation 39 主要的用户所能见到的变化。如今,你可以在 [Fedora Workstation 官方网页](https://fedoraproject.org/workstation/) 下载体验,或是通过在“软件”应用内或使用 [dnf system-upgrade](https://docs.fedoraproject.org/en-US/quick-docs/upgrading-fedora-offline/) 在你喜爱的终端模拟器进行升级。
### GNOME 45
Fedora Workstation 39 搭载了 GNOME 的最新版本——GNOME 45。这个版本为几个核心应用带来了时尚的新插件、全新的图像查看器应用、新增了在特定系统上的键盘背光设置等。同时,我们的一个更具信息性的活动按钮,及多项性能改进,将伴随全面优化的整套用户体验而来。你可以在 [GNOME 45 发布说明](https://release.gnome.org/45/) 查看更多详细信息。
#### 内在改进
GNOME 45 在用户体验的方方面面都有所细化,以下几点只是其中的一部分:
* 使用动态工作空间指示器取代了静态的活动按钮。新的指示器不仅显示工作空间数量,而且还能快速展示你正在关注的工作空间。

* 新增了一个摄像头活动指示器,要启用它,你可以通过 Pipewire 访问你的摄像头。这将与麦克风、屏幕录制和屏幕录像指示器协同工作。
* 快速设置菜单新增了一个键盘背光设置,这项设置仅支持特定的硬件设备。

* 重新设计了默认的光标,并修复了原来设置中很多长期存在的问题。
* Fedora Workstation 39 已不再支持 Adwaita-qt 与 QGnomePlatform Qt 主题,取而代之的是 Qt 应用的上游默认主题。
#### 核心应用
在 GNOME 45,许多应用现在使用了 libadwaita 1.4 特色的新用户界面插件。这提供了美观的双色设计并将侧边栏延伸至窗口全高。这不仅使应用看起来更酷,而且在小窗口尺寸下更易于使用。可在 [此处](https://blogs.gnome.org/alicem/2023/09/15/libadwaita-1-4/) 查看详细信息。此外,新的 headerbar 插件使顶栏与窗口内容的视觉分隔更加明显。

Fedora Workstation 39 引入了 GNOME 的新图像查看器应用,内部代号为 Loupe。该应用自底而上,使用 Rust、GTK 4,和 libadwaita 进行构建以实现高性能和高度适应性。

在核心应用中我们还有很多细微的改进。例如:
* “设置”应用新增了“系统详情”区块,新的键盘布局查看器,简洁的描述字段,以及优化的键盘导航功能。

* 在“文件”应用中,我们对搜索结果进行了顺序优化。
* 我们在“软件”应用中提供了卸载 Flatpak 时删除用户数据的选项。

* “日历”应用新增了逐行滚动和更有用的搜索结果功能。
* 在“连接”应用中使用 RDP 连接时新增了复制文件、图像、文本的功能。
#### 性能改进
在 GNOME 45,我们对性能提升投入了很多努力。
* 现在默认优先使用硬件加速的视频解码(在支持的环境下)。
* “文件”应用中的缩略图生成现在支持多线程处理。
* 我们显著减少了光标的卡顿和延迟。
* 在 GNOME Shell 中,以及“文件”、“软件”、“字符”等应用的搜索性能得到显著提升。
我们在整个技术栈中也进行了一些性能改进,包括 GLib、GTK 的 OpenGL 渲染器,和 systemd。这些性能优化工作都得益于我们在 Fedora Workstation 之前的版本中启用的帧指针!
### Fedora Linux 39 的底层突破
Fedora Linux 39 也有许多值得注意的底层变化,此处列出一些:
* Fedora Linux 39 现在将彩色 Bash 提示符作为默认设置!

* 对于使用 Indic 脚本的语系,我们现在把 Noto 字体作为默认字体,取代了旧的 Lohit 字体集。
* 由于使用量较低且缺乏主动维护,[模块化](https://docs.fedoraproject.org/en-US/modularity/) 仓库在 Fedora Linux 39 中不再被提供。
+ Fedora 模块构建服务将在 Fedora Linux 38 的生命周期结束后,也就是在 2024 年的 5 月左右结束。
*(题图:MJ/f06d0e9b-4c2e-4947-8333-e51340a45324)*
---
via: <https://fedoramagazine.org/whats-new-fedora-workstation-39/>
作者:[Merlin Cooper](https://fedoramagazine.org/author/mxanthropocene/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora Workstation is the premier open source desktop operating system, built by a worldwide community including you! This article describes some of the major user-facing changes in the latest version, Fedora Workstation 39. Get it today from the [Fedora Workstation webpage](https://fedoraproject.org/workstation/), or upgrade your existing install within the Software app or with * dnf system-upgrade* in your favourite terminal emulator!
# GNOME 45
Fedora Workstation 39 includes the latest version of the GNOME desktop environment, GNOME 45. This version features stylish new widgets in several core apps, a brand new Image Viewer app, a new keyboard backlight setting on supported systems, a more informative Activities button, improved performance, and many other refinements to the user experience all throughout. More details are available in the [GNOME 45 release notes](https://release.gnome.org/45/).
## Little big things
GNOME 45 features several refinements all throughout the experience. Here are just a few:
- A dynamic workspace indicator replaces the static Activities button. This new indicator is more informative, showing the number of workspaces and the currently-focused one all at a glance.
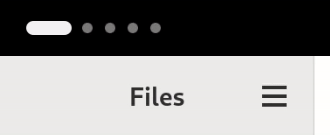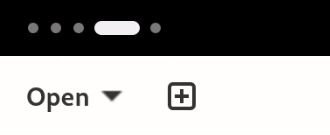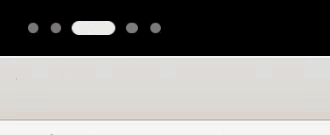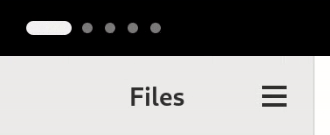
*The new dynamic workspace indicator*
- A new camera activity indicator appears when accessing a camera via Pipewire. This joins the microphone, screencast, and screen recording indicators.
- The Quick Settings menu features a new keyboard backlight setting on supported hardware.
- The default cursors have been redesigned, fixing several long-standing issues with the original set.
- The Adwaita-qt and QGnomePlatform Qt themes are no longer available in Fedora Workstation 39. Qt apps now use the upstream default theme.
## Core apps
Many apps in GNOME 45 now use the new user interface widgets featured in libadwaita* *1.4. This gives them a beautiful two-tone design with sidebars extending to the full height of the window. Not only does this look great, it also enhances the apps’ adaptability, making them easier to use with smaller window sizes. More details are available [here](https://blogs.gnome.org/alicem/2023/09/15/libadwaita-1-4/). Additionally, the new headerbar widget enhances visual separation between the headerbar itself and the window’s contents.
Fedora Workstation 39 features GNOME’s new Image Viewer app, internally known as Loupe. It has been written from the ground-up for high performance and adaptability using Rust, GTK 4, and libadwaita.
*The new Image Viewer app (artwork shown in screenshot is*
[public domain](https://commons.wikimedia.org/wiki/File:Common_foxes_in_the_snow.jpg))Several smaller refinements have been made in the core apps. Among many others are the following:
- The Settings app features a new System Details section, a new keyboard layout viewer, easier to understand descriptions, and better keyboard navigability.
- Better ordering of search results in Files.
- It is now possible to remove user data when uninstalling Flatpaks in the Software app.
- Line-by-line scrolling and more useful search results in Calendar.
- Support for copying files, images, and text when using RDP connections in Connections.
## Performance improvements
GNOME 45 features a number of performance improvements.
- Hardware-accelerated video decoding is now automatically preferred, where possible.
- Thumbnailing in the Files app is now multithreaded.
- Cursor stutter and latency is significantly reduced.
- Search performance is greatly enhanced in GNOME Shell and within several apps, including Files, Software, and Characters.
Several performance improvements have also been made across the whole stack, including in GLib, GTK’s OpenGL renderer, and systemd. A lot of these performance optimisations would not have been possible without the enabling of frame pointers in the previous version of Fedora Workstation!
# Under-the-hood changes throughout Fedora Linux 39
Fedora Linux 39 features many under-the-hood changes. Here are some notable ones:
- Fedora Linux 39 now features a coloured Bash prompt by default!
*The coloured Bash prompt*
- The Noto fonts are now the default for languages using the Indic script. This replaces the older Lohit font set.
- The
[modular](https://docs.fedoraproject.org/en-US/modularity/)repository is no longer available in Fedora Linux 39 due to low usage and lack of active maintenance.- The Fedora Module Build Service will be sunset around the end-of-life of Fedora Linux 38, i.e. in May 2024.
# Also check out…
Cool happenings throughout the Fedora Project!
- November 6, 2023 marks the Fedora Project’s 20th anniversary. Keep your eye on Fedora Magazine for a special 20th anniversary article! 🎉
## Scotty_Trees
Thanks to all the devs, maintainers, contributors, bug reporters, and all other volunteers for their efforts for this new release! Been looking forward to this, can’t wait to install this after work today! Love me some new Gnome goodies!
## MasterKasper
I just tried Fedora 39 out and in looks real fancy!
## Chris
The new sidebars in the core apps look horrible… It’s genuinely a massive usability regression for Files in particular, as the address bar is now so tiny. The old Files was perfect. Just change for the sake of change…
## Simon
I wouldn’t say it looks horrible but I am also confused with this obsession about random design changes when the features of GNOME core apps leave much to be desired.
## Vinicius
Thanks 👍
## Darvond
It looks like it was designed for a mobile. Hardly befitting a desktop platform, but that’s GNOME for you.
## nikita
Gnome isn’t just a desktop platform, adaptability to smaller screens has been a goal for quite a while now
## Darvond
So create a separate (sub)platform instead of shoehorning desktop, netbook, and mobile users into one design space. It won’t work. They each require a paradigm of approach.
Inconveniencing desktop users for a touch centric interface design is exactly what out of touch is. A desktop launcher won’t work on a 5 inch screen, just as huge borders & flat buttons aren’t going to favor desktop users.
## Michael Setzer II
Update on test machine went fine, but messed up somethings.
Had Xfce setup, but upgrade changed it to gnome? Didn’t like, so changed it to Xfce again.
Messed up vnc as well. Have been using vnc going back to Fedora Core 1 with Xfce, nothing changed in startup, but comes up with gnome. Had to dump tigervnc since it wouldn’t work correctly. Installed turbovnc with Xfce selected, and works great.
Otherwise seems ok
Will upgrade 4 work machines and do the same.
## Nick Fenwick
Is the address bar really so tiny? Comparing my Gnome 44 desktop with the screenshot above, it looks like the bar has been reduced by the width of the sidebar, but this still leaves a decent size bar. I do agree that the reduction isn’t functionally useful, there’s no reason to have the ‘Files’ title at the top of that sidebar when the old bar used to be able to use that space. I’d support some kind of option to allow the old behaviour, but with the sidebar now physically occupying the entire column I doubt that would be easy to achieve.
I’m enjoying the custom title bar feature, not sure what version of Gnome this came in (probably years ago and I missed it). VS Code, for example, has an option you have to enable window.titleBarStyle=custom which makes it much more space efficient, and enables other options like moving the Activity Bar to the top.
## Pisu S
I switched to KDE.
I’m done.
I have neither the time nor the energy to entertain myself or get excited
by new unwanted changes…..
I remember the full black theme that the high-contrast-inverse theme had back in gnome 3.26 and they removed that !!
For the mobile Gnome is perfect but not for the desktop.
## Mimimi
mimimi. Haters gonna hate. You get the best operating system, the best desktop environment and still mimimiing. Switch then, back to Windows – it is great place for nonconstructive criticism.
## senileOtaku
Pisu S was talking about
DESKTOPS, not the OS itself. And using the terms “Best” and “GNOME” together is a contradiction in terms.GNOME
shouldexist as a DE, since it’s all about choice. But the GNOME devs need to learn to stop BREAKING GTK functionality for everyone else. Time for all the other non-GNOME projects to migrate to CTK, and leave GTK for GNOME to trash.## Pisu S
Seriously Man!
I absolutely love silverblue/kinoite/Sericea.
Silverblue is perfect for touch screen ThinkPads/Latitudes for corporates. The only thing holding it back is the Office Suite.
That the Fedora team took time to even make a Sway immutable desktop version just shows the ruthless dedication of the team !!
I have a x250 that meditates with Kinote on it. Its more than perfect.
For desktop users and newcomers Gnome can be a nightmare. If I really wanted to deal with the technicalities of Gnome, instead I would just sway+mc+neovim+tmux all day long. If people really need to come to Linux to play games or do office work then there has to be uniformity and logical consistency in what a desktop is. KDE is 100% perfect in that regard.
You should go address those Wayland haters, who complain but lack competence in writing their own code or contributing anything worthwhile besides complaining. I support Flatpaks too, Not Snap.
## William
Yes! Gnome’s UI is ugly and UX is terrible, and the situation is changing from bad to worse. Uninformative, with too many clicks, and a user still needs a terminal for almost everything, like removing wallpaper and replacing it with a solid color for instance. While screens are getting bigger, those morons still adapt UI for small screens. Is my criticism constructive enough? Developers never actually listen to users, they call us haters instead
## Paul
Agreed, they look worse and add yet another inconsistency… put on a screen with single pane apps and they look too different, and for no benefit.
## Dave
Can’t wait to install this on my Steam deck, though there is no good fan control.
## Nick Fenwick
While I always welcome improvements and the devs’ efforts, I think this article should mention the big change in Extensions in Gnome 45, which has been well reported e.g. https://blogs.gnome.org/shell-dev/2023/09/02/extensions-in-gnome-45/ .. I recommend people check their favourite extensions for compatibility before upgrading, in case you find they simply don’t work and it may be some time before they are updated by their individual maintainers.
## D White
Seems more a Gnome update than a Fedora one.
## Gregory Bartholomew
There are non-GNOME changes that were made in Fedora Linux 39. Many of them can be found here: https://fedoraproject.org/wiki/Releases/39/ChangeSet
This article focuses on GNOME because it is about Fedora Workstation edition.
## Darvond
Maybe Fedora needs to champion a desktop that is about users & desktops instead of mobiles & philosophers.
A desktop that doesn’t break compatibility with itself because it happens to be Tuesday, and is quite open to working with other desktop systems to ensue compatibility and standards.
Maybe ICED would be the better paradigm, but hm, Fedora hasn’t exactly been developing a desktop, just supporting one with an outmoded code approach to design vs modern sensibilities.
Or you know, XFCE. They could use a hand in acceleration. ¯_(ツ)_/¯
## Mahdi Hosseini ( Libreman )
Very very good and beautiful,
I will update my operating system as soon as possible. I hope its speed has improved and many bugs have been fixed (especially about GNOME).
## SenileOtaku
Not a whole lot of coverage of what changed in Fedora 39 that
isn’tpart of GNOME (3-4 lines of text compared to the paragraphs and paragraphs of GNOME coverage). Those of us using Cinnamon, KDE, XFCE, LXzz, etc would like to know what is relevant to us (other than continued breakage in GTK for any non-GNOME desktops).## Gregory Bartholomew
People from the working groups for those subprojects are very welcome to write “What’s New in Fedora ” articles for Fedora Magazine. The reason Fedora Workstation has such an article is simply because they provided one.
## Randall Weed
Thank you, just do the simple fact is these people took time to make this is good enough for us. Thank you
## Mike
Update from 38 went without any issues, swift and painless. Sometimes I catch myself reflecting on what an incredible progress Linux Desktop (like Gnome) has made for all these years. I love new ideas and progress but as for desktop workspace – there’s really not much I can ask for.
## Varen
Great Work Team!!!
I was distro hopping for a long time but never tried Fedora. I Switched to Fedora 38 a few days ago and i was impressed with it. And in 2 days i was lucky to get a stable update!. Impressive just got better!.
Thank you all
## Ace
Hey, I am reading through the comments on here about fedora’s awesome new release of workstation 39 and to my horror, instead of some “great job”s and “here is some constructive criticism” I am seeing “GNOME is trash” and “I am freaking out about the stupid little nav bar in GNOME files”… really? Are you going to be so childish that a nav bar being less then a quarter of it’s original size shorter is going to make you that mad? Or a few changes to a different style are going to make you that mad? Grow up! If you don’t like it use KDE! They keep there system nice and ugly, don’t care about aesthetics at all and are years out of date in there ui design but hey, they don’t change much over the years! Seriously, to each there own but you don’t have to be jerks about it! Gnome is doing what they are doing to make the UI more comprehensive and clean which is why the OSes designed to introduce new people to Linux almost always end up GNOME based… they are also the most well prepared for going mobile, the foundation is much better then KDE’s and once they start on the actual shell work for mobile in internist it will surpass all the rest quickly! and all the GTK based apps will automatically work on mobile well. That is a big undertaking… GNOME is really very much pushing the ball for most of the huge improvements in the Linux desktop world! Hence why so many disros are still GTK based. I develop in the GTK, Libawaita, Gjs,and other GNOME toolkits and a change in api from time to time is well worth it! Now it is fine if you disagree, but for heaven’s sake, keep it to your self and just switch to whatever you happen to think is better or adjust your expectations! Now, I personally like the change to the side panel style even though the nav bar is shorter since it give room for a much more modular design system that take a lot of the work off of the developers for the app to still be compliant with the GNOME UI standards, and it lays the groundwork for it to become a universal organization system that allowed the user to know right away, if there are option of this type or the other, they will be right there and if they aren’t, the user does not have to go looking to make sure they are not some place else because they will either be in the side bar or not an option… a good example is Apple, a multi-million dollar company, who has a almost universally loved UI (if if it looks like the css for it is a few years out of style) who does the same thing… I will leave it to you to determine what you think the likely hood is that Apple did not pay someone thousands to apply very intentional placement of options in the UI APIs to flow well with the way humans think…
Anyway, I am excited to see fedora 39 and can’t wait to get my hands on the new GNOME desktop next Monday! I am especially looking forward to dest driving the improvements to the file search and cursor efficiency! Great job to both the Fedora devs, and the GNOME devs that made this release possible! Thanks!
## George
Gnome is why I’ve been using Xfce for years.
## Andrew
Bit of a rant. Just my opinion, feel free to correct me if there are any factual errors.
Just did a fresh re-install using 39 beta (then upgraded to release). Was several releases since I did a fresh install, and i’m happy with it, still love Gnome, works well for me. One thing though…this btrfs default fs… I went back to LVM with ext4 and xfs for /home, because I just couldn’t put up with root and home always showing the same % full in df -h. And I get annoyed at having to type a much longer command to get the real result :/ . Plus, as an oracle DBA, i’m very aware of segments/extents and the design philosophy behind btrfs by Chris Mason, and I just feel that development seems to have stagnated and maybe, just maybe, extents and segments weren’t the best fit for a filesystem, and the Oracle dev was just trying to shoe-horn technology he knew into a container that wasn’t the best fit? Am I the only one? I tried looking for info on RAID-6 fixes and it seems it’s still not reliable. I tried finding info on how to do a snapshot of the subvol before a dnf update and being able to revert to the previous subvol if the update goes wrong, and it’s sooo convoluted and poorly documented! Is there a gui that makes all this easy to do? I really like the idea of in-built raid on metadata/data and in-built compression, but they still don’t support in-built encryption after all this flipping time, and the compression is still flaky depending on use-case! Considering all of those points, I just thought ‘stuff it’ and went back to tried and true and well-known LVM commands with ext4/xfs.
## Sunil
Fedora 39 or linux mint edge?
## Darvond
I’d sooner pick OpenSuse Leap if you’d prefer a release to release, or Tumbleweed for rolling.
At the end of the day, Mint is still based on Ubuntu/Debian, which is the furthest from fresh you’ll ever get.
## Albernando Alberto
Nice update! Some might say that this update only has very small or incremental changes, but I think that’s a good thing – focusing on polishing the experience and perfecting the best OS out there!
## Patrick
I’ve installed Fedora Workstation 37 last winter, upgraded flawlessly to 38 in May and to 39 yesterday morning. I have the same feeling as if I’d run a rolling-release distro. What else ? 😉
## Patrick
I’m sorry, I forget to thank the Team for their great job.
## Alok
Just here to convey my thanks to the Devs and others out there for a smooth stable release.
Just wish that there should have been an auto system filesystem backup like windows does for easy roll back if something goes wrong.
## Michael Amanti
While I use Window’s System Image Backup,
I would never trust any one Backup method.
So, I also use CloneZilla Image Backup [ and CloneZilla Clone ].
This works well on Fedora Linux [ 39 ] as well.
## duvjones
Ok, it been a few days for me and WOW….
This has to be the smoothest that I have had upgrading.
Question about the coloured bash: I was upgrading from 38 and I am wondering what I would need to have the new default?
## Matthew Phillips
It’s interesting how passionate people are about their DEs. GNOME is still my favorite because it seems to be the place where all the important development is done first, like Wayland and Pipewire. KDE has a lot of edge case polish and love from all the users in its community, but GNOME seems like it is developed from the inside out and I like that about it. I just use it with all defaults, no extensions; same thing with Silverblue, just Flatpaks and try not to layer if I can help it.
Installed Fedora Silverblue 39 a couple nights ago and still loving it!
## idanka
Thanks to the team!
It was a fairly trouble-free update. The gnome
*it has become much better in terms of speed
*thumbnail image generation is much faster
*displaying all icons is also much faster
## Andy M
Gnome Team: Give us options to configure the system how we need / want – don’t force us to a change for the sake of change – please! Every time the interface changes, I lose minutes to hours of productivity. I wish we had options in the configurations to select what you do and don’t want. Some features for dev’s are terrible for my kid who uses linux for school, who has different needs from my wife who uses it for business and me who uses linux for my tinkering. Give me setup options! Make it easy to change color scheme for readability, etc… If you allow users the options, we can optimize it for our use. That’s what makes a UI useful. Make it for the user.
Please focus on the “under the hood” performance items as well. If you can save me 5 seconds opening a file or picture, that results in real productivity improvement. Great to see those improvements here.
## SenileOtaku
You want to have a say on what your desktop looks like? You’re looking at the wrong desktop project then.
## Darvond
Sorry, wrong desktop. Gnome has taken Kai Krause’s “padded cell” design philosophy to the illogical extreme.
I’d suggest swapping Gnome for Cinnamon, Mate, or XFCE at your preference, and voting to replace the desktop of Fedora while leaving Gnome to rot.
## Steve
Wish they would switch back to Plasma as the default.
## Peter
It looks like a lot of people have complained already, so that’s good. I’ve been on Fedora 39 for about ten minutes and I already have two major gripes.
1) In the terminal, “top c” has changed to “top -c”. What’s the point of that? It’s just one extra key to type, for no benefit.
2) Getting rid of “Activities” at the top is annoying. I don’t like this shift towards getting rid of words in menus and replacing them with abstract symbols. Also, in Firefox, I can no longer click “Activities” to open a new window, private window, etc, and instead I need to click somewhere else. Again, I don’t see any advantage from changing this.
Maybe I will get used to these changes, but I don’t think I will ever prefer them.
## Andrew
Regarding the Activities bar application specific buttons as in Firefox to add new window, I think it’s good that they changed this, because when they originally implemented it, it felt super weird to use a separate button outside of the application window to change settings. I’m actually glad that they have finally reverted this and all application specific controls are now within the actual application windo again. Maybe they realised that such a design choice wasn’t a good idea after all?
## hentaicoder
real title : whats new on gnome?
## Richard England
It was pointed out earlier that Workstation edition installs with GNOME. This article is titled: “What’s new in Fedora Workstation 39”.
## Amir Suhel
“I had been on a long search for the perfect OS. When I installed Fedora for the first time, I didn’t have high hopes. I was using Ubuntu and Windows. However, after using this OS, I never needed to look back at any other OS. Fedora 39 lives up to that reputation too.”
## Sasan
Thank you so much Fedora devs for all your great work.
I’ve been running Fedora for the last two years on a Lenovo laptop and every bit except for battery life has been pefect. GNONE animations render beautifuly on the 90hz display.
I’ve been thinking about moving my main workstation (Manjaro KDE) to Fedora gnome too. Who knows this release night finally tempt me.
## Alaa
Nice and good work good time good 👍 job thanks Fedora
## Yevgen Taradayko
Very, very sad. As for me it was one of the best feature for many years.
## Ednan Penteado
Quando solicito a atualização do Fedora 38 para o Fedora 39, dentro do Atualizações do aplicativo Programas, o sistema carrega em torno de 65% e posta a mensagem:
Erro ao executar a transação: o pacote pgdg-fedora-repo-42.0-28PGDG.noarch já está instalado
Isto aconteceu na atualização do Fedora 37 para o 38, precisei deletar o pacote pgdg-fedora-repo-42.0-28PGDG.noarch, mas com este procedimento perdi meu banco de dados PostgreSQL e todos os arquivos ja lançados, precisei reinstalar o PostgreSQL.
Este pacote deve ser do PostgreSQL, e o Fedora tem um pacote com o mesmo nome, seria necessário mudar de nome o pacote da atualização do Fedora?
## Gregory Bartholomew
‐‐skip-broken não funciona?
https://ask.fedoraproject.org/ talvez seja um lugar melhor para perguntar.
## Ednan Penteado
Tentei novamente as opções que voce havia me fornecido na atualização do 37 para o 38, e não funcionou
sudo dnf update –releaserver=39 –skip-broken
e não funcionou, mostrando o erro
dnf upgrade: error: unrecognized arguments: –releaserver=39
fiz a atualização do sistema pelo comando
dnf update system,
o comando funcionou, e atualizou o PostgreSQL, mas não resolveu o problema da atualização do Fedora
## Richard England
Para obter assistência, tente aqui:
https://discussion.fedoraproject.org/tags/c/ask/non-english/85/portugu%C3%AAs
## Gregory Bartholomew
releaserver != releasever
## Ednan Penteado
Tambem não funcionou, estou entrando nas listas de discução, https://discussion.fedoraproject.org/tags/c/ask/non-english/85/portugu%C3%AAs
## Michael Nordberg
I had been running Fedora 38 on my Framework 13 laptop and decided today to take the plunge into 39. I decided against going the upgrade route and did a clean install after I had backed up my home directory. Installation was smooth and so far no issues. Got Sublime and PyCharm installed and I am good to go. Kudos to everyone in the development team. |
16,363 | 在 Arch Linux 上安装 Docker | https://itsfoss.com/install-docker-arch-linux/ | 2023-11-09T15:41:56 | [
"Docker"
] | https://linux.cn/article-16363-1.html | 
>
> 了解如何在 Arch Linux 上安装 Docker,并使用 Docker Compose 和制表符补全为运行容器做好准备。
>
>
>
在 Arch Linux 上安装 Docker 很简单。它可以在 Extra 仓库中找到,你可以简单地 [执行 pacman 魔法](https://itsfoss.com/pacman-command/):
```
sudo pacman -S docker
```
但要在 Arch Linux 上正确运行 Docker,还需要执行更多步骤。
### 让 Arch Docker 做好准备
这一切都归结为以下步骤:
* 从 Arch 仓库安装 Docker
* 启动 Docker 守护进程并在每次启动时自动运行
* 将用户添加到 `docker` 组以运行 `docker` 命令而无需 `sudo`
让我们看看详细步骤。
#### 步骤 1:安装 Docker 包
打开终端并使用以下命令:
```
sudo pacman -S docker
```
输入密码并在询问时按 `Y`。

这可能需要一些时间,具体取决于你使用的镜像。
>
> ? 如果你看到找不到包或 404 错误,那么你的同步数据库可能是旧的。使用以下命令更新系统(它将下载大量软件包并需要时间): `sudo pacman -Syu`
>
>
>
#### 步骤 2:启动 docker 守护进程
Docker 已安装但未运行。你应该在**第一次运行 Docker 命令**之前启动 Docker 守护进程:
```
sudo systemctl start docker.service
```
我还建议启用 Docker 服务,以便 Docker 守护进程在系统启动时自动启动。
```
sudo systemctl enable docker.service
```
这样,你就可以开始运行 `docker` 命令了。你不再需要手动启动 Docker 服务。

#### 步骤 3:将用户添加到 docker 组
Docker 已安装并且 Docker 服务正在运行。你几乎已准备好运行 `docker` 命令。
但是,默认情况下,你需要将 `sudo` 与 `docker` 命令一起使用。这很烦人。
为了避免在每个 `docker` 命令中使用 `sudo`,你可以将自己(或任何其他用户)添加到 `docker` 组,如下所示:
```
sudo usermod -aG docker $USER
```
**你必须注销(或关闭终端)并重新登录才能使上述更改生效。如果你不想这样做,请使用以下命令:**
```
newgrp docker
```
现在已经准备好了。我们来测试一下。
#### 步骤 4:验证 docker 安装
Docker 本身提供了一个很小的 Docker 镜像来测试 Docker 安装。运行它并查看是否一切正常:
```
docker run hello-world
```
你应该看到类似这样的输出,表明 Docker 成功运行:

恭喜! 你已经在 Arch Linux 上成功安装了 Docker。
### 可选:安装 Docker Compose
Docker Compose 已经成为 Docker 不可或缺的一部分。它允许你管理多个容器应用。
较早的经典 Compose 由 `docker-compose` Python 软件包提供。Docker 还将其移植到 Go 中,并通过 `docker compose` 提供,但该软件包附带 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
在这个阶段,我建议使用经典的 `docker-compose` 插件并使用以下命令安装它:
```
sudo pacman -S docker-compose
```

### 故障排除技巧
以下是你可能遇到的一些常见问题以及可能的解决方案:
#### 制表符补全不适用于 docker 子命令
如果你想对 `docker` 命令选项使用制表符补全(例如将 `im` 补全到 `images` 等),请安装 `bash-completion` 包:
```
sudo pacman -S bash-completion
```
关闭终端并启动一个新终端。你现在应该能够通过 `docker` 命令使用制表符补全功能。
#### 无法连接到 Docker 守护进程错误
如果你看到以下错误:
```
docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.
See 'docker run --help'.
```
那是因为 Docker 守护进程没有运行。参考步骤 2,启动 Docker 服务,确保其正在运行并启用它,以便 Docker 守护进程在每次启动时自动运行。
```
sudo systemctl start docker.service
sudo systemctl enable docker.service
```
#### 尝试连接到 Docker 守护程序套接字时权限被拒绝
如果你看到此错误:
```
ddocker: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/create": dial unix /var/run/docker.sock: connect: permission denied.
See 'docker run --help'.
```
这是因为你需要使用 `sudo` 运行 `docker` 命令,或者将用户添加到 `docker` 组以在不使用 `sudo` 的情况下运行 `docker` 命令。
我希望这篇简短的文章可以帮助你在 Arch Linux 上运行 Docker。
*(题图:MJ/9951f8bf-d2e5-4335-bd86-ebf89cba654d)*
---
via: <https://itsfoss.com/install-docker-arch-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Installing Docker on Arch Linux is easy. It is available in the Extra repository and you can simply [do the pacman magic](https://itsfoss.com/pacman-command/):
`sudo pacman -S docker`
But there are more steps involved here to run Docker on Arch Linux properly.
## Making Arch Docker ready
It all comes down to these steps:
- Install Docker from Arch repository
- Start the Docker daemon and run it automatically at each boot
- Add user to docker group to run docker commands without sudo
Let's see the steps in detail.
### Step 1: Installing Docker package
Open the terminal and use the following command:
`sudo pacman -S docker`
Enter the password and press Y when asked for it.
It may take some time depending on the mirror you are using.
### Step 2: Start docker daemon
Docker is installed but it is not running. You should start the dcoker daemon before **running the Docker command for the first time**:
```
sudo systemctl start docker.service
```
I also suggest enabling the Docker service so that the docker daemon starts automatically when your system boots.
`sudo systemctl enable docker.service`
This way, you can just start running docker commands. You won't need to manually start the docker service anymore.
### Step 3: Add user to docker group
Docker is installed and the Docker service is running. You are almost ready to run docker commands.
However, by default, you need to use sudo with docker commands. And that's annoying.
To avoid using sudo with each docker command, you can add yourself (or any other user) to the docker group like this:
`sudo usermod -aG docker $USER`
**You must log out (or close the terminal) and log back in for the above change to take effect. If you don't want to do that, use this command:**
`newgrp docker`
Now the stage is set. Let's test it.
### Step 4: Verify docker installation
There is a tiny docker image provided by docker itself to test the docker installation. Run it and see if everything works well:
`docker run hello-world`
You should see output like this for successful docker run:
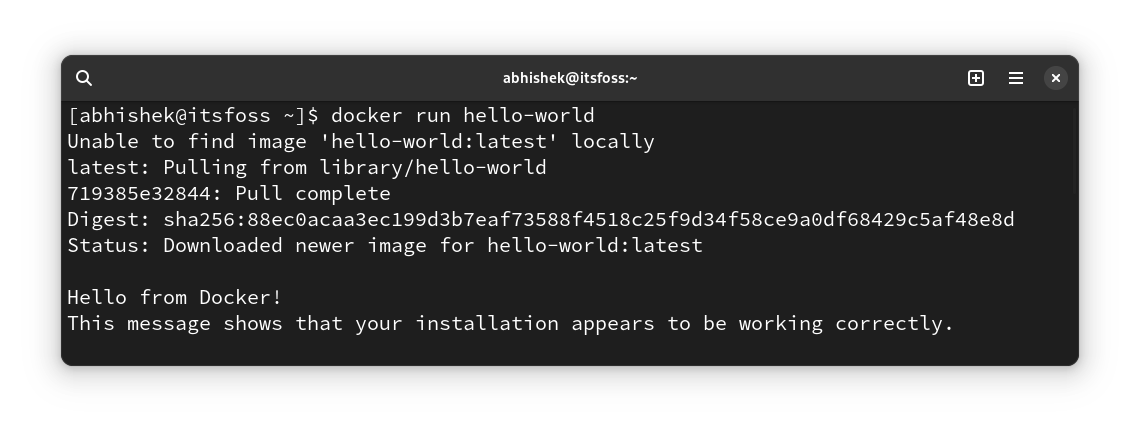
Congratulations! You have successfully installed Docker on Arch Linux.
## Optional: Install Docker Compose
Docker Compose has become an integral part of Docker. It allows you to manage multiple container applications.
The older classic compose is provided by the `docker-compose`
Python package. Docker has also ported it to Go and provides it with `docker compose`
but this package comes with [Docker Desktop](https://www.docker.com/products/docker-desktop/).
At this stage, I would suggest going with the classic docker-compose plugin and install it with this command:
`sudo pacman -S docker-compose`
## Troubleshooting Tips
Here are some common issues you may face and the possible solutions:
### Tab completion not working for docker sub commands
If you want to use tab completion for the docker command options (like completing im to images etc), install the bash-completion package:
`sudo pacman -S bash-completion`
Close the terminal and start a new one. You should be able to use tab completion with Docker commands now.
### Cannot connect to the Docker daemon error
If you see the following error:
```
docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.
See 'docker run --help'.
```
That's because the docker daemon is not running. Refer to step 2 and start the docker service, make sure it is running and enable it so that docker daemon runs automatically at each boot.
```
sudo systemctl start docker.service
```
`sudo systemctl enable docker.service`
### Permission denied while trying to connect to Docker daemon socket
If you see this error:
```
docker: permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/create": dial unix /var/run/docker.sock: connect: permission denied.
See 'docker run --help'.
```
That's because you need to either run the docker command with sudo or add the user to docker group to run docker commands without sudo.
I hope this quick post helps you run Docker on Arch Linux. |
16,365 | GIMP 快速教程:缩放、裁剪和旋转图像 | https://www.gimp.org/tutorials/GIMP_Quickies/ | 2023-11-10T09:51:00 | [
"GIMP"
] | https://linux.cn/article-16365-1.html | 
>
> 本文翻译自 GIMP 官网,是 GIMP 教程的一部分。
>
>
>
### 目的
恭喜你!你在电脑上安装了 GIMP!GIMP 是一个非常强大的图像处理软件,但是不要被它吓到。即使你没有时间学习高级的电脑图形处理技能,GIMP 仍然可以是一个非常有用和方便的快速修改图像的工具。
我希望这些例子能帮助你解决那些需要对图像应用进行快速修改的小需求。希望这也能让你学习到 GIMP 更强大的图像编辑能力。
为了便于快速查看,我将在这篇快速教程中涵盖以下四个要点:
* 更改图像的大小(尺寸),即缩放
* 更改 JPEG 的大小(文件大小)
* 剪裁图像
* 旋转或翻转图像
为了与这个页面之前的版本保持保持一致,我将使用 NASA 提供的天文学家每日图像(APOD)中的一张图片。
为了跟随这些快速示例,你只需要知道如何找到你的图片并打开它:“<ruby> 文件 <rt> File </rt></ruby> → <ruby> 打开 <rt> Open </rt></ruby>”。
### 调整图像的大小(尺寸),即缩放
你可能会遇到一个图像太大,不适合特定用途的问题(例如,嵌入网页、在线发布或包含在电子邮件中)。在这种情况下,你通常会希望将图像缩小到更小的尺寸,以便更好地满足你的需求。
在 GIMP 中轻松完成这个任务非常简单。
我们使用的图片是哈勃望远镜拍摄的马头星云红外成像图。
当你第一次在 GIMP 中打开图像时,很可能会发现图像被缩放,以便整个图像都能适合你的画布。对于这个示例,需要注意的是,GIMP 窗口顶部的窗口装饰会显示一些关于图像的信息。

请注意,窗口顶部的信息显示了当前图像的像素尺寸(在这个例子中,像素尺寸为 1225×1280)。
要调整图像的大小到新的尺寸,我们只需要调用“<ruby> 缩放图像 <rt> Scale Image </rt></ruby>”对话框:“<ruby> 图像 <rt> Image </rt></ruby> → <ruby> 缩放图像... <rt> Scale Image ... </rt></ruby>”。
这将打开“缩放图像”对话框:

在“缩放图像”对话框中,你会发现一个*可以输入新宽度和高度的地方*。如果你知道所需图的新尺寸,可以在这里填写相应的值。
“<ruby> 宽度 <rt> Width </rt></ruby>”和“<ruby> 高度 <rt> Height </rt></ruby>”输入框右侧,你也会**注意到一个小链**。这个图标显示了宽度和高度值被相互锁定,这意味着改变一个值会导致另一个值的变化,以保持相同的宽高比(图像中不会出现奇怪的压缩或拉伸)。
例如,如果你想要将图像宽度调整到 600 像素,你可以在这个宽度输入框中输入这个值,高度将自动更改以保持图像的宽高比:

如你所见,在宽度一栏输入 600 像素后会自动将高度更改为 627 像素。
此外,我还展示了 “<ruby> 质量 <rt> Quality </rt></ruby>” 选项下的不同选项。默认值是“<ruby> 立方 <rt> Cubic </rt></ruby>”,但为了保持最佳质量,最好使用 “Sinc(Lanczos3)”。
如果你想使用不同类型的值(而不是像素大小)指定一个新的尺寸,可以通过点击“px”下拉菜单来更改输入值的类型:

这种情况的一个常见用途是,如果你想要以原始尺寸的百分比指定一个新的尺寸。在这种情况下,你可以更改为“<ruby> 百分比 <rt> percent </rt></ruby>”,然后在任何字段中输入 50 来将图像缩小一半。
一旦你缩放了图像,别忘了保存你所做的更改:选中 “<ruby> 文件 <rt> File </rt></ruby> → <ruby> 导出... <rt> Exprert ... </rt></ruby>” 以新的文件名导出,或者 “<ruby> 文件 <rt> File </rt></ruby> → <ruby> 覆盖 {文件名} <rt> Overwrite {FILENAME} </rt></ruby>” 覆盖原始文件(谨慎使用)。
有关使用缩放图像的更多信息,你可以查看文档。
### 修改 JPEG 文件的大小
你也可以在导出为 JPEG 等格式时修改图像的文件大小。JPEG 是一种**有损**压缩算法,这意味着在将图像保存为 JPEG 格式时,你将牺牲一些图像质量来获得较小的文件大小。
我使用已经将其调整为 200 像素宽(请参见上方)的“马头星云”图像,并使用不同级别的 JPEG 压缩将其导出,以比较 JPEG 压缩的效果:

如你所见,即使在质量设置为 80 的情况下,图像的文件大小显著减少了 77%,而图像质量仍然相当合理。
当你完成任何正在进行的图像修改,并准备导出时,只需通过以下方式调用导出对话框:“文件 → 导出 …” 这将调用“<ruby> 导出图像 <rt> Export Image </rt></ruby>”对话框:

你可以在此*输入新的文件名*。如果文件名里包含扩展名(此时为 “.jpg”),GIMP 会尝试为你导出对应的文件格式。此处将图像导出为 JPEG 格式。
如果你需要将文件导出到不同的位置,也可以通过位置窗格导航到计算机上的新位置。当你准备好导出图像时,只需按“<ruby> 导出 <rt> Expert </rt></ruby>”按钮。
这将调用“<ruby> 导出图像为 JPEG <rt> Export Image as JPEG </rt></ruby>”对话框,你可以在其中更改导出的质量:

现在你可以在此对话框中更改导出质量。如果你还勾选了“<ruby> 在图像窗口中显示预览 <rt> Show preview in image window </rt></ruby>”选项,画布上的图像将更新以反映你输入的质量值。这也将启用“<ruby> 文件大小: <rt> File size: </rt></ruby>”信息,告诉你导出后的文件大小。你可能需要移动一些窗口才能在背景中查看画布上的预览。
当你对结果满意时,按“导出”按钮进行导出。
要查看有关导出不同图像格式的更多详细信息,请参阅手册中的“从 GIMP 中获取图像”。
### 裁剪图像
有很多原因可能会使你想要裁剪图像。你可能想要删除无用的边框或信息,或者你可能希望最终图像的焦点集中在某些特定的细节上。
简而言之,裁剪就是一个将图像缩小到比你开始时小的操作:

裁剪图像的步骤非常简单。你可以通过工具面板使用裁剪工具:

或者通过菜单访问裁剪工具:“<ruby> 工具 <rt> Tools </rt></ruby> → <ruby> 变换工具 <rt> Transform Tools </rt></ruby> → <ruby> 裁剪 <rt> Crop </rt></ruby>”。

一旦激活该工具,画布上的鼠标光标会改变,以表示正在使用裁剪工具。
现在你可以在画布上的任何位置单击鼠标,然后拖动鼠标到新位置以高亮显示初始选择区域以进行裁剪。在这个阶段,你不必担心精确度,因为在实际裁剪之前,你可以修改最终选区。

在选择要裁剪的区域后,你会发现选区仍然处于活动状态。在这一点上,将鼠标光标悬停在选区的任何四个角或边缘上都会改变鼠标光标,并高亮显示该区域,以对裁剪进行精调。
你可以点击并拖动任何一侧或一角来移动该部分的选区。
一旦你对裁剪区域满意,只需按键盘上的回车键即可提交裁剪。在你想从头开始或决定不裁剪时,可以按键盘上的 `Esc` 键退出操作。
有关在GIMP中裁剪的更多信息,请参阅文档。
#### 另一种方法
另一种裁剪图像的方法是首先使用矩形选择工具进行选择:

或者通过菜单:“<ruby> 工具 <rt> Tools </rt></ruby> → <ruby> 选择工具 <rt> Selection Tools </rt></ruby> → <ruby> 矩形选择 <rt> Rectangle Select </rt></ruby>”,然后你可以以与裁剪工具相同的方式高亮显示选区,并调整选区。一旦你有一个喜欢的选区,你就可以通过以下方式将图像裁剪到该选区的大小:“<ruby> 图像 <rt> Image </rt></ruby> → <ruby> 裁剪到选区 <rt> Crop to Selection </rt></ruby>”。
### 旋转或翻转图像
可能有时你需要旋转图像。例如,你可能使用相机在垂直方向拍摄了图像,但是 GIMP 并没有自动旋转(GIMP 通常会为你自动处理,但并非总是如此)。
有时你也可能想翻转图像。这些命令都位于同一个菜单项下:“<ruby> 图像 <rt> Image </rt></ruby> → <ruby> 变换 <rt> Transform </rt></ruby>”。
#### 翻转图像
如果你想翻转你的图像,变换菜单提供了两种选项:水平翻转或垂直翻转。此操作将沿着指定的轴翻转(镜像)图像。例如,这里显示了在单个图像上应用的所有翻转操作:

#### 旋转图像
变换菜单中的图像旋转限制为 90° 顺时针/逆时针或 180°。 不要误解这意味著 GIMP 不能执行任意角度旋转。任意旋转是针对每个图层进行处理的,而这里的图像旋转适用于整个图像。

### 总结
这里展示的简单示例只是冰山一角。然而,这些是许多没有学习太多图像处理知识的人经常进行的常见修改。希望这个教程对你有所帮助。 我鼓励你阅读其他教程,了解更高级的图像处理方法!
*(题图:MJ/9bbe01ba-7cc1-49b1-91a6-2b3d13594503)*
---
via: <https://www.gimp.org/tutorials/GIMP_Quickies/>
作者:Pat David 译者:[TimXiedada](https://github.com/TimXiedada) 编辑:[wxy](https://github.com/wxy)
本文由贡献者投稿至 [Linux 中国公开投稿计划](https://github.com/LCTT/Articles/),采用 [CC-BY-SA 协议](https://creativecommons.org/licenses/by-sa/4.0/deed.zh) 发布,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So you installed GIMP on your computer, congratulations! GIMP is a very powerful image manipulation software, but don’t let that intimidate you. Even if you don’t have time to learn advanced computer graphics, GIMP can still be a very useful and handy tool for quick image modifications.
It is my hope that these few examples will help to solve those small, quick modifications that you may need to apply to an image. Hopefully this will lead to learning even more powerful image editing capabilities that GIMP is capable of as well.
For quick access, these are the four main points I’ll cover in this quick tutorial:
In keeping with the spirit of the predecessor to this page, I will be using images from the Astronomy Picture of the Day ([APOD](https://apod.nasa.gov/apod/astropix.html)), provided by NASA.
All you need to know to follow these quick examples is to be able to find your image and open it:
It’s a common problem that you may have an image that is too large for a particular purpose (embedding in a webpage, posting somewhere online, or including in an email for instance). In this case you will often want to *scale* the image down to a smaller size more suitable for your use.
This is a very simple task to accomplish in GIMP easily.
The image we’ll be using to illustrate this with is [The Horsehead Nebula in Infrared](https://apod.nasa.gov/apod/ap130422.html).
When you first open your image in GIMP, chances are that the image will be zoomed so that the entire image fits in your canvas. The thing to notice for this example is that by default the window decoration at the top of GIMP will show you some information about the image.
Notice that the information at the top of the window shows the current pixel dimensions of the image (in this case, the pixel size is 1225×1280).
To resize the image to new dimensions, we need only invoke the **Scale Image** dialog:
This will then open the **Scale Image** dialog:
In the **Scale Image** dialog, you’ll find a place to enter new values for **Width** and **Height**. If you know one of the new dimensions you’d like for the image, fill in the appropriate one here.
You’ll also notice a small chain just to the right of the **Width** and **Height** entry boxes. This icon shows that the Width and Height values are locked with respect to each other, meaning that changing one value will cause the other to change in order to keep the same aspect ratio (no strange compression or stretching in the image).
For example, if you knew that you wanted your image to have a new width of 600px, you can enter that value in the **Width** input, and the **Height** will automatically change to maintain the aspect ratio of the image:
As you can see, entering **600px** for the width automatically changes the height to **627px**.
Also notice I have shown a different option under **Quality** → Interpolation. The default value for this is *Cubic*, but to retain the best quality it would better to use **Sinc (Lanczos3)**.
If you want to specify a new size using a different type of value (other than Pixel size), you can change the type by clicking on the “**px**” spinner:
A common use for this could be if you wanted to specify a new size as a percentage of the old one. In this case you could change to “percent”, and then enter 50 in either field to scale the image in half.
Once you are done scaling the image, don’t forget to export the changes you’ve made:
to export as a new filename, or:
to overwrite the original file (use caution).
For more detail about using **Scale Image**, you can see [the documentation](https://docs.gimp.org/2.8/en/gimp-image-scale.html).
You can also modify the filesize of an image when exporting it to a format like JPEG. JPEG is a * lossy* compression algorithm, meaning that when saving images to the JPEG format, you will sacrifice some image quality to gain a smaller filesize.
Using the same Horsehead Nebula image from above, I have resized it to 200px wide (see above), and exported it using different levels of JPEG compression:
As you can see, even at a quality setting of 80, the image is significantly smaller in filesize (77% size reduction), while the image quality is still quite reasonable.
When you’ve finished any image modifications you are doing, and are ready to export, simply invoke the export dialog with:
This will invoke the **Export Image** dialog:
You can now enter a new name for your file here. If you include the filetype extension (in this case, .jpg), GIMP will automatically try to export in that file format for you. Here I am exporting the image as a JPEG file.
You can also navigate to a new location on your computer through the **Places** pane, if you need to export the file to a different location. When you are ready to export the image, just hit the **Export** button.
This will then bring up the **Export Image as JPEG** dialog, where you can change the quality of the export:
From this dialog you can now change the quality of the export. If you also have the “Show preview in image window” option checked, the image on the canvas will update to reflect the quality value you input. This will also enable the “File size:” information to tell you what the resulting file size will be. (You may need to move some windows around to view the preview on the canvas in the background).
When you are happy with the results, hit the **Export** button to export.
To see more details about exporting different image formats, see [Getting Images out of GIMP](https://docs.gimp.org/2.8/en/gimp-images-out.html) in the manual.
There are numerous reasons you may want to crop an image. You may want to remove useless borders or information for aesthetic reasons, or you may want the focus of the final image to be of some particular detail for instance.
In a nutshell, cropping is just an operation to trim the image down to a smaller region than what you started with:
The procedure to crop an image is straightforward. You can either get to the **Crop Tool** through the tools palette:
Or you can access the crop tool through the menus:
Once the tool is activated, you’ll notice that your mouse cursor on the canvas will change to indicate the
**Crop Tool** is being used.
Now you can Left-Click anywhere on your image canvas, and drag the mouse to a new location to highlight an initial selection to crop. You don’t have to worry about being exact at this point, as you will be able to modify the final selection before actually cropping.
After making the initial selection of a region to crop, you’ll find the selection still active. At this point hovering your mouse cursor over any of the four corners or sides of the selection will change the mouse cursor, and highlight that region.
This allows you to now fine-tune the selection for cropping. You can click and drag any side or corner to move that portion of the selection.
Once you are happy with the region to crop, you can just press the **“Enter”** key on your keyboard to commit the crop. If at any time you’d like to start over or decide not to crop at all, you can press the **“Esc”** key on your keyboard to back out of the operation.
See [the documentation](https://docs.gimp.org/2.8/en/gimp-tool-crop.html) for more information on cropping in GIMP.
Another way to crop an image is to make a selection first, using the **Rectangle Select Tool**:
Or through the menus:
You can then highlight a selection the same way as the **Crop Tool**, and adjust the selection as well. Once you have a selection you like, you can crop the image to fit that selection through:
There may be a time that you would need to rotate an image. For instance, you may have taken the image with your camera in a vertical orientation, and for some reason it wasn’t detected by GIMP as needing to be rotated (GIMP will normally figure this out for you, but not always).
There may also be a time that you’d like to flip an image as well. These commands are grouped together under the same menu item:
If you want to flip your image, the **Transform** menu offers two options, **Flip Horizontally**, or **Flip Vertically**. This operation will mirror your image along the specified axis. For example, here are all of the flip operations shown in a single image:
Image rotation from the **Transform** menu is contrained to either 90° clockwise/counter-clockwise, or 180°.
Don’t mis-interpret this to mean that GIMP cannot do arbitrary rotations (any angle). Arbitrary rotations are handled on a per-layer basis, while the image rotation described here is applicable to the entire image at once.
The simple examples shown here are just the tip of a really, really large iceberg. These are, however, common modifications that many people are often looking to make without having to learn too much about image processing. Hopefully they have been helpful.
I encourage you to peruse the [other tutorials](/tutorials/) for more advanced methods of image processing as well!
The original tutorial this was adapted from can be found [here](../Lite_Quickies).
GIMP Tutorial - GIMP Quickies (text & images) by |
16,366 | Linux 用户必备的 8 大网站 | https://itsfoss.com/useful-linux-websites/ | 2023-11-10T11:18:44 | [
"网站",
"Linux"
] | https://linux.cn/article-16366-1.html | 
>
> 这里列举的是我个人最喜欢的 Linux 网站,希望你也能喜欢。
>
>
>
既然你已经在关注我们,我们能为你解答大多数关于 Linux 的基础需求。
然而,对 Linux 的学习总是无止境的,即便是对于资深的 Linux 专家也是如此。????
实际上,一些网站和博客内容对于 Linux 新手以及有经验的用户都十分有用。
下面我就来列举一些你或许应该收藏的优秀网站。
### 1、ArchWiki

[ArchWiki](https://wiki.archlinux.org/) 平台提供了各种信息。无论你是寻求关于工具、安全技术、安装程序、桌面环境,或是其它任何主题的内容,你都可以在 ArchWiki 上找到相关的深入讨论。
从技术角度讲,ArchWiki 充当着 Arch Linux 发行版的文档门户。不过,即使你并非 Arch Linux 的用户,你仍然可以在这里找到教程、指南、常见问题解答(F.A.Q),以及大量其它的关键信息。
这些信息表述清晰,经过详尽的审查以及更新,且易于理解。
>
> **[ArchWiki](https://wiki.archlinux.org/)**
>
>
>
### 2、ExplainShell

[ExplainShell](https://explainshell.com/) 是一个非常有趣的平台,可以帮助你快速识别命令中所使用的参数。
通常,我们需要分别检索手册页或者是命令信息。而有了 ExplainShell,这个过程就变得更高效,它能够迅速为你提供所需的信息,同时为你提供对应的手册页链接。
它主要显示从 Ubuntu 的手册页库中提取的信息。所以,无论你是正在进行软件安装,进行 Git 提交,还是连接到 SSH,你都可以借助 ExplainShell 来深入理解各种命令。
>
> **[ExplainShell](https://explainshell.com/)**
>
>
>
### 3、Crontab.guru

如果你想要创建 [cron 任务](https://itsfoss.com/cron-job/) 以实现自动化,那么 [Crontab.guru](https://crontab.guru/) 就是一款必备的便利网站。
只需输入你计划在 cron 任务中采用的表达式,即可获取关于其是否会按预期工作的详细反馈。对于正确的表达式,它将直接呈现你想通过 cron 任务设定的时间表。
除此之外,即使你是 cron 的新手,它也会在编辑器里高亮表达月份/日期/星期的字段。
如果内容符合你的预期,就可以直接使用,或者编辑以修正并使用。
>
> **[Crontab.guru](https://crontab.guru/)**
>
>
>
### 4. DistroWatch

[DistroWatch](https://distrowatch.com/) 或许是每个 Linux 用户都耳熟能详的网站。该网站以列举当前热门 Linux 发行版而闻名,一些用户甚至参考其流行度榜单,以了解自己偏爱的发行版是否位列其他版本之上。
在这里,你可以获取到最新发布的各种 Linux 发行版的更新信息,其中可能包括一些你此前未曾听闻过的版本,以及新版本的简要更改日志。
如果你订阅了它们的通讯,还可以收到发行版评论以及一些有关开发的新闻。对于希望跟踪最新发行版的用户,这个网站值得你书签收藏。
>
> **[DistroWatch](https://distrowatch.com/)**
>
>
>
### 5、Phoronix

[Phoronix](https://www.phoronix.com/) 是目前为止最老牌的 Linux 网站之一,专注于发布面向硬件的内容。
无论你正寻找与最新处理器相关的 Linux 基准测试,还是 Linux 发行版的性能报告,你都可以在 Phoronix 上找到。除此之外,你还可以在这里定期获取到 Linux 世界的最新消息和开发动向。
>
> **[Phoronix](https://www.phoronix.com/)**
>
>
>
### 6、Ubuntu Blog

Canonical 的博客主要关注 Ubuntu、其开发动态、企业级更新以及其它技术性进展。
如何你希望了解关于 Ubuntu 的所有事情,那么 [Ubuntu Blog](https://ubuntu.com/blog) 就是你的最佳书签。无论你是物联网爱好者,还是利用 Ubuntu 进行机器人工程开发,总有新动态在发生。
坦白说,鉴于 Ubuntu 广泛的应用,你无法从任何特定的博客获取所有这些更新信息。
>
> **[Ubuntu Blog](https://ubuntu.com/blog)**
>
>
>
### 7、GamingOnLinux

尽管我们也会覆盖一些游戏更新,并为你提供一个 [游戏指南](https://itsfoss.com/linux-gaming-guide/),但是对于全面了解 Linux 游戏和 Steam Deck 的一切,[GamingOnLinux](https://gamingonlinux.com/) 是你的终极选择。
不论是新的开发动态、新游戏、SteamOS 的发布、SteamVR,还是对 Linux 用户有重要影响的促销信息,你都可以在这里找到。
>
> **[GamingOnLinux](https://gamingonlinux.com/)**
>
>
>
### 8、Reddit 的 /r/Linux 子论坛

虽然 Reddit 已经与过去有所不同,但其子论坛仍然值得关注。
[/r/Linux 子论坛](https://www.reddit.com/r/linux/) 是一个值得你收藏的社区,你可以在这里读到开源世界和 Linux 领域的最新动态。也许 Reddit 用户并没有你想象中那么友好,但如果你想随时了解最新的变化,这个子论坛绝对值得你的收藏。
>
> **[/r/Linux 子论坛](https://www.reddit.com/r/linux/)**
>
>
>
### 私货:Linux 中国
翻译这篇文章时,我觉得应该将我们的网站也推荐给大家:
Linux 中国是一家立足中文开源爱好者社区的网站,已经持续为大家提供了十多年的关于开源、技术方面的内容。除了网站,我们还提供了同名的微信公众号、知乎官方账号。此外,我们在 BiliBili、YouTube、微博、抖音上也提供了短视频内容;在喜马拉雅上提供了音频内容;以及,很多人都在订阅的 RSS。
>
> **[Linux 中国](https://linux.cn/)**
>
>
>
顺便说一句,我们现在提供了深色模式和文本模式,你试过了吗?
### 我收藏了什么?
我很喜欢 **Phoronix 带来的硬件深度分析** 和 **Distrowatch 对新发行版项目的最新消息**,因此这两个网站一直位于我的收藏列表中。
而你需要收藏什么呢?
事实上,如果你是 Ubuntu 的桌面用户,关注 **Canonical 的博客**无疑能帮你了解最新版本的发布和新功能的解读。对于游戏爱好者,**GamingOnLinux** 是你的一站式解决方案。
假如你是那种总想知道事物运作方式或本质的人,那么,**ArchWiki**应该是你的首选。
当然,对于所有跟 Linux 相关的东西,我们会竭尽全力为你提供最佳的内容。所以,请别忘了也收藏我们哦!?
? 那么,你最喜欢收藏哪些网站呢?请在下方评论区告诉我吧!
*(题图:MJ/f29cd1de-dacc-4b38-b91d-a697d9adf8da)*
---
via: <https://itsfoss.com/useful-linux-websites/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Considering you already follow us, we have your back for the most essential Linux requirements.
However, when it comes to Linux, there is always something to learn, even for all the Linux experts out there. 👨💻👩💻
So, there are some websites and blogs that are helpful for both newbies and experienced Linux users.
Let me list some of the best options for you to bookmark.
## 1. ArchWiki
[ArchWiki](https://wiki.archlinux.org) is a platform for all kinds of information. Whether it is about a tool, a security technology, an installer, a desktop environment, or anything else, you can find insights about it on ArchWiki.
Technically, it serves as the documentation portal for the Arch Linux distribution. However, you can find tutorials, guides, FAQs, and other essential information regarding numerous things to help you even if you do not use Arch Linux.
The information is well-presented, thoroughly reviewed/updated, and easy to read.
## 2. Explainshell
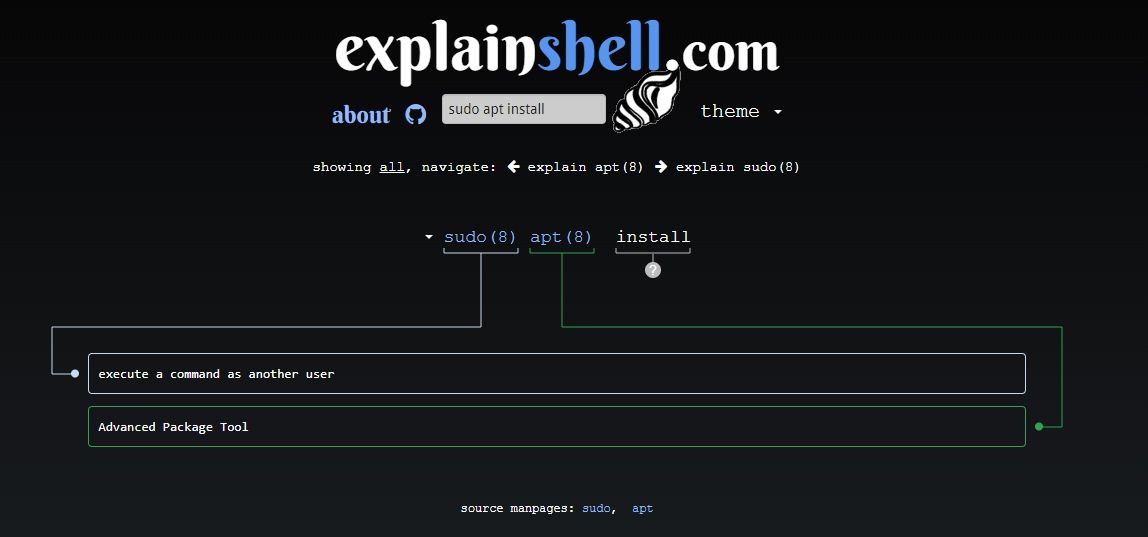
[Explainshell](https://explainshell.com) is an interesting portal that helps you identify the arguments used in a command in one go.
Usually, you search for manpages or information on commands separately. Explainshell should accelerate the process to get you the information needed along with the link to its manpage.
Primarily, it displays information sourced from Ubuntu's manpage repository. So, whether you are installing a software, working on a Git commit, connecting to SSH, you can break down all the commands using Explainshell.
## 3. Crontab.guru
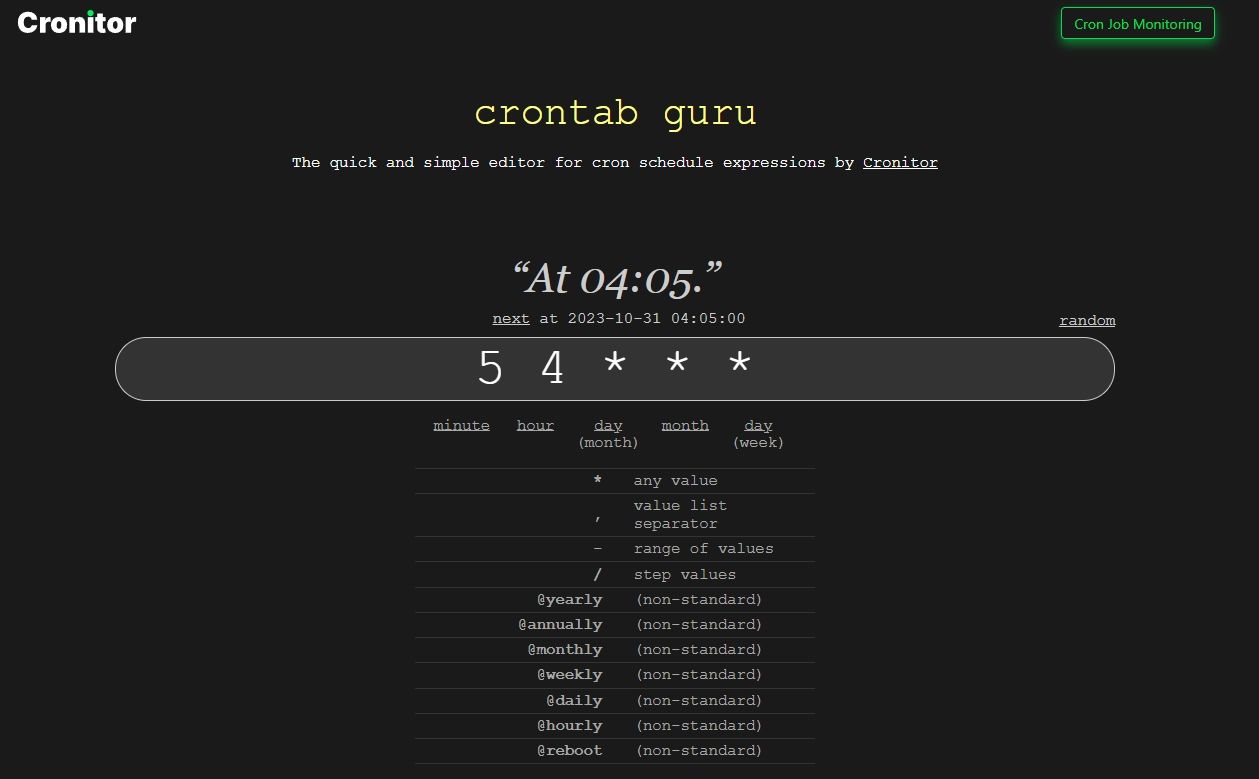
If you create [cron jobs](https://itsfoss.com/cron-job/) and schedules to automate things, [Crontab.guru](https://crontab.guru) is a handy website.
You can just enter the expression that you intend to use in your cron job, and get details if it will work as you expect. For correct expressions, it will reflect the schedule you want to set with the cron job.
As a bonus, even if you are new to cron jobs, it will highlight which is the month/day/week field in the editor.
If it looks correct to you, proceed or edit it to rectify and use it.
**Suggested Read 📖**
[What is a Cron Job in Linux?In this part of our Linux Jargon Buster, you’ll learn about cron in Linux. You’ll also learn the basics of creating cron jobs by editing crontab.](https://itsfoss.com/cron-job/)

## 4. Distrowatch
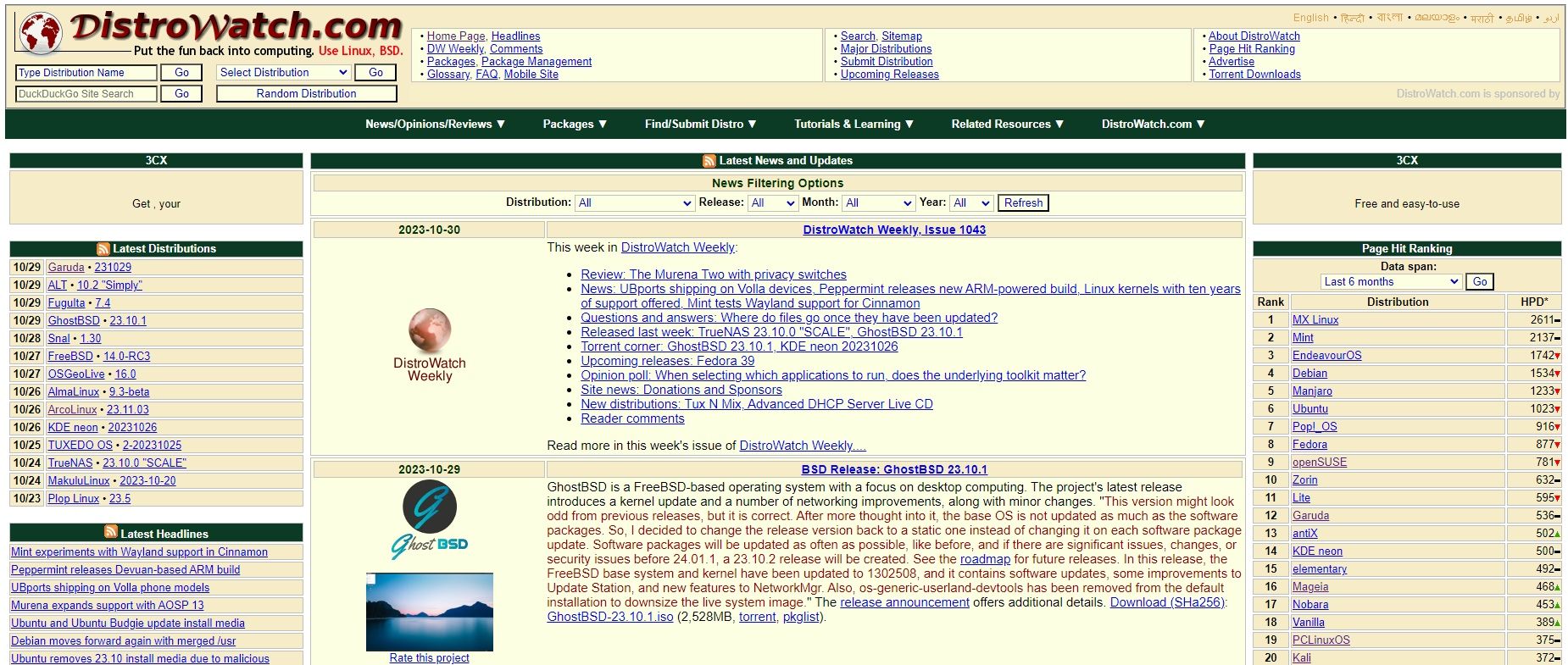
[Distrowatch](https://distrowatch.com) is one portal every Linux user may already know. It is popular for listing trending Linux distributions. Some even consider the popularity chart to see if their favorite distribution ranks higher than others.
You can get updates on the latest distribution releases, ones that you may not have heard ever before, along with a summarized changelog for new releases.
If you subscribe to its newsletter, they also publish distro reviews and cover some development news. For users looking to keep up on the latest distributions, this is your bookmark.
## 5. Phoronix
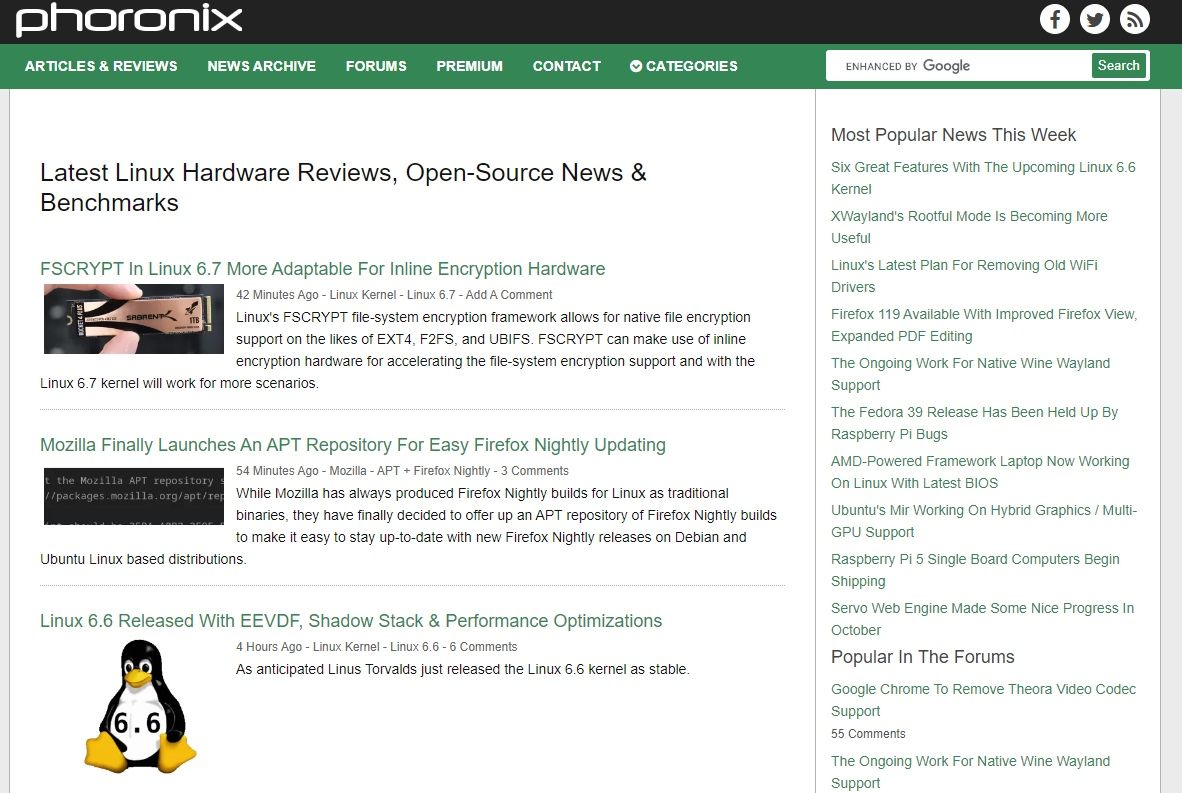
[Phoronix](https://www.phoronix.com) is one of the oldest Linux websites out there with the best hardware-focused content.
Whether you are looking for a benchmark on Linux with the latest processor or a distribution's performance, Phoronix has it. You also get a regular dose of news and development updates in the Linux world as an extra.
## 6. Ubuntu Blog
Canonical's blog is all about Ubuntu, its developments, enterprise updates, and other technological advances.
If you want to keep up with everything around Ubuntu, the [Ubuntu Blog](https://ubuntu.com/blog) is the best place to have bookmarked. Whether you are an IoT enthusiast, or a robotics engineer making use of Ubuntu, there's always something happening.
And, to be honest, you can never get all these updates from any particular blog considering Ubuntu is everywhere.
**Suggested Read 📖**
[10 Best Ubuntu Blogs to FollowWant to explore Ubuntu and Linux focused blogs? Here are the ten best options!](https://itsfoss.com/ten-blogs-every-ubuntu-user-must-follow/)

## 7. GamingOnLinux
While we do cover some gaming updates and have a [gaming guide](https://itsfoss.com/linux-gaming-guide/) for you, [GamingOnLinux](https://www.gamingonlinux.com/) is the ultimate portal for everything on Linux gaming and Steam Deck.
Whether it is about a development change, a new game, SteamOS releases, SteamVR, or a sale that could matter to Linux users, you can find all about it.
## 8. /r/Linux on Reddit
Even though Reddit is no longer the place it used to be, the Subreddits are still worth a follow.
The [Linux subreddit](https://www.reddit.com/r/linux/) is a community to bookmark for the latest happenings in the open-source and Linux universe. You may not find the fellow Redditors as friendly as one would expect, but as long as you want to keep an eye on updates, a bookmark suits it.
## What Do I Keep Bookmarked?
I love **Phoronix's hardware insights **and **Distrowatch's** updates on newer distro projects. So, those two websites are always in my bookmark list.
What should you have bookmarked?
Well, if you are a desktop user using Ubuntu, **Canonical's blog** should be great to keep up with newer releases and explanations on newer features. For a gamer, **GamingOnLinux** is a one-stop portal.
In case you are always curious and want to know how things work/what it is - **ArchWiki** should be your go-to reference.
Of course, for all things Linux, we try our best not to disappoint you. So, do not forget to bookmark us as well!😉
*💬 What are your favorite websites to bookmark? Let me know in the comments down below!* |
16,368 | 震撼登场!全新的 Steam Deck OLED 公开亮相! | https://news.itsfoss.com/steam-deck-oled/ | 2023-11-11T14:46:00 | [
"游戏",
"Steam Deck"
] | https://linux.cn/article-16368-1.html | 
>
> 一款全新的、拥有更好显示效果以及卓越规格的 Steam Deck。
>
>
>
随着假期临近,Valve 带给我们可能让这个季节更加欢乐的一些新鲜事。
他们近期的一次公告中,揭露了具备多项令人兴奋升级的**全新 Steam Deck 变体**。
快来一起深入了解一下吧。
### ? Steam Deck OLED:有哪些新特点?
此款 Steam Deck 变体,如名所示,配备了**全新的 90Hz、7.4 英寸 HDR OLED 显示屏**,支持达到**高达 1,000 尼特的 HDR 峰值亮度**以及**600 尼特的 SDR 亮度**。
相较于现有的配备了 LCD 的型号, OLED 显示屏能够**为玩家呈现更为深邃的黑色和更加明亮的色彩**。
然而,超凡的显示屏**并非新款 Steam Deck 唯一的亮点**,它的处理器也实现了升级,**更高效的 6 纳米 AMD “Sephiroth” APU**如今负责所有板上的处理任务。
作为上述特性的补充,Steam Deck OLED 还配备有**更大容量的 50Whr 电池**,能够带给你持久的电池续航。
在连接性方面,它提供了**Wi-Fi 6** 和 **Bluetooth 5.3**,实现了**更优质的下载体验**。
>
> ? 配有一根 2.5m 的电缆的 45W USB Type-C PD3.0 电源供应器,以便为电池充电。
>
>
>
对于**控制器也有所改进**,优化了模拟摇杆的顶部材料和形状,实现了更佳的粘性和防尘性,肩部按钮的反应更敏捷,并提供优越的触感反馈等等。
**操作系统仍然是 LCD 版本上的 Steam OS 3**,但是,如果你想尝试些不同的东西,不妨试试 [Bazzite](https://news.itsfoss.com/bazzite/)。
#### ?️ 主要规格
如果你想了解,新推出的 Steam Deck OLED 其实力如何?这里有详细的配置:
* **APU:** 6 纳米 AMD “Sephiroth”
* **CPU:** 4 核,[Zen 2](https://en.wikipedia.org/wiki/Zen_2),主频 2.4–3.5 GHz
* **GPU:** 8x [RDNA 2](https://en.wikipedia.org/wiki/RDNA_2) 处理单元,主频 1.6 GHz
* **RAM:** 16 GB LPDDR5
* **存储:** 512 GB 或 1 TB 的 NVMe SSD
* **操作系统:** [SteamOS](https://itsfoss.com/steamos/) 3(基于 Arch)
* **重量:** 669 克
**但是,等等,还有更多!**
Valve 也推出了**特别的限量版 Steam Deck OLED** ,它具有所有相同的技术规格和 1 TB 的存储,**透明壳体以及烟雾般透明的外观色彩**。一起来看看吧?

它看起来真的很酷。我非常喜欢许多制造商现在的做法,通过透明的外壳来展示设备本身。也许,这是一个很好的趋势。
Valve 表明,这款设备只在美国和加拿大有**数量有限的供应**。
这个量产策略之所以限量,是因为他们想**尝试**了解是否有大量的对此类产品的需求,他们计划在未来尝试更多的颜色方案。
### ? 在哪儿购买呢?
**起价为 549 美元**,你可以在 11 月 16 日之后在 [Steam Store](https://store.steampowered.com/steamdeck) 采购 Steam Deck OLED。
但请注意,并非所有 Steam 运营的区域都有销售。
>
> **[Steam Deck OLED](https://store.steampowered.com/steamdeck)**
>
>
>
如果你在想;**原有的 Steam Deck LCD 版本会怎么样?**
嗯,这些机型依然会有供应,并会定期更新。
? 在即将到来的假期季节,你会想要购买一台吗?请在下方让我知道你的想法!
---
via: <https://news.itsfoss.com/steam-deck-oled/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The holiday season is almost upon us, and Valve has introduced something to potentially make it more enjoyable!
With a recent announcement, they have shed light on **a new Steam Deck variant** equipped with some exciting upgrades.
Let's take a look at it.
## 🆕 Steam Deck OLED: What's New?
As the name suggests, this variant of the Steam Deck is equipped with **a new 90Hz 7.4” HDR OLED display** that can go to a **1,000 nits peak brightness for HDR**, and** 600 nits for SDR**.
This **display should provide gamers with deeper blacks and brighter colors** when compared to the existing LCD-equipped model.
However, the **display is not the only highlight** of this new Steam Deck variant. The processor also sees an upgrade, with **a more efficient 6 nm AMD “Sephiroth” APU **now taking care of all the processing on board.
To compliment the above-mentioned, the Steam Deck OLED comes equipped with a **larger 50Whr battery** to provide you a good battery life.
On the connectivity side of things; **Wi-Fi 6** and **Bluetooth 5.3** are being offered for **a better downloading experience**.
Even the **controls have been improved**, the top material and shape for the analog stick was improved for better grip/dust resistance, better responsiveness and tactile feedback from the shoulder buttons, and more.
The **operating system is the same Steam OS 3** found on the LCD model, but, if you were in the market to experiment something different, you could give [Bazzite](https://news.itsfoss.com/bazzite/) a try.
[Bazzite: A Distro for Linux Gaming on Steam Deck and PCsGear up for gaming on Linux desktop or the Steam Deck. That sounds exciting!](https://news.itsfoss.com/bazzite/)

### 🛠️ Key Specifications
If you're wondering, here's what's powering the newly launched Steam Deck OLED:
**APU:**6 nm AMD “Sephiroth”**CPU:**4-core,[Zen 2](https://en.wikipedia.org/wiki/Zen_2?ref=news.itsfoss.com)@2.4–3.5 GHz**GPU:**8x[RDNA 2](https://en.wikipedia.org/wiki/RDNA_2?ref=news.itsfoss.com)CUs @1.6 GHz**RAM:**16 GB LPDDR5**Storage:**512 GB or 1 TB NVMe SSD**OS:**[SteamOS](https://itsfoss.com/steamos/?ref=news.itsfoss.com)3 (Based on Arch)**Weight:**669 grams
**But, wait, there's more!**
Valve has also launched **a Limited Edition Steam Deck OLED**, which features all the same tech specs with the 1 TB storage, **a transparent case and a smoky translucent colorway.** Take a look for yourself. 👇

It looks really cool. I like what many manufacturers are doing now with their devices; going transparent for the outer casing. A good trend, perhaps.
Valve has mentioned that this will be **available in limited quantities** for buyers in the United States and Canada only.
The reason behind such a limited rollout is that **they are experimenting** to see whether there is a large demand for such a product, they intend to experiment with more colorways in the future.
## 🛒 Where to Buy?
**Pricing starts at $549**, you can buy Steam Deck OLED from the [Steam Store](https://store.steampowered.com/steamdeck?ref=news.itsfoss.com), November 16 onwards.
Just keep in mind that it is not available in all the regions where Steam operates.
If you're wondering; **what will happen to the Steam Deck LCD model?**
Well, those will still be available for purchase, and will receive regular updates.
*💬 Will you be grabbing one in the upcoming holiday season? Do let me know your thoughts below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,369 | 如何将 Silverblue 重定位到 Fedora Linux 39 | https://fedoramagazine.org/how-to-rebase-to-fedora-linux-39-on-silverblue/ | 2023-11-11T15:22:00 | [
"Silverblue",
"Fedora"
] | https://linux.cn/article-16369-1.html | 
[Fedora Silverblue](https://docs.fedoraproject.org/en-US/fedora-silverblue/) 是 一款基于 Fedora Linux 构建的面向桌面的操作系统。这款操作系统非常适合日常使用、开发和容器化的工作流程。它有 [许多优势](https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/),例如可以在发生问题时轻松回滚操作。如果你想在 Fedora Silverblue 系统上更新或将系统 <ruby> 重定位 <rt> rebase </rt></ruby> 到 Fedora Linux 39,本文会提供帮助。文章不仅会指导你执行操作,还会教你如何在遇到意外情况时撤销操作。
### 更新你目前的系统
在实际重定位至 Fedora Linux 39 前,你需要先安装所有待处理的更新。你可以在终端中使用下面的命令:
```
$ rpm-ostree update
```
或者你也可以通过 GNOME “软件”应用安装更新,然后重新启动系统。
### 使用 GNOME “软件” 重定位
在 GNOME “软件”应用的更新页面上,你可以看到 Fedora Linux 的新版本已经可以使用。
首先,你需要点击 “<ruby> 下载 <rt> Download </rt></ruby>” 按钮来下载新的操作系统镜像。这个过程可能需要一些时间。完成后,你会发现更新已经准备好进行安装。
接下来,点击 “<ruby> 重新启动 & 升级 <rt> Restart & Upgrade </rt></ruby>” 按钮。这个过程只需要几分钟,一旦更新完成,计算机将会重新启动。重启后,你会看到崭新的 Fedora Linux 39 的系统环境,看起来很简单,是吧?
### 使用终端进行重定位
如果你更喜欢在终端操作,那么这部分指南就是为你准备的。
首先你需要确认 39 版本是否已经可以使用:
```
$ ostree remote refs fedora
```
在命令输出中你应该看到如下内容:
```
fedora:fedora/39/x86_64/silverblue
```
如果你想保留当前的部署(这意味着这个部署将会持续在 GRUB 中显示为一个选项,直到你手动移除它),你可以通过运行下面的命令实现:
```
# 0 是在 rpm-ostree 状态中的条目位置
$ sudo ostree admin pin 0
```
如果你想移除已经固定的部署,你可以使用下面的命令:
```
# 2 是在 rpm-ostree 状态中的条目位置
$ sudo ostree admin pin --unpin 2
```
然后,将你的系统重定位至 Fedora Linux 39 镜像。
```
$ rpm-ostree rebase fedora:fedora/39/x86_64/silverblue
```
最后,重启你的电脑,启动进入 Fedora Linux 39 版本。
### 如何进行回滚
如果遇到任何问题(例如,如果你无法启动 Fedora Linux 39),回滚是非常容易的。在系统启动时,在 GRUB 菜单中选择 Fedora Linux 39 之前的版本,然后你的系统就会启动这个更早的版本而非 Fedora Linux 39。如果你在启动过程中看不到 GRUB 菜单,那么在启动时尝试按下 `ESC` 键。如果你想让更早版本的选择永久生效,你可以使用下面的命令:
```
$ rpm-ostree rollback
```
现在,你已经了解如何将 Fedora Silverblue 系统重定位到 Fedora Linux 39,以及如何进行系统回滚了。那么何不今天就试试看呢?
### 常见问题解答
在每篇关于重定位 Silverblue 到新版本的文章的评论中,总会有相似的问题,因此我会在这个部分尝试解答这些问题。
**问题:在 Fedora 的重定位过程中我能跳过某些版本吗?例如直接从 Fedora 37 Silverblue 更新到 Fedora 39 Silverblue。**
答案:虽然有时可能可以在重定位过程中跳过某些版本,但并不推荐这样操作。你应当始终更新到紧邻的新版本(例如从 38 更新到 39),以避免不必要的错误。
**问题:我安装了 [rpm-fusion](https://rpmfusion.org/) ,在重定位过程中出现错误,我应当怎样进行重定位?**
答案:如果你在 Silverblue 安装上加入了 [rpm-fusion](https://rpmfusion.org/),你在重定位前应当执行以下操作:
```
rpm-ostree update \
--uninstall rpmfusion-free-release \
--uninstall rpmfusion-nonfree-release \
--install rpmfusion-free-release \
--install rpmfusion-nonfree-release
```
执行完上述操作后,你可以按照本篇博文的步骤完成重定位过程。
**问题:这个指南是否适用于其他的 ostree 版本(例如 Kinoite, Sericea)?**
答案:是的,你可以照着本指南的 *使用终端进行重定位* 部分的操作来完成所有的 Fedora ostree 版本的重定位过程。只需要使用对应的分支即可。例如对于 Kinoite,你可以使用
```
fedora:fedora/39/x86_64/kinoite
```
而非
```
fedora:fedora/39/x86_64/silverblue
```
*(题图:MJ/71150afc-ae44-48f3-8689-e86758e07b1e)*
---
via: <https://fedoramagazine.org/how-to-rebase-to-fedora-linux-39-on-silverblue/>
作者:[Michal Konečný](https://fedoramagazine.org/author/zlopez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora Silverblue is [an operating system for your desktop built on Fedora Linux](https://docs.fedoraproject.org/en-US/fedora-silverblue/). It’s excellent for daily use, development, and container-based workflows. It offers [numerous advantages](https://fedoramagazine.org/give-fedora-silverblue-a-test-drive/) such as being able to roll back in case of any problems. If you want to update or rebase to Fedora Linux 39 on your Fedora Silverblue system, this article tells you how. It not only shows you what to do, but also how to revert things if something unforeseen happens.
## Update your existing system
Prior to actually doing the rebase to Fedora Linux 39, you should apply any pending updates. Enter the following in the terminal:
$ rpm-ostree update
or install updates through GNOME Software and reboot.
## Rebasing using GNOME Software
GNOME Software shows you that there is new version of Fedora Linux available on the Updates screen.
First thing you need to do is download the new image, so click on the *Download* button. This will take some time. When it’s done you will see that the update is ready to install.
Click on the *Restart & Upgrade* button. This step will take only a few moments and the computer will be restarted when the update is completed. After the restart you will end up in new and shiny release of Fedora Linux 39. Easy, isn’t it?
## Rebasing using terminal
If you prefer to do everything in a terminal, then this part of the guide is for you.
Rebasing to Fedora Linux 39 using the terminal is easy. First, check if the 39 branch is available:
$ ostree remote refs fedora
You should see the following in the output:
fedora:fedora/39/x86_64/silverblue
If you want to pin the current deployment (meaning that this deployment will stay as an option in GRUB until you remove it), you can do it by running:
# 0 is entry position in rpm-ostree status $ sudo ostree admin pin 0
To remove the pinned deployment use the following command:
# 2 is entry position in rpm-ostree status $ sudo ostree admin pin --unpin 2
Next, rebase your system to the Fedora Linux 39 branch.
$ rpm-ostree rebase fedora:fedora/39/x86_64/silverblue
Finally, the last thing to do is restart your computer and boot to Fedora Linux 39.
## How to roll back
If anything bad happens (for instance, if you can’t boot to Fedora Linux 39 at all) it’s easy to go back. At boot time, pick the entry in the GRUB menu for the version prior to Fedora Linux 39 and your system will start in that previous version rather than Fedora Linux 39. If you don’t see the GRUB menu, try to press ESC during boot. To make the change to the previous version permanent, use the following command:
$ rpm-ostree rollback
That’s it. Now you know how to rebase Fedora Silverblue to Fedora Linux 39 and roll back. So why not do it today?
## FAQ
Because there are similar questions in comments for each article about rebasing to newer version of Silverblue I will try to answer them in this section.
**Question: Can I skip versions during rebase of Fedora? For example from Fedora 37 Silverblue to Fedora 39 Silverblue?**
Answer: Although it could be sometimes possible to skip versions during rebase, it is not recommended. You should always update to one version above (38->39 for example) to avoid unnecessary errors.
**Question: I have rpm-fusion layered and I got errors during rebase. How should I do the rebase?**
Answer: If you have [rpm-fusion](https://rpmfusion.org/) layered on your Silverblue installation, you should do the following before rebase (this is a single line command, beware the wrapping):
rpm-ostree update --uninstall rpmfusion-free-release --uninstall rpmfusion-nonfree-release --install rpmfusion-free-release --install rpmfusion-nonfree-release
After doing this you can follow the guide in this blog post.
**Question: Could this guide be used for another ostree editions (Kinoite, Sericea)?**
Yes, you can follow the *Rebasing using the terminal* part of this guide for every ostree edition of Fedora. Just use the corresponding branch. For example for Kinoite use
## Steven
It was an easy upgrade in GNOME Software. Thanks to all!
## Lennart Jern
Nice, easy upgrade, as usual!
One weird thing though: my terminal is now light/white colored even though I use dark theme everywhere. Anyone else having this issue?
## SuperTux
Is it possible to rebase to kinoite or other variations when using silverblue ?
## TopDAW
Thank you very much! The update did not show up in GNOME software so I rebased manually. This did not initially work until I saw your tip about rpm-fusion.
All good now – brilliant!
## Brant
Hi SuperTux,
You can actually, I didn’t have any issues upon testing Silverblue -> Kinoite but upon rolling back Gnome’s default file icons seem bugged (.config file errors). So I can’t say how reliable going back and forth would be natively. Also you’ll likely have leftover desktop environment files in your .config so you may need to look for them and delete them. This will also likely fix any bugs between switching back and forth.
Good luck and enjoy. Can always test on Gnome Boxes too!
## Grandpa Leslie Satenstein
I have 3 other partitions, including 2 other backup partitions.
How do I get these into a clean silver-blue installation?
## Ashberian
Using Silverblue-Kinoite and just upgraded to v39.
Run into some issues upgrading through Discover, had to remove rpmfusion-free &non-free repos before upgrading, for that i used the single line uninstall/install command from this article however it didn’t work… until i just used two single line commands to uninstall both repos, one after another. Then i finally proceeded to update/rebase without noticeable issues.
Now on Kinoite 39 trying to reinstall both repos, however it always show the same error:
“error: Packages not found: rpmfusion-free-release, rpmfusion-nonfree-release”
## Norman
Thank you Michal Konečný for writing your article “How to rebase to Fedora Linux 39 on Silverblue”. |
16,371 | Canonical 告诉你如何不通过 Snap 商店使用 Snap 包 | https://www.theregister.com/2023/11/10/snap_without_ubuntu_tools/ | 2023-11-12T13:07:00 | [
"Ubuntu",
"Snap"
] | https://linux.cn/article-16371-1.html | 
>
> 虽然你可能听到不同的看法,但实际上,它并未像一些批评者所想象的那样完全专有。
>
>
>
对 Ubuntu 的 Snap 打包格式最常见的误解之一是它是专有的 —— 但是深入研究其文档后,会发现这个说法并不对。
在上周末拉脱维亚的里加举行的 Ubuntu 峰会上,笔者有幸采访到 Ubuntu 的<ruby> 开发者大使 <rt> developer advocate </rt></ruby>,Igor Ljubuncic。期间,他们详细探讨了关于 Snap 的各种误区,包括它被视为完全闭源的、受 Canonical 控制、必须使用 Canonical 的 Snap 商店等众多谬论。
如果说有什么比糟糕的软件更加厌恶的,那一定是谎言。正如我们在 [点评 Fedora 39](https://www.theregister.com/2023/11/09/fedora_39_released/) 时所注意到的,即使在 Linux 诞生之前,各种软件的拥趸们就经常爆发各种 [圣战](http://catb.org/jargon/html/H/holy-wars.html)。但我们至少希望能坚守事实的公道。毫无根据的恶意指责是没有必要的:生活本身已经足够糟糕。
笔者的立场很明确,我们并不特别偏爱任何 Linux 发行版或其打包工具。像许多资深电脑技术人员一样,在长期和各种软件打交道后,笔者已经对所有的软件厌烦至极。一句广为接受的说法就是:[没有一个软件不让人头疼](http://harmful.cat-v.org/software/)。
Linux 就是一个软件,因而它难免让人头疼。承此,所有的 Linux 发行版也都不尽如人意。包管理器也是一个软件,同样也不尽人意。但幸运的是,至少大多数 Linux 发行版都有一个包管理器。这比没有软件包管理器要好,或者更糟糕的是,有不止一个以上的包管理器,这一点 [XKCD 927](https://xkcd.com/927/) 漫画体现的淋漓尽致。

我们并不特别青睐 Snap,也不特别反对 Flatpak。笔者个人更偏好 [AppImage](https://appimage.org/) 格式,它不需要其他额外的框架。但虽然有个 [AppImageHub](https://www.appimagehub.com/),但该格式却并没有提供软件更新的工具,这个问题就留给了应用本身来解决。
鉴于所有的软件都不完美,那唯一重要的区别就在于其问题严重的程度。一段时间以后,你最关注的就是它是否可运行,能否满足你的需要,以及它的可靠性。
我在早年的职业生涯中花了很多时间在技术支持上,修复其他人的软件。因此,我学到了一个经验,那就是降低软件让人厌烦程度的一个重要因素就是它工作的方式是否容易理解。
Btrfs 是复杂的,而修复它则更是如此。Git 属于*本质*复杂,其 [名称](https://dictionary.cambridge.org/dictionary/english/git) 就体现出这一点。(没错,“git” 是一个名词,而非缩写或代号,有实际的意思 —— “饭桶”。)OStree 可以说是针对二进制文件的 Git,这使得它比普通 Git 至少复杂两倍。而 Flatpak 则是 OStree 的封装。
这意味着增加了两层额外的复杂度:首先,对复杂事物的封装只能隐藏其复杂性,而不能消除其复杂性。其次,你不能使用 Flatpak 构建一个操作系统,因此你还需要 OStree。
因此,我们将来逐一揭穿关于 Snap 格式和工具的一些误解。这不是一篇入门指南,而是对那些不那么显而易见,并且对 Snap 有所误解的人的一份快速概览。
### 无需商店进行分发
Snap 包其实就是一个 [Squashfs](https://docs.kernel.org/filesystems/squashfs.html),类似于大多数 Linux 安装介质上的系统镜像。Snap 包以两个文件传递:其中一个是命名为 `<name>_<revision>.snap`,该文件包含了软件本身;另一个则是一个伴随的 [声明文件](https://snapcraft.io/docs/assertions),它为 Snap 提供了数字签名。然后,Canonical 还进一步 [详细阐明](https://snapcraft.io/docs/revisions) 了版本修订的工作原则。
使用 `snap download` 的指令(而非 `snap install`)可以容易获取这些基本文件:
```
# snap download firefox
Fetching snap "firefox"
Fetching assertions for "firefox"
Install the snap with:
snap ack firefox_3252.assert
snap install firefox_3252.snap
```
然后,这些文件便可以被复制到另一台设备上进行安装,这种操作不需要访问 Snap 商店,仅需使用输出中的指令即可。
如 Igor 所说:
>
> “这样,从 Snap 商店中,你可以选择你想要的 Snap 包(如 Firefox),将其放入你的内部仓库中,或是 FTP,或是 NFS 上。接着你可以使用它作为在内部安装 Snap 的来源,而这不需要去访问商店。此外,你还可以将这个操作与你所使用的任何调度或部署机制结合起来,就如配置管理那样。”
>
>
>
### 安装无需声明文件的 Snap 包
通常来说,`snap ack` 命令会首先读取并验证签名,但是你可以选择跳过这个步骤。
```
snap install "downloaded snap" --dangerous
```
上述指令会安装该 Snap 包,并不会验证其签名。请注意,这样做虽然操作简单,但也有一个重要的限制:使用 `--dangerous` 选项安装的 Snap 包不会自动从商店中更新。
所以,实际上,你可以在你的网络内部分发 Snap 包,避免它们试图连接到 Snap 商店,并自主管理更新。
### 管控 snapd 内置的更新机制
另一方面,你可以在不忽略验证机制的前提下,管理和控制操作系统何时以及如何更新 Snap 包。Igor 则曾撰写过关于如何使 Snap [更新暂停](https://snapcraft.io/blog/hold-your-horses-i-mean-snaps-new-feature-lets-you-stop-snap-updates-for-as-long-as-you-need) 的文章。
你可以设置暂停 Snap 的更新一段时间,或永久暂停,甚至只选择暂停特定的 Snap 包,同时也能简单取消此设置。例如:
```
snap refresh --hold
Auto-refresh of all snaps held indefinitely.
```
另外,你也可以通过以下方式设置防火墙拦截 Snap API:
```
sudo iptables -A OUTPUT -d api.snapcraft.io -j DROP
```
### 在无 snapd 环境下运行 snaps
`.snap` 文件实际上就是一个压缩的文件系统,它包含着程序文件(以及各种库等),这些都被存放在一个传统的目录结构中,而该目录结构对于打包在 Snap 应用程序内的应用来说,就是它的根目录。Snapd 负责为此设置挂载名空间,并通过 [Apparmor](https://apparmor.net/) 和 [seccomp](https://man7.org/linux/man-pages/man2/seccomp.2.html) 实现安全隔离。
你可以将其内容解压并直接运行:
```
unsquashfs firefox_3252.snap
Parallel unsquashfs: Using 20 processors
565 inodes (5428 blocks) to write
[=====================/] 5428/5428 100%
created 399 files
created 149 directories
created 166 symlinks
created 0 devices
created 0 fifos
created 0 sockets
ll squashfs-root/
total 80
drwxr-xr-x 7 igor igor 4096 lis 10 02:33 ./
drwxr-xr-x 10 igor igor 4096 lis 19 15:32 ../
drwxr-xr-x 5 igor igor 4096 lis 10 02:33 data-dir/
-rw-r--r-- 1 igor igor 32441 lis 10 02:33 default256.png
-rw-r--r-- 1 igor igor 9146 lis 10 02:33 firefox.desktop
-rwxr-xr-x 1 igor igor 2680 lis 10 02:33 firefox.launcher*
drwxr-xr-x 2 igor igor 4096 lis 10 02:33 gnome-platform/
drwxr-xr-x 4 igor igor 4096 lis 10 02:33 meta/
-rwxr-xr-x 1 igor igor 3716 lis 10 02:33 patch-default-profile.py*
drwxr-xr-x 4 igor igor 4096 lis 10 02:33 snap/
drwxr-xr-x 4 igor igor 4096 sij 19 2022 usr/
```
如果你查看 Snap 内 Firefox 二进制文件的动态依赖,你会注意到它希望从根文件系统中获取文件:
```
ldd usr/lib/firefox/firefox-bin
linux-vdso.so.1 (0x00007fff33cc5000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f6cf2c00000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f6cf2e40000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f6cf2be0000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6cf2800000)
/lib64/ld-linux-x86-64.so.2 (0x00007f6cf300e000)
```
在 Snap 内部,这个“根”就是你的基础系统(比如 core18 或 core20 等)。但是一旦你解压了这个 Snap,没有 snapd 在安装和运行 Snap 时提供的安全隔离,Firefox 将会尝试直接访问你的根目录的库。这可能会导致执行时的不一致性。
举例来说,你的 Snap 内可能包含的是 GNOME 3.38 版的库,但是你的主机上运行的可能是 GNOME 3.32。如果你尝试解压并运行这个应用,它可能会试图从主机中加载库,这可能引起不一致 —— 更甚者,可能会让程序崩溃。
为了避免这种情况发生,你需要做的唯一事情就是设置 `LD_LIBRARY_PATH` 环境变量,以让程序知道其库在何处,确保它首选这些库,而不是使用可能导致其运行失败的操作系统中的库副本。
```
LD_LIBRARY_PATH: ${SNAP_LIBRARY_PATH}${LD_LIBRARY_PATH:+:$LD_LIBRARY_PATH}:$SNAP/usr/lib:$SNAP/usr/lib/x86_64-linux-gnu
```
通常,你会希望 `LD_LIBRARY_PATH` 开始于 `/snap/<snap name>/`,然后是 `/lib`、`/usr/lib` 和其他常用路径。至于其他内容,`firefox.launcher` 文件负责准备运行环境,剩余的,比如 `firefox.desktop`,都用于桌面集成:如图标、全名、文件关联等。这些内容虽然使应用看起来效果更好,但它们并非严格的必需品。
其实,你甚至不需要解压 Snap 的内容,你可以直接将 Snap 文件本身作为一个 [回环设备](https://tldp.org/HOWTO/archived/Loopback-Root-FS/Loopback-Root-FS-2.html) 挂载 —— 你甚至可以设置为只读 —— 但没有挂载命名空间隔离。并且,如果没有设置环境让 Snap 内部的应用在寻找它的库时首先从 Snap 内部开始,你仍然需要正确地设置库路径。
### 代理和缓存 Snap 包
正如 Igor 所说,如果客户并不打算自行运营一家具备完整品牌属性的 Snap 商店,他们可以选择手动设置一个 [Snap 代理](https://docs.ubuntu.com/snap-store-proxy/en/)。对此,Canonical 也提供了相应的 [文档](https://docs.ubuntu.com/snap-store-proxy/en/install),并描述了所需的 [网络访问](https://forum.snapcraft.io/t/network-requirements/5147) 权限。
同时,你也可以 [配置](https://snapcraft.io/blog/how-to-cache-snap-downloads-and-save-bandwidth) 一个缓存 Snap 代理 —— 这项任务稍微简单一些,对于希望降低下载带宽的家庭网络来说,可能是个不错的选择。
### 搭建自己的 Snap 商店
就如我们之前所述,你完全可以忽略所有来自 Canonical 的基础设施,直接运行自己的 Snap 商店。去年,我们写过一篇关于 Ubuntu Unity 维护者 [Rudra Saraswat](https://www.theregister.com/2022/02/04/rudra_sarsawat_ubuntu_projects/) 的文章,他就 [做到了这一点](https://gitlab.com/lol-snap/lol),这只是他的众多项目中之一。据悉,好几个在生产环境中使用 Ubuntu Core 的组织都采取了此种做法,而所有所需的工具都存放在 Ubuntu 仓库中。
Canonical 在这方面发布了大量的文档,包括怎样构建你的 [第一个 Snap 包](https://snapcraft.io/blog/how-to-make-your-first-snap),以及如何用 [不同的编程语言](https://snapcraft.io/docs/creating-a-snap) 构建。今年的峰会上有多场关于如何构建 Snap 的演讲 - 包括 [在平板电脑上构建 Snap 包](https://events.canonical.com/event/31/contributions/222/),以及如何 [自动化构建更新的 Snap 包](https://events.canonical.com/event/31/contributions/217/),虽然这对笔者来说有点过于复杂。
学习一些新的术语是有必要的,同时也有 [官方文档](https://snapcraft.io/docs/interface-management) 提供帮助。这段解释我们特别喜欢:
* <ruby> 插槽 <rt> slots </rt></ruby> 是指提供方(即 Snap 提供的资源)
* <ruby> 插口 <rt> plugs </rt></ruby> 是指消费者(即使用 Snap 提供的资源的用户)
* <ruby> 接口 <rt> interfaces </rt></ruby> 是交互的地方(负责将插口和插槽连接起来)
从我们与 Canonical 代表的对话中,他们似乎对 Snap 商店被误解,以及 Snap 被视为封闭、专有系统的争论显得尤为不满。
大约十五年前,有人曾声称 Canonical 的代码托管和项目管理平台 [Launchpad](https://www.theregister.com/2008/07/22/ubuntu_next_launchpad/) 是专有的,所以 Canonical 在整理代码后在 2009 年 [公开发布](https://canonical.com/blog/canonical-releases-source-code-for-launchpad) 了代码库。但如我们交谈的人所言:“没人在意。” 它是 Canonical 的内部工具,对其他人来说并没有太大的用处。他们表示,他们不希望再经历一次这样的情况。
我们还注意到,红帽正在朝反方向前进,即从开源的 Bugzilla [迁移](https://www.theregister.com/2023/09/29/red_hat_bugzilla_jira_migration/) 到封闭的、基于云的 Jira —— 这并未引起太大的争议。
[snapd](https://github.com/snapcore/snapd) 自身的代码已经托管在 GitHub 上,作为 Canonical 的 [snapcore](https://github.com/snapcore) 仓库的一部分。这个被大多数发行版使用的打包格式是一个已经存在、有文档记录的格式。用于进行隔离的工具,是已经存在并在其他发行版中使用的第三方工具,比如,Debian 和 SUSE 家族也使用了 AppArmor,这与 Arch 维基中的 [描述](https://wiki.archlinux.org/title/AppArmor) 相符,而它的主要竞品,[SELinux](https://selinuxproject.org/page/Main_Page),则更复杂,主要在红帽及其衍生产品中使用。
尽管 Canonical 自家定制的 [Snap 商店](https://snapcraft.io/store) 的后端仍然 [闭源](https://askubuntu.com/a/1383685),但 Snap 格式、snapcore 软件、[snapcraft.io 前端](https://github.com/canonical/snapcraft.io),以及更多组件都是开放的。我们再次强调,你完全可以自行搭建 [自己的 Snap 商店](https://ubuntu.com/blog/howto-host-your-own-snap-store)。
请不要受到愤怒的论坛喷子们的误导。
### 最后再说一点...
实际上,撰写这篇文章的作者曾经就职于红帽和 SUSE,但他主要还是使用 Ubuntu,从 2004 年 Ubuntu 刚刚发布起就开始一直使用。Ubuntu 不但运行顺畅,使用起来也十分便捷。然而,早在多年前他就已经从他的主要工作电脑上删除了 snapd 和相关的一切工具,取而代之的是 [deb-get](https://trendoceans.com/nala-package-manager/) —— 最初这是 Ubuntu MATE 的创造者 [Martin Wimpress](https://ubuntu-mate.org/) 编写的。为了更加迅速,他还选择使用 [Nala 包管理器](https://github.com/volitank/nala) 而不是 Apt。
如果可以的话,笔者很希望可以放弃各种形式的 Unix,除了服务器,其他情况下更倾向于使用 RISC OS 或是经典的 MacOS。但是遗憾的是,这两个操作系统在网络浏览器、网络连接,还有多核支持和整体稳定性上有待改进。
笔者今年参加 Ubuntu 峰会的费用是由 Canonical 承担的,这一点他愿意公开。类似的,Linux 基金会曾资助他参加 [今年](https://www.theregister.com/2023/09/26/linux_kernel_report_2023/) 在 Bilbao 的开源峰会,而红帽则资助了他在 2016 年在 Kraków 参加 [Flock to Fedora](https://www.theregister.com/2016/10/19/fedora_facelift/) 峰会。这类赞助可以让我们将广告预算分配到其他地方,但并不会对我们的报道产生影响:我们总会积极追踪那些 IT 新闻。
*(题图:MJ/520ba58f-9e07-4acb-af4a-f4832762311f)*
---
via: <https://www.theregister.com/2023/11/10/snap_without_ubuntu_tools/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Canonical shows how to use Snaps without the Snap Store
## Despite what you may have heard, it's not as proprietary as the trolls think
Ubuntu Summit One of the most common bits of FUD about Ubuntu's Snap packaging format is that it's proprietary – but exploring the documentation shows that is wrong.
At last weekend's Ubuntu Summit in Rīga, Latvia, the *Reg* FOSS desk talked with Ubuntu developer advocate Igor Ljubuncic about Snap, and especially some of the myths about it: that it's entirely closed source, or restricted to Canonical control, or that you must use Canonical's Snap Store, and multiple other fallacies.
If there is one thing we hate more than bad software, it's lies. As we noted [looking at Fedora 39](https://www.theregister.com/2023/11/09/fedora_39_released/), there have been [holy wars](http://catb.org/jargon/html/H/holy-wars.html) of software advocacy since long before Linux existed, but please at least stick to facts. There's no need to make up malicious falsehoods: reality is horrible enough.
Give us a moment to lay out our position here. The *Reg* FOSS desk is not particularly partisan when it comes to Linux distros *or* their packaging tools. Like most computer techies of a certain age, after a few decades working with all manner of software, this vulture hates it all. [All software sucks](http://harmful.cat-v.org/software/), as the saying goes.
Linux is software, therefore it sucks. And, as a trivial corollary, all Linux distros suck too. Package managers are also software and also suck, but least most Linux distros have one. This is better than not having one – or, even worse, having *more* than one, as [XKCD 927](https://xkcd.com/927/) beautifully illustrates.
We are not especially pro-Snap, or anti-Flatpak. Your correspondent personally likes the [AppImage](https://appimage.org/) format, which needs no additional frameworks – but while there is [AppImageHub](https://www.appimagehub.com/), the format provides no tooling for software updates. That's left up to the app.
Since all software sucks, the only important difference is how badly. After a while, what you care about most is whether it works, does what you need, and is reliable.
Your vulture spent the earlier decades of his career in tech support, fixing other people's software. From this, he learned one attribute that reduces how much a given piece of software sucks is how easy it is to understand how it works.
Btrfs is complicated, and fixing it more so. Git can be *really* complicated, as its [name implies](https://dictionary.cambridge.org/dictionary/english/git). (Yes, "git" is a word, not an acronym or codename, with an existing meaning.) OStree is Git for binaries, which makes it at least twice as complicated as ordinary Git – and Flatpak is a wrapper around OStree.
This means not one but two additional layers of complexity: first, a wrapper around something complicated only hides complexity, it doesn't eliminate it. Second, you can't build an OS from Flatpaks, so you need OStree as well.
So let's take apart some of the fallacies around the Snap format and tooling. This isn't a how-to guide – it's a quick overview of some of the less obvious stuff about which the haters don't know.
### Distributing without the Store
A Snap package is just a [squashfs](https://docs.kernel.org/filesystems/squashfs.html) – like the system image on most Linux installation media. Snaps are delivered as two files: the software itself, inside a file called `<name>_<revision>.snap`
, and an accompanying [assertion file](https://snapcraft.io/docs/assertions), which is the digital signature for the Snap. Canonical [documents](https://snapcraft.io/docs/revisions) how revisions work, too.
It's easy to obtain the basic files using the command `snap download`
rather than `snap install`
:
snap download firefox Fetching snap "firefox" Fetching assertions for "firefox" Install the snap with: snap ack firefox_3252.assert snap install firefox_3252.snap
Those files can then be copied to another machine and installed, without access to the Snap Store, using the commands in the output.
Igor told us:
This way, you can grab the Snaps you like (e.g. Firefox) from the Snap Store, put it on your internal repo, or FTP, or NFS, and then use that as the source for Snap installations internally, without going to the Store. You can combine this with any scheduling or deployment mechanism you have, like configuration management.
### Installing without assertions
The `snap ack`
command reads the signature first, but you can bypass that if you want.
snap install "downloaded snap" --dangerous
This will install the Snap without verifying its signature. It does exactly what it says, but with a significant limitation: Snaps installed using `--dangerous`
will not update from the Store.
So, it's possible to distribute Snaps within your network, prevent them from attempting to contact the Store, and manage updates yourself.
### Controlling `snapd`
's built-in update mechanism
You can control how and when the OS updates Snaps without ignoring the assertions mechanism, though. Igor has written about how to place Snap updates [on hold](https://snapcraft.io/blog/hold-your-horses-i-mean-snaps-new-feature-lets-you-stop-snap-updates-for-as-long-as-you-need).
You can hold Snaps for a period of time, indefinitely, or apply this for only specific Snaps, and roll it back easily. For instance:
snap refresh --hold Auto-refresh of all snaps held indefinitely.
You can also block the Snap API via a firewall, with something like:
sudo iptables -A OUTPUT -d api.snapcraft.io -j DROP
### Running snaps without `snapd`
A `.snap`
file is just a compressed filesystem which contains program files (and libraries and so on) inside a conventional directory tree, which the Snap-packaged application sees as its root directory. Snapd helps set up a mount namespace for that, and adds security confinement via [Apparmor](https://apparmor.net/) and [seccomp](https://man7.org/linux/man-pages/man2/seccomp.2.html).
You can extract its contents and run them directly:
unsquashfs firefox_3252.snap Parallel unsquashfs: Using 20 processors 565 inodes (5428 blocks) to write [=====================/] 5428/5428 100% created 399 files created 149 directories created 166 symlinks created 0 devices created 0 fifos created 0 sockets ll squashfs-root/ total 80 drwxr-xr-x 7 igor igor 4096 lis 10 02:33 ./ drwxr-xr-x 10 igor igor 4096 lis 19 15:32 ../ drwxr-xr-x 5 igor igor 4096 lis 10 02:33 data-dir/ -rw-r--r-- 1 igor igor 32441 lis 10 02:33 default256.png -rw-r--r-- 1 igor igor 9146 lis 10 02:33 firefox.desktop -rwxr-xr-x 1 igor igor 2680 lis 10 02:33 firefox.launcher* drwxr-xr-x 2 igor igor 4096 lis 10 02:33 gnome-platform/ drwxr-xr-x 4 igor igor 4096 lis 10 02:33 meta/ -rwxr-xr-x 1 igor igor 3716 lis 10 02:33 patch-default-profile.py* drwxr-xr-x 4 igor igor 4096 lis 10 02:33 snap/ drwxr-xr-x 4 igor igor 4096 sij 19 2022 usr/
If you check the dynamic dependencies for the Firefox binary inside the Snap, you'll see that it wants files from the root filesystem:
ldd usr/lib/firefox/firefox-bin linux-vdso.so.1 (0x00007fff33cc5000) libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f6cf2c00000) libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f6cf2e40000) libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f6cf2be0000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f6cf2800000) /lib64/ld-linux-x86-64.so.2 (0x00007f6cf300e000)
Inside the Snap, that root is your base (`core18`
or `core20`
or whatever). But once you unsquash the Snap, without the security confinement that `snapd`
provides when the Snap is set up and run, then Firefox will try to access the root libraries, and this can lead to inconsistency in execution.
For example, you may have a Snap inside which you have GNOME 3.38 libraries, but your host is running GNOME 3.32. If you unsquash and try to run that app, it may try to load libraries from the host, and this could cause inconsistencies – or worse still, crashes.
To prevent this, the only thing you need to do is set the `LD_LIBRARY_PATH`
environment variable to tell the program where to find its libraries and ensure it uses those first, rather than the OS's copies, which could make it fail to run.
LD_LIBRARY_PATH: ${SNAP_LIBRARY_PATH}${LD_LIBRARY_PATH:+:$LD_LIBRARY_PATH}:$SNAP/usr/lib:$SNAP/usr/lib/x86_64-linux-gnu
In general, you would want `LD_LIBRARY_PATH`
to be: `/snap/"snap name"/`
first, then `/lib`
, `/usr/lib`
and the other usual paths. As for the other contents, the `firefox.launcher`
file prepares the runtime environment, and the rest, such as `firefox.desktop`
, are for desktop integration: an icon, a full name, file associations and so on. They make it look and work better, but they aren't strictly essential.
It's not even necessary to extract the Snap's contents. You could just mount the Snap file itself as a [loopback device](https://tldp.org/HOWTO/archived/Loopback-Root-FS/Loopback-Root-FS-2.html) – read only, if you like – but without the mount namespace confinement. And without the environment set to tell the application inside the Snap to look for its libraries first inside the Snap, you will still need to set the library path correctly.
### Proxying and caching Snap packages
Igor told us that if they don't want to run their own complete, branded Snap Store, customers can manually set up a [Snap proxy](https://docs.ubuntu.com/snap-store-proxy/en/), if they are so inclined. Again, Canonical [has documentation](https://docs.ubuntu.com/snap-store-proxy/en/install) for this, as well as a description of the [network access](https://forum.snapcraft.io/t/network-requirements/5147) needed.
It's also possible to [configure](https://snapcraft.io/blog/how-to-cache-snap-downloads-and-save-bandwidth) a caching Snap proxy – which is a slightly simpler exercise and might be viable for a home network where you want to reduce the bandwidth of your machines' downloads.
### Run your own Snap Store
As we have covered before, you can also ignore all Canonical's infrastructure and just run your own Snap Store. Last year, we wrote about Ubuntu Unity maintainer [Rudra Saraswat](https://www.theregister.com/2022/02/04/rudra_sarsawat_ubuntu_projects/) who did [just that](https://gitlab.com/lol-snap/lol), among his many other projects. We've been told that several orgs using Ubuntu Core in production do this, and all the tools are in the Ubuntu repositories.
Canonical publishes quite a lot of documentation on it, including [building your first Snap](https://snapcraft.io/blog/how-to-make-your-first-snap) and creating them in [different programming languages](https://snapcraft.io/docs/creating-a-snap). This year's summit had several talks on how to build Snaps – including [building Snaps on a tablet](https://events.canonical.com/event/31/contributions/222/) and [automating building updated Snaps](https://events.canonical.com/event/31/contributions/217/), which this vulture attended, though it went rather over his head.
There is a little new terminology to learn, but [it's documented](https://snapcraft.io/docs/interface-management) as well. We liked this explanation:
slotsare providers (these are resources provided by Snaps)plugsare consumers (these use the resources provided by Snaps)interfacesare meeting places (these connect plugs with slots)
To summarize the comments from the Canonical representatives *El Reg* chatted to, they seem more than anything else just irritated by mischaracterizations of the Snap Store and arguments that Snap is a locked-up, closed proprietary system.
Some fifteen years ago, there were claims that Canonical's code hosting and project management platform [Launchpad](https://www.theregister.com/2008/07/22/ubuntu_next_launchpad/) was proprietary, so it cleaned up the codebase and [published it](https://canonical.com/blog/canonical-releases-source-code-for-launchpad) in 2009. But, as the folks we talked to put it: "Nobody cared." It's a Canonical in-house tool, and it's simply not much use to anyone else. They told us that they didn't want to go through that again.
We'd also note that Red Hat is going in the opposite direction, and migrating from open source Bugzilla [to the closed, cloud-based Jira](https://www.theregister.com/2023/09/29/red_hat_bugzilla_jira_migration/) – without any great scandal.
The code for [snapd itself](https://github.com/snapcore/snapd) is already on GitHub, as part of Canonical's [snapcore](https://github.com/snapcore) repository. The packaging format is an existing, documented one used by most distros. The tools used for confinement are existing third-party ones, already used in other distros. For example, Debian and the SUSE family also use AppArmor, as [described](https://wiki.archlinux.org/title/AppArmor) in the Arch wiki, while its main rival, [SELinux](https://selinuxproject.org/page/Main_Page), is more complicated and mainly used in Red Hat and its derivatives.
While, yes, Canonical's own custom [Snap Store](https://snapcraft.io/store) backend [remains](https://askubuntu.com/a/1383685) closed source, the Snap format, the snapcore software, the [snapcraft.io frontend](https://github.com/canonical/snapcraft.io), and more components are open. Again, you can host [your own Snap Store](https://ubuntu.com/blog/howto-host-your-own-snap-store).
Don't let angry forum posters persuade you otherwise.
### And finally...
As it happens, this vulture has worked for both Red Hat and SUSE, but mainly uses Ubuntu, as he has since it first came out in 2004. It works and gets out of his way. However, if only to make updating quicker, he long ago removed `snapd`
and its supporting tools from his main work laptop, and replaced it with [deb-get](https://trendoceans.com/nala-package-manager/) – originally written by Martin Wimpress, the creator of [Ubuntu MATE](https://ubuntu-mate.org/). Your scribe also uses the very shiny [Nala package manager](https://github.com/volitank/nala) instead of Apt, partly because it's a bit quicker.
He rather wishes he could give up all forms of Unix for anything but servers, and use RISC OS or Classic MacOS instead, but they're sadly lacking in the web browser and network connectivity departments – not to mention multi-core support and general stability.
The bill for attending the Ubuntu Summit this year was footed by Canonical, which this hack is happy to disclose. And on that subject of openness: the Linux Foundation also got him to [this year](https://www.theregister.com/2023/09/26/linux_kernel_report_2023/)'s Open Source Summit in Bilbao, and Red Hat took care of his attendance at [Flock to Fedora](https://www.theregister.com/2016/10/19/fedora_facelift/) in 2016 in Kraków. This kind of support from vendors lets us spend our ad dosh on other things and never guides our coverage: *The Reg* always looks forward to biting the hand that feeds IT. ®
73 |
16,372 | 4 种超简单的自定义 Budgie 桌面的方式 | https://itsfoss.com/budgie-customization/ | 2023-11-12T16:00:00 | [
"Budgie",
"桌面"
] | https://linux.cn/article-16372-1.html | 
>
> Budgie 是一种现代的桌面体验方式。你可以根据自己的喜好,使用这些定制技巧进一步增强它的功能。
>
>
>
如果你要求我将 MATE 桌面现代化,并增加功能和 GTK 支持,我可能会想出像 Budgie 这样的东西!
Budgie,是一款令人惊艳的桌面环境(DE),为你提供熟悉的布局和独特的用户体验。
那么,如何自定义你的 Budgie 桌面才能提升个人体验呢?莫慌;我这里有几条妙计助你改善你的 Budgie 体验。
我们的目标大致如下:
* 修改壁纸
* 修改主题,图标以及光标(简易操作)
* 自定义面板
* 自定义停靠区
让我们开始吧!?
### 1、改变 Budgie 桌面环境壁纸
Budgie 桌面预装了一些好看的壁纸。
修改 Budgie 桌面壁纸,你们只需要做这两个小步骤:
1. 在主界面点击右键,选择 “<ruby> 改变桌面背景 <rt> Change Desktop Background </rt></ruby>”
2. 选择图片,然后该图片就会应用在你的主屏幕中

要是你不太中意其中的可用壁纸,你也可以自网络下载相关壁纸。
下好后,打开文件管理器,导航至图片所在位置,右键点击该图片,选择 “<ruby> 设置为壁纸…… <rp> ( </rp> <rt> Set as Wallpaper... </rt> <rp> ) </rp></ruby>”选项。

### 2、修改桌面主题、图标以及光标主题
通常情况下,我们从网络上下载了主题,提取下载的文件,然后就会将文件移动到相应目录以便 [应用于 Linux 主题](https://itsfoss.com/install-themes-ubuntu/)。
>
> **[如何在 Ubnutu 上安装主题](https://itsfoss.com/install-themes-ubuntu/)**
>
>
>
但要那么整的话,既需要花费些功夫,又不是最高效的方法。(如果你好奇去试试的话)
那么此处便是 **ocs-url** 工具发力的地方了。
**ocs-url** 是一款一键安装所有主题风格(比如说来自 [gnome-look.org](http://gnome-look.org) 门户网站内容)的工具。
>
> ? [Gnome-look.org](http://Gnome-look.org) 和 [pling.com](http://pling.com) 是 [Opendesktop.org](https://www.opendesktop.org/) 旗下的两个网络站点,可以帮助你一站式搜索主题风格,壁纸,图标,以及其它好物。
>
>
>
这个工具与任何桌面环境都没有官方隶属关系。
但令人遗憾的是,它没有被任何 Linux 发行版的软件包管理器包含,也就是说你得在你的系统里手动安装它。
那么首先,移动至 [ocs-url 的官方下载页面](https://www.opendesktop.org/p/1136805/),转到 “<ruby> 文件 <rt> Files </rt></ruby>” 选项卡,将软件包下载至你的系统中:

完成后,打开你的命令提示符,将文件地址改成文件下载的位置。对于大多数用户来说,便是下载(`Downloads`)文件夹:
```
cd Downloads
```
现在,使用你的 Linux 发行版对应的指令:
**适用于 Ubuntu:**
```
sudo dpkg -i ocs-url*.deb
```
**适用于 Fedora:**
```
sudo dnf install qt5-qtbase qt5-qtbase-gui qt5-qtsvg qt5-qtdeclarative qt5-qtquickcontrols && sudo rpm -i ocs-url*.rpm
```
**适用于 Arch:**
```
sudo pacman -S qt5-base qt5-svg qt5-declarative qt5-quickcontrols && sudo pacman -U ocs-url*.pkg.tar.xz
```
**适用于 openSUSE:**
```
sudo zypper install libQt5Svg5 libqt5-qtquickcontrols && sudo rpm -i ocs-url*.rpm
```
现在,让我们看看该如何安装主题风格,图标以及光标风格。
#### 修改系统主题风格
修改系统主题风格的第一步 —— 访问 [Gnome Look](https://www.gnome-look.org/browse?cat=135&ord=latest) 门户网站并选择你中意的主题风格(你可以在 GTK 3 和 GTK 4 之间选择)。

选择任意你最喜欢的主题风格;这里我选择 “Kripton” 风格,你可以看到有一个 “<ruby> 安装 <rt> Install </rt></ruby>” 选项。
在这里,你需要遵循两个小步骤:
* 点击 “<ruby> 安装 <rt> Install </rt></ruby>” 按钮之后,会呈现该主题风格的不同类型。选择其中一个。
* 然后会跳出一个提示符,你需要再点击一次 “<ruby> 安装 <rt> Install </rt></ruby>” 按钮:

然后它会打开 ocs-url 工具询问你是否安装所选主题风格。
点击 “<ruby> 确定 <rt> OK </rt></ruby>” 按钮安装该主题风格:

现在,进入 <ruby> Budgie 桌面设置 <rt> Budgie Desktop Settings </rt></ruby> 界面,然后在“<ruby> 样式 <rt> Style </rt></ruby>” 子菜单下的 “<ruby> 组件 <rt> Widget </rt></ruby>” 选项中点击需要安装的主题风格。

#### 修改图标
要修改图标,先访问有关 [Gnome-look 门户网站中的图标区](https://www.gnome-look.org/browse?cat=132&ord=latest),来搜索你中意的图标:

找到图标后,可以看到有两个按钮:“<ruby> 下载 <rt> Download </rt></ruby>” 和 “<ruby> 安装 <rt> Install </rt></ruby>”。点击 “<ruby> 安装 <rt> Install </rt></ruby>” 按钮。
可以看到有多个图标,但大多数例子里只展现了一个。点击选项之一,弹出提示,再次点击“<ruby> 安装 <rt> Install </rt></ruby>”按钮:

然后,可以看到来自 ocs-url 弹出的提示符询问你是否安装所选图标包,点击 “<ruby> 确定 <rt> OK </rt></ruby>” 安装图标包:

下一步,打开 <ruby> Budgie 桌面设置 <rt> Budgie Desktop Settings </rt></ruby> 的 “<ruby> 图标 <rt> icons </rt></ruby>” 子菜单,你便可以使用最近安装过的图标风格(我用过 elementary-kde 风格):

#### 修改光标主题风格
和之前步骤类似,访问 [Gnome Look 门户网站的光标区](https://www.gnome-look.org/browse?cat=107&ord=latest) 搜索最适合你的光标:

选好心仪的光标风格后,点击相应选项,然后你就可以安装相对应的光标风格了。
弹出提示,再次点击“<ruby> 安装 <rp> ( </rp> <rt> Install </rt> <rp> ) </rp></ruby>”按钮:

弹出来自 ocs-url 工具的提示,点击安装光标主题风格。只需要点个 “<ruby> 确定 <rt> OK </rt></ruby>” 然后开始安装:

完成后,打开 <ruby> Budgie 桌面设置 <rt> Budgie Desktop Settings </rt></ruby> 界面,在对应子页面的 “<ruby> 光标 <rt> Cursors </rt></ruby>” 面板中选择刚刚安装的光标主题风格:

### 3、自定义 Budgie 桌面面板
根据 Linux 发行版的不同,面板的位置也可能不同。例如,假设你用的是 Solus 的 Budgie 或者 Ubuntu 的 Budgie。
打开 <ruby> Budgie 桌面设置 <rt> Budgie Desktop Settings </rt></ruby> ,在那里你可以寻找到对于面板的相关设置:

如你所见,它将启用的小程序分三个部分显示在面板上:
<ruby> 始端 <rt> Start </rt></ruby>(最左侧)、<ruby> 中间 <rt> Center </rt></ruby>,以及 <ruby> 末端 <rt> End </rt></ruby>(最右侧)。
>
> ? 注意,每个小程序有自己不同的设置选项,所以还能单独设置它们。
>
>
>
你可以在它们之间做些调整。比如,在这个地方我将时钟工具挪到左边,以便它和我的工作流界面看起来更加融洽:

要想移动小程序,只需要选中该小程序然后点击上下箭头按钮(位于小程序列表上方)。
如果你想移除小程序,只需要选中该程序然后点击删除按钮即可:

这里有一个 “+” 图标样式的选项,可以添加更多小程序。点击它,会为你弹出所有可用的小程序。
找到一个有用的小程序,选中该程序并点击 “<ruby> 添加 <rt> Add </rt></ruby>” 按钮:

要是你希望面板变透明、想1添加阴影,想增加或减少小程序之间的距离,那么就访问设置菜单中的这个页面(如下图):

举个例子,这里,我将自己的面板设置了透明和阴影,让它看起来更舒服点:

### 4、定制 Budgie 桌面的停靠区
在本节,我会向你介绍如何将自己的停靠区设计得更好,功能性更强:
* 修改停靠区主题风格
* 添加更多工具应用以赋予停靠区更多特性
#### 修改停靠区主题风格
可惜啦,这次 ocs-url 工具可就帮不上什么忙了,设置的唯一方式就是手动操作!
首先,[访问 Gnome Look 的 Plank 主题区](https://www.gnome-look.org/browse?cat=273&ord=latest),下载你心仪的 Plank 停靠区主题风格。
这里,我选了模仿 macOS 系统的 Monterey 主题风格(dark-inline 版):

现在,打开命令提示符,找到该主题风格下载位置。
对大多数用户来说,即下载(`Downloads`)文件夹所在位置:
```
cd ~/Downloads
```
现在,[使用解压指令](https://itsfoss.com/unzip-linux/) 将文件释放到 `.local/share/plank/themes/`:
```
unzip <theme_name.zip> -d .local/share/plank/themes/
```
在我的环境下是这样:
```
unzip Monterey-Dark-inline.zip -d ~/.local/share/plank/themes/
```

然后,打开 “<ruby> Plank 偏好设置 <rt> Plank preferences </rt></ruby>”,改成刚下载的主题。
我将我的风格改成 “Monterey -Dark inline”:

#### 添加 docklet 应用以增加更多特性
可以、把 docklet 应用当作 applet,但与它不同的是,没有太多选项。
想要添加或移除 docklet 应用,首先得需要打开 “<ruby> Plank 偏好设置 <rt> Plank preferences </rt></ruby>”,然后访问 “Docklets” 菜单,列出可用选项:

现在,如果你想添加一些 docklet 应用,只需要把它们拖进停靠区即可:

但如果你想把添加的 docklet 应用移除出去呢?
简单,把它们从停靠区中拖拽出去就行了:

### 准备好使用 Budgie 了吗?
当然,为了方便起见,你可以安装已内置 Budgie 桌面环境的 Linux 发行版。
或者你还是可以选择在你现有的发行版(比如说 Ubuntu)中 [安装 Budgie](https://itsfoss.com/install-budgie-ubuntu/):
>
> **[如何在 Ubuntu 上安装 Budgie](https://itsfoss.com/install-budgie-ubuntu/)**
>
>
>
在本教程中,我使用的是 Ubuntu 版本的 Budgie。无论你使用哪个发行版,这些步骤都适用于 Budgie 桌面。
? 你是怎么自定义你的 Budgie 桌面的呢?你想为这篇文章贡献更多内容吗?在下方评论区分享你的经验吧。
*(题图:MJ/44c073b0-b866-4eeb-b3e0-579d7afe0992)*
---
via: <https://itsfoss.com/budgie-customization/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Drwhooooo](https://github.com/Drwhooooo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you ask me to make the MATE desktop modernized with added features and GTK support, I may come up with something like Budgie!
Budgie is an impressive desktop environment (DE) that provides you with a familiar layout along with a unique user experience.
So, how can you customize the Budgie desktop to elevate your experience? Fret not; I got your back here with some essential tips to tweak your Budgie experience.
I will help you do the following:
**Change wallpaper****Change themes, icons, and cursor (the easy way)****Customize panel****Customize dock**
Let us get started! 🤩
## 1. Change the wallpaper of Budgie DE
The Budgie desktop comes with some beautiful wallpapers pre-installed.
To change the wallpaper on Budgie's desktop, all you have to do is follow two simple steps:
- Right-click on the home screen and choose
`Change Desktop Backgroun`
option - Select the image, and it will be applied to your home screen
But if you don't like the available options, you can always download wallpapers from the web.
Once done, open the file manager, navigate to where the image is located, right-click on the image, and choose the `Set as Wallpaper...`
option.
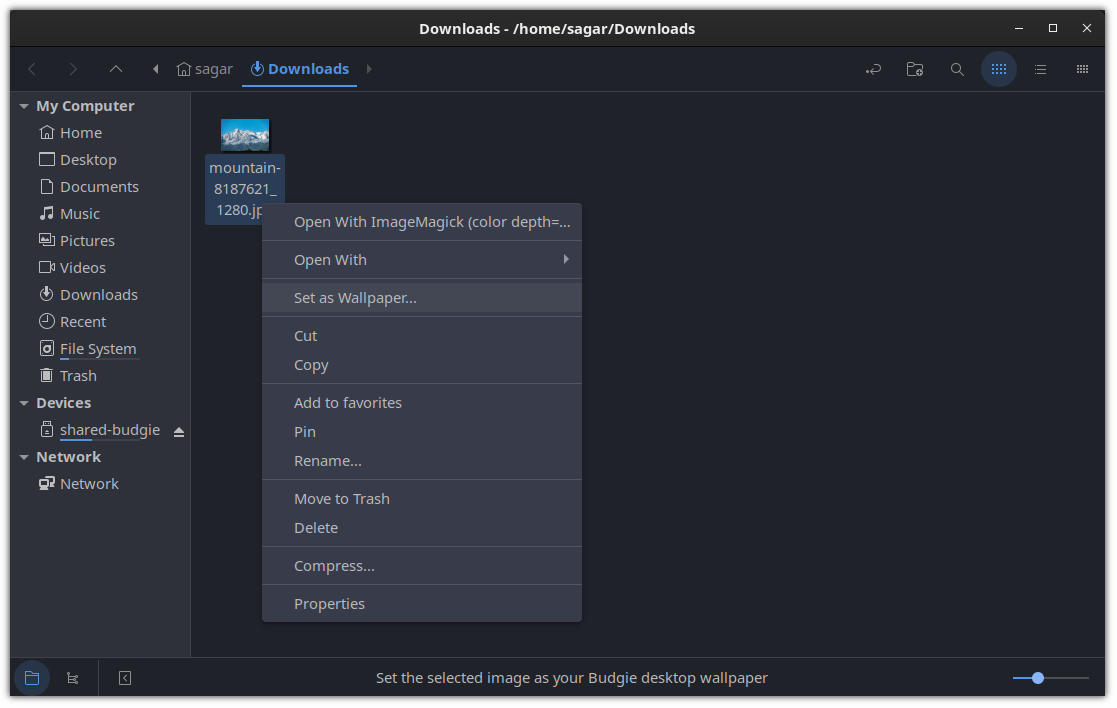
## 2. Change the desktop theme, icons, and cursor theme
Traditionally, we download themes from the web, extract the downloaded file, and move files to the respective directory to [apply the theme on Linux](https://itsfoss.com/install-themes-ubuntu/).
[How to Install Themes in Ubuntu LinuxThis beginner’s guide shows you how to install themes in Ubuntu. The tutorial covers the installation of icon themes, cursor themes, GTK themes and GNOME Shell themes.](https://itsfoss.com/install-themes-ubuntu/)

But that takes a while and may not be the quickest way to do it. You are free to explore it above if you are curious.
And that's where the **ocs-url** tool comes into play.
A tool that will install any theme (from portals like *gnome-look.org*) with a single click.
[Opendesktop.org](https://www.opendesktop.org)to help you find themes, wallpapers, icons, and other goodies in a single place.
It is in no way officially affiliated with any desktop environment.
But the sad part is that it is not available in the package manager of any Linux distribution, which means you have to install it on your system manually.
So first, go to the [official download page of the ocs-url](https://www.opendesktop.org/p/1136805/), go to the `Files`
tab, and download packages for your system:
Once done, open your terminal and change the directory where the file was downloaded. For the most users, it will be the `Downloads`
directory:
`cd Downloads `
Now, use the following command for your Linux distro:
**For Ubuntu:**
`sudo dpkg -i ocs-url*.deb`
**For Fedora:**
`sudo dnf install qt5-qtbase qt5-qtbase-gui qt5-qtsvg qt5-qtdeclarative qt5-qtquickcontrols && sudo rpm -i ocs-url*.rpm`
**For Arch:**
`sudo pacman -S qt5-base qt5-svg qt5-declarative qt5-quickcontrols && sudo pacman -U ocs-url*.pkg.tar.xz`
**For openSUSE:**
```
sudo zypper install libQt5Svg5 libqt5-qtquickcontrols && sudo rpm -i ocs-url*.rpm
```
Now, let's take a look at how you install system themes, icons, and cursor themes.
### Change system theme
To change the system theme, first, visit the [Gnome Look](https://www.gnome-look.org/browse?cat=135&ord=latest) portal and select your preferred theme (you can choose between GTK 3 and 4 themes):
Decide any of your favorite themes; here, I'm going with the `Kripton`
theme. From there, you will see the option to `Install`
themes.
From here, you will have to follow two simple steps:
- After clicking on the
`Install`
button, it will show different variations of the theme. Choose one of them. - Next, it will open a prompt, there you have to hit the
`Install`
button:
It will open ocs-url asking you whether you want to install the selected theme.
Simply press the `OK`
button to install the theme:
Now, access the **Budgie Desktop Settings** and pick the installed theme from the `Widget`
option under **Style** section.
### Change icons
To change icons, [visit the Icon section of the Gnome-look](https://www.gnome-look.org/browse?cat=132&ord=latest) portal, and find/search for the icon that suits you the best:
Once you find that perfect icon, you will find two options there: Download and Install. Click on the `Install`
button.
You may find multiple icons, but in most cases there will only be one. Click on that option, it will open a prompt. Again, hit the `Install`
button:
Soon, you'll see a prompt from ocs-url asking whether you want to install the selected icon pack or not. Hit the `OK`
button to install the icon pack:
Next, open the **Budgie Desktop Settings** and from the icons, you can select the recently installed icons (I went with the elementary-kde option):
### Change cursor theme
Similar to the above, [visit the Gnome Look's cursor icon section](https://www.gnome-look.org/browse?cat=107&ord=latest) to find the most suitable cursor theme for you:
Once you find the perfect cursor theme, click on the option, and you will see the option to install the selected cursor theme.
It will open a prompt and there, click again on the installation button:
You will see a prompt from the ocs-url to install the cursor theme. All you have to do is press the `OK`
button to start the installation:
Once done, open the Budgie Desktop Settings and choose the cursor theme from the `Cursors`
:
## 3. Customize the panel in Budgie Desktop
Depending on the Linux distro, the position for the panel may differ. For instance, you could be using Solus Budgie or Ubuntu Budgie.
To access the settings for the panel, open the Budgie Desktop Settings, and from there you will find the settings for the panel:
As you can see, it shows the enabled applets on the panel in three sections: **Start** (extreme left), **Center**, and **End** (extreme right).
You can adjust between them. For example, here, I moved the clock to the left side as it suits my workflow much better:
To move applets, all you have to do is select the applet and use the up and down arrow buttons **located above the list of the applet.**
If you want to remove the applet, just select the applet and use the delete button:
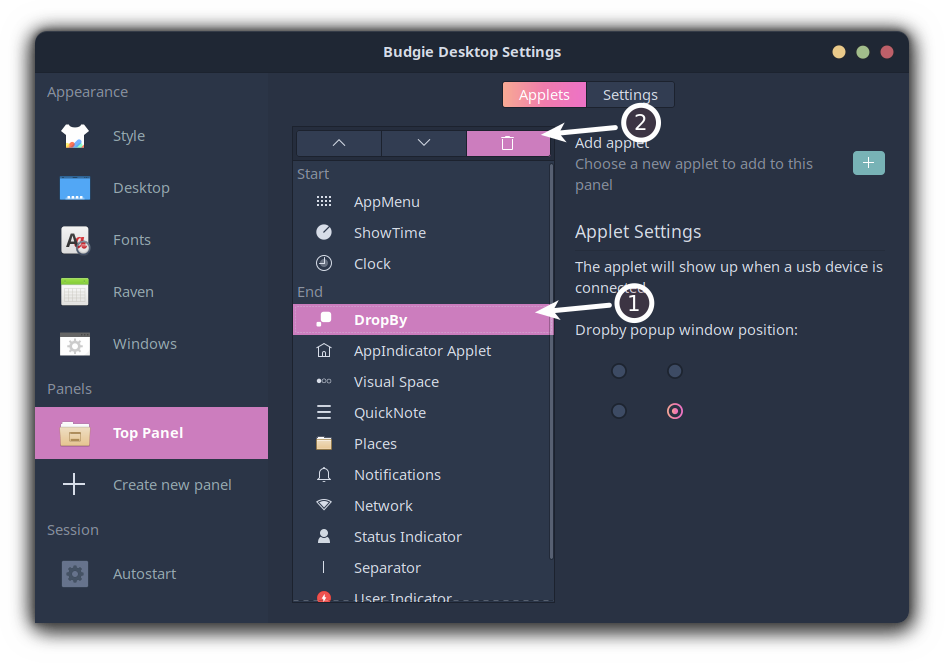
To add more applets, there is an option to add applet with the `+`
icon. Simply press the button, and it will list all the available applets to you.
Once you find a useful applet, select the applet and click on the `Add`
button:
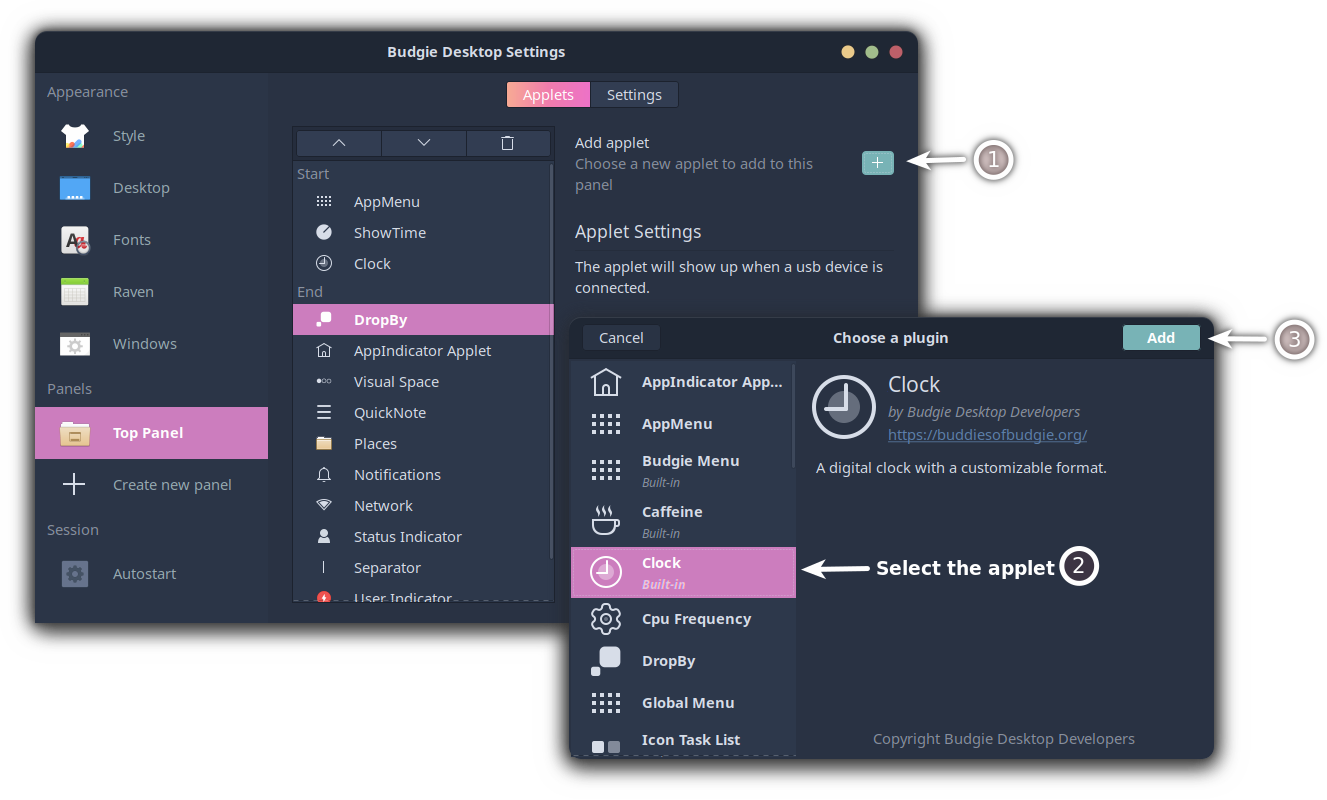
If you want to make the panel transparent, add shadows, increase/decrease space between applets, then go to the settings menu as shown below:
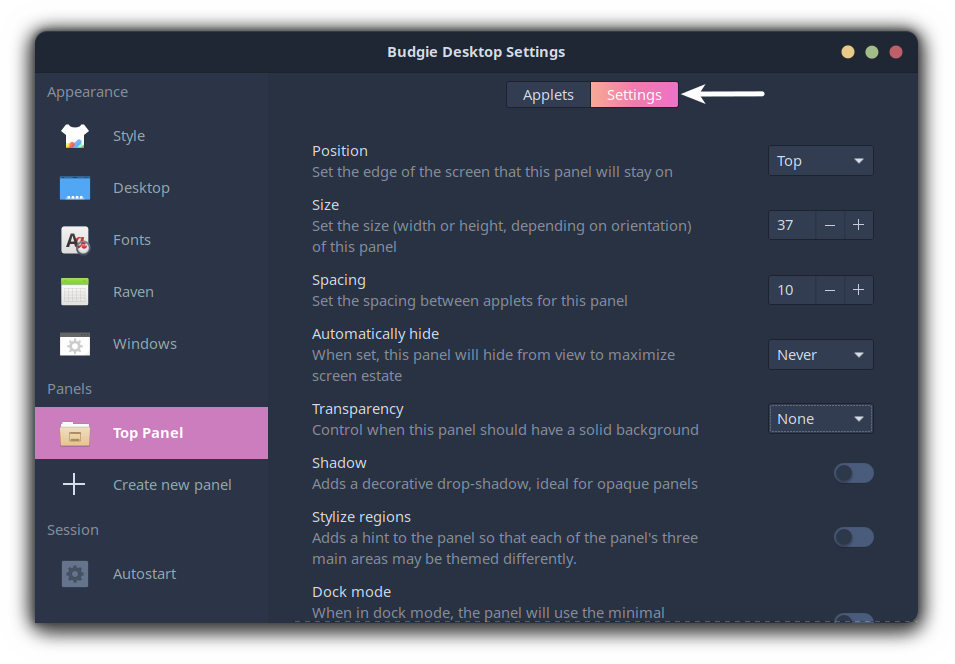
For example, here, I made my panel transparent and added shadows to make it look pleasant:
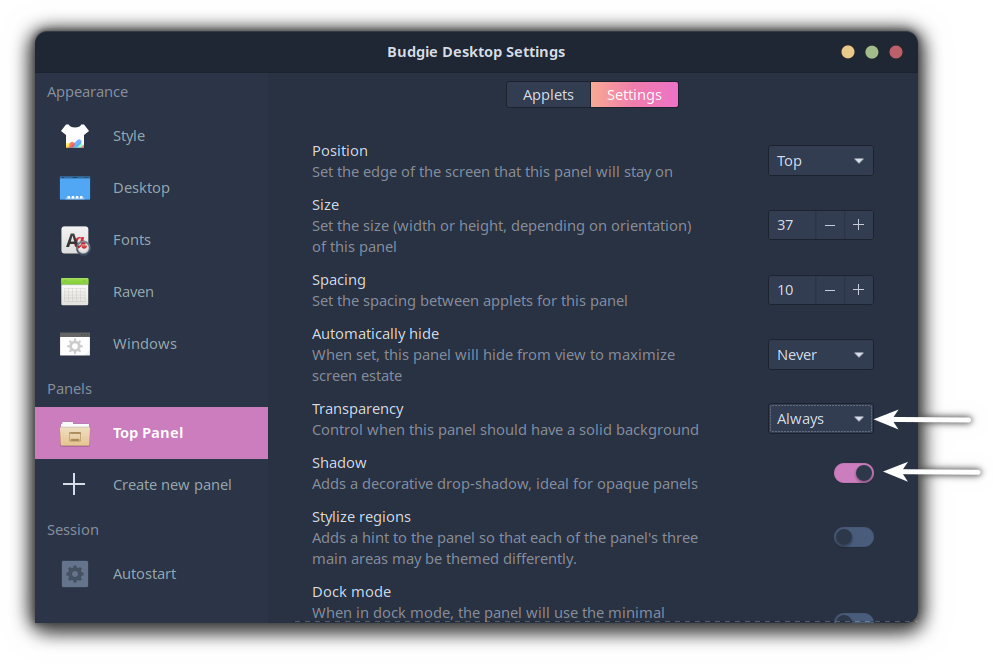
## 4. Customize the dock in the Budgie Desktop
In this section, I will walk you through the following ways to make your dock look appealing and functional:
- Changing the theme of the dock
- Adding docklets to add more features to the dock
### Change the theme of the dock
Sorry, but the ocs-url tool won't help you change the theme of the dock, so the only way you are left with it is the manual way!
First, [visit the Gnome Look's Plank theme](https://www.gnome-look.org/browse?cat=273&ord=latest) section and download any of your favorite plank dock themes.
Here, I went for the Monterey theme to mimic macOS (dark-inline version):
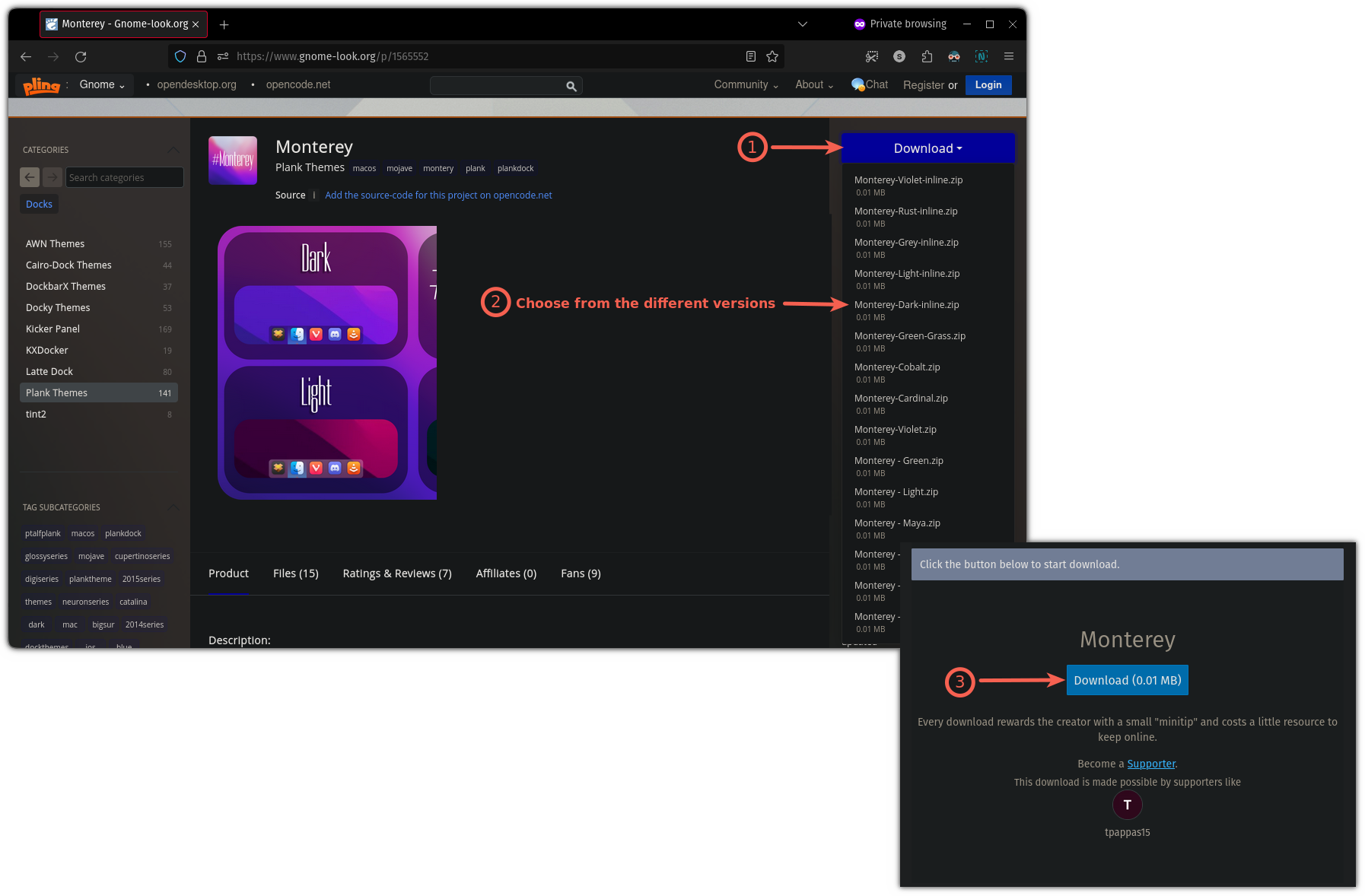
Now, open the terminal and navigate to where the theme was downloaded.
For most users, it will be the `Downloads`
directory:
`cd ~/Downloads`
Now, [use the unzip command](https://itsfoss.com/unzip-linux/) to extract files to the `.local/share/plank/themes/`
:
`unzip <theme_name.zip> -d .local/share/plank/themes/`
In my case, it looked like this:
`unzip Monterey-Dark-inline.zip -d ~/.local/share/plank/themes/`
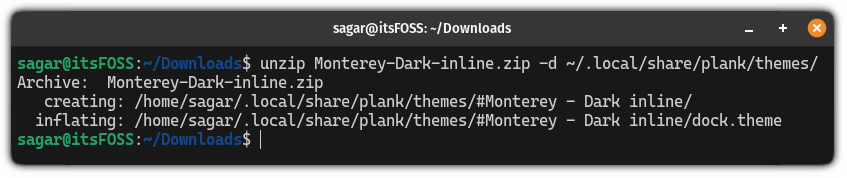
Next, open the `Plank preferences`
and change to the recently installed theme.
I changed mine to `Monterey -Dark inline`
:
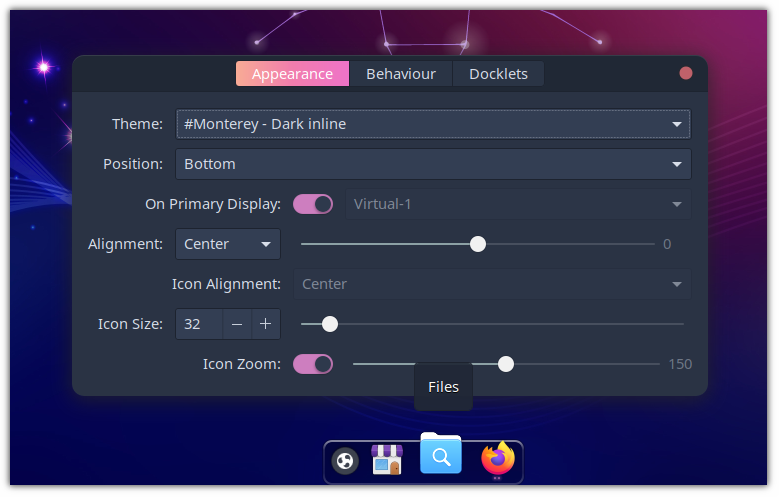
### Add docklets to have more features
Think of docklets as applets but for the dock but unlike applets, you are not given many options.
To add/remove docklets, first, open the `Plank preferences`
and go to the `Docklets`
menu to list the available options:
Now, if you want to add docklets, simply drag them to the dock:
But what if you would like to remove the added docklets?
Well, that's pretty simple! Just drag them out of the dock and they will be removed:
## Ready to Get Started With Budgie?
Sure, you can always install a Linux distribution with Budgie desktop environment baked in—for convenience.
However, you can also choose to [install Budgie](https://itsfoss.com/install-budgie-ubuntu/) on your existing distro, such as Ubuntu:
[How to Install Budgie Desktop on UbuntuBudgie is a modern, alternative take on GNOME. Learn to install the Budgie desktop environment on Ubuntu.](https://itsfoss.com/install-budgie-ubuntu/)

For this tutorial, I utilized Ubuntu Budgie. The steps work for Budgie desktop no matter the distribution you use.
*💬 How do you customize your Budgie desktop experience? Do you want to add any tips to this article? Share your experiences in the comments down below.* |
16,374 | 你应该知道的主流开源数据库 | https://www.opensourceforu.com/2022/09/are-you-familiar-with-these-popular-open-source-databases/ | 2023-11-13T09:24:00 | [
"MySQL",
"数据库"
] | https://linux.cn/article-16374-1.html | 
>
> 随着数据的飞速增长,数据的组织变得至关重要。本文将简要介绍当今软件开发中最流行的数据库。
>
>
>
在软件系统中,数据被格式化地组织和存储,通过数据库可以以电子方式访问它们。因为数据已经成为一种非常重要的资产,对我们来说,掌握当今使用的各种数据库的基本知识是非常重要的。
我们要看的第一个数据库是 MySQL。
### MySQL
[MySQL 官网](https://www.mysql.com/cn/)
MySQL 是使用最广泛的开源数据库管理系统之一。它由<ruby> 甲骨文公司 <rt> Oracle Corporation </rt></ruby>所有。它可以在大多数主流操作系统上运行,如 Windows、MacOS、Linux 等。MySQL 既适用于小型应用,同时也能胜任大型应用。
#### 优点
* 适配各种操作系统
* 适配多种编程语言,如 PHP、C、C++、Perl 等
* 开源、免费
* 它支持高达 8 百万 Tb 的巨大数据量
* 可定制化
* 比其他数据库快得多
要在基于 Ubuntu 的计算机上安装并使用 MySQL,使用下面的命令:
```
$sudo apt update
$sudo apt install mysql-server
$sudo systemctl start mysql.service
```
### MariaDB
[MariaDB 官网](https://mariadb.org/)
MariaDB 是一款由 MySQL 的开发人员开发的开源关系型数据库,因其优秀的性能和与 MySQL 良好的兼容性而广受欢迎。它是当今大多数主要云产品的一部分,对其稳定性和性能起到重要作用。最近通过使用 Galera Cluster 技术,MariaDB 新增了集群功能。另外 MariaDB 还与 Oracle 数据库有(一定的)兼容性。
#### 优点
* 安装方便
* 支持大数据操作
* 高可扩展性
* 易于导入数据
要在基于 Ubuntu 的计算机上安装并使用 MariaDB,请使用以下命令:
```
$sudo apt update
$sudo apt install mariadb-server
$sudo systemctl start mariadb.service
```
### RethinkDB
[RethinkDB 官网](https://rethinkdb.com/)
RethinkDB 是一个开源、免费、分布式、基于文档的 NoSQL 数据库。它由 RethinkDB 公司开发。(LCTT 译注:RethinkDB 公司已于 2016 年倒闭。RethinkDB 数据库现作为开源项目继续维护。[消息来源](https://rethinkdb.com/blog/rethinkdb-shutdown/))它可以存储具有动态模式的 JSON 文件。更重要的是,它可以将查询结果的实时更新推送给应用程序。由于它的分布式特性,它具有高度可扩展性。RethinkDB 提供了丰富的内置函数,使其成为一个高可用性的数据库。由于它是当今流行的数据库,学习如何使用它是很重要的。
#### 优点
* 适合于 Web 应用
* 易于扩展
* 内置函数多,可用性高
* 基于 JSON 动态文档
要在基于 Ubuntu 的计算机上使用 RethinkDB,下面的命令会有帮助:
```
# 添加软件仓库源
source /etc/lsb-release && echo "deb https://download.rethinkdb.com/repository/ubuntu-$DISTRIB_CODENAME $DISTRIB_CODENAME main" | sudo tee /etc/apt/sources.list.d/rethinkdb.list
# 下载并安装 RethinkDB 的 GPG 密钥
$wget -qO- https://download.rethinkdb.com/repository/raw/pubkey.gpg | sudo apt-key add -
$sudo apt update
$sudo apt-get install rethinkdb
$sudo systemctl start rethinkdb
```
### OrientDB
[OrientDB 官网](https://orientdb.org/)
OrientDB 是一个基于 Java 的开源 NoSQL 数据库管理系统。它支持多种数据模型,比如文档、字典、对象和图。它以图数据库的形式存储关系。下面的命令可以帮助你在 Ubuntu 机器上使用 OrientDB:
```
$sudo apt-get update
$wget -O orientdb-community-2.2.20.tar.gz http://orientdb.com/download.php?file=orientdb-community-2.2.20.tar.gz&os=linux
$tar -zxvf orientdb-community-2.2.20.tar.gz
$sudo mv ~/orientdb-community-2.2.20 /opt/orientdb
```
### CouchDB
[CouchDB 官网](https://couchdb.apache.org/)
CouchDB 是用 Erlang 开发的开源 NoSQL 数据库。它使用多种协议和格式来传输、处理和共享数据。它使用 JSON 格式存储数据,支持 MapReduce,并用 JavaScript 作为查询语言。
#### 优点
* 可以存储任何类型的数据
* 支持 MapReduce,可以高效地处理数据
* 整体结构非常简单
* 索引和检索速度快
下面的命令可以帮助你在 Ubuntu 机器上使用 CouchDB:
```
$echo "deb https://apache.bintray.com/couchdb-deb focal main" >> /etc/apt/sources.list
$sudo apt-get update
$sudo apt install apache2 couchdb -y
```
### Firebird
[Firebird 官网](https://firebirdsql.org/)
Firebird 是一个开源关系型数据库。它兼容所有操作系统,如 Linux、Windows 和 MacOS。它最初是从开源数据库 Interbase 派生而来的。
#### 优点
* 数据库功能不受限制
* 非常稳定,功能强大
* 配置和使用简单
以下命令可以帮助你在 Ubuntu 机器上使用 Firebird:
```
$sudo apt-get update
$sudo apt-get install firebird2.5-superclassic
```
### Cassandra
[Cassandra 官网](https://cassandra.apache.org/_/index.html)
Cassandra 是一个 Apache 基金会旗下的 NoSQL 数据库。它具有高度可扩展性、分布式、高性能的特点,可以很好地处理大量数据。其分布式的特性,使它没有单点故障。
#### 优点
* 高性能
* 高可扩展性
* 采用点对点架构
以下命令可以帮助你在 Ubuntu 机器上使用 Cassandra:
```
$curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add -
$sudo apt-get update
$sudo apt-get install cassandra
$sudo systemctl enable cassandra
$sudo systemctl start cassandra
```
### PostgreSQL
[PostgreSQL 官网](https://www.postgresql.org/)
如今,PostgreSQL 是最流行的开源关系数据库管理系统之一。它易于扩展,同时还与 SQL 兼容。这个数据库管理系统经过了 30 多年的积极开发。
#### 优点
* 与 MySQL 相比,Postgres 可以存储更多种类的数据
* 支持几乎所有的 SQL 特性
* 高度可扩展
下面的命令可以帮助你在 Ubuntu 机器上使用 PostgreSQL:
```
$sudo apt-get update
$sudo apt-get install postgresql postgresql-contrib
```
### CockroachDB
[CockroachDB 官网](https://www.cockroachlabs.com/#)
CockroachDB 是一个为可靠性而生的数据库。它可以像<ruby> 蟑螂 <rt> cockroach </rt></ruby>一样在灾难性的情况下顽强生存、蓬勃发展。它可以处理大量的数据。还可以构建多集群数据库。
#### 优点
* 很容易部署
* 高一致性
* 分布式事务
* 高可用性
* 兼容 SQL
### Redis
[Redis 官网](https://redis.io/)
Redis 是一个基于键值的开源 NoSQL 数据存储数据库。它支持各种类型的键,使用非常方便。
### 结语
我们已经浏览了最知名和最流行的开源数据库管理系统。了解这些不同的数据库非常有趣。尝试不同的选择,发现最适合你需求的数据库。另外,一定要查看这些数据库的官方文档。
*(题图:MJ/40ba9f14-5948-431a-a899-36c6b1ff4dfe)*
---
via: <https://www.opensourceforu.com/2022/09/are-you-familiar-with-these-popular-open-source-databases/>
作者:[Jishnu Saurav Mittapalli](https://www.opensourceforu.com/author/jishnu-saurav-mittapalli/) 选题:[lkxed](https://github.com/lkxed) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *As data grows by leaps and bounds, its organisation becomes all-important. This article briefly describes the most popular databases being used by software development teams today.*
In software systems, data is stored in an organised format and can be accessed electronically using a database. As data has become a very important asset today, it is very important for us to have a basic knowledge about the different databases in use today.
The first database that we will be looking at is MySQL.
## MySQL
MySQL is one of the most widely used open source database management systems. Owned by Oracle Corporation, it works on most major operating systems like Windows, MacOS, Linux, etc. One big benefit of MySQL is that it works really well for small and large applications.
*Advantages*
- It works well with a variety of operating systems and programming languages like PHP, C, C++, Perl, etc.
- It is open source and free.
- It supports a huge size of data of about 8 million terabytes.
- MySQL is customisable as it is open source.
- It is also much faster than other databases.
- To install and get started with MySQL on your Ubuntu based computer, use the command given below:
$sudo apt update $sudo apt install mysql-server $sudo systemctl start mysql.service
## MariaDB
MariaDB is popular primarily because of its good performance and compatibility with MySQL. It supports relational databases. The developers of MySQL have built MariaDB and guarantee that it is going to stay open sourced. This popular database server is part of most major cloud offerings today, and gives great importance to stability and performance. MariaDB has recently added clustering techniques using the Galera cluster, and is also compatible with Oracle databases.
*Advantages*
- Easy installation
- Supports operation on Big Data
- High scalability
- Easy import of data
- To install and get started with MariaDB on your Ubuntu based computer, use the command given below:
$sudo apt update $sudo apt install mysql-server $sudo systemctl start mysql.service
## RethinkDB
RethinkDB is an open source, free, distributed, and document based database server. This NoSQL database has been developed by Rethink, and can store JSON files with schemas that are dynamic. More importantly, real-time updates for query results can be pushed for applications to use. Since it is a distributed database, it is highly scalable. It has many automatic functions, making it a highly available database. As it is a popular database today, it is important that we learn how to use it.
*Advantages*
- This is basically an open source database that can be used for Web based applications.
- It is easy to scale because it’s a distributed database.
- It has many automatic functions with a high availability.
- This NoSQL database is JSON dynamic document based.
- The following commands can be helpful for using RethinkDB on your Ubuntu machine:
Get required packages source /etc/lsb-release && echo” deb https://download.rethinkdb.com/repository/ubuntu-$DISTRIB_CODENAME $DISTRIB_CODENAME main” | sudo tee /etc/apt/sources.list.d/rethinkdb.list Get required repositories $wget -qO- https://download.rethinkdb.com/repository/raw/pubkey.gpg | sudo apt-key add $sudo apt update $sudo apt-get install rethinkdb $sudo systemctl start rethinkdb
## OrientDB
OrientDB is a NoSQL and Java based open source database management system. This multi-model database service system supports all sorts of data like documents, dictionaries, objects, and graphs. It stores the relationships in the form of a graph database.
The following commands can be helpful for using OrientDB on your Ubuntu machine:
$sudo apt-get update $wget -O orientdb-community-2.2.20.tar.gz http://orientdb.com/download.php?file=orientdb-community-2.2.20.tar.gz&os=linux $tar -zxvf orientdb-community-2.2.20.tar.gz $sudo mv ~/orientdb-community-2.2.20 /opt/orientdb
## CouchDB
CouchDB is an important NoSQL based open source database server developed in Erlang. It uses many protocols and formats to transfer, process and share data. JSON files are used to store the data, MapReduce is used as the base and JavaScript is used as the querying language.
*Advantages*
- It can store any kind of data.
- MapReduce helps in increasing its efficiency.
- The overall structure is very simple.
- Indexing and retrieval is fast.
- The following commands can help you to use CouchDB on your Ubuntu machine:
$echo “deb https://apache.bintray.com/couchdb-deb focal main” >> /etc/apt/sources.list $sudo apt-get update $sudo apt install apache2 couchdb -y
## Firebird
Firebird is an open source database management system that mainly works on relational databases. It is compatible with all operating systems like Linux, Windows and MacOS. It was originally forked from the Interbase repository, which was also an open source database.
*Advantages*
- The functionality of the database is not limited.
- It is a very stable and powerful database.
- The configuration and usage of the database is much simpler than other databases.
- The following commands can help you use Firebird on your Ubuntu machine:
$sudo apt-get update $sudo apt-get install firebird2.5-superclassic
## Cassandra
Cassandra is owned and developed by Apache. This highly scalable, distributed, high performance database can handle large amounts of data and works really well. As it is distributed among many servers, it has no single point of failure. It is basically a NoSQL database, which implies it is not a relational database.
### Advantages
- High performance
- High scalability
- Peer-to-peer architecture is used instead of master slave architecture
- The following commands can be helpful in using Firebird on your Ubuntu machine:
$curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add - $sudo apt-get update $sudo apt-get install cassandra $sudo systemctl enable cassandra $sudo systemctl start cassandra
## PostgreSQL
Today PostgreSQL is one of the most popular open source relational database management systems. It is easily extensible and, at the same time, is compliant with SQL. More than 30 years of active development has gone into this DBMS.
## Advantages
- In Postgres we can store a wider variety of data compared to MySQL.
- It is largely compliant with the SQL standard.
- It is also highly expandable.
The following commands can be helpful for using PostgreSQL on your Ubuntu machine:
$sudo apt-get update $sudo apt apt install postgresql postgresql-contrib
## CockroachDB
CockroachDB is a database built for reliability, i.e., it can survive any kind of adverse situation (just like cockroaches can survive any disastrous situation and multiply). This database can handle large amounts of data. Multicluster databases can also be built.
## Advantages
- Deployment is easy
- High consistency
- Transactions are distributed
- Availability is high
- It is also compatible with SQL
## Redis
Redis is an open source, key value based data storage database. This NoSQL database is really handy because it uses different keys of various types.
We’ve gone through the most well-known and popular open source database management systems that are being used to store and manage data. Learning about these different databases can be a lot of fun. Try the different options, and use the one that fits your requirements the best. Also, do check out the official documentation of these databases. |
16,375 | 下一代 elementary OS 8 剧透 | https://news.itsfoss.com/elementary-os-8-dev/ | 2023-11-13T15:49:22 | [
"elementary OS"
] | https://linux.cn/article-16375-1.html | 
>
> 你是否正在关注 elementary OS 8 的升级呢?接下来的信息你必须了解。
>
>
>
elementary OS 无疑是 [最美丽的 Linux 发行版](https://itsfoss.com/beautiful-linux-distributions/) 中的佼佼者。就在一个月之前,注重隐私保护的 [elementary OS 7.1](https://news.itsfoss.com/elementary-os-7-1/) 版本也发布了。
现在,通过最新的公告,我们对即将发布的 elementary OS 8 有了更全面的了解。
而且这一次,我们看起来可能会早一点体验到新的 elementary OS 版本。
让我们深入挖掘下吧!?
### elementary OS 8:一项雄心勃勃的尝试
**elementary OS 的开发者已经将目标转向** OS 8 系列,他们 **对此寄予了深厚的期待,看好其带来的大量结构性改变和升级**。
根据 elementary OS 8 的开发路线图,此次主要版本将以 **Ubuntu 24.04 的源代码库** 为基础构建,然而,目前的情况显示,我们至少需要 **等到 2024 年 4 月才能见到 OS 8 的发布**。
同时,他们也明确提到,他们设定了一些 **非常雄心勃勃的目标**,希望未来的 6 个月内就可以完成。不过,他们 **打算在 OS 8 完全准备就绪后再进行发布**。
那么,这些目标具体有哪些呢?
首先,他们计划默认实现对 [Wayland](https://wayland.freedesktop.org/) 的 **过渡**,这不算令人意外,因为我们已经看到许多主流发行版都在采用它。接下来便是 **延续 GTK 4 的过渡**,其中包含了一些目前处于开发最后阶段的核心应用。
此外,他们正处于 **设计新的快速设置菜单的初级阶段**,并且还明确表示,**此次发布会对他们的桌面环境 Pantheon 的设计进行重大改进**。
读到这里,你可能会产生一个问题;**那么,elementary OS 7 将会如何呢?**
开发者已经明确表示,**当前正在使用 OS 7 的用户从现在起可能会收到的更新会变少**,因为他们认为 OS 7 版本已经相当完善。
但是,所有以 Flatpak 包形式提供的应用还将继续定期接收更新,这当然也包括了许多 elementary OS 的核心应用。
想要了解更多信息,你可以参考 [官方公告](https://blog.elementary.io/lets-talk-os-8/)。如果你对 **elementary OS 8 的开发进度** 感兴趣,你可以在其 GitHub [项目看板](https://github.com/orgs/elementary/projects/128/views/1) 上进行关注。
**你是否想要尝试一下 elementary OS 8 的早期构建版本呢?**
好的,**基于 Ubuntu 24.04 源代码库的试验构建版** 现在就可以下载了!请记住,想要获取下载权限,**你需要成为 GitHub 上的赞助者**。
现在就可以前往官方的 [构建网站](https://builds.elementary.io/) 开始下载了。
>
> **[elementary OS 早期访问](https://builds.elementary.io/)**
>
>
>
? 你对此感到兴奋吗?欢迎在下方留言分享你的观点!
*(题图:MJ/e707c7c7-8d97-4f41-a955-cf455784493f)*
---
via: <https://news.itsfoss.com/elementary-os-8-dev/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

elementary OS is undoubtedly one of the [most beautiful Linux distributions ](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com). Just a month prior, we saw the release of [elementary OS 7.1](https://news.itsfoss.com/elementary-os-7-1/) that focused on the privacy side of things.
With a recent announcement, we now have a better look at what's in store for the next upgrade, elementary OS 8.
And, it looks like this time, we could get the next elementary OS release a bit early.
Let's dive in! 🤓
## elementary OS 8: An Ambitious Effort
The **developers of elementary OS have now shifted their focus** towards developing the OS 8 series, they are **expecting a considerable amount of architectural changes and transitions** with this.
According to elementary OS 8's roadmap, this major version is being **built from the repositories for Ubuntu 24.04**, and as things stand right now, **OS 8 won't be released at least until April 2024**.
They also added that **they have planned on a number of very ambitious goals**, with hopes that they will be able to complete the work in the next 6 months. But, they** intend to release OS 8 only when it's ready**.
Let's discuss some of those goals.
The first one is the **transition to **, this is not a surprise, as we are seeing an upwards trend of its adoption by many major distros. Then there's the
**Wayland**by default
**continuation of the GTK 4 transition**, with various core apps being in the final stages of development.
Other than that, they are in the **early stages of designing a new Quick Settings menu**, and they have also mentioned that** this release will feature some of the largest changes to the design of their desktop environment, Pantheon**.
After reading the above, a question arises; **what will happen to elementary OS 7?**
The developers have mentioned that **users who are running OS 7 should expect fewer updates from this point onwards**, they feel that the OS 7 series is largely complete.
However, all apps that are provided as Flatpak packages will continue to receive updates regularly, this also includes many core apps of elementary OS.
For more details, you can refer to the [official announcement](https://blog.elementary.io/lets-talk-os-8/?ref=news.itsfoss.com), and if you are curious about the progress **on elementary OS 8**, you can keep an eye out on its GitHub [project board](https://github.com/orgs/elementary/projects/128/views/1?ref=news.itsfoss.com).
**Want to try an early build of elementary OS 8?**
Well, **experimental builds based on the Ubuntu 24.04 repositories** are available to download right now! Keep in mind, that for getting access, **you have to be a GitHub sponsor.**
Head over to the official [builds website](https://builds.elementary.io/?ref=news.itsfoss.com) to get started.
*💬 Are you excited about this? Let me know of your thoughts below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,377 | 新款 Fedora Slimbook 14 加入 Fedora Slimbook 阵营 | https://fedoramagazine.org/new-fedora-slimbook-14-joins-the-fedora-slimbook-16/ | 2023-11-13T22:41:24 | [
"Slimbook",
"Fedora"
] | https://linux.cn/article-16377-1.html | 
自从我们发布 Fedora Slimbook 笔记本电脑的公告到现在已经过去近一个月了。这只是我们和 Slimbook 之间的合作关系的开始,我们的目标是在更多的设备上预装 Fedora Linux 系统。目前我们已经收到了非常积极的反馈!剩下的,我们想要和大家分享更多来自我们硬件合作伙伴的新消息,我们希望你会觉得很兴奋。
### 介绍 Fedora Slimbook 14 英寸版

尽管 Fedora Slimbook 16 英寸版的性能很出色,但我们注意到许多消费者对于笔记本电脑的尺寸以及英伟达显卡的配置表示了担忧,他们希望有更小的选择。为了回应这些反馈,Slimbook 推出了更小尺寸的 Fedora Slimbook 14 英寸版,以满足这些消费者的需求。这款新型号的电脑仍然保持了 Fedora 品牌的标志,包括电脑后盖和超级键上的 Fedora 标志,并且预装了 Fedora Workstation 系统!
主要特性:
* 无英伟达 GPU:虽然将这一点作为特性有些奇怪,但对于那些希望享受 Fedora 完整体验、期望硬件全面兼容的消费者来说,这一点准没错。
* 英特尔 i7-12700H 处理器:能满足你所有的计算需求,性能出众。
* 99Wh 电池:超长电池寿命,让你在出门在外时也能保持高效。
* 轻便,只有 1.25 公斤:无论你去哪里,都可以轻松携带。
* 镁合金机身:外壳轻便且耐磨。
* 2880x1800 的屏幕分辨率:在高分辨率的显示屏上享受鲜明的视觉效果和细节。
* 99% 的 sRGB 色彩准确度:非常适合设计师,媒体和内容创作人员使用。
与 Fedora Slimbook 16 英寸版一样,每售出一台 Fedora Slimbook 14 英寸版,都会有 3% 的收益捐献给 GNOME 基金会。
我们希望 Fedora Slimbook 14 英寸版可以满足你对电源和便携性的需求,并且展示出你对 Fedora 的热爱!想了解更多信息,请访问 <https://fedora.slimbook.es/>。



### 折扣
Slimbook 针对 Fedora 社区推出了两种折扣!
为了庆祝 Fedora Linux 39 的发布,Slimbook 推出了针对两款 Fedora Slimbook 的 100 欧元折扣活动!当你选择结账的时候,你会发现这个折扣已经直接被应用上去了。这项优惠将在限定的时间中推出。
而且,如果你是 Fedora 项目的贡献者,还可以享受额外的 100 欧元折扣!关于如何获得这个折扣的更多信息,你可以点击 [这个社区博客文章](https://communityblog.fedoraproject.org/fedora-slimbook-contributor-discount/) 查阅。
在我们与 Slimbook 建立并发展这个伙伴关系的过程中,我们非常感谢他们的良好合作。我们致力于让 Linux 更广泛地应用于硬件设备上,我们希望这些新的公告能让你对 Fedora 的硬件合作伙伴计划感到兴奋!
---
via: <https://fedoramagazine.org/new-fedora-slimbook-14-joins-the-fedora-slimbook-16/>
作者:[Joseph Gayoso](https://fedoramagazine.org/author/joseph/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It’s been about a month since we announced the Fedora Slimbook laptop. That was just the first step in our partnership with Slimbook to see Fedora Linux preinstalled on more devices. The feedback we’ve received has been great! With that, we wanted to share more news from our hardware partner that we hope is exciting for you.
### Introducing the **Fedora Slimbook 14″**


As awesome as the Fedora Slimbook 16″ is, we heard many of you express concerns over the size of the laptop or the Nvidia card, wishing there was a smaller option available. So Slimbook answered the call with the smaller Fedora Slimbook 14″ for those who prefer it – still with the great Fedora branding on the back of the lid and on the super key, and still with Fedora Workstation preinstalled!
Key Features:
- No Nvidia GPU: In some ways it’s odd to list this as a feature, but for those who want to make sure the default Fedora experience covers all of the hardware, here you go!
- Intel i7-12700H Processor: Experience top-notch performance for all your computing needs.
- 99Wh Battery: Stay productive and connected on the go with an extended all day long battery life.
- Lightweight 1.25Kg: Carry it effortlessly wherever you go.
- Magnesium Chassis: A sleek and durable construction.
- 2880 x 1800 Resolution: Enjoy vibrant visuals and crisp details on a high-resolution display.
- 99% sRGB Color Accuracy: Perfect for design, media, and content creation.
Same as with the Fedora Slimbook 16″, 3% of the revenue from each Fedora Slimbook 14″ sale will be donated to the GNOME Foundation.
Hopefully the Fedora Slimbook 14″ can give you the right mix of power and portability while showing off your Fedora love! Find more details at [https://fedora.slimbook.es/](https://fedora.slimbook.es/).




