
url
stringlengths 60
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 74
75
| comments_url
stringlengths 69
70
| events_url
stringlengths 67
68
| html_url
stringlengths 48
51
| id
int64 754M
1.76B
| node_id
stringlengths 18
32
| number
int64 955
5.95k
| title
stringlengths 1
290
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 69
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).\r\n\r\n[^1]: More or less, see https://github.com/yargs/yargs/issues/873.",
"Opened https://github.com/huggingface/datasets/pull/5436 unpinning again the container image.",
"Hi @0x2b3bfa0, thanks a lot for the investigation, the context about the the root cause and for fixing it!!\r\n\r\nWe are reviewing your PR to unpin the container image."
] | 2023-01-17T09:06:08Z | 2023-01-18T06:29:08Z | 2023-01-18T06:29:08Z | MEMBER | null | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5432/comments | https://api.github.com/repos/huggingface/datasets/issues/5432/events | https://github.com/huggingface/datasets/pull/5432 | 1,535,893,019 | PR_kwDODunzps5HhEA8 | 5,432 | Fix CI benchmarks by temporarily pinning Docker image version | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008519 / 0.011353 (-0.002834) | 0.004451 / 0.011008 (-0.006558) | 0.102401 / 0.038508 (0.063893) | 0.029779 / 0.023109 (0.006669) | 0.302654 / 0.275898 (0.026756) | 0.366002 / 0.323480 (0.042522) | 0.007044 / 0.007986 (-0.000942) | 0.003350 / 0.004328 (-0.000978) | 0.078213 / 0.004250 (0.073963) | 0.035208 / 0.037052 (-0.001844) | 0.312980 / 0.258489 (0.054491) | 0.344217 / 0.293841 (0.050376) | 0.033089 / 0.128546 (-0.095457) | 0.011443 / 0.075646 (-0.064203) | 0.353143 / 0.419271 (-0.066128) | 0.040851 / 0.043533 (-0.002682) | 0.304501 / 0.255139 (0.049362) | 0.329118 / 0.283200 (0.045918) | 0.087399 / 0.141683 (-0.054284) | 1.500200 / 1.452155 (0.048046) | 1.536176 / 1.492716 (0.043459) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209626 / 0.018006 (0.191619) | 0.425551 / 0.000490 (0.425061) | 0.001168 / 0.000200 (0.000968) | 0.000069 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023664 / 0.037411 (-0.013748) | 0.096792 / 0.014526 (0.082266) | 0.105652 / 0.176557 (-0.070905) | 0.140796 / 0.737135 (-0.596340) | 0.109319 / 0.296338 (-0.187019) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414802 / 0.215209 (0.199593) | 4.152619 / 2.077655 (2.074964) | 1.814403 / 1.504120 (0.310283) | 1.611392 / 1.541195 (0.070198) | 1.667350 / 1.468490 (0.198860) | 0.691855 / 4.584777 (-3.892922) | 3.406584 / 3.745712 (-0.339128) | 1.940332 / 5.269862 (-3.329530) | 1.279061 / 4.565676 (-3.286615) | 0.082938 / 0.424275 (-0.341337) | 0.012388 / 0.007607 (0.004781) | 0.521738 / 0.226044 (0.295693) | 5.233764 / 2.268929 (2.964835) | 2.306573 / 55.444624 (-53.138051) | 1.954631 / 6.876477 (-4.921845) | 2.048315 / 2.142072 (-0.093757) | 0.816921 / 4.805227 (-3.988306) | 0.150983 / 6.500664 (-6.349681) | 0.066628 / 0.075469 (-0.008842) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235939 / 1.841788 (-0.605849) | 14.047114 / 8.074308 (5.972806) | 14.149842 / 10.191392 (3.958450) | 0.152836 / 0.680424 (-0.527588) | 0.028837 / 0.534201 (-0.505364) | 0.396232 / 0.579283 (-0.183051) | 0.409950 / 0.434364 (-0.024414) | 0.460296 / 0.540337 (-0.080041) | 0.556787 / 1.386936 (-0.830149) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006582 / 0.011353 (-0.004771) | 0.004491 / 0.011008 (-0.006518) | 0.100093 / 0.038508 (0.061585) | 0.026826 / 0.023109 (0.003717) | 0.413971 / 0.275898 (0.138073) | 0.445625 / 0.323480 (0.122145) | 0.004892 / 0.007986 (-0.003094) | 0.003295 / 0.004328 (-0.001034) | 0.077879 / 0.004250 (0.073628) | 0.039177 / 0.037052 (0.002125) | 0.353299 / 0.258489 (0.094810) | 0.406566 / 0.293841 (0.112725) | 0.031633 / 0.128546 (-0.096913) | 0.011517 / 0.075646 (-0.064130) | 0.320939 / 0.419271 (-0.098332) | 0.041487 / 0.043533 (-0.002046) | 0.353735 / 0.255139 (0.098596) | 0.434786 / 0.283200 (0.151586) | 0.087722 / 0.141683 (-0.053961) | 1.515134 / 1.452155 (0.062979) | 1.588908 / 1.492716 (0.096191) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225312 / 0.018006 (0.207305) | 0.398324 / 0.000490 (0.397834) | 0.000453 / 0.000200 (0.000253) | 0.000064 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024645 / 0.037411 (-0.012766) | 0.099399 / 0.014526 (0.084873) | 0.107006 / 0.176557 (-0.069550) | 0.145090 / 0.737135 (-0.592045) | 0.110046 / 0.296338 (-0.186292) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.450573 / 0.215209 (0.235364) | 4.498030 / 2.077655 (2.420375) | 2.193164 / 1.504120 (0.689044) | 1.940103 / 1.541195 (0.398908) | 1.957137 / 1.468490 (0.488647) | 0.697599 / 4.584777 (-3.887178) | 3.465146 / 3.745712 (-0.280566) | 1.918209 / 5.269862 (-3.351653) | 1.183921 / 4.565676 (-3.381756) | 0.082540 / 0.424275 (-0.341735) | 0.012495 / 0.007607 (0.004888) | 0.549702 / 0.226044 (0.323658) | 5.526841 / 2.268929 (3.257912) | 2.658611 / 55.444624 (-52.786014) | 2.259542 / 6.876477 (-4.616935) | 2.310139 / 2.142072 (0.168066) | 0.810550 / 4.805227 (-3.994677) | 0.152369 / 6.500664 (-6.348295) | 0.066295 / 0.075469 (-0.009174) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289240 / 1.841788 (-0.552547) | 14.032143 / 8.074308 (5.957834) | 13.973492 / 10.191392 (3.782100) | 0.140082 / 0.680424 (-0.540342) | 0.017113 / 0.534201 (-0.517088) | 0.386534 / 0.579283 (-0.192749) | 0.393723 / 0.434364 (-0.040641) | 0.448891 / 0.540337 (-0.091446) | 0.533085 / 1.386936 (-0.853851) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-17T07:15:31Z | 2023-01-17T08:58:22Z | 2023-01-17T08:51:17Z | MEMBER | null | This PR fixes CI benchmarks, by temporarily pinning Docker image version, instead of "latest" tag.
It also updates deprecated `cml-send-comment` command and using `cml comment create` instead.
Fix #5431. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5432/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5432/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5432.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5432",
"merged_at": "2023-01-17T08:51:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5432.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5432"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5431/comments | https://api.github.com/repos/huggingface/datasets/issues/5431/events | https://github.com/huggingface/datasets/issues/5431 | 1,535,862,621 | I_kwDODunzps5bi2dd | 5,431 | CI benchmarks are broken: Unknown arguments: runnerPath, path | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | 2023-01-17T06:49:57Z | 2023-01-18T06:33:24Z | 2023-01-17T08:51:18Z | MEMBER | null | Our CI benchmarks are broken, raising `Unknown arguments` error: https://github.com/huggingface/datasets/actions/runs/3932397079/jobs/6724905161
```
Unknown arguments: runnerPath, path
```
Stack trace:
```
100%|██████████| 500/500 [00:01<00:00, 338.98ba/s]
Updating lock file 'dvc.lock'
To track the changes with git, run:
git add dvc.lock
To enable auto staging, run:
dvc config core.autostage true
Use `dvc push` to send your updates to remote storage.
cml send-comment <markdown file>
Global Options:
--log Logging verbosity
[string] [choices: "error", "warn", "info", "debug"] [default: "info"]
--driver Git provider where the repository is hosted
[string] [choices: "github", "gitlab", "bitbucket"] [default: infer from the
environment]
--repo Repository URL or slug
[string] [default: infer from the environment]
--driver-token, --token CI driver personal/project access token (PAT)
[string] [default: infer from the environment]
--help Show help [boolean]
Options:
--target Comment type (`commit`, `pr`, `commit/f00bar`,
`pr/42`, `issue/1337`),default is automatic (`pr`
but fallback to `commit`). [string]
--watch Watch for changes and automatically update the
comment [boolean]
--publish Upload any local images found in the Markdown
report [boolean] [default: true]
--publish-url Self-hosted image server URL
[string] [default: "https://asset.cml.dev/"]
--publish-native, --native Uses driver's native capabilities to upload assets
instead of CML's storage; not available on GitHub
[boolean]
--watermark-title Hidden comment marker (used for targeting in
subsequent `cml comment update`); "{workflow}" &
"{run}" are auto-replaced [string] [default: ""]
Unknown arguments: runnerPath, path
Error: Process completed with exit code 1.
```
Issue reported to iterative/cml:
- iterative/cml#1319 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5431/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Some of the shard files now have 0 number of rows.\r\n\r\nWe have opened an issue in the Apache Beam repo:\r\n- https://github.com/apache/beam/issues/25041"
] | 2023-01-17T06:42:12Z | 2023-01-17T16:12:18Z | null | MEMBER | null | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5429/comments | https://api.github.com/repos/huggingface/datasets/issues/5429/events | https://github.com/huggingface/datasets/pull/5429 | 1,535,192,687 | PR_kwDODunzps5HeuyT | 5,429 | Fix CI by temporarily pinning apache-beam < 2.44.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2023-01-16T16:20:09Z | 2023-01-16T16:51:42Z | 2023-01-16T16:49:03Z | MEMBER | null | Temporarily pin apache-beam < 2.44.0
Fix #5426. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5429/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5429",
"merged_at": "2023-01-16T16:49:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5429"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5428/comments | https://api.github.com/repos/huggingface/datasets/issues/5428/events | https://github.com/huggingface/datasets/issues/5428 | 1,535,166,139 | I_kwDODunzps5bgMa7 | 5,428 | Load/Save FAISS index using fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dref360",
"id": 8976546,
"login": "Dref360",
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"repos_url": "https://api.github.com/users/Dref360/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dref360"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! Sure, feel free to submit a PR. Maybe if we want to be consistent with the existing API, it would be cleaner to directly add support for `fsspec` paths in `Dataset.load_faiss_index`/`Dataset.save_faiss_index` in the same manner as it was done in `Dataset.load_from_disk`/`Dataset.save_to_disk`.",
"That's a great idea! I'll do that instead. "
] | 2023-01-16T16:08:12Z | 2023-03-27T15:18:22Z | 2023-03-27T15:18:22Z | CONTRIBUTOR | null | ### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In my case, I'm saving faiss index in cloud storage and use `fsspec` to load them. It would be ideal if I could send the stream directly instead of copying the file locally (or mounting the bucket) and then load the index.
### Your contribution
I can submit the PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5428/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5428/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5427/comments | https://api.github.com/repos/huggingface/datasets/issues/5427/events | https://github.com/huggingface/datasets/issues/5427 | 1,535,162,889 | I_kwDODunzps5bgLoJ | 5,427 | Unable to download dataset id_clickbait | {
"avatar_url": "https://avatars.githubusercontent.com/u/45941585?v=4",
"events_url": "https://api.github.com/users/ilos-vigil/events{/privacy}",
"followers_url": "https://api.github.com/users/ilos-vigil/followers",
"following_url": "https://api.github.com/users/ilos-vigil/following{/other_user}",
"gists_url": "https://api.github.com/users/ilos-vigil/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ilos-vigil",
"id": 45941585,
"login": "ilos-vigil",
"node_id": "MDQ6VXNlcjQ1OTQxNTg1",
"organizations_url": "https://api.github.com/users/ilos-vigil/orgs",
"received_events_url": "https://api.github.com/users/ilos-vigil/received_events",
"repos_url": "https://api.github.com/users/ilos-vigil/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ilos-vigil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ilos-vigil/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ilos-vigil"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @ilos-vigil.\r\n\r\nWe have transferred this issue to the corresponding dataset on the Hugging Face Hub: https://huggingface.co/datasets/id_clickbait/discussions/1 "
] | 2023-01-16T16:05:36Z | 2023-01-18T09:51:28Z | 2023-01-18T09:25:19Z | NONE | null | ### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>NoSuchBucket</Code><Message>The specified bucket does not exist</Message><BucketName>md-datasets-cache-zipfiles-prod</BucketName><RequestId>NVRM6VEEQD69SD00</RequestId><HostId>W/SPDxLGvlCGi0OD6d7mSDvfOAUqLAfvs9nTX50BkJrjMny+X9Jnqp/Li2lG9eTUuT4MUkAA2jjTfCrCiUmu7A==</HostId></Error>
```
### Steps to reproduce the bug
Code snippet:
```
from datasets import load_dataset
load_dataset('id_clickbait', 'annotated')
load_dataset('id_clickbait', 'raw')
```
Link to Kaggle notebook: https://www.kaggle.com/code/ilosvigil/bug-check-on-id-clickbait-dataset
### Expected behavior
Successfully download and load `id_newspaper` dataset.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5427/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5427/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5426/comments | https://api.github.com/repos/huggingface/datasets/issues/5426/events | https://github.com/huggingface/datasets/issues/5426 | 1,535,158,555 | I_kwDODunzps5bgKkb | 5,426 | CI tests are broken: SchemaInferenceError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | 2023-01-16T16:02:07Z | 2023-06-02T06:40:32Z | 2023-01-16T16:49:04Z | MEMBER | null | CI test (unit, ubuntu-latest, deps-minimum) is broken, raising a `SchemaInferenceError`: see https://github.com/huggingface/datasets/actions/runs/3930901593/jobs/6721492004
```
FAILED tests/test_beam.py::BeamBuilderTest::test_download_and_prepare_sharded - datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
```
Stack trace:
```
______________ BeamBuilderTest.test_download_and_prepare_sharded _______________
[gw1] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
self = <tests.test_beam.BeamBuilderTest testMethod=test_download_and_prepare_sharded>
@require_beam
def test_download_and_prepare_sharded(self):
import apache_beam as beam
original_write_parquet = beam.io.parquetio.WriteToParquet
expected_num_examples = len(get_test_dummy_examples())
with tempfile.TemporaryDirectory() as tmp_cache_dir:
builder = DummyBeamDataset(cache_dir=tmp_cache_dir, beam_runner="DirectRunner")
with patch("apache_beam.io.parquetio.WriteToParquet") as write_parquet_mock:
write_parquet_mock.side_effect = partial(original_write_parquet, num_shards=2)
> builder.download_and_prepare()
tests/test_beam.py:97:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:864: in download_and_prepare
**download_and_prepare_kwargs,
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/builder.py:1976: in _download_and_prepare
num_examples, num_bytes = beam_writer.finalize(metrics.query(m_filter))
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:694: in finalize
shard_num_bytes, _ = parquet_to_arrow(source, destination)
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:740: in parquet_to_arrow
num_bytes, num_examples = writer.finalize()
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <datasets.arrow_writer.ArrowWriter object at 0x7f6dcbb3e810>
close_stream = True
def finalize(self, close_stream=True):
self.write_rows_on_file()
# In case current_examples < writer_batch_size, but user uses finalize()
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
# If schema is known, infer features even if no examples were written
if self.pa_writer is None and self.schema:
self._build_writer(self.schema)
if self.pa_writer is not None:
self.pa_writer.close()
self.pa_writer = None
if close_stream:
self.stream.close()
else:
if close_stream:
self.stream.close()
> raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
E datasets.arrow_writer.SchemaInferenceError: Please pass `features` or at least one example when writing data
/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/arrow_writer.py:593: SchemaInferenceError
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5426/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5426/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"events_url": "https://api.github.com/users/rocco-fortuna/events{/privacy}",
"followers_url": "https://api.github.com/users/rocco-fortuna/followers",
"following_url": "https://api.github.com/users/rocco-fortuna/following{/other_user}",
"gists_url": "https://api.github.com/users/rocco-fortuna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rocco-fortuna",
"id": 101344863,
"login": "rocco-fortuna",
"node_id": "U_kgDOBgpmXw",
"organizations_url": "https://api.github.com/users/rocco-fortuna/orgs",
"received_events_url": "https://api.github.com/users/rocco-fortuna/received_events",
"repos_url": "https://api.github.com/users/rocco-fortuna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rocco-fortuna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rocco-fortuna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rocco-fortuna"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\n`Dataset.sort` calls `df.sort_values` internally, and `df.sort_values` brings all the \"sort\" columns in memory, so sorting on multiple keys could be very expensive. This makes me think that maybe we can replace `df.sort_values` with `pyarrow.compute.sort_indices` - the latter can also sort on multiple keys and currently loads the data into memory; however, there is a plan to eventually implement \"memory-map\" friendly kernels for the Arrow compute ops (using the Acero execution engine). \r\n\r\nSo to address this issue, you should replace `df.sort_values` with `pyarrow.compute.sort_indices` in `Dataset.sort` and adjust the signature of this function (deprecate the `kind` parameter, etc.).\r\n\r\nPS: Feel free to ping us if you need some additional help/pointers",
"@mariosasko If I understand the code right, using `pyarrow.compute.sort_indices` would also require changes to the `select` method if it is meant to sort multiple keys. That's because `select` only accepts 1D input for `indices`, not an iterable or similar which would be required for multiple keys unless you want some looping over selects. Doesn't seem that straight-forward but I might be missing something here... ",
"@MichlF No, it doesn't require modifying select because sorting on multiple keys also returns a 1D array.\r\n\r\nIt's easier to understand with an example:\r\n```python\r\n>>> import pyarrow as pa\r\n>>> import pyarrow.compute as pc\r\n>>> table = pa.table({\r\n... \"name\": [\"John\", \"Eve\", \"Peter\", \"John\"],\r\n... \"surname\": [\"Johnson\", \"Smith\", \"Smith\", \"Doe\"],\r\n... \"age\": [20, 40, 30, 50],\r\n... })\r\n>>> indices = pc.sort_indices(table, sort_keys=[(\"name\", \"ascending\"), (\"surname\", \"ascending\")])\r\n>>> print(indices)\r\n[\r\n 1,\r\n 3,\r\n 0,\r\n 2\r\n]\r\n```\r\n\r\n",
"Thanks for clarifying.\r\nI can prepare a PR to address this issue. This would be my first PR here so I have a few maybe silly questions but:\r\n- What is the preferred input type of `sort_keys` for the sort method? A sequence with name, order tuples like pyarrow's `sort_indices` requires?\r\n- What about backwards compatability: is it supposed to also accept the old way of calling sort() or should both `column` and `kind` be deprecated?\r\n- If `sort_keys` is provided in the same format as for pyarrow's `sort_indices` - i.e. along with order for each column -, `reverse` doesn't make much sense either and should be deprecated as well I assume.",
"I think we can have the following signature:\r\n```python\r\ndef sort(\r\n self,\r\n column_names: Union[str, Sequence[str]],\r\n reverse: Union[bool, Sequence[bool]] = False,\r\n kind=\"deprecated\",\r\n null_placement: str = \"last\",\r\n keep_in_memory: bool = False,\r\n load_from_cache_file: bool = True,\r\n indices_cache_file_name: Optional[str] = None,\r\n writer_batch_size: Optional[int] = 1000,\r\n new_fingerprint: Optional[str] = None,\r\n ) -> \"Dataset\":\r\n``` \r\n\r\nSo we should:\r\n* rename`column` to `column_names`. `column` is a positional argument, so it's OK to rename it (not marked as positional-only with \"/\", but still should be fine)\r\n* deprecate `kind`\r\n* keep `reverse` instead of introducing `sort_keys`, but we should allow passing a list of booleans that defines the sort order of each column from `column_names` to it (`reverse = False` would be equal to `[False] * len(column_names)` and `reverse = True` to `[True] * len(column_names)`)",
"I am pretty much done with the PR. Just one clarification: `Sequence` in `arrow_dataset.py` is a custom dataclass from `features.py` instead of the `type.hinting` class `Sequence` from Python. Do you suggest using that custom `Sequence` class somehow ? Otherwise signature currently reads instead:\r\n```Python\r\n def sort(\r\n self,\r\n column_names: Union[str, List[str]],\r\n reverse: Union[bool, List[bool]] = False,\r\n kind = \"deprecated\",\r\n null_placement: str = \"last\",\r\n keep_in_memory: bool = False,\r\n load_from_cache_file: bool = True,\r\n indices_cache_file_name: Optional[str] = None,\r\n writer_batch_size: Optional[int] = 1000,\r\n new_fingerprint: Optional[str] = None,\r\n )\r\n```\r\n\r\nAlso, to maintain backwards compatibility, I added conditionals for `null_placement`, because pyarrow's `null_placement` only accepts `at_start` and `at_end`, and not `last` and `first`.\r\nIf that is all good, I think I can open the PR.",
"I meant `typing.Sequence` (`datasets.Sequence` is a feature type). \r\n\r\nRegarding `null_placement`, I think we can support both `at_start` and `at_end`, and `last` and `first` (for backward compatibility; convert internally to `at_end` and `at_start` respectively).",
"> I meant typing.Sequence (datasets.Sequence is a feature type).\r\n\r\nSorry, I actually meant `typing.Sequence` and not `type.hinting`. However, the issue is still that `dataset.Sequence` is imported in `arrow_dataset.py` so I cannot import and use `typing.Sequence` for the `sort`'s signature without overwriting the `dataset.Sequence` import. The latter is used in the `align_labels_with_mapping` method so it's a necessary import for `arrow_dataset.py`. \r\nTo import `typing.Sequence` as something else than `Sequence` to avoid overwriting may only be confusing and doesn't seem good practice!? The other solution is to keep `List` type hinting as in the signature I posted in my previous post but this excludes other Sequence types and may cause problems further down the line.\r\nPlease advise,\r\nThanks for all the clarifications!",
"You can avoid the name collision by renaming `typing.Sequence` to `Sequence_` when importing:\r\n```python\r\nfrom typing import Sequence as Sequence_\r\n```",
"Resolved via #5502 "
] | 2023-01-16T09:22:26Z | 2023-02-24T16:15:11Z | 2023-02-24T16:15:11Z | NONE | null | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to pandas and be able to specify multiple columns for sorting. We’re already using pandas under the hood to do the sorting in datasets.
The suggested workaround:
> convert your dataset to pandas and use `df.sort_values()`
### Motivation
Preserved ordering when sorting is very handy when one needs to sort on multiple columns, A and B, so that e.g. whenever A is equal for two or more rows, B is kept sorted.
Having a parameter to do this in 🤗datasets would be cleaner than going through pandas and back, and it wouldn't add much complexity to the library.
Alternatives:
- the possibility to specify multiple keys to sort by with decreasing priority (suggested solution),
- the ability to provide a key function for sorting, so that one can manually specify the sorting criteria.
### Your contribution
I'll be happy to contribute by submitting a PR. Will get documented on `CONTRIBUTING.MD`.
Would love to get thoughts on this, if anyone has anything to add. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5424/comments | https://api.github.com/repos/huggingface/datasets/issues/5424/events | https://github.com/huggingface/datasets/issues/5424 | 1,534,394,756 | I_kwDODunzps5bdQGE | 5,424 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/25720695?v=4",
"events_url": "https://api.github.com/users/macabdul9/events{/privacy}",
"followers_url": "https://api.github.com/users/macabdul9/followers",
"following_url": "https://api.github.com/users/macabdul9/following{/other_user}",
"gists_url": "https://api.github.com/users/macabdul9/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/macabdul9",
"id": 25720695,
"login": "macabdul9",
"node_id": "MDQ6VXNlcjI1NzIwNjk1",
"organizations_url": "https://api.github.com/users/macabdul9/orgs",
"received_events_url": "https://api.github.com/users/macabdul9/received_events",
"repos_url": "https://api.github.com/users/macabdul9/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/macabdul9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/macabdul9/subscriptions",
"type": "User",
"url": "https://api.github.com/users/macabdul9"
} | [] | closed | false | null | [] | null | [
"Hi! You can get a `DatasetDict` if you pass a dictionary with read instructions as follows:\r\n```python\r\ninstructions = [\r\n ReadInstruction(split_name=\"train\", from_=0, to=10, unit='%', rounding='closest'),\r\n ReadInstruction(split_name=\"dev\", from_=0, to=10, unit='%', rounding='closest'),\r\n ReadInstruction(split_name=\"test\", from_=0, to=5, unit='%', rounding='closest')\r\n]\r\n\r\ndataset = load_dataset('csv', data_dir=\"data/\", data_files={\"train\":\"train.tsv\", \"dev\":\"dev.tsv\", \"test\":\"test.tsv\"}, delimiter=\"\\t\", split={inst.split_name: inst for inst in instructions})\r\n```\r\n"
] | 2023-01-16T06:54:28Z | 2023-02-24T16:19:00Z | 2023-02-24T16:19:00Z | NONE | null | ### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduce the behaviour:
1. Import
`from datasets import load_dataset, ReadInstruction`
2. Instruction to load the dataset
```
instructions = [
ReadInstruction(split_name="train", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="dev", from_=0, to=10, unit='%', rounding='closest'),
ReadInstruction(split_name="test", from_=0, to=5, unit='%', rounding='closest')
]
```
3. Load
`dataset = load_dataset('csv', data_dir="data/", data_files={"train":"train.tsv", "dev":"dev.tsv", "test":"test.tsv"}, delimiter="\t", split=instructions)`
### Expected behavior
**Current behaviour**
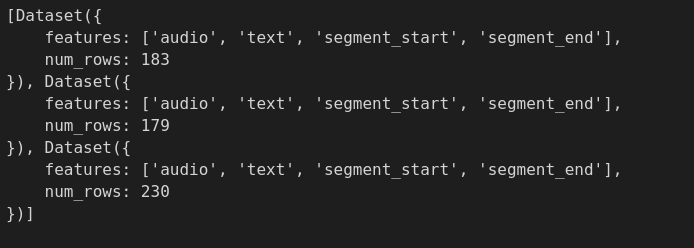
:
**Expected behaviour**
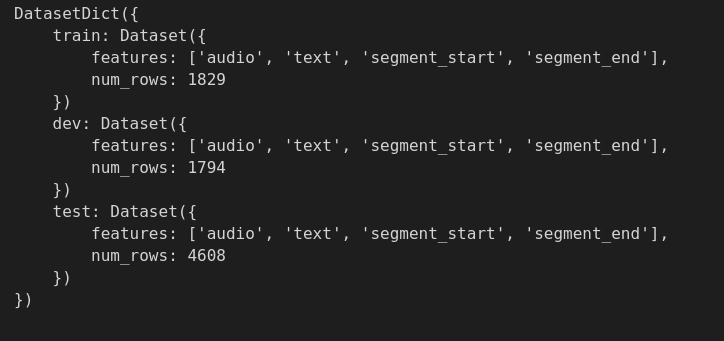
### Environment info
``datasets==2.8.0
``
`Python==3.8.5
`
`Platform - Ubuntu 20.04.4 LTS` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5424/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5424/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5422/comments | https://api.github.com/repos/huggingface/datasets/issues/5422/events | https://github.com/huggingface/datasets/issues/5422 | 1,533,385,239 | I_kwDODunzps5bZZoX | 5,422 | Datasets load error for saved github issues | {
"avatar_url": "https://avatars.githubusercontent.com/u/7360564?v=4",
"events_url": "https://api.github.com/users/folterj/events{/privacy}",
"followers_url": "https://api.github.com/users/folterj/followers",
"following_url": "https://api.github.com/users/folterj/following{/other_user}",
"gists_url": "https://api.github.com/users/folterj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/folterj",
"id": 7360564,
"login": "folterj",
"node_id": "MDQ6VXNlcjczNjA1NjQ=",
"organizations_url": "https://api.github.com/users/folterj/orgs",
"received_events_url": "https://api.github.com/users/folterj/received_events",
"repos_url": "https://api.github.com/users/folterj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/folterj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/folterj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/folterj"
} | [] | open | false | null | [] | null | [
"I can confirm that the error exists!\r\nI'm trying to read 3 parquet files locally:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n)\r\n```\r\n\r\nBut you can fix it, by specifying `features` for `load_dataset()` function like this:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nfeatures = Features(\r\n {\r\n \"label\": ClassLabel(\r\n num_classes=3,\r\n names=[\"negative\", \"neutral\", \"positive\"],\r\n ),\r\n \"text\": Value(dtype=\"string\"),\r\n }\r\n)\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.parquet\"),\r\n \"validation\": os.path.join(sentiment_analysis_data_path, \"validation.parquet\"),\r\n \"test\": os.path.join(sentiment_analysis_data_path, \"test.parquet\"),\r\n },\r\n features=features,\r\n)\r\n\r\nprint(review_dataset)\r\n```",
"@Extremesarova I think this is a different issue, but understand using features could be a work-around.\r\nIt seems the field `closed_at` is `null` in many cases.\r\n\r\nI've not found a way to specify only a single feature without (succesfully) specifiying the full and quite detailed set of expected features. Using this features set gives an error the column names don't match.\r\n`features = Features({'closed_at': Value(dtype='timestamp[s]', id=None)})`\r\n\r\n",
"Found this when searching for the same error, looks like based on #3965 it's just an issue with the data. I found that changing `df = pd.DataFrame.from_records(all_issues)` to `df = pd.DataFrame.from_records(all_issues).dropna(axis=1, how='all').drop(['milestone'], axis=1)` from the fetch_issues function fixed the issue. \r\nThe \"milestone\" column seemed to be problematic (only ~50 non null rows) and dropped any columns that were all null as well just in case.",
"I have this same issue. I saved a dataset to disk and now I can't load it.",
"Ok the solution was to use load_from_disk instead of load_dataset."
] | 2023-01-14T17:29:38Z | 2023-05-05T19:25:08Z | null | NONE | null | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
A work-around I found was to use streaming.
### Steps to reproduce the bug
Reproduce by executing the code provided:
https://huggingface.co/course/chapter5/5?fw=pt
From the heading:
'let’s create a function that can download all the issues from a GitHub repository'
### Expected behavior
No error
### Environment info
Datasets version 2.8.0. Note that version 2.6.1 gives the same error (related to null timestamp).
**[EDIT]**
This is the complete error trace confirming the issue is related to the timestamp (`Couldn't cast array of type timestamp[s] to null`)
```
Using custom data configuration default-950028611d2860c8
Downloading and preparing dataset json/default to [...]/.cache/huggingface/datasets/json/default-950028611d2860c8/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51...
Downloading data files: 100%|██████████| 1/1 [00:00<?, ?it/s]
Extracting data files: 100%|██████████| 1/1 [00:00<00:00, 500.63it/s]
Generating train split: 2619 examples [00:00, 7155.72 examples/s]Traceback (most recent call last):
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1831, in _prepare_split_single
writer.write_table(table)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\arrow_writer.py", line 567, in write_table
pa_table = table_cast(pa_table, self._schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2282, in table_cast
return cast_table_to_schema(table, schema)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2241, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1807, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in cast_array_to_feature
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2035, in <listcomp>
arrays = [_c(array.field(name), subfeature) for name, subfeature in feature.items()]
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 2101, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1809, in wrapper
return func(array, *args, **kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\table.py", line 1990, in array_cast
raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
TypeError: Couldn't cast array of type timestamp[s] to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 1, in <module>
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_bundle\pydev_umd.py", line 198, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "C:\Program Files\JetBrains\PyCharm 2022.1.3\plugins\python\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "[...]\PycharmProjects\TransformersTesting\dataset_issues.py", line 20, in <module>
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\load.py", line 1757, in load_dataset
builder_instance.download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 860, in download_and_prepare
self._download_and_prepare(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 953, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1706, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "[...]\miniconda3\envs\HuggingFace\lib\site-packages\datasets\builder.py", line 1849, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset
Generating train split: 2619 examples [00:19, 7155.72 examples/s]
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5422/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5422/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5421/comments | https://api.github.com/repos/huggingface/datasets/issues/5421/events | https://github.com/huggingface/datasets/issues/5421 | 1,532,278,307 | I_kwDODunzps5bVLYj | 5,421 | Support case-insensitive Hub dataset name in load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Closing as case-insensitivity should be only for URL redirection on the Hub. In the APIs, we will only support the canonical name (https://github.com/huggingface/moon-landing/pull/2399#issuecomment-1382085611)"
] | 2023-01-13T13:07:07Z | 2023-01-13T20:12:32Z | 2023-01-13T20:12:32Z | CONTRIBUTOR | null | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from datasets import load_dataset
load_dataset('GLUE', 'cola')
```
It breaks because the loading script `GLUE.py` does not exist (`glue.py` should be selected instead).
Minor additional comment: in other cases without a loading script, we can load the dataset, but the automatically generated config name depends on the casing:
- `load_dataset('severo/danish-wit')` generates the config name `severo--danish-wit-e6fda5b070deb133`, while
- `load_dataset('severo/danish-WIT')` generates the config name `severo--danish-WIT-e6fda5b070deb133`
### Motivation
To follow the same UX on the Hub and in the datasets library.
### Your contribution
... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5421/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5420/comments | https://api.github.com/repos/huggingface/datasets/issues/5420/events | https://github.com/huggingface/datasets/pull/5420 | 1,532,265,742 | PR_kwDODunzps5HVAhL | 5,420 | ci: 🎡 remove two obsolete issue templates | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008450 / 0.011353 (-0.002902) | 0.004478 / 0.011008 (-0.006530) | 0.100440 / 0.038508 (0.061931) | 0.029568 / 0.023109 (0.006459) | 0.296705 / 0.275898 (0.020807) | 0.354565 / 0.323480 (0.031085) | 0.006887 / 0.007986 (-0.001098) | 0.003415 / 0.004328 (-0.000914) | 0.078876 / 0.004250 (0.074626) | 0.034927 / 0.037052 (-0.002125) | 0.307695 / 0.258489 (0.049206) | 0.340917 / 0.293841 (0.047076) | 0.033630 / 0.128546 (-0.094916) | 0.011626 / 0.075646 (-0.064020) | 0.322644 / 0.419271 (-0.096627) | 0.040254 / 0.043533 (-0.003279) | 0.297419 / 0.255139 (0.042280) | 0.321584 / 0.283200 (0.038384) | 0.086202 / 0.141683 (-0.055481) | 1.465579 / 1.452155 (0.013425) | 1.521456 / 1.492716 (0.028740) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200890 / 0.018006 (0.182884) | 0.410300 / 0.000490 (0.409811) | 0.001647 / 0.000200 (0.001447) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022569 / 0.037411 (-0.014843) | 0.096062 / 0.014526 (0.081536) | 0.102474 / 0.176557 (-0.074082) | 0.138596 / 0.737135 (-0.598539) | 0.106262 / 0.296338 (-0.190077) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415976 / 0.215209 (0.200766) | 4.144322 / 2.077655 (2.066667) | 1.871783 / 1.504120 (0.367663) | 1.669478 / 1.541195 (0.128283) | 1.718214 / 1.468490 (0.249724) | 0.687870 / 4.584777 (-3.896907) | 3.362084 / 3.745712 (-0.383628) | 1.844127 / 5.269862 (-3.425735) | 1.149611 / 4.565676 (-3.416066) | 0.081410 / 0.424275 (-0.342865) | 0.012278 / 0.007607 (0.004671) | 0.518245 / 0.226044 (0.292200) | 5.185164 / 2.268929 (2.916236) | 2.299029 / 55.444624 (-53.145595) | 1.960021 / 6.876477 (-4.916456) | 2.009751 / 2.142072 (-0.132322) | 0.803759 / 4.805227 (-4.001468) | 0.147340 / 6.500664 (-6.353324) | 0.063896 / 0.075469 (-0.011573) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.254142 / 1.841788 (-0.587646) | 13.799683 / 8.074308 (5.725375) | 13.940387 / 10.191392 (3.748995) | 0.151246 / 0.680424 (-0.529178) | 0.028709 / 0.534201 (-0.505491) | 0.391600 / 0.579283 (-0.187683) | 0.405750 / 0.434364 (-0.028614) | 0.455479 / 0.540337 (-0.084858) | 0.541022 / 1.386936 (-0.845914) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006462 / 0.011353 (-0.004891) | 0.004462 / 0.011008 (-0.006547) | 0.096588 / 0.038508 (0.058080) | 0.026931 / 0.023109 (0.003822) | 0.344595 / 0.275898 (0.068697) | 0.378743 / 0.323480 (0.055264) | 0.005672 / 0.007986 (-0.002314) | 0.003345 / 0.004328 (-0.000984) | 0.074363 / 0.004250 (0.070112) | 0.037300 / 0.037052 (0.000248) | 0.346895 / 0.258489 (0.088406) | 0.388585 / 0.293841 (0.094744) | 0.031459 / 0.128546 (-0.097088) | 0.011522 / 0.075646 (-0.064124) | 0.318507 / 0.419271 (-0.100764) | 0.041145 / 0.043533 (-0.002388) | 0.343866 / 0.255139 (0.088727) | 0.366490 / 0.283200 (0.083291) | 0.086793 / 0.141683 (-0.054890) | 1.483859 / 1.452155 (0.031704) | 1.574006 / 1.492716 (0.081290) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220436 / 0.018006 (0.202430) | 0.402988 / 0.000490 (0.402498) | 0.000435 / 0.000200 (0.000235) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024573 / 0.037411 (-0.012838) | 0.099190 / 0.014526 (0.084664) | 0.106796 / 0.176557 (-0.069761) | 0.142387 / 0.737135 (-0.594748) | 0.109991 / 0.296338 (-0.186347) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473452 / 0.215209 (0.258243) | 4.749554 / 2.077655 (2.671899) | 2.433482 / 1.504120 (0.929362) | 2.224276 / 1.541195 (0.683082) | 2.261579 / 1.468490 (0.793088) | 0.699876 / 4.584777 (-3.884901) | 3.378366 / 3.745712 (-0.367346) | 1.835062 / 5.269862 (-3.434799) | 1.161249 / 4.565676 (-3.404427) | 0.082967 / 0.424275 (-0.341308) | 0.012745 / 0.007607 (0.005138) | 0.580006 / 0.226044 (0.353962) | 5.789868 / 2.268929 (3.520939) | 2.909496 / 55.444624 (-52.535128) | 2.539196 / 6.876477 (-4.337280) | 2.617737 / 2.142072 (0.475665) | 0.810320 / 4.805227 (-3.994907) | 0.152501 / 6.500664 (-6.348163) | 0.067201 / 0.075469 (-0.008268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257844 / 1.841788 (-0.583943) | 13.865295 / 8.074308 (5.790987) | 14.169073 / 10.191392 (3.977680) | 0.135655 / 0.680424 (-0.544769) | 0.016597 / 0.534201 (-0.517604) | 0.374915 / 0.579283 (-0.204368) | 0.382771 / 0.434364 (-0.051593) | 0.431934 / 0.540337 (-0.108403) | 0.524617 / 1.386936 (-0.862319) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008748 / 0.011353 (-0.002605) | 0.004489 / 0.011008 (-0.006519) | 0.100923 / 0.038508 (0.062415) | 0.031436 / 0.023109 (0.008326) | 0.306508 / 0.275898 (0.030610) | 0.365110 / 0.323480 (0.041630) | 0.007161 / 0.007986 (-0.000824) | 0.005489 / 0.004328 (0.001160) | 0.078909 / 0.004250 (0.074658) | 0.036097 / 0.037052 (-0.000955) | 0.307907 / 0.258489 (0.049418) | 0.370277 / 0.293841 (0.076436) | 0.034184 / 0.128546 (-0.094362) | 0.011613 / 0.075646 (-0.064033) | 0.322896 / 0.419271 (-0.096375) | 0.041829 / 0.043533 (-0.001704) | 0.299669 / 0.255139 (0.044530) | 0.322217 / 0.283200 (0.039017) | 0.087751 / 0.141683 (-0.053932) | 1.476277 / 1.452155 (0.024122) | 1.548196 / 1.492716 (0.055480) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183002 / 0.018006 (0.164995) | 0.415627 / 0.000490 (0.415138) | 0.003272 / 0.000200 (0.003072) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024881 / 0.037411 (-0.012531) | 0.103424 / 0.014526 (0.088898) | 0.106446 / 0.176557 (-0.070110) | 0.142806 / 0.737135 (-0.594330) | 0.110938 / 0.296338 (-0.185401) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421669 / 0.215209 (0.206460) | 4.207457 / 2.077655 (2.129802) | 1.882176 / 1.504120 (0.378056) | 1.677609 / 1.541195 (0.136415) | 1.734065 / 1.468490 (0.265575) | 0.695915 / 4.584777 (-3.888862) | 3.416731 / 3.745712 (-0.328981) | 1.872575 / 5.269862 (-3.397286) | 1.163612 / 4.565676 (-3.402064) | 0.082710 / 0.424275 (-0.341565) | 0.012659 / 0.007607 (0.005052) | 0.528785 / 0.226044 (0.302741) | 5.305328 / 2.268929 (3.036399) | 2.299850 / 55.444624 (-53.144774) | 1.968137 / 6.876477 (-4.908339) | 2.028326 / 2.142072 (-0.113746) | 0.813157 / 4.805227 (-3.992070) | 0.149997 / 6.500664 (-6.350668) | 0.066739 / 0.075469 (-0.008730) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206332 / 1.841788 (-0.635456) | 13.795510 / 8.074308 (5.721202) | 14.367695 / 10.191392 (4.176303) | 0.138106 / 0.680424 (-0.542318) | 0.028760 / 0.534201 (-0.505441) | 0.394822 / 0.579283 (-0.184461) | 0.403291 / 0.434364 (-0.031073) | 0.463273 / 0.540337 (-0.077065) | 0.540881 / 1.386936 (-0.846055) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006830 / 0.011353 (-0.004523) | 0.004606 / 0.011008 (-0.006402) | 0.097763 / 0.038508 (0.059255) | 0.027832 / 0.023109 (0.004723) | 0.422970 / 0.275898 (0.147072) | 0.460313 / 0.323480 (0.136833) | 0.005110 / 0.007986 (-0.002876) | 0.003428 / 0.004328 (-0.000901) | 0.075047 / 0.004250 (0.070797) | 0.038374 / 0.037052 (0.001322) | 0.422762 / 0.258489 (0.164273) | 0.469886 / 0.293841 (0.176045) | 0.032391 / 0.128546 (-0.096155) | 0.011804 / 0.075646 (-0.063843) | 0.320439 / 0.419271 (-0.098832) | 0.041939 / 0.043533 (-0.001594) | 0.422521 / 0.255139 (0.167382) | 0.446420 / 0.283200 (0.163220) | 0.090715 / 0.141683 (-0.050968) | 1.484578 / 1.452155 (0.032423) | 1.556154 / 1.492716 (0.063438) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260735 / 0.018006 (0.242728) | 0.415586 / 0.000490 (0.415096) | 0.026960 / 0.000200 (0.026760) | 0.000296 / 0.000054 (0.000241) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024926 / 0.037411 (-0.012486) | 0.099651 / 0.014526 (0.085125) | 0.107810 / 0.176557 (-0.068747) | 0.148685 / 0.737135 (-0.588451) | 0.112725 / 0.296338 (-0.183614) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472669 / 0.215209 (0.257460) | 4.718827 / 2.077655 (2.641172) | 2.475583 / 1.504120 (0.971463) | 2.260862 / 1.541195 (0.719667) | 2.307820 / 1.468490 (0.839330) | 0.699464 / 4.584777 (-3.885313) | 3.376282 / 3.745712 (-0.369431) | 1.872650 / 5.269862 (-3.397211) | 1.176399 / 4.565676 (-3.389277) | 0.082854 / 0.424275 (-0.341421) | 0.012845 / 0.007607 (0.005237) | 0.582088 / 0.226044 (0.356044) | 5.861609 / 2.268929 (3.592681) | 2.930728 / 55.444624 (-52.513896) | 2.624310 / 6.876477 (-4.252167) | 2.762130 / 2.142072 (0.620058) | 0.811902 / 4.805227 (-3.993325) | 0.152516 / 6.500664 (-6.348149) | 0.067670 / 0.075469 (-0.007799) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289790 / 1.841788 (-0.551997) | 14.267607 / 8.074308 (6.193299) | 14.120655 / 10.191392 (3.929263) | 0.128442 / 0.680424 (-0.551982) | 0.017079 / 0.534201 (-0.517121) | 0.381807 / 0.579283 (-0.197476) | 0.400546 / 0.434364 (-0.033818) | 0.447629 / 0.540337 (-0.092709) | 0.532006 / 1.386936 (-0.854930) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-13T12:58:43Z | 2023-01-13T13:36:00Z | 2023-01-13T13:29:01Z | CONTRIBUTOR | null | add-dataset is not needed anymore since the "canonical" datasets are on the Hub. And dataset-viewer is managed within the datasets-server project.
See https://github.com/huggingface/datasets/issues/new/choose
<img width="1245" alt="Capture d’écran 2023-01-13 à 13 59 58" src="https://user-images.githubusercontent.com/1676121/212325813-2d4c30e2-343e-4aa2-8cce-b2b77f45628e.png">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5420/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5420/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5420.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5420",
"merged_at": "2023-01-13T13:29:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5420.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5420"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5419/comments | https://api.github.com/repos/huggingface/datasets/issues/5419/events | https://github.com/huggingface/datasets/issues/5419 | 1,531,999,850 | I_kwDODunzps5bUHZq | 5,419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | {
"avatar_url": "https://avatars.githubusercontent.com/u/172385?v=4",
"events_url": "https://api.github.com/users/CreatixEA/events{/privacy}",
"followers_url": "https://api.github.com/users/CreatixEA/followers",
"following_url": "https://api.github.com/users/CreatixEA/following{/other_user}",
"gists_url": "https://api.github.com/users/CreatixEA/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/CreatixEA",
"id": 172385,
"login": "CreatixEA",
"node_id": "MDQ6VXNlcjE3MjM4NQ==",
"organizations_url": "https://api.github.com/users/CreatixEA/orgs",
"received_events_url": "https://api.github.com/users/CreatixEA/received_events",
"repos_url": "https://api.github.com/users/CreatixEA/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/CreatixEA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CreatixEA/subscriptions",
"type": "User",
"url": "https://api.github.com/users/CreatixEA"
} | [] | open | false | null | [] | null | [
"Hi! Thanks for pointing out this inconsistency. Changing the default value at this point is probably not worth it, considering we've started discussing the state of the task API internally - we will most likely deprecate the current one and replace it with a more robust solution that relies on the `train_eval_index` field stored in the YAML section of the dataset cards."
] | 2023-01-13T09:40:07Z | 2023-01-19T15:46:51Z | null | NONE | null | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column accordingly to the expected name : `label` or `label_ids`
### Steps to reproduce the bug
```python
from datasets import TextClassification, AutoTokenized, DataCollatorWithPadding
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0'))
print(ds_prepared)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
ds_tokenized = ds_prepared.map(lambda x: tokenizer(x['text'], truncation=True), batched=True)
print(ds_tokenized)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_data = model.prepare_tf_dataset(ds_tokenized, shuffle=True, batch_size=16, collate_fn=data_collator)
print(tf_data)
```
### Expected behavior
Without renaming the the column, the target column is not in the final tf_data since it is not in the column name expected by the data_collator.
To correct this, we have to rename the column:
```python
ds_prepared = my_dataset.prepare_for_task(TextClassification(text_column='TEXT', label_column='MY_LABEL_COLUMN_1_OR_0')).rename_column('labels', 'label')
```
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
- `transformers` version: 4.26.0.dev0
- Platform: Linux-5.15.79.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): 2.11.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in> | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5419/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5419/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5418/comments | https://api.github.com/repos/huggingface/datasets/issues/5418/events | https://github.com/huggingface/datasets/issues/5418 | 1,530,111,184 | I_kwDODunzps5bM6TQ | 5,418 | Add ProgressBar for `to_parquet` | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/zanussbaum",
"id": 33707069,
"login": "zanussbaum",
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"type": "User",
"url": "https://api.github.com/users/zanussbaum"
}
] | null | [
"Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have!",
"@albertvillanova I’m happy to make a quick PR for the feature! let me know ",
"That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review",
"Closing as this has been merged @lhoestq "
] | 2023-01-12T05:06:20Z | 2023-01-24T18:18:24Z | 2023-01-24T18:18:24Z | CONTRIBUTOR | null | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5418/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5416/comments | https://api.github.com/repos/huggingface/datasets/issues/5416/events | https://github.com/huggingface/datasets/pull/5416 | 1,526,988,113 | PR_kwDODunzps5HDLmR | 5,416 | Fix RuntimeError: Sharding is ambiguous for this dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"By the way, do we know how many datasets are impacted by this issue?\r\n\r\nMaybe we should do a patch release with this fix.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009256 / 0.011353 (-0.002097) | 0.005033 / 0.011008 (-0.005975) | 0.099346 / 0.038508 (0.060838) | 0.035204 / 0.023109 (0.012095) | 0.303017 / 0.275898 (0.027119) | 0.335632 / 0.323480 (0.012152) | 0.007953 / 0.007986 (-0.000033) | 0.005806 / 0.004328 (0.001477) | 0.076121 / 0.004250 (0.071871) | 0.041164 / 0.037052 (0.004112) | 0.305536 / 0.258489 (0.047047) | 0.348452 / 0.293841 (0.054611) | 0.037704 / 0.128546 (-0.090842) | 0.011982 / 0.075646 (-0.063664) | 0.333264 / 0.419271 (-0.086008) | 0.047738 / 0.043533 (0.004205) | 0.310126 / 0.255139 (0.054987) | 0.318719 / 0.283200 (0.035519) | 0.098933 / 0.141683 (-0.042750) | 1.421058 / 1.452155 (-0.031096) | 1.554771 / 1.492716 (0.062054) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.258627 / 0.018006 (0.240620) | 0.450814 / 0.000490 (0.450324) | 0.011288 / 0.000200 (0.011088) | 0.000136 / 0.000054 (0.000081) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027004 / 0.037411 (-0.010407) | 0.109067 / 0.014526 (0.094541) | 0.120401 / 0.176557 (-0.056155) | 0.158336 / 0.737135 (-0.578799) | 0.126244 / 0.296338 (-0.170094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401847 / 0.215209 (0.186638) | 4.006003 / 2.077655 (1.928348) | 1.806342 / 1.504120 (0.302223) | 1.619751 / 1.541195 (0.078556) | 1.709660 / 1.468490 (0.241170) | 0.692444 / 4.584777 (-3.892333) | 3.853691 / 3.745712 (0.107979) | 2.143910 / 5.269862 (-3.125951) | 1.471600 / 4.565676 (-3.094076) | 0.084589 / 0.424275 (-0.339686) | 0.012276 / 0.007607 (0.004669) | 0.506529 / 0.226044 (0.280485) | 5.028361 / 2.268929 (2.759432) | 2.277660 / 55.444624 (-53.166964) | 1.930365 / 6.876477 (-4.946112) | 1.965494 / 2.142072 (-0.176579) | 0.826752 / 4.805227 (-3.978475) | 0.165050 / 6.500664 (-6.335614) | 0.062702 / 0.075469 (-0.012767) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.234539 / 1.841788 (-0.607249) | 15.067401 / 8.074308 (6.993093) | 14.041920 / 10.191392 (3.850528) | 0.162590 / 0.680424 (-0.517834) | 0.028941 / 0.534201 (-0.505260) | 0.438518 / 0.579283 (-0.140765) | 0.443787 / 0.434364 (0.009423) | 0.516671 / 0.540337 (-0.023666) | 0.609036 / 1.386936 (-0.777900) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007535 / 0.011353 (-0.003818) | 0.005283 / 0.011008 (-0.005725) | 0.097116 / 0.038508 (0.058608) | 0.033357 / 0.023109 (0.010247) | 0.383398 / 0.275898 (0.107500) | 0.425516 / 0.323480 (0.102037) | 0.006039 / 0.007986 (-0.001947) | 0.004074 / 0.004328 (-0.000255) | 0.073207 / 0.004250 (0.068956) | 0.052153 / 0.037052 (0.015101) | 0.386385 / 0.258489 (0.127896) | 0.429900 / 0.293841 (0.136059) | 0.038341 / 0.128546 (-0.090205) | 0.012417 / 0.075646 (-0.063230) | 0.333859 / 0.419271 (-0.085413) | 0.051157 / 0.043533 (0.007625) | 0.395022 / 0.255139 (0.139883) | 0.402462 / 0.283200 (0.119262) | 0.105207 / 0.141683 (-0.036475) | 1.510679 / 1.452155 (0.058524) | 1.584205 / 1.492716 (0.091489) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225805 / 0.018006 (0.207799) | 0.452109 / 0.000490 (0.451619) | 0.000429 / 0.000200 (0.000229) | 0.000057 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029653 / 0.037411 (-0.007759) | 0.112609 / 0.014526 (0.098083) | 0.121828 / 0.176557 (-0.054728) | 0.159003 / 0.737135 (-0.578133) | 0.129306 / 0.296338 (-0.167033) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.453001 / 0.215209 (0.237792) | 4.514882 / 2.077655 (2.437228) | 2.277494 / 1.504120 (0.773374) | 2.073870 / 1.541195 (0.532675) | 2.153346 / 1.468490 (0.684856) | 0.698363 / 4.584777 (-3.886414) | 3.921763 / 3.745712 (0.176051) | 2.123133 / 5.269862 (-3.146729) | 1.347618 / 4.565676 (-3.218058) | 0.085654 / 0.424275 (-0.338621) | 0.012059 / 0.007607 (0.004452) | 0.568183 / 0.226044 (0.342139) | 5.720047 / 2.268929 (3.451119) | 2.777973 / 55.444624 (-52.666651) | 2.453426 / 6.876477 (-4.423051) | 2.523977 / 2.142072 (0.381905) | 0.841979 / 4.805227 (-3.963248) | 0.167958 / 6.500664 (-6.332706) | 0.064929 / 0.075469 (-0.010540) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235297 / 1.841788 (-0.606491) | 15.883598 / 8.074308 (7.809290) | 14.395328 / 10.191392 (4.203936) | 0.162401 / 0.680424 (-0.518022) | 0.017806 / 0.534201 (-0.516394) | 0.423853 / 0.579283 (-0.155430) | 0.423266 / 0.434364 (-0.011098) | 0.490351 / 0.540337 (-0.049986) | 0.588116 / 1.386936 (-0.798820) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010759 / 0.011353 (-0.000594) | 0.005748 / 0.011008 (-0.005260) | 0.119195 / 0.038508 (0.080687) | 0.033476 / 0.023109 (0.010367) | 0.364081 / 0.275898 (0.088183) | 0.422456 / 0.323480 (0.098976) | 0.009780 / 0.007986 (0.001795) | 0.006170 / 0.004328 (0.001841) | 0.093242 / 0.004250 (0.088991) | 0.041049 / 0.037052 (0.003997) | 0.372132 / 0.258489 (0.113643) | 0.442501 / 0.293841 (0.148660) | 0.054889 / 0.128546 (-0.073657) | 0.018302 / 0.075646 (-0.057345) | 0.378899 / 0.419271 (-0.040373) | 0.058455 / 0.043533 (0.014922) | 0.356141 / 0.255139 (0.101002) | 0.400866 / 0.283200 (0.117666) | 0.103384 / 0.141683 (-0.038299) | 1.629867 / 1.452155 (0.177713) | 1.693939 / 1.492716 (0.201222) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240484 / 0.018006 (0.222478) | 0.509137 / 0.000490 (0.508648) | 0.000450 / 0.000200 (0.000250) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025856 / 0.037411 (-0.011555) | 0.113214 / 0.014526 (0.098689) | 0.119420 / 0.176557 (-0.057136) | 0.158663 / 0.737135 (-0.578473) | 0.123542 / 0.296338 (-0.172797) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.555900 / 0.215209 (0.340691) | 5.580295 / 2.077655 (3.502640) | 2.216640 / 1.504120 (0.712520) | 1.904944 / 1.541195 (0.363749) | 1.865839 / 1.468490 (0.397349) | 1.158325 / 4.584777 (-3.426452) | 5.097420 / 3.745712 (1.351708) | 2.881775 / 5.269862 (-2.388087) | 2.068896 / 4.565676 (-2.496780) | 0.129028 / 0.424275 (-0.295247) | 0.014075 / 0.007607 (0.006468) | 0.698874 / 0.226044 (0.472830) | 7.131225 / 2.268929 (4.862296) | 2.901686 / 55.444624 (-52.542939) | 2.186146 / 6.876477 (-4.690330) | 2.251172 / 2.142072 (0.109100) | 1.342264 / 4.805227 (-3.462963) | 0.232045 / 6.500664 (-6.268619) | 0.073520 / 0.075469 (-0.001949) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.431314 / 1.841788 (-0.410474) | 16.313055 / 8.074308 (8.238747) | 18.451552 / 10.191392 (8.260160) | 0.232875 / 0.680424 (-0.447549) | 0.042170 / 0.534201 (-0.492031) | 0.495261 / 0.579283 (-0.084022) | 0.582901 / 0.434364 (0.148537) | 0.582049 / 0.540337 (0.041712) | 0.681122 / 1.386936 (-0.705814) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008131 / 0.011353 (-0.003222) | 0.006162 / 0.011008 (-0.004847) | 0.113721 / 0.038508 (0.075213) | 0.030797 / 0.023109 (0.007688) | 0.413108 / 0.275898 (0.137210) | 0.449968 / 0.323480 (0.126488) | 0.006126 / 0.007986 (-0.001860) | 0.004848 / 0.004328 (0.000519) | 0.085465 / 0.004250 (0.081214) | 0.045817 / 0.037052 (0.008764) | 0.419360 / 0.258489 (0.160871) | 0.489077 / 0.293841 (0.195236) | 0.050841 / 0.128546 (-0.077705) | 0.020646 / 0.075646 (-0.055000) | 0.379838 / 0.419271 (-0.039434) | 0.068897 / 0.043533 (0.025365) | 0.422182 / 0.255139 (0.167043) | 0.435529 / 0.283200 (0.152330) | 0.115299 / 0.141683 (-0.026384) | 1.655134 / 1.452155 (0.202979) | 1.835198 / 1.492716 (0.342481) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207041 / 0.018006 (0.189034) | 0.491263 / 0.000490 (0.490773) | 0.003554 / 0.000200 (0.003354) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030830 / 0.037411 (-0.006582) | 0.127003 / 0.014526 (0.112477) | 0.142901 / 0.176557 (-0.033656) | 0.177570 / 0.737135 (-0.559565) | 0.137758 / 0.296338 (-0.158580) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.632820 / 0.215209 (0.417611) | 6.215535 / 2.077655 (4.137880) | 2.615310 / 1.504120 (1.111190) | 2.261431 / 1.541195 (0.720236) | 2.220570 / 1.468490 (0.752080) | 1.215820 / 4.584777 (-3.368957) | 5.247680 / 3.745712 (1.501968) | 3.120054 / 5.269862 (-2.149807) | 1.950947 / 4.565676 (-2.614730) | 0.149980 / 0.424275 (-0.274295) | 0.015241 / 0.007607 (0.007634) | 0.879714 / 0.226044 (0.653670) | 7.941913 / 2.268929 (5.672984) | 3.512456 / 55.444624 (-51.932168) | 2.693833 / 6.876477 (-4.182644) | 2.772780 / 2.142072 (0.630708) | 1.459581 / 4.805227 (-3.345646) | 0.264820 / 6.500664 (-6.235844) | 0.076698 / 0.075469 (0.001228) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.437719 / 1.841788 (-0.404068) | 16.750309 / 8.074308 (8.676001) | 18.646776 / 10.191392 (8.455384) | 0.227858 / 0.680424 (-0.452566) | 0.024239 / 0.534201 (-0.509962) | 0.486172 / 0.579283 (-0.093111) | 0.574731 / 0.434364 (0.140367) | 0.557776 / 0.540337 (0.017439) | 0.672921 / 1.386936 (-0.714015) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-10T08:43:19Z | 2023-01-18T17:12:17Z | 2023-01-18T14:09:02Z | MEMBER | null | This PR fixes the RuntimeError: Sharding is ambiguous for this dataset.
The error for ambiguous sharding will be raised only if num_proc > 1.
Fix #5415, fix #5414.
Fix https://huggingface.co/datasets/ami/discussions/3. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5416/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5416/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5416.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5416",
"merged_at": "2023-01-18T14:09:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5416.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5416"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [] | 2023-01-10T07:36:11Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:03Z | MEMBER | null | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1415 fpath = path_join(self._output_dir, fname)
1416
-> 1417 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1418 if num_input_shards <= 1 and num_proc is not None:
1419 logger.warning(
.../huggingface/datasets/src/datasets/utils/sharding.py in _number_of_shards_in_gen_kwargs(gen_kwargs)
10 lists_lengths = {key: len(value) for key, value in gen_kwargs.items() if isinstance(value, list)}
11 if len(set(lists_lengths.values())) > 1:
---> 12 raise RuntimeError(
13 (
14 "Sharding is ambiguous for this dataset: "
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key samples_paths has length 6
- key ids has length 7
- key verification_ids has length 6
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
This behavior was introduced when implementing multiprocessing by PR:
- #5107
### Steps to reproduce the bug
```python
ds = load_dataset("ami", "microphone-single", split="train", revision="2d7620bb7c3f1aab9f329615c3bdb598069d907a")
```
### Expected behavior
No error raised.
### Environment info
Since datasets 2.7.0 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5414/comments | https://api.github.com/repos/huggingface/datasets/issues/5414/events | https://github.com/huggingface/datasets/issues/5414 | 1,525,733,818 | I_kwDODunzps5a8Nm6 | 5,414 | Sharding error with Multilingual LibriSpeech | {
"avatar_url": "https://avatars.githubusercontent.com/u/19574344?v=4",
"events_url": "https://api.github.com/users/Nithin-Holla/events{/privacy}",
"followers_url": "https://api.github.com/users/Nithin-Holla/followers",
"following_url": "https://api.github.com/users/Nithin-Holla/following{/other_user}",
"gists_url": "https://api.github.com/users/Nithin-Holla/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Nithin-Holla",
"id": 19574344,
"login": "Nithin-Holla",
"node_id": "MDQ6VXNlcjE5NTc0MzQ0",
"organizations_url": "https://api.github.com/users/Nithin-Holla/orgs",
"received_events_url": "https://api.github.com/users/Nithin-Holla/received_events",
"repos_url": "https://api.github.com/users/Nithin-Holla/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Nithin-Holla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nithin-Holla/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Nithin-Holla"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @Nithin-Holla.\r\n\r\nThis is a known issue for multiple datasets and we are investigating it:\r\n- See e.g.: https://huggingface.co/datasets/ami/discussions/3",
"Main issue:\r\n- #5415",
"@albertvillanova Thanks! As a workaround for now, can I use the dataset in streaming mode?",
"Yes, @Nithin-Holla, in the meantime you can use this dataset in streaming mode."
] | 2023-01-09T14:45:31Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:04Z | NONE | null | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/2.1.0/1904af50f57a5c370c9364cc337699cfe496d4e9edcae6648a96be23086362d0...
Downloading data files: 100%
3/3 [00:00<00:00, 107.23it/s]
Downloading data files: 100%
1/1 [00:00<00:00, 35.08it/s]
Downloading data files: 100%
6/6 [00:00<00:00, 303.36it/s]
Downloading data files: 100%
3/3 [00:00<00:00, 130.37it/s]
Downloading data files: 100%
1049/1049 [00:00<00:00, 4491.40it/s]
Downloading data files: 100%
37/37 [00:00<00:00, 1096.78it/s]
Downloading data files: 100%
40/40 [00:00<00:00, 1003.93it/s]
Extracting data files: 100%
3/3 [00:11<00:00, 2.62s/it]
Generating train split:
469942/0 [34:13<00:00, 273.21 examples/s]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-74fa6d092bdc> in <module>
----> 1 mls = load_dataset(MLS_DATASET,
2 LANGUAGE,
3 cache_dir="~/datadrive/cache/huggingface/datasets",
4 ignore_verifications=True)
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1755
1756 # Download and prepare data
-> 1757 builder_instance.download_and_prepare(
1758 download_config=download_config,
1759 download_mode=download_mode,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
858 if num_proc is not None:
859 prepare_split_kwargs["num_proc"] = num_proc
--> 860 self._download_and_prepare(
861 dl_manager=dl_manager,
862 verify_infos=verify_infos,
/anaconda/envs/py38_default/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1609
1610 def _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs):
...
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_archives has length 1049
- key local_extracted_archive has length 1049
- key limited_ids_paths has length 1
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
### Steps to reproduce the bug
Here is the code to reproduce it:
```python
from datasets import load_dataset
MLS_DATASET = "facebook/multilingual_librispeech"
LANGUAGE = "german"
mls = load_dataset(MLS_DATASET,
LANGUAGE,
cache_dir="~/datadrive/cache/huggingface/datasets",
ignore_verifications=True)
```
### Expected behavior
The expected behaviour is that the dataset is successfully loaded.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-1094-azure-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 10.0.1
- Pandas version: 1.2.4 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5414/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5414/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5413/comments | https://api.github.com/repos/huggingface/datasets/issues/5413/events | https://github.com/huggingface/datasets/issues/5413 | 1,524,591,837 | I_kwDODunzps5a32zd | 5,413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | {
"avatar_url": "https://avatars.githubusercontent.com/u/38279341?v=4",
"events_url": "https://api.github.com/users/ZeguanXiao/events{/privacy}",
"followers_url": "https://api.github.com/users/ZeguanXiao/followers",
"following_url": "https://api.github.com/users/ZeguanXiao/following{/other_user}",
"gists_url": "https://api.github.com/users/ZeguanXiao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ZeguanXiao",
"id": 38279341,
"login": "ZeguanXiao",
"node_id": "MDQ6VXNlcjM4Mjc5MzQx",
"organizations_url": "https://api.github.com/users/ZeguanXiao/orgs",
"received_events_url": "https://api.github.com/users/ZeguanXiao/received_events",
"repos_url": "https://api.github.com/users/ZeguanXiao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ZeguanXiao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZeguanXiao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ZeguanXiao"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"Hi ! Thanks for reporting :)\r\n\r\nI managed to reproduce the hub using\r\n```python\r\n\r\nfrom datasets import concatenate_datasets, Dataset, load_from_disk\r\n\r\nDataset.from_dict({\"a\": range(9)}).save_to_disk(\"tmp/ds1\")\r\nds1 = load_from_disk(\"tmp/ds1\")\r\nds1 = concatenate_datasets([ds1, ds1])\r\n\r\nDataset.from_dict({\"b\": range(6)}).save_to_disk(\"tmp/ds2\")\r\nds2 = load_from_disk(\"tmp/ds2\")\r\nds2 = concatenate_datasets([ds2, ds2, ds2])\r\n\r\nconcatenate_datasets([ds1, ds2], axis=1)\r\n```\r\nand I get\r\n```python\r\nTraceback (most recent call last): \r\n File \"test.py\", line 98, in <module>\r\n dds = concatenate_datasets([ds1, ds2], axis=1)\r\n File \"/Users/.../datasets/combine.py\", line 182, in concatenate_datasets\r\n return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)\r\n File \"/Users/.../datasets/arrow_dataset.py\", line 5499, in _concatenate_map_style_datasets\r\n table = concat_tables([dset._data for dset in dsets], axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1778, in concat_tables\r\n return ConcatenationTable.from_tables(tables, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1483, in from_tables\r\n blocks = _extend_blocks(blocks, table_blocks, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1477, in _extend_blocks\r\n result[i].extend(row_blocks)\r\nIndexError: list index out of range\r\n```\r\n\r\nIt appears to happen when the two datasets have a number of shards that is not the same"
] | 2023-01-08T17:01:52Z | 2023-01-26T09:27:21Z | 2023-01-26T09:27:21Z | NONE | null | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 5499, in _concatenate_map_style_datasets
table = concat_tables([dset._data for dset in dsets], axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1778, in concat_tables
return ConcatenationTable.from_tables(tables, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1483, in from_tables
blocks = _extend_blocks(blocks, table_blocks, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1477, in _extend_blocks
result[i].extend(row_blocks)
IndexError: list index out of range
```
### Steps to reproduce the bug
dataset = concatenate_datasets([dataset1, dataset2], axis = 1)
### Expected behavior
The datasets are correctly concatenated.
### Environment info
datasets==2.8.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5413/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5412/comments | https://api.github.com/repos/huggingface/datasets/issues/5412/events | https://github.com/huggingface/datasets/issues/5412 | 1,524,250,269 | I_kwDODunzps5a2jad | 5,412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/destigres/events{/privacy}",
"followers_url": "https://api.github.com/users/destigres/followers",
"following_url": "https://api.github.com/users/destigres/following{/other_user}",
"gists_url": "https://api.github.com/users/destigres/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/destigres",
"id": 7139344,
"login": "destigres",
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"organizations_url": "https://api.github.com/users/destigres/orgs",
"received_events_url": "https://api.github.com/users/destigres/received_events",
"repos_url": "https://api.github.com/users/destigres/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/destigres/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/destigres/subscriptions",
"type": "User",
"url": "https://api.github.com/users/destigres"
} | [] | closed | false | null | [] | null | [
"Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.\r\n\r\nYou can also specify another cache directory by passing `cache_dir=` to `load_dataset()`.",
"Thank you! What do you mean by prepare it beforehand? I am unclear how to conduct dataset preparation outside of using the `load_dataset` function.",
"You can have a separate script that does load_dataset + map + save_to_disk to save your prepared dataset somewhere. Then in your training script you can reload the dataset with load_from_disk",
"Thank you! I believe I was running additional map steps after loading, resulting in the cache conflict. "
] | 2023-01-08T00:44:32Z | 2023-01-19T20:28:43Z | 2023-01-19T20:28:43Z | NONE | null | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would solve my problem too.
I am using datasets version 2.8.0.