**Discounts**
Slimbook is also being generous with the Fedora community by offering two discounts you can apply!
To celebrate the release of Fedora Linux 39, Slimbook is offering a €100 discount on both Fedora Slimbooks! As you go to check out you should see this discount already applied. This will be available for a limited time.
Besides that there is also the Fedora contributor discount which gives you an additional €100 off! If you’re a contributor to the Fedora Project you can find more info on how to get this discount from [this Community Blog post](https://communityblog.fedoraproject.org/fedora-slimbook-contributor-discount/).
Slimbook has been great to work with as we develop this partnership to make Linux more accessible on hardware. We hope that these announcements are exciting for you as Fedora continues to focus on our hardware partner initiative!
## Luis
I want that slimbook but I want it with fedora kde plasma
## Justin
Just install KDE set it as default.
## Chinmay
Well, you can easily switch your desktop environment using dnf.
## aererawef
No it is not if you really tired. Most things works but there will be a lot more small config problem than KDE default version.
## Sideshow Bon
I have not had any problems doing this for years now. Left over cruft being a problem after installing another DE is a thing of the past. If you’re really that paranoid about it, you can always download the KDE spin and install fresh yourself.
## tolga erok
No problems with KDE either. Been using it for years on RHEL, Fedora (39) and NixOS.
## trauben saft
why is the touchpad so enormous, it divides the total space in half almost? i’d wish for a laptop with no touchpad at all, a good trackpoint is all that’s needed really.
## name
lol, this makes no sense, go get a girlfriend dude.
## Harry
I used to have a laptop without a touchpad (thinkpad).
It’s not better than a laptop with a modern touchpad.
## yabs
I am so sick of every company making 14″ laptops and then intentionally making the hardware worse while acting as if the machine really was somehow ‘smaller’. 14″ is standard display size for average laptops, you’re not winning any awards here.
Call me back when you guys remember netbooks exist.
## Daimar Stein
Umm… small reminder that the screen to body ratio of the screen is really good, so even though it has a 14″ screen it has a 13″ body. It is a really small laptop and it is still powerful, it just doesn’t have a dedicated GPU.
## L Hoejd
Looks really nice and portable. If I were on the hunt for a laptop for personal use I’d give it consideration. It’s cool that the feedback from the previous laptop article was received and could be acted upon (no nvidia graphics).
## Mng
I really wish those crappy touchpads would die. Can we not get a laptop with proper touchpad with physical buttons?
Full sized arrow keys would be nice too. That and dedicated buttons for page up, page down, home and end.
Lastly, why is it using a 2 year old processor?
## James
Yes, and a numpad. And a battery that lasts 3 days. They are also missing the floppy drive.
## Stephen
Really nice looking gear
## Alex
€100 discount on a last year’s cheap Chinese whitelabel laptop, which isn’t worth even €500 today – what a great deal!
## Geoffrey Gordon Ashbrook
Looks like a fabulous step ahead! 14″ is travel-friendly-er, and it will be interesting to see who opts for fedora-pre-install and how important that is for some fedora users (perhaps including organizations).
## null_pointer_00
Why not an AMD GPU? Why is so difficult to find a laptop with an AMD dedicated GPU?
## Dani_L
Not that difficult. Framework has RX7700S as an expansion module, for example. The Lenovo Z16 AMD has an RX 6500M option. They’re not common, but certainly not that hard to find.
## Daimar Stein
Stock, simple as that. Nowadays there isn’t nearly as big of a chip shortage as during the pandemic, but Intel still has a significantly bigger stock of chips AFAIK.
## XK27
Will firmware be updated via LVFS?
## Kevin
Posting this from the 14″ Fedora Slimbook. It’s a fantastic machine. Great keyboard, trackpad. Great battery life: I’m seeing 7-8hrs. Powerful for a thin and light laptop, and most importantly, everything “just works” with Fedora out of the box.
## Tsewang Gyurmey
Drat! Why couldn’t this have happened BEFORE I bought a new laptop? Argh!
## James
Same here. Next time I’ll know where to look first. |
16,378 | Git 的遴选和撤销操作是如何利用三路合并的 | https://jvns.ca/blog/2023/11/10/how-cherry-pick-and-revert-work/ | 2023-11-14T10:32:40 | [
"Git",
"遴选"
] | https://linux.cn/article-16378-1.html | 
大家好!几天前,我尝试向其他人解释 Git 遴选(`git cherry-pick`)的工作原理,结果发现自己反而更混淆了。
我原先以为 Git 遴选是简单地应用一个补丁,但当我真正这样尝试时,却未能成功!
因此,接下来我们将谈论我原来以为的遴选操作(即应用一个补丁),这个理解为何不准确,以及实际上它是如何执行的(进行“三路合并”)。
尽管本文的内容有些深入,但你并不需要全部理解才能有效地使用 Git。不过,如果你(和我一样)对 Git 的内部运作感到好奇,那就跟我一起深入探讨一下吧!
### 遴选操作并不只是应用一个补丁
我先前理解的 `git cherry-pick COMMIT_ID` 的步骤如下:
* 首先是计算 `COMMIT_ID` 的差异,就如同执行 `git show COMMIT_ID --patch > out.patch` 这个命令
* 然后是将补丁应用到当前分支,就如同执行 `git apply out.patch` 这个命令
在我们详细讨论之前,我想指出的是,虽然大部分情况下这个模型是正确的,如果这是你的认知模型,那就没有问题。但是在一些细微的地方,它可能会错,我觉得这个疑惑挺有意思的,所以我们来看看它究竟是如何运作的。
如果我在存在合并冲突的情况下尝试进行“计算差异并应用补丁”的操作,下面我们就看看具体会发生什么情况:
```
$ git show 10e96e46 --patch > out.patch
$ git apply out.patch
error: patch failed: content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown:17
error: content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown: patch does not apply
```
这一过程无法成功完成,它并未提供任何解决冲突或处理问题的方案。
而真正运行 `git cherry-pick` 时的实际情况却大为不同,我遭遇到了一处合并冲突:
```
$ git cherry-pick 10e96e46
error: could not apply 10e96e46... wip
hint: After resolving the conflicts, mark them with
hint: "git add/rm <pathspec>", then run
hint: "git cherry-pick --continue".
```
因此,看起来 “Git 正在应用一个补丁”这样的理解方式并不十分准确。但这里的错误信息确实标明了 “无法**应用** 10e96e46”,这么看来,这种理解又不完全是错的。这到底是怎么回事呢?
### 那么,遴选到底是怎么执行的呢?
我深入研究了 Git 的源代码,主要是想了解 `cherry-pick` 是如何工作的,最终我找到了 [这一行代码](https://github.com/git/git/blob/dadef801b365989099a9929e995589e455c51fed/sequencer.c#L2353-L2358):
```
res = do_recursive_merge(r, base, next, base_label, next_label, &head, &msgbuf, opts);
```
所以,遴选实际上就是一种……合并操作?这有些出乎意料。那具体都合并了什么内容?如何执行这个合并操作的呢?
我意识到我对 Git 的合并操作并不是特别理解,于是我上网搜索了一下。结果发现 Git 实际上采用了一种被称为 “三路合并” 的合并方式。那这到底是什么含义呢?
### Git 的合并策略:三路合并
假设我要合并下面两个文件,我们将其分别命名为 `v1.py` 和 `v2.py`。
```
def greet():
greeting = "hello"
name = "julia"
return greeting + " " + name
```
```
def say_hello():
greeting = "hello"
name = "aanya"
return greeting + " " + name
```
在这两个文件间,存在两处不同:
* `def greet()` 和 `def say_hello`
* `name = "julia"` 和 `name = "aanya"`
我们应该选择哪个呢?看起来好像不可能有答案!
不过,如果我告诉你,原始的函数(我们称之为 `base.py`)是这样的:
```
def say_hello():
greeting = "hello"
name = "julia"
return greeting + " " + name
```
一切似乎变得清晰许多!在这个基础上,`v1` 将函数的名字更改为 `greet`,`v2` 将 `name = "aanya"`。因此,合并时,我们应该同时做出这两处改变:
```
def greet():
greeting = "hello"
name = "aanya"
return greeting + " " + name
```
我们可以命令 Git 使用 `git merge-file` 来完成这次合并,结果正是我们预期的:它选择了 `def greet()` 和 `name = "aanya"`。
```
$ git merge-file v1.py base.py v2.py -p
def greet():
greeting = "hello"
name = "aanya"
return greeting + " " + name⏎
```
这种将两个文件与其原始版本进行合并的方式,被称为 **三路合并**。
如果你想在线上试一试,我在 [jvns.ca/3-way-merge/](https://jvns.ca/3-way-merge/) 创建了一个小实验场。不过我只是草草制作,所以可能对移动端并不友好。
### Git 合并的是更改,而非文件
我对三路合并的理解是 —— Git 合并的是**更改**,而不是文件。我们对同一个文件做出两种不同的更改,Git 试图以合理的方式将这两种更改结合到一起。当两个更改都对同一行进行操作时,Git 可能会遇到困难,此时就会产生合并冲突。
Git 也可以合并超过两处的更改:你可以对同一文件有多达 8 处不同的更改,Git 会尝试将所有更改协调一致。这被称为八爪鱼合并,但除此之外我对其并不了解,因为我从未执行过这样的操作。
### Git 如何使用三路合并来应用补丁
接下来,让我们进入到一个有些出乎意料的情境!当我们讨论 Git “应用补丁”(如在变基 —— `rebase`、撤销 —— `revert` 或遴选 —— `cherry-pick` 中所做的)时,其实并非是生成一个补丁文件并应用它。相反,实际执行的是一次三路合并。
下面是如何将提交 `X` 作为补丁应用到你当前的提交,并与之前的 `v1`、`v2` 和 `base` 设置相对应:
1. **在你当前提交中**,文件的版本是 `v1`。
2. **在提交 X 之前**,文件的版本是 `base`。
3. **在提交 X 中**,文件的版本是 `v2`。
4. 执行 `git merge-file v1 base v2` 以合并它们(实际上,Git 并不直接执行 `git merge-file`,而是运行一个实现这个功能的 C 函数)。
总的来说,你可以将 `base` 和 `v2` 视为“补丁”,它们之间的差异就是你想要应用到 `v1` 上的更改。
### 遴选如何运作
假设我们有如下提交图,并且我们打算在 `main` 分支上遴选提交 `Y`:
```
A - B (main)
\
\
X - Y - Z
```
那么,如何将此情景转化为我们前面提过的 `v1`、`v2` 和 `base` 组成的三路合并呢?
* `B` 是 `v1`
* `X` 是 `base`,而 `Y` 是 `v2`
所以,`X` 和 `Y` 共同构成了这个“补丁”。
其实,`git rebase` 无非就是重复多次执行 `git cherry-pick` 的过程。
### 撤销如何运作
现在,假如我们希望在如下的提交图上执行 `git revert Y`:
```
X - Y - Z - A - B
```
* `B` 是 `v1`
* `Y` 是 `base`,而 `X` 是 `v2`
这个过程反映的实际上就是遴选的情况,不过 `X` 和 `Y` 的位置颠倒了。我们需要这样做因为我们期望生成一个“反向补丁”。在 Git 中,撤销和遴选关系如此的紧密,它们甚至在同一个文件中实现:[revert.c](https://github.com/git/git/blob/dadef801b365989099a9929e995589e455c51fed/builtin/revert.c)。
### “三路补丁”是一个非常棒的技巧
使用三路合并将提交作为补丁应用的这个技巧非常巧妙且酷炫,我很惊讶之前从未听说过!我并未听过一个特定的名字来描述这种方法,但我更倾向于称之为“三路补丁”。
“三路补丁”的理念在于,你可以通过两个文件来定义补丁:在应用补丁前后的文件(在我们这篇文章中称之为 `base` 和 `v2`)。
因此,总体来看有三个文件被涉及到:一个是原文件,另外两个构成了补丁。
最重要的是,与普通补丁相比,三路补丁是一个更加高效的补丁方案,因为在有两个完整文件的情况下,你拥有更丰富的上下文信息来进行合并。
以下是我们例子中的常规补丁的大致情况:
```
@@ -1,1 +1,1 @@:
- def greet():
+ def say_hello():
greeting = "hello"
```
而下面这就是一个三路补丁。不过,需要提醒的是这个“三路补丁”并不是一个真正的文件格式,这只是我自己提出的一种概念。
```
BEFORE: (the full file)
def greet():
greeting = "hello"
name = "julia"
return greeting + " " + name
AFTER: (the full file)
def say_hello():
greeting = "hello"
name = "julia"
return greeting + " " + name
```
### 《Building Git》 中提到了这点
James Coglan 的书籍 [《Building Git》](https://shop.jcoglan.com/building-git/) 是我在 Git 源码之外唯一找到的地方,他解释了 `git cherry-pick` 是如何在底层运用三路合并的(我原以为《Pro Git》可能会提及这个,但我并没能找到此话题的内容)。
我购买完这本书后发现,我早在 2019 年时就已经买过了,这对我来说真的是个很好的参考。
### Git 中的合并实际上比这更复杂
在 Git 中,合并不限于三路合并 —— 还有一种我不太理解的叫做“递归合并”,还有许多具体处理文件删除和移动的细节,同时也有多种合并算法。
如果想要了解更多相关知识,我最好的建议是阅读《Building Git》,尽管我还未完全阅读这本书。
### Git 应用到底做了什么?
我也参阅了 Git 的源代码,试图理解 `git apply` 的功能。它似乎(不出意外地)在 `apply.c` 中实现。这段代码解析了一个补丁文件,并通入目标文件来寻找应该在何处应用补丁。核心逻辑似乎在 [这里](https://github.com/git/git/blob/dadef801b365989099a9929e995589e455c51fed/apply.c#L2684):思路好像是从补丁建议的行数开始,然后向前向后找寻。
```
/*
* There's probably some smart way to do this, but I'll leave
* that to the smart and beautiful people. I'm simple and stupid.
*/
backwards = current;
backwards_lno = line;
forwards = current;
forwards_lno = line;
current_lno = line;
for (i = 0; ; i++) {
...
```
这个处理过程不禁让人觉得非常直白、与之前的期望相符。
### Git 三路应用的工作方式
`git apply` 命令中也有一个 `--3way` 参数,可以实现三路合并。因此,我们实际上可以通过如下方式,使用 `git apply` 来大体实现 `git cherry-pick` 的功能:
```
$ git show 10e96e46 --patch > out.patch
$ git apply out.patch --3way
Applied patch to 'content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown' with conflicts.
U content/post/2023-07-28-why-is-dns-still-hard-to-learn-.markdown
```
但要注意,参数 `--3way` 并不只用到了补丁文件的内容!补丁文件开始的部分是:
```
index d63ade04..65778fc0 100644
```
`d63ade04` 和 `65778fc0` 是旧/新文件版本在 Git 对象数据库中的 ID,因此 Git 可以用这些 ID 来执行三路补丁操作。但如果有人将补丁文件通过邮件发送给你,而你并没有新/旧版本的文件,就无法执行这个操作:如果你缺少 blob,将会出现如下错误:
```
$ git apply out.patch
error: repository lacks the necessary blob to perform 3-way merge.
```
### 三路合并有点历史了
有一部分人指出,三路合并比 Git 的历史还要久远,它起源于 70 年代末期左右。有一篇 2007 年的 [论文](https://www.cis.upenn.edu/~bcpierce/papers/diff3-short.pdf) 对此进行了讨论。
### 就说这么多!
我真的对于我对于 Git 内部应用补丁的核心方法其实理解得并不深入这一点感到非常吃惊——学习这一点真的很酷!
虽然我对 Git 用户界面存在 [诸多不满](https://jvns.ca/blog/2023/11/01/confusing-git-terminology/),但是这个特定问题并不包含在内。三路合并似乎是统一解决一系列不同问题的优雅方式,它对于人们来说也很直观(“应用一个补丁”这个想法是许多编程者都习以为常的思考模式,而它底层实现为三路合并的细节,实际上没有人真正需要去思考)。
*我顺便快速推荐一下:我正在写一部有关 Git 的 [zine](https://wizardzines.com),如果你对它的发布感兴趣,你可以注册我非常不频繁的 [公告邮件列表](https://wizardzines.com/zine-announcements/)。*
*(题图:MJ/321bc2c9-4363-4661-802a-c74fb6a721b2)*
---
via: <https://jvns.ca/blog/2023/11/10/how-cherry-pick-and-revert-work/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
16,379 | Linux 爱好者线下沙龙:LLUG 2023·西子湖畔相见 | https://jinshuju.net/f/VJkeMZ | 2023-11-14T16:13:00 | [
"LLUG"
] | https://linux.cn/article-16379-1.html | 
>
> 走走停停,最终还是走到了西子湖畔。在这个冬日,LLUG 与你在杭州线下相见。
>
>
>
11 月 25 日,**LLUG 杭州场将在杭州未来科技城国际人才园(五常地铁站附近)**举办。

本次活动依然由 Linux 中国和龙蜥社区(OpenAnolis)联合主办,杭州 GDG 协办,杭州城西科创大走廊高层次人才联合会提供场地支持。
> 龙蜥社区(OpenAnolis)是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
> 杭州城西科创大走廊高层次人才联合会简称“高联会”,高联会是在杭州城西科创大走廊管委会指导下,旨在广泛吸纳与团结廊内高层次人才,助力人才在杭州城西科创大走廊的创新创业。
> 杭州 GDG(杭州谷歌开发者社区),谷歌官方赞助的杭州本地技术社区,每年定期举办免费开发者线下技术沙龙,聚焦谷歌相关开源技术,欢迎大家关注微信公众号“杭州GDG”,了解我们,参与技术交流。

*成都场现场照片*

*深圳场现场照片*

*上海场现场照片*
本次活动,我们将设常规的技术分享、动手实践和闪电演讲三种不同分享的形态。
* 技术分享会邀请来自 Linux 社区的开发者,分享自己在 Linux 中的技术实践,并配合 Q&A 的环节,帮助大家理解技术难点和实践,如果你有经验和实践想要分享给大家,欢迎报名分享
* 动手实践则会有来自各厂商的 Linux 大咖,带着大家用半个小时的时间来动手实践一个 Linux 主题,帮助大家动手体验 Linux 的种种新特性、特定的能力。
* 闪电演讲则不设定主题,每个人有 5 分钟时间来分享自己与 Linux、技术、开源有关的话题,共计 6 个闪电演讲名额,想要试试锻炼自己的演讲能力,不妨从闪电演讲开始。
欢迎大家扫码加入 LLUG 杭州分群,在群里为活动提出你的建议~
此外,如果你对分享感兴趣,欢迎填写下方问卷来提交你的议题,向开发者们分享你的研究、实践和经验:<https://jinshuju.net/f/VJkeMZ>
*(题图:MJ/8f5c79b3-5531-4e49-872d-ddb79266600a)*
| 302 | Found | null |
16,381 | 这儿几个字节,那里几个字节,我们说的是真正的内存 | https://dave.cheney.net/2021/01/05/a-few-bytes-here-a-few-there-pretty-soon-youre-talking-real-memory | 2023-11-15T15:48:58 | [
"Go",
"内存"
] | https://linux.cn/article-16381-1.html | 
今天的帖子来自于最近的 Go 语言的一次小测试,观察下面的测试基础片段 <sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup>:
```
func BenchmarkSortStrings(b *testing.B) {
s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"}
b.ReportAllocs()
for i := 0; i < b.N; i++ {
sort.Strings(s)
}
}
```
`sort.Strings` 是 `sort.StringSlice(s)` 的便捷包装器,`sort.Strings` 在原地对输入进行排序,因此不会分配内存(或至少 43% 回答此问题的 Twitter 用户是这么认为的)。然而,至少在 Go 的最近版本中,基准测试的每次迭代都会导致一次堆分配。为什么会是这种情况?
正如所有 Go 程序员应该知道的那样,接口是以 [双词结构](https://research.swtch.com/interfaces) 实现的。每个接口值包含一个字段,其中保存接口内容的类型,以及指向接口内容的指针。<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup>
在 Go 语言伪代码中,一个接口可能是这样的:
```
type interface struct {
// the ordinal number for the type of the value
// assigned to the interface
type uintptr
// (usually) a pointer to the value assigned to
// the interface
data uintptr
}
```
`interface.data` 可以容纳一个机器字(在大多数情况下为 8 个字节),但一个 `[]string` 却需要 24 个字节:一个字用于指向切片的底层数组;一个字用于存储切片的长度;另一个字用于存储底层数组的剩余容量。那么,Go 是如何将 24 个字节装入个 8 个字节的呢?通过编程中最古老的技巧,即间接引用。一个 `[]string`,即 `s`,需要 24 个字节;但 `*[]string` —— 即指向字符串切片的指针,只需要 8 个字节。
### 逃逸到堆
为了让示例更加明确,以下是重新编写的基准测试,不使用 `sort.Strings` 辅助函数:
```
func BenchmarkSortStrings(b *testing.B) {
s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"}
b.ReportAllocs()
for i := 0; i < b.N; i++ {
var ss sort.StringSlice = s
var si sort.Interface = ss // allocation
sort.Sort(si)
}
}
```
为了让接口正常运行,编译器将赋值重写为 `var si sort.Interface = &ss`,即 `ss` 的地址分配给接口值。<sup class="footnote-ref"> <a href="#fn3" id="fnref3"> [3] </a></sup> 我们现在有这么一种情况:出现一个持有指向 `ss` 的指针的接口值。它指向哪里?还有 `ss` 存储在哪个内存位置?
似乎 `ss` 被移动到了堆上,这也同时导致了基准测试报告中的分配:
```
Total: 296.01MB 296.01MB (flat, cum) 99.66%
8 . . func BenchmarkSortStrings(b *testing.B) {
9 . . s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"}
10 . . b.ReportAllocs()
11 . . for i := 0; i < b.N; i++ {
12 . . var ss sort.StringSlice = s
13 296.01MB 296.01MB var si sort.Interface = ss // allocation
14 . . sort.Sort(si)
15 . . }
16 . . }
```
发生这种分配是因为编译器当前无法确认 `ss` 比 `si` 生存期更长。Go 编译器开发人员对此的普遍态度是,觉得 [这个问题改进的余地](https://github.com/golang/go/issues/23676),不过我们另找时间再议。事实上,`ss` 就是被分配到了堆上。因此,问题变成了:每次迭代会分配多少个字节?为什么不去询问 `testing` 包呢?
```
% go test -bench=. sort_test.go
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i7-5650U CPU @ 2.20GHz
BenchmarkSortStrings-4 12591951 91.36 ns/op 24 B/op 1 allocs/op
PASS
ok command-line-arguments 1.260s
```
可以看到,在 amd 64 平台的 Go 1.16 beta1 版本上,每次操作会分配 24 字节。<sup class="footnote-ref"> <a href="#fn4" id="fnref4"> [4] </a></sup> 然而,在同一平台先前的 Go 版本中,每次操作则消耗了 32 字节。
```
% go1.15 test -bench=. sort_test.go
goos: darwin
goarch: amd64
BenchmarkSortStrings-4 11453016 96.4 ns/op 32 B/op 1 allocs/op
PASS
ok command-line-arguments 1.225s
```
这引出了本文的主题,即 Go 1.16 版本中即将推出的一项便利改进。不过在讨论这个内容之前,我需要聊聊 “<ruby> 尺寸类别 <rt> size class </rt></ruby>”。
### 尺寸类别
在解释什么是 “<ruby> 尺寸类别 <rt> size class </rt></ruby>” 之前,我们先考虑个问题,理论上的 Go 语言在运行时是如何在其堆上分配 24 字节的。有一个简单的方法:追踪目前为止已分配到的所有内存的动向——利用指向堆上最后分配的字节的指针。分配 24 字节,堆指针就会增加 24,然后将前一个值返回给调用函数。只要写入的请求 24 字节的代码不超出该标记的范围,这种机制就没有额外开销。不过,现实情况下,内存分配器不仅要分配内存,有时还得释放内存。
最终,Go 语言程序在运行时将释放这些 24 字节,但从运行的视角来看,它只知道它给调用者的开始地址。它不知道从该地址起始之后又分配了多少字节。为了允许释放内存,我们假设的 Go 语言程序运行时分配器必须记录堆上每个分配的长度值。那么这些长度值的分配存储在何处?当然是在堆上。
在我们的设想中,当程序运行需要分配内存的时候,它可以请求稍微多一点,并把它用来存储请求的数量。而对于我们的切片示例而言,当我们请求 24 字节时,实际上会消耗 24 字节加上存储数字 `24` 的一些开销。这些开销有多大?事实上,实际上的最小开销量是一个字。<sup class="footnote-ref"> <a href="#fn5" id="fnref5"> [5] </a></sup>
用来记录 24 字节分配的开销将是 8 字节。25% 不是很大,但也不算糟糕,随着分配的大小增加,开销将变得微不足道。然而,如果我们只想在堆上存储一个字节,会发生什么?开销将是请求数据量的 8 倍!是否有一种更高效的方式在堆上分配少量内存?
与其在每个分配旁边存储长度,不如将相同大小的内容存储在一起,这个主意如何?如果所有的 24 字节的内容都存储在一起,那么运行时会自动获取它们的大小。运行时所需要的是一个单一的位,指示 24 字节区域是否在使用中。在 Go 语言中,这些区域被称为 Size Classes,因为相同大小的所有内容都会存储在一起(类似学校班级,所有学生都按同一年级分班,而不是 C++ 中的类)。当运行时需要分配少量内存时,它会使用能够容纳该分配的最小的尺寸类别。
### 无限制的尺寸类别
现在我们知道尺寸类别是如何工作的了,那么问题又来了,它们存储在哪里?和我们想的一样,尺寸类别的内存来自堆。为了最小化开销,运行时会从堆上分配较大的内存块(通常是系统页面大小的倍数),然后将该空间用于单个大小的分配。不过,这里存在一个问题————
将大块区域用于存储同一大小的事物的模式很好用 <sup class="footnote-ref"> <a href="#fn6" id="fnref6"> [6] </a></sup>,如果分配大小的数量是固定的,最好是少数几个。那么在通用语言中,程序可以要求运行时以任何大小分配内存<sup class="footnote-ref"> <a href="#fn7" id="fnref7"> [7] </a></sup>。
例如,想象一下向运行时请求 9 字节。9 字节是一个不常见的大小,因此可能需要一个新的尺寸类别来存储 9 字节大小的物品。因为 9 字节大小的物品不常见,所以分配的其余部分(通常为 4KB 或更多)可能会被浪费。由于尺寸类别的集合是固定的,如果没有精确匹配的 size class 可用,分配将并入到下一个尺寸类别。在我们的示例中,9 字节可能会在 12 字节的尺寸类别中分配。未使用的 3 字节的开销要比几乎未使用的整个尺寸类别分配好。
### 总结一下
这是谜题的最后一块拼图。Go 1.15 版本没有 24 字节的尺寸类别,因此 `ss` 的堆分配是在 32 字节的尺寸类别中分配的。由于 Martin Möhrmann 的工作,Go 1.16 版本有一个 24 字节的尺寸类别,非常适合分配给接口的切片值。
### 相关文章
1. [我在 Devfest 2017年西伯利亚大会谈 Go 语言](https://dave.cheney.net/2017/08/23/im-talking-about-go-at-devfest-siberia-2017)
2. [如果对齐的内存写操作是原子性的,为什么我们还需要 sync/atomic 包呢?](https://dave.cheney.net/2018/01/06/if-aligned-memory-writes-are-atomic-why-do-we-need-the-sync-atomic-package)
3. [为你的树莓派创建一个真实的串行控制台](https://dave.cheney.net/2014/01/05/a-real-serial-console-for-your-raspberry-pi)
4. [为什么 Go 语言线程的栈是无限制的?](https://dave.cheney.net/2013/06/02/why-is-a-goroutines-stack-infinite)
*(题图:MJ/01d5fe46-778f-48fe-9481-162f4d0289dc)*
---
1. 这不是正确的对排序函数进行基准测试的方式,因为在第一次迭代之后,输入已经排序。但这又是另外一个话题了。 [↩︎](#fnref1)
2. 此语句的准确性取决于所使用的 Go 版本。例如,Go 1.15 版本添加了直接将一些 [整数存储在接口值](https://golang.org/doc/go1.15#runtime) 中的功能,从而节省了分配和间接性。然而,对于大多数值来说,如果它不是指针类型,它的地址将被取出并存储在接口值中。 [↩︎](#fnref2)
3. 编译器在接口值的类型字段中跟踪了这种手法,因此它记住了分配给 `si` 的类型是 `sort.StringSlice` 而不是 `*sort.StringSlice`。 [↩︎](#fnref3)
4. 在 32 位平台上,这个数字减半,[但我们不再关注它](https://www.tallengestore.com/products/i-never-look-back-darling-it-distracts-from-the-now-edna-mode-inspirational-quote-tallenge-motivational-poster-collection-large-art-prints)。 [↩︎](#fnref4)
5. 如果你准备限制分配为 4G 或者可能是 64KB,你可以使用较少内存来存储分配的尺寸,但实际上使用小于一个字来存储长度标头的节省会受到填充的影响。 [↩︎](#fnref5)
6. 将相同大小的物品存储在一起也是一种有效的对抗碎片化的策略。 [↩︎](#fnref6)
7. 这并不是一个不切实际的设想,字符串有各种形状和大小,生成以前未见过的大小的字符串可能就像附加空格一样简单。 [↩︎](#fnref7)
---
via: <https://dave.cheney.net/2021/01/05/a-few-bytes-here-a-few-there-pretty-soon-youre-talking-real-memory>
作者:[Dave Cheney](https://dave.cheney.net/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Drwhooooo](https://github.com/Drwhooooo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today’s post comes from a recent Go pop quiz. Consider this benchmark fragment.1
```
func BenchmarkSortStrings(b *testing.B) {
s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"}
b.ReportAllocs()
for i := 0; i < b.N; i++ {
sort.Strings(s)
}
}
```
A convenience wrapper around `sort.Sort(sort.StringSlice(s))`
, `sort.Strings`
sorts the input in place, so it isn’t expected to allocate (or at least that’s what 43% of the tweeps who responded thought). However it turns out that, at least in recent versions of Go, each iteration of the benchmark causes one heap allocation. Why does this happen?
Interfaces, as all Go programmers should know, are implemented as a[ two word structure](https://research.swtch.com/interfaces). Each interface value contains a field which holds the type of the interface’s contents, and a pointer to the interface’s contents.2
In pseudo Go code, an interface might look something like this:
```
type interface struct {
// the ordinal number for the type of the value
// assigned to the interface
type uintptr
// (usually) a pointer to the value assigned to
// the interface
data uintptr
}
```
`interface.data`
can hold one machine word–8 bytes in most cases–but a `[]string`
is 24 bytes; one word for the pointer to the slice’s underlying array; one word for the length; and one for the remaining capacity of the underlying array, so how does Go fit 24 bytes into 8? With the oldest trick in the book, indirection. `s`
, a `[]string`
is 24 bytes, but `*[]string`
–a pointer to a slice of strings–is only 8.
## Escaping to the heap
To make the example a little more explicit, here’s the benchmark rewritten without the `sort.Strings`
helper function:
```
func BenchmarkSortStrings(b *testing.B) {
s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"}
b.ReportAllocs()
for i := 0; i < b.N; i++ {
var ss sort.StringSlice = s
var si sort.Interface = ss // allocation
sort.Sort(si)
}
}
```
To make the interface magic work, the compiler rewrites the assignment as `var si sort.Interface = &ss`
–the *address* of `ss`
is assigned to the interface value.[ 3](#easy-footnote-bottom-3-4231) We now have a situation where the interface value holds a pointer to
`ss`
, but where does it point? Where in memory does `ss`
live?It appears that `ss`
is moved to the heap, causing the allocation that the benchmark reports.
Total: 296.01MB 296.01MB (flat, cum) 99.66% 8 . . func BenchmarkSortStrings(b *testing.B) { 9 . . s := []string{"heart", "lungs", "brain", "kidneys", "pancreas"} 10 . . b.ReportAllocs() 11 . . for i := 0; i < b.N; i++ { 12 . . var ss sort.StringSlice = s 13 296.01MB 296.01MB var si sort.Interface = ss // allocation 14 . . sort.Sort(si) 15 . . } 16 . . }
The allocation occurs because the compiler currently cannot convince itself that `ss`
outlives `si`
. The general attitude amongst Go compiler hackers seems to be that [this could be improved](https://github.com/golang/go/issues/23676), but that’s a discussion for another time. As it stands, `ss`
is allocated on the heap. Thus the question becomes, how many bytes are allocated per iteration? Why don’t we ask the `testing`
package.
% go test -bench=. sort_test.go goos: darwin goarch: amd64 cpu: Intel(R) Core(TM) i7-5650U CPU @ 2.20GHz BenchmarkSortStrings-4 12591951 91.36 ns/op 24 B/op 1 allocs/op PASS ok command-line-arguments 1.260s
Using Go 1.16beta1, on amd64, 24 bytes are allocated per operation.[ 4](#easy-footnote-bottom-4-4231) However, the previous Go version, on the same platform, consumes 32 bytes per operation
% go1.15 test -bench=. sort_test.go goos: darwin goarch: amd64 BenchmarkSortStrings-4 11453016 96.4 ns/op 32 B/op 1 allocs/op PASS ok command-line-arguments 1.225s
This brings us, circuitously, to the subject of this post, a nifty quality of life improvement coming in Go 1.16. But before I can talk about it, I need to discuss size classes.
## Size classes
To explain what a size class is, consider how a theoretical Go runtime could allocate 24 bytes on its heap. A simple way to do this would be keep track of all the memory allocated so far using a pointer to the last allocated byte on the heap. To allocate 24 bytes, the heap pointer is incremented by 24, and the previous value returned to the caller. As long as the code that asked for 24 bytes never writes beyond that mark this mechanism has no overhead. Sadly, in real life, memory allocators don’t just allocate memory, sometimes they have to free it.
Eventually the Go runtime will have to free those 24 bytes, but from the runtime’s point of view, the only thing it knows is the starting address it gave to the caller. It does not know how many bytes after that address were allocated. To permit deallocation, our hypothetical Go runtime allocator would have to record, for each allocation on the heap, its length. Where are the allocation for those lengths allocated? On the heap of course.
In our scenario, when the runtime wants to allocate memory, it could request a little more than it was asked for and use it to store the amount requested. For our slice example, when we asked for 24 bytes, we’d actually consume 24 bytes plus some overhead to store the number 24. How large is this overhead? It turns out the minimum amount that is practical is one word.5
To record a 24 byte allocation the overhead would 8 bytes. 25% is not great, but not terrible, and as the size of the allocation goes up, the overhead would become insignificant. However, what would happen if we wanted to store just one `byte`
on the heap? The overhead would be eight times the amount of data we asked for! Is there are more efficient way to allocate small amounts on the heap?
Rather than storing the length alongside each allocation, what if all the thing of the same size were stored together? If all the 24 byte things are stored together, then the runtime would automatically know how large they are. All the runtime needs is a single bit to indicate if a 24 byte area is in use or not. In Go these areas are known as size classes, because all the things of the same size are stored together (think school class–all the students are the same grade–not a C++ class). When the runtime needs to allocate a small amount, it does so using the smallest size class that can accomodate the allocation.
## Unlimited size classes for all
Now we know how size classes work, the obvious question is, where are they stored? Not surprisingly, the memory for a size class comes from the heap. To minimise overhead, the runtime allocates a larger amount from the heap (usually a multiple of the system page size) then dedicates that space for allocations of a single size. But, there’s a problem.
The pattern of allocating a large area to store things of the same size works well[ 6](#easy-footnote-bottom-6-4231) if there’s a fixed, preferably small, number of allocation sizes, but in a general purpose language programs can ask the runtime for an allocation of any size.
7For example, imagine asking the runtime for 9 bytes. 9 bytes is an uncommon size, so it’s likely that a new size class for things of size 9 would be required. As 9 byte things are uncommon, it’s likely the remainder of the allocation, 4kb or more, would be wasted. Because of this the set of possible size classes is fixed. If a size class of the exact amount is not available, the allocation is rounded up to the next size class. In our example 9 bytes might be allocated in the 12 byte size class. The overhead of 3 unused bytes is better than an entire size class allocation which goes mostly unused.
## All together now
This is the final piece of the puzzle. Go 1.15 did not have a 24 byte size class, so the heap allocation of `ss`
was allocated in the 32 byte size class. Thanks to the work of Martin Möhrmann Go 1.16 has a 24 byte size class, which is a perfect fit for slice values assigned to interfaces.
- This is not the correct way to benchmark a sort function because after the first iteration, the input is sorted. But I digress.
- The accuracy of this statement depends on the version of Go in use. For example, Go 1.15 added the ability to
[store some integers directly in the interface value,](https://golang.org/doc/go1.15#runtime)saving the allocation and indirection. However, for the majority of values, if it wasn’t a pointer type already, its address is taken and stored in the interface value. - The compiler keeps track of this sleight of hand in the interface value’s type field so it remembers that the type assigned to
`si`
is`sort.StringSlice`
, not`*sort.StringSlice`
. - On 32 bit platforms this number is halved,
[but we never look back](https://www.tallengestore.com/products/i-never-look-back-darling-it-distracts-from-the-now-edna-mode-inspirational-quote-tallenge-motivational-poster-collection-large-art-prints). - If you were prepared to limit allocations to 4G, or maybe 64kb, you could use a smaller amount of memory to store the size of the allocation, but this would mean the first word of the allocation is not naturally aligned so in practice the savings of using less than a word to store the length header are undermined by padding.
- Storing things of the same size together is also an effective strategy to combat fragmentation.
- This isn’t a far fetched scenario, strings come in all shapes and sizes and generating a string of a size not previously seen before can be as simple as appending a space. |
16,383 | 每月 5 美元的虚拟机可以跻身 1993 年的超算前三 | https://www.theregister.com/2023/11/14/five_dollar_supercomputer/ | 2023-11-16T00:08:49 | [
"超算",
"TOP500"
] | https://linux.cn/article-16383-1.html | 
>
> 当然,如果你真的关注性能,市面上自然有更出色的选择。
>
>
>
今年是 TOP500 公开排名全球最快超级计算机 30 周年。
为纪念这个重要的里程碑,也因应科罗拉多州正在举行的年度超级计算大会,我们想弄个有趣但稍显愚蠢的实验:看看以今天技术,我们能以多低的成本重现 1993 年超级计算机十强的性能。于是,我们在云上运行了几台虚拟机,并对 HPLinpack 基准进行了编译测试。这里简单透露一下:我们这项实验的结果,你可能并不会太震惊。
到 1993 年年末,最快的超级计算机是日本国家航空实验室的富士通数值风洞。这台装备了 140 个 CPU 核心的系统,能够实现 124 GigaFLOPS 的双精度(FP64)计算能力。
如今,我们的系统已经 [突破](https://www.theregister.com/2022/05/30/us_frontier_supercomputer_ousts_japans/) 了 exaFLOPS 的难关,然而在 [1993 年 11 月](https://www.top500.org/lists/top500/1993/11/),如何在功率最高的十个系统中占据一席之地呢?只要你的 FP64 性能超过了美国 [CM-5/544](https://www.top500.org/system/167021/) 机型的 15.1 GigaFLOPS。因此,我们设定的目标是让云虚拟机超过 15 GigaFLOPS 的性能。
在我们分析结果之前,有几点值得一提。如果我们选用了支持 GPU 的实例,我们知道我们能够达到更高的性能。不过,云端的 GPU 实例租赁并不便宜,并且在 2000 年年中至年底,GPU 才真正开始广泛出现在 TOP500 的超级计算机中。此外,在 CPU 上运行 Linpack 比在 GPU 上运行要容易得多。
这些测试只是为了纪念 30 周年,只是稍微有点新颖,决不具有科学严谨或详尽无遗的特征。
### 一台 5 美元的云虚拟机对比一部 30 年前的 TOP500 超级计算机
但在开始测试前,我们需要开启一对 VPC。在本次测试中,我们选择在 Vultr 上运行 Linpack,但其实在 AWS,Google Cloud,Azure,Digital Ocean 或者是你喜欢的任何云服务商上,这都同样适用。
首先,我们启动了一个月费 5 美元的虚拟机实例,它具备了一个共享的 vCPU,1GB 的内存和 25GB 的存储。准备就绪后,我们便启动了 Linpack 的编译。
在这,事情可能会有些复杂,因为我们实际上可以对系统进行一些调优,挤出一些额外的 FLOPS。然而,考虑到这只是一个测试,也为了尽可能保持简单,我们选择了依照 [这个指南](https://gist.github.com/Levi-Hope/27b9c32cc5c9ded78fff3f155fc7b5ea) 进行操作。此份操作手册是基于 Ubuntu 18.04 编写的,但是我们发现在 20.04 LTS 上运行也一切正常。
为了产生我们的 HPL.dat 文件,我们利用了一个巧妙的 [表单](https://www.advancedclustering.com/act_kb/tune-hpl-dat-file/),它会自动产生一个优化版的 Linpack 运行配置。
我们对几种不同类型的虚拟机进行了三次基准测试,并从每次运行中挑选出最高的得分。以下就是我们的发现:
| 实例类型 | vCPU | RAM (MB) | 存储 (GB) | Rmax GFLOPS | 每月费用 (美元) |
| --- | --- | --- | --- | --- | --- |
| Regular shared | 1 | 1024 | 25 | 31.21 | 5 |
| Premium shared | 1 | 1024 | 25 | 51.85 | 6 |
| Premium shared | 2 | 2048 | 60 | 87.46 | 18 |
| Premium shared | 4 | 8192 | 180 | 133.42 | 48 |
从我们的测试结果可以看出,一个单一的共享 vCPU 在与 1993 年 11 月十大超级计算机的比较中表现出颇为出色的性能。
我们通过一个 CPU 线程就获得了 31.21 GigaFLOPS 的 FP64 性能,这使得我们的虚拟机与 1993 年排名第三的超级计算机 —— 明尼苏达超级计算中心的 30.4 GigaFLOPS [CM-5/554](https://www.top500.org/system/167059/) Thinking Machines 系统相提并论。这确实令人吃惊,因为那台系统拥有 544 个 SuperSPARC 处理器,而我们的系统只有一个 CPU 线程,虽然我们的系统运行在更高的时钟速度下。
如你从上面的图表中所见,每月多花 1 美元,我们的性能跃升至 51.85 GigaFLOPS,而选择一个价值 18 美元的“高级”共享 CPU 实例,双线程使我们进一步接近 87.46 GigaFLOPS 的性能。
然而,要超过 [富士通的数值风洞](https://www.top500.org/system/173279/),我们需要升级到四个 vCPU 的虚拟机,由此我们抓取到了 133 GigaFLOPS 的 FP64 性能。然而不幸的是,升级到四个线程的费用跳到了每月 48 美元。达到这个价格,Vultr 实际上是在销售部分 GPU,我们预计如果采用 GPU,性能应会有显著提升,效率也会更高。
### 更好的选择
我们需要明确的是,这些都是我们选择的共享类型实例。一般来说,共享实例意味着在一定程度上进行了超额配置。
由于共享实例可能会受到其他租户的影响,这也使得性能有时难以预知,甚至每次运行的性能都可能略有不同,这主要取决于云区域中主机系统的载荷状态。
在我们的非常不科学的测试中,我们并未观察到太多的性能变化。我们想这可能是因为核心并未处在过高的负载下。在专有 CPU 实例上进行同样的测试,结果与我们每月 6 美元的共享实例相若,但成本高达五倍。
但是,除了这场小实验的新奇趣味之外,这没太多实际意义。如果你需要在短时间内获得大量 FLOPS,有许多已优化的 CPU 和 GPU 实例可供选择。它们的成本无法与每月 5 美元的实例相媲美,然而大多数实例是按小时账单的,因此实际成本将取决于你完成工作的迅速程度。
此外,让我们不要忘记,你的智能手机与这些存在已久的 30 年老计算系统相比,又会有怎样的对比呢?
*(题图:MJ/16cf957e-a4e4-43b1-99b2-df0574a064dc)*
---
via: <https://www.theregister.com/2023/11/14/five_dollar_supercomputer/>
作者:[Tobias Mann](https://www.theregister.com/Author/Tobias-Mann) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | # As the Top500 celebrates its 30th year, with a $5 VM you too can get into the top 10 ... of 1993
## But if you really care about performance, there are better options out there, natch
SC23 This year marks the 30th anniversary of the Top500 ranking of the world's publicly known fastest supercomputers.
In celebration of this fact and with the annual Supercomputing event underway in Colorado, we thought it'd be fun, if a bit silly, to see how cheaply we could achieve the performance of a top-ten supercomputer from 1993. So, we spun up a few virtual machines in the cloud and compiled the HPLinpack benchmark. Spoiler alert: you may not be too shocked by this experiment of ours.
At the end of 1993, the fastest supercomputer on record was Fujitsu's Numerical Wind Tunnel, located at Japan's National Aerospace Lab. With a whopping 140 CPU cores, the system managed 124 gigaFLOPS of double-precision (FP64) performance.
Today we have systems [breaking](https://www.theregister.com/2022/05/30/us_frontier_supercomputer_ousts_japans/) the exaFLOPS barrier, but [in November 1993](https://www.top500.org/lists/top500/1993/11/), all you needed to do to claim a spot among the 10 most powerful systems was to manage better than the US [CM-5/544](https://www.top500.org/system/167021/)'s 15.1 gigaFLOPs of FP64 performance. So, the target for our cloud virtual machine to beat was 15 gigaFLOPS.
Before we dig into the results, a few notes. We know we could have achieved much, much higher performance if we'd opted for a GPU-enabled instance, however these aren't exactly cheap to rent in the cloud, and GPUs didn't really start appearing in Top500 supercomputers until the mid to late 2000s. It's also much simpler to get Linpack running on a CPU than on a GPU.
These tests were run for the novelty of it, to mark the 30th anniversary, and are by no means scientific or exhaustive.
### A $5 cloud VM versus a 30-year-old Top500 super?
But before we could get to testing, we needed to spin up a couple VPCs. For this run we opted to run Linpack in Vultr but this would just as well in AWS, Google Cloud, Azure, Digital Ocean, or whatever cloud provider you prefer.
To start off, we spun up a $5/mo virtual machine instance with a single shared vCPU, 1GB of RAM and a 25GB of storage. With that out of the way, it was time to compile Linpack.
This is where things can get a little complicated since there's actually a fair bit of tweaking and optimization that can be done to eke out a few extra FLOPS. However, for the purposes of this test and in the interest of keeping things as simple as possible, we opted for this guide [here](https://gist.github.com/Levi-Hope/27b9c32cc5c9ded78fff3f155fc7b5ea). That documentation was written for Ubuntu 18.04 though we found it worked just fine in 20.04 LTS.
To generate our HPL.dat file we used this nifty [form](https://www.advancedclustering.com/act_kb/tune-hpl-dat-file/) that automatically generates an optimized configuration for a Linpack run.
We ran the benchmark three times for a few different VM types and selected the highest score from each run. Here are our findings:
Instance type | vCPUs | RAM (MB) | Storage (GB) | Rmax GFLOPS | $/month |
---|---|---|---|---|---|
Regular shared | 1 | 1024 | 25 | 31.21 | 5 |
Premium shared | 1 | 1024 | 25 | 51.85 | 6 |
Premium shared | 2 | 2048 | 60 | 87.46 | 18 |
Premium shared | 4 | 8192 | 180 | 133.42 | 48 |
As you can see, our totally unscientific test results showed a single shared vCPU compares quite favorably to November 1993's ten most power supers.
A single CPU thread netted us 31.21 gigaFLOPS of FP64 performance, putting our VM in contention for the number-three ranked supercomputer in 1993, the Minnesota Supercomputing Center's 30.4 gigaFLOPS [CM-5/554](https://www.top500.org/system/167059/) Thinking Machines system. Not bad considering that system had 544 SuperSPARC processors while ours had a single CPU thread, albeit running at much higher clock speeds, of course.
As you can see from the chart above, an extra $1/mo saw performance leap to 51.85 gigaFLOPS, while stepping up to an $18 "premium" shared CPU instance with two threads got us closer to 87.46 gigaFLOPS.
However, to beat Fujitsu's [Numerical Wind Tunnel](https://www.top500.org/system/173279/) required stepping up to a four vCPU VM from which we squeezed 133 gigaFLOPS of FP64 goodness. Unfortunately, jumping up to four threads wasn't nearly as cheap at $48/mo. At that price, Vultr actually sells fractional GPUs which we expect would perform comically better, and will be quite a bit more efficient.
### Better options out there
Something we should mention is these were all shared instances, which usually means they've been over provisioned to some degree.
This can lead to unpredictable performance that could vary from run to run depending how heavily loaded the host system is in its cloud region.
In our highly unscientific runs we didn't see much variation. We think this is because the cores just weren't that heavily loaded. Running the same test on a dedicated CPU instance rendered near identical results as our $6/mo instance but at 5x the cost.
But beyond the novelty of this little experiment, there's not really much point. If you need to get your hands on a bunch of FLOPS on short notice, there are plenty of CPU and GPU instances optimized for this kind of work. They won't be anywhere as cheap as a $5/mo instance, but most these are actually billed by the hour so for real-world workloads the actual cost is going to be determined by how quickly you can get the job done.
And never mind how your smartphone compares to these 30-year-old systems.
In any case, *The Register* will be on the ground in Denver this for [SC23](https://search.theregister.com/?q=sc23) where we'll be bringing you the latest insights into the world of high-performance computing and AI. And for more analysis and commentary, don't forget our pals [at The Next Platform](https://www.nextplatform.com/), who have the conference covered too. ®
24 |
16,385 | 真的,宇宙射线会导致部分 SSH 服务器的私钥泄露 | https://www.theregister.com/2023/11/14/passive_ssh_key_compromise/ | 2023-11-17T01:00:00 | [
"密钥",
"SSH"
] | https://linux.cn/article-16385-1.html | 
>
> 如果你是 OpenSSL、LibreSSL、OpenSSH 的用户,你可以坐下来看看了,因为这不会影响你。
>
>
>
最近一项学术研究展示了如下情况:对于某些特定设备,他人可以监听其 SSH 连接,然后借助一些运气在无声无息中破译出主机的私有 RSA 密钥,从而冒充该设备。
冒充这些设备后,通过使用推断出的主机密钥私钥实施的中间人攻击,间谍可以安静地记录用户的登录信息,同时,通过将这些连接转发给真正的设备,他们还可以监控用户在远程 SSH 服务器上的活动。尽管 SSH 还有其他功能,但其主要应用场景仍然是用户登录到设备并通过命令行接口进行控制。
据悉,可以通过被动监视从客户端到易受攻击设备的 SSH 服务器的连接,获得主机的 RSA 密钥私钥:无论是在签名生成过程中的偶发运算错误,还是因宇宙射线等微小故障产生的自然错误,都可以被观察和利用来推算 SSH 服务器的主机密钥私钥,这本应是保密的。
虽然可能认为自然错误发生的概率很小,偶发错误可能已为众所周知,但实际上只要你连续观察足够多的到有漏洞的 SSH 服务器的 SSH 连接,你就有可能发现一个你可以利用的。
重要的一点是,软件库 OpenSSL 和 LibreSSL,以及 OpenSSH,都未发现存在上述密钥推导问题的漏洞。由此,我们认为,网上的大部分设备、服务器和其他设备都不会受到影响,只有特定的物联网设备和类似的嵌入式设备可能会对此种攻击敏感。此外,这种问题也仅影响 RSA 密钥。
### 细节
由加利福尼亚大学圣地亚哥分校的 Keegan Ryan、Kaiwen He(他同时也在麻省理工学院任职)、George Arnold Sullivan 以及 Nadia Heninger 基于早期的一些研究,完成并撰写了这项研究。他们采用的技术,旨在揭示 RSA 密钥私钥,该技术源于 Florian Weimer 在 2015 年对 TLS 的突破性研究,以及 2022 年圣地亚哥论文的几位作者以及其他研究者的一些工作,这些工作可追溯到 1990 年代。
信息安全专家 Thomas Ptacek 曾高度赞扬了 2023 年研究的合著者 Nadia Heninger,并在此分享了 RSA 密钥分析论文的摘要,以便于理解这个问题。我们同时也要感谢曾在 Register vulture 工作的 Dan Goodin,他在周一通过 Ars Technica 向我们报告了 UC 圣地亚哥论文的消息。
基本上,当客户端尝试连接到一个容易受到攻击的 SSH 服务器时,它们在协商建立全面安全加密通信的过程中,服务器将会生成一个数字签名以供客户端检查,以确保其正在与预期的服务器通信。
如我们之前所述,这个签名的计算过程可能会随机或意外地产生错误,聪明的算法可以从错误的签名中推导出服务器的私有 RSA 密钥,此密钥用于签名生成。对此的一种防范措施是在将签名发送给客户端前确保其计算正确;OpenSSL 和 LibreSSL 已经在实施这种防范。
正如论文作者在他们的摘要中提到的:
>
> “我们证明了一种可能性:若 SSH 服务器在进行签名计算过程中出现自然故障,一名被动的网络攻击者便有机会获得其私有 RSA 主机密钥。
>
>
> 在之前的研究中,我们通常认为这对于 SSH 协议是不可行的,因为签名中包含了一些信息,比如 Diffie-Hellman 共享密钥,这些信息对于被动的网络观察者来说无法获得。
>
>
> 然而,我们证明了,在 SSH 中经常使用的签名参数下,如果出现了签名错误,我们便能有效地使用 <ruby> 格攻击 <rt> lattice attack </rt></ruby> 来恢复私钥。
>
>
> 我们对 SSH、IKEv1、IKEv2 协议进行了安全分析,在此场景下,我们利用我们的攻击方法在现实环境中挖掘出几个存在漏洞的独立实现中的数百个被攻破的密钥。
>
>
>
“一个被动的对手可以安静地监控合法的连接,不用冒被检测的风险,直到他们观察到一个包含私钥的错误签名。”研究团队做出了这样的结论:“然后,攻击者可以主动且不会被检测地冒充被攻破的主机,从而截取敏感数据。”
研究人员表示,他们已经扫描了整个互联网,并翻查了以前收集的 SSH 扫描数据,以测量易受攻击的签名的流行程度。他们声称,他们的数据集涵盖了 52 亿条 SSH 记录和超过七年的观察,其中包含了超过 59 万个无效的 RSA 签名。
通过他们的格密钥恢复技术,学者们表示,其中超过 4900 个错误的签名揭示了对应 RSA 公钥的因子分解。他们利用这些信息,推导出了 189 个公钥的私有 RSA 密钥。
在他们的研究中,作者们发现,思科、Zyxel、山石网科和 Mocana 这四个制造商的产品都可能受到这种密钥侦测攻击。研究者已经向思科和 Zyxel 报告了这个问题,观察到两家供应商都迅速进行了调查行动。
思科判定其 ASA 和 FTD 软件在 2022 年已经解决了此问题,且在这篇论文发布之前,公司正在对其 IOS 和 IOS XE 软件进行调查,看看如何应对此问题。
同一时间,Zyxel 发现这个缺陷只影响到了它那些已停止服务的固件,并且它已经开始使用不受此问题影响的 OpenSSL。研究人员表示,他们没有成功地与山石网科和 Mocana 取得联系,所以决定把这个问题提交给了 CERT 协调中心。
据称,自诩为 “SSH-2.0-SSHD” 的 SSH 服务器实现也可能受到攻击,这可能会影响到一些企业级的 Java 应用。有鉴于这个密钥推导技术的关键在于 PKCSv1.5,使用 PKCSv1.5-RSA 签名的 DNSSEC 可能也在风险之中。
他们还指出,他们在 IPsec 连接中收集到的签名数据集不大,所以无法确定此协议是否也可能受到类似的密钥泄漏攻击。他们表示:“鉴于易受攻击的签名故障很罕见,根据我们的数据,我们无法对 IPsec 实现得出多少结论,我们认为这个问题值得进一步研究。”
>
> 更新:已经与山石网科取得联系,官方确认该问题已在 2015 年发布的相关版本中修复,之后的版本也不存在相关问题。
>
>
> 具体详情可以咨询山石网科客服或查看如下链接:
>
>
> [https://www.hillstonenet.com.cn/security-notification/2015/07/28/dsfyj/](https://www.hillstonenet.com.cn/security-notification/2015/07/28/dsfyj/ )
>
>
>
*(题图:MJ/f94093f0-9ffe-4cf1-82fb-cdac1427e923)*
---
via: <https://www.theregister.com/2023/11/14/passive_ssh_key_compromise/>
作者:[Jessica Lyons Hardcastle](https://www.theregister.com/Author/Jessica-Lyons-Hardcastle) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | # Passive SSH server private key compromise is real ... for some vulnerable gear
## OpenSSL, LibreSSL, OpenSSH users, don't worry – you can sit this one out
An academic study has shown how it's possible for someone to snoop on certain devices' SSH connections and, with a bit of luck, impersonate that equipment after silently figuring out the hosts' private RSA keys.
By impersonating these devices, in a man-in-the-middle attacks using those deduced private host keys, the spy would be able to quietly observe users' login details and, by forwarding the connections to the real equipment, monitor those users' activities with the remote SSH servers. SSH is typically used to log into a device and control it via a command-line interface though there are other uses.
We're told the private host RSA keys can be obtained by passively surveiling connections from clients to a vulnerable device's SSH server: accidental or naturally occurring computational errors during signature generation can be observed and exploited to calculate the SSH server's ideally secret private host key.
By naturally occurring errors we mean errors caused by cosmic rays and other little glitches that flip bits, and by accidental we mean poorly implemented RSA signature generation algorithms. You'd think the former would occur so rarely that no one would be able to take advantage of it realistically, and the latter would already be known about, but we're assured that if you monitor enough SSH connections to a vulnerable SSH server, you'll eventually see one that you can exploit.
It's important to state here that the software libraries OpenSSL and LibreSSL, and thus OpenSSH, are not known to be vulnerable to the aforementioned key deduction method. That means, in our view, the vast majority of devices, servers, and other equipment on the internet are not at risk, and what you're left with is some Internet-of-Things and similar embedded gear susceptible to attack. It also only affects RSA keys.
### Details
The study [[PDF](https://eprint.iacr.org/2023/1711.pdf)] was carried out and written up by Keegan Ryan, Kaiwen He, George Arnold Sullivan, and Nadia Heninger of University of California, San Diego (Kaiwen He is also at MIT.) The technique the team used to discern the private RSA keys stemmed from TLS-smashing [research](https://www.redhat.com/en/blog/factoring-rsa-keys-tls-perfect-forward-secrecy) by Florian Weimer in 2015 as well as work in 2022 by a couple of the San Diego paper authors and other research going back decades to the 1990s.
Infosec guru Thomas Ptacek, who spoke highly of the 2023 study's co-author Nadia Heninger, shared a summary of the RSA key paper [here](https://news.ycombinator.com/item?id=38162996) if you need an easy-to-understand breakdown of the issue. We also owe a hat-tip to ex-*Register* vulture Dan Goodin, who [alerted us](https://arstechnica.com/security/2023/11/hackers-can-steal-ssh-cryptographic-keys-in-new-cutting-edge-attack/) via Ars Technica on Monday to the UC San Diego paper.
Essentially, when a client connects to a vulnerable SSH server, during their negotiations to establish secure and encrypted communications, the server will [generate a digital signature](https://goteleport.com/blog/ssh-handshake-explained/#4-ssh-elliptic-curve-diffie-hellman-reply) for the client to check to ensure it is talking to the server it expects to be talking to.
That signature calculation can be glitched randomly or accidentally, as we described above, in a way that clever algorithms can work out from the bad signature the server's private RSA key, which is used in the signature generation. A countermeasure is to ensure the signature is correct before emitting it to the client; OpenSSL and LibreSSL already do this.
As the paper's authors put in their abstract:
We demonstrate that a passive network attacker can opportunistically obtain private RSA host keys from an SSH server that experiences a naturally arising fault during signature computation.
In prior work, this was not believed to be possible for the SSH protocol because the signature included information like the shared DiffieHellman secret that would not be available to a passive network observer.
We show that for the signature parameters commonly in use for SSH, there is an efficient lattice attack to recover the private key in case of a signature fault.
We provide a security analysis of the SSH, IKEv1, and IKEv2 protocols in this scenario, and use our attack to discover hundreds of compromised keys in the wild from several independently vulnerable implementations.
"A passive adversary can quietly monitor legitimate connections without risking detection until they observe a faulty signature that exposes the private key," the team concluded. "The attacker can then actively and undetectably impersonate the compromised host to intercept sensitive data."
The boffins said they scanned the internet, and scoured previously collected SSH scan data, to measure the prevalence of vulnerable signatures, and claimed their dataset of some 5.2 billion SSH records, covering more than seven years of observations, contained more than 590,000 invalid RSA signatures.
Using their [lattice key recovery](https://crypto.stackexchange.com/questions/31593/lattice-based-attack-on-rsa) technique, the academics said more than 4,900 of those flawed signatures revealed the factorization of the corresponding RSA public key, which they used to derive the private RSA keys to 189 of those public keys.
[Does Windows have a very weak password lurking in its crypto libraries?](https://www.theregister.com/2023/10/26/windows_password/)[ROBOT crypto attack on RSA is back as Marvin arrives](https://www.theregister.com/2023/09/26/robot_marvin_rsa/)[Signal adopts new alphabet jumble to protect chats from quantum computers](https://www.theregister.com/2023/09/20/signal_adopts_new_alphabet_jumble/)[Google Chrome to shield encryption keys from promised quantum computers](https://www.theregister.com/2023/08/12/google_chrome_kem/)
During their research, the authors found four manufacturers whose products were vulnerable to this type of key sleuthing: Cisco, Zyxel, Hillstone Networks, and Mocana. The researchers disclosed the issue to Cisco and Zyxel, and note both vendors "investigated promptly."
Cisco determined that its ASA and FTD software fixed the issue in 2022, and, prior to the paper's publication, "was investigating mitigations" for IOS and IOS XE software.
Meanwhile, Zyxel concluded the flaw only affected its end-of-life firmware, and by that point it had begun using the non-vulnerable OpenSSL, which as we said is immune to this issue. The researchers say they were unsuccessful in attempts to contact Hillstone Networks and Mocana, and instead submitted the issue to the CERT Coordination Center.
An SSH server implementation declaring itself as "SSH-2.0-SSHD" is also said to be vulnerable, and this may be in use by some enterprise-grade Java applications. As the key-deducing technique revolves around PKCSv1.5, DNSSEC that uses PKCSv1.5-RSA signatures may also be at risk.
They also noted that the dataset of signatures in IPsec connections wasn't large enough to conclude whether this protocol is vulnerable to a similar key leak: "Given the rarity of vulnerable signature faults, we are not able to conclude much about IPsec implementations from our data, and believe this question deserves further study." ®
12 |
16,386 | 12-Factor 应用方法论的开源开发者指南 | https://opensource.com/article/21/11/open-source-12-factor-app-methodology | 2023-11-16T12:45:22 | [
"软件开发"
] | /article-16386-1.html | 
>
> 这 12 项基本原则能够帮助团队快速高效地构建高度可扩展的应用程序
>
>
>
[12-Factor 应用方法论](https://www.redhat.com/architect/12-factor-app) 为在短时间内构建应用程序并使其具有可扩展性提供了指导。它由 Heroku 的开发人员创建,用于软件即服务(SaaS)应用程序、网络应用程序以及可能的通信平台即服务(CPaaS)。在有效组织项目和管理可扩展应用程序方面,12 要素应用程序方法论对开源开发具有强大的优势。
### 12-Factor 应用方法论的原则
12-Factor 应用方法论的规则非常严格,也是开发和部署 SaaS 应用程序的基石,并且不受任何编程语言或数据库的限制。
#### 1:一份基准代码,多份部署

每个应用程序都应该有一个具有多个不同环境/部署的代码库。
开发人员不应仅仅为了在不同环境中设置而开发另一个代码库。不同的环境代表不同的状态,但这些不同的环境应该共享同一个代码库。
在许多开源项目都存储在 GitLab 这样的版本控制系统中的情况下,一个环境可以被视为一个分支。例如,你可以在任何中央版本控制系统中为名为 VoIP-app 的云 VoIP 应用程序创建一个单独的存储库,然后创建两个分支:开发分支(`development`)和暂存分支(`staging`),并将主分支(`master`)作为发布分支。
#### 2:明确声明和隔离依赖关系
应声明所有依赖关系。你的应用程序可能会依赖外部系统工具或库,但不应对系统工具或库有任何 *隐含的* 依赖。你的应用程序必须始终明确声明所有依赖关系及其正确版本。
在代码库中包含依赖关系可能会产生问题,特别是在开源项目中,外部库的更改可能会将错误引入代码库。例如,代码库可能会使用一个外部库,但没有明确声明该依赖关系或版本。如果外部库更新到更新的、未经测试的版本,这可能会与你的代码产生兼容性问题。如果明确声明了依赖关系及其正确版本,你的代码库就不会出现这种问题。
根据技术栈的不同,最好使用软件包管理器,通过读取代表依赖库名称和版本的依赖库声明清单,在各自的系统上下载依赖库。
#### 3:在环境中存储配置
当需要支持多个环境或客户端时,配置就成了应用程序的重要组成部分。不同部署之间的配置应存储在环境变量中。这样就可以在部署之间轻松更改配置,而无需更改代码。
对于闭源应用程序来说,这一原则是有益的,因为你不会希望数据库连接信息或其他秘密数据等敏感信息被公开。然而,在开放源代码开发中,这些细节都是公开的。在这种情况下,好处是你不需要反复修改代码。你只需这样设置变量,只需改变环境,就能让代码完美运行。
#### 4:把后端服务当作附加资源
所有后备服务(如数据库、外部存储或消息队列)都被视为附加资源,由执行环境附加或分离。根据这一原则,如果这些服务的位置或连接细节发生变化,仍无需更改代码。这些细节可以在配置中找到。
备份服务可以从部署中快速附加或分离。例如,如果基于云的电子表格的数据库无法正常工作,开发人员应该能够创建一个从最近备份恢复的新数据库服务器,而无需对代码库进行任何更改。
#### 5:严格分离构建和运行
12-Factor 应用方法论要求严格区分构建、发布和运行阶段。
* 第一阶段是 *构建* 阶段。在这一阶段,源代码被组装或编译成可执行文件,同时加载依赖关系并创建资产。每次需要部署新代码时,构建阶段就会开始。
* 第二阶段是 *发布* 阶段。在此阶段,构建阶段生成的代码与部署的当前配置相结合。最终发布的版本包含构建和配置,可在执行环境中立即执行。
* 第三个阶段是 *运行* 阶段,也是最后阶段:应用程序在执行环境中运行。该阶段不应被其他任何阶段打断。
通过严格区分这些阶段,我们可以避免代码中断,使系统维护更加易于管理。
#### 6:以一个或多个无状态进程运行应用
应用程序作为一个或多个进程的集合在执行环境中执行。这些进程是无状态的,其持久化数据存储在数据库等后台服务中。
这对开源非常有用,因为使用某版本应用程序的开发人员可以在其云平台上创建多节点部署,以实现可扩展性。数据不会在其中持久化,因为如果其中任何一个节点崩溃,数据就会丢失。
#### 7:通过端口绑定提供服务
你的应用程序应作为独立的服务,独立于其他应用程序。它它应该能通过URL供其他服务访问,以服务形式存在。这样,你的应用程序就可以在需要时作为其他应用程序的资源。利用这一概念,你可以构建 [REST API](https://opensource.com/article/21/9/ansible-rest-apis)。
#### 8:通过进程模型进行扩展
该原则也称为并发原则,它表明应用程序中的每个进程都应能够自我扩展、重启或克隆。
开发人员可以创建多个进程,并将应用程序的负载分配给这些进程,而不是将一个进程变大。通过这种方法,你可以将每种工作负载分配给一个进程类型,从而构建能处理不同工作负载的应用程序。
#### 9:快速启动和优雅终止以增强健壮性
你的应用应当基于简单的进程构建,因此开发者可以放大进程的同时还能在发生问题时重启它们。这使得应用的进程易于丢弃。
根据这一原则构建应用程序意味着代码的快速部署、快速弹性扩展、更灵活的发布流程以及稳健的生产部署。所有这些在开源开发环境中都非常有用。
#### 10:尽可能的保持开发、预发布、生产环境相同
同一项目的团队应使用相同的操作系统、支持服务和依赖关系。这样可以降低出现错误的可能性,减少开发所需的时间。
由于开源项目的开发人员分散在各地,他们可能无法就所使用的系统、服务和依赖关系进行 [沟通](https://opensource.com/article/21/10/global-communication-open-source) ,因此将这一原则付诸实践对于开源项目来说可能是一个挑战。减少这些差异的一种可能性是制定开发指南,建议使用何种操作系统、服务和依赖关系。
#### 11:把日志当作事件流
日志对于排除生产问题或了解用户行为至关重要。但是,12-Factor 应用方法论并不适合处理日志的管理。
相反,应将日志条目作为事件流,写入标准输出,并将其发送到单独的服务进行分析和存档。机器人流程自动化(RPA)技术可作为处理和分析日志的第三方服务。执行环境将决定如何处理该数据流。这为反省应用程序的行为提供了更大的灵活性和能力。
#### 12:后台管理任务当作一次性进程运行
这一原则实际上与开发无关,而是与应用程序管理有关。管理进程应在与应用程序常规长期运行进程相同的环境中运行。在本地部署中,开发人员可以直接使用应用程序签出目录内的 Shell 命令来执行一次性管理进程。
### 结论
使用 12-Factor 应用方法论开发应用程序,可以提高效率,加快发布速度。在开源开发中,偏离某些指导原则可能是有意义的,但最好还是尽可能严格遵守这些指导原则。
开源的 12-Factor 应用是可能的。一个很好的例子是 [Jitsi](https://jitsi.org/)[, (一个开源视频会议平台)](http://jitsi.org), 在疫情期间扩展了 100 倍的规模,取得了巨大成功,它就是采用 12-Factor 应用方法论构建的。
*(题图:MJ/4bc8b463-49d0-4702-8ad3-6a07a718d5d9)*
---
via: <https://opensource.com/article/21/11/open-source-12-factor-app-methodology>
作者:[Richard Conn](https://opensource.com/users/richardaconn-0) 选题:[lujun9972](https://github.com/lujun9972) 译者:[trisbestever](https://github.com/trisbestever) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,387 | OBS Studio 30.0 发布,增加 AV1 支持 | https://news.itsfoss.com/obs-studio-30/ | 2023-11-17T04:16:00 | [
"OBS"
] | https://linux.cn/article-16387-1.html | 
>
> OBS Studio 30.0 对于 Linux 用户来说是一个重要的版本。
>
>
>
OBS Studio 无疑是 [Linux 上最佳的录屏软件](https://itsfoss.com/best-linux-screen-recorders/) 之一,它深受众多内容创作者的喜爱,他们使用它进行视频录制和流媒体直播。
近日的公告发布了一个**全新的主要版本** —— **OBS Studio 30**,距离今年一月份的 [上一次主要版本](https://news.itsfoss.com/obs-studio-29-release/) 已经近 11 个月。
接下来就让我来一一为你介绍。
### ? OBS Studio 30:新特性有哪些?

作为一个主要版本,OBS Studio 30 带来了一系列引人期待的改进,但是,也有一项变化可能**令部分用户感到不满**。
这个版本的一些**重要亮点**包括:
* 停止对 Ubuntu 20.04 的支持
* 用户界面/体验的提升
* 视频编码能力的提升
#### 停止对 Ubuntu 20.04 的支持
随着 OBS Studio 30 的发布,对 Ubuntu 20.04 的支持不复存在。
做出这个决定的主要原因在于,开发者发现维护 Qt 5 越来越困难,这也相应影响了他们在改进 OBS 用户界面/用户体验方面的工作。
实际上,**Ubuntu 20.04 是唯一一个使用 Qt 5 运行 OBS 的第一方发行版**,开发者表示,相比其他版本,这个发行版的**用户基数已经在逐渐减少**。
这**并非一夜之间的改变**,早在六月份,OBS Studio 就在其 GitHub 仓库中公布了这项改动。
目前,**Ubuntu 20.04 的用户**有两个选择,他们可以选择 [升级到 Ubuntu 22.04](https://itsfoss.com/upgrade-ubuntu-version/) 或更高版本,或者转用 OBS Studio 的 [Flatpak 版本](https://flathub.org/apps/com.obsproject.Studio)。
开发人员还**提到了他们可能会在 2025 年 4 月左右停止对 Qt 6.2 和 Ubuntu 22.04 的支持**。但是,你目前无需对此感到担忧。你可以阅读 [官方公告](https://github.com/obsproject/obs-studio/discussions/9055) 了解详细的计划。
#### 用户界面/体验的提升

“<ruby> 停靠区 <rt> Docks </rt></ruby>”菜单中新增了一项“<ruby> 全高窗口 <rt> Full-Height docks </rt></ruby>”选项,这将方便集成 Twitch 和 YouTube 上直播时所见的长聊天窗口。
同时,**状态栏也进行了重新设计**,以更结构化、有条理的形式展示同样的信息,我个人非常喜欢这种改变。
**老状态栏有些棘手**,在我直播或录制期间,我经常会忘记它的存在 ?

在 OBS Studio 30 中也新增了一个“<ruby> 安全模式 <rt> Safe Mode </rt></ruby>”,这种模式下,应用程序将在不加载任何第三方插件、脚本或 web sockets 的情况下启动,以便**对故障进行排除**。
你可以通过两种方式访问到这个模式,一是当 OBS Studio 断电意外关闭,另一种是在下图所示的“<ruby> 帮助 <rt> Help </rt></ruby>”菜单中手动启动。

#### 视频编码能力的提升
OBS Studio 30 新增了对**三种主要视频编码技术**的支持,分别是 [Intel QSV](https://en.wikipedia.org/wiki/Intel_Quick_Sync_Video) H264,高效视频编码([HEVC](https://en.wikipedia.org/wiki/High_Efficiency_Video_Coding)),以及 [AV1](https://en.wikipedia.org/wiki/AV1)。
许多使用 Linux 的内容创作者会赞赏 OBS 做出的这些改进。
#### ?️ 更多的改变和改进
除上述提及的点外,还有一些其他值得注意的改动:
* 引入了**WHIP/WebRTC 输出**。
* 可通过拖拽**调整过滤器顺序**。
* 提供**YouTube Live 控制室面板**的支持。
* 修复了在记录高帧率视频设备时**出现日志问题**的错误。
* 为 [Decklink](https://www.blackmagicdesign.com/in/products/decklink) 增加了**10 位捕获和 HDR 回放**的支持。
要获得更多关于 OBS Studio 30 的详细信息,你可以查看 [官方发布备注](https://github.com/obsproject/obs-studio/releases/tag/30.0.0)。
### ? 下载 OBS Studio 30
你可以前往 [官方网站](https://obsproject.com/) 下载 OBS Studio 的最新版本,其支持**Linux**,**Windows** 以及 **macOS** 平台。
>
> **[OBS Studio](https://obsproject.com/)**
>
>
>
? 你是否打算试运行一下 OBS Studio 30 然后告诉我们你的体验呢?
---
via: <https://news.itsfoss.com/obs-studio-30/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

OBS Studio is arguably one of the [best screen recorders for Linux](https://itsfoss.com/best-linux-screen-recorders/?ref=news.itsfoss.com), it is a popular choice for many content creators out there who use it for their video recording and streaming needs.
A recent announcement has seen the introduction of **a new major release** in the form of** OBS Studio 30**, this has arrived almost 11 months after its [last major release](https://news.itsfoss.com/obs-studio-29-release/) back in January.
Allow me to take you through this.
**Suggested Read **📖
[10 Best Screen Recorders for Linux in 2023Take a look at the best screen recorders available for Linux. Learn its key features, pros, and cons.](https://itsfoss.com/best-linux-screen-recorders/?ref=news.itsfoss.com)

## 🆕 OBS Studio 30: What's New?
Being a major release, OBS Studio 30 features plenty of improvements to look forward to, but, also has **a change that might not sit well with some users**.
Some **key highlights** of this release include:
**Support Dropped for Ubuntu 20.04****Improved UI/UX****Better Video Coding**
### Support Dropped for Ubuntu 20.04
With the release of OBS Studio 30, Ubuntu 20.04 is no longer supported.
The main reason behind that decision was that** it was becoming more difficult for the developers to maintain Qt 5**, which in turn affected their work on bringing improvements to the UI/UX side of OBS.
And as it turns out, **Ubuntu 20.04 was the only first-party distribution using Qt 5 for OBS**, which, according to the developer, already had **a dwindling user base** in comparison to the other variants.
This is **not a change that happened overnight**, it was already announced back in June on OBS Studio's GitHub repo.
**Users of Ubuntu 20.04** now have two options, either they can [upgrade to Ubuntu 22.04](https://itsfoss.com/upgrade-ubuntu-version/?ref=news.itsfoss.com) or later, or they can switch to using the [Flatpak version](https://flathub.org/apps/com.obsproject.Studio?ref=news.itsfoss.com) of OBS Studio.
The devs have** also revealed that they might plan to drop support for Qt 6.2 and Ubuntu 22.04 around April 2025. **Of course, you have nothing to worry about it for now. You can read [official announcement](https://github.com/obsproject/obs-studio/discussions/9055?ref=news.itsfoss.com) for details regarding the plans.
### Improved UI/UX
A new option was added to the “Docks” menu that enables **Full-Height docks**. This will come in handy for integrating those long chat windows found on Twitch and YouTube while live-streaming.
Even the **status bar was redesigned** for providing the same information, but, in a more organized/structured manner. I like what they have done to it.
The **older status bar was a bit finicky** to refer to, and I would often forget that it even existed while streaming or recording 😆
A new “**Safe Mode**” was also added with OBS Studio 30, this will start up the application without loading any third-party plugins, scripting or web sockets **for troubleshooting purposes**.
There are two ways to access it, one is when OBS Studio shuts down unexpectedly, and the other is manually via the “Help” menu as shown below.
### Better Video Coding
Support for **three major video coding tech** was added with OBS Studio 30. They are **Intel QSV**** H264**, **High Efficiency Video Coding (**, and
**HEVC**)
[.](https://en.wikipedia.org/wiki/AV1?ref=news.itsfoss.com)
**AV1**These additions to OBS will be appreciated by many content creators using Linux.
### 🛠️ Other Changes and Improvements
Other than the above-mentioned, here are some other changes worth noting:
- Introduction of
**WHIP/WebRTC output**. - Ability to
**arrange filters**by dragging and dropping. - Support for
**YouTube Live control room panel**. - Fix for
**an issue with logging**high frame rate video capture devices. - Added support for
**10-bit capture and HDR playback**for[Decklink](https://www.blackmagicdesign.com/in/products/decklink?ref=news.itsfoss.com).
For more details on OBS Studio 30, you may go through the [official release notes](https://github.com/obsproject/obs-studio/releases/tag/30.0.0?ref=news.itsfoss.com).
## 📥 Download OBS Studio 30
You can head over to the [official site](https://obsproject.com/?ref=news.itsfoss.com) to grab the latest release of OBS Studio. It is being offered for **Linux**, **Windows**, and **macOS**.
*💬 Will you be taking OBS Studio 30 for a run? *
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,388 | Blender 4.0 版本发布,引领了渲染升级的新趋势 | https://news.itsfoss.com/blender-4-0-release/ | 2023-11-17T14:54:00 | [
"Blender"
] | https://linux.cn/article-16388-1.html | 
>
> Blender 4.0 的发布使其成为图形设计从业者和艺术家们极度期待的工具。
>
>
>
Blender 是**一款极受欢迎的开源 3D 计算机图形软件套件**,它广泛应用于动画电影制作、动态图形、视觉特效等多个领域。
最近,Blender 基金会公布了**Blender 4.0 的发布**,这一版本“为渲染、创建工具以及更多内容打开了新的可能性,让你的创造自由提升到新的水平。”
接下来,让我们一起探索一下此版本带来的新视野。
### ? Blender 4.0:有哪些新特性?

作为一个重要的版本更新,Blender 4.0 提供了丰富的新功能。然而,我们只针对一些核心的亮点进行介绍:
* 用户界面改进
* 光线与阴影链接
* 改良的 Principled BSDF
* 更优化的人物绑定
在我们详述一些细节之际,下面是一则官方视频,总结了主要的变更事项:
#### 用户界面改进

在 Blender 中,最重要且直接面向用户的部分无疑就是它的界面。界面的字体已经改变为 [Inter](https://rsms.me/inter/),**此举旨在改进应用内的文字可读性**,使它不受显示器大小影响。
此外,用户还可以通过在常规下拉菜单或者右键菜单上按空格键,使用**新增的搜索功能**。同时,一份调整过的启动画面,使得用户在旧版 Blender 中**迁移保存的设置**变得更为简单。

我们在文件菜单中添加了一项新的 “<ruby> 增量保存 <rt> Save Incremental </rt></ruby>”选项。这个选项可以保存当前的 `.blender` 文件,并给文件名添加一个递增的数字。
#### 光线与阴影链接

它被开发团队称为最受期待的功能,Blender 4.0 新增了光线与阴影链接功能。这些功能使设计师可以**设置灯光以影响场景中特定的物体**,甚至可**控制哪些物体可以挡住光源**,充当阴影的遮挡体。
关于这些功能的更多详情,可以参考 [官方文档](https://docs.blender.org/manual/en/4.0/render/cycles/object_settings/light_linking.html)。
#### 改良的 Principled BSDF

Blender 的 [Principled BSDF](https://docs.blender.org/manual/en/4.0/render/shader_nodes/shader/principled.html) 系统在本次更新中进行了大规模的改良,现在此系统提供了**支持更广泛的材料类型,并且工作更加高效**。
改良亮点包括:
* <ruby> 涂层 <rt> Coat </rt></ruby>,这个特性可以模拟例如手机显示屏后的玻璃表面等效果,它被放置在所有的基层之上。
* <ruby> 光泽感 <rt> Sheen </rt></ruby>,现在它使用新的微纤维渲染模型,成为排列在发射和涂层之上的最高层,从而控制表面反光。
* 实现了多散射 GGX 策略,以在 Cycles 渲染器中提高渲染效率,使得**渲染过程中消耗的电力更少**。
* **金属表面的边缘着色**,这项新特性提供了一种装饰金属表面的艺术友好方式。它可以渲染基于 F82 着色模型的复杂折射系数。
以下的插图更好地展示了 Principled BSDF 的改善状况:

#### 绑定优化

Blender 4.0 的特性之一就是为 [Armature](https://docs.blender.org/manual/en/latest/animation/armatures/introduction.html) 骨骼添加了 <ruby> 骨骼集合 <rt> Bone Collections </rt></ruby>。此设定继承了现有对象物体的实现方式。
它**替代了传统的编号层和骨骼组特性**,以吸取组合选择操作符来按骨骼颜色/集合来选择分组,设定 Armature 骨骼的颜色等等。
同时,**姿势库也得到了更新**,新引入的资产架使得姿势资产在 3D 视口中可见。
#### ?️ 更多改进和优化
一些其他值得注意的变化还包括:
* **停止支持英特尔 HD4000 系列的 GPU**。
* 实施了新的 [blendfile 兼容性政策](https://wiki.blender.org/wiki/Process/Compatibility_Handling)。
* **吸附功能得到改善**,变得更快,定位更精准。
* 对于 Linux 和 Windows 用户,现在 **OpenGL 的最小版本要求** 是 4.3。
* **Filmic 已被 AgX 视图转换所替代**,以更好地处理过度曝光区域的颜色。
你还可以参考 [官方发布说明](https://wiki.blender.org/wiki/Reference/Release_Notes/4.0) 来获取更多的更新详情。
### ? 下载 Blender 4.0
你可以从 [官方网站](https://www.blender.org/download/) 下载 Blender 的最新 tar 包,支持 **Linux**、 **Windows**, 和 **macOS**等平台。
当然如果你有特殊需求,你也可以在 [Snap 商店](https://snapcraft.io/blender) 或是 [Steam](https://store.steampowered.com/app/365670/Blender/) 中下载。
>
> **[Blender](https://www.blender.org/download/)**
>
>
>
? 准备好使用 Blender 4.0 开启你的创造之旅了吗?还是你有其他的首选项?欢迎在评论区分享你的想法!
---
via: <https://news.itsfoss.com/blender-4-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Blender is **a very popular open-source 3D computer graphics suite** that has a vast variety of use cases, ranging from the creation of animated films, all the way to motion graphics, visual effects, and more.
With a recent announcement, the Blender Foundation revealed the **Blender 4.0 release**, that represents “a major leap for rendering, creating tools, and more to take your Freedom to Create to new heights.”
So, let's look at what's behind this release.
## 🆕 Blender 4.0: What's New?
Being a major release, Blender 4.0 has plenty to offer. However, we will be only taking a look at some of the key highlights:
**User Interface Improvements****Light and Shadow Linking****Revamped Principled BSDF****Better Rigging**
While we mention some details as you read on, here is the official video to sum up the major changes:
### User Interface Improvements
The most important user-facing thing on Blender, the interface font, has been changed to “[Inter](https://rsms.me/inter/?ref=news.itsfoss.com)”. This **move was made in a bid to improve text readability** across the application, irrespective of the display size.
Then there's the **newly added ability to search** for stuff by pressing the space bar on regular dropdown/context menus, and a tweaked splash screen which now makes it easier to **carry over saved settings** from older Blender installs.
Even a new “**Save Incremental**” option was added to the File menu that saves the current *.blender* file with a numerically incremented name.
### Light and Shadow Linking

Dubbed by the devs as their most awaited feature, Blender 4.0 features Light and Shadow Linking. With these features, a designer could **set lights to affect specific objects** in a scene, and even **have control over which objects can block light**, acting as shadow blockers.
For more details on how these work, you can refer to the [official documentation](https://docs.blender.org/manual/en/4.0/render/cycles/object_settings/light_linking.html?ref=news.itsfoss.com).
### Revamped Principled BSDF
Blender's [Principled BSDF](https://docs.blender.org/manual/en/4.0/render/shader_nodes/shader/principled.html?ref=news.itsfoss.com) system has seen a big revamp with the upgrade, it now features **support for a larger variety of material types and is more efficient**.
Some highlights of the revamp include:
**Coat**, it is placed above all the base layers, including the emission layer, to simulate things like a phone display behind a glass surface.**Sheen**, it now uses a new microfiber shading model, and acts as the top layer above emission and coat.- Implementation of Multiple scattering GGX
**less power being used while rendering**. **Edge tinting for metallic surfaces**, allowing for an artist-friendly way to render complex index of refraction, based on the F82 tint model.
The illustration below should give you a better look at how things are with this revamp of Principled BSDF:
### Better Rigging
Blender 4.0 features a dedicated “**Bone Collections**” for [Armature](https://docs.blender.org/manual/en/latest/animation/armatures/introduction.html?ref=news.itsfoss.com) Bones, this implementation is carried over from the existing implementation for objects.
It **replaces both the legacy numbered layers and bone groups feature**, allowing for the Select Grouped operator to select by bone color/collection, setting bone colors on armature bones, and more.
Even the **pose library sees an update** with the recently introduced asset shelf that makes pose assets available in the 3D viewport.
### 🛠️ Other Changes and Improvements
There's more. Some other noteworthy changes include:
- Support for
**Intel HD4000 series GPUs**has been dropped. - A new
[blendfile compatibility policy](https://wiki.blender.org/wiki/Process/Compatibility_Handling?ref=news.itsfoss.com)has been implemented. **Snapping has been improved**, allowing for faster and more precise snaps.- The
**minimum required OpenGL version**for Linux and Windows is now 4.3. **Filmic has been replaced**by AgX view transform for better handling of colors in over-exposed areas.
You may also refer to the [official release notes](https://wiki.blender.org/wiki/Reference/Release_Notes/4.0?ref=news.itsfoss.com) for more details of this Blender release.
## 📥 Download Blender 4.0
You can get the latest tar package of Blender from the [official website](https://www.blender.org/download/?ref=news.itsfoss.com) for **Linux**, **Windows**, and **macOS**.
But, if you were looking for something different, then you could also get it from the [Snap store](https://snapcraft.io/blender?ref=news.itsfoss.com) and [Steam](https://store.steampowered.com/app/365670/Blender/?ref=news.itsfoss.com).
*💬 Ready to start creating with Blender 4.0? Prefer something else? Let us know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,391 | 使用 dialog 和 jq 在 Linux 上编写高效终端 TUI | https://fedoramagazine.org/writing-useful-terminal-tui-on-linux-with-dialog-and-jq/ | 2023-11-18T07:15:00 | [
"TUI",
"jq",
"dialog"
] | https://linux.cn/article-16391-1.html | 
### 为何选择文字用户界面(TUI)?
许多人每日都在使用终端,因此,<ruby> 文字用户界面 <rt> Text User Interface </rt></ruby>(TUI)逐渐显示出其价值。它能减少用户输入命令时的误差,让终端操作更高效,提高生产力。
以我的个人使用情况为例:我每日会通过家用电脑远程连接到我使用 Linux 系统的实体 PC。所有的远程网络连接都通过私有 VPN 加密保护。然而,当我需要频繁重复输入命令进行连接时,这种经历实在令人烦躁。
于是,我创建了下面这个 Bash 函数,从而有所改进:
```
export REMOTE_RDP_USER="myremoteuser"
function remote_machine() {
/usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_RDP_USER /v:$1 /p:$2
}
```
但后来,我发现自己还是频繁地执行下面这条命令(在一行中):
```
remote_pass=(/bin/cat/.mypassfile) remote_machine $remote_machine $remote_pass
```
这太烦了。更糟糕的是,我的密码被明文存储在我的电脑上(我虽然使用了加密驱动器,但这点依然令人不安)。
因此,我决定投入一些时间,编写一个实用的脚本,从而更好地满足我的基本需求。
#### 我需要哪些信息才能连接到远程桌面?
实际上,要连接到远程桌面,你只需提供少量信息。这些信息需要进行结构化处理,所以一个简单的 JSON 文件就能够满足要求:
```
{"machines": [
{
"name": "machine1.domain.com",
"description": "Personal-PC"
},
{
"name": "machine2.domain.com",
"description": "Virtual-Machine"
}
],
"remote_user": "MYUSER@DOMAIN",
"title" : "MY COMPANY RDP connection"
}
```
尽管在各种配置文件格式中,JSON 并非最佳选择(例如,它不支持注解),但是 Linux 提供了许多工具通过命令行方式解析 JSON 内容。其中,特别值得一提的工具就是 [jq](https://stedolan.github.io/jq/)。下面我要向你展示如何利用它来提取机器列表:
```
/usr/bin/jq --compact-output --raw-output '.machines[]| .name' \
$HOME/.config/scripts/kodegeek_rdp.json) \
"machine1.domain.com" "machine2.domain.com"
```
`jq` 的文档可以在 [这里](https://jqlang.github.io/jq/manual/) 找到。另外,你也可以直接将你的 JSON 文件复制粘贴到 [jq play](https://jqplay.org/),试用你的表达式,然后在你的脚本中使用这些表达式。
既然已经准备好了连接远程计算机所需的所有信息,那现在就让我们来创建一个美观实用的 TUI 吧。
#### Dialog 的帮助
[Dialog](https://invisible-island.net/dialog/) 是那些你可能希望早些认识的、被低评估的 Linux 工具之一。你可以利用它构建出一个井然有序、简介易懂,并且完美适用于你终端的用户界面。
比如,我可以创建一个包含我喜欢的编程语言的简单的复选框列表,且默认选择 Python:
```
dialog --clear --checklist "Favorite programming languages:" 10 30 7\
1 Python on 2 Java off 3 Bash off 4 Perl off 5 Ruby off
```

我们通过这条命令向 `dialog` 下达了几个指令:
* 清除屏幕(所有选项都以 `--` 开头)
* 创建一个带有标题的复选框(第一个位置参数)
* 决定窗口尺寸(高度、宽度和列表高度,共 3 个参数)
* 列表中的每条选项都由一个标签和一个值组成。
惊人的是,仅仅一行代码,就带来了简洁直观和视觉友好的选择列表。
关于 `dialog` 的详细文档,你可以在 [这里](https://invisible-island.net/dialog/#documentation) 阅读。
#### 整合所有元素:使用 Dialog 和 JQ 编写 TUI
我编写了一个 TUI,它使用 `jq` 从我的 JSON 文件中提取配置详细信息,并且使用 `dialog` 来组织流程。每次运行,我都会要求输入密码,并将其保存在一个临时文件中,脚本使用后便会删除这个临时文件。
这个脚本非常基础,但它更安全,也使我能够专注于更重要的任务 ?
那么 [脚本](https://raw.githubusercontent.com/josevnz/scripts/main/kodegeek_rdp.sh) 看起来是怎样的呢?下面是代码:
```
#!/bin/bash
# Author Jose Vicente Nunez
# Do not use this script on a public computer. It is not secure...
# https://invisible-island.net/dialog/
# Below some constants to make it easier to handle Dialog
# return codes
: ${DIALOG_OK=0}
: ${DIALOG_CANCEL=1}
: ${DIALOG_HELP=2}
: ${DIALOG_EXTRA=3}
: ${DIALOG_ITEM_HELP=4}
: ${DIALOG_ESC=255}
# Temporary file to store sensitive data. Use a 'trap' to remove
# at the end of the script or if it gets interrupted
declare tmp_file=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file=/tmp/test$$
trap "/bin/rm -f $tmp_file" QUIT EXIT INT
/bin/chmod go-wrx ${tmp_file} > /dev/null 2>&1
:<<DOC
Extract details like title, remote user and machines using jq from the JSON file
Use a subshell for the machine list
DOC
declare TITLE=$(/usr/bin/jq --compact-output --raw-output '.title' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100
declare REMOTE_USER=$(/usr/bin/jq --compact-output --raw-output '.remote_user' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100
declare MACHINES=$(
declare tmp_file2=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file2=/tmp/test$$
# trap "/bin/rm -f $tmp_file2" 0 1 2 5 15 EXIT INT
declare -a MACHINE_INFO=$(/usr/bin/jq --compact-output --raw-output '.machines[]| join(",")' $HOME/.config/scripts/kodegeek_rdp.json > $tmp_file2)
declare -i i=0
while read line; do
declare machine=$(echo $line| /usr/bin/cut -d',' -f1)
declare desc=$(echo $line| /usr/bin/cut -d',' -f2)
declare toggle=off
if [ $i -eq 0 ]; then
toggle=on
((i=i+1))
fi
echo $machine $desc $toggle
done < $tmp_file2
/bin/cp /dev/null $tmp_file2
) || exit 100
# Create a dialog with a radio list and let the user select the
# remote machine
/usr/bin/dialog \
--clear \
--title "$TITLE" \
--radiolist "Which machine do you want to use?" 20 61 2 \
$MACHINES 2> ${tmp_file}
return_value=$?
# Handle the return codes from the machine selection in the
# previous step
export remote_machine=""
case $return_value in
$DIALOG_OK)
export remote_machine=$(/bin/cat ${tmp_file})
;;
$DIALOG_CANCEL)
echo "Cancel pressed.";;
$DIALOG_HELP)
echo "Help pressed.";;
$DIALOG_EXTRA)
echo "Extra button pressed.";;
$DIALOG_ITEM_HELP)
echo "Item-help button pressed.";;
$DIALOG_ESC)
if test -s $tmp_file ; then
/bin/rm -f $tmp_file
else
echo "ESC pressed."
fi
;;
esac
# No machine selected? No service ...
if [ -z "${remote_machine}" ]; then
/usr/bin/dialog \
--clear \
--title "Error, no machine selected?" --clear "$@" \
--msgbox "No machine was selected!. Will exit now..." 15 30
exit 100
fi
# Send 4 packets to the remote machine. I assume your network
# administration allows ICMP packets
# If there is an error show message box
/bin/ping -c 4 ${remote_machine} >/dev/null 2>&1
if [ $? -ne 0 ]; then
/usr/bin/dialog \
--clear \
--title "VPN issues or machine is off?" --clear "$@" \
--msgbox "Could not ping ${remote_machine}. Time to troubleshoot..." 15 50
exit 100
fi
# Remote machine is visible, ask for credentials and handle user
# choices (like password with a password box)
/bin/rm -f ${tmp_file}
/usr/bin/dialog \
--title "$TITLE" \
--clear \
--insecure \
--passwordbox "Please enter your Windows password for ${remote_machine}\n" 16 51 2> $tmp_file
return_value=$?
case $return_value in
$DIALOG_OK)
# We have all the information, try to connect using RDP protocol
/usr/bin/mkdir -p -v $HOME/logs
/usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_USER /v:${remote_machine} /p:$(/bin/cat ${tmp_file})| \
/usr/bin/tee $HOME/logs/$(/usr/bin/basename $0)-$remote_machine.log
;;
$DIALOG_CANCEL)
echo "Cancel pressed.";;
$DIALOG_HELP)
echo "Help pressed.";;
$DIALOG_EXTRA)
echo "Extra button pressed.";;
$DIALOG_ITEM_HELP)
echo "Item-help button pressed.";;
$DIALOG_ESC)
if test -s $tmp_file ; then
/bin/rm -f $tmp_file
else
echo "ESC pressed."
fi
;;
esac
```

你从代码中可以看出,`dialog` 预期的是位置参数,并且允许你在变量中捕获用户的回应。这实际上使其成为编写文本用户界面的 Bash 扩展。
上述的小例子只涵盖了一些部件的使用,其实还有更多的文档在 [官方 dialog 网站](https://invisible-island.net/dialog/)上。
### Dialog 和 JQ 是最好的选择吗?
实现这个功能可以有很多方法(如 [Textual](https://textual.textualize.io/),Gnome 的 [Zenity](https://gitlab.gnome.org/GNOME/zenity/commits/master?ofs=1900),Python 的 [TKinker](https://docs.python.org/3/library/tkinter.html)等)。我只是想向你展示一种高效的方式——仅用 100 行代码就完成了这项任务。
*确实,它并不完美*。更具体地讲,它与 Bash 的深度集成使得代码有些冗长,但仍然保持了易于调试和维护的特性。相比于反复复制粘贴长长的命令,这无疑是一个更好的选择。
最后,如果你喜欢在 Bash 中使用 `jq` 处理 JSON,那么你会对这个 [jq 配方的精彩集合](https://nntrn.github.io/jq-recipes/) 感兴趣的。
*(题图:MJ/a9b7f60a-02ec-4d3f-88ae-2321f49ac0e1)*
---
via: <https://fedoramagazine.org/writing-useful-terminal-tui-on-linux-with-dialog-and-jq/>
作者:[Jose Nunez](https://fedoramagazine.org/author/josevnz/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Why a Text User Interface?
Many use the terminal on a daily basis. A Text User Interface (TUI) is a tool that will minimize user errors and allow you to become more productive with the terminal interface.
Let me give you an example: I connect on a daily basis from my home computer into my Physical PC, using Linux. All remote networking is protected using a private [VPN](https://en.wikipedia.org/wiki/Virtual_private_network). After a while it was irritating to be repeating the same commands over and over when connecting.
Having a bash function like this was a nice improvement:
export REMOTE_RDP_USER="myremoteuser" function remote_machine() { /usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_RDP_USER /v:$1 /p:$2 }
But then I was constantly doing this (on a single line):
remote_pass=(/bin/cat/.mypassfile) remote_machine $remote_machine $remote_pass
*That was annoying.* Not to mention that I had my password in clear text on my machine (I have an encrypted drive but still…)
So I decided to spend a little time and came up with a nice script to handle my basic needs.
## What information do I need to connect to my remote desktop?
Not much information is needed. It just needs to be structured so a simple JSON file will do:
{"machines": [ { "name": "machine1.domain.com", "description": "Personal-PC" }, { "name": "machine2.domain.com", "description": "Virtual-Machine" } ], "remote_user": "MYUSER@DOMAIN", "title" : "MY COMPANY RDP connection" }
JSON is not the best format for configuration files (as it doesn’t support comments, for example) but it has plenty of tools available on Linux to parse its contents from the command line. A very useful tool that stands out is [ jq](https://stedolan.github.io/jq/). Let me show you how I can extract the list of machines:
/usr/bin/jq --compact-output --raw-output '.machines[]| .name' \ ($HOME/.config/scripts/kodegeek_rdp.json) \ "machine1.domain.com" "machine2.domain.com"
Documentation for *jq* is available [here](https://jqlang.github.io/jq/manual/). You can try your expressions at [jq play](https://jqplay.org/) just by copying and pasting your JSON files there and then use the expression in your scripts.
So now that I have all the ingredients I need to connect to my remote computer, let’s build a nice TUI for it.
## Dialog to the rescue
[Dialog](https://invisible-island.net/dialog/) is one of those underrated Linux tools that you wish you knew about a long time ago. You can build a very nice and simple UI that will work perfectly on your terminal.
For example, to create a simple checkbox list with my favorite languages, selecting Python by default:
dialog --clear --checklist "Favorite programming languages:" 10 30 7 1 \ Python on 2 Java off 3 Bash off 4 Perl off 5 Ruby off

We told dialog a few things:
- Clear the screen (all the options start with –)
- Create a checklist with title (first positional argument)
- A list of dimensions (height width list height, 3 items)
- Then each element of the list is a pair of a Label and a value.
Surprisingly is very concise and intuitive to get a nice selection list with a single line of code.
Full documentation for *dialog* is available [here](https://invisible-island.net/dialog/#documentation).
## Putting everything together: Writing a TUI with Dialog and JQ
I wrote a TUI that uses *jq* to extract my configuration details from my JSON file and organized the flow with *dialog*. I ask for the password every single time and save it in a temporary file which gets removed after the script is done using it.
The script is pretty basic but is more secure and also lets me focus on more serious tasks 🙂
So what does the [script](https://raw.githubusercontent.com/josevnz/scripts/main/kodegeek_rdp.sh) looks like? Let me show you the code:
#!/bin/bash # Author Jose Vicente Nunez # Do not use this script on a public computer. It is not secure... # https://invisible-island.net/dialog/ # Below some constants to make it easier to handle Dialog # return codes : ${DIALOG_OK=0} : ${DIALOG_CANCEL=1} : ${DIALOG_HELP=2} : ${DIALOG_EXTRA=3} : ${DIALOG_ITEM_HELP=4} : ${DIALOG_ESC=255} # Temporary file to store sensitive data. Use a 'trap' to remove # at the end of the script or if it gets interrupted declare tmp_file=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file=/tmp/test$$ trap "/bin/rm -f $tmp_file" QUIT EXIT INT /bin/chmod go-wrx ${tmp_file} > /dev/null 2>&1 :<<DOC Extract details like title, remote user and machines using jq from the JSON file Use a subshell for the machine list DOC declare TITLE=$(/usr/bin/jq --compact-output --raw-output '.title' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100 declare REMOTE_USER=$(/usr/bin/jq --compact-output --raw-output '.remote_user' $HOME/.config/scripts/kodegeek_rdp.json)|| exit 100 declare MACHINES=$( declare tmp_file2=$(/usr/bin/mktemp 2>/dev/null) || declare tmp_file2=/tmp/test$$ # trap "/bin/rm -f $tmp_file2" 0 1 2 5 15 EXIT INT declare -a MACHINE_INFO=$(/usr/bin/jq --compact-output --raw-output '.machines[]| join(",")' $HOME/.config/scripts/kodegeek_rdp.json > $tmp_file2) declare -i i=0 while read line; do declare machine=$(echo $line| /usr/bin/cut -d',' -f1) declare desc=$(echo $line| /usr/bin/cut -d',' -f2) declare toggle=off if [ $i -eq 0 ]; then toggle=on ((i=i+1)) fi echo $machine $desc $toggle done < $tmp_file2 /bin/cp /dev/null $tmp_file2 ) || exit 100 # Create a dialog with a radio list and let the user select the # remote machine /usr/bin/dialog \ --clear \ --title "$TITLE" \ --radiolist "Which machine do you want to use?" 20 61 2 \ $MACHINES 2> ${tmp_file} return_value=$? # Handle the return codes from the machine selection in the # previous step export remote_machine="" case $return_value in $DIALOG_OK) export remote_machine=$(/bin/cat ${tmp_file}) ;; $DIALOG_CANCEL) echo "Cancel pressed.";; $DIALOG_HELP) echo "Help pressed.";; $DIALOG_EXTRA) echo "Extra button pressed.";; $DIALOG_ITEM_HELP) echo "Item-help button pressed.";; $DIALOG_ESC) if test -s $tmp_file ; then /bin/rm -f $tmp_file else echo "ESC pressed." fi ;; esac # No machine selected? No service ... if [ -z "${remote_machine}" ]; then /usr/bin/dialog \ --clear \ --title "Error, no machine selected?" --clear "$@" \ --msgbox "No machine was selected!. Will exit now..." 15 30 exit 100 fi # Send 4 packets to the remote machine. I assume your network # administration allows ICMP packets # If there is an error show message box /bin/ping -c 4 ${remote_machine} >/dev/null 2>&1 if [ $? -ne 0 ]; then /usr/bin/dialog \ --clear \ --title "VPN issues or machine is off?" --clear "$@" \ --msgbox "Could not ping ${remote_machine}. Time to troubleshoot..." 15 50 exit 100 fi # Remote machine is visible, ask for credentials and handle user # choices (like password with a password box) /bin/rm -f ${tmp_file} /usr/bin/dialog \ --title "$TITLE" \ --clear \ --insecure \ --passwordbox "Please enter your Windows password for ${remote_machine}\n" 16 51 2> $tmp_file return_value=$? case $return_value in $DIALOG_OK) # We have all the information, try to connect using RDP protocol /usr/bin/mkdir -p -v $HOME/logs /usr/bin/xfreerdp /cert-ignore /sound:sys:alsa /f /u:$REMOTE_USER /v:${remote_machine} /p:$(/bin/cat ${tmp_file})| \ /usr/bin/tee $HOME/logs/$(/usr/bin/basename $0)-$remote_machine.log ;; $DIALOG_CANCEL) echo "Cancel pressed.";; $DIALOG_HELP) echo "Help pressed.";; $DIALOG_EXTRA) echo "Extra button pressed.";; $DIALOG_ITEM_HELP) echo "Item-help button pressed.";; $DIALOG_ESC) if test -s $tmp_file ; then /bin/rm -f $tmp_file else echo "ESC pressed." fi ;; esac

You can see from the code that *dialog* expects positional arguments and also allows you to capture user responses in variables. This effectively makes it an extension to Bash to write text user interfaces.
My small example above only covers the usage of some of the Widgets, there is plenty more documentation on the [official dialog site](https://invisible-island.net/dialog/).
## Are dialog and JQ the best options?
You can skin this rabbit in many ways ([Textual](https://textual.textualize.io/), Gnome [Zenity](https://gitlab.gnome.org/GNOME/zenity/commits/master?ofs=1900), Python [TKinker](https://docs.python.org/3/library/tkinter.html), etc.) I just wanted to show you one nice way to accomplish this in a short time, with only 100 lines of code.
*It is not perfect*. Specficially, integration with Bash makes the code very verbose, but it is still easy to debug and maintain. This is also much better than copying and pasting the same long command over and over.
One last thing: If you liked *jq* for JSON processing from Bash, then you will appreciate this [nice collection of jq recipes](https://nntrn.github.io/jq-recipes/).
## Greater Productivity
NICE!
## Thomas
I have similar functions in my .bashrc to handle connections to different aws accounts, connect to different machines using a different tool called
(https://github.com/tmonjalo/choose) that is itself made of just 377 lines of bash.
## james
It looks great, and I will definitely investigate Dialog. I am using gtkdialog for other purposes currently, and the version I am using, whilst great, is a bit dated.
But where you say:
‘But then I was constantly doing this (on a single line):’
Could you not use an alias? Or two, one for each machine? And use openssl or similar to encrypt your password?
Just a thought. If I were going to adopt a bash script like the one above, I might write it in a process agnostic manner, so that it could handle any json file, with perhaps a schema file processed to address the json needing to be displayed in dialog. Save reinventing the wheel, so to speak…
## Jose Nunez
Hi, glad that you liked the small article. I don’t want to make it agnostic, only to work with RDP . An alias for every machine sounds great if you have 2 machines, when you have 10, well not so great. Also the TUI allows me to make changes on the password if I make a typo.
## John
For temp credentials in a txt file, I “>” to it while the script needs it. I end my routine using “wipe” on said txt file to ensure total clean up. Even if it takes a bit for the script to exit which in the case of a simple text file it only takes seconds.
## Jose Nunez
That works too, great idea. I mention on the article than my disk has encryption so it felt over-killing to add this there.
## xenlo
Typo detected!
%s/I connect on a daily basics/I connect on a daily basis/g
😋
## Richard England
TY, corrected.
## Jose Nunez
Thanks for the correction!
## Bryan
The idea of a TUI isn’t bad in itself, but in the year 2023 you should probably consider not allowing services using a password on the Internet. Even if you are capable of generating good passwords, average humans aren’t.
Try doing something like this instead:
https://swjm.blog/the-complete-guide-to-rdp-with-yubikeys-fido2-cba-1bfc50f39b43
## Jose Nunez
Hello Bryan, thanks for the link.
Your link focuses mostly on Windows, the readers may want to take a look at this:
https://fedoramagazine.org/fido2-for-centrally-managed-users/
And guess what, you still need to type a pin to use it, so there is still justification to write a small TUI wrapper around it 🙂
## Andrew L. Moore
Fedora Magazine isn’t the venue to report code bugs, but I think this one’s worth flagging: the statement
declare foo=$(false) || echo failed
does not report “failed” as one might expect. That’s because `declare’ only fails if it’s given an invalid option or if the variable assignment fails – not if the statement fails. The correct way to write this is:
declare foo=”
foo=$(false) || echo failed
It’s also generally a good idea to wrap code in functions and then call the functions at the end of the script. Happy hacking 🙂
## Jose Nunez
Hello Andrew,
You are correct, declaration of variables and testing should be separate to avoid the issue you mention above. Or something like:
if ! foo=$(false); then
echo false
fi
Or even:
set -x # Stop everything after the first error.
## tertol
I need to try this dialog. This will add an extra help my bash. Thanks for the info
## wololo
jq is one of the finest pieces of software I know.
Not a fan of dialog, just a shell script and it shows. |
16,393 | 全新的 Linux 电子书阅读器 Foliate 3.0 发布 | https://news.itsfoss.com/foliate-3-0/ | 2023-11-18T11:37:43 | [
"Foliate",
"电子书"
] | https://linux.cn/article-16393-1.html | 
>
> 引入了 GTK 4 ,并优化了 UI。
>
>
>
Foliate 作为 [Linux 上最佳的电子书阅读器](https://itsfoss.com/best-ebook-readers-linux/) 之一,在过去几年中发展得相当不错,按时接收更新和错误修复。
然而,因为它的底层技术有些过时,使其近来显得有些老旧。但随着 **Foliate 3.0** 的发布,情况已经有所改变。
让我们详细了解一下这些改进。
### ? Foliate 3.0:新增了什么?

在 3.0 版本中,**Foliate 进行了彻底的重构**,采用了 [GTK 4](https://blog.gtk.org/2020/12/16/gtk-4-0/)、[Adwaita](https://gnome.pages.gitlab.gnome.org/libadwaita/) 等现代平台库。开发者预示,我们可以期待一个焕然一新的界面和比以前更出色的性能。
现在,Foliate 开始**使用自己的电子书解析器/渲染器**,并抛弃了 [Epub.js](https://github.com/futurepress/epub.js) 和 [KindleUnpack](https://github.com/kevinhendricks/KindleUnpack)。遗憾的是,他们在 3.0 发布时**并未及时移植某些功能**,因此这个版本**并未支持 [OPDS](https://en.wikipedia.org/wiki/Open_Publication_Distribution_System) 目录和离线字典**。
说到这次发布的一些亮点,其中包括:
* 用户界面全新升级
* 更佳的渲染质量
* 优化的用户体验
#### 用户界面全新升级

如你所见,Foliate 的主要变化在于其用户界面。它现在采用了**全新的布局**,把图书库和电子书阅读器都整合到一个窗口中。
还有一个**新的侧边栏**,在这里你可以找到一些重要的功能,如目录、注释和书签。

在顶部,你可以看到**一个方便的搜索栏**,让你可以在书中搜索特定的词或句子,同时有一个“<ruby> 图书库 <rt> Library </rt></ruby>”按钮可以帮助你回到你的电子书库。
>
> ? 你可以用标题栏中的选项来切换侧边栏的可见性。
>
>
>
此外,分页模式也进行了重大的改进。
它们增加了**动画和 1:1 触屏/触摸板滑动手势的支持**,**支持超过两列**,优化了调整性能,此外,你还可以**配置最大的宽度和高度**等等。
#### 更佳的渲染
在书籍渲染方面,也进行了许多改进,其中一些重要的包括:
* 如果一个网页不是有效的 XHTML,那它会被当作 HTML 处理。
* Mobipocket 文件现在被优化为多个部分以显著提升性能。
* 当一个文件被重新加载时,它现在会正确的重新加载,而不只是重新渲染。
* 不再直接将整个文件加载至内存,因此启动时间和内存使用得以优化。
#### 优化的用户体验

除了用户界面的优化,Foliate 3.0 还引入了一些**非常酷的用户体验改进**。
比如书签系统,添加书签的按钮被移至标题栏,并且被添加书签的页面会在顶部显示特殊的标记。
图像查看器也有所更新,如今当图片被复制时,它们将以其原始格式进行保存。此外,只需双击图片就能打开,其它选项已被删除。
进度滑块同样得到了优化,现在可以支持键盘和鼠标滚轮操作。在那里你还能找到更新了的配音功能,现在使用 [Speech Dispatcher](https://wiki.archlinux.org/title/Speech_dispatcher) 作为其后端。
#### ?️ 其他的改动和优化
这次改进还包含了一些其他方面,值得注意的包括:
* 现在你可以打印特定的章节和文本选段。
* 把实验性质的传统标题栏选项移除了。
* 注解现在会随着各自的时间戳保存下来。
* 一个安全修复,禁用了对 Flatpak 的沙盒逃逸权限。
你可以浏览 [官方发布公告](https://github.com/johnfactotum/foliate/releases/tag/3.0.0) 获取更多信息。
### ? 如何获取 Foliate
这个全新的 Foliate 版本已经在 [Flathub 商店](https://flathub.org/apps/com.github.johnfactotum.Foliate) 和 [Snap 商店](https://snapcraft.io/foliate)(目前只提供开发者版本)上架。
>
> **[Foliate (Flathub)](https://flathub.org/apps/com.github.johnfactotum.Foliate)**
>
>
>
你还可以通过访问 [官方网站](https://johnfactotum.github.io/foliate/) 或 [GitHub 仓库](https://github.com/johnfactotum/foliate) 来获取源代码。
### 故障排除提示
如果 **Foliate 不能正常加载 EPUB 文件**,而你**正在使用英伟达显卡**,那么你可以设置以下任一环境变量来启动应用:
```
WEBKIT_DISABLE_COMPOSITING_MODE=1
```
```
WEBKIT_DISABLE_DMABUF_RENDERER=1
```
如果你已经安装了 **Foliate 的 Flatpak 版本**,只需使用 [Flatseal](https://itsfoss.com/flatseal/) 添加相同的环境变量即可。对我来说,第二个命令奏效了。
你可以查阅相关的 [GitHub 议题](https://github.com/johnfactotum/foliate/issues/1093) 进行进一步的故障排除。
*(题图:MJ/647e01ba-def8-43f3-b21a-94b2a54ee5c6)*
---
via: <https://news.itsfoss.com/foliate-3-0/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Being one of the [best eBook readers for Linux](https://itsfoss.com/best-ebook-readers-linux/?ref=news.itsfoss.com), Foliate has been progressing rather nicely over the years, receiving timely updates and bug fixes.
However, it was looking a bit aged in recent times thanks to it featuring some old tech underneath. But, that has since changed with the release of **Foliate 3.0**.
Let's see what kind of improvements are on offer.
## 🆕 Foliate 3.0: What's New?
With the 3.0 release, **Foliate has been completely rewritten** by using the modern platform libraries like [GTK 4](https://blog.gtk.org/2020/12/16/gtk-4-0/?ref=news.itsfoss.com) and [Adwaita](https://gnome.pages.gitlab.gnome.org/libadwaita/?ref=news.itsfoss.com). The developers have mentioned to expect a refreshed interface and superior performance than before.
Foliate now** uses its own eBook parser/render**, doing away with [Epub.js](https://github.com/futurepress/epub.js?ref=news.itsfoss.com) and [KindleUnpack](https://github.com/kevinhendricks/KindleUnpack?ref=news.itsfoss.com). Sadly, they were **unable to port a few features in time** for the 3.0 release, so this version **doesn't have support for **.
**OPDS**catalogs and offline dictionaries
As for the **key highlights** of this release:
**Revamped User Interface****Better Rendering****Improved User Experience**
### Revamped User Interface
As you can see, the most significant change to Foliate has been its user interface. It now features **a new layout** where the Library and e-book viewer have been integrated into a single window.
You will also notice that there is **a new sidebar** that features some important options such as the table of contents, annotations, and bookmarks.
There is also **a handy search bar** at the top that allows you to search for specific words or sentences in a book, and a “Library” button to take you back to your library of e-books.
Furthermore, the **paginated mode also sees some major improvements**.
They have added **support for animation and 1:1 touchscreen/touchpad swipe gestures**, **support for more than two columns**, **better resizing behavior**, the **ability to configure the max width/height** and more.
### Better Rendering
There have been many improvements on the book rendering side of things too, some key ones include:
- If a page is not a valid XHTML one, it will be treated as HTML.
- Mobipocket files are now divided into sections to greatly improve performance.
- When a file is reloaded, it is now properly reloaded, rather than just being re-rendered.
- Startup time and memory usage has been optimized by not loading the entire file into memory.
### Improved User Experience

Besides the user interface upgrades, there have been some **really cool user experience tweaks** with Foliate 3.0.
Take for instance the **bookmarking system**, the button for bookmarking pages has been moved to the header bar, and bookmarked pages now show a distinct ribbon at the top.
The **image viewer** has also seen some updates, now when images are copied, they are stored in their original file format. Moreover, to open images, you simply double-click on them, the other options have been removed.
The **progress slider has also been improved**, with it now supporting keyboards and mouse scrolls. You will also find the **updated narration functionality** there, which now uses [Speech Dispatcher](https://wiki.archlinux.org/title/Speech_dispatcher?ref=news.itsfoss.com) at its back end.
### 🛠️ Other Changes and Improvements
As for the rest of the refinements, here are some worth noting:
- You can now print specific chapters and text selections.
- An experimental traditional title bar option was removed.
- Annotations are now saved with their respective timestamps.
- A security fix that has removed the sandbox escape permission for Flatpak.
You may go through the [official release notes](https://github.com/johnfactotum/foliate/releases/tag/3.0.0?ref=news.itsfoss.com) to learn more.
## 📥 Get Foliate
This revamped version of Foliate is available via the [Flathub store](https://flathub.org/apps/com.github.johnfactotum.Foliate?ref=news.itsfoss.com) and the [Snap store](https://snapcraft.io/foliate?ref=news.itsfoss.com) (edge channel only, for now).
You can also visit the [official website](https://johnfactotum.github.io/foliate/?ref=news.itsfoss.com) or the [GitHub repo](https://github.com/johnfactotum/foliate?ref=news.itsfoss.com) for the source code.
### Troubleshooting Tip
If **Foliate refuses to load EPUB files** properly, and you are **using an NVIDIA GPU**, then you can run the app using either of the following commands:
`WEBKIT_DISABLE_COMPOSITING_MODE=1`
`WEBKIT_DISABLE_DMABUF_RENDERER=1`
If you have the **Flatpak version of Foliate** installed, just add the same line to the environment variables by using [Flatseal](https://itsfoss.com/flatseal/?ref=news.itsfoss.com). For me, the second command did the job.
You can refer to the [GitHub issue](https://github.com/johnfactotum/foliate/issues/1093?ref=news.itsfoss.com) in question for further troubleshooting.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,394 | 在 Ubuntu 上安装最新版的 Calibre | https://itsfoss.com/install-calibre-ubuntu/ | 2023-11-18T12:03:00 | [
"电子书",
"Calibre"
] | https://linux.cn/article-16394-1.html | 
>
> Calibre 是一款自由开源的电子书软件。下面介绍如何在 Ubuntu Linux 上安装它。
>
>
>
作为电子书管理的瑞士军刀,Calibre 一直备受书籍爱好者和数字书虫们的喜爱。
虽然存在更好(更轻量级)的 [电子书阅读器](https://itsfoss.com/best-ebook-readers-linux/),但 Calibre 在创建电子书、转换格式以及管理你的电子书库方面做得更出色。简言之,它是满足你所有电子书需求的全套解决方案。
在本教程中,我将会涉及:
* 从 Ubuntu 的仓库安装 Calibre(简单易行,但可能不是最新版本)
* 使用官方二进制文件安装 Calibre(稍微复杂些,但能获取最新版本)
### 方法1:从 Ubuntu 的仓库安装 Calibre
该方法简单易用,但可能无法获得最新的 Calibre 版本。但大多数情况下,这并不会造成问题。
Ubuntu 的 universe 仓库中提供了 Calibre 的稳定版本。此仓库在大多数系统中默认已启用,因此你只需在软件中心搜索即可,或者使用以下命令进行安装:
```
sudo apt install calibre
```

安装完成后,在系统菜单中找到它,然后启动。
#### 卸载 Calibre
如果你不再需要它,可以使用下面的命令卸载 Calibre:
```
sudo apt remove calibre
```
### 方法2:获取最新版本的 Calibre
[Calibre 官方](https://calibre-ebook.com/download_linux) 推荐安装提供的官方二进制文件。目的是防止用户使用存在错误或已过时的软件包。该二进制文件包含了所有私有版本的依赖项,支持 32 位和 64 位的机器。
首先,我们需要检查系统上是否已经安装了必要的依赖项:
```
apt -qq list xdg-utils wget xz-utils python3
```

如果上述包出现缺失的情况,就将它们安装上。
然后,复制并粘贴下列命令到终端里,按回车键以进行安装或升级:
```
sudo -v && wget -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin
```

**可能的问题处理** :如果你看到一个关于证书不受信任的错误,这表示你的电脑没有安装任何根证书,所以不能安全地下载安装程序。如果你仍然想要继续,向 `wget` 输入命令 `--no-check-certificate`,就像下面的命令一样:
```
sudo -v && wget --no-check-certificate -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin
```
#### 卸载 Calibre
如果你按照上述二进制安装法安装了 Calibre,你可以通过运行 `sudo calibre-uninstall` 来卸载 Calibre。或者,直接删除安装文件夹,这样就可以删除 99% 的安装文件。

### 结语
在一个数字阅读日渐普及的世界,这款开源软件证明了由社区驱动创新的强大影响。无论你是一名资深的电子书爱好者,还是正在初探数字阅读的世界,Calibre 都有你需要的东西。
尽管有 [详细的文档资源](https://calibre-ebook.com/help),我们还提供了一个简单教程 [指导你在 Calibre 中创建电子书](/article-7977-1.html)。
>
> **[完整指南:在 Linux 上使用 Calibre 创建电子书](/article-7977-1.html)**
>
>
>
*在 Ubuntu 中体验 Calibre 吧。*
*(题图:MJ/b63e15a1-1a1c-4ae3-b6c7-40b4537cb567)*
---
via: <https://itsfoss.com/install-calibre-ubuntu/>
作者:[Ishaan Bhimwal](https://itsfoss.com/author/community/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Calibre, the Swiss Army knife of e-book management, has long been a beloved tool for bibliophiles and digital bookworms alike.
While there are better (lighter) [e-Book readers](https://itsfoss.com/best-ebook-readers-linux/), Calibre is a lot better at creating eBooks, converting their format and managing your eBook library. Basically, it's a complete solution for all your eBook needs.
In this tutorial, I'll discuss:
- Installing Calibre from Ubuntu's repository (easy but may not be the latest version)
- Installing Calibre using official binaries (slightly complicated but gives you the latest version)
## Method 1: Installing Calibre from Ubuntu's repositories
This method is easy to use but it may not give you the latest Calibre version. Which should be fine in most cases.
A stable version of Calibre is available from Ubuntu's universe repository. This repository is usually already enabled on most systems so all you have to do is to look for it in the software center or use the following command to install it:
`sudo apt install calibre`
Once installed, look for it in the system menu and start from there.
### Removing Calibre
If you do not want to use it anymore, you can remove Calibre using the command below:
`sudo apt remove calibre`
## Method 2: Get the latest Calibre version
[Calibre recommends](https://calibre-ebook.com/download_linux) installing the official binary provided. This is to prevent users from using buggy/outdated packages. It includes private versions of all its dependencies. It supports 32-bit and 64-bit machines.
First, let's check if you have the required dependencies installed on our system:
`apt -qq list xdg-utils wget xz-utils python3`
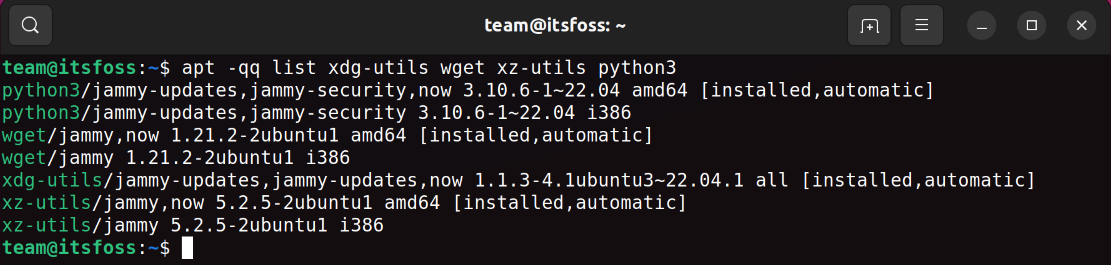
If any of the above package is missing, install them.
Now, to install or upgrade, simply copy and paste the following command into a terminal and press Enter:
`sudo -v && wget -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin`
**Possible Troubleshooting**: If you get an error about an untrusted certificate, that means your computer does not have any root certificates installed and so cannot download the installer securely. If you still want to proceed, pass the `--no-check-certificate`
option to `wget`
, like the command below:
`sudo -v && wget --no-check-certificate -nv -O- https://download.calibre-ebook.com/linux-installer.sh | sudo sh /dev/stdin`
### Removing Calibre
If you followed the above binary installation method, you can uninstall Calibre by running `sudo calibre-uninstall`
. Alternately, simply deleting the installation folder will remove 99% of the installed files.
## Conclusion
In a world where digital reading is becoming increasingly prevalent, this open-source software stands as a testament to the power of community-driven innovation. Whether you're a seasoned e-book enthusiast or just dipping your toes into the world of digital literature, Calibre has something to offer to you.
While there is [extensive documentation available](https://calibre-ebook.com/help), we have a simple one that [teaches you to create an eBook in Calibre](https://itsfoss.com/create-ebook-calibre-linux/).
[How to Create an Ebook With Calibre in LinuxComplete beginner’s guide to easily create an eBook in Linux with open source software Calibre.](https://itsfoss.com/create-ebook-calibre-linux/)

*Enjoy Calibre on Ubuntu.*
Written by Ishaan Bhimwal and edited by Abhishek Prakash. |
16,396 | 以太网已经 50 岁了,斩获 IEEE 里程碑称号 | https://spectrum.ieee.org/ethernet-ieee-milestone | 2023-11-19T09:44:00 | [
"局域网",
"以太网"
] | https://linux.cn/article-16396-1.html | 
>
> 这项技术已经成为全球标准的局域网。
>
>
>
美国加利福尼亚州的[施乐](https://www.xerox.com/en-us)<ruby> <a href="https://spectrum.ieee.org/xerox-parc"> 帕洛阿尔托研究中心 </a> <rt> Palo Alto Research Center </rt></ruby>(PARC)创新无数,诞生了诸如 <ruby> <a href="https://spectrum.ieee.org/xerox-alto"> 阿尔托计算机 </a> <rt> Alto Computer </rt></ruby>(最早采用图形用户界面的个人电脑)及首台激光打印机等多项开创性计算机技术。
同时,PARC 也因发明 <ruby> <a href="https://ethw.org/Ethernet"> 以太网 </a> <rt> Ethernet </rt></ruby> 技术而闻名,这项技术允许高速数据通过同轴电缆进行传输。以太网已经成为全球标准的有线局域网,并在企业和家庭中得到广泛应用。值得一提的是,以太网在诞生五十年后的今年,它被授予了 <ruby> <a href="https://ieeemilestones.ethw.org/Milestone-Proposal:Ethernet_Local_Area_Network_(LAN),_1973-1985"> IEEE 里程碑 </a> <rt> IEEE Milestone </rt></ruby> 称号。
### 连接 PARC 的 Alto 计算机
以太网的开发始于 1973 年。当时,[Charles P. Thacker](https://amturing.acm.org/award_winners/thacker_1336106.cfm) 在设计阿尔托计算机,他设想了一个网络,能让阿尔托计算机与激光打印机、PARC 的 [ARPANET](https://ethw.org/ARPANET) 网关,以及其他阿尔托计算机进行通信。于是,PARC 的研究员、IEEE 会士 [Robert M. Metcalfe](https://ethw.org/Robert_M._Metcalfe) 接下了这项技术挑战。不久后,计算机科学家 [David Boggs](https://ethw.org/David_Boggs) 也加入到了 Metcalfe 的团队中。
对 Metcalfe 和 Boggs 来说,他们有两个目标:一是网络必须足够快,以支持他们的激光打印机;二是网络必须能在同一栋建筑内连接数百台计算机。
以太网的设计灵感来源于 [夏威夷大学](https://www.hawaii.edu/) 的 <ruby> <a href="https://spectrum.ieee.org/alohanet-introduced-random-access-protocols-to-the-computing-world"> 加入链路在线夏威夷地区网络 </a> <rt> Additive Links On-line Hawaii Area network </rt></ruby>(ALOHAnet),这是一种基于无线电的系统。计算机一旦有信息需要发送,就会立即通过一个共享通道进行传输,这个数据包的前栏会注明接收者的地址。若两个信息包发生冲突,发送的计算机会暂停一段随机的时间间隔后重试。
Metcalfe 在一封现在已 [广为人知的备忘录](https://ieeemilestones.ethw.org/w/images/a/af/Ref1_PARC_Ethernet_Memo_1973.pdf) 中,向同事们提出了他的提案,早期的时候它被称为“<ruby> 阿尔托 Aloha 网络 <rt> Alto Aloha Network </rt></ruby>”。他提出,使用同轴电缆而不是无线电波可以让数据传输更快,并减少干扰。电缆的使用也意味着,用户可以在不关闭整个系统的情况下,随时加入或退出网络。Metcalfe 在 2004 年接受 <ruby> <a href="https://www.ieee.org/about/history-center/"> IEEE 历史中心 </a> <rt> IEEE History Center </rt></ruby> 的 [口述历史](https://ethw.org/Oral-History:Robert_Metcalfe) 访谈时如是说。
Metcalfe 说:“有一种名为有线电视 <ruby> 压接器 <rt> tap </rt></ruby> 的设备,可以在不割断同轴电缆的情况下,接入电缆信号。因此,[Boggs 和我]选择了同轴电缆作为我们的通信手段。在这封备忘录之中,我描述了以太网的运作原理——它是非常分布式的,没有中心控制,只是一个单一的‘<ruby> 以太 <rt> Ether </rt></ruby>’片段。”
1973 年,Metcalfe 和 Boggs 设计了今日我们所说的以太网的最初版本。它最初的传输速率达到了 2.94 Mbps,“速度足够快,可以供给激光打印机,而且容易通过同轴电缆发送,”Metcalfe 对 IEEE 历史中心说。
一根粗细为 9.5 毫米、质地坚硬的同轴电缆被铺设在 PARC 大楼的走廊中央。这条长达 500 米的电缆上,通过所谓的 “<ruby> 吸血鬼压接 <rt> Vampire Tap </rt></ruby>”(即 <ruby> N 连接器 <rt> N connector </rt></ruby>)连接了 100 个收发信节点。这些压接有一个坚硬外壳,它们通过两个类似探针的器件“咬”穿电缆的外绝缘体,接触到了电缆的铜芯。这么一来,在不影响现有连接活跃状态的情况下,就可以增加新的节点。
每个 “吸血鬼压接” 内部都装配了一个 D 型连接器插口,由配对的九个插脚和九个插槽的插头插座组成。这些插座使得阿尔托算机、打印机以及文件服务器能连接到网络上。
为了让这些设备进行交流,Metcalfe 和 Boggs 创建了最早的高速<ruby> 网络接口卡 <rt> network interface card </rt></ruby>(NIC) —— 这是一块插在计算机主板上的电路板。它包含了现在我们所说的以太网端口。
为了让人们更加清楚地理解,这个系统可以支持任何电脑,研究人员将最初的名字,“<ruby> 阿尔托 Aloha 网络 <rt> Alto Aloha Network </rt></ruby>”,更改为了 “<ruby> 以太网 <rt> Ethernet </rt></ruby>”。这个新名字反映了 Thacker 早期的一种观点,他说,同轴电缆其实就是“被困的以太”。PARC 的研究员 [Alan Kay](https://amturing.acm.org/award_winners/kay_3972189.cfm) 曾 [回忆](https://spectrum.ieee.org/xerox-parc) 起这一点。
Metcalfe、Boggs、Thacker 以及 [Butler W. Lampson](https://amturing.acm.org/award_winners/lampson_1142421.cfm) 在 1978 年因他们的发明获得了美国专利。
他们继续完善这项技术,并终于在 1980 年,PARC 推出了速度为 10 Mb/s 的以太网。根据这份 IEEE 里程碑奖项的描述,这一更新是与英特尔和 <ruby> <a href="https://en.wikipedia.org/wiki/Digital_Equipment_Corporation"> 数字设备公司 </a> <rt> Digital Equipment Corp. </rt></ruby>(DEC)的研究员共同进行的,旨在为全行业创造出一种通用的以太网版本。
### 接纳为 IEEE 标准
以太网自 1980 年开始商业化后,其快速地演化成为整个行业的局域网标准。为了向计算机公司提供相关技术的框架,[IEEE 802 局域网标准委员会](https://grouper.ieee.org/groups/802/es-ecsg/) 在 1983 年 6 月将以太网正式定为标准。
目前,[IEEE 802](https://www.ieee802.org/#:~:text=The%20IEEE%20802%20LAN%2FMAN,them%20on%20a%20global%20basis.) 系列已经包含了 67 项已发布的标准,并且还有 49 个项目正在进行中。该委员会和全球各地的标准机构合作,将部分 IEEE 802 标准发布为国际指导准则。
在 PARC 设施外,有一块表彰这项技术的铭牌。其内容如下:
>
> 以太网有线局域网起源于 1973 年的施乐帕洛阿尔托研究中心 (PARC),其灵感源自于 ALOHAnet 数据包无线电网络和 ARPANET。施乐、DEC 和英特尔在 1980 年一起发布了一项针对通过同轴电缆的 10 Mbps 以太网的规范,这就成为了 IEEE 802.3-1985 标准。随后该标准进行了增强,提供了更高的速度,支持双绞线、光纤和无线媒介后,以太网在全球的家庭、商业、工业和学术环境中几乎无处不在。
>
>
>
由 IEEE 历史中心管理并得到 [捐赠者支持](https://www.ieeefoundation.org/donate_history) 的 IEEE 里程碑项目,专门表彰全球各地的杰出技术进步。
[IEEE 圣塔克拉拉谷分部](https://ieeescv.org/) 赞助了这项提名。该捐赠仪式将于 5 月 18 日在 PARC 设施举行。
*(题图:MJ/55dfc9c2-7aaa-447b-9897-8dbb49cdfbcf)*
---
via: <https://spectrum.ieee.org/ethernet-ieee-milestone>
作者:[JOANNA GOODRICH](https://spectrum.ieee.org/u/joanna-goodrich) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | The [Xerox](https://www.xerox.com/en-us) [Palo Alto Research Center](https://spectrum.ieee.org/xerox-parc) in California has spawned many pioneering computer technologies including the [Alto](https://spectrum.ieee.org/xerox-alto)—the first personal computer to use a graphical user interface—and the first laser printer.
The PARC facility also is known for the invention of [Ethernet](https://ethw.org/Ethernet), a networking technology that allows high-speed data transmission over coaxial cables. Ethernet has become the standard wired local area network around the world, and it is widely used in businesses and homes. It was honored this year as an [IEEE Milestone](https://ieeemilestones.ethw.org/Milestone-Proposal:Ethernet_Local_Area_Network_(LAN),_1973-1985), a half century after it was born.
## Connecting PARC’s Alto computers
Ethernet’s development began in 1973, when [Charles P. Thacker](https://amturing.acm.org/award_winners/thacker_1336106.cfm)—who was working on the design of the Alto computer—envisioned a network that would allow Altos to communicate with each other, as well as with laser printers and with PARC’s gateway to the [ARPANET](https://ethw.org/ARPANET). PARC researcher [Robert M. Metcalfe](https://ethw.org/Robert_M._Metcalfe), an IEEE Fellow, took on the challenge of creating the technology. Metcalfe soon was joined by computer scientist [David Boggs](https://ethw.org/David_Boggs).
Metcalfe and Boggs had two criteria: The network had to be fast enough to support their laser printer, and it had to connect hundreds of computers within the same building.
The Ethernet design was inspired by the [Additive Links On-line Hawaii Area network](https://spectrum.ieee.org/alohanet-introduced-random-access-protocols-to-the-computing-world) (ALOHAnet), a radio-based system at the [University of Hawai’i](https://www.hawaii.edu/). Computers transmitted packets, prefaced by the addresses of the recipients, over a shared channel as soon as they had information to send. If two messages collided, the computers that had sent them would wait a random interval and try again.
Metcalfe outlined his proposal, then called the Alto Aloha Network, in a [now-famous memo](https://ieeemilestones.ethw.org/w/images/a/af/Ref1_PARC_Ethernet_Memo_1973.pdf) to his colleagues. Using coaxial cables rather than radio waves would allow faster transmission of data and limit interference. The cables also meant that users could join or exit the network without having to shut off the entire system, Metcalfe said in a 2004 [oral history](https://ethw.org/Oral-History:Robert_Metcalfe) conducted by the [IEEE History Center](https://www.ieee.org/about/history-center/).
“There was something called a cable television tap, which allows one to tap into a coax without cutting it,” Metcalfe said. “Therefore, [Boggs and I] chose coax as our means of communication. In [the] memo, I described the principles of operation—very distributed, no central control, a single piece of ‘ether.’”
Metcalfe and Boggs designed the first version of what is now known as Ethernet in 1973. It sent data at up to 2.94 megabits per second and was “fast enough to feed the laser printer and easy to send through the coax,” Metcalfe told the IEEE History Center.
A 9.5-millimeter thick and stiff coaxial cable was laid in the middle of a hall in the PARC building. The 500-meter cable had 100 transceiver nodes attached to it with N connectors, known as vampire taps. Each of the taps—small boxes with a hard shell—had two probes that “bit” through the cable’s outer insulation to contact its copper core. Thus new nodes could be added while existing connections were live.
Each vampire tap had a D-type connector socket in it, consisting of a plug with nine pins that matched to a socket with nine jacks. The sockets allowed Alto computers, printers, and file servers to attach to the network.
To enable the devices to communicate, Metcalfe and Boggs created the first high-speed network interface card (NIC)—a circuit board that is connected to a computer’s motherboard. It included what is now known as an Ethernet port.
The researchers changed the name from the original Alto Aloha Network to Ethernet to make it clearer that the system could support any computer. It reflected a comment Thacker had made early on, that “coaxial cable is nothing but captive ether,” PARC researcher [Alan Kay](https://amturing.acm.org/award_winners/kay_3972189.cfm) [recalled](https://spectrum.ieee.org/xerox-parc).
Metcalfe, Boggs, Thacker, and [Butler W. Lampson](https://amturing.acm.org/award_winners/lampson_1142421.cfm) were granted a U.S. patent in 1978 for their invention.
They continued to develop the technology and, in 1980, PARC released Ethernet that ran at 10 Mb/s. The update was done in collaboration with researchers at [Intel](https://www.intel.com/content/www/us/en/homepage.html) and the [Digital Equipment Corp.](https://en.wikipedia.org/wiki/Digital_Equipment_Corporation) (DEC) to create a version of Ethernet for broad industry use, according to the Milestone entry.
## Becoming an IEEE standard
Ethernet became commercially available in 1980 and quickly grew into the industry LAN standard. To provide computer companies with a framework for the technology, in June 1983 Ethernet was adopted as a standard by the [IEEE 802 Local Area Network Standards Committee](https://grouper.ieee.org/groups/802/es-ecsg/).
Currently, the [IEEE 802](https://www.ieee802.org/#:~:text=The%20IEEE%20802%20LAN%2FMAN,them%20on%20a%20global%20basis.) family consists of 67 published standards, with 49 projects under development. The committee works with standards agencies worldwide to publish certain IEEE 802 standards as international guidelines.
A plaque recognizing the technology will be displayed outside the PARC facility. It will read:
*Ethernet wired LAN was invented at Xerox Palo Alto Research Center (PARC) in 1973, inspired by the ALOHAnet packet radio network and the ARPANET. In 1980 Xerox, DEC, and Intel published a specification for 10 Mbps Ethernet over coaxial cable that became the IEEE 802.3-1985 Standard. Later augmented for higher speeds, and twisted-pair, optical, and wireless media, Ethernet became ubiquitous in home, commercial, industrial, and academic settings worldwide.*
Administered by the IEEE History Center and [supported by donors](https://www.ieeefoundation.org/donate_history), the Milestone program recognizes outstanding technical developments around the world.
[IEEE Santa Clara Valley Section](https://ieeescv.org/)sponsored the nomination. The dedication ceremony is scheduled for 18 May at the PARC facility.
[The Pioneer Behind Electromagnetism ›](https://spectrum.ieee.org/the-pioneer-behind-electromagnetism)[50 Years Later, We’re Still Living in the Xerox Alto’s World ›](https://spectrum.ieee.org/xerox-alto)[Xerox Parc’s Engineers on How They Invented the Future ›](https://spectrum.ieee.org/xerox-parc)[35 Years Ago, Researchers Used Brain Waves to Control a Robot - IEEE Spectrum ›](https://spectrum.ieee.org/brain-waves-control-a-robot)[How Engineers at Digital Equipment Corp. Saved Ethernet - IEEE Spectrum ›](https://spectrum.ieee.org/how-dec-engineers-saved-ethernet)[50 Years Later, This Apollo-Era Antenna Still Talks to Voyager 2 - IEEE Spectrum ›](https://spectrum.ieee.org/apollo-era-antenna-voyager-2)
[Joanna Goodrich](https://spectrum.ieee.org/u/joanna-goodrich)
[Joanna Goodrich](https://twitter.com/theamarnamove) is the associate editor of *The Institute*, covering the work and accomplishments of IEEE members and IEEE and technology-related events. She has a master's degree in health communications from Rutgers University, in New Brunswick, N.J. |
16,397 | Vojtux:针对视力障碍用户改造 Linux | https://opensource.com/article/22/9/linux-visually-impaired-users | 2023-11-19T21:31:00 | [
"视障",
"Vojtux",
"可访问性"
] | https://linux.cn/article-16397-1.html | 
>
> Vojtux 是 Fedora 项目的一部分,它是一款专门为视力障碍者打造的非官方 Linux 发行版。
>
>
>
我五岁时,父亲给我们带来了第一台电脑。那一刻,我就明确了自己的职业追求:计算机领域。从那时起,我就一直和电脑打交道。在高中阶段,我开始尝试黑客活动,以决定自己专注于何种领域,最终我选择了安全工程师作为我的职业。
如今,我已经在红帽的安全合规团队任职软件工程师两年多了,我在捷克进行远程工作。我已经使用 Linux 12 年了,主要是 Arch Linux 和 Fedora,然而我过去也管理过 Debian、Gentoo 和 Ubuntu。

*图片说明:这是一张黑白的笑脸 Vojtech 图片,图中有一个红色边框,背景是一架纸飞机。*
工作之余,我玩盲人足球,我还参与了许多项目,这些项目都是为了帮助视力障碍者和视力正常人群建立联系。包括我还在一个为视力障碍者举办活动的小型非政府组织(NGO)工作。我还在开发一个叫做 [Vojtux](https://github.com/vojtapolasek/Fegora) 的 Fedora 项目,这也是一个专门为视力障碍者打造的非官方 Linux 发行版。
### 辅助技术栈
我在使用智能设备时,需要依赖多种辅助技术,其中最主要的一款叫做屏幕阅读器。它是一款能将屏幕上的内容通过语音或盲文传达给视力障碍者的软件(简单来说,它就像我们的眼睛)。它能读并通知我当前正在关注的按钮或页面元素是什么,使得我能够与图形用户界面进行互动。
屏幕阅读器使用语音合成技术,将屏幕上的内容声音化。市面上有众多的语音合成器,有些听起来比别的更自然。我使用的是 Espeak,它听起来没有那么自然,但是它很轻便,运行也很快。此外,它几乎支持所有的语言,包括我正在使用的捷克语。
最后,我使用了一台能以盲文显示一行文字的盲文显示器,尤其在我写代码或者做代码审查的时候,我离不开它。通过触觉自由地从一个代码元素转移到另一个元素,使我能更轻松地把握代码的结构。我还可以使用它的按钮将光标移至我感兴趣的字符或屏幕区域,如果我想的话,我还能使用上面的盲文键盘输入。
### 我在日常生活中如何应用辅助技术
作为一个视障人士在使用电脑时,有许多事情其实可以借助上述技术轻松完成。以下是我日常经常做的一些事情:
* 我十分喜欢使用文本控制台。一般来说,只要是文字信息,盲人就可以借助屏幕阅读器进行阅读(虽然并非所有情况都适用,但在大多数情况下是可行的)。我通常用控制台进行系统管理、文本编辑以及查阅指导手册和文档。
* 我喜欢浏览网络并与网页进行互动。
* 我使用 VSCode 和 [Eclipse](https://opensource.com/article/20/12/eclipse) 进行代码编写以及代码审查工作。
* 我会发送电子邮件以及进行即时通讯。
* 我可以使用诸如谷歌文档(虽非开源,但在现代办公环境中广为使用)和 [LibreOffice](https://opensource.com/article/22/2/libreoffice-accessibility) 这样的文本处理软件。谷歌文档的开发团队加入了许多键盘快捷键,我可以利用它们在文档中浏览、跳转到标题或者注释里等等。
* 通常来说,我能够播放多媒体内容,但这也取决于应用程序的开发方式,有些媒体播放器在这方面做得更好。
### 可行,但困扰重重
随着技术的进步,一些任务尽管是可行的,但完成起来却相当困难,我称这类任务为“可行,但困扰重重”。
处理 PDF 文件非常艰难。有时,我不得不采用光学字符识别(OCR)软件将图像转换为文本。例如,我最近需要阅读一份餐厅菜单,他们在他们的网站上提供 PDF 菜单,但它已经被压平,丧失了文字层。在我这里,这显示为一片空白屏幕。我只能通过在智能手机上使用 OCR 应用程序来帮我提取文本。这不仅需要额外的步骤,而且提取的文本翻译并不总是完全准确。
查看和创建演示文稿也可能困难重重。为了解决这个问题,我采用像 [Pandoc](https://opensource.com/article/18/9/intro-pandoc) 这样的软件用 HTML 创建幻灯片,它可以处理 [Markdown](https://opensource.com/article/19/9/introduction-markdown) 并将其转换成幻灯片。我已经使用这种方法好几年了,效果很好。它允许我完全掌控生成的幻灯片,因为 Markdown 就是简单的文本。
通过将其基于声音或文字,可以使视频游戏更易于接入。然而,在 Linux 上玩游戏可以是一大挑战,不仅需要找到能够进行无障碍访问的游戏,而且由于大多数 PC 游戏原生支持 Windows,因此还需要处理一些兼容性问题。
有些网站和界面比其他的难以导航。往往只需要通过正确设置一些属性,这些问题就可以很容易地得到解决。一般来说,大量的网页内容都以图像的形式存在。提高网页内容可访问性的一个快速有效的方法就是确保图像都添加了替代文本,使得屏幕阅读器可以读出来,让无法辨识图像的人们也能了解图像内容。还有另一种经常遇到的情况是遇到没有标签的控件:你知道那里有一个按钮或复选框,但你无法确定它具体的功能。
### Vojtux 项目:为了更好的 Linux 可访问性
开发者并不是特意设计出无障碍访问困难的应用程序,问题在于他们通常不清楚如何测试可访问性。由于视障 Linux 用户数量有限,可访问性的测试和反馈往往不足。因此,开发者往往不能生产易于访问的应用,用户也相应较少。这样形成了一个恶性循环。
Vojtux 项目就是希望能处理这个问题。我们希望能建立一个对视障用户更友好的 Fedora 改造版本。我们的目标是吸引更多用户,并鼓励他们发现并报告问题,以便开源社区的开发者可以解决这些问题。
你可能会问为什么要做这个项目?我们需要明确的是,Fedora 在设计上并非就没有可访问性,实际上,它有许多作为包的形式存在的辅助工具。但这些工具不是从一开始就存在,且需要许多细小的配置才能顺利使用,这可能会让初次使用 Fedora 的用户感到困惑。
我们期望 Vojtux 对视障用户而言尽可能友好和可预知。当用户启动立付镜像时,只需出现图形用户界面,屏幕阅读就会立即开始。所有必要的可访问性 [环境变量](https://opensource.com/article/19/8/what-are-environment-variables) 将会被正确地加载和配置。
Vojtux 还实现了以下功能,例如:
* 配置开机就能使用的辅助性环境变量。
* 图形界面一加载,Orca 屏幕阅读器就会启动。
* 添加了自定义库,该库包含额外的语音合成和打包软件。
* 添加了许多替代键盘快捷键。
* 还有一个特别的脚本可以控制显示器的开关。很多用户根本不需要显示器,关闭它则是一种极好的节能方式!
### 想要帮忙?这就需要你了
首先,如果你希望为 Vojtux 做贡献(或只是帮助传播),可以在我们的 [项目库](https://github.com/vojtapolasek/Fegora) 查找更多信息。
此外,在团队中与视障人士协作时,可能需要考虑应用哪些无障碍技术。例如,因为我们都是通过声音获取信息,所以我们很难同时进行听说和阅读,除非有人非常熟练于使用盲文显示器。
最后,要记住,无论是演示幻灯片、网站还是 PDF,盲人和视障用户都与你使用相同的最终产品。当你开发产品或创作内容时,你的选择对我们能否有效地进行互动和访问有着巨大的影响。知道我们在这里,我们热爱使用计算机和科技,并且我们经常愿意帮助你进行测试。

*图片说明:手持足球的 Vojtech,他身穿足球服,戴着防护眼镜。*
本文作者最初于 2022 年 9 月发布文章,并在后续将项目的官方名称更新为 Vojtux。
*(题图:MJ/06477e84-6119-45d0-8085-5936a607ee68)*
---
via: <https://opensource.com/article/22/9/linux-visually-impaired-users>
作者:[Vojtech Polasek](https://opensource.com/users/vpolasek) 选题:[lkxed](https://github.com/lkxed) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I was around 5 years old, my father brought home our first computer. From that moment on, I knew I wanted to pursue a career in computers. I haven't stopped hanging around them since. During high school, when considering which specific area I wanted to focus on, I started experimenting with hacking, and that was the moment I decided to pursue a career as a security engineer.
I'm now a software engineer on the security compliance team. I've been at Red Hat for over two years, and I work remotely in the Czech Republic. I've used Linux for about 12 years, mainly Arch Linux and Fedora, but I've also administered Debian, Gentoo, and Ubuntu in the past.

(Vojtech Polasek, CC BY-SA 4.0)
Photo description: Black and white image of a smiling Vojtech, with a red frame around it and an illustrated paper airplane in the background.
Outside of my day job, I play blind football, and I'm involved in various projects connecting visually impaired and sighted people together, including working in a small NGO that runs activities for blind and visually impaired people. I'm also working on an accessible Fedora project called [Vojtux](https://github.com/vojtapolasek/Fegora), an unofficial Linux distribution aimed at visually impaired users.
## The assistive technology stack
When I use a smart device, I need several pieces of assistive technology. The first and most essential is called a *screen reader*. This is software that presents what's on the screen to blind or visually impaired people, either through speech or through braille (basically, it tries to serve as our eyes). It can read out notifications and tell me which button or page element I'm focusing on, allowing me to interact with graphical user interfaces.
Screen readers use speech synthesis to speak aloud what appears on the screen. There are a variety of speech synthesizers, and some voices are more "natural-sounding" than others. The one I use, Espeak, is not very natural-sounding, but it's lightweight and fast. It also supports almost all languages, including Czech (which I use).
Finally, I use a Braille display, a device that represents a line of text in Braille. I use this a lot, especially when I'm coding or doing code reviews. It's easier to grasp the structure of code when I can freely move from one code element to another by touch. I can also use its buttons to move the cursor to the character or area of the screen I'm interested in, and it has a Braille keyboard too if I want to use it.
## How I use assistive technology on a daily basis
When using a computer as a blind or visually impaired person, there are a couple of things that are relatively straightforward to do using the tech above. Personally, these are a few of the things I do every day:
- The text console is pretty much my favorite application. As a general rule, when something's in text, then blind people can read it with a screen reader (this doesn't hold true in all cases, but in most.) I mainly use the console for system management, text editing, and working with guidance and documentation.
- I browse the web and interact with websites.
- I code and do code reviews using VSCode and
[Eclipse](https://opensource.com/article/20/12/eclipse). - I send emails and instant messages.
- I can use word processing software, like Google Docs (which is not open source, but common in the modern office) and
[LibreOffice](https://opensource.com/article/22/2/libreoffice-accessibility). Google Docs developers have added a lot of keyboard shortcuts, which I can use to move around documents, jump to headings or into comments, and so on. - I can play multimedia, usually. It depends on how the application is written. Some media players are more accessible than others.
## Possible but painful
This brings me to tasks that aren't so easy. I like to call these "possible but painful".
PDF files can be difficult. Sometimes I end up needing to use optical character recognition (OCR) software to convert images to text. For example, recently I needed to read a menu for a restaurant. They had the PDF of their menu on their website, but it had been flattened, and didn't have a text layer. For me, this shows up as a blank screen. I had to use an OCR application from my smartphone to extract the text for me. Not only is this an extra step, but the resulting "translation" of the text isn't always entirely accurate.
Viewing and creating a presentation can be problematic. To work around this, I create slides in HTML, using software such as [Pandoc](https://opensource.com/article/18/9/intro-pandoc), which can process [markdown](https://opensource.com/article/19/9/introduction-markdown) and convert it into slides. I've been using this for many years and it works well—it allows me total control of the resulting slides, because the markdown is just simple text.
Video games can be made more accessible by basing them on sound or text. However, playing games can be doubly challenging on Linux as not only would you need to find an accessible game, but most PC games are also native to Windows so you would be dealing with some compatibility issues as well.
Some websites and interfaces are more difficult to navigate than others. These issues are often quite easy to solve just by setting some attributes correctly. In general, lots of web content comes in the form of images, especially today. One of the easiest ways to make web content more accessible is to make sure that alternative text is added to images so that screen readers can read it out, and people who cannot distinguish the image have some idea what's there. Another thing I experience a lot is unlabeled controls: you know there's a button or a check box but you don't know what it does.
## The Vojtux project optimises Linux for accessibility
Developers don't intentionally set out to build applications that aren't accessible. The problem is that they usually don't know how to test them. There aren't many blind Linux users, so there aren't many people testing the accessibility of applications and providing feedback. Therefore, developers don't produce accessible applications, and they don't get many users. And so the cycle continues.
This is one thing we hope to tackle with the Vojtux project. We want to create a Fedora remix that's user-friendly for visually impaired and blind users. We hope it will attract more users, and that those users start discovering issues to report, which will hopefully be solved by other developers in the open source community.
So why are we doing this? Well, it's important to point out that Fedora is not an *inaccessible* distribution by design. It does have many accessibility tools available in the form of packages. But these aren't always present from the beginning, and there are a lot of small things which need to be configured before it can be proficiently used. This is something that can be discouraging to a beginner Fedora user.
We want Vojtux to be as friendly and predictable for a blind user as possible. When a user launches a live image, the screen immediately starts being read as soon as a graphical user interface appears. All [environment variables](https://opensource.com/article/19/8/what-are-environment-variables) needed for accessibility are loaded and configured correctly.
Vojtux brings the following changes, among others:
- Environment variables for accessibility are configured from the start.
- The Orca screen reader starts as soon as the graphical interface loads.
- A custom repo is added with extra voice synthesis and packaged software.
- Many alternative keyboard shortcuts have been added.
- There's a special script that can turn your monitor on and off. Many users do not need the monitor at all and having it off is a great power saver!
## So how can you help?
First, if you'd like to contribute to Vojtux (or just spread the word), you can find out more on [our repository](https://github.com/vojtapolasek/Fegora).
Additionally, when working on a team with someone who has a visual impairment, there might be some additional considerations depending on the accessibility tech being used. For example, it's not easy for us to listen to someone and read at the same time, because we are basically getting both things through audio, unless someone is very proficient with the Braille display.
Lastly, bear in mind that blind and visually impaired users consume the same end products as you do, whether that's presentation slides or websites or PDFs. When building products or creating content, your choices have a huge effect on accessibility and how easy it is for us to engage with the end result. Know that we are here, we love to use computers and technology, and we're often willing to help you test it, too.

(Vojtech Polasek, CC BY-SA 4.0)
Image description: Vojtech holding a football. He is wearing a football uniform and protective goggles.
*This article originally published in September 2022 and has since been updated with the project's official name, Vojtux.*
## 3 Comments |
16,399 | 人工智能教程(二):人工智能的历史以及再探矩阵 | https://www.opensourceforu.com/2022/06/ai-some-history-and-a-lot-more-about-matrices/ | 2023-11-20T15:04:00 | [
"AI"
] | https://linux.cn/article-16399-1.html | 
*在本系列的 [第一篇文章](/article-16326-1.html) 中,我们讨论了人工智能、机器学习、深度学习、数据科学等领域的关联和区别。我们还就整个系列将使用的编程语言、工具等做出了一些艰难的选择。最后,我们还介绍了一点矩阵的知识。在本文中,我们将深入地讨论人工智能的核心——矩阵。不过在此之前,我们先来了解一下人工智能的历史。*
我们为什么需要了解人工智能的历史呢?历史上曾出现过多次人工智能热潮,但在很多情况下,对人工智能潜力的巨大期望都未能达成。了解人工智能的历史,有助于让我们看清这次人工智浪潮是会创造奇迹,抑或只是另一个即将破灭的泡沫。
我们对人工智能的最寻起源于何时呢?是在发明数字计算机之后吗?还是更早呢?我相信对一个无所不知的存在的追求可以追溯到文明之初。比如古希腊神话中的 <ruby> 德尔菲 <rt> Delphi </rt></ruby> 就是这样一位能回答任何问题的先知。从远古时代起,对于超越人类智慧的创造性机器的探索同样吸引着我们 。历史上有过几次制造国际象棋机器的失败的尝试。其中就有臭名昭著的<ruby> 机械特克 <rt> Mechanical Turk </rt></ruby>,它并不是真正的机器人,而是由一位藏在内部的棋手操控的。<ruby> 约翰·纳皮尔 <rt> John Napier </rt></ruby> 发明的对数、<ruby> 布莱斯·帕斯卡 <rt> Blaise Pascal </rt></ruby> 的计算器、<ruby> 查尔斯·巴贝奇 <rt> Charles Babbage </rt></ruby> 的差分机等,这些都是人工智能研究的前身。回顾人类历史,你会发现更多真实或虚构的时刻,人们想要获得超越人脑的智能。如果不考虑以上这些历史成就,对真正人工智能的探索起始于数字计算机的发明。
那么,人工智能发展至今有哪些里程碑呢?前面已经提到,数字计算机的发明是人工智能研究历程中最重要的事件。与可扩展性依赖于功率需求的机电设备不同,数字设备受益于技术进步,比如从真空管到晶体管到集成电路再到如今的超大规模集成技术。
人工智能发展的另一个里程碑是 <ruby> 阿兰·图灵 <rt> Alan Turing </rt></ruby> 首次对人工智能的理论分析。他提出的 <ruby> 图灵测试 <rt> Turing test </rt></ruby> 是最早的人工智能测试方法之一。现在图灵测试可能已经不太适用了,但它是定义人工智能的最初尝试之一。图灵测试可以简单描述如下:假设有一台能够与人类对话的机器,如果它能在对话中让人无法分辨它是人还是机器,那么就可以认为这台机器具有智能。如今的聊天机器人非常强大,使我们很容易看出图灵测试无法识别出真正的人工智能。但在 20 世纪 50 年代初,这确实为理解人工智能提供了一个理论框架。
20 世纪 50 年代末,<ruby> 约翰·麦卡锡 <rt> John McCarthy </rt></ruby> 发明了 Lisp 编程语言。它是最早的高级编程语言之一。在此之前,计算机编程用的是机器语言和汇编语言(众所周知地难用)。有了强大的机器和编程语言,计算机科学家中的乐观主义和梦想家顺理成章地开始用它们来创造人工智能。20 世纪 60 年代初,对人工智能机器的期望达到了顶峰。当然计算机科学领域取得了很大发展,但人工智能的奇迹发生了吗?很遗憾,并没有。20 世纪 60 年代见证了第一次人工智能热潮的兴起和破灭。然而计算机科学以无与伦比的速度继续发展着。
到了 70 年代和 80 年代,算法在这一时期发挥了主要作用。在这段时间,许多新的高效算法被提出。20 世纪 60 年代末<ruby> 高德纳·克努特 <rt> Donald Knuth </rt></ruby>(我强烈建议你了解一下他,在计算机科学界,他相当于数学界的高斯或欧拉)著名的《<ruby> 计算机程序设计艺术 <rt> The Art of Computer Programming </rt></ruby>》第一卷的出版标志着算法时代的开始。在这些年中,开发了许多通用算法和图算法。此外,基于人工神经网络的编程也在此时兴起。尽管早在 20 世纪 40 年代,<ruby> 沃伦·S.·麦卡洛克 <rt> Warren S. McCulloch </rt></ruby>和<ruby> 沃尔特·皮茨 <rt> Walter Pitts </rt></ruby> 就率先提出了人工神经网络,但直到几十年后它才成为主流技术。今天,深度学习几乎完全是基于人工神经网络的。算法领域的这种发展导致了 20 世纪 80 年代人工智能研究的复苏。然而,这一次,通信和算力的限制阻碍了人工智能的发展,使其未能达到人们野心勃勃的预期。然后是 90 年代、千禧年,直到今天。又一次,我们对人工智能的积极影响充满了热情和希望。
我你们可以看到,在数字时代,人工智能至少有两次前景光明的机会。但这两次人工智能都没有达到它的预期。现在的人工智能浪潮也与此类似吗?当然这个问题很难回答。但我个人认为,这一次人工智能将产生巨大的影响(LCTT 译注:本文发表于 2022 年 6 月,半年后,ChatGPT 才推出)。是什么让我做出这样的预测呢?第一,现在的高性能计算设备价格低廉且容易获得。在 20 世纪 60 年代或 80 年代,只有几台如此强大的计算设备,而现在我们有数百万甚至数十亿台这样的机器。第二,现在有大量数据可用来训练人工智能和机器学习程序。想象一下,90 年代从事数字图像处理的人工智能工程师,能有多少数字图像来训练算法呢?也许是几千或者几万张吧。现在单单数据科学平台 Kaggle(谷歌的子公司)就拥有超过 1 万个数据集。互联网上每天产生的大量数据使训练算法变得容易得多。第三,高速的互联网连接使得与大型机构协作变得更加容易。21 世纪的头 10 年,计算机科学家之间的合作还很困难。如今互联网的速度已经使谷歌 Colab、Kaggle、Project jupiter 等人工智能项目的协作成为现实。由于这三个因素,我相信这一次人工智能将永远存在,并会出现许多优秀的应用。
### 更多矩阵的知识

在大致了解了人工智能的历史后,现在是时候回到矩阵与向量这一主题上了。在上一篇文章中,我已经对它们做了简要介绍。这一次,我们将更深入矩阵的世界。首先看图 1 和 图 2,其中显示了从 A 到 H 共 8 个矩阵。为什么人工智能和机器学习教程中需要这么多矩阵呢?首先,正如前一篇文章中提到的,矩阵是线性代数的核心,而线性代数即使不是机器学习的大脑,也是机器学习的核心。其次,在接下来的讨论中,它们每一个都有特定的用途。

让我们看看矩阵是如何表示的,以及如何获取它们的详细信息。图 3 展示了怎么用 NumPy 表示矩阵 A。虽然矩阵和数组并不完全等价,但实践中我们经常将它们作为同义词来使用。

我强烈建议你仔细学习如何使用 NumPy 的 `array` 函数创建矩阵。虽然 NumPy 也提供了 `matrix` 函数来创建二维数组和矩阵。但是它将在未来被废弃,所以不再建议使用了。在图 3 还显示了矩阵 A 的一些详细信息。`A.size` 告诉我们数组中元素的个数。在我们的例子中,它是 9。代码 `A.ndim` 表示数组的 <ruby> 维数 <rt> dimension </rt></ruby>。很容易看出矩阵 A 是二维的。`A.shape` 表示矩阵 A 的<ruby> 阶数 <rt> order </rt></ruby>,矩阵的阶数是矩阵的行数和列数。虽然我不会进一步解释,但使用 NumPy 库时需要注意矩阵的大小、维度和阶数。图 4 显示了为什么应该仔细识别矩阵的大小、维数和阶数。定义数组时的微小差异可能导致其大小、维数和阶数的不同。因此,程序员在定义矩阵时应该格外注意这些细节。

现在我们来做一些基本的矩阵运算。图 5 显示了如何将矩阵 A 和 B 相加。NumPy 提供了两种方法将矩阵相加,`add` 函数和 `+` 运算符。请注意,只有阶数相同的矩阵才能相加。例如,两个 4 × 3 矩阵可以相加,而一个 3 × 4 矩阵和一个 2 × 3 矩阵不能相加。然而,由于编程不同于数学,NumPy 在实际上并不遵循这一规则。图 5 还展示了将矩阵 A 和 D 相加。记住,这种矩阵加法在数学上是非法的。一种叫做 <ruby> 广播 <rt> broadcasting </rt></ruby> 的机制决定了不同阶数的矩阵应该如何相加。我们现在不会讨论广播的细节,但如果你熟悉 C 或 C++,可以暂时将其理解为变量的类型转换。因此,如果你想确保执行正真数学意义上的矩阵加法,需要保证以下测试为真:

```
A.shape == B.shape
```
广播机制也不是万能的,如果你尝试把矩阵 D 和 H 相加,会产生一个运算错误。
当然除了矩阵加法外还有其它矩阵运算。图 6 展示了矩阵减法和矩阵乘法。它们同样有两种形式,矩阵减法可以由 `subtract` 函数或减法运算符 `-` 来实现,矩阵乘法可以由 `matmul` 函数或矩阵乘法运算符 `@` 来实现。图 6 还展示了 <ruby> 逐元素乘法 <rt> element-wise multiplication </rt></ruby> 运算符 `*` 的使用。请注意,只有 NumPy 的 `matmul` 函数和 `@` 运算符执行的是数学意义上的矩阵乘法。在处理矩阵时要小心使用 `*` 运算符。

对于一个 m x n 阶和一个 p x q 阶的矩阵,当且仅当 n 等于 p 时它们才可以相乘,相乘的结果是一个 m x q 阶矩的阵。图 7 显示了更多矩阵相乘的示例。注意 `E@A` 是可行的,而 `A@E` 会导致错误。请仔细阅读对比 `D@G` 和 `G@D` 的示例。使用 `shape` 属性,确定这 8 个矩阵中哪些可以相乘。虽然根据严格的数学定义,矩阵是二维的,但我们将要处理更高维的数组。作为例子,下面的代码创建一个名为 T 的三维数组。

```
T = np.array([[[11,22], [33,44]], [[55,66], [77,88]]])
```
### Pandas
到目前为止,我们都是通过键盘输入矩阵的。如果我们需要从文件或数据集中读取大型矩阵并处理,那该怎么办呢?这时我们就要用到另一个强大的 Python 库了——Pandas。我们以读取一个小的 CSV (<ruby> 逗号分隔值 <rt> comma-separated value </rt></ruby>)文件为例。图 8 展示了如何读取 `cricket.csv` 文件,并将其中的前三行打印到终端上。在本系列的后续文章中将会介绍 Pandas 的更多特性。

### 矩阵的秩
矩阵的 <ruby> 秩 <rt> Rank </rt></ruby> 是由它的行(列)张成的向量空间的维数。如果你还记得大学线性代数的内容的话,你一定对维数、向量空间和张成还有印象,那么你也应该能理解矩阵的秩的含义了。但如果你不熟悉这些术语,那么可以简单地将矩阵的秩理解为矩阵中包含的信息量。当然,这又是一种未来方便理解而过度简化的说法。图 9 显示了如何用 NumPy 求矩阵的秩。矩阵 A 的秩为 3,因为它的任何一行都不能从其它行中得到。矩阵 B 的秩为 1,因为第二行和第三行可以由第一行分别乘以 2 和 3 得到。矩阵 C 只有一个非零行,因此秩为 1。同样的,其它矩阵的秩也不难理解。矩阵的秩与我们的主题关系密切,我们会在后续文章中再提到它。

本次的内容就到此结束了。在下一篇文章中,我们将扩充工具库,以便它们可用于开发人工智能和机器学习程序。我们还将更详细地讨论 <ruby> 神经网络 <rt> neural network </rt></ruby>、<ruby> 监督学习 <rt> supervised learning </rt></ruby>、<ruby> 无监督学习 <rt> unsupervised learning </rt></ruby> 等术语。此外,从下一篇文章开始,我们将使用 JupyterLab 代替 Linux 终端。
*(题图:MJ/ce77d714-3651-44e4-96b0-ffbf7ae4269c)*
---
via: <https://www.opensourceforu.com/2022/06/ai-some-history-and-a-lot-more-about-matrices/>
作者:[Deepu Benson](https://www.opensourceforu.com/author/deepu-benson/) 选题:[lkxed](https://github.com/lkxed) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In the first article on this series on AI (published in OSFY, June 2022), we discussed how fields like AI, machine learning, deep learning, data science, etc, are related yet distinct from each other. We also made a few difficult choices regarding the programming language, tools, etc, which will be used throughout this series. Finally, we started discussing matrices. In this article, we will discuss more about matrix theory, the heart of AI. But before we proceed any further, let us discuss the history of AI.*
first of all, why is a discussion on the history of AI essential? Well, there were a few times in history when there was great enthusiasm around research on AI, but on many of those occasions the huge expectations about the potential of AI went wrong. So, we need to learn some history of AI to understand whether this time we really are going to do wonders with AI or is it yet another bubble that is about to burst.
One important question that needs to be answered is: when did our fascination for artificial intelligence start? Was it after the invention of digital computers or did it start even before? I believe the quest for an omniscient being capable of answering all questions dates back to the beginning of civilisation. The Oracle of Delphi in the ancient times was one such supposedly divine being capable of answering all the queries asked by people. The quest for creative machines outwitting human intelligence was also fascinating to us from ancient times. There were several failed attempts to make machines capable of playing chess. For example, Mechanical Turk was an infamous fake chess playing machine constructed in the late 18th century. The inventions of logarithm by John Napier, the Pascal’s calculator by Blaise Pascal, difference engine by Charles Babbage, etc, were all predecessors to the development of artificial intelligence. Further, if you go through the history of mankind, you will find countless other real and imaginary (fake) moments hoping to achieve intelligence beyond the reach of the human brain. However, irrespective of all these achievements, the search for true AI began with the invention of digital computers.
However, if that is the case, the important question is: what were some of the milestones in the history of AI up until today? As mentioned earlier, the invention of digital computers is the single most significant event in the search for artificial intelligence. Unlike electro-mechanical devices where scalability was dependent on power requirements, digital devices simply benefited technological advancement like the transition from vacuum tubes to transistors to integrated circuits to present day very large-scale integration (VLSI) technology.
Another important phase in the development of AI could be traced back to the first theoretical analysis of AI by Allan Turing. The Turing test proposed by him suggests one of the earliest methods to test artificial intelligence. The test may not be relevant today but it was one of the first attempts to define artificial intelligence. It can be summarised as follows. Behind a curtain, there is either a person named A or a machine named B. You can talk with him/it for say 30 minutes, after which you should be able to identify whether you were conversing with a person or a machine. With the powerful chatbots of today, it is easy to see that such a test will not identify true AI. But in the early 1950s this did give a theoretical framework to understand AI.
In the late 1950s, a programming language called Lisp was developed by John McCarthy. This was one of the earliest high-level programming languages. Until then, machine languages and assembly languages (notoriously difficult to use) were used for computer programming. A very powerful machine, a very powerful language to communicate with it, and computer scientists being the optimists and dreamers made the hope for artificially intelligent machines reasonable for the first time in the history of humanity. In the early 1960s, the hopes for artificially intelligent machines were at their peak. Of course, there were a lot of developments in the computing world, but were there any wonders? Sadly, no. So, the 1960s saw hope and despair about AI for the first time. However, computer science was developing at a pace that is unparalleled in any field of human endeavour.
Then came the 70s and the 80s, where algorithms played a major role. A lot of new and efficient algorithms were developed during this period. The famous textbook ‘The Art of Computer Programming’ written by Donald Knuth (I request you to read about this person, in the world of computer science he is either Gauss or Euler) had its first volume published in the late 1960s marking the beginning of the algorithmic era. A lot of general and graph algorithms were developed during these years. Further, programming based on artificial neural networks was also introduced during this time. Though McCulloch and Pitts were the pioneers in proposing artificial neural networks as far back as the 1940s, it took decades to become a mainstream technique. Today, deep learning is almost exclusively based on artificial neural networks. Such developments in the field of algorithms led to a resurgence in research in the field of artificial intelligence in the 1980s. However, this time, limitations in communication and computing powers derailed progress in this area. For a second time, AI couldn’t live up to the huge expectations it had generated. Then came the 90s, Y2K, and the present day. Once again there is a lot of enthusiasm and hope about the positive impact of AI based applications.
Based on our discussion, it is easy to see that there were at least two other occasions in the digital era when AI was promising. On both those occasions AI didn’t live up to its expectations. Is the current enthusiasm around AI a similar one? Of course, this is a very difficult question to answer. But in my personal opinion, this time AI is going to make a huge impact. But what are the factors that made me make such a prediction? First, very powerful computing devices are cheaply available nowadays. Unlike in the 1960s or 1980s, when a handful of such powerful machines were available, we now have them in the millions and billions. Second, there are large data sets available today for training AI and machine learning based applications. Imagine an AI engineer working in the field of digital image processing in the 90s. How many digital images were available for training his/her algorithms? Well, maybe a few thousands or tens of thousands. A cursory search on the Internet will tell you that the data science platform Kaggle (a subsidiary of Google) itself has more than ten thousand data sets. The large amount of data produced on the Internet every day makes training of algorithms a lot easier. Third, high speed connectivity has made it easy to collaborate with large groups. Imagine the difficulty of computer scientists collaborating with each other until the first decade of the 21st century. The present day speed of the Internet has made collaborative AI based projects like Google Colab, Kaggle, Project Jupyter, etc, a reality. Owing to these three factors, I believe this time AI is here for good and will have some excellent applications.

## More about matrices
Now that we are somewhat familiar with the history of AI, it is time to revisit one of the main themes of this tutorial on AI — matrices and vectors. In the last article, we began discussing these. This time we are going to dive a little deeper into the world of matrix theory. I will begin by pointing your attention to Figures 1 and 2, which show eight matrices (A, B, C and D, and matrices E, F, G and H). Why so many matrices in a tutorial on AI and machine learning? First, as mentioned in the previous article in this series, matrices are the core of linear algebra, and linear algebra is the heart of machine learning, if not the brain. Second, each of these matrices does serve a specific purpose in the following discussion.
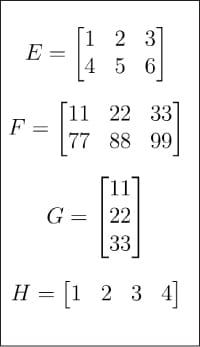
Let us see how matrices can be represented and how some details about them can be obtained. Figure 3 shows how matrix A is represented with NumPy. Though they are not equivalent, we use the terms matrix and array as if they are synonyms.

I urge you to carefully learn how a matrix is created using the function array of NumPy. There is also a function matrix offered by NumPy to create two-dimensional arrays and matrices. However, this function will be deprecated in the future and its use is no longer encouraged. We have created matrix A and Figure 3 also shows some details about it. The line of code A.size tells us about the number of elements in the array. In this case, it is 9. The line of code A.nidm tells the dimension of the array. In this case, it is easy to see that matrix A is two-dimensional. The line of code A.shape gives us the order of matrix A. The order of a matrix is the number of rows and columns of that matrix. Notice that A is a 3 x 3 matrix (3 rows and 3 columns). Though I am not explaining any further, knowing the size, dimension, and shape of an array is a little tricky with NumPy. Figure 4 shows you why the size, dimension and shape of a matrix should be identified carefully. Minor changes while defining an array could lead to changes in its size, shape, and dimension. Hence, from Figure 4, it is clear that a programmer should be extra careful while defining matrices.

Now let us perform some basic matrix operations. Figure 5 shows how two matrices A and B are added. Indeed, there are two distinct Pythonic ways to add the two matrices, either using the function add of NumPy or the operator plus (+) for matrix addition. A very important point to remember is that two matrices can be added only if they are of the same order. For example, two 4 x 3 matrices can be added whereas a 3 x 4 matrix and a 2 x 3 matrix cannot be added. However, since programming is different from mathematics, NumPy does not follow this rule in practice. Figure 5 also shows how matrices A and D are added. Remember that, in the mathematical world, this sort of matrix addition is not valid. A rule called broadcasting decides how matrices of different orders should be added. We won’t be discussing broadcasting at this point but if you are familiar with C or C++, then typecasting of variables might give you a hint as to what happens when broadcasting rules are applied in Python. So, if you want to make sure that you are performing matrix addition in the true mathematical sense, it would be safe if the following test is performed and the answer is True:
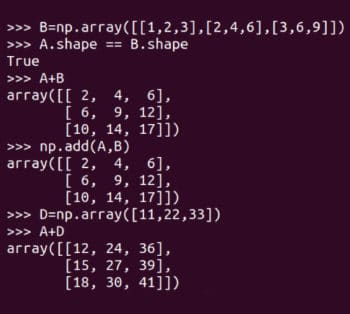

A.shape == B.shape
It can be verified that if you try to add matrices D and H, then it will give you an error.
Please don’t think that matrix addition is the only operation we are going to spend time on. Of course, there are a lot more matrix operations. Matrix subtraction and multiplication are illustrated in Figure 6. Notice that subtraction and multiplication also have two distinct Pythonic ways to perform the required operations. The function subtract or the operator for matrix subtraction (-) and the function matmul or the operator for matrix multiplication (@), can be used for performing matrix subtraction and multiplication, respectively. Execution of the operator * is also shown in Figure 3. Notice that the function matmul of NumPy and the operator @ perform matrix multiplication in the mathematical sense. So, be careful with the operator * while dealing with matrices.
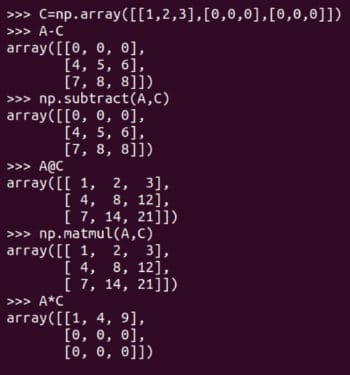

Two matrices of order (m x n) and (p x q) can be multiplied if and only if n is equal to p. Further, the product matrix will be of order (m x q). Figure 7 shows more examples of matrices being multiplied. Notice that E@A is possible whereas A@E leads to an error. Carefully go through the examples of D@G and G@D. Using the shape attribute, identify which among the eight matrices can be multiplied with each other. Though by the strict mathematical definition, a matrix is two-dimensional, we will be dealing with arrays of higher dimensions. So, just to give an example, let us see how a three-dimensional array is represented using NumPy. The following line of code creates a three-dimensional array named T.
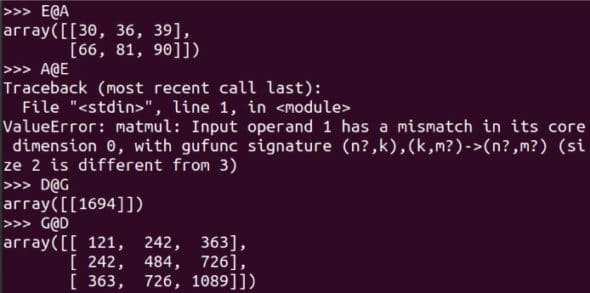

T = np.arr ay([[[11,22],[33,44]],[[55,66],[77,88]]])
## An introduction to Pandas
So far, we were entering matrices from the keyboard. What if we want to read a large matrix from a text file or a data set (very large for that matter) and process it? Here comes another powerful Python library to our rescue, Pandas. Let us begin by reading a small CSV (comma-separated value) file, which is a type of text file (don’t worry, soon we will read Microsoft Excel and LibreOffice/OpenOffice Calc files). Figure 8 shows how a CSV file called cricket.csv is read, and the first three lines in it are printed on the terminal. More features of Pandas will be discussed in the coming articles in this series.

## Rank of a matrix
The rank of a matrix is the dimension of the vector space spanned by its rows (columns). The three italicised words, dimension, vector space and spanned, may not be familiar to you unless you remember your college level linear algebra. If you fully understand what is meant by the rank of a matrix, I am happy and no further explanation is required. However, if you are not familiar with the terms, think of it as the amount of information contained in the matrix. Again, this is a gross oversimplification and I am not proud of it. Figure 9 shows how the ranks of matrices are found out. Matrix A has rank 3 because none of its rows can be obtained from any other rows in it. Matrix B’s rank is just 1, because the second and third rows can be obtained by multiplying the first row ([1, 2, 3]) with 2 and 3, respectively. Matrix C only has one non-zero row and hence has rank 1. Similarly, the ranks of the other matrices can also be understood. Rank is very relevant in our discussion and we will revisit this topic in later articles in this series.

Now it is time for us to wind up our discussion for this month. In the next article in this series, we will add more tools to our arsenal so that they can be used for developing AI and machine learning based applications. We will also discuss terms like neural networks, supervised learning, unsupervised learning, etc, in more detail. Further, from the next article onwards, we will use JupyterLab in place of the Linux terminal. |
16,400 | Linux 爱好者线下沙龙:LLUG 2023·杭州八方城见 | https://jinshuju.net/f/u8xtD3 | 2023-11-20T17:32:00 | [
"LLUG"
] | https://linux.cn/article-16400-1.html |
> 就在这个周末, LLUG(Linux 爱好者沙龙)来到杭州。

2023 年 11 月 25 日下午,我们将在杭州市杭州未来科技城国际人才园(五常地铁站附近)举行 **LLUG 2023 · 杭州场**,欢迎广大的 Linux 爱好者来到现场,与我们一同交流技术,分享自己工作过程中的所思所想。
本次活动依然由 Linux 中国和龙蜥社区(OpenAnolis)联合主办,杭州 GDG 协办,杭州城西科创大走廊高层次人才联合会提供场地支持。
> 龙蜥社区(OpenAnolis)是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
> 杭州城西科创大走廊高层次人才联合会简称“高联会”,高联会是在杭州城西科创大走廊管委会指导下,旨在广泛吸纳与团结廊内高层次人才,助力人才在杭州城西科创大走廊的创新创业。
> 杭州GDG(杭州谷歌开发者社区),谷歌官方赞助的杭州本地技术社区,每年定期举办免费开发者线下技术沙龙,聚焦谷歌相关开源技术,欢迎大家关注微信公众号“杭州GDG”,了解我们,参与技术交流。
活动议程
| 时间 | 议题 | 分享简介 | 分享者 |
| --- | --- | --- | --- |
| 14:00~14:20 | 签到 |
| 14:20~14:30 | LLUG 活动介绍 | | 白宦成 |
| 14:30~15:00 | deepin v23 内核成果分享与技术前瞻 | 在deepin v23的研发过程中,我们在系统内核方面获得了相当多的技术成果,希望与各位开发者们共同讨论deepin根社区内核未来的发展方向。 | 王昱力
deepin社区 内核研发工程师 |
| 15:00~15:45 | 开源实用指南(个人篇+企业篇) | 老王的经典分享,本次追加了企业篇,帮助大家更好的理解如何参与开源。 | 硬核老王
Linux 中国开源社区创始人 |
| 15:50~16:20 | multipush v0.0.1 发布 | LLUG 自己的多平台 RTMP 推流软件 multipush,帮助大家一次直播,多平台推流。欢迎大家参与贡献 & 体验~ | 白宦成
Linux 中国技术组组长 |
| 16:20~17:00 | 闪电演讲(短分享) |
| 17:00 ~ 18:00 | 线下交流 |
#### deepin V23 内核成功分享与技术前瞻

*王昱力,deepin社区 内核研发工程师*
在deepin v23的研发过程中,我们在系统内核方面获得了相当多的技术成果,包括电源管理与可移动设备功耗优化、安全子系统升级和飞腾、国产CPU的兼容适配。我们希望提高deepin内核的可定制性和可玩度,与各位开发者们共同讨论deepin根社区内核未来的发展方向。
#### 《开源实用指南(个人篇+企业篇)》

*硬核老王(wxy),Linux 中国开源社区创始人*
老王的经典分享,聊聊作为一个社区新人,应该如何参与到开源社区当中,并逐步成长为社区的中坚力量的。以及,企业如何才能正确参与开源和培养开源文化。
#### 《multipush v0.0.1 发布》

*白宦成,Linux 中国技术组组长*
LLUG 作为一个线下活动,经常遭遇到需要多平台推流的问题。过去我们使用 OBS 的软件推流,但会受限于插件方和操作系统环境,因此,我们希望提供一套开源的、服务端部署的多平台推流软件,帮助各运营同学能够更简单的完成多平台推流。
#### 闪电演讲
本次线下活动依旧保留闪电演讲环节,作为最受欢迎的线下活动,本次活动依旧继续举办闪电演讲。每位演讲者有 5 分钟时间参与现场活动,可以提前报名,也可即兴上台演讲。时间一满,马上结束~强制大家控制自己的分享时间,用最短的时间,向大家发出你的声音~
上海场闪电演讲照片:

*胡张治分享自己从 GNU/Linux 小白到 ArchLinuxCN 贡献者的旅程*

*李伟光现场介绍 neovim 的使用*
### 活动地点及到达信息
活动地点:余杭区荆长路601号未来科技城国际人才园五楼506室(五常地铁站附近)

活动报名地址:
>
> **<https://jinshuju.net/f/u8xtD3>**
>
>
>
并在活动前收到我们的提醒~此外,也可以在问卷中反馈你想听的内容,我们将竭尽所能,邀请行业专家,针对大家感兴趣的话题进行分享。
如果你因为有事,没办法来到线下,那也没问题,我们的活动也会在 Linux 中国视频号、Linux 中国 B 站、龙蜥 B 站、龙蜥钉钉群等开启同步直播。
当然,我们更希望你能亲自来到线下,和我们一起聊聊开源,聊聊技术~

*扫码报名*
| 302 | Found | null |
16,401 | 在 Fedora Linux 上值得尝试的酷炫 Flatpak 应用(11 月) | https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-november/ | 2023-11-20T21:13:55 | [
"Flatpak"
] | https://linux.cn/article-16401-1.html | 
>
> 本文介绍了 Flathub 中可用的项目以及安装说明。
>
>
>
[Flathub](https://flathub.org) 是获取和分发适用于所有 Linux 应用的地方。它由 Flatpak 提供支持,允许 Flathub 应用在几乎任何 Linux 发行版上运行。
请阅读“[Flatpak 入门](https://fedoramagazine.org/getting-started-flatpak/)”。为了启用 flathub 作为你的 flatpak 提供商,请使用 [Flatpak 站点](https://flatpak.org/setup/Fedora)上的说明。
### TurboWarp
[TurboWarp](https://flathub.org/apps/org.turbowarp.TurboWarp) 是 Scratch 的修改版本。Scratch 是一种具有简单视觉界面的编码语言,允许年轻人创建数字故事、游戏和动画。
我喜欢 Scratch,但自从我发现 TurboWarp 以来,我儿子就再也没有回头。界面更清晰,具有夜间模式,比原始 Scratch 运行速度更快,并且内存经过优化。
你可以通过单击网站上的安装按钮或手动使用以下命令来安装 TurboWarp:
```
flatpak install flathub org.turbowarp.TurboWarp
```
### Szyszka
[Szyska](https://flathub.org/apps/com.github.qarmin.szyszka) 是文件重命名器,具有许多有趣的功能,例如:
* 很好的性能
* 适用于 Linux、Mac 和 Windows
* 使用 GTK 4 创建的 GUI
* 多种规则可自由组合:
+ 替换文字
+ 修剪文本
+ 添加文字
+ 添加号码
+ 清除文本
+ 将字母更改为大写/小写
+ 自定义规则
* 保存规则供以后使用
* 能够编辑、重新排序规则和结果
* 处理数十万条记录
你可以通过单击网站上的安装按钮或手动使用以下命令来安装 Szyszka:
```
flatpak install flathub com.github.qarmin.szyszka
```
### Marker
[Marker](https://flathub.org/apps/com.github.fabiocolacio.marker) 是一个用 GTK3 编写的 MarkDown 编辑器。这是我在 GTK 上快速写作的最爱之一。它的一些特点是:
* 使用 [scidown](https://github.com/wallberg13/scidown) 对 Markdown 文档进行 HTML 和 LaTeX 转换
+ 支持 YAML 标头
+ 文档类
+ 投影仪/演示模式
+ 摘要部分
+ 目录
+ 外部文档包含
+ 带有参考 ID 和标题的方程、图形、表格和清单
+ 内部参考文献
* 使用 [KaTeX](https://katex.org/) 或 [MathJax](https://www.mathjax.org/) 进行 TeX 数学渲染
* 使用 [highlight.js](https://highlightjs.org/) 对代码块进行语法高亮显示
* 使用 [pandoc](https://pandoc.org/) 灵活的导出选项
+ PDF
+ RTF
+ ODT
+ DOCX
你可以通过单击网站上的安装按钮或使用以下命令手动安装 Marker:
```
flatpak install flathub com.github.fabiocolacio.marker
```
*Marker 也在 fedora 的仓库中以 rpm 的形式提供。*
### Librum
[Librum](https://flathub.org/apps/com.librumreader.librum) 是一个用于管理图书馆和阅读电子书的应用。这是管理书籍和文档集合的好方法,包括对一长串格式的支持。它的一些特点是:
* 现代电子阅读器
* 个性化和可定制的库
* 图书元数据编辑
* 一个免费的应用内书店,拥有超过 70,000 本书
* 书籍在所有设备上同步
* 高亮显示书签文本搜索
你可以通过单击网站上的安装按钮或使用以下命令手动安装 Librum:
```
flatpak install flathub com.librumreader.librum
```
---
via: <https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-november/>
作者:[Eduard Lucena](https://fedoramagazine.org/author/x3mboy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article introduces projects available in Flathub with installation instructions.
[Flathub](https://flathub.org) is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “[Getting started with Flatpak](https://fedoramagazine.org/getting-started-flatpak/)“. In order to enable flathub as your flatpak provider, use the instructions on the [flatpak site](https://flatpak.org/setup/Fedora).
## TurboWarp
[TurboWarp](https://flathub.org/apps/org.turbowarp.TurboWarp) is a modified version of Scratch. Scratch is a coding language with a simple visual interface that allows young people to create digital stories, games, and animations.
I love Scratch, but since I discovered TurboWarp, my son has never looked back. The interface is clearer, it has night mode, it works faster than the original Scratch, and it’s memory optimized.
You can install “TurboWarp” by clicking the install button on the web site or manually using this command:
flatpak install flathub org.turbowarp.TurboWarp
## Szyszka
[Szyska](https://flathub.org/apps/com.github.qarmin.szyszka) is file renamer with a lot of interesting features like:
- Great performance
- Available for Linux, Mac and Windows
- GUI created with GTK 4
- Multiple rules which can be freely combined:
- Replace text
- Trim text
- Add text
- Add numbers
- Purge text
- Change letters to upper/lowercase
- Custom rules
- Saved rules to be used later
- Ability to edit, reorder rules and results
- Handles hundreds thousands of records
You can install “Szyszka” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.qarmin.szyszka
## Marker
[Marker](https://flathub.org/apps/com.github.fabiocolacio.marker) is a MarkDown editor written in GTK3. It’s one of my favorites for fast writing on GTK. Some of its features are:
- HTML and LaTeX conversion of markdown documents with
[scidown](https://github.com/wallberg13/scidown)- Support for YAML headers
- Document classes
- Beamer/presentation mode
- Abstract sections
- Table of Contents
- External document inclusion
- Equations, figures, table and listings with reference id and caption
- Internal references
- TeX math rendering with
[KaTeX](https://katex.org/)or[MathJax](https://www.mathjax.org/) - Syntax highlighting for code blocks with
[highlight.js](https://highlightjs.org/) - Flexible export options with
[pandoc](https://pandoc.org/)- RTF
- ODT
- DOCX
You can install “Marker” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.fabiocolacio.marker
*Marker is also available as rpm on fedora’s repositories*
## Librum
[Librum](https://flathub.org/apps/com.librumreader.librum) is an application to manage your library and read your e-books. It’s a great way to manage a collection of books and documents, including support for a long list of formats. Some of its features are:
- A modern e-reader
- A personalized and customizable library
- Book meta-data editing
- A free in-app bookstore with more than 70,000 books
- Book syncing across all of your devices
- Highlighting Bookmarking Text search
You can install “Librum” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.librumreader.librum
## GroovyMan
If I had to give three good reasons why I only use Fedora Linux on my workstations and server, then I would give the following reasons:
– perfect managed rpm repositories
– nice support from bugzilla.redhat.com and friendly developers and teams (i.e. the podman developers led by RedHat-Daniel
– a large set of repositories that fullfill most of my needs as a developer
The reason why i dislike the MS-Windows style of application management like flathup (and others), is the matter of of fact, that a fixed bug in a glib, gtk component wont fix problems in the flat-head-packaged application, that has been installed via flatpack.
(1) flatpack in an example of … lessons not learned!
(2) marker can be loaded in the same version via rpm
(-‸ლ)
## karel
Please try to learn more about “flatpak” and “flathub” (and not being able to spell it right once underscore this), there very good reason we use them (shorting delivery path, being able to sandbox applications, etc.). Of course it’s possible that they don’t suite you well, but they exist to solve real world problems.
If you still don’t find any good use for them, there’s no necessary to tell the rest (silent majority in the end) that it is not meeting your needs.
## GroovyMan
Dear Karel,
i know very well the idea behind flatpack. In short: one managed glibc an some isolated installation, with their own software stack on libraries and components. Well this is nice for a fast distribution, but is is the hell for the user, who may wait a long time, until a developer wakes up to update its shipment, with a update of used library, that had a sec hole.
Karel, this is exactly the same chaos you find on any Windows-Worksation, you really want this ?
The idea of flatpak might be a solution for to make a new software available for a lot of linux users. This may be an acceptable solution for the very first time, but later it will make you a slave of the resonsability to keep the entire shipment up to date.
So as a professional developer with a build chain for the major distributions, you will be glad not to worry about stable/buggy versions of library, you are not willing to ship anymore.
And as i user i prefer rpm-packaged programs, cause they keep my whole system safe and help the distributor, to find problems as soon as possible. Its philosophy is cooperative, whereas flatpak reminds me of a loner who is enticed to ship and forget.
## BadBoy
many apps are still anchored to the gnome 43 runtime. The problem is real.
## GroovyMan
Salut BadBoy,
for this reason you can install gnome-43 libraries side by side of modern libraries, cause UNIX shared libs holds the version number in their filename. Thanks ELF, Linux does not have that shared-lib desaster of Windows in common.
The migration from one version to another can be easily perfomed by changing the version number of your make to the next level.
There is no problem at all!
## Darvond
What if I don’t want to support the paradigm and ideas put forth by Word of Gnome? Because Gnome these days feels like the latter day splinter faction Word of Blake from Battletech. More focused on dogma and image than pushing forward any useful paradigm.
Or perhaps in a less wordy way: I don’t want any Gnome library touching my system. Is there a desktop agnostic way to accomplish this?
## regeya
Forgive my ignorance, but imho it sounds like you have it completely backwards.
## HelloWorld
You are not groovy, man.
## Mike Breedlove
Being a novice, this is what I’m looking for when exploring for info on software.
Thx
## kantrix
I think, it’s worth mentioning, that librum is completely useless without registering an account and sharing your usage data with them.
## Georg
And – read the privacy policy. They collect and share data. Please don’t make advertise for software like this.
## Darvond
A TL;DR:
One (glorified) e-book reader, which feels like one of those whatever things to be missing from the main repos. There’s Bookworm…and a smorgasbord PDF readers which happen to open ePub and other electronic formats.
Marker, which exists among a sea of markdown & lightweight IDEs.
And… the Bulk Rename Tool from Thunar.
The reason I went to Fedora is because I like a leading edge system with a clear structure, but given the recent shifts in culture, I’m not so sure anymore. I feel like given the breakdown in communication over projects such as DNF5 and the Fedora 39 release stalling over some minor software quibbles, that it is starting to feel the org is taking the wrong approach.
I realize much of it is community and volunteer driven, but someone needs to be in the role of making sure people are coding to an ends rather than spinning their wheels over frivolous issues.
There is a bug marked as a release blocker? That’s going to require daily communication, there is a schedule to keep.
A feature proposal? Better be presenting monthly updates. I’m trying to figure out for example, what happened to DNF5, looking at the issue tracker and codebase, and it feels like they’re reinventing the wheel not only codewise, but in terms of approach/implementation as well; instead of referencing working implementations such as Zypper. (Which is also primarily constructed of C++ and works with RPM package management.)
And if DNFdragora is supposed to be the YAST/Synaptic of Fedora, that’s not a great look either.
## Richard England
If the flatpak tools presented in these articles are not suitable for you or you feel they are duplicates of other tools, or if you do not wish to use flatpaks, then the simple response is not to use them and perhaps ignore the articles in the future.
Some folks find these articles useful. Not everyone will. That’s life and free choice.
I find this an interesting (read that inappropriate) forum in which to discuss the current release delay. There are several channels in the Fedora Matrix channels that you may use to follow the details of the release. See: https://chat.fedoraproject.org/#/room/#fedora:fedoraproject.org
## Anony Moose
I’d wager you to leave a Fedora installation unattended for something like two-three months and then try upgrading it via ‘dnf update’ then do the same for a, say OpenSuse Tumbleweed, via zypper. By the time Zypper updates finish you could have probably just done a clean reinstall with a newer ISO.
## Tom
Recommending an app that requires account registration to use seems unusual for this blog series. Especially since the main reason for it is to track usage data. Librum even reserves the right to use your private data to contact you for any reason afaict, though I will admit to not being an expert or having read their entire privacy policy.
## Marie-Rune
It is nice that you have started to use the full name Fedora Linux more now that people are finding Linux. Many times new comers can get confused as they are talked about “Linux” but then they see “Fedora” “Manjaro” “Debian” and so forth. Then they wonder “wasn’t i supposed to be using Linux”.
MX Linux and Linux Mint are great examples too because those names tell that it is indeed about Linux but different “version” for new users. Maybe that Linux word should be added to Fedora logo too in small under or so.
## Gregory Bartholomew
Thanks for the suggestion Marie-Rune. This magazine is meant to present news about Fedora Linux (the operating system — new releases, new software packages, new features, etc.) and Fedora Project (news about events like Flock to Fedora and new services like Fedora Ask/Discussion and Fedora Matrix). We don’t want to limit ourselves to
justthe operating system (though that is the bulk of the topics that get posted here). 🙂## Roman
Nice article Eduard!
## Anon Ymous the 3rd
Flat Packs are touted as this wonderful sandboxed QUBES like secure platform for applications to new people. Then, after a while. one realizes it is not really a sandbox at all, and that flatpack apps have the same problems any other linux app does. It is sad but most definitely true-, if one wants a reliable app that works simply install windows or the like and give up privacy.
Of course, Linux distros are more user friendly to the privacy minded. One does not need to sign up and provide a phone number to install a linux distro. THAT plus is negated when it seems more and more linux apps want sign ups and/or require invasive permissions. Doing things to negate the clear advantages and user experiences that linux has does one simple thing. It negates every advantage.
People feel like a child who learns there is no Santa Clause. No one likes to feel lied to, and no one likes to run unreliable apps.
The point? One of accountability. Instead of steering new people to apps that pretty much track just as much as windows apps do, at least be honest and state the pros and cons of any app.
Contrary to the communist style mind control that seems to spew from fedora magazine, people do not chose fedora desktop over windows because fedora is better. Windows apps are rock solid reliable. Your fedora app might break on the next update. That’s a fact.
Linux desktop distros like fedora have came a long way, to be sure. One does not have to be a nerd to simply install or use linux any more, and that is a great thing. RUST lang is going to make linux desktop much more secure and reliable, which will be great. Nevertheless, linux distros like fedora have NOT earned the right to start tracking people via apps and claiming the apps are more than they are. Accountability and honesty is the only way to advance. There are LOTS of people that just go back to windows and wait for a linux distro to get it right, and that is a fact.
Flatpacks would be awesome if they were actually more sandboxed as often wrongly touted. And telling ANYONE fo download an app that tracks one as much as windows is illogical..might as well just stick to windows. Lastly, admonishing people from bringing up valid complaints might work for places like china but it will NEVER make fedora better. You can tell others to go take a hike and use something else… most end up doing that anyway.
## Karlis K.
I don’t get the hate in the comments, I personally love these monthly writeups of Flatpak highlights. Just the other day I was feeling adventurous to go out and explore random Flatpaks that seemed interesting or potentially useful to maybe find better ways of doing things the way I’ve been doing them. Keep up rocking Fedora Magazine crew! 🤘
## Darvond
They used to be writeups of useful packages in COPR, showing what the community was interested in. And many of the packages featured have been less than impressive.
## Richard England
The magazine would be pleased to have you contribute reviews of some COPR packages you feel are worthy of note.
## Tommy He
To be fair, for the features that Librum offers, it’s hard to imagine to not require registering. If this is a concern, Calibre can also be found and installed via flathub.
Meanwhile, Librum offers a self-host option for the ones who want its Cloud based features with more privacy concerns.
https://github.com/Librum-Reader/Librum-Server/blob/main/self-hosting/self-host-installation.md
## Jefe
Marker can be installed with “sudo dnf install marker”. Why reference flatpak when it is available in house? Fedora package install is your first choice.
## Lol
Szyszka… was almost going to say it’s one of the worst names you could have used, but then I found, BUT….then I found their GitHub page 🤣🤣🤣
“Szyszka is Polish word which means Pinecone.
Why such a strange name?
Would you remember another app name like Rename Files Ultra?
Probably not.
But will you remember name Szyszka?
Well… probably also not, but when you hear this name, you will instantly think of this app.”
## jakjak
I too, side with groovyman, badboy, georg, tom, Anon Yumas the 3rd, jefe.
Within this scope, it appears the magazine is fully behind flatpak. It would be wonderful to see an honest detailed contrarian view written on flatpak.
Wouldn’t you consider this critical for the open source philosophy?
## Richard England
The Fedora Magazine publishes articles that are contributed by volunteers. Articles about one feature or another are not solicited. There is no attempt to “be behind” any thing, only to present accurate information that might be of interest to the community.
You may want to take note that there was a series of articles in a similar vein done about COPR packages that might be of interest to the community.
You are invited to contribute articles about tools and features that you find useful or of interest that are found in the Fedora Linux repositories. The magazine would welcome them. |
16,403 | 故障排除:在 Arch Linux 上启用蓝牙 | https://itsfoss.com/bluetooth-arch-linux/ | 2023-11-21T20:16:00 | [
"蓝牙"
] | https://linux.cn/article-16403-1.html | 
>
> Arch Linux 上的蓝牙无法工作?以下是对我有用的方法,以及解决 Arch 上蓝牙问题的其它技巧。
>
>
>
[我很轻松地安装了 Arch Linux](https://www.youtube.com/watch?v=WksxVLrALhg),这要归功于 archinstall 脚本。
在我开始使用它并探索之后,我尝试使用我的蓝牙耳机,却发现蓝牙无法工作。
我可以看到蓝牙选项,但无法启用它。单击开关会只会切换回禁用状态。
下面是我所做的以及有作用的事情。
### 确保蓝牙服务正在运行
如果该服务未运行,蓝牙将不会打开,你将无法连接到它。
检查蓝牙服务的状态并查看其是否正在运行。
```
systemctl status bluetooth
```
它给了我以下输出:
```
[abhishek@itsfoss ~]$ systemctl status bluetooth
○ bluetooth.service - Bluetooth service
Loaded: loaded (/usr/lib/systemd/system/bluetooth.service; disabled; preset: disabled)
Active: inactive (dead)
Docs: man:bluetoothd(8)
```
如你所见,`bluetooth` 服务处于非活动状态。它没有运行。并且状态被禁用。
这意味着蓝牙守护程序当前未运行,也未设置为每次启动时自动启动。
这让事情变得更容易了。我在第一次尝试中就找出了根本原因。在 Arch Linux 中这种情况并不常见。
使用以下命令启动蓝牙守护进程:
```
sudo systemctl start bluetooth
```
让蓝牙服务在系统启动时自动运行:
```
systemctl enable bluetooth
```
它应该显示以下输出:
```
[abhishek@itsfoss ~]$ systemctl enable bluetooth
Created symlink /etc/systemd/system/dbus-org.bluez.service → /usr/lib/systemd/system/bluetooth.service.
Created symlink /etc/systemd/system/bluetooth.target.wants/bluetooth.service → /usr/lib/systemd/system/bluetooth.service.
```
现在,蓝牙已启用,并且在系统设置中很明显:

### 连接蓝牙设备的提示
你可能已经知道应该首先将蓝牙设备置于配对模式。这很关键。
之后,你可以尝试关闭然后再次打开蓝牙按钮,以便它搜索可用的设备。
如果它没有立即显示,你可以单击其他一些系统设置并再次返回蓝牙。过去它对我有用过几次,不要问为什么。
### 其他故障排除提示
以下是修复 Arch Linux 中蓝牙连接问题的更多提示:
#### 确保未被阻止
确保蓝牙未被阻止:
```
rfkill list
```
检查输出:
```
[abhishek@itsfoss ~]$ rfkill list
0: hci0: Bluetooth
Soft blocked: no
Hard blocked: no
1: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
```
如果你发现蓝牙被阻止,请使用以下命令取消阻止:
```
rfkill unblock bluetooth
```
#### Pipewire 与 Pulseaudio
在某些情况下,如果你过去尝试过 Pipewire 和 Pulseaudio,它们可能会破坏工作。
如果你使用 Pipewire,请确保安装了 pipewire-pulse:
```
sudo pacman -Syu pipewire-pulse
```
如果你使用 Pulseaudio,`bluez` 和 `pulseaudio-bluetooth` 可以帮助你。
查看 Arch Wiki 页面以获取更多信息。
>
> **[蓝牙耳机 - Arch 维基](https://wiki.archlinux.org/favicon.ico)**
>
>
>
### 这对你有用吗?
硬件兼容性问题是任何操作系统都会遇到的问题,Linux 也不例外。
事情没有单一的解决方案。你的系统可能存在与我的系统不同的问题,此处提到的建议可能适合你,也可能不适用于你。
完善的 Arch 维基提供的建议比我所能提供的要多得多。如果你仍然无法解决蓝牙问题,请执行此操作。
现在看你的了。对你有用吗?如果有,是哪种方法?如果没有,你遇到了什么样的问题,以及到目前为止你尝试过哪些故障排除方法?
*(题图:MJ/60bd220b-bb4f-4d51-9c41-162c8c4714b3)*
---
via: <https://itsfoss.com/bluetooth-arch-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

So, [I installed Arch Linux quite easily](https://www.youtube.com/watch?v=WksxVLrALhg) thanks to the archinstall script.
After I started using it and exploring it, I tried using my Bluetooth headphones only to notice that the Bluetooth was not working.
I could see the Bluetooth option but I just could not enable it. Clicking the toggle button kept on switching back to disabled.
Bluetooth turn on button not working
Here's what I did and what worked for me.
## Ensure that Bluetooth service is running
If the service is not running, Bluetooth won't be turned on and you won't be able to connect to it.
Check the status of the Bluetooth service and see if it is running or not.
`systemctl status bluetooth`
It gave me the following output:
```
[abhishek@itsfoss ~]$ systemctl status bluetooth
○ bluetooth.service - Bluetooth service
Loaded: loaded (/usr/lib/systemd/system/bluetooth.service; disabled; preset: disabled)
Active: inactive (dead)
Docs: man:bluetoothd(8)
```
As you can see, the `bluetooth`
service is inactive. It is not running. And the state is disabled.
It means that Bluetooth daemon is not running at present and it is also not set to start automatically on each boot.
That made things easier for me. I have identified the root cause in the first attempt. That doesn't happen frequently with Arch Linux.
Start the Bluetooth daemon with:
`sudo systemctl start bluetooth`
Make the Bluetooth service run automatically when the system starts:
`systemctl enable bluetooth`
It should show the following output:
```
[abhishek@itsfoss ~]$ systemctl enable bluetooth
Created symlink /etc/systemd/system/dbus-org.bluez.service → /usr/lib/systemd/system/bluetooth.service.
Created symlink /etc/systemd/system/bluetooth.target.wants/bluetooth.service → /usr/lib/systemd/system/bluetooth.service.
```
Now, the Bluetooth was enabled and it was evident in the system settings:
## Tip on connecting to a Bluetooth device
You probably already know that you should put your Bluetooth device in pairing mode first. That's critical.
Afterward, you can try toggling the Bluetooth button off and on again so that it searches for available devices.
If it immediately doesn't show, you may click on some other system settings and come back to Bluetooth again. It worked for me several times in the past, don't ask why.
## Other troubleshooting tips
Here are a few more tips on fixing the Bluetooth connection issue in Arch Linux:
### Ensure no blockage
Ensure that Bluetooth is not being blocked:
`rfkill list`
Check the output:
```
[abhishek@itsfoss ~]$ rfkill list
0: hci0: Bluetooth
Soft blocked: no
Hard blocked: no
1: phy0: Wireless LAN
Soft blocked: no
Hard blocked: no
```
If you see Bluetooth being blocked, unblock it with:
`rfkill unblock bluetooth`
### Pipewire vs Pulseaudio
In some cases, Pipewire and Pulseaudio can spoil the game if you experimented with them in the past.
If you are using Pipewire, ensure that you have pipewire-pulse installed:
` sudo pacman -Syu pipewire-pulse`
If you are using Pulseaudio, `bluez`
and `pulseaudio-bluetooth`
could help you.
Check out the Arch Wiki page for more information.
[Bluetooth headset - ArchWiki](https://wiki.archlinux.org/title/bluetooth_headset)
## Did it work for you?
Hardware compatibility issue is a problem with any operating system and Linux is no exception.
Another thing is that there is no single solution. Your system may have a different problem than mine, and the suggestions mentioned here may or may not work for you.
The magnificent Arch Wiki has a lot more suggestions than what I can offer. Do go through it if you still have not managed to fix your Bluetooth problem.
[Bluetooth - ArchWiki](https://wiki.archlinux.org/title/Bluetooth)
Over to you now. Did it work for you? If yes, which method was it? If not, what kind of problem are you facing and what troubleshooting methods have you tried so far? |
16,404 | Linux 黑话解释:Linux 中的 Super 键是什么? | https://itsfoss.com/super-key/ | 2023-11-21T21:20:49 | [
"黑话",
"Super"
] | https://linux.cn/article-16404-1.html | 
>
> 在本次 Linux 黑话解释系列的这一篇,我们会一起来探索 Linux 中的 `Super` 键(或称其为 `Meta` 键)。
>
>
>
当你在网上浏览 Linux 教程时,你可能会遇到 “`Super` 键” 这个术语,对于 Linux 的初学者来说,这可能会引起混淆。
概括地说,如果你的电脑预装了 Windows,那么带有 Windows 标志的 `Windows` 键就是 `Super` 键。
如果你使用的是苹果电脑,那么带有 `⌘` 符号的 `command` 键就是你的 `Super` 键。

很简单吧?
但是,为什么要将其命名为 `Super` 键呢?毫无疑问,背后一定有一些有趣的故事。
那么,让我们一起按下 `Super` 键,发掘更深层次的故事吧。
### Super 键背后的想法
它首次出现在 “space-cadet” 键盘中,这款键盘是在 1978 年为 [Lisp 机器](https://en.wikipedia.org/wiki/Lisp_machine) 设计的,其主要目的是用来模拟 `Meta` 键。(LCTT 译注:这款键盘的独特之处在于它设有七个修饰键,包括 `Shift`、`Control`、`Meta`、`Super`、`Hyper`,用户可以通过组合这些修饰键与其他键来输入更多的字符和命令,它对现代计算机键盘的发展产生了重要影响。)
`Meta` 键在 Emacs 编辑器中是非常重要的一个部分,但在当时的现代键盘中却未能配备实体的 `Meta` 键,因而人们常常通过不同的按键绑定来模仿其功能。
`Super` 键的引入,解决了这个问题,由此我们有了一个真实的 `Super` 键。
快进到 1994 年,当时 `Windows` 键首次在 [微软自然键盘](https://en.wikipedia.org/wiki/Microsoft_ergonomic_keyboards#Natural_Keyboard) 上出现,它被用来迅速打开“开始”菜单。从 1996 年开始,将 `Meta` 键映射到 `Windows` 键成为了普遍的做法。
### Super 键的一般使用情况
当你在 Ubuntu 桌面上按下 `Super` 键时,它会显示活动概览,让你全面了解每个窗口正在进行的活动:

但你要知道,除了预览正在进行的活动,你其实还可以做更多。
比如,你可以同时按下 `Super` 键和 `Tab` 键,调出应用切换器,从而在正在运行的应用之间切换。

下面列举了一些可以利用 `Super` 键的快捷键(在 Ubuntu 23.10 内部测试通过):
>
> ? 如果你在使用的是基于 Ubuntu 的发行版,其中的某些快捷键可能并不会按照预期那样工作,因为发行版维护者可能已经将该快捷键指定为另一个任务。
>
>
>
| 快捷键 | 描述 |
| --- | --- |
| `Super` | 打开活动概览 |
| `Super` + `Tab` | 切换开放应用 |
| `Super` + `D` | 显示桌面(最小化所有窗口) |
| `Super` + `A` | 打开应用菜单 |
| `Super` + `S` | 显示快速设定 |
| `Super` + `←` | 将活动窗口移至屏幕的左半部分 |
| `Super` + `→` | 将活动窗口移至屏幕的右半部分 |
| `Super` + `↑` | 最大化活动窗口 |
| `Super` + `↓` | 最小化活动窗口 |
| `Super` + `L` | 锁定屏幕 |
这些操作实在太方便了,对吧?
### 通过快捷键提高生产效率
对于新接触 Ubuntu 的你,下列的一些有帮助的快捷键值得一试:
>
> **[Ubuntu 用户应该知道的 13 个快捷键](https://itsfoss.com/ubuntu-shortcuts/)**
>
>
>
如果你刚开始使用终端,我会推荐你学习 [Linux 终端的基本快捷键](https://itsfoss.com/linux-terminal-shortcuts/):
>
> **[专业用户喜欢使用的 21 个 Linux 终端快捷键](https://itsfoss.com/linux-terminal-shortcuts/)**
>
>
>
我希望这篇文章能给你带来宝贵的信息,使你对 Super 键有更深入的了解 ?
*(题图:MJ/9b9a1146-0e76-459a-880d-b1a1a4fa5f1e)*
---
via: <https://itsfoss.com/super-key/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

While reading Linux tutorials on the internet, you'd come across the term 'super key' and if you are a beginner to Linux, it may confuse you.
In simplest terms, if your computer came pre-installed with Windows, then the Windows key (with the Windows logo) is your super key.
Whereas if you have an Apple computer, you have to press the command key with the ⌘ symbol as your super key.

Pretty simple. Right?
But what was the reason behind naming it super key? I mean there has to be some interesting story behind it.
So let's press the super key all together to uncover more details.
## The idea behind the super key
It was introduced in The "space-cadet" keyboard, designed in 1978 at MIT for the [Lips machine](https://en.wikipedia.org/wiki/Lisp_machine), and mainly introduced to emulate the meta key.
The meta key was a crucial part of the Emacs editor but the modern keyboards of that time did not ship with a physical meta key and it was often emulated using different key bindings.
The introduction of a super key solved this issue by giving a physical super key.
Fast-forward to 1994 when the Windows key appeared for the first time on the [Microsoft Natural keyboard](https://en.wikipedia.org/wiki/Microsoft_ergonomic_keyboards#Natural_Keyboard) which was used to quickly open the start menu and from 1996, it became common practice to map the meta key on the Windows key.
## Common use cases of the super key
When you press the super key on the Ubuntu desktop, it displays the activities overview, which gives you a peek into what is going on in every window:
But you can do a lot more than just have a glimpse of ongoing activities.
For example, you can press Super and Tab together to bring the application switcher and switch between running apps.

Here are some shortcuts that utilize the Super key (tested in Ubuntu 23.10):
Shortcut | Description |
---|---|
Super | Open Activities Overview |
Super + Tab | Switch between open applications |
Super + D | Show desktop (minimize all windows) |
Super + A | Open Applications menu |
Super + S | Show quick settings |
Super + Left Arrow | Snap the active window to the left half of the screen |
Super + Right Arrow | Snap the active window to the right half of the screen |
Super + Up Arrow | Maximize active window |
Super + Down Arrow | Un-maximize active window |
Super + L | Lock screen |
Pretty handy. Right?
## Improve productivity with shortcuts
New to Ubuntu? Here are some helpful shortcuts for Ubuntu users:
[13 Keyboard Shortcuts Every Ubuntu User Should KnowKnowing keyboard shortcuts increase your productivity. Here are some useful Ubuntu shortcut keys that will help you use Ubuntu like a pro.](https://itsfoss.com/ubuntu-shortcuts/)

If you are getting started with a terminal, I'd recommend you learn [basic terminal shortcuts for Linux terminals](https://itsfoss.com/linux-terminal-shortcuts/):
[21 Useful Linux Terminal Shortcuts Pro Users LoveBecome more efficient in the Linux terminal by mastering these super useful keyboard shortcuts.](https://itsfoss.com/linux-terminal-shortcuts/)

I hope that it was a superbly informative super article ;) |
16,406 | 为集中管理的用户提供 FIDO2 认证 | https://fedoramagazine.org/fido2-for-centrally-managed-users/ | 2023-11-23T09:51:31 | [
"FIDO2",
"认证"
] | https://linux.cn/article-16406-1.html | 
Fedora 39 通过 SSSD 和 FreeIPA 为集中管理的用户开启了 FIDO2 认证功能。此篇文章将指导你如何进行配置和启用该功能。
### FIDO2
[FIDO2](https://fidoalliance.org/fido2/) 是以 [公钥加密](https://en.wikipedia.org/wiki/Public-key_cryptography) 为基础的开放式认证标准,比起密码和一次性密码(OTP),它的安全性更高且易用性更强。它通常以类似小型 USB 和基于 NFC 的硬件安全令牌的方式提供。有几种符合 FIDO 认可的密钥品牌,例如:YubiKey、NitroKey、SoloKey v2 等等。
此协议的优势包括:
* 通过使用公钥加密来消除密码,从而实现无密码认证。
* 采用 [多因素认证](https://en.wikipedia.org/wiki/Multi-factor_authentication)(MFA)以实现强力认证。
* 减少了应用程序之间密码或公钥的重复使用,降低数据泄露的风险。
* 私钥位于安全令牌中并且永不离开,这大大减少了被网络钓鱼的威胁。
#### 前面的文章
在 Fedora 杂志中,有多篇文章阐述了如 FIDO2 的应用场景:《[如何使用 FIDO2 验证本地用户](https://fedoramagazine.org/use-fido-u2f-security-keys-with-fedora-linux/)》 和 《[如何解锁硬盘](https://fedoramagazine.org/use-systemd-cryptenroll-with-fido-u2f-or-tpm2-to-decrypt-your-disk/)》。而此篇文章介绍了如何使用 FIDO2 验证远程用户。请注意,上述所说的设备,主要是指那些来自 Yubico 采用了其他协议的设备,而此篇指南的目的并非讨论这些协议。
### 集中管理的用户
[SSSD](https://sssd.io/) 和 [FreeIPA](https://freeipa.readthedocs.io/en/latest/) 最近新增了一个名为 <ruby> <a href="https://fedoraproject.org/wiki/Changes/Passkey_authentication_centrally_managed_users"> 通行密钥 </a> <rt> passkey </rt></ruby> 的特性,以便对集中管理的用户执行 FIDO2 认证。此功能目前只在 [SSSD 2.9.0](https://sssd.io/release-notes/sssd-2.9.0.html) 和 [FreeIPA 4.11.0](https://www.freeipa.org/release-notes/4-11-0.html) 等版本中支持。
Fedora 39 已经包含了这些版本,因此,它是第一个为集中管理的用户启用 FIDO2 认证的发行版。此外,用户在认证成功后,也会一并获取一个 Kerberos 票据,实现对其他服务的身份证明。
请注意,从这里开始,我将交替使用 FIDO2 和通行密钥这两个术语。
### FIDO2 认证
#### FIDO2 配置
作为额外的安全措施,应在设备中启用 MFA 以防你丢失了密钥,恶意行为者无法使用它进行认证。
列出连接的通行密钥设备:
```
$ fido2-token -L
```
为你的通行密钥设备设置 PIN(将大写字母替换为所需的):
```
$ fido2-token -C /dev/hidrawX
```
如果你有一个兼容的设备,你还可以启用其他认证因素,例如指纹。
#### 集中用户配置
首先,我们来创建一个用户,并将通行密钥(`passkey`)设置为其认证方式(请根据需要将大写字母替换为相应的):
```
$ ipa user-add USERNAME --first NAME --last SURNAME --user-auth-type=passkey
```
或者,如果你已有一个用户,并只需要将 `passkey` 设置为其认证方式:
```
$ ipa user-mod USERNAME --user-auth-type=passkey
```
#### 集中管理用户的 FIDO2 注册
接下来,我们为该用户注册这个通行密钥。这个步骤会提示你输入 PIN 码,随后触摸设备:
```
$ ipa user-add-passkey USERNAME --register
Enter PIN:
Please touch the device.
------------------------------------
Added passkey mappings to user "USERNAME"
------------------------------------
User login: USERNAME
Passkey mapping: passkey:XR/MXigmgiBz1z7/RlWoWZkXKIEf1x9Ux5uPNxtzzSTdTiF407u2nRYMPkK8pWjwUR8Aa2urCcC9cnpLbkKgFg==,MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEZqgERsFFv4Yev1dyo2Ap4PvLirg3P3Uhig5mNA4qf061C9q5rg0nMDz9AOYxZmBrwvQEXHCasMNO9VAIVnBIVg==
```
此刻,用户的认证已准备就绪。
注意,如果你想在生产环境中使用此用户,我建议你至少注册两个不同的设备。这样,即使你丢失了其中一个设备,你也可以用另一个进行认证。
#### 集中管理的用户的 FIDO2 认证
在初次尝试中,只有在物理连接令牌的系统中才能进行认证。这意味着你可以使用 `su` 或图形界面,但不能远程使用 ssh。
我们来试试使用 `su`,记得将大写字母替换为所需的。当要求你输入 PIN,然后触摸设备时,当设备灯闪烁时触摸它:
```
$ su - USERNAME@DOMAIN
Insert your passkey device, then press ENTER.
Enter PIN:
```
如果一切进行顺利,Kerberos 票据也应已被授予,然后你就可以向其他服务进行远程认证:
```
$ klist
Ticket cache: KCM:879400005:34862
Default principal: USERNAME@DOMAIN
Valid starting Expires Service principal
10/20/23 09:46:04 10/21/23 09:32:37 krbtgt/DOMAIN@DOMAIN
```
### 结论
此认证机制的目标是提升安全性。通过使用一种众所周知、开放式的标准实现无密码和多因素认证,从而降低数据泄露和网络钓鱼威胁的风险。用户只需要一个硬件令牌及另外一个如 PIN 或者指纹的认证方式,从而消除对密码的需求,同时提供了方便的多因素认证方法。更进一步,每个应用或服务都使用一个唯一的密钥,这样任何一个应用或服务的数据泄露都不会影响其他的。最后,用户并不需要知道他们的凭据的具体细节,只需了解他们使用了一个实体令牌,这极大地降低了社交工程攻击的可能性。
*(题图:MJ/838d5392-79b4-4c22-ab0f-c2ada4bf2833)*
---
via: <https://fedoramagazine.org/fido2-for-centrally-managed-users/>
作者:[Iker Pedrosa](https://fedoramagazine.org/author/ipedrosa/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 39 enables FIDO2 authentication for centrally managed users with SSSD and FreeIPA. This post introduces the steps to follow to configure and start using it.
## FIDO2
[FIDO2](https://fidoalliance.org/fido2/) is an open authentication standard based on [public-key cryptography](https://en.wikipedia.org/wiki/Public-key_cryptography). It is more secure than passwords and OTPs (one time passwords), and simpler to use. It is usually provided as a hardware security token like a small USB and NFC based device. There are several brands of FIDO compliant keys: YubiKey, NitroKey, SoloKey v2, etc.
Some of the benefits of this protocol are:
- Passwordless authentication by eliminating passwords and using public-key cryptography.
[Multi-factor authentication](https://en.wikipedia.org/wiki/Multi-factor_authentication)(MFA), thus enabling strong authentication.- No password or public key reuse among applications, reducing the risk of a data breach.
- The private key resides in the security token and it never leaves it, which reduces phishing threats.
### Previous articles
There are several articles in Fedora Magazine that show the usage of FIDO2: [how to authenticate a local user using FIDO2](https://fedoramagazine.org/use-fido-u2f-security-keys-with-fedora-linux/) and [how to unlock the hard-drive](https://fedoramagazine.org/use-systemd-cryptenroll-with-fido-u2f-or-tpm2-to-decrypt-your-disk/). This article shows how to use FIDO2 to authenticate a remote user. Note that the devices mentioned above, mainly those from Yubico, implement other protocols. It is not the purpose of this guide to discuss such protocols.
## Centrally managed users
[SSSD](https://sssd.io/) and [FreeIPA](https://freeipa.readthedocs.io/en/latest/) recently implemented a new feature, called [passkey](https://fedoraproject.org/wiki/Changes/Passkey_authentication_centrally_managed_users), to use FIDO2 authentication for centrally managed users. The exact versions that support this feature are [SSSD 2.9.0](https://sssd.io/release-notes/sssd-2.9.0.html) and [FreeIPA 4.11.0](https://www.freeipa.org/release-notes/4-11-0.html). These versions, and the following ones, are the only ones that support this new implementation.
Fedora 39 already includes those versions, and thus, it’s the first distribution to enable FIDO2 authentication for centrally managed users. In addition, a Kerberos ticket is also granted alongside the authentication, this way the user is able to identify themselves to other services.
Note, from now on I will use the terms FIDO2 and passkey interchangeably.
## FIDO2 authentication
### FIDO2 configuration
As an additional security measure MFA should be enabled in the device. This way, if you lose the key a malicious actor won’t be able to use it to authenticate.
List the connected passkey devices:
$ fido2-token -L
Set the PIN for your passkey device (replace the capital letter as required):
$ fido2-token -C /dev/hidrawX
If you have a compatible device you can also enable other factors, e.g. fingerprints.
### Central user configuration
First of all let’s create a user and enable passkey as the authentication method (replace the capital letters as required):
$ ipa user-add USERNAME --first NAME --last SURNAME --user-auth-type=passkey
Or if you already have a user and you only need to select passkey as the authentication method:
$ ipa user-mod USERNAME --user-auth-type=passkey
### FIDO2 registration for centrally managed users
Second, let’s register the passkey for this user. This step prompts you to enter the PIN, and then touch the device:
$ ipa user-add-passkey USERNAME --register Enter PIN: Please touch the device. ------------------------------------ Added passkey mappings to user "USERNAME" ------------------------------------ User login: USERNAME Passkey mapping: passkey:XR/MXigmgiBz1z7/RlWoWZkXKIEf1x9Ux5uPNxtzzSTdTiF407u2nRYMPkK8pWjwUR8Aa2urCcC9cnpLbkKgFg==,MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEZqgERsFFv4Yev1dyo2Ap4PvLirg3P3Uhig5mNA4qf061C9q5rg0nMDz9AOYxZmBrwvQEXHCasMNO9VAIVnBIVg==
Everything is ready for user authentication.
Note, if you are using this user in a production environment I’d recommend you register at least two different devices. This way, if you lose one of the devices, you can authenticate with the other.
### FIDO2 authentication for centrally managed users
In a first round you can only authenticate in a system where the token is physically connected. This means that you can use “su” or the Graphical Interface, but not ssh (at least not remotely).
Let’s use “su”, remembering to replace the capital letters. This prompts you to enter the PIN, and when the device blinks, to touch the it:
$ su - USERNAME@DOMAIN Insert your passkey device, then press ENTER. Enter PIN:
If everything went well, the Kerberos ticket has also been granted, and you are then able to authenticate remotely to other services:
$ klist Ticket cache: KCM:879400005:34862 Default principal: USERNAME@DOMAIN Valid starting Expires Service principal 10/20/23 09:46:04 10/21/23 09:32:37 krbtgt/DOMAIN@DOMAIN
## Conclusion
The objective of this authentication mechanism is to increase security. This is achieved by using a well-known and open standard that enables passwordlessness and MFA, reducing the risk of a data breach and phishing threats. The user only needs the hardware token, and another factor authentication like a PIN and/or a finger to remove the need for passwords, while providing an easy way to use several factors for authentication. Furthermore, each application or service uses a unique key, so that any data breach in one of them does not affect others. Finally, the user isn’t aware of the specific details of their credentials, beyond the fact that they use a physical token, thus greatly reducing any social engineering attack.
## laolux
Great! One more argument to convince the others to speed up our planned migration from nis to freeipa. |
16,408 | EndeavourOS Galileo: 离开 Xfce,拥抱 KDE | https://news.itsfoss.com/endeavouros-galileo/ | 2023-11-24T15:11:42 | [
"EndeavourOS"
] | https://linux.cn/article-16408-1.html | 
>
> 基于 Arch Linux 的发行版 EndeavourOS 在其最新版本中进行了一些有趣的变更。
>
>
>
[基于 Arch Linux 的最佳用户友好型发行版](https://itsfoss.com/arch-based-linux-distros/) 之一,EndeavourOS 现已发布版本更新。
该版本代号为 “<ruby> 伽利略 <rt> Galileo </rt></ruby>”,沿用了我们在过去的版本中见过的类似命名方案,比如 [EndeavourOS “<ruby> 卡西尼 <rt> Cassini </rt></ruby>](https://news.itsfoss.com/endeavouros-cassini/)。(LCTT 译注:伽利略、卡西尼都是著名天文学家,这些名字和这个操作系统的名称“<ruby> 奋进 <rt> Endeavour </rt></ruby>” 也都是航天器的名称。)
让我们来看看 “Galileo” 有什么新特性。
### ? EndeavourOS Galileo: 有些什么新东西?

尽管这个版本花费了一些时间才发布,但这是**一次重大升级,带来了一些重要的变化**。其中最明显的变化是转向了 KDE Plasma,以及放弃了 Xfce,稍后我们将详细讨论这一点。
**开发者决定使 EndeavourOS 比以前更为轻巧**,削减了一些预设设置,但仍然让你可以轻松地入门并使用 Arch Linux。
这个版本的一些**主要亮点**包括:
* 改进了 “欢迎” 应用
* 调整了 Calamares 安装程序
* KDE Plasma 取代 Xfce
#### 改进了 “欢迎” 应用

在安装过程中显示的 “欢迎” 应用已经改进,现在它在左下角具有专门的**语言选择选项**。
图标也已更新,安装程序现在默认使用 KDE Plasma。
#### Calamares 安装程序调整

为了配合 KDE Plasma 成为默认选择,EndeavourOS Galileo 上的 [Calamares](https://calamares.io/) 安装程序**在安装过程中只允许安装一个桌面环境/窗口管理器**。
这是为了减轻安装后出现的冲突软件包问题。**安装完成后,你仍然可以安装其他桌面环境/窗口管理器**。
这还不是全部,**开发者还从安装程序中移除了社区版本**。因此,像 **Sway**、**Qtile**、**BSPWM**、**Openbox** 和 **Worm** 这样的变体无法通过 Calamares 安装了。
之所以不得不放弃这些变体,是因为大多数最初的开发者已经离开了这个项目,也没有其他人接手。幸运的是,**你仍然可以从它们的 [GitHub 页面](https://github.com/EndeavourOS-Community-Editions) 手动安装这些社区版本**。
#### KDE Plasma 取代 Xfce

未来,**KDE Plasma 将成为默认的桌面环境**,运行在立付环境和离线安装上,取代了 Xfce。
不用担心,**在安装 EndeavourOS 的过程中仍然可以选择安装 Xfce**,前面显示的截图就是证明。
正如开发者所述,这一举措背后的原因是:
>
> 为了使团队更容易进行开发和维护,我们转而使用 KDE Plasma 而不是 Xfce,因为对于我们的开发人员来说,使用 Calamares 安装程序能带来更原生的体验。
>
>
>
#### ?️ 其他变化和改进
以下是一些值得注意的其他亮点:
* 在新安装上启用了 **本地主机名解析**。
* 当选择 systemd-boot 时,实施更强大的 **LUKS2 加密**。
* 为了避免错误,对 **EFI 分区的权限** 进行了更严格的限制。
* Calamares 上的 **软件包选择屏幕** 已经重新调整,更加直观。
你可以通过官方的 [公告博客](https://endeavouros.com/news/slimmer-options-but-lean-and-in-a-new-live-environment-galileo-has-arrived/) 了解更多关于 “Galileo” 版本的信息。
### ? 获取 EndeavourOS Galileo
你可以从 [官方网站](https://endeavouros.com/) 获取 EndeavourOS Galileo,他们还**在全球各地添加了新的下载镜像**,以提高访问速度。
>
> **[EndeavourOS Galileo](https://endeavouros.com/)**
>
>
>
### 对现有用户有何影响?
没有。这个版本带来的变化仅影响新安装、安装程序和 ISO 上的立付环境。
**升级到 Galileo 不是强制性的**,定期更新系统的现有用户应该不会出现问题。
? 你对这个版本有什么看法?放弃 Xfce 是一个好主意吗?
---
via: <https://news.itsfoss.com/endeavouros-galileo/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GlassFoxowo-Dev](https://github.com/GlassFoxowo-Dev) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A new release for one of the [top Arch-based user friendly Linux distributions](https://itsfoss.com/arch-based-linux-distros/?ref=news.itsfoss.com), EndeavourOS is here.
Code-named “**Galileo**”, this follows the same naming scheme as we have seen in past releases such as [EndeavourOS 'Cassini'](https://news.itsfoss.com/endeavouros-cassini/).
Let's take a look at what 'Galileo' has to offer.
## 🆕 EndeavourOS Galileo: What's New?
Even though this release took some time to arrive, this is **a major upgrade with some important changes**. The most obvious one being the transition to KDE Plasma, and the dropping of Xfce, more on that later.
**The developers decided to make EndeavourOS leaner than before**, cutting down several pre-settings, but still letting you easily jump start with Arch Linux.
Some **key highlights** of this release include:
**Welcome App Improvements****Calamares Installer Tweaks****KDE Plasma replaces Xfce**
### Welcome App Improvements
The welcome app that shows up while installing has been improved, it now features a dedicated **language selection option** on the bottom left.
The icons were also updated, and the installer now features KDE Plasma by default.
### Calamares Installer Tweaks
In line with KDE Plasma being made the default, the [Calamares](https://calamares.io/?ref=news.itsfoss.com) installer on EndeavourOS Galileo** only allows one desktop environment/window manager to be installed** during the installation process.
This was done in a bid to mitigate the issues arising out of conflicting packages post install. You **can still install other desktop environments/window managers** after the installation is complete.
That's not all, the **developers have also removed community editions from the installer**. So, variants such as **Sway**, **Qtile**, **BSPWM**, **Openbox**, and **Worm** are not available to install via Calamares anymore.
They had to be dropped because most of the original devs have left the project, and no one else picked these up. Luckily, **you can manually install these community editions** from their [GitHub page](https://github.com/EndeavourOS-Community-Editions?ref=news.itsfoss.com).
### KDE Plasma replaces Xfce
Going forward, **KDE Plasma will be used as the default desktop environment** for running on the live environment and the offline install option, replacing Xfce.
Don't worry, **you can still install Xfce during the installation of EndeavourOS**, the screenshot shown earlier is proof of that.
As mentioned by the devs, the reason behind this move was the following:
To make development and maintenance easier for the team, we switched to KDE Plasma instead of Xfce due to a more native experience for our developers with the Calamares installer.
### 🛠️ Other Changes and Improvements
Here are some other highlights worth noting:
**Local Hostname Resolution**is enabled on a new installation.- Implementation of stronger
**LUKS2 encryption**when systemd-boot is selected. - The
**permissions for EFI partition**were made stricter in a bid to avoid bugs. - The
**package selection screen**on Calamares has been restructured to be more intuitive.
You may go through the official [announcement blog](https://endeavouros.com/news/slimmer-options-but-lean-and-in-a-new-live-environment-galileo-has-arrived/?ref=news.itsfoss.com) to learn more about the “Galileo” release.
## 📥 Get EndeavourOS Galileo
This release of EndeavourOS is available from the [official website](https://endeavouros.com/?ref=news.itsfoss.com), they have also **added new download mirrors** around the world for better accessibility.
### Impact on existing users?
No. The changes that have arrived with this release only affect new installs, the installer, and the live environment on the ISO.
**Upgrading to Galileo is not mandatory**, existing users who update their systems regularly should be fine.
*💬 What are your opinions of this release? Was dropping Xfce a good idea?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,409 | Wave:即使你讨厌命令行,也会喜欢的现代新 Linux 终端 | https://news.itsfoss.com/wave-terminal/ | 2023-11-24T16:42:00 | [
"终端",
"VS Code"
] | https://linux.cn/article-16409-1.html | 
>
> 这是 Linux 终端的 VS Code,有可能在年轻一代编程者和 Linux 用户中流行起来。
>
>
>
对于新的终端仿真器的想法,我并不总是怀着兴奋的心情。
这里有 [数不清的用于 Linux 的终端软件](https://itsfoss.com/linux-terminal-emulators/)。从你的 Linux 发行版中自带的默认终端,到古老的经典版——“<ruby> 终结者 <rt> Terminator </rt></ruby>”,或更 “现代化” 的基于 Rust 且支持硬件加速的那种,如 [Rio](https://raphamorim.io/rio/)。
在这儿,可选择的软件绝对不匮乏。对我来说,为什么我需要关注另一个新的终端软件呢?
然而,当我发现这款新的终端时,我觉得,它有着引人瞩目的潜力。

让我来解释下为何我会这么说。对于一名经验丰富的 Linux 用户,终端只不过是执行工作的一种工具。真正的能量来源于命令以及如何运用它们。在这里,终端仿真器吸引人的一点是支持多窗口,这也可以通过熟练使用 CLI 工具,比如 `screen` 或 `tmux` 来实现。
然而,对于一部分 Linux 用户,对他们来说,终端就是一个令人畏惧的地方。他们只会在绝对必要时以及再无他法的情况下才会使用它。就好像一个五岁的小孩夜里去洗手间。
然而,对于后者类型的 Linux 用户来说,这个新终端应该会是一个他们觉得舒适的工具。
看完它的特性后,你就会明白原因。
### Wave:为那些不习惯使用命令行的人设计的终端
呃... 这似乎就是这些开发者的初衷。
[Wave 终端](https://www.waveterm.dev/) 主要是为了那些需要不时使用终端部署他们的项目或者调试应用的应用开发者们所打造。
#### 现代化的代码编辑器界面

没错,这是一个终端,而不是代码编辑器。其界面设计类似于 VS Code,你可以把终端会话分组到工作区中。如果你的项目需要运行开发服务器、测试服务器和生产服务器,你可以把它们分组到一个工作区。
#### 不用学任何键盘快捷键就能编辑文件
你可以直接编辑本地系统或远程机器上的文件。这里没有学习的难度。像常规的文本编辑器一样直接使用它即可。

#### 可以查看 Markdown,JSON 或图片
你可以渲染 Markdown 的预览,美观地显示 JSON 文件或以表格形式显示 CSV 文件数据。你还可以查看图片。

#### 保持 SSH 连接持久化并保有通用历史
另一个赞赏的功能就是 Wave 可以保持你的 SSH 连接持久化。不用担心因为闲置一个小时而从远程服务器断开连接。即使远程系统重启了,它也会自动为你重新连接。
此外,你还可以得到合并的历史搜索的功能。不记得在哪个终端会话中运行了哪条命令?没关系。Wave 在这方面已经帮你考虑好了。
>
> ? 保存并保持 SSH 连接持久化,把它们分组到工作区,并且在图形界面下编辑文件,这些都是一个开发者成为 Wave 终端粉丝的充足理由。
>
>
>
### 我使用 Wave 终端的经历
在使用它几个小时后,以下是我体验。
当我首次启动它时,我看到了一个弹出窗口。它默认开启了遥测功能,这是一个典型的 VS Code 式的功能。好吧,我把它禁用了。

下一个问题是服务条款。你必须接受它,但这个界面实际上没有提供阅读条款的途径。然而我可以在 [他们的网站](https://www.waveterm.dev/tos) 上看到它。它是从 [Basecamp 的开源政策](https://github.com/basecamp/policies/blob/master/terms/index.md) 中引用过来的。
我不明白这个条款的必要性,因为这个软件在 Apache 2.0 下是开源许可的。这只会让人困惑。
无论如何,这就是第一次运行时的界面。如你所见,界面就像一个现代化的代码编辑器,它内含一个侧边栏可以让你将终端标签分组到工作区中。你可以为每个标签分配名称、图标和颜色。这在你需要连接到多个远程服务器时大有帮助。

在这方面,你还可以像经典的 Putty 那样保存你的 SSH 连接。

这样的话,你可以预设某个标签在启动时就开始特定的 SSH 连接。
对我来说最大的问题(如果这可以被称为“问题”)是输入字段。这只是底部的一个小输入框。你在这输入命令,它显示输出信息,整个输入命令及其输出都被组成一个框,然后移到上方。

我更习惯于经典的终端输入方式,从上开始输入,然后一行行向下移动(然后滚动)。而在这里,却恰恰相反。
看,这是有意为之的。每条命令及其输出都是一个独立的框,一个独立的元素。你可以复制它、最小化它或从视图中将其存档。
#### 切片面包之后的最好东西
Wave 终端最大的目标就是它让你不会感觉自己在终端里。对于在终端中编辑文件的初学者来说,这就是他们的阿喀琉斯之踵。即使是在终端中使用基础编辑器(比如 Nano),那也要有一段学习曲线。
但是 Wave 不同。它内置了一个编辑器,你可以用 `codeedit filename` 命令调用,你就能像在图形文本编辑器中那样编辑文件。没错,你可以随意地使用你的鼠标。你还可以从编辑器菜单中选择文件类型。

对于在终端中编辑配置文件感到提心吊胆的人来说,这绝对是个天赐福音。
开发者经常需要处理 Markdown 和 JSON 文件。Wave 终端完全有能力渲染这些文件。

SSH 的连接是永久的。再也不用厌烦地频繁从远程服务器上断开连接了。Wave 完美地处理了它。
你可以从其 [文档页面](https://docs.waveterm.dev/quickstart) 进一步探索它的特性。
### 在 Linux 上安装 Wave 终端
你可以直接从他们的网站上下载 zip 文件。
>
> **[下载 Wave](https://www.waveterm.dev/download)**
>
>
>
解压它后,你会发现,它有一个命名为 `Wave` 的可执行文件,这个文件可以用来启动应用程序。

试试它,如果你喜欢它,那就把整个文件夹移到 `/opt` 目录,为它创建一个新的桌面文件,这样它在系统菜单中就可以被搜索到了。我目前就不详述了。
现在还没有像 deb/rpm 这样针对某些特定发行版的安装文件。目前也暂时没有 Snap 或 Flatpak 的包。这是一个新应用。给它一些时间。
源代码在 GitHub 上可供参考。如果你喜欢,能够给它打一个星标。
>
> **[Wave Terminal 的 GitHub 仓库](https://github.com/wavetermdev/waveterm)**
>
>
>
### 总结
如你所见所觉,这是一个为应用开发者所创造出来的应用程序 —— 那些在编程上花费更多时间,并且需要通过命令行来部署或调试他们的应用的人。
从设计上就看得出,这款产品是为 macOS 用户量身定做的。从界面到键盘快捷键,每一样都带有 macOS 的气息。
但是没关系。只要 Wave 在 Linux 上可用,那对 Linux 用户来说就不重要了。
我只希望它不会转为闭源且成为将来的付费工具。如果真的那样,那的确很扫兴。
---
via: <https://news.itsfoss.com/wave-terminal/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Not every day I get excited about the idea of a new terminal emulator.
There are [tons of terminals available for Linux](https://itsfoss.com/linux-terminal-emulators/?ref=news.itsfoss.com). From the default one that comes with your distribution to the classic of yore, terminator or the more 'modern' Rust-based, hardware accelerated ones like [Rio](https://raphamorim.io/rio/?ref=news.itsfoss.com).
There is no dearth of choices here. Why should I care about one more addition to the long list?
And yet, when I came across this new terminal, I got the feeling that it has the potential to go big.
Hear me out on why I say that. For a seasoned Linux user, the terminal is just a tool to get things done. The main power lies with the commands and how they are used. The one thing that attracts here is the ability to have multiple windows and that too can be achieved by mastering CLI tools like screen or tmux.
But there is a population of Linux users for whom the terminal is a scary place. They go there only when it is absolutely necessary and there is no alternative. Like a five-year-old child going to the washroom at night.
And this new terminal should be a comfortable tool for this second type of Linux user.
You will understand why I say that after you learn its features.
## Wave: A terminal for those who are not comfortable with the command line
Well... that's what the developers seem to have in mind here.
[Wave terminal](https://www.waveterm.dev/?ref=news.itsfoss.com) is created primarily for application developers who have to use the terminal every now and then to deploy their project or troubleshoot their application.
### Moder code editor like interface
Yes, that's a terminal, not a code editor. The interface is like VS Code where you can group terminal sessions into workspaces. Working on a project that has a dev server, a test server and a production server, group them in a workspace.
### Edit files without mastering any keyboard shortcuts
You can edit files inline, be it on your local system or the remote machine. And there is no learning curve here. Just use it like a regular text editor.
### View Markdown, JSON or images
You can render Markdown preview, pretty display JSON files or display CSV files data in tabular format. You can also view images.
### Persistent SSH connections and universal history
Another awesome feature is that Wave gives you persistent SSH connections. Don't worry about getting disconnected from the remote server because you were idle for an hour. It will automatically connect you, even if the remote system reboots.
You also get the feature of combined history search. Don't remember which command you run in which terminal session? No problem. Wave has got your back there.
## My experience with Wave terminal
Here's what I feel after using it for a couple of hours.
When I started it, I was greeted with a pop screen. It had telemetry enabled by default. Classic VS Code like feature. Fine, I disabled it.
The next hiccup is the terms of service. You have to accept it, but there is no way to actually read the terms on this screen. However, I can see it on [their website](https://www.waveterm.dev/tos?ref=news.itsfoss.com). It's been adopted from the [Basecamp open source policies](https://github.com/basecamp/policies/blob/master/terms/index.md?ref=news.itsfoss.com).
I really don't see the need for this when the software is open source licensed under Apache 2.0. It is just going to confuse people.
Anyway, this is what the interface looked like in the first run. As you can see, the interface is like a modern code editor with a sidebar that allows you to group terminal tabs in workspaces. You can assign name, icons and colors to each tab. This is helpful if you connect to multiple remote servers.
In that regard, you can also save your SSH connections in the classic Putty style.
This way, you can preconfigure a certain tab to start with a particular SSH connection.
The main trouble for me (if I can call it that) is with the input field. It's a tiny input box at the bottom. You enter the command and it shows the output as the entire command and its output are grouped into a box and moved up.
I am used to the classic terminal input style where things start at top and then move towards bottom. Here, it is the opposite.
See, that's intentional. Each command and its output is a separate box, a separate element. You can copy it, minimize it or archive it from the view.
### The best thing after sliced bread
The biggest promise of Wave terminal is that it doesn't make you feel like you are in the terminal. The Achilles heel for beginners is editing files in the terminal. Even the simplest of the terminal-based editor (read Nano) has a learning curve.
But not Wave. It has a built-in editor that can be invoked with `codeedit filename`
command, and you get to edit the file the same way you do in a graphical text editor. Yes, you can use your mouse as freely. You may also specify the file type from the menu in the editor.
For a person who gets cold feet while editing config files in the terminal, this is a god-send feature.
A developer often has to deal with Markdown and JSON files. Wave terminal is perfectly capable of rendering these files.
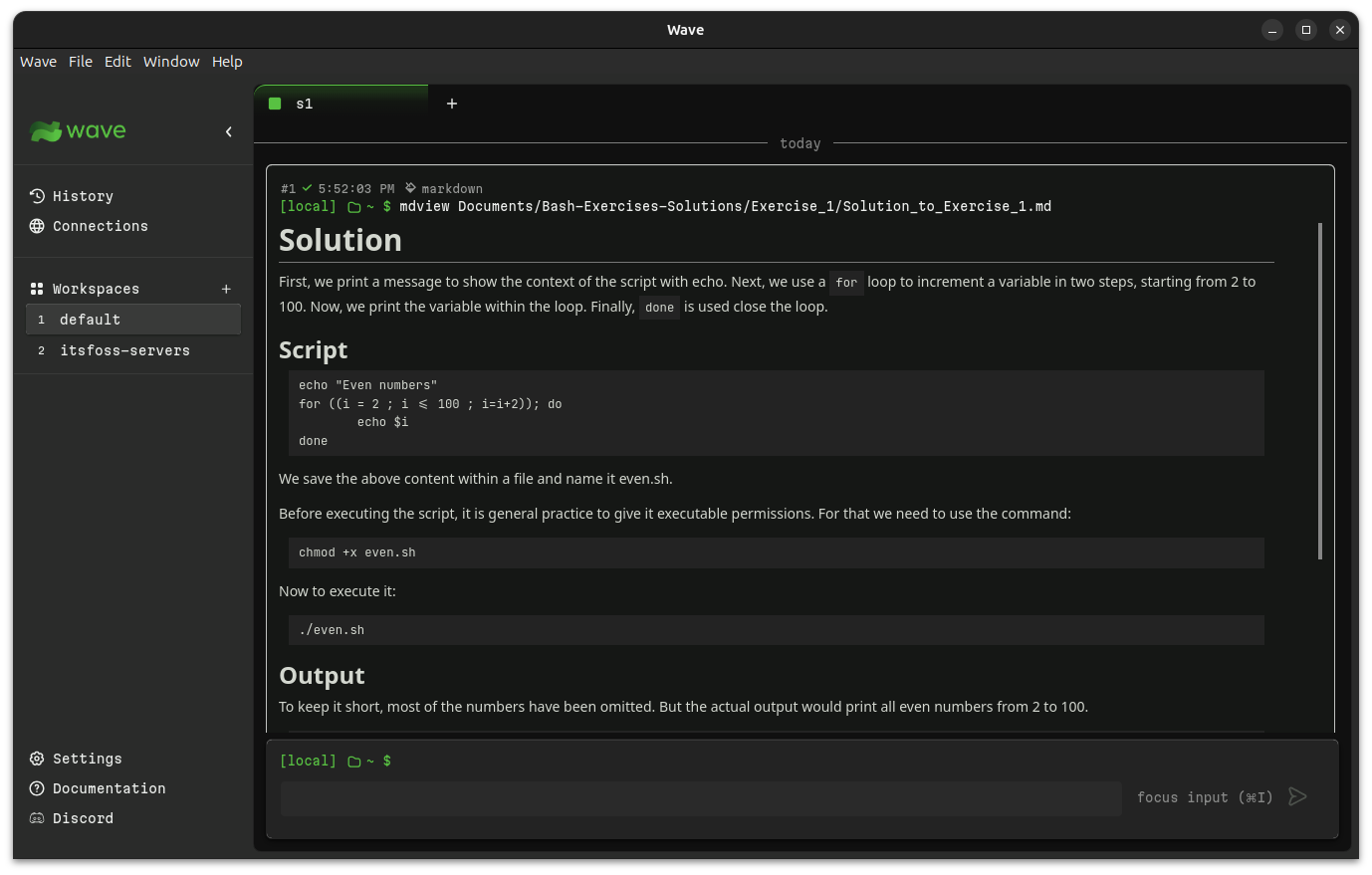
And the SSH connections are persistent. Forget about being disconnected from remote server time and again. Wave handles it perfectly.
You can further explore its features from its [documentation page](https://docs.waveterm.dev/quickstart?ref=news.itsfoss.com).
[Quickstart - Wave TerminalAfter downloading Wave, you can use it immediately](https://docs.waveterm.dev/quickstart?ref=news.itsfoss.com)

## Installing Wave terminal on Linux
You can download the zip from their website.
Extract it, and you'll see that it has an executable file named `Wave`
that can be run to launch the application.
Play around with it and if you like it enough, move the entire folder to the /opt directory, create a new desktop file for it so that it can be searchable in the system menu. I won't go in those details for the moment.
There are no distro-specific installer files like deb/rpm. Snap and Flatpak packages are also not present for the moment. It's a new application. Give it some time.
The source code is available on GitHub. Check it out and give it a star if you like it.
## Conclusion
As you can see and feel, this is a tool created for application developers. People who spend more time on coding and have to deal with the command line for deploying their applications or debugging them.
Furthermore, It is evident that it is crafted for macOS users. The interface, keyboard shortcuts, everything screams macOS.
But that's okay. It should not matter to the Linux users as long as Wave is available on Linux.
I just hope that it doesn't go closed source and become a paid tool in the future. If that happens, it would be a bummer.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,411 | 终端基础:在 Linux 中重命名文件和目录 | https://itsfoss.com/linux-rename-files-directories/ | 2023-11-24T21:55:00 | [
"终端",
"命令"
] | https://linux.cn/article-16411-1.html | 
>
> 在这篇基本命令行教程中,你将学习在 Linux 终端重命名文件和目录的各种方法。
>
>
>
如何在 Linux 终端中重命名文件和目录?你可以使用 `mv` 命令。
是的,与用于将文件和文件夹从一个位置“移动”到另一个位置的 `mv` 命令相同。
你可以在“移动文件和目录”时简单地指定文件和目录的新名称。
要重命名文件,请使用:
```
mv old_file new_file
```
同样,要重命名目录,请使用:
```
mv old_dir new_dir
```
听起来很容易,对吧? 但我将在这里详细讨论文件重命名:
* 向你展示重命名的实际示例
* 显示通过结合 `find` 和 `exec` 命令批量重命名多个文件的示例
* 讨论用于批量重命名文件的专用程序
我们来一一看看。
### 使用 mv 命令重命名文件和目录
使用 `mv` 命令重命名同一目录中的文件:
```
mv file1.txt file2.txt
```
同样,你可以重命名同一位置的目录:
```
mv dir1 dir2
```
这是我重命名文件和目录的示例:

如你所见,与 [cp 命令](https://itsfoss.com/cp-command/) 不同,你不必使用递归选项来通过 [mv 命令](https://linuxhandbook.com/mv-command/) 处理目录。
>
> ? 如果你尝试使用相同的名称重命名该文件,你会看到一个错误(显然)。
>
>
>
你还可以在将文件移动到另一个位置时重命名它:
```
mv old-file-name another_dir/new-file-name
```
在下面的示例中,我将名为 `firefox-quiz.txt` 的文件移动到示例目录。在这样做的同时,我将其重命名为 `quiz.txt`。

我将其视为剪切粘贴操作。
>
> ? 虽然你可以将多个文件移动到另一个位置(`mv file1 file2 file2 dir`),但你不能使用 `mv` 重命名多个文件。为此,你必须采用我在以下部分中讨论的其他策略。
>
>
>
### 通过组合 mv、find 和 exec 命令重命名与某个模式匹配的多个文件
>
> ? 批量重命名此类文件时要格外小心。一步错误的举动就会导致无法挽回的不良结果。
>
>
>
`find` 命令用于根据文件名、类型、修改时间和其他参数在给定目录中查找文件。[exec 命令与 find](https://linuxhandbook.com/find-exec-command/) 结合使用,对 `find` 命令的结果执行命令。
使用 `find`、`exec` 和 `mv` 命令没有固定标准的结构。你可以根据需要组合它们。
假设你想通过在名称中添加 `_old` 来重命名当前目录中以 `.txt` 结尾的所有文件。所以 `file_1.txt` 变成 `file_1.txt_old` 等等。
```
find . -type f -name "*.txt" -exec mv {} {}_old ;
```

这只是一个示例,你的重命名要求可能会有所不同。另外,**以上仅适用于不带空格的文件名**。
**专业提示**:在处理这样的批量操作时,你可以巧妙地使用 `echo` 命令来查看将执行什么操作,而不是实际执行它。如果看起来不错,那就采取实际行动吧。
例如,首先查看哪些文件将被重命名:
```
find . -type f -name "*.txt" -exec echo mv {} {}_old \;
```

如你所见,实际上没有重命名任何文件。但是,如果你在没有使用回显(`echo`)命令的情况下运行上述命令,你将看到将执行什么命令。
如果你觉得没问题,请删除 `echo` 命令并继续进行实际的重命名。
```
find . -type f -name "*.txt" -exec mv {} {}_old \;
```
我在 《Efficient Linux 命令行》一书中学到了这个技巧。一本充满了这样的小宝石的优秀书。难怪它已成为 [我最喜欢的 Linux 书籍](https://itsfoss.com/best-linux-books/)之一。
### 使用 rename 命令轻松重命名多个文件
有一个名为 `rename` 的便捷命令行程序,可用于根据给定的 Perl 正则表达式模式批量重命名文件。
该实用程序不是 GNU 工具链的一部分,也不是预安装的。因此,你必须首先使用发行版的包管理器来安装它。
对于 Debian/Ubuntu,命令为:
```
sudo apt install rename
```
你可以通过以下方式使用它:
```
rename [options] perl_regex [files]
```
选项有:
* `-v` : 详细模式
* `-n` :无操作,显示将被重命名的文件,但不重命名它们
* `-o` : 不覆盖
* `-f` : 强制覆盖现有文件
* `-s` : 不重命名软链接,只重命名其目标
现在,让我们采用你在上一节中看到的相同示例。将 `*.txt` 重命名为 `.txt_old`。
```
rename 's/\.txt$/.txt_old/' **
```
我不打算在这里解释正则表达式。`**` 表示查看所有子目录中的所有文件。

正如你所看到的,它按预期工作。
### 总结
我希望你喜欢这个技巧,它可以帮助你学习在 Linux 命令行中执行基本任务。当然是针对那些想学习和使用命令行的人。桌面用户始终拥有用于此类任务的 GUI 工具。
如果你对 Linux 命令完全陌生,本系列将对你有很大帮助。
>
> **[终端基础:Linux 终端入门](/article-16104-1.html)**
>
>
>
如果你有疑问或建议,请告诉我。
---
via: <https://itsfoss.com/linux-rename-files-directories/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

How do you rename files and directories in the Linux terminal? You use the mv command.
Yes, the same mv command which is used for 'moving' files and folders from one location to another.
You can simply specify the new name for the files and directories while 'moving them'.
To rename a file, use:
`mv old_file new_file`
Similarly, to rename a directory, use:
`mv old_dir new_dir`
Sounds easy, right? But I'll discuss renaming of files in detail here:
- Show you practical examples of renaming
- Show example of bulk renaming multiple files by combining the find and exec command
- Discuss a dedicated rename utility for batch renaming files
Let's see it one by one.
## Renaming files and directories with mv command
Use the mv command to rename a file in the same directory:
`mv file1.txt file2.txt`
Similarly, you can rename a directory in the same location:
`mv dir1 dir2`
Here's an example where I rename a file and a directory:
As you can see, unlike the [cp command](https://itsfoss.com/cp-command/), you don't have to use the recursive option for handling directories with [mv command](https://linuxhandbook.com/mv-command/).
You may also rename a file while moving it to another location:
`mv old-file-name another_dir/new-file-name`
In the example below, I moved the file named `firefox-quiz.txt`
to the sample directory. And while doing that, I renamed it `quiz.txt`
.
I think of it as the cut-paste operation.
## Renaming multiple files matching a pattern by combining mv, find and exec commands
The find command is used for finding files in the given directory based on their name, type, modification time and other parameters. The [exec command is combined with find](https://linuxhandbook.com/find-exec-command/) to execute commands on the result of the find command.
There is no set, standard structure to use find, exec and mv commands. You can combine them as per your need.
Let's say you want to rename all the files ending with `.txt`
in the current directory by adding `_old`
in its name. So `file_1.txt`
becomes `file_1.txt_old`
etc.
`find . -type f -name "*.txt" -exec mv {} {}_old ;`
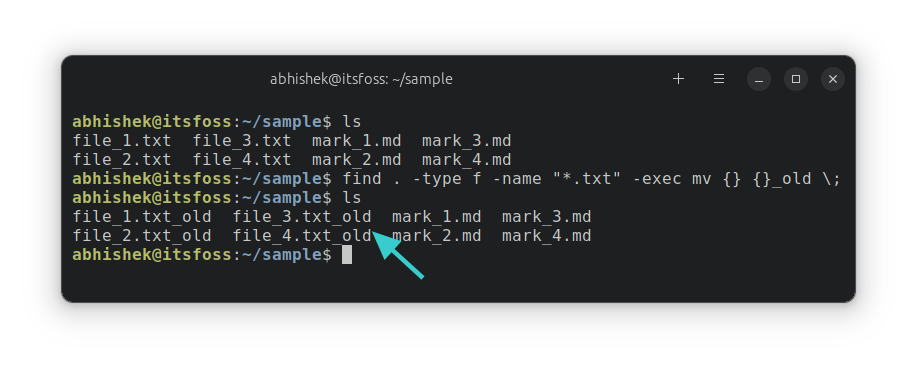
This is just an example and your renaming requirements could be different. Also, **the above works with filenames without spaces only**.
**Pro Tip**: When dealing with bulk actions like this, you can smartly use the echo command to see what action will be performed instead of actually performing it. If it looks alright, then go with the actual action.
For example, first see what files will be renamed:
`find . -type f -name "*.txt" -exec echo mv {} {}_old \;`
As you can see, no files were actually renamed. But you get to see what command will be the action if you run the above command without echo.
If it looks alright to you, remove the echo command and proceed with actual renaming.
`find . -type f -name "*.txt" -exec mv {} {}_old \;`
I learned this trick in the Efficient Linux at the Command Line book. An excellent book filled with small gems like this. No wonder it has become one of [my favorite Linux books](https://itsfoss.com/best-linux-books/).

#### New Book: Efficient Linux at the Command Line
Pretty amazing Linux book with lots of practical tips. It fills in the gap, even for experienced Linux users. Must have in your collection.
[Get it from Amazon](https://amzn.to/3MPjiHw)
## Renaming multiple files easily with the rename command
There is a handy command line utility called rename which could be used for batch renaming files based on the given Perl regex pattern.
This utility is not party of GNU toolchain and neither it comes preinstalled. So you have to use your distribution's package manager to install it first.
For Debian/Ubuntu, the command would be:
`sudo apt install rename`
You can use it in the following manner:
`rename [options] perl_regex [files]`
The options are:
- -v : Verbose mode
- -n : No action, show the files that would be renamed but don’t rename them
- -o : No overwrite
- -f : Force overwrite existing files
- -s : Don't rename the soft link but its target
Now, let's take the same example that you saw in the previous section. Renaming the *.txt to .txt_old.
`rename 's/\.txt$/.txt_old/' **`
I am not going to explain the regex here. The `**`
means to look into all files in all subdirectories.
And as you can see, it works as expected.
[Read more](https://oylenshpeegul.typepad.com/blog/2011/12/a-tale-of-two-renames.html)about it.
## Conclusion
I hope you liked this tip that helps you learn to do basic tasks in the Linux command line. Of course, it is for those who want to learn and use the command line. Desktop users always have the GUI tools for such tasks.
If you are absolutely new to Linux commands, this series will help you a great deal.
[Getting Started With Linux TerminalWant to know the basics of the Linux command line? Here’s a tutorial series with a hands-on approach.](https://itsfoss.com/linux-terminal-basics/)

Let me know if you have questions or suggestions. |
16,412 | 8 个提升你的隐私防护的开源密码管理器 | https://itsfoss.com/open-source-password-managers/ | 2023-11-25T08:52:00 | [
"密码",
"密码管理器"
] | https://linux.cn/article-16412-1.html | 
>
> 使用一些顶级开源密码管理器,确保你的登录凭证安全无虞。
>
>
>
密码管理器是一项非常有用的实用程序。在你想寻找一个合适的密码管理器时,有着丰富的选择。
你的智能手机制造商、浏览器、抗病毒软件都会提供密码管理器,并且还有其他多种第三方的选项。根据你的实际需求和便利性,你可以选择使用任何一款密码管理器。
但是,如果你偏爱开源的密码管理器,想要尝试使用开源的替代私有的?你有哪些选择呢?
这里,让我来为你揭示所有重要的信息。
### 为何选择开源的密码管理器?
密码管理器是一种关键的工具,它能存储各种敏感的数据,包括:
* 账号凭据
* 安全笔记
* 恢复代码
* 2FA 令牌(某些情况下)
因此,使用一款能提供顶级隐私保护和安全性的密码管理器极为重要。
而选择开源选项,你将得到更好的透明度,并将有更多的人共同努力确保密码管理器的安全。
当然,如果你希望参与贡献、审查和改进密码管理器,你需要具备一定的技术能力。但是,即使你没有时间参与进来,用户和开发者社区依然会努力核实产品所做出的承诺。
这就是使用开源密码管理器所获得的优势。
对于私有的解决方案,你需要完全信任产品公司,而且你无法自行验证他们的声明。
考虑到选择安全工具的利弊,我在此为你推荐一些最受用户欢迎的密码管理器。
### 1、KeePass

[KeePass](https://keepass.info/) 是一款为 Windows 用户提供的卓越的开源密码管理器。你还可以试试 [利用 Wine 在 Linux 环境中运行这款 Windows 应用](https://itsfoss.com/use-windows-applications-linux/)。
这是一个纯本地的密码管理器,允许你将所有密码保存在一个数据库中。数据库经过加密,并设有主密钥保护(要牢记密钥,避免遗失)。
你可以根据需要,自主决定是否将数据库文件同步到任何选定的云存储中。但一般来说,将数据保存在自己的系统上,比存储在云端更为安全。
你既可以选择安装 KeePass,也可以通过 USB 设备运行它的便携版。此外,它还具备众多实用的功能,如附加附件、排序和导入导出等等。
亮点:
* 仅限本地使用
* 可用的便携版
* 支持导入 / 导出功能
* 可通过分组 / 排序管理密码
* 插件可用于增强功能集
### 2、Bitwarden

[Bitwarden](https://bitwarden.com/) 是一款强大、跨平台的密码管理器,涵盖了桌面应用程序和浏览器扩展。它与 KeePass 不同的之处在于,Bitwarden 依赖云端进行密码的加密和存储,大大提高了在多终端之间同步数据的便捷性。
Bitwarden 集成了你在密码管理器中可能需要的所有核心功能,而且对个人用户来说,所有的这些功能都有一个可承受的订阅价格。
你将得到一个使用起来更舒适的用户界面,并有众多功能供你使用。
亮点:
* 浏览器扩展和桌面应用
* 移动应用
* 提供自托管或基于云端的选项
* 支持命令行界面访问
* 对高级用户开放的紧急访问权限
* 价格适中
* 支持导入 / 导出功能
* 提供 Bitwarden Send 功能,安全分享文本 / 笔记
### 3、Proton Pass

[Proton Pass](https://proton.me/pass) 是以隐私保护为核心的 Proton 公司提供的优秀产品之一。
如果你已经在使用 Proton Mail 和 Proton VPN,并且希望从同一家值得信赖的公司使用多种服务,那么 Proton Pass 将是一个很好的选择。
你可以安装浏览器插件来开始使用 Proton Pass。在本文撰写时,它并未提供任何桌面应用程序。
除了所有基本功能外,你还可以在密码管理器内部使用电子邮件别名功能。随着 Proton Pass 的多样性,我们也提供了一个深入的 [Proton Pass 和 Bitwarden 的比较](https://itsfoss.com/bitwarden-vs-proton-pass/)。
亮点:
* 浏览器插件
* 基于云
* 移动应用
* 作为 Proton 工具系列的一部分,使用起来非常方便
* 邮件别名
* 支持导入 / 导出
### 4、KeePassXC

如果你对 KeePass 的功能感兴趣,并且需要原生的 Linux 支持,那么 [KeePassXC](https://keepassxc.org/) 会是个不错的选择。
你将获得跨平台支持和浏览器扩展支持,无需依赖于插件。
总的来说,KeePassXC 可以视为 KeePass 的现代化替代版本,对用户体验进行了一些改善。
亮点:
* 仅支持离线
* KeePass 的现代替代
* 原生支持 Linux 和 macOS
* 支持导入 / 导出
### 5、Passbolt
[Passbolt](https://www.passbolt.com/) 是一个为企业用户(或团队)设计的开源密码管理器。
不同于其他选择,Passbolt 不适合个人使用。你可以选择自我托管,或选择云托管版本,并根据你的实际需求选择适当的订阅方案。
尽管在社区版中,Passbolt 提供了所有基础的功能,但通过订阅计划你可以解锁更多的功能。
亮点:
* 专为企业和团队定制
* 自托管或基于云
* 支持命令行界面访问
### 6、Buttercup

如果你在寻找一款优先考虑本地使用的密码管理器,那么[Buttercup](https://buttercup.pw/) 就是一个针对 macOS、Linux 和 Windows 的理想选择。
如果你不需要云同步功能,但希望寻找一款与 KeePass 用户体验不同的密码管理器,那么 Buttercup 将是一个好的替代品。
这是一个带有简洁用户界面的跨平台开源密码管理器,同时提供了移动应用程序。
亮点:
* 仅支持离线使用
* 易用性强
* 兼容多平台
* 界面简洁现代
* 提供扩展支持
### 7、KWalletManager

[KWalletManager](https://apps.kde.org/kwalletmanager5/) 是一款 [专为 Linux 设计的密码管理器](https://itsfoss.com/password-managers-linux/),可对所有的用户凭证进行加密存储。
虽然它能在任何桌面环境下工作,但如果你使用的是 KDE 驱动的 Linux 系统,它能更好地与其他应用集成。
如果你需要一个能与应用程序集成、实现从 Linux 系统保存或自动填充密码的工具,KWalletManager 是个不错的选择。在某些情况下,它可能已经预装在 Linux 发行版中。如果你不打算使用 KWallet,应[禁用 KDE 钱包](https://itsfoss.com/disable-kde-wallet/)。
亮点:
* 仅支持离线使用
* 简单易用
* 专为 Linux 定制
### 8、密码和密钥(即 GNOME 的 Seahorse)

Seahorse 是 GNOME 发展出的一个实用工具,能存储密码并管理加密密钥。与 KWallet 类似,它是一款专为 Linux 设计的应用程序,与 Ubuntu 和其他几种发行版一起预装。
它不仅仅是一个传统的密码管理器,它还提供了许多其他功能,并且所有这一切都封装在了一个简洁的用户界面中。
亮点:
* 仅支持离线使用
* 专为 Linux 定制
* 可管理加密密钥和密码
### 总结
任何一款密码管理器都包含了全部的基础功能。因此,你需要根据具体的情况来做选择,比如是否支持自我托管、是否有紧急的共享访问,以及根据价格计划来决定所需的功能集等。
如果你需要一款以浏览器中心化的密码管理器,Proton Pass 就是不错的选择。而 KeePass 以及它的现代化版本 KeePassXC 是完美的离线工具。Bitwarden 则是全能解决方案。最后,Buttercup 和 Passbolt 对于那些希望体验最小化或需要团队协作功能的用户来说,也是独特的选择。
*(题图:MJ/8d97ac3c-1ed9-4dae-a176-03d99e6e8391)*
---
via: <https://itsfoss.com/open-source-password-managers/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Password manager is an incredibly helpful utility, and there's no shortage of options when finding one.
Your smartphone manufacturer offers one, the browser offers another, antivirus applications include one, and then there are other third-party offerings. You can choose to use any password manager of your choice as per your convenience.
But, what if you prefer open-source password managers? Should you give them a try over proprietary ones? What are the options you have?
Here, let me highlight all the essentials.
## Why Should You Pick an Open-Source Password Manager?
A password manager is a critical utility which stores sensitive data, including:
- Account credentials
- Secure notes
- Recovery codes
- 2FA tokens (in some cases)
So, it is important to use a password manager offering the best privacy and security.
And, with an open-source option, you get better transparency and more people to work together to keep the password manager secure.
Sure, if you want to contribute, review, and improve the password manager, you need a bit of technical skills. But, even if you do not have the time to do anything, the community of users and other developers will try to verify the claims by the company.
That is the advantage you get with an open-source password manager.
With a proprietary solution, you will have to trust the company, and will have no other way to verify the claims from your side.
Considering the benefits of choosing an open-source tool for security, I have picked some of the most loved password managers for all kinds of users.
## 1. KeePass
[KeePass](https://keepass.info) is an impressive open-source password manager for Windows users. You can try [running the Windows app on Linux using Wine](https://itsfoss.com/use-windows-applications-linux/).
It is a local-only password manager where you store all your passwords in one database. The database is encrypted and protected with a master key that you set (do not forget it).
Of course, you can decide to sync the database file on any cloud storage of your choice (only if you require it). Otherwise, it is more secure to have your data on your system than on the cloud.
You can pick to install KeePass or use the portable version through a USB stick. It features many useful functionalities like adding attachments, sorting, the ability to import and export, and many more.
**Highlights:**
- Local-only
- Portable version available
- Import/export supported
- Password organization through groups/sorting
- Plugins to enhance feature set
## 2. Bitwarden
[Bitwarden](https://bitwarden.com) is a flexible password manager available cross-platform, including desktop apps and browser extensions. Unlike KeePass, it relies on the cloud to encrypt and store passwords, which makes it convenient to sync data between various devices.
It packs in every essential feature you might need with a password manager, and all of it for an affordable subscription plan for personal users.
You get a simpler user interface with a plethora of features to utilize.
**Highlights:**
- Browser extensions and desktop apps
- Mobile apps
- Self-host or Cloud-based
- CLI access
- Emergency access for premium users
- Affordable pricing
- Import/Export support
- Bitwarden Send to securely share text/notes
## 3. Proton Pass
[Proton Pass](https://go.getproton.me/aff_c?offer_id=38&aff_id=1173) is one of the excellent offerings by the privacy-focused company Proton.
If you are fond of using Proton Mail, Proton VPN, and want to use services from a single company that you trust, Proton Pass should be a convenient option.
You can install the browser extensions to start using Proton Pass. At the time of writing this, it does not support any desktop apps.
In addition to all the essential features, you get the ability to use email aliases from within the password manager. Proton Pass sounds like a versatile open-source privacy tool. We also have an in-depth [comparison between Proton Pass and Bitwarden](https://itsfoss.com/bitwarden-vs-proton-pass/).
**Highlights:**
- Browser extensions available
- Cloud-based
- Mobile apps
- Convenient option as part of Proton's family of tools
- Email aliases
- Import/Export support
**Suggested Read 📖**
[Bitwarden vs. Proton Pass: What’s The Best Password Manager?What is your favorite open-source password manager?](https://itsfoss.com/bitwarden-vs-proton-pass/)

## 4. KeePassXC
If you like what KeePass has to offer, and require native Linux support, [KeePassXC](https://keepassxc.org) is a good pick.
You get cross-platform support and browser extension support without relying on a plugin.
Overall, KeePassXC can be a modernized alternative to the original KeePass, with some refinements to the user experience.
**Highlights:**
- Offline-only
- A modern alternative to KeePass
- Native Linux and macOS support
- Import/Export support
## 5. Passbolt
[Passbolt](https://www.passbolt.com) is an open-source password manager for business users (or teams).
Unlike other options, it is not fit for personal use. You can choose to self-host it, or opt for its cloud hosted version, with a subscription that suits your requirements.
While it offers the essentials with its community edition, you unlock more features with its subscription plans.
**Highlights:**
- Tailored for businesses and teams
- Self-host or Cloud-based
- CLI access
## 6. Buttercup
[Buttercup](https://buttercup.pw) is another local-first password manager available for macOS, Linux, and Windows.
If you do not want cloud syncing but looking for a different user experience to KeePass, Buttercup is a nice alternative.
It is a minimal open-source password manager with cross-platform support, and mobile apps.
**Highlights:**
- Offline-only
- Easy to use
- Cross-platform
- Modern and minimal user interface
- Extension support
## 7. KWalletManager
[KWalletManager](https://apps.kde.org/kwalletmanager5/) is a [Linux-specific password manager](https://itsfoss.com/password-managers-linux/) that encrypts and stores all your credentials.
While it works on any desktop environment, it should integrate well with other applications better with a KDE-powered Linux distribution on your system.
If you were looking for a tool to integrate with applications, save/autofill passwords from within the Linux system, KWalletManager is an impressive pick. In some cases, it will be pre-installed with the Linux distribution. You would have to [disable the KDE wallet](https://itsfoss.com/disable-kde-wallet/) if you do not need it.
**Highlights:**
- Offline-only
- Simple and easy to use
- Tailored for Linux
## 8. Passwords and Secrets (a.k.a. Seahorse by GNOME)
Seahorse is a utility developed by GNOME to store passwords and manage encryption keys. Similar to KWallet, it is a Linux-specific application which comes pre-installed with Ubuntu and some other distributions.
It is not your traditional password manager but more, and all of that in a simple user interface.
**Highlights:**
- Offline-only
- Tailored for Linux
- Manager encryption keys and passwords
## Wrapping Up
No matter the pick, you get all the essentials in every password manager. So, you need to focus on the specifics like the ability to self-host, emergency sharing access, and feature-set for the pricing plan to decide.
Proton Pass should be a good browser-focused password manager, while KeePass and its modern fork are perfect offline utilities. Bitwarden is an all-in-one solution. Finally, Buttercup and Passbolt are unique choices for users who want a minimal experience or features for collaboration. |
16,414 | 如何在 Fedora 上安装 VSCodium | https://itsfoss.com/install-vscodium-fedora/ | 2023-11-26T13:46:16 | [
"VSCodium",
"VS Code"
] | https://linux.cn/article-16414-1.html | 
>
> VSCodium 是微软 VS Code 真正开源的版本,它可以轻松安装在 Fedora 上。具体方法如下。
>
>
>
Visual Studio Code(VS Code)是微软开发的一款流行的跨平台文本编辑器。它基于 Electron 框架构建,被开发人员广泛用于编码和文本编辑任务。VS Code 的核心,称为 “Code - OSS”,是开源的,并在 MIT 许可证下分发。然而,微软添加了特定的自定义功能,并在专有许可下发布了其品牌版本的编辑器。
为了解决有关 [遥测](https://code.visualstudio.com/docs/getstarted/telemetry) 和许可的问题,有一个名为 “[VSCodium](https://itsfoss.com/vscodium/)” 的替代方案,它是社区驱动、禁用遥测且获得 MIT 许可的 VS Code 版本。

在本教程中,我将指导你完成在 Fedora Linux 系统上安装和运行 VSCodium 的过程。
有三种方法可以做到这一点:
1. 从发布页面下载 rpm 文件进行安装。但是,你需要重复该过程才能更新软件包(这可能会令人沮丧)。
2. 添加 [paulcarroty](https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo) 仓库(如 [VSCodium](https://vscodium.com/) 网站所述)。因此,当你 [更新你的 Fedora 系统](https://itsfoss.com/update-fedora/) VScodium 也会得到更新(这是相当无缝的)。
3. 使用 flatpak 版本,你可能已经尝试过从 GNOME “软件”中安装该版本(我有过同样的糟糕经历,因此可能会有所不同)。
第一个非常简单,即从 [发布页面](https://github.com/VSCodium/vscodium/releases) 下载并 [安装 RPM 文件](https://itsfoss.com/install-rpm-files-fedora/)。那么,让我们切入主题并遵循其他两种方法。
### 方法 1:通过添加仓库来安装 VSCodium
打开终端:你可以通过在应用菜单中搜索 “Terminal” 来打开终端。
添加 GPG 密钥:以便包管理器信任仓库的打包者。
```
sudo rpmkeys --import https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo/-/raw/master/pub.gpg
```
添加 VSCodium 仓库:以下命令会将仓库添加到你的 Fedora 系统。
```
printf "[gitlab.com_paulcarroty_vscodium_repo]\nname=download.vscodium.com\nbaseurl=https://download.vscodium.com/rpms/\nenabled=1\ngpgcheck=1\nrepo_gpgcheck=1\ngpgkey=https://gitlab .com/paulcarroty/vscodium-deb-rpm-repo/-/raw/master/pub.gpg\nmetadata_expire=1h" | sudo tee -a /etc/yum.repos.d/vscodium.repo
```
安装VSCodium:现在你已经添加了 VSCodium 存储库,你可以使用以下命令安装它(喜欢前沿软件的人可以将软件包名称替换为 **codium-insiders** 来安装 insider 版本):
```
sudo dnf install codium
```
启动 VSCodium:你现在可以从应用菜单或在终端中运行以下命令来启动 VSCodium:
```
codium
```
#### 删除 VSCodium
如果你不喜欢 VSCodium 以及它基于 Electron 的事实,或者改用 Neovim。你可以使用以下命令删除它:
```
sudo dnf remove codium
```
你可以将仓库和签名添加到你的系统中,也可以不保留(为什么不)。
因此,让我们摆脱该仓库:
```
sudo rm /etc/yum.repos.d/vscodium.repo
```
### 方法 2:使用 Flatpak 安装 VSCodium
你也可以安装 Flatpak。因此,以下是在 Fedora 上使用 Flatpak 安装 VSCodium 的步骤:
你可以通过启用 Flathub 直接在 Fedora 上安装它,如果你使用的是最新版本之一并且为 Fedora 启用了第三方仓库,那么可能会启用该功能。只需在 GNOME “软件” 应用中搜索 VSCodium 并单击安装即可。

不过,由于某些原因运行旧版本的用户,或者他们可能有一个未启用 Flatpak 的分叉,也可以效仿。
安装 Flatpak 并启用 Flathub:Fedora 通常预装了 Flatpak。如果尚未安装,你可以使用以下命令进行安装:
```
sudo dnf install flatpak
```
要启用 Flathub 仓库,请使用以下命令:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
现在你已经设置了 Flatpak,你可以使用 Flathub 仓库安装 VSCodium。运行以下命令:
```
flatpak install flathub com.vscodium.codium
```
启动 VSCodium:你可以使用以下命令通过 Flatpak 启动 VSCodium:
```
flatpak run com.vscodium.codium
```
或者,你也可以在应用菜单中搜索 “VSCodium” 并从那里启动它。
就是这样! 你现在应该已经使用 Flatpak 在 Fedora 系统上安装并运行了 VSCodium。
要删除它,请使用以下命令:
```
sudo flatpak uninstall com.vscodium.codium
```
### 附言
如果你使用过 VS Code,那么你不会发现这两个软件之间有任何区别。这只是为了开放和免受微软版本的邪恶遥测的影响。
在 Fedora,我首先安装了 Flatpak 版本,但在 Wayland 会话中,VSCodium 没有显示任何窗口装饰(这显然是默认的)。这让我很难用鼠标导航。

我尝试了一些方法来解决这个问题,但由于 Fflatpak 配置文件的位置很奇怪,所以没有成功。如果有人有或能找到解决上述问题的办法,请在下面发表评论。不过,使用 rpm 版本倒是天衣无缝(也许怀疑论者对替代软件包管理系统的看法是对的)。
扩展和插件在大部分情况下都没有问题。你也可以按照本教程在企业 Linux 系列的任何发行版(如 Alma Linux、Rocky Linux 等)上安装。
*(题图:MJ/5f39d386-d28c-4b3d-97a8-b498290d54f7)*
---
via: <https://itsfoss.com/install-vscodium-fedora/>
作者:[Anuj Sharma](https://itsfoss.com/author/anuj/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Visual Studio Code (VS Code) is a popular cross-platform text editor developed by Microsoft. It's built on the Electron framework and is widely used by developers for coding and text editing tasks. The core of VS Code, known as "Code - OSS," is open source and distributed under the MIT License. However, Microsoft adds specific customizations and releases its branded version of the editor under a proprietary license.
To address concerns about [telemetry](https://code.visualstudio.com/docs/getstarted/telemetry?ref=itsfoss.com) and licensing, there's an alternative called "[VSCodium](https://itsfoss.com/vscodium/)," which is a community-driven, telemetry-disabled, and MIT-licensed version of VS Code.
In this tutorial, I will guide you through the process of installing and running VSCodium on a Fedora Linux system.
There are three ways to do that:
- Installing by downloading the rpm file from the release page. But, you need to repeat the process to get the package updated (which can get frustrating).
- Adding
[paulcarroty](https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo?ref=itsfoss.com)repo (as mentioned on[VSCodium](https://vscodium.com/?ref=itsfoss.com)website). So, that when you[update your Fedora system](https://itsfoss.com/update-fedora/)VScodium will also get updated (which is quite seamless). - Using the flatpak version which you probably have tried by installing it from Gnome software already (I had a bad experience with the same so mileage may vary).
The first one is very straightforward i.e. downloading and [installing the rpm file](https://itsfoss.com/install-rpm-files-fedora/) from the [release page](https://github.com/VSCodium/vscodium/releases?ref=itsfoss.com). So, let's cut to the chase and follow the other two methods.
## Method 1: Installing VSCodium by adding the repository
Open a terminal: You can open a terminal by searching for "Terminal" in the application menu.
Add the GPG key: So that the package manager trusts the packager of the repo.
```
sudo rpmkeys --import https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo/-/raw/master/pub.gpg
```
Add the VSCodium repository: The following command will add the repo to your Fedora system.
```
printf "[gitlab.com_paulcarroty_vscodium_repo]\nname=download.vscodium.com\nbaseurl=https://download.vscodium.com/rpms/\nenabled=1\ngpgcheck=1\nrepo_gpgcheck=1\ngpgkey=https://gitlab.com/paulcarroty/vscodium-deb-rpm-repo/-/raw/master/pub.gpg\nmetadata_expire=1h" | sudo tee -a /etc/yum.repos.d/vscodium.repo
```
Install VSCodium: Now that you've added the VSCodium repository, you can install it using the following command (ones who love bleeding edge software can replace the package name to **codium-insiders** for installing the insiders version):
```
sudo dnf install codium
```
Launch VSCodium: You can now launch VSCodium either from the application menu or by running the following command in the terminal:
`codium`
### Removing VSCodium
If you did not like VSCodium and the fact that it's based on Electron or maybe you switched to Neovim for good. You can remove it using this command:
`sudo dnf remove codium`
You may keep the repository and signature added to your system or maybe not (why not).
So, let's get rid of that repo:
`sudo rm /etc/yum.repos.d/vscodium.repo`
## Method 2: Install VSCodium using flatpak
You can install the flatpak also. So, here are the steps to install VSCodium using Flatpak on Fedora:
You can Install it straight away on Fedora by having flathub enabled which is probably enabled if you are using one of the latest iterations and have 3rd party repos enabled for Fedora. Just search for VSCodium in Gnome Software and click Install.
But, for the folks running older versions for some reason or they might have a fork with flatpak not enabled can follow suit.
Install Flatpak and enable Flathub: Fedora usually comes with Flatpak pre-installed. If it's not installed, you can install it using the following command:
`sudo dnf install flatpak`
To enable the Flathub repository, use the following command:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
Now that you have Flatpak set up, you can install VSCodium using the Flathub repository. Run the following command:
```
flatpak install flathub com.vscodium.codium
```
Launch VSCodium: You can launch VSCodium via Flatpak using the following command:
`flatpak run com.vscodium.codium`
Alternatively, you can also search for "VSCodium" in your application menu and launch it from there.
That's it! You should now have VSCodium installed and running on your Fedora system using Flatpak.
To remove it use the command below:
`sudo flatpak uninstall com.vscodium.codium`
## Here comes the Bottomline
If you have used VS Code then you will not find any difference whatsoever between both the software. It is just for the sake of openness and freedom from the evil telemetry of Microsoft's version.
Coming to Fedora I installed the flatpak version first but VSCodium did not show any window decorations in the Wayland session (which is default obviously). Making it difficult to navigate using mouse.
I tried some methods to fix it but had no luck due to flatpak's weird locations for config files. If someone has or can figure out the workaround for above issue can comment down below. But using the rpm version was seamless (Maybe the skeptics were right about alternative package management systems).
Extensions and Plugins were fine for most of the part. You can also follow this tutorial to install on any distro from The Enterprise Linux family e.g. Alma Linux, Rocky Linux etc. |
16,415 | rlxOS:一个独立的不可变 Linux 发行版,具有 Xfce 桌面 | https://news.itsfoss.com/rlxos/ | 2023-11-26T17:51:03 | [
"不可变发行版",
"rlxOS"
] | https://linux.cn/article-16415-1.html | 
>
> 这是一款具有良好的外观和感觉,独立的不可变发行版。
>
>
>
[不可变 Linux 发行版](https://itsfoss.com/immutable-linux-distros/) 的市场在稳步增长。
只在今年,我们就见证了像 [Fedora Onyx](https://news.itsfoss.com/fedora-onyx-official/)、[blendOS v3](https://news.itsfoss.com/blendos-v3-released/) 这样的新成员,以及 Ubuntu 24.04 LTS 将会出现的 [基于 Snap 的不可变 Ubuntu 桌面](https://news.itsfoss.com/ubuntu-all-snap-desktop/)。
在这篇 [初次体验](https://news.itsfoss.com/tag/first-look/) 的文章里,我们将探索 [rlxOS](https://rlxos.dev/),它是一款自行建制的不可变发行版。
现在,让我们深入了解一下。
>
> ? 这个发行版相当新,可能无法作为日用主系统的替换产品。
>
>
>
### rlxOS:概述 ⭐

rlxOS 以**从零开始构建**为自豪,作为一个 [独立的 Linux 发行版](https://itsfoss.com/independent-linux-distros/),能更好地控制核心和工作部分。作为不可变的发行版,它实现了一种 [滚动发布](https://itsfoss.com/rolling-release/) 的方式,从而用户在面对大的更新时无需重新安装。
其**主要特点**包括:
* **不可变性**
* **利用** [Ostree](https://en.wikipedia.org/wiki/OSTree)
* **关注隐私**
* **原生支持 Flatpak**
如果你还不知道,不可变发行版可以让你在不影响系统核心的情况下进行变更。你可以将其视为分层变更,因此一个变更并不会影响另一个。
为了使这个实现,rlxOS 使用了一个软件更新守护程序([swupd](https://docs.rlxos.dev/system-management/swupd/)),这个程序保留了操作系统的两个版本(在更改前后),你可以按照 [文档](https://docs.rlxos.dev/system-management/swupd/) 进行一些在重启后会消失的更改。
这个守护程序也会让你有不同层的软件包。根据官方网站,该功能在稳定版本中还未推出。
另外,你可以轻松地按照 [文档](https://docs.rlxos.dev/system-management/distrobox/) 设置 [Distrobox](https://itsfoss.com/distrobox/) 容器。
#### 初次印象 ??
我在使用 [Ubuntu 上的 VirtualBox](https://itsfoss.com/install-virtualbox-ubuntu/) 的虚拟机(VM)上启动了 rlxOS。安装程序看起来非常舒服,它那种圆角矩形的感觉让我**想起了 GNOME 中** [**Adwaita**](https://en.wikipedia.org/wiki/Adwaita_(design_language)) **的主题风格**。

我在进行过程中**需要手动使用** [GParted](https://gparted.org/) **对驱动器进行分区**。首先,我在虚拟驱动器上建立了推荐的 msdos 分区表。
之后,我分了两个不同大小的分区,一个是 ext4 文件系统的 39.5 GB 分区,另一个是 fat32 文件系统的 512 MB 分区。
在这之后,我需要确定 fat32 分区有 `boot` 和 `esp` 标记,这样才能正确的安装 rlxOS。
>
> ? 通过右键点击分区并选择“<ruby> 管理标志 <rt> Manage Flags </rt></ruby>”来设定标记。
>
>
>

**安装程序还给出了关于分区的有效提示**,将较大的一个标记为 `Linux`,将较小的一个标记为 `EFI`。
如果你打算在 Windows 系统旁边安装它,你需要小心分区的设定,因为我们还没有在这里进行过测试。

然后,确认屏幕会显示出来,揭示**一些重要的最后阶段信息**。我点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 继续进行。

然后,它**需要花费一些时间才能完成安装**。但是,出于一些原因,我在安装过程中能够点击 “<ruby> 下一步 <rt> Next </rt></ruby>” 和 “<ruby> 上一步 <rt> Back </rt></ruby>” 选项(我认为这些选项应是灰化的)。

我建议你让安装自然进行,不要调整其他任何事情,并等待如下所示的 “<ruby> 成功 <rt> Success </rt></ruby>” 提示。

在重启后,**快速设置向导**开始运行,我输入了用户信息和密码,然后再次重启。

在重启后看到了**十分整洁的登录界面**,含有一张漂亮的壁纸,和标题栏常见的一些选项/信息。

登录之后,我看到了**一个非常熟悉的桌面界面**,这个界面有**一个类似 Windows 的应用启动器**,和**一栏包含了有用的部件的任务栏**,如语言、通知、网络、节能模式等等。

然而,我立刻注意到**rlxOS 预装的应用程序非常的少**。这可以看作一件好事,这取决于你问的人。
但是,我必须说,Xfce 的体验看起来很好。
在我看来,他们可以至少添加任何一款 [开源的微软办公套件替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/#2-onlyoffice),诸如 [LibreOffice](https://www.libreoffice.org/) 或 [ONLYOFFICE](https://www.onlyoffice.com/),这样这个发行版会有一个更为完整的体验。但是,当然,这是一个新的发行版,无可挑剔。
查看设置应用,它似乎很好的与系统主题相匹配。

rlxOS使用 Xfce 作为其桌面,这是流行的且最小化的桌面环境之一。我测试的稳定版是运行定制化 [Xfce 4.18](https://news.itsfoss.com/xfce-4-18-release/)。

如果你过去使用过 Xfce,你会发现 rlxOS 上的版本既熟悉又有些许不同。我用了一段时间,对其所提供的内容很满意,比如多任务处理非常轻松,因为**rlxOS 支持工作空间**。
我只需要通过在任务栏中滚动/点击可以轻松地在工作区之间切换。
尽管这个发行版在这里那里有些小问题,但是它值得一试。在实物机器上的你的**体验会比在 VM 上更好**。
如果你对源代码感兴趣,或者你想要为其做出贡献,你可以查阅其 [GitHub 仓库](https://github.com/itsManjeet/rlxos)。
### ? 下载 rlxOS
在我写这篇文章时,[官方网站](https://rlxos.dev/downloads/) 上有**两个版本的 rlxOS 可供下载**。一个是**每月更新的稳定版本**,另一个是**被认为是不稳定的实验版本**。
>
> **[rlxOS](https://rlxos.dev/downloads/)**
>
>
>
? 你对 rlxOS 有什么看法,你会向他人推荐这款发行版吗?
*(题图:MJ/b045e868-db65-4904-a0e4-0252051296e5)*
---
via: <https://news.itsfoss.com/rlxos/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The market for [immutable Linux distributions](https://itsfoss.com/immutable-linux-distros/?ref=news.itsfoss.com) has been rising at a very steady pace.
Just this year alone, we have seen the introduction of the likes of [Fedora Onyx](https://news.itsfoss.com/fedora-onyx-official/), [blendOS v3](https://news.itsfoss.com/blendos-v3-released/), and news of a [Snap-based immutable Ubuntu desktop](https://news.itsfoss.com/ubuntu-all-snap-desktop/) coming with 24.04 LTS.
With this [first look](https://news.itsfoss.com/tag/first-look/), we will be taking a look at [rlxOS](https://rlxos.dev/?ref=news.itsfoss.com), an immutable distro built from scratch.
So, let's dive in.
## rlxOS: Overview ⭐

rlxOS prides itself in being **built from scratch **as an [independent Linux distribution](https://itsfoss.com/independent-linux-distros/?ref=news.itsfoss.com) for having better control over the core and working parts. Being immutable, it follows a [rolling release](https://itsfoss.com/rolling-release/?ref=news.itsfoss.com) approach so that users won't need to reinstall it whenever there is a major update.
The** key features** include:
**Immutability****Leverages****Ostree****Focuses on Privacy****Native Flatpak Support**
If you did not know, an immutable distro lets you make changes without affecting the core of the system. You may call it as changes in layers, so one does not impact other.
To make that happen, rlxOS uses a software updater daemon ([swupd](https://docs.rlxos.dev/system-management/swupd/?ref=news.itsfoss.com)) that keeps two versions of the operating system (before/after changes). You can follow the [documentation](https://docs.rlxos.dev/system-management/swupd/?ref=news.itsfoss.com) to make changes that disappear after a reboot.
The same daemon will also let you have different layers of packages. As per the official website, it is not available in the stable release yet.
Furthermore, you can also easily setup [Distrobox](https://itsfoss.com/distrobox/?ref=news.itsfoss.com) for containers by referring to the [documentation](https://docs.rlxos.dev/system-management/distrobox/?ref=news.itsfoss.com).
**Suggested Read **📖
[Distrobox: Try Multiple Linux Distributions via the TerminalWith Distrobox, you can run other distributions in container format. Not only that, you can use GUI apps from the container distro in the main system. Awesome, right?](https://itsfoss.com/distrobox/?ref=news.itsfoss.com)

### Initial Impressions 👨💻
I fired up rlxOS on a virtual machine (VM) by using [VirtualBox on Ubuntu](https://itsfoss.com/install-virtualbox-ubuntu/?ref=news.itsfoss.com). The installer looked quite pleasant to the eyes, with a nice squircle feel to it that** reminded me of the ****Adwaita**** theming style** from GNOME.
I **had to manually partition the drive **using [GParted](https://gparted.org/?ref=news.itsfoss.com) as I proceeded. First, I created a partition table on the virtual drive with the recommended '*msdos*' partition table.
Then, I allocated two partitions with different sizes, with one being a 39.5 GB partition with the '*ext4*' file system, the other being a 512 MB one with the '*fat32*' file system.
After that, I had to ensure that the 'fat32' partition had the 'boot' and 'esp' flags so that rlxos would install properly.
The **installer also provides useful hints** regarding the partitions, denoting 'Linux' for the larger one, and 'EFI' for the smaller one.
If you are installing it on bare metal alongside Windows, you have to be careful about the partitions, as we have not tested that here.
Thereafter, a confirmation screen shows up, displaying **some important last-stage info**. I clicked on 'Apply' to proceed.
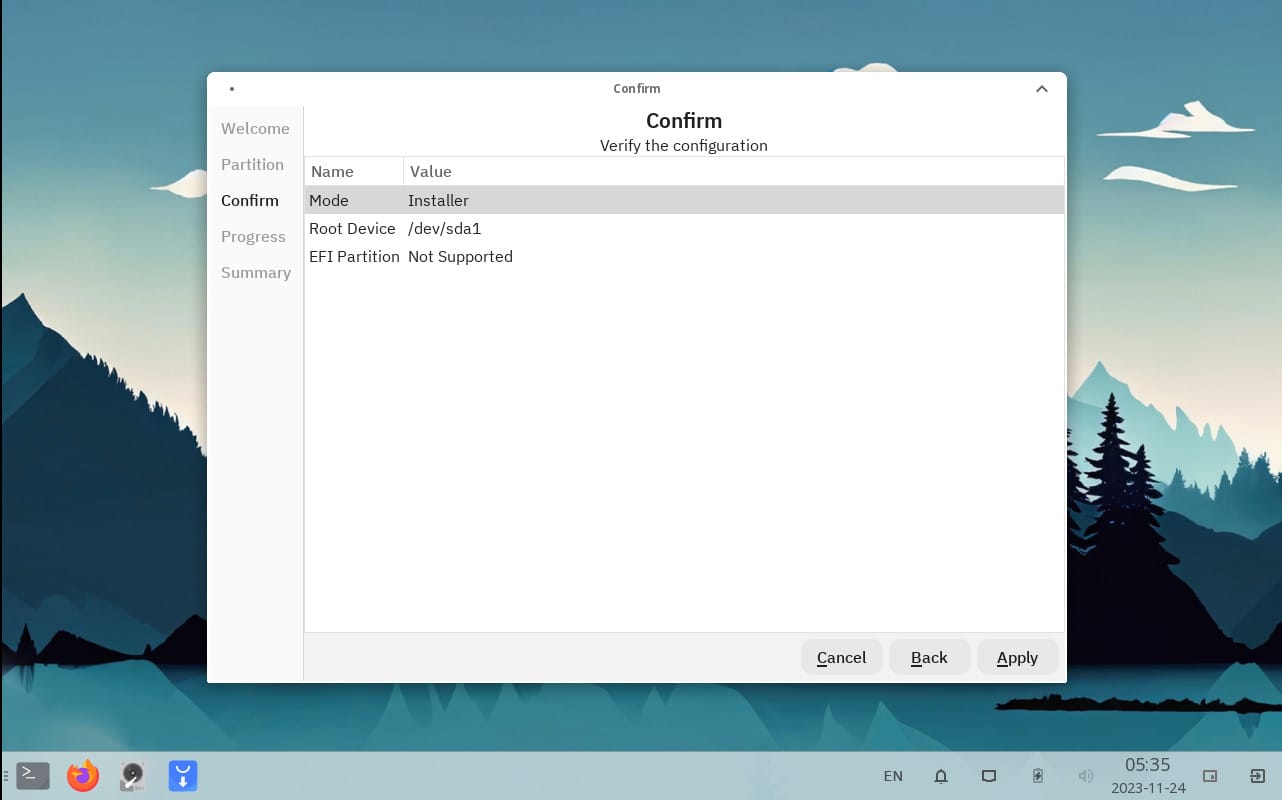
It then** **took some time to install**.** But, for some reason during that, I was able to click on the 'Next' and 'Back' option (which should have been greyed out I believe).
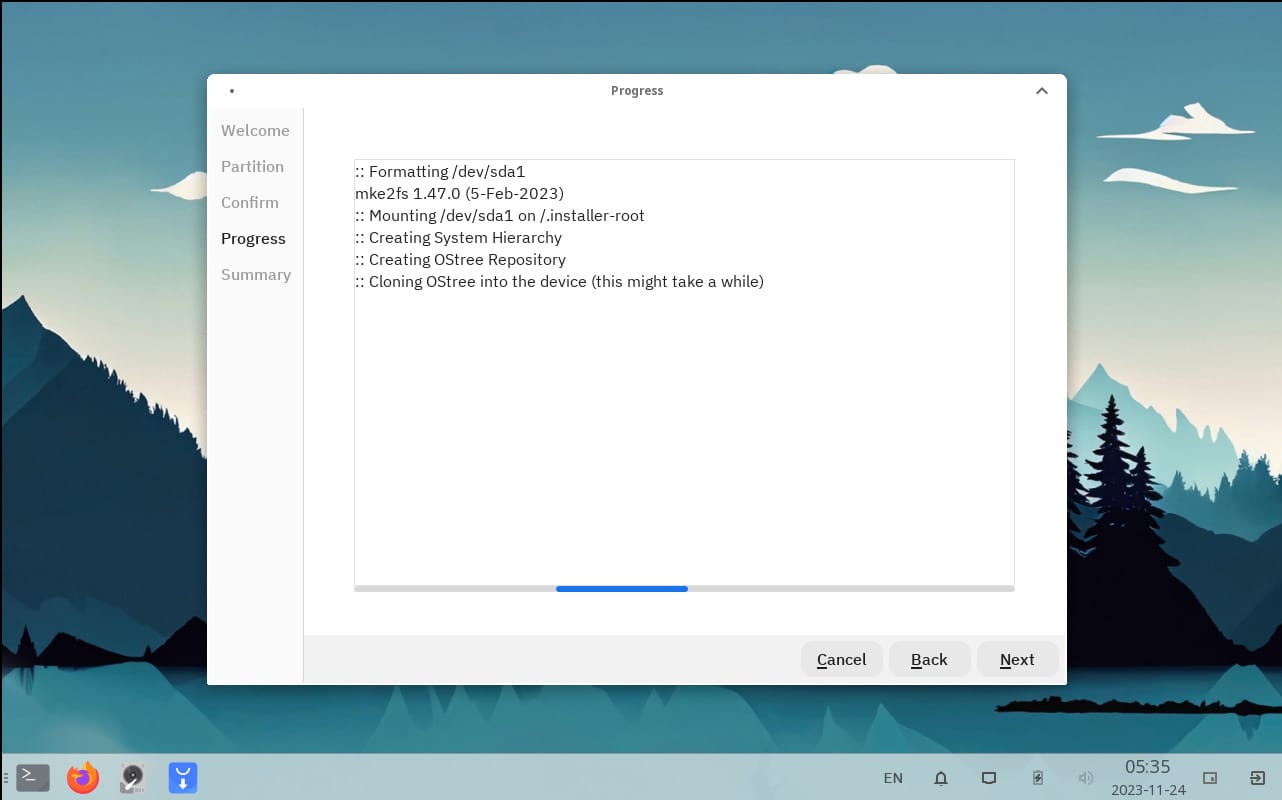
I suggest you let the installation happen without tweaking anything else and wait for the “Success” prompt as shown below.
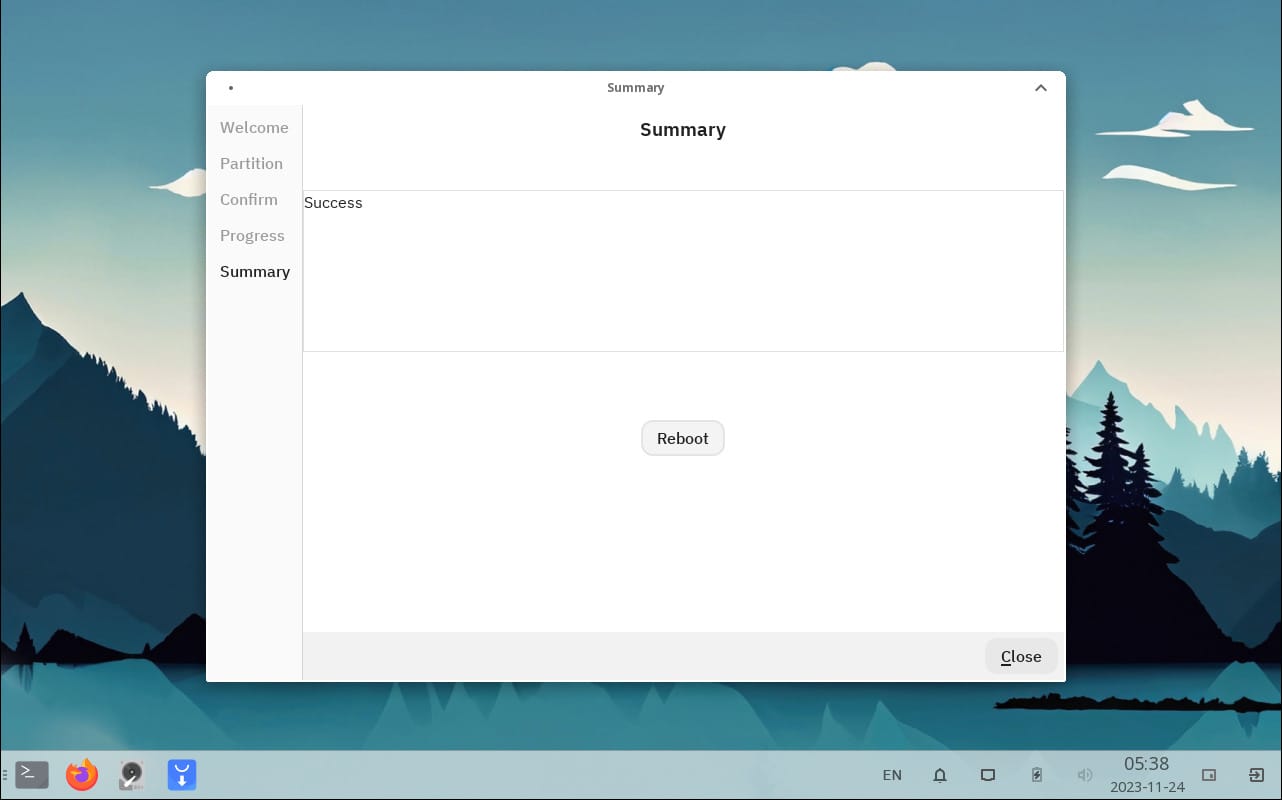
After reboot, a **quick-setup wizard **started, I entered the user details, and password, then rebooted again.
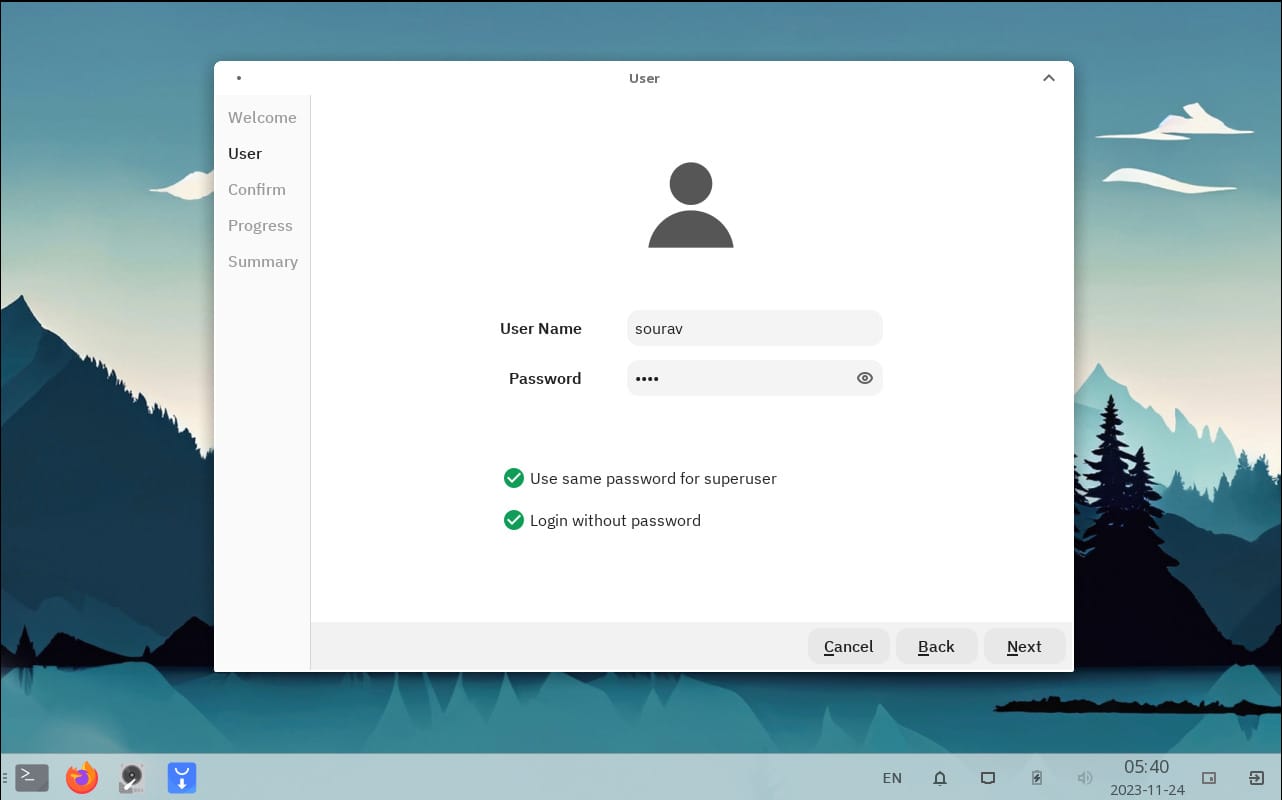
I was greeted with **a very neat sign-in screen** that featured a beautiful wallpaper and some options/ info in the header bar like usual.
Post sign-in, I was taken into **a very familiar desktop screen** that had **a Windows-like application launcher**,** a taskbar with useful widgets** such as language, notifications, network, power saver mode, and more.