### Steps to reproduce the bug
1. Start training run of GPU 0 loading dataset from
```
load_dataset(
"json",
data_files=tr_dataset_path,
split=f"train",
download_mode="force_redownload",
)
```
2. While GPU 0 is training, start an identical run on GPU 1. GPU 1 will produce the following error:
```
Traceback (most recent call last):
File "/local-scratch1/data/mt/code/qq/train.py", line 198, in <module>
main()
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/username/.local/lib/python3.8/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/local-scratch1/data/mt/code/qq/train.py", line 113, in main
load_dataset(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1734, in load_dataset
builder_instance = load_dataset_builder(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/load.py", line 1518, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/builder.py", line 366, in __init__
self.info = DatasetInfo.from_directory(self._cache_dir)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/datasets/info.py", line 313, in from_directory
with fs.open(path_join(dataset_info_dir, config.DATASET_INFO_FILENAME), "r", encoding="utf-8") as f:
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1094, in open
self.open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/spec.py", line 1106, in open
f = self._open(
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 175, in _open
return LocalFileOpener(path, mode, fs=self, **kwargs)
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 273, in __init__
self._open()
File "/home/username/miniconda3/envs/qq3/lib/python3.8/site-packages/fsspec/implementations/local.py", line 278, in _open
self.f = open(self.path, mode=self.mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/username/.cache/huggingface/datasets/json/default-43d06a4aedb25e6d/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51/dataset_info.json'
```
### Expected behavior
Expected behavior: 2nd GPU training run should run the same as 1st GPU training run.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.8.0
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 9.0.0
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5412/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5411/comments | https://api.github.com/repos/huggingface/datasets/issues/5411/events | https://github.com/huggingface/datasets/pull/5411 | 1,523,297,786 | PR_kwDODunzps5G23-T | 5,411 | Update docs of S3 filesystem with async aiobotocore | {
"avatar_url": "https://avatars.githubusercontent.com/u/5677912?v=4",
"events_url": "https://api.github.com/users/maheshpec/events{/privacy}",
"followers_url": "https://api.github.com/users/maheshpec/followers",
"following_url": "https://api.github.com/users/maheshpec/following{/other_user}",
"gists_url": "https://api.github.com/users/maheshpec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/maheshpec",
"id": 5677912,
"login": "maheshpec",
"node_id": "MDQ6VXNlcjU2Nzc5MTI=",
"organizations_url": "https://api.github.com/users/maheshpec/orgs",
"received_events_url": "https://api.github.com/users/maheshpec/received_events",
"repos_url": "https://api.github.com/users/maheshpec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/maheshpec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maheshpec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/maheshpec"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008587 / 0.011353 (-0.002766) | 0.004613 / 0.011008 (-0.006395) | 0.100446 / 0.038508 (0.061938) | 0.029606 / 0.023109 (0.006497) | 0.302102 / 0.275898 (0.026204) | 0.357364 / 0.323480 (0.033884) | 0.007031 / 0.007986 (-0.000954) | 0.003593 / 0.004328 (-0.000735) | 0.078110 / 0.004250 (0.073860) | 0.035495 / 0.037052 (-0.001557) | 0.312522 / 0.258489 (0.054033) | 0.349336 / 0.293841 (0.055495) | 0.033719 / 0.128546 (-0.094827) | 0.011449 / 0.075646 (-0.064197) | 0.321760 / 0.419271 (-0.097512) | 0.043697 / 0.043533 (0.000165) | 0.304476 / 0.255139 (0.049337) | 0.333126 / 0.283200 (0.049926) | 0.092756 / 0.141683 (-0.048927) | 1.506734 / 1.452155 (0.054579) | 1.547381 / 1.492716 (0.054664) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178177 / 0.018006 (0.160171) | 0.427814 / 0.000490 (0.427324) | 0.002505 / 0.000200 (0.002305) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023039 / 0.037411 (-0.014372) | 0.097113 / 0.014526 (0.082587) | 0.105014 / 0.176557 (-0.071543) | 0.141185 / 0.737135 (-0.595950) | 0.108843 / 0.296338 (-0.187495) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424148 / 0.215209 (0.208939) | 4.247599 / 2.077655 (2.169944) | 2.130720 / 1.504120 (0.626600) | 1.916349 / 1.541195 (0.375154) | 1.831515 / 1.468490 (0.363025) | 0.688301 / 4.584777 (-3.896476) | 3.381749 / 3.745712 (-0.363963) | 2.900045 / 5.269862 (-2.369817) | 1.576248 / 4.565676 (-2.989428) | 0.082354 / 0.424275 (-0.341921) | 0.012200 / 0.007607 (0.004593) | 0.525753 / 0.226044 (0.299709) | 5.277672 / 2.268929 (3.008743) | 2.603870 / 55.444624 (-52.840754) | 2.296203 / 6.876477 (-4.580273) | 2.308014 / 2.142072 (0.165942) | 0.809056 / 4.805227 (-3.996171) | 0.148122 / 6.500664 (-6.352542) | 0.066097 / 0.075469 (-0.009372) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.214059 / 1.841788 (-0.627728) | 13.671332 / 8.074308 (5.597024) | 13.694554 / 10.191392 (3.503162) | 0.151454 / 0.680424 (-0.528970) | 0.028514 / 0.534201 (-0.505687) | 0.391480 / 0.579283 (-0.187804) | 0.404499 / 0.434364 (-0.029865) | 0.458111 / 0.540337 (-0.082226) | 0.539454 / 1.386936 (-0.847482) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006795 / 0.011353 (-0.004558) | 0.004463 / 0.011008 (-0.006545) | 0.099542 / 0.038508 (0.061034) | 0.027588 / 0.023109 (0.004479) | 0.423023 / 0.275898 (0.147125) | 0.458459 / 0.323480 (0.134979) | 0.004981 / 0.007986 (-0.003005) | 0.003321 / 0.004328 (-0.001008) | 0.075727 / 0.004250 (0.071477) | 0.040541 / 0.037052 (0.003489) | 0.423724 / 0.258489 (0.165235) | 0.468334 / 0.293841 (0.174493) | 0.031732 / 0.128546 (-0.096814) | 0.011478 / 0.075646 (-0.064168) | 0.319807 / 0.419271 (-0.099465) | 0.041215 / 0.043533 (-0.002318) | 0.423060 / 0.255139 (0.167921) | 0.446157 / 0.283200 (0.162957) | 0.088884 / 0.141683 (-0.052799) | 1.553404 / 1.452155 (0.101250) | 1.607797 / 1.492716 (0.115080) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208314 / 0.018006 (0.190307) | 0.411627 / 0.000490 (0.411137) | 0.002416 / 0.000200 (0.002216) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024641 / 0.037411 (-0.012770) | 0.101047 / 0.014526 (0.086521) | 0.108410 / 0.176557 (-0.068147) | 0.142860 / 0.737135 (-0.594276) | 0.112486 / 0.296338 (-0.183852) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.485520 / 0.215209 (0.270311) | 4.864009 / 2.077655 (2.786355) | 2.541865 / 1.504120 (1.037745) | 2.339569 / 1.541195 (0.798374) | 2.378258 / 1.468490 (0.909768) | 0.698000 / 4.584777 (-3.886777) | 3.343137 / 3.745712 (-0.402575) | 1.842264 / 5.269862 (-3.427597) | 1.154707 / 4.565676 (-3.410969) | 0.082826 / 0.424275 (-0.341449) | 0.012379 / 0.007607 (0.004772) | 0.583335 / 0.226044 (0.357291) | 5.885934 / 2.268929 (3.617006) | 2.997769 / 55.444624 (-52.446856) | 2.653681 / 6.876477 (-4.222796) | 2.761656 / 2.142072 (0.619583) | 0.799883 / 4.805227 (-4.005344) | 0.151398 / 6.500664 (-6.349266) | 0.067445 / 0.075469 (-0.008024) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.292009 / 1.841788 (-0.549779) | 13.976180 / 8.074308 (5.901872) | 14.219469 / 10.191392 (4.028077) | 0.127810 / 0.680424 (-0.552614) | 0.016919 / 0.534201 (-0.517282) | 0.376401 / 0.579283 (-0.202882) | 0.388563 / 0.434364 (-0.045801) | 0.444904 / 0.540337 (-0.095433) | 0.532290 / 1.386936 (-0.854646) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-06T23:19:17Z | 2023-01-18T11:18:59Z | 2023-01-18T11:12:04Z | CONTRIBUTOR | null | [s3fs has migrated to all async calls](https://github.com/fsspec/s3fs/commit/0de2c6fb3d87c08ea694de96dca0d0834034f8bf).
Updating documentation to use `AioSession` while using s3fs for download manager as well as working with datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5411/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5411/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5411.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5411",
"merged_at": "2023-01-18T11:12:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5411.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5411"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5410/comments | https://api.github.com/repos/huggingface/datasets/issues/5410/events | https://github.com/huggingface/datasets/pull/5410 | 1,521,168,032 | PR_kwDODunzps5GvnJH | 5,410 | Map-style Dataset to IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009812 / 0.011353 (-0.001540) | 0.005290 / 0.011008 (-0.005719) | 0.099728 / 0.038508 (0.061220) | 0.036712 / 0.023109 (0.013602) | 0.305924 / 0.275898 (0.030026) | 0.349844 / 0.323480 (0.026365) | 0.008353 / 0.007986 (0.000368) | 0.004464 / 0.004328 (0.000135) | 0.075329 / 0.004250 (0.071079) | 0.046146 / 0.037052 (0.009094) | 0.304197 / 0.258489 (0.045708) | 0.354245 / 0.293841 (0.060404) | 0.039270 / 0.128546 (-0.089276) | 0.012496 / 0.075646 (-0.063151) | 0.334390 / 0.419271 (-0.084882) | 0.049428 / 0.043533 (0.005896) | 0.297318 / 0.255139 (0.042179) | 0.315646 / 0.283200 (0.032447) | 0.106746 / 0.141683 (-0.034937) | 1.443562 / 1.452155 (-0.008593) | 1.546022 / 1.492716 (0.053305) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.303419 / 0.018006 (0.285413) | 0.536971 / 0.000490 (0.536481) | 0.001335 / 0.000200 (0.001135) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030484 / 0.037411 (-0.006927) | 0.110043 / 0.014526 (0.095518) | 0.125265 / 0.176557 (-0.051291) | 0.171410 / 0.737135 (-0.565725) | 0.128978 / 0.296338 (-0.167361) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398354 / 0.215209 (0.183145) | 3.984180 / 2.077655 (1.906526) | 1.781134 / 1.504120 (0.277014) | 1.589656 / 1.541195 (0.048462) | 1.704192 / 1.468490 (0.235702) | 0.682271 / 4.584777 (-3.902506) | 3.731504 / 3.745712 (-0.014208) | 2.243520 / 5.269862 (-3.026342) | 1.511334 / 4.565676 (-3.054343) | 0.084243 / 0.424275 (-0.340032) | 0.012261 / 0.007607 (0.004654) | 0.507499 / 0.226044 (0.281454) | 5.066037 / 2.268929 (2.797109) | 2.246107 / 55.444624 (-53.198517) | 1.921032 / 6.876477 (-4.955444) | 2.144111 / 2.142072 (0.002039) | 0.845233 / 4.805227 (-3.959995) | 0.165392 / 6.500664 (-6.335272) | 0.064201 / 0.075469 (-0.011268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.217649 / 1.841788 (-0.624138) | 15.890487 / 8.074308 (7.816179) | 14.772039 / 10.191392 (4.580647) | 0.192901 / 0.680424 (-0.487523) | 0.029119 / 0.534201 (-0.505082) | 0.442904 / 0.579283 (-0.136380) | 0.451035 / 0.434364 (0.016671) | 0.520788 / 0.540337 (-0.019550) | 0.623588 / 1.386936 (-0.763348) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007452 / 0.011353 (-0.003901) | 0.005426 / 0.011008 (-0.005582) | 0.096488 / 0.038508 (0.057980) | 0.033575 / 0.023109 (0.010465) | 0.375688 / 0.275898 (0.099790) | 0.412393 / 0.323480 (0.088913) | 0.006050 / 0.007986 (-0.001936) | 0.004424 / 0.004328 (0.000095) | 0.073102 / 0.004250 (0.068852) | 0.052672 / 0.037052 (0.015620) | 0.379352 / 0.258489 (0.120862) | 0.436065 / 0.293841 (0.142224) | 0.036594 / 0.128546 (-0.091952) | 0.012380 / 0.075646 (-0.063266) | 0.332899 / 0.419271 (-0.086373) | 0.048859 / 0.043533 (0.005326) | 0.373215 / 0.255139 (0.118076) | 0.386990 / 0.283200 (0.103791) | 0.105166 / 0.141683 (-0.036517) | 1.490762 / 1.452155 (0.038607) | 1.611310 / 1.492716 (0.118593) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.333142 / 0.018006 (0.315136) | 0.537137 / 0.000490 (0.536647) | 0.000452 / 0.000200 (0.000252) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030368 / 0.037411 (-0.007043) | 0.109608 / 0.014526 (0.095083) | 0.124220 / 0.176557 (-0.052336) | 0.162834 / 0.737135 (-0.574301) | 0.128037 / 0.296338 (-0.168302) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440991 / 0.215209 (0.225782) | 4.400825 / 2.077655 (2.323170) | 2.158768 / 1.504120 (0.654648) | 1.968158 / 1.541195 (0.426963) | 2.085115 / 1.468490 (0.616625) | 0.710757 / 4.584777 (-3.874020) | 3.835441 / 3.745712 (0.089729) | 2.204118 / 5.269862 (-3.065744) | 1.378909 / 4.565676 (-3.186767) | 0.089149 / 0.424275 (-0.335126) | 0.013066 / 0.007607 (0.005459) | 0.539165 / 0.226044 (0.313121) | 5.414176 / 2.268929 (3.145248) | 2.677020 / 55.444624 (-52.767604) | 2.328334 / 6.876477 (-4.548143) | 2.518933 / 2.142072 (0.376860) | 0.840902 / 4.805227 (-3.964325) | 0.170365 / 6.500664 (-6.330299) | 0.063909 / 0.075469 (-0.011561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237205 / 1.841788 (-0.604583) | 15.678776 / 8.074308 (7.604468) | 14.118576 / 10.191392 (3.927184) | 0.167236 / 0.680424 (-0.513188) | 0.018177 / 0.534201 (-0.516024) | 0.426680 / 0.579283 (-0.152603) | 0.425126 / 0.434364 (-0.009238) | 0.501755 / 0.540337 (-0.038582) | 0.592754 / 1.386936 (-0.794182) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008708 / 0.011353 (-0.002645) | 0.004462 / 0.011008 (-0.006546) | 0.100159 / 0.038508 (0.061651) | 0.029543 / 0.023109 (0.006434) | 0.304056 / 0.275898 (0.028158) | 0.367098 / 0.323480 (0.043618) | 0.007049 / 0.007986 (-0.000937) | 0.003294 / 0.004328 (-0.001034) | 0.076954 / 0.004250 (0.072703) | 0.036850 / 0.037052 (-0.000202) | 0.307556 / 0.258489 (0.049067) | 0.348327 / 0.293841 (0.054486) | 0.033520 / 0.128546 (-0.095026) | 0.011312 / 0.075646 (-0.064334) | 0.317588 / 0.419271 (-0.101684) | 0.040196 / 0.043533 (-0.003337) | 0.298330 / 0.255139 (0.043191) | 0.333821 / 0.283200 (0.050622) | 0.086584 / 0.141683 (-0.055099) | 1.480205 / 1.452155 (0.028050) | 1.520975 / 1.492716 (0.028259) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186641 / 0.018006 (0.168635) | 0.414420 / 0.000490 (0.413930) | 0.003021 / 0.000200 (0.002821) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022953 / 0.037411 (-0.014458) | 0.097338 / 0.014526 (0.082812) | 0.104985 / 0.176557 (-0.071572) | 0.139208 / 0.737135 (-0.597927) | 0.108031 / 0.296338 (-0.188307) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417969 / 0.215209 (0.202759) | 4.173189 / 2.077655 (2.095534) | 1.862813 / 1.504120 (0.358693) | 1.653226 / 1.541195 (0.112031) | 1.725917 / 1.468490 (0.257426) | 0.701038 / 4.584777 (-3.883739) | 3.350500 / 3.745712 (-0.395213) | 1.913156 / 5.269862 (-3.356705) | 1.267597 / 4.565676 (-3.298079) | 0.082197 / 0.424275 (-0.342078) | 0.012499 / 0.007607 (0.004892) | 0.520173 / 0.226044 (0.294128) | 5.219981 / 2.268929 (2.951053) | 2.306029 / 55.444624 (-53.138595) | 1.948169 / 6.876477 (-4.928307) | 2.013160 / 2.142072 (-0.128912) | 0.813325 / 4.805227 (-3.991902) | 0.149729 / 6.500664 (-6.350935) | 0.065492 / 0.075469 (-0.009977) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.194163 / 1.841788 (-0.647625) | 13.739562 / 8.074308 (5.665254) | 13.881988 / 10.191392 (3.690596) | 0.138180 / 0.680424 (-0.542244) | 0.029031 / 0.534201 (-0.505170) | 0.387858 / 0.579283 (-0.191425) | 0.395171 / 0.434364 (-0.039193) | 0.446349 / 0.540337 (-0.093988) | 0.527073 / 1.386936 (-0.859863) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006504 / 0.011353 (-0.004849) | 0.004564 / 0.011008 (-0.006444) | 0.099108 / 0.038508 (0.060599) | 0.027420 / 0.023109 (0.004311) | 0.340712 / 0.275898 (0.064814) | 0.391613 / 0.323480 (0.068133) | 0.004977 / 0.007986 (-0.003009) | 0.003375 / 0.004328 (-0.000953) | 0.076403 / 0.004250 (0.072152) | 0.036650 / 0.037052 (-0.000402) | 0.341948 / 0.258489 (0.083459) | 0.392065 / 0.293841 (0.098224) | 0.031802 / 0.128546 (-0.096745) | 0.011659 / 0.075646 (-0.063987) | 0.320099 / 0.419271 (-0.099173) | 0.041615 / 0.043533 (-0.001918) | 0.342125 / 0.255139 (0.086986) | 0.372833 / 0.283200 (0.089633) | 0.089032 / 0.141683 (-0.052650) | 1.486691 / 1.452155 (0.034536) | 1.567326 / 1.492716 (0.074610) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193123 / 0.018006 (0.175117) | 0.404062 / 0.000490 (0.403573) | 0.003460 / 0.000200 (0.003260) | 0.000079 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024565 / 0.037411 (-0.012846) | 0.098958 / 0.014526 (0.084432) | 0.108701 / 0.176557 (-0.067855) | 0.142567 / 0.737135 (-0.594569) | 0.111048 / 0.296338 (-0.185290) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474549 / 0.215209 (0.259340) | 4.753776 / 2.077655 (2.676121) | 2.435528 / 1.504120 (0.931409) | 2.234491 / 1.541195 (0.693297) | 2.269474 / 1.468490 (0.800984) | 0.695636 / 4.584777 (-3.889141) | 3.367816 / 3.745712 (-0.377896) | 1.854828 / 5.269862 (-3.415034) | 1.159729 / 4.565676 (-3.405948) | 0.082267 / 0.424275 (-0.342008) | 0.012483 / 0.007607 (0.004876) | 0.578490 / 0.226044 (0.352446) | 5.814490 / 2.268929 (3.545561) | 2.893310 / 55.444624 (-52.551314) | 2.540555 / 6.876477 (-4.335922) | 2.573705 / 2.142072 (0.431633) | 0.800545 / 4.805227 (-4.004682) | 0.151306 / 6.500664 (-6.349358) | 0.067925 / 0.075469 (-0.007544) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294645 / 1.841788 (-0.547142) | 13.641842 / 8.074308 (5.567534) | 14.015200 / 10.191392 (3.823808) | 0.128829 / 0.680424 (-0.551595) | 0.016870 / 0.534201 (-0.517331) | 0.389137 / 0.579283 (-0.190146) | 0.388384 / 0.434364 (-0.045980) | 0.447711 / 0.540337 (-0.092627) | 0.540637 / 1.386936 (-0.846299) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012282 / 0.011353 (0.000929) | 0.006328 / 0.011008 (-0.004680) | 0.129666 / 0.038508 (0.091158) | 0.039403 / 0.023109 (0.016294) | 0.375464 / 0.275898 (0.099566) | 0.463167 / 0.323480 (0.139687) | 0.010329 / 0.007986 (0.002344) | 0.005111 / 0.004328 (0.000782) | 0.108727 / 0.004250 (0.104476) | 0.047156 / 0.037052 (0.010103) | 0.381869 / 0.258489 (0.123380) | 0.441936 / 0.293841 (0.148095) | 0.054750 / 0.128546 (-0.073796) | 0.019809 / 0.075646 (-0.055837) | 0.436389 / 0.419271 (0.017118) | 0.066585 / 0.043533 (0.023052) | 0.402108 / 0.255139 (0.146969) | 0.424571 / 0.283200 (0.141371) | 0.118326 / 0.141683 (-0.023357) | 1.870175 / 1.452155 (0.418020) | 1.878720 / 1.492716 (0.386004) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.012863 / 0.018006 (-0.005144) | 0.528670 / 0.000490 (0.528181) | 0.006057 / 0.000200 (0.005857) | 0.000124 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030091 / 0.037411 (-0.007320) | 0.136143 / 0.014526 (0.121618) | 0.148931 / 0.176557 (-0.027626) | 0.179578 / 0.737135 (-0.557558) | 0.144528 / 0.296338 (-0.151810) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.594080 / 0.215209 (0.378871) | 6.029101 / 2.077655 (3.951446) | 2.443084 / 1.504120 (0.938964) | 2.123949 / 1.541195 (0.582754) | 2.183021 / 1.468490 (0.714531) | 1.235453 / 4.584777 (-3.349324) | 5.585121 / 3.745712 (1.839408) | 3.208510 / 5.269862 (-2.061351) | 2.090334 / 4.565676 (-2.475342) | 0.150353 / 0.424275 (-0.273922) | 0.016787 / 0.007607 (0.009180) | 0.797561 / 0.226044 (0.571516) | 7.756291 / 2.268929 (5.487363) | 3.283638 / 55.444624 (-52.160986) | 2.527441 / 6.876477 (-4.349036) | 2.590765 / 2.142072 (0.448692) | 1.446818 / 4.805227 (-3.358409) | 0.250563 / 6.500664 (-6.250101) | 0.077919 / 0.075469 (0.002450) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.612022 / 1.841788 (-0.229765) | 18.363316 / 8.074308 (10.289008) | 22.578570 / 10.191392 (12.387178) | 0.232801 / 0.680424 (-0.447623) | 0.048232 / 0.534201 (-0.485969) | 0.549518 / 0.579283 (-0.029766) | 0.624663 / 0.434364 (0.190299) | 0.674745 / 0.540337 (0.134408) | 0.803489 / 1.386936 (-0.583447) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009872 / 0.011353 (-0.001481) | 0.006593 / 0.011008 (-0.004415) | 0.139248 / 0.038508 (0.100740) | 0.035708 / 0.023109 (0.012598) | 0.551335 / 0.275898 (0.275437) | 0.544995 / 0.323480 (0.221515) | 0.007085 / 0.007986 (-0.000900) | 0.004742 / 0.004328 (0.000413) | 0.095823 / 0.004250 (0.091572) | 0.051674 / 0.037052 (0.014621) | 0.463405 / 0.258489 (0.204916) | 0.640392 / 0.293841 (0.346551) | 0.055242 / 0.128546 (-0.073304) | 0.022602 / 0.075646 (-0.053044) | 0.419171 / 0.419271 (-0.000100) | 0.062986 / 0.043533 (0.019453) | 0.503683 / 0.255139 (0.248544) | 0.568719 / 0.283200 (0.285519) | 0.113906 / 0.141683 (-0.027777) | 1.825248 / 1.452155 (0.373094) | 1.985667 / 1.492716 (0.492951) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237478 / 0.018006 (0.219472) | 0.528861 / 0.000490 (0.528371) | 0.008507 / 0.000200 (0.008307) | 0.000158 / 0.000054 (0.000103) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033536 / 0.037411 (-0.003875) | 0.144202 / 0.014526 (0.129677) | 0.139472 / 0.176557 (-0.037084) | 0.184540 / 0.737135 (-0.552596) | 0.147818 / 0.296338 (-0.148520) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.671654 / 0.215209 (0.456445) | 6.616368 / 2.077655 (4.538713) | 2.805634 / 1.504120 (1.301514) | 2.482890 / 1.541195 (0.941695) | 2.547686 / 1.468490 (1.079195) | 1.289169 / 4.584777 (-3.295608) | 5.551436 / 3.745712 (1.805724) | 5.228500 / 5.269862 (-0.041362) | 2.456706 / 4.565676 (-2.108970) | 0.148556 / 0.424275 (-0.275720) | 0.015290 / 0.007607 (0.007683) | 0.837090 / 0.226044 (0.611045) | 8.373561 / 2.268929 (6.104632) | 3.663910 / 55.444624 (-51.780714) | 2.927117 / 6.876477 (-3.949360) | 2.976785 / 2.142072 (0.834712) | 1.501618 / 4.805227 (-3.303609) | 0.263321 / 6.500664 (-6.237343) | 0.082644 / 0.075469 (0.007175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.707419 / 1.841788 (-0.134368) | 18.371117 / 8.074308 (10.296809) | 22.015154 / 10.191392 (11.823762) | 0.232066 / 0.680424 (-0.448357) | 0.027149 / 0.534201 (-0.507052) | 0.544450 / 0.579283 (-0.034833) | 0.605134 / 0.434364 (0.170770) | 0.656063 / 0.540337 (0.115725) | 0.788121 / 1.386936 (-0.598815) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008952 / 0.011353 (-0.002401) | 0.005592 / 0.011008 (-0.005416) | 0.101138 / 0.038508 (0.062630) | 0.035573 / 0.023109 (0.012464) | 0.295959 / 0.275898 (0.020060) | 0.365347 / 0.323480 (0.041867) | 0.008136 / 0.007986 (0.000150) | 0.004479 / 0.004328 (0.000150) | 0.078806 / 0.004250 (0.074556) | 0.045180 / 0.037052 (0.008127) | 0.321687 / 0.258489 (0.063198) | 0.345874 / 0.293841 (0.052033) | 0.038720 / 0.128546 (-0.089826) | 0.012534 / 0.075646 (-0.063112) | 0.335571 / 0.419271 (-0.083700) | 0.049048 / 0.043533 (0.005515) | 0.294756 / 0.255139 (0.039617) | 0.327496 / 0.283200 (0.044296) | 0.109181 / 0.141683 (-0.032502) | 1.417068 / 1.452155 (-0.035087) | 1.455473 / 1.492716 (-0.037244) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267774 / 0.018006 (0.249768) | 0.538546 / 0.000490 (0.538056) | 0.001755 / 0.000200 (0.001555) | 0.000090 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026839 / 0.037411 (-0.010572) | 0.105862 / 0.014526 (0.091336) | 0.118278 / 0.176557 (-0.058279) | 0.157926 / 0.737135 (-0.579209) | 0.124700 / 0.296338 (-0.171638) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399060 / 0.215209 (0.183851) | 3.991409 / 2.077655 (1.913754) | 1.763569 / 1.504120 (0.259449) | 1.579602 / 1.541195 (0.038407) | 1.652928 / 1.468490 (0.184438) | 0.692962 / 4.584777 (-3.891815) | 3.784635 / 3.745712 (0.038922) | 3.249341 / 5.269862 (-2.020521) | 1.815711 / 4.565676 (-2.749966) | 0.084384 / 0.424275 (-0.339891) | 0.012546 / 0.007607 (0.004939) | 0.521397 / 0.226044 (0.295352) | 5.075824 / 2.268929 (2.806895) | 2.258353 / 55.444624 (-53.186272) | 1.925220 / 6.876477 (-4.951256) | 2.002821 / 2.142072 (-0.139252) | 0.830507 / 4.805227 (-3.974720) | 0.165845 / 6.500664 (-6.334819) | 0.063905 / 0.075469 (-0.011565) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.198726 / 1.841788 (-0.643061) | 14.804448 / 8.074308 (6.730139) | 12.855167 / 10.191392 (2.663775) | 0.167932 / 0.680424 (-0.512492) | 0.028643 / 0.534201 (-0.505558) | 0.441224 / 0.579283 (-0.138059) | 0.434924 / 0.434364 (0.000560) | 0.516188 / 0.540337 (-0.024150) | 0.605017 / 1.386936 (-0.781919) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007031 / 0.011353 (-0.004322) | 0.005157 / 0.011008 (-0.005851) | 0.086943 / 0.038508 (0.048434) | 0.031377 / 0.023109 (0.008268) | 0.334810 / 0.275898 (0.058912) | 0.368590 / 0.323480 (0.045110) | 0.005973 / 0.007986 (-0.002013) | 0.004173 / 0.004328 (-0.000155) | 0.067033 / 0.004250 (0.062783) | 0.054070 / 0.037052 (0.017018) | 0.332232 / 0.258489 (0.073743) | 0.384982 / 0.293841 (0.091141) | 0.034023 / 0.128546 (-0.094524) | 0.011301 / 0.075646 (-0.064345) | 0.295644 / 0.419271 (-0.123628) | 0.045589 / 0.043533 (0.002056) | 0.330739 / 0.255139 (0.075600) | 0.352841 / 0.283200 (0.069642) | 0.104829 / 0.141683 (-0.036854) | 1.329360 / 1.452155 (-0.122794) | 1.437956 / 1.492716 (-0.054760) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.299187 / 0.018006 (0.281181) | 0.563407 / 0.000490 (0.562917) | 0.004179 / 0.000200 (0.003979) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027405 / 0.037411 (-0.010006) | 0.097498 / 0.014526 (0.082972) | 0.114265 / 0.176557 (-0.062292) | 0.146823 / 0.737135 (-0.590313) | 0.117948 / 0.296338 (-0.178391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.378756 / 0.215209 (0.163547) | 3.774804 / 2.077655 (1.697150) | 1.804149 / 1.504120 (0.300029) | 1.626312 / 1.541195 (0.085117) | 1.731111 / 1.468490 (0.262620) | 0.633493 / 4.584777 (-3.951284) | 3.488220 / 3.745712 (-0.257492) | 3.064710 / 5.269862 (-2.205151) | 1.690647 / 4.565676 (-2.875029) | 0.076093 / 0.424275 (-0.348182) | 0.010820 / 0.007607 (0.003213) | 0.465091 / 0.226044 (0.239046) | 4.676842 / 2.268929 (2.407913) | 2.297381 / 55.444624 (-53.147244) | 1.960355 / 6.876477 (-4.916122) | 1.983742 / 2.142072 (-0.158330) | 0.739525 / 4.805227 (-4.065702) | 0.152663 / 6.500664 (-6.348001) | 0.057316 / 0.075469 (-0.018153) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.104721 / 1.841788 (-0.737067) | 14.577171 / 8.074308 (6.502863) | 13.680402 / 10.191392 (3.489010) | 0.182234 / 0.680424 (-0.498190) | 0.018853 / 0.534201 (-0.515348) | 0.426194 / 0.579283 (-0.153089) | 0.429202 / 0.434364 (-0.005162) | 0.543125 / 0.540337 (0.002788) | 0.645887 / 1.386936 (-0.741049) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010055 / 0.011353 (-0.001298) | 0.005576 / 0.011008 (-0.005432) | 0.100059 / 0.038508 (0.061551) | 0.038535 / 0.023109 (0.015425) | 0.297538 / 0.275898 (0.021640) | 0.368117 / 0.323480 (0.044637) | 0.008540 / 0.007986 (0.000555) | 0.004469 / 0.004328 (0.000141) | 0.075801 / 0.004250 (0.071551) | 0.046604 / 0.037052 (0.009552) | 0.307242 / 0.258489 (0.048753) | 0.343949 / 0.293841 (0.050108) | 0.039353 / 0.128546 (-0.089194) | 0.012446 / 0.075646 (-0.063200) | 0.334628 / 0.419271 (-0.084643) | 0.051628 / 0.043533 (0.008095) | 0.298726 / 0.255139 (0.043587) | 0.316010 / 0.283200 (0.032810) | 0.120564 / 0.141683 (-0.021119) | 1.459396 / 1.452155 (0.007241) | 1.493682 / 1.492716 (0.000965) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011702 / 0.018006 (-0.006304) | 0.570261 / 0.000490 (0.569771) | 0.003760 / 0.000200 (0.003560) | 0.000091 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028806 / 0.037411 (-0.008605) | 0.112150 / 0.014526 (0.097625) | 0.123140 / 0.176557 (-0.053417) | 0.173055 / 0.737135 (-0.564080) | 0.130060 / 0.296338 (-0.166279) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398216 / 0.215209 (0.183007) | 3.978677 / 2.077655 (1.901022) | 1.754229 / 1.504120 (0.250109) | 1.561892 / 1.541195 (0.020697) | 1.679138 / 1.468490 (0.210648) | 0.690254 / 4.584777 (-3.894523) | 3.817698 / 3.745712 (0.071986) | 2.177854 / 5.269862 (-3.092008) | 1.361860 / 4.565676 (-3.203816) | 0.084108 / 0.424275 (-0.340167) | 0.012640 / 0.007607 (0.005033) | 0.504385 / 0.226044 (0.278341) | 5.034103 / 2.268929 (2.765174) | 2.254032 / 55.444624 (-53.190593) | 1.910439 / 6.876477 (-4.966038) | 2.003515 / 2.142072 (-0.138558) | 0.839747 / 4.805227 (-3.965480) | 0.165654 / 6.500664 (-6.335010) | 0.063483 / 0.075469 (-0.011986) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.187521 / 1.841788 (-0.654267) | 15.381121 / 8.074308 (7.306812) | 14.579418 / 10.191392 (4.388026) | 0.199221 / 0.680424 (-0.481202) | 0.029335 / 0.534201 (-0.504866) | 0.443159 / 0.579283 (-0.136124) | 0.447772 / 0.434364 (0.013408) | 0.545071 / 0.540337 (0.004733) | 0.650494 / 1.386936 (-0.736442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007675 / 0.011353 (-0.003677) | 0.005364 / 0.011008 (-0.005644) | 0.097921 / 0.038508 (0.059413) | 0.033645 / 0.023109 (0.010536) | 0.404818 / 0.275898 (0.128920) | 0.429983 / 0.323480 (0.106503) | 0.006106 / 0.007986 (-0.001879) | 0.005281 / 0.004328 (0.000953) | 0.073762 / 0.004250 (0.069512) | 0.053065 / 0.037052 (0.016012) | 0.400657 / 0.258489 (0.142168) | 0.447743 / 0.293841 (0.153902) | 0.036782 / 0.128546 (-0.091765) | 0.012593 / 0.075646 (-0.063054) | 0.332825 / 0.419271 (-0.086446) | 0.049424 / 0.043533 (0.005891) | 0.400397 / 0.255139 (0.145258) | 0.414794 / 0.283200 (0.131594) | 0.106555 / 0.141683 (-0.035128) | 1.466917 / 1.452155 (0.014762) | 1.571351 / 1.492716 (0.078635) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254337 / 0.018006 (0.236331) | 0.568360 / 0.000490 (0.567870) | 0.000445 / 0.000200 (0.000245) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031044 / 0.037411 (-0.006367) | 0.112282 / 0.014526 (0.097756) | 0.127205 / 0.176557 (-0.049352) | 0.166551 / 0.737135 (-0.570584) | 0.130520 / 0.296338 (-0.165818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442906 / 0.215209 (0.227697) | 4.430218 / 2.077655 (2.352563) | 2.287251 / 1.504120 (0.783132) | 2.112345 / 1.541195 (0.571150) | 2.240952 / 1.468490 (0.772462) | 0.713800 / 4.584777 (-3.870977) | 3.884161 / 3.745712 (0.138449) | 2.166901 / 5.269862 (-3.102960) | 1.374490 / 4.565676 (-3.191187) | 0.087548 / 0.424275 (-0.336727) | 0.012369 / 0.007607 (0.004761) | 0.540783 / 0.226044 (0.314739) | 5.396187 / 2.268929 (3.127258) | 2.779636 / 55.444624 (-52.664988) | 2.434220 / 6.876477 (-4.442257) | 2.508180 / 2.142072 (0.366107) | 0.852470 / 4.805227 (-3.952757) | 0.171266 / 6.500664 (-6.329398) | 0.065463 / 0.075469 (-0.010006) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.241720 / 1.841788 (-0.600067) | 15.332568 / 8.074308 (7.258260) | 13.688723 / 10.191392 (3.497331) | 0.145150 / 0.680424 (-0.535273) | 0.017694 / 0.534201 (-0.516507) | 0.426078 / 0.579283 (-0.153205) | 0.441189 / 0.434364 (0.006825) | 0.540284 / 0.540337 (-0.000054) | 0.657548 / 1.386936 (-0.729388) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008604 / 0.011353 (-0.002749) | 0.004566 / 0.011008 (-0.006442) | 0.099607 / 0.038508 (0.061099) | 0.029628 / 0.023109 (0.006519) | 0.300481 / 0.275898 (0.024583) | 0.342596 / 0.323480 (0.019116) | 0.007003 / 0.007986 (-0.000982) | 0.003408 / 0.004328 (-0.000920) | 0.079076 / 0.004250 (0.074826) | 0.034104 / 0.037052 (-0.002948) | 0.303856 / 0.258489 (0.045367) | 0.348729 / 0.293841 (0.054888) | 0.033752 / 0.128546 (-0.094794) | 0.011497 / 0.075646 (-0.064149) | 0.321568 / 0.419271 (-0.097704) | 0.041472 / 0.043533 (-0.002061) | 0.303396 / 0.255139 (0.048257) | 0.331121 / 0.283200 (0.047921) | 0.086203 / 0.141683 (-0.055480) | 1.476995 / 1.452155 (0.024840) | 1.539428 / 1.492716 (0.046712) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215810 / 0.018006 (0.197803) | 0.414292 / 0.000490 (0.413802) | 0.000388 / 0.000200 (0.000188) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023441 / 0.037411 (-0.013970) | 0.098463 / 0.014526 (0.083938) | 0.105435 / 0.176557 (-0.071121) | 0.139736 / 0.737135 (-0.597399) | 0.109467 / 0.296338 (-0.186872) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418244 / 0.215209 (0.203035) | 4.160693 / 2.077655 (2.083039) | 1.878895 / 1.504120 (0.374775) | 1.679338 / 1.541195 (0.138143) | 1.730384 / 1.468490 (0.261894) | 0.688603 / 4.584777 (-3.896174) | 3.393542 / 3.745712 (-0.352170) | 1.901337 / 5.269862 (-3.368525) | 1.447269 / 4.565676 (-3.118408) | 0.083003 / 0.424275 (-0.341272) | 0.012574 / 0.007607 (0.004967) | 0.526363 / 0.226044 (0.300318) | 5.275159 / 2.268929 (3.006230) | 2.323642 / 55.444624 (-53.120982) | 1.982929 / 6.876477 (-4.893548) | 2.014081 / 2.142072 (-0.127991) | 0.809466 / 4.805227 (-3.995761) | 0.149038 / 6.500664 (-6.351626) | 0.064394 / 0.075469 (-0.011075) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.207439 / 1.841788 (-0.634349) | 13.691048 / 8.074308 (5.616740) | 13.880965 / 10.191392 (3.689573) | 0.148553 / 0.680424 (-0.531871) | 0.028397 / 0.534201 (-0.505804) | 0.391818 / 0.579283 (-0.187465) | 0.407181 / 0.434364 (-0.027183) | 0.481163 / 0.540337 (-0.059175) | 0.570689 / 1.386936 (-0.816247) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006361 / 0.011353 (-0.004992) | 0.004520 / 0.011008 (-0.006488) | 0.097679 / 0.038508 (0.059171) | 0.027223 / 0.023109 (0.004113) | 0.407966 / 0.275898 (0.132068) | 0.439868 / 0.323480 (0.116388) | 0.004625 / 0.007986 (-0.003360) | 0.004039 / 0.004328 (-0.000289) | 0.074548 / 0.004250 (0.070298) | 0.034957 / 0.037052 (-0.002095) | 0.412762 / 0.258489 (0.154273) | 0.449716 / 0.293841 (0.155875) | 0.031272 / 0.128546 (-0.097274) | 0.011598 / 0.075646 (-0.064049) | 0.320922 / 0.419271 (-0.098349) | 0.041250 / 0.043533 (-0.002283) | 0.411439 / 0.255139 (0.156300) | 0.429722 / 0.283200 (0.146523) | 0.087161 / 0.141683 (-0.054522) | 1.512573 / 1.452155 (0.060418) | 1.569385 / 1.492716 (0.076668) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222612 / 0.018006 (0.204606) | 0.409086 / 0.000490 (0.408596) | 0.004246 / 0.000200 (0.004046) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024324 / 0.037411 (-0.013087) | 0.099055 / 0.014526 (0.084530) | 0.106809 / 0.176557 (-0.069748) | 0.141275 / 0.737135 (-0.595860) | 0.109426 / 0.296338 (-0.186913) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469736 / 0.215209 (0.254527) | 4.686900 / 2.077655 (2.609246) | 2.413392 / 1.504120 (0.909272) | 2.217366 / 1.541195 (0.676171) | 2.266957 / 1.468490 (0.798467) | 0.698647 / 4.584777 (-3.886129) | 3.389317 / 3.745712 (-0.356395) | 1.862315 / 5.269862 (-3.407546) | 1.160931 / 4.565676 (-3.404746) | 0.082829 / 0.424275 (-0.341446) | 0.012627 / 0.007607 (0.005020) | 0.568027 / 0.226044 (0.341983) | 5.683220 / 2.268929 (3.414291) | 2.865701 / 55.444624 (-52.578924) | 2.522401 / 6.876477 (-4.354076) | 2.542395 / 2.142072 (0.400323) | 0.801224 / 4.805227 (-4.004003) | 0.149946 / 6.500664 (-6.350718) | 0.065447 / 0.075469 (-0.010023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.283756 / 1.841788 (-0.558032) | 13.903662 / 8.074308 (5.829354) | 13.238389 / 10.191392 (3.046997) | 0.142304 / 0.680424 (-0.538120) | 0.016922 / 0.534201 (-0.517279) | 0.377797 / 0.579283 (-0.201487) | 0.382460 / 0.434364 (-0.051904) | 0.464645 / 0.540337 (-0.075692) | 0.556270 / 1.386936 (-0.830666) |\n\n</details>\n</details>\n\n\n",
"> I think this would be more of a Conceptual Guide doc since this is more explanatory and compares the differences between a Dataset and an IterableDataset\r\n\r\nsounds good to me !\r\n\r\n> There are definitely places in the docs where we can add a nice and link to this doc though to build up the user's understanding of this topic. For example, in the Know your dataset [tutorial](https://huggingface.co/docs/datasets/access), we only introduce the regular Dataset object and not the IterableDataset. We can add a section there for IterableDataset and then link to this doc that explains the difference between the two 🙂\r\n\r\ngood idea, thanks :)",
"I'll open a PR to add a section on `IterableDataset`'s in the tutorial, and once you're done editing this doc I can give it a final polish! 😄 ",
"I moved the doc page to conceptual guides and took your suggestions into account :)\r\n\r\nI think this is ready for final review now",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009890 / 0.011353 (-0.001463) | 0.005156 / 0.011008 (-0.005852) | 0.099493 / 0.038508 (0.060984) | 0.036671 / 0.023109 (0.013562) | 0.304686 / 0.275898 (0.028788) | 0.339070 / 0.323480 (0.015590) | 0.008466 / 0.007986 (0.000481) | 0.005863 / 0.004328 (0.001534) | 0.075082 / 0.004250 (0.070832) | 0.045926 / 0.037052 (0.008874) | 0.303157 / 0.258489 (0.044668) | 0.363710 / 0.293841 (0.069870) | 0.038497 / 0.128546 (-0.090049) | 0.012063 / 0.075646 (-0.063583) | 0.334463 / 0.419271 (-0.084808) | 0.048161 / 0.043533 (0.004628) | 0.300431 / 0.255139 (0.045292) | 0.330344 / 0.283200 (0.047145) | 0.105509 / 0.141683 (-0.036174) | 1.475242 / 1.452155 (0.023087) | 1.550624 / 1.492716 (0.057908) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245749 / 0.018006 (0.227743) | 0.575091 / 0.000490 (0.574601) | 0.001556 / 0.000200 (0.001357) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030447 / 0.037411 (-0.006964) | 0.110982 / 0.014526 (0.096456) | 0.126760 / 0.176557 (-0.049797) | 0.173375 / 0.737135 (-0.563760) | 0.128799 / 0.296338 (-0.167539) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.392861 / 0.215209 (0.177651) | 3.911231 / 2.077655 (1.833576) | 1.757413 / 1.504120 (0.253293) | 1.563287 / 1.541195 (0.022093) | 1.658678 / 1.468490 (0.190188) | 0.677244 / 4.584777 (-3.907533) | 3.754917 / 3.745712 (0.009205) | 3.779417 / 5.269862 (-1.490444) | 1.993159 / 4.565676 (-2.572517) | 0.084425 / 0.424275 (-0.339850) | 0.012500 / 0.007607 (0.004893) | 0.501788 / 0.226044 (0.275743) | 5.003173 / 2.268929 (2.734244) | 2.273547 / 55.444624 (-53.171077) | 1.909766 / 6.876477 (-4.966711) | 1.968287 / 2.142072 (-0.173785) | 0.834895 / 4.805227 (-3.970332) | 0.165312 / 6.500664 (-6.335352) | 0.062202 / 0.075469 (-0.013267) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203080 / 1.841788 (-0.638708) | 15.158284 / 8.074308 (7.083976) | 14.174484 / 10.191392 (3.983092) | 0.171540 / 0.680424 (-0.508883) | 0.028604 / 0.534201 (-0.505597) | 0.438379 / 0.579283 (-0.140904) | 0.429447 / 0.434364 (-0.004917) | 0.540979 / 0.540337 (0.000642) | 0.630322 / 1.386936 (-0.756614) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007600 / 0.011353 (-0.003753) | 0.005400 / 0.011008 (-0.005608) | 0.097983 / 0.038508 (0.059475) | 0.033407 / 0.023109 (0.010297) | 0.384429 / 0.275898 (0.108531) | 0.415880 / 0.323480 (0.092400) | 0.006085 / 0.007986 (-0.001900) | 0.004330 / 0.004328 (0.000002) | 0.074654 / 0.004250 (0.070403) | 0.053076 / 0.037052 (0.016024) | 0.383958 / 0.258489 (0.125469) | 0.427289 / 0.293841 (0.133448) | 0.036710 / 0.128546 (-0.091836) | 0.012400 / 0.075646 (-0.063246) | 0.332712 / 0.419271 (-0.086560) | 0.058390 / 0.043533 (0.014857) | 0.377747 / 0.255139 (0.122608) | 0.398997 / 0.283200 (0.115798) | 0.117370 / 0.141683 (-0.024313) | 1.464211 / 1.452155 (0.012057) | 1.596465 / 1.492716 (0.103749) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212989 / 0.018006 (0.194983) | 0.554968 / 0.000490 (0.554479) | 0.004305 / 0.000200 (0.004105) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029167 / 0.037411 (-0.008244) | 0.109156 / 0.014526 (0.094631) | 0.122575 / 0.176557 (-0.053982) | 0.163058 / 0.737135 (-0.574077) | 0.127431 / 0.296338 (-0.168908) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445395 / 0.215209 (0.230185) | 4.447534 / 2.077655 (2.369879) | 2.259186 / 1.504120 (0.755066) | 2.082956 / 1.541195 (0.541761) | 2.259126 / 1.468490 (0.790636) | 0.692271 / 4.584777 (-3.892506) | 3.795759 / 3.745712 (0.050047) | 3.603000 / 5.269862 (-1.666862) | 1.948556 / 4.565676 (-2.617120) | 0.084589 / 0.424275 (-0.339687) | 0.012751 / 0.007607 (0.005144) | 0.544783 / 0.226044 (0.318738) | 5.452278 / 2.268929 (3.183349) | 2.809467 / 55.444624 (-52.635157) | 2.479297 / 6.876477 (-4.397180) | 2.587756 / 2.142072 (0.445683) | 0.832258 / 4.805227 (-3.972970) | 0.167424 / 6.500664 (-6.333240) | 0.066064 / 0.075469 (-0.009405) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262719 / 1.841788 (-0.579069) | 15.917869 / 8.074308 (7.843561) | 13.879301 / 10.191392 (3.687909) | 0.187712 / 0.680424 (-0.492712) | 0.018175 / 0.534201 (-0.516026) | 0.425840 / 0.579283 (-0.153443) | 0.426164 / 0.434364 (-0.008200) | 0.527465 / 0.540337 (-0.012872) | 0.629478 / 1.386936 (-0.757458) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009064 / 0.011353 (-0.002289) | 0.004824 / 0.011008 (-0.006184) | 0.100869 / 0.038508 (0.062361) | 0.030803 / 0.023109 (0.007694) | 0.350880 / 0.275898 (0.074982) | 0.423816 / 0.323480 (0.100336) | 0.007581 / 0.007986 (-0.000405) | 0.003642 / 0.004328 (-0.000686) | 0.077682 / 0.004250 (0.073432) | 0.039856 / 0.037052 (0.002803) | 0.366097 / 0.258489 (0.107608) | 0.409226 / 0.293841 (0.115385) | 0.033698 / 0.128546 (-0.094848) | 0.011730 / 0.075646 (-0.063916) | 0.321683 / 0.419271 (-0.097588) | 0.041794 / 0.043533 (-0.001739) | 0.351175 / 0.255139 (0.096036) | 0.374328 / 0.283200 (0.091128) | 0.091833 / 0.141683 (-0.049850) | 1.507082 / 1.452155 (0.054927) | 1.543289 / 1.492716 (0.050572) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010670 / 0.018006 (-0.007337) | 0.429674 / 0.000490 (0.429184) | 0.003246 / 0.000200 (0.003046) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025015 / 0.037411 (-0.012397) | 0.102155 / 0.014526 (0.087629) | 0.107010 / 0.176557 (-0.069546) | 0.144265 / 0.737135 (-0.592870) | 0.110635 / 0.296338 (-0.185703) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414211 / 0.215209 (0.199002) | 4.125582 / 2.077655 (2.047928) | 1.997856 / 1.504120 (0.493736) | 1.847676 / 1.541195 (0.306481) | 1.994100 / 1.468490 (0.525610) | 0.694975 / 4.584777 (-3.889802) | 3.373629 / 3.745712 (-0.372083) | 2.863255 / 5.269862 (-2.406606) | 1.565723 / 4.565676 (-2.999953) | 0.082539 / 0.424275 (-0.341736) | 0.012650 / 0.007607 (0.005043) | 0.522989 / 0.226044 (0.296945) | 5.205720 / 2.268929 (2.936792) | 2.352292 / 55.444624 (-53.092332) | 2.080467 / 6.876477 (-4.796010) | 2.231014 / 2.142072 (0.088942) | 0.811252 / 4.805227 (-3.993975) | 0.149171 / 6.500664 (-6.351493) | 0.065207 / 0.075469 (-0.010262) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203137 / 1.841788 (-0.638651) | 14.244903 / 8.074308 (6.170595) | 14.454368 / 10.191392 (4.262976) | 0.139090 / 0.680424 (-0.541334) | 0.028738 / 0.534201 (-0.505463) | 0.396394 / 0.579283 (-0.182889) | 0.407207 / 0.434364 (-0.027156) | 0.478036 / 0.540337 (-0.062302) | 0.568488 / 1.386936 (-0.818448) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006878 / 0.011353 (-0.004475) | 0.004636 / 0.011008 (-0.006372) | 0.099118 / 0.038508 (0.060610) | 0.028076 / 0.023109 (0.004967) | 0.416097 / 0.275898 (0.140199) | 0.451722 / 0.323480 (0.128242) | 0.005364 / 0.007986 (-0.002622) | 0.003506 / 0.004328 (-0.000822) | 0.075791 / 0.004250 (0.071541) | 0.041373 / 0.037052 (0.004321) | 0.416358 / 0.258489 (0.157869) | 0.458440 / 0.293841 (0.164599) | 0.031870 / 0.128546 (-0.096676) | 0.011751 / 0.075646 (-0.063896) | 0.321748 / 0.419271 (-0.097524) | 0.041780 / 0.043533 (-0.001752) | 0.425037 / 0.255139 (0.169898) | 0.444169 / 0.283200 (0.160969) | 0.093145 / 0.141683 (-0.048538) | 1.472151 / 1.452155 (0.019996) | 1.542942 / 1.492716 (0.050226) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224287 / 0.018006 (0.206281) | 0.415303 / 0.000490 (0.414813) | 0.003180 / 0.000200 (0.002980) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026377 / 0.037411 (-0.011035) | 0.106222 / 0.014526 (0.091696) | 0.113873 / 0.176557 (-0.062684) | 0.143255 / 0.737135 (-0.593880) | 0.112642 / 0.296338 (-0.183697) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444149 / 0.215209 (0.228940) | 4.421434 / 2.077655 (2.343779) | 2.082198 / 1.504120 (0.578078) | 1.879909 / 1.541195 (0.338715) | 1.968526 / 1.468490 (0.500036) | 0.697230 / 4.584777 (-3.887546) | 3.430800 / 3.745712 (-0.314912) | 1.893353 / 5.269862 (-3.376509) | 1.173271 / 4.565676 (-3.392406) | 0.082636 / 0.424275 (-0.341639) | 0.012357 / 0.007607 (0.004750) | 0.544008 / 0.226044 (0.317964) | 5.465472 / 2.268929 (3.196543) | 2.530017 / 55.444624 (-52.914608) | 2.178462 / 6.876477 (-4.698014) | 2.279570 / 2.142072 (0.137498) | 0.804890 / 4.805227 (-4.000337) | 0.152091 / 6.500664 (-6.348573) | 0.069442 / 0.075469 (-0.006027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256722 / 1.841788 (-0.585065) | 14.554131 / 8.074308 (6.479823) | 13.499913 / 10.191392 (3.308521) | 0.144350 / 0.680424 (-0.536074) | 0.016977 / 0.534201 (-0.517224) | 0.378836 / 0.579283 (-0.200447) | 0.392004 / 0.434364 (-0.042360) | 0.468423 / 0.540337 (-0.071914) | 0.584711 / 1.386936 (-0.802225) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004552 / 0.011008 (-0.006456) | 0.100543 / 0.038508 (0.062035) | 0.029717 / 0.023109 (0.006608) | 0.301948 / 0.275898 (0.026050) | 0.360211 / 0.323480 (0.036731) | 0.006881 / 0.007986 (-0.001105) | 0.003433 / 0.004328 (-0.000896) | 0.077760 / 0.004250 (0.073510) | 0.037069 / 0.037052 (0.000017) | 0.314084 / 0.258489 (0.055595) | 0.347759 / 0.293841 (0.053918) | 0.033255 / 0.128546 (-0.095291) | 0.011487 / 0.075646 (-0.064160) | 0.323873 / 0.419271 (-0.095399) | 0.041203 / 0.043533 (-0.002330) | 0.298397 / 0.255139 (0.043258) | 0.327174 / 0.283200 (0.043974) | 0.088892 / 0.141683 (-0.052791) | 1.560114 / 1.452155 (0.107959) | 1.532475 / 1.492716 (0.039759) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226080 / 0.018006 (0.208074) | 0.467492 / 0.000490 (0.467003) | 0.002198 / 0.000200 (0.001998) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023627 / 0.037411 (-0.013784) | 0.096696 / 0.014526 (0.082170) | 0.106196 / 0.176557 (-0.070360) | 0.140496 / 0.737135 (-0.596639) | 0.108859 / 0.296338 (-0.187480) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422335 / 0.215209 (0.207126) | 4.214879 / 2.077655 (2.137224) | 1.865866 / 1.504120 (0.361747) | 1.660914 / 1.541195 (0.119719) | 1.691869 / 1.468490 (0.223379) | 0.688164 / 4.584777 (-3.896613) | 3.432708 / 3.745712 (-0.313004) | 1.856852 / 5.269862 (-3.413010) | 1.243685 / 4.565676 (-3.321991) | 0.081552 / 0.424275 (-0.342723) | 0.012491 / 0.007607 (0.004884) | 0.524331 / 0.226044 (0.298287) | 5.255090 / 2.268929 (2.986162) | 2.269705 / 55.444624 (-53.174919) | 1.936722 / 6.876477 (-4.939755) | 2.018958 / 2.142072 (-0.123114) | 0.800658 / 4.805227 (-4.004569) | 0.148665 / 6.500664 (-6.351999) | 0.064210 / 0.075469 (-0.011259) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235422 / 1.841788 (-0.606365) | 14.156755 / 8.074308 (6.082447) | 14.005916 / 10.191392 (3.814524) | 0.150983 / 0.680424 (-0.529441) | 0.028500 / 0.534201 (-0.505701) | 0.393013 / 0.579283 (-0.186270) | 0.408191 / 0.434364 (-0.026173) | 0.481017 / 0.540337 (-0.059320) | 0.581711 / 1.386936 (-0.805225) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006950 / 0.011353 (-0.004403) | 0.004575 / 0.011008 (-0.006434) | 0.076702 / 0.038508 (0.038194) | 0.028050 / 0.023109 (0.004941) | 0.342916 / 0.275898 (0.067018) | 0.378861 / 0.323480 (0.055381) | 0.005315 / 0.007986 (-0.002671) | 0.004822 / 0.004328 (0.000494) | 0.075560 / 0.004250 (0.071310) | 0.040441 / 0.037052 (0.003388) | 0.344284 / 0.258489 (0.085795) | 0.386519 / 0.293841 (0.092678) | 0.032122 / 0.128546 (-0.096424) | 0.011843 / 0.075646 (-0.063803) | 0.085798 / 0.419271 (-0.333473) | 0.043027 / 0.043533 (-0.000506) | 0.342910 / 0.255139 (0.087771) | 0.366618 / 0.283200 (0.083418) | 0.094766 / 0.141683 (-0.046917) | 1.492981 / 1.452155 (0.040827) | 1.566994 / 1.492716 (0.074278) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.166083 / 0.018006 (0.148076) | 0.409315 / 0.000490 (0.408826) | 0.003189 / 0.000200 (0.002989) | 0.000127 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024753 / 0.037411 (-0.012658) | 0.099112 / 0.014526 (0.084586) | 0.106668 / 0.176557 (-0.069889) | 0.142562 / 0.737135 (-0.594573) | 0.110648 / 0.296338 (-0.185690) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452668 / 0.215209 (0.237459) | 4.501188 / 2.077655 (2.423534) | 2.086197 / 1.504120 (0.582077) | 1.873955 / 1.541195 (0.332761) | 1.935610 / 1.468490 (0.467120) | 0.708290 / 4.584777 (-3.876487) | 3.426986 / 3.745712 (-0.318726) | 2.805852 / 5.269862 (-2.464009) | 1.516918 / 4.565676 (-3.048759) | 0.084067 / 0.424275 (-0.340208) | 0.012776 / 0.007607 (0.005169) | 0.548853 / 0.226044 (0.322809) | 5.488198 / 2.268929 (3.219270) | 2.704464 / 55.444624 (-52.740161) | 2.377817 / 6.876477 (-4.498660) | 2.366152 / 2.142072 (0.224079) | 0.818192 / 4.805227 (-3.987035) | 0.152649 / 6.500664 (-6.348015) | 0.066914 / 0.075469 (-0.008555) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.273803 / 1.841788 (-0.567985) | 14.071633 / 8.074308 (5.997325) | 13.655586 / 10.191392 (3.464194) | 0.149471 / 0.680424 (-0.530953) | 0.016745 / 0.534201 (-0.517456) | 0.386850 / 0.579283 (-0.192434) | 0.393595 / 0.434364 (-0.040769) | 0.480396 / 0.540337 (-0.059942) | 0.573708 / 1.386936 (-0.813228) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008173 / 0.011353 (-0.003180) | 0.004461 / 0.011008 (-0.006547) | 0.100284 / 0.038508 (0.061776) | 0.028900 / 0.023109 (0.005791) | 0.293639 / 0.275898 (0.017741) | 0.359450 / 0.323480 (0.035971) | 0.007567 / 0.007986 (-0.000418) | 0.003434 / 0.004328 (-0.000894) | 0.077913 / 0.004250 (0.073663) | 0.036313 / 0.037052 (-0.000740) | 0.308484 / 0.258489 (0.049995) | 0.347575 / 0.293841 (0.053734) | 0.033367 / 0.128546 (-0.095179) | 0.011508 / 0.075646 (-0.064138) | 0.323490 / 0.419271 (-0.095782) | 0.042285 / 0.043533 (-0.001248) | 0.295696 / 0.255139 (0.040557) | 0.332475 / 0.283200 (0.049276) | 0.089980 / 0.141683 (-0.051703) | 1.461851 / 1.452155 (0.009697) | 1.493030 / 1.492716 (0.000314) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191068 / 0.018006 (0.173062) | 0.396768 / 0.000490 (0.396278) | 0.002355 / 0.000200 (0.002155) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023117 / 0.037411 (-0.014294) | 0.096155 / 0.014526 (0.081630) | 0.102424 / 0.176557 (-0.074132) | 0.142148 / 0.737135 (-0.594987) | 0.105954 / 0.296338 (-0.190384) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421227 / 0.215209 (0.206018) | 4.200403 / 2.077655 (2.122748) | 1.899410 / 1.504120 (0.395290) | 1.684091 / 1.541195 (0.142896) | 1.698084 / 1.468490 (0.229594) | 0.696195 / 4.584777 (-3.888582) | 3.364116 / 3.745712 (-0.381596) | 1.899133 / 5.269862 (-3.370728) | 1.281405 / 4.565676 (-3.284272) | 0.082958 / 0.424275 (-0.341317) | 0.012433 / 0.007607 (0.004826) | 0.521856 / 0.226044 (0.295812) | 5.217626 / 2.268929 (2.948698) | 2.309228 / 55.444624 (-53.135396) | 1.956828 / 6.876477 (-4.919648) | 2.018964 / 2.142072 (-0.123108) | 0.816855 / 4.805227 (-3.988373) | 0.152867 / 6.500664 (-6.347798) | 0.064764 / 0.075469 (-0.010705) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219020 / 1.841788 (-0.622768) | 13.509058 / 8.074308 (5.434750) | 13.637826 / 10.191392 (3.446434) | 0.156620 / 0.680424 (-0.523804) | 0.028518 / 0.534201 (-0.505683) | 0.399138 / 0.579283 (-0.180146) | 0.399931 / 0.434364 (-0.034433) | 0.482902 / 0.540337 (-0.057435) | 0.574089 / 1.386936 (-0.812847) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006232 / 0.011353 (-0.005121) | 0.004467 / 0.011008 (-0.006542) | 0.075494 / 0.038508 (0.036986) | 0.026891 / 0.023109 (0.003782) | 0.356603 / 0.275898 (0.080705) | 0.371977 / 0.323480 (0.048497) | 0.004709 / 0.007986 (-0.003276) | 0.003230 / 0.004328 (-0.001099) | 0.074338 / 0.004250 (0.070088) | 0.035588 / 0.037052 (-0.001464) | 0.349554 / 0.258489 (0.091065) | 0.389672 / 0.293841 (0.095831) | 0.031524 / 0.128546 (-0.097022) | 0.011493 / 0.075646 (-0.064153) | 0.084584 / 0.419271 (-0.334688) | 0.041945 / 0.043533 (-0.001588) | 0.341057 / 0.255139 (0.085918) | 0.367876 / 0.283200 (0.084677) | 0.090113 / 0.141683 (-0.051569) | 1.507104 / 1.452155 (0.054949) | 1.567810 / 1.492716 (0.075094) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210939 / 0.018006 (0.192933) | 0.392600 / 0.000490 (0.392110) | 0.002188 / 0.000200 (0.001988) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024294 / 0.037411 (-0.013118) | 0.100325 / 0.014526 (0.085799) | 0.104027 / 0.176557 (-0.072530) | 0.141189 / 0.737135 (-0.595947) | 0.107438 / 0.296338 (-0.188901) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443314 / 0.215209 (0.228105) | 4.429612 / 2.077655 (2.351957) | 2.129275 / 1.504120 (0.625156) | 1.940016 / 1.541195 (0.398821) | 2.008975 / 1.468490 (0.540485) | 0.695434 / 4.584777 (-3.889343) | 3.355137 / 3.745712 (-0.390575) | 2.606262 / 5.269862 (-2.663600) | 1.451283 / 4.565676 (-3.114394) | 0.082875 / 0.424275 (-0.341400) | 0.012398 / 0.007607 (0.004791) | 0.544262 / 0.226044 (0.318218) | 5.450829 / 2.268929 (3.181900) | 2.582074 / 55.444624 (-52.862550) | 2.220037 / 6.876477 (-4.656439) | 2.232473 / 2.142072 (0.090401) | 0.802094 / 4.805227 (-4.003134) | 0.150188 / 6.500664 (-6.350476) | 0.066543 / 0.075469 (-0.008926) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269098 / 1.841788 (-0.572690) | 13.764780 / 8.074308 (5.690472) | 13.461490 / 10.191392 (3.270098) | 0.143841 / 0.680424 (-0.536583) | 0.016687 / 0.534201 (-0.517514) | 0.388548 / 0.579283 (-0.190736) | 0.385229 / 0.434364 (-0.049135) | 0.478966 / 0.540337 (-0.061371) | 0.570355 / 1.386936 (-0.816581) |\n\n</details>\n</details>\n\n\n",
"I took your comments into account :)\r\n\r\n> Regarding the docs, I think it would be better to add this info as notes/tips/sections to the existing docs (Process/Stream; e.g. a tip under Dataset.shuffle that explains how to make this operation more performant by using to_iterable + shuffle, etc.) rather than introducing a new doc page.\r\n\r\nI added a paragraph in the Dataset.shuffle docstring, and a note in the Process doc page",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010906 / 0.011353 (-0.000447) | 0.005995 / 0.011008 (-0.005014) | 0.120183 / 0.038508 (0.081675) | 0.042166 / 0.023109 (0.019057) | 0.350945 / 0.275898 (0.075046) | 0.433055 / 0.323480 (0.109575) | 0.009093 / 0.007986 (0.001107) | 0.004695 / 0.004328 (0.000366) | 0.090362 / 0.004250 (0.086112) | 0.051402 / 0.037052 (0.014350) | 0.368677 / 0.258489 (0.110188) | 0.410926 / 0.293841 (0.117086) | 0.044471 / 0.128546 (-0.084075) | 0.014051 / 0.075646 (-0.061595) | 0.397765 / 0.419271 (-0.021507) | 0.057227 / 0.043533 (0.013694) | 0.357587 / 0.255139 (0.102448) | 0.377470 / 0.283200 (0.094270) | 0.119482 / 0.141683 (-0.022201) | 1.719799 / 1.452155 (0.267645) | 1.758228 / 1.492716 (0.265511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224385 / 0.018006 (0.206379) | 0.505070 / 0.000490 (0.504580) | 0.004863 / 0.000200 (0.004663) | 0.000379 / 0.000054 (0.000324) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030366 / 0.037411 (-0.007046) | 0.130481 / 0.014526 (0.115955) | 0.136429 / 0.176557 (-0.040128) | 0.182263 / 0.737135 (-0.554872) | 0.142871 / 0.296338 (-0.153468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467623 / 0.215209 (0.252414) | 4.665522 / 2.077655 (2.587868) | 2.130885 / 1.504120 (0.626766) | 1.903810 / 1.541195 (0.362615) | 2.019077 / 1.468490 (0.550587) | 0.820868 / 4.584777 (-3.763909) | 4.543118 / 3.745712 (0.797406) | 2.491541 / 5.269862 (-2.778321) | 1.585377 / 4.565676 (-2.980299) | 0.101850 / 0.424275 (-0.322426) | 0.014737 / 0.007607 (0.007129) | 0.597241 / 0.226044 (0.371197) | 5.938445 / 2.268929 (3.669516) | 2.695799 / 55.444624 (-52.748825) | 2.286890 / 6.876477 (-4.589587) | 2.363064 / 2.142072 (0.220991) | 0.986670 / 4.805227 (-3.818557) | 0.194407 / 6.500664 (-6.306257) | 0.074767 / 0.075469 (-0.000702) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.420630 / 1.841788 (-0.421158) | 17.537702 / 8.074308 (9.463394) | 16.521804 / 10.191392 (6.330412) | 0.173622 / 0.680424 (-0.506802) | 0.033944 / 0.534201 (-0.500257) | 0.520461 / 0.579283 (-0.058822) | 0.541283 / 0.434364 (0.106919) | 0.651906 / 0.540337 (0.111569) | 0.771724 / 1.386936 (-0.615212) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008448 / 0.011353 (-0.002905) | 0.005893 / 0.011008 (-0.005115) | 0.087995 / 0.038508 (0.049487) | 0.038602 / 0.023109 (0.015493) | 0.400048 / 0.275898 (0.124150) | 0.436998 / 0.323480 (0.113518) | 0.006414 / 0.007986 (-0.001572) | 0.004478 / 0.004328 (0.000149) | 0.086444 / 0.004250 (0.082194) | 0.056535 / 0.037052 (0.019483) | 0.402066 / 0.258489 (0.143577) | 0.458730 / 0.293841 (0.164889) | 0.041622 / 0.128546 (-0.086924) | 0.014014 / 0.075646 (-0.061632) | 0.101382 / 0.419271 (-0.317889) | 0.056986 / 0.043533 (0.013453) | 0.404527 / 0.255139 (0.149388) | 0.428105 / 0.283200 (0.144906) | 0.118321 / 0.141683 (-0.023361) | 1.716940 / 1.452155 (0.264785) | 1.834683 / 1.492716 (0.341967) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.252917 / 0.018006 (0.234910) | 0.485950 / 0.000490 (0.485461) | 0.000489 / 0.000200 (0.000289) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035023 / 0.037411 (-0.002388) | 0.139055 / 0.014526 (0.124529) | 0.144165 / 0.176557 (-0.032392) | 0.189559 / 0.737135 (-0.547577) | 0.153213 / 0.296338 (-0.143126) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.505069 / 0.215209 (0.289860) | 5.024620 / 2.077655 (2.946965) | 2.429469 / 1.504120 (0.925349) | 2.186210 / 1.541195 (0.645015) | 2.275971 / 1.468490 (0.807481) | 0.829432 / 4.584777 (-3.755345) | 4.518600 / 3.745712 (0.772888) | 2.466418 / 5.269862 (-2.803443) | 1.558910 / 4.565676 (-3.006767) | 0.102017 / 0.424275 (-0.322258) | 0.015191 / 0.007607 (0.007584) | 0.619092 / 0.226044 (0.393048) | 6.241105 / 2.268929 (3.972176) | 3.044213 / 55.444624 (-52.400411) | 2.630194 / 6.876477 (-4.246282) | 2.723685 / 2.142072 (0.581613) | 0.994018 / 4.805227 (-3.811210) | 0.198722 / 6.500664 (-6.301942) | 0.075812 / 0.075469 (0.000343) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.545497 / 1.841788 (-0.296291) | 18.305250 / 8.074308 (10.230942) | 16.035275 / 10.191392 (5.843883) | 0.209339 / 0.680424 (-0.471085) | 0.020903 / 0.534201 (-0.513298) | 0.499909 / 0.579283 (-0.079374) | 0.488775 / 0.434364 (0.054411) | 0.581990 / 0.540337 (0.041653) | 0.697786 / 1.386936 (-0.689150) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011706 / 0.011353 (0.000353) | 0.008406 / 0.011008 (-0.002602) | 0.130887 / 0.038508 (0.092379) | 0.037468 / 0.023109 (0.014359) | 0.385043 / 0.275898 (0.109145) | 0.458837 / 0.323480 (0.135357) | 0.013400 / 0.007986 (0.005414) | 0.004885 / 0.004328 (0.000557) | 0.107156 / 0.004250 (0.102905) | 0.046958 / 0.037052 (0.009906) | 0.419314 / 0.258489 (0.160825) | 0.456061 / 0.293841 (0.162220) | 0.058859 / 0.128546 (-0.069687) | 0.016682 / 0.075646 (-0.058965) | 0.428401 / 0.419271 (0.009129) | 0.062908 / 0.043533 (0.019376) | 0.370902 / 0.255139 (0.115763) | 0.433897 / 0.283200 (0.150697) | 0.125672 / 0.141683 (-0.016011) | 1.818279 / 1.452155 (0.366124) | 1.935767 / 1.492716 (0.443050) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011928 / 0.018006 (-0.006078) | 0.591995 / 0.000490 (0.591506) | 0.008416 / 0.000200 (0.008216) | 0.000122 / 0.000054 (0.000067) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029640 / 0.037411 (-0.007772) | 0.121044 / 0.014526 (0.106518) | 0.141840 / 0.176557 (-0.034716) | 0.195856 / 0.737135 (-0.541280) | 0.146460 / 0.296338 (-0.149879) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.591838 / 0.215209 (0.376629) | 5.817309 / 2.077655 (3.739654) | 2.411864 / 1.504120 (0.907744) | 2.098517 / 1.541195 (0.557323) | 2.214609 / 1.468490 (0.746119) | 1.217542 / 4.584777 (-3.367235) | 5.658394 / 3.745712 (1.912682) | 5.155807 / 5.269862 (-0.114055) | 2.797313 / 4.565676 (-1.768363) | 0.141309 / 0.424275 (-0.282967) | 0.014462 / 0.007607 (0.006855) | 0.772274 / 0.226044 (0.546230) | 7.547357 / 2.268929 (5.278429) | 3.150178 / 55.444624 (-52.294446) | 2.500130 / 6.876477 (-4.376347) | 2.572036 / 2.142072 (0.429964) | 1.434498 / 4.805227 (-3.370729) | 0.257355 / 6.500664 (-6.243309) | 0.087491 / 0.075469 (0.012022) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.483899 / 1.841788 (-0.357889) | 17.990741 / 8.074308 (9.916433) | 20.398965 / 10.191392 (10.207573) | 0.239529 / 0.680424 (-0.440895) | 0.046118 / 0.534201 (-0.488083) | 0.528349 / 0.579283 (-0.050934) | 0.614333 / 0.434364 (0.179969) | 0.653621 / 0.540337 (0.113284) | 0.794654 / 1.386936 (-0.592282) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008732 / 0.011353 (-0.002621) | 0.006432 / 0.011008 (-0.004576) | 0.090811 / 0.038508 (0.052303) | 0.030154 / 0.023109 (0.007045) | 0.407885 / 0.275898 (0.131987) | 0.452457 / 0.323480 (0.128977) | 0.006966 / 0.007986 (-0.001020) | 0.006449 / 0.004328 (0.002120) | 0.094439 / 0.004250 (0.090188) | 0.050628 / 0.037052 (0.013576) | 0.401815 / 0.258489 (0.143326) | 0.451814 / 0.293841 (0.157973) | 0.047456 / 0.128546 (-0.081090) | 0.019019 / 0.075646 (-0.056628) | 0.112941 / 0.419271 (-0.306331) | 0.057677 / 0.043533 (0.014145) | 0.406160 / 0.255139 (0.151021) | 0.434469 / 0.283200 (0.151269) | 0.110515 / 0.141683 (-0.031167) | 1.601393 / 1.452155 (0.149238) | 1.745581 / 1.492716 (0.252865) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.280264 / 0.018006 (0.262258) | 0.630074 / 0.000490 (0.629585) | 0.006900 / 0.000200 (0.006700) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027338 / 0.037411 (-0.010073) | 0.114772 / 0.014526 (0.100246) | 0.130436 / 0.176557 (-0.046121) | 0.168990 / 0.737135 (-0.568145) | 0.135842 / 0.296338 (-0.160496) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.666739 / 0.215209 (0.451530) | 6.212953 / 2.077655 (4.135298) | 2.781716 / 1.504120 (1.277596) | 2.369975 / 1.541195 (0.828781) | 2.338807 / 1.468490 (0.870317) | 1.174138 / 4.584777 (-3.410639) | 5.420297 / 3.745712 (1.674585) | 4.972669 / 5.269862 (-0.297192) | 2.214294 / 4.565676 (-2.351382) | 0.135429 / 0.424275 (-0.288846) | 0.013877 / 0.007607 (0.006270) | 0.750805 / 0.226044 (0.524761) | 7.145429 / 2.268929 (4.876500) | 3.215081 / 55.444624 (-52.229544) | 2.598307 / 6.876477 (-4.278170) | 2.690479 / 2.142072 (0.548406) | 1.344673 / 4.805227 (-3.460554) | 0.241536 / 6.500664 (-6.259128) | 0.075544 / 0.075469 (0.000074) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.473595 / 1.841788 (-0.368192) | 17.372237 / 8.074308 (9.297929) | 18.586588 / 10.191392 (8.395196) | 0.209300 / 0.680424 (-0.471124) | 0.030878 / 0.534201 (-0.503323) | 0.509131 / 0.579283 (-0.070152) | 0.617884 / 0.434364 (0.183520) | 0.633721 / 0.540337 (0.093383) | 0.727624 / 1.386936 (-0.659312) |\n\n</details>\n</details>\n\n\n",