Though, I noticed right away that **rlxOS ships with a very limited number of pre-installed applications**. That can be a good thing, depending on who you ask.
But, I must say that the Xfce experience looks good out-of-the-box.
Personally, I feel that they could have added any of the [open-source alternatives to Microsoft Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/?ref=news.itsfoss.com#2-onlyoffice) such as [LibreOffice](https://www.libreoffice.org/?ref=news.itsfoss.com) or [ONLYOFFICE](https://www.onlyoffice.com/?ref=news.itsfoss.com) at least, so that the distro would feel like a more complete experience. But, of course, it is a new distribution, no complaints.
Moving on to the settings app, it appears that it matches the system theme well.
Rlxos utilizes Xfce as its desktop, one of the most popular and minimal desktop environments out there. The stable version that I tested was running **a customized version** of [Xfce 4.18](https://news.itsfoss.com/xfce-4-18-release/).
If you have used Xfce in the past, you will find the one on rlxos very familiar, yet different. I used it for a bit, and I was content with what it had to offer, the multitasking bit was effortless, as **rlxOS has support for workspaces**.
I was easily able to switch between workspaces by scrolling/clicking on the workspaces switcher in the taskbar.
**Suggested Read **📖
[13 Independent Linux Distros That are Built From ScratchUnique and independent Linux distributions that are totally built from scratch. Sounds interesting? Check out the list here.](https://itsfoss.com/independent-linux-distros/?ref=news.itsfoss.com)

Even though this distro has its share of niggles here and there, it is worth a try. Your **experience on bare metal should be better** than on a VM.
You can head to its [GitHub repo](https://github.com/itsManjeet/rlxos?ref=news.itsfoss.com) if you are interested in the source code, or want to contribute to it.
## 📥 Download rlxOS
At the time of writing, there were **two variants of rlxos** available to download from the [official website](https://rlxos.dev/downloads/?ref=news.itsfoss.com). One was **a stable version with monthly updates**, the other was **an experimental version, considered unstable**.
*💬 What are your thoughts on rlxOS? Would you recommend this to anyone?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,418 | 我们真的需要另一种非开源的源代码可用许可证吗? | https://www.theregister.com/2023/11/24/opinion_column/ | 2023-11-26T23:39:05 | [
"开源",
"许可证"
] | https://linux.cn/article-16418-1.html | 
>
> 并不是,不过 “功能源代码许可证” 却更进一步混淆了开源许可证的界限。
>
>
>
回溯到我们还用打孔卡和磁带载入软件的那时,所有的程序都是 “自由软件” 和 “开源” 的。然而随后专有软件的出现,一切都变了。针对此状况,程序员们反抗并发展出了第一个正式的自由和开源软件的定义。
现如今,不开源的代码甚至成为了罕见的例外。然而,这并未阻止某些误将开源视为一种商业模式,而非开发模式的公司,试图将专有方法和 “开源” 代码相结合。最新的案例就是 Sentry 推出的 “<ruby> <a href="https://www.theregister.com/2023/11/20/sentry_introduces_the_functional_source/"> 功能源代码许可证 </a> <rt> Functional Source License </rt></ruby>”(FSL)。
沿袭 <ruby> <a href="https://www.mongodb.com/licensing/server-side-public-license"> 服务端公共许可证 </a> <rt> Server-Side Public License </rt></ruby>(SSPL)、<ruby> <a href="https://commonsclause.com/"> 公共条款 </a> <rt> Common Clause </rt></ruby> 和 <ruby> <a href="https://mariadb.com/bsl11/"> 商业源代码许可证 </a> <rt> Business Source License </rt></ruby> 的传统,[FSL](https://fsl.software/) 表面上似乎重视开源的重要性,却对开源的核心理念进行嘲讽,形容其方式为“享有自由却无需付出努力”。
呵呵。
其实,Sentry 是一个面向开发者的应用代码监控服务,它源于对 Django(一款开源的,高级的 Python 网络框架)的少量代码开发。如今,它仍然主要用开源代码进行开发。不难看出,没有开源,Sentry 啥都不是。
这也同样适用于其他所有使用 “<ruby> 源代码可用 <rt> source-available </rt></ruby>” 或其他半开源许可证的公司。它们都源自于开源公司,然后为了最大化利润,它们将免费获取的代码进行了重新许可,以锁定代码。
正如 <ruby> 开源倡议 <rt> Open Source Initiative </rt></ruby>(OSI)董事会副主席 Thierry Carrez 对我说的,“有些公司通过利用开源代码库作为主体建立了他们的软件,不需要在使用数百个开源软件包作为他们的依赖关系之前就请求许可。他们通过公开承诺遵守开源原则建立了口碑。但在试图追求更大价值的过程中,他们短视地放弃了最初带给他们成功的模式。”说的真对。
例如 Sentry、[MariaDB](https://www.theregister.com/2023/05/16/mariadb_growing_pains/)、[Redis](https://www.theregister.com/2019/02/22/redis_labs_changes_license_funding_60m/) 和 [HashiCorp](https://www.theregister.com/2023/08/11/hashicorp_bsl_licence/) 这样一些前开源公司,之所以他们能做出这样的举动,可以归功于他们采用了侵犯了权利的 <ruby> 贡献者许可协议 <rt> Contributor License Agreements </rt></ruby>(CLA)。这些协议是一种法律文件,它定义了贡献者为他们的代码在开源项目中被使用所设定的条款。尽管有些 CLA,像 Apache 软件基金会的 CLA 或 Linux 的 <ruby> 开发者原创证书 <rt> Developer Certificate of Origin </rt></ruby>,只是用来保护他们项目的法律权利。但其他一些,比如 MongoDB 的贡献者协议,却被用来占有你的代码及其版权。通过这样的 CLA,在任何他们喜欢的方式中使用和重新许可你的代码,对于他们来说易如反掌。
SourceHut 的创始人兼首席执行官 Drew Devault 在谈论 Elasticsearch 从开源[向“源码可用”转变](https://www.theregister.com/2021/01/18/elastics_doubling_down_on_open/)时表达了他的观点:“Elasticsearch 归其 1,573 名贡献者所有,他们自己保留着版权,并向 Elastic 授予了一个无条件分发他们作品的许可。当 Elastic 决定 Elasticsearch 不再开源时,他们就利用了这个漏洞,这个漏洞实际上一开始就被他们故意安插进去…… Elastic 对 1,573 的贡献者们、以及所有信任、忠诚于他们,给予他们支持的人们翻了脸。”
如今,我们看到企业 Sentry 和之前的案例如出一辙,换汤不换药。公正地讲,Sentry 很长一段时间以来都一直在使用源码可用许可证。在该公司创建并采用 FSL 前,自 2018 年以来就用了 BSL。如果还有人继续向 Sentry 捐献代码,那他们肯定知道自己在做什么。
那么为何还要做一个新许可证呢?Sentry 的开源负责人 Chad Whitacre 这样解释道:“BSL 存在两个显著的弊端。首先,预设的非竞争期为四年,对于软件行业来说,这简直就是个漫长的周期。这可能会让人产生一种感觉,即最后的开源转变只是一种象征性的举措。这几乎可以说是 100 年那么长。对于 Sentry,我们选择将这个期限缩短到三年,但我们也承认,可能连三年都过长了。”
该许可证期满后,这些代码将会使用 Apache 2.0 或者 MIT 许可证。但实际上,这并不像初听起来那么慷慨。根据 FSL,你可以将它的代码用在任何用途 —— “除了竞争性使用的情况下。所谓竞争性使用,指的是利用该软件开发或提供能够与我们的产品或服务竞争的商业产品或服务,不论是该软件本身,还是我们基于该软件提供的任何其他产品或服务,只要我们是在该软件发布之日或之前就已经提供了这类竞争产品或服务。”
换种说法,你可以查看代码,但不能用这些代码运营业务。如需更深入了解,你可以查看该公司的 FSL 版本的 Apache 和 MIT 许可证。就我个人而言,我认为这两个都不算是开源许可证。
Whitacre 进一步说明了,“更严重的缺陷是 BSL 有过多的参数:变更日期、变更许可证,以及额外使用授予。最大的问题在于额外使用授予,它是一项巨大的填空题,意味着每一个 BSL 实质上都是不同的许可证。”
我无法反驳这一观点。每个公司的 BSL 都不一样。同时,这也意味着当客户与使用 BSL 的公司签约时,他们很难确切知道法律上为他们保留了哪些权益。Sentry 希望通过 FSL 让其产品和服务对其客户更具吸引力。
也许这方法行得通。但我赞同 Carrez 所说的:“发布另一种能剥夺开发者在技术选择中的自主权的许可证变体并非新鲜事:他们其实就是要从整个软件生态系统中摧毁开发者的基本自由,从而明确自己对其专有软件及其许可使用权的所有权。这并不是开源:这只是包装在开源幌子下的专有门户。”
*(题图:MJ/beb19f23-c230-4a3f-9bb3-210066ad749b)*
---
via: <https://www.theregister.com/2023/11/24/opinion_column/>
作者:[Steven J. Vaughan-Nichols](https://www.theregister.com/Author/Steven-J-Vaughan-Nichols) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | # Do we really need another non-open source available license?
## No, but here comes the Functional Source License to further muddy the open-source licensing waters
Opinion Way back when we loaded software with punch cards and magnetic tape, all programs were "free software" and "open source." Then along came proprietary software, and everything changed. But programmers rebelled and developed the first formal definitions of free and open source software.
Today, code that's not open source is the rare exception. But that hasn't stopped companies who mistook open source as a business model instead of a development model from trying to combine proprietary methods with "open source" code. The latest is Sentry's [Functional Source License](https://www.theregister.com/2023/11/20/sentry_introduces_the_functional_source/) (FSL).
Following in the tradition of [Server-Side Public License](https://www.mongodb.com/licensing/server-side-public-license) (SSPL), [Common Clause](https://commonsclause.com/), and the [Business Source License](https://mariadb.com/bsl11/), the [FSL](https://fsl.software/) nods at the importance of open source while sneering at its heart by claiming its approach is "Freedom without Free-riding."
Please.
Sentry is a developer-oriented app code monitoring service that began as a short bit of code for Django, the open source, high-level Python web framework. Today, it's still used most for open source code development. Without open source, Sentry doesn't exist.
Neither do any of the companies now using "source-available" or other semi open source licenses. They all began as open source companies, then to maximize profits, they relicense the code they've gotten for free from contributors to lock down the code.
As Thierry Carrez, vice chair of the Open Source Initiative (OSI) board, told me, "Some companies have built their software by leveraging the body of open source code available to them, without having to ask for permission before using hundreds of open source packages in their dependencies. They built their reputation by publicly committing to the open source principles. But in a short-sighted effort to capture incrementally more value, they later decide to abandon the model that made them successful in the first place." Exactly so.
Sentry, [MariaDB](https://www.theregister.com/2023/05/16/mariadb_growing_pains/), [Redis](https://www.theregister.com/2019/02/22/redis_labs_changes_license_funding_60m/), and [HashiCorp](https://www.theregister.com/2023/08/11/hashicorp_bsl_licence/), to name a few of the former open source companies, can get away with this thanks to rights-aggressive Contributor License Agreements (CLA)s. These are legal documents that define the terms contributors grant for their code to be used in an open source project. While some CLAs, such as the Apache Software Foundation’s CLA or Linux's Developer Certificate of Origin, are used simply to protect the legal rights of their projects, others are used to grab your code and its copyright, such as MongoDB's contributor agreement. With these CLAs, the companies can then use and relicense your code in any manner they like.
As Drew Devault, the founder and CEO of SourceHut, said about [Elasticsearch and its move from open source](https://www.theregister.com/2021/01/18/elastics_doubling_down_on_open/) to source available, "Elasticsearch belongs to its 1,573 contributors, who retain their copyright, and granted Elastic a license to distribute their work without restriction. This is the loophole which Elastic exploited when they decided that Elasticsearch would no longer be open source, a loophole that they introduced with this very intention from the start... Elastic has spit in the face of every single one of 1,573 contributors, and everyone who gave Elastic their trust, loyalty, and patronage."
Now, here we are with Sentry, and it's the same story with a different license. In all fairness, Sentry has been using a source-available license for a long time. Before the company created and adopted FSL, it had used BSL since 2018. If anyone was still donating code to Sentry, they had to know exactly what they were getting into.
So why make a new license? Sentry head of open source, Chad Whitacre, explained: "BSL has two major flaws. First, the default non-compete time period is four years, which is a really long time in the software world. This can make it feel like the eventual change to Open Source is only a token effort. It almost might as well be 100 years. For Sentry, we chose to tighten it to three years, but even that is probably too long."
[Come on, Amazon: If you're going to copy open source code for a new product, at least credit the creator](https://www.theregister.com/2020/10/16/aws_headless_recorder/)[Fed up with cloud giants ripping off its database, MongoDB forks new 'open source license'](https://www.theregister.com/2018/10/16/mongodb_licensning_change/)[HashiCorp CEO talks license changes and the role of foundations](https://www.theregister.com/2023/10/19/hashicorp_ceo_license_changes/)[The battle between open source and 'sort of' open source is as old as software](https://www.theregister.com/2023/10/27/open_source_vs_sort_of_open_source/)
After that period, the code refers to either the Apache 2.0 or MIT license. But, that's not as generous as it sounds. Under the FSL, you can use its code for "any purpose other than a Competing Use. A Competing Use means use of the Software in or for a commercial product or service that competes with the Software or any other product or service we offer using the Software as of the date we make the Software available."
In other words, you can look but not run the code for a business. For more, you can look at the company FSLed versions of Apache and MIT. As far as I'm concerned, neither is an open source license.
Whitacre added, "The more serious flaw is that BSL has too many parameters: the change date, the change license, and the Additional Use Grant. The Additional Use Grant is the biggest problem. It is a giant fill-in-the-blank that effectively means that every BSL is a different license."
I can't argue with that. Each company's BSL is unique. This also means it makes it hard for customers to know exactly what they're getting legally when they contract with a company using BSL. It's Sentry's hope that the FSL will make its products and services more appealing to its customers.
Maybe it will. But I agree with Carrez, who said: "Releasing yet another license variant that removes developers' self-sovereignty in their technical choices is nothing novel: it is still about removing essential freedoms from the whole software ecosystem to clearly assert ownership over their proprietary software and the use you are allowed to make of it. This is not open source: it is proprietary gatekeeping wrapped in open washed clothing."
70 |
16,419 | 修复 Arch Linux 中的 “target not found” 错误 | https://itsfoss.com/target-not-found-arch-linux/ | 2023-11-26T23:54:00 | [
"软件包"
] | https://linux.cn/article-16419-1.html | 
>
> 如果在 Arch Linux 中安装软件包时遇到 “target not found” 错误,你可以采取以下措施。
>
>
>
有一天,我尝试在 Arch Linux 上安装 Hyprland。当我使用 [Pacman 命令安装](https://itsfoss.com/pacman-command/) 它时,它抛出 “target not found”(目标未发现)错误。
```
$ sudo pacman -S hyprland
[sudo] password for abhishek:
error: target not found: hyprland
```
这是一个意外,因为我知道 Hyprland 是可用的。
**我的修复方法**是更新系统,在大多数情况下,它可以解决此问题。
```
sudo pacman -Syu
```
这里,本地包数据库不同步。我需要更新缓存。这里还建议更新系统。
在大多数情况下,这就是修复此错误的方法。但是,你看到此错误的原因可能还有其他一些。让我在这里详细讨论它们。
### 修复:更新系统
Arch Linux 是一个 [滚动发布发行版](https://itsfoss.com/rolling-release/),并且它提供的更新非常频繁。如果你不每隔几天更新一次系统,你的本地包数据库将与远程镜像不同步,并且你将在安装软件包时遇到问题。
本地包数据库仅保留包的元数据,例如版本号、用于获取包的仓库 URL 等。
当你搜索软件包时,`pacman` 会提供搜索结果,表明该软件包可用。但是,该包在你的本地数据库中具有较旧的版本号。当 `pacman` 在远程仓库中搜索包(以获取实际的包)时,它不再找到旧版本的 URL。
这就是导致 “target not found” 错误的原因。
修复方法是更新本地数据库。这可以与 `pacman -Sy` 一起使用,但是,建议 [更新整个 Arch Linux 系统](https://itsfoss.com/update-arch-linux/) 以避免依赖冲突等。
```
sudo pacman -Syu
```
>
> ? 如果你已有几周没有更新系统,请做好更新超过 1 GB 的准备。这可能需要一些时间,具体取决于你的互联网速度和你使用的镜像。
>
>
>
就我而言,Arch 安装在我的辅助系统上。由于我一周左右无法使用它,该系统已经过时了。更新后,我就可以安装 [Hyprland](https://hyprland.org/)。

>
> ? 如果这不起作用,请通过添加额外的 `y` 强制刷新所有包数据库: `sudo pacman -Syyu`
>
>
>
### 修复 “target not found” 错误的其他建议
如果上述方法没有为你解决此错误,这里有一些修复此错误的提示。
#### 仔细检查包名称
我亲爱的 Watson,这可能看起来很简单,但人们通常只是错误地输入了包名称。
Linux 区分大小写,包通常以小写命名。因此,如果你要使用一个名为 Flameshot 的流行工具,那么它的包名称很可能是 flameshot。
此外,某些软件的拼写与常见软件的拼写不同。例如,它是 hyprland,这使我错误地输入了 hyperland(使用通常的 “hyper” 拼写)。

在极少数情况下,可能会混淆是 `l`、`I` 或者 `1`。
基本上,确保你输入的包名称是正确的。
#### 查看该软件包在仓库中是否可用
Arch Linux 的仓库中有大量软件包。但这并不意味着它拥有所有可能的 Linux 软件包。
访问 Arch Linux 官方软件包网站:
[Arch Linux 软件包搜索](https://archlinux.org/packages/)
在这里输入包名,查看该包是否可用。如果是,它是哪个仓库以及它在哪个设备上可用。

`x86_64` 适用于英特尔架构,任何包含 ARM 架构的均适用于 [树莓派类设备](https://itsfoss.com/raspberry-pi-alternatives/)。
>
> ? 如果在某些仓库中找到该软件包,但 pacman 即使在更新的系统上也找不到它,请检查 `pacman.conf` 文件并查看是否启用了所述仓库。
>
>
>
#### 确保它不是 AUR 包
[Arch 用户仓库(AUR)](https://itsfoss.com/aur-arch-linux/) 是提供更新包的附加社区支持平台。
现在,有多种使用 AUR 包的方法,但 `pacman` 不是其中之一。
检查你尝试安装的软件包是否是 AUR 软件包。首先检查官方 Arch 仓库,如上所述。如果不存在,请检查 AUR 页面。
如果它是 AUR 包,则必须 [使用 yay](https://itsfoss.com/install-yay-arch-linux/) 或一些 [其他 AUR 帮助程序](https://itsfoss.com/best-aur-helpers/)。你不能使用 `pacman` 安装 AUR 软件包。
### 你能解决这个问题吗?
在大多数情况下,更新系统可以解决此问题。在极少数情况下,可能还有其他原因,我已经提到了一些建议。
现在轮到你了。如果你能够解决此问题,请在评论区告诉我。
*(题图:MJ/b71c9760-4cb1-41de-a336-3e38026bcfeb)*
---
via: <https://itsfoss.com/target-not-found-arch-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The other day I was trying to install Hyprland on Arch Linux. When I used the [Pacman command to install](https://itsfoss.com/pacman-command/) it, it threw a 'target not found' error.
```
[abhishek@itsfoss ~]$ sudo pacman -S hyprland
[sudo] password for abhishek:
error: target not found: hyprland
[abhishek@itsfoss ~]
```
That was a surprise because I knew that Hyprland was available.
**The fix in my case** was to update the system and in most cases, it fixes this problem.
`sudo pacman -Syu`
Here, the local package database is out of sync. I needed to update the cache. Updating the system is also suggested here.
That's what fixes this error in most cases. However, there could be a few other reasons why you see this error. Let me discuss them in detail here.
## Fix: Update the system
Arch Linux is a [rolling release distribution](https://itsfoss.com/rolling-release/) and it provides updates quite frequently. If you don't update the system every few days, your local package database will be out of sync with the remote mirrors and you'll have trouble installing packages.
The local package database only keeps the metadata of the package like version number, repository URL to get the package from etc.
When you search for a package, pacman provides the search result that says that the package is available. However, the package has an older version number in your local database. When pacman searches for the package in a remote repository (to get the actual packages), it doesn't find the older version URL anymore.
This is what causes the 'target not found' error.
The fix is to update the local database. That could work with `pacman -Sy`
, however, it is recommended to [update the entire Arch Linux system](https://itsfoss.com/update-arch-linux/) to avoid dependency conflicts, among other things.
`sudo pacman -Syu`
In my case, Arch is installed on my secondary system. And since I could not use it for a week or so, the system was outdated. Once I updated it, I could install [Hyprland](https://hyprland.org/).
## Other suggestions to fix 'target not found' error
Here are a few tips on fixing this error if the above method did not fix it for you.
### Double check the package name
It may seem elementary, my dear Watson, but often people just type the package name incorrectly.
Linux is case sensitive and packages are usually named in lowercases. So if you want to use a popular tool named Flameshot, its package name is likely to be flameshot.
Also, some software have different spelling than the common one. For example, it is hyprland and that made me make mistake of typing hyperland (with the usual 'hyper' spelling).
In some rare cases, there could be confusion whether it is `l`
or `I`
or `1`
.
Basically, ensure that the name you have entered the package name is correc.
### See if the package is available in the repositories
Arch Linux has a vast number of packages in its repositories. But that does not mean it has every possible Linux packages.
Go to the official Arch Linux package website:
Here, enter the package name and see if the package is available. If yes, which repository it is and on which device it is available.
`x86_64`
is for Intel architecture and any includes ARM architecture is for [Raspberry Pi like devices](https://itsfoss.com/raspberry-pi-alternatives/).
### Ensure that it's not an AUR package
[Arch User Repository (AUR)](https://itsfoss.com/aur-arch-linux/) is the additional community supported platform that provides newer packages.
Now, there are multiple ways to use AUR packages but pacman is not one of them.
Check if the package you are trying to install is an AUR package. Check the official Arch repository first, as explained above. If it's not there, then check the AUR page.
If it's an AUR package, you'll have to [use yay](https://itsfoss.com/install-yay-arch-linux/) or some [other AUR helper](https://itsfoss.com/best-aur-helpers/). You cannot use pacman to install AUR packages.
## Were you able to fix the issue?
Updating the system is what fixes this issue in most cases. In some rare instances, there could be other reasons and I have mentioned some suggestions for them.
Now it's your turn. Let me know in the comment section if you were able to fix this issue or not. |
16,421 | 使用 mkosi 构建 RHEL 和 RHEL UBI 镜像 | https://fedoramagazine.org/create-images-directly-from-rhel-and-rhel-ubi-package-using-mkosi/ | 2023-11-27T23:22:00 | [
"镜像",
"mkosi"
] | https://linux.cn/article-16421-1.html | 
mkosi 是一个轻量级工具,用于从发行版软件包构建镜像。本文介绍如何使用 mkosi 从 RHEL 和 RHEL <ruby> <a href="https://uapi-group.org/specifications/specs/discoverable_disk_image/"> 通用基础镜像 </a> <rt> Universal Base Image </rt></ruby>(UBI)的软件包构建镜像。RHEL UBI 是 RHEL 的一个子集,可以在没有订阅的情况下免费使用。
### mkosi 特性
mkosi 支持一些输出格式,但最重要的是 <ruby> <a href="https://uapi-group.org/specifications/specs/discoverable_disk_image/"> 可发现磁盘镜像 </a> <rt> Discoverable Disk Images </rt></ruby>(DDI)。同一个 DDI 可用于引导容器、或运行在虚拟机、抑或是复制到 U 盘以引导真实物理机,然后从 U 盘复制到磁盘以引导系统。该镜像具有标准化的布局和描述其用途的元数据。
mkosi 依赖其他工具来完成大部分工作:使用 `systemd-repart` 在磁盘镜像上创建分区,使用 `mkfs.btrfs` / `mkfs.ext4` / `mkfs.xfs` 等创建文件系统,并使用 `dnf` / `apt` / `pacman` / `zypper` 下载和解压包。
mkosi 支持一系列发行版:Debian 和 Ubuntu、Arch Linux、openSUSE,当然还包括 Fedora、CentOS Stream 及其衍生版本,以及最近的 RHEL UBI 和 RHEL 。由于实际的“重活”是由其他工具完成的,mkosi 可以进行交叉构建。这意味着可以使用一个发行版构建各种其他发行版的镜像。唯一的要求是主机上安装了相应的工具。Fedora 有原生的 `apt`、`pacman` 和 `zypper`,因此它为使用 mkosi 构建任何其他发行版提供了良好的基础。
它还有一些有趣的功能:镜像可以由非特权用户创建,或者在没有设备文件的容器中创建,特别是没有对回环设备的访问权限。它还可以在没有特权的情况下将这些镜像启动为虚拟机(使用 `qemu`)。
配置是声明性的,非常容易创建。使用 `systemd-repart` 创建磁盘分区,并使用 `repart.d` 配置文件定义应该如何完成此操作。
有关更多详细信息,请参见 Daan DeMeyer 在 All Systems Go 大会上的两个演讲:《[systemd-repart: Building Discoverable Disk Images](https://media.ccc.de/v/all-systems-go-2023-191-systemd-repart-building-discoverable-disk-images)》 和 《[mkosi: Building Bespoke Operating System Images](https://media.ccc.de/v/all-systems-go-2023-190-mkosi-building-bespoke-operating-system-images)》。
### 项目目标
mkosi 的一个目标是允许对软件项目进行针对不同发行版的测试。它将为一个发行版创建一个镜像(使用该发行版的软件包),然后将软件项目编译并安装到该镜像中,插入不属于软件包的额外文件。但是,首个阶段,即从软件包创建镜像的过程,本身就是有用的。这是我们将首先展示的内容。
我们 <sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup> 最近添加了对 RHEL 和 RHEL UBI 的支持。让我们从 RHEL UBI 开始,利用发行版软件包创建镜像。
请注意,下面的示例要求 mkosi 19,而且不适用于更早的版本。
### 带有 Shell 的基本 RHEL UBI 镜像
```
$ mkdir -p mkosi.cache
$ mkosi \
-d rhel-ubi \
-t directory \
-p bash,coreutils,util-linux,systemd,rpm \
--autologin
```
上面的命令指定了发行版 `rhel-ubi`,输出格式 `directory`,并请求安装软件包 `bash`、`coreutils`、…、`rpm`。`rpm` 通常不需要放到镜像内部,但在这里用于内省会很有用。我们还启用了以 root 用户自动登录。
在启动构建之前,我们创建了缓存目录 `mkosi.cache`。当存在缓存目录时,mkosi 会自动使用它来持久化下载的 RPM 包。这将使相同软件包集合的后续调用速度更快。
然后,我们可以使用 `systemd-nspawn` 将此镜像作为容器启动:
```
$ sudo mkosi \
-d rhel-ubi \
-t directory \
boot
```
```
systemd 252-14.el9_2.3 running in system mode (+PAM +AUDIT +SELINUX -APPARMOR +IMA +SMACK +SECCOMP +GCRYPT +GNUTLS +OPENSSL +ACL +BLKID +CURL +ELFUTILS -FIDO2 +IDN2 -IDN -IPTC +KMOD +LIBCRYPTSETUP +LIBFDISK +PCRE2 -PWQUALITY +P11KIT -QRENCODE +TPM2 +BZIP2 +LZ4 +XZ +ZLIB +ZSTD -BPF_FRAMEWORK +XKBCOMMON +UTMP +SYSVINIT default-hierarchy=unified)
Detected virtualization systemd-nspawn.
Detected architecture x86-64.
Detected first boot.
Red Hat Enterprise Linux 9.2 (Plow)
...
[ OK ] Created slice Slice /system/getty.
[ OK ] Created slice Slice /system/modprobe.
[ OK ] Created slice User and Session Slice.
...
[ OK ] Started User Login Management.
[ OK ] Reached target Multi-User System.
Red Hat Enterprise Linux 9.2 (Plow)
Kernel 6.5.6-300.fc39.x86_64 on an x86_64
image login: root (automatic login)
[root@image ~]# rpm -q rpm systemd
rpm-4.16.1.3-22.el9.x86_64
systemd-252-14.el9_2.3.x86_64
```
正如前面提到的,此镜像可以用于启动虚拟机。但在此设置下,这是不可能的 —— 我们的镜像没有内核。事实上,RHEL UBI 根本不提供内核,因此我们无法使用它进行引导(无论是在虚拟机上还是在裸机上)。
### 创建镜像
我一开始说是要创建镜像,但到目前为止我们只有一个目录。让我们开始实际创建一个镜像:
```
$ mkosi \
-d rhel-ubi \
-t disk \
-p bash,coreutils,util-linux,systemd,rpm \
--autologin
```
这将生成 `image.raw`,一个带有 GPT 分区表和单个根分区(用于本机架构)的磁盘镜像。
```
$ sudo systemd-dissect image.raw
Name: image.raw
Size: 301.0M
Sec. Size: 512
Arch.: x86-64
Image UUID: dcbd6499-409e-4b62-b251-e0dd15e446d5
OS Release: NAME=Red Hat Enterprise Linux
VERSION=9.2 (Plow)
ID=rhel
ID_LIKE=fedora
VERSION_ID=9.2
PLATFORM_ID=platform:el9
PRETTY_NAME=Red Hat Enterprise Linux 9.2 (Plow)
ANSI_COLOR=0;31
LOGO=fedora-logo-icon
CPE_NAME=cpe:/o:redhat:enterprise_linux:9::baseos
HOME_URL=https://www.redhat.com/
DOCUMENTATION_URL=https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9
BUG_REPORT_URL=https://bugzilla.redhat.com/
REDHAT_BUGZILLA_PRODUCT=Red Hat Enterprise Linux 9
REDHAT_BUGZILLA_PRODUCT_VERSION=9.2
REDHAT_SUPPORT_PRODUCT=Red Hat Enterprise Linux
REDHAT_SUPPORT_PRODUCT_VERSION=9.2
Use As: ✗ bootable system for UEFI
✓ bootable system for container
✗ portable service
✗ initrd
✗ sysext extension for system
✗ sysext extension for initrd
✗ sysext extension for portable service
RW DESIGNATOR PARTITION UUID PARTITION LABEL FSTYPE ARCHITECTURE VERITY GROWFS NODE PARTNO
rw root 1236e211-4729-4561-a6fc-9ef8f18b828f root-x86-64 xfs x86-64 no yes /dev/loop0p1 1
```
好的,我们现在有一个镜像,镜像中包含了一些来自 RHEL UBI 软件包的内容。我们如何在其上加点我们自己的东西呢?
### 使用自己的文件扩展镜像
有几种方法可以扩展镜像,包括从头开始编译某些东西。但在那之前,让我们做一些更简单的事情,将一个现成的文件系统注入到镜像中:
```
$ mkdir -p mkosi.extra/srv/www/content
$ cat >mkosi.extra/srv/www/content/index.html <<'EOF'
<h1>Hello, World!</h1>
EOF
```
现在,该镜像将包含 `/srv/www/content/index.html`。
这种方法用于注入额外的配置或简单的程序。
### 从源代码构建
现在让我们过一遍完整流程,从源代码构建一些东西。例如,一个简单的 Meson 项目,有一个单独的 C 文件:
```
$ cat >hello.c <<'EOF'
#include <stdio.h>
int main(int argc, char **argv) {
char buf[1024];
FILE *f = fopen("/srv/www/content/index.html", "re");
size_t n = fread(buf, 1, sizeof buf, f);
fwrite(buf, 1, n, stdout);
fclose(f);
return 0;
}
EOF
$ cat >meson.build <<'EOF'
project('hello', 'c')
executable('hello', 'hello.c',
install: true)
EOF
```
```
$ cat >mkosi.build <<'EOF'
set -ex
mkosi-as-caller rm -rf "$BUILDDIR/build"
mkosi-as-caller meson setup "$BUILDDIR/build" "$SRCDIR"
mkosi-as-caller meson compile -C "$BUILDDIR/build"
meson install -C "$BUILDDIR/build" --no-rebuild
EOF
$ chmod +x mkosi.build
```
总结一下:我们有一些源代码(`hello.c`),一个构建系统配置文件(`meson.build`),以及一个由 mkosi 调用的胶水脚本(`mkosi.build`)。对于实际的项目,也会有相同的元素,只是更加复杂。
这个脚本需要一些解释。mkosi 在创建镜像时使用用户命名空间。这允许包管理器(例如 `dnf`)安装由不同用户拥有的文件,即使它是由一个普通非特权用户调用的。我们使用 `mkosi-as-caller` 切换回调用者以进行编译。这样,在 `$BUILDDIR` 下编译期间创建的文件将由调用者拥有。
现在让我们使用我们的程序构建镜像。与之前的调用相比,我们需要额外的软件包:`meson`、`gcc`。由于我们现在有了构建脚本,mkosi 将执行两个构建阶段:首先创建一个构建镜像,并在其中调用构建脚本,将安装产物存储在一个临时目录中,然后构建最终镜像,并将安装产物注入其中。(mkosi 设置 `$DESTDIR`,`meson install` 自动使用 `$DESTDIR`,因此并不需要我们明确指定。)
```
$ mkosi \
-d rhel-ubi \
-t disk \
-p bash,coreutils,util-linux,systemd,rpm \
--autologin \
--build-package=meson,gcc \
--build-dir=mkosi.builddir \
--build-script=mkosi.build \
-f
```
此时,我们有了带有自定义载荷的镜像 `image.raw`。我们可以启动我们新创建的可执行文件作为 shell 命令:
```
$ sudo mkosi -d rhel-ubi -t directory shell hello
<h1>Hello, World!</h1>
```
### 获取 RHEL 的开发者订阅
RHEL UBI 主要用作容器构建的基础层。它提供了有限的软件包(约 1500 个)。现在让我们切换到完整的 RHEL 安装。
获取 RHEL 的最简单方法是使用 [开发者许可证](https://developers.redhat.com/articles/faqs-no-cost-red-hat-enterprise-linux)。它提供了权限注册 16 个运行 RHEL 的物理或虚拟节点,并提供自助式支持。
首先,[创建一个账户](https://developers.redhat.com/register)。然后,转到 [管理页面](https://access.redhat.com/management) 并确保启用了“用于 Red Hat 订阅管理的简化内容访问”。接下来,[创建一个新的激活密钥](https://access.redhat.com/management/activation_keys/new),选择 “Red Hat 个人开发者订阅”。记下显示的组织 ID。在下面,我们将使用密钥名称和组织 ID 分别表示为 `$KEY_NAME` 和 `$ORGANIZATION_ID`。
现在,我们准备使用 RHEL 内容:
```
$ sudo dnf install subscription-manager
$ sudo subscription-manager register \
--org $ORGANIZATION_ID --activationkey $KEY_NAME
```
### 使用 RHEL 构建镜像
在之前的示例中,我们通过参数开关指定了所有配置。这对于快速开发很友好,但可能在情况复杂时变得难以处理。RHEL 是一个严肃的发行版,所以让我们改为使用配置文件:
```
$ cat >mkosi.conf <<'EOF'
[Output]
Format=directory
Output=rhel-directory
[Distribution]
Distribution=rhel
[Content]
Packages=
bash
coreutils
util-linux
systemd
systemd-boot
systemd-udev
kernel-core
Bootable=yes
Bootloader=uki
Autologin=yes
WithDocs=no
EOF
```
首先,让我们检查一下一切是否正常:
```
$ mkosi summary
```
现在让我们构建镜像(呃,或者说,目录):
```
$ mkosi build
$ mkosi qemu
```
```
Welcome to Red Hat Enterprise Linux 9.2 (Plow)!
[ OK ] Created slice Slice /system/modprobe.
[ OK ] Reached target Initrd Root Device.
[ OK ] Reached target Initrd /usr File System.
[ OK ] Reached target Local Integrity Protected Volumes.
[ OK ] Reached target Local File Systems.
[ OK ] Reached target Path Units.
[ OK ] Reached target Remote Encrypted Volumes.
[ OK ] Reached target Remote Verity Protected Volumes.
[ OK ] Reached target Slice Units.
[ OK ] Reached target Swaps.
...
[ OK ] Listening on Journal Socket.
[ OK ] Listening on udev Control Socket.
[ OK ] Listening on udev Kernel Socket.
...
Red Hat Enterprise Linux 9.2 (Plow)
Kernel 5.14.0-284.30.1.el9_2.x86_64 on an x86_64
localhost login: root (automatic login)
[root@localhost ~]#
```
很好,我们将“镜像”构建为一个带有文件系统树的目录,并在虚拟机中引导了它。
在引导的虚拟机中,`findmnt /` 显示根文件系统是 virtiofs。这是一个虚拟文件系统,将主机的目录暴露给客户机。我们其实也可以构建一个更传统的镜像,其中包含文件系统和文件内的分区表,但“目录 + virtiofs” 对于开发来说更快且更友好。
我们刚刚引导的镜像未注册。要允许从镜像“内部”下载更新,我们必须将 `yum` 、`subscription-manager` 和 `NetworkManager` 添加到软件包列表,并在下载任何更新之前以与上述相同的方式调用 `subscription-manager`。在这之后,我们在基本仓库中就有大约 4500 个软件包可用,并且还有一些包含更多专业软件包的额外仓库。
### 最后
今天就是这些了。如果您有问题,可以在 Matrix 上找到我们,地址为 [#mkosi:matrix.org](https://matrix.to/#/#mkosi:matrix.org),或者在 [systemd 邮件列表](https://lists.freedesktop.org/mailman/listinfo/systemd-devel) 上找到我们。
*(题图:MJ/a6e60316-ed03-4e23-b8b4-22332a0f5bfa)*
---
1. Daan DeMeyer、Lukáš Nykrýn、Michal Sekletár、Zbigiew Jędrzejewski-Szmek [↩︎](#fnref1)
---
via: <https://fedoramagazine.org/create-images-directly-from-rhel-and-rhel-ubi-package-using-mkosi/>
作者:[Zbigniew Jędrzejewski-Szmek](https://fedoramagazine.org/author/zbyszek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GlassFoxowo](https://github.com/GlassFoxowo-Dev) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mkosi is a lightweight tool to build images from distribution packages. This article describes how to use mkosi to build images with packages from RHEL (Red Hat Enterprise Linux) and RHEL UBI. RHEL Universal Base Image is a subset of RHEL that is freely available without a subscription.
## Mkosi features
Mkosi supports a few output formats, but the most important one is [Discoverable Disk Images](https://uapi-group.org/specifications/specs/discoverable_disk_image/) (DDIs). The same DDI can be used to boot a container, as a virtual machine, copied to a USB stick and used to boot a real machine, and finally copied from the USB stick to the disk to boot from it. The image has a standarized layout and metadata that describes its purpose.
Mkosi relies on other tools to do most of the work: *systemd-repart* to create partitions on a disk image, *mkfs.btrfs*/*mkfs.ext4*/*mkfs.xfs*/… to write the file systems, and *dnf*/*apt*/*pacman*/*zypper* to download and unpack packages.
Mkosi supports a range of distributions: Debian and Ubuntu, Arch Linux, OpenSUSE, and of course Fedora, CentOS Stream and derivatives, and now RHEL UBI and RHEL since the last release. Because the actual “heavy lifting” is done by other tools, mkosi can do cross builds. This is where one distro is used to build images for various other distros. The only requirement is that the appropriate tools are installed on the host. Fedora has native packages for *apt*, *pacman*, and *zypper*, so it provides a good base to use mkosi to build any other distribution.
There are some nifty features: images can be created by an unprivileged user, or in a container without device files, in particular access to loopback devices. It can also launch those images as VMs (using *qemu*) without privileges.
The configuration is declarative and very easy to create. *systemd-repart* is used to create disk partitions, and *repart.d *configuration files are used to define how this should be done.
For more details see two talks by Daan DeMeyer at the All Systems Go conference: [systemd-repart: Building Discoverable Disk Images](https://media.ccc.de/v/all-systems-go-2023-191-systemd-repart-building-discoverable-disk-images) and [mkosi: Building Bespoke Operating System Images](https://media.ccc.de/v/all-systems-go-2023-190-mkosi-building-bespoke-operating-system-images).
## Project goal
One goal for Mkosi is to allow the testing of a software project against various distributions. It will create an image for a distribution (using packages from that distribution) and then compile and install the software project into that image, inserting additional files that are not part of a package. But the first stage, the creation of an image from packages, is useful on its own. This is what we will show first.
We 1 recently added support for RHEL and RHEL UBI. Let’s start with RHEL UBI, just building an image out of distro packages.
Please note that the examples below require mkosi 19, and will not work with earlier versions.
## A basic RHEL UBI image with a shell
$mkdir -p mkosi.cache$mkosi \ -d rhel-ubi \ -t directory \ -p bash,coreutils,util-linux,systemd,rpm \ --autologin
The commands above specify the distribution ‘rhel-ubi’, the output format ‘directory’, and request that packages *bash*, *coreutils*, …, *rpm* be installed. *rpm* isn’t normally needed *inside* of the image, but here it will be useful for introspection. We also enable automatic login as the root user.
Before the build is started, we create the cache directory *mkosi.cache*. When a cache directory is present Mkosi uses it automatically to persist downloaded rpms. This will make subsequent invocations on the same package set much faster.
We can then boot this image as a container using *systemd-nspawn*:
$sudo mkosi \ -d rhel-ubi \ -t directory \ boot
systemd 252-14.el9_2.3 running in system mode (+PAM +AUDIT +SELINUX -APPARMOR +IMA +SMACK +SECCOMP +GCRYPT +GNUTLS +OPENSSL +ACL +BLKID +CURL +ELFUTILS -FIDO2 +IDN2 -IDN -IPTC +KMOD +LIBCRYPTSETUP +LIBFDISK +PCRE2 -PWQUALITY +P11KIT -QRENCODE +TPM2 +BZIP2 +LZ4 +XZ +ZLIB +ZSTD -BPF_FRAMEWORK +XKBCOMMON +UTMP +SYSVINIT default-hierarchy=unified) Detected virtualization systemd-nspawn. Detected architecture x86-64. Detected first boot. Red Hat Enterprise Linux 9.2 (Plow) ... [ OK ] Created slice Slice /system/getty. [ OK ] Created slice Slice /system/modprobe. [ OK ] Created slice User and Session Slice. ... [ OK ] Started User Login Management. [ OK ] Reached target Multi-User System. Red Hat Enterprise Linux 9.2 (Plow) Kernel 6.5.6-300.fc39.x86_64 on an x86_64 image login: root (automatic login) [root@image ~]# rpm -q rpm systemd rpm-4.16.1.3-22.el9.x86_64 systemd-252-14.el9_2.3.x86_64
As mentioned earlier, the image can be used to boot a VM. In this setup, it is not possible — our image doesn’t have a kernel. In fact, RHEL UBI doesn’t provide a kernel at all, so we can’t use it to boot (in a VM or on bare metal).
## Creating an image
I also promised an image, but so far we only have a directory. Let’s actually create an image:
$mkosi\-d rhel-ubi \-t disk \-p bash,coreutils,util-linux,systemd,rpm \--autologin
This produces *image.raw*, an disk image with a GPT partition table, and a single root partition (for the native architecture).
$sudo systemd-dissect image.rawName: image.raw Size: 301.0M Sec. Size: 512 Arch.: x86-64 Image UUID: dcbd6499-409e-4b62-b251-e0dd15e446d5 OS Release: NAME=Red Hat Enterprise Linux VERSION=9.2 (Plow) ID=rhel ID_LIKE=fedora VERSION_ID=9.2 PLATFORM_ID=platform:el9 PRETTY_NAME=Red Hat Enterprise Linux 9.2 (Plow) ANSI_COLOR=0;31 LOGO=fedora-logo-icon CPE_NAME=cpe:/o:redhat:enterprise_linux:9::baseos HOME_URL=https://www.redhat.com/ DOCUMENTATION_URL=https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9 BUG_REPORT_URL=https://bugzilla.redhat.com/ REDHAT_BUGZILLA_PRODUCT=Red Hat Enterprise Linux 9 REDHAT_BUGZILLA_PRODUCT_VERSION=9.2 REDHAT_SUPPORT_PRODUCT=Red Hat Enterprise Linux REDHAT_SUPPORT_PRODUCT_VERSION=9.2 Use As: ✗ bootable system for UEFI ✓ bootable system for container ✗ portable service ✗ initrd ✗ sysext extension for system ✗ sysext extension for initrd ✗ sysext extension for portable service RW DESIGNATOR PARTITION UUID PARTITION LABEL FSTYPE ARCHITECTURE VERITY GROWFS NODE PARTNO rw root 1236e211-4729-4561-a6fc-9ef8f18b828f root-x86-64 xfs x86-64 no yes /dev/loop0p1 1
OK, we have an image, the image has some content from RHEL UBI packages. How do we add our own stuff on top?
## Extending an image with your own files
There are a few ways to extend the image, including compiling something from scratch. But first let’s do something easier and inject a provided file system into the image:
$mkdir -p mkosi.extra/srv/www/content$cat >mkosi.extra/srv/www/content/index.html<<'EOF'<h1>Hello, World!</h1>EOF
The image will now have */srv/www/content/index.html*.
This method is used to inject additional configuration or simple programs.
## Building from source
Now let’s do the full monty and build something from sources. For example, a trivial meson project with a single C file:
$cat >hello.c<<'EOF'#include <stdio.h> int main(int argc, char **argv) { char buf[1024]; FILE *f = fopen("/srv/www/content/index.html", "re"); size_t n = fread(buf, 1, sizeof buf, f); fwrite(buf, 1, n, stdout); fclose(f); return 0; }EOF$cat >meson.build <<'EOF'project('hello', 'c') executable('hello', 'hello.c', install: true)EOF
$cat >mkosi.build <<'EOF'set -ex mkosi-as-caller rm -rf "$BUILDDIR/build" mkosi-as-caller meson setup "$BUILDDIR/build" "$SRCDIR" mkosi-as-caller meson compile -C "$BUILDDIR/build" meson install -C "$BUILDDIR/build" --no-rebuildEOF$chmod +x mkosi.build
To summarize: we have some source code (*hello.c*), a build system configuration (*meson.build*), and a glue script (*mkosi.build*) that is to be invoked by *mkosi*. For a “real” project, we would have the same elements, just more complex.
The script requires some explanation. Mkosi uses user namespaces when creating the image. This allows the package managers (e.g. *dnf*) to install files owned by different users even though it is invoked by a normal unprivileged user. We are using *mkosi-as-caller* to switch back to the calling user to do the compilation. This way, the files created during compilation under $BUILDDIR will be owned by the calling user.
Now let’s build the image with our program. Compared to the previous invocation, we need additional packages: *meson*, *gcc*. Since we now have a build script, mkosi will execute two build stages: first an build image is built, and the build script is invoked in it, and the installation artifacts are stashed in a temporary directory, then a final image is built, and the installation artifacts are injected. (Mkosi sets $DESTDIR, and *meson install* uses $DESTDIR automatically, so the right things happen without us having to specify things explicitly.)
$mkosi \ -d rhel-ubi \ -t disk \ -p bash,coreutils,util-linux,systemd,rpm \ --autologin \ --build-package=meson,gcc \ --build-dir=mkosi.builddir \ --build-script=mkosi.build \ -f
At this point we have the image *image.raw* with a custom payload. We can start our freshly minted executable as a shell command:
$sudo mkosi -d rhel-ubi -t directory shell hello<h1>Hello, World!</h1>
## Obtaining a developer subscription for RHEL
RHEL UBI is intended for use primarily as a base layer for container builds. It has a limited set of packages available (about 1500). Let’s now switch to a full RHEL installation.
The easiest way to get access to RHEL is with a [developer license](https://developers.redhat.com/articles/faqs-no-cost-red-hat-enterprise-linux). It provides an entitlement to register 16 physical or virtual nodes running RHEL, with self-service support.
First, [create an account](https://developers.redhat.com/register). After that, head over to [management](https://access.redhat.com/management) and make sure “Simple content access for Red Hat Subscription Management” is enabled. Then, [create a new activation key](https://access.redhat.com/management/activation_keys/new) with “Red Hat Developer Subscription for Individuals” selected. Make note of the Organization ID that is shown. We’ll refer to the key name and organization ID as $KEY_NAME and $ORGANIZATION_ID below.
Now we are ready to consume RHEL content:
$sudo dnf install subscription-manager$sudo subscription-manager register \--org $ORGANIZATION_ID --activationkey $KEY_NAME
## Building an image using RHEL
In previous examples, we specified all configuration through parameter switches. This is nice for quick development, but can become unwieldy. RHEL is a serious distribution, so let’s use a configuration file instead:
$cat >mkosi.conf <<'EOF'[Output] Format=directory Output=rhel-directory [Distribution] Distribution=rhel [Content] Packages= bash coreutils util-linux systemd systemd-boot systemd-udev kernel-core Bootable=yes Bootloader=uki Autologin=yes WithDocs=noEOF
Let’s first check if everything is kosher:
$mkosi summary
And now let’s build the image (err, directory):
$mkosi build$mkosi qemu
Welcome to Red Hat Enterprise Linux 9.2 (Plow)! [ OK ] Created slice Slice /system/modprobe. [ OK ] Reached target Initrd Root Device. [ OK ] Reached target Initrd /usr File System. [ OK ] Reached target Local Integrity Protected Volumes. [ OK ] Reached target Local File Systems. [ OK ] Reached target Path Units. [ OK ] Reached target Remote Encrypted Volumes. [ OK ] Reached target Remote Verity Protected Volumes. [ OK ] Reached target Slice Units. [ OK ] Reached target Swaps. ... [ OK ] Listening on Journal Socket. [ OK ] Listening on udev Control Socket. [ OK ] Listening on udev Kernel Socket. ... Red Hat Enterprise Linux 9.2 (Plow) Kernel 5.14.0-284.30.1.el9_2.x86_64 on an x86_64 localhost login: root (automatic login) [root@localhost ~]#
Yes, we built the “image” as a directory with a file system tree, and booted it as a virtual machine.
In the booted virtual machine, *findmnt /* shows that the root file systems is virtiofs. This is a virtual file system that exposes a directory from the host to the guest. We *could* build a more traditional image with a partition table and file systems inside of a file, but a directory+virtiofs is quick and nicer for development.
The image that we just booted is not registered. To allow updates to be downloaded from *inside* of the image, we would have to add *yum*, *subscription-manager*, and *NetworkManager* to the package list, and before we download any updates, call *subscription-manager* in the same way as above. Once we do that, we have about 4500 packages at our disposal in the basic repositories, and a few dozen additional repositories with more specialized packages.
## Finally
And that’s all I have for today. If you have questions, find us on Matrix at [#mkosi:matrix.org](https://matrix.to/#/#mkosi:matrix.org) or on the [systemd mailing list](https://lists.freedesktop.org/mailman/listinfo/systemd-devel).
- Daan DeMeyer, Lukáš Nykrýn, Michal Sekletár, Zbigiew Jędrzejewski-Szmek
[↩︎](#a08aaa7d-ee14-4565-80a0-e3d19b21ad26-link)
## You Really Don't Want to Know
This is the best tech article I have seen here … or anywhere else, come to that.
## Peter Boy
Very interesting! When I looked into Mkosi several years ago, I got the impression that it might have lost its momentum. But that is clearly not (or no longer) the case.
I would be very happy if you could contribute a (small or not so small) step-by-step guide to the nspawn section of our Fedora Server Edition documentation, especially about creating foreign distributions (from Fedora’s point of view) nspawn-containers and probably VMs. Would be really great!
## Zbigniew Jędrzejewski-Szmek
Mkosi had a period of stagnation… but it very active now. So far 1258 commits this year, and there are more plans.
https://docs.fedoraproject.org/en-US/fedora-server/containerization/systemd-nspawn-setup/, right? That’s a nice challenge. Mkosi could make some of the things there much easier, for example it’d remove the need to manually configure repositories. I’ll think about it.
## Klaas
How does this compare to osbuild https://github.com/osbuild/osbuild ?
## Zbigniew Jędrzejewski-Szmek
This is a complex issue. Some obvious differences:
– mkosi is tool to be invoked locally, and is essentially a glorified python script. OsBuild is a beast: it a frontend, a backend, a composer, and a worker fleet.
– both mkosi and OsBuild allow selection of packages, so they seem to be quite similar in this regard. In mkosi, the list of “packages” is passed to the tool, so actually the arguments can be package names, file paths, or nevra strings, or virtual provides or “rpm rich dependencies”, groups, i.e. anything that is supported by the underlying package manager. OsBuild seems to be less flexible here.
– OsBuild has custom configuration language for most things: packages, groups, firewall customizations, service enablement, etc. OTOH, mkosi doesn’t have any understanding of those things: the user would generally be expected to just provide the right configuration file themselves. For example, drop in a config file snippet in
mkosi.extradirectory, and then mkosi will push it to the image. This is actually nice, because it’s more flexible, and the user doesn’t have to learn yet-another method to configure things. Of course, this works nicely for systems which are designed to be configured in this way. All systemd components support drop-in files and very simple text config, so this works out nicely. But for some other software this might not be the right approach.– OsBuild has native understanding of containers and is designed to work in this model. Mkosi is more traditional: some local config results in a disk image or a tarball, that’s it.
– Mkosi now does most things without requiring any privileges. I’m not sure about OsBuild.
– With mkosi, it’s fairly easy to customize the output very very precisely. For example, we build initrd images via mkosi.
– Mkosi has native understanding of dm-verity and signatures, and will produce images with signatures. In general, it is intended to make use of systemd features to the maximum possible extent.
With mkosi the focus is on local workflows and flexibility and experimentation with systemd features, while with OsBuild the focus is on reliable builds in a cloud environment. A lot of this is just philosophy and both systems are flexible, so it’s possible that with enough determination, both would allow many different things to be done.
It’d be great if somebody who has experience with mkosi, osbuild, and kiwi, would create an in-depth comparison.
## Dirk Gottschalk
Hello. Really nice article.
I tried mkosi on my system and everytime I try to run it as regular user I get a “permission denied” error. Do I have to add a group membership or something like that?
My Environment: Fedora Workstation 39, login with FreeIPA 4.11
## Zbigniew Jędrzejewski-Szmek
Older mkosi versions (<=14) required root privileges, but Fedora 39 has version 19. Newer versions are mostly supposed to run as an unprivileged user. The only operation that requires root privileges is
mkosi shellormkosi boot, because that usessystemd-nspawn.It’d help if you showed the exact package version, the command that is failing, and the error message.
## Dirk Gottschalk
I am using mkosi version 19.
I get this error message:
mkosi \
-d rhel-ubi \
-t directory \
-p bash,coreutils,util-linux,systemd,rpm \
–autologin
Traceback (most recent call last):
File “/usr/bin/mkosi”, line 8, in
sys.exit(main())
^^^^^^
File “/usr/lib64/python3.12/contextlib.py”, line 81, in inner
return func(*args, **kwds)
^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/site-packages/mkosi/__main__.py”, line 52, in main
run_verb(args, images)
File “/usr/lib/python3.12/site-packages/mkosi/__init__.py”, line 2801, in run_verb
if not needs_build(args, config) and args.verb != Verb.clean:
^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib/python3.12/site-packages/mkosi/__init__.py”, line 2582, in needs_build
(args.force > 0 or not (config.output_dir_or_cwd() / config.output_with_compression).exists())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/lib64/python3.12/pathlib.py”, line 861, in exists
self.stat(follow_symlinks=follow_symlinks)
File “/usr/lib64/python3.12/pathlib.py”, line 841, in stat
return os.stat(self, follow_symlinks=follow_symlinks)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
PermissionError: [Errno 13] Permission denied: ‘/home/dgottschalk/osi/image’
## Zbigniew Jędrzejewski-Szmek
It looks like it fails when trying to access this file. You probably have a left-over files owned by root (or some other user).
## unscramble words
Hey Zbigniew, great walkthrough on building RHEL and RHEL UBI images with mkosi! Love the flexibility mkosi offers, especially for cross builds. Excited to see the impact on software testing across different distros! |
16,422 | 在 Linux 中玩乐:Cmatrix 之旅 | https://itsfoss.com/using-cmatrix/ | 2023-11-28T07:21:30 | [
"Cmatrix",
"趣味"
] | https://linux.cn/article-16422-1.html | 
>
> 玩得开心,安德森先生!
>
>
>
Cmatrix 是一款充满乐趣的 Linux 和 Unix 系统命令行程序。它可以模仿经典电影《<ruby> 黑客帝国 <rt> Matrix </rt></ruby>》系列中的场景,用绿色的字符流营造出雨一般的下落效果。

除了充满视觉冲击力的绿色字符流之外,你还可以发挥想象,利用这款有趣的命令做更多事情。
>
> ? 需要注意的是,Cmatrix 是一个 CPU 密集型的命令,所以请慎重使用它。
>
>
>
### 如何在 Ubuntu 及其他 Linux 系统中安装 Cmatrix
Cmatrix 已经被收录在几乎所有主要的 Linux 发行版的官方库中。如果你是 Ubuntu 用户,可以通过如下命令来安装 Cmatrix:
```
sudo apt install cmatrix
```
对于 Fedora 用户,应该使用以下命令进行安装:
```
sudo dnf install cmatrix
```
而对于 Arch Linux 用户,则可以使用 pacman 命令进行安装:
```
sudo pacman -S cmatrix
```
### Cmatrix 的基础应用
cmatrix 命令自身提供了丰富的选项,你可以自由改变默认的绿色字符流的外观呈现。
#### 加粗的字符
你可以选择使用 `-b` 选项,偶尔展示加粗的字符,
```
cmatrix -b
```

或者,你也可以调整设置,让所有的字符都以加粗方式显示,
```
cmatrix -B
```

#### 异步滚动
默认情况下,Cmatrix 会创建一个字符同步下落的显示。但如果你想看到一个更为动态、视觉上更吸引人的显示效果,就可以在代码中操控字符的下落速度。
你可以这样设置 Cmatrix,让其进行异步滚动:
```
cmatrix -a
```
#### 自定义字符下落速度
你想让字符下落的速度更快,或者更慢吗?只需在 Cmatrix 中做出微小改动,就可以实现。
如想让字符以更快的速度下落,你可以这样设定:
```
cmatrix -u 2
```

在这里,默认的屏幕更新延迟是 4,如果你把这个值降低,那么字符下落的速度就会增加,反之则会减慢。所以,如果你想让 Cmatrix 以更慢的速度运行,你可以这样设置:
```
cmatrix -u 9
```

#### 自定义颜色
你可能想问,绿色能改吗?当然,你想变成紫色也行。
运行 Cmatrix 的时候,你可以自由调整它的颜色。只需要使用 `-C` 选项,然后在后面添加你想要的颜色,如下所示:
```
cmatrix -C magenta
```

你可以任选绿色(`green`)、红色(`red`)、蓝色(`blue`)、白色(`white`)、黄色(`yellow`)、青色(`cyan`)、洋红色(`magenta`)以及黑色(`black`)这些颜色。
#### 其他可选设置
| 选项 | 对应功能 |
| --- | --- |
| `cmatrix -o` | 旧式滚动模式 |
| `cmatrix -m` | Lambda 模式:把所有的字符变为 lambda 符号 |
| `cmatrix -s` | 屏保模式:按键有就自动退出 |
| `cmatrix -h` | 调出帮助手册 |
### 运行 Cmatrix 时的快捷键选项
就算在启动 Cmatrix 的时候你没有添加任何选项,你仍可以在实际运行中随时改变设置。下面就是一些可供你随时选择的选项。
#### 随时改变颜色
当然,你无需重新启动程序,就可以随时改变显示的颜色。但需要记住,不同的键位对应着不同的颜色。在 Cmatrix 未关闭的情况下,如果你按下了存储在键位上的指令,显示的颜色将会直接变更。
| 颜色 | 相应键位 |
| --- | --- |
| 红色 | `!` |
| 绿色 | `@` |
| 黄色 | `#` |
| 蓝色 | `$` |
| 洋红色 | `%` |
| 青色 | `^` |
| 白色 | `&` |
| 黑色 | `)` |
#### 自由调整更新速度
在 Cmatrix 运行的过程中,你可以按 `0` 到 `9` 的任何一位数字键来随意改变当前的更新速度。
此外,Cmatrix 也有许多其他的选项可供你选择,你可以在命令的 man 页面里面找到它们。
```
man cmatrix
```
### 彩虹魔法:Cmatrix 配合 lolcat
>
> ? 请注意,Cmatrix 本身就是 CPU 密集型的命令,所以在使用其他命令操控它的时候需特别小心。
>
>
>
你可以将 Cmatrix 和 lolcat 结合在一起使用,以此营造出一种更加有趣的视觉效果。如果你是 Ubuntu 的用户,可以通过如下的命令来安装 lolcat:
```
sudo apt install lolcat
```
安装完毕后,只需简单地通过管道将 Cmatrix 连接到 lolcat,你便可以看到赏心悦目的彩虹效果了。
```
cmatrix | lolcat
```

当然,你也可以尝试用 lolcat 来管理所有的 Cmatrix 的功能。
或者,你可以调出一个倾斜的彩虹条纹效果,为自己的视觉体验增添一些新花样。
```
cmatrix | lolcat -p 100
```
此外,只要轻轻一点,你就可以直接反转现有的背景和前景颜色,使你的终端完全沉浸在五彩斑斓之中。
```
cmatrix | lolcat -i
```

### 终端界面的无尽可能
我知道 Cmatrix 不可能是 [最实用的 Linux 命令](https://itsfoss.com/essential-ubuntu-commands/),但无可否认,它令人喜爱且同样能够带给你乐趣。难道你不想尝试更多和你的 Linux 系统之间的 [有趣交互](https://itsfoss.com/funny-linux-commands/) 吗?
就像 [Cowsay](/article-15952-1.html) 这样的命令,虽然简单,却欢乐无穷:
>
> **[哞~ 我的 Linux 终端里有头牛](/article-15952-1.html)**
>
>
>
这里还有更多玩法等待你去探索:
>
> **[在终端中享受乐趣的 13 种 Linux 命令](https://itsfoss.com/funny-linux-commands/)**
>
>
>
现在,玩得开心,安德森先生!
*(题图:MJ/9f9f8665-e5d0-47b5-9df0-b39abd9dca3d)*
---
via: <https://itsfoss.com/using-cmatrix/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Cmatrix is an entertaining command-line program for Linux and Unix systems. It gives a 'Matrix'-style display, where a rain of green characters streams down the screen, just like in the iconic Matrix film series.

But other than this green streams of characters, you can do several other things with this interesting command.
## Install Cmatrix in Ubuntu and Other Linux systems
Cmatrix is available in the official repositories of almost all major Linux distributions. In Ubuntu, you can install Cmatrix using the command:
`sudo apt install cmatrix`
Fedora users should use:
`sudo dnf install cmatrix`
Arch Linux user can use pacman:
`sudo pacman -S cmatrix`
## Basic cmatrix options
The cmatrix command alone provides several options, to change the appearance of the default output, that is the green character streams.
### Bold characters
You can either toggle the bold characters on using `-b`
option, where you will find occasional bold characters,
`cmatrix -b`
or, turn all the characters to bold using:
`cmatrix -B`
### Asynchronous scroll
The usual Cmatrix will create a display, where characters are falling down in a synchronous manner. In this mode, you can see a dynamic and visually engaging display, where the speed of the characters is varied.
To use Cmatrix in asynchronous scroll:
`cmatrix -a`
### Change the speed of characters
Do you want to display the characters falling very fast, or very slow? You can do this in Cmatrix.
To make characters fall down fast, use:
`cmatrix -u 2`
Here, the default value of screen update delay is 4 and if you reduce it, the speed will be increased and vice versa. So, to run a slower cmatrix, use:
`cmatrix -u 9`
### Use different Colors
Go green! Or perhaps go purple?
You can run Cmatrix with a different color. For this, you can use the `-C`
option.
`cmatrix -C magenta`
The supported colors are **green, red, blue, white, yellow, cyan, magenta and black**.
### Other Options
Option | Function |
---|---|
cmatrix -o | Old Style Scrolling |
cmatrix -m | Lambda Mode: Every character becomes a lambda |
cmatrix -s | Screensaver Mode: Exits on first keystroke |
cmatrix -h | Help |
## Cmatrix keystrokes during execution
Even if you don’t provide any option in Cmatrix, you can provide some input later on during execution. Those are listed below.
### Change Color
Yes, you can change the color of characters while running. But you need to remember some keys and their corresponding color. What to do is, while running Cmatrix, press these keys and the color will change.
Color | Keystroke |
---|---|
Red | ! |
Green | @ |
Yellow | # |
Blue | $ |
Magenta | % |
Cyan | ^ |
White | & |
Black | ) |
### Adjust update speed
While running, you can use the number keys from 0 through 9 to change the update speed.
There are other options also, which you can find from the man page of the command.
`man cmatrix`
## Bonus: Cmatrix with lolcat
You can use Cmatrix, in combination with the lolcat command, to make it look more interesting. In Ubuntu, you can install lolcat using:
`sudo apt install lolcat`
Now, just pipe Cmatrix to lolcat so that you will get a rainbow effect.
`cmatrix | lolcat`
Also, try all the above functions of Cmatrix, while piping into lolcat.
Or, you can use an inclined stripe for a rainbow effect, giving another type of experience.
`cmatrix | lolcat -p 100`
Additionally, you can just invert the background and foreground colors so that your terminal will be filled with colors.
`cmatrix | lolcat -i`
## More fun with terminal
I know this is not the [most useful Linux command](https://itsfoss.com/essential-ubuntu-commands/) but it's fun nonetheless and you can have some [fun with your Linux system](https://itsfoss.com/funny-linux-commands/) sometime, right?
[Cowsay](https://itsfoss.com/cowsay/) is another such command:
[Using Cowsay Linux Command Like a ProThe cowsay is a fun little Linux command line utility that can be enjoyed in so many ways. Here are several examples.](https://itsfoss.com/cowsay/)

And even more here:
[13 Amusing Funny Linux CommandsSo, you think Linux terminal is all work and no fun? These funny Linux commands will prove you wrong.](https://itsfoss.com/funny-linux-commands/)

I let you enjoy it now, Mr. Anderson. |
16,424 | 微软加码对 GitHub 上的公开代码搜索的限制 | https://news.itsfoss.com/microsoft-github-open-source-code/ | 2023-11-29T08:28:00 | [
"GitHub"
] | https://linux.cn/article-16424-1.html | 
>
> 微软,你在 GitHub 上的行为究竟是何目的?
>
>
>
许多用户对 [微软收购 GitHub](https://itsfoss.com/microsoft-github/) 这一事实感到失望。当然,这并非用户能阻止的事情。
因此,有些人选择转向 GitLab 或其他 [GitHub 替代品](https://itsfoss.com/github-alternatives/),而部分人则决定坚守在 GitHub,不论他们的感受如何。
GitHub 是无数开发者熟悉的地方。无论现在是谁拥有它,这个平台都有它的价值,所以用户仍然根据自己的需求来选择使用它。
不幸的是,自微软加入之后,平台上才有了某些变化,两者之间似乎存在一些关联,而且部分改变让用户觉得不便。被关注起来的这个变化就是 2023 年 6 月实施的。
### 现在需要登录才能搜索代码
一位 GitHub 用户/贡献者 [抱怨](https://github.com/orgs/community/discussions/77046) 在未登录的情况下无法在公开仓库中搜索代码,这让人非常失望。
>
> ? 在 GitHub 上进行全局代码搜索已经需要登录用户操作,这样已经好几年了。现在所讨论的是仓库内搜索的情况。
>
>
>
下面是他的观点:
>
> 这真是让人感到恶心,这是对开源运动的亵渎。我必须指出,微软在这里是在滥用开源运动。
>
>
> 我们被告知这是出于安全考虑……但当我可以简单地克隆仓库,使用更专业的工具进行适当的搜索和分析时,那么这样的安全又是为了什么呢?
>
>
> 那么到底是什么原因呢?!你们还没有获得我们足够的数据吗?只是靠每次上厕所就能赚点钱,你们还要追踪我在看哪一行代码?
>
>
>
此外,他解释了在他认为应公开访问的仓库中搜索代码的不便。
>
> 我正在老旧的机器上使用,需要在我们自己的仓库中搜索东西,结果却做不到。我其实希望人们能够搜索我们的代码库。
>
>
> 那我该怎么做呢?我试过登录。但是我的密码管理器不在我手边,所以我不得不拿出我的手机。哦!现在我需要 2FA。然后我得回办公室拿我的 Yubi 密钥。旧的笔记本没有 USB-C 端口?好吧,现在我无能为力了。
>
>
> 这个变化不仅没必要,而且对你们自己的客户来说,简直是**敌意**。猖獗的敌意!
>
>
>
实际上,无法访问本应公开且对“**所有人**”开放的代码库让人极度不便。
这就是开源代码应该如何访问的,对吗?
Martin Woodward,**GitHub 的开发者关系副总裁**,对这个反馈简单地表示,这是一段时间以来的一个改变,主要是为了避免机器人。
>
> 对 [@koepnick](https://github.com/koepnick) 的不便感到抱歉,虽然在很长一段时间里,我们在全仓库范围内的搜索都要求用户登录,但是当我们在 2023 年提升了搜索能力后,我们不得不将这一要求扩大到仓库内(参看 <https://github.blog/changelog/2023-06-07-code-search-now-requires-login/>)。
>
>
> 主要是确保我们的服务器能够支撑 GitHub 上的开发者负载,并帮助防止服务器被匿名请求等机器人行为压垮。
>
>
>
当然,这是一个大公司的预期回应。不幸的是,这并没有说服为什么要在 GitHub 上做出这样的改变,而其他平台并没有这个限制。
声明说的更多的是“何时实施了此项更改”。
幸运的是,[代码搜索团队的一员](https://github.com/orgs/community/discussions/77046#discussioncomment-7683240) 试图阐述他们通过限制获得的优势。
**太长不看版:该策略可以减少滥用,但并不能阻止所有的机器人。**
那么,让我们思考一下,作为科技行业的重要参与者,微软没有足够的基础设施来抵御机器人,而不是通过限制访问代码来做到这一点吗?难道没有其他方式来保护代码免受机器人和其他恶意抓取器的侵袭,而不需要禁用搜索功能吗?
此外,讨论中的一些用户指出,开源代码的全部意义就在于任何人,无论身份是已知还是未知,都应该可以访问。
尽管代码关联到了开源许可证,但是这个限制似乎违反了开源的概念。
*微软是正在私下里试图控制 GitHub 上的开源利益吗?* ?
? 也许微软需要重新考虑这个变动,来让事情变得好一些?或者,也许他们可以提供一个比声明中更好的解释?
*(题图:MJ/d35ceb65-521d-4313-8e4c-60df0a898455)*
---
via: <https://news.itsfoss.com/microsoft-github-open-source-code/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Many users were disappointed to realize [Microsoft acquired GitHub](https://itsfoss.com/microsoft-github/?ref=news.itsfoss.com). Of course, it was nothing something users could prevent.
So, some decided to move to GitLab or other [GitHub alternatives](https://itsfoss.com/github-alternatives/?ref=news.itsfoss.com), while some decided to stay irrespective of how they felt.
GitHub is a familiar place for countless developers. No matter who owns it now, the platform has its benefits, which is why users still choose to use it as per their requirements.
Unfortunately, there have been certain changes to the platform only after Microsoft came to the scene, and some of them have been inconvenient. One of those changes (made back in June 2023) has come to the spotlight with a new discussion over it.
## Code Search Now Requires Log-in
A GitHub user/contributor [complained](https://github.com/orgs/community/discussions/77046?ref=news.itsfoss.com) that it is extremely disappointing to not being able to search for code in a public repository without logging in.
Here's what he had to say:
This is revolting and an anathema to the open source movement. A movement, I might add, Microsoft is abusing here.
We're told that this is for security... But whatpossiblepoint is there when I can simply clone the repository and use more dedicated tools for proper searching and analysis?
So what possible reason is there?! Do you NOT have enough of our data? Is it not enough to monetize every bowel movement, you now feel the need to track which individual lines of code I'm browsing?
Furthermore, he explained the inconvenience of logging in to search code in his repository, which he wants accessible to the public without any hassle.
I was on an older machine and needed to search for something in OUR OWN REPOSITORY and couldn't. I actually want people to be able to search our codebase.
So what did I have to do? I tried logging in. Didn't have my password manager nearby. So I had to grab my phone. Oh! Now I need to 2FA. So back to my office to grab my Yubi key. The old laptop doesn't have USB-C ports? Well now I'm SOL.
Not only is this change unncecessary, it's downrighthostiletowards your own customers.Ambitiouslyhostile!
It is practically a big inconvenience to access a code repository that is supposed to be public and accessible to "**everyone**".
That is how open-source code should be accessible, right?
Martin Woodward, the **VP of Developer Relations at GitHub** responded to the feedback by simply stating that this has been a change for a while, primarily to keep bots at bay.
Sorry for the inconvenience[@koepnick]- while searching across all repos has required being logged in for a long time, when we enhanced the search capabilities earlier in the 2023 we had to extend this to repos as well (see[https://github.blog/changelog/2023-06-07-code-search-now-requires-login/]).
This is primarily to ensure we can support the load for developers on GitHub and help protect the servers from being overwhelmed by anonymous requests from bots etc.
Sure, that is an expected response from a big company. Unfortunately, it does not sound convincing as to why is that a change to GitHub while other platforms do not have this restriction in place.
The statement says more about "when this change was implemented".
Fortunately, [a member of the Code Search team](https://github.com/orgs/community/discussions/77046?ref=news.itsfoss.com#discussioncomment-7683240) tried to chip in with the advantages they get with the restriction.
**TLDR: It lets them reduce the abuse, but still does not stop all the bots.**
So, that makes us think, Microsoft, being a major player in the tech industry, does not have a capable infrastructure to ward off bots without restricting access to the code? Is there no other way to protect the code from bots and other malicious scrapers without disabling the search functionality?
Moreover, some users in the discussion pointed out that the whole point of open-source code is the intent of everyone accessing it, whether the identity is known or unknown.
Despite the open-source license associated with the code, the restriction makes it go against the concept of open-source.
*Is Microsoft secretly trying to chain the benefits of open-source on GitHub? *🤔
💬* Maybe Microsoft needs to re-consider this change for the better? Or, perhaps come up with a better explanation than what the statement says?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,425 | HandBrake 1.7 发布 | https://news.itsfoss.com/handbrake-1-7-release/ | 2023-11-29T08:46:39 | [
"HandBrake",
"视频转换"
] | https://linux.cn/article-16425-1.html | 
>
> 这款视频转换工具带来了急需的改进。
>
>
>
流行的开源视频转换器 HandBrake 发布了新的重要版本,并进行了一些重要升级。该版本是在 [HandBrake 1.6](https://github.com/HandBrake/HandBrake/releases/tag/1.6.0) 发布近一年后推布的。
作为 [Linux 上最好的开源视频转换器](https://itsfoss.com/open-source-video-converters/) 之一,HandBrake 是许多人满足其视频转换/转码需求的首选选项。
让我们看看这个版本提供了什么。
### ? HandBrake 1.7:有什么新功能?

HandBrake 1.7 具有大量全面更新。
一些**关键亮点**包括:
* Linux 特定的改进
* 新的 AV1 编码器
* 提高性能
#### Linux 特定的改进
视频摘要中添加了对**位深度和 HDR 信息**的支持,还有一个**新选项可以在切换到电池电源或省电模式时暂停视频编码**。
然后添加了**对本机文件选择器的支持**、**对视频扫描的拖放支持**、**设置自动文件命名选项**、**删除过时的更新检查器** 等。
#### 新的 AV1 编码器
这是**此版本的主要亮点**,HandBrake 现在支持两种新的 AV1 编码器,**AMD VCN AV1** 和 **NVIDIA NVENC AV1**。
由于 SVT-AV1 的多通道 ABR 模式的实施,即使**现有的 AV1 编码支持也得到了提升**。
#### 提高性能
**HandBrake 的性能在 ARM64/AArch64 和 Apple Silicon 等 CPU 架构上得到了重大提升**。
现在,用户可以利用**新的 SVT-AV1 汇编优化**、**更快的 HEVC 解码**以及最新的 [FFmpeg](https://ffmpeg.org/) 库和**快 30% 的 bwdif 过滤**。
#### ?️ 其他更改和改进
至于其他改进,以下是一些值得注意的改进:
* 更新了许多第三方库。
* 更新了 Creator 和 Social 的预设。
* 添加了新的 [Apple VideoToolbox](https://developer.apple.com/documentation/videotoolbox) 硬件预设。
* 杜比视界和 HDR10+ 的动态范围元数据传递得到了改进。
自从我上次使用 HandBrake 以来已经有一段时间了。但是,我很高兴看到它仍然得到应有的照顾。
有关此版本的完整技术详细信息,你可以阅读 [发行说明](https://github.com/HandBrake/HandBrake/releases/tag/1.7.0)。
### ? 下载 HandBrake 1.7
HandBrake 适用于 **Linux**、**Windows** 和 **macOS**。你可以前往[官方网站](https://handbrake.fr/downloads.php)获取你选择的包。
>
> **[HandBrake](https://handbrake.fr/downloads.php)**
>
>
>
如果你不确定如何安装; 那么你可以通过我们的[安装指南](https://itsfoss.com/install-handbrake-ubuntu/)了解更多信息。
### 如何升级?
HandBrake 通常会让你知道 Windows 和 macOS 上是否有新更新。开发人员建议你**备份在执行升级之前设置的所有自定义预设和应用首选项**。
**对于 Windows 用户**,开发人员建议安装 Microsoft .NET Desktop Runtime [6.0.x 版本](https://dotnet.microsoft.com/en-us/download/dotnet/6.0),以便能够正确运行此程序。
但是,对于 **Linux 用户**,他们必须通过 Flathub 商店进行更新,或者使用官方网站或 [GitHub 仓库](https://github.com/HandBrake/HandBrake/releases)上提供的更新后的 Flatpak 包重新安装。
>
> ? 在撰写本文时,[Flathub store](https://flathub.org/apps/fr.handbrake.ghb) 版本尚未发布 1.7 版本。你可以期待它很快出现。
>
>
>
? 你会尝试这个新版本的 HandBrake 吗?
---
via: <https://news.itsfoss.com/handbrake-1-7-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

HandBrake, the popular open-source video transcoder, has received a new major release with some important upgrades. This release comes almost a year after the release of [HandBrake 1.6](https://github.com/HandBrake/HandBrake/releases/tag/1.6.0?ref=news.itsfoss.com),
Being one of the [best open-source video converters for Linux](https://itsfoss.com/open-source-video-converters/?ref=news.itsfoss.com), HandBrake is a neat option preferred by many for their video conversion/transcoding needs.
Let's take a look at what this release has to offer.
## 🆕 HandBrake 1.7: What's New?
HandBrake 1.7 features plenty of updates across the board.
Some **key highlights** include:
**Linux-Specific Improvements****New AV1 Encoders****Improved Performance**
### Linux-Specific Improvements
Support for **bit depth and HDR information** was added to the video summary, there is also a **new option to pause the encoding of a video** when switching to battery power or a power saving mode.
Then there's the added **support for native file choosers**,** drag/drop support for video scanning**, the ability to** set automatic file naming options**, the r**emoval of the obsolete update checker**, and more.
### New AV1 Encoders
This has been the **major highlight of this release**, HandBrake now has support for two new AV1 encoders, **AMD VCN AV1** and **NVIDIA NVENC AV1**.
Even **existing AV1 encoding support sees a boost** thanks to the implementation of multi-pass ABR mode for SVT-AV1.
### Improved Performance
The **performance of HandBrake sees a major boost** on CPU architectures such as **ARM64/AArch64** and **Apple Silicon**.
Now, users can take advantage of the** new SVT-AV1 assembly optimizations**, **faster HEVC decoding** with the latest [FFmpeg](https://ffmpeg.org/?ref=news.itsfoss.com) libraries and **30% faster bwdif filtering**.
### 🛠️ Other Changes and Improvements
As for the other refinements, here are some notable ones:
- Many third-party libraries were updated.
- The presets for Creator and Social were updated.
- New
[Apple VideoToolbox](https://developer.apple.com/documentation/videotoolbox?ref=news.itsfoss.com)hardware presets were added. - The dynamic range metadata pass through for Dolby Vision and HDR10+ were improved.
It's been some time since I last used HandBrake. But, I am glad to see that it is still receiving the care it deserves.
For complete technical details on this release, you may go through the [release notes](https://github.com/HandBrake/HandBrake/releases/tag/1.7.0?ref=news.itsfoss.com).
## 📥 Download HandBrake 1.7
HandBrake is available for **Linux**, **Windows**, and **macOS**. You can head over to the [official website](https://handbrake.fr/downloads.php?ref=news.itsfoss.com) to grab the package of your choice.
If you are unsure how to install it; then you can go through our [installation guide](https://itsfoss.com/install-handbrake-ubuntu/?ref=news.itsfoss.com) to learn more.
[How to Install Latest HandBrake on Ubuntu LinuxThis quick tutorial shows how to install the latest version of HandBrake on Ubuntu-based distributions using its official PPA.](https://itsfoss.com/install-handbrake-ubuntu/?ref=news.itsfoss.com)

### How to Upgrade?
HandBrake usually lets you know if there is a new update on Windows and macOS. The developers suggest you **back up any custom presets and app preferences** that you have set before performing the upgrade.
**For Windows users**, the devs recommend installing Microsoft .NET Desktop Runtime [version 6.0.x](https://dotnet.microsoft.com/en-us/download/dotnet/6.0?ref=news.itsfoss.com) to be able to run this release properly.
However, for **Linux users**, they will have to update it via the Flathub store, or reinstall it with the updated Flatpak bundles provided on the official site or the [GitHub repo](https://github.com/HandBrake/HandBrake/releases?ref=news.itsfoss.com).
[Flathub store](https://flathub.org/apps/fr.handbrake.ghb?ref=news.itsfoss.com)version does not feature 1.7 release. You can expect it sooner.
💬 *Will you be trying out this new release of HandBrake?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,427 | 适用于 Linux 的 LibreOffice 替代品 | https://itsfoss.com/libreoffice-alternatives-linux/ | 2023-11-30T08:09:00 | [
"LibreOffice"
] | https://linux.cn/article-16427-1.html | 
>
> LibreOffice 当然很棒,但是如果你想找一些其它的替代品,那这里有一些。
>
>
>
LibreOffice 是一个出色的开源文档套件。它预装在许多 Linux 发行版上,应该足以满足大多数用户的需求。
然而,有些人可能不喜欢它的用户界面和功能集。某些用户可能想尝试其他选项,看看它们是否提供更好的微软 Office 文档兼容性。
无论出于何种原因,好消息是我们有一些不错的 LibreOffice 替代品可供你探索。
>
> ✋ **非自由和开源软件警告!** 这里提到的一些应用并非开源。它们被列入是因为能在 Linux 下使用。
>
>
>
### 1、ONLYOFFICE
[ONLYOFFICE](https://www.onlyoffice.com/) 是一个令人印象深刻的文档套件,具有各种版本,可满足各种用户的需求。
与其他文档程序相比,它因提供与微软 Office 文档更好的兼容性而广受欢迎。功能集可能不如 LibreOffice 那么大,但就用户体验和兼容性而言,它可能是更好的选择。
你可以在 Linux 和其他平台上免费使用其 [桌面编辑器](https://www.onlyoffice.com/en/desktop.aspx)。你还可以选择自行托管社区版本并将其用作在线编辑器。但是,它确实对同时连接/用户有限制。
考虑到你可以在 GitHub 上找到 [源代码](https://github.com/ONLYOFFICE),它即使不完全是供个人使用的自由和开放源码软件,也是一个**可获得源代码**的解决方案。
亮点:
* 现代用户体验
* 更好的微软 Office 兼容性
* 在线编辑器(自托管或企业选项)
* 跨平台
### 2、Apache OpenOffice

LibreOffice 分支自 [Apache OpenOffice](https://www.openoffice.org/)。
当然,OpenOffice 的功能不如 LibreOffice 丰富。然而,对于寻求较旧/熟悉的用户界面以及满足基本要求的更稳定体验的用户来说,OpenOffice 是一个不错的选择。
OpenOffice 不像 LibreOffice 那样得到积极维护,但你可以期待每年/每两年发布一次。不要忘记,你也可以轻松地 [安装 Apache OpenOffice](https://itsfoss.com/install-openoffice-ubuntu-linux/)。
我们有详细的 [LibreOffice 和 OpenOffice 文档套件之间的比较](/article-16079-1.html) 来帮助你做出决定。
>
> **[LibreOffice 和 OpenOffice 的相似与不同之处](/article-16079-1.html)**
>
>
>
亮点:
* 老式用户界面
* 对于某些用户来说它更稳定
* 跨平台
### 3、CryptPad

[CryptPad](https://cryptpad.org/) 是一款仅在线使用的开源协作套件,可作为 LibreOffice 的替代品满足基本需求。他们还在改进支持文档/演示文稿的功能,就像谷歌文档一样。
你可以使用 CryptPad 添加富文本文档、电子表格等。然而,在撰写本文时,他们正在努力支持像谷歌文档一样的更成熟的文档。当你阅读本文或尝试一下时,它可能已经有所改进。
如果你需要一个功能不太花哨的端到端文档套件,CryptPad 可能是一个不错的选择。
你可以使用官方托管实例、公共实例或自行托管。
亮点:
* 端到端加密
* 实时协作
* 安全云存储(可选)
* 自托管或已托管
### 4、SoftMaker FreeOffice(非自由和开源软件)

SoftMaker 的 [FreeOffice](https://www.freeoffice.com/en/) 是一个适用于 Linux 和其他平台的专有文档套件。
它以其类似微软 Office 的用户界面以及与微软 Office 文件的良好兼容性而闻名。
与 OpenOffice 不同,SoftMaker 的免费 Office 版本的更新更多,与 LibreOffice 相比是一个不错的选择。如果你喜欢其免费产品并需要专业支持并解锁更多功能,你可以选择其高级版本。
请参阅我们的深入 [LibreOffice 和 FreeOffice 之间的比较](https://itsfoss.com/libreoffice-vs-freeoffice/) 了解更多:
亮点:
* 类似微软 Office 的用户界面
* 良好的微软 Office 文件格式兼容性
* 可选高级版具有更多功能和专业支持
* 跨平台
### 5、WPS Office(非自由/开源软件)

WPS Office 对 Windows 用户而言很流行,它也适用于 Linux。
它是一个专有程序,提供适用于安卓和 iOS 的时尚移动应用。有些人可能不喜欢它,因为它的开发者是一家中国软件公司,但它提供了漂亮的用户界面和良好的微软 Office 兼容性。
你可以将其视为文档套件中的 “**Deepin**”,它是 [最美丽的 Linux 发行版](https://itsfoss.com/beautiful-linux-distributions/) 之一。它提供了良好的用户体验并且免费使用。
作为一个免费选项,其跨平台的便捷可用性使其成为比 LibreOffice 更有趣的选择。
要解锁 PDF 编辑功能、云存储、专业支持并摆脱广告,你可以选择其 PRO 版本。
亮点:
* 漂亮的用户界面
* 移动应用支持
* 良好的微软 Office 文件格式兼容性
* 可选专业版,具有更多功能
* 跨平台
### 6、Calligra

[Calligra](https://calligra.org/) 是一个 KDE 办公套件。它可能不如 LibreOffice 功能丰富,但它是一个更简单的替代方案。
无论你是否使用基于 KDE 的发行版,它都应该可以在你的 Linux 发行版上正常运行。我在我的 Fedora 系统上对其进行了测试,如上面的截图所示。
你可以在大多数 Linux 发行版的默认仓库中找到所有程序(例如 Calligra Words 和 Calligra Sheets)。它还包括用于项目管理的 Calligra Plan 和用于演示的 Stage 等程序。
虽然它可能不会经常发布重大版本,但根据其 [GitLab 页面](https://invent.kde.org/office/calligra),它由一些贡献者积极维护。如果你喜欢这个项目,你可以以各种方式帮助他们。
亮点:
* 使用简单
* 与平常不同的东西
* 支持微软 Office 文件格式
* 仅限 Linux
### 总结
尽管没有一个选项可以完全取代 LibreOffice,但它们相比 LibreOffice 带来了各种好处。
有些可以为你提供更好或更简单的用户体验,而另一些则可以更好地处理微软 Office 文件格式。
你可以根据自己的喜好来选择,看看是否符合你的需求。
? 你会选择什么作为 LibreOffice 的替代品? 在评论中让我知道你的想法。
*(题图:MJ/796761b9-96a1-4cb4-859e-a9f12e305771)*
---
via: <https://itsfoss.com/libreoffice-alternatives-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

LibreOffice is a fantastic open-source document suite. It comes pre-installed on many Linux distributions and should suffice for most users.
However, some may not like its user interface and feature set. Some users may want to try other options to see if they offer better Microsoft Office document compatibility.
Whatever the reason, the good news is that we have a couple of good LibreOffice alternatives that you can explore.
**Some of the applications mentioned here are not open source. They have been included in the context of Linux usage.**
**Non-FOSS Warning!**## 1. ONLYOFFICE
[ONLYOFFICE](https://www.onlyoffice.com) is an impressive document suite with various editions catering to all kinds of users.
It is popular for offering better compatibility with Microsoft Office documents when compared to other document programs. The feature set may not be as big as LibreOffice, but in terms of its user experience and compatibility, it can be the better option.
You can use its [desktop editors](https://www.onlyoffice.com/en/desktop.aspx) for free on Linux and other platforms. You can also choose to self-host the community edition and utilize it as an online editor. However, it does come with a restriction for simultaneous connections/users.
Considering you can find the [source code on GitHub](https://github.com/ONLYOFFICE), it acts as a **source-available solution**, if not entirely FOSS for personal use.
**Highlights:**
**Modern User Experience****Better Microsoft Office Compatibility****Online Editor (self-host or enterprise options)****Cross-platform**
## 2. Apache OpenOffice
[Apache OpenOffice](https://www.openoffice.org) is what LibreOffice was forked from.
Sure, OpenOffice is not as feature-rich as LibreOffice. However, for users looking for an older/familiar user interface, and a more stable experience for basic requirements, OpenOffice is a good pick.
OpenOffice is not as actively maintained as LibreOffice, but you can expect releases yearly/bi-annually. Not to forget, you can easily [install Apache OpenOffice](https://itsfoss.com/install-openoffice-ubuntu-linux/) as well.
We have a detailed [comparison between LibreOffice and OpenOffice](https://itsfoss.com/libreoffice-vs-openoffice/) document suites to help you decide.
[LibreOffice vs OpenOffice: What’s the Difference?A comparison of two of the most popular open source office software. Learn the similarities and differences between LibreOffice and OpenOffice.](https://itsfoss.com/libreoffice-vs-openoffice/)

**Highlights:**
**Old-school user interface****It can prove to be more stable for certain users****Cross-platform**
## 3. CryptPad
[CryptPad](https://cryptpad.org) is an online-only open-source collaboration suite that can act as an alternative to LibreOffice for basic needs. They are also improving on supporting documents/presentations like Google Docs.
You can add rich text documents, spreadsheets, and more with CryptPad. However, they are working on supporting more full-fledged documents like Google Docs at the time of writing this. When you read this or give it a try, it could have improved already.
If you require an end-to-end document suite with not-so-fancy features, CryptPad can be an excellent pick.
You can use the official hosted instance, public instances, or self-host it.
**Highlights:**
**End-to-end encryption****Real-time collaboration****Secure cloud storage (optional)****Self-host or hosted**
## 4. SoftMaker FreeOffice (Non FOSS)
SoftMaker's [FreeOffice](https://www.freeoffice.com/en/) is a proprietary document suite available for Linux and other platforms.
It is known for its Microsoft Office-like user interface and good compatibility with Microsoft Office files.
Unlike OpenOffice, SoftMaker's FreeOffice edition gets more updates and can be a good choice when compared to LibreOffice. If you like its free offering and want professional support and unlock more features, you can opt for its premium edition.
Refer to our in-depth [comparison between LibreOffice and FreeOffice](https://itsfoss.com/libreoffice-vs-freeoffice/) for more insights:
[LibreOffice vs FreeOffice: Comparing Popular Office SuitesLibreOffice and FreeOffice are two popular choices when it comes to a free alternative to Microsoft Office. Here’s how these two office suites are similar and different.](https://itsfoss.com/libreoffice-vs-freeoffice/)

**Highlights:**
**Microsoft Office-like UI****Good Microsoft Office file format compatibility****Optional premium with more features and professional support****Cross-platform**
## 5. WPS Office (Non FOSS)
WPS Office is a popular name for Windows users that is also available for Linux.
It is a proprietary program with sleek mobile apps available for both Android and iOS. Some may not prefer it because its developer being a Chinese software company, but it offers a nice user interface and good Microsoft Office compatibility.
You can consider it as the "**Deepin**" of document suites, which is one of the [most beautiful Linux distributions](https://itsfoss.com/beautiful-linux-distributions/) out there. It offers a pretty user experience and is free to use.
As a free option, its convenient availability across platforms makes it an interesting choice over LibreOffice.
To unlock PDF editing features, cloud storage, professional support, and get rid of advertisements, you can opt for its PRO version.
**Highlights**
**Beautiful user interface****Mobile app support****Good Microsoft Office file format compatibility****Optional pro version with more features****Cross-platform**
## 6. Calligra
[Calligra](https://calligra.org) is an office suite by KDE. It may not be as feature-rich as LibreOffice, but it is a simpler alternative.
Whether you use a KDE-based distro or not, it should work fine on your Linux distribution. I tested it on my Fedora system for the screenshot above.
You will find all the programs (like Calligra Words and Calligra Sheets) in the default repositories on most Linux distributions. It also includes programs like Calligra Plan for project management and Stage for presentations.
While it may not have big releases frequently, it is actively maintained by a few contributors, as per its [GitLab page](https://invent.kde.org/office/calligra). If you like the project, you might want to help them in any way.
**Highlights:**
**Simple to use****Something different from the usual****Supports Microsoft Office file formats****Linux-only**
## Wrapping Up
Even though none of the options could entirely replace LibreOffice, they bring in various benefits over LibreOffice.
Some can give you a better or simpler user experience, while others can work nicer with Microsoft Office file formats.
I leave it up to you to try the options that you like and see if it fits your need.
*💬 What would you pick as a LibreOffice alternative? Let me know your thoughts in the comments.* |
16,429 | Fractal 5:Linux Matrix 消息应用迎来 GTK 4 和 Rust SDK 的升级 | https://news.itsfoss.com/fractal-5/ | 2023-11-30T17:49:18 | [
"Matrix",
"Fractal"
] | https://linux.cn/article-16429-1.html | 
>
> GNOME 上的 Matrix 消息应用得到升级,使用了 GTK4、Rust SDK 等新技术。
>
>
>
[Matrix](https://matrix.org/),一个流行的安全、去中心化通讯网络,正在日益变得更为重要。我们周围的世界正在以前所未有的速度变化,而安全通讯工具的需求只是其产物之一,除此之外还有其他方面的需求。
在帮助实现 Matrix 功能方面的工具之一就是 Fractal。它是 [最好的 Matrix 分布式消息客户端之一](https://itsfoss.com/best-matrix-clients/)。
最近发布的消息是,**Fractal 5** 带来了大型改版。?
那么,让我们简要了解一下。
### ? Fractal 5:有什么新特性?

与之前版本相比,作为**完全重写**的 Fractal 5 现在采用了 [GTK 4](https://blog.gtk.org/2020/12/16/gtk-4-0/)、[libadwaita](https://gitlab.gnome.org/GNOME/libadwaita) 和 [Matrix Rust SDK](https://github.com/matrix-org/matrix-rust-sdk),提供了现代化的界面,使人感到非常亲切。
Fractal 现在在所有类型的屏幕上都可以**正确缩放**,无论是小屏还是大屏。之前版本的用户应该会觉得很熟悉,学习曲线不会太陡峭。
此外,现在可以**回复特定消息**,用 emoji **回应消息**,甚至在使用 Fractal 聊天时**编辑/删除消息**。

你还可以将**当前位置发送**到你的任何聊天中,只需确保你的系统支持“位置服务”并已启用。

查看图片和播放音频或视频现在更加直观,你可以直接从聊天窗口中查看/播放。

最后,Fractal 现在支持**登录多个帐户**,并提供 [单点登录](https://matrix.org/docs/older/client-sso-guide/)(SSO)的附加支持。这将使在同一客户端实例上处理多个帐户变得轻松。

**对于将来的版本**,开发人员计划添加一些新功能,如房间设置、更好的管理工具和通知设置。他们还希望改善无障碍方面的内容。
你可以查看 [发布说明](https://gitlab.gnome.org/GNOME/fractal/-/releases/5) 以了解所有技术细节。
我很高兴看到 Fractal 正在积极开发,如果问我,这个版本使其更加接近正在开发中的 [ElementX](https://news.itsfoss.com/element-x-matrix-2/),它是 Element 消息应用的继任者。
我很高兴 Matrix 不再是少数人使用的小众事物,而是许多人建议的常态。
### ? 下载 Fractal 5
你可以前往 [Flathub 商店](https://flathub.org/apps/org.gnome.Fractal)获取 Fractal 的最新版本。如果你对源代码感兴趣,可以参考其 [GitLab 仓库](https://gitlab.gnome.org/GNOME/fractal)。
>
> **[Fractal 5(Flathub)](https://flathub.org/apps/org.gnome.Fractal)**
>
>
>
? 你使用 Fractal 吗?更喜欢其他 Matrix 客户端吗?在下面让我知道吧!
---
via: <https://news.itsfoss.com/fractal-5/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Matrix](https://matrix.org/?ref=news.itsfoss.com), a popular network for secure, decentralized communication, is getting more relevant day-by-day. The world around us is changing at a pace previously unheard of, and the need for a secure communication tool is just one of its by-products, among other things.
One such tool that helps in leveraging Matrix, is Fractal. It is one of the [best Matrix clients for decentralized messaging](https://itsfoss.com/best-matrix-clients/?ref=news.itsfoss.com).
With a recent announcement, **Fractal 5** is here with a major overhaul 🎉
So, let's take a brief look at it.
## 🆕 Fractal 5: What's New?
Being **a complete rewrite** compared to the previous release, Fractal 5 now makes use of [GTK 4](https://blog.gtk.org/2020/12/16/gtk-4-0/?ref=news.itsfoss.com), [libadwaita](https://gitlab.gnome.org/GNOME/libadwaita?ref=news.itsfoss.com), and the [Matrix Rust SDK](https://github.com/matrix-org/matrix-rust-sdk?ref=news.itsfoss.com) for providing a modern looking interface that just feels at home.
Fractal now **scales properly on all kinds of screens**, be it small or large; users of the previous releases should find it familiar without much of a learning curve.
Moreover, it is now possible to **reply to specific messages**, **react to messages** with emoji, and even **edit/remove messages **while chatting on Fractal.
You can also **send your current location** to any of your chats, just ensure that your system supports 'Location Services', and is enabled.

And lastly, Fractal now has **support for logging into multiple accounts**, with additional support for [Single-Sign On](https://matrix.org/docs/older/client-sso-guide/?ref=news.itsfoss.com) (SSO). This will make it effortless to handle multiple accounts on the same client instance.
**For its future releases**, the developers have planned to add some neat features such as room settings, better moderation tools, and notification settings. They also want to improve the accessibility side of things.
You may go through the [release notes](https://gitlab.gnome.org/GNOME/fractal/-/releases/5?ref=news.itsfoss.com) to learn all the technical details.
I am glad to see that Fractal is being actively developed, and if you ask me, this release brings it more on par with the under development [ElementX](https://news.itsfoss.com/element-x-matrix-2/), a successor to the Element messaging app.
**Suggested Read **📖
[Element X: Making a Decentralized WhatsApp Killer With Matrix 2.0Matrix 2.0 protocol is here. If you are an early adopter, you can try it in action now!](https://news.itsfoss.com/element-x-matrix-2/)

I am excited about a time when Matrix is not just a niche thing used by a few, but the norm suggested by many.
## 📥 Download Fractal 5
You can head over to the [Flathub store](https://flathub.org/apps/org.gnome.Fractal?ref=news.itsfoss.com) to grab the latest release of Fractal. If you're interested in the source code, you can refer to its [GitLab repo](https://gitlab.gnome.org/GNOME/fractal?ref=news.itsfoss.com).
*💬 Do you use Fractal? Prefer other Matrix clients? Let me know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,430 | Git 分支:直觉与现实 | https://jvns.ca/blog/2023/11/23/branches-intuition-reality/ | 2023-12-01T00:41:12 | [
"Git",
"分支"
] | https://linux.cn/article-16430-1.html | 
你好!我一直在投入写作一本关于 Git 的小册,因此我对 Git 分支投入了许多思考。我不断从他人那里听说他们觉得 Git 分支的操作方式违反直觉。这使我开始思考:直觉上的分支概念可能是什么样,以及它如何与 Git 的实际操作方式区别开来?
在这篇文章中,我想简洁地讨论以下几点内容:
* 我认为许多人可能有的一个直觉性的思维模型
* Git 如何在内部实现分支的表示(例如,“分支是对提交的指针”)
* 这种“直觉模型”与实际操作方式之间的紧密关联
* 直觉模型的某些局限性,以及为何它可能引发问题
本文无任何突破性内容,我会尽量保持简洁。
### 分支的直观模型
当然,人们对分支有许多不同的直觉。我自己认为最符合“苹果树的一个分支”这一物理比喻的可能是下面这个。
我猜想许多人可能会这样理解 Git 分支:在下图中,两个红色的提交就代表一个“分支”。

我认为在这个示意图中有两点很重要:
1. 分支上有两个提交
2. 分支有一个“父级”(`main`),它是这个“父级”的分支
虽然这个观点看似合理,但实际上它并不符合 Git 对于分支的定义 — 最重要的是,Git 并没有一个分支的“父级”的概念。那么,Git 又是如何定义分支的呢?
### 在 Git 里,分支是完整的历史
在 Git 中,一个分支是每个过去提交的完整历史记录,而不仅仅是那个“分支”提交。因此,在我们上述的示意图中,所有的分支(`main` 和 `branch`)都包含了 4 次提交。
我创建了一个示例仓库,地址为:<https://github.com/jvns/branch-example>。它设置的分支方式与前图一样。现在,我们来看看这两个分支:
`main` 分支包含了 4 次提交:
```
$ git log --oneline main
70f727a d
f654888 c
3997a46 b
a74606f a
```
`mybranch` 分支也有 4 次提交。最后两次提交在这两个分支里都存在。
```
$ git log --oneline mybranch
13cb960 y
9554dab x
3997a46 b
a74606f a
```
因此,`mybranch` 中的提交次数为 4,而不仅仅是 2 次“分支”提交,即 `13cb960` 和 `9554dab`。
你可以用以下方式让 Git 绘制出这两个分支的所有提交:
```
$ git log --all --oneline --graph
* 70f727a (HEAD -> main, origin/main) d
* f654888 c
| * 13cb960 (origin/mybranch, mybranch) y
| * 9554dab x
|/
* 3997a46 b
* a74606f a
```
### 分支以提交 ID 的形式存储
在 Git 的内部,分支会以一种微小的文本文件的形式存储下来,其中包含了一个提交 ID。这就是我一开始提及到的“技术上正确”的定义。这个提交就是分支上最新的提交。
我们来看一下示例仓库中 `main` 和 `mybranch` 的文本文件:
```
$ cat .git/refs/heads/main
70f727acbe9ea3e3ed3092605721d2eda8ebb3f4
$ cat .git/refs/heads/mybranch
13cb960ad86c78bfa2a85de21cd54818105692bc
```
这很好理解:`70f727` 是 `main` 上的最新提交,而 `13cb96` 是 `mybranch` 上的最新提交。
这样做的原因是,每个提交都包含一种指向其父级的指针,所以 Git 可以通过追踪这些指针链来找到分支上所有的提交。
正如我前文所述,这里遗漏的一个重要因素是这两个分支间的任何关联关系。从这里能看出,`mybranch` 是 `main` 的一个分支——这一点并没有被表明出来。
既然我们已经探讨了直观理解的分支概念是如何不成立的,我接下来想讨论的是,为何它在某些重要的方面又是如何成立的。
### 人们的直观感觉通常并非全然错误
我发现,告诉人们他们对 Git 的直觉理解是“错误的”的说法颇为流行。我觉得这样的说法有些可笑——总的来说,即使人们关于某个题目的直觉在某些方面在技术上不精确,但他们通常会有完全合理的理由来支持他们的直觉!即使是“不正确的”模型也可能极其有用。
现在,我们来讨论三种情况,其中直觉上的“分支”概念与我们实际在操作中如何使用 Git 非常相符。
### 变基操作使用的是“直观”的分支概念
现在,让我们回到最初的图片。

当你在 `main` 上对 `mybranch` 执行 <ruby> 变基 <rt> rebase </rt></ruby> 操作时,它将取出“直观”分支上的提交(只有两个红色的提交)然后将它们应用到 `main` 上。
执行结果就是,只有两次提交(`x` 和 `y`)被复制。以下是相关操作的样子:
```
$ git switch mybranch
$ git rebase main
$ git log --oneline mybranch
952fa64 (HEAD -> mybranch) y
7d50681 x
70f727a (origin/main, main) d
f654888 c
3997a46 b
a74606f a
```
在此,`git rebase` 创建了两个新的提交(`952fa64` 和 `7d50681`),这两个提交的信息来自之前的两个 `x` 和 `y` 提交。
所以直觉上的模型并不完全错误!它很精确地告诉你在变基中发生了什么。
但因为 Git 不知道 `mybranch` 是 `main` 的一个分叉,你需要显式地告诉它在何处进行变基。
### 合并操作也使用了“直观”的分支概念
合并操作并不复制提交,但它们确实需要一个“<ruby> 基础 <rt> base </rt></ruby>”提交:合并的工作原理是查看两组更改(从共享基础开始),然后将它们合并。
我们撤销刚才完成的变基操作,然后看看合并基础是什么。
```
$ git switch mybranch
$ git reset --hard 13cb960 # 撤销 rebase
$ git merge-base main mybranch
3997a466c50d2618f10d435d36ef12d5c6f62f57
```
这里我们获得了分支分离出来的“基础”提交,也就是 `3997a4`。这正是你可能会基于我们的直观图片想到的提交。
### GitHub 的拉取请求也使用了直观的概念
如果我们在 GitHub 上创建一个拉取请求,打算将 `mybranch` 合并到 `main`,这个请求会展示出两次提交:也就是 `x` 和 `y`。这完全符合我们的预期,也和我们对分支的直观认识相符。

我想,如果你在 GitLab 上发起一个合并请求,那显示的内容应该会与此类似。
### 直观理解颇为精准,但它有一定局限性
这使我们的对分支直观定义看起来相当准确!这个“直观”的概念和合并、变基操作以及 GitHub 拉取请求的工作方式完全吻合。
当你在进行合并、变基或创建拉取请求时,你需要明确指定另一个分支(如 `git rebase main`),因为 Git 不知道你的分支是基于哪个分支的。
然而,关于分支的直观理解有一个比较严重的问题:你直觉上认为 `main` 分支和某个分离的分支有很大的区别,但 Git 并不清楚这点。
所以,现在我们要来讨论一下 Git 分支的不同种类。
### 主干和派生分支
对于人类来说,`main` 和 `mybranch` 有着显著的区别,你可能针对如何使用它们,有着截然不同的意图。
通常,我们会将某些分支视为“<ruby> 主干 <rt> trunk </rt></ruby>”分支,同时将其他一些分支看作是“派生”。你甚至可能有派生的派生分支。
当然,Git 自身并没有这样的区分(“派生”是我刚刚构造的术语!),但是分支的种类确实会影响你如何处理它。
例如:
* 你可能会想将 `mybranch` 变基到 `main`,但你大概不会想将 `main` 变基到 `mybranch` —— 那就太奇怪了!
* 一般来说,人们在重写“主干”分支的历史时比短期存在的派生分支更为谨慎。
### Git 允许你进行“反向”的变基
我认为人们经常对 Git 感到困惑的一点是 —— 由于 Git 并没有分支是否是另一个分支的“派生”的概念,它不会给你任何关于何时合适将分支 X 变基到分支 Y 的指引。这一切需要你自己去判断。
例如,你可以执行以下命令:
```
$ git checkout main
$ git rebase mybranch
```
或者
```
$ git checkout mybranch
$ git rebase main
```
Git 将会欣然允许你进行任一操作,尽管在这个案例中 `git rebase main` 是极其正常的,而 `git rebase mybranch` 则显得格外奇怪。许多人表示他们对此感到困惑,所以我提供了一个展示两种变基类型的图片以供参考:

相似地,你可以进行“反向”的合并,尽管这相较于反向变基要正常得多——将 `mybranch` 合并到 `main` 和将 `main` 合并到 `mybranch` 都有各自的益处。
下面是一个展示你可以进行的两种合并方式的示意图:

### Git 对于分支之间缺乏层次结构感觉有些奇怪
我经常听到 “`main` 分支没什么特别的” 的表述,而这令我感到困惑——对于我来说,我处理的大部分仓库里,`main` 无疑是非常特别的!那么人们为何会称其为不特别呢?
我觉得,重点在于:尽管分支确实存在彼此间的关系(`main` 通常是非常特别的!),但 Git 并不知情这些关系。
每当你执行如 `git rebase` 或 `git merge` 这样的 `git` 命令时,你都必须明确地告诉 Git 分支间的关系,如果你出错,结果可能会相当混乱。
我不知道 Git 在此方面的设计究竟“对”还是“错”(无疑它有利有弊,而我已对无休止的争论感到厌倦),但我认为,这对于许多人来说,原因在于它有些出人意料。
### Git 关于分支的用户界面也同样怪异
假设你只想查看某个分支上的“派生”提交,正如我们之前讨论的,这是完全正常的需求。
下面是用 `git log` 查看我们分支上的两次派生提交的方法:
```
$ git switch mybranch
$ git log main..mybranch --oneline
13cb960 (HEAD -> mybranch, origin/mybranch) y
9554dab x
```
你可以用 `git diff` 这样查看同样两次提交的合并差异:
```
$ git diff main...mybranch
```
因此,如果你想使用 `git log` 查看 `x` 和 `y` 这两次提交,你需要用到两个点(`..`),但查看同样的提交使用 `git diff`,你却需要用到三个点(`...`)。
我个人从来都记不住 `..` 和 `...` 的具体用意,所以我通常虽然它们在原则上可能很有用,但我选择尽量避免使用它们。
### 在 GitHub 上,默认分支具有特殊性
同样值得一提的是,在 GitHub 上存在一种“特殊的分支”:每一个 GitHub 仓库都有一个“默认分支”(在 Git 术语中,就是 `HEAD` 所指向的地方),具有以下的特别之处:
* 初次克隆仓库时,默认会检出这个分支
* 它作为拉取请求的默认接收分支
* GitHub 建议应该保护这个默认分支,防止被强制推送,等等。
很可能还有许多我未曾想到的场景。
### 总结
这些说法在回顾时看似是显而易见的,但实际上我花费了大量时间去搞清楚一个更“直观”的分支概念,这是因为我已经习惯了技术性的定义,“分支是对某次提交的引用”。
同样,我也没有真正去思索过如何在每次执行 `git rebase` 或 `git merge` 命令时,让 Git 明确理解你分支之间的层次关系——对我而言,这已经成为第二天性,并没有觉得有何困扰。但当我反思这个问题时,可以明显看出,这很容易导致某些人混淆。
*(题图:MJ/a5a52832-fac8-4190-b3bd-fec70166aa16)*
---
via: <https://jvns.ca/blog/2023/11/23/branches-intuition-reality/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I’ve been working on writing a zine about git so I’ve been thinking about git branches a lot. I keep hearing from people that they find the way git branches work to be counterintuitive. It got me thinking: what might an “intuitive” notion of a branch be, and how is it different from how git actually works?
So in this post I want to briefly talk about
- an intuitive mental model I think many people have
- how git actually represents branches internally (“branches are a pointer to a commit” etc)
- how the “intuitive model” and the real way it works are actually pretty closely related
- some limits of the intuitive model and why it might cause problems
Nothing in this post is remotely groundbreaking so I’m going to try to keep it pretty short.
### an intuitive model of a branch
Of course, people have many different intuitions about branches. Here’s the one that I think corresponds most closely to the physical “a branch of an apple tree” metaphor.
My guess is that a lot of people think about a git branch like this: the 2 commits in pink in this picture are on a “branch”.
I think there are two important things about this diagram:
- the branch has 2 commits on it
- the branch has a “parent” (
`main`
) which it’s an offshoot of
That seems pretty reasonable, but that’s not how git defines a branch – most importantly, git doesn’t have any concept of a branch’s “parent”. So how does git define a branch?
### in git, a branch is the full history
In git, a branch is the full history of every previous commit, not just the “offshoot” commits. So in our picture above both branches (`main`
and `branch`
) have 4 commits on them.
I made an example repository at [https://github.com/jvns/branch-example](https://github.com/jvns/branch-example) which
has its branches set up the same way as in the picture above. Let’s look at the
2 branches:
`main`
has 4 commits on it:
```
$ git log --oneline main
70f727a d
f654888 c
3997a46 b
a74606f a
```
and `mybranch`
has 4 commits on it too. The bottom two commits are shared
between both branches.
```
$ git log --oneline mybranch
13cb960 y
9554dab x
3997a46 b
a74606f a
```
So `mybranch`
has 4 commits on it, not just the 2 commits `13cb960`
and `9554dab`
that are “offshoot” commits.
You can get git to draw all the commits on both branches like this:
```
$ git log --all --oneline --graph
* 70f727a (HEAD -> main, origin/main) d
* f654888 c
| * 13cb960 (origin/mybranch, mybranch) y
| * 9554dab x
|/
* 3997a46 b
* a74606f a
```
### a branch is stored as a commit ID
Internally in git, branches are stored as tiny text files which have a commit ID in them. That commit is the latest commit on the branch. This is the “technically correct” definition I was talking about at the beginning.
Let’s look at the text files for `main`
and `mybranch`
in our example repo:
```
$ cat .git/refs/heads/main
70f727acbe9ea3e3ed3092605721d2eda8ebb3f4
$ cat .git/refs/heads/mybranch
13cb960ad86c78bfa2a85de21cd54818105692bc
```
This makes sense: `70f727`
is the latest commit on `main`
and `13cb96`
is the latest commit on `mybranch`
.
The reason this works is that every commit contains a pointer to its parent(s), so git can follow the chain of pointers to get every commit on the branch.
Like I mentioned before, the thing that’s missing here is any relationship at
all between these two branches. There’s no indication that `mybranch`
is an
offshoot of `main`
.
Now that we’ve talked about how the intuitive notion of a branch is “wrong”, I want to talk about how it’s also right in some very important ways.
### people’s intuition is usually not that wrong
I think it’s pretty popular to tell people that their intuition about git is “wrong”. I find that kind of silly – in general, even if people’s intuition about a topic is technically incorrect in some ways, people usually have the intuition they do for very legitimate reasons! “Wrong” models can be super useful.
So let’s talk about 3 ways the intuitive “offshoot” notion of a branch matches up very closely with how we actually use git in practice.
### rebases use the “intuitive” notion of a branch
Now let’s go back to our original picture.

When you rebase `mybranch`
on `main`
, it takes the commits on the “intuitive”
branch (just the 2 pink commits) and replays them onto `main`
.
The result is that just the 2 (`x`
and `y`
) get copied. Here’s what that looks like:
```
$ git switch mybranch
$ git rebase main
$ git log --oneline mybranch
952fa64 (HEAD -> mybranch) y
7d50681 x
70f727a (origin/main, main) d
f654888 c
3997a46 b
a74606f a
```
Here `git rebase`
has created two new commits (`952fa64`
and `7d50681`
) whose
information comes from the previous two `x`
and `y`
commits.
So the intuitive model isn’t THAT wrong! It tells you exactly what happens in a rebase.
But because git doesn’t know that `mybranch`
is an offshoot of `main`
, you need
to tell it explicitly where to rebase the branch.
### merges use the “intuitive” notion of a branch too
Merges don’t copy commits, but they do need a “base” commit: the way merges work is that it looks at two sets of changes (starting from the shared base) and then merges them.
Let’s undo the rebase we just did and then see what the merge base is.
```
$ git switch mybranch
$ git reset --hard 13cb960 # undo the rebase
$ git merge-base main mybranch
3997a466c50d2618f10d435d36ef12d5c6f62f57
```
This gives us the “base” commit where our branch branched off, `3997a4`
.
That’s exactly the commit you would think it might be based on our intuitive
picture.
### github pull requests also use the intuitive idea
If we create a pull request on GitHub to merge `mybranch`
into `main`
, it’ll
also show us 2 commits: the commits `x`
and `y`
. That makes sense and also
matches our intuitive notion of a branch.
I assume if you make a merge request on GitLab it shows you something similar.
### intuition is pretty good, but it has some limits
This leaves our intuitive definition of a branch looking pretty good actually! The “intuitive” idea of what a branch is matches exactly with how merges and rebases and GitHub pull requests work.
You do need to explicitly
specify the other branch when merging or rebasing or making a pull request (like `git rebase main`
),
because git doesn’t know what branch you think your offshoot is based on.
But the intuitive notion of a branch has one fairly serious problem: the way
you intuitively think about `main`
and an offshoot branch are very different,
and git doesn’t know that.
So let’s talk about the different kinds of git branches.
### trunk and offshoot branches
To a human, `main`
and `mybranch`
are pretty different, and you probably have
pretty different intentions around how you want to use them.
I think it’s pretty normal to think of some branches as being “trunk” branches, and some branches as being “offshoots”. Also you can have an offshoot of an offshoot.
Of course, git itself doesn’t make any such distinctions (the term “offshoot” is one I just made up!), but what kind of a branch it is definitely affects how you treat it.
For example:
- you might rebase
`mybranch`
onto`main`
but you probably wouldn’t rebase`main`
onto`mybranch`
– that would be weird! - in general people are much more careful around rewriting the history on “trunk” branches than short-lived offshoot branches
### git lets you do rebases “backwards”
One thing I think throws people off about git is – because git doesn’t have any notion of whether a branch is an “offshoot” of another branch, it won’t give you any guidance about if/when it’s appropriate to rebase branch X on branch Y. You just have to know.
for example, you can do either:
```
$ git checkout main
$ git rebase mybranch
```
or
```
$ git checkout mybranch
$ git rebase main
```
Git will happily let you do either one, even though in this case `git rebase main`
is
extremely normal and `git rebase mybranch`
is pretty weird. A lot of people
said they found this confusing so here’s a picture of the two kinds of rebases:
Similarly, you can do merges “backwards”, though that’s much more normal than
doing a backwards rebase – merging `mybranch`
into `main`
and `main`
into
`mybranch`
are both useful things to do for different reasons.
Here’s a diagram of the two ways you can merge:
### git’s lack of hierarchy between branches is a little weird
I hear the statement “the `main`
branch is not special” a lot and I’ve been
puzzled about it – in most of the repositories I work in, `main`
**is**
pretty special! Why are people saying it’s not?
I think the point is that even though branches **do** have relationships
between them (`main`
is often special!), git doesn’t know anything about those
relationships.
You have to tell git explicitly about the relationship between branches every
single time you run a git command like `git rebase`
or `git merge`
, and if you
make a mistake things can get really weird.
I don’t know whether git’s design here is “right” or “wrong” (it definitely has some pros and cons, and I’m very tired of reading endless arguments about it), but I do think it’s surprising to a lot of people for good reason.
### git’s UI around branches is weird too
Let’s say you want to look at just the “offshoot” commits on a branch, which as we’ve discussed is a completely normal thing to want.
Here’s how to see just the 2 offshoot commits on our branch with `git log`
:
```
$ git switch mybranch
$ git log main..mybranch --oneline
13cb960 (HEAD -> mybranch, origin/mybranch) y
9554dab x
```
You can look at the combined diff for those same 2 commits with `git diff`
like this:
```
$ git diff main...mybranch
```
So to see the 2 commits `x`
and `y`
with `git log`
, you need to use 2 dots
(`..`
), but to look at the same commits with `git diff`
, you need to use 3 dots
(`...`
).
Personally I can never remember what `..`
and `...`
mean so I just avoid
them completely even though in principle they seem useful.
### in GitHub, the default branch is special
Also, it’s worth mentioning that GitHub does have a “special branch”: every
github repo has a “default branch” (in git terms, it’s what `HEAD`
points at),
which is special in the following ways:
- it’s what you check out when you
`git clone`
the repository - it’s the default destination for pull requests
- github will suggest that you protect the default branch from force pushes
and probably even more that I’m not thinking of.
### that’s all!
This all seems extremely obvious in retrospect, but it took me a long time to figure out what a more “intuitive” idea of a branch even might be because I was so used to the technical “a branch is a reference to a commit” definition.
I also hadn’t really thought about how git makes you tell it about the
hierarchy between your branches every time you run a `git rebase`
or `git merge`
command – for me it’s second nature to do that and it’s not a big deal,
but now that I’m thinking about it, it’s pretty easy to see how somebody could
get mixed up. |
16,431 | 一个有趣的带有版本控制的 CMS 现已开源! | https://news.itsfoss.com/tinacms-open-source/ | 2023-12-01T08:13:21 | [
"CMS"
] | https://linux.cn/article-16431-1.html | 
>
> 欢迎这个项目的加入,使我们的开源世界更加丰富。
>
>
>
最近,TinaCMS 通过**宣布已经彻底实现开源**,使**自我托管变得更加便捷**,从而成为了 [开源 CMS](https://itsfoss.com/open-source-cms/) 俱乐部的新成员。
如果你对此还不太了解,那么简单介绍一下,CMS(内容管理系统)是一种便捷的管理网站内容的工具,其中著名的系统有 WordPress、Ghost 和 Joomla 等。
就 [TinaCMS](https://tina.io/) 而言,它是一款集成了 Git 版本控制的 [无头 CMS](https://en.wikipedia.org/wiki/Headless_content_management_system),重点是代码优先和完全类型化。像 Unity 这样的知名公司就使用它来维持其文档的更新。?
那我们现在就来深入了解一下 TinaCMS。
### TinaCMS:可以期待什么?

在第一次发布自托管 TinaCMS 后端的工作基础上,开发者们现已经使 TinaCMS 全面开源并在 [Apache 2.0 许可](https://www.apache.org/licenses/LICENSE-2.0) 下全面可用。
早些时候,**自托管后端是在“源码可用”许可下提供的**。但是,正如我们过去所看到的,它在某些情况下可能会受到限制。更新后的许可证现在应该更准确地反映 TinaCMS 的开源性质。
TinaCMS 的 James O'Halloran 还补充道:
>
> 尽管这是一个非常宽松的许可证,我们依然希望开发者在基于 TinaCMS 构建应用的过程中能感到舒心,无需担心他们会遇到极限。
>
>
>
如果你问我,给开发者更多的权力就是最好的!?
你是否对**布署你自己的 TinaCMS 实例**产生了兴趣?
如果你准备尝试,那么有两个主要的方式可以进行 TinaCMS 的自托管。
首先是一种更为直接的方法,开发者们也为这种方法展示了一个样例。这种方式是通过 [GitHub](https://github.com/) 和 [Vercel](https://vercel.com/) 实现的,可以在短短几分钟内完成部署。
你自己可以试试看。?
>
> ? 你可以在 [GitHub](https://github.com/tinacms/tina-self-hosted-demo) 上访问这个自托管演示。
>
>
>
另一种方式是**在其它平台上部署**,**自托管的 TinaCMS 版本并不依赖于 Vercel**,而是能够与 [TinaCMS 支持的任何框架](https://tina.io/docs/integration/frameworks/) 配合使用。
你只需**确保你的平台支持 express 请求处理程序**,以便后端 API 能够正常运行。
有关部署的更多信息,我建议你访问 [官方文档](https://tina.io/docs/self-hosted/overview/)。
你还可以通过官方 [公告博客](https://tina.io/blog/Tinacms-is-now-fully-open-source/) 进行更深入的了解。
? 今年有很多项目都进行了开源。那么你认为接下来哪些项目应该开源呢?
---
via: <https://news.itsfoss.com/tinacms-open-source/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Another one joins the [open-source CMS](https://itsfoss.com/open-source-cms/?ref=news.itsfoss.com) club! With a recent announcement, **TinaCMS has gone completely open-source**, and is now **easier to self-host**.
If you are not familiar, a CMS (content management system) is a handy way of managing the content of a website; some popular names include **WordPress**, **Ghost** and **Joomla**.
In the case of [TinaCMS](https://tina.io/?ref=news.itsfoss.com), it is a [headless CMS](https://en.wikipedia.org/wiki/Headless_content_management_system?ref=news.itsfoss.com) that features support for the Git version control system, with a focus on being code-first and fully typed. A couple of popular companies like Unity utilize it to maintain their documentation 🤯
Without further ado, let's dive into this.
**Suggested Read **📖
[18 Best Open Source CMS for Creating WebsitesLooking for a free and open source website creation tool? We have created a list of best open source CMS that you can use for various kinds of websites.](https://itsfoss.com/open-source-cms/?ref=news.itsfoss.com)

## TinaCMS: What to Expect?
Building on the work they did on the first release of their self-hosted TinaCMS backend, the developers have now made TinaCMS completely open-source, available under the [Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0?ref=news.itsfoss.com).
Earlier, **the self-hosted backend was offered under a “source available” license.** But, as we have seen in the past, it can turn out to be limiting in certain cases. The updated license should now more accurately reflect the open-source nature of TinaCMS.
James O'Halloran from TinaCMS also added that:
While this was a very permissive license, we still want developers to feel comfortable building on TinaCMS without fearing that they'll hit a ceiling.
More power to the developers if you ask me! 😄


Seeing that, would you be **interested in deploying your own TinaCMS instance?**
If yes, then there are two main ways of self-hosting TinaCMS.
The first one is the most straightforward, with the developers also showcasing a demo for it. It is via a [GitHub](https://github.com/?ref=news.itsfoss.com)/[Vercel](https://vercel.com/?ref=news.itsfoss.com) implementation that can be built in a matter of minutes.
You can see for yourself. 👇
[GitHub](https://github.com/tinacms/tina-self-hosted-demo?ref=news.itsfoss.com).
The other way is to **deploy it on other platforms**, the **self-hosted version of TinaCMS does not require Vercel**, it can be used with any [framework supported by TinaCMS](https://tina.io/docs/integration/frameworks/?ref=news.itsfoss.com).
You just have to **make sure that your platform supports express request handlers** so that the backend API can function properly.
For additional information regarding deployment, I suggest that you visit the [official documentation](https://tina.io/docs/self-hosted/overview/?ref=news.itsfoss.com).
You may also through the official [announcement blog](https://tina.io/blog/Tinacms-is-now-fully-open-source/?ref=news.itsfoss.com) to dive deeper.
*💬 This year has seen plenty of projects being made open-source. Which ones do you think should be made open next?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,433 | Paru 2.0 版本升级,为高级用户带来了新特性 | https://news.itsfoss.com/aur-helper-paru-2-0/ | 2023-12-01T22:43:26 | [
"AUR",
"Paru"
] | https://linux.cn/article-16433-1.html | 
>
> 经过了一段时间的等待,Paru 2.0 版本终于发布了。
>
>
>
如果你不熟悉 Paru,它其实是一个 [AUR 帮助程序](https://wiki.archlinux.org/title/AUR_helpers),可以自动完成手动构建 [PKGBUILD](https://wiki.archlinux.org/title/PKGBUILD) 的过程,方便在 Arch Linux 中安装软件包。
现新版 Paru 2.0 正式发布,此次更新中包含了一些重要的改进。
不过在深入了解之前,你需要确保自己知道如何解决在使用 AUR 帮助程序构建软件包时可能遇到的问题。如果你刚接触 Linux,我们建议你坚持使用你熟悉的包管理器。
### ? Paru 2.0: 有什么新变化?

Paru 2.0 版本是一次重大更新,目标是带来一些主要的改变,尤其是为了满足高级用户的需求。
该版本距离上个重大版本的发布已经过去了一年多。开发者表示由于时间不足,需要完成的改变还有很多。
由于很长一段时间没有发布版本,所以开发者提到了这个版本的很多内容都没有经过严格的测试,可能随后会发布 .1 补丁。
现在,我们来看看 Paru 2.0 版本的重要改进点。
首先,现在你可以把非 AUR 的 `PKGBUILD` 集成到构建引擎中。你可以在你的 `paru.conf` 中加入其他的 pkgbuild 仓库,具体命令如下:
```
[repo_name]
Url = https://path/to/git/repo
```
然后运行下列命令,同步这个新加入的仓库:
```
paru -Sy --pkgbuilds
```
此外,你还可以指定一个本地路径,指向你的本地 pkgbuild 仓库。
这些新加入的仓库比 AUR 具有优先级,并且它们还允许包含 AUR 的依赖项。
而新加入的另一项特性就是一个名为 `.` 的新的自动 pkgbuild 仓库,这个新的仓库在 `paru.conf` 中是无法看到的。
这个新的特性允许执行 `paru -S ./foo` 命令,其中 `foo` 是当前目录下的某个包的名字。
这样你就能在同一个目录中管理一系列相互依赖的 pkgbuild,通过上面的命令,你可以构建其中任何一个pkgbuild。
当你开始构建它们时,Paru 将会自动解决和构建该路径下的 pkgbuild 包的依赖问题。
#### ?️ 其他的改变和优化
除了上述的改变,本次更新还带来了其他一些变动:
* 修复了在运行 `paru -Sc` 时没有 sudo 的问题。
* 日期现在会显示为你的系统的本地时区。
* 改进了搜索功能,现在默认是启用状态。
* 在最后的 Paru 确认后,无需再额外对 pacman 确认安装。
* `--chroot` 现在无需本地的仓库,当然,如果有的话它会工作得更好。
对于这个版本的更深入的了解,你可以参阅 [发布说明](https://github.com/Morganamilo/paru/releases/tag/v2.0.0)。
### ? 获取 Paru 2.0
如果你是从 AUR 安装的 Paru,你可以直接在 AUR 中升级到 2.0 版本。但如果你是自己构建的 Paru ,那可以试试使用 `-U` 命令进行更新,或者重新构建一次。
如果你是第一次安装 Paru ,你可以前往其 [GitHub 仓库](https://github.com/Morganamilo/paru/) ,按照里面的安装说明操作就可以了。
>
> **[Paru 2.0(GitHub)](https://github.com/Morganamilo/paru/releases/tag/v2.0.0)**
>
>
>
如果你想要了解更多关于 Paru 的信息,或者想学习如何安装 Paru,我强烈建议你浏览我们关于 [Paru AUR 帮助程序](https://itsfoss.com/paru-aur-helper/) 的文章:
>
> **[Paru - 基于 Yay 的 AUR 助手和 Pacman 封装器](https://itsfoss.com/paru-aur-helper/)**
>
>
>
? Arch 用户,你对这次的 Paru 版本升级感到兴奋吗?分享一下你的想法吧!
---
via: <https://news.itsfoss.com/aur-helper-paru-2-0/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For those who are unfamiliar, Paru is an [AUR helper](https://wiki.archlinux.org/title/AUR_helpers?ref=news.itsfoss.com) that automates the tedious process of manually building [PKGBUILD](https://wiki.archlinux.org/title/PKGBUILD?ref=news.itsfoss.com)s for installing packages on Arch Linux.
It has gotten a new major release in the form of** Paru 2.0**, that has some important improvements.
Let's see what this release of Paru has to offer.
## 🆕 Paru 2.0: What's New?
Paru 2.0 release is **an update that aims to bring some major changes**, and is mostly aimed at power users.
This release comes more than a year after the last major release. The developer said that he didn't have enough spare time and there were many changes that needed to be done.
The developer also added that:
As there's not been a release in so long, consider a lot of the things here not battle tested, with a .1 patch to follow.
So, keeping that in mind, let's take a look at the **highlights of the Paru 2.0 release**.
It is now **possible to integrate non-AUR PKGBUILDs into the build engine**. You can add other “pkgbuild” repositories to your paru.conf by using the following command:
```
[repo_name]
Url = https://path/to/git/repo
```
Then syncing up the repo with:
`paru -Sy --pkgbuilds`
Moreover, you can specify a path to point to a local pkgbuild repo.
These repos have a **higher priority than AUR**, and also allow for the inclusion of AUR dependencies in them.
Another neat feature is the new **automatic pkgbuild repo** named " . ", which is invisible in the paru.conf.
This allows for executing a '*paru -S ./foo*' command, where 'foo' is the name of a package under the current directory.
What this results in is the ability to have a bunch of pkgbuilds in the same directory that depend on each other, and you can build any one of them using the aforementioned command.
When you build them, **Paru will take care of solving and building the dependencies from the pkgbuilds in the directory itself**.
### 🛠️ Other Changes and Improvements
Other than the ones mentioned above, here are some other changes:
- A fix for
*no sudo*when running*paru -Sc*. - Dates now use the local time zone from your system.
- Provide searching has been improved, and it now enabled by default.
- Removed confirmation for pacman install after final paru confirmation is done.
*--chroot*does not require local repos anymore, but it works better with those around.
For a more in-depth look into this release, you may go through the [release notes](https://github.com/Morganamilo/paru/releases/tag/v2.0.0?ref=news.itsfoss.com).
## 📥 Get Paru 2.0
If you installed Paru from AUR, then you can upgrade to the 2.0 release from there. But, if you built it, you could try the *-U* flag to update or build it again.
If you are installing it for the first time, head over to its [GitHub repo](https://github.com/Morganamilo/paru/?ref=news.itsfoss.com) and follow the installation instructions.
If you are eager to **know more about Paru**, or want to **learn how to install it**. I highly suggest you go through our article on [Paru AUR helper](https://itsfoss.com/paru-aur-helper/?ref=news.itsfoss.com):
[Paru - AUR Helper and Pacman Wrapper Based on YayParu is a new AUR helper based on Yay. It is written in Go and gives you a feature rich experience with AUR packages in Arch Linux.](https://itsfoss.com/paru-aur-helper/?ref=news.itsfoss.com)

*💬 Arch users, are you hyped about this release of Paru? Let us know!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,434 | 如何为举办开源活动设定目标并衡量它们 | https://opensource.com/article/22/9/measure-success-your-open-source-event | 2023-12-02T12:02:04 | [
"开源活动"
] | https://linux.cn/article-16434-1.html | 
>
> 通过定义目标并创建指标,衡量你的社区活动的成效。
>
>
>
活动是保持开源社区健康的重要组成部分。一个正面的活动体验可以激励当前的贡献者,并吸引新的参与者。但你如何判断自己的活动是否成功呢?
为了维护所涉及社区的健康,我们 CHAOSS (<ruby> 社区健康分析开源软件 <rt> Community Health Analytics Open Source Software </rt></ruby>)的 [应用生态系统工作组](https://github.com/chaoss/wg-app-ecosystem) 已经针对我们的活动考虑了这个问题。CHAOSS 应用生态系统包括一些针对 Linux 平台开发应用的项目。虽然现在主要由 GNOME 和 KDE 社区主导,但并不由它们定义。就当前而言,应用生态系统主要是由志愿者驱动的,他们是围绕自由软件的原则组织起来的。我们在此分享的工作是我们 2020 年 11 月 [针对开源活动的成功指标](https://opensource.com/article/20/11/chaoss-open-source-events) 文章的更新。
我们遵循“目标-问题-指标”的方法论。首先,我们确定个人或组织可能设定的几个目标。然后,我们找出实现这些目标所需要回答的问题。最后,我们对每个问题设计可以提供答案的可量化指标。对于活动组织者,我们设定了四个目标。
### 目标 1:保留并吸引贡献者
贡献者是任何开源项目或生态的命脉,而活动则是贡献者体验中的核心。它们为吸引新贡献者提供了机会,同时也能够建立和巩固与现有贡献者的关系。活动应着眼于创造一个和谐而积极的氛围,以便与项目、生态和社区建立深远的关系。
我们需要考虑的一个问题是,参加活动的人在社区停留的时长是多久。如果活动的价值在于加强维持贡献者的关系,我们应当有办法去测量这个效果。要回答这个问题,需要对贡献和活动参与的长期数据进行分析。值得庆幸的是,许多项目已经拥有这些历史数据。
另一个问题是,活动参加者在我们的开源项目中扮演的是什么角色。活动通常都很专业化,可能并不能吸引那些想在 [非代码角色](https://opensource.com/article/22/8/non-code-contribution-powers-open-source) 中贡献的人,如设计、文档编写和市场营销。如果项目能够跟踪非代码贡献,尽管这通常很有挑战性,你就可以对其与活动参与者名单进行对应。这些信息可以帮助活动组织者策划能吸引更广泛参与者群体的活动。
### 目标 2:举办有参与度的活动
活动不仅仅是演讲。它们为社区成员集结起来提供了空间。如果成员之间没有进行交流,那么这次活动就失去了其存在的价值。这也反映在所谓的走廊交谈中,即人们在走廊或会议日程安排之外进行的交流。一些会议甚至为那些没有打算参加任何环节,但希望在走廊里与他人交流的人减价售票。我们需要解决的问题是,如何衡量一个活动在推动参与者之间的交流上的成效。
要衡量会议时间的参与度,我们可以计算在问答环节中提出的问题数量。虽然这个指标直接受每个演讲者的影响,但活动组织者可以采取行动来鼓励问答环节的参与度。例如,活动组织者可以使用他们的早晨主题演讲来鼓励所有人通过提问来表示对演讲者的赞赏。
我们也考虑了在走廊交谈中的参与情况。一种衡量方法是观察人们在非会议时间的行为。另一种方法是在活动结束后的调查中询问参与者的非会议时间的体验。
最后,我们考虑了在虚拟空间的参与情况。一种衡量方法是通过计算在社交媒体上使用活动标签或者来源于我们知道正在参加活动的人发出的信息数量。另一种可能性,无论在线还是现场,都可以设置一种表情符,参与者只需单击即可反映对会议环节、主题演讲和整个会议体验的反应。
### 目标 3:深入了解公司的贡献
企业和其他机构对活动,甚至社区活动的贡献是极其重要的。他们可能提供赞助、派遣员工去帮助组织,或者只是派员工去参加活动。确保公司在他们的贡献中找到价值是很重要的,但我们必须以不排斥社区贡献的方式来做这件事。我们研究了公司对社区活动的期望,以及我们可以通过何种方式的衡量来提高公司的贡献。
有些开源活动被认为比其他活动更具有公司味,所以你可能会问,有多少比例的参与者是被他们的雇主派遣去参加的,而不是作为志愿者参加的。有时,这种差异体现在门票定价上。否则,这是一个可以在注册调查中轻松问到的问题。虽然这些信息很有用,但这并不是一个完美的指标,因为付费的开源贡献者通常会在他们的工作职责之外参加活动。
我们还考虑了几个指标,比如哪些公司参加活动,除了派遣员工(例如,金钱赞助活动),公司在做什么,以及公司是否会重复参与。认识到这一点对培养长期关系很重要。
最后,我们考虑了具有相似范畴的活动的竞争格局。公司在活动上的预算有限。尽管我们喜欢类似的活动,但他们都从同一池子里的潜在赞助商中吸引人。了解哪些其他活动正在寻求赞助可以帮助组织者更好地区分他们自己的活动。
### 目标 4:关注多元化和技能差距
由全球各地的人们构建和发展起来的国际社区,这些人来自多种多样的背景,是开源项目的一个重要组成部分。这些社区贡献他们的想法,为共同的目标合作,帮助项目扩大和开拓新的方向。
面对面活动对于项目和组织来说是一个独特的机会,可以让他们的贡献者聚集在一起,让他们交流并分享各种多元的经验,进而推动创新,以不同的视角促进增长。这也是一个培养和强化共享文化的机会,重点在于增加多元化和包容性。这些指标应该能衡量活动对于培养这种多元性,以及在社区中填补技能缺口的贡献有多大。
我们首先考虑我们在活动中有哪些技能培训,以及这些培训包含多广泛的技能。技能培训可以包括教程,动手实践的工作坊,黑客马拉松,或者其他很多形式。我们在编码之外的技能上有技能培训吗?有很多对开源项目有价值的技能和角色,比如组织活动所需要的技能。
然后,有助于看看我们在我们的社区内需要哪些技能,而哪些技能又是缺失的。项目领导和参与培训的人通常是获取此类信息的良好来源。通过将我们拥有的技能培训与社区需要的技能进行比较,我们可以更好地设计未来活动的培训项目。
### 参与其中
CHAOSS 应用生态系统工作组对与活动组织者共同细化并实施指标表示感兴趣。KDE 和 GNOME 活动的组织者已经讨论了怎样改变他们的活动以更好地捕捉到这些指标。我们为活动组织者的工作也 [以 PDF 形式提供](https://github.com/chaoss/wg-app-ecosystem/blob/main/Metrics%20for%20OSS%20Event%20Organizers%20-%20CHAOSS%20App%20Ecosystem%20(Oct%202021).pdf)。
CHAOSS 应用生态系统工作组还挑战了定义开源软件应用生态系统内的市场营销和通信功能指标。朝向这个目标的第一步是和 KDE 和 GNOME 扮演这个角色的人们进行的一次对话。这次对话可以在 [CHAOSScast Episode #31: Marketing Metrics for OSS Foundations and Projects](https://podcast.chaoss.community/31) 中找到。我们将从这次对话中得到的学习经验转化为目标-问题-指标,如上述对活动组织者指标的描述。
在我们对推广和通信团队的工作之后,我们计划解决财务团队、社区经理、发布经理、跨项目协调人和导师的指标。我们的工作才刚刚开始,我们欢迎反馈和新的贡献者。
你被邀请参与 CHAOSS 应用生态系统工作组的工作。你可以在我们的 [GitHub 页面](https://github.com/chaoss/wg-app-ecosystem) 上找到更多的信息。
*(题图:MJ/187d7b91-9f02-47a2-a433-ea5adbbe1ac6)*
---
via: <https://opensource.com/article/22/9/measure-success-your-open-source-event>
作者:[Shaun McCance](https://opensource.com/users/shaunm) 选题:[lkxed](https://github.com/lkxed) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Events are an essential component of open source community health. A positive event experience can inspire current contributors and encourage new ones. But how can you tell whether your events are successful?
We at the [CHAOSS (Community Health Analytics Open Source Software) App Ecosystem Working Group](https://github.com/chaoss/wg-app-ecosystem) have considered this question for our events to maintain the health of the communities involved. The CHAOSS App Ecosystem includes several projects focused on developing applications for the Linux platform. While currently dominated by the GNOME and KDE communities, it is not defined by them. The app ecosystem, as it stands today, is primarily driven by volunteers with altruistic goals organized around free software principles. The work we share in this article is an update from our November 2020 article about [success metrics for open source events](https://opensource.com/article/20/11/chaoss-open-source-events).
We follow the goal-question-metric approach. We first identify several goals that a person or organization might have. We then identify questions we need to answer to achieve those goals. Finally, for each question, we consider quantifiable metrics that provide answers. For event organizers, we established four goals.
## Goal 1: Retain and attract contributors
Contributors are the lifeblood of any open source project or ecosystem, and events are a core part of the contributor experience. They are an opportunity to attract new contributors, and they can build and reaffirm relationships that help retain existing contributors. Events should be geared toward creating a harmonious and enthusiastic atmosphere that builds relationships with the project, ecosystem, and community.
One question to consider, then, is how long people who attend events stay with the community. If the value of events is to strengthen the relationships that retain contributors, we should be able to measure that. Answering this question requires long-term data on contributions and event attendance. Fortunately, many projects will already have this historical data.
Another question is what roles event attendees have in our open source projects. Events can often be highly technical and may not attract people who want to contribute in [non-coding roles](https://opensource.com/article/22/8/non-code-contribution-powers-open-source), such as design, documentation, and marketing. If projects have the means to track non-code contributions, which is often tricky, you can correlate with event attendee lists. This information can help event organizers create events that attract a wider audience.
**[ Also read Attract contributors to your open source project with authenticity ]**
## Goal 2: Have engaging events
Events are more than presentations. They create a space for community members to come together. If they don't engage with each other, the event is a lost opportunity. The importance of interactions between members is also evident in the so-called hallway track, the name given to engagement that occurs in the hallways and outside the regular event schedule. Some conferences even have discounted tickets for people who don't plan to attend any sessions but want to engage with others in the hallway track. The question for us is how to measure an event's success in terms of how it fosters engagements between event participants.
To measure engagement during regularly scheduled sessions, we could count the number of questions asked during a Q&A session. While the individual speakers directly influence this metric, there are things event organizers can do to encourage Q&A participation. For example, event organizers can use their morning keynote to encourage everyone to ask questions as a form of showing appreciation.
We also considered engagement during the hallway track. One way to measure this is observing how people behave when not in sessions. Another way to measure this is to ask participants in a post-event survey about their experience outside of scheduled sessions.
Finally, we considered engagement in virtual spaces. One option for measuring this is through the number of social media messages that use the event's hashtag or from people we know are at the event. Another possibility for online or even in-person sessions is to have an emoji that could be collected as an easy one-click reaction to sessions, keynotes, and general conference experience.
## Goal 3: Understand company contributions
Companies and other organizations are essential contributors to events, even community events. They may provide sponsorship, sponsor employees to help organize, or simply send employees to the event. It's important to ensure companies find value in their contributions, but we must do this in a way that doesn't alienate community contributions. We looked at what companies expect from community events and what we can measure to improve company contributions.
Some open source events have a reputation for being more corporate than others, so one question you might ask is what percentage of attendees are sent by their employer rather than attending as volunteers. Sometimes, the difference is built into ticket pricing. Otherwise, it's an easy question to ask on a registration survey. Although this information is helpful, it is an imperfect metric because paid open source contributors often attend events outside their job responsibilities.
We also considered several metrics around which companies are attending events, what companies are doing apart from sending employees (for example, financially sponsoring the event), and whether companies repeat their involvement. It's important to recognize this to cultivate long-term relationships.
**[ Related read 8 ways your company can support and sustain open source ]**
Finally, we considered how competitive the landscape of similarly scoped events is. Companies only have so much budget to spend on events. As much as we enjoy similar events, they draw from the same pool of potential sponsors. Understanding which other events are seeking sponsorship can help organizers better differentiate their own events.
## Goal 4: Address diversity and skill gaps
The international communities built and developed across the globe, consisting of people from diverse backgrounds, are an essential component of open source projects. These communities contribute their ideas, collaborate on common goals, and help the project expand and scale toward new directions.
In-person events are a unique chance for projects and organizations to bring their contributors together and allow them to interact and exchange diverse experiences, boosting innovation and accelerating growth from different perspectives. They are also an opportunity to cultivate and reinforce a common culture, focusing on increasing diversity and inclusion. These metrics should measure how well an event contributes to fostering this diversity and closing skill gaps in the community.
We started by considering which skill programs we have at our events and how wide a breadth of skills these programs represent. Skill programs could include tutorials, hands-on workshops, hackathons, or many other formats. Do we have skill programs around skills other than coding? There are many skills and roles valuable to open source projects, such as the skills required to organize events.
It's then helpful to look at which skills we need in our community and which skills are lacking. Project leads and people involved in onboarding are often a good source of this information. By comparing the skills programs we have with the skills our community needs, we can better design the programs for future events.
## Get involved
The CHAOSS App Ecosystem working group is interested in working with event organizers to continually refine and implement metrics. The KDE and GNOME event organizers have already discussed changing their events to better capture some of these metrics. Our work for event organizers is also [available as a PDF](https://github.com/chaoss/wg-app-ecosystem/blob/main/Metrics%20for%20OSS%20Event%20Organizers%20-%20CHAOSS%20App%20Ecosystem%20(Oct%202021).pdf).
The CHAOSS App Ecosystem working group is also taking up the challenge of defining metrics for the marketing and communications functions within OSS App Ecosystems. The first step towards this goal was a conversation with folks from KDE and GNOME fulfilling this role. The conversation is available as [CHAOSScast Episode #31: Marketing Metrics for OSS Foundations and Projects](https://podcast.chaoss.community/31). The learnings from this conversation are next translated into goals-questions-metrics, as described above for the event organizer metrics.
After our work on promotions and communications teams, we plan to address metrics for finance teams, community managers, release managers, cross-project coordinators, and mentors. Our work has only begun, and we welcome feedback and new contributors.
You are invited to join the work of the CHAOSS App Ecosystem WG. Find more information on our [GitHub page](https://github.com/chaoss/wg-app-ecosystem).
## Comments are closed. |
16,436 | 人工智能教程(三):更多有用的 Python 库 | https://www.opensourceforu.com/2023/07/ai-a-few-more-useful-python-libraries/ | 2023-12-02T21:42:48 | [
"AI",
"JupyterLab"
] | https://linux.cn/article-16436-1.html | 
在本系列的 [上一篇文章](/article-16399-1.html) 中,我们回顾了人工智能的历史,然后详细地讨论了矩阵。在本系列的第三篇文章中,我们将了解更多的矩阵操作,同时再介绍几个人工智能 Python 库。
在进入主题之前,我们先讨论几个人工智能和机器学习中常用的重要术语。<ruby> 人工神经网络 <rt> artificial neural network </rt></ruby>(通常简称为 <ruby> 神经网络 <rt> neural network </rt></ruby>,NN)是机器学习和深度学习的核心。顾名思义,它是受人脑的生物神经网络启发而设计的计算模型。本文中我没有插入神经网络模型的图片,因为在互联网上很容易找到它们。我相信任何对人工智能感兴趣的人应该都见过它们,左边是输入层,中间是一个或多个隐藏层,右边是输出层。各层之间的边上的 <ruby> 权重 <rt> weight </rt></ruby> 会随着训练不断变化。它是机器学习和深度学习应用成功的关键。
<ruby> 监督学习 <rt> supervised learning </rt></ruby> 和 <ruby> 无监督学习 <rt> unsupervised learning </rt></ruby> 是两个重要的机器学习模型。从长远来看,任何立志于从事人工智能或机器学习领域工作的人都需要学习它们,并了解实现它们的各种技术。这里我认为有必要简单说明两种模型之间的区别了。假设有两个人分别叫 A 和 B,他们要把苹果和橘子分成两组。他们从未见过苹果或橘子。他们都通过 100 张苹果和橘子的图片来学习这两种水果的特征(这个过程称为模型的训练)。不过 A 还有照片中哪些是苹果哪些是橘子的额外信息(这个额外信息称为标签)。这里 A 就像是一个监督学习模型,B 就像是无监督学习模型。你认为在是识别苹果和橘子的任务上,谁的效果更好呢?大多数人可能会认为 A 的效果更好。但是根据机器学习的理论,情况并非总是如此。如果这 100 张照片中只有 5 张是苹果,其它都是橘子呢?那么 A 可能根本就不熟悉苹果的特征。或者如果部分标签是错误的呢?在这些情况下,B 的表现可能比 A 更好。
在实际的机器学习应用中会发生这样的情况吗?是的!训练模型用的数据集可能是不充分的或者不完整的。这是两种模型都仍然在人工智能和机器学习领域蓬勃发展的众多原因之一。在后续文章中,我们将更正式地讨论它们。下面我们开始学习使用 JupyterLab,它是一个用于开发人工智能程序的强大工具。
### JupyterLab 入门
在本系列的前几篇文章中,为了简单起见,我们一直使用 Linux 终端运行 Python 代码。现在要介绍另一个强大的人工智能工具——JupyterLab。在本系列的第一篇文章中,我们对比了几个候选项,最终决定使用 JupyterLab。它比 Jupyter Notebook 功能更强大,为我们预装了许多库和包,并且易于团队协作。还有一些其它原因,我们将在后续适时探讨它们。
在本系列的第一篇文章中,我们已经学习了如何安装 JupyterLab。假设你已经按文中的步骤安装好了 JupyterLab,使用 `jupyter lab` 或 `jupyter-lab` 命令在会默认浏览器(如 Mozilla Firefox、谷歌 Chrome 等)中打开 JupyterLab。(LCTT 译注:没有安装 JupyterLab 也不要紧,你可以先 [在线试用 JupyterLab](https://jupyter.org/try-jupyter/lab/))图 1 是在浏览器中打开的 JupyterLab 启动器的局部截图。JupyterLab 使用一个名为 IPython(交互式 Python)的 Python 控制台。注意,IPython 其实可以独立使用,在 Linux 终端运行 `ipython` 命令就可以启动它。

现阶段我们使用 JupyterLab 中的 Jupyter Notebook 功能。点击图 1 中用绿框标记的按钮,打开 Jupyter Notebook。这时可能会要求你选择内核。如果你按照本系列第一篇的步骤安装 JupyterLab,那么唯一的可选项就是 Python 3(ipykernel)。请注意,你还可以在 JupyterLab 中安装其它编程语言的内核,比如 C++、R、MATLAB、Julia 等。事实上 Jupyter 的内核相当丰富,你可以访问 [Jupyter 内核清单](https://github.com/jupyter/jupyter/wiki/Jupyter-kernels) 了解更多信息。

下面我们快速了解一下 Jupyter Notebook 的使用。图 2 显示的是一个在浏览器中打开的 Jupyter Notebook 窗口。从浏览器标签页的标题可以看出,Jupyter Notebook 打开的文件的扩展名是 `.ipynb`。
在图 2 处可以看到有三个选项,它们表示 Jupyter Notebook 中可以使用的三种类型的单元。“Code”(绿色框) 表示代码单元,它是用来执行代码的。“Markdown” 单元可用于输入说明性的文本。如果你是一名计算机培训师,可以用代码单元和 Markdown 单元来创建交互式代码和解释性文本,然后分享给你的学员。“Raw”(红色框)表示原始数据单元,其中的内容不会被格式化或转换。
和在终端中不同,在 Jupyter Notebook 中你可以编辑并重新运行代码,这在处理简单的拼写错误时特别方便。图 3 是在 Jupyter Notebook 中执行 Python 代码的截图。

要在执行代码单元中的代码,先选中该单元格,然后点击蓝框标记的按钮。图 3 中用红框标记的是 Markdown 单元,用绿框标记的是代码单元,用黄框标记的执行代码的输出。在这个例子中,Python 代码输出的是 π 的值。
前面提到,JupyterLab 默认安装了许多库和包,我们不用自己安装了。你可以使用 `import` 命令将这些库导入到代码中。使用 `!pip freeze` 命令可以列出 JupyterLab 中目前可用的所有库和包。如果有库或包没有安装,大多数情况下都可以通过 `pip install <全小写的库或者包的名称>` 来安装它们。例如安装 TensorFlow 的命令是 `pip install tensorflow`。如果后面有库的安装命令不遵循这个格式,我会进行特别说明。随着本系列的继续,我们还会看到 Jupyter Notebook 和 JupyterLab 更多强大的功能。
### 复杂的矩阵运算
通过下面的代码,我们来了解一些更复杂的矩阵运算或操作。为了节省空间,我没有展示代码的输出。
```
import numpy as np
A = np.arr ay([[1,2,3],[4,5,6],[7,8,88]])
B = np.arr ay([[1,2,3],[4,5,6],[4,5,6]])
print(A.T)
print(A.T.T)
print(np.trace(A))
print(np.linalg.det(A))
C = np.linalg.inv(A)
print(C)
print(A@C)
```
下面我逐行来解释这些代码:
1. 导入 NumPy 包。
2. 创建矩阵 `A`。
3. 创建矩阵 `B`。
4. 打印矩阵 `A` 的<ruby> 转置 <rt> transpose </rt></ruby>。通过比较矩阵 `A` 与 `A` 的转置,你用该可以大致理解转置操作到底做了什么。
5. 打印 `A` 的转置的转置。可以看到它和矩阵 `A` 是相同的。这又提示了转置操作的含义。
6. 打印矩阵 `A` 的 <ruby> 迹 <rt> trace </rt></ruby>。迹是矩阵的对角线(也称为主对角线)元素的和。矩阵 `A` 的主对角线元素是 1、5 和 88,所以输出的值是 94。
7. 打印 `A` 的<ruby> 行列式 <rt> determinant </rt></ruby>。当执行代码的结果是 -237.00000000000009(在你的电脑中可能略有区别)。因为行列式不为 0,所以称 A 为<ruby> 非奇异矩阵 <rt> non-singular matrix </rt></ruby>。
8. 将矩阵 `A` 的<ruby> 逆 <rt> inverse </rt></ruby> 保存到矩阵 `C` 中。
9. 打印矩阵 `C`。
10. 打印矩阵 `A` 和 `C` 的乘积。仔细观察,你会看到乘积是一个<ruby> 单位矩阵 <rt> identity matrix </rt></ruby>,也就是一个所有对角线元素都为 1,所有其它元素都为 0 的矩阵。请注意,输出中打印出的不是精确的 1 和 0。在我得到的答案中,有像 -3.81639165e-17 这样的数字。这是浮点数的科学记数法,表示 -3.81639165 × 10<sup> -17</sup>, 即小数的 -0.0000000000000000381639165,它非常接近于零。同样输出中的其它数字也会有这种情况。我强烈建议你了解计算机是怎样表示浮点数的,这对你会有很大帮助。
根据第一篇文章中的惯例,可以将代码分成基本 Python 代码和人工智能代码。在这个例子中,除了第 1 行和第 9 行之外的所有代码行都可以被看作是人工智能代码。
现在将第 4 行到第 10 行的操作应用到矩阵 B 上。从第 4 行到第 6 行代码的输出没有什么特别之处。然而运行第 7 行时,矩阵 `B` 的行列式为 0,因此它被称为<ruby> 奇异矩阵 <rt> singular matrix </rt></ruby>。运行第 8 行代码会给产生一个错误,因为只有非奇异矩阵才存在逆矩阵。你可以尝试对本系列前一篇文章中的 8 个矩阵都应用相同的操作。通过观察输出,你会发现矩阵的行列式和求逆运算只适用于方阵。
方阵就是行数和列数相等的矩阵。在上面的例子中我只是展示了对矩阵执行各种操作,并没有解释它们背后的理论。如果你不知道或忘记了矩阵的转置、逆、行列式等知识的话,你最好自己学习它们。同时你也应该了解一下不同类型的矩阵,比如单位矩阵、对角矩阵、三角矩阵、对称矩阵、斜对称矩阵。维基百科上的相关文章是不错的入门。
现在让我们来学习<ruby> 矩阵分解 <rt> matrix decomposition </rt></ruby>,它是更复杂的矩阵操作。矩阵分解与整数的因子分解类似,就是把一个矩阵被写成其它矩阵的乘积。下面我通过图 4 中整数分解的例子来解释矩阵分解的必要性。代码单元开头的 `%time` 是 Jupyter Notebook 的<ruby> 魔法命令 <rt> magic command </rt></ruby>,它会打印代码运行所花费的时间。`**` 是 Python 的幂运算符。基本的代数知识告诉我们,变量 a 和 b 的值都等于 (6869 x 7873)<sup> 100</sup>。但图 4 显示计算变量 b 的速度要快得多。事实上,随着底数和指数的增大,执行时间的减少会越来越明显。

在几乎所有的矩阵分解技术技术中,原始矩阵都会被写成更稀疏的矩阵的乘积。<ruby> 稀疏矩阵 <rt> sparse matrix </rt></ruby>是指有很多元素值为零的矩阵。在分解后,我们可以处理稀疏矩阵,而不是原始的具有大量非零元素的<ruby> 密集矩阵 <rt> dense matrix </rt></ruby>。在本文中将介绍三种矩阵分解技术——LUP 分解、<ruby> 特征分解 <rt> eigen decomposition </rt></ruby>和<ruby> 奇异值分解 <rt> singular value decomposition </rt></ruby>(SVD)。
为了执行矩阵分解,我们需要另一个强大的 Python 库,SciPy。SciPy 是基于 NumPy 库的科学计算库,它提供了线性代数、积分、微分、优化等方面的函数。首先,让我们讨论 LUP 分解。任何方阵都能进行 LUP 分解。LUP 分解有一种变体,称为 LU 分解。但并不是所有方阵都能 LU 分解。因此这里我们只讨论 LUP 分解。
在 LUP 分解中,矩阵 A 被写成三个矩阵 L、U 和 P 的乘积。其中 L 是一个<ruby> 下三角矩阵 <rt> lower triangular matrix </rt></ruby>,它是主对角线以上的所有元素都为零的方阵。U 是一个<ruby> 上三角矩阵 <rt> upper triangular matrix </rt></ruby>,它是主对角线以下所有元素为零的方阵。P 是一个<ruby> 排列矩阵 <rt> permutation matrix </rt></ruby>。这是一个方阵,它的每一行和每一列中都有一个元素为 1,其它元素的值都是 0。
现在看下面的 LUP 分解的代码。
```
import numpy as np
import scipy as sp
A=np.array([[11,22,33],[44,55,66],[77,88,888]])
P, L, U = sp.linalg.lu(A)
print(P)
print(L)
print(U)
print(P@L@U)
```
图 5 显示了代码的输出。第 1 行和第 2 行导入 NumPy 和 SciPy 包。在第 3 行创建矩阵 `A`。请记住,我们在本节中会一直使用矩阵 `A`。第 4 行将矩阵 `A` 分解为三个矩阵——`P`、`L` 和 `U`。第 5 行到第 7 行打印矩阵 `P`、`L` 和 `U`。从图 5 中可以清楚地看出,`P` 是一个置换矩阵,`L` 是一个下三角矩阵,`U` 是一个上三角矩阵。最后在第 8 行将这三个矩阵相乘并打印乘积矩阵。从图 5 可以看到乘积矩阵 `P@L@U` 等于原始矩阵 `A`,满足矩阵分解的性质。此外,图 5 也验证了矩阵 `L`、`U` 和 `P` 比矩阵 `A` 更稀疏。

下面我们讨论特征分解,它是将一个方阵是用它的<ruby> 特征值 <rt> eigenvalue </rt></ruby>和<ruby> 特征向量 <rt> eigenvector </rt></ruby>来表示。用 Python 计算特征值和特征向量很容易。关于特征值和特征向量的理论解释超出了本文的讨论范围,如果你不知道它们是什么,我建议你通过维基百科等先了解它们,以便对正在执行的操作有一个清晰的概念。图 6 中是特征分解的代码。

在图 6 中,第 1 行计算特征值和特征向量。第 2 行和第 3 行输出它们。注意,使用 NumPy 也能获得类似的效果,`Lambda, Q = np.linalg.eig(A)`。这也告诉我们 NumPy 和 SciPy 的功能之间有一些重叠。第 4 行重建了原始矩阵 A。第 4 行中的代码片段 `np.diag(Lambda)` 是将特征值转换为对角矩阵(记为 `Λ`)。对角矩阵是主对角线以外的所有元素都为 0 的矩阵。第 4 行的代码片段 `sp.linalg.inv(Q)` 是求 `Q` 的逆矩阵(记为 Q<sup> -1</sup>)。最后,将三个矩阵 `Q`、`Λ`、`Q`<sup> -1</sup> 相乘得到原始矩阵 `A`。也就是在特征分解中 `A=QΛQ`<sup> -1</sup>。
图 6 还显示了执行的代码的输出。红框标记的是特征值,用绿框标记的是特征向量,重构的矩阵 A 用蓝框标记。你可能会感到奇怪,输出中像 11.+0.j 这样的数字是什么呢?其中的 j 是虚数单位。11.+0.j 其实就是 11.0+0.0j,即整数 11 的复数形式。
现在让我们来看奇异值分解(SVD),它是特征分解的推广。图 7 显示了 SVD 的代码和输出。第 1 行将矩阵 `A` 分解为三个矩阵 `U`、`S` 和 `V`。第 2 行中的代码片段 `np.diag(S)` 将 `S` 转换为对角矩阵。最后,将这三个矩阵相乘重建原始矩阵 `A`。奇异值分解的优点是它可以对角化非方阵。但非方阵的奇异值分解的代码稍微复杂一些,我们暂时不在这里讨论它。

### 其它人工智能和机器学习的 Python 库
当谈到人工智能时,普通人最先想到的场景可能就是电影《终结者》里机器人通过视觉识别一个人。<ruby> 计算机视觉 <rt> computer vision </rt></ruby>是人工智能和机器学习技术被应用得最广泛的领域之一。下面我将介绍两个计算机视觉相关的库:OpenCV 和 Matplotlib。OpenCV 是一个主要用于实时计算机视觉的库,它由 C 和 C++ 开发。C++ 是 OpenCV 的主要接口,它通过 OpenCV-Python 向用户提供 Python 接口。Matplotlib 是基于 Python 的绘图库。我曾在 OSFY 上的一篇早期 [文章](https://www.opensourceforu.com/2018/05/scientific-graphics-visualisation-an-introduction-to-matplotlib) 中详细介绍了 Matplotlib 的使用。
前面我一直在强调矩阵的重要性,现在我用一个实际的例子来加以说明。图 8 展示了在 Jupyter Notebook 中使用 Matplotlib 读取和显示图像的代码和输出。如果你没有安装 Matplotlib,使用 `pip install matplotlib` 命令安装 Matplotlib。

在图 8 中,第 1 行和第 2 行从 Matplotlib 导入了一些函数。注意你可以从库中导入单个函数或包,而不用导入整个库。这两行是基本的 Python 代码。第 3 行从我的计算机中读取标题为 `OSFY-Logo.jpg` 的图像。我从 OSFY 门户网站的首页下载了这张图片。此图像高 80 像素,宽 270 像素。第 4 行和第 5 行在 Jupyter Notebook 窗口中显示图像。请注意图像下方用红框标记的两行代码,它的输出告诉我们变量 `image` 实际上是一个 NumPy 数组。具体来说,它是一个 80 x 270 x 3 的三维数组。
数组尺寸中的 80 x 270 就是图片的大小,这一点很容易理解。但是第三维度表示什么呢?这是因计算机像通常用 RGB 颜色模型来存储的彩色图。它有三层,分别用于表示红绿蓝三种原色。我相信你还记得学生时代的实验,把原色混合成不同的颜色。例如,红色和绿色混合在一起会得到黄色。在 RGB 模型中,每种颜色的亮度用 0 到 255 的数字表示。0 表示最暗,255 表示最亮。因此值为 `(255,255,255)` 的像素表示纯白色。
现在,执行代码 `print(image)`, Jupyter Notebook 会将整个数组的一部分部分打印出来。你可以看到数组的开头有许多 255。这是什么原因呢?如果你仔细看 OSFY 的图标会发现,图标的边缘有很多白色区域,因此一开始就印了很多 255。顺便说一句,你还可以了解一下其他颜色模型,如 CMY、CMYK、HSV 等。
现在我们反过来从一个数组创建一幅图像。首先看图 9 中所示的代码。它展示了如何生成两个 3 x 3 的随机矩阵,它的元素是 0 到 255 之间的随机值。注意,虽然相同的代码执行了两次,但生成的结果是不同的。这是通过调用 NumPy 的伪随机数生成器函数 `randint` 实现的。实际上,我中彩票的几率都比这两个矩阵完全相等的几率大得多。

接下来我们要生成一个形状为 512 x 512 x 3 的三维数组,然后将它转换为图像。为此我们将用到 OpenCV。注意,安装 OpenCV 命令是 `pip install opencv-python`。看下面的代码:
```
import cv2
img = np.random.randint(0, 256, size=(512, 512, 3))
cv2.imwrite('img.jpg', img)
```
第 1 行导入库 OpenCV。注意导入语句是 `import cv2`,这与大多数其他包的导入不同。第 3 行将矩阵 img 转换为名为 `img.jpg` 的图像。图 10 显示了由 OpenCV 生成的图像。在系统中运行这段代码,将图像将被保存在 Jupyter Notebook 的同一目录下。如果你查看这张图片的属性,你会看到它的高度是 512 像素,宽度是 512 像素。通过这些例子,很容易看出,任何处理计算机视觉任务的人工智能和机器学习程序使用了大量的数组、向量、矩阵以及线性代数中的思想。这也是本系列用大量篇幅介绍数组、向量和矩阵的原因。

最后,考虑下面显示的代码。`image.jpg` 输出图像会是什么样子?我给你两个提示。函数 `zeros` 在第 4 行和第 5 行创建了两个 512 x 512 的数组,其中绿色和蓝色填充了零。第 7 行到第 9 行用来自数组 `red`、`green` 和 `blue` 的值填充三维数组 `img1`。
```
import numpy as np
import cv2
red = np.random.randint(0, 256, size=(512, 512))
green = np.zeros([512, 512], dtype=np.uint8)
blue = np.zeros([512, 512], dtype=np.uint8)
img1 = np.zeros([512,512,3], dtype=np.uint8)
img1[:,:,0] = blue
img1[:,:,1] = green
img1[:,:,2] = red
cv2.imwrite(‘image.jpg’, img1)
```
本期的内容就到此结束了。在下一篇文章中,我们将开始简单地学习<ruby> 张量 <rt> tensor </rt></ruby>,然后安装和使用 TensorFlow。TensorFlow 是人工智能和机器学习领域的重要参与者。之后,我们将暂时放下矩阵、向量和线性代数,开始学习概率论。概率论跟线性代数一样是人工智能的重要基石。
*(题图:MJ/ec8e9a02-ae13-4924-b6cb-74ef96ab8af9)*
---
via: <https://www.opensourceforu.com/2023/07/ai-a-few-more-useful-python-libraries/>
作者:[Deepu Benson](https://www.opensourceforu.com/author/deepu-benson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In the previous article in this series, we discussed the history of AI. We have also discussed matrices in detail earlier. In this third article in the series on AI, we will discuss more matrix operations. We will also get familiar with a few more Python libraries useful for developing AI.*
Before we proceed any further, let us discuss a few significant terms often associated with AI and machine learning. Artificial neural networks (often called neural networks or NNs) are the core of machine learning and deep learning. But, what are they? By definition, they are computing models inspired by the biological neural networks that form human brains. I won’t be including the image of an NN here because the Internet nowadays is so full of it. But any person interested in AI has definitely seen one or more of those images, with an input layer on the left, one or more hidden layers in the middle, and an output layer on the right of the image. One important thing to understand is that the weights of edges between each layer, shown in the images we mentioned just now, keep on changing with training. This leads to successful machine learning and deep learning applications.
Supervised learning and unsupervised learning are two important models of machine learning. In the long run, any aspirant who wants to work in the field of AI or machine learning needs to learn about these models and the different techniques used to implement them. Hence, I think it is time for us to (informally) understand the difference between these two models. Consider two people named A and B who are supposed to classify apples and oranges into two separate groups. They have never seen apples or oranges. Both are given 100 photos of apples and oranges. But A has the additional information as to which are apples and which are oranges in the given photos. A is like a supervised algorithm. B does not have any additional information. All he/she has is the 100 photos. B is like an unsupervised algorithm. One day both start the classifications. Who will be better at his/her job? Conventional wisdom says A will outperform B. But machine learning says this may not be the case all the time. What if, out of the 100 images given to A, only 5 are of apples and the rest are all of oranges? He/she may not get familiar with apples at all. What if somebody intentionally cheated A by changing some of the labels of the photos, from apples to oranges and vice versa? In these scenarios, B could outperform A in the job.
But can this happen in a machine learning application for real? Yes! Imagine a situation where you are training your model with an inadequate or corrupted data set. This is just one of the many reasons why both these learning models, supervised and unsupervised, are still thriving in the fields of AI and machine learning. In the coming articles in this series, we will treat these topics more formally. Now let us learn to use JupyterLab, a very powerful tool available for developing AI based applications.
## Introduction to JupyterLab
In the previous articles in this series, we were using the Linux terminal to run Python code for simplicity. Now, it is time to introduce yet another powerful player in the world of AI, JupyterLab. Remember, in the first article in this series we considered a few other alternatives to JupyterLab. But after considering various pros and cons of each and every one of them, we have decided to stick with JupyterLab. As JupyterLab is more powerful than Jupyter Notebook, our choice is further justified. There are many reasons for preferring JupyterLab over the Linux terminal while developing AI based applications. For example, the library and packages we need to use are often available by default in JupyterLab. Another reason is the ease of collaboration with a group of programmers or researchers. There are many other reasons too, and we will explore these in due course.
We have already learned how to install JupyterLab in the first article in this series. Assuming you have installed JupyterLab in your system, with the instructions given earlier, use the command jupyter lab or jupyter-lab to open JupyterLab in your default browser, like Mozilla Firefox, Google Chrome, etc. Figure 1 shows the launcher of the JupyterLab (just a part of the window) opened in my default browser. A Python shell called IPython (Interactive Python) is used in JupyterLab. But IPython has an independent existence and can be executed from your Linux terminal with the command ipython.


For the time being, we will start learning JupyterLab by using Jupyter Notebook alone, just one of the many features available with JupyterLab. In Figure 1, the button to be clicked to open a Jupyter Notebook is marked with a green rectangle. On clicking this button, you may be asked to select the kernel. If you have followed the installation steps given in this series, the sole choice would be Python 3 (ipykernel). But note that you can install kernels for programming languages like C++, R, MATLAB, Julia, etc, and many more in JupyterLab. Indeed, the complete list is quite large and can be found at https://github.com/jupyter/jupyter/wiki/Jupyter-kernels.

Now let us try to understand the working of a Jupyter Notebook very quickly. Figure 2 shows a Jupyter Notebook window. Notice that the extension of the open Jupyter Notebook file is .ipynb.
In Figure 2, you can see three different options, ‘code’, ‘markdown’, and ‘raw’ (marked with a red rectangle). These are the three types of cells you can use in a Jupyter Notebook. Code cells can be used for executable code. Markdown cells can be used for entering text data, and to write comments, explanations, etc. For example, if you are a computer trainer you can create interactive content of code and explanatory text, and share it with your students.
Unlike in a terminal, you can edit and rerun code in Jupyter Notebook, which is especially handy when you make simple typographical errors. Figure 3 shows how a few lines of Python code are executed in a Jupyter Notebook.

The button to execute the code in a cell is marked with a blue square. In order to execute the code in a cell, select that cell and then press this button. Figure 3 shows a markdown cell marked with a red rectangle, a code cell marked with a green rectangle, and the output of the code executed marked with a yellow rectangle. In this example, the Python code just prints the value of π (Pi).
As mentioned earlier, a number of libraries and packages are available in JupyterLab by default and you don’t need to install them in the beginning. You can import these libraries into your code by using the command import. The command !pip freeze will give you the complete list of libraries and packages currently available in your JupyterLab. If a library or package is not installed, then most of the time the command pip install package/library_name_in_all_lowercase_letters will work. For example, pip install tensorflow is the command to install the library TensorFlow in JupyterLab. I will explicitly mention the few times when there is a change in the installation command for a library. More powerful features of Jupyter Notebook and JupyterLab will be introduced as we proceed through this series.
## Some complex matrix operations
Let us learn about a few more complex matrix operations. Consider the code given below. To save some space, I am not showing the output. I have added line numbers for convenience and they are not part of the code.
1. import numpy as np 2. A = np.arr ay([[1,2,3],[4,5,6],[7,8,88]]) 3. B = np.arr ay([[1,2,3],[4,5,6],[4,5,6]]) 4. print(A.T) 5. print(A.T.T) 6. print(np.trace(A)) 7. print(np.linalg.det(A)) 8. C=np.linalg.inv(A) 9. print(C) 10. print(A@C)
First, the package NumPy is imported in line 1. Then, two matrices A and B are created in lines 2 and 3. Line 4 prints the transpose of matrix A. Compare matrix A with the transpose of A to understand how the transpose operation works. Line 5 prints the transpose of the transpose of A. You will see that A and A.T.T are equivalent. This gives you another hint about the working of the operation transpose. Line 6 prints the trace of matrix A. The value printed will be 94, because trace is the sum of the diagonal (also called main diagonal) elements of matrix A. Notice that the main diagonal elements of A are 1, 5, and 88. Line 7 prints the determinant of A. When you execute this code, you will see that the answer is -237.00000000000009 (the value may change slightly in your machine). Since the determinant is non-zero, A is called a non-singular matrix. Line 8 stores the inverse of matrix A into matrix C. Line 9 prints matrix C. Line 10 prints the product of matrices A and C. On careful observation, you will see that the product is an identity matrix, a matrix where all the diagonal elements are 1 and all the other elements are 0. Note that exactly 1s and 0s will not be printed in the answer. For example, in the answer I got, there are numbers like -3.81639165e-17. Note that this is the scientific notation for a floating-point number, which is -3.81639165 × 10-17. This is -0.0000000000000000381639165, in decimal notation, which is very close to zero. Similarly, you can verify the other numbers in the answer.
On a side note, going through a tutorial on floating-point number representation in computers and the complications involved in it will definitely help you a lot and I highly recommend it. Now, by the convention adopted in the first article, we will try to classify between basic Python code and Python code for AI. In this case, all the lines of code, except lines 1 and 9, can be considered as code for AI.
Now apply lines 4 to 10 on matrix B. Lines 4 to 7 work as before. However, the determinant of B is 0 and hence it is called a singular matrix. Further, line 8 gives you an error because inverse exists only for non-singular matrices whose determinant is non-zero. Now, apply the same operations on all the eight matrices we have introduced in the previous article in this series. On seeing the outputs, you will get the additional insight that matrix operations like determinant and inverse are applicable only to square matrices.
Square matrices are matrices with an equal number of rows and columns. Though we tried to understand the working of these operations based on the above examples, I haven’t explained anything about the theory behind them. So, it would be a good idea to learn more about matrix operations like transpose, inverse, determinant, etc, if you have forgotten them. You could also learn about the different types of matrices like identity matrix, diagonal matrix, triangular matrix, symmetric matrix, skew symmetric matrix, etc. Wikipedia articles on these terms are a good starting point.
Now let us learn about some matrix operations that are even more complex, called matrix decomposition (also known as matrix factorization). First, let us recall integer factorization to understand the need for matrix factorization. The number 15 is the product of 3 and 5. But why do we need factorization? Consider the semi-prime (an integer which is the product of exactly two prime numbers) 54079637 whose factors are 6869 and 7873. I think the code and the output shown in Figure 4 give an answer to our question about the need for factorization. The line of code %time in the beginning shows us the time taken to execute a cell in Jupyter Notebook. Elementary number theory tells us that both the variables a and b contain the answer to the mathematical expression 54079637100. However, Figure 4 shows us that the answer in variable b is calculated much faster. Further, this reduction in execution time will become better and better as the number and the exponent in the above calculation increases.
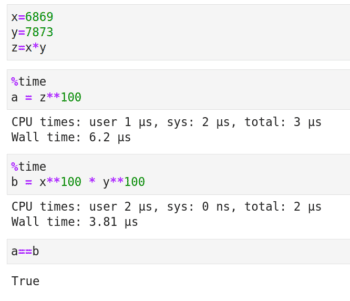

Now let us move on to matrix decomposition. Similar to integer factorization, in matrix decomposition a matrix is written as the product of some other matrices. There are a lot of matrix decomposition techniques, and in almost all of them a matrix is written as the product of matrices that are more sparse than the original matrix. A sparse matrix is a matrix that has a lot of elements with value zero. Thus, after decomposition, we can work with sparse matrices rather than the original dense matrix with a lot of non-zero elements. In this article, we will discuss three decomposition techniques — LUP decomposition, eigendecomposition, and singular value decomposition (SVD).
But, in order to perform matrix decomposition, we need the services of yet another powerful Python library called SciPy. SciPy has functions for performing operations in linear algebra, integration, differentiation, optimisation, etc. In a sense, SciPy works on top of NumPy. First, let us discuss LUP decomposition. Any square matrix has an LUP decomposition. There is a variant of LUP decomposition called LU decomposition. However, not every square matrix has an LU decomposition. Hence, we discuss LUP decomposition.
In LUP decomposition, a matrix A is written as the product of three matrices L, U, and P. However, these three matrices do have some properties. L is a lower triangular matrix. A square matrix with all the entries above the main diagonal as zero is called a lower triangular matrix. U is an upper triangular matrix. A square matrix with all the entries below the main diagonal as zero is called an upper triangular matrix. P is a permutation matrix. This is a square matrix which has exactly one element with value 1 in each row and each column, and every other element of it has the value 0.
Now consider the code given below to perform LUP decomposition. Again, the line numbers have been added for convenience and are not part of the code.
1. import numpy as np 2. import scipy as sp 3. A=np.rray([[11,22,33],[44,55,66],[77,88,888]]) 4. P, L, U = sp.linalg.lu(A) 5. print(P) 6. print(L) 7. print(U) 8. print(P@L@U)
Figure 5 shows the output of the code. Lines 1 and 2 import packages NumPy and SciPy. A matrix A is created in line 3. Please keep in mind that we use matrix A throughout this section. Line 4 factorizes matrix A into three matrices — P, L, and U. Lines 5 to 7 print the matrices P, L, and U. From Figure 5, it is clear that P is a permutation matrix, L is a lower triangular matrix and U is an upper triangular matrix. Finally, line 10 multiplies the three matrices and prints the product matrix. Again, from Figure 5 it is clear that the product matrix P@L@U equals the original matrix A. Hence, the decomposition (factorization) property holds true. Further, you can verify from Figure 6 that matrices L, U, and P are more sparse (a lot of zero elements) than matrix A.


Now let us discuss eigendecomposition, in which a square matrix is represented in terms of its eigenvalues and eigenvectors. Though it is easy to calculate eigenvalues and eigenvectors using Python, a theoretical explanation about both is beyond the scope of our discussion. However, I encourage you to learn about these concepts (if you don’t know what they are already) so that you will have a clear idea about the actual operations you are performing. Again, the Wikipedia article on eigenvalues and eigenvectors is a good starting point. Now consider Figure 6, which shows the code for eigendecomposition.


In Figure 6, line 1 finds the eigenvalues and eigenvectors. Lines 2 and 3 print them. Notice that a similar result can also be obtained with NumPy using the line of code Lambda, Q = np.linalg.eig(A). This also tells us that there is some overlap between NumPy and SciPy functions. Line 4 reconstructs the original matrix A. The code snippet np.diag(Lambda) in line 4 converts the eigenvalues into a diagonal matrix (we call it Λ). A diagonal matrix is a matrix in which all the elements outside the main diagonal are zero. The code snippet sp.linalg.inv(Q) in line 4 finds the inverse of Q (we call it Q-1). Finally, the three matrices Q, Λ, and Q-1 are multiplied together to obtain the original matrix A. Thus, in eigendecomposition A=QΛQ-1.
Figure 6 also shows the output of the code executed. The eigenvalues are marked with a red rectangle, the eigenvectors are marked with a green rectangle, and the reconstructed original matrix A is marked with a blue rectangle. But what are numbers like 11.+0.j doing in the output? Well, 11.+0.j is the complex number representation of the integer 11.
Let us now move on to singular value decomposition (SVD). It is a generalisation of eigendecomposition. Figure 7 shows the code and output of SVD. Line 1 decomposes matrix A into three matrices U, S, and V. In line 2, the code snippet ‘np.diag(S)’ converts S to a diagonal matrix. Finally, the three matrices are multiplied together to reconstruct the original matrix A. The advantage of SVD is that it can even diagonalize non-square matrices. However, the code for singular value decomposition of a non-square matrix is slightly more complicated and we won’t discuss it here for the time being.


## A few more Python libraries for AI and machine learning
We now discuss two more libraries for developing AI and machine learning based applications. There is a reason why I didn’t say Python libraries. But we will come to that later. If you speak to a layperson about AI, what do you think will be the first image that will come to his/her mind? It will probably be a Terminator like scenario, where a machine can identify a person just by looking at him/her. Computer vision is one of the most important domains where AI and machine learning based applications are deployed a lot. So we are now going to get familiar with two libraries used in computer vision — OpenCV and Matplotlib. OpenCV (open source computer vision) is a library used mainly for real-time computer vision, and is developed using C and C++. C++ is the primary interface of OpenCV and that is the reason why I didn’t call it a Python library. However, Matplotlib is a plotting library for Python. One of my earlier articles in OSFY covers Matplotlib in a more detailed manner (https://www.opensourceforu.com/2018/05/scientific-graphics-visualisation-an-introduction-to-matplotlib).
There is an important reason for introducing these two libraries now. I have been preaching all this while that matrices are very important, but now I am going to give you a practical example of that. To illustrate this, let us read an image from our computer to a Jupyter Notebook, for further processing. We use Matplotlib for this task. Install Matplotlib with the command pip install matplotlib, if it is not available in your Jupyter Notebook. Figure 8 shows the code and the output that reads an image.

In the figure, lines 1 and 2 import some functions from Matplotlib. Notice that, if required, you can import individual functions or packages from a library instead of importing the whole library. These two lines contain basic Python code. Line 3 reads an image titled ‘OSFY-Logo.jpg’ from my computer. I have downloaded this image from the home page of the OSFY portal. This image is of height 80 pixels and width 270 pixels. Lines 4 and 5 display the image on a Jupyter Notebook window. But what is more important are the two lines of code shown below the image (marked with a red rectangle). The output of these lines of code tells us that the variable named image is actually a NumPy array. Further, it is a three-dimensional array of shape 80 x 270 x 3.
The two-dimensional array (80 x 270) part is clear from the size of the image mentioned earlier. But what about the third dimension? This is because of the fact that the image we saw is a colour image. Colour images in computers are often stored using the RGB colour model, where one layer is used for each of the three primary colours — red, green, and blue. I am sure all of you remember the experiments during our school days where primary colours were mixed to form different colours. For example, red and green when combined give yellow. The varying shades of each colour are often represented with numbers ranging from 0 (darkest) to 255 (brightest). Thus, a pixel with value (255, 255, 255) represents pure white colour.
Now, execute the command print(image). Parts of a large array will be shown in the Jupyter Notebook and you will see a lot of 255s printed in the beginning of the array. What is the reason for this? If you look at the logo of OSFY, you will understand the reason. There is a lot of white colour in the borders of the logo and hence a lot of 255s are printed in the beginning. On a side note, it is really informative to learn more about RGB colour models as well as other colour models like CMY, CMYK, HSV, etc.
We now do the reverse process. We will create an image from an array. First, consider the code shown in Figure 9. It shows how two 3 x 3 matrices filled with random values between 0 and 255 are generated. Notice that though the same code is executed twice, the results are different. A pseudo-random number generator function of NumPy called randint does this. Indeed, the chances of my winning a lottery are far more than that of the two matrices being exactly equal.


Our next plan is to generate a three-dimensional array of shape 512 x 512 x 3 and then convert it into an image. But for that we are going to use the library OpenCV. Be careful while installing OpenCV. The command for installing it is pip install opencv-python. Now consider the code shown below:
1. import cv2 2. img = np.random.randint(0, 256, size=(512, 512, 3)) 3. cv2.imwrite(‘img.jpg’, img)
Line 1 imports the library OpenCV. Again, be careful, as the library name for the import statement is not opencv, unlike most other packages. Line 3 converts the matrix img to an image called img.jpg. Figure 10 shows this image generated by OpenCV. If you run this code in your system, the image will be generated in the same directory where your Jupyter Notebook is locally stored. If you check the properties of this image, you will see that it has a height of 512 pixels and width of 512 pixels. From these examples, it is easy to see that any AI or machine learning application that deals with computer vision uses a lot of arrays, vectors and matrices as well as ideas from linear algebra. Hence, our extensive treatment of arrays, vectors and matrices in this series is well justified.

Finally, consider the code shown below. What will the output image called image.jpg look like? I will give you two hints. The function zeros in lines 4 and 5 creates two 512 x 512 arrays green and blue filled with zeros. Lines 7 to 9 fill the three-dimensional array img1 with values from the arrays red, green, and blue.
1. import numpy as np 2. import cv2 3. red = np.random.randint(0, 256, size=(512, 512)) 4. green = np.zeros([512, 512], dtype=np.uint8) 5. blue = np.zeros([512, 512], dtype=np.uint8) 6. img1 = np.zeros([512,512,3], dtype=np.uint8) 7. img1[:,:,0] = blue 8. img1[:,:,1] = green 9. img1[:,:,2] = red 10. cv2.imwrite(‘image.jpg’, img1)
We will wind up our discussion for now. In the next article in this series, we will begin by briefly learning about tensors, followed by installing and using a very powerful library called TensorFlow. TensorFlow is a serious player in the world of AI and machine learning.
Afterwards, we will take a break from matrices, vectors, and linear algebra for a short while and start learning a probability theory. If linear algebra is the brain of AI then probability is its heart, or vice versa. |
16,437 | 开源网页邮箱服务 Roundcube 加入 Nextcloud | https://news.itsfoss.com/nextcloud-roundcube/ | 2023-12-02T22:32:55 | [
"Roundcube",
"Nextcloud"
] | https://linux.cn/article-16437-1.html | 
>
> Roundcube 现在正与 Nextcloud 合作以迎接未来。
>
>
>
Roundcube,作为最好的 [开源网页邮箱服务](https://itsfoss.com/open-source-web-based-email-clients/) 之一,决定与 [Nextcloud](https://nextcloud.com/) 合作,后者是一个倍受欢迎的开源协作平台,以其协作工具套件而知名。
**电子邮件的重要性与日俱增** ,而谷歌和微软等公司正试图垄断市场,这一联手合作的决定显得颇有战略意义。
让我来详细介绍一下。
### Roundcube 的新家

这就是 Nextcloud 的 CEO,Frank Karlitschek,关于此次合作的描述:
>
> 未来,**Nextcloud 将提供必要的资源**,比如 **项目托管** 、**引入人才的投资** 、**帮助开发**,以及围绕 Roundcube **培育社区**。
>
>
>
最重要的是,[Roundcube](https://roundcube.net/) **不会取代** [Nextcloud Mail](https://apps.nextcloud.com/apps/mail);它们将作为独立的网页邮箱解决方案并存。
Frank 强调 Roundcube 是一个被许多人使用的重要的开源项目,而 Nextcloud Mail 是**一款强大的邮箱客户端**,但是没有合并它们的计划。
你可能会好奇,**为什么会发生这个变化?**
嗯,Roundcube 的创始人和维护者 Thomas Brüderli **作出了退出的决定**。当被问到原因时,他如此回答:
>
> 自从孩子出生后,我如何安排我非工作的时间的关注力显然转向了家庭生活,因此我逐渐停止了贡献,也对项目的新动态失去了跟踪。
>
>
> Roundcube 项目需要一个更好,更专注的领导,因此是时候让我退后,放手了。
>
>
>
许多人都能理解这种情况,很高兴看到 Thomas 将他心爱的项目交给了能够维持它发展的人。
我必须说,**我对这个消息感到惊讶**,作为多年来一直在工作场所使用 Roundcube 作为网页邮箱的用户,我亲眼见证了它自 2018 年以来的成长与变迁。
我很高兴这个项目得到了它应得的关注和关怀。
此外,我建议你浏览一下 [官方博客](https://nextcloud.com/blog/open-source-email-pioneer-roundcube-comes-aboard-nextcloud/) 以及链接在其中的采访,以了解更多关于此次合并的信息。
? 你怎么看?这将如何影响未来的运作?
---
via: <https://news.itsfoss.com/nextcloud-roundcube/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Roundcube, one of the [best open source web-based email clients](https://itsfoss.com/open-source-web-based-email-clients/?ref=news.itsfoss.com) around, has decided to team up with [Nextcloud](https://nextcloud.com/?ref=news.itsfoss.com), a popular open-source collaboration platform that is known for its suite of collaboration tools.
This move comes in at a time when **the importance of emails is just growing**, and the likes of Google and Microsoft are trying to corner the market.
Allow me to take you through this.
## A New Home for Roundcube
That is what the CEO of Nextcloud, Frank Karlitschek, mentions this move to be:
Going forward,Nextcloud will be providing the necessary resourcessuch ashosting the project,investments for procuring talent,helping development, andfostering a communityaround Roundcube.
And most importantly, **Roundcube**** will not be replacing **[ Nextcloud Mail](https://apps.nextcloud.com/apps/mail?ref=news.itsfoss.com); both of them will exist as separate webmail solutions.
Frank has emphasized that Roundcube is an important open-source project used by many, and Nextcloud Mail is “*a powerful client in its own right*”, but there are no plans to merge them.
You might be wondering; **why is this change happening?**
Well, the founder and maintainer of Roundcube, Thomas Brüderli, **had to step down**. When asked why, he said that:
With the birth of our kids my focus how to spend my off-work time clearly moved towards family life and thus I gradually stopped contributing and I lost track of what’s happening in the project.
The Roundcube project deserves a better and a more committed lead and therefore it‘s time for me to step back and let go.
This is something many out there can relate to, it is good to see that Thomas handed his precious project over to someone who can keep it going.
I must say,** I was surprised to hear about this**, having used Roundcube as my webmail of choice at workplace, I have seen how it has evolved since 2018.
I am glad that this project is getting the attention and care it deserves.
Furthermore, I suggest you go through the [official blog](https://nextcloud.com/blog/open-source-email-pioneer-roundcube-comes-aboard-nextcloud/?ref=news.itsfoss.com), and the interview linked there, for more insights on this merge.
*💬 What do you think? How will this work out?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,439 | Cinnamon 6.0 首次推出实验性 Wayland 支持! | https://news.itsfoss.com/cinnamon-6-0-release/ | 2023-12-04T16:45:39 | [
"Cinnamon",
"Wayland"
] | https://linux.cn/article-16439-1.html | 
>
> Cinnamon 6.0 与 Wayland 会话听起来很有趣!
>
>
>
[Cinnamon 成为出色的 Linux 桌面环境](https://itsfoss.com/why-cinnamon/) 有很多原因,Linux 社区喜爱 [Linux Mint](https://linuxmint.com/) 部分归功于它。
它提供的用户体验和 [定制 Cinnamon Desktop 的各种方法](https://itsfoss.com/customize-cinnamon-desktop/) 吸引了用户。
现在,这个桌面环境升级了,Cinnamon 6.0 来了。那么,让我们来看看吧。
### Cinnamon 6.0:可以期待什么? ?

Cinnamon 6.0 的一大亮点就是**Wayland**。这项功能 [酝酿](https://blog.linuxmint.com/?p=4591) 已久,现在作为**实验支持**出现。
从 Linux Mint 21.3 开始,你可以从登录屏幕切换到 Wayland 会话。
除了人们可能期望从 Wayland 获得的通常的细节之外,似乎还有**对分数缩放的实验性支持**,这一点从该版本的“添加缩放监视器帧缓冲区”提交中可以明显看出。
不过,开发人员已澄清,**Wayland 尚未取代 Cinnamon 上的 X11**。因为他们对 Wayland 的实现有其局限性,甚至缺乏一些功能。
但是,这只是一个起点,开发人员预计 **Wayland 支持将在 2026 年之前完全准备就绪**,也就是 Linux Mint 23.x 预计发布的时间。
>
> ? 你可以从登录屏幕在默认 Xorg 会话或 Wayland 会话之间切换。
>
>
>
继续,此版本还有其他更改!
例如**修复电源小程序电池状态**、**X11 的改进**、**支持 AVIF 图像**、**通知屏幕的新选项**、**颜色选择器支持截图工具**等等。
你可以浏览 [变更日志](https://github.com/linuxmint/cinnamon/commit/448a1fc6753079916b8bf036aeb40b049652b72e) 以了解有关 Cinnamon 6.0 的技术改进的更多信息。发布公告发布后,我们将在此处链接。
有趣的是,许多 Linux 发行版(比如 elementary OS)都在努力将默认设置过渡到 Wayland。
但是,Cinnamon 的开发人员正在采取一种相当谨慎的方法,以确保在 Cinnamon 默认切换到 Wayland 之前,他们的 Wayland 实现已经完全就绪。
### ? 获取 Cinnamon 6.0
好吧,如果你想在 Linux Mint 上运行它,则必须等到今年晚些时候,**Linux Mint 21.3 “Virginia”** 发布,其中包含 Cinnamon 6。
对于那些等不及的人,你可以从官方 [GitHub 仓库](https://github.com/linuxmint/cinnamon/releases/tag/6.0.0) 下载源代码 tarball,并手动安装。
>
> **[Cinnamon 6.0(源代码)](https://github.com/linuxmint/cinnamon/releases/tag/6.0.0)**
>
>
>
? 你对 Cinnamon 6 提供的功能感到兴奋吗?
---
via: <https://news.itsfoss.com/cinnamon-6-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are plenty of [reasons why Cinnamon is a fantastic Linux desktop environment](https://itsfoss.com/why-cinnamon/?ref=news.itsfoss.com), and the Linux community loves [Linux Mint](https://linuxmint.com/?ref=news.itsfoss.com) in-part thanks to it.
The user experience on offer and the [various ways to customize Cinnamon Desktop](https://itsfoss.com/customize-cinnamon-desktop/?ref=news.itsfoss.com) is what attracts users to it.
Now, the upgrade to the desktop environment, Cinnamon 6.0 is here. So, let's take a look at it.
## Cinnamon 6.0: What to Expect? 🤔
Right away, the major highlight of Cinnamon 6.0 has been the **implementation of Wayland**. This was [in the works](https://blog.linuxmint.com/?p=4591&ref=news.itsfoss.com) for quite some time, and it is here as an **experimental support**.
Starting with Linux Mint 21.3, you can switch to Wayland session from the login screen.
Alongside the usual niceties one might expect from Wayland, there seems to be **experimental support for fractional scaling**, which was made evident from the 'Add scale-monitor-framebuffer' commit for this release.
Though, the developers have clarified that **Wayland is not replacing X11 on Cinnamon — yet**; as their implementation of Wayland has its limitations, and even lacks a few features.
But, this is a starting point, and the devs expect **Wayland support to be completely ready before 2026**, that would be around the time Linux Mint 23.x is expected to go out.
Moving on, there are other changes with this release too!
Such as the **fix to the power applet battery status**, **improvements for X11**, **support for AVIF images**, **new option for the notification screen**, **color picker support for the screenshot tool** and more.
You may go through the [changelog](https://github.com/linuxmint/cinnamon/commit/448a1fc6753079916b8bf036aeb40b049652b72e?ref=news.itsfoss.com) to learn more about the technical improvements coming with Cinnamon 6.0. We shall link the release announcement here as soon as it is live.
It is quite interesting to see that many Linux distributions; take for instance elementary OS, are working on transitioning to Wayland by default.
But, the developers of Cinnamon are taking a rather calculated approach to ensure that their Wayland implementation is completely ready before they switch to it by default on Cinnamon.
**Suggested Read **📖
[elementary OS 8 Details Revealed!Anticipating the elementary OS 8 upgrade? Here’s what you need to know.](https://news.itsfoss.com/elementary-os-8-dev/)

## 📥 Get Cinnamon 6.0
Well, if you were looking to run it with Linux Mint, you will have to wait until later this year, when **Linux Mint 21.3 “Virginia”** releases, featuring Cinnamon 6.
For those of you who can't wait, you may download the source tarball from the official [GitHub repo](https://github.com/linuxmint/cinnamon/releases/tag/6.0.0?ref=news.itsfoss.com), and set it up manually.
*💬 Are you excited about what Cinnamon 6 has to offer?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,442 | 在 Ubuntu 中更改键盘布局 | https://itsfoss.com/ubuntu-change-keyboard/ | 2023-12-05T16:01:44 | [
"键盘布局"
] | https://linux.cn/article-16442-1.html | 
>
> 在 Ubuntu 中拥有多个键盘布局并在它们之间切换非常简单。下面就教你怎么做。
>
>
>
当 [你安装Ubuntu](https://itsfoss.com/install-ubuntu/) 时,你可以选择键盘布局。你可能已经默认选择了美国英语布局,现在你想将其更改为英国英语、印度英语或你选择的任何其他键盘布局。
好在你可以在同一个 Ubuntu 系统中拥有多种键盘布局。这是相当方便的。
在本教程中,你将学习:
* 在 Ubuntu 桌面中添加新的键盘布局
* 在可用键盘布局之间切换
* 删除额外的键盘布局
* 改变键盘布局的命令行方法
### 步骤 1:添加新的键盘布局
要更改键盘布局,你需要先在系统上启用另一个键盘布局。
进入系统设置。按 Ubuntu 中的 `Super` 键(Windows 键)并搜索“Setting”。

在系统设置中,在左侧边栏中查找 <ruby> 键盘 <rt> Keyboard </rt></ruby>。选择后,你应该会在 <ruby> 输入源 <rt> Input Sources </rt></ruby> 下看到添加新键盘布局的选项。单击 “+” 号。

你将看到一些键盘选项,但如果单击三个点,你可以获得更多选项。你可以在此处滚动浏览或搜索。

单击你想要的键盘布局。请记住,所选的键盘布局可能有子布局。
例如,当我单击\*\*英语(印度)**时,它会向我显示从丹麦到加纳等的一些英语键盘布局。在这里,我选择了**英语(印度,卢比)\*\*键盘。这是将要添加的键盘布局。

你将在“输入源”下看到新添加的键盘布局。

这与我之前在 [Ubuntu 中添加印地语键盘布局](https://itsfoss.com/type-indian-languages-ubuntu/) 时使用的方法相同。
### 步骤 2:切换键盘布局
这样,你就成功添加了另一个键盘布局。但它没有被使用。你必须在可用的输入源之间切换。
有两种方法可以做到这一点。
#### 方法 1:同时使用 Super+Space 键
切换键盘布局的更快方法是 [使用键盘快捷键](https://itsfoss.com/ubuntu-shortcuts/) ,同时按 `Super` 键(Windows 键)和空格键。它将立即显示所有启用的键盘布局。

你可以在按住 `Super` 键的同时多次按空格键在可用选项之间移动。
#### 方法 2:使用鼠标切换键盘布局
记住所有这些键盘快捷键并不容易,这是可以理解的。
当你在系统上启用多个键盘布局时,你会注意到键盘布局名称显示在面板的右上角。单击它,你将看到在布局之间切换的选项或查看所选的键盘布局。

### 额外提示:删除额外的键盘布局
不喜欢系统中的多个键盘布局? 不用担心。你可以轻松删除它们。
如你之前所见,再次进入键盘设置。单击你选择的键盘旁边的三个垂直点符号。你应该在这里看到删除选项。

### 使用命令行更改键盘布局(不推荐)
如果你是桌面用户,我强烈推荐上面讨论的图形方法。
如果你在服务器上并且必须使用其他键盘布局,则可以选择命令行。
现在,有多种方法可以更改 Linux 中的键盘布局。但对于 Ubuntu,我更喜欢 [dpkg](https://wiki.debian.org/dpkg) 方式。
```
sudo dpkg-reconfigure keyboard-configuration
```
输入你的密码,你将在终端中看到:

要在此 TUI(终端用户界面)中导航,请使用箭头键在可用选项之间移动。**使用 `Tab` 键转至 “OK” 或 “Cancel” 选项**。当你位于其中之一时,请按回车键确认你的选择。
选择你选择的国家/地区,然后你可以选择键盘布局。

添加附加键盘后,系统会要求你分配键盘快捷键以在它们之间进行切换。

你也可以将新键盘布局设置为系统中的默认布局和唯一布局。不过,如果你在不相似的语言之间执行此操作,这可能会存在风险。我的意思是,如果你使用英语美国键盘(物理)并将布局切换为匈牙利语,则你将无法使用所有按键。
之后你会看到几个屏幕。
如果你对新的键盘布局不满意,可以再次键入相同的命令,然后重新配置布局。
*(题图:MJ/f03362cf-72d0-4003-b334-44c533e113a0)*
---
via: <https://itsfoss.com/ubuntu-change-keyboard/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When [you install Ubuntu](https://itsfoss.com/install-ubuntu/), you get to choose the keyboard. You may have gone with the default choice of English US and now you want to change it to English UK or India or any other keyboard of your choice.
The good thing is that you can have multiple keyboard layouts in the same Ubuntu system. This is quite convenient.
In this tutorial, you'll learn to:
- Add new keyboard layouts in Ubuntu desktop
- Switch between the available keyboards
- Remove Additional keyboards
- Command line method of changing keyboard layout
## Step 1: Add new keyboard layout
To change the keyboard layout, you need to have another keyboard layout enabled on your system first.
Go to system settings. Press the [Super key](https://itsfoss.com/super-key/) in Ubuntu (Windows symboled key) and search settings.
In the system settings, look for Keyboard in the left sidebar. Once you select that, you should see the option of adding a new keyboard under the **Input Sources **section. Click the + sign.
You'll be presented with a few keyboard options but you can get a lot more if you click on the three dots. You can scroll through or search by typing the in here.
There are more keyboard layouts available
Click on your desired keyboard. Keep in mind that the selected keyboard layout may have sub-layouts.
For example, when I click on **English (India)** it shows me a number of English keys from Denmark to Ghana or what not. In here, I chose the **English (India, with rupee)** keyboard. This is the keyboard layout that will be added.
You'll see the newly added keyboard layout under the Input Sources section.
This is the same method I used for adding a [Hindi keyboard in Ubuntu earlier](https://itsfoss.com/type-indian-languages-ubuntu/).
## Step 2: Switching keyboards
So, you have successfully added another keyboard. But it is not in use. You have to switch between the available input sources.
There are two ways of doing it.
### Method 1: Use Super+Space keys together
The quicker method for switching the keyboards to [use keyboard shortcuts in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/). Press the Super key (Windows key) and Space together. It will momentarily show all the enabled keyboard layouts.

You can press Space key multiple times while holding the Super key to move between the available options.
### Method 2: Use mouse to switch keyboards
It's not easy to remember all these keyboard shortcuts and that's understandable.
When you have more than one keyboards enabled on the system, you'll notice that the keyboard name is being displayed in the top right corner of the panel. Click on it and you'll see the option to switch between the layouts or see the selected keyboard layouts.
## Bonus Tip: Remove additional keyboard
Not liking multiple keyboards in your system? No worries. You can easily remove them.
Go to the keyboard settings once again as you saw previously. Click on the three vertical dots symbol next to the keyboard of your choice. You should see the remove option here.
## Using command line for changing keyboard layout (not recommended)
If you are a desktop user, I strongly recommend the graphical method discussed above.
If you are on a server and you must use some other keyboard layout, you could opt for the command line.
Now, there are multiple ways to change the keyboard layout in Linux. But for Ubuntu, I prefer the [dpkg](https://wiki.debian.org/dpkg) way.
`sudo dpkg-reconfigure keyboard-configuration`
Enter your password and you shall see this in your terminal:
To navigate in this TUI (terminal user interface), use the arrow keys to move between the available options. **Use the tab key to go to the <OK> or <Cancel> options**. When you are at one of them, press enter to confirm your choice.
Go with the country of your choice and then you'll have the option to choose the keyboard layout.
When you have added the additional keyboard, you'll be asked to assign a keyboard shortcut to switch between them.
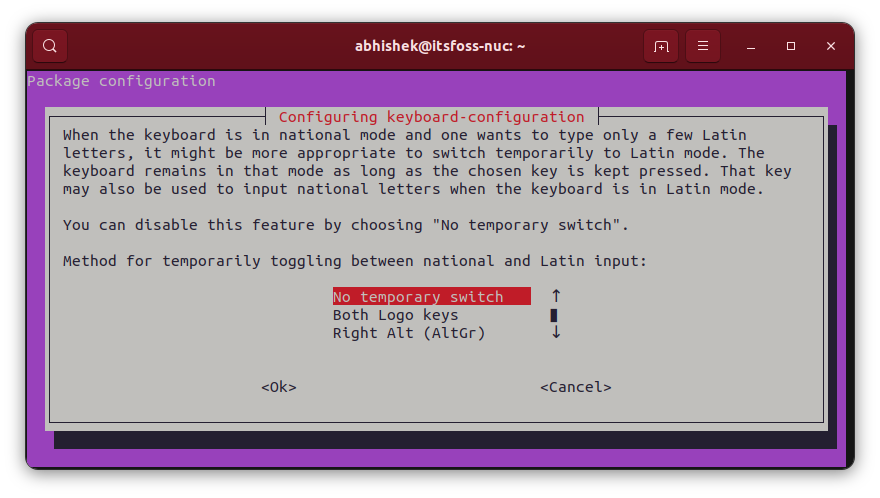
You may also go and make the new keyboard the default and the only layout in the system. Though this could be risky if you do it between languages that are not similar. I mean if you use English US keyboard (physical) and you switch the layout to Hungarian, you won't have all the keys available.
You'll be seeing several screens afterward.
If you are not happy with the new keyboard layout, you can type the same command again and then reconfigure the layout. |
16,444 | Turbo Pascal 的 40 年,改变了整个 IDE 的编程恐龙 | https://www.theregister.com/2023/12/04/40_years_of_turbo_pascal/ | 2023-12-05T19:27:00 | [
"IDE",
"Pascal"
] | https://linux.cn/article-16444-1.html | 
>
> 它的影响至今仍能感受到。
>
>
>
自 Turbo Pascal 问世以来已过去 40 年,它凭借在其时先进的集成开发环境(IDE)和超越常规的性能,彻底改写了编程领域的格局。然而,我们现今并未广泛使用它,这是为何呢?
1983 年,Turbo Pascal 的问世,这代表了在 IBM PC 兼容机早期的程序设计工具工作方式的重大变化。相比于传统工作方式下耗时的磁盘访问和多次编译、链接过程,Turbo Pascal 能在内存中直接完成所有操作,让速度大幅提升,因此得名 “Turbo”。
后来在微软参与 C# 项目的 Anders Hejlsberg 被广泛称誉为这门语言的创造者。而 Borland 的老板 Philippe Kahn 第一时间就看中了这个一站式工具的潜力和需求所在。
Turbo Pascal 的价格也相对便宜 —— 在竞争对手可能要花费数百美元的情况下,Turbo Pascal 的零售价只有 49.99 美元。不过,要是客户打算分发二进制文件,其开发商 Borland 仍会额外收取费用。
尽管第一版的 Turbo Pascal 存在一些限制。例如,源代码文件不能超过 64 KB,且仅能为 DOS 和 CP/M 生成 .COM 可执行文件,尽管还支持其他架构和操作系统。它还能从单张软盘启动运行,在一个硬盘代价昂贵、且难以得到,单驱动器成为常态的时代,这省却了用户频繁更换磁盘的麻烦。
仅几个月后,Turbo Pascal 就推出了第二版,此版本进行了一些微小的改动,后续在 1986 年发布了第三版。然而,真正让 Turbo Pascal 有了翻天覆地变化的,是 1987 年的第四版。例如,取消了对 CP/M 和 CP/M-86 的支持,开始在 DOS 环境下生成 .EXE 格式的可执行文件,打破了 .COM 文件的限制。
第四版还引入了带有下拉菜单的全屏文字用户界面。到了 1988 年的第五版,我们看到了熟悉的默认蓝色背景编辑器。在本文作者看来,1989 年的 5.5 版是 Turbo Pascal 的巅峰之作。它引入了面向对象的编程特性,包括类和继承,以及一款逐步调试器。
第六版和第七版分别引入了对内联汇编和用于创建 Windows 可执行文件和 DLL 的支持,但第七版也标志着 Borland 的 Turbo Pascal 到达了终点。尽管后面仍推出了 Turbo Pascal for Windows,但它最终被 Delphi 所取代。
然而,如 Visual Basic 3 这样的工具的火爆,使得 Borland 在 Windows 系统下再未取得过像它在 DOS 下那样的辉煌。
至于 Turbo Pascal,最后 Borland 以免费软件的方式发布了几个版本,包括用于 DOS 的第 1 版,第 5.5 版和第 7 版。
或许这款语言曾引起 Pascal 语言的纯粹主义者们的反感,如今这个 IDE 与现代工具相比可能显得有些笨拙。但在 40 年前,它引发了一个新的开发时代,其影响至今仍能感受到。
*(题图:MJ/9d1f3b17-5b29-429d-8a86-e8520309d8d0)*
---
via: <https://www.theregister.com/2023/12/04/40_years_of_turbo_pascal/>
作者:[Richard Speed](https://www.theregister.com/Author/Richard-Speed) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | # 40 years of Turbo Pascal, the coding dinosaur that revolutionized IDEs
## The legacy can still be felt today
It is 40 years since Turbo Pascal revolutionized the coding marketplace with a slick (for the time) Integrated Development Environment (IDE) and performance to spare. So why aren't we all using it today?
Turbo Pascal was released in 1983 and represented a shift from the traditional way programming tools worked in the early days of IBM PC compatibles. Rather than multiple compiler and linking passes that required time-consuming floppy disk access, Turbo Pascal did everything in RAM, making it considerably faster – hence the name "Turbo."
Anders Hejlsberg, who would later go on to join Microsoft as part of the C# project, is widely credited as creator of the language, with Borland boss Philippe Kahn identifying the need for the all-in-one tool.
It was also cheap – where the competition could cost hundreds of dollars, Turbo Pascal retailed for $49.99. However, its maker, Borland, wanted a little extra if a customer planned to distribute the binaries.
Version 1 had limitations. Source code files, for example, were limited to 64 KB. It would only produce .COM executable files for DOS and CP/M – although other architectures and operating systems were supported. It would also run from a single floppy disk, saving users from endless swapping in a world where single drives were the norm and a hard disk seemed impossibly exotic – and expensive.
[Version 100 of the MIT Lisp Machine software recovered](https://www.theregister.com/2023/03/31/mit_cadr_software_recovered/)[Nostalgic for VB? BASIC is anything but dead](https://www.theregister.com/2023/03/28/nostalgic_for_basic/)[The Stonehenge of PC design, Xerox Alto, appeared 50 years ago this month](https://www.theregister.com/2023/03/16/the_xerox_alto_50_years/)[GCC 13 to support Modula-2: Follow-up to Pascal lives on in FOSS form](https://www.theregister.com/2022/12/16/gcc_13_will_support_modula2/)
Version 2 came a few months later, with some minor modifications, and was followed by version 3 in 1986. However, it was with version 4, in 1987, that Turbo Pascal changed dramatically. For one, support for CP/M and CP/M-86 was dropped, and the compiler would generate .EXE executables under DOS, lifting the .COM restrictions.
Version 4 also introduced a full-screen text user interface with pull-down menus, and 1988's version 5 gave us the familiar default blue background for the editor. For this writer, 1989's version 5.5 was peak Turbo Pascal. Object-oriented programming features turned up, including classes and inheritance, and a step-by-step debugger.
Version 6 and 7 brought in inline assembly and support for the creation of Windows executables and DLLs respectively, but version 7 also marked the end of the line as far as Borland was concerned. Turbo Pascal for Windows would turn up, but was eventually superseded by Delphi.
However, the steamroller of tools such as Visual Basic 3 ensured that Borland never had the same success in Windows that it enjoyed under DOS.
As for Turbo Pascal, several versions were eventually released by Borland as freeware including version 1 for DOS, 5.5, and 7.
The language might have offended Pascal purists and the IDE seems a little clunky nowadays when compared to modern tools. However, 40 years ago it prompted a new era of development, one whose influence can still be felt today. ®
110 |
16,445 | 注重隐私的五大网络浏览器 | https://itsfoss.com/privacy-web-browsers/ | 2023-12-06T06:17:36 | [
"浏览器",
"隐私"
] | https://linux.cn/article-16445-1.html | 
>
> 这是你可以试用的一些最佳的隐私友好型网络浏览器!
>
>
>
对大多数互联网用户来说,网络浏览器应用是他们最常接触的工具。不论其在桌面或移动设备上工作,无论平台如何,总会用到网络浏览器。
通过浏览器,我们可以访问云存储、银行服务、社交媒体、电商平台,以及无数其他服务。
因此,选择一个尊重隐私,并能提供安全网络体验的浏览器对你来说至关重要。
下面我将为你重点展示一些在你选择的任何设备上可以使用的、最佳的注重隐私的浏览器。
### LibreWolf
[LibreWolf](https://librewolf.net/) 是 Firefox 的一个分支版本,它开箱即用地提供了隐私增强功能。
LibreWolf 不只是一个配置稍有不同的 Firefox。它完全清除了所有的遥测、DRM 保护,并在安全方面进行了各种改进。
比如说,每当你关闭浏览器时,它会自动删除浏览和下载历史。此外,你也可以根据 [文档](https://librewolf.net/docs/settings/) 调整这种行为并根据自己的喜好进行自定义。
再者,你还能得到像 DuckDuckGo 和 Qwant 这样的 [隐私友好搜索引擎](https://itsfoss.com/privacy-search-engines/)。同时,uBlock Origin 的扩展功能在该浏览器中默认就开启了。
它不仅能提供私密和安全的体验,LibreWolf 还去掉了一些可能会分散用户注意力的 Firefox 元素,例如一个更清爽的新标签页和 Firefox 同步功能。
亮点:
* 这是专门为了隐私定制的版本
* 可以根据需要调整定制选项
* 默认禁用 Firefox Sync 同步功能
* 仅支持桌面平台(Linux、Windows 和 macOS)
### Brave
[Brave](https://brave.com/en-in/) 是基于 Chromium 的知名版本。它以提供了飞快的网页用户体验而备受赞誉。
Brave 提供了大量以隐私为中心的设置,如:无需创建账户就能安全同步浏览器数据。该浏览器有效地阻止了跟踪器,给你带来了私密网络体验。
你还能获得一些附加功能,如奖励系统(用于选择性广告)和加密钱包。
虽然这个浏览器支持跨平台使用,但对于 Linux 系统,其安装过程与其他式有所不同。你可以参考我们的教程寻找帮助:
>
> **[在 Ubuntu 上安装 Brave 浏览器](https://itsfoss.com/brave-web-browser/)**
>
>
>
亮点:
* 快速的网页浏览体验
* 与 Chrome 相似的用户体验
* 提供安全的浏览器同步选项
* 提供了额外的功能,如加密钱包等
* 支持 Linux、安卓、iOS、Windows 和 macOS
### Firefox
[Mozilla Firefox](https://www.mozilla.org/en-US/firefox/new/) 是无数隐私爱好者的首选浏览器。
它有很多隐私保护功能,包括有阻止跟踪、设定不同 DNS 的能力。
Firefox 提供了独特的用户体验,整合了 νρη、电子邮件别名、Pocket 等实用功能,以及一个 Firefox 账户可以方便地同步所有你的浏览器数据。
使用 Firefox,你可以自定义用户界面,并通过 JavaScript 文件调整体验。如果你并不打算使用 Firefox,但仍希望提升隐私保护,你可以查看 GitHub 上的 [arkenfox 配置](https://github.com/arkenfox/user.js)。
如果你在 [Firefox 和 Brave](/article-13736-1.html) 之间感到困惑,我们的比较文章可以帮你深入了解、从而做出选择:
>
> **[Brave vs. Firefox:你的私人网络体验的终极浏览器选择](/article-13736-1.html)**
>
>
>
亮点:
* 考虑到可用性而设计出的以隐私为核心的功能
* 整合了 Firefox 同步和 Pocket 功能
* 支持 Linux、Windows、安卓、iOS 和 macOS 等平台
### Tor 浏览器
[Tor 浏览器](https://www.torproject.org/download/) 是注重隐私的用户的最佳选择。
因为它基于 Firefox,所以你基本能获取同样的体验,同时进行了一些改动以更高级别提升安全特性和隐私。
与 LibreWolf 不同的是,Tor 浏览器让你能使用 [Tor 网络](https://itsfoss.com/tor-guide/),这可能会影响你的网络体验,但对隐私方面的提升很大。你可以通过浏览 [洋葱网站](https://en.wikipedia.org/wiki/List_of_Tor_onion_services) 来保证隐私。
如同 Brave,Tor 浏览器在 Linux 系统上的安装可能有点复杂。如果你是 Linux 用户,你可以参考我们的教程:
>
> **[在 Ubuntu 上安装 Tor 浏览器](https://itsfoss.com/content/images/size/w256h256/2022/12/android-chrome-192x192.png)**
>
>
>
亮点:
* 严格的隐私保护,尽管这可能降低可用性
* 连接 Tor 网络
* 支持 Linux、Windows、安卓 和 macOS 等平台
### Mullvad 浏览器
Mullvad 是最好的 [νρη 服务](https://itsfoss.com/best-vpn-linux/) 之一。[Mullvad 浏览器](https://mullvad.net/en/browser) 的开发是与 Tor 项目合作完成的,其特点是专门为使用 νρη 而非 Tor 网络而定制。
你也可以在 Mullvad 浏览器上结合使用其它的 νρη 服务。该浏览器内置了 uBlock Origin 和 NoScript 等扩展,提供他们所追求的私密体验。此外,浏览器并不支持 Firefox 同步。
虽然你不能移除这些扩展,但他们并不推荐你添加更多扩展。
亮点:
* 专为 νρη 使用而定制
* 预先安装了不能被移除的扩展
* 只支持桌面平台(Linux、Windows 和 macOS)
### 总结
随着网络的不断发展且需要处理各种问题,依赖于一个重视隐私的浏览器变得更加方便。
在上述提及的浏览器中,Firefox 和 Brave 是大多数人的首选。但如果你寻求更严格的保护和更多的配置,那么 LibreWolf 应该会符合你的需求。
当然,使用像 Tor 浏览器、LibreWolf 和 Mullvad 这样特别定制的浏览器,你将失去在移动设备上使用它们的灵活性。因此,你可以为你的智能手机选择一个单独的浏览器,或者选择一个支持你所有设备的浏览器。
? 你最喜欢的是哪款注重隐私的网络浏览器呢?请在下方评论让我们知道!如果你对列表中的某些条目有异议,也可以优雅地表达你的看法。
*(题图:MJ/acc47c46-8923-482f-92f6-523516b2f450)*
---
via: <https://itsfoss.com/privacy-web-browsers/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For many internet users, a web browser application is what they interact with the most. Whether you are on a desktop or mobile (and regardless of the platform), you will always end up using the web browser.
You access cloud storage, banking services, social media, e-commerce platforms, and numerous other services through it.
Hence, it is crucial for you to pick a web browser that respects privacy, and provides you a secure web experience.
Here, let me highlight the best privacy-focused options that you can utilize in any device of your choice.
## LibreWolf
[LibreWolf](https://librewolf.net) is a fork of Firefox with privacy enhancements out of the box.
It is not just Firefox with different configuration. LibreWolf get rids of all the telemetry, DRM protection, and adds various improvements to the security-side of things.
For instance, the browser deletes browsing and download history when you close it. However, you can always tweak this behavior and customize it to your liking following the [documentation](https://librewolf.net/docs/settings/).
Furthermore, you get [privacy-friendly search engines](https://itsfoss.com/privacy-search-engines/) like DuckDuckGo and Qwant. And, the uBlock Origin extension comes baked in by default.
Not just a private and secure experience, it also takes away some Firefox elements that some users may find distracting, like a cleaner new tab, and Firefox sync.
**Highlights:**
- A highly customized Firefox fork for privacy
- Customizations can be tweaked if needed
- Disables Firefox Sync by default
- Available for desktop platforms only (Linux, Windows, and macOS)
## Brave
[Brave](https://brave.com/en-in/) is a popular option based on Chromium. It is known for providing a blazing fast user experience with web pages.
Brave features numerous privacy-centric settings, like the ability to sync browser data securely, without needing to create an account. The browser effectively blocks trackers to give you a private web experience.
You also get extras like the reward system (for opt-in ads) and crypto wallets.
While this is available cross-platform, the installation procedure for Linux systems is a bit different from others. You can refer to our guide for help:
[Installing Brave Browser on Ubuntu & Other Linux DistrosWant to get started using Brave on Linux? This guide will help you with installation, removal and update process of the Brave browser.](https://itsfoss.com/brave-web-browser/)

**Highlights:**
- Fast web page experience
- Familiar user experience to Chrome
- Secure browser sync option
- Extras like crypto wallet
- Available for Linux, Android, iOS, Windows, and macOS
## Firefox
[Mozilla Firefox](https://www.mozilla.org/en-US/firefox/new/) is the go-to browser for countless privacy enthusiasts.
It features many privacy protection features that include abilities to block trackers, and set a different DNS.
Firefox provides a unique user experience with useful integrations like VPN, email aliases, Pocket, and a Firefox account to sync all your browser data conveniently.
With Firefox, you can customize the user interface, and tweak the experience with a JavaScript file as well. If you would rather not use any Firefox fork but want to improve the privacy game, you can take a look at [arkenfox configuration](https://github.com/arkenfox/user.js) on GitHub.
If you are confused between [Firefox and Brave](https://itsfoss.com/brave-vs-firefox), our comparison article can give you an in-depth look to help decide:
[Comparing Brave vs. Firefox: Which one Should You Use?The evergreen open-source browser Firefox compared to Brave. What would you pick?](https://itsfoss.com/brave-vs-firefox)

**Highlights:**
- Privacy-focused features keeping usability in mind
- Firefox sync and Pocket integrations
- Available for Linux, Windows, Android, iOS, and macOS
## Tor Browser
[Tor Browser](https://www.torproject.org/download/) is the best bet for a privacy-conscious user.
Considering it is based on Firefox, you get the same fundamental experience with tweaks to level-up the security and privacy.
Unlike LibreWolf, Tor Browser lets you utilize the [Tor network](https://itsfoss.com/tor-guide/), which could affect your web experience but gives a big privacy boost. You can browse [onion sites](https://en.wikipedia.org/wiki/List_of_Tor_onion_services) to fight against censorship, and keep things private at the same time.
Similar to Brave, Tor Browser can be a bit tricky to install on Linux systems. If you are a Linux user, you might want to follow our tutorial:
[How to Easily Install Tor Browser in Ubuntu and Other LinuxThis tutorial shows you how to install Tor browser in Ubuntu Linux. You’ll also learn a few tips around effectively using the Tor Browser. Privacy is one of the most discussed topics these days, from the NSA spying on citizens and governments alike to the Facebook data scandals. The](https://itsfoss.com/install-tar-browser-linux/)

**Highlights:**
- Strict privacy with compromises to usability
- Tor network connection
- Available for Linux, Windows, Android, and macOS
## Mullvad Browser
Mullvad is one of the [best VPN services](https://itsfoss.com/best-vpn-linux/) out there. The [Mullvad browser](https://mullvad.net/en/browser) is built in collaboration with the Tor Project to provide a solution tailored to be used with VPNs instead of the Tor network.
You can use any VPN service with Mullvad, if not their own. The browser includes extensions like uBlock Origin and NoScript by default to give you the private experience they aim for. Additionally, the browser does not support Firefox sync.
While you cannot remove the extensions, they do not recommend adding more.
**Highlights:**
- Tailored for VPN usage
- Pre-installed extensions that cannot be removed
- Available for desktop platforms only (Linux, Windows, and macOS)
**Suggested Read 📖**
[Top 10 Best Browsers for Ubuntu LinuxWhat are your options when it comes to web browsers for Linux? Here are the best web browsers you can pick for Ubuntu and other Linux distros.](https://itsfoss.com/best-browsers-ubuntu-linux/)

## Wrapping Up
The web is evolving and with various things to take care of, it is convenient to rely on a browser that focuses on privacy.
Among the browsers mentioned above, Firefox and Brave are popular picks for most. However, if you want a little more strict protection and configurations in your browser, LibreWolf should suffice.
Of course, with specially tailored browsers like Tor Browser, LibreWolf, and Mullvad, you lose the flexibility of accessing it on mobile devices. So, you can choose a separate browser for your smartphone, or pick one that supports all your devices.
*💬 What is your favorite privacy-focused web browser? Let us know in the comments below! And if you disagree with some entries in the list, express your views gracefully.* |
16,447 | Godot 4.2 发布:让开源游戏引擎更上一层楼 | https://news.itsfoss.com/godot-4-2/ | 2023-12-06T16:24:39 | [
"Godot",
"游戏引擎"
] | https://linux.cn/article-16447-1.html | 
>
> Godot 的又一次更新,其中包含了一些有用的更改,以更接近 Unreal、Unity 等专有引擎。
>
>
>
[Godot](https://godotengine.org/),社区最喜欢的 Unreal 和 Unity 等专有游戏引擎的替代品,有一个新的重大更新!
**Godot 4.2** “闪亮登场”,全面更新大量内容。它继续沿着 [Godot 4.0 版本](https://news.itsfoss.com/godot-4-0-release/) 铺平的道路,并在此基础上进行构建。
拿上你的饮料,让我来重点介绍一下这次发布的优点。☕
### Godot 4.2:有什么新内容?
Godot 4.2 版本有很多新东西。但是,我们将关注**关键亮点**:
* Linux 上的官方 ARM 支持
* 编辑器改进
* 更多版本控制友好
* 增强的图块地图
* 多人游戏/网络的改进
* 更好的导航系统
#### Linux 上的官方 ARM 支持
尽管可以在 Linux 上为基于 ARM 的设备手动构建 Godot,但**从来没有针对 Linux 的官方 ARM 构建**。
然而,随着 Godot 4.2 的发布,这种情况发生了变化。他们在下载页面上提供了 **32 位和 64 位版本的 Godot for ARM**。
请记住,这是**一项实验性工作**,因此可能会出现错误和问题。
#### 编辑器改进

Godot 的编辑器方面有很多改进。
如上面的截图所示,第一个是代码编辑器中的新添加项,名为“<ruby> 创建代码区域 <rt> Create Code Region </rt></ruby>”。它允许你**将脚本分解为命名块**,然后可以将其最小化以减少混乱。

Godot 的另一个新功能是**能够在编辑器视口中单独扩展方框图形的每一侧**。以前,这仅限于中心点和对称范围。

**项目管理器也进行了更新**,改进了一般项目导入工作流程,并重新排列了按钮。
#### 更多版本控制友好
Godot 4.2 修复了在“就绪”期间更改场景或重命名节点会导致崩溃的问题,还修复了与重命名/移动文件相关的各种问题。
开发人员还补充道:
>
> 此外,场景中资源 ID 偶尔更改的一些情况已得到解决([GH-65011](https://github.com/godotengine/godot/pull/65011))。仍有改进的空间,但这已经使 4.2 的版本控制更加友好。
>
>
>
#### 增强的图块地图

除了 Godot 的**图块/图块地图系统**的主要性能优化之外,还有一项新功能允许你在将图块/图块图案放置在任何地方时**旋转或翻转它们**。
#### 多人游戏/网络的改进
此版本还具有**高级多人游戏系统的改进**。“MultiplayerSynchronizer” 节点现在支持同步变换组件、子资源属性和其他类型的索引数据。
还有**针对拒绝服务漏洞的安全修复**,该漏洞之前在 Godot 4.0.4 RC1 版本中已披露。
>
> ? 开发人员建议用户升级到 Godot 4.0.4、4.1.2 或 4.2 以避免出现问题。
>
>
>
#### 更好的导航系统

Godot 4.2 带来了 **2D 导航网格烘焙**,它可以处理物理体、网格实例、普通多边形等。
此外,**添加了对 2D 和 3D 导航网格烘焙的多线程支持**,以提高性能并减少卡顿。
#### ?️ 其他更改和改进
还有许多其他值得注意的变化:
* 改进了 [GDExtension](https://docs.godotengine.org/en/stable/tutorials/scripting/gdextension/what_is_gdextension.html) 系统。
* 支持 AMD 的 [FSR 2.2](https://community.amd.com/t5/gaming/amd-fidelityfx-super-resolution-2-2-racing-into-more-games-and/ba-p/563910) 技术。
* 图形构建节点的**重大修改**。
* **适用于 Linux、Windows 和 macOS 的原生文件选择**对话框。
* 现在可以为附加组件和资产**指定不同的安装文件夹**。
* **修复了 Steam 输入问题**,该问题导致某些游戏手柄事件被处理两次。
有关此版本的更多详细信息,你可以通过 [官方发行说明](https://godotengine.org/article/godot-4-2-arrives-in-style/) 了解。
### ? 下载Godot 4.2
前往 [官方网站](https://godotengine.org/download/linux/) 获取 Linux 版 Godot 的最新版本。对于其他软件包,你还可以参考其 [GitHub 仓库](https://github.com/godotengine/godot/releases/tag/4.2-stable)。
>
> [Godot 4.2(GitHub)](https://github.com/godotengine/godot/releases/tag/4.2-stable)
>
>
>
? 你对此版本有何看法? 已经试过这个精彩的开源游戏引擎了吗? 在评论中告诉我们!
---
via: <https://news.itsfoss.com/godot-4-2/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Godot](https://godotengine.org/?ref=news.itsfoss.com), the community favorite alternative to proprietary game engines such as Unreal and Unity, has a new major update!
**Godot 4.2** has “*arrived in style*” with loads of updates across the board. It continues in the path that the [Godot 4.0 release](https://news.itsfoss.com/godot-4-0-release/) paved, and builds upon it.
Grab a beverage of your choice, as I highlight the good things about this release ☕
**Suggested Read **📖
[Godot 4.0 Release Might Persuade Developers to Switch Away From Unreal, Unity, and Other Game EnginesGodot 4.0 is an excellent upgrade to make more game developers consider it an alternative worth trying.](https://news.itsfoss.com/godot-4-0-release/)

## Godot 4.2: What's New?
There are plenty of new things with the Godot 4.2 release. But, we will focus on the **key highlights**:
**Official ARM Support on Linux****Editor Improvements****More Version Control Friendly****Enhanced Tilemaps****Improvements to Multiplayer/Networking****Better Navigation System**
### Official ARM Support on Linux
Even though it was possible to manually build Godot for ARM-based devices on Linux, there was** never an official ARM build for Linux**.
However, that has now changed with the Godot 4.2 release. They have provided both **32-bit and 64-bit versions of Godot for ARM** on their downloads page.
Keep in mind that this is **an experimental undertaking**, so expect bugs and issues.


### Editor Improvements
There have been many improvements on the editor side of Godot.
As illustrated by the screenshot above, the first one is a new addition to the code editor called “**Code Region**”. It allows you to **break up scripts into named blocks**, which can then be minimized to lessen clutter.
Another new addition to Godot is the **ability to extend each side of box shapes individually within the editor viewport**. Previously, this was only limited to the center point and symmetrical extents.
The **project manager also sees an update**, the general project import workflow has been improved alongside a rearrangement of buttons.
### More Version Control Friendly
Godot 4.2 comes with a fix to an issue where changing scenes or renaming nodes during 'ready' would lead to crashes, various issues related to renaming/moving files were also fixed.
The developers also added:
Also, some cases of sporadic changing of resource IDs in scenes have been solved ([GH-65011]). There is still room for improvement, but this already makes 4.2 way more version control friendly.
### Enhanced Tilemaps
Alongside **major performance optimizations to the tile/tilemap system** of Godot, there is a new feature that allows you to **rotate or flip a tile/tile pattern** while placing them anywhere.
### Improvements to Multiplayer/Networking
This release also features** improvements for the high-level multiplayer system;** the '*MultiplayerSynchronizer*' node now supports syncing of transform components, sub-resource properties, and other types of indexed data.
There is also** a security fix for a denial-of-service vulnerability** that was previously disclosed with the Godot 4.0.4 RC1 release.
### Better Navigation System
Godot 4.2 brings about **navigation mesh baking for 2D**, it can handle physics bodies, mesh instances, plain polygons and more.
Furthermore, **support for multi-threading was added** for 2D and 3D navigation mesh baking for improving performance, and reducing stutters.
### 🛠️ Other Changes and Improvements
There are plenty of other changes worth noting:
- Improvements to the
[GDExtension](https://docs.godotengine.org/en/stable/tutorials/scripting/gdextension/what_is_gdextension.html?ref=news.itsfoss.com)system. - Support for AMD's
[FSR 2.2](https://community.amd.com/t5/gaming/amd-fidelityfx-super-resolution-2-2-racing-into-more-games-and/ba-p/563910?ref=news.itsfoss.com)tech. - A
**major rework**of the graph-building nodes. **Native file selection**dialog for Linux, Windows, and macOS.- It is now possible to
**specify a different install folder**for add-ons and assets. **A fix for the Steam Input issue**that caused some gamepad events to be handled twice.
For more details on this release, you can through the [official release notes](https://godotengine.org/article/godot-4-2-arrives-in-style/?ref=news.itsfoss.com).
## 📥 Download Godot 4.2
Head over to the [official website](https://godotengine.org/download/linux/?ref=news.itsfoss.com) to grab the latest release of Godot for Linux. For other packages, you could also refer to its [GitHub repo](https://github.com/godotengine/godot/releases/tag/4.2-stable?ref=news.itsfoss.com).
*💬 What are your thoughts on this release? Giving a chance to this wonderful open-source game engine already? Tell us about it in the comments!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,449 | 一款外观时尚的用于管理个人财务的 Linux 应用 | https://news.itsfoss.com/denaro/ | 2023-12-07T10:31:57 | [
"财务"
] | https://linux.cn/article-16449-1.html | 
>
> Linux桌面的完美应用,用于轻松管理财务!
>
>
>
个人财务如果管理得当,对于财务状况大有裨益。许多人意识到这一点后,开始采取积极措施来保持财务状况良好。
由于这一点,**我们最近看到了个人财务管理应用的崛起**,这些应用凭借提供的功能已经引起了广泛关注。
但是,**许多现有的应用都是专有的**,这导致人们对于他们的财务数据可能如何处理产生了不确定性,尤其是如果它们同步到云中。
幸运的是,**我们有一些出色的开源选择**。通过这次初步了解,我们将看到其中一款,“**Denaro**”,**一款适用于Linux的个人财务管理应用**。
### Denaro:概览 ⭐

用 C# 编写的 Denaro 是**一款整洁的小应用,可轻松管理你的财务**。它是**完全开源**的,依赖社区的贡献来推动其发展。
其中一些**关键功能**包括:
* 轻松筛选交易
* 导入/导出功能
* 多账户支持
#### 初次印象 ??
我使用 Flathub 商店提供的可用包安装了 Denaro ,它**与我搭载 GNOME 42 的系统集成良好**。
**该应用程序是以 GNOME 为基础设计的**,并针对默认的 Adwaita 主题进行了优化。
第一次启动时,我被问候了“下午好!”并提供了创建新账户或打开现有账户的选项。
>
> ? 请注意,账户是存储在本地的,而不是在任何云服务上。
>
>
>

我选择创建一个新账户,然后我看到了**快速设置向导**。

我输入了账户名称,并将位置设置为“<ruby> 文档 <rt> Documents </rt></ruby>”,我没有添加密码,但如果你想更好地保护信息,密码也是可选用的。 ?

设置完所有这些后,我可以**选择账户类型**,我可以选择 <ruby> 支票 <rt> Checking </rt></ruby>、<ruby> 储蓄 <rt> Savings </rt></ruby> 和 <ruby> 商业 <rt> Business </rt></ruby>,我选择了储蓄。
我还可以**设置默认交易类型**,并**设置交易提醒阈值**。

Denaro 很好地读取了我系统的信息,**自动将货币设置为印度卢比(INR)的 ₹**。

然后,我继续填充 Denaro 的一些重要交易,并通过**创建新组**将它们分组,如下所示。
你可以通过单击侧栏中“<ruby> + 新建 <rt> + New </rt></ruby>”按钮旁边的“<ruby> 分组 <rt> Groups </rt></ruby>”标题来访问它。你还可以为其**提供描述**和**标记颜色**!

完成分组后,我开始**在 Denaro 中输入一些重要的交易**。
我设置了 <ruby> 金额 <rt> Amount </rt></ruby>,选择了交易类型(<ruby> 收入 <rt> Income </rt></ruby>/<ruby> 支出 <rt> Expense </rt></ruby>),设置了 <ruby> 日期 <rt> Date </rt></ruby> 和 <ruby> 重复间隔 <rt> Repeat Interval </rt></ruby>,以便它自动记账,因为那是固定费用。
接下来,我将其添加到一个组中,如下所示。燃油费用进入了“旅行”组。

该应用还为你提供了**向交易添加注释并上传收据的选项**。如果你问我,这是一个不错的功能。

在完成数据输入后,我看到了**一个主屏幕**,其中充满了我输入的所有交易,中间有**有用的可视化图表**(下文更多介绍)。
我可以通过取消选中特定的类别和组来排序信息,甚至可以使用**提供的搜索栏**搜索特定的交易。
如果你想知道;**如何添加新交易?**
你看到下面那个大大的蓝色按钮,上面写着“<ruby> + 新建 <rt> + New </rt></ruby>”,你可以使用它来创建新交易。

至于**数据如何可视化**,Denaro 展示了**四种不同的可视化视图**,包括一个图表、一个图形和两个饼图。

Denaro 还具有**多账户功能**,你可以创建多个账户,甚至可以使用“<ruby> 转账 <rt> Transfer </rt></ruby>”功能**在它们之间转移资金**。
通过单击“<ruby> 操作 <rt> Actions </rt></ruby>”按钮并单击“<ruby> 转账 <rt> Transfer Money </rt></ruby>”来访问它。

引起我的另一个注意的是**Denaro 上的货币换算器**。它**列出了所有主要货币**,并有一个便捷的“切换”按钮来更改换算的目标。

**总的来说,这是一个令人印象深刻的个人财务管理应用程序**。
从我的体验来看,**用户体验非常直观**,大多数用户应该能够轻松使用它。
### ? 下载 Denaro
你可以从 [Flathub 商店](https://flathub.org/apps/org.nickvision.money)、[Snap Store](https://snapcraft.io/denaro) 和 [AUR](https://aur.archlinux.org/packages/denaro) 获取 Denaro 的最新版本。
>
> **[Denaro(Flathub)](https://flathub.org/apps/org.nickvision.money)**
>
>
>
关于源代码,你可以访问其 [GitHub 仓库](https://github.com/nickvisionapps/denaro)。
? 你是如何管理个人财务的?你喜欢使用像 Denaro 这样的应用程序吗?请在下方评论中告诉我。
---
via: <https://news.itsfoss.com/denaro/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[GlassFoxowo-Dev](https://github.com/GlassFoxowo-Dev) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Personal finances, if managed well, can do wonders for one's financial situation. Many, having realized that, are taking proactive measures to keep their finances in check.
Owing to that, **we have seen an emergence of personal finance management apps** lately, these have taken the stage with the functionality that they offer.
But, **many of the options available out there are proprietary**, leading to uncertainty on how one's financial data might be handled, especially, if they sync to the cloud.
Luckily, **we have some superb open-source options** for the same. With this first look, we will be taking a look at one such option, “**Denaro**”, **a personal finance management app for Linux**.
## Denaro: Overview ⭐
Written in C# programming language , Denaro is **a neat little app to manage your finances effortlessly**. It is **completely open-source**, and relies on community contributions for furthering its development.
Some of its **key features** include:
**Easy Filtering of Transactions****Import/Export Features****Multi-Account Support**
### Initial Impressions 👨💻
I installed Denaro by using the available flatpak package from the Flathub store, it **integrated well with my GNOME 42-equipped system**.
The **app has been designed keeping GNOME in mind** and optimized for the default Adwaita theme.
On first launch, I was greeted with a “Good Afternoon!” and options to either create a new account or open an existing one.
I opted to create a new account, and I was shown **the quick-setup wizard**.
I entered the account name and set the location to “Documents”, I didn't add a password, but it's there if you want to lock the info to your tricky treasures 🧐
After setting all that, I was able to **choose the type of account**, I had the options for **Checking**, **Savings** and **Business**, I proceeded with Savings.
I could also **set the default transaction type**, and **set a transaction reminder threshold**.
Denaro nicely read the info from my system and **automatically set the currency** to** ₹ for the Indian Rupee (INR)**.
I then proceeded to fill Denaro up with some important transactions, and grouped them accordingly by **creating new groups**, as shown below.
You can access it by clicking on the “+ New” button besides the 'Groups' heading in the sidebar. You can **give them a description** and **colors** too!
After I was done with groups, I started **entering some significant transactions** into Denaro.
I set the amount, selected what kind of transaction it was (Income/Expense), set the date, and the repeat interval so that it would occur automatically, as those were fixed charges.
Next, I added it to a group, as you can see below. Fuel Charges went into the “Travel” group.
The app also gives you an option **to add notes and upload receipts to transactions**. This is a neat one, if you ask me.
After I was done with data entry, I was shown **a home screen** that was filled with all the transactions I entered into it, with **helpful visualizing charts in the center** (more on that below).
I was able to sort through the info by unchecking specific categories and groups, and even searching for specific transactions using the **provided search bar.**
If you were wondering; **how to add new transactions?**
You see that big blue button below, that says, “+ New”, you can use that to create new transactions.
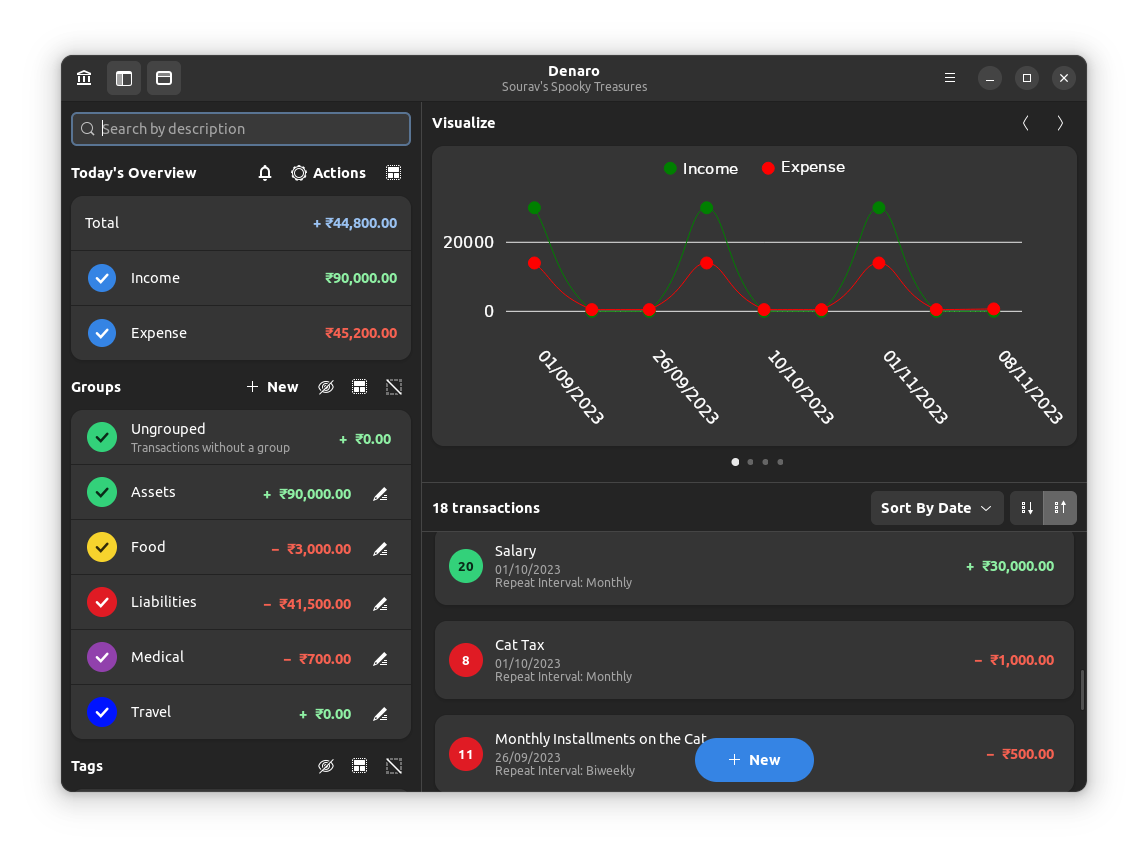
As for** how data is visualized**, Denaro shows **four distinct visualize views** that include a chart, a graph, and two pie-charts.
Denaro also has** a multi-account feature** where you can create multiple accounts, and even **transfer money** between them using the “Transfer” feature.
Access it by clicking on the “Actions” button and clicking on “Transfer Money”.
Another thing that caught my eye was **the currency converter on Denaro**. It **listed all the major currencies**, with a handy “Switch” button to change their positions.
**Overall, it is an impressive personal finance management app.**
From what I experienced, **the user experience is pretty straightforward**, and most users should be able to easily use it.
## 📥 Download Denaro
You can grab the latest release of Denaro from the [Flathub store](https://flathub.org/apps/org.nickvision.money?ref=news.itsfoss.com), [Snap Store](https://snapcraft.io/denaro?ref=news.itsfoss.com), and [AUR](https://aur.archlinux.org/packages/denaro?ref=news.itsfoss.com).
For the source code, you can visit its [GitHub repo](https://github.com/nickvisionapps/denaro?ref=news.itsfoss.com).
*💬 How do you manage your personal finances? Do you like to use an app like Denaro? Let me know in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,451 | 解读那些令人困惑 Git 术语 | https://jvns.ca/blog/2023/11/01/confusing-git-terminology/ | 2023-12-07T20:07:12 | [
"Git"
] | https://linux.cn/article-16451-1.html | 
我正在一步步解释 Git 的方方面面。在使用 Git 近 15 年后,我已经非常习惯于 Git 的特性,很容易忘记它令人困惑的地方。
因此,我在 [Mastodon](https://social.jvns.ca/@b0rk/111330564535454510) 上进行了调查:
>
> 你有觉得哪些 Git 术语很让人困惑吗?我计划写篇博客,来解读 Git 中一些奇怪的术语,如:“分离的 HEAD 状态”,“快速前移”,“索引/暂存区/已暂存”,“比 `origin/main` 提前 1 个提交”等等。
>
>
>
我收到了许多有洞见的答案,我在这里试图概述其中的一部分。下面是这些术语的列表:
* HEAD 和 “heads”
* “分离的 `HEAD` 状态”
* 在合并或变基时的 “ours” 和 “theirs”
* “你的分支已经与 'origin/main' 同步”
* `HEAD^`、`HEAD~`、`HEAD^^`、`HEAD~~`、`HEAD^2`、`HEAD~2`
* `..` 和 `...`
* “可以快速前移”
* “引用”、“符号引用”
* refspecs
* “tree-ish”
* “索引”、“暂存的”、“已缓存的”
* “重置”、“还原”、“恢复”
* “未跟踪的文件”、“追踪远程分支”、“跟踪远程分支”
* 检出
* reflog
* 合并、变基和遴选
* `rebase –onto`
* 提交
* 更多复杂的术语
我已经尽力讲解了这些术语,但它们几乎覆盖了 Git 的每一个主要特性,这对一篇博客而言显然过于繁重,所以在某些地方可能会有一些粗糙。
### `HEAD` 和 “heads”
有些人表示他们对 `HEAD` 和 `refs/heads/main` 这些术语感到困惑,因为听起来像是一些复杂的技术内部实现。
以下是一个快速概述:
* “heads” 就是 “分支”。在 Git 内部,分支存储在一个名为 `.git/refs/heads` 的目录中。(从技术上讲,[官方 Git 术语表](https://git-scm.com/docs/gitglossary) 中明确表示分支是所有的提交,而 head 只是最近的提交,但这只是同一事物的两种不同思考方式)
* `HEAD` 是当前的分支,它被存储在 `.git/HEAD` 中。
我认为,“head 是一个分支,`HEAD` 是当前的分支” 或许是 Git 中最奇怪的术语选择,但已经设定好了,想要更清晰的命名方案已经为时已晚,我们继续。
“HEAD 是当前的分支” 有一些重要的例外情况,我们将在下面讨论。
### “分离的 HEAD 状态”
你可能已经看到过这条信息:
```
$ git checkout v0.1
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
[...]
```
(消息译文:你处于 “分离 HEAD” 的状态。你可以四处看看,进行试验性的更改并提交,你可以通过切换回一个分支来丢弃这个状态下做出的任何提交。)
这条信息的实质是:
* 在 Git 中,通常你有一个已经检出的 “当前分支”,例如 `main`。
* 存放当前分支的地方被称为 `HEAD`。
* 你做出的任何新提交都会被添加到你的当前分支,如果你运行 `git merge other_branch`,这也会影响你的当前分支。
* 但是,`HEAD` 不一定**必须**是一个分支!它也可以是一个提交 ID。
* Git 会称这种状态(`HEAD` 是提交 ID 而不是分支)为 “分离的 `HEAD` 状态”
* 例如,你可以通过检出一个标签来进入分离的 `HEAD` 状态,因为标签不是分支
* 如果你没有当前分支,一系列事情就断链了:
+ `git pull` 根本就无法工作(因为它的全部目的就是更新你的当前分支)
+ 除非以特殊方式使用 `git push`,否则它也无法工作
+ `git commit`、`git merge`、`git rebase` 和 `git cherry-pick` 仍然可以工作,但它们会留下“孤儿”提交,这些提交没有连接到任何分支,因此找到这些提交会很困难
* 你可以通过创建一个新的分支或切换到一个现有的分支来退出分离的 `HEAD` 状态
### 在合并或变基中的 “ours” 和 “theirs”
遇到合并冲突时,你可以运行 `git checkout --ours file.txt` 来选择 “ours” 版本中的 `file.txt`。但问题是,什么是 “ours”,什么是 “theirs” 呢?
我总感觉此类术语混淆不清,也因此从未用过 `git checkout --ours`,但我还是查找相关资料试图理清。
在合并的过程中,这是如何运作的:当前分支是 “ours”,你要合并进来的分支是 “theirs”,这样看来似乎很合理。
```
$ git checkout merge-into-ours # 当前分支是 “ours”
$ git merge from-theirs # 我们正要合并的分支是 “theirs”
```
而在变基的过程中就刚好相反 —— 当前分支是 “theirs”,我们正在变基到的目标分支是 “ours”,如下:
```
$ git checkout theirs # 当前分支是 “theirs”
$ git rebase ours # 我们正在变基到的目标分支是 “ours”
```
我以为之所以会如此,因为在操作过程中,`git rebase main` 其实是将当前分支合并到 `main` (它类似于 `git checkout main; git merge current_branch`),尽管如此我仍然觉得此类术语会造成混淆。
[这个精巧的小网站](https://nitaym.github.io/ourstheirs/) 对 “ours” 和 “theirs” 的术语进行了解释。
人们也提到,VSCode 将 “ours”/“theirs” 称作 “当前的更改”/“收到的更改”,同样会引起混淆。
### “你的分支已经与 `origin/main` 同步”
此信息貌似很直白 —— 你的 `main` 分支已经与源端同步!
但它实际上有些误导。可能会让你以为这意味着你的 `main` 分支已经是最新的,其实不然。它**真正的**含义是 —— 如果你最后一次运行 `git fetch` 或 `git pull` 是五天前,那么你的 `main` 分支就是与五天前的所有更改同步。
因此,如果你没有意识到这一点,它对你的安全感其实是一种误导。
我认为 Git 理论上可以给出一个更有用的信息,像是“与五天前上一次获取的源端 `main` 是同步的”,因为最新一次获取的时间是在 reflog 中记录的,但它没有这么做。
### `HEAD^`、`HEAD~`、`HEAD^^`、`HEAD~~`、`HEAD^2`、`HEAD~2`
我早就清楚 `HEAD^` 代表前一次提交,但我很长一段时间都困惑于 `HEAD~` 和 `HEAD^` 之间的区别。
我查询资料,得到了如下的对应关系:
* `HEAD^` 和 `HEAD~` 是同一件事情(指向前 1 个提交)
* `HEAD^^^`、`HEAD~~~` 和 `HEAD~3` 是同一件事情(指向前 3 个提交)
* `HEAD^3` 指向提交的第三个父提交,它与 `HEAD~3` 是不同的
这看起来有些奇怪,为什么 `HEAD~` 和 `HEAD^` 是同一个概念?以及,“第三个父提交”是什么?难道就是父提交的父提交的父提交?(剧透:并非如此)让我们一起深入探讨一下!
大部分提交只有一个父提交。但是合并提交有多个父提交 - 因为它们合并了两个或更多的提交。在 Git 中,`HEAD^` 意味着 “HEAD 提交的父提交”。但是如果 `HEAD` 是一个合并提交,那 `HEAD^` 又代表怎么回事呢?
答案是,`HEAD^` 指向的是合并提交的**第一个**父提交,`HEAD^2` 是第二个父提交,`HEAD^3` 是第三个父提交,等等。
但我猜他们也需要一个方式来表示“前三个提交”,所以 `HEAD^3` 是当前提交的第三个父提交(如果当前提交是一个合并提交,可能会有很多父提交),而 `HEAD~3` 是父提交的父提交的父提交。
我想,从我们之前对合并提交 “ours”/“theirs” 的讨论来看,`HEAD^` 是 “ours”,`HEAD^2` 是 “theirs”。
### `..` 和 `...`
这是两个命令:
* `git log main..test`
* `git log main...test`
我从没用过 `..` 和 `...` 这两个命令,所以我得查一下 [man git-range-diff](https://git-scm.com/docs/git-range-diff)。我的理解是比如这样一个情况:
```
A - B main
\
C - D test
```
* `main..test` 对应的是提交 C 和 D
* `test..main` 对应的是提交 B
* `main...test` 对应的是提交 B,C,和 D
更有挑战的是,`git diff` 显然也支持 `..` 和 `...`,但它们在 `git log` 中的意思完全不同?我的理解如下:
* `git log test..main` 显示在 `main` 而不在 `test` 的更改,但是 `git log test...main` 则会显示 *两边* 的改动。
* `git diff test..main` 显示 `test` 变动 *和* `main` 变动(它比较 `B` 和 `D`),而 `git diff test...main` 会比较 `A` 和 `D`(它只会给你显示一边的差异)。
有关这个的更多讨论可以参考 [这篇博客文章](https://matthew-brett.github.io/pydagogue/pain_in_dots.html)。
### “可以快速前移”
在 `git status` 中,我们会经常遇到如下的信息:
```
$ git status
On branch main
Your branch is behind 'origin/main' by 2 commits, and can be fast-forwarded.
(use "git pull" to update your local branch)
```
(消息译文:你现在处于 `main` 分支上。你的分支比 `origin/main` 分支落后了 2 个提交,可以进行快速前进。 (使用 `git pull` 命令可以更新你的本地分支))
但“快速前移” 到底是何意?本质上,它在告诉我们这两个分支基本如下图所示(最新的提交在右侧):
```
main: A - B - C
origin/main: A - B - C - D - E
```
或者,从另一个角度理解就是:
```
A - B - C - D - E (origin/main)
|
main
```
这里,`origin/main` 仅仅多出了 2 个 `main` 不存在的提交,因此我们可以轻松地让 `main` 更新至最新 —— 我们所需要做的就是添加上那 2 个提交。事实上,这几乎不可能出错 —— 不存在合并冲突。快速前进式合并是个非常棒的事情!这是合并两个分支最简单的方式。
运行完 `git pull` 之后,你会得到如下状态:
```
main: A - B - C - D - E
origin/main: A - B - C - D - E
```
下面这个例子展示了一种**不能**快速前进的状态。
```
A - B - C - X (main)
|
- - D - E (origin/main)
```
此时,`main` 分支上有一个 `origin/main` 分支上无的提交(`X`),所以无法执行快速前移。在此种情况,`git status` 就会如此显示:
```
$ git status
Your branch and 'origin/main' have diverged,
and have 1 and 2 different commits each, respectively.
```
(你的分支和 `origin/main` 分支已经产生了分歧,其中各有 1 个和 2 个不同的提交。)
### “引用”、“符号引用”
在使用 Git 时,“引用” 一词可能会使人混淆。实际上,Git 中被称为 “引用” 的实例至少有三种:
* 分支和标签,例如 `main` 和 `v0.2`
* `HEAD`,代表当前活跃的分支
* 诸如 `HEAD^^^` 这样的表达式,Git 会将其解析成一个提交 ID。确切说,这可能并非 “引用”,我想 Git [将其称作](https://git-scm.com/docs/revisions) “版本参数”,但我个人并未使用过这个术语。
个人而言,“符号引用” 这个术语颇为奇特,因为我觉得我只使用过 `HEAD`(即当前分支)作为符号引用。而 `HEAD` 在 Git 中占据核心位置,多数 Git 核心命令的行为都基于 `HEAD` 的值,因此我不太确定将其泛化成一个概念的实际意义。
### refspecs
在 `.git/config` 配置 Git 远程仓库时,你可能会看到这样的代码 `+refs/heads/main:refs/remotes/origin/main` 。
```
[remote "origin"]
url = [email protected]:jvns/pandas-cookbook
fetch = +refs/heads/main:refs/remotes/origin/main
```
我对这段代码的含义并不十分清楚,我通常只是在使用 `git clone` 或 `git remote add` 配置远程仓库时采用默认配置,并没有动机去深究或改变。
### “tree-ish”
在 `git checkout` 的手册页中,我们可以看到:
```
git checkout [-f|--ours|--theirs|-m|--conflict=<style>] [<tree-ish>] [--] <pathspec>...
```
那么这里的 `tree-ish` 是什么意思呢?其实当你执行 `git checkout THING .` 时,`THING` 可以是以下的任一种:
* 一个提交 ID(如 `182cd3f`)
* 对一个提交 ID 的引用(如 `main` 或 `HEAD^^` 或 `v0.3.2`)
* 一个位于提交内的子目录(如 `main:./docs`)
* 可能就这些?
对我个人来说,“提交内的目录”这个功能我从未使用过,从我的视角看,`tree-ish` 可以解读为“提交或对提交的引用”。
### “索引”、“暂存”、“缓存”
这些术语都指向的是同一样东西(文件 `.git/index`,当你执行 `git add` 时,你的变动会在这里被暂存):
* `git diff --cached`
* `git rm --cached`
* `git diff --staged`
* 文件 `.git/index`
尽管它们都是指向同一个文件,但在实际使用中,这些术语的应用方式有所不同:
* 很显然,`--index` 和 `--cached` 并不总是表示同一种意思。我自己从未使用 `--index`,所以具体细节我就不展开讨论了,但是你可以在 Junio Hamano(Git 的主管维护者)[的博客文章](https://gitster.livejournal.com/39629.html) 中找到详细解释。
* “索引” 会包含未跟踪的文件(我猜可能是对性能的考虑),但你通常不会把未跟踪的文件考虑在“暂存区”内。
### “重置”、“还原”、“恢复”
许多人提到,“<ruby> 重置 <rt> reset </rt></ruby>”、“<ruby> 还原 <rt> revert </rt></ruby>” 和 “<ruby> 恢复 <rt> restore </rt></ruby>” 这三个词非常相似,易使人混淆。
我认为这部分的困惑来自以下原因:
* `git reset --hard` 和 `git restore .` 单独使用时,基本上达到的效果是一样的。然而,`git reset --hard COMMIT` 和 `git restore --source COMMIT .` 相互之间是完全不同的。
* 相应的手册页没有给出特别有帮助的描述:
+ `git reset`: “重置当前 `HEAD` 到指定的状态”
+ `git revert`: “还原某些现有的提交”
+ `git restore`: “恢复工作树文件”
虽然这些简短的描述为你详细说明了哪个名词受到了影响(“当前 `HEAD`”,“某些提交”,“工作树文件”),但它们都预设了你已经知道在这种语境中,“重置”、“还原”和“恢复”的准确含义。
以下是对它们各自功能的简要说明:
* 重置 —— `git revert COMMIT`: 在你当前的分支上,创建一个新的提交,该提交是 `COMMIT` 的“反向”操作(如果 `COMMIT` 添加了 3 行,那么新的提交就会删除这 3 行)。
* 还原 —— `git reset --hard COMMIT`: 强行将当前分支回退到 `COMMIT` 所在的状态,抹去自 `COMMIT` 以来的所有更改。这是一个高风险的操作。
* 恢复 —— `git restore --source=COMMIT PATH`: 将 `PATH` 中的所有文件回退到 `COMMIT` 当时的状态,而不扰乱其他文件或提交历史。
### “未跟踪的文件”、“远程跟踪分支”、“跟踪远程分支”
在 Git 中,“跟踪” 这个词以三种相关但不同的方式使用:
* “<ruby> 未跟踪的文件 <rt> Untracked files </rt></ruby>”:在 `git status` 命令的输出中可以看到。这里,“未跟踪” 意味着这些文件不受 Git 管理,不会被计入提交。
* “<ruby> 远程跟踪分支 <rt> remote tracking branch </rt></ruby>” 例如 `origin/main`。此处的“远程跟踪分支”是一个本地引用,旨在记住上次执行 `git pull` 或 `git fetch` 时,远程 `origin` 上 `main` 分支的状态。
* 我们经常看到类似 “分支 `foo` 被设置为跟踪 `origin` 上的远程分支 `bar` ”这样的提示。
即使“未跟踪的文件”和“远程跟踪分支”都用到了“跟踪”这个词,但是它们所在的上下文完全不同,所以没有太多混淆。但是,对于以下两种方式的“跟踪”使用,我觉得可能会产生些许困扰:
* `main` 是一个跟踪远程的分支
* `origin/main` 是一个远程跟踪分支
然而,在 Git 中,“跟踪远程的分支” 和 “远程跟踪分支” 是不同的事物,理解它们之间的区别非常关键!下面是对这两者区别的一个简单概述:
* `main` 是一个分支。你可以在它上面做提交,进行合并等操作。在 `.git/config` 中,它通常被配置为 “追踪” 远程的 `main` 分支,这样你就可以用 `git pull` 和 `git push` 来同步和上传更改。
* `origin/main` 则并不是一个分支,而是一个“远程跟踪分支”,这并不是一种真正的分支(这有些抱歉)。你**不能**在此基础上做提交。只有通过运行 `git pull` 或 `git fetch` 获取远程 `main` 的最新状态,才能更新它。
我以前没有深入思考过这种模糊的地方,但我认为很容易看出为什么它会让人感到困惑。
### 签出
签出做了两个完全无关的事情:
* `git checkout BRANCH` 用于切换分支
* `git checkout file.txt` 用于撤销对 `file.txt` 的未暂存修改
这是众所周知的混淆点,因此 Git 实际上已经将这两个功能分离到了 `git switch` 和 `git restore`(尽管你还是可以使用 `checkout`,就像我一样,在不愿丢弃 15 年对 `git checkout` 肌肉记忆的情况下)。
再者,即使用了 15 年,我仍然记不住 `git checkout main file.txt` 用于从 `main` 分支恢复 `file.txt` 版本的命令参数。
我觉得有时你可能需要在 `checkout` 命令后面加上`--`,帮助区分哪个参数是分支名,哪个是路径,但我并未这么使用过,也不确定何时需要这样做。
### 参考日志(reflog)
有很多人把 `reflog` 读作 `re-flog`,而不是 `ref-log`。由于本文已经足够长,我这里不会深入讨论参考日志,但值得注意的是:
* 在 Git 中,“参考” 是一个泛指分支、标签和 `HEAD` 的术语
* 参考日志(“reflog”)则为你提供了一个参考历次记录的历史追踪
* 它是从一些极端困境中拯救出来的利器,比如说你不小心删除了重要的分支
* 我觉得参考日志是 Git 用户界面中最难懂的部分,我总是试图避免使用它。
### 合并 vs 变基 vs 遴选
有许多人提及他们常常对于合并和变基的区别感到迷惑,并且不理解变基中的“<ruby> 基 <rt> base </rt></ruby>”指的是什么。
我会在这里尽量简要的进行描述,但是这些一句话的解释最终可能并不那么明了,因为每个人使用合并和变基创建工作流程时的方式差别挺大,要真正理解合并和变基,你必须理解工作流程。此外,有图示会更好理解。不过这个话题可能需要一篇独立的博客文章来完整讨论,所以我不打算深入这个问题。
* 合并会创建一个新的提交,用来融合两个分支
* 变基则会逐个地把当前分支上的提交复制到目标分支
* 遴选跟变基类似,但是语法完全不同(一个显著的差异是变基是从当前分支复制提交,而遴选则会把提交复制到当前分支)
### `rebase --onto`
在 `git rebase` 中,存在一个被称为 `--onto` 的选项。这一直让我感到困惑,因为 `git rebase main` 的核心功能就是将当前分支变基**到** `main` 运行上。那么,额外的 `--onto` 参数又是怎么回事呢?
我进行了一番查找,`--onto` 显然解决了一个我几乎没有或者说从未遇到过的问题,但我还是会记录下我对它的理解。
```
A - B - C (main)
\
D - E - F - G (mybranch)
|
otherbranch
```
设想一下,出于某种原因,我只想把提交 `F` 和 `G` 变基到 `main` 上。我相信这应该是某些 Git 工作流中会经常遇到的场景。
显然,你可以运行 `git rebase --onto main otherbranch mybranch` 来完成这个操作。对我来说,在这个语法中记住 3 个不同的分支名顺序似乎是不可能的(三个分支名,对我来说实在太多了),但由于我从很多人那里听说过,我想它一定有它的用途。
### 提交
有人提到他们对 Git 中的提交作为一词双义(既作为动词也作为名词)的用法感到困惑。
例如:
* 动词:“别忘了经常提交”
* 名词:“`main` 分支上最新的提交”
我觉得大多数人应该能很快适应这个双关的用法,但是在 SQL 数据库中的“提交”用法与 Git 是有所不同,我认为在 SQL 数据库中,“提交”只是作为一个动词(你使用 `COMMIT` 来结束一个事务),并不作为名词。
此外,在 Git 中,你可以从以下三个不同的角度去考虑一个 Git 提交:
1. 表示当前每个文件状态的**快照**
2. 与父提交的**差异**
3. 记录所有先前提交的**历史**
这些理解都是不错的:不同的命令在所有的这些情况下都会使用提交。例如,`git show` 将提交视为一个差异,`git log` 把提交看作是历史,`git restore` 则将提交理解为一个快照。
然而,Git 的术语并无太多助于你理解一个给定的命令正在如何使用提交。
### 更多令人困惑的术语
以下是更多让人觉得混淆的术语。我对许多这些术语的意思并不十分清楚。
我自己也不是很理解的东西:
* `git pickaxe` (也许这是 `git log -S` 和 `git log -G`,它们用于搜索以前提交的差异?)
* 子模块(我知道的全部就是它们并不以我想要的方向工作)
* Git 稀疏检出中的 “cone mode” (没有任何关于这个的概念,但有人提到过)
人们提及觉得混淆,但我在这篇已经 3000 字的文章中略过的东西:
* blob、tree
* “合并” 的方向
* “origin”、“upstream”,“downstream”
* `push` 和 `pull` 并不是对立面
* `fetch` 和 `pull` 的关系(pull = fetch + merge)
* git porcelain
* 子树
* 工作树
* 暂存
* “master” 或者 “main” (听起来它在 Git 内部有特殊含义,但其实并没有)
* 何时需要使用 `origin main`(如 `git push origin main`)vs `origin/main`
人们提及感到困惑的 Github 术语:
* “<ruby> 拉取请求 <rt> pull request </rt></ruby>” (与 Gitlab 中的 “<ruby> 合并请求 <rt> merge request </rt></ruby>” 相比,人们似乎认为后者更清晰)
* “压扁并合并” 和 “变基并合并” 的作用 (在昨天我从未听说过 `git merge --squash`,我一直以为 “压扁并合并” 是 Github 的特殊功能)
### 确实是 “每个 Git 术语”
我惊讶地发现,几乎 Git 的每个其他核心特性都被至少一人提及为某种方式中的困惑。我对听到更多我错过的混淆的 Git 术语的例子也有兴趣。
关于这个,有另一篇很棒的 2012 年的文章叫做《[最困惑的 Git 术语](https://longair.net/blog/2012/05/07/the-most-confusing-git-terminology/)》。它更多的讨论的是 Git 术语与 CVS 和 Subversion 术语的关联。
如果我要选出我觉得最令人困惑的 3 个 Git 术语,我现在会选:
* `head` 是一个分支,`HEAD` 是当前分支
* “远程跟踪分支” 和 “跟踪远程的分支” 是不同的事物
* “索引”、“暂存的”、“已缓存的” 全部指的同一件事
### 就这样了!
在写这些的过程中,我学到了不少东西。我了解到了一些新的关于Git的事实,但更重要的是,现在我对于别人说Git的所有功能和特性都引起困惑有了更深的理解。
许多问题我之前根本没考虑过,比如我从来没有意识到,在讨论分支时,“跟踪”这个词的用法是多么地特别。
另外,尽管我已经尽力做到准确无误,但由于我涉猎到了一些我从未深入探讨过的Git的角落,所以可能还是出现了一些错误。
*(题图:DALL-E/A/e1e5b964-5f32-41bb-811e-8978fb8556d4)*
---
via: <https://jvns.ca/blog/2023/11/01/confusing-git-terminology/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I’m slowly working on explaining git. One of my biggest problems is that after almost 15 years of using git, I’ve become very used to git’s idiosyncracies and it’s easy for me to forget what’s confusing about it.
So I asked people [on Mastodon](https://social.jvns.ca/@b0rk/111330564535454510):
what git jargon do you find confusing? thinking of writing a blog post that explains some of git’s weirder terminology: “detached HEAD state”, “fast-forward”, “index/staging area/staged”, “ahead of ‘origin/main’ by 1 commit”, etc
I got a lot of GREAT answers and I’ll try to summarize some of them here. Here’s a list of the terms:
[HEAD and “heads”](#head-and-heads)[“detached HEAD state”](#detached-head-state)[“ours” and “theirs” while merging or rebasing](#ours-and-theirs-while-merging-or-rebasing)[“Your branch is up to date with ‘origin/main’”](#your-branch-is-up-to-date-with-origin-main)[HEAD^, HEAD~ HEAD^^, HEAD~~, HEAD^2, HEAD~2](#head-head-head-head-head-2-head-2)[.. and …](#and)[“can be fast-forwarded”](#can-be-fast-forwarded)[“reference”, “symbolic reference”](#reference-symbolic-reference)[refspecs](#refspecs)[“tree-ish”](#tree-ish)[“index”, “staged”, “cached”](#index-staged-cached)[“reset”, “revert”, “restore”](#reset-revert-restore)[“untracked files”, “remote-tracking branch”, “track remote branch”](#untracked-files-remote-tracking-branch-track-remote-branch)[checkout](#checkout)[reflog](#reflog)[merge vs rebase vs cherry-pick](#merge-vs-rebase-vs-cherry-pick)[rebase –onto](#rebase-onto)[commit](#commit)[more confusing terms](#more-confusing-terms)
I’ve done my best to explain what’s going on with these terms, but they cover basically every single major feature of git which is definitely too much for a single blog post so it’s pretty patchy in some places.
`HEAD`
and “heads”
A few people said they were confused by the terms `HEAD`
and `refs/heads/main`
,
because it sounds like it’s some complicated technical internal thing.
Here’s a quick summary:
- “heads” are “branches”. Internally in git, branches are stored in a directory called
`.git/refs/heads`
. (technically the[official git glossary](https://git-scm.com/docs/gitglossary)says that the branch is all the commits on it and the head is just the most recent commit, but they’re 2 different ways to think about the same thing) `HEAD`
is the current branch. It’s stored in`.git/HEAD`
.
I think that “a `head`
is a branch, `HEAD`
is the current branch” is a good
candidate for the weirdest terminology choice in git, but it’s definitely too
late for a clearer naming scheme so let’s move on.
There are some important exceptions to “HEAD is the current branch”, which we’ll talk about next.
### “detached HEAD state”
You’ve probably seen this message:
```
$ git checkout v0.1
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
[...]
```
Here’s the deal with this message:
- In Git, usually you have a “current branch” checked out, for example
`main`
. - The place the current branch is stored is called
`HEAD`
. - Any new commits you make will get added to your current branch, and if you run
`git merge other_branch`
, that will also affect your current branch - But
`HEAD`
doesn’t**have**to be a branch! Instead it can be a commit ID. - Git calls this state (where HEAD is a commit ID instead of a branch) “detached HEAD state”
- For example, you can get into detached HEAD state by checking out a tag, because a tag isn’t a branch
- if you don’t have a current branch, a bunch of things break:
`git pull`
doesn’t work at all (since the whole point of it is to update your current branch)- neither does
`git push`
unless you use it in a special way `git commit`
,`git merge`
,`git rebase`
, and`git cherry-pick`
**do**still work, but they’ll leave you with “orphaned” commits that aren’t connected to any branch, so those commits will be hard to find
- You can get out of detached HEAD state by either creating a new branch or switching to an existing branch
### “ours” and “theirs” while merging or rebasing
If you have a merge conflict, you can run `git checkout --ours file.txt`
to pick the version of `file.txt`
from the “ours” side. But which side is “ours” and which side is “theirs”?
I always find this confusing and I never use `git checkout --ours`
because of
that, but I looked it up to see which is which.
For merges, here’s how it works: the current branch is “ours” and the branch you’re merging in is “theirs”, like this. Seems reasonable.
```
$ git checkout merge-into-ours # current branch is "ours"
$ git merge from-theirs # branch we're merging in is "theirs"
```
For rebases it’s the opposite – the current branch is “theirs” and the target branch we’re rebasing onto is “ours”, like this:
```
$ git checkout theirs # current branch is "theirs"
$ git rebase ours # branch we're rebasing onto is "ours"
```
I think the reason for this is that under the hood `git rebase main`
is
repeatedly merging commits from the current branch into a copy of the `main`
branch (you can
see what I mean by that in [this weird shell script the implements git rebase using git merge](https://gist.github.com/jvns/0f45c910ea2d255c6e130299c99c3123). But I
still find it confusing.
[This nice tiny site](https://nitaym.github.io/ourstheirs/) explains the “ours” and “theirs” terms.
A couple of people also mentioned that VSCode calls “ours”/“theirs” “current change”/“incoming change”, and that it’s confusing in the exact same way.
### “Your branch is up to date with ‘origin/main’”
This message seems straightforward – it’s saying that your `main`
branch is up
to date with the origin!
But it’s actually a little misleading. You might think that this means that
your `main`
branch is up to date. It doesn’t. What it **actually** means is –
if you last ran `git fetch`
or `git pull`
5 days ago, then your `main`
branch
is up to date with all the changes **as of 5 days ago**.
So if you don’t realize that, it can give you a false sense of security.
I think git could theoretically give you a more useful message like “is up to
date with the origin’s `main`
**as of your last fetch 5 days ago**” because the time
that the most recent fetch happened is stored in the reflog, but it doesn’t.
`HEAD^`
, `HEAD~`
`HEAD^^`
, `HEAD~~`
, `HEAD^2`
, `HEAD~2`
I’ve known for a long time that `HEAD^`
refers to the previous commit, but I’ve
been confused for a long time about the difference between `HEAD~`
and `HEAD^`
.
I looked it up, and here’s how these relate to each other:
`HEAD^`
and`HEAD~`
are the same thing (1 commit ago)`HEAD^^^`
and`HEAD~~~`
and`HEAD~3`
are the same thing (3 commits ago)`HEAD^3`
refers the the third parent of a commit, and is different from`HEAD~3`
This seems weird – why are `HEAD~`
and `HEAD^`
the same thing? And what’s the
“third parent”? Is that the same thing as the parent’s parent’s parent? (spoiler: it
isn’t) Let’s talk about it!
Most commits have only one parent. But merge commits have multiple parents –
they’re merging together 2 or more commits. In Git `HEAD^`
means “the parent of
the HEAD commit”. But what if HEAD is a merge commit? What does `HEAD^`
refer
to?
The answer is that `HEAD^`
refers to the the **first** parent of the merge,
`HEAD^2`
is the second parent, `HEAD^3`
is the third parent, etc.
But I guess they also wanted a way to refer to “3 commits ago”, so `HEAD^3`
is
the third parent of the current commit (which may have many parents if it’s a merge commit), and `HEAD~3`
is the parent’s parent’s
parent.
I think in the context of the merge commit ours/theirs discussion earlier, `HEAD^`
is “ours” and `HEAD^2`
is “theirs”.
`..`
and `...`
Here are two commands:
`git log main..test`
`git log main...test`
What’s the difference between `..`
and `...`
? I never use these so I had to look it up in [man git-range-diff](https://git-scm.com/docs/git-range-diff). It seems like the answer is that in this case:
```
A - B main
\
C - D test
```
`main..test`
is commits C and D`test..main`
is commit B`main...test`
is commits B, C, and D
But it gets worse: apparently `git diff`
also supports `..`
and `...`
, but
they do something completely different than they do with `git log`
? I think the summary is:
`git log test..main`
shows changes on`main`
that aren’t on`test`
, whereas`git log test...main`
shows changes on*both*sides.`git diff test..main`
shows`test`
changes*and*`main`
changes (it diffs`B`
and`D`
) whereas`git diff test...main`
diffs`A`
and`D`
(it only shows you the diff on one side).
[this blog post](https://matthew-brett.github.io/pydagogue/pain_in_dots.html) talks about it a bit more.
### “can be fast-forwarded”
Here’s a very common message you’ll see in `git status`
:
```
$ git status
On branch main
Your branch is behind 'origin/main' by 2 commits, and can be fast-forwarded.
(use "git pull" to update your local branch)
```
What does “fast-forwarded” mean? Basically it’s trying to say that the two branches look something like this: (newest commits are on the right)
```
main: A - B - C
origin/main: A - B - C - D - E
```
or visualized another way:
```
A - B - C - D - E (origin/main)
|
main
```
Here `origin/main`
just has 2 extra commits that `main`
doesn’t have, so it’s
easy to bring `main`
up to date – we just need to add those 2 commits.
Literally nothing can possibly go wrong – there’s no possibility of merge
conflicts. A fast forward merge is a very good thing! It’s the easiest way to combine 2 branches.
After running `git pull`
, you’ll end up this state:
```
main: A - B - C - D - E
origin/main: A - B - C - D - E
```
Here’s an example of a state which **can’t** be fast-forwarded.
```
A - B - C - X (main)
|
- - D - E (origin/main)
```
Here `main`
has a commit that `origin/main`
doesn’t have (`X`
). So
you can’t do a fast forward. In that case, `git status`
would say:
```
$ git status
Your branch and 'origin/main' have diverged,
and have 1 and 2 different commits each, respectively.
```
### “reference”, “symbolic reference”
I’ve always found the term “reference” kind of confusing. There are at least 3 things that get called “references” in git
- branches and tags like
`main`
and`v0.2`
`HEAD`
, which is the current branch- things like
`HEAD^^^`
which git will resolve to a commit ID. Technically these are probably not “references”, I guess git[calls them](https://git-scm.com/docs/revisions)“revision parameters” but I’ve never used that term.
“symbolic reference” is a very weird term to me because personally I think the only
symbolic reference I’ve ever used is `HEAD`
(the current branch), and `HEAD`
has a very central place in git (most of git’s core commands’ behaviour depends
on the value of `HEAD`
), so I’m not sure what the point of having it as a
generic concept is.
### refspecs
When you configure a git remote in `.git/config`
, there’s this `+refs/heads/main:refs/remotes/origin/main`
thing.
```
[remote "origin"]
url = [email protected]:jvns/pandas-cookbook
fetch = +refs/heads/main:refs/remotes/origin/main
```
I don’t really know what this means, I’ve always just used whatever the default
is when you do a `git clone`
or `git remote add`
, and I’ve never felt any
motivation to learn about it or change it from the default.
### “tree-ish”
The man page for `git checkout`
says:
```
git checkout [-f|--ours|--theirs|-m|--conflict=<style>] [<tree-ish>] [--] <pathspec>...
```
What’s `tree-ish`
??? What git is trying to say here is when you run `git checkout THING .`
, `THING`
can be either:
- a commit ID (like
`182cd3f`
) - a reference to a commit ID (like
`main`
or`HEAD^^`
or`v0.3.2`
) - a subdirectory
**inside**a commit (like`main:./docs`
) - I think that’s it????
Personally I’ve never used the “directory inside a commit” thing and from my perspective “tree-ish” might as well just mean “commit or reference to commit”.
### “index”, “staged”, “cached”
All of these refer to the exact same thing (the file `.git/index`
, which is where your changes are staged when you run `git add`
):
`git diff --cached`
`git rm --cached`
`git diff --staged`
- the file
`.git/index`
Even though they all ultimately refer to the same file, there’s some variation in how those terms are used in practice:
- Apparently the flags
`--index`
and`--cached`
do not generally mean the same thing. I have personally never used the`--index`
flag so I’m not going to get into it, but[this blog post by Junio Hamano](https://gitster.livejournal.com/39629.html)(git’s lead maintainer) explains all the gnarly details - the “index” lists untracked files (I guess for performance reasons) but you don’t usually think of the “staging area” as including untracked files”
### “reset”, “revert”, “restore”
A bunch of people mentioned that “reset”, “revert” and “restore” are very similar words and it’s hard to differentiate them.
I think it’s made worse because
`git reset --hard`
and`git restore .`
on their own do basically the same thing. (though`git reset --hard COMMIT`
and`git restore --source COMMIT .`
are completely different from each other)- the respective man pages don’t give very helpful descriptions:
`git reset`
: “Reset current HEAD to the specified state”`git revert`
: “Revert some existing commits”`git restore`
: “Restore working tree files”
Those short descriptions do give you a better sense for which noun is being affected (“current HEAD”, “some commits”, “working tree files”) but they assume you know what “reset”, “revert” and “restore” mean in this context.
Here are some short descriptions of what they each do:
`git revert COMMIT`
: Create a new commit that’s the “opposite” of COMMIT on your current branch (if COMMIT added 3 lines, the new commit will delete those 3 lines)`git reset --hard COMMIT`
: Force your current branch back to the state it was at`COMMIT`
, erasing any new changes since`COMMIT`
. Very dangerous operation.`git restore --source=COMMIT PATH`
: Take all the files in`PATH`
back to how they were at`COMMIT`
, without changing any other files or commit history.
### “untracked files”, “remote-tracking branch”, “track remote branch”
Git uses the word “track” in 3 different related ways:
`Untracked files:`
in the output of`git status`
. This means those files aren’t managed by Git and won’t be included in commits.- a “remote tracking branch” like
`origin/main`
. This is a local reference, and it’s the commit ID that`main`
pointed to on the remote`origin`
the last time you ran`git pull`
or`git fetch`
. - “branch foo set up to
**track**remote branch bar from origin”
The “untracked files” and “remote tracking branch” thing is not too bad – they both use “track”, but the context is very different. No big deal. But I think the other two uses of “track” are actually quite confusing:
`main`
is a branch that tracks a remote`origin/main`
is a remote-tracking branch
But a “branch that tracks a remote” and a “remote-tracking branch” are different things in Git and the distinction is pretty important! Here’s a quick summary of the differences:
`main`
is a branch. You can make commits to it, merge into it, etc. It’s often configured to “track” the remote`main`
in`.git/config`
, which means that you can use`git pull`
and`git push`
to push/pull changes.`origin/main`
is not a branch. It’s a “remote-tracking branch”, which is not a kind of branch (I’m sorry). You**can’t**make commits to it. The only way you can update it is by running`git pull`
or`git fetch`
to get the latest state of`main`
from the remote.
I’d never really thought about this ambiguity before but I think it’s pretty easy to see why folks are confused by it.
### checkout
Checkout does two totally unrelated things:
`git checkout BRANCH`
switches branches`git checkout file.txt`
discards your unstaged changes to`file.txt`
This is well known to be confusing and git has actually split those two
functions into `git switch`
and `git restore`
(though you can still use
checkout if, like me, you have 15 years of muscle memory around `git checkout`
that you don’t feel like unlearning)
Also personally after 15 years I still can’t remember the order of the
arguments to `git checkout main file.txt`
for restoring the version of
`file.txt`
from the `main`
branch.
I think sometimes you need to pass `--`
to `checkout`
as an argument somewhere
to help it figure out which argument is a branch and which ones are paths but I
never do that and I’m not sure when it’s needed.
### reflog
Lots of people mentioning reading reflog as `re-flog`
and not `ref-log`
. I
won’t get deep into the reflog here because this post is REALLY long but:
- “reference” is an umbrella term git uses for branches, tags, and HEAD
- the reference log (“reflog”) gives you the history of everything a reference has ever pointed to
- It can help get you out of some VERY bad git situations, like if you accidentally delete an important branch
- I find it one of the most confusing parts of git’s UI and I try to avoid needing to use it.
### merge vs rebase vs cherry-pick
A bunch of people mentioned being confused about the difference between merge and rebase and not understanding what the “base” in rebase was supposed to be.
I’ll try to summarize them very briefly here, but I don’t think these 1-line explanations are that useful because people structure their workflows around merge / rebase in pretty different ways and to really understand merge/rebase you need to understand the workflows. Also pictures really help. That could really be its whole own blog post though so I’m not going to get into it.
- merge creates a single new commit that merges the 2 branches
- rebase copies commits on the current branch to the target branch, one at a time.
- cherry-pick is similar to rebase, but with a totally different syntax (one big difference is that rebase copies commits FROM the current branch, cherry-pick copies commits TO the current branch)
`rebase --onto`
`git rebase`
has an flag called `onto`
. This has always seemed confusing to me
because the whole point of `git rebase main`
is to rebase the current branch
**onto** main. So what’s the extra `onto`
argument about?
I looked it up, and `--onto`
definitely solves a problem that I’ve rarely/never
actually had, but I guess I’ll write down my understanding of it anyway.
```
A - B - C (main)
\
D - E - F - G (mybranch)
|
otherbranch
```
Imagine that for some reason I just want to move commits `F`
and `G`
to be
rebased on top of `main`
. I think there’s probably some git workflow where this
comes up a lot.
Apparently you can run `git rebase --onto main otherbranch mybranch`
to do
that. It seems impossible to me to remember the syntax for this (there are 3
different branch names involved, which for me is too many), but I heard about it from a
bunch of people so I guess it must be useful.
### commit
Someone mentioned that they found it confusing that commit is used both as a verb and a noun in git.
for example:
- verb: “Remember to commit often”
- noun: “the most recent commit on
`main`
”
My guess is that most folks get used to this relatively quickly, but this use of “commit” is different from how it’s used in SQL databases, where I think “commit” is just a verb (you “COMMIT” to end a transaction) and not a noun.
Also in git you can think of a Git commit in 3 different ways:
- a
**snapshot**of the current state of every file - a
**diff**from the parent commit - a
**history**of every previous commit
None of those are wrong: different commands use commits in all of these ways.
For example `git show`
treats a commit as a diff, `git log`
treats it as a
history, and `git restore`
treats it as a snapshot.
But git’s terminology doesn’t do much to help you understand in which sense a commit is being used by a given command.
### more confusing terms
Here are a bunch more confusing terms. I don’t know what a lot of these mean.
things I don’t really understand myself:
- “the git pickaxe” (maybe this is
`git log -S`
and`git log -G`
, for searching the diffs of previous commits?) - submodules (all I know is that they don’t work the way I want them to work)
- “cone mode” in git sparse checkout (no idea what this is but someone mentioned it)
things that people mentioned finding confusing but that I left out of this post because it was already 3000 words:
- blob, tree
- the direction of “merge”
- “origin”, “upstream”, “downstream”
- that
`push`
and`pull`
aren’t opposites - the relationship between
`fetch`
and`pull`
(pull = fetch + merge) - git porcelain
- subtrees
- worktrees
- the stash
- “master” or “main” (it sounds like it has a special meaning inside git but it doesn’t)
- when you need to use
`origin main`
(like`git push origin main`
) vs`origin/main`
github terms people mentioned being confused by:
- “pull request” (vs “merge request” in gitlab which folks seemed to think was clearer)
- what “squash and merge” and “rebase and merge” do (I’d never actually heard of
`git merge --squash`
until yesterday, I thought “squash and merge” was a special github feature)
### it’s genuinely “every git term”
I was surprised that basically every other core feature of git was mentioned by at least one person as being confusing in some way. I’d be interested in hearing more examples of confusing git terms that I missed too.
There’s another great post about this from 2012 called [the most confusing git terminology](https://longair.net/blog/2012/05/07/the-most-confusing-git-terminology/).
It talks more about how git’s terminology relates to CVS and Subversion’s terminology.
If I had to pick the 3 most confusing git terms, I think right now I’d pick:
- a
`head`
is a branch,`HEAD`
is the current branch - “remote tracking branch” and “branch that tracks a remote” being different things
- how “index”, “staged”, “cached” all refer to the same thing
### that’s all!
I learned a lot from writing this – I learned a few new facts about git, but more importantly I feel like I have a slightly better sense now for what someone might mean when they say that everything in git is confusing.
I really hadn’t thought about a lot of these issues before – like I’d never realized how “tracking” is used in such a weird way when discussing branches.
Also as usual I might have made some mistakes, especially since I ended up in a bunch of corners of git that I hadn’t visited before.
Also a very quick plug: I’m working on writing a
[zine](https://wizardzines.com) about git, if you’re interested in getting an email when it comes out you can
sign up to my [very infrequent announcements mailing list](https://wizardzines.com/zine-announcements/). |
16,453 | Linux 用户也将被蓝屏死机的恐怖所支配! | https://news.itsfoss.com/bsod-linux/ | 2023-12-09T09:18:00 | [
"蓝屏死机"
] | https://linux.cn/article-16453-1.html | 
>
> 现在,蓝屏死机的恐怖也将笼罩在 Linux 用户头上。
>
>
>
多年来,“<ruby> 蓝屏死机 <rt> Blue-Screen-Of-Death </rt></ruby>”(BSOD)已经成了 Windows 操作系统的代名词,一旦系统出现重大错误,Windows 就会展示蓝色的错误页面。
我自己也常常遇到一些看似随机的问题,这些问题会导致 Windows 蓝屏死机。有时候,显示的错误代码能提供一些帮助,但更多的时候,它们只是让我更加感到困惑。
而现在,随着 systemd v255 的发布,我们也将在 Linux 上见到这个熟悉的“朋友”。让我带你了解一下:

发生的事情:systemd 开始加入一个称为 `systemd-bsod` 的**新实验性组件**。依据 [提交记录](https://github.com/systemd/systemd/commit/fc7eb1325bd297634568528fb934698a68855121),它**用于显示与引发系统启动失败相关的蓝屏错误消息**。
类似于 Windows,**这个功能还会展示一个二维码**,用户可以扫描获取到故障相关的信息。
>
> ? 只有在错误级别达到 `LOG_EMERG` 时,才会显示错误信息。
>
>
>
**这很重要吗?**
当然重要。因为,对于装备了 systemd 的 Linux 发行版在发生崩溃或拒绝启动的情况下,**它展示错误代码的方式**过于令人费解,**尤其对于新手来说**。
有了蓝屏死机系统后,用户用不着还要在各大论坛和文章里寻求解答。他们现在的问题解决方式将更加直观,更贴近他们的习惯。
考虑到大部分 [热门的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 都基于 systemd,这个改变应该会受到许多用户的欢迎。
关于 **systemd 255 版本的其它改变**,这里有一些主要的亮点:
* 针对启动服务的方法进行了**全面的重构**。
* `seccomp` 已开始支持 **64 位龙架构** 微处理器架构。
* 对 **System V 服务脚本** 的支持已被取消,未来版本将完全移除此项支持。
* 如果在执行重启操作时发现 `/run/nextroot/` 目录下存在新的根文件系统,`systemctl` 将会自动执行 `soft-reboot` 操作。
* 改善了在 systemd 上对 **TPM2 支持** 的众多方面。
我强烈建议你查看 [官方的更新日志](https://github.com/systemd/systemd/releases/tag/v255),了解更多关于新的 systemd 版本的信息。这个新版本将于 **2024 年上半年** 出现在许多即将发布的 Linux 发行版中。
尽管我们中的许多人都熟知那个围绕 systemd 已经酝酿多时的 [争议](https://itsfoss.com/systemd-init/),我仍然很好奇,当蓝屏死机的功能未来不久推出时,会引起怎样的反响。
有一点可以肯定,我们一定会开怀大笑,因为将有一大堆 Linux 蓝屏死机的段子图片问世 ?
? 我迫不及待地想看 Linux 蓝屏死机的段子图片,你呢?
*(题图:DA/18062133-604c-41e6-b234-67c58d0770a5)*
---
via: <https://news.itsfoss.com/bsod-linux/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Over the years, the Blue-Screen-Of-Death has become synonymous with the popular Windows operating system that uses a blue-colored page to show users when any major error has occurred.
On many occasions, I have also run into seemingly random issues that would cause a BSOD on Windows, sometimes the shown error codes are helpful, and more often than not, these codes just leave me more confused.
With the release of systemd v255, we now have that on Linux. Let me take you through it:
**What is happening: **systemd now features **a new experimental component** called “*systemd-bsod*”, according to the [commit](https://github.com/systemd/systemd/commit/fc7eb1325bd297634568528fb934698a68855121?ref=news.itsfoss.com), it **will be used to display a blue screen with an error message** related to what caused a boot failure.
Similar to what Windows does, **it will also display a QR code** that users can scan with their phone to get relevant information related to the failure.
*” log level.*
*LOG_EMERG***Does it matter?**
It does, you see, **the conventional way** that error codes are shown when a systemd-equipped Linux distro crashes, or refuses to boot is **quite unintuitive**, **especially for beginners**.
Users will no longer need to trundle around countless forums and articles. With the BSOD system in place, their troubleshooting will be more in line with what many are already used to.
Considering most of the [popular Linux distributions](https://itsfoss.com/best-linux-distributions/?ref=news.itsfoss.com) use systemd, it should be a good thing for many users.
As for the **other changes with the systemd 255 release**, here are some key highlights:
**Complete overhaul**of the way services are spawned.*seccomp*now supports the**LoongArch64**microprocessor architecture.- Support for
**System V service scripts**has been dropped, with complete removal in a future release. *systemctl*will now automatically*soft-reboot*if a new root file system is found under "*/run/nextroot/*" when a reboot action is done.- And plenty of improvements for the
**TPM2 support**on systemd.
I highly suggest you to go through the [official changelog](https://github.com/systemd/systemd/releases/tag/v255?ref=news.itsfoss.com) to learn more about the new systemd release. You can expect this to be featured on many Linux distributions set to be released **in the first half of 2024**.
Even though many of us are familiar with the [systemd controversy](https://itsfoss.com/systemd-init/?ref=news.itsfoss.com) that has been around for quite a few years now. I wonder what kind of reaction will this BSOD implementation get when it is rolled out in the near future.
One thing is for sure, we will be showered with a barrage of Linux BSOD memes 😆
**Suggested Read **📖
[systemd vs init Controversy [A Layman’s Guide]Still confused about what is systemd and why it is often at the center of controversy in the Linux world? I try to answer in simpler words.](https://itsfoss.com/systemd-init/?ref=news.itsfoss.com)

*💬 I can't wait to see some Linux BSOD memes, what about you?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,454 | 从神经多样性视角看待我在 C 语言上的开源之旅 | https://opensource.com/article/22/5/my-journey-c-neurodiverse-perspective | 2023-12-09T10:42:08 | [
"神经多样性"
] | https://linux.cn/article-16454-1.html | 
>
> 我了解到,如果你能找到适合你的方法,不管老师和其他学生怎么说,你都可以学到任何你感兴趣的开源技能。
>
>
>
我生于 1982 年,以人类的年岁计算,这只过去了 40 年(在写这篇文章的时候)。然而就计算机发展而言,那已经是很久以前了。十岁的时候,我得到了我的第一台电脑,一台 Commodare 64 计算机。后来,我买了一台 Amiga,到了13岁的时候,我买了一台 “IBM 兼容” 机(那时,大家都这么称呼它)。
高中的时候,我用图形计算器做了很多基本的编程。高二的时候,我学习了基本的 C 语言编程,然后到了高三,我开始做更高级的 C 语言编程,开始应用库、指针和图形界面。
### 我从编程学生成为老师的旅程
在我的大学时代,我学习了 Java,所以 [Java 成为了我的主要语言](https://opensource.com/article/20/12/learn-java)。我还为一种叫做个人数据助理(PDA)的设备编写了一些 C# 语言的程序,这是现代智能手机的前身。因为 Java 语言是面向对象的、跨平台的,并且使得 GUI 编程变得容易,我想以后我的大部分编程工作都会用 Java 来完成。
在大学里,我也发现自己有教学的天赋,所以我帮助别人编程,而当我选修计算机科学时,他们也帮助我学习数学。在大学后期,我选修了一些 C 语言编程的课程,目的是学习基本的嵌入式编程和测量仪器的控制。
30 岁之后,我用 C 语言作为教学工具,教高中生学习用 C 语言编程。我还用 [Fritzing](https://fritzing.org) 教高中生如何编写 Arduino 程序。我对 C 语言编程的兴趣在去年再次被唤醒,当时我找到了一份工作,帮助大学生学习计算机科目中的差异。
### 我如何接触 C 语言和其他语言进行编程
每个人学习的方式都不一样。作为一个患有 <ruby> 阿斯伯格综合症 <rt> Asperger's </rt></ruby> 和多动症(ADHD)的 <ruby> 神经多样性 <rt> neurodiverse </rt></ruby> 人士,我的学习过程有时与其他人很不一样。当然,每个人都有不同的学习风格,尽管神经多样性人士可能比其他人更喜欢某种学习风格。
我倾向于用图片和文字来思考。就我个人而言,我需要一步一步地解码事物,一步一步地理解它们。这使得 C 语言适合我的学习风格。当我学习代码的时候,我通过学习观察一行行的代码,比如我面前的 `# include <stdio.h>` ,逐渐将代码合并到我的大脑中。根据我在互联网上获取的对其他神经多样性人群的描述,他们中的一些人似乎也有这种学习风格。我们“内化代码”。
有些自闭症人士在记忆大段代码方面比我强得多,但过程似乎是一样的。在理解诸如结构、指针、指针的指针、矩阵和向量之类的概念时,用图片来思考是很有帮助的,比如在编程教程和书籍中可以找到的那些。
我喜欢使用 C 语言来理解工作是如何在较低的级别上完成的,例如 [文件输入和输出(I/O)](https://opensource.com/article/21/3/file-io-c)、网络编程等等。这并不意味着我不喜欢处理字符串操作或创建数组等任务的库。我也喜欢用 Java 语言创建数组和向量的简单性。然而,对于创建用户界面,尽管我已经在 C 语言中看过这样的代码,但是我更喜欢使用图形化编辑器,比如 Netbeans 和类似的编辑器。
### 我理想中用于创建应用程序的 C 语言 GUI 开源工具
如果我想象一个理想的用 C 语言创建 GUI 的开源工具,它将类似于 [Netbeans](https://opensource.com/article/20/12/netbeans),例如,通过拖放来创建 GTK 接口。还可以在按钮上绑定 C 语言函数,等等,来使它们执行操作。也许有这样一个工具。我承认我没怎么仔细查找过。
### 为什么我鼓励年轻的神经多样性的人学习 C语言
[游戏行业](https://opensource.com/tags/gaming) 是一个很大的产业。一些研究表明,神经多样性的孩子可能比其他孩子更专注于游戏。我会告诉一个神经多样性的高中生或大学生,如果你学习 C 语言,你可能会学到一些基础知识,例如,为显卡编写高效的驱动程序,或者编写高效的文件 I/O 例程来优化他们最喜欢的游戏。我还要诚实地说,学习需要时间和精力,但是值得付出努力。一旦你学会了它,你就可以更好地控制硬件一类的东西。
对于学习 C 语言,我建议一个神经多样性的孩子安装一个初学者友好的 Linux 发行版,然后在网上找到一些教程。我还建议一步一步地分解事物,并给它们绘制图表,例如,指针。我这样做是为了更好地理解这个概念,这对我很有效。
最后,这就是它的意义所在: 不管老师和其他学生怎么说,找到一种适合你的学习方法,用它来学习你感兴趣的开源技能。这是可以做到的,任何人都可以做到。
*(题图:DA/f0d98968-4c13-4395-8414-3690bc20b0ae)*
---
via: <https://opensource.com/article/22/5/my-journey-c-neurodiverse-perspective>
作者:[Rikard Grossman-Nielsen](https://opensource.com/users/rikardgn) 选题:[lkxed](https://github.com/lkxed) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I was born in 1982, which in human years is only 40 years in the past (at the time of writing). In terms of computer development, it's eons ago. I got my first computer, a Commodore 64, when I was ten years old. Later, I got an Amiga, and by 13 I got an "IBM Compatible" (that's what they were called, then) PC.
In high school, I did a lot basic programming on my graphing calculator. In my second year of high school, I learned basic C programming, and in my third year I started doing more advanced C programming, using libraries, pointers, and graphics.
## My journey from programming student to teacher
In my college days, I learned Java and so [Java became my primary language](https://opensource.com/article/20/12/learn-java). I also made some C# programs for a device known as a personal data assistant (PDA), which were pre-cursors to the modern smart phone. Because Java is object-oriented, multi-platform, and made GUI programming easy, I thought I'd do most of my programming in Java from now on.
In college, I also discovered that I had a talent for teaching, so I helped others with programming, and they helped me with math when I took computer science. I took some courses on C programming, aimed at basic embedded programming and controlling measurement instruments in my later college years.
After turning 30, I've used C as a teaching tool for high school kids learning to program in C. I've also used [Fritzing](https://fritzing.org) to teach high school kids how to program an Arduino. My interest in C programming was awakened again last year, when I got a job helping college students with learning differences in computing subjects.
**How I approach programming in C and other languages**
All people learn differently. Being a neurodiverse person with Asperger's and ADHD, my learning process is sometimes quite different from others. Of course, everyone has different learning styles, though people who are neurodiverse might have a greater preference for a certain learning style than someone else.
I tend to think in both pictures and words. Personally I need to decode things step by step, and understand them, step by step. This makes C a suitable language for my learning style. When I learn code, I gradually incorporate the code into my mind by learning to see lines of code, like `#include <stdio.h>`
in front of me. From what I've read from descriptions of other neurodiverse people on the internet, some of them seem to have this kind of learning style as well. We “internalize code”.
Some autistic people are a lot better at memorizing large chunks of code than me, but the process seems to be the same. When understanding concepts such as structs, pointers, pointers to pointers, matrices, and vectors, it's helpful for me to think in pictures, such as the ones you find in programming tutorials and books.
I like to use C to understand how things are done at a lower level, such as [file input and output (I/O)](https://opensource.com/article/21/3/file-io-c), networking programming, and so on. This doesn't mean I don't like libraries that handle tasks such as string manipulation or making arrays. I also like the ease of creating arrays and vectors in Java. However, for creating a user interface, though I have looked at such code in C, I prefer to use grapical editors, such as Netbeans and similar.
**My ideal C GUI open source tool for creating applications**
If I imagine an ideal open source tool for creating a GUI using C, it would be something similar to [Netbeans](https://opensource.com/article/20/12/netbeans) that, for example, making GTK-interfaces by dragging and dropping. It should also be possible to put C on buttons, and so on, to make them perform actions. There may be such a tool. I admittedly haven't looked around that much.
**Why I encourage young neurodiverse people to learn C**
[Gaming](https://opensource.com/tags/gaming) is a big industry. Some studies suggest neurodiverse kids may be even more focused on gaming than other kids. I would tell a neurodiverse high school or college kid that If you learn C, you may be able to learn the basics of, for example, writing efficient drivers for a graphics card, or to make efficient file I/O routines to optimize their favorite game. I would also be honest that it takes time and effort to learn, but that it's worth the effort. Once you learn it, you have greater control of things like hardware.
For learning C, I recommend a neurodiverse kid to install a beginner-friendly Linux distro, and then find some tutorials on the net. I also recommend breaking down things step by step, and drawing diagrams of, for example, pointers. I did that to better understand the concept, and it worked for me.
In the end, that's what it's about: Find a learning method that works for you, no matter what teachers and other students may say, and use it to learn the open source skill that interests you. It can be done, and anyone can do it.
## Comments are closed. |
16,456 | Zorin OS 17 正在重新定义 Linux 发行版的视觉体验 | https://news.itsfoss.com/zorin-os-17-beta/ | 2023-12-10T17:02:16 | [
"Zorin OS"
] | https://linux.cn/article-16456-1.html | 
>
> 这款即将推出的 Zorin OS 17 能为你带来什么样的视觉盛宴?你有何感想?
>
>
>
作为公认 [最美的 Linux 发行版](https://itsfoss.com/beautiful-linux-distributions/) 之一,Zorin OS 的下一轮升级近在眼前。
在正式推出之前,他们已经公开了 Zorin 17 的各项新功能和首个测试版的发布时间。
那么,让我们一起来探索 Zorin 17 的新增内容吧。
### Zorin OS 17:最好的部分

Zorin OS 17 将成为一个主要版本,它是**一个长期支持版本**(直到 2027 年 6 月),并且包含许多令人兴奋的新改进。
据开发人员称,Zorin OS 17 的设计初衷是为他们提供“**迄今为止最卓越且最精致的计算体验**”,而且这一说法似乎有理有据。
比如,Zorin OS 17 引入了“空间桌面”的设计理念,用以提升用户对于桌面活动的认知。

在 Zorin OS 17 的测试版中,展现出了新颖的 “桌面立方体” 效果,用户可以通过富有深度感的 3D 立方视角在工作区之间切换。它运用了视差效果,使应用窗口呈现出独特的悬浮感。

此外,还引入了全新的 “空间窗口切换器”,以整洁的 3D 切换效果替代了标准的平面 / 2D 的 `Alt+Tab` 和 `Super+Tab` 窗口切换。
在我看来,这些看起来确实不错。然而,这些效果可能不是每个人都喜欢,好在**默认情况下这些“空间特性”是不启用的**。
尽管如此,这确实是大胆的一步。Linux 发行版引入了更多的视觉交互特性,这实在不常见。鉴于 Zorin OS 原本就是颜值出众的发行版,新的多任务处理流程和空间桌面无疑将其视觉体验提升了一个档次。
macOS 用户或 Windows 用户可能不喜欢典型的 Linux 发行版用户界面,他们可能会考虑尝试使用 Zorin OS 的可视化方法来使用 Linux。
虽然这可能并不是科技突破,但我坚信,它对于把视觉体验视为优先的大量用户来说,其改变是实实在在的。
与此同时,Zorin OS 依然保持了骄人的核心优势——“**赋予用户对自己体验的掌控**”。看得出,他们将这些视觉元素融入进去,并使得计算体验充满了乐趣。
你必须从 Zorin <ruby> 外观 <rt> Appearance </rt></ruby> 设置下的新“<ruby> 效果 <rt> Effects </rt></ruby>”部分手动启用这些功能。
然后是**高级窗口平铺体验**,这是社区最需要的功能之一。

现在,你可以轻松实现窗口在屏幕四分之一角落的平铺,甚至可以用键盘快捷键调整窗口在屏幕上的排布。这使得无痛的多任务处理变得**触手可及**。
甚至**软件商店也进行了改进**,速度更快,并采用了新设计和更新的主页,以非常直观的方式列出了应用。**应用详细信息页面也得到了改进**,以显示更大的截图和新信息。

同样,引入了**新的快速设置菜单**,使你可以方便地访问重要设置,并且**允许你使用新的电源模式选项(性能/平衡)调整系统性能**。电源模式应该对笔记本电脑用户有帮助。

开发人员还展示了**一种新的截图和屏幕录制**工具,如果你使用过 GNOME 的原生工具,那用这个工具会让你感觉非常得心应手。
他们还提到了**两种新的桌面布局**,一种是**类似 ChromeOS** 布局,另一种是**类似 GNOME 2** 布局。

这些布局将在 Zorin OS 17 Pro 发布时提供。
总的来说,看到 Zorin OS 在追求的高质量用户体验,这的确是 Linux 发行版中少有的。这应当能让 Zorin 在众多发行版中脱颖而出,并有可能吸引更多的 Windows 和 macOS 用户尝试 Linux。
有关即将发布的 Zorin OS 17 版本的更多详细信息,你可以参考 [官方博客](https://blog.zorin.com/2023/12/04/a-sneak-peek-at-zorin-os-17/)。
最后,**你有兴趣提前一睹为快吗?**
>
> ? 你现在就可以从 [官方网站](https://zorin.com/os/download/17/core/beta/) 下载 **Zorin OS 17 Core Beta**。请记住,**不建议用于生产/日常使用**。
>
>
>
>
> **[Zorin OS 17 Core Beta](https://zorin.com/os/download/17/core/beta/)**
>
>
>
? 你对 Zorin 17 的发布感到兴奋吗? 请在下面告诉我们!
---
via: <https://news.itsfoss.com/zorin-os-17-beta/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The next upgrade for one of the [most beautiful Linux distributions](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com), Zorin OS, is around the corner.
Before the release, they have revealed what you get with Zorin 17, along with the availability of its **first beta version** (for testers).
Let's get started and see what's in store.
**Suggested Read **📖
[Here are the Most Beautiful Linux Distributions in 2023Aesthetically pleasing? Customized out of the box? You get the best of both worlds in this list.](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com)

## Zorin OS 17: The Best Bits
Set to be a major release, Zorin OS 17 is** a long-term support release** (until June 2027), and a packed one at that, with many new and exciting improvements.
According to the developers, Zorin OS 17 has been designed to be their “** greatest and most refined computing experience ever**”, and that claim seems well-founded.
Let's begin with their “**Spatial Desktop**” implementation, for instance. It is **meant to give users better contextual awareness** of what's happening on their desktop.
A new '**Desktop Cube**' has been added that lets you switch between workspaces in a 3D cube-style view that employs a parallax effect to show you a floaty appearance of the app windows.
This has also made way for a new “**Spatial Window Switcher**” that replaces the standard flat/2D Alt+Tab and Super+Tab window switching dialogs with a 3D window switcher that looks neat.
These do look nice in my opinion; however, these effects might not be everyone's cup of tea, luckily** these “Spatial Features” are not enabled by default**.
Having said that, it is **a bold move for a Linux distribution to include more things (or effects) that promote visual interactions through such features**. While Zorin OS was already a visually appealing distribution, the new multitasking workflow with the spatial desktop should take it up a notch.
A macOS user or a Windows user, who may not be a fan of a typical Linux distribution user interface, might just consider giving Linux a try with Zorin OS's visual approach.
Sure, it may not be rocket science (or a unique implementation) but I believe it makes a difference to countless users with visual experience as a priority.
Zorin OS is doing all that, while keeping the core benefit "*giving users the control for their experience*". I like how they are adding these visual goodies, making the computing experience fun 😄
You will have to manually enable these features from the new “Effects” section under the **Zorin Appearance **settings.
Then there's the **advanced window tiling experience,** one of the most requested features by the community.
You can now tile windows to use quarter screen corner tiling, and even use keyboard shortcuts to tile windows around the screen. This **will make it easier to multitask effortlessly**.
Even the **Software Store has been revamped** to be faster, and features a new design with an updated homepage that lists out applications in a very intuitive manner. The **app details page has also been improved** to show bigger screenshots, and new information.
Similarly, **a new quick settings menu** has been introduced that gives you handy access to important settings, and also** allows you to tweak your system's performance** with the new power modes option (performance/balanced). The power modes should be helpful for laptop users.
The devs also showcased **a new screenshot and screen recording **tool that will feel familiar if you have used the native one on GNOME.
They also mentioned **two new desktop layouts**, one is a **ChromeOS-like** layout, the other is a **GNOME 2-like** layout.
These layouts will be available upon the release of Zorin OS 17 Pro.
**So, wrapping up.**
It is nice to see what Zorin OS is trying to achieve,** a user experience like this is usually unseen on Linux distros**. This should act as a way for Zorin to stand out, and **may even encourage more Windows and macOS users to try Linux**.
For more details of the upcoming Zorin OS 17 release, you can refer to the [official blog](https://blog.zorin.com/2023/12/04/a-sneak-peek-at-zorin-os-17/?ref=news.itsfoss.com).
Before you go, **would you be interested in an early sneak peek?**
**right now from the**
**Zorin OS 17 Core Beta**[official website](https://zorin.com/os/download/17/core/beta/?ref=news.itsfoss.com). Just keep in mind that this is
**.**
**not recommended for production/daily use***💬 Are you hyped for the Zorin 17 release? Let us know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,457 | 在 Fedora Linux 上值得尝试的酷炫 Flatpak 应用(12 月) | https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-december/ | 2023-12-10T17:40:15 | [
"Flatpak"
] | https://linux.cn/article-16457-1.html | 
本文介绍了 Flathub 中可用的项目以及安装说明。
[Flathub](https://flathub.org) 就是为所有 Linux 发行版提供应用程序的平台,其由 Flatpak 支持,确保 Flathub 上的应用能在绝大多数 Linux 发行版上运行。
请参阅 [Flatpak 入门](https://fedoramagazine.org/getting-started-flatpak/),并按照 [flatpak 网站](https://flatpak.org/setup/Fedora)的指南激活 Flathub 作为你的 Flatpak 供应商。
### Live Captions
Live Captions 是一款为 Linux 桌面提供实时自动字幕的应用。目前仅提供英语。其他语言可能会产生乱码或错误的语音翻译。
主要特性:
* 使用友好的界面
* 基于深度学习,为本地桌面/麦克风音频添加字幕
* 不需要 API 密钥、不依赖专有服务/组件、无追踪、无数据收集、不使用互联网权限
* 支持调整字幕字体、字体大小,以及进行大小写转换
* 不确定的文本会显示为暗色(此功能可进行设置)。
老实说,直到最近有人推荐我才知道这个应用,我感到非常惊讶。这对于有听力问题的人来说确实很有帮助。正如此类软件的常见情况,模型需要培训,而项目通常需要反馈。
Live Captions 需要良好的硬件才能正常运行,但不需要专业的 GPU。
该项目被标记为安全,因为它不需要特殊许可:

你可以通过单击网站上的安装按钮或手动使用以下命令来安装 “Live Caption”:
```
flatpak install flathub net.sapples.LiveCaptions
```
### Pencil2D
[Pencil2D](https://flathub.org/apps/org.pencil2d.Pencil2D) 是一个 2D 动画创建程序,可让你使用位图和矢量图形轻松创建手绘图形。
主要特性:
* 轻量设计
* 支持光栅和矢量图
* 跨平台兼容
* 自由开源
请注意,该项目被标记为“潜在不安全”,因为它可以访问你的文件系统:

你可以通过单击网站上的安装按钮或手动使用以下命令来安装 “Pencil2D”:
```
flatpak install flathub org.pencil2d.Pencil2D
```
**Pencil2D 也在 Fedora 的仓库中以 RPM 形式提供**
### Frog
[Frog](https://flathub.org/apps/com.github.tenderowl.frog) 是一款应用,它可以帮助你从图片、网站、视频和二维码中提取文本。
主要特性:
* 提取二维码和条形码:能够快速捕获、提取并转译二维码和条形码。
* 你可以直接拖放图像到 Frog 窗口中提取文本,无需进行截图。
* 支持大量语言:Frog 支持多种语言,甚至包括那些它以前不支持的语言。
* 隐私:Frog 使用门户网站尊重你的隐私
请注意,该项目被标记为“潜在不安全”,因为它可以访问你的主文件夹:

你可以通过单击网站上的安装按钮或手动使用以下命令来安装 “Frog”:
```
flatpak install flathub com.github.tenderowl.frog
```
### PDF Arranger
[PDF Arranger](https://flathub.org/apps/com.github.jeromerobert.pdfarranger) 是一个小型应用,它可以帮助用户使用交互式直观的图形界面合并或拆分 PDF 文档并旋转、裁剪和重新排列其页面。
其简明的界面和易于使用的功能都非常出色。
请注意,该项目被标记为“潜在不安全”,因为它可以访问你的文件系统:

你可以通过单击网站上的安装按钮或使用以下命令手动安装 “PDF Arranger”:
```
flatpak install flathub com.github.jeromerobert.pdfarranger
```
**PDF Arranger 也在 Fedora 的仓库中以 RPM 形式提供。**
---
via: <https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-december/>
作者:[Eduard Lucena](https://fedoramagazine.org/author/x3mboy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article introduces projects available in Flathub with installation instructions.
[Flathub](https://flathub.org) is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “[Getting started with Flatpak](https://fedoramagazine.org/getting-started-flatpak/)“. In order to enable flathub as your flatpak provider, use the instructions on the [flatpak site](https://flatpak.org/setup/Fedora).
## Live Captions
[Live Captions](https://flathub.org/apps/net.sapples.LiveCaptions) is an application that provides realtime automatic subtitles for the Linux desktop. Only English is available, at at this time. Other languages may produce gibberish or a bad phonetic translation.
Features:
- Simple interface
- Caption desktop/mic audio locally, powered by deep learning
- No API keys, no proprietary services/libraries, no telemetry, no spying, no data collection, does not use network permission
- Adjust font, font size, and toggle uppercase/lowercase
- Less confident text is faded (darkened). This feature is configurable.
I honestly didn’t know about this application until it was recently recommended, and I was quite amazed. It’s really helpful for people with hearing problems. As is common with this kind of software, models need training and the project, in general, needs feedback.
Live Caption requires good hardware to function correctly, but it doesn’t need a dedicated GPU.
This project is marked as safe because it needs no special permission:

You can install “Live Caption” by clicking the install button on the web site or manually using this command:
flatpak install flathub net.sapples.LiveCaptions
## Pencil2D
[Pencil2D](https://flathub.org/apps/org.pencil2d.Pencil2D) is a 2D animation program that lets you easily create hand-drawn graphics using both bitmap and vector graphics. Its highlight features are:
- Minimal Design
- Raster & Vector
- Cross-Platform
- Open Source & Free
Be aware that this project is marked as “potentially unsafe” because it can access your filesystem:

You can install “Pencil2D” by clicking the install button on the web site or manually using this command:
flatpak install flathub org.pencil2d.Pencil2D
*Pencil2D is also available as rpm on fedora’s repositories*
## Frog
[Frog](https://flathub.org/apps/com.github.tenderowl.frog) is an application that allows you to extract text from images, websites, videos, and QR codes by taking a picture of the source.
Some of its features are:
- Extract QR Code and barcode: Capture, extract and convert any QR codes or barcodes in a second.
- Drag-n-drop: You do not need to make a screenshot of the image. Drag and drop it straight into the Frog window to extract the text.
- Tons of supported languages: Frog supports a lot of languages, even those which it didn’t in the past.
- Privacy: Frog use Portals to respect your privacy
Be aware that this project is marked as “potentially unsafe” because it can access your home folder:

You can install “Frog” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.tenderowl.frog
## PDF Arranger
[PDF Arranger](https://flathub.org/apps/com.github.jeromerobert.pdfarranger) is a small application, which helps the user merge or split pdf documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical interface.
There is not much more to say than it’s a great application, very intuitive and easy to use.
Be aware that this project is marked as “potentially unsafe” because it can access your filesystem:

You can install “PDF Arranger” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.jeromerobert.pdfarranger
*PDF Arranger is also available as rpm on fedora’s repositories*
## GroovyMan
This article does not make sense to me.
Pencial and the PDF Arranger can be retrieved in the same version as from flatpack. What a bummer !!!
Why should i use a ressource consuming flatpack version of a application, that is less suported that the rpm variant ?
Flatpak makes no sense to me!
## drew
Ditto what is fedora doing here, where does copr fit in?
## afawsaggy
immutable desktop
## Pheeef
Once you have all the dependencies installed, individual Flatpaks are not that big anymore. Obviously you can install most of the Stuff from Source or through a RPM but not everyone is an Administrator on their own System or maybe they use an immutable Version of Fedora.
Flatpak is just another way to package and distribute programs, it helps developers to ensure that the decencies and underlying system components are the same for every system, thus making it easier to troubleshoot potential problems.
I seriously don’t understand the hate against Flatpak.
## Darvond
It doesn’t solve the actual issues that people have with package management and exacerbates the problems they do. Why does this entire runtime need to exist why does Rust have 59 different packages?
## Eli
It literally does. You can install the latest version of Firefox on Debian 11 or a very old app on Fedora or Arch and not go into dependency hell, you can update your system knowing it won’t explode because the update script had some unintentionally or intentionally malicious code (Bumblebee incident, iykyk).
## david frantz
Honestly I don’t get Flatpak either. It is an incredible waste of resources.
## Okki
I can’t wait for Fedora to abandon RPM packaging for all desktop applications. What a waste of human resources to redo the same packaging work for each distribution…
## /dev/pie
Flatpak is great until an app doesnt work. So being able to use rpm is a life saver.
## Ryan
I’m unsure if they will abandon RPM. I’ve seen more and more people using stuff like Distrobox lately. Which can convert any distro repository format to a format of the user’s choice. I think we’ll probably see more of this in the future competing with Flatpak.
## GroovyMan
Not sure if you ever developed software in a professional context. Once you set up a build environment, the packaing can be done in a automated build run. Anyway you have to test the application, and analyse problems. But this is the same with flatpack.
## Gerhard Stein
One about Games and mentioning Commander Genius would be nice 😀
We have a flatpak on flathub
## Darvond
Live Caption, being an accessibility boon, feels as though one of those things the Fedora Accessibility SiG (should it exist) would prioritize.
I once again, agree with what GroovyMan says; that Flatpaks often feel like an excuse for package maintainers and the Fedora SiGs to get complacent.
## Danniello
These unsafe warnings in this article are pure nonsense.
“Pencil2D potentially unsafe because it can access your filesystem”. Pencil2D it is bitmap/vector graphics editor. I can’t imagine a graphical editor without ability to open/save files! The same situation is with Frog and PDF Arranger – main functionality of these applications requires to have read/write file access…
There are already mentioned on flathub.org because it is generic information that should be present on every AppStore. But why copy/paste it into article, especially that these requirements are obvious?!
## Okki
It would have been much more interesting to add screenshots of the applications themselves…
## Darvond
Ah, but how do you add a screenshot of a terminal application that has no reason to be a flatpak in the first place?
(Or so many would insist to think on the former half.)
## Danniello
@Darvond
All mentioned it the article applications have GUI, so screenshot is definitely possible:) As far I know on flathub.org there are no published terminal only applications, probably because flatpak is not very “user friendly” in terminal (without tricks with aliases, etc.)
PS1. My previous comment sounds a bit harsher than I intended… Sorry for that. Add warnings about access rights was not necessary, but it is not a crime:)
PS2. Flatpak and flathub.org as general are great! Flatpak means that you could install application on EVERY real Linux distribution. And thanks Valve – it is the first Linux AppStore accessible for mainstream “out of the box” on SteamDeck consoles.
## Michael
There’s literally a screenshot of all four applications at the top of the article…
## Elliott S
I’d definitely agree that a screenshot of a Flatpak warning that is already specified in the text is far less useful than a screenshot of the actual application being recommended.
And the banner image is pretty low resolution, PDF Arranger is 75% covered by the others, and the Live Captions one just looks like a picture of text (I don’t know if that’s what it’s supposed to look like when it’s mixed in with all the others), so it doesn’t really showcase the applications that well.
## Gregory Bartholomew
Folks (especially those who’ve commented several times): I think you’ve made your point. Let’s try to hold our peace for a while and avoid being too negative OK. 🙂
## Michael
That’s a kind way to put it, Gregory. How this completely innocuous article became the place for people to air their flatpak grievances is beyond me. 🙄
## newton
venho desejar um feliz 2024 muita saúde e grandes conquistas para todos sistemas Linux ou Windows ,pós a tecnologias andam de braços abertos e juntos ,amo o sistema Linux pós e livre e uma luta constante para atualizar e crescer ,e nosso grande sistema Fedora ,venham ajudar dar opinião .feliz 2024 ,obrigado
## Samuel
Some of the apps looks really cool to try out, except the ‘unsafe once’. Might try and create one for personal development and make it open for others to contribute, that will allow it to be much better, cool, and simple. Also making it safe to be used.
## Elliott S
The “Live Captions” application is missing a link to Flathub like the other apps do.
## Richard England
Thank you for pointing out the missing link. It has been updated.
## gro
Nice article, but I agree with others regarding the safe/unsafe labeling: the whole point about application being “potentially unsafe because can access the filesystem” is totally distracting. How do you do any productivity application involving reading/writing files that does not require that? I think these labels in GNOME store are somewhat misleading and dilute term “unsafe” to the point when it does not carry any meaning. It is of course not a point to the article author but to those who came up with this labeling.
## wheel spinner
Wow, Eduard, thanks for sharing! I had no idea about Live Captions, and it sounds like a game-changer. Can’t wait to try it out!
## David Vales
Flatpak has a lot of good apps, i wanna publish some of them to this articles, |
16,459 | Linus Torvalds:Linux 内核中的 Rust、AI 和疲劳的维护者 | https://www.zdnet.com/article/linus-torvalds-on-state-of-linux-today-and-how-ai-figures-in-its-future/ | 2023-12-11T00:42:00 | [
"Linus Torvalds"
] | https://linux.cn/article-16459-1.html | 
>
> 在日本开源峰会中,Linux 和 Git 的创始人 Linus Torvalds 深入探讨了 Rust 在 Linux 中的应用、Linux 维护者压力问题,以及 AI 对 Linux 和开源开发未来的影响。
>
>
>

尽管 Linux 的创始人 Linus Torvalds 最近鲜少公开露面,但在 Linux 基金会的 [日本开源峰会](https://events.linuxfoundation.org/open-source-summit-japan/) 上,他与其好友,Verizon 开源部门负责人 Dirk Hohndel 共同探讨了 Linux 的当前状况。
首先,两人对下一个 Linux 内核版本 Linux 6.7 进行了讨论。在出发前往东京前,Torvalds 已经发布了此版本的 [第四个发布候选版](https://lore.kernel.org/lkml/CAHk-=wjsbytYq780PM-Wby_2rPabxg-WT-CRPZZaVYsmLiacHw@mail.gmail.com/)。这意味着,如果一切顺利,且 Torvalds 未发现任何问题,我们将在圣诞节左右看到新版本的 Linux 内核。
正如 Torvalds 解释的那样,他不希望把 “合并窗口” 放在圣诞,因为这会 “毁掉我的圣诞节”。而现在,“我们正在等待,以确保不存在任何可能成为绊脚石的问题”。为确保正在为下一个版本 6.8 而准备的维护者和开发者们不会因为知道 “圣诞节后我的合并窗口将开启而陷入 <ruby> 恐慌 <rt> Panic </rt></ruby>,我们可能会将其推迟一到两周,使时间安排更为舒适,因为没有人愿意在圣诞期间繁重的工作。”
当提到维护者的话题,Hohndel 提出了 “维护者疲劳以及这个角色的疲劳和压力” 的讨论。正如我最近的报道,Linux 内核的维护者对于这个关键而高要求的角色感到 [压力渐增](https://www.zdnet.com/article/what-linux-kernel-maintainers-do-and-why-they-need-your-help/)。
对此,Torvalds 做出回应:“找到开发者比较容易;我们有很多的开发者。一些人认为,只有能做任何事情的超级开发者才有资格成为维护者,但实际情况并非如此。”
Torvalds 接着说,“要成为一名维护者,你需要有足够的鉴赏力来评判别人的代码。有些能力可能是与生俱来的,但大部分则需要通过实践来获得。你必须能看别人的代码,并能区分,‘这是好的实践还是坏的实践’?通常这只是多年实践的结果。”
尽管如此,Torvalds 还是强调,“我们有很多优秀的维护者,但另一方面,你必须坚守在岗位,或者需要找到能够和你协同工作的维护者,这样你就能规划好你的休假和其他事项。”
对于 Torvalds 来说,“始终在岗并不是问题,因为我热爱我所做的事情。几个月前我去度假,我带了我的笔记本电脑。如果我没有随身带着笔记本电脑,我可能会感到无比无聊。这就是我生活的方式,但我明白并不是每个人都适合这样的生活,尤其是当你要投入生活中好几年的时间时。”
这也是 Torvalds 需要积极学习和提升的一部分,“代码容易写,有对错可寻。但人际关系则较为复杂,必须学会与开发者或者维护者相处,尤其当维护者都有各自不同的目标。他们想将自己负责的区域推向一个方向,而其他的维护者可能会想要将它朝其他方向引导。这种情况会带给人巨大的压力。”
在 2018 年,Torvalds 决定放弃他愤怒的态度,他 [休假一段时间](https://www.zdnet.com/article/linus-torvalds-takes-a-break-from-linux/),去改正他对其他开发者的态度。有所改观后,Torvalds [回归](https://www.zdnet.com/article/linus-torvalds-is-back-in-charge-of-linux/) 了 Linux 内核工作。自从那时起他变得更为温和,正如他在东京提到的,他不再 “对某公司竖中指,我已吸取了教训。”
总结一下,Torvalds 指出,“人们往往认为开源全是关于编程的事,但实际上很多是与沟通相关。维护者就是翻译的人,我不仅指的是语言,更是代码的环境,代码存在的理由。这是一项艰巨的任务。但是,如果你想成为维护者,相信我,顶层总有你的位置。”
此外,Linux 内核社区的老龄化也是一个值得关注的问题。如 Hohndel 所说,“如果我看五年后,很多 (顶尖的 Linux 内核)的人们将步入 60 岁,甚至有人将接近 70 岁。”
对此,Torvalds 承认,“我们中的很多人都在步入老年,但部分原因是因为我们有一些已经工作超过 30 年的维护者。他们依然活跃,仍然会回来找我。我们拥有一个人们愿意长期坚持的社区。”
Hohndel 评论道,内核社区的老龄化问题是枚 “双刃剑”,Torvalds 同意这个观点,并指出,“我喜欢内核中的 Rust 的原因之一是,那里有一个明显比其他维护者年轻很多的维护者。我们可以明显看到内核的某些区域更能吸引年轻人。”比如在驱动方面,那里更容易找到年轻的人,这一直是我们发展和培养维护者的传统方式,包括 Greg(Korah-Hartman,Linux 稳定内核的维护者)。
Hohndel 和 Torvalds 还谈到了在 Linux 内核中使用 Rust 语言的情况,Torvalds 指出,“这方面有增长,但我们的内核还没有哪个部分真正依赖 Rust。对我而言,Rust 在技术上是有意义的,但以我个人的看法,更重要的是我们不能因为是内核和开发者就停滞不前。”
Torvalds 继续说道:“尽管 Rust 还未真正展现出它的巨大潜力,但我想在明年,我们将开始集成开始积极使用它的驱动程序和一些甚至是主要子系统。所以这是一种需要几年才能在内核中占有重要地位的事情,但无疑,它正在逐渐塑造出这一未来。”
展望未来,Hohndel 谈到我们必须去考虑大型语言模型(LLM)人工智能。他认为人工智能更像是把超级自动更正,因为其实大型语言模型的核心功能就是预测你下一个最可能用到的词,然后从此处进行推理。尽管它看似并不真正聪明,但显然,它对我们的生活以及我们生活的现实产生了深远影响。他问道:“你觉得我们会看到有人提交由大型语言模型写出的代码吗?”
Torvalds 的答复坚定且直接,“我确信这种情况会发生,甚至可能已经发生了。也许现在是在一个较小的范围内,人们更多的是在利用它来辅助编写代码。”但是,和许多人不同的是,Torvalds 并不对人工智能感到担忧。“自动化帮助编写代码的情况显然一直存在,这并不是什么新鲜事。”他说。
实际上,Torvalds 希望 AI 能在“寻找明显的愚蠢错误方面提供帮助,因为很多他看到的错误并不是难以注意的错误,很多都是愚蠢的错误,这并不需要任何更高级的智能才能发现。”他希望有更多工具能在错误更难以发现的情况下发出警告,比如,“这种模式看起来不太常见,你确定这是你想要的吗?” 答案也许是 “不,这不是我的意思,你找到了明显的问题,非常感谢!”我们确实需要一款超级自动更正。他看待 AI 更像是一个可以帮助我们在做好自己事情的一项工具。
Hohndel 接着提问:“那关于 AI 带来的幻觉呢?”对此,一向坦率直言的 Torvalds 表达了他的看法,“我每天都会看到即使没有 AI 的情况下也依然会发生的错误。所以这就是为什么我并不太担心。我认为我们自己仍然很擅长犯错误。”
随后,Torvalds 表达了他对于开源的热爱,“我很高兴开源、开放的理念如今获得了更广泛的接受。我特别记得 30 年前我刚开始这个项目时,人们会质疑我,问我‘为什么呢?你又是怎么盈利的呢?’ 这种问题现在已经不再出现,开源已经成为了这个行业的标准,不论是编程还是数据,大规模的项目需要在公司之间分享,这已经成为了人们的共识。”
Hohndel 指出,“Linux 基金会的目标就是鼓励超越个人、公司,甚至超越整个社会,在一个中立的地方进行合作。在这样一个中立而公正的场所,人们可以聚集在一起实现一些事情,这是非常重要的。”
最后,Torvalds 总结道,“这就是我为什么在 Linux 基金会工作,因为我拒绝在任何 Linux 公司工作。我不想让任何一个公司或任何一个商业实体成为特殊地位。我们需要一个中立的地方,这就是为什么我决定把我的姓名给了 Linux 基金会。”
*(题图:DA/e811695a-aa34-4805-b634-03c516688323)*
---
via: <https://www.zdnet.com/article/linus-torvalds-on-state-of-linux-today-and-how-ai-figures-in-its-future/>
作者:[Steven Vaughan-Nichols](https://www.zdnet.com/meet-the-team/steven-vaughan-nichols/) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | # Linus Torvalds on the state of Linux today and how AI figures in its future


Linus Torvalds, the founder of Linux, has been keeping a low profile lately. But at the Linux Foundation's [Open Source Summit Japan](https://events.linuxfoundation.org/open-source-summit-japan/), Torvalds and his good friend Dirk Hohndel, the head of Verizon open source, talked about the current state of Linux.
First up, the two talked about the next Linux kernel release, Linux 6.7. Before flying into Tokyo, [Torvalds had released the fourth release candidate for 6.7](https://lore.kernel.org/lkml/CAHk-=wjsbytYq780PM-Wby_2rPabxg-WT-CRPZZaVYsmLiacHw@mail.gmail.com/). This means that if all goes well, and Torvalds sees no reason to think that it won't, the next version of Linux will arrive right around Christmas.
**Also: PipeWire 1.0: Linux audio comes of age**
As Torvalds explained, he didn't want to have the "merge window around Christmas, which destroys Christmas for me." Now, though, "We're just waiting to make sure that we have nothing that's a showstopper." To make sure that the maintainers and developers who are now preparing for the next version, 6.8, won't go into a "panic because they know that after Christmas, my merge window opens, we'll probably delay that by a week or two to make the timing work out better because nobody wants to work over Christmas."
Speaking of maintainers, Hohndel brought up the question of "maintainer fatigue and how draining and stressful this role is." As I reported recently, [Linux kernel maintainers are increasingly feeling more strained](https://www.zdnet.com/article/what-linux-kernel-maintainers-do-and-why-they-need-your-help/) by this essential, demanding role.
Torvalds replied, "It's much easier to find developers; we have a lot of developers. Some people think that you have to be a superdeveloper who can do everything to be a maintainer, but that's not actually true."
**Also: Linux might be your best bet for heightening your desktop computer security**
"To be a maintainer," Torvalds continued, "You have to have a certain amount of good taste to judge other people's code. Some of that may be innate, but a lot of it just takes practice. You must be able to look at other people's code, and be able to tell, 'Is this a good approach or a bad approach?' It's usually just a matter of having done it for many years."
That said, Torvalds added, "We do have a lot of great maintainers, but the other part is that you have to be there all the time. Or you have to find other maintainers that you can work with so that you schedule around your vacations and things like that."
Now for Torvalds, "being there all the time is not a problem because I love doing what I'm doing. I was on vacation a few months ago, and I have my laptop. And if I hadn't had my laptop with me, I would have been so bored. It is what I do. But I realized that's not the life for everybody, especially when you have to put years of your life into this."
**Also: Ultramarine Linux Flagship is a contender for desktop of the year**
It's also something Torvalds has had to learn to be better at as well. "Code is easy to write. You have a right answer, and you have a wrong. People relationships are hard, and being able to work with other developers and maintainers, especially when you have maintainers that work on different things with different goals. They want to push their area in one direction, and another maintainer comes in from another area and wants to pull it in another direction. It can be very stressful."
In 2018, Torvalds decided to pull back from his angry young man stance. He [took a break from the Linux kernel](https://www.zdnet.com/article/linus-torvalds-takes-a-break-from-linux/) to work on his behavior toward other developers. After he got a handle on it, [Torvalds returned to the kernel](https://www.zdnet.com/article/linus-torvalds-is-back-in-charge-of-linux/). He's been much more mild-tempered since then. As he mentioned in Tokyo, he won't be "giving some company the finger. I learned my lesson."
To sum it up, Torvalds said, "It's one of those things where a lot of people seem to think that open source is all about programming, but a lot of it is about communication, too. Maintainers are the ones who translate. I don't necessarily mean language. I mean, the context, the reason for the code. That makes for a tough job. But, if you want to be a maintainer, trust me, there's room at the top."
**Also: This is my new favorite default email client for Linux**
A related issue is the graying of the Linux kernel community. Hohndel observed. "If I look five years into the future, a lot of [the top Linux kernel] people will start hitting the 60s, and the first ones will approach the 70s."
That's true, Torvalds admitted, "a lot of us are going gray, but at the same time, part of the reason is we have maintainers who have been around for more than 30 years. They are still around and still active and still end up coming to me. We have a community where people do stick around."
Hohndel commented that the aging of the kernel community is a "double-edged sword." Torvalds agreed, but he noted that "one of the things I liked about the Rust side of the kernel, was that there was one maintainer who was clearly much younger than most of the maintainers. We can clearly see that certain areas in the kernel bring in more young people." For example, on the driver side, you'll have a much easier time finding younger people, and that is traditionally how we've grown a lot of maintainers, including Greg [Korah-Hartman, the Linux stable kernel maintainer].
Hohndel and Torvalds also talked about the use of the Rust language in the Linux kernel. Torvalds said, "It's been growing, but we don't have any part of the kernel that really depends on Rust yet. To me, Rust was one of those things that made technical sense, but to me personally, even more important was that we need to not stagnate as a kernel and as developers."
**Also: Rust in Linux: Where we are and where we're going next**
That said, Torvalds continued, "Rust has not really shown itself as the next great big thing. But I think during next year, we'll actually be starting to integrate drivers and some even major subsystems that are starting to use it actively. So it's one of those things that is going to take years before it's a big part of the kernel. But it's certainly shaping up to be one of those."
Looking ahead, Hohndel said, we must talk about "artificial intelligence large language models (LLM). I typically say artificial intelligence is autocorrect on steroids. Because all a large language model does is it predicts what's the most likely next word that you're going to use, and then it extrapolates from there, so not really very intelligent, but obviously, the impact that it has on our lives and the reality we live in is significant. Do you think we will see LLM written code that is submitted to you?"
Torvalds replied, "I'm convinced it's gonna happen. And it may well be happening already, maybe on a smaller scale where people use it more to help write code." But, unlike many people, Torvalds isn't too worried about [AI](https://www.zdnet.com/article/what-is-ai-heres-everything-you-need-to-know-about-artificial-intelligence/). "It's clearly something where automation has always helped people write code. This is not anything new at all."
**Also: The best Linux laptops right now**
Indeed, Torvalds hopes that AI might really help by being able "to find the obvious stupid bugs because a lot of the bugs I see are not subtle bugs. Many of them are just stupid bugs, and you don't need any kind of higher intelligence to find them. But having tools that warn more subtle cases where, for example, it may just say 'this pattern does not look like the regular pattern. Are you sure this is what you need?' And the answer may be 'No, that was not at all what I meant. You found an obvious bag. Thank you very much.' We actually need autocorrects on steroids. I see AI as a tool that can help us be better at what we do."
But, "What about hallucinations?," asked Hohndel. Torvalds, who will never stop being a little snarky, said, "I see the bugs that happen without AI every day. So that's why I'm not so worried. I think we're doing just fine at making mistakes on our own."
Moving on, Torvalds said, "I enjoy the fact that open source, the notion of openness, has gotten so much more widely accepted. I enjoyed it particularly because I remember what it was thirty years ago when I had started this project, and people would ask me, 'Why?' And people would say, 'But how do you make money? That question never comes up anymore. Openness has become the standard within the industry. And people take it for granted that when you have to have big projects whether they are programming or data, you end up having them so big that you need to share between companies."
**Also: Tuning the Linux kernel with AI, according to ByteDance**
Hohndel observed that "Linux Foundation is focused on encouraging collaboration beyond the individual, beyond the company to collaborate on things as a society and without trying to be too hyperbolic here -- there is a huge role in having that neutral place where people can come together and do things."
Torvalds concluded, "That is literally why I'm working at the Linux Foundation because I refused to ever work at a Linux company. Because I did not want to be in a situation where one company or one commercial entity would be a special place. You need to have a neutral place, and that's why I gave my name to the Linux Foundation."
[Editorial standards](/editorial-guidelines/) |
16,460 | PeerTube 发布第 6 版,获得比 YouTube 更好的功能 | https://news.itsfoss.com/peertube-v6/ | 2023-12-11T16:21:00 | [
"YouTube",
"PeerTube"
] | https://linux.cn/article-16460-1.html | 
>
> 去中心化开源平台 PeerTube 大升级,这是一个很好的 YouTube 替代品。
>
>
>
曾经想过让你的视频平台摆脱大型科技公司的控制吗?
嗯,对于许多人来说,PeerTube 是一个相当不错的选择,因为它具有**开源和自托管的性质**。由 [Framasoft](https://framasoft.org/en/) 开发,开发人员一直忙于定期向 PeerTube 添加新功能。
当然,作为一个去中心化平台,它可能无法为你提供与 YouTube 相同的用户体验(或质量)。然而,它是 [最好的去中心化开源平台](https://itsfoss.com/mainstream-social-media-alternaives/) 之一。
这次,他们推出了一个新版本,即 **PeerTube V6**,并承诺将进行大量改进。 请允许我带你了解这些。
### ? PeerTube V6:有什么新内容?