"Took your last comments into account !\r\n\r\n> so maybe a better title for it would be \"Optimize processing\" (or \"Working with datasets at scale\" as I mentioned earlier on Slack)\r\n\r\nI think the content would be slightly different, e.g. focus more on multiprocessing/sharding or what data formats to use. This can be a complementary page IMO\r\n\r\n> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nAdded a link in the how-to stream page. We may want to include it in the tutorial at one point at well - right now none of the tutorials mention streaming",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009167 / 0.011353 (-0.002186) | 0.005345 / 0.011008 (-0.005663) | 0.098302 / 0.038508 (0.059794) | 0.035649 / 0.023109 (0.012540) | 0.295597 / 0.275898 (0.019699) | 0.358843 / 0.323480 (0.035364) | 0.008011 / 0.007986 (0.000025) | 0.004229 / 0.004328 (-0.000100) | 0.075123 / 0.004250 (0.070872) | 0.046098 / 0.037052 (0.009046) | 0.310581 / 0.258489 (0.052092) | 0.343230 / 0.293841 (0.049389) | 0.038318 / 0.128546 (-0.090229) | 0.011954 / 0.075646 (-0.063693) | 0.331056 / 0.419271 (-0.088216) | 0.052875 / 0.043533 (0.009342) | 0.302758 / 0.255139 (0.047619) | 0.340596 / 0.283200 (0.057396) | 0.113676 / 0.141683 (-0.028007) | 1.448272 / 1.452155 (-0.003883) | 1.498008 / 1.492716 (0.005291) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240524 / 0.018006 (0.222518) | 0.555823 / 0.000490 (0.555333) | 0.003143 / 0.000200 (0.002943) | 0.000098 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027764 / 0.037411 (-0.009647) | 0.105006 / 0.014526 (0.090480) | 0.120550 / 0.176557 (-0.056007) | 0.167052 / 0.737135 (-0.570084) | 0.124521 / 0.296338 (-0.171818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401758 / 0.215209 (0.186549) | 3.989629 / 2.077655 (1.911974) | 1.767307 / 1.504120 (0.263187) | 1.579451 / 1.541195 (0.038257) | 1.637642 / 1.468490 (0.169152) | 0.702524 / 4.584777 (-3.882253) | 3.714326 / 3.745712 (-0.031386) | 2.131829 / 5.269862 (-3.138033) | 1.487410 / 4.565676 (-3.078267) | 0.084901 / 0.424275 (-0.339374) | 0.012292 / 0.007607 (0.004685) | 0.505211 / 0.226044 (0.279166) | 5.074479 / 2.268929 (2.805551) | 2.243068 / 55.444624 (-53.201556) | 1.880199 / 6.876477 (-4.996278) | 2.003757 / 2.142072 (-0.138315) | 0.870719 / 4.805227 (-3.934508) | 0.167626 / 6.500664 (-6.333039) | 0.062024 / 0.075469 (-0.013445) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.192969 / 1.841788 (-0.648819) | 14.830812 / 8.074308 (6.756504) | 14.331178 / 10.191392 (4.139786) | 0.199222 / 0.680424 (-0.481202) | 0.029292 / 0.534201 (-0.504909) | 0.440427 / 0.579283 (-0.138857) | 0.437893 / 0.434364 (0.003529) | 0.547155 / 0.540337 (0.006818) | 0.645255 / 1.386936 (-0.741681) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007465 / 0.011353 (-0.003888) | 0.005386 / 0.011008 (-0.005622) | 0.073609 / 0.038508 (0.035100) | 0.033550 / 0.023109 (0.010440) | 0.341730 / 0.275898 (0.065832) | 0.371518 / 0.323480 (0.048038) | 0.005986 / 0.007986 (-0.001999) | 0.004264 / 0.004328 (-0.000065) | 0.073749 / 0.004250 (0.069498) | 0.051452 / 0.037052 (0.014399) | 0.347385 / 0.258489 (0.088896) | 0.392284 / 0.293841 (0.098444) | 0.036981 / 0.128546 (-0.091566) | 0.012431 / 0.075646 (-0.063216) | 0.086421 / 0.419271 (-0.332850) | 0.053014 / 0.043533 (0.009481) | 0.336660 / 0.255139 (0.081521) | 0.359155 / 0.283200 (0.075956) | 0.107666 / 0.141683 (-0.034017) | 1.424324 / 1.452155 (-0.027830) | 1.543027 / 1.492716 (0.050310) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260862 / 0.018006 (0.242855) | 0.552057 / 0.000490 (0.551567) | 0.000449 / 0.000200 (0.000249) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029184 / 0.037411 (-0.008227) | 0.108799 / 0.014526 (0.094274) | 0.125136 / 0.176557 (-0.051421) | 0.157436 / 0.737135 (-0.579699) | 0.126333 / 0.296338 (-0.170005) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424054 / 0.215209 (0.208845) | 4.227847 / 2.077655 (2.150192) | 2.051102 / 1.504120 (0.546983) | 1.848651 / 1.541195 (0.307457) | 1.922728 / 1.468490 (0.454238) | 0.705903 / 4.584777 (-3.878874) | 3.800977 / 3.745712 (0.055265) | 2.099345 / 5.269862 (-3.170517) | 1.342919 / 4.565676 (-3.222757) | 0.086128 / 0.424275 (-0.338147) | 0.012539 / 0.007607 (0.004932) | 0.528767 / 0.226044 (0.302723) | 5.299989 / 2.268929 (3.031061) | 2.534280 / 55.444624 (-52.910345) | 2.229532 / 6.876477 (-4.646945) | 2.326704 / 2.142072 (0.184632) | 0.838533 / 4.805227 (-3.966694) | 0.168446 / 6.500664 (-6.332218) | 0.065158 / 0.075469 (-0.010311) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.250091 / 1.841788 (-0.591697) | 14.988651 / 8.074308 (6.914343) | 13.655103 / 10.191392 (3.463711) | 0.165079 / 0.680424 (-0.515345) | 0.017829 / 0.534201 (-0.516372) | 0.425903 / 0.579283 (-0.153381) | 0.419771 / 0.434364 (-0.014593) | 0.534309 / 0.540337 (-0.006028) | 0.635563 / 1.386936 (-0.751373) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010569 / 0.011353 (-0.000784) | 0.005790 / 0.011008 (-0.005218) | 0.118626 / 0.038508 (0.080118) | 0.040455 / 0.023109 (0.017346) | 0.342309 / 0.275898 (0.066411) | 0.411828 / 0.323480 (0.088349) | 0.008824 / 0.007986 (0.000839) | 0.005426 / 0.004328 (0.001098) | 0.088740 / 0.004250 (0.084489) | 0.050042 / 0.037052 (0.012990) | 0.352350 / 0.258489 (0.093861) | 0.396030 / 0.293841 (0.102189) | 0.043385 / 0.128546 (-0.085162) | 0.013805 / 0.075646 (-0.061841) | 0.396489 / 0.419271 (-0.022783) | 0.055667 / 0.043533 (0.012135) | 0.336165 / 0.255139 (0.081026) | 0.372912 / 0.283200 (0.089713) | 0.115343 / 0.141683 (-0.026340) | 1.656412 / 1.452155 (0.204257) | 1.708993 / 1.492716 (0.216277) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011650 / 0.018006 (-0.006357) | 0.444415 / 0.000490 (0.443926) | 0.003985 / 0.000200 (0.003785) | 0.000136 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031718 / 0.037411 (-0.005693) | 0.119640 / 0.014526 (0.105114) | 0.138519 / 0.176557 (-0.038037) | 0.188847 / 0.737135 (-0.548288) | 0.137891 / 0.296338 (-0.158448) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.447540 / 0.215209 (0.232331) | 4.577189 / 2.077655 (2.499534) | 2.106992 / 1.504120 (0.602872) | 1.889631 / 1.541195 (0.348436) | 1.972256 / 1.468490 (0.503766) | 0.778209 / 4.584777 (-3.806568) | 4.430279 / 3.745712 (0.684567) | 2.401226 / 5.269862 (-2.868636) | 1.481251 / 4.565676 (-3.084425) | 0.094244 / 0.424275 (-0.330031) | 0.013961 / 0.007607 (0.006354) | 0.570962 / 0.226044 (0.344917) | 5.809224 / 2.268929 (3.540295) | 2.663290 / 55.444624 (-52.781334) | 2.201228 / 6.876477 (-4.675249) | 2.319240 / 2.142072 (0.177168) | 0.938340 / 4.805227 (-3.866887) | 0.185546 / 6.500664 (-6.315118) | 0.069087 / 0.075469 (-0.006382) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.448597 / 1.841788 (-0.393191) | 17.188573 / 8.074308 (9.114265) | 16.197532 / 10.191392 (6.006140) | 0.194064 / 0.680424 (-0.486360) | 0.033694 / 0.534201 (-0.500507) | 0.507585 / 0.579283 (-0.071699) | 0.505470 / 0.434364 (0.071106) | 0.623270 / 0.540337 (0.082932) | 0.729964 / 1.386936 (-0.656972) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008529 / 0.011353 (-0.002824) | 0.005705 / 0.011008 (-0.005304) | 0.085594 / 0.038508 (0.047086) | 0.038377 / 0.023109 (0.015268) | 0.384221 / 0.275898 (0.108323) | 0.414678 / 0.323480 (0.091199) | 0.006195 / 0.007986 (-0.001791) | 0.004549 / 0.004328 (0.000221) | 0.082710 / 0.004250 (0.078460) | 0.054899 / 0.037052 (0.017847) | 0.404017 / 0.258489 (0.145528) | 0.450309 / 0.293841 (0.156468) | 0.040620 / 0.128546 (-0.087926) | 0.013774 / 0.075646 (-0.061872) | 0.099231 / 0.419271 (-0.320041) | 0.057183 / 0.043533 (0.013650) | 0.390806 / 0.255139 (0.135667) | 0.419334 / 0.283200 (0.136134) | 0.116449 / 0.141683 (-0.025234) | 1.709124 / 1.452155 (0.256969) | 1.812769 / 1.492716 (0.320052) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225206 / 0.018006 (0.207199) | 0.440530 / 0.000490 (0.440040) | 0.002982 / 0.000200 (0.002782) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032256 / 0.037411 (-0.005155) | 0.127086 / 0.014526 (0.112560) | 0.138133 / 0.176557 (-0.038424) | 0.176168 / 0.737135 (-0.560968) | 0.146072 / 0.296338 (-0.150267) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474374 / 0.215209 (0.259165) | 4.785106 / 2.077655 (2.707452) | 2.319344 / 1.504120 (0.815225) | 2.075239 / 1.541195 (0.534045) | 2.179231 / 1.468490 (0.710741) | 0.832124 / 4.584777 (-3.752653) | 4.376302 / 3.745712 (0.630590) | 3.966837 / 5.269862 (-1.303024) | 1.820230 / 4.565676 (-2.745446) | 0.100692 / 0.424275 (-0.323583) | 0.014748 / 0.007607 (0.007141) | 0.568702 / 0.226044 (0.342657) | 5.771548 / 2.268929 (3.502619) | 2.747431 / 55.444624 (-52.697193) | 2.448482 / 6.876477 (-4.427994) | 2.497206 / 2.142072 (0.355133) | 0.960842 / 4.805227 (-3.844385) | 0.192855 / 6.500664 (-6.307809) | 0.072494 / 0.075469 (-0.002975) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.474542 / 1.841788 (-0.367245) | 17.344804 / 8.074308 (9.270496) | 15.336082 / 10.191392 (5.144690) | 0.200134 / 0.680424 (-0.480290) | 0.020728 / 0.534201 (-0.513473) | 0.488854 / 0.579283 (-0.090429) | 0.490781 / 0.434364 (0.056418) | 0.626288 / 0.540337 (0.085950) | 0.721130 / 1.386936 (-0.665806) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004624 / 0.011008 (-0.006384) | 0.100749 / 0.038508 (0.062241) | 0.029587 / 0.023109 (0.006478) | 0.298680 / 0.275898 (0.022782) | 0.359659 / 0.323480 (0.036180) | 0.007001 / 0.007986 (-0.000984) | 0.003398 / 0.004328 (-0.000930) | 0.078654 / 0.004250 (0.074404) | 0.036440 / 0.037052 (-0.000612) | 0.313245 / 0.258489 (0.054756) | 0.342776 / 0.293841 (0.048936) | 0.033195 / 0.128546 (-0.095352) | 0.011500 / 0.075646 (-0.064146) | 0.323957 / 0.419271 (-0.095314) | 0.039878 / 0.043533 (-0.003655) | 0.298189 / 0.255139 (0.043050) | 0.325488 / 0.283200 (0.042289) | 0.087276 / 0.141683 (-0.054407) | 1.480846 / 1.452155 (0.028691) | 1.507016 / 1.492716 (0.014300) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189570 / 0.018006 (0.171564) | 0.406407 / 0.000490 (0.405917) | 0.003062 / 0.000200 (0.002862) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022865 / 0.037411 (-0.014546) | 0.096103 / 0.014526 (0.081578) | 0.106462 / 0.176557 (-0.070094) | 0.140888 / 0.737135 (-0.596247) | 0.108172 / 0.296338 (-0.188167) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415951 / 0.215209 (0.200742) | 4.172187 / 2.077655 (2.094532) | 1.842210 / 1.504120 (0.338090) | 1.636997 / 1.541195 (0.095802) | 1.706078 / 1.468490 (0.237588) | 0.695825 / 4.584777 (-3.888952) | 3.337354 / 3.745712 (-0.408358) | 1.877880 / 5.269862 (-3.391982) | 1.153882 / 4.565676 (-3.411794) | 0.082923 / 0.424275 (-0.341352) | 0.012814 / 0.007607 (0.005207) | 0.521793 / 0.226044 (0.295748) | 5.275980 / 2.268929 (3.007051) | 2.279230 / 55.444624 (-53.165394) | 1.941777 / 6.876477 (-4.934700) | 1.981297 / 2.142072 (-0.160775) | 0.809669 / 4.805227 (-3.995558) | 0.148753 / 6.500664 (-6.351911) | 0.064909 / 0.075469 (-0.010560) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.226757 / 1.841788 (-0.615031) | 13.717354 / 8.074308 (5.643046) | 12.925885 / 10.191392 (2.734493) | 0.137926 / 0.680424 (-0.542498) | 0.028788 / 0.534201 (-0.505413) | 0.396654 / 0.579283 (-0.182630) | 0.401931 / 0.434364 (-0.032432) | 0.460515 / 0.540337 (-0.079823) | 0.537903 / 1.386936 (-0.849033) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006757 / 0.011353 (-0.004596) | 0.004474 / 0.011008 (-0.006534) | 0.076571 / 0.038508 (0.038063) | 0.027580 / 0.023109 (0.004471) | 0.348231 / 0.275898 (0.072333) | 0.398403 / 0.323480 (0.074923) | 0.005089 / 0.007986 (-0.002897) | 0.004676 / 0.004328 (0.000347) | 0.076444 / 0.004250 (0.072194) | 0.038508 / 0.037052 (0.001456) | 0.348515 / 0.258489 (0.090026) | 0.401456 / 0.293841 (0.107615) | 0.031630 / 0.128546 (-0.096916) | 0.011698 / 0.075646 (-0.063949) | 0.085805 / 0.419271 (-0.333467) | 0.041962 / 0.043533 (-0.001570) | 0.343415 / 0.255139 (0.088276) | 0.383001 / 0.283200 (0.099801) | 0.090231 / 0.141683 (-0.051452) | 1.488114 / 1.452155 (0.035960) | 1.569039 / 1.492716 (0.076323) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261751 / 0.018006 (0.243745) | 0.411354 / 0.000490 (0.410865) | 0.015103 / 0.000200 (0.014903) | 0.000262 / 0.000054 (0.000208) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025423 / 0.037411 (-0.011988) | 0.101334 / 0.014526 (0.086808) | 0.108835 / 0.176557 (-0.067722) | 0.143995 / 0.737135 (-0.593140) | 0.111751 / 0.296338 (-0.184588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446507 / 0.215209 (0.231298) | 4.461543 / 2.077655 (2.383888) | 2.104648 / 1.504120 (0.600528) | 1.895900 / 1.541195 (0.354706) | 1.985481 / 1.468490 (0.516991) | 0.699029 / 4.584777 (-3.885748) | 3.371064 / 3.745712 (-0.374648) | 1.883445 / 5.269862 (-3.386416) | 1.166150 / 4.565676 (-3.399527) | 0.082639 / 0.424275 (-0.341636) | 0.012605 / 0.007607 (0.004998) | 0.544860 / 0.226044 (0.318815) | 5.513223 / 2.268929 (3.244294) | 2.570661 / 55.444624 (-52.873963) | 2.206066 / 6.876477 (-4.670411) | 2.256346 / 2.142072 (0.114273) | 0.801142 / 4.805227 (-4.004085) | 0.150412 / 6.500664 (-6.350252) | 0.067742 / 0.075469 (-0.007727) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303477 / 1.841788 (-0.538310) | 14.287767 / 8.074308 (6.213458) | 13.525563 / 10.191392 (3.334171) | 0.148202 / 0.680424 (-0.532222) | 0.016868 / 0.534201 (-0.517333) | 0.380729 / 0.579283 (-0.198555) | 0.388177 / 0.434364 (-0.046187) | 0.477410 / 0.540337 (-0.062927) | 0.569343 / 1.386936 (-0.817593) |\n\n</details>\n</details>\n\n\n",
"> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nJust merged #5485, which references this new doc! Will look for other pages in the docs where it'd make sense to add them :)"
] | 2023-01-05T18:12:17Z | 2023-02-01T18:11:45Z | 2023-02-01T16:36:01Z | MEMBER | null | Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
TODO:
- [x] tests
- [x] docs
Fix https://github.com/huggingface/datasets/issues/5265 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5410/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5410",
"merged_at": "2023-02-01T16:36:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5410"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5409/comments | https://api.github.com/repos/huggingface/datasets/issues/5409/events | https://github.com/huggingface/datasets/pull/5409 | 1,520,374,219 | PR_kwDODunzps5Gs3nL | 5,409 | Fix deprecation warning when use_auth_token passed to download_and_prepare | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008627 / 0.011353 (-0.002726) | 0.004572 / 0.011008 (-0.006436) | 0.099653 / 0.038508 (0.061145) | 0.030010 / 0.023109 (0.006901) | 0.300492 / 0.275898 (0.024594) | 0.360443 / 0.323480 (0.036963) | 0.007125 / 0.007986 (-0.000860) | 0.003431 / 0.004328 (-0.000897) | 0.078103 / 0.004250 (0.073852) | 0.036884 / 0.037052 (-0.000168) | 0.312289 / 0.258489 (0.053800) | 0.345795 / 0.293841 (0.051954) | 0.034001 / 0.128546 (-0.094545) | 0.011405 / 0.075646 (-0.064242) | 0.321258 / 0.419271 (-0.098013) | 0.040591 / 0.043533 (-0.002942) | 0.301114 / 0.255139 (0.045975) | 0.337226 / 0.283200 (0.054027) | 0.088055 / 0.141683 (-0.053628) | 1.451892 / 1.452155 (-0.000263) | 1.494881 / 1.492716 (0.002164) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186749 / 0.018006 (0.168743) | 0.414089 / 0.000490 (0.413600) | 0.002475 / 0.000200 (0.002275) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022413 / 0.037411 (-0.014999) | 0.097547 / 0.014526 (0.083021) | 0.104196 / 0.176557 (-0.072361) | 0.139819 / 0.737135 (-0.597316) | 0.108345 / 0.296338 (-0.187994) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424750 / 0.215209 (0.209541) | 4.261513 / 2.077655 (2.183859) | 2.150888 / 1.504120 (0.646768) | 1.935925 / 1.541195 (0.394730) | 1.867456 / 1.468490 (0.398966) | 0.694384 / 4.584777 (-3.890393) | 3.370539 / 3.745712 (-0.375173) | 1.886714 / 5.269862 (-3.383148) | 1.256542 / 4.565676 (-3.309135) | 0.082841 / 0.424275 (-0.341434) | 0.012344 / 0.007607 (0.004737) | 0.529801 / 0.226044 (0.303757) | 5.315438 / 2.268929 (3.046509) | 2.460517 / 55.444624 (-52.984107) | 2.261840 / 6.876477 (-4.614637) | 2.338710 / 2.142072 (0.196638) | 0.818433 / 4.805227 (-3.986794) | 0.150571 / 6.500664 (-6.350093) | 0.066524 / 0.075469 (-0.008945) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253086 / 1.841788 (-0.588702) | 13.862614 / 8.074308 (5.788306) | 14.145149 / 10.191392 (3.953757) | 0.165867 / 0.680424 (-0.514557) | 0.029269 / 0.534201 (-0.504932) | 0.397579 / 0.579283 (-0.181704) | 0.401113 / 0.434364 (-0.033251) | 0.463269 / 0.540337 (-0.077068) | 0.551494 / 1.386936 (-0.835442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006610 / 0.011353 (-0.004743) | 0.004583 / 0.011008 (-0.006425) | 0.096680 / 0.038508 (0.058172) | 0.027352 / 0.023109 (0.004242) | 0.409292 / 0.275898 (0.133394) | 0.445790 / 0.323480 (0.122310) | 0.004987 / 0.007986 (-0.002999) | 0.003462 / 0.004328 (-0.000866) | 0.074472 / 0.004250 (0.070221) | 0.037875 / 0.037052 (0.000822) | 0.411496 / 0.258489 (0.153007) | 0.454721 / 0.293841 (0.160880) | 0.031884 / 0.128546 (-0.096662) | 0.011682 / 0.075646 (-0.063964) | 0.318831 / 0.419271 (-0.100441) | 0.041781 / 0.043533 (-0.001752) | 0.411247 / 0.255139 (0.156108) | 0.436215 / 0.283200 (0.153016) | 0.090021 / 0.141683 (-0.051662) | 1.492385 / 1.452155 (0.040231) | 1.565182 / 1.492716 (0.072465) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221263 / 0.018006 (0.203257) | 0.399074 / 0.000490 (0.398584) | 0.000405 / 0.000200 (0.000205) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025139 / 0.037411 (-0.012272) | 0.097952 / 0.014526 (0.083426) | 0.106078 / 0.176557 (-0.070479) | 0.143231 / 0.737135 (-0.593904) | 0.109177 / 0.296338 (-0.187161) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441668 / 0.215209 (0.226459) | 4.403247 / 2.077655 (2.325592) | 2.072749 / 1.504120 (0.568629) | 1.866248 / 1.541195 (0.325053) | 1.906418 / 1.468490 (0.437927) | 0.697234 / 4.584777 (-3.887543) | 3.412016 / 3.745712 (-0.333696) | 1.852572 / 5.269862 (-3.417289) | 1.168270 / 4.565676 (-3.397407) | 0.082132 / 0.424275 (-0.342144) | 0.013191 / 0.007607 (0.005584) | 0.548932 / 0.226044 (0.322888) | 5.503891 / 2.268929 (3.234962) | 2.539784 / 55.444624 (-52.904841) | 2.181292 / 6.876477 (-4.695184) | 2.242197 / 2.142072 (0.100125) | 0.804027 / 4.805227 (-4.001200) | 0.151649 / 6.500664 (-6.349015) | 0.067088 / 0.075469 (-0.008381) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.296267 / 1.841788 (-0.545520) | 13.986484 / 8.074308 (5.912176) | 13.440705 / 10.191392 (3.249313) | 0.140787 / 0.680424 (-0.539637) | 0.017132 / 0.534201 (-0.517069) | 0.381899 / 0.579283 (-0.197384) | 0.385535 / 0.434364 (-0.048829) | 0.439957 / 0.540337 (-0.100380) | 0.532980 / 1.386936 (-0.853956) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-05T09:10:58Z | 2023-01-06T11:06:16Z | 2023-01-06T10:59:13Z | MEMBER | null | The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, so that no deprecation warning is raised.
Fix #5407. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5409/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5409/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5409.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5409",
"merged_at": "2023-01-06T10:59:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5409.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5409"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | https://api.github.com/repos/huggingface/datasets/issues/5408/events | https://github.com/huggingface/datasets/issues/5408 | 1,519,890,752 | I_kwDODunzps5al7FA | 5,408 | dataset map function could not be hash properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_url": "https://api.github.com/users/Tungway1990/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Tungway1990",
"id": 68179274,
"login": "Tungway1990",
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"organizations_url": "https://api.github.com/users/Tungway1990/orgs",
"received_events_url": "https://api.github.com/users/Tungway1990/received_events",
"repos_url": "https://api.github.com/users/Tungway1990/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Tungway1990/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Tungway1990/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Tungway1990"
} | [] | closed | false | null | [] | null | [
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you try to call `Hasher.hash` on the the tokenizer and the feature extractor to see which one can't be hashed ?",
"Thanks for your prompt reply.\r\n\r\nI update datasets version to 2.8.0 and the warning is gong."
] | 2023-01-05T01:59:59Z | 2023-01-06T13:22:19Z | 2023-01-06T13:22:18Z | NONE | null | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)`
> Parameter 'function'=<function prepare_dataset at 0x000001D1D9D79A60> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
I read https://github.com/huggingface/datasets/issues/4521 and https://github.com/huggingface/datasets/issues/3178 but cannot solve the issue.
### Steps to reproduce the bug
```python
from datasets import load_dataset, DatasetDict
common_voice = DatasetDict()
common_voice["train"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="train+validation")
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "zh-HK",
split="test")
common_voice = common_voice.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"])
from transformers import WhisperFeatureExtractor, WhisperTokenizer, WhisperProcessor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
processor = WhisperProcessor.from_pretrained("openai/whisper-small", language="chinese", task="transcribe")
from datasets import Audio
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"],
sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch["sentence"]).input_ids
return batch
common_voice = common_voice.map(prepare_dataset,
remove_columns=common_voice.column_names["train"], num_proc=1)
```
### Expected behavior
Should be no warning shown.
### Environment info
- `datasets` version: 2.7.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5
- dill version: 0.3.4
- multiprocess version: 0.70.12.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5408/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"events_url": "https://api.github.com/users/msummerfield/events{/privacy}",
"followers_url": "https://api.github.com/users/msummerfield/followers",
"following_url": "https://api.github.com/users/msummerfield/following{/other_user}",
"gists_url": "https://api.github.com/users/msummerfield/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/msummerfield",
"id": 21002157,
"login": "msummerfield",
"node_id": "MDQ6VXNlcjIxMDAyMTU3",
"organizations_url": "https://api.github.com/users/msummerfield/orgs",
"received_events_url": "https://api.github.com/users/msummerfield/received_events",
"repos_url": "https://api.github.com/users/msummerfield/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/msummerfield/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msummerfield/subscriptions",
"type": "User",
"url": "https://api.github.com/users/msummerfield"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting @msummerfield. We are fixing it."
] | 2023-01-05T00:43:17Z | 2023-01-06T10:59:14Z | 2023-01-06T10:59:14Z | NONE | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the bug
Any valid call to `Datasets.from_sql()` will produce the deprecation warning.
### Expected behavior
No warning.
The fix should be simply to remove the parameter `use_auth_token` from the call to `builder.download_and_prepare()` at line 43 of `io/sql.py` (it is set to `None` anyway, and is not needed).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-4.15.0-169-generic-x86_64-with-glibc2.27
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5406/comments | https://api.github.com/repos/huggingface/datasets/issues/5406/events | https://github.com/huggingface/datasets/issues/5406 | 1,519,140,544 | I_kwDODunzps5ajD7A | 5,406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | open | false | null | [] | null | [
"I still get this error on 2.9.0\r\n<img width=\"1925\" alt=\"image\" src=\"https://user-images.githubusercontent.com/7208470/215597359-2f253c76-c472-4612-8099-d3a74d16eb29.png\">\r\n",
"Hi ! I just tested locally and or colab and it works fine for 2.9 on `sst2`.\r\n\r\nAlso the code that is shown in your stack trace is not present in the 2.9 source code - so I'm wondering how you installed `datasets` that could cause this ? (you can check by searching for `[0:{label_ids[-1] + 1}]` in the [2.9 codebase](https://github.dev/huggingface/datasets/tree/b5672a956d5de864e6f5550e493527d962d6ae55) - it doesn't find anything)\r\n\r\nAnyway you can try uninstalling `datasets` and install it again",
"For what it's worth, I've also gotten this error on 2.9.0, and I've tried uninstalling an reinstalling\r\n\r\n\r\nI'm very new to this package (I was following this tutorial: https://huggingface.co/docs/transformers/training), so there's a good chance I was doing something wrong 😅 but thought I'd pass along the feedback",
"@ntrpnr @mtwichel Did you install `datasets` with conda ?\r\n\r\nI suspect that `datasets` 2.9 on conda still have this issue for some reason. When I install `datasets` with `pip` I don't have this error.",
"> @ntrpnr @mtwichel Did you install datasets with conda ?\r\n\r\nI did yeah, I wonder if that's the issue",
"I just checked on conda at https://anaconda.org/HuggingFace/datasets/files\r\n\r\nand everything looks fine, I got\r\n```python\r\n\r\nf\"ClassLabel expected a value for all label ids [0:{int(label_ids[-1]) + 1}] but some ids are missing.\"\r\n```\r\nas expected in features.py line 1760 (notice the \"int()\") to not have the TypeError.\r\n\r\nFrom where on conda did you install `datasets` ? You should use the `HuggingFace` official channel\r\n\r\nedit: the conda-forge one [here](https://anaconda.org/conda-forge/datasets/files) seems ok as well",
"Could you also try this in your notebook ? In case your python kernel doesn't match the `pip` environment in your shell\r\n```python\r\nimport datasets; datasets.__version__\r\n```\r\nand\r\n```\r\n!which python\r\n```\r\n```python\r\nimport sys; sys.executable\r\n```",
"Mmmm, just a potential clue:\r\n\r\nWhere are you running your Python code? Is it the Spyder IDE?\r\n\r\nI have recently seen some users reporting conflicting Python environments while using Spyder...\r\n\r\nMaybe related:\r\n- #5487",
"Other potential clue:\r\n- Had you already imported `datasets` before pip-updating it? You should first update datasets, before importing it. Otherwise, you need to restart the kernel after updating it.",
"I installed `datasets` with Conda using `conda install datasets` and got this issue.\r\n\r\nThen I tried to reinstall using\r\n`\r\nconda install -c huggingface -c conda-forge datasets\r\n`\r\nThe issue is now fixed."
] | 2023-01-04T15:10:04Z | 2023-02-08T10:25:01Z | null | MEMBER | null | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadata of those datasets to a format that is not supported in 2.6.1 and 2.7.0
This change is required or those datasets won't be supported by the Hugging Face Hub.
Therefore if you encounter this error or if you're using `datasets` 2.6.1 or 2.7.0, we encourage you to update to a newer version.
For example, versions 2.6.2 and 2.7.1 patch this issue.
```python
pip install -U datasets
```
All the datasets affected are the ones with a ClassLabel feature type and YAML "dataset_info" metadata. More info [here](https://github.com/huggingface/datasets/issues/5275).
We apologize for the inconvenience. | {
"+1": 10,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5406/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5406/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5405/comments | https://api.github.com/repos/huggingface/datasets/issues/5405/events | https://github.com/huggingface/datasets/issues/5405 | 1,517,879,386 | I_kwDODunzps5aeQBa | 5,405 | size_in_bytes the same for all splits | {
"avatar_url": "https://avatars.githubusercontent.com/u/1609857?v=4",
"events_url": "https://api.github.com/users/Breakend/events{/privacy}",
"followers_url": "https://api.github.com/users/Breakend/followers",
"following_url": "https://api.github.com/users/Breakend/following{/other_user}",
"gists_url": "https://api.github.com/users/Breakend/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Breakend",
"id": 1609857,
"login": "Breakend",
"node_id": "MDQ6VXNlcjE2MDk4NTc=",
"organizations_url": "https://api.github.com/users/Breakend/orgs",
"received_events_url": "https://api.github.com/users/Breakend/received_events",
"repos_url": "https://api.github.com/users/Breakend/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Breakend/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Breakend/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Breakend"
} | [] | open | false | null | [] | null | [
"Hi @Breakend,\r\n\r\nIndeed, the attribute `size_in_bytes` refers to the size of the entire dataset configuration, for all splits (size of downloaded files + Arrow files), not the specific split.\r\nThis is also the case for `download_size` (downloaded files) and `dataset_size` (Arrow files).\r\n\r\nThe size of the Arrow files for a specific split can be accessed: e.g. size of the \"test\" split only\r\n```python\r\nds[\"train\"].info.splits[\"test\"].num_bytes\r\n```\r\n\r\nI agree this is confusing and maybe we should improve it."
] | 2023-01-03T20:25:48Z | 2023-01-04T09:22:59Z | null | NONE | null | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
Found cached dataset glue (/Users/breakend/.cache/huggingface/datasets/glue/wnli/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1097.70it/s]
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
>>>
```
### Steps to reproduce the bug
```
>>> from datasets import load_dataset
>>> x = load_dataset("glue", "wnli")
>>> x["train"].size_in_bytes
186159
>>> x["validation"].size_in_bytes
186159
>>> x["test"].size_in_bytes
186159
```
### Expected behavior
The expected behavior is that it should return the separate sizes for all splits.
### Environment info
- `datasets` version: 2.7.1
- Platform: macOS-12.5-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5405/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5405/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | https://api.github.com/repos/huggingface/datasets/issues/5404/events | https://github.com/huggingface/datasets/issues/5404 | 1,517,566,331 | I_kwDODunzps5adDl7 | 5,404 | Better integration of BIG-bench | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi, I made my version : https://huggingface.co/datasets/tasksource/bigbench"
] | 2023-01-03T15:37:57Z | 2023-02-09T20:30:26Z | null | MEMBER | null | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5404/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5403/comments | https://api.github.com/repos/huggingface/datasets/issues/5403/events | https://github.com/huggingface/datasets/pull/5403 | 1,517,466,492 | PR_kwDODunzps5Gi3d9 | 5,403 | Replace one letter import in docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/1065417?v=4",
"events_url": "https://api.github.com/users/MKhalusova/events{/privacy}",
"followers_url": "https://api.github.com/users/MKhalusova/followers",
"following_url": "https://api.github.com/users/MKhalusova/following{/other_user}",
"gists_url": "https://api.github.com/users/MKhalusova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/MKhalusova",
"id": 1065417,
"login": "MKhalusova",
"node_id": "MDQ6VXNlcjEwNjU0MTc=",
"organizations_url": "https://api.github.com/users/MKhalusova/orgs",
"received_events_url": "https://api.github.com/users/MKhalusova/received_events",
"repos_url": "https://api.github.com/users/MKhalusova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/MKhalusova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MKhalusova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/MKhalusova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the docs fix for consistency.\r\n> \r\n> Again for consistency, it would be nice to make the same fix across all the docs, e.g.\r\n> \r\n> https://github.com/huggingface/datasets/blob/310cdddd1c43f9658de172b85b6509d07d5e31a1/docs/source/image_classification.mdx?plain=1#L41\r\n\r\nExcellent point!",
"@albertvillanova Should be all of them now :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008776 / 0.011353 (-0.002576) | 0.004534 / 0.011008 (-0.006474) | 0.101921 / 0.038508 (0.063413) | 0.029995 / 0.023109 (0.006886) | 0.307180 / 0.275898 (0.031282) | 0.371001 / 0.323480 (0.047521) | 0.007089 / 0.007986 (-0.000896) | 0.003474 / 0.004328 (-0.000855) | 0.079498 / 0.004250 (0.075248) | 0.036522 / 0.037052 (-0.000531) | 0.311729 / 0.258489 (0.053240) | 0.349861 / 0.293841 (0.056020) | 0.033815 / 0.128546 (-0.094731) | 0.011435 / 0.075646 (-0.064211) | 0.322924 / 0.419271 (-0.096347) | 0.040981 / 0.043533 (-0.002552) | 0.306174 / 0.255139 (0.051035) | 0.331979 / 0.283200 (0.048780) | 0.091293 / 0.141683 (-0.050389) | 1.480935 / 1.452155 (0.028780) | 1.522022 / 1.492716 (0.029306) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195053 / 0.018006 (0.177047) | 0.424898 / 0.000490 (0.424408) | 0.003869 / 0.000200 (0.003669) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024323 / 0.037411 (-0.013088) | 0.098061 / 0.014526 (0.083535) | 0.105770 / 0.176557 (-0.070787) | 0.145799 / 0.737135 (-0.591336) | 0.109109 / 0.296338 (-0.187230) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420434 / 0.215209 (0.205225) | 4.194781 / 2.077655 (2.117126) | 2.030498 / 1.504120 (0.526378) | 1.885314 / 1.541195 (0.344120) | 1.996485 / 1.468490 (0.527995) | 0.708540 / 4.584777 (-3.876237) | 3.400694 / 3.745712 (-0.345018) | 2.888704 / 5.269862 (-2.381157) | 1.578100 / 4.565676 (-2.987577) | 0.082150 / 0.424275 (-0.342125) | 0.012277 / 0.007607 (0.004669) | 0.527312 / 0.226044 (0.301268) | 5.289566 / 2.268929 (3.020637) | 2.369997 / 55.444624 (-53.074628) | 2.040365 / 6.876477 (-4.836112) | 2.298857 / 2.142072 (0.156785) | 0.808446 / 4.805227 (-3.996781) | 0.149355 / 6.500664 (-6.351309) | 0.065993 / 0.075469 (-0.009477) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.231829 / 1.841788 (-0.609959) | 13.874762 / 8.074308 (5.800454) | 13.464379 / 10.191392 (3.272987) | 0.151105 / 0.680424 (-0.529319) | 0.028689 / 0.534201 (-0.505512) | 0.398720 / 0.579283 (-0.180564) | 0.402108 / 0.434364 (-0.032256) | 0.463426 / 0.540337 (-0.076912) | 0.541919 / 1.386936 (-0.845017) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006979 / 0.011353 (-0.004373) | 0.004723 / 0.011008 (-0.006285) | 0.099172 / 0.038508 (0.060664) | 0.027970 / 0.023109 (0.004861) | 0.415096 / 0.275898 (0.139198) | 0.455916 / 0.323480 (0.132437) | 0.005950 / 0.007986 (-0.002036) | 0.003423 / 0.004328 (-0.000906) | 0.075512 / 0.004250 (0.071262) | 0.040894 / 0.037052 (0.003842) | 0.419810 / 0.258489 (0.161321) | 0.461913 / 0.293841 (0.168072) | 0.033014 / 0.128546 (-0.095532) | 0.011613 / 0.075646 (-0.064033) | 0.320983 / 0.419271 (-0.098289) | 0.049902 / 0.043533 (0.006369) | 0.426378 / 0.255139 (0.171239) | 0.445594 / 0.283200 (0.162394) | 0.098978 / 0.141683 (-0.042705) | 1.485724 / 1.452155 (0.033570) | 1.563978 / 1.492716 (0.071262) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232137 / 0.018006 (0.214131) | 0.432785 / 0.000490 (0.432296) | 0.006173 / 0.000200 (0.005973) | 0.000085 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024924 / 0.037411 (-0.012487) | 0.102878 / 0.014526 (0.088352) | 0.107976 / 0.176557 (-0.068581) | 0.143581 / 0.737135 (-0.593554) | 0.111644 / 0.296338 (-0.184694) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.490902 / 0.215209 (0.275693) | 4.914060 / 2.077655 (2.836405) | 2.569465 / 1.504120 (1.065345) | 2.346872 / 1.541195 (0.805677) | 2.412047 / 1.468490 (0.943557) | 0.704975 / 4.584777 (-3.879802) | 3.443669 / 3.745712 (-0.302043) | 3.172055 / 5.269862 (-2.097807) | 1.332152 / 4.565676 (-3.233525) | 0.083023 / 0.424275 (-0.341252) | 0.012699 / 0.007607 (0.005092) | 0.592511 / 0.226044 (0.366466) | 5.916376 / 2.268929 (3.647448) | 3.028472 / 55.444624 (-52.416152) | 2.691159 / 6.876477 (-4.185318) | 2.786132 / 2.142072 (0.644060) | 0.814045 / 4.805227 (-3.991182) | 0.156630 / 6.500664 (-6.344034) | 0.071330 / 0.075469 (-0.004139) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.277936 / 1.841788 (-0.563852) | 14.331367 / 8.074308 (6.257059) | 13.685694 / 10.191392 (3.494302) | 0.138915 / 0.680424 (-0.541509) | 0.016844 / 0.534201 (-0.517357) | 0.390307 / 0.579283 (-0.188976) | 0.385207 / 0.434364 (-0.049157) | 0.448128 / 0.540337 (-0.092210) | 0.532609 / 1.386936 (-0.854327) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-03T14:26:32Z | 2023-01-03T15:06:18Z | 2023-01-03T14:59:01Z | CONTRIBUTOR | null | This PR updates a code example for consistency across the docs based on [feedback from this comment](https://github.com/huggingface/transformers/pull/20925/files/9fda31634d203a47d3212e4e8d43d3267faf9808#r1058769500):
"In terms of style we usually stay away from one-letter imports like this (even if the community uses them) as they are not always known by beginners and one letter is very undescriptive. Here it wouldn't change anything to use albumentations instead of A."
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5403/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5403",
"merged_at": "2023-01-03T14:59:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5403"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5402/comments | https://api.github.com/repos/huggingface/datasets/issues/5402/events | https://github.com/huggingface/datasets/issues/5402 | 1,517,409,429 | I_kwDODunzps5acdSV | 5,402 | Missing state.json when creating a cloud dataset using a dataset_builder | {
"avatar_url": "https://avatars.githubusercontent.com/u/22022514?v=4",
"events_url": "https://api.github.com/users/danielfleischer/events{/privacy}",
"followers_url": "https://api.github.com/users/danielfleischer/followers",
"following_url": "https://api.github.com/users/danielfleischer/following{/other_user}",
"gists_url": "https://api.github.com/users/danielfleischer/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danielfleischer",
"id": 22022514,
"login": "danielfleischer",
"node_id": "MDQ6VXNlcjIyMDIyNTE0",
"organizations_url": "https://api.github.com/users/danielfleischer/orgs",
"received_events_url": "https://api.github.com/users/danielfleischer/received_events",
"repos_url": "https://api.github.com/users/danielfleischer/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danielfleischer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielfleischer/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danielfleischer"
} | [] | open | false | null | [] | null | [
"`load_from_disk` must be used on datasets saved using `save_to_disk`: they correspond to fully serialized datasets including their state.\r\n\r\nOn the other hand, `download_and_prepare` just downloads the raw data and convert them to arrow (or parquet if you want). We are working on allowing you to reload a dataset saved on S3 with `download_and_prepare` using `load_dataset` in #5281 \r\n\r\nFor now I'd encourage you to keep using `save_to_disk`",
"Thanks, I'll follow that issue. \r\n\r\nI was following the [cloud storage](https://huggingface.co/docs/datasets/filesystems) docs section and perhaps I'm missing some part of the flow; start with `load_dataset_builder` + `download_and_prepare`. You say I need an explicit `save_to_disk` but what object needs to be saved? the builder? is that related to the other issue?",
"Right now `load_dataset_builder` + `download_and_prepare` is to be used with tools like dask or spark, but `load_dataset` will support private cloud storage soon as well so you'll be able to reload the dataset with `datasets`.\r\n\r\nRight now the only function that can load a dataset from a cloud storage is `load_from_disk`, that must be used with a dataset serialized with `save_to_disk`."
] | 2023-01-03T13:39:59Z | 2023-01-04T17:23:57Z | null | NONE | null | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
As a comparison, if you use the non lazy `load_dataset`, it works and the S3 folder has different structure + state.json files. Example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_dataset, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
dataset = load_dataset("imdb",)
dataset.save_to_disk(output_dir, fs=fs)
load_from_disk(output_dir, fs=fs) # WORKS
```
You still want the 1st option for the laziness and the parquet conversion. Thanks!
### Steps to reproduce the bug
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_datase, load_dataset_builder
import s3fs
storage_options = {"session": Session()}
fs = s3fs.S3FileSystem(**storage_options)
output_dir = "s3://bucket/imdb"
builder = load_dataset_builder("imdb")
builder.download_and_prepare(output_dir, storage_options=storage_options)
load_from_disk(output_dir, fs=fs) # ERROR
# [Errno 2] No such file or directory: '/tmp/tmpy22yys8o/bucket/imdb/state.json'
```
BTW, you need the AioSession as s3fs is now based on aiobotocore, see https://github.com/fsspec/s3fs/issues/385.
### Expected behavior
Expected to be able to load the dataset from S3.
### Environment info
```
s3fs 2022.11.0
s3transfer 0.6.0
datasets 2.8.0
aiobotocore 2.4.2
boto3 1.24.59
botocore 1.27.59
```
python 3.7.15. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5402/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5401/comments | https://api.github.com/repos/huggingface/datasets/issues/5401/events | https://github.com/huggingface/datasets/pull/5401 | 1,517,160,935 | PR_kwDODunzps5Gh1XQ | 5,401 | Support Dataset conversion from/to Spark | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5401). All of your documentation changes will be reflected on that endpoint.",
"Cool thanks !\r\n\r\nSpark DataFrame are usually quite big, and I believe here `from_spark` would load everything in the driver node's RAM, which is quite limiting. Same for `to_spark` which would load everything in the driver node's RAM before sending the data to the executor. Maybe we can mention this in the docstring ?\r\n\r\nTo transfer big datasets from/into the HF ecosystem using Spark maybe we can just make sure that `pyspark` can read/write to the HF Hub, and that `datasets` can read from HDFS/S3/etc.",
"Yes @lhoestq , consider this as a first integration of the Datasets library with Spark.\r\n- This PR implements the basic conversion between both.\r\n - And yes, we are using the Spark's `pandas` API (that uses `pyarrow` under the hood): everything is transferred to the driver.\r\n - Note that we are converting from/to a Datasets dataset: this is not distributed\r\n\r\nThe next step is to support the integration of the HF Hub with Spark, that I think should be done using `hffs`.",
"Thinking more about it I don't really see how those two methods help in practice, since one can already do `datasets` <-> pandas <-> spark and those two methods don't add value over this.\r\n\r\nHowever I think it can be good documentation to explain that it's possible to do it and it's super simple"
] | 2023-01-03T09:57:40Z | 2023-01-05T14:21:33Z | null | MEMBER | null | This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5401/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5401/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5400/comments | https://api.github.com/repos/huggingface/datasets/issues/5400/events | https://github.com/huggingface/datasets/pull/5400 | 1,517,032,972 | PR_kwDODunzps5GhaGI | 5,400 | Support streaming datasets with os.path.exists and Path.exists | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008638 / 0.011353 (-0.002715) | 0.004565 / 0.011008 (-0.006444) | 0.098984 / 0.038508 (0.060476) | 0.030118 / 0.023109 (0.007009) | 0.321779 / 0.275898 (0.045881) | 0.366905 / 0.323480 (0.043426) | 0.006931 / 0.007986 (-0.001055) | 0.004728 / 0.004328 (0.000399) | 0.078358 / 0.004250 (0.074108) | 0.037755 / 0.037052 (0.000702) | 0.312694 / 0.258489 (0.054205) | 0.351781 / 0.293841 (0.057940) | 0.033266 / 0.128546 (-0.095280) | 0.011397 / 0.075646 (-0.064250) | 0.323501 / 0.419271 (-0.095771) | 0.040779 / 0.043533 (-0.002754) | 0.303533 / 0.255139 (0.048394) | 0.340940 / 0.283200 (0.057740) | 0.088701 / 0.141683 (-0.052982) | 1.472058 / 1.452155 (0.019904) | 1.529535 / 1.492716 (0.036818) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191803 / 0.018006 (0.173797) | 0.409773 / 0.000490 (0.409283) | 0.002704 / 0.000200 (0.002504) | 0.000217 / 0.000054 (0.000163) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023520 / 0.037411 (-0.013891) | 0.096967 / 0.014526 (0.082441) | 0.107911 / 0.176557 (-0.068646) | 0.146425 / 0.737135 (-0.590710) | 0.109025 / 0.296338 (-0.187314) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418565 / 0.215209 (0.203356) | 4.183429 / 2.077655 (2.105774) | 1.886534 / 1.504120 (0.382414) | 1.689015 / 1.541195 (0.147820) | 1.710757 / 1.468490 (0.242267) | 0.693211 / 4.584777 (-3.891566) | 3.380062 / 3.745712 (-0.365650) | 2.619910 / 5.269862 (-2.649952) | 1.457512 / 4.565676 (-3.108164) | 0.082421 / 0.424275 (-0.341854) | 0.012126 / 0.007607 (0.004519) | 0.525249 / 0.226044 (0.299205) | 5.244541 / 2.268929 (2.975613) | 2.305908 / 55.444624 (-53.138717) | 1.945298 / 6.876477 (-4.931178) | 2.015618 / 2.142072 (-0.126455) | 0.816746 / 4.805227 (-3.988481) | 0.148325 / 6.500664 (-6.352339) | 0.063939 / 0.075469 (-0.011530) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255790 / 1.841788 (-0.585998) | 13.433219 / 8.074308 (5.358911) | 13.916957 / 10.191392 (3.725565) | 0.153468 / 0.680424 (-0.526956) | 0.028722 / 0.534201 (-0.505479) | 0.398245 / 0.579283 (-0.181038) | 0.399067 / 0.434364 (-0.035296) | 0.457525 / 0.540337 (-0.082812) | 0.542391 / 1.386936 (-0.844545) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006411 / 0.011353 (-0.004942) | 0.004552 / 0.011008 (-0.006456) | 0.098036 / 0.038508 (0.059527) | 0.026532 / 0.023109 (0.003422) | 0.412270 / 0.275898 (0.136372) | 0.442771 / 0.323480 (0.119291) | 0.004891 / 0.007986 (-0.003094) | 0.003488 / 0.004328 (-0.000841) | 0.075437 / 0.004250 (0.071186) | 0.036228 / 0.037052 (-0.000824) | 0.413246 / 0.258489 (0.154757) | 0.453546 / 0.293841 (0.159705) | 0.031054 / 0.128546 (-0.097492) | 0.011589 / 0.075646 (-0.064058) | 0.318477 / 0.419271 (-0.100794) | 0.041075 / 0.043533 (-0.002457) | 0.411182 / 0.255139 (0.156043) | 0.436991 / 0.283200 (0.153792) | 0.086563 / 0.141683 (-0.055120) | 1.511948 / 1.452155 (0.059793) | 1.570925 / 1.492716 (0.078208) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200510 / 0.018006 (0.182504) | 0.403450 / 0.000490 (0.402960) | 0.000397 / 0.000200 (0.000197) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023950 / 0.037411 (-0.013461) | 0.097334 / 0.014526 (0.082808) | 0.105228 / 0.176557 (-0.071328) | 0.137699 / 0.737135 (-0.599436) | 0.107063 / 0.296338 (-0.189275) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474420 / 0.215209 (0.259211) | 4.748212 / 2.077655 (2.670557) | 2.407318 / 1.504120 (0.903198) | 2.198949 / 1.541195 (0.657755) | 2.220377 / 1.468490 (0.751887) | 0.704022 / 4.584777 (-3.880755) | 3.366128 / 3.745712 (-0.379584) | 1.839454 / 5.269862 (-3.430408) | 1.151183 / 4.565676 (-3.414493) | 0.082818 / 0.424275 (-0.341457) | 0.012765 / 0.007607 (0.005158) | 0.571913 / 0.226044 (0.345868) | 5.722544 / 2.268929 (3.453615) | 2.858279 / 55.444624 (-52.586346) | 2.513479 / 6.876477 (-4.362998) | 2.574227 / 2.142072 (0.432154) | 0.803282 / 4.805227 (-4.001945) | 0.150603 / 6.500664 (-6.350061) | 0.066594 / 0.075469 (-0.008875) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.301161 / 1.841788 (-0.540627) | 13.580745 / 8.074308 (5.506436) | 13.301551 / 10.191392 (3.110159) | 0.141424 / 0.680424 (-0.539000) | 0.016579 / 0.534201 (-0.517622) | 0.380726 / 0.579283 (-0.198557) | 0.383011 / 0.434364 (-0.051353) | 0.438717 / 0.540337 (-0.101620) | 0.527085 / 1.386936 (-0.859851) |\n\n</details>\n</details>\n\n\n"
] | 2023-01-03T07:42:37Z | 2023-01-06T10:42:44Z | 2023-01-06T10:35:44Z | MEMBER | null | Support streaming datasets with `os.path.exists` and `pathlib.Path.exists`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5400/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5400/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5400.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5400",
"merged_at": "2023-01-06T10:35:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5400.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5400"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | https://api.github.com/repos/huggingface/datasets/issues/5399/events | https://github.com/huggingface/datasets/issues/5399 | 1,515,548,427 | I_kwDODunzps5aVW8L | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | {
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"events_url": "https://api.github.com/users/alhuri/events{/privacy}",
"followers_url": "https://api.github.com/users/alhuri/followers",
"following_url": "https://api.github.com/users/alhuri/following{/other_user}",
"gists_url": "https://api.github.com/users/alhuri/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alhuri",
"id": 46427957,
"login": "alhuri",
"node_id": "MDQ6VXNlcjQ2NDI3OTU3",
"organizations_url": "https://api.github.com/users/alhuri/orgs",
"received_events_url": "https://api.github.com/users/alhuri/received_events",
"repos_url": "https://api.github.com/users/alhuri/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alhuri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alhuri/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alhuri"
} | [] | closed | false | null | [] | null | [] | 2023-01-01T13:00:11Z | 2023-01-02T07:21:52Z | 2023-01-02T07:21:52Z | NONE | null | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Image(decode=True),
'caption': Value(dtype='string'),
})
#make sure u r logged in to HF
ds = Dataset.from_pandas(df, features=features)
ds.features
ds.push_to_hub("x/x")
```
I got the below error and It always stops at the same progress
```
100%|██████████| 4/4 [23:53<00:00, 358.48s/ba]
100%|██████████| 4/4 [24:37<00:00, 369.47s/ba]%|▍ | 1/22 [00:06<02:09, 6.16s/it]
100%|██████████| 4/4 [25:00<00:00, 375.15s/ba]%|▉ | 2/22 [25:54<2:36:15, 468.80s/it]
100%|██████████| 4/4 [24:53<00:00, 373.29s/ba]%|█▎ | 3/22 [51:01<4:07:07, 780.39s/it]
100%|██████████| 4/4 [24:01<00:00, 360.34s/ba]%|█▊ | 4/22 [1:17:00<5:04:07, 1013.74s/it]
100%|██████████| 4/4 [23:59<00:00, 359.91s/ba]%|██▎ | 5/22 [1:41:07<5:24:06, 1143.90s/it]
100%|██████████| 4/4 [24:16<00:00, 364.06s/ba]%|██▋ | 6/22 [2:05:14<5:29:15, 1234.74s/it]
100%|██████████| 4/4 [25:24<00:00, 381.10s/ba]%|███▏ | 7/22 [2:29:38<5:25:52, 1303.52s/it]
100%|██████████| 4/4 [25:24<00:00, 381.24s/ba]%|███▋ | 8/22 [2:56:02<5:23:46, 1387.58s/it]
100%|██████████| 4/4 [25:08<00:00, 377.23s/ba]%|████ | 9/22 [3:22:24<5:13:17, 1445.97s/it]
100%|██████████| 4/4 [24:11<00:00, 362.87s/ba]%|████▌ | 10/22 [3:48:24<4:56:02, 1480.19s/it]
100%|██████████| 4/4 [24:44<00:00, 371.11s/ba]%|█████ | 11/22 [4:12:42<4:30:10, 1473.66s/it]
100%|██████████| 4/4 [24:35<00:00, 368.81s/ba]%|█████▍ | 12/22 [4:37:34<4:06:29, 1478.98s/it]
100%|██████████| 4/4 [24:02<00:00, 360.67s/ba]%|█████▉ | 13/22 [5:03:24<3:45:04, 1500.45s/it]
100%|██████████| 4/4 [24:07<00:00, 361.78s/ba]%|██████▎ | 14/22 [5:27:33<3:17:59, 1484.97s/it]
100%|██████████| 4/4 [23:39<00:00, 354.85s/ba]%|██████▊ | 15/22 [5:51:48<2:52:10, 1475.82s/it]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:16:58<2:28:37, 1486.31s/it]Got disconnected from remote data host. Retrying in 5sec [1/20]
Got disconnected from remote data host. Retrying in 5sec [2/20]
Got disconnected from remote data host. Retrying in 5sec [3/20]
Got disconnected from remote data host. Retrying in 5sec [4/20]
Got disconnected from remote data host. Retrying in 5sec [5/20]
Got disconnected from remote data host. Retrying in 5sec [6/20]
Got disconnected from remote data host. Retrying in 5sec [7/20]
Got disconnected from remote data host. Retrying in 5sec [8/20]
Got disconnected from remote data host. Retrying in 5sec [9/20]
...
Got disconnected from remote data host. Retrying in 5sec [19/20]
Got disconnected from remote data host. Retrying in 5sec [20/20]
75%|███████▌ | 3/4 [24:47<08:15, 495.86s/ba]
Pushing dataset shards to the dataset hub: 73%|███████▎ | 16/22 [6:41:46<2:30:39, 1506.65s/it]
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
<ipython-input-1-dbf8530779e9> in <module>
16 ds.features
```
### Expected behavior
I was trying to upload an image dataset and expected it to be fully uploaded
### Environment info
- `datasets` version: 2.8.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.9
- PyArrow version: 10.0.1
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5399/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5399/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5398/comments | https://api.github.com/repos/huggingface/datasets/issues/5398/events | https://github.com/huggingface/datasets/issues/5398 | 1,514,425,231 | I_kwDODunzps5aREuP | 5,398 | Unpin pydantic | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [] | 2022-12-30T10:37:31Z | 2022-12-30T10:43:41Z | 2022-12-30T10:43:41Z | MEMBER | null | Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5398/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5398/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5397/comments | https://api.github.com/repos/huggingface/datasets/issues/5397/events | https://github.com/huggingface/datasets/pull/5397 | 1,514,412,246 | PR_kwDODunzps5GYirs | 5,397 | Unpin pydantic test dependency | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012922 / 0.011353 (0.001569) | 0.006568 / 0.011008 (-0.004440) | 0.139567 / 0.038508 (0.101059) | 0.039362 / 0.023109 (0.016253) | 0.444238 / 0.275898 (0.168340) | 0.529102 / 0.323480 (0.205622) | 0.010275 / 0.007986 (0.002290) | 0.006134 / 0.004328 (0.001805) | 0.107506 / 0.004250 (0.103255) | 0.047948 / 0.037052 (0.010896) | 0.460469 / 0.258489 (0.201980) | 0.516817 / 0.293841 (0.222976) | 0.058637 / 0.128546 (-0.069909) | 0.019516 / 0.075646 (-0.056130) | 0.464111 / 0.419271 (0.044839) | 0.062140 / 0.043533 (0.018607) | 0.445004 / 0.255139 (0.189865) | 0.460117 / 0.283200 (0.176917) | 0.116591 / 0.141683 (-0.025092) | 1.936834 / 1.452155 (0.484680) | 1.941837 / 1.492716 (0.449120) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.284130 / 0.018006 (0.266124) | 0.588109 / 0.000490 (0.587619) | 0.004383 / 0.000200 (0.004183) | 0.000143 / 0.000054 (0.000089) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032984 / 0.037411 (-0.004427) | 0.132811 / 0.014526 (0.118285) | 0.150932 / 0.176557 (-0.025625) | 0.203759 / 0.737135 (-0.533377) | 0.149612 / 0.296338 (-0.146726) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.677666 / 0.215209 (0.462457) | 6.627611 / 2.077655 (4.549956) | 2.679526 / 1.504120 (1.175406) | 2.272536 / 1.541195 (0.731342) | 2.371179 / 1.468490 (0.902689) | 1.205282 / 4.584777 (-3.379495) | 5.733537 / 3.745712 (1.987825) | 3.165279 / 5.269862 (-2.104583) | 2.287918 / 4.565676 (-2.277759) | 0.144581 / 0.424275 (-0.279695) | 0.016812 / 0.007607 (0.009205) | 0.841719 / 0.226044 (0.615675) | 8.379119 / 2.268929 (6.110191) | 3.507169 / 55.444624 (-51.937456) | 2.756666 / 6.876477 (-4.119811) | 2.814091 / 2.142072 (0.672018) | 1.495835 / 4.805227 (-3.309392) | 0.253651 / 6.500664 (-6.247013) | 0.081258 / 0.075469 (0.005789) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.651586 / 1.841788 (-0.190202) | 19.039628 / 8.074308 (10.965320) | 21.269814 / 10.191392 (11.078421) | 0.241024 / 0.680424 (-0.439400) | 0.047975 / 0.534201 (-0.486225) | 0.563727 / 0.579283 (-0.015556) | 0.666808 / 0.434364 (0.232445) | 0.661065 / 0.540337 (0.120728) | 0.762884 / 1.386936 (-0.624052) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010141 / 0.011353 (-0.001212) | 0.006216 / 0.011008 (-0.004792) | 0.135491 / 0.038508 (0.096983) | 0.035439 / 0.023109 (0.012330) | 0.482789 / 0.275898 (0.206891) | 0.520673 / 0.323480 (0.197193) | 0.006358 / 0.007986 (-0.001627) | 0.005432 / 0.004328 (0.001104) | 0.094448 / 0.004250 (0.090197) | 0.048379 / 0.037052 (0.011326) | 0.509359 / 0.258489 (0.250870) | 0.539583 / 0.293841 (0.245742) | 0.054621 / 0.128546 (-0.073925) | 0.021382 / 0.075646 (-0.054265) | 0.435539 / 0.419271 (0.016267) | 0.060630 / 0.043533 (0.017097) | 0.469593 / 0.255139 (0.214454) | 0.507838 / 0.283200 (0.224639) | 0.112062 / 0.141683 (-0.029621) | 1.829694 / 1.452155 (0.377539) | 1.972266 / 1.492716 (0.479549) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291669 / 0.018006 (0.273663) | 0.590104 / 0.000490 (0.589614) | 0.000661 / 0.000200 (0.000461) | 0.000082 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034933 / 0.037411 (-0.002479) | 0.134867 / 0.014526 (0.120341) | 0.138892 / 0.176557 (-0.037665) | 0.192619 / 0.737135 (-0.544516) | 0.153787 / 0.296338 (-0.142551) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.666762 / 0.215209 (0.451553) | 6.741736 / 2.077655 (4.664082) | 2.988712 / 1.504120 (1.484592) | 2.554823 / 1.541195 (1.013628) | 2.655651 / 1.468490 (1.187161) | 1.276603 / 4.584777 (-3.308174) | 5.827960 / 3.745712 (2.082247) | 5.046876 / 5.269862 (-0.222985) | 2.829775 / 4.565676 (-1.735902) | 0.151525 / 0.424275 (-0.272750) | 0.016504 / 0.007607 (0.008897) | 0.849749 / 0.226044 (0.623704) | 8.331675 / 2.268929 (6.062747) | 3.664529 / 55.444624 (-51.780096) | 2.976495 / 6.876477 (-3.899982) | 3.034737 / 2.142072 (0.892664) | 1.499036 / 4.805227 (-3.306191) | 0.261027 / 6.500664 (-6.239637) | 0.088306 / 0.075469 (0.012837) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.693506 / 1.841788 (-0.148282) | 18.939914 / 8.074308 (10.865605) | 20.685460 / 10.191392 (10.494068) | 0.218316 / 0.680424 (-0.462108) | 0.029010 / 0.534201 (-0.505191) | 0.565246 / 0.579283 (-0.014037) | 0.633573 / 0.434364 (0.199209) | 0.656895 / 0.540337 (0.116558) | 0.781975 / 1.386936 (-0.604961) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-30T10:22:09Z | 2022-12-30T10:53:11Z | 2022-12-30T10:43:40Z | MEMBER | null | Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367810049
```
On behalf of spacy-related packages: would it be possible for you to temporarily yank v1.10.3?
To address this and be compatible with v1.10.4, we'd have to release new versions of a whole series of packages and nearly everyone (including me) is currently on vacation. Even if v1.10.4 is released with a fix, pip would still back off to v1.10.3 for spacy, etc. because of its current pins for typing_extensions. If it could instead back off to v1.10.2, we'd have a bit more breathing room to make the updates on our end.
```
Close #5398.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5397/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5397",
"merged_at": "2022-12-30T10:43:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5397"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5396/comments | https://api.github.com/repos/huggingface/datasets/issues/5396/events | https://github.com/huggingface/datasets/pull/5396 | 1,514,002,934 | PR_kwDODunzps5GXMhp | 5,396 | Fix checksum verification | {
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"events_url": "https://api.github.com/users/daskol/events{/privacy}",
"followers_url": "https://api.github.com/users/daskol/followers",
"following_url": "https://api.github.com/users/daskol/following{/other_user}",
"gists_url": "https://api.github.com/users/daskol/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/daskol",
"id": 9336514,
"login": "daskol",
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"organizations_url": "https://api.github.com/users/daskol/orgs",
"received_events_url": "https://api.github.com/users/daskol/received_events",
"repos_url": "https://api.github.com/users/daskol/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/daskol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daskol/subscriptions",
"type": "User",
"url": "https://api.github.com/users/daskol"
} | [] | closed | false | null | [] | null | [
"Hi ! If I'm not mistaken both `expected_checksums[url]` and `recorded_checksums[url]` are dictionaries with keys \"checksum\" and \"num_bytes\". So we need to check whether `expected_checksums[url] != recorded_checksums[url]` (or simply `expected_checksums[url][\"checksum\"] != recorded_checksums[url][\"checksum\"]`)\r\n\r\nBut in your fix you're checking `expected_checksums[url] != recorded_checksums[url]['checksum']`.\r\n\r\nSo I think it's fine to keep this as is",
"No, the issue is that there is comparison of sclar value and dictionary.",
"Acording to [`DatasetInfo`][1], we need specify a dictionary which maps a URL to a checksum as follows.\r\n\r\n```python\r\nCHECKSUMS = {\r\n URL: 'a5dc6bf63ea088ade6e98594bfa386f45211c38b2a3db3dd11b33bd530f3c481',\r\n}\r\n\r\nclass FancyDataset:\r\n def _info(self):\r\n return DatasetInfo(..., download_checksums=CHECKSUMS)\r\n```\r\n\r\nHowever, `load_dataset` fails with this checksum definition.\r\n\r\n[1]: https://github.com/huggingface/datasets/blob/main/src/datasets/info.py#L124-L125",
"I think it has to be formatted like this right now. Maybe the DatasetInfo doc is unclear and we can improve it\r\n```python\r\nCHECKSUMS = {\r\n URL: {\"checksum\": checksum, \"num_bytes\": num_bytes},\r\n}\r\n```",
"Right. I am not sure that this is a correct way to do it. People usually calculate sha256, md5, or whatever else but not size in bytes. Also, people use only some of checksum algorithms. This means that comparing dictionaries in `verify_checksums` is too strict (requires equality of all items) and raises compatibility issues in the future. Another issue is that a comparison of dictionaries assumes type constraints which imply type equality. \r\n\r\nSince almost noone uses checksums as far as I known, my PR suggests a minimal change to mitigate these issues except support of a specific checksum algorithm which is a separated feature and should be contributed in a separate PRs from my perspective.",
"Applying this change will break the verification code, since the `expected_checksums` is a dict with those two keys.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5396). All of your documentation changes will be reflected on that endpoint."