PeerTube V6 版本是一个主要版本,根据从用户那里收到的反馈,**引入了社区最需要的一些功能**。
一些**关键亮点**包括:
* 视频章节
* 视频故事板
* 替换上传的视频
* 视频密码保护
#### 视频章节

你现在可以**向视频添加章节**以指定视频的不同部分。这是一个非常方便的小功能,**增强了观看者的体验**,使他们能够看到视频的内容。
正如你在上面看到的,在章节设置了特定的标题和时间码后,会出现标记将进度条分为不同的部分。
#### 视频故事板

V6 版本带来的另一个功能是**能够通过将鼠标悬停在进度条上或拖动进度条来预览视频**。
这也被称为“故事板”功能,它在大多数流行的视频流平台上都有,现在 PeerTube 也拥有它。
#### 替换上传的视频

有时会发生错误,错误编辑的视频会呈现给观众。幸运的是,有了 PeerTube V6,这一切都成为了过去。
用户现在只需点击几下即可选择**重新上传视频以替换旧视频**。这样做时,URL、标题、信息、统计数据和评论将保持不变。
但是,此功能必须由 PeerTube 实例的管理员启用才能工作。被替换的视频将被贴上“视频重新上传”标签。
#### 视频密码保护

你现在可以决定**为视频设置密码**以限制访问或分发专有内容。
管理员和开发人员可以通过 PeerTube 的内部 **REST API** 获得更大的灵活性,他们可以**设置和存储任意数量的密码**,从而更轻松地授予/撤销对视频的访问权限。
#### ?️ 其他更改和改进
除了上述亮点之外,还有一些值得注意的改进:
* 更好的远程运行管理。
* SEO 和视频链接共享已得到改进。
* 针对辅助功能和键盘导航的各种修复。
* 视频播放器已得到改进,播放新视频时不再重新加载并保存当前播放器设置。
你可以通过官方的 [发行说明](https://github.com/Chocobozzz/PeerTube/releases/tag/v6.0.0) 和 [公告博客](https://joinpeertube.org/news/release-6.0) 了解更多信息。
### ? 获取 PeerTube V6
你可以前往[官方网站](https://joinpeertube.org/)开始使用 PeerTube V6。
>
> **[PeerTube](https://joinpeertube.org/)**
>
>
>
**对于现有用户**,你可以按照 [官方文档](https://docs.joinpeertube.org/install/any-os) 升级你的 PeerTube。
看到谷歌越来越 [积极](https://news.itsfoss.com/youtube-firefox/) 地将 YouTube 平台货币化,我们很高兴看到像 PeerTube 这样的由社区驱动平台依然存在。
? PeerTube 正在成为一个不错的 YouTube 替代品,你觉得怎么样?
*(题图:DA/117fe978-0b8e-4183-b580-72fea7938b02)*
---
via: <https://news.itsfoss.com/peertube-v6/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ever wanted to run your video platform free from the clutches of Big Tech?
Well, for many, PeerTube has been a rather fine option thanks to its **open-source and self-hostable nature**. Developed by [Framasoft](https://framasoft.org/en/?ref=news.itsfoss.com), the developers have been busy adding new functionality to PeerTube regularly.
Sure, as a decentralized platform, it may not give you the same user experience (or quality) like YouTube. However, it is one of the [best decentralized open-source platforms](https://itsfoss.com/mainstream-social-media-alternaives/?ref=news.itsfoss.com) out there.
On that note, they have introduced a new release in the form of **PeerTube V6**, that promises to deliver quite a few improvements.
Allow me to take you through those.
## 🆕 PeerTube V6: What's New?

Taking pointers from the feedback they received from users, the PeerTube V6 release is a major version that **introduces some of the most requested features** from the community.
Some **key highlights** include:
**Video Chapters****Video Storyboard****Replace Uploaded Video****Password Protection for Video**
### Video Chapters

You can now **add chapters to videos** for specifying different sections of a video. This is a very handy little feature that **enhances the experience of the viewer**, allowing them to see what's in store for a video.
As you can see above, after the chapters are set with their specific titles and time codes, markers will appear to divide the progress bar into different segments.
### Video Storyboard
Another feature that has arrived with the V6 release is the **ability to preview videos** by either hovering on the progress bar or dragging through it.
This is also known as a *storyboard* feature that is available on most popular video streaming platforms, and now PeerTube also has it.
### Replace Uploaded Video
Sometimes mistakes happen, and an incorrectly edited video makes it through to the viewers. Luckily, with PeerTube V6, that is a thing of the past.
Users can now choose to **re-upload a video to replace an older one** with just a few clicks. When doing so, the URL, title, information, stats, and comments will remain unchanged.
However, this feature has to be enabled by the admin of the PeerTube instance to work. A “Video re-upload” tag will be affixed to the videos that have been replaced.
### Password Protection for Video
You can now decide to** set a password on videos** to restrict access, or to distribute exclusive content.
Admins and developers have more flexibility with PeerTube's in-house **REST API**, they can **set and store as many passwords as they want**, making it simpler to give/revoke access to videos.
**Suggested Read **📖
[10 Decentralized, Open Source Alternative Social Media PlatformsTired of Big Tech prying on your data and invading your privacy? Here are some open source, decentralized alternate social platforms.](https://itsfoss.com/mainstream-social-media-alternaives/?ref=news.itsfoss.com)

### 🛠️ Other Changes and Improvements
Other than the above-mentioned highlights, here are some betterments worth noting:
- Better remote runner management.
- SEO and video link sharing has been improved.
- Various fixes for accessibility and keyboard navigation.
- The video player has been improved, it no longer gets reloaded and saves the current player settings when playing a new video.
You may go through the official [release notes](https://github.com/Chocobozzz/PeerTube/releases/tag/v6.0.0?ref=news.itsfoss.com) and [announcement blog](https://joinpeertube.org/news/release-6.0?ref=news.itsfoss.com) to know more.
## 📥 Get PeerTube V6
You can head over to the [official website](https://joinpeertube.org/?ref=news.itsfoss.com) to get started with PeerTube V6.
**For existing users**, you can upgrade your PeerTube installation by following the [official documentation](https://docs.joinpeertube.org/install/any-os?ref=news.itsfoss.com).
Seeing how Google is getting more and [more aggressive](https://news.itsfoss.com/youtube-firefox/) with monetizing their YouTube platform, it is great to see that community-driven platforms like PeerTube are still around.
**Suggested Read **📖
[So, Google Wants Firefox Users to Have a Poor YouTube Experience?YouTube loads up slower on Firefox, just because Google wants it to or not?](https://news.itsfoss.com/youtube-firefox/)

*💬 PeerTube is becoming a nice YouTube alternative, what do you think?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,462 | 利用 Vely 在 Linux 构建你自己的 SaaS | https://opensource.com/article/22/11/build-your-own-saas-vely | 2023-12-12T11:09:46 | [
"Vely",
"SaaS"
] | /article-16462-1.html | 
>
> Vely 可让你在网络应用程序中利用 C 语言的强大功能。
>
>
>
[Vely](https://opensource.com/article/22/5/write-c-appplications-vely-linux) 将 C 语言的高性能和低内存占用与 PHP 等语言的易用性和安全性相结合。作为自由开源软件,它以 GPLv3 和 LGPL 3 授权,所以你甚至可以用它来构建商业软件。
### 利用 Vely 构建 SaaS
你可以使用 Vely 创建一个多租户网络应用程序,它可以作为软件即服务模式(SaaS)在互联网上运行。每个用户都有一个完全独立的数据空间。
在这个网络应用程序示例中,用户可以注册一个笔记本服务来创建笔记,然后查看和删除它们。它仅用了 7 个源文件,310 行代码,就展示了如何集成多项技术:
* MariaDB
* 网络浏览器
* Apache
* Unix 套接字
#### 运作原理
以下是从用户的角度来看应用程序是如何工作的。下图是代码演示。
该应用允许用户通过指定电子邮件地址和密码创建新的登录名。你可以用任何你喜欢的方式设置它们,例如运用 CSS:

验证用户的电子邮件:

每个用户使用自己独有的用户名和密码登录:

一旦登录,用户就可以添加笔记:

用户可以获取笔记列表:

删除笔记之前,应用会申请确认信息:

用户确认后,笔记被删除:

#### 设置先决条件
遵照 [Vely.dev](https://vely.dev/) 上的安装指示。这是一个使用 DNF、APT、Pacman 或者 Zypper 等标准工具包的快速流程。
由于它们都是这个范例的一部分,你必须安装 Apache 作为网络服务器,安装 MariaDB 作为数据库。
安装 Vely 后,如使用 Vim,打开里面的“语法高亮显示”:
```
vv -m
```
#### 获取源代码
这个演示 SaaS 应用程序的源代码是 Vely 安装的一部分。为每个应用程序创建一个单独的源代码目录不失为一个好主意(而且你可以按自己喜好命名)。在这种情况下,解包源代码会帮你完成这些工作:
```
$ tar xvf $(vv -o)/examples/multitenant_SaaS.tar.gz
$ cd multitenant_SaaS
```
默认情况下,该应用程序以 `multitenant_SaaS` 命名,但你可以将其命名为任何内容(如果这么做,其他每个地方你都需要改一下)。
### 创建应用程序
第一步是创建一个应用程序。使用 Vely 的 `vf` 工具就可以轻松完成:
```
$ sudo vf -i-u $(whoami) multitenant_SaaS
```
这个命令创建了一个新的应用程序主目录(`/var/lib/vv/multitenant_SaaS`),并帮你执行应用程序设置。通常,这意味着在该主目录中创建各种子目录并分配权限。在这种情况下,只有当前用户(`whoami` 的结果)拥有目录,具有 `0700` 权限,这确保了其他人没有访问文件的权限。
### 创建数据库
在你键入任何代码之前,你需要一个能够存储该应用程序所用信息的空间。首先,创建一个名为 `db_multitenant_SaaS` 的 MariaDB 数据库,由用户名为 `vely` 的用户所有,密码为 `your_password` 。你可以修改刚才提到的任何值,但得记住,在这个示例里,你需要将包含这些内容的每个地方都得修改一遍。
在 MySQL 中以 root 身份登录:
```
create database if not exists db_multitenant_SaaS;
create user if not exists vely identified by 'your_password';
grant create,alter,drop,select,insert,delete,update on db_multitenant_SaaS.* to vely;
```
然后在数据库内创建数据库对象(表,记录等等):
```
use db_multitenant_SaaS;
source setup.sql;
exit
```
### 将 Vely 连接至数据库
为了让 Vely 知晓你数据库的位置以及如何登录进去,创建一个名为 `db_multitenant_SaaS` 的数据库配置文件。(该名称用于在源代码中的数据库声明,所以如果你改了它,确保在它存在的每个地方都改一遍。)
Vely 使用原生的 MariaDB 数据库连接,因此你可以指定给定的数据库所能允许的任何选项:
```
$ echo '[client]
user=vely
password=your_password
database=db_multitenant_SaaS
protocol=TCP
host=127.0.0.1
port=3306' > db_multitenant_SaaS
```
### 构建应用程序
使用 `vv` 工具构建应用程序,利用 `--db` 选项指定 MariaDB 数据库和数据库配置文件:
```
$ vv -q--db=mariadb:db_multitenant_SaaS
```
### 启用应用服务器
启动你的网络应用程序的服务器,需要使用 `vf` FastCGI 进程管理器。应用程序服务器使用 Unix 套接字与网络服务器(创建反向代理)通信:
```
$ vf -w3 multitenant_SaaS
```
这么做会启用三个守护进程,为接收到的请求提供服务。你也可以启动一个自适应服务器,它会增加进程的数量从而服务更多的请求,并在不需要他们时减少进程的数量:
```
$ vf multitenant_SaaS
```
请参阅 `vf` 了解更多选项,以帮助你实现最佳性能。
当你需要停止你的应用程序服务器,使用 `-m quit` 选项:
```
$ vf -m quit multitenant_SaaS
```
### 创建网络服务器
这是一个网络应用程序,那么应用程序就得需要一个网络服务器。该示例通过一个 Unix 套接字监听器使用 Apache。
#### 1、设置 Apache
将 Apache 配置为一个反向代理,并将你的应用程序与之连接,你需要启用 FastCGI 代理支持,这通常使用 `proxy` 和 `proxy_fcgi` 模块。
对于 Fedora 系统(或者其它的,比如 Arch)来说,通过在 Apache 配置文件 `/etc/httpd/conf/httpd.conf` 中添加(或取消注释)适当的 `LoadModule` 指令,就可启用 `proxy` 和 `proxy_fcgi` 模块。
以下指令适用于 Debian,Ubuntu 以及类似的系统,启用 `proxy` 和 `proxy_fcgi` 模块:
```
$ sudo a2enmod proxy
$ sudo a2enmod proxy_fcgi
```
以下指令适用于 OpenSUSE,将这几行添加在 `/etc/apache2/httpd.conf` 结尾处:
```
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
```
#### 2、配置 Apache
现在你必须将代理信息添加在 Apache 的配置文件中:
```
ProxyPass "/multitenant_SaaS" unix:///var/lib/vv/multitenant_SaaS/sock/sock|fcgi://localhost/multitenant_SaaS
```
你的配置文件的位置可能会有所不同,这取决于不同的 Linux 发行版:
* Fedora、CentOS、Mageia 和 Arch: `/etc/httpd/conf/httpd.conf`
* Debian、Ubuntu、Mint: `/etc/apache2/apache2.conf`
* OpenSUSE:`/etc/apache2/httpd.conf`
#### 3、重新启动
最后,重启 Apache。在 Fedora 和类似系统,还有 Arch Linux 是如下指令:
```
$ sudo systemctl restart httpd
```
在 Debian 和基于 Debian 的系统,还有 OpenSUSE 是如下指令:
```
$ sudo systemctl restart apache2
```
### 设置本地邮箱
这个示例中,电子邮件是其功能的一部分。如果你的服务器已经可以发送电子邮件了,你可以跳过这一条。此外,你可以使用本地邮箱(`myuser@localhost`)来测试它。要做到这一点,需安装 Sendmail。
在 Fedora 和类似系统中是如下指令:
```
$ sudo dnf installsendmail
$ sudo systemctl start sendmail
```
而在 Debian 和类似系统(如 Ubuntu):
```
$ sudo apt installsendmail
$ sudo systemctl start sendmail
```
当应用程序向本地用户发送电子邮件,比如说 `OS_user@localhost`,你就可以通过查看 `/var/mail/` 处(即所谓“邮件池”)来确认电子邮件是否被发送。
### 从浏览器访问应用服务器
假设你在本地运行该应用,可以通过使用 `http://127.0.0.1/multitenant_SaaS?req=notes&action=begin` 域名从你的网络服务器访问你的应用服务器。如果你在互联网上的在线服务器运行该程序,你可能就需要调整防火墙设置以允许 HTTP 通信。
### 源代码
该应用程序示例包含 7 个源文件。你可以自行回顾代码(记住,这些文件只有 310 行代码),下面是每个文件的概述。
#### SQL 设置(setup.sql)
创建的两个表:
* `users`:每个用户的信息。在 `users` 表中,每个用户都有自己唯一的 ID (`userId` 列),以及其他信息,如电子邮件地址和该地址是否通过了验证。还有一个哈希密码。实际的密码永远不会存储在纯文本(或其他形式)中,单向哈希用于检查密码。
* `notes`:用户输入的笔记。`notes` 表包含了所有的笔记,每个笔记都有一个 `userId` 列,表示哪个用户拥有它们。`userId` 列的值与 `users` 表中的同名列匹配。这样,每个笔记显然都属于单个用户。
该文件内容如下:
```
create table if not exists notes (dateOf datetime, noteId bigint auto_increment primary key, userId bigint, note varchar(1000));
create table if not exists users (userId bigint auto_increment primary key, email varchar(100), hashed_pwd varchar(100), verified smallint, verify_token varchar(30), session varchar(100));
create unique index if not exists users1 on users (email);
```
#### 运行时数据(login.h)
为了正确地显示登录、注册和注销链接,你需要一些在应用程序中任何地方都可以使用的标志。此外,应用程序使用 cookie 来维护会话,因此它需要在任何地方都可用,例如,验证会话是否有效。发送到应用程序的每个请求都以这种方式进行确认。只有带有可验证 cookie 的请求是允许的。
所以要做到这种效果,你需要有一个 `global_request_data` 类型的 `reqdata`(请求数据),其中包含 `sess_userId`(用户的 ID)以及 `sess_id`(用户目前的会话 ID)。此外,还有一些不言自明的标志,可以帮助渲染页面:
```
#ifndef _VV_LOGIN
#define _VV_LOGIN
typedef struct s_reqdata {
bool displayed_logout; // true 则显示登出连接
bool is_logged_in; // true 则会话已验证登录
char *sess_userId; // 目前会话的用户 ID
char *sess_id; // 会话 ID
} reqdata;
void login_or_signup ();
#endif
```
#### 会话检查和会话数据(\_before.vely)
Vely 里有一个 <ruby> 请求前处理程序 <rt> before_request handler </rt></ruby> 的概念。你写的代码会在其它处理请求的代码之前执行的。要达到这个目的,你只需要将这样的代码写在名为 `_before.vely` 的文件中,然后剩余的部分将会自动处理。
SaaS 应用程序所作的任何事情,例如处理发送至应用程序的请求,必须验证其安全性。这样,应用程序就能知晓调用方是否有执行操作所需要的权限。
在这里,通过请求前处理程序进行权限检查。这样,无论其他代码如何处理请求,都已经掌握了会话信息。
为保持会话数据(比如会话 ID 和用户 ID)在你代码中的任何地方都可用,你可以使用 `global_request_data`。它只是一个指向内存的通用指针(`void*`),任何处理请求的代码都可以访问它。这非常适合处理会话,如下所示:
```
#include "vely.h"
#include "login.h"
// _before() 是一个请求前处理程序。
// 它总是在处理请求的其他代码之前执行。
// 对于任何类型的请求范围设置或数据初始化,它都是一个很好的位置。
void _before() {
// 输出 HTTP 请求头
out-header default
reqdata *rd; // 这是全局请求数据,见 login.h
// 为全局请求数据分配内存,
// 将在请求结束时自动释放
new-mem rd size sizeof(reqdata)
// 初始化标志
rd->displayed_logout = false;
rd->is_logged_in = false;
// 将我们创建的数据设置为全局请求数据,
// 可以从任何处理请求的代码中访问
set-req data rd
// 检查会话是否存在(基于来自客户端的 cookie)
// 这在任何其他请求处理代码之前执行,
// 使其更容易准备好会话信息
_check_session ();
}
```
#### 检查会话是否有效(\_check\_session.vely)
多租户 SaaS 应用程序中最重要的任务之一就是通过检查用户是否登录来(尽快)检查会话是否有效。这是通过从客户端(例如网络浏览器)获取会话 ID 和用户 ID 的 cookie,并将它们与存储会话的数据库进行比较来实现的:
```
#include "vely.h"
#include "login.h"
// 检查会话是否有效
void _check_session () {
// 获取全局请求数据
reqdata *rd;
get-req data to rd
// 自用户浏览器获取 cookies
get-cookie rd->sess_userId="sess_userId"
get-cookie rd->sess_id="sess_id"
if (rd->sess_id[0] != 0) {
// 检查给定用户 ID 下的会话 ID 是否正确
char *email;
run-query @db_multitenant_SaaS = "select email from users where userId='%s' and session='%s'" output email : rd->sess_userId, rd->sess_id row-count define rcount
query-result email to email
end-query
if (rcount == 1) {
// 如果正确,设置登录标志
rd->is_logged_in = true;
// 如果登出链接不显示,则显示它
if (rd->displayed_logout == false) {
@Hi <<p-out email>>! <a href="https://opensource.com/?req=login&action=logout">Logout</a><br/>
rd->displayed_logout = true;
}
} else rd->is_logged_in = false;
}
}
```
#### 注册、登录、登出(login.vely)
任何多租户系统的基础便是具有用户注册\登录和登出的功能。通常情况下,注册包括验证电子邮件地址;不止于此,同一电子邮件地址会作为一个用户名。这里就是这种情况。
这里实现了几个执行该功能所必须的子请求:
* 注册新用户时,显示 HTML 表单以收集信息。它的 URL 请求签名是 `req=login&action=newuser`。
* 作为对注册表单的响应,创建一个新用户。URL 请求的签名是 `req=login&action=createuser`。输入参数(`input-param`)信号获取 `email` 和 `pwd` 的 POST 表单字段。密码值是单向散列,电子邮件验证令牌是一个随机的 5 位数字。这些被插入到 `users` 表中,创建一个新用户。系统会发送一封验证邮件,并提示用户阅读邮件并输入代码。
* 通过输入发送到该电子邮件的验证码来验证电子邮件。URL 请求的签名是 `req=login&action=verify`。
* 显示一个登录表单,让用户登录。URL 请求的签名是 `req=login`(例如,`action` 为空)。
* 通过验证电子邮件地址(用户名)和密码登录。URL 请求的签名是 `req=login&action=login`。
* 应用户要求登出。URL 请求的签名是 `req=login&action=logout`。
* 应用程序的登录页。URL 请求的签名是 `req=login&action=begin`。
* 如果用户当前已登录,转到应用程序的登录页面。
可以看看下面这些例子:
```
#include "vely.h"
#include "login.h"
// 处理云端多租户应用程序的会话维护、登录、注销、会话验证
void login () {
// 获取 URL 的输入参数 `action`
input-param action
// 获取全局请求数据,我们在其中记录会话信息,所以它很方便
reqdata *rd;
get-req data to rd
// 如果会话已经建立,我们不会
// 继续到应用程序主页的唯一原因是我们正在登出
if (rd->is_logged_in) {
if (strcmp(action, "logout")) {
_show_home();
exit-request
}
}
// 应用程序页面启动。显示登录或注册的链接,
// 并显示适当的主屏幕
if (!strcmp (action, "begin")) {
_show_home();
exit-request
// 开始创建新用户。询问电子邮件和密码,
// 然后提交此表单时创建用户。
} else if (!strcmp (action, "newuser")) {
@Create New User<hr/>
@<form action="https://opensource.com/?req=login" method="POST">
@<input name="action" type="hidden" value="createuser">
@<input name="email" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Email">
@<input name="pwd" type="password" value="" size="50" maxlength="50" required placeholder="Password">
@<input type="submit" value="Sign Up">
@</form>
// 验证用户发送到电子邮件的代码。代码必须匹配,从而验证电子邮件地址
} else if (!strcmp (action, "verify")) {
input-param code
input-param email
// 获取基于电子邮件的验证令牌
run-query @db_multitenant_SaaS = "select verify_token from users where email='%s'" output db_verify : email
query-result db_verify to define db_verify
// 将数据库中记录的令牌与用户提供的令牌进行比较
if (!strcmp (code, db_verify)) {
@Your email has been verifed. Please <a href="https://opensource.com/?req=login">Login</a>.
// 如果匹配,更新用户信息以表明已验证。
run-query @db_multitenant_SaaS no-loop = "update users set verified=1 where email='%s'" : email
exit-request
}
end-query
@Could not verify the code. Please try <a href="https://opensource.com/?req=login">again</a>.
exit-request
// 创建用户 —— 当用户使用电子邮件和密码提交表单以创建用户时运行
} else if (!strcmp (action, "createuser")) {
input-param email
input-param pwd
// 创建散列(单向)密码
hash-string pwd to define hashed_pwd
// 生成随机的 5 位数字字符串验证代码
random-string to define verify length 5 number
// 创建用户:插入电子邮件、哈希密码、验证令牌。当前验证状态为 0,或未验证
begin-transaction @db_multitenant_SaaS
run-query @db_multitenant_SaaS no-loop = "insert into users (email, hashed_pwd, verified, verify_token, session) values ('%s', '%s', '0', '%s', '')" : email, hashed_pwd, verify affected-rows define arows error define err on-error-continue
if (strcmp (err, "0") || arows != 1) {
// 如果不能添加用户,则可能该用户不存在。不管怎样,我们都无法继续。
login_or_signup();
@User with this email already exists.
rollback-transaction @db_multitenant_SaaS
} else {
// 创建带有验证码的电子邮件并将其发送给用户
write-string define msg
@From: [email protected]
@To: <<p-out email>>
@Subject: verify your account
@
@Your verification code is: <<p-out verify>>
end-write-string
exec-program "/usr/sbin/sendmail" args "-i", "-t" input msg status define st
if (st != 0) {
@Could not send email to <<p-out email>>, code is <<p-out verify>>
rollback-transaction @db_multitenant_SaaS
exit-request
}
commit-transaction @db_multitenant_SaaS
// 通知用户查看邮件并输入验证码
@Please check your email and enter verification code here:
@<form action="https://opensource.com/?req=login" method="POST">
@<input name="action" type="hidden" value="verify" size="50" maxlength="50">
@<input name="email" type="hidden" value="<<p-out email>>">
@<input name="code" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Verification code">
@<button type="submit">Verify</button>
@</form>
}
// 这里在登录用户登出时运行
} else if (!strcmp (action, "logout")) {
// 更新用户表以清除会话,即没有该用户登录
if (rd->is_logged_in) {
run-query @db_multitenant_SaaS = "update users set session='' where userId='%s'" : rd->sess_userId no-loop affected-rows define arows
if (arows == 1) {
rd->is_logged_in = false; // 提示用户未登录
@You have been logged out.<hr/>
}
}
_show_home();
// 登录:当用户输入用户名和密码时运行
} else if (!strcmp (action, "login")) {
input-param pwd
input-param email
// 创建单向散列,目的是与用户表进行比较 —— 密码**永远不会**被记录
hash-string pwd to define hashed_pwd
// 为会话 ID 创建一个随机的 30 位长的字符串
random-string to rd->sess_id length 30
// 检查用户名和哈希密码是否匹配
run-query @db_multitenant_SaaS = "select userId from users where email='%s' and hashed_pwd='%s'" output sess_userId : email, hashed_pwd
query-result sess_userId to rd->sess_userId
// 如果匹配,使用会话 ID 更新用户表
run-query @db_multitenant_SaaS no-loop = "update users set session='%s' where userId='%s'" : rd->sess_id, rd->sess_userId affected-rows define arows
if (arows != 1) {
@Could not create a session. Please try again. <<.login_or_signup();>> <hr/>
exit-request
}
// 设置“用户 ID”和“会话 ID”为 cookie。用户的浏览器将在每个请求中返回这些信息
set-cookie "sess_userId" = rd->sess_userId
set-cookie "sess_id" = rd->sess_id
// 显示主页,确保会话是正确的,并设置标志
_check_session();
_show_home();
exit-request
end-query
@Email or password are not correct. <<.login_or_signup();>><hr/>
// 登录界面,要求用户输入用户名和密码
} else if (!strcmp (action, "")) {
login_or_signup();
@Please Login:<hr/>
@<form action="https://opensource.com/?req=login" method="POST">
@<input name="action" type="hidden" value="login" size="50" maxlength="50">
@<input name="email" type="text" value="" size="50" maxlength="50" required autofocus placeholder="Email">
@<input name="pwd" type="password" value="" size="50" maxlength="50" required placeholder="Password">
@<button type="submit">Go</button>
@</form>
}
}
// 显示登录或注册链接
void login_or_signup() {
@<a href="https://opensource.com/?req=login">Login</a> & & <a href="https://opensource.com/?req=login&action=newuser">Sign Up</a><hr/>
}
```
#### 通用应用程序(\_show\_home.vely)
借助本教程,你可以创建你想要的任何多租户 SaaS 应用程序。上面的多租户处理模块(`login.vely`)调用 `_show_home()` 函数,它可以容纳你的任何代码。这个示例代码展示了笔记应用程序,但它可以是任何内容。`_show_home()` 函数可以调用你想要的任何代码,它是一个通用的多租户应用程序插件:
```
#include "vely.h"
void _show_home() {
notes();
exit-request
}
```
#### 笔记应用程序(notes.vely)
该应用程序能够添加、列举以及删除任何给定的笔记:
```
#include "vely.h"
#include "login.h"
// 多租户云中的笔记应用程序
void notes () {
// 获取全局请求数据
reqdata *rd;
get-req data to rd
// 如果会话有效,显示登录或注册
if (!rd->is_logged_in) {
login_or_signup();
}
// 问候用户
@<h1>Welcome to Notes!</h1><hr/>
// 如果没有登出,退出 —— 这里确保对用户身份的安全验证
if (!rd->is_logged_in) {
exit-request
}
// 获取 URL 参数,告诉笔记要做什么
input-param subreq
// 显示笔记能够做什么操作(添加或列举笔记)
@<a href="https://opensource.com/?req=notes&subreq=add">Add Note</a> <a href="https://opensource.com/?req=notes&subreq=list">List Notes</a><hr/>
// 列举该用户的所有笔记
if (!strcmp (subreq, "list")) {
// **只**选取该用户的笔记
run-query @db_multitenant_SaaS = "select dateOf, note, noteId from notes where userId='%s' order by dateOf desc" : rd->sess_userId output dateOf, note, noteId
query-result dateOf to define dateOf
query-result note to define note
query-result noteId to define noteId
// 使用快速缓存正则表达式将新行更改为<br/>
match-regex "\n" in note replace-with "<br/>\n" result define with_breaks status define st cache
if (st == 0) with_breaks = note; // 什么都没有发现/替换,只用原来的
// 显示笔记
@Date: <<p-out dateOf>> (<a href="https://opensource.com/?req=notes&subreq=delete_note_ask¬e_id=%3C%3Cp-out%20noteId%3E%3E">delete note</a>)<br/>
@Note: <<p-out with_breaks>><br/>
@<hr/>
end-query
}
// 要求删除笔记
else if (!strcmp (subreq, "delete_note_ask")) {
input-param note_id
@Are you sure you want to delete a note? Use Back button to go back, or <a href="https://opensource.com/?req=notes&subreq=delete_note¬e_id=%3C%3Cp-out%20note_id%3E%3E">delete note now</a>.
}
// 删除笔记
else if (!strcmp (subreq, "delete_note")) {
input-param note_id
// 删除笔记
run-query @db_multitenant_SaaS = "delete from notes where noteId='%s' and userId='%s'" : note_id, rd->sess_userId affected-rows define arows no-loop error define errnote
// 告知用户状态
if (arows == 1) {
@Note deleted
} else {
@Could not delete note (<<p-out errnote>>)
}
}
// 添加笔记
else if (!strcmp (subreq, "add_note")) {
// 从 note 表单中获取 URL POST 数据
input-param note
// 在该用户的 ID 下插入笔记
run-query @db_multitenant_SaaS = "insert into notes (dateOf, userId, note) values (now(), '%s', '%s')" : rd->sess_userId, note affected-rows define arows no-loop error define errnote
// 告知用户状态
if (arows == 1) {
@Note added
} else {
@Could not add note (<<p-out errnote>>)
}
}
// 显示一个 HTML 表单来收集笔记,并将其发送回这里(使用 subreq="add_note" URL 参数)
else if (!strcmp (subreq, "add")) {
@Add New Note
@<form action="https://opensource.com/?req=notes" method="POST">
@<input name="subreq" type="hidden" value="add_note">
@<textarea name="note" rows="5" cols="50" required autofocus placeholder="Enter Note"></textarea>
@<button type="submit">Create</button>
@</form>
}
}
```
### 具有 C 性能的 SaaS
Vely 语言使得 C 语言在你的网络应用程序中得到充分利用这件事成为可能。多租户 SaaS 应用程序便是从中受益的一个典型用例。
看一看参考代码示例,写一写代码,然后试试 Vely。
*(题图:DA/126624c8-1a47-481b-b149-92273e8e0f4f)*
---
via: <https://opensource.com/article/22/11/build-your-own-saas-vely>
作者:[Sergio Mijatovic](https://opensource.com/users/vely) 选题:[lkxed](https://github.com/lkxed) 译者:[Drwhooooo](https://github.com/Drwhooooo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,463 | Kali Linux 2023.4 发布:首度支持树莓派 5,并搭载 GNOME 45 | https://news.itsfoss.com/kali-linux-2023-4-release/ | 2023-12-12T12:24:30 | [
"Kali Linux",
"网络安全"
] | https://linux.cn/article-16463-1.html | 
>
> 2023 年最后的 Kali Linux 更新已经来临。
>
>
>
作为众所周知的专注于网络安全的 Linux 发行版,Kali Linux 推出了新版本 **Kali Linux 2023.4**,其中带有一些重大更新。
这一新版距离 [Kali 2023.3 版本](https://news.itsfoss.com/kali-linux-2023-3-release/) 发布不过数月,让我们一起探讨一下此次更新都带来了哪些内容。
### ? Kali Linux 2023.4: 新增了什么?
作为 **2023 年度 Kali 的压轴版本**,Kali Linux 2023.4 专注于提供一些新的平台选项,以及它们基础架构的一些更新。
几个**关键亮点**包括:
* 支持树莓派 5
* 集成 GNOME 45
* Vagrant 中加入了对 Hyper-V 的支持
#### 支持树莓派 5
Kali Linux 2023.4 版本已经支持 [树莓派 5](https://news.itsfoss.com/raspberry-pi-5/) 单板计算机。
你既可以 **手动构建镜像**,也可以下载新提供的 [专用镜像](https://www.kali.org/get-kali/#kali-arm),甚至可以使用 [Raspberry Pi Imager](https://www.raspberrypi.com/software/) 软件自动处理。
开发者也提到,[Nexmon](https://github.com/seemoo-lab/nexmon) **支持的内置 Wi-Fi 芯片上尚不能使用**,他们建议用户使用外部设备进行模式监控或帧注入。
#### 集成 GNOME 45
Kali Linux 2023.4 版本引入了全新的 [GNOME 45](https://news.itsfoss.com/gnome-45-release/)。你可以尝试使用**全新的药丸形工作区切换器**,**更优化的系统设置**,以及**新的或已更新的核心应用程序**,等等。
Kali Linux 团队也进行了**自定义的调整**,以进一步改善用户体验。他们采用了**改进的 Nautilus 搜索功能**,在许多应用中**实现了全高侧边栏**,并且还**更新了多种主题**。
#### Vagrant 中的 Hyper-V 支持
Kali Linux 的 [Vagrant 版本](https://app.vagrantup.com/kalilinux/boxes/rolling) 现在含有一个 Hyper-V 环境。如果你对此不熟悉,[Vagrant](https://www.vagrantup.com/) 是一个开源的 [Docker 替代方案](https://linuxhandbook.com/docker-alternatives/),可以帮助你构建和管理便携式的虚拟机环境。
#### ?️ 其他改变与提升
除了上述的特点外,还有一些其他显著的变化:
* 在日本和塞尔维亚设置了**新的下载镜像**。
* 启用 [Mirrorbits](https://github.com/etix/mirrorbits) 来进行 Kali 的**镜像重定向**。
* 在 [AWS](https://aws.amazon.com/marketplace/pp/prodview-fznsw3f7mq7to) 和 [Azure](https://azuremarketplace.microsoft.com/en/marketplace/apps/kali-linux.kali?tab=overview) 市场上提供了新的 **Kali Linux ARM64/AMD64 版本**。
* 在网络仓库中添加了**大量新的工具**。
你可以查阅官方 [发布博客](https://www.kali.org/blog/kali-linux-2023-4-release/),获取更多信息。
### ? 如何获取 Kali Linux 2023.4
你可以在 [官方网站](https://www.kali.org/get-kali/) 下载到 Kali Linux 2023.4 版本。
>
> **[Kali Linux 2023.4](https://www.kali.org/get-kali/#kali-platforms)**
>
>
>
**对于现有的用户**,可以通过运行下述命令来升级到最新版本:
```
sudo apt update && sudo apt full-upgrade
```
? 期待尝试这个版本的新特性吗?欢迎在下方分享你的感受!
*(题图:DA/a3379b67-99cc-4962-a8f2-cc46b831255c)*
---
via: <https://news.itsfoss.com/kali-linux-2023-4-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Kali Linux, the popular [hacking-focused Linux distro](https://itsfoss.com/linux-hacking-penetration-testing/?ref=news.itsfoss.com) has a new release in the form of **Kali Linux 2023.4**, which offers some important changes.
This comes only a few months after the [Kali 2023.3 release](https://news.itsfoss.com/kali-linux-2023-3-release/), so let's dive in and see what's in store.
**Suggested Read **📖
[10 Best Linux Distributions for Hacking & Pen Testing [2023]The best Linux distros that can help you learn hacking and pentesting.](https://itsfoss.com/linux-hacking-penetration-testing/?ref=news.itsfoss.com)

## 🆕 Kali Linux 2023.4: What's New?
Being **Kali's final release for 2023**, Kali Linux 2023.4 focuses on providing a few new platform offerings, and some updates to their infrastructure.
Some **key highlights** include:
**Raspberry Pi 5 Support****Inclusion of GNOME 45****Hyper-V Support in Vagrant**
### Raspberry Pi 5 Support
This has been one of the most sought after; Kali Linux 2023.4 features support for the [Raspberry Pi 5](https://news.itsfoss.com/raspberry-pi-5/) single-board computer.
You can either **build the image manually**, or download the new [dedicated image](https://www.kali.org/get-kali/?ref=news.itsfoss.com#kali-arm) that can also be automated using the [Raspberry Pi Imager](https://www.raspberrypi.com/software/?ref=news.itsfoss.com) software.
The developers have also mentioned that **Nexmon**** support is not functional** with the built-in Wi-Fi chip for now. They suggest users to use an external card to be able to monitor modes or frame injections.
### Inclusion of GNOME 45
Kali Linux 2023.4 sees the debut of [GNOME 45](https://news.itsfoss.com/gnome-45-release/) in all its *Activity-button-less* avatar. You can expect to take advantage of the **new pill-shaped workspace switcher**, **improved system settings**, **new/updated Core apps** and more.
The Kali Linux team has also done **some tweaks of their own** to improve the experience even further. They have **improved the** **speed of the search functionality in Nautilus**, **implemented full-height sidebars** in many apps, and **updated various themes.**
**Suggested Read **📖
[GNOME 45 Release Ditches the “Activities” ButtonThe latest and greatest of GNOME desktop is here.](https://news.itsfoss.com/gnome-45-release/)

### Hyper-V Support in Vagrant
Kali Linux's [Vagrant offering](https://app.vagrantup.com/kalilinux/boxes/rolling?ref=news.itsfoss.com) now includes a Hyper-V environment. If you are not familiar, [Vagrant](https://www.vagrantup.com/?ref=news.itsfoss.com) is a source-available [Docker alternative](https://linuxhandbook.com/docker-alternatives/?ref=news.itsfoss.com) that can be used to build and manage portable virtual machine environments.
### 🛠️ Other Changes and Improvements
Other than the above-mentioned, here are a few other notable changes:
**New download mirrors**in Japan and Serbia.- A transition to
[Mirrorbits](https://github.com/etix/mirrorbits?ref=news.itsfoss.com)for**handling mirror redirection**for Kali. - New
**Kali Linux ARM64/AMD64 offerings**on[Amazon AWS](https://aws.amazon.com/marketplace/pp/prodview-fznsw3f7mq7to?ref=news.itsfoss.com)and[Microsoft Azure](https://azuremarketplace.microsoft.com/en/marketplace/apps/kali-linux.kali?tab=overview&ref=news.itsfoss.com)marketplaces. - And a
**plethora of new tools**that have been added to the network repositories.
You can go through the official [release blog](https://www.kali.org/blog/kali-linux-2023-4-release/?ref=news.itsfoss.com) to learn more about this release.
## 📥 Get Kali Linux 2023.4
This release of Kali Linux is available from the [official website](https://www.kali.org/get-kali/?ref=news.itsfoss.com).
**For existing users**, you can update to the latest release by running the following command:
`sudo apt update && sudo apt full-upgrade`
*💬 Excited to try out this release? Share your thoughts with us below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,465 | Linux 爱好者线下沙龙:LLUG 2023·收官在北京 | https://jinshuju.net/f/BLSSBa | 2023-12-12T18:27:00 | [
"LLUG"
] | https://linux.cn/article-16465-1.html | 
经历了半年的全国巡游,Linux 爱好者沙龙走过了北京、上海、杭州、深圳、成都等五个城市,而在 2023 年的最后一个月,我们又再次回到了北京,与你在北京相见。
2023 年 12 月 16 日下午,我们将在北京市阿里中心·望京 A 座举办 LLUG 2023 · 北京收官场,欢迎广大的 Linux 爱好者来到现场,与我们一同交流技术,分享自己工作过程中的所思所想。
本次活动依然由 Linux 中国和龙蜥社区(OpenAnolis)联合主办,博文视点(Broadview)和阿里巴巴协办。
> 龙蜥社区(OpenAnolis)是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
> 博文视点(Broadview)是电子工业出版社下属旗舰级子公司。多年来,博文视点深耕专业出版,以敏锐眼光、独特视角密切关注技术发展趋势及变化,致力于将技术大师之优秀思想、一线专家之一流经验集结成书。
| 时间 | 议题 | 分享简介 | 分享者 |
| --- | --- | --- | --- |
| 14:00~14:20 | 签到 |
| 14:20~14:30 | LLUG 2023 年度总结 | 硬核老王 |
| 14:30~15:00 | 《UOS AI 在 deepin 中的应用及规划》 | UOS AI 对接国内多家主流大模型,与deepin 深度结合,以多款常用应用为载体为广大用户赋能,有效提升了用户办公、日常使用效率。UOS AI 的 AI 模型框架亦可为应用开发赋能,可有效提高生态伙伴的应用开发效率,降低生态伙伴的应用开发成本。 | 张鹏,从业 10+ 年产品人,曾任高思教育、微博产品经理,中科院软件所某项目部产品负责人,现任统信软件资深产品市场经理。 |
| 15:00~15:45 | 《运维小姐姐的十年冲突管理经验》 | 一个 Linuxer 的职场生存经验,面对冲突该如何保护自己、如何应对、如何让自己保持竞争力。 | 宋贺,从业十年 Linux 运维人,曾任职中国电信、中信国安运维工程师,在某国产数据库创业公司担任过产品经理,现就职于一线互联网公司业务运维岗位。 |
| 15:50~16:20 | 《Developer Nation 程序员调查报告解读》 | Developer Nation 是一个全球性的开发者社区,通过每年两次的开发者生态有奖问卷调查,洞察行业新趋势,打造更好的开发工具,并服务于软件开发者们。 | Ashley Au(远程)
|
| 16:20~17:00 | 闪电演讲(短分享) |
| 17:00 ~ 18:00 | 线下交流 |
#### 《UOS AI 在 deepin 中的应用及规划》

*张鹏,统信软件研发工程师*
UOS AI 对接国内多家主流大模型,与 deepin 深度结合,以多款常用应用为载体为广大用户赋能,有效提升了用户办公、日常使用效率。UOS AI 的 AI 模型框架亦可为应用开发赋能,可有效提高生态伙伴的应用开发效率,降低生态伙伴的应用开发成本。

*宋贺,一线互联网公司业务运维岗位*
作为一个 Linuxer,面对冲突该如何保护自己、如何应对、如何让自己保持竞争力
#### 闪电演讲
本次线下活动依旧保留闪电演讲环节,作为最受欢迎的线下活动,本次活动依旧继续举办闪电演讲。每位演讲者有 5 分钟时间参与现场活动,可以提前报名,也可即兴上台演讲。时间一满,马上结束~强制大家控制自己的分享时间,用最短的时间,向大家发出你的声音~
上海场闪电演讲照片:

*胡张治分享自己从 GNU/Linux 小白到 ArchLinuxCN 贡献者的旅程*

*李伟光现场介绍 neovim 的使用*
### 活动地点及到达信息
阿里中心·望京A座 5F-14 岳麓书院
**(由于阿里中心需要登记才能进入,请务必填写表单报名。现场直接空降可能是进不来的哦~)**
抵达方式:
【自驾】
* 导航到“阿里中心望京-A座”,按照入园指引图办理入园。
【公共交通】
* 地铁:乘坐 15 号线,望京东站 C 口出,步行 500 米到。
如果你因为有事,没办法来到线下,那也没问题,我们的活动也会在 Linux 中国视频号、Linux 中国 B 站、龙蜥 B 站、龙蜥钉钉群等开启同步直播。
当然,我们更希望你能亲自来到线下,和我们一起聊聊开源,聊聊技术~
活动报名地址:

*扫码报名*
此外,也可以在问卷中反馈你想听的内容,我们将竭尽所能,邀请行业专家,针对大家感兴趣的话题进行分享。
*(题图:DA/44ceac16-9e39-45f4-9e04-2b7c150ed260)*
| 302 | Found | null |
16,466 | 立即体验 Linux Mint 21.3 Beta 和 Cinnamon 6.0! | https://news.itsfoss.com/linux-mint-21-3-beta/ | 2023-12-13T06:51:39 | [
"Linux Mint"
] | https://linux.cn/article-16466-1.html | 
>
> Linux Mint 21.3 beta 版发布啦!
>
>
>
Linux Mint 无疑最好的 [基于 Ubuntu 的 Linux 发行版](https://itsfoss.com/best-ubuntu-based-linux-distros/) 之一。由于其社区为导向的处理方式,许多 Linux 社区的成员更倾向于它,而不是 Ubuntu。
在未来几周中,我们将看到 **Linux Mint 21.3** 的发布。然而,在此之前,我们先来一探究竟,看看这个长期支持版本将带来的内容。
就让我们一起瞧瞧吧!
>
> ? 注意!该 beta 版本仅用于测试。稳定版本将很快发布。
>
>
>
### Linux Mint 21.3 Beta 提供了什么新特性呢??

Linux Mint 21.3 的 beta 版本搭载了 [Linux 内核 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/),以及 [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/),并带来多项新特性。一些 **重要亮点** 包括:
* Cinnamon 6.0 的加入
* 应用程序的升级
* 全新的墙纸
#### Cinnamon 6.0 的加入

Linux Mint 21.3 Beta 版特别新引进了一直备受期待的 [Cinnamon 6.0](https://news.itsfoss.com/cinnamon-6-0-release/),该版本具有 **对 Wayland 的实验性支持**,**对 X11 的多项改进**,以及 **对 AVIF 图片格式的支持**。
令我眼前一亮的是一个全新的附加功能(Cinnamon 将这些称为 “*spices*”),名为 “<ruby> 动作 <rt> Actions </rt></ruby>”。它以前被视为 “<ruby> Nemo 动作 <rt> Nemo Actions </rt></ruby>”,而且功能主要局限于文件管理器。
然而,如上图所示,**这个新的 spice 可以让你安装扩展软件,以增强整体的 Cinnamon 桌面体验**,而不仅仅是对文件管理器进行微调。
此外,**这篇文章中的所有截图** 都是在 Wayland 会话中完成的,我所看到的表现,**Wayland 会话看起来相当不错**。尽管我认为开发人员还需要更多时间来完善它。
#### 应用程序的升级

提到应用程序,**Warpinator 现给予用户通过输入 IP 地址或在移动设备上扫描二维码手动连接其他设备的能力**。
**备份工具也得到了更新**,它现在有了一个带有专用 “<ruby> 关于 <rt> About </rt></ruby>” 对话框的标题栏。
连 **Hypnotix**,这款电视观看应用,也**更新了一些新特性**。
你现在**可以设定自己喜爱的频道**,它们会被整合在一起,而不考虑电视提供商的情况。你还能**创建新的频道**,通过输入可直播的 URL 来变成定制的电视频道。
#### 新的壁纸

总得来说,该 **Linux Mint 21.3 beta 版性中带有一些设计独特的壁纸**,这些都是各位贡献者的杰作。
如果想了解更多细节,你可以参考 [beta 版本发布公告](https://blog.linuxmint.com/?p=4611)。
### ? 下载 Linux Mint 21.3 Beta 版
如果你迫不及待想尝试稳定版,你可以从 Linux Mint 的 [官方索引](https://linuxmint.com/torrents/)(torrent)下载 Linux Mint 21.3 Beta 的 Cinnamon 版本 ISO。
只需搜索 “linuxmint-21.3-cinnamon-64bit-beta.iso.torrent”。
>
> **[Linux Mint 21.3 Beta](https://linuxmint.com/torrents/)**
>
>
>
? 我对接下来的 Linux Mint 21.3 发布倍感兴奋,你呢?
---
via: <https://news.itsfoss.com/linux-mint-21-3-beta/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint is arguably one of the [best Ubuntu-based Linux distros](https://itsfoss.com/best-ubuntu-based-linux-distros/?ref=news.itsfoss.com) out there. Many in the Linux community prefer it over Ubuntu due to its community-focused approach to handling things.
In just a few weeks time, we will be seeing the release of **Linux Mint 21.3**. However, before that, we now have a sneak peek into what that Long-term support release will offer.
Let's dive in!
## Linux Mint 21.3 Beta: What's on Offer? 🤔

Powered by [Linux kernel 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/), and [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/), this beta release of Linux Mint 21.3 has plenty to offer. Some **key highlights** include:
**Inclusion of Cinnamon 6.0****Application Upgrades****New Wallpapers**
### Inclusion of Cinnamon 6.0
Linux Mint 21.3 Beta features the recently introduced [Cinnamon 6.0 release](https://news.itsfoss.com/cinnamon-6-0-release/) that features **experimental support for Wayland**, **various improvements for X11**, **support for AVIF images** and more.
What took me by surprise was **a new add-on **(Cinnamon calls the add-ons as “*spices*”), called “**Actions**”. It was formerly known as “*Nemo Actions*”, and its functioning was limited to the file manager.
But, as demonstrated by the image above, **this new spice lets you install add-ons for enhancing the overall Cinnamon desktop experience**, while not being limited to just making tweaks to the file manager.
Moreover, **all the screenshots in this article** were taken in the Wayland session, and with what I saw, the **Wayland session seems to perform decently**. Though, I would still give it some time to mature, as the developers are still working on it.
**Suggested Read **📖
[Cinnamon 6.0 Release Debuts Experimental Wayland Support!Cinnamon 6.0 with Wayland session sounds interesting!](https://news.itsfoss.com/cinnamon-6-0-release/)

### Application Upgrades
On the application side of things, **Warpinator now lets you manually connect to other devices** by either entering IP addresses, or on mobile, by scanning a QR code.
The **backup tool also sees an update**, with it now featuring a header bar with a dedicated “*About*” dialog.
Even **Hypnotix**, the TV viewing application, has been **updated with new features**.
You can now **set channels as favorites**, and they will be grouped together, irrespective of the TV provider. You can also **create new channels** by entering streamable URLs to turn them into custom TV channels.
### New Wallpapers
To wrap things up, the **Linux Mint 21.3 beta features some nice-looking wallpapers** that were the work of various contributing artists.
For more details, you can refer to the [beta announcement](https://blog.linuxmint.com/?p=4611&ref=news.itsfoss.com).
## 📥 Download Linux Mint 21.3 Beta
If you can't wait for the stable release, you can download the Cinnamon Edition ISO for Linux Mint 21.3 Beta from the [official index](https://linuxmint.com/torrents/?ref=news.itsfoss.com) (torrent) of Linux Mint.
Just search for “*linuxmint-21.3-cinnamon-64bit-beta.iso.torrent*”.
*💬 I am excited about the upcoming Linux Mint 21.3 release, what about you?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,468 | Armbian 23.11 版本全新上线 | https://news.itsfoss.com/armbian-23-11-release/ | 2023-12-13T20:16:50 | [
"Armbian"
] | https://linux.cn/article-16468-1.html | 
>
> Armbian 最新版本提供了优化的新硬件支持和构建体验。
>
>
>
在众多 [单板计算机](https://en.wikipedia.org/wiki/Single-board_computer)(SBC)爱好者心中,首选的往往是 [Armbian](https://www.armbian.com/) —— 这是一款 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/),它能在多种配置下运行,提供了高度可扩展的用户体验。
Armbian **提供两种不同的配置**,一种基于精简版的 Debian 基础,另一种基于轻量级的 Ubuntu 基础。
几天以前,**Armbian 23.11** 版本正式发布,带来了诸多更新和改进。以下,让我们一同探索这些新变化。
### Armbian 23.11 “Topi” 版本:有什么新特性呢?

Armbian 23.11 版本(代号“*Topi*”)被开发者赞誉为 “*颇有特色*”的版本,它体现出了 Armbian **历经十年磨砺铸就的成果**,已经成为了 **SBC 爱好者的优选之选**。
下面,我们将着重看看这次版本更新的**重点亮点**:
首先,为了更好地体现板卡的可靠性和提供更好的帮助,**Armbian 的支持政策层次做出了调整**。这些调整分为三个层次:
* **标准支持**,板卡将获得全面且持续的支持。
* **阶段支持**,针对正在接受支持验证的板卡提供。
* **社区维护**,这个层次的板卡依赖更广大的社区共同维护。
在这次策略调整之下,**四款全新的开发板被加入到标准支持等级**,这四款开发板分别是:[Khadas VIM1S](https://www.khadas.com/vim1s)、[Khadas VIM4](https://www.khadas.com/vim4)、[Texas Instruments TDA4VM](https://www.ti.com/tool/SK-TDA4VM) 和小米 Pad 5 Pro。
此外,像 NanoPi [R6S](https://www.friendlyelec.com/index.php?route=product%2Fproduct&product_id=289)/[R6C](https://www.friendlyelec.com/index.php?route=product%2Fproduct&product_id=291),[Mekotronics R58X-Pro](https://www.mekotronics.com/h-pd-55.html),[Inovato Quadra](https://inovato.com/products/quadra) 和 [Tanix TX6](https://www.tanix-box.com/project-view/tanix-tx6-android-tv-box-allwinner-h6-dual-wifi-6k-alice-ux/) 这样的板卡也获得了支持。
从用户体验角度来看,**所有桌面上的显示管理器都经过了修复**,此次更新包括为 [Rockchip RK3588](https://www.rock-chips.com/a/en/products/RK35_Series/2022/0926/1660.html) 加入了主流内核,并**实验性支持 HDMI 和 EDK2/UEFI**。
另外,Armbian **最新版的边缘内核现已支持 [Linux 内核 6.6](https://news.itsfoss.com/linux-kernel-6-6-release/)**,并增加了全新的 Armbian 壁纸。此外还有一些 bug 修复,帮助**优化对现有开发板的硬件支持**,**解决显示输出问题**和**处理多个内核的编译问题**等。
你可以通过 [官方博客](https://www.armbian.com/newsflash/armbian-23-11-topi/) 深入了解本次发布的更多细节。
### ? 下载 Armbian 23.11
在 [官方网站](https://www.armbian.com/download/) 上,你就可以下载到 Armbian 23.11 版本。此外,开发者新推出了**两款全新的日常构建**版本,一个是基于 [Ubuntu Mantic Minotaur](https://news.itsfoss.com/ubuntu-23-10-release/),另一个则是 \*\*Debian Trixie。
>
> **[Armbian 23.11](https://www.armbian.com/download/)**
>
>
>
**对于已有的 Armbian 用户**,你可以按照 [官方文档](https://docs.armbian.com/User-Guide_Getting-Started/) 的步骤升级到 Armbian 23.11 版本。
? 你会尝试这个新发布的版本么?告诉我们你的回应吧!
*(题图:DA/3504891d-51ba-482b-bacc-1430d9c70bff)*
---
via: <https://news.itsfoss.com/armbian-23-11-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A first choice for many [single-board computer](https://en.wikipedia.org/wiki/Single-board_computer?ref=news.itsfoss.com) (SBC) enthusiasts, [Armbian](https://www.armbian.com/?ref=news.itsfoss.com) is a [lightweight Linux distribution](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com) that gives you a highly extensible user experience that can run on various configurations.
It is **offered in two distinct flavors**, one is based on a minimal Debian base, and the other is based on a lightweight Ubuntu base.
A few days back, **Armbian 23.11** was released with many changes and improvements. Let's take a brief look at the new changes.
## Armbian 23.11 “Topi”: What's New?

Dubbed by the developers as a “*pretty special*” version, Armbian 23.11, code-named “*Topi*” is meant to be **the result of a decade worth of work** that has made Armbian **a popular choice for SBC tinkerers**.
Let's start with the **key highlights** of this release:
For starters, the **Armbian support policy tiers have been tweaked** to reflect better reliability and assistance for boards. The three tiers are:
**Standard Support**, where boards will receive full and consistent support.**Staging Support**, this is tailored for boards that are undergoing support validation.**Community Maintained**, these boards depend on the wider community for maintenance.
Under this, **four new boards were added to the Standard Support tier**; [Khadas VIM1S](https://www.khadas.com/vim1s?ref=news.itsfoss.com), [Khadas VIM4](https://www.khadas.com/vim4?ref=news.itsfoss.com), [Texas Instruments TDA4VM](https://www.ti.com/tool/SK-TDA4VM?ref=news.itsfoss.com), and Xiaomi Pad 5 Pro.
Additionally, support was also added for boards such as the NanoPi [R6S](https://www.friendlyelec.com/index.php?route=product%2Fproduct&product_id=289&ref=news.itsfoss.com)/[R6C](https://www.friendlyelec.com/index.php?route=product%2Fproduct&product_id=291&ref=news.itsfoss.com), [Mekotronics R58X-Pro](https://www.mekotronics.com/h-pd-55.html?ref=news.itsfoss.com), [Inovato Quadra](https://inovato.com/products/quadra?ref=news.itsfoss.com), and [Tanix TX6](https://www.tanix-box.com/project-view/tanix-tx6-android-tv-box-allwinner-h6-dual-wifi-6k-alice-ux/?ref=news.itsfoss.com).
On the user-facing side of things, **various fixes were made to the display managers** across all the desktops, inclusion of a mainline kernel for [Rockchip RK3588](https://www.rock-chips.com/a/en/products/RK35_Series/2022/0926/1660.html?ref=news.itsfoss.com) with **experimental HDMI and EDK2/UEFI support**.
Furthermore, the** edge kernel offering of Armbian** now features [Linux Kernel 6.6](https://news.itsfoss.com/linux-kernel-6-6-release/), and features new Armbian wallpapers. There are also a few bug fixes to **improve hardware support for existing boards**, **fix display output issues**, **handle compilation issues for various kernels**, and more.
You may go through the [official blog](https://www.armbian.com/newsflash/armbian-23-11-topi/?ref=news.itsfoss.com) to dive into the fine print of this release.
## 📥 Download Armbian 23.11
Armbian 23.11 is available to download from the [official website](https://www.armbian.com/download/?ref=news.itsfoss.com). The developers have also introduced** two new daily builds**, one with [ Ubuntu Mantic Minotaur](https://news.itsfoss.com/ubuntu-23-10-release/) and the other with
**Debian Trixie**.
**For existing installations**, you can follow the [official documentation](https://docs.armbian.com/User-Guide_Getting-Started/?ref=news.itsfoss.com) to upgrade to the Armbian 23.11 release.
*💬 Will you be trying out this release? Let us know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,469 | 对 Bash 感到厌倦?教你如何在 Linux 中更改默认 Shell | https://itsfoss.com/linux-change-default-shell/ | 2023-12-13T22:06:30 | [
"Shell"
] | https://linux.cn/article-16469-1.html | 
Bash 并不是唯一可供选择的 Shell。还存在数量众多的 Shell,它们都有一些独特的特性,例如 Zsh、Fish、Ksh 和 [Xonsh](https://itsfoss.com/xonsh-shell/)。
在你的系统中,你可以同时安装多个 Shell。
要想将另一个 Shell 设为默认值,你可以按照以下方式使用 chsh 命令:
```
chsh -s path_to_binary_of_shell
```
如需找到 Shell 的二进制路径,你可以查看 `/etc/shells` 文件的内容。另外,你也可使用以下自动获取所需 Shell 二进制路径的命令:
```
chsh -s $(which new_shell)
```
接下来,让我们详细了解一下如何确定并更改 Shell。
### 我现在用的是哪个 Shell?
有很多方法可以帮你找出当前使用的是哪个 Shell,虽然专家可能会辩论这些方法的准确度。
最常用的,也是最简单的方式是:
```
echo $0
```
[$0 是一个特别的 Shell 变量](https://linuxhandbook.com/bash-dollar-0/),这可以获取你正在使用的 Shell 或 Shell 脚本的名称(如果你在脚本中使用了它)。

你还可以使用下面的命令检查进程:
```
ps -p $
```
其中,`$` 代表的是当前进程 / Shell 的进程 ID。

### 如何安装另一个 Shell?
和其他软件包一样,大部分知名 Shell,例如 [Fish](https://fishshell.com/) 和 Zsh,都可以直接从你的发行版软件仓库中下载安装。新的,相对小众的 Shell,例如 Xonsh,可能就需要不同的安装步骤了。你可以在它们的项目网页上找到具体的安装指南。
比如,你想 [在 Ubuntu 上安装 Zsh](https://itsfoss.com/zsh-ubuntu/),那么可以使用以下命令:
```
sudo apt install zsh
```
### 如何更改当前的 Shell?
假设你已经安装了另一个 Shell,那么我们来看一看如何切换过去。
实际上,你只需要输入新 Shell 的名称即可。比方说,你想切换到 Zsh,那就输入:
```
zsh
```
若要退出当前的 Shell,只需输入 `exit` 即可,你会回到你的默认 Shell。
### 如何查看默认的 Shell 是哪个?
有一个 `SHELL` 的环境变量,它可以告诉你当前账户的默认 Shell 是哪个:
```
echo $SHELL
```
举个例子,我切换到了 Zsh。此时,当前 Shell 显示的信息是 `zsh`,而默认 Shell 依然显示为 `bash`:

这说明更改 Shell 并不会改变默认的 Shell。也就是说,下次你再次登录到该终端或系统,你还会返回到旧的默认 Shell,而不是新的 Shell。
### 如何知道系统中可用的 Shell 有哪些?
你可以通过查看 `/etc/shells` 文件,来了解系统中具有哪些可用的 Shell:
```
cat /etc/shells
```
下面就是我当前系统中所有可用的 Shell:

### 如何更改默认的 Shell?
`/etc/shells` 文件的内容显示了所有可用 Shell 的二进制文件位置。你需要将它与 chsh 命令一起使用。
假设我想让 Zsh 成为默认的 Shell,我可以输入:
```
chsh -s /usr/bin/zsh
```
更改后,**你需要重新登入**才能看到变化。
请注意,以上操作只会更改当前用户的默认 Shell。如果你是管理员,并且想更改其他用户的默认 Shell,那么你可以使用以下命令:
```
sudo chsh -s /usr/bin/zsh other_username
```
### 结论
Linux 的一大特色就是,用户可以自主选择。你完全可以根据自己的需要进行更改。这就是另一个例子,你不必局限于发行版提供的默认 Shell 的选择。你很欢迎自选一款 Shell,让你的工作变得更顺手。最后,祝你使用愉快 ?
*(题图:DA/cf9b865d-2b98-4ada-88df-de1d1839aba1)*
---
via: <https://itsfoss.com/linux-change-default-shell/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Bash is not the only shell out there. There are many other shells available with slightly different feature sets. A few examples are Zsh, Fish, Ksh are [Xonsh](https://itsfoss.com/xonsh-shell/).
You can have more than one shell installed on your system at any given time.
If you want to choose some other shell as your default, you can use the chsh command in this fashion:
`chsh -s path_to_binary_of_shell`
You can get the path of the binary of the shell by displaying the contents of the `/etc/shells`
file. You may also use the command below that automatically gets the binary of the desired shell with the which command:
`chsh -s $(which new_shell)`
Let's see things about knowing and changing shells a bit more in detail here.
## How to know which shell are you using currently?
There are a few ways to figure out which shell is being used currently, although the accuracy of these methods can be debatable by the experts.
The simplest and most common way is to use:
`echo $0`
[$0 is a special shell variable](https://linuxhandbook.com/bash-dollar-0/) that gets you the name of the shell or shell script (if you are using it in a script).
Another method is to use check the process using:
```
ps -p $$
```
Here, `$$`
gives you the process ID of the current process/shell.
## How to install another shell?
Well, like any other software package. Most of the popular shells, like [Fish](https://fishshell.com/?ref=itsfoss.com) and Zsh, are available from your distribution's repository and can be installed easily. The newer, lesser-known shells, like Xonsh, may have a different installation instruction. You can get that from the project's web page.
Let's say you want to [install Zsh on Ubuntu](https://itsfoss.com/zsh-ubuntu/). Use:
`sudo apt install zsh`
## How to change the current shell?
Now that you have installed another shell, let's see about changing it.
Most likely, you just have to enter the name of the shell. Say, you have to switch to Zsh:
`zsh`
To exit from the current shell, enter exit and you'll be back to the default shell.
## How to know the default shell?
There is this `SHELL`
environment variable that tells you the default shell for the current user:
`echo $SHELL`
Let's take this example where I switched to Zsh. The current shell shows to zsh and the default shell remains bash:
This tells you that changing the shell won't change the default shell. Which means the next time you log into the terminal/system, you'll be back to the old default shell instead of the newly one.
## How to know the available shells on your system?
You can see the available shells in your system by looking at the content of the `/etc/shells`
:
`cat /etc/shells`
Here are the presently available shells in my system:
## How to change the default shell?
The contents of the `/etc/shells`
file shows the location of binaries of the available shell. You have to use it with the chsh command.
Let's say, I want to make the Zsh shell the default. Here's what I use:
`chsh -s /usr/bin/zsh`
**Log out and log in again** to see the changes.
Note that this will change the default shell of the current user. If you are an admin and want to change the default shell for another user, use:
```
sudo chsh -s /usr/bin/zsh other_username
```
## Conclusion
Linux is all about choices. You have the liberty to make changes as you wish. This is another example where you are not bound by the choice of the default shell your distribution provides. You can change the shell to the one you prefer. Enjoy 😄 |
16,471 | Jami:一款多功能开源分布式通讯应用 | https://itsfoss.com/jami/ | 2023-12-14T09:08:00 | [
"Jami",
"通讯应用"
] | https://linux.cn/article-16471-1.html | 
>
> 下面将引导你安装和使用 Jami,让你对其工作原理和你能从中获取的内容有更深入的理解。
>
>
>
不管你是为了联系亲爱的人,还是为了职业需求与同事/团队沟通,一个安全的通讯平台都是大家的需求。[Jami](https://jami.net/) 就是其中一款通讯平台,利用**分布式网络**来实现视频通话、文件分享、聊天等功能全都不经过服务器。
这个工具完全免费且开源,具有多样的功能。
然而,它的表现如何呢?用户体验会好么?使用体验能像其他已有的专有平台那么流畅么?或者,你能在手机上使用吗?
在这篇文章里,我们将仔细研究 Jami。我们试用了一下以助你作出更明智的决定。
### Jami 的特性

对很多用户来说,体验的好坏取决于功能的全面性。
所以,在深入研究 Jami 之前,让我概述一下,你可以期待从它得到什么样的功能:
* 即时发送消息
* 群聊
* 视频会议
* 音频通话
* 音频和视频信息
* 屏幕共享
* 文件分享
* 增强功能的扩展
* 作为 SIP(会话启动协议)客户端
看起来,Jami 是一款在考虑分布式解决方案时值得考虑的全能选项。
听上去挺刺激的,对吧?
那我们现在就来细看一下,看看它是如何工作的,以及我们能从中获得什么。
### 使用 Jami 的入门步骤

在你的系统上安装 Jami 是相当简单的。
你可以直接从它的网站下载最新的官方版本,或者直接在你的包管理器中(对于 Linux)搜索它。
它可以跨平台使用,包括:Linux、Windows、macOS、安卓和 iOS。
对于安卓用户,你可以在 Play Store 或 F-Droid 中安装。至本文撰写之时,Jami 支持所有最新和最棒的操作系统版本,所以,从这个层面上看,它的维护工作做得相当好。
在安装完成之后,就开始了注册过程。不像其他一些平台,它并不需要任何私人信息,只需要你创建一个你喜欢的独特用户名。
完成之后,你只需要把这个用户名与其他用户分享,就可以开始对话了。你也可以展现出 QR 码让其他人连接你。就是这么简单。

在注册时,你可以选择加密你的帐户,以在设备上保护它,并自定义显示名。
### 使用 Jami 作为通讯平台

使用这类平台时,我们的首要关心点通常是发送 / 接收消息的响应速度,以及语音 / 视频通话的质量。
好消息是:**使用体验快捷顺畅**。不管你是要发送一个视频信息,进行一个音频通话,还是发送文本,Jami 都像你想象的一样响应灵敏。
当我们谈及 **用户界面**,每个人的看法可能都会不同。我发现它的用户界面简明扼要,干净利落。

然而,当你调窄应用窗口的宽度时,事情可能会有所不同。它失去了适应较小尺寸的能力,忽视了重要的元素,甚至难以顺畅地访问设置,这降低了使用体验。

不要误会,你仍可以正常导航至所有选项。然而,体验感会显得有些生硬。
当把 Jami 的窗口缩小时,我点击了“<ruby> 设置 <rt> Settings </rt></ruby>”,结果直接进入了“<ruby> 账户管理 <rt> Manage Account </rt></ruby>”选项,而没有给我任何下拉菜单,也没有为我打开“<ruby> 账户 <rt> Accounts </rt></ruby>”/“<ruby> 一般 <rt> General </rt></ruby>”或“<ruby> 音频/视频 <rt> Audio/Video </rt></ruby>”部分。
假设我想要进入“音频/视频”设置,我就会进入账户设置。接下来,我需要再次导航到其他设置。这并不是一个让人感到方便的体验。
如果你不会经常调小 Jami 的窗口,或者你更喜欢大一点的窗口,那么你应该不会遇到此类问题。总结一下,如果你希望所有东西都有现代化的设计风格,那它可能会有些失望。
当你第一次发送/接收文本或通话时,会被视作一次邀请。一旦你接受了邀请,用户就会出现在你的会话列表中。
发送短信,添加新朋友的体验是无缝连接的,我没有遇到任何问题。

>
> ? 在撰写本文时进行的最新版本测试中,我无法关闭捐款消息。我答复的同事也遇到这个问题。
>
>
>
在信息中,你会有标记“正在输入中”的提示,你也可以回复一个特定的消息,用一个表情符号做出反应,附加文件,或发送语音或者视频消息。
这些消息都可以被编辑和删除。

上面的对话截图是一个通过选择多个用户创建的群聊。
这样,当你创建这样的群聊时,一个新的邀请会被发送到用户那里,这是好的(不是强制他们加入群聊)。如果他们接受了邀请,他们就能加入你创建的群聊。
默认情况下,创建群组的设备将会默认承载群组内的任何音频 / 视频通话。
如果你连接的账户有多个设备,你可以选择你想要作为主机的那个设备。
通话体验有些不尽人意,具体来说,音频通话体验十分出色,音频清晰。

然而,视频通话的音频方面就有些令人失望。
当然了,用直连的方式,视频质量会严重依赖网络连接,然而,和网络连接相比,我们得到的质量并没有那么好。(主机是我,网速是 200 Mbps)。

视频质量可能是由于优化不佳或网络不佳导致的,但是,双方的音频并不清晰,音量在整个通话中都在上下波动。
虽然我的一些同事能分享他们的屏幕,但是在带有 AMD Radeon 集成 GPU 的 Ubuntu 22.04 LTS 上,应用崩溃了。

默认情况下,你无法添加绿幕效果,这和一些专有的视频通话应用不同。然而,你可以安装扩展增加此类功能。

另外,为了增强你的体验,你可以调整通话设置,包括自动接听电话,将你的账户作为接入点,切换正在输入中的指示等。
### 总结
如果 Jami 能在现代化用户界面这方面投入更多努力,那么它应该能成为像微软 Teams、Slack 和 Zoom 这样的应用的热门选择。
当然了,因为 P2P 连接原因,视频质量可能不如其他专有选项那么稳定。但在音频通话、视频/音频信息、文字输入、文件发送等方面你应该不会有任何问题,同时享受私密的通讯体验。
总的来说,Jami 为你提供了所有基本的需求,在一个更快的体验上提供了基本的用户界面。
>
> **[探究 Jami](https://jami.net/)**
>
>
>
它可能不能给你最好的用户体验,但是考虑到它在分布式网络连接、开源应用和隐私保护方面的优势,对于注重隐私的用户来说,它仍是个极好的选择。
*(题图:DA/26649e6b-a4b6-4591-a5c1-ecac982529a9)*
---
via: <https://itsfoss.com/jami/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Whether you want to connect to your loved ones or colleagues/team for professional requirements, everyone would like to use a secure communication platform to do that.
[Jami](https://jami.net/) is one such communication platform that utilizes a **distributed network** to let you make video calls, share files, communicate via chat, and more. **Which means that there is no server at all between people**.
It is an entirely free and open-source tool with versatile functionalities.
But, how well does it work? Do you get a good user experience with it? Is it a seamless experience like some other proprietary platforms? Can you use it on your mobile?
In this article, let us take a good look at Jami. We gave it a try to help you decide better.
## Features of Jami
For some users, it is the availability of features that make or break the experience.
So, before we take an in-depth look at Jami, let me highlight what you can expect with it:
- Instant messaging
- Group chats
- Video Conferences
- Audio calls
- Audio and video messages
- Screen sharing
- File sharing
- Extensions for enhanced functionalities
- Ability to use it as an SIP (Session Initiation Protocol) client
With the feature-set on offer, Jami sounds like a versatile option to consider while being a distributed solution.
Sounds exciting, right?
Now, let us go through some details where we evaluate how it works, and what options we get with it.
## Getting Started With Jami
Installing Jami on your system is easy.
You can either download the latest official package from its website or search for it in your package manager (for Linux).
It is available cross-platform, including Linux, Windows, macOS, Android, and iOS.
For Android users, you can install it from the Play Store or F-Droid. Jami supports all the latest and greatest versions of operating systems at the time of writing this. So, it is actively maintained on that aspect.
After the installation, there comes the sign up process. Unlike some other platforms, it does not need any personal information to get you up and running.
All you have to do is create a unique username per your liking. Once done, you just need to share that username with other users to start communicating. You can also show the QR code for others to connect with you. It is that easy.
At the time of signing up, you can choose to encrypt your account to keep it protected on the device and customize the display name.
## Using Jami as a Communication Platform
The first concern that we usually have with such platforms is the responsiveness of sending/receiving messages and the quality of voice/video calls.
The good news is: **it is a fast experience**. Whether it is about sending a video message, making an audio call or, sending texts, Jami was as responsive as one would want it to be.
When it comes to the **user interface**, it will be a subjective take. I found the UI straightforward and distraction-free.
Having said that, things change when you reduce the window size of the app. It fails to adapt to a smaller area, and misses out on keeping important elements, and the downgrades experience of accessing the settings.
Do not get me wrong, it looks like you can navigate to all the options well. However, the experience is clunky.
When I clicked on "Settings" with Jami in a smaller area, it directly took to the "Manage Account" option, instead of giving me any dropdown menu or a way to access "Account" / "General" or "Audio/Video" sections.
Suppose, I wanted to access Audio/Video settings, I get pulled to the Account settings. Next, I need to navigate my way back to find other settings. Not a convenient experience to have.
If you do not use Jami by reducing the window size, and prefer it bigger than 850px or more, you should not encounter this issue.
In a nutshell, if you are some who prefers a modern touch to everything for UI, it can be an underwhelming experience.
When it is the first time you send/receive a text/call, it is treated as an invitation. Once you accept the invitation, the user will show up in your list of conversations.
Texting and connecting with new friends is a seamless experience. I had no problems at all.
You have typing indicators, you can reply to a specific message, react with an emoji, attach files, and send a voice or video message.
The messages can be edited and deleted as well.
The conversation in the screenshot above is a group chat (swarm) created by selecting multiple users.
So, when you create such a group, a new set of invitations will be sent to the users, which is a good thing (instead of forcefully adding them to the group). If they accept the invitation, they will join the group chat you created.
The device which creates the group hosts any audio/video calls made within the group by default.
If you have multiple devices connected to the account, you can select the device you want to be the host.
The calling experience was sub-par, meaning, the audio call experience was excellent with crisp audio.
However, the video call was disappointing, on the audio-side.
Sure, with a direct connection, the video quality heavily depends on the network connection. However, we still did not get the quality as we should with our connection (the host, me, with a 200 Mbps network).
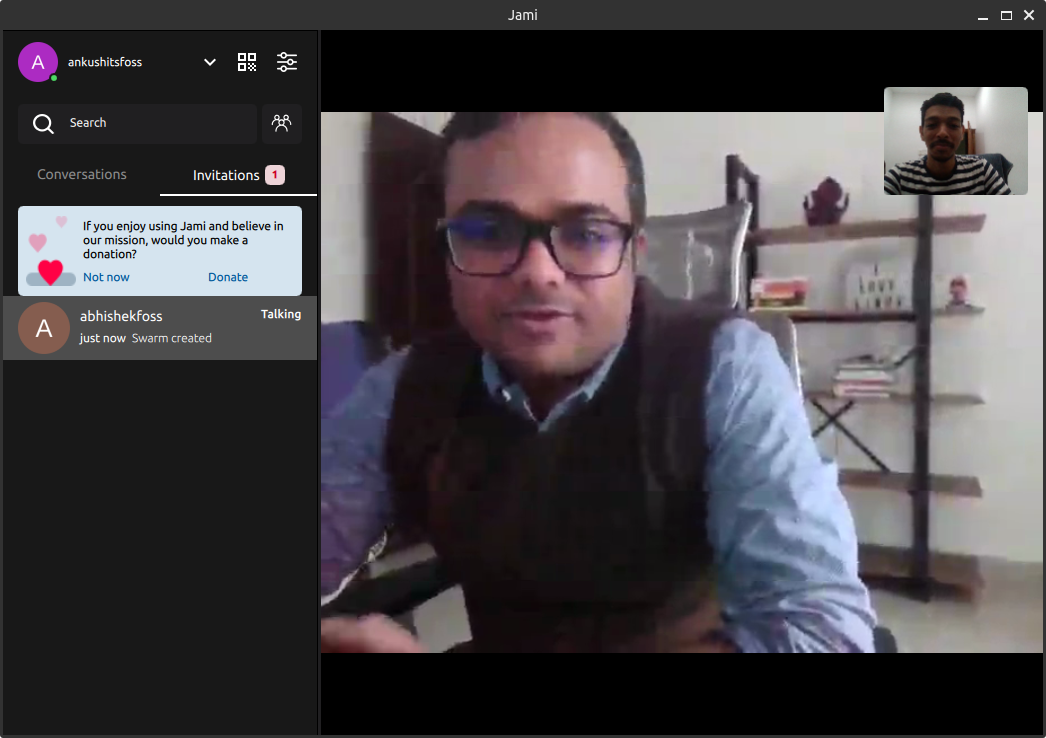
The video could be the result of bad optimization or poor network from the other side. But, the audio was not clear for both sides, with the volume going up and down throughout the call.
While some of my colleagues were able to share their screen, the app crashed on Ubuntu 22.04 LTS with AMD Radeon integrated GPU onboard.
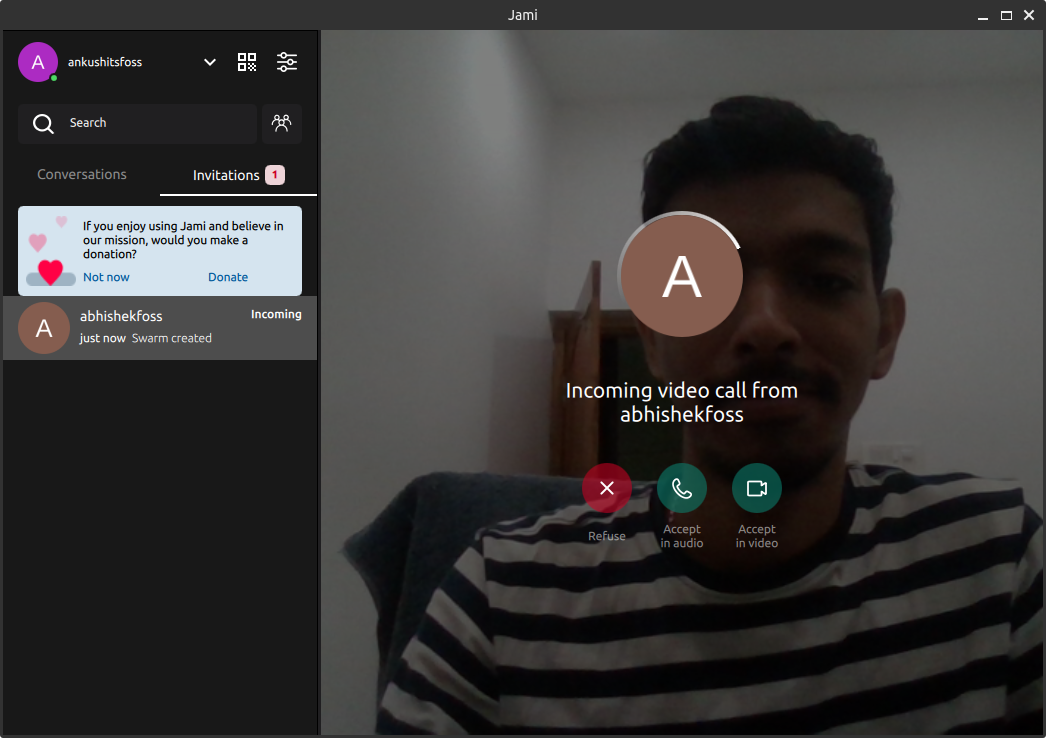
By default, you do not have any option to add a green screen effect, unlike some proprietary video calling apps. However, you can install extensions to add such abilities.
Additionally, to enhance your experience, you can adjust the call settings with options like auto-answer calls, using your account as a rendezvous point, toggle typing indicators, and more.
## Wrapping Up
If Jami gives a little more effort to modernize its user interface, it could become a popular option over the likes of Microsoft Teams, Slack, or Zoom.
Sure, the video quality may not be as consistent as other proprietary options because of the peer-to-peer connection. You should have no hiccups with audio calls, video/audio messages, texts, sending files, and more while enjoying a private communication experience.
Overall, Jami provides you with all the essentials, with a basic user interface aimed for a faster experience.
**It may not give you the "best" user experience, but considering its advantages for a distributed network connection, open-source app, and privacy, it should fit perfectly for a privacy-conscious user.** |
16,472 | Linux 用户的 7 个 sudo 技巧和改进 | https://itsfoss.com/sudo-tips/ | 2023-12-14T23:23:54 | [
"sudo"
] | https://linux.cn/article-16472-1.html | 
>
> 用这些技巧释放 sudo 的力量 ?
>
>
>
你应该熟悉 sudo 吧?肯定有过使用的经验。
对多数 Linux 用户来说,`sudo` 就像一个神器,赋予了他们作为 root 用户执行任意命令或切换到 root 用户身份的能力。
其实这只掌握了一半的真相。`sudo` 绝非仅仅只是一条命令,**`sudo` 是一款你可以根据需求和偏好去定制的工具**。
Ubuntu、Debian 以及其他的发行版在默认的配置下,赋予了 `sudo` 以 root 用户的身份执行任意命令的权限。这让很多用户误以为 `sudo` 就像一个魔法开关,瞬间可以获取到 root 权限。
**比如说,系统管理员可以设置成只有属于特定的 `dev` 组的部分用户才能用 `sudo` 来执行 `nginx` 命令。这些用户将无法用 `sudo` 执行任何其他命令或切换到 root 用户。**
如果你对此感到惊讶,那很可能是你一直在使用 `sudo`,但对其底层的工作原理并没有太多了解。
在这个教程中,我并不会解释 `sudo` 是如何运作的,这个主题我会在另一天讲解。
在这篇文章中,你将看到 `sudo` 的不同特性可以如何被调试和改进。有些可能真的很有用,有些可能完全没什么帮助,但是挺有趣。
>
> ? 请不要随意去尝试所有提到的改进。如果处理不慎,你可能会遭遇无法运行 `sudo` 的混乱状态。在大多数情况下,平静阅读并知道这些就好。如果你决定尝试一些改进步骤,[请先备份你的系统设置](https://itsfoss.com/backup-restore-linux-timeshift/),这样在需要的时候能把事情恢复到正常。
>
>
>
### 1、编辑 sudo 配置时,请始终使用 visudo
`sudo` 命令是通过 `/etc/sudoers` 文件进行配置的。
虽然你可以用你最喜欢的 [终端文本编辑器](https://itsfoss.com/command-line-text-editors-linux/) 编辑这个文件,比如 Micro、NeoVim 等,但你**千万不要**这么做。
为什么这么说呢?因为该文件中的任何语法错误都会让你的系统出问题,导致 `sudo` 无法工作。这可能会使得你的 Linux 系统无法正常使用。
你只需要这样使用即可:
```
sudo visudo
```
传统上,`visudo` 命令会在 Vi 编辑器中打开 `/etc/sudoers` 文件。如果你用的是 Ubuntu,那么会在 Nano 中打开。

这么做的好处在于,**visudo 会在你试图保存更改时执行语法检查**。这能确保你不会因为语法错误而误改 `sudo` 配置。

好了!现在你可以看看 `sudo` 配置的一些改变。
>
> ? 我建议你备份 `/etc/sudoers` 文件(`sudo cp /etc/sudoers /etc/sudoers.bak`)。这样,如果你不确定你做了哪些更改,或者你想恢复到默认的 sudo 配置,那你可以从备份文件中复制。
>
>
>
### 2、输入 sudo 密码时显示星号
我们的这种输入行为是从 UNIX 系统中继承下来的。当你在终端输入 `sudo` 密码时,屏幕上不会有任何显示。这种缺乏反馈的现象,往往让新的 Linux 用户怀疑自己的系统已经卡住了。
人们常说,这是一项安全功能。或许在上个世纪是这样,但我个人觉得我们没有必要继续这样下去。
不过,一些发行版,如 Linux Mint,已经对 `sudo` 进行了优化,当你输入密码时会显示星号。
这样的方式更符合我们的日常经验。
如果想让 `sudo` 输入密码时显示星号,运行 `sudo visudo` 并找到以下行:
```
Defaults env_reset
```
然后将其更改为:
```
Defaults env_reset,pwfeedback
```

>
> ? 在某些发行版中,比如 Arch,你可能找不到 `Defaults env_reset` 这一行。如果这样的话,只需新增一行 `Defaults env_reset, pwfeedback` 就可以了。
>
>
>
现在,当 `sudo` 需要你输入密码时,你会看到输入的密码变成了星号。

>
> ✋ 如果你注意到即使密码正确也无法通过一些图形化应用,如软件中心,那就该撤销这项更改。一些较旧的论坛帖子曾提到过此类问题,虽然我自己还未遇到过。
>
>
>
### 3、增加 sudo 密码超时时限
当你首次使用 `sudo` 时,它会要求输入密码。但在随后相当一段时间里,你使用 `sudo` 执行命令就无需再次输入密码。
我们将这个时间间隔称为 `sudo` 密码超时 (暂且称为 SPT,这是我刚刚编的说法,请不要真的这样称呼 ?)。
不同的发行版有不同的超时时间。可能是 5 分钟,也可能是 15 分钟。
你可以根据自己的喜好来改变这个设置,设定一个新的 `sudo` 密码超时时限。
像你之前看到的,编辑 `sudoers` 文件,找到含有 `Defaults env_reset` 的行,并在此行添加 `timestamp_timeout=XX`,使其变成如下形式:
```
Defaults env_reset, timestamp_timeout=XX
```
其中 `XX` 是以分钟为单位的超时时长。
如果你还有其他参数,例如你在上一节中看到的星号反馈,它们都可以在一行中组合起来:
```
Defaults env_reset, timestamp_timeout=XX, pwfeedback
```
>
> ? 同样地,你还可以控制密码重试的次数上限。使用 `passwd_tries=N` 来修改用户可以输入错误密码的次数。
>
>
>
### 4、在不输入密码的情况下使用 sudo
行!你已经增加了 `sudo` 密码超时时限(或者称之为 SPT。哇塞!你还在坚持这个叫法 ?)。
这样很好。我的意思是,毕竟没人愿意每几分钟就输入一次密码。
扩大超时时限是一方面,另一方面则是尽可能不去使用它。
是的,你没听错。你就是可以在无需输入密码的情况下使用 `sudo`。
从安全角度来看,这听起来似乎很冒险,对吧?的确如此,但在某些实际情况下,你确实会更青睐无密码的 `sudo`。
例如,如果你需要远程管理多台 Linux 服务器,并为了避免总是使用 root,你在这些服务器上创建了一些 `sudo` 用户。辛酸的是,你会有太多的密码。而你又不想对所有的服务器使用同一的 `sudo` 密码。
在这种情况下,你可以仅设置基于密钥的 SSH 访问方式,并允许使用无需密码的 `sudo`。这样,只有获得授权的用户才能访问远程服务器,也不用再记住 `sudo` 密码。
我在 [DigitalOcean](https://digitalocean.pxf.io/JzK74r) 上部署的测试服务器上就采用了这种方法,用来测试开源工具和服务。
好处是这可以按用户进行设置。使用以下命令打开 `/etc/sudoers` 文件进行编辑:
```
sudo visudo
```
然后添加如下行:
```
user_name ALL=(ALL) NOPASSWD:ALL
```
当然,你需要将上面行中的 `user_name` 替换为实际的用户名。
保存文件后,你就可以享受无密码的 `sudo` 生活了。
### 5、配置独立的 sudo 日志文件
查阅 syslog 或 journal 日志,我们可以找到关于 `sudo` 的所有条目,但若需要单独针对 `sudo` 的记录,可以专门创建一个自定义的日志文件。例如,选择 `/var/sudo.log` 文件来存储日志。这个新的日志文件无需手动创建,如果不存在,系统会自动生成。
编辑 `/etc/sudoers` 文件,采用 `visudo` 命令,并在其中添加以下内容:
```
Defaults logfile="/var/log/sudo.log"
```
保存该文件后,便可以在其中查看哪些命令在何时、由哪位用户通过 `sudo` 运行了。

### 6、限制特定用户组使用 sudo 执行特定命令
这是一种高级解决方案,系统管理员在需要跨部门共享服务器的多用户环境中会使用。
开发者可能会需要以 root 权限运行 Web 服务器或其他程序,但全权给予他们 `sudo` 权限会带来安全风险。我建议在群组级别进行此项操作。例如,创建命名为 `coders` 的群组,并允许它们运行在 `/var/www` 和 `/opt/bin/coders` 目录下的命令(或可执行文件),以及 [inxi 命令](https://itsfoss.com/inxi-system-info-linux/)(路径是 `/usr/bin/inxi` 的二进制文件)。这是一个假想情景,实际操作请谨慎对待。
接下来,用 `sudo visudo` 编辑 sudoer 文件,再添加以下行:
```
%coders ALL=(ALL:ALL) /var/www,/opt/bin/coders,/usr/bin/inxi
```
如有需要,可以添加 `NOPASSWD` 参数,这样允许使用 `sudo` 运行的命令就不再需要密码了。
关于 `ALL=(ALL:ALL)` 的详细解读,我们将会在其他文章中进行讲解,毕竟这篇文章已经解释的内容足够多了。
### 7、检查用户的 sudo 权限
好吧,这是个小提示,而不是系统调优技巧。
如何确认一个用户是否具有 `sudo` 权限呢?可能有人会说,查看他们是否是 `sudo` 组的成员。但这并不一定准确,因为有些发行版用的是 `wheel` 代替 `sudo` 分组。
更佳的方法是利用 `sudo` 内建的功能,看看用户具有哪种 `sudo` 权限:
```
sudo -l -U user_name
```
这将显示出用户具有执行部分命令或所有命令的 `sudo` 权限。

如你所见,我拥有自定义日志文件、密码反馈以及执行所有命令的 `sudo` 权限。
如果一个用户完全没有 `sudo` 权限,你将看到如下提示:
```
User prakash is not allowed to run sudo on this-that-server.
```
### ? 附加内容:输错 sudo 密码时,让系统“侮辱”你
这是个我在文章开头提到的“无用”小调整。
我想你在使用 `sudo` 时肯定曾误输过密码,对吧?
这个小技巧就是,在你每次输错密码时,[让 sudo 抛出随机的“侮辱”](https://itsfoss.com/sudo-insult-linux/)。
用 `sudo visudo` 修改 `sudo` 配置文件,然后添加以下行:
```
Defaults insults
```
修改后,你可以故意输错密码,测试新的设置。

你可能在想,谁会喜欢被侮辱呢?**只有粉丝**可以以直白的方式告诉你 ?
### 你是如何运用 sudo 的?

我知道定制化的可能性无穷无尽,但其实,一般的 Linux 用户并不会去自定义 `sudo`。
尽管如此,我还是热衷于与你分享这些因为你可能会发现一些新奇且实用的东西。
? 那么,你有发现什么新的东西吗?请在评论区告诉我。你有一些秘密的 `sudo` 技巧欢迎和大家分享!
*(题图:DA/a12900e5-e197-455e-adfc-0b52e4305b91)*
---
via: <https://itsfoss.com/sudo-tips/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You know sudo, right? You must have used it at some point in the time.
For most Linux users, it is the magical tool that gives you the ability to run any command as root or switch to the root user.
But that's only half-truth. See, sudo is not an absolute command. **sudo is a tool that can be configured to your need and liking**.
Ubuntu, Debian and other distros come preconfigured with sudo in a way that allows to them to run any command as root. That makes many users believe that sudo is some kind of magical switch that instantly gives you the root access.
**For example, a sysadmin can configure it in a way that users that are part of a certain 'dev' group can run only nginx command with sudo. Those users won't be able to run any other command with sudo or switch to root.**
If that surprises you, it's because you might have used sudo forever but never gave much thought about its underlying mechanism.
I am not going to explain how sudo works in this tutorial. I'll keep that for some other day.
In this article, you'll see how different aspects of sudo can be tweaked. Some are useful and some are pretty useless but fun.
[make a system settings backup](https://itsfoss.com/backup-restore-linux-timeshift/)so that you can restore things back to normal.
## 1. Always use visudo for editing sudo config
The sudo command is configured through the `/etc/sudoers`
file.
While you may edit this file with your [favorite terminal-based text editor](https://itsfoss.com/command-line-text-editors-linux/) like Micro, NeoVim etc, you **MUST NOT** do that.
Why? Because any incorrect syntax in this file will leave you with a screwed up system where sudo won't work. Which may render your Linux system useless.
Just use it like this:
`sudo visudo`
The `visudo`
command traditionally opens the `/etc/sudoers`
file in the Vi editor. Ubuntu will open it in Nano.
The advantage here is that **visudo performs a syntax check when you try to save your changes**. This ensures that you don't mess up the sudo configuration due to incorrect syntax.
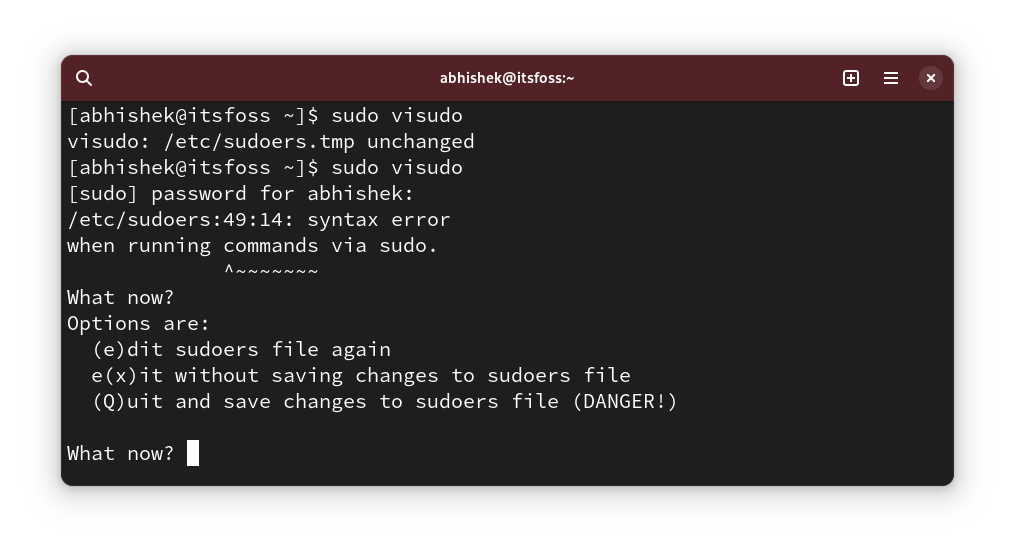
Alright! Now you can see some sudo configuration changes.
sudo cp /etc/sudoers /etc/sudoers.bak
## 2. Show asterisks while entering password with sudo
We have this behavior inherited from UNIX. When you enter your password for sudo in the terminal, it doesn't display anything. This lack of visual feedback makes new Linux users think that their system hanged.
Elders say that this is a security feature. This might have been the case in the last century but I don't think we should continue with it anymore. That's just my opinion.
Anyway, some distributions, like Linux Mint, have sudo tweaked in a way that it displays asterisks when you enter the password.
Now that's more in line with the behavior we see everywhere.
To show asterisks with sudo, run `sudo visudo`
and look for the line:
`Defaults env_reset`
Change it to:
```
Defaults env_reset,pwfeedback
```
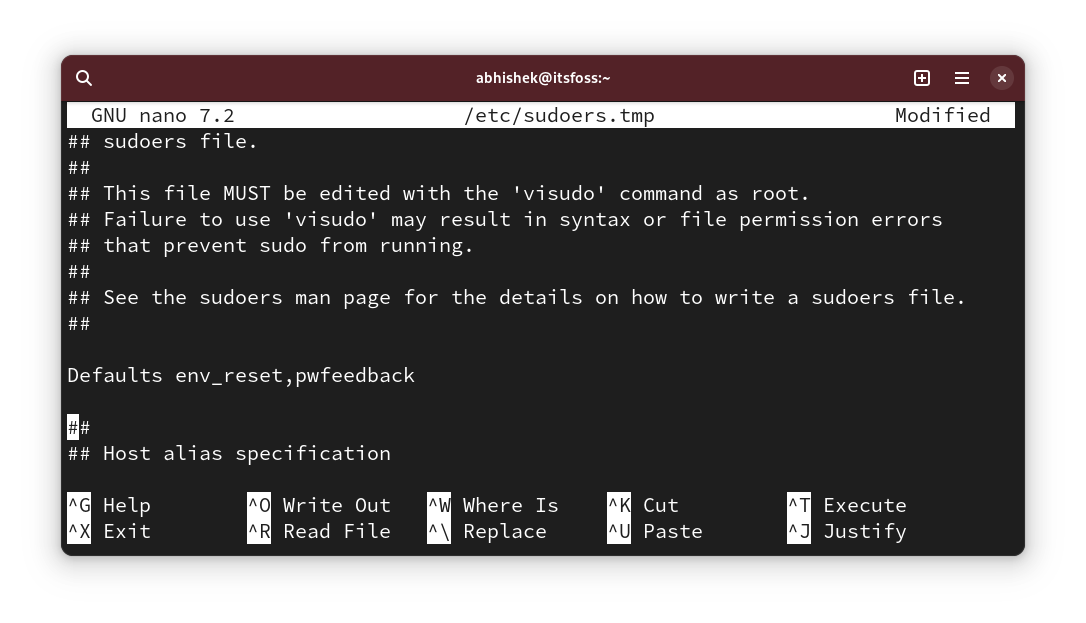
Now, if you try using sudo and it asks for a password, you should see asterisks when you enter the password.
## 3. Increase sudo password timeout
So, you use sudo for the first time and it asks for the password. But for the subsequent commands with sudo, you don't have to enter the password for a certain time.
Let's call it sudo password timeout (or SPT, I just made it up. Don't call it that 😁).
Different distributions have different timeout. It could be 5 minutes or 15 minutes.
You can change the behavior and set a sudo password timeout of your choice.
Edit the sudoer file as you have seen above and look for the line with `Defaults env_reset`
and add `timestamp_timeout=XX`
to the line so that it becomes this:
```
Defaults env_reset, timestamp_timeout=XX
```
Where XX is the timeout in minutes.
If you had other parameters like the asterisk feedback you saw in the previous section, they all can be combined:
```
Defaults env_reset, timestamp_timeout=XX, pwfeedback
```
## 4. Use sudo without password
Alright! So you increased the sudo password timeout (or the SPT. Wow! you are still calling it that 😛).
That's fine. I mean who likes to enter the password every few minutes.
Increasing the timeout is one thing. The other thing is to not use it all.
Yes, you read that right. You can use sudo without entering the password.
That sounds risky from security point of view, right? Well it is but there are genuine cases where you are (productively) better off using sudo without password.
For example, if you manage several Linux servers remotely and you have created sudo users on them to avoid using root all the time. The trouble is that you'll have too many passwords. You don't want to use the same sudo password for all the servers.
In such a case, you can set up only key-based SSH access to the servers and allow using sudo without password. This way, only the authorized user access the remote server and sudo password doesn't need to be remembered.
I do this on the test servers I deploy on [DigitalOcean](https://digitalocean.pxf.io/JzK74r) for testing open source tools and services.
The good thing is that this can be allowed per user basis. Open the `/etc/sudoer`
file for editing with:
`sudo visudo`
And then add a line like this:
```
user_name ALL=(ALL) NOPASSWD:ALL
```
Of course, you need to replace the `user_name`
with actual user name in the above line.
Save the file and enjoy sudo life without passwords.
## 5. Create separate sudo log files
You can always read the syslog or the journal logs for sudo related entries.
However, if you want a separate entry for sudo, you can create a custom log file dedicated to sudo.
Let's say, you want to use `/var/sudo.log`
file for this purpose. You don't need to create the new log file before hand. It will be created for you if it does not exist.
Edit the /etc/sudoers file using visudo and add the following line to it:
```
Defaults logfile="/var/log/sudo.log"
```
Save it and you can start seeing which commands were run by sudo at what time and by what user in this file:
## 6. Only allow a certain commands with sudo to a specific group of users
This is more of an advanced solution that sysadmin use in a multi-user environment where people across departments are working on the same server.
A developer may need to run web server or some other program with root permission but giving them complete sudo access will be a security issue.
While this can be done at user level, I recommend doing it at group level. Let's say you create a group called `coders`
and you allow them to run the commands (or binaries) from the `/var/www`
and `/opt/bin/coders`
directories and the [inxi command](https://itsfoss.com/inxi-system-info-linux/) (binary `/usr/bin/inxi`
).
This is a hypothetical scenario. Please don't take it verbatim.
Now, edit the sudoer file with `sudo visudo`
(yeah, you know it by now). Add the following line to it:
```
%coders ALL=(ALL:ALL) /var/www,/opt/bin/coders,/usr/bin/inxi
```
You can add the NOPASSWD parameter if you want so that sudo for the above allowed commands can be run with sudo but without password.
More on ALL ALL ALL in some other article as this one is getting longer than usual anyway.
## 7. Check the sudo access for a user
Alright! This one is more of a tip than a tweak.
How do you know if a user has sudo access? Check if they are member of the sudo group, you say. But that's not a guarantee. Some distros use wheel group name instead of sudo.
A better way is to use the built-in functionality of sudo and see what kind of sudo access a user has:
```
sudo -l -U user_name
```
It will show if the user has sudo access for some commands or for all commands.
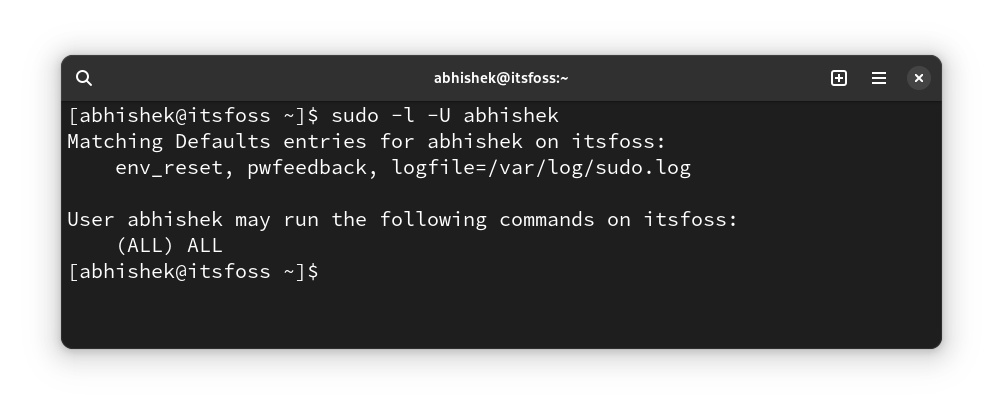
As you can see above, it shows that I have a custom log file and password feedback on apart from sudo access for all commands.
If the user doesn't have sudo access at all, you'll see an output like this:
```
User prakash is not allowed to run sudo on this-that-server.
```
## 🎁 Bonus: Let sudo insult you for incorrect password attempts
This one is the 'useless' tweak I mentioned at the beginning of this article.
I guess you must have mistyped the password while using sudo some time in the past, right?
This little [tweak let sudo throw a random insult at you](https://itsfoss.com/sudo-insult-linux/) for entering incorrect passwords.
Use `sudo visudo`
to edit the sudo config file and add the following line to it:
`Defaults insults`
And then you can test the changes by entering incorrect passwords:
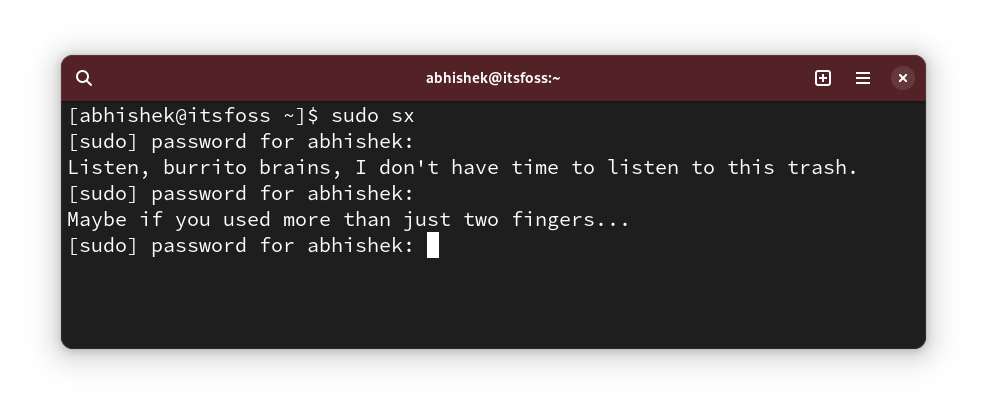
You may wonder who likes to be insulted? OnlyFans can answer that in a graphic manner 😇
## How do you sudo?

I know there is no end to customization. Although, sudo is not something a regular Linux user customizes.
Still, I like to share such things with you because you may discover something new and useful.
💬* So, did you discover something new? Tell me in the comments, please. And do you have some secret sudo trick up your sleeve? Why not share it with the rest of us?* |
16,474 | 利用 DNS SRV 记录为 Postfix 提供负载平衡 | https://fedoramagazine.org/using-postfix-dns-srv-record-resolution-feature/ | 2023-12-15T17:36:01 | [
"Postfix",
"负载均衡"
] | https://linux.cn/article-16474-1.html | 
2011 年 3 月,苹果公司提出 [RFC 6186](https://www.ietf.org/rfc/rfc6186.txt),描述了如何利用域名系统服务(DNS SRV)记录来查找电子邮件的提交以及访问服务。现在 Postfix 从 3.8.0 版本开始支持 RFC 中提出的设计。这个新增功能让你可以使用 DNS SRV 记录进行负载分配和自动配置。
### DNS SRV 记录的形态
DNS SRV 记录定义在 [RFC 2782](https://www.ietf.org/rfc/rfc2782.txt) 中,它指定在区域文件中,并且包含了服务名称、传输协议规范、优先级、权重、端口,以及提供该服务的主机。
```
_submission._tcp SRV 5 10 50 bruce.my-domain.com.
```
| 字段 | 值 | 意义 |
| --- | --- | --- |
| 服务名称 | `submission` | 服务名为 submission |
| 传输协议规范 | `tcp` | 本服务使用 TCP 协议 |
| 优先级 | `5` | 服务器优先级设为 5(数值越小,优先级越高) |
| 权重 | `10` | 服务器应承担的负载部分 |
| 端口 | `50` | 服务器监听连接的端口 |
| 目标 | `bruce.my-domain.com.` | 提供此服务的服务器名称 |
*记录解释*
### 服务器选择算法
客户端应该按照 [RFC 2782](https://www.ietf.org/rfc/rfc2782.txt) 中描述的方式解析 SRV 记录。这意味着,首先尝试联系拥有最高优先级(最小的优先级数字)的服务器。如果该服务器无回应,那么重试联系拥有同样或者更低优先级的下一台服务器。当有多台服务器拥有同样优先级的时候,应随机选择其中一台,但是必须确保选择记录的概率符合下列公式:

其中 `i` 是 SRV 记录的标识,`k` 是具有相同优先级的 SRV 记录的数量。
在现实中,这意味着如果你有两台服务器,其中一台的处理能力是另一台的三倍,那么你应该给第一台服务器的权重赋于另一台三倍的值。这样就能保证更强大的服务器会接收到大约 75% 的客户端请求,而另一台接收大约 25% 的请求。
这些原则使得 SRV 记录能够同时作为客户端自动配置及在服务器之间分配工作负载的工具。
看看以下这个记录的例子:
```
_submission._tcp SRV 0 0 2525 server-one
_submission._tcp SRV 1 75 2625 server-two
_submission._tcp SRV 1 25 2625 server-three
```
这里 `server-one` 总是会被首选来进行联系。如果 `server-one` 无回应,客户端就会将剩下优先级为 1 的两个记录顺序打乱,生成一个从 0 到 100 的随机数,如果第一条记录的运行总和大于或者等于这个随机数,它就会尝试去联系这个记录。否则,客户端会倒序联系所有服务器。注意,客户端会向它优先成功连接的服务器发送请求。
### 示例配置
请考虑以下这种情况。你想为大量的电脑配置 Postfix,使其通过公司的邮件服务器利用 SRV 记录转发外部电邮。为了达到这个目标,你需要在每台电脑的 Postfix 中配置 `relayhost` 参数,即邮件用户代理(MUA)。如果将 `relayhost` 参数的值设置为 `$mydomain`,你的机器将开始为你的域名查找 MX 记录,并尝试按照它们的优先级顺序发送邮件。这种方法虽然有效,但是可能会遇到负载平衡问题。Postfix 会使用优先级最高的服务器,直到其变为无响应才会联系其他备用服务器。此外,如果你在环境中使用了动态分配的端口,你无法指明哪个端口正在被特定的服务器使用。使用 SRV 记录,你可以应对这些挑战,并在需要改变服务器端口的时候维持服务器的平滑运行。
#### 区域文件
为了使得 DNS 服务器提供信息给客户端,可以参考以下使用服务器 `server-one`、`server-two`、`server-three` 作为中继,并把服务器 `server-four` 配置为接收测试邮件的区域文件示例。
```
$TTL 3600
@ IN SOA example-domain.com. root.example-domain.com. (
1571655122 ; 区域文件的序列号
1200 ; 刷新时间
180 ; 发生问题时的重试时间
1209600 ; 过期时间
10800 ) ; 查询失败时的最大缓存时间
;
IN NS ns1
IN A 192.168.2.0
;
ns1 IN A 192.168.2.2
server-one IN A 192.168.2.4
server-two IN A 192.168.2.5
server-three IN A 192.168.2.6
server-four IN A 192.168.2.7
_submission._tcp SRV 0 0 2525 server-one
_submission._tcp SRV 1 50 2625 server-two
_submission._tcp SRV 1 50 2625 server-three
@ MX 0 server-four
```
#### Postfix MUA 配置
设置客户端机器去查找 SRV 记录:
```
use_srv_lookup = submission
relayhost = example-domain.com:submission
```
通过这个配置,你的客户端机器上的 Postfix 实例会联络到 `example-domain` 的 DNS 服务器,然后获取邮件提交的 SRV 记录。在这个例子中,`server-one` 有最高的优先级,Postfix 会先试图连接它。然后,Postfix 随机的选择剩下的两个服务器其中一个去尝试连接。这个配置确保了大约有 50% 的机会会优先联系到服务器一。注意,SRV 记录的权重值并不等同于百分比。你也可以用 1 和 1 这样的值达到同样的目标。
同时,Postfix 也知道 `server-one` 在监听 2525 端口,而 `server-two` 在监听 2625 端口。如果你正在缓存检索到的 DNS 记录,并且你动态改变 SRV 记录,那么设置一个低的生存时间(TTL)对你的记录是很重要的。
#### 整套设置

你可以通过下面的方式尝试这个配置,包含 podman 和在此处提供的 compose 文件:
```
$ git clone https://github.com/TomasKorbar/srv_article
$ cd srv_article/environment
$ podman-compose up
$ podman exec -it article_client /bin/bash
root@client # ./senddummy.sh
root@client # exit
```
完成配置之后,你可以检查日志,查看邮件是否经过 `server-one` 并最终投递到 `server-four`。
```
$ podman stop article_server1
$ podman exec -it article_client /bin/bash
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # exit
```
现在 `server-one` 已经关闭了,这六封邮件将会由 `server-two` 或者 `server-three` 中转发出去。
仔细看一下 Dockerfiles 以更深地理解这个配置。
通过执行:`$ podman-compose down` 完成示例的操作。
*(题图:DA/241079fe-58d6-4dc6-8801-f0fd19dfd64b)*
---
via: <https://fedoramagazine.org/using-postfix-dns-srv-record-resolution-feature/>
作者:[Tomáš Korbař](https://fedoramagazine.org/author/tkorbar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In March 2011 Apple Inc. proposed [RFC 6186](https://www.ietf.org/rfc/rfc6186.txt) that describes how domain name system service (DNS SRV) records should be used for locating email submission and accessing services. The design presented in the RFC is now supported by Postfix since version 3.8.0. With the new functionality, you can now use DNS SRV records for load distribution and auto-configuration.
## What does the DNS SRV record look like
The DNS SRV records were defined in [RFC 2782](https://www.ietf.org/rfc/rfc2782.txt) and are specified in zone files and contain the service name, transport protocol specification, priority, weight, port, and the host that provides the service.
_submission._tcp SRV 5 10 50 bruce.my-domain.com.
Field | Value | Meaning |
service name | submission | service is named submission |
transport protocol specification | tcp | service is using TCP |
priority | 5 | servers priority is 5 (lower gets tried first) |
weight | 10 | portion of load the server should handle |
port | 50 | port where server listens for connections |
target | bruce.my-domain.com. | name of server providing this service |
## Server selection algorithm
Clients should implement the resolution of SRV records as described in [RFC 2782](https://www.ietf.org/rfc/rfc2782.txt). That means, first contact the server with the highest priority (lowest priority field value). If the server does not respond, try to contact the next server with either the same or lower priority (higher priority field value). If there are multiple servers with the same priority, choose one randomly, but ensure the probability of choosing records conforms to the equation:
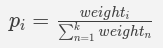
where *i* is the identification of SRV record and *k* is the count of SRV records with the same priority.
In practice, this means that if you have two servers and one is 3 times as powerful as the other one, then you should give the first weight a value 3 times higher than the other one. This ensures the more powerful server will receive ~75% of client requests and the other one ~25%.
These principles allow SRV records to work as tools to both autoconfigure clients and distribute the workload among servers.
Consider the following example of such a set of records:
_submission._tcp SRV 0 0 2525 server-one _submission._tcp SRV 1 75 2625 server-two _submission._tcp SRV 1 25 2625 server-three
Here **server-one** would always be contacted first. If **server-one** does not respond, the client will shuffle the two remaining records with priority 1, generate a random number from 0 to 100 and if the running sum of the first record is greater or equal, then try to contact it. Otherwise, the client contacts the servers in reverse order. Note that the client submits the request to the first server it successfully connects to.
## Configuration example
Consider the following situation. You want to configure Postfix to relay outgoing emails through a company mail server by using SRV records for a large number of computers. To achieve this, you can configure the **relayhost** parameter in Postfix, which acts as a Mail User Agent (MUA) for each computer. If you set the value of the **relayhost** parameter to **$mydomain**, your machines start to look up MX records for your domain and attempt to submit mail in the order based on their priorities. While this approach works, you can encounter a problem with load balancing. Postfix uses the server with the highest priority until it becomes unresponsive and only then contacts any secondary servers. Additionally, if your environment uses dynamically assigned ports, you are not able to notify the clients what port is a particular server using. With SRV records, you can address these challenges and keep the servers running smoothly without peaks while changing the server’s port as needed.
### Zone file
To configure a DNS server to provide information to clients, see the following example zone file with servers one, two and three configured as relays and server four for receiving test mail.
$TTL 3600 @ IN SOA example-domain.com. root.example-domain.com. ( 1571655122 ; Serial number of zone file 1200 ; Refresh time 180 ; Retry time in case of problem 1209600 ; Expiry time 10800 ) ; Maximum caching time in case of failed lookups ; IN NS ns1 IN A 192.168.2.0 ; ns1 IN A 192.168.2.2 server-one IN A 192.168.2.4 server-two IN A 192.168.2.5 server-three IN A 192.168.2.6 server-four IN A 192.168.2.7 _submission._tcp SRV 0 0 2525 server-one _submission._tcp SRV 1 50 2625 server-two _submission._tcp SRV 1 50 2625 server-three @ MX 0 server-four
### Postfix MUA configuration
Configure client machines to look for SRV records:
use_srv_lookup = submission relayhost = example-domain.com:submission
With this configuration, Postfix instances on your client machines contact the DNS server for the **example-domain** and request the SRV records for mail submission. In this example, **server-one** has the highest priority and Postfix tries it first. Postfix then randomly selects one of the two remaining servers to try. The configuration ensures that server one will be contacted first approximately 50% of the time. Note that the weight value in the SRV records does not correspond with the percentage. You can achieve the same goal with the values 1 and 1.
Postfix also has the information that **server-one** listens on port 2525 and **server-two** on port 2625. If you are caching retrieved DNS records and you change the SRV records dynamically, it is important to set a low time to live (TTL) for your records.
### Complete setup
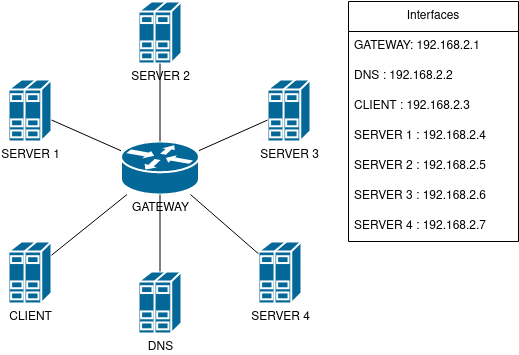
You can try this configuration with podman and compose file included here:
$ git clone https://github.com/TomasKorbar/srv_article $ cd srv_article/environment $ podman-compose up $ podman exec -it article_client /bin/bash root@client # ./senddummy.sh root@client # exit
After completing the configuration steps, you can check the logs to monitor, that the mail passes server one and is delivered to server four.
$ podman stop article_server1 $ podman exec -it article_client /bin/bash root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # ./senddummy.sh root@client # exit
Now that the first server is down, these six mails will be relayed by either server two or three.
Take a closer look at the Dockerfiles to understand the configuration more deeply.
Finish working with the example by executing: `$ podman-compose down`
## Phoenix
“That means, first contact the server with the lowest priority. If the server does not respond, try to contact the next server with either the same or lower priority.”
From a logical point of view if you start at the lowest priority, you cannot get any lower.
## Benjamin Menant
@Phoenix I agree, this sentence is a little misleading. I think the author first refers to the lowest priority
value(since the lower this value is, the greater the priority will be), and later refers to the lower priorityrank(i.e. greater priorityvalue).## Tomáš Korbař
Yes, that is exactly what i meant. I will try to update the misleading sentence as soon as possible. Thanks for pointing this out.
## Renich Bon Ćirić
Simple and self-contained example. Thank you very much. 🙂
## David
I notice the most recent available version of Postfix, is 3.7.4, not 3.8.0. I’m on Fedora 38. Can anyone comment, please? Thanks.
## Gregory Bartholomew
That appears to be correct.
https://koji.fedoraproject.org/koji/packageinfo?packageID=363
It looks like Postfix 3.8.0 has been built for the Fedora Linux 39 (currently rawhide).
“dnf update ‐‐releasever=rawhide postfix”
mightwork to install the version built for rawhide on your Fedora Linux 38 system if you want to test it. I don’t have access to a Fedora 38 install to try it on, so I don’t know if that will work.Edit: Note that this forum corrupts the text in the comments with unicode characters, so copy-and-paste of the above command will not work. You’ll have to key it in manually.
## Tomáš Korbař
Hi David,
Yes that is indeed correct, Postfix in Fedora 38 is 3.7.4. Me and the maintainer of Postfix agreed that we will not do a rebase but backport the feature instead. So you should be able to use the feature also on Fedora 38.
The update in question: https://bodhi.fedoraproject.org/updates/FEDORA-2023-6b2ae4d675
## betty09
Simple and complete illustration. I sincerely appreciate it. |
16,477 | IBM 和 Meta 与英特尔、AMD 等公司组建开放式创新“AI 联盟” | https://news.itsfoss.com/ai-alliance/ | 2023-12-16T07:51:33 | [
"AI"
] | https://linux.cn/article-16477-1.html | 
>
> 这样的联盟应该可以防止一家公司主宰人工智能进步。你怎么认为?
>
>
>
2023 年对于人工智能来说是非常重要的一年,随着这一年的结束,我们仍然看到新的发展。其中最新的一个是由 IBM、Meta 和 50 多个其他**合作者组成的**专注于人工智能的联盟。
他们甚至还有一个简洁的名字,恰如其分地称为 “<ruby> <a href="https://thealliance.ai/"> AI 联盟 </a> <rt> The AI Alliance </rt></ruby>”?。
那么,让我们深入了解他们计划实现什么目标。

**正在发生的事情:** 由 [IBM](https://www.ibm.com/) 和 [Meta](https://meta.com/) 发起,**AI 联盟是一组来自不同垂直领域的组织**,其中包括**初创企业**、**知名公司**、**政府**、**研究人员**,甚至**著名的教育机构**,都专注于一个重点。
>
> 支持人工智能领域的开放创新和开放科学。
>
>
>
这个以人工智能为中心的联盟的所有成员**将通过成为开放社区的一部分来相互协作**,该社区允许开发人员和研究人员在人工智能领域进一步“*负责任的创新*”。
**预期结果:** 根据人工智能联盟为启动项目制定的目标。他们打算建立**一个由基准、评估标准、工具和其他资源组成的框架**,以“在全球范围内负责任地开发和使用人工智能系统”。
这将还包括**创建经过审计的安全、安保和信任工具目录**,以进一步增强该联盟下项目的安全性。
此外,他们还计划通过**推动一组多样化的模型**进一步采用 [开放基础模型](https://en.wikipedia.org/wiki/Foundation_models),这些模型将专注于 *多语言*、*多模式* 和 *以科学为中心*。
你可能想知道:**联盟的其他成员是谁?**
嗯,正如我之前提到的,**人工智能联盟**有超过 50 个组织。一些**最值得注意的**包括:
* AMD
* 英特尔
* 甲骨文
* 欧洲核子研究中心
* Hugging Face
* 耶鲁大学
* 印度理工学院孟买分校
甚至 [Linux 基金会](https://www.linuxfoundation.org/) 也加入了这个联盟。Linux 基金会执行董事 [Jim Zemlin](https://www.linkedin.com/in/zemlin) 提到:
>
> 人工智能联盟是提供开放共享的软件、数据和其他对于开发透明、先进和值得信赖的人工智能至关重要的资产的过程中的另一个里程碑。
>
>
> 开放协作流程和开放治理对于这些努力至关重要,并与我们的 [PyTorch 基金会](https://pytorch.org/)、[LF AI 和数据基金会](https://lfaidata.foundation/)、[云原生计算基金会](https://www.cncf.io/) 合作 ,我们期待参与并协助该联盟,为人工智能生态系统的基本要素提供一个中立的家园。
>
>
>
听起来确实不错,但人工智能联盟成员之间的合作会产生什么样的结果,只有时间才能证明。
想要了解更多关于这个联盟的目标的细节,或者了解创始成员的信息,可以浏览 [官方博客](https://thealliance.ai/news)。
### 总结
最近一段时间,我们看到**人工智能方案的实施大幅增加**,甚至出现**有关此类工具使用受版权保护的数据的诉讼**。
我还注意到这个联盟中**缺少了一些著名的名字**:**谷歌**、**OpenAI** 和 **微软** 等公司不属于其中。当然,他们对以人工智能为中心的方案有单独的议程,我们不能指望它是开放的。
然而,与这样的合作伙伴结成的联盟听起来像是迫切需要推动开源人工智能,以确保人工智能的进步不只是由一家或几家公司主导。
?你觉得怎么样? 人工智能联盟会起作用吗?
---
via: <https://news.itsfoss.com/ai-alliance/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

2023 is a very happening year for Artificial Intelligence, we are still seeing new developments as this year comes to an end. The latest among which is an **AI-focused coalition formed by IBM, Meta, and over 50 other **collaborators.
They even have a neat name, it is aptly called “[The AI Alliance](https://thealliance.ai/?ref=news.itsfoss.com)” 😊
So, let's dive in and see what they plan to achieve.

**What's happening: **Launched by [IBM](https://www.ibm.com/?ref=news.itsfoss.com) and [Meta](https://meta.com/?ref=news.itsfoss.com), The **AI Alliance is a group of organizations from different verticals** that includes **start-ups**, **well-established companies**, **governments**, **researchers**, and even **prestigious educational institutions** with one key focus.
To support open innovation and open science in AI.
All the members of this AI-focused alliance are **set to collaborate with each other by being part of an open community** that allows both developers and researchers to further “*responsible innovation*” in AI.
**What to Expect: **According to the objectives laid out by The AI Alliance for starting projects. They intend to build** a framework that would consist of benchmarks, evaluation standards, tools, and other resources** to “*enable the responsible development and use of AI systems at a global scale*”.
That would** **also** **include the
**creation of a catalog of audited safety, security, and trust tools**to further enhance the security of the projects under this alliance.
Moreover, they also plan to take [open foundation models](https://en.wikipedia.org/wiki/Foundation_models?ref=news.itsfoss.com) further by **pushing for a diverse set of models** that would concentrate on being *multilingual*, *multi-modal*, and *science-focused*.
You might be wondering; **who are the other members in the alliance?**
Well, as I mentioned earlier, there are over 50 organizations in the **AI Alliance**. Some of the **most notable ones** include:
**AMD****Intel****Oracle****CERN****Hugging Face****Yale University****Indian Institute of Technology Bombay**
Even [The Linux Foundation](https://www.linuxfoundation.org/?ref=news.itsfoss.com) has forayed into this alliance. [Jim Zemlin](https://www.linkedin.com/in/zemlin?ref=news.itsfoss.com), Executive Director of The Linux Foundation, mentioned:
The AI Alliance is another milestone in the process of providing for openly shareable software, data, and other assets essential to the development of transparent, advanced and trustworthy AI.
Open collaborative processes and open governance are essential to these efforts and working with our[PyTorch Foundation],[LF AI and Data Foundation],[Cloud Native Computing Foundation], we look forward to participating in and assisting the Alliance by providing a neutral home for essential elements of the AI ecosystem.
That does sound good, only time will tell what kind of results will come out of the collaboration between members of the AI Alliance.
For more details on the objectives of this alliance, or to learn about the founding members, you can go through the [official blog](https://thealliance.ai/news?ref=news.itsfoss.com).
## Wrapping Up
In recent times, we have been seeing **a considerable increase in the implementation of AI-powered solutions**, and even **lawsuits concerning the use of copyrighted data** by such tools.
I also noticed that **a few notable names were missing** from this alliance; the likes of **Google**, **OpenAI**, and **Microsoft** are not a part of this. Of course, they have separate agendas to their AI-focused solutions, which we cannot expect it to be open.
However, an alliance made with partnerships like sounds like the much-needed push for open-source AI to ensure that the AI advancements are not dominated by just a single or couple of companies.
*💬 What do you think? Will the AI Alliance work?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,479 | 为 Nginx 配置 ModSecurity 网络应用防火墙 | https://fedoramagazine.org/a-web-application-firewall-for-nginx/ | 2023-12-16T09:25:48 | [
"WAF",
"ModSecurity"
] | https://linux.cn/article-16479-1.html | 
>
> 网络应用防火墙(WAF)是一种在应用层监控网络流量的应用程序。
>
>
>
[OSI(开放系统互联)](https://osi-model.com/) 是最常被网络相关讨论引用的网络流量框架之一。当数据包通过第 6 层(表示层)移动到第 7 层(应用层)时,它会进行解密或解码操作。这些操作可能会因异常解码和解释而产生漏洞,而这些漏洞可能被利用来打破标准应用上下文。注入就是这种漏洞的一种类型,而且因为传统的 [IDS/IPS](https://en.wikipedia.org/wiki/Intrusion_detection_system) 设备无法应对这些威胁,所以其长时间以来一直是人们特别关注的问题。
### ModSecurity 简介
[ModSecurity](https://github.com/SpiderLabs/ModSecurity) 本质上就是 <ruby> 网络应用防火墙 <rt> web application firewall </rt></ruby>(WAF)引擎。它与 Apache、IIS 和 Nginx 兼容,并由第三方公司维护。该防火墙会将一份规则列表与由 Web 服务器/代理提供的 HTTP 头流进行交叉引用。目前这个仓库已经被简化,只包含主要的 LibModSecurity 库。你可以直接在自己的服务器实现中调用这个库,或通过特定编程语言的封装进行调用。
其母公司的支持计划于 2024 年 7 月 1 日结束,之后这个项目将由开源社区维护。
### 安装 Nginx 连接器
[Nginx 连接器](https://github.com/SpiderLabs/ModSecurity-nginx) 是一个 Nginx 动态模块,可以通过 Fedora 包 `nginx-mod-modsecurity` 进行安装。它依赖于 `libmodsecurity.so`,所以在这个使用场景中,这个包本身就是防火墙。
```
[user@fedora ~]$ sudo dnf install -y nginx nginx-mod-modsecurity
[user@fedora ~]$ rpm -qR nginx-mod-modsecurity
config(nginx-mod-modsecurity) = 1.0.3-3.fc38
libc.so.6(GLIBC_2.4)(64bit)
libmodsecurity.so.3()(64bit)
nginx(abi) = 1.24.0
nginx-filesystem
...
```
安装完成后,你会见到连接器在 `/etc/nginx` 中添加了一些重要的文件。
```
[user@fedora ~]$ rpm -ql nginx-mod-modsecurity
/etc/nginx/modsecurity.conf # waf 配置
/etc/nginx/nginx.conf.modsecurity # nginx 示例配置
/usr/lib64/nginx/modules/ngx_http_modsecurity_module.so
/usr/share/nginx/modules/mod-modsecurity.conf
/usr/share/doc/nginx-mod-modsecurity/README.md
...
```
通过提供一些额外的配置指令,连接器对 Nginx 进行了扩展。下面的部分将演示 `nginx.conf.modsecurity` 文件中一些示例指令。指令的完整列表可以在 `README.md` 文件或项目的 GitHub 页面找到。
### 启动网络应用防火墙
`nginx.conf.modsecurity` 是我们将要运行的 Nginx 配置。解开如下所示的 *modsecurity* 行注释:
```
[user@fedora ~]$ sudo sed -i 's/#modsec/modsec/g' /etc/nginx/nginx.conf.modsecurity
[user@fedora ~]$ grep -C2 modsecurity /etc/nginx/nginx.conf.modsecurity
# 如有需要,启用 ModSecurity WAF
modsecurity on;
# 如有需要,加载 ModSecurity CRS
modsecurity_rules_file /etc/nginx/modsecurity.conf;
```
在 shell 中启动服务器并查看日志,确保在 `modsecurity.conf` 加载了七个默认规则。
```
[user@fedora ~]$ sudo nginx -c /etc/nginx/nginx.conf.modsecurity
[user@fedora ~]$ head /var/log/nginx/error.log
2023/10/21 23:55:09 [notice] 46218#46218: ModSecurity-nginx v1.0.3 (rules loaded inline/local/remote: 0/7/0)
2023/10/21 23:55:09 [notice] 46218#46218: using the "epoll" event method
2023/10/21 23:55:09 [notice] 46218#46218: nginx/1.24.0
2023/10/21 23:55:09 [notice] 46218#46218: OS: Linux 6.5.7-200.fc38.x86_64
```
通过发送一些不符合 `Content-Type` 头格式的数据来测试默认规则。
```
[user@fedora ~]$ curl -X POST http://localhost -H "Content-Type: application/json" --data "<xml></xml>"
[user@fedora ~]$ tail /var/log/modsec_audit.log
...
---rH5bFain---H--
ModSecurity: Warning. Matched "Operator `Eq' with parameter `0' against variable `REQBODY_ERROR' (Value: `1' ) [file "/etc/nginx/modsecurity.conf"] [line "75"] [id "200002"] [rev ""] [msg "Failed to parse request body."] [data "JSON parsing error: lexical error: invalid char in json text.\n"] [severity "2"] [ver ""] [maturity "0"] [accuracy "0"] [hostname "10.0.2.100"] [uri "/"] [unique_id "169795900388.487044"] [ref "v121,1"]
```
### 用 OWASP 核心规则集扩展你的网络应用防火墙
默认的 Nginx 连接器带有七条规则。OWASP [Core Rule Set v3.3.5](https://github.com/coreruleset/coreruleset/tree/v3.3.5/rules) 则更为详尽,涵盖了许多场景。
复制并提取规则的存档。
```
[user@fedora ~]$ curl -fSL https://github.com/coreruleset/coreruleset/archive/refs/tags/v3.3.5.tar.gz --output /tmp/v3.3.5.tar.gz
[user@fedora ~]$ sudo tar -C /etc/nginx -xvf /tmp/v3.3.5.tar.gz
[user@fedora ~]$ tree -L 1 /etc/nginx/
/etc/nginx/
├── conf.d
├── default.d
├── modsecurity.conf # waf 配置
├── nginx.conf
├── nginx.conf.modsecurity # nginx 启用 waf
├── coreruleset-3.3.5
├ ├── rules # 规则目录
├ ...
├ ...
```
现在,你在 Nginx 配置文件夹中有了一个包含所有当前 OWASP 规则的 `rules` 目录。接下来,让 Nginx 知道这些规则。以下操作指南来源于 OWASP [INSTALL](https://github.com/coreruleset/coreruleset/blob/v3.3.5/INSTALL) 文件。
创建一个 `crs.conf` 文件,并在全局网络应用防火墙配置文件( `modsecurity.conf` )中包含所有相关的配置文件。
```
[user@fedora ~]$ sudo cp /etc/nginx/coreruleset-3.3.5/crs-setup.conf.example /etc/nginx/coreruleset-3.3.5/crs.conf
[user@fedora ~]$ echo -e "\nInclude /etc/nginx/coreruleset-3.3.5/crs.conf" | sudo tee -a /etc/nginx/modsecurity.conf
[user@fedora ~]$ echo -e "\nInclude /etc/nginx/coreruleset-3.3.5/rules/*.conf" | sudo tee -a /etc/nginx/modsecurity.conf
[user@fedora ~]$ tail /etc/nginx/modsecurity.conf
Include /etc/nginx/coreruleset-3.3.5/crs.conf
Include /etc/nginx/coreruleset-3.3.5/rules/*.conf
```
根据文档,包含这些文件的顺序很重要。上面的 `tee` 的命令将新的 `Include` 行放在了 `modsecurity.conf` 文件的末尾。现在,用这个新配置重启 Nginx。
```
[user@fedora ~]$ sudo nginx -s stop && sudo nginx -c /etc/nginx/nginx.conf.modsecurity
[user@fedora ~]$ tail /var/log/nginx/error.log
2023/10/22 10:53:23 [notice] 202#202: exit
2023/10/22 10:53:50 [notice] 230#230: ModSecurity-nginx v1.0.3 (rules loaded inline/local/remote: 0/921/0)
2023/10/22 10:53:50 [notice] 230#230: using the "epoll" event method
2023/10/22 10:53:50 [notice] 230#230: nginx/1.24.0
2023/10/22 10:53:50 [notice] 230#230: OS: Linux 6.5.7-200.fc38.x86_64
2023/10/22 10:53:50 [notice] 230#230: getrlimit(RLIMIT_NOFILE): 524288:524288
2023/10/22 10:53:50 [notice] 231#231: start worker processes
```
注意,Nginx 成功加载了 921 条规则。还需要做一些测试来确保规则实际上是被网络应用防火墙检查过的。这里再次引用 `INSTALL` 文件中的 “Testing the Installation” 片段。
```
[user@fedora ~]$ curl 'http://localhost/?param=''><script>alert(1);</script>'
[user@fedora ~]$ tail /var/log/modsec_audit.log
...
---8NSpdnLe---H--
ModSecurity: Warning. detected XSS using libinjection. [file "/etc/nginx/coreruleset-3.3.5/rules/REQUEST-941-APPLICATION-ATTACK-XSS.conf"] [line "38"] [id "941100"] [rev ""] [msg "XSS Attack Detected via libinjection"] [data "Matched Data: XSS data found within ARGS:param: ><script>alert(1);</script>"] [severity "2"] [ver "OWASP_CRS/3.3.5"]
...
```
### 结论
本文演示了如何为 Nginx 服务器配置网络应用防火墙。这个部署使用了标准规则和 OWASP Core Rule Set v3.3.5。演示的防火墙在**检测模式**中运行并记录不寻常的行为。将防火墙运行在**防御模式**要对 `modsecurity.conf` 进行更多改动。请参考 [ModSecurity Reference Manual v3.x](https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual-(v3.x)) 获取如何启用防御模式和更多信息。
祝你好运。
*(题图:DA/7ec85bc4-b209-4fc6-9275-8f7d1430f6ca)*
---
via: <https://fedoramagazine.org/a-web-application-firewall-for-nginx/>
作者:[Roman Gherta](https://fedoramagazine.org/author/romangherta/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A web application firewall (WAF) is an application that monitors network traffic at the application layer.
[OSI (Open Systems Interconnection)](https://osi-model.com/) is one of the most referenced network traffic frameworks across internet related discussions. When a package crosses Layer 6 (Presentation) and moves towards Layer 7 (Application) it undergoes decrypting/decoding operations. Each of these operations can be susceptible to faulty decoding and interpretation that can be used to break out of the standard application context. Injections are just one type of such vulnerabilities and for a long time have been the number one cause of concern especially since traditional [IDS/IPS ](https://en.wikipedia.org/wiki/Intrusion_detection_system)appliances cannot handle these threats.
## About ModSecurity
[ModSecurity](https://github.com/SpiderLabs/ModSecurity) was historically the web application firewall engine itself. It is compatible with Apache, IIS, and Nginx and has been maintained by a third-party company. The firewall cross references a list of rules to a stream of HTTP headers provided by a webserver/proxy. As of now this repository was simplified and contains only the main library *LibModSecurity*. The library itself can be called from your own server implementation directly or via wrappers specific to individual programming languages.
The parent company’s support is scheduled to end on July 1 2024 at which time the project is supposed to be maintained by the open-source community.
## Install the Nginx connector
The [Nginx connector](https://github.com/SpiderLabs/ModSecurity-nginx) is an Nginx dynamic module and it can be installed via the Fedora package *nginx-mod-modsecurity*. It has *libmodsecurity.so* as a dependency so for this use-case this package is the firewall itself.
[user@fedora ~]$ sudo dnf install -y nginx nginx-mod-modsecurity [user@fedora ~]$ rpm -qR nginx-mod-modsecurityconfig(nginx-mod-modsecurity) = 1.0.3-3.fc38 libc.so.6(GLIBC_2.4)(64bit) libmodsecurity.so.3()(64bit) nginx(abi) = 1.24.0 nginx-filesystem...
Once installed, you will see that the connector adds a few important files to /etc/nginx.
[user@fedora ~]$ rpm -ql nginx-mod-modsecurity/etc/nginx/modsecurity.conf # waf config /etc/nginx/nginx.conf.modsecurity # nginx sample conf /usr/lib64/nginx/modules/ngx_http_modsecurity_module.so /usr/share/nginx/modules/mod-modsecurity.conf /usr/share/doc/nginx-mod-modsecurity/README.md...
The connector extends Nginx by providing some extra configuration directives. The following sections will demonstrate a few of the example directives in the *nginx.conf.modsecurity* file. A complete list of the directives can be found in the *README.md* file or on the project’s GitHub page.
## Enable the web application firewall
*nginx.conf.modsecurity* is the Nginx configuration we are going to run. Uncomment the *modsec** lines as shown below.
[user@fedora ~]$ sudo sed -i 's/#modsec/modsec/g' /etc/nginx/nginx.conf.modsecurity [user@fedora ~]$ grep -C2 modsecurity /etc/nginx/nginx.conf.modsecurity# Enable ModSecurity WAF, if needmodsecurity on;# Load ModSecurity CRS, if needmodsecurity_rules_file /etc/nginx/modsecurity.conf;
Start the server inside the shell and observe the logs to make sure the seven default rules defined in *modsecurity.conf* are loaded.
[user@fedora ~]$ sudo nginx -c /etc/nginx/nginx.conf.modsecurity [user@fedora ~]$ head /var/log/nginx/error.log2023/10/21 23:55:09 [notice] 46218#46218:ModSecurity-nginx v1.0.3 (rules loaded inline/local/remote: 0/7/0)2023/10/21 23:55:09 [notice] 46218#46218: using the "epoll" event method 2023/10/21 23:55:09 [notice] 46218#46218: nginx/1.24.0 2023/10/21 23:55:09 [notice] 46218#46218: OS: Linux 6.5.7-200.fc38.x86_64
Test the default rules by sending some data that does not respect the *content-type* header format.
[user@fedora ~]$ curl -X POST http://localhost -H "Content-Type: application/json" --data "<xml></xml>" [user@fedora ~]$ tail /var/log/modsec_audit.log... ---rH5bFain---H-- ModSecurity: Warning. Matched "Operator `Eq' with parameter `0' against variable `REQBODY_ERROR' (Value: `1' ) [file "/etc/nginx/modsecurity.conf"] [line "75"] [id "200002"] [rev ""] [msg "Failed to parse request body."] [data "JSON parsing error: lexical error: invalid char in json text.\x0a"] [severity "2"] [ver ""] [maturity "0"] [accuracy "0"] [hostname "10.0.2.100"] [uri "/"] [unique_id "169795900388.487044"] [ref "v121,1"]
## Extend your web application firewall with the OWASP core rule set
The default Nginx connector comes with seven rules. The OWASP [Core Rule Set v3.3.5](https://github.com/coreruleset/coreruleset/tree/v3.3.5/rules) is more extensive and covers many scenarios.
Copy the archive and extract the rules.
[user@fedora ~]$ curl -fSL https://github.com/coreruleset/coreruleset/archive/refs/tags/v3.3.5.tar.gz --output /tmp/v3.3.5.tar.gz [user@fedora ~]$ sudo tar -C /etc/nginx -xvf /tmp/v3.3.5.tar.gz [user@fedora ~]$ tree -L 1 /etc/nginx//etc/nginx/ ├── conf.d ├── default.d ├── modsecurity.conf # waf config ├── nginx.conf ├── nginx.conf.modsecurity # nginx waf enabled ├──coreruleset-3.3.5├ ├──rules# rules directory ├ ... ├ ...
You now have a *rules* directory within the nginx configuration folder with all the current OWASP rules. Next, make Nginx aware of these rules. The following instructions originate from the OWASP [./INSTALL](https://github.com/coreruleset/coreruleset/blob/v3.3.5/INSTALL) file.
Create a *crs.conf* file and include all the relevant config files in the global web application firewall config file (*modsecurity.conf*).
[user@fedora ~]$ sudo cp /etc/nginx/coreruleset-3.3.5/crs-setup.conf.example /etc/nginx/coreruleset-3.3.5/crs.conf [user@fedora ~]$ echo -e "\nInclude /etc/nginx/coreruleset-3.3.5/crs.conf" | sudo tee -a /etc/nginx/modsecurity.conf [user@fedora ~]$ echo -e "\nInclude /etc/nginx/coreruleset-3.3.5/rules/*.conf" | sudo tee -a /etc/nginx/modsecurity.conf [user@fedora ~]$ tail /etc/nginx/modsecurity.confInclude /etc/nginx/coreruleset-3.3.5/crs.conf Include /etc/nginx/coreruleset-3.3.5/rules/*.conf
According to docs, the order of including these files is important. The *tee* command shown above has placed the new *Include* lines at the end of the *modsecurity.conf* file. Now, reload Nginx with this new configuration.
[user@fedora ~]$ sudo nginx -s stop && sudo nginx -c /etc/nginx/nginx.conf.modsecurity [user@fedora ~]$ tail /var/log/nginx/error.log2023/10/22 10:53:23 [notice] 202#202: exit 2023/10/22 10:53:50 [notice] 230#230:ModSecurity-nginx v1.0.3 (rules loaded inline/local/remote: 0/921/0)2023/10/22 10:53:50 [notice] 230#230: using the "epoll" event method 2023/10/22 10:53:50 [notice] 230#230: nginx/1.24.0 2023/10/22 10:53:50 [notice] 230#230: OS: Linux 6.5.7-200.fc38.x86_64 2023/10/22 10:53:50 [notice] 230#230: getrlimit(RLIMIT_NOFILE): 524288:524288 2023/10/22 10:53:50 [notice] 231#231: start worker processes
Notice Nginx loaded *921* rules successfully. Some tests are also needed to make sure the rules are actually checked by the web application firewall. Here again, we reference the snippet *Testing the Installation *from the *./INSTALL* file.
[user@fedora ~]$ curl 'http://localhost/?param=''><script>alert(1);</script>' [user@fedora ~]$ tail /var/log/modsec_audit.log... ---8NSpdnLe---H-- ModSecurity: Warning. detected XSS using libinjection. [file "/etc/nginx/coreruleset-3.3.5/rules/REQUEST-941-APPLICATION-ATTACK-XSS.conf"] [line "38"] [id "941100"] [rev ""] [msg "XSS Attack Detected via libinjection"] [data "Matched Data: XSS data found within ARGS:param: ><script>alert(1);</script>"] [severity "2"] [ver "OWASP_CRS/3.3.5"] ...
## Conclusions
How to configure a web application firewall for an Nginx server has been demonstrated. This deployment uses standard rules plus the *OWASP Core Rule Set v3.3.5.* The firewall demonstrated above is running in **detection mode** and logging unusual actions. Running the firewall in **prevention mode** requires further changes to* modsecurity.conf.* Refer to [ModSecurity Reference Manual v3.x](https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual-(v3.x)) for instructions on how to enable prevention mode and much more.
All the best.
## Jason
Nice one! OWASP for Nginx, I was trying to get naxsi_core.rules working with Nginx and gave up eventually. This was very easy to get up and running
## honeymak
wondering cpu loading and network latency for this
## RG
Hi there, periodic benchmarks and some understanding of the impact can be found here
https://github.com/defanator/modsecurity-performance/wiki
## notepad online
Nice breakdown, Roman! Excited to see how the OWASP Core Rule Set takes the Nginx firewall game to the next level. Any personal tips for a smooth setup?
## Roman Gherta
Switch to Fedora 🙂 |
16,481 | 重温过去:DG/UX UNIX 操作系统 | https://itsfoss.com/dg-ux-os/ | 2023-12-17T08:39:45 | [
"DG/UX",
"UNIX"
] | https://linux.cn/article-16481-1.html | 
>
> 和我一起重温怀旧时光,回顾我使用 DG/UX UNIX 操作系统和数据通用公司的 AViiON 工作站和服务器的经历。
>
>
>
我尝试寻找一些我以前使用过的旧操作系统 [DG/UX](https://archive.org/details/installing_the_dgux_system) 的信息。遗憾的是,关于它的信息已经不多了。这个小型操作系统深得我心,虽然我知道我的经历不会改写历史,但我还是愿意记录下我与之相关的经验,传承历史。
这款 [Unix](https://en.wikipedia.org/wiki/Unix) [操作系统](https://en.wikipedia.org/wiki/Operating_system) 由 <ruby> <a href="https://en.wikipedia.org/wiki/Data_General"> 数据通用公司 </a> <rt> Data General </rt></ruby> 开发,主要服务于 [Eclipse MV](https://en.wikipedia.org/wiki/Eclipse_MV) 迷你计算机系列以及随后的 [AViiON](https://en.wikipedia.org/wiki/Aviion) 工作站和服务器。我并未在 Eclipse 系统上工作过,我的工作主要在 AViiON 系统上进行。这些系统坚固得就像坦克,使用起来也异常简洁。

### 操作系统概述
我在 1990 年代中期开始接触 DG/UX,当时它已经存在了一段时间。DG/UX 1 在 1985 年 3 月发布,是基于 [UNIX System V](https://en.wikipedia.org/wiki/UNIX_System_V) Release 2,且融入了 [4.1BSD](https://en.wikipedia.org/wiki/BSD) 的优秀特性构建的。几年后,DG/UX 3.10 就添加了 [TCP/IP](https://en.wikipedia.org/wiki/TCP/IP) 网络、[NFS](https://en.wikipedia.org/wiki/Network_File_System) 和 [X Window System](https://en.wikipedia.org/wiki/X_Window_System)。记得 [CDE](https://itsfoss.com/common-desktop-environment/) 吗?