] | 2022-12-29T19:45:17Z | 2023-02-13T11:11:22Z | 2023-02-13T11:11:22Z | CONTRIBUTOR | null | Expected checksum was verified against checksum dict (not checksum). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5396/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5396",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5396"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5395/comments | https://api.github.com/repos/huggingface/datasets/issues/5395/events | https://github.com/huggingface/datasets/pull/5395 | 1,513,997,335 | PR_kwDODunzps5GXLUl | 5,395 | Temporarily pin pydantic test dependency | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012220 / 0.011353 (0.000867) | 0.005943 / 0.011008 (-0.005065) | 0.128223 / 0.038508 (0.089715) | 0.037352 / 0.023109 (0.014242) | 0.397143 / 0.275898 (0.121245) | 0.483935 / 0.323480 (0.160455) | 0.010279 / 0.007986 (0.002293) | 0.004842 / 0.004328 (0.000513) | 0.101403 / 0.004250 (0.097153) | 0.042935 / 0.037052 (0.005883) | 0.421642 / 0.258489 (0.163153) | 0.456328 / 0.293841 (0.162487) | 0.065639 / 0.128546 (-0.062907) | 0.019820 / 0.075646 (-0.055826) | 0.426090 / 0.419271 (0.006818) | 0.069583 / 0.043533 (0.026051) | 0.402662 / 0.255139 (0.147523) | 0.428826 / 0.283200 (0.145626) | 0.116760 / 0.141683 (-0.024923) | 1.806216 / 1.452155 (0.354061) | 1.852629 / 1.492716 (0.359913) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226555 / 0.018006 (0.208548) | 0.584693 / 0.000490 (0.584203) | 0.008612 / 0.000200 (0.008412) | 0.000205 / 0.000054 (0.000150) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028393 / 0.037411 (-0.009018) | 0.123355 / 0.014526 (0.108829) | 0.134423 / 0.176557 (-0.042133) | 0.188536 / 0.737135 (-0.548600) | 0.141595 / 0.296338 (-0.154743) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.589359 / 0.215209 (0.374150) | 5.974655 / 2.077655 (3.897001) | 2.465580 / 1.504120 (0.961460) | 2.007618 / 1.541195 (0.466424) | 2.078788 / 1.468490 (0.610298) | 1.216646 / 4.584777 (-3.368131) | 5.217516 / 3.745712 (1.471804) | 3.107188 / 5.269862 (-2.162674) | 2.251641 / 4.565676 (-2.314036) | 0.138640 / 0.424275 (-0.285635) | 0.015046 / 0.007607 (0.007439) | 0.780092 / 0.226044 (0.554048) | 7.749564 / 2.268929 (5.480635) | 3.080708 / 55.444624 (-52.363917) | 2.393897 / 6.876477 (-4.482579) | 2.387738 / 2.142072 (0.245665) | 1.458844 / 4.805227 (-3.346384) | 0.252476 / 6.500664 (-6.248188) | 0.076594 / 0.075469 (0.001125) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.540868 / 1.841788 (-0.300919) | 17.295684 / 8.074308 (9.221376) | 19.669300 / 10.191392 (9.477908) | 0.250315 / 0.680424 (-0.430109) | 0.045068 / 0.534201 (-0.489133) | 0.538840 / 0.579283 (-0.040443) | 0.584443 / 0.434364 (0.150079) | 0.614476 / 0.540337 (0.074138) | 0.729928 / 1.386936 (-0.657008) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009218 / 0.011353 (-0.002135) | 0.006261 / 0.011008 (-0.004747) | 0.125541 / 0.038508 (0.087033) | 0.034405 / 0.023109 (0.011296) | 0.468381 / 0.275898 (0.192483) | 0.503336 / 0.323480 (0.179856) | 0.006839 / 0.007986 (-0.001146) | 0.004724 / 0.004328 (0.000396) | 0.097875 / 0.004250 (0.093625) | 0.051278 / 0.037052 (0.014225) | 0.473323 / 0.258489 (0.214834) | 0.537392 / 0.293841 (0.243551) | 0.055588 / 0.128546 (-0.072958) | 0.021041 / 0.075646 (-0.054605) | 0.416952 / 0.419271 (-0.002320) | 0.070128 / 0.043533 (0.026595) | 0.465224 / 0.255139 (0.210085) | 0.504678 / 0.283200 (0.221478) | 0.112504 / 0.141683 (-0.029179) | 1.865865 / 1.452155 (0.413710) | 1.988296 / 1.492716 (0.495580) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.314170 / 0.018006 (0.296164) | 0.526726 / 0.000490 (0.526236) | 0.018691 / 0.000200 (0.018491) | 0.000128 / 0.000054 (0.000073) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033772 / 0.037411 (-0.003639) | 0.124796 / 0.014526 (0.110270) | 0.134700 / 0.176557 (-0.041856) | 0.190595 / 0.737135 (-0.546541) | 0.143205 / 0.296338 (-0.153133) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.656708 / 0.215209 (0.441499) | 6.470503 / 2.077655 (4.392848) | 2.866430 / 1.504120 (1.362310) | 2.506846 / 1.541195 (0.965651) | 2.548669 / 1.468490 (1.080179) | 1.226695 / 4.584777 (-3.358082) | 5.117866 / 3.745712 (1.372153) | 3.032822 / 5.269862 (-2.237040) | 1.999152 / 4.565676 (-2.566524) | 0.142974 / 0.424275 (-0.281301) | 0.015011 / 0.007607 (0.007404) | 0.799729 / 0.226044 (0.573684) | 8.286313 / 2.268929 (6.017385) | 3.636482 / 55.444624 (-51.808142) | 2.888038 / 6.876477 (-3.988439) | 2.924982 / 2.142072 (0.782910) | 1.471996 / 4.805227 (-3.333231) | 0.257119 / 6.500664 (-6.243545) | 0.077294 / 0.075469 (0.001825) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.608290 / 1.841788 (-0.233497) | 17.599119 / 8.074308 (9.524811) | 18.917086 / 10.191392 (8.725694) | 0.236237 / 0.680424 (-0.444187) | 0.026061 / 0.534201 (-0.508140) | 0.527359 / 0.579283 (-0.051925) | 0.589176 / 0.434364 (0.154812) | 0.602310 / 0.540337 (0.061973) | 0.726756 / 1.386936 (-0.660180) |\n\n</details>\n</details>\n\n\n",
"Issue reported to `pydantic`: \r\n- https://github.com/pydantic/pydantic/issues/4885\r\n\r\nFixing PR at `pydantic`:\r\n- https://github.com/pydantic/pydantic/pull/4886"
] | 2022-12-29T19:34:19Z | 2022-12-30T06:36:57Z | 2022-12-29T21:00:26Z | MEMBER | null | Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5395/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5395",
"merged_at": "2022-12-29T21:00:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5395"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | https://api.github.com/repos/huggingface/datasets/issues/5394/events | https://github.com/huggingface/datasets/issues/5394 | 1,513,976,229 | I_kwDODunzps5aPXGl | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"I still getting the same error :\r\n\r\n`python -m spacy download fr_core_news_lg\r\n`.\r\n`import spacy`",
"@MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.\r\n\r\nNote that `datasets` does not depend on `spacy`."
] | 2022-12-29T18:58:44Z | 2022-12-30T10:40:51Z | 2022-12-29T21:00:27Z | MEMBER | null | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 142, in _get_module_details
return _get_module_details(pkg_main_name, error)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 109, in _get_module_details
__import__(pkg_name)
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/__init__.py", line 6, in <module>
from .errors import setup_default_warnings
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/errors.py", line 2, in <module>
from .compat import Literal
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/spacy/compat.py", line 3, in <module>
from thinc.util import copy_array
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/__init__.py", line 5, in <module>
from .config import registry
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/thinc/config.py", line 2, in <module>
import confection
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/confection/__init__.py", line 10, in <module>
from pydantic import BaseModel, create_model, ValidationError, Extra
File "pydantic/__init__.py", line 2, in init pydantic.__init__
File "pydantic/dataclasses.py", line 46, in init pydantic.dataclasses
# | None | Attribute is set to None. |
File "pydantic/main.py", line 121, in init pydantic.main
TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
```
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565
### Steps to reproduce the bug
```shell
pip install .[tests,metrics-tests]
python -m spacy download en_core_web_sm
```
### Expected behavior
No error.
### Environment info
See: https://github.com/huggingface/datasets/actions/runs/3793736481/jobs/6466356565 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5394/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5394/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5393/comments | https://api.github.com/repos/huggingface/datasets/issues/5393/events | https://github.com/huggingface/datasets/pull/5393 | 1,512,908,613 | PR_kwDODunzps5GTg0a | 5,393 | Finish deprecating the fs argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/15098095?v=4",
"events_url": "https://api.github.com/users/dconathan/events{/privacy}",
"followers_url": "https://api.github.com/users/dconathan/followers",
"following_url": "https://api.github.com/users/dconathan/following{/other_user}",
"gists_url": "https://api.github.com/users/dconathan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dconathan",
"id": 15098095,
"login": "dconathan",
"node_id": "MDQ6VXNlcjE1MDk4MDk1",
"organizations_url": "https://api.github.com/users/dconathan/orgs",
"received_events_url": "https://api.github.com/users/dconathan/received_events",
"repos_url": "https://api.github.com/users/dconathan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dconathan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dconathan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dconathan"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the deprecation. Some minor suggested fixes below...\r\n> \r\n> Also note that the corresponding tests should be updated as well.\r\n\r\nThanks for the suggestions/typo fixes. I updated the failing test - passing locally now",
"Nice thanks !\r\n\r\nI believe you also need to update `_load_info` and `_save_info` in `builder.py` - they're still passing `fs=self._fs` instead of `storage_options=self._fs.storage_options`\r\n\r\nThis should remove the remaining warnings in the CI such as \r\n\r\n```python\r\ntests/test_builder.py::test_builder_with_filesystem_download_and_prepare_reload\r\ntests/test_load.py::test_load_dataset_local[False]\r\ntests/test_load.py::test_load_dataset_local[True]\r\ntests/test_load.py::test_load_dataset_zip_csv[csv_path-False]\r\ntests/test_load.py::test_load_dataset_then_move_then_reload\r\n /opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/info.py:344: FutureWarning: 'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\r\n You can remove this warning by passing 'storage_options=fs.storage_options' instead.\r\n```",
"re: docstring, I assume passing in `storage_options=s3.storage_options` is correct/necessary to pass the secrets?",
"what about \r\nhttps://github.com/huggingface/datasets/blob/5b793dd8c43bf6e85f165238becb3c64f6cd3ed0/src/datasets/filesystems/__init__.py#L43-L54\r\nleave as is? Is this function no longer necessary?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008877 / 0.011353 (-0.002475) | 0.004725 / 0.011008 (-0.006283) | 0.100738 / 0.038508 (0.062230) | 0.030251 / 0.023109 (0.007141) | 0.301483 / 0.275898 (0.025585) | 0.374161 / 0.323480 (0.050681) | 0.007225 / 0.007986 (-0.000761) | 0.003654 / 0.004328 (-0.000674) | 0.078400 / 0.004250 (0.074149) | 0.035786 / 0.037052 (-0.001267) | 0.309744 / 0.258489 (0.051255) | 0.355834 / 0.293841 (0.061994) | 0.034344 / 0.128546 (-0.094202) | 0.011584 / 0.075646 (-0.064062) | 0.321462 / 0.419271 (-0.097810) | 0.041201 / 0.043533 (-0.002332) | 0.298808 / 0.255139 (0.043669) | 0.332626 / 0.283200 (0.049426) | 0.089131 / 0.141683 (-0.052552) | 1.477888 / 1.452155 (0.025734) | 1.530365 / 1.492716 (0.037649) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191647 / 0.018006 (0.173640) | 0.424339 / 0.000490 (0.423849) | 0.002941 / 0.000200 (0.002741) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023442 / 0.037411 (-0.013969) | 0.097264 / 0.014526 (0.082738) | 0.105655 / 0.176557 (-0.070901) | 0.145055 / 0.737135 (-0.592081) | 0.108750 / 0.296338 (-0.187588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422925 / 0.215209 (0.207716) | 4.216022 / 2.077655 (2.138367) | 1.876441 / 1.504120 (0.372322) | 1.665115 / 1.541195 (0.123920) | 1.711105 / 1.468490 (0.242615) | 0.701820 / 4.584777 (-3.882957) | 3.389319 / 3.745712 (-0.356393) | 1.909868 / 5.269862 (-3.359994) | 1.270482 / 4.565676 (-3.295195) | 0.083680 / 0.424275 (-0.340595) | 0.012347 / 0.007607 (0.004740) | 0.531076 / 0.226044 (0.305031) | 5.344045 / 2.268929 (3.075117) | 2.310897 / 55.444624 (-53.133728) | 1.971953 / 6.876477 (-4.904524) | 2.113748 / 2.142072 (-0.028325) | 0.823766 / 4.805227 (-3.981462) | 0.150864 / 6.500664 (-6.349800) | 0.066263 / 0.075469 (-0.009206) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253190 / 1.841788 (-0.588598) | 13.757887 / 8.074308 (5.683579) | 13.888195 / 10.191392 (3.696803) | 0.137285 / 0.680424 (-0.543139) | 0.029151 / 0.534201 (-0.505050) | 0.387402 / 0.579283 (-0.191881) | 0.401673 / 0.434364 (-0.032691) | 0.450474 / 0.540337 (-0.089863) | 0.533757 / 1.386936 (-0.853179) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006919 / 0.011353 (-0.004434) | 0.004655 / 0.011008 (-0.006353) | 0.096946 / 0.038508 (0.058438) | 0.028697 / 0.023109 (0.005588) | 0.420020 / 0.275898 (0.144122) | 0.460193 / 0.323480 (0.136713) | 0.005189 / 0.007986 (-0.002796) | 0.003425 / 0.004328 (-0.000904) | 0.074900 / 0.004250 (0.070649) | 0.041844 / 0.037052 (0.004792) | 0.421538 / 0.258489 (0.163049) | 0.468497 / 0.293841 (0.174656) | 0.032573 / 0.128546 (-0.095973) | 0.011731 / 0.075646 (-0.063916) | 0.320221 / 0.419271 (-0.099050) | 0.042113 / 0.043533 (-0.001420) | 0.422757 / 0.255139 (0.167618) | 0.445372 / 0.283200 (0.162172) | 0.090300 / 0.141683 (-0.051383) | 1.458598 / 1.452155 (0.006443) | 1.550060 / 1.492716 (0.057344) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235489 / 0.018006 (0.217483) | 0.418207 / 0.000490 (0.417718) | 0.002511 / 0.000200 (0.002311) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025603 / 0.037411 (-0.011808) | 0.100237 / 0.014526 (0.085711) | 0.108617 / 0.176557 (-0.067939) | 0.148417 / 0.737135 (-0.588719) | 0.110163 / 0.296338 (-0.186176) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474804 / 0.215209 (0.259595) | 4.745370 / 2.077655 (2.667715) | 2.417819 / 1.504120 (0.913699) | 2.209892 / 1.541195 (0.668697) | 2.263296 / 1.468490 (0.794806) | 0.695537 / 4.584777 (-3.889240) | 3.381028 / 3.745712 (-0.364684) | 2.952271 / 5.269862 (-2.317591) | 1.507041 / 4.565676 (-3.058636) | 0.083334 / 0.424275 (-0.340941) | 0.012554 / 0.007607 (0.004947) | 0.578861 / 0.226044 (0.352817) | 5.795241 / 2.268929 (3.526313) | 2.858544 / 55.444624 (-52.586080) | 2.516270 / 6.876477 (-4.360207) | 2.557350 / 2.142072 (0.415278) | 0.801799 / 4.805227 (-4.003428) | 0.151579 / 6.500664 (-6.349085) | 0.068765 / 0.075469 (-0.006704) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279935 / 1.841788 (-0.561853) | 14.049065 / 8.074308 (5.974757) | 13.972703 / 10.191392 (3.781311) | 0.140551 / 0.680424 (-0.539873) | 0.016831 / 0.534201 (-0.517370) | 0.383886 / 0.579283 (-0.195397) | 0.385661 / 0.434364 (-0.048703) | 0.444525 / 0.540337 (-0.095813) | 0.532197 / 1.386936 (-0.854739) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-28T15:33:17Z | 2023-01-18T12:42:33Z | 2023-01-18T12:35:32Z | CONTRIBUTOR | null | See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.load`). This PR adds a similar behavior, warnings and the `storage_options=` arg to these functions and methods.
One question: should the "deprecated" / "added" versions be `2.8.1` for the docs/warnings on these? Right now I'm going with "fs was deprecated in 2.8.0" but "storage_options= was added in 2.8.1" where appropriate.
@mariosasko | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5393/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5393",
"merged_at": "2023-01-18T12:35:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5393"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5392/comments | https://api.github.com/repos/huggingface/datasets/issues/5392/events | https://github.com/huggingface/datasets/pull/5392 | 1,512,712,529 | PR_kwDODunzps5GS2DF | 5,392 | Fix Colab notebook link | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011196 / 0.011353 (-0.000157) | 0.006039 / 0.011008 (-0.004969) | 0.122497 / 0.038508 (0.083989) | 0.043884 / 0.023109 (0.020774) | 0.372982 / 0.275898 (0.097084) | 0.444229 / 0.323480 (0.120749) | 0.009489 / 0.007986 (0.001503) | 0.004612 / 0.004328 (0.000284) | 0.093921 / 0.004250 (0.089670) | 0.052698 / 0.037052 (0.015646) | 0.372327 / 0.258489 (0.113838) | 0.426586 / 0.293841 (0.132745) | 0.046755 / 0.128546 (-0.081792) | 0.014848 / 0.075646 (-0.060799) | 0.410474 / 0.419271 (-0.008798) | 0.058206 / 0.043533 (0.014674) | 0.367051 / 0.255139 (0.111912) | 0.389950 / 0.283200 (0.106750) | 0.120857 / 0.141683 (-0.020826) | 1.795195 / 1.452155 (0.343040) | 1.823938 / 1.492716 (0.331222) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215199 / 0.018006 (0.197192) | 0.482420 / 0.000490 (0.481930) | 0.001834 / 0.000200 (0.001634) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034483 / 0.037411 (-0.002928) | 0.135503 / 0.014526 (0.120977) | 0.149991 / 0.176557 (-0.026565) | 0.198482 / 0.737135 (-0.538653) | 0.153556 / 0.296338 (-0.142783) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.504492 / 0.215209 (0.289283) | 4.950949 / 2.077655 (2.873294) | 2.251186 / 1.504120 (0.747067) | 2.049195 / 1.541195 (0.508000) | 2.123325 / 1.468490 (0.654835) | 0.865651 / 4.584777 (-3.719126) | 4.652297 / 3.745712 (0.906585) | 4.417260 / 5.269862 (-0.852602) | 2.362390 / 4.565676 (-2.203287) | 0.098845 / 0.424275 (-0.325430) | 0.014675 / 0.007607 (0.007068) | 0.608048 / 0.226044 (0.382003) | 6.063863 / 2.268929 (3.794935) | 2.753041 / 55.444624 (-52.691583) | 2.340961 / 6.876477 (-4.535516) | 2.511934 / 2.142072 (0.369862) | 0.989297 / 4.805227 (-3.815930) | 0.195770 / 6.500664 (-6.304894) | 0.076027 / 0.075469 (0.000558) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.479617 / 1.841788 (-0.362170) | 18.917860 / 8.074308 (10.843552) | 18.219594 / 10.191392 (8.028202) | 0.218494 / 0.680424 (-0.461930) | 0.037207 / 0.534201 (-0.496994) | 0.571543 / 0.579283 (-0.007741) | 0.527884 / 0.434364 (0.093520) | 0.658661 / 0.540337 (0.118324) | 0.755449 / 1.386936 (-0.631487) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008762 / 0.011353 (-0.002591) | 0.006019 / 0.011008 (-0.004989) | 0.118756 / 0.038508 (0.080248) | 0.039584 / 0.023109 (0.016474) | 0.400127 / 0.275898 (0.124229) | 0.468114 / 0.323480 (0.144634) | 0.006771 / 0.007986 (-0.001215) | 0.004689 / 0.004328 (0.000360) | 0.087274 / 0.004250 (0.083023) | 0.055548 / 0.037052 (0.018496) | 0.419901 / 0.258489 (0.161412) | 0.459516 / 0.293841 (0.165675) | 0.044197 / 0.128546 (-0.084349) | 0.014162 / 0.075646 (-0.061484) | 0.409634 / 0.419271 (-0.009638) | 0.058668 / 0.043533 (0.015135) | 0.404758 / 0.255139 (0.149619) | 0.431562 / 0.283200 (0.148363) | 0.122361 / 0.141683 (-0.019322) | 1.726597 / 1.452155 (0.274442) | 1.798977 / 1.492716 (0.306260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250831 / 0.018006 (0.232825) | 0.489811 / 0.000490 (0.489321) | 0.000490 / 0.000200 (0.000290) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035666 / 0.037411 (-0.001745) | 0.134899 / 0.014526 (0.120374) | 0.153156 / 0.176557 (-0.023401) | 0.202409 / 0.737135 (-0.534726) | 0.157350 / 0.296338 (-0.138989) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.522464 / 0.215209 (0.307254) | 5.204449 / 2.077655 (3.126794) | 2.617410 / 1.504120 (1.113290) | 2.406246 / 1.541195 (0.865052) | 2.494487 / 1.468490 (1.025997) | 0.834923 / 4.584777 (-3.749854) | 4.794186 / 3.745712 (1.048474) | 2.617939 / 5.269862 (-2.651922) | 1.648310 / 4.565676 (-2.917367) | 0.109785 / 0.424275 (-0.314490) | 0.015217 / 0.007607 (0.007610) | 0.682970 / 0.226044 (0.456926) | 6.853894 / 2.268929 (4.584966) | 3.277150 / 55.444624 (-52.167475) | 2.832502 / 6.876477 (-4.043975) | 2.984874 / 2.142072 (0.842802) | 1.005307 / 4.805227 (-3.799921) | 0.200623 / 6.500664 (-6.300041) | 0.076852 / 0.075469 (0.001383) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.556656 / 1.841788 (-0.285131) | 19.088978 / 8.074308 (11.014669) | 16.946406 / 10.191392 (6.755014) | 0.204419 / 0.680424 (-0.476004) | 0.021456 / 0.534201 (-0.512745) | 0.523603 / 0.579283 (-0.055680) | 0.530067 / 0.434364 (0.095703) | 0.604058 / 0.540337 (0.063721) | 0.731531 / 1.386936 (-0.655405) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-28T11:44:53Z | 2023-01-03T15:36:14Z | 2023-01-03T15:27:31Z | MEMBER | null | Fix notebook link to open in Colab. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5392/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5392/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5392.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5392",
"merged_at": "2023-01-03T15:27:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5392.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5392"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | https://api.github.com/repos/huggingface/datasets/issues/5391/events | https://github.com/huggingface/datasets/issues/5391 | 1,510,350,400 | I_kwDODunzps5aBh5A | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | {
"avatar_url": "https://avatars.githubusercontent.com/u/12885107?v=4",
"events_url": "https://api.github.com/users/catswithbats/events{/privacy}",
"followers_url": "https://api.github.com/users/catswithbats/followers",
"following_url": "https://api.github.com/users/catswithbats/following{/other_user}",
"gists_url": "https://api.github.com/users/catswithbats/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/catswithbats",
"id": 12885107,
"login": "catswithbats",
"node_id": "MDQ6VXNlcjEyODg1MTA3",
"organizations_url": "https://api.github.com/users/catswithbats/orgs",
"received_events_url": "https://api.github.com/users/catswithbats/received_events",
"repos_url": "https://api.github.com/users/catswithbats/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/catswithbats/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/catswithbats/subscriptions",
"type": "User",
"url": "https://api.github.com/users/catswithbats"
} | [] | open | false | null | [] | null | [
"Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448). \r\n\r\nThere are two options here:\r\n1. Increase the model's `max_length` parameter: \r\n```python\r\nmodel.config.max_length = 512\r\n```\r\n2. Filter data with labels longer than max length: https://discuss.huggingface.co/t/open-to-the-community-whisper-fine-tuning-event/26681/21?u=sanchit-gandhi\r\n\r\nNote that the datasets repo is reserved for issues directly related to the HF datasets library. Issues related to custom fine-tuning implementations are more applicable to the HF Forum: https://discuss.huggingface.co. You're more likely to get a response by posting your issue in the most applicable place and boost the chance of someone sharing a working solution!"
] | 2022-12-25T15:17:14Z | 2023-01-05T12:56:02Z | null | NONE | null | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 - WEB](https://discuss.huggingface.co/t/trainer-runtimeerror-the-size-of-tensor-a-462-must-match-the-size-of-tensor-b-448-at-non-singleton-dimension-1/26010/10 ) - another person experiencing the same issue. But could not resolve the issue with the google/fleurs data. __Not clear what can be modified in the PY code to resolve the input data size mismatch, as the training data is already very small__.
Tried posting on Discord, @sanchit-gandhi and @vaibhavs10. Was hoping that the event is over and some input/help is now available. [Hugging Face - whisper-small-amet](https://huggingface.co/drmeeseeks/whisper-small-amet).
The paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356) am_et is a low resource language (Table E), with the WER results ranging from 120-229, based on model size. (Whisper small WER=120.2).
# ---> Initial Training Output
/usr/local/lib/python3.8/dist-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
[INFO|trainer.py:1641] 2022-12-18 05:23:28,799 >> ***** Running training *****
[INFO|trainer.py:1642] 2022-12-18 05:23:28,799 >> Num examples = 446
[INFO|trainer.py:1643] 2022-12-18 05:23:28,799 >> Num Epochs = 72
[INFO|trainer.py:1644] 2022-12-18 05:23:28,799 >> Instantaneous batch size per device = 16
[INFO|trainer.py:1645] 2022-12-18 05:23:28,799 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:1646] 2022-12-18 05:23:28,799 >> Gradient Accumulation steps = 2
[INFO|trainer.py:1647] 2022-12-18 05:23:28,800 >> Total optimization steps = 1000
[INFO|trainer.py:1648] 2022-12-18 05:23:28,801 >> Number of trainable parameters = 241734912
# ---> Error
14% 9/65 [07:07<48:34, 52.04s/it][INFO|configuration_utils.py:523] 2022-12-18 05:03:07,941 >> Generate config GenerationConfig {
"begin_suppress_tokens": [
220,
50257
],
"bos_token_id": 50257,
"decoder_start_token_id": 50258,
"eos_token_id": 50257,
"max_length": 448,
"pad_token_id": 50257,
"transformers_version": "4.26.0.dev0",
"use_cache": false
}
Traceback (most recent call last):
File "run_speech_recognition_seq2seq_streaming.py", line 629, in <module>
main()
File "run_speech_recognition_seq2seq_streaming.py", line 578, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1534, in train
return inner_training_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 1859, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2122, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 78, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 2818, in evaluate
output = eval_loop(
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer.py", line 3000, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/usr/local/lib/python3.8/dist-packages/transformers/trainer_seq2seq.py", line 213, in prediction_step
outputs = model(**inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1197, in forward
outputs = self.model(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 1066, in forward
decoder_outputs = self.decoder(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/whisper/modeling_whisper.py", line 873, in forward
hidden_states = inputs_embeds + positions
RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1
100% 1000/1000 [2:52:21<00:00, 10.34s/it]
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5391/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5391/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | https://api.github.com/repos/huggingface/datasets/issues/5390/events | https://github.com/huggingface/datasets/issues/5390 | 1,509,357,553 | I_kwDODunzps5Z9vfx | 5,390 | Error when pushing to the CI hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926",
"Maybe related to the discussions in https://github.com/huggingface/datasets/pull/5196",
"Maybe the current version of moonlanding in Hub CI is the issue.\r\n\r\nI relaunched tests that were working two days ago: now they are failing. https://github.com/huggingface/datasets-server/commit/746414449cae4b311733f8a76e5b3b4ca73b38a9 for example\r\n\r\ncc @huggingface/moon-landing ",
"Hi! I don't think this has anything to do with `datasets`. Hub CI seems to be the culprit - the identical failure can be found in [this](https://github.com/huggingface/datasets/pull/5389) PR (with unrelated changes) opened today.",
"OK! Thanks for looking at it. Closing then."
] | 2022-12-23T13:36:37Z | 2022-12-23T20:29:02Z | 2022-12-23T20:29:02Z | CONTRIBUTOR | null | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:01<00:00, 1.93s/it]
Traceback (most recent call last):
File "reproduce_hubci.py", line 16, in <module>
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
File "/home/slesage/hf/datasets/src/datasets/arrow_dataset.py", line 5025, in push_to_hub
HfApi(endpoint=config.HF_ENDPOINT).upload_file(
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1346, in upload_file
raise err
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/huggingface_hub/hf_api.py", line 1337, in upload_file
r.raise_for_status()
File "/home/slesage/.pyenv/versions/datasets/lib/python3.8/site-packages/requests/models.py", line 953, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_DATASETS_SERVER_USER__/bug-16718047265472/upload/main/README.md
```
### Steps to reproduce the bug
```python
# reproduce.py
from datasets import Dataset
import time
USER = "__DUMMY_DATASETS_SERVER_USER__"
USER_TOKEN = "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"
dataset = Dataset.from_dict({"a": [1, 2, 3]})
repo_id = f"{USER}/bug-{int(time.time() * 10e3)}"
dataset.push_to_hub(repo_id=repo_id, private=False, token=USER_TOKEN, embed_external_files=True)
```
```bash
$ HF_ENDPOINT="https://hub-ci.huggingface.co" python reproduce.py
```
### Expected behavior
No error and the dataset should be uploaded to the Hub with the README file (which generates the error).
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.15.0-1026-aws-x86_64-with-glibc2.35
- Python version: 3.9.15
- PyArrow version: 7.0.0
- Pandas version: 1.5.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5390/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5390/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5389/comments | https://api.github.com/repos/huggingface/datasets/issues/5389/events | https://github.com/huggingface/datasets/pull/5389 | 1,509,348,626 | PR_kwDODunzps5GHsOo | 5,389 | Fix link in `load_dataset` docstring | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008935 / 0.011353 (-0.002417) | 0.004582 / 0.011008 (-0.006426) | 0.100950 / 0.038508 (0.062442) | 0.030305 / 0.023109 (0.007196) | 0.299759 / 0.275898 (0.023861) | 0.378577 / 0.323480 (0.055097) | 0.007834 / 0.007986 (-0.000152) | 0.003399 / 0.004328 (-0.000930) | 0.078568 / 0.004250 (0.074318) | 0.037990 / 0.037052 (0.000938) | 0.313025 / 0.258489 (0.054536) | 0.359543 / 0.293841 (0.065702) | 0.033631 / 0.128546 (-0.094916) | 0.011681 / 0.075646 (-0.063966) | 0.324542 / 0.419271 (-0.094729) | 0.041014 / 0.043533 (-0.002519) | 0.302884 / 0.255139 (0.047745) | 0.337059 / 0.283200 (0.053859) | 0.089403 / 0.141683 (-0.052280) | 1.491262 / 1.452155 (0.039108) | 1.521626 / 1.492716 (0.028910) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.172627 / 0.018006 (0.154621) | 0.419406 / 0.000490 (0.418917) | 0.001974 / 0.000200 (0.001775) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023598 / 0.037411 (-0.013814) | 0.098127 / 0.014526 (0.083601) | 0.105611 / 0.176557 (-0.070946) | 0.142612 / 0.737135 (-0.594523) | 0.121687 / 0.296338 (-0.174651) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418512 / 0.215209 (0.203303) | 4.173099 / 2.077655 (2.095444) | 1.865900 / 1.504120 (0.361780) | 1.664053 / 1.541195 (0.122858) | 1.726289 / 1.468490 (0.257799) | 0.693214 / 4.584777 (-3.891563) | 3.499982 / 3.745712 (-0.245730) | 1.894278 / 5.269862 (-3.375583) | 1.178214 / 4.565676 (-3.387463) | 0.082391 / 0.424275 (-0.341884) | 0.012486 / 0.007607 (0.004878) | 0.532190 / 0.226044 (0.306145) | 5.286612 / 2.268929 (3.017684) | 2.316680 / 55.444624 (-53.127944) | 1.964020 / 6.876477 (-4.912457) | 2.016457 / 2.142072 (-0.125616) | 0.812290 / 4.805227 (-3.992937) | 0.149102 / 6.500664 (-6.351562) | 0.064215 / 0.075469 (-0.011254) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281919 / 1.841788 (-0.559869) | 14.107509 / 8.074308 (6.033201) | 13.892369 / 10.191392 (3.700977) | 0.146164 / 0.680424 (-0.534260) | 0.028740 / 0.534201 (-0.505460) | 0.395218 / 0.579283 (-0.184066) | 0.406321 / 0.434364 (-0.028043) | 0.460880 / 0.540337 (-0.079458) | 0.545975 / 1.386936 (-0.840961) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006797 / 0.011353 (-0.004556) | 0.004522 / 0.011008 (-0.006486) | 0.098440 / 0.038508 (0.059932) | 0.027722 / 0.023109 (0.004613) | 0.423995 / 0.275898 (0.148097) | 0.456164 / 0.323480 (0.132684) | 0.005156 / 0.007986 (-0.002830) | 0.003439 / 0.004328 (-0.000889) | 0.075307 / 0.004250 (0.071057) | 0.039599 / 0.037052 (0.002547) | 0.423671 / 0.258489 (0.165181) | 0.463841 / 0.293841 (0.170001) | 0.032473 / 0.128546 (-0.096073) | 0.011674 / 0.075646 (-0.063972) | 0.320548 / 0.419271 (-0.098723) | 0.041618 / 0.043533 (-0.001915) | 0.426133 / 0.255139 (0.170994) | 0.443018 / 0.283200 (0.159819) | 0.091103 / 0.141683 (-0.050579) | 1.468758 / 1.452155 (0.016604) | 1.532695 / 1.492716 (0.039978) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255314 / 0.018006 (0.237308) | 0.422982 / 0.000490 (0.422492) | 0.015405 / 0.000200 (0.015205) | 0.000103 / 0.000054 (0.000049) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025260 / 0.037411 (-0.012152) | 0.102062 / 0.014526 (0.087537) | 0.108161 / 0.176557 (-0.068395) | 0.144205 / 0.737135 (-0.592930) | 0.111686 / 0.296338 (-0.184653) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.482633 / 0.215209 (0.267424) | 4.824777 / 2.077655 (2.747123) | 2.488626 / 1.504120 (0.984506) | 2.285410 / 1.541195 (0.744215) | 2.336793 / 1.468490 (0.868303) | 0.701894 / 4.584777 (-3.882883) | 3.506908 / 3.745712 (-0.238804) | 3.399789 / 5.269862 (-1.870072) | 1.536359 / 4.565676 (-3.029317) | 0.083621 / 0.424275 (-0.340655) | 0.012702 / 0.007607 (0.005094) | 0.581259 / 0.226044 (0.355215) | 5.829640 / 2.268929 (3.560711) | 2.932201 / 55.444624 (-52.512424) | 2.577175 / 6.876477 (-4.299301) | 2.621782 / 2.142072 (0.479710) | 0.812074 / 4.805227 (-3.993153) | 0.152840 / 6.500664 (-6.347824) | 0.067982 / 0.075469 (-0.007487) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.274915 / 1.841788 (-0.566873) | 14.345800 / 8.074308 (6.271492) | 14.242475 / 10.191392 (4.051083) | 0.143636 / 0.680424 (-0.536788) | 0.016824 / 0.534201 (-0.517377) | 0.376449 / 0.579283 (-0.202834) | 0.394219 / 0.434364 (-0.040145) | 0.435368 / 0.540337 (-0.104969) | 0.518393 / 1.386936 (-0.868544) |\n\n</details>\n</details>\n\n\n",
"I also fixed the rest of the links that point to the markdown files. \r\n\r\nPS: the CI failures are unrelated ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008641 / 0.011353 (-0.002712) | 0.004560 / 0.011008 (-0.006448) | 0.100559 / 0.038508 (0.062051) | 0.029744 / 0.023109 (0.006635) | 0.300580 / 0.275898 (0.024682) | 0.359100 / 0.323480 (0.035620) | 0.007016 / 0.007986 (-0.000970) | 0.003393 / 0.004328 (-0.000936) | 0.078649 / 0.004250 (0.074399) | 0.038138 / 0.037052 (0.001086) | 0.307730 / 0.258489 (0.049241) | 0.347678 / 0.293841 (0.053837) | 0.033630 / 0.128546 (-0.094917) | 0.011452 / 0.075646 (-0.064194) | 0.320903 / 0.419271 (-0.098369) | 0.042659 / 0.043533 (-0.000874) | 0.298886 / 0.255139 (0.043747) | 0.324371 / 0.283200 (0.041171) | 0.092582 / 0.141683 (-0.049101) | 1.490017 / 1.452155 (0.037863) | 1.512825 / 1.492716 (0.020109) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.178965 / 0.018006 (0.160958) | 0.420001 / 0.000490 (0.419512) | 0.002686 / 0.000200 (0.002486) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023568 / 0.037411 (-0.013843) | 0.097027 / 0.014526 (0.082502) | 0.104721 / 0.176557 (-0.071836) | 0.148757 / 0.737135 (-0.588378) | 0.110849 / 0.296338 (-0.185489) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415034 / 0.215209 (0.199825) | 4.155249 / 2.077655 (2.077594) | 1.837027 / 1.504120 (0.332907) | 1.627754 / 1.541195 (0.086559) | 1.687958 / 1.468490 (0.219468) | 0.699542 / 4.584777 (-3.885235) | 3.376707 / 3.745712 (-0.369005) | 2.900778 / 5.269862 (-2.369083) | 1.556168 / 4.565676 (-3.009508) | 0.082438 / 0.424275 (-0.341837) | 0.012339 / 0.007607 (0.004732) | 0.524952 / 0.226044 (0.298907) | 5.269852 / 2.268929 (3.000924) | 2.278770 / 55.444624 (-53.165854) | 1.917987 / 6.876477 (-4.958490) | 1.955000 / 2.142072 (-0.187072) | 0.821169 / 4.805227 (-3.984058) | 0.149019 / 6.500664 (-6.351645) | 0.064604 / 0.075469 (-0.010865) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.199768 / 1.841788 (-0.642020) | 13.760897 / 8.074308 (5.686589) | 13.911550 / 10.191392 (3.720158) | 0.161727 / 0.680424 (-0.518697) | 0.028615 / 0.534201 (-0.505586) | 0.393917 / 0.579283 (-0.185366) | 0.392524 / 0.434364 (-0.041840) | 0.451763 / 0.540337 (-0.088574) | 0.536880 / 1.386936 (-0.850056) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006407 / 0.011353 (-0.004946) | 0.004420 / 0.011008 (-0.006588) | 0.097244 / 0.038508 (0.058736) | 0.027114 / 0.023109 (0.004005) | 0.412512 / 0.275898 (0.136614) | 0.448189 / 0.323480 (0.124709) | 0.005831 / 0.007986 (-0.002155) | 0.005423 / 0.004328 (0.001095) | 0.076051 / 0.004250 (0.071801) | 0.038828 / 0.037052 (0.001776) | 0.414586 / 0.258489 (0.156097) | 0.457196 / 0.293841 (0.163355) | 0.031615 / 0.128546 (-0.096931) | 0.011542 / 0.075646 (-0.064104) | 0.316967 / 0.419271 (-0.102304) | 0.041278 / 0.043533 (-0.002254) | 0.411371 / 0.255139 (0.156232) | 0.436376 / 0.283200 (0.153177) | 0.090212 / 0.141683 (-0.051471) | 1.461831 / 1.452155 (0.009677) | 1.606515 / 1.492716 (0.113799) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221453 / 0.018006 (0.203447) | 0.404140 / 0.000490 (0.403650) | 0.000422 / 0.000200 (0.000222) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024588 / 0.037411 (-0.012824) | 0.098604 / 0.014526 (0.084078) | 0.113682 / 0.176557 (-0.062874) | 0.141141 / 0.737135 (-0.595994) | 0.110069 / 0.296338 (-0.186270) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.477267 / 0.215209 (0.262058) | 4.775086 / 2.077655 (2.697431) | 2.445449 / 1.504120 (0.941329) | 2.242220 / 1.541195 (0.701025) | 2.303542 / 1.468490 (0.835051) | 0.693448 / 4.584777 (-3.891329) | 3.413319 / 3.745712 (-0.332393) | 3.052734 / 5.269862 (-2.217127) | 1.434075 / 4.565676 (-3.131602) | 0.082429 / 0.424275 (-0.341846) | 0.012594 / 0.007607 (0.004987) | 0.584259 / 0.226044 (0.358214) | 5.865098 / 2.268929 (3.596169) | 2.926301 / 55.444624 (-52.518324) | 2.572555 / 6.876477 (-4.303921) | 2.608584 / 2.142072 (0.466512) | 0.805029 / 4.805227 (-4.000198) | 0.151247 / 6.500664 (-6.349417) | 0.067142 / 0.075469 (-0.008327) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285454 / 1.841788 (-0.556334) | 14.296425 / 8.074308 (6.222117) | 14.147278 / 10.191392 (3.955886) | 0.151698 / 0.680424 (-0.528726) | 0.016876 / 0.534201 (-0.517325) | 0.383302 / 0.579283 (-0.195981) | 0.388461 / 0.434364 (-0.045902) | 0.438286 / 0.540337 (-0.102051) | 0.525249 / 1.386936 (-0.861687) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008677 / 0.011353 (-0.002676) | 0.004863 / 0.011008 (-0.006145) | 0.096606 / 0.038508 (0.058098) | 0.034004 / 0.023109 (0.010895) | 0.296362 / 0.275898 (0.020464) | 0.323445 / 0.323480 (-0.000035) | 0.007341 / 0.007986 (-0.000644) | 0.005518 / 0.004328 (0.001189) | 0.073584 / 0.004250 (0.069334) | 0.041471 / 0.037052 (0.004419) | 0.302183 / 0.258489 (0.043694) | 0.339369 / 0.293841 (0.045528) | 0.037375 / 0.128546 (-0.091171) | 0.011827 / 0.075646 (-0.063819) | 0.330723 / 0.419271 (-0.088549) | 0.048751 / 0.043533 (0.005218) | 0.298370 / 0.255139 (0.043231) | 0.317781 / 0.283200 (0.034582) | 0.097488 / 0.141683 (-0.044195) | 1.456242 / 1.452155 (0.004088) | 1.530149 / 1.492716 (0.037433) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.207053 / 0.018006 (0.189046) | 0.438165 / 0.000490 (0.437675) | 0.001161 / 0.000200 (0.000961) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025353 / 0.037411 (-0.012059) | 0.105536 / 0.014526 (0.091010) | 0.116122 / 0.176557 (-0.060434) | 0.151605 / 0.737135 (-0.585530) | 0.121777 / 0.296338 (-0.174561) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.402780 / 0.215209 (0.187571) | 4.017882 / 2.077655 (1.940227) | 1.813111 / 1.504120 (0.308991) | 1.620000 / 1.541195 (0.078805) | 1.649186 / 1.468490 (0.180696) | 0.687523 / 4.584777 (-3.897254) | 3.712595 / 3.745712 (-0.033117) | 2.038535 / 5.269862 (-3.231326) | 1.414794 / 4.565676 (-3.150882) | 0.083357 / 0.424275 (-0.340918) | 0.012032 / 0.007607 (0.004425) | 0.502899 / 0.226044 (0.276854) | 5.038914 / 2.268929 (2.769985) | 2.250476 / 55.444624 (-53.194148) | 1.919954 / 6.876477 (-4.956523) | 1.930928 / 2.142072 (-0.211144) | 0.826634 / 4.805227 (-3.978593) | 0.161599 / 6.500664 (-6.339066) | 0.061356 / 0.075469 (-0.014113) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.228998 / 1.841788 (-0.612790) | 14.587914 / 8.074308 (6.513606) | 14.237514 / 10.191392 (4.046122) | 0.190913 / 0.680424 (-0.489510) | 0.029104 / 0.534201 (-0.505097) | 0.436160 / 0.579283 (-0.143123) | 0.431464 / 0.434364 (-0.002900) | 0.511670 / 0.540337 (-0.028668) | 0.609046 / 1.386936 (-0.777890) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006980 / 0.011353 (-0.004373) | 0.005260 / 0.011008 (-0.005748) | 0.095288 / 0.038508 (0.056780) | 0.032465 / 0.023109 (0.009356) | 0.410799 / 0.275898 (0.134901) | 0.423814 / 0.323480 (0.100334) | 0.005533 / 0.007986 (-0.002452) | 0.005764 / 0.004328 (0.001436) | 0.070713 / 0.004250 (0.066462) | 0.048193 / 0.037052 (0.011141) | 0.405742 / 0.258489 (0.147253) | 0.458773 / 0.293841 (0.164932) | 0.036415 / 0.128546 (-0.092131) | 0.012192 / 0.075646 (-0.063454) | 0.330655 / 0.419271 (-0.088617) | 0.055945 / 0.043533 (0.012412) | 0.407497 / 0.255139 (0.152358) | 0.421496 / 0.283200 (0.138296) | 0.106285 / 0.141683 (-0.035398) | 1.459837 / 1.452155 (0.007683) | 1.573147 / 1.492716 (0.080431) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.205776 / 0.018006 (0.187770) | 0.441523 / 0.000490 (0.441033) | 0.003073 / 0.000200 (0.002873) | 0.000092 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029207 / 0.037411 (-0.008205) | 0.110295 / 0.014526 (0.095770) | 0.130233 / 0.176557 (-0.046324) | 0.157489 / 0.737135 (-0.579647) | 0.125374 / 0.296338 (-0.170965) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440942 / 0.215209 (0.225733) | 4.389647 / 2.077655 (2.311992) | 2.234883 / 1.504120 (0.730763) | 2.029510 / 1.541195 (0.488315) | 2.082503 / 1.468490 (0.614013) | 0.698046 / 4.584777 (-3.886731) | 3.769127 / 3.745712 (0.023415) | 2.058511 / 5.269862 (-3.211351) | 1.324302 / 4.565676 (-3.241375) | 0.085695 / 0.424275 (-0.338580) | 0.012122 / 0.007607 (0.004515) | 0.552406 / 0.226044 (0.326362) | 5.527073 / 2.268929 (3.258145) | 2.711354 / 55.444624 (-52.733270) | 2.328848 / 6.876477 (-4.547629) | 2.340750 / 2.142072 (0.198678) | 0.846300 / 4.805227 (-3.958927) | 0.167465 / 6.500664 (-6.333199) | 0.063419 / 0.075469 (-0.012050) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262452 / 1.841788 (-0.579336) | 15.043537 / 8.074308 (6.969229) | 14.212563 / 10.191392 (4.021171) | 0.170229 / 0.680424 (-0.510194) | 0.017696 / 0.534201 (-0.516505) | 0.423194 / 0.579283 (-0.156089) | 0.430908 / 0.434364 (-0.003456) | 0.491733 / 0.540337 (-0.048604) | 0.599267 / 1.386936 (-0.787669) |\n\n</details>\n</details>\n\n\n",
"Program enthusiastic "
] | 2022-12-23T13:26:31Z | 2023-01-25T19:00:43Z | 2023-01-24T16:33:38Z | CONTRIBUTOR | null | Fix https://github.com/huggingface/datasets/issues/5387, fix https://github.com/huggingface/datasets/issues/4566 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5389/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5389/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5389.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5389",
"merged_at": "2023-01-24T16:33:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5389.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5389"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5388/comments | https://api.github.com/repos/huggingface/datasets/issues/5388/events | https://github.com/huggingface/datasets/issues/5388 | 1,509,042,348 | I_kwDODunzps5Z8iis | 5,388 | Getting Value Error while loading a dataset.. | {
"avatar_url": "https://avatars.githubusercontent.com/u/51160232?v=4",
"events_url": "https://api.github.com/users/valmetisrinivas/events{/privacy}",
"followers_url": "https://api.github.com/users/valmetisrinivas/followers",
"following_url": "https://api.github.com/users/valmetisrinivas/following{/other_user}",
"gists_url": "https://api.github.com/users/valmetisrinivas/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/valmetisrinivas",
"id": 51160232,
"login": "valmetisrinivas",
"node_id": "MDQ6VXNlcjUxMTYwMjMy",
"organizations_url": "https://api.github.com/users/valmetisrinivas/orgs",
"received_events_url": "https://api.github.com/users/valmetisrinivas/received_events",
"repos_url": "https://api.github.com/users/valmetisrinivas/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/valmetisrinivas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/valmetisrinivas/subscriptions",
"type": "User",
"url": "https://api.github.com/users/valmetisrinivas"
} | [] | closed | false | null | [] | null | [
"Hi! I can't reproduce this error locally (Mac) or in Colab. What version of `datasets` are you using?",
"Hi [mariosasko](https://github.com/mariosasko), the datasets version is '2.8.0'.",
"@valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n\r\nPlease, restart your Colab runtime and execute the install commands before importing `datasets`:\r\n```python\r\n!pip install datasets\r\n!pip install zstandard\r\n\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\r\n \"json\",\r\n data_files=\"https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst\",\r\n split=\"train\",\r\n streaming=True,\r\n)\r\nnext(iter(ds))\r\n```",
"> @valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n> \r\n> Please, restart your Colab runtime and execute the install commands before importing `datasets`:\r\n> \r\n> ```python\r\n> !pip install datasets\r\n> !pip install zstandard\r\n> \r\n> from datasets import load_dataset\r\n> \r\n> ds = load_dataset(\r\n> \"json\",\r\n> data_files=\"https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst\",\r\n> split=\"train\",\r\n> streaming=True,\r\n> )\r\n> next(iter(ds))\r\n> ```\r\n\r\nI guess that was the problem, importing datasets before the installation of zstandard. Thank you for the feedback. "
] | 2022-12-23T08:16:43Z | 2022-12-29T08:36:33Z | 2022-12-27T17:59:09Z | NONE | null | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-12-5b4fdcb8e6d5>](https://localhost:8080/#) in <module>
6 )
7
----> 8 next(iter(law_dataset_streamed))
17 frames
[/usr/local/lib/python3.8/dist-packages/fsspec/core.py](https://localhost:8080/#) in get_compression(urlpath, compression)
485 compression = infer_compression(urlpath)
486 if compression is not None and compression not in compr:
--> 487 raise ValueError("Compression type %s not supported" % compression)
488 return compression
489
ValueError: Compression type zstd not supported
```
### Steps to reproduce the bug
```
!pip install zstandard
from datasets import load_dataset
lds = load_dataset(
"json",
data_files="https://the-eye.eu/public/AI/pile_preliminary_components/FreeLaw_Opinions.jsonl.zst",
split="train",
streaming=True,
)
```
### Expected behavior
I expect an iterable object as the output 'lds' to be created.
### Environment info
Windows laptop with Google Colab notebook | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5388/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5387/comments | https://api.github.com/repos/huggingface/datasets/issues/5387/events | https://github.com/huggingface/datasets/issues/5387 | 1,508,740,177 | I_kwDODunzps5Z7YxR | 5,387 | Missing documentation page : improve-performance | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "https://api.github.com/users/astariul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/astariul",
"id": 43774355,
"login": "astariul",
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"organizations_url": "https://api.github.com/users/astariul/orgs",
"received_events_url": "https://api.github.com/users/astariul/received_events",
"repos_url": "https://api.github.com/users/astariul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/astariul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/astariul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/astariul"
} | [] | closed | false | null | [] | null | [
"Hi! Our documentation builder does not support links to sections, hence the bug. This is the link it should point to https://huggingface.co/docs/datasets/v2.8.0/en/cache#improve-performance."
] | 2022-12-23T01:12:57Z | 2023-01-24T16:33:40Z | 2023-01-24T16:33:40Z | NONE | null | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce the bug
Access the page and see it's missing.
### Expected behavior
Not missing page
### Environment info
Doesn't matter | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5387/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5387/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | https://api.github.com/repos/huggingface/datasets/issues/5386/events | https://github.com/huggingface/datasets/issues/5386 | 1,508,592,918 | I_kwDODunzps5Z600W | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | {
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https://api.github.com/users/salieri/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/salieri",
"id": 1086393,
"login": "salieri",
"node_id": "MDQ6VXNlcjEwODYzOTM=",
"organizations_url": "https://api.github.com/users/salieri/orgs",
"received_events_url": "https://api.github.com/users/salieri/received_events",
"repos_url": "https://api.github.com/users/salieri/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/salieri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/salieri/subscriptions",
"type": "User",
"url": "https://api.github.com/users/salieri"
} | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nThis behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L4627) the external file size). We plan to address this in the next major release by always embedding external bytes. In the meantime, you can either shuffle the dataset with `.shuffle().flatten_indices()` to make the estimation more precise or embed the bytes in the table like so:\r\n```python\r\nfrom datasets.table import embed_table_storage\r\nformat = ds.format\r\nds = ds.with_format(\"arrow\")\r\nds = ds.map(embed_table_storage, batched=True)\r\nds = ds.with_format(**format)\r\n...\r\nds.push_to_hub(...)\r\n```",
"Embedding the bytes worked like charm. Thanks @mariosasko!"
] | 2022-12-22T21:50:58Z | 2022-12-26T23:45:51Z | 2022-12-26T23:45:51Z | NONE | null | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_size='100MB'` results in shard files that are `>2GB` in size. Setting `max_shard_size` to another value, such as `1GB` or `500MB` does not fix this problem.
**The real problem is this:** When the shard file size grows too big, the entire dataset breaks because of #4721 and ultimately https://issues.apache.org/jira/browse/ARROW-5030. Since `max_shard_size` does not let one accurately control the size of the shard files, it becomes very easy to build a large dataset without any warnings that it will be broken -- even when you think you are mitigating this problem by setting `max_shard_size`.
```
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/builder.py", line 1763, in _prepare_split_single
for _, table in generator:
File " /path/to/sd-test-suite-v1/venv/lib/site-packages/datasets/packaged_modules/parquet/parquet.py", line 69, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
```
### Steps to reproduce the bug
1. Clone [example repo](https://github.com/salieri/hf-dataset-shard-size-bug)
2. Follow steps in [README.md](https://github.com/salieri/hf-dataset-shard-size-bug/blob/main/README.md)
3. After uploading the dataset, you will see that the shard file size varies between `30MB` and `200MB` -- way beyond the `max_shard_size='75MB'` limit (example: `train-00003-of-00131...` is `155MB` in [here](https://huggingface.co/datasets/slri/shard-size-test/tree/main/data))
(Note that this example repo does not generate shard files that are so large that they would trigger #4721)
### Expected behavior
The shard file size should remain below or equal to `max_shard_size`.
### Environment info
- `datasets` version: 2.8.0
- Platform: Linux-5.10.157-139.675.amzn2.aarch64-aarch64-with-glibc2.17
- Python version: 3.7.15
- PyArrow version: 10.0.1
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5386/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5385/comments | https://api.github.com/repos/huggingface/datasets/issues/5385/events | https://github.com/huggingface/datasets/issues/5385 | 1,508,535,532 | I_kwDODunzps5Z6mzs | 5,385 | Is `fs=` deprecated in `load_from_disk()` as well? | {
"avatar_url": "https://avatars.githubusercontent.com/u/15098095?v=4",
"events_url": "https://api.github.com/users/dconathan/events{/privacy}",
"followers_url": "https://api.github.com/users/dconathan/followers",
"following_url": "https://api.github.com/users/dconathan/following{/other_user}",
"gists_url": "https://api.github.com/users/dconathan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dconathan",
"id": 15098095,
"login": "dconathan",
"node_id": "MDQ6VXNlcjE1MDk4MDk1",
"organizations_url": "https://api.github.com/users/dconathan/orgs",
"received_events_url": "https://api.github.com/users/dconathan/received_events",
"repos_url": "https://api.github.com/users/dconathan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dconathan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dconathan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dconathan"
} | [] | closed | false | null | [] | null | [
"Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR? ",
"> Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR?\r\n\r\nYeah I can do that sometime next week. Should the storage_options be a new arg here? I’ll look around for anywhere else where fs is an arg.",
"Closed by #5393."
] | 2022-12-22T21:00:45Z | 2023-01-23T10:50:05Z | 2023-01-23T10:50:04Z | CONTRIBUTOR | null | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the same thing shouldn't also apply to `datasets.load.load_from_disk()` as well ?
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/load.py#L1779
### Steps to reproduce the bug
n/a
### Expected behavior
n/a
### Environment info
n/a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5385/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5384/comments | https://api.github.com/repos/huggingface/datasets/issues/5384/events | https://github.com/huggingface/datasets/pull/5384 | 1,508,152,598 | PR_kwDODunzps5GDmR6 | 5,384 | Handle 0-dim tensors in `cast_to_python_objects` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010576 / 0.011353 (-0.000777) | 0.006010 / 0.011008 (-0.004998) | 0.109375 / 0.038508 (0.070867) | 0.037780 / 0.023109 (0.014670) | 0.381552 / 0.275898 (0.105654) | 0.446039 / 0.323480 (0.122559) | 0.009004 / 0.007986 (0.001019) | 0.005653 / 0.004328 (0.001324) | 0.087027 / 0.004250 (0.082776) | 0.040346 / 0.037052 (0.003293) | 0.398827 / 0.258489 (0.140338) | 0.407281 / 0.293841 (0.113440) | 0.051723 / 0.128546 (-0.076824) | 0.020254 / 0.075646 (-0.055392) | 0.376841 / 0.419271 (-0.042430) | 0.055505 / 0.043533 (0.011972) | 0.383464 / 0.255139 (0.128325) | 0.436130 / 0.283200 (0.152930) | 0.117403 / 0.141683 (-0.024280) | 1.569016 / 1.452155 (0.116862) | 1.889831 / 1.492716 (0.397115) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.297962 / 0.018006 (0.279956) | 0.683699 / 0.000490 (0.683210) | 0.000918 / 0.000200 (0.000718) | 0.000100 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026742 / 0.037411 (-0.010669) | 0.125293 / 0.014526 (0.110768) | 0.128769 / 0.176557 (-0.047787) | 0.179447 / 0.737135 (-0.557688) | 0.142032 / 0.296338 (-0.154306) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.588389 / 0.215209 (0.373180) | 5.943514 / 2.077655 (3.865859) | 2.631163 / 1.504120 (1.127043) | 1.865446 / 1.541195 (0.324252) | 2.055610 / 1.468490 (0.587120) | 1.090288 / 4.584777 (-3.494489) | 5.457151 / 3.745712 (1.711439) | 5.645614 / 5.269862 (0.375752) | 2.849492 / 4.565676 (-1.716184) | 0.140447 / 0.424275 (-0.283828) | 0.015421 / 0.007607 (0.007813) | 0.735528 / 0.226044 (0.509484) | 7.394097 / 2.268929 (5.125169) | 3.219714 / 55.444624 (-52.224911) | 2.504134 / 6.876477 (-4.372342) | 2.524291 / 2.142072 (0.382219) | 1.452776 / 4.805227 (-3.352452) | 0.256142 / 6.500664 (-6.244522) | 0.093809 / 0.075469 (0.018340) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.570046 / 1.841788 (-0.271742) | 17.360385 / 8.074308 (9.286077) | 20.750595 / 10.191392 (10.559203) | 0.218486 / 0.680424 (-0.461938) | 0.048527 / 0.534201 (-0.485674) | 0.549568 / 0.579283 (-0.029715) | 0.633993 / 0.434364 (0.199629) | 0.632585 / 0.540337 (0.092248) | 0.712817 / 1.386936 (-0.674119) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010524 / 0.011353 (-0.000829) | 0.006307 / 0.011008 (-0.004701) | 0.129671 / 0.038508 (0.091162) | 0.038952 / 0.023109 (0.015842) | 0.421936 / 0.275898 (0.146038) | 0.489911 / 0.323480 (0.166431) | 0.007661 / 0.007986 (-0.000325) | 0.005430 / 0.004328 (0.001102) | 0.091851 / 0.004250 (0.087600) | 0.059755 / 0.037052 (0.022703) | 0.449810 / 0.258489 (0.191321) | 0.519498 / 0.293841 (0.225657) | 0.061644 / 0.128546 (-0.066902) | 0.018950 / 0.075646 (-0.056696) | 0.399149 / 0.419271 (-0.020122) | 0.067670 / 0.043533 (0.024137) | 0.441091 / 0.255139 (0.185952) | 0.459327 / 0.283200 (0.176128) | 0.122476 / 0.141683 (-0.019207) | 1.760129 / 1.452155 (0.307974) | 1.767945 / 1.492716 (0.275228) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.276675 / 0.018006 (0.258669) | 0.606798 / 0.000490 (0.606308) | 0.000449 / 0.000200 (0.000249) | 0.000078 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027762 / 0.037411 (-0.009649) | 0.108330 / 0.014526 (0.093805) | 0.134714 / 0.176557 (-0.041843) | 0.175666 / 0.737135 (-0.561470) | 0.134917 / 0.296338 (-0.161421) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.676756 / 0.215209 (0.461547) | 6.746519 / 2.077655 (4.668864) | 2.660869 / 1.504120 (1.156750) | 2.273688 / 1.541195 (0.732494) | 2.392580 / 1.468490 (0.924090) | 1.127848 / 4.584777 (-3.456929) | 5.356499 / 3.745712 (1.610787) | 2.933006 / 5.269862 (-2.336855) | 1.872877 / 4.565676 (-2.692799) | 0.139504 / 0.424275 (-0.284771) | 0.013501 / 0.007607 (0.005894) | 0.749888 / 0.226044 (0.523843) | 8.157031 / 2.268929 (5.888103) | 3.627751 / 55.444624 (-51.816874) | 2.713152 / 6.876477 (-4.163324) | 2.934585 / 2.142072 (0.792512) | 1.376398 / 4.805227 (-3.428829) | 0.251537 / 6.500664 (-6.249127) | 0.083995 / 0.075469 (0.008526) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.635446 / 1.841788 (-0.206342) | 18.435807 / 8.074308 (10.361498) | 21.395291 / 10.191392 (11.203899) | 0.247238 / 0.680424 (-0.433186) | 0.030503 / 0.534201 (-0.503698) | 0.553096 / 0.579283 (-0.026187) | 0.597583 / 0.434364 (0.163219) | 0.594135 / 0.540337 (0.053797) | 0.673815 / 1.386936 (-0.713122) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-22T16:15:30Z | 2023-01-13T16:10:15Z | 2023-01-13T16:00:52Z | CONTRIBUTOR | null | Fix #5229 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5384/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5384/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5384.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5384",
"merged_at": "2023-01-13T16:00:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5384.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5384"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5383 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5383/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5383/comments | https://api.github.com/repos/huggingface/datasets/issues/5383/events | https://github.com/huggingface/datasets/issues/5383 | 1,507,293,968 | I_kwDODunzps5Z13sQ | 5,383 | IterableDataset missing column_names, differs from Dataset interface | {
"avatar_url": "https://avatars.githubusercontent.com/u/933687?v=4",
"events_url": "https://api.github.com/users/iceboundflame/events{/privacy}",
"followers_url": "https://api.github.com/users/iceboundflame/followers",
"following_url": "https://api.github.com/users/iceboundflame/following{/other_user}",
"gists_url": "https://api.github.com/users/iceboundflame/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/iceboundflame",
"id": 933687,
"login": "iceboundflame",
"node_id": "MDQ6VXNlcjkzMzY4Nw==",
"organizations_url": "https://api.github.com/users/iceboundflame/orgs",
"received_events_url": "https://api.github.com/users/iceboundflame/received_events",
"repos_url": "https://api.github.com/users/iceboundflame/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/iceboundflame/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iceboundflame/subscriptions",
"type": "User",
"url": "https://api.github.com/users/iceboundflame"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"events_url": "https://api.github.com/users/patrickloeber/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickloeber/followers",
"following_url": "https://api.github.com/users/patrickloeber/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickloeber/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickloeber",
"id": 50772274,
"login": "patrickloeber",
"node_id": "MDQ6VXNlcjUwNzcyMjc0",
"organizations_url": "https://api.github.com/users/patrickloeber/orgs",
"received_events_url": "https://api.github.com/users/patrickloeber/received_events",
"repos_url": "https://api.github.com/users/patrickloeber/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickloeber/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickloeber/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickloeber"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"events_url": "https://api.github.com/users/patrickloeber/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickloeber/followers",
"following_url": "https://api.github.com/users/patrickloeber/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickloeber/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickloeber",
"id": 50772274,
"login": "patrickloeber",
"node_id": "MDQ6VXNlcjUwNzcyMjc0",
"organizations_url": "https://api.github.com/users/patrickloeber/orgs",
"received_events_url": "https://api.github.com/users/patrickloeber/received_events",
"repos_url": "https://api.github.com/users/patrickloeber/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickloeber/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickloeber/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickloeber"
}
] | null | [
"Another example is that `IterableDataset.map` does not have `fn_kwargs`, among other arguments. It makes it harder to convert code from Dataset to IterableDataset.",
"Hi! `fn_kwargs` was added to `IterableDataset.map` in `datasets 2.5.0`, so please update your installation (`pip install -U datasets`) to use it.\r\n\r\nRegarding `column_names`, I agree we should add this property to `IterableDataset`. In the meantime, you can use `list(dataset.features.keys())` instead.",
"Thanks! That's great news.\n\nOn Thu, Dec 22, 2022, 07:48 Mario Šaško ***@***.***> wrote:\n\n> Hi! fn_kwargs was added to IterableDataset.map in datasets 2.5.0, so\n> please update your installation (pip install -U datasets) to use it.\n>\n> Regarding column_names, I agree we should add this property to\n> IterableDataset. In the meantime, you can use\n> list(dataset.features.keys()) instead.\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5383#issuecomment-1362993633>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AAHD6N2EQUFEOUFDW3VHSILWORZ45ANCNFSM6AAAAAATGKWVGM>\n> .\n> You are receiving this because you authored the thread.Message ID:\n> ***@***.***>\n>\n",
"I'm marking this issue as a \"good first issue\", as it makes sense to have `IterableDataset.column_names` in the API. Besides the case when `features` are `None` (e.g., `features` are `None` after `map`), in which we can also return `column_names` as `None`, adding this property should be straightforward,",
"Hi @mariosasko, I can work on this if that's ok?",
"Yes! I've assigned you the issue."
] | 2022-12-22T05:27:02Z | 2023-03-13T19:03:33Z | 2023-03-13T19:03:33Z | NONE | null | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.column_names` does not exist on IterableDataset. I cannot find any clear explanation on why this is not available, is it an oversight? We do have `iterable_ds.features` available.
### Steps to reproduce the bug
See above
### Expected behavior
Dataset and IterableDataset would be expected to have the same interface, with any differences noted in the documentation.
### Environment info
n/a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5383/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5383/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5382/comments | https://api.github.com/repos/huggingface/datasets/issues/5382/events | https://github.com/huggingface/datasets/pull/5382 | 1,504,788,691 | PR_kwDODunzps5F4Q0V | 5,382 | Raise from disconnect error in xopen | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Could you review this small PR @albertvillanova ? :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011200 / 0.011353 (-0.000153) | 0.006156 / 0.011008 (-0.004852) | 0.119072 / 0.038508 (0.080564) | 0.042616 / 0.023109 (0.019507) | 0.348329 / 0.275898 (0.072431) | 0.418550 / 0.323480 (0.095070) | 0.009302 / 0.007986 (0.001316) | 0.004596 / 0.004328 (0.000267) | 0.090111 / 0.004250 (0.085860) | 0.053341 / 0.037052 (0.016289) | 0.361234 / 0.258489 (0.102745) | 0.400427 / 0.293841 (0.106586) | 0.045601 / 0.128546 (-0.082945) | 0.013806 / 0.075646 (-0.061841) | 0.393178 / 0.419271 (-0.026094) | 0.056809 / 0.043533 (0.013276) | 0.344090 / 0.255139 (0.088951) | 0.370610 / 0.283200 (0.087410) | 0.125728 / 0.141683 (-0.015955) | 1.671931 / 1.452155 (0.219776) | 1.703143 / 1.492716 (0.210427) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226534 / 0.018006 (0.208527) | 0.496487 / 0.000490 (0.495998) | 0.002235 / 0.000200 (0.002035) | 0.000094 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031298 / 0.037411 (-0.006113) | 0.137740 / 0.014526 (0.123214) | 0.153497 / 0.176557 (-0.023059) | 0.204201 / 0.737135 (-0.532934) | 0.162324 / 0.296338 (-0.134014) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.475922 / 0.215209 (0.260712) | 4.682344 / 2.077655 (2.604689) | 2.107387 / 1.504120 (0.603267) | 1.884792 / 1.541195 (0.343597) | 2.003180 / 1.468490 (0.534690) | 0.810212 / 4.584777 (-3.774564) | 4.631047 / 3.745712 (0.885334) | 4.467606 / 5.269862 (-0.802256) | 2.334196 / 4.565676 (-2.231480) | 0.099713 / 0.424275 (-0.324562) | 0.014732 / 0.007607 (0.007125) | 0.604587 / 0.226044 (0.378543) | 5.951679 / 2.268929 (3.682751) | 2.704761 / 55.444624 (-52.739863) | 2.280695 / 6.876477 (-4.595781) | 2.279489 / 2.142072 (0.137417) | 0.962474 / 4.805227 (-3.842753) | 0.195279 / 6.500664 (-6.305385) | 0.071503 / 0.075469 (-0.003966) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.558037 / 1.841788 (-0.283751) | 17.722140 / 8.074308 (9.647832) | 16.229016 / 10.191392 (6.037624) | 0.177148 / 0.680424 (-0.503276) | 0.034162 / 0.534201 (-0.500039) | 0.513945 / 0.579283 (-0.065338) | 0.533542 / 0.434364 (0.099178) | 0.672457 / 0.540337 (0.132119) | 0.762390 / 1.386936 (-0.624546) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009739 / 0.011353 (-0.001613) | 0.006095 / 0.011008 (-0.004914) | 0.105968 / 0.038508 (0.067460) | 0.046229 / 0.023109 (0.023120) | 0.449156 / 0.275898 (0.173258) | 0.462182 / 0.323480 (0.138702) | 0.006981 / 0.007986 (-0.001004) | 0.004867 / 0.004328 (0.000539) | 0.082142 / 0.004250 (0.077891) | 0.058652 / 0.037052 (0.021600) | 0.454542 / 0.258489 (0.196052) | 0.494910 / 0.293841 (0.201069) | 0.047159 / 0.128546 (-0.081387) | 0.014677 / 0.075646 (-0.060969) | 0.370819 / 0.419271 (-0.048452) | 0.064603 / 0.043533 (0.021070) | 0.441514 / 0.255139 (0.186375) | 0.442802 / 0.283200 (0.159603) | 0.138603 / 0.141683 (-0.003080) | 1.692810 / 1.452155 (0.240655) | 1.894596 / 1.492716 (0.401880) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.281681 / 0.018006 (0.263675) | 0.532693 / 0.000490 (0.532203) | 0.005484 / 0.000200 (0.005284) | 0.000156 / 0.000054 (0.000102) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032994 / 0.037411 (-0.004417) | 0.134614 / 0.014526 (0.120088) | 0.142286 / 0.176557 (-0.034270) | 0.187220 / 0.737135 (-0.549916) | 0.144897 / 0.296338 (-0.151441) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.519536 / 0.215209 (0.304327) | 5.214429 / 2.077655 (3.136775) | 2.612575 / 1.504120 (1.108455) | 2.369085 / 1.541195 (0.827891) | 2.503157 / 1.468490 (1.034667) | 0.834827 / 4.584777 (-3.749950) | 4.586789 / 3.745712 (0.841077) | 4.472605 / 5.269862 (-0.797257) | 2.314471 / 4.565676 (-2.251205) | 0.095817 / 0.424275 (-0.328458) | 0.014086 / 0.007607 (0.006478) | 0.605875 / 0.226044 (0.379831) | 6.153143 / 2.268929 (3.884214) | 3.187456 / 55.444624 (-52.257169) | 2.755377 / 6.876477 (-4.121100) | 2.777118 / 2.142072 (0.635046) | 0.967285 / 4.805227 (-3.837942) | 0.199202 / 6.500664 (-6.301462) | 0.075979 / 0.075469 (0.000510) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.481758 / 1.841788 (-0.360030) | 18.053769 / 8.074308 (9.979461) | 15.558780 / 10.191392 (5.367388) | 0.226135 / 0.680424 (-0.454288) | 0.021668 / 0.534201 (-0.512533) | 0.562618 / 0.579283 (-0.016666) | 0.518183 / 0.434364 (0.083819) | 0.628580 / 0.540337 (0.088243) | 0.740368 / 1.386936 (-0.646568) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-20T15:52:44Z | 2023-01-26T09:51:13Z | 2023-01-26T09:42:45Z | MEMBER | null | this way we can know the cause of the disconnect
related to https://github.com/huggingface/datasets/issues/5374 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5382/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5382.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5382",
"merged_at": "2023-01-26T09:42:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5382.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5382"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5381/comments | https://api.github.com/repos/huggingface/datasets/issues/5381/events | https://github.com/huggingface/datasets/issues/5381 | 1,504,498,387 | I_kwDODunzps5ZrNLT | 5,381 | Wrong URL for the_pile dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/45738728?v=4",
"events_url": "https://api.github.com/users/LeoGrin/events{/privacy}",
"followers_url": "https://api.github.com/users/LeoGrin/followers",
"following_url": "https://api.github.com/users/LeoGrin/following{/other_user}",
"gists_url": "https://api.github.com/users/LeoGrin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LeoGrin",
"id": 45738728,
"login": "LeoGrin",
"node_id": "MDQ6VXNlcjQ1NzM4NzI4",
"organizations_url": "https://api.github.com/users/LeoGrin/orgs",
"received_events_url": "https://api.github.com/users/LeoGrin/received_events",
"repos_url": "https://api.github.com/users/LeoGrin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LeoGrin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeoGrin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LeoGrin"
} | [] | closed | false | null | [] | null | [
"Hi! This error can happen if there is a local file/folder with the same name as the requested dataset. And to avoid it, rename the local file/folder.\r\n\r\nSoon, it will be possible to explicitly request a Hub dataset as follows:https://github.com/huggingface/datasets/issues/5228#issuecomment-1313494020"
] | 2022-12-20T12:40:14Z | 2023-02-15T16:24:57Z | 2023-02-15T16:24:57Z | NONE | null | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message": "Unable to resolve any data file that matches '['**']' at /storage/store/work/lgrinszt/memorization/the_pile with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'BLP', 'BMP', 'DIB', 'BUFR', 'CUR', 'PCX', 'DCX', 'DDS', 'PS', 'EPS', 'FIT', 'FITS', 'FLI', 'FLC', 'FTC', 'FTU', 'GBR', 'GIF', 'GRIB', 'H5', 'HDF', 'PNG', 'APNG', 'JP2', 'J2K', 'JPC', 'JPF', 'JPX', 'J2C', 'ICNS', 'ICO', 'IM', 'IIM', 'TIF', 'TIFF', 'JFIF', 'JPE', 'JPG', 'JPEG', 'MPG', 'MPEG', 'MSP', 'PCD', 'PXR', 'PBM', 'PGM', 'PPM', 'PNM', 'PSD', 'BW', 'RGB', 'RGBA', 'SGI', 'RAS', 'TGA', 'ICB', 'VDA', 'VST', 'WEBP', 'WMF', 'EMF', 'XBM', 'XPM', 'aiff', 'au', 'avr', 'caf', 'flac', 'htk', 'svx', 'mat4', 'mat5', 'mpc2k', 'ogg', 'paf', 'pvf', 'raw', 'rf64', 'sd2', 'sds', 'ircam', 'voc', 'w64', 'wav', 'nist', 'wavex', 'wve', 'xi', 'mp3', 'opus', 'AIFF', 'AU', 'AVR', 'CAF', 'FLAC', 'HTK', 'SVX', 'MAT4', 'MAT5', 'MPC2K', 'OGG', 'PAF', 'PVF', 'RAW', 'RF64', 'SD2', 'SDS', 'IRCAM', 'VOC', 'W64', 'WAV', 'NIST', 'WAVEX', 'WVE', 'XI', 'MP3', 'OPUS', 'zip']"
### Expected behavior
`the_pile` dataset should be dowloaded.
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-4.15.0-112-generic-x86_64-with-glibc2.27
- Python version: 3.10.8
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5381/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5380/comments | https://api.github.com/repos/huggingface/datasets/issues/5380/events | https://github.com/huggingface/datasets/issues/5380 | 1,504,404,043 | I_kwDODunzps5Zq2JL | 5,380 | Improve dataset `.skip()` speed in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/173537?v=4",
"events_url": "https://api.github.com/users/versae/events{/privacy}",
"followers_url": "https://api.github.com/users/versae/followers",
"following_url": "https://api.github.com/users/versae/following{/other_user}",
"gists_url": "https://api.github.com/users/versae/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/versae",
"id": 173537,
"login": "versae",
"node_id": "MDQ6VXNlcjE3MzUzNw==",
"organizations_url": "https://api.github.com/users/versae/orgs",
"received_events_url": "https://api.github.com/users/versae/received_events",
"repos_url": "https://api.github.com/users/versae/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/versae/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/versae/subscriptions",
"type": "User",
"url": "https://api.github.com/users/versae"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues",
"id": 3761482852,
"name": "good second issue",
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue"
}
] | open | false | null | [] | null | [
"Hi! I agree `skip` can be inefficient to use in the current state.\r\n\r\nTo make it fast, we could use \"statistics\" stored in Parquet metadata and read only the chunks needed to form a dataset. \r\n\r\nAnd thanks to the \"datasets-server\" project, which aims to store the Parquet versions of the Hub datasets (only the smaller datasets are covered currently), this solution can also be applied to datasets stored in formats other than Parquet. (cc @severo)",
"@mariosasko do the current parquet files created by the datasets-server already have the required \"statistics\"? If not, please open an issue on https://github.com/huggingface/datasets-server with some details to make sure we implement it.",
"Yes, nothing has to be changed on the datasets-server side. What I mean by \"statistics\" is that we can use the \"row_group\" metadata embedded in a Parquet file (by default) to fetch the requested rows more efficiently.",
"Glad to see the feature could be of interest. \r\n\r\nI'm sure there are many possible ways to implement this feature. I don't know enough about the datasets-server, but I guess that it is not instantaneous, in the sense that user-owned private datasets might need hours or days until they are ported to the datasets-server (if at all), which could be cumbersome. Having optionally that information in the `dataset_infos.json` file would make it easier for users to control the skip process a bit.",
"re: statistics:\r\n\r\n- https://arrow.apache.org/docs/python/generated/pyarrow.parquet.FileMetaData.html\r\n- https://arrow.apache.org/docs/python/generated/pyarrow.parquet.RowGroupMetaData.html\r\n\r\n```python\r\n>>> import pyarrow.parquet as pq\r\n>>> import hffs\r\n>>> fs = hffs.HfFileSystem(\"glue\", repo_type=\"dataset\", revision=\"refs/convert/parquet\")\r\n>>> metadata = pq.read_metadata(\"ax/glue-test.parquet\", filesystem=fs)\r\n>>> metadata\r\n<pyarrow._parquet.FileMetaData object at 0x7f4537cec400>\r\n created_by: parquet-cpp-arrow version 7.0.0\r\n num_columns: 4\r\n num_rows: 1104\r\n num_row_groups: 2\r\n format_version: 1.0\r\n serialized_size: 2902\r\n>>> metadata.row_group(0)\r\n<pyarrow._parquet.RowGroupMetaData object at 0x7f45564bcbd0>\r\n num_columns: 4\r\n num_rows: 1000\r\n total_byte_size: 164474\r\n>>> metadata.row_group(1)\r\n<pyarrow._parquet.RowGroupMetaData object at 0x7f455005c400>\r\n num_columns: 4\r\n num_rows: 104\r\n total_byte_size: 13064\r\n```",
"> user-owned private datasets might need hours or days until they are ported to the datasets-server (if at all)\r\n\r\nprivate datasets are not supported yet (https://github.com/huggingface/datasets-server/issues/39)",
"@versae `Dataset.push_to_hub` writes shards in Parquet, so this solution would also work for such datasets (immediately after the push). ",
"@mariosasko that is right. However, there are still a good amount of datasets for which the shards are created manually. In our very specific case, we create medium-sized datasets (rarely over 100-200GB) of both text and audio, we prepare the shards by hand and then upload then. It would be great to have immediate access to this download skipping feature for them too.",
"From looking at Arrow's source, it seems Parquet stores metadata at the end, which means one needs to iterate over a Parquet file's data before accessing its metadata. We could mimic Dask to address this \"limitation\" and write metadata in a `_metadata`/`_common_metadata` file in `to_parquet`/`push_to_hub`, which we could then use to optimize reads (if present). Plus, it's handy that PyArrow can also parse these metadata files.",
"So if Parquet metadata needs to be in its own file anyway, why not implement this skipping feature by storing the example counts per shard in `dataset_infos.json`? That would allow:\r\n- Support both private and public datasets\r\n- Immediate access to the feature upon uploading of shards\r\n- Use any dataset, not only those uploaded using `.push_to_hub()`\r\n\r\nA proper Parquet metadata file could still be created and \"overwrite\" the `dataset_infos.json` info in the datasets-server."
] | 2022-12-20T11:25:23Z | 2023-03-08T10:47:12Z | null | CONTRIBUTOR | null | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT it should speed up the skipping process.
### Motivation
When resuming from a checkpoint after a crashed run, using `dataset.skip()` is very convenient to recover the exact state of the data and to not train again over the same examples (assuming same seed, no shuffling). However, I have noticed that for audio datasets in streaming mode this is very costly in terms of time, as shards need to be downloaded every time before skipping the right number of examples.
### Your contribution
I took a look already at the code, but it seems a change like this is way deeper than I am able to manage, as it touches the library in several parts. I could give it a try but might need some guidance on the internals. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5380/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5380/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | https://api.github.com/repos/huggingface/datasets/issues/5379/events | https://github.com/huggingface/datasets/pull/5379 | 1,504,010,639 | PR_kwDODunzps5F1r2k | 5,379 | feat: depth estimation dataset guide. | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
}
] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the changes, looks good to me!",
"@stevhliu I have pushed some quality improvements both in terms of code and content. Would you be able to re-review? ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008325 / 0.011353 (-0.003028) | 0.004432 / 0.011008 (-0.006576) | 0.099794 / 0.038508 (0.061286) | 0.029469 / 0.023109 (0.006360) | 0.306554 / 0.275898 (0.030656) | 0.367373 / 0.323480 (0.043893) | 0.007532 / 0.007986 (-0.000454) | 0.003310 / 0.004328 (-0.001018) | 0.077453 / 0.004250 (0.073203) | 0.034836 / 0.037052 (-0.002216) | 0.311696 / 0.258489 (0.053207) | 0.349683 / 0.293841 (0.055842) | 0.033089 / 0.128546 (-0.095457) | 0.011339 / 0.075646 (-0.064307) | 0.321699 / 0.419271 (-0.097573) | 0.040213 / 0.043533 (-0.003320) | 0.304741 / 0.255139 (0.049602) | 0.331569 / 0.283200 (0.048369) | 0.090397 / 0.141683 (-0.051285) | 1.526001 / 1.452155 (0.073847) | 1.558863 / 1.492716 (0.066146) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.179446 / 0.018006 (0.161440) | 0.416308 / 0.000490 (0.415818) | 0.002390 / 0.000200 (0.002190) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023641 / 0.037411 (-0.013770) | 0.096672 / 0.014526 (0.082147) | 0.104330 / 0.176557 (-0.072227) | 0.146338 / 0.737135 (-0.590797) | 0.108278 / 0.296338 (-0.188060) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420194 / 0.215209 (0.204985) | 4.196981 / 2.077655 (2.119326) | 1.861206 / 1.504120 (0.357086) | 1.658748 / 1.541195 (0.117554) | 1.704309 / 1.468490 (0.235819) | 0.691639 / 4.584777 (-3.893138) | 3.346303 / 3.745712 (-0.399409) | 1.932962 / 5.269862 (-3.336900) | 1.299395 / 4.565676 (-3.266281) | 0.081869 / 0.424275 (-0.342406) | 0.012415 / 0.007607 (0.004808) | 0.530805 / 0.226044 (0.304761) | 5.293486 / 2.268929 (3.024558) | 2.328327 / 55.444624 (-53.116297) | 1.964956 / 6.876477 (-4.911521) | 2.002793 / 2.142072 (-0.139280) | 0.813380 / 4.805227 (-3.991847) | 0.150030 / 6.500664 (-6.350634) | 0.065194 / 0.075469 (-0.010275) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259421 / 1.841788 (-0.582367) | 13.667796 / 8.074308 (5.593488) | 13.819121 / 10.191392 (3.627729) | 0.136718 / 0.680424 (-0.543706) | 0.028510 / 0.534201 (-0.505691) | 0.402246 / 0.579283 (-0.177037) | 0.405279 / 0.434364 (-0.029085) | 0.467185 / 0.540337 (-0.073153) | 0.554213 / 1.386936 (-0.832723) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006738 / 0.011353 (-0.004615) | 0.004616 / 0.011008 (-0.006393) | 0.096978 / 0.038508 (0.058470) | 0.027750 / 0.023109 (0.004640) | 0.411505 / 0.275898 (0.135607) | 0.441796 / 0.323480 (0.118316) | 0.005073 / 0.007986 (-0.002913) | 0.003360 / 0.004328 (-0.000968) | 0.074445 / 0.004250 (0.070194) | 0.040654 / 0.037052 (0.003602) | 0.414277 / 0.258489 (0.155788) | 0.448665 / 0.293841 (0.154824) | 0.032346 / 0.128546 (-0.096200) | 0.011533 / 0.075646 (-0.064114) | 0.317349 / 0.419271 (-0.101923) | 0.041934 / 0.043533 (-0.001599) | 0.409102 / 0.255139 (0.153963) | 0.429977 / 0.283200 (0.146777) | 0.089459 / 0.141683 (-0.052224) | 1.518127 / 1.452155 (0.065973) | 1.569902 / 1.492716 (0.077186) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232648 / 0.018006 (0.214642) | 0.413751 / 0.000490 (0.413261) | 0.000404 / 0.000200 (0.000204) | 0.000057 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025468 / 0.037411 (-0.011943) | 0.098195 / 0.014526 (0.083669) | 0.108882 / 0.176557 (-0.067674) | 0.150059 / 0.737135 (-0.587076) | 0.110742 / 0.296338 (-0.185597) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445326 / 0.215209 (0.230117) | 4.449200 / 2.077655 (2.371545) | 2.098939 / 1.504120 (0.594819) | 1.861207 / 1.541195 (0.320012) | 1.901385 / 1.468490 (0.432894) | 0.695287 / 4.584777 (-3.889490) | 3.461775 / 3.745712 (-0.283938) | 2.998566 / 5.269862 (-2.271296) | 1.555036 / 4.565676 (-3.010641) | 0.082789 / 0.424275 (-0.341486) | 0.012772 / 0.007607 (0.005165) | 0.564855 / 0.226044 (0.338811) | 5.631049 / 2.268929 (3.362120) | 2.543771 / 55.444624 (-52.900854) | 2.194378 / 6.876477 (-4.682099) | 2.267168 / 2.142072 (0.125095) | 0.803330 / 4.805227 (-4.001898) | 0.151336 / 6.500664 (-6.349328) | 0.067015 / 0.075469 (-0.008454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.298422 / 1.841788 (-0.543366) | 13.933637 / 8.074308 (5.859329) | 13.570848 / 10.191392 (3.379456) | 0.150787 / 0.680424 (-0.529637) | 0.016911 / 0.534201 (-0.517290) | 0.384771 / 0.579283 (-0.194512) | 0.397505 / 0.434364 (-0.036858) | 0.450931 / 0.540337 (-0.089406) | 0.534501 / 1.386936 (-0.852435) |\n\n</details>\n</details>\n\n\n",
"@lhoestq @nateraw made some changes as per the comments. PTAL and approve as necessary. ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009037 / 0.011353 (-0.002316) | 0.004970 / 0.011008 (-0.006038) | 0.099223 / 0.038508 (0.060715) | 0.034935 / 0.023109 (0.011826) | 0.297027 / 0.275898 (0.021129) | 0.352861 / 0.323480 (0.029382) | 0.007558 / 0.007986 (-0.000427) | 0.003903 / 0.004328 (-0.000425) | 0.075663 / 0.004250 (0.071413) | 0.042577 / 0.037052 (0.005524) | 0.307182 / 0.258489 (0.048693) | 0.344237 / 0.293841 (0.050396) | 0.041438 / 0.128546 (-0.087108) | 0.012159 / 0.075646 (-0.063487) | 0.333771 / 0.419271 (-0.085501) | 0.047847 / 0.043533 (0.004314) | 0.290797 / 0.255139 (0.035658) | 0.320517 / 0.283200 (0.037318) | 0.098334 / 0.141683 (-0.043349) | 1.446187 / 1.452155 (-0.005968) | 1.495506 / 1.492716 (0.002789) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203704 / 0.018006 (0.185698) | 0.441325 / 0.000490 (0.440835) | 0.001173 / 0.000200 (0.000973) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026694 / 0.037411 (-0.010718) | 0.103819 / 0.014526 (0.089294) | 0.116377 / 0.176557 (-0.060179) | 0.158280 / 0.737135 (-0.578856) | 0.119797 / 0.296338 (-0.176541) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.405723 / 0.215209 (0.190514) | 4.047633 / 2.077655 (1.969979) | 1.805652 / 1.504120 (0.301532) | 1.611382 / 1.541195 (0.070187) | 1.663117 / 1.468490 (0.194627) | 0.692589 / 4.584777 (-3.892188) | 3.689970 / 3.745712 (-0.055742) | 2.089760 / 5.269862 (-3.180101) | 1.450576 / 4.565676 (-3.115101) | 0.085276 / 0.424275 (-0.338999) | 0.012042 / 0.007607 (0.004434) | 0.513159 / 0.226044 (0.287115) | 5.123235 / 2.268929 (2.854306) | 2.281864 / 55.444624 (-53.162761) | 1.926170 / 6.876477 (-4.950307) | 2.035093 / 2.142072 (-0.106979) | 0.857457 / 4.805227 (-3.947770) | 0.166088 / 6.500664 (-6.334576) | 0.062115 / 0.075469 (-0.013354) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197776 / 1.841788 (-0.644012) | 14.674452 / 8.074308 (6.600144) | 14.275990 / 10.191392 (4.084598) | 0.170848 / 0.680424 (-0.509576) | 0.028613 / 0.534201 (-0.505588) | 0.438650 / 0.579283 (-0.140633) | 0.439323 / 0.434364 (0.004959) | 0.515090 / 0.540337 (-0.025247) | 0.614216 / 1.386936 (-0.772720) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007159 / 0.011353 (-0.004194) | 0.005142 / 0.011008 (-0.005866) | 0.096953 / 0.038508 (0.058445) | 0.033036 / 0.023109 (0.009927) | 0.391790 / 0.275898 (0.115892) | 0.427120 / 0.323480 (0.103640) | 0.005691 / 0.007986 (-0.002294) | 0.004848 / 0.004328 (0.000519) | 0.072258 / 0.004250 (0.068008) | 0.049017 / 0.037052 (0.011965) | 0.387267 / 0.258489 (0.128778) | 0.437112 / 0.293841 (0.143272) | 0.036360 / 0.128546 (-0.092186) | 0.012249 / 0.075646 (-0.063397) | 0.336246 / 0.419271 (-0.083025) | 0.048777 / 0.043533 (0.005244) | 0.397872 / 0.255139 (0.142733) | 0.399768 / 0.283200 (0.116568) | 0.101283 / 0.141683 (-0.040400) | 1.443999 / 1.452155 (-0.008156) | 1.575496 / 1.492716 (0.082779) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220952 / 0.018006 (0.202946) | 0.442220 / 0.000490 (0.441730) | 0.000406 / 0.000200 (0.000206) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028626 / 0.037411 (-0.008786) | 0.109929 / 0.014526 (0.095403) | 0.120989 / 0.176557 (-0.055568) | 0.157377 / 0.737135 (-0.579758) | 0.125522 / 0.296338 (-0.170816) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.436565 / 0.215209 (0.221356) | 4.380771 / 2.077655 (2.303117) | 2.200003 / 1.504120 (0.695883) | 2.013289 / 1.541195 (0.472094) | 2.052658 / 1.468490 (0.584168) | 0.703706 / 4.584777 (-3.881071) | 3.823289 / 3.745712 (0.077577) | 2.064882 / 5.269862 (-3.204980) | 1.330834 / 4.565676 (-3.234842) | 0.085945 / 0.424275 (-0.338330) | 0.012511 / 0.007607 (0.004904) | 0.544171 / 0.226044 (0.318127) | 5.476059 / 2.268929 (3.207130) | 2.695586 / 55.444624 (-52.749039) | 2.330239 / 6.876477 (-4.546238) | 2.429290 / 2.142072 (0.287218) | 0.843154 / 4.805227 (-3.962073) | 0.169334 / 6.500664 (-6.331330) | 0.064261 / 0.075469 (-0.011209) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.268344 / 1.841788 (-0.573444) | 14.934342 / 8.074308 (6.860034) | 13.555389 / 10.191392 (3.363997) | 0.142725 / 0.680424 (-0.537699) | 0.017891 / 0.534201 (-0.516310) | 0.424833 / 0.579283 (-0.154450) | 0.420035 / 0.434364 (-0.014329) | 0.491009 / 0.540337 (-0.049329) | 0.586953 / 1.386936 (-0.799983) |\n\n</details>\n</details>\n\n\n",
"Merging this PR with approvals from @stevhliu @lhoestq. ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008586 / 0.011353 (-0.002767) | 0.004659 / 0.011008 (-0.006350) | 0.100343 / 0.038508 (0.061835) | 0.029861 / 0.023109 (0.006751) | 0.301090 / 0.275898 (0.025192) | 0.369528 / 0.323480 (0.046048) | 0.006920 / 0.007986 (-0.001065) | 0.003513 / 0.004328 (-0.000815) | 0.078514 / 0.004250 (0.074263) | 0.035285 / 0.037052 (-0.001767) | 0.311257 / 0.258489 (0.052768) | 0.353995 / 0.293841 (0.060154) | 0.033733 / 0.128546 (-0.094813) | 0.011489 / 0.075646 (-0.064157) | 0.323095 / 0.419271 (-0.096176) | 0.040808 / 0.043533 (-0.002725) | 0.301779 / 0.255139 (0.046640) | 0.348517 / 0.283200 (0.065318) | 0.086962 / 0.141683 (-0.054721) | 1.496270 / 1.452155 (0.044115) | 1.514260 / 1.492716 (0.021544) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189502 / 0.018006 (0.171496) | 0.419326 / 0.000490 (0.418837) | 0.002160 / 0.000200 (0.001960) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023669 / 0.037411 (-0.013742) | 0.096574 / 0.014526 (0.082048) | 0.105970 / 0.176557 (-0.070587) | 0.148531 / 0.737135 (-0.588605) | 0.109948 / 0.296338 (-0.186391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424968 / 0.215209 (0.209759) | 4.246292 / 2.077655 (2.168637) | 1.911062 / 1.504120 (0.406943) | 1.700733 / 1.541195 (0.159538) | 1.760756 / 1.468490 (0.292266) | 0.696966 / 4.584777 (-3.887811) | 3.372320 / 3.745712 (-0.373392) | 2.886281 / 5.269862 (-2.383581) | 1.553082 / 4.565676 (-3.012594) | 0.082835 / 0.424275 (-0.341440) | 0.012688 / 0.007607 (0.005081) | 0.536352 / 0.226044 (0.310308) | 5.382510 / 2.268929 (3.113582) | 2.365664 / 55.444624 (-53.078960) | 1.995631 / 6.876477 (-4.880845) | 2.073865 / 2.142072 (-0.068207) | 0.819109 / 4.805227 (-3.986118) | 0.150278 / 6.500664 (-6.350386) | 0.065201 / 0.075469 (-0.010268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239835 / 1.841788 (-0.601953) | 13.911847 / 8.074308 (5.837539) | 13.500433 / 10.191392 (3.309041) | 0.137153 / 0.680424 (-0.543271) | 0.028451 / 0.534201 (-0.505750) | 0.394659 / 0.579283 (-0.184625) | 0.404915 / 0.434364 (-0.029449) | 0.458944 / 0.540337 (-0.081394) | 0.542288 / 1.386936 (-0.844648) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006791 / 0.011353 (-0.004562) | 0.004590 / 0.011008 (-0.006419) | 0.098697 / 0.038508 (0.060189) | 0.027634 / 0.023109 (0.004525) | 0.344383 / 0.275898 (0.068485) | 0.385607 / 0.323480 (0.062127) | 0.005413 / 0.007986 (-0.002573) | 0.003447 / 0.004328 (-0.000881) | 0.077268 / 0.004250 (0.073018) | 0.041823 / 0.037052 (0.004770) | 0.342904 / 0.258489 (0.084414) | 0.399371 / 0.293841 (0.105530) | 0.032668 / 0.128546 (-0.095879) | 0.011598 / 0.075646 (-0.064048) | 0.319973 / 0.419271 (-0.099299) | 0.041760 / 0.043533 (-0.001773) | 0.340510 / 0.255139 (0.085371) | 0.377929 / 0.283200 (0.094730) | 0.090889 / 0.141683 (-0.050793) | 1.496068 / 1.452155 (0.043913) | 1.574884 / 1.492716 (0.082168) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230489 / 0.018006 (0.212483) | 0.425234 / 0.000490 (0.424745) | 0.000406 / 0.000200 (0.000206) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024650 / 0.037411 (-0.012761) | 0.102706 / 0.014526 (0.088180) | 0.108017 / 0.176557 (-0.068539) | 0.143645 / 0.737135 (-0.593490) | 0.110556 / 0.296338 (-0.185782) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.468038 / 0.215209 (0.252829) | 4.670514 / 2.077655 (2.592860) | 2.446620 / 1.504120 (0.942500) | 2.241255 / 1.541195 (0.700060) | 2.286409 / 1.468490 (0.817919) | 0.698923 / 4.584777 (-3.885854) | 3.401121 / 3.745712 (-0.344592) | 1.892399 / 5.269862 (-3.377462) | 1.163101 / 4.565676 (-3.402575) | 0.082567 / 0.424275 (-0.341708) | 0.012662 / 0.007607 (0.005055) | 0.571262 / 0.226044 (0.345218) | 5.731740 / 2.268929 (3.462812) | 2.879649 / 55.444624 (-52.564975) | 2.533846 / 6.876477 (-4.342631) | 2.654789 / 2.142072 (0.512717) | 0.811345 / 4.805227 (-3.993882) | 0.152495 / 6.500664 (-6.348169) | 0.067748 / 0.075469 (-0.007721) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.267852 / 1.841788 (-0.573935) | 14.114920 / 8.074308 (6.040612) | 14.355403 / 10.191392 (4.164011) | 0.150393 / 0.680424 (-0.530031) | 0.016855 / 0.534201 (-0.517346) | 0.378710 / 0.579283 (-0.200573) | 0.385380 / 0.434364 (-0.048984) | 0.439054 / 0.540337 (-0.101284) | 0.524343 / 1.386936 (-0.862593) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-20T05:32:11Z | 2023-01-13T12:30:31Z | 2023-01-13T12:23:34Z | MEMBER | null | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5379/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"merged_at": "2023-01-13T12:23:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5379"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5378/comments | https://api.github.com/repos/huggingface/datasets/issues/5378/events | https://github.com/huggingface/datasets/issues/5378 | 1,503,887,508 | I_kwDODunzps5Zo4CU | 5,378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "https://api.github.com/users/shaoyuta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shaoyuta",
"id": 52023469,
"login": "shaoyuta",
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"organizations_url": "https://api.github.com/users/shaoyuta/orgs",
"received_events_url": "https://api.github.com/users/shaoyuta/received_events",
"repos_url": "https://api.github.com/users/shaoyuta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shaoyuta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shaoyuta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shaoyuta"
} | [] | closed | false | null | [] | null | [
"Thanks for reporting @shaoyuta. We are investigating it.\r\n\r\nWe are transferring the issue to \"the_pile\" Community tab on the Hub: https://huggingface.co/datasets/the_pile/discussions/4"
] | 2022-12-20T02:19:13Z | 2022-12-20T07:52:54Z | 2022-12-20T07:52:54Z | NONE | null | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset("the_pile","enron_emails")
### Expected behavior
Load dataset "the_pile", "enron_emails" successfully.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 2.7.1
- Platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- PyArrow version: 10.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5378/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5377/comments | https://api.github.com/repos/huggingface/datasets/issues/5377/events | https://github.com/huggingface/datasets/pull/5377 | 1,503,477,833 | PR_kwDODunzps5Fz5lw | 5,377 | Add a parallel implementation of to_tf_dataset() | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Failing because the test server uses Py3.7 but the `SharedMemory` features require Py3.8! I forgot we still support 3.7 for another couple of months. I'm not sure exactly how to proceed, whether I should leave this PR until then, or just gate the feature behind a version check and skip the tests until the Python version catches up.",
"I haven't played with `NumpyMultiprocessingGenerator` so I can't really help here, but this sounds promising :) Otherwise I think it's also fine to allow `num_workers` only for py>=3.8 for now. You can skip the test on 3.7 and make sure to raise an informative error if someone wants to use `num_workers` with 3.7",
"Lots of comments here - I'll reply to the specific code comments underneath them, but in response to the general comments:\r\n\r\n@gante: I think this approach is much more performant than a `multiprocessing.Pool`. The reason is that when results are returned from a process `Pool`, the returned Python objects are pickled by the child processes, sent down a pipe and unpickled by the parent process. This creates a huge single-process bottleneck as the parent has to unpickle lots of large NumPy arrays, which is quite slow.\r\n\r\nWhen you use a `SharedMemory` approach, the data is just **there** for the parent process - the child and the parent are writing to exactly the same array in memory, and no pickling or unpickling occurs. This means the parent can just immediately copy the array (which is much faster than unpickling) and yield it to `tf.data`. We're taking advantage of the fact that we know the data is just big NumPy arrays and we don't need the full generality of `pickle`.\r\n\r\n@lhoestq: Sounds good! I'll add a clear error and skip the tests on Py<=3.7.",
"Also, an extra technicality, just for information in case anyone looks at this PR later: Recent versions of Python allow [pickled objects to store out-of-band data](https://peps.python.org/pep-0574/). This allows for very efficient zero-copy unpickling of objects like NumPy arrays, with the unpickled object having a view on the same memory as the original. \r\n\r\nHowever, this explicitly does **not** work when the object is unpickled by a different process than the one that created it. For this to work you must explicitly allocate shared memory and create the array there, which pickle cannot handle for you. As a result, if you just benchmark unpickling vs copying of NumPy arrays it can seem like unpickling is very fast - but this is only true when the pickle was created in the unpickling process!",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008666 / 0.011353 (-0.002687) | 0.004624 / 0.011008 (-0.006384) | 0.099247 / 0.038508 (0.060739) | 0.029766 / 0.023109 (0.006657) | 0.303347 / 0.275898 (0.027449) | 0.370022 / 0.323480 (0.046542) | 0.007128 / 0.007986 (-0.000857) | 0.003446 / 0.004328 (-0.000883) | 0.076670 / 0.004250 (0.072420) | 0.038892 / 0.037052 (0.001840) | 0.313035 / 0.258489 (0.054546) | 0.350503 / 0.293841 (0.056662) | 0.033732 / 0.128546 (-0.094815) | 0.011644 / 0.075646 (-0.064003) | 0.323295 / 0.419271 (-0.095977) | 0.040336 / 0.043533 (-0.003196) | 0.302253 / 0.255139 (0.047114) | 0.337199 / 0.283200 (0.053999) | 0.089454 / 0.141683 (-0.052229) | 1.624906 / 1.452155 (0.172752) | 1.546187 / 1.492716 (0.053470) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.184614 / 0.018006 (0.166608) | 0.427397 / 0.000490 (0.426907) | 0.003342 / 0.000200 (0.003142) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023684 / 0.037411 (-0.013727) | 0.100095 / 0.014526 (0.085569) | 0.104996 / 0.176557 (-0.071560) | 0.144719 / 0.737135 (-0.592416) | 0.110759 / 0.296338 (-0.185579) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421108 / 0.215209 (0.205899) | 4.214094 / 2.077655 (2.136440) | 1.906231 / 1.504120 (0.402111) | 1.698000 / 1.541195 (0.156806) | 1.744856 / 1.468490 (0.276366) | 0.693671 / 4.584777 (-3.891106) | 3.362522 / 3.745712 (-0.383190) | 1.878470 / 5.269862 (-3.391392) | 1.167563 / 4.565676 (-3.398113) | 0.082455 / 0.424275 (-0.341820) | 0.012261 / 0.007607 (0.004654) | 0.525196 / 0.226044 (0.299152) | 5.257553 / 2.268929 (2.988624) | 2.298286 / 55.444624 (-53.146339) | 1.956106 / 6.876477 (-4.920371) | 2.006308 / 2.142072 (-0.135764) | 0.811069 / 4.805227 (-3.994158) | 0.150368 / 6.500664 (-6.350296) | 0.065699 / 0.075469 (-0.009771) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.224516 / 1.841788 (-0.617272) | 13.619084 / 8.074308 (5.544776) | 14.096666 / 10.191392 (3.905274) | 0.151068 / 0.680424 (-0.529356) | 0.028819 / 0.534201 (-0.505382) | 0.402071 / 0.579283 (-0.177212) | 0.408647 / 0.434364 (-0.025717) | 0.466605 / 0.540337 (-0.073733) | 0.547094 / 1.386936 (-0.839842) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006935 / 0.011353 (-0.004418) | 0.004590 / 0.011008 (-0.006419) | 0.099398 / 0.038508 (0.060890) | 0.028145 / 0.023109 (0.005036) | 0.426582 / 0.275898 (0.150684) | 0.465712 / 0.323480 (0.142233) | 0.005254 / 0.007986 (-0.002731) | 0.004956 / 0.004328 (0.000627) | 0.075616 / 0.004250 (0.071365) | 0.039871 / 0.037052 (0.002819) | 0.428859 / 0.258489 (0.170370) | 0.470839 / 0.293841 (0.176998) | 0.032150 / 0.128546 (-0.096396) | 0.011778 / 0.075646 (-0.063868) | 0.322358 / 0.419271 (-0.096913) | 0.041974 / 0.043533 (-0.001559) | 0.427459 / 0.255139 (0.172320) | 0.446685 / 0.283200 (0.163485) | 0.092000 / 0.141683 (-0.049683) | 1.509231 / 1.452155 (0.057076) | 1.578950 / 1.492716 (0.086234) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.168047 / 0.018006 (0.150041) | 0.418993 / 0.000490 (0.418503) | 0.002855 / 0.000200 (0.002655) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025652 / 0.037411 (-0.011759) | 0.100141 / 0.014526 (0.085616) | 0.107293 / 0.176557 (-0.069264) | 0.142857 / 0.737135 (-0.594278) | 0.110933 / 0.296338 (-0.185406) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.477556 / 0.215209 (0.262347) | 4.777951 / 2.077655 (2.700296) | 2.461885 / 1.504120 (0.957765) | 2.252307 / 1.541195 (0.711112) | 2.307983 / 1.468490 (0.839493) | 0.697570 / 4.584777 (-3.887207) | 3.370323 / 3.745712 (-0.375389) | 3.131333 / 5.269862 (-2.138529) | 1.594839 / 4.565676 (-2.970838) | 0.082333 / 0.424275 (-0.341942) | 0.012574 / 0.007607 (0.004967) | 0.583704 / 0.226044 (0.357660) | 5.817675 / 2.268929 (3.548746) | 2.927054 / 55.444624 (-52.517570) | 2.582929 / 6.876477 (-4.293548) | 2.634275 / 2.142072 (0.492202) | 0.806407 / 4.805227 (-3.998821) | 0.151438 / 6.500664 (-6.349226) | 0.067429 / 0.075469 (-0.008040) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.267011 / 1.841788 (-0.574776) | 13.989515 / 8.074308 (5.915207) | 14.087968 / 10.191392 (3.896576) | 0.142130 / 0.680424 (-0.538293) | 0.017201 / 0.534201 (-0.517000) | 0.383394 / 0.579283 (-0.195889) | 0.381921 / 0.434364 (-0.052443) | 0.439169 / 0.540337 (-0.101168) | 0.524215 / 1.386936 (-0.862721) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008489 / 0.011353 (-0.002864) | 0.004617 / 0.011008 (-0.006391) | 0.102035 / 0.038508 (0.063527) | 0.029850 / 0.023109 (0.006741) | 0.296789 / 0.275898 (0.020891) | 0.367270 / 0.323480 (0.043790) | 0.006934 / 0.007986 (-0.001052) | 0.004923 / 0.004328 (0.000595) | 0.079150 / 0.004250 (0.074900) | 0.036884 / 0.037052 (-0.000169) | 0.305747 / 0.258489 (0.047258) | 0.348510 / 0.293841 (0.054669) | 0.034074 / 0.128546 (-0.094472) | 0.011650 / 0.075646 (-0.063997) | 0.324226 / 0.419271 (-0.095045) | 0.041763 / 0.043533 (-0.001770) | 0.300887 / 0.255139 (0.045748) | 0.333393 / 0.283200 (0.050193) | 0.093838 / 0.141683 (-0.047844) | 1.499801 / 1.452155 (0.047646) | 1.505988 / 1.492716 (0.013272) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198610 / 0.018006 (0.180604) | 0.407380 / 0.000490 (0.406891) | 0.000367 / 0.000200 (0.000167) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022858 / 0.037411 (-0.014554) | 0.095727 / 0.014526 (0.081202) | 0.104014 / 0.176557 (-0.072543) | 0.138764 / 0.737135 (-0.598371) | 0.105860 / 0.296338 (-0.190478) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.416352 / 0.215209 (0.201143) | 4.150007 / 2.077655 (2.072352) | 1.878727 / 1.504120 (0.374607) | 1.678978 / 1.541195 (0.137783) | 1.711990 / 1.468490 (0.243500) | 0.691722 / 4.584777 (-3.893055) | 3.386466 / 3.745712 (-0.359246) | 1.835730 / 5.269862 (-3.434132) | 1.149975 / 4.565676 (-3.415702) | 0.081914 / 0.424275 (-0.342362) | 0.012238 / 0.007607 (0.004631) | 0.522945 / 0.226044 (0.296900) | 5.251793 / 2.268929 (2.982864) | 2.306907 / 55.444624 (-53.137717) | 1.968400 / 6.876477 (-4.908076) | 1.981154 / 2.142072 (-0.160919) | 0.810126 / 4.805227 (-3.995101) | 0.147876 / 6.500664 (-6.352788) | 0.064042 / 0.075469 (-0.011428) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.199150 / 1.841788 (-0.642637) | 13.913473 / 8.074308 (5.839165) | 14.079132 / 10.191392 (3.887740) | 0.137387 / 0.680424 (-0.543037) | 0.028456 / 0.534201 (-0.505745) | 0.394162 / 0.579283 (-0.185122) | 0.402051 / 0.434364 (-0.032313) | 0.461944 / 0.540337 (-0.078394) | 0.542648 / 1.386936 (-0.844288) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006393 / 0.011353 (-0.004960) | 0.004599 / 0.011008 (-0.006409) | 0.097389 / 0.038508 (0.058881) | 0.027719 / 0.023109 (0.004610) | 0.341060 / 0.275898 (0.065162) | 0.379604 / 0.323480 (0.056124) | 0.004955 / 0.007986 (-0.003030) | 0.003369 / 0.004328 (-0.000959) | 0.075390 / 0.004250 (0.071139) | 0.038518 / 0.037052 (0.001466) | 0.347085 / 0.258489 (0.088596) | 0.393468 / 0.293841 (0.099627) | 0.031482 / 0.128546 (-0.097064) | 0.011585 / 0.075646 (-0.064061) | 0.317969 / 0.419271 (-0.101302) | 0.041389 / 0.043533 (-0.002144) | 0.343812 / 0.255139 (0.088673) | 0.371047 / 0.283200 (0.087848) | 0.090020 / 0.141683 (-0.051663) | 1.461690 / 1.452155 (0.009536) | 1.552458 / 1.492716 (0.059741) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.188691 / 0.018006 (0.170684) | 0.415635 / 0.000490 (0.415145) | 0.005285 / 0.000200 (0.005085) | 0.000087 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024695 / 0.037411 (-0.012716) | 0.098939 / 0.014526 (0.084413) | 0.108472 / 0.176557 (-0.068085) | 0.152635 / 0.737135 (-0.584501) | 0.109947 / 0.296338 (-0.186391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471975 / 0.215209 (0.256766) | 4.716437 / 2.077655 (2.638782) | 2.420148 / 1.504120 (0.916028) | 2.219864 / 1.541195 (0.678669) | 2.238647 / 1.468490 (0.770157) | 0.697628 / 4.584777 (-3.887149) | 3.530720 / 3.745712 (-0.214993) | 3.327354 / 5.269862 (-1.942508) | 1.665877 / 4.565676 (-2.899800) | 0.082650 / 0.424275 (-0.341625) | 0.012593 / 0.007607 (0.004986) | 0.576109 / 0.226044 (0.350065) | 5.744691 / 2.268929 (3.475762) | 2.863473 / 55.444624 (-52.581152) | 2.529616 / 6.876477 (-4.346861) | 2.562802 / 2.142072 (0.420730) | 0.805631 / 4.805227 (-3.999597) | 0.150788 / 6.500664 (-6.349876) | 0.065743 / 0.075469 (-0.009726) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.295134 / 1.841788 (-0.546654) | 14.096046 / 8.074308 (6.021738) | 13.901399 / 10.191392 (3.710007) | 0.127481 / 0.680424 (-0.552943) | 0.016666 / 0.534201 (-0.517535) | 0.381819 / 0.579283 (-0.197464) | 0.382629 / 0.434364 (-0.051735) | 0.439354 / 0.540337 (-0.100984) | 0.527662 / 1.386936 (-0.859274) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008509 / 0.011353 (-0.002844) | 0.004523 / 0.011008 (-0.006485) | 0.100616 / 0.038508 (0.062108) | 0.029573 / 0.023109 (0.006464) | 0.306414 / 0.275898 (0.030516) | 0.377034 / 0.323480 (0.053554) | 0.007621 / 0.007986 (-0.000365) | 0.003335 / 0.004328 (-0.000993) | 0.078598 / 0.004250 (0.074348) | 0.036902 / 0.037052 (-0.000150) | 0.318146 / 0.258489 (0.059657) | 0.355626 / 0.293841 (0.061785) | 0.033441 / 0.128546 (-0.095105) | 0.011552 / 0.075646 (-0.064094) | 0.322973 / 0.419271 (-0.096299) | 0.040564 / 0.043533 (-0.002968) | 0.306451 / 0.255139 (0.051312) | 0.337591 / 0.283200 (0.054392) | 0.086822 / 0.141683 (-0.054861) | 1.484601 / 1.452155 (0.032447) | 1.542777 / 1.492716 (0.050061) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201711 / 0.018006 (0.183705) | 0.418387 / 0.000490 (0.417898) | 0.002753 / 0.000200 (0.002553) | 0.000263 / 0.000054 (0.000209) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023016 / 0.037411 (-0.014395) | 0.097313 / 0.014526 (0.082787) | 0.103435 / 0.176557 (-0.073122) | 0.142665 / 0.737135 (-0.594470) | 0.107397 / 0.296338 (-0.188942) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422739 / 0.215209 (0.207530) | 4.220126 / 2.077655 (2.142471) | 1.865447 / 1.504120 (0.361327) | 1.649647 / 1.541195 (0.108453) | 1.711655 / 1.468490 (0.243165) | 0.704269 / 4.584777 (-3.880508) | 3.407390 / 3.745712 (-0.338322) | 1.929224 / 5.269862 (-3.340638) | 1.281225 / 4.565676 (-3.284452) | 0.082924 / 0.424275 (-0.341351) | 0.012588 / 0.007607 (0.004981) | 0.531025 / 0.226044 (0.304980) | 5.339441 / 2.268929 (3.070512) | 2.298969 / 55.444624 (-53.145656) | 1.952145 / 6.876477 (-4.924332) | 2.034754 / 2.142072 (-0.107318) | 0.823672 / 4.805227 (-3.981555) | 0.151465 / 6.500664 (-6.349199) | 0.066663 / 0.075469 (-0.008807) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.258981 / 1.841788 (-0.582807) | 13.791640 / 8.074308 (5.717332) | 14.001514 / 10.191392 (3.810122) | 0.149805 / 0.680424 (-0.530619) | 0.028614 / 0.534201 (-0.505587) | 0.400266 / 0.579283 (-0.179017) | 0.405891 / 0.434364 (-0.028473) | 0.471903 / 0.540337 (-0.068435) | 0.563656 / 1.386936 (-0.823280) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006751 / 0.011353 (-0.004601) | 0.004665 / 0.011008 (-0.006343) | 0.098362 / 0.038508 (0.059854) | 0.027451 / 0.023109 (0.004342) | 0.421859 / 0.275898 (0.145961) | 0.458089 / 0.323480 (0.134609) | 0.004885 / 0.007986 (-0.003101) | 0.003459 / 0.004328 (-0.000870) | 0.075871 / 0.004250 (0.071621) | 0.036591 / 0.037052 (-0.000462) | 0.423307 / 0.258489 (0.164818) | 0.467040 / 0.293841 (0.173199) | 0.031837 / 0.128546 (-0.096710) | 0.011604 / 0.075646 (-0.064042) | 0.321132 / 0.419271 (-0.098140) | 0.041806 / 0.043533 (-0.001727) | 0.421653 / 0.255139 (0.166514) | 0.445896 / 0.283200 (0.162696) | 0.087998 / 0.141683 (-0.053685) | 1.475818 / 1.452155 (0.023664) | 1.559487 / 1.492716 (0.066770) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203096 / 0.018006 (0.185090) | 0.401381 / 0.000490 (0.400892) | 0.004037 / 0.000200 (0.003837) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023757 / 0.037411 (-0.013654) | 0.099919 / 0.014526 (0.085393) | 0.108384 / 0.176557 (-0.068173) | 0.143780 / 0.737135 (-0.593355) | 0.111528 / 0.296338 (-0.184811) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.475896 / 0.215209 (0.260686) | 4.754567 / 2.077655 (2.676912) | 2.444986 / 1.504120 (0.940866) | 2.231055 / 1.541195 (0.689860) | 2.283646 / 1.468490 (0.815156) | 0.701303 / 4.584777 (-3.883474) | 3.381597 / 3.745712 (-0.364115) | 1.878714 / 5.269862 (-3.391148) | 1.171566 / 4.565676 (-3.394111) | 0.083106 / 0.424275 (-0.341169) | 0.012575 / 0.007607 (0.004967) | 0.582570 / 0.226044 (0.356526) | 5.813677 / 2.268929 (3.544748) | 2.908578 / 55.444624 (-52.536046) | 2.548459 / 6.876477 (-4.328017) | 2.581211 / 2.142072 (0.439139) | 0.807925 / 4.805227 (-3.997302) | 0.153516 / 6.500664 (-6.347148) | 0.068763 / 0.075469 (-0.006706) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.249595 / 1.841788 (-0.592193) | 14.208573 / 8.074308 (6.134265) | 14.179174 / 10.191392 (3.987781) | 0.156005 / 0.680424 (-0.524419) | 0.017045 / 0.534201 (-0.517156) | 0.377414 / 0.579283 (-0.201869) | 0.395291 / 0.434364 (-0.039073) | 0.444642 / 0.540337 (-0.095695) | 0.531626 / 1.386936 (-0.855311) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008871 / 0.011353 (-0.002482) | 0.004616 / 0.011008 (-0.006392) | 0.100910 / 0.038508 (0.062402) | 0.030381 / 0.023109 (0.007272) | 0.304636 / 0.275898 (0.028737) | 0.384258 / 0.323480 (0.060778) | 0.007019 / 0.007986 (-0.000966) | 0.004262 / 0.004328 (-0.000066) | 0.077082 / 0.004250 (0.072832) | 0.035235 / 0.037052 (-0.001817) | 0.318293 / 0.258489 (0.059804) | 0.356578 / 0.293841 (0.062737) | 0.033568 / 0.128546 (-0.094978) | 0.011583 / 0.075646 (-0.064063) | 0.322442 / 0.419271 (-0.096830) | 0.041941 / 0.043533 (-0.001592) | 0.310469 / 0.255139 (0.055330) | 0.335626 / 0.283200 (0.052427) | 0.088195 / 0.141683 (-0.053487) | 1.466778 / 1.452155 (0.014623) | 1.512459 / 1.492716 (0.019743) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.184126 / 0.018006 (0.166120) | 0.413392 / 0.000490 (0.412902) | 0.002191 / 0.000200 (0.001992) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023426 / 0.037411 (-0.013985) | 0.096240 / 0.014526 (0.081715) | 0.105908 / 0.176557 (-0.070648) | 0.146331 / 0.737135 (-0.590804) | 0.107441 / 0.296338 (-0.188898) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420018 / 0.215209 (0.204809) | 4.198129 / 2.077655 (2.120474) | 1.998726 / 1.504120 (0.494606) | 1.870410 / 1.541195 (0.329215) | 1.925160 / 1.468490 (0.456670) | 0.688790 / 4.584777 (-3.895987) | 3.430629 / 3.745712 (-0.315083) | 2.875616 / 5.269862 (-2.394246) | 1.566269 / 4.565676 (-2.999408) | 0.082431 / 0.424275 (-0.341844) | 0.012409 / 0.007607 (0.004802) | 0.536178 / 0.226044 (0.310134) | 5.342918 / 2.268929 (3.073989) | 2.410814 / 55.444624 (-53.033811) | 2.056518 / 6.876477 (-4.819958) | 2.240148 / 2.142072 (0.098075) | 0.804848 / 4.805227 (-4.000379) | 0.147325 / 6.500664 (-6.353340) | 0.064217 / 0.075469 (-0.011252) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285725 / 1.841788 (-0.556063) | 13.909739 / 8.074308 (5.835431) | 14.025774 / 10.191392 (3.834382) | 0.142413 / 0.680424 (-0.538011) | 0.028390 / 0.534201 (-0.505811) | 0.402345 / 0.579283 (-0.176939) | 0.404341 / 0.434364 (-0.030023) | 0.463055 / 0.540337 (-0.077282) | 0.556811 / 1.386936 (-0.830125) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006557 / 0.011353 (-0.004795) | 0.004668 / 0.011008 (-0.006340) | 0.098839 / 0.038508 (0.060331) | 0.027618 / 0.023109 (0.004508) | 0.409338 / 0.275898 (0.133440) | 0.444048 / 0.323480 (0.120568) | 0.004881 / 0.007986 (-0.003105) | 0.003434 / 0.004328 (-0.000895) | 0.076497 / 0.004250 (0.072247) | 0.038932 / 0.037052 (0.001880) | 0.411419 / 0.258489 (0.152930) | 0.451167 / 0.293841 (0.157326) | 0.031649 / 0.128546 (-0.096897) | 0.011691 / 0.075646 (-0.063955) | 0.321586 / 0.419271 (-0.097685) | 0.041984 / 0.043533 (-0.001549) | 0.407717 / 0.255139 (0.152578) | 0.434687 / 0.283200 (0.151487) | 0.086419 / 0.141683 (-0.055264) | 1.491755 / 1.452155 (0.039601) | 1.569081 / 1.492716 (0.076364) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231746 / 0.018006 (0.213739) | 0.412271 / 0.000490 (0.411781) | 0.000403 / 0.000200 (0.000203) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024264 / 0.037411 (-0.013147) | 0.100478 / 0.014526 (0.085952) | 0.107065 / 0.176557 (-0.069491) | 0.140724 / 0.737135 (-0.596412) | 0.110631 / 0.296338 (-0.185707) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472476 / 0.215209 (0.257267) | 4.738919 / 2.077655 (2.661265) | 2.438049 / 1.504120 (0.933929) | 2.237855 / 1.541195 (0.696660) | 2.282885 / 1.468490 (0.814395) | 0.690420 / 4.584777 (-3.894357) | 3.426487 / 3.745712 (-0.319225) | 1.842443 / 5.269862 (-3.427418) | 1.154466 / 4.565676 (-3.411210) | 0.082166 / 0.424275 (-0.342109) | 0.012309 / 0.007607 (0.004701) | 0.574730 / 0.226044 (0.348686) | 5.737566 / 2.268929 (3.468638) | 2.882405 / 55.444624 (-52.562220) | 2.540276 / 6.876477 (-4.336201) | 2.552356 / 2.142072 (0.410283) | 0.796413 / 4.805227 (-4.008815) | 0.152705 / 6.500664 (-6.347959) | 0.068273 / 0.075469 (-0.007196) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244423 / 1.841788 (-0.597365) | 13.827750 / 8.074308 (5.753442) | 14.074083 / 10.191392 (3.882691) | 0.140291 / 0.680424 (-0.540133) | 0.017337 / 0.534201 (-0.516864) | 0.389314 / 0.579283 (-0.189969) | 0.390914 / 0.434364 (-0.043450) | 0.450333 / 0.540337 (-0.090004) | 0.543860 / 1.386936 (-0.843076) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009490 / 0.011353 (-0.001863) | 0.005211 / 0.011008 (-0.005798) | 0.100884 / 0.038508 (0.062376) | 0.035834 / 0.023109 (0.012725) | 0.293623 / 0.275898 (0.017724) | 0.378118 / 0.323480 (0.054638) | 0.008106 / 0.007986 (0.000120) | 0.005339 / 0.004328 (0.001010) | 0.076311 / 0.004250 (0.072061) | 0.045954 / 0.037052 (0.008902) | 0.308163 / 0.258489 (0.049674) | 0.353470 / 0.293841 (0.059629) | 0.038539 / 0.128546 (-0.090008) | 0.012174 / 0.075646 (-0.063472) | 0.334875 / 0.419271 (-0.084396) | 0.048602 / 0.043533 (0.005069) | 0.295803 / 0.255139 (0.040664) | 0.318894 / 0.283200 (0.035695) | 0.105487 / 0.141683 (-0.036195) | 1.433628 / 1.452155 (-0.018526) | 1.466843 / 1.492716 (-0.025873) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.203426 / 0.018006 (0.185419) | 0.456877 / 0.000490 (0.456387) | 0.001452 / 0.000200 (0.001252) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028308 / 0.037411 (-0.009103) | 0.108965 / 0.014526 (0.094439) | 0.119552 / 0.176557 (-0.057005) | 0.156371 / 0.737135 (-0.580765) | 0.124141 / 0.296338 (-0.172197) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400183 / 0.215209 (0.184973) | 3.990983 / 2.077655 (1.913329) | 1.806729 / 1.504120 (0.302609) | 1.611944 / 1.541195 (0.070750) | 1.740019 / 1.468490 (0.271529) | 0.699600 / 4.584777 (-3.885177) | 3.868711 / 3.745712 (0.122999) | 3.249758 / 5.269862 (-2.020103) | 1.832213 / 4.565676 (-2.733463) | 0.085282 / 0.424275 (-0.338993) | 0.012726 / 0.007607 (0.005119) | 0.509385 / 0.226044 (0.283341) | 5.066913 / 2.268929 (2.797984) | 2.325710 / 55.444624 (-53.118914) | 1.962238 / 6.876477 (-4.914239) | 2.017576 / 2.142072 (-0.124496) | 0.839444 / 4.805227 (-3.965783) | 0.166936 / 6.500664 (-6.333728) | 0.064546 / 0.075469 (-0.010923) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.196396 / 1.841788 (-0.645392) | 15.077063 / 8.074308 (7.002755) | 14.268103 / 10.191392 (4.076711) | 0.163782 / 0.680424 (-0.516642) | 0.028794 / 0.534201 (-0.505407) | 0.440564 / 0.579283 (-0.138719) | 0.439826 / 0.434364 (0.005463) | 0.514786 / 0.540337 (-0.025551) | 0.603353 / 1.386936 (-0.783583) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007874 / 0.011353 (-0.003479) | 0.005347 / 0.011008 (-0.005661) | 0.099461 / 0.038508 (0.060953) | 0.034010 / 0.023109 (0.010901) | 0.384650 / 0.275898 (0.108752) | 0.423827 / 0.323480 (0.100347) | 0.006201 / 0.007986 (-0.001784) | 0.004212 / 0.004328 (-0.000117) | 0.074354 / 0.004250 (0.070104) | 0.051675 / 0.037052 (0.014623) | 0.392488 / 0.258489 (0.133999) | 0.425828 / 0.293841 (0.131987) | 0.037444 / 0.128546 (-0.091103) | 0.012388 / 0.075646 (-0.063258) | 0.334482 / 0.419271 (-0.084789) | 0.050715 / 0.043533 (0.007182) | 0.378323 / 0.255139 (0.123184) | 0.395450 / 0.283200 (0.112250) | 0.108403 / 0.141683 (-0.033280) | 1.426803 / 1.452155 (-0.025352) | 1.532417 / 1.492716 (0.039701) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219989 / 0.018006 (0.201982) | 0.454101 / 0.000490 (0.453611) | 0.000407 / 0.000200 (0.000207) | 0.000056 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030590 / 0.037411 (-0.006822) | 0.113483 / 0.014526 (0.098957) | 0.122603 / 0.176557 (-0.053954) | 0.161031 / 0.737135 (-0.576104) | 0.128039 / 0.296338 (-0.168300) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.430458 / 0.215209 (0.215249) | 4.286594 / 2.077655 (2.208940) | 2.056666 / 1.504120 (0.552546) | 1.861142 / 1.541195 (0.319948) | 1.937185 / 1.468490 (0.468695) | 0.701881 / 4.584777 (-3.882896) | 3.970144 / 3.745712 (0.224432) | 2.107118 / 5.269862 (-3.162744) | 1.351561 / 4.565676 (-3.214115) | 0.085470 / 0.424275 (-0.338805) | 0.012366 / 0.007607 (0.004759) | 0.525212 / 0.226044 (0.299168) | 5.301553 / 2.268929 (3.032625) | 2.593862 / 55.444624 (-52.850763) | 2.287315 / 6.876477 (-4.589161) | 2.368249 / 2.142072 (0.226176) | 0.855656 / 4.805227 (-3.949571) | 0.167846 / 6.500664 (-6.332818) | 0.064521 / 0.075469 (-0.010948) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237008 / 1.841788 (-0.604779) | 15.784303 / 8.074308 (7.709995) | 14.613081 / 10.191392 (4.421689) | 0.161012 / 0.680424 (-0.519412) | 0.017928 / 0.534201 (-0.516273) | 0.423905 / 0.579283 (-0.155378) | 0.428316 / 0.434364 (-0.006048) | 0.500226 / 0.540337 (-0.040112) | 0.606725 / 1.386936 (-0.780211) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008874 / 0.011353 (-0.002479) | 0.004581 / 0.011008 (-0.006428) | 0.100180 / 0.038508 (0.061672) | 0.029990 / 0.023109 (0.006880) | 0.301616 / 0.275898 (0.025718) | 0.343662 / 0.323480 (0.020183) | 0.007111 / 0.007986 (-0.000875) | 0.003428 / 0.004328 (-0.000900) | 0.078031 / 0.004250 (0.073780) | 0.037332 / 0.037052 (0.000279) | 0.301977 / 0.258489 (0.043488) | 0.345581 / 0.293841 (0.051740) | 0.034305 / 0.128546 (-0.094241) | 0.011660 / 0.075646 (-0.063986) | 0.322289 / 0.419271 (-0.096982) | 0.041488 / 0.043533 (-0.002045) | 0.301612 / 0.255139 (0.046473) | 0.328174 / 0.283200 (0.044974) | 0.085561 / 0.141683 (-0.056122) | 1.482114 / 1.452155 (0.029959) | 1.556194 / 1.492716 (0.063478) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186989 / 0.018006 (0.168983) | 0.421499 / 0.000490 (0.421009) | 0.001193 / 0.000200 (0.000993) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023551 / 0.037411 (-0.013861) | 0.099868 / 0.014526 (0.085343) | 0.105233 / 0.176557 (-0.071324) | 0.141628 / 0.737135 (-0.595507) | 0.109004 / 0.296338 (-0.187335) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415189 / 0.215209 (0.199979) | 4.145716 / 2.077655 (2.068061) | 1.837917 / 1.504120 (0.333797) | 1.635043 / 1.541195 (0.093848) | 1.683299 / 1.468490 (0.214809) | 0.688538 / 4.584777 (-3.896239) | 3.412628 / 3.745712 (-0.333084) | 1.877456 / 5.269862 (-3.392405) | 1.154129 / 4.565676 (-3.411547) | 0.081850 / 0.424275 (-0.342425) | 0.012309 / 0.007607 (0.004702) | 0.522830 / 0.226044 (0.296785) | 5.238685 / 2.268929 (2.969756) | 2.277840 / 55.444624 (-53.166784) | 1.941787 / 6.876477 (-4.934690) | 1.999688 / 2.142072 (-0.142385) | 0.807590 / 4.805227 (-3.997637) | 0.148157 / 6.500664 (-6.352507) | 0.064898 / 0.075469 (-0.010571) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253859 / 1.841788 (-0.587929) | 13.676097 / 8.074308 (5.601789) | 14.237837 / 10.191392 (4.046444) | 0.137178 / 0.680424 (-0.543246) | 0.028971 / 0.534201 (-0.505230) | 0.400380 / 0.579283 (-0.178903) | 0.409990 / 0.434364 (-0.024374) | 0.462552 / 0.540337 (-0.077786) | 0.552153 / 1.386936 (-0.834783) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006831 / 0.011353 (-0.004522) | 0.004627 / 0.011008 (-0.006381) | 0.099883 / 0.038508 (0.061375) | 0.028072 / 0.023109 (0.004962) | 0.343556 / 0.275898 (0.067658) | 0.386792 / 0.323480 (0.063312) | 0.005080 / 0.007986 (-0.002906) | 0.003508 / 0.004328 (-0.000820) | 0.077803 / 0.004250 (0.073552) | 0.040038 / 0.037052 (0.002985) | 0.345089 / 0.258489 (0.086600) | 0.396078 / 0.293841 (0.102238) | 0.032241 / 0.128546 (-0.096305) | 0.011711 / 0.075646 (-0.063935) | 0.320531 / 0.419271 (-0.098740) | 0.043658 / 0.043533 (0.000125) | 0.344696 / 0.255139 (0.089557) | 0.389847 / 0.283200 (0.106648) | 0.092328 / 0.141683 (-0.049355) | 1.477290 / 1.452155 (0.025136) | 1.548698 / 1.492716 (0.055982) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236073 / 0.018006 (0.218067) | 0.422113 / 0.000490 (0.421624) | 0.000431 / 0.000200 (0.000231) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024738 / 0.037411 (-0.012673) | 0.100546 / 0.014526 (0.086020) | 0.107550 / 0.176557 (-0.069006) | 0.146056 / 0.737135 (-0.591079) | 0.112665 / 0.296338 (-0.183674) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.490259 / 0.215209 (0.275050) | 4.907994 / 2.077655 (2.830339) | 2.547175 / 1.504120 (1.043055) | 2.344419 / 1.541195 (0.803224) | 2.403985 / 1.468490 (0.935495) | 0.696011 / 4.584777 (-3.888766) | 3.442426 / 3.745712 (-0.303286) | 1.878702 / 5.269862 (-3.391159) | 1.158280 / 4.565676 (-3.407396) | 0.082300 / 0.424275 (-0.341975) | 0.012513 / 0.007607 (0.004906) | 0.602696 / 0.226044 (0.376651) | 6.014592 / 2.268929 (3.745663) | 3.014466 / 55.444624 (-52.430159) | 2.669376 / 6.876477 (-4.207101) | 2.724485 / 2.142072 (0.582412) | 0.799795 / 4.805227 (-4.005432) | 0.151220 / 6.500664 (-6.349444) | 0.067486 / 0.075469 (-0.007983) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281265 / 1.841788 (-0.560523) | 14.362284 / 8.074308 (6.287976) | 14.313690 / 10.191392 (4.122298) | 0.142870 / 0.680424 (-0.537554) | 0.017206 / 0.534201 (-0.516995) | 0.380084 / 0.579283 (-0.199199) | 0.388161 / 0.434364 (-0.046203) | 0.442617 / 0.540337 (-0.097721) | 0.528487 / 1.386936 (-0.858449) |\n\n</details>\n</details>\n\n\n",
"@lhoestq @amyeroberts @gante I did a substantial rewrite and all tests are passing now (Windows seems to time out or something and I can't figure out why - not sure if that's related to this PR!). I also confirmed tests are passing locally with Py==3.10. \r\n\r\nAside from incorporating everyone's comments, I also made a context manager to create and handle shared memory - this ensures that shared memory is cleaned up even if execution is interrupted. Also, shared memory names include a UUID string now to avoid collisions. Finally, string arrays are now split up into fixed-width character arrays in the workers so that they can be passed through shared memory, and the parent process reconstructs them into string arrays.",