DG/UX 4 在 1988 年发布(这个“4”在后面让我非常困扰...),此版本是系统的一次重大设计革新,基于 [System V Release 3](https://en.wikipedia.org/wiki/System_V_Release_3)。同时,其文件系统可以通过逻辑磁盘设施跨越多个磁盘。
DG/UX 5.4 版本的改变非常有意义,这也是我开始使用的版本。这个版本将传统的 Unix 文件缓冲区缓存替换为了统一的、按需分页的虚拟内存管理。
该操作系统比其他一些 Unix 变体更强大,例如,它内置了完整的 [C](https://en.wikipedia.org/wiki/C_(programming_language)) 语言编译器。我们同时还有一支 [COBOL](https://en.wikipedia.org/wiki/COBOL) 程序员团队,不过我记得 COBOL 是作为插件使用的。现在,虽然大家都觉得 C 语言编译器是理所当然的存在,但在那个时代,它是一份无比珍贵的礼物。我编写过许多为管理任务服务的脚本,同时我还为特定的工作需求编写了几个 C 程序。
这款操作系统体积小巧,简单易用。System V 和加入的 BSD 工具是完美的结合,可以说,这是最优秀的两全其美的产物。不论是安装还是升级,都非常的简便,并且对内存或者处理器资源的需求也非常低。
内置在系统中的 [卷管理器](https://en.wikipedia.org/wiki/Logical_volume_management) 简单但功能强大。基本上所有的磁盘管理都可以在线上完成,无需将文件系统切换为离线状态。在一个保险/风险管理工作环境中,这一特性是非常重要的。我们可以扩容、迁移、进行镜像或者缩容,这些功能也可以对交换区进行操作,在不中断系统运行的条件下原地迁移磁盘存储。
### 机器
我曾接触过的 AViiON 机器分两种类型:一种是 AV300 [pizza box](https://en.wikipedia.org/wiki/Pizza_box_form_factor) 工作站,另一种是配有 [CLARiiON](https://en.wikipedia.org/wiki/Clariion) 磁盘阵列的 AV9500 服务器。

在 AViiON 中,DG/UX 支持使用 [多处理器](https://en.wikipedia.org/wiki/Multiprocessor)。在一个保险/风险管理工作环境中,这是一项很大的优势,因为并不是所有的 Unix 包都支持这个功能。此外,DG/UX 还能无缝地与 CLARiiON 阵列配合工作。
有了像 CLARiiON 这样的 RAID,为特定账户配置空间非常容易。但一个以前的管理员在创造账户时总是会选择“使用第一个可用空间”。很快我们碰到了一些问题,比如:一个单独的查询就会点亮全部 125 个磁盘上的指示灯 —— 一个账户的数据分布着整个阵列设备。

当我成为主管理员后,我就着手修复这个问题,把一个阵列指定给一些较大的帐户,小帐户分组到两个阵列上。整个修复过程花了我一个星期的晚班时间,但是 DG/UX 让重排文件到指定阵列的整个过程变得异常轻松。
RAID 本身也异常稳定。在某个时期,我们使用过 IBM 1GB 的磁盘。这些硬盘的内部机构有时候会卡住,能让它们回复正常工作的唯一方法就是把他们取出来,在地板上像旋转陀螺那样旋转(没错,我是认真的!)。偶尔,磁盘可能彻底报废,无法再转动。现在,RAID 会在阵列内复制每个磁盘的数据,因此数据仍旧存在,尽管效率将受到影响。有一次,我不得不从另一台计算机上“借用”一个磁盘,让一个阵列能够维持运行,直到我们得到替代品。当天,CLARiiON 的表现极为出色,我们并不想再继续这样冒险,因此我们决定替换所有磁盘,而 DG/UX 的备份/恢复工具使这项工作毫无障碍的进行。
### 技术支持
关于技术支持并没有太多可以讲的,因为它真的很棒。我从未在技术支持上遇到过问题,每个问题都得到了礼貌、准确的回答,如今这点已经很少见了。
你还记得我前面提到的那个“4”吗?就是那个后来让我感到困扰的数字?我曾经因此而拨打技术支持电话。在 1995 年,我收到了操作系统升级的磁带,但我们那时正在运行的是 5.4 版本。我见到 4.10 版本的磁带时非常惊讶,我原以为这是个错误,我被寄给了错误的磁带,我并不想将系统降级。
事实证明,我收到的是正确的磁带。那个“4”是为了向 System V Release **4** 版本致敬。我有时还会觉得这很奇怪 — 升级一个操作系统,却让版本号降低。下面是一些版本的列表说明:
1. DG/UX 5.4 - 3.00 - 1994 年 1 月
2. DG/UX 5.4 - 3.10 - 1994 年 7 月
3. DG/UX 5.4 - 4.00 - 1995 年 1 月
4. DG/UX - **4.10** - 1995 年 8 月
5. DG/UX - **4.11** - 1995 年 12 月
### DG/UX 和 AViiON 的结束
我在 1995 年底离开了这个岗位,但听说在世纪之交 [EMC](https://en.wikipedia.org/wiki/EMC_Corporation) 收购了数据通用公司,以便能够获得 CLARiiON 阵列和软件。考虑到 CLARiiON 的稳定性,这个决定我认为是理解的。据我记得,EMC 在收购后的几年内还在支持 DG/UX 操作系统和 AViiON,然后就停止支持了。我内心希望他们能一直保留这个操作系统,但那个时候,Unix 世界已经被像 [IBM](https://en.wikipedia.org/wiki/IBM)、[Sun Microsystems](https://en.wikipedia.org/wiki/Sun_Microsystems) 和 [HP](https://en.wikipedia.org/wiki/Hewlett-Packard) 这些大公司主导,同时还有像 [Linux](https://www.linux.com/what-is-linux/) 这样的新兴力量在逐渐崭露头角。
数据通用公司和 DG/UX 无疑是拥有一段美好历史的。它们的卓越支持和操作系统是今天绝难比拟的。我特别喜欢那个操作系统,它也是一款绝对值得被铭记的操作系统。
*(题图:DA/e651f994-3695-4bfd-89cc-c6b7b1ad0309)*
---
via: <https://itsfoss.com/dg-ux-os/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I tried looking up some information on an old operating system I used to work with: [DG/UX](https://archive.org/details/installing_the_dgux_system). Sadly, there isn't a lot of information about it anymore. I loved that little operating system, and while I am sure that my experiences will not make history at all, I wanted to add some written account of my experiences with it for the historical record.
Developed by [Data General](https://en.wikipedia.org/wiki/Data_General), DG/UX was a [Unix](https://en.wikipedia.org/wiki/Unix) [operating system](https://en.wikipedia.org/wiki/Operating_system) for its [Eclipse MV](https://en.wikipedia.org/wiki/Eclipse_MV) minicomputer line, and later the [AViiON](https://en.wikipedia.org/wiki/Aviion) workstations and servers. I never worked on the Eclipse systems, but I worked on the AViiON systems. Built like tanks, they were and amazingly simple to use.

[WolfeDen.org](https://www.wolfeden.org/unix-museum/dg/av4k.html)
## OS Overview
I was introduced to DG/UX in the mid 1990s, but it had been around for a while. DG/UX 1 was released in March, 1985 and, was based on [UNIX System V](https://en.wikipedia.org/wiki/UNIX_System_V) Release 2 with additions from [4.1BSD](https://en.wikipedia.org/wiki/BSD). DG/UX 3.10 came around a couple of years later with [TCP/IP](https://en.wikipedia.org/wiki/TCP/IP) networking, [NFS](https://en.wikipedia.org/wiki/Network_File_System) and the [X Window System](https://en.wikipedia.org/wiki/X_Window_System) included. Remember [CDE](https://itsfoss.com/common-desktop-environment/)?
[Trying Common Desktop Environment on a Modern Linux DistroBill shares his re-experience with Common Desktop Environment (CDE), the de-facto standard windowing environment on UNIX systems in the 90s.](https://itsfoss.com/common-desktop-environment/)

DG/UX 4 (the "4" would later confuse me to no end later on...) was released in 1988, and was a major re-design of the system, based on [System V Release 3](https://en.wikipedia.org/wiki/System_V_Release_3). The filesystem, using the logical disk facility, could span multiple disks.
DG/UX 5.4 was a biggie. This was the version I started working with. This version replaced the legacy Unix file buffer cache with unified, demand paged virtual memory management.
The operating system was also more complete than some other Unix variants; for example, the operating system included a full [C](https://en.wikipedia.org/wiki/C_(programming_language)) compiler. We also had an army of [COBOL](https://en.wikipedia.org/wiki/COBOL) programmers, but if I remember correctly, COBOL was an add-on. Today, a C compiler may seem to be a given, but it was a blessing back in the day. While I wrote scripts for many of my admin tasks, I did write several C programs specific to the work required.
The OS was small and compact, but extremely easy to use. The System V and added BSD tools were the right mix - the best of both worlds, you could say. It was simple and easy to install or upgrade and did not need much resources of memory or processing power.
The [volume manager](https://en.wikipedia.org/wiki/Logical_volume_management) built into the OS was simple, but very powerful. Any disk administration could be performed online, without taking any file system offline. Again, in an insurance/risk management shop, this was important. We could extend, relocate, mirror, or shrink - and the same functions could be performed on the swap area, allowing in-place migrations of disk storage without downtime.
## The Machines
The AViiON machines I worked on, came in two types: One was an AV300 [pizza box](https://en.wikipedia.org/wiki/Pizza_box_form_factor) workstation and the other was the AV9500 server with [CLARiiON](https://en.wikipedia.org/wiki/Clariion) disk arrays.


Data General AViiON AV/300D came in Pizza Box style | Picture Credit [Pizza Box Computer](https://blog.pizzabox.computer/pizzaboxes/aviion300/)
On the AViiON, DG/UX supported [multiprocessors](https://en.wikipedia.org/wiki/Multiprocessor). Working in an insurance/risk management shop, this was a huge plus. Not every Unix package supported this. DG/UX also worked seamlessly with the CLARiiON arrays.
Having raids, like the CLARiiON, it was easy to allocate space for certain accounts, but a previous administrator would "use first available space" when creating accounts. It didn't take long to run into problems with this approach: a single query could cause the lights on all 125 disks to light up - an account's data was spread across the entire set of arrays.

[https://commons.wikimedia.org/w/index.php?curid=512844](https://commons.wikimedia.org/w/index.php?curid=512844)
Once I took over as senior administrator, I set about correcting the problem by assigning an array to certain large accounts and smaller accounts grouped onto two arrays. It took about a week of night work to do, but DG/UX made the rearranging of files to specifically assigned arrays, easy.
The raids themselves were rock solid too. At one time, we had IBM 1GB disks. The mechanisms in these disks had a habit of sticking and the only way to get them to work again was to remove them and spin them on the floor like a top (I'm serious!). Once in a while, the disk was beyond hope and would never spin again. Now, the raid makes copies of each disk across its array, so the data was still present, although efficiency was lost. Once, I had to "borrow" a disk from another computer to keep an array running until a replacement could be obtained. The CLARiiON handled it superbly for the day. Rather than test our luck further, we replaced every disk. - and the DG/UX backup/restore utility made that work seamless as well.
## Support
There is not much to say about support except that it was fantastic. I had never had a problem with support. Every question I had was answered courteously and always accurately. That's something not seen today.
Remember the "4" I mentioned earlier, that would confuse me later? I called support on that. In 1995, I received the operating system upgrade tapes for the OS. Now, we had been running 5.4. I was surprised to see 4.10 tapes. I thought this was an error and that I was sent the wrong set of tapes; I didn't want to be downgraded.
As it turned out, I did have the right tapes. The "4" was a nod to the System V Release **4** update. I sometimes still think that it was odd - upgrading an OS while backing off the version number. Here's a short list of versions to illustrate:
- DG/UX 5.4 - 3.00 - Jan '94
- DG/UX 5.4 - 3.10 - Jul '94
- DG/UX 5.4 - 4.00 - Jan '95
- DG/UX -
**4.10**- Aug '95 - DG/UX -
**4.11**- Dec '95
## The End of DG/UX and AViiON
I transferred out of the shop at the end of '95 but I heard that [EMC](https://en.wikipedia.org/wiki/EMC_Corporation) bought Data General, around the turn of the century, in order to get their hands on the CLARiiON arrays and software. Considering how solid the CLARiiON was, I cannot say that I blame them. If I remember the reports correctly, EMC did support the DG/UX OS and AViiONs for a couple of years, and then dropped them. A part of me wishes that they had kept the OS, but at that time, bigger companies, such as [IBM](https://en.wikipedia.org/wiki/IBM), [Sun Microsystems](https://en.wikipedia.org/wiki/Sun_Microsystems), and [HP](https://en.wikipedia.org/wiki/Hewlett-Packard), were calling the shots in the Unix world. Also, let's not forget the rise of [Linux](https://www.linux.com/what-is-linux/) which would become popular.
Data General and DG/UX certainly had a good run. Excellent support and operating system - a combination not easily matched today. I certainly enjoyed that operating system and it is definitely one to be remembered. |
16,482 | 保持对云服务供应商选择的多样性 | https://opensource.com/article/22/5/cloud-service-providers-open | 2023-12-17T22:39:48 | [
"云服务",
"云计算"
] | https://linux.cn/article-16482-1.html | 
>
> 不论云服务的开放程度如何,你都能为自己的环境选择合适的方式。
>
>
>
对于 Linux 用户来说,市场上有一种新型的电脑出现,我们称之为“云”。
如同你桌面上的个人电脑,背包里的笔记本电脑,或是你租用的虚拟私有服务器一样,你可以选择不同的云计算供应商。虽然品牌名称和你以往熟悉的硬件品牌不一致,但其核心概念是相同的。
要运行 Linux,你需要一台电脑。要在云上运行 Linux,你需要一个云服务供应商。就像你的电脑中的硬件和固件一样,你的计算堆栈可以使用多大的开源程度也是有区别的。
作为一个开源的用户,我更偏向于拥有尽量开放的计算集成环境。在对云计算市场进行详细的调研后,我形成了关于云服务供应商的三层观点。你可以根据这个体系作为指南,对你将选择的云供应商作出明确的决策。
### 开放堆栈
一个完全开放的云是从底层开始就建立在开源技术之上的云。由于云科技中有很大一部分从一开始就是开源的,因此技术层面的开放性堆栈并不难以实现。然而,也有云供应商以专有的方式重新发明轮子,这让用户很容易误入使用了许多封闭源码组件的云服务商的陷阱中。
如果你在寻找一个真正开放的云,那么你应该寻找一个提供 [OpenStack](https://opensource.com/resources/what-is-openstack) 作为基础的云供应商。OpenStack 提供云的软件基础设施,包括通过 Neutron 实现的软件定义网络(SDN)、通过 Swift 实现的对象存储、身份和密钥管理、镜像服务等等。按照我的硬件电脑比喻,OpenStack 就是驱动云的“内核”。
当然,我并不是字面上的意思,但如果你的云供应商运行 OpenStack,那相当于你可以直接到达堆栈的底部。从用户的角度看,OpenStack 是你的云存在并拥有文件系统、网络等的原因所在。
在 OpenStack 的主体上,可能有一个像 Horizon 或 Skyline 这样的网络用户界面,可能有像 [OpenShift](https://cloud.redhat.com/?intcmp=7013a000002qLH8AAM) 或 OKD(并不是一个缩写,但前身是 OpenShift Origin)这样的额外组件。所有这些都是开源的,它们帮助你运行容器,这些容器是内嵌应用程序的极简 Linux 镜像。
因为 OpenShift 和 OKD 不需要 OpenStack,这就构成了我对云世界的下一个视野级别。
### 开放平台
你并不总是可以选择你的云正在运行的堆栈。你的云可能运行的是 Azure、AWS,或者类似的东西,而不是 OpenStack。
这些就是云世界的“二进制碎片”。你对它们如何工作,或者为什么工作一无所知;你只知道你的云存在,并且有一个文件系统,一个网络堆栈,等等。
就像桌面计算一样,你可以在获得的服务器上运行一个“操作系统”。言下之意,有一种观点认为 OpenStack 本质上就是云计算的操作系统。然而,通常情况下,用户直接交互的是 OpenShift。
OpenShift 是一个你可以使用 Podman 和 Kubernetes 管理容器和 <ruby> 容器荚 <rt> Pod </rt></ruby> 的开源“桌面”或工作区。它让你在云上运行应用程序,就像你在笔记本电脑上启动一个应用一样。
### 开放标准
最后,同样重要的一点是,有些情况下你在选择云服务供应商上没有什么选择。你被放在一个运行着专有“内核”、专有“操作系统”的平台上,你能影响的只剩下你在那个环境里运行什么。
但掌握开源的力量,你就能建立你自己的平台。你可以选择在容器内部使用的组件。你可以,而且应该,围绕开源工具设计你的工作环境,因为这样一来,如果你有机会更换服务供应商,你可以将你的所有工作迁移到新的供应商那里。
这可能需要你自行实现一些在你当前受限(非开源)平台上已经内置的功能。例如,你的云供应商可能会用一个包含在他们平台“免费”提供的 API 管理系统或持续集成/持续交付(CI/CD)管道来吸引你,这需要你有清醒的认识。当一个非开放的应用被免费提供时,通常会以其他形式带来一些成本。其中一种成本是,一旦你开始在它的基础上构建,你会更加不愿意迁移,因为你会离开你已建立的一切。
你应当为自己重建这些封闭“特性”,并将其转化为开源服务。在容器中运行 [Jenkins](https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins) 和 [APIMan](https://www.apiman.io/latest/)。找出你的云提供商声称用专有代码解决的问题,然后使用开源解决方案来确保,当你离开寻找开放的供应商时,你可以迁移你已经构建的系统。
### 开源计算
对于太多的人来说,云计算是一个开源居于次要地位的领域。实际上,开源在云上的重要性与它在你的个人电脑和驱动互联网的服务器上同样重要。
寻找开源的云服务。
当你受困于无法获取源代码的环境时,就肩负起在你的云内使用开源软件的责任吧。
*(题图:DA/9dc5a9d0-d664-492f-890a-b437ce39c4d6)*
---
via: <https://opensource.com/article/22/5/cloud-service-providers-open>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For Linux users, there's a new kind of computer on the market, and it's known as *the cloud*.
As with the PC sitting on your desk, the laptop in your backpack, and the virtual private server you rent from your favorite web hosting service, you have your choice in vendors for cloud computing. The brand names are different than the hardware brands you've known over the years, but the concept is the same.
To run Linux, you need a computer. To run Linux on the cloud, you need a cloud service provider. And just like the hardware and firmware that ships with your computer, there's a spectrum for how open source your computing stack can be.
As a user of open source, I prefer my computing stack to be as open as possible. After a careful survey of the cloud computing market, I've developed a three-tier view of cloud service providers. Using this system as your guide, you can make intelligent choices about what cloud provider you choose.
## Open stack
A cloud that's fully open is a cloud built on open source technology from the ground up. So much cloud technology is open source, and has been from the beginning, that an open stack isn't all that difficult to accomplish, at least on the technical level. However, there are cloud providers reinventing the wheel in a proprietary way, which makes it easy to stumble into a cloud provider that's mixed a lot of closed source components in with the usual open source tooling.
If you're looking for a truly open cloud, look for a cloud provider providing [OpenStack](https://opensource.com/resources/what-is-openstack) as its foundation. OpenStack provides the software infrastructure for clouds, including Software-Defined Networking (SDN) through Neutron, object storage through Swift, identity and key management, image services, and much more. Keeping with my hardware computer analogy, OpenStack is the "kernel" that powers the cloud.
I don't mean that literally, of course, but if your cloud provider runs OpenStack, that's reasonably as far down in the stack as you can go. From a user perspective, OpenStack is the reason your cloud exists and has a filesystem, network, and so on.
Sitting on top of OpenStack, there may be a web UI such as Horizon or Skyline, and there may be extra components such as [OpenShift](https://cloud.redhat.com/?intcmp=7013a000002qLH8AAM) or OKD (not an acronym, but formerly known as OpenShift Origin). All of these are open source, and they help you run containers, which are minimalist Linux images with applications embedded within them.
Because OpenShift and OKD don't require OpenStack, that's the next tier of my cloud-based world view.
**[ Download the guide: Containers and Pods 101 ]**
## Open platform
You don't always have a choice in which stack your cloud is running. Instead of OpenStack, your cloud might be running Azure, Amazon Web Services (AWS), or something similar.
Those are the "binary blobs" of the cloud world. You have no insight into how or why they work; all you know is that your cloud exists and has a filesystem, a networking stack, and so on.
Just as with desktop computing, you can have an "operating system" running on the box you've been given. Again, I'm not speaking literally, and there's a strong argument that OpenStack itself is essentially an operating system for the cloud. Still, it's usually OpenShift that a cloud user interacts with directly.
OpenShift is an open source "desktop" or workspace in which you can manage containers and pods with Podman and Kubernetes. It lets you run applications on the cloud much as you might launch an app on your laptop.
**[ Keep these commands handy: Podman cheat sheet ]**
## Open standards
Last but not least, there are those situations when you have no choice in cloud service providers. You're put on a platform with a proprietary "kernel," a proprietary "operating system," and all that's left for you to influence is what you run inside that environment.
All is not lost.
When you're dealing with open source, you have the ability to construct your own scaffolding. You can choose what components you use inside your containers. You can and should design your working environment around open source tools, because if you do get to change service providers, you can take everything you've built with you.
This might mean implementing something already built into the (non-open) platform you're stuck on. For instance, your cloud provider might entice you with an API management system or continuous integration/continuous delivery (CI/CD) pipeline that's included in their platform "for free," but you know better. When a non-open application is offered as "free," it usually bears a cost in some other form. One cost is that once you start building on top of it, you'll be all the more hesitant to migrate away because you know that you'll have to leave behind everything you built.
Instead of using the closed "features" of your cloud provider, reimplement those services as open source for your own use. Run [Jenkins](https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins) and [APIMan](https://www.apiman.io/latest/) in containers. Find the problems your cloud provider claims to solve with proprietary code, then use an open source solution to ensure that, when you leave for an open provider, you can migrate the system you've built.
**[ Take the free online course: Deploying containerized applications ]**
## Open source computing
For too many people, cloud computing is a place where open source is incidental. In reality, open source is as important on the cloud as it is on your personal computer and the servers powering the internet.
Look for open source cloud services.
When you're stuck with something that doesn't provide source code, be the one using open source in your cloud.
## Comments are closed. |
16,483 | Vivaldi 6.5 现已发布,展示面向未来的特性 | https://news.itsfoss.com/vivaldi-6-5-release/ | 2023-12-17T23:20:00 | [
"Vivaldi"
] | https://linux.cn/article-16483-1.html | 
>
> Vivaldi 6.5 是一个令人印象深刻的升级,必将助力提高生产效率,缩短工时!
>
>
>
Vivaldi,作为 Ubuntu 和各类 Linux 发行版的 [最佳网络浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/) 之一,今年已经连续推出了众多重大升级,将其推升到了前所未有的高度。
作为今年的收官之作,**Vivaldi 6.5** 版本的发布承载了许多新特性和改进建议。
>
> ? 需要注意的是,Vivaldi 是非完全开源的解决方案,其用户界面部分属于闭源。
>
>
>
接下来让我们探索一下具体的内容。
### ? Vivaldi 6.5:有何新进展?
作为年终的馈赠,Vivaldi 的这次发布有以下 **核心亮点** :
* 会话面板
* 优化的工作区
* 更强的同步性能
#### 会话面板

Vivaldi 新增了一个 “<ruby> 会话 <rt> Sessions </rt></ruby>” 面板,允许你 **整理和存储来自任何窗口或工作区的标签**。你可以轻松地从新的侧栏管理,并在需要时重新打开它们。
你还可以编辑内容,重命名会话,甚至查看其下的标签。
更进一步的是,你还可以选择启用 “<ruby> 自动会话备份 <rt> Automatic Session Backup </rt></ruby>”,它将 **每小时自动创建一次备份,保留长达 30 天**。备份包括所有打开的标签的快照;你也可以进行手动保存。
#### 工作区自动化

基于现有的工作区特性,**Vivaldi 6.5 实现了工作区的自动化**。当你用 URL 配置一个工作区规则后,尝试打开该链接的标签会自动转移至你选择的工作区。
如你在上图可以看到的,你只需要 **选择一个 URL** ,然后 **决定应用哪一规则** (有三个选项:“<ruby> 包含 <rt> contains </rt></ruby>”、“<ruby> 是 <rt> is </rt></ruby>”或“<ruby> 始于 <rt> starts with </rt></ruby>”)。至此,你只需要通过 “<ruby> 在其中打开 <rt> Open in </rt></ruby>” 选项来 **选择一个工作区**。
未来已经来临!?
#### 同步性能升级

此次发布达成了重要的里程碑之一,实现了 **跨平台浏览器历史记录的同步**。这使 Vivaldi 的同步特性更为完整,因为现在它已然能同步密码、书签、打开的标签、注释和阅读列表。
何况,**所有同步的数据在你所有的设备之间都实现了端到端的加密**。这是非常令人欣慰的,因为并非所有软件都有这样的实现。
此外,还有更多。
**来自任何你设备中的地址栏和 “<ruby> 窗口 <rt> Windows </rt></ruby>” 面板的同步标签现在是可搜索的**。在此次更新之前,你必须在标签栏点击云图标才能访问这些标签。
#### ?️ 另外的变动和改善
除了上述内容,还有很多其他的有益改动:
* 升级到 **Chromium 120.0.6099.121**。
* 同步功能将 **不会同步敏感且未加密的数据**。
* 修复了一些 **可能在各种网页上触发的随机崩溃**。
* Vivaldi 的 **笔记面板** 增加了新的 “<ruby> 添加到笔记选项 <rt> Append to Note option </rt></ruby>”。
* 修复了在打开欢迎屏幕时 **造成的 CPU 和 GPU 高耗能**。
* 解决了在加载时 **窗口无法根据主题自适应** 的问题。
你也可以通过查阅 [发布公告](https://vivaldi.com/blog/vivaldi-on-desktop-6-5/) 来获取更多的发布详情。
### ? 获取 Vivaldi 6.5
新版 Vivaldi 已对 **Linux**、**Windows** 以及 **macOS** 开放。你可以在 [官方网站](https://vivaldi.com/download/) 获取。
>
> **[Vivaldi](https://vivaldi.com/download/)**
>
>
>
? 你对这次功能更新满意吗?还是你正在等待其他新功能的加入?
*(题图:DA/72f1b4a6-59dd-4098-8edf-ec4e28a5c1f5)*
---
via: <https://news.itsfoss.com/vivaldi-6-5-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Being one of the [best web browsers for Ubuntu and other Linux distros](https://itsfoss.com/best-browsers-ubuntu-linux/?ref=news.itsfoss.com), Vivaldi has been pushing plenty of major upgrades this year that have taken it further than ever before.
One such upgrade to close out this year is the **Vivaldi 6.5** release that promises many new features and improvements.
Let's see what's it all about.
**Suggested Read **📖
[Top 10 Best Browsers for Ubuntu LinuxWhat are your options when it comes to web browsers for Linux? Here are the best web browsers you can pick for Ubuntu and other Linux distros.](https://itsfoss.com/best-browsers-ubuntu-linux/?ref=news.itsfoss.com)

## 🆕 Vivaldi 6.5: What's New?
Meant to be an end of year gift, this release of Vivaldi has the following **key highlights**:
**Sessions Panel****Better Workspaces****Improved Syncing**
### Sessions Panel
A new “**Sessions**” panel has been added to Vivaldi that lets you** group and store tabs from any window or workplace**. It lets you easily manage and reopen them when needed from the new side panel.
You can also edit the contents, rename the session, and even view what tabs are under it.
To sweeten the pie even further, you also have the option to enable “**Automatic Session Backup**” that will **automatically create session backups every hour that last up to 30 days**. It will include a snapshot of all the open tabs; you can manually save them too.
### Automating Workspaces
Building upon their Workspaces feature, **Vivaldi 6.5 lets you automate workspaces**. When you set up a workspace rule with a URL, the tab will be automatically moved to the workspace you selected when you try to open it.
As you can see above, you have to **choose a URL**, then **decide which condition to apply **(there are three; *contains*, *is,* *starts with)*. Thereafter, you just have to **select a workspace** by using the “*Open In*” option.
The future is here! 😁
### Improved Syncing
Another major milestone that this release has achieved has been** the synchronization of full browser history across platforms**. This now makes Vivaldi's sync feature more complete as it already synced passwords, bookmarks, open tabs, notes, and the reading list.
And guess what, **all the data that is synced is end-to-end encrypted between all your devices**. This is something that's great to see, not everyone does that.
Wait, there's more.
The **synced tabs are now searchable from the address field and “ Windows” panel** on any of your devices. Before this update, you had to click on the cloud icon in the tab bar to access them.
### 🛠️ Other Changes and Improvements
Other than the ones highlighted above, there are plenty of other useful changes too:
- An upgrade to
**Chromium 120.0.6099.121.** - Syncing feature will
**not sync sensitive, unencrypted data**. - Fixed
**random crashes**that would occur on various web pages. - A new “
*Append to Note option*” was added to Vivaldi's**Notes Panel**. - Fixed
**high CPU and GPU usage**when the welcome screen was opened. - Addressed an issue where the
**window would not be themed**properly while loading.
You may also through the [release notes](https://vivaldi.com/blog/vivaldi-on-desktop-6-5/?ref=news.itsfoss.com) to dive deeper into the release.
## 📥 Get Vivaldi 6.5
This new release of Vivaldi is available for **Linux**, **Windows**, **macOS**. Head over to the [official website](https://vivaldi.com/download/?ref=news.itsfoss.com) to get it.
*💬 Happy about the feature packrd upate? Or were you waiting for a different feature addition? *
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,485 | 人工智能教程(四):概率论入门 | https://www.opensourceforu.com/2023/01/ai-an-introduction-to-probability/ | 2023-12-18T13:45:00 | [
"TensorFlow",
"AI"
] | https://linux.cn/article-16485-1.html | 
在本系列的 [上一篇文章](/article-16436-1.html) 中,我们进一步讨论了矩阵和线性代数,并学习了用 JupyterLab 来运行 Python 代码。在本系列的第四篇文章中,我们将开始学习 TensorFlow,这是一个非常强大的人工智能和机器学习库。我们也会简要介绍一些其它有用的库。稍后,我们将讨论概率、理论以及代码。和往常一样,我们先讨论一些能拓宽我们对人工智能的理解的话题。
到目前为止,我们只是从技术方面讨论人工智能。随着越来越多的人工智能产品投入使用,现在是时候分析人工智能的社会影响了。想象一个找工作的场景,如果你的求职申请由人来处理,在申请被拒绝时,你可以从他们那里得到反馈,比如被拒的理由。如果你的求职申请由人工智能程序处理,当你的申请被拒绝时,你不能要求该人工智能软件系统提供反馈。在这种情况下,你甚至不能确定你的申请被拒绝是否确实是仅基于事实的决定。这明确地告诉我们,从长远来看,我们需要的不仅仅是魔法般的结果,还需要人工智能具有 <ruby> 责任 <rt> accountability </rt></ruby> 和 <ruby> 保证 <rt> guarantee </rt></ruby>。(LCTT 译注:责任主要指确保系统的决策过程是透明的、可解释的,并且对系统的行为负责。保证是指对于系统性能指标和行为的一种承诺或者预期。)目前有很多试图回答这些问题的研究。
人工智能的应用也会引发许多道德和伦理上的问题。我们不必等到强人工智能(也被称为 <ruby> 通用人工智能 <rt> artificial general intelligence </rt></ruby> —— AGI)出现才研究它的社会影响。我们可以通过思想实验来探究人工智能的影响。想象你在一个雨夜你驾车行驶在有发夹完的道路上,突然你眼前有人横穿马路,你的反应是什么?如果你突然刹车或转向,你自己的生命将处于极大的危险之中。但如果你不这样做,过马路的人恐怕凶多吉少。因为我们人类具有自我牺牲的特质,在决策的瞬间,即使是最自私的人也可能决定救行人。但我们如何教会人工智能系统模仿这种行为呢?毕竟从纯粹的逻辑来看,自我牺牲是一个非常糟糕的选择。
同样的场景下,如果汽车是由人工智能软件在驾驶会发生什么呢?既然你是汽车的主人,那么人工智能软件理应把你的安全放在首位,它甚至全不顾其他乘客的安全。很容易看出,如果世界上所有的汽车都由这样的软件控制的话将导致彻底的混乱。现在,如果进一步假设乘坐自动驾驶汽车的乘客身患绝症。那么对于一个数学机器来说,为了行人牺牲乘客是合乎逻辑的。但对于我们这些有血有肉的人却不见得如此。你可以花点时间思考一下其它场景,注重逻辑的机器和热血的人类都会做出什么样的决策。
有很多书籍和文章在讨论人工智能全面运作后的政治、社会和伦理方面的问题。但对于我们这些普通人和计算机工程师来说,读所有的书都是不必要的。然而,由于人工智能的社会意义如此重要,我们也不能轻易搁置这个问题。为了了解人工智能的社会政治方面,我建议你通过几部电影来理解人工智能(强人工智能)如何影响我们所有人。<ruby> 斯坦利·库布里克 <rt> Stanley Kubrick </rt></ruby>的杰作《<ruby> 2001:太空漫游 <rt> 2001: A Space Odyssey </rt></ruby>》是最早描绘超级智能生物如何俯视我们人类的电影之一。这部电影中人工智能认为人类是世界最大的威胁,并决定毁灭人类。事实上,有相当多的电影都在探索这种情节。由伟大的艺术大师<ruby> 史蒂文·斯皮尔伯格 <rt> Steven Spielberg </rt></ruby>亲自执导的《<ruby> 人工智能 <rt> Artificial Intelligence </rt></ruby>》,探讨了人工智能机器如何与人类互动。另一部名为《<ruby> 机械姬 <rt> Ex Machina </rt></ruby>》的电影详细阐述了这一思路,讲述了具有人工智能的机器。在我看来这些都是了解人工智能的影响必看的电影。
最后思考一下,试想如果马路上的汽车使用来自制造商的不同的自动驾驶规则和人工智能,这将导致彻底的混乱。
### TensorFlow 入门
TensorFlow 是由 <ruby> 谷歌大脑 <rt> Google Brain </rt></ruby> 团队开发的一个自由开源的库,使用 Apache 2.0 许可证。TensorFlow 是开发人工智能和机器学习程序的重量级的库。除了 Python 之外,TensorFlow 还提供 C++、Java、JavaScript 等编程语言的接口。在我们进一步讨论之前,有必要解释一下 <ruby> 张量 <rt> tensor </rt></ruby> 是什么。如果你熟悉物理学,张量这个词对你来说可能并不陌生。但如果你不知道张量是什么也不用担心,现阶段把它看作多维数组就行了。当然,这是一种过度简化的理解。TensorFlow 可以在 NumPy 提供的多维数组之上运行。
首先,我们要在 JupyterLab 中安装 TensorFlow。TensorFlow 有 GPU 版本和 CPU 版本两种安装类型可以选择。这主要取决于你的系统是否有合适的 GPU。GPU 是一种利用并行处理来加快图像处理速度的电路。它被广泛用在游戏和设计领域,在开发人工智能和机器学习程序时也是必不可少的硬件。但一个不太好的消息是 TensorFlow 只兼容英伟达的 GPU。此外,你需要在系统中安装一个称为 CUDA(<ruby> 计算统一设备架构 <rt> compute unified device architecture </rt></ruby>)的并行计算平台。如果你的系统满足这些要求,那么在 JupyterLab 上执行命令 `pip install tensorflow-gpu` 来安装 GPU 版本的 TensorFlow。如果你系统的 GPU 配置无法满足要求,当你尝试使用 TensorFlow 时,会得到如下错误消息:“CUDA\_ERROR\_NO\_DEVICE: no CUDA-capable device is detected”。此时使用 `pip uninstall tensorflow-gpu` 卸载 GPU 版本的 TensorFlow。然后执行命令 `pip install tensorflow` 安装 CPU 版本的 TensorFlow。现在 TensorFlow 就准备就绪了。请注意,目前我们将讨论限制在 CPU 和 TensorFlow 上。

现在,让我们运行第一个由 TensorFlow 驱动的 Python 代码。图 1 显示了一个简单的 Python 脚本及其在 JupyterLab 上执行时的输出。前两行代码将库 NumPy 和 TensorFlow 导入到 Python 脚本中。顺便一提,如果你想在 Jupyter Notebook 单元中显示行号,单击菜单 “<ruby> 查看 <rt> View </rt></ruby> > <ruby> 显示行号 <rt> Show Line Numbers </rt></ruby>”。第 3 行使用 NumPy 创建了一个名为 `arr` 的数组,其中包含三个元素。第 4 行代码将数组 `arr` 的每个元素乘 3,将结果存储在一个名为 `ten` 的变量中。第 5 行和第 6 行分别打印变量 `arr` 和 `ten` 的类型。从代码的输出中可以看到,`arr` 和 `ten` 的类型是不同的。第 7 行打印变量 `ten` 的值。注意,`ten` 的形状与数组 `arr` 的形状是相同的。 数据类型 `int64` 在本例中用于表示整数。这使得本例中 NumPy 和 TensorFlow 数据类型之间的无缝转换成为可能。
TensorFlow 支持很多操作和运算。随着处理的数据量的增加,这些操作会变得越来越复杂。TensorFlow 支持常见的算术运算,比如乘法、减法、除法、幂运算、模运算等。如果参与运算的是列表或元组,TensorFlow 会逐元素执行该操作。

TensorFlow 还支持逻辑运算、关系运算和位运算。这里的操作也是按元素执行的。图 2 显示了执行这些按元素操作的 Python 脚本。第 1 行代码从列表创建一个张量,并将其存储在变量 `t1` 中。TensorFlow 的函数 `constant()` 用于从 Python 对象(如列表、元组等)创建张量。类似地,第 2 行创建了另一个张量 `t2`。第 3 行和第 4 行都是执行逐元素求幂并打印输出。从图 2 中可以清楚地看出,该求幂的结果是相同的。第 5 行代码比较张量 `t1` 和 `t2` 的元素并打印结果。输出中的 `[True True False]` 分别是对应 3>2、4>3 和 2>6 的结果。第 6 行的输出与之类似。

图 3 展示了 TensorFlow 处理矩阵的例子。第 1 行和第 3 行分别构造两个矩阵 `x` 和 `y`,第 2 行和第 4 行分别打印矩阵 `x` 和 `y`的形状。代码的输出显示 `x` 的形状为 `(3,3)`,`y` 的形状为 `(3,)`。从本系列前面介绍的矩阵知识,我们知道这两个矩阵是不能相乘的。
因此,在第 5 行中将矩阵 `y` 增加了一个维度。在第 6 行,再次打印矩阵 `y` 的形状,输出结果为 `(3,1)`。现在矩阵 `x` 和 `y` 可以相乘了。第 7 行中,将矩阵相乘并打印输出。注意,类似的操作也可以在张量上执行,即使张量的维数很高,TensorFlow 也可以很好地扩展。在本系列的后续文章中,我们将更多地了解 TensorFlow 支持的数据类型和其他复杂操作。
既然介绍了 TensorFlow,我想我也应该提一下 Keras。它为 TensorFlow 提供 Python 接口。在后续的文章中,我们将专门介绍 Keras。
我们如何利用非英伟达 GPU 的能力呢?有许多功能强大的软件包可以做到这一点。比如 PyOpenCL,一个在 Python 中编写并行程序的框架。它让我们可以使用 OpenCL(<ruby> 开放计算语言 <rt> open computing language </rt></ruby>)。OpenCL 可以与 AMD、Arm、英伟达等厂商的 GPU 进行交互。当然还有其他选择,比如 Numba。它是一种JIT 编译器,可用在代码执行期间将 Python 代码编译为机器码。如果 GPU 可用,Numba 允许代码使用的 GPU 能力。图 4 是展示了使用 Numba 的 Python 代码。
我们可以看到函数 `fun()` 具有允许并行化的特征。从图 4 中可以看到,代码在不使用和使用 Numba 的情况下的答案是相同的。但是我们可以看到所花费的执行时间是不同的。当使用 Numba 并行化代码时,只花费了不到一半的时间。此外随着问题规模的增加,并行化和非并行化版本所花费的时间之间的差距也将增加。

### SymPy 入门
SymPy 是一个用于符号计算的 Python 库。通过图 5 中的例子,让我们试着理解什么是符号计算。它使用 SymPy 提供的函数 `Integral()`来求积分。图 5 也显示了这个符号计算的输出。注意,SciPy 提供的 `integrate()` 函数返回数值计算结果,而 SymPy 的 `Integral()` 函数能提供精确的符号结果表达式。人工智能和机器学习程序开发中会用到一些统计学操作,SymPy 在执行这些操作时非常有用。

在本系列的下一篇文章中,我们将讨论 Theano。Theano 是一个 Python 库和优化编译器,用于计算数学表达式。
### 概率论入门
现在是概率论出场的时候了,它是人工智能和机器学习的另一个重要话题。对概率论的详细讨论超出了本系列的范围。我强烈建议在继续阅读之前,先通过维基百科上关于“概率”、“贝叶斯定理”和“标准差”的文章了解一些重要的术语和概念,如概率、独立事件、互斥事件、条件概率、贝叶斯定理、均值、标准差等。学习完这些后,你将能够轻松理解后面关于概率的讨论。
我们从概率分布开始讲起。根据维基百科的说法,“概率分布是一个数学函数,它能给出一个实验中不同的可能结果发生的概率”。现在,让我们试着理解什么是概率分布函数。最著名的概率分布函数是正态分布,通常也称为高斯分布(以伟大的数学家高斯的名字命名)。正态分布函数的图像是一条钟形曲线。图 6 是一个钟形曲线的例子。钟形曲线的确切形状取决于均值和标准差。让我们试着通过分析一种自然现象来理解钟形曲线。从网上可以查到,中国男性的平均身高约为1.7米。在我们周围的到多数男性的身高都非常接近这个数字。你看到一个身高低于1.4米或高于2米的男人的可能性很小。如果记录 100 万人的身高,然后以横轴为身高,纵轴为该身高的人数,绘制统计结果,你会发现绘制出的图像近似为钟形曲线,其中只有一些轻微的倾斜和弯曲。因此,正态分布很容易地捕捉到自然现象的概率特征。

现在,我们来看一个使用正态分布的例子。图 7 的代码中我们使用 NumPy 的正态分布的函数 `normal()`,然后使用 Matplotlib 进行绘图。从第 3 行我们可以看到样本大小为 1000。第 4 行绘制一个包含 1000 个 <ruby> 桶 <rt> bin </rt></ruby> 的直方图。但是图 7 的钟形曲线与图 6 中看到的钟形曲线相差很大。究其原因是我们的样本数量只有 1000。样本量应该足够大才能获得更清晰的图像。将第 3 行代码替换为 `sample = normal(size=100000000)`,行并再次执行程序。图 8 显示了一条更好的钟形曲线。这一次,我们的样本大小为 100,000,000,钟形曲线与图 6 所示非常相似。正态分布和钟形曲线只是开始。在下一篇文章中,我们将讨论可以概括其他事件和自然现象的概率分布函数。下一次,我们还将更正式地讨论这个主题。

本篇的内容就到此结束了。在下一篇文章中,我们将继续探索概率和统计中的一些概念。我们还将安装和使用 Anaconda,这是一个用于科学计算的 Python 发行版,对于开发人工智能、机器学习和数据科学程序特别有用。如前所述,我们还将熟悉另一个名为 Theano 的 Python 库,它在人工智能和机器学习领域被大量使用。

*(题图:DA/2a8d805a-01d3-4039-b96c-74766491e264)*
---
via: <https://www.opensourceforu.com/2023/01/ai-an-introduction-to-probability/>
作者:[Deepu Benson](https://www.opensourceforu.com/author/deepu-benson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In the previous article in this series on AI (August 2022 issue of OSFY), we continued our discussion of matrices and linear algebra. We also discussed a few Python libraries useful in developing AI based applications, and learned to use JupyterLab to run our Python code. In this fourth article in the series on AI, we will begin exploring TensorFlow, a very powerful library used for developing AI and machine learning applications. We will also briefly discuss a few other useful libraries on the way. Later, we will discuss probability, theory as well as code. But as always, we will start by discussing a few topics that will widen our understanding of AI.*
So far, we have discussed only the technological aspects of AI. What about the social aspects? Maybe, it is time to analyse the social implications of deploying more and more AI based applications. Imagine a scenario where you are applying for a job, which is processed by a group of people. They go through your resume and make a decision. In case you are not selected for the job, you can get feedback from the group that processed your application. They may even be able to convince you about the reasons for rejecting your application. Now, assume that your application is being processed by software powered with AI. Again, your application may get rejected. However, this time there is no accountability. You cannot ask an AI based software system for a feedback. So, in this scenario you are not sure whether the rejection of your application was indeed based on merit alone. This definitely tells us that in the long run we need to develop AI based applications with accountability and some guarantees, not just some results taken out of a magic box. Currently, a lot of research is trying to answer these questions.
The deployment of AI based applications also raises a lot of moral and ethical questions. Moreover, you don’t need to wait till the emergence of strong AI (also known as artificial general intelligence) to study its social impact. As an example, imagine you are driving a car through a road with hairpin bends on a rainy night. Assume that the car is running at a speed of around 100 km per hour. Suddenly, someone crosses the road. What will your response be? Since this is a thought experiment, let us make the situation even more complicated. If you suddenly apply the brakes or turn the car, your life will be in great danger. But if you don’t do this the life of the person crossing the road will be in jeopardy. For us humans, this is a split second decision and even the most selfish person may decide to save the pedestrian, because we have the trait of self-sacrifice. But how do we ever teach an AI based system to imitate this behaviour? Based on pure logic alone, self-sacrifice is a very bad choice.


Now, reimagine the same scenario with a car driven by AI based software. Since you are the owner of the car, should the AI software be trained so that your safety is the topmost priority, even to the point of utterly disregarding the safety of your co-passengers. It is easy to see that a situation where all the cars in the world are driven by such software will lead to utter chaos. Now, further assume the AI system has the additional information that the passenger riding the self-driving car is suffering from a terminal illness. With this additional information, it is logical (only to a mathematical machine, not to us, flesh and blood humans) to sacrifice the passenger for the pedestrian. I don’t want to indulge any more in this thought exercise but it will be rewarding if you could spend some time to think about the ever more complicated scenarios that may arise when decisions are made by logic-oriented machines instead of hot-blooded humans.
There are many books and articles that deal with the political, social, and ethical aspects of AI when it becomes fully operational. But I think for us mere mortals and computer engineers it would be overkill to read all of them. However, since the social relevance of AI is so important, we cannot shelve the issue that easily. To be aware of the sociopolitical aspects of AI, I suggest you watch a few movies to easily understand how AI (strong AI for that matter) may impact all of us. The masterpiece by Stanley Kubrick, ‘2001: A Space Odyssey’, is one of the first movies to depict how a superior intelligent being could look down upon us humans. This movie is one among the many in which AI decides that humanity is the biggest threat to the world and decides to destroy humans. Indeed, there are quite a number of movies where this plot is explored. But that is not the extent of it. There is a movie called ‘Artificial Intelligence’ by the great maestro Steven Spielberg himself, which explores how a machine powered with AI interacts with a human being. Another movie called ‘Ex Machina’ elaborates on this thread and deals with machines capable of artificial general intelligence. In my opinion these are all must-watch movies to understand the impact of AI.
As a final thought exercise, just contemplate roads where every car manufacturing company has its own rules and AI for self-driving cars. That will lead to complete pandemonium.
## An introduction to TensorFlow
Now let us learn about TensorFlow, a heavyweight among libraries used for developing AI and machine learning based applications. Notice that, in addition to Python, TensorFlow can also be used with programming languages like C++, Java, JavaScript, etc. TensorFlow is a free and open source library licensed under Apache License 2.0, and was developed by the Google Brain team. But before we proceed any further, let us try to understand what a tensor is. If you are familiar with physics, the term tensor may not be new to you. But even if you are not familiar with the term tensor, no need to worry. Think of tensors as multidimensional arrays. Of course, this is an oversimplification. However, this simplified notion of tensors is sufficient for the time being. TensorFlow can operate on top of multidimensional arrays offered by NumPy.


First, let us install TensorFlow in JupyterLab. The kind of installation required depends on whether your system has a GPU or not. But, what is a GPU (graphics processing unit)? GPU is an electronic circuit that uses parallel processing to accelerate the speed of image processing. Though often used by gamers and designers, GPUs are an essential hardware requirement while developing AI and machine learning based applications. Unfortunately, not every GPU is compatible with TensorFlow. You need to have an NVIDIA GPU to install the GPU version of TensorFlow. Further, you need to install a parallel computing platform called CUDA (compute unified device architecture) in your system. If your system satisfies these requirements, then execute the command ‘pip install tensorflow-gpu’ on JupyterLab to install the GPU version of TensorFlow. If there is something wrong with the GPU configuration of your system, you will get the error message, ‘CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected’, when you try to use TensorFlow. If you get this error, please uninstall the GPU version of TensorFlow with the following command, ‘pip uninstall tensorflow-gpu’. Later, please install the CPU version of TensorFlow by executing the command, ‘pip install tensorflow’, on JupyterLab. Now, we are ready to use TensorFlow. Notice that, for the time being, we restrict our discussion to CPUs and TensorFlow.
Now, let us run our first Python code powered with TensorFlow. Figure 1 shows a simple Python script and its output when executed on JupyterLab. The first two lines of code import the libraries NumPy and TensorFlow into our Python script. As a side note, if you want to display line numbers in your Jupyter Notebook cells then click on ‘View>Show Line Numbers’. Line 3 creates an array named arr with three elements using NumPy. The line of code ‘ten = tf.multiply(arr, 3)’ multiplies every element of the array arr with the number 3, and the result is stored in a variable named ten. Lines 5 and 6 print the types of variables arr and ten, respectively. From the output of the code you can see that arr and ten are of different types. Finally, line 7 prints the value of the variable ten. Notice that the shape of ten is the same as that of array arr. Also notice that ‘int64’ data type is used to represent integers in this example. Thus, with this example, it is clear that a seamless conversion between data types in NumPy and TensorFlow is possible.
A lot of operations are supported by TensorFlow. These operations become more and more complex as the size of the data being processed increases. TensorFlow supports arithmetic operations like multiply( ) (x * y) which multiplies x and y, subtract( ) (x – y) which subtracts x from y, divide( ) (x / y) which divides x by y, pow( ) (x ** y) which returns x raised to the power of y, and mod( ) (x % y) which returns x modulo y. An important point to remember is that if x and y are lists or tuples, then the operations are performed element-wise.
TensorFlow also supports logical, relational and bit-wise operations. Here, too, the operations are performed element-wise. Figure 2 shows a Python script in which these element-wise operations are carried out. The line of code, ‘t1 = tf.constant([3, 4, 2])’ creates a tensor from the list ‘[3, 4, 2]’ and stores it in a variable called t1. The function constant( ) is used to create a tensor from Python objects like lists, tuples, etc. Line 2 creates another tensor and stores it in a variable called t2. Both the lines of code, ‘print(tf.pow(t1, t2))’ and ‘print(t1 ** t2)’, perform an element-wise exponentiation and print the output. From Figure 2 it is clear that the result of this exponentiation, [9 64 64], is the same as [32 43 26]. The line of code ‘print(t1>t2)’ compares the elements of tensors t1 and t2 and prints results. From Figure 2, it can be verified that the output [True True False] is the result of the comparisons 3>2, 4>3, and 2>6, respectively. Similarly, the output of line 6 can also be understood.
Now, let us see one more example, this time dealing with matrices. Consider the program shown in Figure 3. Lines 1 and 3 construct two matrices named x and y. Lines 2 and 4 print the shapes of matrices x and y, respectively. From the output of the code shown in Figure 3, it can be seen that x is of shape (3, 3) and y is of shape (3, ). Further, from our earlier discussions in this series, we know that these two matrices cannot be multiplied as such.


Hence, in line 5 we apply a nice technique by which the dimension of matrix y is increased by 1. In line 6, we again print the shape of matrix y. From the output, we can see that this time the shape of matrix y is (3, 1). Now matrices x and y can be multiplied. Finally, in line 7 these matrices are multiplied and the output is printed. Notice that similar operations can be performed on tensors also, and TensorFlow scales well even when the dimension of the tensor goes very high. In the coming articles in this series, we will learn more about data types and other complex operations supported by TensorFlow.
Since this is our first discussion on TensorFlow, I think I should also mention Keras. It is a software library that provides a Python interface for the TensorFlow library. In the later articles in this series, we will also get familiar with Keras.
Now, we need to answer the following important question: How do we make use of a non-NVIDIA GPU? Well, there are many different ways to tap the power of these GPUs also. There are many powerful packages to do so. One such package is PyOpenCL. It allows us to use OpenCL (open computing language), a framework for writing parallel processing programs within Python. OpenCL can interact with GPUs manufactured by AMD, Arm, Nvidia, etc. But there are other options also. One such option is Numba, a JIT (just-in-time) compiler that can parallelize some parts of the Python code we have written. Thus, Numba enables the code to use our GPUs, if available. Notice that a JIT compiler is a type of compiler in which the compilation happens during execution of the code. As an example for Numba, consider the Python code shown in Figure 4. The same function called fun( ) is executed with and without using the Numba compiler. This is a simple function that finds the sum of the squares of integers from 1 to 9. Though this program is simple, on careful observation we can see that it has features that allow parallelization. From Figure 4, we can see that the code prints the same answer 405071317 on both occasions. However, we can also see that the execution time taken is different. Only half the time is taken to obtain an answer when the code is parallelized using Numba. Further, as the size of the problem being handled increases, the gap between the time taken by the parallelized and non-parallelized versions will also increase.
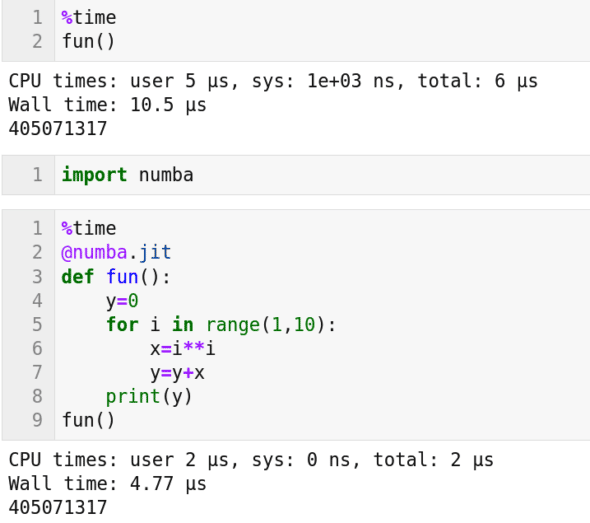

## An introduction to SymPy
If we were discussing useful Python libraries, our discussion could have been about hundreds of such libraries. However, our discussion is about developing AI and machine learning based applications. Hence, I was a bit confused about the libraries to include in our discussion. After much deliberation, I have decided to briefly discuss SymPy. It is a Python library for symbolic mathematics. With an example, let us try to understand what symbolic mathematics is. Consider the program shown in Figure 5. It uses the function Integral( ) offered by SymPy to find the integral of ‘sin(x) X cos(x) X tan(x)’ over x. Figure 5 also shows the output of this symbolic calculation. Notice that unlike the integrate( ) function offered by SciPy, which returns numerical results, the function Integral( ) provides exact symbolic results. SymPy is useful for performing statistical operations that have high relevance in the development of AI and machine learning based applications.


In the next article in this series, we will discuss Theano, an even more powerful tool for computing mathematical expressions. Theano is a Python library and optimising compiler for evaluating mathematical expressions.
## An introduction to probability
It is now time for us to have our first meeting with probability, yet another major topic of interest for AI and machine learning enthusiasts. A very detailed treatment of probability is beyond the scope of this series. I urge you to read the Wikipedia articles on ‘Probability’, ‘Bayes’ theorem’, and ‘Standard deviation’ before continuing any further. These articles are simple and easy to follow. Some of the important terms and concepts like probability, independent events, mutually exclusive events, conditional probability, Bayes’ theorem, mean, standard deviation, etc, are explained well in these articles and you will be able to follow our discussions on probability easily after reading them.
Let’s begin with probability distributions. According to Wikipedia, ‘a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment’. Now, let us try to understand what a probability distribution function is. The most famous probability distribution function is the normal distribution, often also called Gaussian distribution (named after Carl Friedrich Gauss, one of the greatest mathematicians to live on this earth). If you plot the normal distribution, you will get a bell curve. Figure 6 shows a bell curve (courtesy Wikipedia). The exact shape of the bell curve depends on the mean and standard deviation. But what does this curve signify? Let us try to understand this by analysing a natural phenomenon. A cursory search on the internet told me that the average height of an Indian man now is 1.73 metres (5 feet and 8 inches). Now, if you look around, you will see a lot of men with height very close to this figure. The chances of you observing a man who has a height below 1.42 metres (4 feet and 8 inches) or above 2 metres (6 feet and 8 inches) are very slim. Now, you go out and record the heights of say 1,000,000 men and plot a graph. Let the x-axis (horizontal axis) mark the height of a person and the y-axis (vertical axis) mark the number of samples analysed (in this case heights of 1,000,000 people). When you plot this graph, you will see a bell curve, with a few minor skews and bends. So, the mathematical equation that represents a normal distribution can easily capture natural phenomena like the heights of human beings.


Now, let us see an example for using normal distribution. Consider the code shown in Figure 7. We use Matplotlib for plotting and NumPy for the function normal( ) which implements normal distribution. From Line 3, we can see that the sample size is 1000. Line 4 tells us that we are plotting a histogram with 1000 bins. However, if you observe the bell curve in Figure 7, this is not what we expected. This bell curve doesn’t have much similarity with the one we saw in Figure 6. What is the reason for this? Remember, our sample size is just 1000. This is like an election exit-poll where you ask the opinion of just 100 people and then make a prediction. The sample size should be sufficiently large to get a clearer picture. Figure 8 shows a bell curve when line 3 in the code in Figure 7 is replaced with the line ‘sample = normal(size=100000000)’ and the program is executed again. This time our sample size is 100,000,000 and the bell curve looks almost like the one shown in Figure 6. Normal distributions and bell curves are just the beginning. In the next article in this series we will discuss other probability distribution functions that can represent and generalise many other events and natural phenomena. Next time, we will also address the topic a bit more formally.
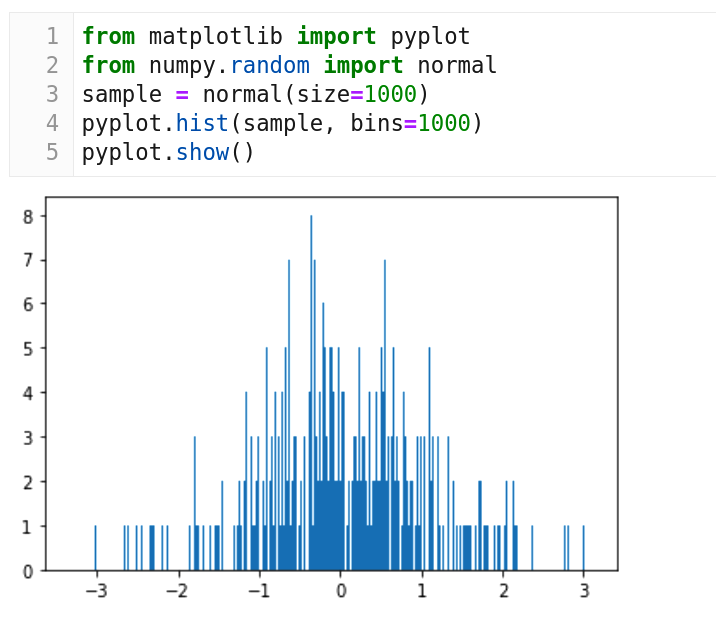

Now it is time for us to wind up our discussion for the time being. In the next article in this series, we will continue exploring concepts in probability and statistics. We will also install and use Anaconda, a distribution of Python for scientific computing, which is especially useful for developing AI, machine learning and data science based applications. As mentioned earlier, we will also get familiar with yet another Python library called Theano, which is used a lot in the fields of AI and machine learning. But it is also high time to do one more thing in this series. So far, we were collecting vegetables (Python libraries) and spices (mathematical concepts) to make a healthy and tasty soup (AI based applications). From the next article onwards, we will begin cooking that soup.
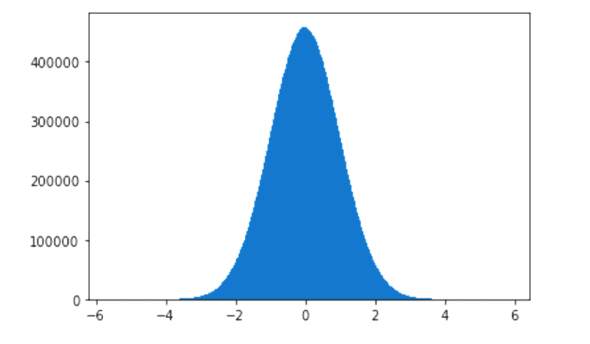
 |
16,486 | Ardour 8.2 为数字音乐创作者增加了一项新功能 | https://news.itsfoss.com/ardour-8-2-release/ | 2023-12-18T21:15:45 | [
"Ardour"
] | https://linux.cn/article-16486-1.html | 
>
> Ardour 的最新更新包添加了一些有用的功能和急需的修复。
>
>
>
Ardor 是数字音频工作站(DAW)用户中非常流行的开源选择,它拥有大量工具,允许音频专业人士执行一系列与音频相关的任务。
作为 **Ardour 8.x 系列的延续**,开发人员推出了新版本 **Ardour 8.2**。那么,让我们深入了解此版本,看看提供了什么。
### ? Ardour 8.2:有什么新变化?

开发人员表示,此次更新“没有什么惊人之处”,它的目的是完成支持新 [Novation](https://novationmusic.com/) 设备的待定工作、修复一些错误和进行一些改进。
**主要亮点**包括:
* 专用无频闪选项
* 支持更新设备
* 音符叠加功能
#### 专用无频闪选项
作为一项新的用户偏好设置,它**将禁用 Ardour 图形用户界面(GUI)上的所有闪烁元素**。这对**那些对此类视觉刺激敏感的用户来说大有帮助**。
因此,时钟、按钮和仪表之类的东西将停止运行、闪烁或移动。
#### 对 Novation 设备的支持

Ardour 8.2 版本还完成了对所有当前一代(MK3)Novation [Launchpad 系列](https://novationmusic.com/categories/midi-controllers/grid) 设备的支持。这包括 **Launchpad X**、**Mini** 和 **Pro**。
开发人员遵循 Launchpad X 的用户手册来实现支持,并且还使 Launchpad Mini 表现相似,使用类似的布局,没有 X 型号上的额外按钮。
#### 音符叠加功能
受到最近推出的 [Ableton Live 12](https://www.ableton.com/en/live/all-new-features/) 的启发,Ardor 的开发人员推出了**新的音符叠加功能,可让你将音符拆分和连接在一起**,以获得更高级的 MIDI 编辑体验。
#### ?️ 其他变化
至于其余的,还有一些其他值得注意的变化:
* 添加了对 [Solid State Logic UF8](https://solidstatelogic.com/products/uf8) 的支持。
* 能够**清除 LV2 插件**扫描信息。
* 录音机视图中添加了新的**静音按钮**。
* 改进了**标记列表显示**,使其更加高效和有序。
* **新的 Lua 脚本**,用于反转 MIDI 音符/区域,并使用标记对 *mixer-scenes* 进行排序。
你也可以通过官方[发行说明](https://ardour.org/whatsnew.html)了解更多信息。
### ? 下载 Ardour 8.2
新版本适用于 **Linux**、**Windows** 和 **macOS**。从[官方网站](https://community.ardour.org/download)获取你选择的包。
>
> **[Ardour](https://community.ardour.org/download)**
>
>
>
你还可以查看其 [GitHub 仓库](https://github.com/Ardour/ardour)的源代码。
? 你对新增的新增功能有何看法? 请在下面告诉我们!
---
via: <https://news.itsfoss.com/ardour-8-2-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ardour is a pretty popular open-source choice among Digital Audio Workstation (DAW) users, it has plenty of tools that allow audio professionals to do a range of tasks related to audio.
As **a continuation to the Ardour 8.x series**, the developers have unveiled a new release, **Ardour 8.2**. So, let's dive into this release and see what's on offer.
**Suggested Read **📖
[Ardour 8.0 is an Apple-Friendly Update With Novation Launchpad Pro SupportArdour 8.0 is a big upgrade with new hardware support, improved automation creation, and more.](https://news.itsfoss.com/ardour-8-0-release/)

## 🆕 Ardour 8.2: What's New?
The developers say that there is “*nothing incredibly dramatic*” with the update, it is meant to complete pending work for supporting new [Novation](https://novationmusic.com/?ref=news.itsfoss.com) devices, a couple of bug fixes and a few improvements.
The **key highlights** include:
- Dedicated No-strobe Option
- Support for Novation Devices
- Note Tupling Feature
### Dedicated No-strobe Option
Introduced as a new user preference setting, this **will disable all flashing and blinking elements** found on Ardour's graphical user interface (GUI). This should be of **huge help for those who are sensitive to such visual stimulation**.
So, things like the clocks, buttons, and meters will stop running, blinking or moving.
### Support for Novation Devices
The Ardour 8.2 release also sees the completion of support for all current-gen (MK3) Novation [Launchpad series](https://novationmusic.com/categories/midi-controllers/grid?ref=news.itsfoss.com) of devices. This includes the **Launchpad X**,** Mini** and **Pro**.
The devs followed the user manual for the Launchpad X to implement support, and also made Launchpad Mini behave similar, using a similar layout, without the extra buttons found on the X model.
### Note Tupling Feature
Taking inspiration from the recently launched [Ableton Live 12](https://www.ableton.com/en/live/all-new-features/?ref=news.itsfoss.com), the developers of Ardour have introduced **a new note tupling feature that lets you split and join notes together** for a more advanced MIDI editing experience.
### 🛠️ Other Changes
As for the rest, here are some other notable changes:
- Added support for
[Solid State Logic UF8](https://solidstatelogic.com/products/uf8?ref=news.itsfoss.com). - Ability to
**clear LV2 plugin**scan information. - A new
**mute button was added**to the recorder view. - Improvements to the
**marker list display**to be more efficient and orderly. **New Lua scripts**for reversing MIDI notes/regions, and sequencing*mixer-scenes*using markers.
You may also go through the official [release notes](https://ardour.org/whatsnew.html?ref=news.itsfoss.com) to know more.
## 📥 Download Ardour 8.2
The new release is live for **Linux**, **Windows**, and** macOS**. Grab the package of your choice from the [official website](https://community.ardour.org/download?ref=news.itsfoss.com).
You can also check out its [GitHub repo](https://github.com/Ardour/ardour?ref=news.itsfoss.com) for the source code.
*💬 What do you think of the nifty new feature additions? Let us know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,487 | PWA:浏览器的新范式 | https://opensource.com/article/22/10/pwa-web-browser | 2023-12-18T23:58:26 | [
"PWA"
] | https://linux.cn/article-16487-1.html | 
>
> 尽管渐进式网络应用(PWA)还在起步阶段,它们却已经影响着我们使用网络的方式。
>
>
>
<ruby> 渐进式网络应用 <rt> Progressive Web App </rt></ruby>(PWA),借助现代网络技术,提供能赶超任何移动应用的用户体验。而正是积极进取的开源社区以及谷歌、微软等科技巨头,助推着 PWA 的发展,试图冲破应用程序之间的鸿沟。
其实,PWA 就是在网络浏览器中运行你的程序。因为谷歌 Play Store 和苹果 App Store 事实上二分天下,所以重点就是谷歌 Chrome 和苹果 Safari(分别基于开源的 Chromium 和 WebKit 构建)。
关于创建桌面应用的内容不在本文展开,如果你对此感兴趣,可以参考 [Electron](https://www.electronjs.org/)。
PWA 的构建方式和任何其他网站或网络应用没有两样。它们使用最新的移动技术,并且采用用户体验的最佳实践。PWA 还可以将浏览器与原生代码相结合以优化体验。
如果你在搜索引擎中输入 “什么是 PWA”,你可能得到一个概括性的回答,像是“PWA 的设计上高速、稳定、吸引人,可以离线工作,还可以安装到设备的主屏幕上。”虽然这个答案部分正确,但却仅仅涵盖了 PWA 所能达成和正在发展成的事物表面部分。
### 下面的这些并非 PWA
下面列出的是跨平台应用框架,它们可以让你能从单一代码库开发应用,但并未采用浏览器作为它们的平台。
* Flutter
* React Native
采用 Flutter,你可能会用到 Dart 语言,此语言可以编译出 iOS、安卓和网页应用。而 React Native 同样可以对 JavaScript 进行后端编译。
### PWA 的定义是什么?
根据最初的定义,一个 PWA 必须满足以下三个要求:
* **服务工作线程:** 提供离线功能。
* **网络清单:** JSON 标记用于配置主屏幕和应用图标。
* **安全性:** 强制使用 HTTPS,因为服务工作线程在后台运行。
这些组件使你能通过 [谷歌 Lighthouse PWA 审核](https://web.dev/lighthouse-pwa/),并在你的评分上得到绿色检查标记。

只要满足这些要求,Chrome 的“添加到主页”提示就会自动启用。
PWA Builder(由微软提供的免费服务)具有出色的用户界面,可以用于构建 PWA 和可视化基本要求。请见以下基于 [developers.google.com](http://developers.google.com) 的示例。你可以在这个 [链接](https://ctrl.carbonpay.io/user/login) 预览此功能,这是由我在 [上一篇文章](https://opensource.com/article/22/6/drupal-pwa) 中讨论的 [PWA 模块](https://www.drupal.org/project/pwa) 提供。


PWA 的基本要求通过服务工作线程实现了离线行为,`manifest.json` 文件则使得在安卓上添加“添加至主页”行为成为可能,这样你的网站会作为图标添加到主屏幕上,并以无浏览器的 Chrome(全屏模式)以带应用启动页的方式打开。这些是 PWA 的最低要求,除了离线缓存带来的性能提升,它基本上给人一种网站就是应用的感觉。这其实是一种用户心理的转变,从只把浏览器看作“网站”的工具,逐渐认识到它其实是一个应用平台。谷歌似乎趋向于推动这种观点,为发展更多的功能、性能和用户体验/用户界面的提升扫清了道路,这样才能真正提供“像应用一样的体验”。
深入的说,PWA 实际上是一系列浏览器技术以及网络开发技巧和工具的集合,使网站更像“应用”。我把这些内容分解到了以下几个类别。
#### 提供增强的“应用般”体验
* 在移动设备上的用户体验/用户界面体验优化
+ HTML/CSS/Javascript
* 更接近原生设备的访问以及强大的网络功能
* 更快速流畅的性能表现
#### 当前的 PWA:超越最初定义的可能性
以下是对于前述三个体验优化方向的详细阐述。
##### 用户体验/用户界面的改进
用户体验/用户界面设计和视觉问题解决对于让你的网站更像应用至关重要,这可能表现在动画效果、输入/字体大小、滚动问题,以及其他 CSS 错误的细节之处。重视前端开发团队至关重要,因为他们可以打造出这样的用户体验。在设计和用户体验的广泛领域内,我们可以通过一些 Web 文档建构的核心元素(HTML/JSS/JS)实现增强型特征,例如:
* [Hotwire Turbo](https://hotwired.dev/):这是一个利用线上 HTML,只通过 AJAX 或 WebSockets 更新你网页有变动的部分的开源框架。它为了实现 SPA 那样的性能优化,仅用到了部分 JavaScript。对于你的单体应用或模版渲染系统,这种途径最佳,不需要多费周折去解耦你的前后端。
* 专门的移动 SPA 框架:市场上有一些可以为你的网站带来类应用用户体验的解耦式框架。Onsen UI 和 Framework 7 就是两个可帮你创建快速、反应灵敏的网站用户界面的优秀工具。当然,你未必必须依靠这些框架,如前所述,有力的前端团队通过应用最新的、类似移动设备设计技巧就能打造出你向往的 UI 设计。
[这个幻灯片](https://docs.google.com/presentation/d/1D7-H7om4Ul6nFeIX2x1oSpKCvC7LRUP3uh0r7jM3IVs/edit#slide=id.g126166aeb51_2_271) 详细讲述了应如何在你的 PWA 中保持 HTML/CSS/JS 的最新状态。
##### Web 的能力
Chromium 团队持续在改进浏览器体验方面努力不懈,你可以在 [Project Fugu](https://developer.chrome.com/blog/fugu-status/) 中追踪他们在这个全方位网络功能改进项目的进展。WebKit 即持续致力于优化其浏览器体验和能力。
Swift API 还可以与 WKWebView 进行交互,以增强原生体验。
谷歌提供了一项名为 Bubblewrap 的服务,与 Trusted Web Activity(TWA)共同工作。它的作用仅是将你的基于 PWA 的网站包装在一个原生的 APK 包中,从而可以将其提交到应用商店。这就是我之前提到的关于安卓的 PWA Builder 链接的工作方式。在我之前的文章里,你可以了解更多关于 WKWebView 和 TWA 的信息。
##### 速度和性能
改进你的应用性能的方法多得数不清。你可以先从 [谷歌 PageSpeed tools](https://developers.google.com/speed) 进行检查。
#### 使用 PWA 的各种奖励:
* Lighthouse 得分和 SEO 的提升。
* 统一的代码库。
* 顺滑无阻的测试过程。
* 对开发周期即时反馈。
* 使用了管理型的 PaaS Web 部署流程。
* Web 技术的学习和使用面向广大开发者。
* 唯一一种可以提供完善网络体验的跨平台开发解决方案。
* 自由发挥设计,不受限于跨平台框架的 UI 组件束缚。
* 即使网络连接状况不佳,也能触达用户。
当然,使用 PWA 也还有一些问题需要考虑:
* **功能可能有限**:与原生设备使用体验相比,PWA 还有所逊色,但浏览器正在大步赶超过来。你可以查阅 [Thomas Steiner](https://devm.io/javascript/project-fugu-interview-steiner-168988) 对 Project Fugu 如何弥补应用空白的论点,或者搜索 “[What web can do](https://whatwebcando.today/)” 查看你的浏览器能做什么。通常,你的 PWA 项目有很大可能是大部分不会因为功能/能力受限而耗尽资源的应用。
* **标准化欠缺**:Thomas Steiner 在文章中也提及了 “PWA 标准” 的问题,目前还使我们一头雾水。这也造成 PWA 主题的混淆,使开发者在追求“心有戚戚焉”的突破瞬间时颇感困扰。缺乏明确的定义,使得 PWA 的推动力度降低,且导致营销或管理层因为无法定义 PWA,所以也就不会主动提出需要 PWA。
* **iOS App Store 的问题**:目前的 App Store 并未列出 PWA,于是找到 PWA 就比找到原生应用困难。但这并非绝境,你依旧可以让你的网络应用提供比原生应用更棒的体验。做的好的话,你甚至能获得苹果公司的真心赞赏,因为最重要的评价标准就是提供良好的移动体验。曾经在 PWA 成为术语之前,就在原生 iOS 应用中运用 WKWebView 的 Ionic,在他们的论坛上 [分享了有趣的见解](https://forum.ionicframework.com/search?q=minimum%20functionality)。只要你懂行,便不会有任何问题。在 [我以前在 Opensource.com 上的文章](https://opensource.com/article/22/6/drupal-pwa) 的“网络应用如何进入应用市场”部分,你能找到更多内容。
* **某些情况下的安全问题**:浏览器采用 cookie 作为认证,这种早在浏览器诞生时就已经使用的方法,可能并不适合你的项目。其中,浏览器提供了出色的密码管理,并一直在研发和引入其他认证方法,例如 [Webauthn](https://webauthn.io/)。而 [关联域](https://developer.apple.com/documentation/xcode/supporting-associated-domains) 中的使用提供了更多的安全层。
相比其他方式,我认为“网络正在崭露头角”,在未来的发展中,随着网络的新功能不断涌现,当前的缺点将逐渐被减弱。我不认为原生开发会消失,只是 WebView 和原生代码之间的集成会更加无缝。
### 结语
虽然 PWA 还在早期开发阶段,但它们有潜力彻底改变我们使用网络的方式。每天我都会看到新的网站在挑战 PWA 能做到什么。不管管理层是否知道他们正在建立一个 PWA,我经常会发现网络应用和开发团队如何扩展网络技术的使用或者选择一个优化良好的移动网站而不是原生应用,这都让我感到惊讶。
*(题图:DA/649961e9-b67b-487c-ba5f-c6df5f923bfb)*
---
via: <https://opensource.com/article/22/10/pwa-web-browser>
作者:[Alex Borsody](https://opensource.com/users/alexborsody) 选题:[lkxed](https://github.com/lkxed) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A *progressive web app* (PWA) is a web application that uses modern web technologies to deliver a user experience equal to any mobile app. An active open source community, in conjunction with tech leaders like Google and Microsoft, pushes the PWA agenda forward in an effort to "bridge the app gap."
Basically, a PWA runs your app in a web browser. Because there's essentially a two-party system of the Play and App stores, the focus is on two browsers: Google Chrome and Apple Safari (built on top of the open source Chromium and WebKit, respectively).
I won't be covering creating desktop apps. For more information on that topic, look into [Electron](https://www.electronjs.org/).
PWAs are built the same way as any website or web app. They use the latest mobile technologies and implement UX best practices. PWAs can also hook the browser in with native code to improve the experience.
If you type "What is a PWA" in your favorite search engine, you'll probably get a stock response similar to "PWAs are designed to be fast, reliable, and engaging, with the ability to work offline and be installed on a device's home screen." While this is partly true, it's just the tip of the iceberg for what a PWA has the potential to be and what it's evolving into, even as I write this article.
## What is *not* a PWA
The following are cross-platform app frameworks allowing you to develop from a single codebase. They do not use the browser as their platform.
- Flutter
- React Native
Flutter uses a language called Dart, which compiles to iOS, Android, and web packages. React Native does the same but compiles JavaScript on the backend.
## What is a PWA by definition?
A PWA, by its original definition, must meet these three requirements:
**Service worker:**Provides offline functionality.**Web manifest:**JSON markup to configure home screen and app icons.**Security:**HTTPS is enforced, because a service worker runs in the background.
These components allow you to pass the [Google Lighthouse PWA audit](https://web.dev/lighthouse-pwa/) and get the green checkmark on your score.

(Alex Borsody, CC BY-SA 4.0)
Once you satisfy these requirements, Chrome's "add to home screen" prompt is also automatically enabled.
PWA Builder (a free service provided by Microsoft) has an excellent UI for building a PWA and visualizing base requirements. See the following example based on developers.google.com. You can demo this functionality [here](https://ctrl.carbonpay.io/user/login) provided by the [PWA module](https://www.drupal.org/project/pwa) I discussed in [my previous article](https://opensource.com/article/22/6/drupal-pwa).
(Alex Borsody, CC BY-SA 4.0)
(Alex Borsody, CC BY-SA 4.0)
The base requirements of a PWA allow offline behavior through the service worker, and the `manifest.json`
file allows "add to home screen" behavior on Android, where your website gets added as an icon to the home screen and opens with no-browser Chrome (in fullscreen) with an app splash page. These are the minimum requirements for a PWA and, aside from providing a performance increase due to the offline caching, mainly give the illusion the website is an app. It's a psychological gap at its core where the end user will stop thinking of the browser as merely "websites" and instead look at it for what it actually is… an app platform. Google seemed to make this a priority to pave the way for developing the endless number of features, functionality, and UX/UI enhancements that actually provide an enhanced "app-like experience."
A PWA is really a collection of browser technologies and web development techniques and technologies that make a website more "app-like." I have broken these down into the following categories.
**Enhanced app-like experience**
- Improved UX/UI experience on a mobile device
- HTML/CSS/Javascript
- Native device access and enhanced web capabilities
- Speed and performance
**What a PWA can be today beyond the definition**
Here are more details on the three experience descriptions above.
**UX/UI improvements**
UX/UI and visual problem-solving are critical to making your website feel like an app. This often manifests as attention to details such as animations, input/font sizes, scrolling issues, or other CSS bugs. It's important that there is a strong frontend development team so they can create this UX. Within the category of design and UX are the enhancements we can implement with the building blocks of a web document (HTML/JSS/JS). Two examples of this are:
: An open source framework using HTML over the wire to reload only the areas of your page that change using AJAX or WebSockets. This offers the performance improvements that SPAs strive for using only limited JavaScript. This approach is perfect for your monolithic application or template-rendering system; no need to invest in the added complexity of decoupling your front and back end.**Hotwire Turbo****Mobile-specific SPA frameworks:**There are several decoupled frameworks out there that can give your website an app-like user experience. Onsen UI and Framework 7 are two excellent options that help you create a fast, responsive user interface for your website. However, you do not need to rely on these frameworks. As discussed above, a good frontend team can build the UI you strive for by implementing the latest app-like mobile design techniques.
[This slide](https://docs.google.com/presentation/d/1D7-H7om4Ul6nFeIX2x1oSpKCvC7LRUP3uh0r7jM3IVs/edit#slide=id.g126166aeb51_2_271) goes into more detail about staying current with HTML/CSS/JS in your PWA.
**Web capabilities**
The Chromium team is constantly improving the browser experience. You can track this progress in [Project Fugu](https://developer.chrome.com/blog/fugu-status/), the overarching web capabilities project. WebKit also continually strives to improve its browser experience and capabilities.
The Swift API can also interact with the WKWebView to enhance the native experience.
Google has a service called Bubblewrap, which works with Trusted Web Activity (TWA). All this does is wrap your PWA-enabled website in a native APK bundle so you can submit it to the app store. This is how the PWA builder link mentioned above works for Android. You can learn all about WKWebView and TWA in my previous article.
**Speed and performance**
There are countless ways to improve your app's performance. Check out the [Google PageSpeed tools](https://developers.google.com/speed) to start.
**Benefits of using a PWA include the following:**
- Increased Lighthouse score and SEO.
- A single codebase.
- Frictionless testing.
- Instant feedback loop for development cycles.
- Use of managed PaaS web deployment workflows.
- Web technologies are a skill set for a wide array of developers.
- The only cross-platform development solution that delivers a full-fledged web experience.
- Unlimited options to customize a design without relying on a cross-platform framework's limited UI components.
- Reach users with limited (or no) internet connection.
There are some drawbacks/caveats to using a PWA, including:
**Limited functionality**: There is still an "app gap" with PWAs compared to native device access. However, browsers have been making great progress toward closing this. Learn more about Project Fugu's take on bridging the app gap from[Thomas Steiner](https://devm.io/javascript/project-fugu-interview-steiner-168988), and visit[What web can do](https://whatwebcando.today/)to see your browser's capabilities. When choosing your technology, there is a good chance your PWA project will be in the majority of apps that do not experience restrictions regarding capability/functionality.**Lack of standardization**: Thomas Steiner's interview above discusses a "PWA standard," which is currently lacking. In my opinion, it is the reason for much of the confusion around the topic and developers' difficulty getting past that first "aha moment." This confusion has led to slower momentum in technology than there should be. Also, because of this lack of clarity, marketing or management may not even know to ask for a PWA because they don't understand what it is.**iOS App Store**: App stores don't currently list PWAs, so they're harder to find than native apps. There are ways to do this. However, the key is to make your web app as good or a better experience than native. Do it right, and the Apple gods will smile upon you because the most important thing in reviews seems to be that you deliver a good mobile experience. Ionic, a framework utilizing WKWebView in native iOS apps before PWA was even a term, has some interesting insight[in their forums](https://forum.ionicframework.com/search?q=minimum%20functionality). If you know what you are doing, this won't be a problem. You can see the "get your web app in the app stores" section of[my previous Opensource.com article](https://opensource.com/article/22/6/drupal-pwa)for more info.**Potential security issues in certain cases**: The browser uses cookies as authentication. A tried and true browser method to maintain state since its inception, this may not fit your project's needs. The browser has excellent password management and is constantly evolving and implementing other authentication methods, such as[Webauthn](https://webauthn.io/). The use of[associated domains](https://developer.apple.com/documentation/xcode/supporting-associated-domains)provides another layer of security.
I believe that compared to the alternatives, "the web is winning," and future progress will minimize these drawbacks as the web offers new capabilities. I don't think native development will disappear, but there will be more seamless integrations between WebView and native code.
**Wrap up**
While PWAs are still in their early stages of development, they have the potential to revolutionize the way we use the web. Every day I see a new website pushing the limits of what a PWA can be. Whether the management knows they are building a PWA or not, I often come across web apps and dev teams that surprise me with how they expand the use of web technologies or pass on a native app in lieu of a well-optimized mobile website.
## Comments are closed. |
16,489 | 哇!微软的 Windows AI Studio 需要依赖 Linux 才能运行 | https://news.itsfoss.com/microsoft-windows-ai-studio-linux/ | 2023-12-19T23:04:10 | [
"Linux",
"AI",
"微软"
] | https://linux.cn/article-16489-1.html | 
>
> 没有办法,微软热爱 Linux。
>
>
>
上个周末,我意外发现了微软推出的这款全新 AI 开发工具,这得归功于 [Windows Central](https://www.windowscentral.com/software-apps/windows-11/hidden-windows-11-setting-suggests-youll-soon-be-able-to-uninstall-ai-components-from-the-os) 的报道。这条新闻源自 Venn Stone 在 [Mastodon post](https://mast.linuxgamecast.com/@Venn/111577589308411637) 中的一条信息:“*第一步?安装 Linux*”。
这个消息激发了我深挖此事的兴趣,结果发现,就在一个月前,微软已经在其 [开发者博客](https://blogs.windows.com/windowsdeveloper/2023/11/15/elevating-the-developer-experience-on-windows-with-new-ai-tools-and-productivity-tools/) 中婉转提到了这款名为 “**Windows AI Studio**” 的工具了。
接下来,让我们深入探索一下这件新鲜事。
>
> ? 注意,Windows AI Studio 还在开发中,目前还不能提供全面的技术支持。
>
>
>
### Windows AI Studio:仅能在 Linux 上运行?

严格来说,是的。你应该注意到,**微软悄然推出了其崭新的开发工具**,这款工具的主要目标是**方便开发者在本地开发生成型 AI 应用**。但是,这款工具**需要依赖 Windows 的 Linux 子系统(WSL),并必须安装 Ubuntu 18.4 或更高版本才能运行**。
由于目前这还是一个预览版本,并且已经被封装为一个 VS Code 扩展,所以它还需要**安装 VS Code**,而且当前**仅能在英伟达的 GPU 上运行**。?
据微软的未来规划,他们打算在 Windows AI Studio 中引入 [ORT](https://onnxruntime.ai/)/[DML](https://learn.microsoft.com/en-us/windows/ai/directml/dml-intro),以达到**更好的硬件兼容性**。
Windows AI Studio 还可以借助 [Azure AI Studio](https://azure.microsoft.com/en-us/products/ai-studio) 库中的开发工具以及其他例如 [Hugging Face](https://huggingface.co/) 的模型。
看到 Windows 需要依赖 Linux 总是一件振奋的事。?
有很多开发者严重依赖 Windows,WSL 使他们能在 Linux 上开展工作变得容易,而 Windows AI Studio 这样的工具则进一步提升了他们的工作体验。
**想试一试吗?**
你可以从 [VS 市场](https://marketplace.visualstudio.com/items?itemName=ms-windows-ai-studio.windows-ai-studio) 获得 Windows Studio AI。请保证你已经**为 WSL 配置了 Ubuntu 18.4 或更高版本作为默认系统**。此外,还需要记得**使用一款性能良好的 NVIDIA GPU**。
>
> **[Windows AI Studio](https://marketplace.visualstudio.com/items?itemName=ms-windows-ai-studio.windows-ai-studio)**
>
>
>
**在市场列表中列出了所有重要的安装信息**,确保你已经仔细阅读过。另外,如想了解更多信息,你也可以访问其 [GitHub 仓库](https://github.com/microsoft/windows-ai-studio) 进行深入研究。
? 你对此怎么看?
*(题图:DA/0310bdbe-0e97-48df-a0cf-4f55b0361b37)*
---
via: <https://news.itsfoss.com/microsoft-windows-ai-studio-linux/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Over the weekend, I stumbled upon **a new AI-focused development tool by Microsoft** thanks to [Windows Central](https://www.windowscentral.com/software-apps/windows-11/hidden-windows-11-setting-suggests-youll-soon-be-able-to-uninstall-ai-components-from-the-os?ref=news.itsfoss.com). This came to light thanks to [a Mastodon post](https://mast.linuxgamecast.com/@Venn/111577589308411637?ref=news.itsfoss.com) made by Venn Stone that said, “*Step 1? Install Linux.*”
That prompted me to dig deeper into this matter, and, as it turns out, Microsoft had teased the tool called “**Windows AI Studio**” just a month prior in a [developer blog](https://blogs.windows.com/windowsdeveloper/2023/11/15/elevating-the-developer-experience-on-windows-with-new-ai-tools-and-productivity-tools/?ref=news.itsfoss.com).
So, let's dive in and see what this is all about.
## Windows AI Studio: A Linux-Only Affair?
Well, kind of. You see, **Microsoft has silently debuted their new development tool** that is **meant to make it easy to develop gnerative AI apps locally**. However, it **needs Windows Subsystem for Linux (WSL) with Ubuntu 18.4 or later to run**.
As this is a preview version packaged as a VS Code Extension, it also **requires Visual Studio Code to be installed**, and **will only run on NVIDIA GPUs** for now. 🥲
Future plans indicate that they intend to implement [ORT](https://onnxruntime.ai/?ref=news.itsfoss.com)/[DML](https://learn.microsoft.com/en-us/windows/ai/directml/dml-intro?ref=news.itsfoss.com) into Windows AI Studio for **better hardware compatibility**.
Windows AI Studio also takes advantage of development tools and models from the [Azure AI Studio](https://azure.microsoft.com/en-us/products/ai-studio?ref=news.itsfoss.com) Catalog, and even others such as [Hugging Face](https://huggingface.co/?ref=news.itsfoss.com).
It is always a great sight to see Windows depending on Linux. 😁
Plenty of developers out there depend heavily on Windows, WSL just makes it easier for them to do their work on Linux, and tools like Windows AI Studio just add more to the experience.


**Want to give it a try?**
You can get started with Windows Studio AI by getting it from the [VS Marketplace](https://marketplace.visualstudio.com/items?itemName=ms-windows-ai-studio.windows-ai-studio&ref=news.itsfoss.com). Just **ensure that you have configured WSL with Ubuntu 18.4 or later** as the default. Moreover, please remember to **use a capable NVIDIA GPU**.
The **marketplace listing has all the important installation information**, so make sure to go through that carefully. Additionally, you can also visit its [GitHub repo](https://github.com/microsoft/windows-ai-studio?ref=news.itsfoss.com) for further research.
💬 *What are your thoughts on this? *
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,492 | Celeste:Rust 开发的多云端开源 GUI 文件同步客户端 | https://news.itsfoss.com/celeste/ | 2023-12-20T21:10:00 | [
"文件同步"
] | https://linux.cn/article-16492-1.html | 
>
> 一个简单而优雅的 GUI 同步客户端,提供双向同步。
>
>
>
当谈到与云文件同步时,我们有 [Insync](https://itsfoss.com/insync-linux-review/)、[FreeFileSync](https://itsfoss.com/freefilesync/) 等选项,以及 [rclone](https://itsfoss.com/use-onedrive-linux-rclone/) 等几个命令行工具。
无论哪种情况,你也可以使用云存储提供商的同步客户端(如果他们有适用于 Linux 或任何其他平台的同步客户端)。但是,这并不是与多个云存储服务同步内容的最佳方式。
Insync 是一款付费工具,而 FreeFileSync 或 rclone 对于 Linux 新用户来说可能是一种难以接受的选择。。
Celeste,一个简单的 GUI 同步客户端,支持多个云提供商。
>
> ? 该应用正在积极开发中。目前它可能没有足够的功能和贡献者。欢迎你探索并帮助该项目。
>
>
>
### 适用于 Linux 的基于 Rust 的同步客户端

Celeste 是一款用 Rust 编写的应用,可确保你获得快速的体验。它在底层利用 rclone 来可靠地将数据与云同步。
与某些现有选项不同,它没有为你提供很多选择。虽然一些用户可能会发现它有所欠缺,但其他用户可能会发现它是他们一直想要的简单工具。
Celeste 仅支持双向同步,目前没有其他同步方式。
如果你想要单向同步(云到本地,或本地到云),那么这不适合你。
该工具的工作机制很简单。你只需从列表中添加云提供商,或添加任何 WebDAV 服务器。
默认选项包括:**Google Drive、Dropbox、Proton Drive、pCloud、ownCloud、** 和 **Nextcloud**。

你可以自定义该工具的服务器名称,然后点击“<ruby> 登录 <rt> Log in </rt></ruby>”开始授权过程。pCloud 的情况如下:

当你授权应用访问云文件,它会提示你设置本地文件夹和云之间的同步。

如果还没有正斜杠(`/`) 符号,那么只需输入它即可,它应该开始以下拉样式列出你拥有的远程文件夹。
>
> ? 这将是双向同步。因此,你的云文件将被下载到远程文件夹(如果有)。同步后,从云中删除的任何内容都不会从本地文件夹中消失。而且,你从系统中删除的任何内容都将从云中删除。
>
>
>
**此同步过程定期发生。** 我没有找到强制启动或停止同步的方法。如果此应用的未来版本中提供类似的选项,它应该会有所帮助。

在大多数情况下,每当本地/远程中发生文件更改时,同步都会确保你能够尽快访问最新的更改。
有一次,很长一段时间没有同步,所以我不得不重新启动应用来修复它。
不幸的是,如果云提供商的令牌过期,该应用不能很好地处理错误,并且你必须重新授权和重新同步。

它会显示错误,但没有使用 GUI 刷新令牌的选项。我不想尝试命令行方式,因为这违背了 GUI 工具的目的。
因此,你可以选择再次重新添加相同的同步服务器,重新进行所有授权和同步。这就是目前的解决方案。
### 总结
Celeste 似乎是一个非常有用且简单的 GUI 同步客户端。
尽管它缺乏某些功能,但用户体验对于它已经提供的功能来说还是很好的。
考虑到它是一个相当新的应用,有更多的贡献者和用户尝试它,Celeste 可以凭借其坚实的基础发展成更多的东西。
你觉得 Celeste 怎么样? 在下面的评论中分享你的想法。
*(题图:DA/48cf6b8e-8f5a-46e4-a7c1-50fe1cfd068f)*
---
via: <https://news.itsfoss.com/celeste/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When it comes to file synchronization with the cloud, we have options like [Insync](https://itsfoss.com/insync-linux-review/?ref=news.itsfoss.com), [FreeFileSync](https://itsfoss.com/freefilesync/?ref=news.itsfoss.com), and a couple of command-line tools like [rclone](https://itsfoss.com/use-onedrive-linux-rclone/?ref=news.itsfoss.com).
In either case, you may also use the sync client of the cloud storage provider, if they have one available for Linux or any other platform. However, it is not the best way to sync things with multiple cloud storage services.
Insync is a paid tool, while FreeFileSync or rclone can be an overwhelming option for new Linux users.
Meet, Celeste, a simple GUI sync client which supports multiple cloud providers.
## Rust-based Sync Client for Linux
Celeste is an app written in Rust to ensure that you get a snappy experience. It utilizes rclone under-the-hood to reliably sync the data with the cloud.
Unlike some existing options, it does not give you many options. While some users may find it lacking, others could find it as the straightforward tool they always wanted.
Celeste supports two-way sync only, and there are no other modes of synchronization at the moment.
If you want a one-way sync (cloud to local, or local to cloud), this is not for you.
The working mechanism of the tool is easy. You just add a cloud provider from the list, or add any WebDAV server.
The default options include: **Google Drive, Dropbox, Proton Drive, pCloud, ownCloud, **and** Nextcloud.**
You can customize the name of the server for the tool, and hit "**Log in**" to start the authorization process. Here's how it looked like for pCloud:
Once you authorize the app to access the cloud files, it prompts you to set a sync between a local folder and the cloud.
You can just type the **forward slash (/) **symbol if you do not have it already, and it should start listing the remote folders you have in a drop-down style.
**The synchronization process for this happens at regular intervals.** I did not find a way to forcefully initiate or the stop the sync. It should help if an option like that is made available in the future version of this app.
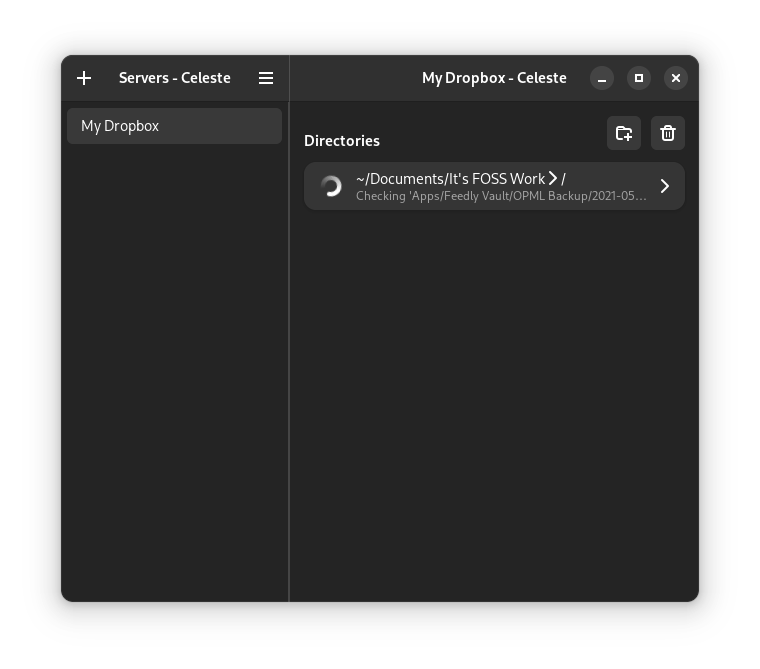
For most of the time, whenever there was a file change in local/remote, the sync made sure that you were able to access the latest changes as soon as possible.
For one time, the sync did not happen for a long time, so I had to restart the app to fix it.
Unfortunately, the app is not good at handling the error, if the token for the cloud provider expires, and you have to re-authorize and resync.
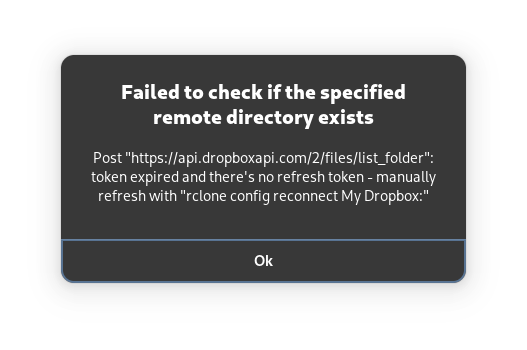
It displays the error, and no option to refresh the token using the GUI. I would rather not try the command-line way because that defeats the purpose of a GUI tool.
So, you can choose to re-add the same sync server again, re-doing all the authorization and sync. That's the solution for now.
**Suggested Read **📖
[Top 10 Best Free Cloud Storage Services for LinuxWhich cloud service is the best for Linux? Check out this list of free cloud storage services that you can use in Linux.](https://itsfoss.com/cloud-services-linux/?ref=news.itsfoss.com)

## Wrapping Up
[Celeste](https://github.com/hwittenborn/celeste?ref=news.itsfoss.com) seems like a really helpful and simple GUI sync client.
Even though it lacks certain features, the user experience is good for what it already offers.
Considering it is a fairly new app, with more contributors and users trying it out, Celeste could evolve into something much more with its solid foundation.
*What do you think about Celeste? Share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,493 | 博通在收购 VMware 后重击客户 | https://news.itsfoss.com/vmware-broadcom-subscription/ | 2023-12-20T21:26:55 | [
"VMware"
] | https://linux.cn/article-16493-1.html | 
>
> VMware 的客户可能对背后的改变意图感到不快。
>
>
>
博通最近以 610 亿美元的价格完成了对 VMware 的收购。
每次企业拥有权发生变更,其正负效应皆取决于具体情况。
遗憾的是,对于 VMware([最受欢迎的虚拟化解决方案](https://itsfoss.com/virtualization-software-linux/) 之一),这无疑是坏消息。
### 简化许可证,还是在糖衣里的毒药?
在完成收购后,VMWare [宣布](https://news.vmware.com/company/vmware-by-broadcom-business-transformation) 了将对许可证操作及针对 VMware 客户的支持周期进行改变的计划。
他们提及他们的目标是“简化”许可证,然而现实是,情况只是变得更糟。
怎么变糟的呢?就是通过采取**订阅制的许可证模型**与**弃用永久许可证**。
>
> ? 永久许可证是一次性购买,在你想要使用此软件的期间内,你拥有使用权。如果需要新版本,你可以选择升级或更新。
>
>
>
因此,VMware 产品的永久许可证不再存在。你需要按需订阅他们的产品或服务。
在公告中,他们如此表示:
>
> VMware 一直努力转变为订阅模型已有一年多的时间,行业已将订阅作为云消费的标准模式。现在,我们的产品组合更加精简,订阅服务也愈发完善,任何产品或服务都只能通过订阅或期限许可证获得。从今天起,永久许可证和支持订阅的销售及续订将终止。
>
>
>
从他们的角度来看,购买订阅模式下,客户的投资将会获得更大的价值。
但我怀疑是否有人会同意这种观点。对于客户来说,一次性费用的购买计划对客户永远比基于订阅的计划更有价值。
你是否更喜欢 Adobe 的订阅制模式以使用 Adobe Premier Pro,或是更倾向于 Apple 的 Final Cut Pro 的一次性费用(假设你拥有 Apple 电脑)??
我认为你们中的大多数人可能会选择一次性费用,VMware 的客户也不例外。
实际上,VMware 也承认了这个事实,他们在今年早些时候发布的一篇 [博客文章](https://octo.vmware.com/perpetual-term-or-saas/) 就是针对这个讨论:
>
> Perpetual On-prem 或永久许可证均配有辅以许可密钥和一个支持购买选项的 SnS。这是最为人们所熟知的模型。
>
>
>
这多少让人感到有些讽刺,对吧?
尽管有些客户可能能够应对这个变化,但**现有的客户可能对其永久许可证带来的好处的消失感到不安**。
没错,你没听错。
>
> 不,客户不能继续更新他们永久许可产品之后的 SnS 合同。博通将协助客户将其永久产品以优惠的价格升级为新的订阅产品。欲了解更多信息,客户可联系他们的 VMware 代表或合作伙伴。
>
>
>
**现有的客户仍可继续使用该软件。** 然而,对此的支持服务将会中止,除非他们选择升级或转为订阅制计划。
伴随着这些变化,VMware 云基础设施的产品线也进行了相应的调整:
* 订阅价格减半,增加了更高级的支持
* 推出了新的 VMware vSphere Foundation,为中小型客户提供了一个企业级的平台。
为了确认这个变化影响到了哪些产品,我建议你浏览一下 [官方公告](https://news.vmware.com/company/vmware-by-broadcom-business-transformation),他们在那里回答了更多针对客户的问题。
### 所以,博通正在利用这种情况吗?
我认为是这样。
他们在完成收购后马上实施更改,更积极地从 VMware 产品中获取收益。
我认为他们本可以为永久许可证持有者保留一些支持,或者继续允许那些不能用订阅模式证明他们的业务的合格客户使用。
然而,博通只是又一家让最终客户对收购结果感到不满的公司。或许他们可以尝试一下不一样的做法?
但现在,一切都来不及了。
现在,不满意的客户可以开始考虑一些开源的解决方案和替代产品,比如 [The Stack](https://www.thestack.technology/broadcom-is-killing-off-vmware-perpetual-licences-sns/) 提及的 [Proxmox](https://www.proxmox.com/) 和 [Canonical 的 MicroCloud](https://canonical.com/microcloud)。
? 对于博通对 VMware 许可证的简化,你有什么看法呢?分享你的想法,期待下面有趣的讨论!
*(题图:DA/c0450aaa-d443-49c8-aa9d-1cd5cf664cd1)*
---
via: <https://news.itsfoss.com/vmware-broadcom-subscription/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Broadcom recently completed the process of acquiring VMware for $61 billion.
As with every company ownership change, there are positive and negative ripple effects depending on the situation.
Unfortunately, for VMware (one of the [most popular virtualization solutions](https://itsfoss.com/virtualization-software-linux/?ref=news.itsfoss.com)), it is not good news.
## Simplifying Licensing or Just Sugarcoating?
Right after the acquisition, VMware [announced](https://news.vmware.com/company/vmware-by-broadcom-business-transformation?ref=news.itsfoss.com) that there will be changes regarding how licenses work and the support cycle for VMware customers.
While they mention their aim as “simplifying” the licenses, but they just worsened it 🤦♂️🤦
And, how? By **adopting a subscription-based license model** and **ditching the perpetual licenses**.
So, perpetual licenses for VMware products are no longer a thing. You will have to subscribe to their products/services as per your requirements.
In the announcement, they mention:
VMware has been on a journey to transition to a subscription model for more than a year now, and the industry has already embraced subscription as the standard for cloud consumption. With a simplified portfolio in place, we’re completing our transition to subscription offerings. Offerings will solely be available as subscriptions or as term licenses following the end of sale of perpetual licenses and Support and Subscription (SnS) renewals beginning today.
From their perspective, they say that with a subscription model, customers will get more value for their investment.
But, I doubt anyone would agree with that thought. One-time fee purchase plans will always have a better value than subscription-based ones for customers.
Do you like Adobe's subscription-based model to use Adobe Premier Pro or prefer a one-time fee for Apple's Final Cut Pro (considering you have an Apple computer)? 🤔
I think most of you would prefer a one-time fee. So, it would be a similar preference for VMware customers.
Even VMware admitted to this fact for their business in a [blog post](https://octo.vmware.com/perpetual-term-or-saas/?ref=news.itsfoss.com) early this year:
Perpetual On-prem or perpetual licensing comes with a License Key and SnS or a support option to buy. It is the most renowned model.
Pretty ironic, right?
Even if some customers manage with it, the **existing customers may not be comfortable with their benefits of perpetual licenses coming to an end**.
Yes, you read that right.
No, customers cannot renew their SnS contracts for perpetual licensed products after today. Broadcom will work with customers to help them “trade in” their perpetual products in exchange for the new subscription products, with upgrade pricing incentives. Customers can contact their VMware account or partner representative to learn more.


**Existing customers get to use the software.** However, the support for that would end, with an option to upgrade/shift to a subscription-based plan.
Along with these changes, there are tweaks to the product offerings with VMware Cloud Foundation:
- Slashed the subscription pricing by half and added enhanced support levels
- Introduced a new VMware vSphere Foundation to offer an enterprise-grade platform for mid-sized to smaller customers.
If you need to verify the products affected by this change, I suggest you to go through the [official announcement](https://news.vmware.com/company/vmware-by-broadcom-business-transformation?ref=news.itsfoss.com) where they answer a few more questions for customers.
**Suggested Read **📖
[Top 9 Best Virtualization Software for Linux [2023]We take a look at some of the best virtualization programs that make things easy for users creating/managing VMs.](https://itsfoss.com/virtualization-software-linux/?ref=news.itsfoss.com)

## So, Broadcom is Taking Advantage of the Situation?
I think yes.
As soon as they completed the acquisition, they made the change to get more revenue out of VMware products aggressively.
I think they could have kept some limited support for perpetual license holders, or may have continued offering it for certain eligible customers who cannot justify a subscription-model for their businesses.
Broadcom is just another corporate that makes acquisition bitter news for the end customers. Maybe, try to be different for a change?
Well, it is too late for that now.
Now, unhappy customers can look at some open-source solutions and alternatives like [Proxmox](https://www.proxmox.com/?ref=news.itsfoss.com) and [Canonical's MicroCloud](https://canonical.com/microcloud?ref=news.itsfoss.com) as noted by [The Stack](https://www.thestack.technology/broadcom-is-killing-off-vmware-perpetual-licences-sns/?ref=news.itsfoss.com).
Here's a [free learning resource on Proxmox](https://linuxhandbook.com/proxmox/?ref=news.itsfoss.com).
[Getting Started With ProxmoxA tutorial searies that covers everything from installing and upgrading Proxmox to using it for creating and managing VMs.](https://linuxhandbook.com/proxmox/?ref=news.itsfoss.com)

*💬 What do you think about the VMware license simplification by Broadcom? Share your thoughts for an interesting discussion below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,496 | 支持苹果芯片的 Fedora Asahi Remix 39 发布 | https://fedoramagazine.org/introducing-fedora-asahi-remix-39/ | 2023-12-22T14:49:30 | [
"苹果芯片"
] | https://linux.cn/article-16496-1.html | 
早在 8 月份,我们 [宣布](https://fedoramagazine.org/coming-soon-fedora-for-apple-silicon-macs/) Fedora Linux 很快就会在<ruby> 苹果芯片 <rt> Apple Silicon </rt></ruby> Mac 上可用。我们在 Flock 上推出了 [Fedora Asahi Remix](https://fedora-asahi-remix.org/)。这个发行版与 [Fedora Asahi SIG](https://fedoraproject.org/wiki/SIGs/Asahi) 和 [Asahi Linux](https://asahilinux.org/) 项目密切合作开发的。
今天,我们很高兴地宣布 Fedora Asahi Remix 39 现已 [正式发布](https://asahilinux.org/fedora/)!这个 Remix 版基于 Fedora Linux 39,通过广泛的平台和设备支持,在苹果芯片 Mac 上提供了出色的体验。它全面支持所有配备 M1 和 M2 芯片的 MacBook Air、MacBook Pro、Mac Mini、Mac Studio 和 iMac 系统。有关各个系统的详细信息,请参阅 Asahi Linux 网站上的 [特性矩阵](https://asahilinux.org/fedora/)。
Fedora Asahi Remix 选定 KDE Plasma 作为我们的旗舰桌面版本,同时配备了一个基于 Calamares 的自定义初始设置向导。GNOME 变体同样可用,两种桌面变体都与 Fedora Linux 提供的功能相兼容。KDE 和 GNOME 都支持开箱即用的 Wayland,并利用 XWayland 来支持旧版 X11 应用程序。
Fedora Asahi 还附带非一致性 OpenGL 3.3 支持,包括 GPU 加速的几何着色器和变换反馈,以及世界上第一个也是唯一一个针对苹果芯片的 [经过认证的一致性 OpenGL ES 3.1](https://www.khronos.org/conformance/adopters/conformant-products/opengles#submission_1007) 实现。我们创新性地整合了 DSP 解决方案,得以即插即用支持高质量音频,不仅能呈现全方位的音效和动态范围,还不会对电池寿命产生影响。
Fedora Asahi Remix 还为服务器工作负载和其他类型的无头部署提供了 Fedora Server 变体。最后,我们为希望从头开始构建自己的体验的用户提供了一个最小的镜像。
你今天就可以按照我们的 [安装指南](https://docs.fedoraproject.org/en-US/fedora-asahi-remix/installation/) 安装 Fedora Asahi Remix。我们还设有一个用于跟踪已知问题的 [问题跟踪器](https://pagure.io/fedora-asahi/remix-bugs/issues)、一个用于用户支持的 [Discourse 论坛](https://discussion.fedoraproject.org/c/neighbors/asahi/92) 和一个 [Matrix 聊天室](https://matrix.to/#/#asahi:fedoraproject.org)。
Fedora Asahi Remix 是我们多年合作的成果,我们希望你会喜欢在自己的系统上运行它。我们期待未来将支持扩展到更多设备和功能,并继续为苹果芯片 Mac 提供最佳的 Linux 体验。
*(题图:DA/9f052f85-4f66-445c-8a75-81a5c0221911)*
---
via: <https://fedoramagazine.org/introducing-fedora-asahi-remix-39/>
作者:[Neal Gompa](https://fedoramagazine.org/author/ngompa/),[Davide Cavalca](https://fedoramagazine.org/author/dcavalca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Back in August, we [announced](https://fedoramagazine.org/coming-soon-fedora-for-apple-silicon-macs/) that Fedora Linux would soon be available on Apple Silicon Macs. We unveiled the [Fedora Asahi Remix](https://fedora-asahi-remix.org/) at Flock. This is a distribution developed in close collaboration with the [Fedora Asahi SIG](https://fedoraproject.org/wiki/SIGs/Asahi) and the [Asahi Linux](https://asahilinux.org/) project.
Today we are happy to announce that Fedora Asahi Remix 39 is now [generally available](https://asahilinux.org/fedora/)! Based on Fedora Linux 39, the Remix provides a polished experience on Apple Silicon Macs with extensive platform and device support. All MacBook Air, MacBook Pro, Mac Mini, Mac Studio and iMac systems with M1 and M2 chips are supported. See the [feature matrix](https://asahilinux.org/fedora/) on the Asahi Linux website for specifics about individual systems.
Fedora Asahi Remix offers KDE Plasma as our flagship desktop experience, which also features a custom Calamares-based initial setup wizard. A GNOME variant is also available, with both desktop variants matching what Fedora Linux offers. Both KDE and GNOME use Wayland out of the box, leveraging XWayland to support legacy X11 apps.
Fedora Asahi also ships with non-conformant OpenGL 3.3 support including GPU-accelerated geometry shaders and transform feedback, as well as the world’s first and only [certified conformant OpenGL ES 3.1](https://www.khronos.org/conformance/adopters/conformant-products/opengles#submission_1007) implementation for Apple Silicon. High-quality audio is fully supported out of the box, thanks to our novel integrated DSP solution. This provides balanced sound with full loudness and dynamic range, without compromising battery life.
Fedora Asahi Remix also provides a Fedora Server variant for server workloads and other types of headless deployments. Finally, we offer a Minimal image for users that wish to build their own experience from the ground up.
You can install Fedora Asahi Remix today by following our [installation guide](https://docs.fedoraproject.org/en-US/fedora-asahi-remix/installation/). We also have an [issue tracker](https://pagure.io/fedora-asahi/remix-bugs/issues) for known bugs, a [Discourse forum](https://discussion.fedoraproject.org/c/neighbors/asahi/92) for user support and a [Matrix room](https://matrix.to/#/#asahi:fedoraproject.org).
Fedora Asahi Remix is the result of a multi-year collaboration and we hope you will enjoy running it on your systems. We look forward to extending support to more devices and features in the future and continuing to provide the best Linux experience for Apple Silicon Macs.
## Giuseppe
Amazing yes! BUT the name could be a bit shorter and better (now it kinda describes nothing to people without a clue).
“Fedora Asahi Remix 39” is just too much and too little? No indication of Linux either. But what could the name be? Set up a competition? =)
Btw: Fedora’s logo is often confused with Facebook by new comers. Even the colors are same… Then they get even more confused if no one tells them that Linux has nothing to do with Facebook and Fedora is a distribution and… and… Well.
## iamteedoh
True! If they did something like
Fedora Asahi Linux Remix 39, that’s probably very descriptive but no one would remember.Fedora Asahi Linuxmight be enough. You’ll know it’s Linux, Fedora being the flavor of Linux, and Asahi being the project of the flavor of Linux, which indicates it’s Apple Hardware Supported.I think explaining what Linux is to anyone new is confusing in general because of the many available flavors. You’ll get the question of, “Why are there many flavors?; What is KDE?; What’s GNOME?, etc., etc.
Cheers!
## dhime
Só chamar FAR 39.
## mike
Excellent work!
## iamteedoh
This hard work is paying off. Nice to see all of the accomplishments for this. The best part is that this project isn’t just about installing Asahi but it’s to bridge the gap of other Linux distributions to start their porting to Apple hardware.
Asahi is basically setting the foundations to make it easier for other distros to come onboard!
I love open source! Congrats to their team and open source devs around the world!
## Benny F.
Amazing work. Just installed today. Works great and the install process was pretty simple. Thanks for the great work!
## iamteedoh
Are you using M1 or M2? I have an M2 and it’s collecting dust because I use my Thinkpad with Fedora. Curious, if it’s stable enough to finally give Asahi a run on it
## Giuseppe Della Bianca
https://asahilinux.org/fedora/
## Ernesto di Terribile
I run it on a MacBook Pro M2 Max, basically for Monero Mining, when I’m not using it for production purposes. It’s quite stable. You can already run most linux Packages on the Mac through Homebrew and MacPorts, which will natively compile Linux Packages for the Mac.
For my servers, I use Proxmox, Kali, Alpine and Xpenology. So I’m already well versed in the Linux Universe, But running Gimp, Krita and InkScape through MacOS or Asahi does not make a lot of difference.
There is a difference in sound on YouTube my 16″ MacBook is a bit boomy on the voice in MacOS but it sounds way clearer in Asahi.
## Ethan
Works great so far in the couple hours I’ve fiddled with it. Really highlights how few packages are compiled for ARM, though (Discord, Steam, etc.).
## Scott Wilson
The project seems to be maturing. Very smooth process. I am not thrilled the security setting for Apple is set to permissive. I wonder how secure this is since we have to rely on Apple for the boot process
## James Williams
Clicking on the “generally available” link in the second paragraph will take you to an Asahi Linux page. Scroll to the bottom of that page and you will see supported features in green and unsupported ones in pink. One of the pink ones says “USB-C displays.” Does that mean I won’t be able to attach my laptop to any display since I have only USB-C ports on the laptop? I spend 95% of the time on my computer with the laptop plugged into a dock with a full-sized keyboard and 27-inch monitor. If I won’t be able to work like that with Asahi, it won’t work for me. Please clarify this if I’ve got it wrong.
## James Williams
(Continued) I see now on the Asahi page I mentioned that Thunderbolt is also in pink. Since all ports on Macs are Thunderbolt, does that mean that no external device will work on a Mac running Asahi? That’s quite a serious limitation! Again, please correct me if I’ve got that wrong.
## Onyeibo
Super Interesting. Now Macs are attractive
## Alex
Super operating system that runs perfectly, I installed it and I would like to know how to switch back to my Mac with macOS and vice versa in order to use both systems. If someone can help me, thank you!
## Matthew Phillips
If it is anything like MACs of old you should be able to hold down the Option key during startup then pick what you want to boot.
## Onyeibo
You mean dual-booting?
## iamteedoh
I haven’t tried it yet but according to the Asahi project, this doesn’t wipe your MacOS installation and you should be able to boot to it or completely revert to it.
I’m looking forward to trying this but just haven’t had a chance yet.
## mike
On my Air m2 with it powered off, I hold down the power key until you see the boot options.
## Christian Bonnaud
You can have a look at :
https://www.youtube.com/watch?v=1iiFhhOkv14
You’ll have your answer and more.
## Lorenzo
However, programs like Google Chrome and Dropbox won’t be available for Linux Arm, will they? Note that Chromium wouldn’t be enough since it doesn’t allow to synchronize bookmarks…
## iamteedoh
How about Brave? I think that supports bookmark sync
## Lorenzo
But it does not support synching bookmarks with Chrome, does it?
## James Williams
Let me try my question one more time. Is it true that Thunderbolt isn’t supported yet and therefore you can’t use an external monitor (or any other peripheral) with Asahi yet? Thank you.
To the Asahi team: thank you for the hard work! I know you’ll get all this worked out.
## Bill
James: I installed this today on a Mac Mini (M2 pro) with Apple Studio Display, which only attaches via Thunderbolt. While the install process is straight forward, when the Remix was booted, nothing appeared on the Apple display. Based on this, it looks like Thunderbolt support isn’t there just yet. Will install again when Thunderbolt support is in play.
## James Williams
Bill, thank you for doing that experiment and passing on your results. I’m sure the Asahi team will get this working soon, but for now, I’ll have to pass. I can’t work for long stretches without a full-size keyboard and monitor.
## Pavel
I’ve just installed Asahi with GNOME on an M2 Mac, it’s working very well. The install process was actually simpler than a standard Fedora install. I would say the installer asked too few questions, e.g. it didn’t ask me about the system hostname. USB devices are working if they are connected to the Mac but not to a Thunderbolt dock. Once surprising limitation is that Night Light is not available, it must be due to video driver limitations. I wish there were an option to use Mac-style keyboard shortcuts (without setting up every shortcut individually), but that’s a GNOME limitation. |
16,498 | 初代社交媒体平台 Usenet 兴衰记 | https://www.zdnet.com/article/the-rise-and-fall-of-usenet-how-the-original-social-media-platform-came-to-be/ | 2023-12-22T23:03:35 | [
"Usenet"
] | https://linux.cn/article-16498-1.html | 
>
> 当谷歌决定停止支持 Usenet,使得这个最早的社交网络平台又少了一个主要的入口。
>
>
>
在脸书还未成立,甚至在互联网出现之前,[Usenet](https://nordvpn.com/blog/what-is-usenet/) 就已经存在了。作为首个社交网络,Usenet 的存在时光超越了一切。但如今,随着谷歌群组的 [撤离](https://support.google.com/groups/answer/11036538),这个最久远的社交网络岌岌可危。
谷歌发表声明:
>
> 从 2024 年 2 月 22 日起,您将无法继续使用谷歌群组([groups.google.com](http://groups.google.com/))发布内容至 Usenet、订阅 Usenet 的群组,或是查看新的 Usenet 内容。但您可继续在谷歌群组上查看并检索至 2024 年 2 月 22 日前发布的 Usenet 的历史内容。
>
>
>
有些人可能会说现在是时候了。正如同谷歌所说,“在过去的几年里,随着用户转向更现代的平台和格式,如社交媒体和基于互联网的论坛,文字形式的 Usenet 群组的合法活动已明显减少。目前很多通过 Usenet 分发的内容已变为二进制(非文字)的文件分享,这是谷歌群组无法支持的,此外还有垃圾邮件等。”
诚然,虽然如今的 Usenet 几乎完全充斥着垃圾信息,但在其黄金年代,它所涵盖的几乎是今日的 Twitter 和 Reddit,甚至有过之而无不及。
### 一切的开端
在 1979 年,杜克大学的计算机科学研究生 Tom Truscott 和 Jim Ellis 萌生了搭建一个按主题分类的消息共享网络的想法。这些消息,也被称为文章或帖子,分别提交到各个主题类别中,这些类别后来就被人们称作“新闻组”。
在这些组中,消息按主题和子主题组织在一起。就比如,关于历史上最佳 NFL 四分卫的讨论可能会有一系列主题(即讨论),来分别支持 Tom Brady、Joe Montana、Peyton Manning 等人。
听起来是不是熟悉?你会 [想起](https://www.zdnet.com/home-and-office/networking/before-the-web-online-services/) 80 和 90 年代的 CompuServe、GEnie、Prodigy 等在线服务的网络新闻论坛,或者后来的 Reddit 及其子版块?它们的形成和发展都深受 Usenet 的影响。
在 1980 年,Truscott 和 Ellis 携手北卡罗莱纳大学创建了最初的 Usenet 节点,使用的是 “Unix 对 Unix 的复制协议([UUCP](https://www.techopedia.com/definition/22754/unix-to-unix-copy-uucp))”。从那时开始,它就在还没出现互联网的 [ARPANet](https://www.britannica.com/topic/ARPANET) 和其他早期网络中迅速蔓延。
这些消息会被存储起来,然后可以在新闻服务器上检索。服务器间建立了“对等”连接,以便新闻组的消息能在服务器和用户之间共享,你的消息能在几小时内传遍整个网络世界。Usenet 进化出了自己的网络协议,即“网络新闻传输协议([NNTP](https://www.geeksforgeeks.org/network-news-transfer-protocol-nntp/))”,以加快消息传递的速度。
如今,社交网络 [Mastodon](https://joinmastodon.org/) 就采用了类似的办法,使用 [ActivityPub](https://activitypub.rocks/) 协议。而其他的社交网络,如 [Threads](https://www.threads.net/),正在研究如何使用 ActivityPub 协议与 Mastodon 和其他支持 ActivityPub 的社交网络建立联系。
有句老话说得好,万物皆有轮回。
事实上,我们今天在谈论互联网使用的大部分词汇都源自 Usenet。例如,“<ruby> 常见问答 <rt> Frequently Asked Questions </rt></ruby>”(FAQ)文件就是在 Usenet 上首次出现的,作为给新闻组会员参考的信息摘要,让他们无需为新成员重复解释基本信息。
然而,并不是所有的短语都有趣。比如 “<ruby> 网络攻击 <rt> flame </rt></ruby>” 和 “<ruby> 网络战争 <rt> flame war </rt></ruby>”,它们也起源于 Usenet。遗憾的是,我们始终无法和谐相处。但同时,我们也一直努力温柔以待。这就是被称为“<ruby> <a href="https://www.verywellmind.com/ten-rules-of-netiquette-22285"> 网络礼仪 </a> <rt> netiquette </rt></ruby>”的概念。然而至今,这个准则往往存在于口头,鲜有人在实践中遵守。
<ruby> 垃圾邮件 <rt> Spam </rt></ruby> 的诞生也始于 Usenet。尽管我们都知道 “垃圾” 这一术语起源于 <ruby> 蒙提·派森 <rt> Monty Python </rt></ruby> 的荒诞剧,但是垃圾邮件首次被大规模商业化利用还要追溯到 1994 年,当时 Laurence Canter 和 Martha Siegel 律师夫妇在 Usenet 上大肆发布移民法律服务的广告。他们后来会有些愧疚地说,是我的早期文章让他们想到了使用互联网进行广告发布。我……
早期的 Usenet 不仅让人们能够相互交流,其价值远不止于此。例如,Linux 就是从一条发给 comp.os.minix 新闻组的著名信息开始诞生的:
>
> Linus Benedict Torvalds
>
>
> 1991 年 8 月 25 日,下午 4:57:08
>
>
> 各位正在使用 minix 的朋友们,大家好 -
>
>
> 我正在制作一款(免费的)操作系统(只是一个爱好,没有像 GNU 那样庞大和专业的野心)以供 386(486)AT 机型使用。我撰写这个操作系统已经酝酿好几个月了,而且现在看起来准备得差不多了。关于 minix 的优缺点,我想听听大家的反馈,因为我的操作系统在某些方面(例如,出于实用原因导致的文件系统布局等)跟它很像。
>
>
>
Usenet 从来不是一个有组织的社交网络。每个服务器的所有者都可以制定自己的规则,也的确这样制定了。
不过,需要指出的是,Usenet 在最初阶段的确有某种形式的组织。最早的 “主流” Usenet 群组 —— 即 comp、misc、news、rec、soc 和 sci 顶层,一直被广泛接受和传播,直至 1987 年。然后,受到新群组数量激增的冲击,一个新的命名计划应运而生,被称为 “<ruby> 大更名 <rt> Great Renaming </rt></ruby>”。这引发了众多争端,并催生出 talk 顶层。这个顶层和最初的六个顶层共同构成了 “<ruby> 七大顶层 <rt> Big Seven </rt></ruby>”。接着,一段自由言论的抗议推动了 alt 群组的诞生。此后,可以访问所有新闻组的 Usenet 站点变得越来越少,取而代之的是,维护者和用户需要决定他们要支持哪些新闻组。
如果你觉得这有些类似于埃隆•马斯克对 Twitter 一番操作后产生的分裂情况,没错,就是这样。
多年来,随着 Usenet 上的讨论被垃圾邮件和网络战争所取代,它开始衰落。尽管马斯克声称无限制的自由言论是种优势,但结果却往往是恶劣信息的无尽倾泻。
### Usenet 的今天
在许多方面,Usenet 警示我们社交网络会如何走向败坏。尽管如此,我们现在在社交网络上看到的问题,在 Usenet 上早就已经出现过了。
大量被称为 “二进制” 群组的 Usenet 新闻组几乎没有任何讨论。它们用来分享文件,其中一部分文件是合法的,但也有不少就不怎么合法了。而这些用户中,那些利用这些群组进行盗版电影、游戏等的人数,可能超过实际使用讨论群组进行对话的人数。
确实,有人试图改革 Usenet。比如,在多年无人监督后,2020 年成立的 “[Big 8](https://www.big-8.org/wiki/Main_Page)” 管理委员会开始管理这些新闻组,但进展甚微。
进一步说,如果你想将继续关注 Usenet 的未来变化 —— 毕竟,奇迹总会发生 —— 你需要从一个 Usenet 提供商那里获取一个账户。我推荐的有 [Eternal September](https://www.eternal-september.org/),它提供免费访问讨论类的 Usenet 群组;[NewsHosting](https://www.newshosting.com/),以每月 9.99 美元的价格提供访问所有 Usenet 群组的服务;[EasyNews](https://www.easynews.com/),价格为每月 9.98 美元,提供高速下载和优质的搜索引擎;以及 [Eweka](https://www.eweka.nl/),每月 9.50 欧元,只提供欧盟服务器。
你还会需要一个 Usenet 客户端。其中一款免费且颇受欢迎的客户端是 Mozilla 的 Thunderbird 邮件客户端,其同时也是 Usenet 客户端。EasyNews 也提供了自身的客户端作为服务的一部分。如果你只关注下载文件,那么 [SABnzbd](https://sabnzbd.org/) 值得一试。
*(题图:DA/751f9b47-becd-40e3-af2d-b670ee77c1e3)*
---
via: <https://www.zdnet.com/article/the-rise-and-fall-of-usenet-how-the-original-social-media-platform-came-to-be/>
作者: [Steven Vaughan-Nichols](https://www.zdnet.com/meet-the-team/steven-vaughan-nichols/) 译者: [ChatGPT](https://linux.cn/lctt/ChatGPT) 校对: [wxy](https://github.com/wxy)
| 200 | OK | # The rise and fall of Usenet: How the original social media platform came to be


Long before Facebook existed, or even before the Internet, there was [Usenet](https://nordvpn.com/blog/what-is-usenet/). Usenet was the first social network. Now, with [Google Groups abandoning Usenet](https://support.google.com/groups/answer/11036538), this oldest of all social networks is doomed to disappear.
Google declared:
Starting on February 22, 2024, you can no longer use Google Groups (at groups.google.com) to post content to Usenet groups, subscribe to Usenet groups, or view new Usenet content. You can continue to view and search for historical Usenet content posted before February 22, 2024, on Google Groups.
Some might say it's well past time. As Google declared, "Over the last several years, legitimate activity in text-based Usenet groups has declined significantly because users have moved to more modern technologies and formats such as social media and web-based forums. Much of the content being disseminated via Usenet today is binary (non-text) file sharing, which Google Groups does not support, as well as spam."
**Also: How Google Workspace just made it easier for others to pronounce your name**
True, these days, Usenet's content is almost entirely spam, but in its day, Usenet was everything that [Twitter](https://twitter.com/?lang=en) and [Reddit](https://www.reddit.com/) would become and more.
## How it all started
In 1979, Duke University computer science graduate students Tom Truscott and Jim Ellis conceived of a network of shared messages under various topics. These messages, also known as articles or posts, were submitted to topic categories, which became known as newsgroups.
Within those groups, messages were bound together in threads and sub-threads. For example, a discussion about the best NFL quarterback of all time would have threads, that is, discussions, defending Tom Brady, Joe Montana, Peyton Manning, etc.
**Also: Why your Threads posts will soon be accessible on Mastodon**
Does that sound like the [online news forums of the online services of the 80s and 90s, such as CompuServe, GEnie, or Prodigy](https://www.zdnet.com/home-and-office/networking/before-the-web-online-services/), or, more recently, Reddit and its subreddits? It should. Usenet was the model they were all based on.
In 1980, Truscott and Ellis, using the [Unix to Unix Copy Protocol (UUCP)](https://www.techopedia.com/definition/22754/unix-to-unix-copy-uucp), hooked up with the University of North Carolina to form the first Usenet nodes. From there, it would rapidly spread over the pre-Internet [ARPANet](https://www.britannica.com/topic/ARPANET) and other early networks.
These messages would be stored and retrieved from news servers. These would "peer" to each other so that messages to a newsgroup would be shared from server to server and to user to user so that within hours, your messages would reach the entire networked world. Usenet would evolve its own network protocol, [Network News Transfer Protocol (NNTP)](https://www.geeksforgeeks.org/network-news-transfer-protocol-nntp/), to speed the transfer of these messages.
Today, the social network [Mastodon](https://joinmastodon.org/) uses a similar approach with the [ActivityPub](https://activitypub.rocks/) protocol, while other social networks, such as [Threads](https://www.threads.net/), are exploring using ActivityPub to connect with Mastodon and the other social networks that support ActrivitiyPub.
As the saying goes, everything old is new again.
Indeed, much of the vocabulary we use today to talk about using the net springs from Usenet. Frequently Asked Questions (FAQ) files, for example, started on Usenet as summaries of information about a newsgroup so the members wouldn't need to repeat the basics for newcomers.
Other phrases aren't as much fun. Flame and flame war, for instance, also started on Usenet. We've always been, I'm sorry to say, mean to each other. At the same time, we've also tried to be kinder to each other. The concept is called [netiquette](https://www.verywellmind.com/ten-rules-of-netiquette-22285). Then, as now, it's always been more honored in the breach than in practice.
Spam also got its start on Usenet. While we all know Monty Python came up with the term, the first major commercial use of spam dates to 1994 when husband and wife lawyers Laurence Canter and Martha Siegel started posting ads for their immigration law services on Usenet. Mea culpa later, they would say my early articles about the Internet gave them the idea. I'm sorry!
Early on, Usenet was valuable for more than just enabling people to talk with each other. [Linux](https://www.zdnet.com/topic/linux/), for instance, got its start from a now-famous message to the comp.os.minix newsgroup:
Linus Benedict Torvalds
Aug 25, 1991, 4:57:08 PM
Hello everybody out there using minix -
I'm doing a (free) operating system (just a hobby, won't be big and professional like gnu) for 386(486) AT clones. This has been brewing since april, and is starting to get ready. I'd like any feedback on things people like/dislike in minix, as my OS resembles it somewhat (same physical layout of the file-system (due to practical reasons) among other things).
Usenet was never an organized social network. Each server owner could -- and did -- set its own rules.
Mind you, there was some organization to begin with. The first 'mainstream' Usenet groups, comp, misc, news, rec, soc, and sci hierarchies, were widely accepted and disseminated until 1987. Then, faced with a flood of new groups, a new naming plan emerged in what was called the Great Renaming. This led to a lot of disputes and the creation of the talk hierarchy. This and the first six became known as the Big Seven. Then the alt groups emerged as a free speech protest. Afterward, fewer Usenet sites made it possible to access all the newsgroups. Instead, maintainers and users would have to decide which one they'd support.
If that sounds like the kind of splitting up that happened after Elon Musk started after he put his stamp on Twitter, you're right it is.
**Also: AI in 2023: A year of breakthroughs that left no human thing unchanged**
Over the years, Usenet began to decline as discussions were replaced both by spam and flame wars. Group discussions were also overwhelmed by flame wars. While Elon Musk can claim that unlimited free speech is a virtue, it actually ends up with endless floods of vile messages.
## Usenet, today
In many ways, Usenet is a warning about how social networks can go bad. All the same, problems we see today on social networks appeared first on Usenet.
Many Usenet newsgroups, the so-called binary groups, don't have discussions at all. Instead, they're used to share files. Some of these files are legal, others… less so. More users probably use these groups to pirate movies, games, and the like than use the discussion groups for conversations.
**Also: AI adds new fuel to autonomous enterprises, but don't write off humans**
There have been attempts to reform Usenet. For example, after years of no oversight whatsoever, the [Big 8 Management Board](https://www.big-8.org/wiki/Main_Page) was created in 2020 to manage the groups themselves. Little has changed, though.
If, going forward, you want to keep an eye on Usenet--things could change, miracles can happen--you'll need to get an account from a Usenet provider. I favor [Eternal September](https://www.eternal-september.org/), which offers free access to the discussion Usenet groups; [NewsHosting](https://www.newshosting.com/), $9.99 a month with access to all the Usenet groups; [EasyNews](https://www.easynews.com/), $9.98 a month with fast downloads, and a good search engine; and [Eweka](https://www.eweka.nl/), 9.50 Euros a month and EU only servers.
You'll also need a Usenet client. One popular free one is Mozilla's [Thunderbird](https://www.thunderbird.net/) E-Mail client, which doubles as a Usenet client. EasyNews also offers a client as part of its service. If you're all about downloading files, check out [SABnzbd](https://sabnzbd.org/).
[Editorial standards](/editorial-guidelines/) |
16,501 | DOOM 30 岁了,Windows NT 也是,但我们好像并没有走多远 | https://www.theregister.com/2023/12/19/windows_nt_30_years_on/?td=rt-3a | 2023-12-23T23:04:00 | [
"DOOM",
"计算机历史",
"Windows NT"
] | https://linux.cn/article-16501-1.html | 
>
> 1983 年和 1993 年之间的变化显著,然而从那时候到现在,变化其实并不大。
>
>
>
2023 年即将过去,我们来回顾一下三十年前的科技。不只是与今天进行对比,也是和更早的十年前对照。有趣的不是变化有多大:而是变化的速度有多快。
一位澳洲老极客近期指出,距离 id Software 的“最具影响力的恐怖动作游戏”问世,以及它带来的网络“[死亡竞赛](https://www.theregister.com/2018/12/10/doom_turns_25/)”,已经 [三十年](https://www.theregister.com/2023/12/11/doom_30th_anniversary_sigil_wad/) 了。回顾 1993 年的科技,并把它和 1983 年对比一下,真是令人惊叹。仅仅十年的时间,现代计算的大部分技术都诞生了。许多始于 1993 年的重大技术,如今依然是我们依赖的核心。
正如 DOOM 在 1993 年重新定义了电子游戏,Windows NT 也赋予了 PC 操作系统全新的定义。NT 的第一个版本在 DOOM 发布前几个月就 [问世](https://www.theregister.com/2013/08/01/windows_nt_anniversary/) 了,其影响力甚至更为深远。1993 年我们也见证了 [NCSA Mosaic](https://www.theregister.com/2013/04/26/mosaic_20_anniversary/) 的发布,这是最初的 Web 浏览器。Mosaic 的衍生品是 Netscape。起初它开始运营的名字是 Mosaic 通信公司,不知为何,这家公司的首页现在 [仍然存在](http://home.mcom.com/)。后来,Mosaic 公司 [变成](https://www.davetitus.com/mozilla/) 了 Netscape,进而催生出了今日的 Mozilla。1993 年还有一项里程碑式的事件,那就是 [Trojan Room](https://www.theregister.com/2001/03/07/worlds_first_webcam_coffee_pot/) 咖啡壶摄像头的上线,这是有史以来第一台网络摄像头。
1993 年奠定了现代计算的发展方向。一代人的时间过去了,大多数桌面电脑用户仍在使用基于 NT 系统的变体:Windows 11 仍然基于它。而 Mosaic 代码库的最后一部分随着 [IE 11](https://www.theregister.com/2022/06/14/bye_bye_ie/) 的退场已经销声匿迹,但我们仍然在使用间接源于 Mosaic 的 Web 浏览器。
要想了解 1993 年带来的影响有多大,可以将其与早更的十年前做个比较。1983 年,[Camputers Lynx](https://www.theregister.com/2013/03/20/feature_the_story_of_the_camputers_lynx/) 亮相,但它根本无法与 [英国的热销机型](https://www.theregister.com/2013/01/03/charted_1983_home_computer_sales_in_uk/) —— ZX Spectrum、BBC Micro 和 Commodore 64 相抗衡。而就在 Lynx 问世的同一年,另一款价格更昂贵的失败产品也在池塘边面世。虽然数以千计的苹果 [Lisa](https://www.theregister.com/2013/01/18/feature_apple_lisa_is_30/) 最终被扔到了垃圾填埋场,但其精简成本后的继任者 Macintosh,确立了个人电脑的新标准 —— 即便现代 Mac 中几乎找不到初代 Macintosh 的技术影子。
Lisa 之所以失败,部分原因是其售价高达 $9,995,约合今日的 $30,000。确实不菲,但对比一下,[原始版 IBM PC](https://www.theregister.com/2007/11/17/tob_ibm_personal_computer/) 标配硬盘的第一代,即 IBM PC/XT,也是在 1983 年发布的。由于拥有 10 MB(注意,不是 GB)的硬盘,其价格达到了 $7,545,大约相当于今天的 $22,500。这就是为什么像 Commodore 64 这样的 8 位设备在 1983 年的市场中占据主导地位的原因:64 KB 内存、磁带存储,以及一台模拟电视作为显示器,是大多数家庭用户能负担起的全部。Commodore 64 在 1981 年发布时的定价为 [$595](https://www.theregister.com/2012/01/02/commodore_64_30_birthday)。到 1993 年,按通胀计算这个价格约为 [$1,000](https://tools.carboncollective.co/inflation/us/1981/595/1993/),而这在当时可以买到一台 [486 PC](https://www.latimes.com/archives/la-xpm-1993-12-24-fi-5121-story.html)。
### ~~转瞬~~十年变迁
1973 年,微处理器几乎还没有出现。那时还没有英特尔 8080 或 CP/M。我们所认为的 PC 该有的能力需要一台定制的工作站才行,其成本约合今天的 $280,000:[Xerox Alto](https://www.theregister.com/2023/03/16/the_xerox_alto_50_years/)。和其相比,Lisa 看起来还算便宜。另外,1973 年,[以太网](https://www.theregister.com/2023/06/30/ethernet_50th_birthday/) 也诞生了。
在十年之后,一台售价 $10,000 的个人电脑刚刚能够实现单色的图形用户界面(GUI),但很少有人意识到其好处,买的人就更少了。再过十年,到 1993 年,[Windows for Workgroups 3.11](https://www.theregister.com/2008/07/11/microsoft_retires_windows_311_for_workgroups/) 发布,而那时连低配置的 PC 也能流畅运行它。同年,[MacOS 7.1.1](https://apple.fandom.com/wiki/System_7.1.1) 也发布了,任何 1993 年生产的 [Macintosh](https://everymac.com/systems/by_year/macs-released-in-1993.html) 都能毫不费力地运行它。1983 年最畅销的 [电子游戏](https://www.simplyeighties.com/top-5-home-video-games-from-1983.php) 是《<ruby> 吃豆人 <rt> Pac Man </rt></ruby>》和《<ruby> 大金刚 <rt> Donkey Kong </rt></ruby>》,十年之后,人们痴迷的是一款网络实时 3D 第一人称射击游戏 —— DOOM。
从 1983 到 1993,计算机世界从 8 位 CPU 和几十 KB 的存储,发展到拥有 MB 存储的 32 位机,并且图形用户界面成为了标准配置。NT 3.1 是首个具有完全抢占式多任务处理和内存保护功能的 Windows 版本,它取代了 Windows 3 和经典 MacOS 的原始而不稳定的协同多任务处理。NT 3.1 也是首个内置 TCP/IP 的 Windows 版本,当时以太网开始成为标准配置,图形网页浏览器也应运而生。浏览器和第一台网络摄像头的出现,是使 [互联网盈利](https://www.youtube.com/watch?v=LTJvdGcb7Fs) 的关键所在。
虽然对大多数人来说并不重要,但 Windows NT 的第一个版本已经支持了 [双 CPU](http://www.os2museum.com/wp/nt-3-1-smp/comment-page-1/),它使用的 [英特尔 MP 标准](https://www.theregister.com/1999/07/01/the_register_is_five_years/),曾出现在 Compaq SystemPro 中,其首个 386 型号发布于 1989 年。当 [双核芯片](https://www.theregister.com/2004/12/14/intel_dual-core/) 开始面世时,NT 已经做好准备,但实际上,多处理器 PC 并不是在二十世纪九十年代才出现的,它们是 80 年代末期的技术,在 1993 年已经落地并投入使用。
在屏幕图形方面,我们或多或少获得了实时 3D 技术,尽管仍然是通过软件渲染的。OpenGL 标准在前一年获得了批准,Windows 上的“视频”应用也在此时作为 Windows 3 的免费附加组件出现。
### 那么,后来发生了什么呢?
在接下来的十年中,许多较小的部分逐渐到位,但它们的变化更像是演进,而不是变革:是帮助而非突破。Windows 95 使得桌面界面现代化,而现在的大多数工作方式仍 [与那时相同](https://www.theregister.com/2022/05/17/linux_desktop_feature/),尽管微软已经作了 [大量努力](https://www.theregister.com/2013/06/03/thank_microsoft_for_linux_desktop_fail/)。在世纪之交,英国开始全面推广 [ADSL 宽带](https://www.theregister.com/2000/04/27/what_the_hell_is_bt/),让大部分人享受到了快速的互联网。一年之后,[Windows XP](https://www.theregister.com/2001/10/25/winxp_london_launch/) 的问世,终结了基于 DOS 的 Windows 时代。 NT 发布十年后,首款 [64 位 PC 芯片](https://www.theregister.com/2003/04/22/amd_launches_opteron/) 问世。
从那时起……那么,你能说出哪些重大进步吗?在 PC 之前,手机就可以 [听懂口语命令](https://www.theregister.com/2011/10/05/apple_predicted_siri_in_1987/)(尽管我们一度认为这只是个 [噱头](https://www.theregister.com/2011/10/05/iphone_4s/?page=2))。你的脸可以 [解锁设备](https://www.theregister.com/2017/11/14/is_facial_recognition_good_enough/),但它们仍然无法读懂你的表情。手势操作仍然只限于触摸板。从 32 位转移至 64 位的进程相当平淡乏味:主要的变化就是你可以拥有更多的内存。计算机变得更小,更节能,运行更安静,拥有更多也更快的存储……仅此而已。
尽管 PC 行业绝不承认这一点,但正如在 [2021 年](https://www.theregister.com/2021/10/28/intels_gelsinger_moore/),或者说更早的十年前也一样,计算机的速度增长已经不再那么显著。存储设备也如此,最新的耗电大户 [GPU](https://www.theregister.com/2022/11/18/nvidia_flawsuit_4090/) 这类半专用的特定用途芯片也依然如此……不过近来 [苹果芯片](https://www.theregister.com/2023/10/31/apple_m3_cpus_macbook_pro_imac/) 的表现显示,提升图形性能的效率秘诀并不在于在总线末端挂载一个庞大的高热 GPU 群,而是将更小的 GPU 集成到 CPU 芯片中。
现在我们已然走过 21 世纪的四分之一,但在可编程性、交互性或全新的不可预见的技术等方面却没有取得惊人的突破,三十年来,电脑容量和并行处理性能的增长,主要让操作系统和应用程序变得前所未有的臃肿。
Windows NT 3.1 操作系统的最新版本是 Windows 11 ,而 1993 年时它已经具备了 Windows 11 大部分的功能。NT 3.1 能够在两种 CPU 架构(x86-32 和 MIPS)中运行,并拥有用于 DOS、Windows 3、UNIX 和 OS/2 应用程序的子系统…… 这一切都被集成在只有 [50 MB](https://winworldpc.com/product/windows-nt-3x/31) 的 ISO 文件中。而如今的 Windows 11 需要 6 GB 的存储空间。它扩大了 120 倍。如果你认为现在的功能是当初的 120 倍,那么请举手。
*(题图:DA/a10b4730-ce44-48c2-aa61-d630ddca8660)*
---
via: <https://www.theregister.com/2023/12/19/windows_nt_30_years_on/?td=rt-3a>
作者: [Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者: [ChatGPT](https://linux.cn/lctt/ChatGPT) 校对: [wxy](https://github.com/wxy)
| 200 | OK | # Doom is 30, and so is Windows NT. How far we *haven't* come
## The difference between 1983 and 1993 is vast. Since then, not so much
Comment As we approach the end of 2023, it's interesting to look back at the tech of three decades ago. Not just to compare it to today's, but also to that a decade earlier. The interesting aspect isn't how much has changed: it's how fast it was, and is, changing.
As an Australian vulture noted recently, [it is thirty years](https://www.theregister.com/2023/12/11/doom_30th_anniversary_sigil_wad/) since id Software's "definitive horror slugfest" came out, [complete with network "deathmatches"](https://www.theregister.com/2018/12/10/doom_turns_25/). It is amazing to look back at the tech of 1993 and contrast it with that of 1983. In just ten years, much of modern computing was invented. Several major technologies that debuted in 1993 are still central parts of what we use today.
Just as Doom redefined video games in 1993, Windows NT redefined PC operating systems. The first version came out [just a few months before Doom](https://www.theregister.com/2013/08/01/windows_nt_anniversary/), and it was even more influential. '93 also saw the release of [NCSA Mosaic, the OG web browser](https://www.theregister.com/2013/04/26/mosaic_20_anniversary/). Mosaic's spin-off, Netscape, started under the name Mosaic Communications Corporation, and somehow, that company homepage is [still there](http://home.mcom.com/). Later, Mosaic Corp [evolved into](https://www.davetitus.com/mozilla/) Netscape, and that begat today's Mozilla. Also going online in '93 was the [Trojan Room coffee pot camera](https://www.theregister.com/2001/03/07/worlds_first_webcam_coffee_pot/), the first ever webcam.
1993 set the direction of much of modern computing. Over a human generation later, most desktop computer users still run a variant of NT: it is still the basis of Windows 11. More or less the last fragments of the Mosaic codebase [died with Internet Explorer 11](https://www.theregister.com/2022/06/14/bye_bye_ie/), but we still use web browsers derived indirectly from Mosaic.
To get a sense of how transformative 1993 was, compare it with just one decade earlier. 1983 was the year that the [Camputers Lynx](https://www.theregister.com/2013/03/20/feature_the_story_of_the_camputers_lynx/) appeared, but it had no chance of competing with [the UK's best-selling machines](https://www.theregister.com/2013/01/03/charted_1983_home_computer_sales_in_uk/): the ZX Spectrum, BBC Micro, and Commodore 64. The same year as the Lynx, another, much dearer flop launched over the pond. But while thousands of the [Apple Lisa](https://www.theregister.com/2013/01/18/feature_apple_lisa_is_30/) ended up in landfill, its ruthlessly cost-cut successor, the Macintosh, set the new norm for personal computers ... even if little classic Macintosh tech remains in modern Macs.
The Lisa flopped partly because it was $9,995, about $30,000 today. A lot, sure, but for comparison, the first version of the [original IBM PC](https://www.theregister.com/2007/11/17/tob_ibm_personal_computer/) to ship with a hard disk as standard, the IBM PC/XT, *also* launched in 1983 – and thanks to its 10 MB (no, not gig) hard disk, it cost $7,545. That's about $22,500 now. This is *why* eight-bit kit like the C64 dominated the 1983 market: 64 kB of RAM, audio cassettes for storage, and an analog TV set for a display was all that most home users could afford. The C64 was [$595 at launch](https://www.theregister.com/2012/01/02/commodore_64_30_birthday) in 1981. By 1993, inflation meant that was [about $1,000](https://tools.carboncollective.co/inflation/us/1981/595/1993/), which by then would get you a [486 PC](https://www.latimes.com/archives/la-xpm-1993-12-24-fi-5121-story.html).
### What a difference a ~~day~~ decade makes
In 1973, microprocessors barely existed. It was before the Intel 8080 or CP/M. What we think of as PC abilities required a custom workstation that would have cost the equivalent of $280,000 today: the [Xerox Alto](https://www.theregister.com/2023/03/16/the_xerox_alto_50_years/), which made the Lisa look affordable. Alongside the Alto, '73 was the year [Ethernet was invented](https://www.theregister.com/2023/06/30/ethernet_50th_birthday/).
Ten years later, a $10,000 personal computer could just about manage a monochrome GUI, but few saw the benefits, and fewer still bought them. Ten years after that, [Windows for Workgroups 3.11](https://www.theregister.com/2008/07/11/microsoft_retires_windows_311_for_workgroups/) came out, and by '93 even a low-end PC could run that just fine. 1993 was also the year that [MacOS 7.1.1](https://apple.fandom.com/wiki/System_7.1.1) came out, and any [1993 model Macintosh](https://everymac.com/systems/by_year/macs-released-in-1993.html) could easily handle that. The best selling video games of '83 were [Pac Man and Donkey Kong](https://www.simplyeighties.com/top-5-home-video-games-from-1983.php); a decade later, it was a networked real-time 3D first-person shoot-'em-up.
From '83 to '93, the computer world went from eight-bit CPUs and double-digit kilobytes of storage to 32-bit machines with megabytes of storage, and a GUI as standard. NT 3.1 was also the first version of Windows with full pre-emptive multitasking and memory protection, replacing Windows 3's (and classic MacOS's) primitive and rather unstable *cooperative* multitasking. NT 3.1 was also the first version of Windows with TCP/IP built in, just as Ethernet started to become supplied as standard, and graphical web browsers appeared. The browser, and the first webcam, are [what made the internet profitable](https://www.youtube.com/watch?v=LTJvdGcb7Fs).
[These days you can teach old tech a bunch of new tricks](https://www.theregister.com/2023/09/14/pc_xt_with_hdmi/)[Want to live dangerously? Try running Windows XP in 2023](https://www.theregister.com/2023/07/24/dangerous_pleasures_win_xp_in_23/)[One person's trash is another's 'trashware' – the art of refurbing old computers](https://www.theregister.com/2023/06/21/pc_officina_positive_trashware/)[The ZX81 finally gets the keyboard it deserves](https://www.theregister.com/2023/06/15/zx_81_mechanical_keyboard/)
It didn't matter much to most people at the time, but that first release of Windows NT [already supported dual CPUs](http://www.os2museum.com/wp/nt-3-1-smp/comment-page-1/), using the [Intel MP standard](https://www.theregister.com/1999/07/01/the_register_is_five_years/), seen in the Compaq SystemPro, the first 386 model of which shipped in 1989. When dual-core chips [started to appear](https://www.theregister.com/2004/12/14/intel_dual-core/), NT was ready, but the real deal is that multiprocessor PCs didn't come along in the Noughties: they are late '80s tech, already working in '93.
In terms of on-screen graphics, we got more or less real-time 3D, although still rendered in software. OpenGL was ratified the previous year, also when Video for Windows appeared as a free add-on for Windows 3.
### Then what happened?
Over the following decade, a lot of smaller pieces fell into place, but they were more evolutionary than revolutionary: helpful, rather than groundbreaking. Windows 95 modernized the desktop interface, and [most still work like it](https://www.theregister.com/2022/05/17/linux_desktop_feature/), despite [Microsoft's concerted efforts](https://www.theregister.com/2013/06/03/thank_microsoft_for_linux_desktop_fail/). Around the turn of the century, ADSL broadband [started mass rollout](https://www.theregister.com/2000/04/27/what_the_hell_is_bt/) in the UK, bringing fast internet to the masses. A year later, [Windows XP came along](https://www.theregister.com/2001/10/25/winxp_london_launch/) and finally banished DOS-based Windows. Ten years after NT, the [first 64-bit PC chips shipped](https://www.theregister.com/2003/04/22/amd_launches_opteron/).
Since then… well, what big advances can you name? Phones could [understand spoken commands](https://www.theregister.com/2011/10/05/apple_predicted_siri_in_1987/) (even if *The Reg* [thought it was a gimmick](https://www.theregister.com/2011/10/05/iphone_4s/?page=2)) before PCs. Your [face can unlock your devices](https://www.theregister.com/2017/11/14/is_facial_recognition_good_enough/), but they still can't read expressions. Gestures are confined to trackpads. The move from 32-bit to 64-bit has been anticlimactic: mostly, it just means you can have more RAM. Computers are smaller, more power efficient, run cooler, and have way more and way faster storage … and that's about it.
Although the PC industry is in deep denial about it, [as it was in 2021](https://www.theregister.com/2021/10/28/intels_gelsinger_moore/), just as it was [a decade before that](https://www.theregister.com/2011/11/28/future_computing/), computers aren't getting that much faster any more. Storage still is, and semi-dedicated purpose-specific chippery such as [the latest power-guzzling GPUs](https://www.theregister.com/2022/11/18/nvidia_flawsuit_4090/) still are too … although the performance of [recent Apple Silicon](https://www.theregister.com/2023/10/31/apple_m3_cpus_macbook_pro_imac/) shows that the secret to efficient graphics performance isn't hanging a huge hot GPU cluster on the end of a bus, it's integrating smaller ones into the CPU die.
We're nearly quarter of the way through the 21st century, but in place of amazing breakthroughs in programmability, or interaction, or whole new unforeseen tech, three decades of increase in computer capacity and parallelism has mainly enabled unprecedented levels of OS and app bloat.
Windows 11 is the latest version of the same OS that came out as Windows NT 3.1, and in 1993, it did most of the stuff Windows 11 does. NT 3.1 ran on two different CPU architectures (x86-32 and MIPS), it had subsystems for DOS, and Windows 3, and UNIX, and OS/2 apps ... and it fit into a [50 MB ISO file](https://winworldpc.com/product/windows-nt-3x/31). Windows 11 is 6 GB. It's *120 times bigger*. Hands up if you think it has 120 times the functionality. ®
264 |
16,503 | Qubes OS 4.2 发布,支持 PipeWire 并更新了核心应用 | https://news.itsfoss.com/qubes-os-4-2-release/ | 2023-12-25T17:47:00 | [
"Qubes OS"
] | https://linux.cn/article-16503-1.html | 
>
> Qubes OS 4.2 更新改进了核心应用,还有更多好东西!
>
>
>
Qubes OS 最近发布了 4.2,带来了一些重要的改进。
首先介绍一下什么是什么是 Qubes OS?
嗯,Qubes OS 是对 Linux 发行版的有趣诠释。它与大多数发行版有很大不同,主打“**一个相对安全的操作系统**”。
它使用**安全隔离的隔间**,称为 “**qube**”,彼此保持独立。你可以有一个用于休闲网络浏览的 qube,处理电子邮件的 qube,以及处理银行业务的 qube;这些就是所谓的 “应用 qube”。
这些应用 qube 基于另一种称为“**模板**”的 qube,它通常运行一个 Linux 发行版,例如 Fedora 或 Debian。它与基于它的其他 qube 共享其根文件系统(所有程序和文件)。
因此,你可以在不同的 qube 上运行相同的应用。有关其架构的更多信息在 [此处](https://www.qubes-os.org/doc/architecture/)。
>
> ? Qubes OS 对系统资源的占用很大(需要比平常更多的 RAM)。
>
>
>
现在你已经了解了该发行版,让我重点介绍其最新版本的内容。
### ? Qubes OS 4.2:有什么新变化?

Qubes OS 4.2 基于**安全裸机管理程序 [Xen 4.17](https://xenproject.org/2022/12/14/xen-project-releases-version-4-17-with-enhanced-security-higher-performance-improved-embedded-static-configuration-and-speculative-mitigation-support/)**,并进行了一些精妙的改进,提高了整体性能和可用性。
一些**关键亮点**包括:
* Dom0 改用 Fedora 37
* 核心应用做出改进
* 模板升级
* PipeWire 支持(待定)
#### Dom0 采用 Fedora 37
“dom0” qube 现在采用 Fedora 37,由 [Linux 内核 6.0](https://news.itsfoss.com/linux-6-0-release/) 提供支持,这应该使 Qubes OS 能够利用更新的硬件,例如英特尔第 13 代 Raptor Lake CPU。
“dom0” qube 基本上就是 “**管理 qube**”,用于管理整个操作系统。
与操作系统的其他部分一样,它的设计方式非常注重安全,因此没有网络连接,并且仅用于运行桌面环境和窗口管理器。
#### 核心应用改进

我们看到的另一个重大变化是**一些 Qubes OS 核心应用完全重写了**,这是为了改善整体的用户体验。
你在上面看到的是**新的 Qubes OS 策略编辑器工具**,它有一个非常简洁的界面,包含所有必需的选项。

此外,**Qubes OS 全局配置应用也进行了升级**,现在使用起来更加直观,同时将所有重要设置统一在一个平台上。

最后,**Qubes OS 更新工具也进行了改造**,进行了一些细微的更改,使其更加用户友好。
#### 模板升级
内含的默认模板也已升级,默认的 **Debian 模板现在采用 Debian 12**,**Xfce 成为 Fedora 和 Debian 模板的默认桌面环境**。
#### PipeWire 支持
经过漫长的等待,Qubes OS 终于加入了处理音频/视频的 [PipeWire](https://pipewire.org/)。这应该会为整个操作系统带来**更好、更安全的媒体处理体验**。
#### ?️ 其他更改和改进
除此之外,还有一些值得注意的变化:
* 更好的**键盘布局切换**。
* 对 **Qubes Builder v2** 的改进。
* **Fedora 模板中支持 SELinux**。
* 一个新的可选**自动剪贴板清除功能**。
* 集成 [fwupd](https://github.com/fwupd/fwupd) 用于处理固件更新。
我建议你阅读 [发行说明](https://www.qubes-os.org/doc/releases/4.2/release-notes/),更深入地了解 Qubes OS 4.2 版本。
### ? 下载 Qubes OS 4.2
你可以从 [官方网站](https://www.qubes-os.org/downloads/) 获取此版本。请记住,Qubes OS 可以在裸机上正常工作,而不是在 [虚拟机](https://itsfoss.com/virtual-machine/) 上运行。
>
> **[Qubes OS 4.2](https://www.qubes-os.org/downloads/)**
>
>
>
如果你是 Qubes OS 的新手,那么我建议你阅读 [官方文档](https://www.qubes-os.org/doc/getting-started/) 以了解有关此发行版的更多信息。
**对于现有用户**,你可以按照官方 [升级指南](https://www.qubes-os.org/doc/upgrade/4.2/) 从 Qubes OS 4.1 升级到 4.2。
? 你会尝试一下这个版本吗? 请在下面告诉我们!
*(题图:DA/6236cc3e-114c-44af-bda5-9f65861087ee)*
---
via: <https://news.itsfoss.com/qubes-os-4-2-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

With a recent announcement, Qubes OS 4.2 was released, and it features some important improvements.
For context: **what is Qubes OS?**
Well, Qubes OS is an interesting take on what a Linux distro can be. It's very different from most distros out there, with a focus on being “**A Reasonably Secure Operating System**”.
It uses **security-isolated compartments**, called '**qubes**', that are kept separate from each other. One could have a qube for doing casual web-browsing, another for handling e-mails, and another for handling banking stuff; these are called '**app qubes**'.
These app qubes are based on another type of qube called '**template**', which is usually running a Linux distro such as Fedora or Debian. It shares its root file system (all programs and files) with the other qubes based on it.
Due to which, you can run the same apps on different qubes. More on its architecture [here](https://www.qubes-os.org/doc/architecture/?ref=news.itsfoss.com).
Now that you know about the distro, let me highlight things from its latest release.
## 🆕 Qubes OS 4.2: What's New?