"Update: `test_arrow_dataset.py` ran fine in this branch on my Windows machine (Py 3.10), so I have no idea what's up with those tests",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008852 / 0.011353 (-0.002500) | 0.004545 / 0.011008 (-0.006464) | 0.099814 / 0.038508 (0.061306) | 0.030314 / 0.023109 (0.007205) | 0.310426 / 0.275898 (0.034528) | 0.366893 / 0.323480 (0.043413) | 0.007183 / 0.007986 (-0.000802) | 0.003476 / 0.004328 (-0.000853) | 0.077566 / 0.004250 (0.073315) | 0.038269 / 0.037052 (0.001217) | 0.319133 / 0.258489 (0.060644) | 0.352399 / 0.293841 (0.058558) | 0.033847 / 0.128546 (-0.094700) | 0.011568 / 0.075646 (-0.064078) | 0.321355 / 0.419271 (-0.097917) | 0.040719 / 0.043533 (-0.002814) | 0.304812 / 0.255139 (0.049673) | 0.329512 / 0.283200 (0.046312) | 0.088045 / 0.141683 (-0.053638) | 1.514182 / 1.452155 (0.062027) | 1.529459 / 1.492716 (0.036742) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216749 / 0.018006 (0.198743) | 0.409909 / 0.000490 (0.409419) | 0.002790 / 0.000200 (0.002590) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023390 / 0.037411 (-0.014021) | 0.095955 / 0.014526 (0.081430) | 0.104749 / 0.176557 (-0.071807) | 0.143414 / 0.737135 (-0.593721) | 0.109011 / 0.296338 (-0.187328) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.420410 / 0.215209 (0.205201) | 4.185745 / 2.077655 (2.108090) | 1.910207 / 1.504120 (0.406087) | 1.679330 / 1.541195 (0.138135) | 1.727134 / 1.468490 (0.258644) | 0.692379 / 4.584777 (-3.892398) | 3.358731 / 3.745712 (-0.386982) | 2.914657 / 5.269862 (-2.355205) | 1.506083 / 4.565676 (-3.059594) | 0.081922 / 0.424275 (-0.342353) | 0.012691 / 0.007607 (0.005084) | 0.530942 / 0.226044 (0.304897) | 5.357642 / 2.268929 (3.088714) | 2.387347 / 55.444624 (-53.057277) | 2.030001 / 6.876477 (-4.846476) | 2.026405 / 2.142072 (-0.115667) | 0.809406 / 4.805227 (-3.995821) | 0.149003 / 6.500664 (-6.351661) | 0.066910 / 0.075469 (-0.008559) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.278160 / 1.841788 (-0.563627) | 13.632742 / 8.074308 (5.558434) | 13.995537 / 10.191392 (3.804145) | 0.136507 / 0.680424 (-0.543917) | 0.028817 / 0.534201 (-0.505384) | 0.394842 / 0.579283 (-0.184441) | 0.399526 / 0.434364 (-0.034838) | 0.459174 / 0.540337 (-0.081163) | 0.536877 / 1.386936 (-0.850059) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006814 / 0.011353 (-0.004539) | 0.004456 / 0.011008 (-0.006552) | 0.098386 / 0.038508 (0.059878) | 0.028124 / 0.023109 (0.005015) | 0.409004 / 0.275898 (0.133106) | 0.446746 / 0.323480 (0.123266) | 0.005108 / 0.007986 (-0.002877) | 0.004807 / 0.004328 (0.000479) | 0.075751 / 0.004250 (0.071500) | 0.039297 / 0.037052 (0.002244) | 0.413198 / 0.258489 (0.154709) | 0.452124 / 0.293841 (0.158283) | 0.032534 / 0.128546 (-0.096012) | 0.011689 / 0.075646 (-0.063957) | 0.325465 / 0.419271 (-0.093806) | 0.041347 / 0.043533 (-0.002185) | 0.411489 / 0.255139 (0.156350) | 0.447120 / 0.283200 (0.163920) | 0.093058 / 0.141683 (-0.048625) | 1.489903 / 1.452155 (0.037748) | 1.580771 / 1.492716 (0.088055) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.192619 / 0.018006 (0.174613) | 0.399201 / 0.000490 (0.398711) | 0.002894 / 0.000200 (0.002694) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025120 / 0.037411 (-0.012292) | 0.100126 / 0.014526 (0.085600) | 0.108669 / 0.176557 (-0.067887) | 0.148687 / 0.737135 (-0.588448) | 0.112286 / 0.296338 (-0.184052) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.438866 / 0.215209 (0.223657) | 4.382418 / 2.077655 (2.304764) | 2.106450 / 1.504120 (0.602330) | 1.885105 / 1.541195 (0.343910) | 1.922948 / 1.468490 (0.454458) | 0.693145 / 4.584777 (-3.891632) | 3.378206 / 3.745712 (-0.367506) | 1.867295 / 5.269862 (-3.402566) | 1.164999 / 4.565676 (-3.400678) | 0.081918 / 0.424275 (-0.342357) | 0.012225 / 0.007607 (0.004618) | 0.547114 / 0.226044 (0.321069) | 5.454208 / 2.268929 (3.185279) | 2.532112 / 55.444624 (-52.912512) | 2.192573 / 6.876477 (-4.683904) | 2.225364 / 2.142072 (0.083291) | 0.797165 / 4.805227 (-4.008062) | 0.151185 / 6.500664 (-6.349480) | 0.067512 / 0.075469 (-0.007957) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303905 / 1.841788 (-0.537883) | 14.107678 / 8.074308 (6.033370) | 14.147630 / 10.191392 (3.956238) | 0.156597 / 0.680424 (-0.523827) | 0.017037 / 0.534201 (-0.517164) | 0.383202 / 0.579283 (-0.196081) | 0.385340 / 0.434364 (-0.049024) | 0.443338 / 0.540337 (-0.097000) | 0.542345 / 1.386936 (-0.844591) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009982 / 0.011353 (-0.001371) | 0.005327 / 0.011008 (-0.005681) | 0.099092 / 0.038508 (0.060584) | 0.035824 / 0.023109 (0.012715) | 0.303258 / 0.275898 (0.027360) | 0.335379 / 0.323480 (0.011899) | 0.008192 / 0.007986 (0.000207) | 0.004242 / 0.004328 (-0.000087) | 0.076277 / 0.004250 (0.072026) | 0.043851 / 0.037052 (0.006799) | 0.307750 / 0.258489 (0.049261) | 0.348459 / 0.293841 (0.054618) | 0.038943 / 0.128546 (-0.089604) | 0.012128 / 0.075646 (-0.063519) | 0.334143 / 0.419271 (-0.085128) | 0.047865 / 0.043533 (0.004332) | 0.300909 / 0.255139 (0.045770) | 0.320879 / 0.283200 (0.037680) | 0.103812 / 0.141683 (-0.037871) | 1.468646 / 1.452155 (0.016491) | 1.557660 / 1.492716 (0.064944) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244108 / 0.018006 (0.226102) | 0.554895 / 0.000490 (0.554405) | 0.005311 / 0.000200 (0.005111) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028771 / 0.037411 (-0.008640) | 0.108133 / 0.014526 (0.093608) | 0.120098 / 0.176557 (-0.056458) | 0.159815 / 0.737135 (-0.577320) | 0.125437 / 0.296338 (-0.170901) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397675 / 0.215209 (0.182466) | 3.975839 / 2.077655 (1.898184) | 1.797803 / 1.504120 (0.293683) | 1.612517 / 1.541195 (0.071322) | 1.659086 / 1.468490 (0.190596) | 0.679822 / 4.584777 (-3.904955) | 3.688321 / 3.745712 (-0.057391) | 2.155285 / 5.269862 (-3.114576) | 1.466453 / 4.565676 (-3.099223) | 0.084102 / 0.424275 (-0.340173) | 0.012074 / 0.007607 (0.004467) | 0.503744 / 0.226044 (0.277699) | 5.075599 / 2.268929 (2.806670) | 2.312149 / 55.444624 (-53.132476) | 1.975028 / 6.876477 (-4.901449) | 2.069554 / 2.142072 (-0.072519) | 0.828329 / 4.805227 (-3.976898) | 0.162816 / 6.500664 (-6.337849) | 0.063813 / 0.075469 (-0.011656) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.173327 / 1.841788 (-0.668461) | 15.281584 / 8.074308 (7.207276) | 14.450851 / 10.191392 (4.259459) | 0.165621 / 0.680424 (-0.514802) | 0.028779 / 0.534201 (-0.505422) | 0.438483 / 0.579283 (-0.140800) | 0.438477 / 0.434364 (0.004113) | 0.517703 / 0.540337 (-0.022634) | 0.615119 / 1.386936 (-0.771817) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007013 / 0.011353 (-0.004340) | 0.005272 / 0.011008 (-0.005736) | 0.097203 / 0.038508 (0.058695) | 0.033103 / 0.023109 (0.009994) | 0.380203 / 0.275898 (0.104305) | 0.414868 / 0.323480 (0.091388) | 0.006326 / 0.007986 (-0.001659) | 0.005433 / 0.004328 (0.001104) | 0.074299 / 0.004250 (0.070049) | 0.049418 / 0.037052 (0.012366) | 0.388771 / 0.258489 (0.130282) | 0.435169 / 0.293841 (0.141328) | 0.036170 / 0.128546 (-0.092377) | 0.012452 / 0.075646 (-0.063195) | 0.331215 / 0.419271 (-0.088056) | 0.048577 / 0.043533 (0.005044) | 0.381491 / 0.255139 (0.126352) | 0.396731 / 0.283200 (0.113531) | 0.106435 / 0.141683 (-0.035248) | 1.446437 / 1.452155 (-0.005718) | 1.542337 / 1.492716 (0.049621) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216714 / 0.018006 (0.198707) | 0.562460 / 0.000490 (0.561970) | 0.003636 / 0.000200 (0.003436) | 0.000100 / 0.000054 (0.000045) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028726 / 0.037411 (-0.008686) | 0.111993 / 0.014526 (0.097467) | 0.125325 / 0.176557 (-0.051232) | 0.157779 / 0.737135 (-0.579356) | 0.130633 / 0.296338 (-0.165705) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440520 / 0.215209 (0.225311) | 4.396283 / 2.077655 (2.318628) | 2.204714 / 1.504120 (0.700594) | 2.011667 / 1.541195 (0.470473) | 2.050518 / 1.468490 (0.582028) | 0.695204 / 4.584777 (-3.889573) | 3.779699 / 3.745712 (0.033987) | 2.096064 / 5.269862 (-3.173798) | 1.325446 / 4.565676 (-3.240230) | 0.085315 / 0.424275 (-0.338960) | 0.012178 / 0.007607 (0.004570) | 0.550478 / 0.226044 (0.324434) | 5.471872 / 2.268929 (3.202943) | 2.687147 / 55.444624 (-52.757478) | 2.348465 / 6.876477 (-4.528011) | 2.409700 / 2.142072 (0.267628) | 0.839468 / 4.805227 (-3.965760) | 0.167030 / 6.500664 (-6.333635) | 0.063243 / 0.075469 (-0.012226) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.257347 / 1.841788 (-0.584441) | 15.157821 / 8.074308 (7.083512) | 14.646381 / 10.191392 (4.454989) | 0.185550 / 0.680424 (-0.494874) | 0.018441 / 0.534201 (-0.515760) | 0.423330 / 0.579283 (-0.155954) | 0.426204 / 0.434364 (-0.008160) | 0.498985 / 0.540337 (-0.041352) | 0.608432 / 1.386936 (-0.778504) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010856 / 0.011353 (-0.000497) | 0.005897 / 0.011008 (-0.005111) | 0.117826 / 0.038508 (0.079317) | 0.041899 / 0.023109 (0.018790) | 0.353804 / 0.275898 (0.077906) | 0.431021 / 0.323480 (0.107541) | 0.009288 / 0.007986 (0.001303) | 0.004556 / 0.004328 (0.000227) | 0.089344 / 0.004250 (0.085094) | 0.052224 / 0.037052 (0.015172) | 0.373242 / 0.258489 (0.114753) | 0.420667 / 0.293841 (0.126826) | 0.044191 / 0.128546 (-0.084355) | 0.014083 / 0.075646 (-0.061564) | 0.400373 / 0.419271 (-0.018898) | 0.056119 / 0.043533 (0.012586) | 0.363302 / 0.255139 (0.108163) | 0.382073 / 0.283200 (0.098873) | 0.118646 / 0.141683 (-0.023037) | 1.696576 / 1.452155 (0.244422) | 1.756518 / 1.492716 (0.263802) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216388 / 0.018006 (0.198382) | 0.485732 / 0.000490 (0.485242) | 0.004012 / 0.000200 (0.003812) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032095 / 0.037411 (-0.005316) | 0.128954 / 0.014526 (0.114429) | 0.137564 / 0.176557 (-0.038993) | 0.184315 / 0.737135 (-0.552820) | 0.144707 / 0.296338 (-0.151631) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472792 / 0.215209 (0.257583) | 4.723044 / 2.077655 (2.645390) | 2.115075 / 1.504120 (0.610955) | 1.898993 / 1.541195 (0.357798) | 1.972894 / 1.468490 (0.504404) | 0.807210 / 4.584777 (-3.777567) | 4.493139 / 3.745712 (0.747427) | 2.501053 / 5.269862 (-2.768808) | 1.686121 / 4.565676 (-2.879556) | 0.099545 / 0.424275 (-0.324730) | 0.014360 / 0.007607 (0.006753) | 0.596235 / 0.226044 (0.370191) | 5.944285 / 2.268929 (3.675357) | 2.654944 / 55.444624 (-52.789681) | 2.281451 / 6.876477 (-4.595026) | 2.448407 / 2.142072 (0.306334) | 1.000512 / 4.805227 (-3.804716) | 0.196413 / 6.500664 (-6.304251) | 0.075810 / 0.075469 (0.000341) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.435707 / 1.841788 (-0.406081) | 17.931070 / 8.074308 (9.856762) | 16.635522 / 10.191392 (6.444130) | 0.189119 / 0.680424 (-0.491304) | 0.034392 / 0.534201 (-0.499809) | 0.519041 / 0.579283 (-0.060242) | 0.516159 / 0.434364 (0.081795) | 0.601180 / 0.540337 (0.060843) | 0.713180 / 1.386936 (-0.673756) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008741 / 0.011353 (-0.002612) | 0.006102 / 0.011008 (-0.004906) | 0.114787 / 0.038508 (0.076279) | 0.039610 / 0.023109 (0.016501) | 0.451730 / 0.275898 (0.175832) | 0.488820 / 0.323480 (0.165340) | 0.006979 / 0.007986 (-0.001006) | 0.006458 / 0.004328 (0.002130) | 0.086505 / 0.004250 (0.082254) | 0.057684 / 0.037052 (0.020632) | 0.451354 / 0.258489 (0.192865) | 0.523143 / 0.293841 (0.229302) | 0.043224 / 0.128546 (-0.085323) | 0.014671 / 0.075646 (-0.060975) | 0.398030 / 0.419271 (-0.021241) | 0.063650 / 0.043533 (0.020117) | 0.448324 / 0.255139 (0.193185) | 0.476560 / 0.283200 (0.193361) | 0.125772 / 0.141683 (-0.015911) | 1.801051 / 1.452155 (0.348896) | 1.872736 / 1.492716 (0.380020) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256146 / 0.018006 (0.238139) | 0.486915 / 0.000490 (0.486425) | 0.000513 / 0.000200 (0.000313) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035242 / 0.037411 (-0.002170) | 0.134322 / 0.014526 (0.119797) | 0.144786 / 0.176557 (-0.031770) | 0.188786 / 0.737135 (-0.548349) | 0.151737 / 0.296338 (-0.144602) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.506047 / 0.215209 (0.290838) | 5.028253 / 2.077655 (2.950598) | 2.393070 / 1.504120 (0.888950) | 2.157847 / 1.541195 (0.616652) | 2.229412 / 1.468490 (0.760922) | 0.828973 / 4.584777 (-3.755804) | 4.741470 / 3.745712 (0.995758) | 4.048118 / 5.269862 (-1.221744) | 2.573818 / 4.565676 (-1.991859) | 0.101019 / 0.424275 (-0.323256) | 0.014640 / 0.007607 (0.007033) | 0.632591 / 0.226044 (0.406546) | 6.289153 / 2.268929 (4.020224) | 2.977261 / 55.444624 (-52.467363) | 2.554396 / 6.876477 (-4.322081) | 2.619446 / 2.142072 (0.477374) | 0.988376 / 4.805227 (-3.816851) | 0.196895 / 6.500664 (-6.303769) | 0.076355 / 0.075469 (0.000886) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.493570 / 1.841788 (-0.348218) | 18.422758 / 8.074308 (10.348449) | 17.007352 / 10.191392 (6.815960) | 0.191903 / 0.680424 (-0.488521) | 0.020974 / 0.534201 (-0.513227) | 0.500573 / 0.579283 (-0.078710) | 0.489381 / 0.434364 (0.055017) | 0.580765 / 0.540337 (0.040428) | 0.698907 / 1.386936 (-0.688029) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008979 / 0.011353 (-0.002374) | 0.004497 / 0.011008 (-0.006511) | 0.102227 / 0.038508 (0.063719) | 0.031302 / 0.023109 (0.008193) | 0.298488 / 0.275898 (0.022590) | 0.372589 / 0.323480 (0.049109) | 0.007261 / 0.007986 (-0.000725) | 0.003542 / 0.004328 (-0.000786) | 0.078503 / 0.004250 (0.074253) | 0.039474 / 0.037052 (0.002422) | 0.310991 / 0.258489 (0.052502) | 0.353245 / 0.293841 (0.059404) | 0.033798 / 0.128546 (-0.094749) | 0.011634 / 0.075646 (-0.064012) | 0.321141 / 0.419271 (-0.098131) | 0.041264 / 0.043533 (-0.002268) | 0.300900 / 0.255139 (0.045761) | 0.326255 / 0.283200 (0.043055) | 0.092477 / 0.141683 (-0.049205) | 1.478921 / 1.452155 (0.026766) | 1.514915 / 1.492716 (0.022198) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.184415 / 0.018006 (0.166408) | 0.428986 / 0.000490 (0.428497) | 0.002590 / 0.000200 (0.002390) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023730 / 0.037411 (-0.013681) | 0.099846 / 0.014526 (0.085320) | 0.107075 / 0.176557 (-0.069482) | 0.147475 / 0.737135 (-0.589661) | 0.111802 / 0.296338 (-0.184537) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413704 / 0.215209 (0.198494) | 4.144498 / 2.077655 (2.066843) | 1.855900 / 1.504120 (0.351780) | 1.647958 / 1.541195 (0.106763) | 1.712437 / 1.468490 (0.243947) | 0.688382 / 4.584777 (-3.896395) | 3.432136 / 3.745712 (-0.313576) | 2.837211 / 5.269862 (-2.432651) | 1.519004 / 4.565676 (-3.046672) | 0.082429 / 0.424275 (-0.341846) | 0.012610 / 0.007607 (0.005003) | 0.525078 / 0.226044 (0.299034) | 5.272932 / 2.268929 (3.004003) | 2.340482 / 55.444624 (-53.104143) | 2.007372 / 6.876477 (-4.869104) | 2.060567 / 2.142072 (-0.081506) | 0.806476 / 4.805227 (-3.998752) | 0.149421 / 6.500664 (-6.351243) | 0.066252 / 0.075469 (-0.009218) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235078 / 1.841788 (-0.606710) | 13.870758 / 8.074308 (5.796450) | 14.104582 / 10.191392 (3.913190) | 0.159375 / 0.680424 (-0.521049) | 0.029233 / 0.534201 (-0.504968) | 0.392184 / 0.579283 (-0.187099) | 0.407909 / 0.434364 (-0.026455) | 0.458757 / 0.540337 (-0.081581) | 0.547681 / 1.386936 (-0.839255) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007194 / 0.011353 (-0.004159) | 0.004578 / 0.011008 (-0.006431) | 0.098936 / 0.038508 (0.060428) | 0.029639 / 0.023109 (0.006530) | 0.347241 / 0.275898 (0.071343) | 0.378838 / 0.323480 (0.055358) | 0.005632 / 0.007986 (-0.002353) | 0.003469 / 0.004328 (-0.000860) | 0.075536 / 0.004250 (0.071285) | 0.043301 / 0.037052 (0.006249) | 0.348091 / 0.258489 (0.089602) | 0.388595 / 0.293841 (0.094754) | 0.033512 / 0.128546 (-0.095034) | 0.011754 / 0.075646 (-0.063892) | 0.321003 / 0.419271 (-0.098268) | 0.044634 / 0.043533 (0.001101) | 0.346688 / 0.255139 (0.091549) | 0.366346 / 0.283200 (0.083147) | 0.093650 / 0.141683 (-0.048033) | 1.509913 / 1.452155 (0.057759) | 1.596414 / 1.492716 (0.103698) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230466 / 0.018006 (0.212459) | 0.417106 / 0.000490 (0.416617) | 0.000959 / 0.000200 (0.000759) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025581 / 0.037411 (-0.011830) | 0.105246 / 0.014526 (0.090720) | 0.108997 / 0.176557 (-0.067560) | 0.144342 / 0.737135 (-0.592794) | 0.113911 / 0.296338 (-0.182427) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.479608 / 0.215209 (0.264399) | 4.766081 / 2.077655 (2.688426) | 2.446597 / 1.504120 (0.942477) | 2.228278 / 1.541195 (0.687083) | 2.289943 / 1.468490 (0.821453) | 0.703146 / 4.584777 (-3.881631) | 3.414150 / 3.745712 (-0.331562) | 2.957730 / 5.269862 (-2.312132) | 1.531524 / 4.565676 (-3.034152) | 0.083449 / 0.424275 (-0.340826) | 0.012684 / 0.007607 (0.005077) | 0.587622 / 0.226044 (0.361578) | 5.888791 / 2.268929 (3.619863) | 2.884200 / 55.444624 (-52.560424) | 2.543739 / 6.876477 (-4.332737) | 2.596245 / 2.142072 (0.454173) | 0.813070 / 4.805227 (-3.992157) | 0.152706 / 6.500664 (-6.347958) | 0.069257 / 0.075469 (-0.006212) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.302945 / 1.841788 (-0.538842) | 14.484051 / 8.074308 (6.409743) | 14.216143 / 10.191392 (4.024751) | 0.154537 / 0.680424 (-0.525886) | 0.016909 / 0.534201 (-0.517292) | 0.389433 / 0.579283 (-0.189850) | 0.393280 / 0.434364 (-0.041084) | 0.446884 / 0.540337 (-0.093453) | 0.534394 / 1.386936 (-0.852542) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008822 / 0.011353 (-0.002530) | 0.004826 / 0.011008 (-0.006182) | 0.102710 / 0.038508 (0.064202) | 0.030353 / 0.023109 (0.007244) | 0.297224 / 0.275898 (0.021326) | 0.371861 / 0.323480 (0.048381) | 0.007266 / 0.007986 (-0.000720) | 0.003632 / 0.004328 (-0.000696) | 0.079960 / 0.004250 (0.075710) | 0.036908 / 0.037052 (-0.000144) | 0.309582 / 0.258489 (0.051093) | 0.350108 / 0.293841 (0.056267) | 0.034280 / 0.128546 (-0.094266) | 0.011739 / 0.075646 (-0.063907) | 0.323217 / 0.419271 (-0.096054) | 0.043491 / 0.043533 (-0.000042) | 0.298454 / 0.255139 (0.043315) | 0.326735 / 0.283200 (0.043535) | 0.093955 / 0.141683 (-0.047728) | 1.494313 / 1.452155 (0.042159) | 1.562104 / 1.492716 (0.069388) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.182796 / 0.018006 (0.164790) | 0.420133 / 0.000490 (0.419643) | 0.002537 / 0.000200 (0.002337) | 0.000070 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023143 / 0.037411 (-0.014269) | 0.098560 / 0.014526 (0.084034) | 0.105060 / 0.176557 (-0.071496) | 0.140269 / 0.737135 (-0.596866) | 0.109120 / 0.296338 (-0.187219) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419907 / 0.215209 (0.204698) | 4.196179 / 2.077655 (2.118524) | 1.887663 / 1.504120 (0.383543) | 1.686232 / 1.541195 (0.145037) | 1.741741 / 1.468490 (0.273251) | 0.696222 / 4.584777 (-3.888555) | 3.400250 / 3.745712 (-0.345462) | 1.875058 / 5.269862 (-3.394803) | 1.159466 / 4.565676 (-3.406211) | 0.082520 / 0.424275 (-0.341755) | 0.012408 / 0.007607 (0.004801) | 0.525212 / 0.226044 (0.299168) | 5.283691 / 2.268929 (3.014762) | 2.314487 / 55.444624 (-53.130138) | 1.966212 / 6.876477 (-4.910265) | 2.023458 / 2.142072 (-0.118615) | 0.808896 / 4.805227 (-3.996331) | 0.148973 / 6.500664 (-6.351691) | 0.065378 / 0.075469 (-0.010091) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.223833 / 1.841788 (-0.617955) | 14.053651 / 8.074308 (5.979343) | 14.072165 / 10.191392 (3.880773) | 0.156006 / 0.680424 (-0.524418) | 0.028665 / 0.534201 (-0.505536) | 0.392099 / 0.579283 (-0.187184) | 0.401460 / 0.434364 (-0.032904) | 0.462184 / 0.540337 (-0.078153) | 0.540459 / 1.386936 (-0.846477) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006907 / 0.011353 (-0.004446) | 0.004585 / 0.011008 (-0.006423) | 0.099027 / 0.038508 (0.060519) | 0.028317 / 0.023109 (0.005208) | 0.421068 / 0.275898 (0.145170) | 0.450712 / 0.323480 (0.127233) | 0.005229 / 0.007986 (-0.002756) | 0.004873 / 0.004328 (0.000545) | 0.077374 / 0.004250 (0.073124) | 0.042530 / 0.037052 (0.005477) | 0.417392 / 0.258489 (0.158903) | 0.462605 / 0.293841 (0.168764) | 0.032195 / 0.128546 (-0.096351) | 0.011777 / 0.075646 (-0.063870) | 0.321927 / 0.419271 (-0.097344) | 0.041999 / 0.043533 (-0.001533) | 0.419402 / 0.255139 (0.164263) | 0.437179 / 0.283200 (0.153979) | 0.089549 / 0.141683 (-0.052134) | 1.469525 / 1.452155 (0.017370) | 1.586407 / 1.492716 (0.093691) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209533 / 0.018006 (0.191526) | 0.413886 / 0.000490 (0.413396) | 0.003357 / 0.000200 (0.003157) | 0.000121 / 0.000054 (0.000067) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026133 / 0.037411 (-0.011278) | 0.103128 / 0.014526 (0.088602) | 0.110604 / 0.176557 (-0.065952) | 0.153055 / 0.737135 (-0.584080) | 0.112257 / 0.296338 (-0.184081) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471281 / 0.215209 (0.256072) | 4.708361 / 2.077655 (2.630706) | 2.572681 / 1.504120 (1.068561) | 2.370536 / 1.541195 (0.829341) | 2.456010 / 1.468490 (0.987520) | 0.694173 / 4.584777 (-3.890603) | 3.434511 / 3.745712 (-0.311201) | 1.877169 / 5.269862 (-3.392693) | 1.158387 / 4.565676 (-3.407289) | 0.081849 / 0.424275 (-0.342426) | 0.012176 / 0.007607 (0.004569) | 0.581736 / 0.226044 (0.355692) | 5.803173 / 2.268929 (3.534245) | 3.040003 / 55.444624 (-52.404621) | 2.704698 / 6.876477 (-4.171779) | 2.760138 / 2.142072 (0.618065) | 0.802557 / 4.805227 (-4.002671) | 0.151397 / 6.500664 (-6.349268) | 0.068308 / 0.075469 (-0.007161) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.304062 / 1.841788 (-0.537725) | 14.364809 / 8.074308 (6.290501) | 14.192131 / 10.191392 (4.000739) | 0.150025 / 0.680424 (-0.530399) | 0.017020 / 0.534201 (-0.517181) | 0.389235 / 0.579283 (-0.190048) | 0.387557 / 0.434364 (-0.046807) | 0.454636 / 0.540337 (-0.085702) | 0.558182 / 1.386936 (-0.828754) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008519 / 0.011353 (-0.002834) | 0.004538 / 0.011008 (-0.006470) | 0.102066 / 0.038508 (0.063558) | 0.029700 / 0.023109 (0.006591) | 0.304573 / 0.275898 (0.028675) | 0.366232 / 0.323480 (0.042752) | 0.007154 / 0.007986 (-0.000832) | 0.003497 / 0.004328 (-0.000831) | 0.079119 / 0.004250 (0.074868) | 0.036088 / 0.037052 (-0.000964) | 0.311076 / 0.258489 (0.052587) | 0.352205 / 0.293841 (0.058364) | 0.033706 / 0.128546 (-0.094840) | 0.011657 / 0.075646 (-0.063990) | 0.324024 / 0.419271 (-0.095247) | 0.040777 / 0.043533 (-0.002756) | 0.302661 / 0.255139 (0.047522) | 0.329091 / 0.283200 (0.045891) | 0.086774 / 0.141683 (-0.054909) | 1.485874 / 1.452155 (0.033720) | 1.535726 / 1.492716 (0.043009) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.194284 / 0.018006 (0.176277) | 0.412875 / 0.000490 (0.412385) | 0.003348 / 0.000200 (0.003148) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022432 / 0.037411 (-0.014979) | 0.095008 / 0.014526 (0.080482) | 0.103268 / 0.176557 (-0.073288) | 0.140121 / 0.737135 (-0.597014) | 0.106619 / 0.296338 (-0.189719) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414786 / 0.215209 (0.199577) | 4.146345 / 2.077655 (2.068690) | 1.873703 / 1.504120 (0.369583) | 1.673498 / 1.541195 (0.132303) | 1.716993 / 1.468490 (0.248502) | 0.692098 / 4.584777 (-3.892679) | 3.380991 / 3.745712 (-0.364721) | 1.846811 / 5.269862 (-3.423050) | 1.159617 / 4.565676 (-3.406059) | 0.081867 / 0.424275 (-0.342408) | 0.012371 / 0.007607 (0.004764) | 0.526228 / 0.226044 (0.300184) | 5.273139 / 2.268929 (3.004211) | 2.327147 / 55.444624 (-53.117477) | 1.968366 / 6.876477 (-4.908111) | 2.018053 / 2.142072 (-0.124019) | 0.816098 / 4.805227 (-3.989130) | 0.149438 / 6.500664 (-6.351226) | 0.065000 / 0.075469 (-0.010469) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244408 / 1.841788 (-0.597380) | 13.774354 / 8.074308 (5.700046) | 14.178923 / 10.191392 (3.987531) | 0.150032 / 0.680424 (-0.530392) | 0.029736 / 0.534201 (-0.504465) | 0.399134 / 0.579283 (-0.180149) | 0.404214 / 0.434364 (-0.030150) | 0.462096 / 0.540337 (-0.078242) | 0.542256 / 1.386936 (-0.844680) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006776 / 0.011353 (-0.004577) | 0.004586 / 0.011008 (-0.006422) | 0.097658 / 0.038508 (0.059150) | 0.027627 / 0.023109 (0.004517) | 0.423794 / 0.275898 (0.147896) | 0.447443 / 0.323480 (0.123963) | 0.005099 / 0.007986 (-0.002886) | 0.004846 / 0.004328 (0.000517) | 0.075135 / 0.004250 (0.070884) | 0.038068 / 0.037052 (0.001016) | 0.420999 / 0.258489 (0.162510) | 0.460368 / 0.293841 (0.166527) | 0.032107 / 0.128546 (-0.096439) | 0.011775 / 0.075646 (-0.063871) | 0.323854 / 0.419271 (-0.095418) | 0.045538 / 0.043533 (0.002005) | 0.420949 / 0.255139 (0.165810) | 0.441906 / 0.283200 (0.158706) | 0.091955 / 0.141683 (-0.049728) | 1.523736 / 1.452155 (0.071581) | 1.587865 / 1.492716 (0.095148) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.263297 / 0.018006 (0.245290) | 0.416170 / 0.000490 (0.415680) | 0.023161 / 0.000200 (0.022961) | 0.000243 / 0.000054 (0.000188) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024000 / 0.037411 (-0.013412) | 0.097787 / 0.014526 (0.083262) | 0.106884 / 0.176557 (-0.069672) | 0.140861 / 0.737135 (-0.596274) | 0.108228 / 0.296338 (-0.188111) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.477222 / 0.215209 (0.262013) | 4.774729 / 2.077655 (2.697074) | 2.451575 / 1.504120 (0.947455) | 2.251255 / 1.541195 (0.710060) | 2.281154 / 1.468490 (0.812664) | 0.699394 / 4.584777 (-3.885383) | 3.421575 / 3.745712 (-0.324137) | 2.704713 / 5.269862 (-2.565148) | 1.508464 / 4.565676 (-3.057212) | 0.082199 / 0.424275 (-0.342076) | 0.012586 / 0.007607 (0.004979) | 0.588783 / 0.226044 (0.362739) | 5.878434 / 2.268929 (3.609505) | 2.927422 / 55.444624 (-52.517202) | 2.574357 / 6.876477 (-4.302120) | 2.603626 / 2.142072 (0.461554) | 0.804706 / 4.805227 (-4.000521) | 0.152919 / 6.500664 (-6.347745) | 0.069316 / 0.075469 (-0.006153) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.280025 / 1.841788 (-0.561763) | 13.968407 / 8.074308 (5.894099) | 13.874506 / 10.191392 (3.683114) | 0.154711 / 0.680424 (-0.525713) | 0.016827 / 0.534201 (-0.517374) | 0.377775 / 0.579283 (-0.201508) | 0.393035 / 0.434364 (-0.041329) | 0.439405 / 0.540337 (-0.100932) | 0.528135 / 1.386936 (-0.858801) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009035 / 0.011353 (-0.002318) | 0.004518 / 0.011008 (-0.006490) | 0.102077 / 0.038508 (0.063569) | 0.030169 / 0.023109 (0.007060) | 0.297713 / 0.275898 (0.021815) | 0.364976 / 0.323480 (0.041496) | 0.007079 / 0.007986 (-0.000906) | 0.003438 / 0.004328 (-0.000890) | 0.079667 / 0.004250 (0.075416) | 0.035890 / 0.037052 (-0.001162) | 0.306065 / 0.258489 (0.047576) | 0.352133 / 0.293841 (0.058292) | 0.033800 / 0.128546 (-0.094746) | 0.011613 / 0.075646 (-0.064034) | 0.322917 / 0.419271 (-0.096354) | 0.040973 / 0.043533 (-0.002560) | 0.300896 / 0.255139 (0.045757) | 0.331540 / 0.283200 (0.048341) | 0.089579 / 0.141683 (-0.052103) | 1.466755 / 1.452155 (0.014600) | 1.522120 / 1.492716 (0.029404) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193172 / 0.018006 (0.175166) | 0.408878 / 0.000490 (0.408389) | 0.001586 / 0.000200 (0.001386) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023496 / 0.037411 (-0.013915) | 0.098046 / 0.014526 (0.083520) | 0.104599 / 0.176557 (-0.071957) | 0.139054 / 0.737135 (-0.598081) | 0.111163 / 0.296338 (-0.185175) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417374 / 0.215209 (0.202165) | 4.145808 / 2.077655 (2.068153) | 1.847101 / 1.504120 (0.342981) | 1.637207 / 1.541195 (0.096012) | 1.676906 / 1.468490 (0.208416) | 0.689851 / 4.584777 (-3.894926) | 3.402099 / 3.745712 (-0.343614) | 1.896808 / 5.269862 (-3.373054) | 1.257876 / 4.565676 (-3.307801) | 0.081744 / 0.424275 (-0.342531) | 0.012206 / 0.007607 (0.004599) | 0.524830 / 0.226044 (0.298786) | 5.251344 / 2.268929 (2.982416) | 2.277907 / 55.444624 (-53.166717) | 1.933985 / 6.876477 (-4.942491) | 2.038500 / 2.142072 (-0.103573) | 0.808696 / 4.805227 (-3.996532) | 0.149488 / 6.500664 (-6.351176) | 0.065323 / 0.075469 (-0.010146) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.204294 / 1.841788 (-0.637493) | 13.696526 / 8.074308 (5.622218) | 13.947195 / 10.191392 (3.755802) | 0.136812 / 0.680424 (-0.543611) | 0.028625 / 0.534201 (-0.505576) | 0.397662 / 0.579283 (-0.181621) | 0.403423 / 0.434364 (-0.030941) | 0.465288 / 0.540337 (-0.075049) | 0.551919 / 1.386936 (-0.835017) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006467 / 0.011353 (-0.004886) | 0.004562 / 0.011008 (-0.006447) | 0.097514 / 0.038508 (0.059006) | 0.027471 / 0.023109 (0.004362) | 0.425504 / 0.275898 (0.149606) | 0.458856 / 0.323480 (0.135376) | 0.004816 / 0.007986 (-0.003169) | 0.003264 / 0.004328 (-0.001065) | 0.074947 / 0.004250 (0.070697) | 0.037147 / 0.037052 (0.000095) | 0.429513 / 0.258489 (0.171024) | 0.463971 / 0.293841 (0.170130) | 0.031638 / 0.128546 (-0.096908) | 0.011545 / 0.075646 (-0.064101) | 0.320261 / 0.419271 (-0.099010) | 0.041570 / 0.043533 (-0.001963) | 0.424809 / 0.255139 (0.169670) | 0.447158 / 0.283200 (0.163959) | 0.088418 / 0.141683 (-0.053265) | 1.492242 / 1.452155 (0.040087) | 1.545523 / 1.492716 (0.052807) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.217865 / 0.018006 (0.199859) | 0.399925 / 0.000490 (0.399436) | 0.004853 / 0.000200 (0.004653) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024275 / 0.037411 (-0.013137) | 0.098249 / 0.014526 (0.083723) | 0.107110 / 0.176557 (-0.069446) | 0.143870 / 0.737135 (-0.593265) | 0.108796 / 0.296338 (-0.187542) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.470856 / 0.215209 (0.255647) | 4.687921 / 2.077655 (2.610266) | 2.448631 / 1.504120 (0.944511) | 2.247748 / 1.541195 (0.706553) | 2.287713 / 1.468490 (0.819223) | 0.687534 / 4.584777 (-3.897243) | 3.421099 / 3.745712 (-0.324613) | 2.977280 / 5.269862 (-2.292582) | 1.274837 / 4.565676 (-3.290839) | 0.081611 / 0.424275 (-0.342664) | 0.012603 / 0.007607 (0.004996) | 0.574600 / 0.226044 (0.348556) | 5.802826 / 2.268929 (3.533898) | 2.913178 / 55.444624 (-52.531446) | 2.589486 / 6.876477 (-4.286991) | 2.630004 / 2.142072 (0.487932) | 0.790087 / 4.805227 (-4.015140) | 0.150019 / 6.500664 (-6.350645) | 0.067346 / 0.075469 (-0.008123) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266521 / 1.841788 (-0.575267) | 13.818770 / 8.074308 (5.744462) | 13.872277 / 10.191392 (3.680885) | 0.147375 / 0.680424 (-0.533049) | 0.016837 / 0.534201 (-0.517363) | 0.376421 / 0.579283 (-0.202862) | 0.400236 / 0.434364 (-0.034128) | 0.436623 / 0.540337 (-0.103714) | 0.527173 / 1.386936 (-0.859763) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009341 / 0.011353 (-0.002012) | 0.005188 / 0.011008 (-0.005820) | 0.101831 / 0.038508 (0.063323) | 0.035141 / 0.023109 (0.012032) | 0.299324 / 0.275898 (0.023426) | 0.334749 / 0.323480 (0.011269) | 0.007958 / 0.007986 (-0.000027) | 0.005482 / 0.004328 (0.001153) | 0.077070 / 0.004250 (0.072820) | 0.044733 / 0.037052 (0.007680) | 0.310398 / 0.258489 (0.051909) | 0.347925 / 0.293841 (0.054084) | 0.038141 / 0.128546 (-0.090405) | 0.012135 / 0.075646 (-0.063512) | 0.333799 / 0.419271 (-0.085472) | 0.048881 / 0.043533 (0.005348) | 0.301336 / 0.255139 (0.046197) | 0.314592 / 0.283200 (0.031393) | 0.103635 / 0.141683 (-0.038048) | 1.437321 / 1.452155 (-0.014833) | 1.598781 / 1.492716 (0.106065) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.248911 / 0.018006 (0.230905) | 0.528932 / 0.000490 (0.528442) | 0.002495 / 0.000200 (0.002295) | 0.000094 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027903 / 0.037411 (-0.009509) | 0.106716 / 0.014526 (0.092190) | 0.122650 / 0.176557 (-0.053907) | 0.162481 / 0.737135 (-0.574654) | 0.126402 / 0.296338 (-0.169937) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.352819 / 0.215209 (0.137610) | 3.522761 / 2.077655 (1.445106) | 1.576761 / 1.504120 (0.072641) | 1.411631 / 1.541195 (-0.129563) | 1.449689 / 1.468490 (-0.018801) | 0.608987 / 4.584777 (-3.975790) | 3.705121 / 3.745712 (-0.040592) | 2.085071 / 5.269862 (-3.184790) | 1.308653 / 4.565676 (-3.257024) | 0.083763 / 0.424275 (-0.340512) | 0.011957 / 0.007607 (0.004350) | 0.502182 / 0.226044 (0.276137) | 5.008829 / 2.268929 (2.739900) | 2.244687 / 55.444624 (-53.199937) | 1.891411 / 6.876477 (-4.985065) | 1.940789 / 2.142072 (-0.201284) | 0.825966 / 4.805227 (-3.979261) | 0.165267 / 6.500664 (-6.335397) | 0.063020 / 0.075469 (-0.012449) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.196707 / 1.841788 (-0.645081) | 14.236877 / 8.074308 (6.162569) | 14.872954 / 10.191392 (4.681562) | 0.168560 / 0.680424 (-0.511864) | 0.029038 / 0.534201 (-0.505163) | 0.440192 / 0.579283 (-0.139091) | 0.437021 / 0.434364 (0.002657) | 0.519612 / 0.540337 (-0.020725) | 0.612013 / 1.386936 (-0.774923) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007170 / 0.011353 (-0.004183) | 0.005303 / 0.011008 (-0.005705) | 0.098503 / 0.038508 (0.059995) | 0.032573 / 0.023109 (0.009463) | 0.398203 / 0.275898 (0.122305) | 0.446075 / 0.323480 (0.122595) | 0.005712 / 0.007986 (-0.002274) | 0.004165 / 0.004328 (-0.000164) | 0.074273 / 0.004250 (0.070023) | 0.049587 / 0.037052 (0.012534) | 0.399458 / 0.258489 (0.140969) | 0.459167 / 0.293841 (0.165327) | 0.036063 / 0.128546 (-0.092483) | 0.012394 / 0.075646 (-0.063253) | 0.332559 / 0.419271 (-0.086713) | 0.048499 / 0.043533 (0.004967) | 0.404044 / 0.255139 (0.148905) | 0.410462 / 0.283200 (0.127262) | 0.104104 / 0.141683 (-0.037579) | 1.488141 / 1.452155 (0.035986) | 1.535517 / 1.492716 (0.042801) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.292976 / 0.018006 (0.274970) | 0.569139 / 0.000490 (0.568649) | 0.000553 / 0.000200 (0.000353) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030144 / 0.037411 (-0.007267) | 0.098699 / 0.014526 (0.084173) | 0.114437 / 0.176557 (-0.062120) | 0.156657 / 0.737135 (-0.580478) | 0.117449 / 0.296338 (-0.178890) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441921 / 0.215209 (0.226712) | 4.413090 / 2.077655 (2.335435) | 2.190458 / 1.504120 (0.686338) | 2.008919 / 1.541195 (0.467724) | 2.049657 / 1.468490 (0.581167) | 0.691751 / 4.584777 (-3.893026) | 3.767524 / 3.745712 (0.021812) | 3.395564 / 5.269862 (-1.874297) | 1.633480 / 4.565676 (-2.932196) | 0.084880 / 0.424275 (-0.339395) | 0.012133 / 0.007607 (0.004526) | 0.555372 / 0.226044 (0.329327) | 5.522820 / 2.268929 (3.253892) | 2.723331 / 55.444624 (-52.721293) | 2.337583 / 6.876477 (-4.538894) | 2.368746 / 2.142072 (0.226674) | 0.830127 / 4.805227 (-3.975100) | 0.166239 / 6.500664 (-6.334425) | 0.064279 / 0.075469 (-0.011190) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.123421 / 1.841788 (-0.718367) | 14.413392 / 8.074308 (6.339084) | 12.865143 / 10.191392 (2.673751) | 0.132198 / 0.680424 (-0.548226) | 0.016138 / 0.534201 (-0.518063) | 0.380760 / 0.579283 (-0.198523) | 0.387223 / 0.434364 (-0.047141) | 0.445574 / 0.540337 (-0.094764) | 0.535658 / 1.386936 (-0.851278) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008316 / 0.011353 (-0.003037) | 0.004503 / 0.011008 (-0.006505) | 0.100565 / 0.038508 (0.062057) | 0.030388 / 0.023109 (0.007279) | 0.304417 / 0.275898 (0.028519) | 0.369655 / 0.323480 (0.046175) | 0.007796 / 0.007986 (-0.000190) | 0.003450 / 0.004328 (-0.000878) | 0.078694 / 0.004250 (0.074443) | 0.038068 / 0.037052 (0.001016) | 0.316353 / 0.258489 (0.057864) | 0.352344 / 0.293841 (0.058503) | 0.033271 / 0.128546 (-0.095276) | 0.011427 / 0.075646 (-0.064220) | 0.322367 / 0.419271 (-0.096904) | 0.041497 / 0.043533 (-0.002036) | 0.305876 / 0.255139 (0.050737) | 0.332279 / 0.283200 (0.049079) | 0.086719 / 0.141683 (-0.054964) | 1.488367 / 1.452155 (0.036212) | 1.528943 / 1.492716 (0.036227) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.171072 / 0.018006 (0.153066) | 0.421048 / 0.000490 (0.420558) | 0.003622 / 0.000200 (0.003422) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022632 / 0.037411 (-0.014779) | 0.095304 / 0.014526 (0.080778) | 0.106254 / 0.176557 (-0.070302) | 0.138437 / 0.737135 (-0.598698) | 0.107258 / 0.296338 (-0.189080) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.423201 / 0.215209 (0.207992) | 4.208397 / 2.077655 (2.130742) | 1.899800 / 1.504120 (0.395680) | 1.682782 / 1.541195 (0.141587) | 1.708840 / 1.468490 (0.240350) | 0.694492 / 4.584777 (-3.890285) | 3.380369 / 3.745712 (-0.365344) | 1.851731 / 5.269862 (-3.418130) | 1.151615 / 4.565676 (-3.414061) | 0.082446 / 0.424275 (-0.341829) | 0.012483 / 0.007607 (0.004876) | 0.533688 / 0.226044 (0.307643) | 5.373434 / 2.268929 (3.104505) | 2.346403 / 55.444624 (-53.098221) | 1.978505 / 6.876477 (-4.897971) | 2.005875 / 2.142072 (-0.136198) | 0.820785 / 4.805227 (-3.984442) | 0.150728 / 6.500664 (-6.349936) | 0.065761 / 0.075469 (-0.009708) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.244550 / 1.841788 (-0.597237) | 13.219096 / 8.074308 (5.144788) | 13.960463 / 10.191392 (3.769071) | 0.135572 / 0.680424 (-0.544852) | 0.028746 / 0.534201 (-0.505455) | 0.393082 / 0.579283 (-0.186201) | 0.402852 / 0.434364 (-0.031512) | 0.461191 / 0.540337 (-0.079147) | 0.543500 / 1.386936 (-0.843436) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006316 / 0.011353 (-0.005037) | 0.004394 / 0.011008 (-0.006615) | 0.096478 / 0.038508 (0.057970) | 0.026965 / 0.023109 (0.003855) | 0.340371 / 0.275898 (0.064473) | 0.368334 / 0.323480 (0.044854) | 0.004744 / 0.007986 (-0.003242) | 0.004652 / 0.004328 (0.000324) | 0.074479 / 0.004250 (0.070228) | 0.036358 / 0.037052 (-0.000694) | 0.342968 / 0.258489 (0.084479) | 0.383675 / 0.293841 (0.089834) | 0.031439 / 0.128546 (-0.097107) | 0.011529 / 0.075646 (-0.064117) | 0.319560 / 0.419271 (-0.099711) | 0.041370 / 0.043533 (-0.002163) | 0.342594 / 0.255139 (0.087455) | 0.363237 / 0.283200 (0.080038) | 0.087316 / 0.141683 (-0.054367) | 1.468690 / 1.452155 (0.016535) | 1.553974 / 1.492716 (0.061257) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.198366 / 0.018006 (0.180360) | 0.401581 / 0.000490 (0.401091) | 0.000400 / 0.000200 (0.000200) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023150 / 0.037411 (-0.014261) | 0.097797 / 0.014526 (0.083271) | 0.106198 / 0.176557 (-0.070359) | 0.139599 / 0.737135 (-0.597536) | 0.108361 / 0.296338 (-0.187978) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472962 / 0.215209 (0.257753) | 4.702688 / 2.077655 (2.625033) | 2.401002 / 1.504120 (0.896882) | 2.193857 / 1.541195 (0.652663) | 2.219188 / 1.468490 (0.750697) | 0.689993 / 4.584777 (-3.894784) | 3.369409 / 3.745712 (-0.376304) | 1.824801 / 5.269862 (-3.445061) | 1.150815 / 4.565676 (-3.414862) | 0.082197 / 0.424275 (-0.342078) | 0.012287 / 0.007607 (0.004679) | 0.581963 / 0.226044 (0.355918) | 5.786943 / 2.268929 (3.518015) | 2.871235 / 55.444624 (-52.573389) | 2.516009 / 6.876477 (-4.360468) | 2.535669 / 2.142072 (0.393597) | 0.804733 / 4.805227 (-4.000494) | 0.150545 / 6.500664 (-6.350119) | 0.066964 / 0.075469 (-0.008505) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285431 / 1.841788 (-0.556356) | 14.097108 / 8.074308 (6.022800) | 13.821497 / 10.191392 (3.630105) | 0.141922 / 0.680424 (-0.538502) | 0.016964 / 0.534201 (-0.517237) | 0.374784 / 0.579283 (-0.204500) | 0.381034 / 0.434364 (-0.053330) | 0.435487 / 0.540337 (-0.104850) | 0.521894 / 1.386936 (-0.865042) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009486 / 0.011353 (-0.001867) | 0.005363 / 0.011008 (-0.005645) | 0.101008 / 0.038508 (0.062500) | 0.036355 / 0.023109 (0.013246) | 0.290575 / 0.275898 (0.014677) | 0.391634 / 0.323480 (0.068154) | 0.009085 / 0.007986 (0.001099) | 0.005780 / 0.004328 (0.001451) | 0.077848 / 0.004250 (0.073598) | 0.049062 / 0.037052 (0.012009) | 0.310900 / 0.258489 (0.052411) | 0.358224 / 0.293841 (0.064383) | 0.038838 / 0.128546 (-0.089708) | 0.012244 / 0.075646 (-0.063402) | 0.333701 / 0.419271 (-0.085570) | 0.048021 / 0.043533 (0.004488) | 0.289584 / 0.255139 (0.034445) | 0.317556 / 0.283200 (0.034356) | 0.109807 / 0.141683 (-0.031876) | 1.465966 / 1.452155 (0.013811) | 1.526341 / 1.492716 (0.033625) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246221 / 0.018006 (0.228215) | 0.580659 / 0.000490 (0.580169) | 0.000627 / 0.000200 (0.000427) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028352 / 0.037411 (-0.009059) | 0.110569 / 0.014526 (0.096043) | 0.126456 / 0.176557 (-0.050100) | 0.163633 / 0.737135 (-0.573503) | 0.128252 / 0.296338 (-0.168087) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397271 / 0.215209 (0.182062) | 3.975336 / 2.077655 (1.897682) | 1.786957 / 1.504120 (0.282837) | 1.598468 / 1.541195 (0.057273) | 1.645299 / 1.468490 (0.176809) | 0.686221 / 4.584777 (-3.898556) | 3.753184 / 3.745712 (0.007472) | 2.089505 / 5.269862 (-3.180356) | 1.325799 / 4.565676 (-3.239878) | 0.084608 / 0.424275 (-0.339667) | 0.012343 / 0.007607 (0.004736) | 0.509951 / 0.226044 (0.283907) | 5.092102 / 2.268929 (2.823174) | 2.297551 / 55.444624 (-53.147073) | 1.938177 / 6.876477 (-4.938300) | 2.012448 / 2.142072 (-0.129625) | 0.835206 / 4.805227 (-3.970021) | 0.166373 / 6.500664 (-6.334291) | 0.063996 / 0.075469 (-0.011473) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.212936 / 1.841788 (-0.628851) | 15.067370 / 8.074308 (6.993062) | 14.165214 / 10.191392 (3.973822) | 0.157041 / 0.680424 (-0.523383) | 0.029612 / 0.534201 (-0.504589) | 0.440006 / 0.579283 (-0.139277) | 0.439165 / 0.434364 (0.004801) | 0.524970 / 0.540337 (-0.015368) | 0.608305 / 1.386936 (-0.778631) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007433 / 0.011353 (-0.003920) | 0.005310 / 0.011008 (-0.005698) | 0.097194 / 0.038508 (0.058686) | 0.033265 / 0.023109 (0.010156) | 0.369908 / 0.275898 (0.094010) | 0.411508 / 0.323480 (0.088028) | 0.006000 / 0.007986 (-0.001986) | 0.005647 / 0.004328 (0.001319) | 0.075597 / 0.004250 (0.071347) | 0.051951 / 0.037052 (0.014899) | 0.378469 / 0.258489 (0.119980) | 0.424849 / 0.293841 (0.131008) | 0.036700 / 0.128546 (-0.091846) | 0.012535 / 0.075646 (-0.063111) | 0.333197 / 0.419271 (-0.086074) | 0.049046 / 0.043533 (0.005513) | 0.381845 / 0.255139 (0.126706) | 0.397846 / 0.283200 (0.114646) | 0.109152 / 0.141683 (-0.032531) | 1.432407 / 1.452155 (-0.019748) | 1.555509 / 1.492716 (0.062793) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.265433 / 0.018006 (0.247427) | 0.559590 / 0.000490 (0.559100) | 0.000492 / 0.000200 (0.000292) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029748 / 0.037411 (-0.007663) | 0.110490 / 0.014526 (0.095964) | 0.124125 / 0.176557 (-0.052431) | 0.160089 / 0.737135 (-0.577046) | 0.128755 / 0.296338 (-0.167583) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443976 / 0.215209 (0.228767) | 4.416960 / 2.077655 (2.339305) | 2.239408 / 1.504120 (0.735288) | 2.055341 / 1.541195 (0.514147) | 2.093479 / 1.468490 (0.624988) | 0.688846 / 4.584777 (-3.895930) | 3.797526 / 3.745712 (0.051814) | 3.578137 / 5.269862 (-1.691725) | 2.015073 / 4.565676 (-2.550603) | 0.084126 / 0.424275 (-0.340149) | 0.012581 / 0.007607 (0.004974) | 0.549774 / 0.226044 (0.323730) | 5.492185 / 2.268929 (3.223256) | 2.739851 / 55.444624 (-52.704773) | 2.371091 / 6.876477 (-4.505386) | 2.400178 / 2.142072 (0.258105) | 0.831227 / 4.805227 (-3.974001) | 0.166156 / 6.500664 (-6.334508) | 0.063901 / 0.075469 (-0.011568) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.236127 / 1.841788 (-0.605660) | 15.236884 / 8.074308 (7.162576) | 14.434351 / 10.191392 (4.242959) | 0.163725 / 0.680424 (-0.516699) | 0.018009 / 0.534201 (-0.516192) | 0.430612 / 0.579283 (-0.148671) | 0.420426 / 0.434364 (-0.013938) | 0.497062 / 0.540337 (-0.043275) | 0.590924 / 1.386936 (-0.796012) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010862 / 0.011353 (-0.000491) | 0.005741 / 0.011008 (-0.005267) | 0.111911 / 0.038508 (0.073403) | 0.042316 / 0.023109 (0.019207) | 0.347665 / 0.275898 (0.071767) | 0.377335 / 0.323480 (0.053855) | 0.009400 / 0.007986 (0.001414) | 0.006814 / 0.004328 (0.002486) | 0.087194 / 0.004250 (0.082943) | 0.046878 / 0.037052 (0.009826) | 0.348920 / 0.258489 (0.090430) | 0.393347 / 0.293841 (0.099507) | 0.044212 / 0.128546 (-0.084334) | 0.013925 / 0.075646 (-0.061722) | 0.386076 / 0.419271 (-0.033195) | 0.054195 / 0.043533 (0.010662) | 0.358486 / 0.255139 (0.103347) | 0.360132 / 0.283200 (0.076932) | 0.109783 / 0.141683 (-0.031900) | 1.679875 / 1.452155 (0.227720) | 1.794379 / 1.492716 (0.301663) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221927 / 0.018006 (0.203921) | 0.487352 / 0.000490 (0.486863) | 0.003494 / 0.000200 (0.003294) | 0.000091 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032201 / 0.037411 (-0.005210) | 0.125861 / 0.014526 (0.111335) | 0.133905 / 0.176557 (-0.042652) | 0.183319 / 0.737135 (-0.553817) | 0.142646 / 0.296338 (-0.153693) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442720 / 0.215209 (0.227511) | 4.602619 / 2.077655 (2.524964) | 2.050214 / 1.504120 (0.546094) | 1.837968 / 1.541195 (0.296773) | 1.961199 / 1.468490 (0.492709) | 0.793426 / 4.584777 (-3.791351) | 4.472078 / 3.745712 (0.726366) | 2.364903 / 5.269862 (-2.904959) | 1.515076 / 4.565676 (-3.050600) | 0.103087 / 0.424275 (-0.321188) | 0.014676 / 0.007607 (0.007068) | 0.576887 / 0.226044 (0.350843) | 5.785525 / 2.268929 (3.516596) | 2.765231 / 55.444624 (-52.679393) | 2.365364 / 6.876477 (-4.511113) | 2.448335 / 2.142072 (0.306262) | 0.978726 / 4.805227 (-3.826501) | 0.191417 / 6.500664 (-6.309247) | 0.073295 / 0.075469 (-0.002174) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.378995 / 1.841788 (-0.462792) | 16.583655 / 8.074308 (8.509347) | 14.944731 / 10.191392 (4.753339) | 0.168916 / 0.680424 (-0.511508) | 0.035272 / 0.534201 (-0.498928) | 0.489729 / 0.579283 (-0.089554) | 0.496231 / 0.434364 (0.061867) | 0.576218 / 0.540337 (0.035880) | 0.673558 / 1.386936 (-0.713378) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008104 / 0.011353 (-0.003249) | 0.005179 / 0.011008 (-0.005829) | 0.103908 / 0.038508 (0.065400) | 0.034661 / 0.023109 (0.011552) | 0.398119 / 0.275898 (0.122221) | 0.411765 / 0.323480 (0.088286) | 0.006016 / 0.007986 (-0.001970) | 0.005637 / 0.004328 (0.001308) | 0.073662 / 0.004250 (0.069412) | 0.052411 / 0.037052 (0.015359) | 0.391826 / 0.258489 (0.133337) | 0.455217 / 0.293841 (0.161376) | 0.039924 / 0.128546 (-0.088622) | 0.013390 / 0.075646 (-0.062256) | 0.390319 / 0.419271 (-0.028953) | 0.054312 / 0.043533 (0.010779) | 0.395492 / 0.255139 (0.140353) | 0.446324 / 0.283200 (0.163124) | 0.116461 / 0.141683 (-0.025222) | 1.502163 / 1.452155 (0.050008) | 1.731541 / 1.492716 (0.238825) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.282612 / 0.018006 (0.264606) | 0.503170 / 0.000490 (0.502680) | 0.005307 / 0.000200 (0.005107) | 0.000100 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029071 / 0.037411 (-0.008340) | 0.123831 / 0.014526 (0.109306) | 0.133284 / 0.176557 (-0.043272) | 0.172029 / 0.737135 (-0.565106) | 0.140639 / 0.296338 (-0.155700) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.496812 / 0.215209 (0.281603) | 4.958915 / 2.077655 (2.881260) | 2.559188 / 1.504120 (1.055068) | 2.262434 / 1.541195 (0.721240) | 2.371126 / 1.468490 (0.902636) | 0.780150 / 4.584777 (-3.804627) | 4.417060 / 3.745712 (0.671348) | 2.401909 / 5.269862 (-2.867953) | 1.527943 / 4.565676 (-3.037733) | 0.100074 / 0.424275 (-0.324201) | 0.014853 / 0.007607 (0.007246) | 0.630192 / 0.226044 (0.404147) | 6.409685 / 2.268929 (4.140757) | 3.224718 / 55.444624 (-52.219906) | 2.795301 / 6.876477 (-4.081176) | 2.927205 / 2.142072 (0.785132) | 0.989537 / 4.805227 (-3.815690) | 0.199775 / 6.500664 (-6.300889) | 0.076725 / 0.075469 (0.001256) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.433504 / 1.841788 (-0.408284) | 17.117134 / 8.074308 (9.042825) | 16.606367 / 10.191392 (6.414975) | 0.165653 / 0.680424 (-0.514771) | 0.020818 / 0.534201 (-0.513383) | 0.496782 / 0.579283 (-0.082501) | 0.473895 / 0.434364 (0.039531) | 0.576796 / 0.540337 (0.036459) | 0.703272 / 1.386936 (-0.683664) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012501 / 0.011353 (0.001148) | 0.006437 / 0.011008 (-0.004571) | 0.129387 / 0.038508 (0.090878) | 0.035847 / 0.023109 (0.012737) | 0.339243 / 0.275898 (0.063345) | 0.423274 / 0.323480 (0.099794) | 0.008489 / 0.007986 (0.000503) | 0.004596 / 0.004328 (0.000268) | 0.103322 / 0.004250 (0.099071) | 0.043570 / 0.037052 (0.006517) | 0.357004 / 0.258489 (0.098515) | 0.426511 / 0.293841 (0.132670) | 0.062923 / 0.128546 (-0.065623) | 0.021168 / 0.075646 (-0.054478) | 0.387485 / 0.419271 (-0.031787) | 0.059745 / 0.043533 (0.016213) | 0.341101 / 0.255139 (0.085962) | 0.365530 / 0.283200 (0.082331) | 0.102110 / 0.141683 (-0.039573) | 1.729408 / 1.452155 (0.277253) | 1.759510 / 1.492716 (0.266794) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.187065 / 0.018006 (0.169059) | 0.499685 / 0.000490 (0.499196) | 0.004677 / 0.000200 (0.004478) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025827 / 0.037411 (-0.011584) | 0.113780 / 0.014526 (0.099255) | 0.146060 / 0.176557 (-0.030496) | 0.158169 / 0.737135 (-0.578966) | 0.136133 / 0.296338 (-0.160206) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.608421 / 0.215209 (0.393211) | 5.907395 / 2.077655 (3.829741) | 2.193140 / 1.504120 (0.689021) | 1.870315 / 1.541195 (0.329120) | 1.885660 / 1.468490 (0.417170) | 1.227637 / 4.584777 (-3.357140) | 5.319242 / 3.745712 (1.573530) | 2.991595 / 5.269862 (-2.278267) | 2.043906 / 4.565676 (-2.521771) | 0.151829 / 0.424275 (-0.272447) | 0.018974 / 0.007607 (0.011367) | 0.778035 / 0.226044 (0.551991) | 7.705796 / 2.268929 (5.436868) | 2.990156 / 55.444624 (-52.454468) | 2.372643 / 6.876477 (-4.503834) | 2.240847 / 2.142072 (0.098775) | 1.407209 / 4.805227 (-3.398018) | 0.242336 / 6.500664 (-6.258328) | 0.069847 / 0.075469 (-0.005622) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.445817 / 1.841788 (-0.395970) | 16.059632 / 8.074308 (7.985324) | 18.541971 / 10.191392 (8.350579) | 0.237830 / 0.680424 (-0.442594) | 0.041060 / 0.534201 (-0.493141) | 0.496765 / 0.579283 (-0.082518) | 0.609666 / 0.434364 (0.175302) | 0.584614 / 0.540337 (0.044277) | 0.680858 / 1.386936 (-0.706078) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009037 / 0.011353 (-0.002315) | 0.005961 / 0.011008 (-0.005047) | 0.127204 / 0.038508 (0.088696) | 0.030664 / 0.023109 (0.007555) | 0.417968 / 0.275898 (0.142070) | 0.515316 / 0.323480 (0.191836) | 0.006549 / 0.007986 (-0.001436) | 0.004456 / 0.004328 (0.000128) | 0.083715 / 0.004250 (0.079464) | 0.043701 / 0.037052 (0.006648) | 0.521153 / 0.258489 (0.262664) | 0.565456 / 0.293841 (0.271615) | 0.055298 / 0.128546 (-0.073248) | 0.018103 / 0.075646 (-0.057544) | 0.403990 / 0.419271 (-0.015282) | 0.060162 / 0.043533 (0.016629) | 0.486383 / 0.255139 (0.231244) | 0.470342 / 0.283200 (0.187142) | 0.102269 / 0.141683 (-0.039414) | 1.643241 / 1.452155 (0.191086) | 1.763850 / 1.492716 (0.271133) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185602 / 0.018006 (0.167596) | 0.489163 / 0.000490 (0.488674) | 0.000426 / 0.000200 (0.000226) | 0.000086 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026689 / 0.037411 (-0.010722) | 0.111520 / 0.014526 (0.096994) | 0.119838 / 0.176557 (-0.056719) | 0.153698 / 0.737135 (-0.583437) | 0.130969 / 0.296338 (-0.165370) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.616170 / 0.215209 (0.400961) | 6.219702 / 2.077655 (4.142048) | 2.533554 / 1.504120 (1.029434) | 2.256009 / 1.541195 (0.714815) | 2.217617 / 1.468490 (0.749127) | 1.156920 / 4.584777 (-3.427857) | 5.175759 / 3.745712 (1.430046) | 2.848419 / 5.269862 (-2.421442) | 1.943864 / 4.565676 (-2.621813) | 0.138342 / 0.424275 (-0.285933) | 0.013140 / 0.007607 (0.005533) | 0.782105 / 0.226044 (0.556060) | 7.602003 / 2.268929 (5.333075) | 3.629577 / 55.444624 (-51.815047) | 2.713849 / 6.876477 (-4.162628) | 2.663888 / 2.142072 (0.521816) | 1.418381 / 4.805227 (-3.386847) | 0.250649 / 6.500664 (-6.250015) | 0.073564 / 0.075469 (-0.001905) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.483739 / 1.841788 (-0.358049) | 16.386204 / 8.074308 (8.311896) | 20.685262 / 10.191392 (10.493870) | 0.237084 / 0.680424 (-0.443340) | 0.039097 / 0.534201 (-0.495104) | 0.525399 / 0.579283 (-0.053884) | 0.587541 / 0.434364 (0.153177) | 0.566605 / 0.540337 (0.026268) | 0.677384 / 1.386936 (-0.709552) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.014050 / 0.011353 (0.002697) | 0.005981 / 0.011008 (-0.005028) | 0.126307 / 0.038508 (0.087799) | 0.035400 / 0.023109 (0.012290) | 0.387821 / 0.275898 (0.111923) | 0.462785 / 0.323480 (0.139305) | 0.009427 / 0.007986 (0.001441) | 0.005081 / 0.004328 (0.000753) | 0.097273 / 0.004250 (0.093023) | 0.044699 / 0.037052 (0.007647) | 0.396025 / 0.258489 (0.137536) | 0.450137 / 0.293841 (0.156296) | 0.055660 / 0.128546 (-0.072886) | 0.022710 / 0.075646 (-0.052936) | 0.443784 / 0.419271 (0.024513) | 0.065756 / 0.043533 (0.022223) | 0.379350 / 0.255139 (0.124211) | 0.396783 / 0.283200 (0.113583) | 0.114088 / 0.141683 (-0.027594) | 1.856834 / 1.452155 (0.404679) | 1.839292 / 1.492716 (0.346576) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.206748 / 0.018006 (0.188742) | 0.517711 / 0.000490 (0.517222) | 0.008302 / 0.000200 (0.008102) | 0.000494 / 0.000054 (0.000440) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033987 / 0.037411 (-0.003424) | 0.131067 / 0.014526 (0.116542) | 0.155539 / 0.176557 (-0.021018) | 0.188598 / 0.737135 (-0.548537) | 0.156000 / 0.296338 (-0.140338) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.641413 / 0.215209 (0.426204) | 6.156680 / 2.077655 (4.079025) | 2.428858 / 1.504120 (0.924738) | 2.086195 / 1.541195 (0.545000) | 2.109604 / 1.468490 (0.641114) | 1.209426 / 4.584777 (-3.375351) | 5.139398 / 3.745712 (1.393686) | 3.041337 / 5.269862 (-2.228524) | 2.294809 / 4.565676 (-2.270868) | 0.142206 / 0.424275 (-0.282069) | 0.015167 / 0.007607 (0.007560) | 0.816269 / 0.226044 (0.590224) | 7.953931 / 2.268929 (5.685002) | 3.201793 / 55.444624 (-52.242832) | 2.448620 / 6.876477 (-4.427857) | 2.521670 / 2.142072 (0.379597) | 1.484094 / 4.805227 (-3.321133) | 0.255069 / 6.500664 (-6.245595) | 0.076031 / 0.075469 (0.000561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.590951 / 1.841788 (-0.250836) | 17.661353 / 8.074308 (9.587045) | 21.097837 / 10.191392 (10.906445) | 0.229265 / 0.680424 (-0.451159) | 0.042618 / 0.534201 (-0.491583) | 0.535942 / 0.579283 (-0.043342) | 0.590195 / 0.434364 (0.155831) | 0.623985 / 0.540337 (0.083648) | 0.742637 / 1.386936 (-0.644299) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009264 / 0.011353 (-0.002088) | 0.008798 / 0.011008 (-0.002210) | 0.122208 / 0.038508 (0.083700) | 0.034835 / 0.023109 (0.011726) | 0.462618 / 0.275898 (0.186720) | 0.505632 / 0.323480 (0.182152) | 0.006320 / 0.007986 (-0.001665) | 0.005383 / 0.004328 (0.001054) | 0.091229 / 0.004250 (0.086979) | 0.045828 / 0.037052 (0.008775) | 0.477507 / 0.258489 (0.219018) | 0.539616 / 0.293841 (0.245775) | 0.061913 / 0.128546 (-0.066633) | 0.019390 / 0.075646 (-0.056257) | 0.420016 / 0.419271 (0.000745) | 0.065958 / 0.043533 (0.022425) | 0.468603 / 0.255139 (0.213464) | 0.486246 / 0.283200 (0.203046) | 0.107924 / 0.141683 (-0.033759) | 1.843614 / 1.452155 (0.391459) | 1.988159 / 1.492716 (0.495442) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.247043 / 0.018006 (0.229037) | 0.515580 / 0.000490 (0.515090) | 0.005630 / 0.000200 (0.005430) | 0.000115 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030674 / 0.037411 (-0.006737) | 0.130783 / 0.014526 (0.116258) | 0.147669 / 0.176557 (-0.028888) | 0.175656 / 0.737135 (-0.561479) | 0.138317 / 0.296338 (-0.158022) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.727119 / 0.215209 (0.511909) | 6.848208 / 2.077655 (4.770553) | 3.121418 / 1.504120 (1.617298) | 2.701799 / 1.541195 (1.160604) | 2.749179 / 1.468490 (1.280689) | 1.312058 / 4.584777 (-3.272719) | 5.400562 / 3.745712 (1.654850) | 3.058142 / 5.269862 (-2.211719) | 2.076361 / 4.565676 (-2.489316) | 0.142169 / 0.424275 (-0.282106) | 0.014340 / 0.007607 (0.006733) | 0.853534 / 0.226044 (0.627490) | 8.734484 / 2.268929 (6.465556) | 3.968130 / 55.444624 (-51.476495) | 3.118032 / 6.876477 (-3.758444) | 3.078757 / 2.142072 (0.936684) | 1.460694 / 4.805227 (-3.344533) | 0.261858 / 6.500664 (-6.238806) | 0.081089 / 0.075469 (0.005620) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.611473 / 1.841788 (-0.230315) | 17.660545 / 8.074308 (9.586237) | 20.526023 / 10.191392 (10.334631) | 0.223320 / 0.680424 (-0.457103) | 0.027939 / 0.534201 (-0.506261) | 0.542704 / 0.579283 (-0.036579) | 0.563826 / 0.434364 (0.129462) | 0.639936 / 0.540337 (0.099599) | 0.755974 / 1.386936 (-0.630962) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008776 / 0.011353 (-0.002577) | 0.004532 / 0.011008 (-0.006476) | 0.100373 / 0.038508 (0.061865) | 0.029706 / 0.023109 (0.006597) | 0.304374 / 0.275898 (0.028476) | 0.337223 / 0.323480 (0.013743) | 0.007021 / 0.007986 (-0.000965) | 0.003420 / 0.004328 (-0.000908) | 0.077754 / 0.004250 (0.073504) | 0.034411 / 0.037052 (-0.002642) | 0.302926 / 0.258489 (0.044437) | 0.342654 / 0.293841 (0.048813) | 0.034528 / 0.128546 (-0.094018) | 0.011926 / 0.075646 (-0.063721) | 0.322971 / 0.419271 (-0.096301) | 0.041384 / 0.043533 (-0.002149) | 0.306433 / 0.255139 (0.051294) | 0.332293 / 0.283200 (0.049093) | 0.084972 / 0.141683 (-0.056711) | 1.493426 / 1.452155 (0.041271) | 1.570446 / 1.492716 (0.077729) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189090 / 0.018006 (0.171084) | 0.433904 / 0.000490 (0.433414) | 0.001323 / 0.000200 (0.001124) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023531 / 0.037411 (-0.013880) | 0.097774 / 0.014526 (0.083248) | 0.106383 / 0.176557 (-0.070174) | 0.139158 / 0.737135 (-0.597977) | 0.109443 / 0.296338 (-0.186896) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419078 / 0.215209 (0.203869) | 4.182657 / 2.077655 (2.105002) | 1.887276 / 1.504120 (0.383156) | 1.679542 / 1.541195 (0.138347) | 1.718035 / 1.468490 (0.249545) | 0.692628 / 4.584777 (-3.892149) | 3.361354 / 3.745712 (-0.384358) | 1.928583 / 5.269862 (-3.341278) | 1.317291 / 4.565676 (-3.248386) | 0.081799 / 0.424275 (-0.342476) | 0.012318 / 0.007607 (0.004711) | 0.525927 / 0.226044 (0.299883) | 5.285905 / 2.268929 (3.016977) | 2.317524 / 55.444624 (-53.127100) | 1.966478 / 6.876477 (-4.909998) | 2.054869 / 2.142072 (-0.087204) | 0.807579 / 4.805227 (-3.997649) | 0.149854 / 6.500664 (-6.350810) | 0.065285 / 0.075469 (-0.010184) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.180516 / 1.841788 (-0.661271) | 13.889734 / 8.074308 (5.815426) | 14.076163 / 10.191392 (3.884771) | 0.156276 / 0.680424 (-0.524148) | 0.029187 / 0.534201 (-0.505013) | 0.403859 / 0.579283 (-0.175424) | 0.404998 / 0.434364 (-0.029366) | 0.471467 / 0.540337 (-0.068871) | 0.564526 / 1.386936 (-0.822410) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006739 / 0.011353 (-0.004614) | 0.004644 / 0.011008 (-0.006364) | 0.097326 / 0.038508 (0.058818) | 0.027728 / 0.023109 (0.004619) | 0.413537 / 0.275898 (0.137639) | 0.452012 / 0.323480 (0.128532) | 0.005346 / 0.007986 (-0.002639) | 0.003338 / 0.004328 (-0.000991) | 0.075670 / 0.004250 (0.071420) | 0.038825 / 0.037052 (0.001772) | 0.415612 / 0.258489 (0.157123) | 0.454680 / 0.293841 (0.160839) | 0.031866 / 0.128546 (-0.096680) | 0.011616 / 0.075646 (-0.064031) | 0.319527 / 0.419271 (-0.099745) | 0.041283 / 0.043533 (-0.002250) | 0.412046 / 0.255139 (0.156907) | 0.435244 / 0.283200 (0.152044) | 0.088400 / 0.141683 (-0.053283) | 1.478125 / 1.452155 (0.025970) | 1.553677 / 1.492716 (0.060960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229919 / 0.018006 (0.211913) | 0.415446 / 0.000490 (0.414956) | 0.000386 / 0.000200 (0.000186) | 0.000058 / 0.000054 (0.000003) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024365 / 0.037411 (-0.013046) | 0.098225 / 0.014526 (0.083699) | 0.106674 / 0.176557 (-0.069883) | 0.144755 / 0.737135 (-0.592380) | 0.109221 / 0.296338 (-0.187117) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457665 / 0.215209 (0.242456) | 4.597849 / 2.077655 (2.520195) | 2.171275 / 1.504120 (0.667155) | 1.945547 / 1.541195 (0.404352) | 2.014043 / 1.468490 (0.545553) | 0.699732 / 4.584777 (-3.885045) | 3.420711 / 3.745712 (-0.325001) | 3.298702 / 5.269862 (-1.971159) | 1.390324 / 4.565676 (-3.175353) | 0.082668 / 0.424275 (-0.341607) | 0.012556 / 0.007607 (0.004949) | 0.550406 / 0.226044 (0.324361) | 5.501060 / 2.268929 (3.232132) | 2.659841 / 55.444624 (-52.784783) | 2.243443 / 6.876477 (-4.633034) | 2.266006 / 2.142072 (0.123934) | 0.806295 / 4.805227 (-3.998933) | 0.151399 / 6.500664 (-6.349265) | 0.067048 / 0.075469 (-0.008421) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.291404 / 1.841788 (-0.550384) | 14.164728 / 8.074308 (6.090419) | 13.980219 / 10.191392 (3.788827) | 0.140599 / 0.680424 (-0.539824) | 0.016880 / 0.534201 (-0.517321) | 0.379073 / 0.579283 (-0.200210) | 0.385770 / 0.434364 (-0.048594) | 0.442516 / 0.540337 (-0.097822) | 0.533569 / 1.386936 (-0.853367) |\n\n</details>\n</details>\n\n\n",
"Tests seem to be failing for unrelated reasons.",
"Tests are failing because of a bug on the Hub side - this is being fixed :)\r\n\r\nlmk once the TF documentation page is updated and we can merge !",
"@lhoestq Docs updated!"
] | 2022-12-19T19:40:27Z | 2023-01-25T16:28:44Z | 2023-01-25T16:21:40Z | MEMBER | null | Hey all! Here's a first draft of the PR to add a multiprocessing implementation for `to_tf_dataset()`. It worked in some quick testing for me, but obviously I need to do some much more rigorous testing/benchmarking, and add some proper library tests.
The core idea is that we do everything using `multiprocessing` and `numpy`, and just wrap a `tf.data.Dataset` around the output. We could also rewrite the existing single-threaded implementation based on this code, which might simplify it a bit.
Checklist:
- [X] Add initial draft
- [x] Check that it works regardless of whether the `collate_fn` or dataset returns `tf` or `np` arrays
- [x] Check that it works with `tf.string` return data
- [x] Check indices are correctly reshuffled each epoch
- [x] Make sure workers don't try to initialize a GPU device!!
- [x] Check `fit()` with multiple epochs works fine and that the progress bar is correct
- [x] Check there are no memory leaks or zombie processes
- [x] Benchmark performance
- [x] Tweak params for dataset inference - can we speed things up there a bit?
- [x] Add tests to the library
- [x] Add a PR to `transformers` to expose the `num_workers` argument via `prepare_tf_dataset` (will merge after this one is released)
- [x] Stop TF console spam!! (almost)
- [x] Add a method for creating SHM that doesn't crash if it was left and still linked
- [x] Add a barrier for Py <= 3.7 because it doesn't support SharedMemory
- [x] Support string dtypes by converting them into fixed-width character arrays | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5377/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5377.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5377",
"merged_at": "2023-01-25T16:21:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5377.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5377"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5376/comments | https://api.github.com/repos/huggingface/datasets/issues/5376/events | https://github.com/huggingface/datasets/pull/5376 | 1,502,730,559 | PR_kwDODunzps5FxWkM | 5,376 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5376). All of your documentation changes will be reflected on that endpoint."
] | 2022-12-19T10:56:56Z | 2022-12-19T11:01:55Z | 2022-12-19T10:57:16Z | MEMBER | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5376/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5376",
"merged_at": "2022-12-19T10:57:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5376"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5375/comments | https://api.github.com/repos/huggingface/datasets/issues/5375/events | https://github.com/huggingface/datasets/pull/5375 | 1,502,720,404 | PR_kwDODunzps5FxUbG | 5,375 | Release: 2.8.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-19T10:48:26Z | 2022-12-19T10:55:43Z | 2022-12-19T10:53:15Z | MEMBER | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5375/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"merged_at": "2022-12-19T10:53:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5375"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5374/comments | https://api.github.com/repos/huggingface/datasets/issues/5374/events | https://github.com/huggingface/datasets/issues/5374 | 1,501,872,945 | I_kwDODunzps5ZhMMx | 5,374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Muennighoff",
"id": 62820084,
"login": "Muennighoff",
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Muennighoff"
} | [] | open | false | null | [] | null | [
"The data files are hosted on HF at https://huggingface.co/datasets/allenai/c4/tree/main\r\n\r\nYou have 200 runs streaming the same files in parallel. So this is probably a Hub limitation. Maybe rate limiting ? cc @julien-c \r\n\r\nMaybe you can also try to reduce the number of HTTP requests by increasing the block size of each request. This can be done by increasing `DEFAULT_BLOCK_SIZE` in `fsspec.implementations.http`. Default is `5 * 2**20` (5MiB)\r\n\r\nAnyway maybe it's just better to save the dataset locally in that case ?",
"you don't get an HTTP error code or something in your stack trace? Kinda hard to debug with this info",
"You could try to re-run using this `datasets` branch: [raise-err-when-disconnect](https://github.com/huggingface/datasets/compare/raise-err-when-disconnect?expand=1)\r\nIt should raise the fsspec error",
"The weird thing is that I already have it saved locally & it seems to indeed be using the cached one 🧐 ; I'm also using offline mode, so I don't think it has something to do with the Hub.\r\n```\r\nWARNING:datasets.load:Using the latest cached version of the module from /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/df532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01 (last modified on Mon Dec 12 10:45:02 2022) since it couldn't be found locally at c4.\r\n```\r\n\r\n",
"No, you passed `streaming=True` so it streams the data from the Hub.\r\nThis message just shows that you use the cached version of the `c4` **module**, aka the python script that is run to generate the examples from the raw data files.\r\n\r\nMaybe the offline mode should also disable `fsspec`/`aiohttp` HTTP calls in `datasets` and not just the `requests` ones.",
"> This message just shows that you use the cached version of the c4 module\r\n\r\nAh my bad you're right about the module, but it's also using the downloaded & cached c4 dataset. There's no internet during the runs so it wouldn't work otherwise",
"You don't have internet, therefore you get an error while trying to stream ;)"
] | 2022-12-18T11:38:58Z | 2022-12-19T16:33:31Z | null | CONTRIBUTOR | null | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/huggingface/datasets/pull/3050
### Steps to reproduce the bug
Running
```python
c4 = datasets.load_dataset("c4", "en", split="train", streaming=True).skip(args.start).take(args.end-args.start)
df = pd.DataFrame(c4, index=None)
```
with different start & end arguments on 200 CPUs in parallel yields:
```
WARNING:datasets.load:Using the latest cached version of the module from /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/df532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01 (last modified on Mon Dec 12 10:45:02 2022) since it couldn't be found locally at c4.
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [1/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [2/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [3/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [4/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [5/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [6/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [7/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [8/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [9/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [10/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [11/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [12/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [13/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [14/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [15/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [16/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [17/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [18/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [19/20]
WARNING:datasets.download.streaming_download_manager:Got disconnected from remote data host. Retrying in 5sec [20/20]
╭───────────────────── Traceback (most recent call last) ──────────────────────╮
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/dec-2022-tasky/inference │
│ _c4.py:68 in <module> │
│ │
│ 65 │ model.eval() │
│ 66 │ │
│ 67 │ c4 = datasets.load_dataset("c4", "en", split="train", streaming=Tru │
│ ❱ 68 │ df = pd.DataFrame(c4, index=None) │
│ 69 │ texts = df["text"].to_list() │
│ 70 │ preds = batch_inference(texts, batch_size=args.batch_size) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/site-packages/pandas/core/frame.p │
│ y:684 in __init__ │
│ │
│ 681 │ │ # For data is list-like, or Iterable (will consume into list │
│ 682 │ │ elif is_list_like(data): │
│ 683 │ │ │ if not isinstance(data, (abc.Sequence, ExtensionArray)): │
│ ❱ 684 │ │ │ │ data = list(data) │
│ 685 │ │ │ if len(data) > 0: │
│ 686 │ │ │ │ if is_dataclass(data[0]): │
│ 687 │ │ │ │ │ data = dataclasses_to_dicts(data) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:751 in __iter__ │
│ │
│ 748 │ │ yield from ex_iterable.shard_data_sources(shard_idx) │
│ 749 │ │
│ 750 │ def __iter__(self): │
│ ❱ 751 │ │ for key, example in self._iter(): │
│ 752 │ │ │ if self.features: │
│ 753 │ │ │ │ # `IterableDataset` automatically fills missing colum │
│ 754 │ │ │ │ # This is done with `_apply_feature_types`. │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:741 in _iter │
│ │
│ 738 │ │ │ ex_iterable = self._ex_iterable.shuffle_data_sources(self │
│ 739 │ │ else: │
│ 740 │ │ │ ex_iterable = self._ex_iterable │
│ ❱ 741 │ │ yield from ex_iterable │
│ 742 │ │
│ 743 │ def _iter_shard(self, shard_idx: int): │
│ 744 │ │ if self._shuffling: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:617 in __iter__ │
│ │
│ 614 │ │ self.n = n │
│ 615 │ │
│ 616 │ def __iter__(self): │
│ ❱ 617 │ │ yield from islice(self.ex_iterable, self.n) │
│ 618 │ │
│ 619 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 620 │ │ """Doesn't shuffle the wrapped examples iterable since it wou │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:594 in __iter__ │
│ │
│ 591 │ │
│ 592 │ def __iter__(self): │
│ 593 │ │ #ex_iterator = iter(self.ex_iterable) │
│ ❱ 594 │ │ yield from islice(self.ex_iterable, self.n, None) │
│ 595 │ │ #for _ in range(self.n): │
│ 596 │ │ # next(ex_iterator) │
│ 597 │ │ #yield from islice(ex_iterator, self.n, None) │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/iterable_dataset.py:106 in __iter__ │
│ │
│ 103 │ │ self.kwargs = kwargs │
│ 104 │ │
│ 105 │ def __iter__(self): │
│ ❱ 106 │ │ yield from self.generate_examples_fn(**self.kwargs) │
│ 107 │ │
│ 108 │ def shuffle_data_sources(self, generator: np.random.Generator) -> │
│ 109 │ │ return ShardShuffledExamplesIterable(self.generate_examples_f │
│ │
│ /users/muennighoff/.cache/huggingface/modules/datasets_modules/datasets/c4/d │
│ f532b158939272d032cc63ef19cd5b83e9b4d00c922b833e4cb18b2e9869b01/c4.py:89 in │
│ _generate_examples │
│ │
│ 86 │ │ for filepath in filepaths: │
│ 87 │ │ │ logger.info("generating examples from = %s", filepath) │
│ 88 │ │ │ with gzip.open(open(filepath, "rb"), "rt", encoding="utf-8" │
│ ❱ 89 │ │ │ │ for line in f: │
│ 90 │ │ │ │ │ if line: │
│ 91 │ │ │ │ │ │ example = json.loads(line) │
│ 92 │ │ │ │ │ │ yield id_, example │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:313 in read1 │
│ │
│ 310 │ │ │
│ 311 │ │ if size < 0: │
│ 312 │ │ │ size = io.DEFAULT_BUFFER_SIZE │
│ ❱ 313 │ │ return self._buffer.read1(size) │
│ 314 │ │
│ 315 │ def peek(self, n): │
│ 316 │ │ self._check_not_closed() │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/_compression.py:68 in readinto │
│ │
│ 65 │ │
│ 66 │ def readinto(self, b): │
│ 67 │ │ with memoryview(b) as view, view.cast("B") as byte_view: │
│ ❱ 68 │ │ │ data = self.read(len(byte_view)) │
│ 69 │ │ │ byte_view[:len(data)] = data │
│ 70 │ │ return len(data) │
│ 71 │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:493 in read │
│ │
│ 490 │ │ │ │ self._new_member = False │
│ 491 │ │ │ │
│ 492 │ │ │ # Read a chunk of data from the file │
│ ❱ 493 │ │ │ buf = self._fp.read(io.DEFAULT_BUFFER_SIZE) │
│ 494 │ │ │ │
│ 495 │ │ │ uncompress = self._decompressor.decompress(buf, size) │
│ 496 │ │ │ if self._decompressor.unconsumed_tail != b"": │
│ │
│ /opt/cray/pe/python/3.9.12.1/lib/python3.9/gzip.py:96 in read │
│ │
│ 93 │ │ │ read = self._read │
│ 94 │ │ │ self._read = None │
│ 95 │ │ │ return self._buffer[read:] + \ │
│ ❱ 96 │ │ │ │ self.file.read(size-self._length+read) │
│ 97 │ │
│ 98 │ def prepend(self, prepend=b''): │
│ 99 │ │ if self._read is None: │
│ │
│ /pfs/lustrep4/scratch/project_462000119/muennighoff/nov-2022-bettercom/venv/ │
│ lib/python3.9/site-packages/datasets/download/streaming_download_manager.py: │
│ 365 in read_with_retries │
│ │
│ 362 │ │ │ │ ) │
│ 363 │ │ │ │ time.sleep(config.STREAMING_READ_RETRY_INTERVAL) │
│ 364 │ │ else: │
│ ❱ 365 │ │ │ raise ConnectionError("Server Disconnected") │
│ 366 │ │ return out │
│ 367 │ │
│ 368 │ file_obj.read = read_with_retries │
╰──────────────────────────────────────────────────────────────────────────────╯
ConnectionError: Server Disconnected
```
### Expected behavior
There should be no disconnect I think.
### Environment info
```
datasets=2.7.0
Python 3.9.12
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5374/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5373/comments | https://api.github.com/repos/huggingface/datasets/issues/5373/events | https://github.com/huggingface/datasets/pull/5373 | 1,501,484,197 | PR_kwDODunzps5FtRU4 | 5,373 | Simplify skipping | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Muennighoff",
"id": 62820084,
"login": "Muennighoff",
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Muennighoff"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-17T17:23:52Z | 2022-12-18T21:43:31Z | 2022-12-18T21:40:21Z | CONTRIBUTOR | null | Was hoping to find a way to speed up the skipping as I'm running into bottlenecks skipping 100M examples on C4 (it takes 12 hours to skip), but didn't find anything better than this small change :(
Maybe there's a way to directly skip whole shards to speed it up? 🧐 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5373/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5373.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5373",
"merged_at": "2022-12-18T21:40:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5373.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5373"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5372/comments | https://api.github.com/repos/huggingface/datasets/issues/5372/events | https://github.com/huggingface/datasets/pull/5372 | 1,501,377,802 | PR_kwDODunzps5Fs9w5 | 5,372 | Fix streaming pandas.read_excel | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009517 / 0.011353 (-0.001835) | 0.005210 / 0.011008 (-0.005798) | 0.098916 / 0.038508 (0.060408) | 0.036123 / 0.023109 (0.013014) | 0.301564 / 0.275898 (0.025666) | 0.358086 / 0.323480 (0.034606) | 0.008159 / 0.007986 (0.000174) | 0.004122 / 0.004328 (-0.000206) | 0.075899 / 0.004250 (0.071648) | 0.046082 / 0.037052 (0.009030) | 0.302871 / 0.258489 (0.044382) | 0.351162 / 0.293841 (0.057321) | 0.038215 / 0.128546 (-0.090331) | 0.012026 / 0.075646 (-0.063620) | 0.330988 / 0.419271 (-0.088284) | 0.048351 / 0.043533 (0.004818) | 0.291840 / 0.255139 (0.036701) | 0.320387 / 0.283200 (0.037187) | 0.105018 / 0.141683 (-0.036665) | 1.447158 / 1.452155 (-0.004997) | 1.491205 / 1.492716 (-0.001511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250870 / 0.018006 (0.232863) | 0.562974 / 0.000490 (0.562484) | 0.001789 / 0.000200 (0.001589) | 0.000252 / 0.000054 (0.000197) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028208 / 0.037411 (-0.009203) | 0.110897 / 0.014526 (0.096371) | 0.120394 / 0.176557 (-0.056163) | 0.164980 / 0.737135 (-0.572156) | 0.126283 / 0.296338 (-0.170056) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397922 / 0.215209 (0.182713) | 3.969233 / 2.077655 (1.891578) | 1.766422 / 1.504120 (0.262302) | 1.577503 / 1.541195 (0.036308) | 1.672344 / 1.468490 (0.203854) | 0.695708 / 4.584777 (-3.889069) | 3.770763 / 3.745712 (0.025051) | 3.369592 / 5.269862 (-1.900269) | 1.851122 / 4.565676 (-2.714554) | 0.084063 / 0.424275 (-0.340212) | 0.012156 / 0.007607 (0.004549) | 0.534639 / 0.226044 (0.308594) | 5.021955 / 2.268929 (2.753027) | 2.215438 / 55.444624 (-53.229186) | 1.890459 / 6.876477 (-4.986018) | 2.071361 / 2.142072 (-0.070712) | 0.834623 / 4.805227 (-3.970604) | 0.165588 / 6.500664 (-6.335076) | 0.064336 / 0.075469 (-0.011133) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.205651 / 1.841788 (-0.636136) | 14.916871 / 8.074308 (6.842563) | 14.559495 / 10.191392 (4.368103) | 0.166889 / 0.680424 (-0.513535) | 0.028645 / 0.534201 (-0.505556) | 0.433634 / 0.579283 (-0.145649) | 0.429849 / 0.434364 (-0.004515) | 0.508617 / 0.540337 (-0.031720) | 0.595261 / 1.386936 (-0.791675) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007696 / 0.011353 (-0.003657) | 0.005434 / 0.011008 (-0.005574) | 0.099234 / 0.038508 (0.060725) | 0.033904 / 0.023109 (0.010795) | 0.379181 / 0.275898 (0.103283) | 0.401858 / 0.323480 (0.078379) | 0.006257 / 0.007986 (-0.001729) | 0.004406 / 0.004328 (0.000077) | 0.073174 / 0.004250 (0.068923) | 0.056033 / 0.037052 (0.018981) | 0.379375 / 0.258489 (0.120886) | 0.425928 / 0.293841 (0.132087) | 0.037476 / 0.128546 (-0.091071) | 0.012520 / 0.075646 (-0.063127) | 0.364975 / 0.419271 (-0.054297) | 0.049341 / 0.043533 (0.005808) | 0.370519 / 0.255139 (0.115380) | 0.390585 / 0.283200 (0.107385) | 0.113339 / 0.141683 (-0.028344) | 1.460575 / 1.452155 (0.008421) | 1.564951 / 1.492716 (0.072235) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.246217 / 0.018006 (0.228210) | 0.554358 / 0.000490 (0.553869) | 0.000451 / 0.000200 (0.000251) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029557 / 0.037411 (-0.007855) | 0.110472 / 0.014526 (0.095946) | 0.122652 / 0.176557 (-0.053904) | 0.159396 / 0.737135 (-0.577739) | 0.128852 / 0.296338 (-0.167486) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.447927 / 0.215209 (0.232718) | 4.448292 / 2.077655 (2.370637) | 2.228874 / 1.504120 (0.724754) | 2.030231 / 1.541195 (0.489036) | 2.116417 / 1.468490 (0.647927) | 0.702713 / 4.584777 (-3.882064) | 3.774063 / 3.745712 (0.028351) | 3.521662 / 5.269862 (-1.748200) | 1.476700 / 4.565676 (-3.088976) | 0.084921 / 0.424275 (-0.339354) | 0.012862 / 0.007607 (0.005255) | 0.559142 / 0.226044 (0.333098) | 5.512233 / 2.268929 (3.243305) | 2.750024 / 55.444624 (-52.694600) | 2.388845 / 6.876477 (-4.487632) | 2.541786 / 2.142072 (0.399714) | 0.842256 / 4.805227 (-3.962971) | 0.168088 / 6.500664 (-6.332576) | 0.064211 / 0.075469 (-0.011258) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239001 / 1.841788 (-0.602787) | 15.286345 / 8.074308 (7.212036) | 13.883981 / 10.191392 (3.692589) | 0.186212 / 0.680424 (-0.494212) | 0.018305 / 0.534201 (-0.515896) | 0.420459 / 0.579283 (-0.158824) | 0.421039 / 0.434364 (-0.013325) | 0.487348 / 0.540337 (-0.052989) | 0.587730 / 1.386936 (-0.799206) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-17T12:58:52Z | 2023-01-06T11:50:58Z | 2023-01-06T11:43:37Z | MEMBER | null | This PR fixes `xpandas_read_excel`:
- Support passing a path string, besides a file-like object
- Support passing `use_auth_token`
- First assumes the host server supports HTTP range requests; only if a ValueError is thrown (Cannot seek streaming HTTP file), then it preserves previous behavior (see [#3355](https://github.com/huggingface/datasets/pull/3355)).
Fix https://huggingface.co/datasets/bigbio/meqsum/discussions/1
Fix:
- https://github.com/bigscience-workshop/biomedical/issues/801
Related to:
- #3355 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5372/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5372/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5372.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5372",
"merged_at": "2023-01-06T11:43:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5372.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5372"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | https://api.github.com/repos/huggingface/datasets/issues/5371/events | https://github.com/huggingface/datasets/issues/5371 | 1,501,369,036 | I_kwDODunzps5ZfRLM | 5,371 | Add a robustness benchmark dataset for vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
}
] | null | [
"Ccing @nazneenrajani @lvwerra @osanseviero "
] | 2022-12-17T12:35:13Z | 2022-12-20T06:21:41Z | null | MEMBER | null | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also correlated to the robustness aspects of vision models.
Researchers use different benchmark datasets to evaluate the robustness aspects of vision models. ImageNet-C is one of them.
Having this dataset in 🤗 Datasets would allow researchers to evaluate and study the robustness aspects of vision models. Since the metric associated with these evaluations is top-1 accuracy, researchers should be able to easily take advantage of the evaluation benchmarks on the Hub and perform comprehensive reporting.
ImageNet-C is a large dataset. Once it's in, it can act as a reference and we can also reach out to the authors of the other robustness benchmark datasets in vision, such as ObjectNet, WILDS, Metashift, etc. These datasets cater to different aspects. For example, ObjectNet is related to assessing how well a model performs under sub-population shifts.
Related thread: https://huggingface.slack.com/archives/C036H4A5U8Z/p1669994598060499 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5371/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5369/comments | https://api.github.com/repos/huggingface/datasets/issues/5369/events | https://github.com/huggingface/datasets/pull/5369 | 1,500,622,276 | PR_kwDODunzps5Fqaj- | 5,369 | Distributed support | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright all the tests are passing - this is ready for review",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.015146 / 0.011353 (0.003793) | 0.006683 / 0.011008 (-0.004326) | 0.125994 / 0.038508 (0.087486) | 0.041345 / 0.023109 (0.018235) | 0.378609 / 0.275898 (0.102711) | 0.483139 / 0.323480 (0.159659) | 0.009669 / 0.007986 (0.001684) | 0.005143 / 0.004328 (0.000814) | 0.092015 / 0.004250 (0.087765) | 0.052728 / 0.037052 (0.015676) | 0.397166 / 0.258489 (0.138677) | 0.465820 / 0.293841 (0.171979) | 0.051025 / 0.128546 (-0.077521) | 0.018451 / 0.075646 (-0.057196) | 0.397311 / 0.419271 (-0.021960) | 0.054842 / 0.043533 (0.011309) | 0.391203 / 0.255139 (0.136064) | 0.412743 / 0.283200 (0.129543) | 0.111356 / 0.141683 (-0.030327) | 1.697526 / 1.452155 (0.245372) | 1.795017 / 1.492716 (0.302301) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.253737 / 0.018006 (0.235731) | 0.583071 / 0.000490 (0.582581) | 0.005958 / 0.000200 (0.005758) | 0.000110 / 0.000054 (0.000056) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030397 / 0.037411 (-0.007014) | 0.112242 / 0.014526 (0.097716) | 0.138807 / 0.176557 (-0.037749) | 0.209820 / 0.737135 (-0.527316) | 0.139530 / 0.296338 (-0.156808) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.574111 / 0.215209 (0.358902) | 5.623713 / 2.077655 (3.546058) | 2.416880 / 1.504120 (0.912760) | 1.951013 / 1.541195 (0.409819) | 2.124565 / 1.468490 (0.656075) | 1.268854 / 4.584777 (-3.315923) | 5.942368 / 3.745712 (2.196656) | 5.413814 / 5.269862 (0.143952) | 2.931638 / 4.565676 (-1.634038) | 0.135070 / 0.424275 (-0.289205) | 0.014290 / 0.007607 (0.006683) | 0.708384 / 0.226044 (0.482340) | 7.487994 / 2.268929 (5.219065) | 3.074210 / 55.444624 (-52.370414) | 2.380583 / 6.876477 (-4.495893) | 2.522298 / 2.142072 (0.380226) | 1.336741 / 4.805227 (-3.468486) | 0.236761 / 6.500664 (-6.263903) | 0.076592 / 0.075469 (0.001123) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.629415 / 1.841788 (-0.212373) | 19.000640 / 8.074308 (10.926332) | 21.474058 / 10.191392 (11.282666) | 0.231227 / 0.680424 (-0.449197) | 0.046213 / 0.534201 (-0.487988) | 0.565703 / 0.579283 (-0.013580) | 0.662956 / 0.434364 (0.228592) | 0.656475 / 0.540337 (0.116137) | 0.762534 / 1.386936 (-0.624402) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010952 / 0.011353 (-0.000400) | 0.006259 / 0.011008 (-0.004749) | 0.132430 / 0.038508 (0.093922) | 0.037920 / 0.023109 (0.014811) | 0.483565 / 0.275898 (0.207667) | 0.528190 / 0.323480 (0.204710) | 0.008116 / 0.007986 (0.000130) | 0.006768 / 0.004328 (0.002440) | 0.100520 / 0.004250 (0.096270) | 0.055208 / 0.037052 (0.018155) | 0.484672 / 0.258489 (0.226183) | 0.556937 / 0.293841 (0.263096) | 0.057938 / 0.128546 (-0.070609) | 0.020821 / 0.075646 (-0.054826) | 0.430735 / 0.419271 (0.011464) | 0.066317 / 0.043533 (0.022785) | 0.496652 / 0.255139 (0.241513) | 0.502004 / 0.283200 (0.218804) | 0.125403 / 0.141683 (-0.016280) | 1.833396 / 1.452155 (0.381241) | 1.974517 / 1.492716 (0.481800) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269198 / 0.018006 (0.251191) | 0.620314 / 0.000490 (0.619824) | 0.000535 / 0.000200 (0.000335) | 0.000083 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032373 / 0.037411 (-0.005039) | 0.130043 / 0.014526 (0.115517) | 0.146217 / 0.176557 (-0.030339) | 0.200187 / 0.737135 (-0.536948) | 0.152839 / 0.296338 (-0.143499) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.677478 / 0.215209 (0.462268) | 6.678856 / 2.077655 (4.601201) | 3.025870 / 1.504120 (1.521750) | 2.678196 / 1.541195 (1.137001) | 2.740640 / 1.468490 (1.272150) | 1.237163 / 4.584777 (-3.347614) | 5.752621 / 3.745712 (2.006908) | 3.170435 / 5.269862 (-2.099427) | 2.049174 / 4.565676 (-2.516502) | 0.147663 / 0.424275 (-0.276612) | 0.016107 / 0.007607 (0.008500) | 0.849666 / 0.226044 (0.623621) | 8.395212 / 2.268929 (6.126283) | 3.741120 / 55.444624 (-51.703505) | 3.102926 / 6.876477 (-3.773550) | 3.233655 / 2.142072 (1.091583) | 1.520349 / 4.805227 (-3.284878) | 0.267159 / 6.500664 (-6.233505) | 0.083646 / 0.075469 (0.008177) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.640458 / 1.841788 (-0.201330) | 19.043169 / 8.074308 (10.968861) | 22.786126 / 10.191392 (12.594734) | 0.218040 / 0.680424 (-0.462384) | 0.032948 / 0.534201 (-0.501253) | 0.569574 / 0.579283 (-0.009710) | 0.658746 / 0.434364 (0.224382) | 0.650501 / 0.540337 (0.110164) | 0.730588 / 1.386936 (-0.656348) |\n\n</details>\n</details>\n\n\n",
"just added a note :)"
] | 2022-12-16T17:43:47Z | 2023-01-16T13:36:12Z | 2023-01-16T13:33:32Z | MEMBER | null | To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This works for both map-style datasets and iterable datasets.
The dataset is split for the node at rank `rank` in a pool of nodes of size `world_size`.
For map-style datasets:
Each node is assigned a chunk of data, e.g. rank 0 is given the first chunk of the dataset.
For iterable datasets:
If the dataset has a number of shards that is a factor of `world_size` (i.e. if `dataset.n_shards % world_size == 0`),
then the shards are evenly assigned across the nodes, which is the most optimized.
Otherwise, each node keeps 1 example out of `world_size`, skipping the other examples.
This can also be combined with a `torch.utils.data.DataLoader` if you want each node to use multiple workers to load the data.
This also supports shuffling. At each epoch, the iterable dataset shards are reshuffled across all the nodes - you just have to call `iterable_ds.set_epoch(epoch_number)`.
TODO:
- [x] docs for usage in PyTorch
- [x] unit tests
- [x] integration tests with torch.distributed.launch
Related to https://github.com/huggingface/transformers/issues/20770
Close https://github.com/huggingface/datasets/issues/5360 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5369/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5369.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5369",
"merged_at": "2023-01-16T13:33:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5369.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5369"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5368/comments | https://api.github.com/repos/huggingface/datasets/issues/5368/events | https://github.com/huggingface/datasets/pull/5368 | 1,500,322,973 | PR_kwDODunzps5FpZyx | 5,368 | Align remove columns behavior and input dict mutation in `map` with previous behavior | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-16T14:28:47Z | 2022-12-16T16:28:08Z | 2022-12-16T16:25:12Z | CONTRIBUTOR | null | Align the `remove_columns` behavior and input dict mutation in `map` with the behavior before https://github.com/huggingface/datasets/pull/5252. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5368/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5368/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5368.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5368",
"merged_at": "2022-12-16T16:25:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5368.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5368"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5367/comments | https://api.github.com/repos/huggingface/datasets/issues/5367/events | https://github.com/huggingface/datasets/pull/5367 | 1,499,174,749 | PR_kwDODunzps5FlevK | 5,367 | Fix remove columns from lazy dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-15T22:04:12Z | 2022-12-15T22:27:53Z | 2022-12-15T22:24:50Z | MEMBER | null | This was introduced in https://github.com/huggingface/datasets/pull/5252 and causing the transformers CI to break: https://app.circleci.com/pipelines/github/huggingface/transformers/53886/workflows/522faf2e-a053-454c-94f8-a617fde33393/jobs/648597
Basically this code should return a dataset with only one column:
```python
from datasets import *
ds = Dataset.from_dict({"a": range(5)})
def f(x):
x["b"] = x["a"]
return x
ds = ds.map(f, remove_columns=["a"])
assert ds.column_names == ["b"]
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5367/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5367/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5367.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5367",
"merged_at": "2022-12-15T22:24:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5367.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5367"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-15T14:23:05Z | 2022-12-15T14:44:47Z | 2022-12-15T14:41:45Z | MEMBER | null | fix typing and ExamplesIterable.shard_data_sources | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"merged_at": "2022-12-15T14:41:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | https://api.github.com/repos/huggingface/datasets/issues/5365/events | https://github.com/huggingface/datasets/pull/5365 | 1,498,422,466 | PR_kwDODunzps5Fi6ZD | 5,365 | fix: image array should support other formats than uint8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"events_url": "https://api.github.com/users/vigsterkr/events{/privacy}",
"followers_url": "https://api.github.com/users/vigsterkr/followers",
"following_url": "https://api.github.com/users/vigsterkr/following{/other_user}",
"gists_url": "https://api.github.com/users/vigsterkr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vigsterkr",
"id": 30353,
"login": "vigsterkr",
"node_id": "MDQ6VXNlcjMwMzUz",
"organizations_url": "https://api.github.com/users/vigsterkr/orgs",
"received_events_url": "https://api.github.com/users/vigsterkr/received_events",
"repos_url": "https://api.github.com/users/vigsterkr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vigsterkr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vigsterkr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vigsterkr"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! \r\n\r\nI agree that the current type-casting (always cast to `np.uint8` as Tensorflow Datasets does) is a bit too harsh. However, not all dtypes are supported in `Image.fromarray` (e.g. np.int64), so we need to treat these with special care (e.g. downcast to the closest supported dtype, maybe with warnings to let the user know what's happening).\r\n\r\nPS: To avoid the CI failures, we need to handle two more instances of the cast to `np.uint8` (both are in the `image.py` file).",
"I've made some changes to the PR.\r\n\r\nNow the encoding procedure behaves as follows:\r\n* for multi-channel arrays: if their dtype is `int`/`uint`, cast to np.uint8 (the only supported dtype for multi-channel arrays), throw an error otherwise\r\n* if the array dtype is of valid kind (\"u\", \"i\", \"f\", ...):\r\n * don't do anything if Pillow natively supports it\r\n * otherwise, downcast until it becomes compatible with Pillow\r\n* raise an error if nothing from above is true",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009537 / 0.011353 (-0.001816) | 0.004946 / 0.011008 (-0.006062) | 0.100552 / 0.038508 (0.062043) | 0.035119 / 0.023109 (0.012009) | 0.295989 / 0.275898 (0.020091) | 0.361326 / 0.323480 (0.037846) | 0.007608 / 0.007986 (-0.000378) | 0.004151 / 0.004328 (-0.000177) | 0.077301 / 0.004250 (0.073050) | 0.042921 / 0.037052 (0.005869) | 0.304804 / 0.258489 (0.046315) | 0.345934 / 0.293841 (0.052093) | 0.038987 / 0.128546 (-0.089559) | 0.012055 / 0.075646 (-0.063591) | 0.334035 / 0.419271 (-0.085236) | 0.052679 / 0.043533 (0.009146) | 0.291700 / 0.255139 (0.036561) | 0.335423 / 0.283200 (0.052223) | 0.107002 / 0.141683 (-0.034680) | 1.516780 / 1.452155 (0.064625) | 1.514137 / 1.492716 (0.021420) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.014719 / 0.018006 (-0.003287) | 0.545251 / 0.000490 (0.544761) | 0.004719 / 0.000200 (0.004519) | 0.000275 / 0.000054 (0.000220) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026633 / 0.037411 (-0.010779) | 0.106911 / 0.014526 (0.092385) | 0.120258 / 0.176557 (-0.056299) | 0.156196 / 0.737135 (-0.580940) | 0.123132 / 0.296338 (-0.173207) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398018 / 0.215209 (0.182809) | 3.973992 / 2.077655 (1.896337) | 1.776436 / 1.504120 (0.272316) | 1.579036 / 1.541195 (0.037841) | 1.643345 / 1.468490 (0.174855) | 0.692408 / 4.584777 (-3.892369) | 3.757243 / 3.745712 (0.011531) | 3.226212 / 5.269862 (-2.043649) | 1.797845 / 4.565676 (-2.767831) | 0.085878 / 0.424275 (-0.338398) | 0.012451 / 0.007607 (0.004844) | 0.509755 / 0.226044 (0.283711) | 5.029035 / 2.268929 (2.760107) | 2.255507 / 55.444624 (-53.189117) | 1.892868 / 6.876477 (-4.983609) | 1.900017 / 2.142072 (-0.242055) | 0.853965 / 4.805227 (-3.951263) | 0.167268 / 6.500664 (-6.333396) | 0.062796 / 0.075469 (-0.012673) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.183361 / 1.841788 (-0.658427) | 15.103797 / 8.074308 (7.029489) | 14.112931 / 10.191392 (3.921539) | 0.167234 / 0.680424 (-0.513190) | 0.029487 / 0.534201 (-0.504713) | 0.444121 / 0.579283 (-0.135162) | 0.437821 / 0.434364 (0.003457) | 0.544900 / 0.540337 (0.004562) | 0.642142 / 1.386936 (-0.744794) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007078 / 0.011353 (-0.004275) | 0.004983 / 0.011008 (-0.006026) | 0.097106 / 0.038508 (0.058598) | 0.033747 / 0.023109 (0.010637) | 0.382030 / 0.275898 (0.106132) | 0.410193 / 0.323480 (0.086713) | 0.006658 / 0.007986 (-0.001327) | 0.005358 / 0.004328 (0.001029) | 0.073878 / 0.004250 (0.069628) | 0.049292 / 0.037052 (0.012240) | 0.384053 / 0.258489 (0.125564) | 0.427826 / 0.293841 (0.133985) | 0.036780 / 0.128546 (-0.091766) | 0.012469 / 0.075646 (-0.063178) | 0.332989 / 0.419271 (-0.086283) | 0.059531 / 0.043533 (0.015998) | 0.378431 / 0.255139 (0.123292) | 0.402672 / 0.283200 (0.119473) | 0.110782 / 0.141683 (-0.030901) | 1.484570 / 1.452155 (0.032416) | 1.608081 / 1.492716 (0.115365) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232356 / 0.018006 (0.214350) | 0.545648 / 0.000490 (0.545158) | 0.003113 / 0.000200 (0.002913) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028138 / 0.037411 (-0.009273) | 0.110786 / 0.014526 (0.096260) | 0.123615 / 0.176557 (-0.052941) | 0.165773 / 0.737135 (-0.571362) | 0.126401 / 0.296338 (-0.169937) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440518 / 0.215209 (0.225309) | 4.393821 / 2.077655 (2.316166) | 2.295479 / 1.504120 (0.791359) | 2.116679 / 1.541195 (0.575485) | 2.215561 / 1.468490 (0.747071) | 0.722343 / 4.584777 (-3.862434) | 3.783360 / 3.745712 (0.037647) | 3.302242 / 5.269862 (-1.967620) | 1.681535 / 4.565676 (-2.884142) | 0.085738 / 0.424275 (-0.338537) | 0.012373 / 0.007607 (0.004766) | 0.540499 / 0.226044 (0.314455) | 5.384915 / 2.268929 (3.115986) | 2.766346 / 55.444624 (-52.678279) | 2.451994 / 6.876477 (-4.424483) | 2.505720 / 2.142072 (0.363647) | 0.833006 / 4.805227 (-3.972221) | 0.168206 / 6.500664 (-6.332458) | 0.064971 / 0.075469 (-0.010498) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253499 / 1.841788 (-0.588289) | 15.381840 / 8.074308 (7.307532) | 13.519493 / 10.191392 (3.328101) | 0.165559 / 0.680424 (-0.514865) | 0.017682 / 0.534201 (-0.516519) | 0.422248 / 0.579283 (-0.157035) | 0.422750 / 0.434364 (-0.011614) | 0.524546 / 0.540337 (-0.015792) | 0.626956 / 1.386936 (-0.759980) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-15T13:17:50Z | 2023-01-26T18:46:45Z | 2023-01-26T18:39:36Z | CONTRIBUTOR | null | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#concept-modes).
although maybe some further metadata could be supplied via the [Image](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Image) object. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5365/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"merged_at": "2023-01-26T18:39:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5365"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | https://api.github.com/repos/huggingface/datasets/issues/5364/events | https://github.com/huggingface/datasets/pull/5364 | 1,498,360,628 | PR_kwDODunzps5Fiss1 | 5,364 | Support for writing arrow files directly with BeamWriter | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5364). All of your documentation changes will be reflected on that endpoint.",
"Deleting `BeamPipeline` and `upload_local_to_remote` would break the existing Beam scripts, so I reverted this change.\r\n\r\nFrom what I understand, we need these components in our scripts for the pattern:\r\n```python\r\nif not pipeline.is_local():\r\n dl_manager.ship_files_with_pipeline()\r\n```\r\n\r\nI plan to address this in a subsequent PR by (implicitly) downloading the files directly to the remote storage of the non-local runners.",
"I got `AttributeError: 'Pipeline' object has no attribute 'is_local'` when running\r\n```python\r\nload_dataset(\"wikipedia\", language=\"af\", date=\"20230101\", beam_runner=\"DirectRunner\")\r\n```\r\n```python\r\n~/.cache/huggingface/modules/datasets_modules/datasets/wikipedia/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559/wikipedia.py in _split_generators(self, dl_manager, pipeline)\r\n 965 # Use dictionary since testing mock always returns the same result.\r\n 966 downloaded_files = dl_manager.download({\"xml\": xml_urls})\r\n--> 967 if not pipeline.is_local():\r\n 968 downloaded_files = dl_manager.ship_files_with_pipeline(downloaded_files, pipeline)\r\n 969 \r\n\r\nAttributeError: 'Pipeline' object has no attribute 'is_local'\r\n```",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010649 / 0.011353 (-0.000704) | 0.006116 / 0.011008 (-0.004892) | 0.115568 / 0.038508 (0.077060) | 0.041704 / 0.023109 (0.018595) | 0.360459 / 0.275898 (0.084561) | 0.425679 / 0.323480 (0.102200) | 0.008992 / 0.007986 (0.001006) | 0.006321 / 0.004328 (0.001993) | 0.090223 / 0.004250 (0.085973) | 0.049877 / 0.037052 (0.012824) | 0.382447 / 0.258489 (0.123958) | 0.406567 / 0.293841 (0.112726) | 0.045138 / 0.128546 (-0.083409) | 0.014203 / 0.075646 (-0.061444) | 0.388897 / 0.419271 (-0.030375) | 0.057176 / 0.043533 (0.013644) | 0.358729 / 0.255139 (0.103590) | 0.386086 / 0.283200 (0.102887) | 0.119221 / 0.141683 (-0.022462) | 1.731574 / 1.452155 (0.279419) | 1.744103 / 1.492716 (0.251386) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230380 / 0.018006 (0.212373) | 0.493690 / 0.000490 (0.493201) | 0.005150 / 0.000200 (0.004950) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030771 / 0.037411 (-0.006641) | 0.123196 / 0.014526 (0.108671) | 0.134097 / 0.176557 (-0.042459) | 0.190442 / 0.737135 (-0.546693) | 0.138416 / 0.296338 (-0.157923) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469763 / 0.215209 (0.254554) | 4.682847 / 2.077655 (2.605192) | 2.076717 / 1.504120 (0.572597) | 1.843721 / 1.541195 (0.302527) | 1.923486 / 1.468490 (0.454996) | 0.817680 / 4.584777 (-3.767097) | 4.482409 / 3.745712 (0.736697) | 3.898695 / 5.269862 (-1.371167) | 2.078291 / 4.565676 (-2.487386) | 0.100285 / 0.424275 (-0.323990) | 0.014761 / 0.007607 (0.007154) | 0.611261 / 0.226044 (0.385217) | 5.926919 / 2.268929 (3.657990) | 2.685080 / 55.444624 (-52.759544) | 2.232179 / 6.876477 (-4.644298) | 2.305576 / 2.142072 (0.163504) | 0.993729 / 4.805227 (-3.811498) | 0.194491 / 6.500664 (-6.306173) | 0.074176 / 0.075469 (-0.001293) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.388592 / 1.841788 (-0.453196) | 17.146945 / 8.074308 (9.072636) | 15.989570 / 10.191392 (5.798178) | 0.200147 / 0.680424 (-0.480277) | 0.034009 / 0.534201 (-0.500192) | 0.517531 / 0.579283 (-0.061753) | 0.533966 / 0.434364 (0.099602) | 0.637024 / 0.540337 (0.096687) | 0.749166 / 1.386936 (-0.637770) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008240 / 0.011353 (-0.003113) | 0.006139 / 0.011008 (-0.004869) | 0.112258 / 0.038508 (0.073750) | 0.039001 / 0.023109 (0.015891) | 0.449467 / 0.275898 (0.173569) | 0.483422 / 0.323480 (0.159942) | 0.006176 / 0.007986 (-0.001810) | 0.006340 / 0.004328 (0.002012) | 0.083105 / 0.004250 (0.078855) | 0.047002 / 0.037052 (0.009950) | 0.458564 / 0.258489 (0.200075) | 0.513704 / 0.293841 (0.219863) | 0.041359 / 0.128546 (-0.087188) | 0.014515 / 0.075646 (-0.061131) | 0.392599 / 0.419271 (-0.026673) | 0.055222 / 0.043533 (0.011690) | 0.446956 / 0.255139 (0.191817) | 0.469194 / 0.283200 (0.185994) | 0.118212 / 0.141683 (-0.023471) | 1.682647 / 1.452155 (0.230492) | 1.780076 / 1.492716 (0.287360) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.259124 / 0.018006 (0.241117) | 0.507559 / 0.000490 (0.507069) | 0.001080 / 0.000200 (0.000880) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031969 / 0.037411 (-0.005442) | 0.126997 / 0.014526 (0.112471) | 0.139593 / 0.176557 (-0.036963) | 0.182735 / 0.737135 (-0.554400) | 0.145871 / 0.296338 (-0.150468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.530894 / 0.215209 (0.315685) | 5.284979 / 2.077655 (3.207324) | 2.592886 / 1.504120 (1.088766) | 2.407202 / 1.541195 (0.866007) | 2.434079 / 1.468490 (0.965589) | 0.829382 / 4.584777 (-3.755395) | 4.481710 / 3.745712 (0.735998) | 3.912280 / 5.269862 (-1.357581) | 1.962291 / 4.565676 (-2.603386) | 0.101840 / 0.424275 (-0.322435) | 0.014528 / 0.007607 (0.006921) | 0.639956 / 0.226044 (0.413911) | 6.414685 / 2.268929 (4.145756) | 3.240290 / 55.444624 (-52.204334) | 2.795208 / 6.876477 (-4.081269) | 2.912122 / 2.142072 (0.770050) | 0.992188 / 4.805227 (-3.813039) | 0.200701 / 6.500664 (-6.299964) | 0.074235 / 0.075469 (-0.001234) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.455075 / 1.841788 (-0.386712) | 17.186669 / 8.074308 (9.112361) | 15.404357 / 10.191392 (5.212965) | 0.168267 / 0.680424 (-0.512157) | 0.020774 / 0.534201 (-0.513427) | 0.502603 / 0.579283 (-0.076680) | 0.506500 / 0.434364 (0.072136) | 0.624245 / 0.540337 (0.083907) | 0.735529 / 1.386936 (-0.651407) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-15T12:38:05Z | 2023-01-25T15:49:25Z | null | CONTRIBUTOR | null | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5364/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | https://api.github.com/repos/huggingface/datasets/issues/5363/events | https://github.com/huggingface/datasets/issues/5363 | 1,498,171,317 | I_kwDODunzps5ZTEe1 | 5,363 | Dataset.from_generator() crashes on simple example | {
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"events_url": "https://api.github.com/users/villmow/events{/privacy}",
"followers_url": "https://api.github.com/users/villmow/followers",
"following_url": "https://api.github.com/users/villmow/following{/other_user}",
"gists_url": "https://api.github.com/users/villmow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/villmow",
"id": 2743060,
"login": "villmow",
"node_id": "MDQ6VXNlcjI3NDMwNjA=",
"organizations_url": "https://api.github.com/users/villmow/orgs",
"received_events_url": "https://api.github.com/users/villmow/received_events",
"repos_url": "https://api.github.com/users/villmow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/villmow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/villmow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/villmow"
} | [] | closed | false | null | [] | null | [] | 2022-12-15T10:21:28Z | 2022-12-15T11:51:33Z | 2022-12-15T11:51:33Z | NONE | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5363/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "https://api.github.com/users/shaoyuta/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/shaoyuta",
"id": 52023469,
"login": "shaoyuta",
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"organizations_url": "https://api.github.com/users/shaoyuta/orgs",
"received_events_url": "https://api.github.com/users/shaoyuta/received_events",
"repos_url": "https://api.github.com/users/shaoyuta/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/shaoyuta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shaoyuta/subscriptions",
"type": "User",
"url": "https://api.github.com/users/shaoyuta"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
}
] | null | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at the Hugging Face Hub, we are not hosting their data for this dataset, but only a script that downloads the data from their servers. We are updating the data URL to one in another server.\r\n\r\nIn the meantime, please note that you can train your model in the entire \"the_pile\" dataset, by passing the \"all\" config (instead of the \"enron_emails\" one).",
"We have transferred this issue to the corresponding dataset Community tab: https://huggingface.co/datasets/the_pile/discussions/2\r\n\r\nPlease, follow the updates there."
] | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | NONE | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to reproduce the bug
Steps to reproduce this issue:
git clone https://github.com/huggingface/transformers
cd transformers
python examples/pytorch/language-modeling/run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --dataset_name the_pile --dataset_config_name enron_emails --do_eval --output_dir /tmp/output --overwrite_output_dir
### Expected behavior
This issue looks like due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst " couldn't be reached.
Is there another way to download the dataset "the_pile" ?
Is there another way to cache the dataset "the_pile" but not let the hg to download it when runtime ?
### Environment info
huggingface_hub version: 0.11.1
Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.35
Python version: 3.9.12
Running in iPython ?: No
Running in notebook ?: No
Running in Google Colab ?: No
Token path ?: /home/taosy/.huggingface/token
Has saved token ?: False
Configured git credential helpers:
FastAI: N/A
Tensorflow: N/A
Torch: N/A
Jinja2: N/A
Graphviz: N/A
Pydot: N/A | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bayartsogt-ya",
"id": 43239645,
"login": "bayartsogt-ya",
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bayartsogt-ya"
} | [] | open | false | null | [] | null | [
"You can try something like this ?\r\n```python\r\ndef mapper_function(batch):\r\n return {\"concatenated_audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset = dataset.map(\r\n mapper_function,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n```",
"Thanks for the snippet!\r\n\r\nOne more question. I wonder why those two mappers are working so different that one taking 4 sec while other taking over 1 min :\r\n\r\n```python\r\n%%time\r\ndef mapper_function1(batch):\r\n # list_audio\r\n return {\r\n \"audio\": [\r\n {\r\n \"array\": np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]]),\r\n \"sampling_rate\": 16_000,\r\n }\r\n ]\r\n }\r\n\r\ndataset.map(\r\n mapper_function1,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n\r\n# 100%\r\n# 135/135 [01:13<00:00, 1.93ba/s]\r\n# CPU times: user 1min 10s, sys: 3.21 s, total: 1min 13s\r\n# Wall time: 1min 13s\r\n# Dataset({\r\n# features: ['audio'],\r\n# num_rows: 135\r\n# })\r\n\r\n# --------------------------------\r\n%%time\r\ndef mapper_function2(batch):\r\n # list_audio\r\n return {\"audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset.map(\r\n mapper_function2,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n\r\n# 100%\r\n# 135/135 [00:03<00:00, 40.69ba/s]\r\n# CPU times: user 1.88 s, sys: 1.48 s, total: 3.36 s\r\n# Wall time: 4.8 s\r\n# Dataset({\r\n# features: ['audio'],\r\n# num_rows: 135\r\n# })\r\n```\r\n",
"In the first one you get a dataset with an Audio type, and in the second one you get a dataset with a sequence of floats type.\r\n\r\nThe Audio type encodes the data as WAV to save disk space, so it takes more time to create.\r\nThe Audio type is automatically inferred because you modify the column \"audio\" which was already an Audio type. If you name it to something else, type inference will use a type struct with array and sampling rate fields."
] | 2022-12-14T18:13:55Z | 2022-12-15T10:53:28Z | null | NONE | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batch), 3)
dataset = dataset.map(mapper_function, batch=True, batch_size=24)
print(dataset)
# Expected output:
# Dataset({
# features: ['path', 'audio'],
# num_rows: 8
# })
```
I tried to construct `result={}` dictionary inside the mapper function, I just found it will not work because it needs `byte` also needed :((
I'd appreciate if your share any use cases similar to my problem or any solutions really. Thanks!
cc: @lhoestq
### Steps to reproduce the bug
1. load audio dataset
2. try to merge every k audios and return as one
### Expected behavior
Merged dataset with a fewer rows. If we merge every 3 rows, then `n // 3` number of examples.
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | https://api.github.com/repos/huggingface/datasets/issues/5360/events | https://github.com/huggingface/datasets/issues/5360 | 1,496,947,177 | I_kwDODunzps5ZOZnp | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | [
"If you use huggingface trainer, you will find the trainer has wrapped a `IterableDatasetShard` to avoid duplication.\r\nSee:\r\nhttps://github.com/huggingface/transformers/blob/dfd818420dcbad68e05a502495cf666d338b2bfb/src/transformers/trainer.py#L835\r\n",
"If you want to support it by datasets natively, maybe we also need to change the code in `transformers` ?",
"Opened https://github.com/huggingface/transformers/issues/20770 to discuss this :)",
"Maybe something like this then ?\r\n```python\r\nfrom datasets.distributed import split_dataset_by_node\r\nds = split_dataset_by_node(ds, rank=rank, world_size=world_size)\r\n```\r\n\r\nFor map-style datasets the implementation is trivial (it can simply use `.shard()`).\r\n\r\nFor iterable datasets we would need to implement a new ExamplesIterable that would only iterate on a subset of the (possibly shuffled and re-shuffled after each epoch) list of shards, based on the rank and world size.",
"My plan is to skip examples by default to not end up with duplicates.\r\n\r\nAnd if a dataset has a number of shards that is a factor of the world size, then I'd make it more optimized by distributing the shards evenly across nodes instead.",
"Opened a PR here: https://github.com/huggingface/datasets/pull/5369\r\n\r\nfeel free to play with it and share your feedbacks :)",
"@lhoestq I add shuffle after split_dataset_by_node, duplicated data still exist. \r\nFor example, we have a directory named `mock_pretraining_data`, which has three files, `part-00000`, `part-00002`,`part-00002`. \r\nText in `part-00000` is like this: \r\n{\"id\": 0}\r\n{\"id\": 1}\r\n{\"id\": 2}\r\n{\"id\": 3}\r\n{\"id\": 4}\r\n{\"id\": 5}\r\n{\"id\": 6}\r\n{\"id\": 7}\r\n{\"id\": 8}\r\n{\"id\": 9}\r\n\r\nand `part-00001`\r\n{\"id\": 10}\r\n{\"id\": 11}\r\n{\"id\": 12}\r\n{\"id\": 13}\r\n{\"id\": 14}\r\n{\"id\": 15}\r\n{\"id\": 16}\r\n{\"id\": 17}\r\n{\"id\": 18}\r\n{\"id\": 19}\r\n\r\nand `part-00002`\r\n{\"id\": 20}\r\n{\"id\": 21}\r\n{\"id\": 22}\r\n{\"id\": 23}\r\n{\"id\": 24}\r\n{\"id\": 25}\r\n{\"id\": 26}\r\n{\"id\": 27}\r\n{\"id\": 28}\r\n{\"id\": 29}\r\n\r\nAnd code in `test_dist.py` like this,\r\n```python\r\nimport torch\r\nfrom torch.utils.data import Dataset, DataLoader\r\nfrom datasets import load_dataset\r\nimport os\r\nfrom transformers import AutoTokenizer, NezhaForPreTraining\r\nfrom transformers import AdamW, get_linear_schedule_with_warmup\r\nimport torch.nn.functional as F\r\nimport torch.nn as nn\r\nimport torch.distributed as dist\r\nfrom datasets.distributed import split_dataset_by_node\r\nfrom torch.nn.parallel import DistributedDataParallel as DDP\r\n\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = '5,6,7'\r\n\r\ndist.init_process_group(\"nccl\")\r\nlocal_rank = int(os.environ['LOCAL_RANK'])\r\nworld_size = torch.distributed.get_world_size()\r\ndevice = torch.device('cuda', local_rank)\r\ndata_dir = './'\r\n\r\ndef load_trainset(train_path):\r\n dataset = load_dataset('json', data_dir=os.path.join(data_dir, train_path), split='train', streaming=True)\r\n return dataset\r\n\r\ndef collate_fn(examples):\r\n input_ids = []\r\n for example in examples:\r\n input_ids.append(example['id'])\r\n return torch.LongTensor(input_ids).to(device)\r\n\r\n\r\ndataset = load_trainset('mock_pretraining_data')\r\ndataset = split_dataset_by_node(dataset, rank=local_rank, world_size=world_size).shuffle(buffer_size=512)\r\n# train_sampler = torch.utils.data.distributed.DistributedSampler(dataset)\r\nbatch_size = 3\r\nprint('batch_size: {}'.format(batch_size))\r\ntrain_dataloader = DataLoader(dataset, batch_size=batch_size, collate_fn=collate_fn)\r\n\r\nfor x in train_dataloader:\r\n print({'rank': local_rank, 'id': x})\r\n```\r\nrun `python -m torch.distributed.launch --nproc_per_node=3 test_dist.py`\r\nThe output is\r\n```\r\n{'rank': 1, 'id': tensor([12, 15, 14], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([16, 10, 18], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([17, 13, 19], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([11], device='cuda:1')}\r\n{'rank': 0, 'id': tensor([0, 2, 9], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([4, 8, 1], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([5, 3, 6], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([7], device='cuda:0')}\r\n{'rank': 2, 'id': tensor([13, 15, 14], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([19, 17, 18], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([12, 16, 11], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([10], device='cuda:2')}\r\n```\r\n`part-00001` is loaded twice, `part-00002` isn't loaded.\r\n\r\nIf I run `python -m torch.distributed.launch --nproc_per_node=2 test_dist.py`\r\nThe output is weirder,many numbers appear twice\r\n```\r\n{'rank': 1, 'id': tensor([26, 8, 13], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([22, 19, 20], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([12, 28, 11], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([24, 2, 14], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([ 6, 27, 3], device='cuda:1')}\r\n{'rank': 0, 'id': tensor([ 8, 25, 1], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([20, 4, 12], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([14, 29, 5], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([ 7, 18, 23], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([19, 17, 11], device='cuda:0')}\r\n``` ",
"Hi ! Thanks for reporting, you need to pass `seed=` to `shuffle()` or the processes won't use the same seed to shuffle the shards order before assigning each shard to a node.\r\n\r\nThe issue is that the workers are not using the same seed to shuffle the shards before splitting the shards list by node.",
"Opened https://github.com/huggingface/datasets/issues/5696"
] | 2022-12-14T16:06:19Z | 2023-04-03T10:21:52Z | 2023-01-16T13:33:33Z | MEMBER | null | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5360/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | https://api.github.com/repos/huggingface/datasets/issues/5359/events | https://github.com/huggingface/datasets/pull/5359 | 1,495,297,857 | PR_kwDODunzps5FYHWm | 5,359 | Raise error if ClassLabel names is not python list | {
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"events_url": "https://api.github.com/users/freddyheppell/events{/privacy}",
"followers_url": "https://api.github.com/users/freddyheppell/followers",
"following_url": "https://api.github.com/users/freddyheppell/following{/other_user}",
"gists_url": "https://api.github.com/users/freddyheppell/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/freddyheppell",
"id": 1475568,
"login": "freddyheppell",
"node_id": "MDQ6VXNlcjE0NzU1Njg=",
"organizations_url": "https://api.github.com/users/freddyheppell/orgs",
"received_events_url": "https://api.github.com/users/freddyheppell/received_events",
"repos_url": "https://api.github.com/users/freddyheppell/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/freddyheppell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/freddyheppell/subscriptions",
"type": "User",
"url": "https://api.github.com/users/freddyheppell"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your proposed fix, @freddyheppell.\r\n\r\nCurrently the CI fails because in a test we pass a `tuple` instead of a `list`. I would say we should accept `tuple` as a valid input type as well...\r\n\r\nWhat about checking for `Sequence` instead?",
"Fixed that @albertvillanova, can you approve CI again please? Had some issues related to Pytorch .so files when running tests on my M1 mac, so wasn't able to test locally first. Have got them working on my desktop now though."
] | 2022-12-13T23:04:06Z | 2022-12-22T16:35:49Z | 2022-12-22T16:32:49Z | CONTRIBUTOR | null | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5359/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"merged_at": "2022-12-22T16:32:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5359"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5358/comments | https://api.github.com/repos/huggingface/datasets/issues/5358/events | https://github.com/huggingface/datasets/pull/5358 | 1,495,270,822 | PR_kwDODunzps5FYBcq | 5,358 | Fix `fs.open` resource leaks | {
"avatar_url": "https://avatars.githubusercontent.com/u/297847?v=4",
"events_url": "https://api.github.com/users/tkukurin/events{/privacy}",
"followers_url": "https://api.github.com/users/tkukurin/followers",
"following_url": "https://api.github.com/users/tkukurin/following{/other_user}",
"gists_url": "https://api.github.com/users/tkukurin/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tkukurin",
"id": 297847,
"login": "tkukurin",
"node_id": "MDQ6VXNlcjI5Nzg0Nw==",
"organizations_url": "https://api.github.com/users/tkukurin/orgs",
"received_events_url": "https://api.github.com/users/tkukurin/received_events",
"repos_url": "https://api.github.com/users/tkukurin/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tkukurin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tkukurin/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tkukurin"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko Sorry, I didn't check tests/style after doing a merge from the Git UI last week. Thx for fixing. \r\n\r\nFYI I'm getting \"Only those with [write access](https://docs.github.com/articles/what-are-the-different-access-permissions) to this repository can merge pull requests.\" so it seems somebody else needs to merge this.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008816 / 0.011353 (-0.002536) | 0.004691 / 0.011008 (-0.006317) | 0.100039 / 0.038508 (0.061531) | 0.035422 / 0.023109 (0.012313) | 0.312600 / 0.275898 (0.036702) | 0.378684 / 0.323480 (0.055204) | 0.007593 / 0.007986 (-0.000392) | 0.005183 / 0.004328 (0.000855) | 0.078040 / 0.004250 (0.073790) | 0.041845 / 0.037052 (0.004793) | 0.325251 / 0.258489 (0.066762) | 0.363459 / 0.293841 (0.069618) | 0.038006 / 0.128546 (-0.090540) | 0.011911 / 0.075646 (-0.063735) | 0.335020 / 0.419271 (-0.084251) | 0.048765 / 0.043533 (0.005233) | 0.305913 / 0.255139 (0.050774) | 0.337620 / 0.283200 (0.054420) | 0.101867 / 0.141683 (-0.039816) | 1.450091 / 1.452155 (-0.002064) | 1.437303 / 1.492716 (-0.055413) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225650 / 0.018006 (0.207644) | 0.492480 / 0.000490 (0.491990) | 0.002857 / 0.000200 (0.002658) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026231 / 0.037411 (-0.011180) | 0.105479 / 0.014526 (0.090953) | 0.118438 / 0.176557 (-0.058119) | 0.167313 / 0.737135 (-0.569822) | 0.119416 / 0.296338 (-0.176923) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396233 / 0.215209 (0.181024) | 3.943325 / 2.077655 (1.865671) | 1.778864 / 1.504120 (0.274744) | 1.587957 / 1.541195 (0.046763) | 1.615404 / 1.468490 (0.146914) | 0.709427 / 4.584777 (-3.875350) | 3.823310 / 3.745712 (0.077598) | 3.461376 / 5.269862 (-1.808486) | 1.888330 / 4.565676 (-2.677346) | 0.086910 / 0.424275 (-0.337365) | 0.012215 / 0.007607 (0.004608) | 0.504877 / 0.226044 (0.278833) | 5.051513 / 2.268929 (2.782584) | 2.249389 / 55.444624 (-53.195235) | 1.890949 / 6.876477 (-4.985528) | 2.015584 / 2.142072 (-0.126489) | 0.862313 / 4.805227 (-3.942914) | 0.166295 / 6.500664 (-6.334369) | 0.061131 / 0.075469 (-0.014338) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.201804 / 1.841788 (-0.639984) | 14.589425 / 8.074308 (6.515117) | 13.855522 / 10.191392 (3.664130) | 0.193406 / 0.680424 (-0.487018) | 0.028614 / 0.534201 (-0.505587) | 0.439857 / 0.579283 (-0.139426) | 0.443330 / 0.434364 (0.008966) | 0.514078 / 0.540337 (-0.026259) | 0.608245 / 1.386936 (-0.778691) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007087 / 0.011353 (-0.004265) | 0.005024 / 0.011008 (-0.005985) | 0.096852 / 0.038508 (0.058344) | 0.032870 / 0.023109 (0.009761) | 0.397790 / 0.275898 (0.121892) | 0.420717 / 0.323480 (0.097237) | 0.005552 / 0.007986 (-0.002434) | 0.003742 / 0.004328 (-0.000586) | 0.074788 / 0.004250 (0.070537) | 0.048030 / 0.037052 (0.010977) | 0.398520 / 0.258489 (0.140031) | 0.460919 / 0.293841 (0.167078) | 0.037652 / 0.128546 (-0.090894) | 0.012249 / 0.075646 (-0.063397) | 0.333077 / 0.419271 (-0.086194) | 0.052364 / 0.043533 (0.008831) | 0.394358 / 0.255139 (0.139219) | 0.414193 / 0.283200 (0.130994) | 0.103569 / 0.141683 (-0.038114) | 1.499208 / 1.452155 (0.047053) | 1.619481 / 1.492716 (0.126764) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.229476 / 0.018006 (0.211470) | 0.448670 / 0.000490 (0.448180) | 0.000399 / 0.000200 (0.000199) | 0.000056 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027550 / 0.037411 (-0.009862) | 0.109180 / 0.014526 (0.094654) | 0.118372 / 0.176557 (-0.058185) | 0.153136 / 0.737135 (-0.583999) | 0.122689 / 0.296338 (-0.173650) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445163 / 0.215209 (0.229954) | 4.426350 / 2.077655 (2.348695) | 2.194902 / 1.504120 (0.690782) | 2.019049 / 1.541195 (0.477854) | 2.032795 / 1.468490 (0.564305) | 0.700752 / 4.584777 (-3.884025) | 3.797616 / 3.745712 (0.051903) | 2.046414 / 5.269862 (-3.223447) | 1.345037 / 4.565676 (-3.220639) | 0.085389 / 0.424275 (-0.338886) | 0.012824 / 0.007607 (0.005217) | 0.553875 / 0.226044 (0.327831) | 5.550252 / 2.268929 (3.281323) | 2.702822 / 55.444624 (-52.741803) | 2.346257 / 6.876477 (-4.530220) | 2.410772 / 2.142072 (0.268699) | 0.848271 / 4.805227 (-3.956957) | 0.170787 / 6.500664 (-6.329877) | 0.064344 / 0.075469 (-0.011125) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266222 / 1.841788 (-0.575566) | 14.501194 / 8.074308 (6.426886) | 13.413678 / 10.191392 (3.222286) | 0.589048 / 0.680424 (-0.091375) | 0.018246 / 0.534201 (-0.515955) | 0.425221 / 0.579283 (-0.154062) | 0.425900 / 0.434364 (-0.008464) | 0.494023 / 0.540337 (-0.046314) | 0.604324 / 1.386936 (-0.782612) |\n\n</details>\n</details>\n\n\n"
] | 2022-12-13T22:35:51Z | 2023-01-05T16:46:31Z | 2023-01-05T15:59:51Z | CONTRIBUTOR | null | Invoking `{load,save}_from_dict` results in resource leak warnings, this should fix.
Introduces no significant logic changes. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5358/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5358",
"merged_at": "2023-01-05T15:59:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5358"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5357/comments | https://api.github.com/repos/huggingface/datasets/issues/5357/events | https://github.com/huggingface/datasets/pull/5357 | 1,495,029,602 | PR_kwDODunzps5FXNyR | 5,357 | Support torch dataloader without torch formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Need some more time to fix the tests, especially with pickle",
"> And I actually don't quite understand the idea - what's the motivation behind making only IterableDataset compatible with torch DataLoader without setting the format explicitly?\r\n\r\nSetting the format to pytorch = set the output types of the dataset to be pytorch tensors. However sometimes your dataset is not made of tensors but you still want to be able to use a pytorch DataLoader",
"A bit more context. \r\n\r\nThe arrow-backed `Dataset` supports `DataLoader(ds)` (even if the format is not \"torch\"), and we want to be able to do the same with `IterableDataset` for consistency. However, this is when the PyTorch internals come into play - an iterable dataset needs to be an instance of `torch.utils.data.IterableDataset` due to [this](https://github.com/pytorch/pytorch/blob/abc54f93145830b502400faa92bec86e05422fbd/torch/utils/data/dataloader.py#L276) check (notice there is no check for the map-style version). Hence the explicit subclassing in this PR.",
"Exactly :) Btw I just took your comments into account @polinaeterna , so feel free to review again",
"@lhoestq just checking, does this change still preserve the fix to the \"data duplicate when setting num_works > 1 with streaming data\" issue from before?\r\n\r\nhttps://github.com/huggingface/datasets/issues/3423",
"Yes :)"
] | 2022-12-13T19:39:24Z | 2023-01-04T12:45:40Z | 2022-12-15T19:15:54Z | MEMBER | null | In https://github.com/huggingface/datasets/pull/5084 we make the torch formatting consistent with the map-style datasets formatting: a torch formatted iterable dataset will yield torch tensors.
The previous behavior of the torch formatting for iterable dataset was simply to make the iterable dataset inherit from `torch.utils.data.Dataset` to make it work in a torch DataLoader. However ideally an unformatted dataset should also work with a DataLoader. To fix that, `datasets.IterableDataset` should inherit from `torch.utils.data.IterableDataset`.
Since we don't want to import torch on startup, I created this PR to dynamically make the `datasets.IterableDataset` class inherit form the torch one when a `datasets.IterableDataset` is instantiated and if PyTorch is available.
```python
>>> from datasets import load_dataset
>>> ds = load_dataset("c4", "en", streaming=True, split="train")
>>> import torch.utils.data
>>> isinstance(ds, torch.utils.data.IterableDataset)
True
>>> dataloader = torch.utils.data.DataLoader(ds, batch_size=32, num_workers=4)
>>> for example in dataloader:
...: ...
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5357/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5357/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5357.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5357",
"merged_at": "2022-12-15T19:15:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5357.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5357"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | https://api.github.com/repos/huggingface/datasets/issues/5356/events | https://github.com/huggingface/datasets/pull/5356 | 1,494,961,609 | PR_kwDODunzps5FW-c9 | 5,356 | Clean filesystem and logging docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-13T18:54:09Z | 2022-12-14T17:25:58Z | 2022-12-14T17:22:16Z | MEMBER | null | This PR cleans the `Filesystems` and `Logging` docstrings. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5356/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"merged_at": "2022-12-14T17:22:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5355/comments | https://api.github.com/repos/huggingface/datasets/issues/5355/events | https://github.com/huggingface/datasets/pull/5355 | 1,493,076,860 | PR_kwDODunzps5FQcYG | 5,355 | Clean up Table class docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-13T00:29:47Z | 2022-12-13T18:17:56Z | 2022-12-13T18:14:42Z | MEMBER | null | This PR cleans up the `Table` class docstrings :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5355/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5355.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5355",
"merged_at": "2022-12-13T18:14:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5355.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5355"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | https://api.github.com/repos/huggingface/datasets/issues/5354/events | https://github.com/huggingface/datasets/issues/5354 | 1,492,174,125 | I_kwDODunzps5Y8MUt | 5,354 | Consider using "Sequence" instead of "List" | {
"avatar_url": "https://avatars.githubusercontent.com/u/15568078?v=4",
"events_url": "https://api.github.com/users/tranhd95/events{/privacy}",
"followers_url": "https://api.github.com/users/tranhd95/followers",
"following_url": "https://api.github.com/users/tranhd95/following{/other_user}",
"gists_url": "https://api.github.com/users/tranhd95/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tranhd95",
"id": 15568078,
"login": "tranhd95",
"node_id": "MDQ6VXNlcjE1NTY4MDc4",
"organizations_url": "https://api.github.com/users/tranhd95/orgs",
"received_events_url": "https://api.github.com/users/tranhd95/received_events",
"repos_url": "https://api.github.com/users/tranhd95/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tranhd95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tranhd95/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tranhd95"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avinashsai",
"id": 22453634,
"login": "avinashsai",
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avinashsai"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/avinashsai",
"id": 22453634,
"login": "avinashsai",
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"type": "User",
"url": "https://api.github.com/users/avinashsai"
}
] | null | [
"Hi! Linking a comment to provide more info on the issue: https://stackoverflow.com/a/39458225. This means we should replace all (most of) the occurrences of `List` with `Sequence` in function signatures.\r\n\r\n@tranhd95 Would you be interested in submitting a PR?",
"Hi all! I tried to reproduce this issue and didn't work for me. Also in your example i noticed that the variables have different names: `list_of_filenames` and `list_of_files`, could this be related to that?\r\n```python\r\n#I found random data in parquet format:\r\n!wget \"https://github.com/Teradata/kylo/raw/master/samples/sample-data/parquet/userdata1.parquet\"\r\n!wget \"https://github.com/Teradata/kylo/raw/master/samples/sample-data/parquet/userdata2.parquet\"\r\n\r\n#Then i try reproduce\r\nlist_of_files = [\"userdata1.parquet\", \"userdata2.parquet\"]\r\nds = Dataset.from_parquet(list_of_files)\r\n```\r\n**My output:**\r\n```python\r\nWARNING:datasets.builder:Using custom data configuration default-e287d097dc54e046\r\nDownloading and preparing dataset parquet/default to /root/.cache/huggingface/datasets/parquet/default-e287d097dc54e046/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...\r\nDownloading data files: 100%\r\n1/1 [00:00<00:00, 40.38it/s]\r\nExtracting data files: 100%\r\n1/1 [00:00<00:00, 23.43it/s]\r\nDataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/default-e287d097dc54e046/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec. Subsequent calls will reuse this data.\r\n```\r\nP.S. This is my first experience with open source. So do not judge strictly if I do not understand something)",
"@dantema There is indeed a typo in variable names. Nevertheless, I'm sorry if I was not clear but the output is from `mypy` type checker. You can run the code snippet without issues. The problem is with the type checking.",
"However, I found out that the type annotation is actually misleading. The [`from_parquet`](https://github.com/huggingface/datasets/blob/5ef1ab1cc06c2b7a574bf2df454cd9fcb071ccb2/src/datasets/arrow_dataset.py#L1039) method should also accept list of [`PathLike`](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/typing.py#L8) objects which includes [`os.PathLike`](https://docs.python.org/3/library/os.html#os.PathLike). But if I would ran the code snippet below, an exception is thrown.\r\n\r\n**Code**\r\n```py\r\nfrom pathlib import Path\r\n\r\nlist_of_filenames = [Path(\"foo.parquet\"), Path(\"bar.parquet\")]\r\nds = Dataset.from_parquet(list_of_filenames)\r\n```\r\n**Output**\r\n```py\r\n[/usr/local/lib/python3.8/dist-packages/datasets/arrow_dataset.py](https://localhost:8080/#) in from_parquet(path_or_paths, split, features, cache_dir, keep_in_memory, columns, **kwargs)\r\n 1071 from .io.parquet import ParquetDatasetReader\r\n 1072 \r\n-> 1073 return ParquetDatasetReader(\r\n 1074 path_or_paths,\r\n 1075 split=split,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/io/parquet.py](https://localhost:8080/#) in __init__(self, path_or_paths, split, features, cache_dir, keep_in_memory, streaming, **kwargs)\r\n 35 path_or_paths = path_or_paths if isinstance(path_or_paths, dict) else {self.split: path_or_paths}\r\n 36 hash = _PACKAGED_DATASETS_MODULES[\"parquet\"][1]\r\n---> 37 self.builder = Parquet(\r\n 38 cache_dir=cache_dir,\r\n 39 data_files=path_or_paths,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/builder.py](https://localhost:8080/#) in __init__(self, cache_dir, config_name, hash, base_path, info, features, use_auth_token, repo_id, data_files, data_dir, name, **config_kwargs)\r\n 298 \r\n 299 if data_files is not None and not isinstance(data_files, DataFilesDict):\r\n--> 300 data_files = DataFilesDict.from_local_or_remote(\r\n 301 sanitize_patterns(data_files), base_path=base_path, use_auth_token=use_auth_token\r\n 302 )\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)\r\n 794 for key, patterns_for_key in patterns.items():\r\n 795 out[key] = (\r\n--> 796 DataFilesList.from_local_or_remote(\r\n 797 patterns_for_key,\r\n 798 base_path=base_path,\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in from_local_or_remote(cls, patterns, base_path, allowed_extensions, use_auth_token)\r\n 762 ) -> \"DataFilesList\":\r\n 763 base_path = base_path if base_path is not None else str(Path().resolve())\r\n--> 764 data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)\r\n 765 origin_metadata = _get_origin_metadata_locally_or_by_urls(data_files, use_auth_token=use_auth_token)\r\n 766 return cls(data_files, origin_metadata)\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/data_files.py](https://localhost:8080/#) in resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)\r\n 357 data_files = []\r\n 358 for pattern in patterns:\r\n--> 359 if is_remote_url(pattern):\r\n 360 data_files.append(Url(pattern))\r\n 361 else:\r\n\r\n[/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py](https://localhost:8080/#) in is_remote_url(url_or_filename)\r\n 62 \r\n 63 def is_remote_url(url_or_filename: str) -> bool:\r\n---> 64 parsed = urlparse(url_or_filename)\r\n 65 return parsed.scheme in (\"http\", \"https\", \"s3\", \"gs\", \"hdfs\", \"ftp\")\r\n 66 \r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in urlparse(url, scheme, allow_fragments)\r\n 373 Note that we don't break the components up in smaller bits\r\n 374 (e.g. netloc is a single string) and we don't expand % escapes.\"\"\"\r\n--> 375 url, scheme, _coerce_result = _coerce_args(url, scheme)\r\n 376 splitresult = urlsplit(url, scheme, allow_fragments)\r\n 377 scheme, netloc, url, query, fragment = splitresult\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in _coerce_args(*args)\r\n 125 if str_input:\r\n 126 return args + (_noop,)\r\n--> 127 return _decode_args(args) + (_encode_result,)\r\n 128 \r\n 129 # Result objects are more helpful than simple tuples\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in _decode_args(args, encoding, errors)\r\n 109 def _decode_args(args, encoding=_implicit_encoding,\r\n 110 errors=_implicit_errors):\r\n--> 111 return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n 112 \r\n 113 def _coerce_args(*args):\r\n\r\n[/usr/lib/python3.8/urllib/parse.py](https://localhost:8080/#) in <genexpr>(.0)\r\n 109 def _decode_args(args, encoding=_implicit_encoding,\r\n 110 errors=_implicit_errors):\r\n--> 111 return tuple(x.decode(encoding, errors) if x else '' for x in args)\r\n 112 \r\n 113 def _coerce_args(*args):\r\n\r\nAttributeError: 'PosixPath' object has no attribute 'decode'\r\n```\r\n\r\n@mariosasko Should I create a new issue? ",
"@mariosasko I would like to take this issue up. ",
"@avinashsai Hi, I've assigned you the issue.\r\n\r\n@tranhd95 Yes, feel free to report this in a new issue."