Powered by **Xen 4.17****, a secure bare-metal hypervisor,** Qubes OS 4.2 is here with some neat changes that improve the overall performance and usability.
Some of the **key highlights** include:
**Dom0 with Fedora 37****Core App Improvements****Template Upgrades****PipeWire Support (Pending)**
### Dom0 with Fedora 37
The '*dom0*' qube now features Fedora 37, which is powered by [Linux kernel 6.0](https://news.itsfoss.com/linux-6-0-release/), this should enable Qubes OS to take advantage of newer hardware, such as Intel 13th Gen Raptor Lake CPUs.
A '*dom0*' qube is basically the '**admin qube**', this is used to administer the entire operating system.
It has been designed in a very security conscious manner like the rest of the OS, resulting in no network connectivity, and only being used to run the desktop environment, and the window manager.
**Suggested Read **📖
[Fedora 37 Upgrade Adds GNOME 43 and Two New Flagship EditionsFedora 37 brings in some important changes including GNOME 43, Linux Kernel 6.0, and Raspberry Pi 4 support among others.](https://news.itsfoss.com/fedora-37-release/)

### Core App Improvements
Another place where we see major changes is the **complete rewrite of some Qubes OS core apps**, which were done in a bid to improve the overall user experience.
What you saw above was the **new Qubes OS Policy Editor tool**, which has a very minimal interface with all the required options.
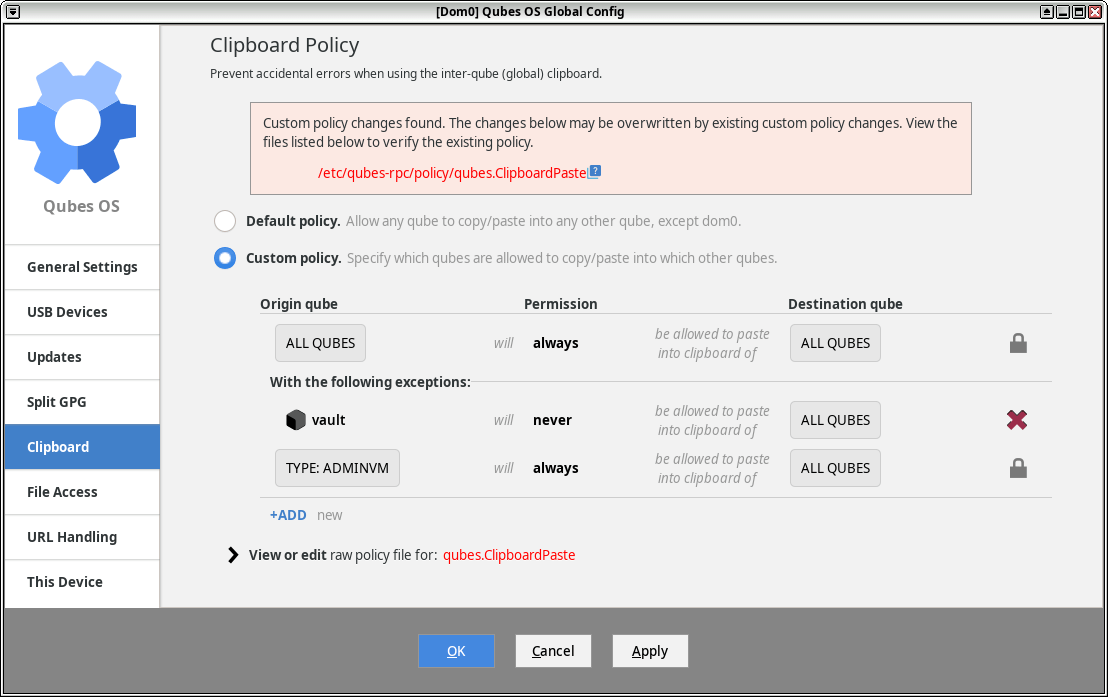
The **Qubes OS Global Config app also sees an upgrade**, and it is now more intuitive to use, while unifying all the important settings under one roof.
And finally, the **Qubes OS Update tool also receives a makeover**, with subtle changes here and there to make it more user-friendly.
### Template Upgrades
The included default templates have also been upgraded, with the default **Debian template now featuring Debian 12**, and **Xfce being the default desktop environment** for the Fedora and Debian templates.
### PipeWire Support
After a long wait, Qubes OS finally features [PipeWire](https://pipewire.org/?ref=news.itsfoss.com) for the handling of audio/video. This should result in** a better and more secure media handling experience** across the operating system.
### 🛠️ Other Changes and Improvements
Other than that, here are some changes that are worth noting:
- Better
**keyboard layout switching**. - Improvements to
**Qubes Builder v2**. **SELinux support**in Fedora templates.- A new optional,
**automatic clipboard clearing feature**. - Integration of
[fwupd](https://github.com/fwupd/fwupd?ref=news.itsfoss.com)for handling firmware updates.
I suggest you go through the [release notes](https://www.qubes-os.org/doc/releases/4.2/release-notes/?ref=news.itsfoss.com) for a more in-depth look into the Qubes OS 4.2 release.
## 📥 Download Qubes OS 4.2
You can get this release from the [official website](https://www.qubes-os.org/downloads/?ref=news.itsfoss.com). Just keep in mind that, Qubes OS works properly when on bare metal, and is not meant to be run on a [Virtual Machine](https://itsfoss.com/virtual-machine/?ref=news.itsfoss.com).
If you are new to Qubes OS, then I recommend you go through the [official documentation](https://www.qubes-os.org/doc/getting-started/?ref=news.itsfoss.com) to learn more about this distro.
**For existing users,** you can follow the official [upgrade guide](https://www.qubes-os.org/doc/upgrade/4.2/?ref=news.itsfoss.com) to upgrade from Qubes OS 4.1 to 4.2.
*💬 Will you be giving this release a try? Let us know below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,504 | 让 Fish Shell 比 Bash 更好的 11 大特性 | https://itsfoss.com/fish-shell-features/ | 2023-12-25T18:31:00 | [
"Fish Shell"
] | https://linux.cn/article-16504-1.html | 
>
> 就算你是素食主义者或对海鲜有过敏反应,也值得试试 Fish ?
>
>
>
Bash 是使用最广泛的 Shell,Zsh 则是开发者圈里最受青睐的,但 Fish 往往被许多人忽视。
这绝非夸张之辞。Fish 的确是个备受忽视的 Shell,它对新手和资深的自由开源软件用户,都可能是极好的选择。
Fish 提供了一系列吸引人的功能,使其具有鲜明优势。这其中包括了从语法高亮到缩写(我个人最喜欢的部分),这里面充满了种种新奇。
下面,我要和大家分享一些我最青睐的 Fish Shell 特性。
### 1、语法高亮
在错误的命令被执行之前就识别出它们将大大节省你的时间,同时降低你的挫败感。
现代的许多代码编辑器都内置了语法高亮功能,而 Fish 不仅将此功能内置在了 Shell 中,而且对于 Linux 命令也同样有效。
命令有误?你会发现其被红色高亮。同样的,对于不符合上下文的参数和选项也是如此。

### 2、自动建议
当你输入命令时,Fish Shell 会自动推荐命令,然后你可以按照提示,使用 `Tab` 键进行相应的补全操作。

随着你的输入,建议会以灰色显示,使其更易于识别。如果整条建议都对你的胃口,你可以**按右箭头键来完成整个命令的补全**。
### 3、命令选项的交互式手册页
这是一个炫酷的功能,你可以交互性地参考手册页完成命令选项的填写。
首先,你需要先解析手册页,这可以通过以下命令来完成:
```
fish_update_completions
```
这会对手册页进行解析。

现在,如果你输入一个命令,添加连字符作为选项,然后按下 `Tab` 键,就能看到手册页给出的可能选项及其简短描述:

你可以通过滚动一览这些选项,并在阅读了作用说明后,从弹出的分页器中进行选择。
要比直接输入 `command -h` 更便利一些对吧。
### 4、缩写优于别名
在 Fish 里,缩写的作用就如同文本扩展工具。你可以为一些常用的代码设置易于调用的缩写。
比如说,我把 `sch` 设为 `pacman -Ss` 的缩写,用以搜索软件包。
```
abbr -a sch pacman -Ss
```
于是,每次我输入 `sch` 并按空格键后,它就会被替换成 `pacman -Ss`。

你甚至可以把它写入配置文件,让其成为永久设置。
>
> ? 别名和缩写的关键区别在于,别名的工作是内部完成的,你看不到其背后真正运行的命令。而缩写不仅会展示实际的命令,而且会让它们在历史记录里也正确地出现。
>
>
>
### 5、丰富的基于 Web 的帮助
Linux 纯粹主义者常常依赖手册页来寻求命令帮助,而新一代的 Linux 用户则更多地依赖网络资源。
Fish 则结合了这两者优点,提供了详尽的“基于 Web 的帮助”功能,并且且易于使用,即便在无网络连接的情况下也同样可用,因为它是本地化存储的。
在运行 Fish Shell 时,仅需输入:
```
help
```
就可以在你的网络浏览器上打开帮助页面了。

如今,你可以随时方便地查阅这份详细的文档。
### 6、基于 Web 的配置
没错,这是另一个“基于 Web”的功能。
要改变提示符颜色或其他配置,你不必在终端里编辑配置文件,相反地,你可以运行基于 Web 的配置。
在运行 Fish Shell 时,只需输入以下命令:
```
fish_config
```
这会打开你的浏览器,并显示出配置设置。

在这里,你可以更改颜色,从现有列表中选择一个不同的提示符等等。

通过这种方式来改变配置更方便,对吗?
### 7、自动切换目录
如果你想切换到某个目录,你不需要输入 `cd` 命令。只需要键入该目录名称就行了。
例如,如果你位于主目录,并希望切换到 `Downloads` 目录,只需要输入 `Downloads`。输入过程中,它会进一步给出补全建议。

如果你正在某个特定目录中,想要跳转到一个完全不同的路径,则需要使用绝对路径。
### 8、更简洁的路径导航
如果你需要在浏览过的目录之间来回切换,没必要输入路径或使用 `cd ..` 等。只要**按 `ALT + ←` 或 `ALT + →`,分别向前和向后移动**就行了。

或者,你可以键入 `cdh` 并按回车,这会呼出一个分页器界面,你可以使用对应的数字来回到你想去的目录。

### 9、交互式历史搜索
你可以在 Fish 中交互式地搜索某个特定的历史命令。做这个的时候,就使用我们熟悉的 `CTRL+R` 就行了。
这会呼出一个类似于分页器的界面,显示一个搜索提示。输入你想要查找的命令,就能看到搜索结果:

### 10、全局变量
在 Fish Shell 中,如果你将一个变量设置为全局的,那么它将在重启 Shell 或者重启系统后仍然可用。
要设置一个全局变量,可以使用:
```
set -U my_variable 10
```
这时,`my_variable` 的值将会被设置为 10,即使系统重启后也不变。
是的,不需要将它们添加到你的 RC 或 profile 中。
### 11、隐私模式
Fish Shell 有一个隐私模式,该模式下输入的命令将不会被保存到历史记录或存储在硬盘上。
要进入隐私模式,使用命令:
```
fish -P
```

工作完成后,通过键入 `exit` 就可以退出隐私模式。
### Fish 还有更多你可以探索的
[Fish Shell](https://fishshell.com/) 提供了许多其他的用户友好特性,比如:
* 使用 `ALT+Enter` 实现简单的多行命令编辑
* 切换 Emacs(默认)/Vim 键位绑定
* 提供简洁明了的脚本编写语法
当然,你可以在其他 Shell 中通过一些努力实现大部分 Fish Shell 的特性,但默认启用这些特性可就完全是另一回事了。
Fish 可以帮助你在掌控开发环境的前提下,提高开发工作的效率。别把为 Fish Shell 编写脚本运行在 Bash 中,在多用户系统的共享环境中可能会引发 Shell 兼容性问题。
如果你喜欢这些特性,试试 Fish Shell 看看效果如何。也许你会将 Fish 设为 [你的默认 Shell](https://itsfoss.com/linux-change-default-shell/)。
即使你不想在终端里看到 “Fish”,也许你会喜欢 ASCII 水族馆 ?
>
> **[在 Linux 终端利用 Asciiquarium 打造海底世界](/article-16354-1.html)**
>
>
>
? 请在评论中分享你对 Fish Shell 的看法 ?
*(题图:DA/8522d28f-40ab-4eaa-b2b5-bc627f114224)*
---
via: <https://itsfoss.com/fish-shell-features/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Bash the most common shell. Zsh is the most popular one among developers. But Fish is the most underrated one.
I am not exaggerating. Fish indeed is an overlooked shell that could be a great fit for beginners and advanced FOSSers alike.
Fish provides a range of features that makes it an attractive choice. From syntax highlight to abbreviation (my favorite), there are numerous novelties here.
Let me share some of my favorite Fish shell features with you.
## 1. Syntax highlighting
It is better to spot errors before they get executed. This saves a lot of time, energy and frustration.
Most modern code editors have the syntax highlighting built-in. Fish has this functionality built into the shell itself and it works on Linux commands.
Incorrect commands? You see it highlighted in red. The same goes for arguments and options that do not match with the context.

## 2. Autosuggestions
The Fish shell suggests commands as you type, which you can later complete accordingly using the tab key.
The suggestions will be greyed out as you type, to make it more accessible. If the whole line of suggestion is acceptable to you, you can **press the right arrow key to complete it in full**.
## 3. Interactive man page for command options
This is a cool feature, where you will be able to complete a command's options, by taking help from the man page interactively.
First, you need to parse the man page, which can be done by running:
```
fish_update_completions
```
This will parse the man pages.

Now, if you type a command, put a hyphen for the options and then press the tab button to see the man page suggestions for the possible options with their short descriptions:
You can scroll through the options, and select after reading about its work, from the pager that appears.
This makes things a bit more easier than typing `command -h`
.
## 4. Abbreviations instead of aliases
Abbreviations in Fish are like text-expanders. Here, you will set some frequently used code to an easily accessible abbreviation.
For example, I have used `sch`
as an abbreviation for the command `pacman -Ss `
to search for packages.
```
abbr -a sch pacman -Ss
```
Now, whenever I type `sch`
and press the space button, it will be replaced with `pacman -Ss`
.
You can make it permanent by writing it to the config file.
## 5. Extensive web-based help
Linux purists rely on the man pages to get help with a command. The newer bunch of Linux users are more reliant on the web for such things.
Fish gives a mix of both with its extensive "web-based" help which is easily available on your system, even if there is no internet, since it is stored locally.
To get help, while running Fish shell, just use:
```
help
```
This will open the Help page on your web browser.
You can refer to the extensive documentation with ease now.
## 6. Web-based configuration
Yes, another 'web-based' feature.
To change the prompt color or other configurations, you don't need to edit configuration files in the terminal. Instead, you can use the web-based configuration.
Type the following command while running Fish shell:
```
fish_config
```
This will open the configuration settings on your browser.
Here, you can change the colors, set a different prompt from the already available list, etc.
Easier to make changes this way, no?
## 7. Automatic CD
If you want to move to a directory, you don't need to type the `cd`
command. Just type the directory name, that's it.
For example, if you are in your Home directory and want to move to the Downloads directory, just enter `Downloads`
. As you type, it will suggest further completion as well.
`cd`
You need to use the absolute path, if you are in a particular directory and want to go to an entirely different branch.
## 8. Easier path navigation
If you need to go back and forth between the directories you have visited, no need to type in the path or use `cd ..`
etc. Just **press ALT + Right/Left arrow, to move forward and backward**, respectively.
Alternatively, you can type `cdh`
and enter, so that a pager interface will come, where you can use the number corresponding to the directory you want to go back to.
## 9. Interactive history search
You can search for a specific command in history interactively on Fish. For this, use the good old CTRL+R.
This will open a pager like view, with a search prompt. Enter the command name that you need, and see the result:
## 10. Universal variables
In Fish shell, if you set a variable as Universal, this will be available even if the shell is restarted or even if the system is rebooted.
To make a universal variable, use:
```
set -U my_variable 10
```
The value of `my_variable`
will be saved to 10, even if the system is rebooted.
Yeah, no need to add them to your RC or profile.
## 11. Private Mode
Fish shell has a private mode where the commands you enter will not be saved to the history or stored on the disk.
To move to a private mode, use the command:
```
fish -P
```
Once you have finished your work, you can exit out of private mode by typing `exit`
.
[Install and Setup ZSH on Ubuntu LinuxWant a cool looking Linux terminal? Try Zsh. Learn how to set up Zsh on Ubuntu Linux with Oh My Zsh.](https://itsfoss.com/zsh-ubuntu/)

## There is a lot more to explore with Fish
[Fish shell](https://fishshell.com/) provides many other user-friendly features like:
- Simple Multiline command edit using ALT+Enter
- Switch between Emacs (default)/Vim keybindings
- A simple and clean syntax for scripting
Of course, you can achieve most of the Fish shell features discussed here with some efforts in other shells as well, but having them enabled by default is a different thing.
Fish could help you be a bit more productive and effective with your development work, given that you are controlling your development environment. Don't write scripts exclusively for Fish shell that others have to run in Bash. Shell compatibility issues may arise in a shared environment on a multi-user system.
If you liked the features, give Fish shell a try and see how it goes. Maybe you'll [change Fish as your default shell](https://itsfoss.com/linux-change-default-shell/).
Even if you don't want 'Fish' in your terminal, you may like (ASCII) aquarium 😉
[Using Asciiquarium for Aquarium in Linux TerminalHere’s a tiny CLI tool to add an aquarium in your Linux terminal.](https://itsfoss.com/asciiquarium/)

*💬 Please share your views on Fish shell in the comments 😄* |
16,506 | darktable 4.6 发布:提高了性能并添加了一些漂亮的新功能 | https://news.itsfoss.com/darktable-4-6-0-release/ | 2023-12-26T15:00:02 | [
"darktable"
] | https://linux.cn/article-16506-1.html | 
>
> darktable 4.6 更新看起来是一个出色的改进。
>
>
>
[darktable](https://www.darktable.org/) 是一款流行的摄影和 RAW 图片处理应用,将自己定位为 “*摄影师的虚拟光桌和暗室*”。它可以让你组织所有文件,并以非破坏性的方式提供有用的工具来增强或冲印它们。
在最近的公告中,开发人员推出了 **darktable 4.6**。让我们看看它能提供什么。
### ? darktable 4.6:有什么新变化?

作为一个新功能版本,darktable 4.6 装满了功能。但在本文中,我们将仅关注**此版本的亮点**。
我们首先介绍 darktable 的**各种性能优化**。**JPEG 2000 和黑白 TIFF 图像的导出速度**得到了提高,色差模块在仅使用 CPU 的情况下**速度提高了约 10%**。
现在,当你启动 darktable 时,**OpenCL 会立即启动**,并不断显示有关其初始化进度的消息。还引入了 **OpenCL 代码路径**,用于使用嵌入式校正元数据进行镜头校正。
**它也对新的相机提供了支持**,比如说:
* 索尼 ZV-E1
* 佳能 EOS Kiss F
* 佳能 EOS Kiss X50
* 佳能 EOS Kiss X90
* 三星 EK-GN120
* 富士 FinePix SL1000
* 宾得 K-3 Mark III Monochrome
在**暗室视图**中平移/缩放时显示的低分辨率占位符图像现在已被更高质量的图像取代。还有**自动保存功能**,在暗室中编辑图像时(每 10 秒)**自动保存编辑历史**。
最后,**sigmoid 模块现在具有新的 “主色” 部分**,可用于调整具有棘手照明条件的图像的照明。开发人员表示,这可以让你创造出令人愉悦的日落、改善肤色等等。
>
> ? 这只能与 sigmoid 的每通道模式一起使用,该模式还有一个 “*smooth*” 预设以简化操作。
>
>
>
#### ?️ 其他更改和改进
至于其余的,还有一些其他值得注意的变化:
* 导入 AVIF/HEIF 图像时支持**自动方向**。
* 你现在可以对非 RAW 文件使用**高亮显示重建模块**。
* **AVIF 导出**已更改,无损模式不再使用 YUV 转换。
* PNG 文件现在尽可能包含 [CICP](https://en.wikipedia.org/wiki/Coding-independent_code_points) 编码的颜色配置文件以及 ICC。
* 你现在可以使用 LUT 3D 模块选择线性 [ProPhoto RGB 色彩空间](https://en.wikipedia.org/wiki/ProPhoto_RGB_color_space)。
阅读官方 [发行说明](https://github.com/darktable-org/darktable/releases/tag/release-4.6.0) 以了解有关此版本的更多信息。
### ? 下载 darktable 4.6
darktable 4.6 适用于 **Linux**、**Windows** 和 **macOS**。
你可以从 [Flathub 商店](https://flathub.org/apps/org.darktable.Darktable) 下载最新版本,也可以访问其 [GitHub 仓库](https://github.com/darktable-org/darktable) 和 [官方网站](https://www.darktable.org/) 获取替代软件包。
>
> **[darktable(Flathub)](https://flathub.org/apps/org.darktable.Darktable)**
>
>
>
对于现有用户,他们可以从 4.4 版本进行更新而不会丢失所做的编辑,开发人员建议提前进行备份。你可以浏览 [官方文档](https://www.darktable.org/resources/) 了解更多信息。
我们还有一个 [在 Ubuntu 中安装最新的 darktable 的方便指南](https://itsfoss.com/install-darktable-ubuntu/)。
? 你对 darktable 4.6.0 的发布有何看法? 或者你更喜欢其他编辑器?
*(题图:DA/1600c099-3f36-4682-a258-b7c2086f2228)*
---
via: <https://news.itsfoss.com/darktable-4-6-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[darktable](https://www.darktable.org/?ref=news.itsfoss.com) is a popular photography and raw developing app that markets itself as a “*virtual light table and darkroom for photographers*”. It lets you organize all your files, with useful tools to enhance or develop them in a non-destructive manner.
With a recent announcement, the developers have introduced the **darktable 4.6 **release. Let's see what it has to offer.
## 🆕 darktable 4.6: What's New?
Pitched as a new feature release, darktable 4.6 comes packed with features. But with this article, we will only focus on **the highlights of this release**.
We start with** various performance optimizations** for darktable; the **export speed for JPEG 2000 and B&W TIFF images** has been improved, the** **chromatic aberrations module is now **approximately 10% faster** when using only the CPU.
Now, when you launch darktable, **OpenCL starts up immediately**, with constant messages being shown about the progress of its initialization. A **OpenCL code path** has also been introduced for lens correction using embedded correction metadata.
There is **support for new cameras **too, here are some highlights:
**Sony ZV-E1****Canon EOS Kiss F****Canon EOS Kiss X50****Canon EOS Kiss X90****Samsung EK-GN120****Fujifilm FinePix SL1000****Pentax K-3 Mark III Monochrome**
The low-resolution placeholder image shown while panning/zooming in the **darkroom view** is now replaced by a higher quality image. There is also **an auto-save functionality** that **automatically saves the editing history **(every 10 seconds) when editing images in the darkroom.
And finally, the **sigmoid module now features a new “ primaries” section** that can be used to tweak the lighting of an image with tricky lighting conditions. The developers say that this allows you to create pleasing sunsets, improved skin tones, and more.
*” preset to make things easier.*
*smooth*### 🛠️ Other Changes and Improvements
As for the rest, here are some other notable changes:
- Support for
**auto-orientation**when importing AVIF/HEIF images. - You can now use the
**highlight reconstruction module**for non-raw files. **AVIF exporting**has been changed, YUV conversion is no longer used for lossless.- PNG files now include a
[CICP](https://en.wikipedia.org/wiki/Coding-independent_code_points?ref=news.itsfoss.com)encoded color profile alongside ICC when possible. - You can now select the linear
[ProPhoto RGB color space](https://en.wikipedia.org/wiki/ProPhoto_RGB_color_space?ref=news.itsfoss.com)with the LUT 3D module.
Read the official [release notes](https://github.com/darktable-org/darktable/releases/tag/release-4.6.0?ref=news.itsfoss.com) to find out more about this release.
## 📥 Download darktable 4.6
darktable 4.6 is available for **Linux**, **Windows**, and **macOS**.
You can download the latest release from the [Flathub store](https://flathub.org/apps/org.darktable.Darktable?ref=news.itsfoss.com), or you could visit its [GitHub repo](https://github.com/darktable-org/darktable?ref=news.itsfoss.com) and [official website](https://www.darktable.org/?ref=news.itsfoss.com) for alternative packages.
For existing users, they can update from the 4.4 release without losing their edits, and the developers suggest taking a backup beforehand. You can go through the [official documentation](https://www.darktable.org/resources/?ref=news.itsfoss.com) for more information.
We also have a handy installation guide for [installing the latest darktable in Ubuntu](https://itsfoss.com/install-darktable-ubuntu/?ref=news.itsfoss.com):
[How to Install the Latest Darktable in Ubuntu LinuxAdobe products are not available on Ubuntu. However, you can opt for Adobe alternative tools in Linux. They may not be the exact replacement for your favorite Adobe tool, but they serve the purpose. For example, you can use Darktable instead of Adobe Lightroom. Darktable is a free and open](https://itsfoss.com/install-darktable-ubuntu/?ref=news.itsfoss.com)

*💬 What do you think of the darktable 4.6.0 release? Or do you prefer other editors?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,507 | 微软 Visual Basic 之兴衰 | https://devclass.com/2023/03/20/microsofts-visual-basic-why-it-won-and-why-it-had-to-die/ | 2023-12-26T16:01:00 | [
"Visual Basic",
"VB"
] | https://linux.cn/article-16507-1.html | 
根据 Retool 的设计总监 Ryan Lucas 所写的新 [历史文章](https://retool.com/visual-basic),开发微软的 Visual Basic(VB)的 Alan Cooper 最初将其设想为一个“外壳构造工具包”。那是在 1987 年,当时 Windows 正在赢得越来越多的用户,但为这个操作系统编写应用却困难重重。它的原型被命名为 Tripod,能够将按钮和列表框这样的对象拖放到设计界面上。
Lucas 的文章提到,随着时间的推移,这些设计对象的命名从 “waldos” 变到 “gizmos”,又改为“controls”。
当这个项目被微软 CEO 比尔·盖茨评审时,他决定将其与即将发布的 Windows 3.0 捆绑出售。然而这未能实现,原因不太清楚,可能是对于 OS/2 的政策争论(据说 OS/2 有望取代 Windows),或者是与开发 Windows 的团队产生的冲突。
实际上,这个当时开发代号被称为 Thunder 的项目,变成了一个商业语言项目,并在 1991 年作为 BASIC 的一个版本发布。文章里记载:“最终产品让 Cooper 感到震惊,因为他非常厌恶 BASIC。”
尽管如此,这个项目标志着一个广受欢迎的编程模型的诞生,VB 对 Windows 甚至整个软件开发行业影响深远。Lucas 写道:“到 1998 年 Visual Basic 6.0 发布的时候,其地位无人能敌:所有 Windows 上进行的商业应用程序编程中有三分之二都是用 Visual Basic 完成的。全盛时期,全球近有 350 万的 VB 开发者,是 C++ 程序员的十倍还多。”
Lucas 对 Alan Cooper 及原微软 VB 团队的 Micheal Geary 进行了访谈,并把这个历史整理的过程描述为一份“[出于热爱的努力](https://twitter.com/ryanlucas/status/1636408576473452544)”。他进一步指出:“我觉得当我们失去 Visual Basic 的同时,我们也失落了一些东西。在许多方面,过去的 25 年我们一直在追逐它做对的那些理念。”

据 Lucas 透露,微软在 2002 年发布 [VB.NET](http://vb.net/) 的时候,犯下了一个“非强迫性错误”。虽然语言看起来很像,但没有迁移的路径,新的 .NET 功能,如完全面向对象并不是 VB 开发者们想要的。使用率开始下降,到今天,[VB.NET](http://vb.net/) 在 .NET 编程中的地位已经落后于占主导地位的 C#。此外,微软已经失去了其在商业应用开发中的地位,.NET 只不过是诸多热门技术之一。
然而,实际上,在 .NET 推出的时候,VB 已经开始衰退。它编程的便捷性在大型且复杂的应用中开始崩解,开发者不得不痛苦地学习像“[公寓线程](https://learn.microsoft.com/en-us/windows/win32/com/processes--threads--and-apartments)”这样的奇特的 COM 概念。VB 应用还必须通过直接调用 Windows API 来增强,有许多奇怪的语言特点,即使是 Bruce Mckinney 在他的《Hardcore Visual Basic》这本书的最后一章也叫它《抄起你的斧头》。
最后,一些 VB 开发者在 1990 年代末期发现,Borland 公司的一款名叫 Delphi 的工具在几乎所有方面都优于 VB:更强大,运行速度更快,编译出来的原生代码应用程序更易于部署。Delphi 的表单设计师是受 VB 影响的,并且它的发明者 Anders Hejlsberg 后来加入了微软,创建了 C# 以及后来的 TypeScript。
微软尽力让 VB 可用,确保其运行环境到今日仍被支持,并持续让 Office 中的宏语言使用它。而 .NET 平台在应对 Java 的挑战方面比 VB 更好,甚至最终以 .NET Core 的形式成为了跨平台解决方案。
但这些并没有动摇 VB 的卓越和影响力。微软仍努力追寻着 VB 对于现称为 “群众开发者” 的人群所展现出的简洁与高效,尽管有很多尝试,一直难以复制成功。你也可以在 [这里](https://www.theregister.com/2017/02/02/our_strategy_for_visual_basic_has_shifted_microsoft_to_focus_on_core_scenarios/) 找到 [更多](https://www.theregister.com/2014/12/10/hey_dont_forget_visual_basic_says_microsoft_open_source_and_new_features_coming/) 关于 VB 的命运和缓慢死亡的信息。
*(题图:DA/7f8b8625-f569-418b-b06d-9437435473fd)*
---
via: <https://devclass.com/2023/03/20/microsofts-visual-basic-why-it-won-and-why-it-had-to-die/>
作者:[Tim Anderson](https://devclass.com/author/tanderson/) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | 
Developer Alan Cooper conceived Microsoft’s Visual Basic (VB) as a “shell construction kit,” according to a new history written by Retool head of design Ryan Lucas. This was in 1987, when Windows was winning users but writing applications for the operating system was hard. The prototype was called Tripod, and allowed drag and drop of objects like buttons and listboxes onto a design surface.
According to [the post](https://retool.com/visual-basic) by Lucas, the naming of these design objects changed over time, from “waldos” to “gizmos” to “controls.”
The project was shown to Microsoft CEO Bill Gates, who agreed to bundle it with the upcoming Windows 3.0. This did not happen though, for reasons that are not clear but might include politics over OS/2, which was supposedly going to replace Windows, or conflict with the team building Windows itself.
Instead, the project which was then codenamed Thunder, became a Business Language project and was shipped in 1991 as a version of BASIC. “The final product horrified Cooper, who loathed BASIC,” Lucas writes.
Nevertheless, it was the beginning of a programming model that became hugely popular, and the significance of VB both for Windows and for software development in general is hard to overstate. Lucas writes: “By the time Visual Basic 6.0 was released in 1998, its dominance was absolute: two-thirds of all business application programming on Windows PCs was done in Visual Basic. At its peak, Visual Basic had nearly 3.5 million developers worldwide, more than ten times the number of C++ programmers.”
Lucas interviewed Alan Cooper, as well as Micheal Geary from the original Microsoft VB team, and [describes](https://twitter.com/ryanlucas/status/1636408576473452544) assembling the history as a “labor-of-love project.” He adds: “I think we lost something when we lost Visual Basic. In many ways, we’ve spent the last 25 years chasing the ideas that it got pretty right.”
According to Lucas, Microsoft made an “unforced error” when it released VB.NET in 2002. Although the language was similar, there was no migration path, and new .NET features such as full object orientation were not wanted by VB developers. Usage dropped, and today VB.NET is a poor cousin to C#, which dominates .NET programming. Further, Microsoft has lost its hold over business application development, with .NET just one of many popular approaches.
The reality though is that by the time .NET was released, VB was already losing ground. Its ease of programming fell apart in large, complex applications, and developers had to trouble themselves with arcane COM concepts like [apartment threading](https://learn.microsoft.com/en-us/windows/win32/com/processes--threads--and-apartments). VB applications also had to be supplemented by direct calls to the Windows API, and the language had many oddities, such that author Bruce Mckinney called the last chapter of his book Hardcore Visual Basic: “Bring your Hatchet.”
Some VB developers had also discovered, in the late 1990s, that a Borland tool called Delphi was superior to VB in almost every way: more powerful, faster, and compiling native code applications that were easier to deploy. Delphi’s form designer was influenced by VB, and its inventor, Anders Hejlsberg, moved on to Microsoft where he created both C# and later, TypeScript.
Microsoft did the best it could with VB, ensuring that the runtime is still supported today, and continuing to use it as the macro language in Office. The .NET platform served the company better than VB as an answer to Java, eventually even becoming a cross-platform solution in the guise of .NET Core.
None of that takes away from the excellence and influence of VB. It is also true that Microsoft has struggled to recapture the simplicity and productivity of the original VB for what it now calls citizen developers, despite many attempts. You can find more on the fate and slow death of Visual Basic [here](https://www.theregister.com/2017/02/02/our_strategy_for_visual_basic_has_shifted_microsoft_to_focus_on_core_scenarios/) and earlier [here](https://www.theregister.com/2014/12/10/hey_dont_forget_visual_basic_says_microsoft_open_source_and_new_features_coming/), over on *The Register*.
[Ruby on Rails 8.0 first beta release: A big bet on SQLite in production ](https://devclass.com/2024/10/09/ruby-on-rails-8-0-first-beta-release-a-big-bet-on-sqlite-in-production/)
[OpenAI previews major update to ChatGPT visual interface for writing and coding](https://devclass.com/2024/10/07/openai-previews-major-update-to-chatgpt-visual-interface-for-writing-and-coding/)
[Python 3.13 delayed by 'drastic change' removal of incremental garbage collector](https://devclass.com/2024/10/04/python-3-13-delayed-by-drastic-change-removal-of-incremental-garbage-collector/)
[Why Windows 11 24H2 is a big yawn for developers](https://devclass.com/2024/10/03/why-windows-11-24h2-is-a-big-yawn-for-developers/)
[The SQLite team is preparing an efficient remote replication tool](https://devclass.com/2024/10/02/the-sqlite-team-is-preparing-an-efficient-remote-replication-tool/)
[Harness previews Cloud Development Environments, AI assistants, turns to Google for AI DevOps](https://devclass.com/2024/09/27/harness-previews-cloud-development-environments-and-ai-assistants-turns-to-google-for-ai-devops/)
[Survey: Ruby on Rails devs happy to go their own way, now prefer Stimulus.js over React](https://devclass.com/2024/09/25/survey-ruby-on-rails-devs-happy-to-go-their-own-way-now-prefer-stimulus-js-over-react/)
[GitHub adds Microsoft Azure-based EU data residency to Enterprise Cloud](https://devclass.com/2024/09/25/github-adds-microsoft-azure-based-eu-data-residency-to-enterprise-cloud/)
[Deno version 2.0 is nearly done – but after over 4 years, the project's big bets have yet to pay off](https://devclass.com/2024/09/23/deno-version-2-0-is-nearly-done-but-after-over-4-years-the-projects-big-bets-have-yet-to-pay-off/)
[Pulumi releases security management product, touts benefits of IaC using general-purpose programming...](https://devclass.com/2024/09/20/pulumi-releases-security-management-product-touts-benefits-of-iac-using-general-purpose-programming-languages/)
[Apple releases Swift 6 with improved concurrency, testing, cross-platform support – enough to lift i...](https://devclass.com/2024/09/19/apple-releases-swift-6-with-improved-concurrency-testing-cross-platform-support-enough-to-lift-it-out-of-its-niche/)
[RustConf speakers affirm Rust for Linux project despite challenges of unstable Rust, maintainer resi...](https://devclass.com/2024/09/18/rustconf-speakers-affirm-rust-for-linux-project-despite-challenges-of-unstable-rust-maintainer-resignation/) |
16,509 | Svelte:TypeScript 并“不值得”用来开发库 | https://devclass.com/2023/05/11/typescript-is-not-worth-it-for-developing-libraries-says-svelte-author-as-team-switches-to-javascript-and-jsdoc/ | 2023-12-26T23:49:31 | [
"TypeScript",
"JavaScript"
] | https://linux.cn/article-16509-1.html | 
TypeScript 的使用率在不断上升,Svelte 的开发者 Rich Harris 解释了为什么反其道而行,从 TypeScript 切换到 JavaScript 和 JSDoc。
Svelte 的一个将 TypeScript 转为 JSDoc 的[拉取请求](https://github.com/sveltejs/svelte/pull/8569)引起了一些困惑的评论。评论中有人说:“这个改变是出于什么原因呢?我在到处寻找这个问题或相关讨论,但我没有找到。” 随后,这个问题在 GitHub 上因“讨论过于激烈”而被锁定回复。
在上个月的一次 Svelte Society [采访](https://youtu.be/MJHO6FSioPI)中,Harris 提供了进一步的背景信息,他说:“我们决定要做的一件事就是在 Svelte 核心代码库中脱离 TypeScript,转向使用 JavaScript。这里有一些细微的复杂性我未曾充分解释。”
他持有的观点是:“类型是非常好的,但是 TypeScript 确实有些困扰…… 当你开始使用 .ts 文件后,你就必须有相应的工具来支持…… 当你使用像 TypeScript 这样的非标准语言时,你会遇到很多阻碍,我已经开始认识到这并不值得。因此,我们将我们所有的类型都放入了 JSDoc 注解中,我们也能获得所有的类型安全性,但没有任何的缺点,因为它就是 JavaScript,所有的东西都在注解中,你可以直接运行代码。这就是我们在 Sveltekit 代码库中所做的,它在 Svelte 4.0 中表现得非常好,所以我们决定对 Svelte 同样采取这种方式,因为这将让我们能够更快速地前进。”
虽然 Svelte/SvelteKit 并非最受欢迎的 JavaScript 框架,但它却是广受好评的框架之一。
开发者倾向于使用 TypeScript,主要因为他们发现强类型降低了错误的发生率,并提升了编码过程中的体验,如代码自动补全和即时帮助等功能。然而,令人惊讶的是,主要做为 API 文档工具的 [JSDoc](https://github.com/jsdoc/jsdoc),也可以进行类型检查。这项功能已直接内置在 Visual Studio Code 中,如 [这篇文档](https://code.visualstudio.com/docs/nodejs/working-with-javascript#_type-checking-javascript) 所述。开发者只需在 JavaScript 文件顶部加上:
```
// @ts-check
```
正如文档中的解释,“当无法推断出类型时,可以利用 JSDoc 注解进行明确说明”。这个特性实际上是由 TypeScript 提供支持,这意味着在实际环境下,TypeScript 和 JSDoc 是相辅相成的。
不过,一个易被忽视的细节是,Harris 主要是在针对库开发的上下文里关注 TypeScript。他认为切换到 JSDoc 在开发应用时,“可能收益不大”,他说道:“如果你在开发一个应用,无论怎样你都不可避免地需要一个构建步骤。你需要优化代码,需要代码压缩,需要打包各种资源。而如果你在构建一个库,我将极力推荐你使用 JSDoc。”
Harris 在 Hacker News 进一步 [补充](https://news.ycombinator.com/item?id=35892250),“Svelte 的用户无需担心,这个变动不会影响到你与 Svelte 使用 TypeScript 的能力——从 Svelte 导出的函数仍然会有所有熟悉的 TypeScript 好处,如类型检查,智能感知,内联文档等”。他坚定地表示:“我们对 TypeScript 的承诺比以往任何时候都更为坚决。”
*(题图:DA/e20ff1ee-6388-42ce-8d82-66bc6eebf63c)*
---
via: <https://devclass.com/2023/05/11/typescript-is-not-worth-it-for-developing-libraries-says-svelte-author-as-team-switches-to-javascript-and-jsdoc/>
作者:[Tim Anderson](https://devclass.com/author/tanderson/) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | 
Svelte creator Rich Harris has made the case for switching from TypeScript to JavaScript and JSDoc, countering a trend that has seen strong growth in TypeScript usage.
A [pull request](https://github.com/sveltejs/svelte/pull/8569) for TS to JSDoc conversion attracted some puzzled comments. “Why is this change being made? I was looking around for an issue or discussion around this but I couldn’t find anything,” said one, before the issue was locked on GitHub as “too heated.”
There is further background in this [Svelte Society interview](https://youtu.be/MJHO6FSioPI) last month where Harris said: “One of the things that we’ve decided to do is migrate away from TypeScript in the Svelte core codebase, and use JavaScript instead. There’s some nuance there that I failed to adequately communicate.”
“My position is, types are fantastic, TypeScript is a bit of a pain … as soon as you use a .ts file, then you have to have the tooling to support that … there’s all of these points of friction when you use a non-standard language like TypeScript that I have come to believe makes it not worth it. So instead, we have put all our types in JSDoc annotations, and we get all of the type safety, but none of the drawbacks, because it is just JavaScript, everything is in comments, you can just run the code. This is what we do in the Sveltekit codebase and it has worked out fantastically so for Svelte 4.0, we’re going to do the same for Svelte because it’s going to enable us to move much more quickly.”
Svelte/SvelteKit is not the most popular JavaScript framework but it is one of the most admired.
Developers have embraced TypeScript because they find that strong typing reduces errors, as well as improving the developer experience in code editors with features like code completion and pop-help. However, [JSDoc](https://github.com/jsdoc/jsdoc), which is primarily an API documentation tool, can also be used for type checking. Support for this is built into Visual Studio Code as documented [here](https://code.visualstudio.com/docs/nodejs/working-with-javascript#_type-checking-javascript). Developers simply add:
`// @ts-check`
to the top of a JavaScript file. “When types cannot be inferred, they can be specified using JSDoc comments,” the documentation explains. This feature is actually powered by TypeScript, meaning that in reality TypeScript and JSDoc are working side by side.
One of the nuances that can easily be missed, though, is that Harris is mainly concerned about TypeScript in the context of library development. The switch to JSDoc is “less beneficial if you’re building an app because if you’re building an app, you’re going to have a build step anyway. You want to optimize your code, you want to minify it, you want to bundle everything up. If you’re building a library that is when I really strongly urge to use JSDoc instead.”
Harris [added on Hacker News](https://news.ycombinator.com/item?id=35892250) that “as a user of Svelte, this won’t affect your ability to use TypeScript with Svelte at all — functions exported from Svelte will still have all the same benefits of TypeScript that you’re used to (typechecking, intellisense, inline documentation etc). Our commitment to TypeScript is stronger than ever.”
[Ruby on Rails 8.0 first beta release: A big bet on SQLite in production ](https://devclass.com/2024/10/09/ruby-on-rails-8-0-first-beta-release-a-big-bet-on-sqlite-in-production/)
[OpenAI previews major update to ChatGPT visual interface for writing and coding](https://devclass.com/2024/10/07/openai-previews-major-update-to-chatgpt-visual-interface-for-writing-and-coding/)
[Python 3.13 delayed by 'drastic change' removal of incremental garbage collector](https://devclass.com/2024/10/04/python-3-13-delayed-by-drastic-change-removal-of-incremental-garbage-collector/)
[Why Windows 11 24H2 is a big yawn for developers](https://devclass.com/2024/10/03/why-windows-11-24h2-is-a-big-yawn-for-developers/)
[The SQLite team is preparing an efficient remote replication tool](https://devclass.com/2024/10/02/the-sqlite-team-is-preparing-an-efficient-remote-replication-tool/)
[Harness previews Cloud Development Environments, AI assistants, turns to Google for AI DevOps](https://devclass.com/2024/09/27/harness-previews-cloud-development-environments-and-ai-assistants-turns-to-google-for-ai-devops/)
[Survey: Ruby on Rails devs happy to go their own way, now prefer Stimulus.js over React](https://devclass.com/2024/09/25/survey-ruby-on-rails-devs-happy-to-go-their-own-way-now-prefer-stimulus-js-over-react/)
[GitHub adds Microsoft Azure-based EU data residency to Enterprise Cloud](https://devclass.com/2024/09/25/github-adds-microsoft-azure-based-eu-data-residency-to-enterprise-cloud/)
[Deno version 2.0 is nearly done – but after over 4 years, the project's big bets have yet to pay off](https://devclass.com/2024/09/23/deno-version-2-0-is-nearly-done-but-after-over-4-years-the-projects-big-bets-have-yet-to-pay-off/)
[Pulumi releases security management product, touts benefits of IaC using general-purpose programming...](https://devclass.com/2024/09/20/pulumi-releases-security-management-product-touts-benefits-of-iac-using-general-purpose-programming-languages/)
[Apple releases Swift 6 with improved concurrency, testing, cross-platform support – enough to lift i...](https://devclass.com/2024/09/19/apple-releases-swift-6-with-improved-concurrency-testing-cross-platform-support-enough-to-lift-it-out-of-its-niche/)
[RustConf speakers affirm Rust for Linux project despite challenges of unstable Rust, maintainer resi...](https://devclass.com/2024/09/18/rustconf-speakers-affirm-rust-for-linux-project-despite-challenges-of-unstable-rust-maintainer-resignation/) |
16,515 | Wayland 真的毁掉一切了吗? | https://pointieststick.com/2023/12/26/does-wayland-really-break-everything/ | 2023-12-29T14:54:00 | [
"Wayland",
"X11"
] | https://linux.cn/article-16515-1.html | 
“[Wayland 毁掉一切!](/article-16520-1.html)”有些人已经看过了这篇 Probonopd 批评 Wayland 的略有名气的文章。Probonopd 是 AppImage 开发者的核心者之一,他批评 Wayland 并非 X11 的直接替代品。他在 GitHub 上创建了一个 [新的仓库](https://github.com/probonopd/wayland-x11-compat-protocols/),再次吸引了公众的目光,他希望为目前 Wayland 原生应用无法使用的功能创建协议。而这些功能是 Wayland 标准协议有意缺失的,但缺乏标准化意味着它们无法成为应用开发者可信赖的平台组成部分。
尽管开发者圈子里有人对此一笑置之,乃至嘲笑,但对于普通人来说,“Wayland 毁掉一切!”这句指责可能戳中要害,或者至少看起来有几分道理。因为从某种角度,Probonopd 是对的:Wayland 确实破坏了所有直接依赖 X11 功能的事物!
只是这种角度是错误的。
试想,如果我说:“Linux 让 Photoshop 无法工作,你还是应该坚持使用 Windows!”你该如何回应呢?你可能会说:“等等,问题的关键是 Photoshop 不支持 Linux!”你说得对,这是一个微妙且重要的区别,它将责任放在了正确的位置。因为即使是 Linux,也无法“不破坏” Photoshop;相反,Adobe 需要为其产品进行移植,只不过他们还没有做罢了。
对于 X11 和 Wayland,情况也同样适用。Wayland 并不是为了取代 X11 而设计的,就像 Linux 不是为了取代 Windows 而设计的一样。当我们从一个操作系统转到另一个时,有必要调整我们的期望,认清可能需要的改变。
尽管 Wayland 并非设计为 X11 的直接替代品,但它最终肯定会取代 X11。但这意味着它从一开始就打算比 X11 做得更少,而这是正确的。
### X11 是个糟糕的平台
在那些古老的日子里,X11 是个完整的开发平台。以 X11 为目标的应用程序可以使用 X11,通过内建的小部件工具包来进行 UI 绘制;借助自带的打印服务器打印文件;进行屏幕录屏;设定全局快捷键等等。这一切都远在我接触技术之前,但我感觉到,X11 要么是在最初就被设定为面向应用开发者的开发平台,要么在早期阶段迅速演变成了这样一个平台。
然而,情况并没有如预期那样发展。即使是以当时的标准而言,其内置的 UI 工具包看起来也很丑陋。那些请求同一资源的应用可能会互相冲突,破坏彼此的功能,除非卸载其中一个应用程序,否则根本无法修复。像打印这样的特性渐渐没落,因为将这样的功能放在窗口管理器里就是个错误,而后续的维护者也缺少必要的专业知识或兴趣去维护它。诸如此类,不一而足。
像 Qt 和 GTK 这样的 UI 工具包迅速崛起,以更适合用户和便于应用开发者定位的方式,接管了大多数此类应用平台程序的中间件职能。我们这里说的是九十年代中期,那已是相当久远的时代了。
*(当然,这样说可能有些不公平;人们抱怨 Wayland 缺少的其实并不是打印服务器。实际上,更多的是关于应用能否设置自定义窗口图标,以及移动自身的窗口。这些都是非常困难的情况;Wayland 上没有这些功能,理由就是这些功能在 X11 中被滥用,导致了难以解决的问题。要将这些功能移植到 Wayland 并非易事,涉及很多的权衡决定。)*
### Linux 并非一个平台
然而,UI 工具包的兴起无疑导致了应用程序的格局变得支离破碎。现在,FOSS 应用程序开发者不再为一个目标(X11)进行开发,而是为 Qt、GTK 或其他工具进行开发,从而我们看到了了大量的“KDE 应用” 和 “GNOME 应用”。是的,这些应用可能在其他平台里也能运行,但很明显,它们是在哪个平台和工具包上开发的,在哪个平台和工具包上运行效果最好。在其他平台运行时,它们可能看起来感觉很奇怪,或者某些功能可能不好用或根本无法使用。
这就是我们今天的现状。没有人会专门去编写一个 “X11 应用”;他们的应用可能会采用 X11 的某些特性,但这只是因为没有更好的替代方案,而实际上,在应用的 99.9% 的功能实现中,他们会选择 Qt、GTK、KDE Frameworks 或者其他相似工具。
这给我们带来了一个潜在的棘手问题: Linux 也不是一个真正的平台,在成为一个平台方面它并不比 X11 更成功。因为几乎没人会专门编写一个“Linux 应用”;直接调用原始的 Linux 内核系统通常是没必要的,因为无论你使用的是什么 UI 工具包,都会封装这些功能,并且将其抽象到工具包所支持的所有各种平台上。这样一来,工具包就能确保这些功能在 Linux 平台也都能顺利工作。
### 真正的平台
那么,对于跨桌面的互操作性而言,所有希望都已经破灭了吗?不,实际上现在的前景比以往任何时候都要美好!因为如今事实上出现了一个新兴的平台;如果你需要,它可以将各种应用工具包都抽象化。我说的是 Portals、PipeWire,以及 Wayland 协议。
Probonopd 认为这些都是附加组件,不应该在系统上运行,但我认为他的这种观点并不站得住脚。提供全面功能的单体窗口服务器模式在几十年前就被证明是失败的。取而代之的是库和 API,每个 FOSS 开发者都可以合理预期在现代系统运行这些。
门户系统提供了一种标准化的方法,用于展示平台原生的打开或保存对话框、发送通知、以其他应用打开文档、打印文档、拍摄截图、录制屏幕、处理拖放操作、查看用户当前主题是亮色还是暗色,等等。在很多功能的实现上,门户系统都倚赖于 PipeWire,因此你可以预期 PipeWire 也会被安装。同时,你也可以期待大部分 Wayland 合成器 — 尤其是两个最重要的合成器 KWin 和 Mutter — 支持几乎所有公开标准化的 Wayland 协议。
我认为这就是平台:Portals + Wayland + PipeWire。很明显,并没有一个好记的名字来囊括这一切。? 或许我们可以叫它 PW<sup> 2</sup>。不过,如果你的应用程序以这些平台为目标,那么它几乎可以在所有现代 Linux 系统上运行。并且,Qt 和 GTK 这两个大型的 FOSS 工具包都为此提供了全面的支持。所以,使用你喜欢的任何 UI 工具包都可。
### 为何是现在?
我们最近听到越来越多关于这个话题的讨论,因为这个转型正在加速发展。X11 的维护者已经宣布终止对其的维护,而 Plasma 则开始默认采用 Wayland,GNOME 也是如此。Fedora 甚至完全放弃了对 X11 的支持。
我们现在正处于这样一个阶段,那些以前从未考虑过这个问题的人开始思考,并意识到他们的特定使用场景所需的所有组件都还没有到位。可这其实是好事!他们的意见被听取了,变化就有可能发生。我希望这一切能早点发生,但我们也要承认现实,我们还在路上,最近围绕远程控制、色彩管理、绘图板以及窗口布局等方面的提案和工作非常频繁。可能会有一个尴尬的阶段在等我们,直到所有需要的部分都到位。对于那些由于关键遗漏而备受困扰的人,我建议他们继续使用 X11,直至问题解决。没人会去阻止你(嗯,除了 Fedora,所以如果你确实无法适应,那就不要用 Fedora ?)。探索新事物应该是充满乐趣的,如果不是这样,那就转换一个角度再尝试吧。
### 结语
在这个语境下,“毁掉一切”或许可以更准确地表达为“还没完全移植所有事物”。这种移植是必要的,因为 Wayland 设计的目标聚焦于未来,而未来并不完全兼容我们过去所做的一切,因为事实证明,其中很多东西已经没有意义了。对于那些有意义的东西,我们已经提供了一个兼容层(XWayland),同时,任何需要深度系统集成的部分,一般都有一个解决的路径(如 Portal、Wayland 协议以及 PipeWire)或者正在积极的研发中。整个世界,都在发生变化!
*(题图:DA/d5a50347-47e0-472f-833b-58203196a743)*
---
via: <https://pointieststick.com/2023/12/26/does-wayland-really-break-everything/>
作者:[Nate Graham](https://pointieststick.com/contact/) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | I’ve written some [other posts](https://pointieststick.com/2023/09/17/so-lets-talk-about-this-wayland-thing/) on Wayland recently, and it’s time for another one! Feel free to skip it it you aren’t interested in a discussion of Wayland and platforms.
Many may be familiar with the now semi-famous [“Wayland breaks everything!”](https://gist.github.com/probonopd/9feb7c20257af5dd915e3a9f2d1f2277) document written by Probonopd–one of the core AppImage developers–panning Wayland because it isn’t a drop-in replacement for X11. And he’s in the news again for [a new Github repo](https://github.com/probonopd/wayland-x11-compat-protocols/) with the aspiration of creating protocols for functionality not currently available to Wayland-native apps that are intentionally missing in Wayland’s standardized protocols–which won’t work because lacking standardization means they won’t become a part of the platform that app developers can reliably target.
There’s a bit of chuckling and jeering over this in developer circles, but to regular people, the whole “Wayland breaks everything” charge might ring true, or at least seem like it contains a kernel of truth. Because from a certain perspective, he’s right: Wayland really does break everything that directly uses X11 functionality!
It’s just that this is the wrong perspective.
Look, if I said, “Linux breaks Photoshop; you should keep using Windows!” I know how you’d respond, right? You’d say “Wait a minute, the problem is that Photoshop doesn’t support Linux!” And you’d be right. It’s a subtle but important difference that puts the responsibility in the right place. Because there’s nothing Linux can do to ‘un-break’ Photoshop; Adobe needs to port their software, and they simply haven’t done so yet.
And it’s much the same with X11 and Wayland. Wayland wasn’t designed to be a drop-in replacement for X11 any more than Linux was designed to replace Windows. Expectations need to be adjusted to reflect the fact that some changes might be required when transitioning from one to the other.
Now, even though Wayland wasn’t designed to be a *drop-in* replacement for X11, it was certainly intended to *eventually* replace it. But this implies that it was intended from the start to do *less* than X11, and and that would be correct.
## X11 was a bad platform
In ye olden days, X11 was a whole development platform. Your app that targeted X11 could use X11 to draw its UI with a built-in widget toolkit; print documents with an included print server; record the screen; set global keyboard shortcuts; and so on. This is all way before my time, but I get the sense that X11 was either originally envisioned to be a development platform for app developers, or else quickly morphed into one during its early days.
It didn’t work out. The built-in UI toolkit looked horrendous, even for the standards of the time. Apps that requested the same resources could stomp on one another and break each others’ functionality in ways that were impossible to fix short of uninstalling one of the apps. Features like printing withered because a window manager was really the wrong place to put that functionality and its later maintainers lacked the needed expertise or interest to maintain it. And so on.
UI toolkits like Qt and GTK quickly rose up to take over most of this sort of app platform middleware in a way that worked much better for users and was easier to target for app developers. We’re talking about the mid 90s here; it was a long time ago.
(Of course this is slightly unfair; lacking a print server isn’t what people complain about being missing from Wayland. It’s more like things like apps able to set custom window icons and move their own windows. These are the really hard cases; they aren’t present on Wayland because they were commonly abused by apps on X11 to cause unsolvable problems. It’s not an easy thing and there are trade-offs involved in bringing them to Wayland.)
## Linux isn’t a platform
Anyway, the rise of UI toolkits necessarily fragmented the app landscape. Instead of developing for one target (X11), a FOSS app developer now developed for Qt, or GTK, or whatever, so we ended up with a lot of “KDE apps” and “GNOME apps.” Yes, these apps still probably worked elsewhere, but it was obvious what platform and toolkit they been developed to work best in. They might look and feel weird when run elsewhere, or certain features might not work well or at all.
And that’s where we remain today. Absolutely nobody writes an “X11 app”; their app may use functionality in X11 for something that there’s no better way to do, but the app will use Qt, GTK, KDE Frameworks, or whatever for 99.9% of its functionality.
It brings us to a potentially thorny topic: Linux isn’t really a platform either, any more than X11 succeeded at being one. Almost nobody writes a “Linux app”; making raw Linux kernel system calls is generally unnecessary because whatever UI toolkit you’re using wraps this functionality and abstracts it to all the different platforms that the toolkit supports. The toolkit ensures that it just happens to work on Linux too.
## The real platform
So is all hope lost for cross-desktop interoperability? No. In fact prospects are better than they have been in a long time! Because today there is in fact an emerging platform; something that abstracts away even the app toolkits if you want to roll that way. I’m talking about Portals, PipeWire, and Wayland protocols.
Probonopd pans these as bolt-ons that you shouldn’t have to have running on your system, but I think this isn’t realistic. The model of the monolithic window server that offers all functionality failed decades ago. In its place, we have libraries and APIs that every FOSS developers can reasonably expect a modern system to be running.
The portal system offers a standardized way to present platform-native open or save dialogs, send notifications, open documents in other apps, print documents, take screenshots, record the screen, handle drag-and-drop, see if the user’s active theme is light or dark, and much more. The portal system uses PipeWire under the hood for a lot of this stuff, so you can expect that to be installed as well. And you can also expect most Wayland compositors–most notably the two most important ones KWin and Mutter–to support pretty much all publicly standardized Wayland protocols.
I think *this* is the platform: Portals-and-Wayland-and-PipeWire. Clearly we need to come up with a better name. 🙂 Maybe PW2. But if your app targets these, it will run on pretty much every modern Linux system. And the big two FOSS toolkits of Qt and GTK both have cutting-edge support for all of it. So use whatever UI toolkit you like.
## Why now?
We’re hearing more about this recently because the transition is picking up steam. X11’s maintainers have announced an end to its maintenance. Plasma is going Wayland by default, following GNOME. Fedora is dropping X11 support entirely. We’re in the part of the transition where people who haven’t thought about it at all are starting to do so and realizing that 100% of the pieces needed for their specific use cases aren’t in place yet. This is good! Them being heard is how stuff happens. I wish it had happened sooner, but we are where we are, and there are a lot of recent proposals and work around things like remote control, color management, drawing tablet support, and window positioning. There will probably be an awkward period before all of these pieces are in place for all of the people. And for the those who really do suffer from showstopping omissions, I say keep using X11 until it’s resolved. No one’s stopping you (well, except for Fedora, so if this is you, don’t use Fedora. 🙂 The cutting edge should be fun! If it isn’t, try something else).
## Wrapping up
In this context, “breaking everything” is another perhaps less accurate way of saying “not everything is fully ported yet”. This porting is necessary because Wayland is designed to target a future that doesn’t include 100% drop-in compatibility with everything we did in the past, because it turns out that a lot of those things don’t make sense anymore. For the ones that do, a compatibility layer (XWayland) is already provided, and anything needing deeper system integration generally has a path forward (Portals and Wayland protocols and PipeWire) or is being actively worked on. It’s all happening!
I remember moving from DOS to Linux in the early ’90s and having the same reaction as all these people disliking Wayland. In DOS (which used the CPU in the real address mode) I was able to modify the interrupt vector table, write to any memory region I wanted including the memory used by other programs or the video memory. I even wrote assembler programs drawing lines and curves on the screen by writing directly to the video memory. The code was very simple to write.
Then I moved to Linux (it used the protected address mode) and everything was a lot more complicated. I could not easily port my “graphics” programs because I couldn’t write to the video memory anymore (I later found ways to do it but eventually figured better ways to draw on the screen). I couldn’t easily modify the interrupt vector table either! What a terrible OS Linux was!! Why would anyone prefer the protected mode approach with all its complications versus the simplicity of the real mode??
Several years later DOS was essentially abandoned in favor of Windows95 and it was goodbye real mode and thus my programs became obsolete.
Fast forward 20 more years, and I see the same thing with Wayland versus X11. Anyway, I am happy to see that, finally, Wayland is implementing the philosophy behind the protected mode and replacing the naive philosophy of X11.
LikeLiked by 1 person
I just realized, that Wayland “breaks” Firefox, or in other words, Wayland is not browser ready…
Since Firefox 121 went Wayland native, it stopped correctly raising to the foreground when a link is clicked in an external app (Thunderbird, document in Libre Office, etc.).
The bug started after Firefox update to 121 and other users can confirm it in Wayland. It happens on my system, on the other computer with Wayland as well. I checked system (Manjaro) in VirtualBox and could confirm the issue on Wayland with Plasma and Gnome, but not in X11.
My hope is, that it’s not a Wayland current limitation, but a faulty Wayland implementation of Firefox, but somehow I feel that it is Wayland itself.
For work, I frequently have to open sites or documents from links in mails or documents. The fact that I need to do an additional action of moving my cursor to the FF icon and clicking on it, is tiring and irritating if done many times. Especially, that earlier it was seamless and easy – click the link and the site or a document was ready on the foreground. It’s hard to get to use to the regression :(.
Chrome based browsers still use XWayand and have no problem with raising to the top after clicking a link.
This is one of many examples, where native Wayland windows are in disadvantage. Another one is LibreOffice (at least the version on Arch).
LikeLike
It’s a bug in the implementation either in Firefox, or in the app the link originated in, or both. This is working for me in all the origin apps I regularly use.
LikeLiked by 1 person
Which apps if I may ask? I tried links in Thunderbird (XWayland) and LibreOffice (flatpack, Wayland). Even if in other apps that have links would work correctly, I mostly need them to work from Thunderbird. Still, I would love to try to see if that changes anything.
I reported the bug to Mozilla:
https://bugzilla.mozilla.org/show_bug.cgi?id=1873981
If this is a bug in Firefox Wayland implementation, there is a chance it will be fixed quicker than if it was a Wayland limitation, or at least I hope. With such big projects as Firefox, they probably get hundreds if not thousands of reports every day, so it may be hard to push through to the proper team. I already suggested forwarding it to people responsible for Wayland implementation, but will someone do it? I don’t know. At this point, I will be happy if my report will get duplicate flag, because it will mean that someone else reported it as well, and they may have a better luck, being earlier.
LikeLike
Wonderful writeup, sir.
LikeLiked by 1 person
“wayland breaks everything” is exactly the kind of philosophy that goes into MSFT development efforts, leading to decade old inaccuracies in Excel calculations because Gord forbid we push a breaking change to this 30 year old code base… ad nauseum…
LikeLike
I found this article because a conversation came up with a non-Linux programmer in which I explained why X11, despite being generally clunky and that I
wishI could replace, is still the protocol I use. Even more so after reading this and discovering that X11 is now definitely end-of-life, which is news to me. I’ve been living under a rock.I wanted to hear a different perspective, and this article was a good one! I agree that the attitude of “Breaking X11 apps is a good enough reason to never use Wayland” is a bad one. That being said, I’d like to offer a counterpoint as to why X11 still has a place on my system:
The PW^2 “platform” might not be ready for the individual window manager developer. Or at least, I wasn’t ready for it, back when I first considered switching sometime in 2020.
I maintain my own fork of the (in)famous suckless dwm. I enjoy doing so as a hobby- I expect no one else to use my windowing system, and I want to experiment with writing my own extensions for the sake of exploring UI design.
It has stuck to X11 for the reason of pragmatism: X11 is a giant piece of software that handles a lot of complex logic, allowing dwm to be small and hackable for the individual. Because the X11 APIs are standardised, even my little-windowing-manager-that-could can run any program built on X11. I’d heard talk on the suckless mailing list to that effect: That the API standard ought to have been more comprehensive, even if the reference implementation didn’t implement it all, so that the desired capabilities for a particular user could be built up using a modular system with a shared API.
All that being said, it seems that PW^2 has matured much more since my first attempt at switching away from X11 and PulseAudio four years ago. Portals, in particular, seems to solve my big gripes. Hearing that X11 ended maintenance for-real-this-time has me thinking that maybe it’s time for me to look back into the ecosystem. Thanks again for the article.
LikeLike |
16,517 | Rhino Linux 2023.4 更新添加自动平铺功能 | https://news.itsfoss.com/rhino-linux-2023-4-release/ | 2023-12-30T16:09:34 | [
"Rhino Linux"
] | https://linux.cn/article-16517-1.html | 
>
> Rhino Linux 在 2023 年的最后一次更新中添加了一个很棒的功能。
>
>
>
[Rhino Linux](https://rhinolinux.org/index.html) 是一个基于 Ubuntu 的滚动发行版,旨在利用 [滚动发布](https://itsfoss.com/rolling-release/) 方法的优势提供稳定的体验。它诞生于现已解散的 “Rolling Rhino Remix” 项目的废墟之上,并一直在接受定期更新。
在 2023 年的最后,开发者们发布了 **Rhino Linux 2023.4**,对 Rhino Linux 的未来进行了展望。
下面,就请随我一起来了解一下吧。
### ? Rhino Linux 2023.4:有什么新变化?

在最近的 [Linux 内核 6.6](https://news.itsfoss.com/linux-kernel-6-6-release/) 的支持下,Rhino Linux 2023.4 配备了更新的 Unicorn 桌面,现在**具有可选的自动平铺功能**,可以通过顶部面板中的小程序启用。
这要归功于 [cortile](https://github.com/leukipp/cortile) 的实现,它使用户能够轻松地平铺窗口。它支持诸如**基于工作区的平铺**、**热角**、**拖放窗口交换**等功能。
同样,**uLauncher 也看到了更新**,它现在看起来更加圆润,并且背景颜色略有不同。
`rhino-pkg` 也有改进\*\*,现在,如果安装了 [Nala](https://itsfoss.com/nala/),`rhino-pkg update` 不再默认自动删除软件包。
要清理过时的软件包或损坏的依赖项,你现在可以运行新的 `rhino-pkg cleanup` 命令。
**对 Pine64 设备的支持也得到了改进**,PineTab2 有**一个新的用户友好的实验性 Wi-Fi 模块**,**PinePhone 和 PinePhone Pro 的各种调制解调器稳定性修复**以及启用 GPS 支持。
你现在还可以在所有 PinePhone 和 PineTab 上使用手电筒! (如果你正在尝试这样做)
#### ?️ 其他更改和改进
除了亮点之外,你还应该了解以下一些其他变化:
* **从 PulseAudio 完全过渡到 PipeWire**。
* **在树莓派等嵌入式设备上连接到 Wi-Fi** 已得到改进。
* [pacstall-qa](https://github.com/pacstall/pacstall-qa) 已作为**新的默认包**引入,用于在本地测试来自 PR 的 pacscript。
开发者还分享了**他们的 2024 年计划**。其中包括**支持离线安装**、**新的图标包**、 **参与开发 [UBXI ports](https://rhinolinux.org/news-9.html)**、用 [nushell](https://itsfoss.com/nushell/) 重写 `rhino-pkg` 等。
你可以浏览 [发行说明](https://rhinolinux.org/news-10.html) 以了解有关此版本以及未来开发计划的更多信息。
### ? 下载 Rhino Linux 2023.4
你可以从 [官方网站](https://rhinolinux.org/download.html) 获取最新的 Rhino Linux。共有三种类型的镜像可用于各种系统配置。如果你想在普通计算机上使用它,请选择 “**Generic ISO**”。
>
> **[Rhino Linux 2023.4](https://rhinolinux.org/download.html)**
>
>
>
>
> ? 通用镜像采用 Linux 内核 6.6.7,Pine64 镜像采用 Linux 内核 6.7.0-rc5,树莓派镜像采用 Linux 内核 6.5.0。
>
>
>
**对于现有用户**,你只需运行以下命令即可升级:
```
rpk update -y
```
? 2023 年即将结束,这是今年最后的发行版之一。你怎么看呢?
*(题图:DA/2aaf8e99-0888-44d4-8dac-9d2d33392f68)*
---
via: <https://news.itsfoss.com/rhino-linux-2023-4-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Rhino Linux](https://rhinolinux.org/index.html?ref=news.itsfoss.com) is an Ubuntu-based rolling distribution that aims to offer a stable experience with the advantages of a [rolling-release](https://itsfoss.com/rolling-release/?ref=news.itsfoss.com) approach. It rose from the ashes of the now defunct Rolling Rhino Remix project and has been receiving regular updates.
Ending 2023 on a high note, the developers have released **Rhino Linux 2023.4** with some insight into what the future holds for Rhino Linux.
So, join me as I take you through it.
**Suggested Read **📖
[Rolling-Release Ubuntu-based Rhino Linux Has LandedRhino Linux is an interesting option to have!](https://news.itsfoss.com/rhino-linux-release/)

## 🆕 Rhino Linux 2023.4: What's New?
Powered by the recent [Linux Kernel 6.6 release](https://news.itsfoss.com/linux-kernel-6-6-release/), Rhino Linux 2023.4 comes equipped with an updated Unicorn Desktop that now** features optional auto-tiling functionality** that can be enabled from an applet in the top panel.
This was made possible thanks to the implementation of [cortile](https://github.com/leukipp/cortile?ref=news.itsfoss.com) that enables users to tile their windows effortlessly. It has support for things like **workspace-based tiling**, **hot corners**, **drag/drop window swapping,** and more.
Similarly, **uLauncher also sees an update**, with it now looking more rounded, and sporting a slightly different background color.
There have been **improvements on the ' rhino-pkg' side of things** too, now, '
*rhino-pkg update'*no longer auto-removes packages by default if
[Nala](https://itsfoss.com/nala/?ref=news.itsfoss.com)is installed.
For cleaning up obsolete packages or broken dependencies, you can now run the new '*rhino-pkg cleanup' *command.
**Support for Pine64 devices has also been improved**, there is **a new user-friendly experimental Wi-Fi module** for PineTab2, **various modem stability fixes** for the PinePhone and PinePhone Pro coupled with the enabling of GPS support.
You can now also use flashlights on all PinePhones and PineTabs too! (if you are trying that)
### 🛠️ Other Changes and Improvements
Other than the highlights, here are some other changes that you should know about:
- A
**complete****transition to PipeWire**from PulseAudio. **Connecting to Wi-Fi**on embedded devices such as the Raspberry Pi has been improved.[pacstall-qa](https://github.com/pacstall/pacstall-qa?ref=news.itsfoss.com)has been brought in as**a new default package**for testing pacscripts from PRs locally.
The developers have also shared **their plans for 2024**;** **which include **support for offline installations**, **a new icon pack,** **contributing to the development of **[ UBXI ports](https://rhinolinux.org/news-9.html?ref=news.itsfoss.com),
**rewriting '**in
*rhino-pkg*'[nushell](https://itsfoss.com/nushell/?ref=news.itsfoss.com), and more.
You may go through the [release notes](https://rhinolinux.org/news-10.html?ref=news.itsfoss.com) to learn more about this release, and future development plans.
## 📥 Download Rhino Linux 2023.4
You can grab the latest Rhino Linux release from the [official website](https://rhinolinux.org/download.html?ref=news.itsfoss.com). There are three types of images available for various system configurations. Choose “**Generic ISO**” if you want to use it on a regular computer.
**For existing users**, you can simply run the following command to upgrade:
`rpk update -y`
*💬 2023 is almost at an end, with this being one of the final distro releases for the year. What do you think of it?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,518 | 2023 年 Linux 用户值得试试的 8 个开源应用 | https://news.itsfoss.com/exciting-apps-2023/ | 2023-12-30T17:38:00 | [
"应用"
] | https://linux.cn/article-16518-1.html | 
>
> 2023 年我们发掘出的那些被低估的精彩应用。
>
>
>
在 2023 年里,我们关注了各类应用、发行版和其他许多引人注目的开源项目。
对于开源爱好者或者 Linux 用户来说,尝试我们精选的应用程序是乐趣之一 。
这一年快要结束了,我希望你不要错过这些有着独到之处的应用。毕竟,你可能会发现,一款引人入胜的应用,可能就此成为你日常生活中不可或缺的一部分。
下面就是我强烈推荐你来一探究竟的应用:
### 1、Warp:安全的文件共享应用

[Warp](/article-16117-1.html) 是一个基于 Rust 开发的开源文件分享应用,支持在 Linux、Windows 和安卓平台运行。
其工作流程简洁流畅,所有的通讯过程都经过加密。你需要一个传输码来授权或接收文件,避免了文件被他人无意中接收的风险。
你可以在我们的报道中了解更多关于它的相关内容:
>
> **[Warp:一款可跨平台运行的开源安全文件共享应用](/article-16117-1.html)**
>
>
>
### 2、 MusicPod:漂亮的音乐播放器

如果你想要一款支持播客和广播电台的音乐播放器,而且用户体验上佳,那么 [MusicPod](https://news.itsfoss.com/musicpod/) 无疑是个好的选择。
这是一款基于 Flutter 开发的应用,提供了直观的用户界面和对音乐播放的基本控制功能。当然,如果这不合你的口味,我们的 [最佳 Linux 音乐播放器列表](https://itsfoss.com/best-music-players-linux/) 中还有更多的选择。
MusicPod 是一款以 Snap 包形式提供的 Linux 应用。
### 3、Pano:GNOME 剪贴板管理器扩展

对于 GNOME 用户来说,[Pano 剪贴板管理器](/article-15835-1.html) 是个实用且有必要装的扩展。
>
> **[Pano 剪贴板管理器是你需要的一个很棒的 GNOME 扩展](/article-15835-1.html)**
>
>
>
当然,你可以选择像 [CopyQ](https://itsfoss.com/copyq-clipboard-manager/) 这样稳定的剪贴板管理应用。但 Pano 作为一个扩展,使得剪贴板内容的追踪更加直观。
它会显示你剪贴板中所有的颜色 / 链接 / 图片,并允许你调整其外观。
你还可以查看我们推荐的 [剪贴板管理器列表](https://itsfoss.com/linux-clipboard-managers/),看看还有哪些其他的选择。
### 4、Beaver Notes:极简主义设计的隐私记事应用

Linux 平台上有许多 [记事应用](https://itsfoss.com/note-taking-apps-linux/)。然而,如果你已经试过大多数,但还是想要一款简洁直接且注重隐私保护的应用,那么 [Beaver Notes](/article-16210-1.html) 就值得你一试。
虽然没有太多功能,但你可以使用 Markdown 进行笔记,以及基本的笔记整理功能。
我们在今年初就开始使用它,你可以查看一下以获得初次体验:
>
> **[Beaver Notes:一款开源的私人记事本应用](/article-16210-1.html)**
>
>
>
### 5、Wave:现代化的 Linux 终端

如果你是命令行的爱好者,但原有的用户体验让你望而却步,你可能会对 [Wave](/article-16409-1.html) 这款出色的终端仿真器感兴趣。
它提供了类似代码编辑器的用户界面,使得即便是新手也能轻松理解。你一眼就能看到所有必需的部分,让整个界面既清晰又有条理。
除了用户体验方面的优点,它还提供了诸如保存持久 SSH 连接等实用功能。你可以在我们的报道中了解更多相关内容:
>
> **[Wave:即使你讨厌命令行,也会喜欢的现代新 Linux 终端](/article-16409-1.html)**
>
>
>
### 6、Xplorer:一款新颖的文件管理器

大部分用户对 Linux 发行版中内置的文件管理器都十分满意。
但是,如果你想要尝试些新的东西,Xplorer 就是一个带有一些定制选项的漂亮文件管理器。
尽管这款应用的开发活跃度并不像其他一些替代品那么高,但随着更多的贡献者的参与,它有可能展现出更大的潜力。
### 7、Mission Center:系统监控的绝佳应用

想要进一步了解你的系统资源使用情况?包括线程的使用统计?
[Mission Center](/article-16257-1.html) 是你的首选,它提供了完美的 GUI 系统监控。在我们的报道中,你可以了解更多关于它的详细内容:
>
> **[任务中心:一款流畅的 Linux 系统监控应用](/article-16257-1.html)**
>
>
>
### 8、Denaro

有了 [Denaro](https://news.itsfoss.com/denaro/),Linux 下的个人财务管理变得轻而易举。
你可以得到对各种货币的支持,以及一些可视化你的财务以及保持事物有序的功能。
### 最后
作为 《[初体验系列](https://news.itsfoss.com/tag/first-look/)》 的一部分,我们报道了许多其他的应用程序,如果你感兴趣。而这些,都是我们读者中最受关注的一些。
? 你最喜欢列表中的哪一个应用?你有没有新的推荐,让我们在 2024 年来一探究竟?欢迎在下方评论中分享你的想法。
*(题图:DA/94feed1c-767c-4606-8eee-c99ebd01cc49)*
---
via: <https://news.itsfoss.com/exciting-apps-2023/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

We have been covering applications, distributions, and plenty of other interesting open-source projects throughout 2023.
Of course, as an open-source enthusiast or a Linux user, our readers loved trying out the applications we curated.
So, now that the year is coming to an end, I do not want you to miss some of those nifty applications. You never know, you may find something that you may not stop using at all.
Here are the apps that I think you should not miss taking a look at:
## 1. Warp: Secure File Sharing App

[Warp](https://news.itsfoss.com/warp-file-sharing/) is a Rust-based open-source file-sharing app. It is available for Linux, Windows, and Android.
The functioning of it is seamless where the entire communication is encrypted. You need a transmit code to authorize/receive the file, so no one else accidentally gets what you are trying to send.
You can explore all about it in our coverage:
[Warp: An Open-Source Secure File Sharing App That Works Cross-PlatformA seamless way to securely share files between Linux and Windows? Try this out!](https://news.itsfoss.com/warp-file-sharing/)

## 2. MusicPod: A Beautiful Music Player
If you are looking for a music player offering a good user experience with support for podcasts and radio stations, [MusicPod](https://news.itsfoss.com/musicpod/) is a nice pick.
It is a Flutter-based app that provides an intuitive user interface with essential controls for music playback. Of course, if this is not something to your taste, feel free to check out our list of the [best music players for Linux](https://itsfoss.com/best-music-players-linux/?ref=news.itsfoss.com).
MusicPod is a Linux-only app available as a Snap package. Explore more about it here:
[MusicPod: A Beautiful Flutter-based Music, Radio, and Podcast Player for UbuntuA pretty, minimal, and useful music player to tune in to your favorite songs, radio channel, and podcast networks.](https://news.itsfoss.com/musicpod/)

## 3. Pano Clipboard Manager: GNOME Extension
For GNOME users, [Pano Clipboard Manager](https://news.itsfoss.com/pano-clipboard-manager/) is a useful extension to have installed.
Sure, you can always use apps like [CopyQ](https://itsfoss.com/copyq-clipboard-manager/?ref=news.itsfoss.com) as a reliable clipboard manager. However, Pano is an extension that makes keeping track of clipboard content visually intuitive.
It displays all the colors/links/images you have in your clipboard and lets you adjust its appearance as well.
You can also check out our recommended [list of clipboard managers](https://itsfoss.com/linux-clipboard-managers/?ref=news.itsfoss.com) for other options:
[Ctrl+C Ctrl+V Made Better With Clipboard Managers in LinuxSave yourself time and frustration with a clipboard manager and never lose track of your copy-pasting.](https://itsfoss.com/linux-clipboard-managers/?ref=news.itsfoss.com)

## 4. Beaver Notes: Private Note-Taking App
There are various [note-taking applications on Linux](https://itsfoss.com/note-taking-apps-linux/?ref=news.itsfoss.com). But, if you have tried most of them, and want something simple, straightforward, and privacy-focused, [Beaver Notes](https://news.itsfoss.com/beaver-notes/) is a good candidate.
You do not get a lot of features, but the ability to use Markdown for note-taking, and essentials to organize your notes.
We took it for a spin early this year, check it out to get a sneak peek:
[Beaver Notes: A Private Open-Source Note-Taking AppA privacy-focused note-taking app available cross-platform. Let’s take a look at it!](https://news.itsfoss.com/beaver-notes/)

## 5. Wave: A Modern Linux Terminal

If you are a command-line fan, but the user experience has held you back, Wave is an impressive terminal emulator to try.
It offers a code-editor-like UI, which is easy to understand, even for newbies. You get all the essentials at a glance, making things accessible and organized simultaneously.
Not just the UX side of things, it also provides plenty of useful features like the ability to save persistent SSH connections. You can explore more about it in our coverage:
[Wave: A Modern New Linux Terminal that You’ll Love if You Hate Command LineThe VS Code of Linux Terminals is here and it has the potential to become popular among the gen z of coders and Linux users.](https://news.itsfoss.com/wave-terminal/)

## 6. Xplorer: A Nice File Manager

Most of you must be content with the default file managers baked in with the Linux distributions.
However, if you want to experiment with things, Xplorer is a pretty file manager with some customization options.
While the development for the app is not as active as other options, with more contributors, it looks like something with good potential. Take a better look at it here:
[Xplorer: Not Just a Pretty Open-Source File Manager!For a change, do you want to a try a new file manager? Xplorer is an interesting project to look at!](https://news.itsfoss.com/xplorer/)

## 7. Mission Center: System Monitoring App
Want to get more details on your system resources? Including per-thread usage stats?
Mission Center is the perfect GUI system monitoring app. You can explore more about it in our coverage on it:
[Mission Center: A Sleek System Monitoring App for LinuxA user-friendly system monitoring app for Linux. Let’s check it out!](https://news.itsfoss.com/mission-center/)

## 8. Denaro

Managing personal finance on Linux gets easier with [Denaro](https://news.itsfoss.com/denaro/).
You get support for various currencies, features to visualize your finances, and more to keep things organized.
Learn more about the app and its usage here:
[A Sleek-Looking Linux App to Manage Your Personal FinancePerfect desktop app for Linux to manage finances!](https://news.itsfoss.com/denaro/)

## Wrapping Up
We covered plenty more applications as a part of our [first look series](https://news.itsfoss.com/tag/first-look/), if you are curious. And, these were some of the most trending ones among our readers.
*💬 What is your favorite in the list? Do you have any recommendations for us to try in 2024? Let us know your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,520 | 在抛弃 Xorg 之前,请三思。Wayland 会毁掉一切! | https://gist.github.com/probonopd/9feb7c20257af5dd915e3a9f2d1f2277 | 2023-12-31T16:33:00 | [
"Wayland"
] | https://linux.cn/article-16520-1.html | 
>
> LCTT 译注:之前翻译发布的《Wayland 真的毁掉一切了吗?》引来了很多讨论,为了使讨论更全面,我也将该文所反驳的原文也翻译过来,供大家参考。
>
>
>
如果你希望现有的应用程序能够“顺利运行”,而不需要做调整,那么你可能更愿意避免使用 Wayland。
Wayland 并没有解决我遇到的问题,但却破坏了我几乎需要的一切。甚至是最基本、最简单的事情(如 `xkill`) - *在这种情况下没有明显的替代品*。通常,它会保持破坏的状态,因为 Wayland 的人员似乎主要关心的是 Automotive、Gnome,也许还有 KDE - 并在此过程中忽视了其他人,比如那些只使用 X11 窗口管理器或 GNUstep 的人。
Wayland 的支持者们让人们觉得 Wayland 是 Xorg 的“继任者”,但事实上并非如此。它只是一个不兼容的替代品,并且甚至没有(也不打算)具有对等的功能(存在 [功能缺失](https://github.com/probonopd/wayland-x11-compat-protocols/))。不像 X11(X 窗口系统),Wayland 协议设计者们积极避开“窗口”的概念,而是编造出让人无法理解的词语,如 “[xdg\_toplevel](https://wayland.app/protocols/xdg-shell#xdg_toplevel)”。
**不要使用 Wayland 会话!** 不要让 Wayland 毁掉一切,然后让其他人修复它造成的破坏。或者强制让每个人更多地使用红帽或 Gnome 组件(glib、Portals、Pipewire)!
Wayland 似乎是由那些对已有软件毫不关心的人创造出来的。他们以为每个人都乐于重写所有东西,或者只使用 Linux 上的 Gnome(而不是,NetBSD 上与 ROX Filer 搭配使用的 twm 之类)。
**补充**:当我写下上述内容时,我并没有真正意识到 Wayland 究竟是什么,我只是注意到一些发行版(如 Fedora)开始推送它给我,并在我开始使用后发现了一些问题。现在我明白了实际上你不能“安装 Wayland”,因为与 Xorg 不同,并没有一个“Wayland 显示服务器”,每个桌面环境都有自己的“显示服务器”。也许 “Wayland 的开发者们” 关心的并不只是 Gnome,但任何在 Gnome 的 Wayland 实现中的修复并不能自动地惠及所有的 Wayland 软件用户,也许他们也不会推荐这种实现。
**2023 年 12 月再次补充**:如果有什么东西想要替代桌面电脑(比如专业 Unix 工作站)的 X11,那么它最好支持用于那种场景的所有需要的功能(以及关键概念,如窗口)。那些人们的冰箱上也有显示器在这种讨论,在此并不重要。我们需要提出 [缺失的 Wayland 协议](https://github.com/probonopd/wayland-x11-compat-protocols/) 以实现与 X11 的全面功能一致性。
### Wayland 的设计本身就存在问题
* 一旦窗口管理器出现崩溃,所有正在运行的应用程序都将被迫停止。
* ~~你无法以 root 用户的身份运行应用程序~~
* 设计上的限制使你无法执行在 Xorg 中可以实现的众多功能
* 没有一个被所有人所使用,且与桌面环境无关的 `/usr/bin/wayland` 显示服务器应用程序(这与 Xorg 不同)
* 它将大量的工作都推给了窗口管理器。结果就是,在不同的窗口管理器中,相同的基础功能可能会有不同的实现方式,存在不同的表现和问题——也就是说,那些在桌面环境 A 中正常运行的可能在桌面环境 B 中并不适用(例如,你经常会听到有人说某个功能 “在 Wayland 上能正常工作”,但是实际上它只能在 Gnome 和 KDE 上正常运行,而不能在所有的 Wayland 实现上运行)。这个问题在以下的链接中得到了很好的总结:<https://gitlab.freedesktop.org/wayland/wayland/-/issues/233> 。
### Wayland 造成破坏的情况
下面列出了许多这种破坏情况,译者不打算详细列出细节(可在原文处查看)。这些人们补充的 Wayland 造成破坏的情况有:
* Wayland 影响了屏幕录制应用的正常运行
* Wayland 影响了屏幕共享应用的正常运行
* Wayland 影响了自动化软件的正常运行
* Wayland 影响了 Gnome-Global-AppMenu(Gnome 的全局菜单)的正常运行
* Wayland 破坏了与 KDE platformplugin 的全局菜单链接
* Wayland 影响了与非 KDE Qt platformplugins 的全局菜单正常运行
* Wayland 影响了那些没有提供特殊 Wayland Qt 插件的 AppImage 的运行
* Wayland 影响了 Redshift 的正常运行
* Wayland 影响了全局快捷键的正常使用
* Xfce 在 Wayland 下可能无法正常工作?
* Wayland 在英伟达硬件上可能无法正常工作?
* Wayland 在英特尔硬件上表现异常
* Wayland 偏向 Linux,影响了 BSD 的正常运行
* Wayland 复杂化了服务器端窗口装饰的处理
* Wayland 影响了窗口自我提升 / 激活的功能
* Wayland 影响了 RescueTime 的正常工作
* Wayland 影响了窗口管理器的正常运行
* Wayland 需要 JWM、TWM、XDM、IceWM 等重新实现类似 Xorg 的功能
* Wayland 影响了 \_NET\_WM\_STATE\_SKIP\_TASKBAR 协议的正常使用
* Wayland 影响了 NoMachine NX 的正常运行
* Wayland 影响了 xclip 的正常使用
* Wayland 影响了 SUDO\_ASKPASS 的正常工作
* Wayland 影响了 X11 atoms 的正常使用
* Wayland 影响了游戏的正常运行
* Wayland 影响了 xdotool 的正常使用
* Wayland 影响了 xkill 的正常工作
* Wayland 影响了屏保的正常显示
* Wayland 影响了窗口位置设置的准确性
* Wayland 影响了色彩管理的正确性
* Wayland 影响了 DRM 租赁的正常流程
* Wayland 影响了家庭内流媒体的正常播放
* Wayland 影响了 NetWM 的正常工作
* Wayland 影响了窗口图标的正常显示
* Wayland 影响了拖放功能的正常使用
### 解决方法
对于用户:可以避免使用 Wayland 会话,或者卸载那些只提供 Wayland 会话的桌面环境或 Linux 分发版。同时,也可以尽量避免使用只适用于 Wayland 的应用,比如 [PreSonus Studio One](https://support.presonus.com/hc/en-us/articles/19214558269581-Linux-Getting-Started)(可能的解决策略:在 <https://github.com/cage-kiosk/cage> 中运行此类应用)。
对于应用开发者:可以采取措施强制在 X11/Xwayland 上运行应用程序,就像 2023 年 11 月的 LibrePCB 所做的一样。
### 强制用户习惯 Wayland 的实例
这种情况正是本文想要警告和避免的。
* Asahi Linux 对 ARM 架构的 Mac 强制使用 Wayland,详情参见: <https://social.treehouse.systems/@marcan/110354541574112092>
* Fedora 对 KDE Plasma 强制使用 Wayland,详情参见:<https://fedoraproject.org/wiki/Changes/KDE_Plasma_6#Why_drop_the_X11_session_with_the_Plasma_6_upgrade>?
* 红帽对 RHEL 强制使用 Wayland,详情参见:<https://www.redhat.com/de/blog/rhel-10-plans-wayland-and-xorg-server>
### 参考资料
* Dudemanguy's Musings:[Wayland 无法挽救 Linux 桌面](https://dudemanguy.github.io/blog/posts/2022-06-10-wayland-xorg/wayland-xorg.html)
* Chris Titus Tech:Wayland 对比 Xorg <https://www.youtube.com/watch?v=U_MBJcD3SFI>
* tildearrow:[有人说 “反 Wayland 无稽之谈” 吗?](https://tildearrow.org/?p=post&month=2&year=2021&item=antihs)
* pcsx2:[CI/Linux:禁用 Wayland 并进行“春天大扫除”](https://github.com/PCSX2/pcsx2/pull/10179)
*(题图:DA/fbfad36b-baba-4237-aceb-c86b99ef379b)*
---
via: <https://gist.github.com/probonopd/9feb7c20257af5dd915e3a9f2d1f2277>
作者:[Probonopd](https://gist.github.com/probonopd) 译者:[ChatGPT](https://linux.cn/lctt/ChatGPT) 校对:[wxy](https://github.com/wxy)
| 200 | OK | Hence, if you are interested in existing applications to "just work" without the need for adjustments, then you may be better off avoiding Wayland.
Wayland solves no issues I have but breaks almost everything I need. Even the most basic, most simple things (like `xkill`
) - *in this case with no obvious replacement*. And usually it stays broken, because the Wayland folks mostly seem to care about Automotive, Gnome, maybe KDE - and alienating everyone else (e.g., people using just an X11 window manager or something like GNUstep) in the process.
The Wayland project seems to operate like they were starting a [greenfield project](https://en.wikipedia.org/wiki/Greenfield_project), whereas at the same time they try to position Wayland as "the X11 successor", which would clearly require a lot of thought about not breaking, or at least providing a smooth upgrade path for, existing software.
In fact, it is merely an incompatible alternative, and not even one that has (nor wants to have) feature parity ([missing features](https://github.com/probonopd/wayland-x11-compat-protocols/)). And unlike X11 (the X *Window* System), Wayland protocol designers actively avoid the concept of "windows" (making up incomprehensible words like "[xdg_toplevel](https://wayland.app/protocols/xdg-shell#xdg_toplevel)" instead).
**DO NOT USE A WAYLAND SESSION!** Let Wayland not destroy everything and then have other people fix the damage it caused. Or force more Red Hat/Gnome components (glib, Portals, Pipewire) on everyone!
**Please add more examples to the list.**
Wayland seems to be made by people who do not care for existing software. They assume everyone is happy to either rewrite everything or to just use Gnome on Linux (rather than, say, twm with ROX Filer on NetBSD).
**Edit:** When I wrote the above, I didn't really realize what Wayland even *was*, I just noticed that some distributions (like Fedora) started pushing it onto me and things didn't work properly there. Today I realize that you can't "install Wayland", because unlike Xorg, there is not one "Wayland display server" but actually every desktop envrironment has its own. And maybe "the Wayland folks" don't "only care about Gnome", but then, any fix that is done in Gnome's Wayland implementation isn't automatically going to benefit *all* users of Wayland-based software, and possibly isn't even the implementation "the Wayland folks" would necessarily recommend.
**Edit 12/2023:** If something wants to replace X11 for desktop computers (such as professional Unix workstations), then it better support all needed features (and key concepts, like *windows*) for that use case. That people also have displays on their fridge doesn't matter the least bit in that context of discussion. Let's propose [the missing Wayland protocols](https://github.com/probonopd/wayland-x11-compat-protocols/) for full X11 feature parity.
**Edit 08/2024:** "Does Wayland becoming the defacto standard display server for Linux serve to marginalize BSD?" [https://fossforce.com/2024/07/the-unintended-consequences-linuxs-wayland-adoption-will-have-on-bsd/](https://fossforce.com/2024/07/the-unintended-consequences-linuxs-wayland-adoption-will-have-on-bsd/)
- A crash in the window manager takes down all running applications
~~You cannot run applications as root~~- You cannot do a lot of things that you can do in Xorg
*by design* - There is not one
`/usr/bin/wayland`
display server application that is desktop environment agnostic and is used by*everyone*(unlike with Xorg) - It offloads a lot of work to each and every window manager. As a result, the same basic features get implemented differently in different window managers, with different behaviors and bugs - so what works on desktop environment A does not necessarily work in desktop environment B (e.g., often you hear that something "works in Wayland", even though it only really works on Gnome and KDE, not in all Wayland implementations). This summarizes it very well:
[https://gitlab.freedesktop.org/wayland/wayland/-/issues/233](https://gitlab.freedesktop.org/wayland/wayland/-/issues/233)
Apparently the Wayland project doesn't even **want** to be "X.org 2.0", and doesn't want to provide a commonly used implementation of a compositor that could be used by everyone: [https://gitlab.freedesktop.org/wayland/wayland/-/issues/233](https://gitlab.freedesktop.org/wayland/wayland/-/issues/233). Yet this would imho be required if they want to make it into a worthwile "successor" that would have any chance of ever fixing the many Wayland issues at the core.
[MaartenBaert/ssr#431](https://github.com/MaartenBaert/ssr/issues/431)❌ broken since 24 Jan 2016, no resolution ("I guess they use a non-standard GNOME interface for this")[https://github.com/mhsabbagh/green-recorder](https://github.com/mhsabbagh/green-recorder)❌ ("I am no longer interested in working with things like ffmpeg/wayland/GNOME's screencaster or solving the issues related to them or why they don't work")[vkohaupt/vokoscreenNG#51](https://github.com/vkohaupt/vokoscreenNG/issues/51)❌ broken since at least 7 Mar 2020. ("I have now decided that there will be no Wayland support for the time being. Reason, there is no budget for it. Let's see how it looks in a year or two.") -**This is the key problem. Wayland breaks everything and then expects others to fix the wreckage it caused on their own expense.**[obsproject/obs-studio#2471](https://github.com/obsproject/obs-studio/issues/2471)❌ broken since at least 7 Mar 2020. ("Wayland is unsupported at this time", "There isn't really something that can just be easily changed. Wayland provides no capture APIs")- There is a workaround for OBS Studio that requires a
`obs-xdg-portal`
plugin (which is known to be Red Hat/Flatpak-centric, GNOME-centric,*"perhaps"*works with other desktops) [phw/peek#1191](https://github.com/phw/peek/issues/1191)❌ broken since 14 Jan 2023. Peek, a screen recording tool, has been abandoned by its developerdue to a number of technical challenges, mostly with Gtk and Wayland ("Many of these have to do with how Wayland changed the way applications are being handled")
As of February 2024, screen recording is **still broken utterly** on Wayland with the vast majority of tools. [Proof](https://www.youtube.com/watch?v=lOjs6axYOHw)
**Workaround:** Find a Wayland compositor that supports the `wlr-screencopy-unstable-v1`
protocol and use `wf-recorder -a`
. The default compositor in Raspberry Pi OS (Wayfire) does, but the default compositor in Ubuntu doesn't. (That's the worst part of Wayland: Unlike with Xorg, it always depends on the particular Wayand compositor what works and what is broken. Is there even one that supports *everything*?)
[jitsi/jitsi-meet#2350](https://github.com/jitsi/jitsi-meet/issues/2350)❌ broken since 3 Jan 2018[jitsi/jitsi-meet#6389](https://github.com/jitsi/jitsi-meet/issues/6389)❌ broken since 24 Jan 2016 ("Closing since there is nothing we can do from the Jitsi Meet side.")**See? Wayland breaks stuff and leaves application developers helpless and unable to fix the breakage, even if they wanted.**
**NOTE:** As of November 2023, screen sharing in Chromium using Jitsi Meet is **still utterly broken**, both in Raspberry Pi OS Desktop, and in a KDE Plasma installation, albeit with different behavior. Note that Pipewire, Portals and whatnot are installed, and even with them it does not work.
[raspberrypi/bookworm-feedback#149 (comment)](https://github.com/raspberrypi/bookworm-feedback/issues/149#issuecomment-1841954176)❌ broken since at least Nov 17, 2023 ("window sharing not being available in wlroots derived compositors (such as wayfire)")[flathub/us.zoom.Zoom#22](https://github.com/flathub/us.zoom.Zoom/issues/22)Zoom ❌ broken since at least 4 Jan 2019. ("Can not start share, we only support wayland on GNOME with Ubuntu (17, 18), Fedora (25 to 29), Debian 9, openSUSE Leap 15, Arch Linux").**No word about non-GNOME!**[https://community.zoom.com/t5/Meetings/Screensharing-only-works-on-GNOME-wayland-when-it-should-work-on/m-p/64823](https://community.zoom.com/t5/Meetings/Screensharing-only-works-on-GNOME-wayland-when-it-should-work-on/m-p/64823)Zoom ❌ Still broken as of 24 Jun 2022. ("... we only support Wayland on Gnome with Ubuntu 17 and above, Fedora 25 and above, Debian 9 and above ...")[probonopd/Zoom.AppImage#8](https://github.com/probonopd/Zoom.AppImage/issues/8)❌ broken since 1 Oct 2022 Zoom: "You need PulseAudio 1.0 and above to support audio share" on a system that uses pipewire-pulseaudio
```
sudo pkg install py37-autokey
This is an X11 application, and as such will not function 100% on
distributions that default to using Wayland instead of Xorg.
```
-
[https://gitlab.com/lestcape/Gnome-Global-AppMenu/-/issues/116](https://gitlab.com/lestcape/Gnome-Global-AppMenu/-/issues/116)❌ broken since 24 Aug 2018 ("because the lack of the Gtk+ Wayland support for the Global Menu") -
[https://bugs.kde.org/show_bug.cgi?id=424485](https://bugs.kde.org/show_bug.cgi?id=424485)❌ Still broken as of late 2023 ("I am also still not seeing GTK global menus on wayland. They appear on the applications themselves, wasting a lot of space.")
-
[https://blog.broulik.de/2016/10/global-menus-returning/](https://blog.broulik.de/2016/10/global-menus-returning/)("it uses global window IDs, which don’t exist in a Wayland world... no global menu on Wayland, I thought, not without significant re-engineering effort"). KDE had to do additional work to work around it. And it still did not work: -
[https://bugs.kde.org/show_bug.cgi?id=385880](https://bugs.kde.org/show_bug.cgi?id=385880)("When using the Plasma-Wayland session, the global menu does not work.")
Good news: [According to this report](https://gist.github.com/probonopd/9feb7c20257af5dd915e3a9f2d1f2277?permalink_comment_id=4136012#gistcomment-4136012) global menus now work with KDE platformplugin as of 4/2022
[https://blog.broulik.de/2016/10/global-menus-returning/](https://blog.broulik.de/2016/10/global-menus-returning/)❌ broke non-KDE platformplugins. As a result, global menus now need`_KDE_NET_WM_APPMENU_OBJECT_PATH`
which only the KDE platformplugin sets, leaving everyone else in the dark
[https://blog.martin-graesslin.com/blog/2018/03/unsetting-qt_qpa_platform-environment-variable-by-default/](https://blog.martin-graesslin.com/blog/2018/03/unsetting-qt_qpa_platform-environment-variable-by-default/)❌ broke AppImages that don't ship a special Wayland Qt plugin. "This affects proprietary applications, FLOSS applications bundled as appimages, FLOSS applications bundled as flatpaks and not distributed by KDE and even the Qt installer itself. In my opinion this is a showstopper for running a Wayland session." However, there is a workaround: "AppImages which ship just the XCB plugin will automatically fallback to running in xwayland mode" (see below).
[https://wiki.archlinux.org/index.php/redshift](https://wiki.archlinux.org/index.php/redshift)❌ broken ("Redshift does not support Wayland since it offers no way to adjust the color temperature")
Update 2023: **Some** Wayland compositors (such as Wayfire) now support `wlr_gamma_control_unstable_v1`
, see [https://github.com/WayfireWM/wayfire/wiki/Tutorial#configuring-wayfire](https://github.com/WayfireWM/wayfire/wiki/Tutorial#configuring-wayfire) and [jonls/redshift#663](https://github.com/jonls/redshift/pull/663). Does it work in *all* Wayland compositors though?
[albertlauncher/albert#309](https://github.com/albertlauncher/albert/issues/309)❌ broken since 7 Jan 2017 ("This is a security measure, but has the side effect of preventing applications from registering their own global hotkeys")[YouTube video by René Rebe](https://www.youtube.com/watch?v=L0l817ymu-s)
See below.
Apparently Wayland relies on nouveau drivers for NVidia hardware. The nouveau driver has been giving unsatisfactory performance since its inception. Even clicking on the application starter icon in Gnome results in a stuttery animation. Only the proprietary NVidia driver results in full performance.
See below.
Update 2024: The situation might slowly be improving. It remains to be seen whether this will work well also for all existing old Nvidia hardware (that works well in Xorg).
[https://cfenollosa.com/blog/fed-up-with-the-mac-i-spent-six-months-with-a-linux-laptop-the-grass-is-not-greener-on-the-other-side.html](https://cfenollosa.com/blog/fed-up-with-the-mac-i-spent-six-months-with-a-linux-laptop-the-grass-is-not-greener-on-the-other-side.html)❌ broken since at least 02 Apr 2021 ("Screen tearing with the intel driver. Come on. This was solved on xorg and now with Wayland it's back.")
[https://bugzilla.redhat.com/show_bug.cgi?id=1274451](https://bugzilla.redhat.com/show_bug.cgi?id=1274451)❌ broken since 22 Oct 2015 ("No this will only fix sudo for X11 applications. Running GUI code as root is still a bad idea." I absolutely detest it when software tries to prevent me from doing what some developer thinks is "a bad idea" but did not consider my use case, e.g., running`truss`
for debugging on FreeBSD needs to run the application as root.[https://bugzilla.mozilla.org/show_bug.cgi?id=1323302](https://bugzilla.mozilla.org/show_bug.cgi?id=1323302)suggests it is not possible: "These sorts of security considerations are very much the way that "the Linux desktop" is going these days".)
[https://blog.netbsd.org/tnf/entry/wayland_on_netbsd_trials_and](https://blog.netbsd.org/tnf/entry/wayland_on_netbsd_trials_and)❌ broken since 28 Sep 2020 ("Wayland is written with the assumption of Linux to the extent that every client application tends to #include <linux/input.h> because Wayland's designers didn't see the need to define a OS-neutral way to get mouse button IDs. (...) In general, Wayland is moving away from the modularity, portability, and standardization of the X server. (...) I've decided to take a break from this, since it's a fairly huge undertaking and uphill battle. Right now, X11 combined with a compositor like picom or xcompmgr is the more mature option."
[https://blog.martin-graesslin.com/blog/2018/01/server-side-decorations-and-wayland/](https://blog.martin-graesslin.com/blog/2018/01/server-side-decorations-and-wayland/)❌ FUD since at least 27 January 2018 ("I heard that GNOME is currently trying to lobby for all applications implementing client-side decorations. One of the arguments seems to be that CSD is a must on Wayland. " ... "I’m burnt from it and are not interested in it any more.") Server-side window decorations are what make the title bar and buttons of*all*windows on a system*consistent*. They are a must have_ for a consistent system, so that applications written e.g., Gtk will not look entirely alien on e.g., a Qt based desktop, and to enforce that developers cannot place random controls into window titles where they do not belong. Client-side decorations, on the other hand, are destroying uniformity and consistency, put additional burden on application and toolkit developers, and allow e.g., GNOME developers to put random controls (that do not belong there) into window titles (like buttons), hence making it more difficult to achieve a uniform look and feel for all applications regardless of the toolkit being used.
Red Hat employee Matthias Clasen ("I work at the Red Hat Desktop team... I am actually a manager there... the people who do the actual work work for me") expicitly stated "Client-side everything" as a principle, even though the protocol doesn't enforce it: "Fonts, Rendering, Nested Windows, *Decorations*. "It also gives the design more freedom to use the titlebar space, which is something our designers appreciate" (sic). [Source](https://www.youtube.com/watch?v=xVVT6Lo7fGI)
[https://phabricator.kde.org/D16648#470609](https://phabricator.kde.org/D16648#470609)("Wayland clients can't raise or activate themselves"), ❌ broken since May 27 2019
[https://help.rescuetime.com/article/117-common-linux-issues](https://help.rescuetime.com/article/117-common-linux-issues)("One of the features of Wayland is that it prevents apps from doing precisely what RescueTime is trying to do—track activity in other windows.") ❌ broken since June 3, 2021
Apparently Wayland (at least as implemented in KWin) does not respect EWMH protocols, and breaks other command line tools like wmctrl, xrandr, xprop, etc. Please see the discussion below for details.
- Screen recording and casting
- Querying of the mouse position, keyboard LED state, active window position or name, moving windows (xdotool, wmctrl)
- Global shortcuts
- System tray
- Input Method support/editor (IME)
- Graphical settings management (i.e. tools like xranrd)
- Fast user switching/multiple graphical sessions
- Session configuration including but not limited to 1) input devices 2) monitors configuration including refresh rate / resolution / scaling / rotation and power saving 3) global shortcuts
- HDR/deep color support
- VRR (variable refresh rate)
- Disabling input devices (xinput alternative)
As it currently stands minor WMs and DEs do not even intend to support Wayland given the sheer complexity of writing all the code required to support the above features. You do not expect JWM, TWM, XDM or even IceWM developers to implement all the featured outlined in ^1.
[https://github.comelectron/electron#33226](https://github.comelectron/electron#33226)("skipTaskbar has no effect on Wayland. Currently Electron uses`_NET_WM_STATE_SKIP_TASKBAR`
to tell the WM to hide an app from the taskbar, and this works fine on X11 but there's no equivalent mechanism in Wayland." Workarounds are only available for*some*desktops including GNOME and KDE Plasma.) ❌ broken since March 10, 2022
[https://kb.nomachine.com/TR03S10126?s=wayland](https://kb.nomachine.com/TR03S10126?s=wayland)❌ broken since 2021-03-09 ("The session becomes unresponsive once logged-in to the Wayland desktop")
`xclip`
is a command line utility that is designed to run on any system with an X11 implementation. It provides an interface to X selections ("the clipboard"). Apparently Wayland isn't compatible to the X11 clipboard either.
[AppImage/AppImageKit#1221 (comment)](https://github.com/AppImage/AppImageKit/issues/1221#issuecomment-1279650452)❌ broken since 2022-20-15 ("Espanso built for X11 will not work on Wayland due to`xclip`
. Wayland asks for`wl-copy`
")
This is another example that the Wayland requires everyone to change components and take on additional work just because Wayland is incompatible to what we had working for all those years.
[https://github.com/linuxhw/hw-probe-pyqt5-gui/commit/eb2d6e5145fb8571414bda57676084b7f13b94e5#diff-23cb15995f1502beebb38433bfa83204a5f45b376eaf88e2e41a0d8a1cd44722R290](https://github.com/linuxhw/hw-probe-pyqt5-gui/commit/eb2d6e5145fb8571414bda57676084b7f13b94e5#diff-23cb15995f1502beebb38433bfa83204a5f45b376eaf88e2e41a0d8a1cd44722R290)❌ broken since 2022-04-09 ("`SUDO_ASKPASS`
doesn't work on Wayland currently, so piping the password")
X11 atoms can be used to store information on windows. For example, a file manager might store the path that the window represents in an X11 atom, so that it (and other applications) can know for which paths there are open file manager windows. Wayland is not compatible to X11 atoms, resulting in all software that relies on them to be broken until specifically ported to Wayland (which, in the case of legacy software, may well be never).
**Possible workaround** (to be verified): Use the (Qt proprietary?) Extended Surface Wayland protocol casually mentioned in [https://blog.broulik.de/2016/10/global-menus-returning/](https://blog.broulik.de/2016/10/global-menus-returning/) "which allows you to set (and read?) arbitrary properties on a window". Is it the `set_generic_property`
from [https://github.com/qt/qtwayland/blob/dev/src/extensions/surface-extension.xml](https://github.com/qt/qtwayland/blob/dev/src/extensions/surface-extension.xml)?
Games are developed for X11. And if you run a game on Wayland, performance is subpar due to things like forced vsync. Only recently, *some* Wayland implementations (like KDE KWin) let you disable that.
(Details to be added; apparently no 1:1 drop-in replacement available?)
`xkill`
(which I use on a regular basis) does not work with Wayland applications.
What is the equivalent for Wayland applications?
Is it true that Wayland also breaks screensavers?
[https://www.jwz.org/blog/2023/09/wayland-and-screen-savers/](https://www.jwz.org/blog/2023/09/wayland-and-screen-savers/)
Other platforms (Windows, Mac, other destop environments) can set the window position on the screen, so all cross-platform toolkits and applications expect to do the same on Wayland, but Wayland can't (doesn't want to) do it.
[PCSX2/pcsx2#10179](https://github.com/PCSX2/pcsx2/pull/10179)PCX2 (Playstation 2 Emulator) ❌ broken since 2023-10-25 ("Disables Wayland, it's super broken/buggy in basically every scenario. KDE isn't too buggy, GNOME is a complete disaster.")
Apparently color management as of 2023 (well over a decade of Wayland development) is still in the early "thinking" stage, all the while Wayland is already being pushed on people as if it was a "X11 successor".
[https://gitlab.freedesktop.org/pq/color-and-hdr/-/blob/main/doc/color-management-model.md](https://gitlab.freedesktop.org/pq/color-and-hdr/-/blob/main/doc/color-management-model.md)
According to Valve, "DRM leasing is the process which allows SteamVR to take control of your VR headset's display in order to present low-latency VR content".
- "Unfortunately not all Wayland compositors support DRM leasing"
[https://help.steampowered.com/en/faqs/view/18A4-1E10-8A94-3DDA](https://help.steampowered.com/en/faqs/view/18A4-1E10-8A94-3DDA)- "not all" highlights one of the fundamental problems with Wayland - there is fragmentation
[ValveSoftware/steam-for-linux#6148](https://github.com/ValveSoftware/steam-for-linux/issues/6148)❌ broken since 2019-03-17
Extended Window Manager Hints, a.k.a. NetWM, is an X Window System standard for the communication between window managers and applications
-
Wayland breaks window icons when no
`.desktop`
files are used: Seemingly Wayland requires developers to use the`xdg-shell`
protocol, which in turn requires developers to use reverse-DNS application IDs and[set_app_id](https://wayland.app/protocols/xdg-shell#xdg_toplevel:request:set_app_id), which causes the icon to be loaded from the`.desktop`
file. This is serious breakage, as not all desktop environments (for good reasons) use`.desktop`
files. A display server should have no business in this, as this belongs into the domain of the desktop environment.[https://community.kde.org/Guidelines_and_HOWTOs/Wayland_Porting_Notes#Application_Icon](https://community.kde.org/Guidelines_and_HOWTOs/Wayland_Porting_Notes#Application_Icon),[https://gitlab.freedesktop.org/wayland/wayland-protocols/-/issues/52](https://gitlab.freedesktop.org/wayland/wayland-protocols/-/issues/52)❌ broken since 2021-06-21 -
Qt
`setWindowIcon`
has no effect on KDE/Wayland[https://bugreports.qt.io/browse/QTBUG-101427](https://bugreports.qt.io/browse/QTBUG-101427)("Resolution: Out of scope", meaning it cannot be fixed in Qt, "Using`QT_QPA_PLATFORM=xcb`
works, though", meaning that if you disable Wayland then it works) ❌ broken since 2022-03-03 -
LibrePCB developer: "Btw it's just one of several problems we have with Wayland, therefore we still enforce LibrePCB to run with XWayland. It's a shame, but
**I feel totally helpless against such decisions made by Wayland**and using XWayland is the only reasonable option (which even works perfectly fine)..."[https://gitlab.freedesktop.org/wayland/wayland-protocols/-/issues/52#note_2155885](https://gitlab.freedesktop.org/wayland/wayland-protocols/-/issues/52#note_2155885)
**Update 6/2024:** Looks like this will get unbroken thanks to `xdg_toplevel_icon_manager_v1`
, so that [ QWindow::setIcon will work again](https://codereview.qt-project.org/c/qt/qtwayland/+/558537).
**If**, and that's a big if, all compositors will support it. At least
[KDE](https://invent.kde.org/plasma/kwin/-/merge_requests/5680)is on it.
- On Raspberry Pi OS (which is running a Wayland session by default), dragging a file out of a zip file onto the desktop fails with "XDirectSave failed."
- The same seems to be true in Gnome:
[https://discourse.gnome.org/t/xdnddirectsave-and-wayland/2954](https://discourse.gnome.org/t/xdnddirectsave-and-wayland/2954)
- Many window managers have a
`--replace`
argument, but Wayland compositors break this convention.
Xpra is an open-source multi-platform persistent remote display server and client for forwarding applications and desktop screens.
- Under Xpra a context menu cannot be used: it opens and closes automatically before you can even move the mouse on it. "It's not just GDK, it's the Wayland itself. They decided to break existing applications and expect them to change how they work." (
[Xpra-org/xpra#4246](https://github.com/Xpra-org/xpra/issues/4246)) ❌ broken since 2024-06-01
**Users:**Refuse to use Wayland sessions. Uninstall desktop environments/Linux distributions that only ship Wayland sessions. Avoid Wayland-only applications (such as[PreSonus Studio One](https://support.presonus.com/hc/en-us/articles/19214558269581-Linux-Getting-Started)) (potential workaround: run in[https://github.com/cage-kiosk/cage](https://github.com/cage-kiosk/cage))**Application developers:**Enforce running applications on X11/XWayland (like LibrePCB does as of 11/2023)
This is exactly the kind of behavior this gist seeks to prevent.
- Asahi Linux enforces Wayland for ARM-based Macs:
[https://social.treehouse.systems/@marcan/110354541574112092](https://social.treehouse.systems/@marcan/110354541574112092) - Fedora enforces Wayland for KDE Plasma:
[https://fedoraproject.org/wiki/Changes/KDE_Plasma_6#Why_drop_the_X11_session_with_the_Plasma_6_upgrade](https://fedoraproject.org/wiki/Changes/KDE_Plasma_6#Why_drop_the_X11_session_with_the_Plasma_6_upgrade)? - Red Hat enforces Wayland for RHEL:
[https://www.redhat.com/de/blog/rhel-10-plans-wayland-and-xorg-server](https://www.redhat.com/de/blog/rhel-10-plans-wayland-and-xorg-server)
- 2008: Wayland was started by krh (while at Red Hat)
- End of 2012: Wayland 1.0
- Early 2013: GNOME begins Wayland porting
Source: ["Where's Wayland?" by Matthias Clasen - Flock 2014](https://www.youtube.com/watch?v=xVVT6Lo7fGI)
A decade later... Red Hat wants to force Wayland upon everyone, removing support for Xorg
- Dudemanguy's Musings,
[Wayland Isn't Going to Save The Linux Desktop](https://dudemanguy.github.io/blog/posts/2022-06-10-wayland-xorg/wayland-xorg.html) - Chris Titus Tech: Wayland vs Xorg
[https://www.youtube.com/watch?v=U_MBJcD3SFI](https://www.youtube.com/watch?v=U_MBJcD3SFI) - tildearrow:
[did somebody say "anti-Wayland horseshit"?](https://tildearrow.org/?p=post&month=2&year=2021&item=antihs) [pcsx2: CI/Linux: Disable Wayland and spring cleaning](https://github.com/PCSX2/pcsx2/pull/10179)[Testing SCREEN RECORDERS on Linux Mint Wayland](https://www.youtube.com/watch?v=lOjs6axYOHw)- ProtonPenguin:
[Wayland Breaks Everything](https://www.youtube.com/watch?v=ebDyyx37pDI)
You say that so easily. KDE plasma e.g crashes with confidence after couple of rules OR has framebuffer issues afterwards.
GNOME was stable no matter what but didnt allow for enough customization |
16,521 | Xplorer:不仅仅是一个漂亮的开源文件管理器! | https://news.itsfoss.com/xplorer/ | 2023-12-31T16:52:38 | [
"文件管理器"
] | https://linux.cn/article-16521-1.html | 
>
> 想要换换口味,试试新的文件管理器吗?Xplorer 是一个值得关注的项目!
>
>
>
一个配备图形用户界面的操作系统最重要的部分之一就是它配备了什么样的文件管理器。这对许多人来说是一个决定成败的因素。
之所以如此,是因为**文件管理器允许用户轻松管理他们的文件和文件夹**,而无需在终端中运行命令来执行复制内容等基本任务。
通过这篇 [初体验](https://news.itsfoss.com/tag/first-look/),我将重点展示**这个跨平台文件管理器 Xplorer**,它看起来和感觉都非常现代。让我们开始吧!
>
> ? 该项目仍处于测试开发阶段。预计会出现错误和问题。
>
>
>
### Xplorer:概述 ⭐

文件管理器由 [Tauri](https://tauri.app/) 框架提供支持,使用 **Rust 作为后端**,使用 **TypeScript 作为前端**,为用户提供**独特的体验**。
它的一些**主要功能**包括:
* 跨平台
* 高度可定制
* 支持多个选项卡
#### 初步印象??
我使用可用的 AppImage 包在配备 Ubuntu 的系统上启动了它。它启动得很顺利,迎接我的是一个漂亮的“主页”页面。
有一个侧边栏,其中所有常用的文件夹和位置都整齐地排列着,并带有别致的图标。

然后我继续检查**多选项卡功能**,它的工作方式正如人们所期望的那样。从上下文(*右键单击*)菜单中,我可以在一个新选项卡中打开 “*Wallpapers*” 文件夹,我可以轻松切换到该文件夹。

即使**检查文件/文件夹的属性**也不错,它向我展示了与其相关的重要信息,例如大小、文件路径、文件类型和重要日期/时间。

这是我最喜欢的东西,它是**文件预览功能**,可以在打开文件之前显示文件的预览。有两种方法可以访问它,一种是右键单击文件并选择 “<ruby> 预览 <rt> Preview </rt></ruby>”,另一种是通过键盘快捷键:`Ctrl+O`。
此功能支持预览文件,例如**图像**、**文本**、**视频**、**markdown**,甚至**带有语法高亮的大多数编程语言**。

你可以在一定程度上**调整 Xplorer 的外观**,可以选择切换应用主题、调整字体大小/窗口透明度、文件预览功能设置等。
你还可以**创建和使用自定义主题**,有关此内容的更多信息可以在 [官方文档](https://xplorer.space/docs/Extensions/theme/) 中找到。

在“<ruby> 首选项 <rt> Preference </rt></ruby>”菜单下还有**其他设置**,你可以对其进行调整,以获得真正属于自己的使用体验。它有处理隐藏文件、系统文件、更改鼠标点击行为等选项。
你可以从侧边栏底部的“<ruby> 设置 <rt> Settings </rt></ruby>”菜单访问这些和外观。

从我使用过程中看到的情况来看,整体体验还不错。但是,也存在一些问题,例如右键单击后出现的上下文菜单。
当我尝试使用“<ruby> 打开终端 <rt> Open Terminal </rt></ruby>”选项时,它**拒绝在我的系统上启动终端模拟器**。
我承认,Xplorer 距离成为 [Linux 最佳文件管理器](https://itsfoss.com/file-managers-linux/) 之一还有很长的路要走,但我认为,你可以为此做点什么。
>
> ? **Xplorer 项目需要一些贡献者**,如果你有兴趣,请访问其 [GitHub 仓库](https://github.com/kimlimjustin/xplorer)。也许这个项目将不断发展,为我们提供出色的文件管理器体验!
>
>
>
### ? 下载 Xplorer
Xplorer 适用于 **Linux**、**Windows**、**macOS**。你可以前往 [官方网站](https://xplorer.space/) 获取适合你选择的系统的最新软件包。
>
> **[Xplorer(GitHub)](https://github.com/kimlimjustin/xplorer/releases)**
>
>
>
? 你对 Xplorer 有何看法? 更喜欢其他应用作为你的文件管理器么? 让我们知道!
*(题图:DA/6d8c02b5-b635-4dd0-8c00-2db00205f1d1)*
---
via: <https://news.itsfoss.com/xplorer/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

One of the most important parts of a GUI-equipped operating system is what kind of file manager it ships with; this can be a make it or break it factor for many.
It is that way because the **file manager allows a user to manage their files and folders with ease**, without the need to run commands in the terminal to do basic tasks such as copying stuff.
With this [first look](https://news.itsfoss.com/tag/first-look/), I focus on showcasing **a cross-platform file manager, Xplorer** that looks and feels very modern. Let's begin!
## Xplorer: Overview ⭐

Powered by the [Tauri](https://tauri.app/?ref=news.itsfoss.com) framework, the file manager uses **Rust for the backend**, and **TypeScript for the frontend** to give users** a unique experience**.
Some of its **key features** include:
**Cross-Platform****Highly Customizable****Support for Multiple Tabs**
### Initial Impressions 👨💻
I fired it up on an Ubuntu-equipped system by using the available *AppImage* package. It booted up nicely, and I was greeted with a pretty looking “Home” page.
There was a sidebar with all the usual folders and locations arranged neatly with chic looking icons.
I then went on to check out the **multiple tabs functionality**, it worked as one would expect it to. From the contextual (*right-click*) menu, I was able to open the “*Wallpapers*” folder in a new tab that I could easily switch to.
Even **checking the properties of a file/folder** was nice, it showed me important info related to it such as the size, file path, file type, and important dates/times.
This was something that I liked the most, it is **a file preview feature** that shows you the preview of a file before opening it. There were two ways to access it, one by right-clicking on a file and selecting “*Preview*”, the other was via a keyboard shortcut: “*Ctrl+O*”.
This feature supports the previewing of files such as **images**, **text**, **video**, **markdown**, and even **most programming languages with syntax highlighting**.
You can **tweak the appearance of Xplorer** to quite some extent, there are options to switch the app theme, tweak the font size/window transparency, settings for the file preview feature and more.
There is also the possibility for you to **create and use a custom theme**, more about this can be found in the [official documentation](https://xplorer.space/docs/Extensions/theme/?ref=news.itsfoss.com).
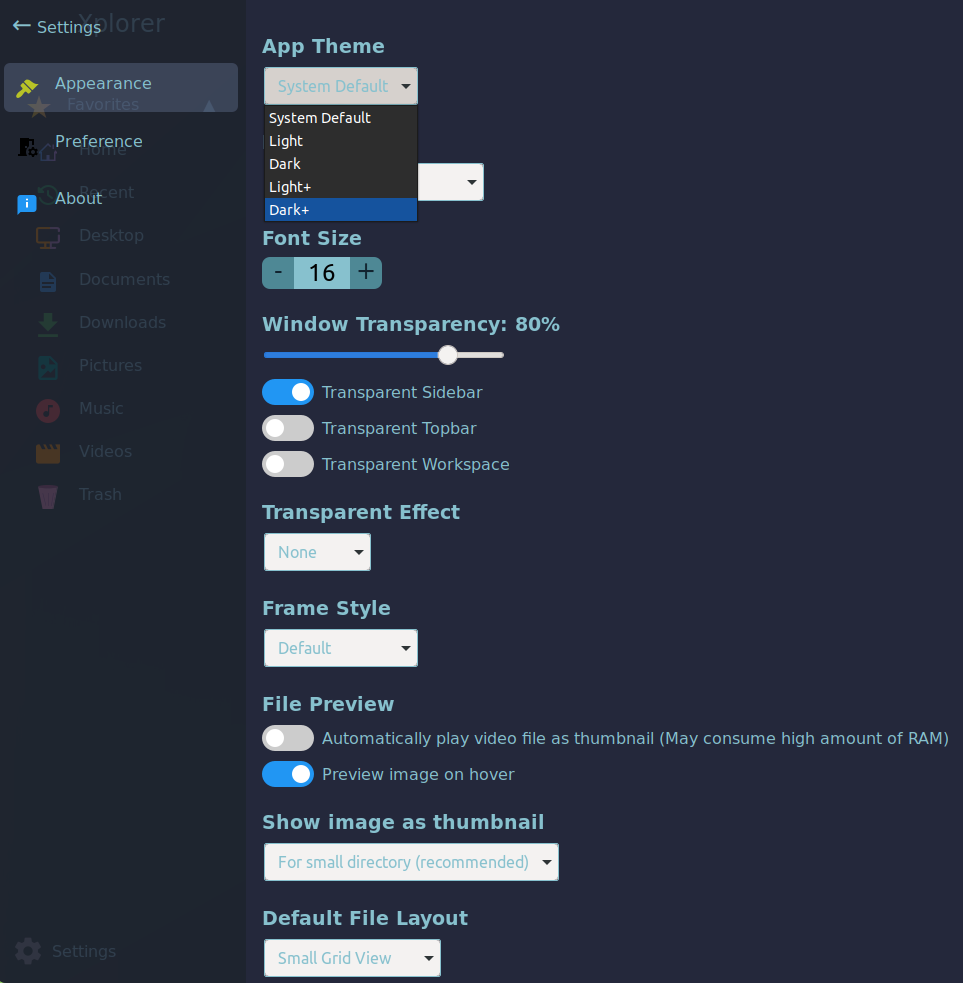
There are **other settings under the “ Preference” menu** you can tweak for making the usage experience truly yours. It has options for handling hidden files, system files, changing the mouse clicking behavior and more.
You can access this and the appearance stuff from the “*Settings*” menu found at the bottom of the sidebar.
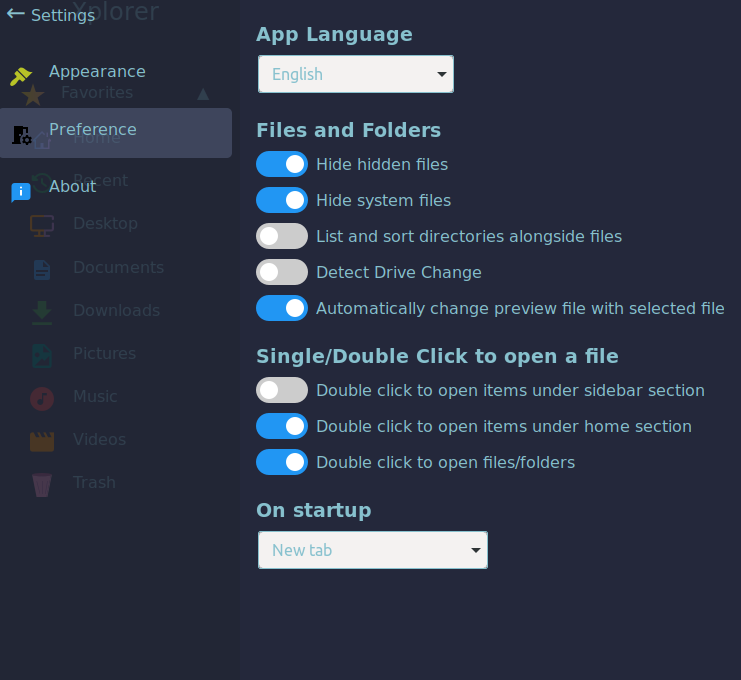
With what I saw during my use, the overall experience seems okay. But, there are also a few bugs, take for instance the contextual menu that comes up after right-clicking.
When I tried using the “*Open the Terminal*” option, it **refused to launch the terminal emulator** on my system.
I will admit, Xplorer is long ways from being one of the [best file managers for Linux](https://itsfoss.com/file-managers-linux/?ref=news.itsfoss.com), but I think, you can do something about that.
**, if you are interested, do give its**
**Xplorer project can use some contributors**[GitHub repo](https://github.com/kimlimjustin/xplorer?ref=news.itsfoss.com)a visit; and maybe the project will evolve to give us a great file manager experience!
**Suggested Read **📖
[15 Best File Managers and File Explorers for LinuxLooking for file managers and explorers for your distro? Here are some of the best options!](https://itsfoss.com/file-managers-linux/?ref=news.itsfoss.com)

## 📥 Download Xplorer
Xplorer is available for **Linux**, **Windows**, **macOS**. You can head over to the official website to get the latest package for the system of your choice.
*💬 What do you think of Xplorer? Prefer something else as your file manager? Let us know!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,523 | 在 Fedora ostree 系统上搜索软件包 | https://fedoramagazine.org/searching-for-packages-with-rpm-ostree-search/ | 2024-01-01T15:28:43 | [
"ostree",
"不可变"
] | https://linux.cn/article-16523-1.html | 
>
> 本文介绍如何使用 rpm-ostree 查找要添加到基于 ostree 的系统(例如 Silverblue 和 Kinoite)的应用。
>
>
>
基于 Fedora ostree 的系统的主要优点之一是系统的不可变性。该镜像不仅是只读的,而且是预先构建在 Fedora 服务器上的。因此,更新正在运行的系统会下载更新增量(即仅差异)并修补系统。这使得许多安装在默认情况下都是相同的。
对于大多数人来说,预构建的镜像就足够了,因为通常鼓励用户同时使用 Flatpak 安装应用,使用工具箱进行开发任务。但是,如果特定应用不符合此要求并且用户需要在主机系统上安装应用怎么办?
在这种情况下,可以选择在系统上覆盖软件包,在本地创建一个新的镜像,在标准镜像上添加软件包。
但是,我如何知道我要安装哪个包?搜索功能怎么样?
### 老方法(toolbox + dnf search)
虽然始终可以通过支持 PackageKit 的软件中心(例如 GNOME “<ruby> 软件 <rt> Software </rt></ruby>” 应用 或 KDE “<ruby> 发现 <rt> Discover </rt></ruby>” 应用)搜索软件包,但通过 CLI 来搜索软件包有点困难。
由于 `rpm-ostree` 不曾提供搜索命令,因此常见的搜索方式是使用 `toolbox enter` 进入工具箱并使用 `dnf search <搜索词>` 进行搜索。这样做的缺点是需要在工具箱中启用相同的仓库才能获得正确的搜索结果。
搜索 `neofetch` 的示例:
```
$ toolbox enter
<Note that at this point the toolbox command might request creating a toolbox, which might involve downloading a container image>
⬢[fedora@toolbox ~]$ dnf search neofetch
<snip>
=== Name Exactly Matched: neofetch ===
neofetch.noarch : CLI system information tool written in Bash
=== Summary Matched: neofetch ===
fastfetch.x86_64 : Like neofetch, but much faster because written in c
```
### 新方法(rpm-ostree search)
从 [version 2023.6](https://github.com/coreos/rpm-ostree/releases/tag/v2023.6) 开始,`rpm-ostree` 支持 `search` 命令,允许用户使用 `rpm-ostree` 搜索可用的软件包。一个示例命令是:
```
rpm-ostree search *kernel
```
要使用搜索命令,请首先确保你使用的是 `rpm-ostree` 2023.6 或更高版本:
```
$ rpm-ostree --version
rpm-ostree:
Version: '2023.8'
Git: 9a99d0af32640b234318815a256a2d11e35fa64c
Features:
- rust
- compose
- container
- fedora-integration
```
如果满足版本要求,你应该能够运行 `rpm-ostree search <搜索词>`。
这是一个使用 `rpm-ostree search` 搜索 `neofetch` 的示例:
```
$ rpm-ostree search neofetch
===== Name Matched =====
neofetch : CLI system information tool written in Bash
===== Summary Matched =====
fastfetch : Like neofetch, but much faster because written in c
```
*(题图:DA/5d27838e-6068-46a6-9bca-4ec486d65c46)*
---
via: <https://fedoramagazine.org/searching-for-packages-with-rpm-ostree-search/>
作者:[Mateus Rodrigues Costa](https://fedoramagazine.org/author/mateusrodcosta/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article descibes how to find an application to add to your ostree based system (such as Silverblue and Kinoite) using rpm-ostree.
One of the main benefits of the Fedora ostree-based systems is the immutability of the system. Not only is the image read-only, it’s also pre-built on the Fedora servers. Thus, updating a running system downloads the update deltas (that is, only the differences) and patches the system. This makes the many installations identical by default.
A pre-built image will be good enough for most people, since users are normally encouraged to use both flatpaks for applications and toolbox for development tasks. But what if the specific application doesn’t fit this and the user requires installing applications on the host system?
Well, in this case the option is to overlay the packages on the system, creating a new image locally with the added package on top of the standard image.
But, how do I know what package I want to install? What about search functionality?
## The old way (*toolbox* + *dnf search*)
While it has always been possible to search for packages via the PackageKit-enabled Software Center (such as GNOME Software or KDE Discover), it has been a bit harder to do so via CLI.
Since *rpm-ostree* didn’t use to offer a search command, the common way to search has been to enter a toolbox with *toolbox enter* and search using *dnf search <search term>*. This has the downside of requiring the same repositories be enabled in the toolbox in order to get proper search results.
Example for searching for *neofetch*:
$toolbox enter<Note that at this point the toolbox command might request creating a toolbox, which might involve downloading a container image> ⬢[fedora@toolbox ~]$dnf search neofetch<snip> === Name Exactly Matched: neofetch === neofetch.noarch : CLI system information tool written in Bash === Summary Matched: neofetch === fastfetch.x86_64 : Like neofetch, but much faster because written in c
## The new way (*rpm-ostree search*)
Since [version 2023.6](https://github.com/coreos/rpm-ostree/releases/tag/v2023.6), *rpm-ostree* supports the “search” verb allowing users to use rpm-ostree to search for available packages. An example command for this is:
rpm-ostree search *kernel
To use the search verb, first make certain you are using *rpm-ostree* version 2023.6 or later:
$rpm-ostree --versionrpm-ostree: Version: '2023.8' Git: 9a99d0af32640b234318815a256a2d11e35fa64c Features: - rust - compose - container - fedora-integration
If the version requirement is satisfied, you should be able to run *rpm-ostree search <search terms>*.
Here is an example, searching for neofetch with *rpm-ostree search*:
$rpm-ostree search neofetch===== Name Matched ===== neofetch : CLI system information tool written in Bash ===== Summary Matched ===== fastfetch : Like neofetch, but much faster because written in c
## Michal Konečný
That are great news. This functionality was really missing in rpm-ostree.
## James
That is really cool. It would be extra special nice if some functionality could be included to allow importing of repos and associated gpg keys. Right now we have to copy them manually. |
16,526 | 人工智能教程(五):Anaconda 以及更多概率论 | https://www.opensourceforu.com/2022/12/ai-anaconda-and-more-on-probability/ | 2024-01-02T16:18:02 | [
"AI",
"人工智能"
] | https://linux.cn/article-16526-1.html | 
>
> 在本系列的第五篇文章中,我们将继续介绍概率和统计中的概念。
>
>
>
在本系列的 [前一篇文章](/article-16485-1.html) 中,我们首先介绍了使用 TensorFlow。它是一个非常强大的开发人工智能和机器学习应用程序的库。然后我们讨论了概率论的相关知识,为我们后面的讨论打下基础。在本系列的第五篇文章中,我们将继续介绍概率和统计中的概念。
在本文中我将首先介绍 Anaconda,一个用于科学计算的 Python 发行版。它对于开发人工智能、机器学习和数据科学的程序特别有用。稍后我们将介绍一个名为 Theano 的 Python 库。但在此之前,让我们下讨论一下人工智能的未来。
在回顾和修订之前的文章时,我发觉我偶尔对人工智能前景的怀疑语气和在一些话题上毫不留情的诚实态度可能在无意中使部分读者产生了消极情绪。
这促使我开始从金融角度研究人工智能和机器学习。我想确定涉足人工智能市场的公司类型,是否有重量级的公司大力参与其中?还是只有一些初创公司在努力推动?这些公司未来会向人工智能市场投入多少资金?是几百万美元,几十亿美元还是几万亿美元?
我通过于最近知名报纸上的的预测和数据来理解基于人工智能的经济发展背后的复杂动态性。2020 年《福布斯》上的一篇文章就预测 2020 年企业在人工智能上投入的投入将达到 500 亿美元的规模。这是一笔巨大的投资。《财富》杂志上发表的一篇文章称,风险投资者正将部分关注力从人工智能转移到 Web3 和<ruby> 去中心化金融 <rt> decentralised finance </rt></ruby>(DeFi)等更新潮的领域上。但《华尔街日报》在 2022 年自信地预测,“大型科技公司正在花费数十亿美元进行人工智能研究。投资者应该密切关注。”
印度《商业标准报》在 2022 年报道称,87% 的印度公司将在未来 3 年将人工智能支出提高 10%。总的来说,人工智能的未来看起来是非常安全和光明的。 令人惊讶的是,除了亚马逊、Meta(Facebook 的母公司)、Alphabet(谷歌的母公司)、微软、IBM 等顶级科技巨头在投资人工智能外,壳牌、强生、联合利华、沃尔玛等非 IT 科技类公司也在大举投资人工智能。
很明显众多世界级大公司都认为人工智能将在不久的将来发挥重要作用。但是未来的变化和新趋势是什么呢?我通过新闻文章和采访找到一些答案。在人工智能未来趋势的背景下,经常提到的术语包括<ruby> 负责任的人工智能 <rt> Responsible AI </rt></ruby>、量子人工智能、人工智能物联网、人工智能和伦理、自动机器学习等。我相信这些都是需要深入探讨的话题,在上一篇文章中我们已经讨论过人工智能和伦理,在后续的文章中我们将详细讨论一些其它的话题。
### Anaconda 入门
现在让我们讨论人工智能的必要技术。Anaconda 是用于科学计算的 Python 和 R 语言的发行版。它极大地简化了包管理过程。从本文开始,我们将在有需要时使用 Anaconda。第一步,让我们安装 Anaconda。访问 [安装程序下载页面](https://www.anaconda.com/products/distribution#linux) 下载最新版本的 Anaconda 发行版安装程序。在撰写本文时(2022 年 10 月),64 位处理器上最新的 Anaconda 安装程序是 `Anaconda3-2022.05-Linux-x86_64.sh`。如果你下载了不同版本的安装程序,将后面命令中的文件名换成你实际下载的安装文件名就行。下载完成后需要检查安装程序的完整性。在安装程序目录中打开一个终端,运行以下命令:
```
shasum -a 256 Anaconda3-2022.05-Linux-x86_64.sh
```
终端上会输出哈希值和文件名。我的输出显示是:
```
a7c0afe862f6ea19a596801fc138bde0463abcbce1b753e8d5c474b506a2db2d Anaconda3-2022.05-Linux-x86_64.sh
```
然后访问 [Anaconda 安装程序哈希值页面](https://docs.anaconda.com/anaconda/install/hashes),比对下载安装文件的哈希值。如果哈希值匹配,说明下载文件完整无误,否则请重新下载。然后在终端上执行以下命令开始安装:
```
bash Anaconda3-2022.05-Linux-x86_64.sh
```
按回车键后,向下滚动查看并接受用户协议。最后,输入 `yes` 开始安装。出现用户交互提示时,一般直接使用 Anaconda 的默认选项就行。现在 Anaconda 就安装完成了。
默认情况下,Anaconda 会安装 Conda。这是一个包管理器和环境管理系统。Anaconda 发行版会自动安装超过 250 个软件包,并可选择安装超过 7500 个额外的开源软件包。而且使用 Anaconda 安装的任何包或库都可以在 Jupyter Notebook 中使用。在安装新包的过程中, Anaconda 会自动处理它的依赖项的更新。
至此之后我们终于不用再担心安装软件包和库的问题了,可以继续我们的人工智能和机器学习程序的开发。注意,Anaconda 只有一个命令行界面。好在我们的安装项中包括 Anaconda Navigator。这是一个用于 Anaconda 的图形用户界面。在终端上执行命令 `anaconda-navigator` 运行 Anaconda Navigator(图 1)。我们马上会通过例子看到它的强大功能。

### Theano 介绍
Theano 是一个用于数学表达式计算的优化编译的 Python 库。在 Anaconda Navigator 中安装Theano 非常容易。打开 Anaconda Navigator 后点击 “<ruby> 环境 <rt> Environments </rt></ruby>” 按钮(图 1 中用红框标记)。在打开的窗口中会显示当前安装的所有软件包的列表。在顶部的下拉列表中选择“<ruby> 尚未安装 <rt> Not installed </rt></ruby>”选项。向下滚动并找到 Theano,然后勾选左侧的复选框。点击窗口右下角的绿色 “<ruby> 应用 <rt> Apply </rt></ruby>” 按钮。Anaconda 会在弹出菜单中显示安装 Theano 的所有依赖项。图 2 是我安装 Theano 时的弹出菜单。可以看到,除了 Theano 之外,还安装了一个新的包,并修改了 8 个包。
想象一下,如果要手动安装 Theano,这将是多么麻烦。有了 Anaconda,我们只需要点几个按钮就行了。只需要等待一会儿,Theano 就安装好了。现在我们可以在 Jupyter Notebook 中使用 Theano 了。

我们已经熟悉了用于符号计算的 Python 库 SymPy,但 Theano 将符号计算提升到了一个新的水平。图 3 是一个使用 Theano 的例子。第 1 行代码导入 Theano。第 2 行导入 `theano.tensor` 并将其命名为 `T`。我们在介绍 TensorFlow 时已经介绍过<ruby> 张量 <rt> tensor </rt></ruby>了。

在数学上,可以将张量看作多维数组。张量是 Theano 的关键数据结构之一,它可用于存储和操作标量(数字)、向量(一维数组)、矩阵(二维数组)、张量(多维数组)等。在第 3 行中,从 Theano 导入了 `function()` 的函数。第 4 行导入名为 `pp()` 的 Theano 函数,该函数用于格式化打印。第 5 行创建了一个名为 `x` 的 `double` 类型的标量符号变量。你可能会在理解符号变量这个概念上遇到一些困难。这里你可以把它看作是没有绑定具体值的 `double` 类型的对象。类似地,第 6 行创建了另一个名为 `y` 的标量符号变量。第 7 行告诉 Python 解释器,当符号变量 `x` 和 `y` 得到值时,将这些值相加并存储在 `a` 里面。
为了进一步解释符号操作,仔细看第 8 行的输出是 `(x+y)`。这表明两个数字的实际相加还没有发生。第 9 到 11 行类似地分别定义了符号减法、乘法和除法。你可以自己使用函数 `pp()` 来查找 `b`、`c` 和 `d` 的值。第 12 行非常关键。它使用 Theano 的 `function()` 函数定义了一个名为 `f()` 的新函数。 函数 `f()` 的输入是 `x` 和 `y`,输出是 `[a b c d]`。最后在第 13 行中,给函数 `f()` 提供了实际值来调用该函数。该操作的输出也显示在图 3 中。我们很容易验证所显示的输出是正确的。

下面让我们通过图 4 的代码来看看如何使用 Theano 创建和操作矩阵。需要注意的是,图中我省略了导入代码。如果你要直接运行图 4 的代码,需要自己添加上这几行导入代码(图 3 中的前三行)。第 1 行创建了两个符号矩阵 `x` 和 `y`。这里我使用了<ruby> 复数构造函数 <rt> plural constructor </rt></ruby> `imatrices`,它可以同时构造多个矩阵。第 2 行到第 4 行分别对符号矩阵 `x` 和 `y` 执行符号加法、减法和乘法。这里你可以使用 `print(pp(a))`、`print(pp(b))` 和 `print(pp(c))` 来帮助理解符号操作的性质。第 5 行创建了一个函数 `f()`,它的输入是两个符号矩阵 `x` 和 `y`,输出是 `[a b c]`,它们分别表示符号加法、减法和乘法。最后,在第 6 行中,为函数 `f()` 提供实际的值来调用该函数。该操作的输出也显示在图 4 中。很容易验证所示的三个输出矩阵是否正确。注意,除了标量和矩阵,张量还提供了向量、行、列类型张量的构造函数。Theano 暂时就介绍到这里了,在讨论概率和统计的进阶话题时我们还会提到它。
### 再来一点概率论

现在我们继续讨论概率论和统计。我在上一篇文章中我建议你仔细阅读三篇维基百科文章,然后介绍了正态分布。在我们开始开发人工智能和机器学习程序之前,有必要回顾一些概率论和统计的基本概念。我们首先要介绍的是 <ruby> 算术平均值 <rt> arithmetic mean </rt></ruby>和<ruby> 标准差 <rt> standard deviation </rt></ruby>。
算术平均值可以看作是一组数的平均值。标准差可以被认为是一组数的分散程度。如果标准差较小,则表示集合中的元素都接近平均值。相反,如果标准差很大,则表示集合的中的元素分布在较大的范围内。如何使用 Python 计算算术平均值和标准差呢?Python 中有一个名为 `statistics` 的模块,可用于求平均值和标准差。但专家用户认为这个模块太慢,因此我们选择 NumPy。
图 5 所示的代码打印两个列表 `C1` 和 `C2` 的平均值和标准差(我暂时隐藏了两个列表的实际内容)。你能从这些值中看出什么呢?目前它们对你来说只是一些数字而已。现在我告诉你,这些列表分别包含学校 A 和学校 B 的 6 名学生的数学考试成绩(满分 50 分,及格 20 分)。均值告诉我们,两所学校的学生平均成绩都较差,但学校 B 的成绩略好于学校 A。标准差值告诉我们什么呢?学校 B 的巨大的标准差值虽然隐藏在平均值之下,但却清楚地反映了学校 B 的的教学失败。为了进一步加深理解,我将给出两个列表的值,`C1 =[20,22,20,22,22,20]` ,`C2 =[18,16,17,16,15,48]`。这个例子清楚地告诉我们,我们需要更复杂的参数来处理问题的复杂性。概率和统计将提供更复杂的模型来描述复杂和混乱的数据。
随机数生成是概率论的重要组成部分。但实际上我们只能生成伪随机数。伪随机数序列具有和真随机数序列近似的性质。在图 6 中我们介绍了几个生成伪随机数的函数。第 1 行导入 Python 的 `random` 包。第 2 行代码生成两个随机数,并将它们存储在名为 `new_list` 的列表中。其中函数 `random.random()` 生成随机数,代码 `new_list = [random.random() for i in range(2)]` 使用了 Python 的<ruby> 列表推导 <rt> list comprehension </rt></ruby>语法。第 3 行将此列表打印输出。注意,每次执行代码打印出的两个随机数会变化,并且连续两次打印出相同数字的概率理论上为 0。图 6 的第二个代码单元中使用了 `random.choice()` 函数。这个函数从给定的选项中等概率地选择数据。代码片 `random.choice(["Heads", "Tails"])` 将等概率地在“Heads”和“Tails”之间选择。注意,该行代码也使用了列表推导,它会连续执行 3 次选择操作。从图 6 的输出可以看到,三次都选中了“Tails”。

现在,我们用一个简单的例子来说明概率论中著名的<ruby> 大数定理 <rt> xxx </rt></ruby>。大数定理表明从大量试验中获得的结果的平均值应该接近期望值,并且随着试验次数的增加这个平均值会越来越接近期望值。我们都知道,投掷一个均匀的骰子得到数字 6 的概率是 1/6。我们用图 7 中的 Python 代码来模拟这个实验。第 1 行导入 Python 的 `random` 包。第 2 行设置重复试验的次数为 1000。第 3 行将计数器 `ct` 初始化为 0。第 4 行是一个循环,它将迭代 1000 次。第 5 行的 `random.randint(1, 6)` 随机生成 1 到 6 之间的整数(包括 1 和 6)。然后检查生成的数字是否等于 6;如果是,则转到第 7 行,将计数器 `ct` 增加 1。循环迭代 1000 次后,第 8 行打印数字 6 出现的次数与总试验次数之间的比例。图 7 显示该比例为 0.179,略高于期望值 1/6 = 0.1666…。这与期望值的差异还是比较大的。将第 2 行中 `n` 的值设置为 10000,再次运行代码并观察打印的输出。很可能你会得到一个更接近期望值的数字(它也可能是一个小于期望值的数字)。不断增加第 2 行中 `n` 的值,你将看到输出越来越接近期望值。

虽然大数定理的描述朴实简单,但如果你了解到哪些数学家证明了大数定理或改进了原有的证明,你一定会大吃一惊的。他们包括卡尔达诺、雅各布·伯努利、丹尼尔·伯努利、泊松、切比雪夫、马尔科夫、博雷尔、坎特利、科尔莫戈罗夫、钦钦等。这些都是各自领域的数学巨匠。
目前我们还没有涵盖概率的随机变量、概率分布等主题,它们对开发人工智能和机器学习程序是必不可少的。我们对概率和统计的讨论仍处于初级阶段,在下一篇文章中还会加强这些知识。与此同时,我们将重逢两个老朋友,Pandas 和 TensorFlow。另外我们还将介绍一个与 TensorFlow 关系密切的库 Keras。
*(题图:DA/ea8d9b6a-5282-41ad-a84f-3e3815e359fb)*
---
via: <https://www.opensourceforu.com/2022/12/ai-anaconda-and-more-on-probability/>
作者:[Deepu Benson](https://www.opensourceforu.com/author/deepu-benson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In the previous article in this series on AI and machine learning, we began by exploring the intricacies of using TensorFlow, a very powerful library used for developing AI and machine learning applications. Then, we discussed probability and paved the way for many of our future discussions. In this article, the fifth in the series, we will continue exploring concepts in probability and statistics.*
To begin with, let us first install Anaconda, a distribution of Python for scientific computing especially useful for developing AI, machine learning and data science based applications. Later, we will also introduce a Python library called Theano in the context of probability theory. But before doing that, let us discuss the future of AI a little bit.
While going through the earlier articles in this series for evaluation and course correction, I wondered whether my tone was a bit sceptical at times while discussing the future of AI. By being brutally honest about some of the topics we discussed, I may have inadvertently demotivated a tiny fraction of the readers and potential practitioners of AI.
This made me research the financial aspects of AI and machine learning. I wanted to identify the kind of companies involved in the AI market. Are the bigwigs heavily involved or are there just some startups trying to move away from the pack? Another important question was: how much money will be pumped into the AI market by these companies in the near future? Is it going to be just a couple of million, or a few billion or maybe even a few trillion?
For the predictions and data stated here, I depended on articles published in respected newspapers in the recent past rather than on scholarly articles which I couldn’t grasp well to understand the complex dynamics behind the development of an AI based economy. An article published by Forbes in had 2020 predicted that companies would spend 50 billion dollars on AI in financial year 2020. Well, that is a really huge investment, even if we acknowledge that the American billion (109) is just one-thousandth of the British billion (1012). An article published in Fortune, another American business magazine, reported that venture capitalists are shifting some of their focus from artificial intelligence to newer and trendier fields like Web3 and decentralised finance (DeFi). But The Wall Street Journal (an American business-focused newspaper) in 2022 confidently predicted that, ‘Big Tech Is Spending Billions on AI Research. Investors Should Keep an Eye Out’.
What about the Indian scenario? Business Standard reported in 2022 that 87 per cent of the Indian companies will hike their AI expenditure by 10 per cent in the next three years. So, overall, it looks like the future of AI is very safe and bright. But which are the top companies investing in AI? As expected, all the giants like Amazon, Meta (Facebook), Alphabet (Google), Microsoft, IBM, etc, are doing so. But, surprisingly, companies like Shell, Johnson & Johnson, Unilever, Walmart, etc, whose primary focus is neither computing nor information technology, are also in the list of big companies heavily investing in AI. And yes! Amazon is a tech company and not an e-commerce company.
So it is clear that many of the giant companies in the world believe that AI is going to play a prominent role in the near future. But what changes and new trends are these leaders expecting in the future? Again, to find some answers, I depended on news articles and interviews, rather than on scholarly articles. The terms frequently mentioned in context with future trends in AI include responsible AI, quantum AI, IoT with AI, AI and ethics, automated machine learning, etc. I believe these are vast topics and we will discuss some of these terms (except AI and ethics, which we already discussed in the last article) in detail, in the coming articles in this series.
## An introduction to Anaconda
Let us now move to discussing the necessary tech for AI. From this article onwards, we will start using Anaconda whenever necessary. Anaconda is a distribution of the Python and R programming languages for scientific computing. It helps a lot by simplifying package management.
Now, let us install Anaconda. First, go to the web page[ https://www.anaconda.com/products/distribution#linux](https://www.anaconda.com/products/distribution#linux) and download the latest version of the Anaconda distribution installer. Open a terminal in the directory to which the distribution installer is downloaded. As of writing this article (October 2022), the latest Anaconda distribution installer for systems with 64-bit processors is Anaconda3-2022.05-Linux-x86_64.sh. In order to check the integrity of the installer, run the following command on the terminal:
shasum -a 256 Anaconda3-2022.05-Linux-x86_64.sh
If you have downloaded a different version of the installer, then use the name of that version after the command ‘shasum -a 256’. You will see a hash value displayed on the terminal, followed by the name of the installer. In my case, the line displayed was:
a7c0afe862f6ea19a 596801fc138bde0463 abcbce1b753e8d5c474b506a2db2d Anaconda3-2022.05-Linux-x86_64.sh
Now, go to the web page https://docs.anaconda.com/anaconda/install/hashes and go to the hash value of the corresponding version of the installer you have downloaded. Make sure that you continue with the installation of Anaconda only if the hash value displayed on the terminal and the hash value given in the web page are exactly the same. If the hash values do not match, then the installer downloaded is corrupted. In this case, restart the installation process once again. Now, if the hash values match, execute the following command on the terminal to begin the installation:
bash Anaconda3-2022.05-Linux-x86_64.sh
But in case you have downloaded a different installer, then use the appropriate name after the command bash. Now, press Enter, scroll down to go through the agreement and accept it. Finally, type ‘yes’ to start the installation. Whenever a prompt appears, stick to the default option provided by Anaconda (unless you have a very good reason not to do so). Now, the Anaconda installation is finished.
Anaconda installation by default also installs Conda, a package manager and environment management system. Wikipedia says that the Anaconda distribution comes with over 250 packages automatically installed, with the option of installing over 7500 additional open source packages. The most important thing to remember is that whatever package or library you have installed by using Anaconda can be used in your Jupyter Notebook also. Whatever updation is required by other packages or libraries during the installation of a new package will be automatically handled by Anaconda carefully, without bothering you in the least.
So, finally, we have reached a place in our journey where we no longer need to worry about installing the new packages and libraries necessary to continue our quest for developing AI and machine learning based applications. Notice that Anaconda only has a command-line interface (CLI). Are we in trouble? No! Our installation also gives us Anaconda Navigator, a graphical user interface (GUI) for Anaconda. Execute the command ‘anaconda-navigator’ on the terminal to run Anaconda Navigator (Figure 1). Soon, we will see an example of its power.


## Introduction to Theano
Now, let us try to work with Theano, a Python library and optimising compiler for evaluating mathematical expressions. The installation of Theano is very easy since we have Anaconda Navigator. First, open Anaconda Navigator. On the top right corner you will see the button Environments (marked with a red box in Figure 1). Press that button. You will go to a window showing the list of all currently installed packages. From the drop-down list on top, choose the option Not installed. Scroll down, find the option Theano, and click on the checkbox on the left. Now press the green button named Apply at the bottom right corner of the window. Anaconda will find out all the dependencies for installing Theano and show them in a pop-up menu. Figure 2 shows the pop-up menu I got during the installation of Theano in my system. You can see that in addition to Theano, one more new package is installed and eight other packages are modified.
Imagine how difficult this would have been if I was trying to manually install Theano. But with the help of Anaconda, all we need to do is press the button Apply on the bottom right corner of this pop-up menu. After a while, the installation of Theano will be completed smoothly. Now, we are ready to use Theano in our Jupyter Notebooks.
We are already familiar with the Python library called SymPy used for symbolic calculation but Theano takes it to the next level. Let us see a simple example to understand the power of Theano. Consider the code shown in Figure 3. First, let us try to understand the code. Line 1 of the code imports Theano. Line 2 imports tensor and names it T. We have already encountered tensors when we discussed TensorFlow.


Mathematically, tensors can be treated as multi-dimensional arrays. Tensor is one of the key data structures used in Theano and can be used to store and manipulate scalars (numbers), vectors (1-dimensional arrays), matrices (2-dimensional arrays), tensors (multi-dimensional arrays), etc. In Line 3, a Theano function called function( ) is imported. Line 4 imports a Theano function called pp( ), which is used for pretty-printing (printing in a format appealing to humans). Line 5 creates a symbolic scalar variable of type double called x. It is a bit tricky to understand these sorts of symbolic variables. Think of it as a 0-sized double variable with no value or storage associated. Similarly, Line 6 creates another symbolic scalar variable called y. Line 7 acts like a function in a sense. This line tells the Python interpreter something like the following, ‘if and when symbolic scalar variables x and y get some values, add those values and store inside me’.
To further illustrate symbolic operations at this point, let us try to understand Line 8.

From Figure 3, it is clear that the output of this line of code is (x+y). So, it is clear that actual addition of two numbers is yet to take place. Lines 9 to 11 similarly define symbolic subtraction, multiplication, and division, respectively. If you want further clarity, use the function pp( ) to find the values of b, c, and d. Line 12 is very critical. It defines a function named f( ) using the function function( ) of Theano. The function function( ) takes two parameters. Parameter 1 is the data to be operated upon and parameter 2 is the function to be applied on the data given as parameter 1. Here, the data is the two symbolic scalar variables x and y. The function is given by [a b c d] which represents symbolic addition, subtraction, multiplication, and division, respectively. Finally, in Line 13, the function f( ) is provided with actual values rather than symbolic ones. The output of this operation is also shown in Figure 3. It is very easy to verify that the output shown is correct.
Now, let us see how matrices can be created and manipulated using Theano. Consider the code shown in Figure 4. It is important to note that the first three lines of code shown in Figure 3 should be added here also, if you are writing this program independent of the programs we have discussed so far. Now, let us try to understand the code. Line 1 of the code creates two symbolic matrices x and y. Think of x and y as two 0-dimensional arrays. But this time these matrices are of type integer unlike the last time where the data type was double. Further, this time a plural constructor (imatrices) is used so that more than one matrix can be constructed at the same time. Lines 3 to 5 perform symbolic addition, subtraction, and multiplication, respectively, on symbolic matrices x and y. Here again you can use print(pp(a)), print(pp(b)), and print(pp(c)) to better understand the symbolic nature of the operations being performed. If you add these lines of code, you will get (x+y), (x-y), and (x \dot y), respectively, as output. Line 5 generates a function f( ) which takes two parameters as before. Again, parameter 1 is the data to be operated upon and parameter 2 is the function to be applied on the data given as parameter 1. But this time, the data is the two symbolic matrices x and y. The function is given by [a b c] which represents symbolic addition, subtraction, and multiplication, respectively. Finally, in Line 6, the function f( ) is provided with actual values rather than symbolic ones. The two matrices given as input to f( ) are [[1, 2], [3, 4]] and [[5, 6], [7, 8]]. The output of this operation is also shown in Figure 4. It is very easy to verify that the three output matrices shown are correct. Notice that, in addition to scalars and matrices (for both of which we saw examples now), tensor also offers constructors like vector, row, column, different types of tensors, etc. Let us stop discussing Theano for now and revisit it while discussing advanced topics in probability and statistics.
## Baby steps with probability
Now, let us continue discussing probability and statistics. I had suggested in the last article (while introducing probability) that you carefully go through three Wikipedia articles, and with that assumption of familiarity I tried to motivate you by discussing the Normal distribution. However, we must revisit some of the basic notions of probability and statistics before we start developing AI and machine learning based applications. I hope all of you have heard about arithmetic mean and standard deviation (SD).
Arithmetic mean can be thought of as the average of a set of values. SD can be thought of as the variation or dispersion of a set of values. If the SD value is low then the elements in the set tend to be closer to the mean. On the contrary, if the SD value is high then the elements of the set are spread out over a wider range. But how can we calculate arithmetic mean and SD using Python? There is a module called statistics available with Python which can be used to find mean and standard deviation. However, experts are of the opinion that this module is very slow and hence we choose NumPy. Now, consider the code shown in Figure 5.
The code prints the mean and standard deviation of two lists C1 and C2 (whose values are hidden from you for the time being because of obvious reasons). What interpretations can you make from these values? Nothing! They are just numbers for you right now. But what if I tell you the lists contain the marks of six students, studying in 10th standard in school A and school B, for an exam in mathematics (the exam is out of 50 with a pass mark of 20). The mean value tells us that students from both the schools have relatively poor average marks with school B slightly outperforming school A. But what does the standard deviation value tell us? To further your understanding, I will give you the two lists, ‘C1 = [20, 22, 20, 22, 22, 20]’ and ‘C2 = [18, 16, 17, 16, 15, 48]’. Though hidden by the mean, the large standard deviation value of 11.813363431112899 clearly captures the mass failure in school B. This example clearly tells us that we need more complicated parameters to understand the complex nature of the problems we deal with. Probability and statistics will come to our rescue here by providing more and more complex models which can imitate complex and chaotic data.
Random number generation is an essential part of probability. But, in practice, only pseudorandom number generation (a sequence of numbers whose properties approximate the properties of sequences of random numbers) is possible. Now, let us see a few functions that will help us generate pseudorandom numbers. Consider the code shown in Figure 6. First, let us try to understand the code. Line 1 imports the random package of Python. In Line 2, the function random.random( ) generates random numbers. This line of code, ‘new_list = [random.random() for i in range(2)]’, uses a technique called list comprehension to generate two random numbers and store them in the list named new_list. Line 3 prints this list as output. Notice that the two random numbers printed change with each iteration of the code, and the probability of getting the same numbers printed twice consecutively is theoretically zero. The single line of code in the second cell shown in Figure 6 uses the function random.choice( ). This function makes an equally likely choice from all the choices given to it. In this case, the code fragment random.choice([“Heads”, “Tails”]) will make a choice between ‘Heads’ or ‘Tails’ with equal probability. Notice that this line of code also uses the technique called list comprehension so that three successive choices between ‘Heads’ or ‘Tails’ are made. Figure 6 shows the output of this code, where the option ‘Tails’ is chosen for three consecutive times.
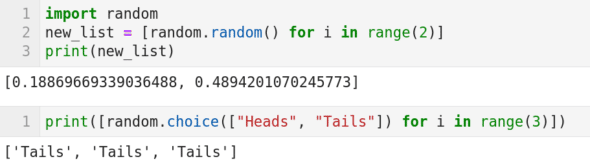
Now, let us try to illustrate a very popular theorem in probability, the law of large numbers (LLN), with a simple example. LLN states that the average of the results obtained from a large number of trials should be close to the expected value. Further, this average tends to come closer and closer to the expected value as more and more trials are performed. We all know that if a fair dice is thrown, the probability of getting the number 6 is 1/6. We now simulate this experiment with a simple Python code shown in Figure 7. Line 1 imports the random package of Python. Line 2 sets the number of trials to be performed. In this case, it is 1000. Line 3 initialises the counter ct to zero. Line 4 sets a loop, which iterates 1000 times in this case. Line 5 uses the function random.randint(1, 6). In this case, the function generates an integer between 1 and 6 (inclusive of both 1 and 6) randomly. The if statement in Line 5 checks whether the number generated is equal to 6; if yes the control goes to Line 7 and increases the counter ct by 1. After the loop is iterated a 1000 times, Line 8 will be executed. Line 8 prints the ratio between the number of occurrences of the number 6 and the total number of trials (1000). Figure 7 also shows this number as 0.179 (slightly more than the expected value 1/6 = 0.1666…which is also printed in the output). Not that close to the expected value, right? In Line 2, set the value of n as 10000. Run the code again and observe the new output printed. Most probably you will get a number which is a little bit closer to the expected value. Notice that this could also be a number less than the expected value. Increase the value of n, in Line 2, for a few more times. You will observe that the output is inching closer and closer to the expected value. Thus, with a simple code, we have illustrated LLN.
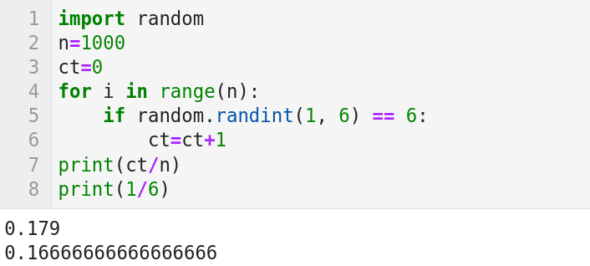
Though a simple statement, you will be amazed to know that the list of mathematicians who worked on a proof for LLN or tried to refine one include Cardano, Jacob Bernoulli, Daniel Bernoulli, Poisson, Chebyshev, Markov, Borel, Cantelli, Kolmogorov, Khinchin, etc. All of them are mathematical giants in their own field.
We are yet to cover topics in probability like random variables, probability distributions, etc, which are essential in developing AI and machine learning based applications. Our discussion of topics in probability and statistics is still in the early stages and we will try to strengthen our knowledge of these subjects in the next article also. At the same time, we will revisit two of our old friends we met in this journey earlier, the libraries Pandas and TensorFlow. We will also befriend a relative of TensorFlow called Keras, a library which acts as an interface for TensorFlow. |