] | 2022-12-12T15:39:45Z | 2023-02-24T16:15:46Z | null | NONE | null | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
list_of_filenames = ["foo.parquet", "bar.parquet"]
ds = Dataset.from_parquet(list_of_filenames)
```
**Expected mypy output:**
```
Success: no issues found
```
**Actual mypy output:**
```py
test.py:19: error: Argument 1 to "from_parquet" of "Dataset" has incompatible type "List[str]"; expected "Union[Union[str, bytes, PathLike[Any]], List[Union[str, bytes, PathLike[Any]]]]" [arg-type]
test.py:19: note: "List" is invariant -- see https://mypy.readthedocs.io/en/stable/common_issues.html#variance
test.py:19: note: Consider using "Sequence" instead, which is covariant
```
**Env:** mypy 0.991, Python 3.10.0, datasets 2.7.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5354/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | https://api.github.com/repos/huggingface/datasets/issues/5353/events | https://github.com/huggingface/datasets/issues/5353 | 1,491,880,500 | I_kwDODunzps5Y7Eo0 | 5,353 | Support remote file systems for `Audio` | {
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"events_url": "https://api.github.com/users/OllieBroadhurst/events{/privacy}",
"followers_url": "https://api.github.com/users/OllieBroadhurst/followers",
"following_url": "https://api.github.com/users/OllieBroadhurst/following{/other_user}",
"gists_url": "https://api.github.com/users/OllieBroadhurst/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/OllieBroadhurst",
"id": 46894149,
"login": "OllieBroadhurst",
"node_id": "MDQ6VXNlcjQ2ODk0MTQ5",
"organizations_url": "https://api.github.com/users/OllieBroadhurst/orgs",
"received_events_url": "https://api.github.com/users/OllieBroadhurst/received_events",
"repos_url": "https://api.github.com/users/OllieBroadhurst/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/OllieBroadhurst/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/OllieBroadhurst/subscriptions",
"type": "User",
"url": "https://api.github.com/users/OllieBroadhurst"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Just seen https://github.com/huggingface/datasets/issues/5281"
] | 2022-12-12T13:22:13Z | 2022-12-12T13:37:14Z | 2022-12-12T13:37:14Z | NONE | null | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datasets across first, so if you're working off a system with smaller disk specs (like a VM), you can run out of space very quickly.
### Your contribution
Something like this (for Google Cloud Platform in this instance):
```python
from datasets import Dataset, Audio
import gcsfs
fs = gcsfs.GCSFileSystem()
list_of_audio_fp = {'audio': ['1', '2', '3']}
ds = Dataset.from_dict(list_of_audio_fp)
ds = ds.cast_column("audio", Audio(sampling_rate=16000, fs=fs))
```
Under the hood:
```python
import librosa
from io import BytesIO
def load_audio(fp, sampling_rate=None, fs=None):
if fs is not None:
with fs.open(fp, 'rb') as f:
arr, sr = librosa.load(BytesIO(f), sr=sampling_rate)
else:
# Perform existing io operations
```
Written from memory so some things could be wrong. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5353/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5352/comments | https://api.github.com/repos/huggingface/datasets/issues/5352/events | https://github.com/huggingface/datasets/issues/5352 | 1,490,796,414 | I_kwDODunzps5Y279- | 5,352 | __init__() got an unexpected keyword argument 'input_size' | {
"avatar_url": "https://avatars.githubusercontent.com/u/82662111?v=4",
"events_url": "https://api.github.com/users/J-shel/events{/privacy}",
"followers_url": "https://api.github.com/users/J-shel/followers",
"following_url": "https://api.github.com/users/J-shel/following{/other_user}",
"gists_url": "https://api.github.com/users/J-shel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/J-shel",
"id": 82662111,
"login": "J-shel",
"node_id": "MDQ6VXNlcjgyNjYyMTEx",
"organizations_url": "https://api.github.com/users/J-shel/orgs",
"received_events_url": "https://api.github.com/users/J-shel/received_events",
"repos_url": "https://api.github.com/users/J-shel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/J-shel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/J-shel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/J-shel"
} | [] | open | false | null | [] | null | [
"Hi @J-shel, thanks for reporting.\r\n\r\nI think the issue comes from your call to `load_dataset`. As first argument, you should pass:\r\n- either the name of your dataset (\"mrf\") if this is already published on the Hub\r\n- or the path to the loading script of your dataset (\"path/to/your/local/mrf.py\").",
"Hi, following your suggestion, I changed my call to load_dataset. Below is the latest:\r\nreader = load_dataset('data/mrf.py',\"default\", input_size=1024, split=split, streaming=True, keep_in_memory=None)\r\nHowever, I still got the same error.\r\nI have one question that is if I only define input_size=2048 in BUILDER_CONFIGS, may I specify input_size=1024 when loading the dataset? Cause I found that I could only specify name=\"default\" since I only define name=\"default\" in BUILDER_CONFIGS."
] | 2022-12-12T02:52:03Z | 2022-12-19T01:38:48Z | null | NONE | null | ### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I got an error "__init__() got an unexpected keyword argument 'input_size'"
### Steps to reproduce the bug
Following is the code to define the dataset:
class CsvConfig(datasets.BuilderConfig):
"""BuilderConfig for CSV."""
input_size: int = 2048
class MRF(datasets.ArrowBasedBuilder):
"""Archival MRF data"""
BUILDER_CONFIG_CLASS = CsvConfig
VERSION = datasets.Version("1.0.0")
BUILDER_CONFIGS = [
CsvConfig(name="default", version=VERSION, description="MRF data", input_size=2048),
]
...
def _generate_examples(self):
input_size = self.config.input_size
if input_size > 1000:
numin = 10000
else:
numin = 15000
Below is the code to load the dataset:
reader = load_dataset("default", input_size=1024)
### Expected behavior
I hope to pass the "input_size" parameter to MRF datasets, and change "input_size" to any value when loading the datasets.
### Environment info
- `datasets` version: 2.5.1
- Platform: Linux-4.18.0-305.3.1.el8.x86_64-x86_64-with-glibc2.31
- Python version: 3.9.12
- PyArrow version: 9.0.0
- Pandas version: 1.5.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5352/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5351/comments | https://api.github.com/repos/huggingface/datasets/issues/5351/events | https://github.com/huggingface/datasets/issues/5351 | 1,490,659,504 | I_kwDODunzps5Y2aiw | 5,351 | Do we need to implement `_prepare_split`? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"events_url": "https://api.github.com/users/jmwoloso/events{/privacy}",
"followers_url": "https://api.github.com/users/jmwoloso/followers",
"following_url": "https://api.github.com/users/jmwoloso/following{/other_user}",
"gists_url": "https://api.github.com/users/jmwoloso/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jmwoloso",
"id": 7530947,
"login": "jmwoloso",
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"organizations_url": "https://api.github.com/users/jmwoloso/orgs",
"received_events_url": "https://api.github.com/users/jmwoloso/received_events",
"repos_url": "https://api.github.com/users/jmwoloso/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jmwoloso/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmwoloso/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jmwoloso"
} | [] | closed | false | null | [] | null | [
"Hi! `DatasetBuilder` is a parent class for concrete builders: `GeneratorBasedBuilder`, `ArrowBasedBuilder` and `BeamBasedBuilder`. When writing a builder script, these classes are the ones you should inherit from. And since all of them implement `_prepare_split`, you only have to implement the three methods mentioned above.",
"Thanks so much @mariosasko for the fast response! I've been referencing [this page in the docs](https://huggingface.co/docs/datasets/v2.4.0/en/about_dataset_load) because it it pretty comprehensive in terms of what we have to do and I figured since we subclass the `BuilderConfig` the same pattern would hold, but I've also seen the page with those sub-classed builders as well, so that fills in a knowledge gap for me.",
"cc @stevhliu who may have some ideas on how to improve this part of the docs.",
"one more question for my understanding @mariosasko. the requirement of a loading script has always seemed counterintuitive to me. if i have to provide a script with every dataset, what is the point of using `datasets` if we're doing all the work of loading it, I can just do that in my code and skip the datasets integration (this of course discounts other potential benefits around metadata management, etc., my example is just simplest use case though for the sake of discussion).\r\n\r\nso i figured I would implement my own `BuilderConfig` and `DatasetBuilder` to handle that portion of it and not have to make a script. i _thought_ this would result in `datasets` (via `download_and_prepare`) then making me something that I could load using `load_dataset` moving forward.\r\n\r\nConcretely, i envisioned this pattern being possible:\r\n\r\n ```\r\nclass MyBuilderConfig(BuilderConfig):\r\n def __init__(self, name=\"my_named_dataset\", ...):\r\n super().__init__(name, ...)\r\n\r\nclass MyDatasetBuilder(GeneratorBasedBuilder):\r\n BUILDER_CONFIG_CLASS = MyBuilderConfig\r\n ....\r\n\r\nmy_builder = MyDatasetBuilder(...)\r\n\r\n# this doesn't exactly work like I thought; I don't get a dataset back, but NoneType instead\r\n# though I can see it loading the files and it generates the cache, etc.\r\nmy_dataset = my_builder.download_and_prepare()\r\n\r\n# load the dataset in the future by referencing it by name and loading from the cached arrow version\r\nnew_instance_of_my_dataset = load_dataset(\"my_named_dataset\")\r\n```\r\n\r\nI've seen references to the `save_to_disk` method which might be the next step I need in order to load it by name, in which case, that makes sense, then i just need to debug why `download_and_prepare` isn't returning me a dataset, but I feel like I still have a larger conceptual knowledge gap on how to use the library correctly.\r\n\r\nThanks again in advance!",
"> the requirement of a loading script has always seemed counterintuitive to me\r\n\r\nThis is a requirement only for datasets not stored in standard formats such as CSV, JSON, SQL, Parquet, ImageFolder, etc. \r\n\r\n> if i have to provide a script with every dataset, what is the point of using datasets if we're doing all the work of loading it, I can just do that in my code and skip the datasets integration (this of course discounts other potential benefits around metadata management, etc., my example is just simplest use case though for the sake of discussion)\r\n\r\nOur README/documentation lists the main features... \r\n\r\nOne of the main ones is that our library makes it easy to work with datasets larger than RAM (thanks to Arrow and the caching mechanism), and this is not trivial to implement.\r\n\r\nRegarding the step-by-step builder, this is the pattern:\r\n```python\r\nfrom datasets import load_dataset_builder\r\nbuilder = load_dataset_builder(\"path/to/script\") # or direct instantiation with MyDatasetBuilder(...)\r\nbuilder.download_and_prepare()\r\ndset = builder.as_dataset()\r\n```",
"ok, that makes sense. thank you @mariosasko. I realized i'd never looked on the hub at any of the files associated with any datasets. just did that now and it appears that i'll need to have a script regardless _but_ that will just contain my custom config and builder classes, so without realizing it I was already making my script, I just need to wrap that in a file that sits alongside my data (I looked at Glue and realized I was already doing what I thought didn't make sense to have to do, lol).\r\n\r\n`download_and_prepare` isn't returning me a dataset though, but I'll look into that and open another issue if I can't figure it out.",
"`download_and_prepare` downloads and prepares the arrow files. You need to call `as_dataset` on the builder to get the dataset.",
"ok, I think I was assigning the output of `builder.download_and_prepare` but it's an inplace op, so that explains the `NoneType` i was getting back. Now I'm getting:\r\n\r\n```\r\nArrowInvalid Traceback (most recent call last)\r\n<ipython-input-7-3ed50fb87c70> in <module>\r\n----> 1 ds = dataset_builder.as_dataset()\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/builder.py in as_dataset(self, split, run_post_process, ignore_verifications, in_memory)\r\n 1020 \r\n 1021 # Create a dataset for each of the given splits\r\n-> 1022 datasets = map_nested(\r\n 1023 partial(\r\n 1024 self._build_single_dataset,\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, parallel_min_length, types, disable_tqdm, desc)\r\n 442 num_proc = 1\r\n 443 if num_proc <= 1 or len(iterable) < parallel_min_length:\r\n--> 444 mapped = [\r\n 445 _single_map_nested((function, obj, types, None, True, None))\r\n 446 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/utils/py_utils.py in <listcomp>(.0)\r\n 443 if num_proc <= 1 or len(iterable) < parallel_min_length:\r\n 444 mapped = [\r\n--> 445 _single_map_nested((function, obj, types, None, True, None))\r\n 446 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)\r\n 447 ]\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/utils/py_utils.py in _single_map_nested(args)\r\n 344 # Singleton first to spare some computation\r\n 345 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):\r\n--> 346 return function(data_struct)\r\n 347 \r\n 348 # Reduce logging to keep things readable in multiprocessing with tqdm\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/builder.py in _build_single_dataset(self, split, run_post_process, ignore_verifications, in_memory)\r\n 1051 \r\n 1052 # Build base dataset\r\n-> 1053 ds = self._as_dataset(\r\n 1054 split=split,\r\n 1055 in_memory=in_memory,\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/builder.py in _as_dataset(self, split, in_memory)\r\n 1120 \"\"\"\r\n 1121 cache_dir = self._fs._strip_protocol(self._output_dir)\r\n-> 1122 dataset_kwargs = ArrowReader(cache_dir, self.info).read(\r\n 1123 name=self.name,\r\n 1124 instructions=split,\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/arrow_reader.py in read(self, name, instructions, split_infos, in_memory)\r\n 236 msg = f'Instruction \"{instructions}\" corresponds to no data!'\r\n 237 raise ValueError(msg)\r\n--> 238 return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)\r\n 239 \r\n 240 def read_files(\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/arrow_reader.py in read_files(self, files, original_instructions, in_memory)\r\n 257 \"\"\"\r\n 258 # Prepend path to filename\r\n--> 259 pa_table = self._read_files(files, in_memory=in_memory)\r\n 260 # If original_instructions is not None, convert it to a human-readable NamedSplit\r\n 261 if original_instructions is not None:\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/arrow_reader.py in _read_files(self, files, in_memory)\r\n 192 f[\"filename\"] = os.path.join(self._path, f[\"filename\"])\r\n 193 for f_dict in files:\r\n--> 194 pa_table: Table = self._get_table_from_filename(f_dict, in_memory=in_memory)\r\n 195 pa_tables.append(pa_table)\r\n 196 pa_tables = [t for t in pa_tables if len(t) > 0]\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/arrow_reader.py in _get_table_from_filename(self, filename_skip_take, in_memory)\r\n 327 filename_skip_take[\"take\"] if \"take\" in filename_skip_take else None,\r\n 328 )\r\n--> 329 table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n 330 if take == -1:\r\n 331 take = len(table) - skip\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/arrow_reader.py in read_table(filename, in_memory)\r\n 348 \"\"\"\r\n 349 table_cls = InMemoryTable if in_memory else MemoryMappedTable\r\n--> 350 return table_cls.from_file(filename)\r\n 351 \r\n 352 \r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/table.py in from_file(cls, filename, replays)\r\n 1034 @classmethod\r\n 1035 def from_file(cls, filename: str, replays=None):\r\n-> 1036 table = _memory_mapped_arrow_table_from_file(filename)\r\n 1037 table = cls._apply_replays(table, replays)\r\n 1038 return cls(table, filename, replays)\r\n\r\n/databricks/python/lib/python3.8/site-packages/datasets/table.py in _memory_mapped_arrow_table_from_file(filename)\r\n 48 def _memory_mapped_arrow_table_from_file(filename: str) -> pa.Table:\r\n 49 memory_mapped_stream = pa.memory_map(filename)\r\n---> 50 opened_stream = pa.ipc.open_stream(memory_mapped_stream)\r\n 51 pa_table = opened_stream.read_all()\r\n 52 return pa_table\r\n\r\n/databricks/python/lib/python3.8/site-packages/pyarrow/ipc.py in open_stream(source)\r\n 152 reader : RecordBatchStreamReader\r\n 153 \"\"\"\r\n--> 154 return RecordBatchStreamReader(source)\r\n 155 \r\n 156 \r\n\r\n/databricks/python/lib/python3.8/site-packages/pyarrow/ipc.py in __init__(self, source)\r\n 43 \r\n 44 def __init__(self, source):\r\n---> 45 self._open(source)\r\n 46 \r\n 47 \r\n\r\n/databricks/python/lib/python3.8/site-packages/pyarrow/ipc.pxi in pyarrow.lib._RecordBatchStreamReader._open()\r\n\r\n/databricks/python/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()\r\n\r\n/databricks/python/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()\r\n\r\nArrowInvalid: Tried reading schema message, was null or length 0\r\n```\r\n\r\n",
"looks like my arrow files are all empty @mariosasko \r\n\r\n\r\n\r\n\r\ni also see the `incomplete_info.lock` file a level up too. seems like the data isn't being persisted to disk when I call `download_and_prepare`. is there something else i need to do before then, perhaps?",
"quick update @mariosasko. i got it working! i had to downgrade to `datasets==2.4.0`. testing other versions now and will let you know the results.",
"I've tested with every version of `datasets>2.4.0` and i get the same error with all of them."
] | 2022-12-12T01:38:54Z | 2022-12-20T18:20:57Z | 2022-12-12T16:48:56Z | NONE | null | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to implement, hence the genesis of my question):
```
Traceback (most recent call last):
File "/home/jason/source/python/prism_machine_learning/examples/create_hf_datasets.py", line 28, in <module>
dataset_builder.download_and_prepare()
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/jason/.virtualenvs/pml/lib/python3.8/site-packages/datasets/builder.py", line 1124, in _prepare_split
raise NotImplementedError()
NotImplementedError
```
### Steps to reproduce the bug
I will share implementation if it turns out that everything should be working (i.e. we only need to implement those 3 methods the docs mention), but I don't want to distract from the original question.
### Expected behavior
I just need to know if there are additional methods we need to implement when subclassing `DatasetBuilder` besides what the documentation specifies -> `_info`, `_split_generators` and `_generate_examples`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-135-generic-x86_64-with-glibc2.2.5
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5351/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5350/comments | https://api.github.com/repos/huggingface/datasets/issues/5350/events | https://github.com/huggingface/datasets/pull/5350 | 1,487,559,904 | PR_kwDODunzps5E8y2E | 5,350 | Clean up Loading methods docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-09T22:25:30Z | 2022-12-12T17:27:20Z | 2022-12-12T17:24:01Z | MEMBER | null | Clean up for the docstrings in Loading methods! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5350/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5350",
"merged_at": "2022-12-12T17:24:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5350"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | https://api.github.com/repos/huggingface/datasets/issues/5349/events | https://github.com/huggingface/datasets/pull/5349 | 1,487,396,780 | PR_kwDODunzps5E8N6G | 5,349 | Clean up remaining Main Classes docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-09T20:17:15Z | 2022-12-12T17:27:17Z | 2022-12-12T17:24:13Z | MEMBER | null | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5349/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"merged_at": "2022-12-12T17:24:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5349"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | https://api.github.com/repos/huggingface/datasets/issues/5348/events | https://github.com/huggingface/datasets/issues/5348 | 1,486,975,626 | I_kwDODunzps5YoXKK | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://api.github.com/users/SaulLu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SaulLu",
"id": 55560583,
"login": "SaulLu",
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"organizations_url": "https://api.github.com/users/SaulLu/orgs",
"received_events_url": "https://api.github.com/users/SaulLu/received_events",
"repos_url": "https://api.github.com/users/SaulLu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SaulLu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SaulLu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SaulLu"
} | [] | open | false | null | [] | null | [
"note, that `datasets` already did some of that umask fixing in the past and also at the hub - the recent work on the hub about the same: https://github.com/huggingface/huggingface_hub/pull/1220\r\n\r\nAlso I noticed that each file has a .json counterpart and the latter always has the correct perms:\r\n\r\n```\r\n-rw------- 1 uue59kq cnw 173M Dec 9 01:37 537596e64721e2ae3d98785b91d30fda0360c196a8224e29658ad629e7303a4d\r\n-rw-rw---- 1 uue59kq cnw 101 Dec 9 01:37 537596e64721e2ae3d98785b91d30fda0360c196a8224e29658ad629e7303a4d.json\r\n```\r\n\r\nso perhaps cheating is possible and syncing the perms between the 2 will do the trick."
] | 2022-12-09T15:46:27Z | 2022-12-09T17:21:26Z | null | CONTRIBUTOR | null | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the command (and no permissions to the group). In our case, those permissions don't respect the `umask` of this user, which was `0007`.
Traceback:
```
Using custom data configuration default
Downloading and preparing dataset text_caps/default to /gpfswork/rech/cnw/commun/datasets/HuggingFaceM4___text_caps/default/1.0.0/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141...
Downloading data files: 100%|████████████████████| 3/3 [00:00<00:00, 921.62it/s]
---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
Cell In [3], line 1
----> 1 ds = load_dataset(dataset_name)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/load.py:1746, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1743 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1745 # Download and prepare data
-> 1746 builder_instance.download_and_prepare(
1747 download_config=download_config,
1748 download_mode=download_mode,
1749 ignore_verifications=ignore_verifications,
1750 try_from_hf_gcs=try_from_hf_gcs,
1751 use_auth_token=use_auth_token,
1752 )
1754 # Build dataset for splits
1755 keep_in_memory = (
1756 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1757 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:704, in DatasetBuilder.download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
702 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
703 if not downloaded_from_gcs:
--> 704 self._download_and_prepare(
705 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
706 )
707 # Sync info
708 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:1227, in GeneratorBasedBuilder._download_and_prepare(self, dl_manager, verify_infos)
1226 def _download_and_prepare(self, dl_manager, verify_infos):
-> 1227 super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/builder.py:771, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
769 split_dict = SplitDict(dataset_name=self.name)
770 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 771 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
773 # Checksums verification
774 if verify_infos and dl_manager.record_checksums:
File /gpfswork/rech/cnw/commun/modules/datasets_modules/datasets/HuggingFaceM4--TextCaps/2b9ad220cd90fcf2bfb454645bc54364711b83d6d39401ffdaf8cc40882e9141/TextCaps.py:125, in TextCapsDataset._split_generators(self, dl_manager)
123 def _split_generators(self, dl_manager):
124 # urls = _URLS[self.config.name] # TODO later
--> 125 data_dir = dl_manager.download_and_extract(_URLS)
126 gen_kwargs = {
127 split_name: {
128 f"{dir_name}_path": Path(data_dir[dir_name][split_name])
(...)
133 for split_name in ["train", "val", "test"]
134 }
136 for split_name in ["train", "val", "test"]:
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:431, in DownloadManager.download_and_extract(self, url_or_urls)
415 def download_and_extract(self, url_or_urls):
416 """Download and extract given url_or_urls.
417
418 Is roughly equivalent to:
(...)
429 extracted_path(s): `str`, extracted paths of given URL(s).
430 """
--> 431 return self.extract(self.download(url_or_urls))
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:324, in DownloadManager.download(self, url_or_urls)
321 self.downloaded_paths.update(dict(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())))
323 start_time = datetime.now()
--> 324 self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
325 duration = datetime.now() - start_time
326 logger.info(f"Checksum Computation took {duration.total_seconds() // 60} min")
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/download/download_manager.py:229, in DownloadManager._record_sizes_checksums(self, url_or_urls, downloaded_path_or_paths)
226 """Record size/checksum of downloaded files."""
227 for url, path in zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten()):
228 # call str to support PathLike objects
--> 229 self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(
230 path, record_checksum=self.record_checksums
231 )
File /gpfswork/rech/cnw/commun/conda/lucile-m4_3/lib/python3.8/site-packages/datasets/utils/info_utils.py:82, in get_size_checksum_dict(path, record_checksum)
80 if record_checksum:
81 m = sha256()
---> 82 with open(path, "rb") as f:
83 for chunk in iter(lambda: f.read(1 << 20), b""):
84 m.update(chunk)
PermissionError: [Errno 13] Permission denied: '/gpfswork/rech/cnw/commun/datasets/downloads/1e6aa6d23190c30885194fabb193dce3874d902d7636b66315ee8aaa584e80d6'
```
### Steps to reproduce the bug
I think the following will reproduce the bug.
Given 2 users belonging to the same group with `umask` set to `0007`
- first run with User 1:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/VQAv2"
ds = load_dataset(ds_name)
```
- then run with User 2:
```python
from datasets import load_dataset
ds_name = "HuggingFaceM4/TextCaps"
ds = load_dataset(ds_name)
```
### Expected behavior
No `PermissionError`
### Environment info
- `datasets` version: 2.4.0
- Platform: Linux-4.18.0-305.65.1.el8_4.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 7.0.0
- Pandas version: 1.4.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5348/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5347/comments | https://api.github.com/repos/huggingface/datasets/issues/5347/events | https://github.com/huggingface/datasets/pull/5347 | 1,486,920,261 | PR_kwDODunzps5E6jb1 | 5,347 | Force soundfile to return float32 instead of the default float64 | {
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"events_url": "https://api.github.com/users/qmeeus/events{/privacy}",
"followers_url": "https://api.github.com/users/qmeeus/followers",
"following_url": "https://api.github.com/users/qmeeus/following{/other_user}",
"gists_url": "https://api.github.com/users/qmeeus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qmeeus",
"id": 25608944,
"login": "qmeeus",
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"organizations_url": "https://api.github.com/users/qmeeus/orgs",
"received_events_url": "https://api.github.com/users/qmeeus/received_events",
"repos_url": "https://api.github.com/users/qmeeus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qmeeus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qmeeus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qmeeus"
} | [] | open | false | null | [] | null | [
"cc @polinaeterna",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5347). All of your documentation changes will be reflected on that endpoint.",
"Cool ! Feel free to add a comment in the code to explain that and we can merge :)",
"I'm not sure if this is a good change since we plan to get rid of `torchaudio` in the next couple of months...",
"What do you think @polinaeterna @patrickvonplaten ? Models are usually using float32 (e.g. Wev2vec2 in `transformers`) IIRC",
"IMO we can safely assume that float32 is always good enough when using audio models in inference or training. Nevertheless there might be use cases for audio datasets in the future where float64 is needed. \r\n\r\n=> I would by default always cast to float32, but then possible allow the user to cast to float64 ",
"> I'm not sure if this is a good change since we plan to get rid of torchaudio in the next couple of months...\r\n\r\n@mariosasko I agree but who knows how long we will have to wait until we are really able to do so (https://github.com/bastibe/libsndfile-binaries/pull/17 is a draft. so as @patrickvonplaten is okay with float32, I'd merge.\r\n\r\n\r\n",
"@polinaeterna Can you comment on the linked PR to see why it's still a draft? Maybe we can help somehow to get this merged finally.\r\n\r\nI think it's weird to align `soundfile` with `torchaudio` when the latter is only used for MP3 (and prob for not much longer). "
] | 2022-12-09T15:10:24Z | 2023-01-17T16:12:49Z | null | NONE | null | (Fixes issue #5345) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5347/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5347/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5347.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5347",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5347.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5347"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5346/comments | https://api.github.com/repos/huggingface/datasets/issues/5346/events | https://github.com/huggingface/datasets/issues/5346 | 1,486,884,983 | I_kwDODunzps5YoBB3 | 5,346 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik"
} | [] | closed | false | null | [] | null | [
"As the survey is finished, can we close this issue, @LysandreJik ?",
"Yes! I'll post a public summary on the forums shortly.",
"Is the summary available? I would be interested in reading your findings."
] | 2022-12-09T14:48:02Z | 2023-06-02T20:24:44Z | 2023-01-25T19:35:40Z | MEMBER | null | Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops](https://github.com/skops-dev/skops) libraries were born. `timm` joined the Hugging Face ecosystem. There were 25 new releases of `transformers`, 21 new releases of `datasets`, 13 new releases of `accelerate`.
If you have a couple of minutes and want to participate in shaping the future of the ecosystem, please share your thoughts:
[**hf.co/oss-survey**](https://docs.google.com/forms/d/e/1FAIpQLSf4xFQKtpjr6I_l7OfNofqiR8s-WG6tcNbkchDJJf5gYD72zQ/viewform?usp=sf_link)
(please reply in the above feedback form rather than to this thread)
Thank you all on behalf of the HuggingFace team! 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5346/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5345/comments | https://api.github.com/repos/huggingface/datasets/issues/5345/events | https://github.com/huggingface/datasets/issues/5345 | 1,486,555,384 | I_kwDODunzps5Ymwj4 | 5,345 | Wrong dtype for array in audio features | {
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"events_url": "https://api.github.com/users/qmeeus/events{/privacy}",
"followers_url": "https://api.github.com/users/qmeeus/followers",
"following_url": "https://api.github.com/users/qmeeus/following{/other_user}",
"gists_url": "https://api.github.com/users/qmeeus/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/qmeeus",
"id": 25608944,
"login": "qmeeus",
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"organizations_url": "https://api.github.com/users/qmeeus/orgs",
"received_events_url": "https://api.github.com/users/qmeeus/received_events",
"repos_url": "https://api.github.com/users/qmeeus/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/qmeeus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qmeeus/subscriptions",
"type": "User",
"url": "https://api.github.com/users/qmeeus"
} | [] | open | false | null | [] | null | [
"After some more investigation, this is due to [this line of code](https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L279). The function `sf.read(file)` should be updated to `sf.read(file, dtype=\"float32\")`\r\n\r\nIndeed, the default value in soundfile is `float64` ([see here](https://pysoundfile.readthedocs.io/en/latest/#soundfile.read)). \r\n",
"@qmeeus I agree, decoding of different audio formats should return the same dtypes indeed!\r\n\r\nBut note that here you are concatenating datasets with different sampling rates: 48000 for CommonVoice and 16000 for Voxpopuli. So you should cast them to the same sampling rate value before interleaving, for example:\r\n```\r\ncv = cv.cast_column(\"audio\", Audio(sampling_rate=16000))\r\n```\r\notherwise you would get the same error because features of the same column (\"audio\") are not the same.\r\n\r\nAlso, the error you get is unexpected. Could you please confirm that you use the latest main version of the `datasets`? We had an issue that could lead to an error like this after using `rename_column` method, but it was fixed in https://github.com/huggingface/datasets/pull/5287 ",
"Hi Polina,\r\nSorry for the late answer\r\nIt is possible that the issue was due to a bug that is now fixed. I installed an editable version of datasets from github, but I don't recall whether I had updated it at the time of the issue. My research led me to other directions so I did not follow through on the interleave datasets.\r\n"
] | 2022-12-09T11:05:11Z | 2023-02-10T14:39:28Z | null | NONE | null | ### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets cannot be merged.
### Steps to reproduce the bug
For example, for `facebook/voxpopuli` and `mozilla-foundation/common_voice_11_0`:
```
from datasets import load_dataset, interleave_datasets
covost = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True)
voxpopuli = datasets.load_dataset("facebook/voxpopuli", "nl", split="train", streaming=True)
sample_cv, = covost.take(1)
sample_vp, = voxpopuli.take(1)
assert sample_cv["audio"]["array"].dtype == sample_vp["audio"]["array"].dtype
# Fails
dataset = interleave_datasets([covost, voxpopuli])
# ValueError: The features can't be aligned because the key audio of features {'audio_id': Value(dtype='string', id=None), 'language': Value(dtype='int64', id=None), 'audio': {'array': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None), 'path': Value(dtype='string', id=None), 'sampling_rate': Value(dtype='int64', id=None)}, 'normalized_text': Value(dtype='string', id=None), 'gender': Value(dtype='string', id=None), 'speaker_id': Value(dtype='string', id=None), 'is_gold_transcript': Value(dtype='bool', id=None), 'accent': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None)} has unexpected type - {'array': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None), 'path': Value(dtype='string', id=None), 'sampling_rate': Value(dtype='int64', id=None)} (expected either Audio(sampling_rate=16000, mono=True, decode=True, id=None) or Value("null").
```
### Expected behavior
The audio should be loaded to arrays with a unique dtype (I guess `float32`)
### Environment info
```
- `datasets` version: 2.7.1.dev0
- Platform: Linux-4.18.0-425.3.1.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5345/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5344/comments | https://api.github.com/repos/huggingface/datasets/issues/5344/events | https://github.com/huggingface/datasets/pull/5344 | 1,485,628,319 | PR_kwDODunzps5E2BPN | 5,344 | Clean up Dataset and DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-09T00:02:08Z | 2022-12-13T00:56:07Z | 2022-12-13T00:53:02Z | MEMBER | null | This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5344/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5344.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5344",
"merged_at": "2022-12-13T00:53:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5344.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5344"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5343/comments | https://api.github.com/repos/huggingface/datasets/issues/5343/events | https://github.com/huggingface/datasets/issues/5343 | 1,485,297,823 | I_kwDODunzps5Yh9if | 5,343 | T5 for Q&A produces truncated sentence | {
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"events_url": "https://api.github.com/users/junyongyou/events{/privacy}",
"followers_url": "https://api.github.com/users/junyongyou/followers",
"following_url": "https://api.github.com/users/junyongyou/following{/other_user}",
"gists_url": "https://api.github.com/users/junyongyou/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/junyongyou",
"id": 13484072,
"login": "junyongyou",
"node_id": "MDQ6VXNlcjEzNDg0MDcy",
"organizations_url": "https://api.github.com/users/junyongyou/orgs",
"received_events_url": "https://api.github.com/users/junyongyou/received_events",
"repos_url": "https://api.github.com/users/junyongyou/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/junyongyou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junyongyou/subscriptions",
"type": "User",
"url": "https://api.github.com/users/junyongyou"
} | [] | closed | false | null | [] | null | [] | 2022-12-08T19:48:46Z | 2022-12-08T19:57:17Z | 2022-12-08T19:57:17Z | NONE | null | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to train the T5-large model. I have two questions.
For example, I set both the max_length, max_input_length, max_output_length to 128.
How to deal with those long answers? I just left them as is and the T5Tokenizer can automatically handle. I would assume the tokenizer just truncates an answer at the position of 128th word (or 127th). Is it possible that I manually split an answer into different parts, each part has 128 words; and then all these sub-answers serve as a separate answer to the same question?
Another question is that I get incomplete (truncated) answers when using the fine-tuned model in inference, even though the predicted answer is shorter than 128 words. I found a message posted 2 years ago saying that one should add at the end of texts when fine-tuning T5. I followed that but then got a warning message that duplicated were found. I am assuming that this is because the tokenizer truncates an answer text, thus is missing in the truncated answer, such that the end token is not produced in predicted answer. However, I am not sure. Can anybody point out how to address this issue?
Any suggestions are highly appreciated.
Below is some code snippet.
`
import pytorch_lightning as pl
from torch.utils.data import DataLoader
import torch
import numpy as np
import time
from pathlib import Path
from transformers import (
Adafactor,
T5ForConditionalGeneration,
T5Tokenizer,
get_linear_schedule_with_warmup
)
from torch.utils.data import RandomSampler
from question_answering.utils import *
class T5FineTuner(pl.LightningModule):
def __init__(self, hyparams):
super(T5FineTuner, self).__init__()
self.hyparams = hyparams
self.model = T5ForConditionalGeneration.from_pretrained(hyparams.model_name_or_path)
self.tokenizer = T5Tokenizer.from_pretrained(hyparams.tokenizer_name_or_path)
if self.hyparams.freeze_embeds:
self.freeze_embeds()
if self.hyparams.freeze_encoder:
self.freeze_params(self.model.get_encoder())
# assert_all_frozen()
self.step_count = 0
self.output_dir = Path(self.hyparams.output_dir)
n_observations_per_split = {
'train': self.hyparams.n_train,
'validation': self.hyparams.n_val,
'test': self.hyparams.n_test
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.em_score_list = []
self.subset_score_list = []
data_folder = r'C:\Datasets\MedQuAD-master'
self.train_data, self.val_data, self.test_data = load_medqa_data(data_folder)
def freeze_params(self, model):
for param in model.parameters():
param.requires_grad = False
def freeze_embeds(self):
try:
self.freeze_params(self.model.model.shared)
for d in [self.model.model.encoder, self.model.model.decoder]:
self.freeze_params(d.embed_positions)
self.freeze_params(d.embed_tokens)
except AttributeError:
self.freeze_params(self.model.shared)
for d in [self.model.encoder, self.model.decoder]:
self.freeze_params(d.embed_tokens)
def lmap(self, f, x):
return list(map(f, x))
def is_logger(self):
return self.trainer.proc_rank <= 0
def forward(self, input_ids, attention_mask=None, decoder_input_ids=None, decoder_attention_mask=None, labels=None):
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=labels
)
def _step(self, batch):
labels = batch['target_ids']
labels[labels[:, :] == self.tokenizer.pad_token_id] = -100
outputs = self(
input_ids = batch['source_ids'],
attention_mask=batch['source_mask'],
labels=labels,
decoder_attention_mask=batch['target_mask']
)
loss = outputs[0]
return loss
def ids_to_clean_text(self, generated_ids):
gen_text = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return self.lmap(str.strip, gen_text)
def _generative_step(self, batch):
t0 = time.time()
generated_ids = self.model.generate(
batch["source_ids"],
attention_mask=batch["source_mask"],
use_cache=True,
decoder_attention_mask=batch['target_mask'],
max_length=128,
num_beams=2,
early_stopping=True
)
preds = self.ids_to_clean_text(generated_ids)
targets = self.ids_to_clean_text(batch["target_ids"])
gen_time = (time.time() - t0) / batch["source_ids"].shape[0]
loss = self._step(batch)
base_metrics = {'val_loss': loss}
summ_len = np.mean(self.lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=targets)
em_score, subset_match_score = calculate_scores(preds, targets)
self.em_score_list.append(em_score)
self.subset_score_list.append(subset_match_score)
em_score = torch.tensor(em_score, dtype=torch.float32)
subset_match_score = torch.tensor(subset_match_score, dtype=torch.float32)
base_metrics.update(em_score=em_score, subset_match_score=subset_match_score)
# rouge_results = self.rouge_metric.compute()
# rouge_dict = self.parse_score(rouge_results)
return base_metrics
def training_step(self, batch, batch_idx):
loss = self._step(batch)
tensorboard_logs = {'train_loss': loss}
return {'loss': loss, 'log': tensorboard_logs}
def training_epoch_end(self, outputs):
avg_train_loss = torch.stack([x['loss'] for x in outputs]).mean()
tensorboard_logs = {'avg_train_loss': avg_train_loss}
# return {'avg_train_loss': avg_train_loss, 'log': tensorboard_logs, 'progress_bar': tensorboard_logs}
def validation_step(self, batch, batch_idx):
return self._generative_step(batch)
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss}
if len(self.em_score_list) <= 2:
average_em_score = sum(self.em_score_list) / len(self.em_score_list)
average_subset_match_score = sum(self.subset_score_list) / len(self.subset_score_list)
else:
latest_em_score = self.em_score_list[:-2]
latest_subset_score = self.subset_score_list[:-2]
average_em_score = sum(latest_em_score) / len(latest_em_score)
average_subset_match_score = sum(latest_subset_score) / len(latest_subset_score)
average_em_score = torch.tensor(average_em_score, dtype=torch.float32)
average_subset_match_score = torch.tensor(average_subset_match_score, dtype=torch.float32)
tensorboard_logs.update(em_score=average_em_score, subset_match_score=average_subset_match_score)
self.target_gen = []
self.prediction_gen = []
return {
'avg_val_loss': avg_loss,
'em_score': average_em_score,
'subset_match_socre': average_subset_match_score,
'log': tensorboard_logs,
'progress_bar': tensorboard_logs
}
def configure_optimizers(self):
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hyparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = Adafactor(optimizer_grouped_parameters, lr=self.hyparams.learning_rate, scale_parameter=False,
relative_step=False)
self.opt = optimizer
return [optimizer]
def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, optimizer_closure=None,
on_tpu=False, using_native_amp=False, using_lbfgs=False):
optimizer.step(closure=optimizer_closure)
optimizer.zero_grad()
self.lr_scheduler.step()
def get_tqdm_dict(self):
tqdm_dict = {"loss": "{:.3f}".format(self.trainer.avg_loss), "lr": self.lr_scheduler.get_last_lr()[-1]}
return tqdm_dict
def train_dataloader(self):
n_samples = self.n_obs['train']
train_dataset = get_dataset(tokenizer=self.tokenizer, data=self.train_data, num_samples=n_samples,
args=self.hyparams)
sampler = RandomSampler(train_dataset)
dataloader = DataLoader(train_dataset, sampler=sampler, batch_size=self.hyparams.train_batch_size,
drop_last=True, num_workers=4)
# t_total = (
# (len(dataloader.dataset) // (self.hyparams.train_batch_size * max(1, self.hyparams.n_gpu)))
# // self.hyparams.gradient_accumulation_steps
# * float(self.hyparams.num_train_epochs)
# )
t_total = 100000
scheduler = get_linear_schedule_with_warmup(
self.opt, num_warmup_steps=self.hyparams.warmup_steps, num_training_steps=t_total
)
self.lr_scheduler = scheduler
return dataloader
def val_dataloader(self):
n_samples = self.n_obs['validation']
validation_dataset = get_dataset(tokenizer=self.tokenizer, data=self.val_data, num_samples=n_samples,
args=self.hyparams)
sampler = RandomSampler(validation_dataset)
return DataLoader(validation_dataset, shuffle=False, batch_size=self.hyparams.eval_batch_size, sampler=sampler, num_workers=4)
def test_dataloader(self):
n_samples = self.n_obs['test']
test_dataset = get_dataset(tokenizer=self.tokenizer, data=self.test_data, num_samples=n_samples, args=self.hyparams)
return DataLoader(test_dataset, batch_size=self.hyparams.eval_batch_size, num_workers=4)
def on_save_checkpoint(self, checkpoint):
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
import os
import argparse
import pytorch_lightning as pl
from question_answering.t5_closed_book import T5FineTuner
if __name__ == '__main__':
args_dict = dict(
output_dir="", # path to save the checkpoints
model_name_or_path='t5-large',
tokenizer_name_or_path='t5-large',
max_input_length=128,
max_output_length=128,
freeze_encoder=False,
freeze_embeds=False,
learning_rate=1e-5,
weight_decay=0.0,
adam_epsilon=1e-8,
warmup_steps=0,
train_batch_size=4,
eval_batch_size=4,
num_train_epochs=2,
gradient_accumulation_steps=10,
n_gpu=1,
resume_from_checkpoint=None,
val_check_interval=0.5,
n_val=4000,
n_train=-1,
n_test=-1,
early_stop_callback=False,
fp_16=False,
opt_level='O1',
max_grad_norm=1.0,
seed=101,
)
args_dict.update({'output_dir': 't5_large_MedQuAD_256', 'num_train_epochs': 100,
'train_batch_size': 16, 'eval_batch_size': 16, 'learning_rate': 1e-3})
args = argparse.Namespace(**args_dict)
checkpoint_callback = pl.callbacks.ModelCheckpoint(dirpath=args.output_dir, monitor="em_score", mode="max", save_top_k=1)
## If resuming from checkpoint, add an arg resume_from_checkpoint
train_params = dict(
accumulate_grad_batches=args.gradient_accumulation_steps,
gpus=args.n_gpu,
max_epochs=args.num_train_epochs,
# early_stop_callback=False,
precision=16 if args.fp_16 else 32,
# amp_level=args.opt_level,
# resume_from_checkpoint=args.resume_from_checkpoint,
gradient_clip_val=args.max_grad_norm,
checkpoint_callback=checkpoint_callback,
val_check_interval=args.val_check_interval,
# accelerator='dp'
# logger=wandb_logger,
# callbacks=[LoggingCallback()],
)
model = T5FineTuner(args)
trainer = pl.Trainer(**train_params)
trainer.fit(model)
` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5343/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | https://api.github.com/repos/huggingface/datasets/issues/5342/events | https://github.com/huggingface/datasets/issues/5342 | 1,485,244,178 | I_kwDODunzps5YhwcS | 5,342 | Emotion dataset cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/78887193?v=4",
"events_url": "https://api.github.com/users/cbarond/events{/privacy}",
"followers_url": "https://api.github.com/users/cbarond/followers",
"following_url": "https://api.github.com/users/cbarond/following{/other_user}",
"gists_url": "https://api.github.com/users/cbarond/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cbarond",
"id": 78887193,
"login": "cbarond",
"node_id": "MDQ6VXNlcjc4ODg3MTkz",
"organizations_url": "https://api.github.com/users/cbarond/orgs",
"received_events_url": "https://api.github.com/users/cbarond/received_events",
"repos_url": "https://api.github.com/users/cbarond/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cbarond/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cbarond/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cbarond"
} | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | [] | null | [
"Hi @cbarond there's already an open issue at https://github.com/dair-ai/emotion_dataset/issues/5, as the data seems to be missing now, so check that issue instead 👍🏻 ",
"Thanks @cbarond for reporting and @alvarobartt for pointing to the issue we opened in the author's repo.\r\n\r\nIndeed, this issue was first raised in the \"emotion\" dataset Community tab: https://huggingface.co/datasets/emotion/discussions/3\r\n\r\nI'm closing this issue and leave the issue above for the subsequent updates.\r\n\r\nDuplicate of: https://huggingface.co/datasets/emotion/discussions/3",
"try using \"SetFit/emotion\" instead",
"> try using \"SetFit/emotion\" instead\r\n\r\nI' replaced \"emotion\" with \"SetFit/Emotion\", but the code is getting stuck at\r\n\r\n`emotions = load_dataset(\"SetFit/emotion\")`\r\n\r\nI pause execution using the debugger, and it takes me to filelock.py:226\r\n\r\n`with self._thread_lock:`\r\n\r\nDo you know a way to get past this issue?",
"thanks @honeyimholm - worked for me",
"> try using \"SetFit/emotion\" instead\r\n\r\nIt really helps a lot, thank you!",
"The dataset loading script has been fixed: https://huggingface.co/datasets/emotion/discussions/4"
] | 2022-12-08T19:07:09Z | 2023-02-23T19:13:19Z | 2022-12-09T10:46:11Z | NONE | null | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("emotion")
```
### Expected behavior
The dataset should load properly.
### Environment info
- `datasets` version: 2.7.1
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.9.13
- PyArrow version: 10.0.1
- Pandas version: 1.5.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5342/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5341/comments | https://api.github.com/repos/huggingface/datasets/issues/5341/events | https://github.com/huggingface/datasets/pull/5341 | 1,484,376,644 | PR_kwDODunzps5Exohx | 5,341 | Remove tasks.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-08T11:04:35Z | 2022-12-09T12:26:21Z | 2022-12-09T12:23:20Z | MEMBER | null | After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5341/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5341",
"merged_at": "2022-12-09T12:23:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5341"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5340/comments | https://api.github.com/repos/huggingface/datasets/issues/5340/events | https://github.com/huggingface/datasets/pull/5340 | 1,483,182,158 | PR_kwDODunzps5EtWo3 | 5,340 | Clean up DatasetInfo and Dataset docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-08T00:17:53Z | 2022-12-08T19:33:14Z | 2022-12-08T19:30:10Z | MEMBER | null | This PR cleans up the docstrings for `DatasetInfo` and about half of the methods in `Dataset`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5340/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5340",
"merged_at": "2022-12-08T19:30:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5340"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5339/comments | https://api.github.com/repos/huggingface/datasets/issues/5339/events | https://github.com/huggingface/datasets/pull/5339 | 1,482,817,424 | PR_kwDODunzps5EsC8N | 5,339 | Add Video feature, videofolder, and video-classification task | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5339). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think I need some serious help with the tests 😅...I started this locally but it got too time consuming.\n\nOne issue I remember running into is with lossless audio encoding/decoding. I started thinking of using the underlying Audio feature instead of PyAV so I didn't have to rewrite similar logic here...but assumed that would turn into a mess w/ underlying logic"
] | 2022-12-07T20:48:34Z | 2023-01-05T23:54:12Z | null | CONTRIBUTOR | null | This PR does the following:
- Adds `Video` feature (Resolves #5225 )
- Adds `video-classification` task
- Adds `videofolder` packaged module for easy loading of local video classification datasets
TODO:
- [ ] add tests
- [ ] add docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5339/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5339/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5339.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5339",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5339.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5339"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5338/comments | https://api.github.com/repos/huggingface/datasets/issues/5338/events | https://github.com/huggingface/datasets/issues/5338 | 1,482,646,151 | I_kwDODunzps5YX2KH | 5,338 | `map()` stops every 1000 steps | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bayartsogt-ya",
"id": 43239645,
"login": "bayartsogt-ya",
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bayartsogt-ya"
} | [] | closed | false | null | [] | null | [
"Hi !\r\n\r\n> It starts using all the cores (I am not sure why because I did not pass num_proc)\r\n\r\nThe tokenizer uses Rust code that is multithreaded. And maybe the `feature_extractor` might run some things in parallel as well - but I'm not super familiar with its internals.\r\n\r\n> then progress bar stops at every 1k steps. (starts using a single core)\r\n\r\nEvery 1000 examples we flush the processed examples to disk. It is this way because Arrow is a columnar format: you must write data chunk by chunk. The processing in on hold while writing right now - maybe this can be improved in the future.",
"Hi @lhoestq \r\nThanks for the explanation! it was so helpful! Let me check why `feature_extractor` is running on multiple cpus."
] | 2022-12-07T19:09:40Z | 2022-12-10T00:39:29Z | 2022-12-10T00:39:28Z | NONE | null | ### Describe the bug
I am passing the following `prepare_dataset` function to `Dataset.map` (code is inspired from [here](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_speech_recognition_seq2seq_streaming.py#L454))
```python3
def prepare_dataset(batch):
# load and resample audio data from 48 to 16kHz
audio = batch["audio"]
# compute log-Mel input features from input audio array
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# encode target text to label ids
batch["labels"] = tokenizer(batch[text_column]).input_ids
return batch
...
train_ds = train_ds.map(prepare_dataset)
```
Here is the exact code I am running https://github.com/bayartsogt-ya/whisper-multiple-hf-datasets/blob/main/train.py#L70-L71
It starts using all the cores (I am not sure why because I did not pass `num_proc`)
then progress bar stops at every 1k steps. (starts using a single core)
then come back to using all the cores again.
link to [screen record](https://youtu.be/jPQpQQGp6Gc)
Can someone explain this process and maybe provide a way to improve this pipeline? cc: @lhoestq
### Steps to reproduce the bug
1. load the dataset
2. create a Whisper processor
3. create a `prepare_dataset` function
4. pass the function to `dataset.map(prepare_dataset)`
### Expected behavior
- Use a single core per a function
- not to stop at some point?
### Environment info
- `datasets` version: 2.7.1.dev0
- Platform: Linux-5.4.0-109-generic-x86_64-with-glibc2.27
- Python version: 3.8.10
- PyArrow version: 10.0.1
- Pandas version: 1.5.2 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5338/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5337/comments | https://api.github.com/repos/huggingface/datasets/issues/5337/events | https://github.com/huggingface/datasets/issues/5337 | 1,481,692,156 | I_kwDODunzps5YUNP8 | 5,337 | Support webdataset format | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko"
}
] | null | [
"I like the idea of having `webdataset` as an optional dependency to ensure our loader generates web datasets the same way as the main project.",
"Webdataset is the one of the most popular dataset formats for large scale computer vision tasks. Upvote for this issue. ",
"Any updates on this?",
"We haven't had the bandwidth to implement it so far, but if someone wants to give it a shot please don't hesitate ^^"
] | 2022-12-07T11:32:25Z | 2023-05-26T10:34:45Z | null | MEMBER | null | Webdataset is an efficient format for iterable datasets. It would be nice to support it in `datasets`, as discussed in https://github.com/rom1504/img2dataset/issues/234.
In particular it would be awesome to be able to load one using `load_dataset` in streaming mode (either from a local directory, or from a dataset on the Hugging Face Hub). Some datasets on the Hub are already in webdataset format.
It terms of implementation, we can have something similar to the Parquet loader.
I also think it's fine to have webdataset as an optional dependency. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5337/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5336/comments | https://api.github.com/repos/huggingface/datasets/issues/5336/events | https://github.com/huggingface/datasets/pull/5336 | 1,479,649,900 | PR_kwDODunzps5Egzed | 5,336 | Set `IterableDataset.map` param `batch_size` typing as optional | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/alvarobartt",
"id": 36760800,
"login": "alvarobartt",
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"type": "User",
"url": "https://api.github.com/users/alvarobartt"
} | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5336). All of your documentation changes will be reflected on that endpoint.",
"Hi @mariosasko, @lhoestq I was wondering whether we should include `batched` as a `pytest.mark` param for the functions testing `IterableDataset.map` so as to ensure that the changes done in this PR work fine without breaking anything of the actual functionality.\r\n\r\nI've pushed updated tests just for one of the unit testing functions to be run as `pytest tests/test_iterable_dataset.py::test_mapped_examples_iterable -s --durations 0`, but some are still missing `batched` param, it was just to ask you whether we're supposed to do this for the rest of the functions or not, if it's a yes I'll push the commit as it's ready, but didn't want to push extra stuff that may be discarded later!\r\n\r\nThanks :hugs:",
"Thanks for the feedback @lhoestq, I agree with keeping `Optional` instead of `Union[type, None]` for now 👍🏻"
] | 2022-12-06T17:08:10Z | 2022-12-07T14:14:56Z | 2022-12-07T14:06:27Z | CONTRIBUTOR | null | This PR solves #5325
~Indeed we're using the typing for optional values as `Union[type, None]` as it's similar to how Python 3.10 handles optional values as `type | None`, instead of using `Optional[type]`.~
~Do we want to start using `Union[type, None]` for type-hinting optional values or just keep on using `Optional`?~ -> Keeping `Optional` still for consistency with the rest of the code in `datasets`
Also we now allow `batch_size` to be `None` for `IterableDataset.map` and `IterableDataset.filter`e.g. `MappedExamplesIterable` as `map` is internally instantiating those and propagating the `batch_size` param so if it can be `None` for `map` it should also do so for `MappedExamplesIterable`, as well as for `FilteredExamplesIterable` when calling `IterableDataset.filter`.
## TODOs
- [x] Add integration tests
- [x] Handle scenario where `batched=True` and `batch_size=None` or `batch_size<=0` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5336/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5336.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5336",
"merged_at": "2022-12-07T14:06:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5336.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5336"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5335 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5335/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5335/comments | https://api.github.com/repos/huggingface/datasets/issues/5335/events | https://github.com/huggingface/datasets/pull/5335 | 1,478,890,788 | PR_kwDODunzps5EeHdA | 5,335 | Update tasks.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/sayakpaul",
"id": 22957388,
"login": "sayakpaul",
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"type": "User",
"url": "https://api.github.com/users/sayakpaul"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think the only place where we need to add it is here https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts\r\n\r\nAnd I think we can remove tasks.json completely from this repo",
"Isn't tasks.json used anymore in this repo?",
"> I think the only place where we need to add it is here https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts\r\n> \r\n> And I think we can remove tasks.json completely from this repo\r\n\r\nWhat about the warning I mentioned in https://github.com/huggingface/datasets/issues/5255#issuecomment-1339013527? Also, the depth estimation entry is already present in https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts. ",
"The update is based on what I received in the output of the export job (c.f. https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195). \r\n\r\nEdit: Oh, are you referring to the dataset card of NYU Depth V2?",
"Yes, my suggestion was for the dataset card: you got the error message because you tried to set `depth-estimation` in `class_ids` instead of `class_categories`.",
"> What about the warning I mentioned in https://github.com/huggingface/datasets/issues/5255#issuecomment-1339013527? Also, the depth estimation entry is already present in https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts.\r\n\r\nif you place it in `task_categories` you should be good :)",
"yes i would suggest rm'ing tasks.json here for clarity",
"Closing it. ",
"It's not clear if we can remove it btw, since old versions of `evaluate` rely on it (see https://github.com/huggingface/evaluate/pull/309)\r\n\r\ncc @lvwerra ",
"Actually it can be removed without incidence in old versions of evaluate since we kept an hardcoded `known_task_ids` that is marked \"DEPRECATED\""
] | 2022-12-06T11:37:57Z | 2022-12-08T11:05:33Z | 2022-12-07T12:46:03Z | MEMBER | null | Context:
* https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195
Cc: @osanseviero | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5335/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5335/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5335.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5335",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5335.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5335"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5334/comments | https://api.github.com/repos/huggingface/datasets/issues/5334/events | https://github.com/huggingface/datasets/pull/5334 | 1,477,421,927 | PR_kwDODunzps5EY9zN | 5,334 | Clean up docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stevhliu",
"id": 59462357,
"login": "stevhliu",
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stevhliu"
} | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! Let us know if we can help :)\r\n\r\nSmall pref for having multiple PRs",
"Awesome, thanks! Sorry this one is a little big, I'll open some smaller ones next :)"
] | 2022-12-05T20:56:08Z | 2022-12-09T01:44:25Z | 2022-12-09T01:41:44Z | MEMBER | null | As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you prefer one big PR with all the cleaned changes or multiple smaller ones)! 🧼 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5334/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5334.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5334",
"merged_at": "2022-12-09T01:41:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5334.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5334"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5333/comments | https://api.github.com/repos/huggingface/datasets/issues/5333/events | https://github.com/huggingface/datasets/pull/5333 | 1,476,890,156 | PR_kwDODunzps5EXGQ2 | 5,333 | fix: 🐛 pass the token to get the list of config names | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo"
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-05T16:06:09Z | 2022-12-06T08:25:17Z | 2022-12-06T08:22:49Z | CONTRIBUTOR | null | Otherwise, get_dataset_infos doesn't work on gated or private datasets, even with the correct token. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5333/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5333.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5333",
"merged_at": "2022-12-06T08:22:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5333.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5333"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5332 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5332/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5332/comments | https://api.github.com/repos/huggingface/datasets/issues/5332/events | https://github.com/huggingface/datasets/issues/5332 | 1,476,513,072 | I_kwDODunzps5YAc0w | 5,332 | Passing numpy array to ClassLabel names causes ValueError | {
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"events_url": "https://api.github.com/users/freddyheppell/events{/privacy}",
"followers_url": "https://api.github.com/users/freddyheppell/followers",
"following_url": "https://api.github.com/users/freddyheppell/following{/other_user}",
"gists_url": "https://api.github.com/users/freddyheppell/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/freddyheppell",
"id": 1475568,
"login": "freddyheppell",
"node_id": "MDQ6VXNlcjE0NzU1Njg=",
"organizations_url": "https://api.github.com/users/freddyheppell/orgs",
"received_events_url": "https://api.github.com/users/freddyheppell/received_events",
"repos_url": "https://api.github.com/users/freddyheppell/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/freddyheppell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/freddyheppell/subscriptions",
"type": "User",
"url": "https://api.github.com/users/freddyheppell"
} | [] | closed | false | null | [] | null | [
"Should `datasets` allow `ClassLabel` input parameter to be an `np.array` even though internally we need to cast it to a Python list? @lhoestq @mariosasko ",
"Hi! No, I don't think so. The `names` parameter is [annotated](https://github.com/huggingface/datasets/blob/582236640b9109988e5f7a16a8353696ffa09a16/src/datasets/features/features.py#L892) as `List[str]` (**NumPy arrays are not lists**), and considering that type checking is not a common practice in Python, I think we can leave the code as-is.",
"I appreciate it is the wrong type, and that type checking is not common, but I think there's a few circumstances that make it a good idea from a usability perspective.\r\n\r\nIt's quite a difficult error to debug because it comes from a utility function (so it's not immediately obvious which parameter caused it). What makes it even more difficult is the exception happens when the features instance is used to instantiate the dataset, **not** when when the wrong type is actually passed when the features is instantiated. When I was debugging the error, I didn't really consider it could be an issue with the features instance because it had instantiated fine. It's also not one of the more common exceptions caused by trying to use a non-list as a list.\r\n\r\nIt's also relatively easy to accidentally get a numpy array of class types (e.g. calling `unique()` on a pandas dataframe column). Additionally, passing in a `set` instead of the list (again, relatively easy because people may run `set(classes)` to generate uniques) causes an error when the features instance is used, albeit a slightly more obvious one.\r\n\r\nThe names list is already being processed and validated in the `__post_init__` method anyway, so it would not really be adding any complexity to check it is actually a list here too. I'm happy to contribute this change if you change your mind about whether it's worthwhile.",
"I agree that it's not easy to debug this issue, so perhaps we could add some basic type checking (e.g. `not isinstance(names, list)` -> error) to make debugging easier. Feel free to submit a PR.\r\n\r\n> Additionally, passing in a set instead of the list (again, relatively easy because people may run set(classes) to generate uniques) causes an error when the features instance is used, albeit a slightly more obvious one.\r\n\r\n`set` is an unordered structure (it's ordered in Python 3.6+, but this is CPython's implementation detail), and the order of ClassLabel `names` matters, so this doesn't require a fix.",
"What about checking for `Sequence` instead? I think users can pass a list or a tuple as well."
] | 2022-12-05T12:59:03Z | 2022-12-22T16:32:50Z | 2022-12-22T16:32:50Z | CONTRIBUTOR | null | ### Describe the bug
If a numpy array is passed to the names argument of ClassLabel, creating a dataset with those features causes an error.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1cV_es1PWZiEuus17n-2C-w0KEoEZ68IX
TLDR:
If I define my classes as:
```
my_classes = np.array(['one', 'two', 'three'])
```
Then this errors:
```py
features = Features({'value': Value('string'), 'label': ClassLabel(names=my_classes)})
dataset = Dataset.from_list(my_data, features=features)
```
```
ValueError Traceback (most recent call last)
[<ipython-input-8-a8a9d53ec82f>](https://localhost:8080/#) in <module>
----> 1 dataset = Dataset.from_list(my_data, features=features)
11 frames
[/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py](https://localhost:8080/#) in _asdict_inner(obj)
183 for f in fields(obj):
184 value = _asdict_inner(getattr(obj, f.name))
--> 185 if not f.init or value != f.default or f.metadata.get("include_in_asdict_even_if_is_default", False):
186 result[f.name] = value
187 return result
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
```
But this works:
```
features2 = Features({'value': Value('string'), 'label': ClassLabel(names=list(my_classes))})
dataset2 = Dataset.from_list(my_data, features=features2)
```
### Expected behavior
If I provide a numpy array of class names, I would expect either an error that the names list is the wrong type, or for it to be cast internally.
### Environment info
- `datasets` version: 2.7.1
- Platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 10.0.1
- Pandas version: 1.5.2
Additionally:
- Numpy version: 1.23.5
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5332/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5332/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5331 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5331/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5331/comments | https://api.github.com/repos/huggingface/datasets/issues/5331/events | https://github.com/huggingface/datasets/pull/5331 | 1,473,146,738 | PR_kwDODunzps5EKDpr | 5,331 | Support for multiple configs in packaged modules via metadata yaml info | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/polinaeterna",
"id": 16348744,
"login": "polinaeterna",
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"type": "User",
"url": "https://api.github.com/users/polinaeterna"
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5331). All of your documentation changes will be reflected on that endpoint.",
"feel free to merge `main` into your PR to fix the CI :)",
"Let me see if I can fix the pattern thing ^^'",
"Hmm I think it would be easier to specify the `data_files` in the end, because having a split pattern like `{split}-...` at the root of the repository can lead to unexpected behaviors IMO, and we probably don't want to have a different behavior for `data_files` depending if it's inside a `data_dir` or not\r\n\r\nMaybe something like\r\n```yaml\r\nbuilder_config:\r\n data_dir: data_dir\r\n data_files:\r\n - split: train\r\n pattern: train-[0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]*.*\r\n```",
" > Also, I'm not sure if it's a good idea to have this field in the YAML metadata - Transformers use this part of the card only for Hub-related stuff (widgets, tags, CO2 emission, etc.), and I think we should aim to do the same in Datasets. We could achieve this by having these kwargs in a special file (they can be seen as a faster way of defining a builder (builder script) that subclasses a packaged builder) and removing the dataset_info field (the only useful info there seem to be features and we can fetch those directly from a dataset script/Parquet files).\r\n\r\nSomething like `config.json`?\r\n\r\n```json\r\n{\r\n \"data_dir\": \"data\"\r\n \"data_files\": {\r\n \"train\": \"train-[0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]*.*\"\r\n }\r\n}\r\n```\r\n\r\nwe could also support lists for several configs",
"opened https://github.com/huggingface/datasets/issues/5694",
"I opened a PR to this PR to add data_files in YAML: https://github.com/polinaeterna/datasets/pull/1\r\n\r\n```yaml\r\nbuilder_config:\r\n data_files:\r\n - split: train\r\n pattern: data/train-*\r\n```",
"Let me open a PR to see if I can move the data files resolution outside of the MetadataConfigs to not modify it in-place",
"I wonder if we can make the cache backward compatible: we could just check if the cache directory with the old path exists. It will be useful for the research team which has a big datasets cache",
"> I wonder if we can make the cache backward compatible: we could just check if the cache directory with the old path exists. It will be useful for the research team which has a big datasets cache\r\n\r\n\r\n\r\nIn the next PR maybe? :D \r\nIt's possible but requires some additional logic to correctly pass old `config_kwargs` (which used to include `data_files` but now it's `None` for builders from metadata) to generate the hash which is used to create the path.",
"If we only consider datasets that were pushed to hub, it's just a matter of using `\"{username}__parquet\"` instead of `\"{username}__{dataset_name}\"` in the cache directory name. The hashes stay the same :)\r\n\r\nEDIT: and the config name\r\nEDIT2: and the arrow file names",
"Did a small PR for backward compatibility, it was easy to add in the end: https://github.com/polinaeterna/datasets/pull/3",
"Just created a branch [dev-3.0](https://github.com/huggingface/datasets/tree/dev-3.0) in which we can merge this one and the other datasets 3.0 related PRs",
"@lhoestq why can't we merge it in main?",
"We can, it was just in case we had other things to merge after @mariosasko or @albertvillanova 's reviews",
"@lhoestq @albertvillanova @mariosasko we agreed on having `configs` (in plural) as a metadata field in readme but apparently Hub's yaml validation doesn't allow it to be not a list :D \r\n\r\n(with `config` (in singular) it works)\r\n\r\nedit: and now the tests for hub datasets with metadata configs are failing because I cannot change the yaml there...",
"> we agreed on having configs (in plural) as a metadata field in readme but apparently Hub's yaml validation doesn't allow it to be not a list :D\r\n\r\nIf the `configs` field is specified in the YAML, the Hub can use it to [improve](https://github.com/huggingface/moon-landing/blob/97aca4cac32fbb7d84ce5eba9b18afad87968c4a/server/views/components/DatasetLibraryModal/datasetLibrarySnippets.ts#L11) the `Use in dataset library` snippet by listing the possible config values in `load_dataset`. So I think this needs to be fixed on the Hub side.\r\n\r\nPS: I couldn't find an instance of someone using this field on the Hub, so I think using it for this feature is OK.",
"> I couldn't find an instance of someone using this field on the Hub, so I think using it for this feature is OK.\r\n\r\n@mariosasko I think it's because @lhoestq renamed `configs` to `config_names` in all canonical datasets :D so yes, `configs` field is now supposed to include custom configuration parameters introduced in this PR, and `config_names` is used (not really used lol) for list of strings of config names. It's being fixed on the Hub's side https://github.com/huggingface/moon-landing/pull/6490",
"after more thought I agree it's maybe overkill to do a major release for this one, since we have a good backward compatibility",
"There is one edge case I forgot to mention in the reviews - I think it's a good idea to support passing config params that are functions (Pandas uses them a lot) using this API (e.g. `converters` in the CSV config for converting a string column into a sequence). I see two solutions: string blocks with Python code in YAML or PyYAML [tags](https://pyyaml.org/wiki/PyYAMLDocumentation#yaml-tags-and-python-types). \r\n\r\nBut I think this can be addressed later."
] | 2022-12-02T16:43:44Z | 2023-06-13T17:15:22Z | null | CONTRIBUTOR | null | will solve https://github.com/huggingface/datasets/issues/5209 and https://github.com/huggingface/datasets/issues/5151 and many other...
Config parameters for packaged builders are parsed from `“builder_config”` field in README.md file (separate firs-level field, not part of “dataset_info”), example:
```yaml
---
dataset_info:
...
builder_config:
- config_name: v1
data_dir: v1
drop_labels: true
- config_name: v2
data_dir: v2
drop_labels: false
```
I tried to align packaged builders with custom configs parsed from metadata with scripts dataset builder as much as possible. Their builders are created dynamically (see `configure_builder_class()` in load.py`) and have `BUILDER_CONFIGS` attribute filled with `BuilderConfig` objects in the same way as for datasets with script.
## load_dataset
1. If there is single config in meta and it doesn’t have a name, the name becomes “default” (as we do for “dataset_info”), [example](https://huggingface.co/datasets/polinaeterna/audiofolder_one_default_config_in_metadata/blob/main/README.md):
```python
load_dataset("ds") == load_dataset("ds", "default") # load with the params provided in metadata
load_dataset("ds", "random name") # ValueError: BuilderConfig 'random_name' not found. Available: ['default']
```
2. If there is single config in metadata with `config_name` provided, it becomes a default one (loaded when no `config_name` is specified, [example](https://huggingface.co/datasets/polinaeterna/audiofolder_one_nondefault_config_in_metadata)
```python
load_dataset("ds") == load_dataset("ds", "custom") # load with the params provided in meta
load_dataset("ds", "random name") # ValueError: BuilderConfig 'random_name' not found. Available: ['custom']
```
3. If there are several configs in metadata with names [example](https://huggingface.co/datasets/polinaeterna/audiofolder_two_configs_in_metadata/blob/main/README.md)
```python
load_dataset("ds", "v1") # load with "v1" params
load_dataset("ds", "v2") # load with "v2" params
load_dataset("ds") # ValueError: BuilderConfig 'default' not found. Available: ['v1', 'v2']
```
Thanks to @lhoestq and [this change](https://github.com/polinaeterna/datasets/pull/1), it's possible to add `"default"` field in yaml and set it to True, to make the config a default one (loaded when no config is specified):
```yaml
builder_config:
- config_name: v1
drop_labels: true
default: true
- config_name: v2
...
```
then `load_dataset("ds") == load_dataset("ds", "v1")`.
## dataset_name and cache
I decided that it’s reasonable to add a `dataset_name` attribute to `DatasetBuilder` class which would be equal to `name` for scripts dataset but reflect a real dataset name for packaged builders (last part of path/name from hub). This is mostly to reorganize cache structure (I believe we can do this in the major release?) because otherwise, with custom configs for packaged builders which were all stored in the same directory, i it was becoming a mess. And in general it makes much more sense like this, from datasets server perspective too, though it’s a breaking change
So the cache dir has the following structure: `"{namespace__}<dataset_name>/<config_name>/<version>/<hash>/"` and arrow/parquet filenames are also `"<dataset_name>-<split>.arrow"`.
For example `polinaeterna___audiofolder_two_configs_in_metadata/v1-5532fac9443ea252/0.0.0/6cbdd16f8688354c63b4e2a36e1585d05de285023ee6443ffd71c4182055c0fc/` for `polinaeterna/audiofolder_two_configs_in_metadata` Hub dataset, train arrow file is `audiofolder_two_configs_in_metadata-train.arrow`.
For script datasets it remains unchanged.
## push_to_hub
To support custom configs with `push_to_hub`, the data is put under directory named either as `<config_name>` if `config_name` is **not** "default" or "data" if `config_name` is omitted or "default" (for backward compatibility). `"builder_config"` field is added to README.md, with `config_name` (optional) and `data_files` fields. for `"data_files"`, `"pattern"` parameter is introduced, to resolve data files correctly, see https://github.com/polinaeterna/datasets/pull/1.
- `ds.push_to_hub("ds")` --> one config ("default"), put under "data" directory, [example](https://huggingface.co/datasets/polinaeterna/push_to_hub_single_config/blob/main/README.md)
```yaml
dataset_info:
...
builder_config:
data_files:
- split: train
pattern: data/train-*
...
```
- `ds.push_to_hub("ds", "custom")` --> put under "custom" directory, [example](https://huggingface.co/datasets/polinaeterna/push_to_hub_singe_nondefault_config/blob/main/README.md)
```yaml
builder_config:
config_name: custom
data_files:
- split: train
pattern: custom/train-*
...
```
- for many configs, [example](https://huggingface.co/datasets/polinaeterna/push_to_hub_many_configs/blob/main/README.md):
```yaml
builder_config:
- config_name: v1
data_files:
- split: train
pattern: v1/train-*
...
- config_name: v2
data_files:
- split: train
pattern: v2/train-*
...
```
Thanks to @lhoestq and https://github.com/polinaeterna/datasets/pull/1, when pushing to datasets created **before** this change, README.md is updated accordingly (config for old data is added along with the one that is being pushed).
`"dataset_info"` yaml field is updated accordingly (new configs are added).
This shouldn't break anything!
TODO in separate PRs:
- [ ] docs
- [ ] probably update test cli util (make --save_info not rewrite `builder_config` in readme) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5331/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5331/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5331.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5331",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5331.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5331"
} | true |